Transcription
1. Intro sur l'analyse de données: Bonjour les amis. Commençons par
ce programme de formation, analyse des données de
coins
à l'aide de MiniTab. Qu'allez-vous
apprendre dans ce cours ? Les compétences que
vous allez acquérir dans
ce cours sont donc quelques
notions de base en statistiques. Nous aborderons les statistiques
descriptives, les résumés
graphiques, les
distributions, l'histogramme, moustaches, les graphiques à barres
et les graphiques en secteurs. Je vais mettre en place une nouvelle
série sur le test d'hypothèse, que je partagerai dans le lien sous forme de lien
dans la dernière vidéo. Mais commençons par comprendre tous les différents types
d'analyse graphique. Qui devrait suivre ce cours ? Toute personne qui l'a fait, qui est un
étudiant de Lean Six Sigma, qui souhaite obtenir la
certification Green Belt, Black Belt, ou qui
souhaite appliquer statistiques et des
analyses graphiques sur son lieu de travail. Même si vous êtes
un entrepreneur ou un
étudiant et que vous souhaitez comprendre les
statistiques à l'aide de Minitab. Je vais tout couvrir. Nous allons apprendre quelles sont les erreurs qui se produisent le plus souvent
lorsque nous analysons. Parce que lorsque nous faisons des analyses à l'aide
de points de données théoriques simples, tout semble normal. Je vais donc
vous montrer quelques pièges dans lesquels notre analyse échouera et comment vous devriez
les éviter. Nous essaierons,
à la fin de ce programme, de vous, que retirerez-vous
de ce programme ? Vous comprendrez comment
faire quelques analyses de base. Vous saurez quels
sont les outils nécessaires pendant
votre phase de mesure, tels que
les calculs de capabilité, etc. Nous utiliserons pendant la phase
d'analyse donc si possible, pour couvrir le test d'hypothèse. Sinon, si elle grandit, la vidéo devient plus grande, je la
mettrai séparément. Ivan explique également quel graphique
utiliser lorsque nous
avons des erreurs courantes et nous effectuons une analyse
graphique
et créons des graphiques. Et comment puis-je tirer des informations et des conclusions
de ces graphiques ? Cela vous aidera vraiment à bien
comprendre ce
programme. Voyons ce qu'est un Minitab ? Minitab est un
logiciel de statistiques disponible et doté de
plusieurs régions. Je vais donc trouver un nouveau projet. écran de mon Minitab
ressemble à ceci. J'ai un navigateur
sur le côté gauche. J'ai mon
écran de sortie en haut, j'ai ma feuille de données, qui
ressemble beaucoup à une feuille Excel, avec
laquelle je peux travailler. Je peux continuer à ajouter ces
feuilles et j'ai plein de données. Je peux faire de nombreuses analyses
en utilisant mes options. Nous allons couvrir les
statistiques de base, la régression. Nous allons couvrir de nombreuses statistiques de base et nombreux graphiques utilisant
différents types de données, n'est-ce pas ? Donc, si vous souhaitez
connaître ces choses, vous devez absolument vous
inscrire et regarder ma vidéo. Merci beaucoup.
2. Récapitulatif de l'introduction à Lean Six Sigma: Comprendre la
fonction de transfert en six sigma. Explorons maintenant la fonction et sa pertinence en six sigma Cela commence par comprendre la relation mathématique. Y est une fonction de X. Dans cette équation, Y
représente la sortie et les résultats ou le
résultat que nous voulons améliorer. X représente la
variable d'entrée ou le modèle. F représente la fonction ou la transformation qui peut
être appliquée à ces entrées. Fix Sigma consiste essentiellement à identifier et à
optimiser le facteur X, les entrées qui
pilotent la sortie En améliorant les X, nous devons améliorer le Y ou nous
concentrer sur l'amélioration du Y.
L' exemple de fonction de transfert dans Dmth. Prenons un exemple appeler un support technique
pour résoudre un ratio informatique. Dans la phase définie, nous définissons un problème, temps qu'il faut pour qu'un client
reçoive une solution. Y, qui est égal
au temps de résolution, O est le temps total nécessaire pour résoudre
le problème du client. Au cours de la phase de mesure,
nous identifions et mesurons les différents facteurs
impliqués dans l'appel. Comme le temps passé dans la file d'attente, le temps passé avec le support, le temps passé à transférer
les appels entre les agents, le temps de résolution. analyse de la phase, nous
déterminons quels X sont critiques et quelles sont les variations
typiques entre les facteurs. Au cours de la phase d'amélioration, nous mettons en œuvre des modifications afin de
réduire le temps
consacré à chaque étape. Peut-être que l'automatisation de
certaines réponses ou l'optimisation de la logique de routine
sont ce qui y est abordé Pendant la phase de contrôle, nous surveillons le système pour assurer que le Y
qui correspond au temps nécessaire à la
résolution s'est effectivement amélioré et qu'il est resté stable au fil du temps. Ce processus peut être répété en continu pour apporter de
nouvelles améliorations. Lorsqu'elle est suivie
rigoureusement, la DMAC est une puissante
méthodologie reproductible
permettant d'obtenir Amélioration supplémentaire,
méthodologies en six Sigma que nous avons au stylo Sixema nan par d'autres outils,
techniques et pratiques
éprouvés techniques et pratiques y compris le contrôle statistique des
processus Il utilise le graphique de contrôle pour surveiller la
variation au fil du temps. Il utilise les limites de contrôle supérieure et
inférieure pour identifier les cas où le processus est statistiquement incontrôlable. outils SPC peuvent déclencher le cycle DMX lorsque la variation et le défaut dépassent le seuil
acceptable. outils de variation et
de réduction des défauts Les outils de variation et
de réduction des défauts sont couramment inclus dans la gestion
de la qualité totale. Ils aident à identifier
la cause première et les opportunités d'optimisation. Ces outils jouent
un rôle clé lors la phase d'analyse et
d'amélioration du DMC Travail d'équipe et cercles de qualité. À l'origine de Teta, l'accent était mis sur une approche
d'équipe pour l'amélioration des processus Les employés de tous les niveaux
collaborent régulièrement pour résoudre un problème en utilisant les outils et méthodologies fournis
dans Six Sigma Les cercles de qualité
intègrent souvent des outils statistiques, des techniques DMAT et DPAtrduction Ensuite, les projets Six Sigma
et la route de la ceinture jaune. Dans la section suivante,
nous aborderons
les projets Six Sigma et
soulignerons les projets Six Sigma et ce qu'une
ceinture jaune doit savoir, notamment les rôles et les
responsabilités liés au projet, ainsi que la valeur la ceinture jaune apporte
à l'équipe d'amélioration Généralement, la durée d' un projet Six Sigma peut
varier considérablement Un projet à court terme peut
ne durer que quelques heures ou quelques jours, en particulier lorsqu'il est piloté par petite équipe chargée de la qualité qui vise à
obtenir des documents supplémentaires. Un projet à long terme
peut s'étendre sur plus d'un an, en particulier lorsque la portée est complexe et interfonctionnelle. C'est là que la
ceinture noire entre en jeu. Cependant, les projets
Six Sigma les plus courants, qui constituent une ceinture verte, durent
environ quatre à huit semaines, ce qui laisse suffisamment de temps
pour recueillir les données, passent par toutes les
phases du cycle DMC Rôles d'adolescents dans les projets Six
Sigma. Chaque membre de l'équipe joue un rôle
distinct et essentiel. Comprenons-les. Une ceinture noire de maître et un Blag. Ces personnes dirigent
et gèrent des projets. Ils veillent à l'alignement sur la stratégie et encadrent
les membres de l'équipe. Ceintures vertes. Ils ont géré
une analyse détaillée, collecte de
données et ont aidé à
mettre en œuvre l'amélioration des processus. Les ceintures jaunes sont les personnes
qui fournissent des informations clés, aident à la collecte de données et soutiennent les activités de
mise en œuvre. Bien que ce ne soit pas en tant que chefs de projet, Yellow Bells
jouent un rôle
essentiel au sein de l'équipe, qui dirige
l'exécution quotidienne du projet
Six Sigma Quels sont les objectifs communs des projets
Six Sigma ? portée du projet varie et vise souvent à réduire les
variations de l'expérience client. Dans le monde d'aujourd'hui,
l'expérience compte beaucoup. Accélérer les délais de mise sur le marché, éliminer les erreurs et les défauts, réduire les coûts opérationnels, voici
quelques éléments essentiels à prendre en compte lors de la
mise en œuvre Six Sigma et une offre de
parrainage et de gestion par les dirigeants projet sans un soutien, un financement
et une visibilité solides de la part de la
direction sont très différents d'ecofaxe Pertinence de
la méthodologie. Pi Sigma est si puissant, mais il ne
convient pas à tous les problèmes Évitez d'adopter une
méthodologie ou une mentalité universelle. Commencez petit, puis agrandissez. Renforcez la confiance
et les compétences nécessaires petits
projets gérables avant vous
lancer dans un effort de
transformation plus large Savez-vous quand
utiliser d'autres approches ? Dans certains cas, d'
autres méthodologies peuvent être plus appropriées. Initiative Lean, réingénierie des
processus métier, nous l'appelons BPR, Business Process
Management ou Ou l'autre méthodologie
qui peut être utilisée. Le contrôle de la portée est très important. Si la portée du projet est trop large et que le résultat n'
est pas clair, il devient ingérable Coûts par rapport aux avantages. Tenez compte du retour sur investissement avant
d'investir du temps et des ressources. Par exemple, dépenser
100 heures pour économiser seulement 10 heures par an
n'est pas un compromis efficace. est très important de procéder à une évaluation de l'état de
préparation Il est très important de procéder à une évaluation de l'état de
préparation
avant d'entreprendre un projet. Cela permet à votre
organisation de se préparer
avant que nous ne nous lancions dans
la prise en charge d'un projet. Définissez le résultat souhaité. Qu'est-ce que nous
essayons de réaliser et pourquoi ? Établissez des critères de réussite. À quoi ressemble le succès,
tant pour l'organisation que pour
les personnes impliquées ? Évaluez la disponibilité des données. Disposons-nous de données fiables, pertinentes et actualisées
pour étayer l'analyse ? Constituez la bonne équipe. Avons-nous des personnes
ayant les compétences, influence et l'engagement nécessaires pour
assurer le succès du produit ? Élaborez une analyse de rentabilisation. Quelle est la valeur
de l'amélioration ? Qui a tendance à en bénéficier
et qui pourrait résister ? Quel est le retour sur investissement attendu ? Il est très
important de contribuer à la
préparation organisationnelle lorsque vous planifiez
un projet Six Sigma Ce sont là des questions clés parce
qu'elles sont très importantes. quoi
ressemblera l'état futur par rapport à la situation
actuelle ? Sommes-nous en train de résoudre un
problème réel dans notre entreprise ? Est-ce le bon moment
pour mettre en œuvre le Six Sigma ? Une évaluation minutieuse
garantit que le projet Six Sigma
est non seulement pertinent, mais également réalisable et impactant pour Est-ce que nous évaluons
les performances ? Avons-nous de solides
arguments en l'application du Six Sigma dans
notre analyse de rentabilisation Enfin, y a-t-il autre
chose qui se
passe dans votre projet qui
mérite votre attention ? Dans Six Sigma, existe-t-il
réellement la bonne approche ? Ces questions peuvent
être certaines que notre organisation est prête à six SEMA pour
un problème donné Il existe trois étapes clés pour
évaluer l' état de
préparation de l'organisation. Première étape, évaluez les perspectives
et le chemin futur. Posez la question,
ma chaîne est-elle critique ? Les entreprises en ont besoin dès maintenant. Évaluez les
performances actuelles. Posez la question. Existe-t-il une solide justification
stratégique faveur de l'application du Six Sigma
dans nos activités ? Passez en revue les systèmes et
leur capacité de changement. Posez-vous la question suivante :
les améliorations existantes
peuvent-elles apporter le niveau de changement
nécessaire à notre réussite et à notre compétitivité sans
recourir au Six Sigma ? Pour commencer, considérez
l'importance de l' expérience
client, de la satisfaction
client. Nous nous concentrons sur la voix du
client pour susciter le changement. Les améliorations sont essentielles
et le client en a besoin. C'est là que les outils d'
analyse de données Six Sigma sont utiles. Cela nous aide à comprendre en quoi le client se soucie
vraiment. Six Sigma fournit un outil
puissant planification stratégique
future en améliorant
l'efficacité du marketing, faisant les choses correctement du premier
coup et en identifiant ce qui compte
vraiment pour le client qui concerne nos projets
et services L'un de ces outils précieux de la boîte à outils
Six Sigma
est le modèle CO, qui nous aide à comprendre et à
hiérarchiser les besoins des clients de manière plus efficace Le modèle CO est une méthode qui permet
de recueillir des données
auprès des clients et de comprendre ce qui compte vraiment pour eux. Qu'est-ce qui différencie nos
offres des autres ? Cela nous aide à identifier des éléments
importants, tels que
les fonctionnalités qui peuvent améliorer la
satisfaction du client lorsqu'elles sont
bien livrées au client. Quels sont les
insatisfaisants potentiels qui pourraient nuire à l'
expérience client s'ils ne sont pas traités ? En analysant ces commentaires, nous pouvons prioriser les
améliorations susceptibles créer une plus grande valeur
pour nos clients Passons maintenant à la planification
stratégique. analyse Six Sigma peut jouer un rôle essentiel en identifiant les facteurs clés qui
motivent les clients Satisfaction des clients, intégration de ceux-ci dans la planification
stratégique. L'amélioration
des performances est particulièrement nécessaire. Si
la culture organisationnelle fait partie d'
une approche standard de TIC Sigma grâce à une charte de projet efficace, au développement de
métriques, à des systèmes de
contrôle
et à un cercle de qualité, les
équipes peuvent
améliorer de manière significative l'alignement des performances au
sein de l' La rentabilité demeure
une priorité absolue. Six Sigma est particulièrement efficace pour réduire le
coût de la qualité De nombreuses organisations
dépensent de 20 à 75 % des coûts simplement pour garantir la qualité
des produits et des services. En réduisant ces coûts, nous restons en phase avec les attentes de
nos clients et livrons
toujours mieux et plus rapidement que nos concurrents. OK. Concept de lentille. La fabrication allégée, en
particulier dans un
environnement du secteur des services, implique reconnaître les initiatives
d'amélioration continue. N se concentre essentiellement sur la
rationalisation et l'amélioration des processus afin de créer plus de
valeur avec vos ressources TahiOo, souvent considéré comme le père
de la pensée moderne en matière de privilège, a souligné que l'essence du privilège repose sur un principe
simple calculer le temps entre la réception de commande
du
client
et la réception du paiement pour l'exécuter, puis travailler
continuellement pour réduire ce délai le plus possible Len vise fondamentalement à
éliminer le gaspillage sur l'ensemble de la chaîne de valeur, en réduisant le temps, les
efforts et les ressources inutiles. Le résultat est de maximiser la valeur, d'améliorer l'efficacité, d'
améliorer la qualité et d'accroître la
satisfaction des clients. Dans une installation de fabrication, réussites sont nombreuses. Actuellement, nous en avons beaucoup, même dans le secteur des services.
3. Travail de projet: Laissez-nous comprendre quel est le travail de projet
que nous allons
effectuer dans ce
programme d'analyse de données à l'aide de MiniTab. Comme je vous l'ai dit, nous allons
travailler avec MiniTab. Voici le Minitab
que je vais utiliser. Je vais également partager
avec vous une fiche technique, fiche technique de
votre projet, où j'ai plusieurs exemples, où nous effectuons
des calculs de capacité. Nous allons essayer de voir les
distributions et vous pouvez voir qu'il
existe différents onglets. Exemple un exemple
deux exemple trois, nous allons essayer de faire une analyse de
tendance. Nous allons essayer de voir les graphiques
de Pareto. Nous avons beaucoup de données qui ont
été partagées avec vous, ce qui vous donnera une expérience
pratique de l' utilisation
des données, n'est-ce pas ? Commençons donc.
4. Bases des statistiques: Bienvenue sur notre prochain sujet
important, les bases des statistiques. Dans cette vidéo, vous
découvrirez ce que sont les statistiques, statistiques descriptives et les
statistiques inférentielles Commençons par
la première question. Qu'est-ce que les statistiques ? Les statistiques
concernent la collecte, l'analyse et la
présentation des données. Par exemple, si nous
voulons déterminer si le sexe a une influence sur le journal préféré, genre
et le journal sont que l'on appelle les variables
que nous voulons analyser. Analyser si le genre a une influence sur le journal
préféré. Nous devons d'abord collecter des données. Pour ce faire, nous créons
un questionnaire qui pose des questions sur le genre et le journal
préféré. Nous enverrons ensuite le
questionnaire et attendrons deux semaines. Ensuite, nous pouvons afficher les réponses reçues dans
un tableau de ce tableau. Nous avons une colonne
pour chaque variable, une pour le sexe et
une pour le journal. D'autre part, chaque ligne représente la réponse
d'une personne. Par exemple, le
premier répondant est un homme et a indiqué
l'époque de l'Inde. La seconde est une femme, et a déclaré l'Hindou, et ainsi de suite. Bien entendu, il n'est pas nécessaire
que les données proviennent d'une enquête. Les données peuvent également provenir d'
une expérience dans laquelle. Par exemple, vous souhaitez étudier l'effet de deux médicaments
sur la tension artérielle. Prenons un autre exemple
concret. Imaginez que vous êtes directeur de
magasin et que vous voulez savoir si la
présentation d'un nouveau produit augmente les ventes. Vous pouviez collecter des
données sur les ventes auparavant. Et une fois le nouvel
affichage configuré, ces données vous aideront à analyser l'efficacité
de l'affichage, ou supposons que votre administrateur
scolaire souhaite comprendre si
des sessions de tutorat
supplémentaires
aident les élèves à améliorer
leurs résultats en mathématiques Tu pouvais collecter
des scores avant ? Après les séances de tutorat
pour analyser l'impact. La première étape est maintenant terminée. Nous avons collecté des données et nous pouvons commencer à les analyser. Mais que
voulons-nous réellement analyser ? Nous n'avons pas interrogé l'
ensemble de la population
, mais nous avons prélevé un échantillon. Maintenant, la grande question est voulons-nous simplement
décrire les données de l'échantillon ou voulons-nous
faire une déclaration concernant l'ensemble de la population ? Si notre objectif se limite
à l'échantillon lui-même. C'est-à-dire que nous voulons uniquement
décrire les données collectées. Nous utiliserons des
statistiques descriptives. Les statistiques descriptives
fourniront un résumé détaillé
de l'échantillon. Par exemple, si nous interrogions 100 personnes sur leur journal
préféré, statistiques
descriptives nous
indiqueraient combien de personnes préfèrent l'époque de
l'Inde ou l'époque hindoue. Cependant, si nous voulons tirer des conclusions sur la
population dans son ensemble. Nous utilisons des statistiques inférentielles. Cette approche
nous permet de tirer des conclusions sur la population à
partir de nos données d'échantillonnage Par exemple, à l'aide de statistiques
inférentielles, nous pouvons estimer
la proportion de tous les adultes d'une ville qui préfèrent un journal spécifique sur la base d'un échantillon de 500 personnes interrogées Les statistiques inférentielles peuvent également nous
aider à déterminer si un
certain groupe démographique,
comme le sexe, influence de manière significative les
préférences en matière de journaux. En analysant nos échantillons de données, nous pouvons tirer des conclusions sur les préférences de l'ensemble de la population en matière de
journaux. En utilisant à la fois des statistiques descriptives
et inférentielles, nous pouvons mieux
comprendre nos résultats et prendre
des décisions
éclairées concernant les stratégies
marketing ou la création de contenu pour
différents journaux Dans la prochaine leçon, nous
aborderons de manière plus approfondie les applications
pratiques des
statistiques. Restez à l'affût.
5. Importance des niveaux de mesure ou des types de données: Importance des niveaux
de mesure. Comprendre le niveau de mesure est crucial
pour plusieurs raisons. Analyse appropriée. Les différents niveaux de mesure nécessitent
des techniques statistiques différentes. L'utilisation de la mauvaise méthode peut
mener à des conclusions erronées. Interprétation des données. Connaître le niveau permet de
mal interpréter les résultats. Par exemple, les valeurs moyennes sont
significatives pour les données d'intervalle et de ratio, mais pas pour les données
nominales ou ordinales Visualisation : les techniques efficaces de
visualisation des données varient en fonction du
niveau de mesure. Les diagrammes à barres
conviennent aux données nominales, tandis que les histogrammes
conviennent mieux aux données d'intervalle et de ratio Examinons plus en détail
chaque niveau de mesure. Niveau de mesure nominal. Les variables nominales
catégorisent les données sans établir d'ordre significatif Par exemple, demander aux personnes interrogées quel leur mode de
transport pour se rendre à l'école, en autobus, en voiture, à vélo
ou à pied est une mince affaire. Chaque catégorie est distincte, mais il n'y a pas de
classement ou d'ordre inhérent entre elles. L'analyse des données nominales
implique le comptage des fréquences ou l'utilisation diagrammes à
barres pour visualiser
les distributions. Niveau de mesure ordinal, variables
ordinales introduisent
un ordre
ou un classement significatif entre les catégories, mais les différences entre les grades ne sont pas
toujours Par exemple, demander
aux élèves d'évaluer leur satisfaction
à l'égard de leur mode de transport comme étant
très
satisfait, satisfait, neutre, satisfait ou très satisfait démontre une mesure
ordinale Bien que nous puissions classer
ces réponses du moins satisfaisant au plus satisfait, la différence numérique entre satisfait et très satisfait
n'est pas quantifiable L'analyse implique généralement des calculs
médians et des tests non paramétriques Niveaux d'intervalle et
de ratio de mesure, variables
métriques. variables d'intervalle et de ratio Les variables d'intervalle et de ratio sont considérées comme des variables métriques. Elles partagent la
caractéristique que intervalles entre
les
valeurs sont espacés de manière égale, mais que les variables de ratio
ont également un point zéro réel, ce qui rend toutes les
opérations arithmétiques valides Les exemples incluent la mesure de
l'âge, du poids ou du revenu. Par exemple, demander aux
personnes interrogées le nombre
de minutes qu'il faut pour se rendre à
l'école mesure les données sur de minutes qu'il faut pour se rendre à les intervalles, où les intervalles
entre les réponses, par exemple 10 minutes, 20 minutes, sont
cohérents et significatifs. Cela permet d'effectuer des
mesures statistiques telles que le calcul moyennes et l'utilisation techniques statistiques
avancées
telles que l'analyse de régression Résumé. Il est essentiel
de comprendre
ces niveaux de mesure pour concevoir des enquêtes et choisir les analyses
statistiques appropriées. Les données nominales nous informent sur les catégories
sans aucune commande. Les données ordinales permettent classement mais pas la
mesure précise des différences, tandis intervalle
et le ratio des données métriques permettent mesure
précise et prennent en charge un large éventail d'analyses
statistiques Qu'il s'agisse de créer des tables de
fréquences , des diagrammes à
barres ou des histogrammes, le
choix du bon niveau de mesure garantit
une interprétation précise des données et des informations pertinentes dans divers domaines
d'étude et de recherche Examinons de plus près
chaque niveau de mesure. Niveau de mesure nominal. Les données nominales constituent le niveau
de mesure le plus élémentaire. Les variables nominales
catégorisent les données, mais ne permettent pas un
classement significatif des catégories Les exemples incluent le
sexe, le mâle, la femelle, types d'animaux, les chiens, chats, les oiseaux, les journaux préférés. Dans tous ces cas, vous pouvez faire la distinction
entre les valeurs, mais vous ne pouvez pas classer les
catégories de manière significative Par exemple, pour
déterminer si le sexe influence le journal
préféré fait appel à des variables nominales. Dans un questionnaire, vous
listeriez les réponses possibles
pour les deux variables. Comme il n'y a pas d'ordre inhérent, la disposition des catégories dans le questionnaire
n'a pas d'importance. Les données collectées peuvent
être affichées dans un tableau et des tableaux de fréquences ou des diagrammes à
barres peuvent être utilisés pour
visualiser les distributions. Niveau de mesure ordinal. Les données ordinales peuvent être catégorisées et classées
dans un ordre significatif, mais les différences entre les rangs ne sont pas
mathématiquement égales Les exemples incluent les
classements, premier,
deuxième, troisième, les
taux de satisfaction, les taux de satisfaction, les taux de satisfaction, neutralité, de
satisfaction, de satisfaction, niveaux d'études, les niveaux d'études
secondaires, les bacheliers, les masters,
dans ce cas, alors que l' Les intervalles entre les grades ne
sont pas nécessairement égaux. Par exemple, si un
questionnaire vous demande dans
quelle mesure êtes-vous satisfait de
votre emploi actuel, avec des
options allant de très
insatisfait à très satisfait ? Les catégories de réponses sont ordonnées, mais la différence exacte entre chaque niveau de satisfaction n'
est pas quantifiable L'analyse des
données ordinales implique souvent calcul de médianes et
l'utilisation de tests non paramétriques Niveau d'intervalle de mesure. Les données d'intervalle comportent des
intervalles égaux entre les valeurs, mais il n'y a pas de véritable point zéro. Les exemples incluent la température
en degrés Celsius ou Fahrenheit. Les données d'intervalle permettent
de mesurer
les différences entre les valeurs. Mais comme il n'
y a pas de vrai zéro, les ratios ne sont pas significatifs. Des opérations statistiques
telles que le calcul de moyennes et l'utilisation de techniques telles que analyse de
régression
sont possibles Niveau de mesure du ratio. Les données de ratio présentent
des intervalles égaux entre les valeurs et incluent
un point zéro réel. Les exemples incluent l'âge, le
poids ou le revenu, car les données du ratio
incluent un zéro vrai. Toutes les
opérations arithmétiques sont valides. Ce niveau permet de
calculer des ratios et moyennes et d'utiliser
des méthodes statistiques avancées Oh. Ce que nous avons appris présent à l'aide d'un exemple. Imaginez que vous
menez une enquête dans une école pour comprendre
comment les élèves arrivent à l'école. Voici les questions
que vous pourriez vous poser. Chacun correspondant à un niveau de mesure
différent. La première question pourrait être quel mode de transport
utilisez-vous pour vous rendre à l'école ? options peuvent inclure le bus, voiture, le vélo ou la marche. Il s'agit d'une variable nominale. Les réponses peuvent être classées par catégories, mais il n'y a pas d'ordre
significatif. Cela signifie que le bus
n'est pas plus haut que le vélo. Marcher n'est pas
plus haut que la voiture et ainsi de suite. Si vous souhaitez analyser les
résultats de cette question, vous pouvez compter le nombre d'
élèves utilisant chaque mode de transport et
le présenter sous forme de graphique à barres. Ensuite, vous vous demandez peut-être quelle mesure êtes-vous satisfait votre mode
de transport actuel ? choix peuvent inclure «
très insatisfait »,
« insatisfait neutre », «
satisfait » ou « très Il s'agit d'une variable ordinale. Vous pouvez classer les réponses
pour voir quel mode de transport est le
plus satisfait. Mais c'est exactement la différence entre satisfait et très satisfait. Par exemple,
n'est pas quantifiable. Pour la dernière question, combien de minutes vous
faut-il pour vous rendre à l'école ? Ici, le nombre de minutes nécessaires pour se rendre à
l'école est une variable métrique. Vous pouvez calculer le
temps moyen nécessaire pour vous rendre à l'école et utiliser toutes les mesures
statistiques standard. Nous pouvons visualiser ces données à l'aide d'un histogramme montrant la
distribution des temps nécessaires pour
se rendre à l'école et comparer les différents modes de
transport Ainsi, en utilisant des données nominales, nous pouvons classer
et compter les réponses, mais nous ne pouvons en déduire aucun ordre Les données ordinales
nous permettent de classer les réponses, mais pas de mesurer
les différences précises entre les grades Les données métriques
nous permettent de mesurer les différences
exactes
entre les points de données. Comme déjà mentionné,
les niveaux de mesure métriques peuvent être subdivisés en intervalle et échelle de ratio Mais quelle est la différence entre les niveaux d'intervalle
et de ratio ? Explorons la
différence entre les niveaux d'intervalle et de ratio de
mesure à l'aide d'un exemple. Intervalle par rapport
au niveau de mesure. Lors d'un marathon, le
temps mis par les coureurs pour terminer la course
sert d'exemple pratique. Imaginons un scénario dans
lequel le coureur le plus rapide termine en 2 heures et le
plus lent en 6 heures Voici comment nous classons le niveau de mesure en
fonction des informations fournies. Niveau de mesure du ratio. Un niveau de mesure à ratio se
caractérise par un point zéro réel où zéro représente l'absence de
la quantité mesurée. Dans l'exemple du marathon, tous les coureurs partent à la même heure
0,0 lorsqu'ils
commencent la course. Avec un vrai point zéro, nous pouvons faire des
comparaisons significatives, par exemple en affirmant que le coureur le plus rapide a mis trois fois moins de temps
que le coureur le plus lent, 2 heures contre 6 heures Ce niveau permet des opérations de multiplication
et de division
significatives. Par exemple, si
un coureur termine en 4 heures et
un autre en 12 heures, on peut dire avec précision que le premier coureur était trois
fois plus rapide que le second. Niveau d'intervalle de mesure. Un niveau d'intervalle de mesure
ne possède pas de véritable point zéro. Dans le contexte d'un marathon, si le chronomètre démarre en
retard et que nous ne mesurons le décalage horaire coureur
le plus rapide
ayant pris le départ à l'heure, nous perdons la véritable référence zéro Bien que les intervalles entre les
valeurs soient toujours également espacés et que les opérations
arithmétiques telles que l'addition et la
soustraction soient valides, multiplication et la division
peuvent ne pas avoir Par exemple, dire qu'un coureur a terminé 4 heures d'avance sur
un autre est significatif. Mais on ne peut pas affirmer qu'
un coureur était quatre fois plus rapide qu'un autre sans connaître le temps total des deux. En résumé, la
mesure du niveau d'intervalle permet d' intervalles
égaux
entre les valeurs et prend en charge des opérations telles que l'
addition et la soustraction, mais ne
possède pas le véritable point zéro nécessaire
pour des ratios significatifs Maintenant, un petit exercice pour vérifier si tout
est clair pour vous. Tout d'abord, nous avons l'État des États-Unis, qui est un
niveau de mesure nominal. Cela signifie que les données sont utilisées pour étiqueter ou nommer des catégories sans aucune valeur quantitative. Dans ce cas, les États sont des noms sans
ordre ni classement inhérents. Ensuite, nous avons des
évaluations de produits sur une échelle de 1 à 5. Il s'agit d'un exemple
de données ordinales. Ici, les numéros
ont un ordre ou un rang. Cinq vaut mieux qu'un, mais les intervalles entre
les notes ne sont pas
nécessairement égaux. En ce qui concerne les noms des départements
tels que les achats, les ventes, les opérations, les finances,
cela est également nominal. Les catégories présentées ici,
telles que les différents départements sont destinées à la catégorisation et
n'impliquent aucun ordre Ensuite, nous avons les
émissions de CO 2 par an, qui sont mesurées sur
une échelle de ratio métrique. Ce niveau permet d'effectuer toute
la gamme des opérations
mathématiques,
y compris des ratios significatifs. Zéro émission signifie
aucune émission du tout. Ensuite, nous avons les numéros de téléphone. Bien que
les numéros de téléphone soient numériques, ils sont classés comme nominaux Ce ne sont que des identifiants
sans valeur numérique pour l'analyse Le niveau de confort est
un autre exemple ordinal. Cela peut inclure des niveaux
tels que faible,
moyen ou élevé, qui
indiquent une commande, mais pas la différence exacte
entre ces niveaux. surface habitable en mètres carrés est mesurée sur une échelle de ratio. Tout comme les émissions de CO 2, mètre
carré signifie qu'il n'
y a pas d'espace habitable et les comparaisons telles que le double
ou la moitié sont significatives. Enfin, nous avons la
satisfaction au travail sur une échelle de 1 à 4. Il s'agit de données ordinales. Il classe les niveaux de satisfaction, mais la différence entre
chaque niveau n'est pas quantifiée. Dans la prochaine leçon, nous
approfondirons applications
pratiques de la conception d'expériences. Restez à l'affût.
6. Mesures de centre et mesures de dispersion: Examinons les deux méthodes, commençant par les statistiques
descriptives. Pourquoi les
statistiques descriptives sont-elles importantes ? Par exemple, si une entreprise souhaite comprendre comment ses
employés se rendent au travail Il peut créer une enquête pour
recueillir ces informations. Une fois que suffisamment de données sont collectées,
elles peuvent être analysées à l'aide de statistiques
descriptives. Alors, en quoi consistent exactement les statistiques
descriptives, leur objectif est de décrire et de résumer un ensemble de données
de manière significative. Cependant, il est essentiel de noter que les
statistiques descriptives ne reflètent les données collectées et ne permettent
pas de tirer des conclusions sur
une population plus importante. En d'autres termes, le fait de savoir
comment certains employés une entreprise se déplacent ne nous
permet pas d'évaluer le comportement de
tous les travailleurs Maintenant, pour décrire les
données de manière descriptive, nous nous concentrons sur quatre éléments clés, les mesures de tendance centrale, mesures de dispersion, les tables de
fréquences et les graphiques Commençons par les mesures
de la tendance centrale, qui incluent la moyenne, la
médiane, etc. Tout d'abord, la moyenne, la moyenne
arithmétique, est calculée en
additionnant toutes les observations et en divisant par le
nombre d'observations Par exemple, si nous avons les résultats des
tests de cinq étudiants, nous les additionnons
et les divisons par cinq pour trouver que le
score moyen au test est de 86,6 Vient ensuite la médiane. Lorsque les valeurs d'un ensemble de données sont classées par ordre croissant, la médiane est la valeur médiane S'il y a un
nombre impair de points de données, il s'agit simplement de la valeur moyenne. S'il y a un nombre pair, la médiane est la moyenne
des deux valeurs intermédiaires. Un aspect important de
la médiane est qu'elle résiste aux
valeurs extrêmes ou aux valeurs aberrantes Par exemple, quelle que soit
sa taille, la dernière personne figure
dans un ensemble de données élevé. La médiane restera la même. Bien que la moyenne puisse changer manière significative
en fonction de cette valeur, elle reste inchangée quelle que soit la taille de la
dernière personne. Cela signifie qu'il n'est pas
affecté par les valeurs aberrantes. En revanche, les hommes peuvent changer manière significative en fonction de la taille de
cette dernière personne, ce qui la rend sensible aux valeurs aberrantes Parlons maintenant du mode. Le mode est la ou les valeurs
les plus
fréquentes dans un ensemble de données. Par exemple, si 14 personnes
se déplacent en voiture, six à vélo, cinq marchent et cinq
empruntent les transports en commun, voiture est le mode de transport puisqu'
il apparaît le plus souvent Nous passons ensuite aux
mesures de dispersion, qui décrivent la répartition des valeurs d'
un ensemble de données. Les principales mesures de dispersion
incluent les variantes. Plage d'écart type
et plage interéquatale, en
commençant
par l' commençant
par Il indique la distance
moyenne entre chaque
point de données et la moyenne. Cela nous indique dans
quelle mesure les points de
données individuels s'écartent
de la moyenne Par exemple, si l'
écart
moyen par rapport à la moyenne est de
11,5 centimètres, nous pouvons calculer l'
écart type à l' aide de la formule Sigma est égal à la racine carrée de la somme de chaque valeur
moins la moyenne Au carré, divisé par n, où Sigma est l'
écart type N est le nombre d'individus. X sub i est la valeur de chaque
individu, et x bar est la moyenne. Il est important de
noter qu'il existe deux formules pour l'
écart type. On divise par n, tandis que l'autre divise
par n moins un. Ce dernier est utilisé
lorsque notre échantillon ne couvre pas l'
ensemble de la population, comme dans les études cliniques. Ce dernier est utilisé
lorsque notre échantillon ne couvre pas l'
ensemble de la population, comme dans les études cliniques. Maintenant, en quoi l'
écart type diffère-t-il de la variance ? L'écart type mesure la distance moyenne
par rapport à la moyenne. Alors que la variance est simplement la valeur au carré de
l'écart type Ensuite, discutons de la plage
et de la plage intequatale. La plage est la
différence entre
les valeurs maximales et minimales d'un ensemble de données. D'autre part,
la plage inéquartile représente la
moitié médiane des données,
calculée comme la différence
entre le premier quartile,
Q un, et le troisième
quartile, qu Cela signifie que 25 %
des valeurs se situent dessous et 25 % au-dessus de la
plage interquartile Avant de passer
aux derniers points, comparons brièvement
ces concepts, les mesures de tendance centrale
et les mesures de dispersion. Envisageons de mesurer la
tension artérielle des patients. Les mesures de
tendance centrale fournissent une valeur unique qui représente
l'ensemble de données dans son intégralité. Aider à identifier
un point central autour duquel les
points de données ont tendance à se regrouper. D'autre part, les
mesures de dispersion, telles que l'écart type, plage et la plage InteQatile indiquent l'étendue des points
de données Qu'ils soient étroitement regroupés autour du centre ou
largement dispersés. En résumé, alors que les mesures de tendance
centrale mettent en évidence le point central
de l'ensemble de données, les mesures de dispersion
décrivent
la manière dont les données sont distribuées
autour de ce centre. Passons maintenant aux tableaux, en concentrant sur les types les plus
importants, fréquence et les tables de
contingence Un tableau de fréquence
indique la fréquence laquelle chaque valeur distincte
apparaît dans un ensemble de données. Par exemple, une entreprise a interrogé ses employés sur
leurs options de trajet domicile-travail, voiture, à vélo, à pied
et en transports Voici les résultats de 30 employés avec
leurs réponses. Nous pouvons créer un
tableau des fréquences pour résumer ces données en listant les quatre options dans
la première colonne et en comptant leurs
occurrences dans le tableau. Il est clair que le mode
de transport le
plus courant chez les
employés est la voiture. 14 employés ont
choisi cette option. Le tableau des fréquences fournit un résumé concis des données. Mais que se passerait-il si nous avions deux variables
catégorielles
au lieu d'une ? C'est là qu'un tableau de
contingence, également appelé
tabulation croisée, entre en jeu Imaginez que l'entreprise
possède deux usines, l'une à Détroit et l'
autre à Cleveland ? Si nous interrogeons également les employés
sur leur lieu de travail, nous pouvons afficher les deux variables à
l'aide d'un tableau de contingence Ce tableau nous permet d' analyser et de comparer
la relation entre les deux variables
catégorielles Les lignes représentent les
catégories d'une variable. Alors que les colonnes représentent
les catégories des autres, chaque cellule du tableau
indique le nombre d' observations correspondant à la combinaison de
catégories correspondante. Par exemple, la première cellule indique le nombre d'
employés qui se déplacent en voiture et travaillent à Détroit
a été indiqué six fois. Merci. Je vous verrai dans la prochaine leçon de statistiques.
7. Minitab: Dans ce cours, nous allons
en apprendre davantage sur les tests d'hypothèses. Je vais vous apprendre à
tester des hypothèses à l'aide de MiniTab. Je vais également vous apprendre à tester des
hypothèses à
l'aide de Microsoft Office. C'est utiliser Excel et Microsoft Office pour
ceux qui souhaitent utiliser MiniTab. Laissez-moi vous montrer où
vous pouvez télécharger Minitab. Minitab.com sous Téléchargements. Nous arrivons ici à la section de
téléchargement. Vous disposez d'un logiciel
statistique MiniTab, qui est disponible gratuitement
pendant 30 jours. J'ai également téléchargé la version
d'essai sur mon système et l'analyse de Dando et
je vous l'ai montrée. N'oubliez pas qu'il n'est disponible que
pendant 30 jours. Assurez-vous
de suivre
l'intégralité du programme de formation
au cours des 30 premiers jours. Lorsque vous en ressentez la valeur, vous devriez absolument vous
tourner vers la
version sous licence de MiniTab, qui est disponible ici. Il me suffit de cliquer sur Télécharger
et télécharger Woodstock. Cela commence par un essai
gratuit de 30 jours. Et c'est
assez de temps
pour pratiquer tous les
exercices qui sont entraînés. Il vous
demandera certaines
informations personnelles afin qu'il
puisse vous contacter et qu'il puisse vous aider
avec certaines réductions. S'il y en a. Vous avez une section appelée Dr. MiniTab ou vous avez
un numéro de téléphone. Si vous appelez du Royaume-Uni, il vous sera facile
d'appeler là-bas. Mais si vous parlez
depuis d'autres endroits, parler à MiniTab est une option
beaucoup plus simple. C'est un très bon outil
statistique et les
fonctionnalités sont régulièrement mises à jour. Personnellement, je pense que cet investissement en
vaudra la peine. Mais pour ceux qui n'ont pas les
moyens d'opter pour la licence, ils peuvent utiliser Microsoft Office au moins certaines fonctionnalités, pas toutes, mais certaines
fonctionnalités sont disponibles. Donc, dans un premier temps, je vais vous montrer l'ensemble de l'exercice différents types d'
hypothèses à l'aide de MiniTab. Ensuite, nous
passerons à Microsoft Excel, resterons connectés et
continuerons à apprendre.
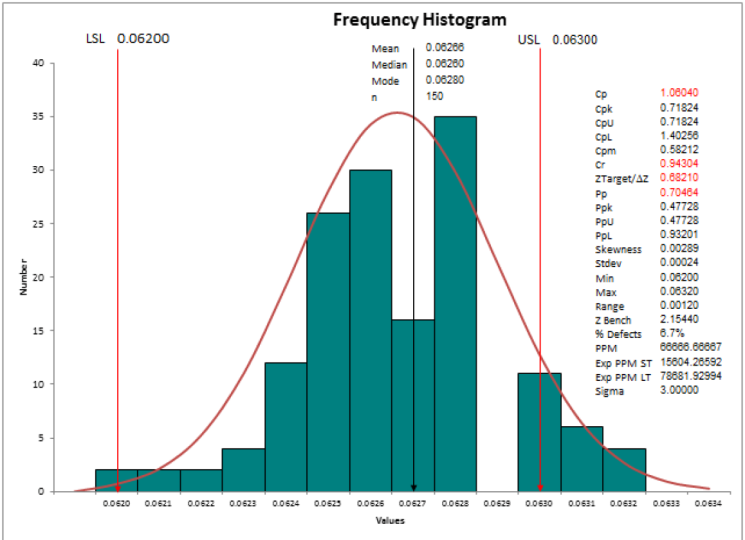
8. Statistiques descriptives: Au cours de la séance d'aujourd'hui, nous allons en
apprendre davantage sur les statistiques
descriptives. Les statistiques descriptives
signifient que je veux comprendre les mesures du centre. Comme les mesures du mode centre,
moyenne, médiane. Je veux comprendre les
mesures de la propagation. Il ne s'agit que d'une plage, écart type
et d'une variance. Prenons une simple
donnée que j'ai. J'ai un temps de cycle en minutes pour près de 100 points de données. Je vais prendre
la durée du cycle en
minutes à partir de la fiche technique de mon
projet journalier. Je vais aller dans Minitab et je
vais coller mes données
là où je veux faire des statistiques
descriptives. Statistiques. Cliquez sur Statistiques de base et dites Afficher les statistiques
descriptives. Lorsque je fais cela, une option apparaît dans la fenêtre contextuelle, appelée as, qui m'indique les champs de
données disponibles dont je dispose. J'ai une durée de cycle en quelques minutes. Cela
me dit donc que je veux analyser le temps de
cycle variable en minutes. Je vais simplement cliquer sur OK, et vous le trouverez
immédiatement dans ma fenêtre de sortie. Je peux juste tirer ça vers le bas. Dans ma fenêtre de sortie. Cela me montre
qu'il a fait quelques analyses statistiques pour le
temps de cycle variable en minutes. J'ai 100
points de données ici. Le nombre de valeurs manquantes est 0. La moyenne est de 10,064. L'erreur type de la moyenne est de 0,103, écart type est de 1
et la valeur minimale est de 7,5. Un n'est rien, mais votre
quartile un est 9,1. Médiane, c'est-à-dire que
votre Q2 est 10,35, Q3 est 10,868 et la valeur
maximale est 12,490. Si j'ai besoin de plus d'analyses
statistiques, je peux poursuivre et
répéter cette analyse. Cette fois, je vais
cliquer sur Statistiques. Et je peux regarder les autres points de
données dont j'ai besoin. Supposons que si j'ai besoin de la plage, je n'ai pas besoin d'erreur type, j'ai besoin d'une plage
interquartile. Je veux identifier
quelle est l'ambiance. Je veux identifier quelle est
l'asymétrie et mes données. Qu'est-ce que le kurtosis dans mes données ? Je peux tout sélectionner et dire, OK, je vais cliquer sur OK. Lorsque je fais cela, tous les autres paramètres
statistiques que j'ai sélectionnés
apparaîtront dans ma fenêtre de sortie. Il s'agit de ma fenêtre de sortie. Il m'indique donc à nouveau le point de données
supplémentaire
que j'ai sélectionné. Le rayon n'est donc rien d'autre que votre
écart type au carré. Il est de 0,0541. Il m'indique la plage
maximale moins minimale. C'est 4,95. L'intervalle interquartile est de 1,707. Il n'y a aucun mode dans mes données. Et le nombre de points de données à
0 parce qu'il n'y en a plus, les données ne sont pas asymétriques. Les valeurs sont très proches de 0, c'est 0,05, mais
il y a kurtosis. Cela signifie que mes données n'
apparaissent pas comme des données non professionnelles. C'est tellement bien, nous aimons voir à
quoi ressemble ma distribution. Faisons ça. Je clique sur Statistiques, je clique sur Statistiques de base et je clique sur Résumé
graphique. Je sélectionne la
durée du cycle en minutes. Et je dis que je veux voir un intervalle de confiance de
95 %. Je clique sur, OK,
voyons le résultat. Le résumé des minutes du
cycle diamant. Il me montre la moyenne, l'
écart type, la variance. Toutes les statistiques
sont affichées sur
le côté droit. Moyenne, écart type,
variance, asymétrie, aplatissement, nombre de points de données
minimum du premier quartile médian, troisième quartile maximum. Ces points de données, que vous
voyez comme Q1 minimum, médian, T3 et maximum, seront
couverts dans la boîte à moustaches. La boîte à moustaches est encadrée
en utilisant ces points de données. Et quand vous regardez le Velcro, il indique que la cloche n'
est pas une courbe raide, c'est une courbe un peu plus grosse, et donc la
valeur d'aplatissement est une valeur négative. Nous poursuivrons notre apprentissage plus en détail dans
la prochaine vidéo. Merci.
9. Statistiques descriptives ou inférentielles: Examinons les deux méthodes, commençant par les statistiques
descriptives. Pourquoi les
statistiques descriptives sont-elles importantes ? Par exemple, si une entreprise souhaite comprendre comment ses
employés se rendent au travail Il peut créer une enquête pour
recueillir ces informations. Une fois que suffisamment de données sont collectées,
elles peuvent être analysées à l'aide de statistiques
descriptives. Alors, en quoi consistent exactement les statistiques
descriptives, leur objectif est de décrire et de résumer un ensemble de données
de manière significative. Cependant, il est essentiel de noter que les
statistiques descriptives ne reflètent les données collectées et ne permettent
pas de tirer des conclusions sur
une population plus importante. En d'autres termes, le fait de savoir
comment certains employés une entreprise se déplacent ne nous
permet pas d'évaluer le comportement de
tous les travailleurs Maintenant, pour décrire les
données de manière descriptive, nous nous concentrons sur quatre éléments clés, les mesures de tendance centrale, mesures de dispersion, les tables de
fréquences et les graphiques Commençons par les mesures
de la tendance centrale, qui incluent la moyenne, la
médiane, etc. Tout d'abord, la moyenne, la moyenne
arithmétique, est calculée en
additionnant toutes les observations et en divisant par le
nombre d'observations Par exemple, si nous avons les résultats des
tests de cinq étudiants, nous les additionnons
et les divisons par cinq pour trouver que le
score moyen au test est de 86,6 Vient ensuite la médiane. Lorsque les valeurs d'un ensemble de données sont classées par ordre croissant, la médiane est la valeur médiane S'il y a un
nombre impair de points de données, il s'agit simplement de la valeur moyenne. S'il y a un nombre pair, la médiane est la moyenne
des deux valeurs intermédiaires. Un aspect important de
la médiane est qu'elle résiste aux
valeurs extrêmes ou aux valeurs aberrantes Par exemple, quelle que soit
sa taille, la dernière personne figure
dans un ensemble de données élevé. La médiane restera la même. Bien que la moyenne puisse changer manière significative
en fonction de cette valeur, elle reste inchangée quelle que soit la taille de la
dernière personne. Cela signifie qu'il n'est pas
affecté par les valeurs aberrantes. En revanche, les hommes peuvent changer manière significative en fonction de la taille de
cette dernière personne, ce qui la rend sensible aux valeurs aberrantes Parlons maintenant du mode. Le mode est la ou les valeurs
les plus
fréquentes dans un ensemble de données. Par exemple, si 14 personnes
se déplacent en voiture, six à vélo, cinq marchent et cinq
empruntent les transports en commun, voiture est le mode de transport puisqu'
il apparaît le plus souvent Nous passons ensuite aux
mesures de dispersion, qui décrivent la répartition des valeurs d'
un ensemble de données. Les principales mesures de dispersion
incluent les variantes. Plage d'écart type
et plage interéquatale, en
commençant
par l' commençant
par Il indique la distance
moyenne entre chaque
point de données et la moyenne. Cela nous indique dans
quelle mesure les points de
données individuels s'écartent
de la moyenne Par exemple, si l'
écart
moyen par rapport à la moyenne est de
11,5 centimètres, nous pouvons calculer l'
écart type à l' aide de la formule Sigma est égal à la racine carrée de la somme de chaque valeur
moins la moyenne Au carré, divisé par n, où Sigma est l'
écart type N est le nombre d'individus. X sub i est la valeur de chaque
individu, et x bar est la moyenne. Il est important de
noter qu'il existe deux formules pour l'
écart type. On divise par n, tandis que l'autre divise
par n moins un. Ce dernier est utilisé
lorsque notre échantillon ne couvre pas l'
ensemble de la population, comme dans les études cliniques. Ce dernier est utilisé
lorsque notre échantillon ne couvre pas l'
ensemble de la population, comme dans les études cliniques. Maintenant, en quoi l'
écart type diffère-t-il de la variance ? L'écart type mesure la distance moyenne
par rapport à la moyenne. Alors que la variance est simplement la valeur au carré de
l'écart type Ensuite, discutons de la plage
et de la plage intequatale. La plage est la
différence entre
les valeurs maximales et minimales d'un ensemble de données. D'autre part,
la plage inéquartile représente la
moitié médiane des données,
calculée comme la différence
entre le premier quartile,
Q un, et le troisième
quartile, qu Cela signifie que 25 %
des valeurs se situent dessous et 25 % au-dessus de la
plage interquartile Avant de passer
aux derniers points, comparons brièvement
ces concepts, les mesures de tendance centrale
et les mesures de dispersion. Envisageons de mesurer la
tension artérielle des patients. Les mesures de
tendance centrale fournissent une valeur unique qui représente
l'ensemble de données dans son intégralité. Aider à identifier
un point central autour duquel les
points de données ont tendance à se regrouper. D'autre part, les
mesures de dispersion, telles que l'écart type, plage et la plage InteQatile indiquent l'étendue des points
de données Qu'ils soient étroitement regroupés autour du centre ou
largement dispersés. En résumé, alors que les mesures de tendance
centrale mettent en évidence le point central
de l'ensemble de données, les mesures de dispersion
décrivent
la manière dont les données sont distribuées
autour de ce centre. Passons maintenant aux tableaux, en concentrant sur les types les plus
importants, fréquence et les tables de
contingence Un tableau de fréquence
indique la fréquence laquelle chaque valeur distincte
apparaît dans un ensemble de données. Par exemple, une entreprise a interrogé ses employés sur
leurs options de trajet domicile-travail, voiture, à vélo, à pied
et en transports Voici les résultats de 30 employés avec
leurs réponses. Nous pouvons créer un
tableau des fréquences pour résumer ces données en listant les quatre options dans
la première colonne et en comptant leurs
occurrences dans le tableau. Il est clair que le mode
de transport le
plus courant chez les
employés est la voiture. 14 employés ont
choisi cette option. Le tableau des fréquences fournit un résumé concis des données. Mais que se passerait-il si nous avions deux variables
catégorielles
au lieu d'une ? C'est là qu'un tableau de
contingence, également appelé
tabulation croisée, entre en jeu Imaginez que l'entreprise
possède deux usines, l'une à Détroit et l'
autre à Cleveland ? Si nous interrogeons également les employés
sur leur lieu de travail, nous pouvons afficher les deux variables à
l'aide d'un tableau de contingence Ce tableau nous permet d' analyser et de comparer
la relation entre les deux variables
catégorielles Les lignes représentent les
catégories d'une variable. Alors que les colonnes représentent
les catégories des autres, chaque cellule du tableau
indique le nombre d' observations correspondant à la combinaison de
catégories correspondante. Par exemple, la première cellule indique le nombre d'
employés qui se déplacent en voiture et travaillent à Détroit
a été indiqué six fois. Merci. Je vous verrai dans la prochaine leçon de statistiques.
10. Notions de statistiques inférentielles, partie 2: Passons aux statistiques
inférentielles. Nous allons commencer par un bref
aperçu de ce que c'est. Suivi d'une explication
des six éléments clés. Alors, qu'est-ce que les
statistiques inférentielles ? Cela nous permet de tirer
des conclusions sur une population à partir
des données d'un échantillon. Pour clarifier les choses, la population est l'ensemble du groupe qui
nous intéresse. Par exemple, si
nous voulons étudier la taille moyenne de tous les
adultes aux États-Unis, notre population inclut
tous les adultes du pays. L'échantillon, quant à lui, est un sous-ensemble plus petit issu
de cette population Par exemple, si nous sélectionnons
150 adultes américains,
nous pouvons utiliser cet échantillon pour tirer conclusions sur l'
ensemble de la population Voici maintenant les six
étapes de ce processus. Hypothèse. Nous partons
d'une hypothèse. Quelle est la déclaration
que nous voulons tester ? Par exemple, nous pourrions
vouloir déterminer si un médicament a un impact positif sur tension artérielle chez les personnes
souffrant d'hypotension. Oh, dans ce cas, notre population est composée de toutes les personnes souffrant d'
hypertension artérielle aux États-Unis, car il n'est pas pratique de recueillir données auprès de l'ensemble de la population Nous nous appuyons sur un échantillon pour tirer des conclusions sur la
population à l'aide de notre échantillon Nous utilisons des tests d'hypothèses. Il s'agit d'une méthode utilisée pour
évaluer une affirmation concernant un paramètre de population sur la
base d'un échantillon de données. Différents tests d'
hypothèses sont disponibles, et à la fin de cette vidéo. Je vais vous expliquer comment
choisir le bon. Comment fonctionnent les
tests d'hypothèses ? Nous commençons par une hypothèse
de recherche. Également connue sous le nom d'hypothèse
alternative, c'est
ce que nous recherchons des
preuves dans notre étude. Également appelée hypothèse
alternative. C'est pour cela que nous
essayons de trouver des preuves. Dans notre cas, l'hypothèse est que le médicament
affecte la tension artérielle. Cependant, nous ne pouvons pas le
tester directement avec un test d'
hypothèse classique. Nous testons donc l'hypothèse
inverse, savoir que le médicament n'a aucun
effet sur la tension artérielle. Voici le processus. Premièrement,
supposons l'hypothèse du non. Nous supposons que le médicament n'
a aucun effet, c'
est-à-dire que les personnes
qui le prennent et celles qui n'ont pas la
même tension artérielle moyenne. T, collectez et
analysez des échantillons de données. Nous prélevons un échantillon aléatoire. Si le médicament présente un
effet important sur l'échantillon, nous déterminons ensuite la
probabilité de prélever un
tel échantillon ou un échantillon
qui s'écarte encore plus, si le médicament n'
a réellement aucun effet, ou un échantillon qui s'écarte encore plus, si le médicament n'
a réellement aucun effet,
T, évaluez la valeur de
probabilité p. Si la probabilité d'observer un
tel résultat sous l'
hypothèse nulle est très faible. Nous envisageons la possibilité que le médicament
ait un effet. Si nous avons suffisamment de preuves, nous pouvons rejeter l'hypothèse
nulle. La valeur p est la
probabilité qui mesure la force des preuves par
rapport à l'hypothèse nulle. En résumé, l'
hypothèse nulle indique qu'il n'y a aucune différence
dans la population, et le test d'hypothèse
calcule la probabilité observer les résultats de l'échantillon si l'hypothèse nulle est vraie Nous voulons trouver des preuves à l'appui de
notre hypothèse de recherche. Le médicament affecte la tension artérielle. Cependant, nous ne pouvons pas le tester
directement, nous testons
donc l'
hypothèse opposée, l'hypothèse nulle. Le médicament n'a aucun effet
sur la pression artérielle. Voici comment cela fonctionne. Supposons l'hypothèse du non. Supposons que le médicament n'ait aucun effet. Cela signifie que les personnes qui
prennent le médicament et celles qui n'ont pas la
même tension artérielle moyenne collectent et analysent des données. Prélevez un échantillon aléatoire. Si le médicament présente un
effet important dans l'échantillon. Nous déterminons la probabilité
d'obtenir un tel résultat, ou un résultat plus extrême. Si le médicament n'a vraiment aucun effet, calculez la valeur p. La valeur p est la
probabilité d' observer un échantillon
aussi extrême que le nôtre. En supposant que
l'hypothèse nulle est vraie. Importance statistique. Si la valeur p est inférieure à un seuil défini, généralement 0,05 Le résultat est
statistiquement significatif, ce qui signifie qu'il est peu probable qu'il
soit le fruit du seul hasard. Nous avons alors suffisamment de preuves pour rejeter l'hypothèse nulle. Une faible valeur p suggère que les données observées ne correspondent pas à
l'hypothèse nulle. qui nous amène à la rejeter au profit de l'hypothèse
alternative. Une valeur p élevée suggère que les données sont cohérentes
avec l'hypothèse nulle. Nous ne le rejetons pas. Points importants Une faible valeur p ne
prouve pas que l'
hypothèse alternative est vraie. Cela indique simplement
qu'un tel résultat est peu probable si l'
hypothèse nulle est vraie. De même, une valeur p élevée ne prouve pas que l'
hypothèse nulle est vraie. Cela suggère que les données observées sont probablement soumises à l'hypothèse
nulle. Merci. Je vous verrai dans la prochaine leçon de statistiques.
11. Notions de tests d'hypothèses en détail: Bon retour. Comprenons l'
hypothèse plus en détail. Hypothèse de Nous avons une population entière que
nous aimerions étudier. Mais il y aurait
toujours des contraintes de temps et de ressources pour étudier
l'ensemble de la population. Par conséquent, nous prélevons un échantillon
de la population en utilisant différentes techniques d'échantillonnage
et en retirons un échantillon. Nous étudions l'échantillon et tirons des conclusions
sur la population, sous forme
de statistiques
inférentielles Qu'est-ce qu'une hypothèse exactement ? Une hypothèse est une hypothèse qui ne peut être ni
encline ni désapprouvée Dans un processus de recherche, l'hypothèse est formulée
au tout début, et le but est de la rejeter
ou de ne pas la rejeter. Afin de rejeter ou de ne pas
rejeter l'hypothèse, des exemples de données provenant de l'
expérience ou d'une enquête sont nécessaires, qui sont ensuite évalués à
l'aide d'un test d'hypothèse. En utilisant des hypothèses, les hypothèses sont
généralement réalisées en commençant par
un examen littéral Sur la base de l'examen littéral, vous pouvez soit justifier pourquoi vous avez formulé l'
hypothèse de cette manière Un exemple d'
hypothèse pourrait être les hommes gagnent plus que les femmes pour
le même travail en Autriche. L'hypothèse est l'hypothèse d'une association attendue. Votre objectif est de rejeter ou de ne pas rejeter
l'hypothèse nulle. Vous pouvez tester votre hypothèse sur la
base des données. L'analyse des données est effectuée à l'aide des tests d'
hypothèses. Les hommes gagnent plus que les femmes pour
le même travail en Autriche. Vous avez réalisé une enquête auprès de près de 1 000 employés
travaillant en Australie, un test T auprès d'un échantillon indépendant. Dans ce test, l'
hypothèse dont vous avez besoin à partir de l'enquête est adaptée à des tests d'
hypothèse
tels que le test T ou le test d'analyse de
corrélation. Nous pouvons utiliser des outils en ligne tels que l'onglet
Données ou
les outils Excel pour résoudre ce problème. Comment formuler une hypothèse ? Pour formuler
une hypothèse, il faut
d'abord définir une question de recherche. Une
hypothèse précise sur la population peut ensuite être dérivée de la question de
recherche. Les hommes gagnent plus que les femmes pour
le même travail en Australie. Au sujet, quelle est la question que nous voulons poser
et quelle en est l'hypothèse ? Vous
fournirez ensuite les données
au test d'hypothèse et en
tirerez la conclusion. Il s'agit d'une très belle représentation
visuelle de la façon dont un
test d'hypothèse est effectué. Les hypothèses ne sont pas de
simples déclarations. Ils sont formulés de
manière à pouvoir être testés avec Ils peuvent être testés avec des données collectées au cours du processus de
recherche. Pour tester une hypothèse, il
est nécessaire de définir exactement quelles variables sont impliquées et comment ces
variables sont liées. Les hypothèses sont donc des hypothèses
concernant la relation de cause à
effet de l'association
entre les variables. Qu'est-ce qu'une variable dans ce cas ? variable n'est rien
d'autre qu'une propriété d'un objet ou d'un événement qui peut
prendre différentes valeurs. Par exemple, la
couleur des yeux est une variable. S'il s'agit de la propriété de l'objet, je peux prendre différentes valeurs. Si vous faites des recherches
dans le domaine des sciences sociales, vos variables peuvent
être le sexe, le revenu, les attitudes,
la protection de l'environnement, etc. Si vous faites des
recherches dans le domaine médical, vos variables
peuvent être le poids corporel, le
tabagisme,
le rythme cardiaque, etc. Alors, en quoi consiste exactement l'hypothèse nulle
et alternative ? Il y a toujours deux
hypothèses qui sont exactement opposées l'une à l'autre et qui prétendent être opposées Ces
hypothèses opposées sont
appelées hypothèses nulles et alternatives et sont représentées par H zéro
et H A ou H un, H zéro et
H L'hypothèse nulle de H zéro suppose qu'
il n'y a aucune différence entre deux ou plusieurs groupes en ce qui
concerne les caractéristiques que nous essayons d'étudier Les hypothèses nulles sont alors. L'hypothèse nulle suppose qu'il n'y a aucune
différence entre deux groupes ou plus en ce qui
concerne les caractéristiques. Par exemple, le salaire des hommes et des femmes n'est pas
différent en Autriche. L'hypothèse alternative
est l'hypothèse que nous voulons prouver ou que nous
collectons des données pour la prouver. L'hypothèse alternative,
quant à elle, suppose qu'il existe une différence entre
les deux ou plusieurs groupes. Par exemple, le salaire
des hommes et des femmes
est différent en Autriche. L'hypothèse que vous
voulez tester ou ce que vous voulez déduire de la théorie
indique généralement l'effet. Le sexe a un
effet sur le salaire. Cette hypothèse est appelée
hypothèse alternative. C'est une très belle
déclaration, non ? Il existe une autre
façon de l'écrire, savoir que le sexe a
un effet sur le salaire, et le test d'hypothèse est
appelé hypothèse alternative. L'hypothèse nulle
indique généralement qu'il n'y a aucun effet. Le sexe n'a aucun effet sur le salaire. Dans le test d'hypothèse, seule l'hypothèse nulle
peut être testée. L'objectif est de savoir si l'hypothèse
nulle est
rejetée ou non. Il existe différents
types d'hypothèses. Quels sont les types d'hypothèses
disponibles ? distinction la plus courante
est entre les différences, hypothèse de
corrélation, elle peut être directionnelle et une hypothèse non
directionnelle. Hypothèse différentielle et de
corrélation. Les hypothèses différentielles sont utilisées lorsque différents groupes doivent être distingués entre le groupe d' hommes et le groupe de femmes Les hypothèses de corrélation sont utilisées lorsqu'ils veulent établir une relation ou qu'une corrélation entre la variable
doit être testée La relation
entre l'âge et la taille. Hypothèse de différence. L'hypothèse de différence
est un test qui consiste à déterminer s'il existe une différence entre
deux ou plusieurs groupes. Exemple d'hypothèse
de
différence le groupe d'hommes
gagne plus que les femmes. risque de
crise cardiaque est plus élevé chez les fumeurs que chez les non-fumeurs. Il existe une différence
entre l'Allemagne, l'Autriche et la France en termes d'
heures travaillées par semaine. Ainsi, une variable est toujours une
variable catégorique comme le sexe, statut
tabagique ou le pays D'autre part,
l'autre variable est
une variable ordinale ou
une variable du salaire, du pourcentage de risque de crise cardiaque et des heures de travail par semaine Maintenant, comprenons
un peu plus en détail l'hypothèse de
corrélation . Un test d'hypothèse de corrélation, relations entre
deux variables. Par exemple, la taille
et le poids du corps. À mesure que la taille de la
personne augmente, le poids corporel est affecté. L'
hypothèse de corrélation, par exemple, est que plus une personne est grande, est lourde, plus
la puissance d'une voiture est élevée, sa consommation
de carburant est élevée la note en mathématiques est bonne, plus
le futur salaire est élevé. Comme vous pouvez le voir dans les exemples, les hypothèses
de corrélation prennent
souvent la forme
suivante plus le taux est
élevé, plus le taux est bas. Ainsi, au moins deux variables d'
échelle ordinale sont
examinées Hypothèse directionnelle et non
directionnelle, les
hypothèses sont divisées en directionnelles et non directionnelles. C'est-à-dire qu'il s'agit d' hypothèses
unilatérales ou bilatérales. Si l'hypothèse contient des
mots tels que « meilleur », pire », l'hypothèse
est généralement directionnelle. Cela peut être positif
ou négatif. Dans le cas d'une hypothèse non
directionnelle, on découvre souvent
les éléments de base, exemple s'il existe une différence
entre les formulations, mais on ne précise pas dans quelle direction se situe la
différence. Pour l'
hypothèse non directionnelle, la seule chose intéressante
est de savoir s'il existe une différence de valeur entre les
variables considérées. Dans une hypothèse directionnelle, quel intérêt y a-t-il à ce qu'
un groupe soit supérieur ou
inférieur à l'autre ? Vous avez une hypothèse à deux faces, ou vous pouvez avoir une hypothèse
unilatérale comme du côté gauche ou du côté droit. non directionnelle,
hypothèse non directionnelle permettant de vérifier s' il existe une différence
ou une relation. Peu importe la direction
dans laquelle la relation existe
ou les différents coûts. Dans le cas d'une hypothèse de
différence, cela signifie qu'il existe une
différence entre deux groupes, mais cela ne dit pas si
l'un des groupes a une valeur plus élevée. Il existe une différence entre le salaire des hommes et celui des femmes, mais cela ne dit pas
qui gagne le plus. Il existe une différence
dans le risque de crise cardiaque entre
fumeurs et non-fumeurs, mais cela ne permet pas de savoir qui
est le plus à risque. En ce qui concerne l'hypothèse de
corrélation, elle signifie une relation ou une corrélation
entre deux variables. Mais il
n'est pas dit si
la relation est positive ou négative. Il existe une corrélation entre taille et le poids et il existe une corrélation
entre la puissance et la consommation de carburant de la voiture. Dans les deux cas, on ne dit pas que la corrélation est
positive ou négative. Lorsque vous parlez d'une hypothèse
directionnelle, nous indiquons également le sens de la
relation ou de la différence. En cas d'hypothèse
différente, une déclaration est faite : quel groupe
a la valeur la plus élevée ou la plus faible ? Les hommes gagnent plus que les femmes. Les fumeurs ont un risque plus élevé de crise cardiaque
que les non-fumeurs. Dans le cas d'une hypothèse de
corrélation, la relation est établie pour savoir si une corrélation est
positive ou négative. Plus une personne
est grande, plus elle est lourde. Plus la puissance d'une voiture est élevée, plus sa consommation de carburant est élevée. L'hypothèse
alternative directionnelle unilatérale inclut uniquement les
valeurs qui diffèrent dans un sens des valeurs
de l'hypothèse nulle. Maintenant, comment interpréter la valeur p dans une hypothèse
directionnelle ? Habituellement, les
logiciels statistiques vous aident
toujours à
calculer la valeur p. Excel est également devenu très intelligent dans
le calcul de la valeur p, et il aide à calculer le test non directionnel et aide
également à donner
la valeur p pour cela. Pour obtenir la valeur p pour une hypothèse
directionnelle, il faut vérifier si l'
effet est dans la bonne direction, puis la valeur p
est divisée par deux et si le
seuil de signification n'est pas accéléré de deux, mais d'un seul côté De plus, nous avons
un tutoriel sur la valeur P. Alors, s'il vous plaît, allez regarder cela dans la phase analysée de mon cours. Si vous sélectionnez une hypothèse
alternative dirigée dans un type de données logiciel, pour le calcul
de l'hypothèse, la conversion est
effectuée automatiquement et vous ne pouvez que lire. Maintenant, instructions étape par étape
pour tester l'hypothèse. Vous devez effectuer une recherche
documentaire, formuler l'hypothèse,
définir le niveau d'échelle,
déterminer le niveau de
signification, déterminer le test d'hypothèse,
quel test d'hypothèse
convient aux niveaux d'échelle et au style d'
hypothèse ? Le prochain tutoriel porte
sur les tests d'hypothèses. Vous en apprendrez davantage sur les tests d'
hypothèses et
découvrirez lequel est le meilleur
et comment le lire.
12. Introduction aux outils 7Qc: T. Bienvenue dans le nouveau cours
sur sept outils de qualité. C'est l'un des concepts les plus
importants si vous envisagez d'apporter une
petite amélioration continue à
votre processus, à vos opérations
ou à votre configuration de fabrication. Même si vous travaillez dans
le secteur des services, ces outils vous aideront
à assurer le suivi de la qualité. C'est avec ça que nous allons commencer. Alors, les sept outils de contrôle qualité, que vais-je aborder dans
le cadre de ce programme de
formation ? Il s'agit des sept outils de contrôle
qualité. Premièrement, les objets catapultent, l'histogramme, l'
histogramme, l'analyse de
Pareto, le diagramme de
Fishburn, également appelé diagramme d'
Ishikawa, les feuilles de contrôle Ishikawa Nous n'allons pas seulement couvrir ces outils à un niveau élevé. Nous allons donner
quelques exemples façon de dessiner ces choses en utilisant Microsoft Excel dans la mesure du
possible. Nous allons également vous donner quelques exemples d'exercices avec des données qui peuvent vous aider à effectuer
ces activités très facilement. Nous allons
parler de ce qu'est l'outil, comment l'utiliser, quand l'utiliser, certaines erreurs
courantes à éviter et d'un guide étape par étape pour créer le résultat
requis.
13. Checksheet: Passons à l'outil de qualité
suivant parmi les sept outils de contrôle qualité, la feuille de contrôle. Apprenons-en plus
sur la feuille de contrôle. Les fiches de contrôle sont utilisées pour enregistrer
et compiler
systématiquement les données À partir des sources historiques
ou des observations au fur et à mesure qu'elles se produisent. Il peut être utilisé pour collecter des
données à des endroits où les données sont réellement
générées au fil du temps. Il peut être utilisé pour saisir des données
quantitatives et
qualitatives. Je vous ai donc montré une simple feuille de
contrôle où vous trouverez types de
défauts et le nombre de fois ce
défaut particulier se produit. Cela peut être utilisé
pour
enregistrer et compiler systématiquement les données provenant de sources historiques ou d'
observations au fur et à mesure qu'elles se produisent. Il peut être utilisé pour
collecter des données à des endroits où les données sont
générées en temps réel. Ce type de données peut être aussi bien
quantitatif
que qualitatif. La feuille de contrôle est l'un
des sept contrôles de qualité de base. À quoi sert la feuille de contrôle ? Il est utilisé pour créer des
données
faciles à comprendre et cela s'accompagne d'un processus
simple et efficace À chaque entrée, créez
une image claire des faits tels qu'ils sont proposés à l'opinion
de chaque membre de l'équipe. C'est pourquoi c'est l'un
des systèmes axés sur les données. Il normalise l'accord sur les définitions
de chaque condition. Comment utilise-t-on une forme de chèque ? Nous sommes d'accord sur la définition des événements ou
des conditions observés. Exemple. Si nous cherchons la cause première des défauts de
gravité 1, accord pour en
faire une cause de gravité 1. Décidez qui collecte les données, choisissez la personne qui
participera à cette activité. Notez les sources à partir
desquelles les données sont collectées. Les données doivent prendre la forme d'
un échantillon ou de l'ensemble de la population. Il peut être à la fois
qualitatif et quantitatif. Décidez du
niveau de connaissance requis pour la personne impliquée
dans le plan de collecte de données. Décidez de la fréquence
de collecte des données, si les données
doivent être collectées, une base
hebdomadaire, horaire, quotidienne
ou mensuelle. Décidez de la durée de la collecte
des données, c'est-à-dire durée pendant laquelle les données doivent être collectées pour en faire
un résultat significatif. Construisez une feuille de contrôle
simple à utiliser, concise, complète et permettant d'accumuler des
données de manière cohérente tout au long de la période de
collecte Veuillez noter que les fiches de contrôle
ont été créées comme
l'un des outils de qualité lorsque nous
étions à l'ère industrielle. Nous sommes actuellement à
l'ère de l'information. Nous avons tellement de logiciels ERP, machines capturent
des données grâce à l'informatique, et il existe divers autres rapports générés par
ordinateur
qui sont applicables Essayez d'utiliser une feuille de contrôle
uniquement et uniquement lorsque vous êtes dans un processus de saisie de données entièrement
manuel C'est l'un des
outils les moins utilisés ces derniers mois. Permettez-moi de reformuler : utilisez le moins
d'outils ces dernières années. À moins et jusqu'à ce que votre
entreprise
n'ait absolument aucune
approche systématique pour capturer les données. C'est un très bon outil si vous
faites appel à des employés de couleur
bleue
et que vous ne
disposez pas de systèmes de haute technologie
pour saisir les données. J'ai donc joint le modèle de feuille de contrôle dans la section
projet et ressources. Vous pouvez vous y référer.
Donne-moi juste une seconde. Je vais vous montrer la
feuille de contrôle à l'écran. Je peux donc utiliser une feuille de contrôle que je vous ai donnée dans le cadre de
mon modèle de parado Vous pouvez noter les
catégories ici, en me
disant qu'il s'agit d'un
défaut, un défaut, deux. répertorier Quel que soit le
nom
de votre défaut, veuillez répertorier tous les
défauts ici, n'est-ce pas ? Et ensuite, vous pouvez le commercialiser À quelle fréquence cela
se produit-il ? Où que cela se passe, veuillez commencer à en écrire un. À quelle fréquence le
voyez-vous et quand le voyez-vous ? Ceci, en conjonction avec le fait que je pourrai utiliser ultérieurement ces données
pour mon analyse de Pareto, pour laquelle j'ai créé une vidéo séparée,
vous pouvez les utiliser Vous n'avez pas besoin d'une feuille de
contrôle séparée dans le monde d'aujourd'hui. Vous pouvez utiliser celui que
j'ai donné ici. Merci. Je
te verrai au prochain cours.
14. Boxplot: Aujourd'hui, nous allons en
apprendre davantage sur boxplot et le comprendre
en détail Nous aurions tous vu Boxplot
à plusieurs reprises. Mais voyons ce qu'
il interprète. Alors, qu'est-ce qu'un boxplot exactement ? Avec un boxplot,
vous pouvez généralement afficher
graphiquement de nombreuses
informations sur vos données La case indique la fourchette
des 50 % intermédiaires de l'endroit
où se situe votre valeur. Comprenons le
diagramme à cases, comment il est divisé. Si le début de la
boîte est appelé Q un, il s'agit de l'extrémité inférieure de la boîte et il est également
appelé premier quartile Q est l'extrémité supérieure de la
boîte ou le troisième quartile. La distance entre Q 3 et Q est appelée plage
interquartile,
qui correspond à la
moitié médiane de vos données Les 25 % des données se situent en
dessous du point 1. Dans la case, vous avez 50 % des données, et par conséquent, 25 % des
données se trouvent au-dessus de la case. Vous avez une ligne principale et une ligne
médiane à l'intérieur de la boîte, qui divise à nouveau les
données en 25 et 25 % Supposons donc que lorsque nous affichons
l'âge du participant, sur le graphique, il soit 31 ans. Cela signifie que 25 %
des participants ont
moins de 31 ans. Q trois, c'est 63 ans. Cela signifie que 25 % des
participants ont plus de 63 ans. 50 % des participants ont entre
31 et 63 ans. La moyenne et la médiane. La médiane est de 42 ans, ce qui signifie que
la moitié des participants sont âgés de plus de 42 ans et l'autre moitié de
moins de 42 ans. La ligne en tiret est également appelée ligne moyenne
ou valeur principale, qui représente la moyenne. Comme la moyenne est
éloignée de la médiane, cela indique clairement
que les données le sont. La ligne continue représente la médiane et la
ligne pointillée représente la moyenne Les points les plus
éloignés sont appelés valeurs aberrantes. La hauteur de la moustache est environ 1,5 fois la plage
interquartale La moustache ne peut pas
maintenir le ping indéfiniment. La valeur aberrante et la moustache
en forme de pointe. S'il n'y a pas de valeur aberrante, la valeur maximale est ici S'il y a une valeur aberrante, la moustache en forme de T est
le dernier point correspondant à 1,5 fois l'
intervalle interquaral, les autres points étant considérés comme des valeurs aberrantes Comment créer un boxplot ? Vous disposez d'une feuille Excel pour
créer votre boxplot, et vous pouvez également le faire à
l'aide d'outils en ligne Oui, donc je peux juste
opter pour les graphiques. Sur ce, je peux dire que je
prends la variable métrique, puis vous avez une
option d'histogramme, et vous avez également une
option de boxplot, qui indique clairement
que le Q est 29, 66, la médiane est 42, Man 46 Le maximum est de 99, la clôture
supérieure est de 99. Il n'y a pas de valeurs aberrantes. Allons-y et modifions les données. Laissez-moi en faire 126. Dès que je change la valeur d' une personne à 126,
à votre retour,
vous constaterez qu'il y a
une valeur aberrante dans l'histogramme,
et il est très évident
ici que 126 est une Et ici, la clôture supérieure est de 92. Le Q trois est toujours le même, le Q est toujours le même. La taille de la boîte ne
change donc pas et ainsi de suite. Hein ? Et si la personne est un euro ? Dans ce cas, vous
verrez qu'il ne fait pas
partie d'une valeur aberrante, mais qu'il fait tout de même partie du disque. Je peux réduire le graphique, je peux montrer la ligne zéro. Je peux montrer l'
écart type. Je peux montrer les points. Je peux le faire à l'
horizontale et à la verticale. Toutes ces options
sont donc possibles grâce à un outil
statistique en ligne. Je peux évidemment télécharger le fichier
Zip et travailler avec. OK. Comment puis-je faire du boxplot
en utilisant une feuille Excel ? J'ai donc copié les
mêmes données ici. j'ai différents groupes, j'ai
choisi mon âge comme donnée. Et maintenant, je vais insérer le graphique
recommandé, accéder à tous les graphiques, et j'ai un tableau à cases et à
moustaches Et je peux voir ma
boîte et mon tableau à moustaches. Je peux supprimer mes lignes de quadrillage et
ajouter les étiquettes de données, et cela montre clairement mon chemin. Je peux peut-être simplement
l'augmenter pour le rendre plus visible. Je peux changer la couleur de
mon graphique pour qu'elle soit différente. Oh et je peux choisir le Ma moyenne
est ici. Ma médiane est 421, trois et. Maintenant, le même graphe, je peux également le regrouper
en fonction des racines. Je prends le
groupe et l'âge. Je clique sur dedans, je peux cliquer
sur le graphique recommandé, accéder à tous les graphiques et
faire des cases et des moustaches. Cette fois, j'ai quatre boîtes
pour chacun des groupes. Je peux changer la couleur
de mon graphique. C'est bon. Je peux inclure les étiquettes de données. Lorsque je l'inclus ici
et que je clique sur le signe virgule, vous constaterez que
les points de égalité ont été. Il est donc très
facile de dessiner un graphique à l'aide d'
Excel ou à l'aide de
certains outils en ligne Donc, pour les groupes, j'ai
pris le groupe plus le A, et pour cela, j'ai pris. Donc, pour A, disons
pour le groupe C, si je change
la valeur à 100, vous constaterez qu'il
y a une valeur aberrante là-bas La valeur minimale est dix, changeons les valeurs 25. Vous vous rendrez compte que c'est ainsi que les
valeurs changent. Génial. Je te verrai donc
au prochain cours. Oh.
15. Partie 1 de la parcelle de boîte: Dans cette leçon, nous allons en savoir plus sur la boîte
à moustaches. Une boîte à moustaches est
l'une des techniques graphiques qui nous
aide à identifier les
valeurs aberrantes, n'est-ce pas ? Voyons comment se forme
une boîte à moustaches. Comprenons d'abord
le concept avant de passer
aux travaux pratiques. Une boîte à moustaches est appelée
boîte à moustaches parce qu'elle
ressemble à une boîte et qu'elle est
visqueuse comme le chat. Le chat a sur son visage. Maintenant, tout comme le chat ne peut pas avoir et moins visqueux, la taille de la moustache de
la boîte à moustaches sera décidée en
fonction de certains paramètres. Vous verrez certaines terminologies
importantes lorsque vous formerez une boîte à moustaches. Premièrement, quelle est
la valeur minimale ? Quel est le premier quartile ? Qu'est-ce que la médiane ? Qu'est-ce que le noyau serré ? Troisièmement, quelle est la taille
de la moustache maximale ? Et quelle est la
valeur maximale du point de données ? Ici ? Le nombre minimum de chiens au-dessus du point minimum et où
la moustache peut être étendue. Q1 représente le premier trimestre, soit 25 % des données. Supposons que nous ayons 100 points de données. 25 % des données
seront inférieures à ce seuil. Entre le premier et le deuxième trimestre. Vingt-cinq pour cent
de vos données seront formées, seront présentes. Q2 est également appelé la médiane ou le
centre de vos données. Donc, si je range mes données dans l'ordre
croissant ou décroissant, le
point de données du milieu est appelé médiane et il est appelé Q2. Q3, ou autrement
appelé quartile supérieur, parle des
vingt-cinq pour cent des données après le milieu. Donc techniquement, à ce jour, vous avez couvert soixante-quinze pour cent
de vos données seront inférieures à votre
troisième quartile, soixante-quinze pour cent
de vos données
seront inférieures à votre
troisième quartile,
25 pour cent en dessous du premier trimestre, 50 % des données en dessous du deuxième trimestre, soixante-quinze pour cent
les données sont inférieures au troisième trimestre. Techniquement, sur 100 %
des données, 75 % des données sont inférieures au troisième trimestre. Cela signifie que vingt-cinq pour cent de mes points de données seront supérieurs au troisième trimestre. Maintenant, la distance entre
Q1 et Q3 est appelée, est appelée comme la taille de la boîte. Et cette taille de boîte est également
appelée plage interquartile. Q3 moins Q1 est appelé
intervalle interquartile. Comme je vous l'ai dit
au début du cours, la taille des
moustaches
dépend de l'intervalle interquartile
ou IQR. Q3. Je peux former cette ligne 1,5
fois la taille de la boîte. Donc 1,5 fois dans IQR plus q3 sera la
limite supérieure pour ma moustache. Sur le côté droit.
Sur la face supérieure. Si je veux dessiner la
moustache sur le côté gauche, ce n'est rien d'autre que la même 1,5 fois dans la plage
interquartile. Mais je soustrais cette valeur de Q1 et je l'ai étendue jusqu'à cette valeur. Il définit donc la limite inférieure. Vous pouvez avoir des
points de données qui
se situent en dessous du point minimum. Vous pouvez avoir des
points de données
qui dépassent la taille
maximale
du risque que ces points de données
soient appelés valeurs aberrantes. La beauté de la boîte à moustaches
est qu'elle vous aidera à identifier s'il existe des
valeurs aberrantes dans votre jeu de données. Voyons comment
créer une boîte à moustaches ? Parce que physiquement, je
n'ai pas à m'
inquiéter de trouver 2525% pour cent. Et vraiment par personne, nous allons
aller sur Minitab et ensuite faire le travail. Voyons donc cette fiche technique. Dans notre cours précédent, nous avons fait quelques
statistiques descriptives à ce sujet. Et nous avons trouvé les points de données. Nous avons trouvé des points de données minimum
Q1, Q2, Q3 et maximum. Essayons de créer
une boîte à moustaches pour la durée
du cycle en minutes. Je vais donc cliquer sur le graphique. Je vais aller à la boîte à moustaches et voir une boîte à moustaches simple
et cliquer sur, OK, je vais sélectionner la durée
du cycle en minutes. Et je vais dire, OK, voyons la vue des données. Si vous regardez cette boîte à moustaches, la ligne ci-dessous est
appelée celle. Il est 9,16. La médiane est la ligne médiane, et il n'est pas nécessaire qu'elle soit
exactement au centre. Le haut de la boîte est Q3, soit 10,86 dans
cette plage de données, et l'intervalle interquartile
est 1,7. Ma boîte peut s'étendre
1,5 fois sur le coude et elle peut aller 1,5 fois
sur le ballon. Et vous constatez
qu'il
n'y a pas d'astérisque
dans cette boîte à moustaches, qui indique
très clairement qu'il
n'y a aucune valeur aberrante dans mon jeu de données
actuel. Reprenons d'
autres ensembles de données. Dans notre prochaine vidéo pour
comprendre comment faire une boîte à moustaches.
16. Partie 2 de la parcelle de la boîte: Poursuivons notre voyage mieux comprendre les boîtes à moustaches
. Si vous accédez à la feuille
de votre fichier de projet, appelée boîte à moustaches. J'ai collecté des données sur la durée
du cycle pour cinq scénarios
différents. Comme vous pouvez le voir à
certains endroits, j'ai plus
de points de données, comme j'ai presque 401745 données. À certains endroits, je
n'ai que 14 points de données. Essayons donc d'analyser cela
plus en détail pour comprendre
comment fonctionne la boîte à moustaches. J'ai copié ces
données sur Minitab, cas un, deux, T3 et T4. La première chose que je
voudrais faire est de faire quelques
statistiques descriptives de base pour toutes les clés étrangères. Je suis en train de tout sélectionner. Et puis je vois,
quand je vois ma sortie, je peux voir que dans
trois cas,
j'ai 45 points de données. Dans le quatrième cas, j'ai 18 points de données. Dans le cinquième cas, j'
ai 14 points de données. Donc le nombre de
points de données est très, si vous regardez ma valeur minimale, si vous regardez ma valeur minimale,
elle varie de 1, un, vingt et un, vingt-deux. Et la valeur maximale se situe
quelque part entre 4090. Dans un scénario, j'ai
développé des valeurs allant de 21 à 40. Dans un scénario, j'ai
des valeurs de deux à 90, ce qui montre très clairement que le nombre de
points de données ou le faire. Mais ma fourchette de valeurs est blanche. Donc, si vous regardez le taux, il varie de
18,8 à 99 points. Donc dans le deuxième cas, j'ai 1200 comme
fourchette, donc 99 ans. Et la même chose peut également être
observée en tant qu'écart type. Vous pouvez voir que l'
asymétrie des données est différente et que le kurtosis
est différent. Commençons par comprendre
la boîte à moustaches en détail. Et dans la vidéo suivante, lorsque je
parlerai de l'histogramme, nous allons comprendre le modèle de
distribution en utilisant le même ensemble de données. Commençons.
Je clique sur le graphique. Je peux cliquer sur boîte à moustaches
et je clique sur simple. Ce que je peux faire, c'est que je peux prendre 11 cas à la fois
pour analyser mes données. premier cas
me montre une boîte à moustaches et
cette boîte à moustaches montre très clairement qu'il n'y a pas de
valeur aberrante dans mes données. Et la plage se situe entre. Quand je place le curseur ici, j'ai 45 points de données. Ma moustache
varie de 21,6 à 4,4, et ma
plage interquartile est de 5,95. Ma médiane est de 30,3. Mon premier quartile est de 26,9. Mon troisième quartile est 32,85. Refaisons
ça pour le deuxième cas. Quand je fais mes clés aussi, si vous regardez maintenant, la boîte est très petite car ici mes
points de données sont les mêmes. Fortified by Vickery
va encore de 21,6 à 40 pour ressembler à
mon scénario précédent. Mais j'ai des valeurs aberrantes ici, qui vont bien au-delà. Si vous vous souvenez, les statistiques
descriptives pour les enfants jusqu'à ma valeur minimale sont de un
et ma valeur maximale est de 100. Ma médiane ressemblait à
mon scénario précédent. Mon Q1 est également similaire, pas pareil, mais similaire. Et Q3 est également similaire. Mais quand vous
regardez la boîte à moustaches, la boîte est très petite, ce qui indique
très clairement
que mon intervalle interquartile
est de 6,95. Mon visqueux ne peut aller que 1,5 fois et tout
point de données au-delà, Misko sera appelé
comme une valeur aberrante. Je peux sélectionner ces
valeurs aberrantes, n'est-ce pas ? Et c'est très clairement voir, k est deux, la valeur est 100
et c'est dans la ligne numéro un. Ligne numéro 37, j'ai
une valeur appelée 90. Dans la ligne numéro 30, j'ai
une valeur appelée est 88. Et dans la ligne numéro 21, j'ai
une valeur appelée un, qui est une taille minimale. J'ai donc des valeurs aberrantes
des deux côtés. Comprenons le cas trois. Quand je regarde la chimie, je place mon curseur sur la boîte à moustaches. J'ai les mêmes 45 points de données. Ma viscose ou de 21,6 à 40 pour ça ressemble à mon
cas un, cas deux. Mais dans ce scénario, j'ai beaucoup de valeurs aberrantes. À l'extrémité inférieure. C'est-à-dire, au fond de
mon cœur, serré, non ? Il est facile pour nous de cliquer sur chacune d'entre elles et de
voir comment sont mes boîtes. qui est beau ici, c'est que
je n'ai que 18 points de données, mais j'ai quand même une valeur aberrante. Allons-y pour que k soit cinq. Et comprenez cela également. J'ai une boîte plus petite. Je n'ai que 14 points de données et j'ai une valeur aberrante
sur le bouton haut et une valeur aberrante
sur l'extrémité inférieure. Ici, la valeur est 23. Mais le fait de voir ces
intrigues différemment me
rend difficile de faire une comparaison. Est-ce que je peux tout afficher
sur un seul écran ? Donc je vais au graphique,
je vais à la boîte à moustaches. Je vais faire un
environnement simple sélectionné. Je sélectionne tous les cas ensemble et je vois
plusieurs graphiques. Je vois de la peau et je vois que
l'axe doit être vu. Les lignes de la grille doivent être visibles. Et je clique sur, OK. J'obtiens les
cinq points de données, cinq scénarios de cas
dans un graphique. Cela me facilitera la tâche de faire l'analyse, dans ce cas. Alors faites-le individuellement quand
j'ai vu le cas, si nous nous montrons une grande bande. Mais quand je compare l'un à côté
de l'autre, je peux savoir que dans le cas deux, j'
ai des valeurs aberrantes en
haut et en bas. le troisième cas, j'ai des
valeurs aberrantes en bas. Dans le cas quatre, j'ai des
valeurs aberrantes en haut. Dans le cas 5, j'ai
des prises des deux côtés. Le nombre de
points de données est différent. Les gros seront tirés au sort. La taille de la boîte ne peut pas être déterminée par le
nombre de points de données. J'ai 45 points de données, mais ma boîte est très étroite. J'ai 14 points de données
et ma boîte est blanche. Donc, la taille de la boîte. Donc, si j'ai 14 points de données, cela va diviser mes
données en quatre parties. Ainsi, trois points de données en dessous du premier trimestre, trois points de données
entre le premier et le deuxième trimestre, trois points de données
entre le deuxième et le troisième trimestre et trois points de données au-delà du troisième trimestre. Alors que lorsque j'avais
45 points de données, il est
distribué en tant que 11111111. Ma médiane serait
le chiffre du milieu. L'apprentissage de
cet exercice est qu' en
examinant la taille de la boîte, vous ne pouvez pas déterminer le
nombre de points de données. Mais ce que vous pouvez certainement déterminer, c'est que,
compte tenu de cet ensemble de données, est-ce que j'ai des points de données qui
sont extrêmement élevés ou très bas ? Le but du dessin d'
une boîte à moustaches est donc de voir la distribution et d'
identifier les valeurs aberrantes, le cas échéant. J'espère que le concept est clair. Si vous avez des questions, vous êtes libre de les poser
dans le groupe de discussion. Je me ferai un plaisir
d'y répondre. Merci.
17. Pareto analysis: Bonjour les amis. Poursuivons notre apprentissage sur sept outils de contrôle qualité. L'outil que nous
allons apprendre aujourd'hui est diagrammes de
Pareto sont également
appelés analyse de parto Ceci est basé sur
le célèbre statisticien et
non sur le statisticien Permettez-moi de me corriger, économiste qui a fait le tour du monde pour étudier la proportion de richesse par rapport
à la population. Ce faisant, M. Pareto a découvert le principe du 80 20 Plongeons-y en profondeur. Donc, l'analyse de Pareto, le principe qui vous
aide à vous concentrer sur le plus important pour en
tirer le maximum d'avantages Il décrit le phénomène selon lequel une petite quantité
de valeur élevée contribue davantage au total qu'un grand nombre
de valeurs faibles. L'objectif est de savoir quels sont ces
attributs de grande valeur sur lesquels je dois me
concentrer plutôt que sur
tant d'éléments de faible valeur. En bref, cela s'appelle
identifier les quelques personnes essentielles au
lieu de celles qui sont insignifiantes Quels sont ces blocs rouges
qui ne sont que trois ou quatre ? Mais la contribution est majeure. Au lieu de regarder des centaines
de petites choses où la
contribution totale est mineure. Même si je considère mes dépenses
personnelles, revenu total que je gagne, majeure partie de mon argent
est consacrée au paiement d'EMI, au
paiement des loyers et des factures. agit donc de quelques points essentiels pour moi, plutôt que de nombreux articles triviaux, où j'essaie de
regarder les billets de bus, la nourriture que je mange ou les petits achats
que je fais Donc, si je veux
faire de bonnes économies, je dois me concentrer sur la manière dont
je peux rembourser mon EMI plus rapidement, comment je peux avoir un loyer qui respecte mon budget. L'analyse de Pareto est basée
sur la célèbre règle des 80-20. Il indique qu'environ 80 %
des résultats proviennent de
20 % de l'effort. Très bien dit, les 80 %
d'effort proviennent de 20 % d'efforts. De même, 80 %
des problèmes ou des effets proviennent de 20 % des causes. Nous l'utilisons pour notre analyse
des causes. Le pourcentage exact peut varier d'une situation
à l'autre, alors que nous pensons qu'
il est de 80 20, même s'il s'agit de 75 à 25, nous devrions continuer
à fixer ces quelques points essentiels. Parfois, nous pouvons l'
obtenir sous la forme d'un 70 30, parfois nous pouvons
même l'obtenir sous la forme d'un 88 12. Ce ne sont là que quelques
exemples. Le problème est de savoir quelles sont
ces causes majeures que je peux corriger avec un minimum d'effort pour
obtenir le maximum de résultats. Dans de nombreux cas, peu d'efforts sont généralement
responsables de la plupart des résultats. Quelques causes sont généralement responsables de
la plupart des efforts. Pour en revenir à mon examen, certains
chapitres de mon livre plus
d'importance
lors de mon examen final Si je lis attentivement
ces chapitres, ma probabilité d'obtenir
60 à 70 % devient très facile. Au lieu d'essayer de lire les 20 chapitres
de mon classeur, je pourrais me concentrer sur quelques
chapitres pour obtenir les résultats L'analyse de Sparto est utilisée par décideurs pour identifier
les efforts les plus importants afin décider lequel sélectionner en
premier, la prise de décision Il est utilisé pour les projets
d'amélioration des processus afin de se concentrer sur les causes qui contribuent le plus à un problème particulier. Cela permettra de hiérarchiser
les causes potentielles, les facteurs et les principaux éléments
du processus du problème
étudié. Il s'agit d'une boîte à outils
d'amélioration continue. L'analyse de Pareto est utilisée lors de la priorisation
des projets afin de se concentrer sur
des projets importants qui
apporteront de la valeur au client
et à l'entreprise Plutôt que de réaliser
tous les projets dans
ma liste de projets, je me concentrerais sur
les quelques projets, deux ou trois projets majeurs, qui peuvent m'apporter le
maximum d'avantages. Vous pouvez faire attention lors la définition du cadrage du
projet si vous utilisez le parto Aysis ou si vous
hiérarchisez vos ressources, à savoir
qui est la principale personne requise pour qui est la principale personne requise Nous pouvons également utiliser l'
analyse parto pour visualiser vos données afin de savoir rapidement
où vous devez vous concentrer Par exemple, j'ai beaucoup de données sur les
défauts, comme ten
tear off dense catch. Je fais l'analyse
et j'ai ces données. Si je le place dans l'
ordre décroissant des défauts,
je trouve que l' arrachage
est l'effort maximal Et suivi d'un sténopé, puis, et ainsi de suite Sur ceux qui sont en gris, je ne vais pas trop me concentrer car ils ne
contribuent pas de manière majeure. Si je répare la déchirure, j'obtiendrai un
maximum de résultats. Si je dois corriger
les trois premiers, je vais obtenir une réduction majeure des défauts qui se
produisent dans mon processus. Par exemple, si vous collectez des données sur
les types de défauts, l'analyse par l'opérateur peut révéler quel type de défaut
est le plus fréquent. Vous pouvez vous concentrer sur vos
efforts pour résoudre la cause qui a
le plus d'effet. L'avantage de l'analyse parto est de vous aider à vous concentrer sur
ce qui compte vraiment Il distingue les causes majeures du problème
des causes mineures. Il permet de mesurer l'impact de l'amélioration en couvrant
avant et après. Cela permet de parvenir à un consensus sur ce qui
doit être traité en premier. Le principe de Pareto s'est
avéré vrai pour de nombreux frais, 20 % d'efforts pour obtenir 80 % de résultats Au lieu de travailler ou
nous pouvons aussi dire
que 20 % des causes
me donnent 80 % d'effet. Donc, si je pense à l'analyse
des causes et des effets, il s'agit encore une fois de 20 % de
causes, 80 % d'efforts. effet, si je regarde également l'analyse des résultats de l'
effort, nous disons qu'il faut faire moins d'efforts
pour obtenir le maximum de résultats. 20 % des clients de l'entreprise sont responsables de
80 % de son chiffre d'affaires ou 80 % des ventes
proviennent de 20 % des clients. C'est donc le concept d'un effort de 20 % contre un
résultat de 80 %. Le bureau de Pardo Analysis
Act peut être considéré comme étant donné que 20 % des
travailleurs effectuent 80 % du travail 20 % du temps passé sur une tâche aboutit à 80 %
des résultats. 20 % de la population possède
80 % de la richesse du pays. N'est-ce pas vrai, même
dans notre pays, notre État, notre communauté ? Nous constatons que très peu de personnes
possèdent le
maximum de richesse. Vous pouvez utiliser 20 %
des outils ménagers,
80 % du temps. Vous pouvez porter 20 % de vos
vêtements, 80 % du temps. Il est donc temps pour vous de simplement
appliquer une analyse partielle à votre vie personnelle pour nettoyer votre garde-robe si vous croyez au concept de minimalisme 20 % des automobilistes sont à l'
origine de 80 % des accidents. 80 % des plaintes des clients proviennent de 20 % des clients. Quelques causes seulement expliquent majeure partie
de l'effet
sur la perche à poisson. Si je convertis mon analyse parto en une
analyse à la perche à poissons, vous constaterez que
peu de causes contribuent
à la principale En écoutant tous
ces exemples, vous auriez compris
que Pareto n'est pas limité à s'appliquer uniquement à
votre bureau ou à votre lieu de travail Vous pouvez même appliquer l'
analyse partielle à votre vie personnelle. Si je m'adresse à Twitter ou une
plateforme de médias sociaux comme celle-ci, la
plupart des 20 %
d'utilisateurs actifs de Twitter sont responsables
de 80 % des tweets au total. Le graphique Parto est
un type spécial de graphique à
barres qui trace la
fréquence des données historiques Vous devez donc comprendre que
ces données datent d' hier, d'aujourd'hui
matin ou du mois dernier. Il s'agit donc d'une donnée catégorique. L'axe x indique très
clairement qu'il s'agit d'une donnée catégorique et l'axe y indique la
fréquence d'occurrence L'analyse Parto ne peut donc pas être utilisée pour
des données continues, veuillez noter Donc, si vous le voyez, vous aurez des données catégoriques fréquence est tracée
par ordre décroissant, dont
la fréquence est tracée
par ordre décroissant, les principales causes étant
le moins d'efforts pour
obtenir Les données catégoriques, c'
est le niveau de
données le plus bas qui permet de classer des
personnes, des objets ou des événements Je peux le rendre plus simple. Tout ce qui est créé avec des mots est appelé donnée
catégorique Emplacement géographique,
météo, couleur, type d'
appareil, groupe sanguin, groupe sanguin, type de compte
bancaire, comme
épargne ou courant, FD ou
prêt personnel , type d'erreur ou de
défaut, type de donnée. Analyse de Pareto,
l'axe vertical représente la fréquence
des données catégorielles. L'axe X représente les
catégories des étiquettes. L'axe horizontal représente les données catégoriques à l'
origine d'un ou de plusieurs problèmes La barre est disposée par ordre décroissant
de gauche à droite La plus fréquente
est du côté gauche, la
moins fréquente est du côté droit. Vous n'avez pas à vous inquiéter si
vous avez Microsoft Excel, il le dessinera pour vous. Si vous utilisez une
ancienne version d'Excel, je partagerai un modèle dans la section projet et
ressources ci-dessous. Si vous avez trop de catégories, vous pouvez regrouper ces petites catégories
peu fréquentes dans la catégorie
appelée « La dernière barre est généralement un peu plus haute que
les précédentes. Vous pouvez éventuellement placer une courbe de fréquence
cumulée au-dessus la barre en lui donnant un axe y secondaire pour représenter le pourcentage
cumulé. Cela permet simplement d'
interpréter les résultats plus facilement et d'identifier
la connexion 80 20. L'analyse parto
met l'accent sur
les efforts déployés dans les catégories dont la barre
verticale représente 80 % des résultats Vous devez rechercher quelque chose
qui soit une cause majeure, un effet maximal et un minimum
d'effort pour obtenir le maximum de résultats. Si vous regardez les
deux modèles de parto, A et B, lequel est la meilleure illustration
du modèle de parto Je suggère que c'est
le modèle A parce que modèle B montre
que la plupart d' entre eux
contribuent presque également. Comme il s'agit d'une distribution uniforme, je ne suis pas d'accord. Je choisirais celui
qui est de catégorie A. Et c'est faux. Si les graphiques obtenus illustrent
clairement
un modèle de parto. Cela suggère que
seules quelques causes sont à l'origine d'environ
80 % du problème. Cela signifie qu'il
y a un effet de parto et que vous pouvez concentrer vos efforts sur lutte contre ces quelques causes
pour obtenir le maximum de résultats Si vous avez reçu
un modèle tel que le graphe B, l'analyse parto ne
fonctionnera pas et nous devrons également
utiliser un autre QC. Cependant, si aucun
schéma paradoxal n'est trouvé, on ne peut pas dire que certaines causes sont plus importantes que d'autres Comme je viens de le dire. Assurez-vous que votre diagramme paradoxal contient suffisamment de points de données pour qu'il
soit significatif Dans le monde
d'aujourd'hui, de nombreuses données sont disponibles, alors assurez-vous capturer autant de
données que possible. L'analyse de Pareto sur la façon
de construire un diagramme de Parto. Si vous faites partie de votre équipe, définissez le problème que
vous essayez de résoudre, identifiez les causes possibles à l' aide du brainstorming ou de techniques
similaires Décidez de la méthode
de mesure à utiliser pour
la comparaison, de la fréquence,
du coût, du temps, etc. Comment construire un graphique de Parto, collecter les données et exiger que les données catégorielles
soient analysées Calculez la fréquence
des données catégorielles. Tracez une ligne horizontale et placez la barre verticale pour indiquer
la fréquence de la catégorie. Tracez une ligne verticale sur la
gauche pour placer la fréquence sur la gauche de la ligne au cas où vous la
dessineriez sur du papier millimétré. Microsoft Excel peut créer automatiquement
un diagramme paradoxal. Mais si vous le faites manuellement, triez les catégories ordre de fréquence
d'occurrence du plus
petit au plus grand
sur le côté gauche. Vous devez calculer votre courbe de fréquence
cumulée
et une courbe de pourcentage cubultive Si vous observez le
défilé porter ses fruits, concentrez vos efforts d'amélioration sur les quelques catégories
dont la barre
verticale est la plus importante. Ces causes sont susceptibles d'avoir le plus d'impact sur le résultat de
votre processus. J'ai prélevé un échantillon de
Pareto pour analyser la raison pour
laquelle le patient utilise bien
un appel dans un
hôpital lorsqu'il est admis Ils ont donc besoin d'une aide aux toilettes, nourriture ou d'eau, de
repositionnement de leur
lit, de problèmes intraveineux, médicaments contre
la douleur, d'un
rappel urgent au lit, d'obtenir tous ceux
qui sont en gris arrivent pas fréquemment et ne
sont pas importants Donc, si nous nous concentrons sur les
trois premiers, ou sur les quatre premiers. Donc,
si je dois dire
que quatre facteurs contribuent à
40 % de l'effort, vous
obtiendrez 70 % de l'effet. Je pourrais donc décider de
travailler uniquement sur les trois premiers, soit 30 %
d'efforts, pour obtenir tout de même 68 % d'efforts Tout va bien. L'idée étant que je dois faire moins d'efforts
pour obtenir le maximum de résultats. Réclamations
de clients dans une usine. Une équipe de l'usine a réalisé
une analyse paradoxale pour répondre au nombre croissant de
plaintes du point de vue du
client D'une certaine manière, la direction
peut comprendre. Il s'agit d'un type de
plainte d'un client, d'une plainte concernant un produit , d'un
document colis ou d'une
livraison. Nous pouvons constater que
les clients se plaignent un maximum de fois
du type de produit ou du
défaut du produit. Suivi par les problèmes
liés au document. Réclamation d'un client dans une usine, les principales catégories
peuvent être trop génériques et peuvent être
divisées en sous-catégories Donc, si je pense aux plaintes relatives aux
produits, c'est à un
niveau élevé, je pourrais les considérer comme des sous-éléments
du problème A.
S'
agit-il d'un problème de rayure, de bosse, d'
un trou d'épingle, d'une paire de HMA ou autre Vous pourrez également appliquer à nouveau le point sur la
plainte relative au produit, à que si vous voulez régler les problèmes liés
aux rayures et aux
bosses dans le cadre
d'une plainte relative au produit, la majorité des
plaintes relatives au produit seront rejetées Type de réclamation relative aux documents, nous pouvons constater que les informations
manquantes sont la principale cause,
suivies d'une erreur de facturation, mauvaise quantité, etc. Le diagramme de Parto
peut faire l'objet d'une analyse plus approfondie utilisant les principales
catégories à
diviser en sous-catégories ou les
sous-composants où le problème spécifique survient plus souvent sont appelés Réclamations
de clients dans une usine. Les résultats suggèrent
que trois sous-catégories apparaissent
le plus souvent Notez qu'il est possible de
fusionner deux graphiques en un seul. J'ai donc un type de réclamation concernant un
produit
et un type de document, et je peux continuer
et les marginaliser. Pero Principles doit son nom l'économiste italien
Wilfredo Peto Joseph Juran a appliqué principes de
Peto à la gestion de la qualité pour la production
commerciale Dans votre analyse, pensez
à utiliser des données contextuelles, des
métadonnées et des colonnes
contenant des données textuelles bases de données contiennent souvent de nombreuses données
catégoriques
sur l'environnement à partir duquel les données sont extraites Ces données peuvent être très
utiles lors d'analyses ultérieures
lors de l'étude des concepts et des idées qui sont à l'origine des
causes. Les principes de Pareto peuvent
vous aider à mesurer l'impact de l'amélioration en comparant
l'avant et l'après Si vous constatez que le travail bleu
a été un obstacle majeur, après les projets,
vous constatez qu'il
y a une amélioration majeure
dans cette catégorie Le nouveau graphique de Parto
peut montrer qu'il y a une réduction importante de
la dose primaire. Statistiquement,
les principes du paradoxe peuvent être décrits par la distribution des centrales électriques et de nombreux phénomènes naturels pour
illustrer cette distribution. J'en viens à la fin du concept de l'
analyse partielle Dans la vidéo suivante, je
vais vous montrer comment je fais une analyse de Pareto à
l'aide de Microsoft cel Rendez-vous au prochain cours.
18. Tests d'hypothèses et signification statistique (1): Découvrons les
concepts liés aux tests d' hypothèses et à la signification
statistique. Premièrement, les tests d'hypothèses lorsque nous effectuons un test d'
hypothèse, nous commençons par une hypothèse de
recherche, également appelée hypothèse
alternative. Dans votre cas, l'
hypothèse de recherche est que le médicament a
un effet sur la tension artérielle. Cependant, nous ne pouvons pas tester directement cette hypothèse à l'aide d'un test d'hypothèse
classique. Nous testons plutôt l'hypothèse
inverse selon
laquelle le médicament n'a aucun
effet sur la tension artérielle. Nous partons du principe
qu'en moyenne, les personnes qui prennent le médicament
et celles qui ne
le prennent pas ont la même
tension artérielle dans la population. Si nous observons un
effet important du médicament dans un échantillon, nous nous demandons alors s'il
est probable qu'un
tel échantillon soit prélevé ou encore plus extrême si le
médicament n'a aucun effet. La probabilité d'
obtenir un tel échantillon, en supposant l'hypothèse
nulle, sans effet est appelée valeur P. La valeur P indique la probabilité d'obtenir
un échantillon qui s'écarte autant que notre
échantillon observé ou encore plus extrême si l'
hypothèse nulle était vraie Si la valeur p est très faible, généralement inférieure à 0,05, nous avons des preuves pour rejeter l'hypothèse nulle en faveur de l'hypothèse
alternative Une faible valeur p suggère que les données ou l'échantillon observés sont incompatibles avec
l'hypothèse nulle. Donc, troisièmement,
signification statistique. Lorsque la valeur p est inférieure à un
seuil prédéterminé, souvent 0,05 Le résultat est considéré comme
statistiquement significatif. Cela signifie qu'
il est peu probable que le résultat
observé soit le fruit du seul
hasard, et nous disposons de suffisamment de preuves pour rejeter l'hypothèse nulle. Le seuil de valeur p
est fixé à 5 %, soit 0,05, une faible valeur p suggère que les données ou l'
échantillon observés ne sont pas
conformes à l'hypothèse nulle Inversement, une
valeur p élevée suggère que les données observées sont cohérentes
avec l'hypothèse nulle, et nous ne la rejetons pas. Quatrièmement, des erreurs dans les tests d'
hypothèses. N'oubliez pas qu'une faible valeur de
p ne
prouve pas que l'
hypothèse alternative est vraie. Cela suggère simplement que le résultat observé est peu probable dans l'hypothèse
nulle. De même, une valeur P élevée ne prouve pas que l'
hypothèse nulle est vraie. Cela suggère simplement que le résultat observé est probable
dans l'hypothèse nulle. Comprenons maintenant
les deux types d'erreurs. L'erreur de type 1 et
l'erreur de type 2. Une erreur de type 1 se produit lorsque nous rejetons
par erreur une
véritable hypothèse nulle Dans votre exemple, cela signifierait conclure que le médicament agit
alors qu'il ne fonctionne pas réellement. L'erreur de type 1 se produit
lorsque vous rejetez l'hypothèse nulle,
alors qu'en réalité, l'hypothèse nulle est vraie, mais que votre décision concernant l'hypothèse
nulle est rejetée. Une erreur de type 2 se produit lorsque nous ne rejetons pas une fausse hypothèse
nulle. L'erreur de type 2 se produit
lorsque vous ne rejetez pas l'hypothèse nulle,
alors qu'en réalité, l'hypothèse nulle est fausse, mais que votre décision concernant l'hypothèse
nulle est acceptée. Dans votre exemple, cela signifierait ne pas tenir compte du
fait que le médicament fonctionne. L'échantillon prélevé n'a pas
montré de grande différence. J'ai pensé à tort que
le médicament ne fonctionnait pas. Dans la prochaine leçon, nous approfondirons les applications
pratiques de la conception d'expériences.
Restez à l'affût.
19. TestofHypothesis: Bonjour les amis. Poursuivons notre voyage
sur l'analyse de données Minitab. Aujourd'hui, nous allons en apprendre davantage
sur les tests d'hypothèses. Vous avez peut-être entendu dire que nous effectuons des tests d'
hypothèses
pendant la phase d'analyse et d'amélioration
de notre projet. Donc, pour comprendre comment fonctionne le test d'
hypothèse, comprenons un scénario de cas
simple. Je vais revenir sur ce graphique et
vous expliquer que c'est le cas. Comme vous le savez, lorsque nous nous adressons
au tribunal, le système judiciaire peut être utilisé pour expliquer le concept
de test d'hypothèse. Le juge commence toujours par
une déclaration qui dit que la personne est présumée
innocente jusqu'à ce que sa culpabilité soit prouvée. Ce n'est rien d'autre que votre
hypothèse nulle, le statu quo. Quand ils sont attrapés
cas qui continue. Les avocats ont essayé de
produire des données et des preuves. Et tant que nous
n'avons pas de données solides
et de preuves solides, la personne est dans le
statut d'innocente. L'accusé ou
l'avocat de l'opposition essaie donc toujours de dire que
cette personne est coupable et j'ai des données et des
preuves pour le prouver. Il essaie de travailler sur une hypothèse
alternative. Et le juge dit que je suis d'accord avec le statu quo de l' hypothèse
nulle par défaut. Permettez-moi de vous
expliquer de manière plus simple. Vous et moi, nous ne sommes pas traduits en justice
parce que par défaut, nous sommes tous dans l'OSA, c'est le statu quo. Qui sont traduits devant
le tribunal. Les personnes qui ont
une chance de venir
ont commis un crime. Ça peut être n'importe quoi.
De la même façon. quoi essayons-nous de tester des
hypothèses Sur quoi essayons-nous de tester des
hypothèses lorsque je fais ma
phase d'analyse du projet. J'ai donc plusieurs causes qui peuvent contribuer
à mon projet. Pourquoi ? Nous faisons une analyse des causes profondes et nous apprenons à le savoir, d'accord ? Peut-être que l'expédition a été retardée. Peut-être que la machine pose problème, peut-être que le
système de mesure pose problème. Peut-être que la matière première n'
est pas de bonne qualité. Nous avons plusieurs raisons
qui existent. Maintenant, je veux le prouver
à l'aide de données, et c'est là que j'ai essayé d'utiliser des tests d'hypothèse. Tous les processus
présentent des variations. Nous savons que tous les processus
suivent la courbe en cloche. Nous n'ajoutons jamais le centre. Il y a quelques
variations dans chaque processus. Maintenant les données ou l'
échantillon que vous avez mis à jour, s'agit-il d'un échantillon aléatoire
provenant du même Banco ? Ou s'agit-il d'un échantillon
provenant d' une courbe en cloche complètement
différente ? Les tests d'hypothèse vous
aideront donc à les analyser. Chaque fois que nous
établissons un test d'hypothèse, nous avons deux types d'hypothèses, comme je vous l'ai dit, le statu quo
ou l'hypothèse par défaut, qui est votre hypothèse nulle. Par défaut, nous supposons que
l'hypothèse nulle est vraie. Pour rejeter l'hypothèse
nulle, nous devons produire des preuves. L'hypothèse alternative
est l'endroit où il y a une différence. Et c'est la raison pour laquelle le test d'hypothèse a
effectivement été initié, n'est-ce pas ? Nous allons comprendre
avec de nombreux exemples. Alors restez connecté. Donc, quand je suis en train de formuler une hypothèse nulle
et alternative, disons que je dis que mes mu ne
sont rien d'autre que ma moyenne, ma moyenne de population
est égale à une certaine valeur. Souvenez-vous toujours que votre hypothèse alternative
s'exclut mutuellement. Si mu est égal à une certaine valeur, l'hypothèse alternative
indiquerait que mu n'est pas égal
à cette valeur. Par exemple, mu est inférieur à une certaine valeur
en tant qu'hypothèse nulle. Par exemple, si je
vends Domino's Pizza, je constate que mon délai de livraison moyen est inférieur
à 30 minutes. Le client vient
me dire, sachez que le délai de livraison moyen
est de plus de 30 minutes, cela devient mon remplaçant. Parfois, si nous avons l'hypothèse nulle,
mu est supérieur à
égal à une certaine valeur. Par exemple, ma qualité moyenne est supérieure à 90 %. Ensuite, le client
revient et me dit que vous savez que votre qualité moyenne est
inférieure à ce pourcentage. Souvenez-vous donc toujours que l'hypothèse
nulle et les hypothèses
alternatives s'
excluent mutuellement et
se complètent. Nous reprendrons de nombreux autres
exemples au fur et à mesure que nous irons plus loin.
20. Notion d'hypothèse nulle et alternative: Passons aux statistiques
inférentielles. Nous allons commencer par un bref
aperçu de ce que c'est. Suivi d'une explication
des six éléments clés. Alors, qu'est-ce que les
statistiques inférentielles ? Cela nous permet de tirer
des conclusions sur une population à partir
des données d'un échantillon. Pour clarifier les choses, la population est l'ensemble du groupe qui
nous intéresse. Par exemple, si
nous voulons étudier la taille moyenne de tous les
adultes aux États-Unis, notre population inclut
tous les adultes du pays. L'échantillon, quant à lui, est un sous-ensemble plus petit issu
de cette population Par exemple, si nous sélectionnons
150 adultes américains,
nous pouvons utiliser cet échantillon pour tirer conclusions sur l'
ensemble de la population Voici maintenant les six
étapes de ce processus. Hypothèse. Nous partons
d'une hypothèse. Quelle est la déclaration
que nous voulons tester ? Par exemple, nous pourrions
vouloir déterminer si un médicament a un impact positif sur tension artérielle chez les personnes
souffrant d'hypotension. Oh, dans ce cas, notre population est composée de toutes les personnes souffrant d'
hypertension artérielle aux États-Unis, car il n'est pas pratique de recueillir données auprès de l'ensemble de la population Nous nous appuyons sur un échantillon pour tirer des conclusions sur la
population à l'aide de notre échantillon Nous utilisons des tests d'hypothèses. Il s'agit d'une méthode utilisée pour
évaluer une affirmation concernant un paramètre de population sur la
base d'un échantillon de données. Différents tests d'
hypothèses sont disponibles, et ce, à la fin de cette vidéo. Je vais vous expliquer comment
choisir le bon. Comment fonctionnent les
tests d'hypothèses ? Nous commençons par une hypothèse
de recherche. Également connue sous le nom d'hypothèse
alternative, c'est
ce que nous recherchons des
preuves dans notre étude. Également appelée hypothèse
alternative. C'est pour cela que nous
essayons de trouver des preuves. Dans notre cas, l'hypothèse est que le médicament
affecte la tension artérielle. Cependant, nous ne pouvons pas le
tester directement avec un test d'
hypothèse classique. Nous testons donc l'hypothèse
inverse, savoir que le médicament n'a aucun
effet sur la tension artérielle. Voici le processus. Premièrement,
supposons l'hypothèse du non. Nous supposons que le médicament n'
a aucun effet, c'
est-à-dire que les personnes
qui le prennent et celles qui n'ont pas la
même tension artérielle moyenne. T, collectez et
analysez des échantillons de données. Nous prélevons un échantillon aléatoire. Si le médicament présente un
effet important sur l'échantillon, nous déterminons ensuite la
probabilité de prélever un
tel échantillon ou un échantillon
qui s'écarte encore plus, si le médicament n'
a réellement aucun effet, ou un échantillon qui s'écarte encore plus, si le médicament n'
a réellement aucun effet,
T, évaluez la valeur de
probabilité p. Si la probabilité d'observer un
tel résultat sous l'
hypothèse nulle est très faible. Nous envisageons la possibilité que le médicament
ait un effet. Si nous avons suffisamment de preuves, nous pouvons rejeter l'hypothèse
nulle. La valeur p est la
probabilité qui mesure la force des preuves par
rapport à l'hypothèse nulle. En résumé, l'
hypothèse nulle indique qu'il n'y a aucune différence
dans la population, et le test d'hypothèse
calcule la probabilité observer les résultats de l'échantillon si l'hypothèse nulle est vraie Nous voulons trouver des preuves à l'appui de
notre hypothèse de recherche. Le médicament affecte la tension artérielle. Cependant, nous ne pouvons pas le tester
directement, nous testons
donc l'
hypothèse opposée, l'hypothèse nulle. Le médicament n'a aucun effet
sur la pression artérielle. Voici comment cela fonctionne. Supposons l'hypothèse du non. Supposons que le médicament n'ait aucun effet. Cela signifie que les personnes qui
prennent le médicament et celles qui n'ont pas la
même tension artérielle moyenne collectent et analysent des données. Prélevez un échantillon au hasard. Si le médicament présente un
effet important dans l'échantillon. Nous déterminons la probabilité
d'obtenir un tel résultat, ou un résultat plus extrême. Si le médicament n'a vraiment aucun effet, calculez la valeur p. La valeur p est la
probabilité d' observer un échantillon
aussi extrême que le nôtre. En supposant que
l'hypothèse nulle est vraie. Importance statistique. Si la valeur p est inférieure à un seuil défini, généralement 0,05 Le résultat est
statistiquement significatif, ce qui signifie qu'il est peu probable qu'il
soit le fruit du seul hasard. Nous avons alors suffisamment de preuves pour rejeter l'hypothèse nulle. Une faible valeur p suggère que les données observées ne correspondent pas à
l'hypothèse nulle. qui nous amène à la rejeter au profit de l'hypothèse
alternative. Une valeur p élevée suggère que les données sont cohérentes
avec l'hypothèse nulle. Nous ne le rejetons pas. Points importants Une faible valeur p ne
prouve pas que l'
hypothèse alternative est vraie. Cela indique simplement
qu'un tel résultat est peu probable si l'
hypothèse nulle est vraie. De même, une valeur p élevée ne prouve pas que l'
hypothèse nulle est vraie. Cela suggère que les données observées sont probablement soumises à l'hypothèse
nulle. Merci Je vous verrai dans la prochaine leçon de statistiques.
21. Statistiques Comprendre la valeur P: Qu'est-ce que la valeur p et
comment est-elle interprétée ? C'est ce dont nous
parlerons dans cette vidéo. Commençons par un exemple. Nous aimerions vérifier s'il existe une
différence de taille entre l'
Américain moyen et le
basketteur américain moyen. L'homme mesure en moyenne
1,77 mètre. Nous voulons donc savoir si le basketteur moyen
mesure également 1,77 mètre Nous formulons donc l'hypothèse
nulle. La taille moyenne d'un joueur de basket
américain est de 1,77 mètre. Nous supposons que dans la population de basketteurs américains, la taille moyenne
est de 1,77 mètre. Cependant, comme nous ne pouvons pas
sonder l'ensemble de la population, nous tirons un échantillon. En ce qui concerne le monoxyde de carbone, cet échantillon ne
donnera pas une moyenne exacte
de 1,77 mètre. Cela serait très peu probable. Oh. Il se peut que l'échantillon prélevé
par hasard s'écarte 3 centimètres sur
8 centimètres 15 centimètres ou
de toute autre valeur Puisque nous testons une hypothèse
non dirigée, c'
est-à-dire que nous voulons seulement savoir
s'il existe une différence Peu nous importe dans quelle
direction va la différence. Passons maintenant à la valeur p. Comme mentionné, nous supposons
que dans la population, il existe une valeur moyenne
de 1,77 mètre. Si nous tirons un échantillon, il différera de la
population d'une certaine valeur. La valeur p nous indique probabilité de
prélever un échantillon qui s'écarte de la population d' un montant
égal ou supérieur à la valeur observée Regardons encore une fois de plus près. Nous avons un échantillon
différent de la population. Nous nous intéressons maintenant à probabilité de tirer un échantillon qui s'écarte autant que le nôtre ou plus
de la population Ainsi, la valeur p indique la probabilité de tirer un échantillon dont la moyenne
se situe dans cette plage. Par exemple, si par
hasard l' échantillon s'écarte de 3
centimètres par rapport à 1,77 La valeur p nous indique la
probabilité de prélever un échantillon qui s'écarte 3 centimètres ou plus
de la population Si, par hasard, l'échantillon s'écarte de
9 centimètres par rapport à 1,65 mètre, la valeur p nous indique la
probabilité de tirer un échantillon qui s'écarte de 9 centimètres
ou plus de Prenons un exemple où
nous obtenons une différence de 9 centimètres avec notre logiciel de statistiques
préféré Comme Mini tab, calcule
la valeur p de 0,03. Cela représente 3 %. Cela nous indique qu'il
n'y a que 3 % de chances de prélever un
échantillon dont la différence est égale ou
supérieure à 9 centimètres
par rapport à
la moyenne de la population
de 1,77 mètre Pour les données normalement distribuées. Cela signifie que la probabilité que la moyenne se situe
dans cette plage est 1,5 % dans un sens et de
1,5 % dans l'autre Pour un total de 3 %. Si cette
probabilité est très faible. On peut bien sûr se demander si
l'échantillon provient d'une population d'une moyenne
de 1,65 mètre Si cette probabilité est très faible. On peut bien sûr se demander si
l'échantillon provient d'une population d'une moyenne
de 1,77 mètre Ce n'est qu'une hypothèse selon
laquelle la valeur moyenne des joueurs de basket
est de 1,77 mètre. Et c'est précisément cette
hypothèse que nous voulons tester. Par conséquent, si nous calculons
une très petite valeur p, cela prouve
que la moyenne de
la population n'est pas du tout de
1,77 mètre Ainsi, nous rejetterions
l'hypothèse nulle, qui suppose que la
moyenne est de 1,77 mètre. Ainsi, nous rejetterions
l'hypothèse nulle, qui suppose que la
moyenne est de 1,77 mètre. Mais à quel moment la valeur p est-elle suffisamment
petite pour rejeter
l'hypothèse nulle ? Ceci est déterminé avec ce
que l'on appelle le niveau de signification, également appelé niveau Alpha. Il y a deux
points importants à noter ici. Premièrement, le seuil de signification est toujours déterminé
avant l'étude et ne peut pas être modifié
par la suite
afin d'obtenir finalement
les résultats souhaités. Deuxièmement, pour garantir un certain
degré de comparabilité, le seuil de signification est
généralement fixé à 5 % ou 1 % Une valeur AP inférieure à 1 % est considérée comme
très significative. Moins de 5 % est dit significatif et plus de
5 % est dit significatif. En résumé, la valeur p nous
indique si nous rejetons ou non l'hypothèse
nulle. Pour rappel, l'hypothèse
nulle part du principe qu'il n'
y a pas de différence. Alors que l'hypothèse alternative suppose qu'il
existe une différence. En général, l'hypothèse
nulle est rejetée si la valeur p
est inférieure à 0,05 Ce n'est toujours qu'une probabilité, et nous pouvons nous tromper
dans notre déclaration. Si l'hypothèse nulle est
vraie dans la population,
I, la moyenne est de 1,77 mètre. Mais nous en tirons un échantillon qui
se trouve être assez éloigné. Il se peut que la
valeur p soit inférieure à 0,05. Nous rejetons à tort
l'hypothèse nulle. C'est ce qu'on appelle une erreur de type 1. Si dans la population, l'hypothèse nulle est fausse. C'est-à-dire que la moyenne n'est pas de 1,77 mètre, mais nous tirons un échantillon
qui se trouve être très proche de 1,77 La valeur p peut être
supérieure à 0,05, et nous ne pouvons pas rejeter
l'hypothèse nulle C'est ce qu'on appelle une erreur de type 2. Merci d'avoir appris avec moi. Je vous verrai dans la prochaine
leçon de statistiques.
22. Types d'erreurs: Voyons d'autres
exemples d'
hypothèses nulles et alternatives. Supposons donc que si mon projet
est sur le point de vous
abandonner, mon hypothèse nulle
est une valeur fixe. Je dirais donc que ma moyenne
actuelle de mon
temps moyen actuel pour construire pour partager les 70% de
Julie est. Actuel. La moyenne de P à S est de 70 %. L'hypothèse alternative
signifierait qu'il n'est pas de 70 %. Supposons que je pense à la teneur en humidité
d'un projet. Je suis dans une
configuration de fabrication et je souhaite mesurer si la teneur en humidité
doit être égale à 5 %. Ou 5 % est ce qui est
acceptable pour mon client, alors je peux dire que mon
taux d'humidité est inférieur
à 5 %. Ensuite, l'
hypothèse alternative prétendrait que la teneur en humidité est
supérieure à 5 %. Le cas où la
moyenne est supérieure à, alors l'hypothèse nulle. Ce problème ne nous
intéresse pas. Comprenons-le davantage. La question était la suivante :
est-ce qu'un récent processus d'
approbation de prêt de TED pour
les petites entreprises a réduit le temps de cycle moyen
pour le traitement du prêt ? La réponse est peut-être non. La durée moyenne du cycle n'a pas changé. Ou le responsable peut constater que oui, la durée moyenne du cycle
est inférieure à 7,5 %. Le statu quo est donc
égal à 7,514 minutes. Et l'alternative dit, non, c'est moins de 7,414
minutes ou jours, quelle que soit l'unité de
mesure principale que nous
mesurons, n'est-ce pas ? Donc, par défaut, votre
statu quo est une hypothèse nulle. Et l'exemple ou
le statut dont vous souhaitez prouver une hypothèse
alternative plus facile. Il peut y avoir des
flèches lorsque nous prenons des décisions. Revenons donc
à notre cas de code. L'accusé n'est en
réalité pas coupable, n'est-ce pas ? Laisse-moi prendre mon rayon laser. Par défaut, l'accusé ou la réalité est que l'
accusé n'est pas coupable. Le verdict vient également
que l'accusé, la personne n'est pas coupable. C'est une bonne décision, non ? Donc oui, nous avons pris une très bonne décision selon laquelle
la personne est innocente. En réalité, l'
accusé est coupable. Et le verdict de culpabilité
vient également. La décision est une bonne décision. Ce qui se passe, c'est qu'en réalité, la personne n'est pas garantie, mais le verdict arrive qu'elle est coupable et qu'
une personne innocente est condamnée. C'est une erreur. C'est une très grosse erreur. Dans le cas d'une personne du Nord,
condamnée et mise en prison, sanctionnée par une peine,
c'est une erreur. L'erreur peut même se produire
de l'autre côté, où en réalité la
personne est coupable, mais le verdict vient
qu'elle n'est pas coupable. Le coupable est déclaré innocent et il est prêt à le faire. C'est aussi une flèche, mais c'est une erreur plus importante. La plus grande erreur que vous pouvez écrire dans la
zone de commentaires, qu'en pensez-vous ? Quelle est l'erreur la plus grande ? Est-ce que l'erreur est une erreur plus grande ou est-ce que l'erreur est
la plus grande flèche ? Si aucune personne saine d'esprit ne se fait
condamner est une plus grande erreur ou si une personne coupable se déplace librement sur les routes,
soit une flèche plus grande ? J'espère que vous avez déjà
écrit les commentaires. La réalité est donc que cela
devient ma plus grande erreur. Et c'est ce
qu'on appelle une erreur de type un. Parce que si un innocent
est condamné, nous ne pouvons pas rendre le
temps qu'il a perdu. On ne peut pas comprendre qu'il irait à
beaucoup de traumatisme émotionnel. Si un coupable est
déclaré innocent, nous pouvons l'amener devant
la cour supérieure et la Cour suprême et pour
lui faire prouver que oui, il ne l'est pas, il est coupable, non ? Je peux donc décider
ici que la personne est condamnée. Il devrait être condamné
et il devrait être déclaré coupable et
puni. Cette erreur est donc
appelée erreur de type deux. Si quelqu'un vous demande quelle
erreur est la plus grande, tapez une erreur, elle est également
appelée erreur alpha. Et c'est ce
qu'on appelle une erreur bêta. Bon ? Continuons
davantage dans notre prochain cours.
23. Types d'erreurs part2: Revoyons les types
de flèches. Donc, comme nous savons que si la personne n'
est pas coupable ou si la
personne est innocente, le verdict dit
également que la
personne n'est pas coupable. C'est une bonne décision. Si la personne est coupable, le verdict est qu'elle est coupable. Encore une fois, la décision est
une bonne décision. Le condamné ne l'est pas, doit être condamné ou
doit être puni. Le problème se produira lorsqu' une personne innocente sera prouvée
coupable et qu'elle souffrira. Le deuxième type de problème qui se produit lorsque le coupable, une personne avec un criminel
est déclarée innocente. Et il a dit, C'est ce
qu'on appelle une erreur de type 1. C'est-à-dire qu'une
personne innocente
condamnée ou punie
est une erreur de type 1. Elle est également
appelée flèche alpha. Un coupable, criminel libéré est appelé erreur de type
deux ou erreur bêta, qui est également une erreur
que nous voulons éviter. Le niveau de signification
est défini par la valeur Alpha. quelle mesure
voulez-vous prendre la
bonne décision ? Donc, l'erreur de type 1 se produit lorsque la valeur null est vraie,
mais nous l'avons rejetée. Une erreur de type deux se produit alors qu'
en réalité le null est faux, mais nous ne le rejetons pas. Comment cela nous
aide-t-il à traiter ? Donc, comprenons cela
tous les jours pour la feuille de déjeuner. Bon ? Comprenons
cela plus en détail. C'est le scénario réel. Écrivons le
réel en haut. Et ces mythes
comme le jugement. Bon, maintenant,
réfléchissons au processus. Le processus n'a pas changé. N'a pas changé. Aucune alternative ne
sera modifiée. Maintenant, le jugement est noté. Et le jugement est que le
processus s'est amélioré. Ok. Je vais maintenant vous poser une question
très importante. Si un processus n'a pas changé et que l'on juge qu'il n'
y a pas de changement, s'agit de la bonne décision. processus a changé et le jugement est également que
le processus s'est amélioré. C'est également une bonne décision. Maintenant, imaginez que le processus n'
a pas changé, mais nous avons déclaré que j'ai
maintenant
un processus amélioré et un produit amélioré et j'informe le client : Est-ce correct ? C'est une erreur. Et cela s'appelle
une erreur de type 1 car cela semble ancien, mais notre dette est vendue au
client en tant que produit neuf. Pouvez-vous comprendre
ce qu'il adviendra de la réputation de l'entreprise ? L'équipe ou le produit est vendu au client en tant que nouveaux produits. Nouveau produit de base unique. Qu'adviendra-t-il de la
réputation de l'entreprise ? Il va être jeté
et nous disons donc ce n'est pas une bonne décision. Maintenant, comprenez ici aussi
que le processus a changé. Le processus s'est amélioré, mais le jugement n'
a pas été amélioré. Il s'agit également d'une erreur. Je ne le nie pas. C'est ce qu'on appelle une erreur de
type deux ou un
audit est également
appelé erreur bêta. Juste ici. Ce qui se passe, c'est que
nous ne communiquons pas
au client que l'amélioration
s'est produite, n'est-ce pas ? Nous ne
conservons donc pas les articles améliorés
dans le produit de couvain
dans l'entrepôt. Ce n'est pas correct non plus, mais la plus grande erreur est ici où nous
n'avons pas fait d'amélioration, mais j'informe le client que vous êtes de mauvaises personnes.
24. Jingle: Lorsque nous faisons un test d'hypothèse, il y a toujours deux hypothèses. L'une est l'hypothèse par défaut, qui est l'hypothèse nulle, et la seconde est l'hypothèse
alternative que vous souhaitez prouver. Et c'est la raison pour laquelle vous
faites cette hypothèse. Donc, lorsque vous faites l'hypothèse, la raison pour laquelle nous le faisons est que nous n'avons jamais accès
à l'ensemble de la population. Donc, lorsque nous collectons l'échantillon, nous voulons comprendre s'il
provient de la courbe en cloche ou la distribution
d'où nous comprenons la
variation que vous voyez, c'
est en raison de la
propriété naturelle de l'ensemble de données. Parfois, l'échantillon peut se trouver au coin d'extrémité du Velcro. Et c'est un endroit où nous avons la confusion selon laquelle ces données appartiennent
au Velcro d'origine ou
appartiennent-elles au Velcro d'origine ou au
deuxième alternatif ? Bienvenue. C'est là. Nous ferons des exercices
qui vous
permettront de comprendre cela de
manière plus facile à faire. Hypothèse, vous obtenez
des informations telles que la valeur de p en dehors des résultats des statistiques de
test. Vous obtenez également la valeur de p. Nous comparons toujours la valeur de p avec la valeur nulle
que nous avons définie. Supposons que vous vouliez
être confiant à 95 %. Ensuite, vous définissez la valeur de p sur 5 %. Et si vous définissez le niveau de
confiance à 90 %, votre valeur Alpha
est de dix pour cent ou votre valeur de p est de 0,10. La raison pour laquelle nous utilisons une valeur de p est que si vous pouvez
voir cette courbe en cloche, l'observation la plus probable fait partie du
centre de la cloche. Des observations très improbables viennent de la queue. Cette valeur de p, la raison verte, vous
aide à dire
s'il appartient
au Velcro d'
origine ou s'il appartient à la majeure partie
alternative, c'est-à-dire que vous essayez de prouver par
l'hypothèse alternative. Par conséquent, la valeur de
p aide à vous en souvenir
facilement. Rappelez-vous le jingle. Ci-dessous, null. Cela signifie que si la valeur de p est
inférieure à la valeur alpha, je vais rejeter
l'hypothèse nulle. P vol à haut niveau. Si la valeur de p est
supérieure à la valeur alpha, nous ne rejetons pas
l'hypothèse nulle, concluant que nous n'avons pas suffisamment de preuves statistiques que l'hypothèse alternative existe. Nous allons faire beaucoup d'
exercice et je vais chanter ce jingle plusieurs fois pour
qu' il soit facile pour
vous de vous en souvenir. En dessous de null, passez derrière nullcline. Certains des participants avec, quand je fais l'atelier,
s'embrouillent, ils disent que rien ne
veut dire quoi ? L'autre chose dont
je leur dis de
se souvenir facilement est f pour
vol et F pour champ. Donc si P est nul, nous volerons. Cela signifie que vous ne
rejetez pas l'hypothèse nulle. L'hypothèse nulle existera. L'autre hypothèse
sera rejetée. Rappelez-vous encore une chose qui est principalement posée
pendant l'entretien. La valeur de p était de 1,230,123. Rejetteriez-vous
l'hypothèse nulle ou accepteriez-vous
l'hypothèse nulle ? Ou accepteriez-vous l'
autre hypothèse ? Ou accepterez-vous
l'hypothèse nulle ? En tant que statisticien ? Nous n'acceptons aucune hypothèse. Soit nous rejetons
l'hypothèse nulle soit nous ne rejetons pas
l'hypothèse nulle. Nous le disons toujours
du point de vue de null car le statu
quo par défaut plus facile hypothèse
nulle. Si le P est élevé, nous n'acceptons pas l'hypothèse nulle
et alternative. N'acceptons-nous pas
l'hypothèse nulle. Nous disons que nous ne rejetons pas
l'hypothèse nulle. Si le p est faible, nous n'acceptons pas l'alternative, mais nous disons, je rejette
l'hypothèse nulle, concluant qu'il existe suffisamment de preuves statistiques que les données proviennent de
l'autre Bellcore . Nous continuerons avec de
nombreux exercices. Cela
vous donnera confiance façon de pratiquer, d'
interpréter et d'utiliser les statistiques
inférentielles dans votre analyse lorsque
vous le faites.
25. Sélection des tests: L'une des questions
les plus fréquemment posées à mes participants lorsque je participe au projet est quelle
hypothèse
dois-je utiliser le loyer ? Il s'agit donc d'une analyse simple qui vous aidera à
comprendre cela. Quels tests dois-je utiliser ? Tout comme lorsqu'un
patient consulte un médecin, le médecin ne lui
prescrit pas tous les tests. Il lui a juste mis le test approprié en fonction du problème que le
patient pêche. Si le patient voit que
j'ai eu un accident, le médecin dira que je pense que vous devriez faire
votre radiographie. Il ne lui
demanderait pas de passer son test COVID ou son test RT-PCR. Si la personne tousse
et souffre de fièvre,
la RT-PCR est suggérée. Et à ce moment-là, nous
ne sommes pas en mesure de satisfaire la radiographie. Il en va de même lorsque nous faisons de simples tests d'hypothèses, que
nous essayons de comprendre
ou de comparer cela
avec la population. Nous voulons savoir quel
test devons-nous effectuer ? Lorsque, si je teste les moyennes, c'est votre moyenne, vous comparez la moyenne d' un échantillon à la valeur
attendue. Je compare donc l'
échantillon avec ma population. Ensuite, je passe mon test T à
un échantillon. Je n'ai qu'un seul échantillon
que je compare. Je veux comparer si la performance
moyenne de l', si les ventes moyennes
sont égales à x montant, qui est la valeur attendue. Nous nous attendions donc à ce que
les ventes soient,
disons, de 5 millions. Ma moyenne s'élève à 4,8. J'ai rencontré qui ne le sont pas. Alors je peux faire
un test T à un échantillon. Comparez la moyenne des échantillons avec deux proportions différentes. Donc, si j'ai deux T
indépendants,
disons que je donne
une formation en ligne. Je mène une
formation hors ligne. C'est le Shrina et j'ai un groupe d'étudiants qui
suivent mon programme en ligne. J'ai un
groupe différent d'étudiants qui suivent
mon programme. Je veux comparer l'
efficacité de l'entraînement. J'ai donc deux échantillons, et ce sont deux échantillons
indépendants parce que les participants
sont différents. Ensuite, je vais faire un test T à deux échantillons. Si je veux comparer
les deux échantillons pour
que les gens viennent suivre ma formation. Avant
mon programme de formation, je fais une évaluation mon programme de formation leur compréhension de
ce que Lean Six Sigma. Et je peux suivre le programme de
formation et le même groupe de participants assiste au test après
le programme d'entraînement. Donc les participants
ou la scène. Mais le changement
qui s'
est produit est la formation qui
a eu un impact sur eux. J'ai les résultats des tests avant l'entraînement et j'ai les résultats des
tests après l'entraînement, je veux comparer l'
entraînement est efficace. Ensuite, j'opte pour un test T
apparié à deux échantillons. Progresser davantage. Supposons que si je
teste la fréquence, j'ai des données discrètes
et que je souhaite tester la fréquence car dans données
discrètes, je n'ai
pas de moyennes. Je prends des fréquences. Ainsi, lorsque je compare
le nombre d' une variable dans un échantillon à
la distribution attendue, tout comme j'ai
eu un test t d'échantillon. L'équivalent pour une donnée discrète serait mon ajustement du
Khi deux. I, par défaut, devrait être une valeur normale, une
valeur particulière ou une valeur inattendue. Et je compare ça. À quelle distance se trouvent mes données ? J'opte pour un ajustement du
Khi deux. Ce test est disponible
sur MiniTab dans Excel. Il n'est pas disponible. Je vais donc créer un
modèle et vous le donner, ce qui vous permettra de
faire facilement le test du chi carré. Les trois différents types de tests du
Khi deux utilisant
le modèle Excel. Si je dois compter certaines des variables
entre deux échantillons. Ce sera donc un test T
homogène du chi carré. Je vérifie un échantillon
simple pour voir si les
variables discrètes sont indépendantes. Je fais le test d'
indépendance du chi carré. Si j'ai une certaine proportion de données, comme de bonnes ou de mauvaises candidatures, je les accepte plutôt que je les rejette. Et je dis que d'accord, 50 % des candidatures
sont acceptées, ou vingt-cinq pour cent
des personnes sont placées. J'ai une proportion
que je veux tester. Si je n'ai qu'un seul échantillon, j'opte pour un test de proportion. Si je veux comparer la
proportion de commerce
par rapport aux diplômés en sciences ou à la proportion de diplômés en finance, MBA, personnes ayant un MBA en
marketing, j'ai deux échantillons différents, donc je peux optez pour le test à deux
proportions. Donc pour résumer, quand je teste, est-ce que je
teste des moyennes ? Est-ce que je teste des
fréquences comme des données
discrètes ou est-ce que je
teste des proportions ? En fonction de cela,
vous choisissez le test approprié
et vous y travaillez. Nous allons tout
pratiquer en utilisant Men dab et exit. Le jeu de données est disponible dans
la section description. Dans la section projet, je vous invite tous à le
mettre en pratique et à mettre vos projets, votre analyse dans la section
projets. Si vous avez des doutes, vous pouvez les mettre dans la section discussion et je me
ferai un plaisir de répondre à vos doutes. Bon apprentissage.
26. Les concepts de T test en détail: Que vous apprend cette vidéo ? À propos du test T ? Cette vidéo couvre tout ce que vous
devez savoir sur le test T. À la fin de cette vidéo, vous découvrirez ce qu'est le
test AT, quand l'utiliser, les différents types de tests
t, d'hypothèses et d'hypothèses
impliqués, comment le test AT est calculé et comment
interpréter les résultats Qu'est-ce qu'un test T ? Commençons par les bases. Un test t est une procédure de
test statistique. Cela permet d'analyser s'il existe une différence significative entre
les moyennes de deux groupes. Par exemple, nous pouvons comparer la tension artérielle des patients
recevant le médicament A par rapport à. Médicament B, types de tests t. Il existe trois principaux
types de tests t le test t à un échantillon,
le test t à échantillons indépendants,
ou test à deux t,
et le test t à échantillons appariés. Qu'est-ce qu'un test t pour un échantillon ? Nous utilisons un test
t à un échantillon lorsque nous voulons comparer la moyenne d' un échantillon à une moyenne de
référence connue. Par exemple, un fabricant de tablettes de
chocolat affirme que ses tablettes pèsent en moyenne 50 grammes. Nous prélevons un échantillon. Trouvez son poids moyen. Supposons que le
poids de l'échantillon soit de 48 grammes et utilisez un test
t sur un échantillon pour voir s'il diffère
significativement
des 50 grammes déclarés. Qu'est-ce qu'un test t pour des échantillons
indépendants ? Les échantillons indépendants
à tester comparent les moyennes de deux
groupes ou échantillons indépendants. Par exemple, nous pouvons
comparer l'efficacité de deux colorants antidouleur en assignant au hasard 60
personnes à deux groupes recevant le médicament A
et l'autre médicament B. Puis en utilisant un test t
indépendant pour évaluer toute
différence significative dans le soulagement de la douleur. Qu'est-ce qu'un test t
pour les échantillons jumelés ? Les échantillons appariés à tester comparent les moyennes de
deux groupes dépendants. Par exemple, pour évaluer l'
efficacité d'un régime, nous pourrions peser 30 personnes auparavant. Après le régime, à l'aide d'un test par
paires d'échantillons, nous déterminons s'il y a une différence
de poids significative auparavant. Après le régime. Il est
essentiel de comprendre
la différence entre les échantillons
dépendants et
indépendants pour choisir
le type de test t adapté à votre analyse. Échantillons dépendants
ou échantillons appariés, référence aux cas où
chaque observation d'
un échantillon est associée à
une observation spécifique. Dans l'autre échantillon, cette association est due à la nature de la collecte de
données, par exemple avant et
après les mesures Sur les mêmes individus, paires
appariées dans le cadre d'une expérience. Le test t d'échantillons appariés
est utilisé pour déterminer si. La différence moyenne entre ces observations appariées est
statistiquement significative. D'autre part, les
échantillons indépendants sont des observations, tirées de deux groupes distincts, ou de populations qui ne sont pas apparentées ou associées de manière systématique. Chaque observation
d'un échantillon est totalement indépendante des
autres observations. Dans l'autre échantillon, les échantillons
indépendants, test
T évalue
si les moyennes de ces deux groupes indépendants diffèrent significativement l'une
de l'autre Le choix entre ces types de tests
t dépend de la
manière dont les données ont été collectées et de la relation entre les échantillons
comparés. L'utilisation du
test t correct garantit que votre analyse statistique reflète
avec précision la nature de votre question de
recherche et la structure de vos données. Voici une note intéressante. Le test t à échantillons appariés est très similaire au test t à échantillon
unique. Nous pouvons également considérer
les échantillons jumelés à tester comme un échantillon qui a été mesuré à deux moments différents. Nous calculons ensuite la différence entre les valeurs appariées, en nous donnant une valeur
pour un échantillon. La différence est de
un moins cinq plus deux moins un moins trois, et ainsi de suite. Nous voulons maintenant tester
si la valeur moyenne de
la différence qui vient d' être calculée s'écarte d'une valeur de référence Dans ce cas, zéro, c'est exactement ce que fait le test t sur
un échantillon. Quelles sont les hypothèses ? Pour un test t, bien sûr, nous avons d'abord besoin d'un échantillon approprié
dans le test t à échantillon unique, nous avons besoin d'un échantillon et la valeur de référence dans
le test t indépendant. Nous avons besoin de deux échantillons indépendants, et dans le cas d'
un test t apparié, un échantillon apparié, la
variable pour laquelle nous voulons tester s'il existe une différence entre les
moyennes doit être métrique. L'âge, le poids
corporel et le revenu sont des exemples de
variables métriques . Par exemple, le niveau d'éducation
d'une personne n'est pas
une variable métrique. En outre, la variable métrique doit être distribuée normalement dans les trois variantes de test pour savoir comment tester si vos
données sont distribuées normalement. Dans le cas d'un test t
indépendant, les variances entre les deux groupes doivent être approximativement égales Vous pouvez vérifier si
les variances sont égales en utilisant le test L evens. Quelles sont les hypothèses
du test t ? Commençons par le test t à
un échantillon
dans le test à un échantillon t. L'hypothèse nulle
est que la
moyenne de l'échantillon est égale à la valeur de référence
donnée. y a donc aucune différence, et l'
hypothèse alternative est la moyenne de l'échantillon n'est pas égale à la valeur de
référence donnée. Qu'en est-il des
échantillons indépendants à tester ? Dans le test t indépendant, l'hypothèse nulle est que
les valeurs moyennes des deux
groupes sont les mêmes. n'y a donc aucune différence
entre les deux groupes, et l'
hypothèse alternative est que
les valeurs moyennes des deux
groupes ne sont pas égales. Il y a donc une différence
entre les deux groupes. Enfin, les échantillons
appariés sont testés dans un test par paires t, l'hypothèse nulle
est que la moyenne de la différence entre
les paires est nulle, et l'
hypothèse alternative est que
la moyenne de la différence
entre les paires n'est pas nulle. Nous savons maintenant quelles sont
les hypothèses. Avant de voir comment le test
t est calculé. Voyons un exemple
de la raison pour laquelle nous avons réellement
besoin d'un test t. Supposons qu'il y ait une
différence dans la durée des études pour un
baccalauréat entre les hommes. Et des femmes en Allemagne. Notre population est
donc composée de tous les bacheliers
ayant étudié en Allemagne. Cependant, comme nous ne pouvons pas sonder
tous les bacheliers, nous tirons un échantillon aussi
représentatif que possible. Nous utilisons maintenant le test pour tester l'hypothèse nulle selon laquelle il n'y a aucune différence
dans la population. S'il n'y a pas de différence
dans la population, s'il n'y a pas de différence
dans la population, nous verrons certainement quand même une différence dans la
durée de l'étude dans l'échantillon. Il est très
peu probable que nous ayons tiré un échantillon où la différence
serait exactement nulle. En termes simples, nous voulons maintenant
savoir à quelle différence est
mesurée dans un échantillon. On peut dire que la
durée de l'étude des hommes et des femmes est
significativement différente. Et c'est exactement ce à quoi répond
le test T. Mais comment
calculer un test t ? Pour faire ça ? Nous
calculons d'abord la valeur t pour
calculer la valeur t. Nous avons besoin de deux valeurs. Nous avons d'abord besoin de la différence
entre les moyennes, puis de l'
écart type par rapport à la moyenne. Cette erreur est également connue sous
le nom d'erreur standard. Dans le test t à un échantillon, nous calculons la
différence entre la moyenne de l'échantillon et la moyenne de référence
connue. S est l'écart type
des données collectées, et n est le nombre de cas. S divisé par la racine carrée de n est alors l'
écart type par rapport à la moyenne. Quelle est l'erreur standard ? Dans le test t des échantillons dépendants, nous calculons simplement
la différence entre les moyennes des deux échantillons. Pour calculer l'erreur type, nous avons besoin de l'
écart type et du nombre de cas du
premier et du deuxième échantillon, selon que
nous pouvons supposer variance
égale ou inégale pour nos données Il existe différentes formules
pour l'erreur type. Dans un test t à échantillon apparié
, il suffit de calculer
la différence entre
les valeurs appariées et de
calculer la moyenne à partir de cela. L'erreur type est alors la même que pour un test t sur un échantillon. Qu'avons-nous appris jusqu'à
présent sur la valeur t ? Quel que soit le
test t, nous calculons. La valeur t
sera plus grande si la différence
entre les moyennes est plus grande, et la valeur t sera plus petite si la différence entre
les moyennes est plus petite. De plus, la valeur t
diminue lorsque la
dispersion de la moyenne est importante.
Ainsi, plus les données sont dispersées, moins
les différences moyennes sont
significatives. Nous voulons maintenant utiliser le test t pour voir si nous pouvons rejeter l'hypothèse
nulle ou non. Pour ce faire, nous pouvons désormais utiliser
la valeur t de deux manières. Soit nous lisons la valeur critique
t dans un tableau, soit nous calculons simplement la valeur
p à partir de la valeur t. Nous allons passer en revue
les deux dans un instant. Mais qu'est-ce que la valeur p ? Un test t teste toujours l'hypothèse nulle selon laquelle
il n'y a aucune différence. Tout d'abord, nous supposons qu' il n'y a aucune différence
dans la population. Lorsque nous tirons un échantillon, celui-ci s'écarte de l'hypothèse
nulle dans une certaine mesure La valeur p nous indique la
probabilité que nous
tirions un échantillon dont l'
écart par rapport à la population est écart par rapport à la population égal ou supérieur à celui de
l'échantillon
que nous avons prélevé. Ainsi, plus l'échantillon s'écarte de l'hypothèse
nulle, plus
la valeur p diminue Si cette probabilité
est très faible, on peut bien sûr se demander si l'hypothèse nulle est valable
pour la population Il y a peut-être une différence, mais à quel moment peut-on
rejeter l'hypothèse nulle ? Cette limite est appelée seuil
de signification, qui est généralement fixé à 5 %. S'il n'y a que 5 % de chances
que nous tirions un tel échantillon. Ou un autre qui soit plus différent. Nous avons alors suffisamment de preuves pour supposer que nous rejetons
l'hypothèse nulle. En termes simples, nous supposons
qu'il existe une différence, que l'
hypothèse alternative est vraie. Maintenant que nous savons
quelle est la valeur p, nous pouvons enfin voir comment
la valeur t est utilisée pour déterminer si l'hypothèse
nulle est rejetée ou non. Commençons par le chemin
passant par la valeur critique t, que vous pouvez lire dans
un tableau. Pour ce faire. Nous avons d'abord besoin d'un tableau
des valeurs t critiques, que nous pouvons trouver
dans l'onglet Données sous les didacticiels et la distribution
T. Commençons par
le boîtier à deux embouts. Nous allons examiner brièvement
le boîtier à queue unique à
la fin de cette vidéo. Ci-dessous, nous voyons le tableau. abord, nous devons
décider du niveau de signification que
nous voulons utiliser. Choisissons un
seuil de signification de 0,05 %. Ensuite, nous examinons dans cette colonne
120,05, soit 0,95. Nous avons maintenant besoin des
degrés de liberté du test t à un échantillon et
du test t à échantillons jumelés. Les degrés de liberté sont simplement le nombre
de cas moins un. Si nous avons un échantillon
de dix personnes, il y a neuf
degrés de liberté. Dans le test
des échantillons indépendants, nous ajoutons le nombre de
personnes des deux échantillons et nous le calculons moins deux
parce que nous avons deux échantillons. Notez que les degrés de
liberté peuvent être déterminés différemment
selon
que nous supposons
une variance égale ou égale. Donc, si nous avons un seuil de
signification de 5 % et neuf degrés de liberté, nous obtenons une valeur
t critique de 2,262 Maintenant, d'une part, nous avons calculé une valeur t avec le test t et nous avons
la valeur t critique. Si notre valeur t calculée est supérieure à la valeur t
critique. Nous rejetons l'hypothèse nulle. Supposons, par exemple, que nous
calculions une valeur t de 2,5. Cette valeur est
supérieure à 2,262
et, par conséquent, les
deux moyennes sont tellement différentes que nous pouvons
rejeter l'hypothèse nulle D'autre part, nous pouvons également calculer la valeur p pour la valeur
t que nous avons calculée. Si nous saisissons 2,5 pour la valeur t et neuf pour les
degrés de liberté, nous obtenons une valeur p de 0,034 La valeur p est inférieure à 0,05, et nous rejetons donc l'hypothèse
nulle comme contrôle Si nous copions la
valeur t de 2,262 ici, nous obtenons exactement une valeur
p de 0,05, qui est exactement Si vous souhaitez calculer le test
AT avec l'onglet Données, vous suffit de copier vos
propres données dans ce tableau. Cliquez sur le test d'hypothèse ,
puis sélectionnez les
variables qui vous intéressent. Par exemple, si vous souhaitez vérifier si le sexe a
un effet sur le revenu, il
vous suffit de cliquer sur
les deux variables et d'obtenir automatiquement le test AT, calculé pour des échantillons
indépendants. Ci-dessous. Vous pouvez
lire la valeur p. Si vous n'êtes toujours pas sûr l'interprétation
des résultats, vous pouvez simplement cliquer sur
interprétation vers l'intérieur Un test à deux points pour des échantillons
indépendants, en supposant des variances
égales, a montré que la différence entre les femmes et les hommes en ce qui concerne le salaire de la variable dépendante n'
était pas statistiquement
significative Ainsi, l'
hypothèse nulle est retenue. La dernière question est maintenant quelle est la différence entre hypothèse
dirigée et
une hypothèse non dirigée ? Dans le cas non dirigé, l'hypothèse alternative est
qu'il existe une différence Par exemple, il
existe une différence entre le salaire des hommes
et celui des femmes en Allemagne. On s'en fout de savoir qui gagne le plus. Nous voulons simplement savoir s'il
y a une différence ou non. Dans une hypothèse dirigée. Nous nous intéressons également à la direction
de la différence. Par exemple, l'hypothèse
alternative pourrait être que les hommes gagnent plus que femmes ou que les femmes gagnent
plus que les hommes. Si nous examinons graphiquement la
distribution t, nous pouvons voir que dans
le cas recto verso, nous avons une plage sur la gauche
et une plage sur la droite. Nous voulons rejeter l'hypothèse
nulle si nous sommes ici
ou là avec
un seuil de signification de 5 %. Les deux plages ont une
probabilité de 2,5 %. Ensemble, seulement 5 %, si nous
effectuons un test T unilatéral, l'hypothèse nulle n'est
rejetée que si nous nous situons dans cette plage
ou, selon la direction dans laquelle
nous voulons tester dans cette plage avec un seuil de
signification de 5 %, A 5 % se situent dans cette plage. Merci d'avoir appris avec moi. Je vous verrai dans la prochaine
leçon de statistiques.
27. 1 test de t d'échantillon: Voyons quels tests d'
hypothèse dois-je utiliser ? Dans Minitab, vous disposez d'un assistant qui peut vous
aider à prendre cette décision. Donc, si vous passez au test d'
hypothèse assistant, cela vous aidera à identifier fonction du nombre d'
échantillons que vous avez. Supposons que si vous
avez un échantillon, vous pouvez faire
un test t à
un échantillon, un écart type d'échantillon, un pourcentage d'échantillon défectueux, qualité d'ajustement du Khi
deux. Si vous avez deux échantillons, vous avez deux
tests t pour des échantillons différents. Test T si les éléments avant et
après sont identiques. Ecart type de l'échantillon par rapport au pourcentage d'échantillon du test d'association du
Khi deux défectueux. Si vous avez
plus de deux échantillons, alors nous avons un test d'
écart type ANOVA unidirectionnel, pourcentage du
Khi deux
est défectueux et test d'association du Khi deux. Nous allons tout mettre en
pratique avec de nombreux exemples. Passons donc
au premier exemple. Nous avons le TDAH des
appels en quelques minutes. Nous avons prélevé un échantillon
de 33 points de données. La moyenne est de sept minutes,
la valeur minimale est de quatre minutes, la valeur
maximale est de dix minutes. La raison pour laquelle nous devons faire un test d'hypothèse est que le
responsable des processus que son équipe est capable de fermer la résolution ou sur
appel en sept minutes. Et la moyenne du processus
est également de sept minutes, minimum est de quatre minutes. Mais le client voit
que les agents les gardent en attente et cela prend plus de
sept minutes sur l'appel. Maintenant, je veux
valider statistiquement si
c'est correct ou non. Chaque fois que nous mettons
en place des tests d'hypothèse, nous devons suivre l'approche en cinq
étapes et six étapes. Étape numéro un, définissez
l'hypothèse alternative. Définissez l'hypothèse nulle, qui n'est rien d'autre que
votre statu quo. Quel est le niveau de signification
ou votre valeur alpha ? Si rien n'est spécifié, recevoir une valeur Alpha
de cinq pour cent. Nous avons d'abord défini l'hypothèse
alternative. Dans notre cas, que dit le client ? Le client constate que le temps de traitement moyen est
supérieur à sept minutes. Le statu quo ou
le SLA convenu est le TDAH doit être
inférieur à sept minutes. Comme je vous l'ai dit,
l'hypothèse nulle et l'hypothèse alternative
s' excluent
mutuellement et se complètent. Maintenant, identifiez le
test à effectuer. Combien d'échantillons ai-je en ma possession ? Je n'ai qu'un seul échantillon de la
HD du centre de contact. Je vais donc
prélever un échantillon de test t. Ok ? Maintenant, je dois faire
les statistiques de test et identifier la valeur de p. Si vous vous souvenez de l'exemple
précédent, nous avons dit que si la valeur de p est
inférieure à la valeur alpha, nous rejetons l'hypothèse nulle. Si la valeur de p est supérieure à
cinq pour cent ou la valeur Alpha, nous ne rejetons pas
l'hypothèse nulle. Laissez-nous faire cela. Donc, si vous vous souvenez, nous avons les données de nos projets. Dans les données du projet, nous avons le test d'hypothèse. Par ici. Je vous ai donné l'
AHG du charbon en quelques minutes. J'ai donc copié ces
données dans Minitab. Nous allons donc le faire de deux manières. La première fois et vous le montrer
à l'aide de l'assistant. Ensuite, je vais vous le montrer
à l'aide de statistiques. Donc, si je passe au test d'
hypothèse assistant, quel est l'objectif que
je souhaite atteindre ? C'est un test T à un échantillon.
J'ai un échantillon. Est-ce que c'est méchant ? S'agit-il d'un écart type ? S'agit-il de numéros séparés, défectueux
ou discrets ? Nous parlons de
la moyenne 100 fois. Je vais donc prendre
un test t d'échantillon. Pour les données en colonnes. Je l'ai sélectionné. Quelle est ma valeur cible ? Ma valeur cible est sept. L'autre hypothèse est que
l'âge moyen de l'appel en minutes est
supérieur à sept ans. C'est ce que le
client se plaint. La valeur alpha est 0,05 par
défaut, je clique sur OK. Voyons le résultat. Pour voir la sortie,
vous allez cliquer sur Afficher et sortie uniquement. Tu vas voir ça. Si vous voyez la valeur de p, la
valeur de p est de 0,278. Vous vous souvenez qu'en dessous de non-but
être élevé nullcline,
cette valeur de 0,278 est-elle supérieure à la valeur alpha de 0,05 ? Oui, ça l'est. Par conséquent, je peux conclure
que la moyenne est d du charbon n'est pas significativement
supérieure à la cible. Quoi que vous considériez
comme supérieur à la cible, ce n'est que par hasard. n'y a donc pas suffisamment de preuves
pour conclure que la moyenne est supérieure à sept avec un niveau
de signification de
5 %. Et cela me montre également
comment est le modèle. n'y a pas de points de données inhabituels car l'
effectif de l'échantillon est d'au moins 20. La normalité n'est pas un problème. Le test est précis. Et il serait bon de
conclure que le temps de traitement moyen
n'est pas significativement
supérieur à sept minutes. Je peux poursuivre et rejeter la réclamation du client. Les quelques appels que nous considérons comme des objectifs de haute qualité et de
grande valeur. Cela ne peut être que par hasard. Le même test. Je peux également le faire en cliquant sur test, statistiques de base. Et je vais enregistrer un test t d'échantillon, un ou plusieurs échantillons,
chacun dans une colonne. Je vais sélectionner votre TDAH. Je souhaite effectuer des tests d'
hypothèse. La moyenne hypothétique est de sept. Je vais dans Option et je dis, quelle est l'
hypothèse alternative que je veux définir. Je veux définir que la moyenne réelle est
supérieure à la moyenne hypothétique. Cliquez sur OK. Si j'ai besoin d'un graphique, je peux mettre ces graphiques en place. Cliquez sur OK,
puis sur OK. Je reçois cette sortie. Donc, les statistiques descriptives, c'est la moyenne, c'est l'
écart type et ainsi de suite. L'hypothèse nulle est
que mu est égal à sept. autre hypothèse est que
mu est supérieur à sept. La valeur de p est de 0,278. En concluant à ce vol nul, nous ne rejetons pas
l'hypothèse nulle, concluant que la
durée moyenne de 100 heures est environ sept minutes.
Continuons. Nous avons reçu nos résultats. Nous avons vu tout cela et nous avons conclu que
le temps de traitement moyen n'
est pas significativement
supérieur à sept minutes.
28. Exemple de test 2 t d'exemple 1: Faisons un autre exemple
de deux équipes, deux échantillons. Dans cet exemple, deux équipes dont les performances
doivent être mesurées. Le manager de DMB a affirmé que son équipe est une équipe plus
performante que l'ADN. Le responsable d'une équipe soutient que cette
réclamation n'est pas valide. Passons à notre jeu de données. Donc, si vous allez
dans le fichier de projet, vous aurez quelque chose
appelé équipe a et équipe B. Alors laissez-moi simplement copier ces données. Ok. Laissez-moi aller ici et placer le
radar sur le côté droit. Pourquoi puis-je également prendre une nouvelle feuille et coller les données. Bon ? Venons-en à un test d' hypothèse, un test t
à deux échantillons. Permettez-moi de supprimer cette valeur. Et TB, l'équipe a est
différente de la VM. Je peux aussi dire
sur la base de l'hypothèse que l'équipe est prétendue que
son équipe est meilleure qu'un. Donc je peux dire que c'est moins que la
télévision. Et je clique sur OK. Encore une fois, dans cet exemple, j'obtiens un résultat qui indique que l'équipe n'est pas
significativement inférieure à TB. Avez-vous les
valeurs de 27,727,3 ? n'y a pas de différence
statistique entre les deux pourboires, n'est-ce pas ? Les deux exemples que
nous avons obtenus étaient donc comme ça. Allons voir
un autre exemple. J'ai pris le temps
de cycle du processus un et le
temps de cycle du processus B. Copions
donc simplement ces données. Il s'agit d'un autre ensemble de données. Et je me demande : « Quelle est mon hypothèse
alternative ? Les deux faisceaux sont différents. Qu'est-ce que l'hypothèse nulle ? Les deux équipes sont identiques. Parce que ces deux
équipes sont différentes. Je vais faire
mon test t à deux échantillons. Les données de chaque
équipe sont distinctes. Et je vois que la valeur alpha
de la tuberculose est différente de 5%, puis je clique sur, OK. Maintenant, si vous voyez la
sortie cette fois, cela indique que oui, le temps de cycle de a est significativement
différent du temps de cycle de dB. Ici, ce 26,8,
vingt-sept virgule six. Mais si je regarde
la distribution, la distribution selon laquelle ce rouge ne chevauche
pas ce rouge. Il y a donc une différence dans le temps de cycle des deux équipes. Si je dois faire la
même chose en utilisant des statistiques, statistiques
de base, un test t
à deux échantillons. Comme lorsque vous
étiez e à l'époque des options
contre la tuberculose, y a-t-il des différences ? Je peux avoir mes graphiques. Je ne veux pas de graphique
individuel. Je vais seulement prendre la
boîte à moustaches et dire, d'accord, mu1 est la moyenne de
la population du temps de
cycle des processus, le temps de cycle du processus B. Maintenant, si vous voyez qu'il y a un écart type
qui est une différence. La valeur de p est 0
, ce qui indique qu' il existe une différence significative
entre les deux équipes. Soyez bas, rien n'est cool. Nous rejetons donc
l'hypothèse nulle, disant qu'il y a une différence significative
entre E et D. est-ce
pas ? J'ai vu la même chose
avec la distribution continue. Il y a donc une distribution
plus importante ou ici et il y a une distribution
plus petite. Je peux faire l'
analyse graphique que j'ai apprise sur votre droite, puis voir comment
l'équipe se comporte. Voici donc le résumé de l'ADN. La moyenne est de 26, l'
écart type est de 1,5. Et si je fais défiler vers le bas, je rejoins l'équipe B et ça
arrive de cette façon. Maintenant, je veux superposer
ces graphiques afin pouvoir cliquer sur un graphique
et un histogramme. Et je dirais un peu en
forme et soyeux. Et je vais sélectionner ces deux graphiques sur un
panneau séparé du même graphique, même vitamine C max. Cliquez sur OK. Cliquez sur OK. Vous voyez que la courbe en cloche des deux est différente ? Faisons un histogramme
graphique superposé. Et en
superposition au sol multiple sur ce graphique. Vous voyez qu'il y a une différence entre le bleu et
le rouge ? Et donc, oui, le
kurtosis est différent, le biais est différent, et c'
est la conclusion mon test t
à deux échantillons, qui indique que la distribution y est significative
différence. Il existe une différence statistiquement
significative entre le temps sacré d'être un combattant
EN et celui de la mort. La deuxième chose que nous allons apprendre sur le test t au lit
dans notre prochain exemple.
29. 2 exemple de test t 2: Revenons à notre exemple. Deux. Il existe deux centres dont les performances
doivent être mesurées. Le responsable de
sensoriel a affirmé que son équipe est une
équipe plus performante que le centre B. L'ampleur du centre soit préconise que la
réclamation est invalide. Encore une fois, je vais suivre
mon processus en cinq étapes. Quelle est l'
hypothèse alternative ? C'est mieux que B. Rendons les choses plus faciles. Il n'est pas égal à T, n'
est pas égal à TB, ou le centre n'est pas
égal au centre. Qu'est-ce que le
centre non
hypothétique a est égal au centre V, niveau de signification,
cinq pour cent. Combien d'échantillons ai-je ? J'ai deux échantillons, éditeur
central et les données du centre B. Comme j'ai deux échantillons, je dois faire un test t à
deux échantillons. Passons à notre feuille Excel. J'ai les données pour
Centauri et le centre B. Je vais les
copier dans Minitab. Je place mes données ici. Faisons le test t à deux échantillons. Je vais donc à Stat, Statistiques
de base et
je dis test t à deux échantillons. Les deux échantillons
se trouvent dans une seule colonne. Chaque échantillon possède sa propre colonne, je vais
donc
sélectionner cet échantillon. L'un est un échantillon sensoriel. Est-ce que tu centres B ? L'option est hybride. Ce n'est pas différent. La différence
entre a et B est donc de 0. Et j'y vais et je le fais. Je peux avoir ma
boîte à moustaches individuelle
et dire OK, et dire OK,
voyons la sortie. Les données sensorielles sont donc
les vôtres et les données TBI sont ici. Et si vous voyez la valeur de p, la valeur de p est élevée. Encore une fois, j'ai un exemple qui
dit que be high null fly, ce qui signifie qu'il n'y a pas de différence entre le centre et le centre B. Si vous voyez la valeur individuelle, mais que vous voyez la même chose. Voyons la boîte à moustaches. La boîte à moustaches indique
que la moyenne n'est pas significativement
différente car elle aurait prélevé un échantillon. C'est la raison pour laquelle c'est le cas, et vous voyez une valeur de 0, ce qui est une valeur aberrante. Nous devrions donc
envisager cela. La même chose. Laissez-moi le faire en utilisant des tests d'
hypothèse. Test t à deux échantillons, moyenne de l'échantillon. L'échantillon est différent. La moyenne du centre
est différente de la moyenne des centres B et C. OK. Il en va de même pour
la différence moyenne, la moyenne de Santa Fe n'est pas significativement
différente de la moyenne décentrée. Bon ? Si vous voyez cette distribution, vous pouvez constater que la partie
rouge se chevauche
complètement, ce qui
indique qu'il
n'y a pas assez de preuves pour conclure à
une différence. Il y a une différence lorsque
vous voyez la moyenne, 6,86,5. Mais c'est peut-être à
cause d'un hasard. Et il y a aussi un
écart type. Par conséquent, ceux-ci le montrent
à l'aide des barres rouges, indiquant qu'il n'y
a pas de différence significative entre la semaine
sensorielle et la semaine centrale. Nous allons continuer à découvrir d'autres exemples dans
la vidéo à venir.
30. Test t couplé: Laissez-nous comprendre
un autre exemple. Voici un exemple
de test t apparié. Si vous regardez cette étude de cas, les psychologues ont
voulu déterminer si un programme de course à pied particulier avait
un effet sur leur fréquence cardiaque au
repos. La fréquence cardiaque de 15
personnes sélectionnées au hasard a été mesurée. Les personnes ont ensuite été mises sur un programme de course à pied et mesurées
à nouveau après un an. Les participants
disent-ils « avant » et « après » ? Oui. Et c'est la raison pour laquelle il
ne s'agit pas d'un test t à deux échantillons, mais d'un test t apparié, la
mesure avant et après de chaque personne ou dans des
bandes d'observation. Donc, si je reviens à mon jeu de données, j'ai quelque chose qui s'appelle
avant et après, il y a une étape différente, je ne prends pas la valeur de
différence. J'ai pris les données des 15 personnes et les ai
mises dans un mini onglet. Bon ? Maintenant, je veux le faire parce que c'est la même personne
avant et après moi, nous voulons comprendre les
différents tests d'hypothèse. Je vais faire un test T apparié. Tout d'abord, quelle est l'hypothèse alternative ? Avant et après, c'est différent. Si vous vous souvenez, le programme
d'avant et d'après, ils veulent déterminer s'ils
ont un effet sur la course. La mesure est avant, l' outil
de mesure est en place. moyenne avant est différente
de la moyenne d'après. C'est donc mon hypothèse
alternative. Donc, quelle est la signification
de mon
hypothèse nulle avant, c'est qu'il n'y a pas de changement. Le remplaçant voit que l'avant
est différent de l'après. La valeur alpha est de 0,05. Cliquons sur OK. Voyons le résultat. La moyenne est-elle différente ? Qu'est-ce qu'une valeur de p de 0,007 ? La moyenne de avant est significativement différente
de la moyenne d'après. Si vous regardez la
valeur moyenne, elle était de 74,572,3. Mais il y a une différence. Donc, si vous voyez que la
différence est supérieure à 0. Et si je regarde ces
valeurs avant par rapport après, le point bleu est après
le point noir est avant. La plupart des participants avaient réduit
leur fréquence cardiaque
après le programme de course à pied. Peu d'entre eux constituaient une exception, mais cela pouvait être une exception. n'y a pas de différences
appariées inhabituelles car
la taille de notre échantillon est d'au moins 20 La normalité n'est pas un problème. L'échantillon est suffisant pour détecter la différence
dans la moyenne. Je peux donc voir qu'il y a une différence
entre les deux. Merveilleux. Encore une fois, révision rapide. Bonjour, objectif nul puisque la valeur de p est inférieure
au seuil de signification, nous concluons qu'il existe une différence significative
entre les deux lectures. Si je dois faire la scène, je clique sur Stat, Statistiques
de base. Mauvaise haine, chaque
échantillon dans une règle. Avant, après l'option
, ils sont différents. Laissez-moi prendre uniquement la
boîte à moustaches et l'histogramme de Je ne veux pas
choisir l'histogramme. Je ne prendrai que la boîte à moustaches. Hypothèse nulle. La différence est de 0. L'hypothèse alternative est que la
différence est non nulle, les valeurs de p faibles, concluant que je rejette
l'hypothèse nulle. Et il y a une différence
en adoptant le programme. Donc, si vous voyez la valeur nulle, le point rouge est très éloigné de la moyenne de l'
intervalle de confiance de la boîte pour
conclure qu'il
existe une différence entre suivre le programme par Ce spécialiste du cœur, c'est ça ? Donc, dans le prochain programme, nous allons apprendre,
prendre plus d'exemples.
31. Un test d'échantillon Z: Le résumé rapide des
différents types de tests que nous avons
appris est que si je regarde les différences entre mon groupe et
la population, je choisis un test t à un échantillon. Lorsque j'ai deux
groupes d'échantillons différents, je fais un test t à deux échantillons. Si ces échantillons
sont indépendants. Si j'opte pour
un test T apparié. Test T apparié. Si le groupe est le
même ensemble de personnes, mais il est ou un
moment différent dans le temps. Comme nous avons vu l'exemple
des battements de cœur. Les gens ont donc été mesurés
sur leur rythme cardiaque. Le rapport via
un programme en cours d'exécution et affiche le programme en cours d'exécution. Comment s'est passé ce
battement de cœur chaud au repos, non ? Ce sont donc les
choses que nous avons triées. Passons maintenant à
d'autres exemples. Nous ajoutons donc au cas d'utilisation numéro cinq, l'analyse du pourcentage de graisse. Les scientifiques d'une entreprise qui fabrique des procédés qui veulent déterminer le pourcentage de graisse dans la source
d'eau de l'entreprise. La date de publication de la publicité
est de 15 % et les scientifiques mesurent que le pourcentage
de graisse est de 20 échantillons aléatoires. La mesure précédente de
l' écart type de la population est de 2,6. Il s'agit maintenant de l'
écart type de la population. L'écart type
de l'échantillon est de 2,2. Lorsque je connais le paramètre de
population, je peux
utiliser un
test z sur un échantillon , car le nombre
d'échantillons que j'ai est égal à un. Et je veux avoir l'écart type connu
de la population. Maintenant, encore une fois, je vais appliquer la même chose que l'hypothèse
alternative, n'est-ce pas ? Alors qu'est-ce que je vais dire ? Quelle est l'hypothèse alternative ? Le pourcentage de matière grasse
n'est pas égal à 603050. Quel est le pourcentage de
graisse de l"hypothèse nulle est égal à 15%. Niveau de signification de
cinq pour cent. Parce que je sais qu'il s'agit
d'un test à un échantillon et que j'ai l'
écart type de la population. Je vais utiliser
un test z d'échantillon. Faisons l'analyse. J'ai ouvert le fichier de
projet et j'ai les exemples d'ID et je provoque des données de
pourcentage de graisse ici. Permettez-moi de copier ces
données dans Minitab. Mais copié le pourcentage de graisse avec les
scientifiques ont fait. Comme nous connaissons l'écart type de
la population, je peux utiliser
un test z à un échantillon. Mes données sont présentes dans une colonne. C'est le fait présenté. L'
écart type connu était de 2,6. Je souhaite effectuer des tests d'
hypothèse. En moyenne, c'est 15 %. Donc mon hypothèse nulle est que le pourcentage de graisse
est égal à 15. Mon hypothèse est que la graisse était un
gros a n'est pas égal à 15. Je peux choisir un graphique de boîte à moustaches
et d'histogramme et dire, OK, je vais
vous montrer le résultat. Donc, l'hypothèse nulle est que le
pourcentage de graisse est égal à 15. Une autre hypothèse
est que le pourcentage de graisse n'
est pas égal à 15. La valeur alpha est de 0,05. Ma valeur de p est de 0,012, car ma valeur de p est
inférieure à la valeur alpha, P faible, aucune cool. Je rejette donc l'hypothèse nulle, concluant que le
pourcentage de graisse n'est pas égal à 50. Si vous voyez ici, le pourcentage de graisse
est supérieur à 50. Je peux refaire le même
test. Cette fois-ci. Je peux y aller et vérifier. Mon pourcentage de graisse est-il
supérieur à la moyenne hypothétique ? Allons-y. Et j'obtiens toujours ma
valeur de p avec plus de confiance, 0,006 très loin de
ma valeur Alpha. En concluant que oui, l'Alpha, la valeur nulle est
hypothétisée, la moyenne est de 15. Mais l'échantillon indique qu'il
y a une forte probabilité que votre pourcentage de graisse dans la
source soit supérieur à 50. Quels sont les conseils que nous
donnerons à l'entreprise ? Nous informerons l'entreprise
que vous ne pouvez pas vendre la dénomination que le conteneur est 15 % parce que notre facteur
est supérieur à 15 %. Donc, pour plus de sécurité, vous pouvez modifier l'
étiquette du produit pour indiquer que
le
pourcentage de graisse est de 18, n'est-ce pas ? Parce que nous avons cinq
pour cent, cela passe par 20. consommateur sera donc heureux de recevoir un produit contenant moins
de matières grasses. Ensuite, pour recevoir un produit
qui contient plus de matières grasses parce que nous sommes tous
soucieux de notre santé, n'est-ce pas ? Continuons donc
dans le cours suivant.
32. Un échantillon de proportion test-1p-test: Nous poursuivrons nos tests d'
hypothèse. Parfois, nous pouvons avoir une part de
l'action, n'est-ce pas ? nous n'avons pas de moyennes écart type
ou de variance à Cependant, nous n'avons pas de moyennes, d'
écart type
ou de variance à
mesurer,
ce que nous faisons. Prenons cet exemple six, l'analyste marketing
veut déterminer si le mâle, publicité pour le
nouveau produit a entraîné un taux de réponse
différent de la moyenne nationale. Normalement, chaque fois que vous mettez une
publicité dans le journal, ils disent que la société de publicité
voit habituellement , c'est que nous serons en mesure d'avoir impact de 6%
ou 10% de résultat ou un certain nombre résultat juste ici. C'est-à-dire que c'est le même
type de scénario. Ici. Ils ont prélevé un échantillon
aléatoire de 1 000 ménages ayant
reçu de la publicité. Et sur ces 10
000 ménages, l'échantillon 87 d'entre eux ont fait des achats après avoir reçu
cette augmentation. Cette société, qui est
une agence de publicité, prétend que j'ai eu un meilleur impact que les
autres publicités. L'analyste doit effectuer
le test z à une proportion pour déterminer si
la proportion de ménages ayant effectué un
achat était différente de la moyenne nationale
de 6,5, car elle est de 8,7. Dans ce cas. Quelle est votre hypothèse
alternative ? Une autre hypothèse est que la
publicité est
différente de la réponse à la publicité est
différente de la moyenne nationale. Nous dirons ici qu'il n'
y a pas de différence. Ils sont tous les deux péché, la valeur
alpha est de cinq pour cent. Et nous allons
prendre une proportion, un
test z, un test de proportion d'événements. Je suis censé
t'emmener à la minute près. Passons donc à Minitab. Je peux aller de l'avant et ces papas, statistiques
de base,
une proportion. Je n'ai pas de données dans ma chronique, mais je les ai résumées, n'est-ce pas ? Alors laisse-moi fermer ça, annuler, laisse-moi fermer ça. J'ai donc fait un test
de proportion d'échantillon. J'ai résumé les données. Combien d'événements avons-nous
absorbés ? Nous observons 87
événements à venir. L'échantillon est de mille. Je dois effectuer un test d'
hypothèse et la proportion hypothétisée, 6,5, 0,0656% .5, non ? Il est donc de 0,065. Cette proportion n'est pas égale
à la proportion hypothétique. Je dis, OK, je vois, OK. Maintenant, l'hypothèse nulle est que la proportion est
égale à 6,5 %. Une autre hypothèse est
que l'impact proportionnel n'
est pas égal à 5,56 %. La valeur de p est de 0,008. Qu'est-ce que cela signifie ? Oui, sois faible, rien n'est cool. Donc nous rejetons l'hypothèse
nulle, concluant que l'effet
de la publicité, Il n'est pas de 6,6,5 pour cent, mais c'est plutôt
parce que si vous voyez l'intervalle de
confiance de 95 pour cent, Ça dit 0,7 % à 10 %, non ? Vous avez obtenu une
proportion de 88,7 %. Et l'
intervalle de confiance à 95% de la proportion est bien en avance sur 6,5,
il commence à 7. Nous pouvons donc conclure qu'il y a un impact significatif de la publicité et nous pouvons
passer en revue cette société de publicité. Continuons dans
notre prochaine leçon.
33. Deux échantillons de proportion test-2p-test: Reprenons cet exercice à l'
aide de l'Assistant. Nous avons donc les
80 produits de bœuf numérotés par le fournisseur E que
nous avons vérifiés. 725 sont défectueux
ou non défectueux. Alors, combien est-ce efficace ? Donc, si je fais une soustraction, ce serait 777802 moins 725 soit 77712 produits d'échantillonnage
du fournisseur B ont été
sélectionnés par 73. Parfait. Alors, combien est
défectueux ? Un, 39. Essayons donc de faire notre test à
deux proportions à l'aide assistant
Minitab,
puis des tests d'hypothèse, échantillons, des selles, du
pourcentage d'échantillon défectueux du fournisseur E, 0 à 7771 à 139. La personne est défectueuse fournisseur E est
inférieur au pourcentage de
défectueux du fournisseur B. Je vais continuer
et cliquer sur OK. Et je comprends. Oui, ce pourcentage de
défectueux ou fournisseur est nettement
inférieur au pourcentage de
défectueux du fournisseur B. Et si je fais défiler vers le bas, Oui. Donc ça dit la différence, ce fournisseur est prêt à
lire. Le test permet de conclure que le pourcentage
représentatif du fournisseur a
est inférieur à celui du fournisseur B à un niveau de signification de
5 %. Lorsque vous voyez
ce pourcentage. De plus, vous pouvez
clairement voir que nous poursuivrons les
prochains tests d'
hypothèse la semaine prochaine. Fais
34. Deux exemples de proportion test-2p-test-Exemple: Voyons maintenant
l'exemple suivant. Il s'agit d'un exemple où
un responsable d'exploitation échantillonne un produit
fabriqué à partir de
matières premières de deux fournisseurs, détermine si
l'un des fournisseurs de matières premières est plus susceptible de produire
une meilleure produit de qualité. 802 produits ont donc été
échantillonnés auprès du fournisseur E 725 ou parfait,
c'est-à-dire non défectueux. 712 produits ont été échantillonnés auprès du
fournisseur B, 573 ou buffet. C'est-à-dire qu'il n'est pas défectueux. Nous voulons donc effectuer
parce que quel est leur pourcentage de données personnelles
non défectueuses ? Oui, j'ai deux proportions, tableau
d'approvisionnement et le fournisseur B. Passons au principal. Je peux aller à Stat, Test à deux
proportions de statistiques de
base. J'ai mes données récapitulatives, les mêmes par la première facilité, 725 ou les deux agissent sur 802. Prenons donc
725025723712572371. L'option avec eux
est qu'il y a une différence et
découvrons-la. Donc la BVA, l'hypothèse nulle, c'est qu'il n'y a pas de différence
entre les proportions. autre hypothèse est qu'il existe une différence entre
les deux proportions. Quand je
regardais la valeur de p, la valeur de p s'avère être Z, pour être nulle faible. Il conclut que je dois rejeter l'hypothèse
nulle. Il existe une différence
de performance entre
les deux fournisseurs. Maintenant, si je pense au
fait que je
parle de parfait ou de
non défectueux, actuellement, l'
échantillon un a 90% de parfait et l'échantillon deux a 80% de parfait. Donc, en concluant que le fournisseur E est un meilleur fournisseur
que le fournisseur B. N' est-ce pas ? Merci beaucoup. Nous allons continuer dans
la leçon suivante.
35. Utiliser Excel = un échantillon t-Test: Nous comprenons souvent le
test de l'hypothèse, mais nous avons un
défi à relever. Le défi, c'est que je
n'ai pas Minitab me. Ne puis-je pas tester l'
hypothèse d'une manière simple plutôt que de passer par un calcul manuel à l'aide d'une calculatrice
statistique. Ne vous inquiétez pas, c'est possible. Je vais vous montrer
comment je peux faire un test d'hypothèse à l'aide de
Microsoft Excel. Accédez au fichier. Accédez aux Options. Lorsque vous accédez à Options,
accédez à Compléments. Lorsque vous cliquez sur Compléments. Laissez-moi cliquer ici. Vous avez une option
appelée complément
Excel dans
l'option Gérer. Sélectionnez donc le complément Excel
et cliquez sur OK. Cliquez sur Analysis ToolPak et assurez-vous que cette
coche est activée. Une fois que vous l'
avez, vous le trouverez
dans votre onglet Données. Vous disposez d'une
analyse de données. Si vous me permettez de cliquer dessus vous comprendrez
ce qui est possible. Dans l'analyse des données. J'ai une corrélation OR, covariance, des
statistiques descriptives, histogramme, un test T, des tests z, une génération de
nombres aléatoires, régression
d'échantillonnage
et tout ça. Il devient donc très facile pour vous de tester des hypothèses. Au moins, l'hypothèse
des données continues également
été testée facilement via
Microsoft Excel. Je vais vous faire un exercice
étape par étape pour le moment. Revenons à
la présentation. Prenons le premier problème. C'est-à-dire que j'ai les statistiques descriptives
pour le HD de l'appel, le responsable des
processus que son équipe
travaille pour clore la résolution l'appel en sept minutes. Mais le client
constate qu'il est resté en attente pendant longtemps et qu'il passe donc
plus de sept minutes. Si je regarde les statistiques
descriptives,
elles me disent dix minutes, médiane est de sept et la moyenne de 7,1. Maintenant, je voudrais faire cette analyse en utilisant
Microsoft exit. Alors allons-y. J'ai ce cas d'utilisation dans les données du projet
que j'ai téléchargées, cliquez sur ASD, bien sûr, cela vous amène à cet endroit. Maintenant, je vais d'abord vous
apprendre à faire des statistiques
descriptives à
l'aide de Microsoft Excel. Je vais cliquer sur
Analyse des données dans l'onglet Données. Je vais chercher des statistiques
descriptives. Cliquez sur, d'accord. Ma plage de saisie va d'
ici vers le bas. J'ai sélectionné. Mes données sont regroupées par colonnes. L'étiquette est présente
dans la première rangée. Et je veux que mes résultats soient
placés dans un nouveau classeur. Je veux des
statistiques récapitulatives et je veux avoir confiance en
moi. Je clique sur OK. Excel est en train de faire quelques calculs et de le préparer. Oui Voici ma sortie. Je clique sur l'ancien ici
pour voir quelle est la sortie. Vous pouvez donc voir que vous êtes la moyenne, mode
médian, l'
écart type, l'aplatissement, asymétrie, la plage, le
minimum, le maximum, somme, le nombre, le niveau de confiance. Tous ces éléments peuvent être facilement calculés en
cliquant sur un bouton. Je n'ai pas besoin d'écrire
autant de formules. Revenons maintenant
à notre ensemble de données. Je veux tester les
hypothèses. Quelle est mon hypothèse nulle ? Lorsque l'hypothèse nulle est que le TDAH est égal
à sept minutes. Hypothèse alternative. Le TDAH ne dure pas sept minutes. Il y a une
valeur alpha différente que je définis à 5 %. Et avec cela, je vais
effectuer les tests que je
vais connecter, c'est
un test t à un échantillon. Lorsque vous effectuez
un test t sur un échantillon à l'aide de Microsoft Excel, vous devez
suivre une petite astuce. L'astuce, c'est que je vais
insérer une colonne ici. Et ça, je vais
l'appeler factice. Parce que Microsoft Excel est livré avec une option de test t
à deux échantillons. J'ai la HD de l'appel en quelques minutes et un factice où j'
ai noté des zéros, des zéros. Cependant, la médiane moyenne, tout pour 0 est toujours égal à 0. Cliquez sur Analyse des données. Je vais descendre et je dirais test t sur
deux échantillons
en supposant une variance égale. Je vais sélectionner ceci. Je vais cliquer sur, OK. Ma plage d'entrée,
l'une est cette ligne. Ma plage d'entrée
passe par ce mannequin. Ma
différence moyenne hypothétique est de sept minutes. L'étiquette est présente dans les deux valeurs Alpha
fixées à 5 %. Et je dis que
mes résultats
doivent figurer dans un nouveau classeur. Je clique sur OK, il fait le calcul
et me donne la sortie. Vous pouvez voir que les chiffres
ont été transmis comme une habitude, il suffit de cliquer sur le karma dans la section Format pour que
les chiffres soient visibles. Je change de vue parce que Dummy
n'a aucune donnée. Je suis libre
de supprimer cette colonne. Maintenant, nous allons comprendre
ce que nous recherchons toujours ? Nous recherchons cette
valeur, la valeur p. Tu te souviens de la formule ? Laissez-moi vous apporter mes
formules ici. Oui Quelle est la conclusion ? La conclusion est P élevé. Je ne peux pas rejeter l'hypothèse
nulle. La fin du TDAH de
l'appel est de sept mois. Je rejette l'hypothèse
alternative car ma valeur de p
est supérieure à 0,05. Je vais prendre d'autres exemples
dans les leçons suivantes. J'ai donc hâte
que vous continuiez cette série. Si vous avez des questions, je vous demande de les déposer dans la section de
discussion ci-dessous, et je me ferai un plaisir
d'y répondre. Merci
36. Analyse de corrélation: Bienvenue à la prochaine leçon de notre phase analysée du cycle de vie DMac d'un projet
Lean Six Sigma Parfois, nous nous
retrouvons dans une situation où nous voudrions effectuer une analyse de
corrélation. donc pensé aujourd'hui que
je devrais
vous expliquer en profondeur ce qu'est corrélation. Quelle
est la différence entre corrélation
et perte ? Comment interpréter corrélation lorsque je
regarde le diagramme de dispersion Quel
niveau de signification puis-je
définir lorsque je fais mes tests d'
hypothèse ? Corrélation de Pearson, corrélation de
Spearman, corrélation série
point b, et comment effectuer ces calculs
en ligne à l'aide de certains
des outils disponibles Commençons donc. Alors, en quoi consiste exactement l'analyse de
corrélation ? L'analyse de corrélation est une technique
statistique qui fournit des informations sur la relation
entre les variables. L'analyse de corrélation peut être calculée pour étudier la
relation entre les
variables, la force de la corrélation déterminée par le coefficient de
corrélation, qui est représenté par
la lettre numérique r, qui varie de
moins un à plus un. L'analyse de corrélation peut
ainsi être utilisée pour faire des déclarations sur la force et la direction
de la corrélation. Par exemple, vous voulez
savoir s'il existe une corrélation
entre l'âge auquel un enfant prononce sa première phrase et la réussite scolaire
ultérieure. Vous pouvez ensuite utiliser l'analyse de
corrélation. Aujourd'hui, chaque fois que nous travaillons avec corrélation, nous sommes
confrontés à un défi. Parfois, nous sommes confondus avec les
choses qui posent problème. Par exemple, si l'analyse de
corrélation montre que deux caractéristiques sont liées l'une à l'autre, il est possible de vérifier de manière substantielle
si une variable peut être utilisée pour
prédire les autres variables. Si la corrélation mentionnée dans l'exemple est
confirmée, par exemple, on peut vérifier si la réussite scolaire
peut être prédite par l'âge auquel l'enfant
prononce sa première phrase, cela signifie qu'il existe une équation de régression
linéaire. J'ai une vidéo séparée
expliquant ce qu'est
une agrégation linéaire. Mais attention, il n'est
pas nécessaire que la corrélation ait une relation causale. Cela signifie
que toute corrélation pouvant être découverte
doit donc être étudiée de plus près par l'
expert en la matière, mais jamais interprétée
immédiatement en termes de contenu, même si elle est très évidente. Voyons quelques exemples de corrélation et
de causalité. Si la corrélation entre le chiffre de vente et
le prix est analysée, une forte
corrélation est identifiée. Il serait logique
de supposer que le chiffre des ventes influencé par le prix
et non par le sage. Le prix ne se produit pas
dans l'autre sens. Cette hypothèse ne peut toutefois en aucun cas être prouvée sur la base d'une analyse de
corrélation. De plus, il peut arriver
que la corrélation entre la variable x et y soit
générée par la variable. Par conséquent, nous aborderons cela en corrélation partielle plus
en détail. Cependant, selon la variable
qui peut être utilisée, vous pourrez peut-être définir
une relation de cause à effet
dès le départ. Prenons un
exemple s'il existe une corrélation entre
le H et le salaire. Il est clair que l'âge
influence le salaire, non l'inverse. Le salaire n'
influence pas l'âge. Donc, ce n'est pas parce que mon
âge augmente ou simplement parce que j'
ai un salaire
plus élevé ou simplement parce que j'
ai un salaire
plus élevé que
je serai vieux. Sinon, tout le monde
voudrait gagner le moins de
salaire possible. C'est juste de l'amour. Interprétez la corrélation. À l'aide de l'analyse de
corrélation, deux affirmations peuvent être faites. L'un sur le sens
de la corrélation, l'autre sur la force. De la relation linéaire entre
les deux métriques ou les variables d'
échelle ordinaires La direction indique si la corrélation est
positive ou négative. Si la force
détermine si la corrélation entre les
variables est forte ou faible Donc, quand je dis qu'il existe une corrélation positive entre les deux, nous essayons de dire que les valeurs les plus élevées de la
variable x sont
accompagnées des plus grandes valeurs de la
variable y et non l'inverse. La taille et la pointure des chaussures, par
exemple, sont
corrélées positivement Le coefficient de corrélation est de
0 à 1. C'est-à-dire que c'est une valeur positive. En revanche, une corrélation
négative existe si une
valeur plus grande de la variable x est accompagnée la plus petite valeur de la variable
y et inversement. Le prix du produit et la quantité vendue
ont généralement une corrélation négative. Plus un produit
est cher , plus la quantité
vendue est faible. Dans ce cas, le coefficient de
corrélation sera compris entre
moins un et zéro, en supposant qu'il s'agit d'une valeur négative. Il en résulte donc un résultat négatif. Comment déterminer la
force de la corrélation ? En ce qui concerne la force
du coefficient de corrélation r, le tableau suivant
peut servir de guide. Si votre valeur est
comprise entre 0,0 et 0,1, nous pouvons clairement affirmer qu'
il n'y a aucune corrélation. Si la valeur est comprise
entre 0,1 et 0,3, nous disons qu'il y a une corrélation faible
ou mineure ou une corrélation. Si la valeur est comprise entre 0,32 et
0,5, corrélation moyenne, si la valeur est comprise entre 0,5 et 0,7, nous disons qu'il y a une
forte corrélation ou une forte corrélation, et si la valeur est
comprise entre 0,7 et un, nous disons que c'est une corrélation très
élevée À la fin de ce module, je vais vous montrer comment calculer le cation de corrélation
directement sur un outil en ligne. Allons donc plus loin. Lorsque vous le faites en ligne, l'un
des outils que nous utilisons pour analyser
la corrélation est un diagramme de dispersion, car le x
et
le y sont des données de type variable ou métrique,
comme vous l'appelez Tout aussi important que de prendre en compte le coefficient
de corrélation sous forme graphique, nous pouvons utiliser un nuage de points. Donc, comme âge, l'axe x contiendra toujours
la variable d'entrée, et l'axe y aura la variable de sortie, car
y est égal à la fonction de x. Et je peux voir qu'à mesure que mon âge augmente, mes
salaires augmentent. Le diagramme de points
vous donne une estimation
approximative l'exactitude de l'
existence d'une corrélation, existence d'une corrélation linéaire ou
non linéaire et de la présence de valeurs aberrantes Lorsque nous effectuons une corrélation, nous pouvons également vouloir effectuer
nos tests d'hypothèses, tester la signification
de la corrélation. S'il existe une corrélation
dans l'échantillon, il est tout de même nécessaire de
vérifier s'il existe suffisamment de preuves que
la corrélation existe
également dans la population. Ainsi, la question se pose lorsque le copion de corrélation est considéré comme statistiquement
significatif La signification du résient de
corrélation peut être testée à l'aide du test t. En règle générale, il est vérifié si le coefficient de corrélation est significativement
différent de zéro C'est-à-dire qu'une
dépendance linéaire est testée. Dans ce cas, l'
hypothèse nulle est qu'il n'y a aucune corrélation entre les
variables étudiées. En revanche, l'hypothèse
alternative suppose qu'il
existe une corrélation. Comme pour tout autre test d'
hypothèse, le seuil de signification
est d'abord fixé à 5 %. La valeur Alpha est fixée à 5 %. Cela signifie que je devrais avoir 95 % de confiance dans l'
analyse que je fais. Si la
valeur p calculée est inférieure à 5 %, l'hypothèse nulle est rejetée et l'
hypothèse alternative s'applique. Si la valeur p est inférieure à 5 %, elle suppose qu'il existe une relation entre
le x et le. La formule du test t que nous
utilisons pour les tests d'hypothèses est r dans la racine inférieure de n moins deux divisée par
la racine inférieure de un moins r carré. Où n est la taille de l'échantillon, r r est la
corrélation déterminée de l'échantillon, et la valeur
p correspondante peut être facilement calculée dans le calculateur de
corrélation. Hypothèse directionnelle et non
directionnelle. L'analyse de corrélation
peut être testée pour des hypothèses de
corrélation directionnelles ou non directionnelles. Qu'entendons-nous par hypothèse de
corrélation
non directionnelle ? Vous souhaitez simplement savoir
s'il existe une relation ou une corrélation
entre deux variables. Par exemple, s'il existe une corrélation entre
l'âge et le salaire, mais l'orientation
des relations ne vous intéresse
pas . Lorsque vous faites une hypothèse de
corrélation directionnelle, vous vous intéressez également à la direction de
la corrélation. S'il existe une corrélation positive ou négative
entre les variables. Votre hypothèse alternative
est alors un exemple. L'âge a une
influence positive sur le salaire. à quoi vous devez
faire attention , c'est que dans le cas d'une hypothèse
directionnelle, vous allez suivre le
bas de l'exemple. Vous allez donc vous demander s'il y a une
influence positive ou non ? Donc, normalement, nous disons qu'il
n'y a pas de corrélation et
qu'il y a une corrélation. Mais ici, nous dirons qu'il
n'y a aucune corrélation, et l'
hypothèse alternative indiquera qu'il y a une
influence positive sur la salade. Passons maintenant
à la partie suivante. C'est l'analyse de
corrélation de Pearson. Avec l'analyse de
corrélation de Pearson, vous obtenez un énoncé concernant la corrélation linéaire entre les variables
de l'échelle métrique La covariance correspondante est
utilisée pour le calcul. La covariance donne
une valeur positive s'il existe une corrélation
positive entre les variables
et une valeur négative s'il existe une corrélation négative
entre les variables La covariance est
calculée sous forme de COV ou covariance de X est calculée à l'aide de la formule
indiquée à l'écran Ne t'inquiète pas. Nous n'avons pas à
le calculer manuellement. Ensuite, nous avons des systèmes et des outils qui peuvent effectuer
cette analyse pour nous. Cependant, la covariance
n'est pas normalisée et peut prendre des valeurs comprises entre
plus et moins l'infini Il est donc
difficile de comparer la force de la relation
entre les variables. Pour cette raison, le coefficient de
corrélation est également une corrélation du
mouvement du produit. Et cela est calculé
d'une manière différente. Le coefficient de corrélation est
obtenu en normalisant
la Pour cette normalisation,
la variance
des deux variables est
calculée comme indiqué par. Le coefficient de corrélation
de Pearson peut désormais prendre des valeurs de moins un à plus un et peut
être interprété comme suit La valeur de moins un
signifie qu'il existe une relation
linéaire entièrement positive, et plus la valeur de moins un indique qu'il existe
une
relation entièrement négative. Le plus et le moins. Avec la valeur zéro, il n'y a pas de relation linéaire. La variable n'est pas
corrélée à chacune d'elles. La corrélation de plus un
ressemblera à ceci, ce qui n'est
possible qu'en théorie. La corrélation de 0,7 et plus
ressemblera à ceci : elle sera
positive et la plupart des
points seront plus proches l'axe de la lumière de
régression. La corrélation de plus
trois sera dispersée, mais elle va dans le
bon sens. Lorsque vous établissez une corrélation,
vous obtenez une corrélation de -0,7, elles sont toutes dispersées
vers le bas Ainsi, à mesure que la valeur de x augmente, la valeur de y diminue et la plupart des points sont dispersés
sur le côté de régression. Nous obtenons la valeur
de corrélation de zéro de plusieurs manières soit les points sont
complètement dispersés, vous pouvez obtenir des lignes
parfaites comme celle-ci ou comme celle-ci, ce qui, encore une fois, serait pas, ce qui
signifie que vous devez effectuer une autre analyse pour interpréter les variables. Enfin, la force
de la relation peut être interprétée et cela peut être illustré par le récit
suivant. La force de la corrélation. S'il est compris entre 0 et 0,1, il n'y a aucune corrélation S'il est compris entre 0,1 et 0,3, il y a une faible corrélation 0,3 à 0,5, corrélation moyenne), 0,52 (0,7), très élevée (désolé, corrélation
élevée), et 0,7 pour un, une corrélation très
élevée Pour vérifier à l'avance s'il existe une relation
linéaire, il convient d'envisager des diagrammes de
dispersion De cette façon, la relation
respective entre les variables peut
également être vérifiée visuellement. La corrélation de Pearson n'
est utile
et utile que si des relations demor existent La corrélation de Pearson
comporte certains ems, que vous devez
garder à l'esprit Pour PSM, chaque fois que
vous l'utilisez, les variables doivent être distribuées
normalement et il doit y avoir une relation
linéaire entre les variables La distribution normale
peut être testée analytiquement ou graphiquement à
l'aide du diagramme QQ, ce que je vais
vous apprendre à faire de vérifier si les variables ont
une corrélation linéaire Il est préférable de vérifier si les variables ont
une corrélation linéaire à l'
aide du diagramme de points Si les conditions ne sont pas remplies, corrélation de Spearman peut être utilisée J'espère donc que vous
avez compris jusqu'ici, et poursuivons notre
apprentissage. Continuons. Que faisons-nous lorsque
mes données ne sont pas normales et que je souhaite établir
une analyse de corrélation Dans ce cas, nous utilisons la corrélation de classement de
Spearman. analyse de corrélation des rangs de Spearman est utilisée pour calculer la relation
entre deux variables ayant un
niveau de mesure ordinal Lorsque vous avez des données variables, ou je peux dire des données continues,
nous utilisons une analyse de
corrélation normale
telle que l'analyse de
correction de Pearson Mais si mes données sont ordinales
ou non paramétriques, je peux poursuivre l'analyse de corrélation de
Spearman Cette procédure est
donc utilisée lorsque la condition préalable à l'analyse de
corrélation, savoir les
procédures paramétriques, n'est pas respectée ou lorsqu'il n'existe aucune donnée métrique ou variable
continue et que les données ne sont pas normales Dans ce contexte, nous
vous proposons de l'appeler corrélation de Spearman
ou ligne de Spearman La
corrélation des grades de Spearman est censée être utilisée. La question peut alors
être traitée comme suit : corrélation de classement de
Spearman est-elle similaire à
celle du coefficient de
corrélation de Percy Des exemples. Existe-t-il une corrélation entre deux variables
ou caractéristiques ? Par exemple,
existe-t-il une corrélation entre l'âge et
la religiosité la population française ? Le calcul de la corrélation de
classement est basé sur le système
de classement de la série de données. Cela signifie que les variables
de mesure du classement ne
sont pas utilisées dans le calcul, mais sont transformées en grades. Le test est ensuite effectué
à l'aide des grades. Pour le
coefficient de corrélation des grades, p, les valeurs comprises entre moins
un et un sont positives. S'il existe une valeur
inférieure à zéro, p est inférieur à zéro, il existe une relation
linéaire négative. Si la valeur est
supérieure à zéro, il existe une relation
linéaire positive. Si la valeur est nulle ou proche
de zéro, par exemple 0,1 à -0,1, on peut dire qu'il
n'y a aucune relation
entre les variables Comme pour le coefficient de
corrélation des spareans, la force de la corrélation peut être Donc, si c'est 0-0 0,1, il n'y a aucune corrélation S'il est de 0,12 0,3, il y a une petite corrélation S'il y a 0,3 à 0,5, il y a une régression moyenne. Il existe une
corrélation élevée de 0,5 à 0,7 et une corrélation
très élevée de 0,7 à un. S'il y a des valeurs
négatives, on parlera de corrélation négative mineure ,
de corrélation négative
élevée, etc. Il existe un autre type
de corrélation appelé
corrélation bisérielle ponctuelle. La
corrélation sérielle point bi est utilisée lorsque l'une des variables
est dichotomique Par exemple, avez-vous
étudié ou non ? L'autre est une
variable métrique comme le salaire. Dans ce cas, nous utilisons une corrélation
ponctuelle par série. La corrélation d'un point
par corrélation en série est identique à la corrélation de
Pearson calculée Pour le calculer, l'une des deux expressions de
la valeur dichotomique
est codée L'autre est codé comme un. Analyse de corrélation calculée, nous vous montrerons à l'aide d'Excel ou d'autres outils disponibles gratuitement. Je vous montrerai le
calcul après un certain temps, mais étudions d'abord le cas. Un étudiant souhaite savoir s'
il existe une corrélation entre taille et le poids des participants
au cours de statistiques À cette fin, l'
étudiant a tiré un échantillon, qui est distribué ci-dessous. J'ai donc la taille
des gens, j'ai le
poids des gens. Pour analyser la relation
linéaire au moyen d'
une analyse de corrélation, vous pouvez calculer la
corrélation à l'aide Excel ou des autres outils
disponibles en ligne. Copiez d'abord le tableau dans
le calculateur de statistiques. Cliquez ensuite sur corrélation
et sélectionnez-la. Enfin, vous
pourrez obtenir les encarts
suivants. Faisons-le donc en ligne. Je suis donc venu sur data tab.net. Il s'agit d'un calculateur
statistique en ligne. Les données ici sont sécurisées à 100 %, car les calculs sont
effectués sur votre navigateur
et les données sont insérées et stockées dans les cookies de votre navigateur. Les données sont de 100 %, et c'est la raison pour laquelle le
calcul fonctionne très rapidement. Les données n'ont donc
pas besoin d'un grand
serveur, et donc de vous. J'ai donc le poids corporel, j'ai le poids
et j'ai l'âge. Je veux donc comprendre. Donc, si je descends,
j'ai une cortation. Je veux comprendre s'
il existe une relation entre la taille du corps
et le poids corporel. Quel type de corrélation je souhaite ? Allons-y d'abord avec Pearsons.
Il existe une corrélation. Il y a une corrélation positive. Le niveau de signification est défini. 5 % Nous pouvons vérifier les hypothèses, et l'entreprise
effectue immédiatement l'analyse. Il fait le complot QQ pour moi. Il dessine l'histogramme et affiche
les résultats, n'est-ce pas ? On peut donc dire que oui, les données sont
plus ou moins distribuées
normalement. Je peux le copier
en cliquant sur Télécharger le fichier PNG, et le fichier sera copié. Et tu pourras le
voir de cette façon. Alors maintenant, permettez-moi de fermer cette tumba, afin qu'elle ait vérifié
les hypothèses Le résumé en vers, le résultat de la
corrélation de Pearson , a montré qu'il existe une très forte corrélation positive entre le poids corporel, la
taille et le poids Les résultats ont montré que la relation entre le poids
corporel, taille et le poids
est statistiquement significative avec une valeur r
positive. R est 0,86 et la valeur
p est 0,01. 001. Ainsi, lorsque vous examinez la
force de la corrélation, si la valeur est
supérieure à 0,7 et un, nous disons qu'il s'agit d'une corrélation très
élevée et d'un décor positif. Lorsque je fais des tests d'
hypothèses, il n'y a aucune corrélation ou une corrélation
négative entre la taille corporelle et le poids. Il existe une corrélation positive
entre la taille du corps et le poids. Combien de cas
avons-nous dix cas ? La valeur r est 0,86 et la valeur p est 0,001, ce qui est inférieur Par conséquent, nous rejetons l'hypothèse
selon laquelle il n'
y a pas de corrélation, et l'hypothèse alternative
s'applique selon laquelle il
existe une corrélation positive entre la
taille du corps et le poids. L'avantage de travailler sur le brouillon de
données est que vous
disposez d'une interprétation basée sur l'IA. Ce tableau résume
les résultats de
l'analyse de la
taille et du poids du corps, montrant le
coefficient de corrélation r et le P va. La valeur du
coefficient de corrélation indique la force et le sens de la
relation entre la variable de
taille et de poids, et la
valeur du coefficient est de 0,86, ce qui suggère
qu'il existe une
corrélation positive très élevée Cela signifie qu'en général, mesure que la taille du corps augmente, le poids a également tendance à
augmenter et vice versa. La valeur P. La
valeur p ici suppose que les données disponibles fournissent des preuves
suffisantes pour
rejeter l'hypothèse nulle. Dans ce cas, l'hypothèse
unilatérale testée et l'hypothèse nulle indiquent qu'
il
n'existe aucune corrélation ou une corrélation négative entre la taille et le
poids de la population. Dans la plupart des cas, la
valeur p est inférieure à 0,05, nous considérons qu'il existe une signification
statistique Dans notre cas, la valeur
p est de 0,001, ce qui est évidemment
inférieur à 0,5 L'hypothèse nulle est rejetée, et le résultat de la corrélation de
Pearson montre qu'il existe une signification statistique d'une corrélation
positive entre
la taille corporelle et le poids Le résultat de la
corrélation de Pearson montre donc qu'il existe
une corrélation très positive
entre la taille et le poids,
et celle-ci est enregistrée par corrélation
positive
statistiquement significative entre la valeur
r de 0,86 et la valeur
P Maintenant, il existe un diagramme de dispersion qui
se fait automatiquement Je peux cliquer ici et
obtenir ma droite de régression. Je peux changer d'essieu si je ne
veux pas repartir de zéro Est-ce que je veux une ligne zéro ? Alors le zéro est inclus, mais je n'en veux pas.
Je peux le changer. Comment est-ce que je veux mon image, le très grand PDM, etc. Je peux cliquer sur Télécharger TNG
pour télécharger cette image. Maintenant, comme je vous l'ai dit,
nous pouvons également faire le calcul de la covariance. Donc, quand je regarde la
taille et le poids du corps, la covariance est de 1,29, n'est-ce pas ? Cela signifie donc qu'il
existe une relation. C'est ainsi que vous
faites le calcul. Maintenant, pour le calculateur point par
série, nous pouvons avoir un autre type de données
que nous voulons analyser La variation du salaire
a-t-elle quelque chose à
voir avec le sexe. Dans ce cas, je sélectionnerais
la valeur métrique comme salaire et la
variable nominale comme sexe, puis je
ferai mon calcul. Cela mettrait le mâle à
zéro et la femelle à un. Diagramme encadré, qui indique que oui, les hommes ont tendance à avoir un salaire plus élevé que les femmes. Ainsi, lorsqu'un étudiant
veut savoir s' il existe une corrélation
entre une augmentation de s, nous avons effectué cette analyse. L'hypothèse, si vous pouvez
opter pour une hypothèse normale, il n'y a aucune corrélation entre la taille du corps et le poids. Il existe une association
entre la taille et le poids, mais j'avais pris une
hypothèse directionnelle dans mon test. La valeur P est la suivante, et nous avons
vu comment
générer la sortie. Tout d'abord, vous obtiendrez l'hypothèse nulle
et l'hypothèse alternative. L'hypothèse nulle indique qu'il n'y a aucune corrélation
entre la taille et le poids, puis nous avons l'hypothèse
alternative qui bloque le contraire Si vous cliquez sur les oiseaux sous-marins, vous obtiendrez l'interprétation,
que nous venons de voir. Nous pouvons aller de l'avant et nous avons
en fait essayé l'hypothèse de
corrélation directionnelle ou unilatérale. Et dans Excel, il
existe d'autres outils qui
peuvent vous aider à calculer. Nous avons donc simplement fait les tests, indiquant qu'il n'y a aucune corrélation
ou qu'il y a une corrélation négative entre les gènes du corps et qu'il existe une corrélation
positive entre l'augmentation du poids corporel. Et quand nous avons vu, nous avons obtenu que
oui, il y avait une très forte
corrélation positive, et donc que la valeur p
était inférieure à 0,01 Dans ce cas, vous devez d'abord vérifier si la corrélation est dans toutes les directions de
l'hypothèse alternative, c'
est-à-dire si la taille et le poids
sont positivement corrélés, et dans ce cas, la
valeur p est divisée par deux Par conséquent, seule la
distribution unilatérale est prise en compte. Cependant, cet outil prend en charge ces deux étapes
et le résumé en vers est donné comme nous l'avons vu. Nous affirmons qu'il existe une corrélation
positive entre la taille et le poids de
l'ensemble de données de l'échantillon. Par conséquent, nous pouvons dire qu'il existe une corrélation
positive entre la signification et nous pouvons voir qu'il existe une corrélation
très positive entre les variables de hauteur et de pt Il existe donc une très forte corrélation
positive entre la
hauteur de l'échantillon et le point de contact. Sur ce, nous allons clore notre analyse de corrélation et je vous verrai dans
le prochain cours.
37. Notion d'analysis de corrélation de Pearsons: Poursuivons notre parcours de
corrélation. Je vais parler de la corrélation de
Pearson aujourd'hui. analyse de corrélation de Pearson est un examen de la relation
entre deux variables Par exemple, il s'agit d'une corrélation entre l'âge et le salaire d'une
personne. Les deux sont des variables
continues, et le diagramme
sera donc dispersé. Donc, à mesure que l'âge de la
personne augmente, le salaire
augmente-t-il ? Maintenant, vous devez vous rappeler que
y est une fonction de x, donc votre axe y
aura le résultat, et l'axe x aura
la variable indépendante. Plus précisément, nous pouvons utiliser
le
coefficient de corrélation de Pearson pour mesurer la relation linéaire
entre deux variables Si la relation n'
est pas linéaire, alors cette équation de corrélation ne
sera pas un enfer. Je pense que vous auriez
remarqué que j'ai changé mon AR pour
cet enregistrement. Si vous l'avez aimé, il vous suffit de mettre un pouce en l'air dans la section des
commentaires Continuons, la force et le sens
de la corrélation. Grâce à l'analyse de corrélation, nous pouvons déterminer
la force de la relation et la direction
dans laquelle elle va. Nous pouvons lire la force et
le sens de la corrélation dans la lettre r du
coefficient de corrélation de Pearson, dont la valeur varie de
moins un à plus un La force de la corrélation, la force de la corrélation, cela se lit sur le tableau. La valeur r comprise entre zéro
et moins un indique qu'
il n'y a aucune corrélation. Si la valeur de
r est comprise entre 0,7 et un, il s'agit d'une corrélation très fortement corrélée et
très forte Maintenant, si les valeurs sont positives, elles sont corrélées positivement, et si les valeurs sont négatives, elles sont corrélées négativement Supposons donc que la valeur r
soit -0,66. On peut alors dire qu'il y a une forte corrélation
négative. C'est ce que j'ai repris dans le livre des statistiques.
Confinons-le. Qu'entendez-vous par
direction de corrélation ? Une corrélation positive
est une corrélation qui existe lorsque de grandes valeurs
d'une variable sont associées à de grandes valeurs
d'une autre variable ou lorsqu' un petit changement dans
une variable est associé à un petit
changement dans l'autre variable. Donc, s'il s'agit d'une
corrélation positive, s'il y a une
valeur plus grande sur l'axe x, cela correspond à une
plus grande valeur sur l'axe y. Et une valeur inférieure sur l'axe x correspond à une
valeur inférieure sur l'axe y, comme vous pouvez le voir sur
ces deux images Une corrélation positive donne des exemples de taille
et de pointure de chaussures. Il en résulte une corrélation
positive. Ainsi, à mesure que la
taille de la personne augmente, la pointure des chaussures augmente
également. Le résultat est un coefficient de
corrélation positive, et r est supérieur Maintenant, avez-vous vu qu'il y a
une erreur dans ce graphique ? L'erreur est que la
pointure est le résultat et que la hauteur est la variable
indépendante, mais nous l'avons mal cartographiée
pour l'éviter Permettez-moi donc de faire part de mes
commentaires ici. Qu'est-ce qui ne va pas dans le graphe Pow ? La question est de savoir si le
spectacle augmente la taille de ou entraîne une augmentation
de la taille de la personne ou est-ce que l'augmentation de la
taille de la personne contribue
à augmenter la pointure des chaussures. Merci d'écrire dans les
dix sections ci-dessous. Oui N'oubliez pas que y est
une fonction de x. Et ici, y est la hauteur de la personne et x est mon erreur. X est la taille de la
personne et y est la taille S. J'espère que ce que
nous essayons de dire est maintenant clair. Y est donc une fonction de x. Permettez-moi de faire de la lettre
un petit y parce que c'est le projet y. X est
la taille de la personne. Donc, ici, l'erreur est que nous
l'avons mal montré. La corrélation négative
se produit lorsqu'une valeur
élevée d'une variable est
associée à une petite valeur de l'autre
variable et vice versa. Ainsi, si l'axe y est grand, la valeur de l'axe x est faible. Et si la valeur de l'axe x est grande, la valeur de l'axe y est faible. C'est ce que l'on appelle
une corrélation négative. Les points coulent. Contrairement à la précédente où les points
circulaient vers le haut. Maintenant, la corrélation négative est trouvée entre la
taille du produit et la valeur des ventes. Il en résulte un cation de
corrélation négative. Que se passe-t-il lorsque
le prix augmente, le volume des ventes diminue ? Et si le prix est réduit, les gens ont tendance à acheter plus de volume. Cela se traduit par une augmentation des ventes. Laissez-moi écrire qu'il s'agit d'augmentations. Très bien Le résultat
est donc une corrélation négative, la valeur coefion de
r est inférieure Plus la corrélation est forte, la valeur se
rapproche de moins un. Et ici, le graphique est correct. Au fur et à mesure que
le prix augmente, les volumes diminuent. Maintenant, comment calculer le coefficient de corrélation de
Pearson ? C'est très
important, non ? Le coefficient de
corrélation de Pearson est calculé à l'aide de l'équation
suivante Ici, r est le client de
corrélation de Pearson. X i est la
valeur individuelle d'une variable. Par exemple, il peut s'agir de
l'âge de la personne. La barre X représente l'âge moyen
de l'ensemble de données de l'échantillon. Y un est la valeur individuelle de l'autre variable ou de la variable de résultat,
et
la barre Y n'est rien le salaire moyen de
l'ensemble de données d'échantillon. Ici, la barre x et la barre y sont respectivement la valeur moyenne de deux
variables. C'est le nombre entier divisé
par
la racine inférieure de x un moins x barre carré, y un moins y bar carré entier. Donc, quand je le quadrillerai
et que je ferai un underroot, je m'en occuperai Ainsi, x un représente les valeurs
individuelles, et y un représente les valeurs
individuelles de la variable de résultat. R est la corrélation de Pearson
et la valeur moyenne. Dans cette équation, nous pouvons voir
que les
valeurs moyennes respectives de la première se soustraient
de l'autre variable Dans notre exemple, nous avons calculé que la principale valeur était
l'âge et le salaire. Nous soustrayons ensuite
la valeur principale de chaque âge et salaire par
rapport à la moyenne Nous multiplions ensuite
les deux valeurs. Nous résumons ensuite les résultats
individuels de
la multiplication. L'expiration
du dénominateur garantit que le
coefficient de corrélation est toujours compris
entre moins un et plus un N'oubliez pas que vous n'avez pas à les calculer
manuellement. Actuellement, ces
fonctionnalités sont disponibles sur
Excel et sur plusieurs sites Web
en ligne. Si vous voulez plusieurs
valeurs positives, nous obtenons une valeur positive. Et si nous multiplions
deux valeurs négatives, nous obtenons
également une valeur positive de
moins en moins e plus. Toutes les valeurs
comprises dans cette plage ont donc une influence positive sur
le coefficient de corrélation À mesure que l'âge augmente, le salaire augmente, mesure que l'âge diminue,
les salaires diminuent. Si nous multiplions une
valeur positive par une valeur négative, nous obtenons une valeur négative
comprise entre moins et plus est moins. tout moment, il
existe une gamme d' influences
négatives sur
le coefficient de corrélation Donc, les éléments
surlignés dans la case violette, si les données
tombent là-bas, cela se traduira par
une corrélation négative. Par conséquent, si notre
valeur est principalement constituée de deux zones vertes des deux chiffres
précédents. Nous obtenons un coefficient de
corrélation positif, donc une corrélation
positive Si nos scores se situent principalement dans la zone rouge des chiffres, nous obtenons un coefficient de
corrélation négatif et avons donc une corrélation négative Si les points sont
répartis entre les quatre domaines, termes
positifs et termes
négatifs, ils s'annulent mutuellement, et nous pouvons nous retrouver avec corrélation
très faible ou nulle. C'est donc une partie très
importante, que vous devez comprendre. Hein ? Si les points sont
distribués globalement, il n'y a aucune
corrélation. Maintenant, en quoi les tests de corrélation et de coefficient sont-ils significatifs ? En général, le coefficient de
corrélation est calculé à partir
des données d'un Dans la plupart des cas, cependant, nous voulons tester l'hypothèse
concernant la population. Comme nous ne pouvons pas étudier la population, nous
prenons un échantillon, puis nous prenons un échantillon et,
en étudiant l'échantillon, nous voulons tirer des conclusions
sur la population Dans ce cas, l'analyse de
corrélation, nous voulons ensuite savoir s'il
existe une corrélation
dans la population. Pour cela, nous testons si le coefficient de
corrélation dans l'échantillon est statistiquement significatif et
différent de zéro Maintenant, comment faisons-nous des tests d'
hypothèses ? Pour la corrélation de Pearson ? L'hypothèse nulle et
l'hypothèse alternative pour les corrélations de
Pearson sont th L'hypothèse nulle indique qu'
il n'y
a pas corrélation et que, par conséquent la valeur R n'est pas significativement
différente de zéro. Il n'y a aucun lien. L'
hypothèse alternative indique qu' il existe une
différence significative ou qu'il existe une
corrélation linéaire entre les données. Attention. Nous testons
toujours si l'hypothèse nulle est
rejetée ou non. C'est très, très important. Nous n'acceptons jamais ou ne
travaillons jamais sur des sujets comme moi. Le fait est que nous nous efforçons toujours de prouver ou de rejeter
l'hypothèse nulle. Nous n'essayons jamais de
prouver l'alternative, bien que nos recherches commencent
parce qu'il existe une alternative. Dans notre exemple, lorsqu'il s' du salaire et de l'
âge de la personne, nous pourrions donc poser la question. Existe-t-il une corrélation
entre l'âge et le salaire pour la population
allemande ? Pour le savoir, nous prélevons un
échantillon et testons si le coefficient de corrélation est significativement
différent de zéro dans cet échantillon. L'hypothèse nulle est donc qu'il n'y a aucune corrélation entre le salaire et l'âge dans
la population allemande. L'
hypothèse alternative est qu'il existe une corrélation entre le salaire et l'âge dans la population
allemande. Importance et test. Lorsque le test du déficit de
corrélation de Pearson est significativement
différent de l'enquête par
sondage à base zéro, nous le testons à l'aide de
la formule du test t. Ici, r est le coefficient de
corrélation, et n est la taille de l'échantillon Encore une fois, je dirais
qu'il est bon de connaître la formule, mais de ne pas
s'y perdre. Hein ? Une valeur P peut être calculée
à partir des statistiques de test t, et la valeur p est inférieure au seuil de
signification spécifié, qui est généralement de 5 %, puis l'hypothèse nulle est
rejetée, sinon non. Nous voulons donc nous assurer que si la valeur p
est supérieure à 0,05, nous ne rejetons pas
l'hypothèse nulle Si la valeur p est
supérieure à 0,05, nous ne rejetons pas
l'hypothèse nulle Maintenant, quelles sont les hypothèses
qui sous-tendent la corrélation de
Pearson Qu'en est-il des hypothèses relatives à
la corrélation de Pearson ? Ici, nous devons
distinguer si nous voulons calculer le client de corrélation de
Pearson ou si nous voulons tester une hypothèse Pour calculer le coefficient de
corrélation de Pearson,
seules deux
variables métriques sont présentes Les variables métriques, par exemple, peuvent être le poids d'une personne, son salaire, sa
consommation d'électricité, etc. Bref, variable continue. Le
client de corrélation de Pearson
nous indique ensuite l'ampleur de la
relation linéaire
et existe-t-il une relation non
linéaire ? Nous ne pouvons pas lire à partir de la coion de corrélation de
Pearson. Il s'agit donc d'une corrélation linéaire, et si vos données sont
effectuées ou s'affichent de cette manière, nous avons tendance à aller de l'avant. Donc, dans ce cas, il n'y a aucune corrélation. Cependant, si nous
voulons vérifier si le
coefficient de corrélation de Pearson est significativement
différent de zéro dans l'échantillon, nous voulons tester l'
hypothèse selon laquelle les deux variables sont également distribuées
normalement Parce que vous ne pouvez pas tester la corrélation de Pearson
pour des données non normales Dans ce cas, les statistiques de
test calculées t et la valeur p ne peuvent pas
être interprétées de manière fiable. Si cette hypothèse n'est pas faite, corrélation de classement de
Pearson sera utilisée Cela signifie que pour les données
non normales, je vais utiliser la corrélation de
classement de Pearson Comment calculer la corrélation de
Pearson en ligne à l'aide d'Excel
et d'autres outils Je vais vous
le montrer sous peu.
38. Corrélation bisérielle de points: Découvrons maintenant la corrélation
sérielle point par point. Je vais aborder la théorie
et l' exemple et expliquer comment nous pouvons faire dans la
pratique avec un calculateur en ligne.
Restez connectés. Qu'est-ce que la corrélation
sérielle point par point ? En avez-vous entendu parler plus tôt ou votre visage a pris une
telle tournure ? On entend surtout parler de régression
linéaire, de régression
logistique Lorsque nous apprenons ce qu'est la corrélation, nous pensons à la corrélation
simple, corrélation
positive ou à la corrélation
négative. Et chaque fois que nous
faisons une corrélation, nous ne pensons qu'à
des variables, des variables
continues sur l'axe x
et sur l'axe y. Voyons donc ce qu'est une corrélation
point par série. Il s'agit d'un cas particulier de corrélation de
Pearson, examine la
relation entre une variable dicotone
et une variable métrique OK. La règle de
corrélation est que vos deux variables doivent être
continues ou métriques. Mais en utilisant la corrélation point par
série, je peux même vérifier l'existence d'une variable
dichotyme, qui peut être oui Comprenons l'exemple
d'une variable dicotone. Une variable dicotyme est une
variable comportant deux valeurs : le
sexe, comme homme et femme, et le statut de fumeur, comme fumeur ou
non-fumeur Les variables métriques,
quant à
elles, sont le poids de la personne, le salaire de
la personne, la
consommation d'électricité, etc. Donc, si nous avons une variable
dichotone et une variable métrique, nous voulons savoir s'il
existe Nous pouvons utiliser une corrélation point par
série. Comprenons-en donc
la définition. corrélation point par série La corrélation point par série est un type particulier
de corrélation, examine la
relation entre dichotyque
et une variable métrique dichotonomes sont
des variables à deux valeurs, variables métriques sont
des variables continues
avec des valeurs infinies,
comme la taille, le poids, le salaire, la consommation
d'énergie, consommation
d'énergie Comment est
calculée exactement la corrélation point par série ? Il utilise le concept de corrélation de
Pearson, mais dans la
corrélation de Pearson, nous avons également une variable
de nature nominale Supposons, par exemple, que vous
souhaitiez étudier la relation entre
le nombre d'heures
étudiées dans le cadre d' un test
et les résultats, c'
est-à-dire que la personne a
réussi ou échoué. Je peux donc voir ici
combien d'heures la personne a passées à étudier et si cela lui
a valu une réussite ou un échec ? Nous avons collecté des données pour
l'échantillon de 20 étudiants. 12 étudiants ont réussi, huit ont échoué. Nous avons enregistré le
nombre d'heures de
chacun des étudiants ayant
étudié dans le cadre du test, et nous avons attribué un score
de un à l'étudiant qui a réussi le test et de zéro à l'étudiant qui a échoué au test. Maintenant, nous pouvons soit calculer la corrélation
de Pearson entre le temps et les résultats du test, soit utiliser l'équation du
point par corrélation CDN. Nous pouvons maintenant calculer
la corrélation de Pearson entre le
temps et les résultats des tests
avec l'équation Maintenant, ici, x y est la valeur moyenne des
personnes qui ont échoué, et X un est la valeur moyenne des
personnes décédées. N représente le
nombre total d'observations. Aucun ne représente le nombre
de personnes décédées, ni deux le nombre
de personnes qui ont échoué. Tout comme le contenu de
corrélation de Pearson, r, corrélation
point par série est rp B varie également entre
moins un et plus un Avec l'aide du cefent, nous pouvons déterminer deux choses C'est à quel point la
relation est solide. S'agit-il d'une corrélation positive ? S'agit-il d'une faible
corrélation positive, et dans quelle direction va
la corrélation ? S'agit-il d'une corrélation positive ou d'une corrélation négative ? La force de la corrélation
peut être lue dans le tableau. Si la valeur est comprise entre
0,0 et moins de 0,1, il n'y a aucune corrélation. Si la valeur est comprise entre
0,1 et moins de 0,3, corrélation est faible. La valeur est comprise entre
0,3 et 0,5, il existe une
corrélation moyenne 0,52 0,7, une
corrélation élevée de 0,7 à un, une corrélation
très élevée Si la valeur est comprise entre
zéro et moins un, on parle de corrélation
négative. Si le coefficient est compris entre
moins un et inférieur à zéro, il s'agit d'une corrélation négative donc une relation négative existe
donc une relation négative entre la variable Si la valeur est comprise entre
zéro et plus un, il s'agit d'une corrélation positive. donc une relation positive existe donc une relation positive entre les variables, et si le résultat
est proche de zéro, nous disons qu'il n'y a pas de corrélation. Le
coefficient de corrélation est généralement calculé à partir des données
extraites de l'échantillon Cependant, nous voulons souvent
tester des hypothèses sur
la population. Nous voulons tester une
hypothèse sur la population car nous
ne pouvons pas étudier la population, nous utilisons une technologie d'échantillonnage. Nous calculons le taux
de corrélation des données de l'échantillon. Nous pouvons maintenant vérifier si le coefficient de corrélation est significativement
différent de zéro L'hypothèse nulle indique que le coefficient de corrélation ne
diffère pas significativement de Il n'y a aucun lien. Une autre hypothèse indique que la cohésion de corrélation est
significativement différente de zéro. Il y a une relation. Ainsi, lorsque nous calculons le point
par corrélation en série, nous obtenons la même
valeur p que nous calculons le test t pour
un échantillon indépendant pour les mêmes données. Ainsi, que nous
testions l'
hypothèse de corrélation avec une corrélation point par série ou une hypothèse
de différence du test t, nous obtenons la même valeur p. Qu'en est-il des hypothèses
que nous devons prendre en compte chaque fois que nous effectuons une corrélation
ponctuelle par série ? Ici, nous devons
déterminer s'il s'agit simplement de calculer
le coefficient de corrélation ou si nous voulons également
tester l'hypothèse Pour calculer le
coefficient de corrélation, une
seule variable métrique et
une variable dichotomique doivent être présentes une
seule variable métrique et
une variable dichotomique doivent . Toutefois, si vous
souhaitez vérifier si le coefficient de corrélation est significativement
différent de zéro, une variable métrique doit également
être distribuée normalement Si ce n'est pas le cas, les statistiques de
test calculées ou la valeur p ne peuvent pas être
interprétées de manière fiable. Nous pouvons utiliser
des calculateurs en ligne tels que l'onglet Données, qui peuvent vous aider à effectuer l'analyse et
que je vais aborder maintenant Nous sommes sur le point d'accéder aux données. J'
ai renseigné certaines données en termes de nombre de résultats de
nos tests d'étude, et j'ai converti zéro et un tant que réussite et échec
en zéro et un. Je peux importer mes données en utilisant ce bouton et je peux effacer
le tableau en utilisant ce bouton. Vous disposez de paramètres qui vous permettent de
décider du type de paramètres
que vous souhaitez utiliser pour les visuels.
Maintenant, descendons. Je suis en corrélation,
et j'ai des options. Ici, ma variable nominale
est le résultat du test. Ma variable métrique
est notre strded. Je veux calculer les plans et le
convolu de Pearson. Pour l'instant, je vais juste le
garder sous le nom de Pearsons. Ma variable nominale
est le résultat du test Dès que j'ai sélectionné la
variable nominale comme résultat du test, ai pu l'identifier comme une corrélation
en série du point pi. L'hypothèse indique qu'il
n'y a aucune corrélation entre les résultats de notre
étude et les résultats des tests. L'hypothèse alternative
indique qu'il existe un lien
entre le nombre d'heures étudiées et
les résultats des tests. L'
échec de la corrélation en série de points prend la
valeur zéro, Ps prend la valeur un. La valeur de
corrélation point par série r est de 0,31 degré de liberté r 18 t
est de 0,14. La valeur p est J'ai le boxplot
ici qui indique que mon boxplot pour les anciens étudiants
est 50 % des participants
étudient entre
8,5 et 19,25 heures et
ont obtenu un laissez-passer Les gens qui ont échoué
étudient de 7 à 13 heures, non ? Je peux même le télécharger
en cliquant sur le bouton de
téléchargement au format PNG. Et vous verrez que
je suis capable de le faire. Maintenant, comment fonctionne le calcul pour la corrélation
en série du point b ? Si vous calculez le point
par corrélation en série, choisissez une variable métrique et une variable nominale
à deux valeurs. Avant d'entrer dans le vif du sujet,
permettez-moi de résumer en quelques mots. La
corrélation en série point b a été effectuée pour déterminer la
relation entre nos études et les résultats des tests. Il existe une corrélation positive entre notre étude
et le résultat du test, qui n'était pas significative, statistiquement significative
car la valeur p est supérieure à 0,05 Si j'avais plus de données comme celles-ci, où j'utilise
plusieurs valeurs pour déterminer zéro et un pour les hommes et les
femmes, puis elles auraient calculé. Il dit donc : y a-t-il une corrélation entre le
salaire et le sexe ? Et nous pouvons très
clairement voir que oui, hommes ont un salaire
nettement plus élevé que les femmes. Mais si vous voyez la valeur p, elle est très proche de 0,05, mais elle est de 0,07 Nous ne rejetons donc pas
l'hypothèse nulle, disant que c'est peut-être à cause de l'erreur d'échantillonnage. O
39. Régression logistique: Bienvenue à la prochaine leçon
sur la régression logistique. Voyons l'exemple théorique
et
la façon dont nous procédons à l'
interprétation. Quand utilisons-nous la régulation
logistique ? Prenons un exemple. Où devons-nous
vérifier si c'est une personne âgée qui
souffrira d'un cancer ou s'il s'agit d'un homme ou d'une femme qui
contracte davantage la maladie ? Est-ce un fumeur qui est à l'
origine de la maladie ? Lorsque je veux vérifier la présence
de plusieurs variables
susceptibles de m'infecter et me dire si la maladie est possible, quelle est la probabilité
de contracter une maladie ? Alors plongeons-nous plus profondément. Qu'est-ce que la régression exactement ? Une analyse de régression
est une méthode de
modélisation des relations
entre des variables. Il permet de
déduire ou de prédire une variable, que le client
soit content ou triste, fonction d'une ou
de plusieurs autres variables J'essaie donc de vérifier
si c'est possible, fonction de la
qualification de la personne,
du temps que cela prend ou de son âge. Quel est le facteur
qui l'affecte ? La variable que
nous voulons déduire ou
prédire est appelée variable dépendante
ou critère,
et les variables
que nous utilisons pour la prédiction sont appelées variables
indépendantes
ou prédicteurs Quelle est la différence entre régression
linéaire et la régulation
logistique ? Dans une régulation linéaire, la variable dépendante
est une variable métrique. Par exemple, le salaire, l'électricité,
la consommation, etc. Cela signifie qu'il s'agit d'une variable
continue. Dans une régression logistique, la variable dépendante est
une variable dichotone Qu'est-ce qu'une variable dichotonyme ? Cela signifie que la variable n'
a que deux valeurs. Par exemple, si
une personne
achètera ou n'achètera pas un produit
en particulier, ou si une maladie
est présente ou non. Comment utiliser la
régulation logistique ? À l'aide de la régulation
logistique, nous pouvons déterminer ce qui a une influence sur la présence ou non d'une certaine maladie Pourrions-nous étudier l'
influence de l'âge, sexe et du statut tabagique sur
cette maladie en particulier ? Dans ce cas, zéro signifie « aucun malade » et « un »
signifie « malade La probabilité d'
apparition d'une maladie ou une caractéristique est un moyens par lesquels la présence de ces caractéristiques
est estimée. Notre site de données rencontré ressemble
à ceci :
mes variables indépendantes pourraient être statut tabagique selon le sexe, et ma
variable dépendante pourrait être une variable composée
de zéros et de uns. Nous pouvons maintenant étudier l'influence de la variable
indépendante
et
déterminer si la maladie a
un effet sur la maladie. S'il y a une influence, nous pouvons prédire la probabilité qu' une personne soit atteinte d'
une certaine maladie. Maintenant, bien sûr, la
question se pose. Pourquoi avons-nous besoin d'une
réglementation logistique dans ce cas ? Pourquoi la
recréation linéaire ne fonctionne-t-elle pas ? Faisons donc un bref résumé de
ce qui s'est passé lors de la régression
linéaire Récapitulons rapidement
ce qu'est la régulation linéaire. Dans la régression linéaire, il s'agit de notre équation de régression. Y est aller à b1x1 plus
b2x2 plus b3x3, et B et xn plus c. Nous avons
la variable dépendante y, et nous avons des
variables indépendantes comme x un, x 2x3tx Et nous avons le coéion de
régression,
b one, b2bt Bn Maintenant, cependant, lorsque vous
examinez cette variable, la variable dépendante est
créée avec zéro ou un. Et par conséquent, votre sortie
ressemblera à ceci. Vous avez beaucoup de points sur la ligne zéro et beaucoup
de points sur une ligne, mais vous n'avez
aucune donnée entre les deux. Quelle que soit
la valeur dont vous disposez, la variable indépendante peut contribuer à
la rendre égale à 0-1 Les résultats sont
toujours nuls ou nuls. Dans une équation de régression, nous devons simplement placer une
droite entre les points et nous constatons qu'
il y a beaucoup d'erreur. Nous pouvons maintenant voir que dans le cas
d'une régression linéaire, valeurs comprises entre plus et
moins l'infini peuvent apparaître. Par conséquent, cette formule ne fonctionne pas.
Quelle est la solution ? Cependant, l'objectif de
la régression logistique est d'estimer la
probabilité d'occurrence La plage de valeurs de prédiction
doit donc être comprise entre 0 et 1. Par conséquent, nous voulons une
ligne qui s'adapte à cette ligne et non une
diagonale comme celle-ci. Nous avons donc besoin d'une fonction
qui ne prend que des
valeurs comprises entre zéro et un. C'est exactement ce que fait la fonction
logistique. Peu importe où vous vous
trouvez sur l'axe X, votre axe Y donnera
soit zéro, soit un. Entre l'infini négatif et
le plus infini, les seuls résultats sont de 0 à 1 Et c'est exactement ce que nous voulons. L'équation de la recoration
logistique ressemblera à ceci La fonction logistique est désormais utilisée dans le cadre de la
recréation logistique. Décomposons donc fois
de plus la
formule de recréation linéaire. Un plus y est égal à b1x1 plus
b2x2 plus t b x, et ainsi de suite. Cette équation va maintenant être
insérée dans la fonction. Lorsque vous faites cela, c'est e à la puissance
moins votre plus grande équation de récréation linéaire, 1/1 plus e à la puissance
de moins de l'équation Ainsi, la probabilité de la variable dépendante
est donnée par cela. À quoi cela
ressemble-t-il dans notre exemple ? Quelle est la probabilité
d'une certaine maladie ? P est un disque. Quelle est la probabilité que la personne soit
malade égale à 1/1 plus e bar
moins B un pour H,
B deux pour le sexe, B deux pour le sexe, P trois pour le fumeur plus Cela dépend du
sexe et du statut tabagique. Pour Z, l'équation de l'équation linéaire est
maintenant simplement insérée. Et lorsque vous faites cela, nous
constatons que la probabilité d' une variable dépendante est égale à
1 dans cet exemple. Dans notre exemple, la probabilité de contracter une certaine maladie en fonction du paramètre du
sexe et du statut tabagique. À quoi cela
ressemble-t-il dans notre exemple ? E à la puissance de moins B un, B deux, B trois sont tous les coefficients de détermination afin que le modèle s'adapte le
mieux aux données données. Pour résoudre ce problème, nous l'appelons
méthode d'allégement maximal À cette fin, il existe bonnes méthodes numériques pour
résoudre le problème de manière efficace. Mais comment interprétez-vous
les résultats d'une réglementation
logistique Jetons un coup d'œil au nombre
de fixitios. Son sexe,
son statut tabagique et sa maladie. 22 femmes non fumeuses
et malades, 25 fumeuses sont malades, 18 fumeurs ne sont pas malades, 25 fumeuses sont malades,
18 fumeurs ne sont pas malades,
ainsi de suite. Lorsque nous le mettons sur un calculateur statistique en ligne
et que nous passons à la régression, puis que nous sélectionnons quelles sont mes variables dépendantes et quelles sont mes variables
indépendantes ? Qu'est-ce qu'une
prédiction selon laquelle on est malade ou non, et ainsi de suite ? Et lorsque nous cliquons dessus, il exécutera l'équation des
loisirs pour nous. Nous voulons donc calculer les loisirs
logistiques, nous devrons
donc cliquer
sur l'onglet loisirs Ensuite, nous y copions nos données et les variables sont
affichées ici. Selon la façon dont vos variables
dépendantes sont utilisées, calculateurs statistiques
en ligne tels que l'onglet
Données calculeront soit la
recréation logistique, soit la recréation linéaire sous
l'onglet Recréation Nous choisissons la maladie comme variable
dépendante et le statut tabagique
selon le sexe comme variable indépendante Maintenant, le calculateur va faire l'
équation de régression logistique pour nous. Maintenant, parcourez lentement tout le
tableau et comprenez, et commençons par le haut. Si vous ne savez pas comment
interpréter les résultats, il existe un schéma appelé
résumé en vers. Vous pouvez le copier dans Word, vous pouvez copier les
résultats dans Excel et vous pouvez également copier le tableau de
classification. Commençons donc. La
première chose qui apparaît dans le
tableau des résultats, ce sont les résultats, où nous disons que
le nombre total de où nous disons que
le nombre total de
cas est de 36
personnes examinées. 26 ont été correctement
estimés soit 72,22 %
en pourcentage de temps. À l'aide du
calcul, le modèle de régression, 26 sur 36 % ont été
correctement assignés. Cela représente 72 %. Passons maintenant au tableau de
classement ci-dessous. Vous avez la possibilité de l'
exporter vers Word et Excel. Ici, vous pouvez voir à quelle
fréquence les catégories « non malade » et « maladie » sont observées et à quelle fréquence
elles sont prédites Les
valeurs observées sont donc 11, cinq, cinq, 15, et les
catégories prédites sont les suivantes. On peut donc dire qu'ils ont fait un moyen de
prédiction correct. En réalité, la personne n'
est pas malade, et le modèle a également
prédit qu'elle ne l'était pas En réalité, la
personne est décédée et le modèle a
prédit la maladie. Les deux sont positifs. Du vrai positif et du vrai négatif. Mais nous avons un concept appelé faux négatif et
faux positif. En réalité, la personne n'
est pas malade, mais le modèle
indique qu'elle l'est Il s'agit donc d'un cas faussement
positif, ce qui n'est pas grave car
vous pouvez certainement demander un deuxième avis
et la personne fait attention. Ce qui est préoccupant, c'est
le faux négatif. En réalité, la
personne est malade, mais mon modèle ne permet pas
de le prévoir Par conséquent, ces cinq
patients ne suivront pas
le traitement s'ils ne
reçoivent pas le diagnostic actuel. Au total, les
observations non liées à la maladie sont 16 11 plus 516. Sur ces 16,
le modèle de loisirs a
correctement noté 11 comme non malade » et a incorrectement classé 5
comme « maladie Sur 20 personnes malades, 15 ont été correctement
notées comme maladie, Pi a été incorrectement
noté comme étant. À noter, pour décider si une
personne est malade ou non, un seuil de 50 % est utilisé Si la probabilité
est supérieure à 50 %, nous le marquons comme malade. Comme la probabilité
est inférieure à 50 %, nous la marquons comme non diminuée. Ainsi, si les
estimations du modèle de régression sont supérieures à 50 %, la personne est déclarée morte,
sinon pas morte. Passons au test du
chi carré. Nous avons une
vidéo détaillée sur Chi Square. La valeur du chi carré est de 8,79
degrés de liberté trois et la valeur p est de 0,32 Si P est faible, nul, vas-y. Nous allons passer aux tests d'
hypothèses. Ici, nous pouvons lire
si le modèle dans son ensemble est
significatif ou non. La réponse est oui.
Maintenant, voyons voir. Il existe deux modèles
à comparer. Dans un modèle, toutes les variables
indépendantes sont utilisées. Dans l'autre modèle, peu de
variables indépendantes sont utilisées. À l'aide du test du
chi carré, nous comparons
la qualité de la prédiction lorsque les variables dépendantes
sont utilisées et sa qualité lorsque les
variables dépendantes ne sont pas utilisées. Et le test du chi carré t
nous indique s'il existe une différence
significative entre les deux résultats L'hypothèse nulle est que
les deux modèles sont identiques. La valeur p est inférieure à 0,05. Cela signifie que l'
hypothèse nulle est rejetée. Ainsi, lorsque l'
hypothèse nulle est rejetée, nous supposons qu'il existe une différence significative
entre les modèles. Le modèle dans
son ensemble est donc significatif. Vient ensuite le résumé du modèle. Dans ce tableau, vous verrez une main avec une valeur de probabilité
logarithmique de moins deux, et d'autre part, vous avez un coefficient
de détermination ou une valeur carrée différents . Le résumé du modèle
ressemble à ceci. Vous pouvez facilement l'
exporter vers Word et Cel. Moins deux log de
vraisemblance sont 40,67, valeur carrée du r de
Cosell est 0,22 Et les autres valeurs
sont également affichées. Le carré R est utilisé pour déterminer dans quelle mesure le modèle de loisirs explique la variable dépendante. Dans la recréation linéaire, le carré R indique
la partie de la variation qui peut être expliquée par les variables
indépendantes. Plus la variance
peut être expliquée, meilleur est
le modèle de régulation. Le carré R est utilisé pour
déterminer dans quelle mesure le modèle de régulation explique
la variable dépendante. Dans une régulation linéaire, le carré R indique
la portion de variance qui peut être expliquée par les variables
indépendantes. Plus la variance peut être expliquée et meilleur est
le modèle de régulation. Cependant, dans le cas de la réglementation
logistique, le sens est différent Il existe différentes manières
de calculer r carré. Malheureusement, il
n'y a
pas encore d'accord sur la
meilleure façon de procéder. Le carré R selon la cellule
à monnaie est 0,22 Nagker ki est de
0,29 et ainsi Et voici le tableau le
plus important, tableau avec le modèle coent Le paramètre le plus important
du client est le rapport de cotes B, p. Les valeurs du coefficient B sont ici, les valeurs p sont ici
et le rapport des cotes est Nous pouvons voir que la
valeur p du sexe est supérieure à 0,05. Cela signifie que le sexe n'est pas un facteur contributif
à la maladie. Dans la première colonne, nous pouvons lire les valeurs des coefficients comme 0,040 0,871 0,4 -2,73, puis nous pouvons insérer ces valeurs au lieu
de Lorsque nous insérons le cypion, nous obtenons une équation comme celle-ci 1/1 plus efface 20,04 dans H,
0,87 dans le sexe plus
1,34 dans le fumeur moins
la constante de 2,73, puis Grâce à cela, nous pouvons maintenant calculer la probabilité qu'
une personne soit décédée. Nous voulons connaître la probabilité qu'une personne
âgée de 55 ans,
femme et fumeuse
, femme et fumeuse Nous remplaçons la valeur
de l'âge par 55, sexe par zéro parce qu'
il ne s'agit pas d'un homme et celui d'un fumeur
, puis nous calculons la valeur Lorsque nous faisons ce calcul, la valeur de probabilité est de 0,69 Cela signifie qu'il y a
69 % de chances qu' une fumeuse
de 55 ans Sur la base de cette prédiction, il serait maintenant
décidé de mener ou
non une enquête approfondie. L'exemple est purement imaginaire. En réalité, il
pourrait y avoir de nombreux autres facteurs et différentes
variables indépendantes comme le poids de la personne, l'âge de la personne et bien d'autres facteurs pour déterminer si la
personne est malade ou non Mais
revenons maintenant à la table des négociations. Dans la colonne, on peut lire coefficient de
différence significative à partir de zéro. L'hypothèse nulle est que le coefficient est nul
dans la population. L'
hypothèse nulle suivante est testée. Le coefficient est nul
dans la population. Comme la variable est
inférieure à 0,05, le coefficient prévu a
une influence significative Dans notre exemple, nous constatons qu'aucun
coefficient n'a d'impact significatif car toutes les valeurs p sont
supérieures à 0,05 Passons maintenant à comprendre
le rapport de cotes. Le ratio de cotes est de
1,042 0,39 83,81. Par exemple, le rapport de
cotes est de 1,04, ce qui
signifie que pour une
augmentation d'une unité de
la variable âge, la probabilité qu' une personne tombe
malade augmente de 1,04 Et nous pouvons constater que pour les fumeurs, le rapport de cotes est très élevé Avec cela, nous arrivons à la
fin des loisirs logistiques. Nous vous verrons lors de la séance
pratique. Restez sur place. Merci
40. Pratique de la régression logistique: Nous utiliserons un calculateur en ligne pour effectuer une analyse de régression, en particulier l'
analyse de régression
logistique présentée dans cette vidéo J'ai mis en ligne une vidéo
séparée sur la façon dont vous pouvez effectuer cette
analyse à l'aide d'Excel. Continuons donc avec le calculateur de
statistiques en ligne. Je peux importer mes
données en cliquant sur le bouton d'importation et en
déposant les fichiers Excel, fichier
SV ou le fichier de l'onglet Données Je peux cliquer sur Parcourir
et accéder à mes données. Hein ? J'ai donc
déjà chargé mes données, que vous pouvez voir à l'écran. Je sais si une personne
est décédée ou non,
son âge, son sexe, son statut tabagique. Nous pouvons constater que le
type de données a
été automatiquement identifié par le calculateur
statistique. Il indique que l'âge est une variable
métrique, sexe est nominal et que
le tabagisme est également normal. La maladie est nominale. Maintenant, ce que je fais c'est de cliquer
sur régression, de faire défiler la page vers le bas. J'ai donc un bon
nombre de cas. Laisse-moi juste faire défiler la page vers le bas. Lorsque je clique sur régression, je peux effectuer une régression
linéaire simple, une régression
multilinéaire
et une régulation logistique Quelles sont mes variables dépendantes ? L'âge est ma variable dépendante. Le sexe est une variable dépendante. Le statut tabagique est une variable
dépendante. Qu'est-ce que je veux prévoir ? Je veux prédire si la
personne est malade ou non. Est-ce que je choisis la bonne solution ? Non Je veux vérifier, quelle est la variable dépendante ? Quel est mon Y ? Mon y indique si la personne
est décédée ou non. Et mes variables indépendantes sont le sexe et le statut tabagique. Donc, pour ce qui est du genre, je prends l'homme comme un. Pour ce qui est du statut tabagique,
je prends les fumeurs comme une seule référence , et le modèle est prédit que la personne
soit malade ou non Maintenant, je peux cliquer sur le
résumé en mots, et il fait une
analyse appropriée et me le montre. Hein ? une
analyse de régénération logistique a été réalisée pour examiner l'
influence de l'âge, du sexe, de la femme et du statut de fumeur en tant que variables en tant que
non-fumeurs, que maladie est prédite
pour la valeur décéder, un
modèle d'analyse logistique a montré que le chi carré pour les trois
est de 8,79,
la valeur p est de 0,32 et le nombre d'observations est Cela montre clairement qu'
une
analyse de régénération logistique a été
réalisée pour examiner l'
influence de l'âge, du sexe, de la
femme et du statut de fumeur en tant que variables en tant que
non-fumeurs, que la
maladie est prédite
pour la valeur décéder, qu'
un
modèle d'analyse logistique a montré que
le chi carré pour les trois
est de 8,79,
la valeur p est de 0,32 et le nombre d'observations est de 36. Le coefficient
de la variable p est de 0,04, ce qui est positif Cela signifie que lorsque l'
augmentation de l'âge est
associée à une augmentation de
la probabilité de la maladie variable dépendante. Cependant, la valeur p est de 0,092, ce qui indique que l'influence n'
est pas statistiquement
significative Le rapport de cotes est de 1,04, ce qui
indique que pour
une augmentation
d'une unité de la variable huit, l'augmentation de la probabilité que la variable dépendante soit supprimée
augmente de 1,04 Le coefficient de la
variable sexe féminin, la valeur
B est négative de 0,87 Comme cette variable
est négative, cela signifie que la valeur de
la variable sexe féminin la probabilité que la variable
dépendante diminue
la probabilité que la variable
dépendante
devienne une maladie. Cependant, la valeur p de 2,0 0,28 indique
que l'influence n'
est pas statistiquement
significative Le rapport de cotes est de 0,42, ce qui signifie que, pour la
variable « sexe féminin », la probabilité de contracter la maladie
variable dépendante augmente de 0,42 fois Le coefficient de la
variable statut fumeur, valeur
p, est de -1,32,
ce qui est négatif, ce
qui signifie que si la
valeur de la variable statut fumeur
est non-fumeur,
la probabilité que
la statut fumeur
est non-fumeur,
la probabilité que
la variable dépendante soit décédée diminue. Cependant, la valeur p est de 0,089, ce qui indique que l'influence n'
est pas statistiquement
significative Le rapport de cotes est 0,26, ce qui signifie que la variable
est le statut de fumeur, probabilité pour les
non-fumeurs que la variable dépendante soit décédée
augmente Maintenant, permettez-moi de reprendre la
référence en tant que non-fumeur et la catégorie «
ceci » et « aucune maladie Passons maintenant au résumé. Nous constatons qu'il y a un léger
changement dans l'analyse. Ils sont désormais tous
devenus négatifs. Hein ? Le
rapport de cotes a changé, indiquant que pour une augmentation d'une
unité d'âge, 0,96 indique que
la personne
ne sera pas décédée, car maintenant nous ciblons les personnes non
décédées, n'est-ce pas Vous devez donc faire attention ce que vous prenez
comme référence. Que croyez-vous
dans votre hypothèse, les hommes sont-ils plus
susceptibles d'être malades Ainsi, lorsque vous considérez
le sexe masculin, la valeur b est de -0,87 Maintenant, ma cible n'
est pas malade. Il semble donc que la
probabilité que l'homme ne soit pas
malade diminue de 0,97 Mais si je regarde le terme « malade », vous constaterez qu'il s'
agit désormais d'une valeur positive Le tabagisme est également une valeur positive. Nous devons donc savoir quelle est la variable cible que
nous voulons étudier. Maintenant, descendons. Voyons les résultats, et j'ai même une
interprétation de l'IA pour m'aider. Le tableau résume
les performances globales de
régression logistique binaire Ici, l'interprétation est nombre
total de cas est de 36, soit le nombre total d' observations.
Le
tableau résume les performances globales
du modèle logistique binaire Ici, l'interprétation est le nombre total de 36 cas. Il s'agit du nombre total d' observations ou d'instances sur
lesquelles le modèle a été testé. Dans ce contexte, le
nombre d'individus élément pour lequel le modèle a tenté de prédire
le résultat, que la personne
soit un acte ou non un acte. L'attribution correcte est de
26 cas sur 36, le modèle a prédit l'
issue de 26 d'entre eux. Cette prédiction correcte incluait à la fois des vrais positifs identifiant
correctement la personne malade et des vrais négatifs identifiant correctement les
cas non malades En pourcentage 72,22 %. Il s'agit de
la précision du modèle indiquant
que le nombre de missions est de 26 divisé par le nombre total de cas 36. Je le multiplie par dix
pour obtenir le pourcentage. Il nous indique comment le modèle
fait la bonne prédiction. Maintenant, comprenons le tableau de
classification. C'est là que nous
essayons de classer. Je peux m'appuyer sur l'
interprétation de l'IA pour le comprendre. Le tableau résume la mesure de
la qualité de l' ajustement issue de l'analyse de
régression logistique Ici, les vrais points positifs
et négatifs sont 11 cas pour lesquels nous avons correctement prédit qu'
ils ne sont pas malades faux positifs sont cinq cas où nous avons commis
une erreur de type 1. faux négatifs sont
cinq cas où nous avons prédit à
tort
qu'ils ne sont pas considérés comme des erreurs de type 2 Les vrais positifs sont correctement
prédits comme étant malades. Exactitude de la prédiction. La prédiction correcte pour les personnes
non malades est de 68,75 %. Le nombre total de cas non malades a
été correctement identifié. Prédictions correctes concernant la maladie, la sensibilité ou nous appelons « sensibilité », 75 %
des cas réels de maladie
ont été correctement identifiés. La précision totale est de 72,22 % toutes les protections,
qu'elles soient malades ou non, nous les avons
correctement identifiées. Maintenant, comprenons le test
du chi carré. L'avantage de ce calculateur
statistique est qu'il vous donne
une interprétation basée sur l'IA. Je n'ai pas besoin d'
aller pour le changer. Le tableau présente les résultats
du test du chi carré associé au modèle de régression
logistique binaire Le test est souvent utilisé pour évaluer la
signification globale du modèle. Ici, l'interprétation
de chaque composant. J'ai mis au carré les statistiques où la réponse est
8,79 dans notre Cela mesure la
différence entre la
fréquence observée et attendue du résultat. Plus la valeur du chi
carré est élevée plus l'écart entre la valeur
attendue et la valeur observée est important, ce qui suggère que les prédicteurs du
modèle ont une relation significative Degrés de liberté, ici, nous avons trois degrés de
liberté représentant le nombre de prédicteurs dans la régression
logistique simple valeur P est la
probabilité d'observer les statistiques du
test du chi carré aussi extrêmes que celles observées
dans l'hypothèse nulle L'hypothèse nulle est qu'il n'existe aucune
relation entre fréquence
observée et attendue du résultat prédit
par le volume. La valeur
P est de 0,032, valeur
P est de 0,032, ce qui suggère qu'il y a une
probabilité de 3,22 % que les
statistiques du chi carré observées Et l'
hypothèse nulle était vraie. La valeur p est
inférieure à 0,32 , ce qui indique qu'elle est
inférieure au seuil de 0,05, ce qui indique qu'il existe
un résultat de
signification statistique Faisons maintenant un résumé du modèle. Donc, ici, il est indiqué que la probabilité de moins
deux log est de 40,67. Il mesure la forme physique des modèles. Plus la valeur est faible,
le modèle s'adapte mieux aux données. Dans notre cas, la valeur est de 40,67, ce qui signifie que c'est
un modèle relativement saturé, un modèle parfaitement ajusté Ce chiffre à lui seul
ne nous dit pas grand-chose. Par conséquent, nous devons le
comparer avec
différents autres nombres. La
valeur carrée R de la cellule Cocin est de 0,22. Il s'agit d'une pseudo-mesure carrée en
R qui indique l'ampleur de la
variation de la variable
prédite expliquée par le
modèle. Il varie de 0 à 1 La valeur de 0,22 indique que la variance de 22 % est
expliquée par le modèle Cependant, il convient de
noter que cette mesure n'atteint jamais un, même
pour un modèle parfait. Passons à la valeur carrée de Nagar
K R. Il est de 0,29. Encore une fois, nous essayons d'ajuster le
carré r pour atteindre un. Mais n'oubliez pas que 29 % de la variation s'
explique par ce modèle. Cela signifie que vous
devez inclure davantage de variables pour mieux comprendre
le modèle. Lorsque nous examinons cela, nous constatons la différence entre les
modèles. Le composant en question
représente les différentes tailles, l'erreur
type, la valeur z, la valeur
p, le ratio attendu
et le niveau de confiance de 95 %. Faisons l'interprétation. Le modèle prédit
que
le résultat de base est de -2,73 lorsque le
prédicteur est nul, le cotes est
de 0,7 Suggérer des
chances de résultat plus faibles lorsque le prédicteur est à
la valeur de référence À chaque
augmentation d'une unité d'âge, la probabilité
que la personne soit décédée augmente de 0,04 Cela représente une augmentation de 4 % des chances. Si le sexe est masculin, il y a une
augmentation de 0,87 %, et ainsi Faisons la prédiction. Si la personne
est âgée de 45 il s'agit d'un homme et
qu'il est probable qu'elle fume, quelle est la probabilité qu' elle soit
malade ? Il y en a 0,81 Est-ce que c'est plus de 0,45 ? 50 % ? Oui Il est probable que la
personne soit malade. Mais si la personne est une femme, la probabilité diminue. De plus, si la personne
est non-fumeuse
, la probabilité
qu'elle soit malade est très
faible qu'elle soit malade est Nous passons maintenant à
l'exemple suivant où nous essayons de vérifier si la personne achètera
un produit ou non. Et les variables sont le sexe, l'âge et le temps
passé en ligne. Je vais donc cliquer
sur l'équation des loisirs. Quelle est la
variable dépendante, le sexe, l'âge, le temps passé en ligne et le comportement d'achat
sont mes variables dépendantes. Il existe trois types de
prédictions, et non deux comme la dernière fois. Nous devons acheter maintenant, acheter plus tard et ne rien
acheter. Catégorie de référence
pour le genre féminin, je la prends en tant que femme, et passons au résumé. Ainsi, l'
analyse de régression logistique réalisée ici indique que l'influence
du sexe masculin, de l'âge et du temps passé en ligne sur la variable comportement d'achat
pour la valeur actuelle L'analyse de régression logistique montre que le modèle est dans
l'ensemble significatif Le nombre d'observations est de 24. Le coefficient selon lequel la
variable genre est
masculine est de 1,53, ce qui est Cela signifie que la valeur
de la variable genre ma, la probabilité que la
personne achète, augmente. La valeur p est de 0,201, ce qui indique que l'influence n'
est pas statistiquement
significative Le rapport de cotes est de 4,63, ce qui signifie que le sexe est masculin, la probabilité que la variable
dépendante augmente désormais de 4,63 Le contenu de la variable ag est p égal à -0,11,
ce qui Cela signifie qu'une augmentation l'âge est
associée à une diminution de la probabilité que la variable
dépendante le soit actuellement. Cependant, la valeur p est de 0,07 ce qui indique que l'influence n'
est pas statistiquement
significative Le rapport de cotes est de 0,9, ce qui indique qu'à chaque augmentation d'une
unité d'âge, la personne n'
augmente désormais que de 0,9 fois. Le coefficient du
temps variable passé sur la boutique en ligne est de b -0,02, ce qui
est Cela signifie que plus ils passent de
temps sur Internet, moins ils
ont de chances d'acheter maintenant. La valeur P est de 0,56 ce
qui indique que ce n'est pas
statistiquement significatif, et le temps passé
en ligne augmente les chances de 0,98 24 cas, 17
ont été correctement prédits en pourcentage 70. Faisons l'analyse. Donc, euh, nombre total de cas 24, attribution
correcte
17 pourcentages 70 Passons maintenant au tableau de
classification. Nous pouvons comprendre
que sont les erreurs de type 1
et de type 2 ? Vrais négatifs 13 cas ont été correctement prédits
selon lesquels ils n'achèteront
pas Les faux positifs
sont trois cas, ce qui a été mal
prédit puisqu'ils sont épinglés maintenant, mais en réalité,
ils n'ont pas acheté Et les faux cas sont que quatre
d'entre eux ont effectivement acheté, mais notre modèle a dit
qu'ils n'en avaient pas acheté. Quatre cas ont été correctement
prédits comme Pi maintenant. L'exactitude de maintenant est de 82 %, exactitude de maintenant est de
50 %, la précision totale est Si vous regardez l'équation du
chi carré, nous obtenons une valeur
p de 0,42 Ici, la probabilité
d'un test du chi carré est extrêmement importante en tant que valeur observée de
l'hypothèse nulle. L'hypothèse nulle est qu'il n'existe aucune
relation entre la observée et la fréquence
attendue et le résultat prédit
par le modèle. Une valeur P de 0,42 devient inférieure à
cette convention de 0,5, ce qui est statistiquement significatif Si je choisis le modèle de quelqu'un, nous pouvons voir que les
valeurs r au carré sont très w. Et j'
ai la valeur p. Alors maintenant
, faisons une prédiction Si la personne est un homme
âgé de 45 ans et que le
temps passé est de 2 secondes Quelle est la probabilité
qu'une personne achète ? Il n'y a pas beaucoup de probabilité. Mais si la personne
a 20 ans, la probabilité
augmente Nous pouvons donc comprendre que la nouvelle génération prête à acheter
plus que les personnes âgées. Si nous avons une personne
de 80 ans, la probabilité est
absolument égale à 0,01 J'espère donc que vous apprendrez à faire de régression
logistique dans
cette vidéo. Oh.
41. Courbe ROC: D. Comprenons la courbe ROC. Nous venons de terminer notre apprentissage
de la régression logistique. L'un des moyens de valider la précision du modèle
consiste à utiliser la courbe ROC. Comprenons la
théorie à l'aide d'exemples. ROC est donc synonyme de caractéristiques de
fonctionnement du récepteur. Il s'agit d'une manière graphique de représenter les performances d' un modèle de classification binaire, également appelé modèle de
régression logistique,
ainsi que pour d'autres seuils de
classification Comprenons à l'
aide d'un exemple. Supposons que nous
effectuons un test de dépistage sur patients afin de déterminer s'ils en bonne santé ou malades. Pour effectuer cette classification
, le pharmacien effectue
des tests sanguins puis décide
qui
sera malade et qui est en bonne santé Après avoir obtenu un
échantillon de dix données, ils ont décidé de fixer un seuil, et toute personne en dessous de ce
seuil sera considérée comme saine et toute personne au-dessus du seuil sera
considérée comme malade Maintenant, comment décidons-nous quel
devrait être le seuil ? Sur la base de laquelle vous
pouvez prédire que le
patient sera malade à l'avenir ? Supposons donc que nous
ayons un échantillon de dix personnes avec
leurs taux sanguins. Nous constatons que la plupart
des personnes malades
ont un taux sanguin
plus élevé Et la plupart des personnes
en bonne santé ont des taux sanguins plus bas. Nous décidons donc de
fixer un seuil à 45. Donc, lorsque nous fixons un
seuil à 45, nous disons que
toute personne âgée de moins de 45 ans sera classée comme étant
en bonne santé. Toute personne âgée de plus de 45 ans sera classée dans
la catégorie des maladies. Nous pouvons maintenant voir qu'il y a
certains problèmes ici, et comprenons
ces problèmes en détail. Donc, dans ce cas, sur
six personnes
classées comme
maladies, deux ou
quatre sont correctement
classées comme maladies, quatre sont correctement
classées comme maladies, mais deux d'entre elles sont incorrectement
classées comme maladies,
mais en réalité, elles sont en bonne santé. Nous en avons donc classé quatre
sur six dans la catégorie des maladies, ce qu'on appelle un taux positif de
deux. Elle est également
appelée sensibilité. D'autre part, parmi les
quatre personnes en bonne santé, nous avons classé à tort une
personne comme étant malade Une personne malade est considérée comme saine, et nous avons correctement classé trois personnes en bonne santé comme étant en bonne santé. Maintenant, lorsque nous classons à tort
un sur quatre comme étant en bonne santé, cela s'appelle un taux de
faux positifs, et il est représenté par FPR ou c'est un taux de spécificité
négatif. Au seuil de 45, nous obtenons un
taux de vrais positifs de 4/5, soit 80 %, et un taux de faux
positifs de 2/5 Alors, qu'est-ce que le TPR
ou deux taux positifs exactement ? Le taux de vrais positifs n'est rien vrais positifs divisés par un
vrai positif plus un
faux négatif. Deux points positifs
concernent les personnes correctement
classées comme malades. Nous avons correctement classé
quatre d'entre elles dans la catégorie des maladies. faux négatifs sont
les personnes qui sont incorrectement
classées comme étant en bonne santé Nous avons donc commis une erreur
avec une personne. Le total est donc de 4/1. vrai positif n'est donc rien, mais quatre d'entre eux ont été correctement
classés comme malades. Mais le problème, c'est que sur les quatre personnes
correctement classées, nous avons oublié l'
une des
personnes malades La raison pour laquelle nous devons connaître le TPR est la suivante :
quel pourcentage de personnes ne seront pas
traitées ? La spécificité est très importante pour comprendre
que 20 % de la population
pourrait ne pas être bien traitée, ou que nous classons correctement 80 % de la population
que nous avons testée Comprenons le FPR,
c'est faussement positif. faux positifs sont des
personnes en bonne santé, classées à tort comme malades, et les deux négatifs sont
des Les individus ont été correctement
classés comme étant en bonne santé. Deux d'entre eux ont donc été classés à
tort dans la catégorie des DC. Nous commençons donc le traitement pour eux, divisé par le nombre total cinq personnes
réellement en bonne santé. Donc, le nombre total de personnes en
bonne santé divisé par le nombre de
personnes faussement positives. Donc, 40 % de la population
a été de 0,4 %, c'est le taux de FPR. Alors, comment calculer le TPR
et le FPR pour chaque seuil ? Dois-je fixer le
seuil à 38 ? Dois-je fixer le seuil
à 65 ans, et ainsi de suite. Dans ce cas, nous calculons le TPR et le FPR pour
chacun des seuils Si je mets ce chiffre à zéro, alors mon
taux de vrais positifs augmente, mais mon
taux de faux positifs est presque nul. Ce sont donc précisément
les deux valeurs qui sont tracées
sur la courbe ROC Le taux de vrais positifs
est tracé sur l'axe y et le taux de faux positifs
est tracé sur l'axe x. Nous voulons décider que
si vous passez à 0,240 0,2, notre taux de faux positifs est là, mais que le vrai positif
augmente,
et de même, à 0,4
0,6 0,8 et un Dessinons maintenant la courbe
ROC complète pour notre exemple. Si nous choisissons
une valeur seuil très faible, c'
est-à-dire si nous la poussons
complètement vers la gauche, nous classons correctement les
cinq personnes malades Mais nous avons également mal classé les cinq
personnes en bonne santé Par conséquent, le taux positif réel est de cinq sur cinq, soit un. De la même manière,
nous avons classé à tort cinq
personnes en bonne santé dans la catégorie des personnes malades Le taux de faux positifs
est donc de cinq sur cinq,
c'est encore une fois un. Pour cette raison, le premier point de
données se trouve à un point un. Donc, lorsque nous repoussons le seuil, nous resterons
correctement classés si je suis à 0,2. Je classe toujours correctement
les cinq personnes
comme malades, mais je classe
également quatre des personnes en bonne santé J'en viens donc au point de données
suivant. Donc, si je prends 0,8
comme seuil, mon véritable taux positif
est de cinq sur cinq J'ai
donc correctement classé toutes les personnes
décédées dans la catégorie des personnes décédées. Mais sur cinq personnes
en bonne santé, nous n'en avons désormais mal classé
que quatre sur cinq Je suis donc à 0,8 en termes de taux de
faux positifs. Pour le prochain roshold, où nous avons un taux
positif de 0,1, nous sommes à 0,3, et
nous constatons que nous avons correctement classé les
cinq personnes comme malades,
mais mes
personnes en bonne santé Ce sera donc mon
troisième point de données. Cinq personnes malades sont
correctement classées. Le taux de faux positifs est que
trois d'entre elles ont été classées à tort dans la catégorie des maladies
sur cinq, soit 0,6 Au seuil suivant, la personne malade est
classée à tort comme étant en bonne santé
pour la première fois C'est le seuil. C'est l'endroit où
la personne malade est mal classée
comme étant Nous assistons donc à une baisse du
taux positif réel, qui est passé de 12,8 Le taux de vrais positifs est de
quatre sur cinq, soit 0,8, et le taux
de faux positifs de trois sur
cinq, soit 0,6. Nous pouvons maintenant le faire pour
tous les autres seuils, et en conséquence, nous
établissons notre courbe ROC. À ce stade, par exemple, 80 % des personnes du DAS ont été correctement
classées comme maladies, 20 % des personnes en bonne santé ont été incorrectement
classées comme maladies. À l'aide de la courbe ROC, nous pouvons comparer différentes méthodes de
classification. Les modèles de classification sont autant meilleurs que la courbe
est haute. Par conséquent, plus l'
aire sous la courbe est grande, meilleur est le modèle de
classification. En utilisant la courbe ROC, nous pouvons comparer différentes méthodes de
classification, et c'est précisément
la zone qui est reflétée par la
zone AUC sous la valeur de la courbe L'aire sous la courbe est utilisée lors de l'évaluation
du modèle de régression linéaire. La valeur AUC varie de 0 à 1. Plus la valeur est élevée, meilleur est
le modèle. Qu'en est-il de la courbe ROC et
de la régression logistique ? Par exemple, nous pourrions créer un nouveau modèle de classification
en utilisant la régression logistique Ici, nous pourrions utiliser des valeurs supplémentaires
telles que la valeur sanguine, l'âge et
le sexe de chaque personne et essayer prédire si la personne
est en bonne santé ou malade À propos de la courbe ROC et de la régression logistique,
continuons Dans une régression logistique, la valeur estimée est alors la probabilité qu'une
personne en particulier soit décédée Très souvent, 50 % d'
entre eux se contentent de prendre comme seuil
le seuil pour déterminer si une personne
est décédée ou non Mais bien entendu, ce n'est
pas ce à quoi nous pensons. Vous ne pouvez donc pas toujours prendre le
seuil de 50 %. Par conséquent, même avec la réglementation
logistique, nous construisons la courbe ROC pour différentes valeurs de seuil
et voyons à quel niveau, nous avons la surface maximale Alors, comment puis-je obtenir la courbe
ROC en ligne ? Voyons maintenant
comment je peux effectuer ce calcul ROC
en utilisant les données. J'ai donc renseigné
des valeurs de données pour plus de 40 personnes, soit
près de 40, taux sanguins
différents et le fait
que la personne
soit malade ou non Je peux donc soit opter pour
mon modèle de libération, dire que je veux indiquer que
la variable est malade. L'état de la variable est oui ou non, et je veux la
variable de test sous forme de valeur sanguine. Nous obtenons donc immédiatement le ROC, et le ROC montre à quels niveaux de spécificité
et de sensibilité. La sensibilité n'est rien d'autre que
mon véritable taux positif. Combien de
personnes malades ai-je correctement
classées ? La spécificité, en revanche, est de savoir combien d'entre elles
ou combien de personnes en bonne santé ont été
classées à tort comme malades Et nous voulons qu'il y en ait un. Les personnes malades ont 19 ans, non malades 22, et le positif est
supérieur à un, la sensibilité est de un et
cela me montre l'intégralité Nous pouvons perdre des échantillons de données. Et fais-le. Je peux également le trouver
dans mon modèle de corrélation. Je vais donc passer à la réglementation, et je dis que ma variable
dépendante est décédée et que la valeur sanguine est
ma variable indépendante. En résumé, si l'
analyse de la régulation logistique a été réalisée pour examiner si
la valeur sanguine d'
une variable permet de
prédire la valeur , c' L'analyse des loisirs logistiques montre que la valeur du chi carré est de 5,23, valeur
P est Cela signifie que le sang est
capable de prédire que le
taux sanguin n'a aucune influence sur la maladie. Nous rejetons l'hypothèse nulle
car la valeur p est lo. Le client de la valeur sanguine B est de 0,03, ce qui est positif Cela signifie que l'
augmentation de la valeur sanguine est associée à l'augmentation de
la probabilité que la variable
dépendante soit oui. La valeur p de 0,32 indique que l'influence est statistiquement significative Le rapport impair est de 1,03, ce qui indique qu'une augmentation d'une
unité la valeur sanguine
augmentera
de 0,13 fois les probabilités que la variable dépendante soit « oui » Ainsi, lorsque nous élaborons la régression
logistique, nous pouvons constater que nous venons lire le résumé
selon lequel la valeur p est 0,03, ce qui indique que la
valeur sanguine a une importance pour le malade Le tableau résume que
sur les 41 cas étudiés ont
été observés
pour l'élaboration du modèle,
dans ce contexte, le
nombre de personnes dont étudiés ont
été observés
pour l'élaboration du modèle,
dans ce contexte, le nombre de personnes avait prédit
qu'
elles étaient malades ou en bonne santé 28 d'entre eux sur 41 ont été
correctement classés, les personnes
malades
classées comme malades et les personnes en bonne santé
classées comme étant en bonne santé Le pourcentage est de 68,29. Il indique le nombre total de personnes
correctement classées par 28
, divisé par 41, puis multiplié
par 100 pour obtenir un pourcentage. Si je vous dis à quelle fréquence le modèle fait
la bonne prédiction, qu'il s'agisse de la
présence ou de l'absence de S. Nous pouvons
donc voir que cela s'appelle une table
de
classification. Des personnes qui ne sont pas réellement malades et dont on a correctement
prédit qu'elles ne le sont pas, des
personnes malades et dont on a
prédit qu'elles ne le sont Ce huit me préoccupe. Pourquoi ? Parce que ce
sont ces personnes qui ne veulent pas se faire soigner
. Et cinq d'entre eux ont été
classés comme malades, alors qu'en réalité, ils ne
souffraient pas Nous allons donc
construire le modèle ROC,
et le ROC (actuellement l'AOC,
A sous la courbe) est de 0,699 Plus la courbe est haute,
meilleur est le modèle. Sur 41 cas, l'attribution correcte a été
effectuée pour 28 cas, et la mauvaise attribution
s'est produite pour 13 cas. Ainsi, 68 % des personnes ont été
correctement classées. Faisons maintenant une interprétation basée sur l'
IA. L'interprétation de l'IA indique
très clairement que le modèle est ajusté à
deux logarithmes de vraisemblance. Plus la valeur est faible, meilleur est
le modèle. Ici, la valeur est de 51,39 ce qui
indique que le modèle
est relativement saturé, un modèle parfaitement ajusté Le chiffre à lui seul
ne dit pas grand-chose. Nous devons le comparer à
d'autres modèles. Passons maintenant à l'
interprétation du modèle. Le tableau montre
que nous avons effectué une analyse de
récursion logistique binaire, qui examine comment les prédicteurs influencent la probabilité
d'un Components, Cefion B. Cela représente l'
effet de chaque Un coefficient positif augmente les probabilités ou les probabilités
logarithmiques du résultat,
tandis coefficient négatif le Erreur standard. Cela mesure l'écart type
de la cohésion estimée, relativement à la
précision avec laquelle le modèle
estime la valeur de cohésion La valeur z. Il s'agit du score z calculé sous la forme d'un coefent
divisé par l'erreur type, il est utilisé pour tester l'hypothèse nulle selon laquelle
le coefficient valeur P indique
la probabilité d' observer les données ou
quelque chose de plus extrême. Si l'hypothèse nulle est vraie, la
valeur inférieure suggérée par P et par mot, la valeur p indique
la probabilité d' observer les données ou
quelque chose de plus extrême. Si l'hypothèse nulle est vraie, la valeur p la plus faible suggère que l'hypothèse nulle d'absence d'
effet est moins probable. Interprétation.
Le modèle prédit les probabilités logarithmiques de la
ligne de base à -1,31, car tous
les prédicteurs Le rapport impair est de 0,27, ce qui suggère que la
probabilité d'un résultat est plus faible lorsque tous les prédicteurs correspondent à la
valeur de référence Valeur sanguine qui
augmente de trois. Maintenant, faisons la prédiction. Si ma valeur sanguine est de 85, il y a 75 % de chances
que je souffre. Je vais également
voir la courbe ROC. Le ROC, l'aire sous
la courbe est de 0,699. Elle chut
42. Comprendre les données non normales: C'est normal ou pas. Essayons de
comprendre comment
fonctionnons-nous lorsque mes données ne sont pas normales ? Ou même avant d'y arriver, laissez-moi vous présenter ce
monsieur. Des suppositions ? Qui est ce monsieur ? Vous pouvez taper dans la
fenêtre de discussion si vous le savez. Et même si vous ne le savez pas,
c'est très bien. n'y a pas de
points de pénalité en cas de mauvaises suppositions. Oui Certains d'entre vous l'ont
deviné, n'est-ce pas ? C'est la personne célèbre à l'origine de
notre distribution normale. M. Carl cos. C'est un grand mathématicien. Et c'est lui
qui a inventé
le concept de distribution
gaussienne ou de distribution normale. Voici donc le cerveau
qui sous-tend le concept de distribution
normale et tous les tests paramétriques
que nous effectuons. Si mes données ne sont pas normales, elles peuvent être faussées. Il peut être biaisé négativement ou
positivement. Si je dis incliné négativement, cela signifie techniquement qu'il
a une queue sur le côté gauche. Une inclinaison positive signifie que
la queue est sur le côté droit. Cela signifie que mes données ne
se comportent pas normalement. Mes données peuvent ne pas être
normales car suivent une distribution uniforme ou une distribution plate
comme celle-ci. De plus, cela ne suit pas
la distribution normale. Mes données peuvent présenter plusieurs pics, quelque chose comme celui-ci, ce
qui signifie qu' il existe plusieurs
groupes de données dans mon ensemble de données. Et ce n'est pas un comportement normal. Parce que mes données contiennent
toutes ces choses. Je dois traiter ces données différemment lorsque je teste
mes hypothèses. Et pourquoi ces données ne sont-elles pas normales ? Cela peut être dû à la
présence de certaines valeurs aberrantes. Cela peut être dû à
l'asymétrie de mes données ou à
l' aplatissement
présent dans les données. La raison pour laquelle vos données ne
se comportent pas normalement
pourrait donc être l'une de ces raisons. Résumons,
qu'avons-nous appris ? Mes données ne sont pas normales si la
distribution présente une asymétrie, si elle est unimodale, si elle n'est pas unimodale, mais s'il s'agit en fait d'une distribution bimodale ou
multimodale. Il s'agit d'une distribution de queue épaisse
contenant des valeurs aberrantes. Ou il peut s'agir d'une distribution
plate comme une distribution uniforme. Voici quelques raisons fondamentales pour lesquelles mes données ne se
comportent pas normalement. Bizarre, ce n'est pas une distribution
normale, alors il y a plusieurs
distributions. Il existe également d'autres
distributions, qui parlent de la distribution
exponentielle, qui modélise le temps
entre les événements. La distribution log-normale. Ce qui signifie que si j'applique
le logarithme aux données, mes données suivront
une distribution normale. Distribution de Poisson, distribution
binomiale, distribution
multinomiale. Laissez-nous comprendre quelques exemples, des scénarios réels où les distributions non normales
peuvent être appliquées. Si vous regardez cela, chaque fois que j'essaie de prédire quelque chose sur un intervalle de temps
fixe. Ensuite, j'utilise la distribution de Poisson pour mon analyse et mon hypothèse. Quelques exemples de
distribution de Poisson ou du numéro du service client appelé
reçu par le centre d'appels. Le nombre de
patients qui se présentent urgences d'
un hôpital un jour donné, le nombre de demandes pour un article particulier dans une boutique
en ligne au cours d'une journée donnée. Le nombre de colis livrés par la société de livraison
au cours d'une journée donnée, le nombre d'articles défectueux produits par une
entreprise de fabrication au cours d'une journée donnée. Si vous observez, il existe
un comportement courant ici. Chaque fois que nous
essayons de comprendre quelque chose sur une période
donnée, cela peut être un jour donné, cela peut être un
mois donné, étant donné B.
Ensuite, nous préférons effectuer notre analyse en utilisant la distribution de
Poisson. Quelques exemples de distribution
log-normale. La taille du fichier
téléchargé sur Internet, la taille des particules présentes
dans un échantillon de sédiments, la hauteur de l'arbre, la taille des revenus
financiers, la taille du jeu d'assurance. Si vous regardez ces exemples, si
je prends l'exemple du rendement
financier de
leurs investissements, vous constaterez peut-être que, dans mon
portefeuille de placements, certains investissements m'ont donné un
très bon rendement de 100 %, 100 %, 150 %, 80 %. Vous constaterez également
que j'ai
investi dans une partie mon portefeuille parce que
cela s'est traduit par un rendement nul ou un
rendement négatif parce que je suis déficitaire. Mais dans l'ensemble, mon
portefeuille me donne un rendement de 12 à 15 %,
soit de 15 à 20 %. Vous essayez de dire que votre distribution n'est techniquement pas une distribution normale. Vous avez des rendements très faibles
et des rendements très élevés. Mais si vous appliquez le
logarithme à vos données, il se comporte comme une distribution normale selon laquelle
l'ensemble de votre portefeuille se
traduira par un rendement d'
environ X pour cent. en va de même
pour la réclamation d'assurance. Essayons de comprendre l'application de la distribution
exponentielle. Le temps entre l'arrivée
des clients dans la file d'attente, le temps entre les pannes
d'une machine, votre usine, le temps entre les achats
dans le magasin de détail, le temps entre les appels téléphoniques
et le centre d'appels, le temps entre les pages
consultées sur le site Web. Maintenant, si vous voyez entre la distribution de Poisson et la distribution exponentielle, il y a un élément commun. Quel est l'élément commun ? Nous essayons d'étudier en nous
référant au temps. Chaque fois que vous effectuez
une distribution normale, ce n'est pas en fonction du temps. Hein ? Voici donc quelques applications. Mais la différence
entre un poison et une exponentielle réside dans une distribution de
Poisson. C'est un jour donné, un
jour donné, une semaine donnée, un mois donné. Nous essayons ici de comprendre le temps qui s'écoule entre les deux événements. Quel est l'écart de temps
entre les deux événements ? La
distribution exponentielle peut alors vous aider. Nous pouvons comprendre
l' application d'une certaine distribution
uniforme, comme la taille de l'
élève dans la classe. Besoins en paquets dans
un camion de livraison. Certains colis sont très volumineux, d'autres sont petits. Si vous le placez dans une distribution, vous constaterez également qu'
il s'agit d'
une distribution plate ou uniforme, car pour chaque catégorie de packages, vous aurez à peu près
le même nombre de packages
similaires. Marchandises que vous livrez. La distribution des résultats d'un examen à choix multiples. Répartition du
temps d'attente à un feu de signalisation, distribution de
l'heure d'arrivée d'un client dans un magasin de détail. Donc, si vous voyez tous ces exemples suivant une distribution uniforme, il ne s'agit pas d'une courbe en cloche. Parce que vous avez
continuellement des personnes qui arrivent
au magasin de détail. Ce n'est pas qu'il
y ait un pic soudain. Et
dans les scénarios réels d'une distribution
intensive, il s'agit de la distribution où
les valeurs aberrantes sont présentes, des signes de perte
financière et d'
un secteur de l'assurance ou d'autres
signes de pertes financières. Si quelqu'un demande à un trader, il verrait ce chiffre extrêmement élevé et extrêmement
faible. L'ampleur des précipitations
extrêmes. Nous n'avons donc pas de
précipitations extrêmes chaque année. Nous ne serions donc pas en mesure de dire
que ce qui s'
est passé est dû à une exception. Et la
distribution à grande échelle
est généralement affectée en raison de
la présence de valeurs aberrantes. Ainsi, si vos données
présentent des valeurs aberrantes, vous pouvez également constater
que la distribution de la charge est une
distribution détaillée. Et nous comprendrons
lors de la prochaine session, quel type de
tests non paramétriques dois-je effectuer ? En fonction du type
de données anormales
que nous commençons. L'ampleur de la consommation d'
énergie, l'ampleur de la
fluctuation
économique due au krach boursier. Ce sont tous des exemples de votre
distribution intensive. Exemples de données bimodales. Ici, vous devez comprendre bimodalité signifie que
nous essayons d'étudier
deux résultats. Répartition
des résultats aux examens des étudiants qui ont étudié
et de ceux qui ne l'ont pas fait. Répartition
des âges des personnes appartenant à deux groupes d'âge distincts, taille de deux espèces différentes, répartition des
salaires des employés de deux départements différents. Bonne chance sur une autoroute avec deux groupes de conducteurs lents
et rapides. Vous pouvez donc voir ici
que j'ai deux groupes de données
différents. Et j'essaie de comprendre le comportement. Je vais poursuivre mes recherches dans le
cadre de mon hypothèse ou de la ressource
que j'essaie de trouver. Si j'ai plus de deux
groupes, deux groupes différents, plus de deux groupes différents, comme trois groupes différents
pour des groupes différents, alors cela devient une distribution
multimodale. Hein ? Je pense donc
que vous avez maintenant
une idée des différentes
distributions qui ne
sont pas des distributions normales. Alors, comment puis-je déterminer si
mes données ne sont pas normales ? Le premier point qui nous
vient à l'esprit
est un test de normalité. Mais avant même
d'effectuer un test de normalité, vous pouvez utiliser des méthodes
graphiques simples pour déterminer si vos
données sont normales ou non. Vous pouvez utiliser un histogramme. Et ici, l'histogramme montre
clairement plusieurs mouvements. Je vois donc clairement qu'il s'agit pas d'une
distribution normale. Si j'essaie de mettre une ligne d'ajustement, je peux également constater qu'
il y a une asymétrie dans mes données. Je peux également utiliser un diagramme à cases pour déterminer si mes
données ne sont pas normales. Vous pouvez donc voir ici que
j'ai une queue épaisse sur le côté gauche indiquant
que mes données sont biaisées. Je peux également avoir des valeurs aberrantes qu' un boxplot peut facilement mettre en évidence. Je peux donc me cacher, identifier la distribution à queue épaisse
à l'aide du boxplot. Également. Je peux utiliser des statistiques
descriptives simples où je peux voir les chiffres
du mode médian moyen. Et lorsque je constate que
ces chiffres ne se chevauchent
pas ou ne sont pas
proches les uns des autres, cela indique simplement
que mes données ne sont pas normales. Je peux examiner l'aplatissement et asymétrie de la distribution
de mes données , puis déterminer si mes données se comportent
normalement ou non. Je vous ai donc montré d'autres moyens de déterminer
si vos données suivent une distribution et non une
distribution anormale ou si vos données suivent une distribution
normale. Maintenant, je voudrais dire encore une chose. Ne vous suicidez pas
si votre moyenne était 23,78 et la médiane de 24, et si le mode
serait 24,2 ou 24. Donc, s'il y a une
légère déflation, nous la considérons
tout de même comme normale. Hein ? asymétrie proche de zéro Une asymétrie proche de zéro indique que
mes données sont normales. Mais si mon asymétrie est supérieure à
moins deux ou plus deux, c'est certainement notre preuve de
non-normalité. La cétose est également un moyen supplémentaire de déterminer si mes données
suivent une distribution normale. La plupart du temps, nous préférons que le nombre d'
aplatissement soit compris entre 0 et 3. Mais si votre
cétose est négative, cela signifie que la courbe est plate. Les audits suivent une distribution
uniforme. L'audit peut être une
distribution trop pointue d' aplatissement élevé, ce qui peut également un
aplatissement élevé, ce qui peut également indiquer que vos
données sont trop parfaites. Et peut-être devez-vous
vérifier s' ils n'ont pas manipulé vos données avant
de les transmettre. Autre test AdText ou
Anderson-Darling préféré, où nous essayons de comprendre
si mes données sont normales ou non. Donc, l'hypothèse nulle de base,
chaque fois que je fais un test NAT, est que mes données suivent
une distribution normale. C'est donc le seul
test pour lequel je veux que
ma valeur de p soit
supérieure à 0,05 Je ne rejette pas l'hypothèse
nulle, concluant que mes
données sont normales, et je m'en remets à mon test paramétrique
préféré, qui
me permet de faire facilement l'analyse. Mais que se passerait-il si, lors du test ADA, vos données et votre analyse montraient que la valeur de p
est significative, qu'elle est inférieure à
0,05, peut-être 0,02 ? Puis il conclut que mes données ne
sont pas une distribution normale. Et je dois étudier de quel type de
non-normalité il s'agit. En conséquence, je vais
devoir mettre en place le
test, puis l'approfondir. Nous poursuivrons notre session
lors de la prochaine journée de Venise. J'espère qu'il vous a plu. Si vous avez des questions, hésitez pas à
commenter sur WhatsApp ou sur la chaîne Telegram ou dans la
section des commentaires ici. Tout sujet que
vous aimeriez
apprendre dans le cadre de la session du
mercredi. Je serais heureuse
de me renseigner à ce sujet. Si vous pouvez mettre ces commentaires dans la boîte de discussion, dans le
groupe WhatsApp ou dans le télégramme. J'aime vraiment t'enseigner et je te remercie d'être merveilleuse. Étudiants. Prends soin de toi.
43. Kruskal Wallis teste 3 groupes ou plus données non normales: Ce tutoriel concerne
le test Crus Walus. Si vous voulez savoir
ce qu'est le test crus c, walus et comment il peut être calculé
et interprété Vous êtes au bon endroit
à la fin de cette vidéo. Je vais vous montrer
comment
calculer facilement le test Walus en ligne Et nous commençons dès maintenant. Le test de Crus Walus est un test d'
hypothèse utilisé lorsque vous souhaitez
vérifier s'il existe une différence entre
plusieurs groupes indépendants Maintenant, vous pouvez vous poser la question un
peu et dire : « Hé, s'il existe plusieurs groupes
indépendants, j'utilise une analyse de variance. C'est exact. Mais si vos données ne sont pas distribuées
normalement et que les hypothèses de l'analyse de
variance ne sont pas satisfaites. Le test WUS est utilisé. Le test de Wace est l'
équivalent non paramétrique de
l'
analyse de variance à facteur unique Je vais maintenant vous montrer
ce que cela signifie. Il existe une différence importante
entre les deux tests. L'analyse des tests de variance, s'il existe une
différence de moyenne. Ainsi, lorsque nous avons nos groupes, nous calculons la
moyenne des groupes et vérifions si toutes les
moyennes sont égales. lorsque nous examinons le test
Crus C Wals, revanche, lorsque nous examinons le test
Crus C Wals,
nous ne
vérifions pas si les moyennes sont égales Nous vérifions si les sommes des classements de
tous les groupes sont égales. Qu'est-ce que cela signifie ?
Maintenant, qu'est-ce qu'un grade ? Et qu'est-ce qu'une somme de rangs dans
le test ALS classique ? Nous n'utilisons pas les valeurs mesurées
réelles, mais nous trions toutes les personnes par taille, puis la personne ayant la plus petite valeur obtient
la nouvelle valeur ou le premier rang. La personne ayant la deuxième
plus petite valeur obtient le deuxième rang. La personne ayant la troisième
plus petite valeur obtient le rang trois, et ainsi de suite et ainsi jusqu'à ce qu'un rang soit attribué à chaque personne
. Nous avons maintenant attribué un
rang à chaque personne, puis nous pouvons simplement
additionner les grades
du premier groupe. Additionnez les grades
du deuxième groupe et additionnez les grades
du troisième groupe. Dans ce cas, nous obtenons une somme de 54 rangs pour
le premier groupe. 70 pour le deuxième groupe et 47 pour le troisième groupe. Le gros avantage est
que si nous ne
regardons pas la différence principale
mais la somme des classements, les données n'
ont pas besoin d'être
distribuées normalement lors
du test croisé. Nos données ne doivent
satisfaire à aucune forme de distribution
et, par conséquent, nous n'avons
pas non plus besoin qu'elles soient distribuées
normalement Exemples du test de
Rusk Wallace
pour le test de Rusk Bien entendu, les mêmes
exemples peuvent être utilisés que pour l'
analyse de variance à facteur unique, mais en ajoutant qu'il n'est pas nécessaire que les données soient distribuées
normalement. Exemple médical. Pour une société
pharmaceutique, vous souhaitez vérifier si un médicament XY a une
influence sur le poids corporel. À cette fin, le médicament est administré à 20 personnes testées. Les personnes testées
reçoivent un placebo et 20 personnes
ne reçoivent aucun médicament ni placebo. Objectif, Déterminer
si le médicament XY a un effet statistiquement
significatif sur le poids
corporel par rapport au
placebo et aux groupes témoins. Exemple de sciences sociales. Trois groupes d'âge diffèrent-ils ? En termes de consommation quotidienne de
télévision, question
de recherche
et hypothèse. La question de recherche pour
le ruskal était peut-être un test. Existe-t-il une différence dans la tendance centrale de
plusieurs échantillons indépendants ? Cette question aboutit à l'hypothèse nulle et
alternative. Aucune hypothèse. Les échantillons indépendants
ont tous la même tendance centrale et proviennent donc de
la même population. Autre hypothèse,
au moins un des
échantillons indépendants n'a pas la même tendance centrale que les autres échantillons et
provient donc d'une population
différente Avant de discuter de la
façon dont l'abattage des crus est calculé, test de
valus est calculé,
ne vous inquiétez pas Ce n'est vraiment pas compliqué. Nous examinons d'abord
les hypothèses. Hypothèses. Quand
utilise-t-on le cru c ? Test de Walus ? Nous utilisons
le test de crus Walus si nous avons une variable nominale
ou ordinale avec plus de deux valeurs Et une variable métrique, une variable nominale ou ordinale avec plus de deux valeurs est, par
exemple, la variable, journal
préféré,
avec les valeurs, Washington Post, New
York Times, USA today Il peut également s'agir de la
fréquence de
visionnage de la télévision quotidienne
plusieurs fois par semaine. En réalité, aucune variable
métrique n'est, par
exemple, le salaire, le bien-être, bien-être ou le poids des personnes. Quelles sont les hypothèses actuelles ? Seuls plusieurs échantillons
aléatoires indépendants présentant au
moins des
caractéristiques à l'échelle normale doivent être disponibles est pas nécessaire que les variables
satisfassent à une courbe de distribution. L'hypothèse nulle est donc
que les échantillons indépendants ont
tous la même tendance
centrale. Et donc issus de la même population
ou en d'autres termes. Il n'y a aucune différence
dans les sommes des rangs, et l'hypothèse alternative
pourrait être qu'au moins un des échantillons indépendants n'a pas la même tendance centrale
que les autres échantillons et provient donc
d'une population différente. Ou pour le redire en
d'autres termes. Au moins un groupe
diffère en termes de sommes de classement. La question suivante est donc de savoir comment calculer un
biscotte. Test de Wallace Ce n'est pas difficile.
Supposons que vous ayez mesuré le
temps de réaction de trois groupes. Groupe A groupe dans le groupe C, et maintenant vous
voulez savoir s'il y a une différence entre les groupes en termes de temps de réaction. Supposons que vous ayez noté le
temps de réaction mesuré dans un tableau. Supposons simplement que les données ne soient pas distribuées
normalement et que vous deviez donc
utiliser le cru k a été testé. Notre hypothèse nulle est donc qu' il n'y a aucune différence
entre les groupes, et nous allons
tester cela dès maintenant. Tout d'abord, nous attribuons un
rang à chaque personne. Il s'agit de la plus petite valeur. Donc, cette personne obtient le premier rang. Il s'agit de la deuxième
plus petite valeur. Cette personne obtient donc le deuxième rang, et nous le faisons maintenant
pour tout le monde. Si les groupes n'ont aucune
influence sur le temps de réaction, les rangs devraient en fait être
distribués de manière purement aléatoire. Dans la deuxième étape, nous calculons maintenant
la somme des rangs et la somme des rangs moyens
pour le premier groupe La somme des rangs est de deux plus
quatre plus sept plus neuf, ce qui est égal à 22, et le groupe compte quatre
personnes. La somme moyenne des rangs est de
22/4, ce qui équivaut à 5,5. Maintenant, nous faisons de même
pour le deuxième groupe. Ici, nous obtenons une somme des rangs de 27 et la somme des
rangs moyens de 6,75, et pour le troisième groupe, nous obtenons une somme de 29 et la somme des rangs moyens de 7,25 Nous pouvons maintenant calculer la valeur
attendue des sommes des classements. La valeur attendue, s'
il n'y a pas de différence entre les groupes, serait que chaque groupe aurait
une somme de rang de 6,5. Nous avons maintenant presque
tout ce dont nous avons besoin. Nous interrogeons 12 personnes. Le nombre de cas est de 12. La valeur attendue
des rangs est de 6,5. Nous avons également calculé
la somme
des classements moyens des différents groupes. Les degrés du cas
pré-Domina sont de deux, et ils sont simplement donnés par le nombre de
groupes moins un, ce qui fait trois moins un Enfin, nous avons besoin de la variance. La variance des rangs est
donnée par n au carré -1/12. N est encore une fois un nombre
de personnes, donc 12. Nous obtenons un écart de 11,92. Nous avons maintenant tout ce dont
nous avons besoin avec ces valeurs. Nous pouvons maintenant calculer
notre valeur de test g. La statistique de test
correspond à la valeur de g carré et est
donnée par cette formule n fois la somme de r bar moins e r carré, le tout divisé
par Sigma au carré Dans notre cas, le
nombre de cas est de 12. Nous avons toujours quatre
personnes par groupe. Nous pouvons donc déduire que E 5,5
est le rang moyen du groupe A, 6,75 est le
rang moyen du groupe B et 7,25 est le rang
moyen du groupe C. Cela nous donne une valeur
arrondie de 0,5,
comme nous venons de comme nous venons Comme nous venons de le dire, cette valeur correspond à la valeur carrée. Nous pouvons maintenant facilement
lire la valeur
carrée critique dans le tableau
des valeurs carrées critiques. Vous trouverez également ce tableau
sur Internet. Nous avons deux degrés de liberté. Et si nous supposons que nous avons un seuil de signification de 0,05, nous obtenons une valeur
carrée critique de 5,991 Bien entendu, notre valeur est inférieure à la valeur
critique de g carré. Ainsi, sur la base de
nos exemples de données, l'hypothèse nulle est retenue Je vais maintenant
vous montrer comment
calculer facilement le
test de Cresco Wallace en ligne avec l'onglet Données Calcul en ligne. Pour ce faire, il
vous suffit de vous rendre sur data tab.net, puis de cliquer sur le calculateur de statistiques et insérer vos propres données
dans ce tableau Ensuite, vous cliquez sur cet onglet, et sous cet onglet, vous trouverez de nombreux tests d'
hypothèse Lorsque vous sélectionnez les
variables que vous souhaitez tester, l'outil suggère
le test approprié. Après avoir copié vos
données dans le tableau, vous verrez le temps de réaction et le groupe
ici en bas. Maintenant, il suffit de cliquer sur le temps de
réaction
et le groupe, et il calcule automatiquement une analyse de variance pour nous Mais nous ne voulons pas d'
analyse de variance. Nous voulons le test non paramétrique. Il suffit de cliquer ici. Maintenant, le calculateur
calcule
automatiquement le test de
Ruskal Wallace Nous obtenons également une valeur e
carrée de 0,5, les degrés de liberté sont de deux et la valeur p calculée est, et ci-dessous, vous pouvez
lire l'interprétation. Ruskal Walus a
montré qu'il
n'y avait pas de différence significative
entre les catégories Sur la base de la valeur p,
nous ne pouvons donc pas rejeter
l'hypothèse nulle
avec les données utilisées . Essayez-le vous-même.
C'est très simple. Restez connectés, continuez à apprendre, continuez à vous développer,
à la prochaine leçon.
44. Conception d'expériences: Bonjour et bienvenue. Dans cette vidéo. Nous allons nous plonger dans le monde
fascinant de la conception d'expériences Communément appelé DOE, nous discutons de ce qu'est le plan d'
expériences ou DOE, des étapes
du processus du projet DOE. Comment le DOE peut vous aider à réduire
le nombre d'expériences. Comment estimer le nombre
d'expériences nécessaires Et nous passons en revue les types de modèles les plus
courants. Alors, en quoi consiste exactement
la conception d'expériences ? La conception d'expériences ? Le
DOE est une
méthode structurée utilisée pour planifier, réaliser et
interpréter des expériences. L'objectif principal du DOE est de
découvrir comment différentes variables
d'entrée, appelées facteurs, affectent
une variable de sortie, appelée variable de réponse. Voici une explication plus
simple. Approche systématique. Le DOE est organisé et méthodique. Il suit un
processus étape par étape pour garantir que les
expériences sont menées de
manière logique et efficace. Variables d'entrée, facteurs. Il s'agit des éléments
que vous modifiez au cours d'une expérience pour voir comment
ils affectent le résultat. Par exemple, si vous
préparez un gâteau, facteurs peuvent inclure
la quantité de sucre, le temps de cuisson ou
la température du four. Variable de sortie, variable de
réponse. C'est ce que vous mesurez
dans l'expérience pour voir l'effet des modifications
que vous avez apportées aux facteurs. Dans l'exemple du gâteau, la variable de réponse peut être le goût ou la texture
du gâteau. L'objectif du DOE est de comprendre la relation
entre ces facteurs et la variable de réponse. Nous vous aidons à déterminer
quels facteurs ont l'impact le plus important et comment ils interagissent les uns
avec les autres. Imaginez que vous faites du vélo. La bonne rotation
des roues dépend de l'état
des roulements. Si les roulements sont
bien lubrifiés, le couple de
frottement
est minimal, ce qui permet de pédaler sans
effort Toutefois, si la lubrification est inadéquate ou si la
température est trop élevée, efforts
supplémentaires sont nécessaires pour maintenir la vitesse en raison de la friction
accrue. Dans de tels cas, le DOE nous permet d'
étudier systématiquement des facteurs tels que les types de lubrification, tels que l'huile ou la graisse, et les variations de températures (basse, moyenne ou élevée) afin de
quantifier avec précision leur impact
sur le bruit de friction Mais pourquoi est-ce important ? La conception d'expériences nous
permet de concevoir des plans de test
efficaces qui permettent de découvrir ces
informations de manière efficace. manipulant soigneusement les
facteurs et leurs niveaux, DOE nous aide à identifier les
variables qui influencent de manière significative le résultat Que ce soit dans des systèmes mécaniques
tels que les roulements ou dans des scénarios
plus complexes impliquant des réponses humaines aux médicaments. Les applications du DOE
sont vastes et diverses Qu'il s'agisse d'optimiser les processus de
fabrication, améliorer la conception des produits ou d'affiner les traitements médicaux, DOE constitue un
outil puissant pour identifier les facteurs
critiques et déterminer conditions
optimales pour
obtenir les résultats souhaités. Il permet aux chercheurs
et aux ingénieurs de prendre des décisions
éclairées sur la base données
empiriques plutôt que de
se fier à des conjectures Dans nos prochains segments, nous explorerons les étapes
essentielles d'un projet
ADOBE, de la conception d' expériences à l'
analyse des résultats Au fur et à mesure que nous avançons
dans le cours, nous découvrons les subtilités de conception des expériences
et découvrons comment cette approche méthodologique peut révolutionner votre approche l'expérimentation et
de la recherche Restez à l'affût pour plus d'informations
et de conseils pratiques.
45. Les domaines d'application pour un DOE: Voyons maintenant quels
sont les domaines d'
application du DOE. Les applications du DOE sont
nombreuses et variées, qu'il
s'agisse d'optimiser les processus de
fabrication, améliorer la conception des produits ou d'affiner les traitements médicaux. Le DOE est un
outil puissant pour identifier les facteurs
clés et déterminer les meilleures conditions pour
obtenir les résultats souhaités. Il aide les chercheurs
et les ingénieurs à prendre des décisions
éclairées basées sur données
réelles plutôt que sur des conjectures Étapes du projet DOE, examinons le
processus d'un projet DOE, la
planification, la sélection,
l'optimisation et la vérification. Dans un premier temps, la planification. Les choses sont importantes. d'abord, il
faut bien comprendre le problème et le système. Ensuite, déterminez une ou
plusieurs variables de réponse. Troisièmement, identifiez les facteurs qui peuvent influencer de manière significative
la variable de réponse. La détermination des facteurs
potentiels influençant la variable de réponse peut être très complexe et prendre beaucoup de temps. Par exemple, un diagramme en arête de poisson
peut être créé dans une équipe. Vient maintenant la deuxième étape. Dépistage, si de nombreux facteurs peuvent
avoir une influence. Habituellement, plus de
quatre à six facteurs. Des expériences de dépistage devraient être réalisées afin de réduire
le nombre de facteurs. Pourquoi est-ce important ? Le nombre de facteurs
à étudier a une influence majeure sur le nombre
d'expériences requises. Notez que dans le plan
d'expériences, les expériences individuelles
sont également simplement appelées essais dans le plan factoriel
complet, ce dont nous parlerons
plus en détail dans un instant Le nombre d'
expériences ou d'essais est n égal à deux
à la puissance de k, où n est le nombre d'essais et k est le nombre de facteurs. Voici un petit aperçu
si nous avons trois facteurs. Par exemple, nous devons effectuer au moins huit essais
avec sept facteurs. Cela fait déjà au moins 128
descentes, avec dix facteurs. Cela fait déjà au
moins 1024 essais. Veuillez noter que ce
tableau s'applique à AD OE, où chaque facteur ne comporte que
deux niveaux, sinon. Il y aura encore plus de tests, en fonction de la complexité d'une expérience
individuelle. Il peut donc être
intéressant de sélectionner ce que l'on appelle des plans de criblage
pour quatre facteurs ou plus. Plus tard, nous aborderons le plan factoriel fractionnaire
et le plan placide de Berman Qui peut être utilisé pour des expériences
de dépistage. Une fois que les
facteurs significatifs ont été identifiés à l'aide de plans de
dépistage, le nombre de
facteurs a, espérons-le, été réduit. D'autres expériences
peuvent désormais être menées. Les données obtenues peuvent ensuite être utilisées pour créer un modèle de
régression, qui aide à déterminer
les variables d'entrée manière à optimiser la
variable de réponse. Après l'optimisation vient la
dernière étape de vérification. Cela implique de vérifier
une fois de plus si les variables
d'entrée optimales calculées ont
réellement l'influence
souhaitée sur la variable de réponse. Selon que nous en sommes à l'étape de sélection ou à
l'étape d'optimisation. Il existe différents
types de designs. Merci de votre attention. Dans la prochaine leçon, nous aborderons plus en profondeur les applications
pratiques
de la conception d'expériences et la manière d'interpréter
efficacement les résultats. Restez à l'affût.
46. Types de designs dans un DOE: Types de modèles dans les expériences
du DOE. Lorsque nous en sommes à
l'étape de sélection ou à l'étape d'optimisation. Nous utilisons différents types
de méthodes de conception. Les plus connus
sont le plan factoriel complet, le plan factoriel
fractionnaire, le plan
Placet Berman, le plan
Box Benkin et le plan Box Benkin Commençons par examiner le plan factoriel complet et
le plan factoriel fractionnaire Nous devons également expliquer pourquoi
nous déployons tous ces efforts. Pourquoi utilisons-nous le plan
d'expériences, le DOE, et pourquoi avons-nous
besoin de statistiques ? La raison en est que les expériences
prennent du temps et coûtent de l'argent. Par conséquent, nous devons
maintenir le nombre d'essais et d' expériences
individuelles
aussi bas que possible. Cependant, si nous effectuons trop peu de courses, nous risquons de passer à côté de différences
importantes et de ne pas obtenir de résultats précis. Imaginons, par exemple,
que nous voulions
savoir quels facteurs influent sur le mécanisme de friction
d'un roulement Nous devons
concevoir nos expériences avec soin
afin d' identifier ces
facteurs de manière efficace sans effectuer de tests inutiles. Comment est estimé le nombre d'
expériences au DOE ? Jetons un coup d'œil à un exemple. Nous voulons étudier les facteurs
qui influencent le frottement
d'un roulement Commençons par un
facteur, la lubrification. Nous voulons savoir si la
lubrification affecte le couple de frottement si un
roulement est huilé ou graissé Pour le savoir, prélevons-nous un
échantillon aléatoire de dix roulements ? Nous huilons la moitié des roulements
et graissons l'autre moitié. Nous pouvons maintenant mesurer
le coefficient de frottement
des cinq roulements huilés et
des cinq roulements graissés Mais pourquoi utiliser dix roulements, dans la plupart des cas, chaque cycle
coûte cher. Peut-être pourrons-nous nous débrouiller
avec moins de courses. Combien d'expériences
devons-nous effectuer pour déterminer si le lubrifiant a un
effet sur l'outil de friction ? Commençons par
les dix roulements. Nous pouvons maintenant calculer
la valeur moyenne
du couple de frottement des roulements
huilés et graissés Ensuite, nous pouvons calculer la différence entre
les deux valeurs moyennes. Dans cet exemple, nous pouvons voir une différence entre les roulements huilés
et les roulements graissés Cependant, nous remarquons également que le couple de frottement dans les
roulements huilés et graissés est Si nous prenons un autre
échantillon aléatoire de dix roulements, la différence peut être plus importante, ou elle peut être dans la direction
opposée. En d'autres termes, le
bruit
de frottement des roulements varie considérablement l'écart est large, plus il est difficile d' identifier une
différence ou un effet spécifique. Heureusement, nous pouvons réduire la variabilité
de la valeur moyenne en augmentant la taille de l'échantillon. Plus la taille de l'échantillon est grande, plus
l'
estimation de la moyenne est précise. Par conséquent,
plus l'effet est faible et plus la variable
de réponse est étendue, plus
la
taille de l'échantillon doit être grande. Mais dans quelle mesure, comment pouvez-vous estimer le
nombre de tirages nécessaires ? Vous pouvez utiliser cette formule comme approximation pour estimer
le nombre d'essais nécessaires, n étant égal à Sigma divisé par Delta Ici, au carré, n est
le nombre de passages. Sigma est l'écart type. Le delta est l'effet
à déterminer. Par exemple, si nous avons
un écart type de trois newtons millimètres et une différence
pertinente de
cinq newtons-millimètres. Nous avons besoin de 22 descentes. Si l'écart type
est de deux newtons-millimètres. Nous n'avons besoin que de dix essais si l'écart type est d'
un newton-millimètre Nous avons besoin de quatre descentes. Nous utiliserions donc deux pistes avec des roulements
graissés et deux
pistes avec des roulements huilés Mais comment le DOE peut-il vous aider à
réduire le nombre de courses ? Nous le verrons en détail
dans la prochaine leçon. Merci de votre attention. Dans la prochaine leçon, nous aborderons plus en profondeur les applications
pratiques
de la conception d'expériences et la manière d'interpréter
efficacement les résultats. Restez à l'affût.
47. Comment réduire le nombre de courses: Mais comment le DOE peut-il vous aider à
réduire le nombre de courses ? Supposons que le
calcul du nombre d'essais donne lieu à
16 expériences. Huit cycles avec roulements huilés et huit cycles avec roulements
graissés Mais que se passerait-il si nous avions
un deuxième facteur ? Disons qu'en plus
de la lubrification, nous avons des niveaux de température
bas et élevés. Ensuite, nous avons besoin de huit essais supplémentaires pour tenir
compte de ces facteurs. Nous avons donc besoin de 16 essais pour vérifier si le
lubrifiant a un effet. Et 16 essais pour vérifier si la
température a un effet. Cela nous donne un
total de 24 descentes. La question qui se pose maintenant est de savoir s'il est possible d'y
parvenir avec moins de séries, qui nous amène au plan factoriel
complet La question qui se pose est la suivante : pourquoi devrions-nous nous
limiter à tester
un seul facteur à la fois ? Nous pourrions plutôt
concevoir un design qui intègre toutes les combinaisons
possibles, telles que la graisse et les températures
élevées. Bien entendu, nous avons encore besoin de
16 essais par facteur. Nous y parvenons en effectuant quatre essais avec chacune
des quatre combinaisons. Ensuite, nous avons huit essais avec de
l'huile et huit avec de la graisse, et de l'autre côté, huit à basse température et huit à haute température. Nous avons maintenant un total de 16
descentes avant d'en avoir 24. Nous avons maintenant besoin de moins d'expériences et d'encore plus d'informations. Pourquoi plus d'informations ? Nous savons désormais également
s'il existe une interaction entre
la température et la lubrification. Par exemple, les
roulements huilés peuvent présenter une variation du couple de frottement
à différentes températures, ce qui n'est pas le cas
avec les roulements graissés Ces informations
auraient déjà été perdues. Maintenant, lorsque nous avons trois
facteurs au lieu de deux, les économies sont encore plus importantes. Si nous testons l'un des
trois facteurs à la fois, nous avons besoin de 32 essais. Si nous exécutons maintenant deux
expériences pour chaque combinaison dans un plan factoriel
complet, nous n'avons encore besoin que de 16 essais Cependant, pour chaque facteur, il
nous reste huit
essais par niveau de facteur. Par exemple, pour le facteur de
lubrification, nous avons huit essais avec de l'huile
et huit essais avec de la graisse. Bien entendu, nous pouvons également créer des plans factoriels
complets
comportant plus de deux niveaux Par exemple, le facteur de
température peut avoir trois niveaux :
faible, moyen et élevé. Cependant, comme indiqué
au début, même avec un
plan factoriel complet comportant deux niveaux pour chaque facteur, le nombre d'essais
requis augmente très rapidement à mesure que le nombre
de facteurs augmente Examinons donc maintenant le plan factoriel
fractionnaire Le plan factoriel fractionnaire est utilisé pour les plans de sélection Autrement dit, si vous avez plus de
quatre à six facteurs, bien
sûr, réduire le nombre d'essais signifie
réduire les informations. Dans les plans factoriels fractionnaires, la résolution est réduite Quelle est la résolution ? La résolution est une
mesure de la capacité du DOE à
distinguer les différents effets. Plus précisément, la
résolution indique dans quelle mesure les effets principaux et les effets
d'interaction sont confondus dans un design Mais que sont les effets moyens
et les effets d'interaction ? Que signifie confondu ? Dans la conception des expériences, le terme effet fait référence
à l'impact d'un certain facteur ou
d'une combinaison de facteurs sur la
variable de réponse d'une expérience. Ils mesurent essentiellement dans
quelle mesure la
variable de réponse change lorsque vous modifiez les facteurs. L'un des principaux effets est
l'influence d' un seul facteur sur la variable de
réponse. Par exemple, quelle est l'influence la lubrification d'un roulement
sur l'outil de friction ? Les effets d'interaction se produisent
lorsque l'effet d'un facteur sur la variable
de réponse dépend du niveau
d'un autre facteur. Par exemple, l'effet
du lubrifiant sur
le frottement
peut dépendre de la température Mais qu'est-ce que cela signifie ? Merci de votre attention. Dans la prochaine leçon, nous
approfondirons applications
pratiques de la conception d'expériences. Restez à l'affût.
48. Type d'effets: Mais quels sont les principaux effets
et effets d'interaction, et que signifie confondu Dans le cadre de la conception d'expériences. Le terme effet fait référence à l'impact d'un
certain facteur ou d'une combinaison de facteurs sur la variable
de réponse d'une expérience. Essentiellement, ils mesurent dans
quelle mesure la
variable de réponse change lorsque vous modifiez les facteurs ? L'un des principaux effets est
l'influence d' un seul facteur sur la variable de
réponse. Par exemple, quelle est l'influence la lubrification d'un roulement sur le couple de frottement ? Les effets d'interaction se produisent
lorsque l'effet d'un facteur sur la variable
de réponse dépend du niveau
d'un autre facteur. Par exemple, l'effet
du lubrifiant sur
l'outil de friction
peut dépendre de la température Mais qu'est-ce que cela signifie ? Supposons que nous ayons une valeur moyenne de couple de
frottement de 102 newtons-millimètres pour les roulements avec de
l'huile
et une valeur moyenne de 108 newtons-millimètres pour les roulements avec de
la graisse Nous avons alors un effet principal de lubrification de six
newtons-millimètres. Mais maintenant, nous pouvons le
décomposer en températures élevées et
basses. À haute température,
nous pouvions obtenir 98 pour l'huile et 102 pour la graisse. La différence entre l'huile et la graisse n'est que de quatre
newtons-millimètres. À basse température, nous
pourrions obtenir 104 et 112. Une différence de huit, donc le facteur de lubrification est
influencé par la température, et nous avons une interaction entre la lubrification
et la température. L'interaction
entraîne une différence de deux nouveaux 10 millimètres par rapport
au résultat d'origine. Nous avons donc un effet d'
interaction de deux newtons-millimètres. plans factoriels complets tiennent compte de
toutes les interactions Dans notre exemple de friction des roulements, outre les facteurs de
température du lubrifiant, nous avons également examiné
l'interaction
entre le lubrifiant
et Cependant, à mesure que le nombre
de facteurs augmente, de nombreuses interactions apparaissent
rapidement. Par exemple, si nous
avons cinq facteurs, A, B, C, D et E, nous obtenons l'interaction
entre deux facteurs. Entre trois facteurs, entre quatre facteurs et
entre les cinq facteurs. Maintenant, bien sûr. La question est de savoir si nous avons vraiment
besoin de toutes ces interactions ou si nous pouvons réduire la résolution. C'est exactement ce que le plan factoriel fractionnaire dans un plan fait
le plan factoriel fractionnaire dans un plan factoriel fractionnaire Les interactions peuvent
être confondues avec d'autres interactions ou avec les
principaux effets de facteurs Que signifie confondu ? Cela signifie que les effets de différents facteurs ou l'effet de l'interaction de facteurs ne peuvent pas être
séparés les uns des autres. La mesure dans laquelle le
nombre de tirages peut être réduit au détriment de résolution est indiquée
dans ce tableau. La résolution est généralement
indiquée par des chiffres romains. Exemple trois, quatre,
cinq, etc. Ici, en diagonale. Nous voyons les plans
factoriels complets. Nous verrons ce que signifient
les résolutions 3, 4 et 5 dans un instant. Par exemple, si nous
avons six facteurs, nous avons besoin d'au moins 64 essais pour
un plan factoriel complet Si nous choisissons un plan
factoriel fractionnaire avec une résolution de six Nous avons besoin de 32 essais avec
une résolution de quatre. Nous avons besoin de 16 essais, et avec une résolution de trois. Nous n'avons besoin que de huit descentes. Mais qu'est-ce que cela signifie ? Comment fonctionne-t-il ? Le plan factoriel
complet est toujours utilisé comme point
de départ Regardons l'
exemple avec huit essais. Dans la prochaine leçon, nous
approfondirons applications
pratiques de la conception d'expériences. Restez à l'affût.
49. Conception factorielle fractionnée: Décrivons les points
clés des plans factoriels
fractionnaires en termes simples Que sont les plans
factoriels fractionnaires ? Les plans factoriels fractionnaires constituent un moyen efficace de tester
plusieurs facteurs simultanément Ils
réduisent considérablement le nombre d'essais expérimentaux nécessaires. Pourquoi utiliser des plans
factoriels fractionnaires ? L'utilisation de plans
factoriels fractionnaires permet d'économiser du temps
et des ressources par rapport aux plans
factoriels complets En outre, ils permettent de tester
les interactions
entre les facteurs, fournissant ainsi des informations précieuses
avec moins d'expériences. Premièrement, Résolution dans les plans
factoriels fractionnaires. Définition, la résolution fait référence à quantité d'informations capturées dans un
plan expérimental. En termes plus simples, cela
nous indique combien de facteurs tels que A, B, C, nous pouvons tester ensemble et dans quelle mesure nous pouvons séparer leurs effets les uns des autres. Haute résolution,
par exemple, trois ou trois. Cela signifie que nous pouvons tester
plusieurs facteurs ensemble, mais cela signifie également
que les effets de ces facteurs peuvent être
confondus avec les interactions. Ces facteurs interagissent les uns
avec les autres. Par exemple, avec la
résolution 3, les effets des principaux
facteurs pourraient être confondus avec des interactions impliquant
deux autres facteurs. Résolution inférieure, par exemple. Dans 5 ou 4, ici, nous ne pouvons pas tester autant de
facteurs ensemble, mais il est plus clair de voir
les principaux effets de chaque facteur, car ils sont moins mêlés aux interactions. Par exemple, à la
résolution 4, les effets des principaux facteurs sont confondus avec les interactions
impliquant trois facteurs Deux,
effets confusionnels, définition. Lorsque nous disons que les effets
sont confondus, cela signifie que nous ne pouvons pas dire exactement quel facteur est à l'origine d'un
certain changement dans les résultats Cela se produit parce que
différentes combinaisons de facteurs peuvent avoir
des effets similaires sur le résultat. Par exemple, imaginez des facteurs de
test, A, B et C, si nous ajoutons un quatrième facteur, D, les résultats pourraient indiquer changements que nous ne pouvons pas
attribuer uniquement à D. L'effet de D peut
être confondu avec la façon dont A, B et C interagissent les uns
avec les autres. Troisièmement, impact de la résolution
sur la conception de l'expérience. Explication. Le choix d'une
résolution influe sur efficacité de notre expérience et sur la clarté de nos résultats. Une résolution plus élevée nous permet de
tester plus de facteurs ensemble, mais nécessite davantage de tests pour
être sûrs de nos résultats. Une résolution inférieure
nécessite moins de tests, mais peut rendre plus difficile l'
imbrication des effets
de différents facteurs Quatre
exemples pratiques, illustration, pour mieux comprendre, pensez à
tester différentes recettes de cuisson
d'un gâteau. Si vous modifiez un ingrédient, comme le sucre, le
goût peut changer. Mais si vous changez
à la fois le sucre et la farine, il est plus difficile de dire quel
changement en est la cause et quel en est le résultat. La conception
nous aide à trouver un équilibre entre le test de nombreux facteurs et la compréhension de
leurs impacts distincts. En comprenant ces points, les chercheurs peuvent concevoir
des expériences qui fournissent réponses
claires sur la façon dont les
facteurs influent sur les résultats, même lorsqu'ils testent
plusieurs facteurs à la fois. Nous verrons ce que signifient
les résolutions 3, 4 et 5 dans un instant. Par exemple, si nous
avons six facteurs, nous avons besoin d'au moins 64 essais pour
un plan factoriel complet Si nous choisissons un
plan factoriel fractionnaire avec une résolution de six, nous avons besoin de 32 essais Avec une résolution de quatre, nous avons besoin de 16 essais, et avec une résolution de trois, nous n'avons besoin que de huit essais. Mais qu'est-ce que cela signifie
et comment fonctionne-t-il ? Le plan factoriel complet est toujours utilisé comme point
de départ Prenons un
exemple avec huit essais. Supposons que nous ayons
les facteurs A, B et C avec un
plan factoriel complet, nous pouvons tester si le facteur A, B ou C a un effet Nous pouvons également tester si les interactions entre
deux facteurs ont un effet et si les
interactions entre les trois
facteurs ont un effet. Si nous voulons maintenant tester non seulement trois facteurs
avec huit essais, mais aussi un quatrième
facteur supplémentaire, le facteur S D, nous devons sacrifier
certaines informations provenant de l'une des interactions. Par exemple, l'
interaction entre A, B, et si nous voulons tester un cinquième
facteur avec huit essais, disons le facteur A, nous devrions sacrifier
une autre interaction. Par exemple, en ce qui concerne l'interaction
entre B et C, nous ne supprimons pas
réellement les informations. Nous mélangeons le nouveau facteur
à l'interaction. Cela signifie que nous avons
confondu le facteur avec l'interaction.
Qu'est-ce que cela signifie ? Cela signifie que nous ne pouvons pas déterminer
si un effet observé est dû au facteur D ou à l'
interaction entre A, B et C. De même, nous ne
pouvons pas dire si un effet est dû au facteur A ou à l'
interaction de B et C de cose. Il est beaucoup moins problématique
de mélanger un facteur avec une interaction de trois facteurs qu'avec une interaction
de deux facteurs. De même, nous ne pouvons pas
distinguer si un effet
résulte du facteur A ou de l'interaction entre B et C. Maintenant, nous avons une bonne transition
vers la résolution. Que signifient les résolutions 3, 4 et 5 ? À la résolution 3, les
principaux effets peuvent être confondus avec
les interactions de deux facteurs Par exemple, le facteur D pourrait être confondu avec l'
interaction des facteurs A et B Les expériences
avec une résolution trois doivent
donc être
considérées comme critiques Ils ne peuvent être utilisés que
si l'interaction de deux facteurs est significativement inférieure aux effets
des principaux facteurs. Sinon, l'interaction
de deux facteurs peut fausser de manière significative
le résultat d'un facteur Les expériences à résolution
4 sont beaucoup moins critiques. Ici, seuls les effets principaux sont confondus avec les
interactions de trois facteurs, et plus il y a de facteurs
impliqués dans une interaction Plus l'effet risque
d'être faible. De plus, dans la résolution quatre, les interactions de deux facteurs sont confondues avec les interactions
de deux autres facteurs O Les expériences à résolution 5 ne sont pas
considérées comme critiques. Les principaux effets ne sont confondus qu'avec les interactions
de quatre facteurs De même, les interactions entre deux
facteurs
ne sont confondues qu'avec
les interactions entre trois facteurs Mais comment confondre un
facteur et une interaction ? Jetons un coup d'
œil à cet exemple. Nous avons ici le plan factoriel
complet des trois facteurs
A, B et C. Ces huit essais
sont effectués au total Nous ne prenons toujours en compte que les
facteurs à deux niveaux, moins l'
un représente un niveau et l'un
représente l'autre. Pour notre exemple de discussion sur la friction, le plan de test ressemblerait ceci pour la température du facteur, moins un pour la
basse température et un pour la température élevée Si nous exécutons maintenant les expériences, nous obtenons une valeur pour la variable de
réponse pour chaque essai. Si le facteur A est égal ou inférieur à un, cela a un certain effet
sur la valeur cible. Il en va de même si le facteur
B est égal à un ou à moins un. L'effet d'interaction
nous indique s'il existe
un effet supplémentaire. facteurs I A et B
sont simultanément égaux un ou moins un, ou si les deux vont exactement dans la direction
opposée. D'un côté, nous avons les
paires avec le même signe, et de l'autre côté,
les paires avec Nous pouvons vérifier s'il existe une différence dans la variable de
réponse entre les valeurs du groupe vert et les
valeurs du groupe rouge. S'il y a une différence, alors il y a une interaction
entre A et B. Cependant, si nous savons à l'avance y a
qu'une très
faible interaction ou qu'il n'y en a aucune, nous pouvons utiliser ces combinaisons. Pour tester un quatrième
facteur, D pour cela, il suffit
de le multiplier. A et B. Nous avons toujours
un, si les facteurs A et B ont le même signe et moins un s'ils ont
un signe différent. Bien entendu, un problème peut survenir. Lors de l'analyse des résultats. S'il existe une différence entre les valeurs vertes et rouges. Dans la variable de réponse, nous ne pouvons pas déterminer si
cet effet provient de l'interaction entre A et B ou du facteur D si nous sommes a. Montrez qu'il ne peut y avoir aucune
interaction entre A et B. Cela ne pose aucun problème. Ensuite, nous pouvons être sûrs que la différence est due
au facteur D de la même manière. Nous pouvons prendre l'interaction
de A et C et également mesurer le facteur A et
l'interaction de A, B et C pour mesurer le
facteur F par conséquent. Dans ce cas, nous mesurons six facteurs en
seulement huit essais, mais nous ne pouvons plus distinguer facteur D de l'interaction entre A et B, le facteur A
de l'interaction entre A et C ou le facteur F
de l'interaction de A, B et C. Dans la prochaine leçon, nous examinerons en détail les autres types de
modèles disponibles dans le DOE. Dans la prochaine leçon, nous
approfondirons applications
pratiques de la conception d'expériences. Restez à l'affût.
50. Conception centrale de Plackett Burman: Bienvenue aujourd'hui. Nous nous intéressons à
différents types de conception d'expériences. Ou DOE, commençons par
le design Placet Berman. Qu'est-ce qu'un design Placet Berman ? Les modèles Placet Berman sont généralement utilisés avec deux niveaux et avec une résolution de trois Le principal avantage de ces modèles est
que l'interaction entre deux facteurs est répartie entre
plusieurs autres facteurs. Par exemple, l'interaction
entre les facteurs A et B est confondue avec tous les autres facteurs sauf
A et B eux-mêmes Cela rend les
designs de Plackett Burman idéaux lorsqu'il
s'agit de nombreux facteurs et lorsque seuls les principaux
effets sont intéressants Cependant, ces modèles
doivent être utilisés avec prudence, si vous supposez que les interactions à deux facteurs
peuvent être négligées. Cependant, cette exigence
est moins stricte que dans les fractionnaires
classiques plans
factoriels fractionnaires
classiques de
résolution trois Passons à autre chose, qu'est-ce qu'une
boîte conçue par Benkin ? Le boîtier, de conception Benkin, ainsi que le design
composite central sont utilisés pour analyser et optimiser
quelques facteurs en détail Et pour identifier les dépendances non
linéaires de détecter les relations non
linéaires. Au moins trois niveaux
par facteur sont nécessaires avec un plan factoriel complet
utilisant trois niveaux Le nombre d'essais
peut augmenter rapidement. Par exemple, avec deux
facteurs à trois niveaux chacun, vous avez besoin de neuf essais et avec trois facteurs
à trois niveaux chacun, cela passe à 27 essais. designs Box et Benkan
répondent à ce problème en créant un plan
factoriel complet à deux niveaux Et en incluant les points centraux, exemple trois fois
pour deux facteurs, ou avec trois facteurs, ce qui réduit le
nombre de points 27 à 15 Bien que cela réduise
le nombre d'essais, cela peut identifier moins de relations non
linéaires. Discutons ensuite de la conception composite
centrale. Ce
plan implique généralement trois types de points de test, dont deux trois types de points de test, dont deux points factoriels plats
qui forment les coins d'
un cube ou d' un hypercube dans des espaces
multidimensionnels Points centraux situés
au centre de l'espace défini par
les points factoriels Points axiaux situés sur les axes de l'
espace factoriel en dehors de la file d'attente. Ces deux derniers types
de points permettent estimer
les effets non linéaires dans votre modèle. Dans la prochaine leçon, nous approfondirons les applications
pratiques de la conception d'expériences.
Restez à l'affût.
51. Conclusion: Je tiens à vous
remercier d'avoir
terminé ce programme. Cela montre que vous êtes très engagé dans votre
cheminement vers l'apprentissage. Vous voulez améliorer vos compétences et j'espère que vous
avez beaucoup appris. J'espère que tous vos concepts
sont également clairs. Je veux m'assurer de vous dire quels sont les autres programmes
que je souhaite partager avec Skillshare. Donc, sur Skillshare, j'ai nombreux autres programmes
qui
existent déjà et beaucoup
apparaîtront dans les semaines
et les mois à venir. En quoi consistent les programmes comme la
narration avec des données, comment je peux utiliser les analyses, la visualisation
des données, analyse
prédictive sans
codage, et bien d'autres encore. En dehors de cela, je travaille également
en tant que formatrice en entreprise. Je veille à ce que tous
mes programmes soient hautement interactifs et maintiennent l'engagement de
tous les participants
. J'ai conçu les livres qui sont personnalisés pour mon atelier, ce qui garantit également
que tous les concepts sont clairement compris
par les participants. Mes jeux sont conçus
de telle sorte que les concepts obtiennent
des prêts pendant qu'ils jouent. Il existe de nombreux jeux conçus pour mes programmes. Et si cela vous intéresse, vous êtes libre de me contacter. J'ai également suivi
plus de 2 000 heures de formation au cours des deux dernières
années pendant la pandémie. Ce ne sont là que quelques-uns
des ateliers. Donc, si votre organisation
souhaite suivre un programme de formation en entreprise hors ligne ou en ligne. Ou si vous pensez personnellement vouloir améliorer
votre apprentissage, vous êtes libre de
me contacter via mon adresse e-mail. Restez en contact avec moi sur LinkedIn Si vous avez
aimé ma formation, n'hésitez pas à
écrire un avis sur LinkedIn. De plus, je dirige également une chaîne
Telegram où je pose beaucoup de
questions où les gens peuvent apprendre les
concepts et ils le feront, leur prendra peut-être quelques
secondes pour le faire. En dehors de cela,
assurez-vous écrire pour laisser un
avis sur Skillshare, comment
s'est passée votre expérience de
formation ? N'oubliez pas de
terminer votre projet. J'aime les gens lorsqu'ils sont engagés et que vous avez prouvé
que vous êtes l'un d'entre eux. Merci de rester connecté. Prends soin de toi, et que Dieu te bénisse.
 Dimple Sanghvi, AI Consultant, Lean Six Sigma Master Black Belt
Dimple Sanghvi, AI Consultant, Lean Six Sigma Master Black Belt