Transcription
1. Intro: Bonjour, les gars. Vous en avez assez
de la lenteur du traitement des données ? Êtes-vous
aux prises avec des ensembles de données volumineux qui poussent votre système
à ses limites Si vous travaillez avec des données et avez besoin de rapidité, d'efficacité
et d'évolutivité, ce cours est exactement
ce qu'il vous faut Faisons connaissance avec
la bibliothèque de Pollard et
comparons-la aux très populaires Pandas Si vous en avez assez d'attendre que de
grandes quantités de données soient chargées et traitées dans Pandas, ce didacticiel est fait pour vous car cette bibliothèque est
conçue pour remplacer Pandas, mais sera-t-elle vraiment
capable de le faire ? Contrairement à Pandas, Polars est
conçu pour gérer facilement de
grands ensembles de données à l'aide traitement parallèle
avancé
et C'est ce que nous allons
explorer au cours de cette session. Nous aborderons les principes
de
base du fonctionnement de Polars, discuterons de ses avantages
et inconvénients et le comparerons à Pandas en termes de performances
et de convivialité Nous passerons également en revue les principales fonctions permettant de travailler avec des données à l'aide
d'exemples principaux pour illustrer ces concepts. Vous découvrirez comment Polars
surpasse les Pandas. Lorsque vous travaillez avec des ensembles de données de
plus de 100 millions de lignes, vous apprendrez à
traiter les données par blocs, ce qui vous permettra de travailler efficacement sans manquer de mémoire Nous explorerons la visualisation des données et les pôles, et
surtout, vous comprendrez le mode paresseux, le secret des polars
et la vitesse correspondante À la fin de ce didacticiel, vous aurez une solide
compréhension de l'utilisation
des polars pour
vos
besoins d'analyse de données et serez en mesure de
décider s'il s'agit de l'outil
adapté à votre projet ou non Alors prêts à faire passer vos compétences au niveau supérieur,
plongeons-nous dans le vif du sujet.
2. Introduction aux polaires : Principales différences avec les pandas et pourquoi c'est plus rapide: Bonjour, les gars, familiarisons-nous
avec la bibliothèque Polars, et nous la comparerons
aux très populaires Pandas Polars est une bibliothèque de blocs de données rapide et
efficace conçue pour travailler
avec de grands ensembles Il est conçu dans un souci de
performance, en utilisant le multithreading et traitement
parallèle pour gérer rapidement les tâches de manipulation des
données Polars est implémenté dans RST, ce qui lui permet d'
offrir une vitesse supérieure à celle d'autres
bibliothèques de trames de données telles que Pandas La bibliothèque prend en charge
des opérations telles que le filtrage, l'agrégation et la
transformation des données, et elle est particulièrement utile
pour les analystes de
données et les scientifiques des données qui doivent
travailler efficacement avec
de gros volumes de données. Grâce à une API Pattern
et à une API Rust, Polars est accessible et puissant pour les flux de travail de
traitement de données modernes Comme je l'ai déjà dit, cette bibliothèque
fournit un large éventail de fonctions pour la manipulation,
l'agrégation et la transformation des données . Mais à mon avis, sa principale
caractéristique est l'évaluation paresseuse. Qu'est-ce que l'évaluation paresseuse ? Car l'évaluation est une
stratégie informatique qui retarde l'exécution d'une opération jusqu'à ce que son résultat soit
réellement nécessaire. Dans le contexte des polars, cela signifie que les opérations de
manipulation des données ne sont pas exécutées immédiatement
lorsqu'elles sont définies Elles sont plutôt enregistrées sous la forme d'une série d'étapes
à exécuter ultérieurement. Cette approche permet à Polars d' optimiser la
séquence complète des opérations, de réduire la
charge de travail informatique globale et d'améliorer les performances en n'exécutant que les calculs
nécessaires
à la fin Une autre caractéristique importante est le traitement
multithread. L'un des principaux avantages
de Polars est sa capacité à traiter des données à l'aide de plusieurs
threads en même temps Cela signifie qu'
au lieu d'exécuter les tâches les
unes après les autres de manière séquentielle, les polars peuvent diviser
la charge de travail en parties
plus petites et les exécuter simultanément sur
plusieurs processeurs Ils
accélèrent considérablement les opérations de données, en particulier lorsque vous travaillez
avec de grands ensembles de données. Polars atteint cette efficacité parce qu'il est construit avec Rust, un
langage de programmation conçu pour performances
élevées et une gestion
sécurisée de la mémoire Rust facilite le travail
avec le calcul parallèle, ce qui signifie que Polars peut
pleinement utiliser la puissance des ordinateurs modernes dotés de processeurs
multicœurs Une autre fonctionnalité puissante de Polars est sa capacité
à mémoriser des données cartographiques Cela signifie qu'au lieu de charger un ensemble de
données volumineux dans Rum, ce qui pourrait
ralentir votre ordinateur ou même le faire tomber en panne, Polars peut lire et traiter uniquement les parties
nécessaires pour le moment Par exemple, si vous
travaillez avec un fichier CSV ou Parki volumineux, Polars n'a pas besoin de charger
le fichier entier en mémoire Au lieu de cela, il accède aux données directement à partir du
fichier selon les besoins, ce qui rend le processus beaucoup plus rapide
et économe en mémoire Ces fonctionnalités font de Polars un excellent choix pour
travailler avec des mégadonnées Comme il aide les analystes et les chercheurs à gérer de
grands ensembles rapidement et efficacement sans
avoir besoin de matériel haut de gamme, Polars repose sur
Apache Arrow,
un format de données conçu pour rendre stockage et le transfert de
données
plus rapides et plus Considérez la flèche comme un moyen
hautement optimisé organiser et de structurer les
données afin qu' puissent être traitées rapidement par différents systèmes. En effet, la
flèche est utilisée par les polaires Elle permet aux polaires de partager des
données de manière fluide avec d'autres outils et systèmes
qui utilisent également Par exemple, si vous travaillez en mode polaire et que vous souhaitez
transférer vos données vers autre système, tel qu'un outil d'apprentissage
automatique ou une autre bibliothèque d'
analyse de données, ou une autre bibliothèque d'
analyse de données, la réalité
augmentée permet un transfert
de données fluide et efficace sans avoir à convertir les données dans un format
différent, ce qui peut être lent et coûteux Autre fonctionnalité qui rend
Polars convivial, c'est une API semblable à des étangs Pandas est l'un des outils les
plus populaires pour l'analyse de données en Python, et de nombreux analystes de données et scientifiques
connaissent déjà son fonctionnement Polars a été conçu pour être
familier aux utilisateurs de Pandas. Donc, si vous connaissez déjà les pandas, vous pouvez commencer à utiliser les polaires sans avoir à
tout apprendre à zéro Cependant, bien que l'
API semble familière, polars présentent l'avantage supplémentaire en termes de
performances d'être plus rapides et
plus efficaces, en particulier lorsqu'il s'agit de grands ensembles
de Donc, si vous
venez de Pandas, vous pouvez bénéficier de la
même syntaxe facile à utiliser, tout en profitant de la vitesse et de l'efficacité de la
mémoire des polars Même si Polars possède
de nombreuses fonctionnalités intéressantes, il y a certaines
limites à prendre en compte Il est important de garder à
l'esprit que, comme tout outil, il se peut qu'il ne soit pas le mieux
adapté à toutes les situations. Nous reviendrons plus en détail sur ces inconvénients ultérieurement. Mais pour l'instant,
examinons certains des défis. L'un des inconvénients potentiels
est que Polars est relativement nouveau par rapport aux bibliothèques
plus établies comme Pandas Comme il ne cesse de croître, il se peut qu'il y ait moins de ressources
disponibles, telles que les didacticiels , le support
communautaire
ou la documentation, ce qui pourrait rendre la tâche plus difficile
pour les débutants. De plus, comme il s'agit d'une nouveauté, il se peut qu'il y ait moins d'
exemples de la façon dont
les entreprises l'utilisent dans le monde réel et dans le cadre de projets à
grande échelle. Polars n'
étant pas encore largement adopté, il existe peu d'
informations sur nombre d'entreprises qui
l'utilisent dans leur
environnement de production, c'est-à-dire dans systèmes
du monde réel lesquels les entreprises mènent
leurs activités La plupart des entreprises qui
utilisent des polars peuvent ne pas partager
publiquement les informations sur manière dont ils s'intègrent à
leurs flux Il est donc plus difficile de
savoir dans quelle mesure il fonctionne avec des charges de travail très importantes
ou complexes Cependant, certaines
entreprises commencent à utiliser des polars pour leurs tâches de traitement des
données, comme vous pouvez en voir
des exemples dans le secteur À mesure que la bibliothèque mûrit, son adoption augmentera
probablement et plus d'entreprises commenceront à
partager leurs expériences. Commençons donc.
3. Installer des polaires, charger des images de données et accéder efficacement aux colonnes: Voici la commande pour
installer la bibliothèque. Commençons. Je vais ouvrir mon terminal car j'ai l'
habitude de l'utiliser. Je vais d'abord activer
mon environnement virtuel. Si vous n'êtes pas familier
avec les environnements virtuels, je vous recommande vivement de regarder
ma vidéo sur la façon de
gérer les environnements virtuels et façon dont ils peuvent
vous faciliter la vie. Mais si vous ne savez pas ce qu'est
un environnement virtuel, vous pouvez exécuter la commande
directement dans le terminal. heure actuelle,
savoir travailler avec un environnement
virtuel n'
est pas une priorité. Après avoir activé mon environnement, je peux exécuter mon
bloc-notes Jupiter directement depuis le terminal en exécutant la
commande Jupiter notebook. Si vous utilisez Anaconda après avoir
démarré Jupiter Notebook, vous pouvez installer cette
bibliothèque directement dans Jupiter en exécutant
la commande suivante Comme vous pouvez le voir, la bibliothèque est
déjà installée, nous pouvons
donc commencer à travailler. abord, je vais importer toutes les bibliothèques nécessaires avec
lesquelles nous travaillerons. J'importe la
bibliothèque Numbi car nous en aurons besoin. Pour ceux qui ne le
connaissent pas, Nampi est une puissante bibliothèque
Python utilisée pour le calcul numérique Dans mon profil, vous pouvez trouver
un tutoriel sur cette bibliothèque. Ensuite, je vais vérifier la
version de Polars. J'ai téléchargé un énorme ensemble de données
de plus d'un gigaoctet, et je vais maintenant l'importer à l'aide de la
fonction Read CSV dans Polars prend un peu de temps, puis à chargement prend un peu de temps, puis à l'aide de la fonction
shape, que vous avez peut-être
entendue de Pandas, nous pouvons vérifier les
dimensions de notre jeu de données Si vous ne la connaissez pas, la fonction shape et
polars renvoient le double représentant le nombre de lignes et de colonnes
du bloc de données Cette fonction est
utile pour
comprendre rapidement la
taille de votre jeu de données. Et ici, nous pouvons voir que le jeu de données contient
plus de 130 millions de lignes. Une autre fonction utile pour comprendre
rapidement
un bloc de données sans charger toutes les
données dans la fonction principale. Par défaut, il affiche
les cinq premières lignes. Comme nous pouvons le constater, l'apparence du bloc de données en polars est légèrement différente de ce que nous avons observé lors du chargement de
données avec Pandas La première
différence notable dans les informations de type de données
affichées pour chaque colonne. En utilisant la
fonction deux Pandas dans Polars, nous pouvons convertir le bloc de données Polars en un
bloc de données Cela est particulièrement utile lorsque vous devez tirer parti des fonctionnalités
spécifiques de Panda ou intégrer bibliothèques qui ne
prennent
en charge que les dataframes de Panda La méthode des deux Pandas assure une transition fluide
entre Polars et Pandas, vous
permettant de
tirer parti des
deux bibliothèques au sein
du même flux Si vous ne souhaitez pas télécharger de grands ensembles de données sur
votre ordinateur, vous pouvez utiliser des ensembles de données
accessibles au public sur Pour ce faire, recherchez un ensemble de
données volumineux sur GitHub. Accédez à la cuve et
copiez le lien direct. Utilisez les lectures telles que nous fonctionnons
en polaire pour le charger. Comme avant, le traitement prend un
peu de temps. Mais finalement, nous
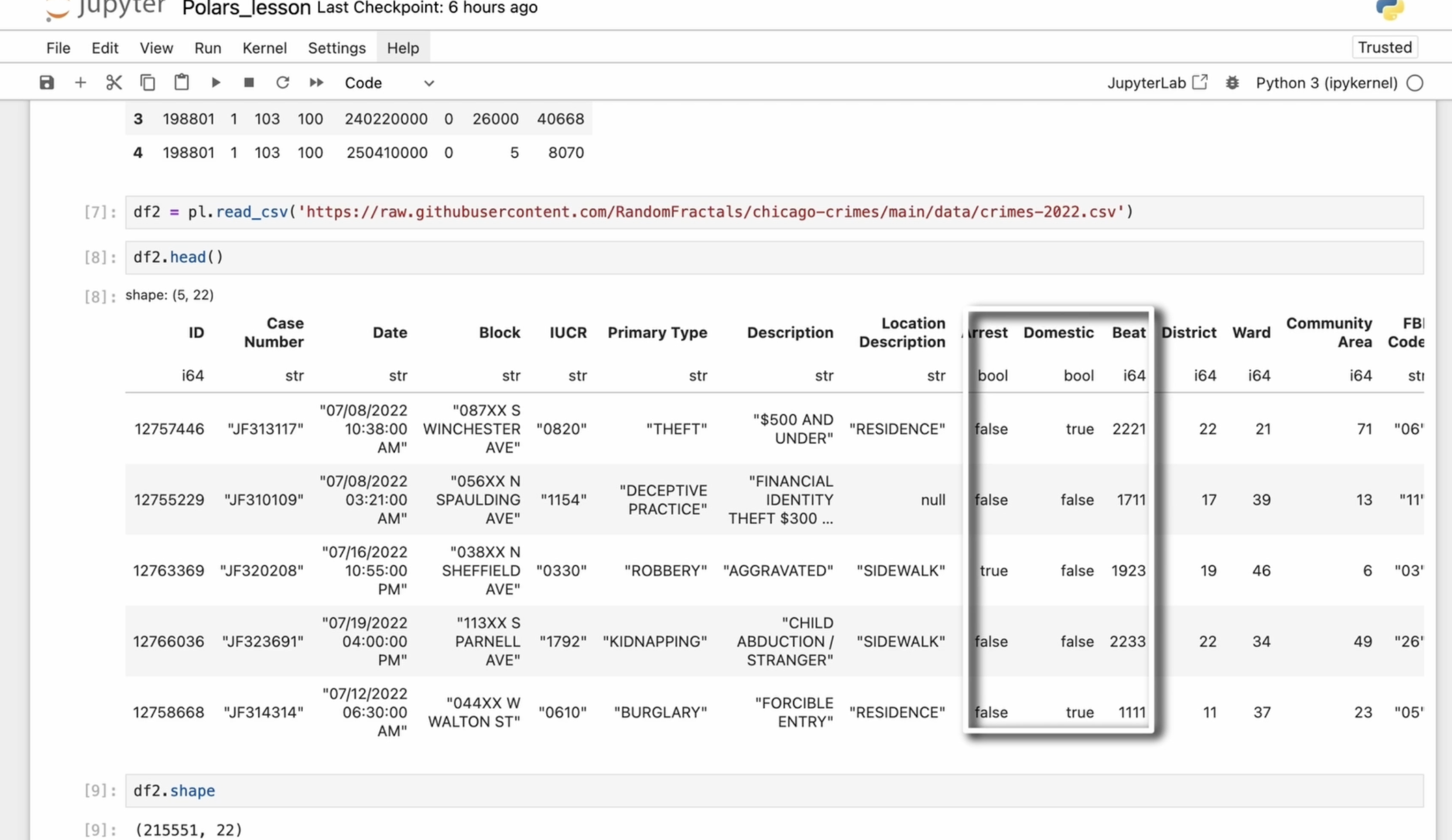
pouvons voir les données. Pour l'exemple d'aujourd'hui,
nous travaillons avec l'ensemble de
données sur la criminalité de Chicago pour 2022. Nous pouvons également vérifier
les types de colonnes, et nous pouvons voir qu'elle
contient 2 525 551 lignes, assez grandes mais pas Pour éviter toute confusion avec le premier bloc de données
que nous avons chargé précédemment, je vais renommer ce nouveau bloc de données. J'utiliserai toujours le
premier bloc de données plus tard, mais pour le moment, nous travaillerons
avec le second, qui a été chargé depuis Github Je vais recharger toutes les cellules, comme dans Pandas En polars, une série est une structure
semblable à
un tableau unidimensionnel qui représente une seule colonne d'un bloc de données. Il peut contenir des types de données
homogènes, tels que des entiers, des flottants, des
chaînes, des bouées Les séries sont les éléments constitutifs
des trames de données et des pôles. Ils nous permettent d'effectuer
diverses opérations de manipulation
et d'analyse des données, telles que le filtrage,
la transformation et l'agrégation. Chaque série possède un
nom et un type de données associés, ce qui permet de la référencer facilement
dans le bloc de données. Nous pouvons extraire une série d'un bloc de données
de plusieurs manières. Le premier utilisant
le nom de colonne. La méthode la plus simple consiste à accéder à la colonne par son nom. Pour éviter de charger l'ensemble de la
série dans de grands ensembles de données, j'utiliserai la fonction head pour n'afficher que les quatre
premières lignes Le second utilise la fonction de colonne
GAD. Cette approche présente des avantages en termes de performances
et de flexibilité par rapport à l'accès direct aux colonnes. Pour moi, la principale raison d'utiliser fonction
Get column est
sa gestion des erreurs. Si vous essayez de récupérer
une colonne inexistante, les extracteurs génèrent immédiatement
une erreur Cela fournit un retour instantané cas de faute de frappe
dans le nom de colonne En revanche, l'accès à
une colonne par son nom peut soit renvoyer silencieusement
non, soit générer une erreur clé, ce qui peut compliquer le débogage La troisième méthode est
la méthode de sélection. Il crée un nouveau bloc de données contenant uniquement la colonne
spécifiée. Cependant, même s'il ne
contient qu'une seule colonne, le résultat reste
une trame de données. Pour travailler directement avec une série, nous devons la convertir à l'
aide de la fonction à deux séries. La méthode de sélection
en polars renvoie un nouveau bloc de données même si nous ne sélectionnons qu'
une seule colonne Cela signifie que si je crée une variable et que je lui attribue
ce résultat,
il ne s'agit pas d'une seule colonne, mais du bloc de données polaire
contenant une colonne Donc, si je vérifie le type
D d'un, je supprime
également la méthode des deux séries. Cela peut entraîner une erreur. Comme le type D est généralement un attribut d'une série,
pas une trame de données. Et voilà,
nous avons une erreur. Si j'utilise à nouveau la méthode à deux
séries, l'une n'
étant plus
un bloc de données, série polaire
du corps et l'attribut de type
D
renverront le type
de données de la colonne de district. Imprimons-le.
Dans le premier cas, nous pouvons voir cette impression comme une seule, déplaçant la valeur de la colonne du
district sous forme de série Ici, nous pouvons voir la forme, le type de données et les valeurs. Le second cas déplace la colonne de district dans
le format de trame de données, affichant le
nom de la colonne et ses données
4. Manipulation de données dans les polaires : opérations arithmétiques, gestion des colonnes et techniques de filtrage: Dans Polars, nous pouvons effectuer des opérations
arithmétiques
sur des séries ou des colonnes en utilisant des opérations
Python standard Par exemple, nous
pouvons utiliser l'addition. Si nous voulons ajouter
dix à une série, nous pouvons constater que chaque nombre de
la série résultante a augmenté exactement de dix par rapport
au nombre de la série d'origine. J'imprime ici la série originale et nous pouvons voir le résultat. La valeur d'âge augmente de dix. Multiplication.
La multiplication d'une série par deux permet de doubler chaque valeur Ici, je compare avec
la série originale, et nous pouvons voir que
chaque valeur est doublée. La soustraction de 20 diminue
chaque valeur de 20. Passons aux méthodes d'
agrégation. Les polars fournissent des
méthodes intégrées pour les agrégations,
telles que La méthode de la somme en pôles est
utilisée pour calculer la somme de tous les éléments d'une série ou d'
une colonne d'un bloc de données Lorsqu'il est appliqué à une colonne
contenant des valeurs entières, il revient à la
somme totale de ces valeurs. La méthode de la moyenne en
pôles calcule la moyenne de tous les éléments d'une série ou
d'une colonne Dans notre exemple, il calcule la moyenne arithmétique de toutes les valeurs
entières de notre Nous pouvons également utiliser des opérateurs de
comparaison
dans les pôles pour créer des séries
booléennes Dans les pôles,
les opérateurs de comparaison vous permettent de comparer les valeurs d'une
colonne avec d'autres valeurs, et le résultat est
une série booléenne Une série booléenne est une séquence
de valeurs vraies ou fausses que vous pouvez utiliser pour filtrer, analyser ou
manipuler vos données Voici comment fonctionnent les séparateurs. Dans ce cas, nous créons une nouvelle série contenant des valeurs
booléennes L'opération compare
chaque valeur de
la colonne à 20
et renvoie une série de même longueur dans
la colonne d'origine où chaque élément est vrai
ou faux. De même, dans les pôles, nous pouvons utiliser
la méthode supérieure à. Au début, il ne
renvoyait que faux, j'ai
donc changé la valeur de
comparaison à 30. Cette méthode est utilisée pour comparer une colonne avec une valeur spécifique, même manière que l'
opérateur supérieur à celui
que nous avons utilisé précédemment. La méthode greater than est une fonction
intégrée qui exécute,
oui, la même opération, mais permet une plus grande flexibilité. Cela peut être utile lorsque vous
travaillez avec des méthodes qui nécessitent des appels de fonction
au lieu d'opérateurs. Dans certains cas, cela peut
être préférable lorsque vous utilisez chaînage de
méthodes ou lorsque vous travaillez avec des expressions personnalisées
dans une requête C'est donc le premier cas que nous pouvons utiliser lors de la vérification de valeurs
dans un bloc de données. La méthode supérieure à celle que
nous avons utilisée dans le second cas peut être utilisée lorsque
nous avons besoin d'un traitement basé sur les
fonctions, tel que le chaînage de méthodes ou compatibilité avec
certaines structures de requête Dans la plupart des cas, les deux approches
aboutissent au même résultat. Cela est utile pour
filtrer ou analyser des données lorsque vous souhaitez vous
concentrer sur des valeurs
répondant à une
condition spécifique, par exemple pour rechercher des enregistrements dont les ventes
sont supérieures à un certain objectif. Entre cet opérateur, je vérifie si une valeur se situe dans une plage de nombres
spécifique. Par exemple, l'utilisation de is 20-30 renverra
true pour toutes les valeurs. Dans la colonne, il y a
entre dix et TG, dont dix et TJ et des chutes Pour ceux qui se situent
en dehors de cette fourchette, cela est particulièrement utile lorsque vous devez filtrer les données ou créer des conditions qui vérifient si les valeurs se situent dans
une plage spécifique, comme l'âge de 18 à 65 ans ou
les prix de 10 à 100$ Dans Polars, l'ajout
d'une nouvelle colonne à un bloc de données se fait à l'aide de la méthode
with columns Il est important de savoir que bloc de
données polaire est immuable, ce qui signifie que le bloc de données
d'origine ne change pas lorsque
vous ajoutez une nouvelle colonne Au lieu de cela, cette méthode crée et renvoie un nouveau bloc de données auquel
une nouvelle colonne a été ajoutée, laissant le bloc de
données d'origine inchangé. Nous utilisons donc la méthode with columns. Il indique aux polaires d'ajouter de nouvelles
colonnes à notre bloc de données. Pour ajouter une
valeur constante à une nouvelle colonne, nous utilisons la fonction lead. Cette fonction crée une valeur
littérale ou fixe qui sera affectée à
chaque ligne de la nouvelle colonne Par exemple, si nous utilisons t un, cela signifie que chaque ligne la nouvelle colonne
aura la valeur un. Après avoir créé une nouvelle colonne, vous pouvez lui donner un nom en utilisant AS. Dans notre cas, je l'
appelle nouvelle colonne. C'est ainsi que vous spécifiez le
nom de la nouvelle colonne dans le bloc de données. Après avoir exécuté ces étapes, nous créons un nouveau
bloc de données basé sur le bloc de données deux avec une nouvelle colonne
nommée nouvelle colonne ajoutée. La nouvelle colonne contient la
valeur un pour toutes les lignes. Et comme prévu, le bloc de données
d'origine reste inchangé. Si vous souhaitez supprimer une
colonne d'un bloc de données, vous pouvez utiliser cette méthode de suppression. Cette méthode permet
de supprimer une colonne en fournissant son nom
comme argument. Vous devez simplement indiquer aux pôles
quelle colonne vous souhaitez
supprimer en spécifiant le nom de
la colonne Il est important de savoir que trames de données
polaires
sont immuables, ce qui signifie que la méthode drop ne modifie pas directement la trame de
données d'origine Au lieu de cela, il crée
un nouveau bloc de données dont la colonne est supprimée. Ceci est fait pour garantir que les données d'origine
restent inchangées. Comme le
bloc de données d'origine ne change pas, si vous souhaitez conserver le bloc de données
modifié, celui sans colonne
supprimée, vous devez réaffecter
le résultat à la variable d'origine ou le
stocker dans une nouvelle variable Dans le cas contraire, le bloc de données
d'origine restera inchangé. Voyons maintenant comment filtrer une série polaire en
fonction de certaines conditions. Par exemple, nous
filtrons ici pour ne conserver que
les nombres pairs. La condition vérifie la présence
de nombres pairs, et la méthode de filtrage
ne conserve que les éléments pour lesquels la condition est évaluée comme vraie C'est très utile, car vous pouvez ajuster la condition et signer le filtre pour filtrer la série en fonction de
différents critères. Par exemple, j'ai filtré
toutes les valeurs supérieures à 20. Si je le change à 30, la condition
devient plus claire. Permettez-moi de le mettre à jour rapidement et de
redémarrer la cellule pour
l'exemple suivant. Créons maintenant deux séries. Il vaut probablement mieux
utiliser uniquement les séries de noms. J'ai supprimé l'opérateur d'impression car le bloc-notes Jupiter
le rend très bien. Et la deuxième série est légèrement
différente de la première. Maintenant, concaténons-les. Lorsque vous travaillez avec des extracteurs, la concaténation des séries
dépend du type de Si vous concaténez deux séries de
types de chaînes à l'aide de
l'opérateur plus,
l' opération effectue une concaténation des chaînes par
élément Cela signifie que chaque
élément de la première série est concaténé avec
l'
élément correspondant de la élément Comme les deux séries
sont de type chaîne, l'opérateur plus
concatène les Toutefois, lorsqu'il s'agit de séries de types
différents, les
polars attribuent automatiquement
à la série le type de données compatible avant d'
effectuer l'opération Ici, polars
convertit automatiquement les entiers chaînes avant d'
effectuer Si vous concaténez deux séries de types
entiers l'aide de l'opérateur plus,
l' opération effectuera une addition par
élément de ces entiers, et non une concaténation
de Par conséquent, la série
contiendra des nombres entiers additionnés.
5. Maîtriser les images de données dans les polaires : découpage, statistiques descriptives et méthode d'exploration avancée des données: Voyons rapidement comment accéder
aux lignes et aux pôles. Dans Polars, vous pouvez accéder aux lignes en utilisant l'indexation et le découpage, comme cela fonctionne dans d' autres
bibliothèques de manipulation de données telles Cependant, il existe des
différences importantes dans la façon dont Polars
gère les lignes en raison de sa structure de données en
colonnes Vous pouvez accéder aux lignes à
l'aide de l'indexation, mais Polars renvoie
un nouveau bloc de données au lieu d'un objet à ligne unique Lorsque vous accédez à une
ligne spécifique à l'aide d'un index, Polars la renvoie sous la forme d'un
nouveau bloc de données
plutôt que sous la forme d'un tuple ou d'un objet de ligne
individuel Ceci est différent de Pandas, où l'accès à une ligne renvoie un objet unidimensionnel en série Polars étant optimisé pour travailler avec des colonnes
plutôt qu'avec des lignes, ce comportement
garantit la
cohérence et l'efficacité des données lors de l'exécution des opérations Vous pouvez également extraire plusieurs
lignes à l'aide de la notation par tranches, qui fonctionne de la même manière que vous découpez des listes ou des rayons en Python. Cela vous permet de
récupérer
efficacement une plage de lignes sans modifier
la structure du bloc de données. Contrairement à Pandas, Polars n'
utilise pas d'index de ligne explicite. Au lieu de cela, les lignes sont identifiées
par leur position, ce qui le rend plus efficace lorsque vous travaillez avec de grands ensembles de données Cette approche en colonnes
permet aux polars d'effectuer des opérations
sur les données beaucoup
plus rapidement que les méthodes d'indexation traditionnelles
basées sur les rôles La
méthode décrite dans Polars est un outil puissant utilisé pour générer des
statistiques descriptives pour une trame de données. Les statistiques descriptives vous aident à résumer et à comprendre les
principales caractéristiques de vos données, ce qui vous permet d'obtenir rapidement une vue d'ensemble de leurs
caractéristiques. Ici, nous pouvons voir ce que fournit la méthode
décrite. Le nombre indique le nombre de valeurs non
nulles dans chaque colonne. Il vous aide à comprendre la
quantité de données disponibles pour chaque variable et à déterminer s'
il manque des valeurs. La moyenne de
chaque colonne numérique vous
donne une idée de la tendance
centrale des données. Quelle est la valeur la plus
courante pour cette colonne ? L'écart type
indique comment répartir les
données autour de la moyenne. Un écart type faible signifie que les valeurs sont
proches de la moyenne, tandis qu'un écart type élevé signifie que les valeurs sont
plus étalées. En fonction des données, les sondeurs peuvent également fournir
d'autres statistiques, qui donnent un meilleur aperçu la distribution des
valeurs dans chaque colonne La
méthode décrite est idéale pour obtenir
rapidement un
aperçu de vos données. Il vous aide à identifier les modèles et à comprendre le
comportement général des données, détecter les valeurs
aberrantes ou généralement
éloignées de la moyenne, à
avoir une idée de l' ampleur des
variations existant dans l'ensemble de données, ce qui peut vous aider à prendre des
décisions quant à la manière de nettoyer ou de
traiter les données plus avant La méthode de la taille estimée
en polars est utilisée pour estimer la quantité de mémoire qu'une trame de données
utilisera dans votre système Il vous donne une
taille approximative du bloc de données, afin que vous puissiez
comprendre l'espace qu'il occupe dans votre mémoire. Lorsque vous appelez
la taille estimée d'une trame de données, il calcule l'utilisation
de la mémoire de la trame de données en mégaoctets Cela est utile lorsque
vous travaillez avec grands ensembles de données et que vous souhaitez vous
assurer que votre système dispose suffisamment de mémoire pour
les traiter efficacement. Au lieu de charger l'
ensemble du bloc de données et voir l'espace
qu'il utilise en mémoire, ce qui peut être lent
ou inefficace, vous pouvez obtenir une estimation rapide La méthode de duplication en
polars est utilisée pour identifier les lignes
dupliquées dans un
bloc de données en fonction de toutes les colonnes Elle renvoie able et series, indiquant si chaque ligne est une copie d'une ligne précédente. Pour obtenir uniquement les lignes dupliquées, nous pouvons filtrer les données Cela supprimera toutes les lignes
non dupliquées, ne
laissant que les doublons
dans le bloc de données obtenu Comme nous pouvons le constater, il n'y a pas de
doublons dans ce cas. Cette méthode
et ces polars vides sont utilisés pour vérifier si un bloc de données
contient des données ou non Essentiellement, il vous aide à déterminer si le bloc de
données est vide, c'
est-à-dire s'il ne contient aucune ligne
ou donnée. Par exemple, vous pouvez avoir un bloc de données avec des noms de colonnes, mais aucune donnée dans les lignes. Ce champ serait considéré comme vide. Lorsque vous utilisez une méthode vide, elle vérifie si le
bloc de données contient des lignes. Si le bloc de données ne comporte aucune ligne, il renvoie la valeur true, ce qui indique que le bloc de
données est vide. Si le bloc de données comporte
une ou plusieurs lignes, il renvoie la valeur false, ce qui signifie que le
bloc de données n'est pas vide. Cette méthode est particulièrement
utile dans les situations où vous souhaiterez effectuer certaines opérations sur un bloc de données, mais uniquement s'il contient des données. Par exemple, avant
d'effectuer un calcul complexe
ou une transformation de données, vous souhaiterez peut-être vous assurer que le bloc de données
contient réellement des données avec lesquelles travailler. Cela permet d'éviter des erreurs ou des calculs
inutiles
sur un ensemble de données vide Cette méthode unique en
polars est utilisée pour vérifier si les valeurs d'une colonne
donnée sont uniques Lorsque vous appelez cette méthode unique sur une colonne d'un bloc
de données polaire, elle vérifie si toutes les valeurs de cette colonne sont uniques La méthode renvoie la valeur
true si chaque valeur de la colonne est unique et diminue si des valeurs
sont répétées. Il permet de nettoyer
ou de valider les données avant d'effectuer des
tâches telles que l'analyse, fusion d'ensembles de données ou
la création d'index Ici, j'ai de nouveau utilisé le filtre pour obtenir des valeurs uniques au lieu
de simplement ou de fausses. Ports fournit également une méthode
unique, qui compte le nombre de valeurs
uniques dans une
série ou un bloc de données. Elle renvoie un entier représentant le nombre
de valeurs uniques. Lorsqu'il est appliqué à une colonne, et unique renvoie le
nombre total de
valeurs distinctes de cette colonne. S'il est utilisé dans un bloc de données, il compte généralement les valeurs
uniques pour chaque colonne séparément. Et une méthode unique est
utile lors de l'analyse des données afin de comprendre leur
diversité ou leur diffusion. Il peut être utilisé pour détecter les valeurs
dupliquées. Par exemple, vérifier
combien d'identifiants de clients, de noms de
produits ou d'
e-mails d'utilisateurs différents existent dans un ensemble de données. Il facilite la validation des données, en garantissant qu'une
colonne censée contenir des valeurs
uniques ne contient pas de doublons
inattendus La méthode de comptage nul et
les polars sont utilisés pour compter le nombre de valeurs manquantes dans une colonne ou un bloc de données
entier Lorsqu'il est appliqué à une colonne, il renvoie le nombre total de valeurs
nulles contenues dans cette colonne. Si je l'utilise sur un bloc de données, il compte généralement les valeurs nulles pour chaque colonne séparément. Les valeurs manquantes peuvent entraîner
des problèmes lors des calculs. savoir combien de valeurs nulles
existent permet donc de décider
comment les gérer. Si une colonne qui doit toujours contenir des données
possède des valeurs nulles, cela peut indiquer
des erreurs de saisie de données. De nombreux modèles d'apprentissage automatique ne peuvent pas gérer directement
les données manquantes. comptage des valeurs
nulles est donc la première étape pour décider
comment les remplir ou les supprimer. La méthode de comptage en polars est
utilisée pour compter le nombre de valeurs
non nulles dans une colonne
ou une trame de données complète Il vous permet de déterminer rapidement combien de
valeurs réelles non manquantes existent dans votre ensemble de données. Lorsque j'applique cette
méthode à une colonne, elle renvoie le nombre total de valeurs non nulles
dans cette colonne. Si je l'utilise sur un bloc de données, il compte généralement
les valeurs non nulles pour chaque colonne séparément. Cela permet de
déterminer la quantité de données
utilisables disponibles dans chaque colonne. En comparant le nombre de valeurs nulles avec le nombre total de lignes, vous pouvez voir combien de valeurs sont
manquantes. De nombreuses étapes de traitement des données
nécessitent des valeurs non nulles. fait de savoir combien d'entrées
valides sont présentes facilite le
nettoyage et le traitement des données. La méthode horizontale moyenne en
pôles est utilisée pour calculer la moyenne ou les valeurs moyennes
sur les lignes horizontales d'un bloc de données Il calcule la moyenne de
chaque ligne individuellement, traitant chaque ligne comme une séquence de valeurs
distincte Cette méthode est utile pour
résumer les données et
mieux la distribution et les caractéristiques des
valeurs au sein d'un ensemble de données Pour trouver les
valeurs minimales ou maximales dans une trame de données, vous pouvez utiliser des méthodes
telles que la moyenne et La fonction de moyenne renvoie
la valeur minimale pour
toutes les colonnes numériques
du bloc de données. La fonction max obtient les valeurs maximales pour
toutes les colonnes numériques. Ces fonctions fonctionnent non
seulement avec des données numériques, mais également avec d'autres types de données tels que des chaînes ou des dates. La fonction produit en polars est utilisée pour calculer
le produit de
toutes les valeurs d' une colonne ou d'une
série ou de plusieurs
colonnes d'un bloc de données Cela signifie qu'il multiplie toutes les valeurs ensemble
et renvoie le résultat Lorsqu'il est appliqué à une colonne, il renvoie un nombre unique représentant le produit de
toutes les valeurs de cette colonne. Pour le bloc de données, il calcule le produit pour chaque colonne
numérique séparément. Il est très utile pour les calculs
mathématiques, les analyses
financières
et la validation des données. Si vous souhaitez estimer l'écart ou l'
écart quadratique des valeurs par rapport à leur moyenne
dans chaque colonne numérique, vous pouvez utiliser la fonction var Il mesure dans quelle mesure les valeurs
moyennes d'une colonne
s'écartent de la moyenne Il est couramment utilisé dans l'analyse
statistique pour comprendre la distribution
et la variabilité des données. La fonction SDD calcule l'écart type des valeurs dans chaque colonne
d'une trame de données Cette fonction renvoie une série contenant l'
écart type pour chaque colonne. Un écart type faible signifie que les valeurs sont
proches de la moyenne, tandis qu'un
écart type élevé indique que les valeurs sont
réparties sur une large plage.
6. Explorer les méthodes de cadres de données polaires : drapeaux, schéma, opérations en colonnes et techniques de conversion de données: La fonction flag
et polars renvoient un dictionnaire d'indicateurs pour chaque
colonne du bloc de données. Chaque indicateur est présenté avec
une valeur booléenne indiquant s'il est défini pour cette colonne ou Par exemple, je vois des drapeaux
triés ici, mais si je veux vérifier
si une colonne est unique, je peux utiliser cette fonction unique. Cette fonction unique
renvoie une valeur booléenne. True si toutes les valeurs
des colonnes spécifiées sont uniques, pas de doublons et false s'il existe des valeurs
dupliquées Et ici, je vérifie si la colonne distincte de mon bloc de données contient
uniquement des valeurs uniques ou non. Dans le premier cas, j'ai vérifié la présence de
valeurs uniques dans la colonne, si elles existent. Ensuite, nous avons découvert si la colonne est
entièrement composée de valeurs uniques. Et comme nous pouvons le constater, il n'
y a pas de valeurs uniques et la colonne n'est pas marquée
par le drapeau unique. Pour récupérer la liste des
noms de colonnes dans le bloc de données, vous pouvez utiliser la méthode columns. Elle renvoie une liste de chaînes où chaque chaîne
est le nom de la colonne. Cela est utile pour
vérifier rapidement la structure
du bloc de données et comprendre
quelles colonnes sont disponibles pour l'analyse
ou le traitement. Le schéma d'un bloc de données
fait référence à sa structure, particulier aux
noms des colonnes et à leurs types de données. comprendre les pôles,
le schéma est important car il vous permet de savoir avec
quel type de données
vous travaillez Le schéma inclut les noms de toutes les colonnes
du bloc de données, ce qui vous permet de
voir rapidement quelles données sont disponibles. Chaque colonne du
bloc de données possède un type de données,
et il est également important de connaître les types de données, car certaines opérations ne fonctionnent que
sur des types de données spécifiques. schéma permet donc de vérifier si les données sont au
bon format avant d'effectuer des opérations. Certaines opérations peuvent échouer si les types de données sont incorrects. La vérification
préalable du schéma peut donc éviter les erreurs. La méthode de la largeur
en pôles est utilisée pour déterminer le nombre de colonnes
présentées dans un bloc de données. Cela est utile lorsque vous travaillez
avec de grands ensembles de données. Là où le comptage manuel
des colonnes n'est pas pratique. Il permet de vérifier rapidement combien de
champs de données différents existent dans votre ensemble de données. Cela peut également être utile lorsque vous travaillez
avec des ensembles de données dynamiques. Connaître le nombre de
colonnes peut vous aider à effectuer des tâches telles que parcourir des colonnes en boucle
ou sélectionner des colonnes spécifiques. La méthode d'aperçu dans Polars est utilisée pour prévisualiser un résumé
de votre bloc de données, vous
donnant ainsi un aperçu rapide de
la structure des données C'est utile lorsque vous
souhaitez comprendre la disposition générale de vos données
sans avoir à afficher l'ensemble de données dans son intégralité, en particulier lorsque vous travaillez
avec de grands ensembles de données La méthode Glimse fournit un aperçu
compact du bloc de données, y compris les noms des colonnes, les types de
données de chaque colonne, un aperçu des premières
valeurs de chaque colonne Cette méthode n'affiche pas
l'ensemble de données dans son intégralité, mais offre plutôt
un instantané rapide, afin que vous puissiez comprendre la structure
des données en un coup d'œil. Il permet de vérifier rapidement
quelles données sont disponibles, quelles sont les colonnes
et les types de données avec lesquels vous travaillez
sans tout afficher. Cela vous permet également d'éviter de vous
submerger grandes quantités de données en n'affichant qu'une petite partie
résumée. Vous pouvez également détecter des problèmes
potentiels
tels que des types de données inattendus, valeurs
manquantes ou des
incohérences
dans les noms de colonnes au cours de
cet examen rapide La méthode des N segments en
pôles est utilisée pour déterminer nombre de segments en lesquels une trame de données
est divisée en interne Dans les polars, les données peuvent être
divisées en morceaux pour un traitement plus
efficace, particulier lorsque vous travaillez avec grands ensembles de données qui ne
rentrent pas tous en même temps dans la mémoire Un fragment est une plus petite partie
de l'ensemble du bloc de données. Polars divise souvent les
grands ensembles de données en morceaux pour les gérer
plus efficacement Chaque segment peut être
traité séparément, ce qui permet aux polars de
fonctionner avec des ensembles de données trop volumineux pour être
entièrement conservés en mémoire à Cela fait partie du système de
gestion de la mémoire
efficace de Polar . Lorsque vous utilisez la méthode
N fragments, elle renvoie le nombre
de segments en lesquels notre trame de données a été
divisée pour le traitement Cela peut être utile pour
comprendre comment Polars gère la mémoire
et la distribution des données pour votre trame de données spécifique Dans certains cas, comprendre le découpage des données vous permet de surveiller et de déboguer la façon dont Polars gère les
données dans Si une trame de données comporte un
grand nombre de segments, les opérations peuvent
être moins efficaces que lorsque les données
sont stockées dans un seul bloc Il est essentiel de comprendre les segments lorsque vous travaillez avec de
grands ensembles de données La fonction à deux flèches
et les pôles sont utilisées pour convertir un bloc de données polaires
en table de flèches Pache Ceci est utile pour l'interopérabilité
des données car Apache Arrow est format
largement utilisé pour un échange de données
efficace entre différents systèmes de
traitement de données. Apache Arrow est un format de mémoire en
colonnes conçu pour le traitement rapide
des données Il permet à différents outils de traitement de
données tels que Pandas ou Spark de partager des données
efficacement sans avoir à les copier ou à les convertir
plusieurs fois. Lorsque vous utilisez la fonction à deux flèches, Poller's transforme son format de données
interne en une table à flèches de correction tout en
conservant la structure en colonnes Il permet un partage de
données plus rapide, une utilisation efficace de la mémoire
et une meilleure compatibilité. Polars fournit également
la fonction deux DigT, qui convertit une trame ou une
série de données en un dictionnaire Python Chaque colonne du
bloc de données devient une clé du dictionnaire avec les valeurs
correspondantes, formant une liste pour cette clé. Nous avons également la méthode des deux dicts. Dans Polars, il convertit un bloc de données en une
liste de dictionnaires De nombreuses fonctions et
bibliothèques Python fonctionnent bien avec des
listes de dictionnaires. Par exemple, si vous devez
convertir vos données
au format JSON, ces étapes
intermédiaires peuvent être utiles, car liste des dictionnaires est
facilement sérialisable Si, pour une raison quelconque, vous avez besoin d'une représentation sous forme
de chaîne du bloc de données, vous pouvez utiliser la méthode de
représentation à deux N. Cela est particulièrement utile pour débogage ou pour les scénarios
dans lesquels vous devez générer du code capable reproduire cette
trame de données exactement telle qu'elle est Peut également utiliser deux méthodes Napi, qui convertit le bloc de
données polaire en tableau NumPy Cela est utile lorsque
vous devez tirer parti de la puissante manipulation de
tableaux
et des fonctions mathématiques de
Napi et des fonctions mathématiques Les matrices Napi étant très efficaces pour les calculs
numériques, cette méthode est
utile pour effectuer opérations qui sont
mieux gérées par Je peux dire la même chose à propos de
la méthode des deux Pandas. Il convertit le bloc de données polaire
en bloc de données de Panda. Cela est utile lorsque
vous souhaitez utiliser fonctionnalités spécifiques de
Pandas ou lorsque vous travaillez dans un
écosystème où Pandas est le principal outil de
manipulation de données La méthode à deux torches convertit une trame de données polaires
en tenseur Pytorch C'est idéal pour préparer les données pour les
modèles d'apprentissage en profondeur dans PyTorch Cependant, comme je n'ai pas installé
cette bibliothèque, je rencontre une erreur. Nous pouvons installer cette
bibliothèque avec cette commande, mais pour le moment nous n'en avons pas besoin, donc je la laisse telle quelle.
7. Manipulation avancée des données dans les polaires : regroupement, agrégation, tri et transformation personnalisée: Passons maintenant à
la méthode du groupe B. Si vous avez déjà travaillé
avec des pandas, vous connaissez
probablement cette méthode Si ce n'est pas le cas, voici une
brève explication. La méthode du groupe B
en pôles est utilisée pour regrouper une trame de données par
une ou plusieurs colonnes Dans notre cas, le regroupement par
la colonne de l'année signifie que toutes les lignes ayant la même valeur dans la colonne de l'année
seront regroupées. Chaque année unique
formera un groupe distinct. Cependant, dans notre cas, nous n'avons qu'une année 2022. Ensuite, nous utilisons l'agrégation. La méthode et les polaires
sont utilisées pour effectuer calculs
agrégés sur des groupes de données au sein d'un bloc de données. Nous spécifions ensuite la colonne, bit, et appliquons la fonction de
comptage. Cela signifie que pour chaque groupe, nous comptons le nombre d'
occurrences de la colonne de bits. Cela compte essentiellement
le nombre de lignes de chaque groupe puisque chaque ligne
représente un incident. Ensuite, nous utilisons la fonction Alias. Pour renommer la colonne
résultante à partir de l'agrégation pour
compter les incidents Ceci est fait pour donner un nom significatif à la colonne agrégée. En théorie, nous pouvons utiliser cette
fonction pour résumer les données et comprendre la
fréquence des incidents par an. Cependant, comme notre ensemble de données ne contient qu'
un an, nous ne voyons le nombre
d'incidents que pour 2022. Prenons maintenant un autre
exemple lorsque je regroupe par année. Mais au lieu d'utiliser une fonction d'
agrégation, j'utilise la méthode L. La méthode OL conserve toutes les
lignes de chaque groupe. La séparation est
utile lorsque vous devez
travailler avec tous les
points de données de chaque groupe
sans effectuer d' agrégation ou de
transformation
susceptible de
réduire le Dans certains cas, lorsque vous souhaitez obtenir un aperçu rapide
de chaque groupe, vous pouvez utiliser la première
méthode au lieu de toutes. Cela est utile lorsque
vous souhaitez extraire échantillons
de points de données de chaque groupe ou réduire le bloc de données à une ligne
par groupe pour une analyse ou un reporting plus approfondis. Je n'ai pas le meilleur
exemple pour cela, alors groupons plutôt par type
principal. Cela rend les choses plus claires. Ici, nous pouvons voir la première
ligne pour chaque groupe. Dans notre cas, la colonne de type
principale. La dernière méthode fonctionne
presque de la même manière , sauf qu'elle ne renvoie que la
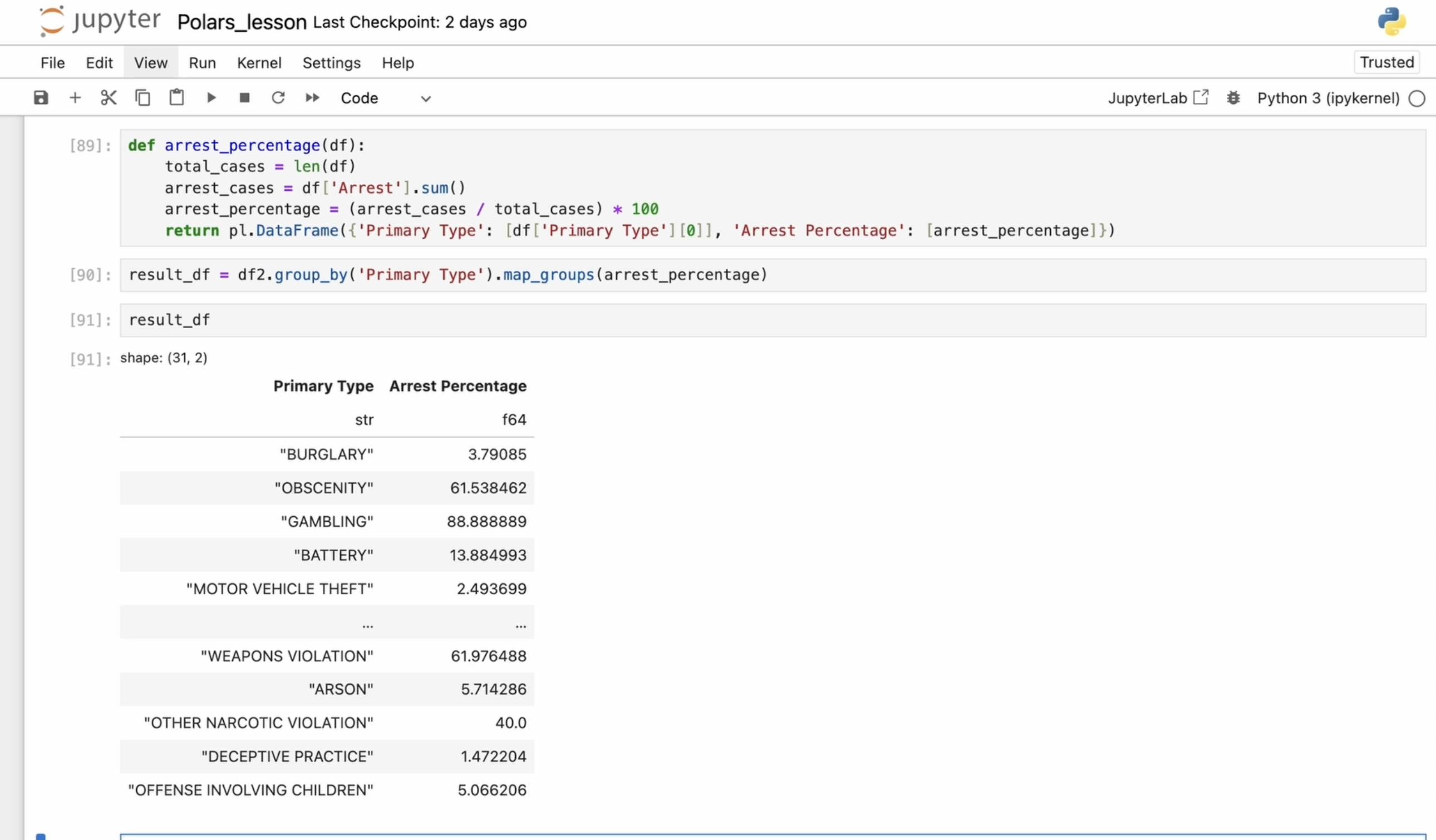
dernière ligne pour chaque groupe. Je souhaite maintenant définir une fonction personnalisée pour calculer
le pourcentage d'arrestations. Tout d'abord, j'obtiens le nombre total de cas en calculant la
longueur de la trame de données. Ensuite, j'obtiens le nombre de cas
d'arrestation en additionnant
la colonne des arrestations Ensuite, je calcule le pourcentage
d'arrestations en divisant le nombre d' arrestations par le
nombre total de cas. Enfin, je renvoie le
bloc de données avec le résultat. Ce code regroupe les
données par type principal et calcule le pourcentage
d'arrestations pour chaque type de crime À partir des résultats, nous
pouvons voir quels types de crimes ont un taux d'arrestation plus élevé ou plus
faible. Maintenant que nous avons créé cette fonction, il est
temps de l'utiliser. Les groupes nab sont une méthode très utile
pour cela. Cette méthode prend les données
groupées en entrée, applique la
fonction personnalisée à chaque groupe, puis renvoie
un nouveau bloc de données avec le résultat de
cette opération. Dans ce cas, nous regroupons
le bloc de données par la
colonne de type principal, puis nous
appliquons notre
fonction personnalisée de pourcentage d'arrestations à chaque groupe. Cette fonction
traite chaque groupe manière indépendante et peut exécuter
toute logique personnalisée nécessaire. Le résultat est une nouvelle
trame de données dans laquelle chaque ligne contient le résultat de l'application de la
fonction de pourcentage d'arrêt à chaque groupe. Il existe également une fonction d'application, qui applique une fonction personnalisée
ou définie par l'utilisateur
dans un groupe en fonction du contexte, mais elle est devenue obsolète
et renommée en groupes de cartes Donc, si vous voyez la fonction d'
application dans ancien code, ne vous y trompez pas. C'est juste une version obsolète. Vous connaissez
probablement la fonction head, qui permet de voir les premières
lignes d'un bloc de données. Cependant, considérons
une autre fonction utile, la queue. Supposons que je ne veuille voir que
les dernières lignes de chaque groupe. L'utilisation de la méthode de la queue au sein d'
un groupe nous permet de nous concentrer sur les
entrées les plus récentes ou les dernières pour chaque catégorie. Cela peut être utile pour examiner les cas
les plus récents de notre ensemble de données. Dans ce cas, des grammes, mais dans d'autres cas, il
peut s'agir de n'importe quel type de données. Vous pouvez également utiliser
la fonction de tri après avoir effectué ces opérations. Il vous permet de trier les entrées extraites
selon une colonne spécifique, par exemple, zone communautaire
pour meilleure lisibilité
ou une analyse plus approfondie Alors, qu'avons-nous fait ici ? Nous les avons regroupés par type principal. Nous avons sélectionné la dernière
ligne pour chaque groupe et nous avons trié les données
par zone communautaire. La séquence des opérations
permet d'analyser les entrées
les plus récentes
tout en améliorant la lisibilité
8. Opérations avancées de données dans Polars : write_csv, tableaux croisés dynamiques et stratégies de joining.: Pour l'exemple suivant, j'ai
besoin de deux trames de données. jonction de trames de données est une opération courante de manipulation de
données où les lignes de deux ou
plusieurs trames de données sont combinées
sur la base de colonnes communes. Polars propose différents
types de jointures, similaires aux jointures de style SQL Imprimons les deux blocs de données et commençons par la jointure interne. Je prends mon premier bloc de données
et j'utilise la fonction de jointure. Ensuite, je spécifie le
deuxième bloc de données que je souhaite joindre
au premier. Ensuite, je définis la
colonne à rejoindre. Il peut s'agir d'un nom de colonne unique ou d'une liste de noms de colonnes. Dans mon cas, c'est un nom. Enfin, je précise
le type de jointure, qui dans notre cas
est une jointure interne. Désolé pour la faute de frappe. Cela
signifie que seules les lignes dont les clés correspondent dans les deux blocs de données
apparaîtront dans le résultat. Nous constatons que Bob et
Charlie sont tous deux présents
dans les deux blocs de données Nous les voyons
donc dans notre résultat. Essayons maintenant une jointure à gauche. Cela signifie que toutes les lignes
du bloc de données de gauche et seules les lignes correspondantes
du bloc de données de droite
figureront dans le résultat. Et nous pouvons constater que tous les noms
et toutes les informations
du bloc de données de gauche apparaissaient dans notre résultat et
du bloc de données de droite, dans notre cas, le
deuxième bloc de données. Nous ne pouvons voir que deux noms, Bob et Charlie,
présents dans les deux blocs de données. Pour un dessin complet, toutes les lignes des deux
blocs de données apparaîtront dans le résultat sans aucune valeur
ne correspondant à aucune correspondance. Et ici, nous pouvons voir les
nuls dans le résultat. Nous avons également une jointure croisée. Il renvoie toutes les
combinaisons possibles de
lignes des deux trames de données,
un produit cartésien Chaque ligne de gauche est combinée à chaque
ligne de droite. Et pour vous montrer tous les
types de jointures, je tiens à
vous expliquer que vous êtes également des semi-jointures. Elle renvoie uniquement les lignes
du bloc de données de gauche dont les clés
correspondent dans le bloc de données de
droite. Vous pourriez me demander
quelle est la différence entre une jointure interne et une jointure semi-interne ? Nous avons obtenu à peu près la même chose. La jointure interne et la
semi-jointure renvoient toutes deux des lignes où il existe une correspondance
entre deux tables, mais elles présentent une différence majeure La jointure interne renvoie toutes les
lignes correspondantes des deux tables, y compris les colonnes des deux tables. Semijoin renvoie
uniquement les lignes
du tableau de gauche qui
correspondent dans le tableau de droite, mais n'inclut pas les colonnes
du tableau de droite Ainsi, même si elles peuvent renvoyer
le même nombre de lignes, la jointure interne inclut des colonnes supplémentaires
provenant du tableau de droite, tandis que la demi-jointure
ne conserve que les colonnes d'origine
du tableau de gauche Et nous avons un antidote. Il s'agit d'un type d'
opération de
jointure dans lequel les
lignes du bloc de données de gauche sont incluses dans le résultat uniquement s'il
n'y a pas de clé correspondante dans
le bloc de données de droite. Essentiellement, il filtre
toutes les lignes du jeu de
données de gauche qui ont une correspondance correspondante dans le jeu de données de droite en fonction de la clé ou de la colonne
spécifiée. Si vous l'avez remarqué, j'utilise
souvent Tap pour éviter de taper
manuellement des
variables existantes à plusieurs reprises. Appuyez sur la touche du haut et le bloc-notes
Dutra
proposera la variable à sélectionner au lieu
de la saisir manuellement Continuons
avec les tableaux croisés dynamiques. Pour cela, je vais légèrement
modifier mon cadre de données. Si vous avez déjà travaillé
avec des pandas, vous savez probablement ce que c'est cas contraire, les opérations de pivot vous
permettent remodeler vos données en les
résumant de différentes manières, en une
fonction d'agrégation spécifiée Ici, je vais vous montrer comment
remodeler mon bloc de données récemment
créé Je précise les
valeurs à pivoter, et dans mon cas, ce
sera la colonne des scores. Ensuite, je précise que les lignes
du nouveau tableau croisé dynamique seront
indexées par la colonne du nom J'utiliserai également la colonne Ville, qui servira base à la nouvelle
colonne du tableau croisé dynamique. Pour la
fonction d'agrégation, je vais d'abord utiliser. Cela signifie que s'il
existe plusieurs valeurs pour une combinaison particulière
de nom et de ville, seule la première
valeur sera utilisée. Le bloc de données résultant
comportera des valeurs de nom uniques sous forme de lignes d'index et des valeurs de
ville uniques dans les colonnes. Les valeurs nulles du tableau croisé dynamique
indiquent qu'il n'y avait aucune combinaison correspondante
de nom et ville dans le
bloc de données d'origine pour ces cellules. Malgré le fait que
nous ayons deux bobs, nous n'obtenons que le premier avec
un score de 90 Ensuite, je vais remplacer la fonction
d'agrégation par sum. Et maintenant, nous obtenons la somme des
scores des deux bobs, des deux Charli et ainsi de suite J'ajoute une ligne sous notre bloc de données pour afficher
les résultats mis à jour. Et bien sûr, la somme est de 160. Nous pouvons voir que le premier
bob a un score de 90. Le deuxième bob a
un score de 70. Il en va de même pour Frank
et les autres noms. La fonction de moyenne indique la valeur carrée moyenne pour chaque combinaison de nom et de ville. La fonction max indique
la valeur maximale du score. Nous pouvons également calculer les valeurs de score
moyennes ou médianes. Dans ce cas, nous ne
voyons aucune différence entre la médiane et la moyenne car notre trame de données
n'est pas le meilleur exemple, mais elle représente différents aspects de la distribution des données. La moyenne représente
la valeur moyenne de l'ensemble de données et
convient aux données
distribuées symétriquement sans La médiane, quant à elle, est la valeur moyenne d'un ensemble de données lorsqu'elle est ordonnée du plus petit
au plus élevé. La médiane convient mieux aux données
asymétriques ou non
distribuées normalement Pour l'exemple suivant, j'ai besoin de
deux trames de données différentes. Je vais copier le premier
et y apporter quelques modifications. Dans les extracteurs, nous pouvons comparer deux trames de données pour vérifier
si elles sont égales Nous pouvons vérifier si les deux
trames de données correspondent exactement. Si les deux trames de données
avaient le même schéma, c'
est-à-dire les mêmes
noms de
colonnes et les mêmes types de données,
ainsi que les mêmes données dans
chaque colonne ainsi que les mêmes données dans correspondante de la ligne, la comparaison renverra la valeur
bull et la valeur true, ce qui indique que
les deux trames de données sont identiques en termes de
schéma et de données. Ou faux s'il existe
une différence de schéma ou de données entre
ces deux blocs de données. Dans le premier exemple, je compare deux
blocs de données différents et j'ai obtenu une valeur fausse. Ensuite, je compare deux trames de données
identiques, les mêmes trames de données,
et je me suis rendu compte que c'est vrai, ce qui est logique puisqu'
elles sont exactement les mêmes. Si j'annule les modifications que j'ai apportées
à la deuxième trame de données, nous nous retrouvons avec deux trames de données
identiques, fois en termes de
schéma et de données, et la fonction renvoie true. L'utilisation de la fonction equals vous
permet de vérifier si deux trames de données
sont complètement identiques, ce qui est utile à des fins de
validation des données et de test. Vous pouvez enregistrer un bloc de données dans
un fichier CSV à l'aide de la méthode CSV. Par exemple, si je souhaite enregistrer notre bloc de données dans un
fichier nommé data CSV, je peux le faire avec
une seule commande. Après avoir exécuté la commande LS, nous pouvons voir que le fichier a
été créé avec succès. L'enregistrement d'
un bloc de données dans un fichier CSV est très utile lorsque vous devez
stocker des données pour une utilisation ultérieure, ce qui facilite le
partage ou le rechargement Les fichiers CSV sont largement pris en charge et peuvent être ouverts par
de nombreux logiciels.
9. Comprendre l'exécution avide et paresseuse dans Polars : une comparaison de vitesse avec Pandas pour les grands formats de données: Polars propose deux modèles
d'exécution pour les opérations sur les trames de
données : le mode
Iger et le mode paresseux. Comprendre la
différence entre ces deux modèles est essentiel
pour optimiser les performances. Eh bien, commençons par
le mode Iger. Les opérations sur une trame de données
sont exécutées immédiatement. Les résultats sont calculés et renvoyés dès qu'une
opération est appelée. Cela signifie que
chaque étape que vous effectuez est exécutée immédiatement
et de manière séquentielle Ce mode est plus facile
à déboguer car vous pouvez voir immédiatement le résultat de
chaque opération Le mode Eager est souvent préféré dans
les environnements interactifs tels bloc-notes
Jupra, car il
vous permet de voir le résultat des
opérations immédiatement Il est particulièrement adapté à l'analyse
interactive des données et aux petits ensembles de données nécessitant
un retour d'information immédiat. Continuons avec le mode paresseux. Au lieu d'exécuter
les opérations immédiatement, polars construit et
optimise d'abord un plan de requête
avant son Cette approche permet
à Polars d'optimiser le plan d'exécution, en réduisant le nombre
d'opérations et la quantité de
données traitées Les polars fondus paresseux font référence
à un moyen d'effectuer des opérations
sur des données
où les calculs ne
sont pas exécutés immédiatement Au lieu de cela,
les opérations sont retardées et exécutées
uniquement lorsque vous demandez
explicitement le résultat. Cette approche permet aux
polars d'optimiser la séquence des opérations
avant de les exécuter,
améliorant ainsi les performances, en particulier avec de grands ensembles Le mode paresseux convient généralement
mieux aux grands ensembles de données ou aux flux de travail
impliquant de nombreuses étapes L'optimisation qu'il
applique peut entraîner une amélioration
significative des performances par rapport à une exécution rapide. Je pense que la fonction
atteint Vans Kansas, nous sommes assez explicites. Mais je vais expliquer brièvement A. La fonction read A
en polars est utilisée pour
lire les données d'un fichier A
dans une trame de données polaires Park est un format de fichier
de stockage en colonnes, optimisé pour une utilisation avec des frameworks de
traitement de données Contrairement aux
formats basés sur des lignes tels que CSV, Park stocke les données par
colonnes plutôt que par lignes, ce qui le rend très efficace fois
pour le stockage et le traitement. Le format en colonnes est
particulièrement utile lorsque vous devez lire uniquement
des colonnes spécifiques à partir de grands ensembles de données, car il vous permet d'éviter charger
des données inutiles en mémoire Si vous n'avez besoin que de quelques
colonnes d'un jeu de données, Park vous permet de
charger uniquement les
données pertinentes en mémoire, améliore la vitesse et
réduit l'utilisation de la mémoire. Applications de mégadonnées. Park est un excellent choix pour les applications de
mégadonnées, en particulier lorsque vous utilisez
des frameworks qui le supportent, tels qu'Apache Park,
Dusk ou Polars Comparons maintenant les
performances de lecture d' fichier
CSV à l'aide de Pandas à celles de
Polars Si vous vous souvenez, nous disposons d'un vaste ensemble de données de
plus de 100 millions de lignes. Je vais donc m'en servir. Tout d'abord, j'importe des Pandas et j'
utilise la fonction read CSV. Pour mesurer le temps d'exécution, j'utilise la
commande Time it magic du bloc-notes Jupiter. Cette commande nous permet de
mesurer le temps d'exécution et de calculer
les résultats moyens sur plusieurs exécutions. Il faudra donc un
certain temps pour le charger. Cela prend vraiment beaucoup de temps. Permettez-moi de vous rappeler
que le bloc de données comporte plus de 100 millions de lignes. L'exécution des opérations sur
celui-ci prend donc un temps
considérable. Après avoir exécuté le
code sept fois, nous obtenons un
temps d'exécution moyen de 32 secondes par boucle. Maintenant, répétons les mêmes
étapes que pour les pandas. Mais cette fois, en utilisant des polars, nous utiliserons
à nouveau le temps pour voir combien de temps il faut
pour charger le bloc de données La différence de temps d'exécution est immédiatement perceptible. Polar charge le bloc de données
beaucoup plus rapidement. J'ai attribué l'expression
précédente à la variable TF afin que nous puissions continuer à travailler
avec la trame de données chargée. Nous venons donc de lire plus de 100 millions de lignes
en utilisant à la fois des pandas et des polaires Si nous examinons le bloc de données, nous pouvons constater que certaines
colonnes n'ont aucun sens Pour
faciliter l'utilisation de nos données, je vais les renommer. abord, je prépare une liste de nouveaux noms de colonnes
, puis j'utilise la fonction de renommage pour renommer les colonnes du bloc de
données Polars Nous pouvons maintenant voir que nous avons
renommé les noms des colonnes. Nous avons un ensemble de données correctement
structuré, et je vais procéder
au regroupement de l'ensemble de données par unités
et par colonnes de niveau. Après le regroupement, je vais effectuer
une opération d'agrégation sur la colonne numérique en
calculant la
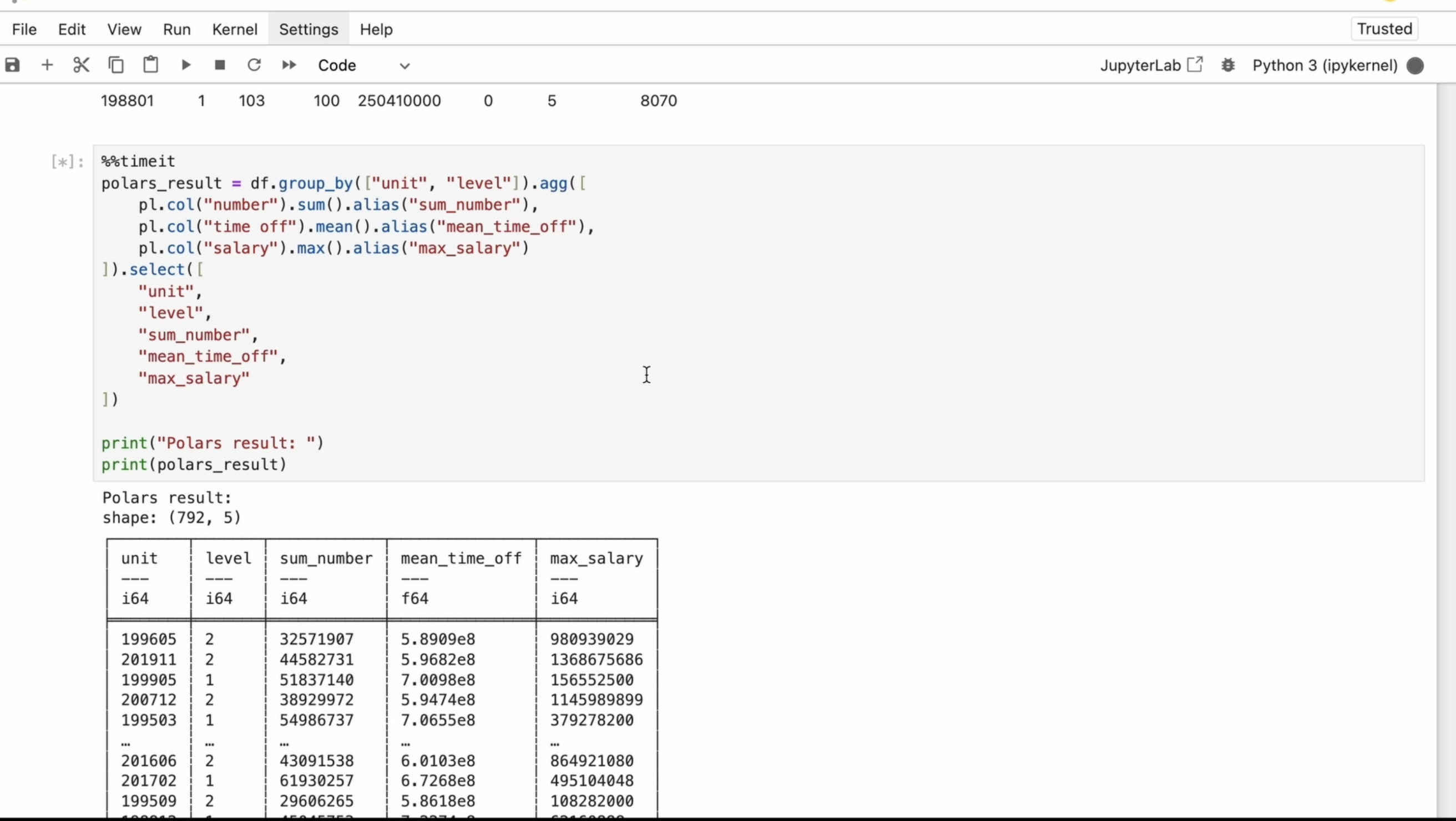
somme de ses valeurs. Tout d'abord, je sélectionne la colonne nommée numéro
dans le bloc de données. J'utilise ensuite une
fonction d'agrégation qui additionne toutes les valeurs
de cette colonne. Au lieu de conserver
le nom par défaut, j'attribue un
nom plus significatif à la colonne de sortie. Pour cela, j'utilise un alias. Pour les congés, je
calcule la moyenne. Pour le salaire, je calcule
la fonction maximale. Enfin, je sélectionnerai les colonnes requises dans
le bloc de données agrégé. La méthode de sélection et
les pôles sont utilisés pour choisir des colonnes spécifiques et leur appliquer
une transformation Il crée un nouveau bloc de données avec uniquement les colonnes sélectionnées, laissant le bloc de
données d'origine inchangé. Désolé pour la faute de frappe. J'utilise la fonction d'impression pour afficher
le résultat ainsi que le titre dans un éditeur de code
classique. Cela est nécessaire
pour voir le résultat. Cependant, dans le bloc-notes Gebr, vous n'avez pas besoin d'imprimer Vous pouvez simplement taper le nom de la
variable, le résultat du pôle, et le résultat s'
affichera automatiquement manière interactive. Et nous y voilà. Maintenant, je vais utiliser la
commande time it pour exécuter le
code plusieurs fois. À la fin, nous verrons
combien de temps il faut pour
effectuer l'opération. Nous voyons le code
s'exécuter plusieurs fois. Et à la fin, nous constatons
qu'il a fallu trois esquives, 83 secondes par boucle, ou je peux dire par opération. Répétons le même
processus avec les pandas. Cela prend plus de temps
qu'avec les pôles. Nous examinons le même bloc de
données et devons renommer les colonnes.
Alors faisons-le. La commande est presque
la même que pour les polars, sauf que nous définissons d'
abord les colonnes , puis que nous transmettons
les nouveaux noms de colonnes Nous pouvons maintenant procéder au même regroupement et à
l'
agrégation que nous avons fait ci-dessus. Nous pouvons voir ici que Pandas utilise un dictionnaire intégré à une fonction d'
agrégation pour spécifier les
noms des colonnes et les opérations Dans le cas des pôles, l'agrégation
a été appliquée aux colonnes
en les sélectionnant d'abord, puis utilisant des fonctions telles que la moyenne
des sommes et les cases. Dans Polars, vous ne pouvez pas utiliser
un dictionnaire directement dans la fonction
d'agrégation la même manière que dans Pandas Polars vous oblige à spécifier chaque opération d'agrégation de
manière explicite pour chaque colonne, et c'est là toute la différence Pandas fournit une
syntaxe plus courte pour l'agrégation. Les deux expressions nous
donneront le même résultat, mais la syntaxe est légèrement différente entre
Pandas et Polars Je recommande vivement
de l'essayer vous-même. Mettez la vidéo en pause et répétez
ce code vous-même. Voici à quoi ressemble le
tableau final. Maintenant, je vais utiliser le temps à
nouveau pour exécuter le
code plusieurs fois. Et il a été diffusé sept fois. Après l'avoir exécutée, nous constatons que cela
a pris 7,34 secondes par boucle. On voit clairement
la différence. Mais nous devons également
prendre en compte les cas où nous
effectuons ces opérations en
même temps que la lecture des données. Je vais réécrire le
code un peu. Nous allons donc lire le
fichier CSV, renommer les colonnes. Effectuez le groupe par
opération, agrégation, puis sélectionnez
des colonnes spécifiques dans une seule chaîne en utilisant la syntaxe de chaînage de la
méthode Polars Cela prend plus de temps. Et
maintenant, cela a pris 11,8 secondes. Ici, j'ai réécrit le code pour que les pandas
fassent la même chose J'ai combiné toutes les étapes en une seule ligne, comme nous l'avons
fait dans le code polaire ci-dessus Même sans le temps, je l'exécute
et mon système n' a plus de mémoire. Oh, oui, mon système est mort. Mais nous pouvons
y arriver même avec des pandas. Si nous commençons à lire le fichier
CSV en morceaux, laissez-moi vous montrer comment nous pouvons
gérer cette situation La lecture du fichier par morceaux
permet de gérer l'utilisation de la mémoire. Tout d'abord, j'ai défini le nombre
de lignes à lire en
mémoire en une seule fois en
définissant la taille des morceaux Ensuite, j'initialise
un bloc de données vide qui stockera les résultats d'
agrégation finaux de chaque segment Je lis le fichier CSV par
morceaux à l'aide des quatre boucles, renomme les colonnes et effectue le même regroupement
et agrégation qu'auparavant À la fin, je peux associer les résultats agrégés de
chaque segment à la
trame de données finale J'ai également utilisé l'index Ignore. Vrai. Cela signifie que lors d'opérations
telles que la concaténation, les valeurs d'index d'origine
seront ignorées et le nouvel index entier par défaut sera attribué au résultat Cela permet d'éviter les valeurs d'index dupliquées ou
non séquentielles lors de la modification de blocs de données Ici, on ne peut pas franchir
les limites comme ça. Je l'ai donc modifié pour une
meilleure lisibilité. Cela prend du temps, mais nous obtenons
enfin le résultat. Pour éviter de manquer de mémoire, nous pouvons utiliser MMIT, une commande magique du package
de profil de mémoire Il mesure et imprime
l'utilisation de la mémoire lors de l'exécution du code
en cours. Cela permet de surveiller
l'utilisation de la mémoire pour chaque segment. Dans cette version, le MMIT se trouve dans la boucle for
avant le début de l'opération Il s'exécutera à chaque
itération de la boucle. Cela est utile pour analyser et optimiser le travail
avec des fichiers volumineux, mais cela peut
ralentir l'exécution du code en raison de mesures supplémentaires. Vous pouvez l'installer en utilisant PIP. Bien entendu, vous devez utiliser cette commande pour l'
activer dans un environnement de
bloc-notes Jupiter. Vous n'utilisez cette commande qu'une seule fois, pas avant chaque utilisation de MMD. Ensuite, vous pouvez utiliser MMIT pour vérifier l'utilisation
maximale de la mémoire Ici, nous avons utilisé cette commande pour la consommation
totale de mémoire
du résultat de Panda Une fois tous les morceaux traités, nous
avons été traités. Donc, si l'objectif est de vérifier
l'utilisation finale de la mémoire, la deuxième variante est meilleure. Si l'objectif est de suivre
la consommation de mémoire au fil du temps, la première variante est
plus informative. Cependant, nous pouvons éviter
complètement ce problème en utilisant des polaires
au lieu de pandas Revenons à la bibliothèque
Polars. Dans l'exemple précédent, nous avons
utilisé read CSV from polars. Cette fonction lit immédiatement
l'intégralité du fichier CSV en
mémoire, chargeant toutes les données
dans un bloc de données. Nous pouvons donc effectuer
des opérations directement dessus. Cependant, si le fichier
CSV est volumineux, cette approche peut
consommer beaucoup de mémoire, comme nous l'avons vu avec Pandas Mais comme je l'ai mentionné plus tôt, Polars possède également un mode paresseux. Si nous vérifions le type
de résultat des polars maintenant, nous verrons qu'il s'agit d'un cadre paresseux au lieu
d'un cadre de données normal Avec l'évaluation paresseuse
ou le mode paresseux, nous utilisons scnCSV
au lieu de ReadCSV scnCSV ne lit pas immédiatement les données
en mémoire. Au lieu de cela, il crée un cadre
paresseux qui enregistre les transformations
et ne
les exécute que lorsqu'elles sont explicitement déclenchées Cela permet d'optimiser les requêtes et de les exécuter plus efficacement. J'ai copié le code précédent et j'ai simplement remplacé ReadCSV par ScanCSV . Si nous vérifions le
type de résultat des polars, nous obtenons un cadre paresseux au lieu d'un cadre
de données normal Comme les frames paresseux utilisent l'exécution
différée, nous pouvons réellement visualiser le plan d'exécution à
l'aide de la méthode show graph. Cette méthode génère une représentation graphique du plan
de requête, qui nous aide à comprendre et déboguer le pipeline de
traitement des données Il fournit des informations sur
les étapes et les optimisations impliquées
dans l'exécution des requêtes Pour utiliser Show graph, Graph with doit être installé
sur votre système. Sur macOS, vous pouvez l'
installer à l'aide graphe d'
installation
Brew sous Windows ou Linux. Vous pouvez consulter la documentation
officielle pour connaître la commande
d'installation appropriée. Vous pouvez choisir ici la commande correspondant à votre système
d'exploitation. En regardant le plan de requête, nous pouvons constater que seules cinq colonnes sur huit
sont sélectionnées. Cela signifie que
Polars ne charge que les colonnes requises au lieu de lire l'ensemble de
données en mémoire Ensuite, j'appelle HAD
sur Polar'sRult, et au lieu d'obtenir
les données réelles, nous voyons Cela se produit parce que les frames paresseux ne s'exécutent pas immédiatement. Ils élaborent simplement le plan
d'exécution. Pour exécuter réellement la requête, nous devons appeler le collect. La méthode collect
déclenche l'exécution, traite toutes les
opérations et renvoie la trame de données normale
au lieu d'une trame paresseuse. Comme notre jeu de données contient
plus d'un million de lignes, son exécution prend un certain temps. À la fin, on obtient le résultat. Si nous vérifions le type
de notre trame de données maintenant, nous voyons qu'il s'agit d'une trame de données
pulsée. Ce n'est plus un cadre laser. Maintenant, je copie le code
précédent à l'aide Scan CSV et je
l'exécute avec Collect. Mesurez ensuite
le temps d'exécution avec le temps. Le code s'exécute plusieurs fois, et à la fin, nous
obtenons le résultat. Comparons cela à
l'exécution précédente. En utilisant read CSV, l'exécution
a pris dix points 7 secondes. Il n'y a pas de grande différence,
mais regardez ça. Si nous activons l'exécution du streaming en définissant le streaming
comme vrai, dans la méthode de collecte, nous traitons données de manière incrémentielle au lieu de tout
charger
en mémoire en une seule fois L'exécution en streaming est idéale pour les grands ensembles de données, car elle réduit l'utilisation de la mémoire en traitant des fragments au lieu
de l'intégralité des ensembles de données, et elle peut potentiellement tirer parti du traitement
parallèle dans le cadre duquel différents fragments sont traités simultanément
sur des parcours CPO distincts L'exécution du streaming
améliore généralement les performances des grands ensembles de données en réduisant l'utilisation de
la mémoire et
en autorisant le traitement parallèle Toutefois, pour les petits ensembles de données, la différence peut
être négligeable Avec Polars, les utilisateurs
n'ont pas besoin de
diviser manuellement leurs données en petits morceaux comme
nous l'avons fait avec Polars le gère automatiquement. Maintenant, nous pouvons constater une
différence significative dans les performances.
10. Visualisation des données dans les polaires. Avantages, limites et une analyse comparative: En ce qui concerne la
visualisation des données et les polars, il est souvent recommandé de
convertir votre trame de données en
une trame de données Pandas Comme je l'ai mentionné plus tôt, nous pouvons utiliser la méthode des deux
Pandas pour cela L'utilisation de Pandas pour le traçage
offre plus de flexibilité. Mais vous pouvez également
utiliser Matplotlip ou Seaborne, deux bibliothèques largement
utilisées pour Seaborne, deux bibliothèques largement
utilisées pour la visualisation des données. Vous pouvez trouver une vidéo sur ces bibliothèques dans mon
profil. Tu peux vérifier. MD plot leap offre
plus de flexibilité et permet un
contrôle précis des tracés. Seaborn facilite quant à
lui la création de diagrammes statistiques
complexes avec une syntaxe plus simple et de
meilleurs styles par défaut Cependant, ce ne sont pas
les seules options. Vous pouvez également utiliser HV Plot, une
bibliothèque de traçage de haut niveau qui fonctionne nativement avec le bloc de données
Polar Il offre une interface puissante
et flexible pour créer des
visualisations interactives Si vous souhaitez en savoir
plus sur HVPlot, vous pouvez consulter
la documentation Bien entendu, vous devez d' abord
l'installer
avant de l'utiliser. Dans Polars, vous pouvez également utiliser la
méthode du tracé intégré pour créer une visualisation
de base
sans convertir en pandas ni utiliser le tracé HV La méthode du tracé comprend
la structure des trames de données
polaires et peut générer des diagrammes à l'aide du
backend de base du tracé MD Vous pouvez spécifier
le type de tracé, tel que Scutter,
ligne ou histogramme Vous définissez également les
noms des colonnes pour les axes X et Y ainsi que des paramètres de tracé
supplémentaires
tels que le titre. Ces types de diagrammes sont adaptés à la création de visualisations
simples. Cependant, gardez à l'esprit que la fonctionnalité de
traçage intégrée dans Polars est limitée par rapport aux bibliothèques telles que HV plot
ou Mod plot Leap, qui offrent des fonctionnalités plus
avancées Pour bénéficier d'avantages supplémentaires, vous devrez peut-être utiliser
d'autres bibliothèques. Nous avons donc abordé beaucoup de choses aujourd'hui. Bien que les pôles offrent
de nombreux avantages, également des limites et des inconvénients.
Voyons ce que c'est. Tout d'abord, Polars est une bibliothèque
relativement nouvelle
par rapport à Pandas, et il se peut qu'elle ne bénéficie pas d'un support communautaire aussi étendu ou nombre d'
extensions tierces disponibles Pandas dispose d'un écosystème plus vaste et mieux
établi avec de nombreuses
bibliothèques et outils tiers conçus pour fonctionner parfaitement
avec les trames de données Pandas Étant une bibliothèque plus récente, Polars peut ne pas avoir
le même niveau de compatibilité avec les bibliothèques et outils d'
analyse de données existants bibliothèques et outils d'
analyse Vous devriez en tenir compte avant de
passer de la
bibliothèque Pandas à Polars Une autre limite
est que Polars n'a pas le même niveau de flexibilité d' indexation que Pandas Bien qu'il prenne en charge l'indexation basée sur les
lignes, il ne dispose pas des puissantes
fonctionnalités d'indexation
multiniveaux et hiérarchiques proposées par Pandas Par exemple, dans les zones polaires, vous ne pouvez définir qu'une seule
colonne comme index de ligne, alors que Pandas permet des structures d' indexation
plus complexes Si vous avez déjà utilisé l'indexation à plusieurs niveaux dans
votre projet, cela peut être un élément à prendre en compte lors du
passage aux polars De plus,
les capacités de visualisation dans les zones polaires sont actuellement
limitées par rapport aux pandas Dans Pandas, il est relativement
simple de visualiser les données directement à partir du bloc de données à l'aide de méthodes de traçage
intégrées ou en s'
intégrant parfaitement des bibliothèques de
visualisation externes Ainsi, si la visualisation est un élément crucial de votre
flux de travail et que vous n'avez pas besoin des avantages en termes de
performances des polars pour vos cas
d'utilisation spécifiques, Pandas pourrait être l'option la plus
pratique pour vous Le passage de
Pandas à Polars peut potentiellement entraîner des comportements
inattendus ou lacunes fonctionnelles en
raison des différences entre les ensembles
de fonctionnalités et les capacités des deux bibliothèques Comme je l'ai mentionné plus tôt,
Pandas existe depuis plus longtemps et possède un ensemble de fonctionnalités plus mature et plus
complet Bien que Polars fournisse de nombreuses fonctions essentielles de manipulation
et d'analyse des données, certaines des fonctionnalités les
plus avancées
ou intéressantes
disponibles dans Pandas peuvent
lui manquer ou intéressantes
disponibles dans Pandas Alors, les gars, félicitations
pour avoir terminé ce cours. Tu as fait du bon travail.
Continuez à apprendre, à coder. Rendez-vous dans les
prochains cours. Au revoir.
 Olha Al, Software engineer
Olha Al, Software engineer