Transcription
1. Introduction: Vous avez probablement entendu le battage médiatique entourant la science des données,
les conférences , les discussions, les grandes visions décennales et les promesses d'une décennie glamour. Cette classe est différente. C' est concret, c'est immédiat. Je veux vous montrer comment les données peuvent vous aider aujourd'hui, demain, semaine
prochaine, comment vous pouvez raconter des histoires avec des données. Hé, je suis Allan. Je suis un data scientiste dans une petite start-up et un doctorant en informatique à l'UC Berkeley. campus, j'ai enseigné plus de 5 000 étudiants, et hors campus, j'ai reçu plus de 50 critiques cinq étoiles pour enseigner aux gens comment coder Airbnb. Dans ce cours, je vais vous enseigner l'essentiel de l'analyse des données, en particulier, vous montrer comment exploiter les données d'une manière spécifique. Comment raconter une histoire avec la bonne visualisation. Si vous êtes un professionnel des affaires à la recherche compétences
basées sur les données ou un aspirant chercheur en données, ce cours est fait pour vous. Si vous êtes un débutant à coder, notez que cette classe s'attend à une certaine familiarité de codage. Vous pouvez les récupérer en seulement une heure en prenant mes cours Coding 101 et SQL 101. Après ce cours, vous serez en mesure de prendre des décisions commerciales basées sur les données. Nous le ferons en trois étapes. Premièrement, la conception de la collecte de données, la deuxième, le prétraitement des données et la troisième, l'analyse des données. Chacune de ces phases évoluera autour d'une étude de cas fictive centrée sur une application appelée Potato time. Je suis heureux de vous donner une idée de la science des données, un test de goût pour les différentes étapes de l'analyse des données. Dans la leçon suivante, nous discuterons de votre étude de cas pour le cours et vous jouerez avec les données en un rien de temps.
2. Projet : Test A/B d'une page Web: Votre objectif est de raconter une histoire avec des données à l'appui d'une décision commerciale. En particulier, prendre une décision entre deux versions d'une page de destination de l'entreprise. Cependant, la décision n'est pas aussi noire et blanche que vous pourriez le penser. Le site Web en question s'appelle Potato Time. Alors que l'application est réelle, l'étude de cas ne l'est pas. Le défi est double. Premièrement, éduquer le public sur les raisons pour lesquelles un synchroniseur de compteur est utile. Deux, augmentez le nombre d'inscriptions. Votre projet consiste à comprendre de grands volumes de données, puis à produire une série de visualisations qui illustrent votre raisonnement pour une recommandation commerciale finale basée sur les données. Ce projet utilise un jeu de données synthétiques. Cependant, cela vous forcera à comprendre pourquoi réactions de secousse peuvent conduire à des conclusions erronées, pourquoi une analyse de niveau de surface ne fera tout simplement pas. Ce projet mettra en évidence l'importance de choisir les bonnes visualisations. Nous parlerons de l'analyse des données en trois étapes : une, collecte des données de
conception, deux, données de
prétraitement et trois, l'analyse des données. Tout ce dont vous avez besoin est d'un compte Google avec accès à Google Colab. Si vous avez un compte Gmail de travail que vous pouvez utiliser, c'est parfait. Sinon, un Gmail personnel semble très bien. Voici trois conseils. Astuce numéro un, pour gagner le côté de la prudence, toujours copier le code exact que j'ai. Le code sera disponible à cette URL. Astuce numéro deux, mettez la vidéo en pause si nécessaire. Je vais expliquer chaque ligne de code que j'écris. Mais si vous avez besoin de temps pour taper et essayer le code vous-même, n'hésitez pas à mettre la vidéo en pause. Astuce numéro trois, vous apprendrez mieux en faisant. Je suggère de vous mettre en place pour le succès en plaçant vos fenêtres Skillshare et Google Colab côte à côte comme indiqué ici. Une dernière note. Le plus important à emporter est les étapes que nous traversons et le concept que nous abordons. Les noms de fonction sont des choses que vous pouvez toujours Google plus tard. Je ne m'inquiéterais pas pour ça. Maintenant, commençons et plongons dans le code.
3. Remise à niveau sur Python: Dans cette leçon, vous allez travailler à travers un rafraîchissement Python rapide. Cette actualisation couvrira la syntaxe Python pour plusieurs concepts. Voici les concepts que nous examinerons. Ne vous inquiétez pas si vous ne vous souvenez pas de ce que signifient tous ces termes, ils devraient simplement avoir l'air familier. Si à un moment donné vous êtes coincé, assurez-vous de vous référer
au cours de Codage 101 original ou de poser une question dans la section de discussion. Allez-y et naviguez sur colab.research.google.com. Vous devriez alors être accueilli avec un écran comme celui-ci. Allez-y et cliquez sur « New Notebook » en bas à droite. Avant de commencer, permettez-moi d'expliquer ce qu'est cette interface. Ce type d'environnement d'exécution est appelé un bloc-notes. Un cahier contient différentes cellules comme celle sur laquelle j'ai cliqué. Nous utilisons un bloc-notes car il est plus simple de voir des visualisations comme des tracés. Il y a trois types de données dont nous aurons besoin pour ce cours. Le premier type de données est un nombre. Le deuxième type de données dont vous aurez besoin est une chaîne. Une chaîne, si vous vous souvenez, est un morceau de texte. Vous aurez toujours besoin de guillemets pour désigner un morceau de texte. Le troisième type de données est appelé un booléen. Un booléen est juste une valeur vraie ou fausse. Il existe plusieurs façons d'opérer sur ces types de données. Voici une telle expression. Vous avez deux numéros et opération d'addition. Comme vous pouvez vous y attendre, une fois que Python évalue cette expression, l'expression aura la valeur 7. Voici une autre expression. Comme vous pouvez vous y attendre, une fois que Python évalue cette expression, l'expression deviendra vraie. Discutons des variables. Ici, nous assignons la variable x à la valeur cinq. Rappelez-vous d'avant, nous avons écrit 5 plus 2. Nous savons que Python évaluera cette expression pour en obtenir sept. Cette fois, disons x est égal à 5, nous pouvons alors remplacer cinq par x. Comme avant, cette expression sera évaluée à sept. Allons de l'avant et écrivons du code. Tout d'abord, les types de données. Voici un nombre, tapez cinq. Une fois que vous appuyez sur Entrée de commande ou Entrée de contrôle sur un Windows, Python lit, évalue et renvoie le résultat de cette expression. Allons de l'avant et faisons la même chose pour une corde. Rappelez-vous vos guillemets, saisissez le texte que vous
souhaitez et appuyez sur Entrée de commande ou Entrée de contrôle. Enfin, nous allons taper un booléen. Exécutez la cellule, et voilà votre sortie. Deuxièmement, écrivons une opération. Allez-y et tapez 5 plus 2. Les espaces sont facultatifs. Une fois que vous appuyez sur Entrée de commande ou Entrée de contrôle, Python à nouveau, lit, évalue et renvoie le résultat de cette expression. Dans ce cas, cette expression est évaluée pour devenir sept, comme vous pouvez vous y attendre. Maintenant, nous allons taper 5 supérieur à 2. Cela, comme vous pouvez vous y attendre, renvoie le booléen vrai. Troisièmement, continuons et définissons une variable x est égale à 5. Encore une fois, les espaces sont facultatifs. Exécutez la cellule et vous pouvez voir qu'il n'y a pas de sortie. Cependant, nous pouvons sortir le contenu de la variable x en tapant x, Entrée de commande. Allons de l'avant et utilisons cette variable. Tapez x plus 2, et cela, comme on pourrait s'y attendre, nous donne 7. En tant que mise à jour, l'une des deux collections que nous avons introduites dans le codage 101 était une liste. Nous utilisons toujours des crochets, un pour commencer la liste et un pour terminer la liste. Nous utilisons également des virgules pour séparer chaque élément de la liste. Dans ce cas, nos articles sont des chiffres. En tant que rafraîchisseur, un dictionnaire, la deuxième collection que nous avons couverte dans Coding 101, mappe les clés aux valeurs. Pensez-y comme votre dictionnaire à la maison qui mappe les mots aux définitions. Nous utilisons toujours des accolades, une pour démarrer le dictionnaire et une pour terminer le dictionnaire. Nous utilisons également un deux-points pour séparer la clé de la valeur. Ici, la clé est une chaîne désignée en utilisant le violet. Ici, la valeur est un nombre marqué en rose. Le dictionnaire mappe la clé « jane » à la valeur trois. Nous utilisons des virgules pour séparer les entrées dans le dictionnaire. Nous pouvons également attribuer une variable à ce dictionnaire. Dans ce cas, le nom de la variable est le nom des cookies. Ensuite, voici comment obtenir des données à partir d'un dictionnaire. Tout ce dont nous avons besoin, c'est la clé qui nous intéresse. Dans ce cas, nous voulons le nombre de cookies de Jane, donc nous aurions besoin de la clé « Jane ». Nous utilisons des crochets et la clé pour obtenir l'article. Ce code retournera le numéro auquel Jane correspond, qui est trois. Remarquez ici la notation entre crochets, où les crochets sont indiqués en noir. De retour à l'intérieur de votre carnet, la première chose que nous allons faire est de définir une liste de nombres. Encore une fois, nous avons besoin de crochets, les chiffres ou le contenu de la liste, et de virgules pour séparer chaque élément. Allez-y et courez la cellule. Allons de l'avant et faisons la même chose pour un dictionnaire. Nous allons utiliser des accolades pour indiquer le début et la fin d'un dictionnaire. Ensuite, nos clés vont être une chaîne et nos valeurs vont être des nombres, ajoutez une virgule pour séparer chaque entrée dans le dictionnaire. Maintenant, allons de l'avant et définissons une variable qui est égale à ce dictionnaire. Ici, nous aurons le nom des cookies est égal à « Jane » de trois et « John » de deux. Exécutez la cellule une fois de plus. Encore une fois, parce que nous avons défini une variable, il n'y a pas de sortie. Allons de l'avant et sortons maintenant le contenu de cette variable. Exécutez la cellule et il y a le contenu de la variable. Allons de l'avant et accédez à la valeur de la clé « jane ». Alors, nom aux cookies de « Jane ». Nous examinerons les fonctions et les méthodes. Nous allons couvrir ces deux concepts avant d'exécuter plus de code. Pensez aux fonctions que vous avez apprises en cours de mathématiques à l'école primaire. Les fonctions acceptent une valeur d'entrée et renvoient une certaine valeur. Par exemple, considérez la fonction absolue, prenez un nombre et retournez la version positive de ce nombre. Comment utiliser une fonction ? Considérez à nouveau la fonction de valeur absolue. En Python, le nom de la fonction est juste abs. Utilisez des parenthèses pour appeler la fonction. Appeler la fonction signifie que nous exécutons la fonction. Entre les parenthèses, ajoutez les entrées dont la fonction a besoin. Cette fonction de valeur absolue prend en une entrée. Nous faisons également référence à l'entrée comme un argument d'entrée ou juste l'argument. Chacun des types de données dont nous avons parlé jusqu'à présent : nombres, chaînes, fonctions, ce sont tous des types d'objets. Une méthode est une fonction qui appartient à un objet. Dans cet exemple, nous allons diviser une chaîne en un certain nombre de chaînes plus petites. Tout d'abord, vous avez besoin d'un objet. Ici, nous avons un objet de chaîne. Ensuite, ajoutez un point. Ce point signifie que nous sommes sur le point d'accéder à une méthode pour l'objet chaîne. Ajoutez le nom de la méthode. Dans ce cas, le nom est divisé. La méthode split séparera la chaîne en plusieurs chaînes, et le reste de ces diapositives ressemblera beaucoup à appeler une fonction. Pour appeler cette méthode, tout comme vous appelleriez des fonctions, ajoutez des parenthèses. Entre vos parenthèses, ajoutez un argument d'entrée. Voici toutes les parties annotées. De gauche à droite, nous avons besoin de l'objet, d'un point, du nom de la méthode et des arguments d'entrée. Essayons d'utiliser des fonctions et des méthodes maintenant. Ici, tapez abs, parenthèses, et tapez cinq. Allez-y et exécutez la cellule, et vous constaterez que nous calculons la valeur absolue de cinq. Allez-y et répétez la même chose, mais maintenant pour les cinq négatifs, exécutez la cellule et nous obtenons cinq positifs comme prévu. Nous pouvons également exécuter des fonctions qui nécessitent deux arguments d'entrée. Ici, nous pouvons taper max et passer en 2 virgule 5, et cela retournera le maximum des deux nombres. Dans ce cas, nous en attendions cinq. Nous pouvons également appeler la méthode split comme nous l'avons couvert dans les diapositives. Allez-y et tapez une liste de lettres et tapez dans .split paréthèses, puis nous allons passer une autre chaîne, qui est ce que vous devez diviser la chaîne. Dans ce cas, nous voulons diviser à chaque virgule. Allez-y et exécutez la cellule, et vous pouvez voir maintenant que nous avons divisé la chaîne avec succès en un certain nombre de parties différentes. Retour aux diapositives du dernier segment de cette revue. La dernière rubrique de cette actualisation est la façon de définir une fonction. Comme nous l'avons mentionné précédemment, pensez aux fonctions de votre classe de mathématiques. En particulier, considérez la fonction carrée. Prenez un nombre x, multipliez x avec lui-même, et renvoyez le nombre carré. Ici, nous commençons par def. C' est ainsi que vous définissez une fonction. Ensuite, nous le suivons avec le nom de la fonction. Dans ce cas, ce sera carré. Ensuite, nous ajoutons des parenthèses suivies d'un deux-points. Entre les parenthèses, nous ajoutons notre argument d'entrée. Dans ce cas, notre carré de fonction ne prend qu'un seul argument, que nous appellerons x. Ensuite, ajoutez deux espaces, ces deux espaces sont extrêmement importants. Ces espaces sont la façon dont Python sait que vous ajoutez maintenant du code à la fonction. Puisque cette fonction est simple, la première et la seule ligne de notre fonction est une déclaration de retour. L' instruction return arrête la fonction et retourne n'importe quelle expression vient ensuite. Dans ce cas, l'expression est x fois elle-même. Voici toutes les parties annotées une fois de plus. Notez que toutes les parties en noir sont nécessaires pour définir n'importe quelle fonction et vous avez toujours besoin de def, parenthèses et d'un deux-points pour indiquer que la fonction démarre. Vous avez également besoin de l'instruction
return pour renvoyer des valeurs au programmeur appelant votre fonction. Le nom de la fonction, les entrées et les expressions peuvent tous changer. De retour à l'intérieur de votre ordinateur portable, allez de l'avant et tapez entre parenthèses carrés def x deux-points. Une fois que vous appuyez sur Entrée, Colab ajoutera automatiquement deux espaces pour vous, alors allez-y et gardez ces espaces dans et tapez en retour x fois x. Exécutez votre cellule, appelez maintenant la fonction, carré de cinq, exécutez la cellule, et nous pouvons essayer cela pour un nombre différent aussi, carré de deux. Ce sont les concepts que nous avons abordés dans cette leçon. Si vous souhaitez accéder à ces diapositives et les télécharger, visitez cette URL, aaalv.in/data101. Cela conclut notre rafraîchissement Python. Dans la leçon suivante, vous allez concevoir l'expérience et déterminer les données à collecter.
4. Conception expérimentale axée sur la confidentialité: Dans cette leçon, nous discuterons de la collecte de données, des principes qui sous-tendent la conception d'une expérience. À la fin de la leçon, nous aurons un ensemble d' hypothèses et les données que nous aurons besoin de recueillir. Voici l'ordre des sujets de cette leçon : philosophie, principes, études de cas, hypothèses et données. Nous commençons par la philosophie d' une conception expérimentale et la façon dont cela guide les données que nous collectons. L' idée sous-jacente est la protection de la vie privée. La première conséquence est que vous devriez collecter ce qui est minimalement nécessaire. Voici le principe numéro un, ne
collectez que ce dont vous avez besoin. Ne collectez pas de données simplement parce que vous le pouvez, ne
collectez que ce qui est nécessaire pour tester l'hypothèse. Par exemple, supposons que votre hypothèse est que les pages plus lentes entraînent moins de clics, alors comme vous pouvez vous y attendre, nous avons seulement besoin de collecter le temps de chargement de la page et les informations de clic. D' autres informations que vous pourriez demander comme l'emplacement n'est pas nécessaire. Principe numéro deux, rapport global. Les statistiques devraient être rapportées dans le cadre d'une foule. En outre, et c'est possible, vous pouvez randomiser des lignes individuelles de données afin protéger les identités individuelles tandis que les statistiques agrégées restent les mêmes. Ces principes régissent la façon dont et le moment de la collecte des données. Regardons notre étude de cas spécifique. Nous allons étudier une application réelle appelée PotatoTime. Cette application synchronise les calendriers Google de sorte que
le temps occupé sur un calendrier est affiché comme occupé sur tous les calendriers. Dans cette classe, nous allons considérer deux variantes de la page de destination. Nous aurons aussi deux hypothèses qui nous aideront à choisir entre les deux pages de destination. C' est la première étape. Nous formulons l'hypothèse. L' hypothèse numéro un est que les utilisateurs ne voient pas l'utilitaire dans notre synchroniseur de calendrier, en particulier, les utilisateurs ne savent pas pourquoi un synchroniseur de calendrier est utile, donc votre vidéo guidée sur la page d'accueil va stimuler les inscriptions pour Web L'hypothèse numéro deux est que les utilisateurs doivent être éduqués pour la tarification, sorte que des niveaux de tarification clairs stimuleront les inscriptions, c'est la page Web B. Nous pouvons maintenant considérer les données nécessaires pour tester chaque hypothèse. C' est la deuxième étape, concevoir la façon dont nous allons collecter des données. Nous pouvons d'abord considérer la page web A, la vidéo, quelles sont les informations dont nous avons besoin ? Nous avons besoin de la durée de la montre, du temps de chargement de la page , des informations de
clic et du moment où la vidéo a été regardée. La suivante concerne la page Web B, quelle information avons-nous besoin ? Nous avons besoin d'informations de défilement, donc combien de temps l'utilisateur a passé à regarder chaque partie de la page, informations de
clic, et aussi quand la page a été accédé. Notez qu'aucune information personnelle n'est nécessaire pour mener l'une ou l'autre de ces études, alors que des informations telles que le groupe d'âge ou le lieu peuvent révéler des informations cachées uniques. Nous n'avons pas formulé d'hypothèse ou de raison pour laquelle l'un de ces facteurs pourrait jouer un rôle. Aux fins de cette classe, nous analysons uniquement les informations consultées ci-dessus. Ce sont les concepts que nous avons abordés dans cette leçon. Pour un résumé, notre conception expérimentale implique la collecte d'informations minimales. Ça sonne bien philosophiquement, qu'en est-il dans la pratique ? Eh bien, en pratique, la collecte ou l'accès à ce dont vous avez besoin est certainement utile, vous risquez une surcharge d'information sinon, et la paralysie de la décision. Si vous souhaitez accéder à ces diapositives et les télécharger, visitez cette URL. Dans la leçon suivante, nous allons écrire du code qui lit et nettoie les données, comment configurer une page Web, comment accéder à la page Web et comment nous stockons des informations sur cet accès à la page Web dépasse le cadre de cette classe, nous allons plutôt nous concentrer sur l'analyse des données dans les sections suivantes.
5. Prétraiter des données dans Pandas: Dans cette étape, vous allez charger des données dans Python à l'aide d'une bibliothèque appelée Pandas. Rappelons, une bibliothèque est juste une collection de code que quelqu'un d'autre a écrit, que nous pouvons utiliser. Puisque Pandas facilite le chargement des données, nous nous concentrerons sur l'utilisation des données chargées. Voici les concepts que nous aborderons : nous discuterons de ce qu'est un bloc de données de la bibliothèque de Pandas, statistiques
que nous pouvons obtenir à partir d'un bloc de données, et enfin, de la façon de nettoyer vos données. Commencez par accéder à aaalv.in/data101/notebook. À l'aide du bloc-notes lié, vous allez charger un ensemble de données contenant des données de trafic Web synthétiques que nous utiliserons. Une fois que vous accédez à cette URL, vous devriez alors être accueilli avec une page comme celle-ci. Allez-y et cliquez sur « Fichier », puis enregistrez une copie dans Drive, cela va créer une copie que vous pouvez maintenant modifier. Sur cette page, je vais cliquer sur ce « X » juste ici pour fermer la barre de navigation. Allez-y et faites défiler vers le bas, puis téléchargez d'abord un fichier contenant le jeu de données. Pour ce faire, exécutez cette première cellule contenant la récupération d'URL, sélectionnez la cellule et appuyez sur « Entrée de commande » ou, si vous êtes sur Windows, appuyez sur « Entrée de contrôle ». Vous pouvez également cliquer sur le bouton de lecture ici. Une fois que ce fichier a été téléchargé, vous verrez cette sortie ici, views.pkl, et cette autre non-sens. Cela signifie que le fichier a été téléchargé avec succès. Ensuite, tout comme l'encodage 101, importer du code que d'autres ont écrit que nous pouvons utiliser. Allez-y et tapez importation Pandas en tant que pd. Cette bibliothèque a une fonction appelée read pickle, allons-y et utilisons-la maintenant pour lire le jeu de données, tapez pd.read pickle. Comme nous l'avons vu ci-dessus, le nom du fichier est views.pkl. Cette fonction lit le fichier pickle et renvoie l'ensemble de données sous la forme d'un bloc de données. Un bloc de données est la façon dont Pandas représente une table de données. Pensez à un bloc de données comme une feuille de calcul Excel ou une table de base de données. Affectons le bloc de données de retour à une variable appelée df. Cette variable est courante pour le codage à l'aide de dataframes. Voyons maintenant à quoi ressemble ce bloc de données, tapez df et exécutez la cellule. Regardez pour voir la structure des données, le nombre de lignes, nombre de colonnes, notez que la première colonne est en gras, ceci est appelé notre index. Pour quelques raisons, l'index ou la
colonne créée à est très efficace à trier ou à regrouper,
nous en tirons parti plus tard. La deuxième colonne, Page Load MS, correspond au nombre de millisecondes que la page Web a pris pour charger. Vidéos regardées S, est le nombre de secondes de la vidéo que l'utilisateur a regardée. Produit S, est le nombre de secondes que les utilisateurs ont passées sur la section produit de la page Web. Pricing S, est le nombre de secondes que l'utilisateur a passées sur la section de tarification de la page. A cliqué est un booléen, true, si l'utilisateur a cliqué sur le bouton d'inscription. La dernière colonne, page Web, est A ou B, indiquant la page de destination que l'utilisateur a vu. dataframes offrent quelques méthodes pour calculer des statistiques agrégées. Par exemple, nous pouvons calculer la moyenne pour chaque colonne, aller de l'avant et taper df.mean, ajouter des parenthèses pour appeler la méthode. La plupart des valeurs moyennes ici semblent raisonnables, cependant, note qui a cliqué a une valeur de 0,34, cela semble bizarre car ci-dessus A cliqué est une colonne de valeurs vraies ou fausses. Comment les valeurs vraies ou fausses deviennent-elles un nombre ? En bref, Pandas a considéré que chaque vrai était un et chaque faux était un zéro, puis il a fallu la moyenne, par conséquent, 0,34 signifie que 34 pour cent des valeurs sont vraies. Allons maintenant et calculons la valeur minimale par colonne. Tapez df.min à nouveau avec des parenthèses, exécutez la cellule et ici vous pouvez voir les valeurs minimales. Maintenant que nous avons couvert quelques statistiques de base offertes par les blocs de données, allons maintenant voir ce que les blocs de données offrent pour le nettoyage des données. Il y a trois étapes courantes à suivre pour nettoyer vos données. abord, vous voudrez supprimer tous les doublons, appeler la méthode drop duplicates sur votre dataframe, tapez df.drop underscore duplicates et ajouter des parenthèses pour appeler la fonction. Allez-y et courez la cellule. Un petit conseil, vous n'avez pas besoin de mémoriser cette méthode en soi, vous pouvez toujours google Pandas trame de données en double. Ce qui est plus important, c'est que vous vous souveniez des étapes du nettoyage des données. Maintenant, dans la cellule suivante, nous allons remplir les valeurs manquantes,
ces valeurs manquantes sont représentées comme NaN ou N-A-N, cela signifie pas un nombre. Des NAN ou des valeurs manquantes peuvent éventuellement se produire en raison de bogues dans le code de collecte de données. Ici, nous pouvons remplir les valeurs manquantes avec la valeur moyenne dans chaque colonne. Rappelez-vous de df.mean ci-dessus à nouveau, vous devriez maintenant taper ceci à l'intérieur de votre cellule, tapez df.mean avec parenthèses, cela calcule la moyenne de chaque colonne. Voici une nouvelle méthode appelée fill NA qui remplit toutes les valeurs NaN avec les valeurs fournies, tapez df.fillna, puis allez de l'avant et passez df.mean comme argument. FillNA ne modifie pas le dataframe, il crée simplement un nouveau dataframe avec les valeurs entrées. En conséquence, nous devons assigner la variable df au résultat, tapez df égal. Enfin, lancez la cellule. Troisièmement, nous vérifions les données. Dans ce cas, nous savons que la vidéo ne dure que 60 secondes alors regardons le temps maximum qu'un utilisateur a passé à regarder la vidéo, assurant qu'elle ne dure que 60 secondes. Pour accéder à une colonne de données dans un dataframe, traitez un dataframe comme un dictionnaire, clé sur le nom de la colonne. Dans ce cas, notre nom de colonne est Video Watched S, comme nous le voyons ici, mais allons de l'avant et appuyez sur le nom de la colonne en tapant dans df carré crochet vidéo regardé s et cela nous récupère une colonne de données. Cependant, nous voulons obtenir la valeur maximale alors allez-y et utilisez la méthode max afin de taper dans dot max. Allez-y et exécutez la cellule et un nombre beaucoup plus grand que 60 secondes, il semble être un bug dans notre code de collecte de données alors nous allons découper toutes les durées supérieures à 60 secondes. Dans un dataframe, tout comme avec les dictionnaires, nous pouvons assigner des valeurs. Allez-y et tapez dans df et carré puis le nom de notre nouvelle colonne, qui sera Video Watched S tronc pour tronqué. Cela crée une nouvelle colonne appelée vidéo regardé S tronc une fois que vous l'affectez à une valeur. Nous allons maintenant calculer les valeurs de la nouvelle colonne. abord, obtenez l'ancienne colonne, qui est df Video Watched S, tout comme nous l'avons fait dans la cellule précédente. Appelez maintenant le clip point ou la méthode clip pour découper toutes les valeurs. Le premier argument est la valeur la plus basse possible donc dans ce cas zéro, nous ne voulons pas que le nombre de secondes surveillées soit inférieur à zéro. Nous ne voulons pas non plus que le nombre de secondes de surveillance soit supérieur à 60. Cela garantit qu'il n'y a pas de valeurs inférieures à zéro ou supérieures à 60. Allez-y et appuyez sur « Entrée » pour créer une nouvelle ligne et tapez df. Cela va maintenant afficher le Dataframe. Allez-y et courez la cellule. Notez que la colonne à l'extrême droite comprend notre toute nouvelle colonne de durées de montre coupées et voilà, qui conclut notre premier traitement de données à Pandas. Ce sont des concepts que nous avons abordés dans ce cours. Les choses à emporter sont comment nettoyer vos données. Étapes typiques, y compris le remplissage des NAN, déduplication des lignes et la vérification de la santé mentale par rapport à votre compréhension des données. Par exemple, vérifiez que les moyennes, les valeurs
maximales et minimales correspondent à votre compréhension. Si vous souhaitez accéder à ces diapositives et les télécharger, visitez cette URL. Assurez-vous d'enregistrer votre bloc-notes en appuyant sur Fichier Enregistrer. La prochaine fois, nous effectuerons une analyse initiale des données.
6. Analyser des données dans Pandas: Dans cette leçon, nous allons analyser le jeu de données synthétiques. Voici les concepts que nous aborderons. Nous commencerons par quelques statistiques sommaires comme les totaux par jour. Ensuite, nous calculerons des corrélations entre différents éléments de données pour comprendre où chercher des modèles,
et pour développer une certaine intuition. Enfin, dans cette étape, nous allons tirer quelques premières conclusions. Si vous avez perdu votre carnet de notes ou si vous venez de commencer la classe à partir de cette leçon, accédez au carnet de démarrage de la leçon 6 à partir de aaalv.in/data101/notebook6. Une fois que vous accédez à cette URL, vous devriez voir une page comme celle-ci. Allez-y et cliquez sur fichier, et enregistrez une copie dans Drive. Je vais cliquer sur X en haut à gauche pour fermer cette barre de navigation. Une fois que vous êtes sur cette page, en haut, cliquez sur runtime et sélectionnez exécuter tout, attendez que toutes les cellules s'exécutent. Vous pouvez le dire une fois que vous avez vu la sortie de toutes les cellules. Allez-y et à partir de cette cellule, commencez par calculer plusieurs statistiques sommaires. Par exemple, calculer combien de jours le jeu de données s'étend. Pour accéder aux dates du bloc de données, utilisez df.index. Allez-y et tapez .max pour obtenir la dernière date, puis soustrayez la première date en utilisant .min. Exécutez la cellule, et ici nous obtenons un objet de données temporelles d'un 100 jours. La deuxième statistique récapitulative est le nombre de pages vues par jour. Pour cela, nous devrons définir une fonction. La fonction comptera le nombre d'événements qui se sont produits chaque jour. Commencez par définir le nom de la fonction, les événements par jour. Cette fonction acceptera un argument appelé df. Ajoutez des parenthèses, tapez df et assurez-vous d'ajouter un deux-points à la toute fin de cette ligne. Allez-y et appuyez sur Entrée. Une fois de plus, Colab ajoute automatiquement deux espaces pour nous. abord, tapez datetimes est égal à df.index. Ceci est le bloc de données, df. DF.index récupère les dates d'heure pour chaque vue. Ensuite, définissez une nouvelle variable. Days est égal à datetimes et use.floor, ajoutez vos parenthèses pour appeler la fonction, puis passez dans une chaîne de d minuscules, .floor convertit datetimes en dates. Les événements de type par jour sont égaux à days.value_counts. Value_count compte le nombre de fois où chaque date apparaît. En d'autres termes, nous comptons le nombre de vues par jour. Appelez le retour events_per_day.sort_index. Cela va trier les comptes par jour. Ne vous inquiétez pas, cette fonction semblait beaucoup. Le plus important à emporter n'est pas de mémoriser le code. Ce code est parfaitement Googleable. plus important est que A, vous pouvez lire le code et comprendre à peu près ce qu'il fait. Puis B, que vous savez quoi Google pour l'avenir. Dans ce cas, pour compter le nombre de vues par jour, nous avons compté le nombre de lignes par jour dans le bloc de données. Voyons ce que notre fonction retourne. Définissez une nouvelle variable, views_per_day, définissez cette variable sur la valeur de retour de notre fonction ci-dessus. Rappelez-vous, cette fonction prend un argument, qui est le bloc de données des données. Affiche le contenu de la variable. Exécutez la cellule, et ici nous obtenons le nombre de vues par jour. Ensuite, définissez une autre fonction qui filtre le bloc de données pour ne contenir que les lignes qui ont donné lieu à un clic. Commencez par définir le nom de la fonction, get_click_events. Cette fonction acceptera un argument appelé df ou le bloc de données. Encore une fois, n'oubliez pas votre côlon au bout de la ligne. Appuyez sur Entrée, Colab ajoute deux espaces pour vous et tapez maintenant, sélecteur est égal à df, entre crochets et le nom de la colonne qui contient les informations de clic. Ici, clicks est égal à df et tapez dans le sélecteur. Maintenant, allez de l'avant et retournez la nouvelle variable que vous avez définie, c'est-à-dire les clics. Cela renvoie un bloc de données avec uniquement les lignes qui ont true dans le sélecteur, et les lignes qui ont true dans ce sélecteur sont celles qui ont donné lieu à un clic. Par conséquent, cette fonction renvoie un bloc de données avec uniquement les lignes qui ont entraîné un clic. Allez-y et courez la cellule. Maintenant, utilisez cette fonction pour obtenir uniquement les lignes avec des clics. Pour rechercher des clics est égal à get_ click_events et passer dans votre bloc de données. Définissez une variable, clicks_per_ jour est égal à, et comme avant, nous allons compter le nombre d'événements par jour. Enfin, sortez le contenu de la variable et exécutez la cellule. Ici, nous pouvons voir le nombre de clics par jour. Pour voir uniquement les valeurs, utilisez l'attribut .values. Contrairement aux méthodes, vous n'avez pas besoin de parenthèses pour accéder à un attribut. Tapez clicks_per_day.values. Encore une fois, aucune parenthèse n'est nécessaire pour accéder à cet attribut, .values. Allez-y et exécutez la cellule, et ici nous obtenons toutes les valeurs. Maintenant, nous avons besoin d'un contrôle de santé mentale. Ici, nous voulons vérifier que le nombre de clics par jour est inférieur ou égal au nombre de vues par jour. Allons et vérifions que maintenant en tapant clicks_per_day.values est inférieur ou égal à views_per_day.values. Allez-y et exécutez cette cellule. Maintenant, vous pouvez voir que tout cela est vrai. On dirait que le contrôle de santé mentale est passé. Beau travail. Ensuite, calculons la corrélation entre les entités de notre jeu de données. Si vous vous souvenez de vos statistiques ou de votre classe de probabilité, corrélation vous indique comment une entité change lorsqu'une autre entité change. Supposons que vous ayez deux fonctionnalités, le temps de chargement de la
page et la durée de visionnage vidéo. À mesure que le temps de chargement des pages augmente, vous vous attendez à moins de personnes à regarder la vidéo. Afin de vérifier et de calculer la corrélation, allez de l'avant et tapez df.corr. Ajoutez vos parenthèses pour appeler la fonction et exécutez la cellule. Cette méthode corr calculera les corrélations entre toutes les paires d'entités. Pour un contrôle de santé mentale, assurez-vous que les coefficients de corrélation ci-dessous reflètent notre intuition. Nous nous attendons à ce qu'à mesure que le temps de chargement de
la page augmente, la probabilité de cliquer diminue. Nous pouvons voir que dans la première colonne, deuxième à la dernière rangée, le contrôle de santé mentale est passé. Une autre chose intéressante à noter est que le temps passé à
regarder la section de tarification de la page Web est très, très faiblement corrélé avec le clic. Vous pouvez voir que la corrélation entre la tarification et le clic est de 0,10. D' autre part, le visionnage de vidéos est, relativement parlant, fortement corrélé avec le clic, avec environ trois fois la valeur. En examinant uniquement les corrélations, il apparaît que la page web A, avec la vidéo, est plus efficace. Finalement, calculons le taux de clics ou CTR pour chaque page de destination. Cela nous indique le rapport entre les clics et les vues. Notre objectif ultime est de recommander une page de destination qui maximisera le taux de clics pour le temps de pomme de terre. Commencez par calculer un sélecteur. Avant, nous avons utilisé has_clicked, qui est une colonne qui contient déjà true ou false pour chaque ligne, donc nous pouvons écrire ce qui suit pour vérifier si une ligne est pour la page Web A ou non. Df, entre crochets, et sélectionnez la colonne de la page Web. Maintenant, nous voulons vérifier si cette colonne est égale à A. Si je lance la cellule, vous verrez que la colonne entière est pleine de trues et de falses. Parfait. Nous pouvons maintenant l'utiliser pour sélectionner des lignes dans le bloc de données. Maintenant, nous pouvons utiliser ce sélecteur. Allez-y et copiez cela et ci-dessous dans la cellule suivante, tapez une nouvelle variable viewSa est égale à df, crochet, puis collez dans le sélecteur. Cela sélectionnera toutes les lignes de telle sorte que la page Web de la colonne soit égale à A. Ensuite, répétez ceci pour la page Web B. Nous voulons obtenir toutes les vues pour B. Définissez cette valeur égale au bloc de données, et encore, avec le même sélecteur sauf pour la page Web B. Tapez dans ViewSA « has_ cliqué » .mean. Rappelez-vous des leçons précédentes que nous pouvons appeler print pour réellement produire cette valeur. Nous allons faire la même chose, mais maintenant pour ViewSB « a cliqué » .mean. Allez-y et courez la cellule, et cela semble nous donner la conclusion opposée. Rappelez-vous d'avant, en regardant les valeurs de corrélation, la page Web A était meilleure. Cependant, cela montre que le taux de clics de la page Web A 0,28 ou 28 pour cent est beaucoup plus faible que celui de la page B, qui est d'environ 40 pour cent. Le taux de clics suggère que la page Web B est meilleure. Ces deux premières conclusions semblent se contredire, ce qui signifie que nous devrons creuser plus profondément pour comprendre pourquoi. Ce sont les concepts que nous avons abordés dans cette leçon, et voici un conseil que nous avons mentionné plusieurs fois dans cette leçon, vérifier la santé mentale souvent. Les erreurs courantes incluent un filtrage incorrect, des fautes de
frappe dans les noms de colonnes ou même des noms de colonnes peu clairs. Les vérifications de santé mentale vous aident à identifier, à isoler et à corriger ces erreurs rapidement. Dans certains cas, voici nos premières conclusions. Nous avons d'abord examiné les corrélations et constaté que visionnage et le clic
vidéo sont fortement corrélés. Nous avons également constaté que la lecture et le clic des prix semblent faiblement corrélés. Cela permet d'ajuster l'efficacité de la vidéo ou de la page Web A. Cependant, nous avons calculé le taux de clics et constaté que la page Web B présentait un taux de clics plus élevé. Nous avons vérifié tous nos calculs jusqu'à présent. Alors pourquoi cette divergence ? Cela semble être une contradiction que nous devrons résoudre. Si vous souhaitez accéder aux diapositives et les télécharger, visitez cette URL. Assurez-vous d'enregistrer votre bloc-notes en appuyant sur le fichier, enregistrez. La prochaine fois, nous allons coder certaines visualisations, résoudre ce mystère et préparer des chiffres pour votre dernier pitch.
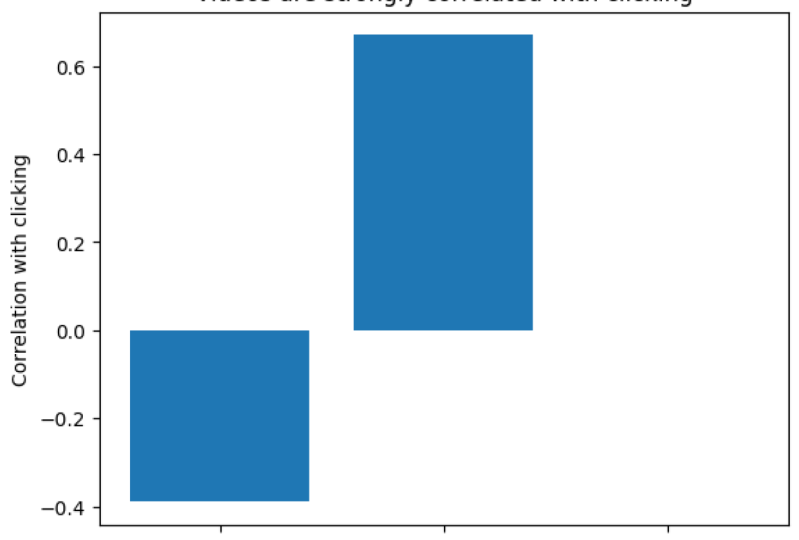
7. Visualiser des données dans Matplotlib: Dans cette étape, vous allez visualiser un jeu de données de trafic Web synthétique que nous avons vu dans les leçons précédentes. Voici les concepts que nous aborderons. Nous allons utiliser une bibliothèque appelée matplotlib pour tracer des utilitaires. Nous faisons ensuite quelques parcelles pour explorer les tendances au fil du temps, allons également raconter des histoires en utilisant des parcelles correctement construites. Le choix de l'intrigue sera intentionnel pour mettre en évidence un plat à emporter que nous souhaitons transmettre. Si vous avez perdu votre dernier carnet de notes ou si vous commencez la classe à partir de cette leçon, accédez à un carnet de démarrage pour la leçon 7 depuis aalv.in/data101/notebook7. Alternativement, vous pouvez utiliser votre propre cahier de la dernière leçon. Une fois que vous accédez à cette URL, vous devriez voir une page comme celle-ci. Allez-y et cliquez sur Fichier et Enregistrer une copie et un lecteur. Cela créera ensuite une nouvelle copie du bloc-notes. Sur cette page, je vais cliquer sur X en haut à gauche pour fermer la barre de navigation. Ensuite, peu importe si vous ouvrez le nouveau bloc-notes ou si vous utilisez votre bloc-notes existant, cliquez sur Exécution et Exécuter tout. Allez-y, puis faites défiler jusqu'au bas. Ici, nous allons commencer par produire les corrélations que nous avons vues auparavant. Allez-y et tapez df.corr avec deux rs, ajoutez vos parenthèses et exécutez la cellule. Remarquez deux choses, le visionnage de vidéos semble être corrélé avec le clic. Nous avons regarder des vidéos et cliquer ici à 0.32. Les prix semblent également être faiblement corrélés avec le fait de cliquer ici, nous avons 0.10. Cependant, la vidéo ne peut être visionnée que sur page Web A et la section de tarification ne peut être lue
que sur la page Web B. Par conséquent, il est plus logique de calculer les corrélations pour chaque page Web séparément. Allez-y et tapez Viewsa.corr. Voici les corrélations pour la page web A seulement, remarquez que la corrélation entre les vidéos et le clic est beaucoup plus élevée à 0,67 que nous le pensions. Ensuite, allez de l'avant et calculez les corrélations pour seulement la page Web B en tapant Viewsb.corr, et maintenant exécutez la cellule. Voici les corrélations pour la page Web B. Notez que la corrélation entre la section de prix et le clic est très faible. Il est beaucoup plus bas que ce que nous pensions. En fait, on peut dire qu'ils ne sont pas du tout corrélés. C' est assez proche de zéro. Notre premier argument pour la page web A est alors que les vidéos sont très indicatives de l'
inscription ou non de l'utilisateur et de la lecture de la section prix ne l'est pas. Une corrélation de 0,67 n'a pas de sens à elle seule, cependant, est-ce élevé ? C' est lent ? Est-ce raisonnable ? Cependant, une corrélation de 0,67 est nettement plus élevée qu'une corrélation de 0,0004. Par conséquent, nous pouvons utiliser un diagramme à barres pour souligner la différence entre les deux. Commencez par importer l'utilitaire de traçage matplotlib, tapez import matplotlib.pyplot comme plt. Maintenant, la première chose que nous allons faire est d'appeler le titre de la méthode pour donner à votre intrigue un titre, tapez plt.title et vous pouvez utiliser le texte que vous voulez entre ces guillemets. Cependant, je vais taper un titre de vidéos sont fortement corrélées avec le clic. Je suggère fortement d'ajouter le plat principal de votre intrigue dans le titre de l'intrigue. Maintenant, nous allons appeler plt.bar. Cela va créer un tracé à barres. Le premier argument de la barre est une liste de chaînes, les noms de chaque barre. Ici, nous allons créer une liste et la chaîne va être le titre. Donc, nous allons dire chargement de la page, dira regarder la vidéo, et la toute dernière barre va être corrélation avec la lecture de la section de prix. Bar prend également une deuxième liste. Nous allons transmettre les chiffres de notre table de corrélation ci-dessus. Au-dessus de notre tableau de corrélation donne une corrélation négative
de 0,39 pour le chargement de la page et le clic. Il s'agit également d'une corrélation de 0,67 pour le visionnage et le clic vidéo. Enfin, nous avons une corrélation de 0.0004 entre la lecture de la section de tarification et le clic. Enfin, nous avons besoin d'un label pour notre axe Y. Donc, nous allons dire l'étiquette y et la corrélation avec le clic. C'est ça. C' est l'argument numéro 1, que les vidéos sont fortement corrélées avec les inscriptions. Allez-y et courez vous-même pour créer votre première intrigue. C' est maintenant votre parcelle de bar. Pour notre prochain point, nous devrons explorer les statistiques quotidiennes comme le taux de clics au fil du temps. Pour ce faire, nous devrons écrire une nouvelle fonction pour calculer les statistiques quotidiennes. Commencez par définir le nom de la fonction, obtenez des statistiques quotidiennes. Donc def get_daily_stats, et nous allons accepter un argument df et comme d'habitude, n'oubliez pas votre deux-points. Cette fonction acceptera qu'un argument appelé df ou DataFrame. La première chose que nous allons regrouper par jour. Pour ce faire, nous allons définir un mérou, et c'est une nouvelle variable qui est égale à pd.grouper, où la fréquence est égale à un jour. Ici, D majuscule signifie jour. PD.Grouper est un utilitaire de panneau générique qui nous
aide à regrouper les lignes dans un DataFrame selon une certaine fréquence. Dans ce cas, notre fréquence est quotidienne. Ensuite, nous allons définir un nouveau groupe de variables est égal à, puis nous allons appeler le DataFrame.GroupBy, mérou. C' est ainsi que nous pouvons calculer des groupes de jours. Enfin, nous allons calculer des statistiques pour chaque groupe. Pour ce faire, nous allons taper quotidiennement est égal à groups.mean, pour chaque groupe, prendre la moyenne de chaque colonne. Enfin, renvoyez les statistiques quotidiennes. Une fois que vous avez terminé avec votre fonction, allez-y et exécutez votre fonction. Maintenant, nous allons utiliser cette fonction pour obtenir des statistiques quotidiennes. Allez-y et tapez les vues quotidiennes A est égal pour obtenir des statistiques quotidiennes, et tapez ou passez toutes les vues de la page Web A. Allez-y et répétez la même chose pour la deuxième page Web B. Tapez get_daily_stats et vues de B. Pour vous donner une idée de ce que contient les vues quotidiennes A, nous allons afficher des vues quotidiennes A. Comme vous pouvez vous y attendre, si vous exécutez la cellule, vous obtiendrez un DataFrame où vous avez maintenant une ligne pour chaque jour et les statistiques journalières pour cette journée. Comme le nombre moyen de secondes vidéo visionnées, le temps moyen de chargement de la page et le pourcentage de spectateurs qui ont cliqué. Maintenant, nous allons explorer une autre parcelle, un tracé en ligne. Allez-y et tapez plt.title pour donner un titre à votre nouvelle intrigue. Dans ce cas, le titre de notre intrigue sera le taux de clics au fil du temps. Heureusement, matplotlib s'intègre assez bien avec les pandas. Tout ce que nous devons faire est de dire à matplotlib quelle colonne nous voulons tracer. Allez-y et tapez plt.plot et passez dans l'une des colonnes de vues quotidiennes A, dans ce cas, la colonne va être cliquée. Maintenant, on peut normalement s'arrêter ici. Cependant, nous voulons étiqueter chacune des lignes de notre tracé de lignes. Dans ce cas, ajoutez une virgule et tapez une étiquette égale à A. Cette syntaxe, étiquette égale à A n'est pas quelque chose que vous avez vu auparavant. Ceci est connu sous le nom d'argument de mot clé. Nous allons passer en revue les détails d'un argument de mot clé pour l'instant,
ce qui est important, c'est que c'est ainsi que vous étiquettez les lignes dans un tracé de lignes. Allons de l'avant et maintenant répéter la même chose pour la page Web B. Tapez dans plt.plot Daily_ViewsB, et sélectionnez la colonne a cliqué. Enfin, la virgule et l'étiquette sont égaux à B, et ces étiquettes sont la deuxième ligne comme B. Ensuite, ajoutons notre légende à l'intrigue. Tapez plt.plot légende appeler la fonction, et c'est tout. Nous allons maintenant ajouter deux lignes supplémentaires pour étiqueter nos axes. Tapez plt.xlabel et l'axe des x sera les dates, et l'axe des y sera le taux de clics. Alors allez-y et courez la cellule et c'est fou. Regardez combien de taux de clics pour la page Web A, la ligne bleue diminue au fil du temps. Je me demande ce qui est arrivé Examinons d'autres statistiques. Nous allons refaire le même code, mais cette fois pour les temps de chargement de la page, nous allons copier et coller le contenu de cette cellule, puis remplacer des parties de celle-ci qui auront besoin de voir les temps de chargement de la page. Allez-y et copiez et collez. Nous allons maintenant remplacer ce titre par des temps de chargement de page Web. Ensuite, ci-dessous, nous allons remplacer la colonne has_clicked par la colonne de chargement de page pour les deux. Ensuite, cela change notre axe y, donc au lieu de cliquer sur notre axe y, nous avons maintenant des temps de chargement des pages. Entre parenthèses, je vais ajouter les unités pour cet axe. Allez-y et courez la cellule et whoa, regardez ça. L' heure de la page Web, pour la page Web A en bleu tire comme un fou. Donc, notre deuxième argument pour la page Web A est que temps de chargement
anormalement lents semblent endommager involontairement son taux de clics, ce qui suggère qu'il y a un potentiel incalculable pour la page Web A. Pour quantifier l'ensemble de la page Web A taux de clic est, nous pouvons quantifier les temps de chargement de la page dégâts sur le taux de clic. Pour ce faire, nous tracons d'abord la relation entre les taux de clics et les temps de chargement payés. Ici, allez de l'avant et tapez les vues de A page_load_ds. Nous allons créer une nouvelle colonne qui contiendra temps de chargement
des pages et leurs taux de clics pour toutes les 20 millisecondes. Allez-y et tapez maintenant les vues de A page_load_ms. On va diviser le plancher par 20. Donc, une division de plancher signifie que si vous avez une fraction, vous arrondissez à l'entier suivant. Une fois que vous avez obtenu cela, continuons et multiplions à nouveau par 20, et ce que cela signifie fondamentalement, c'est que toutes vos valeurs sont par incréments de 20. Donc avant, vous auriez pu avoir une valeur de 34, mais maintenant 34 étage divisé par 20 vous donnera 1, puis multipliez-le par 20 vous donnera 20. Toute valeur comprise entre 20 et 39 sera égale à 20. Toute valeur comprise entre 40 et 59 deviendra 40, et ainsi de suite et ainsi de suite. Cela regroupe efficacement tous les temps de chargement de nos pages en groupes de 20 millisecondes. Maintenant, allons de l'avant et tapez le chargement de la page est égal à ViewSa.set_Index. Donc celui-ci a changé l'index. En d'autres termes, cela changera la colonne que nous pouvons facilement trier ou regrouper. Allez-y et tapez page_load_ds, qui est notre nouvelle colonne. Ensuite, nous allons calculer des groupes pour chaque temps de chargement de page binée. type dans le chargement de la page est égal à ViewSa.GroupBy page_load_ds. Assurez-vous d'avoir ces crochets juste ici. C' est vraiment important pour cette fonction. Cela calculera les groupes pour chaque temps de chargement de page binée. Maintenant, pour chaque groupe, nous allons calculer les statistiques moyennes. Alors allez-y et tapez le chargement de la page est égal à page_load.mean, et cela calculera les statistiques moyennes pour chaque groupe. Enfin, nous voulons trier toutes les données
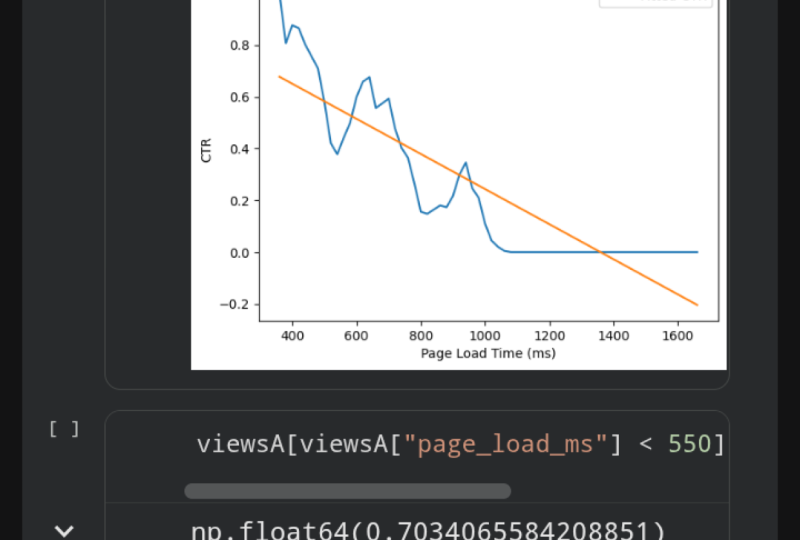
en fonction du temps de chargement de la page binée en appelant l'index de tri de points. Ce DataFrame vous indique maintenant le taux moyen de clics pour chaque temps de chargement de page. Encore une fois, si nous sommes submergés par cette fonction ou par la cellule, c'est tout à fait correct. Tout ce que vous devez vous rappeler, c'est le concept général de ce que nous avons fait ici. Ce que nous avons fait, c'est que nous avons d'abord regroupé toutes les valeurs en groupes de 20 millisecondes. Ensuite, nous avons calculé des statistiques pour chacun de ces groupes. Ces deux choses sont parfaitement utilisables. Alors maintenant, voyons à quoi ressemble ce DataFrame. Tapez chargement de page et exécutez la cellule. Ici, nous pouvons maintenant voir les statistiques pour chacun de ces compartiments de 20 millisecondes. Vous pouvez maintenant créer un tracé de lignes comme avant de contourner la colonne DataFrame. Dans ce cas, nous nous soucions du taux de clics. Alors allez-y et tapez plt.plot et chargement de la page has_clicked, et cela tracera l'impact des temps de chargement de la page sur le taux de clic. Allez-y et appuyez sur « Run ». Maintenant, l'axe x est le temps de chargement de la page en millisecondes, l'axe y est le taux de clics. Comme vous pouvez vous y attendre, le taux de
clics diminue à mesure que le temps de chargement de la page augmente. Ensuite, ajustons une ligne à cela pour obtenir un nombre approximatif vitesse de clic à travers diminue à mesure que les temps de chargement de la page augmentent. Allez-y et importez une autre bibliothèque appelée NumPy. Cette bibliothèque a un algorithme d'ajustement de ligne que nous pouvons utiliser. Allez-y et tapez m, b. En d'autres termes, la pente et le biais de votre ligne sont égaux à une fonction NumPy qui correspondra réellement à une ligne pour nous à un tas de points, appelez np.polyfit et passez dans les valeurs x, qui est tous les temps de chargement de la page. Donc, ici, vous avez page_load.index, et le deuxième argument est le taux de clic, qui est le chargement de la page, puis has_clicked. Le dernier argument est le degré d'un polynôme. Dans ce cas, nous voulons des lignes droites. Le polynôme du degré 1 est tout ce dont nous avons besoin. Maintenant, nous pouvons enfin résumer la ligne d'ajustement. Prenez la pente. Rappelons que la pente est montée sur course ou alternativement, le changement dans y sur le changement dans x. ici, y est le taux de clic et x est le temps de chargement de la page. Donc, la pente est le changement de taux de clics par changement dans le temps de chargement de la page. Nous pouvons multiplier par 100 pour obtenir le changement de
taux de clics par 100 millisecondes de temps de chargement de page. Tapez m fois 100 et allez-y et exécutez la cellule. Ici, nous obtenons 0.068 négatif. Cela signifie que chaque 100 millisecondes plus lente de chargement de page coûte sept pour cent de trafic. Nous faisons quelques simplifications assez radicales ici, mais cela transmet le point que les temps de chargement des pages
plus lents nuisent considérablement au taux de clics pour la page Web A. J'accompagnerais n'importe quelle présentation qui cite un chiffre comme celui-ci avec un complot à expliquer. Faisons un tracé pour que les spectateurs puissent juger eux-mêmes de la façon dont cette ligne correspond aux données. Dans la cellule suivante, nous commencerons par un titre, plt.title. Dans ce cas, notre titre sera toutes les 100 millisecondes de temps de chargement
de page coûte sept pour cent taux de clics . Tracez la ligne d'avant dans la cellule précédente une fois de plus. Ici, le chargement de la page has_clicked et l'étiquette est le taux de clics. Tracez ensuite la ligne d'ajustement. Ici, nous appelons page_load.index et rappelons l'équation pour une ligne est m fois x plus b. Donc ici, nous allons avoir les m fois les valeurs x, juste page_load.index plus b. Nous allons aussi ajouter une étiquette ici. L' étiquette sera la vitesse de clic ajustée. Allez-y et ajoutez maintenant une étiquette pour votre axe X. Ce sera le temps de chargement de la page en millisecondes et nous allons également étiqueter l'axe Y. Voici le taux de clics. Enfin, ajoutez votre légende et exécutez votre cellule. Ceci conclut notre deuxième argument. Nous pouvons maintenant voir que le taux de clics
diminue beaucoup en raison de l'augmentation du temps de chargement des pages. Ensuite, nous voulons comprendre, pour notre troisième argument, que se passe-t-il si la page Web A n'avait pas été affectée par un temps de chargement de page plus lent, que pensez-vous que le taux de clics de la page A aurait été ? observant le graphique ci-dessus, plus haut, ici, nous remarquons que les temps de chargement de page de la page A
semblent tous tomber entre 400 et 550 millisecondes avant qu'il ne semble sauter. Par conséquent, nous calculerons le taux de clics pour la page Web A en utilisant uniquement ces données Nous allons
donc sélectionner toutes les vues dont le temps de chargement de la page est inférieur à 550 millisecondes. Allez-y et tapez les vues A et nous allons sélectionner toutes ces colonnes, tous les temps de chargement de la page qui sont inférieurs à 550. Cela nous donnera seulement les lignes dont le temps de chargement de la page est inférieur à 550 millisecondes. Maintenant, continuons et sélectionnons si oui ou non cette ligne a été cliquée, puis calculons le taux de clics moyen. Allez-y et courez la cellule. C' est un taux de clics de 70 %, assez incroyable. À des fins de comparaison, calculons le taux de clics pour la page Web B. Sélectionnez la colonne de clic et calculez à nouveau la moyenne. Lancez la cellule, et cela nous donne juste un taux de clics de 40 pour cent. Bref, la page Web A aurait dépassé la page Web B d'une grande marge, de 40 %. Cependant, pour vraiment transmettre cette idée, nous aurons besoin d'un tracé de ligne à nouveau. Dans cette cellule, nous utiliserons les fonctions que nous avons définies précédemment. A, obtenez toutes les informations de clic pour chaque page Web, puis B, nous calculerons le nombre de clics par jour pour chaque page Web. Allez-y et définissez une nouvelle variable, ClickSA est égal à, puis obtenez seulement les événements de clic de toutes les vues de la page Web A. Cela ne prend en compte que les clics pour la page Web A. Ensuite, nous allons calculer quotidiennement statistiques. Donc clickSadaily est égal à et puis events_per_day et passe dans la variable que nous venons de définir, cela calcule le nombre de clics par jour pour la page Web A. Allez-y et faites de même pour la page Web B. ClickSB est égal à tous les clics pour la page Web B, puis calculer le nombre de clics par jour pour la page Web B. Ici, ClicksBDaily est égal à l'events_per_day de ClickSB. Pour voir à quoi ressemble ClickSaily, allez de l'avant et tapez ce nom de variable une fois de plus et exécutez la cellule. Ici, nous obtenons pour chaque jour, le nombre de clics. Maintenant, notre dernier morceau de code dans cette dernière cellule. Nous allons en fait tracer ces données, taper plt.title pour donner à cette intrigue un titre, « La page Web A aurait pu augmenter la CTR de 30 pour cent. » Allez-y et maintenant tracez les données que nous venons de calculer, le nombre de clics par jour. Comme avant, nous allons étiqueter cette ligne A. Répétez la même chose pour B, donc clicksBDaily et label est égal à B. Ensuite, notre troisième ligne pour ce tracé sera le nombre projeté de clics pour notre page Web A. Nous allons multiplier les vues par jour par 0,7, puis nous allons multiplier par 0,5 parce que chaque page Web n'a en fait que la moitié du trafic. Ensuite, nous allons taper l'étiquette égale à A projeté, donc estimé. Ceci conclut notre ligne. Allons maintenant et étiquetons l'axe, comme nous le faisons toujours. Nous allons étiqueter la date, puis nous allons étiqueter les clics, puis ajouter la légende. Enfin, cela conclut notre dernière intrigue, allez-y et exécutez-le. Nous pouvons voir ici dans la ligne verte que nos clics projetés par jour pour la page web A auraient été insensés, cela aurait été beaucoup plus élevé que la page B. En conclusion, revenons aux diapositives. Nous avons abordé plusieurs sujets dans cette leçon : matplotlib, intrigue, et comment raconter une histoire. En résumé, voici nos conclusions finales. Nos premières conclusions suggéraient que la page Web B était meilleure, heureusement, nous avons maintenant corrigé cette erreur. En résumé, nous avons produit trois chiffres de qualité qui appuient notre décision commerciale axée sur les données. En résumé, nous vous recommandons de choisir la page Web A avec la vidéo d'information, il y a trois raisons. Regarder une vidéo informationnelle est fortement corrélée avec la cuisson de l'inscription. En revanche, la lecture de la section de tarification a une incidence
presque nulle sur le fait que l'utilisateur clique ou non pour s'inscrire. En commençant par le haut à gauche, nous avons ensuite montré que le taux de clics de la page Web A a chuté précipitamment. En bas à gauche, nous avons montré que le taux de clics abandonnés de la page Web A
se produisait en même temps que les temps de chargement de page de la page Web A augmentaient soudainement. Sur la droite, nous montrons ensuite que l'
augmentation du temps de chargement de page de la page A a entraîné des baisses drastiques du taux de clics. Cela suggère que le taux de clics global de la page Web A ne peut être fiable. Enfin, nous projetons le taux de clics de la page Web A tout au long l'expérience si les temps de chargement des pages n'avaient pas augmenté deux mois après l'expérience. Nous pouvons voir que la page Web A aurait constamment maintenu un taux de clics de 30 pour cent plus élevé que la page Web B, justifie notre recommandation finale de la page Web A. Cela conclut la recommandation commerciale axée sur les données. Notre dernier conseil, connaître vos types de parcelles, la bonne parcelle peut raconter une histoire. Vous devez savoir pour n'importe quel point que vous voulez souligner, quelle intrigue est la mieux adaptée pour souligner ce point. N' hésitez pas à ajouter des annotations supplémentaires, modifier les couleurs ou à donner le titre du tracé de manière appropriée pour vous aider. Si vous souhaitez accéder à ces diapositives et les télécharger, visitez cette URL. Essayez de tracer vos propres données pour voir s'il y a des informations cachées. Si vous cherchez le type de parcelle parfait, consultez les exemples de Matplotlib. L' objectif n'est pas de cliquer sur tous, mais votre objectif est de savoir quelles parcelles vous aideront à raconter la bonne histoire. Parfois, la navigation sur cette page peut vous donner juste assez d'inspiration. Félicitations, ceci conclut votre première étude de cas d'un test AB pour deux pages Web. Ensuite, nous discuterons des prochaines étapes pour que vous puissiez continuer à en apprendre davantage.
8. Conclusion: Félicitations pour avoir terminé les premières étapes de l'analyse des données. Nous avons abordé un certain nombre de sujets : la lecture, nettoyage, l'analyse et la présentation des données. Vous avez également couvert un certain nombre de bibliothèques différentes pour l'analyse des données, y compris Matplotlib pour tracer des données, et Pandas pour conserver des données. C' est un ensemble d'outils divers sous votre ceinture aujourd'hui. C' est la ligne de frappe, le codage avec des données est une compétence qui, lorsqu'il est fait de la bonne façon, peut raconter des histoires convaincantes. Quoi de plus ? Vous avez maintenant le début de cette compétence. Quoi de plus ? Vous avez maintenant les principes fondamentaux pour raconter des histoires convaincantes, un ensemble d'outils pour communiquer des données complexes. Si vous avez une meilleure façon de visualiser ce jeu de données ou un jeu de données à visualiser, assurez-vous de charger vos chiffres dans l'onglet Projets et ressources. Assurez-vous d'inclure à la fois la figure et une légende décrivant ce que la figure tente de nous dire. Si vous souhaitez accéder aux diapositives ou au code rempli, assurez-vous de visiter cette URL. Si vous souhaitez en savoir plus sur la science des données ou l'apprentissage automatique, assurez-vous de consulter mon profil Skillshare avec 101s et d'autres sujets comme la vision par ordinateur. Merci et félicitations encore une fois pour raconter votre toute première histoire avec des données. Jusqu'à la prochaine fois.
 Alvin Wan, Research Scientist
Alvin Wan, Research Scientist