Transcription
1. Introduction au cours: Bonjour à tous et bienvenue dans ce cours. Dans ce cours, je vais vous enseigner le langage de programmation R depuis le début jusqu'à un endroit où nous pourrons devenir experts et résoudre constamment nos problèmes de données. Maintenant, R est le langage des données, il est
donc essentiel pour la science et l'analyse des données. Toutefois, pour ce cours, n'est pas nécessaire d'être un expert. Vous pouvez être un débutant complet, simplement intéressé par l'apprentissage de la science des données. Ou une barre X, qui cherche à faciliter votre analyse quotidienne en apprenant le sont. Maintenant, r devient vraiment populaire ces jours-ci pour une multitude de raisons. Principalement parce que les gens s'intéressent davantage à la science des données. Avec la croissance actuelle du Big Data et du Machine Learning dans presque tous les secteurs, la demande de données continue et la demande d'analystes ne cesse de croître. Cela ouvre de nombreuses possibilités de
travailler dans différents secteurs et domaines différents. Et avec le climat actuel, les gens souhaitent pouvoir travailler à distance et travailler freelance pour avoir un peu plus de flexibilité dans la façon dont ils ont été reconvertis. Donc, avec la science et l'analyse des données, c'est certainement quelque chose que vous pouvez poursuivre. Maintenant, pourquoi sont importants sont, est l'un des principaux langages de la science des données. Python est un autre langage principal. Mais Python est un langage très générique qui peut être utilisé pour de nombreuses choses différentes. Et c'est vraiment le langage des programmeurs. emprunté. R est le langage des scientifiques des données et des statisticiens. L'une des principales raisons pour lesquelles R est génial est qu'il est gratuit et open source. Cela signifie que nos grandes communautés travaillent sur des communautés
très favorables qui peuvent vous aider si vous avez des
questions ou des problèmes d'analyse. Et ils travaillent également continuellement à la fabrication de paquets. Les paquets sont quelque chose que vous pouvez installer et ils sont destinés à des problèmes de données très spécifiques. Cela facilite considérablement leur résolution. Je vais passer trois paquets et les futures vidéos devront les installer et comment les utiliser. Maintenant, l'ADH fait vraiment bien, c'est la visualisation des données. Et c'est quelque chose dont aucun autre langage de programmation ne se rapproche même. La visualisation des données est très importante pour la science des données, surtout parce que nous traitons de graphiques, de graphiques et de données. C'est donc quelque chose qui est vraiment bon et maintenant si vous êtes intéressé par la science des données ou la R, et vous pensez que cela pourrait vous être utile jetez un coup d'œil à ce cours et j'espère que cela vous plaira. Merci.
2. Leçon 1 : installer R et Rstudio: Bonjour à tous et bienvenue dans cette vidéo. Ce sera une brève introduction à notre téléchargement R et RStudio et relié aux bases de nos fonctions et de leur apparence. Ok, donc pour télécharger notre, nous allons simplement dans l'organisation r-project dot. Nous venons ici pour télécharger R et le Pentagone, notre pays dans lequel nous sommes, nous cliquons sur le lien correspondant et il nous faudra avoir un E2. Ou nous pourrions simplement accéder au Cloud, qui nous redirigera automatiquement vers le serveur en fonction de notre pays. Donc, vous cliquez ici et ensuite nous collectons au téléchargement que nous sommes ceux qui sont destinés à nos ordinateurs ou si nous utilisons un Windows ou un Mac et téléchargeons à nouveau le téléchargement LaCo, autre chose ? Ok, donc une fois que nous avons téléchargé R, il est important de disposer d'un bon IDE ou d'une bonne plateforme pour s'en sortir. Et à mon avis, RStudio est vraiment bon. Nous venons donc juste ici pour vous demander les produits do.com, RStudio. Et il existe deux versions de RStudio. Il existe la version open source ou gratuite, et la version précédente avec un prix. Et pour être honnête, la version précédente
n'est vraiment pas nécessaire moins que ce soit une grande institution ou une entreprise de cette saison. Pour les individus, indépendamment de ce qu'ils utilisent gratuitement, ils devraient être plus que suffisants pour leurs besoins. Il vous suffit donc de cliquer ici. Et encore une fois, nous cliquons sur la version gratuite. Et nous avons téléchargé en fonction de notre ordinateur, que nous utilisions Windows ou Mac ou l'un des appareils pertinents. Et nous nous connectons. Ok, une fois que nous avons déjà eu l'industrie F, c'est à quoi ça ressemble. Cela peut sembler un peu compliqué et délicat, mais c'est très simple et facile à utiliser. Il comporte quatre quadrants. Et le premier, c'est ici que nous saisissons notre code, votre droit, ce que nous voulons. Et le code, il serait sorti ici. Donc, selon ce que nous appelons, nous verrons ici en bas. Maintenant, ce troisième quadrant, quel environnement est vide, montre que c'est là qu'il répertorie toutes les fonctions ou objets que nous avons créés. Maintenant, cela pouvait sembler un peu étranger maintenant fonctions et objets. Mais une fois que nous commencerons à utiliser Got, il deviendra une seconde nature. Commencez à utiliser ces mots. C'est très facile. Et deux ans sous la montagne 10 se tiennent debout. Ok, donc le quatrième quadrant semble probablement très familier avec les titres de fichiers et ces différents dossiers que nous avons. C'est donc essentiellement ce qu'il s'agit. ce premier onglet, nous avons nos fichiers plutôt que des tracés. Donc, toutes les parcelles que nous créons ici dans le premier quadrant, nous pouvons les voir ici. Maintenant, les paquets. Les cheveux, j'en ai brièvement parlé. C'est pourquoi nous avons installé des paquets pour nous aider plus facilement avec notre coach et notre manager. Et bien sûr, vous pouvez utiliser l'aide et le spectateur. Maintenant, nous allons aborder tout cela en détail, mais ce n'est qu'un aperçu de base de ce à quoi ressemble RStudio. Ce n'est donc pas si effrayant lorsque vous l'ouvrez pour la première fois. Et bien sûr, ces quadrants, nous pouvons les déplacer en fonction de la façon dont vous l'aimez, ce que nous utilisons le plus, ce que nous regardons le plus. Et c'est vraiment très convivial et la densité est comme nous le découvrirons dans les prochaines vidéos. Merci d'avoir regardé cette vidéo. J'espère que cela a été utile et je vous verrai dans le prochain.
3. Leçon 2 : données et projets: Bonjour à tous et bienvenue à ce cours. Donc, si nous avions eu une brève introduction sur la façon d'installer R et RStudio et un bref aperçu des différents quadrants et de ce qu'ils font. Pour cette leçon, nous allons nous concentrer sur la façon d'importer des
projets de création de données et de petites manipulations de données. OK ? Donc, pour importer des données et les utiliser, la meilleure chose à faire serait de créer un projet. Maintenant, avec la création d'un projet dans des spectacles trop lourds, enseignez la journée à ajouter un nouveau film, tout reste au même endroit. Donc, pour commencer un projet, nous allons ici, créer un projet. Nous lui donnons un nom. Projet 1. Pas très imaginatif, mais il fait le travail. Créez un projet maintenant, ok, attendons juste que ce soit chargé. OK ? Laisse-moi juste arranger ça encore une fois. OK ? Il a donc créé ce projet ici dans notre dossier. Maintenant, il n'a pas seulement créé cela dans RStudio a également créé cela sur notre ordinateur. Donc, si je vais dans mes dossiers, vous verrez ce projet là-bas. Ok, donc c'est la photo de mon ordinateur portable, et elle l'a déjà créée automatiquement pour moi sur mon disque dur. Je n'ai pas eu besoin de venir ici et de créateurs. Donc, si je fais un projet à Ostie, créez-en deux
automatiquement pour moi dans mes propres dossiers. Donc, si je viens ici pour en projeter un, entrez ici, et c'est le dossier supérieur du projet. Maintenant, je peux coller ce que je veux et maintenant j'ai déjà copié les données que je veux. Et j'ai collé les cheveux est Hey, j'aimerais renommer ça pour faciliter la gestion. Juste Theta One. Faisons en sorte que les choses soient plus simples à traiter. OK ? Donc, les données une ou celle-ci sont le fichier que j'ai créé. Maintenant, je choisis de faire du CSV parce que c'est beaucoup plus facile à gérer. C'est très efficace. Maintenant, vous pouvez également le faire avec des feuilles Excel ou n'importe quoi d'autre. Et je vais vous le montrer dans les prochaines vidéos. Mais pour l'instant, je vais juste faire le CSV. Pour clarifier, vous pouvez télécharger ou modifier votre feuille de calcul Excel en fichier CSV. Cela peut également être fait. Bon, maintenant que nous sommes de retour, nous pouvons
maintenant voir que les données que nous avons collées dans notre dossier sont déjà apparues ici. Cependant, ce n'est pas exactement importé dans RStudio, il apparaît simplement parce qu'il se trouve dans ce dossier. Maintenant, nous pouvons l'importer soit en cliquant dessus à partir d'ici, soit en l'important, Hé, je pense que la meilleure façon de le faire est de commencer à écrire du code et à l'importer via du code. Donc, une façon de faire serait de lire CSV. Il apparaît donc automatiquement. Allez-y, vous écrivez le titre de ce que vous souhaitez importer. Dans ce cas, il s'agit de données un, thêta un point CSV. Et nous nous occupons du contrôle Enter et du patrimoine. Ce sont mes données que j'avais et maintenant il est en train de les lire pour moi. Donc, ce sont tous les noms. L'âge en années, le sexe, la hauteur en mètres. Comme vous pouvez le voir, tout est affiché. Cependant, cela n'est pas très utile car nous venons de lire les données. La meilleure façon d'utiliser ces données est de se transformer en objet. Je peux donc donner un autre titre. Je peux appeler ça n'importe quoi, mais je vais repartir avec Data One pour faciliter la sensation avec ce signe flèche. Et laissez-moi juste lire ceci. OK. Comme vous pouvez le voir, il est affiché ici. Maintenant, comme je l'ai dit, chaque fois que nous créons un objet, oh, ou, vous savez, n'importe quelle fonction, il apparaîtra dans notre environnement. Il y a donc notre environnement et ce que nous avons fait maintenant est recréé un objet. C'est le titre de la donnée objet, et nous lui avons attribué quelque chose, et c'est ce fichier. Nous avons attribué ce fichier à Data One. Maintenant, pour afficher les données, il vous suffit cliquer ici et vous pourrez toutes les voir. Neuf observations pour variables. Il s'agit donc de quatre colonnes et de neuf rangées, comme nous pouvons le dire ici. Ok, donc cela a facilement été créé. C'est ainsi que vous importez des données. C'est très simple et très simple. Et c'est ainsi que nous avons créé un objet. Il est donc très facile à utiliser et simple. Maintenant, nous allons continuer à manipuler ces données. Donc, les manipulations ou plus vite nous
allons utiliser si elles sont assez simples. Juste les bases de tout ça. Par exemple, nous
pouvons le faire. OK ? Donc, nouveau droit, avait des données d'une façon. Il nous donne les six premières observations dont nous disposons et toutes les données à partir de là. Maintenant, comme vous le pouvez, bien
sûr, nous avons la queue et ensuite nous faisons des données. Un. Oui, et bien sûr Control Enter. Maintenant, il est très important que nous soyons très clairs sur notre titre, car à l'heure actuelle, ils n'identifient pas les données une avec le t minuscule, d
minuscule parce que nous avons à l'origine une plus grosse casse, alors c'est la seule façon dont ils le reconnaîtrait. Donc si je change la totalité de la majuscule T et que j'essaie de courir. Donc, si vous vous en souvenez, la course est contrôlée. placenta va nous donner le buzzer six. Ok, donc c'était très simplement regarder les têtes et les queues de nos données. Eh bien, nous pouvons aussi rechercher les données en soi. Donc, si VJ, VJ Day 21, et que nous cliquons sur Control Enter, nous obtenons automatiquement ceci ici. Ces données pour nous, nos données sont présentées dans un très beau tableau ici et nous pouvons facilement les voir. Maintenant, nous allons revenir là-dessus. Et vous pouvez revenir en arrière quand nous le voulons. C'est beaucoup plus précis que de dire cela, car il s'agit simplement d'essayer de stocker le plus efficacement possible neuf observations et quatre variables. OK ? Nous pouvons donc revenir ici. Bon, maintenant que nous avons fait cela, essayons d'extraire les données d'ici. Par exemple, nous voulons d'abord écrire l'objet que nous voulons aborder. Ce serait donc une donnée et ce que nous voulons en tirer. Par exemple, je veux voir. Ainsi, le premier numéro que vous saisirez toujours est le RI. Quel est donc le rôle que je veux aborder ? Je veux la troisième ligne et je veux voir quelle colonne, disons la première colonne. Et je contrôle Enter. Maintenant, Zach, ça va me donner l'information. Zach, cependant, le reste est Charlie Query, David, Emily, Molly, et quel type de livre ? Ce que nous avons fait, c'est juste la troisième rangée, si nous revenons ici, que nous sommes rapides. Zach. C'est donc exact. Maintenant, si nous voulons une date précise plutôt qu'une date spécifique et nous pouvons avoir une rangée entière. Nous pouvons donc le faire en tirant vers le bas, par exemple, nous voulons la deuxième rangée, mais nous voulons laisser cette ligne vide. Vous pouvez donc laisser la colonne vide. Et puis il nous donnera toute la rangée. Comme c'est le cas ici. A commencé à être Emily 26 femmes 175, Emily 26, 175 femmes. Et de la même façon, nous pouvons le faire pour Theta One. On peut le faire, laisser ça vide. La quatrième colonne D, nous avons une quatrième colonne seule. Il suffit de vérifier. Oui. Vous pouvez donc effectuer le contrôle Maj Enter et cela nous donnera toutes les données de la quatrième colonne. Donc, si c'est juste pour comparer, c'est là. Et vous l'avez, et ce ne sont que de simples manipulations sur la façon d'extraire des données spécifiques de nos produits. Ok, il y a donc des données musulmanes plutôt que de simplement les écrire comme ce niveau de demande spécifique et vous
parlez à quelqu'un qui peut le faire si nous faisons une donnée. C'est donc notre objet que nous essayons d'aborder, le signe du dollar. Et puis inspirez, nous pouvons choisir la variable spécifique à partir de laquelle nous voulons obtenir des informations. Par exemple, je veux l'ordre du jour. Et si je clique sur Control Enter, cela me donnera toutes les différences qu'il me donnera cette variable particulière. Oh, oui, cette colonne en particulier. Donc, femme-femme, si je peux simplement cliquer ici et le comparer à l'ADN, et nous passons simplement au genre. Femmes, trois hommes à femmes, trois hommes et femmes, hommes, femmes. Il lui donne une colonne entière. Nous pouvons maintenant le faire pour toutes les autres variables. Donc, le dollar signe et puis choisissez n'importe lequel et il devrait vous donner cette information à cet égard. Il s'agissait donc d'un moyen très simple d'extraire des données. J'espère que cette vidéo a été utile. Pour résumer, nous avons eu une donnée importante AKA créant un projet, créant un objet. Donc, comment nous en sommes arrivés ici,
puis en extrayant des données à l'aide de différentes méthodes, ce n'est pas la queue de tête, puis l'extraction de données spécifiques, puis une variable spécifique. J'espère donc que cela a été utile et j'ai hâte de vous voir dans ma prochaine vidéo. Merci.
4. Leçon 3 : Packages: Bonjour à tous et bienvenue dans ce cours. Aujourd'hui, nous allons continuer à en apprendre davantage sur sont, et nous avons déjà eu une brève introduction sur ce qu'est R, comment installer R
et RStudio, et comment importer des données, créer un projet et quelques petites manipulations de données. Aujourd'hui, nous allons nous concentrer sur les forfaits. Je l'ai déjà brièvement mentionné. nous allons approfondir un peu plus de profondeur. Les paquets sont donc de petits ensembles de code ou de fonctions préprogrammées. Nous pouvons, nous pouvons les installer et les utiliser pour des problèmes si spécifiques, des problèmes statistiques
très spécifiques, et pour manipuler les données de la manière que nous voulons. C'est tellement facile une fois que nous les avons parcourus et que nous les comprenons plus clairement. Très vite, nous voulons installer un paquet,
stocker des paquets, un code très simple que nous écrivons. Installons des paquets. Et nous ouvrons des crochets, des marques
vocales, puis vous écrivez le nom du paquet que nous voulons installer. Maintenant, je veux Tidverse. Et à cause des verticales installées, je n'ai pas besoin de l'installer. Ainsi, une fois que vous n'avez pas stocké dans RStudio, vous n'avez plus besoin de l'installer à nouveau. Mais chaque fois que nous voulons l'utiliser, nous devons écrire le décalage de contrôle tidyverse de la bibliothèque ou exiger tidyverse. Et bien sûr, j'ai raté les marques du discours. OK. Il va donc apparaître ici. Il veut être regrettable que nous n'ayons pas à utiliser les deux une seule fois et que nous voulons réduire les paiements. C'est déjà un effet. D'accord ? Donc, la raison pour laquelle je veux installer tidyverse est parce que ce n'est pas un seul paquet. Tidyverse est une collection de paquets très puissante. Il utilise de nombreux paquets différents, tels que de playa, GG plot deux, très bon pour la visualisation des données, mais vous y arriverez au fur et à mesure que nous allons plus loin dans notre cours. Une fois que vous avez installé Tide of nous, nous avons accès à un certain nombre de paquets. Aujourd'hui, nous nous concentrerons principalement sur les paquets liés à la manipulation des données. Par conséquent, les fonctions spécifiques sur lesquelles nous allons nous concentrer sont, par exemple, sélection de variables spécifiques à partir de l'ensemble de données. Filtrage des données spécifiques que nous voulons à partir d'un ensemble de données volumineux. Organiser les données, par exemple, dans un ordre spécifique, muter et les résumer. Pour effectuer cette manipulation,
nous devons donc avoir accès aux données. Et si vous avez regardé ma leçon précédente, nous avons déjà créé un objet. Nous avons transformé nos données en un objet que nous pouvons voir ici. Il s'agit donc de nos données que nous utiliserons aujourd'hui et nous allons manipuler ces données. Bon, donc maintenant que nous avons eu une brève introduction, nous allons commencer par utiliser nos données et en
sélectionner des variables très spécifiques. Donc, pour commencer, nous notons une donnée qui est notre objet, et ce sont ces données que nous traitons. Et ce que nous utilisons s'appelle un opérateur de tuyauterie. Donc, Control Shift plus M et relie ces trois signes ensemble. Et ce qu'est ce point amène les données vers un chemin et les fait passer
comme un système de filtration pour ce que nous voulons en faire. Ce que nous allons donc faire, c'est, par exemple, vous sélectionnez quelques variables telles que IEEE une seule, le nom et la hauteur. Maintenant que j'ai fait le contrôle
et, et nous avons spécifiquement le nom et la hauteur de toutes ces données. Nous avons juste les noms et la hauteur. Très facile à utiliser. Bien sûr, nous pouvons ajouter d'autres variables telles que voulez-vous aussi de l'âge ? Et pour cela, nous avons maintenant le nom « âge augmenté ». Il est donc très facile à utiliser. Nous venons de réduire les données à ce que nous voulons spécifiquement. Il ne s'agit donc que de sélectionner. Ce que nous pouvons également faire, c'est filtrer les données. Donc, pour filtrer les données, c'est le même processus. Nous arrivons à Data One. Et encore une fois, nous utilisons l'opérateur de tuyauterie. Maintenant, nous écrivons un filtre et nous avons 24
ans. Donc, si je passe par là,
cela me donne l'information pour toute personne âgée de moins de 24 ans. Il est donc ressenti dans mes données de chercher exactement ce que je cherche. Donc, si je change ça par un jour, c'est huit. Si je le modifie par quelque chose qui a plus de 20 ans pour plus de 24 ans, donnez-moi
tous le reste des données. Maintenant, si nous regardons ici, c'est en quelque sorte ce
que nous avons maintenant parce que nous le faisions plus ou moins que nous n'avons fait entrer David dans l'un ou l'autre d' entre eux parce que ce n'était pas juste parce que David a
déjà 24 ans et que nous ne l' avons pas fait. faites-le comme l'un de nos jeux de données. Il est donc très important de faire attention à ces choses. C'est ce qu'on appelle le filtrage de nos données. Et bien sûr, nous pouvons en ajouter davantage. Par exemple, nous pouvons faire et, et la hauteur. Essayons donc ça. Il s'agit donc de toute personne âgée de plus de 24 ans et de largeur supérieure à 1,7. Il nous a donc donné tous les jeux de données pour eux. Nous pouvons l'utiliser en combinaison pour que vous puissiez sélectionner et nous ne voulons que le nom, l'âge et la taille. Ensuite, nous pourrons remplir le terme pour les données spécifiques afin que nous n'obtenions pas quelque chose comme Janda. Si nous ne voulons pas que l'ordre du jour soit exclu, nous ne voulons pas les noms. Nous pourrions le faire et me laisser en retirer le nom. Maintenant, nous ne voulons que la taille et l'âge des gens, mais nous voulons également filtrer. Par exemple, exactement pourquoi je l'ai déjà fait pour montrer comment combiner différentes fonctions. Je peux donc vieillir et je peux refaire 24 ans, hauteur. Encore une fois, je peux faire 1.71.7. Et faisons-le. Maintenant, cela me donne les mêmes données, mais nous venons d'en retirer le nom. Nous voulions donc simplement que les âges plus élevés voient le nombre de données, par exemple, que nous avons. C'est ainsi que nous combinons également différentes fonctions. Alors, qui aurait cherché à sélectionner des données et à filtrer ici ? Maintenant, ce que nous pouvons également faire, c'est l'arranger. Par exemple, si je regarde exactement la même fonction que nous avons accomplie, nous pouvons arranger cela. Et pour arranger. Et nous pouvons faire comme arrangeur en hauteur. Il s'est donc arrangé pour que nous allions du côté le plus petit au plus grand. la même manière que nous pouvons le faire, par exemple, l'itérateur d'un TBA élevé l'organise à partir de l'âge. Et parce que de 2006 à Titan II, bien sûr, ce ne sont que les données que nous avons déjà filtrées pour les plus de 24 ans et la taille supérieure à 1,7 ans. D'accord ? Nous avons donc déjà examiné la sélection, le filtrage et l'organisation. Nous allons maintenant passer en revue les données en mutation. Encore une fois, nous utilisons l'opérateur de tuyauterie, sorte que nos données passent par un opérateur de tuyauterie. Par exemple, nous voulons la muter par, disons que nous voulons changer la hauteur et que nous voulons le multiplier par 100. Donc parce que la hauteur est en mètres, si je multiplie une image à 100 pour cent, cela dépend de ce que vous voulez regarder. Par exemple, c'est vraiment facile si vous voulez changer les unités de quelque chose comme l'héroïne ou changer les unités de hauteur de mètres à centimètres. Et c'est là. Ce sont les mêmes données, mais nous en avons une autre, nous avons une autre ligne, une autre, désolé, nous avons une autre variable, c'
est-à-dire les mètres fois 100. Comme vous pouvez le constater, le titre a changé ici parce qu'ils ont changé le titre en hauteur, en mètres fois 100. Il en serait de même pour nous les centimètres et cela nous donne la hauteur de chacun en centimètres. Il est donc très facile de travailler avec des données que vous souhaitez uniquement dans une unité spécifique. Maintenant, c'est quelque chose que nous pouvons, vous savez, c'est un très petit exemple, mais nous pouvons l'utiliser pour des fonctions plus complexes. Et pour vous familiariser avec cela, vous devez,
vous savez, une recherche un peu plus expérimentée, peu plus de trucs en ligne comme un autre type de sites Web pour voir quels autres types de mutations que nous pouvons faire. Parce que c'est vraiment un sujet que nous devons continuer à apprendre. Nous ne pouvons pas apprendre toutes les fonctions de notre cœur, mais nous devons toujours les rechercher. D'accord ? La dernière fonction sur laquelle je veux me concentrer est donc de résumer les données d'un opérateur de tuyau. Résumez. D'accord ? Ce que cela fait, c'est que cela me donne une variable spécifique. Par exemple, la hauteur médiane résume en quelque sorte la variable entière, toutes les variables ou toute la variable de hauteur. Et ça me le donne comme, vous savez, une médiane, la médiane que je peux faire au maximum. Cela me donne donc la hauteur la plus élevée, et c'est 1,82. Et si nous comparons cela à nos données, nous le faisons manuellement. Pourquoi la médiane ne peut-elle pas ? Cela devrait être la même chose. Je résume donc, comme je l'ai mentionné, que ce sont des exemples très petits et très basiques de manipulation de données. Comprenez des fonctions plus complexes ou codes
plus complexes que nous pouvons utiliser à l'aide de tidyverse ou d'autres fonctions. Nous devrions envisager de faire plus de recherches et de
rechercher en fonction de ce dont nous avons besoin dans nos données et de ce que nous manipulons. Parce qu'il existe des tonnes de paquets que nous pouvons utiliser pour nos données afin de nous aider à en
rendre plus faciles et faciles à gérer. Ok, donc maintenant la question se pose où venons-nous les colis et où trouvons-nous ce dont nous avons besoin ? Le moyen le plus simple de le faire est d'accéder au site Web de notre propre chef. Ok, alors maintenant je suis de retour sur le site web avant lequel Ben, hé, bouffonnerie ou téléchargement. Si nous allons ici, revenons à la version automatique. Vous pouvez voir ici qu'il existe une option pour les paquets. Et une fois que nous cliquons ici, nous afficherons un tableau des paquets disponibles triés par date de publication ou par nom. Et puis, hé, nous pouvons, par exemple, chercher exactement ce que nous voulons. C'est donc un peu pareil,
mais c' est ainsi que nous trouverons ce que nous voulons et ensuite nous
pourrons le télécharger en fonction de ce dont nous avons besoin, du package spécifique que nous voulons pour nos données, du type de manipulation que nous voulons. D'accord, j'espère que cela a été utile. Il s'agissait d'une brève introduction à l'installation de paquets et certaines manipulations spécifiques à l'aide du paquet tidyverse ou de playa, qui était le paquet spécifique de tidyverse que nous utilisions. Et vraiment, encore une fois, nous explorons, apprenons et nous amusons à l'utiliser. J'espère donc que vous avez appris quelque chose et je vous verrai dans ma prochaine leçon. Merci.
5. Leçon 4 : lots de dispersion: Bonjour à tous et bienvenue à ce cours. Nous allons donc continuer à examiner les paquets. Nous avons déjà eu la chance d'installer tidyverse et d'utiliser Tide of nous pour manipuler les données. Aujourd'hui, ils seront comme si une application est
anti-diversifiée pour la visualisation des données. Nous pouvons maintenant l'utiliser pour visualiser les données de différentes manières, histogrammes aux boîtes à moustaches en
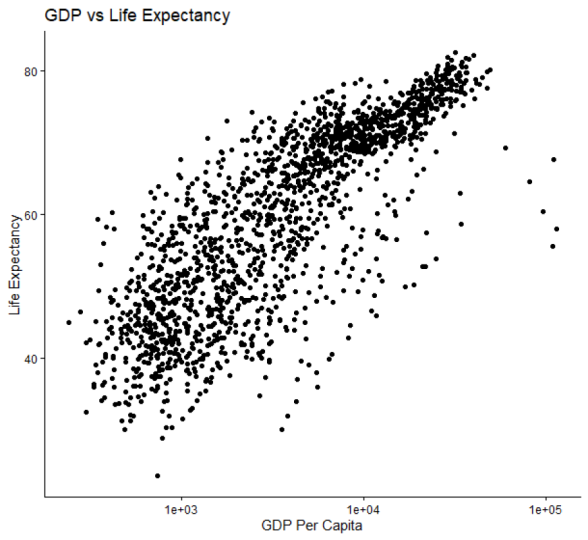
passant par les graphiques linéaires. Mais plus précisément aujourd'hui, nous allons examiner les nuages de points. J'aurai donc des directives sur la façon dont vous pouvez créer un nuage de points et apporter des modifications à l'aide des données dont nous disposons. Et dans les prochaines vidéos nous nous concentrerons sur différents types de visualisation de données pour créer un nuage de points avec accès rapide aux données. Je vais donc que la noirceur n'attache rien à l'iris. Il s'agit de données qui existent avec tidyverse. Donc, si vous l'utilisez, nous pouvons facilement l'attacher et l'afficher. Ok, c'est très bien. Maintenant, je peux voir IRS. C'est très prudent d'être toutes les majuscules verrouillées car très petite différence et apportent un très grand changement dans le code. Maintenant, il ne s'agit que de données qui existent et nous allons investir autant aujourd'hui pour créer un nuage de points de vue correct, donc comme je l'ai déjà dit dans l'une des premières leçons,
je crois, ce que nous avons. maintenant, ce n'est que des données,
mais nous devons en faire un objet que nous pouvons utiliser. Parce qu'il suffit d'avoir du bois au quotidien, c'est vraiment difficile à manipuler. Je vais donc créer un titre IRS maintenant, c'est l'objet que je veux et faire une RI. Ensuite, je veux attribuer quelque chose au sujet. Je vais donc attribuer de l'iris à cela. Maintenant, la plupart des gens veulent changer ce nom,
cet objet a nommé quelque chose différent par la vie pour le garder tel quel, mais il le rend plus facile à utiliser et à comprendre. Bon, nous avons donc créé cet objet à partir
de 150 observations de cinq variables. Nous allons donc utiliser cet objet avec données pour créer notre nuage de points. Et c'est très simple. Nous ferions un complot GG. Nous utilisons maintenant le diagramme GG car il s'agit d'un package spécifique dans tidyverse utilisé pour la visualisation des données. Donc, les données que nous voulons, Iris et V, n'est-ce pas ? Quant à la statique, puis nous ouvrons des
crochets et comme vous pouvez le voir ici nous montre x et y rapidement. Donc, ce que nous voulons comme axe X et ce que nous voulons tous avoir l'axe Y, nous le mettons dans le même ordre. Je veux donc que la longueur de mon motif soit mon x et la largeur de mes pétales soit mon axe Y. Je vais donc simplement taper ça dans le même ordre entre mes crochets. La longueur des pétales, oui. Et puis la largeur des pétales. D'accord. Contrôle, Entrée sur une parcelle apparaît ici. Maintenant, si vous pouvez voir qu'il
n'y a aucun point dans un point géométrique pour les données, il suffit de les tracer sous forme de x et de y. Pour inclure cela,
nous pouvons ajouter un point géom. Et lançons ça. Et nous y voilà. Il nous a également donné les points géométriques des données. C'est vraiment la base de la création d'un nuage de points. Nous mélangeons les parcelles GG, le paquet que vous souhaitez utiliser. Nous planifions, je repose les données que nous voulons, puis une statique, AES, nos x et y. Et puis pour dire que nous voulons aussi les diagrammes de données. Et nous pouvons également changer cela un peu. Par exemple, nous pouvons ajouter que nous voulions la taille de chaque parcelle soit cinq, puis
qu'elle soit beaucoup plus grande. 3, je pense que c'est mieux. D'accord ? Nous pouvons donc effectuer de petits ajustements à notre guise. D'accord ? Maintenant, pour ces données spécifiques,
cette ligne ne fonctionne pas car ce n'est pas quelque chose qui est connecté. Ce sont des pétales différents ou des fleurs
différentes que nous utilisons et il n'est pas logique d'utiliser align hanche. Maintenant, nous allons ajouter une ligne si vous
souhaitez créer un graphique linéaire, mais il s'agit d'un diagramme de points, donc nous n'en avons pas nécessairement besoin. Je suis donc contente de le laisser comme ça. Laissez-moi juste nettoyer ma console. Et il apparaît avec d'autres lignes. Comme je le sais, nous pouvons rendre cela un peu plus complexe,
par exemple en ajoutant une couleur qui n'est pas déterminée uniquement par une couleur aléatoire. Donc, si je suis, la couleur est égale à l'espèce. Et lancez ça. Ok, donc dans nos données, nous avions trois types d'espèces différents. Maintenant, ce qu'ils ont fait, c'est que cela a séparé les
différentes espèces en différentes couleurs en ajoutant simplement le type simple de couleur égale aux espèces. C'est donc un très bon moyen d' analyser nos données et de les rendre plus faciles à lire. Donc avant, il
n'y avait que des points
différents et des nuages de points différents partout. De cette façon, nous pouvons voir des données spécifiques que nous voulons aborder, non écouter, nous l'avons fait. Nous pouvons les manipuler davantage en apportant des modifications à
la taille des différents points au lieu d'en faire seulement trois, disons 50. Ça manque. Je peux venir ici et je peux dire que la taille doit être déterminée par, par exemple, que voulons-nous ? Hé, les données Locard étaient spécifiques, nous voulons par exemple la longueur sépale. Je veux que cela soit déterminé, afin de déterminer la taille des parcelles spécifiques. Je peux donc le faire. C'est là. Et laissez-moi faire ce test. Il possède donc également une autre clé qu'il a créée. Donc la longueur différente qu'elle est, la taille différente de la parcelle comme on peut le voir. Il s'agit donc d'un très bon moyen d'introduire différentes variables de données dans un nuage de points. Nous pouvons modifier la couleur, la taille du point et la façon dont vous présentez les données. Maintenant, c'est bon et facile à lire, mais il existe un autre moyen présenter les données des différentes espèces, par
exemple, ou de les séparer comme vous le souhaitez. Laissez-moi juste vous montrer ça. Donc, si je viens ici et que j'ajoute un plus, je peux faire de l'atout. Maintenant, il va acheter lui-même ou vous pouvez simplement le taper. En ce moment. Dans quoi est-ce que je veux qu'il soit introduit par effraction ? Par exemple, je voulais spécifiquement m'occuper des espèces. Bon, allons juste courir ça. Bon, comme nous pouvons le voir,
ces données ne sont plus simplement séparées par les différentes couleurs de l' espèce ou par
la longueur du sépal et la taille du point est créée son propre nuage de points pour chacun. différentes espèces. D'accord, j'espère que cela a été utile. Nous avons examiné comment créer un nuage de points, devons modifier la taille des données spécifiques et les attribuer à quelque chose comme nous avons fait la longueur du sépal, attribuer la couleur à quelque chose de spécifique, créer différents diagrammes de points dans le même graphique. Il a donc été bref par une introduction suffisamment approfondie dans les nuages de points. Et cela vous donnera la confiance nécessaire pour explorer un peu plus la bonne visualisation des données. C'est un domaine très excitant dans lequel se trouver. Et avec notre visualisation des données et différents graphiques sont présentés, euh, si bien. Je pense donc que c'est certainement l'un des meilleurs points de notre histoire. J'espère que vous avez appris quelque chose et je vous verrai dans ma prochaine leçon. Merci.
6. Leçon 5 : graphiques de barres: Bonjour à tous et bienvenue à ce cours. Nous continuerons d'en apprendre davantage sur la visualisation des données. Et la vidéo précédente nous a appris sur les nuages de points. Et cette vidéo se concentrera sur des graphiques à barres ou des graphiques à barres. La première chose que nous devons savoir, c'est qu'il existe deux types de graphiques à barres différents. Maintenant, si je n'écris que ça ici, barre de
géom, ça arrive en tête. Il existe deux types de graphiques à barres. Maintenant, pour une brève explication des différences entre la barre, barre
géomique, la hauteur de la barre est proportionnelle aux cas de ce groupe. Alors que dans G on Call, c'est ici que nous choisissons la valeur qui doit représenter la hauteur. Ainsi, dans Geom appelé, nous leur donnons deux valeurs, une x et y, et Dingy et Bob, nous leur donnons une valeur. Et selon le nombre de ces valeurs, c'est à quel point le boss sera élevé dans la barre Gm. Cela sera beaucoup mieux expliqué au fur et à mesure que je vais vous montrer des exemples des deux. D'accord ? Donc, juste pour expliquer la géom, géom bar ou la géom appelés, ce sont tous deux des graphiques à barres. Et pour les créer, une fois de plus, nous utiliserons le paquet tidyverse, que nous avons également utilisé pour créer des nuages de points. Et plus précisément l'intrigue GG. Donc, si je viens d'écrire ça ici, j plus GG tracé et ensuite la date que nous voulons. Maintenant, nous en avons déjà discuté avant que les données de l'iris viennent avec tidyverse, et nous avons déjà créé un objet dans la leçon précédente. Donc, nous allons simplement faire référence à ce que j'utilise ici. Alors, l'iris et une statistique x. Ensuite, nous ouvrons cela et nous inspirons que nous
mettons cette variable car nous allons être une barre géomique de zinc, nous ne pouvons peindre qu'une seule variable. Par exemple, je veux tout particulièrement examiner l'espèce. Alors, combien de types d'espèces différents sont en cours de réalisation ? Maintenant, si je regarde ces données, comme vous pouvez le constater, il existe différents types d'espèces ici. Je veux donc voir combien de ces différents types d'espèces nous avons. Comme vous mettez a, hé, comme c'est déjà le cas, le code ne saurait pas quel type de fonction exécuter à moins que nous ne fassions réellement plus g, m barre de soulignement. Et bien sûr, des parenthèses ouvertes et proches. Et un gars lourd. Ok, donc ce n'est pas un bon exemple car les différentes espèces des 50, 50, 50. Donc, cela ne montre pas réellement la différence entre eux car il n'y a pas de différence qui, si elle obtient les données, comme vous pouvez le voir, il y a 150, donc 50 de chaque espèce. Mais c'est toujours un bon moyen de vous montrer la différence entre les différentes façons dont nous pouvons représenter les données dans un graphique à barres. Maintenant, quelques petites manipulations que nous pouvons faire, par exemple, sont que nous pouvons ajouter un basculement de soulignement. Et bien sûr, je suis allé plus les parenthèses. D'accord ? C'est le cas, nous venons de l'inverser,
donc nous avons changé l'axe de ce qu'il était auparavant. Maintenant, c'est très utile si vous avez beaucoup de données et que vous ne
voulez pas que toutes ces écritures soient trop groupées sur l'axe X. Donc, si vous mettez ceci, les écrits sur l'axe des Y, vous pouvez avoir de nombreux types différents de diagrammes à barres différents. barres peuvent être différentes pour le graphique à barres. Je suppose qu'une autre manipulation que nous ne pouvons pas faire est que nous pouvons modifier le titre des différents axes. Nous pouvons le faire par Denke Plus Labs. Et puis notre x, qui sera tout ce que nous mettons ici, virgule, puis y, qui sera tout ce que vous mettrez dans les marques de discours, la virgule, puis le titre. D'accord ? Maintenant, pour notre axe des X, il
faut noter que même si cela ressemble à notre axe X, il
s'agit toujours de l'axe Y. Nous venons de le retourner. L'axe lui-même n'a pas changé. Donc, si nous voulons changer cela, agit toujours de l'axe Y et nous pourrions vouloir le nommer, par exemple, numéroter notre x au lieu de l'espèce, notre nom par exemple SP. Et en ce qui concerne le titre, je
ne suis pas sûr, donc peut-être pas. Et nous allons juste exécuter ça. D'accord. Voici son numéro d'espèce et pas de titre parce qu'on n'a pas donné à un seul. Il s'agissait donc d'une brève introduction dans la barre géomique, qui est un type de graphique à barres. L'autre type d'observateur que nous allons jeter un coup d'œil est un appel géom. Ok, donc une chose que nous devons savoir Fujian, c'est que nous devons lui donner deux variables, et x et la y. Donc, pour cela, nous devons manipuler nos données reviendront à l'une des leçons que nous avons eues au début sur manipuler les données et les mettre en action. Par exemple, je souhaite utiliser les données Iris. Et je veux contrôler Shift M, passer à travers le filtre. Et ensuite, par exemple, lorsqu'un clip sur l'école par espèce. Toutes les données dont nous disposons seront donc regroupées par espèce. Et encore une fois, nous pouvons le faire passer à travers le tuyau, par exemple, et nous pouvons résumer, par exemple. Maintenant, je veux créer une nouvelle variable, par exemple PM et égale à la médiane de la longueur des pétales. D'accord ? Donc maintenant que nous avons créé cette vieille course et c'est ce que nous
obtenons pour les différentes espèces, nous les collectons de longueur moyenne, donc nous n'avons qu'un seul numéro pour chacune. Cela nous facilitera beaucoup la volonté des graphiques à barres. C'est pourquoi je fabrique des données si petites et bien sûr sera la deuxième révision de la façon de manipuler les données, que nous avions apprises dans nos leçons précédentes. Or, ces données en elles-mêmes ne sont pas aussi utiles, nous devons
donc en transformer un objet pour les rendre plus faciles à gérer. Donc SB pour les espèces et la longueur des pétales PL 4. Nous pouvons donc le faire et nous allons le faire. Et nous y voilà. Nous avons créé un autre objet avec trois observations de deux variables. Bon, maintenant que nous avons ces données, nous pouvons tracer cela dans un graphique à barres. Faisons donc GG tracer des crochets ouverts. Maintenant, les données que vous souhaitez utiliser, qui seraient SP, PL, car ce sont les données que nous avons ici. Et AES. Maintenant, comme je l'ai dit précédemment, avec l'utilisation d'un G on call et la barre Gm avec l'appel Jiang, ce que nous allons faire, c'est que nous leur donnons des variables. Donc, ici, nous devons placer deux variables différentes et vous avez déjà deux variables. Il s'agirait donc d'espèces, oui, et pl. D'accord ? Comme vous pouvez le constater, rien n'est apparu parce que nous ne leur avons pas donné de fonction pour travailler. Pensez donc toujours à mettre un G en appel si vous appelez B18 ou une barre géom si vous le souhaitez, Gm bar. D'accord ? Nous avons donc maintenant la longueur médiane des pétales pour les trois types d'espèces différents comme nous l'avons ici. Une chose ce soir, c'est que nous avons Geom appelé HIPAA. Si nous avons changé cela en G on bar, cela ne fonctionnera pas. Vous recevrez un message d'erreur car il indiquera ici il ne peut avoir qu'un x sur y. Nous ne pouvons pas avoir de biais si nous avons une barre Gm, c'est
pourquoi vous utiliseriez G sur appel. Donc oui, encore une fois, c'est apparu. Maintenant, nous pouvons à nouveau utiliser les mêmes manipulations ici. Il retourne donc une fois de plus pour faciliter la tâche s'il y avait beaucoup de variables de données différentes, les différents types d'espèces qui faciliteraient simplement écrite plutôt que de tout le compte ici. D'accord. Mais je n'en veux pas forcément, alors je vais m'en éloigner. Et encore une fois, nous pouvons utiliser des laboratoires pour lui donner un titre. Par exemple, je veux que x soit élevé. Ce n'est pas très pratique. Mais à titre d'exemple, n'oubliez pas les marques du discours. Et alors le titre serait x. Maintenant, ce n'est certainement pas ce que le graphique montre. Cela montre simplement que nous pouvons modifier la variable, les titres de ces différents x, y et le titre de l'ensemble du graphique à barres. Parce que ce n'est pas très pratique. Supprimons donc ce que nous avons fait nommer et montrer que cela peut changer. Et nous pouvons très facilement changer cela. Et nous prendrons une fois de plus son propre titre de relations publiques et d'espèces. Ok, donc c'était des graphiques à barres et des graphiques à barres, j'espère que cela a été utile. Nous avons discuté des deux types différents. Comment les tracer, comment y apporter des modifications, comment modifier le titre. Si vous voulez en savoir plus à ce sujet, c'
est juste une question de jouer avec ça pour être honnête. C'est donc un excellent point de départ. Et j'espère que vous avez appris quelque chose. Je vous verrai dans ma prochaine leçon. Merci.
7. Leçon 6 : plus de visualisation des données: Bonjour à tous et bienvenue à ce cours. Ce sera donc notre dernière leçon sur la visualisation des données. Nous avons déjà examiné la visualisation des données en
ce qui concerne les diagrammes de points et les graphiques à barres. Aujourd'hui, nous allons examiner brièvement les autres types de visualisations de données telles que l'histogramme, boîtes à moustaches et les graphiques linéaires. Bon, donc nous commencerons comme d'habitude. Les crochets Gg, nos données, l'IRS, crochets
ABS et les données, la variable spécifique que nous voulons qu'ils abordent. Donc pour cela plus vite que nous ne ferons un histogramme. Et l'histogramme, nous ne pouvons mettre qu'
une seule variable que l'histogramme devrait nous présenter. Donc ici, je ferais la longueur des pétales. Et comme je l'ai dit, nous devons exprimer la fonction dont nous avons besoin. Il s'agirait donc d'un histogramme de soulignement GO. Et c'est ça. C'est donc notre histogramme. Maintenant, bien sûr, ceux qui connaissent l'histogramme, si vous voulez changer la bande passante, mangent des bonbons que nous pouvons. Comme un inhere dit déjà que c'est parti avec la valeur par défaut. Alors, hé, on va y aller pour changer. Il faudrait qu'il passe à l'intérieur des supports. Ben. Ensuite, largeur, et j'irai avec un qui exécute ça. D'accord, et de l'héritage. Bien sûr, nous pouvons changer cela comme nous le voulons
pour ce qui convient à nos données et les présenter de la manière la plus efficace et la plus efficace possible. Donc 2 est clairement pas bon. On peut même y aller avec 0,5. Bon, merci à tous. Merci de m'avoir écouté. Nous pouvons jouer avec cela pour changer ce qui convient le mieux à nos données. C'est ainsi que nous ferions un histogramme. Un autre type de données et un accent mis sur la création de boîtes à moustaches. Donc, diagramme GG, IRS et VS. Et avec les boîtes à moustaches, nous devons payer en deux variables différentes. Par exemple, je veux l'espèce, puis la longueur du sépal par exemple. Et bien sûr, je devrais lui donner une fonction de création d'une boîte à moustaches, de soulignement géom. Harris dit que ça montre la boîte à moustaches pour les différents types d'espèces. Une boîte à moustaches correspond à la longueur de sépal différente. Il s'agirait donc de notre plage interquartile, Q12 et 3, et de nos valeurs les plus élevées et les plus basses pour chaque espèce. Et ils ont également fait une anomalie ici pour nous. C'est donc un moyen très facile de dessiner une boîte à moustaches. Plus nous avons de l'expérience et commençons à l'utiliser, plus vous pouvez apporter des changements, mais cela concernera l'expérience, le temps et la quantité de recherches qui y sont consacrées. Ok, donc le troisième clic sur une brève touche est un graphique linéaire. Donc, GG plot, IRS, comme par exemple, je veux faire la longueur des
pétales et la largeur des pétales. OK ? Maintenant, nous mettons la fonction, et dans ce cas je veux une ligne de soulignement G M. Et lançons ça. Ok, donc ça nous a montré cette ligne. Toux. Bien sûr, ce n'est pas idéal car dans un graphique linéaire, nous nous attendons à avoir une seule donnée. Il s'agirait d'une donnée pour chaque axe X et Y. Et lorsque nous examinons nos données, ce ne sont pas les meilleures données à utiliser pour dessiner un graphique linéaire. Mais nous avons eu l'idée de comment nous joindre à ce qu'il fallait changer. Maintenant, comme nous pouvons le dire, c'est les mêmes principes. Boîte à moustaches géom, histogramme géom, ligne géomique. Et il y a beaucoup d'autres fonctions que nous pouvons rencontrer sur terre. Je l'ai donc fait, cela a été utile et j'espère que cela ne se contentera pas de
vous dire comment utiliser ces différents aspects compte tenu de la confiance nécessaire pour en apprendre davantage sur vous-même. Parce que je pense que c'est la chose la plus importante dans l'apprentissage de la programmation. Et l'apprentissage est surtout dû au fait que des paquets sont développés tout le temps. Donc, s'il y a quelque chose de spécifique
que vous recherchez, vous devrez creuser et trouver le paquet dont vous avez besoin. Il est vraiment important que nous maîtrisions les compétences nécessaires rechercher et rechercher ce que nous voulons. Bon, merci à tous. Merci de m'avoir écouté.
 Storay Amiri
Storay Amiri