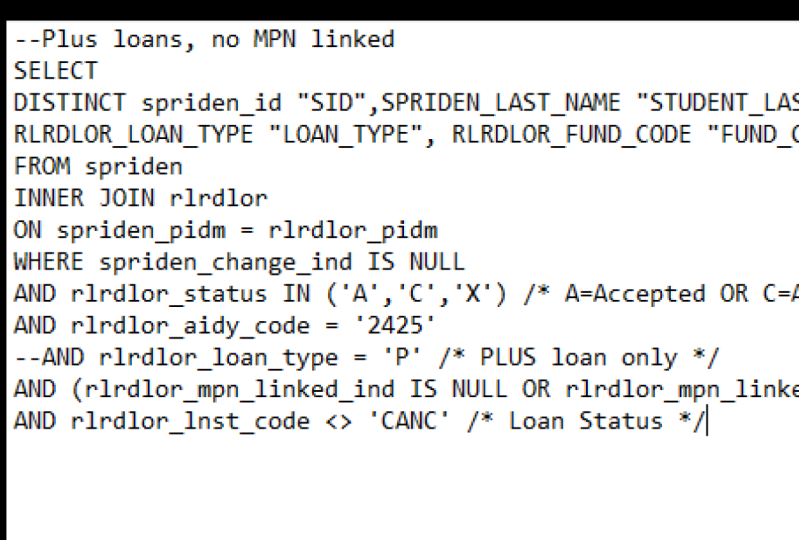
Transcription
1. SQL 1 Intro: Bonjour, je m'appelle Peter. Dans ce cours, nous
allons parler de la suite et de la manière d' extraire des données ou de les extraire d'une base Les
entreprises collectent
davantage de données
sur les clients, sur leurs propres produits et
sur le monde en général. Et il devient de plus en plus utile de savoir comment obtenir
ces données, comment créer des rapports
et prendre des
décisions significatives
à partir de ces données. Vous n'avez plus besoin d'
être ingénieur des données pour découvrir une base de données SQL, sachant comment créer
vos propres rapports, cela peut vous aider à
répondre aux questions, comprendre vos clients et produits mieux et
faites avancer votre carrière. Cela permet également de
mieux comprendre le
fonctionnement des systèmes
informatiques et le fait de ne pas le faire n'est pas possible dans le monde
de la programmation. Ensemble, nous examinerons
quelques exemples impliquant un magasin de crème glacée qui pose de nombreuses questions
concernant ses données. Vous n'avez besoin d'aucune expérience préalable en
programmation
pour suivre ce cours. Sql lui-même est conçu
pour être assez lisible, il devrait
donc être au moins une bonne introduction
à la programmation. C'est également un excellent moyen de
commencer si vous souhaitez devenir analyste de
données ou site. Ce cours abordera la requête de sélection de
séquences, qui sert uniquement à extraire des
informations d'une base de données. Nous n'expliquerons pas
comment saisir des données, comment supprimer des données
ou comment modifier des données. Nous
travaillerons toutefois sur la manière de traiter les données, les
analyser, de les filtrer et de les relier
à d'autres données. Toujours dans le domaine de la base de données, je travaille dans des bases de données
SQL depuis 2010, soit sur mes propres projets, poursuivre
ma carrière, mon travail, soit simplement pour prendre
des décisions basées sur les données. Il existe de
nombreux langages de
programmation basés sur SQL . Une fois que vous savez quoi, il est
assez facile de faire la transition qui connecte un et ce ne seront quelques mots clés, c'est
un peu fastidieux.
Soyons différents, que vous utilisiez le tableau de bord ou les
serveurs Microsoft de la même manière, la requête réellement
exécutée sera identique ou très
proche de la même. Je suis ravie
d'enseigner ce cours. Et j'espère vous voir
dans la prochaine vidéo.
2. SQL 2 Sélectionner: Les bases de données SQL
sont essentiellement des feuilles Excel
très rapides et très grandes. Vous avez différentes colonnes
qui définissent ce qui peut entrer dans la base de données, puis des roses qui remplissent ces colonnes
avec des données réelles. Vous pouvez également avoir
plusieurs tables dans une base de données, tout comme Excel peut avoir plusieurs feuilles
dans une feuille de calcul. Donc, pour notre première requête, nous allons
obtenir toutes les lignes et toutes les colonnes d'
une table spécifique. Passons donc
à l'émulateur et vous pouvez le trouver sur
ce site Web ici. Ajoutez également un lien dans
la description au cas où vous ne
voudriez pas le saisir. Nous allons donc
commencer par le Queer qui y est déjà renseigné, étoile ou
un
astérisque dans les boutiques. Ainsi, lorsque nous l'
exécutons, toutes les colonnes de la table des magasins ainsi que
toutes les lignes de cette table seront
renvoyées. Disséquons donc cela
et passons en revue chaque partie. Select est le mot clé que nous utilisons pour extraire
ou obtenir des données de la base de données si nous voulons supprimer, insérer
ou modifier des données, celles qui contiennent des mots clés
différents. Donc, tant que nous
commençons par sélectionner, nous allons obtenir des données,
la base de données sans toucher à ce qu'elle contient, nous ne modifierons pas ce qu'
elle contient. Ici, une étoile ou un astérisque, généralement appelé étoile en
programmation, est un joker. Cela signifie tout saisir. Il s'agit donc généralement
des colonnes ici, nous saisissons
donc simplement
toutes les colonnes. From est l'autre mot clé
qui nous permet de savoir où se trouvent ces données ou où se trouvent ces données ou
à partir de quel tableau voulons-nous les récupérer ? Et stores est le nom de notre table. Donc, cette table ici
s'appelle magasins. Nous obtenons donc toutes
les lignes et toutes les colonnes
du tableau des magasins. Disons que nous voulions juste
des colonnes spécifiques car cela semble un peu trop long. Nous pouvons simplifier cela. Disons donc que nous voulons simplement cela, la rue, la ville et l'État. Nous pouvons mettre ces trois noms de
colonnes au lieu du caractère générique qui les
sépare par une virgule. Ensuite, nous pourrons l'exécuter. Maintenant, nous nettoyons beaucoup plus
une donnée et nous
examinons simplement les informations
que nous voulons obtenir de manière syntaxique Elles sont généralement
séparées sur une nouvelle ligne, mais cela n'est pas nécessaire pour l'exécution. C'est juste pour donner l'impression que c'est sympa
de changer de table. Nous allons simplement
le remplacer. Si nous rechargeons la page, nous verrons les trois
tables qui figurent dans inventaire et les saveurs de
ce magasin de base de données. Donc, au lieu de sélectionner une
étoile dans les magasins, examinons les saveurs. Ici, nous pouvons voir que
nous avons trouvé nos trois saveurs sur la table de nos magasins, et nous pouvons retourner dans les magasins. Jetez un œil à ce
tableau à la fin de ce cours Nous verrons comment combiner les
données de deux tables. Mais pour l'instant, nous ne
travaillerons qu'un par un. Quelques points secondaires à noter ici, sql ne distingue pas les majuscules, donc cela peut être en minuscules et cela
fonctionnerait toujours très bien. Ou le tableau pourrait être
entièrement en majuscules et cela
fonctionnerait très bien. Habituellement, les commandes SQL
elles-mêmes sont en majuscules et les
tables et
les colonnes sont en minuscules pour
faciliter la lecture. Utilisez donc ce que vous avez appris pour créer une requête qui sélectionne toutes les saveurs et affiche le nom de
la saveur et la
date à laquelle elles ont été créées. Je vais faire une pause de quelques secondes. Allez-y, mettez la vidéo en pause dès maintenant et donnez-vous le
temps de la reconstruire. Très bien, allons-y et
construisons cette requête ensemble. Donc, généralement, si je ne connais le nom de la colonne ou si je ne suis pas
sûr de son orthographe. Je vais juste
commencer par le joker et passer à la bonne table. Nous allons donc sélectionner une étoile parmi saveurs et un TIC dont le nom ou le titre de La saveur
s'appelle Nom et que la création
vient d'être créée. Je vais donc
les changer au profit de je vais les
changer. Faisons donc le nom créé par une virgule. Allons-y, exécutons-le. Et puis nous avons
nos trois saveurs et les trois dates
auxquelles elles ont été créées.
3. SQL 3 OÙ: Obtenir des données à partir d'un
tableau est donc plutôt cool, mais disons que vous n'avez besoin que de
quelques-unes de ces lignes pour apparaître. Comment le filtreriez-vous ? C'est là que la
clause where est utile. C'est donc ici
que vous pouvez filtrer les opérateurs mathématiques
spécifiques qui sont mathématiques de
base que vous
pouvez y mettre. Donc, par exemple, si nous
regardons le tableau de nos magasins, il y a beaucoup de magasins
différents. Disons que nous voulons simplement avoir les magasins les plus rentables. Nous pouvons filtrer
les cas où le bénéfice est
supérieur à un certain nombre. Faisons donc 150 000. Nous n'avons
que les trois magasins les plus rentables. Le type de filtrage
que vous effectuez dépend des données de la colonne
que vous filtrez. Donc, comme il s'agit d'un nombre, je peux utiliser
supérieur, supérieur ou égal à. Ou je pourrais même écrire articles peu rentables d'un montant inférieur
ou égal à 150 000. Je pourrais également vérifier les conditions
exactes où le bénéfice est exactement de 8 000. Il s'agit donc d'un filtrage
basé sur un nombre. Passons à une
chaîne ou à un morceau de texte. Parfois, on les
appelle des cordes. Jetons donc peut-être un coup d'
œil aux États-Unis. Je pourrais utiliser l'opérateur
égal et obtenir tous les États
de Pennsylvanie. Mais en général, lorsque je
travaille avec des textes, j'aime plutôt l'utiliser. Alors, est-ce que c'est la même
chose ? Il se lit simplement plus facilement si vous utilisez des textes
et des sous-numéros. Si je veux le
contraire, je peux y ouvrir pour avoir accès à tous les magasins
où l' État n'est pas la Pennsylvanie, dans ce cas,
il y a juste New York. En général, lorsque je
travaillais avec des textes, j'utilisais Like pour filtrer mes données. Cela me permet de trouver
des sous-chaînes dans la chaîne elle-même ou de rechercher des mots-clés spécifiques
dans un morceau de texte. Disons que je veux que tous
les États qui
ressemblent à des lampadaires principaux
me permettent de rechercher une sous-chaîne
ou un mot dans un
texte afin de trouver toutes les
rues du nord. Comment cela fonctionne, c'est qu'il recherche première chaîne, donc
les guillemets simples, me font savoir s'
il y a un bout de texte ou une chaîne, puis le signe pour cent est
comme le caractère générique pour, juste par exemple, le fait que l'astérisque
est le caractère générique pour sélectionner le
signe de pourcentage signifie que tout
peut apparaître ici un certain nombre de fois jusqu'à ce que vous trouviez la
chaîne North Loops, puis elle peut se terminer
par ce que vous voulez. Si vous voulez qu'il indique «
terminer par North Avenue
», vous devez enlever le signe « pourcentage » à la fin,
puis il doit se terminer North Avenue, ou
disons que nous voulons
commencer par 100 et peu
importe la rue c'est le cas. Recherche en Bosnie où elle
commence par 100 et se
termine par n'importe quoi d'autre. Donc, jusqu'à présent, nous avons passé
en revue les chiffres et textes. Examinons également les
dates et les valeurs nulles. Jetons donc un coup d'
œil à toutes les données. Pour ce faire, je vais
commenter ma clause where. Donc, en plaçant deux
tirets devant elle,
cela indique simplement au compilateur ou à la base de données d'
ignorer cette ligne. Donc, en ignorant ma
clause where, je à nouveau obtenir
toutes les données et
maintenant je peux les consulter. Jetons un coup d'œil à tous les magasins ouverts
depuis 2019. Je vais donc filtrer les cas où ma date d'ouverture est
supérieure à 2019. Nous devons maintenant choisir une date
exacte en 2019. Donc je vais faire Twain le 18
janvier, le jour de l'année, du mois. Je te verrai. Trois histoires ont été
révélées depuis janvier. Les dates fonctionnent beaucoup comme les chiffres. Je peux donc également faire une valeur
supérieure ou égale à cette date. D'accord ? Fais le contraire. Et je peux dire où la
date d'ouverture est inférieure à cette date. Ce sont donc les premiers
magasins que j'ai ouverts. L'autre chose que vous avez
peut-être remarquée est que cette valeur nulle dans certaines de ces dates peut se trouver dans n'importe quel type de colonne. Il
n'est pas nécessaire que ce soit des rendez-vous. Cela m'a coûté, les numéros sont taxés. Et cela
signifie qu'il
n'y a aucune donnée vide dans
cette ligne. Il sera très
utile parfois bases de données ne
suppriment pas les informations, mais qu'elles déduisent la suppression en
fonction de ce qui est nul. Donc, par exemple, au lieu de supprimer la rue
fermée dans le Queens, je suppose que cette porte est ouverte si elle n'a pas de date de fermeture. Voyons donc où
toutes mes boutiques sont nulles. Et nul devrait être, oh désolé, nous sommes fermés est nul. Ce sont donc tous les
magasins qui sont ouverts. Et disons que je veux
trouver tous mes magasins de vêtements. Je vais dire que
là où ils ne sont pas traction
me donnera toujours Y1 de près. OK, jusqu'à présent, nous
en avons beaucoup parlé. Nous avons expliqué comment
filtrer les nombres, comment filtrer
les dates et comment
filtrer le texte ou les chaînes de caractères. Le dernier élément que nous
allons ajouter ici
consiste à ajouter deux filtres
à la même requête. Voyons donc comment trouver
tous les
magasins les plus rentables de New York. Je vais commencer
par filtrer les endroits où l'État est égal à New York. Pour ajouter un autre filtre, je vais ajouter, puis je pourrai ajouter un deuxième filtre comme
je le ferais pour le premier. Donc, dans ce cas, je
vais vérifier quel bénéfice est supérieur à 100 000. Et je peux y ajouter autant de
filtres que je veux. Je peux également ajouter un autre
filtre pour vérifier si la date de clôture n'est pas nulle. Il est conseillé de toujours
ajouter quelques conditions,
même si vous n'en avez pas
besoin pour vous
assurer de
filtrer correctement les données. Pour cette vidéo,
le défi sera donc de
répertorier tous les magasins qui ont ouvert leurs portes à
New York depuis 2020. Faites une pause ici pour vous donner quelques minutes
pour le découvrir. Nous allons donc d'abord filtrer où l'État est
égal à New York. Et nous allons également filtrer la
date d'ouverture supérieure
à 2020, et nous devons simplement
commencer le 1er janvier. En fait, nous voulons
ceux du 1er janvier. Faisons donc plus
ou moins et nous obtenons
un 118 à East River, Philadelphie, New
York, un genou libre. C'est en fait une ville
de New York. C'est tout petit.
4. SQL 4 Types de données: Avant de continuer,
je voudrais passer en revue un autre type de données, à savoir que les booléens
et booléens sont vrais ou faux.
Ils sont allumés ou éteints. Ils sont comme des interrupteurs. Dans notre tableau des saveurs, nous avons notre colonne des meilleures ventes, et il s'agit d'un booléen. Il est également parfois
considéré comme un ou un zéro, ou un est vrai. Zéro est faux. Donc, pour filtrer, je peux sélectionner où se trouve mon
best-seller. Ou je pourrais aussi mettre la
vérité ici. Les articles qui ne sont pas des best-sellers, je peux
filtrer ceux qui sont faux. Je pourrais aussi changer cela
pour qu'il soit égal à zéro. Les milliards sont donc assez simples, mais la façon dont vous
les filtrez semble un
peu chargée selon la méthode
que vous préférez. Rangée. Chaque colonne peut être
filtrée différemment
selon le type
de données qu'elle stocke. Et cela est défini lorsque administrateurs de
votre base de données
configurent la base de données. Si vous ne savez pas quel est un type de colonne
spécifique, vous pouvez exécuter différentes commandes
dans SQL pour
extraire ces informations de la base de données. Parce que c'est l'une des
choses qui va
varier en fonction de la
langue dans laquelle vous parlez. C'est aussi quelque chose
dont je me souviens toujours. C'est quelque chose que je
dois rechercher sur Google à chaque fois. Et généralement, vous écrivez simplement informations de
table pour le langage SQL. Je rechercherais des
informations sur Google pour SQL Light. J'ai donc reçu cette commande. Je vais remplacer cette partie
par mes saveurs de table. Ensuite, j'ai une table
à propos de ma table. Voici donc les informations
sur les saveurs de table. Ici, je peux voir les
différents noms de colonnes dans mon tableau des saveurs. Je peux voir leur type. Integer est ici une
façon de programmer pour dire un nombre. Texte signifie texte ou chaîne de caractères. Cela peut aussi parfois
ressembler à un caractère n var. Et c'est juste une ancienne
façon de dire un texto. flottant est un autre type de nombre. Le nombre entier doit être un nombre entier alors qu'
un nombre flottant peut être un nombre décimal. Nous avons notre date et puis nous avons aussi le booléen dont
nous venons de parler. Le dernier sujet que je souhaite
aborder dans cette vidéo est le concept de données implicites
ou explicites. C'est très
utile à garder à l'esprit si vous expérimentez
dans une nouvelle base de données et que vous ne savez pas exactement ce que signifient
les différentes colonnes ou comment obtenir la datation exacte. Un. Les données explicites sont des données qui sont clairement
indiquées dans la journée. Ainsi, dans notre exemple, si nous examinons
le tableau de nos magasins, il peut être explicitement
indiqué que l'État est la Pennsylvanie
ou New York. Cependant, cela implique
implicitement que le magasin est toujours ouvert en l'absence
de date de fermeture. Parfois, la façon
dont nous concevons les données n'est pas la meilleure façon de les
stocker dans une base de données, par exemple le
cas du magasin, alors qu'il serait
intéressant d'avoir un booléen ici, si le magasin est ouvert ou fermé. Cela signifierait également que deux colonnes
vous
disaient la même chose. Ils ont donc toujours
dû être les mêmes. Et s'il y a
une différence, cela pourrait entraîner des problèmes que vous pourriez avoir une mauvaise perception de vos
données. Il vaut donc mieux avoir
une colonne et tout le reste. Alors, prenons juste une chose
à garder à l'esprit. J'espère que cela vous aidera à
explorer vos propres bases de données.
5. SQL 5:6 Triage et regroupement: Jusqu'à présent, nous avons
travaillé sur des tableaux contenant un très petit
nombre de lignes, afin que vous puissiez
tous les voir sur un seul écran. C'est rarement le
cas dans la nature avec des données
vraiment importantes
dont nous avons
parlé dans l'introduction
de cette vidéo. En général, les tables
peuvent contenir des milliers,
voire des millions de lignes. donc très
utile de placer
les données que vous souhaitez en haut de la page pour que vous puissiez les
voir. C'est là que le classement ou le tri de nos données s'
avérera utile. Pour ce faire, après
notre clause where, nous pouvons commander nos données
filtrées. Alors, par exemple, jetons un coup d'
œil à toutes nos saveurs. Maintenant, si nous voulions
les classer en fonction de leur coût, c'est-à-dire trier nos données. Nous allons utiliser le biais de commande. Je vais vous dire de
commander cette table. Ensuite, je choisis une colonne
spécifique selon laquelle je souhaite
trier le tableau. Je vais donc trier par
coût et par défaut, vous pouvez voir que c'est déjà
trié par ordre croissant, ce qui signifie que les nombres augmentent au fur
et à mesure que vous
descendez pour le modifier ou par ordre décroissant, je peux faire DESC comme mon raccourci pour lui indiquer que je veux que cette colonne soit classée
par ordre décroissant. Et maintenant, j'obtiens le coût le plus élevé premier et le coût le plus bas en dernier. Voyez si nous pouvons l'utiliser sur le tableau des magasins pour répertorier
tous les magasins de New York, en les classant d'
abord par magasin le
plus rentable et par
magasin le moins rentable de New York en dernier. Très bien, construisons
cette carrière ensemble. Jetons donc d'abord un coup d'œil au tableau de
ces magasins et nous n'allons pas
commander par quoi que ce soit. Nous allons donc sélectionner
une étoile dans les magasins. Nous avons notre État et
nos profits. Commençons donc par notre filtre. Nous allons donc filtrer où l'État est égal à New York. Et généralement, j'
utilise des guillemets simples. Mais cela donne les
guillemets doubles de A. Cela dépend simplement de la
langue dans laquelle vous parlez. Sql Light peut utiliser les deux. Certains préfèrent uniquement les
guillemets simples ou doubles. Et maintenant, nous voulons
les commander par le prophète, sauf que ce n'est pas le bon ordre. Nous allons donc procéder
par ordre décroissant pour placer les plus rentables en premier
et les magasins les plus rentables en dernier. Maintenant que nous pouvons classer nos données, passons au
regroupement de nos données. Le regroupement nous permet de le faire,
il nous permet de
combiner plusieurs lignes en une seule ligne et agréger nos données pour obtenir des résumés des informations contenues
dans notre base de données. Cela est extrêmement utile
dans les grandes bases de données. Regroupons donc nos
États et obtenons les bénéfices et les informations sur nombre
de magasins
dans chaque État. Pour ce faire, nous allons d'abord
obtenir quelques données de nos États. Regroupons ensuite nos données
par colonne d'état. Maintenant, pour l'instant, si nous
l'exécutons tel quel, nous verrons simplement les deux lignes et toutes
les colonnes qu'elles contiennent. Il s'agit simplement de choisir la première
ligne parmi ces deux groupes. Si nous
voulons réellement résumer les données, nous devons utiliser des
mots clés spécifiques dans la partie sélectionnée. Donc, au lieu de faire étoile, listons d'abord l'État. C'est maintenant que nous pouvons voir
que nous avons deux États. Très bien, calculons ensuite le nombre de
magasins dans chaque État. Pour cela, nous allons
compter le nombre de magasins. Maintenant, pour ce qui est du nombre de
boutiques, je pourrais transmettre l'identifiant et cela
compterait les uniques, cela compterait le
nombre d'identifiants sur chaque ligne. Ou j'utilise généralement le
joker parce que nous
voulons simplement compter le nombre d'étoiles , ce qui est
généralement plus facile. Enfin, pour obtenir des bénéfices, nous devons additionner
tous nos bénéfices. Nous allons donc appeler
la fonction Sum. Voici donc
la fonction de comptage, compte le nombre de
choses que vous lui donnez. Notre fonction SUM va additionner ou additionner toutes les
colonnes que nous lui donnons. Ou il va additionner toutes les lignes de
la colonne que nous obtenons. Nous allons donc
lui donner la colonne des bénéfices. Nous obtenons notre État, notre compte et nos bénéfices pour chaque État. Une autre
fonction intéressante à utiliser est la fonction moyenne ou AVG. Et cela nous
donnera également la moyenne des bénéfices de chaque magasin. Maintenant, ces données ont l'air
un peu désordonnées. Ces colonnes ici ne sont
pas très agréables à regarder. Nous pouvons donc donner des
noms à ces colonnes en déclarant simplement
leur nom ici. Notre nom apparaîtra donc comme le nombre de magasins
ou peut-être simplement le nombre. Et ça a l'air un peu plus propre. Alors que notre soleil peut être la somme et que notre moyenne peut
apparaître comme la moyenne. L'ajout de noms de colonnes permet simplement de rendre les données un
peu plus
claires lorsque vous consultez le rapport. Et cela vous facilite également la tâche si vous y
revenez pour savoir exactement quelles informations vous
essayez d'obtenir
à certains moments. Une chose à noter est que vous ne
pouvez pas utiliser d'espaces ici. Je ne pourrais donc pas parler de profit total. Cela va générer une erreur. Je vais donc utiliser des traits de soulignement
pour contourner ce problème. Ou si vous voulez vraiment des espaces, vous pouvez mettre des guillemets simples et
cela vous donnera un espace. Cependant,
d'après mon expérience, un
trait de soulignement est généralement utilisé à la place. Enfin, je peux combiner cela avec d'autres requêtes
afin de placer un
point entre mon pouce et le groupe afin
de filtrer les données
avant qu'elles ne soient agrégées. Je n'ai donc pu
regarder que mes magasins
où les bénéfices
sont supérieurs à 100 000. Je peux simplement obtenir le décompte, le bénéfice
total et la moyenne de
mon magasin le plus rentable, en l'occurrence deux dans chaque État. Alors que lorsque nous n'
avons pas ce filtre, nous pouvons voir qu'il
y a trois États, trois magasins à New York. Ce serait également un endroit
idéal pour filtrer nos magasins fermés afin que je
puisse dire où la date la plus proche est nulle. Maintenant, nous examinons simplement les magasins
ouverts et obtenons leur
calendrier et leurs bénéfices. Nous en avons donc
longuement parlé dans cette vidéo, nous avons expliqué comment
trier nos données en utilisant la clause de commande par. apprendrons également comment agréger ou
regrouper nos données
à l'aide de la
clause group by , nous
découvrirons également les différents ordres
dans lesquels elles peuvent se produire, ainsi que les différentes
fonctions que nous pouvons appeler dans notre zone de sélection de colonnes.
6. SQL 7: Jusqu'à présent, nous en avons parlé
beaucoup. Nous avons expliqué comment extraire
des colonnes spécifiques
de nos bases de données, comment filtrer les données
de chaque tableau, comment les trier et
comment agréger nos données pour obtenir des résumés
de ce qu'elles contiennent. Dans les prochaines vidéos, nous allons passer à la
gestion de plusieurs tables. C'est donc le moment idéal
pour faire une pause si vous n'êtes pas à l'aise avec les sujets que
nous avons déjà abordés. répétant quelques vidéos, ou en essayant simplement les requêtes par vous-même,
expérimentez un peu plus. Avant de poursuivre, nous
travaillons sur plusieurs tables, continuons à nous appuyer sur ce que
nous avons déjà examiné, en particulier en ce qui concerne
l'utilisation de la clause where et de
la clause groupe par clause. Assurez-vous donc
de bien les comprendre avant
de
continuer. bases de données SQL utilisent donc
des relations pour connecter les données. Les relations se produisent lorsqu'une ligne fait référence à une autre ligne
et à une autre table. Pour cela, nous allons passer
à la table d'inventaire. Le tableau d'inventaire
comporte donc trois colonnes. Jetons-y un coup d'œil maintenant. Allons tout récupérer
à partir de l'inventaire. Il contient donc de nombreuses lignes
différentes,
mais nous nous intéressons simplement
aux trois colonnes. Nous avons donc d'abord l'identifiant du
magasin, l'identifiant de la saveur, et l'identifiant du magasin de camping est en fait l'identifiant du
magasin sur les tables des magasins. Si nous allons dans les magasins,
trouvons le Store ID1. magasin ID1 est donc notre 100 Pine Street à
Harrisburg, en Pennsylvanie. en revenir à l'inventaire, nous pouvons faire
référence à une saveur spécifique dans la deuxième colonne. Donc, si nous passons à
notre tableau des saveurs, découvrons quelle est la
saveur numéro un. Flavor ID1 est Vanilla Vista. en revenir à l'inventaire, nous pouvons constater qu'il
y a dix points de vue sur la vanille dans notre magasin de
glaces de Harrisburg, mais ce n'est pas
très pratique de devoir utiliser l'identifiant du magasin pour filtrer
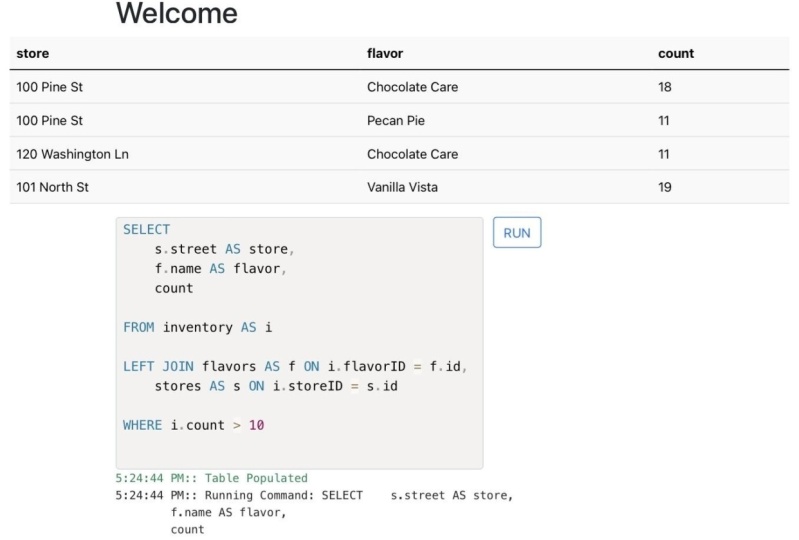
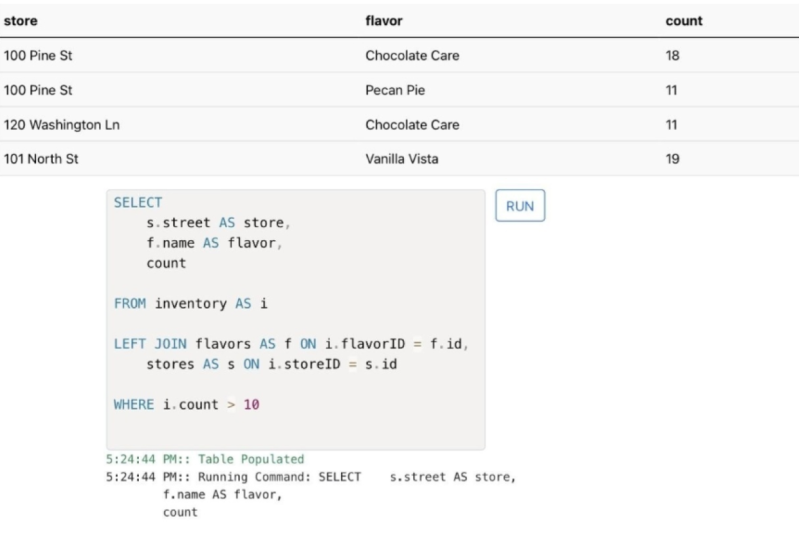
le tableau d'inventaire. Donc, au lieu de cela, nous pouvons réunir ces deux tables sur ces relations spécifiques. Connectons ceux qui
utilisent la clause de jointure, celle-ci est assez longue
et difficile à lire. Joignons donc cela à
notre tableau des saveurs. Je vais utiliser la
clause de jointure ici et je
vais indiquer à quelle table je souhaite participer. Donc, dans ce cas, ce sont les saveurs. Maintenant, nous pouvons l'exécuter et de nombreux résultats différents. C'est parce que
nous ne lui avons pas dit ce que je voulais faire. Certains soldats se sont joints
à nous avec des saveurs. Nous devons maintenant définir
cette relation. Nous allons donc dire où l'identifiant de saveur égal à
l'identifiant est beaucoup plus court. Maintenant, nous voulons où se trouve
la table des saveurs, où l'identifiant des saveurs
de notre inventaire est égal à l'identifiant sur notre table des
doigts. Ici, c'est un peu plus facile à lire. Maintenant, je peux voir que
le magasin numéro un propose peu de snacks. See, le magasin numéro
trois est à court de Vanilla Vista,
par opposition à Flavor ID1. Sur la base de ce que nous avons appris
dans la dernière vidéo, voyez si vous pouvez agréger ces
données et obtenir un résumé du
nombre de saveurs en stock dans l'
ensemble de l'entreprise. Alors, combien de Villanova y
aspirent ? Combien de chocolats ? Quel est le camion à la maison ? Combien de tartes
au chocolat sont en stock et combien de tartes aux pacanes sont en stock ou dans
tous les magasins. Poursuivre notre collaboration pour
commencer à agréger nos données. Nous allons le
dissocier par identifiant.
Maintenant, nous pouvons également le grouper par
identifiant Flight Flavor. Cela n'a pas vraiment d'importance.
Les deux retourneront la même manière parce qu'ils sont
tous les deux fondamentalement identiques. Mais cela ne nous
donne pas
encore tout à fait notre décompte , car nous sommes
toujours en train de sélectionner une étoile. Trouvons donc simplement le
nom de notre saveur. Et comptons le
nombre de lignes, juste pour nous assurer que nous
obtenons une bonne chose. Donc, jusqu'à présent, nous constatons que nous avons nos trois
saveurs et que nous avons quatre inventaires ou
lignes d'inventaire pour chaque saveur. Maintenant, prenons la somme
du décompte pour savoir
combien sont en stock dans
l'ensemble du magasin. Nous pouvons donc voir sur
ce tableau que tarte aux
pacanes est faible. Nous devrions donc probablement en
commander d'autres.
7. SQL 8 Alias: Dans cette vidéo, nous allons
voir comment réunir trois tables
au lieu de deux. À la fin de cette
vidéo, nous allons donc
savoir quels magasins proposent,
quels arômes sont en rupture de stock
et à quelle adresse nous avons besoin
pour expédier ces saveurs également. Alors pour commencer,
récupérons nos informations
d'
adresse dans les différents magasins. Faites venir nos magasins d'ici, ajoutons-les à l'inventaire. Nous pouvons maintenant constater que
nos magasins sont répétés
plusieurs fois. En effet, pour
chaque ligne dans les magasins il y en a trois ou quatre
dans notre tableau d'inventaire. En fait, je vais
obtenir une combinaison de toutes ces lignes. Il s'agit d'un
détail important à noter. Donc, si nous faisions ce
travail en commun et essayions
ensuite de résumer nos bénéfices, nous réaliserions des profits
énormes, ce qui aurait l'air vraiment cool mais finirait par être inexact. En effet,
chaque fois que nous joignons des tables, il s'agit de trouver des correspondances. Et pour chaque match
, une nouvelle ligne est créée. Et nous obtenons ces rangées. Ce que nous voyons, ce
sont ces matches. Donc, pour chaque match,
nous nous déplaçons. Maintenant, filtrons cela pour nous
assurer que nous n'avons
que nos magasins ouverts. Et ajoutons un autre
filtre pour simplement obtenir les saveurs qui sont
en rupture de stock. Allons donc là où le
décompte est inférieur à cinq. Nous n'avons donc que
quelques magasins dont
nous savons avoir besoin pour
expédier de nouvelles saveurs. C'est là que nous
allons rencontrer un problème. Si nous essayions de nous inscrire à nouveau ici, nous rencontrerions un problème. Si nous essayions d'ajouter une autre
pièce à notre tableau des saveurs. Lorsque nous définissons la relation, nous allons rencontrer
un problème dans lequel nous avons maintenant
plusieurs colonnes appelées id. Donc je ne pouvais pas, donc si je faisais où Flavor ID est égal à id, nous allons avoir une erreur. Et c'est parce que
la base de données ne
sait pas de quelle colonne d'identification nous parlons. Nous devons le préciser davantage. Et pour ce faire,
nous allons utiliser la même astuce que nous avons utilisée
précédemment pour nommer les colonnes. Nous allons donc ajouter des
alias à ce tableau. Désormais, les alias
signifient simplement que nous définissons un raccourci ou un
nom abrégé pour ces tables. Nous pourrions écrire
le nom de la table
, puis un point, puis
spécifier le mouvement de colonne. Mais il existe un
moyen plus rapide de le faire qui consiste à ajouter des alias
à nos tableaux. Donc, tout comme nous avons ajouté des alias aux noms de
nos colonnes,
nous allons utiliser S. Ensuite,
je vais créer un S pour les boutiques, module complémentaire pour mon inventaire
et l'appeler ainsi, puis pour mes saveurs,
je vais l'appeler f. En général, la culture de la
suite est que votre alias est une
lettre pour un tableau, peut-être quelques fois si vous
le répétez J'ai essayé de le garder 1 à 3 lettres juste pour que ce soit court et beau. Certaines langues n'
ont pas besoin d'acide. Vous pouvez donc simplement le faire depuis les magasins S et il sait que S est
l'alias de Store. Allez-y,
nettoyez le reste. Je vais préciser
que les fermetures proviennent magasins et que le décompte
provient de l'inventaire. Nous arrivons maintenant aux
mêmes données et elles semblent un peu polluées par les colonnes. Filtrons donc cela pour obtenir uniquement les
informations dont nous avons besoin. Nous allons donc avoir
besoin du décompte. Passons donc au dénombrement de l'
inventaire, à la saveur. Prenons donc le nom de la saveur, puis l'adresse à laquelle
nous devons l'expédier. Ce sera donc la rue
du magasin, ville du
magasin et l'état du magasin. Allons-y, exécutons-le. Voici un compte rendu de
toutes les saveurs, leur inventaire qui est épuisé et de l'actrice
à qui les expédier. Ces défis sont un peu plus
avancés que les nôtres. Donc, si vous
recherchez un défi, voyez si vous pouvez également calculer
le coût qu'il faudrait pour remplir chacun de ces magasins
à dix barils chacun. Référentiel quelques secondes
pendant que vous le découvrez. Très bien, c'était un défi
un peu
plus compliqué que
d'habitude. Nous n'avons pas vraiment
parlé de l'utilisation des mathématiques dans nos déclarations
sélectives, mais nous pouvons les y intégrer discrètement. Nous allons donc
commencer par indiquer le coût de la saveur et j'ai oublié ma virgule
entre les colonnes. Maintenant, nous avons le coût
de chaque saveur et nous voulons le multiplier
par le nombre qu'il faudra pour obtenir
ce chiffre jusqu'à dix. Prenez notre coût et nous
allons le multiplier par dix moins le nombre d'inventaires. Des citrons entre parenthèses, pour lui dire de faire les dix moins, je compte avant qu'il ne le multiplie
par le coût. Allons-y et
exécutons-le et nous verrons combien il en coûte pour remplir chacun de
ces stocks de
sauvegarde à dix unités,
ou peut-être voulons-nous ces stocks de
sauvegarde à dix unités, le remplir jusqu'à 20 unités. Jette un coup d'œil à ça.
8. SQL 9 GAUCHE: Parfois, les tableaux
ne contiennent pas toujours les données que nous voulons
ou attendons. Dans ce cas, s'inscrire, c'est
simplement nous montrer les matchs. C'est ce que l'on
appelle une jointure interne. Il s'agit donc de montrer
ce qui se trouve sur
nos deux tables qui correspond
aux deux. Mais il peut également être intéressant de voir où ces données sont manquantes. Nous savons donc s'il
manque quelque chose ou s'il faut
s'occuper de quelque chose. Dans ce cas, nous
allons vouloir faire ce que l'on appelle une jointure gauche. D'habitude, j'aime considérer
cela comme un diagramme de Venn. Sur la gauche, j'ai ma première
table sur le cercle de droite, j'ai ma deuxième table
où elles se chevauchent. C'est une articulation normale. C'est pourquoi on l'appelle jointure
interne, car elle montre aux deux tables ce qui
correspond aux deux tables. Notre jointure gauche va nous
montrer tout ce qui se trouve sur le tableau de gauche ou le tableau d'origine avec
les données correspondantes. Jetons donc un coup d'œil
à la forme du numéro de magasin. Le magasin numéro quatre
contient donc quatre saveurs. Mais si nous jetons un coup d'
œil à notre tableau des saveurs, nous n'avons que trois saveurs. Nous pouvons voir que la pièce d'identité numéro
trois est manquante. Ce qui
s'est probablement passé, c'est qu'il y avait une saveur mais qu'elle a été
supprimée ou abandonnée. Et au lieu de supprimer une
date ou de supprimer une date, ils ont simplement supprimé les
données de la base de données. Maintenant, nous ne connaissons pas
cette saveur, mais cette mystérieuse saveur numéro trois n'apparaît pas lorsque nous l'inscrivons sur notre tableau d'inventaire. C'est parce que nous n'en
avons pas le goût. Il ne fait donc que
nous montrer ce qui correspond. Faire correspondre la saveur que
j'ajoute à la table des saveurs. Donc, pour récupérer toutes les données de
la correspondance et préserver notre table de gauche ou mon tableau
d'inventaire et obtenir toutes les informations
qu'il contient avec ce qui correspond. Nous allons faire une jointure à gauche, et cela nous
montrera cette saveur dans ID3 et en quoi
elle porte un ancien nom. Vous pouvez également faire une jointure droite, mais en général, je ne le
vois pas aussi souvent Nous n'allons
donc pas
en parler dans ce cours. Il est préférable d'utiliser une
jointure gauche plutôt qu'une jointure droite. C'est juste l'inverse. Cela préservera le tableau de droite
au lieu du tableau de gauche. Il existe également ce que l'on appelle jointures
externes si cela
vous intéresse et
qui préservera le contenu des deux tables. Cela dépasse un peu
le cadre de ce cours. Nous allons donc le
laisser juste avec les jointures gauches.
9. INDICE SQL 10: Très bien, félicitations, vous êtes arrivé à
la dernière vidéo. Nous avons passé en revue toutes les bases. Vous devez commencer à générer
vos propres rapports, à jouer avec le SQL et à expérimenter
avec les données. bases de données sont vraiment amusantes
et vraiment excitantes. Je sais que cela semble un
peu étrange,
mais c'est vraiment cool de voir comment les
données sont stockées et
comment elles sont liées aux différentes tables dans
lesquelles nous pouvons stocker des données
aussi complexes que le comportement humain, je veux pour repartir avec quelques informations supplémentaires alors
que vous vous préparez à travailler dans
vos propres bases de données
plutôt que dans cette base de données de test de
dés. La première est donc que sélectionner est sûr. Select n'
insérera ni ne modifiera de données. Mais l'obtention des données peut prendre beaucoup de temps beaucoup de temps, selon
la
façon dont vous les exécutez. Nous allons donc vous
parler de quelques procédures de
sécurité pour nous
assurer que vous ne
ralentissez pas la
base de données et ne causez aucun problème à une
autre personne qui s'y trouve. En général, la plupart des bases contiennent une copie de la base de données sur laquelle vous travaillez dans
des rapports dégénérés. Assurez-vous donc de consulter un administrateur
de base de données pour savoir si vous travaillez
dans la base de données elle-même ou dans une copie de celle-ci. Vous pouvez ainsi générer
des rapports plus volumineux sans risquer de ralentir la
base de données pour d'autres comportements. Il y a donc deux choses dont
nous allons parler pour accélérer vos requêtes. La première sera de limiter le nombre
de lignes renvoyées. Donc, si nous jetons un coup d'
œil à notre tableau d'inventaire, car c'est le
plus long avec le plus grand nombre de lignes. Nous avons beaucoup de rangées. Maintenant, celui-ci a
peut-être dix ou 12 rangées. Mais lorsque vous avez affaire à des données de
production
contenant des millions de lignes, simple
fait de sélectionner une étoile
peut renvoyer de nombreuses routes. Et si vous le
faites simplement pour obtenir les noms des colonnes
comme je le fais habituellement, c'est une perte de traitement et cela pourrait alourdir la
base de données. Donc, ce que j'ai l'habitude d'ajouter à
la fin de la mienne, c'est une limite ,
puis dix, limite limite limite le nombre
de lignes renvoyées à quatre. Ainsi, même si vous vous trouvez dans
une base de données plus grande, cela s'affiche beaucoup plus rapidement en fonction de votre
langage SQL et de limite de modération. À la fin,
vous pouvez vous classer parmi les
cinq premiers , puis sélectionner une requête. C'est la lumière, donc elle
ne fonctionne pas de cette façon, fonctionne plutôt avec une limite de cinq. Ensuite, le dernier point
que je vais
aborder concerne l'utilisation des index. Donc, comme nous
parlons de relations, ces relations sont
des colonnes non spécifiques. En général, ces colonnes,
qui sont des identifiants, sont indexées, qui signifie que la
base de données utilise cette colonne afin de savoir comment
trouver rapidement les lignes qu'elle contient, en les indexant, indexant et en
effectuant quelque chose à l'avance et ce sont des colonnes
incertaines définies, généralement pour les jointures, elles vont
toutes être indexées, donc la jointure devrait se faire
assez rapidement. Mais sur vous, c'est
dans les clauses que vous risquez de ralentir. Si vous filtrez sur une
colonne qui n'est pas indexée, cela risque d'
être très lent. Ou si vous filtrez
pour rechercher une correspondance entre les textes, cela peut également être très lent. Donc, si vous constatez que l'une de vos
requêtes est lente, voyez s'il existe un autre moyen d'
obtenir ces informations sans filtrer
sur ces colonnes découvrirez
peut-être que les données que vous
recherchez ne se trouvent pas dans une autre table. Dans ce cas, il
sera plus rapide de rejoindre l'autre table et de
filtrer sur une colonne indexée au
lieu de s'en tenir
à une table et de filtrer sur une colonne non indexée. Mais en général, cela se
trouve dans des bases de données
très complexes . Il faut simplement en être conscient au
fur et à mesure que vous continuez. Je m'adresse certainement à l'administrateur
de votre base
de données, aux membres de votre entreprise contentent de
parcourir une base de données
pour voir s'ils ont des
meilleures pratiques ou des avertissements avant de
poursuivre vers l'avant. Avec ça. C'est
tout ce que nous allons aborder dans ce cours. Nous avons donc expliqué
comment obtenir des données, comment filtrer les données, regrouper les données et comment combiner dans
différentes tables. J'espère vraiment que cela vous
a plu, veuillez me faire savoir si quelque chose n'a pas de sens dans
les commentaires ci-dessous. J'adorerais l'
expliquer plus en détail et améliorer ces vidéos afin
que cela ait du sens. Et vous pouvez
jouer avec les données parce que c'est
vraiment une activité amusante. Merci de votre
attention et bonne chance dans vos efforts de reportage. Si vous avez trouvé ce cours utile, j'
apprécierais vraiment que vous
y laissiez une critique qui
aiderait d'autres personnes trouver ce cours
afin qu'elles
puissent également générer les
rapports dont elles ont besoin.
 Peter Flickinger, Filmmaker, Programmer and Teacher
Peter Flickinger, Filmmaker, Programmer and Teacher