Transcription
1. Intro: Bonjour, les gars. Bienvenue dans
le monde de Seaborn, la bibliothèque Python ultime
pour créer des visualisations de
données magnifiques, pertinentes et professionnelles visualisations de
données Dans ce cours, nous
allons explorer Seaborn. L'une des bibliothèques
Python les plus puissantes
et les plus conviviales pour créer des visualisations
époustouflantes À la fin du cours, vous serez capable de transformer n'importe
quel ensemble de données en un jeu de données
visuellement attrayant. Cela raconte une histoire claire. Nous allons commencer par les
bases, configurer Seaborn, comprendre comment il s'intègre d'autres outils tels que Pandas
et découvrir les différents types de parcelles que vous pouvez Nous examinerons également des exemples
concrets pour voir comment Seaborn
s'intègre parfaitement à MD Plot Leap, améliorant ses fonctionnalités et rendant la visualisation des données
encore plus puissante Que vous créiez un
simple graphique à barres, une carte thermique ou un diagramme de points de points, vous
apprendrez à le faire de manière efficace Ce cours est
parfait pour tous ceux qui souhaitent améliorer leurs compétences en analyse de
données, en particulier si vous
travaillez avec Python et souhaitez améliorer
votre jeu de visualisation. Commençons.
2. Démarrer avec Seaborn : de quoi s'agit-il, comment l'installer et à quoi ressemble-t-il de Matplotlib: Bonjour, les gars.
Découvrons Seaborn Seaborn est une bibliothèque Python
utilisée pour la visualisation des données. Il repose sur MD
Plot Leap et s'intègre étroitement à Pandas pour faciliter la manipulation des données
et le traçage Seaborn
simplifie la création graphiques
statistiques
attrayants et informatifs,
tels que des cartes thermiques, des diagrammes à barres, des diagrammes de
dispersion et des diagrammes de
séries chronologiques, Le principal avantage
de Seborn est qu'il est livré avec un ensemble de thèmes
par défaut et de palettes de
couleurs
qui vous aident à créer tracés
visuellement attrayants
avec un minimum d'effort Il fournit également des fonctions de niveau
supérieur pour créer des tracés complexes, sorte que vous n'avez pas besoin d'écrire
un code long et compliqué. Pourquoi apprendre Cburn ? Pour les débutants, CBurn
est excellent car il simplifie de nombreux aspects
fastidieux de la visualisation des
données Vous n'avez pas à vous
soucier des détails
du
style de vos intrigues, puisque CBurn s'en est occupé
pour vous Il est ainsi plus facile
de se concentrer sur les données elles-mêmes plutôt que sur la
façon dont elles seront affichées. De plus, Seborn s'intègre
parfaitement à Pandas, ce qui signifie que vous pouvez directement transmettre trames de données
Pandas aux Cette fonctionnalité est extrêmement
utile car elle réduit le besoin de manipuler des données
supplémentaires
avant le traçage quoi Seaborn diffère-t-il des autres bibliothèques de visualisation ? Bien que MD Boot
Leap soit puissant, il faut souvent plus d'efforts
pour créer des intrigues soignées. Seaborn extrait bon nombre de
ces détails et fournit des fonctions
plus simples qui génèrent
automatiquement Il intègre un support pour visualiser la
distribution des données, les relations entre plusieurs variables
et les comparaisons de données, qui est
plus avancé que ce que
propose directement Mt Bot Leap Seaborn possède une syntaxe plus
conviviale et plus concise, ce qui vous permet de créer des tracés
complexes avec moins La bibliothèque utilise des paramètres de tracé
standard, ce qui les rend plus attrayants
et plus faciles à comprendre. Cela demande également moins d'efforts pour créer des
visualisations présentables Comme je l'ai déjà dit, Seaborn
s'intègre à Pandas, ce qui facilite l'
affichage des données statistiques, ce qui est idéal pour l'
analyse et la visualisation des données Bien que Seaborn et Pandas travaillent ensemble pour la visualisation
des données, ils remplissent Pandas se spécialise dans le traitement et l'analyse de données tabulaires, offrant des
fonctionnalités étendues de filtrage, de regroupement et de
calcul Seaborn se concentre sur la
visualisation de données statiques. La principale différence entre
Pandas Visualization et Seaborn réside dans leur
fonctionnalité et leur complexité Oui, Pandas dispose également de fonctions de
traçage intégrées qui fonctionnent
directement avec les trames de données C'est simple et rapide
pour les tracés de base, mais ils offrent moins d'options de personnalisation et de style
que Seaborn Seaborn propose des outils plus puissants et visuellement attrayants pour une visualisation
avancée des données Eh bien, pour commencer à travailler
avec la bibliothèque Seaborn, vous devez l'installer Vous pouvez utiliser le gestionnaire de
bagages PIP en exécutant la commande
PIP install Vous pouvez également utiliser Anaconda et installer Seaborn à l'aide
de Conda install Seaborn Passons maintenant à
la partie pratique. abord, nous importons Seaborn et l'
affectons à As SNS, qui est un raccourci Ensuite, nous importons Mat Blot Leap, et vous verrez pourquoi Bon, en ce moment, nous avons
affaire au tutoriel Seaborn, et nous savons que
la bibliothèque Seaborn est construite sur Mat Blot Lip Je veux vous montrer la
différence dès maintenant. Pour cela, comme toujours, j'ai besoin de quelques données fictives, que je vais créer maintenant À l'aide de ces données, nous allons construire ensemble le
diagramme le plus simple. Il s'agit de la commande de la bibliothèque
Matplot Leap en Python, spécifiquement utilisée pour
créer un diagramme à deux lignes en D. Ce que vous voyez maintenant a été construit l'aide de Matplot Leap, et non de Seaborn Je vais maintenant utiliser la fonction
SNS set. J'ai simplement copié
la même commande, et nous obtiendrons un résultat
différent. Cela semble très
différent. La fonction SNS set
est un raccourci pour utiliser une fonction
appelée Lorsque nous utilisons cette fonction, nous obtenons automatiquement des paramètres
prédéfinis. Nous avons la fonction qui a styles, des couleurs et du texte
prédéfinis. Tout
ce que nous avons à faire est de l'appliquer pour obtenir une parcelle plus
attrayante. Si nous développons cette
fonction et y jetons un coup d'œil, nous pouvons voir
les paramètres prédéfinis utilisés pour ce graphique. Grâce à la fonction set, nous avons mis à jour les paramètres par défaut de
Md Boot Lip et avons
appliqué ceux utilisés dans Seaborn Explorons maintenant
les styles disponibles et choisissons-en un pour nous-mêmes. Il existe différents
styles, et choisissons par
exemple une grille blanche. Nous utilisons maintenant un style
différent. Après avoir exécuté cette commande, nous obtenons un look complètement
différent. C'est ainsi que Seaborn
collabore avec Matplot Lip ou plutôt la façon dont Seaborne est
construit D'accord, ce que nous avons fait ici, la première ligne indique à Seaborn de définir le
style visuel général de nos Dans ce cas, une
grille blanche signifie que notre graphique aura un arrière-plan de couleur claire
avec des lignes de quadrillage. Cela facilite la lecture
des données, en particulier lorsqu'il s'agit
de données trans ou de comparaisons. La deuxième ligne provient de MD Bot Leap et est utilisée pour
créer un diagramme linéaire de base. Mais il y a un
élément essentiel. Même si nous utilisons Md plot Leap
pour dessiner l'intrigue, le style
vient de Seaborn Seaborn est construit sur
Matplot Leap. Et lorsque nous définissons un
thème dans Seaborn, il s'applique automatiquement
à tous les diagrammes Mdplot Leap Cela signifie que nous n'avons pas à modifier
manuellement des éléments
tels que la couleur d'arrière-plan, quadrillages ou les polices par défaut Seaborn le fait pour nous. Ainsi, avec ces
deux lignes de code, nous démontrons
comment Seaborne influence apparence de
Matplot Lips sans changer la façon dont nous Résultat : une visualisation plus claire et
plus lisible, sans effort supplémentaire. Maintenant, je veux définir le titre. Lorsque nous travaillons avec Seaborn, nous obtenons quelque chose de très similaire à ce que nous avons vu dans Matplot Leap, mais avec une apparence légèrement
meilleure Comme nous pouvons le voir, nous
devons spécifier le titre dans la même cellule où
nous dessinons le graphique si nous séparons le code
de création du graphique et le code de définition du
titre dans différentes cellules. carnet Jupiter peut
afficher la figure sans le graphique,
comme nous l'avons observé ici.
3. Explorer les ensembles de données intégrés à la mer : utiliser les histplots et les scatterplot pour la visualisation des données: Seborn, il y a quelque chose d'assez pratique. Ensembles de données intégrés Cela signifie que Seborn est
déjà fourni avec plusieurs exemples de
jeux de données auxquels vous pouvez facilement accéder et que vous pouvez commencer à
travailler immédiatement Nous pouvons charger cet
ensemble de données intégré à l'aide de la fonction load
dataset. Cette fonction nous permet d'
accéder rapidement à des exemples de jeux sans avoir à télécharger ou à préparer de fichiers manuellement Il n'est pas nécessaire
de rechercher ou de charger vos propres données pour commencer à
explorer la bibliothèque. Par exemple, le jeu de données TIPS, qui contient des informations sur factures de
restaurant et les pourboires, y compris des attributs
tels que le montant des factures, sexe et le
fait qu'il s'agisse d'un déjeuner ou d'un dîner. Un autre
jeu de données de construction fournit des informations sur les fleurs d'iris, notamment le pommier et la
largeur allongée des pétales Il existe également des données
sur le nombre de passagers sur les vols par
mois au cours des différentes années. Nous avons ici des exemples
où l'exercice un impact sur le rythme cardiaque et
le taux d'oxygène dans le sang. Et aussi les caractéristiques
des diamants, telles que le poids,
la qualité et le prix. C'est très utile
pour les débutants car vous pouvez
instantanément vous lancer dans visualisation
des données et
commencer à créer des tracés sans avoir à vous soucier sans avoir à vous soucier de la préparation
des données C'est comme avoir un
terrain de jeu instantané pour Seaborn, où vous pouvez expérimenter et voir comment différentes parcelles fonctionnent
avec des données du monde réel Comme vous pouvez le constater, j'
utilise la fonction tête. Dans Seaborn, nous travaillons avec ensembles de données chargés
sous forme de trame de données Pandas,
et la fonction head est une
fonction de Pandas qui nous
permet de prévisualiser rapidement les premières lignes
du jeu et la fonction head est une
fonction de Pandas qui nous
permet de prévisualiser rapidement du Par défaut,
les cinq premières lignes sont affichées. Pour voir les ensembles de données disponibles, nous pouvons utiliser la méthode des noms de
données Git N'oubliez pas les parenthèses. Cela affichera tous les ensembles de données disponibles par défaut dans Seborn Vous pouvez désormais expérimenter,
sélectionner n'importe quel ensemble données
et découvrir quelles données sont disponibles, ce qui peut être fait avec elles
et comment les utiliser. Par exemple, l'utilisation de l'ensemble de données sur les
accidents de voiture fournira des informations sur les accidents de
voiture, tandis que les réseaux
cérébraux
disposeront de données plus détaillées Revenons cependant
à notre ensemble de données de conseils. Explorons le diagramme, qui est peut-être l'un des
moyens les plus courants de visualisation des données Nous utiliserons le même ensemble de données, et nous ne
prendrons qu'une seule colonne, facture
totale, car nous voulons montrer
la distribution du montant
total de la facture. Nous allons définir l'estimation de la
densité du noyau comme étant vraie, prendre 30 bacs et définir la
couleur comme étant le bleu ciel. Il s'agit du graphique qui en résulte. Ici, nous sélectionnons
une seule colonne dans
le jeu de données et nous l'utilisons
pour créer un histogramme Si vous avez déjà travaillé avec
Pandas, vous reconnaîtrez que
l'utilisation de crochets
permet d'accéder à une
colonne spécifique à partir d'un bloc de données Dans ce cas, nous extrayons uniquement la colonne de la facture totale et la transmettons à Seaborn
pour visualisation. Nous pouvons le redéfinir un peu
en spécifiant le titre, puis l'étiquette X, puis l'étiquette ylabel, rendre le graphique
plus Autrement dit, la définition de l'estimation
de la densité du noyau est vraie. Demandez à Seaborn d'estimer la distribution
des données à l'aide de noyaux au lieu de simplement compter les valeurs comme dans un Cela se traduit par une
représentation plus fluide et plus lisible des données, ce qui permet de mieux
voir les modèles généraux, en particulier lorsque nous ne
disposons pas d'un ensemble de données volumineux. C'est un excellent moyen de se faire une
idée plus précise de la façon dont les données sont distribuées sans recourir à
des groupes d'histogrammes rigides Maintenant, après avoir tracé
l'histogramme, nous avons utilisé le titre PLT, l'étiquette PLT x et l'étiquette
PLT y de Mud plot Lip pour ajouter
des étiquettes au Comme nous pouvons le constater, Cibern se
concentre principalement sur la création
et le style des tracés, tandis que Matt Lip s'occupe des
réglages fins tels que l'ajout de titres, étiquettes et d'autres
personnalisations Et comme le CBRN est construit
sur MD Bot Lip, nous pouvons le modifier à l'aide de la fonction
MD Bot Lips Construisons maintenant un exemple à l'
aide d'un diagramme de points. Nous explorerons la
relation entre le montant total
de la facture
et les pourboires pour les heures supplémentaires. J'utilise la fonction de diagramme de
dispersion du système nerveux central et je transmets les données X représentera la facture totale, et seront nos pourboires ? Nous allons diviser l'ensemble de données en fonction des heures de déjeuner et de dîner, en attribuant une couleur distincte
à chaque fois sur le graphique Ensuite, nous spécifions la source du
jeu de données à partir de laquelle nous prenons toutes
ces informations et définissons la palette égale
à deux pour définir la palette de couleurs permettant de créer différentes catégories
de temps sur le graphique. Ajoutons un titre à l'intrigue. Ce diagramme en cara nous permet de
visualiser la
relation entre le montant total de
la facture et pourboires avec une séparation
basée sur l'heure, le déjeuner ou le dîner, obtenue
grâce à différentes couleurs. Et maintenant, vous pouvez
voir à quoi ça ressemble. Cela ajoute une
dimension supplémentaire à l'analyse. L'observation de la façon dont la distribution
des points varie temps peut mener à des
conclusions ou à des observations intéressantes Ici, nous pouvons voir la corrélation entre les pourboires et la facture totale, ainsi que la façon dont cela
dépend de l'heure de la journée. Nous pouvons remarquer que les pourboires les plus importants sont reçus le soir,
ce qui est logique. Plus la facture est élevée, plus
le pourboire est élevé. Dans Seborn, il existe un autre
paramètre appelé taille. Elle indique la
variable utilisée pour déterminer la taille des
points sur le diagramme de dispersion Spécifions-le. J'
ajoute le paramètre de taille. Dans notre exemple, il s'agira la colonne
de taille de notre jeu de données, qui indique le nombre de personnes dans le groupe qui
commandent le plat. Après l'avoir ajouté, nous
pouvons observer plusieurs
dépendances, notamment l'heure
de la journée et le nombre de personnes dans un
groupe qui affectent les données Revenons à notre diagramme H
et apportons quelques modifications. J'ajouterai le paramètre Hue, qui nous permettra de
voir comment les données sont divisées et marquées différentes couleurs
sur l'histogramme Puisque je veux aussi observer
la dépendance du genre, je vais passer Hue sex. Je veux vous montrer
deux manières différentes de transmettre les données dans le diagramme H. Dans la première approche, nous
sélectionnions directement la colonne de facture totale dans l'ensemble de données et
la
transmettions à Seaborn Maintenant, dans ce cas, je
transmets l'intégralité
des données du bloc de données, mais en séparant
la colonne totale Bill qui doit être utilisée pour l'axe X. Seaborn trouve ensuite cette colonne dans le jeu de données et la trace Pour des tracés simples et rapides, nous pouvons utiliser la première variante. Mais pour les projets plus importants
ou pour un code plus propre, il est préférable de spécifier
explicitement X et les
données. Et regardez ce que nous avons. Cet exemple montre
la répartition du montant total de la facture en fonction de séparation
entre
les hommes et les femmes. Lorsque vous utilisez le hist blot de Seaborn fournissez à la fois des variables X
et Y, cela crée ce que l'on appelle Ceci est différent de l'
histogramme habituel que vous connaissez
peut-être, qui montre la distribution
d'une seule variable Un histogramme bivarié
permet plutôt de visualiser la relation
entre deux L'idée principale ici
est que le graphique divise l'espace en groupes
rectangulaires, même manière qu'un histogramme
normal divise l'axe X
en intervalles Mais au lieu de compter le nombre fois que des valeurs apparaissent
dans chaque intervalle, ce graphique compte la fréquence
à laquelle
différentes combinaisons de valeurs X et Y
apparaissent ensemble. Il colore ensuite chaque
casier en fonction nombre de points de données
inclus dans cette combinaison. L'effet de carte thermique
qui résulte de la coloration rend
ces relations encore plus faciles à repérer en un coup d'œil. De plus, je vais spécifier que cBr est égal à true pour
afficher une barre de couleur. Nous pouvons également remplacer le paramètre de
couleur par le CMP. La différence réside dans le fait que la couleur
définit une couleur spécifique, tandis que le CMP détermine une
palette de couleurs qui s'ajuste dynamiquement en fonction
des valeurs de la troisième variable
dans le diagramme Veuillez ignorer ce doublon.
J'étais en train d'expérimenter
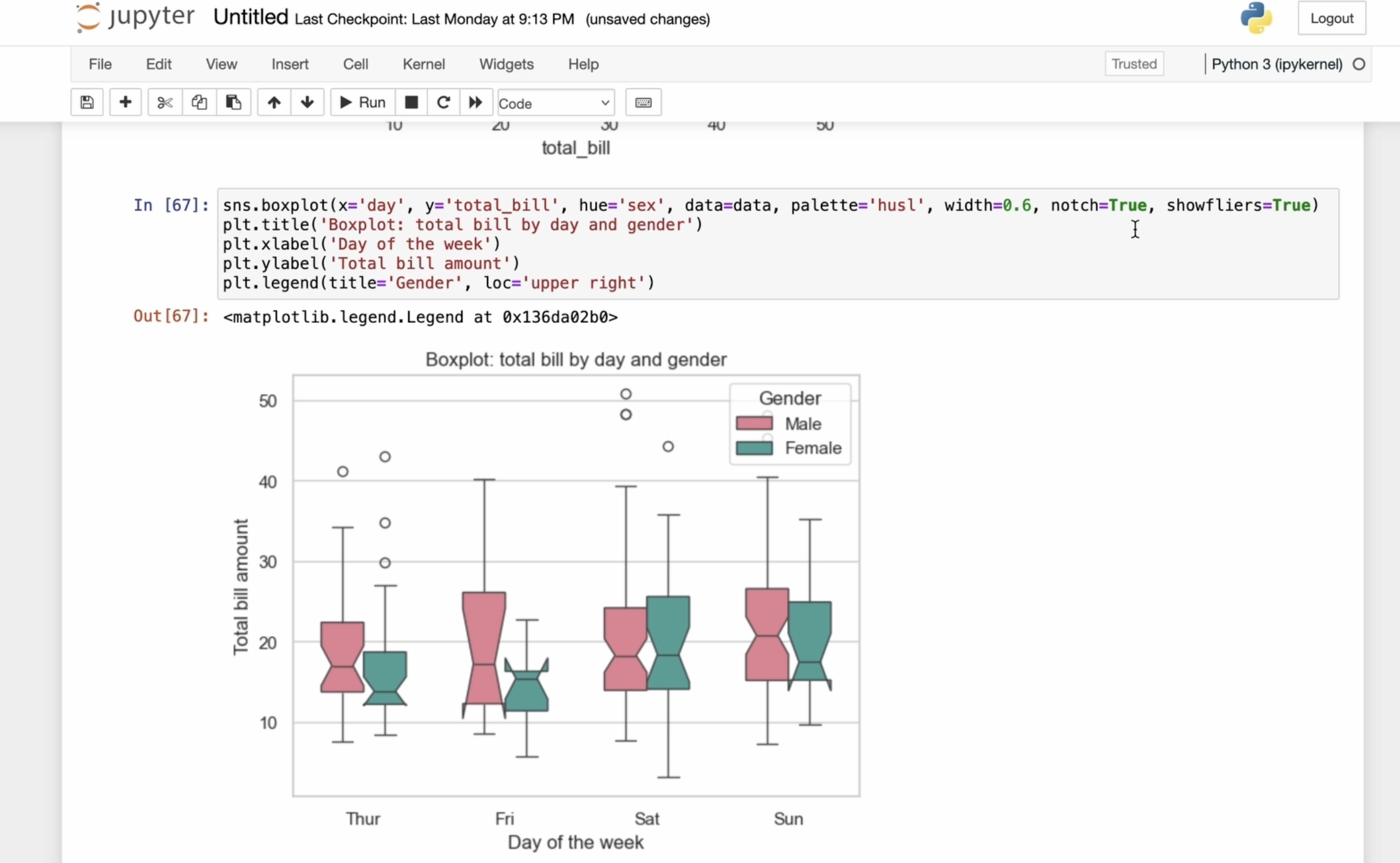
4. Seaborn avancé : exploration du boxplot, du catplot et des paramètres étendus comme la teinte, les showfliers et plus encore: Faisons maintenant connaissance
avec le box plot. Exécutez d'abord la commande
box blot et spécifiez les paramètres X
et Y. Nous utiliserons la variable jour sur l'axe X et la variable
facture totale sur l'axe Y. Ensuite, nous indiquons que
la teinte est égale à Tax, ce qui séparera le diagramme
par sexe pour chaque groupe. Ensuite, nous définissons le paramètre de
données, qui est notre ensemble de données. Dans ce cas, l'ensemble de données de conseils. Ensuite, je spécifierai que
la palette est égale à Haskell, qui définit le schéma de couleurs
pour marquer les différences entre les sexes Nous pouvons également ajuster la
largeur des cases. Par défaut, il est
déterminé automatiquement, mais vous pouvez le modifier
si vous en avez besoin. Le paramètre d'encoche nous permet de voir avec
quelle précision la
médiane est positionnée. Nous avons également défini les
suites de Showfler sur true, ce qui garantit que les valeurs aberrantes, c'est-à-dire
les couches bien supérieures ou inférieures aux autres, apparaissent
réellement sur le graphique Ces valeurs aberrantes apparaissent sous forme points
individuels situés en dehors
de la plage principale, en dehors des moustaches
du graphique Cela nous permet de voir clairement les points de données inhabituels
au lieu de les masquer, ce qui peut être important
pour avoir
une vue d'ensemble des données. Travaillons sur la lisibilité. Et j'ajoute un titre en utilisant
la commande PLT title. Ensuite, j'ajoute l'étiquette pour les axes X et Y à l'aide de l'étiquette
PLT x et de l'étiquette PLT Y. Enfin, nous ajoutons une légende, qui sera positionnée dans le coin supérieur droit.
C'est ce que nous avons obtenu. Nous pouvons expérimenter avec la largeur pour trouver
la valeur optimale. Par exemple, le régler sur
large peut ne pas sembler idéal, nous l'ajustons
donc à 0,8. Ou définissons-le comme égal à 0,6. Discutons maintenant
du paramètre notch. Cette image nous permet de voir
avec quelle précision la médiane
est positionnée. Par défaut, il est réglé sur Falls, et dans la plupart des cas, vous
pouvez l'émettre entièrement. Si nous l'activons, nous voyons
des protubérances ou
des coupures en haut des cases indiquant l'
emplacement approximatif de la médiane Si nous définissons qu'un cran est égal à une chute,
ces encoches disparaissent. Je vais
tout rendre tel quel. Continuons avec l'intrigue CAT. Il s'agit d'une fonction et d'une
bibliothèque Seaborn utilisées pour créer des données
catégoriques combinant
différents types de
diagrammes au sein d'une Avec Cat plot, vous pouvez facilement générer des diagrammes catégoriques,
tels que des diagrammes à barres, des diagrammes à points, etc., en fonction de
vos besoins en matière d'analyse de données Alors plongeons-nous dans le vif du sujet. J'utilise la
fonction Catblot et je spécifie D sur l'axe X et le total
Bill sur l'axe Y. Comme dans le graphique précédent, je souhaite regrouper les
données par sexe,
hommes et femmes, afin que la teinte
passe soit égale au sexe. Ensuite, je spécifie le paramètre de
données, qui est notre bloc de données, et définis le type sur bar
pour créer un diagramme à barres. Je choisis la palette égale à
deux pour le style des couleurs, puis en utilisant les paramètres de hauteur
et d'aspect, nous ajustons la hauteur et le rapport
hauteur/largeur du tracé. Après cela, je spécifie paramètre pour l'intervalle de
confiance. Dans ce cas, en utilisant l'
écart type, l'intervalle de confiance
détermine la plage de valeurs susceptibles contenir la vraie valeur du
paramètre. Par exemple, dans les diagrammes à barres
ou à points, intervalles de
confiance
indiquent le niveau d' incertitude autour de la
valeur moyenne ou d'autres statistiques. Ils vous donnent une idée de la
fiabilité de ce chiffre, comme une petite fourchette indiquant que la valeur réelle se situe probablement
quelque part par ici, mais ne vous inquiétez pas trop à ce
sujet pour le moment. Sachez simplement que
cette option existe. Ensuite, je définis un titre et j'ajoute des étiquettes pour
les axes X et Y à l'aide de l'étiquette
X et de l'étiquette Y. Enfin, nous ajoutons une
légende et la plaçons dans le coin supérieur droit.
Nous avons reçu une erreur. Il suggère de passer en barre car l'ancienne
version est obsolète Cet avertissement indique simplement
que Born améliore positionnement des éléments de la
figure pour une meilleure compacité de la mise en page Vous pouvez l'ignorer en toute sécurité. Voici donc le graphique
que nous avons créé. Dans notre cas, nous utilisons le diagramme CAT pour
créer un diagramme à barres
groupé qui compare le montant total des factures pour différents jours de la semaine et par sexe à partir du jeu de données Tips. Le graphique montre
que presque tous les jours, hommes ont tendance à dépenser davantage. Leur facture totale est
supérieure à celle des femmes. Il existe également un paramètre utile appelé colonne Cal shortf Cela permet de diviser le diagramme
en différents sous-diagrammes en
fonction d'une variable Jetons un coup d'œil à
ça. Je veux diviser l'analyse selon que
quelqu'un fume ou non Je copie donc le nom de la colonne smoker et après avoir ajouté le paramètre call
equal smoker, nous voyons maintenant deux Un pour ceux qui fument et
un pour ceux qui ne fument pas. Et d'ailleurs, on peut observer que ceux qui fument
ont tendance à dépenser plus. Maintenant, je vais supprimer les parties
inutiles, ne
laissant que la palette. Comme je l'ai
déjà mentionné, vous pouvez utiliser différents types de parcelles
avec une parcelle pour chats. Cela signifie que vous pouvez créer
différents types de diagrammes
catégoriques,
comme un diagramme à boîtes, par
exemple, voici ce que nous obtenons Ou nous pouvons le remplacer
par un complot violent. Désolé pour la faute d'orthographe, c'est
ce que nous avons obtenu. Cela est particulièrement
utile lorsque nous
voulons examiner une dépendance
dans les données, mais que nous ne savons pas quel type de diagramme la représente le mieux.
5. Visualisations Seaborn : Travailler avec des trames de violon, des trames de strip et des jointplot pour une analyse avancée des données: Regardons l'
intrigue du violon plus en détail. Un diagramme violent est une
méthode graphique permettant de visualiser la distribution
de données numériques sur une ou plusieurs variables
catégorielles Pour l'utiliser, j'appelle la fonction
Violin Plot. Ensuite, nous transmettons nos données. X sera le jour. Y sera le montant total de la facture. Le principe du sexe égal séparera
les données par sexe. Et les données, c'est notre base de données de conseils. Ensuite, nous voulons diviser l'
intrigue par catégorie, par sexe. Nous utilisons donc split equals true. Nous avons dit que la palette est égale pastel et que le
paramètre interne est égal au quartile, nous montrons les quartiles à
l'intérieur du diagramme Voici ce que nous obtenons.
Affinons un peu, ajoutons un titre, les axes X et Y. Et incluez une légende, en la plaçant sur la gauche. Il s'agit du graphique final. Ici, nous avons utilisé le paramètre interne
pour afficher les quartiles de la distribution totale des constructions pour différents jours de la
semaine et pour les différents sexes Les quartiles divisent les données
en quatre parties égales contenant
chacune
25 % des valeurs À l'intérieur de chaque violon, une ligne indique la médiane qui représente
une certaine tendance La forme de chaque violon donne un aperçu de la distribution
des données, qu'elle
soit
symétrique ou asymétrique,
épaisse ou étroite, fournissant des informations sur
l'endroit où les données sont concentrées À partir de ce graphique, nous pouvons déduire que certains
jours de la semaine, les hommes ont tendance à afficher une distribution plus large
du montant total des factures. La violence
à l'égard des hommes est parfois plus étendue ou concentrée dans des zones à plus forte
valeur ajoutée,
ce qui indique que les hommes ont tendance à dépenser plus que les femmes.
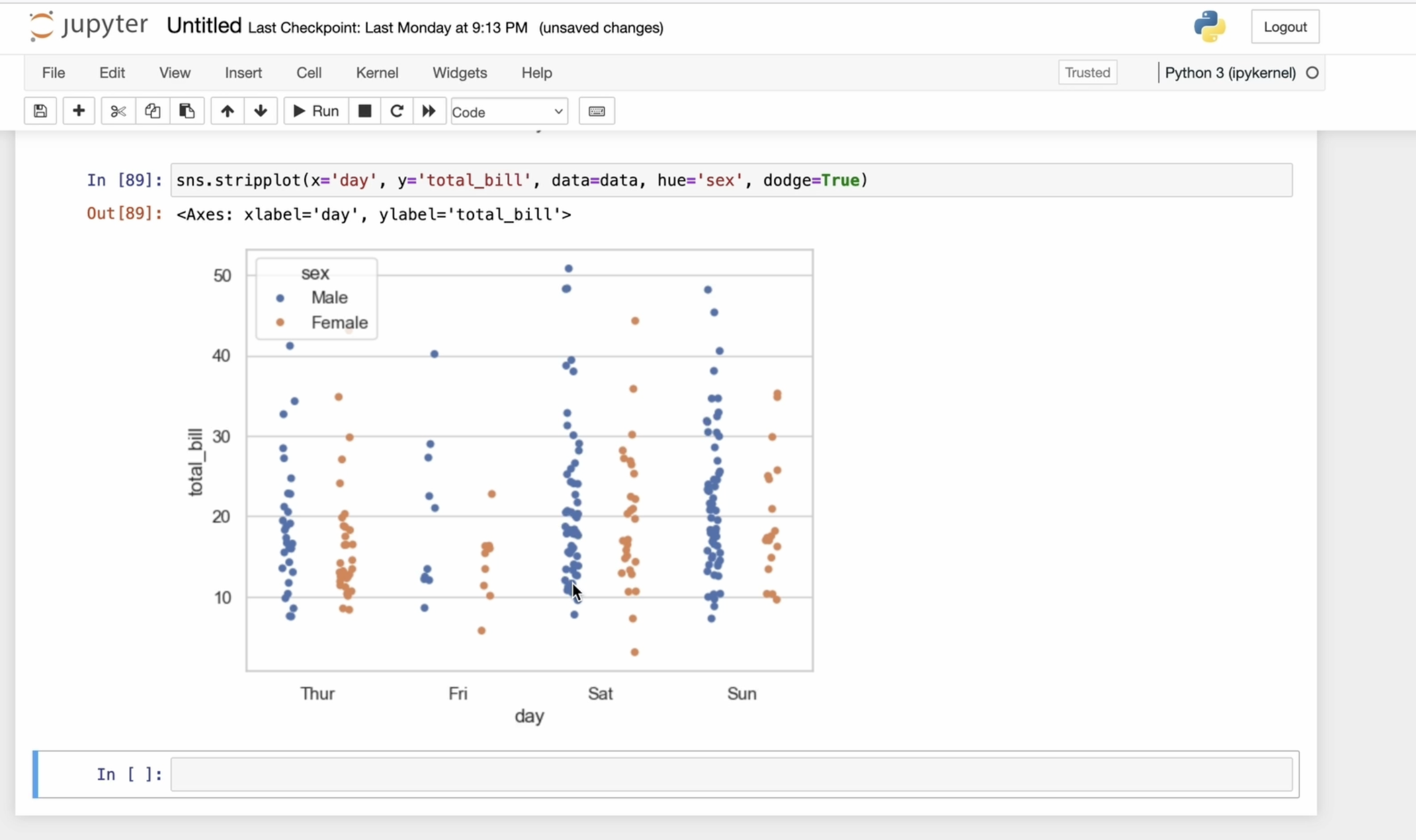
Passons maintenant au strip plot. Il s'agit d'une méthode graphique
permettant d'afficher la distribution de données numériques sur une ou plusieurs variables
catégorielles Il place tous les points de données
le long de l'axe des catégories, ce qui vous permet de voir
la concentration et la distribution des valeurs. En bref, un diagramme en bandes vous
donne une vision claire de la façon dont vos données numériques sont distribuées au sein de
chaque catégorie, vous
aide à comprendre les
modèles et les différences qui peuvent ne pas être évidents dans d'autres types de diagrammes. J'utiliserai les mêmes données. Je vais spécifier X et Y. L'axe X représente
le jour de la semaine, et l'axe Y indique le montant total de
la facture
pour chacun de ces jours Et bien sûr, je transmets le bloc de
données en tant que donnée. Je rencontre une erreur. Que s'est-il passé ? Désolée,
encore une faute d'orthographe Maintenant c'est réparé. Maintenant, je veux diviser davantage le
diagramme par sexe, j'ajoute
donc le paramètre hub. Lorsque le
paramètre Deutsche est défini sur true, je sépare les données indiquant une distribution distincte
pour chaque sexe. Cela permet d'éviter les chevauchements et de rendre les
diagrammes de dispersion plus lisibles Quand je dis que Jitter est égal à vrai, cela signifie que je vais ajouter un
petit bruit aléatoire ou léger mouvement aux positions
du point de données
le long de l'axe X. Ceci est fait pour éviter que les points ne se
chevauchent trop, en particulier lorsqu'il y a plusieurs points dans la même catégorie. Sans Jitter, les points pourraient parfaitement s'empiler
les uns sur les autres, ce qui rendrait difficile de voir la
véritable distribution des données Utilisons des couleurs légèrement
différentes comme celle-ci. Et nous y voilà. Faisons maintenant connaissance avec Joint plot. diagramme conjoint dans Seaborn est utilisé pour visualiser la
relation entre deux variables et
leurs distributions Travaillons avec. J'utiliserai Joint plot, en passant X et Y, X sera le total de Bill, et Y seront des astuces pour spécifier le bloc de données et
choisir le type de
dispersion égale pour le diagramme de dispersion Nous choisissons également une
couleur bleu ciel pour le graphique. Ensuite, j'ajouterai un titre à l'intrigue complète en utilisant
le sous-titre PLT. Ceci est généralement
utilisé lorsque vous avez plusieurs
intrigues secondaires et que vous souhaitez ajouter un titre général indiquant l'idée
générale du thème Vous pouvez expérimenter en modifiant le type pour voir
différents types de diagrammes. Par exemple, vous pouvez essayer d' estimer la densité
du noyau ou spécifier kind equals
reg pour la régression. Je recommande vivement de faire une pause ici et d'expérimenter par
vous-même Consultez la documentation et
essayez différents ensembles de données. Votre propre expérience est
le meilleur moyen d'apprendre.
6. Seaborn avancé : Travailler avec le diagramme PairGrid et la carte thermique à partir du tableau croisé dynamique dans l'ensemble de données Titanic: Voyons maintenant un
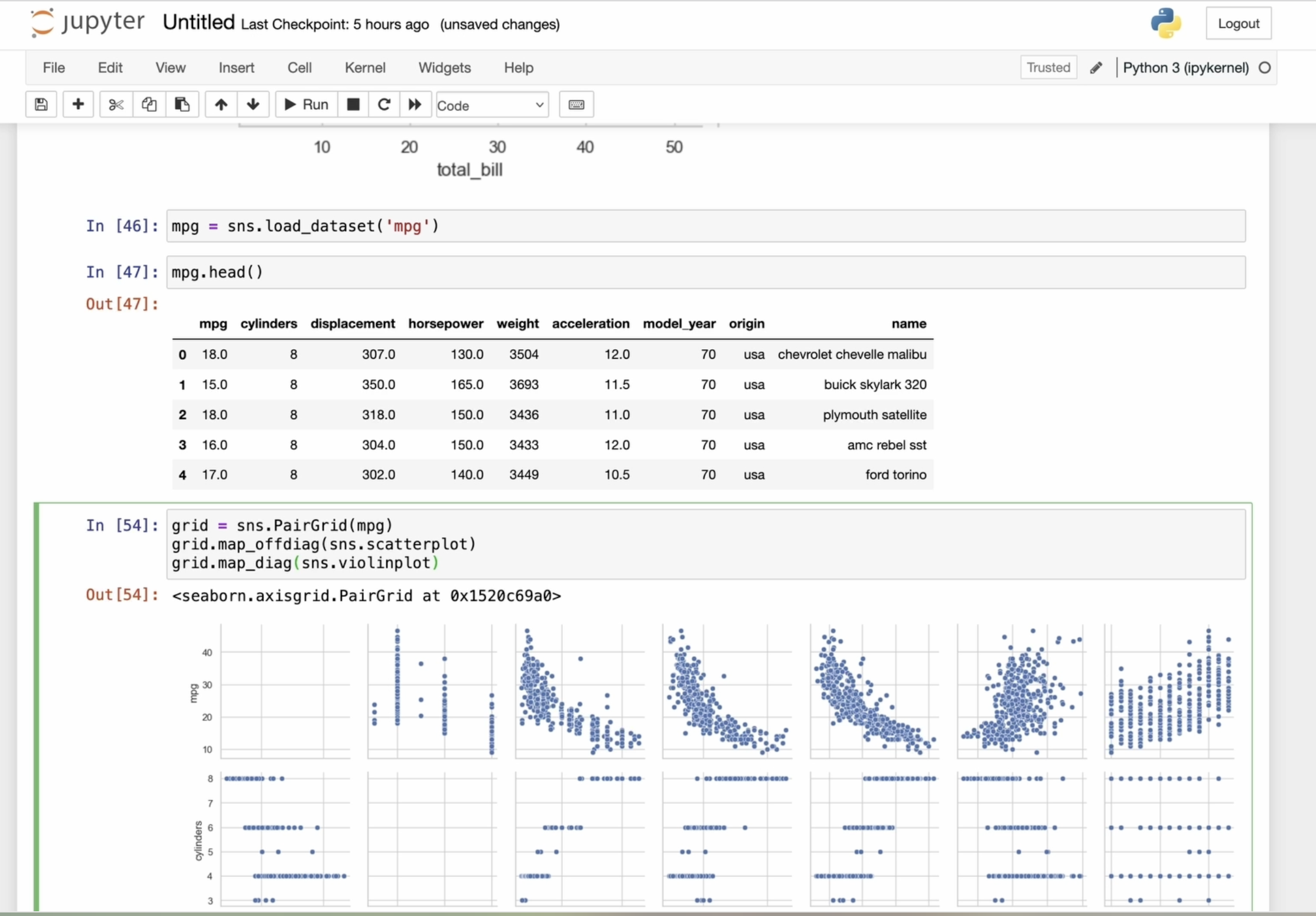
exemple d'utilisation de la grille PAR. Supposons que nous ayons un
ensemble de données sur les voitures. Dans cette ligne de code, nous chargeons le jeu de données intégré
appelé MPG Ce jeu de données contient des
informations sur les voitures avec des colonnes
telles que le nom du modèle, l'année de
sortie, le prix, le volume
du moteur et les lettres, ainsi que
d'autres informations. Chargons le jeu de données et créons une grille de paires
en transmettant les données. Par défaut, cela
créera une grille de graphiques vides pour
chaque paire de colonnes. Pour ajouter des
tracés spécifiques à cette grille, nous pouvons utiliser la méthode cartographique. Par exemple, nous pouvons créer un diagramme de dispersion pour
chaque paire de colonnes Nous pouvons également utiliser un barplot. Voyons comment cela va se passer. Cependant, je n'en suis pas tout à fait
satisfait, alors expérimentons une intrigue. Voici le résultat.
C'est bien mieux. Seaborn nous permet d'appliquer différentes
fonctions de visualisation aux parties diagonales et non diagonales de la grille de tracés Je vais maintenant utiliser la méthode du
tracé des cicatrices pour tous les tracés, sauf ceux en diagonale. De cette façon, nous obtiendrons un
diagramme des cicatrices pour chaque paire de variables, en laissant la diagonale vide. Découvrons la diagonale de la carte. Cette méthode applique
la fonction spécifiée uniquement aux diagrammes en diagonale. Ainsi, le type de tracé pour violon ne sera affiché que sur les tracés en
diagonale comme celui-ci. Seaborn nous donne de
la flexibilité en permettant différentes
fonctions de visualisation pour différentes parties de la grille Nous pouvons également utiliser une
fonction qui applique une visualisation donnée uniquement aux tracés
situés sous la diagonale, exclusion de la diagonale elle-même. Dans ce cas, j'utiliserai le type d'
estimation de la densité du noyau. De même, nous pouvons
appliquer une fonction
aux diagrammes supérieurs en utilisant
la fonction map upper. construction peut prendre un certain
temps, mais voici le résultat. Nous utilisons deux méthodes, la carte supérieure et la carte inférieure, et nous appliquons différents types
de parcelles dans chacune d'elles. Par conséquent, nous avons obtenu la visualisation
suivante. Ajoutons le paramètre habituel du
moyeu et divisons par la variable
cylindres. Le paramètre d'aspect contrôle le rapport largeur/hauteur
des tracés individuels. Par défaut, l'
aspect est défini sur un, ce qui rend les tracés carrés,
mais nous pouvons l'ajuster. Je vais définir l'
aspect comme égal à deux, en rendant les tracés rectangulaires. La hauteur définit la hauteur de chaque
diagramme individuel et de la grille. Je vais le mettre à trois. La reconstruction du
diagramme par grille prend un certain temps. Le réglage de la hauteur et du
rapport hauteur/largeur permet d'obtenir un affichage
optimal de la grille, en fonction du jeu de données
et du style de visualisation. Vous pouvez expérimenter en
fonction des besoins de vos ensembles de données. Changeons maintenant la palette de
couleurs pour en définir deux, ce qui nous donnera des couleurs
complètement différentes. Nous avons ici un
champ d'expérimentation infini. Ensuite, créons
une carte thermique à l'aide la table pivotante et de
la fonction de carte thermique Pour cet exemple,
je vais travailler avec un ensemble de données sur les passagers
du Titanic Perdons l'ensemble de données. Je vais maintenant créer un tableau
pour compter le nombre de passagers
masculins et féminins
qui ont survécu ou sont décédés. Pour cela, je vais
utiliser un tableau croisé dynamique. tableaux croisés dynamiques
sont des tableaux créés à l'aide de la fonction de
tableau croisé dynamique sur un bloc de données, qui vous permet de
résumer et de réorganiser les données en fonction de paires de valeurs d'
index de colonne J'en ai parlé en détail
dans mes scores Panda. Donc, si cela vous intéresse,
jetez un coup d'œil. Définissons l'indice comme genre et les
colonnes comme la survie. Le paramètre ag funk
est réglé sur la taille, comptant le nombre d'
observations dans chaque groupe Cela signifie que pour chaque combinaison
de sexe et de survie, le nombre total de passagers correspondant à ces caractéristiques
sera calculé. Nous avons maintenant un tableau avec des colonnes pour chaque combinaison de
genre et de survie. Construisons une carte thermique à
partir de ce tableau. Je transmets les données à la fonction de
carte thermique, je définis une annotation, égale à true pour afficher
la valeur de chaque cellule, indiquant combien de personnes
ont survécu ou sont mortes. Le paramètre FMT définit le format des
valeurs sous forme d'entiers Nous pouvons également ajuster
les titres des légendes et les étiquettes des axes à l'aide des méthodes des diagrammes
Mbap, comme nous l'avons fait précédemment Vous pouvez définir la palette
de couleurs de la carte thermique à l'aide de la carte C, par
exemple, de cette manière, pour un aspect
complètement différent. Vous pouvez tester
l'apparence de
la carte thermique et définir l'
épaisseur de la ligne entre les cellules. Je vais le régler sur un, mais ce n'est pas très
visible pour le moment. Modifions la palette pour rendre les lignes
plus visibles. Les lignes sont maintenant visibles et vous pouvez également
ajuster la couleur des lignes. Par défaut, la
couleur du trait est absente et l'épaisseur du trait
est définie sur 0,5, mais vous pouvez la
modifier à votre guise. Je recommande vivement d'
expérimenter, lire la documentation, télécharger le jeu de données, de
créer vos propres diagrammes, ajuster les paramètres pour
comprendre ce qu'ils représentent Lorsque vous poursuivez votre exploration
des données,
n'oubliez pas que informations pertinentes
commencent souvent par de simples visualisations. Continuez à vous entraîner, restez curieux et laissez vos intrigues
raconter l'histoire.
 Olha Al, Software engineer
Olha Al, Software engineer