Transcripts
1. Introduction: Hi, my name is Nicholas Felton. I'm an Information designer based in Brooklyn. My work crosses a variety of different projects, but they're all based in data. I'm best known for a series of projects known as the Feltron Annual Reports, which look at a year of my life and encapsulate that into charts, and graphs, and maps, to describe my activities over the course of the year. I've also worked for Facebook helping to design timeline, which of course is an aggregation of your history of posts on the surface. You may have seen my previous Skillshare class. It involve using processing to make a complex map of 34,000 meteorite strikes on the planet. But this class is either a prequel or sequel to that depending on how you see it, and we'll go over general principles for making data visualization in a less technical manner. I've been working with data as a source of design for the last 10 years. I started as a general graphic designer working on magazines, and websites, and logos. In 2005, I discovered that there was a wealth of information in the world, and I could use this to describe behaviors and activities and use it as a source for my designs. Seeing the world through the lens of data is a really compelling way of seeing the world. Your project for this class is to find a local newspaper, I've been using the New York Sunday Times, and to take one section of that newspaper, be it sports, or business, or world, or even the ads and use that as a source. This is something that you're going to ask a question of, and then we're going to come up with a methodology for gathering information from it, organizing it, exploring it, and ultimately turning it into a data visualization. They'll be the same size as one sheet of this newspaper, and it should condense the information inside of it. So, by looking at this visualization, you'll get an idea of what the entire section communicates. Every data visualization should begin with a question. So, it should answer something that you want to know about the world. It doesn't have to be a precise one, but it could be just a a general hunch, or hypothesis, or something that you want to prove. So, the best data visualizations are answers to these questions you leave, knowing something new, and they can be really powerful in that way. I would set aside one to two days for doing this project. Depending on how intensely your data capturing becomes, that could take up to a day. Then after that, the layout can come together relatively quickly, but I'll give up to about a day to work on that as well. You may want to refine it afterwards especially if you share and and get feedback. I think in an ideal posts to the gallery for this project, I'd love to see the question initially. What was the thing you were trying to explore or the answer? We don't need to see the data, but sketches along the way, and then some of the refinements of the graphic as it goes along. I tend to have a lot of little eureka moments along the way or like, "Oh, that thing worked." I think sharing those tips as to how you were able to transform something into another piece of information or create a graph or a visualization, those would be really helpful to other people. We could all do the exact same section of the newspaper, and I think everyone would come up with something completely different, with a different point of view or different designs. So, as long as we're not distorting the data, this is wide open to your creativity and exploration. The big thing to keep in mind here is that there are rules to this, but as long as you are aware of them, it's wide open for exploration.
2. Tools You'll Need: One of the things I love about this assignment is that anyone at any skill level can participate in it. Of course, if you can't get your hands on a physical newspaper, it's probably fine to work off of the Internet. I just worry that it may be too broad there. I like the idea of having a physical object that is confined and so you know exactly the boundaries of your dataset. So, basic materials, I would say absolutely you need the newspaper, is going to be the source of your information, pen and pencil maybe a highlighter, possibly a ruler, definitely a sketchbook. I think that sketching is a huge piece of this process. Then, preferably a laptop or a computer and some knowledge of spreadsheets. So, this is a great way to organize your data once you pull it out and then Internet access for some of the online tools we'll be looking at. At the intermediate level, I think there's more advanced web-based tools that you can use. There's also the typical design tools like Adobe InDesign and Illustrator that will be really helpful for making graphs of your own. The spreadsheet is something that I rely on a lot, but it's not something that everyone has experienced with and it also caters to a range of different abilities from beginner to advanced. For online web-based tools, I've got several resources, some of which we'll look at in this class, and then more links that are available for you to play with. On the advanced end of the scale, there are things like using databases, querying them, using online tools that have APIs to get extra data that will supplement your information, and then finally, touching on a little bit of code. So, for people who are comfortable in that world, there's a lot that can be done to make novel visualizations.
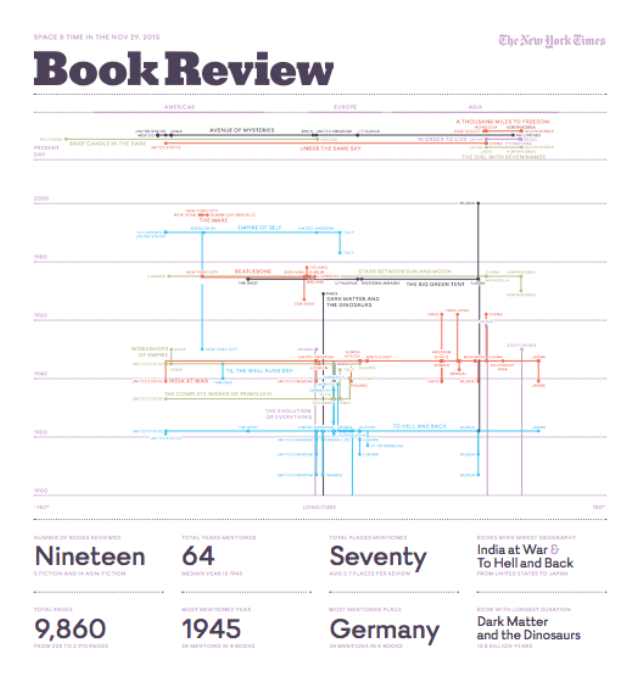
3. Ask a Question: There's a lot of opportunity for diving into a section that you may not know a lot about. I think you can bring an interesting naive point of view to that section. I don't follow sports a lot so I think that when I look at the sports section, I tend to look at it from a further remove. You can imagine taking the sports section and turning that into a map of showing where the games had happened and what the scores were. But you can also think about questioning some of the choices that the newspaper has made. A very journalistic approach to looking at the newspaper would be to test a hypothesis. So for example, looking at the real estate section you might ask, where is the most expensive real estate in your town? And choose to map the prices of different real estate around your city or state that the newspaper covers. A way of critiquing the paper might be to analyze gender or diversity in the newspaper. Who is it talking about, or who is doing the talking in the newspaper? These are ways of delving under the hood and starting to investigate the voice of the newspaper. Formally, you could look at the aesthetic choices of the newspaper like how is color versus black and white used in the newspaper. Additionally, you could look at the relationship of type sizes, you could look at that ADs to the photographs and then start to make a comparison or an audit of the newspaper just through these aesthetic choices. A more traditional data visualization approach might be simply to translate the data from the format of a table or of what you find in the article itself, into something like graphs that describe the same information or a map of the sports scores around the country. I think the best questions here, generate more questions. You keep delving deeper and finding more things that you're curious about and asking more questions. Ultimately, the visualization is the answer to these questions. First thing I did was I bought a Sunday edition of the New York Times, nice and thick and has some unique sections that don't exist for the rest of the week. What I started doing is just flipping through it. I'm starting to look for patterns, for points of connection between different articles within that section. I started to look at the sports section and I noticed the injuries were a big part of the article. So I was thinking, maybe I could look at the newspaper through this lens of injuries. Like, what does a sports section look like when you're just focused on different injuries, then breaking it down by sports, I was also thinking for the sports section maybe a Critical way of looking at this is just, how much space did they dedicate to each sport? Another way of looking at it is not just by the teams but by the regions and how New York might have scored 80 points versus California scoring 240 points. Ultimately, I wound up looking at the book review. I liked the book review because there's a limited number of books, each of the articles is structured and it's just talking about one thing. So, it's got an author, it's got a genre to it like nonfiction or fiction, it has page numbers. One of the questions I was looking at is just the publishers. So, I know that there's a limited number of publishing houses in the world making books, so maybe there's a bias here that might be interesting to look at. So the question here would be, what does the book review look like when you analyze it through the lens of publishers? Of course you could compare and contrast the editorial versus the advertising in the section. Ultimately, as I was reading some of these articles I noticed that there's a lot of mention of place in them. Even in some of the briefest descriptions of the books, different places started being mentioned like Mexico and India. Then time was a big component as well. So the question that I started to formulate was around, what does the book review look like through this lens of time and space? As I was looking at this question of how time and space relates to the different book titles in the book review, it opened up these other questions that I wanted to figure out. An example would be, if a war is mentioned do I include the place where the war happened and the year? Is that a mention of both time and place? There's also the different categories of books. So you can start to look there. How to the times and places involved in fiction relate to nonfiction. Once you've come up with a question I think it's really important to do a close reading of a few of the articles to make sure that there are enough points of connection and enough answers to this question in each piece. So when I started looking at time and space in the book review, I read a couple of articles and I started highlighting the years and the places involved, and making sure that I would wind up with a dataset that was large enough to work with. I think if you're only finding ten connections or ten pieces of data, it's probably going to be on the thin side. I think we should be aiming for around a hundred points of connection is probably a good sized dataset to work with. I think they're purely visual ways that you can approach this problem as well. You could look strictly at the photographs, just at the faces or at the locations represented in the photos. Even looking formally at the color choices in each of the photos I think is a completely valid way of analyzing the newspaper. I've got my question of how is time and space represented in the book review, I'm confident that there's going to be enough data to collect and explore. In the next section, we'll delve into how to actually get that data out of the newspaper and into the computer.
4. Get the Data: At this point, you've selected your section of the newspaper and you have a question in mind. This should mean that you're now going to go article by article or page by page through the section and start to pull out what you need, to answer that question. In my case, I was really interested in highlighting all of the places and dates that occurred in the newspaper. So, I pulled out these two fluorescent highlighters and went through each article, bit by bit, highlighting in one color the places and highlighting in the other, the date. You can go through this simply with a single color pen or a single color pencil and just underline the important things that you're going to be pulling out, or just mark that you've recorded them by crossing them off. You could also go online and get the text for the website and then do more automated analysis of it. If you were just looking for single words or perhaps every number that was mentioned in it, it might be really easy to just do a "find" on the text and get each one of those instances. One of the reasons I like working manually in this way, is because you get to know the data so well. I have read all the articles in here at least twice. So, I have a really good understanding of their content. I think it's fine to work in a digital form and do more automated analysis using, say, other APIs. But when you're first learning data visualization, I feel that having this intimate understanding of the information you're working with really validates the way that you bring it to life later. It's really helpful in finding the mistakes and the flaws in it. Trying to collect too much, too quickly can lead to catastrophic collapses as it takes you four hours to get through a single article. So, start minimally and build up later. Once you're ready to start capturing this information, I would recommend putting this into at least a text editor, if not a spreadsheet. This is gonna keep things really organized and provide you with a lot of flexibility to do some more interesting analysis down the road. You can also consider something like Google forms, this is a way of trying to get more subjective information. So, you could imagine creating survey and asking people to read the newspaper or look at the images in it, and find out what a group of people think about the article that they've read or the photo that they're consuming. To capture the information I need for the visualization I'm working on, I first highlighted the dates and places that I found in each article in the book review. I then used Apple's Numbers to organize all this information. So, I've created a small spreadsheet here where I'm capturing the name of the book, the author, the place that I found and then a start date or an end date, if there is one, and the page. I also think it's really important to keep track of your sources. So, the ways in which I'm doing this are marking the page on which I found it. I'm also just using a little bit of reference text that it came from. So, here, where I have Italy in 1943 as the places, I've just written down the little phrase "Northern Italy in 1943". This is a good way of just validating your work, not getting confused or lost as you go through it. As you're creating a spreadsheet, it's pretty important that in these different columns, you're only gathering the same information. So, you're not mixing, say, text and numbers in the same column. This probably means that you need an extra column. I would say that in general, there's probably three different types of information you should be recording here. One would be this binary thing, a Boolean in code, but it could just be a yes or a no. Is a person married? Yes or no, or is it overseas? Yes or no. Then another type of information would be a number. This could be decimal, positive or negative, an integer. But those should all be in their own column. For me, this is the years. Then, finally, just text. For me, I'm capturing the name of the places. So, in that entire column, I just have words talking about the different countries or cities involved. The number of columns is probably not super important, but certainly the number of rows. So, the number of entries that you have, it's going to have a big impact on the project that you're going to be able to create. I would say that we're going to want to aim for around 100 rows of data. This is going to give us a good amount of complexity, but still allow us to work manually and make something either by hand or using an online tool.
5. Explore the Data: In this section, we're going to start exploring your data. I see this is a cyclical process where we're coming to understand it, we're cleaning it, potentially extending it by adding more data to it, and it involves a lot of tools. I am by no means an expert in any or all of these, but I know enough to get by. I think that you can pick and choose which parts of it you want to work with. So, I think initially, it's useful to look at our spreadsheet. I've got a bunch of different tabs here because I'm versioning the spreadsheet as I add information to it. Sometimes I'm removing columns, but I'm trying to do this in a structured way where I can always go back and fix mistakes or do things over and understand how I got to the end result from the beginning. So, I've got my initial data, I've wound up capturing about 368 different rows. The first thing I'm doing is I've refined my data a little bit. I had a locations column initially and I decided that it would be easy and useful to break that out into both the city and a region and a country column. For instance, where I have Berlin as the city that was mentioned, I now have Germany as a country. The first thing I wanted to do was just get an idea of how many times different things are being mentioned. For one of them, I wanted to see how many different entries do I have for each of my books. Unfortunately, this is not something that I found to be easy to do in a spreadsheet and so I have a couple of ways that I can do this. Typically, I would use a database, but I've found that there's one kind of easy, fast, and very accessible way of getting a count on something, which I'll show you now. So, in my column that has all the book titles, I'm just going to select all of that and copy it into a new text edit file. So, now I've pasted all of that and I need to just get rid of the title here which says book. I'm going to do a Find and Replace on this to remove all the spaces, basically to concatenate all the different words into one thing, so each book title is just going to be one long word. Now, I'm doing a Find and Replace for every space and replacing it with nothing. So now to hold them back is to hold them back. I'm going to copy this out and take it to a website that I use a lot. It's a word frequency counter at this website called WriteWords. So, basically, I'm just going to ask this website how many times does each of these words appear? I paste in the text from my clipboard that came from that text file and I submit it. Now, I've got total counts on each of my titles and I can do this for other categories. I can start to look say at the countries that are used here by copying them and pasting them into this TextEdit file and doing my replace again. Now, I can figure out which country is appearing the most in my dataset and this tells me it's India and Germany tied at 36. So, that's a quick way to start to get a little bit of a sense of what's going on in this dataset. Another website that I really like is called CartoDB. You can create a free account here. I'm going to log into my account. This is primarily a tool for turning a dataset into a map. This can be interactive but they're great ways of understanding your data and even potentially exporting it as a vector file to Illustrator. So, I've got my initial data uploaded here. The way this works is you can both see the data and then represent it as a map. So, this is a split screen view and it'll show me both the data view. So, this is effectively my spreadsheet. Again, the way that I brought the data into CartoDB is by taking my spreadsheet and exploiting everything as a CSV file. So, I'm going to save this to my computer and then in CartoDB. I can click this button for new dataset. Here it's going to ask for a text file. So, I'm just going to drag it. Right now it's pointed to that that data file that I just created, that one is called the initial data. So, I'm uploading that to CartoDB now and it will give me that initial data as both a table and then something that I can work with in more detail. So, here you can see it's brought in this dataset, got my years, my locations. The other side of CartoDB is this Map View. When I click on that Map View tab, it's telling me that I don't have any geo-references. This means I've got the names of places, but it doesn't understand them as locations yet. What's really nice is that I can tell it to simply map what I've given it. So, I have city names, administrative regions which are like countries. So, I'm going to tell it to take the administrative regions from my dataset and try to map those. I just need to tell them what column they appear in. I've got a Country column, so I've selected that and hit continue. Click on this geo-reference with administrative regions and it will work for a minute, but that should give me a map of what I've got so far. It told me that 230 of my 368 rows were geo-coded. If I click the Show button, let's see if I click on the Map View now, there we go. So, these are the countries that were mentioned in my dataset and it looks like there's some tinting going on here. So this is trying to show me which ones are mentioned the most. So, I'm starting to get a sense of my data figuring out which things are being mentioned the most, understanding the number of records for my books, and where things are sitting geographically. Another way to start to understand your data is to use the graphing tools that already exist in the spreadsheet. If you've got it here, you can take any numerical data and start to create a graph from that. So, I do have a column here that's my start date. If I select that, I can make a chart and use this line graph tool. There's some stuff that I understand here I can see that it's giving me a range of 0-2100, so it's following the range of the years that I've given it. What's useful to see here is that there is a bulk of stuff near the top, so most of the stuff that I'm going to be interested in is probably in the 20th century. With some outliers that are that are reaching back into sort of the middle ages like the 12 hundredths here. I think those were references to the Renaissance that were in my dataset. The nice thing about CartoDB is that you can delve right into basic MySQL queries on the data that you've already uploaded here. So, if we go back to the data view, there's a little tab available here now called SQL. This will allow me to do some of the grouping that I was doing using the word frequency counter, but directly on my dataset and without any of the shortcuts like removing all the spaces. I'll show you one little pattern that will be really useful just for getting counts of things in general. This is the pattern of MySQL you say what you want to select and you give it a column name, I want to collect the countries. So, I type country and then I want one other thing which is the count of how many countries are existing. So, this says just count everything from table one and I want to group it by the country and then order it by the count in descending order. So, this will give me the highest count first and the lowest count at the end. If I apply the query, now I can see I've got 67 with no country, 36 with Germany, 35 with India. So, you can apply this to any of the columns just by changing country, to book title, or to author and re-running the same pattern over and over. So far, we've looked at a couple of things, we've looked at a really easy way to use word frequency to figure out how many times something shows up in your dataset, the convenience of CartoDB to start mapping stuff really easily, we did this at a country level, but you can do it for cities as well. Then just now at a quick look at MySQL which I found really useful for figuring out things like word frequency and category counts.
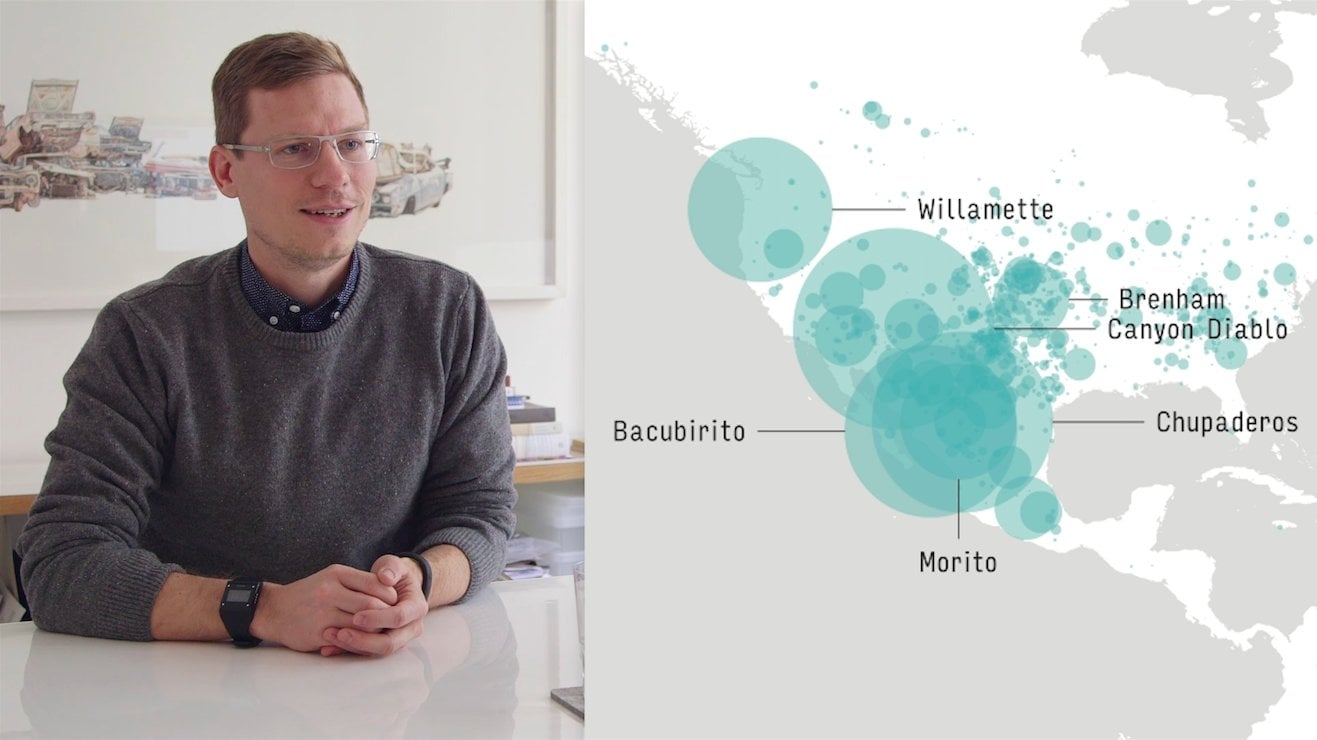
6. Extend the Data: Now we're going to move on to extending the dataset. So, as you familiarize yourself with everything you may want to add more information from other sources. I'm interested in getting more detailed location data for the places that I've looked at. To do this, I'm going to use combination of Google and Wikipedia, but there are other places that might be useful for you to find additional information for your dataset. I can show you a couple of those really quickly. In my next tab in my spreadsheet, I'm going to start adding latitude and longitude information for each of the locations that showed up. This is going to allow me to do some much more precise mapping in the future. To do this I basically just organized all my places by city or country whatever information I have available. Because I don't have that many I just decided to do it manually. So, I'm doing things like copying this mention of Auschwitz into the browser and this will bring me to the Wikipedia page and from there generally every single place has this one little coordinates link here in the right sidebar. So, by clicking on that, I can go to this page that has it nicely formatted in the way I want, which has two decimals. We've got 50.03, I'm going to copy that and paste it into my spreadsheet and 19.178. So copy that in. Basically I just did that for everything but now this will allow me to either use other mapping tools or even processing to start to map these locations. Another way that you can geocode is by using Google Maps. For instance, if I type in Turin, Italy into my browser. It'll show me where that exists on the map and then if you just control-click somewhere and you say what's here? It will actually give you this little window at the bottom that tells you the latitude and longitude for the place. This can be really useful for identifying really specific places like a restaurant or a building that might be mentioned. An API is an application program interface technically but it's like the plugs on the back of your VCR. So, this is how you can connect to a service. Some of the things that I'm showing are meant to be integrated into other applications but what's nice about them is they give you a front end. The consumer entry point where you can play with them and test out their software without being a developer and without committing to building a custom piece of software. I'm going to do a bit of text analysis on the articles rather than going through it manually. What I would do, is I would go to the New York Times. So, in order to work digitally with the text from the book review section, I would simply look for the articles that are mentioned in the physical version of the paper and pull them up here. So, the first article was about the complete works of Primo Levi. I'm going to pull up this article and try and get the text and just to show you what it might look like in one of these texts analysis APIs. I'm thinking an easy way to get this out is to go to the print button and just copy it out as a PDF. So if I open it in the PDF preview, it strips out all the formatting that I don't need and I can just copy this all and I'm going to paste that into an Alchemy API session. So, on the Alchemy API site, I'm going to try the demo and I want to load a sample text. I've just copied out the Primo Levi article and I've pasted it into their little demo text field and I'm going to try it. So, let's see what it gives me here. It's identified Levi and Primo Levi as the most important people there. It's pulled out Auschwitz which was very formative in his life. His experience there as very relevant and of course very negative. The New York Times is being pulled up because I think I included some footer text there. But if I had cleaned up the text a little bit, this might be a really useful way of getting some quantitative analysis of the articles involved. I also realized that in order to connect time and place, I might want this idea of an average year for everything. There's be the starting point. So, I created a new sheet and here for each book, I'm just taking all the mentions of years that I have and averaging them together to get one year that will be the baseline year that I can use in my visualization just in case there wasn't a time and a place that were mentioned at the same time. NewsDiffs is a pretty interesting website that certainly relate to this project as they keep track of articles and how they've changed over time. So, you can imagine taking your section of New York Times articles and starting to see what edits were made to it since they initially published it and start to visualize that. Here we can see the obituary for a famed Russian director and you can see how it's changed in the last 24 hours. NewsDiffs would be really useful for looking at the front section of the newspaper. This is probably were the most controversial and most up to the minute articles are being kept and are probably being corrected continuously. So, I would imagine you could see a lot of activity on breaking news stories as they emerge if you choose to do the front section of the newspaper and there is some big story that happened over the course of the week, I think you might find some really interesting things happening as the article expands and as pieces of it are changed overtime. Imager, is another API and this one is useful for looking at images. In the demo you can play with this for yourself, but you can upload an image and then it will try to identify what's inside of it. Here in the demo I'm using their picture of a wolf and it's coming back with 100 percent wolf, 100% timber wolf, 100% canine and you can imagine giving these photos of places or people that are associated with the articles and starting to use it as a repeatable consistent way of analyzing images. Just for another experiment, this is out of the scope of the project that I'm doing but I'm curious what the image API will say about this image of Primo Levi. I'll go to the imager site. So, here it gives me shop, library, bookshop, building, mercantile establishment, structure, place of business, home, adults and people. Somewhat accurate. If you get enough of these hopefully the accuracy builds but this is early days for this technology. Finally, this other tool. It's interesting just as a formal way of analyzing the colors and images. So, if you look at the travel section you might notice there's a lot of beach blues and greens there and maybe you're interested in quantifying that. So, by giving it these images it will come back to you and tell you what the most prominent colors are with really numerical hard values to go along with it that might be interesting to look at in your analysis of the newspaper. So, before we get involved in visualizing this data, exploring it, familiarizing ourselves with it, cleaning and even extending it is a really important part of the process. This is cyclical as well. So as we look at things we may find that we need more information. So, a location may want a latitude and longitude to go with it to help us graph it or the data that we collected maybe too precise. So, if you've gone and collected 100, 200 city names perhaps we need to categorize them by country or by state in order to be able to make a visualization that is broader and more accessible. I think that starting to visualize the data and get a sense for it's shape, is a really important thing to do before adding a ton more extra data into it. As I was working on my project I found that the most work that I needed to do and refining was in the location data. I had mentioned some places that were broadly different from cities, to countries, to even areas like the West. These needed to be made more precise and ultimately I needed to find coordinates for them. So, I had to look them up in latitude and longitude. This meant adding a couple of different columns and starting to extend the data in that regard.
7. Sketch and Design the Layout: Hopefully, you have a bit of an idea of where you want to take your visualization. You've extended the data and found some things that are interesting about it. Now, is it a good time to step back and think about the entire page that we're going to lay out. This is where sketching becomes really important. I love to sit down at this point with my notebook and just block out where the elements are going to go. This is a time to make sure that all the different dimensions of the dataset are going to be represented. This is also a chance to start sketching on the visualization. Try to figure out what aspects of the dataset are going to come into play and evolve the forms that you're going to use later on. I think that narrative flow throughout the visualization is something that's really critical. So, how do you get people into your document and then move them through it. I like to have an entry point that's going to tell them the big picture and then to move slowly into more and more detail as they read the graphic. With the book review itself, I'm going to make visualization that's going to be the same size as this page. So, I'm actually going to take some cues from it. I think that incorporating the title in the New York Times graphic could be useful as a way to quickly introduce people to what this is, and then using some of the margins will help it feel a bit like the source material. So, I'm doing some sketches now to figure out the rough relationship of elements on my page. I want this graphic to have similar proportions to the book review itself. I know that I want to repeat the title of the book review, up top. To give it context. The question now is how I want to place my large graphic. I actually think that because I want to use some cartographic information here and the world is, wider than it is tall in most maps, and I actually want to reserve a big section in the top middle for this map. So, I got my title and at the bottom, I want a couple of columns to show some general starts about the dataset itself. Up here, this is where I'm going to start thinking about what I want to put in here. Do I want to put a map of where all the books are talking about, or do I want to do something more abstract. I think that after looking at the data in CartoDB, I want to start pushing this graphic somewhere else. One of the things that I noticed is that the data doesn't tend to be represented in South America or Africa. So, in thinking about this graphic, I want to keep this idea of the longitude. So where things are happening sort of in America, in Europe, and Asia, but then for this dimension, I'm thinking about using time because this is what I've been collecting and how I've been starting to think about this. I notice that there are a lot of World War II books that I think would be in the 1940s. There are some present books that are talking about North Korea so they might be up here, there's that book that talks about the dinosaurs, but doesn't have very many locations. So it's kind of going straight down to the beginning and I think that this is how I want to play with the data and build the system so that I can start to see how the data actually fits into my layout. A good starting point can be to just write down on the page where you're going to sketch, what are the different dimensions of data that I have. I don't think latitude is that important. I think longitude is much more interesting names of the books obviously the years, and I'm not really going to focus on the authors because they're as unique as the books. So, I've got these three dimensions and I think the big question now is to figure out how to get these on the page. If they didn't relate to each other or I couldn't figure out a visualization that would combine them all together, I might say for the page, I'm going to split it into three sections. The top might be about longitude, the bottom might be about years and each of these would talk about the books. But I think I have a way of combining it all into one graphic, that's going to be really compelling. So, I've set up an inDesign document. Here, I've got some of the margins from the newspaper itself, and that's going to be my starting point. This will establish where my text boxes are going to go underneath the graphic itself. To do this, I'm just going to create a text box and give it four columns. I'm going to double the gutter to give it a more comfortable measure, so that should be good. Basically, I'm just going to use what it tells me is the width of my columns here and to create four different text boxes. So, they are two-and-a-quarter inches, I'm going to delete that one and then just make a new one, that has the width that I want of two-and-a-quarter and then make four of those to fit across the page, and to establish my grid, and then set my rules based on the location of those text boxes. So, this is going to set up my horizontal grid which will make it much easier to align objects. Now, I've got four text boxes. I'd also like a vertical grid, again that helps me to make units that are the same size so they can be moved around a lot, and this will help me if I need to balance my story, or move elements around. They all have the same height and weight so they can be swapped out as I need. I'm just going to make this 10-unit vertical grid, so I'm making a box that fits within my margins and I'm going to make it 10 percent of the height, and just set my rulers there to break up the page. I think that the main graphic is going to be most of the page. This will allow me to add a lot of detail there and because my dataset got kind of large over 300 data points, I may need the space and the resolution to communicate the data. My 10-unit grid is done and I've got some text boxes here, I'm going to just kind of wire-frame this out to give myself an idea of where everything is going to go. This box will represent where my graphic is going to go maybe, I don't know. It's going to be about two-thirds of the page and then I've scanned the book review title, so I'm going to place that in up top just to give a sense of the scale, and then these are going to be my text boxes. So, I'm going to rough this out with some stats quickly. So, I've kind of got my rough structure that is matching my sketch and that's a good starting point. If you have any ideas now about some of the little details that you want to put in here things have come to mind. Now, there's a nice place to put them into the layout, and to start capturing your ideas as you sketch.
8. Visualization: Tools and Design: I'm back in CartoDB, and I've uploaded my latest version of the spreadsheet. This has latitude and longitude for all the places that I'm discussing and information for the years. Back in the map view, I've created this new view, instead of using the simple approach, in the map layer Wizard, and we have this category.type. This has done a really good job of helping me to understand my data. So, after the last time when I was looking at it and I was just seeing the countries, I went in and I added a bit more detail to it, which has allowed me to bring it back in and see things with more clarity. What's great now that I have everything down to points and not just countries, is that I can see each point is associated with the book. CartoDB has color coated this, so I can now see these purple clusters all have to do with, To Hell and Back, and these red clusters are all India At War. This is really useful and I can even export this right now and bring it into Illustrator and start playing with these markers. Again, CartoDB will allow me to export this as an SVG, which I can open in Illustrator. So, this is really interesting, this is helping me understand my data a bit better, and leading me to where I want to go. But, a map is a little bit too constrained for where I want to go, in my sketches I've been exploring this idea of getting rid of the latitude. So, only showing where items fall on the width of the map, and using time as a vertical dimension. So, CartoDB is very married to the map approach, so I'm not going to be able to explore this idea further here. So, I'm going go to a different application to play with that data. There are a number of online tools that let you upload your data and play with them to make bar graphs and scatter plots, treemaps, all these sort of things, and they all have different advantages and disadvantages. So, some work really well for certain types and not as well for others. One that I found was working well for exploring this dataset was a tool called RAW by density design. You just start off with this empty text field, and what we can do is just paste or drop a file into their online tool to start exploring it. So, I'm going to grab some of my data, this geocodedplaces.csv. I'm going to pull it into the density design interface. Now you can see it's added a new set of options, all these different types of network diagrams, and a tree map, but what I was interested in looking at is a scatter plot. Basically, I want to tell it that on the x axis, I want to use longitude, but on the y axis I want to use year. So, clicking on the scatter plot and I get some more options down here. As I said on the x axis I want to apply the latitude, and on the y axis, I want to apply the start date, and you can see something's happening already here. So, I've got my locations being plotted and you can see some really new stuff, some very old stuff, I think these are empty data that's being plotted at the bottom. So, where I don't have a year, it's automatically putting it at zero. I can add a little bit more, I can change the color here based on book, which is what I was doing in CartoDB. So, dragging in the color, now I'm starting to see a bit of this coming together, I can even put in the labels which is interesting. So, I can play with the cities being talked about or I could remove that and put the book name in as well, and start to get this labeled, but this is a great little playground, I might revisit it and pull out some of the data that's not playing as well here like these zero amounts that are winding up at the bottom. But what's beautiful is once I've got it to a place where I like it, I can export this as an SVG and bring it into Illustrator and do a bit of cleanup and post-processing with it to change the type, the colors, things like that. Another website that was useful, that helped me tinker with this was called Filtergraph. I had uploaded the New York Times data here as well and you can see I basically done just the same thing and I've put latitude onto the x-axis, and at the moment I've got longitude on the y-axis. So, if I can change that to start date, and you'll see how things start to cluster here and this is what I'm interested in seeing, is how things organize themselves. You can also put filters on it, this is one thing that you couldn't do in the raw app. So, for start date, I can say I want to make sure that all my start dates are say, greater than 1900, and less than 2020, and that will refilter it. So, now I can see down at the bottom, I've got these little points that are closer to 1900, and it doesn't go past 2020. I like to use processing to push things even further. So, I've wound up building a little app in processing that lets me take this data and start to play with it and really customize the display of it. Here you can see one of the first iterations of this app where I'm simply putting everything on screen just at its average year and its location on the x-axis. So, in the center is Europe, on the left is America, and on the right is Asia, and as I go through these apps, I'm starting to add more and more complexity to them. These different graphic components that I shared before, so now I'm starting to connect these years, I'd connect the books across these average years. In this sketch, I've started to add labels as we saw in CartoDB db. So, I've got a random color for each book and a title here so that I know which book is being represented by what color. You can see small blobs like this one for The Mare, versus the larger ones. This is probably To Hell and Back, this World War II book that has a lot of locations and dates being mentioned. One of the other things I like about processing is that each time I run it, it's generating a PDF. So, if I run my app, you can see the visualization, but in this folder, it's made a nice PDF that I can then bring into Illustrator, and just like any of these online tools that outputs an SVG, I can clean it up and customize the typography, customize the colors as well, and basically fit it into my layout. This is getting close to where I want to be with my visualization. I've started to both connect books in the x and y axis, I'm starting to see the shapes that these books are making. My hunch about there being a lot of wide books that are not very tall, meaning they have a broad geographic scope with are very narrow temporal scope is proving to be true. I'm seeing these ones at the top, that are all kind of present day that don't have any specific dates mentioned versus these World War II books that tend to happen in a narrow band, but have also have a broad geographic scope. There are a number of other tools like tableau, and data hero, and R, some of them maybe your cup of tea, they may be advanced enough or simple enough that they fit your desires, I've included a list of links to go along with this class, so you can try them all. With all these different tools, having a sketch in mind of how you want to apply these different transformations to your data will be really important, none of them can do it all, but I think having the systematic idea of I want to use this data dimension to control the x position and this one for the y and then scale will be denoted by this data and color will come from another, like having this recipe in mind will really be helpful when you evaluate these tools and you'll have an end goal in mind which I think is the most important. So, you're not just trying a bunch of stuff until something looks cool. It's about trying to get to this endpoint that you've thought of ahead of time and is rational. So, it's certainly possible to do this all manually. I think ideally if you do want to get faster and be able to tackle larger datasets, it is really important to start playing with these tools and exploring what code and automation and dedicated data design tools can add to your workflow.
9. Visualization: Approach and Elements: In this section, we'll look at how to turn your data into a visualization. Again, I like to start in my notebook. Sometimes I'll just write down the different dimensions of the dataset that I have, and start to think about how those could be applied in different ways to create forms. I'll show some of the different techniques and means of building a visualization using a couple of simple transformations. You can see some of the work that went into a project I recently completed which was the cover to my latest annual report. You can see how sketching is useful here as a way of developing ideas and even getting rid of some of them initially. So, I have probably 20 or 30 different ideas sketched here, but only the ones in red are the ones that I chose to investigate more thoroughly. Here you can see the ones that I actually took to code so that I could see how data is influencing these forms in its final state. It's not until I get to the last one on the bottom here that I've found something that was working really well in representing all the different nuances of the data that I wanted to communicate. One of the things I try and do in all the visualization work is to capture the dataset at the small, medium, and large scales. So, at its largest scale, this is some graphic or number that's going to encapsulate everything like the total number of books in my dataset, that's one thing that's at the large extent, or a visualization that captures all the years and all the places, that's at the large scale. The medium size, I'm thinking about parts of categories like, how many countries were mentioned? Or what are all the countries in Europe that are brought up? Then down to the small scale, where I can talk about an individual data point, like a single book or a single place. One entry that is significant and helps you understand the larger picture. By showing data at all these different scales, you're demonstrating your understanding of the dataset and I think expressing it at these resolutions helps people understand it as well. So, when I think about visualizations, I feel like even the most complex ones are simply the result of building up a lot of little techniques into something larger and more complex. I've tried to break down some of those different transformations here, and the first thing that you'd want to start with is some form of mark making. The most rudimentary one would be to use a shape like a circle, or square, or triangle. Anything that you want to represent on the page, starts with this shape. You could also think about using a symbol, a location marker, or a house or an airplane icon. Are these the kind of fundamental markers that should go into creating your visualization? Another thing about shapes and symbols, is that it can be easier to work with simpler shapes, like circles and squares, these are easy to modulate and measure as when we're using scale to create differences. If you start thinking about more asymmetrical shapes, these are going to be a lot harder to work with and harder to control. You can of course strictly use type. So, maybe there aren't even any shapes involved. There's just the topography itself and then we do transformations like using position and scale to create the visualization. Of course, when we get to labeling, type is going to be another important element. Repetition is a really important element. There's a history of things like the isotype system which is simply just repeating a bunch of icons to represent 300 or 500 using three or five different icons. But if you think about something like a bar graph, that's another form of repetition where we're repeating these different bars and then scaling them various amounts to represent the numerical qualities. Position. If you're thinking about mapping position is simply using the X and Y axis that we extrapolate from the latitude and longitude to place a marker on the screen. Scale is a great way of showing quantities. So, using the correct geometric transformations to turn a quantity into a scaled circle or a square, is something that might be useful. When scaling shapes to represent area, it's really important that you define their sizes using the proper geometric rules. So, to create a circle that's representing 12, we can't just give it a diameter of 12. Unfortunately, we have to use a little bit of algebra to figure out the size and I've provided this slide that'll tell you the sizes to use for the sides of a square, the diameter of a circle and the sides of an equilateral triangle. If we simply use the amount that we want to represent as the size of the sides or the size of the diameter of a shape, you're going to distort the data. So, your circles they will not be understandable as representing the amounts that you intend them to, so make sure that you use these formulas or an online area calculator to make sure that they're representing the right sizes. Connections is another transformation or another element that we can use to tie things together. So, you could use this in different network visualizations or a path if you're describing where someone went on a map, that's going to be created using a set of connections. Proximity is another thing. So, how close or far apart are different things. It relates a little bit to position but proximity is the relationship between two markers. So, if we want to say that two things are associated, we may move them closer together, and if they're less associated then we might move them further apart. Rotation is certainly something that's important. You can think of a little dashboard arrow, like your fuel gauge, that's the kind of visualization that is based almost exclusively on rotation and can be a really interesting way to add some extra information to our visualizations. Rotation is also used commonly to sub-divide as in the pie chart that we're all familiar with. Then finally, color. So, all this has been assuming that things would be created just in black and white but of course color can be applied to create more connections within the graphic and to define different categories. You can see some of the transformation principles applied to this graphic from my 2010 Annual Report. Here, I'm using a circle as the base element. I'm using scale to enlarge it based on how much information I had for each year. Then separating it into different segments that are defined by rotation of an angle as well as by color to help show how the pie charts break down based on the year. In this other example I'm creating a map and each point is using a triangle that's then scaled to show the number of records. I'm also using color to encode whether the event happened in 2010 or 2012. Finally, in this example, I'm using rotation. Each of these points that's talking about whether I sent more messages than received to a person or they sent more messages to me, each one of the points in this graph has a proximity to the center which represents how many messages were sent, and then the angle helps define whether I sent more messages or the other person sent more messages.
10. Statistics: In the next three videos, we'll touch on statistics, typography, and color. These are all crucial elements of data visualization, but they have their own little nuances and I think they're worthwhile to talk about individually. As you noticed, I've been pushing you to use a spreadsheet to capture data. One of the great things about this is that the spreadsheet allows us to do some just rudimentary and really useful transformations and calculations. Formula in a spreadsheet is a really useful way of quickly figuring out things about your dataset. In this case, if I want to figure out the average date referenced, I can just type average and click on the prompt here and then select the rest of the column to figure out what the average date being mentioned is. I think with a couple of basic concepts, you can go really far and these are the ones that I've found useful. Clearly, counting the number of entries I found this to be useful in looking at my dataset, summing things, using a total, as I showed you can do this in a spreadsheet. The Max and the Min certainly in terms of years. I think this is going to be interesting. This is the whole range of my dataset. Now, we have a couple of different averages. So, mean is what we normally think of when we average something, it's add everything together and then divide it by the number of entries. A lot of times, this is a really good way to go, but sometimes it can be very distorting. As you saw in this spreadsheet, when I averaged everything, my average ended up being negative 320,896 and that's because I have this one outlier, which is the age of the universe in my dataset. So, I have one -13.8 billion in there, which is throwing everything off when I do the mean. Median is a good way of accounting for that and what it just says is pick the middle entry. So, if you have an odd number, it's the middle one, if you have an even number of entries, it averages the middle two. Finally, mode is another interesting way of looking at dataset, this is just the number that occurs the most frequently. So, this could be the item with the most entries in your dataset. But I always think it's an interesting thing to look at and to consider. In the statistics, I chose to pull out at the bottom of my graphic. I'm using several of these statistical approaches to find and extract different measurements from my dataset. In this first one, I'm looking at the whole dataset, I'm trying to say something that's encompassing, I'm talking about the number 19, which is how many books are in it. I'm subcategorizing that into five fiction and four, so I've got the total here. This is the total number of the dataset. Again for that number of years mentioned, I've got the total, but as I mentioned, the average year is not useful. It's not relevant to the dataset. Nothing there happened 380,000 years ago. It's all very current or very, very old. So, by using the median, I can throw up that outlier and get to a number that is much more representative of this dataset. When I'm asking what does the book review look like in terms of time and place, this is the center of it. The median helps me find that 1943 was the year at the center of this dataset. For the total places mentioned, I'm finally using the average. None of them is going to have 3.7 places mentioned, they're all going to have a whole number of places, but it does give you an idea of how frequently they occur. Finally I'm using a min and max approach for the total number of pages. There's a big variety here. So, if simply the min and max were only separated by 10 or 50 pages, it wouldn't be interesting. But I think the fact that it ranges from 228 to almost 3,000 pages is really useful and maybe inspired you to want to find out what is that book that's 3,000 pages.
11. Typography: When I first started doing data visualization, one of the things that separated me from other people was my attention to detail and typography. This is something that I've tried to maintain and try and communicate to everyone that I give advice to on data visualization. So, one of the biggest things is selecting typefaces. I tend to select condensed and serif typefaces. These allow me to express a lot in a small space, so I can get very tall type in a narrow window and this is useful when I'm merely setting short numbers. But in general, I'm looking for typography that's not going to be distracting. I'd like to have things with even textures that are not going to take your attention away from the visualizations. I've provided a list of a couple of different foundries that I like to look at because there are high quality typefaces, these foundries tend to make typefaces that work really well that are well-crafted and have a lot of the features that I'm looking for. There are also a lot of commonly made typographic mistakes that I see and like to remind people not to make. So, in the world at large, we tend to see tic marks and apostrophes interchanged all the time. But when we're dealing with data and numbers, this can have a huge impact. Tic marks are useful for talking about length, they are useful for talking about minutes and seconds versus apostrophes and quotation marks which are useful for describing speech. So, try not to mix those up. I think it makes a big difference. Also, using an x as a multiplication sign, this tends to be fine in email but they're actually different characters. So, if you want to use a multiplication sign, please go and find the proper character. There's also a big difference between hyphens and en dashes and em dashes, and one character that I tend to use a lot in design is the en dash. This is the middle one, you get it by pressing option hyphen and this is used to denote a range. So, if you're setting from 10 to 20, you would separate this with an en dash or a timespan, like 1960 to 1986 would be set using an en dash. Also, in your high quality typefaces, there's a range of different styles of numbers. There's old style and lining figures. You can see the old style have descenders versus lining figures which all stay between the baseline and the cap height, as well as proportional and tabular figures. So, proportional figures like most letters where they have a range of widths versus tabular figures, which are meant to line up vertically. So, if you set four numbers above another four numbers, they will all line up perfectly. So, think about the right style of number for the job that you're doing. Also, be aware that ones tend to have really wide settings, and so you may need to let a space them in, so they don't look like they're hanging out. There are also typefaces that have proper fractions. So, if you've been making your fractions by using one and then a slash and a two, consider using the glyphs palette again to get to the proper character where you'll have a typographically more correct fraction. There can be a little bit of friction when you see the wrong typographic element as you try and parse something. So, seeing a hyphenated number strikes us as wrong versus seeing one that has the proper length and dash in between it. Similarly, I think seeing an x as a multiplication sign, you think x first then you have to pause for maybe a millisecond, maybe longer to try and extract the proper meaning, what the person was trying to express from the typography. When choosing typefaces, consider legibility above all else. I think appropriateness is a prime consideration, as well as impact. So, there are pieces of my typography that I want to fade away. I want them to be an even texture, and there are other typographic elements that I may want to speak really loudly, where I'm going to use a bolder typeface. This might all be one family or it maybe two different typefaces that fit together to create this kind of impact and contrast that you're after. When we're creating a data visualization, every mark is important. We're creating a general set of contrasts and texture that define the page. When we put ink on the page, it's because we want your eye to go there. I think the heaviest contrast should be the most meaningful pieces of it. So, when labeling or adding extra text, this is a little bit separate, it's a little secondary to the marks of the visualization. So, as a texture, we want it to be very even and we want it to recede a little bit, so it's read after the visualization itself. In my visualization, I chose to use a pretty neutral sense of typeface that I've been relying on a bit recently, it's called firm. What I like about it is that when set it all caps and spaced out a bit, it creates this really even texture that I'm going for. So, there aren't any black pieces that pop out and catch my eye. The marks of the graphic are the things that pull me in, and then the typography is secondary. But I also like that by using the Book Review title, I have this heavy impactful anchor on the top of the page that really sets everything up.
12. Color: We use color to create associations, to encode meaning, and to create contrast and visual interest as well. In Illustrator, you have access to a couple of different ways of thinking about color. We have CMYK and RGB, and this other mode, HSP. What I like about this is it's separating out a bunch of the different dimensions that can be useful in using color to encode information. So, as you can see here, by simply playing with the hue, we can move this red circle through these gradations from orange into yellow. Or if we simply isolate the saturation, we can start to turn this red circle into a much paler pink. Finally, by playing with brightness, we can turn this red circle into a really dark red. You can see how each of these will be useful in encoding information. Some numerical dataset could be applied and you could use that to scale these colors. When I'm picking a palette, I'm thinking about this and I'm thinking about selecting colors that give me opportunities for high and low contrast. I sometimes think would my graphic be legible simply in black and white, and is the color adding something, and can I use these bolder colors to emphasize a more minimal graphic element or use milder, less saturated, less bold colors to de-emphasize something that's really large. I think that keeping colorblind accessibility in mind is really important as well. So, thinking about the ways in which people perceive your colors and even potentially using tools for looking at the layout through colorblind filters can be useful, especially when we want people to keep elements separate. Another way that I'll start working with colors is to start with an image that would be a reference. So, this is some sort of palette that I think is working really well and can provide an inspiration for me to develop colors from. So, in this case, I found this one image that was in a little inspiration folder that had some colors that I responded well to and harmonized as a whole. There's this bright orange, these blues, a little pale gray and the pink, and they're all visually distinct but worked well as a whole. So, I use this a little bit as a starting point to develop the colors that I used in my visualization. When I develop this visualization, I built a key. This has the title of each book and a little circle that has the color. I was using random colors just to set everything up. This is not what I recommend. This is simply a way for me to get the information into the graphic. I think that when you have a key like this, you're simply offloading work to the reader. It was really not clear which one of these books was associated with which one of these marks. So, what I aim to do when I brought it into Illustrator was simply to use this encoding to help me understand which graphic went with which book and then to ultimately remove this key to wind up in a place as you see at the end, where the name of the book is very closely associated with the graphic that it describes. So, there is none of this key that you need to check and create these, carry around a color value in your head while you scan the page, looking for a place where it may occur. Instead, I try and bring the label straight to the graphic so that there is no hunting and searching involved in consuming it. A couple of different ways that color can be used in our data visualization to create association are through varying the the color itself through applying different tints or transparencies, and also through using pattern. So, using hashes or dots, this is another way of using a more limited palette to create more meaning. I started my graphic with a set of 19 random colors, but this is not where I wanted to wind up. I wanted to wind up with a much more minimal palette. So, I think I was able to encode this entire graphic with simply five colors. So, in looking at this graphic, I was limited by all the places in which the lines intersect each other. I would have preferred to have done this graphic with fewer colors, but there are a lot of intersections. So, five is the minimum number of colors I could use to eliminate confusion as to where one graphic element began and another one ended. In the same way that symbols have their own inherent associations, I think that you should consider the associations that colors may have. For instance, if representing men and women, it certainly makes sense to stick with the traditional colors. So, if we see blue on a male silhouette, I think that has less dissonance than trying to reinvent the wheel and create new colors to represent men and women. So, it may not be progressive, but I think this is the kind of visual language that we're accustomed to. It's easier to bend the rules there, to push things a little bit than to try and totally reinvent them. The elements of statistics and typography in color are something that are continuously at play as I'm designing this. So, I will be changing color based on the prominence of different elements, tweaking topography, changing sizes to fit different things or to make things boulder, and then adjusting a color while I'm also playing with statistics to find new stories to put into this graphic. So, it's just an ongoing process of playing with these couple of different components to build up the graphic.
13. Final Thoughts: The design of this graphic started with accrued skeleton, setting up some of the proportions and the grid that I was going to use later on. I later refine this, selecting my typeface that I was going to use throughout and adjusting some of the proportions. Then laying in some of the initial visualizations that I was able to create. This is the first one that brings together all the connections that I wanted to represent. Next, I started to clean it up in Illustrator, starting to play with colors and labels that would show the associations. This point I'm only using the names of the books throughout, and haven't added any of the scales for the longitude or for the years involved. In this next iteration, I was playing with the map, putting in there, seeing if it would add a bit of interesting context but deciding ultimately it wasn't it wasn't necessary. Instead using it to create these captions that define the width of the Americas, and of the Europe, and of Asia, and adding in the scale for the years from 2020 until 1900. At this point I'm also starting to refine the pallete. So, using some of the final colors, and playing with that in the topography to see if that is something I want to pursue. In this next iteration, I`m improving the grid, tightening the typography and establishing how many statistics I'll have at the bottom of the graphic. Next day, I tweak the title a little bit, just figuring out where I want to put this label of space and time, and the date, and adjusting the size dedicated to the visualization. Next, I started adding in some actual facts that I found from the dataset. Adding these first set of pieces of information like the total places mentioned, and the most mentioned place. Finally, getting towards the end, I fleshed out the bottom, all the statistics are here, and the typography is working pretty well. But I decided to go and revisit my sketch one more time, and I realized that in adding the names of the places, I can add just so much more context to this graphic. So, I went back and I did one more iteration of the layout that includes most of the names for the places that are used. So, you get a real sense of not just the graphic width, of the places being discussed, but the actual specific diversity of places that each of these books talked about. I hope that this graphic is answering the question that I put forth at the beginning of the class, which is, what does the book review look like when viewed through the lens of space and time? I find it to be pretty fascinating. I think it's an interesting way of aggregating these books, creating connections between them and if seeing the different dimensions in both space and time that they inhabit. Ultimately, I think that this graphic works and it answers the question that I set out at the beginning. Which is the book review look like through the lens of space and time? I see the connections that are being made both through the dimension of time and space between these books, and the narrow bands that they each inhabit. It is really interesting that the span of times that are being represented here and also what's not being represented. I noticed early on that South America and Africa were really under-represented. I think that's truthful of the world and probably the newspaper at large, that they're not a part of the general narrative. In terms of the year involved, I don't know if we have such inherent biases towards different years, but it is interesting that this one is so heavily focused on World War II, and the intervening years between World War 1 and World War II, but then between sort of 1990s and the present there's very little. This graphic answers the questions for this particular issue of the book review, but it also asks questions about the book review in general. So, I would love to see this happen every week so that we can see these greater patterns or to analyze a year of the book review and to see what that looks like. I rely on an internal litmus test for these graphics. I want to make sure that they are communicating the data that I put into them effectively, that they're not creating confusion, but I'm also comfortable with them pushing the boundaries. So, I don't require that someone understands it immediately. I'm happy for them to look at it for a little while before starting to come to terms with it. It can be hard because, after working on this for a day or sometimes working on a graphic for much longer, you do become so familiar with it that it can be hard to step back and get a sense for whether it's working. If nothing else, one thing that I'd love for you to take from this class is that, seeing the world through the lens of data is a really compelling way of seeing the world. I tend to see the world through this quantified lens. So, all the actions around me I feel like can be counted, and expressed through this language. So, if you haven't started a visualization yet, I encourage you to find that newspaper and dig in. Take your interests into the newspaper, follow them to the sections that you normally read or into new territory. I'd love for you to consider the concepts that I've introduced in this class, is a framework for evaluating your own work and for giving feedback to others.
14. Additional Reading: In this class, I've touched on a number of topics, that can each be a book in it of themselves. If you're interested in learning more, here a bunch of my favorites. In dealing with Grid Systems, this one book is pretty terrific. Even has these great trace overlays, that show you the grid systems involved in making fantastic graphics. Another book is this one, The Designer and The Grid, The Elements of Typographic Style. There's a really useful reference in the back, that harks on a lot of the little typographic details I brought up in the class in much greater detail. In terms of dealing with maps, I think that this, How to Lie with Maps, is a really great read, it's not very hard to get through. This book deals with a lot of the complexities that arise, when you try and flatten out a sphere into a two-dimensional object. If you're looking for inspiration, there's not much of a shortage of infographic collections these days, but this is a good one that came out relatively recently, with some of the best graphics from incredible creators like the New York Times. Semiology of Graphics is a big, heavy collection that deals in depth with a lot of the different transformations, that I went over for building up different graphics. No discussion would be complete without Edward Tufte's tome, The Visual Display of Quantitative Information. I think this is really good read, that deals with a lot of just the basic tenets of information design. If you're interested in processing, Dan Shiffman's book, Learning Processing is a fantastic place to start and it's one of the books that they got me interested and involved in learning to code. Be sure to check out the class resources where I've listed more inspiration, more tools, and more resources for delving deeper into data visualization.
15. Explore Design on Skillshare: way.
 Nicholas Felton, Information Designer
Nicholas Felton, Information Designer