Transcription
1. Intro: Bienvenue dans le cours sur les pandas. Dans ce cours, nous
allons explorer Pandas, l'une des bibliothèques les plus
essentielles pour l'analyse de données en Python Ce cours vous
fournira les connaissances de base nécessaires pour
travailler efficacement avec les données. Nous allons commencer par configurer
notre environnement de travail à l'aide de l'algèbre d' Anaconda et d'un bloc-notes afin de nous assurer que vous disposiez des
bons outils pour le Une fois que ce sera prêt, nous
aborderons les
principes fondamentaux de Pandas, en
apprenant à
créer, à manipuler et à analyser des trames de données, la
structure de données de base de Pandas Après avoir maîtrisé les bases, nous passerons à travailler
avec des ensembles de données du monde réel, téléchargés à partir de sources ouvertes Vous apprendrez
à nettoyer, transformer et organiser les données afin de les
préparer à une analyse plus approfondie. Vous trouverez le lien de téléchargement du jeu
de données dans la description
de la classe. Nous explorerons également l'
indexation multiple et les tableaux croisés dynamiques, puissants outils permettant de structurer
et de résumer
les et de résumer Ensuite, nous aborderons la
visualisation des données et les pandas, en
transformant les chiffres bruts en graphiques
clairs et informatifs Nous apprendrons également à stocker des trames de données dans une base de données, les
récupérer en cas de besoin et à utiliser des requêtes SQL directement dans Pandas pour interagir
avec des données structurées À la fin de ce cours, vous serez
en mesure d'utiliser Pandas pour analyser des
données réelles, qu'il s'agisse d' organiser des
données brutes ou d'extraire pertinentes.
Commençons.
2. Démarrer avec Pandas : installation, configuration d'Anaconda, carnet de notes Jupyter: Bonjour, les gars. Bienvenue dans
le cours sur les pandas De nos jours, les données sont
l'une des ressources
les plus précieuses du monde moderne, et il est crucial de pouvoir les manipuler, les analyser et les visualiser
efficacement. C'est là que Pandas, l'une des bibliothèques
Python
les plus puissantes pour l'analyse de données,
entre en jeu Pandas fournit un moyen
rapide, flexible et convivial de
travailler avec des données structurées Que vous utilisiez des
feuilles de calcul, des ensembles de données
volumineux ou des bases de données, Pandas vous permet de nettoyer, transformer et d'analyser les
données Il est largement utilisé
dans la science des données, la finance, l'apprentissage automatique et dans de nombreux autres domaines où les décisions basées sur les
données
sont essentielles. La maîtrise de cette bibliothèque est essentielle pour
tous ceux qui travaillent avec données, qu'il s'agisse d'analystes, de chercheurs ou de développeurs de
logiciels L'un des principaux avantages
de l'utilisation de Pandas sa capacité à gérer et à
analyser
efficacement de grands volumes
de données grâce à des structures spéciales
qui facilitent le travail avec les tableaux de
données et
leur analyse Avant de commencer à
travailler avec les pandas, nous devons nous préparer Nous allons d'abord explorer la distribution d'anaconda
et les environnements virtuels Nous pouvons donc choisir ce qui vous
convient le mieux. Anaconda est une
distribution de Python. Cela inclut non
seulement PyTon lui-même, mais également de nombreuses autres bibliothèques et
outils
utiles pour l'analyse des données
et le calcul spécifique L'un des principaux avantages
d'Anaconda est qu'
il est livré avec des
bibliothèques préinstallées telles que Napi,
Sky Pie, Mud Blood Leap,
Jupiter et, bien sûr, Pandas Cela simplifie considérablement ce type d'environnement pour l' analyse
des données et vous permet commencer rapidement
à
travailler sur un projet. Conda est un gestionnaire de packages et d'
environnements pour Python. Cela vient avec Anaconda. Il vous permet d'installer, de
mettre à jour et de gérer des
versions de packages Python
et d'autres outils logiciels. L'un des principaux avantages de Conda est sa capacité à créer des environnements
isolés. Dans ces environnements, vous pouvez installer différentes versions
de Python et de ses packages, en évitant les conflits entre les
différents projets et en garantissant la
stabilité de votre code. Passons maintenant à l'entraînement. Tout d'abord, rendez-vous sur la page
d'installation et suivez les instructions. Je vais commencer par
montrer comment l'
installer sur macOS puis sur Ubuntu. Pour macOS, cliquez sur lien
du programme d'installation de macOS
et téléchargez le programme d'installation. Ouvrez le fichier de téléchargement et lancez le processus
d'installation. Suivez les instructions,
autorisez les autorisations, acceptez les conditions et attendez que l'
installation soit terminée Le processus
prendra quelques minutes. Une fois Anaconda installé, il vous sera demandé de mettre à jour Anaconda Navigator Mettons-le donc à jour. Après la mise à jour, vous
pouvez immédiatement démarrer Jupiter Notebook
et commencer à travailler. En haut, vous verrez les environnements virtuels par défaut créés par Conda avec
toutes les dépendances, vous n'avez
donc pas besoin d'installer
Pandas. Il y est déjà. Vous verrez le
serveur Jupiter démarrer et vous pourrez ouvrir un document que vous possédez déjà ou en
créer un nouveau. Comme vous pouvez le constater, tout fonctionne et Pandas
est prêt à être utilisé Maintenant, continuons avec Ubuntu. Accédez au lien Linux Installer. Tout d'abord, installez toutes les dépendances. Téléchargez ensuite le programme d'installation pour Linux. Ouvrez le terminal. Exécutez le fichier téléchargé et lancez l'installation en
suivant les instructions. Acceptez les termes du contrat de licence et suivez les instructions
de la documentation Lorsque vous y êtes invité, sélectionnez Oui
pour initialiser Anaconda. Ensuite, ouvrez le terminal et désactivez l'activation automatique
de l'environnement de base. Lors de l'installation d'
anaconda, la désactivation l'activation automatique de l'environnement de base permet éviter un
encombrement inutile dans le terminal, vous
permet de mieux
contrôler l'environnement à
activer et d'éviter toute
utilisation accidentelle de l'environnement de base,
en particulier lors de la en particulier lors De cette façon, vous pouvez travailler dans une configuration plus
propre et plus flexible. Redémarrez le terminal pour vous assurer que l'environnement de base
est désactivé Vous pouvez répertorier toutes les dépendances à l'aide de la commande Conda list Enfin, lancez
Anaconda Navigator. À partir de là, suivez
les mêmes étapes. Lancez Jupiter, ouvrez un nouveau fichier ou un fichier déjà créé, et commencez à travailler avec Pandas Lorsque vous ouvrez Anaconda Navigator et que vous accédez à l'onglet Environnements, vous verrez l'environnement de
développement de base, créé par défaut par Anaconda Vous pouvez ajouter ou supprimer un nouvel environnement de développement ou gérer l'environnement
de base existant. Ici, vous pouvez voir ce qui est
déjà installé ou utiliser la fonction de recherche pour trouver et installer directement les
packages nécessaires. Si vous préférez, comme moi, utiliser le terminal,
vous pouvez ouvrir l' environnement de développement directement depuis
le terminal et installer toutes les dépendances à l'aide
du gestionnaire de packages P. Vous pouvez également gérer des environnements
virtuels et installer Jupiter et Panda
séparément sans Anaconda Ce serait une façon
complètement différente organiser votre espace de travail. Maintenant, mettons-nous au travail.
3. La série Pandas expliquée : Créer, manipuler et comparer avec les tableaux NumPy: Alors mettons-nous au travail. Si vous décidez de ne pas utiliser Anaconda et de travailler avec un environnement
virtuel, vous pouvez installer Pandas à l'aide de
la commande Pep Install Pandas la commande Pep Pandas fournit des structures de
données robustes
et faciles à utiliser ,
parfaites pour la
manipulation et l'analyse des données Les principales structures de données Pandas sont les séries
et les trames de données. Ces structures sont conçues
pour gérer différents types de données et fournissent de
puissantes méthodes manipulation
et
d'analyse des données. Une série est un objet semblable à un
tableau unidimensionnel. Cela peut contenir des données de tout type, y compris des entiers,
des chaînes, des flottants, etc. Cela ressemble à une colonne
dans une feuille de calcul
ou un tableau de données. Chaque élément d'une série possède une étiquette associée
appelée index,
qui permet un accès
rapide aux données. Un bloc de données est une structure de données
tabulaire bidimensionnelle avec des axes, des
lignes et des colonnes étiquetés C'est similaire aux
feuilles de calcul ou aux tables SQL. Avant de nous plonger dans
ces structures, il est important de
comprendre que Pandas est construit sur une
autre bibliothèque
fondamentale de Python appelée Nam Pi C'est l'abréviation de Python numérique, et c'est une bibliothèque qui prend en charge les tableaux et les matrices Bien qu'une série Panda et tableau
numpi puissent sembler
similaires à première vue, il existe quelques différences importantes Une série possède un index
qui étiquette chaque élément, ce qui facilite l'accès aux données par étiquette plutôt que simplement
par position entière. Un tableau, en revanche, n'utilise que des positions entières. Une série peut contenir des
données de types mixtes, tandis qu'un tableau numpi
est homogène, ce qui signifie que tous les éléments doivent
être du même type Importons la
bibliothèque Pandas et vérifions sa version. Créons maintenant un bloc
de données à partir des données que
nous avons déjà. Et pour cela, je crée
un dictionnaire de listes. Liste. Je vais importer Napi
et utiliser la fonction randint, nous avons
abordée dans
le cours Numpi Je vous suggère de vous y
familiariser. La fonction random génère nombres
aléatoires à virgule flottante à partir de la distribution
normale standard. La fonction SID est
utilisée pour initialiser le générateur de nombres aléatoires
avec une valeur CID spécifique Cela est utile à des fins de
reproductibilité exemple dans les simulations ou scénarios de
test dans lesquels
vous souhaitez pouvoir reproduire la même séquence
de nombres aléatoires Nous pouvons maintenant voir notre trame de données. Il ressemble à un tableau
et se compose de lignes représentées par des étiquettes d'index et de colonnes représentées
par des étiquettes de colonnes. Chaque colonne est une série. Chaque élément du bloc de données est accessible à l'aide des étiquettes de
ligne et de colonne. En bref, une trame de données dans Pandas peut être considérée
comme un ensemble d' objets
sérieux
où chaque série représente une colonne
dans une trame de données J'ai retiré les pièces inutiles. Une série et des pandas peuvent être créés à partir de
différents types de données, y compris des listes. Nous en avons
déjà un. Créons donc une
série à partir de cette liste. Lors de la création d'une
série à partir d'une liste, Bandas convertit la liste en une
structure semblable à un tableau unidimensionnel avec un index
associé Pour créer une série à partir d'une liste, vous utilisez la série DP et vous transmettez
la liste comme argument. Vous pouvez également éventuellement fournir un index pour étiqueter les éléments. Lorsque vous ne fournissez pas d'index, Pandas assigne automatiquement un index entier
à partir de zéro Créons une autre série. En tant que donnée, je passe X, et en tant qu'index, je passe notre première
liste L. Nous pouvons également transmettre des arguments
sans leur nom et obtenir le même résultat. Créons une série
à partir d'un dictionnaire. Si nous utilisons une telle structure de données, nous obtiendrons une série
où les clés agissent
sur l'index et les
valeurs représentent les données. Et ici, nous pouvons clairement
voir que pour le prochain exemple, je vais créer deux séries
contenant des données et des indices. Imaginons une situation dans
laquelle vous souhaitez associer
deux séries Panda à
l'aide de l'opérateur plus. Pandas effectue une addition par
élément en fonction de l'alignement
de ses indices Cela signifie que les valeurs
de chaque indice de la série 1 sont ajoutées aux valeurs
du même indice de la série 2. Nous avons plusieurs indices
identiques ici, donc leurs
numéros correspondants sont ajoutés. Si un indice est présent dans une série mais pas dans l'autre, le résultat pour cet
indice sera aucun, pas un chiffre, indiquant
une valeur manquante. Il est important de noter que même si nous avons initialement
transmis des données entières, le résultat contient des nombres flottants Cela est dû au fait que
Pandas
convertit automatiquement les nombres entiers en nombres flottants lors d'
opérations
mathématiques
afin de gérer les valeurs et
de garantir cohérence lors de la combinaison de
différents types Ce comportement permet une manipulation des données
plus flexible et plus robuste, en tenant compte de manière
fluide des valeurs manquantes
et des types de données mixtes Continuons avec le bloc de données.
4. Maîtriser les images de Pandas : accès, modification, filtrage et indexation: Continuons avec les blocs de données. Je vais commencer par le document et importer toutes les bibliothèques
nécessaires. Créons notre premier
bloc de données avec des données aléatoires. Je vais générer un bloc de données avec quatre lignes et quatre colonnes. Pour remplir ce bloc de données
avec des nombres aléatoires, je vais utiliser une fonction qui
génère des valeurs aléatoires. Je transmettrai également une liste sous forme d'index et définirai les étiquettes des
colonnes. Il en résulte une trame de données
typique. Pour accéder à une colonne, nous utilisons la notation entre crochets
et transmettons le nom de la colonne. Si nous avons besoin de plusieurs colonnes, nous transmettons une liste de noms de colonnes. En fait, nous pouvons
effectuer des opérations sur des colonnes de trames de
données
comme avec des séries, telles que l'addition, la soustraction
et la multiplication Par exemple, ajoutons une nouvelle
colonne au bloc de données. Je vais lui donner un nouveau nom, et il s'agira de certaines des
colonnes T et R. Par conséquent, nous avons maintenant une nouvelle colonne. Pour supprimer une ligne, nous utilisons
la fonction de suppression. Par exemple, si je supprime
la ligne avec l'index A, elle peut sembler supprimée au début. Cependant, si j'appelle à nouveau
la trame de données, la ligne A est toujours là. Cela se produit parce que Pandas ne modifie pas le bloc de données en
place à moins que nous ne spécifiions un paramètre sur place
égal à true La définition de place égale à true garantit que les modifications sont
conservées dans le bloc de données. Dans le cas contraire, le
bloc de données d'origine reste inchangé. De même, pour supprimer une colonne, nous utilisons la fonction de dessin, mais nous devons définir le
paramètre de l'axe égal à un. Puisque l'axe par défaut est égal
à zéro, cela fait référence à la suppression de lignes. J'ajoute « place » égal à
deux pour que les modifications
prennent effet immédiatement. Et ici, nous avons supprimé la ligne, et si je spécifie un axe égal à zéro,
rien ne changera. Il s'agit de la valeur par défaut. L'attribut shape
renvoie un tuple qui indique le nombre de lignes et de colonnes
du bloc de données. C'est utile lorsque vous
devez vérifier rapidement la taille d'un bloc de données ou
valider les dimensions des données. Les lignes peuvent être sélectionnées en transmettant l'étiquette de ligne à
la fonction log. N'oubliez pas que pour
sélectionner une colonne, nous n'avons pas besoin de la fonction de journalisation. Nous pouvons simplement utiliser la notation
entre crochets. Si nous voulons sélectionner des lignes à l'aide d' indexation basée sur des
entiers, nous utilisons Iloc Cela nous permet de
récupérer des lignes en fonction leur position numérique,
quel que soit leur index nommé. Par exemple, en utilisant IoC zéro, nous renverrons la première ligne. Pour plus de commodité, je vais
afficher à nouveau notre bloc de données. Pour extraire un
sous-ensemble spécifique de lignes et de colonnes, nous utilisons la fonction log et transmettons
les étiquettes des lignes et des colonnes à
l'aide d'une notation virgule Si nous voulons un sous-ensemble de lignes et de colonnes
spécifiques, nous transmettons deux listes, une pour les lignes et
une pour les colonnes Et ici, nous pouvons voir le
sous-ensemble de la colonne RT, et sous forme de zéros, il
existe de nombreuses situations où nous avons besoin d'un sous-ensemble de données répondant Et pour cela, Pandas fournit des fonctionnalités
de filtrage. Pandas permet une sélection
conditionnelle
pour filtrer les données en fonction de conditions
spécifiques Par exemple, si
nous voulons sélectionner toutes les valeurs de données
supérieures à zéro, la sortie sera une trame de données
filtrée dans laquelle enregistrements
non correspondants sont remplacés par aucun, et
non par un nombre. Essayons maintenant le filtrage
basé sur les colonnes. J'extrairai les données en fonction de la condition où la colonne E a
des valeurs supérieures à zéro. Au départ, la sortie
affichera des valeurs booléennes, true lorsque la condition est
remplie et false dans le cas Pour récupérer les données réelles qui répondent à la condition, nous devons appliquer la condition
directement au bloc de données. Cela ne renverra que les lignes dont la valeur de la colonne E est
supérieure à zéro. Si nous modifions la
condition, par exemple en sélectionnant des valeurs
supérieures à un, la sortie reflétera cette
nouvelle condition en conséquence. La
méthode de réinitialisation de l'index nous permet de rétablir l'index numérique
par défaut. Lorsque nous réinitialisons l'index, l'ancien index est ajouté sous forme colonne et
un nouvel
index séquentiel est créé La méthode set index nous
permet de définir une colonne existante comme
index du bloc de données. Ici, j'ai pris la colonne T
et je l'ai utilisée comme index. En utilisant la fonction de division intégrée
de Python, nous pouvons
générer efficacement une liste. Nous pouvons générer une
liste de cette manière. Il faut beaucoup moins de temps pour qu'un élément de plusieurs valeurs
soit égal à trois. Ajoutez ensuite cette liste en tant que
nouvelle colonne dans notre bloc de données. La fonction
split de Pandas est utile pour séparer des chaînes
en plusieurs parties sur la
base d'un DelMeterRetracting de données
spécifiques
ou pour créer de nouvelles colonnes à partir de données ou pour créer de nouvelles Si aucun séparateur n'est spécifié, la fonction de division divise la
chaîne par des espaces blancs, des
espaces, des tabulations ou de nouvelles
lignes, comme dans notre cas
5. Travailler avec MultiIndex dans Pandas : L'indexation hiérarchique expliquée: Comme toujours, importons
toutes les bibliothèques nécessaires. L'index multiple ou index
hiérarchique est une version avancée de l'index
standard de Pandas Vous pouvez le considérer comme
un tableau de tuples où chaque dapple représente une combinaison d'index
unique Cette approche permet des structures d'
indexation
plus complexes Commençons par créer
un bloc de données simple. Nous allons ensuite générer un index hiérarchique à l'aide de
la fonction from frame. Cet exemple
nous aidera à comprendre comment créer un
index hiérarchique à partir d'un bloc de données. Commençons par créer
un bloc de données simple. Tout d'abord, nous créons un bloc de données avec une liste de données et de noms de colonnes. Ce bloc de données sera ensuite utilisé pour construire notre index
hiérarchique. Je passe une liste de données
et de noms de colonnes, et notre bloc de données est prêt. Nous avons maintenant une trame de données
typique. Il inclut un index, des noms de
colonnes et des données. Ce bloc de données sera utilisé
pour créer un objet d'index. Nous utilisons la fonction From frame et transmettons notre
trame de données en argument. Nous avons maintenant un objet index, qui représente une
liste de tuples uniques Créons donc un nouveau bloc de données en utilisant ce multi-index terminé. Tout d'abord, je remplis le
bloc de données avec des nombres aléatoires. Ensuite, nous définissons une structure à quatre lignes et deux colonnes. Nous passons le multi-index
au paramètre index. Enfin, nous définissons les
noms des colonnes pour le nouveau bloc de données. Et maintenant, nous pouvons voir
le nouveau bloc de données. Nous avons utilisé from frame pour créer un index multiple à partir d'un bloc de données, permettant ainsi une
indexation hiérarchique pour meilleure organisation des données
et une sélection efficace Et maintenant, nous pouvons créer un nouveau bloc de données à l'aide de
cet index multiple. Toutefois, lors de la création
d'un nouveau bloc de données, le nombre de lignes
des données doit correspondre au nombre de niveaux d'index
pour éviter les incohérences de taille Je vais maintenant
vous montrer comment créer et utiliser un index d'
une manière légèrement différente. Tout d'abord, j'utilise la fonction
split de Python pour créer une liste plus rapidement. Ensuite, j'utilise la fonction Z pour connecter chaque paire
d'éléments ensemble. Enfin, je les
transforme en une liste Taples. La fonction Z en Python associe des éléments provenant de
plusieurs itérables, créant des tuples d'éléments
correspondants C'est utile pour itérer plusieurs séquences
simultanément. Je peux maintenant créer un
index multiple à partir d'un tableau de bandes à l'aide de la fonction
from Taples Nous avons donc notre index multiple et nous pouvons l'
intégrer dans une nouvelle trame de données. Tout d'abord, je remplis le bloc de données avec des données aléatoires
comme nous l'avons fait ci-dessus. Ensuite, je définis la structure avec six lignes et deux colonnes. Ensuite, je passe notre
index multiple, l'attribut index, et enfin, je définis les noms des
colonnes. C'est ici. Nous pouvons voir notre nouveau bloc de données. D'accord, envisageons d'accéder aux
données avec un index multiple. À l'aide de l'attribut names, nous pouvons définir des noms pour les
niveaux du multi-index. Et ici, j'ai défini les noms de
nos colonnes,
unités et travailleurs à index multiples .
Alors pratiquons. Pour plus de clarté, nous pouvons voir deux colonnes marquées,
unités et travailleurs. Pour obtenir le salaire du
troisième travailleur à partir de l'unité deux, j'utilise la fonction log. Tout d'abord, j'indique l'unité deux, puis je spécifie le travailleur trois et enfin, je sélectionne la colonne des
salaires. Le double verrouillage est utilisé car le bloc de données
possède un index multiple. Le premier journal avec l'unité deux sélectionne toutes les lignes de l'unité deux, renvoyant une trame de données plus petite. Le deuxième journal, le travailleur trois, sélectionne
ensuite le travailleur trois dans
ce sous-ensemble, et enfin, salary récupère toutes les valeurs de colonne
spécifiques, et nous avons maintenant
le résultat, Essayons un autre exemple. Obtenir les heures de travail premier travailleur et du travailleur
deux à partir de l'unité deux. Tu peux t'entraîner seul. Publiez la vidéo et essayez de
le faire vous-même. J'utilise la fonction log pour l'unité deux, puis je passe le travailleur un
et le travailleur deux sous forme de liste. Enfin, j'indique
la colonne des heures. Je passe le premier
et le travailleur deux sous forme liste dans une liste pour
sélectionner plusieurs lignes à la fois. Cela nous permet de récupérer
les colonnes d'heures pour les deux travailleurs simultanément à partir
du sous-ensemble de données
de l'unité deux Et maintenant, nous avons les
heures de travail de ces deux travailleurs. Ignorez les valeurs négatives car nous avons rempli le bloc de données
avec des nombres aléatoires. Les données du monde réel
contiendraient des valeurs valides. Entraînons-nous maintenant à sélectionner
plusieurs lignes et colonnes. De quoi avons-nous besoin d'une intersection de plusieurs lignes et de
plusieurs colonnes ? Calculons le salaire et les heures de travail du deuxième travailleur et du
troisième dans l'unité deux. Tout d'abord, utilisez la fonction Log
pour sélectionner l'unité deux. Passez ensuite le travailleur deux et le
travailleur trois sous forme de liste. Enfin, sélectionnez également le salaire
et les heures sous forme de liste. Alors mettez la vidéo en pause et
essayez de le faire vous-même. Comme vous pouvez le constater, nous avons
utilisé la même méthode, la fonction et la notation
entre crochets. Définissez ensuite l'unité deux
au premier niveau, en
passant le travailleur deux et le
travailleur trois sous forme de liste, et enfin en transmettant
deux listes de colonnes,
salaire et heures, en utilisant la notation
entre crochets. Je peux éviter de transmettre les colonnes, salaire et les heures sous
forme de liste, car nous n'
avons que deux colonnes
dans notre cadre de données. Dans ce cas, toutes les colonnes
seront sélectionnées automatiquement. Ces deux versions
donneront le même résultat. Cependant, si nous avions
plus de deux colonnes, nous devrions
répertorier explicitement les noms des colonnes. Il s'agissait donc d'un bref exemple de la façon de travailler avec l'
indexation hiérarchique dans Pandas L'objectif principal de cette leçon
est de comprendre ce que signifie l'indexation
hiérarchique et comment elle s'intègre à la fonctionnalité d'
indexation de Pandas Les index multiples sont
utiles dans Pandas, mais ne constituent pas toujours
le premier choix Ils sont couramment utilisés dans les ensembles de données
hiérarchiques, analyse de séries
chronologiques et lorsque vous travaillez avec des données groupées
ou pivotées Toutefois, dans de nombreux cas
pratiques, un index plat comportant
plusieurs colonnes est préférable pour des raisons de simplicité
et de lisibilité Alors, n'ayez pas peur.
Dans la plupart des cas, nous n'aurons pas besoin de l'utiliser, mais il est essentiel de comprendre sa structure et son fonctionnement.
6. Analyse de Pandas DataFrame : regroupement, agrégation et fonctions mathématiques: Maintenant, je veux vous
présenter une nouvelle méthode chez Pandas. Et pour cela, je vais
créer un bloc de données. Comme toujours, dans un premier temps, j'importe la bibliothèque Pandas Ensuite, je crée un dictionnaire. Ensuite, à partir de ce dictionnaire, je vais créer le bloc de données. La fonction head de Pandas renvoie les premières
lignes de la trame de données, généralement utilisées pour
s'attendre rapidement à la première
position des données Par défaut,
les cinq premières lignes sont affichées. Le filtrage des lignes et des colonnes de la bibliothèque Pandas peut être
effectué à l'aide de la méthode de filtrage En utilisant Shift plus la commande supérieure, vous pouvez développer et afficher les conditions dans
lesquelles nous pouvons filtrer. Cette méthode vous permet de
sélectionner des lignes et des colonnes en fonction de certaines conditions
spécifiées par l'utilisateur. Par conséquent, nous obtenons un bloc de
données avec des lignes ou des colonnes qui répondent
aux conditions spécifiées. Il est important de
noter que le filtrage ne s'applique qu'à l'
index ou aux étiquettes. Les données et le bloc de données
eux-mêmes ne sont pas filtrés. Dans ce cas, en
filtrant avec le paramètre items et
en passant les noms de nos colonnes, nom ou l'âge, nous n'obtenons que
les données demandées. Si le paramètre items
est spécifié, il permet d'indiquer
une liste de colonnes à conserver. Si ce n'est pas spécifié, toutes les
colonnes seront conservées. Je vais maintenant montrer l'
exemple en utilisant le paramètre. Ce paramètre
vous permet de spécifier une sous-chaîne qui doit faire
partie du nom de colonne Seules les colonnes dont le nom contient la chaîne seront conservées. Si je le vérifie, on le
voit clairement. Il existe également le paramètre de
l'axe. Ce paramètre indique s'il faut appliquer le filtrage aux lignes, axes SEQUL à zéro ou aux colonnes, axes SEQUL à un Pour clarifier les choses, j'ajouterai des valeurs uniques au lieu
des indices standard, qui peuvent être lus et filtrés en fonction de
certains critères. Après avoir rechargé les lignes
à l'aide de Shift plus Center, voyons comment cela fonctionne Je veux obtenir une rose qui
contient la sous-chaîne BL, donc je vais spécifier un
paramètre égal à BL et X est égal à zéro Cela
ne renverra que la ligne avec l'index bleu et toutes les informations
nécessaires. Il est parfois utile de trier le bloc de données en fonction de la valeur
d'une ou de plusieurs colonnes. La fonction de tri des valeurs
est très utile pour cela. Vous spécifiez le nom de la
colonne ou
la liste des colonnes selon lesquelles le
tri sera effectué. Par exemple, ici, j'ai
trié en fonction de l'âge de la colonne. Pour l'ordre croissant, le paramètre
croissant
est défini sur true Si vous souhaitez utiliser l'ordre décroissant
, définissez-le sur false. De plus, si vous souhaitez modifier directement le bloc de
données d'origine, vous devez définir le paramètre in
place égal à true, comme nous l'avons fait précédemment. Par défaut, il est défini sur false. Si vous modifiez le bloc de données
puis que vous le rappelez, vous verrez que rien n'a
changé à moins que nous n'ayons mis en
place un paramètre égal à vrai. Pour le prochain exemple, je vais
importer la bibliothèque Seaborn. J'utilise cette
bibliothèque car elle me
permet de charger
le jeu de données Titanic Oui, Seaborn possède un ensemble de
données par défaut que je peux charger. Je vais maintenant charger le jeu de données du
Titanic et l'afficher afin que nous puissions
voir les données disponibles Seborn est la bibliothèque PyTon utilisée pour la visualisation des
données statistiques Il simplifie la création de graphiques informatifs
et attrayants, facilitant ainsi l'exploration
et la compréhension des modèles de données. Vous pouvez trouver un tutoriel pour
cette bibliothèque dans mon profil. Bienvenue. Faisons connaissance
avec le groupe par méthode. La méthode group by est
utilisée pour regrouper les lignes
d'un ensemble de données en fonction des valeurs
d'une ou de plusieurs colonnes. Permettez-moi de vous donner un exemple afin que vous puissiez comprendre
comment cela fonctionne. Dans cet exemple, je vais regrouper toutes les personnes à
bord du navire par classe. Lorsque j'affiche le résultat, nous obtenons un groupe par objet. J'ai regroupé les passagers
par classe de cabine et je souhaite maintenant calculer le tarif moyen pour chaque classe. J'utilise la
fonction mean pour ce faire. Regardez le résultat. Nous pouvons constater un écart important. La première classe coûte très cher. La deuxième classe est plus abordable et la troisième
est la moins chère. De plus, nous pouvons
examiner le tarif maximum pour chaque classe ou le tarif minimum. Cependant, le
tarif minimum indique zéro. Voyons s'il
existe de telles données. peut donc que les passagers aient
voyagé gratuitement ou que nous ayons des
données manquantes sur ce cadre de données. Mais cela n'affecte pas, pour notre exemple, c'est
juste pour la démonstration. Continuons avec l'agrégation. agrégation est le processus
qui consiste à calculer une ou plusieurs mesures statistiques pour chaque groupe formé
lors du regroupement de données. Le regroupement des données est effectué
à l'aide d'une ou de plusieurs clés, colonnes, puis l'agrégation est effectuée séparément
pour chacun de ces groupes. Maintenant que nous connaissons le groupe
par méthode, nous pouvons appliquer une
fonction d'agrégation telle que somme ou la moyenne aux données groupées. Par exemple, j'ai de nouveau regroupé
les passagers par classe de
cabine, puis calculé l'âge moyen
des passagers dans chaque classe. Ici, nous pouvons voir la corrélation. Plus la classe est basse,
plus l'âge moyen est jeune, ce qui est logiquement logique À cette époque, les personnes âgées
étaient souvent plus riches voyageaient
donc
dans des classes supérieures Je vais maintenant vous donner un
exemple utilisant la méthode des œufs. Cette méthode, abréviation d'agrégation,
est utilisée
pour calculer les statistiques
agrégées pour les groupes de lignes formés
à l'aide de la méthode groupe par. J'ai de nouveau regroupé les passagers
par classe de cabine. Je veux maintenant calculer
l'âge moyen et tarif
moyen des
passagers de chaque classe. Cette notation est égale
à ce que nous avons vu ci-dessus, mais écrite sous une forme
plus compacte. Nous utilisons la
méthode Ag pour calculer à la
fois l'âge moyen et le tarif
moyen sur une seule ligne. Si vous le souhaitez, la méthode egg peut également créer plusieurs fonctions
d'agrégation. Par exemple, vous pouvez calculer à la fois la moyenne et la
valeur maximale pour chaque groupe. Le résultat inclura
toutes les mesures demandées, offrant ainsi une
vue plus large des données. Si vous utilisez
plusieurs fonctions, n'oubliez pas de les placer entre
crochets ,
car il s'agit d'une liste
7. Travailler avec des ensembles de données réels : téléchargement, analyse et intégration SQL dans Pandas: Maintenant que nous avons couvert les obligations, il est temps de consolider nos connaissances en travaillant
avec des ensembles de données réels Je vais vous montrer où vous pouvez trouver des données réelles pour
vos projets. Si vous souhaitez pratiquer de manière
plus autonome, je vous recommande vivement de le faire. Aucun didacticiel ou vidéo
ne peut vous en apprendre davantage qu'une expérience pratique
avec des données du monde réel Examinons donc les mauvaises
sources pour les vrais ensembles de données. Et le premier, Cagle. Il s'agit d'une plateforme sur laquelle vous pouvez télécharger gratuitement des ensembles de données, explorer des carnets de notes et apprendre
auprès d'autres passionnés de données C'est l'une des
meilleures ressources pour les projets d'analyse de
données et
d'apprentissage automatique. Le second monde des données. C'est une autre ressource intéressante
où vous pouvez trouver des ensembles sur divers sujets et
les télécharger dans plusieurs formats Ensuite, nous pouvons utiliser
Data Playground. Ce site vous permet de
parcourir les ensembles de données par sujet et par format
avant de les télécharger, afin de
trouver plus facilement les données pertinentes Si vous souhaitez travailler avec des statistiques du monde
réel, l'UNICEF fournit des ensembles de données liés au développement mondial,
à
la santé et à l'éducation Ces ressources sont très utiles, surtout si vous
souhaitez créer un projet favori qui reflète l'état réel d'un sujet sélectionné. Pour ceux qui ne le savent pas, un projet
favori est un projet que vous réalisez chez vous pour le présenter lors
d'un entretien ou simplement pour entraîner et comprendre
comment les choses fonctionnent. De nombreux gouvernements proposent des portails de données
ouvertes où vous pouvez télécharger
des ensembles de données sur l'immobilier, la santé, les finances, etc. Je suis allé sur un site Web de données
ouvertes du gouvernement. Et j'ai décidé de
télécharger un jeu de données contenant des informations sur les ventes
immobilières 2001-2020. J'ai téléchargé l'
ensemble de données au format CSV, qui contient des données sur les transactions
immobilières
au fil des ans. Il s'agit de l'ensemble de données
que je vais utiliser pour notre projet. Tout d'abord, je suis port Pandas et j'utilise la méthode read CSV
pour charger le jeu de données Comme je me trouve dans le même
répertoire que le fichier du jeu de données, je n'ai pas besoin de spécifier le chemin
complet, le nom du fichier. Lorsque vous essayez de charger un ensemble de
données volumineux dans un bloc de données, Pandas tentent de
déterminer automatiquement les types de données
pour chaque colonne Toutefois, pour les grands ensembles de données, ce processus peut consommer beaucoup de mémoire et
prend généralement beaucoup de temps Pour éviter cela, vous
avez deux options spécifier
manuellement les types de
données pour chaque colonne à l'aide du paramètre de type
D ou définir le paramètre low
memory sur false pour
permettre aux Pandas d'utiliser plus de
mémoire pour de meilleures performances Comme notre jeu de données contient
près d'un million de lignes, il n'est pas surprenant
que nous ayons reçu un message d'avertissement
lors de son chargement. Lorsque vous chargez un jeu de données volumineux et que vous souhaitez voir à
quoi il ressemble, n'est pas nécessaire d'afficher
le bloc de données dans son intégralité. La méthode head vous permet de n'en revoir qu'une partie. De même, vous pouvez afficher
un certain nombre de lignes à partir de la fin
en utilisant la méthode de la queue. La méthode info vous permet obtenir une vue d'ensemble de
votre bloc de données, y compris de nombreuses informations telles que nombre
total de
lignes et de colonnes, nombre de
valeurs non nulles dans chaque colonne, l'utilisation de la
mémoire, etc. La méthode de description fournit une description statistique des données
numériques
du bloc de données. À partir de là, vous pouvez facilement vous faire une idée générale de la distribution et
des statistiques de votre jeu de données numériques. Il inclut l'
écart type moyen, les quartiles
minimum et maximum, etc. Il existe également une
puissante bibliothèque Python appelée SQL Alchemy, qui vous permet de travailler avec des bases de données
SQL dans Pandas C'est particulièrement utile si vous souhaitez stocker
ou récupérer et traiter
efficacement de grands ensembles de données à l'aide de requêtes SGWL SQL Alchemy est une bibliothèque populaire pour interagir avec des
bases de données relationnelles en Python SQLite est une autre option, qui est un système
intégré de gestion de
base de données relationnelle
haute performance facile à utiliser et ne nécessitant pas de serveur
séparé Il permet le stockage
et la gestion des données dans un magasin de fichiers local sans avoir besoin d'un serveur de données
distinct. Eh bien, ne vous laissez pas intimider
par ce code. C'est standard. Vous pouvez simplement le copier
depuis la documentation. Tout ce que vous devez faire maintenant,
c'est comprendre ce qu'il fait. Ici, nous importons et créons un moteur pour nous connecter
à la base de données. Supposons que vous deviez
transférer des données d' une trame de données Pandas
vers une base de données, où vous pourrez les utiliser
davantage ou les stocker pour Je vais vous montrer
comment procéder. Nous avons créé un moteur
connecté à la base de données de test. Permettez-moi de vous rappeler que votre cadre de
données ressemble à ceci. Ici, il utilise
la méthode à deux CSV. Nous écrivons ensuite nos
données dans une table, que j'ai nommée Nouvelle table. Le deuxième paramètre,
bien entendu, est notre moteur. Comme nous pouvons le constater, nous venons d'enregistrer près d'un million de lignes dans
la nouvelle table de
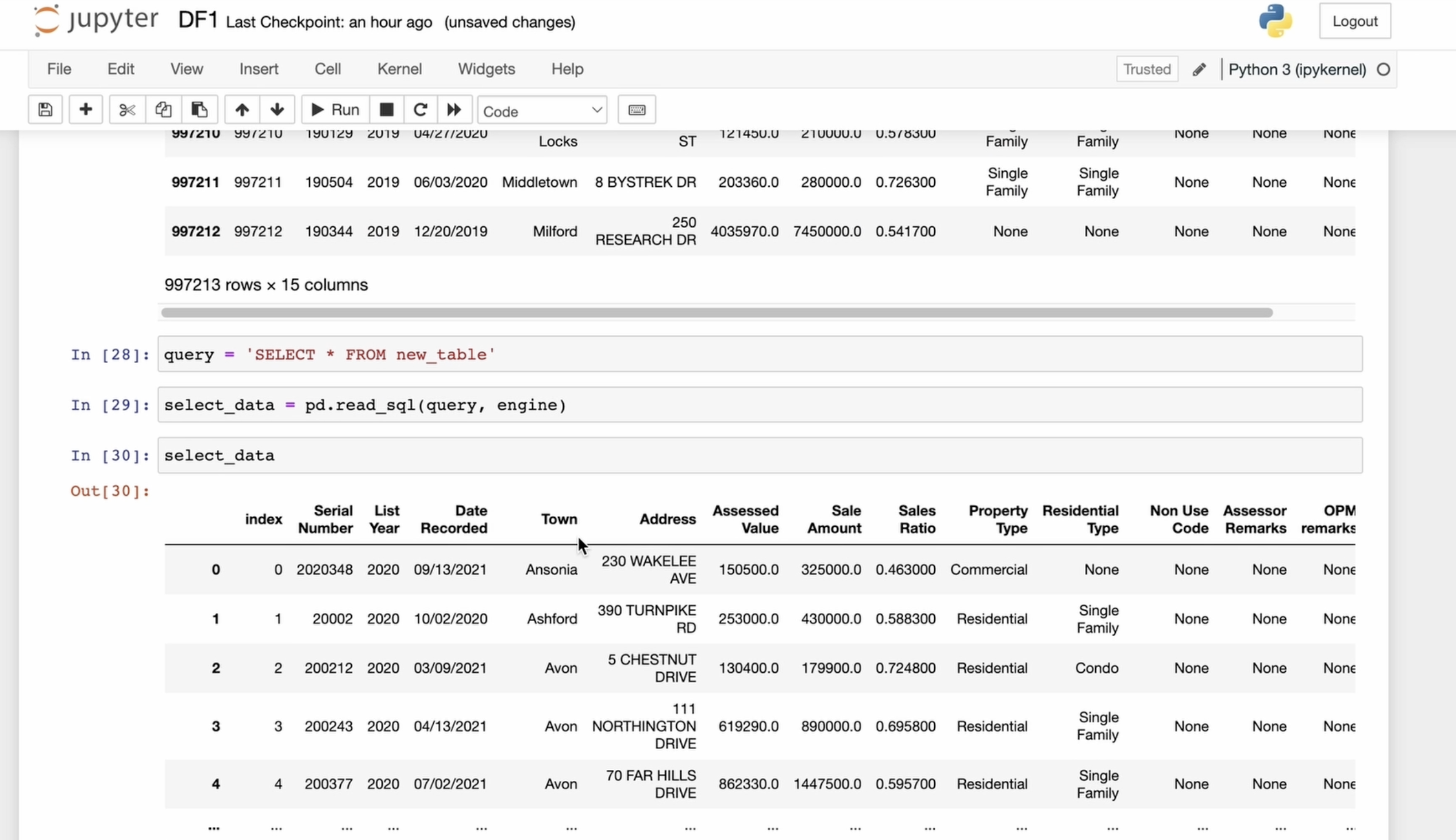
la base de données de test. Essayons de lire tout ce que
nous avons enregistré dans ce tableau. En d'autres termes, nous
voulons extraire et récupérer le bloc de données que nous
venons d'enregistrer dans la base de données. Pour cela, j'utilise
read SQL et plus notre table à partir de
laquelle nous avons l'intention tout
lire
au premier paramètre. Le deuxième paramètre est le moteur par lequel nous sommes connectés à
la base de données du bureau. J'enregistre notre
trame de données extraite dans la variable read DF, et nous pouvons voir ce que nous avons
enregistré dans la base de données. Ensuite, nous avons
pu le récupérer. C'est ici. Mais ne nous attardons
pas là-dessus. Nous pouvons non seulement lire
l'intégralité du bloc
de données de la base de données
dans laquelle nous l'avons enregistré, mais également prendre une partie spécifique avec laquelle nous prévoyons de travailler. Je vais maintenant vous montrer
comment nous pouvons former requêtes
SQL avant de
les passer en paramètre. Savoir travailler
avec des requêtes SQL est très utile pour tout le monde, que vous
soyez analyste de données
ou développeur de logiciels. La compétence sera utile. La première requête, la plus simple, lire tous les
enregistrements de la table, et le symbole astérisque signifie que
je sélectionne tous les enregistrements Ensuite, je passe cette requête et le premier paramètre
à la même fonction que nous avons utilisée pour la lecture. Bien entendu, le deuxième
paramètre est le moteur, qui est notre connexion
à la base de données. Cela prendra un peu de temps. Essentiellement, nous obtenons la même
chose pour l'ensemble du bloc de données. Maintenant, si je remplace l'
astérisque par « ville », je n'obtiendrai pas la trame de données
complète Je n'obtiendrai
que les lignes sélectionnées. Je n'obtiendrai que
ce que nous avons sélectionné. Dans mon cas, ce seront les villes. Pour mieux
comprendre son fonctionnement, essayons autre chose. Je souhaite récupérer toutes les
informations de notre base de données, mais uniquement pour une ville spécifique. Disons Ashford. Et regardez, nous avons
des informations sur ventes
immobilières liées
uniquement à la ville d'Ashford C'est pratique et vous
n'avez pas besoin de faire glisser informations
inutiles
dans votre bloc de données si vous devez uniquement travailler
avec une ville en particulier.
8. Tableaux croisés dynamiques dans Pandas : nettoyage des données et analyse des données réelles: Lorsque nous obtenons des données que nous
devons traiter ou analyser. Dans la plupart des cas, nous ne pouvons pas
commencer à travailler immédiatement car
il s'agit de données brutes. Le résultat obtenu
sera directement influencé par le fait que
chaque colonne a été remplie avec le type de données
approprié et par la présence de valeurs
vides ou nulles. Lorsque nous recevons des données,
une première analyse est extrêmement nécessaire. La commande INL permet d'identifier les valeurs
manquantes ou nulles dans
l'objet du bloc de données Il renvoie une nouvelle trame de données de la même taille que la trame de données
d'entrée où chaque élément est vrai si l'
élément correspondant est manquant ou nul et tombe dans le cas contraire. Cette méthode est très utile pour nettoyer et analyser les
données car elle nous permet d'identifier les endroits où les
données d'origine présentent des valeurs manquantes. Permettez-moi de vous rappeler à quoi ressemble
votre bloc de données après avoir utilisé l'INL. Pour gérer ces valeurs manquantes, nous pouvons utiliser différentes méthodes. Par exemple, fillna
nous permet de remplacer des valeurs vides
par une valeur spécifique Dans mon cas, j'ai utilisé zéro. Une attention particulière doit
être accordée aux noms de colonnes. À l'aide de colonnes, je peux récupérer tous les noms de colonnes sous forme de liste
et évaluer leur validité. Dans de nombreux cas, il
est souhaitable de renommer les colonnes pour une meilleure
lisibilité et Cela inclut la suppression des guillemets
inutiles, élimination des espaces supplémentaires, conversion de toutes les colonnes
nommées en minuscules et le remplacement des espaces par
des traits de soulignement, si le nom d'une colonne est composé
de deux mots ou plus Permettez-moi de commencer par un exemple
simple en Python. Supposons que nous ayons une
variable A contenant la chaîne Nick et que nous lui appliquions
la méthode inférieure. Cela transforme toutes les lettres en minuscules, ce qui donne Nick Cependant, il
n'est pas possible
d'appliquer simplement cette méthode aux colonnes du bloc de données , car
les noms de colonnes ne sont pas directement
traités comme des chaînes. Si nous vérifions le type et le
premier cas et dans le second, nous pouvons voir la différence. Pour les traiter correctement, j'utilise l'accesseur STR qui permet des opérations de chaîne
pour chaque nom de colonne Donc, ce que nous faisons ici, le premier ajoute les noms des
colonnes d'accès en utilisant le SDR, puis les convertit en
minuscules en utilisant la méthode inférieure Enfin, remplacez les espaces par des de soulignement
en utilisant la méthode replace Cette approche nous permet
de nettoyer efficacement les noms de
colonnes sans utiliser de
boucles ou de nommage manuel. Nous pouvons réduire le nombre
de lignes et exécuter toutes les commandes séquentielles sur
une seule ligne en utilisant la notation par
points C'est ce qu'on appelle le chaînage de méthodes. Après avoir effectué
ces modifications, je dois réattribuer les noms des
colonnes traitées au bloc de données. Ce processus
s'appelle le nettoyage des données. Ici, nous remplaçons les valeurs vides, normalisons les
noms de colonnes pour des raisons de commodité et évitons les erreurs potentielles
lors du traitement futur des données Comme je n'ai pas spécifié
le paramètre et la place égale à true lors du remplissage
des valeurs manquantes, vous pouvez voir qu'elles
sont toujours là, mais vous pouvez facilement
les remplacer par zéro vous-même. Exécutez simplement fill N à nouveau et
assurez-vous de sauvegarder le résultat. Une autre
méthode importante est dropna, qui est utilisée pour supprimer des
lignes ou des colonnes
d'un bloc de données contenant des valeurs
manquantes ou nulles Par défaut, si aucun
paramètre supplémentaire n'est spécifié,
supprimez les lignes NREMs
contenant des valeurs manquantes Cependant, cela peut
entraîner la suppression de toutes les
lignes si une
colonne contient des valeurs manquantes. Pour spécifier si nous voulons
supprimer des lignes ou des colonnes, nous utilisons le paramètre axis. L'axe est égal à zéro, valeur par défaut supprime les lignes et l'axe égal à
un supprime les colonnes. Par exemple, définir un
axe égal à un supprimera des colonnes
au lieu de lignes, ce qui produira un résultat complètement
différent. Comment identifier des valeurs
uniques ? Et pour cela, nous
utilisons une méthode unique. C'est utile pour identifier des valeurs
distinctes dans une colonne de trame de données
spécifique. Cela permet d'analyser les données
catégoriques, telles que le comptage du nombre de catégories
différentes ou d'
identifiants uniques dans un Par exemple, pour
déterminer le nombre de villes
uniques dans
la colonne des villes, j'utiliserai DF puis la notation ville entre crochets
et la méthode unique. Et nous avons obtenu le résultat. Contrairement à la
méthode unique et unique, le nombre de valeurs
uniques dans chaque
colonne ou ligne d'
un bloc de données permet d'
analyser la distribution des données. Nous avons ici 18 villes uniques. comptes de valeurs
constituent une autre méthode utile, qui compte les occurrences de chaque valeur unique dans
une colonne de blocs de données. Elle renvoie une série dans laquelle les valeurs
uniques sont
répertoriées sous forme d'index et leur nombre apparaît
sous forme de valeurs correspondantes Cette méthode est
particulièrement utile pour comprendre la distribution
des données catégorielles, identifier les catégories les plus
courantes et analyser la fréquence
des valeurs uniques Par exemple, l'utilisation de comptes
de
valeur dans la colonne des villes nous
permet de voir combien de fois chaque ville apparaît
dans notre bloc de données. Maintenant, permettez-moi de
vous présenter le concept
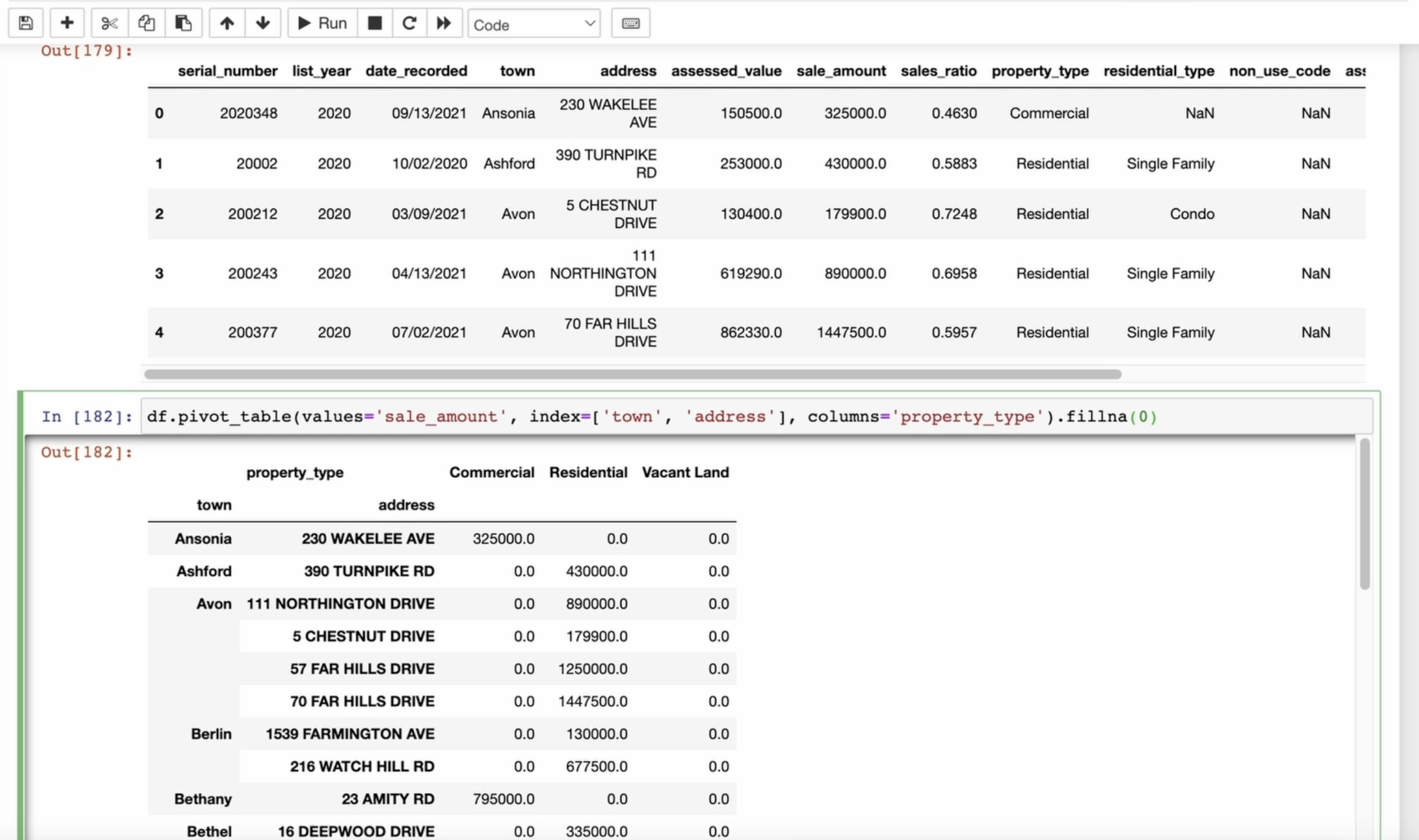
de table pivotante. Un tableau croisé dynamique est utilisé pour créer un tableau récapitulatif à partir des données
contenues dans un bloc de données. Il permet de regrouper et d'
agréger les données selon certains critères et de les organiser dans un format
pratique pour l'analyse Cela nous donne un tableau pratique pour
une
analyse et une visualisation plus poussées. Je vais créer un
tableau croisé dynamique à partir de nos données. Je vais utiliser la somme des ventes, ajouter la valeur et pour l'indice, je veux voir la
ville et l'adresse. Pour les colonnes, je vais
utiliser le type de propriété. Regardez le tableau que nous avons actuellement. Nous ne pouvons désormais travailler qu'
avec les données dont nous avons besoin. Affinons-le encore et
remplissons les valeurs vides. Maintenant que nous avons
affiné nos données, nous pouvons passer à d'autres outils. En principe, 90 % de votre travail impliquera
ce que nous venons de faire. Pandas est largement utilisé pour la manipulation, l'analyse
et la visualisation des
données Il est idéal pour filtrer,
regrouper et remodeler les données, ainsi
que pour effectuer des calculs
tels que des sommes et des moyennes C'est également essentiel pour travailler avec des séries chronologiques et pour
résumer les informations à
l'aide de fonctions telles que describe ou Pivot Table Explorons également la
visualisation des données et les Pandas.
9. Visualisation des données des Pandas : Tableaux, graphiques et informations: visualisation des données
est le processus de
création de représentations graphiques des données afin de comprendre la structure et d'identifier les modèles, les tendances
et les relations. Nous pouvons utiliser divers
graphiques, diagrammes et autres éléments visuels pour transmettre des informations et
faciliter l'analyse des données. Quel format de données est
le plus facile à percevoir pour vous ? Si je vous montre des informations dans un format tbar plutôt que dans
un format visuel Le format visuel est
sans aucun doute plus
convivial et plus facile
à comprendre. L'analyse visuelle peut également
aider à identifier les anomalies, valeurs aberrantes et les
modèles inattendus dans les données Pandas, dont nous avons
parlé précédemment, a intégré des outils de visualisation des données basés
sur la bibliothèque Matlot Lip Mat Blot Lip est une bibliothèque
Python pour visualisation
des données qui
fournit un large éventail de fonctionnalités permettant de créer
différents types de graphiques
et de diagrammes pour l'
analyse et l'affichage des données Je tiens à rappeler
que Pandas et Matlot Leap sont deux bibliothèques
différentes Les outils de
visualisation intégrés et Pandas sont basés
sur Matplot Leap, mais ils fournissent
un niveau d'
abstraction plus élevé et
simplifient le processus
de création de graphiques simples Le choix de la bibliothèque
dépend de vos besoins spécifiques. Si vous avez besoin de
visualiser rapidement des données dans le bloc de données
Pandas
à l'aide d'une syntaxe simple, les outils de
visualisation intégrés à Pandas peuvent être plus pratiques Si vous avez besoin de plus de contrôle sur les graphiques ou si vous avez besoin de créer des visualisations
plus complexes, Matlock Leap peut
être une meilleure option Les deux bibliothèques sont souvent utilisées en fonction
des tâches spécifiques. Commençons par les outils
intégrés les plus simples en Python. Comme toujours,
importons tout ce
dont nous avons besoin et créons un
bloc de données avec des données aléatoires. La principale méthode de
visualisation est le tracé, qui peut être appelé sur un
bloc de données ou un objet de série. J'ai créé un
bloc de données et je l'
ai rempli de nombres aléatoires
à l'aide de la bibliothèque Numbi Comme premier exemple,
tracons un graphique linéaire
pour toutes les colonnes. Dans les dernières versions
des manuels de nœuds Jubter, vous n'avez généralement pas besoin d'
utiliser des commandes telles que PLT show ou Mtlot leap in line Mutlot fait un bond en ligne et cette commande magique
est automatiquement appliquée dans les nouvelles versions
des livres de nœuds de Jupiter Les graphiques seront donc affichés en ligne par défaut sans
avoir besoin de cette commande. Dans de nombreux cas, il n'
est pas non plus nécessaire d'appeler PLT show. Dans les blocs-notes Jupiter, les
tracés sont affichés automatiquement après l'exécution d'une commande de
tracé Toutefois, si vous souhaitez contrôler, lorsque le tracé apparaît comme dans des scripts ou
d'autres environnements, vous pouvez toujours utiliser PLT show. Ainsi, pour la plupart des
tâches de traçage de base dans Jupiter, vous pouvez simplement
créer des tracés sans avoir besoin de ces commandes.
Si vous travaillez dans un environnement différent ou un script Python externe
au bloc-notes et que vous souhaitez que les graphiques s'affichent automatiquement sans
avoir besoin d'appeler PLT show, vous pouvez utiliser cette configuration Ensuite, créons un
histogramme pour la colonne A. Je
vais appeler plot et créer un histogramme sur la série
de notre bloc de données Je peux modifier le paramètre Bins, qui contrôle le nombre de
colonnes de notre histogramme En ajustant le nombre de bacs, je peux obtenir une
vue plus détaillée ou plus générale des données. Ensuite, construisons un nuage de points. Les diagrammes de dispersion sont souvent utilisés pour
identifier des corrélations
ou comparer Ils nous aident à voir comment
deux variables interagissent. Dans notre cas, comme
j'ai des données aléatoires, cela ne révélera pas grand-chose. Mais avec des données réelles, que nous avons abordées dans
la leçon précédente, diagrammes de
dispersion peuvent fournir des informations
précieuses Je vais maintenant vous montrer
comment créer par graphique à
partir des données d'un objet de série. Je crée d'abord la série,
puis je construis le graphique. Nous utilisons la méthode Pipe, qui génère un graphique circulaire basé sur les valeurs
de nos séries. Vous pouvez également afficher
les pourcentages de chaque partie du Pi Dans ce cas, j'affiche les pourcentages avec
une décimale Les diagrammes à secteurs sont généralement
utilisés pour visualiser les proportions ou les relations
en pourcentage entre les différentes catégories. Examinons ensuite le diagramme
à cases. boxplot sont utilisés pour visualiser
la distribution des données indiquant les quartiles
médians, les valeurs minimales et maximales Ils peuvent également aider à détecter les valeurs aberrantes
potentielles. Vous pouvez disposer les
cases verticalement
ou horizontalement en réglant
le paramètre vert. De plus, nous pouvons
personnaliser les couleurs des capuchons des boîtes, qu'il s'
agisse de lignes grises
représentant les médianes et les moustaches Le diagramme en aires montre
les données sous forme de zones empilées pour chaque
colonne du bloc de données. Si vous définissez l'option
Stacked False, elle empêche les zones
de se chevaucher et affiche
les valeurs
agrégées pour chaque colonne séparément Cela est utile pour comparer
la contribution de chaque colonne au total. Ensuite, je vais vous montrer comment
créer un diagramme de dispersion Hg Bin. Nous utilisons la méthode Hg Bin
pour créer ce diagramme. Le paramètre de taille de grille indique le nombre d'
hexagones utilisés dans le diagramme Une taille de grille plus élevée permet d'
obtenir un diagramme plus détaillé, mais peut le rendre
plus difficile à interpréter. Les diagrammes Hexbin sont
parfaits pour visualiser la densité des points de données
dans un espace bidimensionnel, en particulier lorsque vous avez
un grand nombre de Explorons également la création d'
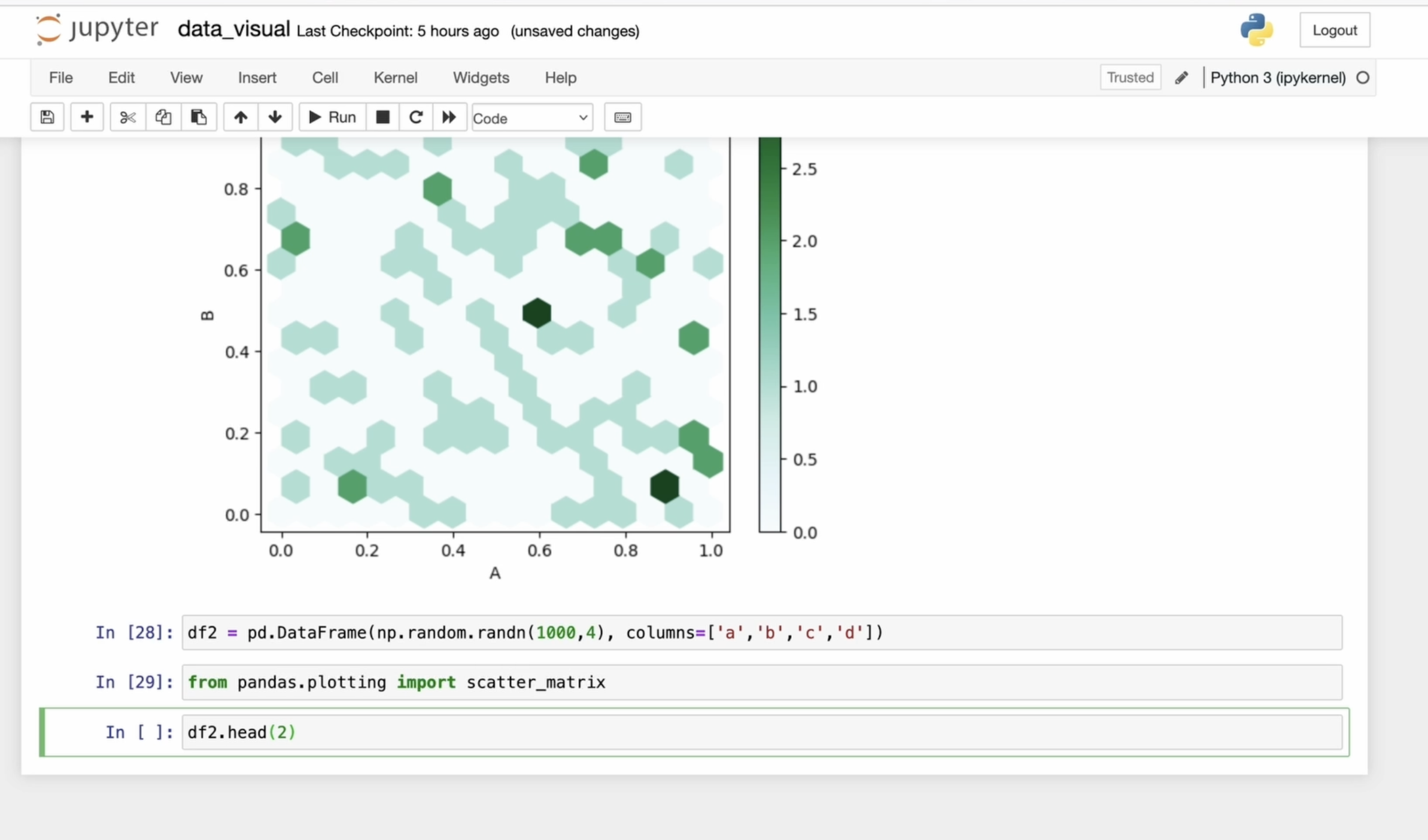
une matrice de nuages de points. Une matrice de diagramme de points permet de visualiser les relations entre plusieurs
colonnes d'un bloc de données Pour cela, j'ai créé, encore une fois, un bloc de données avec
la bibliothèque des arbitres Des méthodes telles que celles que nous avons utilisées auparavant,
telles que la zone de dispersion, la boîte
et d'autres, sont disponibles via Plot et
Pandas, car elles sont intégrées à Mud Plot
Leap
pour les visualisations de base Cependant, la matrice de nuages de points
nécessite une entrée séparée, car elle génère plusieurs
nuages de points à la fois, ce qui la rend plus complexe que les méthodes de diagramme
standard J'appelle donc Scatter Matrix, transmets notre trame de données. Vous pouvez régler la transparence à
l'aide du paramètre Alpha 0-1.
Réglez la taille de la figurine. Il définit la
taille de la figure à six pouces sur 6 pouces, détermine les
dimensions globales du tracé pour une meilleure lisibilité
et un meilleur contrôle de la mise en page, et utilise des estimations de
densité du noyau sur la diagonale pour une visualisation
plus fluide Chaque graphique en diagonale montre la distribution
de chaque colonne. Les matrices de diagrammes de dispersion sont utiles pour comparer
simultanément toutes les paires de variables d'un bloc de données, identifier les corrélations
et les dépendances complexes Bien que la génération de diagrammes de
dispersion pour chaque combinaison de variables puisse nécessiter des calculs
intensifs, la
matrice de nuages de points simplifie ce processus et permet une
analyse aisée Eh bien, nous avons abordé la plupart des
fonctionnalités de Pandas en matière de visualisation
des données, mais il existe
encore d'autres outils et bibliothèques disponibles pour
vous aider dans cette tâche Dans l'écosystème Pandas, plusieurs bibliothèques peuvent
faciliter la visualisation, et vous pouvez choisir
selon vos préférences Félicitations pour avoir terminé
le cours. Pandas dispose désormais d'une base
solide pour l'analyse des données Si vous voulez aller plus loin, consultez mes tutoriels sur
Mud Blot Leap, Seaborne et StreamLTT pour améliorer
vos compétences en visualisation
et en construction,
continuez à vos compétences en visualisation
et en construction, apprendre et rendez-vous
 Olha Al, Software engineer
Olha Al, Software engineer