Transcription
1. Intro: Bonjour, les gars. Bienvenue sur
Discourse on Mastering Nampi, l'une des
bibliothèques les plus essentielles de Python Si vous êtes intéressé par la science
des données ou l'apprentissage
automatique, alors Nampi est votre point
de départ C'est la base de nombreuses
bibliothèques Python puissantes telles que Bandas, modo Leap et Psyched Learn, qui sont largement utilisées
dans l' NumPi est l'épine dorsale de la manipulation des données et de l'informatique
numérique Il est incroyablement rapide et
efficace pour gérer des tableaux, effectuer des
opérations mathématiques et manipuler des données à Que vous
calculiez des statistiques, créiez
des modèles d'apprentissage automatique ou créiez des simulations, Numpi sera également votre Alors, qui a besoin de Numpi Si vous
visez des postes
tels que data scientist, ingénieur en apprentissage
automatique
ou analyste de données, ces bibliothèques
doivent contenir votre boîte à outils Comprendre Nampi vous
donnera les compétences nécessaires pour gérer des ensembles de données, traiter de grandes quantités de données et établir une base solide
pour des outils plus avancés Ce cours est conçu
pour les débutants, alors ne vous inquiétez pas si vous
débutez. Tout ce dont vous aurez besoin, c'est d'une compréhension
de base de Python et de vous assurer que le bloc-notes ou ID Jupiter tel que Pycharm ou
VSCode, est installé Je vais vous guider étape par
étape à travers tout. Dans ce cours, vous
apprendrez à créer et à
manipuler des rayons, effectuer des opérations mathématiques
et statistiques de base, maîtriser les techniques de base pour travailler efficacement avec
des données. À la fin de ce cours, vous aurez une solide
compréhension de Napi et la confiance nécessaire pour l'utiliser
dans des projets du monde réel Plus important encore,
ces compétences serviront de passerelle
vers la maîtrise de l'analyse de données et d'autres bibliothèques
Python avancées Tout au long de ce cours, je vous
recommande vivement d'adopter une approche
active de l'apprentissage. Au fil de chaque leçon, n'hésitez pas à poser la vidéo et à pratiquer le
code vous-même dans votre bloc-notes Jupiter
ou Pi harm ou Viscod Essayez de réécrire le code que vous voyez à l'écran et
testez-le Testez le fonctionnement de chaque fonction. Modifiez certaines valeurs et
observez les différences entre les résultats. Cette pratique
est essentielle pour vraiment comprendre le fonctionnement de Numpy et se
familiariser avec celui-ci N'oubliez pas que la meilleure façon d'
apprendre la programmation est de le faire. Alors ne vous contentez pas de regarder
tout le temps avec moi. Cela
vous aidera non seulement à renforcer votre confiance, mais vous permettra également de
bien comprendre le concept que nous abordons. Alors plongeons-nous et commençons à
développer ces compétences.
2. Installation Python: Et d'abord, vérifions si Python est déjà
installé sur votre système. Si vous utilisez Windows, vous pouvez le faire en
appuyant sur Wind plus R, en tapant CMD
et en appuyant sur Entrée Dans la fenêtre d'invite de commande, tapez la
commande suivante et appuyez sur Entrée. Et nous y voilà, nous
pouvons voir notre Python. Sur macOS et Linux, nous ouvrons également la fenêtre du terminal et tapons la commande suivante,
puis appuyons sur Entrée. Ne faites pas attention à toutes
ces versions de Python. Nous en parlerons plus tard.
Comme nous pouvons le voir, je n'ai pas la version Python de
commande, mais j'ai la version 3 de Command
Python. Les commandes Python version
et Python version 3 sont utilisées pour vérifier la version de l'interpréteur Python
installée sur votre système. Version Python, la commande traditionnellement utilisée pour vérifier
la version de Python deux, tandis que la version Python trois est spécifiquement utilisée pour vérifier la version de l'interpréteur Python
trois. En général, Python 2 était
utilisé sur les anciens systèmes. Si vous préférez, vous pouvez ajuster configuration de
votre système pour que Python pointe
vers Python 3. Mais je préfère continuer avec la commande Python 3 car
elle est couramment pratiquée. Si vous n'avez aucun Python
sur votre système d'exploitation, nous irons sur le site
python.org et
suivrons les Ici, vous choisissez votre système
d'exploitation et la version
de Python dont vous avez besoin. Je travaille sur macOS et Linux, mais installer Python sous Windows n'est pas beaucoup
plus difficile. Vous téléchargez la
version de Python, puis ouvrez le fichier de téléchargement et suivez les instructions
d'installation Ici, nous pouvons télécharger
Python pour Linux. Si nous passons à
Python, le guide de l'utilisateur des packages Python, je choisis ici didacticiels, puis
l'installation des packages. Nous pouvons voir de nombreuses informations sur la façon de vérifier la version de Python et également sur la manière d'
installer Python sur différents systèmes
d'exploitation. Et ici, vous pouvez remarquer que nous pouvons installer Python
de différentes manières. Par exemple, nous pouvons voir ici
les commandes que nous pouvons utiliser pour installer Python sur un
Bunto ou si nous utilisons macOS, nous pouvons utiliser Homebrew Homebrew c'est un gestionnaire de paquets. Vous pouvez en savoir plus sur son site. Avec ce gestionnaire de paquets, nous pouvons installer Python à
l'aide de cette commande. Mais quelle est la différence ?
Eh bien, en bref, le dossier, Homebrew et le programme d'installation officiel utilisent les différents dossiers
pour l'installation Également mis à jour. Homebrew met
facilement à jour Python vers la dernière version avec une seule commande
Brew upgrade Python Homebrew
gère également les dépendances et
nettoie automatiquement les anciennes versions. Lors de la mise à jour officielle du programme d'
installation, vous devez
télécharger manuellement la nouvelle version depuis le site Web et recommencer le
processus d'installation. L'installation via
le programme d'installation officiel est plus autonome, ce qui peut être utile
dans certains scénarios, mais peut compliquer la gestion des
dépendances et des outils
supplémentaires Et il ajoute souvent icônes
d'applications dans le dossier
des applications. Si je veux voir toutes les versions de
Python, je les ai installées avec la commande
Brew install Python, je peux utiliser la Command
Brew List Python, et je vois immédiatement tous les dossiers et toutes les versions de
Python que j'ai. De plus, je tiens à noter
que l'installation unifiée avec Home Brew est
simple avec une seule commande Brew
Uni Install Python, qui supprime complètement la version installée
de votre système. Bien que la
désinstallation officielle du programme d'installation soit plus complexe et nécessite la suppression manuelle de
fichiers de différents répertoires Quant à moi, Homebrew est plus pratique pour
les développeurs et ceux qui travaillent
fréquemment avec Python et d'autres outils via le terminal Le programme d'installation officiel peut
convenir aux utilisateurs qui préfèrent interférence
minimale avec le système et doivent installer Python
une seule fois pour des besoins spécifiques, et qui n'ont pas l'intention de
mettre à jour ou de gérer
plusieurs versions fréquemment . Il en va de même si nous utilisons
Linux, Ubuntu, peu importe, nous pouvons utiliser Sudo Ogat pour installer
Python ou nous pouvons installer
Python à partir des sources Dans le premier cas, il s'agit la méthode la plus simple
pour installer Python, mais vous ne pouvez installer
que
les versions de Python disponibles dans les référentiels de vos
distributions Lors de l'installation à partir des sources, vous pouvez utiliser toutes les versions de Python, y compris les dernières versions. Maintenant que nous avons compris
comment installer Python et la différence entre les méthodes
d'installation, passons à l'
apprentissage de Python lui-même. J'ouvre le terminal et je tape
la commande Python. L'une des caractéristiques uniques de Python
est son mode interactif, qui vous permet d'exécuter du code et de
voir immédiatement les résultats. Cela est rendu possible par
l'interpréteur Python, un programme qui lit et
exécute le code Python Lorsque vous installez Python
sur votre ordinateur, celui-ci inclut un interpréteur
interactif connu sous le nom de boucle Apple
RedeValvePre Il vous permet de saisir le code une ligne à la fois et de
voir le résultat instantanément. En utilisant le mode interactif, vous pouvez rapidement tester différents extraits de code et
voir le résultat immédiatement Pour quitter le mode interactif, utilisez la commande exit. Eh bien, nous avons vu le
mode interactif dans le terminal, mais nous avons également
plusieurs outils qui nous
aident à écrire du code
plus efficacement. Jetons-y un coup d'œil.
3. Installation d'Ide: Aujourd'hui, nous allons examiner
les outils qui rendent codage plus facile et
plus efficace. Les trois éditeurs de code les plus couramment
utilisés sont PyCharm, Visual Studio Code
et Jupiter Notebook Lequel tu vas
choisir, c'est à toi de décider. Le premier, Pycharm. Il existe plusieurs options
communautaires et professionnelles. Cette idée est spécifiquement
conçue pour Python, mais vous pouvez également utiliser
d'autres langages. C'est comme une boîte à outils
pour les développeurs Python. Vous pouvez télécharger
BiHarm Community. C'est totalement gratuit,
et pour être honnête, c'est suffisant pour la première fois. Le processus d'installation
ne prend pas beaucoup de temps. Nous téléchargeons le fichier et
suivons les instructions. Il existe de nombreuses fonctionnalités
telles que les outils de débogage, la gestion de
projet, les suggestions de
code Très utile. C'est mieux pour les grands projets
où vous
devez tout
organiser et efficace. Ensuite, nous avons le code Visual Studio. Il s'agit d'un éditeur de
code léger qui prend en charge de nombreux
langages de programmation, dont Python. Après avoir téléchargé le fichier, ouvrez-le en double-cliquant dessus. Cela permettra d'extraire l'application de code Visual
Studio. Faites glisser l'application de
code Visual Studio dans votre dossier d'applications, et voilà, cela
installe le code VS sur votre Mac Ici, vous pouvez créer un dossier
Fichier ouvert ou afficher
les fichiers récemment ouverts . Ici, nous pouvons
voir plusieurs onglets. Aucun dossier n'a été ouvert. L'onglet apparaît lorsque vous n'avez pas
ouvert de dossier pour Workspace. Il vous invite à ouvrir un dossier pour commencer à
travailler sur un projet Lorsque vous ouvrez un dossier, cet onglet disparaît et les fichiers qu'il
contient s'affichent. L'onglet Ouvrir l'éditeur affiche la liste de tous les fichiers que vous
avez actuellement ouverts dans l'éditeur. Ici, nous pouvons créer un nouveau
fichier à partir de zéro. L'onglet Outline fournit une vue structurée
telle que les fonctions, les variables et les classes
du fichier actuellement ouvert. Il vous permet de
naviguer rapidement dans votre code en accédant à
différentes parties du fichier. Si vous le souhaitez, vous
pouvez également masquer ces onglets. C'est parfait si vous
travaillez sur différents types de projets et que vous souhaitez un éditeur flexible
et tout-en-un. Il est très facile à installer
et à utiliser. Ensuite, nous avons le carnet Jubi. Il s'agit d'un outil basé sur le Web. Vous pouvez l'utiliser pour la
science des données et la recherche. Il vous permet d'écrire et d'
exécuter du code en petits morceaux, et vous pouvez immédiatement
voir les résultats Cela ressemble à un mode interactif, sauf
que cet outil est
idéal pour créer des documents
interactifs combinant code, texte et visualisation. Ordinateur portable Jupiter, vous pouvez
l'installer de différentes manières. Jupiter
en utilisant Anaconda et Conda ou vous avez une alternative,
vous pouvez installer Jupiter avec gestionnaire de packages
PIP si vous
choisissez d'utiliser Anaconda.
Il installe donc Python
et Jupiter Notebook ainsi que
d'autres adresses
de balise couramment utilisées pour l'informatique et d'autres adresses
de balise couramment utilisées pour Installez Jupiter
en utilisant Anaconda et
Conda ou vous avez une alternative,
vous pouvez installer Jupiter avec le gestionnaire de packages
PIP si vous
choisissez d'utiliser Anaconda.
Il installe donc Python
et Jupiter Notebook ainsi que
d'autres adresses
de balise couramment utilisées pour l'informatique et la science des données spécifiques. Vous avez donc le tout en un. Mais pour commencer, vous pouvez vous débrouiller avec le bloc-notes Jupiter en
l'installant à l'aide de PIP. Tu peux utiliser ce que tu veux. C'est à vous de décider dans ce cours, j'utiliserai le code Visual Studio. Eh bien, après toute
cette préparation, commençons à écrire le code.
Rendez-vous dans la prochaine leçon.
4. NumPy pour les débutants : ce que c'est et pourquoi c'est essentiel: Bonjour, les gars. Aujourd'hui,
nous allons discuter d'une bibliothèque fondamentale pour les
spécialistes travaillant avec des données. Nampi est une bibliothèque populaire pour le
calcul scientifique en Python Il sert de base de nombreuses bibliothèques importantes en Python utilisées pour le
traitement et l'analyse des données. Ces bibliothèques incluent Pandas, qui est utilisée pour travailler avec données
tabulaires et résoudre des tâches d'analyse de
données, ainsi que MD Blot
Leap et Seaborn,
qui sont utilisées pour la visualisation des données et qui sont utilisées pour Vous connaissez
peut-être déjà ces bibliothèques. Sinon, je recommande de faire
connaissance avec eux. Vous pouvez
trouver des tutoriels dans mon profil. Sci Pi, une autre bibliothèque clé fournit des fonctions pour le calcul
scientifique, telles que l'optimisation, l'
approximation, l'intégration, etc. Psyched Learn et de nombreuses
autres bibliothèques de
l' écosystème Python
s'appuient largement sur Nampi en tant que bibliothèque
fondamentale NumPi sert de base à
de
nombreuses
bibliothèques de calcul scientifique et d'analyse de
données en Python, fournissant des opérations
numériques efficaces, des structures de
données optimisées pour la
mémoire et une intégration parfaite avec les
autres bibliothèques
de l'écosystème Cette bibliothèque offre une
diffusion et des affichages efficaces, permettant des opérations sur une matrice
sans créer de nouvelles copies. Cela permet de réduire l'utilisation de la mémoire
et d'améliorer les performances. Numbi fournit une structure de données
puissante, tableaux qui permettent de
représenter de grandes matrices et vecteurs ainsi qu' un ensemble de fonctions pour travailler
efficacement avec eux Le principal avantage
de NumPi réside dans sa rapidité de calcul
par rapport aux listes Python Ceci est possible parce que tous les
éléments du tableau Numpi ont le même type de données et
grâce à l'utilisation d' mémoire
compacte et opérations mathématiques
optimisées Passons donc aux principales caractéristiques
et avantages de
l'umpi notamment une
vaste collection de fonctions
mathématiques qui
fonctionnent efficacement sur les rayons La capacité de manipuler grands ensembles de données sans surcharge de mémoire
excessive, renforcement de la prise en charge de
la lecture et de l'écriture données
matricielles vers et depuis
différents formats de fichiers, charge des transformations
rapides du faussaire, cruciales pour le traitement
du signal, traitement d'
images et d'autres applications
scientifiques, puissantes capacités d'indexation et de
découpage de
grands ensembles de données sans surcharge de mémoire
excessive, le
renforcement de la prise en charge de
la lecture et de l'écriture de données
matricielles vers et depuis
différents formats de fichiers, la prise en
charge des transformations
rapides du faussaire,
cruciales pour le traitement
du signal, le traitement d'
images et d'autres applications
scientifiques, de
puissantes capacités d'indexation et de
découpage, permettant
sélection et manipulation de
sous-ensembles de tableaux NumPi peut être utilisé pour
résoudre un large éventail de tâches telles que les opérations
mathématiques, traitement du
signal et de l'image, la simulation
scientifique, la génération de
nombres aléatoires Oui, Numpi fournit des
fonctions permettant de générer des nombres aléatoires
avec différentes distributions Analyse et manipulation des données. Les rayons NumPi peuvent être utilisés pour des tâches telles que le
tri, le filtrage
et le remodelage des données, qui sont souvent conditions préalables à l'analyse des données
et aux et Apprentissage automatique
et apprentissage profond. Numpi fournit la structure de données
sous-jacente et les opérations requises
pour ces tâches Nampi s'intègre parfaitement de nombreuses autres bibliothèques de
calcul scientifique en Python, telles que Pandas, Md Lloyd Leap et Sigi Learn, ainsi un
écosystème riche pour l'analyse des données, visualisation Cette liste met en évidence la
polyvalence de Nampi et sa capacité à traiter un large éventail de tâches dans les domaines du calcul
scientifique, analyse de
données, de
l'apprentissage automatique, etc., ce en
fait une bibliothèque fondamentale de l'écosystème PyTon Passons donc
à son installation.
5. Qu'est-ce qu'un tableau ? Différentes façons de créer des tableaux dans NumPy: Tout d'abord, assurez-vous que NAPA est déjà installé dans
votre environnement Python. Qu'est-ce qu'un environnement Python ? Il vous permet de basculer entre plusieurs versions de Python dans différents environnements de travail sans erreur ni conflit. C'est un outil très utile, et je recommande vivement de l'utiliser. Vous pouvez découvrir comment cela
fonctionne dans ma vidéo bonus. Si vous ne savez pas ce qu'
est
un environnement virtuel ni comment l'
utiliser, ne vous inquiétez pas. Tu n'en as pas besoin pour le moment. Vous pouvez simplement ouvrir le terminal et travailler sans activer d'environnement virtuel en exécutant des commandes directement
dans le terminal. Étant donné que d'autres bibliothèques peuvent installer automatiquement Numpi, vous pouvez vérifier s'il est
déjà présent en exécutant la commande suivante dans l'invite de
commande ou le terminal Bip show Numpi. Si vous recevez une réponse avec le chemin spécifié
vers la bibliothèque, numpi est déjà installé Sinon, pour installer Numpi,
nous utilisons la commande suivante. Installez Numpi par bip. Cette commande
téléchargera et installera automatiquement Numpi
depuis le dépôt Python Une fois l'installation réussie,
vous pouvez utiliser Numpi pour des calculs numériques
et travailler avec des rayons de données Il est recommandé de
mettre régulièrement à jour vos bibliothèques, y compris Mupi, pour obtenir nouvelles fonctionnalités et
corriger d'éventuels problèmes. Pour ce faire, utilisez la commande
suivante, peep Install, upgrade Numpi Je vais l'exécuter aussi, il est
temps pour moi de le mettre à jour également. Cette approche
vous permettra de toujours disposer
des dernières versions de
Numpi pour vos projets Passons maintenant à la
pratique et commençons à nous
familiariser avec l'élément
principal de cette bibliothèque, le tableau de données. Un tableau Numpi est la structure de données de
base qui distingue numpi des listes
Python classiques En bref, il s'agit d'un tableau d'
éléments du même type, qui peuvent être des entiers, des flottants, valeurs
logiques,
des chaînes, etc. Les tableaux Numpi sont
multidimensionnels. Ils prennent généralement la
forme d'un vecteur ou d'une matrice, mais ils peuvent avoir un
nombre arbitraire de dimensions. Le nombre de dimensions
et la forme d'un tableau sont
définis lors de sa création, mais peuvent être modifiés ultérieurement. Les éléments d'un tableau
sont représentés numériquement et stockés de manière compacte et
optimisée dans la mémoire,
ce qui garantit une vitesse de
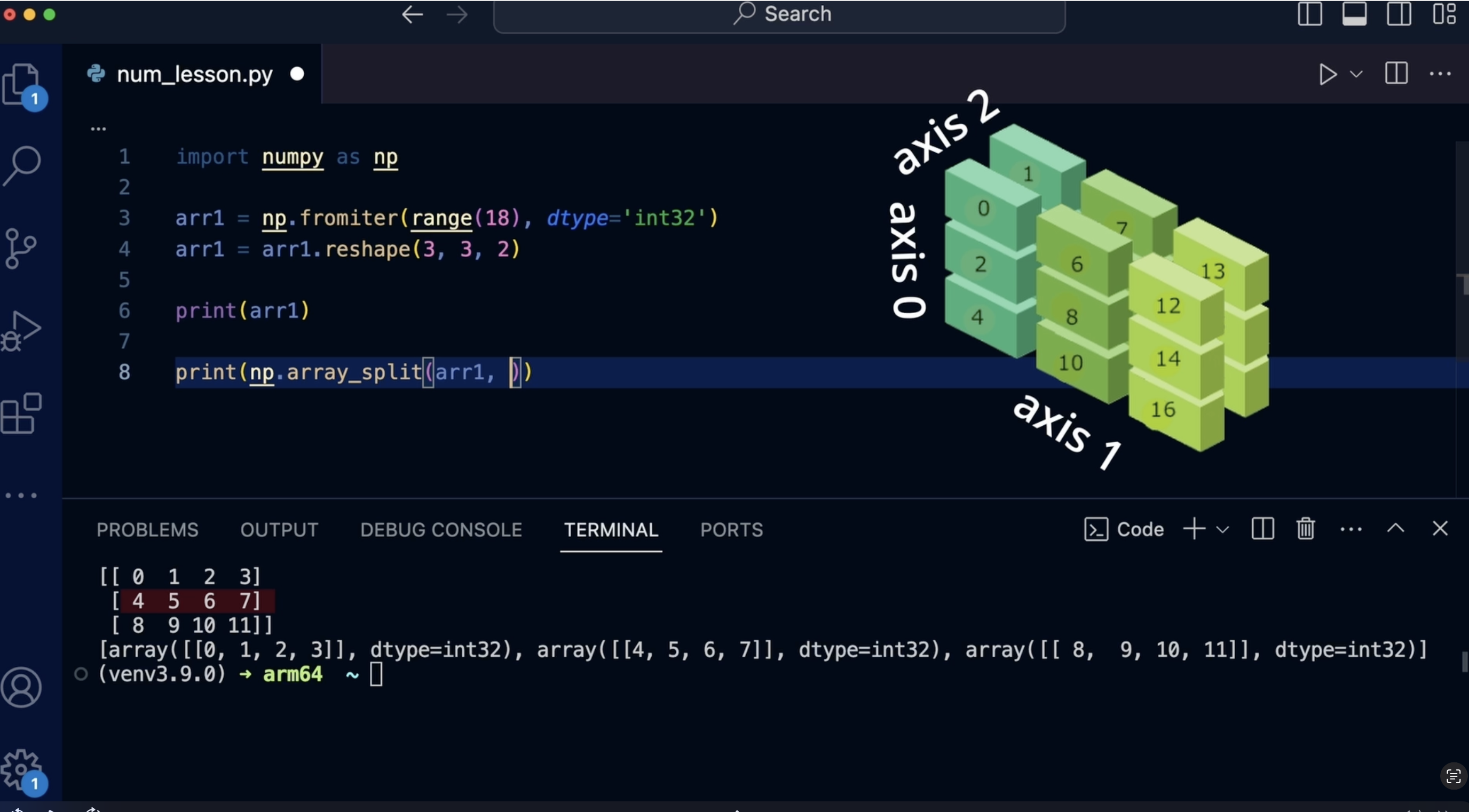
calcul élevée Dans l'axe numpi, aidez-nous à comprendre la direction dans laquelle les données
sont organisées dans un tableau Vous pouvez considérer un axe comme
une direction spécifique le long de
laquelle les valeurs sont disposées. Chaque tableau numpi possède une
ou plusieurs dimensions ou axes, selon le nombre
de niveaux d'organisation dont il dispose Voici une façon simple
d'y réfléchir. Un tableau unidimensionnel, un vecteur n'a qu'un seul axe. Cet axe représente
la séquence de nombres dans le tableau. Imaginez une simple liste de chiffres allant de
gauche à droite. Tableau bidimensionnel,
une matrice possède deux axes. Un axe s'étend verticalement de haut en bas et représente
le nombre de lignes. L'autre axe
s'étend horizontalement, de
gauche à droite, et représente
le nombre de colonnes. Par exemple, imaginez un
tableau dans une feuille de calcul. Les lignes et les colonnes constituent
les deux axes des données. Lorsque vous travaillez avec des données
plus complexes, vous pouvez avoir au moins
trois dimensions dans lesquelles des axes supplémentaires représentent différents niveaux
d'organisation. Les tableaux Numpy sont utilisés dans le calcul
spécifique, l'analyse de
données
et l'apprentissage automatique, car ils stockent et traitent efficacement de grandes quantités de données
numériques Il est important de comprendre les axes car de nombreuses fonctions numpi appliquent des opérations le long d'un axe spécifique, ce qui facilite la manipulation des données En raison de ces propriétés, NumpiRay sont largement utilisés
dans le calcul spécifique, analyse de
données et l'apprentissage
automatique Ils fournissent une représentation compacte et efficace
des données numériques Maintenant, importons
Numpi, bien sûr, nous allons définir un alias Cela le rend plus pratique. Au lieu d'écrire
le nom complet NPi, nous pouvons à
chaque fois simplement
utiliser les deux lettres NP L'utilisation de NP comme alias permet de gagner du temps et
de rendre le code plus lisible. Passons maintenant à la
création d'un tableau d'arbitres. Examinons les méthodes de base pour
générer des tableaux
pour des travaux ultérieurs Nous allons commencer par créer des
tableaux à partir d'une liste Python. Que sont les listes Python ? Les listes Python sont l'un des
types de données de construction qui permettent de stocker des séquences
ou des listes d'autres objets. Par exemple, créons une liste A contenant
uniquement des chiffres. Cependant, vous devez
comprendre que la liste peut contenir des
éléments de différents types, des
nombres, des chaînes, d'autres
listes, il peut s'agir d'objets. Pour le démontrer,
j'ai également créé une liste B contenant des types de données
mixtes. Principales fonctionnalités des listes Python. Les listes sont ordonnées. Chaque élément possède une position d'
index spécifique dans la liste. Ce type de données est également dynamique. Leur longueur (nombre d'éléments peut changer au cours de l'exécution
du programme. Les éléments sont accessibles par index. L'indexation commence à zéro. Par exemple, pour accéder au premier élément de
la liste A, nous utilisons A zéro dans la notation de
rupture. Cela permet de récupérer le
premier élément, qui est à l'indice zéro Les listes peuvent également être itérées
à l'aide de boucles, mais nous en parlerons
plus en détail dans une prochaine
vidéo sur Python La différence entre les listes
Python et Nampirays réside dans le fait que les listes sont pratiques pour stocker des
données de différents types Cependant, les tableaux Numpy sont conçus pour ne stocker qu'
un seul type de données,
ce qui permet une meilleure optimisation de Dans les listes Python, le stockage plusieurs types de données entraîne une consommation de mémoire
plus élevée. Ce n'est pas un gros
problème pour les petites listes, mais lorsqu'il s'agit
de grands ensembles de données, l'utilisation de listes régulières
peut s'avérer inefficace C'est là que
les siestes sont utiles. Nous allons donc râper un
tableau d'arbitres à partir d'une liste Python. Un tableau d'arbitres peut être facilement initialisé à partir d'une liste
Python normale Pour ce faire, nous utilisons la fonction
array et passons R list A en argument,
mais ce n'est pas tout. Comment les nombres sont-ils
stockés dans mpiarray ? Pour vérifier le type
de données des éléments du tableau, nous pouvons utiliser le type D. Si nous voyons en 64, cela signifie que le tableau
utilise des entiers de 64 bits, ce qui permet de stocker des valeurs très
petites à très grandes Dans le type Num Pi et le type D, reportez-vous à différents concepts. Type indique le type
de l'objet lui-même. Par exemple, le type class, NumPi ou A. D, abréviation de type de données indique le type de données des
éléments du tableau, et nous devons nous souvenir de
cette différence Que se passe-t-il si nous créons
un tableau à partir de la liste B, qui contient
différents types de données ? Voyons voir. Même si B
contient différents types de données, Num Pi convertit tous les éléments en un seul type de données
pour plus d'efficacité. Par exemple, si B contient
à la fois des nombres et des chaînes, Num Pi convertit
tout en chaînes. Il se peut que le type D soit égal à U 21, ce qui signifie que
le tableau contient des chaînes
Unicode d'une
longueur maximale de 21 caractères. U est l'abréviation de chaîne Unicode. 21 indique la
longueur maximale de 21 caractères
de chaque élément. Si une chaîne dépasse cette longueur, elle sera tronquée Cela permet à NumPi de stocker et de
traiter
efficacement les données des tableaux Maintenant que nous comprenons comment tableaux
Numpi gèrent les types de données, passons aux opérations de tableau plus
avancées
6. Découpe de tableaux NumPy: Le type de données dans le tableau
NMP étant fixe, mélange de différents
types n'est pas autorisé Lorsqu'une liste contenant des types de données
mixtes est convertie en tableau numérique, tous les éléments sont automatiquement convertis en un type commun Nampi fournit plusieurs fonctions
pratiques
pour générer des rayons sans
spécifier manuellement chaque élément La fonction Arrange crée un tableau avec une
plage de valeurs spécifiée. Par exemple, si nous voulons
un tableau allant de cinq à dix, en excluant dix, nous écrivons function range et plus cinq pour le premier argument
et dix pour le second. Puisque dix n'est pas inclus, la dernière valeur
du tableau est neuf. Numpy dispose d'une variété de fonctions
pratiques pour
générer des tableaux
selon des règles spécifiées sans nécessaire
de
spécifier manuellement chaque élément Pour cela, il existe
la fonction range. Grâce à lui, nous pouvons créer
un tableau unidimensionnel, commençant par cinq, par exemple, et en allant jusqu'à dix, mais sans compter dix. Il existe également la fonction
zéros, qui crée un tableau
unidimensionnel de zéros Créons un
tableau de taille quatre. Et nous obtiendrons quatre zéros. Ou il existe une fonction
similaire aux zéros, mais à la place, nous obtiendrons un tableau
unidimensionnel d'une fois Il y a des moments où
vous devez spécifier le type de données
du tableau dès le début. Pour cela, nous utilisons la fonction array avec plus le paramètre de type
D. Par exemple, créons
un tableau unidimensionnel de type Floyd et imprimons
ce que nous avons obtenu Ces points indiquent que nous
n'avons pas que des chiffres,
mais des nombres à virgule flottante. Si nous exécutons le type D, nous confirmerons qu'actuellement tous nos éléments
sont de type float. Je vais maintenant supprimer les lignes
inutiles et supprimer la fonction d'impression. L'indexation dans un tableau Nampa fonctionne de la
même manière que les listes Python, permettant d'accéder à
des éléments spécifiques en fonction de leur position
dans le De même, nous pouvons prendre des
tranches du tableau. Par exemple, prenons les éléments du tableau
depuis le tout début, mais sans
inclure l'index deux. N'oubliez pas que l'indexation en
Python commence à zéro. Le premier élément du
tableau a donc un indice zéro. Lorsque nous écrivons le nom du
tableau suivi d'une colonne, puis que nous
spécifions un index, cela signifie qu'il faut prendre les éléments depuis le tout début
du tableau jusqu'à l'index spécifié, mais sans inclure
l'index spécifié. Nous prenons la plage allant
du premier élément, indice zéro, jusqu'à l'
indice un inclus. En effet, en Python, les limites des
plages sont toujours spécifiées comme
inclusives, exclusives. C'est ainsi que fonctionne le découpage dans les listes Python
et dans les tableaux numpy L'écriture d'un tableau comme
celui-ci renverra les éléments de l'index
zéro à l'index un. Nous allons donc obtenir deux éléments, la valeur un et la valeur deux. Changeons la tranche
et prenons les éléments du deuxième index jusqu'à
la fin du tableau. Ici, deux est l'indice à partir duquel la tranche
commence inclusivement, suivi d'une colonne,
qui sert délimiteur indiquant les limites de
la tranche Après la colonne,
il n'y a rien, ce qui signifie que nous prenons
les éléments jusqu'à la
fin du tableau. En conséquence, nous avons obtenu
les éléments trois et quatre. Si nous spécifiez un index qui
n'existe pas, par exemple l'index quatre, nous obtiendrons une erreur car l'index trois est le
dernier élément du tableau. découpage en numpi nous
permet d'extraire un sous-ensemble d'un tableau en utilisant une plage d'indices
spécifiée Cela est particulièrement utile pour la manipulation et l'analyse
des données, car cela permet de
sélectionner et
de modifier efficacement les éléments du tableau sans
créer de copies inutiles.
7. Comprendre les propriétés des tableaux et les techniques d'indexation avancées: Créons maintenant un tableau
bidimensionnel. Comment pouvons-nous trouver des
informations sur la forme et les dimensions
du tableau Nampa ? Nous ne compterons pas les éléments
manuellement, bien entendu. Il s'agit d'une
fonction appelée shape, qui renvoie
quelques nombres correspondant à la taille
du tableau dans chaque dimension. Par exemple, pour la matrice
trois par trois que nous venons de créer, nous avons obtenu le résultat suivant. Le long du premier axe, nos lignes, nous avons le chiffre trois,
et le long du deuxième axe, nos colonnes, nous
avons également le chiffre trois. Je vais maintenant modifier le tableau
et ajouter d'autres dimensions. Faites attention à la sortie
de la fonction de forme. Nous avons ajouté d'autres éléments, et nous avons maintenant un tableau
tridimensionnel de taille, deux par trois par trois. N'oubliez pas que la différence
entre une matrice et un tableau réside dans le fait qu'une matrice est la
spécialisation d'un tableau. Il a strictement deux dimensions. Le tableau, cependant, peut
être multidimensionnel. Alors allons-y, et la fonction
suivante est DM. Cette fonction renvoie un
nombre correspondant
aux nombres de xs ou aux
dimensions du tableau. Nous avons ici DM égal à trois. En utilisant également la fonction size, nous pouvons déterminer
le nombre total d'éléments dans le tableau. Dans notre cas, nous
avons 18 éléments, ce qui est correct, puisque multiplier deux par trois
par trois donne 18 Si vous devez
initialiser rapidement un tableau ampi de la forme
souhaitée et le remplir
avec une valeur spécifique, vous pouvez utiliser la fonction complète Cette fonction
nous permet de créer un tableau en spécifiant la forme
sous la forme d'un tuple d'entiers, qui détermine le nombre
d'éléments le long de chaque axe Le deuxième paramètre est la
valeur qui remplit le tableau. Il existe également un
troisième paramètre facultatif de type D, qui spécifie le
type de données des éléments du tableau. Pour mieux comprendre et atténuer, décomposons notre tableau. Nous pouvons voir qu'il
se compose de deux matrices, chacune ayant une dimension
de trois par trois. Nous avons donc un tableau
tridimensionnel de taille deux par trois par trois. En tranchant de 0 à 1, nous extrayons une partie du tableau
tridimensionnel Cette expression
sélectionne un sous-tableau, commençant par l'index
zéro inclus et se terminant à
l'index un exclusif. Par conséquent, nous
n'obtenons qu'une seule couche de plan à partir de
notre matrice tridimensionnelle, qui est une matrice composée de trois lignes et de trois colonnes. Passons maintenant du découpage
à l' imbrication et spécifions-en Nous procédons ainsi pour sélectionner
la deuxième ligne de la matrice que nous venons d'
extraire en utilisant l'indice zéro. L'index 1 sélectionne
la deuxième ligne. Comme l'indexation en Python
part de zéro, cette opération renvoie
la deuxième ligne de la première matrice de notre tableau
tridimensionnel Cet exemple illustre fonctionnement de l'indexation et de l'extraction de
sous-réseaux
dans des tableaux tridimensionnels à n pi Je veux également montrer un autre
moyen d'obtenir le même résultat. Modifions légèrement
la notation et obtenons le même
résultat dans Napi Ces deux notations
sont équivalentes, mais la différence réside dans implémentation
interne
et la rapidité d'exécution La deuxième variante
est généralement plus rapide car Numpi
gère efficacement les axes du tableau Dans la première variante, nous
effectuons deux excès
consécutifs Tout d'abord, extrayez un
sous-tableau en utilisant zéro, puis en extrayant un élément
de ce sous-tableau en utilisant Cette approche peut entraîner des frais
supplémentaires. La principale différence
réside dans l'indexation. Le second cas utilise une
seule opération d'indexation, tandis que le premier nécessite deux opérations
consécutives Dans la plupart des cas, il est recommandé d'utiliser la deuxième variante comme nous l'avons fait, car elle est plus efficace en termes de
rapidité et plus facile à utiliser. Maintenant, je vais
modifier légèrement notre tableau, en changeant les numéros
de la dernière matrice, la seconde, afin que vous puissiez
clairement voir la différence. Si nous indiquons un
indice de moins un, nous indiquons que nous voulons récupérer la dernière
couche du tableau. Cette expression
sélectionne la dernière couche de notre tableau tridimensionnel, quel que soit le nombre de couches que contient le
tableau multidimensionnel Dans notre cas, nous allons
récupérer la deuxième matrice, puisque nous n'en avons que deux. Si vous avez un tableau
multidimensionnel avec plusieurs couches imbriquées, moins une, nous
sélectionnons toujours la dernière Et ici, array moins un
renverra ce qui suit. Dans notre cas, cela équivaut
à utiliser l'index 1. Mais l'utilisation de moins
un rend le code plus flexible car
il n'est pas nécessaire spécifier le
nombre exact de couches dans le tableau. Si nous ajoutons un autre
index séparé par une virgule, il sera utilisé pour accéder à une ligne spécifique de
la dernière couche C'est-à-dire que dans notre matrice, nous allons sélectionner la deuxième ligne, dont l'indice est égal
à un dans la deuxième matrice. Passons maintenant à la pratique. Mettez la vidéo en pause et essayez de
sélectionner différents
éléments dans ce tableau. Essayez d'extraire la dernière
ligne de la première matrice. Puis la première ligne
de la dernière matrice. La pratique est la clé
de la compréhension. La théorie seule ne suffit pas. Plongons plus en profondeur dans la nidification. Maintenant, extrayons le
troisième élément de la ligne. Dans notre cas, c'est 16
avec un indice de deux. En ajoutant simplement un index, nous récupérons le troisième élément, qui a un indice de deux. Ici, nous obtenons la valeur 16. Cette notation est équivalente à une autre que
je vous rappelle. Mettez la vidéo en pause et
essayez de récupérer le premier élément de la dernière ligne du dernier
élément de notre tableau, qui est notre deuxième matrice. J'espère que tu as réussi. Je vais laisser moins un tel
quel pour sélectionner le dernier
élément de notre tableau. Ensuite, nous devons prendre la
dernière ligne de cet élément, alors spécifiez à nouveau moins un. De cette façon, nous sélectionnons
la dernière ligne. Ensuite, nous prenons le premier élément. Puisque l'indexation commence à zéro, nous spécifions zéro, et
nous obtenons ici notre numéro 17 Ajoutons maintenant un troisième
élément à notre tableau. Si nous spécifiez maintenant
un indice de moins un, nous ne récupérerons que l'
élément qui vient d'être créé. Parfois, nous devons extraire une tranche de sous-réseau de notre tableau
multidimensionnel Alors laissez-moi vous montrer comment cela fonctionne. Nous en ajoutons un et une colonne après le sous-tableau
précédemment sélectionné, ce qui signifie que nous
prenons une tranche Dans notre notation,
nous voyons moins un, ce qui indique la dernière
couche du tableau, la dernière matrice dans notre cas. Celui et la colonne. Cette partie signifie que cela
commence à partir de l'index de ligne 1, inclus et jusqu'à
la fin des lignes. Dans ce dernier élément,
nous sélectionnons tout. Maintenant, prenons une autre tranche à partir de la portion
sélectionnée. Je précise la tranche du
premier au dernier élément. Cela extrait essentiellement
une tranche d'un sous-tableau. Si, au lieu d'une tranche, nous devons récupérer
uniquement les éléments ayant un indice de un pour
chaque ligne de la tranche. Il suffit d'en spécifier un et d'obtenir deux
éléments d'indice un. Maintenant, au lieu de sélectionner
uniquement les premiers éléments, prenons une tranche
du sous-tableau composée des deux premiers
éléments de chaque ligne. Il doit contenir les valeurs 14, 115, 116 et 118. Publiez la vidéo et
essayez de le faire vous-même. Nous spécifiez les diapositives de
l'index zéro à l'index deux, excluant, ce qui signifie que nous sélectionnons les éléments avec les indices
zéro et un. Nous avons donc pris le dernier élément de nos matrices avec
un indice moins un. Ensuite, nous avons obtenu la tranche de tableau de l'index
un à la fin. Enfin, nous avons
obtenu la tranche de ce tableau de l'indice de
zéro à l'indice de deux. Et voici notre résultat.
8. Techniques essentielles pour la création et la transformation de tableaux NumPy: Maintenant, je vais supprimer les pièces
inutiles. Enfin, familiarisons-nous
avec la fonction vide. Il existe une situation où
nous devons créer un tableau de taille
spécifiée et
le remplir ultérieurement avec les valeurs. Par exemple, j'ai créé un tableau tridimensionnel à
l'aide de cette fonction. Cependant, il est important de
se rappeler que les tableaux
créés à l'aide la fonction vide peuvent contenir des données
aléatoires provenant de la mémoire Lorsque vous créez un tableau à l'aide de la
fonction vide dans Napi, celui-ci ne contient pas de zéros ni de valeurs
spécifiques Au lieu de cela, il prend
toutes les données prêtes dans la
mémoire de l'ordinateur à ce moment-là. Cela signifie que le tableau peut contenir des nombres
aléatoires ou inattendus
lors de sa création initiale. Pour cette raison,
vous devez toujours attribuer des valeurs au
tableau avant de l'utiliser. Dans le cas contraire, vos
calculs risquent donner des résultats incorrects ou
imprévisibles. Pour créer un tableau
unidimensionnel avec des valeurs réparties uniformément
dans une plage spécifiée, nous utilisons in space. Le premier paramètre
de la fonction définit la
valeur de départ de la plage. Le deuxième paramètre définit la valeur finale de la plage, et le troisième
paramètre indique le nombre d'éléments ou de
points que vous souhaitez obtenir. J'ai créé un tableau
de quatre nombres, répartis
uniformément de
3 à 40 inclus Ou créons un tableau de 40 nombres de la même plage. Cette fonction est utile
lorsque vous devez
créer des
valeurs réparties uniformément, par exemple
pour générer un
vecteur de valeurs, pour tracer des graphiques ou effectuer d'autres tâches
analytiques Vous spécifiez le nombre de
points dont vous avez besoin et les valeurs de plage
que vous
souhaitez couvrir. Très pratique Ajoutons quelques nombres
négatifs à notre tableau car j'en aurai
besoin pour le prochain exemple. Faisons maintenant connaissance
avec la fonction absolue. Cette fonction de la bibliothèque
num pi est utilisée pour calculer les
valeurs absolues des éléments du tableau. Il retourne dans un tableau où chaque valeur est convertie
en valeur absolue. Cela est utile dans de nombreux cas, exemple pour placer des valeurs
dans une plage positive ou simplement obtenir des valeurs absolues pour une analyse plus approfondie des données. Nous avons affiché notre tableau, et maintenant nous voyons qu'il
y a des nombres négatifs. Cependant, après avoir appliqué
la fonction absolue, les signes négatifs sont supprimés. Nous ne voyons donc ici que
des valeurs positives. La fonction diag de la
bibliothèque Napi est utilisée pour créer une matrice carrée avec des valeurs
spécifiées sur
la diagonale principale Dans notre cas, trois, quatre et cinq sont transmis en tant qu'argument de liste
à la fonction. Cette liste contient
les valeurs que vous souhaitez placer sur la
diagonale principale de la matrice. Le résultat sera
une matrice carrée laquelle la diagonale principale contient les valeurs spécifiées tandis que tous les autres
éléments sont des zéros Vous obtiendrez le même résultat avec la fonction diag flag. Mais la différence est que
diag flag aplatit d'abord la liste d'entrée en un tableau unidimensionnel
, puis la place sur
la diagonale Donc, si nous avons un
tableau comme celui-ci, diag flag le produira sous forme matrice diagonale avec tous les
autres éléments mis à zéro Dans cet exemple, nous n'avons
spécifié qu'un seul argument, qui indique la
dimensionnalité de la matrice carrée six
par six dans notre cas La matrice résultante
formera un triangle ou motif avec ceux situés en dessous et à gauche de
la diagonale principale, tandis que tous les autres
éléments resteront nuls. Si je spécifie deux arguments, le premier paramètre définit le nombre de lignes
de la matrice, six dans notre cas, et le second paramètre définit
le nombre de colonnes. Deuxièmement, dans ce cas, la matrice
résultante
formera à nouveau un triangle avec ceux dessous et à gauche
de la diagonale principale, comme dans le premier cas, tous les autres éléments
restant nuls, nous pouvons expérimenter et
modifier sa forme. Il est couramment utilisé
dans l'algèbre linéaire et les opérations matricielles, telles que la résolution d'équations
et l'application de masques aux données
9. Techniques de visualisation de la manipulation des tableaux NumPy, de copie, de remodelage et d'aplatissement: Pour le prochain exemple, je vais créer le tableau
unidimensionnel simple. Faisons connaissance
avec la fonction d'affichage. Il est utilisé pour créer un tableau qui fait référence à notre tableau
nouvellement créé, ce qui signifie que les deux tableaux font
référence aux mêmes données, mais ont des formes différentes Je vais vous expliquer comment cela fonctionne. Toute modification apportée à
un tableau sera reflétée dans l'autre
car il s'agit de deux tableaux stockent des références
au même objet de données Il est important de noter que la fonction view ne
crée pas de copie du tableau. Au lieu de cela, il génère
un nouvel objet qui fait référence aux mêmes données. Pour le démontrer, je vais
modifier le dernier élément
du premier tableau
et le définir sur un. Par conséquent, le changement
apparaît dans les deux tableaux. Alors pourquoi avons-nous besoin de
cette fonction ? Vous pouvez rencontrer des situations dans votre projet
où une variable obtient une référence
au même objet de données
auquel une autre variable fait référence. Même sans changer l'
élément de votre premier tableau, nous pouvons modifier sa forme. Les données restent les mêmes. Nous ne faisons que modifier sa forme. Nous pouvons faire en sorte qu'un tableau
unidimensionnel apparaisse comme un tableau
bidimensionnel. Si nous vérifions ensuite le deuxième rayon, qui fait référence au même objet, nous verrons que sa forme
a également changé. Dans les projets de grande envergure, cela peut
entraîner des erreurs inattendues, en particulier si une fonction attend
un tableau unidimensionnel, mais qu'en raison de
modifications involontaires, elle reçoit un tableau bidimensionnel ou même
tridimensionnel à la place Dans de tels cas, nous utilisons la fonction de visualisation pour garantir manipulation
contrôlée
de la structure des données. Il ne suffit pas de créer
une autre variable et de faire
référence au même
objet de données. Lorsque nous utilisons la fonction view, nous nous assurons de ne
modifier que l'apparence
du tableau tout en conservant la même référence
à l'objet de données. Maintenant, si nous refaçonnons
notre premier tableau, cela n'affectera pas du tout le
second tableau Cependant, si nous créons un
tableau en utilisant la méthode copy, nous générerons un clone complet et dépendant
du tableau d'origine. Le second tableau
sera complètement
séparé de l'original
contenant les mêmes données, mais existant en tant qu'objet
propre en mémoire. Au moment de l'adaptation, les deux tableaux ont un contenu
identique, mais toute modification supplémentaire apportée à l'un n'
affectera pas l'autre Nous pouvons le voir clairement. Après avoir modifié le dernier
élément de notre premier tableau, le second tableau
reste inchangé. Je vais supprimer les pièces inutiles. Et imprimez le tableau précédent juste pour vous rappeler à quoi il ressemblait. Pour modifier la façon dont
Nampa interprète les indices des éléments dans un tableau sans modifier
les données elles-mêmes, nous pouvons utiliser la fonction shape Si nous refaçonnons le tableau en 27, nous obtiendrons un tableau
unidimensionnel Les éléments seront disposés dans le même ordre et ils ont été stockés dans le tableau
tridimensionnel d'origine. Cependant, il est important de
comprendre qu'il s' agit simplement
d'une représentation différente des mêmes données. Les données elles-mêmes
restent inchangées. Nous pouvons expérimenter avec notre matrice et présenter ses données
de différentes manières. Nous ne sommes pas en train de créer un nouveau tableau. Nous modifions simplement la
façon dont le tableau actuel
est représenté. Le principal point à retenir est que le nombre total d'
éléments reste le même Cependant, selon la documentation la
plus récente, n'est
plus recommandé de
modifier
la forme à l'aide de la méthode des formes, car elle pourrait être obsolète dans les futures
versions de Il est recommandé d'utiliser la fonction de remodelage
pour cette approche Je vais changer la forme de la matrice à l'aide de la
fonction de remodelage et l'imprimer Ensuite, j'imprime un tableau avec la forme un par neuf par trois, afin que nous puissions les comparer. Bien que nous ayons créé un nouveau tableau à l'aide de la fonction de remodelage, nous n'avons toujours pas créé de
nouvel ensemble de données Par conséquent, toutes
les modifications apportées au tableau seront également
reflétées dans notre deuxième tableau, et les deux utilisent les mêmes données. Si nous changeons le premier
élément de notre tableau actuel, nous verrons qu'il est également reflété dans le tableau
nouvellement créé. Si vous souhaitez que le tableau soit indépendant
du premier, vous devez créer une copie à
l'aide de la méthode copy. Je vais imprimer à nouveau le tableau, pour me rappeler à quoi
il ressemble. Permettez-moi maintenant de vous
présenter la fonction Ravel. Il est utilisé dans la
bibliothèque Napi pour transformer un tableau multidimensionnel
en un tableau unidimensionnel, pour
ainsi le flatter Ce que nous appelons ravel sur un tableau aplatit toutes ses dimensions et renvoie un tableau
unidimensionnel,
en
plaçant tous les éléments sur une seule en
plaçant tous les éléments sur une Dans l'ordre, ils ont été
stockés dans le tableau d'origine. Il s'agit d'un moyen simple d'accéder à
tous les éléments d'un tableau quelle que soit sa dimensionnalité sous la forme d'un tableau
unidimensionnel C'est utile lorsque vous devez
traiter ou analyser des données dans un format linéaire plus simple sans modifier la structure du tableau
d'origine.
10. Fonctions mathématiques dans NumPy: Maintenant, familiarisons-nous avec les fonctions mathématiques et voyons comment elles fonctionnent sur des tableaux unidimensionnels et
multidimensionnels À l'aide de la fonction d'
arrangement, je vais créer le tableau
unidimensionnel. Par exemple, la
fonction sum renverra la somme de tous les éléments de
notre tableau unidimensionnel. Cependant, si je remodèle notre tableau à l'aide de la
fonction de remodelage pour l'agrandir, disons neuf nombres organisés au format trois par trois Nous avons maintenant un tableau
multidimensionnel. Si nous appliquons simplement
la fonction somme, elle renverra la somme de tous les éléments quel que soit
le nombre de dimensions. Cependant, si nous voulons appliquer la fonction de somme aux lignes
ou aux colonnes spécifiquement, nous devons spécifier
le paramètre d'axe. Si je définis un axe égal à un, nous obtenons une liste de
sommes pour chaque ligne. Si je spécifie que l'
axe est égal à zéro, nous obtenons une liste de sommes
pour chaque colonne. La fonction principale calcule la valeur moyenne des éléments
du tableau Comme précédemment, nous pouvons obtenir la
moyenne de l'ensemble du tableau ou spécifier l'axe pour calculer la moyenne
par lignes ou colonnes. Trouvons la valeur maximale dans notre tableau à l'aide
de la fonction max, et elle sera de huit. De même, la
fonction de moyenne trouve la valeur minimale de notre
tableau et sera alors nulle. Encore une fois, nous pouvons spécifier
le paramètre de l'axe. Si je spécifie un axe égal à un, nous trouvons la
valeur minimale de chaque ligne. Je passe au maximum. Si je spécifie un axe
égal à zéro, nous trouvons la
valeur maximale de chaque colonne. Nous vous sommes maintenant familiarisés
avec les méthodes des tableaux de somme. Si vous souhaitez en savoir
plus en détail, vous pouvez consulter la documentation. Nous voyons ici la méthode de la somme, que nous avons utilisée précédemment, ainsi que de nombreuses autres méthodes. Cependant, Numpi possède également fonctions
autonomes qui ont des objectifs
similaires Il peut parfois y avoir confusion entre les méthodes et
les fonctions dans Numpi Mais pour l'instant, la principale
différence est de comprendre que les
méthodes sont
associées à des objets dans notre cas, tableaux, et qu'elles sont
appelées en notation par points Les fonctions sont globales et peuvent être appelées directement depuis l'
importante bibliothèque Numpi Nous n'allons pas approfondir les concepts de
programmation orientée
objet. Pour cela, j'ai bien entendu, vous pouvez consulter mon
profil et trouver le modèle allant de zéro à la programmation orientée
objet. Près de 6 heures de meilleures
informations pour vous. Calculons
la racine carrée de
chaque élément d' un tableau à
l'aide d'une fonction num pi. Je vais
modifier légèrement le tableau, en supprimant la forme
car ce n'est pas nécessaire
pour le moment. Calculons ensuite l'exposant de notre tableau unidimensionnel Nous pouvons également calculer des fonctions
trigonométriques
comme le sinus ou le cas à
l'aide des fonctions NumPi Ou essayons de calculer le logarithme naturel de
chaque élément du tableau. Oups, nous recevons une erreur car nous ne pouvons pas prendre
le logarithme de zéro Supprimons zéro
de notre tableau. C'est mieux. Maintenant, nous pouvons obtenir la bonne réponse
sans erreur. La méthode arrondie dans les tableaux
NAPA est utilisée pour
arrondir les valeurs des éléments à l'entier
le plus proche Si j'utilise cette méthode
sur le tableau actuel, rien ne changera car le tableau est composé d'entiers Cependant, si j'annule
la fonction log
puis que j'applique la fonction round, nous verrons l'
effet plus clairement La méthode ronde prend également
un argument facultatif, le nombre de
décimales pour arrondir deux Par exemple, nous
pouvons spécifier le
troisième tour pour arrondir à
trois décimales Ou arrondissez un pour arrondir à
un endroit unidimensionnel. Pour clarifier ce que nous avons fait ici, je vais réécrire légèrement le
code J'ai créé une variable et je lui ai
assigné cette expression. J'ai ensuite imprimé le résultat, arrondi à une décimale près Pour le prochain exemple,
je vais générer un tableau contenant des nombres
négatifs. Nous pouvons utiliser la fonction randint pour générer un tableau
d'entiers aléatoires, comprenant des valeurs négatives et
positives comprises dans une plage spécifiée
comprise entre -50 et 50 Bien entendu, vous pouvez modifier la plage des nombres
d'éléments selon vos besoins. Nous obtenons donc un tableau comme celui-ci. Maintenant, familiarisons-nous avec la fonction absolue de la nuque Cette fonction calcule
les valeurs absolues des éléments
du tableau Il renvoie un tableau
où chaque élément est la valeur absolue de l'élément correspondant
dans le tableau d'origine. Cette fonction est utile lorsque vous devez travailler avec des valeurs
absolues, exemple pour analyser des données sans prendre en compte
le signe des nombres. Vous me demandez quelle est la
différence entre fonction
ABS et la fonction absolue que nous avons vue auparavant. Dans NumPi, il n'y a aucune différence
entre ABS et absolu. Ils font la même chose. L'ABS est tout simplement un allié pour une fonctionnalité
absolue. Les deux fonctions
renvoient la valeur absolue de chaque élément du tableau. Cela signifie qu'ils convertissent les nombres
négatifs en positifs tout en laissant les nombres
positifs inchangés. Vous pouvez utiliser l'
un ou l'autre, mais l'ABS est plus court et souvent
préféré pour des raisons de lisibilité Faisons connaissance
avec la fonction argmax. Cette fonction
renvoie l'indice de la première occurrence de valeur
maximale dans le tableau. Nous voyons ici que la valeur
maximale est 42 et que son indice est égal à un. La fonction argmin
fonctionne de la même manière. Elle renvoie l'indice de
la première occurrence, la valeur minimale du tableau. Si le tableau comporte
plusieurs éléments avec les mêmes valeurs maximales
ou minimales, argmax et argmin renverront l'indice de la première
occurrence de ces Ces fonctions sont utiles
pour trouver la position des plus grands et
des plus petits
éléments du tableau numpy Cela peut être utile dans de nombreux
algorithmes et calculs.
11. Randomisation et combinaison de tableaux dans NumPy: Dans certains cas, vous devez générer des
nombres aléatoires pour un tableau, et si nous voulons que ces nombres soient reproduits
dans le même ordre, nous devons nous familiariser
avec la fonction SID. La fonction SID a initialisé
le générateur de nombres aléatoires, vous
permettant de définir une valeur de départ
fixe Cela garantit que
la même séquence de nombres aléatoires est
générée à chaque fois, ce qui rend votre code reproductible Si j'ai dit la valeur
initiale une fois
, qu'elle soit zéro, par exemple. Cela signifie que nous fixons la valeur initiale du générateur de
nombres aléatoires. Cela signifie que chaque
fois que nous générons des nombres
aléatoires à
l'aide de la fonction aléatoire NP, nous obtenons la même
séquence de nombres. Cela est très utile pour la
reproductibilité des résultats. Dans certains cas, vous avez besoin que
vos nombres aléatoires
soient les mêmes à chaque fois que
votre programme s'exécute. Cela peut également être
utile si vous souhaitez montrer quelque chose à quelqu'un et devez reproduire
le comportement avec le même tableau et la
même séquence de nombres. La fonction de permutation de la bibliothèque Numbi est utilisée pour créer des
permutations aléatoires Si j'en spécifie six, ce sera un tableau aléatoire
contenant des nombres de 0 à 5, réorganisé dans un ordre aléatoire Cette fonction est souvent
utilisée lorsque vous devez mélanger ou réorganiser des indices pour travailler
davantage sur les données ou pour sélectionner
au hasard un
sous-ensemble d'éléments d'un tableau Je peux augmenter le bit du tableau. Si je spécifie 16 ici, nous obtiendrons un tableau aléatoire contenant les nombres de
0 à 15 inclus, réorganisés dans un ordre aléatoire Dans notre cas, la fonction aléatoire génère un tableau
trois par trois où chaque élément est un nombre aléatoire avec une distribution normale, ou comme on l'appelle aussi distribution
gaussienne Il est important de noter que la fonction aléatoire
génère un nombre avec une distribution normale avec des paramètres qui peuvent être modifiés. Par exemple, vous pouvez augmenter
ou diminuer le nombre d' éléments du tableau aléatoire en modifiant les arguments
de la fonction. Continuons avec la
fonction d'ajout. La fonction d'ajout de
la bibliothèque Napi est utilisée pour ajouter de nouvelles valeurs
à la fin d'un tableau Elle prend les arguments
suivants. Le premier est
le tableau original auquel nous ajouterons de nouvelles valeurs. La seconde concerne les
valeurs que nous voulons ajouter. Dans notre cas, nous avons
ajouté une nouvelle valeur à notre tableau sous la forme d' une liste composée
de trois trois. La fonction d'insertion de la bibliothèque
Napi est utilisée pour insérer de nouvelles valeurs dans un
tableau à un index spécifié Cette fonction prend trois
arguments : le tableau d'origine, l'index auquel
les valeurs doivent être insérées et les
valeurs à insérer. Dans notre cas, j'insère deux forces dans le tableau
à la position d'index deux La fonction d'insertion ne
modifie pas le tableau d'origine, mais en crée un nouveau avec les valeurs insérées pour supprimer les éléments d'un tableau
aux indices spécifiés. Nous utilisons la fonction de suppression. Il faut trois arguments. Le premier est le tableau. Le second, les indices
de l'élément, nous voulons supprimer, et le
troisième, le paramètre X. Si l'axe est connu, il sera appliqué à
la matrice aplatie. Voyons comment cela fonctionne à l'
aide d'un exemple. Nous avons maintenant supprimé
les éléments avec les indices zéro, un et le dernier
élément de notre tableau. Après avoir appelé la fonction de
suppression, elle revient dans UA sans
les éléments supprimés. Le tableau d'origine
reste inchangé. Si nous devons supprimer une plage d' indices du tableau,
nous pouvons le faire comme ceci. Nous exécutons la
fonction de suppression, spécifions notre tableau et utilisons l'objet
numb pour créer une plage
d'indices Nous spécifiez la plage de 2 à 5. N'oubliez pas que cinq ne
seront pas inclus. Oups, j'ai oublié le soulignement. Maintenant, nous supprimons les éléments
du tableau avec les indices 2 à 4 et renvoyons un UA
sans ces éléments. Pour l'exemple suivant,
je crée un tableau simple. Le tableau sera
bidimensionnel. Oups, j'ai oublié les parenthèses. Désolé, permettez-moi de les ajouter rapidement. Dans la fonction de suppression, il
existe également un axe des paramètres, qui indique la dimension le long de laquelle nous
voulons supprimer des valeurs. Si nous spécifiez un axe
égal à zéro, cela signifie que nous
voulons supprimer des lignes. Ainsi, dans notre exemple, nous supprimons
la ligne avec l'index un, et nous obtenons l'URA sans
le rôle avec l'index un. Cela sera plus lisible. Si je spécifie un axe égal à un, alors la colonne avec l'
index un est supprimée. Je crée un autre tableau simple et nous allons nous familiariser
avec la fonction de concaténation La fonction de concaténation de
la bibliothèque Napi est utilisée pour joindre ou concaténer J'utilise donc la fonction, spécifie le tableau à joindre. Ils sont transmis sous forme de ruban et il existe également un axe de paramètres
optionnel, qui est le
langage dimensionnel pour joindre le rayon Si nous voulons joindre
un tableau le long d'une colonne, nous devons spécifier un
axe égal à un. Par défaut, l'axe est égal à zéro, ce qui signifie qu'il est dessiné
le long des lignes de première dimension. Nous pouvons spécifier zéro ou
ne pas le spécifier du tout. Cette valeur sera la valeur par défaut, et nous obtiendrons notre résultat. La
fonction de concaténation permet donc joindre des tableaux en
plusieurs dimensions, en fonction de la Pour cet exemple, je vais supprimer la partie inutile et
créer des rayons multidimensionnels Nous allons nous familiariser
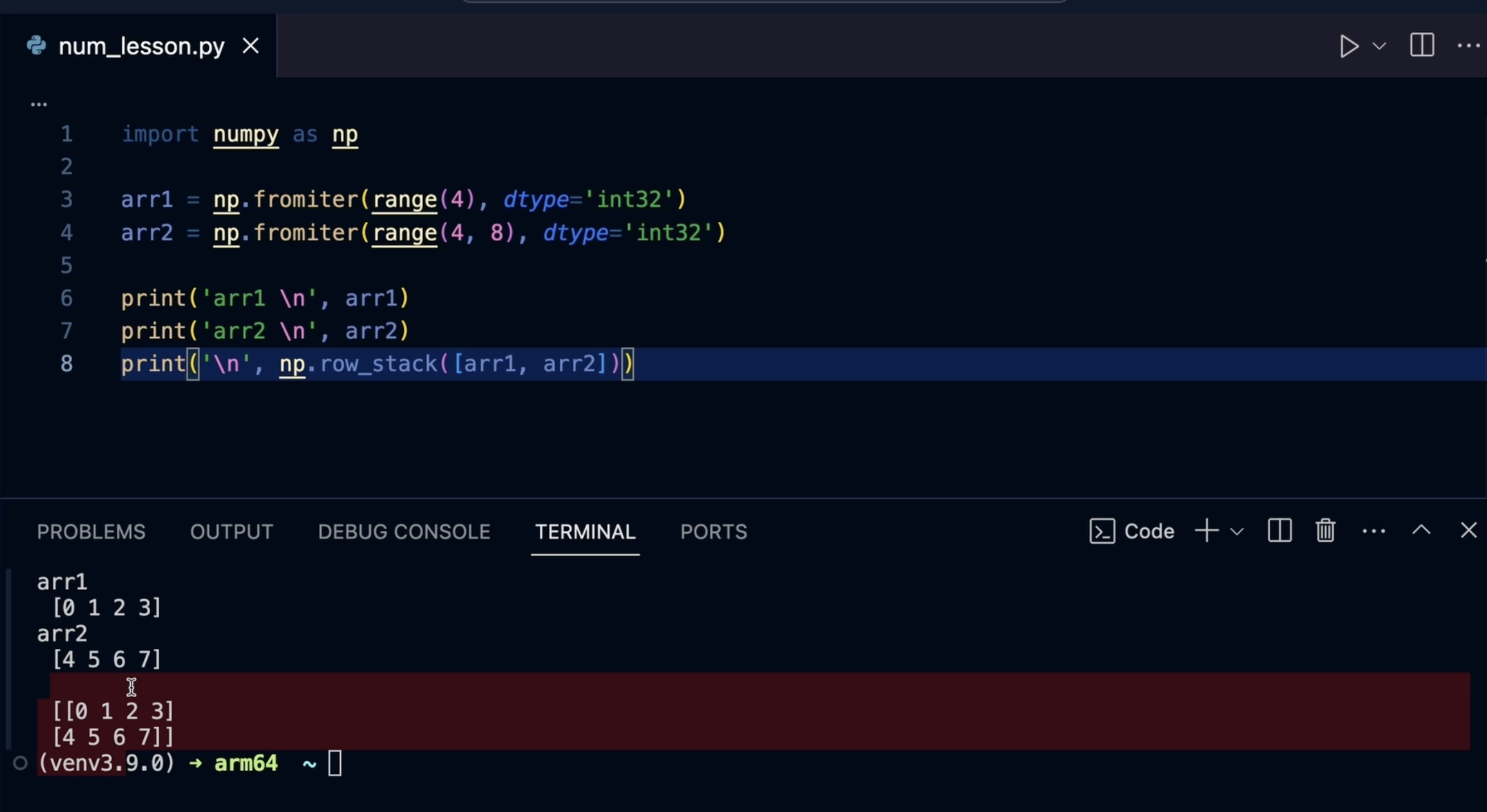
avec la fonction V stack. Cette fonction est utilisée
pour empiler verticalement ou concaténer deux rayons ou plus le
long de la première dimension, les lignes concaténer deux rayons ou plus le
long de la première dimension, les lignes.
J'ai oublié les parenthèses Désolé, permettez-moi de les ajouter rapidement. Nous précisons les rayons. Nous voulons empiler verticalement. Ils sont transmis sous forme de tuple. Par conséquent, nous
obtenons un tableau qui contient des
lignes concaténées provenant de C'est un moyen pratique concaténer un tableau verticalement, et cela fonctionne avec n'importe quel
nombre de tableaux d'entrées. Je vais copier ces deux
lignes pour un nouvel exemple. Il existe également la fonction
H stack. Est destiné à la concaténation horizontale
de deux ou plusieurs tableaux. Vous vous demandez peut-être quelle est la différence entre
concaténer où nous spécifiez l'axe et fonctions telles que
V stack ou H stack La principale différence
entre eux réside dans la syntaxe. C'est ça. Lorsque vous souhaitez joindre un tableau
le long d'une certaine dimension, vous pouvez utiliser n'importe laquelle de ces
fonctions selon vos préférences et votre
commodité, à vous de choisir. La seule chose que je veux
noter, c'est que dans la concaténation, nous pouvons spécifier l'axe, ce qui
nous permet de concaténer tableaux non seulement verticalement
ou horizontalement,
mais aussi le long de n'importe quel axe, car l'axe peut être
non seulement nul ou un,
car les rayons peuvent être nous pouvons spécifier l'axe,
ce qui
nous permet de concaténer des
tableaux non seulement verticalement
ou horizontalement,
mais aussi le long de n'importe quel axe, car l'axe peut être
non seulement nul ou un,
car les rayons peuvent être multidimensionnels.
12. Opérations avancées de tableaux et techniques de division: Je vais retirer les
pièces nécessaires et créer de nouveaux tableaux. Je vais vous montrer une autre
façon de procéder. La fonction FramterFunction de la bibliothèque
Nabi est utilisée pour créer un
tableau unidimensionnel basé sur un Il prend une séquence
de valeurs de l'itérateur et
les convertit en tableau Nous passons un itérateur
ou une séquence de valeurs à partir de laquelle nous
allons créer un tableau Vous pouvez également spécifier
le paramètre de type D, qui est le type de données vers lequel les valeurs de l'itérateur
doivent être converties Il existe un nombre de
paramètres optionnel, qui est le nombre d'entre nous
à extraire de l'itérateur Par défaut, ce
paramètre vaut moins un, qui signifie qu'il faut prendre toutes les valeurs. Dans notre exemple, nous créons le premier tableau de quatre
nombres en utilisant range. Dans le deuxième tableau,
nous utilisons également la plage, en spécifiant que quatre nombres sont pris entre
quatre et huit, ils sont
donc nombres
du premier tableau. Permettez-moi de vous présenter la fonction de pile de
colonnes. La fonction d'empilement de colonnes
de la bibliothèque Napi est utilisée pour la concaténation horizontale
ou Nous transmettons un ensemble de tableaux comme colonnes
du tableau que
nous voulons concaténer Imprimons-le
pour voir ce que nous avons. C'est un outil pratique
pour créer des tableaux, en particulier lorsque vous
souhaitez combiner données de plusieurs
tableaux sous forme de colonnes, et nous voyons nos tableaux Les deux premiers ont été
générés à titre d'exemple, et le troisième est la
somme de nos deux tableaux Il existe une
fonction similaire à la technologie des lignes, mais elle permet de combiner les données
de plusieurs tableaux sous forme de lignes Dans ce cas, le résultat est le même que si nous utilisions
la fonction Vtach Je vais ajouter une ligne vide pour séparer les
tableaux pour plus de clarté Je peux également utiliser np point R. C'est une instance de l'objet de classe
R dans Napi Il agit comme un outil pratique de concaténation de
tableaux vous
permettant de
créer et de fusionner rapidement des rayons
le long de l'axe zéro Je peux également utiliser le C. C'est une instance de l'objet de
classe C dans Nampi C'est un outil pratique pour la concaténation par
colonne, ce qui signifie qu'il fusionne un tableau
le long de l'axe Je vous montre ceci afin que vous
connaissiez les possibilités
de concaténation Vous pouvez choisir ce qui vous
convient le mieux. Je vais supprimer les
parties inutiles pour éviter l' encombrement et générer un
tableau de dix nombres de 0 La fonction H split est utilisée pour diviser
horizontalement un
tableau en sous-tableaux Il divise le tableau
en
sections égales le long de l'axe
horizontal. Il prend le tableau d'origine. Nous voulons diviser le
premier paramètre, et le second paramètre est nombre de parties en lesquelles nous
voulons diviser le tableau. Si j'essaie de diviser le tableau
en trois parties alors sa longueur n'est pas divisible par trois, j'obtiens une erreur Cependant, dans notre cas, si j'en spécifie cinq, le tableau sera divisé
uniformément en cinq sous-réseaux Nous pouvons également diviser le tableau en deux parties égales. Sa
longueur le permet. V split est une fonction de umpi utilisée pour diviser un tableau
verticalement le long des lignes Il divise un tableau donné en plusieurs sous-réseaux
le long de l'axe zéro Comme nous divisons le tableau verticalement, nous avons une erreur Nous ne pouvons pas diviser un tableau
unidimensionnel par colonnes. Je vais générer un tableau légèrement
plus grand et utiliser la fonction de remodelage pour former une nouvelle
forme bidimensionnelle du Allons-y. Une erreur s'est produite car nous ne pouvons pas
diviser ce tableau en deux, mais nous pouvons le diviser en trois. Cette fonction est particulièrement
utile lorsque vous devez séparer une matrice en sections de lignes
plus petites. Permettez-moi d'augmenter le tableau pour l'exemple suivant et de
le rendre tridimensionnel. Si nous devons diviser le tableau, pas seulement horizontalement
ou verticalement, car il peut y avoir plus de dimensions si le tableau est
multidimensionnel L'axe peut être non
seulement nul ou un, nous pouvons utiliser la fonction de
division des rayons. Il divise le tableau en un nombre de parties
spécifié. Le deuxième argument est
le nombre de pièces, qui est de deux dans notre cas. Et le troisième
paramètre est l'axe. Dans notre cas, j'ai spécifié que
l'axe est égal à deux. Il est donc divisé selon
la troisième dimension. Spécifier un axe égal à la fonction
Numbi signifie que nous opérons le long de
la troisième dimension, la
profondeur d'un tableau
tridimensionnel La fonction de division de Numbi permet de diviser selon
la troisième dimension Même si le nombre de pièces
ne se divise pas uniformément, il répartit les
éléments aussi uniformément que possible entre les
sous-ensembles résultants Mais si cela n'est pas possible, cela créera des pièces avec
différents nombres d'éléments. Dans notre cas, nous
aurons trois sous-réseaux. Deux contiendront des données et le troisième sera vide. Nous pouvons également expérimenter
et diviser le long l'axe 1 ou des suites de
l'axe zéro Je suggère de faire une pause ici
et d'expérimenter. Entraîne-toi un peu.
Maintenant, par exemple, je vais créer la liste et le
tableau les plus simples en Python. Les opérations entre les listes et les rayons ont des comportements
naturels différents. Dans le cas des listes, l'opération plus
effectue la concaténation Cela signifie joindre
deux listes en une seule, mais cela n'effectue pas d'addition
arithmétique d'éléments Dans le cas de tableaux numb, l'opération plus effectue une addition par
élément, c'
est-à-dire qu'elle ajoute les
éléments correspondants du Regardez la différence
entre deux fonctions d'impression. L'un, l'ajout de listes et
l'autre, l'ajout d'un tableau. Nous pouvons également effectuer
une multiplication par élément de deux tableaux de même taille Ou multipliez chaque
élément par un nombre. Si je spécifie cette
opération dans une liste, elle répétera la liste entière
au nombre de
fois spécifié plutôt que d' effectuer multiplication par
éléments
comme un tableau d'arbitres. Lorsque vous effectuez l'opération
moins, chaque élément du tableau change de signe
en sens inverse. Le résultat de cette
opération sera un nouveau tableau dans lequel chaque élément du
tableau est divisé par un. Au lieu d'un, il
peut s'agir de n'importe quel chiffre. Cette opération revient
au reste de chaque
élément lorsqu'il est divisé par deux, identifiant
ainsi efficacement les nombres
pairs et impairs
dans le tableau. Si vous soustrayez une liste
d'un tableau Numbi, la liste sera
convertie en tableau et la soustraction de l'élément Y
sera effectuée Cependant, vous ne pouvez pas soustraire liste d'une liste. Vous
allez recevoir un message d'erreur. La multiplication d'une liste par liste
entraînera également une erreur. Maintenant, je veux introduire
un autre concept, et pour cela, je vais créer un tableau
bidimensionnel
et un tableau 11 dimensionnels. Il y a aussi le
concept de diffusion. La diffusion en réseau est un
mécanisme de Napi qui permet d' effectuer des opérations sur
des réseaux de formes
ou de dimensions différentes Si deux rayons ont un
nombre de dimensions différent, nouvelles dimensions sont automatiquement
ajoutées à la matrice avec moins de dimensions jusqu'à ce que
leur taille soit compatible. En d'autres termes, si nous avons le même nombre d'éléments
dans chaque ligne de tableau, lorsque nous ajoutons deux rayons, le plus petit tableau
est concaténé ligne par ligne avec les lignes
du Pour cet exemple, je vais
créer à nouveau un tableau le plus simple. Faisons connaissance avec
l'opérateur combiné. Lorsque nous effectuons l'opération d'
ajout, nous pouvons le faire de manière plus succincte Dans cet exemple, nous
ajoutons le chiffre cinq
à chaque élément
du tableau et mettons à jour sa valeur initiale par
la somme de cinq. Cette opération est équivalente
à l'utilisation de cette notation, mais elle est effectuée directement dans le tableau sans
créer de nouvel objet. C'est utile car cela permet d' augmenter
ou de diminuer
efficacement les valeurs de tous les éléments
du tableau sans avoir
à en créer un nouveau. Cela peut également être appliqué à d'autres
opérations mathématiques.
13. Charger, enregistrer et rechercher dans NumPy: Imaginons que nous ayons le fichier texte à partir duquel nous voulons charger les données. La méthode gen from TXT
est conçue pour lire les données d'un fichier texte et
déterminer automatiquement les types de données. Il s'agit d'un outil puissant
pour travailler avec des données dans des formats tels que CSV, TSV et d'autres formats de texte Maintenant, chargeons les données
à partir du fichier de données TXT. Lorsque les données sont
séparées par des virgules, nous indiquons
que le
limiteur est égal à une virgule Cette méthode peut gérer
automatiquement les valeurs
manquantes et les autres particularités
des données Sortons ces données
dans un ampiray. Si nous utilisons Jen from Txt pour lire nombres séparés par des
virgules dans un fichier texte,
la sortie dans la console
sera généralement
un tableau Numpi avec les
valeurs chargées depuis la sortie dans la console
sera généralement le Les valeurs seront
affichées sous forme de tableau où chaque nombre est un
élément du tableau. La même fonction de la bibliothèque
Numpi est utilisée pour enregistrer les tableaux numpi au format
binaire dans Cela permet de sauvegarder les
données du tableau afin qu'elles puissent être
utilisées ultérieurement sans qu'il soit nécessaire de les recharger ou
de les recalculer Si nous ouvrons le fichier créé
avec le tableau enregistré, nous ne verrons
rien d'utile pour nous. Cependant, la
fonction de chargement est utilisée pour recharger ces tableaux enregistrés
dans la mémoire du programme Il permet d'accéder aux données
du tableau enregistrées à
l'aide de la fonction de sécurité. Ces fonctions sont très utiles pour travailler avec de
grandes quantités de données et
pour
les traiter ultérieurement sans avoir besoin de calculs La fonction
savetixt de la bibliothèque Napi est utilisée pour enregistrer les tableaux Nampi au format texte
dans Cela permet d'enregistrer les données du tableau dans un format pratique
pour la lecture et l'édition. Par exemple, je vais
choisir le format CSV, mais vous pouvez spécifier des extensions
telles que Tixt, CSV ou data Il s'agit d'extensions courantes généralement utilisées pour stocker
des données au format texte. Cependant, SAPTixt
peut réellement enregistrer des données dans n'importe quel fichier texte avec
les extensions que vous souhaitez Nous pouvons voir que notre fichier est apparu dans le répertoire
du projet. Maintenant, chargez-le. La fonction od text
est utilisée pour charger les données d'un fichier texte
dans un AmpIrray. Il permet d'accéder aux données enregistrées à l'aide de la fonction
save Tixt Ceci est très similaire
au mécanisme
dont nous avons parlé plus tôt où nous avons
utilisé la sauvegarde puis le chargement. Mais ce format n'était ni
convivial ni lisible pour nous. Ici, cependant, nous pouvons déjà voir le fichier et
son contenu enregistré. Ces deux fonctions sont très
utiles pour travailler avec des données dans un format
compréhensible pour les humains. Ils permettent de sauvegarder
et de charger facilement des données sans nécessaire de comprendre la structure interne
de Numprays Pour l'exemple suivant,
laissez-moi créer U Supposons que nous ayons un tableau bidimensionnel
représentant certaines données. Eh bien, supposons que ce soit la température
dans différentes régions, et nous voulons trouver
la position de tous les éléments qui dépassent
un certain seuil. Je définis un seuil variable
et la valeur de 30. Il s'agit de la valeur par rapport à laquelle nous voulons trouver
des éléments dans le tableau. Comment pouvons-nous faire cela à Nam Pi ? Il existe une fonction particulièrement utile pour trouver la position des éléments qui satisfont à une condition donnée, et il s'agit de la fonction
arc ware. Notre condition renvoie
les indices de l'élément qui sont vrais dans
le tableau booléen car
cette expression crée
un tableau booléen où chaque élément est
vrai s'il est supérieur à
30 et tombe dans le J'imprime le tableau de données d'origine pour fournir le contexte de la position des éléments, puis j'
imprime les index. Ces indices sont renvoyés
sous forme de tableau bidimensionnel, où chaque ligne représente les
coordonnées d'un élément, l'index de ligne et l'index de colonne dans
le tableau d'origine. La sortie indique que les
éléments supérieurs 30 sont situés à la position suivante
dans le tableau de données, ligne 1, colonne 2, élément 35. Deuxième ligne, colonne zéro, élément 40. Ligne 2, colonne 1 ,
élément 45, etc. Dans cet exemple, j'ai démontré comment la
fonction Arcbar peut être utilisée pour localiser la position
des éléments et du tableau
numpy qui répondent à
une condition spécifique Félicitations. Nous avons
terminé ce cours intensif. J'espère que vous l'avez trouvée
intéressante et pas trop ennuyeuse et que vous avez
trouvé cette leçon utile. Encore une fois, je tiens à souligner que la pratique est
la chose la plus importante. Je recommande vivement de faire une pause
après chaque leçon et expérimenter ou de
répéter quelque chose manuellement, car la théorie est une bonne chose, mais vous n'apprendrez pas
sans pratique La meilleure façon d'apprendre, c'est
par le biais de votre propre pratique. Merci de votre attention continuez
à coder, continuez à apprendre.
 Olha Al, Software engineer
Olha Al, Software engineer