Transcripts
1. Introduction: I think that, as a designer, it can be very hard to make rules about how to create a piece, And I love that working with data is all about generating systems. You build this particular set of rules for how something should be represented, and then you plug-in data and it comes out in a form that follows those rules. It's easy to tweak and change the rules and get different results or to change the data and to find something entirely different. Processing is a language or an extension of Java and was intended to encourage designers to work more with code. Learning to code and Processing has really changed me as a designer. It's liberated me to do a lot of things that I could never do by hand before. So, I'm excited to get deeper into Processing and provide this toolkit of parts so that other designers can use Processing more fully and have a reference for building their own applications. I've taken all these parts that I've found over the past few years and put them in one place into a toolkit. That's what I would have really wanted when I was getting started with Processing. The intention is not to memorize all the code that I'm showing, but to use this as a reference for later on when you have something in mind. We should have the reference right there, and you can grab this piece of code. If you've taken my previous course on generating maps with Processing and Illustrator, this is an excellent follow-up to it. Worthwhile, for designers who are interested in code, but also people who might be working with code already but are more interested in using it for design purposes. My name is Nicholas Felton. I'm an information designer based in Brooklyn and I work with data.
2. Overview: The way I have approached this class is to provide four different types of sketches. Initially, we'll be looking at different ways that you can bring in data into processing. The next set of sketches is all around different structures that you can create like grids, or lines, or radial compositions. Next, as with all coding, you will run into bugs. I have provided a couple of different techniques that I've found helpful in terms of getting to the root of problems and moving on to the final step which is refinement. This is where we're trying to make things look better and get it to a polished state. So, Processing is open-source software, it is free to download and to use for any purpose. You can get it here at processing.org for Mac, and Windows, and Linux. You can make a donation if you care to support the foundation and its work, and here you can get the most recent versions. To get started, I'm going to review some of the fundamental Processing concepts you should be familiar with before moving ahead in this lesson. I've created a set of files that you can download from Skillshare, or data files, or structural ones, debugging and refinement, and then some final examples that bring everything together. So, at the end of this, we'll be making something like this little sketch that looks at all the different exoplanets that have been discovered so far and visualizes them using a combination of some of these different techniques. The basic idea of this toolkit is that you can grab something like a CSV importer combine that with a structural technique like a radial composition, and then use some of the debugging tools to figure out why it's not working or to optimize how it's working, and then finally apply some of these refinements. Like in this case, using hue saturation and brightness color mode instead of RGB. So, I'm going to have a couple of different examples that are similar, and this is another one that will be in the examples set at the end, or finally this set of line charts. The idea is that these are all just based on little code snippets that I'll introduce in the following sections. Hopefully, you have some experience with Processing either on your own or through taking my earlier class on Processing and Illustrator. I think it's important right now just to review some of the basic concepts so that these don't trip us up later as we look at more specific ideas. Just briefly, Processing, again, is an application that you download from the Processing website and is composed of these three different basic elements: the editor where we'll write code, the console that writes out errors or any logging we set up, and finally the canvas which is where all the drawing happens and that looks like this. There's the editor and the console. If we run it, the canvas pops up. Processing has a set up area and a drawing area, and so these are two of the primary kind of structures that we'll rely on. There are basic variable types: integers, floats, and strings. An integer is for any whole number, float is for decimal numbers, and a string holds text, and those are probably the three basic variable types we'll be using. An array is basically a list of different data types. So, like an array of three numbers would be zero, one, and two, and then we address these within the bracket by putting a number in there like zero, one, and two to access different pieces of the list. There's also an example here of an array of strings like a list of people. This is really useful for data visualization. Once we have data in some external format, we usually want to bring it into an array where we can just iterate through the different elements and draw them to screen. You can also make a list of lists. Again, this is all explained bit more in-depth in the previous Processing class, so this is getting a little fuzzy. Please go back and refresh. But a 2D array is basically a list of lists. So, it's more like a matrix, it's a two-dimensional thing, and actually starts to resemble a spreadsheet where we have rows and columns. These again are addressed in the same way you can see here like printing this line at location 0, 0 gives us the number zero. To get through all these, we use a loop. This is a for loop that's going to iterate through our array and print things to screen. This is incredibly useful and we'll be using it throughout the next example's. Finally, one function that was critical to the mapping project that we did earlier is this one function called map. Basically, it takes a single number and the context for it like this initial one, which is a latitude that loops between negative 180 and 180, and then just maps it to another range of numbers. In this case, 0 to 400 and so. This is a function that takes five different parameters. The first being the value, the second being its native range, and a third pair of numbers being the final target range. Finally, I wanted to show this imposing but reassuring overview of Processing. So, on the Processing reference page, they list out all these different attributes and functions that are available in the program, and I've just gone through and highlighted the ones that I know. So, while I feel like I can do most of what I want to in Processing, you can see here that I'm only using about half of the different pieces of this program, and I think with even a smaller amount, like a quarter of them, you can do a ton. So, it's not about mastering the program, it's about learning what you need to to do what you want. I hope to give you a lot of those elements in this course.
3. Data: In this lesson, we're going to look at importing data into Processing. This is a crucial step and the basis of doing any visualization using the app. In my experience, I've encountered three different flavors of data. There's CSV, which is comma-separated values, these are most generally output by spreadsheets and are incredibly common. It might also exist as a TSV, which is just a tab-separated value instead of a comma-separated one. You can see in this slide how compact and efficient the CSV is and it's probably the easiest to work with. But you may encounter a couple of other formats like XML or JSON, these are normally come out of applications or web interfaces like the Google mapping API, it will return something in a JSON or an XML format. They can be a little bit tricky to parse, so we'll have a look at how to step through these and get the values into the same kind of format that we would with a CSV. So, I built seven different little sketches here to demonstrate some of the different techniques you can use to import data. The first one, we're going to look at this little CSV. That is a year of my activity data of walking, and running, and cycling. So, the idea here is the same one that we used in the mapping with Illustrator and Processing project. You've got two different variables here: the CSV that's going to bring in the data and then the split one, which is called myData. This is the two-dimensional array that we're going to put data into. But basically, the idea here is that we bring in all the data into just an array of lines, the CSV, and we can print the CSV. Let me bring it in. I'm going to get rid of this one. You can just see that everything is imported, but it's a blob. So, the next set of commands says split this on the comma and save it into this two-dimensional array. So, now you can see it's a lot cleaner, and in the next structural exercise, you can use this to create different shapes. There are a couple of other ways that you can bring in a CSV into Processing. There's also a table data structure, and so this one shows you how that works. It's quite similar to the split one, the results are almost exactly the same. But in this one, you can address each column by name. So, if you bring in your data as a table, now you can simply say in the column month, I want to get all the values. Or in the column run, I want to get all the values. You do have to say what kind of variable they will be. In this case, months are going to be strings because they're text or the activities themselves are going to be decimal numbers, like walk, and run, and cycle. This is the simplest iteration of it where just we've got one for loop where we're grabbing everything, but we're not really saving it. So, if I want to use it in multiple parts of a sketch, it's useful to put it into a global variable. If you remember, once we define a variable outside of the setup, then it can be accessed throughout the sketch. So, here, when we bring in the table, we say that these containers, these arrays of values are going to be as long as the number of rows in the CSV, and then as we loop through it, we just save each one. That allows us later on in the sketch to be able to address them from different places without having to refetch them each time. Then, one other final convenient thing that you can do. In this example, we're using a function called append, and this is really useful when you don't know how long your set of data is going to be. In this previous example, where we were saving it all to an array, we establish before we start filling the array that it's going to be a certain set of rows long. So, we're establishing the size of this container. But if you're using an API or perhaps one of these other data types that can be useful to use append, in this one, we're just saying add one piece of data to the end, and keep doing this over and over until there's no more data to add. Now, this can be slower to use, but if we're just doing it once in setup, I think it's fine. So, I use this all the time and you can see it's a little bit more compact than the other approach. So, those are four different ways of of pulling in your CSV data. Now, XML is Extensible Markup Language, and it's very verbose, it has all these different tags that get repeated over and over and over again. But this is just a portion of some running data that I downloaded from Strava, and basically you just have to delve into all the different hierarchy here to pull things out. So, I won't go into detail about how this works, but should you need to extract some data from an XML, which is something that I do from time to time, these are the pieces that you'll need. We load it, we pull out some children, we fill our arrays with values. So, if you need to get it out of an XML file, this is the way to do it. The same is true for JSON. This is a hierarchical format, and Processing is probably not the most native thing for Processing to handle. But again, I've shown you how to pull out data from this sample piece of JSON. It's just a matter of digging in there, creating an array, and cycling through it and pulling out elements. The point is just to get it into Processing as an array and to pull out all this information from the structure. If you need JSON, this is the reference for doing that or a working example, and something that I had looked for desperately when trying to work with JSON for the first time myself. Finally, I'm going to show you one other little technique that I find really useful. This is a data set that I've found that's all about movies about different dystopias and the year that they came out, but you can see these different categories here. So, one of the first things that I like to do in working with a piece of data is figure out, well, what is the most popular category? How many of them are there? Processing has a data type. It's really useful for doing that. It's called the dictionary. In this case, it's an IntDict or dictionary of integers. A dictionary is a pair of values, like a key and a value. What this allows us to do is pull in this data set, I'm using a CSV and the table approach to bring it in, and then I set up this dictionary, and I just add each of these phrases to the dictionary one at a time. So, right here, where I'm cycling through all the rows to the index that I've set up above my index, I'm just adding the value of that row right here, which is the name of the type of dystopia and giving a value of one. So, this basically creates a list of all the different values and gets me to this really useful way of looking at the data, which tells me the "Government/Social" are the most prevalent type of dystopia, while "Alien controlled" only has eight, is the least common. So, you could do this for a set of tweaks and figure out what words are used the most in it. At the bottom here, I'm just sorting it by how many times each word appears, and then saving it off into an array of keys and an array of their values. So, I hope that this set of references for working with data comes in handy, and should you encounter some of these more exotic data types, you won't be too scared as you have a reference for pulling out the relevant data.
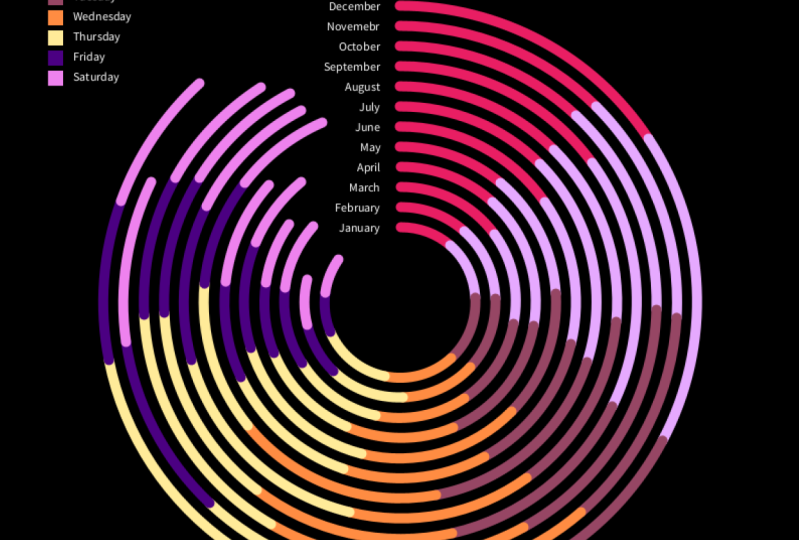
4. Structure: The next chapter is all about different structures. I've given you six basic types and a lot of different iterations of them. Starting with rows, and then turning that into a grid, working with concentric shapes. We have a couple of different examples of how to make lines, both straight and curved, some radial examples, and finally, playing with coordinates. So, the first one is the simplest. This is just using some rectangles to draw some rows and I'll show you what this generates. So, we've got five different bars here. I'm basically just setting up some common values at the top, these are going to be global values. I usually like to have a margin on my sketches so the things aren't squeezing to the side. So, if you make this zero, you'll see it's not as nice as I give it 50 because I'm using these value throughout to both pad out the rectangles on the edges and between each other. We're basically in the bulk of it, we're just making a loop here that says, for the number of rectangles I've specified, which is five, don't outline them. Give them a fill of a gray and then draw them starting at a margin which is 50. As we iterate through, this we'll go from zero to four because it needs to be less than rectcount. So, we want the rectangle sizes to increase and also we need the margin to increase. So, this is the starting position of the rectangle and then there are always going to be the width minus the padding on the edges, margins, wide and this value I specified of rectSize tall. So, that's a simple way of drawing a bunch of rectangles to the screen. Coming to the next, the next iteration of this is or what if we want a bunch of histogram, some little bar charts, but several of them. For this, the critical piece of this is that you need two loops. The first one that we made already which is how many rectangles vertically will there be and then a horizontal loop. So, this is for how many bars we've set up which is 20. We want to roll through that horizontally. So, when I run this, you can see we still got these five vertical areas but within it, we've got 20 vertical bars. Each one of those is getting a value from here with this random function that's saying, I want my bars to be between half my rectSize or half of 100 and 100. Another nice thing you can do is just to make a simple grid of rectangles. So, this is the same idea. We have a nested loop. So, we have the first one that draws vertically, and the other one that draws horizontally. We're just drawing 25 different rectangles in this piece of code. We can do the same with ellipses. We've got our nested code again. Now, we've got 25 by 25 ellipses. The main thing here is that we're just using ellipse to draw it and we have to add this one piece of code which says, "Draw this from the corner rather than the center." Each circle is drawing from the top left corner just like the rectangles did. This one is a bit more interesting. So, if we want to add data to this but have our rectangle scale from the center, we have to change things up a tiny bit. Previously, they were drawing from the top left corner. So, here, specifying as where the circles where I made a corner, I have to specify for the rectangles, draw it from the center. You can see that as I mouse across, they're changing size. Well, this is because instead of setting the rectSize here and always staying with it, I override that later on by saying use the position of the mouse to define the size of the rectangle. We're going to use this mouseX command a lot because it's really useful for adjusting your graphics and seeing how different values impact them. I know that this structure will take different values and allow me to have different sized rectangles because, I can feed it the mouseX value. In this example, we're just drawing a bunch of concentric squares. So, this one is just a single loop for the number of rectangles I want. Draw five rectangles, we start with one that's 400 by 400 here and then just offset each one by 50. So, that's done by using i or a counter in the for loop to multiply the size of the offset, so they get bigger and bigger. We have a circle here, circular one as well. Which is the same basic idea using that offset to grow them each time. There are a couple of different ways of drawing lines in processing. The simplest one is a straight set of lines. Basically, how you do this is it's basically three parts. We've got this beginShape, which says I want to start drawing a line and then for each point, we set a vertex and then use endShape to close it. So, as we go through the for loop, we're taking our random points for the height and evenly spaced points for the width and adding a vertex at each location. There are also easy ways of making curved lines in processing. So, instead of using that normal vertex, we just do use curved vertex. Now, you can see how the graph has got the smoother feel to it. That's just by basically using a curveVertex point instead of the normal vertex. You also need to add these extra ones one right after beginShape and one right after endShape. But there's a little problem with these curved lines. That's they're fine for drawing normally but, they're not the best for drawing data because as you'll see, I've drawn red circles here for every point that is in my dataset, and you can see how the line peaks a little bit above the data there and then this piece goes a little bit below and a little bit below here. So, it's actually exaggerating the data in ways that we don't want. The dataset is not getting that high, but that's what it's representing. So, I would use these where it makes sense but perhaps for drawing data, it's not the best. That could lead you either to use simply straight lines or to use the Bezier curve. Now, this is the final type of line that I'll show you. But, it's a little bit trickier. This is just a single example of one curve. It's not the most intuitive. Basically, you have to set up the control points for all of this with this one bezierVertex. So, now, it takes six different points to draw it. But hopefully, you'll take solace in knowing that every time I try and do this, I screw it up. It takes me about 10 or 15 minutes of debugging to get a nice Bezier curve to work, which is why I'm very happy to now have this simple example where everything works and you can see how to plug in the right values. I'm using mouseX here to control these handles to adjust the tension. So, you can just grab this piece here. The draw bezier curve that starts with beginShape and ends with endShape, and put in your values, and that's what I'll be using from now on. If you have curves that you want to make, I hope that you'll pick up this piece of code as well. Moving onto radial structures. This is a simple one that just puts a bunch of circles in a circle. Now, I'm using both mouseX and mouseY to control different parameters here. So, I've decided that I want the number of shapes to be determined by one-tenth of mouseX and the shape size to be determined by one-tenth of mouseY. So, we go all the way to the left. I'm left with one circle and I can make it bigger or smaller by going up and down, and I can add more circles by going left and right. Think of this as a surface that you can easily add data onto, just like with the curves and with all the previous shapes. We can also do this with lines. Again, this is another set of formulas that I always have to google when I use just for determining what are the X positions and the Y positions of the endpoints of these lines. You could see there's some geometry in there, we're using sines and cosines. Bu, the idea here is not to remember this stuff to have it memorized, but to have a resource for going back to it and getting it to work when you need it. We can do the same with rectangles. We want rectangles coming out of the center, here you can see the code that does it. But, there's one little problem here is that, if we have four, they don't line up precisely, they're not completely centered. That's one little flaw with the way that I've set up. So, I've given you a better example here. This radial rectOffset. So, to get all of our rectangles drawing perfectly centered, I have this other piece of code. This one is using a new thing. That is for doing transforms. This is basically if you want to offset something or rotate it, you can create a context for this using pushMatrix. This says, "Everything after the beginning of pushMatrix I want it be translated or rotated or scaled and then I want the transformers to stop when I put this popMatrix piece of code here." So, initially, and I can turn off one of these so you can see how it's working. If I only use, or I'll turn off both of them actually. So, I don't have anything here, you can just see top of this rectangle moving. This is because all my different rectangles are drawing on top of each other. Now, if I turn on the rotation translation, now, they're all rotating but they're centered around the point zero zero right here, which is where these translations and rotations start. So, once I turn on translate, now I'm moving it across half the width of the canvas and half the height of the canvas. You can see now it's perfectly where I want it. We can use the same technique for text which can be really useful if you want to label those rectangles. Well, how do you get text to not be in a straight line? We use the same approach. This is that pushMatrix, some popMatrix to get a bunch of these words. This is inspired by Bart Simpson. Something you might have to write on the chalkboard many hundreds of times. Finally, just looking at some coordinates, so this goes back to what we were doing with the maps. If you want to put a set of random points on the canvas. We go back to our friend, the mapping function. So, let's take these set of points that I've generated. They're just random ones and map them onto the canvas. I know their values from 0-100 and I want them to be translated between margin and with minus margin. So, just in a nice part of the canvas here that I want to use. Finally, if in addition to having simply coordinates, you want to connect them. I made this little sketch that combines those circles and the curved lines to generate a path here and I'm also numbering them just so that I can understand what's going on. They start at zero and end at nine. In this case, it doesn't matter if the lines overshoot the points because, this is simply a path connecting them. It's not a graph anymore. So, hopefully that's a good way of jump starting your designs with a set of prepackaged compositions. Once you've picked up one of our little import modules from CSV or XML or JSON, you put it in here, fill out an array, and then use one of these compositions to generate a visualization.
5. Debugging: In this lesson, we're going to deal with bugs. These are an inevitable part of writing code and that many of the best programmers in the world kind of wax philosophical about. I found these two quotes that I like. One, by the creator of BitTorrent who says that, "90% of coding is debugging. The other 10% is writing bugs." This other one by one of the engineers that Flipboard who says that, "Debugging is like being the detective in a crime movie where you are also the murderer." I think that's part of the unique satisfaction of working with code as well is that, when you get these things working, you've kind of persevered through your own hurdles and obstacles that you put in your way to get this thing functioning. Along the way, I've picked up a couple of techniques that I found useful for avoiding creating bugs. Because there's a set of code that you will write. This is valid. The processing says this is good code, it makes sense, but it doesn't do exactly what you want. So, how do you get both a valid code that works as intended. Let's start with just some kind of best practices for writing code. One is to pull all your constant. So, anytime you have a single number in the file, like five or 10, gives me the results I want. Try to pull that out into a variable. In this case, we had this first example which is about drawing an ellipse at position X and Y, but I want the data to be scaled 10x. Well, the problem with this is that, 10 is appearing twice here. You might go through and change one of them, but you don't change the other one, or say, you're using this constant in five different places or six different places. Are you going to find all of them every time you want to change it? I think the better practice is to setup a variable for this, like wrecked scale and just use that throughout. Now, you just changed the number ones and can lead to less problems. In terms of naming variables, this is a persistent problem in coding. You want things to be fast and efficient but also descriptive, so you know what they're doing. I tend to avoid these one letter variables that you can see sometimes in other people's code. But, I think it's better to be more explicit while trying to remain concise with your variable names. It will help you understand it later when you come back to it and help others understand your code as well. A big and very common adage for coding is, don't repeat yourself. So, anytime you see yourself writing the same piece of code twice, it's both kind of inefficient but can lead to mistakes. In this example, we have this little formula for getting the area of the diameter of a circle, given the area. But because an ellipse needs both its height and its width, I'm using it twice. Just like using a scaling factor or another constant several times, this can be a recipe for problems if you don't copy it correctly, or you change one little thing in it. It's better to pull that out and have it be its own line where it's only appearing once, and even better but slightly more advanced way of doing this is to create a function. This shows you how you might create a function that will calculate the diameter of a circle which just becomes a piece of code that sits below the set up and the draw regions. Then, any time I want to get a circle diameter, I just send it to area, and this will give me the value back. One of the nice things that processing does is that, it will auto inset your code before you. So, if you press command T on the keyboard, it will take something like the unformatted code on the left and just insert it all. This is a useful practice that I do all the time, and it helps identify where there's going to be problems, where a set of brackets aren't closed or you have other problems with like parentheses. As you go back and refine your code, it's useful to just go through it and make sure that anything that's abandoned, like variables or lines of code, you're not using get pulled out. We're all working really fast and trying different things, but as bits of code get orphaned, it's good to pull those out and keep things clean. So, now we're going to look at a couple of other sketches that show some of these debugging techniques and ways that I've found useful for finding the problems in my code. An error that you will encounter continuously and that I see on a daily basis is this one, array index out of bounds. This just means that you tried to access a piece of data that didn't exist. So, in this case, I have an array with eight values in it, and in my four loop, I'm trying to access each one of those different values. But here, the problem is that, I've said let I be less than or equal the length of my marker set. That basically means that it's trying to go to nine. If I remove the equals portion of it and run it again, it will be fine. Now, one of the ways of debugging this can be, to use the print function. This sketch is going to give me the same error. That there's an out-of-bounds exception. But, by using print lean here, I'm printing every single time it works until it doesn't work. So, I can see that with when I Is equal to seven, it's getting the last value out of my array, which is 700, but it's clearly trying to go further. That's an indication that I'm overshooting the size of my data, and that removing this equals mark should make things run perfectly. Another thing that can be useful and sometimes it's working but it's not drawing what you anticipated. So, in this case, I'm trying to draw eight different circles, but I'm only seeing one. One of the things that I can use sometimes is use opacity. I can either just set the opacity to some other value like 120, and that can be useful for revealing what's happening. In this case, that all my circles are drawing but they're just drawing on top of each other, or another thing that I like to do is use mouse X. Again, this is going to give me all the values of my mouse position and allow me to figure out what's happening. In the transparency case a fixed value is probably fine, but what I like about this is that, mouse X is going to give me values that I understand. I know that on the left here, it's going to be zero. On the right, it's going to be 800 in this case, and so I can use these to work out if a system is working the way I anticipate. Another way to solve that problem with the markers drawing on top of each other is to use a stroke instead of transparency. So here, rather than giving them all fills, I can see that the circles are drawing on top of each other by giving them a stroke. For more complicated compositions, I find it useful to just start annotating the sketch. These might not be things that I would want to see in the finished sketch, but they'll be very useful for understanding what's going on. So here, I've resurrected our earlier processing curve, but I'm showing the control points now and labeling them with text that has their values, and also the tension on these control points. This helps me understand exactly what's happening in the sketch, and you can see here that I've labeled things, so that once I've got to work in the way that I want it, I can pull out all these elements that I don't want. Like remove the control points. Remove the text that's labeling the values that I'm seeing.This can be really value for understanding how a sketch is working. This float precision issue is something that I guarantee will trip some of you up as you are starting to use processing. This is a kind of common occurrence where you want to just evenly distribute a set of points, or lines, or rectangles across the screen. You can see in this top example, it's almost working. These dots are almost fully distributing themselves evenly across the screen. On the bottom one, these two examples show me how it should work. The problem here is that, when I'm asking processing to tell me how far apart these dots should be, the correct answer is 33 and a third pixels. The incorrect answer is 33, which is almost correct. The problem here is that, we need a float to hold our elements spacing. This is a decimal number. But, if we do all the calculations with whole number, as in this first example, so width is a whole number. Two is a whole number, it's an integer. Margin is a whole number and element count, they're are all integers. Even though we say we want to save a decimal number, all the math that it does is with whole numbers, which is why we get 33 out at the end. All you have to do is turn one of these numbers into a float, like instead of multiplying margin by two, we multiplied by 2.0. Or you can say, "I want the element count to be a float by putting this float code around it." Now, when the math is done, it will be precise, and we'll get the correct value here of 33 and a third pixels. If your sketches working but things aren't quite aligning, look for this float precision issues that might be tripping you up. The final example I'll show has to do with the frame rate of sketches. Some of the ones I've been showing you are animated, where the draw loops going over and over and over. You might have something where it starts to feel like this, where it starting to bog down and things are getting slow. You can see I have a little bit of code here at the top, which is telling me how many frames per second this is drawing and how many frames have elapsed. If you feel like it's not operating at 60 frames a second, try putting this single line in the top of your code. So, this will tell you the frames per second, and then as you try different things, you will see the impact of your frame rate and whether that's helping. This piece of code was intentionally written to basically bog down the sketch, so you can see it dropping from 40 to 20 to 10 frames per second. So, I think that these are the tidbits that I have, tips for debugging, and we can move on to the final step, which is going to be polish. If these tips haven't been sufficient for solving a problem that you might have in addition to posting to the project page on Skillshare, you can also go to the forums on processing. There's a really vibrant community there of people who are excited to help novices, and I know that it's the first place I'll go to look for whether someone had the same problem I have already. You can search in the little search bar, or go to the forum itself and start searching for either the warning you're getting, or the thing you're trying to do that's not working.
6. Refining: By the way, I'd like to share a set of different refinements; way to polish your sketch to get things looking even better. First, we've mainly been using lines, and circles and rectangles in our sketches. But there are a couple of other types of shapes available in Processing. There are triangles and arcs. This sketch demonstrates a couple of the other shapes that can be useful for data visualization. In addition to rectangles and circles, triangles are a great way of representing amounts, as well as arcs, which are just sections of circles. In these previous sketches, we've just been using the default type in Processing, but what's nice is you can also load any typeface from your machine. In this case, we're loading Georgia and saving a PDF with the output. So, this is going to have some outlined text. Here's our PDF. Some nice vector, crisp, custom type. In Processing, if you want to figure out how to name a typeface, like here I'm using Georgia, I use this. I go to create font. You don't need to create it, but you can just look through your list of installed typefaces. Today I want to use Calibre-Black. I can just see it's referred to here as Calibre-Black. I don't need the size itself. So, I'll cancel and change Georgia to Calibre-Black, then it will load the typeface and now I have a nice custom piece of type. In that example, the typeface that I was using was all outlined but it can be useful to also have live text. So, this means that if I bring it into an illustrator, I'll be able to edit it. You can see here I can't edit it, it's just shapes. But, if we use this one little addition to the code, this text mode model, this will mean that when we run the code. The PDF that it outputs, will not be outlined. When I bring it into Illustrator, I can edit it, I can change the typeface, and it's really useful for being able to manipulate the output of Processing. Another little piece that I haven't mentioned is that with rectangles, you can give them a fourth parameter. So, in addition to their X and Y location and their within height, you can also give them a corner radius. So, in this sketch I've applied that to the mouse x. So, now I know if it's a very low value and I'm printing it out in the console. This is what three pixel corner radius looks like versus a 32 pixel quarter radius versus almost 70. So, I can go through here, find the value that I like, and then say, if it's 14, and then I can just plop that in and have it be static. There are a couple of different color modes that are also available in Processing, so RGB is a standard one and you don't actually have to define it. It just happens by default. But normally, colors are specified from 0 to 255. By putting a number here after color mode, you can say, "I want all my colors to exist on a scale of 0 to 100." RGB is great but there's no difference in the colors it can represent versus this other color mode hue saturation and brightness.but, from a data perspective, it's easier to manipulate the colors and hue saturation and brightness than it is in our RGB. So, this is a little tour through the RGB color space. You can see I've got I think it's red and green going along these two axes and as I move the mouse the blue channel is added in more. So, you can see there's lots of good colors here but they're spread around the color space, so can be harder to access them which is why you might just put in static values. Whereas with hue saturation and brightness, you're controlling these fixed qualities of the color. So, hue isn't one dimension, how saturated it is. There's another dimension and V or value is the final one. So here, you can see I've got all these good really bright colors that exist simultaneously. This is moving through the color space with full saturation and full brightness and I can lower the brightness and they're still packed together. So, I can just set saturation and brightness value and then apply the hue to a piece of data, or I can say I want the saturation of this to apply to a piece of data. Processing will also output a number of different image formats. This is the built in export, will allow you to save frames as PNGs, JPGs, TGA or TIFs and you simply do that by changing the suffix here in the saveFrame piece of code. I've also shown you a nice way of being able to run a sketch with multiple frames. You can either use this function here the "void keyPressed" one to be able to press a key on the keyboard and save a frame or use mouse pressed. So, you've got a lot of parameters and you're modulating the sketch. Once you get it to a place that you like, say you're rounding the corners based on mouseX, then you can just click the button and save the output. The same is true for PDF's. We need a couple of different pieces, we need to import the processing or the processing PDF library initially. Then we just have a piece that starts the saving process if record and a chunk that ends the saving process. Again, I've included two functions here, so that it's not saving a PDF on every single frame. Just when you want it to, you can click the mouse button or hit P on the keyboard and it will save those frames for you. So, I find that really useful. They generally just don't want to be saved in a PDF all the time but it's nice to have it on keyboards, so that when you find something nice you can you can save it out. Even though I'm generally working with data, it can be useful to have a random component sometimes. One of the nice things I've discovered is that while random is normally going to be different every single time you use it, you can put this line of code in and call randomSeed and just give it a fixed number. This means that every time you run the sketch, you'll get the same random output. So, while it's one each time I run it, these dots are in the same position. But say, I change it to two, now they're in a different position but it will be consistent each time I run it with randomSeed as two. So, say if you want to use this for colours but you find a nice set of random colors that works, it's good to be able to lock that in using randomSeed. It's nice to have control over what gets labelled sometimes, especially with the big data set. So, in this case, I want to know the value of these circles and we do this a couple of different ways. One might be to just play with the mouse here and figure out, where's the threshold where these numbers start to get too big to fit? So, it appears as I mouse around that once I get below 20, they start extending outside of the circles. So right now, I'm using this conditional statement that says, if the value of the ellipse is greater than mouseX, then draw it. Or using these two pipes, this means if this other condition is met, which is if that value is greater than my label threshold rejects it to be 45. Either one of those will cause the labels to show up. So, if I just remove this one, and just have it on mouseX, I can find the place where I'm comfortable with it. So, maybe everything above 30. I don't want to be labeled and then, I can change my label threshold to 30 and remove the mouseX component of it. So now, I label it has over 30, gets applied and this is a nice way of fitting the labeling to the data that you have. Finally, we're going to want to show some numbers and these may not be natively handled as nicely as we would treat them in a design program. So here, I've got this original value 80,472.65. Now, I don't really need the decimals. So, in the next example, I show you how you can round off the decimals just by casting it to an integer. So, by putting this little piece of code around my number, it will now be a whole number. But that could look better if we put in a comma that would be easier to read. So, this other piece of code here, this NFC will put in is a number formatter, nf and c is a comma. So, put in a comma at the right position. Then finally, maybe I don't even want that full precision. I don't want it to be 80,472. So, by dividing it by 100 and then making that and rounding that number and multiplying it back by 100, then I can change the precision. So, I can make this 10 and 10 and run it again. That would give me a little bit more precision or if I divide it by 1,000 and multiply it by a thousand, then it will be a bit rounder. So, that rounded off to the thousands place. So, those are different techniques for making your numbers look a lot better which will be both easier to read and require you to do a bit less work. So, hope those little snippets are useful and will help your sketches look a lot better. In the next lesson, we will put a bunch of these components together and make some finished sketches.
7. Examples: Finally, I'd like to show you how all these pieces can come together and make a finished processing example. First one I have is some exoplanet data that I downloaded. Exoplanets are these potential earths that have been found around stars outside our solar system. You can download this information freely from the web. All these different parameters about the different celestial bodies that have been discovered. So, I want to put these all together in a sketch. This starts as with the other examples by bringing in the data. So, we're going to do this using one of the table import examples. I think it's this approach, "Data_02" So here, we've got a table that we're using, and we define that table as you can see here with the name of our CSV, and we tell it that it has a header. That allows us to address these different pieces of data by their column headers like row ID, or planet hostname. So, just bringing that data, but here, you can see down in the console just like as before. Here's the data that I brought in, and it's just printing out the pieces that I'm bringing in. So, I'm giving each one a number, a name, and it's got a size. In this case, it's how many times the size of Jupiter, it's distance from the sun, and AU is the astronomical unit of how far Earth is from the sun. So, this is a relative distance. So, I've download this data, I brought it in using my CSV table approach. I'd put a little bit of conditional logic in here because not every planet has information. So, I don't want to be trying to draw planets that have a radius of zero or an orbit of zero. So, I'm just saying, if the radius is greater than zero and the planet orbit is greater than zero, then I want to draw these guys. So, I'm obviously going to need some ellipses to represent my planets. So, this is the line I created here, where they can have an x position and a y position, and the size of them is going to be planet radius times the scale planet, constant that I made, which is just three. So, it makes everything nice and visible on screen. Now, to calculate their x and y positions, I'm using this structure that I showed you a little bit earlier. Which is the radial circles. So, this is where we've got a little bit of geometry. We're using sine and cosine to define where these circles appear based on the angle. I got a little bit of of math here. This is basically just to animate them as they draw. So, I'm using the speed of the planet orbit to put them into the right place. I want each of them to have a different color that's based on the planetary mass. So here, I'm setting that up, where I'm mapping their mass from zero to 30. Thirty was about the max into the hue saturation and brightness scale of zero to 100. But I'm just going to apply it to the hue. So, as I calculate their mass, that gets turned into a value between zero and 100, and that defines their color. So, if I run this now, you can see all the different planets orbiting at different speeds. One thing that becomes immediately apparent here is that, the further they are from their star which would be in the center of the canvas, the faster they start to spin. One of the things I've added to this code is a little bit of a zoom. So, that's done with this frame count. So, even if I remove this, and get rid of the zoom. Yeah. Well, now we got rid of the zoom when we're stuck outside. But one of the problems that you can see here, is that it's it's quite chunky like the frame rate is not very high here. That's my perception. So, I'm going to get that piece of code from debug on frame rates and just paste it in to make sure that my intuition is right. You can see in the top here, the frame rate is only about seven frames per second. So, it's not drawing as well as it could. So, what I did in the next example that I have here, is I just changed the the way that data is brought into the sketch, a little bit. I opened both of them so you can see. In this first example, I'm using a simpler approach to get all the data out of the CSV, which basically means, every frame that I'm drawing, I'm getting all the data out of my table. So, this is I think what's bogging down the sketch. I have to just move this into the setup. So, instead of gathering the data on every single frame, I'm just going to do it once when we do the setup. So, it requires a little bit more code. Now to save everything, you can see establishing the names of my variables, and then I'm saying, how long they're going to be based on the raw count of my table, and then going through the whole table and saving them all into into an array. But now, in my draw loop, I can just get those out of the data that I've already established, and you can see now how fast and smooth the sketch is. I'm also using mouse acts as a way to zoom in. But for me, this feels pretty, like it's working pretty well. It's actually not very much code. I think that the trickiest part here is probably just how I'm calculating the x and y position, to use my mouse x to zoom in. But otherwise, I'd say, nearly everything you see here is included in the kit of parts that I provided. In this next example, I've got a pretty simple data set. We've just got 12 rows with four columns each. So, it's a monthly total for walking, running, and cycling distances, and I'm going to bring these into processing using the table method. I'm setting up my variables in top, and then in setup, I'm basically just establishing the size and using the rest of this code to save all the values into my variables. It was my first attempt, and I was just wanting to see that the data relative to each other. I was thinking, maybe it would make sense to have these lines emanating from the center to show the relative distances. What I don't like about this is that, basically, a line can only be about half the size of the canvas. So, it's not give me a lot of links to them. I'm only drawing the walking lines at the moment. But already, I felt like this wasn't going to represent the data in a way that I thought worked that well. So, going to some structural stuff that we were looking at, I thought maybe using these concentric circles would be a good approach. So, using one ring for each month might be a nice way of showing this. But instead of using circles, I could use something that we talked about in the Polish section using some of these different shapes. So, using an arc to represent the length. So, in this next example for the activity, let me show you how I've expanded it to use arcs in concentric circles. So again, I'm bringing in all the data up here, and then as I loop through, I'm calculating the length of the walk relative to all the distance, which is a new variable that I've set up that is just going to hold the sum of walking, and running, and cycling. So, I'm mapping the walk distance against that total distance. Then I'm drawing an arc to that length. So, I'm doing this for all the different data types and scaling these again by mouse x. I think having the mouse x in there is nice, because it can help me dial in how far I want this to be. Do I want this to be more of a complete circle or how close do I want this to appear to the labels? Which would be a lot of work to bounce back and forth, and come up with scaling factors by having our mouse x, I can just pick where it looks good, and then save it out. Basically, it's just three arcs that I'm drawing. I'm mapping each of the distances, that total distance. The one tricky thing is that I have to start one arc where the last one left off, and I could make sure that that's working again by using another technique we discussed which was introducing some transparency. So, if the stroke color now is slightly transparent, I can just make sure as you can see here, that it's drawing right where the last arc leaves off. So, I know that this data is working correctly. I guess if I was going to expand this further, I might give it a custom typeface and then bring in some of the code for saving this out as a PDF. This next example, we're going to take that same data set of monthly distances walked and run and cycled, and apply that to some bezier curves. So, this one again, I have the tension set to mouse x. So, I can find a place where I like it, and I'm bringing the data in much the same way as we've done before. So, I'm setting up these arrays and getting the total distance, getting each of the distances for walking, and running, and cycling, and a month name. But here, you can see that there's a lot of repetition. I've picked up that bezier code, that we had earlier and here lines bezier shape. So, it's this code to draw each one of the different types of data has its own line. You can see that there's a lot of repetition going on here. This makes it both hard to read and potentially creates opportunities for mistakes to arrive. So, in the refinement that I've provided, what I've done is just like the function that I showed you earlier. I've taken this whole piece of the drawing loop, and turned it into a function. So now, what I want to draw these curves, instead of having to call like to write the same code three different times. Right here, it says, "Cycle Line" You can see that I just use this function called, "draw_Bezier", and all it needs me to do is send it to data and the color that I want to use, which I've set up here. I have set up an array of different colors. So, the function takes in that array of values and the color that I send it, and this is exactly the same code. It's just generalized now as a function. So, anytime I want to use a bezier, I could pick this up and use it later on. I've also given this a mouse pressed function so that it will save a PDF when it draws it, and I've labelled all the different points with their values. So now, I can see how many miles were involved? When I like the tension that I have on my curves, I can press the mouse button, and I've now saved the PDF, there it is. I can bring it into illustrator, or place it in InDesign, or simply print it, and do what I want with it. Those are a couple examples of how all these different kits of parts from the toolkit, add up into a complete sketch, and some of the techniques for trying to smooth out the process of getting these various pieces of code to work together and to evolve into more advanced sketches that you might want to design.
8. Conclusion: The assignment of this class is to use Processing to visualize a dataset, whether it's one of the ones I provided or something you find or create on your own. A couple of datasets that I provided, that I think are kind of interesting, one are all the birthdates in 2003 and how many people were born in each of these years. There are some interesting patterns in here that you can discover. There's another smaller one. That is simply the high and low temperatures for various cities around the United States. You can decide to geocode these or simply plot out the different patterns in the temperature. Then if you're feeling very capable or adventurous, there is a six megabyte CSB here that talks about every single tree in Manhattan. I think this is a really juicy dataset and could lead to a lot of pretty interesting visualizations. If you're starting to feel comfortable with all this and looking for the next way to level up using Processing, I recommend all the teaching tools by Dan Shiffman. He has a book that's particularly inspiring to me, called "The Nature of Code", which deals with a lot of natural algorithms in ways of making really beautiful results using Processing. This class is intended for students who have a bit of familiarity with Processing. If you are not comfortable with some of the basic concepts that we discussed initially, please go back and try the Building Maps with Processing and Illustrator class that is a more hands-on introduction to these basic concepts. I hope that you will experiment with these, familiarize yourself with the different pieces of this toolkit, and also post your experiments and questions in the forum on Skillshare.
9. What's Next?:
 Nicholas Felton, Information Designer
Nicholas Felton, Information Designer