Transcripciones
1. Entrada de Analytics de datos: Hola amigos. Comencemos en
este programa de capacitación, esquinas de análisis de datos
usando MinitaB. ¿ Qué vas a
aprender en este curso? Por lo que las habilidades que
aprenderás en este curso son algunos
conceptos básicos de la estadística. Estaremos cubriendo estadística
descriptiva, resumen
gráfico, distribuciones, histograma, gráfica de caja, gráficos de barras
y gráficos circulares. Voy a montar una nueva
serie sobre prueba de hipótesis, que estaré compartiendo en el enlace como enlace
en el último video. Pero primero entendamos todos los diferentes tipos
de análisis gráfico. ¿ Quién debe asistir a esta clase? Cualquier persona que tenga, que sea
estudiante de Lean Six Sigma, que quiera
certificarse como Green Belt, Black Belt, o que
quiera aplicar estadísticas y
análisis gráficos en su lugar de trabajo. A pesar de que usted puede
ser un empresario o puede ser un
estudiante y
desea entender la
estadística usando MinitaB. Voy a cubrirlo todo. Vamos a aprender qué errores ocurren comúnmente
cuando estamos analizando. Porque cuando hacemos análisis utilizando simples puntos de datos
basados en teoría, todo parece ser normal. Entonces
te voy a mostrar algunas trampas en las que fallará
nuestro análisis y cómo debes
evitar esas trampas. Intentaremos, al final de este programa, usted, ¿qué le quitará
a este programa? Comprenderás cómo
hacer algunos análisis básicos. Comprenderá cuáles
son las herramientas que se requieren durante
la fase de medición, como
cálculos de capacidad, etc. Utilizaremos durante la fase de
análisis por lo que si es posible, para cubrir prueba de hipótesis. De lo contrario, si se pone, el video se hace más grande, lo
pondré
como ve aparte. Iván también cubre qué gráfica
usar cuando algunos errores comunes
tenemos y realizamos análisis
gráficos
y creación de gráficos. ¿ Y cómo obtengo insights y conclusiones
a partir de esas gráficas? Esto realmente te ayudará a entender este
programa muy bien. Veamos ¿qué es un Minitab? Minitab es un
software estadístico que está disponible y tiene
múltiples regiones. Entonces voy a buscar un nuevo proyecto. Mi pantalla de Minitab se ve
algo como esto. Tengo un navegador
en el lado izquierdo. Tengo mi
pantalla de salida en la parte superior, tengo mi ficha de datos, que se
parece mucho a una hoja de Excel, con la
que puedo trabajar. Puedo seguir agregando estas
hojas y tengo muchos datos. Puedo hacer mucho análisis
usando mis opciones. Vamos a cubrir
estadística básica, regresión. Estaremos cubriendo muchas estadísticas
básicas y estaremos cubriendo montones de gráficas usando diferentes tipos de datos, ¿verdad? Entonces si te
interesaba saber estas cosas, definitivamente
debes
inscribirte y ver mi video. Muchas gracias.
2. Resumen de la introducción a Lean Six Sigma: Comprender la
función de transferencia en seis sigma. Ahora vamos a explorar la función y su relevancia en seis sigma. Esto comienza por comprender la relación matemática. Y es una función de X. En esta ecuación, Y
representa la salida y los resultados o el
resultado que queremos mejorar. X representa la
variable de entrada o el patrón. F representa la función o la transformación que
se puede aplicar en esas entradas. En esencia, fix Sigma se trata identificar y
optimizar el factor X, las entradas que
impulsan la salida. Al mejorar las Xs, debemos mejorar la Y o
enfocarnos en mejorar la Y.
El ejemplo de función de transferencia en Dmth Consideremos un ejemplo, llamando a un soporte técnico
para resolver una relación informática. En la fase definida, definimos un problema, cuánto tiempo tarda un cliente en
recibir una resolución. Y, que es igual
al tiempo de resolución, O es el tiempo total que se tarda en resolver
el problema del cliente. En la fase de medición,
identificamos y medimos los diversos factores
involucrados en la convocatoria. Al igual que el tiempo en la cola, el tiempo con soporte, el tiempo dedicado a transferir
las llamadas entre agentes, el tiempo de resolución. Analizar fase,
determinamos qué X son críticas y cuáles son las variaciones
típicas
entre los factores. Durante la fase de mejora, implementamos cambios para reducir el tiempo
empleado en cada paso. Quizás automatizar
ciertas respuestas u optimizar la lógica rutinaria
es lo que ahí se cubre Durante la fase de control, monitoreamos el sistema para asegurarnos de que la Y
que es un tiempo resolución efectivamente haya mejorado y se haya mantenido en policía con el tiempo. Este proceso se puede repetir continuamente para impulsar mejoras
adicionales. Cuando se sigue
rigurosamente, el DMAC es una poderosa
metodología repetible para lograr Mejora adicional,
metodologías en seis Sigma que tenemos pluma. Sixema nan por otras herramientas
probadas y
técnicas y prácticas que
incluyen el control estadístico de
procesos Utiliza la tabla de controles para monitorear la
variación a lo largo del tiempo. Utiliza el límite de control superior e
inferior para identificar cuándo el proceso está estadísticamente fuera de control. Las herramientas SPC pueden activar el ciclo DMX cuando la variación y el defecto exceden el umbral
aceptable herramientas de variación y
reducción de defectos Las herramientas de variación y
reducción de defectos incluyen comúnmente en la gestión
de la calidad total. Ayudan a identificar
la causa raíz, las oportunidades de optimización. Estas herramientas juegan
un papel clave durante la fase de análisis y
mejora de DMC Trabajo en equipo y círculos de calidad. Originados en Teta, el énfasis se basó en un enfoque basado en equipos
para la mejora del proceso Empleados de todos los niveles
colaboran regularmente para resolver un problema utilizando las herramientas y metodologías proporcionadas
en seis Sigma. Los círculos de calidad a menudo
integran herramientas estadísticas, DMAT y técnicas de DPatrduction A continuación, los proyectos Six Sigma
y la carretera del Cinturón Amarillo. En la siguiente sección,
discutiremos los proyectos de Six Sigma y destacaremos lo que un
cinturón amarillo necesita saber, incluyendo los roles del proyecto, responsabilidades y el valor aporta
el Cinturón Amarillo
al equipo de mejora. Por lo general, la duración de un proyecto de seis Sigma puede
variar significativamente. Un proyecto a corto plazo puede durar
solo unas horas o un día, especialmente cuando es impulsado por pequeño equipo de calidad que busca
icumentos incrementales Un proyecto a largo plazo
puede abarcar más de un año, particularmente cuando el alcance es complejo y funcional cruzado. Aquí es donde entra en juego el
cinturón negro. Sin embargo, los proyectos más típicos de
Six Sigma, que son un cinturón verde, se ejecutan
alrededor de cuatro a ocho semanas, lo
que permite el tiempo suficiente
para recopilar los datos, se mueven por todas las
fases del ciclo DMC Roles adolescentes en seis proyectos
Sigma. Cada miembro del equipo juega un papel
distinto y crítico. Vamos a entenderlos. Un cinturón maestro negro y un Blag. Estas personas están liderando
y administrando proyectos. Aseguran la alineación con la estrategia y mentan
a los miembros del equipo. Cinturones verdes. Manejaron
un análisis de detalle , recopilación de
datos y ayudan a
implementar la mejora de procesos. Los cinturones amarillos son las
personas que proporcionan insumos clave, ayudan con la recolección de datos y apoyan la actividad de
implementación. Aunque no como líderes de proyectos, Yellow Bells tiene un papel muy
esencial de miembro del equipo que está impulsando la
ejecución diaria del proyecto
Six Sigma. ¿Cuáles son los objetivos comunes que tienen los proyectos
Six Sigma? El proyecto varía en
alcance y a menudo se
enfoca en reducir la variación
en la experiencia del cliente. En el mundo actual,
la experiencia importa mucho. Acelerar el tiempo de comercialización, eliminar errores y defectos, disminuir los costos operativos, alguna consideración crítica
para implementar Six Sigma y oferta ejecutiva de
patrocinio y gestión. Proyecto sin un fuerte apoyo de
liderazgo y financiamiento y visibilidad
son muy diferentes a ecofaxe Adecuación de
la metodología. Pi Sigma es tan potente, pero no es adecuado
para todos los problemas. Evite una
metodología de talla única o una mentalidad. Comienza pequeño y luego escala. Desarrolla confianza
y habilidades que son proyectos
más pequeños y manejables antes de emprender un esfuerzo de
transformación más amplio ¿Sabes cuándo
usar otros enfoques? En algunos casos, las metodologías
alternativas pueden ser más apropiadas. Iniciativa Lean, Reingeniería de
procesos de negocio, lo
llamamos como BPR, Business Process
Management o O la otra metodología
que se pueda utilizar. El control del alcance es muy importante. Si el alcance del proyecto es demasiado amplio y carece de
un resultado claro, se
vuelve inmanejable Costo versus beneficio. Considere el ROI antes de
invertir tiempo y recursos. Ejemplo, gastar
100 horas para ahorrar solo 10 horas anuales
no es una compensación efectiva. realizar una evaluación de
preparación Es muy importante realizar una evaluación de
preparación
antes de emprender un proyecto. Esto ayuda a la preparación de su
organización antes de que nos sumerjamos en
recoger un proyecto. Definir el resultado deseado. ¿Qué estamos tratando de
lograr y por qué? Establecer un criterio de éxito. ¿Cómo es el éxito
tanto para la organización como para
los individuos involucrados? Evaluar la disponibilidad de los datos. ¿Contamos con datos confiables, relevantes y oportunos
para apoyar el análisis? Arme el equipo adecuado. ¿Tenemos personas
con las habilidades, influencia y compromiso para
que el producto sea exitoso? Construya un caso de negocio. ¿Cuál es el valor
de la mejora? ¿Quién tiende a beneficiarse
y quién podría resistirse? ¿Cuál es el ROI esperado? Ayudar a la
preparación organizacional es muy importante cuando planifica
un proyecto de seis Sigma. Son estas preguntas clave porque
son muy importantes. Es, ¿cómo se
ve el estado futuro en comparación con la situación
actual? ¿Estamos resolviendo un
problema de la vida real en nuestro negocio? ¿Ahora es el momento adecuado
para implementar Six Sigma? Una evaluación cuidadosa
asegura que el proyecto Six Sigma no solo
sea relevante, sino que también sea alcanzable e impactante para nuestra organización ¿Estamos evaluando
el desempeño? ¿Tenemos una
justificación sólida aplicar seis sigma en
nuestro caso de negocio Y finalmente, ¿está pasando
algo más en tu proyecto que
necesite tu atención? En Six Sigma, ¿existe
realmente el enfoque correcto? Estas preguntas pueden
estar seguras de que nuestra organización está lista para seis SEMA para
un problema determinado Hay tres pasos clave para evaluar la
preparación organizacional. Paso uno, evaluar las perspectivas
y el camino futuro. Haz la pregunta,
¿encadeno crítico? Los negocios lo necesitan ahora mismo. Evaluar el
desempeño actual. Haz la pregunta. ¿Existe una sólida justificación
estratégica para aplicar seis Sigma
a nuestro negocio? Revisar los sistemas y
la capacidad de cambio. Haz la pregunta, ¿puede
la mejora existente entregar el nivel de cambio
necesario para mantenernos exitosos, competitivos sin
usar seis Sigma? Para comenzar, considere
la importancia de la experiencia del cliente, la satisfacción
del cliente. Nos enfocamos en la voz del
cliente para impulsar el cambio. Las mejoras son esenciales
y el cliente las necesita. Aquí es donde seis herramientas de
análisis de datos Sigma son útiles. Nos ayuda a entender cómo se preocupa
realmente al cliente. Six Sigma proporciona una
poderosa herramienta, planeación
estratégica
futura mejorando la
efectividad del marketing, haciendo las cosas bien a la primera
vez e identificando lo que realmente le importa al cliente con respecto a nuestros proyectos
y servicios. Una de esas herramientas valiosas en Six Sigma Toolkit
es el modelo de CO, que nos ayuda a comprender y priorizar
las necesidades de los clientes de manera más efectiva El modelo de CO es un método
para recopilar datos de los clientes y comprender lo que realmente les importa. ¿Qué diferencia nuestras
ofertas del resto? Nos ayuda a identificar cosas
importantes como cuáles
son las características que pueden aumentar la
satisfacción del cliente cuando se entregan bien
atribuidas al cliente. ¿Cuáles son los potenciales
insatisfactores que podrían perjudicar la
experiencia del cliente si no se dirigen Al analizar estos comentarios, podemos priorizar
mejoras que pueden crear un mayor valor
para nuestro cliente Ahora, consideremos la planeación
estratégica. Six Sigma Analytics puede desempeñar un papel crítico al
identificar los factores clave que
impulsan a los clientes. Satisfacción del cliente, integrándolos en la planeación
estratégica. Las mejoras de rendimiento
son las más necesarias. Yo una
cultura organizacional parte de un enfoque estándar de TIC Sigma a través de fletamento efectivo de
proyectos, desarrollo
métrico, sistemas de
control y
equipos de círculo de calidad pueden
mejorar significativamente la alineación del desempeño
en toda la organización La rentabilidad sigue siendo
una prioridad máxima. Six Sigma es específicamente eficaz en la reducción de
costos de calidad. Muchas organizaciones
gastan del 20 al 75% del costo simplemente asegura la calidad
en los productos y servicios. Al reducir estos costos, nos mantenemos estrechamente alineados con las expectativas de
los clientes y entregamos
consistentemente mejor y más rápido que nuestros competidores. Bien. Concepto de len. Lean manufacturing,
particularmente en un
entorno del sector servicios, significa reconocer la iniciativa de
mejora continua. En esencia, N se enfoca en
agilizar y mejorar los procesos para crear más
valor con sus recursos TaHiOo a menudo considerado como padre
del pensamiento moderno de gravamen, enfatizó que la esencia del gravamen radica en un principio
simple, tiempo
calculado desde la recepción del pedido del
cliente hasta
la recepción del pago por cumplirlo,
y luego trabajar
continuamente para que ese tiempo sea lo más corto posible Len se trata fundamentalmente eliminar el desperdicio en toda
la picadura de valor, reduciendo el tiempo, el
esfuerzo y los recursos innecesarios. El resultado es maximizar el valor, mejorar la eficiencia,
mejor calidad y mayor
satisfacción del cliente. En una configuración de fabricación, las historias de éxito son muchas. Actualmente, tenemos mucho, incluso en el sector servicios.
3. Trabajo de proyecto: Vamos a entender cuál es el trabajo de proyecto
que vamos a hacer en este
programa de análisis de datos usando MinitaB. Como les dije, vamos
a trabajar con MinitaB. Y este es el Minitab
que voy a estar usando. También estaré compartiendo
con ustedes una ficha técnica, su hoja de datos de proyecto, donde tengo múltiples ejemplos, donde estamos haciendo
cálculos sobre capacidad. Vamos a tratar de ver
distribuciones y se
puede ver que
hay varias pestañas. Ejemplo uno ejemplo
dos ejemplo tres, trataremos de hacer algún análisis de
tendencias. Trataremos de ver gráficos de
Pareto. Tenemos muchos datos que se
han compartido contigo, lo
que te dará una experiencia
práctica en el trabajo con datos, ¿verdad? Entonces comencemos.
4. Conceptos básicos de la estadística: Bienvenido a nuestro próximo tema
importante, Fundamentos de la estadística. En este video,
aprenderás qué es la estadística,
qué es la estadística descriptiva
y qué es la
estadística inferencial Empecemos con
la primera pregunta. ¿Qué es la estadística? estadística se
ocupa de la recolección, análisis y
presentación de datos. Por ejemplo, si
queremos investigar si el género influye en el periódico preferido, entonces el género y el periódico son nuestras llamadas variables
que queremos analizar. Analizar si el género
influye en el periódico
preferido. Primero necesitamos recopilar datos. Para ello, creamos
un cuestionario que pregunta sobre género y periódico
preferido. Después enviaremos la
encuesta y esperaremos dos semanas. Posteriormente, podemos mostrar las respuestas recibidas en
una tabla de esta tabla. Tenemos una columna
para cada variable, una para género y
otra para periódico. Por otro lado, cada fila representa la respuesta
de una persona. Por ejemplo, el
primer encuestado es varón y declaró
los tiempos de la India El segundo es femenino, y declaró el hindú, y así sucesivamente. Por supuesto, los datos no
tienen por qué provenir de una encuesta. Los datos también pueden provenir de
un experimento en el que. Por ejemplo, quieren estudiar el efecto de dos fármacos
sobre la presión arterial. Consideremos otro ejemplo de la vida
real. Imagina que eres un gerente de
tienda y quieres saber si una nueva
exhibición de producto aumenta las ventas. Podrías recopilar
datos sobre ventas antes. Y una vez que se configura la nueva
pantalla, estos datos te ayudarán a analizar la efectividad
de la pantalla,
o supongamos que tu administrador
escolar, o supongamos que tu administrador
escolar, y quieres entender si las sesiones de tutoría
adicionales están
ayudando a sesiones de tutoría
adicionales están los estudiantes a mejorar
sus puntajes de matemáticas ¿Podrías cobrar
como puntajes antes? Después de las sesiones de tutoría
para analizar el impacto. Ahora ya está hecho el primer paso. Hemos recopilado datos y podemos comenzar a analizar los datos. Pero, ¿qué es lo
que realmente queremos analizar? No encuestamos a
toda la población
sino que tomamos una muestra. Ahora bien, la gran pregunta es, ¿solo queremos
describir los datos de la muestra, o queremos
hacer una declaración sobre toda la población? Si nuestro objetivo se limita
a la muestra en sí. Es decir, solo queremos
describir los datos recopilados. Utilizaremos
estadísticas descriptivas. estadística descriptiva
proporcionará un resumen detallado
de la muestra. Por ejemplo, si encuestamos 100 personas sobre su periódico
preferido, estadísticas
descriptivas nos
dirían cuántas personas prefieren tiempos de la
India o del hindú No obstante, si queremos sacar conclusiones sobre la
población en su conjunto. Utilizamos estadísticas inferenciales. Este enfoque
nos permite hacer inferencias sobre la población a
partir de nuestros datos de muestra Por ejemplo, usando estadísticas
inferenciales, podríamos estimar
la proporción de todos los adultos en una ciudad que prefieren un periódico específico a partir una muestra de 500 encuestados Las estadísticas inferenciales también pueden ayudarnos a determinar si un
determinado grupo demográfico,
como el género, influye significativamente en las
preferencias de los periódicos Al analizar nuestros datos de muestra, podemos hacer inferencias sobre
las preferencias
periodísticas de toda la población Mediante el uso de estadísticas descriptivas
e inferenciales, podemos obtener una
comprensión más profunda de nuestros hallazgos y tomar decisiones informadas sobre estrategias de
marketing o creación de contenido para
diferentes periódicos En la siguiente lección,
profundizaremos en las aplicaciones
prácticas de la
estadística. Estén atentos.
5. Importancia de los niveles de medida o los tipos de datos: Importancia de los niveles
de medición. Comprender el nivel de medición es crucial
por varias razones. Análisis apropiado. Los diferentes niveles de medición requieren diferentes técnicas
estadísticas. Usar el método incorrecto puede
llevar a conclusiones incorrectas. Interpretación de datos. Conocer el nivel ayuda a interpretar
incorrectamente los resultados. Por ejemplo, los valores medios son
significativos para los datos de intervalo y relación, pero no para los datos
nominales u ordinales Visualización, las técnicas efectivas de
visualización de datos varían en función del
nivel de medición. Los gráficos de barras son adecuados
para datos nominales, mientras que los histogramas son mejores
para los datos de intervalo y relación Profundicemos en
cada nivel de medición. Nivel nominal de medición. Las variables nominales
categorizan los datos sin establecer
ningún orden significativo Por ejemplo, preguntar a los encuestados sobre su modo de
transporte a la escuela, autobús, automóvil, bicicleta
o caminar es nominal. Cada categoría es distinta, pero no hay una
clasificación u orden inherente entre ellas. análisis de datos nominales
implica contar frecuencias o usar gráficos de
barras para visualizar
distribuciones. Nivel ordinal de medición, las variables
ordinales introducen
un orden significativo o clasificación entre categorías, pero las diferencias entre rangos no son
consistentemente Por ejemplo, pedir a
los estudiantes que califiquen su satisfacción
con su modo de transporte como
muy satisfechos, satisfechos, neutrales, satisfechos o muy satisfechos demuestra una medición
ordinal Si bien podemos clasificar
estas respuestas de menos a más satisfechas, la diferencia numérica entre satisfecha y muy satisfecha
no es cuantificable El análisis generalmente implica cálculos de
mediana y pruebas no paramétricas Intervalo y cociente niveles de medición, variables
métricas. Las variables de intervalo y relación se consideran variables métricas. Comparten la
característica de que los intervalos entre
valores están igualmente espaciados, pero las variables de relación también
tienen un verdadero punto cero, haciendo válidas todas las
operaciones aritméticas Los ejemplos incluyen medir
la edad, el peso o los ingresos. Por ejemplo, preguntar a
los encuestados sobre la cantidad de minutos que se tarda en llegar a la escuela mide datos de intervalo, donde los intervalos
entre respuestas, EG, 10 minutos, 20 minutos son
consistentes y significativos. Esto permite
medidas estadísticas como el cálculo promedios y el uso técnicas estadísticas
avanzadas
como el análisis de regresión. Resumen. Comprender
estos niveles de medición es crucial para diseñar encuestas y elegir análisis
estadísticos adecuados. Los datos nominales nos informan sobre categorías
sin ningún pedido. Los datos ordinales permiten clasificación pero no la
medición precisa de las diferencias, y el intervalo
y la relación de datos métricos permiten medición
precisa y admiten una amplia gama de análisis
estadísticos Ya sea creando tablas de
frecuencias, gráficos de
barras o histogramas, seleccionar el nivel correcto de medición garantiza una interpretación
precisa de los datos y conocimientos significativos en diversos campos
de estudio e investigación Echemos un vistazo más de cerca a
cada nivel de medición. Nivel nominal de medición. Los datos nominales son el nivel de medición más
básico. Las variables nominales
categorizan los datos, pero no permiten una
clasificación significativa de las categorías Los ejemplos incluyen
género, macho, hembra, tipos de animales, perro, gato, pájaro, periódicos preferidos. En todos estos casos, se
puede distinguir
entre valores, pero no puede clasificar las
categorías de manera significativa Por ejemplo, investigar
si el género influye en el periódico
preferido involucra variables nominales. En un cuestionario,
enumerarías posibles respuestas
para ambas variables. no existir un orden inherente, la disposición de las categorías en el cuestionario
no importa. Los datos recopilados se
pueden mostrar en una tabla y las tablas de frecuencia o gráficos de
barras se pueden usar para
visualizar las distribuciones. Nivel ordinal de medición. Los datos ordinales pueden
clasificarse y clasificarse en un orden significativo, pero las diferencias entre rangos no son
matemáticamente iguales Ejemplos incluyen
rankings, primero, segundo, tercero,
calificaciones de satisfacción, muy insatisfechos,
insatisfechos , neutrales,
satisfechos, muy satisfechos, niveles de educación,
preparatoria,
licenciatura, maestros,
en este caso, mientras que el Los intervalos entre rangos no
son necesariamente iguales. Por ejemplo, si un
cuestionario pregunta, ¿qué tan satisfecho está con
su trabajo actual con
opciones que van desde muy
insatisfechos hasta muy satisfechos? opciones que van desde muy
insatisfechos hasta muy satisfechos Las categorías de respuesta están ordenadas, pero la diferencia exacta entre cada nivel de satisfacción no
es cuantificable El análisis de
los datos ordinales a menudo implica calcular medianas y
usar pruebas no paramétricas Nivel de medición a intervalos. Los datos de intervalo tienen
intervalos iguales entre valores, pero carecen de un verdadero punto cero. Los ejemplos incluyen la temperatura
en grados Celsius o Fahrenheit. Los datos de intervalo permiten la medición de
diferencias entre valores. Pero debido a que no
hay un verdadero cero, los
ratios no son significativos. operaciones estadísticas
como el cálculo de promedios y el uso de técnicas como Son posibles operaciones estadísticas
como el cálculo de promedios
y el uso de técnicas como el análisis de
regresión. Relación nivel de medición. Los datos de relación tienen
intervalos iguales entre valores e incluyen
un verdadero punto cero. Los ejemplos incluyen la edad, el
peso o los ingresos, porque los datos de relación
incluyen un cero verdadero. Todas las
operaciones aritméticas son válidas. Este nivel permite el
cálculo de ratios y promedios y permite el uso de métodos estadísticos avanzados. Oh. Lo que hemos aprendido hasta ahora usando un ejemplo. Imagina que estás
realizando una encuesta en una escuela para entender
cómo llegan los alumnos a la escuela. Aquí hay preguntas
que podrías hacer. Cada uno corresponde a un nivel de medición
diferente. La primera pregunta podría ser, ¿qué modo de transporte
usas para llegar a la escuela? Las opciones pueden incluir autobús, automóvil, bicicleta o caminar. Esta es una variable nominal. Las respuestas pueden ser categorizadas, pero no hay
un orden significativo. Esto quiere decir que el autobús
no es más alto que la bicicleta. Caminar no es
más alto que el auto y así sucesivamente. Si quieres analizar los
resultados de esta pregunta, puedes contar cuántos
alumnos utilizan cada
medio de transporte y
presentarlo en un gráfico de barras. Siguiente, Podrías preguntar, ¿qué tan satisfecho estás con tu actual modo
de transporte? Las opciones pueden incluir
muy insatisfechos, insatisfechos, neutrales,
satisfechos o muy Esta es una variable ordinal. Puedes clasificar las respuestas
para ver qué modo de transporte ocupa un lugar
más alto en satisfacción. Pero la diferencia exacta entre satisfecho y muy satisfecho. Por ejemplo,
no es cuantificable. Para la pregunta final, ¿cuántos minutos te
lleva llegar a la escuela? Aquí, minutos para llegar a
la escuela es una variable métrica. puede calcular el
tiempo promedio que se tarda en llegar a la escuela y utilizar todas las medidas
estadísticas estándar. Podemos visualizar estos datos con un histograma que muestra la
distribución de los tiempos que se tarda en llegar a la escuela y comparar los diferentes modos de
transporte Entonces, usando datos nominales, podemos categorizar
y contar las respuestas, pero no podemos inferir ningún orden Los datos ordinales
nos permiten clasificar las respuestas, pero no medir
diferencias precisas entre rangos. Los datos métricos
nos permiten medir diferencias
exactas
entre puntos de datos. Como ya se mencionó,
los niveles métricos de medición
se pueden subdividir en intervalos y escala de relación Pero, ¿cuál es la diferencia entre los niveles de intervalo
y relación? Exploremos la
diferencia entre los niveles de
medición de intervalo y relación usando un ejemplo. Intervalo versus relación
nivel de medición. En un maratón, el
tiempo que toman los corredores para completar la carrera
sirve de ejemplo práctico. Considera un escenario
donde el corredor más rápido termine en 2 horas y el
más lento termine en 6 horas. Así es como clasificamos el nivel de medición
en función de la información proporcionada Relación nivel de medición. Un nivel de relación de medición
se caracteriza por tener un verdadero punto cero donde cero representa la ausencia de
la cantidad que se está midiendo. En el ejemplo de Maratón, todos los corredores inician al mismo tiempo
0.0 en el que
inician la carrera. Con un verdadero punto cero, podemos hacer
comparaciones significativas como afirmar que el corredor más rápido tardó tres veces menos tiempo
que el corredor más lento, 2 horas frente a 6 horas Este nivel permite operaciones
significativas de multiplicación
y división Por ejemplo, si
un corredor termina en 4 horas y
otro en 12 horas, podemos decir con precisión que el primer corredor fue tres
veces más rápido que el segundo. Nivel de medición a intervalos. Un nivel de medición de intervalo
carece de un punto cero verdadero. En el contexto maratónico, si el cronómetro arranca
tarde y solo
medimos las diferencias de tiempo al corredor más rápido
que comenzó a tiempo, perdemos la verdadera referencia cero Si bien los intervalos entre
valores todavía están igualmente espaciados y las operaciones
aritméticas como la suma y la
resta son válidas, la multiplicación y la división
pueden no ser significativas Por ejemplo, decir que un corredor terminó 4 horas por delante de
otro es significativo. Pero no podemos afirmar que
un corredor fue cuatro veces más rápido que otro sin saber el tiempo total para ambos. En resumen, la
medición de nivel de intervalo permite intervalos
iguales
entre valores y admite operaciones como
suma y resta, pero no posee un verdadero punto cero necesario
para relaciones significativas Ahora, un poco de ejercicio para comprobar si todo
está claro para ti. Primero, tenemos estado de EU, que es un
nivel nominal de medición. Esto significa que los datos se utilizan para etiquetar o nombrar categorías sin ningún valor cuantitativo En este caso, los estados son nombres sin
orden o clasificación inherente. A continuación, tenemos
calificaciones de productos en una escala 1-5. Este es un ejemplo
de datos ordinales. Aquí, los números sí
tienen un orden o rango. Cinco es mejor que uno, pero los intervalos entre las calificaciones no son
necesariamente iguales. Pasando a nombres de departamentos
como las compras, ventas, operaciones, finanzas,
esto también es nominal. Las categorías aquí,
como diferentes departamentos son para categorización y
no implican ningún orden A continuación, tenemos CO dos
emisiones en un año, que se mide en
una escala de ratio métrico. Este nivel permite
la gama completa de operaciones
matemáticas,
incluyendo proporciones significativas. Cero emisiones significa que
no hay emisiones en absoluto. Entonces tenemos números telefónicos. Aunque
los números de teléfono son numéricos, se clasifican como nominales. Son solo identificadores
sin valor numérico para el análisis. El nivel de comodidad es
otro ejemplo ordinal. Esto podría incluir niveles
como el cuidado bajo, medio y alto, que
indican un orden, pero no la diferencia exacta
entre estos niveles. espacio habitable en metros cuadrados se mide en una escala de proporción. Al igual que las emisiones de CO dos, metros
cuadrados significan
que no hay espacio vital y las comparaciones como el doble
o la mitad son significativas. Por último, tenemos
satisfacción laboral en una escala 1-4. Se trata de datos ordinales. Clasifica los niveles de satisfacción, pero no se cuantifica la diferencia entre
cada nivel En la siguiente lección,
profundizaremos en las aplicaciones
prácticas del diseño de experimentos. Estén atentos.
6. Medidas del centro y medidas de dispersión: Examinemos ambos métodos, comenzando con estadísticas
descriptivas. ¿Por qué es importante la
estadística descriptiva? Por ejemplo, si una empresa quiere entender cómo sus
empleados viajan al trabajo Se puede crear una encuesta para
recabar esta información. Una vez que se recolectan suficientes datos, se pueden analizar mediante estadística
descriptiva. Entonces, qué es exactamente la estadística
descriptiva, su propósito es describir y resumir un conjunto
de datos de manera significativa Sin embargo, es crucial señalar
que las estadísticas descriptivas solo reflejan los datos recopilados y
no llegan a conclusiones sobre
una población mayor. En otras palabras, saber
cómo algunos empleados una empresa viajan diariamente no nos
permite ver cómo les va a
todos los trabajadores Ahora, para describir
los datos descriptivamente, nos enfocamos en cuatro componentes clave, medidas de tendencia central, medidas de dispersión, tablas de
frecuencias y gráficos Empecemos con medidas
de tendencia central, que incluyen la media,
mediana y más. Primero, la media, la
media aritmética se calcula sumando todas las observaciones juntas y dividiendo por el
número de observaciones Por ejemplo, si tenemos los puntajes de las
pruebas de cinco alumnos, sumamos los puntajes, y dividimos entre cinco para encontrar que la
puntuación media de la prueba es de 86.6 Siguiente es la mediana. Cuando los valores de un conjunto de datos se organizan en orden ascendente, la mediana es el valor medio. Si hay un
número impar de puntos de datos, es simplemente el valor medio. Si hay un número par, la mediana es el promedio
de los dos valores medios. Un aspecto importante de
la mediana es que es resistente a
valores extremos o valores atípicos Por ejemplo, independientemente
de la altura, la última persona está
en un conjunto de datos altos. La mediana seguirá siendo la misma. Si bien la media puede cambiar significativamente con base
en ese valor, la mediana permanece sin cambios independientemente de la estatura de la
última persona. Es decir, no se
ve afectado por valores atípicos. En contraste, los hombres pueden cambiar significativamente con base en la estatura de
esa última persona, haciéndola sensible a los valores atípicos Ahora, hablemos del modo. El modo es el valor o valores que ocurren
con mayor frecuencia en un conjunto de datos. Por ejemplo, si 14 personas
viajan en automóvil, seis en bicicleta, cinco a pie y cinco
toman el transporte público, entonces el automóvil es el modo ya
que aparece con mayor frecuencia A continuación, pasamos a las
medidas de dispersión, que describen qué tan
dispersos están los valores en
un conjunto de datos. Las medidas clave de dispersión
incluyen variantes. desviación estándar
y rango intecuatle, comenzando con Indica la distancia
promedio entre cada
punto de datos y la media. Esto nos dice
cuánto se desvían
los puntos de datos individuales del promedio Por ejemplo, si la desviación
promedio de la media es de
11.5 centímetros, podemos calcular la
desviación estándar usando la fórmula. Sigma es igual a la raíz cuadrada de la suma de cada valor
menos la media. cuadrado, dividido por n, donde Sigma es la desviación
estándar N es el número de individuos. X sub i es el valor de cada
individuo, y x bar es la media. Es importante tener
en cuenta que existen dos fórmulas para la desviación
estándar. On divide por n, mientras que el otro divide
por n menos uno Este último se utiliza
cuando nuestra muestra no cubre
toda la población, como en estudios clínicos. Este último se utiliza
cuando nuestra muestra no cubre
toda la población, como en estudios clínicos. Ahora bien, ¿en qué se diferencia
la desviación estándar de la varianza? La desviación estándar mide la distancia promedio
desde la media. Mientras que la varianza es simplemente el valor cuadrado de
la desviación estándar A continuación, discutamos el rango
y el rango intecuatle. El rango es la
diferencia entre los
valores máximo y mínimo en un conjunto de datos. Por otro lado,
el rango inecuartil representa el
50% medio de los datos,
calculado como la diferencia
entre el primer cuartil,
Q uno y el tercer cuartil, Q uno y el Esto significa que 25%
de los valores se encuentran por debajo y 25% por encima del rango del cuartil
inte Antes de pasar a
los puntos finales, comparemos brevemente
estos conceptos, medidas de tendencia central
y medidas de dispersión. Consideremos medir la presión
arterial de los pacientes. Las medidas de
tendencia central proporcionan un único valor que representa todo
el conjunto de datos. Ayudando a identificar
un punto central alrededor del cual los
puntos de datos tienden a agruparse. Por otro lado,
las medidas de dispersión, como la desviación estándar, rango y el rango inteqatile indican qué tan dispersos están
los puntos de datos Ya sea que estén muy agrupados alrededor del centro o
ampliamente dispersos. En resumen, mientras que las medidas de tendencia
central resaltan el punto central
del conjunto de datos, las medidas de dispersión
describen cómo se distribuyen
los datos
alrededor de ese centro. Ahora, pasemos a las mesas, centrándonos en los tipos más
importantes, frecuencias y tablas de
contingencia Una tabla de frecuencias
muestra la frecuencia con cada valor distinto
aparece en un conjunto de datos. Por ejemplo, una empresa encuestó a sus empleados sobre
sus opciones de viaje, automóvil, bicicleta, paseo
y transporte público Aquí están los resultados de 30 empleados mostrando
sus respuestas. Podemos crear una
tabla de frecuencias para resumir estos datos enumerando las cuatro opciones en
la primera columna, y contando sus
ocurrencias desde la tabla Es claro que el modo
de transporte
más común entre los
empleados es en automóvil. Con 14 empleados
eligiendo esta opción. La tabla de frecuencias proporciona un resumen conciso de los datos. Pero, ¿y si tenemos dos variables
categóricas
en lugar de una Aquí es donde entra en juego una tabla de
contingencia, también conocida como
tabulación cruzada ¿Imagina que la compañía
tiene dos fábricas, una en Detroit y
otra en Cleveland? Si también preguntamos a los empleados
sobre su ubicación de trabajo, podemos mostrar ambas variables
usando una tabla de contingencia Esta tabla permite
analizar y comparar
la relación
entre las dos variables
categóricas Las filas representan las
categorías de una variable. Mientras que las columnas representan
las categorías de la otra, cada celda de la tabla
muestra el número de observaciones que encajan en la combinación de
categorías correspondiente. Por ejemplo, la primera celda indica cuántos
empleados viajan en
automóvil y el trabajo en Detroit
se reportó seis veces Gracias. Te veo en la siguiente lección de estadística.
7. Minitab: En esta clase, vamos a aprender sobre las pruebas de hipótesis. Te voy a enseñar
pruebas de hipótesis usando MiniTab. También te voy a enseñar pruebas de
hipótesis
usando Microsoft Office. Eso es usar Excel y Microsoft Office para
quienes estén interesados en
ir por MiniTab. Déjame mostrarte desde donde
puedes descargar Minitab. Minitab.com bajo Descargas. Aquí llegamos a la sección de
descargas. Tienes el software
estadístico MiniTab, y está disponible
por 30 días de forma gratuita. También he descargado la versión de
prueba en mi sistema y análisis Dando y
te lo mostraste. Recuerda, solo está disponible
por 30 días. Por favor,
asegúrate de completar todo
el programa de capacitación
dentro de los primeros 30 días. Cuando sientas el valor en esto, definitivamente
deberías
seguir adelante y
seguir la
versión con licencia de MiniTab, que está disponible aquí. Sólo tengo que dar click en Descargar
y descargar Woodstock. Comienza con una prueba
gratuita de 30 días. Y ya es tiempo
suficiente
para que practiques todos los
ejercicios que se impulsan. Te pedirá algunos
datos personales
para que puedan estar en contacto contigo y te puedan ayudar
con algunos descuentos. Si hay alguno. una sección llamada como Dr. MiniTab o tienes
un número de teléfono. Si llamas desde el Reino Unido, te será
fácil llamar allí. Pero si estás hablando
desde otros lugares, hablar con MiniTab es una opción
mucho más fácil. Esta es una muy buena herramienta
estadística y
siguen actualizando las
características regularmente. Entonces, personalmente, siento que esta inversión
valdrá la pena. Pero para aquellos que no pueden
darse el lujo de ir por la licencia, pueden usar Microsoft Office, al
menos algunas de las características, no todas, pero algunas de las
características están disponibles. Por lo que inicialmente te mostraré todo
el ejercicio de diferentes tipos de
hipótesis usando MiniTab. Y luego pasaremos
a Microsoft Excel, mantendremos conectados y
seguiremos aprendiendo.
8. Estadísticas descriptivas: En la sesión de hoy, vamos
a aprender sobre estadística
descriptiva. Estadística descriptiva
significa que quiero entender medidas de centro. Al igual que las medidas de centro,
media, modo mediano. Quiero entender
las medidas de propagación. Eso no es más que rango, desviación
estándar
y varianza. Tomemos un
dato sencillo que tengo. Tengo tiempo de ciclo en minutos para casi 100 puntos de datos. Voy a tomar
el tiempo de ciclo en minutos de mi hoja de datos
del proyecto de día. Voy a ir a MinitaB y
pegaré mis datos donde aquí quiero hacer alguna estadística
descriptiva. Estadísticas. Da clic en Estadística Básica y di Mostrar estadística
descriptiva. Cuando hago esto, me da una opción en la ventana emergente, que se llama as, que me muestra los campos de
datos disponibles que tengo. Tengo tiempo de ciclo en minutos. Entonces
me está diciendo que quiero
analizar el tiempo de
ciclo variable en minutos. Simplemente haré clic en, Ok, e inmediatamente
lo encontrarás en mi ventana de salida. Yo sólo puedo tirar esto hacia abajo. En mi ventana de salida. Me está mostrando
que ha hecho algún análisis estadístico para el
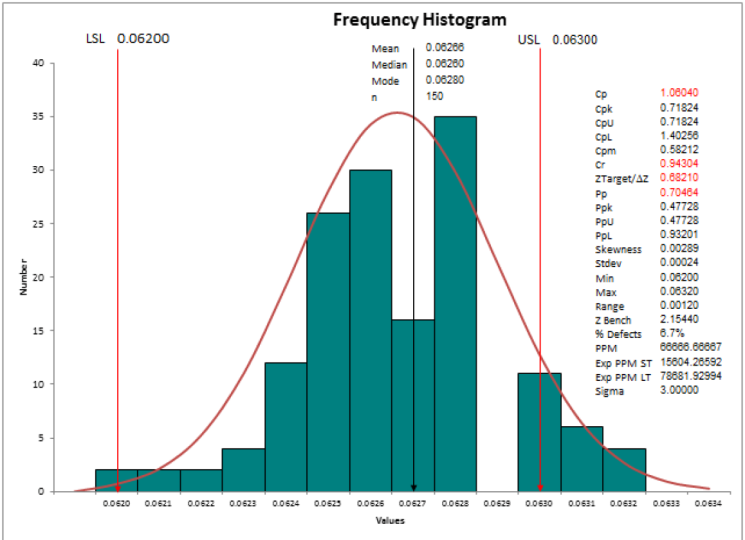
tiempo de ciclo variable en minutos. Tengo 100
puntos de datos por aquí. El número de valores faltantes es 0. La media es 10.064. error estándar de la media es 0.103, desviación
estándar es de 1
al valor mínimo es 7.5. Uno no es más que tu
cuartil uno es 9.1. Mediana, es decir,
su Q2 es 10.35, Q3 es 10.868, y el valor
máximo es 12.490. Si necesito más análisis
estadístico, puedo seguir adelante y
repetir este análisis. Esta vez, voy a dar
clic en Estadísticas. Y puedo mirar los otros puntos de
datos que necesito. Supongamos que si necesito el rango, no necesito error estándar, necesito rango
intercuartil. Quiero identificar
cuál es el estado de ánimo. Quiero identificar cuál es
la asimetría y mis datos. ¿ Cuál es la curtosis en mis datos? Puedo seleccionarlo todo y decir,
está bien, voy a dar clic en, Ok. Cuando haga esto, todos los demás parámetros
estadísticos que he seleccionado saldrán
en mi ventana de salida. Esta es mi ventana de salida. Por lo que es de nuevo me dice ese punto de datos
adicional
que seleccioné. Entonces el radio no es más que tu desviación
estándar al cuadrado. Es 0.0541. Me está diciendo el rango
que es máximo menos mínimo. Es 4.95. rango intercuartil es de 1.707. No hay modo en mis datos. Y número de puntos de datos en
0 porque no hay más, los datos no están sesgados. Los valores muy cercanos a 0, es 0.05, pero
hay curtosis. Significa que mis datos no
están apareciendo como un ir no laboral. Tan bien, nos gusta ver
cómo queda mi distribución. Hagamos eso. Hago clic en estadísticas, hago clic en Estadísticas Básicas, y haré clic en resumen
gráfico. Selecciono el
tiempo de ciclo en minutos. Y digo que quiero ver intervalo de confianza
del 95%. Dé clic en, De acuerdo,
veamos la salida. El resumen de los minutos de diamante de
ciclo. Me está mostrando la media, desviación
estándar, varianza. Todas las cosas estadísticas se
están mostrando en
el lado derecho. Media, desviación estándar,
varianza, asimetría, curtosis, número de puntos de datos
mediana
mínima del primer cuartil , máximo del tercer cuartil. Estos puntos de datos que usted
ve como mínimo Q1, mediana, Q3 y máximo serán
cubiertos en la gráfica de caja. La gráfica de caja se enmarca
utilizando estos puntos de datos. Y cuando se mira el velcro, dice
que la campana no
es curva empinada,
es una curva un poco más gorda, y de ahí que el
valor de curtosis sea un valor negativo. Continuaremos nuestro aprendizaje más a detalle en
el siguiente video. Gracias.
9. Estadísticas descriptivas versus inferenciales: Examinemos ambos métodos, comenzando con estadísticas
descriptivas. ¿Por qué es importante la
estadística descriptiva? Por ejemplo, si una empresa quiere entender cómo sus
empleados viajan al trabajo Se puede crear una encuesta para
recabar esta información. Una vez que se recolectan suficientes datos, se pueden analizar mediante estadística
descriptiva. Entonces, qué es exactamente la estadística
descriptiva, su propósito es describir y resumir un conjunto
de datos de manera significativa Sin embargo, es crucial señalar
que las estadísticas descriptivas solo reflejan los datos recopilados y
no llegan a conclusiones sobre
una población mayor. En otras palabras, saber
cómo algunos empleados una empresa viajan diariamente no nos
permite ver cómo les va a
todos los trabajadores Ahora, para describir
los datos descriptivamente, nos enfocamos en cuatro componentes clave, medidas de tendencia central, medidas de dispersión, tablas de
frecuencias y gráficos Empecemos con medidas
de tendencia central, que incluyen la media,
mediana y más. Primero, la media, la
media aritmética se calcula sumando todas las observaciones juntas y dividiendo por el
número de observaciones Por ejemplo, si tenemos los puntajes de las
pruebas de cinco alumnos, sumamos los puntajes, y dividimos entre cinco para encontrar que la
puntuación media de la prueba es de 86.6 Siguiente es la mediana. Cuando los valores de un conjunto de datos se organizan en orden ascendente, la mediana es el valor medio. Si hay un
número impar de puntos de datos, es simplemente el valor medio. Si hay un número par, la mediana es el promedio
de los dos valores medios. Un aspecto importante de
la mediana es que es resistente a
valores extremos o valores atípicos Por ejemplo, independientemente
de la altura, la última persona está
en un conjunto de datos altos. La mediana seguirá siendo la misma. Si bien la media puede cambiar significativamente con base
en ese valor, la mediana permanece sin cambios independientemente de la estatura de la
última persona. Es decir, no se
ve afectado por valores atípicos. En contraste, los hombres pueden cambiar significativamente con base en la estatura de
esa última persona, haciéndola sensible a los valores atípicos Ahora, hablemos del modo. El modo es el valor o valores que ocurren
con mayor frecuencia en un conjunto de datos. Por ejemplo, si 14 personas
viajan en automóvil, seis en bicicleta, cinco a pie y cinco
toman el transporte público, entonces el automóvil es el modo ya
que aparece con mayor frecuencia A continuación, pasamos a las
medidas de dispersión, que describen qué tan
dispersos están los valores en
un conjunto de datos. Las medidas clave de dispersión
incluyen variantes. desviación estándar
y rango intecuatle, comenzando con Indica la distancia
promedio entre cada
punto de datos y la media. Esto nos dice
cuánto se desvían
los puntos de datos individuales del promedio Por ejemplo, si la desviación
promedio de la media es de
11.5 centímetros, podemos calcular la
desviación estándar usando la fórmula. Sigma es igual a la raíz cuadrada de la suma de cada valor
menos la media. cuadrado, dividido por n, donde Sigma es la desviación
estándar N es el número de individuos. X sub i es el valor de cada
individuo, y x bar es la media. Es importante tener
en cuenta que existen dos fórmulas para la desviación
estándar. On divide por n, mientras que el otro divide
por n menos uno Este último se utiliza
cuando nuestra muestra no cubre
toda la población, como en estudios clínicos. Este último se utiliza
cuando nuestra muestra no cubre
toda la población, como en estudios clínicos. Ahora bien, ¿en qué se diferencia
la desviación estándar de la varianza? La desviación estándar mide la distancia promedio
desde la media. Mientras que la varianza es simplemente el valor cuadrado de
la desviación estándar A continuación, discutamos el rango
y el rango intecuatle. El rango es la
diferencia entre los
valores máximo y mínimo en un conjunto de datos. Por otro lado,
el rango inecuartil representa el
50% medio de los datos,
calculado como la diferencia
entre el primer cuartil,
Q uno y el tercer cuartil, Q uno y el Esto significa que 25%
de los valores se encuentran por debajo y 25% por encima del rango del cuartil
inte Antes de pasar a
los puntos finales, comparemos brevemente
estos conceptos, medidas de tendencia central
y medidas de dispersión. Consideremos medir la presión
arterial de los pacientes. Las medidas de
tendencia central proporcionan un único valor que representa todo
el conjunto de datos. Ayudando a identificar
un punto central alrededor del cual los
puntos de datos tienden a agruparse. Por otro lado,
las medidas de dispersión, como la desviación estándar, rango y el rango inteqatile indican qué tan dispersos están
los puntos de datos Ya sea que estén muy agrupados alrededor del centro o
ampliamente dispersos. En resumen, mientras que las medidas de tendencia
central resaltan el punto central
del conjunto de datos, las medidas de dispersión
describen cómo se distribuyen
los datos
alrededor de ese centro. Ahora, pasemos a las mesas, centrándonos en los tipos más
importantes, frecuencias y tablas de
contingencia Una tabla de frecuencias
muestra la frecuencia con cada valor distinto
aparece en un conjunto de datos. Por ejemplo, una empresa encuestó a sus empleados sobre
sus opciones de viaje, automóvil, bicicleta, paseo
y transporte público Aquí están los resultados de 30 empleados mostrando
sus respuestas. Podemos crear una
tabla de frecuencias para resumir estos datos enumerando las cuatro opciones en
la primera columna, y contando sus
ocurrencias desde la tabla Es claro que el modo
de transporte
más común entre los
empleados es en automóvil. Con 14 empleados
eligiendo esta opción. La tabla de frecuencias proporciona un resumen conciso de los datos. Pero, ¿y si tenemos dos variables
categóricas
en lugar de una Aquí es donde entra en juego una tabla de
contingencia, también conocida como
tabulación cruzada ¿Imagina que la compañía
tiene dos fábricas, una en Detroit y
otra en Cleveland? Si también preguntamos a los empleados
sobre su ubicación de trabajo, podemos mostrar ambas variables
usando una tabla de contingencia Esta tabla permite
analizar y comparar
la relación
entre las dos variables
categóricas Las filas representan las
categorías de una variable. Mientras que las columnas representan
las categorías de la otra, cada celda de la tabla
muestra el número de observaciones que encajan en la combinación de
categorías correspondiente. Por ejemplo, la primera celda indica cuántos
empleados viajan en
automóvil y el trabajo en Detroit
se reportó seis veces Gracias. Te veo en la siguiente lección de estadística.
10. Conceptos de estadísticas inferenciales, parte 2: Vamos a sumergirnos en las estadísticas
inferenciales. Comenzaremos con una breve
descripción de lo que es. Seguido de una explicación
de los seis componentes clave. Entonces, ¿qué son las
estadísticas inferenciales? Nos permite sacar
conclusiones sobre una población a partir de
datos de una muestra. Para aclarar, la población es todo el grupo que
nos interesa. Por ejemplo, si
queremos estudiar la estatura promedio de todos los
adultos en Estados Unidos, nuestra población incluye a
todos los adultos del país. La muestra por otro lado, es un subconjunto menor tomado
de esa población. Por ejemplo, si seleccionamos
150 adultos de EU, podemos usar esta muestra para hacer inferencias sobre la población
más amplia Ahora, aquí están los seis pasos
involucrados en este proceso. Hipótesis. Comenzamos
con una hipótesis. ¿Cuál es una declaración
que pretendemos probar? Por ejemplo, podríamos
querer investigar si un medicamento impacta positivamente la presión arterial en individuos
con hipotensión Oh, en este caso, nuestra población consiste todos los individuos con hipertensión
arterial en EU, ya que no es práctico recabar datos de toda la población Nos basamos en una muestra para hacer inferencias sobre la
población utilizando nuestra muestra Empleamos pruebas de hipótesis. Este es un método utilizado para
evaluar una afirmación sobre un parámetro de población
basado en datos de muestra. Hay varias pruebas de
hipótesis disponibles, y al final de este video. Te guiaré sobre cómo
elegir la correcta. ¿Cómo funcionan
las pruebas de hipótesis? Comenzamos con una hipótesis
de investigación. También conocida como hipótesis
alternativa, que es lo que buscamos
evidencia en nuestro estudio. También se llama hipótesis
alternativa. Esto es para lo que estamos
tratando de encontrar pruebas. En nuestro caso, la hipótesis es que el medicamento
afecta la presión arterial. Sin embargo, no podemos
probarlo directamente con una prueba de
hipótesis clásica. Entonces probamos la hipótesis
opuesta, que la droga no tiene ningún
efecto sobre la presión arterial. Aquí está el proceso. Uno,
asumir la hipótesis de no. Asumimos que el medicamento no
tiene ningún efecto, es
decir, que las personas que toman el medicamento y las que no tienen la
misma presión arterial promedio. T, recopilar y
analizar datos de muestra. Tomamos una muestra aleatoria. Si el medicamento muestra un gran
efecto en la muestra, entonces
determinamos la
probabilidad de extraer dicha muestra o una
que se desvía aún más, si el medicamento realmente no
tiene efecto, o uno que se desvía aún más, si el medicamento realmente no
tiene efecto,
T, evaluar el valor de
probabilidad p. Si la probabilidad de observar tal resultado bajo la
hipótesis nula es muy baja. Consideramos la posibilidad que el medicamento sí
tenga un efecto. Si tenemos pruebas suficientes, podemos rechazar la hipótesis
nula. El valor p es la
probabilidad que mide la fuerza de la evidencia
contra la hipótesis nula. En resumen, la
hipótesis nula establece que no hay diferencia
en la población, y la prueba de hipótesis
calcula qué tan probable es observar los resultados de la muestra si la hipótesis nula es verdadera. Queremos encontrar evidencia para
nuestra hipótesis de investigación. El medicamento afecta la presión arterial. Sin embargo, no podemos probar esto
directamente, así que probamos la
hipótesis opuesta, la hipótesis nula. El medicamento no tiene efecto
sobre la presión arterial. Así es como funciona. Asumir la hipótesis de no. Supongamos que el medicamento no tiene efecto. Es decir, las personas que
toman el medicamento, y las que no tienen la
misma presión arterial promedio, recopilan y analizan datos. Toma una muestra aleatoria. Si el medicamento muestra un gran
efecto en la muestra. Determinamos qué tan probable
es obtener tal resultado, o uno más extremo. Si el medicamento realmente no tiene efecto, calcule el valor p. El valor p es la
probabilidad de observar una muestra
tan extrema como la nuestra. Suponiendo que la
hipótesis nula es verdadera. Significancia estadística. Si el valor p es menor que un umbral establecido, generalmente 0.05. El resultado es
estadísticamente significativo, lo que
significa que es poco probable que haya
ocurrido solo por casualidad. Entonces tenemos evidencia suficiente para rechazar la hipótesis nula. Un pequeño valor de p sugiere que los datos observados son inconsistentes con
la hipótesis nula. Llevándonos a rechazarlo a favor de la hipótesis
alternativa. Un gran valor de p sugiere que los datos son consistentes
con la hipótesis nula. No lo rechazamos. Puntos importantes. Un pequeño valor de p no prueba que la
hipótesis alternativa sea cierta. Simplemente indica
que tal resultado es poco probable si la
hipótesis nula es cierta. Del mismo modo, un valor p grande no prueba que la
hipótesis nula sea cierta. Sugiere que los datos observados son probables bajo la hipótesis
nula. Gracias. Te veré en la siguiente lección de estadística.
11. Conceptos de pruebas de hipótesis en detalle: Bienvenida de nuevo. Entendamos la
hipótesis con más detalle. Hipótesis de Tenemos una población entera que
nos encantaría estudiar. Pero
siempre habría restricción de tiempo y recursos para estudiar a toda
la población. Por lo tanto, se toma una muestra
de la población utilizando diferentes técnicas de muestreo
y se extrae una muestra. Estudiamos la muestra y algunas
inferencias
sobre la población, y eso es como estadística
inferencial ¿Qué es exactamente la hipótesis? Una hipótesis es una suposición que no puede ser
propensa ni desaprobar En un proceso de investigación, la hipótesis se hace desde el
principio, y el objetivo es rechazar
o no rechazar la hipótesis. Para rechazar o no
rechazar la hipótesis, ejemplo de
datos del
experimento se necesita una encuesta, que luego se evalúan
mediante prueba de hipótesis. Usando hipótesis,
generalmente las hipótesis se realizan
a partir de una revisión literal Con base en la revisión literal, puedes justificar por qué
formulaste la
hipótesis de esta manera. Un ejemplo de
hipótesis podría ser los hombres ganan más que las mujeres por
el mismo trabajo en Austria. La hipótesis es un supuesto de asociación esperada. Tu objetivo es rechazar
o no rechazar
la hipótesis nula. Puedes probar tu hipótesis con
base en los datos. El análisis de los datos se realiza mediante la prueba de
hipótesis. El hombre gana más que las mujeres por
el mismo trabajo en Austria. Realizaste una encuesta a casi 1,000 empleados que
trabajan en Australia, una prueba T de muestra independiente. En esta prueba, la
hipótesis que necesita de la encuesta pruebas de
hipótesis adecuadas
como la prueba T o la prueba de análisis de
correlación. Podemos usar herramientas en línea como pestaña
Datos o
herramientas de Excel para resolver esto. ¿Cómo formulo una hipótesis? Para formular
una hipótesis, primero se
debe definir
una pregunta de investigación. Una
hipótesis precisa de formulación sobre la población puede entonces
derivarse de la pregunta de
investigación. El hombre gana más que las mujeres por
el mismo trabajo en Australia. Al tema, ¿cuál es la pregunta que queremos hacer
y cuál es la hipótesis? A continuación,
proporcionará los datos a la prueba de hipótesis y
sacará la conclusión. Esta es una representación
visual muy hermosa de cómo se realiza una
prueba de hipótesis. Las hipótesis no son
simples afirmaciones. Están formulados de tal
manera que se pueden probar con Pueden ser probados con datos recopilados en el transcurso del proceso de
investigación. Para probar hipótesis,
es necesario definir exactamente qué variables están involucradas y cómo se relacionan estas
variables. Hipótesis entonces son supuestos
sobre la relación causa y efecto de la asociación
entre las variables. ¿Qué es una variable en este caso? Variable no es más que
una propiedad de un objeto o un par que puede
tomar diferentes valores. Por ejemplo, un
color de ojos es una variable. Si la propiedad del objeto, puedo tomar diferentes valores. Si estás investigando
una ciencia social, tus variables pueden
ser género, ingresos, actitudes,
protección ambiental, etcétera Si estás investigando
sobre el campo médico, entonces tus variables
podrían ser peso corporal, estado de
tabaquismo,
frecuencia cardíaca, etc. Entonces, ¿cuál es exactamente la hipótesis nula
y alternativa? Siempre hay dos
hipótesis que son exactamente opuestas entre sí y que pretenden ser opuestas Estas
hipótesis opuestas se
denominan hipótesis nula y alternativa
y están representadas por H
nada y H A o H uno, H cero y
H La hipótesis nula de H nada supone que no
hay diferencia entre dos o más grupos con respecto a las características que estamos tratando de estudiar La hipótesis nula son hen. La hipótesis nula asume que no hay
diferencia entre dos o más grupos con respecto
a las características. Ejemplo, el salario de los hombres y mujeres no son
diferentes en Austria. La hipótesis alternativa
es la hipótesis que
queremos probar o estamos
recopilando datos para probarla. Entonces hipótesis alternas,
en cambio, asume que existe una diferencia entre
los dos o más grupos. Ejemplo, el salario de los hombres y mujeres
difiere en Austria. La hipótesis que
quieres probar o lo que quieres bucear de la teoría suele
afirmar el efecto. El género
incide en el salario. Esta hipótesis se denomina como
hipótesis alternativa. Es una
declaración muy bonita, ¿verdad? Hay otra
forma de escribirla, y es decir, un género tiene
un efecto sobre el salario, y la prueba de hipótesis se denomina
como hipótesis alternativa. La hipótesis nula suele afirmar que no hay efecto. El género no tiene efecto sobre el salario. En la prueba de hipótesis, solo se
puede probar la hipótesis nula. El objetivo es averiguar si la hipótesis
nula es
rechazada o no. Existen diferentes
tipos de hipótesis. ¿Qué tipos de hipótesis
están disponibles? La distinción más común
es entre diferencias, hipótesis de
correlación, puede ser hipótesis
direccional y no
direccional. Hipótesis diferencial y
correlación. Se
utilizan hipótesis diferenciales cuando hay que
distinguir
diferentes grupos y el grupo de hombres y el grupo de mujeres Las hipótesis de correlación se utilizan cuando se quiere establecer una relación o
se va a probar una correlación entre la variable La relación
entre edad y estatura. Hipótesis de diferencia. Hipótesis de diferencia
es prueba donde nosotros si hay una diferencia entre
dos o más grupos. El ejemplo de hipótesis de
diferencia es que el grupo de hombres
gana más que las mujeres. Los fumadores tienen mayor riesgo de sufrir ataques
cardíacos que los no fumadores. Hay una diferencia
entre Alemania, Austria y Francia en términos de
horas de trabajo por semana. Así, una variable es siempre una
variable categórica como el género, estado
tabáquico o el país Por otro lado,
la otra variable es una variable ordinal o
una variable de salario, porcentaje de riesgo de infarto, y horas de trabajo por semana Ahora bien, entendamos
un poco más detalladamente la hipótesis de
correlación . Una prueba de hipótesis de correlación, relaciones entre
dos variables. Por ejemplo, la estatura
y el peso corporal. A medida que aumenta la estatura de la
persona, el peso corporal se ve impactado. La
hipótesis de correlación, por ejemplo, es más alta que una persona es, cuanto más pesada es, cuanto
más potencia tiene un automóvil, mayor es su consumo de combustible. Cuanto mejor sea el grado de matemáticas, mayor será
el salario futuro. Como puede ver en
los ejemplos, hipótesis de
correlación
a menudo toma la forma de cuanto más
alto, menor. Así, se están
examinando al menos dos variables de
escala ordinal están
examinando al menos dos variables de
escala Hipótesis
direccional y no direccional, las
hipótesis se dividen en direccionales y no direccionales. Es decir, o son hipótesis
unilateral o bilateral. Si la hipótesis contiene
palabras como mejor que, peor entonces, la hipótesis
suele ser direccional. Podría ser un positivo
o un negativo. En el caso de la hipótesis no
direccional, a menudo se descubren
los bloques de construcción, como hay una diferencia
entre la formulación, pero no se establece en qué dirección se encuentra la
diferencia. Para la
hipótesis no direccional, lo único de interés es si existe una diferencia en el valor entre las
variables bajo consideración. En una hipótesis direccional, ¿cuál es el interés si un grupo es mayor o
menor que el otro? Tienes hipótesis de dos lados, o puedes tener hipótesis de un
lado como el lado izquierdo o el lado derecho. Hipótesis no direccional, una
hipótesis no direccional prueba si existe una diferencia
o una relación. No importa
en qué dirección exista
la relación
o los diferentes cos. En el caso de una hipótesis de
diferencia, significa que hay una
diferencia entre dos grupos, pero no dice si
un grupo tiene un valor mayor. Hay una diferencia entre el salario de hombres y mujeres, pero no dice
quién gana más. Existe una diferencia
en el riesgo de ataques
cardíacos entre
fumadores y no fumadores, pero no dice quién
está en mayor riesgo. En cuanto a la hipótesis de
correlación, significa que una relación o una correlación
entre dos variables. Pero eso Pero
no se dice si
la relación es positiva o negativa. Existe una correlación entre altura y el peso y existe una correlación
entre la potencia del caballo y el consumo de combustible en el automóvil. En ambos casos, no se dice que la correlación sea
positiva o negativa. Cuando se habla de una hipótesis
direccional, además
estamos indicando la dirección de la
relación o la diferencia. En caso de la hipótesis
diferente, se hace
enunciado, ¿qué grupo
es mayor o menor valor? Los hombres ganan más que las mujeres. Los fumadores tienen un mayor riesgo
de sufrir ataques cardíacos
que los no fumadores. En caso de una hipótesis de
correlación, la relación se hace en cuanto a si una correlación es
positiva o negativa. Cuanto más alta
es una persona, más pesada es. Cuanto más potencia tenga un automóvil, mayor será su economía de combustible. hipótesis
alternativa direccional unilateral incluye solo los
valores que difieren en una dirección de los valores
de la hipótesis nula. Ahora bien, ¿cómo interpretamos el valor p en una hipótesis
direccional? Por lo general, los
softwares estadísticos siempre te ayudan a
calcular el valor p. Excel también se ha vuelto muy inteligente en
el cálculo del valor p, y ayuda en
el cálculo de la prueba no direccional y también ayuda a dar
el valor p para esto. Para obtener el valor p para la hipótesis
direccional, se debe verificar si el
efecto está en la dirección correcta, entonces el valor p
se divide por dos, y si el
nivel de significancia no está acelerada por dos, sino solo por un lado. Más que esto, tenemos
un tutorial sobre el valor P. Así que por favor ve a ver eso en la fase analizada de mi curso. Si selecciona una hipótesis
alternativa dirigida en un tipo de datos lil software, para el cálculo
de hipótesis, la conversión se
realiza automáticamente y solo se puede leer. Ahora, instrucción paso a paso
para probar la hipótesis. Se debe hacer una investigación
literaria, formular la hipótesis,
definir el nivel de escala,
determinar el nivel de
significancia, determinar la prueba de hipótesis, ¿qué
prueba de hipótesis es adecuada para niveles de escala y estilo de
hipótesis? El siguiente tutorial trata
sobre las pruebas de hipótesis. Aprenderás sobre las pruebas de
hipótesis y
descubrirás cuál es mejor
y cómo leerla.
12. Introducción a las herramientas 7Qc: T. Bienvenido a la nueva clase
sobre siete herramientas de calidad. Este es uno de los conceptos más
importantes si estás pensando en hacer pequeñas mejoras continuas en tu proceso u operaciones
o configuración de fabricación. Incluso si estás en
la industria de servicios, estas herramientas te
ayudarán a realizar un seguimiento de la calidad. Con eso, comencemos. Entonces las siete herramientas de control de calidad, ¿qué voy a cubrir como parte de este programa de
capacitación? Se trata de las siete herramientas
de control de calidad. Número uno, catapulta de cosas, histograma de diagrama de
flujo Análisis de
Pareto, quemadura de pescado también llamado como diagrama Ishikawa No sólo vamos a cubrir estas herramientas a un alto nivel. Vamos a
hacer algunos ejemplos, cómo dibujar estas cosas usando Microsoft Excel
siempre que sea posible. También te vamos a dar algunos ejercicios de muestra con datos que pueden ayudarte a realizar
estas actividades muy fácilmente. Vamos a hablar
sobre qué es la herramienta, cómo usar la herramienta, cuándo usarla, algunos errores comunes
que debemos evitar, y una guía paso
a paso para crear la salida
que se requiere.
13. Hoja de verificación: Pasemos a la
siguiente herramienta de calidad de
las siete herramientas de control de calidad, esa es la hoja de verificación. Aprendamos más
sobre la hoja de verificación. Las hojas de verificación se utilizan para registrar
y compilar
sistemáticamente los datos A partir de las fuentes históricas u observaciones a medida que ocurren. Se puede utilizar para recopilar
datos en ubicaciones donde los datos se
generan realmente a lo largo del tiempo. Se puede utilizar para capturar datos
tanto cuantitativos como
cualitativos. Entonces te he mostrado una simple hoja de
verificación donde tienes tipos de
defectos y cuántas veces está ocurriendo
este
defecto en particular. Esto puede ser utilizado
para
registrar y compilar sistemáticamente datos de fuentes históricas u
observaciones a medida que ocurren. Se puede utilizar para
recopilar datos en ubicaciones donde se
generan datos en tiempo real. Este tipo de datos pueden ser tanto
cuantitativos
como cualitativos. La hoja de verificación es uno de
los siete QC básicos. ¿Qué hace la hoja de verificación? Se utiliza para crear
datos
fáciles de comprender y que vienen con un proceso
simple y eficiente Con cada entrada, crear
una imagen clara de los hechos como se propone a la opinión
de cada miembro del equipo. Por eso es uno
de los datos impulsados. Se estandariza el acuerdo sobre definiciones de todas
y cada una de las condiciones ¿Cómo se usa una forma de cheque? Acordamos la definición de eventos o condiciones
que se están observando. Ejemplo. Si buscamos la causa raíz de
severidad uno defectos, entonces el acuerdo es
convertirlo como severidad uno. Decidir quién recaba los datos, decidir la persona que
participará en esta actividad. Anote las fuentes de
donde se recogen los datos. Los datos deben ser en forma de muestra o de toda la población. Puede ser tanto cualitativo
como cuantitativo. Decidir el
nivel de conocimiento requerido para la persona involucrada
en el plan de recolección de datos. Decidir sobre la frecuencia
de recolección de datos, si los datos deben ser
necesarios para ser recolectados, semanalmente, por hora, diariamente
o mensualmente. Decidir sobre la duración de la recolección de
datos, es decir, cuánto tiempo deben
recopilarse los datos para que sean
un resultado significativo. Construya una hoja de verificación
que sea simple usar concisa, completa y que tenga consistencia
en la acumulación de
datos a lo largo del período de
recolección Tenga en cuenta que las hojas de verificación
fueron creadas como una de las herramientas de calidad cuando
estábamos en la era industrial. Actualmente, estamos en
la era de la información. Tenemos tantos softwares ERP, Machine ese capturando
datos debido a TI, y hay varios otros informes generados por
computadora
que son aplicables Busca usar una hoja de verificación
solo y solo cuando estés en un proceso de captura de datos completamente
manual Es una de las herramientas, pero la que menos utiliza herramientas
en los últimos meses. Permítanme reformular, usar menos
herramientas en los últimos años. A menos y hasta que su
empresa
no esté completamente teniendo ningún
enfoque sistemático de captura de los datos. Es una muy buena herramienta si estás
usando personas que son empleados de color
azul
y no
tienes sistemas de alta tecnología
para capturar los datos. Por lo que he adjuntado la plantilla para la hoja de verificación en la sección de
proyecto y recursos. Se puede referir a ella.
Sólo dame un segundo. Te mostraré la
hoja de cheques en la pantalla. Entonces puedo usar una hoja de verificación que te he dado como parte de
mi plantilla parado. Puedes anotar las
categorías por aquí, diciéndome que es
defecto un defecto dos. Hight es un problema ahí de cual sea el
nombre de tu defecto, por favor lista todos los
defectos aquí, ¿verdad? Y entonces se puede comercializar eso
¿con qué frecuencia sucede esto? Dondequiera que esté sucediendo, por favor comience a escribir uno. ¿Con qué frecuencia ves esto y cuándo lo ves? Esto en conjunto con puedo
usar más adelante estos datos
para mi análisis de Pareto, para lo cual he creado un video separado,
puedes usar eso No necesitas una hoja de
verificación separada en el mundo actual. Puedes usar el que
te he dado aquí. Gracias.
Te veo en la siguiente clase.
14. diagrama de caja: Hoy, vamos
a aprender sobre boxplot y
entenderlo en detalle Todos hubiéramos visto boxplot
en múltiples instancias. Pero veamos
qué interpreta. Entonces, ¿qué es exactamente una trama de caja? Con una gráfica de caja, normalmente
puede mostrar
gráficamente mucha
información sobre sus datos El cuadro indica el rango
del 50% medio del lugar
donde se encuentra tu valor. Entendamos la
trama de caja, cómo se divide. Si el inicio de la
caja se llama como Q uno, es el extremo inferior de la caja, y también se le llama
como el primer cuartil Q es el extremo superior de la
caja o el tercer cuartil. La distancia entre Q tres y Q se denomina como rango
intercuartil, que es el
50% medio de tus datos El 25% de los datos está
por debajo de Q uno, En la casilla, tiene el 50% de los datos, y por lo tanto, el 25% de los
datos se encuentra por encima de la caja. Tienes una línea principal y la
mediana dentro de la caja, que nuevamente divide los
datos en 25 y 25% Entonces digamos cuando mostramos
la edad del participante,
la trama de caja, uno es 31 años. Significa que 25% de los participantes son
menores de 31 años. Q tres es 63 años. Significa que 25% de los
participantes son mayores de 63 años. El 50% de los participantes
tienen 31-63 años de edad. La media y la mediana. La mediana es de 42 años, lo que significa que
la mitad de los participantes tienen más de 42 años y la otra mitad son
menores de 42 años. La línea de trazos también se llama como la línea promedio
o el valor principal, que representa el promedio. Como la media está
alejada de la mediana, claramente dice
que los datos son. La línea continua representa la mediana y la
línea punteada representa el promedio. El punto que están más
lejos se llama como valores atípicos. La altura del bigote es aproximadamente 1.5 veces el rango
intercuartal El bigote no puede
seguir haciendo ping sin cesar. El valor atípico y los bigotes en forma de
ti. Si no hay un valor atípico, el valor máximo está aquí Si hay un valor atípico, el bigote en forma de T es
el último punto en el que 1.5 veces el
rango interquaral y otros se denominan ¿Cómo creo un boxplot? Tienes hoja de Excel para
crear tu boxplot, y también puedes hacerlo
usando herramientas en línea Sí, así que sólo puedo
ir por los gráficos. Con eso, puedo decir que estoy
tomando la variable métrica, entonces tienes una
opción de histograma, y también tienes una
opción de boxplot, que claramente dice
que el Q uno es 29, es 66, mediana
es 42, Man es 46 Máximo es 99, la barda
superior es 99. No hay valores atípicos. Vamos a cambiar los datos. Déjame hacer esto como 126. En cuanto cambie el valor de una persona a 126,
cuando vuelvas, encontrarás que hay
un valor atípico en el histograma,
y es muy evidente por
aquí que 126 es un Y aquí, la barda superior es 92. El Q tres sigue siendo el mismo, el Q uno sigue siendo el mismo. Entonces el tamaño de la caja no
cambia y así sucesivamente. ¿Verdad? ¿Y si la persona es un ero? En ese caso,
verá que no
forma parte de un valor atípico, sino que sigue siendo parte del isc Puedo hacer el gráfico pequeño, puedo mostrar la línea cero. Puedo mostrar la desviación
estándar. Puedo mostrar los puntos. Puedo hacerlo como
horizontal y vertical. Por lo que todas estas opciones
son posibles utilizando una herramienta
estadística en línea. Obviamente puedo descargar el archivo
Zip y trabajar con él. Bien. ¿Cómo puedo hacer boxplot
usando la hoja de Excel? Entonces he copiado los
mismos datos por aquí. Tengo diferentes grupos, así que he seguido adelante y
seleccioné mi edad como datos. Y ahora voy a insertar, gráfico
recomendado,
voy a todos los gráficos, y tengo cuadro de caja y
bigotes Y puedo ver mi
cuadro de cajas y bigotes. Puedo quitar mis líneas de cuadrícula y
puedo agregar las etiquetas de datos, y muestra claramente mi palmadita. A lo mejor sólo puedo
aumentarlo para que sea más visible. Puedo cambiar el color de
mi gráfica para que sea diferente. Ah y puedo escoger el Mi promedio
está por aquí. Mi mediana es 421, tres y. Ahora, la misma gráfica, también
puedo
agruparla en base a raíces. Estoy tomando el
grupo y la edad. Doy click en en, puedo dar click
en tabla recomendada, ir a todos los gráficos y
hacer caja y bigotes Esta vez, tengo cuatro cajas
para cada uno del grupo. Puedo cambiar el color
de mi gráfica. Todo bien. Puedo incluir las etiquetas de datos. Cuando lo incluyo por aquí
y haga clic en el signo de coma, encontrará que
los puntos tei han sido Así que es muy fácil dibujar gráfico usando Excel además de usar
algunas herramientas en línea Entonces para los grupos, me he
llevado el grupo más la A, y para esto, he tomado. Entonces para A, digamos
para el grupo C, si sigo adelante y cambio
el valor como 100, encontrarás que ahí
hay un valor atípico El valor mínimo es diez, cambiemos los valores 25. Te darás cuenta de que así están cambiando los
valores. Genial. Entonces te veo en
la siguiente clase. Gracias. Oh.
15. Parcela 1: En esta lección, vamos
a aprender más sobre boxplot. Una gráfica de caja es una de las técnicas gráficas que nos
ayuda a identificar
valores atípicos, ¿verdad? Entendamos cómo se forma
una gráfica de caja. Vamos a entender
el concepto primero antes de entrar en
las prácticas. Una gráfica de caja se llama como
gráfica de caja porque se ve como una caja y tiene
viscosa como el gato. El gato tiene en su cara. Ahora, al igual que la forma en que el gato no puede tener y menos viscosa, el tamaño del bigotes de la trama de caja se decidirá
sobre ciertos parámetros. Verás algunas terminologías
importantes cuando estés formando una gráfica de caja. Número uno, ¿cuál es
el valor mínimo? ¿ Cuál es el cuartil? ¿ Cuál es la mediana? ¿ Cuál es el núcleo apretado? Tres, ¿cuál es el tamaño
del bigote máximo? ¿ Y cuál es el
valor máximo en el punto de datos? ¿ Aquí? El mínimo de perros por encima del punto mínimo y donde se puede extender
el bigotes. Q1 representa primer trimestre, lo que significa 25% de los datos. Asumamos para mayor facilidad, tenemos 100 puntos de datos. 25 por ciento de los datos
estarán por debajo de esta marca. Entre Q1 y Q2. formará
el veinticinco por ciento de sus datos , estarán presentes. Q2 también se llama como la mediana o el
centro de sus datos. Entonces si arreglo mis datos en orden
ascendente o descendente, el
punto de datos medio se llama
como mediana y se llama como Q2. Q3, o de otro modo también
llamado como cuartil superior, habla del
veinticinco por ciento de los datos después del medio. Por lo que técnicamente, a estas alturas
ya has cubierto setenta y cinco por ciento
de tus datos estarán por debajo de tus
terceros cuartiles, 25 por ciento por debajo del Q1, 50% de los datos por debajo del segundo trimestre, setenta y cinco por ciento de
los datos están por debajo del tercer trimestre. Por lo que técnicamente,
del 100% de los datos, 75% de los datos está por debajo del tercer trimestre. Significa que el veinticinco por ciento de mis puntos de datos estarán por encima de Q3. Ahora se llama a la distancia entre
Q1 y Q3,
se llama como el tamaño de la caja. Y este tamaño de caja también se
llama como rango intercuartil. Q3 menos Q1 se llama como rango
intercuartil. Como te dije al
inicio de la clase, que el tamaño
del bigotes
depende del rango intercuartílico o IQR. P3. Puedo esta línea formar 1.5
veces el tamaño de la caja. Por lo que 1.5 veces en IQR más q3 será el
límite superior para mi bigotes. Del lado derecho.
Enla parte superior. Si quiero dibujar el
bigotes del lado izquierdo, no
es más que lo mismo 1.5 veces en rango
intercuartil. Pero resto este valor de Q1 y extendido hasta ese valor. Por lo que establece el límite inferior. Es posible que tenga
puntos de datos que están llegando por debajo del punto mínimo. Es posible que tenga
puntos de datos que están llegando más allá del tamaño
máximo
del riesgo de estos puntos de datos
se llaman como valores atípicos. La belleza de boxplot
es que te ayudará a identificar si hay algún valor
atípico en tu conjunto de datos. Veamos ¿cómo puedo
construir una gráfica de caja? Porque físicamente
no tengo que preocuparme por
enterarme del 2525% por ciento. Y realmente por persona, iremos a MinitaB y luego haremos el trabajo. Entonces veamos esta ficha técnica. Entonces en nuestra clase anterior, hicimos algunas
estadísticas descriptivas sobre esto. Y encontramos los puntos de datos. Se encontró un punto de datos mínimo
Q1, Q2, Q3 y máximo. Tratemos de construir una gráfica de caja para el tiempo de
ciclo en minutos. Por lo que voy a dar clic en gráfico. Voy a ir a box plot y ver una gráfica de caja simple
y dar clic en, Ok, voy a seleccionar el tiempo de
ciclo en minutos. Y voy a decir, Ok, vamos a ver la vista de datos. Si nos fijamos en esta gráfica de caja, la línea de abajo se llama
como la. Es 9.16. La mediana es la línea media, y no tiene por
qué estar exactamente en el centro. La parte superior de la caja es Q3, que es 10.86 en
este rango de datos, y el
rango intercuartílico es 1.7. Mi caja se puede extender
1.5 veces en el codo y puede ir 1.5 veces en 1.7
en el globo. Y está viendo
que
no hay marcas de asterisco
en esta gráfica de caja, lo
que indica
muy claramente que
no hay valores atípicos en mi conjunto de datos
actual. Vamos a recoger un conjunto de datos
más. En nuestro siguiente video para
entender cómo hacer box plot.
16. Parcela de caja 2: Continuemos nuestro viaje en la comprensión de los diagramas de caja
más en detalle. Si vas a la hoja
en tu archivo de proyecto, que se llama como boxplot. He recopilado datos de tiempo de ciclo para cinco escenarios
diferentes. Como se puede ver que algunos lugares tengo más
número de puntos de datos, como tengo casi 401745 datos. En algunos lugares,
sólo tengo 14 puntos de datos. Entonces tratemos de analizar esto más detalle para entender
cómo funciona boxplot. He copiado estos
datos en MinitaB, caso uno, caso dos, T3 y T4. Entonces lo primero que me
gustaría hacer es hacer algunas
estadísticas descriptivas básicas para todas las claves foráneas. Yo lo estoy seleccionando todo. Y luego estoy viendo,
cuando veo mi salida, puedo ver que en
tres de los casos, tengo 45 puntos de datos. En el cuarto caso, tengo 18 puntos de datos. En el quinto caso,
tengo 14 puntos de datos. Entonces el número de
puntos de datos son muy, si nos fijamos en mi valor mínimo, va desde 1, uno, veintiuno, veintidós. Y el valor máximo está
en algún lugar entre 4090 ellos. En un escenario he
desarrollado valores de 21 a 40. En un escenario tengo
valores de dos a 90, lo que muestra muy claramente que el número de
puntos de datos o hacer esto. Pero mi rango de valor es blanco. Entonces, si nos fijamos en la tarifa, va de
18.8 a 99 puntos. Entonces en el caso dos, tengo 1200 como
rango, por lo que 99 años. Y lo mismo también se puede
observar como desviación estándar. Se puede ver que la
asimetría de los datos es diferente y la curtosis
es diferente. Primero entendamos
la trama de la caja en detalle. Y en el siguiente video, cuando
hablo del histograma, entenderemos el patrón de
distribución usando el mismo conjunto de datos. Empecemos.
Hagoclic en gráfica. Puedo hacer clic en boxplot
y hago clic en simple. Lo que puedo hacer es tomar 11 casos a la vez
para analizar mis datos. Entonces caso uno,
me muestra un diagrama de caja y esta gráfica de caja muestra muy claramente que no hay
valores atípicos en mis datos. Y el rango es entre. Cuando mantengo el cursor por aquí, tengo 45 puntos de datos. Mi bigotes va
de 21.6 a 4.4, y mi
rango intercuartil es de 5.95. Mi mediana es 30.3. Mi primer cuartil es de 26.9. Mi tercer cuartil es 32.85. Vamos a rehacer
esto para el caso dos. Cuando hago mis llaves también, si ahora miras, la caja se ve muy pequeña porque aquí mis
puntos de datos son los mismos. Fortificado por Vickery
vuelve a ir de 21.6 a 40 para parecer
mi escenario anterior. Pero tengo valores atípicos por aquí, que están mucho más allá. Si lo recuerdan, la estadística
descriptiva para niños a mi valor mínimo es uno
y mi valor máximo es 100. Mi mediana se parecía a
mi escenario anterior. Mi Q1 también es similar, no igual, pero similar. Y Q3 también es similar. Pero cuando
miras la trama de caja, la caja es muy pequeña, indicando
muy claramente que hago mi
rango intercuartil es de 6.95. Mi viscoso sólo puede ir 1.5 veces y cualquier
punto de datos más allá de eso, Misko será llamado
como un valor atípico. Puedo seleccionar estos
valores atípicos, ¿verdad? Y es muy claro ver, k es dos, el valor es 100
y está en la fila número uno. Fila número 37, tengo
un valor llamado como 90. En la fila número 30, tengo
un valor llamado es 88. Y en la fila número 21 tengo
un valor llamado como uno, que es un tamaño mínimo. Entonces tengo valores atípicos
en ambos lados. Entendamos el caso tres. Cuando miro la química, pongo mi cursor en la gráfica de caja. Tengo los mismos 45 puntos de datos. Mi viscosa o de 21.6 a 40 para parecer mi
caso uno, caso dos. Pero en este escenario, tengo muchos valores atípicos. En el extremo inferior. Es decir, en el fondo de
mi núcleo, apretado, ¿verdad? Es fácil para nosotros dar clic en cada una de ellas y
ver cómo están mis cajas. Ahora la belleza por aquí es
que sólo tengo 18 puntos de datos, pero aún así tengo un valor atípico. Hagámoslo por k es cinco. Y entender eso también. Tengo una caja más pequeña. Tengo sólo 14 puntos de datos y tengo un valor atípico
en el botón de arriba, y tengo un valor atípico
en el extremo inferior. Aquí el valor es 23. Pero ver estas
tramas de manera diferente me dificulta hacer una comparativa. ¿ Puedo conseguir todo
en una sola pantalla? Entonces voy a graficar,
voy a boxplot. Haré
ambiente sencillo seleccionado. Estoy seleccionando todos los casos juntos y viendo
múltiples gráficas. Yo estoy viendo piel y estoy viendo
el eje debe ser visto. deben ver las líneas de rejilla. Y hago clic en, Ok. Obtengo todos los
cinco puntos de datos, escenario de
cinco casos
en una gráfica. Esto me hará fácil
hacer el análisis, ese caso uno. Entonces hazlo individualmente cuando
vi el caso uno, si nos estamos mostrando una gran franja. Pero cuando estoy haciendo una comparación de uno al lado del otro, puedo saber que en caso de dos
tengo valores atípicos en la
parte superior y la inferior. En el caso tres, tengo
valores atípicos en la parte inferior. En el caso cuatro, tengo
valores atípicos en la parte superior. En caso de cinco, tengo
tomas de corriente en ambos lados. El número de
puntos de datos es diferente. Se dibujarán los bultos. El tamaño de la caja no puede ser determinado por el
número de puntos de datos. Tengo 45 puntos de datos, pero mi caja es muy estrecha. Y tengo 14 puntos de datos
y mi caja es blanca. Por lo que el tamaño de la caja. Entonces si tengo 14 puntos de datos, va a dividir mis
datos en cuatro partes. Por lo tanto, tres puntos de datos por debajo de Q1, tres puntos de datos
entre Q1 y Q2, tres puntos de datos
entre Q2 y Q3, y tres puntos de datos más allá de Q3. Mientras que cuando tenía
45 puntos de datos, se está
distribuyendo como 11111111. Mi mediana sería
el número medio. Entonces, lo que es el aprendizaje de este ejercicio es que al
mirar el tamaño de la caja, no se
puede determinar el
número de puntos de datos. Pero lo que definitivamente se puede determinar es que en
mente ese conjunto de datos, ¿tengo puntos de datos que
son extremadamente altos o bajos? Por lo que el propósito de dibujar
una gráfica de caja es ver la distribución e
identificar valores atípicos, en su caso. Espero que el concepto sea claro. Si tienes alguna consulta, eres libre de ponerla
en el grupo de discusión. Y estaré encantado de
responderlas. Gracias.
17. Cálculo de pareto: Hola amigos. Continuemos nuestro aprendizaje sobre siete herramientas de control de calidad. La herramienta que hoy
vamos a aprender es cartas de
Pareto también se
llaman como análisis de parto Esto se basa en el famoso estadístico
no estadístico Permítame corregirme, economista que dio la vuelta al mundo para estudiar la proporción de riqueza con respecto
a la población Al hacer esto, el señor Pareto se enteró del principio 80 20 Vamos a sumergirnos profundamente en ello. Entonces el análisis de Pareto, el principio que te
ayuda a enfocarte en el asunto más importante para
obtener el máximo beneficio Describe el fenómeno que una pequeña cantidad
de alto valor contribuye más al total que un número alto
de valores bajos. El foco es, cuáles son esos
atributos de alto valor en los que necesito enfocarme en lugar de
tantos artículos de pequeño valor. Esto en definitiva, se llama como identificar los pocos vitales
en lugar de los muchos triviales ¿Cuáles son esos bloques rojos
que son sólo tres o cuatro? Pero la contribución es mayor. En lugar de mirar cientos
de pequeñas cosas donde la contribución total de la
contribución es menor. Incluso si miro mis gastos
personales, O de mis
ingresos totales que hago, mayor parte de mi dinero
se destina a pagar EMI, pagar los alquileres y facturas Entonces esos son mis pocos vitales, en lugar de muchos triviales, donde estoy tratando de
mirar los boletos de autobús, la comida que estoy comiendo, o las pequeñas compras
que estoy haciendo Entonces, si quiero
hacer buenos ahorros, necesito enfocarme en ver cómo
puedo pagar mi EMI más rápido, cómo puedo tener una renta, que está dentro de mi presupuesto El análisis de Pareto se
basa en la famosa regla 80 20. Afirma que aproximadamente el 80% de los resultados provienen del
20% del esfuerzo. Muy bien dicho, el 80% de
esfuerzo proviene del 20% de esfuerzo. De igual manera, 80% de
los problemas o efectos de 20% de las causas. Utilizamos esto para nuestro análisis de
causas. El porcentaje exacto puede variar de una situación
a otra, mientras
que creemos que es 80 20, aunque sea un 75 25, debemos seguir adelante y perseguir
la fijación de esos pocos vitales. A veces podríamos
obtenerlo como un 70 30, a veces
incluso podríamos obtenerlo como 88 12. Estos son solo algunos
de los ejemplos. El punto es, que son
esas causas principales, que puedo arreglar con el mínimo esfuerzo para
obtener los máximos resultados. En muchos casos, pocos esfuerzos suelen ser
responsables de la mayoría de los resultados. Algunas causas
suelen ser las responsables de la
mayor parte del esfuerzo. Si me relacioné de nuevo con mi examen, hay ciertos
capítulos en mi libro que llevan más peso
en mi examen final Si soy minucioso en
esos capítulos, mi probabilidad de obtener el
60 70% se vuelve muy fácil. En lugar de tratar de leer todos los 20 capítulos
de mi libro de trabajo, podría
enfocarme en pocos
capítulos para obtener los resultados El análisis de Sparto es utilizado por decisiones para identificar
el esfuerzo más significativo para decidir cuál seleccionar
primero, la toma de decisiones Se utiliza para proyectos de
mejora de procesos para
enfocarse en las causas que
más contribuyen a un problema particular. Esto ayudará a priorizar
las posibles causas, factores e insumos clave del proceso del problema
que se investiga Es un kit de herramientas de
mejora continua. El análisis de Pareto se utiliza al priorizar
proyectos para
enfocarse en
proyectos significativos que aporten valor al cliente
y al negocio En lugar de hacer
todos los proyectos que hay en
mi lista de proyectos, me enfocaría en
esos pocos proyectos, dos o tres grandes proyectos, lo que me puede dar el
máximo beneficio. Puedes tener cuidado durante el alcance del
proyecto si estás usando
el parto Aysis o para
priorizar tus recursos, quien es la persona principal que
se requiere para También podemos usar el
análisis de parto para visualizar tus datos para saber rápidamente
dónde se debe poner el foco Por ejemplo, tengo muchos datos de defectos como diez
arrancan captura densa. Yo estoy haciendo el análisis
y tengo estos datos. Si lo pongo en el
orden descendente de los defectos, encuentro que arrancar
es el máximo esfuerzo. Y seguido de estenopeica, entonces entonces, y así sucesivamente El que están en gris, no
voy a enfocarme mucho porque no están
aportando mayoritariamente Si arreglo el desgarro, voy a obtener los
máximos resultados. Si voy a arreglar
los tres primeros, voy a conseguir una reducción importante en los defectos que están
ocurriendo en mi proceso. Por ejemplo, si recopila los datos sobre
los tipos de defectos, análisis
del operador puede revelar qué tipo de defecto
es más frecuente. Puedes enfocarte en tus
esfuerzos para resolver la causa que más efecto tiene
. El beneficio del análisis de parto es ayudarte
a enfocarte en
lo que realmente importa. Separa las principales causas del problema de
la menor. Permite medir el impacto de la mejora cubriendo
antes y después. Permite llegar a consensos sobre lo que hay que abordar primero. Se ha
comprobado que el principio de Pareto es cierto en muchas comisiones, 20% de esfuerzo para dar 80% de resultados En lugar de trabajar o también
podemos llamarlo como 20% causas
dándome 80% de efecto. Entonces, si estoy pensando en el análisis de
causa y efecto, nuevamente
es 20%
causas, 80% esfuerzo. O efecto, si estoy viendo análisis de resultados de
esfuerzo también, decimos poner menos esfuerzo
para obtener los máximos resultados. 20% del cliente de la compañía es responsable del
80% de sus ingresos o el 80% de la venta
proviene del 20% de los clientes. Entonces ese es el concepto de
20% de esfuerzo versus
resultados de 80%. puede
pensar en la oficina de la
ley Pardo Analysis ya que el 20% de
los trabajadores realiza el 80% del trabajo. 20% del tiempo dedicado a una tarea conduce al 80%
de los resultados. El 20% de la población posee el
80% de la riqueza de la nación. ¿No es cierto, incluso
en nuestro país, nuestro estado, en nuestra comunidad? Encontramos que son muy pocas las personas que están poseyendo la máxima
cantidad de riqueza Se puede utilizar el 20% de las herramientas domésticas,
80% de las veces. Puedes usar el 20% de tu
ropa, el 80% del tiempo. Entonces es momento de que solo
apliques el análisis de parto en tu vida personal para limpiar tu vestuario si crees en el concepto de minimalismo El 20% de los conductores de automóviles
causa el 80% de los accidentes. 80% de la queja del cliente proviene del 20% de los clientes. Apenas unas pocas causas dan cuenta de la mayor parte del efecto
en el polo de pescado. Si estoy convirtiendo mi
análisis de parto en un polo de peces, encontrarás que
hay pocas causas que contribuyan
a la mayor. Al escuchar todos
estos ejemplos, habrías entendido
que Pareto no está restringido a aplicar solo en
tu oficina o lugar de trabajo Incluso puedes aplicar el
análisis de parto en tu vida personal. Si lo llevo a Twitter o una
plataforma de redes sociales como esa, mayoría del 20% activo
de los usuarios de Twitter son responsables
del 80% de los tweets en general. El gráfico parto es
un tipo especial de gráfico de barras que traza la
frecuencia de los datos históricos. Por lo que hay que entender que
estos datos son a partir de ayer o a partir de hoy
por la mañana o a partir del mes pasado. Entonces es un dato categórico. El eje x dice muy
claramente que se trata de un dato categórico y el eje y habla de la
frecuencia de ocurrencia Por lo que el análisis Parto no se puede utilizar para
datos continuos, tenga en cuenta. Entonces, si ves, tendrás datos categóricos con frecuencia trazados
en orden descendente, las causas principales que son menos esfuerzo para
obtener los máximos resultados El dato categórico,
es el nivel más bajo de datos que resulta en clasificar a
personas, cosas o eventos Puedo hacerlo más sencillo. Todo lo que se hace con palabras se llama como datos
categóricos Ubicaciones geográficas,
clima, color, tipo de
dispositivo, tipo de sangre, sangre, tipo de cuenta
bancaria, como
ahorro o corriente, FD o
préstamo personal a domicilio tipo de error o
defecto, tipo de dato. Análisis de Pareto,
el eje vertical representa la frecuencia
de los datos categóricos El eje x representa las
categorías de las etiquetas. El eje horizontal representa los datos categóricos que
causan un problema o los problemas La barra está dispuesta en orden descendente
de izquierda a derecha. El que ocurre
más frecuentemente está en el lado izquierdo, el que ocurre
menos frecuente es en el lado derecho. No tienes que preocuparte si
tienes microsoft Excel, lo dibujará para ti. Si está utilizando una versión
anterior de Excel, compartiré una plantilla en la sección de proyectos y
recursos a continuación. Si tienes demasiadas categorías, puedes agrupar esas pequeñas categorías
infrecuentes en la categoría
llamada como otras El último listón suele ser un poco más alto que
los anteriores. Opcionalmente, puede poner una curva de frecuencia
acumulativa por encima la barra dándole un eje y secundario para representar el porcentaje
acumulado. Esto simplemente ayuda a
interpretar los resultados
con mayor facilidad y a identificar
la conexión 80 20 El análisis de parto
se centra en los esfuerzos realizados en aquellas categorías cuya barra
vertical representa el 80% de los resultados. Debes buscar algo
que sean causas mayores, máximo efecto y menor
esfuerzo para obtener los máximos resultados. Si nos fijamos en los
dos patrones
partos, A y B, cuál es la mejor ilustración
del patrón de parto. Yo sugeriría que es
el patrón A porque patrón B está demostrando
que la mayoría de ellos casi
contribuyen por igual. Esto es distribución uniforme, así que no iría con ella. Yo iría con el
que es categoría A. Y esto está mal. Si las gráficas resultantes ilustran
claramente
un patrón parto. Esto sugiere que
solo unas pocas causas representan alrededor del
80% del problema. Esto significa que
hay un efecto parto, y puedes enfocar tu esfuerzo en abordar estas pocas causas
para obtener el máximo resultado Si hubieras recibido
un patrón como gráfico B, entonces el análisis de parto no
funcionará, y también tendremos que
usar algún otro QC. obstante, si no se encuentra un
patrón parado, no
podemos decir que algunas causas son más importantes que otras. Como acabo de decir. Asegúrate de que tu gráfico parado contenga suficientes puntos de datos para
que sea significativo. En el mundo actual, hay muchos datos disponibles,
así que asegúrate de estar
capturando la mayor cantidad de
datos posible. El análisis de Pareto sobre cómo
construir una gráfica parto. Si con tu equipo, define el problema que
estás tratando de resolver, identifica las posibles causas usando brainstorming o técnicas
similares Decidir el método de medición que se utilizará
para la comparación, la frecuencia, el costo
y el tiempo, etcétera Cómo construir una gráfica partográfica, recolectar los datos y requerir que se analicen los datos
categóricos Calcular la frecuencia
de los datos categóricos. Dibuja una línea horizontal y coloca la barra vertical para indicar
la frecuencia de categoría. Dibuja una línea vertical a la
izquierda para colocar la frecuencia
a la izquierda de la línea en caso de que la estés dibujando
en un papel cuadriculado. Microsoft Excel puede hacer gráfico
parado automáticamente. Pero si lo estás haciendo manualmente, entonces ordena las categorías en el orden de frecuencia
de ocurrencia desde el est hasta el más pequeño más grande que viene del
lado izquierdo. Debes calcular tu curva de frecuencia
acumulada y una línea porcentual cubultiva Si observas el
desfile para efectuar, enfoca tu esfuerzo de mejora en esas pocas categorías
cuya barra vertical representa más. Es probable que estas causas tengan un mayor impacto en la producción de
su proceso. He tomado una muestra pareto
para analizar la
razón por la cual el paciente está usando una llamada bien en un
hospital cuando ingresa Por lo que necesitan asistente de baño, necesitan comida o agua, reposicionamiento de su
cama, problemas intravenosos, analgésicos,
llamada urgente de vuelta a la cama, obtener todos los
que están en gris no
están
pasando cosas con frecuencia y no
son importantes Entonces, si nos enfocamos en los
tres primeros, o los cuatro primeros. Entonces, si yo diría
que cuatro factores, lo que contribuye al
40% del esfuerzo, y vas a
obtener el 70% del efecto. Entonces podría decidir simplemente
trabajar en los tres primeros, es
decir 30% de esfuerzo, para seguir obteniendo 68% de esfuerzo. Cualquier cosa está bien. El concepto es que necesito poner menos esfuerzo
para obtener los máximos resultados. Quejas de clientes
en una fábrica. Un equipo de fábrica ha realizado
un análisis parado para atender el creciente número de quejas desde la perspectiva del
cliente. En cierto modo, la gerencia
puede entender. Es un tipo de queja del cliente,
queja de producto, queja relacionada con
documentos, queja relacionada con
paquetes o queja relacionada con la
entrega. Podemos ver personas que los clientes
son el número máximo de veces quejándose del tipo del producto o del
defecto con el producto Seguido de los temas
relacionados con el documento. Queja del cliente en una fábrica, las categorías principales
pueden ser demasiado genéricas y pueden
dividirse en subcategorías Entonces, si pienso en las quejas
del producto, está en un
nivel alto, podría
tomarlo como subcomponentes
del problema A.
Es problema de rasguño, estenopeica, par de HMA u otros También podrá aplicar nuevamente el parto en la
queja del producto, que si va
a solucionar problemas relacionados con rasguños y abolladuras en
una queja de producto, la mayoría de las
quejas del producto bajarán. Tipo de quejas de documentos, podemos ver que la
falta de información es la contribución principal
seguida de error de factura, cantidad
incorrecta y otros. El gráfico parto puede
analizarse más mediante el uso de las
categorías principales a
dividir en subcategorías o
subcomponentes donde el problema específico ocurre mayor frecuencia se denominan
las Quejas de clientes
en una fábrica. Los resultados sugieren
que hay tres subcategorías
que ocurren con mayor frecuencia Tenga en cuenta que es posible
fusionar dos gráficos en uno. Entonces tengo tipo de quejas de productos
y tipo de documento, y puedo seguir adelante
y marge ellos. Pero Principles lleva
el nombre del economista italiano
Wilfredo Peto Joseph Juran ha aplicado los principios de
Peto a la gestión
de la calidad para la producción
empresarial En su análisis, considere el
uso de datos contextuales, meta datos y las columnas
que contienen datos textuales Las bases de datos suelen contener una gran cantidad de datos
categóricos
sobre el entorno del que se toman los datos Estos datos pueden ser muy
útiles en análisis posteriores hora de investigar los conceptos e ideas que
causan. Los principios de Pareto pueden
ayudarte a medir el impacto de la mejora comparando
el antes y el después Si ves que la obra azul
fue un gran aipulor, después de los proyectos,
encuentras que
hay una mejora importante
en esa categoría La nueva gráfica
partográfica puede mostrar que hay una reducción importante en
la cosa primaria. Estadísticamente,
los principios de parado pueden ser descritos por la distribución del lote de energía y muchos fenómenos naturales para
exhibir la distribución Con eso, llego al final del concepto de análisis
parto. En el siguiente video, te
voy a mostrar cómo hago análisis de Pareto
usando Microsoft cel Nos vemos en la siguiente clase.
18. Prueba de hipótesis conceptuales y significación estadística (1): Analicemos los
conceptos relacionados con la prueba de hipótesis y la significación
estadística. Una, la prueba de hipótesis, al realizar una prueba de
hipótesis, comenzamos con una hipótesis de
investigación, también llamada hipótesis
alternativa. En su caso, la
hipótesis de investigación de que el medicamento tiene
un efecto sobre la presión arterial. Sin embargo, no podemos probar directamente esta hipótesis usando una prueba de hipótesis
clásica. En cambio, probamos la hipótesis
opuesta que el medicamento no tiene ningún
efecto sobre la presión arterial. Comenzamos asumiendo
que en promedio, las personas que toman el medicamento
y las personas que no lo toman tienen la misma
presión arterial en la población. Si observamos un gran
efecto del medicamento en una muestra, entonces preguntamos, qué tan probable es que se
extraigan tal muestra o una aún más extrema si el
medicamento en realidad no tiene efecto. La probabilidad de
obtener tal muestra, asumiendo la hipótesis nula, ningún efecto se llama el valor P. El valor P indica la probabilidad de obtener
una muestra que se desvía tanto
como nuestra
muestra observada o incluso más extrema si la
hipótesis nula fuera cierta Si el valor de p es muy bajo, típicamente menor de 0.05, tenemos evidencia para rechazar la hipótesis nula a favor de la hipótesis
alternativa. Un pequeño valor de p sugiere que los datos o muestra observados son inconsistentes con
la hipótesis nula. Entonces Tres,
significancia estadística. Cuando el valor p es menor que un
umbral predeterminado, a menudo 0.05. El resultado se considera
estadísticamente significativo. Esto significa que es
poco probable que el resultado
observado haya ocurrido solo
por casualidad, y tenemos pruebas suficientes para rechazar la hipótesis nula. El umbral del valor p
se establece en 5%, o 0.05, un pequeño valor de p sugiere que los datos o
muestra observados son inconsistentes
con la hipótesis nula. Por el contrario, un gran
valor de p sugiere que los datos observados son consistentes
con la hipótesis nula, y no la rechazamos. Cuatro, errores en las pruebas de
hipótesis. Recuerde que un pequeño valor de
p no prueba que la
hipótesis alternativa sea cierta. Solo sugiere que el resultado observado es poco probable bajo la hipótesis
nula. Del mismo modo, un gran valor de P no prueba que la
hipótesis nula sea cierta. Solo sugiere que el resultado observado es probable
bajo la hipótesis nula. Ahora entendamos
los dos tipos de errores. El error tipo uno y
el error tipo dos. error de tipo uno se produce cuando rechazamos erróneamente una hipótesis nula
verdadera En tu ejemplo, esto significaría concluir que el medicamento funciona
cuando en realidad no lo hace. error tipo uno es
cuando rechazas la hipótesis nula,
cuando en realidad, la hipótesis nula es cierta, pero tu decisión sobre la hipótesis
nula es rechazada. error de tipo dos se produce cuando
fallamos en rechazar una hipótesis
nula falsa. El error de tipo dos es
cuando no
rechazas la hipótesis nula,
cuando en realidad, la hipótesis nula es falsa, pero tu decisión sobre la hipótesis
nula es aceptada. En su ejemplo, esto significaría perderse el
hecho de que el medicamento funciona. La muestra tomada no
mostró mucha diferencia. Pensó erróneamente que
la droga no está funcionando. En la siguiente lección, profundizaremos en las aplicaciones
prácticas del diseño de experimentos.
Estén atentos.
19. TestofHypothesis: Hola amigos. Continuemos nuestro recorrido
en el análisis de datos de MinitaB. hoy vamos a aprender
sobre las pruebas de hipótesis. Es posible que hayas escuchado que hacemos pruebas de
hipótesis
durante la fase
de análisis y mejora de nuestro proyecto. Entonces, para entender cómo funciona la prueba de
hipótesis, entendamos un escenario de caso
simple. Volveremos de nuevo a esta gráfica y les explicaré
que así es. Como ustedes saben, cuando vamos
al tribunal de justicia, se puede utilizar
el sistema de justicia para explicar el concepto
de prueba de hipótesis. El juez siempre comienza con
una declaración que dice, asume que
la persona es
inocente hasta que se demuestre su culpabilidad. Esto no es más que tu
hipótesis nula, el status quo. Cuando se les
capta caso que continúa. Los abogados intentaron
producir datos y evidencias. Y a menos y hasta que
no tengamos datos fuertes
y evidencias contundentes, la persona está En el
estado de ser inocente. Por lo que el acusado o el abogado de la
oposición
siempre está tratando de decir que
esta persona es culpable y yo tengo datos y
pruebas para probarlo. Está tratando de trabajar en hipótesis
alternas. Y dice el juez, voy con el statu quo de hipótesis
nula por defecto. Déjame explicarte
de una manera más fácil. Tú y yo, no nos llevan
al tribunal de justicia
porque por defecto, todos
estamos en OSA, ese es el status quo. A quienes se tiren ante
el tribunal de justicia. Personas que son las que
tienen posibilidades de haber venido, han cometido algún delito. Podría ser cualquier cosa.
Tande la misma manera. ¿ En qué tratamos de hacer pruebas
de
hipótesis cuando estoy haciendo mi
fase de análisis del proyecto? Entonces tengo múltiples causas que podrían estar contribuyendo
a mi proyecto. ¿Por qué? Hacemos un análisis de causa raíz y llegamos a saber eso, ¿de acuerdo? A lo mejor el envío se retrasó. A lo mejor la máquina es un problema, tal vez el
sistema de medición sea un problema. A lo mejor la materia prima no
es de buena calidad. Tenemos múltiples razones las
cuales están ahí. Ahora quiero
probarlo usando datos, y ese es el lugar donde
traté de usar pruebas de hipótesis. Todos los procesos
tienen variación. Sabemos que todos los procesos
siguen la curva de campana. Nunca estamos sumando el centro. Hay un poco de
variación en cada proceso. Ahora los datos o la
muestra que actualizaste, es una muestra aleatoria
proveniente del mismo Banco? ¿ O es una muestra que viene de una curva de campana completamente
diferente? Por lo que la prueba de hipótesis te
ayudará a analizar la misma. Siempre que establecemos
una prueba de hipótesis, tenemos dos tipos de hipótesis, como les dije, el status quo
o la hipótesis por defecto, que es su hipótesis nula. Por defecto, asumimos que
la hipótesis nula es verdadera. Entonces, para rechazar la hipótesis
nula, necesitamos producir evidencias. hipótesis alternativa
es el lugar donde hay una diferencia. Y esta es la razón por la que
realmente se ha iniciado la prueba de hipótesis, ¿verdad? entenderemos
con muchos ejemplos. Así que mantente conectado. Entonces cuando estoy enmarcando hipótesis nula
y alterna, Digamos, estoy diciendo que mi mu no
son más que mi promedio, mi promedio de población
es igual a algún valor. Recuerda siempre, tu hipótesis alternativa
es mutuamente excluyente. Si mu es igual a algún valor, la hipótesis alternativa
diría que mu no es igual
a ese valor. Por ejemplo, mu es menor que igual a algún valor
como hipótesis nula. Por ejemplo, si estoy
vendiendo Domino's Pizza, veo que mi tiempo promedio de entrega es menor que igual
a 30 minutos. El cliente viene
y me dice, sabe, el tiempo promedio de entrega
es de más de 30 minutos, eso se convierte en mi suplente. En ocasiones, si tenemos la hipótesis nula es mu es mayor que
igual a algún valor. Por ejemplo, mi calidad promedio es mayor que igual al 90%. Entonces el cliente
vuelve y me dice que sabe que tu calidad promedio es
menor a ese porcentaje. Por lo que siempre recuerden la hipótesis
nula y las hipótesis
alternas
son mutuamente
excluyentes y complementarias
entre sí. Vamos a retomar muchos más
ejemplos a medida que vayamos más lejos.
20. Concepto de hipótesis nula y alternativa: Vamos a sumergirnos en las estadísticas
inferenciales. Comenzaremos con una breve
descripción de lo que es. Seguido de una explicación
de los seis componentes clave. Entonces, ¿qué son las
estadísticas inferenciales? Nos permite sacar
conclusiones sobre una población a partir de
datos de una muestra. Para aclarar, la población es todo el grupo que
nos interesa. Por ejemplo, si
queremos estudiar la estatura promedio de todos los
adultos en Estados Unidos, nuestra población incluye a
todos los adultos del país. La muestra por otro lado, es un subconjunto menor tomado
de esa población. Por ejemplo, si seleccionamos
150 adultos de EU, podemos usar esta muestra para hacer inferencias sobre la población
más amplia Ahora, aquí están los seis pasos
involucrados en este proceso. Hipótesis. Comenzamos
con una hipótesis. ¿Cuál es una declaración
que pretendemos probar? Por ejemplo, podríamos
querer investigar si un medicamento impacta positivamente la presión arterial en individuos
con hipotensión Oh, en este caso, nuestra población consiste todos los individuos con hipertensión
arterial en EU, ya que no es práctico recabar datos de toda la población Nos basamos en una muestra para hacer inferencias sobre la
población utilizando nuestra muestra Empleamos pruebas de hipótesis. Este es un método utilizado para
evaluar una afirmación sobre un parámetro de población
basado en datos de muestra. Hay varias pruebas de
hipótesis disponibles, y al final de este video. Te guiaré sobre cómo
elegir la correcta. ¿Cómo funcionan
las pruebas de hipótesis? Comenzamos con una hipótesis
de investigación. También conocida como hipótesis
alternativa, que es lo que buscamos
evidencia en nuestro estudio. También se llama hipótesis
alternativa. Esto es para lo que estamos
tratando de encontrar pruebas. En nuestro caso, la hipótesis es que el medicamento
afecta la presión arterial. Sin embargo, no podemos
probarlo directamente con una prueba de
hipótesis clásica. Entonces probamos la hipótesis
opuesta, que la droga no tiene ningún
efecto sobre la presión arterial. Aquí está el proceso. Uno,
asumir la hipótesis de no. Asumimos que el medicamento no
tiene ningún efecto, es
decir, que las personas que toman el medicamento y las que no tienen la
misma presión arterial promedio. T, recopilar y
analizar datos de muestra. Tomamos una muestra aleatoria. Si el medicamento muestra un gran
efecto en la muestra, entonces
determinamos la
probabilidad de extraer dicha muestra o una
que se desvía aún más, si el medicamento realmente no
tiene efecto, o uno que se desvía aún más, si el medicamento realmente no
tiene efecto,
T, evaluar el valor de
probabilidad p. Si la probabilidad de observar tal resultado bajo la
hipótesis nula es muy baja. Consideramos la posibilidad que el medicamento sí
tenga un efecto. Si tenemos pruebas suficientes, podemos rechazar la hipótesis
nula. El valor p es la
probabilidad que mide la fuerza de la evidencia
contra la hipótesis nula. En resumen, la
hipótesis nula establece que no hay diferencia
en la población, y la prueba de hipótesis
calcula qué tan probable es observar los resultados de la muestra si la hipótesis nula es verdadera. Queremos encontrar evidencia para
nuestra hipótesis de investigación. El medicamento afecta la presión arterial. Sin embargo, no podemos probar esto
directamente, así que probamos la
hipótesis opuesta, la hipótesis nula. El medicamento no tiene efecto
sobre la presión arterial. Así es como funciona. Asumir la hipótesis de no. Supongamos que el medicamento no tiene efecto. Es decir, las personas que
toman el medicamento, y las que no tienen la
misma presión arterial promedio, recopilan y analizan datos. Toma una muestra aleatoria. Si el medicamento muestra un gran
efecto en la muestra. Determinamos qué tan probable
es obtener tal resultado, o uno más extremo. Si el medicamento realmente no tiene efecto, calcule el valor p. El valor p es la
probabilidad de observar una muestra
tan extrema como la nuestra. Suponiendo que la
hipótesis nula es verdadera. Significancia estadística. Si el valor p es menor que un umbral establecido, generalmente 0.05. El resultado es
estadísticamente significativo, lo que
significa que es poco probable que haya
ocurrido solo por casualidad. Entonces tenemos evidencia suficiente para rechazar la hipótesis nula. Un pequeño valor de p sugiere que los datos observados son inconsistentes con
la hipótesis nula. Llevándonos a rechazarlo a favor de la hipótesis
alternativa. Un gran valor de p sugiere que los datos son consistentes
con la hipótesis nula. No lo rechazamos. Puntos importantes. Un pequeño valor de p no prueba que la
hipótesis alternativa sea cierta. Simplemente indica
que tal resultado es poco probable si la
hipótesis nula es cierta. Del mismo modo, un valor p grande no prueba que la
hipótesis nula sea cierta. Sugiere que los datos observados son probables bajo la hipótesis
nula. Gracias. Te veré en la siguiente lección de estadística.
21. Estadísticas Comprensión del valor P: ¿Cuál es el valor p y
cómo se interpreta? Eso es lo que
discutiremos en este video. Empecemos con un ejemplo. Nos gustaría investigar si existe una
diferencia de altura entre el hombre
estadounidense promedio y
el jugador de
basquetbol estadounidense promedio. El hombre promedio mide
1.77 metros de altura. Por lo que queremos saber si el jugador de basquetbol promedio también
mide 1.77 metros de altura. Así, declaramos la hipótesis
nula. La estatura promedio de un basquetbolista
estadounidense es de 1.77 metros Suponemos que en la población de basquetbolistas estadounidenses, la estatura promedio
es de 1.77 metros No obstante, como no podemos
encuestar a toda la población, dibujamos una muestra. De co, esta muestra no
arrojará una media exacta
de 1.77 metros Eso sería muy poco probable. Oh. Puede ser que la muestra extraída puramente
por casualidad se desvíe 3 centímetros por
8 centímetros por 15 centímetros o
por cualquier otro valor Ya que estamos probando una hipótesis
no dirigida, es
decir, solo queremos saber
si hay alguna diferencia No nos importa en qué
dirección vaya la diferencia. Ahora llegamos al valor p. Como se mencionó, suponemos
que en la población, hay un valor medio
de 1.77 metros Si dibujamos una muestra, ésta diferirá de la
población por un cierto valor. El valor p nos dice cuán probable es
dibujar una muestra que desvía de la población una cantidad igual o mayor
que el valor observado Volvamos a echar un vistazo más de cerca. Tenemos una muestra que es
diferente a la población. Ahora nos interesa qué tan probable es sacar una muestra que se desvíe tanto como nuestra muestra o más
de la población Así, el valor p indica qué tan probable es dibujar una muestra cuya media
está en este rango. Por ejemplo, si por casualidad la muestra se desvía 3
centímetros de 1.77 El valor p nos dice cuán
probable es dibujar una muestra que se desvía 3 centímetros o más
de la población Si por casualidad la muestra se desvía 9 centímetros de 1.65 metros, el valor de p nos indica qué tan
probable es extraer una muestra que se desvía 9 centímetros
o más de Tomemos un ejemplo donde
obtenemos una diferencia de 9 centímetros y nuestro software estadístico
favorito Al igual que Mini tab, calcula
el valor p de 0.03. Eso es 3%. Esto nos dice que es sólo 3% probable que se dibuje una
muestra que sea igual o
superior a 9 centímetros
diferente de la media poblacional
de 1.77 metros Para datos distribuidos normalmente. Esto significa que la probabilidad que la media se encuentre
en este rango es 1.5% en una dirección y
1.5% en la otra Sumando 3%. Si esta
probabilidad es muy baja. Por supuesto, se puede preguntar si
la muestra proviene de una población con una media
de 1.65 metros en absoluto Si esta probabilidad es muy baja. Por supuesto, se puede preguntar si
la muestra proviene de una población con una media
de 1.77 metros en absoluto Es sólo una hipótesis
que el valor medio de los jugadores de basquetbol
es de 1.77 metros Y es precisamente esta
hipótesis la que queremos probar. Por lo tanto, si calculamos
un valor p muy pequeño, esto nos da evidencia de
que la media de la población no es de
1.77 metros en absoluto Así, rechazaríamos
la hipótesis nula, que asume que la
media es de 1.77 metros Así, rechazaríamos
la hipótesis nula, que asume que la
media es de 1.77 metros Pero ¿en qué momento el valor p es lo suficientemente
pequeño como para rechazar
la hipótesis nula? Esto se determina con el
llamado nivel de significancia, también llamado nivel Alfa. Aquí hay dos
cosas importantes a tener en cuenta. Uno, el nivel de significancia siempre
se determina
antes del estudio y no se puede cambiar
posteriormente para finalmente obtener
los resultados deseados. Dos, para asegurar cierto
grado de comparabilidad, el nivel de significancia
suele establecerse en 5% o 1% El valor AP menor al 1% se considera
altamente significativo. Menos del 5% se llama significativo y más
del 5% se llama significativo. En resumen, el valor p nos da una indicación de si rechazamos o no la hipótesis
nula. Como recordatorio, la hipótesis
nula asume que no
hay diferencia. Mientras que la hipótesis alternativa asume que
hay una diferencia. En general, la hipótesis
nula es rechazada si el valor de p
es menor a 0.05. Siempre es sólo una probabilidad, y podemos equivocarnos
con nuestra afirmación. Si la hipótesis nula es
cierta en la población,
I, la media es de 1.77 metros Pero dibujamos una muestra que
pasa a estar bastante lejos. Podría ser que el
valor de p sea menor a 0.05. Rechazamos erróneamente
la hipótesis nula. A esto se le llama error tipo uno. Si en la población, la hipótesis nula es falsa. IE, la media no es de 1.77 metros, pero dibujamos una muestra
que pasa a estar muy cerca de 1.77 El valor de p puede ser
mayor que 0.05, y no podemos rechazar
la hipótesis nula. A esto se le llama error tipo dos. Gracias por aprender conmigo. Te veo en la siguiente
lección de estadística. Y.
22. Tipos de errores: Entendamos
algunos ejemplos más de
hipótesis nula y alternativa. Entonces supongamos que si mi proyecto
está a punto de arrojarte, mi hipótesis nula
es un valor fijo. Por lo que diría que mi media
actual de mi
tiempo promedio actual para construir para compartir 70% de
Julie son. Corriente. El promedio de P a S es de 70%. La hipótesis alternativa
significaría que no es del 70%. Supongamos que estoy pensando en el contenido
de humedad de un proyecto. Estoy en una
configuración de fabricación y quiero medir si el contenido de humedad
debe ser igual al 5%. O 5% es lo que es
aceptable por mi cliente, entonces puedo decir que mi contenido de
humedad es menor que igual
al cinco por ciento. Entonces la
hipótesis alternativa afirmaría que el contenido de humedad es
mayor al cinco por ciento. El caso donde la
media es mayor que, entonces la hipótesis nula. No tenemos el
interés en ese problema. Vamos a entenderlo más. La pregunta era,
¿un reciente TED ese proceso de
aprobación de préstamos para pequeñas empresas redujo el tiempo promedio de ciclo
para procesar el préstamo? La respuesta podría ser no. tiempo de ciclo medio no cambió. O el directivo puede ver que sí, el tiempo medio de ciclo
es menor al 7.5%. Por lo que el status quo es
igual a 7.514 minutos. Y el suplente dice, no, es menos de 7.414
minutos o días, cualquiera que sea la principal unidad de medida que estamos
midiendo, ¿no? Entonces por defecto, su status
quo es ir hipótesis nula. Y el ejemplo o
el estatus que se quiere demostrar hipótesis
alternativa más fácil. Ahora bien, podría haber algún tipo de flechas cuando tomamos decisiones. Entonces volvamos
a nuestro caso de código. El acusado es en
realidad inocente, ¿verdad? Déjame tomar mi rayo láser. Por defecto, el demandado o la realidad es que el
demandado no es culpable. También llega el veredicto de
que el acusado, la persona no es culpable. Es una buena decisión, ¿no? Entonces sí, hemos tomado una muy buena decisión de que
la persona es inocente. En realidad, el
acusado es culpable. Y también
llega el veredicto de que es culpable. La decisión es una buena decisión. Lo que pasa es que, en realidad, la persona no está garantizada, pero llega el veredicto de que es
culpable y
persona inocente es condenada. Es un error. Es un error muy grande. En persona del Norte, se le da una
sentencia y lo meten a la cárcel, se le da una pena,
eso es un error. El error puede incluso ocurrir
del otro lado, donde en realidad la
persona es culpable, pero llega el veredicto de
que no es culpable. El culpable es
declarado inocente y está listo para ello. Esto también es una flecha, pero que es un error mayor. El error más grande que puedes anotar en la
casilla de comentarios, ¿qué opinas? ¿ Qué error es la flecha más grande? ¿ Es el error un error más grande o el error es
la flecha más grande? se
condene a ninguna persona sensata es un error mayor o es libre un culpable moviéndose por
las carreteras, ¿
o flecha más grande? Espero que ya hayas
escrito los comentarios. Entonces la realidad es que esto
se convierte en mi mayor error. Y esto se llama
como error de tipo uno. Porque si
se condena a un inocente, no
podemos devolverle el
tiempo que ha perdido. No podemos conseguir que iría a
mucho trauma emocional. Si se
declara inocente a un culpable, podemos llevarlo
al tribunal superior y a la
Suprema Corte y lograr
que demuestre que sí, no es culpable, cierto. Para que pueda tomar esta decisión por aquí de que la persona es convicta. Debe ser condenado
y debe ser declarado culpable y
debe ser castigado. Por lo que este error se llama
como error de tipo dos. Si alguien te preguntó qué
error es un error más grande, escribe un error, también se
llama como error alfa. Y esto se llama
como un error beta. ¿ Verdad? Sigamos
más en nuestra próxima clase.
23. Tipos de errores part2: Entendamos una vez más
los tipos de flechas. Entonces como sabemos que si la persona no
es culpable o la
persona es inocente, y el veredicto
también está diciendo que la
persona no es culpable. Es una buena decisión. Si la persona es culpable, veredicto es que es culpable. La decisión es otra vez,
una buena decisión. El condenado no está, tiene que ser sentenciado o
debe ser castigado. El problema ocurrirá cuando se demuestre
la culpabilidad de
una persona inocente y éste sufra. El segundo tipo de problema que ocurre cuando se declara inocente al culpable, a
una persona con un
delincuente. Y dijo: Esto se llama
como error tipo uno. Es decir, que una
persona inocente que sea condenada o castigada
es un error tipo uno. También se le llama
como flecha alfa. A un culpable, criminal liberado se le llama como error tipo
dos o error beta, que también es un error
que queremos evitar. El nivel de significancia
está establecido por el valor Alfa. Entonces, ¿qué tan seguro
quieres en tomar la decisión
correcta? Entonces el error de tipo uno ocurre cuando el nulo es verdadero,
pero rechazamos. error de tipo dos ocurre cuando
en realidad el nulo es falso, pero no lo rechazamos. Ahora, ¿cómo nos
ayuda esto a procesar? Así que vamos a entender esto
todos los días para la hoja del almuerzo. ¿ Verdad? Vamos a entender
esto con más detalle. Este es el escenario real. Escribamos el
real en la parte superior. Y este mitos
como el juicio. De acuerdo, ahora,
pensemos en el proceso. El proceso no ha cambiado. No ha cambiado. Ningún suplente será proceso ha cambiado. Ahora se advierte la sentencia. Y el juicio es que el
proceso ha mejorado. De acuerdo. Ahora les voy a hacer una pregunta
muy importante. Si un proceso no ha cambiado y el juicio es que no
hay cambio, esta es la decisión correcta. El proceso ha cambiado y el juicio es también que
el proceso ha mejorado. Esa también es una decisión correcta. Ahora, imagina que el proceso no
ha cambiado, pero declaramos que ahora
tengo un proceso mejorado y un producto mejorado e informo al cliente, ¿es correcto? Un error. Y esto se llama como un error tipo
uno porque parece viejo, pero nuestra deuda se vende al
cliente como nuevo producto. ¿ Se puede entender
lo que pasará con la reputación de la empresa? El equipo o producto se vende al cliente como nuevos productos. Nuevo producto de un núcleo. Entonces, ¿qué pasará con la
reputación de la empresa? Se irá por un lanzamiento
y de ahí decimos, esta no es una buena decisión. Ahora entiende aquí también
el proceso ha cambiado. El proceso ha mejorado, pero el juicio viene
como no mejorado. Esto también es un error. No lo niego. Esto se llama un error de
tipo dos o auditoría también se llama
como un error beta. Aquí mismo. Lo que pasa es que no
estamos comunicando
al cliente que la mejora
ha sucedido, ¿verdad? Por lo que no estamos manteniendo los artículos mejorados en producto de cría
en el almacén. Ahora esto tampoco es correcto, pero el error más grande es aquí donde en realidad
no hemos hecho una mejora, pero estoy informando al cliente que eres mala gente se une.
24. Canción publicitaria: Cuando hacemos prueba de hipótesis, siempre
hay dos hipótesis. Una es la hipótesis por defecto, que es la hipótesis nula, y la segunda es la hipótesis
alternativa que se quiere probar. Y esa es la razón por la que
estás haciendo la hipótesis. Entonces, cuando haces la hipótesis, la razón por la que hacemos es que
nunca estamos teniendo acceso
a toda la población. Entonces cuando recogemos la muestra, queremos entender, es la muestra que viene
de la curva de campana o la distribución
desde donde estamos entendiendo cualquier
variación que veas, es debido a la
propiedad natural del conjunto de datos. A veces la muestra podría estar en la esquina final del Velcro. Y ese es un lugar donde obtenemos la confusión de que
hace que estos datos pertenezcan al Velcro original o
¿ pertenecen al
segundo suplente? Bienvenida. Eso está ahí. Estaremos haciendo ejercicios
que le estarán dando una comprensión de esto de
manera más fácil de hacer. Hipótesis, obtienes
información como el valor p aparte de los resultados de las estadísticas de
prueba. También obtienes el valor p. Siempre comparamos el valor p con el valor nulo
que hemos establecido. Supongamos que quieres
tener un 95% de confianza. Entonces estableces el valor p como 5%. Y si estableces que el nivel de
confianza es 90%, entonces tu valor Alfa
es diez por ciento, o tu valor p es 0.10. La razón por la que hacemos un valor p es que si puedes
ver esta curva de campana, la observación más probable es parte del
centro de la campana. Muy poco
probable la observación viene de la cola. Este valor p, la razón verde, te
ayuda a decir
si pertenece
al Velcro original o pertenece al grueso
alterno de eso es, estás tratando de probar a través de
la hipótesis alternativa. De ahí que el valor p venga como una ayuda para que puedas recordar esto
fácilmente. Recuerda el tintineo. Abajo, nulo. Significa que si el valor p es
menor que el valor alfa, voy a rechazar
la hipótesis nula. P vuelo de alto nivel. Si el valor p es
mayor que el valor alfa, fallamos en rechazar
la hipótesis nula, Concluyendo que no tenemos suficiente evidencia estadística de que exista
la hipótesis alternativa. Estaremos haciendo mucho
ejercicio y estaré cantando este jingle varias veces para
que sea fácil para
ti recordarlo. Por debajo de nulo, ir detrás de nullcline. Algunos de los participantes con, cuando haga el taller se
confunden, dirán que ninguno
vaya significa ¿qué? La otra cosa que les
digo que
recuerden fácilmente es f para
vuelo y F para campo. Entonces, si P es alto nulo, volaremos. Significa que estás fallando en
rechazar la hipótesis nula. La hipótesis nula existirá. La hipótesis alternativa
será rechazada. Recuerda una cosa más que en su mayoría
se pregunta
durante la entrevista. El valor p fue de 1.230.123. ¿ Rechazarías
la hipótesis nula o aceptarías
la hipótesis nula? ¿ O aceptarías la hipótesis
alternativa? O aceptará
la hipótesis nula? Como estadístico? Nunca aceptamos hipótesis alguna. O rechazamos
la hipótesis nula o fallamos en rechazar
la hipótesis nula. Siempre lo decimos desde
el punto de vista de null porque el
status quo por defecto más fácil hipótesis
nula. Si la P es alta, no aceptamos la hipótesis nula
y alternativa. ¿ No aceptamos
la hipótesis nula? Decimos que no rechazamos
la hipótesis nula. Si la p es baja, no aceptamos alternos, pero decimos, rechazo
la hipótesis nula, concluyendo que hay suficiente evidencia estadística de que los datos provienen
del Bellcore alterno . Seguiremos con
muchos ejercicios. Y esto
te dará confianza sobre cómo practicar e interpretar y usar estadísticas
inferenciales en tu análisis cuando lo
estés haciendo.
25. Selección de pruebas: Una de las preguntas más comunes que
se hacen a mis participantes cuando estoy entrando al proyecto
es ¿qué hipótesis
debo usar renta? Entonces este es un análisis sencillo que te ayudará a
entenderlo. ¿ Qué pruebas debo usar? Al igual que la forma en que un
paciente acude a un médico, el médico no le
prescribe toda la prueba. Simplemente le pone su agarra la prueba apropiada con base en el problema que el
paciente está pescando. Si el paciente ve me
encontré con un accidente, el doctor diría que
creo que deberías
hacerte la radiografía. No le estaría
pidiendo que fuera a su prueba COVID o prueba de RT-PCR. Si la persona está tosiendo
y sufre de fiebre, entonces se sugiere RT-PCR. Y en ese momento
no somos capaces de satisfacer la radiografía. Se ve de manera similar cuando
hacemos pruebas de hipótesis simples, estamos tratando de entenderla u otra compararla
con la población. Queremos entender ¿qué
prueba debemos estar realizando? Cuando, si estoy probando medios, ese es tu promedio, entonces comparas la media de una muestra con el valor
esperado. Entonces estoy comparando la
muestra con mi población. Después voy por mi prueba t
de una muestra. Tengo sólo una muestra
que estoy comparando. Quiero comparar si el rendimiento
promedio del,
si el promedio de ventas
es igual a x cantidad, que es el valor esperado. Entonces esperábamos que
las ventas fueran, digamos 5 millones. Mi promedio viene a decir 4.8. Yo he conocido que no lo son. Entonces puedo ir y hacer
una prueba t de una muestra. Comparar la media de muestras con dos proporciones diferentes. Entonces, si tengo dos T
independientes, digamos que estoy realizando
una capacitación en línea. Estoy realizando una
capacitación fuera de línea. Es el Shrina y tengo un conjunto de alumnos que están
asistiendo a mi programa en línea. Tengo un
grupo diferente de alumnos que están asistiendo a
mi programa mío. Quiero comparar la
efectividad del entrenamiento. Entonces tengo dos muestras, y estas son dos muestras
independientes porque los participantes
son diferentes. Después voy por la prueba t de dos muestras. Si quiero comparar
las dos muestras para
que la gente venga a mi entrenamiento. Hago una evaluación antes de mi programa de formación sobre su comprensión de
lo que Lean Six Sigma. Y puedo tomar el programa de
capacitación y el mismo conjunto de participantes asistir a la prueba después
del programa de capacitación. Entonces los participantes
o la escena. Pero el cambio
que ha ocurrido es el entrenamiento que les
impactó. Tengo los resultados de la prueba antes del entrenamiento y tengo los resultados de la
prueba después del entrenamiento, quiero comparar el
entrenamiento es efectivo. Después voy por la prueba t
pareada de dos muestras. Progresando más. Supongamos que si estoy
probando para frecuencia, tengo datos discretos
y quiero probar la frecuencia porque en datos
discretos
no tengo promedios. Tomo frecuencias. Entonces, cuando estoy comparando
el conteo de alguna variable en una muestra con
la distribución esperada, igual que la forma en que
tuve una prueba t de muestra. El equivalente de esto para un dato discreto sería mi bondad de ajuste
chi-cuadrado. I, por defecto se espera que sea un valor normal o un
valor particular o un valor inesperado. Y eso lo estoy comparando. ¿ Qué tan lejos están mis datos? Voy por un chi-cuadrado
bondad de ajuste. Esta prueba está disponible
en MiniTab en Excel. No está disponible. Entonces estaré creando una
plantilla y dártela, lo
que te hará fácil hacer la prueba de chi-cuadrado. Los tres tipos diferentes de prueba de chi-cuadrado usando
la plantilla de Excel. Si tengo que contar algunas de las variables
entre dos muestras. Por lo que será chi-cuadrado
homogéneamente prueba t. Estoy comprobando una sola muestra
simple para ver si las
variables discretas son independientes. Hago prueba de
independencia de Chi-Cuadrado. Si tengo una proporción de datos, como aplicaciones buenas o malas, he aceptado versus rechazado. Y estoy diciendo que bien, 50% de las solicitudes son aceptadas
, o el veinticinco por ciento de
las personas son colocadas. Tengo una proporción
que quiero probar. Si solo tengo una muestra, voy por una prueba de proporción. Si quiero comparar
proporción de egresados de comercio
versus egresado de ciencias o proporción de finanzas, MBA, personas con
mercadotecnia MBA personas, tengo dos muestras diferentes, así puedo ir por prueba de dos
proporciones. Entonces, para resumir la cosa, cuando estoy probando, ¿estoy
probando promedios? ¿ Estoy probando
frecuencias como datos
discretos o estoy
probando proporciones? Dependiendo de eso,
estás recogiendo la prueba apropiada
y trabajando en ella. Vamos a
practicarlo todo usando Men dab y usando exit. El conjunto de datos está disponible en
la sección de descripción. En la sección de proyectos, invito a todos a
practicarlo y poner sus proyectos, su análisis en la sección de
proyectos. Si tienes alguna duda, puedes ponerlo en
la sección de discusión y
estaré encantado de responder a tus dudas. Feliz aprendizaje.
26. Conceptos de prueba T en detalle: ¿Qué te enseña este video? Acerca de la prueba T? Este video cubre todo lo que necesitas
saber sobre la prueba T. Al final de este video, comprenderás qué es la
prueba AT, cuándo usarla, los diferentes tipos de pruebas
t, hipótesis y suposiciones
involucradas, cómo
se calcula la prueba AT y cómo
interpretar los resultados ¿Qué es una prueba t? Empecemos por lo básico. Una prueba t es un procedimiento
de prueba estadística. Eso analiza si existe una diferencia significativa entre
las medias de dos grupos. Por ejemplo, podríamos comparar la presión arterial de los pacientes
que reciben medicamento A versus. Medicamento B, tipos de pruebas t. Hay tres
tipos principales de pruebas t, la prueba t de una muestra,
la prueba t de muestras independientes o dos pruebas t,
y la prueba t de muestras pareadas. ¿Qué es una prueba t para una muestra? Utilizamos una prueba
t de una muestra cuando
queremos comparar la media de una muestra con una media de
referencia conocida. Por ejemplo, un fabricante de
barras de chocolate afirma que sus barras pesan un promedio de 50 gramos. Tomamos una muestra. Encuentra su peso medio. Supongamos que el
peso de la muestra es de 48 gramos, y usa una prueba de
t de una muestra para ver si difiere
significativamente de
los 50 gramos reclamados. ¿Qué es una prueba t para muestras
independientes? La prueba
t de muestras independientes compara las medias de dos
grupos o muestras independientes. Por ejemplo, podríamos
comparar la efectividad de
dos colores de dolor asignando aleatoriamente a 60
personas a dos grupos Al recibir el medicamento A
y el otro fármaco B. Y luego usar una prueba t
independiente para evaluar cualquier
diferencia significativa en el alivio del dolor. ¿Qué es una prueba t
para muestras pareadas? La prueba t de muestras
pareadas compara las medias de
dos grupos dependientes. Por ejemplo, para evaluar la
efectividad de una dieta, podríamos pesar a 30 personas antes. Después de la dieta, usando una prueba t de muestras
pareadas, determinamos si antes existe una diferencia
significativa de peso. Después de la dieta. Comprender
la diferencia entre muestras
dependientes e
independientes es crucial para elegir
el tipo correcto de prueba t para su análisis. Muestras dependientes
o muestras pareadas, se refieren a casos en los que
cada observación en una muestra se empareja con
una observación específica. En la otra muestra, este emparejamiento surge de la naturaleza de la recolección de
datos, como antes y
después de las mediciones. En los mismos individuos, emparejaron pares en un experimento. Se utiliza la prueba t de
muestras pareadas para evaluar si. La diferencia media entre estas observaciones pareadas es
estadísticamente significativa. Por otro lado,
las muestras independientes son observaciones, extraídas de dos grupos separados, o poblaciones que no están relacionadas o emparejadas de
ninguna manera sistemática. Cada observación
en una muestra es totalmente independiente de
cualquier otra observación. En la otra muestra, las muestras
independientes, prueba
T evalúa
si las medias de estos dos grupos independientes difieren significativamente entre sí La elección entre estos tipos de pruebas
t depende de
cómo se
recolectaron los datos y la relación entre las muestras
que se comparan. El uso de la
prueba t correcta garantiza que su análisis estadístico refleje
con precisión la naturaleza de su pregunta de
investigación y la estructura de sus datos. Aquí tienes una nota interesante. La prueba t de muestras pareadas es muy similar a la prueba t de
una muestra. También podemos pensar que
la prueba t de muestras pareadas tiene una muestra que se midió en dos momentos diferentes. Luego calculamos la diferencia entre los valores emparejados, dándonos un valor
para una muestra. La diferencia es
uno menos cinco más dos menos uno menos tres, y así sucesivamente y así sucesivamente. Ahora, queremos probar
si el valor medio de
la diferencia recién calculada se desvía de un valor de referencia En este caso, cero, esto es exactamente lo que hace la prueba t de
una muestra. ¿Cuáles son los supuestos? Para una prueba t, por supuesto, primero
necesitamos una muestra adecuada
en la prueba t de una muestra, necesitamos una muestra y el valor de referencia en
la prueba t independiente. Necesitamos dos muestras independientes, y en el caso de
una prueba de t pareada, una muestra pareada, la
variable para la que queremos probar si hay diferencia entre las
medias debe ser métrica. Ejemplos de
variables métricas son la edad, el peso corporal y los ingresos. Por ejemplo, el nivel de educación
de una persona no es
una variable métrica. Además, la variable métrica debe distribuirse normalmente en las tres variantes de prueba para aprender a probar si tus
datos están distribuidos normalmente. En caso de una prueba t
independiente, las varianzas en los dos grupos deben ser aproximadamente iguales Se puede verificar si
las varianzas son iguales usando la prueba de L evens ¿Cuáles son las hipótesis
de la prueba t? Comencemos con la prueba t de
una muestra
en la prueba t de una muestra. La hipótesis nula
es que la
media de la muestra es igual al valor de referencia
dado. Entonces no hay diferencia, y la
hipótesis alternativa es que la media de la muestra no es igual al valor de
referencia dado. ¿Qué pasa con la prueba t de
muestras independientes? En la prueba t independiente, la hipótesis nula es que
los valores medios en ambos
grupos son los mismos. Entonces no hay diferencia
entre los dos grupos, y la
hipótesis alternativa es que los valores medios en ambos
grupos no son iguales. Entonces hay una diferencia
entre los dos grupos. Y finalmente, las muestras pareadas
t prueban en un par t test, la hipótesis nula
es que
la media de la diferencia entre
los pares es cero, y la
hipótesis alternativa es la media de la diferencia
entre los pares no es cero. Ahora sabemos cuáles son
las hipótesis. Antes miramos cómo se calcula la prueba
t. Veamos un ejemplo
de por qué realmente
necesitamos una prueba t. Digamos que hay una
diferencia en la duración del estudio para una
licenciatura entre hombres. Y las mujeres en Alemania. Por lo tanto, nuestra población está conformada por
todos los egresados de una licenciatura
que han estudiado en Alemania. No obstante, como no podemos
encuestar a todos los egresados de licenciatura, dibujamos una muestra lo más
representativa posible. Ahora utilizamos la prueba para probar la hipótesis nula de que no
hay diferencia
en la población. Si no hay diferencia
en la población, si no hay diferencia
en la población, sin duda todavía veremos una diferencia en la
duración del estudio en la muestra. Sería muy
poco probable que dibujáramos una muestra donde la diferencia
sería exactamente cero. En términos simples, ahora queremos
saber a qué diferencia
se mide en una muestra. Podemos decir que la
duración del estudio de hombres y mujeres es
significativamente diferente. Y esto es exactamente lo que responde
la prueba t. Pero, ¿cómo
calculamos una prueba t? ¿Para hacer esto? Primero calculamos el valor t para
calcular el valor t. Necesitamos dos valores. Primero, necesitamos la diferencia
entre las medias, y luego necesitamos la
desviación estándar de la media. Esto también se conoce como
el error estándar. En la prueba t de una muestra, se calcula la
diferencia entre la media muestral y la media de referencia
conocida. S es la desviación estándar
de los datos recopilados, y n es el número de casos. S dividido por la raíz cuadrada de n es entonces la
desviación estándar de la media. ¿Cuál es el error estándar? En la prueba t de muestras dependientes, simplemente
calculamos
la diferencia entre las dos medias de la muestra. Para calcular el error estándar, necesitamos la
desviación estándar y el número de casos de la
primera y segunda muestra, dependiendo de si
podemos asumir varianza
igual o desigual para nuestros datos Existen diferentes fórmulas
para el error estándar. En una prueba t de muestra pareada, solo
necesitamos calcular
la diferencia entre los valores emparejados y
calcular la media a partir de eso. El error estándar es entonces el mismo que para una prueba t de una muestra. ¿Qué hemos aprendido hasta
ahora sobre el valor t? No importa qué
prueba t, calculamos. El valor t
será mayor si
tenemos una mayor diferencia
entre las medias, y el valor t será menor si la diferencia entre
las medias es menor. Además, el valor t se vuelve más pequeño cuando tenemos una mayor
dispersión de la media, por lo que cuanto más dispersos sean los datos, menos significativas se
dan diferencias de medias. Ahora queremos usar la prueba t para ver si podemos rechazar la hipótesis
nula o no. Para ello, ahora podemos usar
el valor t de dos maneras. O leemos el valor crítico
t de una tabla, o simplemente calculamos el valor
p a partir del valor t. Pasaremos por
ambos en un momento. Pero, ¿cuál es el valor p? Una prueba t siempre prueba la hipótesis nula de que no
hay diferencia. Primero, suponemos que no
hay diferencia
en la población. Cuando dibujamos una muestra, esta muestra se desvía de la hipótesis
nula en cierta cantidad El valor p nos dice lo probable que es que dibujemos
una muestra que desvíe de la población la misma cantidad o
más que una muestra que dibujamos Así, cuanto más se
desvía la muestra de la hipótesis
nula, menor se vuelve el valor p, si esta probabilidad
es muy, muy pequeña, podemos por supuesto, preguntar si la hipótesis nula se mantiene
para la población Quizás haya una diferencia, pero ¿en qué momento podemos
rechazar la hipótesis nula? A este borde se le llama
el nivel de significancia, que generalmente se establece en 5%. Si sólo hay un 5% de posibilidades de
que saquemos tal muestra. O uno que sea más diferente. Entonces tenemos pruebas suficientes para suponer que rechazamos
la hipótesis nula. En términos simples, asumimos
que hay una diferencia, que la
hipótesis alternativa es cierta. Ahora que sabemos
cuál es el valor p, finalmente
podemos ver cómo se usa
el valor t para determinar si se rechaza o no la hipótesis
nula. Comencemos con el camino
a través del valor t crítico, que puedes leer de
una tabla. Para ello. Primero necesitamos una tabla
de valores críticos de t, que podemos encontrar en la pestaña Datos bajo tutoriales y distribución
T. Empecemos con
el caso de dos colas. Veremos brevemente
el caso de una cola
al final de este video. Aquí abajo, vemos la tabla. Primero, tenemos que decidir qué nivel de significación
queremos usar. Escojamos un
nivel de significancia de 0.05 de 5%. Entonces miramos en esta columna
a 120.05, que es 0.95. Ahora necesitamos los
grados de libertad en la prueba t de una muestra y
la prueba t de muestras pareadas. Los grados de libertad son simplemente el número
de casos menos uno. Si tenemos una muestra
de diez personas, hay nueve
grados de libertad. En la prueba t de
muestras independientes, sumamos el número de
personas de ambas muestras y calculamos eso menos dos
porque tenemos dos muestras. Tenga en cuenta que los grados de
libertad se pueden determinar de
una manera diferente
dependiendo de si
asumimos igual o igual varianza. Entonces, si tenemos un nivel de
significancia del 5%, y nueve grados de libertad, obtenemos un valor
t crítico de 2.262 Ahora, por un lado, hemos calculado un valor t con la prueba t y tenemos
el valor t crítico. Si nuestro valor t calculado es mayor que el valor t
crítico. Rechazamos la hipótesis nula. Por ejemplo, supongamos que
calculamos un valor t de 2.5. Este valor es
mayor que 2.262, y por lo tanto, las
dos medias son tan diferentes que podemos
rechazar la hipótesis nula Por otro lado, también podemos calcular el valor p para el valor
t que hemos calculado. Si ingresamos 2.5 para el valor t, y nueve para los
grados de libertad, obtenemos un valor p de 0.034 El valor p es menor que 0.05, y por lo tanto rechazamos la hipótesis
nula como control, si copiamos aquí el
valor t de 2.262, obtenemos exactamente un valor
p de 0.05, que es exactamente el límite Si quieres calcular la prueba
AT con la pestaña Datos, solo
necesitas copiar tus
propios datos en esta tabla. Haga clic en la prueba de hipótesis y luego seleccione las
variables de interés. Por ejemplo, si quieres
probar si el género tiene
un efecto en los ingresos, simplemente
haces clic en
las dos variables y automáticamente obtienes prueba AT, calculada para muestras
independientes. Aquí abajo. Se puede
leer el valor p. Si aún no le duele
la interpretación
de los resultados, simplemente
puede hacer clic en la
interpretación hacia adentro Una prueba de t de dos colas para muestras
independientes, las varianzas
iguales asumidas mostraron que la diferencia entre mujeres y hombres con respecto a la variable dependiente salario no
fue estadísticamente
significativa Así, se conserva
la hipótesis nula. La pregunta final ahora es, ¿cuál es la diferencia entre hipótesis
dirigida y la hipótesis
no dirigida En el caso no dirigido, la hipótesis alternativa es
que hay una diferencia Por ejemplo,
hay una diferencia entre el salario de hombres
y mujeres en Alemania. No nos importa quién gane más. Sólo queremos saber si
hay una diferencia o no. En una hipótesis dirigida. También nos
interesa la dirección
de la diferencia. Por ejemplo, la hipótesis
alternativa podría ser que los hombres ganan más que las mujeres o las mujeres ganan
más que los hombres. Si miramos la
distribución t gráficamente, podemos ver que en
el caso de dos lados, tenemos un rango a la izquierda
y un rango a la derecha. Queremos rechazar la hipótesis
nula si estamos aquí
o allá con
un nivel de significancia del 5%. Ambos rangos tienen una
probabilidad de 2.5%. Juntos apenas 5%, si
hacemos una prueba T de una cola, la hipótesis nula es
rechazada solo si
estamos en este rango
o dependiendo la dirección que
queramos probar en ese rango con un nivel de
significancia del 5%, A 5% caen dentro de este rango. Gracias por aprender conmigo. Te veré en la siguiente
lección de estadística.
27. 1 prueba t de muestra: ¿ Entendamos qué pruebas de
hipótesis debo usar? En Minitab, usted tiene un asistente que puede
ayudarlo a tomar esa decisión. Por lo que si acudes a pruebas de
hipótesis asistente, te ayudará a identificarte base en el número de
muestras que tengas. Supongamos que si
tiene una muestra, podría estar haciendo
una prueba t de una muestra, una desviación estándar de muestra, un porcentaje de muestra defectuoso, bondad de ajuste de
chi-cuadrado. Si tiene dos muestras, entonces tiene dos
pruebas t de muestra para diferentes muestras. Prueba T si los elementos antes y
después son los mismos. Desviación estándar de la muestra al porcentaje de muestra de la prueba de asociación de
chi-cuadrado defectuosa Si tiene
más de dos muestras, entonces tenemos una prueba de desviación
estándar ANOVA de una vía, porcentaje de
Chi-cuadrado
es defectuoso y prueba de asociación de
chi-cuadrado. Estaremos practicando
todo con montones de ejemplos. Entonces pasemos
al primer ejemplo. Tenemos el TDAH de
llamadas en minutos. Hemos tomado una muestra
de 33 puntos de datos. El promedio es de siete,
el valor mínimo es de cuatro minutos, el valor
máximo es de diez minutos. El motivo por el que tenemos que hacer una prueba de hipótesis es el
gerente de los procesos que su equipo es capaz de cerrar la resolución o en la
llamada en siete minutos. Y el promedio del proceso también
es de siete minutos, mínimo es de cuatro minutos. Pero el cliente ve
que los agentes los mantienen en espera y lleva más de
siete minutos en la llamada. Entonces ahora quiero
validar estadísticamente si
es correcto o no. Siempre que estemos
configurando pruebas de hipótesis, tenemos que seguir el enfoque de cinco
pasos y seis pasos. Paso número uno, definir
la hipótesis alternativa. Define la hipótesis nula, que no es más que
tu status quo. ¿ Cuál es el nivel de significancia
o su valor Alfa? Si no se especifica nada, se enviará valor Alfa
como cinco por ciento. Primero establecemos la hipótesis
alternativa. Entonces en nuestro caso, ¿qué está diciendo el cliente? El cliente ve que el tiempo promedio de manejo es de
más de siete minutos. El status quo o
el SLA acordado es el TDAH debe ser
menor a siete minutos. Como les dije, la hipótesis nula y la alternativa serán mutuamente excluyentes y
complementarias entre sí. Ahora, identifique la
prueba a realizar. ¿ Cuántas muestras tengo? Tengo sólo una muestra del
HD del contact center. Entonces voy a
recoger una prueba t de muestra. ¿ De acuerdo? Ahora necesito hacer
las estadísticas de prueba e identificar el valor p. Si recuerdas la lección
anterior del ejemplo, dijimos que si el valor p es
menor que el valor alfa, rechazamos la hipótesis nula. Si el valor p es mayor al
cinco por ciento o el valor Alfa, no
podemos rechazar
la hipótesis nula. Hagamos este entendimiento. Entonces, si lo recuerdas, tenemos los datos de nuestro proyecto. En los datos del proyecto, tenemos la prueba de hipótesis. Por aquí. Te he dado el
AHG de carbón en minutos. Por lo que he copiado estos
datos en MinitaB. Entonces hagámoslo de dos maneras. Primera vez y muéstralo
usando asistente. Segundo, te lo
mostraré usando estadísticas. Entonces, si voy al asistente de pruebas de
hipótesis, ¿cuál es el objetivo que
quiero lograr? Es una prueba t de una muestra.
Tengouna toma de muestras. ¿ Se trata de mezquino? ¿ Se trata de la desviación estándar? ¿ Es aparte, números defectuosos
o discretos? Estamos hablando
del promedio 100 veces. Entonces voy a tomar
una prueba t de muestra. Para datos en columnas. Yo he seleccionado esto. ¿ Cuál es mi valor objetivo? Mi valor objetivo es siete. La hipótesis alternativa es que
la edad media de la llamada en minutos es
mayor a siete. Esto es de lo que se queja el
cliente. El valor alfa es 0.05 por
defecto, hago clic en, Ok. Veamos la salida. Para ver la salida
vas a dar clic en Ver y solo salida. ya lo verán. Si ve el valor p, el
valor p es 0.278. Te acuerdas por debajo de no meta
ser alta nullclina es este valor de 0.278
mayor que el valor alfa de 0.05? Sí, lo es. De ahí que pueda concluir
que la media es d de carbón no es significativamente
mayor que el objetivo. Sea lo que sea que estés viendo
como mayor que el objetivo, es sólo por casualidad. Por lo que no hay evidencia suficiente
para concluir que la media
sea mayor a siete con un nivel
de significancia del
cinco por ciento. Y también me muestra
cómo es el patrón. No hay puntos de datos inusuales porque el
tamaño de la muestra es de al menos 20. La normalidad no es un tema. La prueba es precisa. Y sería bueno concluir
que el tiempo promedio de manejo
no es significativamente
mayor a siete minutos. Puedo seguir adelante y rechazar el reclamo dado por el cliente. Las pocas llamadas que vemos como objetivos de alta calidad,
de alto valor. Esto podría ser sólo por casualidad. La misma prueba. También lo puedo hacer dando clic en test stat, estadística básica. Y guardaré una prueba t de muestra, una o más muestras,
cada una en una columna. Voy a flick su TDAH selecto. Quiero realizar pruebas de
hipótesis. media hipotética es siete. Voy a Opción y digo, cuál es la
hipótesis alterna que quiero definir. Quiero definir que la media real es
mayor que la media hipotética. Da clic en Ok. Si necesito grafica, puedo poner estas gráficas. Haga clic en Ok, y
haga clic en Ok. Obtengo esta salida. Entonces la estadística descriptiva, esta es la media, esta es la
desviación estándar y así sucesivamente. La hipótesis nula es mu
es igual a siete. La hipótesis alternativa es
mu es mayor que siete. El valor P es 0.278. Concluyendo ese vuelo nulo, no
logramos rechazar
la hipótesis nula, concluyendo que el tiempo
promedio de 100 es alrededor de siete minutos.
Vamosa continuar. Recibimos nuestra salida. Vimos todo esto, y hemos concluido que
el tiempo promedio de manejo no
es significativamente
mayor a siete minutos.
28. Ejemplo de prueba de 2 t 1: Hagamos un ejemplo más
de dos equipos, dos muestras. lo que en este ejemplo, dos equipos cuyo desempeño
debe medirse. El directivo de DMB afirmó que su equipo tiene mejor
desempeño que el ADN. El directivo de un equipo aboga por que esta
afirmación sea inválida. Vayamos a nuestro conjunto de datos. Entonces si vas al archivo
del proyecto, tendrás algo
llamado como equipo a y equipo B. Así que déjame copiar esos datos. De acuerdo. Déjame ir aquí y colocar el
radar del lado derecho. Por qué también puedo hacer puedo tomar una hoja nueva y pegar los datos. ¿ Verdad? Entonces vamos a pasar a como hipótesis, prueba t
de dos muestras. Permítanme eliminar este valor. Y TB, el equipo a es
diferente de la VM. También puedo decir con base
en la hipótesis que es equipo se reclama que
su equipo es mejor que un. entonces puedo decir que es menos que
TV. Y hago clic en Ok. Nuevamente, en este ejemplo, obtengo una salida que dice que el equipo no es
significativamente menor que TB. ¿ Tiene los
valores de 27.727.3? No hay diferencia
estadística entre ambas puntas, ¿verdad? Entonces los dos ejemplos que
obtuvimos fueron así. Entonces vamos a ver
un ejemplo más. He tomado el tiempo
de ciclo del proceso uno y el
tiempo de ciclo del proceso B. Así que solo copiemos estos datos. Este es otro conjunto de datos. Y voy, ¿Cuál es mi hipótesis
alterna? Ambas vigas son diferentes. ¿ Cuál es la hipótesis nula? Ambos equipos son iguales. Porque estos dos
equipos son diferentes. Voy a seguir adelante y hacer
mi prueba t de dos muestras. Los datos de cada
equipo son separados. Y estoy viendo que es
diferente a la TB el valor alfa es del 5%, y luego hago clic en, Ok. Ahora bien, si ves la
salida esta vez, dice
que sí, el tiempo de ciclo de a es significativamente
diferente del tiempo de ciclo de dB. Aquí, este 26.8,
veintisiete punto seis. Pero si miro
la distribución,
la distribución que este rojo no
se superpone
con este rojo. Por lo que hay una diferencia en el tiempo de ciclo de los dos equipos. Si tengo que hacer lo
mismo usando estadísticas, estadística
básica, prueba t
de dos muestras. Al igual que tu momento de
ser e a la hora de las opciones de TB, ¿hay diferentes? Puedo tener mis gráficas. No quiero una gráfica
individual. Solo tomaré la
gráfica de caja y diré, ok, mu1 es media poblacional del tiempo de
ciclo de procesos, tiempo de
ciclo del proceso B. Ahora si verás que hay una desviación estándar
que es una diferencia. El valor p es 0,
diciendo que, sí, hay una diferencia significativa
entre ambos equipos. Sea bajo, ninguno fresco. Entonces aquí estamos rechazando
la hipótesis nula, diciendo que hay una diferencia significativa
entre E y D. ¿
Verdad? Yo he visto lo mismo
con la distribución continúa. Entonces hay una distribución
más grande o aquí y hay una distribución
más pequeña. Puedo hacer mi
análisis gráfico que sí aprendí a
tu derecha y luego ver cómo se está desempeñando
el equipo. Entonces este es el resumen del ADN. La media es 26, la
desviación estándar es 1.5. Y si me desplazo hacia abajo, me pongo por el equipo B y
viene de esta manera. Ahora quiero solapar
estas gráficas para poder clic en gráfica
y un histograma. Y voy a decir un poco en
forma y sedosa. Y seleccionaré estas dos gráficas en
panel separado de la misma gráfica, misma vitamina C max. Da clic en, Ok. Da clic en Ok. ¿ Puedes ver que la curva
de campana de ambos son diferentes? Hagamos un histograma
gráfico superpuesto. Y en
superposición de suelo múltiple en esta gráfica. ¿ Ves que el azul y el rojo,
hay diferencia? Y de ahí, sí, la
curtosis es diferente, el sesgo es diferente, y esa
es la conclusión en mi prueba t de dos muestras, que dice que la distribución allí es una significativa
diferencia. Existe una diferencia estadísticamente
significativa entre el tiempo sagrado de ser combatiente
EN, moribundo. La segunda cosa, vamos a aprender acerca de la cama t-test
en nuestro siguiente ejemplo.
29. Ejemplo 2 de prueba t: Vayamos a nuestro ejemplo. Dos. Existen dos centros cuyo desempeño
debe medirse. El directivo de
sensorial afirmó que su equipo es un
equipo de mejor desempeño que el centro B. La magnitud del centro sea aboga por que el
reclamo sea inválido. Nuevamente, seguiré
mi proceso de cinco pasos. ¿ Cuál es la
hipótesis alternativa? Es mejor que B. Hagámoslo más fácil. No es igual a T, no
es igual a TB, o centro no es
igual a centro. Lo que hace el centro
no hipótesis a es igual al centro V, nivel de significancia,
cinco por ciento. ¿ Cuántas muestras tengo? Tengo dos muestras, editor de
centro y datos del centro B. Debido a que tengo dos muestras, necesito ir para la prueba t
de dos muestras. Vayamos a nuestra hoja de Excel. Tengo los datos para
Centauri y centro B. Voy a
copiarlos en Minitab. Estoy colocando mis datos aquí. Hagamos la prueba t de dos muestras. Entonces voy a Stat, Basic Statistics y
digo test t de dos muestras. Ambas muestras
están en una columna. Cada muestra tiene su propia columna, así que voy a
seleccionar esta muestra. Una es la muestra sensorial. ¿ Centro B? La opción es híbrida. Eso no es diferente. Entonces la diferencia
entre a y B es 0. Y yo sigo adelante y lo hago. Puedo tener mi gráfica
de caja individual y decir OK, y decir Ok,
veamos la salida. Entonces los datos sensoriales son
tuyos y los datos de TBI están aquí. Y si ves el valor p, el valor p es alto. De nuevo, me llegó un ejemplo que
dice que ser alto mosca nula, lo que significa que no hay diferencia entre centro y centro B. Si ves el valor individual, pero ves lo mismo. Veamos el diagrama de caja. La gráfica de caja dice
que la media no es significativamente
diferente porque habría tomado una muestra. Esa es la razón por la que es, y estás viendo un valor de 0, que es un valor atípico. Por lo que deberíamos estar
considerando eso. Lo mismo. Déjame hacerlo usando pruebas de
hipótesis. Prueba t de dos muestras, media de la muestra. La muestra es diferente. La media de centro
es diferente a la media del centro B y C. Bien. También lo hace la diferencia de medias, la media de Santa Fe no es significativamente diferente
de la media fuera del centro. ¿ Verdad? Si ves esta distribución, puedes encontrar que la parte roja está completamente superpuesta
entre sí, diciendo que
no hay evidencia suficiente para concluir que
hay una diferencia. Hay una diferencia cuando
ves la media, 6.86.5. Pero eso podría ser
por una oportunidad. Y hay una
desviación estándar también. De ahí que estos lo muestren
usando las barras rojas, diciendo que no hay una diferencia significativa entre la semana
sensorial y la semana central. Seguiremos aprendiendo sobre otros ejemplos en
el próximo video.
30. Prueba t emparejada: Entendamos
un ejemplo más. Este es un ejemplo
de prueba t pareada. Si nos fijamos en este estudio de caso, los psicólogos
querían determinar si un programa de running en particular tiene un efecto en su frecuencia cardíaca en
reposo. la frecuencia cardíaca de midióla frecuencia cardíaca de
15
personas seleccionadas al azar. Después se puso a la gente en un programa en marcha y se
volvió a medir después de un año. Entonces, ¿están
diciendo los participantes antes versus después? Sí. Y esa es la razón por la que no
es prueba t de dos muestras, sino que es una prueba t pareada, la
medición del antes y el después de cada persona o en
bandas de observación. Entonces si vuelvo a mi conjunto de datos, tengo algo llamado
como antes y después, hay una etapa diferente, no
estoy tomando el valor de
diferencia. He tomado los datos de
las 15 personas y
puesto en mini tabulador. ¿ Verdad? Ahora, quiero hacer porque es la misma persona
antes y después de mí, queremos entender las
diferentes pruebas de hipótesis. Voy a tomar la prueba t emparejada. Lo primero fue, ¿cuál es la hipótesis alternativa? Antes y después es diferente. Si recuerdas, el programa
de antes y después, quieren determinar si
tienen un efecto en la carrera. El de medición está antes, herramienta
de medición está arriba. media de antes es
diferente de la media de después. Entonces esa es mi hipótesis
alternativa. Entonces, ¿cuál es la media
de mi
hipótesis nula de antes es que no hay cambio. El suplente ve que el antes
es diferente al después. El valor alfa es 0.05. Demos click en Ok. Veamos la salida. Entonces, ¿difiere la media? ¿ Qué es un valor p de 0.007? La media de antes es significativamente diferente
de la media de después. Si nos fijamos en el
valor medio, fue 74.572.3. Pero hay una diferencia. Entonces si ves la
diferencia es más de 0. Y si miro estos
valores de antes versus después el punto azul es después
del punto negro es antes. La mayoría de los participantes, su frecuencia cardíaca se había reducido
después del programa de running. Pocos de ellos eran excepciones, pero eso podría ser una excepción. No hay diferencias
pareadas inusuales porque nuestro
tamaño de muestra es de al menos 20. La normalidad no es un tema. La muestra es suficiente para detectar la diferencia
en la media. Entonces puedo ver que, sí, hay una diferencia
entre ambos. Maravilloso. Por lo que de nuevo, revisión rápida. Hola, objetivo nulo ya el valor p es menor que
el nivel de significancia, concluimos que existe una diferencia significativa
entre ambas lecturas. Si tengo que hacer la escena, hago clic en Stat, Estadística
Básica. Mal detesto, cada
muestra en una regla. Antes, después de la opción
es que son diferentes. Déjame tomar sólo la
gráfica de caja y el histograma de no quiero
escoger el histograma. Yo sólo tomaré la trama de caja. Hipótesis nula. La diferencia es 0. La hipótesis alternativa es que la
diferencia es distinta de cero, valores p bajos, concluyendo que rechazo
la hipótesis nula. Y hay una diferencia
al adoptar el programa. Entonces, si ves el valor nulo, el punto rojo está muy lejos de la media del
intervalo de confianza de la caja hacia conclusión de que
hay una diferencia entre someterse al programa por este especialista del corazón, ¿verdad? Por lo que en el próximo programa, aprenderemos,
retomaremos más ejemplos.
31. Una prueba Z de muestra: El rápido repaso de
los diferentes tipos de pruebas que
aprendimos es que si estoy viendo qué tan diferente es mi grupo y entre
la población, voy por una prueba t de una muestra. Cuando tengo dos
grupos diferentes de muestras, entonces voy por la prueba t de dos muestras. Si estas muestras
son independientes. Si voy a ir por
una prueba t emparejada. Prueba t emparejada. Si el grupo el
mismo conjunto de personas, pero es o diferente
punto del tiempo. Al igual que vimos el ejemplo
del latido del corazón. Por lo que la gente se midió
en sus latidos del corazón. El informe a través de
un programa en ejecución y publicar el programa en ejecución. ¿ Cómo estuvo ese
latido caliente en reposo, verdad? Entonces esas son las
cosas que arreglamos. Ahora sigamos
con más ejemplos. Por lo que agregamos en el caso de uso número cinco, análisis de porcentaje de grasa. Los científicos para una empresa que fabrica proceso que quieren S el porcentaje de grasa en la fuente de
agua de la empresa. La fecha de publicación del anuncio
es del 15% y los científicos miden que el porcentaje
de grasa es de 20 muestras aleatorias. La medición previa de la
desviación estándar poblacional es 2.6. Ahora esta es la desviación
estándar de la población. La desviación estándar
de la muestra es 2.2. Cuando conozco el parámetro de
población, puedo seguir adelante y
usar una
prueba z de muestra porque el número
de muestras que tengo es uno. Y quiero, tengo la conocida desviación estándar
de la población. Ahora, de nuevo, voy a aplicar lo mismo definido la hipótesis
alterna, ¿no? Entonces, ¿qué voy a decir? ¿ Cuál es la hipótesis alternativa? El porcentaje de grasa
no es igual a 603050. ¿ Cuál es el porcentaje de
grasa de hipótesis nula es igual al 15%. Nivel de significancia
cinco por ciento. Porque sé que es
una prueba de una muestra y tengo la desviación
estándar poblacional. Voy a usar
una prueba z de muestra. Hagamos el análisis. He abierto el archivo del
proyecto y tengo los ID de muestra y provoco un dato de
porcentaje de grasa por aquí. Permítanme copiar estos
datos en Minitab. Pero copiado el porcentaje de grasa con los
científicos lo han hecho. Debido a que sabemos que
la desviación estándar de la población, puedo seguir adelante y usar la prueba z
de una muestra. Mis datos están presentes en una columna. Es el hecho presentado. La
desviación estándar conocida fue 2.6. Quiero realizar pruebas de
hipótesis. Media hipotética, es 15%. Entonces mi hipótesis nula es que el porcentaje de grasa
es igual a 15. Mi hipótesis es que la grasa era una
gran a no es igual a 15. Puedo escoger una gráfica de boxplot
e histograma y decir, Ok,
te mostraré la salida. Entonces la hipótesis nula es que el
porcentaje de grasa es igual a 15. La hipótesis alternativa
es que el porcentaje de grasa no
es igual a 15. El valor alfa es 0.05. Mi valor p es 0.012, ya que mi valor p es
menor que el valor alfa, P bajo, ninguno fresco. Por lo que rechazo la hipótesis nula, concluyendo que el
porcentaje de grasa no es igual a 50. Si ves por aquí, el porcentaje de grasa
es más de 50. Puedo rehacer la misma
prueba. Esta vez. Yo puedo seguir adelante y comprobar. Es mi porcentaje de grasa
mayor a la media hipotética. Hagámoslo. Y aun así obtengo mi
valor p con más confianza, 0.006 muy lejos de
mi valor Alfa. Concluyendo que sí, el Alfa, se plantea
la
hipótesis del valor nulo, la media es 15. Pero la muestra dice que
hay una alta probabilidad de que su porcentaje de grasa en la
fuente sea superior a 50. ¿ Cuál es la asesoría que le
daremos a la empresa? Aconsejaremos a la empresa
que no se puede vender el naming que el contenedor es del 15% porque nuestro factor
es más del 15%. Entonces, para estar seguros, puede cambiar la
etiqueta del producto por
decir que el
porcentaje de grasa es de 18, ¿verdad? Porque tenemos el cinco por
ciento está pasando por 20. Por lo que un consumidor estará encantado de
recibir un producto que
esté conteniendo menos grasa. Entonces recibir un producto
que esté conteniendo más grasa porque todos somos
conscientes de la salud, ¿verdad? Entonces sigamos
en la siguiente clase.
32. Una prueba de proporción de muestras 1p-test: Continuaremos con nuestras pruebas de
hipótesis. A veces podríamos tener una proporción de
la acción, ¿no? No tenemos promedios o desviación
estándar
o varianza para medir, sin embargo,
que estamos haciendo. Tomemos este ejemplo seis, el analista de mercadotecnia
quiere determinar si el macho, el anuncio del
nuevo producto resultó en una tasa de respuesta
diferente a la media nacional. Normalmente cada vez que pones un
anuncio en el periódico, dicen que hay la empresa publicitaria suele ver es que vamos a poder impactar 6% resultado
o 10% resultado o algún número resultado aquí mismo. Lo que es, es el mismo
tipo de escenario. Aquí. Tomaron una muestra
aleatoria de 1000 hogares que han
recibido publicidad. Y de estos 10
mil hogares, muestra 87 de ellos realizó compras después de recibir
este engrandecimiento. Por lo que esta empresa, que es
una empresa de publicidad, está afirmando que he tenido
un mejor impacto que el de los
demás anuncios publicitarios. El analista tiene que realizar la prueba z de una proporción para determinar si
la proporción de hogares que realizaron una
compra fue
diferente a la media nacional
de 6.5 porque esta es 8.7. En este caso. ¿ Cuál es su hipótesis
alternativa? Hipótesis alternativa es que el
anuncio es
diferente a
la respuesta al anuncio es
diferente de la media nacional. Aquí diremos que no
hay diferencia. Ambos son pecado, el valor
alfa es del cinco por ciento. Y vamos a
tomar una proporción,
prueba z, prueba de proporción de eventos. Se supone que
te lleve al minuto. Entonces vayamos a MinitaB. Yo puedo seguir adelante y estos papás, estadística
básica,
una proporción. No tengo datos en mi columna, pero sí los he resumido, ¿verdad? Entonces déjame cerrar esto, cancelar, déjame cerrar esto. Por lo que he tomado una prueba
de proporción de muestra. Tengo datos resumidos. ¿ Cuántos eventos hemos
estado absorbiendo? Estamos observando 87
eventos por suceder. La muestra es de mil. Necesito realizar prueba de
hipótesis y la proporción hipotética,
6.5, 0.0656% .5, ¿verdad? Por lo que es 0.065. Esta proporción no es igual
a la proporción hipotética. Yo digo: Ok, ya veo, Ok. Ahora la hipótesis nula es que la proporción es
igual a 6.5 por ciento. Hipótesis alternativa es
que el impacto proporcional no
es igual a 5.56 por ciento. El valor P es 0.008. ¿ Qué significa? Sí, sea bajo, ninguno fresco. Por lo que rechazamos la hipótesis
nula, concluyendo que el efecto
del anuncio, Él no es 6.6.5 por ciento, pero es más
porque si se ve el intervalo de
confianza del noventa y cinco por ciento, dice 0.7% a 10%, ¿verdad? Tienes una
proporción del 88.7%. Y el
intervalo de confianza de proporción de 95% está muy por delante de 6.5,
comienza a partir del 7. Por lo que podemos concluir que hay un impacto significativo
del anuncio y podemos
repasar esta empresa publicitaria. Continuemos en
nuestra siguiente lección.
33. Prueba de proporción de dos muestras - 2p-test: Hagamos este ejercicio una vez
más usando Assistant. Por lo que tenemos los
80 productos de carne de res numerados por el proveedor E que
hemos comprobado. 725 son defectuosos
o no defectuosos. Entonces, ¿cuántos es eso efectivo? Entonces si hago una resta, sería 777802 menos 725 es 77712 productos de muestreo el proveedor B fueron
seleccionados por 73. Perfecto. Entonces, ¿cuánto es
defectuoso? Uno, 39. Así que intentemos hacer nuestra prueba de
dos proporciones usando asistente de
Minitab ya que esto
luego prueba de hipótesis, piezas de
muestra, heces,
porcentaje de muestra defectuosa proveedor E, 0 a 7771 a 139. La persona es defectuosa del proveedor E es
menor que el porcentaje defectuoso del proveedor B. Voy a seguir adelante
y dar clic en Ok. Y eso lo consigo. Sí, ese porcentaje
defectuoso o proveedor es significativamente
menor que el porcentaje defectuoso del proveedor B. Y si me desplazo hacia abajo, Sí. Por lo que dice la diferencia, este proveedor a es la preparación de
lectura. Que a partir de la prueba se puede concluir que el porcentaje
representado del proveedor a
es menor que el Proveedor B con un nivel de significancia del
5%. Cuando se está viendo
este porcentaje. Además, se puede ver
claramente que
continuaremos con la
próxima prueba de hipótesis en la próxima semana.
34. Dos muestras proporcionales test-2p-test-Example: Ahora entendamos
el siguiente ejemplo. Este es un ejemplo donde los gerentes de
una operación
muestrean un producto
fabricado con materia prima de dos proveedores, determinan si uno de
los suministros de materia prima es más probable que produzca
una mejor producto de calidad. Por lo que 802 productos fueron
muestreados del proveedor E 725 o perfecto, que no
es defectuoso. muestrearon 712 productos del
Proveedor B, 573 o buffet. Es decir, no es defectuoso. Por lo que queremos realizar
porque ¿cuál es su porcentaje de datos personales
no defectuosos? Sí, tengo dos proporciones, array
de suministro y Proveedor B. Pasemos a principal. Puedo ir a Stat, Estadística
Básica prueba de dos
proporciones. Tengo mis datos de resumen,
los iguala por la primera facilidad, 725 o ambos actúan fuera de 802. Entonces tomemos
725025723712572371. La opción con ellos
viendo es que hay una diferencia y
vamos a averiguarlo. Entonces el BVA, la hipótesis nula, es que no hay diferencia
entre la proporción. Hipótesis alternativa es que hay una diferencia entre
ambas proporciones. Cuando estaba
mirando el valor p, el valor p sale a ser Z, a ser nulo bajo. Se concluye que
tengo que rechazar la hipótesis
nula. Existe una diferencia en el desempeño de
los dos proveedores. Ahora, si pienso en
porque estoy
hablando de perfecto o
no defectuoso, actualmente, muestra uno tiene 90% perfecta y la muestra dos tiene 80% perfecta. Entonces concluyendo que el proveedor E es mejor proveedor
que el Proveedor B. ¿
Verdad? Entonces, muchísimas gracias. Seguiremos en
la siguiente lección.
35. Uso de Excel = un test de t de muestra: Muchas veces entendemos
prueba de hipótesis, pero hay un
reto que tenemos. El reto es que
no tengo minitaB conmigo. ¿ No puedo hacer prueba de
hipótesis con una manera fácil en lugar de pasar por un cálculo manual usando calculadora
estadística? No te preocupes de que sea posible. Te voy a mostrar
cómo puedo llegar a hacer prueba de hipótesis usando
Microsoft Excel. Ir a Archivo. Ir a Opciones. Cuando vaya a Opciones,
vaya a Complementos. Al hacer clic en Complementos. Déjame dar click aquí. Tiene una opción
que se denomina complemento de
Excel en
la opción Administrar. Por lo tanto, seleccione complemento de Excel
y haga clic en Ir. Haga clic en Herramientas de análisis y asegúrese de que esta
marca de verificación esté activada. Una vez que tengas eso, lo encontrarás
en tu pestaña Datos. Tienes disponible
análisis de datos. Si déjame hacer clic en él para que entiendas
lo que es posible. En análisis de datos. Tengo correlación OR, covarianza,
estadística descriptiva, histograma, prueba T, pruebas z, generación de
números aleatorios, regresión de
muestreo
y todas esas cosas. Por lo que se está volviendo muy fácil para ti hacer pruebas de hipótesis. Al menos la hipótesis de
datos continuos se probó fácilmente a través de
Microsoft Excel también. Te voy a llevar por el ejercicio
paso a paso por ahora. Volvamos a
la presentación. Tomemos el primer problema. Es decir, tengo las estadísticas descriptivas
para el HD de la convocatoria, el encargado de los
procesos que su equipo está trabajando para cerrar la resolución sobre la llamada en siete minutos. Pero el cliente
ve que se mantiene en espera durante mucho tiempo, y de ahí que esté gastando
más de siete minutos. Si miro la estadística
descriptiva, me
está diciendo diez minutos, mediana es siete, la media es 7.1. Ahora me gustaría hacer este análisis usando la salida de
Microsoft. Así que comencemos. Tengo este caso de uso en los datos del proyecto
que he subido, click en TEA,
claro, te lleva a este lugar. Ahora, primero te
enseñaré a hacer estadísticas
descriptivas
usando Microsoft Excel. Voy a dar click en el
análisis de datos debajo de la pestaña Datos. Voy a buscar estadísticas
descriptivas. Haga clic en, bien. Mi rango de entrada es de
aquí a abajo. He seleccionado. Mis datos están agrupados por columnas. La etiqueta está presente
en la primera fila. Y quiero que mi salida
vaya a un nuevo libro de trabajo. Quiero
estadísticas resumidas y quiero nivel de
confianza de
mí. Doy clic en Aceptar. Excel está haciendo algunos cálculos y preparándolo para ello. Sí. Aquí está mi salida. Hago clic en ex por aquí
para ver cuál es la salida. Entonces puedes ver que eres media, modo
mediano,
desviación estándar, curtosis, asimetría, rango,
mínimo, máximo,
suma, conteo, nivel de confianza. Todas estas cosas se
calculan fácilmente con un
clic de un botón. No tengo que escribir
tantas fórmulas. Ahora, volvamos
a nuestro conjunto de datos. Yo quiero hacer las pruebas de
hipótesis. ¿ Cuál es mi hipótesis nula? Cuando la hipótesis nula es que el TDAH es igual
a siete minutos. Hipótesis alterna. El TDAH no es de siete minutos. Hay un
valor alfa diferente que estoy configurando como 5%. Y con eso, voy a
realizar las pruebas que
voy a conectar es
una prueba t de una muestra. Cuando estés haciendo
una prueba t de una muestra usando Microsoft Excel, tendrás que
seguir un pequeño truco. El truco es, voy a
insertar una columna por aquí. Y esto, voy
a llamarlo como maniquí. Porque Microsoft Excel viene con una opción de prueba t de
dos muestras. Tengo HD de la llamada en minutos y maniquí donde he
anotado a ceros, ceros. No obstante, la mediana promedio, todo para 0 es siempre 0. Haga clic en el análisis de datos. Voy a bajar y diré dos muestras t-test
asumiendo igual varianza. Voy a seleccionar esto. Voy a hacer click en, Bien. Mi rango de entrada,
uno es esta línea. Mi rango de entrada
a través de este maniquí. Mi
diferencia media hipotética es de siete minutos. Etiqueta está presente
tanto en el valor Alfa
establecido como cinco por ciento. Y estoy diciendo que
mi salida tiene que
estar en un nuevo libro de trabajo. Doy click en Bien, está haciendo el cálculo
y consiguiéndome la salida. Se puede ver que los números se
han transmitido como práctica, simplemente
hago clic en el karma en la sección Formato para que
los números sean visibles. Estoy cambiando la vista porque dummy
no tiene ningún dato. Soy libre de seguir adelante
y eliminar esta columna. Ahora vamos a entender
¿qué buscamos siempre? Buscamos este
valor, el valor p. ¿ Recuerdas la fórmula? Déjame traer mis
fórmulas por aquí. Sí. ¿ Cuál es la conclusión? La conclusión es P alta. No puedo rechazar la hipótesis
nula. Concluir el TDAH de
la convocatoria es de siete meses. Estoy rechazando la hipótesis
alternativa porque mi valor p
está más allá de 0.05. Estaré retomando más ejemplos
en las siguientes lecciones. Por lo que estoy deseando
que continúen con esta serie. Si tiene alguna duda, le
solicitaría que deje caer sus preguntas en la sección de
discusión a continuación, y estaré encantado de
responderlas. Gracias.
36. Análisis de correlación: Bienvenido a la siguiente lección de nuestra fase analizada en el ciclo de vida dMac de un proyecto
Lean Six Sigma A veces nos metemos en
una situación nos gustaría hacer un análisis de
correlación. Y de ahí, pensé que hoy debería estar
sumergiéndote profundamente en lo que es correlación ¿Cuál
es la diferencia entre correlación
y siniestro ¿Cómo interpreto la correlación cuando
miro el diagrama de dispersión? ¿Qué
nivel de significancia puedo
establecer cuando estoy haciendo mi prueba de
hipótesis? La correlación de Pearson, la correlación de
Spearman, correlación serial del
punto b y cómo hacer estos cálculos en línea usando algunas de
las Así que comencemos. Entonces, ¿qué es exactamente el análisis de
correlación? El análisis de correlación es una técnica
estadística que te
da información sobre la relación
entre las variables. análisis de correlación puede
calcularse para investigar la
relación de las variables, qué tan fuerte está determinada la
correlación por el coeficiente de correlación, que se representa por
la letra numérica r, que varía de
menos uno a más uno. Por lo tanto, el análisis de correlación se puede utilizar para hacer declaraciones sobre la fuerza y la dirección
de la correlación. Ejemplo, quieres saber si existe una correlación
entre la edad a la que un niño pronuncia su primera oración y
después el éxito escolar. Entonces se puede utilizar el análisis de
correlación. Ahora, siempre que trabajamos con correlación,
hay un reto. A veces nos confundimos con
cosas que son un problema. Al igual que, si el análisis de
correlación muestra que dos características están relacionadas entre sí, se
puede verificar sustancialmente si una variable puede usarse para
predecir las otras variables. Si se
confirma
la correlación mencionada el ejemplo, por ejemplo, se puede verificar si el éxito escolar
puede predecirse por la edad a la que el niño
pronuncia su primera oración, significa que existe una ecuación de regresión
lineal. Tengo un video separado sobre cómo explicar qué es
una regación lineal Pero cuidado, la correlación
no necesita tener una relación causal Significa que cualquier correlación que pueda descubrirse
debe, por lo tanto ,
ser investigada más de cerca por el
experto en la materia, pero nunca interpretada
inmediatamente en términos de contenido, aunque sea muy evidente. Veamos algunos de los ejemplos de correlación y causalidad. Si se analiza
la correlación entre la cifra de ventas y
el precio, se identifica una fuerte
correlación. Sería lógico suponer
que la cifra de ventas está influenciada por el precio
y no por la persona sabia. El precio no sucede
al revés. Esta suposición, sin embargo, de ninguna manera puede probarse sobre la base de un análisis de
correlación. Además, puede suceder
que la correlación entre la variable x e y sea
generada por la variable. De ahí que lo estaremos cubriendo en correlación parcial con más detalle. Sin embargo, dependiendo de
qué variable se pueda usar, es posible que pueda hablar una relación
causal desde el principio. Veamos un
ejemplo si existe una correlación entre
la H y el salario. Es claro que la edad
influye en el salario, no al revés. El salario no
influye en la edad. Entonces solo porque mi
edad esté aumentando, o simplemente porque
tenga un salario más alto no significa que
voy a ser viejo. De lo contrario, todos
querrían ganar el menor
salario posible. Eso es solo amor. Interpretar la correlación. Con la ayuda del análisis de
correlación, se pueden hacer
dos afirmaciones. Uno sobre la dirección
de la correlación, y otro sobre la fuerza. De la relación lineal de las dos métricas o las variables de escala
ordinariamente La dirección indica si la correlación es
positiva o negativa. Si la fuerza
dicta si la correlación entre la
variable es fuerte o débil Entonces cuando digo que existe una correlación positiva entre nosotros estamos tratando de decir que los valores mayores de la
variable x van
acompañados de los valores mayores de la
variable y y no al revés. La altura y el tamaño del zapato, por ejemplo, están
correlacionados positivamente. La correlación
cofiente se encuentra 0-1. Es decir, es un valor positivo. La correlación
negativa por otro lado existe si un
valor mayor de la variable x va acompañado del menor valor de la variable
y y al revés. El precio del producto y la cantidad de ventas suelen
tener una correlación negativa. Cuanto más caro es un producto menor
es la cantidad
de ventas. En este caso, el coeficiente de
correlación estará entre
menos uno y cero, asumiendo que es un valor negativo. Por lo que resulta en uno negativo. ¿Cómo determino la
fuerza de la correlación? Con respecto a la fuerza
del coeficiente de correlación r, la siguiente tabla
puede actuar como guía. Si tu valor está
entre 0.0 y 0.1, entonces podemos decir claramente que no
hay correlación. Si el valor está
entre 0.1 y 0.3, decimos que hay una correlación pequeña
o menor o una correlación. Si el valor está entre 0.32
0.5, correlación media, si el valor está entre 0.5 0.7, decimos que hay una correlación
alta o una correlación fuerte, y si el valor está
entre 0.7 a uno, decimos que es una correlación muy
alta Al final de este módulo, te
mostraré cómo calcular el catión de correlación
directamente en línea también. Entonces, vayamos más allá. Cuando lo haces en línea, obtendrás una
de las herramientas que utilizamos para analizar
la correlación es un diagrama de dispersión porque
tanto la x como
la y son de tipo de datos variables
o tipo de datos métricos
como lo llamas. Tan importante como considerar el coeficiente de correlación
es una gráfica de manera gráfica, podemos usar una gráfica de dispersión Entonces como la edad, el eje x siempre
tendrá la variable de entrada, y el eje y tendrá la variable de salida porque
y es igual a función de x
Y puedo ver que a medida que mi edad va aumentando, mis
salarios aumentan. La gráfica de dispersión
le da una estimación aproximada si la corre si
hay una correlación, y si hay una correlación lineal o no lineal y si
hay algún Cuando hacemos correlación, es posible
que también queramos hacer
nuestras pruebas de hipótesis,
probar la correlación
para determinar la significación. Si hay correlación
en la muestra, aún es
necesario
probar si hay suficiente evidencia de que
la correlación también existe en la población. Así, surge la pregunta cuando la copión de correlación se considera estadísticamente
significativa La significancia de la
correlación esient se
puede probar usando la prueba t Como regla general, se prueba si el coeent de correlación es significativamente
diferente de cero Es decir, se prueba una
dependencia lineal. En este caso, la
hipótesis nula es que
no existe correlación entre las
variables en estudio. En contraste, la hipótesis
alternativa asume que
existe una correlación. Al igual que con cualquier otra prueba de
hipótesis, el nivel de significancia
se establece primero en 5%. El valor Alfa se establece en 5%. Significa que debería tener 95% de confianza en el
análisis que estoy haciendo. Si el
valor de p calculado está por debajo
del 5%, se rechaza la hipótesis nula y se aplica la
hipótesis alternativa. Si el valor de p está por debajo del 5%, se supone que existe una relación entre
la x y la. La fórmula de prueba t que
usamos para las pruebas de hipótesis es r en bajo raíz de n menos dos dividido por debajo
de raíz de uno menos r cuadrado. Donde n es el tamaño de la muestra, r r es la
correlación determinada de la muestra, y el valor
p correspondiente se puede
calcular fácilmente en la calculadora de
correlación. Hipótesis
direccional y no direccional. Con el análisis de correlación se
puede probar para hipótesis de
correlación
direccional o no direccional. ¿Qué entendemos por hipótesis de
correlación
no direccional? Sólo te interesa
saber si existe una relación o una correlación
entre dos variables. Por ejemplo, si existe una correlación entre
edad y salario, pero no te
interesa la dirección
de las relaciones. Cuando estás haciendo una hipótesis de
correlación direccional, también
te
interesa la dirección de
la correlación. Si existe una correlación positiva o negativa
entre las variables. Tu hipótesis alternativa
es entonces ejemplo. La edad está
influenciada positivamente en el salario. lo que hay que
prestar atención es en el caso de una hipótesis
direccional, irá con el
fondo del ejemplo. Entonces vas a ir diciendo eso, ¿hay una
influencia positiva o no? Entonces normalmente, decimos que
no hay correlación y
hay correlación. Pero aquí diremos que no
hay correlación, y la
hipótesis alternativa dirá que hay una
influencia positiva en la ensalada. Entonces ahora pasemos
a la siguiente parte. Ese es el análisis de
correlación de Pearson. Con el análisis de
correlación de Pearson, se obtiene una declaración sobre la correlación lineal entre las variables de escala métrica Para el cálculo se
utiliza la covarianza respectiva. La covarianza da
un valor positivo si existe una correlación
positiva entre las variables
y un valor negativo si existe una correlación negativa
entre las variables La covarianza se
calcula como COV o covarianza de X se calcula usando la fórmula
dada en la No te preocupes. No tenemos que
calcularlo manualmente. Entonces tenemos sistemas y herramientas que pueden hacer
ese análisis por nosotros. Sin embargo, la covarianza
no está estandarizada y puede asumir valores entre
más y menos infinito Esto hace
difícil comparar la fuerza de la relación
entre las variables. Por esta razón, el coeficiente de
correlación es también una correlación de
movimiento del producto. Y esto se calcula
de una manera diferente. El coeente de correlación se obtiene normalizando Para esta normalización,
la varianza de las dos variables se
calcula según lo dado por. El
coeent de correlación de Pearson ahora puede tomar valores de menos uno a más uno y
se puede interpretar El valor de menos uno
significa que hay una relación
lineal completamente positiva, y cuanto más menos uno indica que existe una
relación completamente negativa. Cuanto más y menos. Con el valor de cero, no
hay relación lineal. La variable no se
correlaciona con cada una. Correlación de más uno se
verá algo así, lo cual sólo es
posible en teoría. Correlación de 0.7 plus se
verá algo así, donde va en
un lado positivo, y la mayoría de los
puntos están más cerca del eje a la luz de
regresión. dispersará una correlación de más
tres, pero va en una dirección
positiva. Cuando haces una correlación
tienes una correlación de -0.7, todas
están dispersas
moviéndose hacia abajo Entonces, a medida que aumenta el valor de x, el valor de y se reduce, y la mayoría de los puntos se encuentran dispersos alrededor de
la regresión ide. Obtenemos el valor
de correlación de cero de múltiples maneras, o los puntos están
completamente dispersos, o podrías obtener algunas líneas
perfectas como esta o así, que de nuevo, no lo
sería, lo que
significa que
necesitas tomar algún otro análisis para interpretar las variables Ahora, finalmente, se
puede interpretar la fuerza
de la relación y esto se puede ilustrar con el
siguiente cuento. La fuerza de la correlación. Si es 0-0 0.1, no
hay correlación Si es de 0.1 a 0.3, hay una pequeña correlación 0.3 a 0.5 correlación media, 0.52 0.7, muy alta perdón, alta correlación, y 0.7 a uno es una correlación muy
alta Para verificar de antemano si existe una relación
lineal, se deben considerar las gráficas de
dispersión. De esta manera,
también se puede verificar visualmente la relación
respectiva entre las variables. La correlación de Pearson solo
es útil
y útil si las relaciones demor La correlación de Pearson
tiene ciertos ems, que debes tener
en cuenta Para PSM, siempre que
estés usando esto, las variables deben estar distribuidas
normalmente, y debe haber una relación
lineal entre las variables La distribución normal se
puede probar ya sea analítica o gráficamente
usando la gráfica QQ, cual
te enseñaré a hacer Si las variables tienen
una correlación lineal, se verifica mejor
con el diagrama de dispersión. Si no se cumplen las condiciones, entonces se puede utilizar la
correlación de Spearman Entonces espero que tengas
claro hasta aquí, y sigamos con nuestro
aprendizaje. Vamos a continuar. Qué hacemos cuando
mis datos no son normales y quiero establecer
un análisis de correlación. En este caso, utilizamos la correlación de rangos de
Spearman. análisis de correlación de rangos de Spearman se utiliza para calcular la relación
entre dos variables que tienen un
nivel de medida ordinal. Cuando se tienen datos variables, o puedo decir datos continuos, estamos usando análisis de
correlación normal
como el análisis de
corrección de Pearson Pero si mis datos son ordinales
o no paramétricos, entonces puedo seguir adelante con el análisis de correlación de
Spearman Por lo tanto, este procedimiento se utiliza cuando el requisito previo del análisis de
correlación, es
decir, no se
cumple
el requisito previo del análisis de
correlación, es
decir,
los procedimientos paramétricos o cuando no
hay datos métricos o variables
continuas,
y los datos no son cumple
el requisito previo del análisis de
correlación, es
decir,
los procedimientos paramétricos o cuando no
hay datos métricos o variables
continuas, normales En este contexto,
ofrecemos referirlo como correlación de
Spearman
o fila de Spearman Se entiende la correlación de rangos de
Spearman. Entonces, la pregunta puede
tratarse como rango de
Spearman es similar a la del coeficiente
de
correlación de Percy? Ejemplos. ¿Existe correlación entre dos variables
o características? Por ejemplo, ¿
existe una correlación entre la edad y
la religiosidad en la población francesa? El cálculo de la correlación de
rangos se
basa en el sistema
de clasificación de las series de datos. Esto significa que las variables
de medida de
rango no se utilizan en el cálculo, sino que se transforman en rangos. Luego se realiza la prueba
utilizando los rangos. Para el
coeficiente de correlación de rango, p, el valor entre menos
uno y uno son positivos. Si hay un valor
menor que cero, p es menor que cero, hay una relación
lineal negativa. Si el valor es
mayor que cero, entonces hay una relación
lineal positiva. Si el valor es cero o cercano
a cero como 0.1 a -0.1, podemos decir que
no hay relación
entre las variables Al igual que con el coefent de
correlación de spareans, la fuerza de la correlación se
puede clasificar de la se
puede Entonces si es 0-0 0.1, no
hay correlación Si es 0.12 0.3, hay una pequeña correlación Si hay 0.3 a 0.5, hay una rretación media Hay 0.5 0.7
correlación alta y 0.7 a uno, correlación
muy alta. Si hay valores negativos, diremos correlación
negativa menor, correlación negativa
alta,
y así sucesivamente y así sucesivamente. Existe otro tipo
de correlación llamada este punto bi correlación
serial. La
correlación puntual bi serial se utiliza cuando una de las variables
es dicotómica Ejemplo, ¿
estudiaste o no estudiaste? El otro es una
variable métrica como salario. En este caso, utilizamos una correlación punto
por serie. La correlación de un punto
por correlación serial es la misma que la correlación calculada de
Pearson Para calcularlo, una de las dos expresiones
del valor dicotómico
se codifica como cero El otro está codificado como uno. Análisis de correlación calculado, te mostraremos usando Excel o las otras herramientas que están disponibles de forma gratuita. Te mostraré el
cálculo después de algún tiempo, pero estudiemos primero el caso. Un alumno quiere saber si
existe correlación entre la estatura y el peso de los participantes en
el curso estadístico Para ello, el
alumno dibujó una muestra, la cual se distribuye a continuación. Entonces tengo las alturas de la gente, tengo los
pesos de la gente. Para analizar la relación
lineal mediante análisis de
correlación, se
puede calcular la
correlación utilizando Excel u otras herramientas
disponibles en línea. Primero copie la tabla en
la calculadora estadística. Después haga clic en correlación
y selecciónela. Y por último,
podrás obtener los
siguientes insertos. Entonces hagámoslo en línea. Entonces he llegado a data tab.net. Se trata de una calculadora
estadística en línea. Los datos de aquí tienen 100% de seguridad de datos porque los cálculos se
realizan en su navegador, y los datos se insertan y almacenan en las cookies de su navegador. Los datos son del 100%, y esa es la razón por la que el
cálculo funciona muy rápido. Los datos por lo tanto
no necesitan un
servidor grande, y por lo tanto usted. Entonces tengo el peso corporal, tengo el peso,
y tengo la edad. Entonces quiero entender. Entonces si bajo,
tengo cortación. Quiero entender si
existe una relación entre la altura de la vía corporal
y el peso corporal. ¿Qué tipo de correlación quiero? Vamos primero con Pearsons.
Hay una correlación. Hay una correlación positiva. Se establece el nivel de significancia. 5% Podemos probar por supuestos, y de inmediato está
haciendo el análisis. Está haciendo la trama QQ por mí. Está dibujando el histograma, y está mostrando
los resultados, ¿verdad? Entonces podemos decir que sí, más o menos los datos se distribuyen
normalmente. Puedo copiar esto haciendo
clic en Descargar PNG, y el archivo se copiará. Y vas a poder
verlo de esa manera. Entonces ahora déjame cerrar esta tumba, así que ha probado para
los supuestos. El resumen en versos, el resultado de la
correlación de Pearson mostró que existe
una correlación positiva muy alta entre el peso corporal, la
estatura y el peso Los resultados mostraron que la relación entre peso
corporal, talla y peso
son estadísticamente significativas con un valor de r
positivo. R es 0.86 y el valor de
p es 0.01. 001. Entonces, cuando se mira la
fuerza de la correlación, si el valor es
mayor que 0.7 y uno, decimos que es una correlación muy
alta y es una decoración positiva. Cuando voy a hacer pruebas de
hipótesis, no
hay correlación o una correlación
negativa entre la altura corporal y el peso. Existe una correlación positiva
entre la estatura corporal y el peso. Cuantos casos
tenemos diez casos. El valor r es 0.86, y el valor p es 0.001, que es menor que 0.5 Por lo tanto, rechazamos la hipótesis diciendo que no
hay correlación, y
se aplica la hipótesis alternativa de que
existe una correlación positiva entre la
altura corporal y el peso. La ventaja de estar en borrador de
datos es que
tienes interpretación de IA. esta tabla se resumen
los resultados
del análisis de
altura corporal y peso, mostrando el
coeficiente de correlación r y el P va El valor del
coeficiente de correlación indica la fuerza y la dirección de la
relación entre la variable de
altura y peso, y el
valor del coeficiente es de 0.86, lo
que sugiere que existe una
correlación positiva muy alta Esto significa que generalmente, medida que aumenta la altura del cuerpo, el peso también tiende a
aumentar y viceversa. El valor P. El
valor p aquí asume que los datos disponibles proporcionan evidencia
suficiente para
rechazar la hipótesis nula. En este caso, la hipótesis
unilateral probada, y la hipótesis nula
estadísticas de que
no hay correlación o correlación negativa entre la altura y el
peso en la población. En la mayoría de los casos, el
valor de p es menor a 0.05, consideramos que existe una significancia
estadística. En nuestro caso, el valor de
p es 0.001, que obviamente es
menor que 0.5. Se rechaza la hipótesis nula, y el resultado de la correlación de
Pearson muestra que existe una significancia estadística de correlación
positiva entre
la altura corporal y el peso Entonces el resultado de la
correlación de Pearson muestra que existe una correlación muy positiva
entre la altura y el peso, y esto se almacena por correlación
positiva
estadísticamente significativa del valor
r como 0.86 y el valor
P es 0.05 Ahora, hay un diagrama de dispersión que se está
haciendo automáticamente. Puedo dar click aquí y
obtener mi línea de regresión. Puedo cambiar mi eje si
quiero no arrancar desde cero, ¿quiero una línea cero? Entonces se incluye el cero, pero no lo quiero.
Puedo cambiarlo. ¿Cómo quiero mi imagen, el PDM extra grande y así Puedo dar click en Descargar TNG
para descargar esta imagen. Ahora, como les dije, también
podemos hacer el cálculo de la covarianza. Entonces, cuando estoy mirando la
altura corporal y el peso corporal, la covarianza es de 1.29, ¿verdad Entonces significa que
hay una relación. Entonces así es como estás
haciendo el cálculo. Ahora bien, para calculadora punto por
serie, podríamos tener un tipo diferente de datos donde
queremos analizar, ¿el cambio de salario tiene algo que
ver con el género Entonces en este caso, estaría seleccionando
el valor métrico como salario y la
variable nominal como género, y luego estaré
haciendo mi cálculo. Establecería al macho como
cero y al femenino como uno. Parcela de caja, que dice que sí, los varones tienden a tener un salario mayor
en comparación con el femenino. Entonces, cuando un estudiante
quiere saber si existe una correlación
entre s intensificados, hemos hecho ese análisis La hipótesis, si se puede
ir por una hipótesis normal, no
hay correlación entre la altura corporal y el peso. Existe una asociación
entre estatura y peso, pero había tomado una
hipótesis direccional en mi prueba. El valor P es este, y
vimos cómo podemos
generar la salida. Primero, obtendrás la hipótesis nula
y alternativa. La hipótesis nula establece que no hay correlación
entre la altura y el peso, y luego tenemos la hipótesis
alternativa que detiene lo contrario Si haces clic en aves submarinas, obtendrás la interpretación,
que acabamos de ver Podemos seguir adelante y
en realidad probamos la hipótesis de
correlación direccional o unilateral. Y en Excel y
hay otras herramientas que
pueden ayudarte a calcular. Entonces acabamos de hacer la prueba, diciendo que no hay correlación
o correlación negativa entre el gen corporal, y hay una correlación
positiva entre el aumento corporal. Y cuando vimos, lo conseguimos,
sí, hay una
correlación positiva positiva, muy fuerte, y de ahí que el valor de p
fue menor que 0.01. En este caso, primero debe verificar si la correlación está en todas las direcciones de
la hipótesis alternativa, es
decir, la altura y el peso
están correlacionados positivamente, y en este caso, el
valor p se divide por dos. De ahí que solo se considere
la distribución unilateral. No obstante, esta herramienta cuida estos dos pasos
y el resumen en verso se da como vimos. Se afirma que existe una correlación
positiva entre la altura y el peso
del conjunto de datos en la muestra. De ahí que podamos decir que hay una significación correlacionada
positivamente, y podemos ver que existe una correlación
muy positiva entre las variables de altura y pt. Así, existe una correlación
positiva muy alta entre la
altura muestral y pt. Con eso, cerraremos nuestro análisis de correlación y veré en
la siguiente clase.
37. Concepto de análisis de correlación de Pearsons: L et's continúan nuestro viaje de
correlación. Hoy voy a cubrir sobre la correlación de
Pearson. análisis de correlación de Pearson es un examen de la relación
entre dos variables Por ejemplo, es una correlación entre la edad de una
persona y el salario. Ambas son variables
continuas, y de ahí que el diagrama
se dispersará. Entonces, a medida que aumenta la edad de la
persona, ¿aumenta el salario? Ahora, debes recordar que
y es una función de x, así tu eje y
tendrá el resultado, y el eje x tendrá
la variable independiente. Más específicamente, podemos usar
el
coeficiente de correlación de Pearson para medir la relación lineal
entre dos variables Si la relación no
es lineal, entonces esta ecuación de correlación no
será de ningún infierno. Creo que habrías
observado que he cambiado mi AR para
esta grabación. Si te gustó, solo pon un pulgar hacia arriba en la sección de
comentarios L et's continúan, la fuerza y la dirección
de correlación. Con el análisis de correlación, podemos determinar qué tan fuerte es
la relación y en qué dirección va
la correlación. Podemos leer la fuerza y
la dirección de correlación en la letra r del
coeficiente de correlación de Pearson, cuyo valor varía de
menos uno a más uno La fuerza de la correlación, la fuerza de la correlación, se puede leer sobre la mesa. El valor r se encuentra entre cero menos uno indica que no
hay correlación. Si la cantidad del valor de
r se encuentra entre 0.7 a uno, es una correlación muy altamente correlacionada,
muy fuerte. Ahora bien, si los valores son positivos, se correlaciona positivamente, y si los valores son negativos, se correlaciona negativamente. Entonces digamos que el valor r
sale como -0.66. Entonces podemos decir que está altamente correlacionado
negativamente. Entonces esto lo he retomado
del libro de estadísticas.
Vamos a contenerlo. ¿Qué quiere decir con la
dirección de correlación? Una correlación positiva
es una correlación existe cuando valores grandes
de una variable se asocian con valores grandes
de otra variable o cuando un pequeño cambio en
una variable se asocia con un pequeño
cambio en la otra variable. Entonces, si es una
correlación positiva, si hay un
valor mayor en el eje x, corresponde a un valor
mayor en el eje y. Y un valor menor en el eje x se correlaciona con un
valor menor en el eje y, como se puede ver en
estas dos imágenes Una correlación positiva da como resultado ejemplos de altura
y talla de calzado. Esto da como resultado una correlación
positiva. Entonces a medida que aumenta la
altura de la persona, el tamaño del zapato
también va aumentando. El resultado es un coefent de
correlación positiva, y r es mayor que cero Ahora bien, ¿viste que hay
un error en esta gráfica? El error es que el
tamaño del zapato es el resultado, y la altura es la variable
independiente, pero lo hemos mapeado sin sentido erróneo para
evitarlo Entonces déjame poner mis
comentarios por aquí. ¿Qué hay de malo en el gráfico de pow? La pregunta es, ¿el
show talla aumenta efecto o da como resultado aumento
de la altura de la persona o hace el aumento de
altura de la persona, sirve aumento
en la talla del zapato Por favor escriba en la sección
diez a continuación. Sí. Recuerda, y es
una función de x. Y aquí, y es la altura de la persona y x es mi error. X es la altura de la
persona e y es el tamaño así. Espero que ahora quede claro lo que
estamos tratando de decir. Entonces y es una función de x. Déjame hacer la letra
una pequeña y porque ese es el proyecto y. X es
la altura de la persona. Entonces aquí, el error es que
lo hemos demostrado de manera equivocada. La correlación negativa
es cuando un valor grande en una variable se
asocia con un valor pequeño en la otra
variable y viceversa. Entonces, si el eje y es grande, el valor del eje x es pequeño. Y si el valor del eje x es grande, el valor del eje y es pequeño. Esto es lo que se llama
correlación negativa. Los puntos están fluyendo. A diferencia de la anterior donde los puntos
fluían hacia arriba. Ahora, la correlación negativa se encuentra entre el
tamaño del producto y el valor de ventas. Esto da como resultado un catión de
correlación negativa. Qué sucede cuando
el precio aumenta, el volumen de ventas disminuye. Y si se reduce el precio, gente tiende a comprar más volumen. Resultando en más ventas. Déjame escribirlo hacer aumentos. Muy bien. Entonces el resultado
es una correlación negativa, el valor coefion de
r es menor que cero Cuanto más fuerte es la correlación, el valor se
acerca a menos uno. Y aquí la gráfica es correcta. A medida que aumenta el precio, los volúmenes van disminuyendo. Ahora bien, ¿cómo calculamos la correlación
cient de Pearson? Eso es algo muy
importante, ¿verdad? El coeficiente de
correlación de Pearson se calcula utilizando la
siguiente ecuación Aquí, r es el coiente de
correlación de Pearson. X i es el
valor individual de una variable. Ejemplo, podría ser
la edad de la persona. X bar es la edad promedio
del conjunto de datos de muestra. Y uno es el valor individual de la otra variable o
la variable de resultado, y la barra Y no es más que el salario promedio
del conjunto de datos de muestra. Entonces aquí, x bar e y bar son el valor medio de dos
variables respectivamente. Este es entero dividido
por debajo
de la raíz de x uno menos x barra cuadrada, y uno menos y barra cuadrada entera. Entonces cuando lo esté cuadrando
y haciendo un under root, se encargará de Entonces x uno son los valores
individuales, e y uno son los valores
individuales de la variable de resultado. R es la correlación de Pearson
y el valor medio. En esta ecuación, podemos ver
que los respectivos
valores medios de la primera restan
de la otra variable En nuestro ejemplo, calculamos que el principal valor
de edad y salario. Luego restamos
el valor principal de cada edad y salario
contra la media Luego multiplicamos
ambos valores. Luego resumimos los resultados
individuales de
la multiplicación. La expiración
del denominador asegura que el
coeficiente de correlación siempre oscila
entre menos uno y más uno. Recuerda, no tienes que calcular
manualmente ninguna de ellas. Actualmente, tenemos estas
características disponibles en Excel y múltiples sitios web
en línea. Si quieres múltiples
dos valores positivos, obtenemos un valor positivo. Y si multiplicamos
dos valores negativos, también obtenemos un valor positivo
menos en menos e más. Entonces, todos los valores que se
encuentran en ese rango son una influencia positiva en
el coeión de correlación A medida que aumenta la edad, el salario va en aumento, medida que la edad va disminuyendo,
los salarios disminuyen. Si multiplicamos
el valor positivo por un valor negativo, obtenemos un valor negativo que
es menos a más es menos. Todo el tiempo,
existe un rango de influencia
negativa en
el coeión de correlación Entonces las cosas que se
resaltan en el cuadro morado, si los datos están
cayendo por ahí, entonces resultará en
una correlación negativa. Por lo tanto, si nuestro
valor es predominantemente dos áreas verdes de las dos cifras
anteriores. Obtenemos una
correlación positiva coeent, y por lo tanto, correlación
positiva Si nuestros puntajes están predominantemente en el área roja de las cifras, obtenemos
correlación negativa coeente y por lo tanto tiene correlación negativa Si los puntos se
distribuyen en las cuatro áreas, términos
positivos y términos
negativos, se cancelan entre sí, y podríamos terminar con correlación
muy pequeña o nula en absoluto. Entonces esta es una parte muy
importante, que hay que entender. ¿Verdad? Si los puntos se
distribuyen en general,
entonces no damos como resultado ninguna
correlación. Ahora bien, ¿cómo son significativas las pruebas de correlación y coeficiente? En general, el coeficiente de
correlación se calcula utilizando un
dato de una muestra En la mayoría de los casos, sin embargo, queremos probar la hipótesis
sobre la población. Debido a que no podemos estudiar la población,
tomamos un muestreo, y tomamos una muestra y
al estudiar la muestra, queremos sacar inferencia
sobre la población En este caso, el análisis de
correlación, entonces
queremos saber si
existe una correlación
en la población. Para ello, probamos si la
correlación coeficiente en la muestra es estadísticamente significativa y
diferente de cero Ahora bien, ¿cómo hacemos las pruebas de
hipótesis? ¿Por la correlación de Pearson? La hipótesis nula y la hipótesis alternativa para las correlaciones de
Pearson son La hipótesis Nulo dice que no
hay correlación y por lo tanto el valor de R no es significativamente
diferente de cero. No hay relación. La
hipótesis alternativa dice que hay una
diferencia significativa, o hay una
correlación lineal a partir de los datos. Atención.
Siempre probamos si la hipótesis nula es
rechazada o no rechazada. Esto es muy, muy importante. Nunca aceptamos o nunca
trabajamos en lo como yo. El caso es que siempre trabajamos para probar o rechazar
la hipótesis nula. Nunca intentamos
probar la alternativa, aunque nuestra investigación inicia
porque hay una alternativa. En nuestro ejemplo, cuando el salario y la
edad de la persona, podríamos así decir la pregunta. ¿Existe correlación
entre la edad y el salario para la población
alemana? Para averiguarlo, dibujamos una
muestra y probamos si el coeficiente de correlación es significativamente
diferente de cero en esta muestra. La hipótesis nula es entonces que no hay correlación entre salario y edad en
la población alemana. La
hipótesis alternativa es que existe una correlación entre el salario y la edad en la población
alemana. La significancia y la prueba. Cuando la prueba de
correlación de Pearson es significativamente diferente encuesta
de
muestra basada en cero, la probamos usando
la fórmula de la prueba t Aquí, r es el coefiente de
correlación, y n es el tamaño de la muestra De nuevo, yo diría
que es bueno conocer la fórmula pero no
perderse en ella. ¿Verdad? Un valor P se puede calcular
a partir de las estadísticas de prueba t, y el valor p es menor que el nivel de
significancia especificado, que suele ser del 5%, luego la hipótesis nula
rechazada, de lo contrario no. Entonces queremos asegurarnos que el valor p es si
es mayor que 0.05, fallamos en rechazar
la hipótesis nula. Si el valor de p es
mayor que 0.05, entonces fallamos en rechazar
la hipótesis nula. Ahora bien, ¿cuáles son algunas suposiciones que hay en la correlación de
Pearson ¿Qué pasa con los supuestos
de la correlación de Pearson? Aquí tenemos que
distinguir si queremos calcular el coiente de correlación de
Pearson, o queremos probar una hipótesis Para calcular el coeión de
correlación de Pearson,
solo están presentes dos
variables métricas Las variables métricas, por ejemplo, pueden ser el peso de la persona, salario,
los consumos eléctricos, etcétera. En definitiva, variable continua. El
coiente de correlación de Pearson
nos dice entonces cuán grande es la
relación lineal, y ¿hay una relación no No podemos leer del coión de correlación de
Pearson. Entonces esta es una correlación lineal, y si tus datos se llevan
a cabo o se muestran así, entonces tendemos a seguir adelante. Entonces, en este caso, no
hay correlación. Sin embargo, si queremos
probar si el
coeficiente de correlación de Pearson es significativamente diferente
de cero en la muestra, queremos probar la
hipótesis de que las dos variables se distribuyen
normalmente también Porque no se puede probar la correlación de Pearson
para datos no normales En esto si los estadísticos de
prueba calculados t y el valor p no pueden
interpretarse de manera confiable. Si no se hace la suposición, se utilizará la
correlación de rango de
Pearson Significa que para datos
no normales, voy a usar la correlación de
rangos de Pearson ¿Cómo calculo la correlación de
Pearson en línea usando Excel
y otras herramientas En breve se
lo estaré mostrando.
38. Correlación biserial de puntos: Aprendamos ahora sobre la correlación serial
bi punto. Voy a estar cubriendo la teoría y el ejemplo y cómo
prácticamente podemos hacer esto con una calculadora en línea.
Mantente conectado. ¿Qué es exactamente la correlación punto
bi serie? ¿Lo has escuchado antes o tu cara se ha vuelto
algo así? En su mayoría oímos hablar regresión
lineal,
regresión logística. Cuando aprendemos sobre correlación, pensamos en correlación
simple, correlación
positiva, correlación
negativa. Y siempre que estamos
haciendo correlación, sólo
estamos
pensando en variables, variables continuas
tanto en el eje x como en el eje y. Entonces entendamos qué es la correlación
punto por serie. Es un caso especial de correlación de
Pearson, y examina la
relación entre una variable dicotonma y una variable
métrica Bien. La regla para la
correlación es que ambas variables deben ser
continuas o métricas. Pero usando correlación punto por
serie, incluso
puedo verificar si hay variables
dicotímicas variables, que pueden ser sí Entendamos el ejemplo
de la variable dicotonosa. Una variable dicotimia es una
variable con dos valores,
género, como masculino y femenino, y estado tabáquico como
fumador, no fumador Las variables métricas,
por otro lado, son el peso de la persona, el salario de
la persona, el
consumo de electricidad, etc. Entonces, si tenemos
una variable
dicotonma y una variable métrica, queremos saber si
existe Podemos usar correlación punto por
serie. Entonces entendamos
la definición de la misma. correlación punto por serie La correlación punto por serie es un tipo especial
de correlación, y examina la
relación entre la dicotiosa
y una variable métrica dicotonómicas son
variables con dos valores, y las métricas son variables continuas
con valores infinitos, como estatura peso, salario, consumo de
energía, consumo de
energía ¿Cómo se
calcula exactamente la correlación punto por serie? Utiliza el concepto de correlación de
Pearson, pero en la
correlación de Pearson, también
tenemos una variable
que es de naturaleza nominal Entonces, por ejemplo, digamos que te
interesa investigar la relación entre
el número de horas estudiadas en una prueba
y los resultados, es
decir, la persona
aprobada o reprobada. Entonces aquí puedo ver
cuántas horas pasó la persona estudiando y ¿
resultó en un pase o un fracaso? Hemos recopilado datos para
la muestra de 20 estudiantes. Han pasado 12 alumnos, ocho estudiantes han fallado. Hemos registrado el
número de horas para cada uno de los alumnos que
han cursado en la prueba, y asignamos una puntuación
de uno al alumno que pasó la prueba y cero al alumno que reprobó la prueba. Ahora, podemos calcular la correlación de Pearson del tiempo y los resultados
de la prueba o podemos usar la ecuación para la correlación
punto por CDN Ahora podemos calcular
la correlación de
tiempo de Pearson y los resultados de las pruebas
con la ecuación Ahora, aquí, x y es el valor medio de las
personas que fallaron, y X uno es el valor medio de las
personas que han pasado. N representa el
número total de observaciones. N uno representa el número
de personas que han pasado, n dos significa el número
de personas que han fallado. Al igual que la
correlación cofent de Pearson, r, correlación
punto por serie es rp B también varía entre
menos uno y más uno Con la ayuda de cefent, podemos determinar dos cosas Que tan fuerte es la
relación. ¿Es una correlación positiva? ¿Es una
correlación positiva débil, y en qué dirección va
la correlación? ¿Es una correlación positiva o es una correlación negativa? La fuerza de la correlación se
puede leer en la tabla. Si el valor está entre
0.0 y menos de 0.1, no
hay correlación. Si el valor está entre
0.1 y menos de 0.3, hay baja correlación. El valor está entre
0.3 y 0.5, hay una
correlación media 0.52 0.7 alta correlación 0.7 a uno, correlación
muy alta Si el valor está entre
cero y menos uno, lo
llamamos como correlación
negativa. Si el coefent está entre
menos uno y menos de cero, es una correlación negativa, ahí que
exista una relación negativa entre la variable Si el valor está entre
cero y más uno, es una correlación positiva. Así,
existe una relación positiva entre la variable, y si el resultado
es cercano a cero, decimos que no hay correlación. El
coeficiente de correlación generalmente se calcula con los datos
tomados de la Sin embargo, muchas veces queremos probar hipótesis sobre
la población. Queremos probar una
hipótesis sobre la población porque
no podemos estudiarla, estamos utilizando una tecnología de muestreo. Se calcula la correlación
cefente de los datos de la muestra. Ahora podemos probar si el coefent de correlación es significativamente
diferente de cero La hipótesis nula dice que la correlación coefent no difiere significativamente de No hay relación. La hipótesis alternativa dice que la cohesión de correlación difiere
significativamente de cero. Hay una relación. Entonces, cuando calculamos el punto
por correlación serial, obtenemos el mismo
valor p que calculamos la prueba t para
muestra independiente para los mismos datos. Entonces, ya sea que probemos la
hipótesis de correlación con correlación punto por serie o una hipótesis
de diferencia de la prueba t, obtenemos el mismo valor p. ¿Qué pasa con los supuestos
que tenemos que considerar cada vez que hacemos una correlación
punto por serie? Aquí, debemos distinguir
si es solo querer calcular
la correlación coeent, o también queremos
probar la hipótesis Para calcular el coeente de
correlación, solo una variable métrica y
una variable dicotómica,
debe estar presente . Sin embargo, si desea
probar si el coefent de correlación es significativamente
diferente de cero, también
se debe distribuir normalmente
una variable métrica Si no se da esto, los estadísticos de
prueba calculados o el valor p no pueden
interpretarse de manera confiable. Podemos usar
calculadoras en línea como la pestaña Datos, que puede ayudarte a hacer el análisis y que
voy a cubrir ahora Estamos en el grifo de datos.
He poblado algunos datos en términos de número de los resultados de
nuestras pruebas de estudio, y he convertido cero y uno como pasar y fallar
como cero y uno. Puedo importar mis datos usando este botón y puedo borrar
la tabla usando este. Tienes ajustes para decidir
qué tipo de ajustes
quieres usar para las visuales.
Ahora bajemos. Estoy en correlación,
y tengo opciones. Aquí, mi variable nominal
son los resultados de las pruebas. Mi variable métrica
es nuestra strded. Quiero calcular las sartenes y
convolu de Pearson. Por ahora, solo lo
guardaré como Pearsons. Mi variable nominal
son los resultados de las pruebas, tan pronto
como seleccioné la
variable nominal como resultados de la prueba, fue capaz de identificar esto como una correlación
serial de punto pi. La hipótesis dice que
no existe correlación entre nuestros resultados
estudiados y los resultados de las pruebas. La hipótesis alternativa
dice que existe una asociación
entre el número de horas estudiadas y
los resultados de las pruebas. El punto de correlación serial falla está tomando el
valor de cero, Ps está tomando el valor de uno. El valor de
correlación punto por serie r es 0.31 grados de libertad r 18 t
es 0.14 p valor es Tengo la trama de caja por aquí diciendo que mi argumento de caja para los alumnos anteriores
es así 50% de los participantes
están estudiando entre 8.5 a 19.25 horas que
han resultado en un pase La gente que fracasó está
estudiando 7-13 horas, ¿verdad? Incluso puedo descargar esto haciendo clic en el botón
descargar PNG. Y verás que
soy capaz de Ahora, ¿cómo funciona el cálculo para la correlación
serial del punto b? Si calcula el punto
por correlación serial, elija una variable métrica y una variable nominal
con dos valores. Antes de ir ahí,
permítanme hacer un resumen en palabras. Se realizó la
correlación serial del punto b para determinar la
relación entre nuestros estudios y los resultados de las pruebas. Existe una correlación positiva entre nuestro estudio
y el resultado de la prueba, cual no fue significativa, estadísticamente significativa
porque el valor de p es mayor a 0.05. Si tuviera más datos como este, donde estoy usando
múltiples valores para determinar el cero masculino y
femenino y uno, y luego se ha calculado. Entonces dice, ¿existe correlación entre el
salario y el género? Y podemos ver muy
claramente que sí, varones tienen un salario mayor significativamente
en comparación con el femenino. Pero si ves el valor p, está muy cerca de 0.05, pero es 0.07 Entonces fallamos en rechazar
la hipótesis nula, diciendo que tal vez sea por el error
de ding de muestra. O
39. Regresión logística: Bienvenido a la siguiente lección
sobre regresión logística. Entendamos
el ejemplo teórico y cómo hacemos la
interpretación. ¿Cuándo utilizamos la regulación
logística? Tomemos como ejemplo. Donde sea que tengamos que
comprobar si es una persona mayor que
va a sufrir de cáncer, o es un hombre o una mujer que está padeciendo
más de una enfermedad? ¿Es un fumador quien está
causando la enfermedad? Cuando quiero comprobar
si hay múltiples variables, que pueden infectar y decirme si la enfermedad es posible, ¿cuál es la probabilidad
de tener alguna enfermedad? Así que vamos a bucear más profundo. ¿Qué es exactamente la regresión? Un análisis de regresión
es un método para
modelar la relación
entre variables. Permite
inferir o predecir una variable, ya sea que el cliente
esté contento o triste, en
base a una o más
de otras variables Entonces estoy tratando de verificar
si esto es posible, base en la
calificación de la persona, el tiempo que lleva o la edad. ¿Cuál es el factor
que lo está afectando? La variable que queremos inferir o
predecir se llama como variable dependiente
o el criterio, y las variables
que utilizamos para la predicción se denominan como variables
independientes
o predictores ¿Cuál es la diferencia entre regresión
lineal y la regulación
logística? En una regulación lineal, la variable dependiente
es una variable métrica. Ejemplo, el salario, la electricidad,
el consumo, etcétera. Significa que es una variable
continua. En una regresión logística, la variable dependiente es
una variable dicotonma. ¿Qué es una variable dicotónima
? Significa que la variable
tiene sólo dos valores. Por ejemplo, si
una persona va a comprar o no comprar un producto
en particular, o si una enfermedad
está presente o no. ¿Cómo se puede utilizar la
regulación logística? Con la ayuda de la regulación
logística, podemos determinar qué influye en si una determinada enfermedad
está presente o no. ¿Podríamos estudiar la
influencia de la edad, género y el estado tabáquico en
esa enfermedad en particular? En este caso, cero significa no enfermo y uno
significa enfermo La probabilidad de
ocurrencia de una enfermedad o una característica es uno los
medios que
se estima que las características están presentes. Nuestro sitio de datos se reunió se ve
algo así donde mis
variables independientes podrían ser un estado de tabaquismo de género, y mi
variable dependiente podría ser una variable
compuesta por ceros y unos. Ahora podríamos investigar qué influencia tiene la variable
independiente y que la enfermedad tiene
el efecto sobre la enfermedad. Si hay alguna influencia, podemos predecir la probabilidad de que una persona tenga
cierta enfermedad. Ahora, por supuesto, surge la
pregunta. ¿Por qué necesitamos
regulación logística en este caso? ¿Por qué no funciona la
recreación lineal? Entonces hagamos un resumen rápido de lo que sucedió en la regresión
lineal Hagamos un resumen rápido de
lo que es la regulación lineal. En la regresión lineal, esta es nuestra ecuación de regresión. Y es ir a b1x1 más
b2x2 más b3x3,
y así sucesivamente y así sucesivamente y así sucesivamente y así B y xn más c. tenemos
la variable dependiente y,
y tenemos
variables independientes como x uno, x 2x3tx Y tenemos la
regresión coeión,
b uno, b2bt Bn Ahora, sin embargo, cuando se
mira esta variable, la variable dependiente se
hace con cero o uno. Y de ahí, su salida se
verá algo así. Tienes muchos puntos en la línea cero y muchos
puntos en una línea, pero no tienes
ningún dato en el medio. No importa cuánto
valor tengas, la variable independiente puede contribuir a que
la variable sea 0-1 Los resultados son
siempre cero o uno. En una ecuación de regresión, tenemos que simplemente poner una línea
recta a través los puntos y vemos que
hay mucho error. Ahora podemos ver que en caso
de una regresión lineal, pueden ocurrir
valores entre más y
menos infinito. Y de ahí, esta fórmula no funciona.
¿Cuál es la solución? Sin embargo, el objetivo de
la regresión logística es estimar la
probabilidad de ocurrencia. Por lo tanto, el rango de valores de predicción
debe ser 0-1. Y de ahí, queremos una
línea que encaje en esta línea y no una
diagonal como esta. Entonces necesitamos una función
que sólo tome valores entre eso da como resultado
un valor cero y uno. Ahí es exactamente donde hace la función
logística. No importa dónde
estés en el eje x, serás tu eje
y resultará
en cero o uno. Entre el menos y
el infinito más, los únicos resultados son 0-1 Y eso es exactamente lo que queremos. La ecuación de la grabación
logística se verá algo así La función logística se utiliza
ahora en la recreación
logística. Entonces, desglosemos vez más
la
fórmula de recreación lineal. Uno más y isqu a b1x1 más
b2x2 más t b x, y así sucesivamente. Esta ecuación se
insertará ahora en la función. Cuando haces eso, es e a la potencia de
menos tu ecuación de recreación lineal más grande, 1/1 más e a la potencia
de la ecuación menos. Así, la probabilidad de la variable dependiente
es una dada por esta. ¿Qué
aspecto tiene esto en nuestro ejemplo? ¿Cuál es la probabilidad
de una determinada enfermedad? P es disa. ¿Cuál es la probabilidad de que la persona esté
enferma es igual a 1/1 más e bar
menos B uno en H, B dos en género, P tres en fumador más Es una función de a, género y estado tabáquico. Para Z, la ecuación de la ecuación lineal
ahora se inserta simplemente. Y cuando haces eso,
encontramos que la probabilidad de una variable dependiente es
una dada ese ejemplo. En nuestro ejemplo, la probabilidad de contraer una determinada enfermedad basada en el parámetro de un
género y estado tabáquico. ¿Qué
aspecto tiene esto en nuestro ejemplo? E a la potencia de menos B uno, B dos, B tres, son todos los coeficientes de determinación para que el modelo se ajuste
mejor a los datos dados. Para resolver este problema, lo
llamamos como método de
máxima luz. Para ello, existen buenos métodos numéricos para
resolver el problema de manera eficiente. Pero, ¿cómo se interpretan los resultados de una regulación
logística? Echemos un vistazo al número
de fixitios. El género
tabaquismo y enfermedad. 22 mujeres no fumadoras
y están enfermas, 25 mujeres fumadoras están enfermas, 18 hombres fumadoras no están enfermas, 25 mujeres fumadoras están enfermas,
18 hombres fumadoras no están enfermas,
así sucesivamente y así sucesivamente. Cuando ponemos esto en una calculadora estadística en línea
y vamos a regresión, y luego seleccionamos ¿cuáles son mis variables dependientes y cuáles son mis variables
independientes? Qué es una
predicción más enferma o no enferma, y así sucesivamente Y cuando hagamos clic en
él, realizará la ecuación de
recreación por nosotros. Entonces queremos calcular la recreación
logística, por lo que tendremos que dar click
en la pestaña de recreación. Luego copiamos nuestros datos ahí y las variables se
muestran aquí abajo. Dependiendo de cómo se utilicen sus variables
dependientes, calculadoras estadísticas
en línea como pestaña
Datos calcularán ya sea la
recreación logística o recreación
lineal bajo
la pestaña recreación Elegimos enfermo como variable
dependiente A
género tabaquismo como variable independiente Ahora, la calculadora
hará la
ecuación de regresión logística por nosotros. Ahora, recorre toda la
mesa lentamente y entienda, y comencemos desde arriba. Si no sabes
interpretar los resultados, hay un patrón que llama a
un resumen en verso. Puedes copiarlo en palabra, puedes copiar los
resultados en Excel, y también puedes copiar la tabla de
clasificación. Entonces comencemos. Lo
primero que se muestra en la
tabla de resultados son los resultados, donde decimos que
el número total de casos son 36 personas que
han sido examinadas. 26 han sido
estimados correctamente y eso es 72.22 porcentaje
en tiempo porcentual Con la ayuda del
cálculo, modelo de regresión, 26 de 36% han sido asignados
correctamente. Eso es 72%. Ahora vamos a la tabla de
clasificación a continuación. Tienes la opción de
exportarlo a word y excel. Aquí puedes ver
con qué frecuencia se
observan las categorías no enfermas y enfermedades enfermas y enfermedades y con qué frecuencia
se predicen Entonces los
valores observados son 11, cinco, cinco, 15, y las
categorías predichas son así. Entonces podemos decir que
han hecho un medio de
predicción correcto. En realidad, la persona no
está enferma, y el modelo también ha
predicho que no ha enfermado En realidad, la
persona ha fallecido, y el modelo ha
pronosticado enfermo Ambos son positivos. Verdadero positivo y verdadero negativo. Pero tenemos un concepto llamado falso negativo y
falso positivo. En realidad, la persona no
está enferma, sino que el modelo
dice que está enferma Entonces este es un caso falso
positivo, lo cual está bien porque definitivamente
puedes ir por la segunda opinión
y la persona es cuidadosa. La preocupación es por
el falso negativo. En realidad, la
persona está enferma, pero mi modelo no es
capaz de predecirlo. De ahí que estos cinco
pacientes falten al tratamiento si no
acuden por el diagnóstico actual. En total no
observación de enfermedades son 16 11 más 516. De estos 16, el modelo de recreación puntuó
correctamente 11 como no enfermos y incorrectamente
almacenó cinco como enfermedad De 20 individuos enfermos, 15 fueron
puntuados correctamente como enfermedad, Pi se
puntuaron incorrectamente como A destacar, para decidir si una
persona está enferma o no, se utiliza un umbral de 50% Si la probabilidad
es mayor al 50%, estamos marcando como enferma Como la probabilidad
es inferior al 50%, marcamos como no desased Entonces, si el modelo de regresión
estima mayores al 50%, la persona se le asigna desased, de
lo contrario, no desaed Vamos a la prueba del
chi cuadrado. Tenemos un
video detallado sobre la plaza chi. El valor de chi cuadrado es 8.79
grados de libertad tres, y el valor p es 0.32 Si P baja nula ir. Entraremos en las pruebas de
hipótesis. Aquí podemos leer
si el modelo es en su conjunto es
significativo o no. La respuesta es, sí.
Ahora vamos a ver. Hay dos modelos
a comparar. En un modelo se utilizan todas las variables
independientes. En el otro modelo, utilizan
pocas de las
variables independientes. Con la ayuda de la prueba de
chi cuadrado, comparamos qué tan buena es
la predicción cuando se utilizan las variables dependientes y qué tan buena es cuando no se utilizan
las variables dependientes. Y la prueba de chi al cuadrado
nos dice si hay una diferencia
significativa entre los dos resultados La hipótesis nula es que ambos
los modelos son iguales. El valor de p es menor a 0.05. Esto quiere decir que la
hipótesis nula es rechazada. Entonces, cuando se rechaza la
hipótesis nula, asumimos que existe una diferencia significativa
entre los modelos. Así, el modelo en
su conjunto es significativo. A continuación viene el resumen del modelo. En esta tabla, verá una mano con menos dos valor de verosimilitud
logarítmica, y por otro lado, tiene diferente coeficiente de determinación r valor cuadrado. El resumen del modelo
se ve así. Se puede exportar
fácilmente a word y cel. Menos dos
verosimilitud logarítmica es 40.67, Cosell r valor cuadrado es Y también
se muestran los otros valores. El cuadrado R se utiliza para averiguar qué tan bien
explica el modelo de recreación la variable dependiente. En la recreación lineal, el cuadrado R indica
la porción de la variación que puede ser explicada por las variables
independientes. Cuanta más varianza se
pueda explicar, mejor será
el modelo de regulación. Se utiliza el cuadrado R para
averiguar qué tan bien explica
el modelo de regulación
la variable dependiente. En una regulación lineal, el cuadrado R indica
la porción de varianza que puede ser explicada por las variables
independientes. Cuanta más varianza se pueda explicar y mejor será
el modelo de regulación. Sin embargo, en el caso de la regulación
logística, el significado es diferente. Existen diferentes formas
de calcular r cuadrado. Desafortunadamente,
aún no
hay acuerdo sobre cuál es la
mejor manera de hacerlo. El cuadrado R
según celda de moneda es 0.22 Nagker ki es
0.29 y así sucesivamente Y ahora viene la mesa
más importante,
mesa con el modelo coeent El parámetro más importante
del coiente es B, p value odds ratio Los coeent B valores están aquí, los valores p están aquí, y el odds ratio está Podemos ver que el
valor de p de género es mayor a 0.05. Significa que el género no es un factor contribuyente
para la enfermedad. En la primera columna, podemos leer los valores del coeficiente como 0.040 0.871 0.4 -2.73, y luego podemos insertar esos valores en lugar
de B Cuando insertamos el cipión, obtenemos una ecuación como esta, 1/1 más borra 20.04 en H, 0.87 en género más
1.34 en fumador menos
la constante de 2.73,
y luego seguimos adelante y calculamos y luego seguimos adelante y Con esto, ahora podemos calcular la probabilidad de que
una persona fallezca. Queremos saber cómo
es la probabilidad de que una persona con la
edad de 55 años, mujer y fumador Sustituimos el valor
de la edad por 55, género como cero
porque no es un varón y uno como fumador y
luego calculamos el valor Cuando hacemos este cálculo, el valor de probabilidad es 0.69 Significa que existe un
69% de probabilidad de que una mujer
fumadora de 55 años Con base en esta predicción, ahora se
decidiría si investigar extensamente o no. El ejemplo es puramente imaginario. En realidad,
podría haber ciertos muchos otros factores y diferentes
variables independientes como el peso de la persona edad de la persona y muchas otras cosas más para determinar si la
persona está enferma o no Pero ahora
volvamos a la mesa. En la columna, podemos leer coeficiente de
diferencia significativa desde cero. La hipótesis nula es coeficiente es cero
en la población. La siguiente
hipótesis nula es la prueba. El coeficiente es cero
en la población. Como la variable es
menor a 0.05, el coeficiente predicho
es una influencia significativa. En nuestro ejemplo, vemos que ninguno
de los coeficientes tiene un impacto significativo ya todos los valores de p son
mayores a 0.05. Ahora vamos a entender
el ratio de probabilidades. La relación de probabilidades es de
1.042 0.39 83.81. Por ejemplo, la razón de
probabilidades es de 1.04, significa que para una unidad de
incremento en la variable edad, el incremento de probabilidad de que una persona pueda
enfermarse es de 1.04 Y podemos ver que para el fumador, el ratio de probabilidades es muy alto Con eso, llegamos al
final de la recreación logística. Te veremos en la sesión
práctica. Permanecer en. Gracias.
40. Práctica de regresión logística: Utilizaremos una calculadora en línea para hacer análisis de regresión, especialmente el
análisis de regresión
logística en este video. He subido un video
separado sobre cómo puedes hacer este
análisis usando Excel. Entonces, continuemos con la calculadora
estadística en línea. Puedo importar mis
datos haciendo clic en el botón de importación y
soltando archivos Excels, archivo
SV o ficha Datos Puedo hacer clic en Navegar
y obtener mis datos dentro. ¿Verdad? Entonces
ya he cargado mis datos, que se pueden ver en la pantalla. Tengo si una persona
ha fallecido o no,
edad, sexo estado de tabaquismo. Podemos ver que el
tipo de datos ha
sido identificado automáticamente por la calculadora
estadística. Dice que la edad es una variable
métrica, género es nominal y el
estado tabáquico también es normal. La enfermedad es nominal. Ahora, lo que hago es dar clic
en regresión, desplazarme hacia abajo. Entonces tengo una buena
cantidad de casos. Déjame desplazarme hacia abajo. Cuando hago clic en regresión, puedo hacer regresión
lineal simple, regresión
multilineal
y regulación logística. ¿Cuáles son mis variables dependientes? La edad es mi variable dependiente. El género es una variable dependiente. El estado tabáquico es una variable
dependiente. ¿Qué quiero predecir? Quiero predecir si la
persona está enferma o no. ¿Estoy seleccionando lo correcto? No. Quiero verificar, ¿cuál es la variable dependiente? ¿Cuál es mi y? Mi y es si la persona
ha fallecido o no. Y mis variables independientes son el género y el estado tabáquico. Entonces, para referencia de género, estoy tomando al varón como uno solo. Para referencia del estado tabáquico, estoy tomando a los fumadores como uno solo, y se predice el modelo si la persona
está enferma o no Ahora puedo dar click en
resumen en palabras, y hace un
análisis adecuado y me lo muestra. ¿Verdad? Se muestra claramente que ha realizado
un
análisis de regresión logística se ha realizado
un
análisis de regresión logística para examinar como variables la
influencia de la edad, género, condición
femenina y fumadora como
no fumadores, se predice
enfermedad
para el valor dease, un
modelo de análisis logístico ha demostrado que el chi cuadrado para los tres
es 8.79 p valor es 0.32, y el número El coeficiente
de la variable p es 0.04, lo que es positivo Esto significa que cuando el
aumento de la edad se asocia con aumento de
la probabilidad de la enfermedad variable dependiente. Sin embargo, el valor de p es 0.092, lo que indica que la influencia no
es estadísticamente significativa El odds ratio es de 1.04, lo que indica que para
un incremento unitario de la variable ocho, el incremento de las probabilidades de que la variable dependiente esté
fallecida aumenta en 1.04 El coeficiente de
variable género femenino, valor
B es 0.87 negativo Debido a que esta variable
es negativa, significa que el valor de
la variable género femenino, la probabilidad de que la variable
dependiente disminuye
la probabilidad de que la variable
dependiente
se convierta en enfermedad. Sin embargo, el valor p de 2.0 0.28 indica
que la influencia no
es estadísticamente
significativa La razón de probabilidades es de 0.42, lo que significa que la
variable género femenino, la probabilidad de la enfermedad
variable dependiente aumenta 0.42 veces El coeficente de la
variable estado fumador, valor
p es -1.32,
lo que es negativo, lo que significa
que si el
valor de la variable del estado tabáquico
es no fumador, disminuye
la probabilidad de que
la la Sin embargo, el valor de p es 0.089, lo que indica que la influencia no
es estadísticamente significativa La razón de probabilidades es 0.26 significa que la variable
es un estado de fumador, probabilidad de
no fumador de que la variable dependiente fallecida
aumente Ahora, permítanme recoger la
referencia como no fumador y la categoría como
esta y ninguna enfermedad Ahora, vamos al resumen. Encontramos que hay un ligero
cambio en el análisis. Todos ellos ahora
se han vuelto negativos. ¿Verdad? El
ratio de probabilidades ha cambiado, diciendo que por una
unidad de aumento de edad, 0.96 indica que
la persona
no va a estar fallecida porque ahora
estamos apuntando a no
fallecidos, ¿verdad? Por lo que debes tener cuidado con lo que estás tomando
como referencia. ¿Qué crees
en tu hipótesis, son los hombres más
propensos a enfermarse Entonces, cuando tomas
el género como masculino, el valor b es -0.87 Ahora aquí mi objetivo no
está enfermo. Entonces parece que la
probabilidad de que la persona del sexo masculino no esté
enferma disminuye en 0.97 Pero si estoy viendo enfermo, se dará cuenta de que esto
es ahora un valor positivo Fumador también es un valor positivo. Entonces debemos saber cuál es la variable objetivo que
queremos estudiar. Ahora bajemos. Veamos los resultados, e incluso tengo una
interpretación de IA para ayudarme. La tabla resume
el desempeño general modelo
de
regresión logística binaria Aquí la interpretación es, número
total de casos son 36, que es el número total de observaciones La
tabla resume el desempeño general
del modelo logístico binario Aquí, la interpretación es el número total de casos de 36. Se trata de un número total de observaciones o instancias en
las que el modelo ha probado. En este contexto, el
número de individuos son ítems en los que el modelo intentó predecir
el resultado, ya sea que la persona
sea escritura o no escritura La asignación correcta es de
26 de 36 casos, el modelo predijo el
resultado de 26 de ellos. Esta correcta predicción incluyó tanto verdaderos positivos que identifican
correctamente la persona que está enferma como verdaderos negativos identificando correctamente
los casos sin En porcentaje 72.22%. Esta es la precisión
del modelo
que indica que el número de asignaciones es de 26
dividido entre el número total de casos 36. Lo multiplico con diez
para obtener el porcentaje. Nos dice cómo el modelo
hace la predicción correcta. Ahora, entendamos la tabla
de clasificación. Es donde estamos
tratando de clasificar. Puedo tomar ayuda de la
interpretación de la IA para entenderlo. La tabla resume
la medida de bondad de ajuste a partir del análisis de
regresión logística Aquí, los verdaderos negativos
verdaderos positivos son 11 casos en los que hemos predicho
correctamente que no
están enfermos falsos positivos son cinco
casos en los que hemos cometido
un error tipo uno. falsos negativos son
cinco casos en los que predijimos incorrectamente que no
están enfermos como error tipo dos Los verdaderos psíticos se
predicen correctamente como enfermos. Corrección de la predicción. La predicción correcta para
no enfermos es de 68.75%. El total de casos no enfermos se
identificaron correctamente. Predicciones correctas de enfermedad, sensibilidad o llamamos, 75% de los casos reales de enfermedad
fueron identificados correctamente. La precisión total es de 72.22% toda la protección
ya sea enfermedad o no enferma, identificamos
correctamente Ahora, entendamos
la prueba del chi cuadrado. La belleza de esta calculadora
estadística es que te da
una interpretación de IA. No tengo que ir a
ChANGeP a ello. En la tabla se muestran los resultados
de la prueba de chi cuadrado asociada al modelo de regresión
logística binaria. La prueba se utiliza a menudo para evaluar la
significancia general del modelo. Aquí, la interpretación
de cada componente. Yo al cuadrado es la estadística donde la respuesta es
8.79 en nuestro Esto mide la
diferencia entre la
frecuencia observada y la esperada del resultado. Cuanto mayor sea el valor de chi
cuadrado indica mayor discrepancia entre el valor
esperado y el observado, lo que sugiere que los predictores de los
modelos tienen una relación significativa Grados de libertad, aquí, tenemos tres grados de
libertad que representan el número de predictores en la regresión
logística simple valor P es la
probabilidad de observar los estadísticos de la
prueba de chi cuadrado tan extremadamente como uno observado
bajo la hipótesis nula La hipótesis nula es que no existe
relación entre frecuencia
observada y la esperada del resultado predicho
por el volumen, el valor de
P es 0.032, lo que sugiere que hay 3.22% probabilidad de que la
estadística chi cuadrada observada sea extrema Y la
hipótesis nula donde era verdadera. El valor de p está 0.32 por debajo indicando que es
menor que 0.05 umbral, lo que indica que hay un resultado de
significancia estadística Ahora, hagamos un resumen del modelo. Entonces aquí dice que la probabilidad logarítmica menos
dos es 40.67. Mide los modelos fitness. Cuanto menor valor mejor se ajuste
el modelo a los datos. En nuestro caso, el valor es de 40.67, que es
un modelo relativamente saturado, un modelo con un ajuste perfecto. Este número por sí solo
no nos dice mucho. De ahí que necesitamos
compararlo con otros números
diferentes. El
valor del cuadrado R de la célula Cocina es de 0.22. Se trata de una pseudo medida cuadrada
R que indica la cantidad de variación en la variable
predicha explicada por el
modelo. Se extiende 0-1 El valor de 0.22 indica que la varianza del 22% es
explicada por el modelo No obstante, vale la pena
señalar que esta medida nunca llega a una ni siquiera
para un modelo perfecto. Vamos a Nagar
K R valor cuadrado. Es 0.29. Nuevamente, tratamos de ajustar el
cuadrado r para llegar a uno. Pero recuerden, hay un 29% de la variación que se
explica por este modelo. Significa que es
necesario incluir más variables para entender mejor
el modelo. Cuando estamos viendo esto, estamos obteniendo la diferencia de
modelo. El componente es pregunta
representa los diversos tamaños, error
estándar, valor z, valor p, relación esperada
y 95% de confianza. Hagamos la interpretación. El modelo predice
El resultado básico como -2.73 donde el
predictor es cero,
el odds ratio es el odds Sugerir menores
probabilidades de resultado cuando el predictor está en
el valor de referencia Con cada
incremento unitario de la edad, la probabilidad de
que la persona
fallezca aumenta en 0.04 Eso es un incremento del 4% en las probabilidades. Si el género es masculino, hay un
incremento de 0.87%, y así Et hacen la predicción. Si la edad de la persona
es de 45 años y la persona es masculina y la probabilidad de
que la persona sea fumador, ¿cuál es la probabilidad de que la persona se
enferme? Hay 0.81 ¿Es más de 0.45? ¿50%? Sí. Existe la probabilidad
de que la
persona esté enferma Pero si la persona es femenina, entonces la probabilidad disminuye. Además, si la persona
es no fumadora, entonces hay una probabilidad muy
menor que la persona esté enferma Ahora hemos pasado
al siguiente ejemplo donde estamos tratando de comprobar si
la persona va a comprar
un producto o no. Y las variables son género, edad y el tiempo
que pasaron en línea. Entonces voy a dar click
en ecuación de recreación. Cuál es la
variable dependiente, el género, la edad y el tiempo en línea y el comportamiento de compra
es mi variable dependiente. Hay tres tipos de
predicciones que están sucediendo, no dos como la última vez. Tenemos compra ahora, compra después y no
compres nada. Categoría de referencia
para género femenino, lo
estoy tomando como femenino, y vamos al resumen. Por lo que el
análisis de regresión logística que se realizó aquí es la influencia
del género masculino, la edad y el tiempo pasado en línea en la variable de comportamiento de compra
por el valor de por ahora. El análisis de regresión logística muestra que el modelo tiene, en su conjunto, fue significativo. El número de observaciones son 24. El coefent de que la
variable género es
masculino es 1.53, lo que Esto significa que aumenta el valor
de la variable género ma, la probabilidad de que la
persona va a comprar. El valor de p es 0.201, lo que indica que la influencia no
es estadísticamente
significativa La razón de probabilidades es de 4.63, decir, que el género es masculino, la probabilidad de que la variable
dependiente aumente en 4.63 veces El cofiente de la variable ag es p igual a -0.11,
lo cual Esto quiere decir que un incremento en la edad se asocia
con una disminución en la probabilidad de que la variable
dependiente sea por ahora. Sin embargo, el valor de p es 0.07 lo que indica que la influencia no
es estadísticamente
significativa La razón de probabilidades es de 0.9, lo que indica con cada
unidad de aumento en
la edad, la persona por ahora solo
aumenta 0.9 veces. El coeent del
tiempo variable empleado en la tienda online es b -0.02, lo que Significa que cuanto más
tiempo se pasa en el online, hay menos probabilidad de
que compren ahora. El valor de P es 0.56 lo
que indica que no es
estadísticamente significativo, y el tiempo pasado
en línea aumenta las probabilidades en 0.98 24 casos 17 correctamente
pronosticados en porcentaje 70. Hagamos el análisis. Así um número total de casos 24, asignación
correcta
17 porcentajes 70. Ahora, vayamos a la tabla
de clasificación. Podemos entender que ¿cuál es el error tipo uno
y el error tipo dos? Verdaderos negativos 13 casos se predijeron correctamente
que no van
a comprar Los falsos positivos
son tres casos, lo que se
predijo incorrectamente ya que son pin ahora, pero en realidad, no
compraron Y los casos falsos son que cuatro
de ellos realmente compraron, pero nuestro modelo dijo
que no compraron. Cuatro casos se
predijeron correctamente como Pi ahora. La corrección de por ahora es 82%, la exactitud de por ahora es
50% la precisión total es 70% Si nos fijamos en la ecuación del
chi cuadrado, estamos obteniendo el valor
p de 0.42 Aquí, la probabilidad
de una prueba de chi cuadrado es extremadamente importante como uno de los valores observados de
la hipótesis nula. La hipótesis nula es que no existe
relación entre la frecuencia
observada y la
esperada y la salida predicha
del modelo. El valor de P de 0.42 se vuelve por debajo esta convención 0.5,
estadísticamente significativo Si voy con el modelo alguien, podemos ver que los
valores r al cuadrado son muy w Y
tengo el valor p Así que ahora
hagamos una predicción. tengo el valor p Así que ahora
hagamos una predicción Si la persona es varón y tiene 45 años y el
tiempo empleado es ¿Cuál es la probabilidad de
que una persona compre? No hay mucha probabilidad. Pero si la persona
tiene 20 años, entonces la podamos entender que la gente de nueva generación está dispuesta a comprar
más que las personas mayores. Si tenemos una persona de
80 años, entonces la probabilidad es
absolutamente igual a 0.01 Entonces espero que aprendan a hacer regresión
logística en
este video. Gracias. Oh.
41. Curva ROC: D. Entendamos la curva ROC Acabamos de terminar de aprender
sobre regresión logística. Una de las formas de validar la precisión del modelo
es utilizando la curva ROC Entendamos la
teoría con ejemplos. Entonces ROC significa características de
funcionamiento del receptor. Es una forma gráfica de representar el desempeño de un modelo de clasificación binaria, también llamado modelo de
regresión logística, y también para otro umbral de
clasificación. Entendamos
con un ejemplo. Supongamos que estamos
realizando una prueba de tamizaje a
los pacientes para identificar si el paciente está
sano o enfermo Para
que se haga esta clasificación, el farmacéutico está realizando
algunas pruebas en la sangre luego decidir
quiénes de ellos
estarán enfermos y quiénes están sanos Cuando obtuvieron la
muestra de diez datos, han decidido que
van a poner un umbral,
y a cualquiera que esté por debajo de ese
umbral se le llamará como saludable y a cualquiera que esté por encima del umbral se le
llamará como enfermo Ahora bien, ¿cómo decidimos cuál
debería ser el umbral? Con base en la cual
se puede predecir que el futuro es que el
paciente se encuentra en situación de enfermedad? Entonces digamos que
tenemos una muestra de diez personas con
sus niveles sanguíneos. Vemos que la mayoría
de las personas enfermas
tienen un nivel sanguíneo
más alto Y la mayoría de las personas que están sanas tienen niveles sanguíneos más bajos. Entonces decidimos que
pongamos un umbral en 45. Entonces cuando ponemos un
umbral en 45, estamos diciendo que
cualquiera que esté por debajo de 45, los
vamos a clasificar como saludables Cualquiera que esté por encima de 45, los
clasificaremos como enfermedad Ahora podemos ver que hay
ciertos temas por aquí, y entendamos
esos temas en detalle. Entonces en este caso, de
seis personas que han sido clasificadas como
enfermedades, dos de ellas, cuatro se
clasifican correctamente como enfermedad, pero dos de ellas se
clasifican incorrectamente como enfermedad, pero en realidad,
están sanas. Por lo que hemos
clasificado cuatro de seis como enfermedad, y esto se llama como
dos tasa positiva. También se le llama
como sensibilidad. Por otro lado, de los
cuatro individuos sanos, clasificamos erróneamente a una
persona como enferma Una persona enferma como sana, y hemos clasificado correctamente tres personas sanas como sanas. Ahora bien, cuando clasificamos mal a
uno de cada cuatro como saludable, esto se llama tasa de
falsos positivos, y se representa por FPR o es una especificidad
menos El umbral de 45, obtenemos
tasa positiva verdadera como 4/5, es
decir 80% y tasa de falsos
positivos como 2/5 como 40% Entonces, ¿qué es exactamente TPR
o dos tasas positivas? La tasa de verdaderos positivos no es más que verdaderos positivos divididos por verdaderos positivos más
falsos negativos Dos positivos son
las personas que se
clasifican correctamente como enfermedad Hemos clasificado correctamente a
cuatro de ellos como enfermedades. Falsos negativos son
las personas que se
clasifican incorrectamente como saludables Entonces cometimos un error
con una persona. Entonces Total es 4/1. Por lo que los verdaderos positivos no son más cuatro de ellos han sido correctamente
clasificados como enfermos Pero el problema era que de los cuatro que estaban
correctamente clasificados, una de las
personas enfermas que extrañamos El motivo por el que necesitamos saber el TPR es que
¿qué porcentaje de personas irán sin
ser atendidas La especificidad es muy importante para entender
que hay 20% de la población que
podría no ser tratada bien, o bien estamos clasificando correctamente 80% de la población
que hemos probado Entendamos FPR,
eso es falso positivamente. falsos positivos son las personas que son individuos sanos, clasificados erróneamente como enfermos, y dos negativos Los individuos se
clasificaron correctamente como sanos. Por lo que dos de ellos han sido clasificados
incorrectamente como DC. Entonces iniciamos el tratamiento para ellos, dividido por el número total que es de cinco que
en realidad estaban sanos. Entonces el número total de personas
sanas dividido por cuántas personas
fueron falsos positivos. Entonces 40% de la gente
ha sido 0.4 es la tasa de FPR. Entonces, ¿cómo calculamos TPR
y FPR para cada umbral? ¿Debo poner el
umbral como 38? Debo poner el umbral
en 65, y así sucesivamente. Entonces en este caso, calculamos el TPR y el FPR para
cada uno de los umbrales Si pongo esto como cero, entonces mi
tasa de verdaderos positivos va en aumento, pero mi
tasa de falsos positivos es casi cero. Entonces estos son precisamente
los dos valores que se están trazando
en la curva ROC La tasa de verdaderos positivos
se grafica en el eje y y la tasa de falsos positivos
se grafica en el eje x Queremos decidir que
si vas a 0.240 0.2, nuestra tasa de falsos positivos está aquí, pero el verdadero positivo
está aumentando, y de manera similar en 0.4
0.6 0.8 y uno Ahora, dibujemos la curva
ROC completa para nuestro ejemplo. Si elegimos que el
valor umbral sea muy pequeño, es
decir, empujar todo el
camino hacia la izquierda, clasificamos correctamente a los
cinco individuos enfermos Pero también clasificamos erróneamente a
los cinco
individuos sanos De ahí que la tasa positiva verdadera sea de cinco de cinco, es decir, uno. De la misma manera, sin embargo, clasificamos erróneamente a cinco
individuos sanos como enfermos Por lo que la tasa de falsos positivos es de cinco de cinco,
eso vuelve a ser uno. Por esa razón, el primer punto de
datos está en un punto uno. Entonces a medida que
empujemos el umbral, seguiremos
clasificando correctamente si estoy en 0.2 Todavía estoy clasificando correctamente los cinco individuos
como enfermos, pero estoy clasificando a cuatro de los individuos sanos
también Entonces ahora llego al
siguiente punto de datos. Entonces, si tomo 0.8
como umbral, mi tasa de verdaderos positivos
es de cinco de cinco, así que he clasificado correctamente todas las personas
fallecidas como fallecidas. Pero de cinco individuos
sanos, ahora
hemos clasificado erróneamente
solo cuatro de cinco Y de ahí, estoy en 0.8 en cuanto a la tasa de
falsos positivos. Para el siguiente roshold, donde tenemos la tasa
positiva de 0.1, estamos en 0.3, y vemos que
hemos clasificado
correctamente a las
cinco personas como enfermas, pero mis
individuos sanos Entonces ese será mi
tercer punto de datos. Cinco personas enfermas están
correctamente clasificadas. La tasa de falsos positivos es de
tres de ellos se han clasificado erróneamente como enfermedad
de cada cinco, es decir 0.6 En el siguiente umbral, la persona enferma se clasifica erróneamente como saludable
por primera vez Este es el umbral. Este es el lugar donde
la persona enferma se está clasificando erróneamente
como saludable Y de ahí vemos una baja en la
tasa verdadera positiva desde 12.8 La tasa de verdaderos positivos es de
cuatro de cinco que es 0.8, y la tasa de falsos positivos es de tres de
cinco que es 0.6. Ahora podemos hacer eso para
todos los demás umbrales, y en consecuencia,
redactamos nuestra curva ROC En este punto, por ejemplo, 80% de los individuos das clasificaron correctamente como enfermedad, 20% de los individuos sanos clasificaron incorrectamente como enfermedad. Usando la curva ROC, podemos comparar diferentes métodos de
clasificación Los modelos de clasificación son mejores es mejor cuanto mayor sea la curva. Por lo tanto, cuanto mayor sea el
área bajo la curva, mejor será el modelo de
clasificación. Usando la curva ROC, podemos comparar diferentes métodos de
clasificación, y es precisamente
el área que se refleja en el valor del
área bajo la curva AUC El área bajo curva se utiliza durante la valoración del
modelo de regresión lineal. El valor del AUC varía 0-1. Cuanto mayor sea el valor, mejor será
el modelo. ¿Qué pasa con la curva ROC y
la regresión logística? Por ejemplo, podríamos construir un nuevo modelo de clasificación
utilizando la regresión logística. Aquí, podríamos usar los valores adicionales
como el valor sanguíneo, la edad y el género de cada una de
las personas y tratar predecir si la persona
está sana o enferma Acerca de la curva ROC y la regresión logística,
continuemos En una regresión logística, el valor estimado es entonces cuán probable es que una
persona en particular fallezca. Muy a menudo,
el 50% de
ellos simplemente toman como umbral para clasificar si una persona ha fallecido o no
Pero claro, esto no
es lo
que estamos pensando Así que no puedes estar tomando el
umbral como 50% siempre. Por lo tanto, incluso con la regulación
logística, construimos la curva ROC para diferentes valores de umbral
y vemos que a qué nivel, tenemos el área máxima Entonces, ¿cómo puedo obtener la curva
ROC en línea? Sí. Entonces ahora vamos a entender
cómo puedo hacer este cálculo ROC
usando los datos Así que he poblado
algunos valores de datos para más de 40
casi 40 personas, diferentes niveles sanguíneos y si la persona
está enferma o no Entonces, o bien puedo ir por
mi modelo de liberación, y digo que quiero declarar
la variable como enferma El estado variable es sí o no, y quiero la
variable de prueba como valor sanguíneo. Entonces de inmediato obtenemos el ROC, y el ROC está demostrando que a qué niveles especificidad
y sensibilidad La sensibilidad no es más que
mi verdadera tasa positiva. ¿Cuántas de ellas
personas enfermas he
clasificado correctamente La especificidad por otro lado, es cuántas de ellas
o cuántas de las personas sanas han sido
mal clasificadas como enfermas Y queremos que haya. Las personas enfermas son 19, no enfermas son 22, y positivo es
mayor que igual a uno, la sensibilidad es uno y
me muestra todos los datos. Podemos loe algunos datos de muestra. Y hazlo. También puedo encontrar esto
bajo mi modelo de correlación. Entonces iré a la regulación, y estoy diciendo que mi variable
dependiente ha fallecido y el valor sanguíneo es
mi variable independiente. El resumen en palabras, si se ha realizado el
análisis de regulación logística para examinar si
el valor sanguíneo de una variable desea
predecir el valor como sí. análisis de recreación logística muestra que el valor del chi cuadrado es de 5.23, valor de
P es 0.02 Significa sangre capaz predecir que
no hay influencia del
nivel sanguíneo en la enfermedad. Rechazamos la hipótesis nula
porque los valores p lo. El coiente del valor B en sangre es 0.03, lo que es positivo Significa que el incremento
en el valor sanguíneo se asocia con el incremento en la probabilidad de la variable
dependiente como sí. El valor p de 0.32 indica que la influencia es estadísticamente significativa El cociente impar es 1.03, lo que indica que una
unidad de incremento en el valor sanguíneo
incrementará las probabilidades de la variable dependiente
como si en 0.13 veces Entonces cuando construimos la regresión
logística, podemos ver que acabamos leer el resumen de
que el valor de p es 0.03 diciendo que hay una significación del
valor de la sangre para los enfermos La tabla resume que
de 41 casos investigados se observan
para construir el modelo,
en este contexto, el
número de individuos que fueron predichos
como enfermos o sanos 28 de los 41 fueron clasificados
correctamente, individuos
enfermos se
clasificaron como enfermos y los sanos se
clasificaron como sanos El porcentaje es de 68.29. Indica el número total de personas que han sido
correctamente clasificadas por 28, que se divide por 41, y luego se multiplica
por 100 para obtener un porcentaje. Si te digo
con qué frecuencia el modelo hace
la predicción correcta, si la predicción es
presencia o ausencia de S. Así podemos ver que de esto se llama como tabla de
clasificación. Personas que en realidad no están enfermas y correctamente
predijeron como no enfermas, personas que están enfermas y
predijeron como no enfermas Este ocho es mi preocupación. ¿Por qué? Porque estas
son las personas que no van a ir por
su tratamiento. Y cinco de ellos han sido
clasificados como enfermos, cuando en realidad, no
estaban sufriendo Entonces entonces estaremos
construyendo el modelo ROC, y el ROC actualmente el AOC,
A bajo la curva Más alta la curva,
mejor el modelo. De 41 casos, la asignación correcta ha
ocurrido para 28 casos, y la asignación incorrecta
ha ocurrido para 13 casos. Por lo que 68% de las personas fueron
correctamente clasificadas. Ahora, hagamos una interpretación de
IA. La interpretación de la IA dice
muy claramente que el modelo se ajusta de
dos verosimilitud logarítmica. Cuanto menor sea el valor, mejor será
el modelo. Aquí, el valor es 51.39 indicando que el modelo
está relativamente saturado, un modelo con un ajuste perfecto. El número por sí solo
no dice mucho. Tenemos que compararlo
con otros modelos. Ahora, hagamos la
interpretación del modelo. La tabla muestra
que hemos realizado un análisis de
recursión logística binaria, que analiza cómo los predictores
influyen en la probabilidad
de un resultado particular Componentes, Cefion B. Esto representa el
efecto de cada Un coeente positivo aumenta las probabilidades probables o las probabilidades
logarítmica del resultado,
y el coeión negativo lo Error estándar. Esto mide la desviación estándar
del coeión estimado, relativamente
con qué precisión el modelo
estima el valor de la coesión El valor z. Esta es la puntuación z calculada como un coefent
dividido por el error estándar, se utiliza para probar la hipótesis nula de que
el coefent valor P indica
la probabilidad de observar los datos o
algo más extremo. Si la hipótesis nula es verdadera, el menor
valor de P y palabra sugiere, el valor p indica
la probabilidad de observar los datos o
algo más extremo. Si la hipótesis nula es verdadera, el valor p inferior sugiere que la hipótesis nula de ningún
efecto es menos probable. Interpretación.
El modelo predice las probabilidades logarítcas de la
línea base como -1.31, para todos los predictores son cero La relación impar es 0.27, lo que sugiere que las
probabilidades más bajas del resultado cuando todos los predictores son
del valor de referencia Valor sanguíneo que
aumenta en tres. Ahora, hagamos la predicción. Si mi valor en sangre es de 85, entonces hay un 75% de probabilidad de
que esté sufriendo. También llegaré a
ver la curva ROC. El ROC, el área bajo
la curva es 0.699. Ella Shh
42. Comprender los datos no normales: Nuestro normal o no. Tratemos de
entender ¿cómo
trabajamos cuando mis datos no son normales? O incluso antes de llegar, déjame presentarte a este
señor. ¿Alguna conjetura? ¿Quién es el señor? Puedes escribir en la
ventana de chat si lo sabes. Y aunque no lo sepas,
eso está perfectamente bien. No hay
puntos de penalización por conjeturas equivocadas. Sí. Algunos de ustedes lo han
adivinado ¿verdad? Es la persona famosa detrás de
nuestra distribución normal. Señor Carl cos. Él es el gran matemático. Y él fue la persona
a quien se le ocurrió el concepto de la distribución
gaussiana o la distribución normal. Entonces aquí está el cerebro
detrás del concepto de distribución
normal y todas las pruebas paramétricas
que estamos tomando. Si mis datos no son normales, entonces pueden ser sesgados. Podría estar sesgada negativamente o podría estar sesgada
positivamente. Si digo sesgada negativamente, técnicamente
es tener
una cola en el lado izquierdo. Positivamente sesgado significa
cola en el lado derecho. Significa que mis datos no se
están comportando de manera normal. Mis datos pueden no ser
normales porque están siguiendo una distribución uniforme o una distribución plana
como esta. Entonces también no está siguiendo
la distribución normal. Mis datos pueden tener múltiples picos, algo así,
lo que representa que hay múltiples
grupos de datos en mi conjunto de datos. Y no es un comportamiento normal. Porque mis datos tienen
todas estas cosas. Necesito tratar estos datos manera diferente cuando estoy haciendo
mis pruebas de hipótesis. ¿Y por qué estos datos no son normales? Podría ser por la
presencia de algunos valores atípicos. Podría ser por
la asimetría de mis datos, o podría ser por
la curtosis que está
presente en los datos. Entonces, la razón por la que tus datos no se
comportan de manera normal
podría ser uno de estos. Resumamos,
¿qué aprendimos? Mis datos no son normales si la
distribución tiene una asimetría, tiene unimodal, no es unimodal, sino de hecho esta distribución bimodal o
multimodal. Es una distribución de cola pesada
que contiene valores atípicos. O podría ser una distribución
plana como una distribución uniforme. Estas son algunas razones básicas mis datos no se están
comportando de manera normal. Impar, no es una distribución
normal, entonces hay múltiples
distribuciones. También hay otras
distribuciones, que habla de la distribución
exponencial, que modela el tiempo
entre el evento. La distribución logarítmica normal. Que dice que si aplico
el logaritmo sobre los datos, entonces mis datos seguirán
una distribución normal. Distribución de Poisson, binomial, distribución
multinomial. Entendamos algunos ejemplos, escenarios de
la vida real donde se pueden aplicar las distribuciones no normales. Si nos fijamos en esto, siempre que estoy tratando de predecir
algo a lo largo de un intervalo de tiempo
fijo. Después utilizo la distribución de Poisson para mi análisis e hipótesis. Algunos ejemplos de
distribución de Poisson o el número de atención al cliente llamado
recibido en el call center. El número de
pacientes que presentan una
sala de urgencias hospitalarias en un día determinado, el número de solicitudes de un artículo en particular en una tienda en
línea en un día determinado. El número de paquetes entregados por la empresa de reparto
en un día determinado, el número de artículos defectuosos producidos por una
empresa manufacturera en un día determinado. Si observas aquí hay
un comportamiento común. Siempre que estamos
tratando de entender algo en un periodo de tiempo
determinado, podría ser un día determinado, podría ser un
mes dado, dado B. Entonces preferimos hacer nuestro análisis usando la distribución de
Poisson. Algunos ejemplos de distribución
logarítmica normal. El tamaño del archivo se
descarga de internet, el tamaño de las partículas
en una muestra de sedimento, la altura del árbol, el tamaño de los rendimientos
financieros, el tamaño del juego de seguros. Si ves estos ejemplos, como si tomara el ejemplo de rendimientos
financieros de
su inversión, podrías ver que de mi
cartera de inversiones, alguna inversión me dio un
muy buen retorno del 100%, 100%, 150 por ciento, 80 por ciento. Y también
verán que he realizado inversiones en alguna parte mi cartera porque
resultó en un rendimiento cero o un
rendimiento negativo porque estoy en pérdida. Pero en general mi
cartera me está dando un rendimiento del 12 al 15%
o del 15 al 20 por ciento. Estás tratando de decir que tu distribución técnicamente
no es una distribución normal. Tienes rendimientos muy bajos
y rendimientos muy altos. Pero si aplicas el
logaritmo en tus datos, entonces se comporta como una distribución normal que en
general tu cartera dará como
resultado un retorno de
algún X porcentaje. Similar aplica incluso en
la reclamación de seguros. Tratemos de entender la aplicación de la distribución
exponencial. El tiempo entre llegadas
de clientes en cola, el tiempo entre fallas en
una máquina, tu fábrica, el tiempo entre compras
en la tienda minorista, El tiempo entre llamadas telefónicas
y el centro de contacto, el tiempo entre páginas
vistas en el sitio web. Ahora bien, si ves entre la distribución de Poisson y la distribución exponencial, hay un elemento común. ¿Cuál es el elemento común? Estamos tratando de estudiar
con referencia al tiempo. Siempre que estés haciendo
una distribución normal, no
es con referencia al tiempo. ¿Correcto? Entonces estas son algunas aplicaciones. Pero la diferencia
entre un veneno y un exponencial está en una distribución de
Poisson. Es en un día determinado, en un día determinado, en una semana determinada se dan mes. Aquí estamos tratando de entender el tiempo entre los dos pares. ¿Qué es una brecha de tiempo
entre los dos eventos? Entonces la
distribución exponencial te puede ayudar. Podemos, vamos a entender la aplicación de alguna distribución
uniforme, como las alturas del
alumno en la clase. Necesidades de paquetes en
un camión de reparto. Algunos paquetes son muy grandes, algunos paquetes son pequeños. Si lo pones en una distribución, también
encontrarás que
es una distribución plana o
una distribución uniforme porque para cada categoría de paquetes, tendrás aproximadamente
el mismo número de paquetes, similar número de paquetes. Mercancías que estás entregando. La distribución de los resultados de las pruebas para un examen de opción múltiple. La distribución del
tiempo de espera en un semáforo, la distribución de
la hora
de llegada de un cliente a una tienda minorista. Entonces, si ves todos estos ejemplos siguiendo una distribución uniforme, no
es una curva de campana. Porque tienes
continuamente gente que está llegando a
la tienda minorista. No es que haya
un pico repentino. Y los escenarios
del mundo real de la distribución de
cola pesada, significa la distribución donde
están presentes los valores atípicos, los signos de la pérdida
financiera y una industria de seguros u otros
signos de pérdida financiera. En unos pocos le preguntan a un comerciante, verían ese número extremadamente alto y un número extremadamente
bajo. El tamaño de la precipitación
extrema. Por lo que no tenemos
lluvias extremas todos los años. Entonces no podríamos decir que lo
que haya pasado, es por un valor atípico. Y la
distribución de cola pesada
generalmente se ve impactada por
la presencia de valores atípicos. Entonces, si tus datos
están teniendo valores atípicos, entonces también puedes ver
que la distribución para carga es una
distribución de cola pesada. Y entenderemos
en la próxima sesión, ¿qué tipo de
pruebas no paramétricas debo estar realizando? Dependiendo del tipo
de datos no normales
que estemos iniciando. El tamaño del consumo de
energía, el tamaño de la fluctuación
económica de la caída bursátil. Todos estos son ejemplos de su distribución de
cola pesada. Ejemplos de datos bimodales. Aquí hay que entender los medios
bimodales que hay dos resultados que
estamos tratando de estudiar. La distribución
de los puntajes de
los exámenes de los alumnos que estudiaron
y los que no. Distribución de edades
del individuo en una población que de
dos grupos de edad distintos, estatura de dos especies diferentes, distribución
salarial de empleados de dos departamentos diferentes. Godspeed en una autopista con dos grupos de conductores lentos
y rápidos. Entonces aquí se puede ver
que estoy teniendo dos grupos de datos
que son diferentes. Y estoy tratando de entender el comportamiento son voy a seguir adelante y hacer mi investigación
como parte de mi hipótesis o el recurso
que estoy tratando de hacer. Si tengo más de dos
grupos, dos diferentes, más de dos grupos diferentes, como tres grupos diferentes
para grupos diferentes, entonces se convierte en una distribución
multimodal. ¿Correcto? Entonces creo que a estas alturas ya
habrías tenido una idea de cuáles son las diferentes
distribuciones que no
son distribuciones normales. Entonces, ¿cómo determino si
mis datos no son normalmente? El primer punto convertido, viene a nuestra mente
es una prueba de normalidad. Pero incluso antes de hacer
una prueba de normalidad, puedes usar métodos
gráficos simples para averiguar si tus
datos son normales o no. Se puede utilizar histograma. Y aquí el histograma está mostrando
claramente múltiples movimientos. Entonces puedo ver claramente que esta no es una
distribución normal. Si traté de poner una línea de ajuste, entonces también puedo ver que
hay asimetría en mis datos. También puedo usar la gráfica de caja para determinar si mis
datos no son normales. Entonces aquí se puede ver que
tengo una cola pesada en el lado izquierdo
que dice que mis datos están sesgados. También puedo tener valores atípicos que una trama de caja puede resaltar fácilmente. Así puedo esconderme, identificar la distribución de cola pesada
usando la gráfica de caja. También. Puedo usar estadísticas
descriptivas simples donde puedo ver los números
del modo de mediana media. Y cuando veo que
estos números
no se superponen o no se
acercan entre sí, eso también simplemente indica
que mis datos no son normales. Puedo ver la curtosis y asimetría de mi distribución de datos y luego llegar a una conclusión si mis datos se están comportando
normal o no. Por lo que le he mostrado otras formas de identificar
si sus datos están siguiendo y no una
distribución no normal o si sus datos están siguiendo una distribución
normal. Ahora yo diría una cosa más. No te mates
si tu media era 23.78 y la mediana es 24, y el modo
sería como 24.2 o 24. Entonces, si hay una
ligera deflación, seguimos
considerándola normal. ¿Correcto? asimetría cercana a cero es una indicación de que
mis datos son normales. Pero si mi asimetría va más allá de
menos dos o más dos, definitivamente
es nuestra prueba de
no normalidad. cetosis es también una forma más de identificar si mis datos están
siguiendo una distribución normal. La mayoría de las veces preferimos que el número de
curtosis esté en 0-3. Pero si eres la
cetosis es negativa, significa que es una curva plana. Las auditorías siguen una distribución
uniforme. La auditoría podría ser una distribución de
cola pesada de alta curtosis también podría ser una indicación de que sus
datos son demasiado perfectos. Y tal vez necesites
investigar si los hay, no
han manipulado tus datos antes de
entregarlos. Otra prueba favorita de AdText o
Anderson-Darling, donde tratamos de entender
si mis datos son normales o no. Entonces la hipótesis nula básica
cada vez que estoy haciendo la prueba NAT, es que mis datos siguen
una distribución normal. Entonces esta es la única
prueba en la que quiero mi valor p sea
mayor a 0.05 que
obtengo, no logro rechazar la hipótesis
nula, concluyendo que mis
datos son normales, y recurro a mi prueba paramétrica
favorita, lo
que
me facilita hacer el análisis. Pero y si durante la prueba ADA, tus datos y tu análisis de datos muestran que el valor p
es significativo, que es menor que
0.05, tal vez sea 0.02. Entonces concluye, mis datos
no son distribución normal. Y necesito investigar qué tipo de
no normalidad tiene. En consecuencia,
tendré que poner la prueba y luego
llevarla más lejos. Continuaremos nuestra sesión
en el próximo día de Venecia. Espero que te haya gustado. Si tienes alguna duda, no
dudes en
comentar en WhatsApp
o en el canal de Telegram o en la
sección de comentarios de aquí. Cualquier tema que
te gustaría
aprender como parte de la sesión del
miércoles y. Estaría encantado
de investigar eso. Si puedes poner esos comentarios en el cuadro de chat o en el
grupo de WhatsApp o en el telegrama. Realmente me encanta enseñarte y te agradezco por ser maravillosa. Alumnos. Cuídate.
43. Prueba de Kruskal Wallis de 3 o más grupos de datos no normales: Este tutorial trata sobre
la prueba de crus walus. Si quieres saber
qué es la prueba crus c, walus y cómo se puede calcular
e interpretar Estás en el lugar correcto
al final de este video. Te mostraré
cómo puedes
calcular fácilmente la prueba de walus en línea Y empezamos ahora mismo. La prueba crus Walus es una prueba de
hipótesis que se utiliza
cuando se quiere probar
si existe una diferencia entre
varios grupos independientes Ahora bien, tal vez te preguntes un
poco y digas: Oye, si hay varios grupos
independientes, utilizo un análisis de varianza. Así es. Pero si sus datos no se distribuyen
normalmente, y no se cumplen
los supuestos para el análisis de
varianza. Se utiliza la prueba wus. La prueba de Wace es la
contraparte no paramétrica
del análisis factorial único de Ahora te voy a mostrar
lo que eso significa. Hay una diferencia importante
entre las dos pruebas. El análisis de las pruebas de varianza, si hay
diferencia en medias. Entonces cuando tenemos nuestros grupos, calculamos la
media de los grupos, y verificamos si todas las
medias son iguales. Cuando miramos la prueba de
crus C wals, otro lado, no
verificamos si las medias son iguales Comprobamos si las sumas de rango de
todos los grupos son iguales. ¿Qué significa eso?
Ahora bien, ¿qué es un rango? Y ¿qué es una suma de rango en
la prueba clásica de als? No usamos los valores medidos
reales, sino que ordenamos a todas las personas por tamaño, y luego la persona con el valor más pequeño obtiene
el nuevo valor o rango uno. La persona con el segundo valor
más pequeño obtiene el rango dos. La persona con el tercer valor
más pequeño obtiene el rango tres, y así sucesivamente y así cuarto hasta que a cada persona se le
haya asignado un rango. Ahora hemos asignado un
rango a cada persona, y luego simplemente podemos
sumar los rangos
del primer grupo. Sumar las filas
del segundo grupo y sumar las filas
del tercer grupo. En este caso, obtenemos una suma de rango de 54 para
el primer grupo. 70 para el segundo grupo y 47 para el tercer grupo. La gran ventaja es
que si no nos
fijamos en la diferencia principal
sino en la suma de rangos, los datos no
tienen que
distribuirse normalmente al usar
la cruz fue prueba. Nuestros datos no tienen que
satisfacer ninguna forma de distribución, y por lo tanto,
tampoco necesitamos que se distribuyan
normalmente Ejemplos para la prueba de
rusk wallace
para la prueba de rusk walus Por supuesto, se pueden utilizar
los mismos
ejemplos para el
análisis factorial único de varianza, pero con la adición de que los datos no necesitan distribuirse
normalmente. Ejemplo médico. Para una compañía
farmacéutica, desea probar si un medicamento XY tiene
influencia en el peso corporal. Para ello, el medicamento se administra a 20 personas de prueba. Las personas con pruebas T
reciben un placebo y 20 personas de prueba
no reciben ningún medicamento ni placebo. Objetivo, Determinar
si el fármaco XY tiene un efecto estadísticamente
significativo sobre el peso
corporal en comparación con los grupos
placebo y control. Ejemplo de ciencias sociales. ¿Se diferencian tres grupos de edad? En cuanto al consumo diario de
televisión, pregunta de
investigación
e hipótesis. La pregunta de investigación para
el ruskal fue prueba tal vez. ¿Hay alguna diferencia en la tendencia central de
varias muestras independientes? Esta pregunta da como resultado la hipótesis nula y
alternativa. Sin hipótesis. Todas las muestras independientes tienen la misma tendencia central
y, por lo tanto, provienen de
la misma población. Hipótesis alternativa, al
menos una de las
muestras independientes no tiene la misma tendencia central las otras muestras y por lo tanto se origina en una población
diferente Antes discutimos
cómo se calcula la prueba de crus cull, walus,
y no te preocupes Realmente no es complicado. Primero echamos un
vistazo a las suposiciones. Supuestos. ¿Cuándo
usamos el crus c Prueba de Walus? Utilizamos
la prueba crus Walus si tenemos una variable nominal
u ordinal con más Y una variable métrica, una variable nominal u ordinal con más de dos valores es, por
ejemplo, la variable, periódico
preferido,
con los valores, Washington Post, New
York Times, USA today. También podría ser
frecuencia de
visualización de televisión con diario
varias veces a la semana. Realmente nunca una variable
métrica es, por ejemplo, salario, bien, ser, o peso de las personas. ¿Cuáles son las suposiciones ahora? Solo
deben estar disponibles varias muestras
aleatorias independientes con al
menos ordinariamente escaladas características Las variables no tienen que
satisfacer una curva de distribución. Entonces la hipótesis nula son
las muestras independientes, todas tienen la misma tendencia
central. Y por lo tanto vienen de la misma población
o en otras palabras. No hay diferencia
en las sumas de rango, y la hipótesis alternativa
podría ser que al menos una de las
muestras independientes no tenga la
misma tendencia central que las otras muestras, y por lo tanto proviene de
una población diferente. O para decirlo de nuevo en
otras palabras. Al menos un grupo
difiere en las sumas de rango. Entonces la siguiente pregunta es, ¿cómo calculamos un
bizcocho? Prueba de Wallace No es difícil.
Digamos que has medido el
tiempo de reacción de tres grupos. Grupo A grupo en el grupo C, y ahora quieres
saber si hay diferencia entre los grupos en cuanto al tiempo de reacción. Digamos que has anotado el
tiempo de reacción medido en una tabla. Solo supongamos que los datos no se distribuyen
normalmente, y por lo tanto, hay que
usar el crus k was test Entonces nuestra hipótesis nula es que no
hay diferencia
entre los grupos, y vamos a
probarlo ahora mismo. Primero, asignamos un
rango a cada persona. Este es el valor más pequeño. Entonces esta persona obtiene el primer rango. Este es el segundo valor
más pequeño. Entonces esta persona obtiene el rango dos, y lo hacemos ahora
para todas las personas. Si los grupos no tienen
influencia en el tiempo de reacción, los rangos en realidad deberían
distribuirse de manera puramente aleatoria. En el segundo paso, ahora
calculamos
la suma de rango y la suma de rango promedio
para el primer grupo, la suma de rango es dos más
cuatro más siete más nueve, que es igual a 22, y tenemos cuatro
personas en el grupo. La suma de rango promedio es
22/4, lo que equivale a 5.5. Ahora hacemos lo mismo
para el segundo grupo. Aquí obtenemos una suma de rango de 27 y la suma de
rango medio de 6.75, y para el tercer grupo, obtenemos una suma de rango de 29, y la suma de rango promedio de 7.25 Ahora podemos calcular el valor
esperado de las sumas de rango. El valor esperado, si no
hay diferencia en los grupos sería que cada grupo tendría
una suma de rango de 6.5. Ya casi tenemos
todo lo que necesitamos. Entrevistamos a 12 personas. El número de casos es de 12. El valor esperado
de los rangos es de 6.5. También hemos calculado
las sumas de rango promedio de los grupos individuales. Los grados de caso pre
Domina son dos, y estos simplemente vienen dados por el número de
grupos menos uno, lo que hace tres menos uno. Por último, necesitamos la varianza. La varianza de rangos viene
dada por n al cuadrado -1/12. N vuelve a ser un número
de personas, por lo que 12. Obtenemos una varianza de 11.92. Ahora tenemos todo lo
que necesitamos con estos valores. Ahora podemos calcular
nuestro valor de prueba g. El estadístico de prueba
corresponde
al valor g cuadrado y viene
dado por esta fórmula n veces la suma de r bar menos e r cuadrado todos divididos
por Sigma al En nuestro caso, el
número de casos es de 12. Siempre tenemos cuatro
personas por grupo. Entonces podemos sacar el E 5.5
es el rango medio del grupo A, 6.75 es el
rango medio del grupo B, y 7.25 es el rango
medio del grupo C. Esto nos da un valor
redondeado de 0.5, como acabamos Como acabamos de decir, este valor corresponde al valor cuadrado. Ahora podemos
leer fácilmente el valor crítico, cuadrado en la tabla
de valores críticos, cuadrados. Esta tabla también se encuentra
en Internet. Tenemos dos grados de libertad. Y si asumimos que tenemos un nivel de significancia de 0.05, obtenemos un valor crítico, cuadrado de 5.991 Por supuesto, nuestro valor es menor que el valor
crítico de g cuadrado, y así con base en
nuestros datos de ejemplo, se conserva
la hipótesis nula, y ahora
te mostraré cómo puedes
calcular fácilmente la
prueba de Cesco Wallace en línea con la pestaña Datos Cálculo en línea. Para ello, simplemente
visita data tab.net, y luego da clic en la calculadora de estadísticas e inserta sus propios datos
en esta tabla Además, haces clic en esta pestaña, y debajo de esta pestaña, encontrarás muchas pruebas de
hipótesis, y cuando selecciones las
variables que quieres probar, la herramienta te sugerirá
la prueba adecuada. Después de haber copiado sus
datos en la tabla, verá el tiempo de reacción y el grupo
aquí mismo en la parte inferior. Ahora simplemente hacemos clic en tiempo de
reacción y grupo, y automáticamente calcula un análisis de varianza para nosotros. Pero no queremos un
análisis de varianza. Queremos la prueba no paramétrica. Simplemente hacemos clic aquí. Ahora, la calculadora
calcula
automáticamente la prueba
Ruskal Wallace También obtenemos un valor e
cuadrado de 0.5, los grados de libertad son dos, y el valor p calculado es, y aquí abajo, puede
leer la interpretación. Ruskal Walus ha
demostrado que
no hay diferencia significativa
entre las categorías Con base en el valor p, por lo tanto, con los datos utilizados, fallamos en rechazar
la hipótesis nula. Solo pruébalo tú mismo.
Es muy fácil. Mantente conectado, sigue aprendiendo, sigue creciendo, nos vemos
en la siguiente lección.
44. Diseño de experimentos: Hola, y bienvenidos. En este video. Nos adentraremos en el
fascinante mundo
del diseño de experimentos Comúnmente conocido como DOE, discutimos qué es el diseño de
experimentos o DOE, los pasos
del proceso del proyecto DOE Cómo DOE puede ayudarle a reducir
el número de experimentos. Cómo estimar el número
de experimentos necesarios. Y pasamos por los tipos de diseños más
comunes. Entonces, ¿qué es exactamente el diseño
de experimentos en su núcleo?, diseño de experimentos, DOE es un
método estructurado utilizado para planificar, llevar a cabo e
interpretar experimentos El propósito principal del DOE es
averiguar cómo diferentes variables de
entrada,
llamadas factores, afectan a
una variable de salida,
llamada variable de respuesta Aquí hay una explicación más
sencilla. Enfoque sistemático. DOE es organizado y metódico. Sigue un
proceso paso a paso para asegurar que los experimentos se lleven a cabo
de manera lógica y eficiente. Variables de entrada, factores. Estos son los elementos
que cambias en un experimento para ver cómo
afectan el resultado. Por ejemplo, si
estás horneando un pastel, los factores podrían incluir
la cantidad de azúcar, el tiempo de horneado o
la temperatura del horno. Variable de salida, variable de
respuesta. Esto es lo que mides
en el experimento para ver el efecto de los cambios
que hiciste a los factores. En el ejemplo de pastel, la variable de respuesta podría ser el sabor o textura
del pastel. El objetivo del DOE es comprender la relación
entre estos factores y la variable respuesta Ayudándote a determinar
qué factores tienen el impacto más significativo y cómo
interactúan entre sí. Imagina que estás montando una bicicleta. La rotación suave
de las ruedas depende del estado
de los rodamientos. Si los rodamientos están
bien lubricados, hay un par de
fricción mínimo, lo que facilita el pedaleo Sin embargo, si la lubricación es inadecuada o la
temperatura es demasiado alta, se requiere
más esfuerzo para
mantener la velocidad debido al
aumento de la fricción. En tales casos, el DOE nos permite investigar sistemáticamente factores
como los tipos de lubricación, como el aceite o la grasa,
y las temperaturas variables bajas, medias, altas para
cuantificar con precisión su impacto
en la plática friccional Pero, ¿por qué es esto importante? El diseño de experimentos nos
permite diseñar planes de prueba
eficientes que
descubran estos
conocimientos de manera efectiva Al manipular cuidadosamente
los factores y sus niveles, DOE nos ayuda a identificar qué variables
influyen significativamente Ya sea en sistemas mecánicos
como rodamientos o en escenarios
más complejos que involucren respuestas
humanas a medicamentos. Las aplicaciones de DOE
son vastas y diversas, ya sea optimizando los procesos de
fabricación, mejorando los diseños de productos o refinando tratamientos médicos, DOE sirve como una poderosa
herramienta para identificar factores
críticos y determinar las condiciones
óptimas para
lograr los resultados deseados Permite a los investigadores
e ingenieros tomar decisiones informadas basadas en datos
empíricos en lugar de
confiar en En nuestros próximos segmentos, exploraremos los pasos
esenciales del proyecto
ADOE, desde el diseño de experimentos hasta el
análisis de resultados A medida que avanzamos
en el curso, descubrimos las complejidades del
diseño de experimentos
y descubrimos cómo este enfoque metodológico puede
revolucionar su enfoque revolucionar su descubrimos las complejidades del
diseño de experimentos
y descubrimos cómo
este enfoque metodológico puede
revolucionar su enfoque de experimentación e investigación. Estén atentos para obtener más información
y consejos prácticos.
45. Las áreas de aplicación de un DOE: Ahora, entendamos cuáles son las áreas de
aplicación para DOE Las aplicaciones de DOE son
amplias y variadas, ya sea para optimizar los procesos de
fabricación, mejorar los diseños de productos o refinar tratamientos médicos DOE es una poderosa
herramienta para identificar factores
clave y determinar las mejores condiciones para
lograr los resultados deseados Ayuda a investigadores
e ingenieros a tomar decisiones informadas basadas en datos
reales en lugar de conjeturas Pasos del proyecto DOE, echemos un vistazo al
proceso de Un proyecto DOE, planeación, cribado,
optimización y En el primer paso, la planeación. Las cosas son importantes. Primero, obtener una
comprensión clara del problema y del sistema. Segundo, determinar una o
más variables de respuesta. Tercero, identificar los factores que pueden influir significativamente en
la variable de respuesta. La tarea de determinar los factores
potenciales que influyen en la variable de respuesta puede ser muy compleja y llevar mucho tiempo. Por ejemplo, se
puede crear un diagrama de espiga en un equipo. Ahora viene el segundo paso. Cribado, si hay muchos factores que podrían
tener influencia. Por lo general, más de
cuatro a seis factores. Se deben
realizar experimentos de tamizaje para reducir
el número de factores. ¿Por qué es importante esto? El número de factores
a investigar tiene una influencia importante en el número
de experimentos requeridos. Tenga en cuenta que en el diseño
de experimentos, los experimentos individuales también
se
denominan simplemente corridas en el diseño factorial
completo, que discutiremos con
más detalle en un momento El número de
experimentos o corridas es n igual a dos
a la potencia de k, donde n es el número de corridas y k es el número de factores. Aquí hay una pequeña visión general
si tenemos tres factores. Por ejemplo, tenemos que hacer al
menos ocho corridas
con siete factores. Ya son al menos 128
carreras, con diez factores. Ya es
por lo menos 1024 carreras. Tenga en cuenta que esta
tabla aplica a AD OE, donde cada factor solo tiene
dos niveles, de lo contrario. Habrá aún más carreras, dependiendo de lo complejo que sea un experimento
individual. Por lo tanto, puede
valer la pena seleccionar llamados diseños de cribado
para cuatro o más factores. Posteriormente, discutiremos el diseño factorial fraccional
y el plácido diseño y el plácido Que se puede utilizar para experimentos
de cribado. Una vez
identificados
los factores significativos mediante diseños de
tamizaje, y ojalá, se haya reducido el número de
factores. Ahora
se pueden realizar más experimentos. Los datos obtenidos pueden entonces ser utilizados para crear un modelo de
regresión, lo que ayuda a determinar
las variables de entrada de
tal manera que se optimice la
variable de respuesta. Después de la optimización viene la verificación del paso
final. Esto implica verificar
una vez más si las variables de
entrada óptimas calculadas realmente tienen la influencia
deseada en la variable de respuesta. Dependiendo de si estamos en el paso de cribado o en
el paso de optimización. Existen diferentes
tipos de diseños. Gracias por su atención. En la siguiente lección, profundizaremos las aplicaciones
prácticas
del diseño de experimentos y cómo interpretar los resultados de
manera efectiva. Estén atentos.
46. Tipos de diseños en un DOE: Tipos de diseños en experimentos
DOE. Cuando estamos en
el paso de cribado o en el paso de optimización. Utilizamos diferentes tipos
de métodos de diseño. Los más conocidos
son el diseño factorial completo, el diseño factorial
fraccional, el diseño
Placet Berman, el diseño
Box Benkin, el diseño Box Benkin Empecemos por mirar el diseño factorial completo y
el diseño factorial fraccional También tenemos que responder por qué
ponemos en todo este esfuerzo. ¿Por qué utilizamos diseño
de experimentos, DOE y por qué
necesitamos estadísticas La razón es que los experimentos
toman tiempo y cuestan dinero. Por lo tanto, necesitamos
mantener el número de corridas, experimentos
individuales
lo más bajo posible. Sin embargo, si hacemos muy pocas corridas, podríamos perder diferencias
importantes y no obtener resultados precisos. Por ejemplo,
digamos que queremos
averiguar qué factores afectan la
plática friccional de un rodamiento Necesitamos
diseñar cuidadosamente nuestros experimentos para identificar estos
factores de manera eficiente sin hacer ejecuciones innecesarias. ¿Cómo se estima el número de
experimentos en DOE? Echemos un vistazo a un ejemplo. Queremos investigar
qué factores influyen en el
tock friccional de un rodamiento Empecemos con un
factor, la lubricación. Queremos saber si la
lubricación afecta par
de fricción si un
rodamiento está engrasado o engrasado Para averiguarlo, ¿tomamos una
muestra aleatoria de diez rodamientos? Engrasamos la mitad de los rodamientos
y engrasamos la otra mitad. Ahora podemos medir
el tok friccional de los cinco rodamientos engrasados y
los cinco cojinetes engrasados Pero por qué usar diez rodamientos, en la mayoría de los casos, cada tirada
cuesta mucho dinero. Quizás podamos manejar
con menos corridas. ¿Cuántos experimentos necesitamos para saber
si el lubricante tiene un
efecto en el tok de fricción
? si el lubricante tiene un
efecto en el tok de fricción Empecemos con
los diez rodamientos. Ahora podemos calcular
el valor medio del par de fricción de los rodamientos
engrasados y engrasados Entonces podemos calcular la diferencia entre
los dos valores medios. En esta muestra, podemos ver una diferencia entre rodamientos engrasados
y engrasados Sin embargo, también notamos que el par de fricción en los
rodamientos engrasados y engrasados es Si tomamos otra
muestra aleatoria de diez rodamientos, la diferencia podría ser mayor, o podría ser en la dirección
opuesta. En otras palabras, la charla
friccional de los rodamientos varía ampliamente Cuanto más amplia es
la propagación, más difícil es
identificar una
diferencia o efecto específico. Afortunadamente, podemos reducir la variabilidad
del valor medio aumentando el tamaño de la muestra. Cuanto mayor sea el tamaño de
la muestra, más precisa es la
estimación de la media. Por lo tanto,
cuanto menor sea el efecto y más amplia sea la dispersión
de la variable de respuesta, mayor será el
tamaño de la muestra. Pero, ¿cuánto más grande, cómo se puede estimar el
número de corridas necesarias? Puede utilizar esta fórmula como aproximación para estimar
el número de corridas necesarias, n es igual a Sigma dividido por Delta A cuadrado aquí, n es
el número de corridas. Sigma es la desviación estándar. Delta es el efecto
a determinar. Por ejemplo, si tenemos
una desviación estándar de tres newton milímetros y una diferencia
relevante de
cinco newton milímetros. Necesitamos 22 carreras. Si la desviación estándar
es de dos newton milímetros. Solo necesitamos diez corridas si la desviación estándar es de
un newton milímetro Necesitamos cuatro carreras. Entonces usaríamos dos tiradas con rodamientos
engrasados y dos
corridas con rodamientos engrasados Pero, ¿cómo puede el DOE ayudarle a
reducir el número de corridas? Lo veremos en detalle
en la siguiente lección. Gracias por su atención. En la siguiente lección, profundizaremos las aplicaciones
prácticas
del diseño de experimentos y cómo interpretar los resultados de
manera efectiva. Estén atentos.
47. Cómo reducir el número de carreras: Pero, ¿cómo puede el DOE ayudarle a
reducir el número de corridas? Supongamos que el
cálculo del número de corridas da como resultado
16 experimentos. Ocho recorridos con rodamientos engrasados y ocho recorridos con rodamientos
engrasados Pero, ¿y si tenemos
un segundo factor? Digamos que además de
la lubricación, tenemos temperatura con niveles
bajos y altos. Entonces necesitamos otras ocho carreras para tomar
en cuenta estos factores. Por lo que necesitamos 16 corridas para comprobar si el
lubricante tiene algún efecto. Y 16 carreras para comprobar si la
temperatura tiene un efecto. Esto nos da un
total de 24 carreras. Ahora surge la pregunta, es posible lograr
esto con menos corridas, y eso nos lleva al diseño factorial
completo La pregunta es, ¿por qué deberíamos limitarnos a probar
un factor a la vez? En cambio, podríamos
idear un diseño que incorpore todas las combinaciones
potenciales, como grasa y
alta temperatura Por supuesto, todavía necesitamos
16 corridas por factor. Esto lo conseguimos haciendo cuatro carreras con cada una de
las cuatro combinaciones. Después tenemos ocho corridas con
aceite y ocho con grasa, y en el otro lado, ocho con baja temperatura y ocho con alta temperatura. Ahora tenemos un total de 16
carreras antes de que tuviéramos 24 carreras. Ahora necesitamos menos experimentos y obtener aún más información. ¿Por qué más información? Ahora también sabemos
si existe una interacción entre
temperatura y lubricación. Por ejemplo, los
rodamientos engrasados pueden mostrar una variación en el par de fricción a diferentes temperaturas, lo que no se observa
con los rodamientos engrasados Esta información se
habría perdido anteriormente. Ahora, cuando tenemos tres
factores en lugar de dos, los ahorros son aún mayores. Si probamos uno de los
tres factores a la vez, necesitamos 32 corridas. Si ahora ejecutamos dos
experimentos para cada combinación en un diseño factorial
completo, todavía solo necesitamos 16 corridas Sin embargo, para cada factor, todavía
tenemos ocho
corridas por nivel de factor. Por ejemplo, para el factor de
lubricación, tenemos ocho corridas con aceite
y ocho corridas con grasa. Por supuesto, también podemos crear diseños factoriales
completos
con más de dos niveles Por ejemplo, el factor de
temperatura podría tener tres niveles, bajo, medio y alto. Sin embargo, como se mencionó
al principio, incluso con un diseño
factorial completo con dos niveles en cada factor, el número de corridas
requeridas aumenta muy rápidamente a medida que aumenta el número
de factores Echemos, pues, ahora un vistazo al diseño factorial
fraccional El diseño factorial fraccional
se utiliza para los diseños de cribado Es decir, si tienes más de aproximadamente
cuatro a seis factores, Por
supuesto, reducir el número de corridas significa
reducir la información. En los diseños factoriales fraccionarios, la resolución se reduce ¿Cuál es la resolución? La resolución es una
medida de lo bien DOE puede distinguir
entre diferentes efectos Más precisamente, la
resolución indica cuánto confunden los efectos principales y
los efectos de
interacción en un diseño Pero, ¿qué son los efectos medios
y los efectos de interacción? ¿Qué significa confounded? En el diseño de experimentos, el término efecto se refiere
al impacto que un determinado factor o
una combinación de factores tiene sobre la
variable de respuesta de un experimento. Esencialmente, miden cuánto cambia la
variable de respuesta cuando cambias los factores. Un efecto principal es
la influencia de un solo factor en la variable de
respuesta. Por ejemplo, ¿qué influencia tiene la lubricación de un rodamiento
en el tok friccional Los efectos de interacción ocurren
cuando el efecto de un factor sobre la variable de respuesta depende del nivel
de otro factor. Por ejemplo, el efecto del lubricante en
la plática friccional podría depender de la temperatura Pero, ¿qué significa eso? Gracias por su atención. En la siguiente lección,
profundizaremos en las aplicaciones
prácticas del diseño de experimentos. Estén atentos.
48. Tipo de efectos: Pero, ¿qué son los efectos principales
y los efectos de interacción, y qué significa confundar? En diseño de experimentos. El término efecto se refiere
al impacto que un
determinado factor o una combinación de factores tiene sobre la variable
de respuesta de un experimento. Esencialmente,
¿miden cuánto cambia la
variable de respuesta cuando cambias los factores? Un efecto principal es
la influencia de un solo factor en la variable de
respuesta. Por ejemplo, ¿qué influencia tiene la lubricación de un rodamiento en el par de fricción Los efectos de interacción ocurren
cuando el efecto de un factor sobre la variable de respuesta depende del nivel
de otro factor. Por ejemplo, el efecto
del lubricante sobre
el tok friccional podría depender de la temperatura Pero, ¿qué significa eso? Digamos que tenemos un valor promedio de par de
fricción de 102 newton milímetros para los rodamientos con aceite
y un valor promedio de 108 newton milímetros para
los rodamientos con grasa Entonces tenemos un efecto principal de lubricación de seis
newton milímetros. Pero ahora podemos
descomponer esto en temperaturas altas y
bajas. A alta temperatura,
podríamos obtener 98 para aceite y 102 para grasa. La diferencia entre aceite y grasa es de sólo cuatro
newton milímetros. A baja temperatura,
podríamos obtener 104 y 112. Una diferencia de ocho, por lo que el factor de lubricación está
influenciado por la temperatura, y tenemos una interacción entre lubricación
y temperatura. La interacción conduce
a una diferencia de dos nuevos 10 milímetros
con respecto al resultado original. Por lo tanto, tenemos un efecto
de
interacción de dos newton milímetros. Los diseños factoriales completos tienen en cuenta todas las interacciones En nuestro ejemplo de fricción de rodamientos, además de los factores de
temperatura del lubricante, también
observamos
la interacción
entre lubricante
y temperatura entre lubricante
y Sin embargo, a medida que aumenta el número
de factores, surgen
rápidamente
numerosas interacciones. Por ejemplo, si
tenemos cinco factores, A, B, C D y E, obtenemos la interacción
entre dos factores. Entre tres factores, entre cuatro factores y
entre los cinco factores. Ahora, claro. La pregunta es, ¿realmente
necesitamos todas las interacciones, o podemos reducir la resolución? Esto es exactamente lo que el diseño factorial fraccional en un diseño hace
el diseño factorial fraccional en un diseño factorial fraccional Las interacciones
pueden confundirse con otras interacciones o con efectos
principales de factores ¿Qué significa confounded? Significa que los efectos de diferentes factores o el efecto de la interacción de factores no pueden
separarse entre sí. se muestra el grado en que se puede
reducir el
número de corridas a expensas esta tabla se muestra el grado en que se puede
reducir el
número de corridas a expensas
de la
resolución. La resolución suele estar
indicada por números romanos. Ejemplo tres, cuatro,
cinco, y así sucesivamente. Aquí en la diagonal. Vemos los diseños
factoriales completos. Pasaremos por lo que significan
las resoluciones tres, cuatro y cinco en un momento. Por ejemplo, si
tenemos seis factores, necesitamos al menos 64 corridas para
un diseño factorial completo Si elegimos un diseño
factorial fraccional con una resolución de seis Necesitamos 32 carreras con
una resolución de cuatro. Necesitamos 16 carreras, y con una resolución de tres. Sólo necesitamos ocho carreras. Pero, ¿qué significa eso? ¿Cómo funciona? El diseño factorial
completo siempre
se utiliza como punto
de partida Echemos un vistazo al
ejemplo con ocho carreras. En la siguiente lección,
profundizaremos en las aplicaciones
prácticas del diseño de experimentos. Estén atentos.
49. Diseño factorial fraccional: Vamos a desglosar los puntos
clave sobre los diseños factoriales
fraccionarios en términos simples ¿Qué son los diseños
factoriales fraccionarios? Los diseños factoriales fraccionarios son una forma eficiente de probar
múltiples factores simultáneamente Reducen significativamente el número de ejecuciones experimentales necesarias. ¿Por qué usar diseños
factoriales fraccionarios? El uso de diseños
factoriales fraccionarios
ahorra tiempo y recursos
en comparación con los diseños
factoriales completos Además, permiten
la prueba de interacciones
entre factores, proporcionando información valiosa
con menos experimentos. Uno, Resolución en diseños
factoriales fraccionarios. Definición, resolución se refiere a cuánta información se captura en un diseño
experimental. En términos más simples,
nos dice cuántos factores como A, B, C, podemos probar juntos y qué tan bien podemos separar sus efectos entre sí. H igher resolución,
ejemplo, tres o tres. Esto significa que podemos probar
más factores juntos, pero también significa
que los efectos de estos factores podrían
mezclarse con las interacciones. Estos factores
interactúan entre sí. Por ejemplo, con la
resolución tres, los efectos de los
factores principales podrían mezclarse con interacciones que involucren otros
dos factores. Menor resolución, ejemplo. I V o cuatro, aquí, no
podemos probar tantos
factores juntos, pero es más claro ver
los efectos principales de cada factor porque están menos mezclados con las interacciones. Por ejemplo, en la
resolución cuatro, los efectos de los factores principales se confunden con interacciones
que involucran tres factores Dos,
efectos confusos, definición. Cuando decimos que los efectos
son confundidos, significa que no podemos decir exactamente qué factor está causando un
cierto cambio en los resultados Esto sucede porque
diferentes combinaciones de factores podrían tener
efectos similares en el resultado. Ejemplo, imagina
probar los factores, A, B y C, si agregamos un cuarto factor, D, los resultados podrían mostrar cambios que no podemos
atribuir únicamente a D. El efecto de D podría
estar mezclado con la forma en que
A, B y C interactúan
entre sí. Tres, impacto de la resolución
en el diseño de experimentos. Explicación. Elegir una
resolución afecta cuán eficiente es nuestro experimento y cuán claros son nuestros resultados. Mayor resolución, nos permite
probar más factores juntos, pero requiere más pruebas para
tener confianza en nuestros resultados. Una resolución más baja
requiere menos pruebas, pero puede hacer que sea más difícil
enredar los efectos
de diferentes factores Cuatro,
ejemplos prácticos, Ilustración, para entender mejor, pensar probar diferentes recetas
para hornear un pastel. Si cambias un ingrediente, como el azúcar, el
sabor podría cambiar. Pero si cambias
tanto el azúcar como la harina, es más difícil decir qué
cambio causó, qué resultado. El diseño
nos ayuda a equilibrar las pruebas muchos factores y comprender
sus impactos separados. Al comprender estos puntos, los investigadores pueden diseñar
experimentos que den respuestas
claras sobre cómo los
factores afectan los resultados, incluso cuando prueban
varios factores a la vez. Pasaremos por lo que significan
las resoluciones tres, cuatro y cinco en un momento. Por ejemplo, si
tenemos seis factores, necesitamos al menos 64 corridas para
un diseño factorial completo Si elegimos un diseño
factorial fraccional con una resolución de seis, necesitamos 32 Con una resolución de cuatro, necesitamos 16 corridas, y con una resolución de tres, solo
necesitamos ocho carreras. Pero, ¿qué significa eso
y cómo funciona? El diseño factorial completo siempre
se utiliza como punto
de partida Echemos un vistazo a un
ejemplo con ocho carreras. Supongamos que tenemos
los factores A, B y C con un diseño
factorial completo, podemos probar si el factor A, B o C tiene un efecto También podemos probar si las interacciones entre
dos factores tienen un efecto y si las interacciones entre los tres
factores tienen un efecto. Si ahora queremos probar no sólo tres factores
con ocho corridas, sino un cuarto
factor adicional, el factor S D, debemos sacrificar
alguna información de una de las interacciones. Por ejemplo, la
interacción de A, B, y si queremos probar un quinto
factor con ocho pruebas, digamos factor A, necesitaríamos sacrificar
otra interacción. Por ejemplo, la interacción
entre B y C, sin embargo, en realidad no estamos
dejando caer la información. Estamos mezclando el nuevo factor
con la interacción. Esto significa que hemos
confundado el factor con la interacción.
¿Qué significa eso? Significa que no podemos determinar
si un efecto observado se debe al factor D o a la
interacción de A, B y C. De manera similar, no
podemos decir si un efecto se debe al factor A o a la
interacción de B y C de la cosa. Es mucho menos problemático
mezclar un factor con una interacción de tres factores que con una interacción
de dos factores. Del mismo modo, no podemos
distinguir si un efecto resulta
del factor A o de la interacción de B y C. Ahora, tenemos una buena transición
a la resolución. ¿Qué significan las resoluciones tres, cuatro y cinco? En la resolución tres, los efectos
principales
pueden confunderse con
interacciones de dos factores Por ejemplo, el factor D podría
confundirse con la
interacción de los factores A y B Experimentos con resolución tres
por lo que se
considerarían críticos Solo se pueden usar
si la interacción de dos factores es significativamente menor que los efectos
de los factores principales. De lo contrario, la interacción
de dos factores puede distorsionar significativamente
el resultado de un factor Los experimentos a la resolución
cuatro son mucho menos críticos. Aquí, solo los efectos principales se confunden con las
interacciones de tres factores, y cuantos más factores
intervienen en una interacción Cuanto menor sea el efecto
es probable que sea. Además, en la resolución cuatro, las interacciones de dos factores se confunden con las interacciones
de otros dos factores O Los experimentos a la resolución cinco no se
consideran críticos. Los efectos principales solo se confunden con interacciones
de cuatro factores De la misma manera, las interacciones de dos
factores
solo se confunden con
interacciones de tres factores Pero, ¿cómo confundes un
factor y una interacción? Echemos un
vistazo a este ejemplo. Aquí tenemos el diseño factorial
completo de los tres factores, A, B y C. Estas ocho corridas se
realizan en total Todavía solo consideramos
factores con dos niveles, menos uno representa un nivel y uno
representa el otro. Para nuestro ejemplo de plática friccional, el plan de prueba se vería
así para el factor temperatura, menos uno es la temperatura
baja, y uno es la temperatura alta Si ahora ejecutamos los experimentos, obtenemos un valor para la variable de
respuesta para cada ejecución. Si el factor A es uno o menos uno, esto tiene cierto efecto
sobre el valor objetivo. Lo mismo se aplica si el factor
B es uno o menos uno. El efecto de interacción
nos dice si hay
un efecto adicional. I factores A y B
son simultáneamente, uno o menos uno, o si ambos van exactamente en sentido
contrario. un lado, tenemos los
emparejamientos con el mismo signo, y por el otro lado,
los emparejamientos con Podemos verificar si existe una diferencia en la variable de
respuesta, entre los valores en el grupo verde y los
valores en el grupo rojo. Si hay una diferencia, entonces hay una interacción
entre A y B. Sin embargo, si sabemos de antemano, que sólo hay una interacción muy
pequeña o ninguna, podemos usar estas combinaciones. Para probar un cuarto
factor, D para hacer esto, simplemente
multiplicamos. A y B. Siempre
tenemos
uno, si los factores, A y B tienen el mismo signo y menos uno si tienen
otro signo diferente. Por supuesto, puede surgir un problema. Al analizar los resultados. Si hay una diferencia entre los valores verde y rojo. En la variable respuesta, no
podemos determinar si
este efecto proviene de la interacción entre A y B o del factor D si somos a. mostrar que no puede haber
interacción entre A y B. Esto no es un problema. Entonces podemos estar seguros de que la diferencia se debe
al factor D de manera similar. Podemos tomar la interacción
de A y C y también medir el factor A y
la interacción de A, B y C para medir el
factor F por lo tanto. En este caso, medimos seis factores con
solo ocho corridas, pero ya no podemos distinguir factor D de la interacción del factor
A y B
de la interacción de A y C o el factor F
de la interacción de A, B y C en la siguiente lección, tomaremos una visión detallada los otros tipos de
diseños disponibles en DOE En la siguiente lección,
profundizaremos en las aplicaciones
prácticas del diseño de experimentos. Estén atentos.
50. Diseño compuesto central de plackett birman: Bienvenida hoy. Nos sumergimos en
diferentes tipos de diseño de experimentos. O DOE, comencemos con
el Placet Berman Design. ¿Qué es un diseño de Placet Berman? Placet, los diseños de Berman se utilizan típicamente con dos niveles, y de resolución tres La principal ventaja de estos diseños es
que la interacción entre dos factores se distribuye entre
varios otros factores. Por ejemplo, la interacción
entre los factores A y B se confunde con todos los demás factores excepto
A y B mismos Esto hace que los
diseños de Plackett Burman sean ideales cuando se trata
de muchos factores, y cuando solo los
efectos principales son Sin embargo, estos diseños
deben usarse con precaución, si se asume que se
pueden descuidar las interacciones de dos factores. Aunque este requisito
es menos estricto que en fraccionales
clásicos diseños
factoriales fraccionales
clásicos de
resolución tres Al seguir adelante, ¿qué es una
caja de diseño Benkin? La caja, diseño Benkin, junto con el diseño
compuesto central se utiliza para analizar y optimizar
algunos factores en detalle Y para identificar dependencias no
lineales para detectar relaciones no
lineales Al menos tres niveles
por factor son necesarios con un diseño factorial completo
utilizando tres niveles El número de ensayos
puede aumentar rápidamente. Por ejemplo, con dos
factores en tres niveles cada uno, necesitas nueve carreras y con tres factores
en tres niveles cada una, aumenta a 27 carreras. Los diseños de Box, Benkan
abordan esto
creando un
diseño factorial completo con dos E incluyendo puntos centrales, como tres veces
para dos factores, o con tres factores, lo que reduce el
número de corridas 27-15 Aunque esto reduce
el número de corridas, puede identificar menos relaciones no
lineales. A continuación, discutamos el diseño compuesto
central. Este diseño generalmente involucra tres tipos de puntos de prueba, dos, puntos factoriales de
nivel
que forman las esquinas de un cubo o hiper cubo en espacios
multidimensionales Puntos centrales ubicados
en el centro
del espacio definido por
los puntos factoriales Puntos axiales que se encuentran en los ejes del
espacio factorial fuera de la cola. Estos dos últimos tipos
de puntos ayudan a estimar
efectos no lineales en su modelo. En la siguiente lección, profundizaremos en las aplicaciones
prácticas del diseño de experimentos.
Estén atentos.
51. Conclusión: Agradezco mucho por
completar el programa. Demuestra que estás altamente comprometido en tu
viaje por el aprendizaje. Te quieres subir de habilidades y confío en
que hayas aprendido mucho. Espero que todos sus conceptos también
sean claros. Quiero asegurarme de que te diga cuáles son los otros programas
que sí quiero skillshare. Entonces en Skillshare, tengo muchos otros programas
que ya están ahí y
surgirán muchos en las próximas semanas
y meses futuros. son los programas
storytelling con datos, cómo puedo usar la analítica, visualización de
datos, analítica
predictiva sin
codificación, y muchos más. Aparte de esto, también trabajo
como formador corporativo. Me aseguro que todos
mis programas sean altamente interactivos y mantenga todos los participantes
muy comprometidos. Diseñé los libros que son personalizados para mi taller, lo que también asegura
que todos los conceptos sean claramente entendidos
por los participantes. Mis juegos están diseñados
de tal manera que los conceptos obtienen préstamos
en un tiempo que juegan. Hay una gran cantidad de juegos
los cuales están diseñados para mis programas. Y si estás interesado, eres libre de contactarme. También he hecho
más de 2 mil horas de entrenamiento en los últimos dos
años durante la pandemia. Estos son sólo algunos
de los talleres. Por lo que si su organización
quiere tomar algún
programa de capacitación corporativa que esté fuera de línea o en línea. O si sientes que personalmente quieres upskill
tu aprendizaje, eres libre de
contactarme a través de mi ID de correo electrónico. Mantente conectado conmigo en LinkedIn si te
gustó mi formación, por favor asegúrate de
escribir una reseña en LinkedIn. Además, también dirijo un canal de
Telegram donde pongo muchas
preguntas donde gente puede aprender los
conceptos y lo
harán, tal vez solo tarden unos
segundos para que lo hagan. Aparte de eso,
por favor asegúrate escribir para dejar una
opinión en Skillshare, que ¿cómo fue tu experiencia
formativa? Por favor, no olvides
completar tu proyecto. Amo a las personas cuando están comprometidas y has demostrado
que eres una de ellas. Por favor, manténgase conectado. Mantente a salvo, y que Dios te bendiga.
 Dimple Sanghvi, AI Consultant, Lean Six Sigma Master Black Belt
Dimple Sanghvi, AI Consultant, Lean Six Sigma Master Black Belt