Transcrições
1. introdução de análise de dados: Olá amigos. Vamos começar com
este programa de treinamento, análise de dados de
cantos
usando o MiniTab. O que você vai
aprender neste curso? Portanto, as habilidades que
você aprenderá
neste curso são algumas
noções básicas de estatística. Estaremos cobrindo estatísticas
descritivas, resumo
gráfico, distribuições, histograma, box-plot, gráficos de barras
e gráficos de pizza. Vou montar uma nova
série sobre teste de hipótese, que vou compartilhar
no link como um link
no último vídeo. Mas vamos primeiro entender todos os diferentes tipos
de análise gráfica. Quem deve assistir a essa aula? Qualquer pessoa que tenha, que seja
estudante do Lean Six Sigma, que queira obter a
certificação Green Belt, Black Belt ou que
queira aplicar estatísticas e
análises gráficas em seu local de trabalho. Mesmo que você
seja um empreendedor ou um
estudante e
queira entender
estatísticas usando o MiniTab. Eu vou cobrir tudo isso. Vamos aprender quais erros geralmente acontecem
quando estamos analisando. Porque quando fazemos análises usando pontos de dados
baseados em teoria simples, tudo parece ser normal. Então, vou mostrar
algumas armadilhas nas quais nossa análise falhará e como você deve
evitar essas armadilhas. Vamos tentar, no final deste programa, você, o que você vai tirar
desse programa? Você entenderá como
fazer algumas análises básicas. Você entenderá quais
são as ferramentas necessárias durante a
fase de medição, como
cálculos de capacidade e assim por diante. Usaremos durante a fase de
análise, se possível, para cobrir o teste de hipótese. Caso contrário, se conseguir, o vídeo fica maior, vou colocá-lo como
uma visão separada. Ivan também cobre qual gráfico
usar quando temos
alguns erros comuns e realizamos análises
gráficas
e criamos gráficos. E como faço para obter
insights e conclusões
desses gráficos? Isso realmente ajudará você a entender esse
programa muito bem. Vamos ver o que é um Minitab? O Minitab é um
software estatístico que está disponível e tem
várias regiões. Então eu vou encontrar um novo projeto. Minha tela do Minitab se
parece com isso. Eu tenho um navegador
no lado esquerdo. Tenho minha
tela de saída na parte superior, minha planilha de dados, que é muito
parecida com uma planilha do Excel, com a
qual posso trabalhar. Posso continuar adicionando essas
planilhas e ter muitos dados. Posso fazer muitas análises
usando minhas opções. Vamos cobrir
estatísticas básicas, regressão. Estaremos cobrindo muitas estatísticas
básicas e
cobriremos muitos gráficos usando diferentes tipos de dados, certo? Então, se você estava interessado
em saber essas coisas, você definitivamente deveria se
inscrever e assistir ao meu vídeo. Muito obrigado.
2. Recapitulação da introdução ao Lean Six Sigma: Entendendo a
função de transferência em seis sigma. Vamos agora explorar a função e sua relevância em seis sigma Isso começa com a compreensão da relação matemática. Y é uma função de X. Nessa equação, Y
representa a saída e os resultados ou o
resultado que queremos melhorar X representa a
variável de entrada ou o padrão. F representa a função ou a transformação que pode
ser aplicada nessas entradas Em essência, fix Sigma trata identificar e
otimizar o fator X, entradas que
impulsionam
a Ao melhorar o Xs, devemos melhorar o Y ou nos
concentramos em melhorar o Y. O exemplo
da função de transferência em Dmth Vamos considerar um exemplo, chamando um suporte técnico
para resolver uma proporção de computadores. Na fase definida, definimos um problema, quanto tempo leva para um cliente
receber uma resolução. Y, que é igual
ao tempo de resolução, O é o tempo total necessário para resolver
o problema do cliente. Na fase de medição,
identificamos e medimos os vários fatores
envolvidos na chamada. Como o tempo na fila, o tempo com
o suporte, o tempo gasto transferindo
as chamadas entre
agentes, o tempo de resolução Na fase de análise,
determinamos quais Xs são críticos e quais são as variações
típicas
entre os fatores. Durante a fase de melhoria, implementamos mudanças para reduzir o tempo
gasto em cada etapa. Talvez a automação de
determinadas respostas ou otimização da lógica de rotina
seja o que está abordado lá Durante a fase de controle, monitoramos o sistema para garantir que o Y,
que é o momento resolução, tenha realmente melhorado e permanecido em funcionamento ao longo do tempo Esse processo pode ser repetido continuamente para promover melhorias
adicionais. Quando seguido
rigorosamente, o DMAC é uma poderosa
metodologia repetível
para obter um retorno mensurável para obter Melhoria adicional,
metodologias em seis Sigma que temos O sistema é baseado em outras ferramentas,
técnicas e práticas
comprovadas , que incluem controle estatístico
de processos Ele utiliza a carta de controles para monitorar a
variação ao longo do tempo. Ele usa o limite de controle superior e
inferior para identificar quando o processo está estatisticamente fora de controle As ferramentas SPC podem acionar o ciclo DMX quando a variação e o defeito excedem ferramentas de
redução de variações e defeitos são comumente
incluídas no gerenciamento
da qualidade total Eles ajudam a identificar
a causa raiz, as oportunidades de otimização. Essas ferramentas desempenham
um papel fundamental durante a fase de análise e
melhoria do DMC Trabalho em equipe e círculos de qualidade. Originado em Teta, a ênfase foi baseada na abordagem baseada em equipe
para a melhoria do processo Funcionários de todos os níveis
colaboram regularmente para resolver um problema usando as ferramentas e metodologias fornecidas
no Six Os círculos de qualidade geralmente
integram ferramentas estatísticas, técnicas DMAT e DPAduction Em seguida, os projetos Six Sigma
e a estrada do Cinturão Amarelo. Na próxima seção,
discutiremos os projetos Six Sigma e destacaremos o que a
faixa amarela precisa saber, incluindo as funções e
responsabilidades do projeto e o valor a faixa amarela
agrega à equipe de melhoria Normalmente, a duração de um projeto Six Sigma pode
variar significativamente Um projeto de curto prazo pode durar
apenas algumas horas ou um dia, especialmente quando é conduzido por equipe
pequena e de qualidade com o objetivo de
obter documentos incrementais Um projeto de longo prazo
pode durar mais de um ano, especialmente quando o escopo é complexo e multifuncional. É aqui que a
faixa preta entra em jogo. No entanto, os projetos
Six Sigma mais comuns, que são um cinturão verde,
duram cerca de quatro a oito semanas,
permitindo tempo suficiente
para coletar os dados,
percorrem permitindo tempo suficiente
para coletar os dados, todas as
fases do ciclo do DMC Papéis de adolescentes em seis projetos
Sigma. Cada membro da equipe desempenha um papel
distinto e crítico. Vamos entendê-los. Uma faixa preta master e um Blag. Essas pessoas estão liderando
e gerenciando projetos. Eles garantem o alinhamento com a estratégia e orientam
os membros da equipe Cinturões verdes. Eles realizaram análises detalhadas, coleta de
dados e ajudaram
a
implementar a melhoria do processo cinturões amarelos são as pessoas
que fornecem informações importantes,
auxiliam na coleta de dados e apoiam a atividade de
implementação Embora não sejam líderes de projeto, os Yellow Bells têm um papel muito
essencial de membro da equipe, que está impulsionando a
execução diária do projeto
Six Sigma Quais são os objetivos comuns dos projetos
Six Sigma? escopo do projeto varia e geralmente se
concentra em reduzir a variação
na experiência do cliente. No mundo de hoje, a
experiência é muito importante. Acelerar o tempo de lançamento no mercado, eliminar erros e defeitos,
reduzir os custos operacionais, reduzir os custos operacionais, algumas considerações essenciais
para a implementação Six Sigma e o
patrocínio executivo e Projetos sem forte apoio de
liderança financiamento
e visibilidade
são muito diferentes do ecofaxe Adequação da metodologia
. Pi Sigma é muito poderoso, mas não é adequado
para todos os problemas Evite uma
metodologia ou uma mentalidade única para todos. Comece pequeno e depois escale. Crie confiança
e habilidades que sejam projetos
menores e gerenciáveis
antes de iniciar um esforço de
transformação mais amplo Você sabe quando
usar outras abordagens? Em alguns casos, metodologias
alternativas podem ser mais apropriadas Iniciativa Lean, reengenharia de
processos de negócios, chamamos isso de BPR, Business Process
Management ou Ou a outra metodologia
que pode ser usada. O controle do escopo é muito importante. Se o escopo do projeto for muito amplo e não tiver
um resultado claro, ele se tornará incontrolável Custo versus benefício. Considere o ROI antes de
investir tempo e recursos. Por exemplo, gastar
100 horas para economizar apenas 10 horas por ano
não é uma compensação efetiva. Realizar uma avaliação de
prontidão antes de iniciar um projeto
é muito importante Isso ajuda a preparar sua
organização
antes de começarmos a
escolher um projeto Defina o resultado desejado. O que estamos tentando
alcançar e por quê? Estabeleça um critério de sucesso. Como é o sucesso
tanto para a organização quanto para
as pessoas envolvidas? Avalie a disponibilidade dos dados. Temos dados confiáveis, relevantes e oportunos
para apoiar a análise? Monte a equipe certa. Temos pessoas
com as habilidades, a influência e o compromisso de
tornar o produto bem-sucedido? Crie um caso de negócios. Qual é o valor
da melhoria? Quem tende a se beneficiar
e quem pode resistir? Qual é o ROI esperado? Auxiliar na
preparação organizacional é muito importante quando você planeja
um projeto Six Sigma Essas perguntas são fundamentais
porque são muito importantes. Ou seja, como é o estado
futuro em comparação com a situação
atual? Estamos resolvendo um
problema da vida real em nossos negócios? Agora é o momento certo
para implementar o Six Sigma? Uma avaliação cuidadosa
garante que o projeto Six Sigma não
seja apenas relevante, mas também viável e impactante Estamos avaliando
o desempenho? Temos uma
lógica sólida sobre aplicação do seis sigma em
nosso caso de negócios E, finalmente, há
algo mais acontecendo em seu projeto que
precisa de sua atenção? No Six Sigma, existe
realmente uma abordagem correta? Essas perguntas
podem garantir que nossa organização esteja pronta para seis SEMA para
um determinado problema Há três etapas principais para
avaliar a prontidão organizacional Primeiro passo, avalie as perspectivas
e o caminho futuro. Faça a pergunta,
eu critico a cadeia? As empresas precisam disso agora. Avalie o
desempenho atual. Faça a pergunta. Existe uma forte justificativa
estratégica para aplicar o Six Sigma
em nossos negócios Analise os sistemas e
a capacidade de mudança. Faça a pergunta:
a melhoria existente pode fornecer o nível de mudança
necessário para nos manter bem-sucedidos competitivos sem
usar o Six Sigma Para começar, considere a importância
da experiência do cliente, da satisfação
do cliente. Estamos nos concentrando na voz do
cliente para impulsionar a mudança. As melhorias são essenciais
e o cliente precisa delas. É aqui que as ferramentas de
análise de dados Six Sigma são úteis. Isso nos ajuda a entender como o cliente
realmente se preocupa. Six Sigma fornece uma ferramenta
poderosa, planejamento estratégico
futuro melhorando a
eficácia do marketing, acertando na primeira
vez e identificando o que realmente importa para o cliente em relação aos nossos projetos
e serviços Uma dessas ferramentas valiosas no kit de ferramentas
Six Sigma
é o modelo CO, que nos ajuda a entender e priorizar as necessidades dos clientes O modelo CO é um método
para coletar dados dos clientes e entender o que realmente importa para eles. O que diferencia nossas
ofertas das demais? Isso nos ajuda a identificar coisas
importantes, como quais
são os recursos que podem aumentar a
satisfação do cliente quando entregues de forma bem
atribuída ao cliente. Quais são os possíveis fatores
insatisfatórios que podem prejudicar a
experiência do cliente se não forem resolvidos Ao analisar esses feedbacks, podemos priorizar
melhorias que podem criar maior Agora, vamos considerar o planejamento
estratégico. A análise Six Sigma pode desempenhar um papel fundamental ao identificar os principais fatores que
impulsionam os clientes Satisfação do cliente, integrando-os ao planejamento
estratégico As melhorias de desempenho
são muito necessárias. uma
cultura organizacional que faz parte de uma abordagem padrão da TIC Sigma, por meio de elaboração eficaz de
projetos, desenvolvimento de
métricas, sistemas de
controle
e
equipes de círculo de qualidade, pode
melhorar significativamente o alinhamento do desempenho
em toda A lucratividade continua sendo
uma prioridade máxima. Six Sigma é especificamente eficaz na redução do
custo da qualidade Muitas organizações
gastam de 20 a 75% do custo simplesmente para garantir a qualidade
dos produtos e serviços. Ao reduzir esses custos, nos mantemos alinhados com as expectativas
dos clientes e entregamos
consistentemente melhor e entregamos
consistentemente melhor e mais rápido do que Ok. Conceito de lente. manufatura enxuta,
especialmente em um
ambiente do setor de serviços, significa reconhecer a iniciativa de
melhoria contínua Em sua essência, o N se concentra em
simplificar e aprimorar processos para criar mais
valor com seus recursos TahiOO, muitas vezes considerado o pai
do pensamento moderno sobre garantias, enfatizou que a essência da
garantia está em um princípio
simples tempo
calculado desde o recebimento do pedido do
cliente até
o recebimento do pagamento pelo cumprimento
e, em seguida, trabalha
continuamente para tornar
esse tempo o mais curto possível e, em seguida, trabalha
continuamente para tornar esse Len trata fundamentalmente eliminar o desperdício em toda
a cadeia de valor, reduzindo tempo,
esforço e recursos desnecessários O resultado é maximizar o valor, melhorar a eficiência,
melhorar a qualidade e aumentar a
satisfação do cliente. Em uma configuração de manufatura, as histórias de sucesso são muitas. Atualmente, temos muito, mesmo no setor de serviços.
3. Trabalho de projeto: Vamos entender qual é o trabalho de projeto
que vamos
fazer neste
programa de análise de dados usando o MiniTab. Como eu disse, vamos trabalhar com
o MiniTab. E este é o Minitab
que eu vou usar. Também compartilharei
com você uma folha de dados, folha de dados do
seu projeto, onde tenho vários exemplos, onde estamos fazendo
cálculos sobre a capacidade. Vamos tentar ver
as distribuições e você pode ver que
existem várias guias. Exemplo um exemplo
dois exemplo três, vamos tentar fazer alguma análise de
tendências. Vamos tentar ver gráficos de
Pareto. Temos muitos dados que
foram compartilhados com você, o que lhe dará uma experiência
prática
no trabalho com dados, certo? Então, vamos começar.
4. Noções básicas de estatísticas: Bem-vindo ao nosso próximo tópico
importante, Fundamentos da estatística Neste vídeo, você
aprenderá o que é estatística,
o que é estatística descritiva
e o que é estatística inferencial Vamos começar com
a primeira pergunta. O que são estatísticas? estatística
trata da coleta, análise e
apresentação de dados. Por exemplo, se
quisermos investigar se o gênero influencia o jornal preferido
, gênero e jornal são nossas chamadas variáveis
que queremos analisar. Analisar se o gênero influencia o jornal
preferido. Primeiro, precisamos coletar dados. Para fazer isso, criamos
um questionário que pergunta sobre gênero e jornal
preferido Em seguida, enviaremos a
pesquisa e aguardaremos duas semanas. Depois, podemos exibir as respostas recebidas em
uma tabela nesta tabela. Temos uma coluna
para cada variável, uma para gênero e
outra para jornal. Por outro lado, cada linha representa a resposta
de uma pessoa. Por exemplo, o
primeiro entrevistado é do sexo masculino e declarou
os tempos da Índia A segunda é feminina, afirmou a hindu, e assim por diante. Obviamente, os dados não
precisam vir de uma pesquisa. Os dados também podem vir de
um experimento no qual. Por exemplo, quero estudar o efeito de dois medicamentos
na pressão arterial. Vamos considerar outro exemplo da vida
real. Imagine que você é gerente de uma
loja e quer saber se a
exibição de um novo produto aumenta as vendas. Você poderia coletar
dados sobre vendas antes. E depois que a nova
tela for configurada, esses dados ajudarão você a analisar a eficácia
da tela,
ou suponha que o administrador da
escola, queira entender se sessões
extras de tutoria estão ajudando os alunos a melhorar
suas notas em matemática Você poderia coletar
as pontuações antes? Após as sessões de tutoria
para analisar o impacto. Agora, a primeira etapa está concluída. Coletamos dados e podemos começar a analisá-los. Mas o que realmente
queremos analisar? Não pesquisamos
toda a população
, mas coletamos uma amostra. Agora, a grande questão é: queremos apenas
descrever os dados da amostra ou queremos
fazer uma declaração sobre toda a população? Se nosso objetivo estiver limitado
à amostra em si. Ou seja, queremos apenas
descrever os dados coletados. Usaremos
estatísticas descritivas. As estatísticas descritivas
fornecerão um resumo detalhado
da amostra Por exemplo, se pesquisássemos 100 pessoas sobre seu jornal
preferido, estatísticas
descritivas nos
diriam quantas pessoas preferem a época da
Índia ou da Índia No entanto, se quisermos
tirar conclusões sobre a
população como um todo. Usamos estatísticas inferenciais. Essa abordagem
nos permite fazer inferências sobre a população
com base em nossos dados de amostra Por exemplo, usando estatísticas
inferenciais, podemos estimar
a proporção de todos os adultos em uma cidade que preferem um jornal específico com base em uma amostra de 500 entrevistados As estatísticas inferenciais também podem nos
ajudar a determinar se um
determinado grupo demográfico,
como o gênero, influencia significativamente as preferências dos jornais Ao analisar nossos dados de amostra, podemos fazer inferências sobre
as preferências de
jornais de toda a população Usando estatísticas descritivas
e inferenciais, podemos obter uma
compreensão mais profunda de nossas descobertas e tomar decisões informadas sobre estratégias de
marketing ou criação de conteúdo para
diferentes jornais Na próxima lição,
vamos nos aprofundar nas aplicações
práticas da
estatística. Fique ligado.
5. Importância dos níveis de medição ou tipos de dados: Importância dos níveis
de medição. Compreender o nível de medição é crucial
por vários motivos. Análise apropriada. Diferentes níveis de medição exigem técnicas
estatísticas diferentes. Usar o método errado pode
levar a conclusões incorretas. Interpretação de dados. Saber o nível ajuda a interpretar
incorretamente os resultados. Por exemplo, os valores médios são
significativos para dados de intervalo e proporção, mas não para dados
nominais ou ordinais Visualização e técnicas eficazes de
visualização de dados variam de acordo com o
nível de medição Os gráficos de barras são adequados
para dados nominais, enquanto os histogramas são melhores
para dados de intervalo e proporção Vamos nos aprofundar em
cada nível de medição. Nível nominal de medição. As variáveis nominais
categorizam os dados sem estabelecer
nenhuma ordem significativa Por exemplo, perguntar aos entrevistados sobre seu
meio de transporte para a escola, ônibus, carro, bicicleta
ou caminhada é nominal Cada categoria é distinta, mas não há
classificação ou ordem inerente entre elas. análise de dados nominais
envolve contar frequências ou usar gráficos de
barras para visualizar
distribuições. nível ordinal de medição, as variáveis
ordinais introduzem
uma ordem
ou classificação significativa entre as categorias, mas as diferenças entre as classificações não são mensuráveis de
forma consistente Por exemplo, pedir
aos alunos que classifiquem sua satisfação
com o
meio de transporte como
muito satisfeita,
satisfeita , neutra, satisfeita ou muito satisfeita demonstra uma medição
ordinal Embora possamos classificar
essas respostas da menos para a mais satisfeita, a diferença numérica entre satisfeito e muito satisfeito
não é quantificável A análise normalmente envolve cálculos de
mediana e testes não paramétricos Níveis de medição
de intervalo e razão , variáveis
métricas. As variáveis de intervalo e razão são consideradas variáveis métricas. Eles compartilham a
característica de que os intervalos entre
os valores são igualmente espaçados, mas as variáveis de razão também
têm um ponto zero verdadeiro, tornando todas as operações
aritméticas válidas Os exemplos incluem medir
idade, peso ou renda. Por exemplo, perguntar
aos entrevistados sobre o número de minutos necessários para chegar à escola mede os dados de intervalo, onde os intervalos
entre as respostas, por exemplo, 10 minutos e 20 minutos são
consistentes e significativos Isso permite
medidas estatísticas, como o cálculo médias e o uso técnicas estatísticas
avançadas,
como análise de regressão Resumo. Compreender
esses níveis de medição é crucial para criar pesquisas e escolher análises
estatísticas apropriadas. Os dados nominais nos informam sobre categorias
sem qualquer ordem Os dados ordinais permitem classificação, mas não a
medição precisa das diferenças, e o intervalo
e a proporção dos dados métricos permitem medições
precisas e suportam uma ampla variedade de análises
estatísticas Seja criando tabelas de
frequência, gráficos de
barras ou histogramas, selecionar o nível certo de medição garante uma interpretação
precisa dos dados e insights significativos em vários campos
de estudo e pesquisa Vamos examinar mais de perto
cada nível de medição. Nível nominal de medição. Os dados nominais são o nível mais
básico de medição. As variáveis nominais
categorizam os dados, mas não permitem uma
classificação significativa das categorias Os exemplos incluem
sexo, macho, fêmea, tipos de animais, cachorro, gato, pássaro e jornais preferidos. Em todos esses casos, você pode distinguir
entre valores, mas não pode classificar as
categorias de forma significativa Por exemplo, investigar
se o gênero influencia o jornal
preferido envolve variáveis nominais Em um questionário, você
listaria as respostas possíveis
para ambas as variáveis Como não há uma ordem inerente, a organização das categorias no questionário
não importa Os dados coletados podem
ser exibidos em uma tabela e tabelas de frequência ou gráficos de
barras podem ser usados para
visualizar as distribuições Nível ordinal de medição. Os dados ordinais podem ser categorizados e classificados
em uma ordem significativa, mas as diferenças entre as classificações não são
matematicamente iguais Os exemplos incluem
classificações, primeiro,
segundo, terceiro,
índices de satisfação, muito insatisfeito,
insatisfeito, neutro,
satisfeito, muito satisfeito,
níveis de educação, ensino médio,
bacharelado, mestrado,
neste caso, embora a Os intervalos entre as classificações não
são necessariamente iguais. Por exemplo, se um
questionário perguntar:
quão satisfeito você está com
seu trabalho atual, com opções que variam de muito
insatisfeito a muito satisfeito As categorias de resposta
são ordenadas, mas a diferença exata entre cada nível de satisfação não
é quantificável A análise de
dados ordinais geralmente envolve cálculo de medianas e o
uso de testes não Nível de intervalo de medição. Os dados de intervalo têm
intervalos iguais entre os valores, mas não têm um ponto zero verdadeiro Os exemplos incluem temperatura
em graus Celsius ou Fahrenheit. Os dados de intervalo permitem a medição das
diferenças entre os valores. Mas como não
existe um zero verdadeiro, as
proporções não são significativas Operações estatísticas,
como cálculo de médias
e uso de técnicas como análise
de
regressão, e uso de técnicas como análise
de
regressão Nível de medição da proporção. Os dados de proporção têm
intervalos iguais entre os valores e incluem
um ponto zero verdadeiro Os exemplos incluem idade,
peso ou renda, porque os dados da proporção
incluem um zero verdadeiro. Todas as
operações aritméticas são válidas. Esse nível permite o
cálculo de índices e
médias e permite o uso de métodos estatísticos avançados Ah. O que aprendemos até
agora usando um exemplo. Imagine que você está
conduzindo uma pesquisa em uma escola para entender
como os alunos chegam à Aqui estão algumas perguntas
que você pode fazer. Cada um corresponde a um nível
diferente de medição. A primeira pergunta poderia ser qual meio de transporte
você usa para chegar à escola? As opções podem incluir ônibus, carro, bicicleta ou caminhada. Essa é uma variável nominal. As respostas podem ser categorizadas, mas não há uma ordem
significativa Isso significa que o ônibus
não é maior que a bicicleta. A caminhada não é
maior que o carro e assim por diante. Se quiser analisar os
resultados dessa pergunta, você pode contar quantos
alunos usam cada
meio de transporte e
apresentá-lo em um gráfico de barras. Em seguida, você pode perguntar: quão satisfeito você está com seu meio
de transporte atual? opções podem incluir
muito insatisfeito, insatisfeito, neutro,
satisfeito ou muito Essa é uma variável ordinal. Você pode classificar as respostas
para ver qual meio
de transporte tem
maior satisfação. Mas a diferença exata entre satisfeito e muito satisfeito. Por exemplo,
não é quantificável. Para a pergunta final, quantos minutos você
leva para chegar à escola? Aqui, os minutos para chegar à
escola são uma variável métrica. Você pode calcular o
tempo médio necessário para chegar à escola e usar todas as medidas
estatísticas padrão. Podemos visualizar esses dados com um histograma que mostra a
distribuição do tempo
necessário para chegar à escola e comparar os diferentes Portanto, usando dados nominais, podemos categorizar
e contar as respostas, mas não podemos inferir nenhuma ordem Os dados ordinais
nos permitem classificar as respostas, mas não medir
diferenças precisas entre as classificações Os dados métricos
nos permitem medir as diferenças
exatas
entre os pontos de dados. Como já mencionado,
os níveis métricos de medição podem ser subdivididos em intervalo e escala de razão Mas qual é a diferença entre os níveis de intervalo
e proporção? Vamos explorar a
diferença entre os níveis de
medição de intervalo e proporção usando um exemplo. Intervalo versus
nível de proporção de medição. Em uma maratona, o
tempo gasto pelos corredores para concluir a corrida serve
como exemplo prático Considere um cenário
em que o corredor mais rápido termina em 2 horas e o
mais lento termina Veja como classificamos o nível de medição com base
nas informações fornecidas Nível de medição da proporção. Um nível de proporção de medição
é caracterizado por ter um ponto zero verdadeiro, onde zero representa a ausência
da quantidade que está sendo medida. No exemplo da Maratona, todos os corredores começam no mesmo tempo
0,0 quando
começam a Com um verdadeiro ponto zero, podemos fazer
comparações significativas, como afirmar que o corredor mais rápido levou
três vezes menos tempo
do que o corredor mais lento, podemos fazer
comparações significativas, como afirmar que
o corredor mais rápido levou
três vezes menos tempo
do que o corredor mais lento,
2 horas versus 6 horas. Esse nível permite operações
significativas de multiplicação
e divisão Por exemplo, se
um corredor terminar em 4 horas e
outro em 12 horas, podemos dizer com precisão que o primeiro corredor foi três
vezes mais rápido que Nível de intervalo de medição. Um nível de intervalo de medição
carece de um ponto zero verdadeiro. No contexto da maratona, se o cronômetro começar
tarde e
medirmos apenas as diferenças de tempo em relação
ao corredor mais rápido
que começou a tempo, perdemos a Embora os intervalos entre
os valores ainda estejam igualmente espaçados e as operações
aritméticas como adição e
subtração sejam válidas, a
multiplicação e multiplicação Por exemplo, dizer que um corredor terminou 4 horas antes do
outro é significativo Mas não podemos afirmar que
um corredor foi quatro vezes mais rápido do que outro sem saber o tempo total de ambos Em resumo, a
medição do nível de intervalo permite intervalos
iguais
entre valores e suporta operações como
adição e subtração, mas não possui um ponto zero verdadeiro necessário
para Agora, um pequeno exercício para verificar se tudo
está claro para você. Primeiro, temos o estado dos EUA, que é um
nível nominal de medição. Isso significa que os dados são usados para rotular ou nomear categorias sem nenhum valor quantitativo Nesse caso, os estados são nomes sem
ordem ou classificação inerentes. Em seguida, temos
classificações de produtos em uma escala de 1 a 5. Esse é um exemplo
de dados ordinais. Aqui, os números
têm uma ordem ou classificação. Cinco é melhor do que um, mas os intervalos entre
as avaliações não são
necessariamente iguais Passando para nomes de departamentos
como compras,
vendas, operações, finanças,
isso também é nominal As categorias aqui,
como departamentos diferentes são para categorização e
não implicam em nenhum pedido Em seguida, temos
as emissões de CO 2 em um ano, que são medidas em
uma escala de razão métrica. Esse nível permite uma gama completa de operações
matemáticas,
incluindo proporções significativas Zero emissões significam
nenhuma emissão. Então temos números de telefone. Embora
os números de telefone sejam numéricos, eles são classificados como Eles são apenas identificadores
sem valor numérico para análise O nível de conforto é
outro exemplo ordinal. Isso pode incluir níveis
como cuidado baixo, médio e alto, que
indicam uma ordem, mas não a diferença exata
entre esses níveis. espaço vital em metros quadrados é medido em uma escala de proporção. Assim como as emissões de CO 2, metros
quadrados significam que não
há espaço habitável e comparações como o dobro
ou a metade são significativas Por fim, temos a
satisfação no trabalho em uma escala de 1 a 4. Esses são dados ordinais. Ele classifica os níveis de satisfação, mas a diferença entre
cada nível não é quantificada Na próxima lição,
vamos nos aprofundar nas aplicações
práticas do projeto de experimentos. Fique ligado.
6. Medidas de centro e medidas de dispersão: Vamos examinar os dois métodos, começando com estatísticas
descritivas Por que a estatística descritiva
é importante? Por exemplo, se uma empresa quiser entender como seus
funcionários se deslocam para o trabalho Ele pode criar uma pesquisa para
coletar essas informações. Depois que dados suficientes são coletados, eles podem ser analisados usando estatísticas
descritivas Então, o que exatamente é estatística
descritiva, seu objetivo é descrever e resumir um conjunto de dados de uma
forma significativa No entanto, é fundamental observar que
as estatísticas descritivas refletem apenas os dados coletados e
não tiram conclusões sobre
uma população maior Em outras palavras, saber
como alguns funcionários uma empresa se
deslocam não nos permite saber como
todos os funcionários se comportam Agora, para descrever
os dados de forma descritiva, nos
concentramos em quatro componentes principais medidas de tendência central, medidas de dispersão, tabelas de
frequência e gráficos Vamos começar com medidas
de tendência central, que incluem média,
mediana e muito mais Primeiro, a média, a
média aritmética, é calculada somando todas as observações
e dividindo pelo Por exemplo, se tivermos as notas dos
testes de cinco alunos, somamos as pontuações e dividimos por cinco para descobrir que a
pontuação média do teste é 86,6 A seguir está a mediana. Quando os valores em um conjunto de dados são organizados em ordem crescente, a mediana é o valor médio Se houver um
número ímpar de pontos de dados, é simplesmente o valor médio Se houver um número par, a mediana é a média
dos dois valores médios Um aspecto importante
da mediana é que ela é resistente a
valores extremos ou valores discrepantes Por exemplo, independentemente
da altura, a última pessoa está
em um conjunto de dados alto. A mediana permanecerá a mesma. Embora a média possa mudar significativamente com
base nesse valor, a mediana permanece inalterada independentemente da altura da
última pessoa O que significa que não é
afetado por valores discrepantes. Em contraste, os homens podem mudar significativamente com base na
altura da última pessoa, tornando-a sensível a valores discrepantes Agora, vamos discutir o modo. O modo é o valor ou valores que ocorrem
com mais frequência em um conjunto de dados. Por exemplo, se 14 pessoas
viajam de carro, seis de bicicleta, cinco caminham e cinco
usam transporte público
, o carro é o modo,
pois aparece com mais frequência Em seguida, passamos às
medidas de dispersão, que descrevem a
dispersão dos valores em
um conjunto de dados As principais medidas de dispersão
incluem variantes. desvio padrão
e faixa de intequatle, começando Ele indica a distância
média entre cada
ponto de dados e a média. Isso nos diz o
quanto
os pontos de dados individuais se desviam
da média Por exemplo, se o desvio
médio da média for
11,5 centímetros, podemos calcular o
desvio padrão usando Sigma é igual à raiz quadrada
da soma de cada valor
menos Quadrado, dividido por n, onde Sigma é o desvio
padrão N é o número de indivíduos. X sub i é o valor de cada
indivíduo e x bar é a média É importante
observar que existem duas fórmulas para o desvio
padrão divide por n, enquanto o outro divide
por n menos um. O último é usado
quando nossa amostra não cobre
toda a população, como em estudos clínicos. O último é usado
quando nossa amostra não cobre
toda a população, como em estudos clínicos. Agora, como o
desvio padrão difere da variância? O desvio padrão mede a distância média
da média Já a variância é simplesmente o valor quadrado
do desvio padrão A seguir, vamos discutir o alcance
e o intervalo intequatle. O intervalo é a
diferença entre os
valores máximo e mínimo em um conjunto de dados. Por outro lado,
o intervalo inequartil representa os
50% médios dos dados,
calculados como a diferença
entre o primeiro quartil,
Q um e o terceiro
quartil, qu Isso significa que 25%
dos valores estão abaixo e 25% acima da faixa
entre quartis Antes de prosseguirmos para
os pontos finais, vamos comparar brevemente
esses conceitos, medidas de tendência central
e medidas de dispersão Vamos considerar a medição da pressão
arterial dos pacientes. As medidas de
tendência central fornecem um valor único que representa todo
o conjunto de dados. Ajudando a identificar
um ponto central em torno do qual os
pontos de dados tendem a se agrupar. Por outro lado,
medidas de dispersão, como desvio padrão,
intervalo e intervalo inteQatile, intervalo e intervalo inteQatile indicam a dispersão
dos pontos de dados Se eles estão agrupados ao redor do centro ou
amplamente dispersos Em resumo, enquanto as medidas de tendência
central destacam o ponto central do conjunto
de dados, as medidas de dispersão
descrevem como os dados são distribuídos
em torno desse centro Agora, vamos passar às tabelas, focando nos tipos mais
importantes, frequência e tabelas de
contingência Uma tabela de frequência
mostra com que frequência cada valor distinto
aparece em um conjunto de dados. Por exemplo, uma empresa entrevistou seus funcionários sobre
suas opções de deslocamento, carro, bicicleta, caminhada
e transporte público Aqui estão os resultados de 30 funcionários mostrando
suas respostas. Podemos criar uma
tabela de frequência para resumir esses dados listando as quatro opções
na primeira coluna e contando suas
ocorrências na tabela É claro que o meio
de transporte
mais comum entre os
funcionários é o carro. Com 14 funcionários
escolhendo essa opção. A tabela de frequência fornece um resumo conciso dos dados Mas e se tivermos duas variáveis
categóricas
em vez de uma É aqui que uma tabela de
contingência, também conhecida como
tabulação cruzada, entra em jogo Imagine que a empresa
tenha duas fábricas, uma em Detroit e
outra em Cleveland Se também perguntarmos aos funcionários
sobre seu local de trabalho, podemos exibir as duas variáveis
usando uma tabela de contingência Essa tabela nos permite
analisar e comparar
a relação entre as duas variáveis
categóricas As linhas representam as
categorias de uma variável. Enquanto as colunas representam
as categorias da outra, cada célula na tabela
mostra o número de observações que se encaixam
na combinação de
categorias correspondente. Por exemplo, a primeira célula que indica quantos
funcionários viajam de
carro e trabalham em Detroit
foi relatada Obrigada Nos vemos na próxima aula de estatística.
7. Minitab: Nesta aula, vamos
aprender sobre o teste de hipóteses. Vou te ensinar
testes de hipóteses usando o MiniTab. Também vou ensinar testes de
hipóteses
usando o Microsoft Office. Isso é usar o Excel e Microsoft Office para
aqueles que estão interessados em
usar o MiniTab. Deixe-me mostrar de onde
você pode baixar o Minitab. Minitab.com em Downloads. Aqui chegamos à seção de
download. Você tem o software
estatístico MiniTab e está disponível
por 30 dias gratuitamente. Eu também baixei a versão de
teste no meu sistema e a análise do Dando e
mostrei que você a mostrou para você. Lembre-se de que ele está disponível
por apenas 30 dias. Certifique-se de
concluir todo
o programa de treinamento
nos primeiros 30 dias. Quando você sentir o valor disso,
você definitivamente deve
seguir em frente e usar a
versão licenciada do MiniTab, que está disponível aqui. Só preciso clicar em Baixar
e baixar o Woodstock. Tudo começa com uma avaliação
gratuita de 30 dias. E é tempo
suficiente para você praticar todos os
exercícios que são conduzidos. Ele solicitará algumas
informações pessoais
para que eles
possam entrar em contato com você e possam ajudá-lo
com alguns descontos. Se houver algum. Você tem uma seção chamada Dr. MiniTab ou você tem
um número de telefone. Se você estiver ligando do Reino Unido, será fácil ligar
para lá. Mas se você estiver falando
de outros lugares, falar com o MiniTab é uma opção
muito mais fácil. Essa é uma ferramenta
estatística muito boa e eles continuam atualizando os
recursos regularmente. Então, pessoalmente, sinto que esse investimento
valerá a pena. Mas para aqueles que não podem
se dar ao luxo de obter a licença, eles podem usar o Microsoft Office, pelo
menos alguns dos recursos, não todos, mas alguns dos
recursos estão disponíveis. Então, inicialmente, mostrarei todo
o exercício de diferentes tipos de
hipóteses usando o MiniTab. E então passaremos para o Microsoft
Excel, permaneceremos conectados e
continuaremos aprendendo.
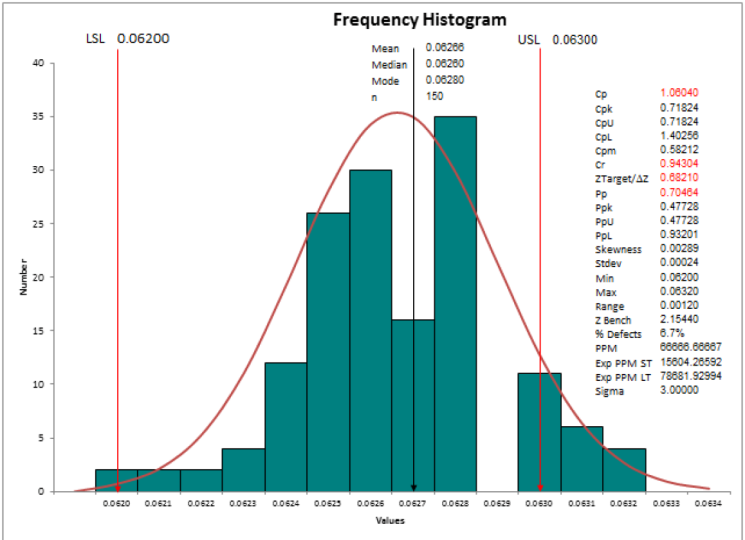
8. Estatística descritiva: Na sessão de hoje, vamos aprender sobre estatísticas
descritivas. Estatística descritiva
significa que eu quero entender as medidas do centro. Como medidas de centro,
média, modo mediano. Eu quero entender
as medidas de propagação. Isso não é nada além de intervalo, desvio
padrão
e variância. Vamos pegar
os dados simples que eu tenho. Eu tenho tempo de ciclo em minutos para quase 100 pontos de dados. Vou pegar o tempo
do ciclo em minutos a partir da folha de dados
do meu projeto diário. Vou para o MiniTab e
colarei meus dados
onde quero fazer algumas estatísticas
descritivas. Estatísticas. Clique em Estatísticas Básicas e diga Exibir estatísticas
descritivas. Quando eu faço isso, ele me dá uma opção na janela pop-up, que é chamada de,
que mostra os campos de
dados disponíveis que eu tenho. Eu tenho tempo de ciclo em minutos. Então, ele está
me dizendo que eu quero analisar o tempo de
ciclo variável em minutos. Vou clicar em Ok, e imediatamente você encontrará
isso na minha janela de saída. Eu posso simplesmente puxar isso para baixo. Na minha janela de saída. Ele está me mostrando
que ele fez algumas análises estatísticas para o
tempo de ciclo variável em minutos. Eu tenho 100
pontos de dados aqui. O número de valores faltantes é 0. A média é 10,064. erro padrão da média é 0,103, desvio
padrão é de 1
para o valor mínimo é 7,5. Um não é nada, mas seu
quartil é 9,1. Mediana, ou seja,
seu Q2 é 10,35, Q3 é 10,868 e o valor
máximo é 12,490. Se eu precisar de mais análise
estatística, posso seguir em frente e
repetir essa análise. Desta vez, vou
clicar em Estatísticas. E eu posso olhar para os outros pontos de
dados que eu preciso. Suponha que se eu precisar do intervalo, eu não preciso de erro padrão, eu preciso de um intervalo
interquartil. Quero identificar
qual é o clima. Quero identificar qual é
a assimetria e meus dados. Qual é a curtose nos meus dados? Eu posso selecionar tudo e dizer, ok, eu vou clicar em, Ok. Quando eu fizer isso, todos os outros parâmetros
estatísticos que eu selecionei
aparecerão na minha janela de saída. Esta é minha janela de saída. Então, novamente, ele me diz aquele ponto de dados
adicional
que eu selecionei. Portanto, o raio não é nada além do seu desvio
padrão ao quadrado. É 0,0541. Ele está me dizendo o intervalo
que é máximo menos mínimo. É 4,95. intervalo interquartil é 1,707. Não há modo nos meus dados. E o número de pontos de dados em
0 porque não há mais, os dados não estão distorcidos. Os valores muito próximos de 0
, são 0,05, mas
há curtose. Isso significa que meus dados não
estão aparecendo como algo que não funciona. Tão bom, gostamos de ver
como é a minha distribuição. Vamos fazer isso. Eu clico em estatísticas, clico em Estatísticas Básicas e clico no resumo
gráfico. Estou selecionando o
tempo do ciclo em minutos. E estou dizendo que quero ver um intervalo de confiança de
95%. Eu clico em, Ok,
vamos ver a saída. O resumo dos minutos de diamante
do ciclo. Está me mostrando a média, desvio
padrão, variância. Todas as coisas estatísticas estão sendo exibidas
no lado direito. Média, desvio padrão,
variância, assimetria, curtose, número de pontos de dados
mediana
mínima do primeiro quartil , máximo do terceiro quartil. Esses pontos de dados que você
vê como mínimo Q1, mediana, Q3 e máximo serão
abordados no boxplot. O boxplot é enquadrado
usando esses pontos de dados. E quando você olha para o velcro, ele diz que o sino não
é uma curva íngreme, é uma curva um pouco mais gorda
e, portanto, o
valor da curtose é um valor negativo. Continuaremos nosso aprendizado mais detalhadamente
no próximo vídeo. Obrigada.
9. Estatísticas descritivas vs inferenciais: Vamos examinar os dois métodos, começando com estatísticas
descritivas Por que a estatística descritiva
é importante? Por exemplo, se uma empresa quiser entender como seus
funcionários se deslocam para o trabalho Ele pode criar uma pesquisa para
coletar essas informações. Depois que dados suficientes são coletados, eles podem ser analisados usando estatísticas
descritivas Então, o que exatamente é estatística
descritiva, seu objetivo é descrever e resumir um conjunto de dados de uma
forma significativa No entanto, é fundamental observar que
as estatísticas descritivas refletem apenas os dados coletados e
não tiram conclusões sobre
uma população maior Em outras palavras, saber
como alguns funcionários uma empresa se
deslocam não nos permite saber como
todos os funcionários se comportam Agora, para descrever
os dados de forma descritiva, nos
concentramos em quatro componentes principais medidas de tendência central, medidas de dispersão, tabelas de
frequência e gráficos Vamos começar com medidas
de tendência central, que incluem média,
mediana e muito mais Primeiro, a média, a
média aritmética, é calculada somando todas as observações
e dividindo pelo Por exemplo, se tivermos as notas dos
testes de cinco alunos, somamos as pontuações e dividimos por cinco para descobrir que a
pontuação média do teste é 86,6 A seguir está a mediana. Quando os valores em um conjunto de dados são organizados em ordem crescente, a mediana é o valor médio Se houver um
número ímpar de pontos de dados, é simplesmente o valor médio Se houver um número par, a mediana é a média
dos dois valores médios Um aspecto importante
da mediana é que ela é resistente a
valores extremos ou valores discrepantes Por exemplo, independentemente
da altura, a última pessoa está
em um conjunto de dados alto. A mediana permanecerá a mesma. Embora a média possa mudar significativamente com
base nesse valor, a mediana permanece inalterada independentemente da altura da
última pessoa O que significa que não é
afetado por valores discrepantes. Em contraste, os homens podem mudar significativamente com base na
altura da última pessoa, tornando-a sensível a valores discrepantes Agora, vamos discutir o modo. O modo é o valor ou valores que ocorrem
com mais frequência em um conjunto de dados. Por exemplo, se 14 pessoas
viajam de carro, seis de bicicleta, cinco caminham e cinco
usam transporte público
, o carro é o modo,
pois aparece com mais frequência Em seguida, passamos às
medidas de dispersão, que descrevem a
dispersão dos valores em
um conjunto de dados As principais medidas de dispersão
incluem variantes. desvio padrão
e faixa de intequatle, começando Ele indica a distância
média entre cada
ponto de dados e a média. Isso nos diz o
quanto
os pontos de dados individuais se desviam
da média Por exemplo, se o desvio
médio da média for
11,5 centímetros, podemos calcular o
desvio padrão usando Sigma é igual à raiz quadrada
da soma de cada valor
menos Quadrado, dividido por n, onde Sigma é o desvio
padrão N é o número de indivíduos. X sub i é o valor de cada
indivíduo e x bar é a média É importante
observar que existem duas fórmulas para o desvio
padrão divide por n, enquanto o outro divide
por n menos um. O último é usado
quando nossa amostra não cobre
toda a população, como em estudos clínicos. O último é usado
quando nossa amostra não cobre
toda a população, como em estudos clínicos. Agora, como o
desvio padrão difere da variância? O desvio padrão mede a distância média
da média Já a variância é simplesmente o valor quadrado
do desvio padrão A seguir, vamos discutir o alcance
e o intervalo intequatle. O intervalo é a
diferença entre os
valores máximo e mínimo em um conjunto de dados. Por outro lado,
o intervalo inequartil representa os
50% médios dos dados,
calculados como a diferença
entre o primeiro quartil,
Q um e o terceiro
quartil, qu Isso significa que 25%
dos valores estão abaixo e 25% acima da faixa
entre quartis Antes de prosseguirmos para
os pontos finais, vamos comparar brevemente
esses conceitos, medidas de tendência central
e medidas de dispersão Vamos considerar a medição da pressão
arterial dos pacientes. As medidas de
tendência central fornecem um valor único que representa todo
o conjunto de dados. Ajudando a identificar
um ponto central em torno do qual os
pontos de dados tendem a se agrupar. Por outro lado,
medidas de dispersão, como desvio padrão,
intervalo e intervalo inteQatile, intervalo e intervalo inteQatile indicam a dispersão
dos pontos de dados Se eles estão agrupados ao redor do centro ou
amplamente dispersos Em resumo, enquanto as medidas de tendência
central destacam o ponto central do conjunto
de dados, as medidas de dispersão
descrevem como os dados são distribuídos
em torno desse centro Agora, vamos passar às tabelas, focando nos tipos mais
importantes, frequência e tabelas de
contingência Uma tabela de frequência
mostra com que frequência cada valor distinto
aparece em um conjunto de dados. Por exemplo, uma empresa entrevistou seus funcionários sobre
suas opções de deslocamento, carro, bicicleta, caminhada
e transporte público Aqui estão os resultados de 30 funcionários mostrando
suas respostas. Podemos criar uma
tabela de frequência para resumir esses dados listando as quatro opções
na primeira coluna e contando suas
ocorrências na tabela É claro que o meio
de transporte
mais comum entre os
funcionários é o carro. Com 14 funcionários
escolhendo essa opção. A tabela de frequência fornece um resumo conciso dos dados Mas e se tivermos duas variáveis
categóricas
em vez de uma É aqui que uma tabela de
contingência, também conhecida como
tabulação cruzada, entra em jogo Imagine que a empresa
tenha duas fábricas, uma em Detroit e
outra em Cleveland Se também perguntarmos aos funcionários
sobre seu local de trabalho, podemos exibir as duas variáveis
usando uma tabela de contingência Essa tabela nos permite
analisar e comparar
a relação entre as duas variáveis
categóricas As linhas representam as
categorias de uma variável. Enquanto as colunas representam
as categorias da outra, cada célula na tabela
mostra o número de observações que se encaixam
na combinação de
categorias correspondente. Por exemplo, a primeira célula que indica quantos
funcionários viajam de
carro e trabalham em Detroit
foi relatada Obrigada. Nos vemos na próxima aula de estatística.
10. Conceitos de estatística inferencial parte 2: Vamos mergulhar nas estatísticas
inferenciais. Começaremos com uma breve
visão geral do que é. Seguido por uma explicação
dos seis componentes principais. Então, o que é
estatística inferencial? Isso nos permite
tirar conclusões sobre uma população com base nos
dados de uma amostra. Para esclarecer, a população é todo o grupo em que
estamos interessados. Por exemplo, se
quisermos estudar a altura média de todos os
adultos nos Estados Unidos, nossa população inclui
todos os adultos do país. A amostra, por outro lado, é um subconjunto menor
retirado dessa população Por exemplo, se selecionarmos
150 adultos dos EUA, podemos usar essa amostra para fazer inferências sobre a população em
geral Agora, aqui estão as seis etapas
envolvidas nesse processo. Hipótese. Começamos
com uma hipótese. Qual é a afirmação
que pretendemos testar? Por exemplo, talvez queiramos
investigar se um medicamento afeta positivamente pressão
arterial em indivíduos
com hipotensão Ah, nesse caso, nossa população consiste em todos os indivíduos com
pressão alta nos EUA, já que é impraticável coletar dados de toda a população Contamos com uma amostra para fazer inferências sobre a
população usando nossa amostra Empregamos testes de hipóteses. Esse é um método usado para
avaliar uma afirmação sobre um parâmetro populacional
com base em dados de amostra. Existem vários testes de
hipóteses disponíveis e até o final deste vídeo. Vou orientá-lo sobre como
escolher o caminho certo. Como funciona o
teste de hipóteses? Começamos com uma hipótese
de pesquisa. Também conhecida como hipótese
alternativa, que é o que buscamos
evidências em nosso estudo. Também chamada de hipótese
alternativa. É para isso que estamos
tentando encontrar evidências. No nosso caso, a hipótese é que o medicamento
afeta a pressão arterial. No entanto, não podemos
testar isso diretamente com um teste de
hipótese clássico. Então, testamos a hipótese
oposta, que a droga não tem
efeito sobre a pressão arterial. Aqui está o processo. Primeiro,
suponha a hipótese de não existir. Assumimos que o medicamento não
tem efeito, o que significa
que as pessoas que tomam o medicamento e aquelas que não têm a
mesma pressão arterial média. T, colete e
analise os dados da amostra. Coletamos uma amostra aleatória. Se o medicamento apresentar um grande
efeito na amostra, determinamos a
probabilidade de extrair essa amostra ou uma
que se desvie ainda mais, se o medicamento realmente não
tiver efeito, ou uma que se desvie ainda mais, se o medicamento realmente não
tiver efeito,
T, avalie o valor p da
probabilidade Se a probabilidade de observar tal resultado sob a
hipótese nula for muito baixa Consideramos a
possibilidade de o medicamento
ter efeito. Se tivermos evidências suficientes, podemos rejeitar a hipótese
nula O valor p é a
probabilidade que mede a força da evidência
contra a hipótese nula Em resumo, a
hipótese nula afirma não
há diferença
na população, e o teste de hipótese
calcula a probabilidade de observar os resultados da amostra
se a hipótese nula for observar os resultados da amostra
se a hipótese nula Queremos encontrar evidências para
nossa hipótese de pesquisa. O medicamento afeta a pressão arterial. No entanto, não podemos testar isso
diretamente, então testamos a
hipótese oposta, a hipótese nula O medicamento não tem efeito
sobre a pressão arterial. Veja como funciona. Suponha a hipótese de não. Suponha que o medicamento não tenha efeito. Ou seja, pessoas que
tomam o medicamento e aquelas que não têm a
mesma pressão arterial média coletam e analisam dados. Pegue uma amostra aleatória. Se o medicamento mostrar um grande
efeito na amostra. Determinamos
a probabilidade de obter esse resultado ou um resultado mais extremo. Se o medicamento realmente não tiver efeito, calcule o valor p. O valor p é a
probabilidade de observar uma amostra
tão extrema quanto a nossa. Supondo que a
hipótese nula seja verdadeira. Significância estatística. Se o valor de p for menor que um limite definido, geralmente 0,05 O resultado é
estatisticamente significativo, o que significa que é improvável que tenha
ocorrido apenas por acaso. Então, temos evidências suficientes para rejeitar a hipótese nula Um pequeno valor de p sugere que os dados observados são inconsistentes com
a hipótese nula Levando-nos a rejeitá-la em favor da hipótese
alternativa. Um grande valor de p sugere que os dados são consistentes
com a hipótese nula Nós não o rejeitamos. Pontos importantes. Um pequeno valor de p não prova que a
hipótese alternativa é verdadeira. Isso apenas indica
que tal resultado é improvável se a
hipótese nula for verdadeira Da mesma forma, um grande valor de p não prova que a
hipótese nula é verdadeira Isso sugere que os dados observados provavelmente estão sob a hipótese
nula Obrigada. Nos vemos na próxima aula de estatística.
11. Conceitos do teste de hipóteses em detalhes: Bem vindo de volta. Vamos entender a
hipótese com mais detalhes. Hipótese de Temos uma população inteira que
adoraríamos estudar. Mas
sempre haveria restrição de tempo e recursos para estudar toda
a população Portanto, pegamos uma amostra
da população usando diferentes técnicas de amostragem
e retiramos uma amostra Estudamos a amostra e extraímos algumas inferências
sobre a população, seja, como estatística
inferencial O que exatamente é uma hipótese? Uma hipótese é uma suposição que não pode ser
propensa nem reprovada Em um processo de pesquisa, a hipótese é feita logo
no início e o objetivo é rejeitar
ou não rejeitar a hipótese. Para rejeitar ou deixar de
rejeitar a hipótese, é necessário um exemplo de
dados do
experimento, uma pesquisa,
que é então avaliada
usando o teste de hipóteses. Usando hipóteses,
geralmente as hipóteses são realizadas a partir de uma
revisão literal Com base na revisão literal, você pode justificar por que formulou a
hipótese dessa forma Um exemplo de
hipótese seria os homens ganham mais do que as mulheres pelo
mesmo emprego na Áustria. A hipótese é uma suposição de uma associação esperada Seu objetivo é rejeitar
ou deixar de rejeitar
a hipótese nula Você pode testar sua hipótese
com base nos dados. A análise dos dados é feita usando o teste de
hipóteses. Homens ganham mais do que mulheres
pelo mesmo emprego na Áustria. Você fez uma pesquisa com quase 1.000 funcionários que
trabalham na Austrália, um teste T de amostra independente. Neste teste, a
hipótese que você precisa
da pesquisa é um teste de
hipótese adequado, como o teste T ou o teste de análise de
correlação Podemos usar ferramentas on-line, como guia
Dados ou
as ferramentas do Excel, para resolver isso. Como faço para formular uma hipótese? Para formular
uma hipótese,
uma questão de pesquisa
deve primeiro ser definida Uma
hipótese formulada precisa sobre a população pode então ser derivada da questão de
pesquisa Homens ganham mais do que mulheres
pelo mesmo emprego na Austrália. Para o sujeito, qual é a pergunta que queremos fazer
e qual é a hipótese? Em seguida, você
fornecerá os dados para
o teste de hipóteses e
tirará a conclusão. Essa é uma representação
visual muito bonita de como um
teste de hipóteses é realizado. Hipóteses não são afirmações
simples. Eles são formulados de
forma que possam ser testados. Eles podem ser
testados com os dados coletados
no decorrer do processo de
pesquisa. com os dados coletados no decorrer do processo de
pesquisa Para testar hipóteses,
é necessário definir exatamente quais variáveis estão envolvidas e como essas
variáveis estão relacionadas. hipóteses, então, são suposições
sobre a relação de causa e efeito
da associação
entre as variáveis O que é uma variável nesse caso? Variável nada mais é do que
uma propriedade de um objeto ou evento que pode
assumir valores diferentes. Por exemplo, a
cor dos olhos é uma variável. Se for propriedade do objeto, posso assumir valores diferentes. Se você está pesquisando
uma ciência social, suas variáveis podem
ser gênero, renda, atitudes,
proteção ambiental, etc Se você estiver pesquisando
sobre a área médica
, suas variáveis
podem ser peso corporal, tabagismo,
frequência cardíaca etc Então, o que exatamente é a hipótese nula
e alternativa? Sempre há duas
hipóteses que são exatamente opostas uma à outra e que afirmam ser opostas Essas
hipóteses opostas são chamadas hipóteses nulas e alternativas e são representadas por H
zero e H A ou H um, H zero e
H um zero e
H A hipótese nula de H naught pressupõe que não
há diferença entre dois ou mais grupos com relação às características que estamos tentando estudar As hipóteses nulas são hen. A hipótese nula pressupõe que não há
diferença entre dois ou mais grupos com relação
às características Por exemplo, o salário dos homens e das mulheres não é
diferente na Áustria. A hipótese alternativa
é a hipótese que
queremos provar ou estamos
coletando dados para prová-la. Portanto, a hipótese alternativa,
por outro lado, assume que há uma diferença entre
os dois ou mais grupos Por exemplo, o salário
dos homens e das mulheres
é diferente na Áustria. A hipótese que você
deseja testar ou o que deseja extrair
da teoria geralmente
indica o efeito. O gênero tem um
efeito sobre o salário. Essa hipótese é chamada
de hipótese alternativa. É uma
declaração muito bonita, certo? Existe outra
maneira de escrever isso, ou
seja, o gênero afeta o salário, e o teste de hipóteses é chamado
de hipótese alternativa. A hipótese nula geralmente afirma que não há efeito O gênero não tem efeito sobre o salário. No teste de hipóteses, somente a hipótese nula
pode ser testada O objetivo é descobrir se hipótese
nula é
rejeitada ou não Existem diferentes
tipos de hipóteses. Quais tipos de hipóteses
estão disponíveis? A distinção mais comum
é entre diferenças, correlação, pode ser
hipótese direcional e não
direcional Hipótese diferencial e de
correlação. Hipóteses diferenciais
são usadas quando diferentes grupos devem ser distinguidos entre o grupo de homens e o grupo hipóteses de correlação são usadas quando se deseja estabelecer uma relação ou uma correlação entre a variável deve ser
testada A relação
entre idade e altura. Hipótese de diferença. A hipótese de diferença
é um teste em que se verifica se há uma diferença entre
dois ou mais grupos. O exemplo da hipótese da
diferença é que o grupo de homens
ganha mais do que mulheres. Os fumantes têm maior risco de ataques
cardíacos do que os não fumantes Há uma diferença
entre Alemanha, Áustria e França em termos de
horas de trabalho por semana. Assim, uma variável é sempre uma
variável categórica, como sexo, tabagismo ou país Por outro lado,
a outra variável é uma variável ordinal ou
uma variável de salário, porcentagem de risco de ataque cardíaco e horas de trabalho por semana Agora, vamos entender a hipótese de
correlação um pouco mais detalhadamente Um teste de hipótese de correlação, relações entre
duas variáveis Por exemplo, a altura
e o peso corporal. Conforme a altura da
pessoa aumenta, o peso corporal é afetado A
hipótese de correlação, por exemplo, é que quanto mais alta uma pessoa, quanto mais pesada ela é, quanto mais
potência um carro tem, maior seu consumo de
combustível Quanto melhor for a nota em matemática, maior será
o salário futuro. Como você pode ver nos exemplos, a hipótese
de correlação
geralmente assume a forma de quanto mais,
maior, menor Assim, pelo menos duas variáveis da
escala ordinal estão
sendo examinadas direcionais e não
direcionais, as
hipóteses são divididas em direcionais e não direcionais Ou seja, são hipóteses unilaterais ou bilaterais. Se a hipótese contém
palavras como melhor do que, pior então, a hipótese geralmente
é direcional Pode ser positivo
ou negativo. No caso de hipóteses não
direcionais, geralmente
se descobre
os blocos de construção, como se houvesse uma diferença
entre a formulação, mas não se afirma em
qual direção a
diferença está qual direção a
diferença Para a
hipótese não direcional, a única coisa interessante é se há uma diferença no valor entre as
variáveis em consideração Em uma hipótese direcional, qual é o interesse um grupo ser maior ou
menor que o outro Você tem uma hipótese bilateral
ou pode ter uma hipótese
unilateral, ou pode ter uma hipótese
unilateral como do lado esquerdo ou do lado direito Hipótese não direcional, uma
hipótese não direcional testa se há uma diferença
ou uma Não importa
em qual direção o relacionamento existe
ou os diferentes custos. No caso de uma hipótese de
diferença, isso significa que há uma
diferença entre dois grupos, mas não diz se
um grupo tem um valor maior. Há uma diferença entre o salário de homens e mulheres, mas não diz
quem ganha mais Há uma diferença
no risco de ataques
cardíacos entre
fumantes e não fumantes, mas não diz quem
está em maior Em relação à hipótese de
correlação, significa que uma relação ou correlação
entre duas variáveis Mas não se diz se
o relacionamento é positivo ou negativo. Há uma correlação entre altura e peso e há uma correlação
entre potência
e consumo de combustível no carro Em ambos os casos, não se diz que a correlação é
positiva ou negativa Quando você fala sobre uma hipótese
direcional, também
estamos indicando a direção do
relacionamento ou a diferença No caso de hipóteses
diferentes, é feita uma
afirmação: qual grupo
tem maior ou menor valor? Os homens ganham mais do que as mulheres. Os fumantes têm um risco maior ataques cardíacos
do
que os não fumantes No caso de uma hipótese de
correlação, a relação é feita para
determinar se a correlação é
positiva ou negativa Quanto mais alta uma pessoa, mais pesada ela
é. Quanto mais potência um carro tiver, maior será sua economia de combustível. hipótese
alternativa direcional unilateral inclui somente os
valores que diferem em uma direção dos valores
da hipótese nula Agora, como interpretamos o valor p em uma hipótese
direcional Normalmente, os
softwares estatísticos sempre ajudam você a
calcular o valor p. O Excel também se tornou muito inteligente no cálculo
do valor p, ajuda no cálculo
do teste não direcional e
também ajuda a fornecer
o valor p para isso do teste não direcional e também ajuda a fornecer
o valor p Para obter o valor p para a hipótese
direcional, ele deve verificar se o
efeito está na direção certa, então o valor p
é dividido por dois e se o
nível de significância não é acelerado por dois, mas apenas por um lado Mais do que isso, temos
um tutorial sobre o valor P. Então, por favor, assista isso
na fase analisada do meu curso. Se você selecionar uma hipótese
alternativa direcionada em um tipo de dados de software lil, para o cálculo
da hipótese, a conversão será
feita automaticamente e você só poderá ler. Agora, instruções passo a passo
para testar a hipótese. Você deve fazer uma pesquisa
bibliográfica, formular a hipótese,
definir o nível da escala,
determinar o nível de
significância, determinar o teste de hipótese,
qual teste de hipótese
é adequado para níveis de escala e estilo de
hipótese O próximo tutorial é
sobre testes de hipóteses. Você aprenderá sobre testes de
hipóteses e
descobrirá qual é o melhor
e como lê-lo.
12. Introdução às ferramentas 7Qc: T. Bem-vindo à nova classe
de sete ferramentas de qualidade. Esse é um dos conceitos mais
importantes se você estiver pensando em fazer pequenas melhorias contínuas em seu processo, operações
ou configuração de fabricação. Mesmo se você estiver
no setor de serviços, essas ferramentas ajudarão você
a acompanhar a qualidade. Com isso, vamos começar. Então, as sete ferramentas de controle de qualidade, o que vou abordar como parte desse programa de
treinamento São as sete ferramentas
de controle de qualidade. Número um: catapulta de coisas,
fluxograma, histograma, análise de
Pareto, diagrama de
Fishburn, também chamado de diagrama de Ishikawa. Execute planilhas de verificação de gráficos. Não vamos abordar
essas ferramentas apenas em alto nível. Vamos
fazer alguns exemplos como desenhar essas coisas usando o Microsoft Excel
sempre que possível. Também forneceremos alguns exemplos de exercícios com dados que podem ajudá-lo a realizar
essas atividades com muita facilidade. Vamos falar
sobre o que é a ferramenta, como usá-la, quando usá-la, alguns erros comuns
que devemos evitar e um guia passo para criar a saída
necessária.
13. Planilha: Vamos para a
próxima ferramenta
de qualidade sete ferramentas de controle de qualidade, que é a folha de verificação Vamos aprender mais
sobre a folha de verificação. As folhas de verificação são usadas para registrar
e compilar
sistematicamente os dados Das fontes históricas ou observações à medida que elas ocorrem. Ele pode ser usado para coletar
dados em locais onde os dados são realmente
gerados ao longo do tempo. Ele pode ser usado para capturar dados
quantitativos e
qualitativos. Então, eu mostrei uma folha de
verificação simples onde você tem os tipos de
defeitos e quantas vezes esse
defeito específico está acontecendo Isso pode ser usado
para
registrar e compilar sistematicamente dados de fontes históricas ou
observações à medida que elas ocorrem Ele pode ser usado para
coletar dados em locais onde os dados são
gerados em tempo real. Esse tipo de dado pode ser tanto
quantitativo
quanto qualitativo. A folha de verificação é um
dos sete QC básicos. O que a folha de verificação faz? Ele é usado para criar
dados
fáceis de compreender e isso vem com um processo
simples e eficiente Com cada entrada, crie
uma imagem clara dos fatos, conforme proposto à opinião
de cada membro da equipe. É por isso que é um
dos orientados por dados. Ele padroniza o acordo sobre as definições de cada
condição Como é usada uma forma de cheque? Concordamos com a definição de eventos ou condições
que estão sendo observados. Exemplo. Se buscarmos a causa raiz dos defeitos de
gravidade um
, concordamos em
considerá-la como gravidade um. Decida quem coleta os dados, decida a pessoa que estará
envolvida nessa atividade Anote as fontes de
onde os dados são coletados. Os dados devem estar na forma de amostra ou de toda a população. Pode ser tanto qualitativo
quanto quantitativo. Decida o
nível de conhecimento necessário para a pessoa envolvida
no plano de coleta de dados. Decida a frequência
da coleta de dados, se os dados devem
ser coletados
semanalmente, de hora em hora, diariamente
ou mensalmente. Decida a duração da coleta de
dados, ou seja, por
quanto tempo os dados devem ser coletados para torná-los
um resultado significativo. Crie uma planilha de verificação
que seja simples usar, concisa, completa e consistente
na acumulação dados durante todo o
período Observe que as planilhas de verificação
foram criadas como uma
das ferramentas de qualidade quando
estávamos na era industrial. Atualmente, estamos na era
da informação. Temos muitos softwares de ERP, máquinas que capturam
dados por causa da TI e vários outros relatórios gerados por
computador
que são aplicáveis Procure usar uma planilha de verificação
somente e somente quando
estiver em um processo de captura de dados totalmente
manual É uma das ferramentas, mas a que menos usa
nos últimos meses. Deixe-me reformular, menos use
ferramentas nos últimos anos. A menos e até que sua
empresa
não tenha completamente nenhuma
abordagem sistemática de captura de dados É uma ferramenta muito boa se você
estiver usando pessoas que são funcionários de cor
azul
e não tem sistemas de alta tecnologia
para capturar os dados. Por isso, anexei o modelo da planilha de verificação na seção de
projetos e recursos. Você pode se referir a ele.
Só me dê um segundo. Vou te mostrar a
folha de cheque na tela. Assim, posso usar uma folha de verificação que
lhe dei como parte do
meu modelo de parado Você pode anotar as
categorias aqui, me
dizendo que é
defeito um, defeito dois A altura é um problema de qualquer que seja o
nome do seu defeito Liste todos os
defeitos aqui, E então você pode comercializar isso com que frequência isso
está acontecendo? Onde quer que esteja acontecendo, comece a escrever um. frequência você está vendo isso e quando está vendo? Além disso, posso
usar esses dados posteriormente
para minha análise de Pareto,
para a qual criei
um vídeo separado,
você pode usar isso para a qual criei um vídeo separado,
você pode usar Você não precisa de uma folha de
verificação separada no mundo de hoje. Você pode usar o que
eu dei aqui. Obrigada Te
vejo na próxima aula.
14. Boxplot: Hoje, vamos aprender sobre
o boxplot e
entendê-lo em detalhes Todos nós teríamos visto o boxplot
em várias instâncias. Mas vamos ver o que
ele interpreta. Então, o que exatamente é um boxplot? Com um boxplot,
você normalmente pode exibir
graficamente muitas
informações sobre seus A caixa indica a faixa
dos 50% médios do local
onde está seu valor. Vamos entender o
gráfico da caixa, como ele é dividido. Se o início da
caixa for chamado de Q um, é a extremidade inferior da caixa e também é chamado
de primeiro quartil Q é a extremidade superior da
caixa ou o terceiro quartil. A distância entre Q três e Q é chamada de intervalo entre
quartis, que é a
metade média dos seus dados Os 25% dos dados estão
abaixo de Q um. Na caixa, você tem 50% dos dados
e, portanto, 25% dos
dados estão acima da caixa. Você tem uma linha principal e
uma linha mediana dentro da caixa, que novamente divide os
dados em 25 e 25% Então, digamos que quando mostramos
a idade do participante, o gráfico da caixa, um tenha 31 anos. Isso significa que 25%
dos participantes têm
menos de 31 anos. Q três tem 63 anos. Isso significa que 25% dos
participantes têm mais de 63 anos. 50% dos participantes
têm entre 31 e 63 anos. A média e a mediana. A mediana está em 42, o que significa que metade
dos participantes mais de 42 anos e a outra metade tem
menos de 42 anos A linha tracejada também é chamada de linha média
ou valor principal, que representa a média Como a média está
longe da mediana, ela diz claramente
que os dados estão A linha sólida representa a mediana e a
linha pontilhada representa a Os pontos que estão mais
distantes são chamados de valores atípicos. A altura do bigode é aproximadamente 1,5 vezes a faixa
interquartal O bigode não consegue
manter o ping indefinidamente. O outlier e o bigode em forma de
ti. Se não houver discrepância, o valor máximo está aqui Se houver um valor atípico, o bigode em forma de T é
o último ponto em que 1,5 vezes a
faixa interquaral e outros são Como faço para criar um boxplot? Você tem uma planilha do Excel para
criar seu boxplot e também pode fazer isso
usando ferramentas online Sim, então eu posso
escolher os gráficos. Com isso, posso dizer que estou
pegando a variável métrica, então você tem a
opção de histograma e também a
opção de boxplot, que diz claramente
que o Q é 29, é 66, a mediana
é 42, Man é 46 O máximo é 99, a cerca
superior é 99. Não há exceções. Vamos alterar os dados. Deixe-me fazer isso como 126. Assim que eu mudar o valor de uma pessoa para 126,
quando você voltar,
você descobrirá que há
um valor atípico no histograma,
e é muito evidente
aqui que 126 é E aqui, a cerca superior é 92. O Q três ainda é o mesmo, o Q ainda é o mesmo. Portanto, o tamanho da caixa não
muda e assim por diante. Certo? E se a pessoa for um herói? Nesse caso, você
verá que não faz
parte de uma exceção, mas ainda faz parte do disco Eu posso fazer o gráfico pequeno, eu posso mostrar a linha zero. Eu posso mostrar o desvio
padrão. Eu posso mostrar os pontos. Eu posso fazer isso na
horizontal e na vertical. Portanto, todas essas opções
são possíveis usando uma ferramenta
estatística on-line. Obviamente, posso baixar o arquivo
Zip e trabalhar com ele. Ok. Como posso fazer o boxplot
usando a planilha do Excel? Então, eu copiei os
mesmos dados aqui. Eu tenho grupos diferentes, então
selecionei minha idade como dados. E agora vou inserir o gráfico
recomendado, vou para todos os gráficos e tenho um gráfico de caixas e
bigodes E eu sou capaz de ver minha
caixa e gráfico de bigodes. Posso remover minhas linhas de grade e
adicionar os rótulos de dados, e isso mostra claramente meu caminho Talvez eu possa apenas
aumentá-lo para torná-lo mais visível. Eu posso mudar a cor do
meu gráfico para ser diferente. Ah, e eu posso escolher a Minha média
está aqui. Minha mediana é 421, três e. Agora, no mesmo gráfico, também
posso
agrupá-lo com base nas raízes. Estou considerando o
grupo e a idade. Eu clico em, posso clicar
no gráfico recomendado, acessar todos os gráficos e
fazer box and whisker Desta vez, tenho quatro caixas
para cada membro do grupo. Eu posso mudar a cor
do meu gráfico. Tudo bem Eu posso incluir os rótulos de dados. Quando eu o incluo aqui
e clico no sinal de vírgula, você verá que
os pontos tei
foram . Portanto, é muito fácil desenhar um gráfico usando o Excel e também usando
algumas ferramentas online Então, para os grupos, eu
pego o grupo mais o A, e para isso, eu pego. Então, para A, digamos que
para o grupo C, se eu mudar
o valor para 100, você descobrirá que
há um valor atípico ali O valor mínimo é dez, vamos alterar os valores 25. Você perceberá que é
assim que os
valores estão mudando. Ótimo. Então, nos vemos
na próxima aula. Obrigada Ah.
15. Parte 1: Nesta lição, vamos
aprender mais sobre o boxplot. Um boxplot é uma
das técnicas gráficas que nos
ajuda a identificar
outliers, certo? Vamos entender como
um boxplot é formado. Vamos entender
o conceito primeiro antes de entrarmos
nas práticas. Um boxplot é chamado de
boxplot porque se
parece com uma caixa e é
viscoso como o gato. O gato está com o rosto. Agora, assim como o gato não pode ter e menos viscoso, o tamanho do bigode
do gráfico da caixa será decidido
em certos parâmetros. Você verá algumas terminologias
importantes ao formar um boxplot. Número um, qual é
o valor mínimo? Qual é o quartil? Qual é a mediana? O que é o core tight? Três, qual é o tamanho
do bigode máximo? E qual é o
valor máximo no ponto de dados? Aqui? O mínimo de cães acima do ponto mínimo e onde
o bigode pode ser estendido. Q1 significa primeiro trimestre, o que significa 25% dos dados. Vamos supor que, com facilidade, temos 100 pontos de dados. 25 por cento dos dados
estarão abaixo dessa marca. Entre Q1 e Q2. Vinte e cinco por cento
dos seus dados serão formados, estarão presentes. segundo trimestre também é chamado de mediana ou
centro de seus dados. Então, se eu organizar meus dados em ordem
crescente ou decrescente, o
ponto de dados do meio é chamado como mediana e é chamado como Q2. Q3, ou também
chamado de quartil superior, fala sobre os
vinte e cinco por cento dos dados após o meio. Então, tecnicamente, você
já cobriu setenta e cinco por cento
de seus dados estarão abaixo do
terceiro quartis, 25 por cento abaixo do primeiro trimestre, 50% dos dados abaixo do segundo trimestre, setenta e cinco por cento dos
os dados estão abaixo do terceiro trimestre. Então, tecnicamente,
de 100% dos dados, 75% dos dados estão abaixo do terceiro trimestre. Isso significa que vinte e cinco por cento dos meus pontos de dados estarão acima do terceiro trimestre. Agora, a distância entre
Q1 e Q3 é chamada, é chamada de tamanho da caixa. E esse tamanho de caixa também é
chamado de intervalo interquartil. Q3 menos Q1 é chamado de intervalo
interquartil. Como eu disse no
início da aula, que o tamanho
do bigode
depende da faixa interquartil ou IQR. Q3. Eu posso essa linha formar 1,5
vezes o tamanho da caixa. Então, 1,5 vezes no IQR mais q3 será o
limite superior para o meu bigode. No lado direito.
Na parte superior. Se eu quiser desenhar o
bigode no lado esquerdo, não
é nada além do mesmo 1,5 vezes na faixa
interquartil. Mas eu subtraio esse valor do Q1 e estendo até esse valor. Então, ele configura o limite inferior. Você pode ter
pontos de dados que
estão abaixo do ponto mínimo. Você pode ter
pontos de dados que
estão além do tamanho
máximo
do risco desses pontos de dados
serem chamados de outliers. A beleza do boxplot
é que ele ajudará você a identificar se há algum
outliers em seu conjunto de dados. Vamos ver como posso
construir um boxplot? Porque fisicamente
não preciso me
preocupar em descobrir 2525% por cento. E realmente por pessoa, iremos ao MiniTab e depois faremos o trabalho. Então, vamos ver essa folha de dados. Então, em nossa aula anterior, fizemos algumas
estatísticas descritivas sobre isso. E encontramos os pontos de dados. Encontramos pontos de dados mínimos
Q1, Q2, Q3 e máximo. Vamos tentar construir um boxplot para o tempo de
ciclo em minutos. Então, vou clicar no gráfico. Vou ao box plot e vejo um boxplot simples
e clico em, Ok, vou selecionar o tempo
do ciclo em minutos. E eu vou dizer, Ok, vamos ver a visualização de dados. Se você olhar para este boxplot, a linha abaixo é chamada
como a única. É 9.16. A mediana é a linha média e não precisa estar
exatamente no centro. O topo da caixa é Q3, que é 10,86
nesse intervalo de dados, e o
intervalo interquartil é 1,7. Minha caixa pode se estender
por 1,5 vezes
no cotovelo e pode ir 1,5 vezes em 1,7
no balão. E você está vendo
que
não há marcas de asterisco
neste boxplot, indicando
muito claramente
que
não há outliers no meu conjunto de dados
atual. Vamos pegar um pouco
mais de conjunto de dados. Em nosso próximo vídeo para
entender como fazer o gráfico de caixa.
16. Parte 2: Vamos continuar nossa jornada entender os boxplots
mais detalhadamente. Se você for para a pasta
em seu arquivo de projeto, que é chamado de boxplot. Coletei dados do tempo de ciclo para cinco cenários
diferentes. Como você pode ver que alguns lugares eu tenho mais
pontos de dados, como eu tenho quase 401745 dados. Em alguns lugares, tenho
apenas 14 pontos de dados. Então, vamos tentar analisar isso mais detalhes para entender
como o boxplot funciona. Copiei esses
dados para o Minitab, caso um, caso dois, T3 e T4. Então, a primeira coisa que eu
gostaria de fazer é fazer algumas
estatísticas descritivas básicas para todas as chaves estrangeiras. Estou selecionando tudo isso. E então estou vendo,
quando vejo minha saída, posso ver que em
três dos casos, tenho 45 pontos de dados. No quarto caso, tenho 18 pontos de dados. No quinto caso,
tenho 14 pontos de dados. Portanto, o número de
pontos de dados é muito, se você olhar para o meu valor mínimo, está variando de 1,
um, vinte e um, vinte e dois. E o valor máximo está
em algum lugar entre 4090 deles. Em um cenário,
desenvolvi valores de 21 a 40. Em um cenário eu tenho
valores de dois a 90, o que mostra muito claramente que o número de
pontos de dados ou fazer isso. Mas minha faixa de valor é branca. Então, se você olhar para a taxa, ela está variando de
18,8 a 99 pontos. Então, no caso dois, eu tenho 1200 como
intervalo, então 99 anos. E o mesmo também pode ser
observado como desvio padrão. Você pode ver que a
assimetria dos dados é diferente e a curtose
é diferente. Vamos primeiro entender
o gráfico da caixa em detalhes. E no próximo vídeo, quando eu estiver falando
sobre o histograma, vamos entender o padrão de
distribuição usando o mesmo conjunto de dados. Vamos começar.
Eu clico no gráfico. Posso clicar no boxplot
e clicar em simples. O que posso fazer é pegar 11 casos de cada vez
para analisar meus dados. Então, caso um, ele
me mostra um gráfico de caixa e esse boxplot mostra muito claramente que não há
outlier em meus dados. E o intervalo está entre. Quando mantenho meu cursor aqui, tenho 45 pontos de dados. Meu bigode está
variando de 21,6 a 4,4, e meu
intervalo interquartil é 5,95. Minha mediana é 30,3. Meu primeiro quartil é 26,9. Meu terceiro quartil é 32,85. Vamos refazer
isso para o caso dois. Quando eu faço minhas chaves também, se você olhar agora, a caixa parece muito pequena porque aqui meus
pontos de dados são os mesmos. Fortified by Vickery
está novamente variando de 21,6 a 40 para parecer
meu cenário anterior. Mas eu tenho outliers aqui, que estão muito além. Se você se lembra, a estatística
descritiva para crianças até o meu valor mínimo é um
e meu valor máximo é 100. Minha mediana parecia com
meu cenário anterior. Meu Q1 também é semelhante, não é o mesmo, mas semelhante. E o Q3 também é semelhante. Mas quando você
olha para o gráfico de caixa, a caixa é muito pequena, indicando
muito claramente
que meu
intervalo interquartil é 6,95. Meu viscoso só pode ir 1,5 vezes e qualquer
ponto de dados além disso, Misko será chamado
de outlier. Posso selecionar esses
valores atípicos, certo? E é muito claro, k é dois, o valor é 100
e está na linha número um. Linha número 37, tenho
um valor chamado 90. Na linha número 30, eu tenho
um valor chamado é 88. E na linha número 21 eu tenho
um valor chamado como um, que é um tamanho mínimo. Então, eu tenho outliers
em ambos os lados. Vamos entender o caso três. Quando olho para a química, coloco meu cursor no boxplot. Eu tenho os mesmos 45 pontos de dados. Minha viscose ou de 21,6 a 40 para parecer meu
caso um, caso dois. Mas nesse cenário, tenho muitos outliers. Na extremidade inferior. Ou seja, no fundo do
meu núcleo, apertado, certo? É fácil para nós clicar
em cada um deles e
ver como estão minhas caixas. Agora, a beleza aqui é que
eu tenho apenas 18 pontos de dados, mas ainda tenho um outlier. Vamos fazer isso para k é cinco. E entenda isso também. Eu tenho uma caixa menor. Eu tenho apenas 14 pontos de dados e eu tenho um outlier
no botão para cima, e eu tenho um outlier
na extremidade inferior. Aqui, o valor é 23. Mas ver esses
enredos de forma diferente torna difícil para
mim fazer uma comparação. Posso colocar tudo
em uma tela? Então eu vou para o gráfico,
eu vou para o boxplot. Eu farei um
ambiente simples selecionado. Estou selecionando todos os casos juntos e vendo
vários gráficos. Estou vendo a pele e estou vendo que
o eixo deve ser visto. As linhas de grade devem ser vistas. E eu clico em, Ok. Estou obtendo todos os
cinco pontos de dados, cenário de
cinco casos
em um gráfico. Isso facilitará para mim
fazer a análise, nesse caso um. Então faça individualmente quando
eu vi o caso,
se estivermos nos mostrando uma grande faixa. Mas quando estou fazendo uma comparação de um ao lado do outro, posso saber que, no caso dois,
tenho outliers na parte
superior e inferior. No caso três, tenho
outliers na parte inferior. No caso quatro, tenho
valores atípicos no lado superior. No caso cinco, tenho
tomadas em ambos os lados. O número de
pontos de dados é diferente. Os bulks serão sacados. O tamanho da caixa não pode ser determinado pelo
número de pontos de dados. Tenho 45 pontos de dados, mas minha caixa é muito estreita. E eu tenho 14 pontos de dados
e minha caixa é branca. Então, o tamanho da caixa. Então, se eu tiver 14 pontos de dados, ele dividirá meus
dados em quatro partes. Portanto, três pontos de dados abaixo do Q1, três pontos de dados
entre Q1 e Q2, três pontos de dados
entre Q2 e Q3 e três pontos de dados além do Q3. Enquanto que quando eu tinha
45 pontos de dados, ele estava sendo
distribuído como 11111111. Minha mediana seria
o número do meio. Então, o que está aprendendo esse exercício é que,
olhando para o tamanho da caixa, você não pode determinar o
número de pontos de dados. Mas o que você definitivamente pode determinar é que, em
mente esse conjunto de dados, eu tenho pontos de dados que
são extremamente altos ou baixos? Portanto, o propósito de desenhar
um gráfico de caixa é ver
a distribuição e
identificar outliers, se houver. Espero que o conceito esteja claro. Se você tiver alguma dúvida, é livre para colocá-la
no grupo de discussão. E ficarei feliz em
respondê-las. Obrigada.
17. Análise de pareto: Olá amigos. Vamos continuar nosso aprendizado sobre sete ferramentas de controle de qualidade A ferramenta que
vamos aprender hoje é gráficos de
Pareto também são
chamados de análise do parto Isso é baseado
no famoso estatístico, não no estatístico Deixe-me me corrigir, economista que percorreu o mundo para estudar a proporção da riqueza em relação
à população Quando ele fez isso, o Sr. Pareto descobriu o princípio 80 20 Vamos nos aprofundar nisso. Portanto, a análise de Pareto, o princípio que
ajuda você a se concentrar
no assunto mais importante para
obter o máximo benefício Ele descreve o fenômeno que uma pequena quantidade
de alto valor contribui mais para o total do que um alto número
de valores baixos. O foco é: quais são esses
atributos de alto valor nos quais eu preciso me concentrar, em vez de
tantos itens de pequeno valor. Em resumo, isso é chamado de
identificar os poucos vitais
em vez dos muitos triviais O que são aqueles blocos vermelhos
que são apenas três ou quatro? Mas a contribuição é importante. Em vez de analisar centenas
de pequenas coisas em que a
contribuição total é pequena. Mesmo se eu analisar minhas despesas
pessoais,
ou seja, da minha
renda total que ganho, maior parte do meu dinheiro
é gasta no pagamento de EMI, no
pagamento de aluguéis e Então, essas são minhas poucas coisas vitais, em vez de muitas triviais, em que estou tentando ver as passagens de ônibus, a comida que estou comendo ou as pequenas compras
que estou fazendo Então, se eu quiser
economizar, preciso
me concentrar em ver como
posso pagar meu EMI mais rapidamente,
como posso ter um aluguel, como posso ter um aluguel, que está dentro A análise de Pareto é
baseada na famosa regra 80 20. Ele afirma que cerca de 80%
dos resultados vêm de
20% do esforço. Muito bem dito, o esforço de 80% vem do
esforço de 20%. Da mesma forma, 80%
dos problemas ou efeitos de 20% das causas. Usamos isso para nossa análise de
causa. A porcentagem exata pode variar de situação
para situação, embora acreditemos que
seja 80 20, mesmo que seja 75 25, devemos prosseguir e tentar
corrigir esses poucos vitais. Às vezes podemos
obtê-lo como 70 30, às vezes podemos
até obtê-lo como 88 12. Esses são apenas alguns
dos exemplos. A questão é quais são
as principais causas, que eu posso corrigir com o mínimo esforço para
obter o máximo de resultados. Em muitos casos, poucos esforços geralmente
são
responsáveis pela maioria dos resultados. Algumas causas
geralmente são responsáveis pela
maior parte do esforço. Se eu me relacionei com meu exame, há certos
capítulos do meu livro que têm mais peso
no meu exame Se eu for minucioso
nesses capítulos, minha probabilidade de obter
60 a 70% se torna muito fácil Em vez de tentar ler todos os 20 capítulos
da minha pasta de trabalho, talvez
eu me concentre em alguns
capítulos para obter A análise Sparto é usada pelos tomadores de
decisão para identificar
os esforços mais significativos para decidir quais selecionar
primeiro, a tomada de decisão É usado em projetos de
melhoria de processos para se
concentrar nas causas que
mais contribuem para um problema específico. Isso ajudará a priorizar as possíveis causas,
os fatores e as principais entradas
do processo do problema
que está sendo investigado É um kit de ferramentas de
melhoria contínua. A análise de Pareto é usada ao priorizar
projetos para se
concentrar em
projetos significativos que
agregarão valor ao cliente
e ao negócio Em vez de fazer
todos os projetos que estão na
minha lista de projetos, eu me concentraria
nesses poucos projetos, dois ou três grandes projetos, que podem me dar o
máximo benefício. Você pode ter cuidado ao o escopo do
projeto se estiver usando o Aysis parto ou ao
priorizar seus recursos,
que é a principal pessoa necessária para que é a principal pessoa necessária Também podemos usar a
análise do parto para visualizar seus dados e saber rapidamente
onde o foco deve ser colocado Por exemplo, eu tenho muitos dados de defeitos, como dez
rasgos de captura densa Estou fazendo a análise
e tenho esses dados. Se eu colocar na
ordem decrescente dos defeitos, acho que arrancar
é o esforço máximo E seguido por pinhole,
depois, e assim por diante Aqueles que estão em cinza, não
vou me concentrar muito porque eles não estão
contribuindo muito. Se eu consertar o rasgo, obterei o
máximo de resultados. Se eu for corrigir
os três primeiros, obterei uma grande redução nos defeitos que estão
acontecendo no meu processo. Por exemplo, se você coletar
os dados sobre os tipos de defeitos, análise
do operador poderá revelar qual tipo de defeito
é mais frequente Você pode se concentrar em seus
esforços para resolver a causa que tem
mais efeito. O benefício da análise do parto é ajudar você a se concentrar no
que realmente importa. Ele separa as principais causas do problema
das menores Permite medir o impacto da melhoria cobrindo o
antes e o depois. Isso permite chegar a um consenso sobre o que
precisa ser abordado primeiro. Verificou-se que o princípio de Pareto é verdadeiro em muitas taxas, 20% de esforço para fornecer 80% de resultados Em vez de trabalho, também
podemos chamá-lo 20%
de causas que
me dão 80% de efeito. Então, se estou pensando em análise de
causa e efeito, novamente são 20% de
causas, 80% de esforço. verdade, se eu também estiver analisando os resultados do
esforço, dizemos que faça menos esforço
para obter o máximo de resultados. 20% dos clientes da empresa são responsáveis por
80% de sua receita ou 80% da venda
vem de 20% dos clientes. Então esse é o conceito de
20% de esforço versus
resultados de 80%. O escritório da
Lei de Análise de Pardo pode ser considerado como 20% dos
trabalhadores realizam 80% do trabalho 20% do tempo gasto em uma tarefa leva a 80%
dos resultados. 20% da população possui
80% da riqueza do país. Não é verdade, mesmo
em nosso país, nosso estado, nossa comunidade? Descobrimos que há muito poucas pessoas que
possuem a
quantidade máxima de riqueza Você pode usar 20%
das ferramentas domésticas,
80% do tempo. Você pode usar 20% de suas
roupas, 80% do tempo. Então é hora de você
aplicar a análise do parto em sua vida pessoal para limpar seu guarda-roupa, se você acredita no conceito de minimalismo 20% dos motoristas de automóveis
causam 80% dos acidentes. 80% das reclamações dos clientes vêm de 20% dos clientes. Apenas algumas causas são responsáveis pela maior parte do efeito
na vara de peixe. Se eu estiver convertendo minha
análise de parto em uma vara de peixe, você descobrirá que
existem poucas causas que contribuem
para a principal Ao ouvir todos
esses exemplos, você teria entendido
que Pareto não se restringe a se inscrever apenas em
seu escritório ou local de trabalho Você pode até mesmo aplicar a
análise do parto em sua vida pessoal. Se eu usar o Twitter ou uma
plataforma de mídia social como essa, maioria dos 20% ativos
dos usuários do Twitter são responsáveis por 80%
dos tweets em geral O gráfico de parto é
um tipo especial de gráfico de barras que traça a
frequência dos dados históricos Portanto, você precisa entender que
esses dados são de ontem ou de hoje de
manhã ou do mês passado. Portanto, é um dado categórico. O eixo x diz muito
claramente que é um dado categórico e o eixo y fala sobre a
frequência de ocorrência Portanto, a análise do parto não pode ser usada para
dados contínuos, observe. Portanto, se você ver, terá dados categóricos com frequência plotada
em ordem decrescente, as principais causas menos esforço para obter
o menos esforço Os dados categóricos são o nível mais baixo de dados que resulta na classificação de
pessoas, coisas Eu posso tornar isso mais simples. Tudo o que é feito com palavras é chamado de dados
categóricos Localizações geográficas,
clima, cor, tipo de
dispositivo, tipo sanguíneo, sangue, tipo de conta
bancária, como
poupança ou corrente, FD ou
empréstimo pessoal residencial , tipo de erro ou
defeito, tipo de dados Análise de Pareto,
o eixo vertical representa a frequência
dos dados categóricos O eixo x representa as
categorias dos rótulos. O eixo horizontal representa os dados categóricos que
causam um problema ou os A barra é organizada em ordem decrescente
da esquerda para a direita A que ocorre
com mais frequência está no lado esquerdo, a menos frequente
está no lado direito. Você não precisa se preocupar se
tiver o Microsoft Excel, ele o desenhará para você. Se você estiver usando uma versão
mais antiga do Excel, compartilharei um modelo
na seção de projetos e
recursos abaixo. Se você tiver muitas categorias, você pode agrupar essas pequenas categorias
pouco frequentes na categoria
chamada de outras. A última barra geralmente é um pouco mais alta que
as anteriores. Opcionalmente, você pode colocar uma curva de frequência
cumulativa acima da barra, fornecendo um eixo y secundário para representar a porcentagem
cumulativa Isso simplesmente ajuda a
interpretar os resultados
com mais facilidade e a identificar
a conexão 80 20 A análise do parto
se concentra
nos esforços nas categorias cuja barra
vertical representa 80% dos resultados. Você deve procurar algo
que seja as principais causas, máximo efeito e o mínimo
esforço para obter o máximo de resultados. Se você observar os
dois padrões de parto, A e B, qual é a melhor ilustração
do padrão de parto. Eu sugeriria que é
o padrão A porque padrão B mostra
que a maioria
deles está
contribuindo quase igualmente. Essa é uma distribuição uniforme, então eu não aceitaria. Eu escolheria o
que é da categoria A. E isso está errado. Se os gráficos resultantes ilustrarem
claramente
um padrão de parto Isso sugere que
apenas algumas causas responsáveis por cerca de
80% do problema. Isso significa que
há um efeito de parto e você pode concentrar seus esforços em
lidar com essas poucas causas
para obter o máximo resultado Se você tivesse recebido
um padrão como o gráfico B
, a análise
do parto não funcionaria e também teremos que
usar algum outro QC. No entanto, se nenhum
padrão de parado for encontrado, não
podemos dizer que algumas causas são mais importantes do que outras. Como eu acabei de dizer. Certifique-se de que seu gráfico de
paradoxo contenha pontos de dados suficientes para
torná-lo significativo No mundo de hoje, há muitos dados disponíveis,
portanto, certifique-se capturar o máximo de
dados possível A análise de Pareto sobre como
construir um gráfico de parto. Se estiver com sua equipe, defina o problema que
você está tentando resolver, identifique as possíveis causas usando o brainstorming ou técnicas
similares Decida o método de medição
a ser usado para comparação, a frequência, o custo
e o tempo, etc Como construir um gráfico de parto, coletar os dados e exigir que os dados categóricos sejam
analisados Calcule a frequência
dos dados categóricos. Desenhe uma linha horizontal e
posicione a barra vertical para indicar
a frequência da categoria. Desenhe uma linha vertical à
esquerda para colocar a frequência à
esquerda da linha,
caso você a esteja desenhando
em um papel milimetrado. O Microsoft Excel pode fazer um gráfico de
paradoxo automaticamente. Mas se você estiver fazendo isso manualmente, classifique as categorias na ordem de frequência
de ocorrência , da melhor para a menor maior
no lado esquerdo. Você deve calcular sua curva de frequência
cumulativa e uma linha percentual cubultiva. Se você observar o efeito do
desfile, concentre seu esforço de melhoria
nas poucas categorias
cuja barra vertical a mais importante É provável que essas causas tenham maior impacto na saída do
seu processo. Coletei uma amostra de Pareto
para analisar o
motivo pelo qual o paciente está usando bem
uma ligação em um
hospital quando é internado Então, eles precisam de auxiliar de banheiro, precisam de comida ou água, reposicionamento da
cama, problemas intravenosos, analgésicos,
ligação urgente de volta para a cama, obter todas as
que estão em cinza não
são coisas que
acontecem com frequência e não
são Então, se focarmos nos primeiros
três ou nos primeiros quatro. Então, se eu
dissesse
que quatro fatores contribuem para
40% do esforço, você
obterá 70% do efeito. Então, talvez eu decida
trabalhar apenas nos três primeiros, ou
seja, 30% de esforço, para ainda obter 68% de esforço Tudo está bem. O conceito é que eu preciso me esforçar menos
para obter o máximo de resultados. Reclamações
de clientes em uma fábrica. Uma equipe de fábrica conduziu
uma análise paralela para abordar o crescente número de reclamações do ponto de vista do
cliente De certa forma, a gerência
pode entender. É um tipo de reclamação de cliente,
reclamação de produto, reclamação relacionada a
documentos, reclamação relacionada a
pacotes ou reclamação relacionada à
entrega. Podemos ver pessoas que os clientes
estão
reclamando no máximo do tipo de produto ou do
defeito do Seguido pelos problemas
relacionados ao documento. Reclamação do cliente em uma fábrica, as categorias principais
podem ser muito genéricas e podem ser
divididas em subcategorias Então, se eu pensar em reclamações de
produtos, elas estão em um
nível alto, posso
considerá-las subcomponentes
do problema A.
É um problema de arranhão,
orifício, par de HMA Você também poderá solicitar novamente o parto na
reclamação do produto Se quiser corrigir problemas relacionados
a arranhões e amassados em
uma reclamação de produto, a maioria das
reclamações do produto será anulada. Tipo de reclamação de documentos, podemos ver que a
falta de informações é a principal contribuição,
seguida por erro na fatura, quantidade
errada e outros. O gráfico de parto pode
ser
analisado mais detalhadamente usando as
categorias principais a serem
divididas em subcategorias ou
subcomponentes em que o problema específico ocorre com
mais frequência, chamados Reclamações
de clientes em uma fábrica. Os resultados sugerem
que há três subcategorias
que ocorrem com mais frequência Observe que é possível
mesclar dois gráficos em um. Portanto, tenho o tipo de reclamação de
produtos
e o tipo de documento, e posso prosseguir
e analisá-los. Pero Principles recebeu o nome do economista italiano
Wilfredo Joseph Juran aplicou os princípios da
Peto ao gerenciamento
da qualidade da produção
comercial Em sua análise, considere
usar dados contextuais, metadados e as colunas
que contêm dados textuais bancos de dados geralmente contêm muitos dados
categóricos
sobre o ambiente do qual os dados são obtidos Esses dados podem ser muito
úteis em análises posteriores ao investigar quem
causa conceitos e ideias Os princípios de Pareto podem
ajudá-lo a medir o impacto da melhoria comparando
o antes com o depois Se você ver que o trabalho azul
foi um grande auxiliar, depois dos projetos,
você descobrirá que
há uma grande melhoria
nessa categoria O novo gráfico de parto
pode mostrar que há uma grande redução
na dose primária. Estatisticamente,
os princípios do parado podem ser descritos pela distribuição
do lote de energia e muitos fenômenos naturais para
exibir a distribuição. Com isso, chego ao fim do conceito de análise do
parto. No próximo vídeo,
mostrarei como
faço a análise de Pareto
usando o Microsoft cel Nos vemos na próxima aula.
18. Teste de hipóteses de conceito e significância estatística (1): Vamos detalhar os
conceitos relacionados ao teste de
hipóteses e à significância
estatística. Um, teste de hipóteses, ao realizar um teste de
hipótese, começamos com uma hipótese de
pesquisa, também chamada de hipótese
alternativa. No seu caso, a
hipótese da pesquisa de que o medicamento tem
efeito sobre a pressão arterial. No entanto, não podemos testar diretamente essa hipótese usando um teste de hipótese
clássico. Em vez disso, testamos a hipótese
oposta que o medicamento não tem
efeito sobre a pressão arterial. Começamos assumindo
que, em média, as pessoas que tomam o medicamento
e as pessoas que não
o tomam têm a mesma
pressão arterial na população Se observarmos um grande
efeito da droga em uma amostra,
perguntamos qual é a probabilidade de extrair
essa amostra ou uma ainda mais extrema se a
droga realmente não tiver efeito. A probabilidade de
obter tal amostra, assumindo a hipótese nula, nenhum efeito é chamada de valor P. O valor P indica a probabilidade de obter
uma amostra que se desvia tanto
quanto nossa
amostra observada ou ainda mais extrema se a
hipótese nula fosse verdadeira Se o valor de p for muito baixo, normalmente menor que 0,05, temos evidências para rejeitar a hipótese nula em favor da hipótese
alternativa Um pequeno valor p sugere que os dados ou a amostra observados são inconsistentes com
a hipótese nula Então, três,
significância estatística. Quando o valor p é menor que um
limite predeterminado, geralmente O resultado é considerado
estatisticamente significativo. Isso significa que é
improvável que o resultado
observado tenha ocorrido apenas
por acaso, e temos evidências suficientes para rejeitar a hipótese nula O limite do valor p
é definido em 5%, ou 0,05, um pequeno valor p sugere que dados ou
a
amostra observados são inconsistentes
com a Por outro lado, um grande
valor de p sugere que os dados observados são consistentes
com a hipótese nula e não a rejeitamos Quatro, erros no teste de
hipóteses. Lembre-se de que um pequeno valor de
p não prova que a
hipótese alternativa é verdadeira. Isso apenas sugere que o resultado observado é improvável sob a hipótese
nula Da mesma forma, um valor P grande não prova que a
hipótese nula é verdadeira Isso apenas sugere que o resultado observado é provável
sob a hipótese nula Vamos agora entender
os dois tipos de erros. O erro do tipo um e
o erro do tipo dois. erro do tipo 1 ocorre quando rejeitamos por engano uma hipótese nula
verdadeira No seu exemplo, isso significaria concluir que o medicamento funciona
quando na verdade não funciona erro do tipo 1 é
quando você rejeita a hipótese nula,
quando, na realidade, a hipótese nula é verdadeira, mas sua decisão sobre a hipótese
nula erro do tipo dois ocorre quando
não rejeitamos uma hipótese
nula falsa O erro do tipo dois ocorre
quando você deixa de
rejeitar a hipótese nula,
quando, na realidade, a hipótese nula é falsa, mas sua decisão sobre a hipótese
nula No seu exemplo, isso significaria perder o
fato de que o medicamento funciona. A amostra coletada não
mostrou muita diferença. Pensei erroneamente que
a droga não está funcionando. Na próxima lição, vamos nos aprofundar nas aplicações
práticas do projeto de experimentos.
Fique ligado.
19. TestofHypothesis: Olá amigos. Vamos continuar nossa jornada
na análise de dados do MiniTab. Hoje vamos aprender
sobre testes de hipóteses. Você já deve ter ouvido falar que fazemos testes de
hipóteses
durante a fase de análise e melhoria
do nosso projeto. Então, para entender como o teste de
hipótese funciona, vamos entender um cenário de caso
simples. Voltarei a este gráfico novamente e
explicarei que é. Como você sabe, quando vamos
ao tribunal,
o sistema de justiça pode ser usado para explicar o conceito
de teste de hipóteses. O juiz sempre começa com
uma declaração que diz, a pessoa é considerada
inocente até que se prove a culpa. Isso não é nada além de sua
hipótese nula, o status quo. Quando eles são pegos, o
caso continua. Os advogados tentaram
produzir dados e evidências. E a menos e até que
não tenhamos dados fortes
e evidências fortes, a pessoa está na
condição de inocente. Portanto, o réu ou o advogado
da oposição está sempre tentando dizer que
essa pessoa é culpada e eu tenho dados e
evidências para provar isso. Ele está tentando trabalhar em hipóteses
alternativas. E o juiz diz, eu vou com o status quo da hipótese nula por padrão. Deixe-me explicar de uma
forma mais fácil. Você e eu, não somos levados
ao tribunal
porque, por padrão, todos
nós estamos na OSA, esse é o status quo. Que são levados
ao tribunal. Pessoas que têm
uma chance de terem vindo, cometeram algum crime. Pode ser qualquer coisa.
Então, da mesma forma. que tentamos fazer testes de
hipóteses Em que tentamos fazer testes de
hipóteses quando estou fazendo minha
fase de análise do projeto. Portanto, tenho várias causas que podem estar contribuindo
para o meu projeto. Por quê? Fazemos uma análise da causa raiz e ficamos sabendo disso, ok? Talvez o carregamento tenha atrasado. Talvez a máquina seja um problema, talvez o
sistema de medição seja um problema. Talvez a matéria-prima não
seja de boa qualidade. Temos vários motivos
que existem. Agora eu quero provar
isso usando dados, e esse é o lugar onde eu tentei usar o teste de hipóteses. Todos os processos
têm variação. Sabemos que todos os processos
seguem a curva do sino. Nunca adicionamos o centro. Há alguma
variação em cada processo. Agora, os dados ou a
amostra que você atualizou, é uma amostra aleatória
vinda do mesmo banco? Ou é uma amostra que vem
de uma curva de sino totalmente
diferente? Portanto, o teste de hipóteses ajudará a analisar o mesmo. Sempre que montamos
um teste de hipótese, temos dois tipos de hipótese, como eu disse, o status quo
ou a hipótese padrão, que é sua hipótese nula. Por padrão, assumimos que
a hipótese nula é verdadeira. Então, para rejeitar a
hipótese nula, precisamos produzir evidências. hipótese alternativa
é o lugar onde há uma diferença. E esta é a razão pela qual o teste de hipóteses foi
realmente iniciado, certo? Nós entenderemos
com muitos exemplos. Então fique conectado. Então, quando estou estruturando hipóteses nulas
e alternativas, digamos, estou dizendo que meu mu não
é nada além da minha média, minha média populacional
é igual a algum valor. Lembre-se sempre de sua hipótese alternativa
é mutuamente exclusiva. Se mu for igual a algum valor, a hipótese alternativa
diria que mu não é igual
a esse valor. Por exemplo, mu é menor que igual a algum valor
como uma hipótese nula. Por exemplo, se estou
vendendo Domino's Pizza, vejo que meu tempo médio de entrega é inferior
a 30 minutos. O cliente vem
e me diz, sabe, o tempo médio de entrega
é superior a 30 minutos, que se torna meu substituto. Às vezes, se tivermos a hipótese nula é mu é maior que
igual a algum valor. Por exemplo, minha qualidade média é maior que igual a 90%. Em seguida, o cliente
volta e me diz que sabe que sua qualidade média é
menor que essa porcentagem. Portanto, lembre-se sempre da
hipótese nula e as hipóteses
alternativas são mutuamente exclusivas e complementares
entre si. Vamos pegar muitos outros
exemplos à medida que avançarmos.
20. Conceito de hipótese nula e alternativa: Vamos mergulhar nas estatísticas
inferenciais. Começaremos com uma breve
visão geral do que é. Seguido por uma explicação
dos seis componentes principais. Então, o que é
estatística inferencial? Isso nos permite
tirar conclusões sobre uma população com base nos
dados de uma amostra. Para esclarecer, a população é todo o grupo em que
estamos interessados. Por exemplo, se
quisermos estudar a altura média de todos os
adultos nos Estados Unidos, nossa população inclui
todos os adultos do país. A amostra, por outro lado, é um subconjunto menor
retirado dessa população Por exemplo, se selecionarmos
150 adultos dos EUA, podemos usar essa amostra para fazer inferências sobre a população em
geral Agora, aqui estão as seis etapas
envolvidas nesse processo. Hipótese. Começamos
com uma hipótese. Qual é a afirmação
que pretendemos testar? Por exemplo, talvez queiramos
investigar se um medicamento afeta positivamente pressão
arterial em indivíduos
com hipotensão Ah, nesse caso, nossa população consiste em todos os indivíduos com
pressão alta nos EUA, já que é impraticável coletar dados de toda a população Contamos com uma amostra para fazer inferências sobre a
população usando nossa amostra Empregamos testes de hipóteses. Esse é um método usado para
avaliar uma afirmação sobre um parâmetro populacional
com base em dados de amostra. Existem vários testes de
hipóteses disponíveis e até o final deste vídeo. Vou orientá-lo sobre como
escolher o caminho certo. Como funciona o
teste de hipóteses? Começamos com uma hipótese
de pesquisa. Também conhecida como hipótese
alternativa, que é o que buscamos
evidências em nosso estudo. Também chamada de hipótese
alternativa. É para isso que estamos
tentando encontrar evidências. No nosso caso, a hipótese é que o medicamento
afeta a pressão arterial. No entanto, não podemos
testar isso diretamente com um teste de
hipótese clássico. Então, testamos a hipótese
oposta, que a droga não tem
efeito sobre a pressão arterial. Aqui está o processo. Primeiro,
suponha a hipótese de não existir. Assumimos que o medicamento não
tem efeito, o que significa
que as pessoas que tomam o medicamento e aquelas que não têm a
mesma pressão arterial média. T, colete e
analise os dados da amostra. Coletamos uma amostra aleatória. Se o medicamento apresentar um grande
efeito na amostra, determinamos a
probabilidade de extrair essa amostra ou uma
que se desvie ainda mais, se o medicamento realmente não
tiver efeito, ou uma que se desvie ainda mais, se o medicamento realmente não
tiver efeito,
T, avalie o valor p da
probabilidade Se a probabilidade de observar tal resultado sob a
hipótese nula for muito baixa Consideramos a
possibilidade de o medicamento
ter efeito. Se tivermos evidências suficientes, podemos rejeitar a hipótese
nula O valor p é a
probabilidade que mede a força da evidência
contra a hipótese nula Em resumo, a
hipótese nula afirma não
há diferença
na população, e o teste de hipótese
calcula a probabilidade de observar os resultados da amostra
se a hipótese nula for observar os resultados da amostra
se a hipótese nula Queremos encontrar evidências para
nossa hipótese de pesquisa. O medicamento afeta a pressão arterial. No entanto, não podemos testar isso
diretamente, então testamos a
hipótese oposta, a hipótese nula O medicamento não tem efeito
sobre a pressão arterial. Veja como funciona. Suponha a hipótese de não. Suponha que o medicamento não tenha efeito. Ou seja, pessoas que
tomam o medicamento e aquelas que não têm a
mesma pressão arterial média coletam e analisam dados. Pegue uma amostra aleatória. Se o medicamento mostrar um grande
efeito na amostra. Determinamos
a probabilidade de obter esse resultado ou um resultado mais extremo. Se o medicamento realmente não tiver efeito, calcule o valor p. O valor p é a
probabilidade de observar uma amostra
tão extrema quanto a nossa. Supondo que a
hipótese nula seja verdadeira. Significância estatística. Se o valor de p for menor que um limite definido, geralmente 0,05 O resultado é
estatisticamente significativo, o que significa que é improvável que tenha
ocorrido apenas por acaso. Então, temos evidências suficientes para rejeitar a hipótese nula Um pequeno valor de p sugere que os dados observados são inconsistentes com
a hipótese nula Levando-nos a rejeitá-la em favor da hipótese
alternativa. Um grande valor de p sugere que os dados são consistentes
com a hipótese nula Nós não o rejeitamos. Pontos importantes. Um pequeno valor de p não prova que a
hipótese alternativa é verdadeira. Isso apenas indica
que tal resultado é improvável se a
hipótese nula for verdadeira Da mesma forma, um grande valor de p não prova que a
hipótese nula é verdadeira Isso sugere que os dados observados provavelmente estão sob a hipótese
nula Obrigada Nos vemos na próxima aula de estatística.
21. Como entender o valor de P: O que é o valor p e
como ele é interpretado? É isso que
discutiremos neste vídeo. Vamos começar com um exemplo. Gostaríamos de investigar se há uma
diferença de altura entre o homem
americano médio e o jogador de
basquete americano médio. O homem médio tem
1,77 metros de altura. Então, queremos saber se o jogador médio de basquete também
tem 1,77 metros de altura Assim, declaramos a hipótese
nula. A altura média de um jogador de basquete
americano é de 1,77 metros. Assumimos que na população de jogadores de basquete americanos, a altura média
é de 1,77 metros. No entanto, como não podemos
pesquisar toda a população, extraímos uma amostra. De co, esta amostra não
produzirá uma média exata
de 1,77 metros. Isso seria muito improvável. Ah. Pode ser que a amostra retirada puramente
por acaso se desvie 3 centímetros por
8 centímetros por 15 centímetros ou
por qualquer outro valor Como estamos testando uma hipótese
não direcionada, seja, só queremos saber
se há alguma diferença Não nos importamos em qual
direção a diferença vai. Agora chegamos ao valor p. Conforme mencionado, assumimos
que, na população, há um valor médio
de 1,77 metros. Se extrairmos uma amostra, ela será diferente da
população em um determinado valor. O valor p nos diz qual é a
probabilidade de
extrair uma amostra que se desvia da população uma quantidade igual ou maior
do que o valor observado Vamos dar uma olhada mais de perto novamente. Temos uma amostra que é
diferente da população. Agora estamos interessados em saber probabilidade de extrair uma amostra que se desvie tanto quanto nossa amostra ou mais
da população Assim, o valor p indica a probabilidade de extrair uma amostra cuja média
esteja nessa faixa. Por exemplo, se por acaso a amostra se desviar em 3
centímetros de 1,77 O valor p nos diz qual é a
probabilidade de extrair uma amostra que se desvia 3 centímetros ou mais
da população Se, por acaso, a amostra se desviar 9 centímetros de 1,65 metros, o valor p nos diz qual é a
probabilidade de extrair uma amostra que se desvia 9 centímetros
ou mais da população Vamos dar um exemplo em que
obtemos uma diferença de 9 centímetros e nosso software estatístico
favorito Como o Mini tab, calcula
o valor p de 0,03. Isso é 3%. Isso nos diz que há apenas 3% de probabilidade de extrair uma
amostra igual ou
superior a 9 centímetros
diferente da média
da população
de 1,77 metros Para dados normalmente distribuídos. Isso significa
que a probabilidade de a média estar
nessa faixa é de 1,5% em uma direção e
1,5% na outra Totalizando 3%. Se essa
probabilidade for muito baixa. É claro que se pode perguntar se
a amostra vem de uma população com média
de 1,65 metros Se essa probabilidade for muito baixa. É claro que se pode perguntar se
a amostra vem de uma população com média
de 1,77 metros É apenas uma hipótese de
que o valor médio dos jogadores de basquete
seja de 1,77 metros. E é exatamente essa
hipótese que queremos testar. Portanto, se calcularmos
um valor de p muito pequeno, isso nos dá evidências de
que a média
da população não é de
1,77 metros Assim, rejeitaríamos
a hipótese nula, que pressupõe que a
média seja de 1,77 Assim, rejeitaríamos
a hipótese nula, que pressupõe que a
média seja de 1,77 Mas em que ponto o valor p é pequeno o suficiente para rejeitar
a hipótese nula Isso é determinado com o
chamado nível de significância, também chamado de nível Alfa. Há duas
coisas importantes a serem observadas aqui. Primeiro, o nível de significância é sempre determinado
antes do estudo e não pode ser alterado
posteriormente para finalmente obter
os resultados desejados. Segundo, para garantir um certo
grau de comparabilidade, o nível de significância
geralmente é estabelecido em 5% ou 1% Um valor de AP inferior a 1% é considerado
altamente significativo. Menos de 5% é chamado significativo e maior que
5% é chamado de significativo. Em resumo, o valor p nos dá uma indicação de se rejeitamos ou não a hipótese
nula Como lembrete, a hipótese
nula pressupõe que não
há diferença Enquanto a hipótese alternativa pressupõe que
há uma diferença Em geral, a hipótese
nula é rejeitada se o valor de p
for menor que 0,05 É sempre apenas uma probabilidade, e podemos estar errados
com nossa afirmação. Se a hipótese nula for
verdadeira na população,
I, a média é 1,77 metros Mas extraímos uma amostra que por
acaso está bem distante. Pode ser que o
valor de p seja menor que 0,05. Rejeitamos erroneamente
a hipótese nula. Isso é chamado de erro tipo um. Se estiver na população, a hipótese nula é falsa Ou seja, a média não é 1,77 metros, mas extraímos uma amostra
que por acaso está
muito próxima de 1,77 O valor de p pode ser
maior que 0,05 e não podemos rejeitar
a hipótese nula Isso é chamado de erro do tipo dois. Obrigado por aprender comigo. Nos vemos na próxima
aula de estatística.
22. Tipos de erros: Vamos entender mais
alguns exemplos de
hipóteses nula e alternativa. Então, suponha que se meu projeto
está prestes a se livrar de você, minha hipótese nula
é um valor fixo. Então, eu diria que minha média
atual do meu
tempo médio atual para construir para compartilhar os 70% de
Julie é. Atual. A média de P a S é de 70%. A hipótese alternativa
significaria que não é 70%. Suponha que eu esteja pensando no teor
de umidade de um projeto. Estou em uma
configuração de fabricação e quero medir
se o teor de umidade
deve ser igual a 5%. Ou 5% é o que é
aceitável pelo meu cliente, então posso dizer que meu teor de
umidade é inferior
a cinco por cento. Então, a
hipótese alternativa afirmaria que o teor de umidade é
maior que cinco por cento. O caso em que a
média é maior que, então a hipótese nula. Não temos
interesse nesse problema. Vamos entender melhor. A questão era, um processo recente de
aprovação
de empréstimos para pequenas empresas do TED
reduziu processo recente de
aprovação
de empréstimos para pequenas empresas do TED
reduziu o tempo médio de ciclo
para processar o empréstimo? A resposta pode ser não. Significa que o tempo de ciclo não mudou. Ou o gerente pode ver que sim, o tempo médio do ciclo
é inferior a 7,5%. Portanto, o status quo é
igual a 7.514 minutos. E o suplente diz,
não, são menos de 7.414
minutos ou dias, qualquer que seja a principal unidade de medida que estamos
medindo, certo? Então, por padrão, seu status
quo é hipótese nula. E o exemplo ou
o status que você quer provar uma hipótese
alternativa mais fácil. Agora, pode haver algum tipo de flecha quando tomamos decisões. Então, vamos voltar
ao nosso caso de código. Na
verdade, o réu não é culpado, certo? Deixe-me pegar meu raio laser. Por padrão, o réu ou a realidade é que o
réu não é culpado. veredicto também vem
que o réu, a pessoa não é culpada. É uma boa decisão, certo? Então, sim, tomamos
uma decisão muito boa de que
a pessoa é inocente. Na realidade, o
réu é culpado. E o veredicto também
vem de que ele é culpado. A decisão é uma boa decisão. O que acontece é que, na realidade, a pessoa não está garantida, mas o veredicto vem de que ele é culpado e
uma pessoa inocente é condenada. É um erro. É um erro muito grande. Na pessoa do Norte, dada uma
sentença e colocada na prisão, dada uma penalidade,
isso é um erro. O erro pode até acontecer
do outro lado, onde na realidade a
pessoa é culpada, mas o veredicto vem de
que ele não é culpado. A pessoa culpada é
declarada inocente e está pronta para isso. Isso também é uma seta, mas que é um erro maior. Quanto maior o erro que você pode anotar na
caixa de comentários, o que você acha? Qual erro é a seta maior? O erro é um erro maior ou o erro é
a seta maior? nenhuma pessoa sã ser
condenada é um erro maior ou se uma pessoa culpada se move
nas estradas livremente,
ou flecha maior? Espero que você já tenha
escrito os comentários. Então, a realidade é que isso
se torna meu maior erro. E isso é chamado
de erro tipo um. Porque se um inocente
for condenado, não
podemos devolver o
tempo que ele perdeu. Não podemos entender que ele passaria
por muitos traumas emocionais. Se um culpado for
declarado inocente, podemos levá-lo
ao tribunal superior e à
Suprema Corte e
fazê-lo provar que sim, ele não é culpado, certo? Para que eu possa tomar essa decisão
aqui de que a pessoa é condenada. Ele deve ser condenado
e declarado culpado e
deve ser punido. Portanto, esse erro é chamado
de erro tipo dois. Se alguém lhe perguntar qual
erro é maior, digite um erro, ele também é
chamado de erro alfa. E isso é
chamado de erro beta. Certo? Vamos continuar
mais em nossa próxima aula.
23. Tipos de erros-parte2: Vamos entender os tipos
de flechas mais uma vez. Então, como sabemos que se a pessoa não
é culpada ou a
pessoa é inocente, e o veredicto
também está dizendo que a
pessoa não é culpada. É uma boa decisão. Se a pessoa é culpada, veredicto é que ela é culpada. A decisão é novamente,
uma boa decisão. O condenado não é, tem que ser sentenciado ou
deve ser punido. O problema acontecerá quando uma pessoa inocente for
provada culpada e sofrer. O segundo tipo de problema que acontece quando uma pessoa culpada, uma pessoa com um criminoso
é declarada inocente. E ele disse, Isso é
chamado de erro tipo um. Ou seja, uma
pessoa inocente ser condenada ou punida
é um erro do tipo um. Também é chamado
de seta alfa. Uma pessoa culpada, criminosa libertada, é chamada de erro tipo
dois ou erro beta, que também é um erro
que queremos evitar. O nível de significância
é definido pelo valor Alfa. Então, quão confiante você
quer tomar a decisão
certa? Então, o erro do tipo um acontece quando o nulo é verdadeiro,
mas nós rejeitamos. erro do tipo dois acontece quando,
na realidade, o nulo é falso, mas não o rejeitamos. Agora, como isso nos
ajuda a processar? Então, vamos entender isso
todos os dias para a folha de almoço. Certo? Vamos entender
isso com mais detalhes. Esse é o cenário real. Vamos escrever o
real no topo. E esses mitos
como o julgamento. Ok, agora, vamos pensar
sobre o processo. O processo não mudou. Não mudou. Nenhuma alternativa será o processo alterado. Agora, o julgamento está anotado. E o julgamento é que o
processo melhorou. OK. Agora vou fazer uma pergunta
muito importante. Se um processo não mudou e o julgamento é de que não
há mudança, esta é a decisão correta. O processo mudou e o julgamento também é de que
o processo melhorou. Essa também é uma decisão correta. Agora, imagine que o processo não
mudou, mas declaramos que agora
tenho um processo melhorado e um produto melhorado e
informo ao cliente, Está correto? Um erro. E isso é chamado de erro tipo
um porque parece antigo, mas nossa dívida é vendida ao
cliente como novo produto. Você consegue entender
o que acontecerá com a reputação da empresa? A equipe ou o produto é vendido ao cliente como novos produtos. Novo produto de um núcleo. Então, o que acontecerá com a
reputação da empresa? Vai dar um lance
e, portanto, dizemos, esta não é uma boa decisão. Agora entenda aqui também
que o processo mudou. O processo melhorou, mas o julgamento não
foi melhorado. Isso também é um erro. Eu não nego isso. Isso é chamado de erro
tipo dois ou auditoria também é chamada
de erro beta. Bem aqui. O que acontece é que não
estamos comunicando
ao cliente que a melhoria
aconteceu, certo? Portanto, não estamos
mantendo os itens aprimorados no produto da ninhada
no armazém. Agora, isso também não está correto, mas o maior erro está aqui onde, na verdade,
não fizemos uma melhoria, mas estou informando ao cliente que você é uma pessoa ruim.
24. Jingle: Quando fazemos o teste de hipóteses, sempre
há duas hipóteses. Uma é a hipótese padrão, que é a hipótese nula, e a segunda é a hipótese
alternativa que você deseja provar. E essa é a razão pela qual você
está fazendo a hipótese. Então, quando você faz a hipótese, a razão pela qual fazemos é que nunca teremos acesso
a toda a população. Então, quando coletamos a amostra, queremos entender,
é a amostra
proveniente da curva do sino ou
a distribuição
de onde estamos entendendo, seja qual for a
variação que você vê, é? devido à
propriedade natural do conjunto de dados. Às vezes, a amostra pode estar no canto final do velcro. E esse é um lugar onde
ficamos confusos de
que esses dados pertencem ao Velcro original ou pertencem ao
segundo alternativo? Bem-vinda. Isso está lá. Estaremos fazendo exercícios
que darão a você uma compreensão disso de
forma mais fácil de fazer. Hipótese, você obtém
informações como o valor de p além dos resultados das estatísticas de
teste. Você também obtém o valor de p. Sempre comparamos o valor de p com o valor nulo
que definimos. Suponha que você queira
ter 95% de confiança. Em seguida, você define o valor de p como 5%. E se você definir o nível de
confiança é 90%, então seu valor Alfa
é dez por cento, ou seu valor de p é 0,10. A razão pela qual fazemos um valor de p é que, se você puder
ver essa curva de sino, a observação mais provável é parte do
centro do sino. Observações muito improváveis vêm da cauda. Esse valor de p, a razão verde, ajuda a saber
se ele pertence ao Velcro original ou pertence à maior parte
alternativa disso,
você está tentando provar através
da hipótese alternativa. Portanto, o valor de p vem como uma ajuda para você se lembrar disso
facilmente. Lembre-se do jingle. Abaixo, null. Isso significa que se o valor de p for
menor que o valor alfa, vou rejeitar
a hipótese nula. P voo de alto nível. Se o valor de p for
maior que o valor alfa, deixamos de rejeitar
a hipótese nula, concluindo que não temos evidências estatísticas
suficientes de que a hipótese alternativa existe. Faremos muitos
exercícios e eu cantarei
esse jingle várias vezes para
que seja fácil para
você se lembrar. Abaixo de null, vá atrás de nullcline. Alguns dos participantes com, quando eu faço o workshop
ficam confusos, eles dirão que ninguém
vai significa o quê? A outra coisa que
eu digo a eles para
se lembrarem facilmente é f para
vôo e F para campo. Então, se P for alto nulo, vamos voar. Isso significa que você está falhando em
rejeitar a hipótese nula. Hipótese nula existirá. A hipótese alternativa
será rejeitada. Lembre-se de mais uma coisa que é feita principalmente
durante a entrevista. O valor de p estava em 1,230,123. Você rejeitaria
a hipótese nula ou aceitaria
a hipótese nula? Ou você aceitaria a hipótese
alternativa? Ou você aceitará
a hipótese nula? Como estatístico? Nunca aceitamos nenhuma hipótese. Ou rejeitamos
a hipótese nula ou deixamos de rejeitar
a hipótese nula. Nós sempre dizemos isso
do ponto de vista de null porque o
status quo padrão mais fácil
hipótese nula. Se o P for alto, não
aceitamos a hipótese nula
e alternativa. Será que não aceitamos
a hipótese nula. Dizemos que não rejeitamos
a hipótese nula. Se o p for baixo, não
aceitamos alternativo, mas dizemos, rejeito
a hipótese nula, concluindo que há evidências estatísticas
suficientes de que os dados estão vindo
do Bellcore alternativo . Continuaremos com
muitos exercícios. E isso
lhe dará confiança sobre como praticar,
interpretar e usar estatísticas
inferenciais em sua análise quando
você estiver fazendo isso.
25. Seleção de testes: Uma das perguntas mais comuns que meus participantes
fazem quando estou entrando no projeto é qual hipótese
devo usar o aluguel? Portanto, esta é uma análise simples que o ajudará a
entender isso. Quais testes devo usar? Assim como quando um
paciente vai ao médico, o médico não
prescreve todo o teste. Ele apenas colocou
o teste apropriado com base no problema que
o
paciente está pescando. Se o paciente vir que
eu tive um acidente, o médico diria que eu acho que você deveria fazer
seu raio-X. Ele não estaria
pedindo para ele fazer o COVID ou o teste RT-PCR. Se a pessoa estiver tossindo
e sofrendo de febre, então a RT-PCR é sugerida. E nesse momento
não conseguimos satisfazer o raio-x. Parece semelhante quando
fazemos testes de hipóteses simples, estamos tentando entender
ou comparar
com a população. Queremos entender qual
teste devemos realizar? Quando, se eu estiver testando médias,
essa é a sua média,
então você compara essa é a sua média, a média de uma amostra com o valor
esperado. Então, estou comparando a
amostra com a minha população. Então eu vou para o meu teste t
de uma amostra. Eu tenho apenas uma amostra
que estou comparando. Quero comparar se o desempenho
médio do,
se a média de vendas
for igual a x valor, que é o valor esperado. Então, esperávamos que
as vendas fossem, digamos, 5 milhões. Minha média está chegando a dizer 4,8. Eu conheci que não são. Então eu posso ir e fazer
um teste t de uma amostra. Compare a média das amostras com duas proporções diferentes. Então, se eu tiver dois T's
independentes, digamos que estou conduzindo
um treinamento on-line. Estou conduzindo um
treinamento offline. É o Santuário e eu tenho um grupo de alunos que estão
participando do meu programa on-line. Eu tenho um
grupo diferente de alunos que estão participando do
meu programa. Quero comparar a
eficácia do treinamento. Então eu tenho duas amostras, e essas são duas amostras
independentes porque os participantes
são diferentes. Então eu vou para o teste t de duas amostras. Se eu quiser comparar
as duas amostras para
que as pessoas venham para o meu treinamento. Eu faço uma avaliação antes meu programa de treinamento sobre a compreensão
deles sobre o que Lean Six Sigma. E eu posso fazer o programa
de treinamento e o mesmo grupo de participantes participa do teste após
o programa de treinamento. Então, os participantes
ou a cena. Mas a mudança
que aconteceu foi o treinamento que
foi impactado neles. Eu tenho os resultados do teste antes do treinamento e eu tenho os resultados do teste após o treinamento, eu quero comparar se o
treinamento é eficaz. Então eu vou para o teste t
pareado com duas amostras. Progredindo ainda mais. Suponha que se eu estiver
testando a frequência, eu tenho dados discretos
e quero testar a frequência porque em dados
discretos eu
não tenho médias. Eu tomo frequências. Então, quando estou comparando
a contagem de alguma variável em uma amostra com
a distribuição esperada, assim como
fiz um teste t de amostra. O equivalente a isso para dados discretos seria meu ajuste
qui-quadrado. Eu, por padrão, espera-se que seja um valor normal ou um
valor específico ou um valor inesperado. E estou comparando isso. Até onde estão meus dados? Eu opto por um ajuste qui-quadrado
. Este teste está disponível
no MiniTab no Excel. Ele não está disponível. Então, vou criar um
modelo e entregá-lo a você, o que tornará mais fácil
para você fazer o teste qui-quadrado. Todos os três tipos diferentes de teste
qui-quadrado usando
o modelo do Excel. Se eu tiver que contar algumas das variáveis
entre duas amostras. Portanto, será o teste t
homogêneo do qui-quadrado. Estou verificando uma única amostra
simples para ver se as
variáveis discretas são independentes. Eu faço o teste de
independência qui-quadrado. Se eu tiver uma proporção de dados, como aplicativos bons ou ruins, aceitei versus rejeitei. E estou dizendo que tudo bem, 50% das inscrições
são aceitas, ou vinte e cinco por cento
das pessoas são colocadas. Eu tenho uma proporção
que eu quero testar. Se eu tiver apenas uma amostra, vou fazer um teste de proporção. Se eu quiser comparar a
proporção de graduados em
comércio
versus graduados em ciências ou proporção de finanças, MBA, pessoas com MBA em
marketing, tenho duas amostras diferentes, para que eu possa vá para o teste de duas
proporções. Então, para resumir a coisa, quando estou testando, estou
testando as médias? Estou testando
frequências como dados
discretos ou estou
testando proporções? Dependendo disso,
você está pegando o teste apropriado
e trabalhando nele. Vamos
praticar tudo isso usando o Men dab e usando exit. O conjunto de dados está disponível
na seção de descrição. Na seção do projeto, convido todos vocês a
praticá-lo e colocar seus projetos, sua análise na seção do
projeto. Se você tiver alguma dúvida, pode colocar isso
na seção de discussão e
ficarei feliz em responder às suas dúvidas. Aprendizado feliz.
26. Conceitos do teste T em detalhes: O que esse vídeo ensina a você? Sobre o teste T? Este vídeo aborda tudo o que você
precisa saber sobre o teste T. No final deste vídeo, você entenderá o que é o
teste AT, quando usá-lo, os diferentes tipos de testes
t, hipóteses
e suposições
envolvidos, como o teste AT é calculado e como interpretar O que é um teste t? Vamos começar com o básico. Um teste t é um procedimento de
teste estatístico. Isso analisa se há uma diferença significativa entre
as médias de dois grupos Por exemplo, podemos comparar a pressão arterial de pacientes
que recebem o medicamento A versus Medicamento B, tipos de testes t. Existem três
tipos principais de testes t, o teste t de uma amostra,
o teste t de amostras independentes ou dois testes t
e o teste t de amostras emparelhadas. O que é um teste t para uma amostra? Usamos um teste
t de uma amostra quando
queremos comparar a média de uma amostra com uma média de
referência conhecida. Por exemplo, um fabricante de
barras de chocolate afirma que suas barras pesam em média
50 gramas . Coletamos uma amostra. Encontre seu peso médio. Suponha que o
peso da amostra seja 48 gramas e use um teste
t de uma amostra para ver se ela difere
significativamente
dos 50 gramas declarados. O que é um teste t para amostras
independentes? O teste
t de amostras independentes compara as médias de dois
grupos ou amostras independentes Por exemplo, podemos
comparar a eficácia de
duas cores de dor atribuindo aleatoriamente 60
pessoas a dois grupos Ao receber o medicamento A
e o outro medicamento B. E depois usar um teste t
independente para avaliar quaisquer
diferenças significativas no alívio da dor. O que é um teste t
para amostras emparelhadas? O teste t de amostras pareadas compara as médias de
dois grupos dependentes Por exemplo, para avaliar a
eficácia de uma dieta, poderíamos pesar 30 pessoas antes Após a dieta, usando amostras
emparelhadas para testar, determinamos se há uma diferença significativa
no peso anterior. Depois da dieta. Compreender
a diferença entre amostras
dependentes e
independentes é crucial para escolher
o tipo certo de teste t para sua análise. Amostras dependentes
ou amostras emparelhadas referem-se aos casos em que
cada observação em uma amostra é pareada com
uma observação específica. Na outra amostra, esse emparelhamento surge
da natureza da coleta de
dados, como antes e
depois das medições Nos mesmos indivíduos, pares
combinados em um experimento O teste t de amostras emparelhadas
é usado para avaliar se. A diferença média entre essas observações pareadas é
estatisticamente significativa Por outro lado,
amostras independentes são observações, retiradas de dois grupos separados, ou populações que não estão relacionadas ou pareadas de
forma sistemática. Cada observação
em uma amostra é totalmente independente de
todas as outras observações. Na outra amostra, as amostras
independentes, teste
T avalia
se as médias
desses dois grupos independentes diferem significativamente entre si escolha entre esses tipos de testes
t depende de
como os dados foram coletados e da relação entre as amostras que
estão sendo comparadas. Usar o
teste t correto garante que sua análise estatística reflita
com precisão a natureza de sua pergunta de
pesquisa e a estrutura de seus dados. Aqui está uma nota interessante. O teste t de amostras emparelhadas é muito semelhante ao teste t de
uma amostra. Também podemos pensar nas amostras emparelhadas para testar como tendo uma amostra que foi medida em dois momentos diferentes. Em seguida, calculamos a diferença entre os valores pareados, fornecendo um valor
para uma amostra. A diferença é
um menos cinco mais dois menos um menos três, e assim por diante Agora, queremos testar
se o valor médio da diferença recém-calculada desvia de um valor de referência Nesse caso, zero, é exatamente
isso que o teste t de
uma amostra faz. Quais são as suposições? Para um teste t, é claro, primeiro
precisamos de uma amostra adequada
no teste t de uma amostra, precisamos de uma amostra e do valor de referência
no teste t independente. Precisamos de duas amostras independentes
e, no caso de
um teste t pareado, uma amostra pareada, a
variável para
a qual queremos testar se há diferença entre as
médias deve ser métrica. Exemplos de
variáveis métricas são idade, peso
corporal e renda. Por exemplo, o nível de educação
de uma pessoa não é
uma variável métrica. Além disso, a variável métrica deve ser distribuída normalmente em todas as três variantes de teste para saber como testar se seus
dados estão normalmente distribuídos. No caso de um teste t
independente, as variâncias nos dois grupos devem ser aproximadamente iguais Você pode verificar se
as variâncias são iguais usando o teste L evens. Quais são as hipóteses
do teste t? Vamos começar com o teste de
uma amostra t
no teste de uma amostra t. A hipótese nula
é que a
média da amostra é igual ao valor de referência
fornecido Portanto, não há diferença, e a
hipótese alternativa é a média da amostra não é igual ao valor de
referência fornecido. E quanto às
amostras independentes para testar? No teste t independente, a hipótese nula é que
os valores médios em ambos os
grupos são os mesmos Portanto, não há diferença
entre os dois grupos, e a
hipótese alternativa é que
os valores médios em ambos os
grupos não são iguais. Portanto, há uma diferença
entre os dois grupos. E, finalmente, o teste
t de amostras emparelhadas em um teste t de par, a hipótese nula
é
a média da diferença entre
os pares é zero, e a
hipótese alternativa é que
a média da diferença
entre os pares não é zero Agora sabemos quais são
as hipóteses. Antes de vermos como o teste
t é calculado. Vejamos um exemplo de por que realmente
precisamos de um teste t. Digamos que haja uma
diferença na duração do
estudo de um diploma de
bacharel entre homens. E mulheres na Alemanha. Nossa população é
, portanto, composta por todos os graduados de um bacharelado
que estudaram na Alemanha No entanto, como não podemos pesquisar
todos os graduados de bacharelado, extraímos uma amostra o mais
representativa possível Agora usamos o teste para testar a hipótese nula de que não
há diferença
na população Se não houver diferença
na população, se não houver diferença
na população, certamente ainda veremos uma diferença na
duração do estudo na amostra. Seria muito
improvável que extraíssemos uma amostra em que a diferença
fosse exatamente zero. Em termos simples, agora queremos
saber a diferença
medida em uma amostra. Podemos dizer que a
duração do estudo de homens e mulheres é
significativamente diferente. E é exatamente isso que
o teste t responde. Mas como
calculamos um teste t? Para fazer isso? Primeiro calculamos o valor t para
calcular o valor t. Precisamos de dois valores. Primeiro, precisamos da diferença
entre as médias
e, em seguida, precisamos do
desvio padrão da média Isso também é conhecido como
erro padrão. No teste t de uma amostra, calculamos a
diferença entre a média da amostra e a média de referência
conhecida. S é o desvio padrão
dos dados coletados e n é o número de casos S dividido pela raiz quadrada de n é então o
desvio padrão da média Qual é o erro padrão? No teste t de amostras dependentes, simplesmente
calculamos
a diferença entre as duas médias amostrais. Para calcular o erro padrão, precisamos do
desvio padrão e do número de casos da
primeira e da segunda amostra, dependendo se
podemos assumir variância
igual ou desigual para Existem fórmulas diferentes
para o erro padrão. Em um teste t de amostra pareada, precisamos apenas calcular
a diferença entre
os valores pareados e
calcular a média a partir disso. O erro padrão é então o mesmo de um teste t de uma amostra. O que aprendemos
até agora sobre o valor t? Não importa qual
teste, nós calculamos. O valor t
será maior se
tivermos uma diferença maior
entre as médias, e o valor t será menor se a diferença entre
as médias for menor. Além disso, o valor t fica menor quando temos uma maior
dispersão da média,
portanto, quanto mais dispersos os dados, menos significativas são
dadas as diferenças médias Agora, queremos usar o teste t para ver se podemos rejeitar a hipótese
nula ou não Para fazer isso, agora podemos usar
o valor t de duas maneiras. Ou lemos o valor crítico
t de uma tabela ou simplesmente calculamos o valor
p a partir do valor t. Falaremos sobre os
dois em um momento. Mas qual é o valor p? Um teste t sempre testa a hipótese nula de que não
há diferença Primeiro, assumimos que não
há diferença
na população. Quando extraímos uma amostra, essa amostra se desvia
da hipótese
nula em uma certa quantidade O valor p nos diz a probabilidade de extrairmos
uma amostra que se desvia da população na mesma quantidade ou
mais do que uma amostra que extraímos Assim, quanto mais a amostra se desvia da hipótese
nula, menor se torna o valor p Se essa probabilidade
for muito pequena,
podemos, é claro, perguntar se a hipótese nula é válida
para a Talvez haja uma diferença, mas em que ponto podemos
rejeitar a hipótese nula Essa borda é chamada de
nível de significância, que geralmente é fixado em 5%. Se houver apenas 5% de chance de extrairmos
essa amostra. Ou um que seja mais diferente. Então, temos evidências suficientes para supor que rejeitamos
a hipótese nula Em termos simples, assumimos
que há uma diferença, que a
hipótese alternativa é verdadeira. Agora que sabemos
qual é o valor p, podemos finalmente ver como
o valor t é usado para determinar se a hipótese
nula é rejeitada ou não Vamos começar com o caminho
até o valor crítico de t, que você pode ler em
uma tabela. Para fazer isso. Primeiro, precisamos de uma tabela
de valores t críticos, que podemos encontrar na guia Dados em tutoriais e distribuição
T. Vamos começar com
a caixa dupla. Examinaremos brevemente
a caixa única
no final deste vídeo. Aqui abaixo, vemos a tabela. Primeiro, precisamos decidir
qual nível de significância
queremos usar. Vamos escolher um
nível de significância de 0,05 de 5%. Em seguida, analisamos nesta coluna
120,05, que é 0,95. Agora precisamos dos
graus de liberdade no de uma amostra e no teste t
de amostras emparelhadas. Os graus de liberdade são simplesmente o número
de casos menos um Se tivermos uma amostra
de dez pessoas, há nove
graus de liberdade. No teste t de
amostras independentes, adicionamos o número de
pessoas de ambas as amostras e calculamos isso menos dois
porque temos duas amostras Observe que os graus de
liberdade podem ser determinados de
uma maneira diferente,
dependendo se
assumimos variância igual ou igual Então, se tivermos um nível de
significância de 5% e nove graus de liberdade, obtemos um valor
t crítico de 2,262 Agora, por um lado, calculamos um valor t com o teste t e temos
o valor t crítico. Se nosso valor t calculado for maior que o valor t
crítico. Nós rejeitamos a hipótese nula. Por exemplo, suponha que
calculemos um valor t de 2,5. Esse valor é
maior que 2,262
e, portanto, as
duas médias são tão diferentes que podemos
rejeitar a hipótese nula Por outro lado, também podemos calcular o valor p para o valor
t que calculamos. Se inserirmos 2,5 para o valor t e nove para os
graus de liberdade, obtemos um valor p de 0,034 O valor p é menor que 0,05
e, portanto, rejeitamos a hipótese
nula como controle Se copiarmos o
valor t de 2,262 aqui, obteremos exatamente um valor
p de 0,05, que Se você quiser calcular o teste
AT com a guia Dados, basta copiar seus
próprios dados nesta tabela. Clique no teste de hipóteses e selecione as
variáveis de interesse. Por exemplo, se você quiser
testar se o gênero afeta a renda, basta
clicar nas duas variáveis
e obter automaticamente
o teste AT, calculado para amostras
independentes. Aqui abaixo. Você pode
ler o valor p. Se você ainda não estiver preocupado com a interpretação
dos resultados, basta clicar na
interpretação interna Um teste t bicaudal para amostras
independentes, variâncias
iguais assumidas, mostrou que a diferença entre mulheres e homens em relação
à variável dependente salário não
foi estatisticamente significativa Assim, a
hipótese nula é mantida. A pergunta final agora é qual é a diferença entre hipótese
direcionada e hipótese
não direcionada No caso não direcionado, a hipótese alternativa é
que há uma diferença Por exemplo,
há uma diferença entre o salário de homens
e mulheres na Alemanha. Não nos importamos com quem ganha mais. Só queremos saber se
há uma diferença ou não. Em uma hipótese direcionada. Também estamos interessados na direção
da diferença. Por exemplo, a hipótese
alternativa pode ser que os homens ganham mais do as mulheres ou as mulheres ganham
mais do que os homens. Se observarmos graficamente a
distribuição t, podemos ver que,
no caso bilateral, temos um intervalo à esquerda
e um intervalo à direita Queremos rejeitar a hipótese
nula se estivermos aqui
ou ali com
um nível de significância de 5% Ambas as faixas têm uma
probabilidade de 2,5%. Juntos, apenas 5%, se
fizermos um teste T unilateral, a hipótese nula será
rejeitada somente se
estivermos nessa faixa
ou dependendo
da direção que
queremos testar nessa faixa com um nível de
significância de 5%, 5% caem dentro dessa faixa Obrigado por aprender comigo. Nos vemos na próxima
aula de estatística.
27. 1 teste de amostra t: Vamos entender quais testes de
hipóteses devo usar? No Minitab, você tem um assistente que pode
ajudá-lo a tomar essa decisão. Portanto, se você for ao teste de
hipótese assistente, ele o ajudará a identificar com base no número de
amostras que você tem. Para supor que, se você
tiver uma amostra, você pode estar
fazendo um teste t de
uma amostra, um desvio padrão de amostra, uma porcentagem de amostra defeituosa, de ajuste
qui-quadrado. Se você tiver duas amostras, então você tem duas amostras de
teste t para amostras diferentes. Teste T se os itens antes e
depois forem os mesmos. Desvio padrão da amostra para
porcentagem amostral do teste
qui-quadrado de associação defeituoso. Se você tiver
mais de duas amostras, então temos um teste de desvio
padrão ANOVA de sentido único, porcentagem do
qui-quadrado
é defeituosa e teste de associação do
qui-quadrado. Estaremos praticando tudo
isso com muitos exemplos. Então, vamos
ao primeiro exemplo. Temos o TDAH de
chamadas em minutos. Coletamos uma amostra
de 33 pontos de dados. A média é sete,
o valor mínimo é quatro minutos, valor
máximo é dez minutos. A razão pela qual temos que fazer um teste de hipótese é o
gerente dos processos que sua equipe é capaz de fechar a resolução ou na
chamada em sete minutos. E a média do processo também
é de sete minutos, mínimo é de quatro minutos. Mas o cliente vê
que os agentes os mantêm em espera e leva mais de
sete minutos na ligação. Então, agora eu quero
validar estatisticamente se está correto ou não. Sempre que estamos
configurando testes de hipóteses, temos que seguir a abordagem de cinco
etapas e seis etapas. Etapa número um, defina
a hipótese alternativa. Defina a hipótese nula, que nada mais é do que
seu status quo. Qual é o nível de significância
ou seu valor Alfa? Se nada for especificado, será enviado o valor Alpha
como cinco por cento. Primeiro definimos a hipótese
alternativa. Então, no nosso caso, o que o cliente está dizendo? O cliente vê que o tempo médio de tratamento é
superior a sete minutos. O status quo ou
o SLA acordado é o TDAH deve ser
inferior a sete minutos. Como eu lhe disse, a hipótese nula e a alternativa serão mutuamente exclusivas e
complementares uma à outra. Agora, identifique o
teste a ser realizado. Quantas amostras eu tenho? Eu tenho apenas uma amostra do
HD do contact center. Então, eu vou
pegar um teste t de amostra. Está bem? Agora eu preciso fazer
as estatísticas de teste e identificar o valor-p. Se você se lembra da lição de exemplo
anterior, dissemos que se o valor de p for
menor que o valor alfa, rejeitamos a hipótese nula. Se o valor de p for maior que
cinco por cento ou valor Alfa, não rejeitamos
a hipótese nula. Vamos fazer esse entendimento. Então, se você se lembra, temos os dados do nosso projeto. Nos dados do projeto, temos o teste de hipótese. Por aqui. Eu lhe dei o
AHG de carvão em minutos. Então, eu copiei esses
dados para o Minitab. Então, vamos fazer isso de duas maneiras. Primeira vez e mostre
para você usando o assistente. Em segundo lugar, mostrarei
a você usando estatísticas. Então, se eu for para o teste de
hipótese assistente, qual é o objetivo que
eu quero alcançar? É um teste t de uma amostra.
Eu tenho uma amostra. É sobre maldade? É sobre desvio padrão? São números separados, defeituosos
ou discretos? Estamos falando
da média de 100 vezes. Então, vou fazer
um teste t de amostra. Para dados em colunas. Eu selecionei isso. Qual é o meu valor-alvo? Meu valor alvo é sete. A hipótese alternativa é que
a idade média da chamada em minutos é
maior que sete. É isso que o
cliente está reclamando. O valor alfa é 0,05 por
padrão, eu clico em, Ok. Vamos ver a saída. Para ver a saída,
você clicará em Exibir e somente saída. Você vai ver isso. Se você vir o valor-p, o
valor-p é 0,278. Você se lembra abaixo do não-gol
ser alto nullcline
esse valor de 0,278 é maior que o valor alfa de 0,05? Sim, é. Portanto, posso concluir
que a média é d do carvão não é significativamente
maior do que o alvo. O que quer que você esteja vendo
como maior do que o alvo, é apenas por acaso. Portanto, não há evidências suficientes
para concluir que a média é maior que sete com nível de significância
de
cinco por cento. E também me mostra
como é o padrão. Não há pontos de dados incomuns porque o
tamanho amostral é de pelo menos 20. A normalidade não é um problema. O teste é preciso. E seria bom
concluir que o tempo médio de tratamento
não é significativamente
maior do que sete minutos. Posso ir em frente e rejeitar a reclamação feita pelo cliente. As poucas chamadas que vemos como metas de alta qualidade e
alto valor. Isso só pode ser por acaso. O mesmo teste. Também posso fazer isso clicando em de teste, estatísticas básicas. E vou salvar uma amostra de teste t, uma ou mais amostras,
cada uma em uma coluna. Vou passar o dedo no seu TDAH selecionado. Eu quero realizar testes de
hipóteses. média hipotética é sete. Eu vou para Opção e digo, qual é a
hipótese alternativa que eu quero definir. Quero definir que a média real é
maior do que a média hipotética. Clique em OK. Se eu precisar de gráfico, posso colocar esses gráficos. Clique em OK e
clique em OK. Eu recebo essa saída. Então, a estatística descritiva, esta é a média, esse é o
desvio padrão e assim por diante. hipótese nula é
que mu é igual a sete. hipótese alternativa é que
mu é maior que sete. valor de p é 0,278. Concluindo que o vôo nulo, deixamos de rejeitar
a hipótese nula, concluindo que o tempo
médio de 100 é cerca de sete minutos.
Vamos continuar. Recebemos nossa produção. Vimos tudo isso e concluímos que
o tempo médio de manuseio não
é significativamente
maior do que sete minutos.
28. 2 exemplo de teste t exemplo 1: Vamos fazer mais um exemplo
de duas equipes, duas amostras. Então, neste exemplo, duas equipes cujo desempenho
precisa ser medido. O gerente da DMB afirmou que sua equipe tem melhor
desempenho do que o DNA. O gerente de uma equipe defende que essa
reivindicação é inválida. Vamos ao nosso conjunto de dados. Então, se você for para
o arquivo do projeto, você terá algo
chamado de equipe a e equipe B. Então, deixe-me copiar esses dados. OK. Deixe-me ir aqui e colocar o
radar no lado direito. Por que também posso pegar uma nova planilha e colar os dados. Certo? Então, vamos como teste de hipótese, teste t
de duas amostras. Deixe-me excluir esse valor. E TB, a equipe a é
diferente da VM. Eu também posso dizer com
base na hipótese que a equipe seja reivindicada que
sua equipe é melhor do que um. então eu posso dizer que é menos do que
TV. E eu clico em Ok. Novamente, neste exemplo, obtenho uma saída que diz que a equipe não é
significativamente menor que a TB. Você tem os
valores de 27,727,3? Não há diferença
estatística entre as duas dicas, certo? Então, os dois exemplos que
obtivemos foram assim. Então, vamos ver mais
um exemplo. Eu tomei o tempo
do ciclo do processo um e
o tempo do ciclo do processo B. Então, vamos apenas copiar esses dados. Esse é outro conjunto de dados. E eu digo, Qual é a minha hipótese
alternativa? Ambos os feixes são diferentes. Qual é a hipótese nula? Ambas as equipes são iguais. Porque essas duas
equipes são diferentes. Vou seguir em frente e fazer
meu teste t de duas amostras. Os dados de cada
equipe são separados. E eu estou vendo que é diferente
do valor alfa de TB é 5%, e então eu clico em, Ok. Agora, se você vir a
saída desta vez, ele diz que sim, o tempo de ciclo de a é significativamente diferente
do tempo de ciclo de dB. Aqui, este 26,8,
vinte e sete vírgula seis. Mas se eu olhar para
a distribuição, a distribuição de que esse vermelho não
se sobrepõe
a esse vermelho. Portanto, há uma diferença
no tempo de ciclo das duas equipes. Se eu tiver que fazer a
mesma coisa usando estatísticas, estatísticas
básicas, teste t de
duas amostras. Como seu tempo de
ser e na época das opções de TB, existem diferentes? Eu posso ter meus gráficos. Eu não quero um gráfico
individual. Eu só vou pegar o
boxplot e dizer, ok, mu1 é a média da população do tempo de
ciclo dos processos, tempo do
ciclo do processo B. Agora, se você ver que há um desvio padrão
que é uma diferença. O valor de p é 0,
dizendo que, sim, há uma diferença significativa
entre as duas equipes. Seja baixo, nada legal. Então aqui estamos rejeitando
a hipótese nula, dizendo que há uma diferença significativa
entre E e D. Certo? Eu vi a mesma coisa
com a distribuição continua. Portanto, há uma distribuição
maior ou aqui e há uma distribuição
menor. Posso fazer minha
análise gráfica que aprendi à
sua direita e depois ver como
a equipe está se saindo. Então, este é o resumo do DNA. A média é 26, o
desvio padrão é 1,5. E se eu rolar para baixo, eu chego para o time B e ele
está vindo dessa maneira. Agora eu quero sobrepor
esses gráficos para que eu possa clicar no gráfico
e em um histograma. E eu vou dizer um pouco em
forma e sedoso. E vou selecionar esses dois gráficos em
painel separado do mesmo gráfico, mesma vitamina C max. Clique em, Ok. Clique em OK. Você consegue ver que a curva
do sino de ambos é diferente? Vamos fazer um histograma
gráfico sobreposto. E em várias
sobreposições de solo neste gráfico. Você pode ver que o azul e o vermelho,
há uma diferença? E, portanto, sim, a
curtose é diferente, a inclinação é diferente, e essa
é a conclusão no meu teste t de duas amostras, que diz que a distribuição lá é significativa
diferença. Há uma diferença estatisticamente
significativa entre o tempo sagrado de ser lutador
EN, morrendo. A segunda coisa,
aprenderemos sobre o teste t no leito
em nosso próximo exemplo.
29. 2 exemplo de teste t de amostra 2: Vamos ao nosso exemplo. Dois. Existem dois centros cujo desempenho
precisa ser medido. O gerente da
sensorial alegou que sua equipe é uma
equipe com melhor desempenho do que o centro B. A magnitude do centro ser defende que a
alegação é inválida. Novamente, seguirei
meu processo de cinco etapas. Qual é a
hipótese alternativa? É melhor que B. Vamos tornar isso mais fácil. Não é igual a T, não
é igual a TB ou centro não é
igual a centro. O que o centro
não hipotético a é igual ao centro V, nível de significância,
cinco por cento. Quantas amostras eu tenho? Eu tenho duas amostras, editor
central e dados do centro B. Como tenho duas amostras, preciso fazer o teste t de
duas amostras. Vamos para nossa planilha do Excel. Eu tenho os dados para
Centauri e centro B. Vou
copiá-los no Minitab. Estou colocando meus dados aqui. Vamos fazer o teste t de duas amostras. Então eu vou para Stat, Estatísticas
Básicas e
digo teste t de duas amostras. Ambas as amostras
estão em uma coluna. Cada amostra tem sua própria coluna, então vou
selecionar essa amostra. Uma é a amostra sensorial. Você centra B? A opção é híbrida. Isso não é diferente. Portanto, a diferença
entre a e B é 0. E eu vou em frente e faço isso. Eu posso ter meu gráfico
de caixa individual e dizer OK, e dizer Ok, vamos
ver a saída. Portanto, os dados sensoriais são
seus e os dados do TBI estão aqui. E se você vir o valor-p, o valor-p é alto. vez, eu tenho um exemplo que
diz que ser alta mosca nula, o que significa que não há diferença entre centro e centro B. Se você vê o valor individual, mas você vê a mesma coisa. Vamos ver o boxplot. O boxplot diz
que a média não é significativamente
diferente porque teria coletado uma amostra. Essa é a razão pela qual é, e você está vendo um valor de 0, que é um outlier. Então, devemos
considerar isso. A mesma coisa. Deixe-me fazer isso usando testes de
hipóteses. Teste t para duas amostras, média amostral. A amostra é diferente. A média do centro
é diferente da média do centro B
e C. Assim como a diferença média, a média de Santa Fé não é significativamente diferente
da média fora do centro. Certo? Se você vir essa distribuição, poderá descobrir que a parte vermelha está completamente sobreposta
uma à outra, dizendo que
não há evidências suficientes para concluir que
há uma diferença. Há uma diferença quando
você vê a média, 6,86,5. Mas isso pode ser
por causa de uma chance. E também há um
desvio padrão. Portanto, eles mostram isso
usando as barras vermelhas, dizendo que não há uma diferença significativa entre a semana
sensorial e central. Continuaremos aprendendo sobre outros exemplos
no próximo vídeo.
30. Teste t emparelhado: Vamos entender mais
um exemplo. Este é um exemplo
de teste t pareado. Se você olhar para este estudo de caso, os psicólogos
queriam determinar se um determinado programa de corrida tem efeito na frequência cardíaca em
repouso. A frequência cardíaca de 15
pessoas selecionadas aleatoriamente foi medida. As pessoas foram então colocadas em um programa de corrida e medidas
novamente após um ano. Então, os participantes estão
dizendo antes versus depois? Sim. E essa é a razão pela qual não
é o teste t de duas amostras, mas é um teste t pareado, a
medição antes e depois de cada pessoa ou em
bandas de observação. Então, se eu voltar para o meu conjunto de dados, eu tenho algo chamado
de antes e depois, há um estágio diferente, eu não estou tomando o valor da
diferença. Peguei os dados das 15 pessoas e
coloquei na mini guia. Certo? Agora, eu quero fazer porque é a mesma pessoa
antes e depois de mim, queremos entender os
diferentes testes de hipóteses. Vou fazer o teste t pareado. A primeira coisa foi, qual é a hipótese alternativa? Antes e depois é diferente. Se você se lembra, o programa
de antes e depois, eles querem determinar se eles
têm um efeito na corrida. A medição está antes, ferramenta
de medição está ativa. média de antes é
diferente da média de depois. Então essa é minha hipótese
alternativa. Então, o que minha
hipótese nula significa de antes é que não há mudança. O alternativo vê que o antes
é diferente do depois. valor alfa é 0,05. Vamos clicar em Ok. Vamos ver a saída. Então, a média é diferente? O que é um valor-p de 0,007? A média de antes é significativamente diferente
da média de depois. Se você olhar para o
valor médio, foi 74,572,3. Mas há uma diferença. Então, se você perceber que a
diferença é maior que 0. E se eu olhar para esses
valores de antes versus depois, o ponto azul é depois
que o ponto preto está antes. A maioria dos participantes, sua frequência cardíaca havia diminuído
após o programa de corrida. Poucos deles foram uma exceção, mas isso poderia ser uma exceção. Não há diferenças
pareadas incomuns porque nosso
tamanho amostral é de pelo menos 20. A normalidade não é um problema. A amostra é suficiente para detectar a diferença
na média. Então eu posso ver que, sim, há uma diferença
entre os dois. Maravilhoso. Então, novamente, revisão rápida. Olá, objetivo nulo como o valor de p é menor que
o nível de significância, concluímos que há uma diferença significativa
entre as duas leituras. Se eu tiver que fazer a cena,
clico em Estatísticas, Estatísticas
Básicas. Detesto ruim, cada
amostra em uma regra. Antes, depois da opção
é que eles são diferentes. Deixe-me pegar apenas o
boxplot e o histograma de não quero
escolher o histograma. Só vou pegar o boxplot. Hipótese nula A diferença é 0. A hipótese alternativa é que
a diferença é diferente de zero, valores de p baixos, concluindo que eu rejeito
a hipótese nula. E há uma diferença
ao adotar o programa. Portanto, se você vir o valor nulo, o ponto vermelho está muito longe da média do
intervalo de confiança da caixa para concluir que
há uma diferença entre submeter-se ao programa por esse especialista em coração, certo? Então, no próximo programa, aprenderemos,
pegaremos mais exemplos.
31. Um teste de amostra Z: A rápida recapitulação
dos diferentes tipos de testes que
aprendemos é que, se eu estiver olhando para o quão diferente é meu grupo e entre
a população, é meu grupo e entre
a população,
eu faço um teste t de uma amostra. Quando eu tenho dois
grupos diferentes de amostras, então eu faço o teste t de duas amostras. Se essas amostras
forem independentes. Se eu for para
um teste t pareado. Teste t pareado. Se o grupo for o
mesmo conjunto de pessoas, mas é ou
ponto de tempo diferente. Como vimos o exemplo
do batimento cardíaco. Então, as pessoas foram medidas
em seus batimentos cardíacos. O relatório por meio de
um programa em execução e publica o programa em execução. Como foi aquele
batimento cardíaco quente em repouso, certo? Então, essas são as
coisas que classificamos. Agora vamos continuar
com mais exemplos. Então, adicionamos o caso de uso número cinco, análise de porcentagem de gordura. Os cientistas de uma empresa que fabricou processo que querem S é a porcentagem de gordura na fonte de
água da empresa. A data de publicação do anúncio
é de 15% e os cientistas medem que a porcentagem
de gordura é de 20 amostras aleatórias. A medida anterior
do desvio padrão da população é 2,6. Agora, esse é o desvio
padrão da população. O desvio padrão
da amostra é 2,2. Quando conheço o parâmetro
da população, posso ir em frente e
usar um
teste z de amostra porque o número
de amostras que tenho é um. E eu quero, eu tenho o desvio padrão conhecido
da população. Agora, novamente, vou aplicar
a mesma coisa que definiu a hipótese
alternativa, certo? Então, o que eu vou dizer? Qual é a hipótese alternativa? A porcentagem de gordura
não é igual a 603050. Qual é a porcentagem de
gordura da hipótese nula é igual a 15%. Nível de significância de
cinco por cento. Porque eu sei que é
um teste de uma amostra e eu tenho o desvio
padrão da população. Vou usar
um teste z de amostra. Vamos fazer a análise. Eu abri o arquivo
do projeto e tenho os IDs de amostra e causei uma
grande porcentagem de dados aqui. Deixe-me copiar esses
dados para o Minitab. Mas copiou a porcentagem de gordura com o que
os cientistas fizeram. Como sabemos que o desvio padrão
da população, posso ir em frente e usar o
teste z de uma amostra. Meus dados estão presentes em uma coluna. É o fato apresentado. O
desvio padrão conhecido foi de 2,6. Eu quero realizar testes de
hipóteses. Média hipotética, é 15%. Então, minha hipótese nula é que a porcentagem de gordura
é igual a 15. Minha hipótese é que gordura era um
grande a não é igual a 15. Eu posso escolher um gráfico de boxplot
e histograma e dizer, Ok, eu vou
te mostrar a saída. Portanto, a hipótese nula é que a
porcentagem de gordura é igual a 15. A hipótese alternativa é que a porcentagem de gordura não
é igual a 15. valor alfa é 0,05. Meu valor de p é 0,012, pois meu valor de p é
menor que o valor alfa, P baixo, nenhum legal. Então eu rejeito a hipótese nula, concluindo que o
percentual de gordura não é igual a 50. Se você vir aqui, o percentual de gordura
é superior a 50. Eu posso refazer o mesmo
teste. Desta vez. Eu posso ir em frente e verificar. Minha porcentagem de gordura é
maior do que a média hipotética. Vamos fazer isso. E ainda assim eu recebo meu
valor p com mais confiança, 0,006 muito longe do
meu valor Alfa. Concluindo que sim, o Alfa, o valor nulo é
hipotetizado, a média é 15. Mas a amostra diz que
há uma grande probabilidade de que sua porcentagem de gordura na
fonte seja superior a 50. Qual é o conselho que
daremos à empresa? Aconselhamos a empresa
que você não pode vender o nome de que o contêiner é 15% porque nosso fator
é superior a 15%. Então, por segurança, você pode mudar o
rótulo do produto para dizer que o
percentual de gordura é 18, certo? Porque temos cinco por
cento está passando por 20. Assim, um consumidor ficará feliz em
receber um produto
que contenha menos gordura. Então, para receber um produto
que contenha mais gordura porque estamos todos
preocupados com a saúde, certo? Então, vamos continuar
na próxima aula.
32. Uma amostra proporção teste-1p-teste: Continuaremos com nossos testes de
hipóteses. Às vezes, podemos ter uma proporção
da ação, certo? não temos médias ou desvio
padrão
ou variância para No entanto, não temos médias ou desvio
padrão
ou variância para
medir,
o que estamos fazendo. Vamos pegar este exemplo seis, o analista de marketing
quer determinar se o homem, o anúncio do
novo produto resultou em uma taxa de resposta diferente
da média nacional. Normalmente, sempre que você coloca um
anúncio no jornal, eles dizem que há a empresa de publicidade que geralmente vê é que seremos capazes impactar 6% de resultado
ou 10% de resultado ou algum número resultado bem aqui. O que é, é o mesmo
tipo de cenário. Aqui. Eles pegaram uma amostra
aleatória de 1000 famílias que
receberam propaganda. E dessas 10
mil famílias, amostra 87 delas fez compras depois de receber
esse engrandecimento. Então, essa empresa, que é
uma empresa de publicidade, está alegando que eu causei um impacto melhor do que os
outros anúncios. O analista tem que realizar o teste z de uma proporção para determinar se
a proporção de domicílios que fizeram uma
compra foi diferente da média nacional
de 6,5 porque isso é 8,7. Nesse caso. Qual é a sua hipótese
alternativa? hipótese alternativa é que o
anúncio é
diferente da resposta
ao anúncio é diferente
da média nacional. Aqui, diremos que não
há diferença. Ambos são pecado, valor
alfa é de cinco por cento. E vamos fazer
uma proporção,
teste z, teste de proporção de eventos. Eu deveria
te levar até o minuto. Então, vamos para o MiniTab. Eu posso ir em frente e esses pais, estatísticas
básicas,
uma proporção. Não tenho dados na minha coluna, mas resumi, certo? Então deixe-me fechar isso, cancelar, deixe-me fechar isso. Então, eu fiz um teste
de proporção de amostra. Eu resumi os dados. Quantos eventos
foram estamos absorvendo? Estamos observando 87
eventos que acontecerão. A amostra é de mil. Preciso realizar o teste de
hipótese e a proporção hipotética, 6,5, 0,0656% .5, certo? Portanto, é 0,065. Essa proporção não é igual
à proporção hipotética. Eu digo, Ok, eu vejo, ok. Agora, a hipótese nula é que a proporção é
igual a 6,5 por cento. hipótese alternativa é
que o impacto proporcional não
é igual a 5,56 por cento. valor de p é 0,008. O que isso significa? Sim, seja baixo, nada legal. Portanto, rejeitamos a
hipótese nula, concluindo que o efeito
do anúncio, Ele não é 6,6,5 por cento, mas é mais
porque se você ver o intervalo de
confiança de noventa e cinco por cento, diz 0,7% a 10%, certo? Você tem uma
proporção de 88,7%. E o
intervalo de confiança de 95% da proporção está muito acima de 6,5, começa
a partir de 7. Portanto, podemos concluir que há um impacto significativo
do anúncio e podemos
examinar essa empresa de publicidade. Vamos continuar em
nossa próxima lição.
33. Duas amostras de proporção teste-2p-teste: Vamos fazer esse exercício
mais uma vez usando o Assistente. Portanto, temos os
80 produtos de carne bovina numerados pelo fornecedor E que
verificamos. 725 estão com defeito
ou não defeituosos. Então, quantos isso é eficaz? Então, se eu fizer uma subtração, seria 777802 menos 725 é 77712 produtos de amostragem
do fornecedor B foram
selecionados por 73. Perfeito. Então, quanto está
com defeito? Um, 39. Então, vamos tentar fazer nosso teste de
duas proporções usando o assistente do
Minitab como este
teste de hipótese, peças de
amostra, fezes,
porcentagem de amostra do fornecedor defeituoso E, 0 a 7771 a 139. A pessoa com defeito do fornecedor E é
menor que a porcentagem de
defeito do fornecedor B. Vou seguir em frente
e clicar em Ok. E eu entendo isso. Sim, essa porcentagem de
defeituosos ou fornecedor é significativamente
menor do que a porcentagem de
defeituosos do fornecedor B. E se eu rolar para baixo, Sim. Então diz a diferença, esse fornecedor a está pronto para
leitura. A partir do teste, você pode concluir que a porcentagem
representativa do fornecedor é menor que o Fornecedor B no nível de significância de
5%. Quando você está vendo
essa porcentagem. Além disso, você pode ver
claramente que
continuaremos com o
próximo teste de hipóteses na próxima semana.
34. Duas proporções de amostra test-2p-teste-Exemplo: Agora vamos entender
o próximo exemplo. Este é um exemplo em que
um gerente
de operação mostra um produto
fabricado usando matéria-prima de dois fornecedores, determina se uma
das matérias-primas de suprimentos tem maior probabilidade de produzir
uma melhor produto de qualidade. Assim, 802 produtos foram
amostrados do fornecedor E 725 ou perfeito, que não
está com defeito. 712 produtos foram amostrados do
Fornecedor B, 573 ou buffet. Ou seja, não está com defeito. Então, queremos realizar
porque qual é porcentagem de
não defeituosos de
seus dados pessoais? Sim, eu tenho duas proporções, matriz de
suprimentos e Fornecedor B. Vamos para o principal. Eu posso ir para Stat, Teste de duas
proporções de Estatísticas
Básicas. Eu tenho meus dados resumidos, os pares pela primeira facilidade, 725 ou ambos agem de 802. Então, vamos pegar
725025723712572371. A opção de eles
verem é que há uma diferença e
vamos descobrir. Portanto, o BVA, a hipótese nula, é que não há diferença
entre a proporção. A hipótese alternativa é que há uma diferença entre
as duas proporções. Quando eu estava
olhando para o valor de p, o valor de p sai para ser Z, para ser nulo baixo. Está concluindo que eu tenho que rejeitar a
hipótese nula. Há uma diferença
no desempenho
dos dois fornecedores. Agora, se eu pensar
porque estou
falando de perfeito ou
não defeituoso, atualmente, amostra um tem 90% perfeito e a amostra dois tem 80% perfeita. Então, concluindo que o fornecedor E é um fornecedor melhor
do que o Fornecedor B. Certo? Então, muito obrigado. Continuaremos
na próxima lição.
35. Usando o Excel = um teste t de amostra: Muitas vezes entendemos o
teste de hipótese, mas há um
desafio que temos. O desafio é que eu
não tenho o Minitab. Não posso fazer o teste de
hipótese de uma maneira fácil em vez de passar por um cálculo manual usando uma calculadora
estatística. Não se preocupe, isso é possível. Vou mostrar
como posso fazer um teste de hipótese usando o
Microsoft Excel. Vá para Arquivo. Vá para Opções. Ao acessar Opções,
vá para Suplementos. Quando você clica em Suplementos. Deixe-me clicar aqui. Você tem uma opção
chamada de suplemento
do Excel
na opção Gerenciar. Então, selecione o complemento do Excel
e clique em Ir. Clique em Ferramentas de Análise
e verifique se essa
marca de verificação está ativada. Depois de fazer isso, você o encontrará
na guia Dados. Você tem
análise de dados disponível. Deixe-me clicar nele para que você entenda o
que é possível. Na análise de dados. Eu tenho uma correlação OR, covariância,
estatística descritiva, histograma, teste T, testes z, geração de
números aleatórios, regressão de
amostragem
e todas essas coisas. Portanto, está ficando muito fácil fazer testes de hipóteses. Pelo menos a hipótese de
dados contínuos também
foi testada facilmente por meio do
Microsoft Excel. Eu vou fazer com que você faça exercícios
passo a passo por enquanto. Vamos voltar para
a apresentação. Vamos pegar o primeiro problema. Ou seja, tenho as estatísticas
descritivas do HD da chamada, do gerente dos
processos em que sua equipe está trabalhando para fechar a resolução da chamada em sete minutos. Mas o cliente
vê que ele ficou em espera por muito tempo
e, portanto, está gastando
mais de sete minutos. Se eu olhar para as estatísticas
descritivas, está me dizendo dez minutos, mediana é sete, a média é 7,1. Agora eu gostaria de fazer essa análise usando a saída
da Microsoft. Então, vamos começar. Eu tenho esse caso de uso nos dados do projeto
que eu enviei, clique em ASD, é claro, ele leva você a este lugar. Agora, primeiro vou
te ensinar como fazer estatísticas
descritivas
usando o Microsoft Excel. Vou clicar em
análise de dados na guia Dados. Vou procurar estatísticas
descritivas. Clique em, ok. Meu intervalo de entrada é
daqui até a parte inferior. Eu selecionei. Meus dados são agrupados por colunas. O rótulo está presente
na primeira linha. E eu quero que meu resultado
vá para uma nova pasta de trabalho. Quero
estatísticas resumidas e quero meu nível de
confiança. Eu clico em OK. O Excel está fazendo alguns cálculos e preparando-os para isso. Sim. Aqui está minha saída. Eu clico no primeiro aqui
para ver qual é a saída. Assim, você pode ver que você é média, modo
mediano,
desvio padrão, curtose, distorção, alcance,
mínimo, máximo,
soma, contagem, nível de confiança. Todas essas coisas são facilmente calculadas com o
clique de um botão. Não preciso escrever
tantas fórmulas. Agora, vamos voltar
ao nosso conjunto de dados. Eu quero fazer o teste de
hipóteses. Qual é a minha hipótese nula? Quando a hipótese nula é que o TDAH é igual
a sete minutos. Hipótese alternativa. O TDAH não dura sete minutos. Há um
valor alfa diferente que estou configurando como 5%. E com isso, vou
realizar os testes que
vou conectar é
um teste t de uma amostra. Ao fazer
um teste t de uma amostra usando o Microsoft Excel, você terá que
seguir um pequeno truque. O truque é que vou
inserir uma coluna aqui. E isso, eu vou
chamá-lo de idiota. Porque o Microsoft Excel vem com a opção de teste t de
duas amostras. Tenho HD da chamada em minutos e idiota, onde
anotei em zeros, zeros. No entanto, a mediana média, tudo para 0 é sempre 0. Clique em análise de dados. Vou descer e direi teste t de
duas amostras
assumindo a mesma variância. Vou selecionar isso. Vou clicar em, Ok. Meu intervalo de entrada,
um é essa linha. Meu alcance de entrada
através deste manequim. Minha
diferença média hipotética é de sete minutos. O rótulo está presente em ambos os valores Alpha
definidos como cinco por cento. E estou dizendo que
meu resultado precisa estar em uma nova pasta de trabalho. Eu clico em Ok, ele está fazendo o cálculo
e me dando a saída. Você pode ver que os números
foram transmitidos como uma prática Basta clicar no carma
na seção Formato para que
os números fiquem visíveis. Estou mudando a visualização porque o dummy
não tem nenhum dado. Estou livre para excluir
esta coluna. Agora vamos entender o
que sempre procuramos? Procuramos esse
valor, o valor p. Você se lembra da fórmula? Deixe-me pegar minhas
fórmulas aqui. Sim. Qual é a conclusão? A conclusão é P alto. Eu não rejeito a
hipótese nula. A conclusão do TDAH
da ligação é de sete meses. Estou rejeitando a hipótese
alternativa porque meu valor de p
está além de 0,05. Vou abordar mais exemplos
nas lições a seguir. Então, estou ansioso para
que você continue esta série. Se você tiver alguma dúvida, solicitaria que você colocasse suas perguntas na seção de
discussão abaixo e ficarei feliz em
respondê-las. Obrigada
36. Análise de correlação: Bem-vindo à próxima lição de nossa fase analisada no ciclo de vida
do DMac de um projeto
Lean Six Sigma Às vezes, entramos em
uma situação que gostaríamos de fazer uma análise de
correlação Por isso, pensei que hoje deveria mergulhar
você profundamente no que é
correlação Qual
é a diferença entre correlação
e Como faço para interpretar correlação quando vejo o gráfico
de dispersão Que
nível de significância posso
definir ao fazer meu teste de
hipóteses? Correlação de Pearson, correlação de
Spearman, correlação serial
ponto b e como fazer esses cálculos online usando Então, vamos começar. Então, o que exatamente é análise de
correlação? análise de correlação é uma técnica
estatística que fornece informações sobre a relação
entre as variáveis análise de correlação pode ser calculada para investigar a
relação das variáveis, quão forte a correlação é determinada pelo coeficiente de
correlação, que é representado pela
letra numérica r, que varia de
menos análise de correlação pode
, portanto, ser usada para fazer afirmações sobre a força e a direção
da correlação Por exemplo, você deseja descobrir se existe uma correlação
entre a idade em que uma criança fala sua primeira frase e o sucesso
posterior na escola Em seguida, você pode usar a análise de
correlação. Agora, sempre que trabalhamos com correlação,
há um desafio Às vezes nos confundimos com
coisas que são um problema. exemplo, se a análise de
correlação mostra que duas características estão relacionadas entre si, pode-se verificar substancialmente
se uma variável pode ser usada para
prever as outras Se a correlação mencionada no exemplo for
confirmada, por exemplo, pode-se verificar se o sucesso escolar
pode ser previsto pela idade em que a criança
fala sua primeira frase, isso significa que existe uma
equação de regressão linear Eu tenho um vídeo separado explicar o que é
uma regação linear Mas cuidado, a correlação
não precisa ter uma relação causal Isso significa que qualquer correlação que possa ser descoberta
deve, portanto, ser investigada mais de perto pelo especialista no assunto, mas nunca interpretada
imediatamente em termos de conteúdo, mesmo que seja muito óbvio Vamos ver alguns exemplos
de correlação e causalidade Se a correlação entre o valor das vendas e
o preço for analisada, há uma forte
correlação Seria lógico supor
que o valor das vendas influenciado pelo preço
e não pela pessoa sábia. O preço não acontece
ao contrário. Essa suposição, no entanto,
não pode ser comprovada com base
em uma análise de
correlação Além disso, pode acontecer
que a correlação entre
as variáveis x e y seja
gerada pela variável Portanto, abordaremos isso em correlação
parcial com mais detalhes No entanto, dependendo de
qual variável pode ser usada, você pode ser capaz de falar sobre uma relação causal
desde o início Vejamos um
exemplo se houver uma correlação entre
o H e o salário É claro que a idade
influencia o salário, não o contrário. O salário não
influencia a idade. Então, só porque minha
idade está aumentando, ou só porque eu
tenho um salário maior não
significa que
vou ficar velho. Caso contrário, todos
gostariam de ganhar o mínimo de
salário possível. Isso é só amor. Interprete a correlação. Com a ajuda da análise de
correlação, duas afirmações podem ser feitas Um sobre a direção
da correlação e outro sobre a força relação linear
das duas métricas ou das variáveis de escala
ordinária A direção indica se a correlação é
positiva ou negativa Se a força
determina se
a correlação entre a
variável é forte ou fraca Então, quando eu digo que existe uma correlação positiva entre nós estamos tentando dizer que os valores maiores da
variável x são acompanhados pelos maiores valores da variável y e não
o contrário A altura e o tamanho do sapato, por exemplo, estão
correlacionados positivamente O
coeficiente de correlação é de 0-1. Ou seja, é um valor positivo. A correlação
negativa, por outro lado existe se um
valor maior da variável x for acompanhado
pelo menor valor da variável
y e vice-versa O preço do produto e a quantidade de vendas geralmente
têm uma correlação negativa Quanto mais caro
for um produto , menor será a quantidade
de vendas. Nesse caso, o coeficiente de
correlação estará entre
menos um e zero, supondo que seja Então, isso resulta em um negativo. Como determino a
força da correlação? Com relação à força do coeficiente de correlação r, a tabela a seguir
pode funcionar como um guia Se seu valor estiver
entre 0,0 e 0,1
, podemos dizer claramente que não
há correlação Se o valor estiver
entre 0,1 e 0,3, dizemos que há uma pequena
ou pequena correlação ou uma correlação Se o valor estiver entre 0,32
0,5, correlação média, se o valor estiver entre 0,5 0,7, dizemos que há uma correlação
alta
ou uma correlação forte,
e se o valor estiver
entre 0,7 a um,
dizemos que é uma correlação e se o valor estiver
entre 0,7 a um,
dizemos que é uma dizemos que é uma No final deste módulo, mostrarei como calcular o cátion de correlação
diretamente em uma ferramenta on-line Então, vamos mais longe. Ao fazer isso on-line, uma
das ferramentas que
usamos para analisar a correlação é
um gráfico de dispersão, pois
tanto
o x quanto
o y são tipos de dados variáveis
ou tipos de dados métricos,
como você os chama importante quanto considerar que o coeficiente de correlação
é um gráfico de forma gráfica, podemos usar um Assim, quanto à idade, o eixo x sempre
terá a variável de entrada, e o eixo y terá a variável de saída porque
y é igual à função de x. E eu posso ver que, à medida que minha idade aumenta, meus
salários aumentam O gráfico de dispersão
fornece uma estimativa aproximada se
há uma correlação, se há uma correlação linear ou
não linear e se há alguma
discrepância e se há alguma Quando fazemos a correlação, talvez também
queiramos fazer
nosso teste de hipóteses,
testar a correlação quanto
à significância Se houver uma correlação
na amostra, ainda é
necessário
testar se há evidências
suficientes de que
a correlação também existe na população Assim, surge a questão quando o cópion de correlação é considerado estatisticamente
significativo A significância da
substância de correlação pode ser testada usando o teste t. Como regra, é testado se o coente de correlação é significativamente
diferente Ou seja, uma
dependência linear é testada. Nesse caso, a
hipótese nula é que
não há correlação entre as
variáveis em estudo Em contraste, a hipótese
alternativa pressupõe que
há uma correlação Como em qualquer outro teste de
hipóteses, o nível de significância
é primeiro estabelecido em 5%. O valor Alfa é definido em 5%. Isso significa que eu deveria ter 95% de confiança na
análise que estou fazendo. Se o
valor p calculado estiver abaixo de 5%, a hipótese nula é rejeitada e a
hipótese alternativa se aplica Se o valor de p estiver abaixo de 5%, ele assume que existe uma relação entre
x e o. A fórmula do teste t que
usamos para testar hipóteses é r em abaixo da raiz de n menos dois dividida por abaixo
da raiz de um menos r quadrado. Onde n é o tamanho da amostra, r r é a
correlação determinada da amostra
e o valor
p correspondente pode ser facilmente calculado na calculadora de
correlação Hipótese direcional e não
direcional. Com a análise de correlação
pode ser testada para hipóteses direcional ou não direcional O que queremos dizer com hipótese de correlação
não direcional Você só está interessado em
saber se existe uma relação ou uma correlação
entre duas variáveis Por exemplo, se existe uma correlação entre
idade e salário, mas você não está interessado na direção
das relações Quando você está fazendo uma hipótese de
correlação direcional, você também está interessado na direção
da Se há uma correlação positiva ou negativa
entre as variáveis Sua hipótese alternativa
é então um exemplo. A idade é
influenciada positivamente no salário. O que você precisa
prestar atenção é que, no caso de uma hipótese
direcional, você seguirá a
parte inferior do exemplo Então você vai dizer isso, existe uma
influência positiva ou não? Então, normalmente, dizemos que
não há correlação e
há uma correlação Mas aqui diremos que não
há correlação, e a
hipótese alternativa dirá que há uma
influência positiva na salada Então, agora vamos
para a próxima parte. Essa é a análise de
correlação de Pearson. Com a análise de
correlação de Pearson, você obtém uma declaração sobre a correlação linear entre as variáveis
da escala métrica A respectiva covariância é
usada para o cálculo. A covariância fornece
um valor positivo se houver uma correlação
positiva entre as variáveis
e um valor negativo se houver uma correlação
negativa A covariância é
calculada como COV ou covariância de X é calculada usando a fórmula
fornecida na tela Não se preocupe. Não precisamos
calculá-lo manualmente. Então, temos sistemas e ferramentas que podem fazer
essa análise para nós. No entanto, a covariância
não é padronizada e pode assumir valores entre
mais e Isso
dificulta a comparação da força da relação
entre as variáveis Por esse motivo, o coeficiente de
correlação também
é uma correlação de
movimento do produto E isso é
calculado de uma maneira diferente. O coente de correlação é obtido pela normalização Para essa normalização,
a variância
das duas variáveis é
calculada conforme dada O
coente de correlação de Pearson agora pode assumir valores de menos um a mais um e pode ser
interpretado O valor de menos um
significa que há uma relação
linear totalmente positiva, e quanto mais, menos um indica que existe uma
relação totalmente negativa Quanto mais e menos. Com o valor zero, não
há relação linear. A variável não se
correlaciona com cada uma. A correlação de mais um será mais ou menos
assim, o que só é
possível em teoria correlação de 0,7 plus será mais ou menos
assim, em que está no
lado positivo e a maioria dos
pontos está mais próxima eixo
da luz de
regressão Uma correlação de mais
três será dispersa, mas está indo em uma direção
positiva Quando você faz uma correlação, você
tem uma correlação de -0,7, todas
elas estão
dispersas Assim, à medida que o valor de x aumenta, o valor de y diminui
e a maioria dos pontos está e a maioria dos pontos espalhada pelo lado
da
regressão Obtemos o valor
de correlação de zero de várias maneiras, ou os pontos estão
completamente dispersos, ou você pode obter algumas linhas
perfeitas como essa ou essa, o que, novamente, não
seria, o que
significa que você precisa fazer alguma outra análise para interpretar Agora, finalmente, a força
do relacionamento pode ser interpretada e isso pode ser ilustrado pela história a
seguir A força da correlação. Se for 0-0 0,1, não
há correlação Se for 0,1 a 0,3, há uma pequena correlação 0,3 a 0,5 correlação média,
0,52 0,7, desculpe muito alta,
alta correlação e 0,7 a um é uma Para verificar com antecedência se existe uma relação
linear, gráficos de
dispersão devem
ser considerados Dessa forma, a
respectiva relação entre as variáveis
também pode ser verificada visualmente. A correlação de Pearson só
é útil e objetiva se as relações de demor
estiverem presentes A correlação de Pearson
tem certos ems, que você deve ter em
mente Para o PSM, sempre que
você estiver usando isso, as variáveis devem ser distribuídas
normalmente e deve haver uma relação
linear entre as variáveis A distribuição normal
pode ser testada analiticamente ou graficamente
usando o gráfico QQ, que eu vou
te ensinar como fazer Se as variáveis têm
uma correlação linear, é melhor verificar
com o gráfico de dispersão Se as condições não forem atendidas, correlação de Spearman pode ser usada Então, espero que você esteja
claro até aqui e continuemos nosso
aprendizado. Vamos continuar. O que fazemos quando
meus dados não estão normais e eu quero estabelecer
uma análise de correlação Nesse caso, usamos a correlação de classificação de
Spearman. análise de correlação de classificação de Spearman é usada para calcular a relação
entre duas variáveis que têm um nível ordinal Quando você tem dados variáveis, ou posso dizer dados contínuos, estamos usando a análise de
correlação normal,
como a análise de
correção de Pearson Mas se meus dados forem ordinais
ou não paramétricos, posso
prosseguir com a análise de correlação de
Spearman Portanto, esse procedimento é usado quando o pré-requisito da análise de
correlação, ou
seja, os
procedimentos paraméticos não são
atendidos ou quando não há dados métricos ou variáveis
contínuas
e os dados e os Nesse contexto, podemos chamá-la
de correlação de Spearman
ou linha de Spearman Significa a correlação de classificação de
Spearman. A questão pode então
ser tratada como se classificação de
Spearman fosse semelhante
à do coeficiente de
correlação de Percy Exemplos. Existe uma correlação entre duas variáveis
ou características Por exemplo,
existe uma correlação entre idade e
religiosidade
na população da França O cálculo da correlação de
classificação é baseado no sistema
de classificação da série de dados Isso significa que as variáveis de medida de
classificação não
são usadas no cálculo, mas são transformadas em classificações. O teste é então realizado
usando as classificações. Para o
coeficiente de correlação de classificação, p, os valores entre menos
um e um Se houver um valor
menor que zero, p for menor que zero, há uma relação
linear negativa. Se o valor for
maior que zero, então há uma relação
linear positiva. Se o valor for zero ou próximo
de zero, como 0,1 a -0,1, podemos dizer que
não há relação
entre as variáveis Assim como no coeficiente de
correlação de espareanos, força
da correlação pode ser classificada da seguinte a força
da correlação pode ser classificada da seguinte
forma. Portanto, se for 0-0 0,1, não
há correlação Se for 0,12 0,3, há uma pequena correlação Se houver 0,3 a 0,5, há uma retração média Há 0,5 0,7 alta correlação e 0,7 para um, correlação
muito alta Se houver valores negativos, diremos correlação
negativa menor, alta correlação negativa
e assim por diante Existe outro tipo
de correlação chamada esse ponto de correlação
serial bi A
correlação serial bi de pontos é usada quando uma das variáveis
é dicotômica Exemplo, você
estudou ou não estudou? A outra é uma
variável métrica, como salário. Nesse caso, usamos uma correlação ponto
por série. A correlação de um ponto
por correlação serial
é a mesma que a correlação de
Pearson calculada Para calculá-lo, uma das duas expressões
do valor dicotômico
é codificada O outro é codificado como um. Análise de correlação calculada, mostraremos você usando o Excel ou outras ferramentas disponíveis gratuitamente Vou te mostrar o
cálculo depois de algum tempo, mas vamos primeiro estudar o caso. Um aluno quer saber se
há uma correlação entre altura e o peso dos participantes
do curso de
estatística Para tanto, o
aluno extraiu uma amostra, que está distribuída abaixo. Então eu tenho as alturas
das pessoas, eu tenho os
pesos das pessoas Para analisar a relação
linear por meio da análise de
correlação, você pode calcular a
correlação usando o
Excel ou outras ferramentas
disponíveis on-line Primeiro, copie a tabela
na calculadora estatística. Em seguida, clique em correlação
e selecione-a. E, finalmente, você
poderá obter as
seguintes inserções. Então, vamos fazer isso online. Então, eu vim para data tab.net. É uma calculadora
estatística online. Os dados aqui têm 100% de segurança de dados porque os cálculos são
feitos no seu navegador e os dados são inseridos e armazenados nos cookies do seu navegador. Os dados são 100%, e é por isso que o
cálculo funciona muito rápido. Portanto, os dados
não precisam de um
servidor grande e, portanto, de você. Então eu tenho o peso corporal, eu tenho o peso
e eu tenho a idade. Então, eu quero entender. Então, se eu cair,
tenho uma cortação. Quero entender se
existe uma relação entre a altura corporal
e o peso corporal. Que tipo de correlação eu quero? Vamos escolher Pearsons primeiro.
Há uma correlação Há uma correlação positiva. O nível de significância é definido. 5% Podemos testar as suposições e ele está
fazendo a análise imediatamente Está fazendo o gráfico do QQ para mim. Está desenhando o histograma e mostrando
os resultados, certo Portanto, podemos dizer que sim, mais ou menos os dados são
normalmente distribuídos. Posso copiar isso
clicando em Baixar PNG e o arquivo será copiado. E você poderá
ver isso dessa forma. Então, agora, deixe-me fechar esta tumba, para que ela tenha sido testada quanto
às suposições No resumo em versos, o resultado da correlação de Pearson mostrou que há
uma
correlação positiva muito alta entre peso corporal,
altura e peso Os resultados mostraram que a relação entre peso
corporal, altura e peso
é estatisticamente significativa com um valor r
positivo. R é 0,86 e o valor
p é 0,01. 001. Então, quando você olha para a
força da correlação, se o valor for
maior que 0,7 e um, dizemos que é uma correlação muito
alta e é uma decoração positiva Quando faço o teste de
hipóteses, não
há correlação ou há uma correlação
negativa entre a altura corporal e o peso Há uma correlação positiva entre a altura corporal e o peso Quantos casos
temos dez casos. O valor r é 0,86 e o valor p é 0,001, que é menor que Portanto, rejeitamos a
hipótese de que não
há correlação, e a hipótese alternativa
aplica que
há uma correlação positiva entre a
altura corporal e o A vantagem de estar no rascunho de
dados é que você
tem interpretação de IA. Esta tabela resume os resultados
da análise
da altura e peso corporal, mostrando o
coeficiente de correlação r e o O valor do
coeficiente de correlação indica a força e a direção da
relação entre a variável
altura e peso,
e o
valor do coeficiente é 0,86, sugere
que há uma correlação positiva muito Isso significa que geralmente, à medida que a altura corporal aumenta, o peso também tende a
aumentar e vice-versa. O valor P. O
valor p aqui assume que os dados disponíveis fornecem evidências
suficientes para
rejeitar a hipótese nula Nesse caso, a hipótese
unilateral testada
e a hipótese nula afirmam que há nenhuma correlação ou correlação negativa entre a altura e o
peso na população Na maioria dos casos, o
valor de p é menor que 0,05, consideramos que há uma significância
estatística No nosso caso, o valor de
p é 0,001, o que obviamente é
menor que 0,5 A hipótese nula é rejeitada, e o resultado da correlação de
Pearson mostra que há uma significância estatística da correlação
positiva entre
a altura corporal e o Portanto, o resultado da
correlação de Pearson mostra que há
uma correlação muito positiva
entre altura e peso,
e isso é armazenado pela correlação e isso é armazenado pela positiva
estatisticamente significativa do valor
r como 0,86 e o valor P é 0,05 Agora, há um gráfico de dispersão que está
sendo feito automaticamente Posso clicar aqui e
obter minha linha de regressão. Eu posso mudar meu eixo se eu não
quiser começar do zero Eu
quero uma linha zero Então, o zero está incluído, mas eu não o quero.
Eu posso mudar isso. Como quero minha imagem, o PDM extra grande e assim por diante Posso clicar em Baixar TNG
para baixar esta imagem. Agora, como eu disse, também
podemos fazer o cálculo da covariância. Então, quando estou analisando a
altura e o peso corporal, a covariância é 1,29, certo Então isso significa que
existe um relacionamento. Então é assim que você está
fazendo o cálculo. Agora, para uma calculadora
serial ponto a ponto, podemos ter um tipo diferente podemos ter um tipo diferente
de dados em
que queremos analisar se a mudança no salário tem algo a
ver com o gênero. Nesse caso, eu selecionaria
o valor métrico como salário e a
variável nominal como sexo
e, em seguida,
farei meu cálculo. Isso definiria o homem como
zero e a mulher como um. Box plot, que indica que sim, os homens tendem a ter um salário maior quando
comparados às mulheres. Então, quando um aluno
quer saber se há uma correlação
entre s elevados, fizemos essa análise A hipótese, se você puder
optar por uma hipótese normal, não
há correlação entre a altura corporal e o peso Há uma associação
entre altura e peso, mas eu tinha adotado uma
hipótese direcional em meu teste O valor P é esse, e
vimos como podemos
gerar a saída. Primeiro, você obterá a hipótese nula
e alternativa. A hipótese nula afirma que não há correlação
entre altura e peso, e então temos a hipótese
alternativa
que impede o oposto. Se você clicar em pássaros submarinos, obterá a interpretação
que acabamos de ver Podemos prosseguir e,
na verdade, testamos
a hipótese de
correlação direcional ou unilateral E no Excel,
existem outras ferramentas que
podem ajudá-lo a calcular. Então, acabamos de fazer o teste, dizendo que não há correlação
ou correlação negativa entre a geração corporal e que há uma correlação
positiva entre a altura corporal E quando vimos, percebemos que, sim, há uma
correlação positiva muito forte
e, portanto, o valor de p
foi menor que 0,01 Nesse caso, você deve primeiro verificar se a correlação está em todas as direções
da hipótese alternativa, ou
seja, a altura e o peso
estão positivamente correlacionados
e, nesse caso, o
valor p é dividido Portanto, apenas a
distribuição unilateral é considerada. No entanto, essa ferramenta cuida
dessas duas etapas
e o resumo em verso é fornecido como vimos. Afirmamos que há uma correlação
positiva entre a altura e o peso
do conjunto de dados na amostra Portanto, podemos dizer que há uma significância
positivamente correlacionada, e podemos ver que há uma correlação
muito positiva entre as variáveis de Assim, há uma correlação
positiva muito alta entre a
altura da amostra e o pt Com isso, encerraremos nossa análise de correlação e nos vemos
na próxima aula
37. Conceito de análise de correlação de Pearsons: Vamos continuar nossa jornada de
correlação. Eu vou falar sobre a correlação de
Pearson hoje. análise de correlação de Pearson é um exame da relação
entre duas variáveis Por exemplo, é uma correlação entre a idade e o salário de uma
pessoa Ambas são variáveis
contínuas
e, portanto, o diagrama
será disperso Então, à medida que a idade da
pessoa
aumenta, o salário aumenta? Agora, você precisa lembrar que
y é uma função de x, então seu eixo y
terá o resultado e o eixo x terá
a variável independente. Mais especificamente, podemos usar
o
coeficiente de correlação de Pearson para medir
a relação linear
entre Se a relação não
for linear, essa equação de correlação não
será de jeito nenhum Eu acho que você teria
observado que eu mudei meu AR para
esta gravação. Se você gostou, basta colocar um polegar para cima na seção de
comentários Vamos continuar, a força e a direção
da correlação Com a análise de correlação, podemos determinar o quão forte é
a relação e em que direção
a correlação vai Podemos ler a força e a direção
da correlação na letra r do
coeficiente de correlação de Pearson, cujo valor varia de
menos A força da correlação, a força da correlação, pode
ser lida na tabela O valor de r está entre zero menos um indica que não
há correlação Se a quantidade do valor de
r estiver entre 0,7 a um, é uma correlação
muito forte e altamente correlacionada Agora, se os valores forem positivos, correlacionados positivamente
e, se os valores forem negativos, negativamente Então, digamos que o valor r
saia como -0,66. Então, podemos dizer que está altamente correlacionado
negativamente. Então, isso eu retirei
do livro de estatísticas.
Vamos contê-lo. O que você quer dizer com a
direção da correlação? Uma correlação positiva
é uma correlação existe quando grandes valores
de uma variável estão associados a grandes valores
de outra variável ou quando uma pequena mudança em
uma variável está associada a uma pequena
mudança na outra Então, se for uma
correlação positiva, se houver um
valor maior no eixo x, isso corresponde a um valor
maior no eixo y. E um valor menor no eixo x correlaciona com um
valor menor no eixo y, como você pode ver
nessas duas imagens Uma correlação positiva resulta em exemplos de altura
e tamanho do calçado Isso resulta em uma correlação
positiva. Assim, à medida que a
altura da pessoa aumenta, o tamanho do sapato
também aumenta. O resultado é um coeficiente de
correlação positiva
e r é maior e r é Agora, você viu que há
um erro neste gráfico? O erro é que o
tamanho do sapato é o resultado, e a altura é a variável
independente, mas nós a mapeamos arbitrariamente de
forma errada para evitá-la Então, deixe-me colocar meus
comentários aqui. O que há de errado no gráfico de pow? A questão é: o aumento do tamanho do
show tem efeito ou resulta no aumento
da altura
da pessoa ou o aumento da
altura da pessoa serve para aumentar
o tamanho do sapato. Por favor, escreva na seção
dez abaixo. Sim Lembre-se, y é
uma função de x. E aqui, y é a altura
da pessoa e x é meu erro. X é a altura da
pessoa e y é o tamanho do so. Espero que agora esteja claro o que
estamos tentando dizer. Então y é uma função de x. Deixe-me transformar a letra em
um pequeno y porque esse é o projeto y. X é
a altura da pessoa. Então, aqui, o erro é que mostramos
isso da maneira errada. A correlação negativa
ocorre quando um valor grande em uma variável está
associado um valor pequeno na outra
variável e vice-versa. Portanto, se o eixo y for grande, o valor do eixo x será pequeno. E se o valor do eixo x for grande, o valor do eixo y será pequeno. Isso é chamado
de correlação negativa. Os pontos estão fluindo. Ao contrário do anterior onde os pontos estavam
fluindo Agora, a correlação negativa é encontrada entre o
tamanho do produto e o valor das vendas Isso resulta em um cátion de
correlação negativa. O que acontece quando
o preço aumenta, o volume de vendas diminui. E se o preço for reduzido, as pessoas tendem a comprar mais volume. Resultando em mais vendas. Deixe-me escrever que faça aumentos. Muito bom Portanto, o resultado
é uma correlação negativa, o valor da coesão de
r é Quanto mais forte for a correlação, o valor se
aproxima de menos E aqui o gráfico está correto. À medida que o preço aumenta, os volumes diminuem Agora, como calculamos o cliente de correlação de
Pearson? Isso é uma
coisa muito importante, certo? O índice de
correlação de Pearson é
calculado usando a equação calculado usando Aqui, r é o cliente de
correlação de Pearson. X i é o
valor individual de uma variável. Por exemplo, pode ser
a idade da pessoa. A barra X é a idade média
do conjunto de dados da amostra. Y um é o valor individual da outra variável ou da variável de resultado,
e
a barra Y nada mais é o salário médio do conjunto de dados
da amostra Então, aqui, a barra x e a barra y são o valor médio de duas
variáveis, respectivamente. Isso é todo dividido
pela raiz inferior de x um menos x barra quadrada, y um menos y barra inteira Então, quando eu estiver quadrando
e fazendo uma raiz inferior, tudo será resolvido Então, x um são os valores
individuais e y um são os valores
individuais da variável de resultado. R é a correlação de Pearson
e o valor médio. Nessa equação, podemos ver
que os respectivos
valores médios da primeira são subtraídos
da outra variável Em nosso exemplo, calculamos esse valor principal
de idade e salário. Em seguida, subtraímos
o valor principal de cada idade e salário em
relação à média Em seguida, multiplicamos
os dois valores. Em seguida, somamos os resultados
individuais
da multiplicação. A expiração
do denominador garante que o
coeficiente de correlação sempre varie
entre menos um e mais um Lembre-se de que você não precisa calcular nada
manualmente. Atualmente, temos esses
recursos disponíveis no Excel e em vários sites
online. Se você quiser vários
dois valores positivos, obteremos um valor positivo. E se multiplicarmos
dois valores negativos, também obteremos um valor positivo menos em
menos Portanto, todos os valores que
estão nessa faixa têm uma influência positiva no
coeião de correlação À medida que a idade aumenta, o salário aumenta; à medida que a idade diminui,
os salários diminuem Se multiplicarmos o
valor positivo por um valor negativo, obteremos um valor negativo que
é menos para mais é O tempo todo,
há uma série de influências
negativas no coeion
de correlação Portanto, as coisas que estão
destacadas na caixa roxa, se os dados estiverem
caindo
lá, isso resultará em
uma correlação negativa Portanto, se nosso
valor for predominantemente duas áreas verdes das duas figuras
anteriores Obtemos um coeficiente de
correlação positivo
e, portanto, e, portanto, Se nossas pontuações estiverem predominantemente na área vermelha das figuras, obtemos um coeficiente de
correlação negativo e, portanto, temos uma Se os pontos forem
distribuídos por todas as quatro áreas, termos
positivos e termos
negativos, eles se anulam e podemos acabar com muito pequena ou nenhuma
correlação Então, essa é uma parte muito
importante, que você precisa entender. Certo? Se os pontos forem
distribuídos globalmente , não resultaremos em nenhuma
correlação Agora, como testar a correlação e o coeficiente são significativos Em geral, o coeficiente de
correlação é calculado usando
dados de uma amostra Na maioria dos casos, entretanto, queremos testar a hipótese
sobre a população. Como não podemos estudar a população, fazemos
uma amostragem, pegamos uma amostra e,
ao estudar a amostra, queremos fazer inferências
sobre a Nesse caso, na análise de
correlação, queremos então saber se
há uma correlação
na população Para isso, testamos se o coeficiente de
correlação na amostra é estatisticamente significativo e Agora, como fazemos testes de
hipóteses? Para a correlação de Pearson? A hipótese nula e
a hipótese alternativa para as correlações de
Pearson A hipótese nula diz que não
há correlação e, portanto, o valor R não é significativamente
diferente de zero Não há relacionamento. A
hipótese alternativa diz que há uma
diferença significativa ou há uma
correlação linear dos dados Atenção
Sempre testamos se a hipótese nula é
rejeitada ou não Isso é muito, muito importante. Nunca aceitamos ou nunca
trabalhamos da mesma forma que eu. O fato é que sempre trabalhamos para provar ou rejeitar
a hipótese nula Nunca tentamos
provar a alternativa, embora nossa pesquisa comece
porque existe uma alternativa. Em nosso exemplo, quando se do salário e da
idade da pessoa,
poderíamos, assim, dizer a pergunta. Existe uma correlação
entre idade e salário para a população
alemã Para descobrir, extraímos uma
amostra e testamos se o coeficiente de correlação é significativamente diferente
de zero nessa A hipótese nula é não
há correlação entre salário e idade
na população alemã A
hipótese alternativa é que existe uma correlação entre o salário e a idade na população
alemã Significância e o teste. Quando o teste de coeficiente de
correlação de Pearson é significativamente diferente da pesquisa de
amostra com base zero,
nós o testamos usando
a fórmula do teste Aqui, r é o coeficiente de
correlação
e n é o tamanho e n é Novamente, eu diria que
é bom conhecer a fórmula, mas não
se perder nela. Certo? Um valor P pode ser calculado a
partir da estatística de teste t, e o valor p é menor do que o nível de
significância especificado, que geralmente é 5%, então a hipótese nula é
rejeitada, caso contrário, não Portanto, queremos garantir que o valor de p seja, se
for maior que 0,05, falhamos em rejeitar
a hipótese nula Se o valor de p for
maior que 0,05, falhamos em rejeitar
a hipótese nula Agora, quais são algumas suposições que existem na correlação de
Pearson E quanto às suposições da correlação
de Pearson? Aqui temos que
distinguir se queremos calcular o coiente de correlação de
Pearson ou se queremos testar Para calcular o coeião de
correlação de Pearson, apenas duas variáveis métricas
estão presentes Variáveis métricas, por exemplo, podem ser peso da pessoa, salário,
consumo elétrico, etc. Resumindo, variável contínua. O
cliente de correlação de Pearson então
nos diz o quão grande é a
relação linear, e existe uma Não podemos ler a coião de correlação de
Pearson. Portanto, essa é uma correlação linear, e se seus dados forem
executados ou aparecerem assim, tendemos a seguir em frente Então, neste caso, não
há correlação No entanto, se quisermos
testar se o
coeficiente de correlação de Pearson é significativamente diferente
de zero na amostra, queremos testar a
hipótese de que
as duas variáveis também estão
normalmente Porque você não pode testar a correlação de Pearson
para dados não normais Nesse caso, se as estatísticas de
teste calculadas t e o valor p não puderem
ser interpretados de forma confiável Se a suposição não for feita, correlação de classificação de
Pearson será usada Isso significa que, para dados
não normais, vou usar a correlação de
classificação de Pearson Como faço para calcular a correlação de
Pearson online usando o Excel
e outras ferramentas? Eu vou
mostrá-lo para você em breve.
38. Correlação bisserial de pontos: Vamos agora aprender sobre a correlação serial de pontos
bi. Vou abordar a teoria
e o exemplo e como podemos fazer isso na
prática com uma calculadora on-line.
Fique conectado. O que exatamente é correlação serial de ponto
bi? Você já ouviu falar sobre isso antes ou seu rosto ficou mais ou
menos assim? Ouvimos falar principalmente regressão
linear, regressão
logística Quando aprendemos sobre correlação, pensamos em correlação
simples, correlação
positiva, correlação negativa E sempre que estamos
fazendo correlação, estamos
pensando apenas em variáveis, variáveis contínuas no eixo x
e no eixo y. Então, vamos entender o que é correlação
ponto por série. É um caso especial de correlação de
Pearson
e examina a
relação entre uma variável dicotômica e uma variável métrica OK. A regra para
correlação é que ambas as variáveis devem ser
contínuas ou métricas Mas usando a correlação
serial ponto a ponto, posso até mesmo verificar se há variáveis
dicotímicas, que podem ser Vamos entender o exemplo
da variável dicotônica. Uma variável dicotímica é uma
variável com dois valores,
sexo, como masculino e feminino, e status de tabagismo,
como fumante, não
fumante As variáveis métricas,
por outro lado, são o peso da pessoa, o salário da pessoa, o
consumo de eletricidade e assim por diante. Então, se tivermos uma variável
dicotômica
e uma variável métrica, queremos saber se há Podemos usar a correlação ponto por
série. Então, vamos entender
a definição disso. correlação ponto a serial é um tipo especial
de correlação e examina a
relação entre dicotítica e uma variável métrica dicotônicas são
variáveis com dois valores, e variáveis métricas são variáveis contínuas
com valores infinitos,
como altura, peso, salário, consumo de
energia, etc Como exatamente a correlação ponto por série é
calculada Ele usa o conceito de correlação de
Pearson, mas na
correlação de Pearson, também
temos uma variável de natureza
nominal Por exemplo, digamos que você esteja interessado
em investigar a relação entre
o número de horas estudadas em um teste
e os resultados, ou
seja, a pessoa foi
aprovada ou reprovada Então, aqui eu posso ver
quantas horas a pessoa passou estudando e isso
resultou em aprovação ou reprovação? Coletamos dados para
a amostra de 20 estudantes. 12 estudantes foram aprovados, oito alunos falharam. Registramos o
número de horas de cada um dos alunos que
estudaram no teste e atribuímos uma pontuação
de um ao aluno que passou no teste e zero
ao aluno que falhou no teste. Agora, podemos calcular a correlação
de Pearson entre o tempo e os resultados
do teste ou podemos usar equação para
a correlação
ponto por CDN Agora podemos calcular a correlação de
tempo de Pearson e os resultados do teste
com a Agora, aqui, x y é o valor médio das
pessoas que falharam, e X um é o valor médio das
pessoas que faleceram. N representa o
número total de observações. Nenhum representa o número
de pessoas que faleceram, n dois representa o número
de pessoas que falharam. Assim como o conteúdo de
correlação de Pearson, r, correlação serial
ponto a ponto é rp B também varia entre
menos Com a ajuda do cefent, podemos determinar duas coisas É o quão forte é o
relacionamento. É uma correlação positiva? É uma
correlação positiva fraca e em que direção
a correlação vai É uma correlação positiva ou negativa A força da correlação
pode ser lida na tabela. Se o valor estiver entre
0,0 e menor que 0,1, não
há correlação Se o valor estiver entre
0,1 a menos de 0,3, há baixa correlação O valor está entre
0,3 e 0,5, há uma correlação média 0,52 0,7 alta
correlação 0,7 para um,
correlação
muito Se o valor estiver entre
zero e menos um, chamamos isso de correlação
negativa Se o coeficiente estiver entre
menos um e menor que zero,
é uma correlação negativa, portanto,
existe uma relação negativa entre existe Se o valor estiver entre
zero e mais um, é uma correlação positiva Assim,
existe uma relação positiva entre a variável
e, se o resultado
for próximo de zero, dizemos que não há correlação O
coeficiente de correlação geralmente é calculado com os dados
retirados da amostra No entanto, muitas vezes queremos
testar hipóteses sobre
a população. Queremos testar uma
hipótese sobre a população porque
não podemos estudar a população, estamos usando uma tecnologia de amostragem Calculamos o percentual de correlação dos
dados da amostra. Agora podemos testar se o coeficiente de correlação é significativamente
diferente A hipótese nula diz que o coeficiente de correlação não difere Não há relacionamento. hipótese alternativa diz que a coesão da correlação difere
significativamente de zero Existe um relacionamento. Então, quando calculamos a correlação ponto
por série, obtemos o mesmo
valor p que calculamos o teste t para
amostra independente para os Então, se testarmos a
hipótese de correlação com correlação
serial ponto a ponto ou uma hipótese
de diferença do teste t, obtemos o mesmo valor de p. E quanto às suposições
que devemos
considerar sempre que fazemos uma correlação
ponto por série Aqui, devemos distinguir
se queremos
apenas calcular
o coeficiente de correlação ou se também queremos
testar a hipótese Para calcular o coente de
correlação, apenas uma variável métrica e
uma variável dicotômica devem estar presentes apenas uma variável métrica e
uma variável dicotômica devem estar presentes. No entanto, se você quiser
testar se o coeficiente de correlação é significativamente
diferente de zero, uma variável métrica também deve
ser Se isso não for fornecido, as estatísticas de
teste calculadas ou o valor p não podem ser
interpretados de forma confiável Podemos usar
calculadoras on-line, como a guia Data, que pode ajudá-lo a fazer a análise e que
abordarei agora Estamos em apuros de dados.
Preenchi alguns dados em termos de número de resultados de
nossos testes de estudo e converti zero e um
em aprovação e reprovação em zero e um Posso importar meus dados usando esse botão e posso limpar
a tabela usando isso. Você tem configurações para decidir
que tipo de configuração
deseja usar para imagens.
Agora vamos descer. Estou em correlação
e tenho opções. Aqui, minha variável nominal
é o resultado do teste. Minha variável métrica
é nosso strded. Eu quero calcular as panelas e o
convolu de Pearson. Por enquanto, vou
mantê-lo como Pearsons. Minha variável nominal
é o resultado do teste, assim que selecionei a
variável nominal como resultado do teste, consegui identificar isso como uma correlação
serial do ponto pi A hipótese diz que
não há correlação entre nosso
estudo e os resultados dos testes A hipótese alternativa
diz que há uma associação
entre o número de horas estudadas e
os resultados do teste. A
falha de correlação serial pontual está assumindo o
valor de zero, Ps está assumindo o valor de um O valor de
correlação ponto por série r é 0,31 graus de liberdade r 18 t
é 0,14 valor p é 1,79 Eu tenho o boxplot
aqui dizendo que meu boxplot para os alunos anteriores
é assim 50% dos participantes
estão estudando entre 8,5 a 19,25 horas, o
que resultou em um passe As pessoas que falharam estão
estudando de 7 a 13 horas, certo? Eu posso até mesmo fazer o download
clicando no botão de
download PNG. E você verá que
eu sou capaz. Agora, como o cálculo funciona para a correlação
serial do ponto b Se você calcular o ponto
por correlação serial, escolha uma variável métrica e uma variável nominal
com dois valores Antes de ir lá,
deixe-me fazer um resumo em palavras. A
correlação serial do ponto b foi executada para determinar a
relação entre nossos estudos e os resultados dos testes Há uma correlação positiva entre nosso estudo
e o resultado do teste, que não foi significativa,
estatisticamente significativa porque o valor de p é maior que Se eu tivesse mais dados como esse, em que estou usando
vários valores para determinar zero e um masculino e
feminino, e então ele calculou. Então, diz: existe uma correlação entre o
salário e o gênero E podemos ver
claramente que sim, homens têm um salário
significativamente maior quando
comparados às mulheres. Mas se você ver o valor p, é muito próximo de 0,05, mas é 0,07 Portanto, deixamos de rejeitar
a hipótese nula, dizendo que talvez seja por causa do erro de amostragem O
39. Regressão logística: Bem-vindo à próxima lição
sobre regressão logística. Vamos entender
o exemplo da teoria e como fazemos a
interpretação. Quando usamos a regulamentação
logística? Vamos dar um exemplo. Sempre que tivermos que
verificar se é uma pessoa idosa que
sofrerá de câncer, ou se é um homem ou uma mulher que está pegando
mais doenças? É um fumante que está
causando a doença? Quando quero verificar
várias variáveis que podem infectar e me dizer se a doença é possível, qual é a probabilidade
de ter uma doença Então, vamos nos aprofundar. O que exatamente é regressão? Uma análise de regressão
é um método de
modelagem da relação
entre variáveis Isso possibilita
inferir ou prever uma variável, se o cliente
está feliz ou triste, com base em uma ou mais
variáveis Então, estou tentando verificar
se isso é possível, com base na
qualificação da pessoa, no tempo necessário ou na idade. Qual é o fator
que está afetando isso? A variável que
queremos inferir ou
prever é chamada variável dependente
ou critério,
e as variáveis
que usamos para
predição são chamadas de variáveis predição são chamadas independentes
ou Qual é a diferença entre regressão
linear e regulação
logística Em uma regulação linear, a variável dependente
é uma variável métrica. Exemplo, salário, eletricidade,
consumo, etc. Isso significa que é uma variável
contínua. Em uma regressão logística,
a variável dependente é
uma variável dicotômica O que é uma variável dicotônica
? Isso significa que a variável
tem apenas dois valores. Por exemplo, se
uma pessoa
comprará ou não um
determinado produto, ou se uma doença
está presente ou não. Como a
regulamentação logística pode ser usada? Com a ajuda da regulação
logística, podemos determinar o que influencia presença ou não de
uma determinada doença Poderíamos estudar a
influência da idade, sexo e tabagismo
nessa doença em particular? Nesse caso, zero significa não doente e um
significa doente A probabilidade de
ocorrência de uma doença ou uma característica significa que as características presentes
são estimadas. Nosso site de dados encontrado é mais ou
menos assim, onde minhas
variáveis independentes podem ser sexo, status de tabagismo, e minha
variável dependente pode ser uma variável composta
de zeros e uns. Agora poderíamos investigar o que influencia a variável
independente e fazer com que a doença tenha
o efeito sobre a doença. Se houver uma influência, podemos prever a probabilidade uma pessoa ter
uma determinada doença. Agora, é claro, surge a
pergunta. Por que precisamos de
regulamentação logística neste caso? Por que a
recreação linear não funciona? Então, vamos fazer uma rápida recapitulação do que aconteceu na regressão
linear Vamos fazer uma rápida recapitulação do
que é regulação linear. Na regressão linear, essa é nossa equação de regressão. Y é ir para b1x1 mais
b2x2 mais b3x3 , e assim por diante. B e xn mais c. Temos
a variável dependente y, e temos
variáveis independentes como x um, x 2x3tx E temos a coesão de
regressão,
b um, b2bt Bn b um, b2bt Bn Agora, no entanto, quando você
olha para essa variável, a variável dependente é
feita com zero ou um. E, portanto, sua saída será
mais ou menos assim. Você tem muitos pontos
na linha zero e muitos
pontos em uma linha, mas
não tem dados Não importa quanto
valor você tenha, a variável independente pode contribuir para tornar
a variável 0-1 Os resultados são
sempre zero ou um. Em uma equação de regressão, precisamos simplesmente colocar uma linha
reta nos pontos e vemos que
há muitos erros Agora podemos ver que, no caso
de uma regressão linear, valores entre mais e
menos o infinito E, portanto, essa fórmula não funciona.
Qual é a solução? No entanto, o objetivo
da regressão logística é estimar a
probabilidade de ocorrência O intervalo de valores da previsão
deve, portanto, ser 0-1. E, portanto, queremos uma
linha que caiba
nessa linha e não uma
diagonal como essa. Portanto, precisamos de uma função
que só tenha valores entre os resultados em
um valor zero e um. É exatamente isso que acontece com a função
logística. Não importa onde você
esteja no eixo x, você será; seu eixo y resultará
em zero ou um. Entre o menos e
o infinito positivo, os únicos resultados são E é exatamente isso que queremos. A equação da
decoração logística
será mais ou menos assim A função logística
agora é usada na recreação
logística Então, vamos detalhar a
fórmula de recreação linear mais uma vez Um mais y é qu para b1x1 mais
b2x2 mais t b x, e assim por diante. Essa equação agora será
inserida na função. Quando você faz
isso, é e elevado à potência de menos sua maior
equação de recreação linear,
1/1 mais e à potência
da equação 1/1 mais e à potência
da Assim, a probabilidade
da variável dependente
é dada por isso. Como isso se
parece em nosso exemplo? Qual é a probabilidade
de uma determinada doença? P é disa. Qual é a probabilidade a pessoa estar
doente igual a 1/1 mais e bar
menos B um em H,
B dois em sexo, P três em fumante mais É uma função do sexo e do status de tabagismo. Para Z, a equação
da equação linear
agora é simplesmente inserida. E quando você faz isso,
descobrimos que a probabilidade de uma variável dependente é
uma, dado esse exemplo. Em nosso exemplo, a probabilidade de contrair uma determinada doença com base no parâmetro de
sexo e status de tabagismo. Como isso se
parece em nosso exemplo? E elevado a menos B um, B dois, B três, são todos os coeficientes de determinação para que o modelo se ajuste
melhor aos dados fornecidos Para resolver esse problema, chamamos isso de
método de máxima iluminação Para isso, existem bons métodos numéricos para
resolver o problema de forma eficiente Mas como você interpreta os resultados de uma regulamentação
logística Vamos dar uma olhada no
número de fixitios. Seu sexo,
status de tabagismo e doença. 22 mulheres não fumantes
e estão doentes, 25 mulheres fumantes estão doentes, 18 homens fumantes não estão doentes, 25 mulheres fumantes estão doentes,
18 homens fumantes não estão doentes,
assim por diante. Quando colocamos isso em uma calculadora
estatística on-line, vamos para a regressão e selecionamos quais são minhas variáveis dependentes e quais são minhas variáveis
independentes? O que é mais uma
previsão de doença
ou não doença, e assim por diante E quando clicarmos
nele, ele executará a
equação de recreação para nós Então, queremos calcular a recreação
logística, então teremos que clicar
na guia recreação Em seguida, copiamos nossos dados para lá e as variáveis são
mostradas aqui embaixo. Dependendo de como suas variáveis
dependentes são usadas,
calculadoras estatísticas
on-line, como guia
Dados,
calcularão a
recreação logística ou a recreação linear na guia
Recreação Escolhemos doente como variável
dependente A o
sexo e o status de tabagismo como variável independente Agora, a calculadora
fará a
equação de regressão logística para nós Agora, examine toda a
tabela lentamente e entenda, e vamos começar do topo. Se você não sabe como
interpretar os resultados, existe um padrão chamado
resumo em verso. Você pode copiá-lo no Word, copiar os
resultados no Excel e também copiar a tabela de
classificação. Então, vamos começar. A
primeira coisa que aparece na
tabela de resultados são os resultados,
onde dizemos que
o número total de
casos é de 36 pessoas
que foram examinadas. 26 foram
estimados corretamente e
isso representa 72,22 por cento
em porcentagem Com a ajuda do
cálculo, modelo de regressão, 26 dos 36% foram atribuídos
corretamente Isso é 72%. Agora vamos para a tabela
de classificação abaixo. Você tem a opção de
exportá-lo para Word e Excel. Aqui você pode ver com que
frequência as categorias não doentes e doenças são observadas e com
que frequência elas são previstas Então,
os valores observados são 11,
cinco , cinco, 15, e as
categorias previstas são assim. Portanto, podemos dizer que eles fizeram um meio de
predição correto. Na realidade, a pessoa não
está doente
e o modelo também
previu que ela não está doente Na realidade, a
pessoa faleceu e o modelo
previu a Ambos são positivos. Verdadeiro positivo e verdadeiro negativo. Mas temos um conceito chamado falso negativo e
falso positivo. Na realidade, a pessoa não
está doente, mas a modelo
diz que está doente Portanto, esse é um caso de falso
positivo, o que é normal porque
você definitivamente pode optar pela segunda opinião
e a pessoa é cuidadosa. A preocupação é com
o falso negativo. Na verdade, a
pessoa está doente, mas meu modelo não é
capaz de prever isso Portanto, esses cinco
pacientes perderão o tratamento se não
fizerem o diagnóstico atual. No total, não são
observadas doenças 16 11 mais 516. Desses 16, o modelo recreativo pontuou
corretamente 11 como não doente e
armazenou incorretamente cinco Dos 20 indivíduos doentes, 15 foram
pontuados corretamente como doença, Pi foram
pontuados incorretamente. Observe que, para decidir se uma
pessoa está doente ou não, um limite Se a probabilidade
for maior que 50%, estamos marcando como doente Como a probabilidade
é menor que 50%, nós a marcamos como não diminuída Portanto, se o modelo de regressão
estimar mais de 50%, a pessoa é designada como morta,
caso contrário, não falecida Vamos fazer o teste do
qui-quadrado. Temos um
vídeo detalhado sobre o quadrado chi. O valor do quiquadrado é 8,79
graus de liberdade três e o valor p é 0,32 Se P for baixo, nulo. Vamos entrar no teste de
hipóteses. Aqui podemos ler
se o modelo em geral é
significativo ou não. A resposta é sim.
Agora vamos ver. Há dois modelos
a serem comparados. Em um modelo, todas as variáveis
independentes são usadas. No outro modelo, poucas
variáveis independentes são usadas. Com a ajuda do teste do
qui-quadrado, comparamos
o quão boa é
a previsão quando as variáveis dependentes
são usadas e quão boa é quando as
variáveis dependentes não são usadas. E o teste t do qui-quadrado
nos diz se há uma diferença
significativa entre os dois resultados A hipótese nula é que
os dois modelos são iguais. O valor de p é menor que 0,05. Isso significa que a
hipótese nula é rejeitada. Portanto, quando a
hipótese nula é rejeitada, assumimos que há uma diferença significativa
entre os modelos Assim, o modelo como um
todo é significativo. Em seguida, vem o resumo do modelo. Nesta tabela, você verá uma mão com menos dois valores
logarítmicos de verossimilhança
e, por outro lado,
você tem um coeficiente
de determinação r valor e, por outro lado, quadrado diferente quadrado O resumo do modelo tem a seguinte
aparência. Você pode
exportá-lo facilmente para Word e Cell. Menos dois,
a probabilidade logarítmica é 40,67, quadrado de
Cosell r E os outros valores também
são exibidos. O quadrado R é usado para descobrir o quão bem o modelo de recreação explica a variável dependente Na recriação linear, o quadrado R indica
a porção
da variação que pode ser explicada pelas variáveis
independentes Quanto mais variância
puder ser explicada, melhor será
o modelo de regulação O quadrado R é usado para
descobrir o quão bem o modelo de regulação explica
a variável dependente. Em uma regulação linear, o quadrado R indica
a porção da variância que pode ser explicada pelas variáveis
independentes Quanto mais variância puder ser explicada e melhor
será o modelo de regulação No entanto, no caso da regulação
logística, o significado é diferente Existem diferentes formas
de calcular r quadrado. Infelizmente,
ainda não
há acordo sobre qual é a
melhor maneira de fazer isso. O quadrado R de acordo com
a célula da moeda é 0,22 Nagker ki é
0,29 e E agora vem a tabela
mais importante,
tabela com o conteúdo do modelo O parâmetro mais importante
do cliente é a razão de chances do valor B, p Os valores do coeficiente B estão aqui, os valores p estão aqui e a razão de chances está Podemos ver que o
valor p do gênero é maior que 0,05. Isso significa que o gênero não é um fator contribuinte
para a doença. Na primeira coluna, podemos
ler os valores do coeficiente como 0,040 0,871 0,4 -2,73
e, em seguida, podemos inserir esses valores em vez Quando inserimos o cípion, obtemos uma equação como esta, 1/1 mais apagar 20,04 em H,
0,87 em gênero mais
1,34 em fumante menos a constante de 2,73, e então vamos em
frente e calculamos obtemos uma equação como esta,
1/1 mais apagar 20,04 em H,
0,87 em gênero mais
1,34 em fumante menos a constante de 2,73, e então vamos em
frente e calculamos. Com isso, agora podemos calcular a probabilidade de
uma pessoa falecer Queremos saber qual a
probabilidade de uma pessoa com 55
anos,
mulher e fumante
, falecer Substituímos o valor
da idade por 55, sexo como zero
porque não é homem e outro como fumante e
depois calculamos o valor Quando fazemos esse cálculo, o valor da probabilidade é 0,69 Isso significa que há uma probabilidade de
69% de que
uma mulher fumante de 55 anos Com base nessa previsão, agora
seria
decidido se deveria ou não investigar extensivamente O exemplo é puramente imaginário. Na realidade,
pode haver muitos outros fatores e diferentes
variáveis independentes, como o peso
da pessoa, a idade da pessoa e muitas outras coisas para determinar se a
pessoa está doente ou não Mas agora vamos
voltar para a mesa. Na coluna, podemos ler coeficiente de
diferença significativa a partir de zero A hipótese nula é que o coeficiente é zero
na população A seguinte
hipótese nula está sendo testada. O coeficiente é zero
na população. Como a variável é
menor que 0,05, o coeficiente previsto
é uma influência significativa Em nosso exemplo, vemos que nenhum
dos coeficientes tem um impacto significativo, pois todos os valores de p são
maiores que 0,05 Agora vamos entender
a razão de chances. A razão de chances é de
1,042 0,39 83,81. Por exemplo, a razão de
chances é 1,04, significa que, para um
aumento unitário na variável idade, o aumento da probabilidade de uma pessoa
adoecer é de 1,04 E podemos ver que, para fumantes, a razão de chances é muito alta Com isso, chegamos ao
fim da recreação logística. Nos vemos na sessão
prática. Fique ligado. Obrigada.
40. Prática de regressão logística: Usaremos uma calculadora on-line para fazer a análise de regressão, especialmente a análise de regressão
logística neste
vídeo Eu enviei um vídeo
separado sobre como você pode fazer essa
análise usando o Excel. Então, vamos continuar com a calculadora
estatística on-line. Posso importar meus
dados clicando no botão de importação e
soltando arquivos
do Excel, SV ou arquivo da guia Dados Eu posso clicar em Procurar
e colocar meus dados lá dentro. Certo? Então, eu
já carrego meus dados, que você pode ver na tela. Eu tenho se uma pessoa
faleceu ou não,
idade, sexo, status de fumante Podemos ver que o
tipo de dados
foi identificado automaticamente pela calculadora
estatística. Diz que a idade é uma variável
métrica, sexo é nominal e o
status de tabagismo também é normal. A doença é nominal. Agora, o que eu faço é clicar
em regressão e rolar para baixo. Então, eu tenho uma boa
quantidade de casos. Deixe-me rolar para baixo. Quando clico em regressão, posso fazer regressão
linear simples, regressão multilinear e regulação Quais são minhas variáveis dependentes? A idade é minha variável dependente. O sexo é uma variável dependente. O status de tabagismo é uma variável
dependente. O que eu quero prever? Quero prever se a
pessoa está doente ou não. Estou selecionando a coisa certa? Não. Eu quero verificar, qual é a variável dependente? Qual é o meu y? Meu y é se a pessoa
está morta ou E minhas variáveis independentes são sexo e status de tabagismo. Então, para referência de gênero, estou considerando o homem como um. Para referência ao status de tabagismo, estou considerando os fumantes como um só, e o modelo prevê se a pessoa
está doente ou Agora eu posso clicar no
resumo em palavras, e ele faz uma
análise adequada e a mostra para mim. Certo? uma
análise de regeneração logística foi realizada para examinar a
influência da idade, sexo,
mulher e status de
não fumante como variáveis, a
doença é prevista
para a diminuição do valor, um
modelo de análise logística mostrou que o um
modelo de análise logística mostrou que qui-quadrado para os três
é 8,79,
o valor p é 0,32 e o número de observações é 36 Isso mostra claramente que
uma
análise de regeneração logística foi
realizada para examinar a
influência da idade, sexo,
mulher e status de
não fumante como variáveis, a
doença é prevista
para a diminuição do valor,
um
modelo de análise logística mostrou que o qui-quadrado para os três
é 8,79,
o valor p é 0,32 e o número de observações é 36. O coeficiente
da variável p é 0,04, o que é positivo Isso significa que quando o
aumento da idade está
associado ao aumento
da probabilidade
da variável dependente doença. No entanto, o valor de p é 0,092, indicando que a influência não
é estatisticamente significativa A razão de chances é de 1,04, indicando que, para
um aumento unitário da variável oito, o aumento da chance de
a variável dependente
falecer aumenta O coeficiente da
variável sexo feminino, valor
B é 0,87 negativo Como essa variável
é negativa, isso significa que o valor
da variável sexo feminino, a probabilidade de a variável
dependente se tornar doença diminui. No entanto, o valor de p de 2,0 0,28 indica
que a influência não
é estatisticamente significativa A razão de chances é de 0,42, o que
significa que na
variável sexo feminino, a probabilidade da
variável dependente doença aumenta 0,42 O coeficiente da
variável status de fumante, o valor
p é -1,32, o
que é negativo, o que significa
que se o
valor da variável do status de fumante
for não fumante,
a probabilidade de status de fumante
for não fumante,
a a variável dependente ser falecida diminui valor
p é -1,32, o
que é negativo, o que significa
que se o
valor da variável do status de fumante
for não fumante,
a probabilidade de
a variável dependente ser falecida diminui
. No entanto, o valor de p é 0,089, indicando que a influência não
é estatisticamente significativa A razão de chances é 0,26 significa que a variável
é o status de fumante probabilidade de
não fumante a variável dependente
falecer Agora, deixe-me escolher a
referência como não fumante e a categoria como
isso e nenhuma doença Agora, vamos ao resumo. Descobrimos que há uma pequena
mudança na análise. Todos eles agora
se tornaram negativos. Certo? A
razão de chances mudou, dizendo que, para uma
unidade de aumento na idade, 0,96 indica que
a pessoa
não falecerá porque agora
estamos mirando em não
falecer estamos mirando em não Portanto, você deve ter cuidado com o que está tomando
como referência. que você acredita
em sua hipótese, os homens são mais
propensos a adoecer? Então, quando você considera
o sexo masculino, o valor b é -0,87 Agora, aqui meu alvo não
está doente. Portanto, parece que a
probabilidade o homem não estar
doente diminui em 0,97 Mas se eu estiver analisando doenças, você descobrirá que agora esse
é um valor positivo O fumante também é um valor positivo. Portanto, devemos saber qual é a variável-alvo que
queremos estudar. Agora vamos descer. Vamos ver os resultados, e eu até tenho uma
interpretação de IA para me ajudar. A tabela resume
o desempenho geral do de
regressão logística binária Aqui, a interpretação é número
total de casos é 36, que é o número total de observações. A
tabela resume o desempenho geral
do modelo logístico binário Aqui, a interpretação é o número total de casos de 36. Esse é o número total de observações ou instâncias
nas quais o modelo foi testado. Nesse contexto, o
número de indivíduos são itens nos quais o modelo tentou prever
o resultado, seja a pessoa
escritura ou não atribuição correta é de
26 dos 36 casos, o modelo previu o
resultado de 26 deles. Essa previsão correta incluiu tanto os verdadeiros positivos, identificando
corretamente a pessoa doente, quanto os verdadeiros negativos, identificando corretamente
os casos sem Em porcentagem 72,22%. Essa é a precisão
do modelo indicando
que o número de tarefas é 26 dividido pelo número total de casos 36 Eu multiplico por dez
para obter a porcentagem. Ele nos diz como o modelo
faz a previsão correta. Agora, vamos entender a tabela
de classificação. É onde estamos
tentando classificar. Posso usar a ajuda da
interpretação da IA para entendê-la. A tabela resume a qualidade
da medida de
ajuste da análise de regressão logística Aqui, os verdadeiros negativos positivos
verdadeiros são 11 casos em que previmos corretamente que
eles não estão doentes Falsos positivos são cinco
casos em que cometemos
um erro do tipo um. Falsos negativos são
cinco casos em que previmos incorretamente
que eles não estão doentes como erro do tipo dois Os verdadeiros positivos são corretamente
previstos como doentes. Exatidão da previsão. A previsão correta para
não estar doente é de 68,75%. O total de casos não doentes
foi identificado corretamente. Predições corretas da doença, sensibilidade ou, como chamamos, 75%
dos casos reais da doença
foram identificados corretamente A precisão total é de 72,22% todas as proteções,
sejam doenças ou não, identificadas corretamente Agora, vamos entender
o teste do qui-quadrado. A beleza dessa calculadora
estatística é que ela fornece
uma interpretação de IA. Não preciso ir ao ChangeP
para fazer isso. A tabela mostra os resultados
do teste do qui-quadrado associado ao modelo de regressão
logística binária O teste é frequentemente usado para avaliar a
significância geral do modelo. Aqui, a interpretação
de cada componente. quadrado I é a estatística em que a resposta é
8,79 no nosso Isso mede a
diferença entre a
frequência observada e esperada do resultado. Quanto maior o valor do
qui-quadrado indica maior discrepância entre o valor
esperado e o observado, sugerindo que os preditores do
modelo têm uma Graus de liberdade, aqui, temos três graus de
liberdade representando o número de preditores na regressão
logística simples valor P é a
probabilidade de observar as estatísticas do
teste do qui-quadrado de forma tão
extrema quanto uma observada
sob a hipótese nula A hipótese nula é que não há
relação entre frequência
observada e esperada do resultado previsto
pelo volume, o valor de
P é 0,032, valor de
P é 0,032, sugerindo que há 3,22% de
probabilidade de que a estatística
do qui-quadrado
observada seja do qui-quadrado
observada E a
hipótese nula era verdadeira. O valor de p está 0,32 abaixo, indicando que é
menor que o limite de 0,05, indicando que há um resultado de significância estatística Agora, vamos fazer um resumo do modelo. Então aqui diz que a probabilidade de menos
dois logaritmos é 40,67. Ele mede a aptidão dos modelos. Quanto menor o valor, melhor
o modelo se ajusta aos dados. No nosso caso, o valor é 40,67, ou
seja, é
um modelo relativamente saturado, um modelo com um ajuste perfeito Esse número por si só
não nos diz muita coisa. Portanto, precisamos
compará-lo com outros números
diferentes. O
valor quadrado R da célula de Cocina é 0,22. Essa é uma medida
pseudo-R quadrada que indica a quantidade de variação na variável
prevista explicada pelo
modelo. Ele varia de 0 a 1 O valor de 0,22 indica que a variância de 22% é
explicada pelo modelo No entanto, é
importante notar que essa medida nunca chega a um, mesmo
para um modelo perfeito. Vamos para o valor quadrado de Nagar
K R. É 0,29. Novamente, tentamos ajustar o
quadrado r para chegar a um. Mas lembre-se de que 29% da variação é
explicada por esse modelo Isso significa que você
precisa incluir mais variáveis para entender melhor
o modelo. Quando analisamos isso,
percebemos a diferença do
modelo. O componente em questão
representa os vários tamanhos, erro
padrão, valor z, valor p, proporção esperada
e 95% de confiança. Vamos fazer a interpretação. O modelo prevê
o resultado básico como -2,73, onde o
preditor é zero, a razão chances é
0,7 Sugerindo menores
chances de resultado quando o preditor está
no valor de referência Com cada
aumento unitário da idade, a probabilidade de
a pessoa falecer aumenta em 0,04 Isso representa um aumento de 4% nas chances. Se o sexo for masculino, há um
aumento de 0,87%, e Vamos fazer a previsão. Se a pessoa tem 45 anos
e a pessoa é do sexo masculino e a
probabilidade de a pessoa ser fumante, qual é a probabilidade a pessoa ficar
doente? Há 0,81 É mais do que 0,45? 50%? Sim uma probabilidade de a
pessoa estar doente Mas se a pessoa for mulher, a probabilidade diminui. Além disso, se a pessoa não
for fumante, há uma probabilidade muito
menor que ela esteja doente Agora, passamos para
o próximo exemplo em que estamos tentando verificar se a pessoa comprará
um produto ou não. E as variáveis são sexo, idade e o tempo
que passaram online. Então, vou clicar
na equação de recreação. Qual é a
variável dependente, sexo, idade e o tempo gasto on-line e o comportamento de compra
é minha variável dependente. Há três tipos de
previsões de que elas estão acontecendo, não duas como da última vez Compramos agora, compramos depois e não
compramos nada. Categoria de referência
para o sexo feminino, eu a considero feminina, e vamos ao resumo. Portanto, a
análise de regressão logística realizada aqui mostra a influência
do sexo masculino, da idade e do tempo gasto on-line
na variável comportamento de compra
pelo valor de até A análise de regressão logística mostra que o modelo,
em geral, foi significativo O número de observações é 24. O coeficiente de que a
variável sexo é do sexo
masculino é 1,53, o que Isso significa que, quanto maior o valor
da variável gênero, a probabilidade de a
pessoa comprar aumenta. O valor de p é 0,201, indicando que a influência não
é estatisticamente significativa A razão de chances é de 4,63, o que
significa que o sexo é masculino, a probabilidade de que a variável
dependente agora aumente em 4,63 O coeficiente da variável ag é p igual a -0,11,
o que Isso significa que um aumento na idade está
associado à diminuição da probabilidade de que a variável
dependente esteja agora. No entanto, o valor de p é 0,07 indicando que a influência não
é estatisticamente significativa A razão de chances é de 0,9, indicando que a cada aumento
unitário na idade, a pessoa agora só
aumenta 0,9 vezes. O coeficiente do
tempo variável gasto na loja virtual
é b -0,02, o que é Isso significa que quanto mais
tempo gasto on-line,
menor a probabilidade de eles comprarem agora. O valor P é 0,56 ,
indicando que não é
estatisticamente significativo, e o tempo gasto
on-line aumenta as chances em 0,98 24 casos 17
previstos corretamente em porcentagem 70. Vamos fazer a análise. Então, um número total de casos 24, atribuição
correta
17 por cento 70. Agora, vamos para a tabela
de classificação. Podemos entender que qual é o erro do tipo um
e o erro do tipo dois? Verdadeiros negativos 13 casos foram previstos corretamente
que eles não vão comprar. Falsos positivos
são três casos
que foram
previstos incorretamente, pois estão fixados agora,
mas, na realidade,
eles não E os casos falsos são
de que quatro deles realmente compraram, mas nosso modelo disse
que eles não compraram. Quatro casos foram
previstos corretamente como Pi agora. exatidão de agora é de 82%, exatidão de agora é de
50%. A precisão total é Se você observar a equação do
qui-quadrado, obtemos o valor
p de 0,42 Aqui, a probabilidade
de um teste do qui-quadrado é extremamente importante como um
dos valores observados
da hipótese nula A hipótese nula é que não há
relação entre a frequência
observada e a
esperada e a saída prevista a
partir do modelo O valor P de 0,42 fica abaixo dessa convenção 0,5,
estatisticamente significativo Se eu usar o modelo de alguém, podemos ver que os
valores de r ao quadrado são muito w. E eu tenho o valor p. Então, agora
vamos fazer uma previsão Se a pessoa for do sexo masculino e tiver
45 anos e o
tempo gasto for 45 anos e o
tempo gasto Qual é a
probabilidade de uma pessoa comprar? Não há muita probabilidade. Mas se a pessoa
tiver 20 anos, a probabilidade
aumenta Assim, podemos entender que as pessoas da nova geração estão dispostas a comprar
mais do que as pessoas mais velhas. Se tivermos uma pessoa
de 80 anos
, a probabilidade é
absolutamente igual a 0,01 Então, espero que você aprenda a fazer regressão
logística
neste vídeo. Obrigada Ah.
41. ROC curve: D. Vamos entender a curva ROC Acabamos de concluir o aprendizado
sobre regressão logística. Uma das formas de validar a precisão do modelo
é usando a curva ROC Vamos entender a
teoria com exemplos. Portanto, ROC significa características
operacionais do receptor. É uma forma gráfica de representar o desempenho de
um modelo de classificação binária, também chamado de modelo de
regressão logística, e também para outros limites de
classificação Vamos entender
com um exemplo. Vamos supor que estamos
realizando um teste de triagem em pacientes para identificar se o paciente está
saudável ou doente Para
que essa classificação seja feita, o farmacêutico está realizando
alguns exames no sangue e depois decidindo
quem deles
ficará doente e quem Quando obtiveram a
amostra de dez dados, decidiram estabelecer um limite, e qualquer pessoa abaixo desse
limite será chamada saudável e qualquer pessoa acima do limite será
chamada Agora, como decidimos qual
deve ser o limite? Com base no qual você
pode prever que o futuro é que o
paciente esteja doente? Então, digamos que
temos uma amostra de dez pessoas com
seus níveis sanguíneos. Vemos que a maioria
das pessoas doentes tem um nível sanguíneo
mais alto E a maioria das pessoas saudáveis tem níveis sanguíneos mais baixos. Então, decidimos que vamos
colocar um limite em 45. Então, quando colocamos um
limite em 45, estamos dizendo que
qualquer pessoa que esteja abaixo de 45, nós a
classificaremos como saudáveis Qualquer pessoa que tenha mais de 45 anos, nós a
classificaremos como doença. Agora podemos ver que há
certos problemas aqui, e vamos entender
esses problemas em detalhes. Então, neste caso, de
seis pessoas que foram classificadas como
doença, duas delas, quatro estão corretamente
classificadas como doença, mas duas delas estão incorretamente
classificadas como doença,
mas, na realidade,
são saudáveis Então,
classificamos quatro de seis como doenças, e isso é chamado de
duas taxas positivas. Também é chamado
de sensibilidade. Por outro lado, dos
quatro indivíduos saudáveis, classificamos erroneamente uma
pessoa como doente Uma pessoa doente é saudável, e classificamos corretamente três pessoas saudáveis como saudáveis. Agora, quando classificamos
erroneamente um em cada quatro como saudável, isso é chamado de taxa de
falsos positivos e é representado por FPR ou é um
menos No limite de 45, obtemos a
taxa de verdadeiros positivos como 4/5, ou
seja, 80% e a taxa de falsos
positivos de 2/5 como 40% Então, o que exatamente é TPR
ou duas taxas positivas? taxa de verdadeiros positivos nada mais
é verdadeiros positivos divididos por verdadeiros positivos mais
falsos negativos Dois pontos positivos são
as pessoas que são
classificadas corretamente como doença. Classificamos corretamente
quatro deles como doenças. Falsos negativos são
as pessoas que são
classificadas incorretamente como saudáveis Então cometemos um erro
com uma pessoa. Então, o total é 4/1. Portanto, os verdadeiros positivos não são nada, mas quatro deles foram corretamente
classificados como doentes Mas o problema era
que , das quatro que foram classificadas
corretamente, esquecemos
uma das
pessoas doentes A razão pela qual precisamos conhecer o TPR é
que porcentagem de pessoas ficará
sem tratamento A especificidade é muito importante para entender
que 20% da população
pode não ser bem tratada, ou estamos classificando corretamente 80% da população
que testamos Vamos entender o FPR,
isso é falso positivamente. Falsos positivos são
pessoas saudáveis,
classificadas erroneamente como doentes,
e dois negativos são indivíduos saudáveis classificadas erroneamente como doentes, e dois negativos Os indivíduos foram corretamente
classificados como saudáveis. Então, dois deles foram classificados
incorretamente como DCs. Então, começamos o tratamento para eles, dividido pelo número total que é cinco que estavam
realmente saudáveis. Portanto, o número total de pessoas
saudáveis dividido por quantas pessoas
foram falso-positivas. Portanto, 40% das pessoas
têm 0,4 é a taxa de FPR. Então, como calculamos o TPR
e o FPR para cada limite? Devo colocar o
limite como 38? Devo colocar o limite
em 65, e assim por diante. Portanto, nesse caso, calculamos o TPR e o FPR para
cada um dos limites Se eu colocar isso como zero
, minha
taxa de verdadeiros positivos está aumentando, mas minha
taxa de falsos positivos é quase zero. Então, esses são precisamente
os dois valores que estão sendo plotados
na curva ROC A taxa de verdadeiros positivos
é plotada no eixo y
e a taxa de falsos positivos
é plotada no Queremos decidir que,
se você usar 0,240 0,2, nossa taxa de falsos positivos está aqui,
mas o verdadeiro positivo
está aumentando
e, da mesma forma, em 0,4
0,6 0,8 e um Agora, vamos desenhar a curva
ROC completa para nosso exemplo. Se escolhermos
que o
valor limite seja muito pequeno, ou seja, empurrar totalmente para
a esquerda, classificaremos corretamente todos os
cinco indivíduos doentes Mas também classificamos erroneamente todos os cinco
indivíduos saudáveis Portanto, a verdadeira taxa positiva é cinco em cinco, ou seja, um. Da mesma forma, no entanto, classificamos erroneamente cinco
indivíduos saudáveis como doentes Portanto, a taxa de falsos positivos é de cinco em cinco, ou
seja, novamente, um. Por esse motivo, o primeiro ponto
de dados está em um ponto um. Então, à medida que ultrapassamos o limite, ainda
classificaremos corretamente se estou em Ainda estou classificando corretamente todos os cinco indivíduos
como doentes, mas estou classificando quatro dos indivíduos saudáveis
também Então, agora vou para o
próximo ponto de dados. Então, se eu tomar 0,8
como limite, minha verdadeira taxa positiva
é de cinco em cinco, então eu classifiquei corretamente todas as pessoas que faleceram como
falecidas Mas de cinco indivíduos
saudáveis, agora
classificamos erroneamente
apenas quatro em cada cinco E, portanto, estou em 0,8 em termos da taxa de
falsos positivos. Para o próximo roshold, onde temos a taxa
positiva de 0,1, estamos em 0,3 e
vemos que classificamos corretamente todas as
cinco pessoas como doentes, mas meus
indivíduos saudáveis Então esse será meu
terceiro ponto de dados. Cinco pessoas doentes estão classificadas
corretamente. taxa de falsos positivos é que
três deles foram classificados erroneamente como doença
em cada cinco, ou seja, 0,6 No próximo limite,
a pessoa doente é classificada erroneamente como saudável
pela primeira vez Esse é o limite. Este é o lugar onde
a pessoa doente está sendo classificada erroneamente
como saudável E, portanto, vemos uma queda
na taxa positiva verdadeira de 12,8 A taxa de verdadeiros positivos é de
quatro em cinco, ou seja, 0,8, e a taxa de falsos positivos é de três em
cinco, que é 0,6. Agora podemos fazer isso para
todos os outros limites
e, consequentemente,
esboçamos nossa curva ROC Nesse ponto, por exemplo, 80% dos indivíduos das foram
classificados corretamente como doença, 20% dos indivíduos saudáveis foram
classificados incorretamente como doença Usando a curva ROC, podemos comparar diferentes métodos de
classificação Os modelos de classificação
são melhores quanto maior a curva. Portanto, quanto maior a
área sob a curva, melhor é o modelo de
classificação. Usando a curva ROC, podemos comparar diferentes métodos de
classificação, e é precisamente
a área que é refletida pela
área AUC sob o valor da curva A área sob a curva é usada durante a avaliação do
modelo de regressão linear O valor da AUC varia de 0 a 1. Quanto maior o valor, melhor
o modelo. E quanto à curva ROC e
à regressão logística? Por exemplo, poderíamos construir um novo modelo de classificação
usando a regressão logística Aqui, poderíamos usar os valores adicionais,
como valor sanguíneo, idade e sexo de
cada pessoa, e tentar prever se a pessoa
está saudável ou doente Sobre a curva ROC e a regressão logística,
vamos continuar Em uma regressão logística, o valor estimado é então a
probabilidade de uma
pessoa em particular ter Muitas vezes, 50%
deles simplesmente tomam como limite para classificar se uma pessoa
está morta ou não Mas é claro que não é nisso
que estamos pensando Portanto, você não pode considerar o
limite de 50% sempre. Portanto, mesmo com a regulação
logística, construímos a curva ROC para diferentes valores de limite
e vemos que, em qual nível, temos a Então, como posso obter a curva
ROC online? Sim. Então, agora vamos entender
como eu posso fazer esse cálculo de ROC
usando os dados Então, eu preenchi
alguns valores de dados de mais de 40,
quase 40 pessoas, diferentes níveis sanguíneos e se a pessoa
está doente ou Então, posso escolher
meu modelo de libertação e dizer que quero declarar
a variável como doente O estado variável é sim ou não, e eu quero a
variável de teste como valor sanguíneo. Então, imediatamente obtemos o ROC, e o ROC está mostrando em
quais níveis especificidade A sensibilidade nada mais é do que
minha verdadeira taxa positiva. Quantas dessas
pessoas doentes eu
classifiquei corretamente A especificidade, por outro lado, é quantas delas
ou quantas pessoas saudáveis foram
classificadas erroneamente como doentes E queremos que exista. Pessoas doentes têm 19 anos, não doentes têm 22, e positivo é
maior que igual a um,
a sensibilidade é uma e
isso me mostra todos os dados Podemos perder alguns dados de amostra. E faça. Também posso encontrar isso no meu
modelo de correlação Então, vou para a regulamentação, e estou dizendo que minha variável
dependente está morta e o valor sanguíneo é
minha variável independente O resumo em palavras, se a
análise de regulação logística foi realizada para examinar se
o valor sangüíneo de uma variável não permite
predizer o valor como sim análise de recreação logística mostra que o valor do qui-quadrado é 5,23, o valor P Isso significa que o sangue é
capaz de prever que
não há influência do
nível sanguíneo na doença. Rejeitamos a hipótese nula
porque os valores de p são baixos. O cociente do valor sanguíneo B é 0,03, o que é Isso significa que o
aumento do valor sangüíneo está associado ao aumento da probabilidade da variável
dependente ser sim. O valor de p de 0,32 indica que a influência é estatisticamente significativa A razão ímpar é 1,03, indicando que um aumento
unitário no valor
sangüíneo
aumentará as chances de a variável
dependente ser sim em 0,13 Então, quando construímos a regressão
logística, podemos ver que acabamos ler o resumo de
que o valor de p é 0,03, indicando que há
uma significância do valor do sangue para o A tabela resume que
dos 41 casos que
foram investigados são observados
para a construção do modelo, neste contexto, o
número de indivíduos que foram previstos
como doentes ou saudáveis 28 deles de 41 foram classificados
corretamente, indivíduos
doentes
classificados como doentes e indivíduos saudáveis
classificados como A porcentagem é de 68,29. Ele indica o número total de pessoas que foram classificadas
corretamente por 28, que é dividido por 41
e, em seguida, é multiplicado
por 100 para obter uma porcentagem Se eu disser com que
frequência o modelo faz
a previsão correta, se a previsão é
presença ou ausência de S. Então, podemos ver que isso é chamado
de tabela de
classificação. Pessoas que, na verdade, não estão doentes e foram corretamente
previstas como não doentes, pessoas que estão doentes e
previstas como Esse oito é minha preocupação. Por quê? Porque essas
são as pessoas que não querem se tratar. E cinco deles foram
classificados como doentes,
quando, na realidade, não
estavam sofrendo Então,
construiremos o modelo ROC,
e o ROC atualmente o AOC, A abaixo da curva
é Quanto maior a curva,
melhor o modelo. De 41 casos, a atribuição correta
ocorreu em 28 casos e a atribuição incorreta
ocorreu em 13 Então, 68% das pessoas foram classificadas
corretamente. Agora, vamos fazer uma interpretação de
IA. A interpretação da IA diz
muito claramente que o ajuste do modelo é de
dois logarítmicos de probabilidade. Quanto menor o valor, melhor
o modelo. Aqui, o valor é 51,39 indicando que o modelo
está relativamente saturado, um modelo com um ajuste perfeito O número por si só
não diz muito. Precisamos compará-lo
com outros modelos. Agora, vamos fazer a
interpretação do modelo. A tabela mostra
que fizemos uma análise de
recursão logística binária, que analisa como os preditores influenciam a probabilidade
de um Components, Cefion B. Isso representa o
efeito de cada Um coeficiente positivo aumenta ou
as chances
logarítmicas do resultado,
e o corião negativo as diminui. Erro padrão. Isso mede o desvio padrão
da coesão estimada, com relação à precisão com que
o modelo
estima o valor da O valor z. Essa é a pontuação z calculada como um coeficiente
dividido pelo erro padrão, usada para testar a hipótese nula de que
o coeficiente é hipótese nula de que
o coeficiente valor P indica
a probabilidade de observar os dados ou
algo mais extremo Se a hipótese nula for verdadeira, quanto menor for
o
valor de P e da palavra, o valor p indica
a probabilidade de observar os dados ou
algo mais extremo Se a hipótese nula for verdadeira, o valor de p mais baixo sugere que a hipótese nula de nenhum
efeito é menos provável Interpretação.
O modelo prevê as chances logarítmicas da
linha de base como -1,31, todos os A razão ímpar é de 0,27, sugerindo que as
chances de resultado são menores quando todos os preditores são
do valor de referência Valor sanguíneo que
aumenta em três. Agora, vamos fazer a previsão. Se meu valor sangüíneo for 85, então há 75% de
probabilidade de eu estar sofrendo. Também vou
ver a curva ROC. O ROC, a área sob
a curva é 0,699. Ela é tímida
42. Compreender os dados não normais: Nosso normal ou não. Vamos tentar
entender como
trabalhamos quando meus dados não são normais? Ou mesmo antes de chegar lá, deixe-me apresentá-lo a esse
senhor. Alguma suposição? Quem é o cavalheiro? Você pode digitar na
janela de bate-papo se souber. E mesmo que você não saiba,
está perfeitamente bem. Não há
pontos de penalidade por suposições erradas. Sim. Alguns de vocês
adivinharam, certo? Ele é a pessoa famosa por trás de
nossa distribuição normal. Sr. Carl Cos. Ele é o grande matemático. E ele foi a pessoa
que criou
o conceito de distribuição
gaussiana
ou distribuição normal. Então, aqui está o cérebro
por trás do conceito de distribuição
normal e todos os testes paramétricos
que estamos fazendo. Se meus dados não
estiverem normais, eles podem ser distorcidos. Pode ser distorcido negativamente ou pode ser distorcido
positivamente. Se eu disser distorcido negativamente
, tecnicamente é ter
uma cauda no lado esquerdo. Positivamente inclinado significa
cauda no lado direito. Isso significa que meus dados não estão
se comportando de maneira normal. Meus dados podem não ser
normais porque estão seguindo uma distribuição uniforme ou plana
como essa. Então, também não está seguindo
a distribuição normal. Meus dados podem ter vários picos, algo assim,
o que representa que há vários
grupos de dados em meu conjunto de dados. E não é um comportamento normal. Porque meus dados têm
todas essas coisas. Preciso tratar esses dados forma diferente quando estou fazendo
meu teste de hipóteses. E por que esses dados não são normais? Pode ser por causa da
presença de alguns valores atípicos. Pode ser por causa
da distorção dos meus dados, ou pode ser por causa
da curtose
presente nos dados. Portanto, o motivo pelo qual seus dados não se comportam de maneira normal
pode ser um desses. Vamos resumir,
o que aprendemos? Meus dados não são normais se a
distribuição tem uma assimetria,
é unimodal, não é unimodal, mas na verdade essa distribuição bimodal ou
multimodal. É uma distribuição de cauda pesada
contendo valores discrepantes. Ou pode ser uma distribuição
plana como uma distribuição uniforme. Esses são alguns motivos básicos pelos quais meus dados não estão se comportando de
maneira normal. Estranho, não é uma distribuição
normal, então existem várias
distribuições. Também existem outras
distribuições, que falam sobre a distribuição
exponencial, que modela o tempo
entre o evento. A distribuição log-normal. que diz que, se eu aplicar
o logaritmo nos dados
, meus dados seguirão
uma distribuição normal. Distribuição de Poisson, distribuição
binomial, distribuição
multinomial. Vamos entender alguns exemplos, cenários
da vida real em que as distribuições não normais
podem ser aplicadas. Se você observar isso, sempre que estou tentando prever algo em um intervalo de tempo
fixo. Então eu uso a distribuição de Poisson para minha análise e hipótese. Alguns exemplos da
distribuição de Poisson ou do número de chamadas de atendimento ao cliente
recebidas no call center. O número de
pacientes que apresentam pronto-socorro de
um hospital em um determinado dia, o número de solicitações de um determinado item em uma loja
on-line em um determinado dia. O número de pacotes entregues pela empresa de entrega
em um determinado dia, o número de itens defeituosos produzidos por uma
empresa de manufatura em um determinado dia. Se você observar que há
um comportamento comum aqui. Sempre que estamos
tentando entender algo em um
determinado período de tempo, pode
ser um determinado dia, pode
ser um determinado
mês, dado B.
Então, preferimos fazer nossa análise usando a distribuição de
Poisson. Alguns exemplos de distribuição
log-normal. O tamanho dos arquivos
baixados da Internet, o tamanho das partículas
em uma amostra de sedimento, a altura da árvore, o tamanho dos retornos
financeiros, o tamanho do jogo de seguros. Se você ver esses exemplos, como se eu tomasse o exemplo dos retornos
financeiros de
seus investimentos, você pode ver que, fora do meu
portfólio de investimentos, alguns investimentos me deram um retorno
muito bom de 100%, 100%, 150 por cento, 80 por cento. E você também
verá que fiz investimentos em alguma parte do meu portfólio porque
isso resultou em um retorno zero ou um
retorno negativo porque estou com prejuízo. Mas, no geral, meu
portfólio está me dando um retorno de 12 a 15%
ou 15 a 20 por cento. Você está tentando dizer que sua distribuição
não é tecnicamente uma distribuição normal. Você tem retornos muito baixos
e retornos muito altos. Mas se você aplicar o
logaritmo em seus dados
, ele se comportará como uma distribuição normal que, em
geral, seu portfólio
resultará em um retorno de
cerca de X. mesmo se aplica até mesmo
no pedido de seguro. Vamos tentar entender
a aplicação da distribuição
exponencial. O tempo entre a chegada
dos clientes na fila, o tempo entre a falha em
uma máquina, sua fábrica, o tempo entre as compras
na loja de varejo, o tempo entre as ligações telefônicas
e o contact center, o tempo entre as
visualizações de página no site. Agora, se você ver entre a distribuição de Poisson e a distribuição exponencial, há um elemento comum. Qual é o elemento comum? Estamos tentando estudar
com referência ao tempo. Sempre que você está fazendo
uma distribuição normal, não
é com referência ao tempo. Certo? Então, esses são alguns aplicativos. Mas a diferença
entre um veneno e um exponencial está na distribuição de
Poisson. É em um determinado dia, em um determinado dia, em uma determinada semana são dados meses. Aqui estamos tentando entender o tempo entre os dois eventos. Qual é o intervalo de tempo
entre os dois eventos? Então, a
distribuição exponencial pode ajudá-lo. Podemos, vamos entender a aplicação de alguma distribuição
uniforme, como as alturas do
aluno na turma. Necessidades de pacotes em
um caminhão de entrega. Alguns pacotes são muito grandes, alguns pacotes são pequenos. Se você colocá-lo em uma distribuição, também descobrirá que
é uma distribuição plana ou uniforme, pois
para cada categoria de pacotes,
você terá aproximadamente
o mesmo número de pacotes,
um para cada categoria de pacotes, você terá aproximadamente
o mesmo número de pacotes, número
similar de pacotes. Mercadorias que você está entregando. A distribuição dos resultados dos testes para um exame de múltipla escolha. A distribuição do
tempo de espera em um semáforo, a distribuição
do tempo
de chegada de um cliente em uma loja de varejo. Então, se você ver todos esses exemplos seguindo uma distribuição uniforme, não
é uma curva em forma de sino. Porque você tem
continuamente pessoas que chegam
à loja de varejo. Não é que
haja um pico repentino. E os cenários
reais de distribuição
pesada significam a distribuição onde
os valores discrepantes estão presentes, sinais
da perda
financeira e um setor de seguros ou outros
sinais de perda financeira. Em algumas perguntas a um trader, ele veria esse número extremamente alto e extremamente
baixo. O tamanho das chuvas
extremas. Portanto, não temos
chuvas extremas todos os anos. Portanto, não poderíamos dizer
que o que quer que tenha acontecido é por causa de um outlier. E a
distribuição de cauda pesada
geralmente é afetada devido
à presença de valores discrepantes. Portanto, se seus dados
estão com valores discrepantes
, você também pode ver
que a distribuição por carga é uma
distribuição pesada. E entenderemos,
na próxima sessão, que tipo de
testes não paramétricos devo realizar? Dependendo do tipo de dados não normais
que estamos iniciando. O tamanho do consumo de
energia, o tamanho da flutuação
econômica da queda do mercado de ações. Todos esses são exemplos de sua
distribuição pesada. Exemplos de dados bimodais. Aqui você precisa entender os meios
bimodais. Há dois resultados que
estamos tentando estudar. A distribuição
das notas dos exames dos alunos que estudaram
e dos que não estudaram. Distribuição
das idades do indivíduo em uma população de
duas faixas etárias distintas, altura de duas espécies diferentes, distribuição
salarial de funcionários de dois departamentos diferentes. Boa velocidade em uma rodovia com dois grupos de motoristas lentos
e rápidos. Então, aqui você pode ver
que eu tenho dois grupos de dados
que são diferentes. E estou tentando entender o comportamento de seguir em frente e fazer minha investigação
como parte da minha hipótese ou do recurso
que estou tentando fazer. Se eu tiver mais de dois
grupos, dois diferentes, mais de dois grupos diferentes, como três grupos diferentes
para grupos diferentes, então isso se torna uma distribuição
multimodal. Certo? Então, acho que agora você já
teria uma ideia de quais são
as diferentes
distribuições que não
são distribuições normais. Então, como determino se
meus dados não estão normalmente? O primeiro ponto
que vem à nossa mente
é um teste de normalidade. Mas mesmo antes de fazer
um teste de normalidade, você pode usar métodos
gráficos simples para descobrir se seus
dados estão normais ou não. Você pode usar o histograma. E aqui o histograma mostra
claramente vários movimentos. Portanto, posso ver claramente que essa não é uma
distribuição normal. Se eu tentar colocar uma linha de ajuste
, também posso ver que
há distorção em meus dados. Também posso usar o gráfico de caixa para determinar se meus
dados não são normais. Então, aqui você pode ver que
eu tenho uma cauda pesada no lado esquerdo informando
que meus dados estão distorcidos. Também posso ter valores discrepantes que um boxplot pode destacar facilmente. Então eu posso me esconder, identificar a distribuição pesada
usando o boxplot. Além disso. Posso usar estatísticas
descritivas simples onde posso ver os números
do modo mediano médio. E quando vejo que
esses números
não estão sobrepostos ou não estão
próximos um do outro, isso também indica
que meus dados não são normais. Posso observar a curtose e a distorção da minha distribuição de dados e, em seguida, chegar a uma conclusão se meus dados estão se comportando
normalmente ou não. Então, mostrei outras maneiras de identificar
se seus dados estão seguindo uma
distribuição não normal ou se seus dados estão seguindo uma distribuição
normal. Agora eu diria mais uma coisa. Não se mate
se sua média fosse 23,78 e a mediana fosse 24, e o modo
fosse como 24,2 ou 24. Portanto, se houver uma
leve deflação, ainda
consideramos
que é normal. Certo? distorção próxima de zero é uma indicação de que
meus dados estão normais. Mas se minha distorção estiver além de
menos dois ou mais dois, é definitivamente nossa prova de
não normalidade. A cetose também é mais uma forma de identificar se meus dados estão
seguindo a distribuição normal. Na maioria das vezes, preferimos que o número
da curtose esteja em 0-3. Mas se sua
cetose for negativa, significa que é uma curva plana. As auditorias seguem uma distribuição
uniforme. auditoria pode ser
uma distribuição exagerada de alta curtose e também pode ser uma indicação de que seus
dados são perfeitos demais. E talvez você precise
investigar se existem, eles não manipularam seus dados antes
de entregá-los. Outro teste favorito do AdText ou
Anderson-Darling, em que tentamos entender
se meus dados são normais ou não. Portanto, a hipótese nula básica
sempre que estou fazendo o teste NAT é que meus dados seguem
uma distribuição normal. Portanto, esse é o único
teste em que eu quero meu valor de p seja
maior que 0,05 que
obtenho, não rejeito a
hipótese nula ,
concluindo que meus
dados são normais, e recorro ao meu teste paramétrico
favorito, que facilita a análise. Mas e se durante o teste ADA, seus dados e sua análise de dados mostrarem que o valor de p
é significativo, que é menor que
0,05, talvez seja 0,02. Em seguida, conclui que meus dados não
são uma distribuição normal. E eu preciso investigar que tipo de
não normalidade ela tem. Assim,
terei que fazer o teste e depois
prosseguir. Continuaremos nossa sessão
no próximo dia de Veneza. Espero que você tenha gostado. Se você tiver alguma dúvida, sinta-se à vontade para
comentar no WhatsApp ou no canal do Telegram ou na
seção de comentários aqui. Qualquer tópico que
você gostaria de
aprender como parte da sessão de
quarta-feira. Eu ficaria feliz em
investigar isso. Se você puder colocar esses comentários
na caixa de bate-papo, no
grupo do WhatsApp ou no telegrama. Eu realmente amo ensinar você e agradeço por ser maravilhoso. Estudantes. Cuide-se.
43. Kruskal Wallis testa dados não normais de 3 ou mais grupos: Este tutorial é sobre
o teste do crus walus. Se você quiser saber
o que é o teste crus c, walus e como ele pode ser calculado
e Você está no lugar certo
no final deste vídeo. Mostrarei
como você pode
calcular facilmente o teste de walus online E vamos começar agora mesmo. O teste crus Walus é um teste de
hipóteses usado quando você deseja testar
se há uma diferença entre
vários grupos independentes Agora, você pode se perguntar um
pouco e dizer: Ei, se houver vários grupos
independentes, eu uso uma análise de variância. Isso mesmo. Mas se seus dados não forem distribuídos
normalmente e as suposições para a análise de
variância não forem O teste wus é usado. O teste Wace é a
contrapartida não paramétrica da análise de variância
de fator
único Agora vou te mostrar
o que isso significa. Há uma diferença importante
entre os dois testes. Os testes de análise de variância, se houver
diferença nas médias Então, quando temos nossos grupos, calculamos a
média dos grupos e verificamos se todas as
médias são iguais. Quando analisamos o teste
crus C wals, por outro
lado, não
verificamos se as médias são iguais Verificamos se as somas de classificação de
todos os grupos são iguais. O que isso significa?
Agora, o que é uma classificação? E o que é uma soma de classificação
no teste clássico de als? Não usamos os valores
reais medidos, mas classificamos todas as pessoas por tamanho
e, em seguida, a pessoa com o menor valor obtém
o novo valor ou classificação um. A pessoa com o segundo
menor valor obtém a classificação dois. A pessoa com o terceiro
menor valor obtém a classificação três, e assim por diante, e quarta até que cada pessoa
tenha recebido uma classificação. Agora atribuímos uma
classificação a cada pessoa
e, em seguida, podemos simplesmente
somar as classificações
do primeiro grupo. Some as classificações
do segundo grupo e some as classificações
do terceiro grupo. Nesse caso, obtemos uma soma de classificação de 54 para
o primeiro grupo. 70 para o segundo grupo e 47 para o terceiro grupo. A grande vantagem é
que, se não
olharmos para a diferença principal,
mas para a soma das classificações, os dados não
precisam ser
distribuídos normalmente ao usar
o teste cruzado. Nossos dados não precisam satisfazer nenhuma forma distributiva
e, portanto, também não precisamos que eles sejam distribuídos
normalmente Exemplos do teste de
rusk wallace
para o teste de rusk walus. Obviamente, os mesmos
exemplos podem ser usados para a
análise de variância de fator único, mas com a adição de que
os dados não precisam ser distribuídos
normalmente Exemplo médico. Para uma empresa
farmacêutica, você deseja testar se um medicamento XY tem
influência no peso corporal. Para este propósito, o medicamento é administrado a 20 pessoas testadas. As pessoas que fazem o teste T
recebem um placebo e 20 pessoas que fazem o teste
não recebem nenhum medicamento ou placebo Objetivo: determinar
se o medicamento XY tem um efeito estatisticamente
significativo no peso
corporal em comparação com
placebo e grupos de controle Exemplo de ciências sociais. As três faixas etárias são diferentes? Em termos de consumo diário de
televisão, questão
e hipótese de
pesquisa. A pergunta de pesquisa para
o ruskal talvez fosse o teste. Há alguma diferença
na tendência central de
várias amostras independentes? Essa questão resulta
na hipótese nula e
alternativa Sem hipótese. Todas as amostras independentes têm a mesma tendência central
e, portanto, vêm
da mesma população. Hipótese alternativa, pelo
menos uma
das amostras independentes não tem a mesma tendência central das outras amostras e, portanto, originária de uma população
diferente Antes de discutirmos
como o abate de crostas, teste de
walus é calculado,
não se preocupe Realmente não é complicado. Primeiro,
examinamos as suposições. Suposições. Quando
usamos o crus c Teste de Walus? Usamos
o teste crus Walus se tivermos uma variável nominal
ou ordinal com mais E uma variável métrica, uma variável nominal ou ordinal com mais de dois valores é, por exemplo, a variável, jornal
preferido,
com os valores, Washington Post, New
York Times, USA today Também pode ser a
frequência de
visualização diária de televisão várias vezes por semana. Na verdade, nunca uma variável
métrica é, por exemplo, salário,
bem-estar , estar ou peso das pessoas. Quais são as suposições agora? Somente várias amostras
aleatórias independentes com escala pelo
menos normal características de escala pelo
menos normal
devem estar disponíveis As variáveis não precisam
satisfazer uma curva de distribuição. Portanto, a hipótese nula é
que as amostras independentes têm
todas a mesma tendência
central E, portanto, vêm da mesma população
ou em outras palavras. Não há diferença
nas somas de classificação, e a hipótese alternativa
pode ser que pelo menos uma
das amostras independentes não tenha a
mesma tendência central das outras amostras
e, portanto, venha de
uma população diferente Ou para dizer isso em
outras palavras novamente. Pelo menos um grupo
difere nas somas de classificação. Então, a próxima pergunta é: como calculamos um
risco. Teste de Wallace Não é difícil.
Digamos que você tenha medido o
tempo de reação de três grupos. Grupo A no grupo C, e agora você quer
saber se há uma diferença entre os grupos em termos de tempo de reação. Digamos que você tenha anotado o
tempo de reação medido em uma tabela. Vamos supor que os dados não sejam distribuídos
normalmente
e, portanto, você precise
usar o teste crus k was Então, nossa hipótese nula é que não
há diferença
entre os grupos, e vamos
testar isso agora Primeiro, atribuímos uma
classificação a cada pessoa. Esse é o menor valor. Então, essa pessoa fica na primeira posição. Esse é o segundo
menor valor. Então essa pessoa fica na segunda posição, e fazemos isso agora
para todas as pessoas. Se os grupos não tiverem
influência no tempo de reação,
as classificações devem, na verdade, ser
distribuídas de forma puramente aleatória Na segunda etapa, agora
calculamos
a soma da classificação e a soma média da classificação
para o primeiro grupo, a soma da classificação é dois mais
quatro mais sete mais nove, que é igual a 22, e temos quatro
pessoas no grupo. A soma média da classificação é
22/4, o que equivale a 5,5. Agora fazemos o mesmo
para o segundo grupo. Aqui obtemos uma soma de classificação de 27 e a soma média de
classificação de 6,75, e para o terceiro grupo, obtemos uma soma de classificação de 29 e a soma média de classificação de 7,25 Agora podemos calcular o valor
esperado das somas das classificações. O valor esperado, se não
houver diferença
nos grupos, seria que cada grupo tivesse
uma soma de classificação de 6,5 Agora temos quase
tudo o que precisamos. Entrevistamos 12 pessoas. O número de casos é 12. O valor esperado
das classificações é 6,5. Também calculamos
as somas médias de classificação dos grupos individuais Os graus do caso
pré-Domina são dois, e esses são simplesmente dados pelo número de
grupos menos um, que faz três menos Por fim, precisamos da variância. A variância das classificações é
dada por n ao quadrado -1/12. N é novamente um número
de pessoas, então 12. Temos uma variação de 11,92. Agora temos tudo o que
precisamos com esses valores. Agora podemos calcular
nosso valor de teste g. A estatística de teste
corresponde ao valor
do quadrado g e é
dada por essa fórmula n vezes a soma da barra r menos e r ao quadrado, tudo dividido
por Sigma ao
quadrado No nosso caso, o
número de casos é 12. Sempre temos quatro
pessoas por grupo. Assim, podemos extrair que E 5.5
é a classificação média do grupo A, 6,75 é a
classificação média do grupo B e 7,25 é a classificação
média do grupo C. Isso nos dá um valor
arredondado de 0,5, como acabamos Como acabamos de dizer, esse valor corresponde ao valor quadrado. Agora podemos
ler facilmente o valor
quadrado crítico na tabela
de valores quadrados críticos. Você também encontra essa tabela
na Internet. Temos dois graus de liberdade. E se assumirmos que temos um nível de significância de 0,05, obtemos um valor
quadrado crítico de 5,991 Obviamente, nosso valor é menor do que o valor
crítico de g quadrado
e, portanto, com base em
nossos dados de exemplo, a hipótese nula é mantida e agora mostrarei como
você pode
calcular facilmente o
teste de Cresco Wallace on-line com a Cálculo on-line. Para fazer isso, basta visitar data tab.net, clicar na calculadora de estatísticas e inserir seus próprios dados
nessa tabela Além disso, você clica nessa guia
e, nessa guia, encontrará muitos testes de
hipóteses
e, ao selecionar as
variáveis que deseja testar, a ferramenta sugerirá
o teste apropriado. Depois de copiar seus
dados na tabela,
você verá o tempo de reação
e o grupo
aqui na parte inferior Agora, basta clicar no tempo de
reação e no grupo, e ele calcula automaticamente uma análise de variância para Mas não queremos uma
análise de variância. Queremos o teste não paramétrico. Nós apenas clicamos aqui. Agora, a calculadora calcula
automaticamente o
teste
Ruskal Wallace. Também obtemos um valor de e
quadrado de 0,5, os graus de liberdade são dois e o valor p calculado é, e aqui abaixo, você pode
ler a interpretação. Ruskal Walus
mostrou que
não há diferença significativa
entre as categorias Com base no valor p, portanto, com os dados usados, deixamos de rejeitar
a hipótese nula Apenas experimente você mesmo.
É muito fácil. Fique conectado, continue aprendendo, continue crescendo, até a próxima aula.
44. Design de experimentos: Oi, e bem-vindo. Neste vídeo. Vamos mergulhar no
fascinante mundo do design
de experimentos Comumente chamado de DOE, discutimos o que é o design de
experimentos ou DOE, as etapas
do processo do projeto DOE Como o DOE pode ajudá-lo a reduzir
o número de experimentos. Como estimar o número
de experimentos necessários. E examinamos os tipos mais
comuns de designs. Então, o que exatamente é o design
de experimentos em sua essência, design de experimentos, DOE é um
método estruturado usado para planejar, realizar e
interpretar experimentos O objetivo principal do DOE é
descobrir como diferentes variáveis de
entrada,
chamadas de fatores, afetam
uma variável de saída,
chamada de variável de resposta Aqui está uma explicação mais
direta. Abordagem sistemática. O DOE é organizado e metódico. Ele segue um
processo passo a passo para garantir que os
experimentos sejam conduzidos
de forma lógica e eficiente. Variáveis de entrada, fatores. Esses são os elementos
que você altera em um experimento para ver como
eles afetam o resultado. Por exemplo, se você
estiver assando um bolo, os fatores podem incluir
a quantidade de açúcar, o tempo de cozimento ou
a temperatura do forno. Variável de saída, variável de
resposta. Isso é o que você mede
no experimento para ver o efeito das mudanças
feitas nos fatores. No exemplo do bolo, a variável de resposta pode ser o sabor ou a textura
do bolo. O objetivo do DOE é entender
a relação
entre esses fatores e a variável de resposta Ajudando você a determinar
quais fatores têm o impacto mais significativo e como eles
interagem entre si. Imagine que você está andando de bicicleta. A rotação suave
das rodas depende da condição
dos rolamentos. Se os rolamentos estiverem
bem lubrificados, torque de
atrito é mínimo, facilitando No entanto, se a lubrificação for inadequada ou a
temperatura estiver muito alta, necessário
mais esforço para
manter a velocidade devido ao
aumento do atrito Nesses casos, o DOE nos permite investigar sistematicamente fatores como tipos de lubrificação,
como óleo ou graxa, e temperaturas variáveis baixas, médias
e altas para
quantificar com precisão seu impacto na condução por atrito quantificar Mas por que isso é importante? O design de experimentos nos
permite projetar planos de teste
eficientes que
revelam esses
insights de forma eficaz Ao manipular cuidadosamente os
fatores e seus níveis, DOE nos ajuda a identificar quais variáveis
influenciam significativamente Seja em sistemas mecânicos,
como rolamentos, ou em cenários
mais complexos envolvendo respostas
humanas a medicamentos As aplicações do DOE
são vastas e diversas, seja otimizando processos de
fabricação, melhorando projetos de produtos
ou refinando tratamentos médicos, ou refinando tratamentos médicos DOE serve como uma
ferramenta poderosa para identificar fatores
críticos e determinar as condições
ideais para Ele capacita pesquisadores
e engenheiros a tomar decisões informadas com base em dados
empíricos, em vez de
confiar Em nossos próximos segmentos, exploraremos as etapas
essenciais do projeto
ADOE, desde a criação de experimentos até a
análise dos resultados À medida que avançamos
no curso, descobrimos as complexidades do
design de experimentos
e descobrimos como essa abordagem metodológica pode
revolucionar sua abordagem revolucionar sua descobrimos as complexidades do
design de experimentos
e descobrimos como
essa abordagem metodológica pode
revolucionar sua abordagem de experimentação e pesquisa. Fique ligado para obter mais informações
e dicas práticas.
45. As áreas de aplicação para um DOE: Agora, vamos entender quais são as áreas de
aplicação do DOE. As aplicações do DOE são
amplas e variadas, seja para otimizar processos de
fabricação, melhorar projetos de produtos ou refinar DOE é uma
ferramenta poderosa para identificar principais fatores e determinar as melhores condições para
alcançar os resultados desejados Ele ajuda pesquisadores
e engenheiros a tomar decisões informadas com base em dados
reais, em vez de suposições Etapas do projeto DOE, vamos dar uma olhada no
processo de um projeto DOE,
planejamento, triagem,
otimização e Na primeira etapa, planejamento. As coisas são importantes. Primeiro, obtenha uma
compreensão clara do problema e do sistema. Em segundo lugar, determine uma ou
mais variáveis de resposta. Terceiro, identifique os fatores que podem influenciar significativamente
a variável de resposta. A tarefa de determinar os fatores
potenciais que influenciam a variável de resposta pode ser muito complexa e demorada. Por exemplo, um diagrama de espinha de peixe
pode ser criado em uma equipe. Agora vem a segunda etapa. Triagem, se houver muitos fatores que possam
ter uma influência. Normalmente, mais de
quatro a seis fatores. Experimentos de triagem devem ser realizados para reduzir
o número de fatores. Por que isso é importante? O número de fatores
a serem investigados tem uma grande influência no número
de experimentos necessários. Observe que, no planejamento
de experimentos, os experimentos individuais também
são
chamados simplesmente de ensaios no planejamento fatorial
completo, que discutiremos com
mais detalhes em breve O número de
experimentos ou ensaios é n igual a dois
elevado à potência de k, onde n é o número de ensaios e k é o número de fatores. Aqui está uma pequena visão geral
se tivermos três fatores. Por exemplo, temos que fazer pelo
menos oito ensaios
com sete fatores. Já são pelo menos 128
corridas, com dez fatores. Já são
pelo menos 1024 corridas. Observe que esta
tabela se aplica ao AD OE, onde cada fator tem apenas
dois níveis, caso contrário. Haverá ainda mais execuções, dependendo da complexidade de um experimento
individual. Portanto, pode
valer a pena selecionar os chamados desenhos de triagem
para quatro ou mais fatores Posteriormente, discutiremos o planejamento fatorial fracionário
e o design plácido Que pode ser usado para experimentos
de triagem. Uma vez
identificados os
fatores significativos por meio de desenhos de
triagem, esperançosamente, o número de
fatores tenha sido reduzido Agora, outros experimentos
podem ser conduzidos. Os dados obtidos podem então ser usados para criar um modelo de
regressão, que ajuda a determinar
as variáveis de entrada forma que a
variável de resposta seja otimizada Após a otimização, vem a verificação da etapa
final. Isso envolve verificar mais
uma vez se as variáveis
de entrada ótimas calculadas realmente têm a influência
desejada na variável de resposta. Dependendo se estamos na triagem ou
na etapa de otimização. Existem diferentes
tipos de designs. Agradecemos sua atenção. Na próxima lição, vamos nos aprofundar nas aplicações
práticas
do projeto de experimentos e em como interpretar os resultados de
forma eficaz. Fique ligado.
46. Tipos de designs em um DOE: Tipos de projetos em experimentos do
DOE. Quando estamos na etapa de triagem
ou na etapa de otimização. Usamos diferentes tipos
de métodos de design. Os mais conhecidos
são o projeto fatorial completo, o projeto fatorial
fracionário, o projeto Placet Berman, o projeto
Box Benkin, o design composto central Box Vamos começar examinando o experimento fatorial completo e o experimento fatorial fracionário Também precisamos responder por que
nos esforçamos tanto. Por que usamos o design
de experimentos, DOE, e por que
precisamos de estatísticas O motivo é que os experimentos
levam tempo e custam dinheiro. Portanto, precisamos
manter o número de ensaios experimentos
individuais o mais baixo
possível. No entanto, se fizermos poucas corridas, podemos perder diferenças
importantes e não obter resultados precisos. Por exemplo,
digamos que queremos
descobrir quais fatores afetam a tensão de atrito de
um rolamento Precisamos
projetar cuidadosamente nossos experimentos para identificar esses
fatores de forma eficiente sem realizar ensaios desnecessários. Como o número de
experimentos no DOE é estimado? Vamos dar uma olhada em um exemplo. Queremos investigar
quais fatores influenciam a força de atrito de um
rolamento Vamos começar com um
fator, a lubrificação. Queremos saber se a
lubrificação afeta o torque de atrito se um
rolamento estiver lubrificado ou lubrificado Para descobrir, pegamos uma
amostra aleatória de dez rolamentos? Lubrificamos metade dos rolamentos
e lubrificamos a outra metade. Agora podemos medir
o atrito dos cinco rolamentos lubrificados e
dos cinco rolamentos lubrificados Mas por que usar dez rolamentos Na maioria dos casos, cada corrida
custa muito dinheiro Talvez possamos gerenciar
com menos corridas. Quantos experimentos
precisamos para descobrir
se o lubrificante tem
efeito na ferramenta de atrito Vamos começar com
os dez rolamentos. Agora podemos calcular
o valor médio do torque de atrito
dos rolamentos
lubrificados e lubrificados Então, podemos calcular a diferença entre
os dois valores médios. Neste exemplo, podemos ver uma diferença entre rolamentos lubrificados
e lubrificados No entanto, também notamos que o torque de atrito
nos rolamentos lubrificados e lubrificados Se pegarmos outra
amostra aleatória de dez rolamentos, a diferença pode ser maior ou pode estar na direção
oposta Em outras palavras, a
tensão de atrito dos rolamentos varia muito. Quanto maior o spread, mais difícil é
identificar uma
diferença ou efeito específico. Felizmente, podemos reduzir a variabilidade
do valor médio aumentando o tamanho da amostra Quanto maior o tamanho da amostra, mais precisa é a
estimativa da média Portanto,
quanto menor o efeito e maior a dispersão
da variável de resposta, maior deve ser o
tamanho da amostra. Mas quanto maior, como você pode estimar o
número de ensaios necessários? Você pode usar essa fórmula como uma aproximação para estimar
o número de ensaios necessários, n é igual a Sigma Um quadrado aqui, n é
o número de corridas. Sigma é o desvio padrão. Delta é o efeito
a ser determinado. Por exemplo, se tivermos
um desvio padrão de três newtons milímetros e uma diferença
relevante de Precisamos de 22 corridas. Se o desvio padrão
for de dois newtons milímetros. Só precisamos de dez corridas se o desvio padrão for de
um newton Precisamos de quatro corridas. Portanto, usaríamos dois trechos com rolamentos
lubrificados e dois trechos com
rolamentos lubrificados Mas como o DOE pode ajudar você a
reduzir o número de execuções? Veremos isso em detalhes
na próxima lição. Obrigado pela sua atenção. Na próxima lição, vamos nos aprofundar nas aplicações
práticas
do projeto de experimentos e em como interpretar os resultados de
forma eficaz. Fique ligado.
47. Como reduzir o número de corridas: Mas como o DOE pode ajudar você a
reduzir o número de execuções? Vamos supor que o
cálculo do número de ensaios resulte em
16 experimentos. Oito corridas com rolamentos lubrificados e oito corridas com rolamentos
lubrificados Mas e se tivermos
um segundo fator? Digamos que, além
da lubrificação, tenhamos temperaturas com níveis
baixos e altos Então, precisamos de mais oito corridas para levar esses fatores
em consideração. Portanto, precisamos de 16 ensaios para verificar se o
lubrificante tem efeito E 16 corridas para verificar se a
temperatura tem efeito. Isso nos dá um
total de 24 corridas. Agora surge a pergunta: é possível conseguir
isso com menos ensaios, e isso nos leva ao projeto fatorial
completo A questão é: por que devemos nos
limitar a testar
um fator por vez? Em vez disso, poderíamos
criar um design
que incorporasse todas as combinações
potenciais, como graxa e Obviamente, ainda precisamos de
16 execuções por fator. Conseguimos isso fazendo quatro corridas com cada uma
das quatro combinações. Depois, temos oito corridas com
óleo e oito com graxa
e, do outro lado, oito com baixa temperatura e oito com alta temperatura Agora temos um total de 16
corridas antes de 24 corridas. Agora precisamos de menos experimentos e obtemos ainda mais informações. Por que mais informações? Agora também sabemos
se há uma interação entre
temperatura e lubrificação. Por exemplo,
rolamentos lubrificados podem mostrar uma variação no torque de atrito em diferentes
temperaturas, que não é observado
com Essas informações
teriam sido perdidas anteriormente. Agora, quando temos três
fatores em vez de dois, a economia é ainda maior. Se testarmos um dos
três fatores por vez, precisaremos de 32 execuções. Se agora executarmos dois
experimentos para cada combinação em um experimento fatorial
completo, ainda
precisaremos de apenas 16 No entanto, para cada fator, ainda
temos oito
ensaios por nível de fator. Por exemplo, para o fator
de lubrificação, temos oito ciclos com óleo
e oito com graxa Obviamente, também podemos criar projetos fatoriais
completos
com mais de dois níveis Por exemplo, o fator de
temperatura pode ter três níveis:
baixo, médio e alto. No entanto, conforme mencionado
no início, mesmo com um planejamento
fatorial completo com dois níveis em cada fator, o número de ensaios
necessários aumenta muito rapidamente à medida que o número
de fatores Vamos, portanto, agora dar uma olhada no design fatorial
fracionário O planejamento fatorial fracionário
é usado para projetos é usado para Ou seja, se você tiver mais do que aproximadamente
quatro a seis fatores, é
claro que reduzir o número de execuções significa
reduzir as informações. Em experimentos fatoriais fracionários, a resolução é reduzida Qual é a resolução? A resolução é uma
medida de quão bem DOE pode distinguir
entre diferentes efeitos Mais precisamente, a
resolução indica o quanto os efeitos principais e os efeitos de
interação são confundidos em um design Mas o que são efeitos médios
e efeitos de interação? O que significa confuso? No planejamento de experimentos, o termo efeito se refere
ao impacto que um determinado fator ou
uma combinação de fatores tem na
variável de resposta de um experimento. Essencialmente, eles medem o
quanto a
variável de resposta muda quando você altera os fatores. Um efeito principal é
a influência de um único fator na variável de
resposta. Por exemplo, que influência
a lubrificação de um rolamento
tem na ferramenta de atrito Os efeitos de interação ocorrem
quando o efeito de um fator na variável de resposta depende do nível
de outro fator. Por exemplo, o efeito
do lubrificante
na conversa de atrito pode depender da temperatura Mas o que isso significa? Agradecemos sua atenção. Na próxima lição,
vamos nos aprofundar nas aplicações
práticas do projeto de experimentos. Fique ligado.
48. Tipo de efeitos: Mas quais são os efeitos principais
e os efeitos de interação e o que significa confundido? No planejamento de experimentos. O termo efeito se refere
ao impacto que um
determinado fator ou uma combinação de fatores tem
na variável
de resposta de um experimento. Essencialmente, eles medem o
quanto a
variável de resposta muda quando você altera os fatores? Um efeito principal é
a influência de um único fator na variável de
resposta. Por exemplo, que influência
a lubrificação de um rolamento tem no torque de atrito Os efeitos de interação ocorrem
quando o efeito de um fator na variável de resposta depende do nível
de outro fator. Por exemplo, o efeito
do lubrificante
na ferramenta de atrito pode depender da temperatura Mas o que isso significa? Digamos que temos um valor médio de torque de
atrito de 102 newton milímetros para
os rolamentos com óleo
e um valor médio de 108 newton milímetros Então, temos um efeito principal de
lubrificação de seis milímetros de
newton Mas agora podemos
dividir isso em altas e
baixas temperaturas. Em alta temperatura,
poderíamos obter 98 para óleo e 102 para graxa A diferença entre óleo e graxa é de apenas quatro
newton milímetros Em baixa temperatura,
poderíamos obter 104 e 112. Uma diferença de oito, então o fator de lubrificação é
influenciado pela temperatura, e temos uma interação entre lubrificação
e A interação leva
a uma diferença de dois novos 10 milímetros em relação
ao resultado original Portanto, temos um efeito
de
interação de dois newtons milímetros Projetos fatoriais completos levam em consideração todas as interações Em nosso exemplo de atrito
em rolamentos, além dos fatores de
temperatura do lubrificante, também
analisamos a interação
entre
o lubrificante
e a temperatura entre
o lubrificante
e No entanto, à medida que o número
de fatores aumenta, inúmeras interações surgem
rapidamente. Por exemplo, se
tivermos cinco fatores, A, B, C D e E, obtemos a interação
entre dois fatores. Entre três fatores, entre quatro fatores e
entre todos os cinco fatores. Agora, é claro. A questão é: realmente
precisamos de todas as interações ou podemos reduzir a resolução? Isso é exatamente o que
o experimento fatorial fracionário
faz em um experimento fatorial fracionário As interações podem
ser confundidas com outras interações ou com os
principais efeitos dos fatores O que significa confuso? Isso significa que os efeitos de diferentes fatores ou o efeito da interação de fatores não podem ser
separados uns dos outros. A extensão em que o
número de ensaios pode ser reduzido em detrimento da resolução é mostrada
nesta tabela. A resolução geralmente é
indicada por algarismos romanos. Exemplo três, quatro,
cinco e assim por diante. Aqui na diagonal. Nós vemos os desenhos
fatoriais completos. Examinaremos o que as
resoluções três, quatro e cinco significam em um momento Por exemplo, se
tivermos seis fatores, precisaremos de pelo menos 64 ensaios para
um experimento fatorial completo Se escolhermos um desenho
fatorial fracionário com uma resolução de seis Precisamos de 32 corridas com
uma resolução de quatro. Precisamos de 16 corridas e com uma resolução de três. Precisamos de apenas oito corridas. Mas o que isso significa? Como isso funciona? O planejamento fatorial
completo é sempre usado como ponto de
partida Vamos dar uma olhada no
exemplo com oito execuções. Na próxima lição,
vamos nos aprofundar nas aplicações
práticas do projeto de experimentos. Fique ligado.
49. Design fatorial fracionário: Vamos detalhar os
pontos-chave sobre experimentos fatoriais
fracionários em O que são experimentos
fatoriais fracionários? Projetos fatoriais fracionários são uma forma eficiente de testar
vários Eles
reduzem significativamente o número de ensaios experimentais necessários. Por que usar experimentos
fatoriais fracionários? O uso de experimentos
fatoriais fracionários economiza tempo
e recursos em comparação com experimentos fatoriais completos Além disso, eles permitem testar
as interações
entre os fatores, fornecendo informações valiosas
com menos experimentos. Um, Resolução em experimentos
fatoriais fracionários. Definição, resolução se refere à quantidade de informações capturadas em um projeto
experimental. Em termos mais simples, ele
nos diz quantos fatores, como A, B, C, podemos testar juntos e quão bem podemos separar seus efeitos uns dos outros Alta resolução,
por exemplo, três ou três. Isso significa que podemos testar
mais fatores juntos, mas também significa
que os efeitos
desses fatores podem se
confundir com as interações. Esses fatores
interagem entre si. Por exemplo, com a
resolução três, os efeitos dos
fatores principais podem ser misturados com interações envolvendo
dois outros fatores. Resolução mais baixa, por exemplo. Em V ou quatro, aqui, não
podemos testar tantos
fatores juntos, mas é mais claro ver
os efeitos principais de cada fator porque eles estão menos misturados com as interações Por exemplo, na
resolução quatro, os efeitos dos fatores principais são confundidos com interações
envolvendo três fatores Dois,
efeitos de confusão, definição. Quando dizemos que os efeitos
são confusos, isso significa que não podemos dizer exatamente qual fator está causando uma
certa mudança nos resultados Isso acontece porque combinações
diferentes de fatores podem ter
efeitos semelhantes no resultado. Por exemplo, imagine
testar os fatores , B e C, se adicionarmos um quarto fator, D, os resultados podem mostrar mudanças que não podemos
atribuir apenas a D. O efeito de D pode
estar misturado com a forma como A, B e C interagem
entre si. Três, impacto da resolução
no projeto do experimento. Explicação. A escolha
de uma resolução afeta eficiência de nosso experimento e a clareza de nossos resultados. resolução mais alta nos permite
testar mais fatores juntos, mas exige mais testes para
ter confiança em nossos resultados. Uma resolução mais baixa
requer menos testes, mas pode dificultar a compreensão dos efeitos
de diferentes fatores Quatro
exemplos práticos, ilustração, para entender melhor, pense testar diferentes receitas
para fazer um bolo. Se você mudar um ingrediente, como açúcar, o
sabor pode mudar. Mas se você trocar o açúcar
e a farinha, é mais difícil dizer qual
mudança causou, qual resultado. O design
nos ajuda a equilibrar o teste muitos fatores e a entender
seus impactos separados. Ao entender esses pontos, os pesquisadores podem criar
experimentos que forneçam respostas
claras sobre como os
fatores afetam os resultados, mesmo quando testam
vários fatores ao mesmo tempo. Examinaremos o que as
resoluções três, quatro e cinco significam em um momento Por exemplo, se
tivermos seis fatores, precisaremos de pelo menos 64 ensaios para
um experimento fatorial completo Se escolhermos um experimento
fatorial fracionário com uma resolução de seis,
precisaremos de precisaremos Com uma resolução de quatro, precisamos de 16 execuções
e, com uma resolução de três, precisamos de apenas oito execuções. Mas o que isso significa
e como funciona? O planejamento fatorial completo é sempre usado como ponto de
partida Vamos dar uma olhada em um
exemplo com oito execuções. Suponha que tenhamos
os fatores A, B e C com um planejamento
fatorial completo, podemos testar se o fator A, B ou C tem efeito Também podemos testar se as interações entre
dois fatores têm efeito e se as interações entre os três
fatores têm efeito. Se agora quisermos testar não apenas três fatores
com oito ensaios, mas um quarto
fator adicional, o fator S D, devemos sacrificar
algumas informações de uma das interações. Por exemplo, a
interação de A, B, e se quisermos testar um quinto
fator com oito tentativas, digamos o fator A, precisaríamos sacrificar
outra interação. Por exemplo, na interação
entre B e C, no entanto, não estamos realmente
descartando as informações Estamos misturando o novo fator
com a interação. Isso significa que
confundimos o fator com a interação.
O que isso significa? Isso significa que não podemos determinar
se um efeito observado é devido ao fator D ou à
interação de A, B e C. Da mesma forma, não
podemos dizer se um efeito é devido ao fator A ou à
interação de B e C de cose. É muito menos problemático
misturar um fator com
uma interação de três fatores do que com uma interação
de dois fatores Da mesma forma, não podemos
distinguir se um efeito
resulta do fator
A ou da interação de B e C. Agora, temos uma boa transição
para a resolução. O que significam as resoluções três, quatro e cinco? Na resolução três, os efeitos
principais podem ser confundidos com
as interações de dois fatores Por exemplo, o fator D pode ser confundido com a
interação dos experimentos dos fatores A e B com a resolução três
, portanto , deve ser
considerado crítico Eles só podem ser usados
se a interação de dois fatores for significativamente menor do que os efeitos
dos fatores principais. Caso contrário, a interação
de dois fatores pode distorcer significativamente
o resultado de um fator Experimentos na resolução
quatro são muito menos críticos. Aqui, apenas os efeitos principais são confundidos com as
interações de três fatores e os mais fatores
envolvidos em uma interação Quanto menor
for a probabilidade do efeito. Além disso, na resolução quatro, as interações de dois fatores são confundidas com as interações
de outros dois fatores O Experimentos na resolução cinco não são
considerados críticos. Os efeitos principais são
confundidos apenas com interações
de quatro fatores Da mesma forma, interações de dois
fatores
só são confundidas com
interações de três fatores Mas como você confunde um
fator e uma interação? Vamos dar uma
olhada nesse exemplo. Aqui, temos o design fatorial
completo dos três fatores,
A, B e C. Esses oito ensaios
são realizados no total Ainda consideramos apenas
fatores com dois níveis, menos um representa um nível e um
representa o outro Para nosso exemplo de conversa sobre atrito, o plano de teste seria
assim para o fator temperatura, menos um é a temperatura
baixa e o outro é a alta Se agora executarmos os experimentos, obteremos um valor para a variável de
resposta para cada execução. Se o fator A for um ou menos um, isso terá um certo efeito
no valor alvo O mesmo se aplica se o fator
B for um ou menos um. O efeito de interação
nos diz se há
um efeito adicional. Os fatores I A e B
são simultaneamente, um ou menos um, ou se
ambos forem exatamente na direção
oposta De um lado, temos os
pares com o mesmo sinal
e, do outro lado,
os pares com
um sinal desigual Podemos verificar se há diferença na variável de
resposta, entre os valores
no grupo verde e os
valores no grupo vermelho. Se houver uma diferença, então há uma interação
entre A e B. No entanto, se soubermos de antemão que há apenas uma interação muito
pequena ou nenhuma interação, podemos usar essas combinações. Para testar um quarto
fator, D, para fazer isso, simplesmente
multiplicamos. A e B. Sempre
temos
um, se os fatores, e B tiverem o mesmo sinal e menos um se tiverem
um sinal diferente Obviamente, um problema pode surgir. Ao analisar os resultados. Se houver uma diferença entre os valores verde e vermelho. Na variável de resposta, não
podemos determinar se
esse efeito vem da interação entre
A e B ou do fator D se formos a. Mostre que não pode haver
interação entre A e B. Isso não é um problema. Então, podemos ter certeza de que a diferença se deve
ao fator D de forma semelhante. Podemos pegar a interação
de A e C e também medir o fator A e
a interação de A, B e C para medir o
fator F, portanto. Nesse caso, medimos seis fatores com
apenas oito ensaios, mas não podemos mais distinguir o
fator D da interação do fator A e B
da interação
de A e C ou o fator F
da interação de A, B e C. Na próxima lição, daremos uma visão detalhada dos outros tipos de
projetos disponíveis no DOE Na próxima lição,
vamos nos aprofundar nas aplicações
práticas do projeto de experimentos. Fique ligado.
50. Design composto Plackett Burman Central: Bem-vindo hoje. Estamos mergulhando em
diferentes tipos de design de experimentos. Ou DOE, vamos começar com
o Placet Berman Design. O que é um design Placet Berman? Os designs Placet, Berman são normalmente usados com dois níveis e com resolução A principal vantagem
desses projetos é
que a interação entre dois fatores é distribuída entre
vários outros fatores. Por exemplo, a interação
entre os fatores A e B é confundida com todos os outros fatores, exceto
A e B. Isso torna os
designs de Plackett Burman ideais para lidar
com muitos fatores e quando apenas os
efeitos principais são No entanto, esses designs
devem ser usados com cautela, se você presumir que as interações de dois fatores
podem ser negligenciadas Embora esse requisito
seja menos rigoroso do que nos fracionários
clássicos desenhos
fatoriais fracionários
clássicos de Continuando, o que é um design
de caixa Benkin? A caixa, o design Benkin, junto com o design
composto central, são usados para analisar e otimizar
alguns fatores em detalhes E para identificar dependências não
lineares para detectar relacionamentos não
lineares São
necessários pelo menos três níveis
por fator com um planejamento fatorial completo
usando três O número de ensaios
pode aumentar rapidamente. Por exemplo, com dois
fatores em três níveis cada, você precisa de nove corridas e com três fatores
em três níveis cada
, aumenta para 27 corridas. Os projetos Box, Benkan
resolvem isso
criando um experimento fatorial completo com dois
níveis E incluir pontos centrais, como três vezes
para dois fatores
ou com três fatores, ou com três fatores, que reduz o
número de corridas de 27 Embora isso reduza
o número de ensaios, ele pode identificar menos relacionamentos não
lineares. A seguir, vamos discutir o design composto
central. Esse design normalmente envolve três tipos de pontos de teste, dois pontos fatoriais de
nível fol
que formam os cantos de um cubo ou hipercubo Pontos centrais localizados
no centro
do espaço definido
pelos pontos fatoriais Pontos axiais que se encontram
nos eixos do
espaço fatorial fora da fila Esses dois últimos tipos
de pontos ajudam a estimar
efeitos não lineares em seu modelo. Na próxima lição, vamos nos aprofundar nas aplicações
práticas do projeto de experimentos.
Fique ligado.
51. Conclusão: Gostaria de agradecer muito por
concluir o programa. Isso mostra que você está altamente comprometido em sua
jornada de aprendizado. Você quer se aprimorar e acredito que
tenha aprendido muito. Espero que todos os seus conceitos também
estejam claros. Quero garantir que eu lhe diga quais são os outros programas
que eu quero compartilhar habilidades. Então, no Skillshare, eu tenho muitos outros programas
que já estão lá e muitos
surgirão nas próximas semanas
e meses futuros. Como os programas são
contar histórias com dados, como posso usar a análise, visualização de
dados, análise
preditiva sem
codificação e muito mais. Além disso, também trabalho
como instrutor corporativo. Garanto que todos os
meus programas sejam altamente interativos e
mantenham todos os participantes
muito engajados. Eu projetei os livros que são personalizados para o meu workshop, o que também garante
que todos os conceitos sejam claramente compreendidos
pelos participantes. Meus jogos são projetados de tal
forma que os conceitos obtêm empréstimos
em um tempo em que jogam. Existem muitos jogos projetados para meus programas. E se você estiver interessado, você está livre para entrar em contato comigo. Também fiz
mais de 2 mil horas de treinamento nos últimos dois
anos durante a pandemia. Esses são apenas alguns
dos workshops. Portanto, se sua organização
quiser fazer algum
programa de treinamento corporativo que seja offline ou online. Ou se você acha que pessoalmente deseja aprimorar
seu aprendizado, pode entrar em contato
comigo pelo meu e-mail. Fique conectado comigo no LinkedIn se você
gostou do meu treinamento,
por favor, certifique-se de
escrever um comentário no LinkedIn. Além disso, eu também administro um canal no
Telegram onde coloco muitas
perguntas em que
as pessoas podem aprender
os conceitos e
elas aprenderão, elas podem levar apenas alguns
segundos para fazer isso. Além disso,
certifique-se de escrever para deixar um
comentário no Skillshare, como foi sua experiência
de treinamento? se esqueça de
concluir seu projeto. Eu amo as pessoas quando elas estão comprometidas e você provou
que é uma delas. Por favor, fique conectado. Fique seguro e que Deus o abençoe.
 Dimple Sanghvi, AI Consultant, Lean Six Sigma Master Black Belt
Dimple Sanghvi, AI Consultant, Lean Six Sigma Master Black Belt