Transcription
1. Introduction au cours: Bonjour, je m'appelle Dimple Sangui et j'ai plus de 25 ans d'
expérience dans la direction de programmes de transformation à grande échelle J'ai dirigé ces programmes dans des entreprises du
Fortune 500
telles que Cognizant, HSBC,
CAP Gemini, et j'ai
également formé des milliers de
professionnels dans les domaines entreprises du
Fortune 500
telles que Cognizant, HSBC,
CAP Gemini, et j'ai de l'analytique, de l' IA et du Lean Six Sigma J'ai également suivi une
formation au leadership dans le monde entier. Dans ce cours, vous
apprendrez à concevoir des agents d'IA
efficaces. Utiliser des modèles pratiques
tels que le chaînage rapide, le
routage, les évaluateurs
et les orchestrateurs Ils sont basés sur les principes de conception d'
agents du monde réel. Ce cours s'adresse aux professionnels
et aux chefs de produit, aux
consultants et aux praticiens de l'IA
qui souhaitent aller au-delà des instructions et créer des flux de travail d'IA structurés
et fiables Vous n'avez pas besoin d'un codage avancé, mais simplement d'une compréhension de base du fonctionnement des grands modèles linguistiques. Votre projet de classe consiste à concevoir un système d'agents d'IA
fonctionnel sous forme de diagramme
pour une tâche réelle. Cartographie du flux de travail,
rédaction d'instructions et réflexion sur
vos choix de conception. J'ai mentionné les détails dans la
section de description du projet de Skillshare Si vous voulez comprendre comment IA
agentic
fonctionne réellement dans la pratique, ce cours vous fournira un cadre
clair et utilisable Commençons. Je te verrai
au premier cours.
2. Créer un LLM efficace: Construire des agents efficaces.
Au cours de l'année écoulée, nous avons travaillé avec
des dizaines d'équipes de création grands modèles linguistiques,
des agents de tous les secteurs. implémentations les plus
réussies
n'ont toujours pas utilisé de frameworks complexes ou de bibliothèques spécialisées Au lieu de cela, ils construisaient avec de simples modèles composables Que sont les agents ? Les agents sont définis
de plusieurs manières. Certains clients définissent les agents comme des systèmes
totalement autonomes qui fonctionnent indépendamment sur de
longues périodes l'aide de divers outils pour
accomplir des tâches complexes. D'autres utilisent le terme pour décrire implémentation
plus prescriptive qui suit des flux de travail
prédéfinis Chez anthropic, nous classons toutes ces variantes dans la catégorie des systèmes
agentiques, mais nous avons établi une distinction
architecturale importante entre Les flux de travail sont des systèmes
dans lesquels les LLM et
les outils sont orchestrés via un chemin de code
prédéfini Les agents, quant à eux, sont des systèmes dans lesquels le LLM dirige
dynamiquement
ses propres processus, outils et utilisations en maintenant le contrôle Quand et quand ne pas utiliser d'agents. Lorsque vous créez
des applications avec LLM, nous vous recommandons de trouver la solution la
plus simple possible. Augmenter la
complexité uniquement en cas de besoin. Cela peut signifier qu'il ne faut pas du tout créer de système
agentic. systèmes agentic
échangent souvent entre latence et coût d'une meilleure performance des tâches Et vous devez vous demander quand
ce compromis a du sens. Lorsqu'une plus grande complexité est justifiée, les flux de travail
offrent prévisibilité cohérence pour des tâches
bien définies, tandis que les agents constituent de meilleures
options lorsque la flexibilité
et la prise de décision basée sur
des modèles sont nécessaires à grande échelle Cependant, pour de nombreuses applications, l'optimisation d'un seul appel LLM avec un
exemple de récupération dans le contexte est généralement suffisante Il existe de nombreux frameworks
lors de l'utilisation du système Augentic, plus facile d'implémenter un
graphe Lang à partir d'une chaîne Lang framework d'
agent AI fondamental d'Amazon, un générateur de flux
de travail
GIM par glisser-déposer,
Valm, un autre constructeur d'interface graphique
pour les tests de création de flux Valm, un autre constructeur d'interface graphique
pour les tests de création pour Ce framework
facilite le démarrage
et simplifie les tâches
standard de bas niveau, comme appeler LM, définir,
féliciter, enchaîner
les appels Cependant, ils créent souvent une couche
d'
abstraction supplémentaire qui n'
observe que l'
invite et les réponses sous-jacentes tout en les rendant
plus difficiles à déboguer Ils peuvent être tentants d'ajouter de la complexité alors qu'une
configuration plus simple suffit
3. Flux de travail sur le chaînage d'invites: Et examinons de plus près un flux
de travail de chaînage rapide Beaucoup d'entre vous ont dirigé des projets de transformation
complexes où le risque ne réside pas dans
la vision
globale, mais dans l'exécution et dans le respect de la
discipline. Il en va de même. Le chaînage rapide ne consiste donc pas simplement à transmettre des données d'
un appel d'IA à un autre Il s'agit d'intégrer des
portes de contrôle entre chaque étape. Et lorsque vous souhaitez intégrer conformité, les contrôles des risques et les audits de qualité
dans les processus métier, le premier appel LLM
crée un projet de résultat Ce brouillon n'est pas
automatiquement transmis. Elle est validée. S'il réussit, le
flux de travail se poursuit. En cas d'échec, le système se ferme
ou s'intensifie. C'est ainsi que nous évitons
les erreurs cumulatives. Pour les dirigeants, l'
essentiel est que la chaîne nous
permet de traiter l'IA
comme un processus géré, et non comme une boîte noire. Chaque étape peut être ajustée,
qu'il s'agisse d'extraire des données, appliquer des règles de conformité ou de
produire une communication avec
le client Cette conception rend l'
IA prévisible, auditable et plus acceptable
pour les régulateurs et les conseils Pour le connecter à votre monde, pensez aux activités des
prestataires de soins de santé. Une IA extrait les informations
du patient. Le portail garantit le respect des règles
HIPA. La seconde IA prépare
le résumé du traitement. Le git valide
le codage médical. Ce n'est qu'alors qu'un nœud de décharge est
généré pour le patient. Chaque point de contrôle garantit
la précision, la conformité et la confiance. C'est pourquoi un chaînage rapide
est une base essentielle. Il transforme l'expérimentation en fiabilité
de niveau professionnel. Comment envisageons-nous un flux de travail de
chaînage rapide ? Considérez-le comme une chaîne de montage. Au lieu de demander
à l'IA de faire les choses en une seule fois, vous divisez le travail en plusieurs étapes. Chaque étape est gérée
par un appel AI distinct, et la sortie d'une étape devient l'entrée de la suivante. Remarquez l'amertume du portail. C'est le point de contrôle qualité. Si la sortie de l'IA à une étape
ne passe pas la validation, le processus s'arrête ou revient en arrière. S'il passe, il s'écoule vers l'avant. Les tâches complexes deviennent gérables
grâce à un flux de travail de chaînage rapide Comme dans Sigma, vous ne vous contentez pas de tout résoudre en une seule étape, vous le décomposez. Le contrôle qualité est intégré. Au lieu de vous fier à un seul appel basé sur l'IA, vous validez
avant Confinement des erreurs. Si quelque chose échoue, vous le détectez tôt sans polluer
le résultat final Prenons un exemple tiré de la
première étape
du règlement des sinistres, où l'IA lit et
numérise le document de réclamation Le portail vérifie si tous les champs
obligatoires sont présents. L'IA prépare la
notation des risques pour le règlement. L'IA extrait les données
financières du candidat. La démarche vérifie la règle de
conformité,
comme si les informations AIC manquaient À la troisième étape, l'IA rédige l'évaluation de l'
éligibilité au prêt Première étape, l'IA élabore une réponse. Deuxième étape, le portail
vérifie le ton, le langage de
conformité
et les règles du SLA Troisième étape, l'IA finalise le message à transmettre au
client. Pensez-y comme à la sécurité d'un
aéroport. On ne passe pas directement de l'
enregistrement à l'embarquement. Vous passez les portes, le contrôle des
bagages, le contrôle
de sécurité, le contrôle de la
carte d'embarquement. Chaque porte garantit que l'étape
suivante est propre. Le chaînage rapide est la version de l'IA processus
de
contrôle qualité par étapes Maintenant que nous avons vu comment le chaînage crée de la
fiabilité, nous allons passer au flux de travail suivant
, plus avancé, à agent
autonome dans lequel l'IA commence à s'améliorer elle-même
dans un environnement réel Considère ça comme une course de relais. Une sortie d'IA est
vérifiée à la porte et seule si elle
passe à l'étape suivante de l'IA. En cas d'échec, il sort plus tôt. Cela rend le processus plus sûr et plus fiable. Réclamation automobile. Un client télécharge les détails de l' accident sur
les photos Le LLM vérifie
les documents. L'IA extrait les détails de la politique et la description de l'accident. Le portail effectue le contrôle
de conformité. L'IA a-t-elle extrait tous les champs obligatoires si la date de l'accident est conforme à
la politique de validation ? S'il passe, il passe
à l'étape suivante. En cas d'échec, il sort ou est
signalé pour une révision manuelle. Les deux appels LLM vérifient
l'estimation des dégâts. AI rédige les estimations de coûts
en utilisant les directives de réparation. LLM rédige trois ébauches de
la réclamation finale. Il crée le
résumé du règlement pour l'expert en sinistres. Seules les
demandes valides conformes aux politiques sont traitées, ce gagner du temps et de réduire la fraude. Prenons maintenant un exemple de
service client. Un client VIP se plaint, ma demande de prêt est
bloquée depuis dix jours. LLM One classe l'IA et identifie la requête comme une
escalade VIP concernant un Le contrôle SLA a
lieu à la porte d'embarquement. Répond-il aux critères
d'escalade de 15 minutes ? Si ça passe, ça continue. En cas d'échec, il envoie une
alerte au responsable. LLM 2, nous rédigerons la note d'escalade
pour le support de niveau 2 LLM Three créera
une réponse au client, un e-mail personnalisé
au client,
et le résultat est le bon
cas, sont rapidement transmis,
évitant ainsi les violations des SLA et
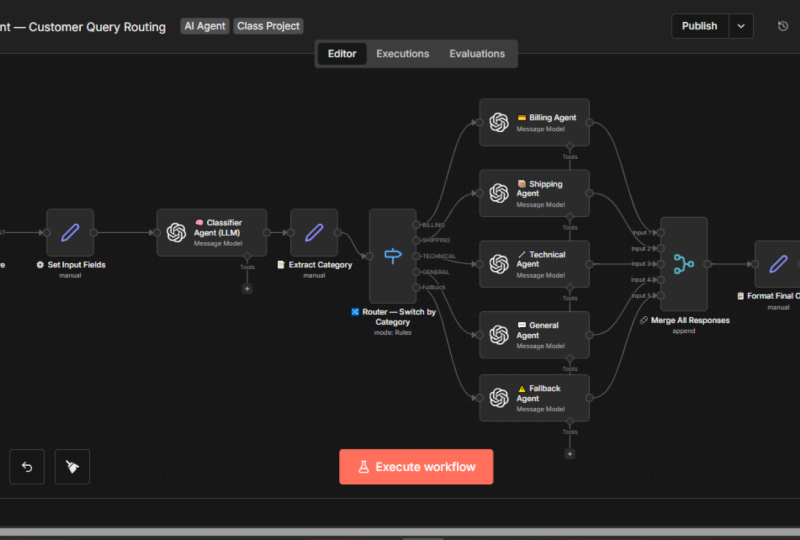
4. Le temps de flux de travail de routage: Découvrons maintenant
un flux de travail de routage. Le moteur de nombreux systèmes d'IA
augentic. Vous avez une entrée, un routeur LM
et il existe trois appels LLM
différents Donc, comme cela fonctionne,
la saisie prend la forme, par
exemple, d'une demande d'un client, d'un formulaire de réclamation ou d'une demande de
prêt. Le système ne l'envoie tout simplement
pas aveuglément à un seul modèle. Au lieu de cela, il passe d'abord
par un routeur d'appels LLM. Le routeur décide quel modèle d'
IA est le mieux
adapté à cette tâche. À partir de là, la demande peut être acheminée vers l'un des nombreux modèles
spécialisés appel LLM peut gérer la classification par
synthèse structurée. Pour gérer le raisonnement, analyses
approfondies telles que la
détection des fraudes et la notation des risques. Les trois peuvent gérer tâches de communication
créatives telles que la rédaction de la réponse du client. Enfin, le meilleur résultat est
transmis sous forme de sortie. Pour vous, en tant que leaders de la
transformation, le point à retenir n'est pas la
flèche sur les graphiques C'est l'avantage commercial. Dans le cadre des services fournis aux prestataires de soins de santé, le routeur enverrait la documentation
médicale
à un modèle formé au langage
clinique tout en acheminant données
de facturation vers un modèle axé sur
la conformité. Dans le cas d'un
accident de la route lié au traitement des réclamations, photos seront envoyées à un modèle de vision pour l'estimation des
dommages, tandis que le texte de la politique
sera envoyé à un modèle linguistique pour
la vérification de l'éligibilité. Dans un service client, FAQ
rapides seraient acheminées vers un modèle léger pour des raisons de rapidité, tandis que l'
escalade VIP sensible serait dirigée vers un modèle
conçu pour favoriser l'empathie Ce flux de travail est important car il empêche une approche
universelle. Cela garantit plutôt que le bon modèle est utilisé
pour le bon travail, tout comme vous n'
attribueriez pas toutes les tâches votre organisation
au même service. Le routage est une
couche de gouvernance pour le flux de travail de l'IA. Cela les rend efficaces, précis et prêts à l'emploi. Maintenant que nous comprenons le routage, nous voulons voir comment plusieurs agents d'
IA peuvent travailler ensemble coordonner les
différentes étapes d'un processus au lieu d'
agir de manière isolée. Pensez-y comme à un contrôleur
de circulation. Le système décide
quelle voie convient le mieux à
la demande entrante au lieu traiter chaque
demande de la même manière. Réclamation concernant une réclamation d'assurance
Pfizer Motors d'un client. Le routeur LLM décide quel
modèle d'IA spécialisé peut le gérer S'il s'agit d'une réclamation pour risque de fraude, le routeur l'acheminera vers un modèle de détection des fraudes. S'il s'agit d'une réclamation standard de
faible valeur, acheminez-la vers l'automatisation
plutôt que vers le règlement. S'il s'agit d'une réclamation médicale complexe, acheminée vers le modèle de conformité, chaque réclamation suit
le bon chemin, réduit le
tri manuel et les erreurs J'ai perdu ma carte de crédit. Le routeur LLM l'achemine vers
l'IA appropriée, l'IA
de sécurité, pour bloquer immédiatement
la carte La FAI explique comment
commander un remplacement. Une IA d'escalade vous connecte
au bureau des fraudes si
une activité inhabituelle est détectée. Le client obtient la
bonne résolution au lieu de devoir passer d'un
agent à l'autre Fixe-moi un rendez-vous et
envoie-moi les résultats du laboratoire. Le routeur LLM
divisera la tâche. Planifier l'IA, prend rendez-vous
chez le médecin. WiCoDei récupère
les résultats du laboratoire IA de facturation vérifie
l'éligibilité
et la couverture de l'assurance patient accomplit toutes les
tâches grâce à une seule interaction acheminée à chaque fois par
l'IA appropriée Le routage est une question d'efficacité et précision au lieu de forcer
un seul système à tout faire. Il achemine le bon flux de travail vers la bonne IA, comme
le fait le processus allégé. Réduit les retouches, erreurs de classification et
accélère la résolution
5. La parallélisation: Passons maintenant à un flux de travail de
parallélisation. Dans le dernier modèle, nous avons vu comment le routage envoie la
tâche au meilleur modèle. Nous verrons ici un modèle
différent, parallélisation du flux de travail Ici, au lieu de
choisir un chemin, l'entrée est envoyée à plusieurs
modèles en même temps. Chaque modèle apporte
une pièce au puzzle. L'agrégateur combine ensuite le résultat dans un résultat final Imaginez cela comme si vous
dirigiez plusieurs équipes en parallèle pour résoudre le même problème
rapidement et de manière approfondie. Pourquoi est-ce important ? Parce que certains
problèmes commerciaux
bénéficient de la rapidité et de
la diversité des réponses. Nous avons compris que la paralysie consiste à exécuter plusieurs appels LLM, puis l'agrégateur les résume Supposons donc que le patient
ait de la fièvre, de la toux, récemment voyagé
et qu'il soit allergique aux antibiotiques. Le LLM one récupère le dossier électronique du patient pour
les affections passées. Le LLM 2 vérifie les directives relatives
aux maladies infectieuses. Le LLM met en évidence le risque d'allergie aux
médicaments. L'agrégateur se fond ensuite dans une suggestion de traitement sûre à l'
intention du médecin Le médecin reçoit un
seul avis, et
non des informations fragmentées. La parallélisation est une question de
rapidité et de compréhension Au lieu d'attendre qu' un système
soit terminé avant que le suivant ne démarre, une IA multiple s'exécute en
parallèle puis converge C'est comme gérer plusieurs équipes de
spécialistes en parallèle lors de la réduction des coûts de
la transformation allégée. Nous examinons le routage lorsque le système décide
du modèle à utiliser. Parallélisation lorsque plusieurs
modèles fonctionnent en même temps.
6. L'orchestration et le Routing2: Nous examinons le routage lorsque le système décide
du modèle à utiliser, parléisation lorsque plusieurs
modèles fonctionnent en même temps Nous
parlons ici d'orchestration. Comment est-ce que l'entrée entre d'
abord dans l'orchestre. Imaginez cela comme un chef de
projet qui répartit ensuite le travail entre
différents agents d'IA L'orchestre décide
quelle tâche doit être effectuée en premier et quel
modèle doit s'en charger. Chaque modèle, comme le LLM 1, 2, 3, aborde différents
aspects du travail Mais au lieu de
travailler de manière isolée, ils sont coordonnés comme une équipe
interfonctionnelle
dans le cadre de votre transformation. Enfin, un
synthétiseur
réunit le tout en une
seule sortie cohérente. La valeur commerciale est puissante. Les notes des patients doivent
être divisées en termes interprétation
clinique,
de code de facturation, de cartographie
et de vérification de conformité, puis synthétisées dans un rapport de sortie
complet Pensons aux sinistres automobiles. Un modèle examine le document, l'autre vérifie la fraude. Le troisième projet de communication avec le
client. Ce synthétiseur les combine
ensuite dans un package de
décision de réclamation prêt à l'emploi Pensons aux affaires
hypothécaires. Vous voulez que la
vérification des revenus, l'évaluation des risques contrôles de conformité
réglementaire soient effectués en séquence, puis orchestrés
et synthétisés dans un seul résumé d'approbation de prêt Une baisse de communiqué de presse peut
être vérifiée par
un modèle adapté à différents marchés
par un autre et par
style par
canal social du troisième. Puis synthétisé dans un package
multicanal. L'orchestration est une
question de coordination. Ce n'est pas une question de calcul. Il reflète la façon dont les responsables de
la transformation gèrent
déjà les programmes
fonctionnels.
7. Merci pour votre temps: Avant de terminer, je voudrais vous
en dire un peu plus sur moi et sur la façon dont
vous pouvez rester connecté. J'ai hâte de partager mes deux décennies d'
expérience avec vous tous. Et l'expérience au cours de laquelle
j'ai aidé des dirigeants et équipes à gérer des
projets de
transformation commerciale,
numérique et artificielle à grande
échelle numérique et artificielle en Inde, aux États-Unis, au Royaume-Uni, en Australie
et au Moyen-Orient. Au fil du temps, j'ai
formé des milliers de professionnels à l'
analyse des données, au lean Sig Sigma, à l'intelligence
artificielle, à l'ingénierie
rapide, à la gestion du changement
et à la formation du
leadership, à la fois sous forme programmes
d'entreprise et de communautés d'apprentissage
ouvertes Si vous regardez ce film
en tant qu'apprenant individuel, j'adorerais que vous
restiez connecté Vous trouverez des liens pour rejoindre mon groupe Whatsapp ou ma communauté de
télégrammes où je
publierais continuellement des articles sur
les différentes opportunités. Je partage régulièrement des informations
pratiques, des ressources
d'apprentissage et des mises à jour sur l'analyse et la
transformation de l'IA. Je partage également quelques
études de cas sur le leadership. Si vous êtes ici en tant que
responsable, consultant ou responsable de l'apprentissage et
du développement, et que vous êtes intéressé par la conception personnalisée, la formation
en entreprise sur l'
IA agentique, l'ingénierie rapide, analyse de
données ou un programme de
transformation, n'
hésitez pas à me
contacter Je travaille en étroite collaboration
avec des organisations pour concevoir
des programmes sur mesure, pratiques, contextuels
et axés sur les affaires Je laisse le lien vers Linden
dans la section de discussion. Merci d'avoir appris avec moi. J'espère que ce cours vous aidera à concevoir un système d'IA de manière
plus réfléchie, et j'ai hâte de
rester en contact avec Merci pour le
temps que vous m'avez accordé. Bon apprentissage.
 Dimple Sanghvi, AI Consultant, Lean Six Sigma Master Black Belt
Dimple Sanghvi, AI Consultant, Lean Six Sigma Master Black Belt