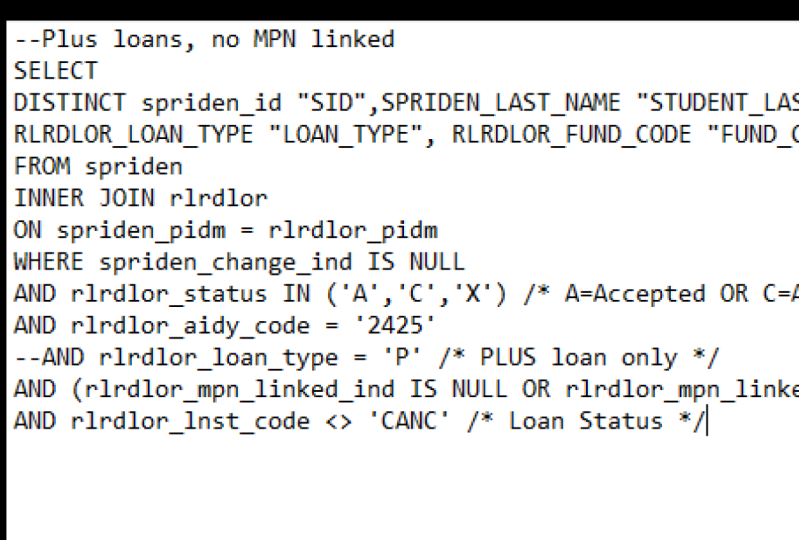
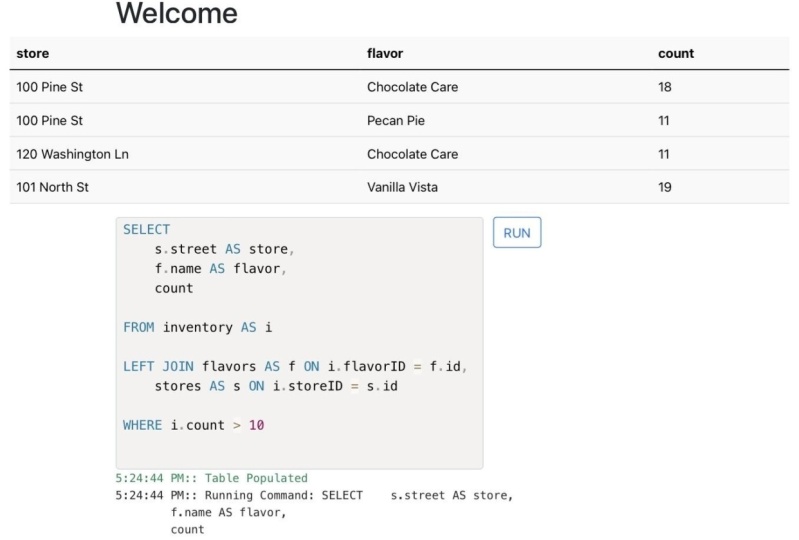
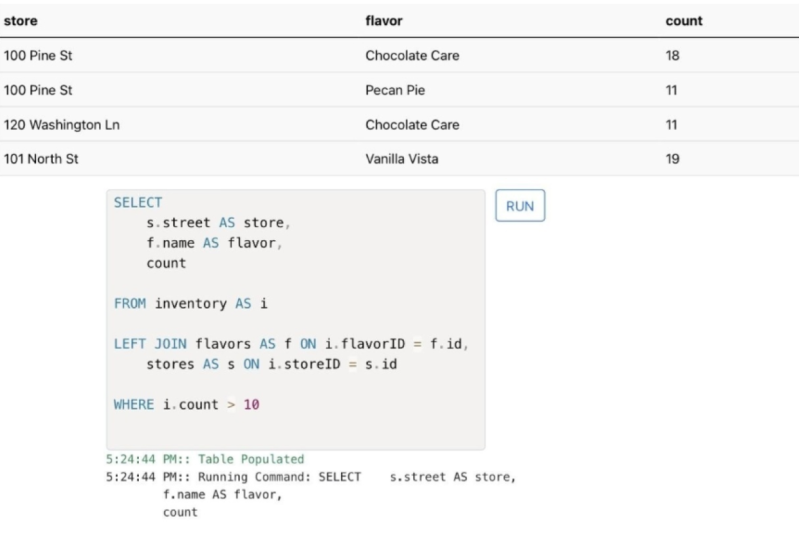
Transkripte
1. SQL 1 Intro: Hi, ich bin Peter. In diesem Kurs
gehen wir auf die Fortsetzung ein und erfahren, wie man Daten
extrahiert oder
Daten aus einer Datenbank herausholt Unternehmen sammeln
mehr Daten über Kunden, über ihr eigenes Produkt und
über die Welt im Allgemeinen. Und es wird immer
nützlicher , zu wissen, wie man an
diese Daten kommt und wie
man Berichte
erstellt und dieser Daten aussagekräftige
Entscheidungen trifft. Sie müssen kein Dateningenieur mehr
sein, um auf eine SQL-Datenbank zu stoßen. Sie
wissen, wie Sie
Ihre eigenen Berichte erstellen.
Dies kann Ihnen helfen, Fragen zu beantworten, Ihre Kunden und Ihr
Produkt
zu verstehen besser und bringen Sie Ihre Karriere
voran. Es hilft auch,
besser zu verstehen, wie Computersysteme
funktionieren und was
nicht, ist in der
Programmierwelt nicht möglich. Gemeinsam werden wir
einige Beispiele mit
einer Eisdiele durcharbeiten , die viele
Fragen zu ihren Daten hat . Für diesen Kurs benötigen
Sie keine Programmiererfahrung. Sql selbst ist so
konzipiert, dass es ziemlich lesbar ist, also sollte es zumindest eine nette Einführung in
die Programmierung sein. Es ist auch ein guter
Einstieg, wenn Sie Datenanalyst oder Site werden
möchten. In diesem Kurs wird die
Sequenzauswahlabfrage
behandelt, die nur dazu dient,
Informationen aus einer Datenbank abzurufen. Wir werden nicht darauf eingehen, wie
man Daten
eingibt, wie man Daten löscht
oder wie man Daten ändert. Wir werden jedoch
daran arbeiten, wie Daten verarbeitet werden, wie man sie analysiert, wie man sie filtert und wie
man sie mit anderen Daten in Beziehung setzt. Auch in der Datenbank arbeite
ich seit 2010 in
SQL-basierten Datenbanken,
entweder an meinen eigenen Projekten, haben meine Karriere, meine Arbeit vorangetrieben
oder einfach nur, um
datengesteuerte Entscheidungen zu treffen. Es gibt viele
verschiedene SQL-basierte Programmiersprachen. Sobald Sie was wissen, ist es
ziemlich einfach, einen Übergang herzustellen, der einen
verbindet, und sie werden nur
ein paar Schlüsselwörter sein , die etwas anstrengend sind.
Lassen Sie uns anders sein, ob Sie
den Dash- oder
Microsoft-Server gleich verwenden , der tatsächliche Abfragelauf
wird derselbe sein
oder sehr ähnlich sein. Ich freue mich, diesen Kurs zu
unterrichten. Und ich hoffe, wir sehen uns
im nächsten Video.
2. SQL 2 Auswählen: SQL-Datenbanken sind im Grunde
genommen sehr schnelle, wirklich große Excel-Tabellen. Sie haben verschiedene Spalten
, die definieren, was in
die Datenbank aufgenommen werden kann , und dann Rosen, die diese Spalten
mit tatsächlichen Daten
füllen. Sie können auch
mehrere Tabellen in
einer Datenbank haben , genau wie Excel mehrere Blätter
in einem Arbeitsblatt
haben kann . Für unsere erste Abfrage werden
wir also alle Zeilen und
alle Spalten aus
einer bestimmten Tabelle abrufen. Gehen wir also
zum Emulator und du findest ihn auf
dieser Website hier. auch einen Link in
der Beschreibung falls Sie ihn nicht eingeben
möchten. Also
fangen wir mit dem Queer an
, das dort bereits besiedelt ist Wähle einen Stern oder ein
Sternchen aus den Geschäften aus. Wenn wir
das ausführen, werden alle Spalten in
der Stores-Tabelle zusammen mit
allen Zeilen in dieser
Tabelle
zurückgegeben der Stores-Tabelle zusammen mit . Lassen Sie uns das analysieren
und jeden Teil durchgehen. Select ist das Schlüsselwort, das wir verwenden, um Daten aus
der Datenbank zu extrahieren
oder abzurufen, wenn wir löschen, einfügen
oder ändern möchten,
also Daten mit
unterschiedlichen Schlüsselwörtern. Solange wir also mit Select
beginnen, werden
wir Daten abrufen,
die Datenbank und das, was drin ist, nicht zu
berühren, ändert nichts
daran, was
in der Datenbank ist. Stern oder Sternchen hier, in der
Programmierung
normalerweise Stern genannt, ist ein Platzhalter. Es bedeutet, schnapp dir alles. Das sind normalerweise
die Spalten hier, also schnappen wir uns einfach
alle Spalten. Von ist das andere Schlüsselwort
, das uns
mitteilt , wo sich diese Daten befinden, oder aus welcher Tabelle möchten
wir sie abrufen? Und Stores ist unser Tabellenname. Diese Tabelle hier
heißt also Stores. Wir holen uns also alle Zeilen und Spalten
aus der Stores-Tabelle. Nehmen wir an, wir wollten nur
bestimmte Spalten das sieht ein bisschen zu viel aus. Wir können das vereinfachen. Nehmen wir an, wir wollen nur diese, die Straße, die Stadt und den Staat. Wir können diese drei
Spaltennamen eingeben,
anstatt den Platzhalter, der sie
jeweils durch ein Komma trennt. Und dann können wir das ausführen. Jetzt haben wir ein Datum viel sauberer
und wir
schauen uns nur die Informationen an
, die wir syntaktisch haben wollen Diese werden normalerweise in einer neuen Zeile
getrennt, aber das ist nicht notwendig, um sie auszuführen. So sieht es einfach nett aus
, den Tisch auszutauschen. Wir werden das
einfach ersetzen. Wenn wir die Seite neu laden, werden
uns die drei
Tabellen angezeigt, die sich im
Inventar und in den Varianten
dieses Datenbankspeichers befinden . Anstatt also
Sterne aus den Geschäften auszuwählen, schauen wir uns die Geschmacksrichtungen an. Hier können wir sehen, dass
wir unsere drei
Geschmacksrichtungen aus unserer Verkaufstabelle haben , und wir können zu den Geschäften zurückkehren. Schauen Sie sich diese Tabelle gegen
Ende dieses Kurses an.
Wir werden besprechen, wie
Daten aus zwei Tabellen kombiniert werden. Aber im Moment
arbeiten wir einfach eins nach dem anderen. Einige Dinge, die Sie hier beachten sollten, ist, dass
SQL nicht zwischen Groß- und Kleinschreibung unterscheidet, also könnte dies in Kleinbuchstaben sein und es würde trotzdem einwandfrei
funktionieren. Oder die Tabelle könnte
komplett in Großbuchstaben geschrieben sein und es
würde problemlos funktionieren. Normalerweise werden die SQL-Befehle
selbst in Großbuchstaben und die
Tabellen und Spalten in Kleinbuchstaben geschrieben, nur um
das Lesen zu erleichtern. Verwenden Sie also das, was Sie gelernt haben ,
um eine Abfrage zu erstellen, die
alle Geschmacksrichtungen auswählt und
den Namen der Geschmacksrichtungen und das
Datum ihrer Erstellung anzeigt . Ich mache eine Pause für ein paar Sekunden. Machen Sie weiter und unterbrechen Sie
das Video jetzt und nehmen Sie sich
etwas Zeit, um wieder aufzubauen. In Ordnung, lassen Sie uns weitermachen und diese Abfrage gemeinsam
erstellen. Also normalerweise, wenn ich
den Spaltennamen nicht kenne oder mir nicht
sicher bin, wie er geschrieben ist. Ich fange einfach
mit dem Platzhalter und gehe zur richtigen Tabelle. Also wählen wir Star aus Flavors und TIC, dass der Name oder Titel von The flavor Name
heißt und kreierte gerade erstellt
wird. Also werde ich sie zugunsten von denen
austauschen. Lassen Sie uns also ein Namenskomma erstellen. Lass uns weitermachen und das erledigen. Und dann haben wir
unsere drei Geschmacksrichtungen und die drei Daten
, an denen sie kreiert wurden.
3. SQL 3 WO: Abrufen von Daten aus einer
Tabelle ist also ziemlich cool, aber nehmen wir an, Sie benötigen nur ein paar dieser Zeilen, um angezeigt zu werden. Wie würdest du es filtern? Hier bietet sich die
Where-Klausel an. Hier können
Sie also
bestimmte mathematische
Operatoren und
grundlegende Mathematik herausfiltern bestimmte mathematische
Operatoren , die Sie dort einfügen
können. Wenn wir uns zum Beispiel die Tabelle unserer Geschäfte ansehen, gibt es dort viele
verschiedene Geschäfte. Nehmen wir an, wir wollen nur Geschäfte mit
dem höchsten Gewinn haben. Wir können filtern, wo der Gewinn größer
als eine bestimmte Zahl ist. Also lass uns 150.000 machen. Wir haben nur die drei Geschäfte
, die hochprofitabel sind. Welche Art der Filterung
Sie durchführen, hängt von den Daten in der Spalte ab
, die Sie filtern. Da dies eine Zahl ist, kann
ich größer als,
größer als oder gleich verwenden . Oder ich könnte
vielleicht sogar Geschichten mit geringem Gewinn machen vielleicht sogar Geschichten mit geringem Gewinn , die weniger als
oder gleich 150.000 sind. Ich könnte auch die
genauen Bedingungen überprüfen, bei denen der Gewinn genau 8.000 beträgt. Das ist also eine Filterung, die auf einer Zahl
basiert. Gehen wir zu einer
Zeichenfolge oder einem Textstück über. Manchmal werden sie Strings
genannt. Schauen wir uns also vielleicht die Staaten an. Ich könnte den
Gleichheitsoperator verwenden und alle Bundesstaaten
in Pennsylvania
abrufen. Aber wenn ich mit Texten
arbeite, verwende
ich es normalerweise lieber. Also ist das
dasselbe wie gleichwertig? Es liest sich einfach einfacher wenn Sie Texte
und Unternummern verwenden. Wenn ich das
Gegenteil will, kann ich dort
einschalten , damit ich alle Geschäfte
bekommen kann, in denen der Staat in diesem Fall nicht Pennsylvania ist,
es gibt nur New York. Normalerweise
habe ich bei der
Arbeit mit Texten Like verwendet, um meine Daten zu filtern. Auf diese Weise kann ich
Teilzeichenketten innerhalb der Zeichenfolge
selbst finden oder nach
bestimmten Schlüsselwörtern
in einem Text suchen . Nehmen wir an, ich möchte, dass alle Bundesstaaten,
die
wie die Hauptstraßenlaterne sind , es
mir ermöglicht , nach einer Teilzeichenfolge
oder einem Wort in einem
Text zu suchen , damit ich alle
Straßen finden kann, die im Norden liegen. Das funktioniert so, dass es nach der
ersten Zeichenfolge sucht , also nach
den einfachen Anführungszeichen, lass mich wissen, dass
da ein Stück Text oder eine Zeichenfolge ist, dann ist das Prozentzeichen
wie der Platzhalter für wie lass mich wissen, dass
da ein Stück
Text oder eine Zeichenfolge ist,
dann ist das Prozentzeichen
wie der Platzhalter für wie für das ausgewählte
Prozentzeichen ist, bedeutet, dass hier alles zum Beispiel, wie
ein Sternchen der Platzhalter
für das ausgewählte
Prozentzeichen ist, bedeutet, dass hier alles beliebig oft stehen
kann bis Sie die
Zeichenfolge North Loops finden, und dann kann es
mit dem enden, was Sie wollen. Wenn du willst,
dass es mit North Avenue
enden soll, nimmst
du das Prozent-Schild am Ende ab und dann muss es in
North Avenue enden , oder
sagen wir, wir wollen
mit 100 beginnen und es ist uns
egal, welche Straße es ist. Bosnien sucht dort, wo es
mit 100 beginnt und
mit etwas anderem endet. Also, bis jetzt haben wir die Zahlen
durchgesehen und wir haben den Text durchgesehen. Schauen wir uns auch
Daten und Nullwerte an. Schauen wir uns also alle Daten
an. Um das zu tun, werde ich meine Where-Klausel
kommentieren. also zwei
Bindestriche davor setzen, wird der Compiler
oder die Datenbank angewiesen, diese Zeile zu
ignorieren. also meine
Where-Klausel ignoriere, erhalte ich wieder
alle Daten und
jetzt kann ich sie mir ansehen. Werfen wir einen Blick auf alle Geschäfte, die
seit 2019 eröffnet wurden. Also werde ich filtern, wo
mein Eröffnungstermin größer ist als 2019. Jetzt müssen wir ein
genaues Datum im Jahr 2019 wählen. Also werde ich Twain am 18. Januar machen, Jahr,
Monat, Tag. Wir sehen uns. Seit Januar wurden
drei Geschichten eröffnet. Daten funktionieren sehr ähnlich wie Zahlen. Ich kann also auch mehr
als oder gleich bis zu diesem Datum machen. In Ordnung? Mach das Gegenteil. Und ich kann sagen, wo das
Datum der Eröffnung kürzer ist als dieses Datum. Das sind also meine ersten
Geschäfte, die ich eröffnet habe. Die andere Sache, die Sie
vielleicht bemerkt haben, ist dieser Nullwert in einigen
dieser Daten in
jedem Spaltentyp stehen kann . Es müssen
keine Termine sein. Es hat mich gekostet, dass Zahlen besteuert werden. Und das bedeutet, es
bedeutet, dass es keine Daten in dieser Zeile gibt
, dass sie leer ist. Es wird wirklich
hilfreich sein, manchmal löschen
Datenbanken keine Informationen, sondern leiten eine Löschung
auf der Grundlage dessen ab, was Null ist. Anstatt also z. B.
die Straße zu löschen , die in Queens
geschlossen wurde, gehe
ich davon aus, dass diese Tür geöffnet ist wenn
sie kein Schließdatum hat. Schauen wir uns also an, wo
alle meine Geschäfte Null sind. Und null sollte sein, oh tut mir leid, wir haben geschlossen ist Null. Das sind also alle
Geschäfte, die geöffnet sind. Und nehmen wir an, ich möchte alle meine Bekleidungsgeschäfte
finden. Ich werde sagen,
wo sie nicht
gezogen werden , wird
mir immer noch Y1 Close Store geben. Okay, bis jetzt haben
wir viel besprochen. Wir haben uns mit dem
Filtern von Zahlen befasst, wir haben uns mit
dem Filtern von Daten befasst, und wir haben darüber gesprochen, wie man Text oder Zeichenketten
filtert. Der letzte Teil, den
wir hier einwerfen ist das Hinzufügen von zwei Filtern
zu derselben Abfrage. Lassen Sie uns also durchgehen, wie Sie
all die gewinnorientierten
Geschäfte in New York finden . Ich werde damit beginnen, zu
filtern, wo der Bundesstaat New York entspricht. Um einen weiteren Filter hinzuzufügen, füge
ich hinzu, und dann kann ich
einen zweiten Filter hinzufügen , genau wie
den ersten. In diesem Fall
werde ich überprüfen, welcher Gewinn größer als 100.000 ist. Und ich kann so viele
Filter hinzufügen, wie ich möchte. Ich kann auch einen weiteren
Filter hinzufügen, um zu überprüfen, wo das Abschlussdatum nicht Null ist. Es ist eine gute Faustregel immer einige Bedingungen hinzuzufügen, auch wenn Sie sie möglicherweise nicht
benötigen, um
sicherzustellen , dass Sie Daten korrekt
filtern. Für dieses Video besteht
die Herausforderung also darin, alle Geschäfte
aufzulisten, die seit 2020 in
New York eröffnet wurden. Machen Sie hier eine Pause, um sich ein paar Minuten Zeit
zu nehmen, um es herauszufinden. Also werden wir zuerst filtern , wo der Bundesstaat New York
entspricht. Und wir werden auch
nach dem
Eröffnungstermin filtern, der höher als 2020 ist, und wir müssen nur am 1. Januar
beginnen. Eigentlich wollen wir die
am 1. Januar haben. Also machen wir mehr als
oder gleich und wir bekommen eine 118 ist East River,
Philadelphia, New
York, Free Crack Knee. Es ist eigentlich eine Stadt
in New York. Es ist winzig.
4. SQL 4 Datentypen: Bevor wir fortfahren,
möchte
ich noch einen Datentyp durchgehen ,
und diese booleschen und booleschen sind wahr oder falsch.
Sie sind an oder aus. Sie sind wie Lichtschalter. In unserer Geschmackstabelle haben
wir unsere Bestseller-Spalte, und dies ist ein boolescher Wert. Es wird manchmal auch als Eins oder Null
angesehen, oder Eins ist wahr. Null ist falsch. Um dort zu filtern, kann
ich auswählen, wo mein
Bestseller einer ist. Oder ich könnte hier auch
wahr sagen. Bei den Nicht-Bestsellern kann ich
filtern, wo es falsch ist. Ich könnte das auch so ändern
, dass es gleich Null ist. Milliarden sind also ziemlich einfach, aber die Art und Weise, wie Sie nach ihnen filtern
, sieht ein bisschen anstrengend aus
, je nachdem, welchen Weg Sie bevorzugen. Reihe. Jede Spalte kann unterschiedlich
gefiltert werden je nachdem, welche Art
von Daten sie speichert. Und dies wird definiert, wenn Ihre Datenbankadministratoren
die Datenbank einrichten. Wenn Sie sich nicht sicher sind, was ein
bestimmter Spaltentyp ist, gibt es verschiedene Befehle
, die Sie in
SQL ausführen können , um diese Informationen
aus der Datenbank zu holen. Weil dies eines der
Dinge ist, die je nachdem, in welcher Sprache Sie
sich befinden,
variieren werden. Daran kann
ich mich auch immer erinnern. Das muss
ich jedes Mal googeln. Und normalerweise schreiben Sie einfach Tabelleninformationen für die SQL-Sprache. Ich würde
Tabelleninformationen für SQL Light googeln. Also habe ich diesen Befehl bekommen. Ich werde diesen Teil
gegen meine Tafelaromen austauschen. Dann besorge ich mir einen Tisch
über meinen Tisch. Das sind also die
Informationen zu den Tafelaromen. Hier kann ich die
verschiedenen Spaltennamen
in meiner Geschmackstabelle sehen . Ich kann ihren Typ sehen. Integer ist hier eine programmierbare
Art, Zahl auszusprechen. Text bedeutet Text oder Zeichenfolge. Dies
kann manchmal auch wie ein n-var-Zeichen sein. Und das ist nur eine ältere
Art, Text zu sagen. Float ist eine andere Art von Zahl. Integer muss eine ganze Zahl sein wobei ein Float eine Dezimalzahl sein kann. Wir haben unser Date und dann haben wir auch einen booleschen Wert, über den
wir gerade gesprochen haben. Das letzte Thema, über das ich in diesem Video
sprechen möchte ist das Konzept impliziter
oder expliziter Daten. Dies ist wirklich
hilfreich, wenn Sie mit einer neuen Datenbank experimentieren
und
sich nicht ganz sicher sind, was
die verschiedenen Spalten bedeuten
oder wie Sie die verschiedenen Spalten bedeuten die genaue Datierung ermitteln können. Eins. Explizite Daten sind Daten, die am Tag eindeutig
angegeben werden. Wenn wir in unserem Beispiel also
einen Blick auf unsere Geschäftstabelle werfen, könnte ausdrücklich
angegeben werden, dass
es dem Bundesstaat um Pennsylvania
oder New York handelt. Es wird jedoch implizit
impliziert, dass das Geschäft immer noch geöffnet
ist,
weil kein Schließdatum vorliegt. Manchmal ist die Art, wie wir Daten
betrachten, nicht die beste Art,
sie in einer Datenbank zu speichern, z. B. wenn das Geschäft, obwohl es
schön wäre, hier einen booleschen Wert zu haben, wenn der Laden geöffnet oder geschlossen ist. Es würde auch bedeuten, dass
es zwei Kolumnen gab , die Ihnen dasselbe sagten. Und so
mussten sie immer gleich sein. Und sollte es
jemals einen Unterschied geben, könnte
dies zu Problemen führen, die Sie möglicherweise falsch mit Ihren
Daten empfinden. Also ist es besser,
eine Spalte und so zu haben. Lassen Sie uns
einfach etwas beachten. Ich hoffe, es hilft euch beim
Erkunden eurer eigenen Datenbanken.
5. SQL 5:6 Sortieren und Gruppieren: Bisher haben wir an Tabellen
gearbeitet , die nur sehr
wenige Zeilen enthalten,
sodass Sie sie alle auf einem Bildschirm sehen können. Selten ist das in freier Wildbahn der
Fall mit wirklich wichtigen Daten
,
über die wir in der Einführung
zu diesem Video gesprochen haben . Normalerweise
können Tabellen Tausende, wenn nicht Millionen von Zeilen enthalten. ist also sehr
hilfreich,
die gewünschten Daten oben zu haben, damit Sie sie
sehen können, und
hier wird es sich als nützlich erweisen, unsere Daten zu ordnen oder zu sortieren. Dazu können
wir nach
unserer Where-Klausel unsere
gefilterten Daten bestellen. Schauen wir uns also z. B. all unsere Geschmacksrichtungen
an. Wenn wir
diese nun nach ihren Kosten sortieren wollten
, sortieren wir unsere Daten. Wir werden Order Bias verwenden. Ich sage,
bestell diesen Tisch. Und dann wähle ich eine
bestimmte Spalte , nach der ich die Tabelle
sortieren möchte. Also werde ich nach
Kosten sortieren und standardmäßig können
Sie sehen, dass es bereits in aufsteigender Reihenfolge
sortiert ist,
was bedeutet, dass die Zahlen
größer werden, wenn Sie nach unten gehen um das zu ändern, oder
absteigend, ich kann DESC machen als meine Abkürzung, um ihm zu sagen, dass ich diese Spalte in
absteigender Reihenfolge haben
möchte. Und jetzt erhalte ich
zuerst die höchsten Kosten und zuletzt die niedrigsten Kosten. Sehen Sie, ob wir dies in
der Geschäftstabelle verwenden können , um
alle Geschäfte in New York aufzulisten, indem wir sie
zuerst nach dem Geschäft mit dem
höchsten Gewinn und zuletzt nach dem
Geschäft mit dem niedrigsten Gewinn in New York sortieren können. In Ordnung, lassen Sie uns
diese Karriere gemeinsam aufbauen. Schauen wir uns zuerst die Tabelle
dieser Geschäfte an und wir werden nach nichts
bestellen. Wählen wir also
Star aus den Geschäften aus. Wir haben unseren Staat und
wir haben unseren Gewinn. Fangen wir also mit unserem Filter an. Also werden wir filtern, wo der Bundesstaat New York entspricht. Und normalerweise
verwende ich einfache Anführungszeichen. Aber das gibt die
doppelten Anführungszeichen von A. Es hängt nur von der
Sprache ab, in der Sie sich befinden. Sql light kann beide verwenden. Manche bevorzugen nur
einfache Anführungszeichen oder doppelte Anführungszeichen. Und jetzt wollen wir sie vom
Propheten bestellen, nur dass das die falsche Reihenfolge ist. Wir werden also
absteigend vorgehen, um zuerst die Geschäfte mit den
höchsten Gewinnen
und zuletzt die profitabelsten Geschäfte zu bekommen zuerst die Geschäfte mit den
höchsten . Jetzt, da wir unsere Daten ordnen können, fahren
wir mit der
Gruppierung unserer Daten fort. Gruppierung ermöglicht
es uns, mehrere Zeilen zu einer
einzigen Zeile zu
kombinieren und unsere Daten zu
aggregieren, um
Zusammenfassungen der Informationen
in unserer Datenbank zu erhalten . Dies ist
in großen Datenbanken äußerst hilfreich. Lassen Sie uns also unsere
Bundesstaaten zusammenfassen und
die Gewinne und Informationen über die
Anzahl der Geschäfte
in jedem Bundesstaat abrufen die Gewinne und Informationen über . Um das zu tun, lassen Sie uns zunächst einige Daten aus unseren Staaten
holen. Dann gruppieren wir unsere Daten
nach der Statusspalte. Wenn wir es jetzt
einfach so ausführen, wie es ist, werden
wir nur
die beiden Zeilen und alle
Spalten darin sehen . Dies ist nur die Auswahl der ersten
Reihe aus diesen beiden Gruppen. Wenn wir Daten tatsächlich zusammenfassen
möchten, müssen
wir in unserem ausgewählten Teil bestimmte
Keywords verwenden. Anstatt also Star zu machen, lassen Sie uns zuerst den Staat auflisten. Jetzt können wir sehen, dass
wir zwei Staaten haben. Ordnung, lassen Sie uns dann die Anzahl der
Geschäfte in jedem Bundesstaat ermitteln. Um das zu tun, werden wir die Anzahl der Geschäfte
zählen. Um nun die Anzahl der
Geschäfte zu machen, könnte ich
die ID übergeben und das würde die eindeutigen
zählen, das würde die
Anzahl der IDs in jeder Zeile zählen. Oder ich mache normalerweise einfach den
Platzhalter, weil wir nur zählen
wollen , wie viele Sterne es gibt und das ist
normalerweise einfacher. Um den Gewinn zu erzielen, müssen
wir schließlich alle unsere Gewinne zusammenrechnen. Also rufen wir
die Sum-Funktion auf. Das hier war also
die Zählfunktion, also zählt sie die Anzahl der
Dinge, die Sie ihr geben. Unsere SUM-Funktion summiert
oder addiert alle
Spalten, die wir ihr geben. Oder es summiert alle Zeilen der Spalte,
die wir erhalten. Also geben wir
ihm die Gewinnkolumne. Wir erhalten unseren Staat, unsere Anzahl und unseren Gewinn für jeden Staat. Eine weitere raffinierte
Funktion, die Sie verwenden können, ist die Durchschnittsfunktion oder AVG. Und das
gibt uns auch den Durchschnitt für den Gewinn in jedem Geschäft. Jetzt sehen diese Daten
irgendwie chaotisch aus. Diese Kolumnen hier oben sind nicht
so schön anzusehen. Wir können diesen Spalten also
Namen geben , indem wir hier einfach
ihren Namen angeben. Unser Name wird also
als Anzahl der Geschäfte
oder vielleicht nur als Anzahl angezeigt . Und das sieht etwas sauberer aus. Während unsere Sonne die Summe sein kann und unser Durchschnitt als Durchschnitt erscheinen kann. Wenn Sie Spaltennamen hinzufügen, sehen
die Daten nur etwas sauberer aus, wenn
Sie im Bericht sind. Und es macht es auch viel einfacher, wenn Sie darauf
zurückgreifen, um
genau zu wissen , welche Informationen Sie an bestimmten Stellen herauszuholen
versuchen. Eine Sache, die Sie beachten sollten, ist, dass Sie hier keine Leerzeichen verwenden
können. Ich konnte also nicht den Gesamtgewinn sagen. Das wird einen Fehler auslösen. Also werde ich Unterstriche verwenden
, um das zu umgehen. Oder wenn Sie wirklich Leerzeichen wollen, können
Sie einfache Anführungszeichen setzen und
das gibt Ihnen ein Leerzeichen. In der Regel wird meiner Erfahrung nach jedoch stattdessen ein Unterstrich
verwendet. Und schließlich kann ich
das mit anderen Abfragen kombinieren, sodass ich ein
Wo zwischen meinem Daumen und meiner Gruppe
platzieren kann Wo zwischen meinem Daumen und meiner Gruppe
platzieren um die Daten zu filtern,
bevor sie aggregiert werden. Ich konnte mir also nur meine Geschäfte
ansehen , in denen der Gewinn über 100.000
liegt. Ich kann einfach die Anzahl und den
Gesamtgewinn und den Durchschnitt meines
Geschäfts mit hohen Einnahmen abrufen , in diesem Fall zwei in jedem Bundesstaat. Wenn wir diesen Filter nicht
haben, können
wir sehen, dass es in New York
drei Bundesstaaten und drei Geschäfte
gibt . Dies wäre auch ein
großartiger Ort, um
unsere geschlossenen Geschäfte herauszufiltern ,
damit ich sagen kann, wo das nächstgelegene Datum Null ist. Jetzt schauen wir uns nur
offene Geschäfte an und holen uns ihren
Kalender und Gewinn. Also haben wir in diesem Video ziemlich
viel besprochen,
wir haben besprochen, wie wir unsere Daten anhand
der Sortier-Klausel
sortieren können. Ich werde auch lernen, wie
wir unsere Daten
mithilfe der
Gruppen-für-Klausel aggregieren oder gruppieren können. Außerdem erfahren wir mehr über die verschiedenen Reihenfolgen, in
denen diese geschehen können, sowie über verschiedene
Funktionen, die wir aufrufen können in unserem ausgewählten Spaltenbereich.
6. SQL 7 BEITRITT: Bisher haben wir
ziemlich viel behandelt. Wir haben besprochen, wie man
bestimmte Spalten aus unseren Datenbanken herausnimmt, wie man die Daten
in jeder Tabelle filtert, wie man sie sortiert und
wie man
unsere Daten aggregiert, um Zusammenfassungen
dessen zu erhalten, was darin enthalten ist. In den nächsten Videos werden
wir uns mit dem Umgang mit mehreren Tabellen befassen. Jetzt ist also ein guter Zeitpunkt,
um eine Pause einzulegen, wenn Sie sich mit den Themen, die
wir bereits besprochen haben, unwohl fühlen. Wenn Sie ein paar Videos wiederholen oder die Abfragen einfach selbst ausprobieren ,
experimentieren Sie ein bisschen mehr. Bevor wir weitermachen,
arbeiten wir an mehreren Tabellen und bauen
weiter auf dem auf, was
wir bereits besprochen haben, insbesondere werden die Where-Klausel und
die Gruppen-by-Klausel verwendet . Stellen Sie also sicher, dass
Sie diese genau verstehen , bevor Sie
fortfahren. SQL-Datenbanken verwenden also
Beziehungen, um Daten zu verbinden. Beziehungen liegen vor, wenn eine Zeile auf eine andere Zeile
und eine andere Tabelle verweist. Dafür gehen wir
zur Inventartabelle. Die Inventartabelle
hat also drei Spalten. Schauen wir uns das jetzt an. Lass uns alles
aus dem Inventar holen. Das hat also viele
verschiedene Zeilen,
aber wir sind nur an den drei Spalten
interessiert. Also zuerst haben wir die
Store-ID, die Flavor-ID, und die Camp-Store-ID ist eigentlich die ID des Ladens in den
Store-Tabellen. Wenn wir in Geschäfte gehen, suchen
wir nach Store ID1. Geschäft ID1 ist also unsere 100 Pine Street in
Harrisburg, Pennsylvania. Zurück zum Inventar können
wir machen, dass die zweite Spalte
auf eine bestimmte Geschmacksrichtung verweist. Wenn wir also zu
unserer Geschmackstabelle gehen, lassen Sie uns herausfinden, was
Geschmack Nummer eins ist. Flavor ID1 ist Vanilla Vista. Und wenn wir zurück zum Inventar gehen, können
wir sehen, dass es
in unserer
Eisdiele in Harrisburg zehn Vanilla Views
gibt , aber es ist nicht so
praktisch,
die Store-ID verwenden zu müssen , um
die Inventartabelle zu filtern. Stattdessen
können wir diese beiden Tabellen zu diesen spezifischen Beziehungen zusammenfügen . Lassen Sie uns diese
mit der Join-Klausel verbinden, diese ist
ziemlich lang und schwer zu lesen. Lassen Sie uns das in
unsere Geschmackstabelle aufnehmen. Ich verwende hier die
Join-Klausel und gebe an, an welcher Tabelle ich teilnehmen möchte. In diesem Fall sind es also Aromen. Jetzt können wir das ausführen und viele verschiedene Ergebnisse erzielen. Das liegt daran, dass wir ihm nicht gesagt
haben, was ich tun soll. Einige Soldaten schlossen
sich Flavors an. Wir müssen
diese Beziehung jetzt definieren. Also werden wir sagen, wo die Flavor-ID,
die der ID entspricht, viel kürzer ist. Jetzt wollen wir, wo
die Geschmackstabelle, in der die Geschmacks-ID
aus unserem Inventar ID auf unserer
Fingertabelle
entspricht. Hier ist es etwas einfacher zu lesen. Jetzt kann ich sehen, dass Laden
Nummer eins wenig nascht. Sehen Sie, dass Vanilla Vista
im
dritten Geschäft knapp wird ,
im Gegensatz zu Flavor ID1. Ausgehend von dem, was wir
im letzten Video gelernt haben, finden Sie heraus, ob Sie diese
Daten aggregieren und eine Zusammenfassung
darüber erhalten können , wie viele Geschmacksrichtungen im
gesamten Unternehmen auf Lager sind. Also, wie viele
Wünsche von Villanova gibt es? Wie viel Schokolade? Was ist der Truck zu Hause? Wie viele Schokoladensorten
oder sie sind auf Lager und wie viele Pekannusstorten sind auf Lager oder durchqueren
alle Geschäfte. unseren Joint fort, um
mit der Aggregierung unserer Daten zu beginnen. Wir werden die
Gruppierung anhand der ID aufheben. Jetzt können wir auch nach
der Flight Flavor ID gruppieren. Es ist wirklich egal.
Beide werden dasselbe zurückgeben, weil sie im Grunde
beide gleich sind. Dies
gibt uns jedoch
noch nicht ganz unsere Anzahl , da wir
immer noch Sterne auswählen. Lassen Sie uns einfach den
Namen unseres Geschmacks herausfinden. Und lassen Sie uns zählen, wie
viele Zeilen es gibt, nur um sicherzugehen, dass wir etwas Gutes
bekommen. Bisher haben wir also gesehen, dass wir unsere drei
Geschmacksrichtungen haben und
vier Inventar- oder
Inventarlinien für jede Geschmacksrichtung haben . Lassen Sie uns nun die Summe
der Anzahl ermitteln, um zu ermitteln, wie viele
im gesamten Geschäft auf Lager sind. Aus
dieser Tabelle können wir also sehen, dass Pekannusskuchen zur Neige geht. Also sollten wir wahrscheinlich noch mehr
bestellen.
7. SQL 8 Alias: In diesem Video erfahren Sie
, wie Sie
drei Tische miteinander
verbinden können, anstatt nur zwei. Am Ende dieses
Videos werden wir also
wissen, welche Geschäfte gerade verfügbar sind
,
welche Geschmacksrichtungen knapp werden und welche Adresse wir auch für
den Versand dieser Geschmacksrichtungen benötigen. Sie uns zunächst Lassen Sie uns zunächst unsere
Adressinformationen
von den verschiedenen Geschäften abrufen . Haben Sie unsere Geschäfte hier, lassen Sie uns sie dem Inventar hinzufügen. Jetzt können wir sehen, dass sich
unsere Geschäfte
mehrfach wiederholt haben . liegt daran, dass für
jede Zeile in Geschäften drei oder vier
in unserer Inventartabelle stehen. Tatsächlich wird
eine Kombination all
dieser Zeilen kombiniert. Dies ist ein wichtiges
Detail, das es zu beachten gilt. Wenn wir das also gemeinsam
machen und
dann versuchen würden , unsere Gewinne zusammenzufassen, hätten
wir
enorm hohe Gewinne, was wirklich cool aussehen würde, aber letztendlich ungenau
wäre. liegt daran, dass
immer, wenn wir an
Tischen teilnehmen , wir nach Übereinstimmungen suchen. Und für jedes Spiel
wird eine neue Zeile erstellt. Und wir bekommen diese Reihen. Was wir sehen,
sind diese Spiele. Also für jedes Spiel, das
wir bekommen. Lassen Sie uns das jetzt filtern, um sicherzustellen, dass wir nur
unsere offenen Geschäfte haben. Und lassen Sie uns einen weiteren
Filter hinzufügen,
um nur die Geschmacksrichtungen zu ermitteln, deren Inventar
knapp wird. Gehen wir also dahin, wo die
Anzahl weniger als fünf beträgt. Wir haben also nur ein
paar Geschäfte, von denen
wir wissen, dass wir neue Geschmacksrichtungen
versenden müssen. Jetzt
werden wir hier auf ein Problem stoßen. Wenn wir erneut versuchen würden,
hier beizutreten , würden wir auf ein Problem stoßen. Wenn wir versuchen würden, unserer Geschmackstabelle einen weiteren
Join hinzuzufügen. Wenn wir die Beziehung definieren, werden
wir auf
ein Problem stoßen, bei dem wir jetzt
mehrere Spalten mit dem Namen id haben . Also konnte ich nicht, also wenn ich es machen würde, wo Flavor ID gleich id ist, erhalten
wir eine Fehlermeldung. Und das liegt daran, dass
die Datenbank nicht weiß, welche ID-Spalte wir meinen. Wir müssen es weiter spezifizieren. Und dazu verwenden
wir denselben Trick, den wir zuvor bei
der Spaltenbenennung verwendet haben. Also werden wir dieser Tabelle
Aliase hinzufügen. Aliase
bedeuten nun nur, dass wir
eine Abkürzung oder einen
Kurznamen für diese Tabellen definieren . Wir könnten
den Tabellennamen und
dann einen Punkt ausschreiben und dann angeben
, welche Spaltenbewegung sich bewegt. Aber es gibt einen schnelleren
Weg, das zu tun, und das ist das Hinzufügen von Aliasen
zu unseren Tabellen. Also genau wie wir
unseren Spaltennamen Aliase hinzugefügt haben, verwenden wir S. Und dann
mache ich ein S für Geschäfte, ein Add-on für mein Inventar
und nenne es ich, und dann für meine Geschmacksrichtungen nenne
ich es f. Normalerweise ist die Kultur
bei Sequel, dass dein Alias aus einem
Buchstaben für eine Tabelle besteht, vielleicht ein paar, wenn du ein paar Wiederholungen
hast.
Ich habe versucht, es 1-3 Buchstaben beizubehalten nur damit es schön und kurz ist. Manche Sprachen
brauchen die Säure nicht. Du kannst es also einfach von Stores S aus machen und es weiß, dass S
der Alias für Store ist. Mach weiter und
räume den Rest auf. Ich gebe an
, dass Abschlüsse aus
Geschäften kommen und die Anzahl aus dem Inventar
stammt. Jetzt kommen wir zu den
gleichen Daten und sie sehen ein bisschen mit Spalten verschmutzt aus. Lassen Sie uns das herausfiltern, um nur die
Informationen zu erhalten, die wir benötigen. Also werden wir die Zählung
brauchen. Also lasst uns die
Inventarzahl nehmen, lasst uns den Geschmack schnappen. Nehmen wir also den Namen der Geschmackssorte und dann holen wir uns die Adresse, an die
wir es versenden müssen. Das werden also
die Store Street, Store City und Store State sein. Lass uns weitermachen und das erledigen. Hier ist ein Bericht über
alle Geschmacksrichtungen, ihr Inventar, das zur
Neige geht und darüber, an welche Schauspielerinnen sie versenden
müssen. Diese Herausforderung ist etwas
fortgeschrittener als unsere anderen. Wenn Sie also nach einer guten Herausforderung
suchen,
schauen Sie nach, ob Sie auch
die Kosten berechnen können, die erforderlich wären, um jedes dieser Geschäfte wieder auf
jeweils zehn Fässer
aufzufüllen. Speichere ein paar Sekunden,
während du es herausfindest. Okay, das war eine etwas
kompliziertere Herausforderung
als
sie es normalerweise tun. Wir haben nicht wirklich
darüber gesprochen, Mathematik
in unseren ausgewählten Aussagen zu verwenden ,
aber wir können sie da hineinschleichen . Also
fangen wir damit an, die Geschmackskosten zu erhöhen und ich habe dort mein Komma
zwischen den Spalten
vergessen. Jetzt haben wir also die Kosten für
jede Geschmacksrichtung und wir wollen sie mit so vielen
multiplizieren. Es wird dauern, bis
diese Zahl auf zehn steigt. Nehmen wir unsere Kosten und wir
multiplizieren sie mit zehn abzüglich der Inventarzahl. Zitronen in Klammern hier,
um ihr zu sagen, sie soll die Zehn minus machen, ich zähle, bevor sie es mit den Kosten multipliziert
. Lassen Sie uns
das also ausführen und wir können sehen, wie viel es kostet , jedes
dieser Inventare
wieder auf zehn Einheiten aufzufüllen , oder vielleicht möchten wir es auf bis zu 20 Einheiten
auffüllen. Schau dir das an.
8. SQL 9 LINKS JOIN: Manchmal enthalten Tabellen
nicht immer die Daten, die wir wollen
oder erwarten. In diesem Fall zeigt uns Join
nur Treffer. Das ist es, was wir tun, ein
sogenannter Inner Join. Es zeigt also,
was auf
unseren beiden Tischen steht und in beiden
zusammen passt. Es kann aber auch schön sein zu sehen ,
wo diese Daten fehlen. So wissen wir, ob etwas
fehlt oder
etwas erledigt werden muss. In diesem Fall
werden wir einen sogenannten Left Join machen
wollen . Normalerweise stelle ich mir
das gerne als Venn-Diagramm vor. Links habe ich meinen ersten
Tisch im rechten Kreis, ich habe meinen zweiten Tisch,
wo sie sich überschneiden. Das ist ein normaler Joint. Deshalb wird es
Inner Join genannt, weil es
den beiden Tabellen zeigt , was in beiden Tabellen
übereinstimmt. Unser Left
Join zeigt uns alles auf der linken Tabelle oder der Originaltabelle mit
den Daten, zu denen es passt. Schauen wir uns also das Formular mit
der Filialnummer an. Geschäft Nummer vier
enthält also vier Geschmacksrichtungen. Aber wenn wir uns unsere Geschmackstabelle
ansehen, haben
wir nur drei Geschmacksrichtungen. Wir können sehen, dass ID Nummer
drei hier fehlt. Was höchstwahrscheinlich
passiert ist, war, dass es
eine Variante gab, die aber
gelöscht oder eingestellt wurde . Und anstatt ein Datum
einzustellen oder ein Datum zu löschen, haben sie die
Daten einfach aus der Datenbank entfernt. Jetzt wissen wir nichts über
diesen Geschmack, aber dieser mysteriöse Geschmack Nummer
drei taucht nicht auf, wenn wir uns auf unserer Inventartabelle
anmelden. Das liegt daran, dass wir keinen Geschmack dafür
haben. Es zeigt
uns also nur, was passt. Die Geschmacksrichtungen, die ich
hinzufüge, an die Geschmackstabelle anpassen. Also, um alle Daten aus
dem Abgleich zu erhalten und unsere linke Tabelle oder
I-Inventartabelle beizubehalten und alle Informationen
darin zu
erhalten, was übereinstimmt. Wir machen einen Links-Join, und das wird uns
zeigen, welche Variante in ID3 existiert und wie sie einen alten Namen
hat. Du kannst auch einen Right Join machen, aber normalerweise
sehe ich das nicht
so oft, daher werden wir in diesem Kurs nicht darauf
eingehen. Bevorzugt wird ein
Links-Join gegenüber einem Rechts-Join verwendet. Es ist nur das Gegenteil. Es wird die rechte Tabelle
anstelle der linken Tabelle beibehalten. Es gibt auch sogenannte Outer Joins, falls
Sie
daran interessiert sind , und dabei wird beibehalten,
was in beiden Tabellen enthalten ist. Das würde
den Rahmen dieses Kurses etwas sprengen. Also belassen wir
es einfach bei Left Joins.
9. SQL 10-INDEX: Okay, herzlichen Glückwunsch, du hast es bis
zum letzten Video geschafft. Wir haben alle Grundlagen durchgesehen. Sie müssen anfangen,
Ihre eigenen Berichte zu erstellen, in SQL herumzuspielen und
mit Daten zu experimentieren. Datenbanken machen wirklich Spaß
und sind wirklich aufregend. Ich weiß, das klingt
komisch, aber es ist wirklich cool zu sehen, wie Daten gespeichert werden und
wie sie sich auf
verschiedene Tabellen beziehen , dass wir
so komplexe Daten
wie menschliches Verhalten speichern können , ich will um mit
ein paar weiteren Informationen zu gehen,
während Sie sich darauf vorbereiten, in
Ihren eigenen Datenbanken zu arbeiten, im
Gegensatz zu dieser
Würfeltestdatenbank. Das erste ist also, dass Select sicher ist. Select
fügt keine Daten ein oder ändert sie nicht. kann es jedoch lange dauern , kann es jedoch lange dauern
, bis Sie
die Daten erhalten Je nachdem,
wie Sie sie ausführen, kann es jedoch lange dauern
, bis Sie
die Daten erhalten. Deshalb werden wir nur über einige
Sicherheitsverfahren
sprechen , um
sicherzustellen, dass Sie die
Datenbank nicht verlangsamen und
keine Probleme für
jemand anderen verursachen , der darin enthalten ist. In der Regel
verfügen die meisten Datenbanken über eine Kopie der Datenbank, Sie in
degenerierten Berichten arbeiten. Stellen Sie also sicher, dass Sie mit einem
Datenbankadministrator sprechen, um zu sehen, ob Sie
in der eigentlichen Datenbank
oder in einer Kopie davon arbeiten . So können Sie größere
Berichte erstellen, ohne Risiko einzugehen, dass die
Datenbank aufgrund anderer Verhaltensweisen verlangsamt wird. Es gibt also zwei Dinge, über die
wir sprechen , um Ihre Anfragen zu beschleunigen. Die erste wird die Anzahl
der zurückgegebenen Zeilen
begrenzen. Wenn wir also einen
Blick auf unsere Inventartabelle werfen, denn das ist die
längste Tabelle mit der meisten Anzahl von Zeilen. Wir haben viele Reihen. Nun, dieser hat
vielleicht zehn oder 12 Reihen. Wenn Sie es jedoch mit
Produktionsdaten zu tun haben , die
Millionen von Zeilen enthalten, könnten durch die Auswahl von Stern aus viele Straßen zurückgegeben werden. Und wenn Sie es nur
tun, um
die Spaltennamen zu erhalten ,
wie ich es normalerweise tue, ist
das
Verarbeitungsverschwendung und es könnte die
Datenbank überlasten. Was ich normalerweise am
Ende von mir festlege, ist ein Limit, und dann zehn Limit,
Limit schränkt die Anzahl
der zurückgegebenen Zeilen auf vier ein. Selbst wenn Sie sich in
einer größeren Datenbank befinden, kommt
dies
je nach
SQL-Sprache und
Subduing-Limit viel schneller heraus je nach
SQL-Sprache und
Subduing-Limit . Am Ende können
Sie die ersten fünf erreichen und dann eine Abfrage auswählen. Das ist das Licht, also
funktioniert es nicht so, funktioniert stattdessen mit Limit fünf. Dann ist der letzte Punkt, den
ich ansprechen werde , die Verwendung von Indizes. Da wir also
über Beziehungen sprechen, sich bei
diesen Beziehungen um
unspezifische Spalten. Normalerweise sind diese Spalten,
die IDs sind, indexiert, was bedeutet, dass die
Datenbank diese Spalte umsortiert sodass sie weiß, wie man Zeilen darin schnell
findet, indexiert, indexiert und etwas,
das sie vorher tun wird und es sind
unsichere Spalten definiert, normalerweise für Joins, diese werden
alle indexiert, also sollte der Join
ziemlich schnell gehen. Aber bei Ihren Where-Klauseln könnten Sie langsamer werden. Wenn Sie nach einer
Spalte filtern, die nicht indexiert ist, kann
es
sehr langsam werden. Oder wenn Sie
nach einer Textübereinstimmung filtern, kann
das auch sehr langsam sein. Wenn Sie also feststellen, dass eine Ihrer
Abfragen langsam läuft, prüfen Sie, ob es eine andere Möglichkeit gibt, diese Informationen abzurufen,
ohne
nach diesen Spalten zu filtern
.
Möglicherweise stellen Sie fest, dass die
gewünschten Daten keine andere Tabelle sind. In diesem Fall ist es schneller,
sich mit
der anderen Tabelle zu verbinden und nach einer indexierten Spalte zu
filtern, anstatt
bei einer Tabelle zu bleiben und nach einer Spalte
zu filtern , die nicht indexiert ist. Aber normalerweise ist das in
sehr komplexen Datenbanken nur etwas, das Sie beachten
sollten, wenn Sie weitermachen. Ich spreche auf jeden Fall mit Ihrem
Datenbankadministrator, mit den Leuten
in Ihrem Unternehmen gerade
in einer Datenbank herumlaufen, um zu sehen, ob sie irgendwelche
Best Practices oder
Warnungen haben , bevor Sie
fortfahren vorwärts. Damit. Das ist
alles, was wir in diesem Kurs behandeln werden. Wir haben also besprochen,
wie man Daten erhält, wie man Daten filtert, Daten
gruppiert und wie man sie in
verschiedenen Tabellen
kombiniert. Ich hoffe wirklich, dass dir das
gefallen hat Bitte lass mich in
den Kommentaren unten wissen, ob etwas keinen Sinn gemacht hat. Ich würde
es gerne weiter erklären und diese Videos verbessern
, damit es Sinn macht. Und Sie können mit Daten
herumspielen , weil es
wirklich Spaß macht. Vielen Dank fürs Zuschauen
und viel Glück
bei Ihren Bemühungen zur Berichterstattung. Wenn Sie diesen Kurs nützlich fanden, würde
ich mich sehr freuen,
wenn Sie
ihm eine Bewertung hinterlassen würden, die anderen Personen
hilft, diesen Kurs zu
finden,
damit auch sie die
Berichte erstellen
können, die sie benötigen.
 Peter Flickinger, Filmmaker, Programmer and Teacher
Peter Flickinger, Filmmaker, Programmer and Teacher