Transkripte
1. Intro für Datenanalysen: Hallo Freunde. Beginnen wir mit
diesem Schulungsprogramm, Eckdatenanalyse
mit MiniTab. Was wirst du in diesem Kurs
lernen? Die Fähigkeiten, die
Sie in
diesem Kurs erlernen, sind also einige
Grundlagen der Statistik. Wir werden
beschreibende Statistiken,
grafische Zusammenfassungen,
Verteilungen, Histogramm,
Box-Plot, Balkendiagramme
und Tortendiagramme behandeln grafische Zusammenfassungen,
Verteilungen, Histogramm,
Box-Plot, . Ich werde eine neue
Serie über den Test der Hypothese einrichten, die ich im
Link als Link
im letzten Video teilen werde . Aber lassen Sie uns
zunächst die verschiedenen Arten
der grafischen Analyse verstehen . Wer sollte an diesem Kurs teilnehmen? Jeder, der Lean Six Sigma
studiert, sich als Green Belt,
Black Belt
zertifizieren lassen möchte oder
Statistiken und grafische
Analysen an seinem Arbeitsplatz anwenden möchte. Auch wenn Sie
Unternehmer oder
Student sind und Statistiken mithilfe von MiniTab verstehen
möchten. Ich werde alles behandeln. Wir werden lernen, welche Fehler häufig
bei der Analyse passieren. Denn wenn wir Analysen mit einfachen theoretischen
Datenpunkten durchführen, scheint
alles normal zu sein. Deshalb zeige ich
Ihnen einige Fallen, in denen unsere Analyse scheitern wird und wie Sie diese Fallen
vermeiden sollten. Wir werden versuchen, am Ende dieses Programms zu sagen, was Sie
aus diesem Programm mitnehmen werden? Sie werden verstehen, wie
man einige grundlegende Analysen durchführt. Sie werden verstehen, welche
Tools während
Ihrer Messphase erforderlich
sind, wie
Fähigkeitsberechnungen usw. Wir werden während der
Analysephase also, wenn möglich, den Test der Hypothese abdecken. Andernfalls, wenn es wird, wird
das Video größer, ich werde es als
separates Bild setzen. Ivan behandelt auch, welches Diagramm
verwendet werden soll , wenn einige häufige Fehler auftreten, und
wir führen grafische Analysen durch
und erstellen Grafiken. Und wie kann ich
aus diesen Grafiken
Erkenntnisse und Schlussfolgerungen ziehen? Dies wird Ihnen wirklich helfen dieses
Programm wirklich gut zu
verstehen. Mal sehen was ist ein Minitab? Minitab ist eine
Statistiksoftware, die
verfügbar ist und über
mehrere Regionen verfügt. Also suche ich mir ein neues Projekt. Mein Minitab-Bildschirm sieht
ungefähr so aus. Ich habe einen Navigator
auf der linken Seite. Ich habe meinen
Ausgabebildschirm oben, ich habe mein Datenblatt, das einem Excel-Blatt sehr
ähnlich ist, mit
dem ich arbeiten kann. Ich kann diese
Blätter weiter hinzufügen und habe viele Daten. Ich kann
mit meinen Optionen viele Analysen durchführen. Wir werden grundlegende
Statistiken behandeln, Regression. Wir werden viele
grundlegende Statistiken behandeln und wir werden viele Grafiken mit
verschiedenen Datentypen
behandeln , oder? Wenn Sie also daran
interessiert waren, diese Dinge zu wissen, sollten
Sie sich auf jeden Fall
anmelden und mein Video ansehen. Ich danke dir sehr.
2. Zusammenfassung der Einführung in Lean Six Sigma: Die
Übertragungsfunktion von Six Sigma verstehen. Lassen Sie uns nun die Funktion
und ihre Relevanz bei Six Sigma untersuchen und ihre Relevanz bei Six Sigma Dies beginnt mit dem Verständnis der mathematischen Beziehung Y ist eine Funktion von X. In dieser Gleichung
steht Y für den Output und die Ergebnisse oder das
Ergebnis, das wir verbessern möchten. X steht für die
Eingabevariable oder das Muster. F steht für die Funktion oder die Transformation, die auf diese Eingaben angewendet
werden kann. Im Wesentlichen geht es bei Fix Sigma darum, den X-Faktor zu identifizieren und zu
optimieren, also die Eingaben, die die Ausgabe
steuern Durch die Verbesserung des Xs müssen
wir das Y verbessern, oder wir
konzentrieren uns auf die Verbesserung des Y. Das Beispiel
der Übertragungsfunktion in Schauen wir uns ein Beispiel an: Wir
rufen einen technischen Support an, um ein Computerproblem zu lösen In der definierten Phase definieren
wir ein Problem, d. h. wie lange es dauert,
bis ein Kunde eine Lösung erhält. Y, was
der Zeit bis zur Lösung entspricht, O ist die Gesamtzeit zur Lösung
des Kundenproblems benötigt wird. In der Maßnahmenphase identifizieren und messen
wir
die verschiedenen Faktoren, die an dem Anruf
beteiligt waren. Wie die Zeit in der Warteschlange, die Zeit mit
dem Support,
die Zeit, die für die Weiterleitung
der Anrufe zwischen den
Agenten aufgewendet wurde, die Lösungszeit. Analysephase
ermitteln wir, welche X
entscheidend sind und welche typischen Abweichungen
zwischen den Faktoren bestehen. Während der Verbesserungsphase führen
wir Änderungen durch, um den
Zeitaufwand für jeden Schritt zu reduzieren. Vielleicht geht es dort um die Automatisierung
bestimmter Reaktionen oder die Optimierung
der Routinelogik Während der Kontrollphase überwachen
wir das System, um sicherzustellen, dass sich das Y
, das die Zeit bis zur
Problemlösung darstellt, tatsächlich verbessert hat
und im Laufe der Zeit in Ordnung geblieben ist Problemlösung darstellt, tatsächlich verbessert hat und im Laufe der Zeit in Ordnung geblieben Dieser Prozess kann
kontinuierlich wiederholt werden , um
weitere Verbesserungen voranzutreiben. Bei
strikter Anwendung ist DMAC
eine leistungsstarke, wiederholbare
Methode
zur Erzielung messbarer Erträge zur Zusätzliche Verbesserungen,
Methoden in Six Sigma Sixema verwendet andere
bewährte Tools,
Techniken und Praktiken, einschließlich statistischer Es verwendet ein Kontrolldiagramm um die
Veränderung im Laufe der Zeit zu überwachen Es verwendet die obere und
untere Kontrollgrenze, um
festzustellen, wann der Prozess statistisch gesehen außer Kontrolle geraten
ist SPC-Tools können
den DMX-Zyklus auslösen , wenn Variation und Fehler den
akzeptablen Schwellenwert überschreiten Tools zur
Reduzierung von Abweichungen und Mängeln gehören üblicherweise zum gesamten
Qualitätsmanagement Sie helfen dabei,
die Grundursache und
Optimierungsmöglichkeiten zu identifizieren . Diese Tools spielen in
der Analyse- und
Verbesserungsphase von DMC
eine Schlüsselrolle der Analyse- und
Verbesserungsphase von DMC Teamwork und Qualitätszirkel. Ursprünglich von Teta ausgehend,
basierte der Schwerpunkt auf einem teambasierten Ansatz
zur Prozessverbesserung Mitarbeiter auf allen Ebenen
arbeiten regelmäßig zusammen, um
ein Problem mithilfe der
in Six Sigma bereitgestellten Tools und Methoden Die Qualitätszirkel
integrieren häufig statistische Tools, DMAT- und DPATrduction-Techniken Als nächstes die Six-Sigma-Projekte
und die Yellow Belt Road. Im nächsten Abschnitt werden
wir uns den Six-Sigma-Projekten befassen und aufzeigen, was ein gelber
Gürtel wissen muss, einschließlich der Rollen und
Verantwortlichkeiten des Projekts und des Werts
, den der Gelbe Gürtel für das
Verbesserungsteam bietet Regel kann die Dauer
eines Six-Sigma-Projekts erheblich
variieren Ein kurzfristiges Projekt kann
nur ein paar Stunden oder Tage dauern, insbesondere wenn es von einem
kleinen Qualitätsteam geleitet wird , das sich
um schrittweise Aufgaben kümmert Ein langfristiges Projekt
kann sich über ein Jahr erstrecken, insbesondere wenn der Umfang komplex und
funktionsübergreifend ist Hier kommt der schwarze
Gürtel ins Spiel. Die typischsten
Six-Sigma-Projekte,
bei denen es sich um ein grünes Band handelt, laufen jedoch etwa vier bis acht Wochen, sodass genügend Zeit
für die Datenerfassung
bleibt, und durchlaufen alle
Phasen des DMC-Zyklus Zehn Rollen in
Six-Sigma-Projekten. Jedes Teammitglied spielt eine
eigene und entscheidende Rolle. Lasst uns sie verstehen. Ein Master Black Belt und ein Blag. Diese Leute leiten
und verwalten Projekte. Sie sorgen für die Ausrichtung an Strategie und betreuen
die Teammitglieder. Grüngürtel. Sie führten detaillierte
Analysen durch, sammelten
Daten und halfen bei der
Implementierung von Prozessverbesserungen. Gelbe Gürtel sind die
Personen, die wichtige Informationen liefern, bei der Datenerfassung helfen und die
Implementierungsaktivitäten unterstützen. zwar keine Projektleiter, haben aber eine sehr
wichtige Rolle als Yellow Bells
sind zwar keine Projektleiter, haben aber eine sehr
wichtige Rolle als Teammitglied, das die tägliche
Umsetzung des
Six Sigma-Projekts vorantreibt Umsetzung des
Six Sigma-Projekts Was sind die gemeinsamen Ziele der
Six-Sigma-Projekte? Die Projekte sind unterschiedlich
umfangreich und konzentrieren sich häufig
darauf , Schwankungen
im Kundenerlebnis zu reduzieren In der heutigen Welt ist
Erfahrung sehr wichtig. Verkürzung der Markteinführungszeit, Beseitigung von Fehlern und Defekten, Senkung der Betriebskosten einige wichtige Aspekte bei der Implementierung von
Six Sigma und der
Ausschreibung durch die Geschäftsleitung und
das Angebot Projekte ohne starke Unterstützung, Finanzierung
und Sichtbarkeit durch die
Unternehmensleitung unterscheiden
sich deutlich Angemessenheit der Methodik. Pi Sigma ist so mächtig, aber es ist nicht
für jedes Problem geeignet Vermeiden Sie eine
Einheitsmethode oder Mentalität. Fangen Sie klein an und skalieren Sie dann. Bauen Sie Selbstvertrauen
und Fähigkeiten auf, die
kleinere, überschaubare
Projekte sind , bevor Sie eine umfassendere
Transformation in Angriff
nehmen. Wissen Sie, wann Sie andere Ansätze
anwenden sollten? In einigen Fällen
können
alternative Methoden besser geeignet sein Lean-Initiative,
Neugestaltung von Geschäftsprozessen, wir nennen das BPR, Geschäftsprozessmanagement Oder die andere Methode
, die verwendet werden kann. Die Kontrolle des Umfangs ist sehr wichtig. Wenn der Projektumfang zu weit
gefasst ist und
kein klares Ergebnis vorliegt, wird
er unüberschaubar Kosten versus Nutzen. Berücksichtigen Sie den ROI, bevor Sie Zeit und Ressourcen
investieren. Ein Beispiel:
100 Stunden aufzuwenden, um
nur 10 Stunden pro Jahr einzusparen , ist
kein effektiver Kompromiss. Eignungsbeurteilung durchzuführen Es ist sehr wichtig,
vor Beginn eines Projekts eine
Eignungsbeurteilung durchzuführen. Dies hilft Ihrer
Organisation, sich darauf vorzubereiten, bevor wir ein Projekt in
Angriff nehmen Definieren Sie das gewünschte Ergebnis. Was versuchen wir
zu erreichen und warum? Legen Sie Erfolgskriterien fest. Wie sieht Erfolg
sowohl für die Organisation als auch für
die beteiligten Personen aus? Bewerten Sie die Datenverfügbarkeit. Verfügen wir über zuverlässige, relevante und aktuelle Daten
zur Unterstützung der Analyse? Stellen Sie das richtige Team zusammen. Haben wir Mitarbeiter
mit den Fähigkeiten, dem Einfluss und dem Engagement, um das Produkt erfolgreich zu
machen? Erstellen Sie einen Geschäftsszenario. Was ist der Wert
einer Verbesserung? Wer profitiert tendenziell davon
und wer könnte widerstehen? Was ist der erwartete ROI? Organisation darauf Bei der Planung eines
Six-Sigma-Projekts ist es sehr
wichtig,
die Sind diese Schlüsselfragen, weil
sie sehr wichtig sind. Ist, wie sieht der zukünftige Staat im Vergleich zur
aktuellen Situation
aus? Lösen wir ein echtes
Problem in unserem Geschäft? Ist jetzt der richtige Zeitpunkt
, Six Sigma zu implementieren? Eine sorgfältige Bewertung
stellt sicher, dass das Six Sigma-Projekt
nicht nur relevant, sondern auch realisierbar und für unser Unternehmen von großer
Wirkung ist Wirkung Evaluieren wir die Leistung? Haben wir eine überzeugende
Begründung für die
Anwendung von Six Sigma in
unserem Geschäftsszenario Und schließlich, passiert in
Ihrem Projekt noch
etwas anderes , das Ihre Aufmerksamkeit
erfordert Gibt es bei Six Sigma
tatsächlich den richtigen Ansatz? Diese Fragen
können sicherstellen, dass unsere Organisation bereit ist Six SEMA
für
ein bestimmtes Es gibt drei wichtige Schritte, um zu
beurteilen, ob die Organisation
bereit Erster Schritt: Beurteilen Sie die Aussichten
und den zukünftigen Weg. Stellen Sie die Frage, ist
meine Kette kritisch? Unternehmen brauchen es jetzt. Bewerten Sie die aktuelle
Leistung. Stellen Sie die Frage. Gibt es eine überzeugende
strategische Begründung für die Anwendung von Six Sigma
in unserem Geschäft? Überprüfen Sie die Systeme und
die Fähigkeit zur Veränderung. Stellen Sie sich die Frage: Kann
die bestehende Verbesserung das Maß an Veränderung
bewirken, das
erforderlich ist, um erfolgreich und
wettbewerbsfähig zu bleiben, ohne Six Sigma zu
verwenden Denken Sie zunächst darüber nach, wie wichtig
das Kundenerlebnis und die
Kundenzufriedenheit Wir konzentrieren uns auf die Stimme des
Kunden, um Veränderungen voranzutreiben. Verbesserungen sind unerlässlich
und der Kunde braucht sie. Hier kommen sechs
Sigma-Datenanalysetools zum Einsatz. Es hilft uns zu
verstehen , was dem Kunden
wirklich wichtig ist Six Sigma bietet ein
leistungsstarkes Tool für die strategische
Zukunftsplanung, strategische
Zukunftsplanung indem es die
Effektivität des Marketings verbessert, die Dinge gleich beim ersten
Mal richtig macht und identifiziert, was den Kunden an unseren
Projekten
und Dienstleistungen
wirklich wichtig ist unseren
Projekten
und Dienstleistungen Ein solches wertvolles Tool im Six Sigma Toolkit
ist das CO-Modell, das uns hilft
, Kundenbedürfnisse besser zu verstehen und zu priorisieren Das CO-Modell ist eine Methode, um Daten
von Kunden zu sammeln und zu verstehen,
was
für von Kunden zu sammeln und zu verstehen sie wirklich wichtig ist Was unterscheidet unsere
Angebote von den anderen? Es hilft uns dabei,
wichtige Dinge zu identifizieren , z. B.
welche Funktionen die
Kundenzufriedenheit erhöhen
können, Kundenzufriedenheit erhöhen
können wenn sie dem Kunden gut
zugeordnet werden Was sind die potenziellen
Unannehmlichkeiten, die das
Kundenerlebnis
beeinträchtigen könnten, wenn sie nicht adressiert Durch die Analyse dieser Rückmeldungen können
wir
Verbesserungen priorisieren, die
einen größeren Mehrwert
für unsere Kunden schaffen können einen größeren Mehrwert
für unsere Kunden schaffen Lassen Sie uns nun über die strategische Planung nachdenken
. Six Sigma-Analysen können
eine entscheidende Rolle spielen , indem sie wichtigsten Faktoren
identifizieren, die Kunden
antreiben Kundenzufriedenheit,
Integration dieser Faktoren in die
strategische Planung Leistungsverbesserungen
sind am dringendsten erforderlich. In einer
Unternehmenskultur, die Teil des Standardansatzes von TIC Sigma ist, können
Teams durch effektive
Projektplanung, Entwicklung von
Kennzahlen,
Kontrollsysteme Entwicklung von
Kennzahlen,
Kontrollsysteme
und Qualitätszirkelteams die Leistungsausrichtung
im gesamten Unternehmen erheblich verbessern Rentabilität hat weiterhin oberste
Priorität. Six Sigma ist besonders wirksam bei der Senkung der
Qualitätskosten Viele Unternehmen
geben 20 bis 75% der
Kosten aus , um lediglich die Qualität ihrer
Produkte und Dienstleistungen sicherzustellen Durch die Senkung dieser Kosten halten
wir uns eng an den Erwartungen unserer
Kunden und liefern
durchweg besser und schneller als unsere Mitbewerber. Okay. Konzept von Len. Lean Manufacturing,
insbesondere im Dienstleistungssektor,
bedeutet Initiativen
zur kontinuierlichen Verbesserung
anzuerkennen. Im Kern konzentriert sich N auf die
Rationalisierung und Verbesserung Prozessen, um mehr
Wert mit Ihren Ressourcen zu schaffen TaHiOo, der oft als Vater
des modernen Pfandrechts angesehen wird,
betonte, dass der Kern des Pfandrechts in einem
einfachen Prinzip besteht Zeit vom Eingang der
Kundenbestellung bis zum Erhalt
der Zahlung für deren Erfüllung zu
berechnen Kundenbestellung bis zum Erhalt und dann
kontinuierlich daran zu arbeiten, und dann
kontinuierlich daran zu arbeiten diese Zeit so kurz wie möglich Bei Len geht es im Wesentlichen darum , Verschwendung
im gesamten Wertbereich zu unnötige Zeit,
Mühe und Ressourcen zu
reduzieren Das Ergebnis ist eine Maximierung des Werts, Verbesserung der Effizienz, eine
bessere Qualität und eine höhere
Kundenzufriedenheit. In einer Fertigungseinrichtung gibt es viele Erfolgsgeschichten. Derzeit haben wir viel, auch im Dienstleistungssektor.
3. Projektarbeit: Lassen Sie uns verstehen, was
die Projektarbeit ist , die wir in diesem
Datenanalyseprogramm mit MiniTab
erledigen werden. Wie ich Ihnen bereits sagte, werden
wir mit MiniTab zusammenarbeiten. Und das ist das Minitab
, das ich verwenden werde. Ich werde
Ihnen auch ein Datenblatt zur Verfügung stellen, Ihr Projektdatenblatt, in dem ich mehrere Beispiele habe, in denen wir
Berechnungen zur Leistungsfähigkeit durchführen. Wir werden versuchen,
Distributionen zu sehen und Sie können sehen, dass es verschiedene Registerkarten
gibt. Beispiel eins Beispiel
zwei Beispiel drei, wir werden versuchen, eine
Trendanalyse durchzuführen. Wir werden versuchen,
Pareto-Charts zu sehen. Wir haben viele Daten, die mit Ihnen geteilt
wurden, was Ihnen eine
praktische Erfahrung
bei der Arbeit mit Daten bietet, oder? Also lass uns anfangen.
4. Grundlagen der Statistik: Willkommen zu unserem nächsten
wichtigen Thema, Grundlagen der Statistik. In diesem Video
erfahren Sie, was Statistik ist, was deskriptive Statistik ist und was
Inferenzstatistik Fangen wir mit
der ersten Frage an. Was ist Statistik? Statistik befasst sich
mit der Erfassung, Analyse und
Präsentation von Daten. Wenn wir beispielsweise untersuchen
wollen, ob das Geschlecht einen Einfluss
auf die bevorzugte Zeitung hat , dann sind Geschlecht und Zeitung unsere sogenannten Variablen
, die wir analysieren möchten. Um zu analysieren, ob das Geschlecht
einen Einfluss auf die
bevorzugte Zeitung hat . Wir müssen zuerst Daten sammeln. Dazu erstellen wir
einen Fragebogen, Geschlecht und
bevorzugter Zeitung
gefragt wird. Wir werden dann die
Umfrage verschicken und zwei Wochen warten. Danach können wir uns
die eingegangenen Antworten in
einer Tabelle in dieser Tabelle anzeigen lassen . Wir haben eine Spalte
für jede Variable, eine für das Geschlecht und
eine für die Zeitung. Andererseits
steht jede Zeile für die Antwort
einer Person. Zum Beispiel
ist der
erste Befragte männlich und gab
die Zeiten Indiens an Der zweite ist weiblich
und gibt an, Hindu zu sein, und so weiter Natürlich
müssen die Daten nicht aus einer Umfrage stammen. Die Daten können auch aus
einem Experiment stammen, bei dem. Sie möchten beispielsweise
die Wirkung von zwei Medikamenten
auf den Blutdruck untersuchen . Betrachten wir ein anderes Beispiel aus dem
wirklichen Leben. Stellen Sie sich vor, Sie sind
Filialleiter und möchten wissen, ob ein neues
Produktdisplay den Umsatz steigert. Sie könnten schon früher
Daten über Verkäufe sammeln. Und wenn das neue
Display eingerichtet ist, können Sie
anhand
dieser Daten die Effektivität
des Displays analysieren.
Oder nehmen Sie an, Ihr
Schulleiter möchte herausfinden, ob zusätzliche Nachhilfestunden den Schülern
helfen,
ihre Mathematikergebnisse zu verbessern Könnten Sie zuvor Ergebnisse sammeln
? Nach den Nachhilfesitzungen
, um die Auswirkungen zu analysieren. Jetzt ist der erste Schritt getan. Wir haben Daten gesammelt und können mit der Analyse der Daten beginnen. Aber was
wollen wir eigentlich analysieren? Wir haben nicht die
gesamte Bevölkerung befragt ,
sondern eine Stichprobe genommen. Die große Frage ist nun, wollen wir nur die Stichprobendaten
beschreiben oder wollen wir eine Aussage
über die gesamte Bevölkerung
treffen ? Wenn unser Ziel auf die Stichprobe selbst
beschränkt ist. Das heißt, wir wollen nur die gesammelten Daten
beschreiben. Wir werden deskriptive
Statistiken verwenden. Deskriptive Statistiken
bieten eine detaillierte Zusammenfassung
der Stichprobe Wenn wir beispielsweise
100 Personen nach ihrer
bevorzugten Zeitung befragen würden, würden
uns
deskriptive Statistiken Aufschluss darüber geben, wie viele Menschen indische oder hinduistische Zeiten
bevorzugen Wenn wir jedoch
Rückschlüsse auf die
Gesamtbevölkerung ziehen wollen Rückschlüsse auf die
Gesamtbevölkerung Wir verwenden Inferenzstatistiken. Dieser Ansatz ermöglicht es
uns,
anhand unserer Stichprobendaten
Rückschlüsse auf die Population zu anhand unserer Stichprobendaten
Rückschlüsse auf die Population Mithilfe von
Inferenzstatistiken könnten
wir beispielsweise anhand einer Stichprobe von 500 Befragten
den Anteil
aller Erwachsenen in
einer Stadt schätzen , die
eine bestimmte Zeitung bevorzugen , die
eine bestimmte Zeitung , die
eine Inferenzstatistiken können uns auch dabei helfen, festzustellen, ob eine
bestimmte demografische Gruppe,
wie das Geschlecht, die
Zeitungspräferenzen signifikant beeinflusst Durch die Analyse unserer Stichprobendaten können
wir Rückschlüsse auf die
Zeitungspräferenzen der gesamten Bevölkerung Durch die Verwendung sowohl deskriptiver
als auch inferentieller Statistiken können
wir ein tieferes
Verständnis
unserer Ergebnisse gewinnen und
fundierte Entscheidungen über
Marketingstrategien oder die Erstellung von Inhalten für In der nächsten Lektion
werden wir uns eingehender mit
praktischen Anwendungen der
Statistik befassen . Bleiben Sie dran.
5. Bedeutung von Messebenen oder Datentypen: Bedeutung der
Messebenen. Das Verständnis der
Messebene ist aus mehreren
Gründen von entscheidender Bedeutung. Angemessene Analyse. Verschiedene Messebenen erfordern unterschiedliche
statistische Techniken. Die Verwendung der falschen Methode kann zu falschen Schlussfolgerungen
führen. Interpretation der Daten. Die Kenntnis des Levels hilft, die Ergebnisse
falsch zu interpretieren. Mittelwerte sind beispielsweise für Intervall
- und Verhältnisdaten
aussagekräftig , nicht jedoch für
nominale oder ordinale Daten Visualisierung und effektive
Datenvisualisierungstechniken variieren je nach
Messebene Balkendiagramme eignen sich
für nominale Daten, während Histogramme besser
für Intervall- und Verhältnisdaten geeignet sind Lassen Sie uns näher auf die
einzelnen Messebenen eingehen. Nominales Messniveau. Nominale Variablen
kategorisieren Daten ohne
eine aussagekräftige Reihenfolge festzulegen Befragten
zum Beispiel nach der Befragten
zum Beispiel nach ihrem
Verkehrsmittel zur Schule, zum
Bus, zum Auto, zum Fahrrad
oder zu Fuß ist nominell Jede Kategorie ist unterschiedlich, aber es gibt keine inhärente
Rangfolge oder Reihenfolge zwischen ihnen. Die Analyse nominaler Daten
beinhaltet das Zählen Häufigkeiten oder die Verwendung von Balkendiagrammen zur Visualisierung von
Verteilungen Ordinale Messebene Ordinalvariablen sorgen für
eine sinnvolle Reihenfolge oder Rangfolge zwischen den Kategorien, aber die Unterschiede zwischen Rängen sind nicht Schüler beispielsweise gebeten werden,
ihre Zufriedenheit
mit ihrem Verkehrsmittel als „
sehr zufrieden“, „zufrieden“, „neutral“, „
zufrieden“
oder „sehr zufrieden“ einzustufen, zeigt dies eine
ordinale Wir können
diese Antworten zwar
von den am wenigsten zufriedenen bis hin zu den am meisten zufriedenen einordnen , der numerische Unterschied zwischen zufrieden und sehr zufrieden
ist nicht quantifizierbar Die Analyse umfasst in der Regel
Medianberechnungen und nichtparametrische Tests Messintervalle und
Mengenverhältnisse ,
metrische Variablen Intervall- und Verhältnisvariablen werden als metrische Variablen betrachtet. gemeinsam,
dass
die Intervalle zwischen den
Werten gleichmäßig verteilt sind, aber Verhältnisvariablen
haben auch einen echten Nullpunkt, sodass alle arithmetischen Beispiele hierfür sind die Messung
von Alter, Gewicht oder Einkommen. Befragten beispielsweise nach der Anzahl
der Minuten gefragt werden, die es dauert, bis sie zur
Schule kommen , werden Intervalldaten gemessen, wobei die Intervalle
zwischen den Antworten, z. B. 10 Minuten, 20 Minuten,
konsistent und aussagekräftig sind. Dies ermöglicht statistische
Messungen wie die Berechnung Durchschnittswerten und den Einsatz fortgeschrittener statistischer Techniken
wie der Regressionsanalyse Zusammenfassung.
Das Verständnis dieser Messebenen ist entscheidend für die Gestaltung von Umfragen und Auswahl geeigneter
statistischer Analysen. nominalen Daten geben uns Aufschluss über Kategorien
ohne jegliche Reihenfolge. Ordinaldaten ermöglichen eine Rangfolge, aber keine genaue
Messung von Unterschieden, und das Intervall
und das Verhältnis metrischer Daten ermöglichen präzise Messung und unterstützen eine Vielzahl
statistischer Analysen ob
Frequenztabellen,
Balkendiagramme oder Histogramme erstellt werden, die
Auswahl der richtigen Messgröße gewährleistet eine
genaue Interpretation der Daten und aussagekräftige Erkenntnisse in verschiedenen Studien- und
Forschungsbereichen Schauen wir uns die
einzelnen Messebenen genauer an. Nominaler Messpegel. Die nominalen Daten sind die
grundlegendste Messebene. Nominale Variablen
kategorisieren Daten, ermöglichen
jedoch keine aussagekräftige Rangfolge der Kategorien Zu den Beispielen gehören
Geschlecht, Mann, Frau, Tierarten, Hund, Katze, Vogel und bevorzugte Zeitungen In all diesen Fällen können
Sie
zwischen Werten unterscheiden, die
Kategorien
jedoch nicht sinnvoll einordnen Um beispielsweise zu untersuchen,
ob das Geschlecht die
bevorzugte Zeitung
beeinflusst werden nominale Variablen verwendet In einem Fragebogen würden Sie mögliche Antworten
für beide Variablen
auflisten. Da es keine inhärente Reihenfolge gibt, die Anordnung der Kategorien im Fragebogen
keine Rolle. gesammelten Daten können in
einer Tabelle dargestellt
werden , und Häufigkeitstabellen oder Balkendiagramme können verwendet werden, um die Verteilungen zu
visualisieren Ordinale Ebene der Messung. Ordinaldaten können in einer sinnvollen Reihenfolge
kategorisiert und geordnet werden, aber die Unterschiede zwischen den Rängen sind
mathematisch gesehen nicht gleich Beispiele hierfür sind
Rankings, erster ,
zweiter, dritter Platz,
Zufriedenheitswerte, sehr unzufrieden, unzufrieden, neutral,
zufrieden, sehr zufrieden,
Bildungsniveau, Gymnasium,
Bachelor, Master, in diesem Fall, obwohl die Reihenfolge aussagekräftig ,
zweiter, dritter Platz,
Zufriedenheitswerte, sehr unzufrieden,
unzufrieden, neutral,
zufrieden, sehr zufrieden,
Bildungsniveau,
Gymnasium,
Bachelor, Master,
in diesem Fall, obwohl die Reihenfolge aussagekräftig ist. Die Abstände zwischen den Rängen sind nicht unbedingt gleich. Wenn Sie beispielsweise in einem
Fragebogen gefragt werden, wie zufrieden Sie mit
Ihrem aktuellen Job sind, wobei Optionen von sehr
unzufrieden bis sehr zufrieden reichen Die Antwortkategorien
sind geordnet, aber der genaue Unterschied zwischen den einzelnen Zufriedenheitsgraden
ist nicht Bei der Analyse von
Ordinaldaten werden häufig Mediane
berechnet und nichtparametrische
Tests verwendet Intervallniveau der Messung. Intervalldaten haben gleiche
Intervalle zwischen den Werten, aber es fehlt ein echter Nullpunkt. Beispiele hierfür sind Temperaturen
in Celsius oder Fahrenheit. Intervalldaten ermöglichen
die Messung von
Unterschieden zwischen Werten Da es jedoch keine echte Null
gibt, sind
Verhältnisse nicht aussagekräftig. Statistische Operationen
wie die Berechnung von Durchschnittswerten und die Verwendung von Techniken wie Regressionsanalyse
sind möglich Verhältnis, Ebene der Messung. Verhältnisdaten weisen gleiche
Intervalle zwischen den Werten auf und beinhalten
einen echten Nullpunkt. Beispiele hierfür sind Alter,
Gewicht oder Einkommen, da Verhältnisdaten eine echte Null
enthalten. Alle arithmetischen
Operationen sind gültig. Diese Stufe ermöglicht die
Berechnung von Verhältnissen und
Durchschnittswerten und ermöglicht die Verwendung fortgeschrittener
statistischer Methoden Oh. Was wir
bisher anhand eines Beispiels gelernt haben . Stellen Sie sich vor, Sie
führen eine Umfrage in einer Schule durch, um zu verstehen,
wie Schüler zur Schule kommen. Hier sind Fragen, die
Sie stellen könnten. Jedes entspricht einer
anderen Messebene. Die erste Frage könnte sein, welchem Verkehrsmittel fahren Sie zur Schule? Zu den Optionen könnten Bus, Auto, Fahrrad oder zu Fuß gehören. Dies ist eine nominale Variable. Die Antworten können kategorisiert werden, aber es gibt keine
sinnvolle Reihenfolge. Das bedeutet, dass der Bus
nicht höher ist als das Fahrrad. Gehen ist nicht höher
als Auto und so weiter. Wenn Sie die
Ergebnisse dieser Frage analysieren möchten, können
Sie zählen, wie viele
Schüler jedes
Verkehrsmittel nutzen , und
dies in einem Balkendiagramm darstellen. Als Nächstes fragen Sie sich vielleicht, wie zufrieden Sie mit
Ihrem aktuellen Verkehrsmittel
sind . Folgende Optionen stehen zur Auswahl:
sehr unzufrieden, unzufrieden, neutral,
zufrieden oder sehr zufrieden Dies ist eine ordinale Variable. Sie können die Antworten in eine Rangfolge einordnen,
um zu sehen, mit welchem Verkehrsmittel
die Zufriedenheit
höher bewertet Aber der genaue Unterschied zwischen zufrieden und sehr zufrieden. Zum Beispiel ist
nicht quantifizierbar. Zur letzten Frage:
Wie viele Minuten brauchst du, um zur Schule zu kommen? Hier sind Minuten bis zur
Schule eine metrische Variable. Sie können die durchschnittliche
Zeit berechnen, die benötigt wird, um zur
Schule zu gehen, und dabei alle gängigen
statistischen Messgrößen verwenden. Wir können diese Daten mit
einem Histogramm visualisieren , das die
Verteilung der Zeiten zeigt den Schulweg
benötigt werden, und die verschiedenen
Verkehrsmittel miteinander vergleichen Anhand nominaler Daten können
wir also die Antworten kategorisieren
und zählen, aber wir können keine Reihenfolge ableiten Ordinaldaten ermöglichen es
uns, Antworten zu ordnen, aber keine genauen
Unterschiede zwischen den Rängen zu messen Metrische Daten ermöglichen es
uns,
genaue Unterschiede
zwischen Datenpunkten zu messen genaue Unterschiede
zwischen Datenpunkten Wie bereits erwähnt, können metrische
Messebenen weiter in
Intervallskalen und Verhältnisskalen unterteilt
werden Intervallskalen und Verhältnisskalen Aber was ist der Unterschied zwischen Intervall
- und Verhältnisniveaus Lassen Sie uns den
Unterschied zwischen den
Messstufen Intervall
und Verhältnis anhand eines Beispiels untersuchen . Messniveau im Vergleich zum Verhältnis zwischen Intervall und Verhältnis. Bei einem Marathon dient die
Zeit, die Läufer benötigen , um das Rennen zu beenden,
als praktisches Beispiel. Stellen Sie sich ein Szenario vor, in
dem der
schnellste Läufer in 2 Stunden und der
langsamste in 6 Stunden ins Ziel So klassifizieren wir das Messniveau
anhand der bereitgestellten Informationen Verhältnis des Messniveaus. Ein Verhältnismaß
ist dadurch gekennzeichnet, dass es einen echten Nullpunkt hat, wobei Null das Fehlen
der zu messenden Menge
bedeutet. Im Marathon-Beispiel starten
alle Läufer zu Beginn des Rennens zur gleichen 0,0-Zeit. Mit einem echten Nullpunkt können
wir aussagekräftige
Vergleiche anstellen und beispielsweise feststellen, dass der schnellste Läufer
dreimal weniger Zeit benötigt hat als der langsamste Läufer, nämlich 2 Stunden gegenüber 6 Stunden Diese Stufe ermöglicht sinnvolle Multiplikations
- und Divisionsoperationen Wenn zum Beispiel
ein Läufer
in 4 Stunden und
ein anderer in 12 Stunden fertig ist, können
wir genau sagen, dass der erste Läufer
dreimal schneller war als der zweite Intervallniveau der Messung. Bei einer Intervallmessung
fehlt ein echter Nullpunkt. im Marathonkontext Wenn im Marathonkontext die Stoppuhr zu
spät startet und wir nur
die Zeitunterschiede zum schnellsten
Läufer messen die Zeitunterschiede zum ,
der pünktlich gestartet ist, verlieren
wir die echte Nullreferenz. Obwohl die Intervalle zwischen den
Werten immer noch
gleichmäßig verteilt sind und
arithmetische Operationen wie Addition und
Subtraktion gültig sind, sind Multiplikation und beispielsweise sinnvoll zu sagen, dass ein Läufer 4 Stunden vor einem anderen ins
Ziel Wir können jedoch nicht sagen, dass
ein Läufer viermal
schneller war als ein anderer, ohne die Gesamtzeit für beide
zu kennen. Zusammenfassend lässt sich sagen, dass die
Messung auf Intervallebene
gleiche Intervalle
zwischen den Werten ermöglicht und Operationen wie
Addition und Subtraktion
unterstützt, aber keinen echten Nullpunkt besitzt , der
für aussagekräftige Verhältnisse erforderlich ist Nun eine kleine Übung, um zu überprüfen, ob dir alles klar
ist Erstens haben wir den Bundesstaat USA, was eine nominale
Messgröße ist. Das bedeutet, dass die Daten zur Kennzeichnung oder Benennung von Kategorien ohne quantitativen Wert verwendet werden. In diesem Fall handelt es sich bei den Staaten um
Namen ohne inhärente
Reihenfolge oder Rangfolge. Als Nächstes haben wir
Produktbewertungen auf einer Skala von 1—5. Dies ist ein Beispiel für
Ordinaldaten. Hier
haben die Zahlen eine Reihenfolge oder einen Rang. Fünf ist besser als eins, aber die Abstände zwischen den Bewertungen sind nicht
unbedingt gleich. Kommen wir nun zu den Namen von Abteilungen
wie Beschaffung, Vertrieb, Betrieb und Finanzen. Auch
das ist nominell gemeint. Die hier verwendeten Kategorien, z.
B. verschiedene Abteilungen dienen der Kategorisierung und implizieren
keine Reihenfolge Als nächstes haben wir die
CO2-Emissionen in einem Jahr, die anhand
eines metrischen Verhältnisses gemessen werden. Dieses Niveau ermöglicht
das gesamte Spektrum
mathematischer Operationen,
einschließlich aussagekräftiger Kennzahlen. Nullemissionen bedeuten überhaupt
keine Emissionen. Dann haben wir Telefonnummern. Telefonnummern sind zwar numerisch, werden aber als Nennnummern eingestuft. Sie sind lediglich Identifikatoren
ohne numerischen Wert für die Analyse Das Komfortniveau ist
ein weiteres ordinales Beispiel. Dazu könnten Stufen
wie niedrige, mittlere
und hohe Pflegestufe gehören , die zwar
auf eine Reihenfolge hinweisen, aber nicht den genauen Unterschied
zwischen diesen Stufen Wohnfläche in Quadratmetern wird auf einer Verhältnisskala gemessen. Wie bei den CO2-Emissionen bedeuten
Quadratmeter, dass es keine Wohnfläche
gibt und Vergleiche wie das Doppelte
oder die Hälfte sind aussagekräftig. Schließlich haben wir die
Arbeitszufriedenheit auf einer Skala von 1—4 angegeben. Das sind Ordinaldaten. Dabei werden die Zufriedenheitsgrade eingestuft, der Unterschied zwischen den
einzelnen Stufen wird
jedoch nicht quantifiziert In der nächsten Lektion
werden wir uns eingehender praktischen Anwendungen der Versuchsplanung befassen.
Bleib dran.
6. Maße der Mitte und Maße der Dispersion: Lassen Sie uns beide Methoden untersuchen, beginnend mit
deskriptiven Statistiken Warum ist deskriptive
Statistik wichtig? Zum Beispiel, wenn ein Unternehmen verstehen
möchte, wie seine
Mitarbeiter zur Arbeit pendeln Es kann eine Umfrage erstellen, um diese Informationen zu
sammeln. Sobald genügend Daten gesammelt wurden, können
sie mithilfe
deskriptiver Statistiken analysiert werden Was genau ist
deskriptive Statistik?
Ihr Zweck besteht darin, einen Datensatz auf sinnvolle
Weise zu beschreiben und zusammenzufassen Es ist jedoch wichtig zu beachten, dass deskriptive
Statistiken nur
die gesammelten Daten widerspiegeln und
keine Rückschlüsse auf
eine größere Mit anderen Worten, wenn wir wissen,
wie einige Mitarbeiter in einem Unternehmen pendeln,
können wir uns keine Sorgen darüber machen, wie es
allen Arbeitnehmern Um
Daten deskriptiv zu beschreiben, konzentrieren
wir uns nun auf vier Hauptkomponenten Messungen der zentralen Tendenz, Streuungsmaße,
Häufigkeitstabellen und Diagramme Beginnen wir mit Messgrößen für
die zentrale Tendenz, zu denen der Mittelwert, der
Median und mehr gehören Zunächst wird der Mittelwert, das arithmetische
Mittel, berechnet, indem alle Beobachtungen
addiert
und durch die
Anzahl der Beobachtungen dividiert werden Wenn wir beispielsweise die
Testergebnisse von fünf Schülern haben, summieren
wir die Ergebnisse
und dividieren sie durch fünf, um zu ermitteln dass das durchschnittliche
Testergebnis 86,6 beträgt Als nächstes folgt der Median. Wenn die Werte in einem Datensatz in aufsteigender Reihenfolge angeordnet
sind, ist
der Median der mittlere Wenn es eine ungerade
Anzahl von Datenpunkten gibt, ist
es einfach der mittlere Wert Wenn es eine gerade Zahl gibt, ist
der Median der Durchschnitt
der beiden Mittelwerte Ein wichtiger Aspekt
des Medians ist, dass er gegen
Extremwerte oder
Ausreißer resistent ist Extremwerte oder
Ausreißer resistent Zum Beispiel, unabhängig
davon, wie groß, die letzte Person
in einem hohen Datensatz ist Der Median bleibt gleich. Der Mittelwert kann sich aufgrund
dieses Werts zwar
erheblich ändern , der Median bleibt jedoch
unabhängig von der Körpergröße der
letzten Person unverändert unabhängig von der Körpergröße der
letzten Person Das bedeutet, dass er nicht von
Ausreißern beeinflusst wird. Im Gegensatz dazu können sich die Männer je
nach Größe der letzten Person
erheblich verändern , sodass sie empfindlich auf Ausreißer reagiert Lassen Sie uns nun den Modus besprechen. Der Modus ist der Wert oder die Werte , die in einem Datensatz am
häufigsten vorkommen. Wenn beispielsweise 14 Personen mit dem Auto, sechs mit dem Fahrrad,
fünf zu Fuß und fünf
Personen mit öffentlichen Verkehrsmitteln
pendeln , ist das Auto der Modus, da
er am häufigsten vorkommt Als Nächstes gehen wir zu den
Streuungsmaßen über, die beschreiben, wie
weit die Werte in
einem Datensatz verteilt sind Zu den wichtigsten Messgrößen für die Streuung
gehören Varianten. Bereich der Standardabweichung
und interquatler Bereich, beginnend mit der
Standardabweichung Sie gibt die
durchschnittliche Entfernung zwischen den einzelnen
Datenpunkten und dem Dies sagt uns, um wie
viel einzelne Datenpunkte
vom Durchschnitt abweichen Wenn die
durchschnittliche Abweichung
vom Mittelwert beispielsweise 11,5 Zentimeter beträgt, können
wir die
Standardabweichung anhand der Formel berechnen Standardabweichung anhand der Sigma entspricht der Quadratwurzel der Summe
der einzelnen Werte
minus dem Mittelwert Quadriert, geteilt durch n, wobei Sigma die Standardabweichung ist N ist die Anzahl der Personen. X sub i ist der Wert jedes
Individuums und x bar ist der Mittelwert. Es ist wichtig zu
beachten, dass es
zwei Formeln für die
Standardabweichung gibt . Eine dividiert durch n, während die andere
durch n minus eins dividiert Letzteres wird verwendet,
wenn unsere Stichprobe nicht die
gesamte Population abdeckt, z. B. in klinischen Studien Letzteres wird verwendet
, wenn unsere Stichprobe nicht die
gesamte Population abdeckt, z. B. in klinischen Studien. Wie unterscheidet sich nun die
Standardabweichung von der Varianz? Die Standardabweichung misst die durchschnittliche Entfernung
vom Mittelwert Dabei ist die Varianz einfach der quadrierte Wert
der Standardabweichung Lassen Sie uns als Nächstes den Bereich
und den ganzzahligen Bereich besprechen. Der Bereich ist die
Differenz zwischen
den Maximal- und
Minimalwerten in einem Datensatz Andererseits stellt der Ungleichheitsbereich
die mittleren
50% der Daten
dar,
berechnet als Differenz
zwischen dem ersten Quartil , Q eins, und dem dritten Quartil, qu Das bedeutet, dass 25%
der Werte
unter und 25% über dem Interquartilbereich liegen unter Bevor wir zu
den letzten Punkten übergehen, wollen wir kurz
diese Konzepte,
Maße der zentralen Tendenz
und Maße der Streuung, miteinander vergleichen Maße der zentralen Tendenz
und Maße der Streuung Betrachten wir die Messung des
Blutdrucks von Patienten. Messungen der zentralen
Tendenz liefern einen einzigen Wert,
der den gesamten Datensatz repräsentiert. Hilft dabei,
einen zentralen Punkt zu identifizieren ,
um den sich
Datenpunkte tendenziell gruppieren. Andererseits
geben
Streuungsmaße
wie Standardabweichung, wie Standardabweichung, Reichweite und Inteqatile-Bereich an Reichweite und Inteqatile-Bereich an, wie weit
die Datenpunkte verteilt Ob sie eng um das Zentrum
herum gruppiert oder
weit verstreut sind Zentrum
herum gruppiert oder
weit verstreut Zusammenfassend lässt sich sagen, dass Messungen der
zentralen Tendenz zwar den zentralen Punkt
des Datensatzes hervorheben , Streuungsmaße jedoch
beschreiben, wie die Daten
um dieses Zentrum herum verteilt sind. Gehen wir nun zu den Tabellen über konzentrieren uns dabei auf die
wichtigsten Typen, Häufigkeitstabellen und
Kontingenztabellen Eine Häufigkeitstabelle
zeigt, wie oft jeder einzelne Wert in einem Datensatz
vorkommt Beispielsweise
befragte ein Unternehmen seine Mitarbeiter zu
ihren Pendelmöglichkeiten,
dem Auto, dem Fahrrad, zu Fuß
und zu den öffentlichen Verkehrsmitteln Hier sind die Ergebnisse von 30 Mitarbeitern mit
ihren Antworten Wir können eine
Häufigkeitstabelle erstellen, um
diese Daten zusammenzufassen , indem wir
die vier Optionen in
der ersten Spalte auflisten die vier Optionen in
der ersten Spalte und ihre
Häufigkeit anhand der Tabelle zählen Es liegt auf der Hand, dass die
Arbeitnehmer
am häufigsten mit dem Auto reisen Mit 14 Mitarbeitern, die
sich für diese Option entscheiden. Die Häufigkeitstabelle bietet eine kurze Zusammenfassung der Daten Aber was ist, wenn wir
statt einer zwei
kategorialen Variablen haben statt einer zwei
kategorialen Variablen Hier kommt eine
Kontingenztabelle ins Spiel, auch
Kreuztabelle genannt Stellen Sie sich vor, das Unternehmen
hat zwei Fabriken, eine in Detroit und eine
weitere in Cleveland? Wenn wir die Mitarbeiter
auch nach ihrem Arbeitsort fragen, können
wir beide Variablen
anhand einer Kontingenztabelle anzeigen Diese Tabelle ermöglicht es uns, die Beziehung
zwischen
den beiden
kategorialen Variablen zu
analysieren und zu vergleichen zwischen
den beiden
kategorialen Die Zeilen stellen die
Kategorien einer Variablen dar. Während die Spalten
die Kategorien der anderen darstellen, zeigt
jede Zelle in der Tabelle die Anzahl der Beobachtungen, die in
die entsprechende
Kategorienkombination passen . Beispielsweise
gibt die erste Zelle an, wie viele
Mitarbeiter mit
dem Auto pendeln , und die Arbeit in Detroit
wurde sechsmal gemeldet Danke. Wir sehen uns in der nächsten Statistikstunde.
7. Minitab: In diesem Kurs
lernen wir etwas über Hypothesentests. Ich werde Ihnen das
Testen von Hypothesen mit MiniTab beibringen. Ich werde Ihnen auch das Testen von
Hypothesen
mit Microsoft Office beibringen . Das verwendet Excel und Microsoft Office für
diejenigen , die sich
für MiniTab interessieren. Lassen Sie mich Ihnen zeigen, von wo
Sie Minitab herunterladen können. Minitab.com unter Downloads. Hier kommen wir zum
Downloadbereich. Sie haben die
Statistiksoftware MiniTab, 30 Tage lang kostenlos verfügbar
ist. Ich habe auch die
Testversion auf mein System
und die Dando-Analyse heruntergeladen und
gezeigt, dass Sie sie Ihnen gezeigt haben. Denken Sie daran, dass es nur 30 Tage
lang verfügbar ist. Bitte stellen Sie sicher
, dass Sie
das gesamte Schulungsprogramm
innerhalb der ersten 30 Tage abschließen. Wenn Sie den Wert darin spüren, sollten
Sie auf jeden Fall die lizenzierte
Version von MiniTab verwenden, die hier verfügbar ist. Ich muss nur auf Herunterladen klicken
und Woodstock herunterladen. Es beginnt mit einer
kostenlosen 30-Tage-Testversion. Und es ist gut
genug Zeit um alle
Übungen zu üben, die angetrieben werden. Sie werden
nach einigen persönlichen
Daten gefragt , damit sie sich mit Ihnen in Verbindung setzen können und
Ihnen mit einigen Rabatten helfen können. Falls es welche gibt. Sie haben einen Bereich namens Dr. MiniTab oder Sie haben
eine Telefonnummer. Wenn Sie aus Großbritannien anrufen
, können
Sie dort leicht anrufen. Wenn Sie jedoch
von anderen Orten aus
sprechen, ist es
viel einfacher, mit MiniTab zu sprechen. Dies ist ein sehr gutes
statistisches Tool und sie aktualisieren die
Funktionen regelmäßig. Ich persönlich bin der Meinung, dass sich diese Investition lohnen
wird. Aber für diejenigen, die
es sich nicht leisten können, sich für die Lizenz zu entscheiden , können
sie Microsoft Office verwenden zumindest einige der Funktionen, nicht alle, aber einige der
Funktionen sind verfügbar. Zunächst werde ich Ihnen
die gesamte Übung
verschiedener Arten von
Hypothesen mit MiniTab zeigen die gesamte Übung
verschiedener Arten von . Und dann werden wir zu Microsoft Excel
übergehen, Verbindung
bleiben und
weiter lernen.
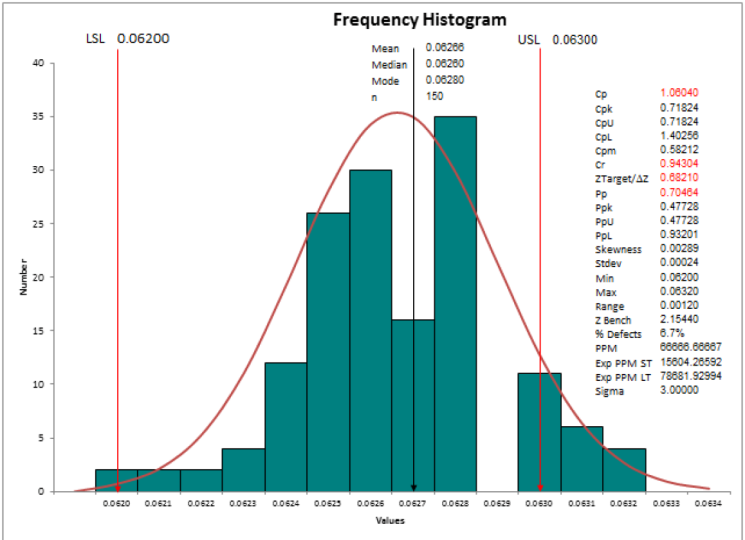
8. Deskriptive Statistik: In der heutigen Sitzung werden wir
uns deskriptiven Statistiken befassen. Deskriptive Statistik
bedeutet, dass ich die Maße des Zentrums
verstehen möchte . Wie Maße für den
mittleren, mittleren, mittleren Modus. Ich möchte die
Maße der Ausbreitung verstehen. Das ist nichts als Bereich, Standardabweichung
und Varianz. Nehmen wir einfache
Daten, die ich habe. Ich habe eine Zykluszeit in Minuten für fast 100 Datenpunkte. Ich werde
die Zykluszeit in Minuten aus meinem
Tagesprojektdatenblatt entnehmen. Ich gehe zu MiniTab und füge meine Daten dort ein, wo ich
hier
beschreibende Statistiken erstellen möchte. Statistiken. Klicken Sie auf Standardstatistiken und sagen Sie
Deskriptive Statistik anzeigen. Wenn ich das mache, gibt es mir im Popup-Fenster
eine Option namens, die mir die verfügbaren
Datenfelder anzeigt, die ich habe. Ich habe eine Zykluszeit in Minuten. Es sagt
mir also, dass ich die variable
Zykluszeit in Minuten
analysieren möchte . Ich klicke einfach auf Okay, und
das findest du sofort in meinem Ausgabefenster. Ich kann das einfach runterziehen. In meinem Ausgabefenster. Es zeigt mir
, dass es
einige statistische Analysen für
die variable
Zykluszeit in Minuten durchgeführt hat einige statistische Analysen für . Ich habe 100
Datenpunkte hier. Die Anzahl der fehlenden Werte ist 0. Der Mittelwert ist 10,064. Standardfehler des Mittelwerts beträgt 0,103, Standardabweichung beträgt 1
bis der Mindestwert 7,5. Eins ist nichts als dein
Quartil eins ist 9.1. Median, das heißt,
Ihr Q2 ist 10,35, Q3 ist 10,868 und der
Maximalwert ist 12,490. Wenn ich mehr
statistische Analysen benötige, kann
ich diese Analyse
wiederholen. Dieses Mal
klicke ich auf Statistiken. Und ich kann mir die anderen
Datenpunkte ansehen, die ich brauche. Angenommen, ich brauche den Bereich, brauche
ich keinen Standardfehler, ich brauche einen
Interquartilbereich. Ich möchte herausfinden,
wie die Stimmung ist. Ich möchte herausfinden, was
die Schiefe ist und welche Daten ich habe. Was ist die Kurtosis in meinen Daten? Ich kann alles auswählen und sagen, okay, ich klicke auf Okay. Wenn ich das mache, werden alle anderen
statistischen Parameter, die ich ausgewählt habe,
in meinem Ausgabefenster angezeigt. Das ist mein Ausgabefenster. Also sagt es mir wieder zusätzlichen Datenpunkt
, den ich ausgewählt habe. Radius ist also nichts anderes als Ihre
Standardabweichung im Quadrat. Sie ist 0,0541. Es sagt mir den Bereich
, der maximal minus minimal ist. Es ist 4,95. Interquartilbereich liegt bei 1,707. In meinen Daten gibt es keinen Modus. Und die Anzahl der Datenpunkte bei
0, weil es keine mehr gibt, die Daten nicht verzerrt. Die Werte liegen sehr nahe bei 0, sie sind 0,05, aber
es gibt eine Kurtosis. Das bedeutet, dass meine Daten nicht als arbeitslos
angezeigt werden. So gut, wir wollen sehen,
wie meine Distribution aussieht. Lass uns das machen. Ich klicke auf Statistiken, ich klicke auf Basisstatistiken und dann auf
grafische Zusammenfassung. Ich wähle die
Zykluszeit in Minuten aus. Und ich sage, ich möchte ein
95% -Konfidenzintervall sehen. Ich klicke auf Okay,
lass uns die Ausgabe sehen. Die Zusammenfassung der
Zyklus-Diamantminuten. Es zeigt mir den Mittelwert, die
Standardabweichung, die Varianz. Alle Statistik-Dinge
werden auf
der rechten Seite angezeigt. Mittelwert, Standardabweichung,
Varianz, Schiefe, Kurtosis, Anzahl der Datenpunkte
minimaler
Median des ersten Quartils , Maximum des dritten Quartils. Diese Datenpunkte, die Sie als Minimum Q1, Median,
Q3 und Maximum
sehen , werden im Boxplot
behandelt. Das Boxplot wird
mithilfe dieser Datenpunkte gerahmt. Und wenn Sie sich den Klettverschluss ansehen, heißt
es, dass die Glocke
keine steile Kurve ist, sondern eine etwas dickere Kurve, und daher ist der
Kurtosis-Wert ein negativer Wert. Wir werden im nächsten Video
weiter
im Detail lernen . Danke.
9. Beschreibende vs. Inferenzstatistiken: Lassen Sie uns beide Methoden untersuchen, beginnend mit der
deskriptiven Statistik Warum ist deskriptive
Statistik wichtig? Zum Beispiel, wenn ein Unternehmen verstehen
möchte, wie seine
Mitarbeiter zur Arbeit pendeln Es kann eine Umfrage erstellen, um diese Informationen zu
sammeln. Sobald genügend Daten gesammelt wurden, können
sie mithilfe
deskriptiver Statistiken analysiert werden Was genau ist
deskriptive Statistik?
Ihr Zweck besteht darin, einen Datensatz auf sinnvolle
Weise zu beschreiben und zusammenzufassen Es ist jedoch wichtig zu beachten, dass deskriptive
Statistiken nur
die gesammelten Daten widerspiegeln und
keine Rückschlüsse auf
eine größere Mit anderen Worten, wenn wir wissen,
wie einige Mitarbeiter in einem Unternehmen pendeln,
können wir uns keine Sorgen darüber machen, wie es
allen Arbeitnehmern Um
Daten deskriptiv zu beschreiben, konzentrieren
wir uns nun auf vier Hauptkomponenten Messungen der zentralen Tendenz, Streuungsmaße,
Häufigkeitstabellen und Diagramme Beginnen wir mit Messgrößen für
die zentrale Tendenz, zu denen der Mittelwert, der
Median und mehr gehören Zunächst wird der Mittelwert, das arithmetische
Mittel, berechnet, indem alle Beobachtungen
addiert
und durch die
Anzahl der Beobachtungen dividiert werden Wenn wir beispielsweise die
Testergebnisse von fünf Schülern haben, summieren
wir die Ergebnisse
und dividieren sie durch fünf, um zu ermitteln dass das durchschnittliche
Testergebnis 86,6 beträgt Als nächstes folgt der Median. Wenn die Werte in einem Datensatz in aufsteigender Reihenfolge angeordnet
sind, ist
der Median der mittlere Wenn es eine ungerade
Anzahl von Datenpunkten gibt, ist
es einfach der mittlere Wert Wenn es eine gerade Zahl gibt, ist
der Median der Durchschnitt
der beiden Mittelwerte Ein wichtiger Aspekt
des Medians ist, dass er gegen
Extremwerte oder
Ausreißer resistent ist Extremwerte oder
Ausreißer resistent Zum Beispiel, unabhängig
davon, wie groß, die letzte Person
in einem hohen Datensatz ist Der Median bleibt gleich. Der Mittelwert kann sich aufgrund
dieses Werts zwar
erheblich ändern , der Median bleibt jedoch
unabhängig von der Körpergröße der
letzten Person unverändert unabhängig von der Körpergröße der
letzten Person Das bedeutet, dass er nicht von
Ausreißern beeinflusst wird. Im Gegensatz dazu können sich die Männer je
nach Größe der letzten Person
erheblich verändern , sodass sie empfindlich auf Ausreißer reagiert Lassen Sie uns nun den Modus besprechen. Der Modus ist der Wert oder die Werte , die in einem Datensatz am
häufigsten vorkommen. Wenn beispielsweise 14 Personen mit dem Auto, sechs mit dem Fahrrad,
fünf zu Fuß und fünf
Personen mit öffentlichen Verkehrsmitteln
pendeln , ist das Auto der Modus, da
er am häufigsten vorkommt Als Nächstes gehen wir zu den
Streuungsmaßen über, die beschreiben, wie
weit die Werte in
einem Datensatz verteilt sind Zu den wichtigsten Messgrößen für die Streuung
gehören Varianten. Bereich der Standardabweichung
und interquatler Bereich, beginnend mit der
Standardabweichung Sie gibt die
durchschnittliche Entfernung zwischen den einzelnen
Datenpunkten und dem Dies sagt uns, um wie
viel einzelne Datenpunkte
vom Durchschnitt abweichen Wenn die
durchschnittliche Abweichung
vom Mittelwert beispielsweise 11,5 Zentimeter beträgt, können
wir die
Standardabweichung anhand der Formel berechnen Standardabweichung anhand der Sigma entspricht der Quadratwurzel der Summe
der einzelnen Werte
minus dem Mittelwert Quadriert, geteilt durch n, wobei Sigma die Standardabweichung ist N ist die Anzahl der Personen. X sub i ist der Wert jedes
Individuums und x bar ist der Mittelwert. Es ist wichtig zu
beachten, dass es
zwei Formeln für die
Standardabweichung gibt . Eine dividiert durch n, während die andere
durch n minus eins dividiert Letzteres wird verwendet,
wenn unsere Stichprobe nicht die
gesamte Population abdeckt, z. B. in klinischen Studien Letzteres wird verwendet
, wenn unsere Stichprobe nicht die
gesamte Population abdeckt, z. B. in klinischen Studien. Wie unterscheidet sich nun die
Standardabweichung von der Varianz? Die Standardabweichung misst die durchschnittliche Entfernung
vom Mittelwert Dabei ist die Varianz einfach der quadrierte Wert
der Standardabweichung Lassen Sie uns als Nächstes den Bereich
und den ganzzahligen Bereich besprechen. Der Bereich ist die
Differenz zwischen
den Maximal- und
Minimalwerten in einem Datensatz Andererseits stellt der Ungleichheitsbereich
die mittleren
50% der Daten
dar,
berechnet als Differenz
zwischen dem ersten Quartil , Q eins, und dem dritten Quartil, qu Das bedeutet, dass 25%
der Werte
unter und 25% über dem Interquartilbereich liegen unter Bevor wir zu
den letzten Punkten übergehen, wollen wir kurz
diese Konzepte,
Maße der zentralen Tendenz
und Maße der Streuung, miteinander vergleichen Maße der zentralen Tendenz
und Maße der Streuung Betrachten wir die Messung des
Blutdrucks von Patienten. Messungen der zentralen
Tendenz liefern einen einzigen Wert,
der den gesamten Datensatz repräsentiert. Hilft dabei,
einen zentralen Punkt zu identifizieren ,
um den sich
Datenpunkte tendenziell gruppieren. Andererseits
geben
Streuungsmaße
wie Standardabweichung, wie Standardabweichung, Reichweite und Inteqatile-Bereich an Reichweite und Inteqatile-Bereich an, wie weit
die Datenpunkte verteilt Ob sie eng um das Zentrum
herum gruppiert oder
weit verstreut sind Zentrum
herum gruppiert oder
weit verstreut Zusammenfassend lässt sich sagen, dass Messungen der
zentralen Tendenz zwar den zentralen Punkt
des Datensatzes hervorheben , Streuungsmaße jedoch
beschreiben, wie die Daten
um dieses Zentrum herum verteilt sind. Gehen wir nun zu den Tabellen über konzentrieren uns dabei auf die
wichtigsten Typen, Häufigkeitstabellen und
Kontingenztabellen Eine Häufigkeitstabelle
zeigt, wie oft jeder einzelne Wert in einem Datensatz
vorkommt Beispielsweise
befragte ein Unternehmen seine Mitarbeiter zu
ihren Pendelmöglichkeiten,
dem Auto, dem Fahrrad, zu Fuß
und zu den öffentlichen Verkehrsmitteln Hier sind die Ergebnisse von 30 Mitarbeitern mit
ihren Antworten Wir können eine
Häufigkeitstabelle erstellen, um
diese Daten zusammenzufassen , indem wir
die vier Optionen in
der ersten Spalte auflisten die vier Optionen in
der ersten Spalte und ihre
Häufigkeit anhand der Tabelle zählen Es liegt auf der Hand, dass die
Arbeitnehmer
am häufigsten mit dem Auto reisen Mit 14 Mitarbeitern, die
sich für diese Option entscheiden. Die Häufigkeitstabelle bietet eine kurze Zusammenfassung der Daten Aber was ist, wenn wir
statt einer zwei
kategorialen Variablen haben statt einer zwei
kategorialen Variablen Hier kommt eine
Kontingenztabelle ins Spiel, auch
Kreuztabelle genannt Stellen Sie sich vor, das Unternehmen
hat zwei Fabriken, eine in Detroit und eine
weitere in Cleveland? Wenn wir die Mitarbeiter
auch nach ihrem Arbeitsort fragen, können
wir beide Variablen
anhand einer Kontingenztabelle anzeigen Diese Tabelle ermöglicht es uns, die Beziehung
zwischen
den beiden
kategorialen Variablen zu
analysieren und zu vergleichen zwischen
den beiden
kategorialen Die Zeilen stellen die
Kategorien einer Variablen dar. Während die Spalten
die Kategorien der anderen darstellen, zeigt
jede Zelle in der Tabelle die Anzahl der Beobachtungen, die in
die entsprechende
Kategorienkombination passen . Beispielsweise
gibt die erste Zelle an, wie viele
Mitarbeiter mit
dem Auto pendeln , und die Arbeit in Detroit
wurde sechsmal gemeldet Danke. Wir sehen uns in der nächsten Statistikstunde.
10. Konzepte von Inferenzstatistiken Teil 2: Lassen Sie uns in die
Inferenzstatistik eintauchen. Wir beginnen mit einem kurzen
Überblick darüber, was es ist. Gefolgt von einer Erläuterung
der sechs Schlüsselkomponenten. Was ist also
Inferenzstatistik? Sie ermöglicht es uns, anhand von
Daten aus
einer Stichprobe
Rückschlüsse auf eine Population Zur Verdeutlichung: Die Population ist die gesamte Gruppe, an der
wir interessiert sind. Wenn
wir zum Beispiel
die durchschnittliche Körpergröße aller
Erwachsenen in den Vereinigten Staaten untersuchen wollen , umfasst
unsere Bevölkerung
alle Erwachsenen des Landes. Bei der Stichprobe
handelt es sich dagegen um eine kleinere Teilmenge
aus dieser Population Wenn wir beispielsweise
150 Erwachsene aus den USA auswählen, können
wir anhand dieser Stichprobe
Rückschlüsse auf die breitere Nun, hier sind die sechs Schritte, die
zu diesem Prozess gehören. Hypothese. Wir beginnen
mit einer Hypothese. Welche Aussage wollen
wir testen? Zum Beispiel
möchten wir vielleicht untersuchen, ob ein Medikament den
Blutdruck bei Menschen
mit Hypotonie positiv beeinflusst Blutdruck bei Menschen
mit Hypotonie Oh, in diesem Fall besteht
unsere Population aus allen Personen mit hohem
Blutdruck in den USA,
da es nicht praktikabel ist, Daten von der gesamten Bevölkerung zu sammeln Daten von der Wir verlassen uns auf eine Stichprobe, um anhand unserer Stichprobe
Rückschlüsse auf die
Population Wir verwenden Hypothesentests. Dies ist eine Methode, die verwendet wird, um eine Aussage über
einen Populationsparameter auf der
Grundlage von Stichprobendaten zu
bewerten . Es sind verschiedene
Hypothesentests verfügbar, und das am Ende dieses Videos. Ich werde dir zeigen, wie du den richtigen
auswählst. Wie funktioniert das
Testen von Hypothesen? Wir beginnen mit einer
Forschungshypothese. Auch bekannt als
Alternativhypothese
, für die wir in unserer Studie nach
Beweisen suchen. Wird auch als
Alternativhypothese bezeichnet. Dafür versuchen wir Beweise
zu finden. In unserem Fall
lautet die Hypothese , dass das Medikament den Blutdruck
beeinflusst. Wir können dies jedoch nicht direkt mit einem klassischen
Hypothesentest testen. Also testen wir die
gegenteilige Hypothese, dass das Medikament keinen
Einfluss auf den Blutdruck hat. Hier ist der Prozess. Erstens,
nimm die Nein-Hypothese an. Wir gehen davon aus, dass das Medikament keine Wirkung
hat, was bedeutet, dass
Menschen, die das Medikament einnehmen und solche, die nicht den
gleichen durchschnittlichen Blutdruck haben. T, sammle und
analysiere Probendaten. Wir nehmen eine Zufallsstichprobe. Wenn das Medikament in der Probe eine große
Wirkung zeigt, bestimmen
wir dann die
Wahrscheinlichkeit, eine
solche oder eine Probe zu ziehen ,
die noch stärker abweicht, wenn das Medikament tatsächlich keine Wirkung
hat,
oder eine, die noch stärker abweicht, wenn das Medikament tatsächlich keine Wirkung
hat,
T, bewerten den
Wahrscheinlichkeits-p-Wert Wenn die Wahrscheinlichkeit, ein
solches Ergebnis unter der
Nullhypothese zu beobachten , sehr gering ist Wir erwägen die Möglichkeit , dass das Medikament
eine Wirkung hat. Wenn wir genügend Beweise haben, können
wir die
Nullhypothese zurückweisen. Der p-Wert ist die
Wahrscheinlichkeit, der die Stärke der Beweise
gegen die Nullhypothese gemessen wird. Zusammenfassend besagt die
Nullhypothese, es keinen Unterschied
in der Grundgesamtheit
gibt, und der Hypothesentest
berechnet, wie wahrscheinlich es ist die Stichprobenergebnisse beobachtet wenn die Nullhypothese wahr ist Wir wollen Beweise für
unsere Forschungshypothese finden. Das Medikament beeinflusst den Blutdruck. Wir können dies jedoch nicht
direkt testen, also testen wir die entgegengesetzte
Hypothese, die Nullhypothese. Das Medikament hat keine Wirkung
auf den Blutdruck. So funktioniert es. Gehen Sie von der Nein-Hypothese aus. Gehen Sie davon aus, dass das Medikament keine Wirkung hat. heißt, Menschen, die das Medikament
einnehmen, und Menschen, die nicht den
gleichen durchschnittlichen Blutdruck haben, sammeln und analysieren Daten. Nehmen Sie eine Zufallsstichprobe. Wenn das Medikament eine große
Wirkung in der Probe zeigt. Wir bestimmen, wie wahrscheinlich es
ist, ein solches
oder ein extremeres Ergebnis zu erzielen . Wenn das Medikament wirklich keine Wirkung hat, berechnen Sie den p-Wert. Der p-Wert ist die
Wahrscheinlichkeit eine Probe
beobachtet wird, die
so extrem ist wie unsere. Unter der Annahme, dass die
Nullhypothese wahr ist. Statistische Signifikanz Wenn der p-Wert unter einem festgelegten Schwellenwert liegt, normalerweise 0,05. Das Ergebnis ist
statistisch signifikant, d. h. es ist unwahrscheinlich, dass es allein durch Zufall
entstanden ist Wir haben dann genügend Beweise , um die Nullhypothese abzulehnen Ein kleiner p-Wert deutet darauf hin, dass die beobachteten Daten nicht mit
der Nullhypothese übereinstimmen führt dazu, dass wir sie
zugunsten der
Alternativhypothese ablehnen zugunsten der
Alternativhypothese Ein großer p-Wert deutet darauf hin, dass die Daten
mit der Nullhypothese übereinstimmen. Wir lehnen es nicht ab. Wichtige Punkte. Ein kleiner p-Wert
beweist nicht , dass die
Alternativhypothese wahr ist. Es zeigt lediglich an
, dass ein solches Ergebnis
unwahrscheinlich ist , wenn die
Nullhypothese wahr ist. Ebenso beweist ein großer p-Wert nicht, dass die
Nullhypothese wahr ist. Dies deutet darauf hin, dass die beobachteten Daten wahrscheinlich unter der
Nullhypothese liegen. Danke. Wir sehen uns in der nächsten Statistikstunde.
11. Konzepte des Hypothesentests im Detail: Willkommen zurück. Lassen Sie uns die
Hypothese genauer verstehen. Hypothese von Wir haben eine ganze Population, die
wir gerne untersuchen würden. Es gäbe jedoch
immer begrenzte
Zeit und Ressourcen, um
die gesamte Bevölkerung zu untersuchen. Daher nehmen wir unter Verwendung
verschiedener Stichprobenverfahren eine Stichprobe
aus der Grundgesamtheit und ziehen eine Stichprobe heraus. Wir untersuchen die Stichprobe und ziehen einige Schlüsse
über die Grundgesamtheit, und zwar als
Inferenzstatistik Was genau ist Hypothese? Eine Hypothese ist eine Annahme , die weder
anfällig noch negativ sein kann. In einem Forschungsprozess wird
die Hypothese ganz
am Anfang aufgestellt,
und das Ziel besteht darin, die Hypothese entweder abzulehnen oder nicht abzulehnen Um die Hypothese, beispielsweise
Daten aus dem
Experiment, abzulehnen oder nicht abzulehnen, ist eine Umfrage erforderlich, die dann
mithilfe eines Hypothesentests ausgewertet werden. Unter Verwendung von Hypothesen werden Hypothesen in der
Regel ausgehend von
einer wörtlichen Überprüfung Auf der Grundlage der wörtlichen Überprüfung können
Sie entweder begründen, warum Sie die
Hypothese auf diese Weise
formuliert haben die
Hypothese auf diese Weise
formuliert Ein Beispiel für eine
Hypothese könnte sein, dass Männer in Österreich für
dieselbe Tätigkeit mehr verdienen als Frauen Die Hypothese basiert auf
der Annahme eines erwarteten Zusammenhangs. Ihr Ziel ist es, die Nullhypothese entweder abzulehnen oder nicht abzulehnen. Sie können Ihre Hypothese
anhand der Daten testen. Die Analyse der Daten
erfolgt mithilfe des
Hypothesentests. In Österreich verdienen Männer für
dieselbe Arbeit mehr als Frauen. Sie haben eine Umfrage unter fast 1.000 in Australien
tätigen Arbeitnehmern durchgeführt, einen T-Test einer unabhängigen Stichprobe. In diesem Test benötigen Sie für die
Hypothese aus der Umfrage geeignete
Hypothesentests
wie den T-Test oder den
Korrelationsanalysetest. Wir können Online-Tools wie
Data Tab oder
Excel-Tools verwenden , um dieses Problem zu lösen. Wie formuliere ich eine Hypothese? Um
eine Hypothese zu formulieren, muss zunächst
eine Forschungsfrage definiert werden eine präzise formulierte
Hypothese über der
Forschungsfrage kann dann eine präzise formulierte
Hypothese über die Population
abgeleitet werden Forschungsfrage kann dann eine präzise formulierte
Hypothese über die Population
abgeleitet In Australien verdienen Männer für
denselben Job mehr als Frauen. Was ist zum Thema
die Frage, die wir stellen wollen,
und was ist die Hypothese? Anschließend
stellen Sie die Daten für
den Hypothesentest zur Verfügung und
ziehen die Schlussfolgerung. Dies ist eine sehr schöne
visuelle Darstellung der Durchführung eines
Hypothesentests. Hypothesen sind keine
einfachen Aussagen. Sie sind so formuliert, dass sie
mit getestet werden können . Sie können
im Laufe des
Forschungsprozesses mit gesammelten Daten
getestet werden mit gesammelten Daten
getestet . Um Hypothesen zu testen, muss
genau definiert werden, um welche Variablen sich handelt und wie diese
Variablen zusammenhängen. Hypothesen sind dann Annahmen
über die
Ursache-Wirkungs-Beziehung der Assoziation
zwischen den Variablen. Was ist in diesem Fall eine Variable? Variable ist nichts anderes als
eine Eigenschaft eines Objekts oder eines Ereignisses, das unterschiedliche Werte
annehmen kann. Zum Beispiel ist eine
Augenfarbe eine Variable. Wenn es die Eigenschaft des Objekts ist, kann
ich verschiedene Werte annehmen. Wenn Sie in
einer Sozialwissenschaft forschen, können
Ihre Variablen Geschlecht, Einkommen ,
Einstellungen,
Umweltschutz usw. sein. Wenn Sie im
medizinischen Bereich forschen, könnten Ihre Variablen Körpergewicht,
Raucherstatus,
Herzfrequenz usw. sein Raucherstatus,
Herzfrequenz usw. Was genau ist also die Null
- und Alternativhypothese? Es gibt immer zwei
Hypothesen, die sich
genau entgegengesetzt sind genau entgegengesetzt und die behaupten, entgegengesetzt zu sein Diese entgegengesetzten
Hypothesen werden
als Null- und Alternativhypothese bezeichnet als Null- und Alternativhypothese und durch H
nichts und H A oder H eins, H Null und
H eins repräsentiert Null und
H Die Nullhypothese von H nichts geht davon aus, dass
es keinen Unterschied zwischen zwei oder mehr Gruppen in
Bezug auf die Merkmale gibt
, die wir untersuchen möchten Die Nullhypothese lautet dann. Die Nullhypothese geht davon aus , dass es keinen
Unterschied zwischen zwei oder mehr Gruppen in Bezug
auf die Merkmale gibt. Beispielsweise
unterscheiden sich die Gehälter der Männer und Frauen in Österreich nicht. Die alternative Hypothese
ist die Hypothese, die wir beweisen
wollen, oder wir
sammeln Daten, um sie zu beweisen. Die alternative Hypothese geht also
davon aus, dass es einen Unterschied zwischen
den zwei oder mehr Gruppen gibt. Beispielsweise
unterscheidet sich das Gehalt
der Männer und Frauen in Österreich. Die Hypothese, die Sie testen
möchten, oder was Sie anhand
der Theorie untersuchen möchten , gibt in der
Regel die Wirkung an. Das Geschlecht
wirkt sich auf das Gehalt aus. Diese Hypothese wird als
alternative Hypothese bezeichnet. Es ist eine sehr schöne
Aussage, oder? Es gibt eine andere
Schreibweise, nämlich das Geschlecht
wirkt sich auf das Gehalt aus, und der Hypothesentest wird
als alternative Hypothese bezeichnet. Die Nullhypothese
besagt normalerweise , dass es keinen Effekt gibt. Das Geschlecht hat keinen Einfluss auf das Gehalt. Im Hypothesentest kann
nur die Nullhypothese getestet werden. Ziel ist es herauszufinden, ob Nullhypothese
abgelehnt wird oder nicht. Es gibt verschiedene
Arten von Hypothesen. Welche Arten von Hypothesen
gibt es? Am häufigsten
wird zwischen Unterschieden Korrelationshypothesen unterschieden. Es kann sich um direktionale und ungerichtete
Hypothesen handeln. Differential- und
Korrelationshypothese. Differentialhypothesen
werden verwendet, wenn verschiedene Gruppen sowie die Gruppe der
Männer und die Gruppe der Frauen
unterschieden werden sollen sowie die Gruppe der
Männer und die Gruppe der Frauen
unterschieden Männer und die Gruppe der Frauen Korrelationshypothesen werden verwendet , wenn
eine Beziehung hergestellt werden soll oder wenn eine Korrelation zwischen der Variablen
getestet werden soll Die Beziehung
zwischen Alter und Größe. Differenzhypothese. Differenzhypothese
ist ein Test, bei dem wir testen, ob es einen Unterschied zwischen
zwei oder mehr Gruppen gibt. Das Beispiel der
Differenzhypothese ist, dass die Gruppe der Männer mehr
verdient als die der Frauen. Raucher haben ein höheres
Herzinfarktrisiko als Nichtraucher Es gibt einen Unterschied
zwischen Deutschland, Österreich und Frankreich in Bezug auf die
Arbeitsstunden pro Woche Somit ist eine Variable immer eine kategoriale
Variable wie Geschlecht, Raucherstatus oder Land Andererseits ist die andere Variable
eine ordinale Variable oder
eine Variable für Gehalt, prozentuales Herzinfarktrisiko und Arbeitsstunden pro Woche Lassen Sie uns nun die
Korrelationshypothese
etwas genauer verstehen etwas genauer Ein Korrelationshypothesentest, Beziehungen zwischen
zwei Variablen. Zum Beispiel die Größe
und das Körpergewicht. die Körpergröße der
Person zunimmt, wird
das Körpergewicht beeinflusst Die
Korrelationshypothese lautet beispielsweise, dass je größer eine Person ist, je schwerer sie ist, je mehr
Pferdestärken ein Auto hat, desto höher ist sein Kraftstoffverbrauch Je besser die Mathe-Note, desto höher das zukünftige Gehalt Wie Sie den Beispielen
entnehmen können, Korrelationshypothesen
häufig
die Form ,
je höher, desto niedriger. Daher werden mindestens zwei ordinale Skalenvariablen
untersucht Direktionale und
ungerichtete Hypothesen, Hypothesen werden in
gerichtete und ungerichtete Hypothesen unterteilt gerichtete und ungerichtete Hypothesen Das heißt, entweder handelt es sich um eine einseitige oder eine zweiseitige Hypothese. Wenn die Hypothese
Wörter wie besser als,
schlechter enthält, dann
ist die Hypothese in der Regel richtungsweisend. Sie könnte positiv
oder negativ sein. Bei ungerichteten
Hypothesen findet
man oft
die Bausteine heraus,
zum Beispiel, dass es einen Unterschied
zwischen den Formulierungen gibt,
aber es wird nicht angegeben, in welcher Richtung der
Unterschied liegt. Bei der
ungerichteten Hypothese
ist
das Einzige von Interesse, das Einzige von Interesse ob es einen Unterschied im Wert zwischen den betrachteten
Variablen gibt. bei einer direktionalen Hypothese, Was interessiert es bei einer direktionalen Hypothese, ob eine Gruppe höher oder
niedriger ist als die andere? Sie haben eine zweiseitige Hypothese, oder Sie können eine
einseitige Hypothese
wie linksseitig oder rechtsseitig haben . Eine ungerichtete Hypothese, eine
ungerichtete Hypothese, testet, ob ein Unterschied
oder eine Beziehung
besteht. Es spielt keine Rolle,
in welcher Richtung die Beziehung besteht
oder welche unterschiedlichen Ursachen es gibt. Im Fall einer
Differenzhypothese bedeutet dies, dass
es einen
Unterschied zwischen zwei Gruppen gibt, aber es sagt nicht aus, ob
eine Gruppe einen höheren Wert hat. Es gibt einen Unterschied zwischen
dem Gehalt von Männern und Frauen, aber es sagt nicht aus
, wer mehr verdient Es gibt einen Unterschied
im
Herzinfarktrisiko zwischen
Rauchern und Nichtrauchern, aber es
wird nicht gesagt, wer ein höheres In Bezug auf die
Korrelationshypothese bedeutet
dies, dass eine Beziehung
oder eine Korrelation
zwischen zwei Variablen besteht Aber es wird nicht gesagt, ob
die Beziehung positiv oder negativ
ist. Es besteht eine Korrelation zwischen Größe und Gewicht und es besteht eine Korrelation
zwischen
Pferdestärke und Kraftstoffverbrauch im Auto. In beiden Fällen wird nicht gesagt, die Korrelation
positiv oder negativ ist. Wenn Sie von einer
Richtungshypothese sprechen, wir zusätzlich die Richtung der
Beziehung oder des Unterschieds an. Im Falle der
anderen Hypothese wird eine
Aussage getroffen, welche Gruppe
hat einen höheren oder niedrigeren Wert? Männer verdienen mehr als Frauen. Raucher haben ein höheres Herzinfarktrisiko als Nichtraucher Im Falle einer
Korrelationshypothese wird
die Beziehung dahingehend hergestellt, wird
die Beziehung dahingehend hergestellt ob eine Korrelation
positiv oder negativ ist Je größer ein Mensch
ist, desto schwerer ist er. Je mehr Pferdestärken ein Auto hat, desto höher ist sein Kraftstoffverbrauch einseitige direktionale
Alternativhypothese umfasst nur die
Werte, die sich in
einer Richtung von den Werten
der Nullhypothese unterscheiden . Wie interpretieren wir nun den p-Wert in einer
Richtungshypothese? Normalerweise hilft Ihnen
Statistiksoftware
immer bei der
Berechnung des p-Werts Excel ist auch bei
der Berechnung des p-Werts sehr
intelligent geworden , und es hilft bei
der Berechnung des ungerichteten Tests und hilft
auch bei
der Angabe des p-Werts dafür. Um den p-Wert für die
Richtungshypothese zu ermitteln, muss geprüft werden, ob der
Effekt in die richtige Richtung ist.
Anschließend wird der p-Wert durch zwei geteilt und ob das
Signifikanzniveau nicht durch zwei,
sondern nur durch eine Seite bestimmt wird sondern nur durch eine Seite Darüber hinaus haben wir
ein Tutorial zum P-Wert. Also schauen Sie sich das bitte in der analysierten Phase meines Kurses an. Wenn Sie
in einem Software-Lil-Datentyp eine gerichtete
Alternativhypothese
für die Berechnung
der Hypothese auswählen in einem Software-Lil-Datentyp eine , erfolgt
die Konvertierung automatisch und Sie können nur lesen. Nun eine schrittweise Anleitung
zum Testen der Hypothese. Sie sollten eine
Literaturrecherche durchführen, die Hypothese
formulieren, das Skalenniveau
definieren, das
Signifikanzniveau
bestimmen, den Hypothesentest
bestimmen.
Welcher
Hypothesentest ist
für die Skalenniveaus und den
Hypothesenstil geeignet für die Skalenniveaus und den
Hypothesenstil Im nächsten Tutorial
geht es um das Testen von Hypothesen. Sie werden etwas über
Hypothesentests lernen und
herausfinden , welche besser ist
und wie man sie liest.
12. Einführung 7Qc-Tools: T. Willkommen zum neuen Kurs
über sieben Qualitätswerkzeuge. Dies ist eines der
wichtigsten Konzepte wenn Sie darüber nachdenken kontinuierlich zu verbessern Ihren Prozess, Ihre Abläufe
oder Ihre Fertigungseinrichtung kontinuierlich zu verbessern. Selbst wenn Sie in
der Dienstleistungsbranche tätig sind, helfen Ihnen
diese Tools dabei, den Überblick über
die Qualität zu behalten. Lassen Sie uns damit anfangen. Also, die sieben QC-Tools, was werde ich im
Rahmen dieses
Schulungsprogramms behandeln Rahmen dieses
Schulungsprogramms Es sind die sieben
Qualitätskontrollwerkzeuge. Erstens: Dinge, Katapult,
Flussdiagramm, Histogramm, Pareto-Analyse,
Fishburn-Diagramm, auch
Ishikawa-Diagramm genannt Ishikawa-Diagramm Wir werden diese Tools nicht nur auf hohem Niveau behandeln. Wir werden einige Beispiele
machen, wie man diese Dinge
mit Microsoft Excel zeichnet ,
wo immer dies möglich ist. Wir werden Ihnen auch
einige Beispielübungen mit
Daten geben einige Beispielübungen mit , die Ihnen helfen können,
diese Aktivitäten sehr einfach durchzuführen. Wir werden
darüber sprechen, was das Tool ist, wie das Tool verwendet wird, wann das Tool verwendet wird, einige häufige Fehler,
die wir vermeiden sollten, und eine schrittweise Anleitung zur Erstellung der erforderlichen Ausgabe
geben.
13. Prüfblatt: Gehen wir zum
nächsten Qualitätswerkzeug der sieben QC-Tools über
, dem Prüfblatt Lassen Sie uns mehr
über das Prüfblatt erfahren. Scheckblätter werden zur systematischen Erfassung
und Zusammenstellung der Daten Aus den historischen Quellen oder Beobachtungen, sobald sie auftreten Es kann verwendet werden, um
Daten an Orten zu sammeln
, an denen Daten im Laufe der Zeit tatsächlich
generiert werden. Es kann verwendet werden, um
sowohl quantitative als auch
qualitative Daten zu erfassen . Deshalb habe ich Ihnen ein einfaches
Prüfblatt gezeigt, auf dem Sie die
Fehlertypen haben und wie oft dieser bestimmte
Fehler auftritt. Dies kann verwendet werden
, um Daten
aus historischen Quellen oder
Beobachtungen systematisch aufzuzeichnen und zusammenzustellen , sobald sie auftreten. Es kann verwendet werden, um Daten an
Orten zu
sammeln , an denen Daten in Echtzeit
generiert werden. Diese Art von Daten kann quantitativ
als auch qualitativ sein. Das Prüfblatt gehört zu
den sieben grundlegenden Qualitätskontrollen. Was macht das Scheckblatt? Es wird verwendet, um
leicht verständliche
Daten zu erstellen, und das ist mit einem
einfachen, effizienten Prozess verbunden Sie sich bei jedem Eintrag
ein klares Bild von den
Fakten, die von den einzelnen
Teammitgliedern vorgeschlagen Aus diesem Grund ist es eines
der datengesteuerten. Es standardisiert die Vereinbarung über Definitionen jeder einzelnen
Bedingung Wie wird eine Scheckform verwendet? Wir einigen uns auf die Definition von Ereignissen oder Bedingungen
, die beobachtet werden. Beispiel. Wenn wir nach der Grundursache für Mängel des
Schweregrads 1 suchen, dann müssen wir uns
darauf einigen, sie als ersten Schweregrad zu bezeichnen. Entscheiden Sie, wer die Daten sammelt, entscheiden Sie, welche Person an dieser Aktivität
beteiligt sein wird. Notieren Sie sich die Quellen
, aus denen die Daten gesammelt werden. Die Daten sollten in Form einer
Stichprobe oder der gesamten Population vorliegen. Sie können sowohl qualitativ
als auch quantitativ sein. Legen Sie fest, welcher
Wissensstand für
die Person erforderlich ist, die am Datenerfassungsplan
beteiligt ist. Entscheiden Sie, wie häufig die Daten gesammelt werden
sollen und
ob die Daten
wöchentlich, stündlich, täglich
oder monatlich erhoben werden müssen. Legen Sie die Dauer der
Datenerhebung fest, d. h.
wie lange die Daten
gesammelt werden sollen, wie lange die Daten
gesammelt werden sollen um
ein aussagekräftiges Ergebnis zu erzielen. Erstellen Sie ein einfach
zu verwendendes Prüfblatt,
das präzise, vollständig
und konsistent
bei der Erfassung der
Daten während des
gesamten Erfassungszeitraums ist zu verwendendes Prüfblatt,
das präzise, vollständig und konsistent
bei der Erfassung der
Daten während des
gesamten Erfassungszeitraums Daten während des
gesamten Bitte beachten Sie, dass
Scheckblätter zu Zeiten
des Industriezeitalters als eines der Qualitätsinstrumente erstellt wurden Derzeit befinden wir uns
im Informationszeitalter. Wir haben so viele ERP-Softwareprogramme,
Maschinen, die
Daten aufgrund der IT erfassen, und es gibt verschiedene andere computergenerierte Berichte
, die anwendbar sind Versuchen Sie, ein Scheckblatt
nur zu verwenden, und zwar nur dann, wenn Sie sich in einem vollständig
manuellen Datenerfassungsprozess befinden Es ist eines der Tools, in den letzten Monaten
jedoch am wenigsten genutzt Lassen Sie mich das anders formulieren:
Tools, die in den letzten Jahren am wenigsten genutzt wurden. Es sei denn, Ihr
Unternehmen hat überhaupt keinen systematischen
Ansatz zur Erfassung der Daten Es ist ein sehr gutes Tool,
wenn Sie Mitarbeiter mit
blauen Farben einsetzen und keine High-Tech-Systeme
zur Erfassung der Daten
haben. Deshalb habe ich die Vorlage
für das Scheckblatt im Bereich
Projekt und Ressourcen beigefügt . Sie können sich darauf beziehen.
Gib mir einfach eine Sekunde. Ich zeige dir das
Scheckblatt auf dem Bildschirm. So kann ich
ein Scheckblatt verwenden , das ich Ihnen als Teil
meiner Parado-Vorlage
gegeben Sie können die
Kategorien hier aufschreiben und mir
sagen, dass es sich um
Fehler eins, Fehler zwei handelt Es
handelt sich um ein Problem wie auch immer Ihr Fehler heißen Bitte listen Sie hier alle
Mängel auf, oder? Und dann können Sie
das vermarkten , wie oft passiert
das? Wo auch immer es passiert, fangen
Sie bitte an, eines zu schreiben. Wie oft siehst du das und wann siehst du es? Dies in Verbindung damit, dass ich diese Daten später
für meine Pareto-Analyse
verwenden kann , für die ich
ein separates Video erstellt habe , das können
Sie verwenden In der heutigen Welt benötigen Sie kein separates
Scheckblatt. Sie können das verwenden, das
ich hier gegeben habe. Danke. Ich sehe
dich in der nächsten Klasse.
14. Box-Plot: Heute werden wir etwas über
Boxplot
lernen und
es im Detail verstehen Wir alle hätten Boxplot
in mehreren Fällen gesehen. Aber mal sehen,
was es interpretiert. Was genau ist also ein Boxplot? Mit einem Boxplot können
Sie in der Regel viele
Informationen zu Ihren Daten
grafisch darstellen Das Feld gibt den Bereich der mittleren 50%
der
Stelle an, an der Ihr Wert liegt Lassen Sie uns den
Boxplot verstehen, wie er aufgeteilt ist. Wenn der Anfang der
Box als Q Eins bezeichnet wird, ist er das untere Ende der Box und wird auch
als erstes Quartil bezeichnet Q ist das obere Ende der
Box oder das dritte Quartil. Die Entfernung zwischen Q 3 und Q wird als
Interquartilbereich bezeichnet, was den mittleren
50% Ihrer Die 25% der Daten liegen
unter Q Eins. In dem Feld
befinden sich 50% der Daten, und daher befinden sich 25% der
Daten über dem Sie haben eine Haupt- und
eine Mittellinie innerhalb des Felds, wodurch die
Daten wiederum in 25 und 25% aufgeteilt werden Nehmen wir also an, wenn wir
das Alter des Teilnehmers,
das Boxplot, anzeigen , sind es 31 Das bedeutet, dass 25%
der Teilnehmer
jünger als 31 Jahre sind. Q drei ist 63 Jahre. Das bedeutet, dass 25% der
Teilnehmer älter als 63 Jahre sind. 50% der Teilnehmer
sind 31-63 Jahre alt. Der Mittelwert und der Median. Der Median liegt bei 42, was bedeutet, dass
die Hälfte der Teilnehmer älter als 42 Jahre und die andere Hälfte
jünger als 42 Die gestrichelte Linie wird auch als
Durchschnittslinie
oder als Hauptwert bezeichnet , der den Durchschnitt
darstellt Da der Mittelwert
vom Median abweicht, bedeutet
dies eindeutig, dass es sich bei den Daten um einen Unterschied handelt Die durchgezogene Linie steht für den Median und die gepunktete
Linie für Die weiter
entfernten Punkte werden als Ausreißer bezeichnet. Die Höhe des Whiskers
entspricht etwa dem 1,5-fachen des Bereichs
zwischen den Quartalen. Der Whisker kann nicht
endlos pingen. Der Ausreißer und der
Ti-förmige Schnurrbart. Wenn es keinen Ausreißer gibt, ist der Maximalwert Wenn es einen Ausreißer gibt, ist der T-förmige Whisker der letzte Punkt, bei
dem das 1,5-fache des
Interquaralbereichs und andere Wie erstelle ich einen Boxplot? Sie haben eine Excel, um Ihren Boxplot zu
erstellen, und Sie können dies auch
mit Online-Tools tun Ja, also kann ich einfach
nach Diagrammen suchen. Damit kann ich sagen, dass ich die metrische Variable
nehme, dann haben Sie die
Option eines Histogramms und Sie haben auch die
Option eines Boxplots,
was eindeutig besagt, dass Q eins 29 ist, 66 ist,
der Median 42 ist, der Mensch 46 ist Das Maximum ist 99, der
obere Zaun ist 99. Es gibt keine Ausreißer. Gehen wir und ändern die Daten. Lass mich das auf 126 machen. Sobald ich den Wert
einer Person auf 126 ändere und Sie zurückkommen,
werden
Sie feststellen, dass es
einen Ausreißer im Histogramm gibt,
und
hier ist sehr offensichtlich, dass 126 ein Ausreißer ist Und hier ist der obere Zaun 92. Q drei ist immer noch
derselbe, Q eins ist immer noch derselbe. Die Boxgröße
ändert sich also nicht und so weiter. Richtig? Was ist, wenn die Person ein Held ist? In diesem Fall werden Sie
feststellen, dass es sich nicht
um einen Ausreißer handelt, sondern dass es immer noch Teil des ISC ist Ich kann die Grafik klein machen, ich kann die Nulllinie anzeigen Ich kann die
Standardabweichung anzeigen. Ich kann die Punkte zeigen. Ich kann es
horizontal und vertikal machen. All diese Optionen
sind also
mit einem
Online-Statistiktool möglich . Ich kann die
Zip-Datei natürlich herunterladen und damit arbeiten. Okay. Wie kann ich Boxplot
mit Excel machen? Also habe ich die
gleichen Daten hierher kopiert. Ich habe verschiedene Gruppen, also habe ich mein Alter als Daten
ausgewählt. Und jetzt gehe ich zum Einfügen eines empfohlenen Diagramms,
gehe zu allen Diagrammen und ich habe ein
Box-and-Whisker-Diagramm Und ich kann mein
Box-and-Whisker-Diagramm sehen. Ich kann meine Rasterlinien entfernen und
die Datenbeschriftungen hinzufügen, und es zeigt deutlich meinen Weg. Vielleicht kann ich es einfach vergrößern, um
es besser sichtbar zu machen. Ich kann die Farbe
meines Diagramms so ändern, dass sie anders ist. Oh und ich kann das
auswählen Mein Durchschnitt
ist hier drüben. Mein Median ist 421, drei und. Jetzt, das gleiche Diagramm, ich kann
es auch nach Wurzeln gruppieren Ich nehme die
Gruppe und das Alter. Ich klicke rein, ich kann
auf das empfohlene Diagramm klicken, zu allen Diagrammen
gehen und Box and Whisker
machen Dieses Mal habe ich vier Boxen
für jedes Mitglied der Gruppe. Ich kann die Farbe
meines Diagramms ändern. In Ordnung. Ich kann die Datenbeschriftungen beifügen. Wenn ich es hier einfüge
und auf das Kommazeichen klicke, wirst
du feststellen, dass
die Bindepunkte
waren . Es ist also sehr einfach, Diagramme mit
Excel sowie mit
einigen Online-Tools zu zeichnen Excel sowie mit
einigen Online-Tools Also für die Gruppen habe ich die Gruppe plus das A
genommen, und dafür habe ich genommen Also für A, sagen wir
für die Gruppe C, wenn ich weitermache und
den Wert auf 100 ändere, wirst
du feststellen, dass
es dort einen Ausreißer gibt Der Mindestwert ist zehn, lassen Sie uns die Werte 25 ändern Sie werden feststellen, dass sich die
Werte auf
diese Weise ändern. Großartig. Also werde ich dich in
der nächsten Klasse sehen. Danke. Oh.
15. Box-Plot Teil 1: In dieser Lektion werden wir
mehr über Boxplot erfahren. Ein Boxplot ist eine
der grafischen Techniken, mit
denen wir
Ausreißer identifizieren können, oder? Lassen Sie uns verstehen, wie
ein Boxplot entsteht. Lassen Sie uns zuerst
das Konzept verstehen bevor wir uns mit
den Praktika befassen. Ein Boxplot wird als
Boxplot bezeichnet, weil es
wie eine Box aussieht und
viskos ist wie die Katze. Die Katze hat im Gesicht. Nun, genau wie die Katze nicht haben kann und weniger viskos ist, die Größe des Whiskers
des wird
die Größe des Whiskers
des Boxplots für bestimmte Parameter festgelegt
. Sie werden einige
wichtige Terminologien sehen , wenn Sie ein Boxplot erstellen. Nummer eins, was ist
der Mindestwert? Was ist das Quartil? Was ist der Median? Was ist der Kern fest? Drittens, was ist die Größe
des maximalen Whiskers? Und was ist der
Maximalwert am Datenpunkt? Hier? Die Mindestanzahl der Hunde über den Minimumpunkt und wo
der Whisker verlängert werden kann. Q1 steht für das erste Quartal, was 25% der Daten bedeutet. Nehmen wir zur Vereinfachung an, wir haben 100 Datenpunkte. 25 Prozent der Daten
werden unter dieser einen Marke liegen. Zwischen Q1 und Q2. Fünfundzwanzig
Prozent Ihrer Daten werden gebildet, werden vorhanden sein. Q2 wird auch als
Median oder
Mittelpunkt Ihrer Daten bezeichnet . Wenn ich also meine Daten in
aufsteigender oder absteigender Reihenfolge anordne, wird
der mittlere
Datenpunkt
als Median und als Q2 bezeichnet. Q3, oder auf andere Weise auch als oberes Quartil
bezeichnet, spricht von den
fünfundzwanzig Prozent der Daten nach dem Medium. Technisch gesehen haben Sie
inzwischen
fünfundsiebzig Prozent
Ihrer Daten abgedeckt fünfundsiebzig Prozent
Ihrer Daten unter Ihrem
dritten Quartil liegen
werden, 25 Prozent unter dem ersten Quartal, 50% der Daten unter dem zweiten Quartal, fünfundsiebzig Prozent von
Die Daten liegen unter Q3. Technisch gesehen liegen
von 100% der Daten 75% der Daten unter dem dritten Quartal. Das bedeutet, dass fünfundzwanzig Prozent
meiner Datenpunkte über dem dritten Quartal liegen werden. Jetzt wird der Abstand zwischen
Q1 und Q3 als Boxgröße bezeichnet. Und diese Kastengröße wird auch als Interquartilbereich
bezeichnet. Q3 minus Q1 wird als
Interquartilbereich bezeichnet. Wie ich Ihnen zu
Beginn des Unterrichts sagte, hängt
die Größe
des Whiskers vom Interquartilbereich oder IQR ab. Q3. Ich kann diese Linie das
1,5-fache der Größe der Box bilden. 1,5-fache IQR
plus Q3 ist also die
Obergrenze für meinen Whisker. Auf der rechten Seite.
Auf der Oberseite. Wenn ich den
Whisker auf der linken Seite zeichnen möchte, ist
es nichts anderes als das gleiche 1,5-fache im
Interquartilbereich. Aber ich subtrahiere diesen Wert von Q1 und verlängere ihn bis zu diesem Wert. Also legt es die Untergrenze fest. Möglicherweise haben Sie
Datenpunkte, die unter
den Minimalpunkt fallen. Möglicherweise werden
Datenpunkte, die über die
maximale Größe
des Risikos dieser Datenpunkte
hinausgehen , als Ausreißer bezeichnet. Das Schöne an Boxplot
ist, dass es Ihnen hilft,
festzustellen , ob Ihr Datensatz
Ausreißer enthält. Mal sehen wie kann ich ein Boxplot
erstellen? Denn physisch muss ich mir
keine
Sorgen machen , 2525% Prozent herauszufinden. Und wirklich persönlich werden wir
zu MiniTab gehen und dann die Arbeit machen. Sehen wir uns dieses Datenblatt an. In unserer vorherigen Klasse haben wir einige beschreibende
Statistiken dazu erstellt. Und wir haben die Datenpunkte gefunden. Wir haben den minimalen Datenpunkt
Q1, Q2, Q3 und maximalen Datenpunkt gefunden. Versuchen wir,
ein Boxplot für die
Zykluszeit in Minuten zu erstellen . Also klicke ich auf Grafik. Ich gehe zum Boxplot und sehe mir ein einfaches Boxplot an
und klicke auf
Okay, ich werde die
Zykluszeit in Minuten auswählen. Und ich sage: Okay, sehen
wir uns die Datenansicht an. Wenn Sie sich dieses Boxplot ansehen, wird
die untere Zeile
als die eine bezeichnet. Es ist 9.16. Der Median ist die Mittellinie und muss nicht
genau in der Mitte liegen. Die Oberseite der Box ist Q3, was 10,86 in
diesem Datenbereich ist, und der
Interquartilbereich ist 1,7. Meine Box kann sich 1,5-mal
am Ellbogen ausdehnen und auf
dem Ballon
1,5 mal in 1,7 gehen . Und Sie sehen
, dass es
in diesem Boxplot
keine Sternchen gibt , sehr deutlich darauf hinweist,
dass es in meinem
aktuellen Datensatz
keine Ausreißer gibt . Holen wir uns
noch einen Datensatz. In unserem nächsten Video zu
verstehen, wie Boxplot funktioniert.
16. Box-Plot Teil 2: Lassen Sie uns unsere Reise fortsetzen um Boxplots
genauer zu verstehen. Wenn Sie
in Ihrer Projektdatei auf das Arbeitsblatt gehen, das als Boxplot bezeichnet wird. Ich habe Daten zur Zykluszeit für fünf
verschiedene Szenarien gesammelt. Wie Sie sehen können, habe ich an
einigen Stellen mehr
Datenpunkte, wie ich fast 401745 Daten habe. An manchen Stellen habe ich
nur 14 Datenpunkte. Versuchen wir also, dies
genauer zu analysieren , um zu verstehen,
wie Boxplot funktioniert. Ich habe diese
Daten auf MiniTab kopiert, Fall eins, Fall zwei, T3 und T4. Als erstes würde ich also
einige grundlegende deskriptive
Statistiken
für alle Fremdschlüssel erstellen
wollen einige grundlegende deskriptive
Statistiken . Ich wähle alles aus. Und dann sehe ich,
wenn ich meine Ausgabe sehe, kann
ich sehen, dass
ich in
drei der Fälle 45 Datenpunkte habe. Im vierten Fall habe ich 18 Datenpunkte. Im fünften Fall
habe ich 14 Datenpunkte. Die Anzahl der
Datenpunkte ist also sehr, wenn man sich meinen Mindestwert anschaut, reicht er von 1,
eins, einundzwanzig, zweiundzwanzig. Und der Maximalwert liegt
irgendwo zwischen 4090. In einem Szenario habe ich Werte von 21 bis 40
entwickelt. In einem Szenario habe ich
Werte von zwei bis 90, was sehr deutlich zeigt, dass die Anzahl der
Datenpunkte oder dies tut. Aber mein Wertebereich ist weiß. Wenn Sie sich also die Rate ansehen, liegt
sie zwischen
18,8 und 99 Punkten. Also im zweiten Fall habe ich 1200 als
Bereich, also 99 Jahre. Und dasselbe kann auch als Standardabweichung
beobachtet werden. Sie können sehen, dass die
Schiefe der Daten
unterschiedlich ist und die Kurtosis unterschiedlich
ist. Lassen Sie uns zunächst
das Boxplot im Detail verstehen. Und im nächsten Video, wenn ich
über das Histogramm spreche, werden
wir das
Verteilungsmuster
anhand desselben Datensatzes verstehen . Lass uns anfangen.
Ich klicke auf Grafik. Ich kann auf Boxplot klicken
und ich klicke auf simple. Was ich tun kann ist, dass ich
11 Fälle gleichzeitig aufnehmen kann ,
um meine Daten zu analysieren. Im ersten Fall zeigt es
mir ein Boxplot und dieses Boxplot zeigt sehr deutlich , dass meine Daten keine
Ausreißer enthalten. Und der Bereich liegt zwischen. Wenn ich den Cursor hier drüben lasse, habe ich 45 Datenpunkte. Mein Whisker reicht
von 21,6 bis 4,4 und mein
Interquartilbereich liegt bei 5,95. Mein Median ist 30,3. Mein erstes Quartil ist 26,9. Mein drittes Quartil ist 32,85. Lassen Sie uns die
Sache für Fall zwei wiederholen. Wenn ich auch meine Schlüssel mache, wenn du jetzt hinschaust, sieht die Box sehr klein weil hier meine
Datenpunkte gleich sind. Verstärkt von Vickery
reicht wieder von 21,6 bis 40 für scheint wie
mein vorheriges Szenario. Aber ich habe hier Ausreißer, die weit darüber hinausgehen. Wenn Sie sich erinnern, ist die
beschreibende Statistik für Kinder bis zu meinem Mindestwert eins
und mein Maximalwert ist 100. Mein Median war wie
mein vorheriges Szenario. Mein Q1 ist auch ähnlich, nicht dasselbe, aber ähnlich. Und Q3 ist auch ähnlich. Aber wenn man sich das Boxplot
anschaut, ist
die Box sehr klein, sehr deutlich zeigt, dass was
sehr deutlich zeigt, dass mein
Interquartilbereich 6,95 beträgt. Meine Viskose kann nur das
1,5-fache erreichen und jeder
Datenpunkt darüber hinaus wird
Misko
als Ausreißer bezeichnet. Ich kann diese
Ausreißer auswählen, oder? Und es ist sehr deutlich zu sehen, k ist zwei, der Wert ist 100
und es ist in Zeile Nummer eins. Zeile Nummer 37, ich habe
einen Wert namens 90. In Zeile Nummer 30 habe ich
einen Wert namens ist 88. Und in Zeile Nummer 21 habe ich
einen Wert namens Eins
, der eine Mindestgröße ist. Ich habe also Ausreißer
auf beiden Seiten. Lass uns Fall drei verstehen. Wenn ich mir die Chemie ansehe, setze
ich den Cursor auf den Boxplot. Ich habe dieselben 45 Datenpunkte. Meine Viskose oder von 21,6 bis 40 für scheint wie mein
Fall eins, Fall zwei. Aber in diesem Szenario habe ich viele Ausreißer. Am unteren Ende. Das ist, auf der Unterseite
meines Kerns, eng, richtig? Es fällt uns leicht,
auf jede einzelne von ihnen zu klicken und zu
sehen, wie meine Boxen sind. Das Schöne hier ist, dass
ich nur 18 Datenpunkte habe, aber immer noch einen Ausreißer habe. Machen wir es für k ist fünf. Und verstehe das auch. Ich habe eine kleinere Kiste. Ich habe nur 14 Datenpunkte und einen Ausreißer
auf der Aufwärts-Taste, und ich habe einen Ausreißer
am unteren Ende. Hier ist der Wert 23. Aber wenn ich diese
Handlungen anders
sehe , ist es für
mich schwierig, einen Vergleich durchzuführen. Kann ich alles
auf einen Bildschirm bekommen? Also gehe ich zum Graphen,
ich gehe zum Boxplot. Ich werde eine einfache
Umgebung auswählen. Ich wähle alle Fälle zusammen aus und sehe
mehrere Grafiken. Ich sehe Haut und ich sehe, dass
die Achse gesehen werden sollte. Rasterlinien sollten sichtbar sein. Und ich klicke auf Okay. Ich erhalte alle
fünf Datenpunkte, fünf Fallszenarien
in einem Diagramm. Das wird es mir leicht machen die Analyse durchzuführen, in diesem Fall. Also individuell, wenn
ich den Fall eins gesehen habe, wenn wir uns ein großes Schwad zeigen. Aber wenn ich einen nebeneinander
vergleiche , kann
ich wissen, dass ich im zweiten Fall Ausreißer
oben und unten habe . Im dritten Fall habe ich
Ausreißer auf der Unterseite. Im vierten Fall habe ich
Ausreißer auf der Oberseite. Im fünften Fall habe ich
Verkaufsstellen auf beiden Seiten. Die Anzahl der
Datenpunkte ist unterschiedlich. Die Bulks werden gezogen. Die Größe der Box kann nicht durch die
Anzahl der Datenpunkte
bestimmt werden . Ich habe 45 Datenpunkte, aber meine Box ist sehr schmal. Und ich habe 14 Datenpunkte
und meine Box ist weiß. Also die Größe der Box. Wenn ich also 14 Datenpunkte habe
, werden meine
Daten in vier Teile aufgeteilt. Also drei Datenpunkte unter Q1, drei Datenpunkte
zwischen Q1 und Q2, drei Datenpunkte
zwischen Q2 und Q3 und drei Datenpunkte hinter Q3. Während ich
45 Datenpunkte hatte, es als 11111111
verteilt. Mein Median wäre
die mittlere Zahl. Aus
dieser Übung lernen Sie also , dass
Sie
anhand der Größe des Quaders die Anzahl der Datenpunkte nicht bestimmen können. Aber was Sie definitiv
feststellen können , ist, dass
ich angesichts dieses Datensatzes Datenpunkte habe, die extrem hoch oder niedrig
sind? Der Zweck des Zeichnens
eines Boxplots besteht also darin,
die Verteilung zu sehen und etwaige Ausreißer zu
identifizieren. Ich hoffe, das Konzept ist klar. Wenn Sie Fragen haben, können Sie diese gerne
in der Diskussionsgruppe veröffentlichen. Und ich beantworte sie
gerne. Danke.
17. Pareto-Analyse: Hallo Freunde. Lassen Sie uns
unser Lernen über sieben QC-Tools fortsetzen unser Lernen über sieben QC-Tools Das Tool, das wir heute lernen
werden, sind Pareto-Diagramme, die auch als
Parto-Analyse bezeichnet werden Dies basiert auf dem berühmten Statistiker, nicht auf dem Statistiker Lassen Sie mich korrigieren, Wirtschaftswissenschaftler, um
die Welt gereist ist, den Anteil des
Wohlstands an der Bevölkerung
zu
untersuchen Wohlstands an der Bevölkerung
zu Dabei
fand Herr Pareto das 80-20-Prinzip heraus Lassen Sie uns tief in das Thema eintauchen. Also die Pareto-Analyse, das Prinzip, das Ihnen
hilft, sich auf
das Wichtigste zu konzentrieren , um den größtmöglichen Nutzen zu
erzielen Sie beschreibt das Phänomen , dass eine geringe
Menge hoher Werte mehr
zur Gesamtsumme beiträgt als eine hohe
Anzahl niedriger Werte Der Schwerpunkt liegt auf den
Attributen mit hohem Wert, auf die ich mich
konzentrieren muss , anstatt auf so
viele Dinge mit geringem Wert. Kurz gesagt: Identifiziere die Wenigen und
nicht die trivialen Vielen Was sind diese roten Blöcke
, die nur drei oder vier sind? Aber der Beitrag ist groß. Anstatt sich Hunderte
von kleinen Dingen anzusehen, bei denen der
Beitrag insgesamt gering ist. Selbst wenn ich mir meine
persönlichen Ausgaben ansehe, O von meinem
Gesamteinkommen, fließt der
Großteil meines Geldes in die Zahlung von EMI, die
Bezahlung der Mieten und Rechnungen. Das sind also meine wenigen lebenswichtigen, und nicht trivialen vielen, bei
denen ich versuche, mir die Bustickets, das Essen,
das ich esse,
oder die kleinen Einkäufe,
die ich tätige, anzusehen Essen,
das ich esse,
oder die kleinen Einkäufe, die ich Wenn ich also gut sparen will
, muss
ich mich darauf konzentrieren, wie
ich meine EMI schneller zurückzahlen kann, wie ich eine Miete haben kann, die innerhalb meines Budgets liegt Die Pareto-Analyse basiert
auf der berühmten 80-20-Regel. Sie besagt, dass rund 80%
der Ergebnisse auf
20% des Aufwands zurückzuführen sind Sehr schön gesagt, der
Aufwand von 80% ergibt sich aus einem Aufwand von 20%. In ähnlicher Weise sind 80%
der Probleme oder Auswirkungen auf 20% der Ursachen zurückzuführen. Wir verwenden dies für unsere
Ursachenanalyse. Der genaue Prozentsatz kann von Situation
zu Situation
variieren, obwohl wir glauben, dass
er bei 80 20 liegt, auch wenn es 75 25 sind, sollten
wir
weitermachen und uns bemühen, diese wenigen lebenswichtigen Probleme zu beheben. Manchmal
bekommen wir einen Wert von 70 30, manchmal
sogar einen Wert von 88 12. Dies sind nur
einige Beispiele. Der Punkt ist, welche sind
die Hauptursachen, die ich mit
minimalem Aufwand beheben kann , um
maximale Ergebnisse zu erzielen. In vielen Fällen
sind nur wenige Anstrengungen für die meisten Ergebnisse verantwortlich. sind einige wenige Ursachen Regel sind einige wenige Ursachen für
den Großteil des Aufwands verantwortlich. Wenn ich auf meine Prüfung zurückblicke, gibt es bestimmte
Kapitel in meinem Buch , die
in meiner Abschlussprüfung mehr Gewicht Wenn ich mich mit
diesen Kapiteln gründlich beschäftige, wird
meine Wahrscheinlichkeit,
60 bis 70% zu erreichen, sehr einfach Anstatt zu versuchen,
alle 20 Kapitel
in meiner Arbeitsmappe zu lesen , könnte
ich mich auf einige
Kapitel konzentrieren, um Ergebnisse zu erzielen Sparto-Analyse wird von
Entscheidungsträgern verwendet , um
den Aufwand zu ermitteln, der
am wichtigsten ist, um dann zu
entscheiden, welcher
zuerst ausgewählt werden am wichtigsten ist, um dann zu soll, die Entscheidungsfindung Sie wird für Projekte zur
Prozessverbesserung verwendet, um sich
auf die Ursachen zu konzentrieren , die
am meisten zu einem bestimmten Problem beitragen am meisten zu einem bestimmten Problem Dies hilft dabei,
die potenziellen Ursachen,
Faktoren und wichtigsten Prozessfaktoren
des
untersuchten Problems zu priorisieren ,
Faktoren und wichtigsten Prozessfaktoren
des
untersuchten Problems zu Es handelt sich um ein Toolkit
zur kontinuierlichen Verbesserung. Pareto-Analyse wird
bei der Priorisierung von
Projekten verwendet , um sich
auf wichtige
Projekte zu konzentrieren , die dem Kunden
und dem Unternehmen einen
Mehrwert bieten Anstatt
alle Projekte zu erledigen
, die auf
meiner Projektliste stehen, würde
ich mich auf
diese wenigen Projekte konzentrieren, zwei oder drei Großprojekte, die mir den
größtmöglichen Nutzen bringen können Sie können bei
der Festlegung des
Projektumfangs vorsichtig sein , ob Sie den Teil Aysis verwenden oder bei
der
Priorisierung Ihrer Ressourcen,
wer die Hauptperson ist, die für Ihr Projekt benötigt
wird Wir können die
Parto-Analyse auch zur Visualisierung
Ihrer Daten verwenden , um schnell zu wissen Ich habe zum Beispiel eine Menge fehlerhafter Daten, wie z. B. zehn
Reißen aus dichtem Fang Ich führe die Analyse durch
und habe diese Daten. Wenn ich es in absteigender
Reihenfolge der Fehler anordne, finde
ich, dass das Abreißen der
größte Aufwand ist Dann folgt eine Lochblende, dann und so weiter Auf die, die grau sind, werde
ich mich nicht besonders konzentrieren, weil sie keinen großen
Beitrag leisten. Wenn ich den Riss repariere, werde
ich
maximale Ergebnisse erzielen Wenn ich
die ersten drei repariere, werde
ich die Fehler, die
in meinem Prozess
auftreten, erheblich reduzieren . Wenn Sie beispielsweise Daten über Fehlertypen sammeln, kann
die Analyse des
Bedieners Aufschluss darüber geben , welche Art von Fehler
am häufigsten auftritt. Sie können sich darauf konzentrieren,
die Ursache zu lösen , die
die meisten Auswirkungen hat. Der Vorteil der Teilanalyse besteht darin, Sie sich auf
das konzentrieren können,
was wirklich wichtig ist Sie trennt die Hauptursachen des Problems von
den kleineren Es ermöglicht die Messung der Auswirkungen von Verbesserungen, indem die Ergebnisse
vorher und nachher erfasst werden. Es ermöglicht es,
einen Konsens darüber zu erzielen
, was zuerst angegangen werden muss. Es hat sich
herausgestellt, dass das Pareto-Prinzip bei vielen Gebühren zutrifft:
20% bemühen sich, 80-prozentige Ergebnisse zu erzielen Anstatt Arbeit oder
wir können es auch
als 20% Ursachen bezeichnen , was
mir zu 80% Wirkung Wenn ich also über
Ursache-Wirkungs-Analyse nachdenke, dann sind es wieder 20%
Ursachen, 80% Aufwand. O Effekt, wenn ich auch die Analyse von
Aufwand und Ergebnissen betrachte, sagen
wir, weniger Aufwand betreiben,
um maximale Ergebnisse zu erzielen. 20% der Kunden des Unternehmens sind für
80% des Umsatzes
verantwortlich oder 80% des Verkaufs
stammen von 20% der Kunden. Das ist also das Konzept von 20% Aufwand gegenüber
Ergebnissen von 80%. Man kann davon ausgehen,
dass das Büro Pardo Analysis
Act so konzipiert ist, dass 20% der
Arbeitnehmer 80% der Arbeit erledigen 20% der für
eine Aufgabe aufgewendeten Zeit führen zu 80%
der Ergebnisse 20% der Bevölkerung besitzen
80% des Reichtums der Nation. Stimmt das nicht, auch
in unserem Land, unserem Staat, unserer Gemeinschaft? Wir stellen fest, dass es nur
sehr wenige Menschen gibt, die das
maximale Vermögen
besitzen Sie können die 20%
der Haushaltsgeräte verwenden ,
80% der Zeit. Sie dürfen 20% Ihrer
Kleidung tragen, 80% der Zeit. Es ist also an der Zeit, dass Sie in
Ihrem Privatleben einfach eine Teilanalyse
anwenden , um
Ihre Garderobe aufzuräumen , wenn Sie
an das Konzept des Minimalismus glauben an das Konzept des Minimalismus 20% der Autofahrer
verursachen 80% der Unfälle. 80% der Kundenbeschwerden stammen von 20% der Kunden. Nur einige wenige Ursachen machen
den größten Teil der Wirkung
auf die Fischrute aus. Wenn ich meine
Parto-Analyse auf eine Fischrute umrechne, werden
Sie feststellen, dass
es nur wenige Ursachen gibt , die
zur Hauptursache beitragen sich all
diese Beispiele angehört haben, hätten
Sie verstanden,
dass Pareto nicht darauf
beschränkt ist , sich nur in
Ihrem Büro oder an Ihrem Arbeitsplatz zu bewerben Sie können die
Parto-Analyse sogar in Ihrem Privatleben anwenden. Wenn ich es auf Twitter oder eine solche
Social-Media-Plattform weitergebe, die
meisten der aktiven 20%
der Twitter-Nutzer sind die
meisten der aktiven 20%
der Twitter-Nutzer für 80%
der gesamten Tweets verantwortlich Das Parto-Diagramm ist
eine spezielle Art von Balkendiagramm, das die
Häufigkeit historischer Daten darstellt Sie müssen also verstehen, dass sich
diese Daten auf den Stand von gestern, heute
Morgen oder auf den Stand des letzten Monats beziehen Es handelt sich also um kategorische Daten. Die X-Achse sagt sehr
deutlich, dass es
sich kategoriale Daten handelt, und die Y-Achse gibt Auskunft über die
Häufigkeit des werden kann Bitte beachten Sie, dass die Parto-Analyse nicht für kontinuierliche
Daten
verwendet Wenn Sie also sehen, werden
Sie über kategoriale Daten
verfügen , deren Häufigkeit
in absteigender Reihenfolge aufgetragen ist.
Die Hauptursachen
sind weniger Aufwand, um deren Häufigkeit
in absteigender Reihenfolge aufgetragen ist.
Die Hauptursachen maximale Ergebnisse zu
erzielen den kategorialen Daten
handelt es sich um die niedrigste
Datenebene , anhand derer
Personen, Dinge oder Ereignisse klassifiziert Ich kann es einfacher machen. Alles, was mit
Wörtern gemacht wurde , wird als
kategoriale Daten bezeichnet Geografische Standorte,
Wetter, Farbe, Gerätetyp, Blutgruppe, Blut,
Bankkontotyp, wie
Sparguthaben oder Girokonto, FD oder
Privatkredit , Art des Fehlers oder
Defekts, Art der Daten Pareto-Analyse:
Die vertikale Achse stellt die Häufigkeit der
kategorialen Daten Die X-Achse stellt die
Kategorien der Beschriftungen dar. Die horizontale Achse stellt die kategorialen Daten dar, die ein Problem oder die Probleme
verursachen Der Balken ist in
absteigender Reihenfolge
von links nach rechts angeordnet absteigender Reihenfolge
von links nach rechts Die am häufigsten vorkommende
ist auf der linken Seite, die am
seltensten vorkommende ist auf der rechten Seite Sie müssen sich keine Sorgen machen, wenn
Sie Microsoft Excel haben, es wird es für Sie zeichnen. Wenn Sie eine
ältere Version von Excel verwenden, werde
ich
im Abschnitt Projekt und
Ressourcen unten eine Vorlage veröffentlichen. Wenn Sie zu viele Kategorien haben, können
Sie diese kleinen,
seltenen Kategorien
in der Kategorie
Andere gruppieren in der Kategorie
Andere Der letzte Balken ist normalerweise
etwas höher als
die vorherigen. Sie können optional eine
kumulative Frequenzkurve über
dem Balken platzieren und ihm
eine sekundäre Y-Achse geben eine sekundäre Y-Achse , die den
kumulativen Prozentsatz darstellt Dies hilft lediglich dabei, die Ergebnisse
leichter zu
interpretieren und
die 80 20-Verbindung zu identifizieren Die
Parto-Analyse
konzentriert sich auf
die Bemühungen in den Kategorien, deren
senkrechter Balken 80% der Ergebnisse ausmacht Sie sollten nach etwas suchen
, bei dem es sich um Hauptursachen, maximale Wirkung und geringsten
Aufwand handelt, um maximale Ergebnisse zu erzielen Wenn Sie sich die
beiden Partomuster
A und B ansehen, welches Muster A und B ansehen, welches ist das beste Beispiel für das
Partomuster Ich würde vorschlagen, dass es
das Muster A ist, weil Muster B zeigt
, dass die meisten von ihnen fast zu gleichen Teilen
beitragen Da es sich
um eine gleichmäßige Verteilung handelt, würde ich mich nicht daran halten. Ich würde mich für die Kategorie A entscheiden. Und das ist falsch. Wenn die resultierenden Diagramme ein Parto-Muster
deutlich veranschaulichen Dies deutet darauf hin, dass
nur wenige
Ursachen für etwa
80% des Problems Dies bedeutet, dass
es einen Teileffekt gibt, und Sie können sich darauf konzentrieren diese wenigen Ursachen
zu
bekämpfen, um ein maximales Ergebnis zu erzielen Wenn Sie
ein Muster wie ein B-Diagramm erhalten hätten, dann funktioniert die
Parto-Analyse nicht, und wir müssen auch eine andere Qualitätskontrolle
verwenden Wenn jedoch kein
Paradomuster gefunden wird, können
wir nicht sagen, dass einige Ursachen wichtiger
sind als Wie ich gerade sagte. Stellen Sie sicher, dass Ihr Parado-Diagramm
genügend Datenpunkte enthält , um es aussagekräftig zu
machen In der heutigen Welt viele Daten verfügbar. Stellen Sie
also sicher, dass Sie so viele
Daten wie möglich
erfassen Die Pareto-Analyse
zur Erstellung eines Parto-Diagramms. Sie gemeinsam mit Ihrem Team das Problem, Definieren Sie gemeinsam mit Ihrem Team das Problem, das
Sie lösen möchten, und
ermitteln Sie die möglichen Ursachen mithilfe von Brainstorming Entscheiden Sie sich für die Messmethode
, die für den Vergleich verwendet werden soll, die Häufigkeit, die Kosten
und die Zeit usw. Wie erstellt man ein Parto-Diagramm, sammelt die Daten und verlangt, dass
die kategorialen Daten analysiert werden
? Berechnet die Häufigkeit
der kategorialen Daten. Zeichnen Sie eine horizontale Linie und platzieren Sie den vertikalen Balken, um
die Häufigkeit der Kategorie anzugeben Zeichnen Sie
links eine vertikale Linie, um die Frequenz
links von der Linie zu platzieren links von der Linie falls Sie
sie auf Millimeterpapier zeichnen. Microsoft Excel kann
Parado-Diagramme automatisch erstellen. Wenn Sie dies jedoch manuell tun, sortieren
Sie die Kategorien in
der Reihenfolge ihrer Häufigkeit, von
der bis zur
kleinsten, größten, die auf der linken Seite erscheint Sie sollten Ihre
kumulative Häufigkeitskurve
und eine kubultive Prozentlinie berechnen und eine kubultive Wenn Sie beobachten, wie die
Parade ihre Wirkung entfaltet, sollten Sie Ihre Verbesserungsbemühungen auf
die wenigen Kategorien konzentrieren , deren senkrechter Balken meisten ausmacht Diese Ursachen haben wahrscheinlich den größten Einfluss auf
Ihre Prozessleistung. Ich habe eine Pareto-Probe entnommen
, um zu analysieren,
warum ein Patient
einen Anruf in einem
Krankenhaus gut nutzt, wenn er aufgenommen wird einen Anruf in einem
Krankenhaus gut nutzt, wenn er aufgenommen Sie brauchen also einen Toilettenassistenten, brauchen Nahrung oder Wasser, ihr
Bett
neu positionieren, intravenöse Probleme,
Schmerzmittel, einen dringenden
Anruf zurück ins Bett,
holen sich all die Dinge, die grau
sind, sind nicht häufig
vorkommende Dinge und
sie sind auch nicht vorkommende Dinge und Also, wenn wir uns auf die ersten
drei oder die ersten vier konzentrieren. Wenn ich also sagen würde
,
dass diese vier Faktoren zu
40% des Aufwands beitragen, werden Sie
70% der Wirkung erzielen. Ich könnte mich also dafür entscheiden, nur an den ersten drei zu
arbeiten, das sind 30% Aufwand, um immer noch 68% Aufwand zu erzielen. Alles ist in Ordnung. Das Konzept ist , dass ich weniger Anstrengungen unternehmen muss
, um maximale Ergebnisse zu erzielen. Kundenbeschwerden
in einer Fabrik. Ein Werksteam hat
eine Parado-Analyse durchgeführt, um der steigenden Anzahl von Beschwerden aus
Kundensicht zu begegnen In gewisser Weise
kann das Management das verstehen. Es handelt sich um eine Art von
Kundenbeschwerde, Produktbeschwerde, dokumentenbezogene Beschwerde, paketbezogene Beschwerde oder
lieferungsbezogene Beschwerde. Wir können sehen, dass
sich Kunden
am häufigsten über die Art
des Produkts oder den
Defekt des Produkts beschweren des Produkts oder den
Defekt des Produkts Gefolgt von Problemen im
Zusammenhang mit dem Dokument. Kundenbeschwerde in einer Fabrik, die Hauptkategorien sind
möglicherweise zu allgemein gehalten und können
in Unterkategorien unterteilt werden Wenn ich also über
Produktreklamationen nachdenke, handelt es sich um ein
übergeordnetes Problem, ich könnte
sie als Unterkomponente
von Problem A betrachten sie als Unterkomponente
von Problem A es
sich um ein Problem mit Kratzern, ein Nadelloch, ein Paar HMA Sie können auch
den Teil der
Produktbeschwerde erneut anwenden , d.
h., wenn Sie Probleme im Zusammenhang mit Kratzern und
Dellen in
einer Produktbeschwerde beheben wollen , wird
der Großteil der
Produktbeschwerden zurückgehen Art der Reklamationen:
Wir können feststellen, dass
fehlende Informationen
der Hauptgrund dafür sind,
gefolgt von Rechnungsfehlern, falscher Menge und anderen Das Parto-Diagramm kann weiter analysiert
werden indem die
Hauptkategorien in Unterkategorien
unterteilt werden , oder
Unterkomponenten, bei denen
das spezifische Problem
am häufigsten auftritt, werden Unterkategorien das spezifische Problem
am häufigsten auftritt genannt Kundenbeschwerden
in einer Fabrik. Die Ergebnisse deuten darauf hin
, dass es
drei Unterkategorien gibt , die am häufigsten vorkommen Beachten Sie, dass es möglich ist, zwei Diagramme zu einem
zusammenzuführen. Ich habe also die Art der Produktbeschwerden
und die Art des Dokuments, und ich kann
sie zusammenfassen. Pero Principles ist nach dem italienischen Ökonomen
Wilfredo Peto benannt italienischen Ökonomen
Wilfredo Joseph Juran hat die Prinzipien von
Peto auf das Qualitätsmanagement der Unternehmensproduktion angewendet Prinzipien von
Peto . Erwägen Sie bei Ihrer Analyse die
Verwendung von Kontextdaten, Metadaten und Spalten
, die Textdaten Datenbanken enthalten oft viele
kategorische Daten
über die Umgebung,
aus der die aus Diese Daten können bei späteren Analysen
bei der Untersuchung der Urheber von Konzepten und Ideen sehr
nützlich bei der Untersuchung der Urheber von Konzepten und Ideen Pareto-Prinzipien können
Ihnen helfen, die Auswirkungen
von Verbesserungen zu messen , indem Sie das Vorher mit
dem Nachher vergleichen Wenn Sie sehen, dass die blaue Arbeit
nach den Projekten eine große Hilfe
war, stellen
Sie fest, dass es
in dieser
Kategorie eine erhebliche Verbesserung gibt in dieser
Kategorie eine erhebliche Verbesserung Das neue Teildiagramm
kann zeigen, dass der
Primärcode erheblich reduziert wurde Statistisch gesehen lassen sich die
Parado-Prinzipien anhand der Verteilung der Strommenge und vieler natürlicher Phänomene beschreiben, die diese Verteilung hervorrufen
. Damit bin ich am Ende
des Konzepts der Parto-Analyse angelangt Im nächsten Video zeige ich Ihnen, wie
ich die Pareto-Analyse
mit Microsoft Cel
durchführe ich die Pareto-Analyse
mit Microsoft Cel
durchführe Wir sehen uns in der nächsten Klasse.
18. Konzepthypothesentests und statistische Signifikanz (1): Lassen Sie uns die
Konzepte im Zusammenhang mit
Hypothesentests und
statistischer Signifikanz aufschlüsseln . Erstens, Hypothesentests Bei der Durchführung eines
Hypothesentests beginnen
wir mit einer
Forschungshypothese, auch
Alternativhypothese genannt. In Ihrem Fall die
Forschungshypothese , dass das Medikament den Blutdruck beeinflusst. Wir können
diese Hypothese jedoch nicht direkt mit einem
klassischen Hypothesentest testen. Stattdessen testen wir die
gegenteilige Hypothese , dass das Medikament keinen
Einfluss auf den Blutdruck hat. Wir gehen davon aus,
dass
Menschen, die das Medikament einnehmen,
und Menschen, die
das Medikament nicht einnehmen, in der Bevölkerung im Durchschnitt Menschen, die das Medikament einnehmen,
und Menschen, die
das Medikament nicht einnehmen den gleichen
Blutdruck haben. Wenn wir in einer Probe
eine starke
Wirkung des Medikaments beobachten , fragen wir dann, wie wahrscheinlich es ist, eine
solche oder eine
noch extremere Probe zu ziehen , wenn das
Medikament tatsächlich keine Wirkung hat. Die Wahrscheinlichkeit, eine solche Stichprobe
zu erhalten, unter der Annahme der Nullhypothese, keine Wirkung besteht, wird als P-Wert bezeichnet. Der P-Wert gibt die Wahrscheinlichkeit an,
eine Stichprobe zu erhalten, die
genauso stark von unserer beobachteten
Stichprobe abweicht oder sogar
noch extremer ist, wenn die
Nullhypothese wahr wäre Wenn der p-Wert sehr niedrig ist, typischerweise weniger als 0,05, haben
wir Belege dafür, dass
die Nullhypothese
zugunsten der
Alternativhypothese zurückgewiesen die Nullhypothese
zugunsten der
Alternativhypothese zugunsten der
Alternativhypothese Ein kleiner p-Wert deutet darauf hin, dass die beobachteten Daten oder Stichproben nicht mit
der Nullhypothese übereinstimmen Also drei, statistische
Signifikanz. Wenn der p-Wert unter einem vorbestimmten
Schwellenwert liegt, oft 0,05. Das Ergebnis wird als
statistisch signifikant angesehen. Dies bedeutet, dass es
unwahrscheinlich ist, dass das
beobachtete Ergebnis allein
durch Zufall zustande gekommen ist, und wir haben genügend Beweise, um die Nullhypothese
abzulehnen Der Schwellenwert für den p-Wert
ist auf 5% oder 0,05 festgelegt.
Ein kleiner p-Wert deutet darauf hin, dass die beobachteten Daten oder Stichproben nicht
mit der Nullhypothese übereinstimmen Umgekehrt deutet ein großer
p-Wert darauf hin, dass die beobachteten Daten
mit der Nullhypothese übereinstimmen, und wir lehnen sie nicht ab Viertens: Fehler beim Testen von
Hypothesen. Denken Sie daran, dass ein kleiner
p-Wert nicht beweist, dass die alternative
Hypothese wahr ist. deutet nur darauf hin, dass das beobachtete Ergebnis unter der
Nullhypothese
unwahrscheinlich ist . Ebenso beweist ein großer P-Wert nicht, dass die
Nullhypothese wahr ist. Er deutet lediglich darauf hin, dass das beobachtete Ergebnis
unter der Nullhypothese wahrscheinlich ist. Lassen Sie uns nun
die beiden Arten von Fehlern verstehen. Der Fehler vom ersten Typ und
der Fehler vom zweiten Typ. Ein Fehler vom Typ eins tritt auf, wenn wir fälschlicherweise eine
echte Nullhypothese ablehnen In Ihrem Beispiel würde dies bedeuten, Schluss zu kommen, dass das Medikament wirkt,
obwohl es tatsächlich nicht Ein Fehler liegt vor,
wenn Sie
die Nullhypothese zurückweisen ,
obwohl
die Nullhypothese in Wirklichkeit wahr ist, Ihre Entscheidung über die
Nullhypothese
jedoch abgelehnt wird Fehler zweiten Typs tritt auf, wenn wir eine falsche
Nullhypothese nicht zurückweisen können. Fehler zweiten Typs liegt vor,
wenn Sie die Nullhypothese nicht
zurückweisen,
obwohl
die Nullhypothese in Wirklichkeit falsch ist, Ihre Entscheidung über die
Nullhypothese
jedoch akzeptiert wird. In Ihrem Beispiel
würde das bedeuten, die
Tatsache zu übersehen, dass das Medikament wirkt. Die entnommene Probe
zeigte keinen großen Unterschied. Ich dachte fälschlicherweise, dass
das Medikament nicht wirkt. In der nächsten Lektion werden
wir uns eingehender mit
praktischen Anwendungen der
Versuchsplanung befassen.
Bleib dran.
19. TestofHypothesis: Hallo Freunde. Lassen Sie uns unsere Reise
zur MiniTab-Datenanalyse fortsetzen. Heute werden wir etwas
über Hypothesentests lernen. Sie haben vielleicht gehört, dass wir während der Analyse-
und Verbesserungsphase
unseres Projekts
Hypothesentests durchführen . Um zu verstehen, wie der
Hypothesentest funktioniert, lassen Sie uns ein
einfaches Fallszenario verstehen. Ich werde
noch einmal auf diese Grafik zurückkommen und
Ihnen erklären, dass es so ist. Wie Sie wissen, kann das Justizsystem verwendet werden,
um
das Konzept
der Hypothesentests
zu erklären, wenn wir vor Gericht gehen kann das Justizsystem verwendet werden,
um
das . Der Richter beginnt immer mit
einer Aussage, die besagt, dass die Person bis zum Nachweis ihrer Schuld als
unschuldig gilt. Das ist nichts als Ihre
Nullhypothese, der Status Quo. Wenn sie erwischt werden, geht der
Fall weiter. Die Anwälte versuchten, Daten und Beweise
vorzulegen. Und solange wir
keine starken Daten
und starken Beweise haben, befindet sich
die Person im
Status der Unschuld. Der Angeklagte oder der
Oppositionsanwalt versucht also immer zu sagen, dass
diese Person schuldig ist, und ich habe Daten und
Beweise, um dies zu beweisen. Er versucht, an einer
alternativen Hypothese zu arbeiten. Und der Richter sagt, ich gehe standardmäßig mit dem Status Quo der Nullhypothese. Lassen Sie
mich das einfacher erklären. Sie und ich, wir werden nicht vor Gericht gestellt,
weil
wir uns standardmäßig alle in OSA befinden, das ist der Status Quo. Wer wird
vor Gericht gezogen. Menschen, die
eine Chance haben, sind gekommen, haben ein Verbrechen begangen. Es könnte alles Mögliche sein.
Auf die gleiche Weise. Woran versuchen wir
Hypothesentests durchzuführen wenn ich meine
Analysephase des Projekts durchführe. Ich habe also mehrere Ursachen , die
zu meinem Projekt beitragen könnten. Warum? Wir führen eine Ursachenanalyse durch und lernen das kennen wir, okay? Vielleicht hat sich die Lieferung verzögert. Vielleicht ist die Maschine ein Problem, vielleicht ist das
Messsystem ein Problem. Vielleicht
ist der Rohstoff nicht von guter Qualität. Wir haben mehrere Gründe
, die es gibt. Jetzt möchte ich
es anhand von Daten beweisen, und das ist der Ort, an dem ich versucht habe, Hypothesentests durchzuführen. Alle Prozesse
sind unterschiedlich. Wir wissen, dass alle Prozesse der Glockenkurve
folgen. Wir werden niemals das Zentrum hinzufügen. jedem Prozess gibt es einige
Abweichungen. Nun die Daten oder die
Stichprobe, die Sie aktualisiert haben, handelt es sich um eine Zufallsstichprobe, die von derselben Banco
stammt? Oder ist es ein Sample, das
aus einer ganz
anderen Glockenkurve stammt ? Hypothesentests
helfen Ihnen also bei der Analyse derselben. Wann immer wir
einen Hypothesentest aufstellen, haben
wir zwei Arten von Hypothesen, wie ich Ihnen bereits sagte, den Status Quo
oder die Standardhypothese, die Ihre Nullhypothese ist. Standardmäßig gehen wir davon aus, dass
die Nullhypothese wahr ist. Um die
Nullhypothese zurückzuweisen, müssen
wir Beweise vorlegen. Alternative Hypothese
ist der Ort
, an dem es einen Unterschied gibt. Und das ist der Grund, warum der Hypothesentest
tatsächlich eingeleitet wurde, oder? Wir werden es
anhand vieler Beispiele verstehen. Also bleib in Verbindung. Wenn ich also eine Null
- und Alternativhypothese aufstelle, sagen
wir, ich sage, dass mein mu
nichts anderes als mein Durchschnitt
ist, mein Bevölkerungsdurchschnitt entspricht einem bestimmten Wert. Denken Sie immer daran, dass sich
Ihre alternative Hypothese
gegenseitig ausschließt. Wenn mu einem Wert entspricht, würde
die alternative Hypothese besagen, dass mu nicht gleich
diesem Wert ist. Beispiel ist mu weniger als gleich einem Wert
als Null-Hypothese. Wenn ich zum Beispiel Domino's Pizza
verkaufe, sehe
ich, dass meine durchschnittliche Lieferzeit weniger als
30 Minuten
beträgt. Der Kunde kommt
und sagt mir, dass die durchschnittliche Lieferzeit mehr als 30 Minuten
beträgt, das wird meine Alternative. Manchmal, wenn wir
die Nullhypothese haben , ist mu größer als
gleich einem Wert. Zum Beispiel
ist meine durchschnittliche Qualität größer als 90%. Dann kommt der Kunde
zurück und teilt mir mit, dass Ihre durchschnittliche Qualität
unter diesem Prozentsatz liegt. Denken Sie also immer an die
Nullhypothese und alternative Hypothesen schließen
sich
gegenseitig aus und ergänzen
sich gegenseitig. Wir werden noch viele weitere
Beispiele aufgreifen, wenn wir weiter gehen.
20. Null und alternatives Hypothesekonzept: Lassen Sie uns in die
Inferenzstatistik eintauchen. Wir beginnen mit einem kurzen
Überblick darüber, was es ist. Gefolgt von einer Erläuterung
der sechs Schlüsselkomponenten. Was ist also
Inferenzstatistik? Sie ermöglicht es uns, anhand von
Daten aus
einer Stichprobe
Rückschlüsse auf eine Population Zur Verdeutlichung: Die Population ist die gesamte Gruppe, an der
wir interessiert sind. Wenn
wir zum Beispiel
die durchschnittliche Körpergröße aller
Erwachsenen in den Vereinigten Staaten untersuchen wollen , umfasst
unsere Bevölkerung
alle Erwachsenen des Landes. Bei der Stichprobe
handelt es sich dagegen um eine kleinere Teilmenge
aus dieser Population Wenn wir beispielsweise
150 Erwachsene aus den USA auswählen, können
wir anhand dieser Stichprobe
Rückschlüsse auf die breitere Nun, hier sind die sechs Schritte, die
zu diesem Prozess gehören. Hypothese. Wir beginnen
mit einer Hypothese. Welche Aussage wollen
wir testen? Zum Beispiel
möchten wir vielleicht untersuchen, ob ein Medikament den
Blutdruck bei Menschen
mit Hypotonie positiv beeinflusst Blutdruck bei Menschen
mit Hypotonie Oh, in diesem Fall besteht
unsere Population aus allen Personen mit hohem
Blutdruck in den USA,
da es nicht praktikabel ist, Daten von der gesamten Bevölkerung zu sammeln Daten von der Wir verlassen uns auf eine Stichprobe, um anhand unserer Stichprobe
Rückschlüsse auf die
Population Wir verwenden Hypothesentests. Dies ist eine Methode, die verwendet wird, um eine Aussage über
einen Populationsparameter auf der
Grundlage von Stichprobendaten zu
bewerten . Es sind verschiedene
Hypothesentests verfügbar, und das am Ende dieses Videos. Ich werde dir zeigen, wie du den richtigen
auswählst. Wie funktioniert das
Testen von Hypothesen? Wir beginnen mit einer
Forschungshypothese. Auch bekannt als
Alternativhypothese
, für die wir in unserer Studie nach
Beweisen suchen. Wird auch als
Alternativhypothese bezeichnet. Dafür versuchen wir Beweise
zu finden. In unserem Fall
lautet die Hypothese , dass das Medikament den Blutdruck
beeinflusst. Wir können dies jedoch nicht direkt mit einem klassischen
Hypothesentest testen. Also testen wir die
gegenteilige Hypothese, dass das Medikament keinen
Einfluss auf den Blutdruck hat. Hier ist der Prozess. Erstens,
nimm die Nein-Hypothese an. Wir gehen davon aus, dass das Medikament keine Wirkung
hat, was bedeutet, dass
Menschen, die das Medikament einnehmen und solche, die nicht den
gleichen durchschnittlichen Blutdruck haben. T, sammle und
analysiere Probendaten. Wir nehmen eine Zufallsstichprobe. Wenn das Medikament in der Probe eine große
Wirkung zeigt, bestimmen
wir dann die
Wahrscheinlichkeit, eine
solche oder eine Probe zu ziehen ,
die noch stärker abweicht, wenn das Medikament tatsächlich keine Wirkung
hat,
oder eine, die noch stärker abweicht, wenn das Medikament tatsächlich keine Wirkung
hat,
T, bewerten den
Wahrscheinlichkeits-p-Wert Wenn die Wahrscheinlichkeit, ein
solches Ergebnis unter der
Nullhypothese zu beobachten , sehr gering ist Wir erwägen die Möglichkeit , dass das Medikament
eine Wirkung hat. Wenn wir genügend Beweise haben, können
wir die
Nullhypothese zurückweisen. Der p-Wert ist die
Wahrscheinlichkeit, der die Stärke der Beweise
gegen die Nullhypothese gemessen wird. Zusammenfassend besagt die
Nullhypothese, es keinen Unterschied
in der Grundgesamtheit
gibt, und der Hypothesentest
berechnet, wie wahrscheinlich es ist die Stichprobenergebnisse beobachtet wenn die Nullhypothese wahr ist Wir wollen Beweise für
unsere Forschungshypothese finden. Das Medikament beeinflusst den Blutdruck. Wir können dies jedoch nicht
direkt testen, also testen wir die entgegengesetzte
Hypothese, die Nullhypothese. Das Medikament hat keine Wirkung
auf den Blutdruck. So funktioniert es. Gehen Sie von der Nein-Hypothese aus. Gehen Sie davon aus, dass das Medikament keine Wirkung hat. heißt, Menschen, die das Medikament
einnehmen, und Menschen, die nicht den
gleichen durchschnittlichen Blutdruck haben, sammeln und analysieren Daten. Nehmen Sie eine Zufallsstichprobe. Wenn das Medikament eine große
Wirkung in der Probe zeigt. Wir bestimmen, wie wahrscheinlich es
ist, ein solches
oder ein extremeres Ergebnis zu erzielen . Wenn das Medikament wirklich keine Wirkung hat, berechnen Sie den p-Wert. Der p-Wert ist die
Wahrscheinlichkeit eine Probe
beobachtet wird, die
so extrem ist wie unsere. Unter der Annahme, dass die
Nullhypothese wahr ist. Statistische Signifikanz Wenn der p-Wert unter einem festgelegten Schwellenwert liegt, normalerweise 0,05. Das Ergebnis ist
statistisch signifikant, d. h. es ist unwahrscheinlich, dass es allein durch Zufall
entstanden ist Wir haben dann genügend Beweise , um die Nullhypothese abzulehnen Ein kleiner p-Wert deutet darauf hin, dass die beobachteten Daten nicht mit
der Nullhypothese übereinstimmen führt dazu, dass wir sie
zugunsten der
Alternativhypothese ablehnen zugunsten der
Alternativhypothese Ein großer p-Wert deutet darauf hin, dass die Daten
mit der Nullhypothese übereinstimmen. Wir lehnen es nicht ab. Wichtige Punkte. Ein kleiner p-Wert
beweist nicht , dass die
Alternativhypothese wahr ist. Es zeigt lediglich an
, dass ein solches Ergebnis
unwahrscheinlich ist , wenn die
Nullhypothese wahr ist. Ebenso beweist ein großer p-Wert nicht, dass die
Nullhypothese wahr ist. Dies deutet darauf hin, dass die beobachteten Daten wahrscheinlich unter der
Nullhypothese liegen. Danke. Wir sehen uns in der nächsten Statistikstunde.
21. Statistiken Verstehen des P-Werts: Was ist der p-Wert und
wie wird er interpretiert? Darüber werden wir in diesem Video
sprechen. Fangen wir mit einem Beispiel an. Wir möchten untersuchen, ob es einen
Größenunterschied
zwischen einem durchschnittlichen
amerikanischen Mann und durchschnittlichen amerikanischen
Basketballspieler gibt. Der durchschnittliche Mann ist
1,77 Meter groß. Wir wollen also wissen, ob der durchschnittliche Basketballspieler auch 1,77 Meter groß
ist Daher geben wir die
Nullhypothese an. Die durchschnittliche Größe eines
amerikanischen Basketballspielers beträgt 1,77 Meter Wir gehen davon aus, dass die der amerikanischen Basketballspieler durchschnittliche Körpergröße
der amerikanischen Basketballspieler 1,77
Meter Da wir jedoch nicht die gesamte Bevölkerung
befragen können, ziehen
wir eine Stichprobe Für Co
ergibt diese Stichprobe keinen exakten Mittelwert
von 1,77 Metern Das wäre sehr unwahrscheinlich. Oh. Es kann sein , dass die rein
zufällig entnommene Probe um
3 Zentimeter mal
8 Zentimeter mal
15 Zentimeter oder
um einen anderen Wert abweicht 3 Zentimeter mal
8 Zentimeter mal
15 Zentimeter oder
um einen anderen Wert Da wir eine
ungerichtete Hypothese testen
, wollen wir also nur wissen,
ob es einen Unterschied gibt Es ist uns egal, in welche
Richtung der Unterschied geht. Jetzt kommen wir zum p-Wert. Wie bereits erwähnt, gehen wir davon aus,
dass
es in der Bevölkerung einen Mittelwert
von 1,77 Metern Wenn wir eine Stichprobe ziehen, wird
sie sich um einen bestimmten Wert von der
Grundgesamtheit unterscheiden Der p-Wert gibt an, wie wahrscheinlich es ist, eine Stichprobe zu
ziehen, die Grundgesamtheit
abweicht gleichen oder
einen größeren Betrag
als den beobachteten Wert von der Schauen wir uns das noch einmal genauer an. Wir haben eine Stichprobe, die sich von der Grundgesamtheit
unterscheidet. Wir sind jetzt daran interessiert, wie wahrscheinlich es ist, eine Stichprobe zu ziehen , die genauso stark wie
unsere Stichprobe oder mehr
von der Grundgesamtheit abweicht unsere Stichprobe oder mehr
von der Grundgesamtheit Somit gibt der p-Wert an, wie wahrscheinlich es ist,
eine Stichprobe zu ziehen , deren Mittelwert in diesem Bereich
liegt Zum Beispiel, wenn die Stichprobe
zufällig um 3
Zentimeter von 1,77 Metern abweicht Der p-Wert gibt an, wie
wahrscheinlich es ist,
eine Stichprobe zu ziehen , die
3 Zentimeter oder mehr
von der Grundgesamtheit abweicht 3 Zentimeter oder mehr
von Wenn die Stichprobe zufällig um
9 Zentimeter von 1,65 Metern abweicht , sagt uns
der p-Wert, wie
wahrscheinlich es ist, eine Stichprobe zu ziehen , die 9 Zentimeter
oder mehr von der Grundgesamtheit abweicht Nehmen wir ein Beispiel, bei dem
wir einen Unterschied von
9 Zentimetern erhalten , und unsere
bevorzugte Berechnet wie Mini Tab
den p-Wert von 0,03. Das sind 3%. Dies zeigt uns, dass die Wahrscheinlichkeit, eine
Stichprobe zu ziehen, die mindestens 9 Zentimeter vom
Mittelwert der Grundgesamtheit von 1,77 Metern
abweicht, mit einer
Wahrscheinlichkeit
von
nur 3% mindestens 9 Zentimeter vom
Mittelwert der Grundgesamtheit von 1,77 Metern
abweicht, mit einer
Wahrscheinlichkeit von Für normalverteilte Daten. Das bedeutet, dass die Wahrscheinlichkeit , dass der Mittelwert
in diesem Bereich liegt einen Richtung bei
1,5% und in der anderen Richtung bei
1,5% Insgesamt 3%. Wenn diese
Wahrscheinlichkeit sehr gering ist Man kann sich natürlich fragen, ob
die Stichprobe überhaupt aus
einer Population mit einem Mittelwert
von 1,65 Metern stammt überhaupt aus
einer Population mit einem Mittelwert
von 1,65 Metern Wenn diese Wahrscheinlichkeit sehr gering ist. Man kann sich natürlich fragen, ob
die Stichprobe überhaupt aus
einer Population mit einem Mittelwert
von 1,77 Metern stammt überhaupt aus
einer Population mit einem Mittelwert
von 1,77 Metern Es ist nur eine Hypothese
, dass der Mittelwert von Basketballspielern 1,77
Meter beträgt Und genau diese
Hypothese wollen wir testen. Wenn wir also
einen sehr kleinen p-Wert berechnen, gibt uns
dies Hinweise darauf
, dass der Mittelwert
der Population überhaupt nicht
1,77 Meter beträgt Daher würden wir
die Nullhypothese ablehnen,
die davon ausgeht, dass der
Mittelwert 1,77 Meter beträgt Daher würden wir
die Nullhypothese ablehnen,
die davon ausgeht, dass der
Mittelwert 1,77 Meter beträgt Aber an welchem Punkt ist der p-Wert klein genug, um
die Nullhypothese abzulehnen Dies wird mit dem
sogenannten Signifikanzniveau,
auch Alpha-Niveau genannt, bestimmt . Dabei sind zwei wichtige
Dinge zu beachten. Erstens
wird das Signifikanzniveau immer
vor der Studie festgelegt und kann
danach nicht mehr geändert werden ,
um letztendlich
die gewünschten Ergebnisse zu erzielen. Zweitens, um ein gewisses
Maß an Vergleichbarkeit zu gewährleisten, wird
das Signifikanzniveau
in der Regel auf 5% oder 1% festgelegt Ein AP-Wert von weniger als 1% wird als
hochsignifikant angesehen Weniger als 5% werden signifikant und mehr als
5% als signifikant bezeichnet. Zusammenfassend gibt uns der p-Wert einen Hinweis darauf, ob wir die
Nullhypothese ablehnen oder nicht. Zur Erinnerung: Die
Nullhypothese geht davon aus, dass
es keinen Unterschied gibt. Die Alternativhypothese
geht zwar davon aus, dass
es einen Unterschied gibt. Im Allgemeinen wird die
Nullhypothese verworfen, wenn der p-Wert kleiner als 0,05
ist Es ist immer nur eine Wahrscheinlichkeit, und wir können
mit unserer Aussage falsch liegen Wenn die Nullhypothese in der Grundgesamtheit
I
zutrifft , liegt der Mittelwert bei 1,77 Metern Aber wir ziehen eine Stichprobe, die
zufällig ziemlich weit entfernt ist. Es könnte sein, dass der
p-Wert kleiner als 0,05 ist. Wir lehnen
die Nullhypothese fälschlicherweise ab. Dies wird als Fehler vom ersten Typ bezeichnet. Wenn es sich um eine Grundgesamtheit handelt, ist
die Nullhypothese falsch. Das heißt, der Mittelwert liegt nicht bei 1,77 Metern, aber wir ziehen eine Stichprobe
, die zufällig sehr nahe bei 1,77 Der p-Wert kann
größer als 0,05 sein, und wir dürfen die Nullhypothese nicht zurückweisen Dies wird als Fehler vom zweiten Typ bezeichnet. Danke, dass du mit mir gelernt hast. Wir sehen uns in der nächsten
Statistikstunde.
22. Arten von Fehlern: Lassen Sie uns
einige weitere
Beispiele für Null- und
Alternativhypothesen verstehen . Nehmen wir also an, wenn mein Projekt Sie vergießen
wird, ist
meine Nullhypothese ein fester Wert. Ich würde also sagen, dass mein
aktueller Mittelwert
meiner aktuellen durchschnittlichen
Zeit, um
Julies 70% zu teilen , beträgt. Aktuell. Der Durchschnitt von P bis S liegt bei 70%. Die alternative Hypothese würde
bedeuten, dass sie nicht bei 70% liegt. Angenommen, ich denke über den Feuchtigkeitsgehalt
eines Projekts nach. Ich bin in einer
Fertigungsanlage und möchte messen ob der Feuchtigkeitsgehalt 5% betragen
sollte. Oder 5% sind für meinen Kunden
akzeptabel, dann kann ich sagen, dass mein
Feuchtigkeitsgehalt weniger als
fünf Prozent
beträgt. Dann würde die alternative
Hypothese behaupten, dass der Feuchtigkeitsgehalt
größer als fünf Prozent ist. Der Fall, in dem der
Mittelwert größer als ist, dann die Nullhypothese. Wir haben kein
Interesse an diesem Problem. Lass es uns weiter verstehen. Die Frage war,
hat ein kürzlich erfolgter
TED-Prozess zur Genehmigung von Krediten für kleine Unternehmen
die durchschnittliche Zykluszeit
für die Bearbeitung des Kredits reduziert ? Die Antwort könnte nein sein. Die Zykluszeit hat sich nicht geändert. Oder der Manager sieht vielleicht, dass die mittlere Zykluszeit unter 7,5%
liegt. Der Status Quo
entspricht also 7,514 Minuten. Und die Alternative sagt, nein, es sind weniger als 7,414
Minuten oder Tage, was auch immer die Hauptmaßeinheit ist wir
messen, oder? Ihr Status
Quo ist also standardmäßig eine Go-Null-Hypothese. Und das Beispiel oder
der Status, Sie leichter beweisen möchten
alternative Hypothese. Jetzt könnte es irgendwelche Pfeile geben, wenn wir Entscheidungen treffen. Kehren wir also
zu unserem Codefall zurück. Der Angeklagte ist in
Wirklichkeit nicht schuldig, oder? Lass mich meinen Laserstrahl aufnehmen. Standardmäßig ist der Angeklagte oder
die Realität, dass der
Angeklagte nicht schuldig ist. Urteil kommt auch
, dass der Angeklagte, die Person nicht schuldig ist. Es ist eine gute Entscheidung, oder? Also ja, wir haben eine sehr gute Entscheidung getroffen, dass
die Person unschuldig ist. In Wirklichkeit ist der
Angeklagte schuldig. Und das Urteil lautet auch
, dass er schuldig ist. Die Entscheidung ist eine gute Entscheidung. Was passiert, ist, dass
die Person in Wirklichkeit nicht garantiert ist, aber das Urteil kommt, dass sie
schuldig ist und
eine unschuldige Person verurteilt wird. Es ist ein Fehler. Das ist ein sehr großer Fehler. In einer Person aus dem Norden, die zu einer
Strafe verurteilt und ins Gefängnis gesteckt
wird, mit einer Strafe, ist
das ein Fehler. Der Fehler kann sogar
auf der anderen Seite passieren, wo die
Person in Wirklichkeit schuldig ist, aber das Urteil kommt,
dass sie nicht schuldig ist. Person wird für unschuldig erklärt und ist bereit dafür. Dies ist auch ein Pfeil, der
aber ein größerer Fehler ist. Der größere Fehler, den Sie in das
Kommentarfeld
schreiben können , was denken Sie? Welcher Fehler ist der größere Pfeil? Ist der Fehler ein größerer Fehler oder ist der Fehler
der größere Pfeil? Wenn keine vernünftige Person, die
verurteilt wird, ein größerer Fehler
ist oder ist eine schuldige Person, die sich frei auf
den Straßen bewegt ,
entweder größerer Pfeil? Ich hoffe, Sie haben die Kommentare bereits
geschrieben. Die Realität ist also, dass dies mein größerer Fehler
wird. Und das wird
als Typ-Eins-Fehler bezeichnet. Denn wenn ein Unschuldiger verurteilt
wird, können
wir die
Zeit, die er verloren hat, nicht zurückgeben. Wir können nicht verstehen, dass er viele emotionale Traumata erleiden würde. Wenn ein Schuldiger für unschuldig
erklärt wird, können
wir ihn vor
das Oberste Gericht und Obersten Gerichtshof bringen und
ihn dazu bringen, zu beweisen,
dass er nicht schuldig ist, richtig. Damit ich
hier die Entscheidung treffen kann , dass die Person ein Sträfling ist. Er sollte verurteilt werden
und er sollte für schuldig erklärt und
bestraft werden. Dieser Fehler wird also
als Typ-2-Fehler bezeichnet. Wenn Sie jemand gefragt hat, welcher
Fehler ein größerer Fehler ist, geben Sie einen Fehler ein, der auch als Alpha-Fehler
bezeichnet wird. Und das wird
als Betafehler bezeichnet. Richtig? Lass uns in unserer nächsten Klasse weiter machen
.
23. Arten von Fehler-part2: Lassen Sie uns die Arten
von Pfeilen noch einmal verstehen. Wie wir also wissen, dass, wenn die Person nicht schuldig
ist oder die
Person unschuldig ist, und das Urteil besagt
auch, dass die
Person nicht schuldig ist. Es ist eine gute Entscheidung. Wenn die Person schuldig ist,
lautet das Urteil, dass sie schuldig ist. Die Entscheidung ist wieder
eine gute Entscheidung. Der Verurteilte ist nicht, muss verurteilt werden oder
sollte bestraft werden. Das Problem tritt auf, wenn eine unschuldige Person
als schuldig bewiesen wird und leidet. Die zweite Art von Problem, das auftritt, wenn eine schuldige Person, eine Person mit einem Verbrecher, als unschuldig erklärt
wird. Und er sagte: Dies wird
als Typ-Eins-Fehler bezeichnet. Das heißt, eine unschuldige
Person, die verurteilt oder bestraft
wird, ist ein Typ-eins-Fehler. Er wird auch Alpha-Pfeil
genannt. Eine schuldige Person, kriminell befreit, wird als
Typ-2-Fehler oder Beta-Fehler bezeichnet, was auch ein Fehler ist
, den wir vermeiden wollen. Das Signifikanzniveau
wird durch den Alpha-Wert festgelegt. Wie sicher
möchten Sie also die
richtige Entscheidung treffen? Also tritt ein Fehler ein, wenn die Null wahr ist,
aber wir haben abgelehnt. Typ-2-Fehler tritt auf, wenn die Null
in Wirklichkeit falsch ist, wir sie
aber nicht ablehnen. Wie
hilft uns das bei der Verarbeitung? Lassen Sie uns das einfach
jeden Tag für das Mittagessen verstehen. Richtig? Lassen Sie uns
das genauer verstehen. Dies ist das eigentliche Szenario. Schreiben wir das
tatsächliche oben. Und diese Mythen
mögen das Urteil. Okay, denken wir jetzt
über den Prozess nach. Der Prozess hat sich nicht geändert. Hat sich nicht geändert. Keine Alternative wird sein Prozess hat sich geändert. Jetzt ist das Urteil zur Kenntnis genommen. Und das Urteil ist, dass sich der
Prozess verbessert hat. Okay. Jetzt stelle ich dir eine
sehr wichtige Frage. Wenn sich ein Prozess nicht geändert hat und das Urteil lautet, dass
es keine Änderung gibt, ist
dies die richtige Entscheidung. Prozess hat sich geändert und das Urteil lautet auch, dass
sich der Prozess verbessert hat. Das ist auch eine richtige Entscheidung. Stellen Sie sich nun vor, der Prozess
hat sich nicht geändert, aber wir
haben erklärt, dass ich jetzt einen verbesserten Prozess und ein verbessertes Produkt habe, und ich informiere den Kunden: Ist das richtig? Ein Fehler. Und dies wird als
Typ-Eins-Fehler bezeichnet, weil sie alt erscheinen, aber unsere Schulden werden als neues Produkt an den
Kunden verkauft. Können Sie verstehen
, was mit
dem Ruf des Unternehmens passieren wird ? Das Team oder Produkt wird als neue Produkte
an den Kunden verkauft . Neues Ein-Kernprodukt. Was wird also mit dem
Ruf des Unternehmens passieren? Es wird ein Wurf sein
und daher sagen wir, dass dies keine gute Entscheidung ist. Jetzt verstehe hier auch
der Prozess hat sich geändert. Der Prozess hat sich verbessert, aber das Urteil ist
nicht verbessert. Dies ist auch ein Fehler. Ich streite es nicht ab. Dies wird als
Typ-2-Fehler bezeichnet oder Audit wird auch
als Betafehler bezeichnet. Gleich hier. Was passiert ist, dass
wir dem Kunden nicht
mitteilen , dass die Verbesserung
eingetreten ist, oder? Wir
behalten die verbesserten Artikel
in Brutprodukten also nicht behalten die verbesserten Artikel im Lager. Das ist auch nicht richtig, aber der größere Fehler ist hier wo wir eigentlich
keine Verbesserung vorgenommen haben, aber ich informiere den Kunden , dass Sie schlechte Leute sind.
24. Jingle: Wenn wir Hypothesen testen, gibt es immer zwei Hypothesen. Eine ist die Standardhypothese, die Nullhypothese, und die zweite ist die
alternative Hypothese , die Sie beweisen möchten. Und das ist der Grund, warum
Sie die Hypothese aufstellen. Wenn Sie also die Hypothese aufstellen, ist
der Grund, warum wir das tun , dass wir
niemals Zugang
zur gesamten Bevölkerung haben. Wenn wir also die Probe sammeln, wollen
wir verstehen, die Probe von der Glockenkurve
stammt oder der Verteilung,
aus der wir verstehen, welche
Variation Sie sehen, ? aufgrund der natürlichen
Eigenschaft des Datensatzes. Manchmal kann sich die Probe an der Endecke des Klettverschlusses befinden. Und das ist ein Ort, an dem wir
die Verwirrung
bekommen , dass diese Daten zum ursprünglichen Klettverschluss gehören oder zur
zweiten Alternative gehören? Willkommen. Das ist da. Wir werden Übungen machen
, die Ihnen ein einfacheres Verständnis dafür vermitteln. Hypothese, Sie erhalten
Informationen wie den p-Wert, abgesehen von den Ergebnissen der
Teststatistik. Sie erhalten auch den p-Wert. Wir vergleichen immer den p-Wert mit dem Nullwert
, den wir gesetzt haben. Angenommen, Sie möchten zu 95% selbstbewusst
sein. Dann legen Sie den p-Wert auf 5% fest. Und wenn Sie festlegen,
dass das Konfidenzniveau 90% beträgt, liegt Ihr Alpha-Wert bei zehn Prozent oder Ihr p-Wert bei 0,10. Der Grund, warum wir einen p-Wert verwenden, ist, dass, wenn Sie diese Glockenkurve
sehen können, die wahrscheinlichste Beobachtung Teil der
Mitte der Glocke
ist. Sehr
unwahrscheinliche Beobachtungen kommen vom Schwanz. Dieser p-Wert, der grüne Grund, hilft Ihnen zu erkennen,
ob er
zum ursprünglichen Klettverschluss gehört oder zu dem
alternativen Großteil davon gehört, das heißt,
Sie versuchen es durch
die alternative Hypothese zu beweisen. Daher hilft Ihnen der p-Wert , sich daran
leicht zu erinnern. Denk an den Jingle. Unten, null. Das heißt, wenn der p-Wert
kleiner als der Alpha-Wert ist, werde
ich
die Nullhypothese zurückweisen. P Flug auf hohem Niveau. Wenn der p-Wert
größer als der Alpha-Wert ist, können
wir
die Nullhypothese nicht zurückweisen. Wir kommen zu
dem Schluss, dass wir nicht
genügend statistische Beweise dafür haben , dass die alternative Hypothese existiert. Wir werden viel
Sport treiben und ich werde
diesen Jingle mehrmals singen , damit du dich leicht daran erinnern kannst. Gehen Sie unter Null hinter Nullcline. Einige der Teilnehmer mit, wenn ich den Workshop
mache, werden
sie sagen, dass None
Go was bedeutet? Die andere Sache, an die
ich ihnen sage, dass sie sich leicht erinnern sollen, ist f für
Flug und F für Feld. Also wenn P hoch Null ist, fliegen wir. Das bedeutet, dass Sie die Nullhypothese nicht
zurückweisen können. Es wird eine Nullhypothese geben. Die alternative Hypothese
wird verworfen. Denken Sie an eine weitere Sache,
die hauptsächlich
während des Interviews gefragt wird. Der p-Wert lag bei 1,230,123. Würden Sie
die Nullhypothese ablehnen oder würden Sie
die Nullhypothese akzeptieren? Oder würden Sie die
alternative Hypothese akzeptieren? Oder akzeptieren Sie
die Nullhypothese? Als Statistiker? Wir akzeptieren niemals eine Hypothese. Entweder lehnen wir
die Nullhypothese oder wir verwerfen
die Nullhypothese nicht. Wir sagen es immer aus
der Sicht von Null, weil der
Standardstatus Quo die
Nullhypothese erleichtert. Wenn das P hoch ist, akzeptieren
wir die Null
- und Alternativhypothese nicht. Akzeptieren wir nicht
die Nullhypothese. Wir sagen, wir können
die Nullhypothese nicht zurückweisen. Wenn das p niedrig ist, akzeptieren
wir keine Alternative, aber wir sagen, ich lehne
die Nullhypothese ab und kommen zu
dem Schluss, dass es
genügend statistische Beweise dafür gibt , dass die Daten vom
alternativen Bellcore stammen . Wir werden mit
vielen Übungen weitermachen. Und dies gibt
Ihnen Sicherheit wie Sie dabei
Inferenzstatistiken üben,
interpretieren und in Ihrer Analyse verwenden können.
25. Testauswahl: Eine der häufigsten Fragen , die meinen Teilnehmern gestellt
werden, wenn ich Projekt teilnehme
, ist , welche Hypothese
sollte ich mieten? Das ist also eine einfache Analyse , die Ihnen hilft, das
zu verstehen. Welche Tests sollte ich verwenden? Genau wie wenn ein
Patient zum Arzt geht, verschreibt ihm
der Arzt nicht den gesamten Test. Er hat ihm einfach den entsprechenden Test gemacht, basierend auf
dem Problem, dass der
Patient fischt. Wenn der Patient sieht, dass
ich einen Unfall hatte, würde
der Arzt sagen, dass ich denke, Sie sollten
Ihre Röntgenaufnahme machen lassen. Er würde ihn nicht
bitten,
seinen COVID-Test oder RT-PCR-Test zu machen . Wenn die Person hustet
und an Fieber leidet,
wird eine RT-PCR empfohlen. Und zu diesem Zeitpunkt sind wir
nicht in der Lage, die Röntgenaufnahme zu befriedigen. Ähnlich sieht es aus, wenn wir
einfache Hypothesentests durchführen,
wir versuchen, sie zu verstehen oder auf
andere Weise einfache Hypothesentests durchführen, wir versuchen, sie zu verstehen oder mit der Bevölkerung zu vergleichen. Wir wollen verstehen, welchen
Test wir durchführen sollten? Wenn ich auf Mittelwerte teste, das Ihr Durchschnitt ist, dann vergleichen Sie den Mittelwert
einer Stichprobe mit dem
erwarteten Wert. Also vergleiche ich die
Stichprobe mit meiner Population. Dann mache ich meinen T-Test
mit einer Stichprobe. Ich habe nur eine Probe
, die ich vergleiche. Ich möchte vergleichen, ob die
durchschnittliche Leistung des, wenn der durchschnittliche Umsatz gleich x
ist, was der erwartete Wert ist. Wir hatten also erwartet,
dass
der Umsatz beispielsweise 5 Millionen betragen würde. Mein Durchschnitt liegt bei 4,8. Ich habe das nicht getroffen. Dann kann ich einen T-Test
mit einer Stichprobe machen. Vergleichen Sie den Mittelwert von Proben mit zwei verschiedenen Proportionen. Wenn ich also zwei
unabhängige Ts habe, nehmen wir an, ich führe online
eine Schulung durch. Ich führe eine
Schulung offline durch. Es ist die Shrina und ich habe eine Reihe von Studenten, die
an meinem Online-Programm teilnehmen. Ich habe eine andere
Gruppe von
Studenten , die an
meinem Programm teilnehmen. Ich möchte die
Effektivität von Schulungen vergleichen. Ich habe also zwei Stichproben, und das sind zwei
unabhängige Stichproben , weil die Teilnehmer unterschiedlich
sind. Dann mache ich einen T-Test mit zwei Stichproben. Wenn ich
die beiden Stichproben
vergleichen möchte kommen die Leute zu meinem Training. Ich mache vor
meinem Trainingsprogramm eine Bewertung über ihr Verständnis von
Lean Six Sigma. Und ich kann das
Schulungsprogramm absolvieren und die gleichen Teilnehmer
nehmen nach
dem Schulungsprogramm am Test teil . Also die Teilnehmer
oder die Szene. Aber die Veränderung
, die stattgefunden hat, ist das Training, das sich auf
sie ausgewirkt hat. Ich habe die Testergebnisse vor
dem Training und ich habe die Testergebnisse nach dem Training, ich möchte vergleichen, ob das
Training effektiv ist. Dann mache ich einen
gepaarten T-Test mit zwei Stichproben. weiter voran. Angenommen, ich
teste auf Frequenz, habe ich diskrete Daten
und möchte
die Frequenz testen , da ich in diskreten Daten
keine Durchschnittswerte habe. Ich nehme Frequenzen. Wenn ich also
die Anzahl Variablen
in einer Stichprobe mit
der erwarteten Verteilung vergleiche, genau wie ich einen Beispiel-T-Test
hatte. Das Äquivalent dazu für diskrete Daten wäre meine
Chi-Quadrat-Güte der Anpassung. I, standardmäßig wird erwartet, dass es sich um einen normalen Wert oder einen bestimmten
Wert oder einen unerwarteten Wert handelt. Und das vergleiche ich. Wie weit sind meine Daten? Ich setze auf eine
chi-quadratische Passform. Dieser Test ist
auf MiniTab in Excel verfügbar. Es ist nicht verfügbar. Also werde ich eine
Vorlage erstellen und sie dir geben, die es dir leicht macht , den Chi-Quadrat-Test durchzuführen. Alle drei verschiedenen Arten von Chi-Quadrat-Tests unter Verwendung
der Excel-Vorlage. Wenn ich
einige der Variablen
zwischen zwei Stichproben zählen muss. Es wird also ein
homogener Chi-Quadrat-T-Test sein. Ich überprüfe eine
einfache einzelne Stichprobe , um festzustellen, ob die diskreten
Variablen unabhängig sind. Ich mache einen Chi-Squared
Unabhängigkeitstest. Wenn ich einen Teil der Daten habe, wie gute oder schlechte Bewerbungen, habe
ich akzeptiert oder abgelehnt. Und ich sage, okay, 50% der Bewerbungen
werden angenommen oder fünfundzwanzig Prozent
der Menschen werden gestellt. Ich habe einen Anteil
, den ich testen möchte. Wenn ich nur eine Probe
habe, mache ich einen Proportionstest. Wenn ich den
Anteil der
Handelsabsolventen mit
dem Absolventen der Naturwissenschaften
oder den Anteil der Finanz-,
MBA- und Personen mit
Marketing-MBA-Mitarbeitern vergleichen Handelsabsolventen mit
dem Absolventen der Naturwissenschaften oder den Anteil der Finanz-, möchte, habe ich zwei verschiedene Stichproben, damit ich mach einen Test mit zwei
Proportionen. Um es zusammenzufassen Wenn ich teste,
teste ich auf Durchschnittswerte? Teste ich auf
Frequenzen wie diskrete Daten oder
teste ich auf Proportionen? Abhängig davon nehmen
Sie
den entsprechenden Test auf
und arbeiten daran. Wir werden das alles
mit Men Dab und Exit
üben . Der Datensatz ist
im Abschnitt Beschreibung verfügbar. Im Projektbereich lade
ich Sie alle ein, es zu üben und Ihre Projekte,
Ihre Analyse, in den
Projektbereich zu stellen . Wenn Sie irgendwelche Zweifel haben, können
Sie dies in den Diskussionsbereich schreiben und ich beantworte
gerne Ihre Zweifel. Viel Spaß beim Lernen.
26. Konzepte von T Test im Detail: Was bringt dir dieses Video bei? Über den T-Test? Dieses Video behandelt alles, was Sie über den T-Test wissen müssen
. Am Ende dieses Videos erfahren
Sie, was ein
AT-Test ist, wann er verwendet werden sollte, verschiedenen Arten von
T-Tests, Hypothesen und Annahmen
involviert sind, wie der AT-Test berechnet
wird und wie die Ergebnisse zu
interpretieren Was ist ein T-Test? Fangen wir mit den Grundlagen an. Ein T-Test ist ein statistisches
Testverfahren. wird analysiert, ob zwischen
den Mittelwerten zweier Gruppen
ein signifikanter Unterschied besteht. Zum Beispiel könnten wir
den Blutdruck von Patienten, die Medikament A erhalten
, mit dem Blutdruck vergleichen . Medikament B, Arten von T-Tests. Es gibt drei
Haupttypen von T-Tests:
den t-Test mit einer Stichprobe,
den t-Test mit unabhängigen Proben
oder den t-Test mit zwei Stichproben
und den t-Test mit gepaarten Stichproben. Was ist ein T-Test für eine Stichprobe? Wir verwenden einen
t-Test mit einer Stichprobe, wenn wir den Mittelwert einer Stichprobe mit
einem bekannten
Referenzmittelwert vergleichen
möchten . Ein Hersteller von
Schokoriegeln gibt beispielsweise an, dass seine Riegel durchschnittlich
50 Gramm wiegen . Wir nehmen eine Probe. Finden Sie das Durchschnittsgewicht heraus. davon aus, dass das
Probengewicht 48 Gramm beträgt, und führen Sie einen
t-Test mit einer Probe durch, um festzustellen, ob es signifikant von
den angegebenen 50 Gramm abweicht. Was ist ein T-Test für
unabhängige Proben? Der
t-Test für unabhängige Stichproben vergleicht die Mittelwerte zweier unabhängiger
Gruppen oder Stichproben. Wir könnten zum Beispiel die Wirksamkeit von
zwei Schmerzfarben
vergleichen , indem 60
Personen
nach dem Zufallsprinzip zwei Gruppen zuordnen Bei der Einnahme von Medikament A
und dem anderen Medikament B. Und dann anhand eines
unabhängigen T-Tests, um signifikante
Unterschiede in der Schmerzlinderung zu bewerten Was ist ein T-Test
für gepaarte Proben? Der t-Test für gepaarte Stichproben vergleicht die Mittelwerte
zweier abhängiger Gruppen. Um beispielsweise die
Wirksamkeit einer Diät zu beurteilen, könnten
wir zuvor 30 Personen wiegen. Nach der Diät
stellen wir anhand von
Stichprobenpaaren fest, ob zuvor
ein signifikanter
Gewichtsunterschied bestand. Nach der Diät.
Das Verständnis des Unterschieds zwischen abhängigen und
unabhängigen Proben ist entscheidend für
die Auswahl
des richtigen T-Tests für Ihre Analyse. Abhängige Stichproben
oder
Stichprobenpaare beziehen sich auf Fälle, in denen
jede Beobachtung in einer Stichprobe mit
einer bestimmten Beobachtung gepaart ist. Bei der anderen Stichprobe ergibt sich
diese Paarung aus der Art der
Datenerhebung, z. B. vor und
nach den Messungen An denselben Personen, übereinstimmende Paare in einem Experiment Der t-Test der gepaarten Stichproben
wird verwendet, um zu beurteilen, ob. Die mittlere Differenz zwischen diesen gepaarten Beobachtungen ist
statistisch signifikant Andererseits handelt es sich bei unabhängigen
Stichproben um Beobachtungen, aus zwei getrennten Gruppen
oder Populationen
stammen, die nicht
miteinander verwandt oder in
keiner systematischen Weise gepaart sind miteinander verwandt oder in
keiner systematischen Weise gepaart Jede Beobachtung
in einer Stichprobe ist völlig unabhängig von
jeder anderen Beobachtung. In der anderen Stichprobe, den
unabhängigen Stichproben, T-Test bewertet,
ob sich die Mittelwerte
dieser beiden unabhängigen Gruppen signifikant
voneinander unterscheiden Die Wahl zwischen diesen Arten von T-Tests hängt davon ab,
wie die Daten
gesammelt wurden und in welchem
Verhältnis die zu vergleichenden Stichproben Durch die Verwendung des richtigen
T-Tests wird sichergestellt, dass Ihre statistische Analyse
die Art Ihrer
Forschungsfrage
und die Struktur Ihrer Daten
genau widerspiegelt die Art Ihrer
Forschungsfrage . Hier ist ein interessanter Hinweis. Der t-Test mit gepaarten Stichproben ist dem t-Test mit
einer Stichprobe
sehr ähnlich. Wir können uns
den t-Test mit gepaarten Stichproben auch so
vorstellen den t-Test mit gepaarten Stichproben auch so , dass eine Probe zu zwei verschiedenen Zeitpunkten
gemessen wurde . Anschließend berechnen wir die Differenz zwischen den gepaarten Werten und erhalten so einen Wert
für eine Stichprobe. Die Differenz ist
eins minus fünf plus zwei minus eins minus drei und so weiter und so fort. Nun wollen wir testen,
ob der Mittelwert
der gerade berechneten Differenz von einem Referenzwert
abweicht In diesem Fall Null, genau das macht der T-Test mit
einer Stichprobe Was sind die Annahmen? Für einen t-Test benötigen
wir natürlich zuerst eine geeignete Probe
im T-Test mit einer Stichprobe, wir benötigen eine Stichprobe und den Referenzwert im
unabhängigen t-Test. Wir benötigen zwei unabhängige Stichproben, und im Fall eines t-Tests mit
einem Paar, eine Stichprobe, wobei die
Variable, für die wir testen
wollen , ob es
einen Unterschied zwischen den
Mittelwerten gibt , metrisch sein muss. Beispiele für metrische
Variablen sind Alter, Körpergewicht und Einkommen. Beispielsweise ist das Bildungsniveau
einer Person keine
metrische Variable. Darüber hinaus
muss die metrische Variable in
allen drei Testvarianten normalverteilt sein , um zu
lernen, wie Sie testen können, ob Ihre
Daten normalverteilt sind. Bei einem
unabhängigen T-Test die Varianzen in den beiden Gruppen müssen
die Varianzen in den beiden Gruppen ungefähr gleich sein dem L-Even-Test können Sie überprüfen, ob die Varianzen Mit
dem L-Even-Test können Sie überprüfen, ob die Varianzen gleich
sind Was sind die Hypothesen
des T-Tests? Beginnen wir mit dem T-Test mit
einer Stichprobe
im T-Test mit einer Stichprobe Die Nullhypothese
besagt, dass der
Mittelwert der Stichprobe dem
angegebenen Referenzwert entspricht. Es gibt also keinen Unterschied, und die alternative
Hypothese lautet der Mittelwert der Stichprobe nicht dem angegebenen
Referenzwert
entspricht. Was ist mit den unabhängigen
Stichproben, die getestet werden sollen? Beim unabhängigen t-Test lautet
die Nullhypothese, lautet
die Nullhypothese dass
die Mittelwerte in beiden
Gruppen identisch sind. Es gibt also keinen Unterschied
zwischen den beiden Gruppen, und die alternative
Hypothese lautet dass
die Mittelwerte in beiden
Gruppen nicht gleich sind. Es besteht also ein Unterschied
zwischen den beiden Gruppen. Und schließlich werden die
Stichprobenpaare in einem T-Paar-Test getestet.
Die Nullhypothese
ist, dass der Mittelwert
der Differenz zwischen
den Paaren Null ist, und die
Alternativhypothese ist dass
der Mittelwert der Differenz
zwischen den Paaren nicht Null ist. Jetzt wissen wir, was
die Hypothesen sind. Bevor wir uns ansehen, wie der
T-Test berechnet wird. Schauen wir uns ein Beispiel
an , warum wir tatsächlich einen T-Test
benötigen. Nehmen wir an, es gibt einen
Unterschied in der
Studiendauer für einen
Bachelor-Abschluss zwischen Männern. Und Frauen in Deutschland. Unsere Bevölkerung setzt sich
also aus allen Bachelor-Absolventen zusammen
, die in Deutschland studiert haben. Da wir jedoch nicht
alle Bachelor-Absolventen befragen können, ziehen
wir eine möglichst
repräsentative Stichprobe. Mit dem Test testen wir nun die Nullhypothese, dass es keinen Unterschied
in der Grundgesamtheit gibt. Wenn es keinen Unterschied
in der Grundgesamtheit gibt, wenn es keinen Unterschied
in der Grundgesamtheit gibt, werden
wir in der Stichprobe sicherlich immer noch
einen Unterschied in der
Studiendauer feststellen . Es wäre sehr
unwahrscheinlich, dass wir
eine Stichprobe ziehen
würden, bei der der Unterschied genau Null wäre. Einfach ausgedrückt wollen wir jetzt
wissen, bei welcher Differenz in einer Stichprobe
gemessen wurde. Wir können sagen, dass die
Studiendauer
von Männern und Frauen
signifikant unterschiedlich ist. Und genau das beantwortet
der T-Test. Aber wie
berechnen wir einen T-Test? Um das zu tun? Wir berechnen zuerst den t-Wert, um den t-Wert zu
berechnen. Wir benötigen zwei Werte. Zuerst benötigen wir die Differenz
zwischen den Mittelwerten und dann die
Standardabweichung vom Mittelwert. Dies wird auch als
Standardfehler bezeichnet. Beim t-Test mit einer Stichprobe berechnen
wir die
Differenz zwischen
dem Stichprobenmittelwert und dem
bekannten Referenzmittelwert. S ist die Standardabweichung
der gesammelten Daten und n ist die Anzahl der Fälle. S geteilt durch die Quadratwurzel von n ist dann die
Standardabweichung vom Mittelwert. Was ist der Standardfehler? Beim t-Test der abhängigen Stichproben berechnen
wir einfach
die Differenz
zwischen den Mittelwerten der beiden Stichproben. Um den Standardfehler zu berechnen, benötigen
wir die
Standardabweichung und die Anzahl der Fälle aus der
ersten und zweiten Stichprobe,
je nachdem, ob
wir für unsere Daten von
gleicher oder ungleicher
Varianz ausgehen können für unsere Daten von
gleicher oder ungleicher
Varianz Für den Standardfehler gibt es unterschiedliche Formeln
. Bei einem t-Test mit einer gepaarten Stichprobe müssen
wir nur
die Differenz zwischen den gepaarten Werten
berechnen und daraus den Mittelwert berechnen. Der Standardfehler ist dann
derselbe wie bei einem t-Test mit einer Stichprobe. Was haben wir
bisher über den T-Wert gelernt? Egal welcher
T-Test, wir rechnen. Der t-Wert ist größer, wenn wir eine größere Differenz
zwischen den Mittelwerten
haben, und der t-Wert ist kleiner wenn die Differenz zwischen
den Mittelwerten kleiner ist. Außerdem wird der t-Wert
kleiner, wenn wir eine größere
Streuung des Mittelwerts haben. Je stärker die Daten gestreut sind, desto weniger aussagekräftig sind die
Mittelwertunterschiede. Jetzt wollen wir den t-Test verwenden um zu sehen, ob wir die
Nullhypothese zurückweisen können oder nicht. Dazu können wir
den t-Wert nun auf zwei Arten verwenden. Entweder lesen wir den kritischen
t-Wert aus einer Tabelle ab, oder wir berechnen einfach den
p-Wert aus dem t-Wert. Wir werden
beide gleich durchgehen. Aber was ist der p-Wert? Ein t-Test testet immer die Nullhypothese, dass
es keinen Unterschied gibt. Zunächst gehen wir davon aus, dass es keinen Unterschied
in der Population gibt. Wenn wir eine Stichprobe ziehen, weicht
diese Stichprobe um einen bestimmten Betrag
von der Nullhypothese Der p-Wert gibt an, wie wahrscheinlich es ist, dass wir eine Stichprobe ziehen
würden, von der Grundgesamtheit
abweicht gleichen Betrag oder mehr von der Grundgesamtheit
abweicht
als eine Stichprobe,
die wir Je mehr also die Stichprobe von der
Nullhypothese
abweicht, desto kleiner wird der p-Wert.
Wenn diese Wahrscheinlichkeit sehr, sehr gering
ist, können
wir natürlich fragen, ob die Nullhypothese
für die Grundgesamtheit gilt Vielleicht gibt es einen Unterschied, aber an welchem Punkt können wir die Nullhypothese
ablehnen Diese Grenze wird als Signifikanzniveau bezeichnet liegt normalerweise bei 5%. Wenn es nur eine Wahrscheinlichkeit von 5% gibt
, dass wir eine solche Stichprobe ziehen. Oder eine, die anders ist. Dann haben wir genügend Beweise, um anzunehmen, dass wir
die Nullhypothese ablehnen. Einfach ausgedrückt gehen wir davon aus,
dass es einen Unterschied gibt, dass die
Alternativhypothese wahr ist. wir nun wissen,
was der p-Wert ist, können
wir uns endlich ansehen, wie
der t-Wert verwendet wird, um
festzustellen, ob die
Nullhypothese abgelehnt wird oder nicht. Beginnen wir mit dem Pfad
durch den kritischen t-Wert
, den Sie aus
einer Tabelle ablesen können. Um das zu tun. Wir benötigen zunächst eine Tabelle
mit kritischen T-Werten, die wir auf der Registerkarte Daten
unter Tutorials und
T-Verteilung finden . Fangen wir mit
den beiden Heckgehäusen an. Wir werden uns am
Ende dieses Videos kurz das Gehäuse mit einem Schwanz ansehen. Hier unten sehen wir die Tabelle. Zunächst müssen wir entscheiden, welches Signifikanzniveau
wir verwenden wollen. Wählen wir ein
Signifikanzniveau von 0,05 von 5%. Dann schauen wir in dieser Spalte
auf 120,05, was 0,95 entspricht. Jetzt benötigen wir die
Freiheitsgrade für den einer Stichprobe und
den t-Test für
die gepaarten Stichproben Die Freiheitsgrade sind einfach die Anzahl
der Fälle minus eins. Wenn wir eine Stichprobe
von zehn Personen haben, gibt es neun
Freiheitsgrade. Beim t-Test der unabhängigen
Stichproben addieren
wir die Anzahl der
Personen aus beiden Stichproben und berechnen diese Zahl minus zwei,
weil wir zwei Stichproben haben. Beachten Sie, dass die
Freiheitsgrade auf unterschiedliche Weise
bestimmt werden können ,
je nachdem, ob wir gleicher oder gleicher Varianz
ausgehen Wenn wir also ein
Signifikanzniveau von 5%
und neun Freiheitsgrade haben , erhalten
wir einen kritischen
t-Wert von 2,262 Nun haben
wir zum einen einen T-Wert mit
dem t-Test berechnet und wir haben
den kritischen t-Wert Wenn unser berechneter
T-Wert größer als der
kritische t-Wert ist. Wir lehnen die Nullhypothese ab. Nehmen wir zum Beispiel an, wir
berechnen einen t-Wert von 2,5. Dieser Wert ist
größer als 2,262, und daher sind die
beiden Mittelwerte so
unterschiedlich, dass wir die Nullhypothese
zurückweisen können Andererseits können wir auch den p-Wert für den
T-Wert
berechnen, den wir berechnet haben Wenn wir 2,5 für den t-Wert
und neun für die
Freiheitsgrade eingeben , erhalten
wir einen p-Wert von 0,034 Der p-Wert ist kleiner als 0,05, und wir lehnen daher die
Nullhypothese als Kontrolle Wenn wir hier den
t-Wert von 2,262 kopieren, erhalten
wir genau einen
p-Wert von 0,05, was genau der Grenzwert ist Wenn Sie den AT-Test mit
der Registerkarte Daten berechnen möchten, müssen
Sie nur Ihre
eigenen Daten in diese Tabelle kopieren Klicken Sie auf Hypothesentest und wählen Sie dann die gewünschten
Variablen aus. Wenn Sie beispielsweise
testen möchten, ob sich das Geschlecht auf das Einkommen auswirkt, klicken
Sie einfach auf die beiden Variablen
und Sie erhalten automatisch den AT-Test, der für
unabhängige Stichproben
berechnet wird. Hier unten. Sie können den p-Wert
ablesen. Wenn Sie sich bei
der Interpretation
der Ergebnisse immer noch nicht sicher sind, können
Sie einfach auf
Interpretation nach innen klicken Ein T-Test für
unabhängige Stichproben, gleiche Varianzen angenommen wurden, ergab , dass der Unterschied zwischen Frauen und Männern in Bezug auf die abhängige Variable Gehalt statistisch nicht signifikant war Somit wird die
Nullhypothese beibehalten. Die letzte Frage ist nun,
was ist der Unterschied zwischen gerichteter Hypothese und
ungerichteter Hypothese Im ungerichteten Fall lautet
die alternative Hypothese, dass es einen Unterschied gibt Zum Beispiel gibt
es in Deutschland einen Unterschied zwischen dem Gehalt von Männern
und Frauen Es ist uns egal, wer mehr verdient. Wir wollen nur wissen, ob es einen Unterschied
gibt oder nicht. In einer gezielten Hypothese. Wir sind auch
an der Richtung
des Unterschieds interessiert . Die
alternative Hypothese
könnte beispielsweise lauten, dass Männer mehr verdienen als Frauen oder Frauen
mehr verdienen als Männer. Wenn wir uns die
T-Verteilung grafisch ansehen, können
wir sehen, dass
wir
im zweiseitigen Fall einen Bereich auf der linken Seite
und einen Bereich auf der rechten Seite haben Wir wollen die
Nullhypothese zurückweisen, wenn wir
entweder hier oder dort
ein Signifikanzniveau von 5% haben Beide Bereiche haben eine
Wahrscheinlichkeit von 2,5%. Zusammen sind es nur 5%. Wenn wir
einen One-Tail-T-Test durchführen, wird
die Nullhypothese nur dann
verworfen, wenn wir uns in diesem Bereich
befinden
oder je
nachdem welcher Richtung
wir testen wollen
, in diesem Bereich mit einem
Signifikanzniveau von 5% liegen
A 5% innerhalb dieses Bereichs Danke, dass du mit mir gelernt hast. Wir sehen uns in der nächsten
Statistikstunde.
27. 1 Probe t Test: Lassen Sie uns verstehen, welche
Hypothesentests ich verwenden sollte? In Minitab haben Sie einen Assistenten, der Ihnen bei dieser Entscheidung
helfen kann. Wenn Sie also zum
Assistenzhypothesentest gehen, können
Sie
anhand der Anzahl der
Proben, die Sie haben, identifizieren . Angenommen, Sie
haben eine Probe, führen Sie möglicherweise einen t-Test bei einer
Stichprobe, eine Standardabweichung der Stichprobe, einen fehlerhaften Prozentsatz der Stichprobe chi-quadrierte Anpassungsgüte durch. Wenn Sie zwei Proben haben, haben Sie zwei
Stichproben-T-Tests für verschiedene Proben. Testen Sie, ob die Vorher- und
Nachher-Elemente identisch sind. Standardabweichung der Stichprobe zum Prozentsatz der Stichprobe des defekten
Chi-Quadrat-Tests der Assoziation. Wenn Sie mehr
als zwei Proben haben, haben wir einen einfachen
ANOVA-Standardabweichungstest, Chi-Quadrat-Prozentsatz
ist defekt und Chi-Quadrat-Test der Assoziation. Wir werden das
alles mit vielen Beispielen üben. Kommen wir also
zum ersten Beispiel. Wir haben ADHS von
Anrufen innerhalb von Minuten. Wir haben eine Stichprobe
von 33 Datenpunkten entnommen. Der Durchschnitt ist sieben, der
Mindestwert beträgt vier Minuten, Maximalwert beträgt zehn Minuten. Der Grund, warum wir
einen Hypothesentest durchführen müssen , ist der
Manager der Prozesse , dass sein Team in der Lage ist,
die Lösung oder den
Anruf in sieben Minuten abzuschließen . Und der Prozessdurchschnitt
liegt ebenfalls bei sieben Minuten, das
Minimum bei vier Minuten. Der Kunde sieht jedoch
, dass die Agenten sie der Warteschleife halten, und das Gespräch dauert mehr als
sieben Minuten. Jetzt möchte ich also statistisch überprüfen, ob
es korrekt ist oder nicht. Wann immer wir Hypothesentests
einrichten, müssen
wir den
fünfstufigen Sechs-Schritte-Ansatz verfolgen. Schritt Nummer eins, definiere
die alternative Hypothese. Definiere die Nullhypothese, die nichts anderes als
dein Status Quo ist. Was ist das Signifikanzniveau
oder Ihr Alpha-Wert? Wenn nichts angegeben ist, wird der Alpha-Wert
als fünf Prozent gesendet. Wir stellen zunächst die
alternative Hypothese auf. in unserem Fall Was sagt der Kunde in unserem Fall? Der Kunde sieht, dass die durchschnittliche Bearbeitungszeit
mehr als sieben Minuten beträgt. Der Status Quo oder
die vereinbarte SLA lautet ADHS weniger als
sieben Minuten betragen sollte. Wie ich Ihnen bereits sagte, schließen sich
die Null- und die Alternativhypothese gegenseitig aus
und ergänzen sich gegenseitig. Identifizieren Sie nun den durchzuführenden
Test. Wie viele Proben habe ich? Ich habe nur eine Probe der
HD des Kontaktzentrums. Also nehme
ich einen T-Test. Okay? Jetzt muss ich
die Teststatistiken erstellen und den p-Wert identifizieren. Wenn Sie sich an die
vorherige Beispielstunde erinnern, sagten
wir, wenn der p-Wert kleiner
als der Alpha-Wert ist, lehnen
wir die Nullhypothese ab. Wenn der p-Wert größer als
fünf Prozent oder der Alpha-Wert ist, können
wir
die Nullhypothese nicht zurückweisen. Lassen Sie uns dieses Verständnis übernehmen. Wenn Sie sich also erinnern, haben
wir unsere Projektdaten. In den Projektdaten haben
wir den Test der Hypothese. Hier drüben. Ich habe dir die
AHG Kohle in wenigen Minuten gegeben. Also habe ich diese
Daten auf MiniTab kopiert. Also lass es uns auf zwei Arten machen. Zum ersten Mal und zeig es
dir mit dem Assistenten. Zweitens werde ich es
dir anhand von Statistiken zeigen. , das ich erreichen möchte, wenn
ich zu den
Hypothesentests gehe Was ist das Ziel, das ich erreichen möchte, wenn
ich zu den
Hypothesentests gehe? Es ist ein t-Test bei einer Stichprobe.
Ich habe eine Probe. Geht es um gemein? Geht es um Standardabweichung? Sind es getrennte, defekte
oder diskrete Zahlen? Wir sprechen über
den Durchschnitt 100 Mal. Also mache ich einen T-Test bei
einer Probe. Für Daten in Spalten. Ich habe das ausgewählt. Was ist mein Zielwert? Mein Zielwert ist sieben. Die alternative Hypothese besagt dass
das Durchschnittsalter des Anrufs in Minuten
größer als sieben ist. Darüber beschwert sich der
Kunde. Der Alpha-Wert ist
standardmäßig 0,05, ich klicke auf Okay. Sehen wir uns die Ausgabe an. Um die Ausgabe zu sehen, klicken
Sie auf Nur anzeigen und ausgeben. wirst du sehen. Wenn Sie den p-Wert sehen, ist der
p-Wert 0,278. Erinnern Sie sich, dass unter Nicht-Ziel
hohe Nulllinie
dieser Wert von 0,278 größer
als der Alpha-Wert von 0,05 ist ? Ja, das ist es. Daher kann ich schlussfolgern
, dass der Mittelwert
von d von Kohle nicht signifikant
größer als das Ziel ist. Was auch immer Sie
als größer als Ziel ansehen, es ist nur ein Zufall. Es gibt also nicht genügend Belege,
um zu dem Schluss zu kommen, dass der Mittelwert über sieben
liegt Signifikanzniveau
von
fünf Prozent aufweist Und es zeigt mir auch,
wie das Muster ist. Es gibt keine ungewöhnlichen Datenpunkte , da die
Stichprobengröße mindestens 20 beträgt. Normalität ist kein Problem. Der Test ist korrekt. Und es wäre gut
zu schlussfolgern, dass die durchschnittliche Bearbeitungszeit
nicht
wesentlich über sieben Minuten liegt . Ich kann den Antrag
des Kunden ablehnen . Die wenigen Aufrufe, die wir
als qualitativ hochwertige und
hochwertige Ziele ansehen . Das konnte nur durch Zufall geschehen. Derselbe Test. Ich kann es auch tun, indem ich auf Teststatistik, grundlegende Statistiken klicke. Und ich speichere einen Proben-T-Test, eine oder mehrere Proben,
jeweils in einer Spalte. Ich werde dein ausgewähltes ADHS umdrehen. Ich möchte
Hypothesentests durchführen. Der hypothetische Mittelwert ist sieben. Ich gehe zu Option und sage, was ist die alternative
Hypothese, die ich definieren möchte. Ich möchte definieren, dass der tatsächliche Mittelwert größer ist
als der hypothetische Mittelwert. Klicke auf Okay. Wenn ich ein Diagramm brauche, kann
ich diese Grafiken erstellen. Klicken Sie auf Okay und
dann auf Okay. Ich erhalte diese Ausgabe. Also die deskriptiven Statistiken, das ist der Mittelwert, das ist die
Standardabweichung und so weiter. Nullhypothese lautet,
dass mu gleich sieben ist. Alternative Hypothese ist
mu ist größer als sieben. p-Wert ist 0,278. diesen Nullflug abschließen, lehnen
wir
die Nullhypothese nicht ab und kommen zu
dem Schluss, dass die
durchschnittliche 100-Zeit bei
etwa sieben Minuten liegt .
Lass uns weitermachen. Wir haben unseren Output erhalten. Wir haben all dies gesehen und sind zu dem Schluss gekommen, dass
die durchschnittliche Bearbeitungszeit nicht wesentlich
über sieben Minuten
liegt.
28. 2 Probe t Testbeispiel 1: Lassen Sie uns noch ein Beispiel
mit zwei Teams machen, zwei Proben. In diesem Beispiel also
zwei Teams, deren Leistung gemessen werden
muss. Der Manager von DMB behauptete, dass sein Team ein
leistungsfähigeres Team sei als DNA. Der Manager eines Teams befürwortet, dass diese
Behauptung ungültig ist. Gehen wir zu unserem Datensatz. Wenn Sie also zur Projektdatei gehen, haben
Sie etwas,
das als Team a und Team B
bezeichnet wird Lassen Sie mich diese Daten
also einfach kopieren. Okay. Lass mich hergehen und das
Radar auf der rechten Seite platzieren. Warum kann ich auch
ein neues Blatt nehmen und die Daten einfügen. Richtig? Kommen wir also zu Hypothesentest, einem t-Test mit
zwei Stichproben. Lassen Sie mich diesen Wert löschen. Und TB, das Team a
unterscheidet sich von der VM. Ich kann auch sagen, basierend
auf der Hypothese , dass das Team behauptet wird, dass
sein Team besser ist als ein. also kann ich sagen, dass es weniger als
TV ist. Und ich klicke auf Okay. Auch in diesem Beispiel erhalte
ich eine Ausgabe, die besagt, dass das Team nicht
wesentlich weniger als TB ist. Haben Sie die
Werte von 27,727,3? Es gibt keinen
statistischen Unterschied zwischen den beiden Tipps, oder? Also waren beide Beispiele, die
wir bekamen, so. Schauen wir uns noch
ein Beispiel an. Ich habe die Zykluszeit
von Prozess eins und die
Zykluszeit von Prozess B genommen von Prozess eins und die
Zykluszeit von Prozess B Kopieren wir
also einfach diese Daten. Dies ist ein weiterer Datensatz. Und ich sage: Was ist meine
alternative Hypothese? Beide Balken sind unterschiedlich. Was ist die Nullhypothese? Beide Teams sind gleich. Weil diese beiden
Teams unterschiedlich sind. Ich werde
meinen t-Test mit zwei Stichproben machen. Die Daten jedes
Teams sind getrennt. Und ich sehe, dass sich der TB-Alpha-Wert
von 5% unterscheidet, und dann klicke ich auf, Okay. Wenn Sie nun die
Ausgabe dieses Mal sehen, heißt
es, dass sich die Zykluszeit von a erheblich
von der Zykluszeit von dB unterscheidet. Hier, diese 26.8,
siebenundzwanzig Punkt sechs. Aber wenn ich mir
die Verteilung ansehe, die Verteilung, dass
sich dieses Rot nicht
mit diesem Rot überschneidet. Es gibt also einen Unterschied in der Zykluszeit der beiden Teams. Wenn ich
dasselbe mit Statistiken machen muss,
grundlegende Statistiken, t-Test mit
zwei Stichproben. wie Ihre Zeit, in der Sie zur Zeit der
TB-Optionen e
waren Gibt es verschiedene Optionen, wie Ihre Zeit, in der Sie zur Zeit der
TB-Optionen e
waren? Ich kann meine Grafiken haben. Ich möchte kein
individuelles Diagramm. Ich werde nur das
Boxplot nehmen und sagen, okay, mu1 ist der Mittelwert der Grundgesamtheit der
Zykluszeit von Prozessen, Zykluszeit von Prozess B. Wenn Sie sehen,
dass es
eine Standardabweichung gibt , ist das ein Unterschied. Der p-Wert ist 0,
was bedeutet, dass es einen signifikanten Unterschied
zwischen den beiden Teams gibt. Sei niedrig, nicht cool. Hier lehnen wir also
die Nullhypothese ab und
sagen, dass es
einen signifikanten Unterschied
zwischen E und D gibt . Richtig? Ich habe das Gleiche
mit der Verteilung gesehen. Es gibt also eine
größere Verteilung oder hier und es gibt eine
kleinere Verteilung. Ich kann meine grafische
Analyse, die ich auf
der rechten Seite gelernt habe , durchführen und dann sehen, wie
das Team abschneidet. Das ist also die Zusammenfassung der DNA. Der Mittelwert ist 26, die
Standardabweichung ist 1,5. Und wenn ich nach unten scrolle, komme
ich zu Team B und
es kommt auf diese Weise. Jetzt möchte ich
diese Diagramme überlappen, damit ich auf ein Diagramm
und ein Histogramm klicken kann. Und ich sage ein bisschen
fit und seidig. Und ich werde
diese beiden Grafiken auf einem separaten
Panel derselben Grafik auswählen , dasselbe Vitamin C max. Klicke auf, okay. Klicke auf Okay. Kannst du sehen, dass die Glockenkurve von beiden unterschiedlich ist? Lassen Sie uns ein überlappendes
Graph-Histogramm erstellen. Und in mehrfacher
Bodenüberlagerung in diesem Diagramm. Kannst du sehen, dass das Blau und das Rot einen Unterschied
gibt? Und daher ist die
Kurtosis anders, die Schiefe ist anders, und das
ist die Schlussfolgerung in meinem t-Test mit zwei Stichproben, besagt, dass die Verteilung dort signifikant ist
Unterschied. Es gibt einen statistisch
signifikanten Unterschied zwischen der heiligen Zeit als
EN-Kämpfer und dem Absterben. Als zweites werden wir
in unserem nächsten Beispiel etwas über den Bett-t-Test
erfahren.
29. 2 Probe t Testbeispiel 2: Kommen wir zu unserem Beispiel. Zwei. Es gibt zwei Zentren , deren Leistung gemessen werden
muss. Der Manager von
Sensory behauptete, sein Team sei ein leistungsfähigeres
Team als das Zentrum B. Die Größe des Zentrums be befürwortet, dass die
Behauptung ungültig sei. Auch hier werde ich
meinen fünfstufigen Prozess verfolgen. Was ist die alternative
Hypothese? Ist besser als B. Machen wir es einfacher. Es ist nicht gleich T, ist nicht gleich TB oder center ist nicht
gleich Zentrum. Was bedeutet das
Nicht-Hypothesenzentrum a ist gleich Zentrum V, Signifikanzniveau,
fünf Prozent. Wie viele Proben habe ich? Ich habe zwei Samples, Center Editor und Center B-Daten. Da ich zwei Proben
habe, muss ich einen t-Test mit
zwei Stichproben machen. Gehen wir zu unserem Excel-Blatt. Ich habe die Daten für
Centauri und Center B. Ich werde sie in Minitab
kopieren. Ich lege meine Daten hier ab. Machen wir den t-Test bei zwei Stichproben. Also gehe ich zu Stat, Basic Statistics und
sage t-Test mit zwei Stichproben. Beide Proben
befinden sich in einer Spalte. Jedes Sample hat seine eigene Spalte, also
wähle ich dieses Beispiel aus. Eine davon ist eine sensorische Probe. Zentrieren Sie B? Option ist hybrid. Das ist nicht anders. Der Unterschied
zwischen a und B ist also 0. Und ich mache es weiter. Ich kann mein individuelles
Boxplot haben und OK sagen und Okay sagen, lass uns die Ausgabe
sehen. Die sensorischen Daten
gehören also Ihnen und die TBI-Daten sind hier. Und wenn Sie den p-Wert sehen, ist
der p-Wert hoch. Wieder habe ich ein Beispiel, das
besagt, dass es sich um eine hohe Nullfliege handelt,
was bedeutet, dass es keinen Unterschied
zwischen Mitte und Mitte B gibt zwischen Mitte und Mitte B Wenn Sie den einzelnen Wert sehen, aber Sie sehen dasselbe. Sehen wir uns das Boxplot an. Das Boxplot besagt
, dass sich der Mittelwert nicht signifikant
unterscheidet, da eine Stichprobe entnommen worden
wäre. Das ist der Grund, warum es so ist, und Sie sehen einen Wert von 0, was ein Ausreißer ist. Also sollten wir
darüber nachdenken. Das Gleiche. Lassen Sie mich das mit
Hypothesentests machen. t-Test bei zwei Stichproben, Mittelwert der Stichprobe Die Probe ist anders. Der Mittelwert von Mittelpunkt
unterscheidet sich
vom Mittelwert von Zentrum B und C. Okay. Ebenso der mittlere Unterschied, der Mittelwert von Santa Fe unterscheidet sich nicht signifikant
vom Mittelwert außermittig. Richtig? Wenn Sie diese Verteilung sehen, können
Sie feststellen, dass
sich der rote Teil vollständig überschneidet
, was darauf hindeutet
, dass es
keine ausreichenden Beweise gibt,
um auf einen Unterschied schließen zu können. Wenn
Sie den Mittelwert sehen, gibt es einen Unterschied, 6,86,5. Aber das könnte
an einer Chance liegen. Und es gibt auch eine
Standardabweichung. Daher zeigen sie es
anhand der roten Balken, zeigen, dass es
keinen signifikanten Unterschied zwischen
sensorischer und zentraler Woche gibt. Wir werden im
kommenden Video weiter über
andere Beispiele lernen .
30. Paired t Test: Lassen Sie uns
ein weiteres Beispiel verstehen. Dies ist ein Beispiel für einen
gepaarten t-Test. Wenn man sich diese Fallstudie anschaut, wollten
die Psychologen herausfinden, ob ein bestimmtes Laufprogramm auf die
Ruheherzfrequenz auswirkt. Die Herzfrequenz von 15 zufällig ausgewählten
Personen wurde gemessen. Die Menschen wurden dann in ein laufendes Programm aufgenommen und nach einem Jahr
erneut gemessen. Also
sagen die Teilnehmer vorher gegen nachher? Ja. Und das ist der Grund, warum es
sich nicht um einen t-Test mit zwei Stichproben handelt, sondern um einen gepaarten t-Test, der Vorher- und
Nachher-Messung jeder Person oder in
Beobachtungsbändern. Wenn ich also zu meinem Datensatz zurückkehre, habe ich etwas, das
wie vorher und nachher heißt, es gibt eine andere Phase, ich nehme nicht den
Differenzwert. Ich habe die Daten für
die 15 Personen
genommen und im Mini-Tab gespeichert. Richtig? Jetzt möchte ich das tun, weil es dieselbe Person
vor und nach mir ist, wir wollen die
verschiedenen Hypothesentests verstehen. Ich mache einen gepaarten T-Test. Die erste Sache war, was ist die alternative Hypothese? Vorher und Nachher ist anders. Wenn Sie sich erinnern, das Programm
von vorher und nachher, wollen
sie feststellen, ob sie Auswirkungen auf den Lauf
haben. Die Messung ist vor, das
Messwerkzeug ist oben. Mittelwert von davor unterscheidet sich
vom Mittelwert von danach. Das ist also meine
alternative Hypothese. Was bedeutet
meine
Nullhypothese davor, dass es keine Änderung gibt. Die Alternative sieht, dass
sich das Vorher von Nachher unterscheidet. Der Alpha-Wert ist 0,05. Lass uns auf Okay klicken. Sehen wir uns die Ausgabe an. Unterscheidet sich der Mittelwert? Was ist ein p-Wert von 0,007? Der Mittelwert von vorher unterscheidet sich signifikant
vom Mittelwert von danach. Wenn man sich den
Mittelwert anschaut, lag er bei 74,572,3. Aber es gibt einen Unterschied. Wenn Sie also sehen, ist der
Unterschied größer als 0. Und wenn ich mir diese
Werte von vorher versus
nachher ansehe ist der blaue Punkt hinter
dem schwarzen Punkt vor. Bei den meisten Teilnehmern war
ihre Herzfrequenz
nach dem Laufprogramm gesunken. Nur wenige von ihnen waren Ausnahmen, aber das könnte eine Ausnahme sein. Es gibt keine ungewöhnlichen
paarweisen Unterschiede , da unsere
Stichprobengröße mindestens 20 beträgt. Normalität ist kein Problem. Die Stichprobe reicht aus, um den Unterschied
im Mittelwert
nachzuweisen. Ich kann also sehen, dass es einen Unterschied
zwischen beiden gibt. Wunderbar. Also nochmal, schnelle Überarbeitung. Hallo, Nullziel, da der p-Wert unter
dem Signifikanzniveau liegt, schlussfolgern
wir, dass zwischen den beiden Messwerten
ein signifikanter Unterschied besteht. Wenn ich die Szene machen muss, klicke
ich auf Statistik,
Basic Statistics. Schlechte Abscheu, jede
Probe in einer Regel. Vorher, nach
der Option sind sie unterschiedlich. Lassen Sie mich nur das
Boxplot und das Histogramm von Ich möchte das Histogramm nicht
auswählen. Ich nehme nur den Boxplot. Null-Hypothese. Der Unterschied ist 0. Alternative Hypothese ist, dass die
Differenz ungleich Null p-Werte niedrig sind, was
zu dem Schluss kommt, dass ich
die Nullhypothese zurückweise Und es gibt einen Unterschied bei
der Übernahme des Programms. Wenn Sie also den Nullwert sehen, ist
der rote Punkt weit vom
Mittelwert des
Konfidenzintervalls der Box entfernt , um zu schließen, dass es einen Unterschied
gibt zwischen dem Durchlaufen des Programms durch dieser Herzspezialist, richtig? Im nächsten Programm werden
wir also lernen, weitere Beispiele
aufzugreifen.
31. Ein Test mit Sample: Die kurze Zusammenfassung
der verschiedenen Arten
von Tests, die wir
gelernt haben, lautet: Wenn ich mir
anschaue , wie unterschiedlich meine Gruppe und zwischen
den Bevölkerungsgruppen sind, mache ich einen t-Test mit einer Stichprobe. Wenn ich zwei verschiedene
Probengruppen habe, mache ich einen t-Test mit zwei Stichproben. Wenn diese Stichproben unabhängig
sind. Wenn ich
einen gepaarten T-Test machen werde. Gepaarte t-Test. Wenn die Gruppe
dieselbe Gruppe von Personen hat, aber es ist oder ein anderer
Zeitpunkt. Wie wir das Beispiel
des Herzschlags gesehen haben. Die Menschen wurden also
an ihrem Herzschlag gemessen. Den Bericht über
ein laufendes Programm und das laufende Programm posten. Wie war der heiße
Ruheherzschlag, oder? Das sind also die
Dinge, die wir sortiert haben. wir nun
mit weiteren Beispielen fort. Also fügen wir den Anwendungsfall Nummer fünf hinzu, die Analyse des Fettanteils. Die Wissenschaftler eines Unternehmens , das Verfahren hergestellt hat, die den Fettanteil in
der
Wasserquelle des Unternehmens S ermitteln
möchten . Das Datum der Veröffentlichung
beträgt 15% und die Wissenschaftler messen, dass
der Fettanteil 20 Zufallsstichproben beträgt. Die bisherige Messung
der Standardabweichung der Grundgesamtheit beträgt 2,6. Dies ist nun die
Standardabweichung der Population. Die Standardabweichung
der Stichprobe beträgt 2,2. Wenn ich den
Populationsparameter kenne, kann
ich einen
Z-Test für die Stichprobe
verwenden , da die Anzahl
der Proben, die ich habe, eins ist. Und ich will, ich habe die bekannte Standardabweichung
der Bevölkerung. Jetzt werde ich wieder dasselbe anwenden, was
die
alternative Hypothese definiert hat, oder? Also was werde ich sagen? Was ist die alternative Hypothese? Der Fettanteil ist
nicht gleich 603050. Was ist der
Fettanteil
der Nullhypothese gleich 15%. Signifikanzniveau
fünf Prozent. Weil ich weiß, dass es sich um
einen Test mit einer Stichprobe und ich die
Standardabweichung der Bevölkerung habe Ich verwende
einen Beispiel-Z-Test. Lass uns die Analyse machen. Ich habe die
Projektdatei geöffnet und habe die Proben-IDs und erstelle hier einen
Fettanteil. Lassen Sie mich diese
Daten in Minitab kopieren. Aber kopierte den
Fettanteil mit den
Wissenschaftlern getan haben. Da wir die Standardabweichung der
Grundgesamtheit kennen, kann
ich den Z-Test
bei einer Stichprobe verwenden. Meine Daten sind in einer Spalte enthalten. Es ist die Tatsache, die präsentiert wird. Die bekannte
Standardabweichung betrug 2,6. Ich möchte
Hypothesentests durchführen. Die Hypothese bedeutet, dass es 15% sind. Meine Nullhypothese ist also der Fettanteil gleich 15
ist. Meine Hypothese ist, dass Fett ein
großes A nicht gleich 15 ist. Ich kann ein Diagramm von Boxplot
und Histogramm auswählen und sagen:
Okay, ich zeige
Ihnen die Ausgabe. Die Nullhypothese lautet also, dass der
Fettanteil gleich 15 ist. Alternative Hypothese
ist, dass der Fettanteil nicht gleich 15
ist. Der Alpha-Wert ist 0,05. Mein p-Wert ist 0,012, da mein p-Wert kleiner
als der Alpha-Wert ist, P niedrig, nicht cool. Daher lehne ich die Nullhypothese ab und komme
zu dem Schluss, dass der
Fettanteil nicht 50 beträgt. Wenn Sie hier sehen, ist
der Fettanteil mehr als 50. Ich kann den gleichen
Test wiederholen. Dieses Mal. Ich kann weitermachen und nachsehen. Ist mein Fettanteil höher
als der hypothetische Mittelwert. Lass es uns machen. Und trotzdem erhalte ich meinen
p-Wert selbstbewusster, 0,006 sehr weit von
meinem Alpha-Wert entfernt. Zusammenfassend lässt sich sagen, dass der Alpha, der Nullwert
hypothetisch ist, der Mittelwert 15 ist. Die Stichprobe besagt jedoch,
dass
Ihr Fettanteil in der
Quelle mit hoher Wahrscheinlichkeit mehr als 50 beträgt. Welchen Rat
werden wir dem Unternehmen geben? Wir werden das Unternehmen
darauf hinweisen, dass Sie
die Bezeichnung nicht verkaufen können , dass der Container
15% beträgt , da unser Faktor
mehr als 15% beträgt. Um sicher zu gehen, können
Sie das
Etikett des Produkts so ändern, dass der
Fettanteil 18 beträgt, oder? Weil wir fünf
Prozent haben, machen wir 20 durch. Ein Verbraucher wird sich also über ein Produkt freuen ,
das weniger Fett enthält. Dann um ein Produkt zu erhalten
, das mehr
Fett enthält , weil wir alle
gesundheitsbewusst sind, oder? Also lasst uns
in der nächsten Klasse weitermachen.
32. Ein Sample test-1p-Test: Wir werden unsere
Hypothesentests fortsetzen. Manchmal haben wir vielleicht einen Teil
der Action, oder? Wir haben jedoch keine Durchschnittswerte Standardabweichung
oder Varianz zu ,
Standardabweichung
oder Varianz zu
messen
, was wir tun. Nehmen wir dieses Beispiel sechs, der Marketinganalyst
möchte feststellen, ob der Mann, die Werbung für
das
neue Produkt, zu
einer Rücklaufquote geführt hat , die sich
vom nationalen Durchschnitt unterscheidet. Normalerweise, wenn Sie eine
Anzeige in der Zeitung platzieren, sagen
sie, dass die Werbefirma normalerweise sieht, dass wir in der Lage sein werden, 6% Ergebnis
oder 10% Ergebnis oder eine
bestimmte Zahl zu beeinflussen Ergebnis genau hier. Was ist, es ist die gleiche
Art von Szenario. Hier. Sie nahmen eine
Zufallsstichprobe von 1000 Haushalten, die Werbung
erhalten haben. Und von diesen
10.000 Haushalten
tätigten 87 von ihnen
Einkäufe, tätigten 87 von ihnen nachdem sie
diese Vergrößerung erhalten hatten. Diese Firma, die
eine Werbefirma
ist, behauptet, dass ich
eine bessere Wirkung erzielt habe als die der
anderen Werbung. Der Analyst muss
den Ein-Prozent-Z-Test durchführen den Ein-Prozent-Z-Test um festzustellen, ob
der Anteil der Haushalte, die einen
Kauf getätigt haben,
vom nationalen Durchschnitt
von 6,5 abweicht , da dieser 8,7 beträgt. In diesem Fall. Was ist Ihre
alternative Hypothese? Alternative Hypothese ist, dass die
Werbung anders ist als
die Reaktion auf die Werbung
vom nationalen Durchschnitt. Hier sagen wir, dass
es keinen Unterschied gibt. Sie sind beide Sünde, Alpha-Wert liegt bei fünf Prozent. Und wir werden einen Proportion-,
Z-Test-, Ereignis-Proportionstest aufnehmen . Ich soll
dich zur Minute bringen. Gehen wir also zu MiniTab. Ich kann weitermachen und diese Väter, grundlegende Statistiken,
ein Anteil. Ich habe keine Daten in meiner Kolumne, aber ich habe sie zusammengefasst, oder? Also lass mich das schließen, abbrechen, lass mich das schließen. Also habe ich einen
Probenanteilstest gemacht. Ich habe Daten zusammengefasst. Wie viele Ereignisse
haben wir aufgenommen? Wir beobachten 87
Ereignisse, die eintreten werden. Die Stichprobe besteht aus Tausend. Ich muss einen
Hypothesentest durchführen und den hypothetischen Anteil von
6,5, 0,06566% ,5, oder? Es ist also 0,065. Dieser Anteil entspricht nicht
dem Hypothesenverhältnis. Ich sage: Okay, ich verstehe, okay. Jetzt lautet die Nullhypothese dass
der Anteil 6,5 Prozent
entspricht. Alternative Hypothese ist, dass
die proportionale Wirkung nicht 5,56 Prozent entspricht. p-Wert ist 0,008. Was heißt das? Ja, sei niedrig, nicht cool. Also lehnen wir die
Nullhypothese ab und
kommen zu dem Schluss, dass
der Effekt der Werbung, Er ist nicht 6,6,5 Prozent, aber es ist mehr,
denn wenn Sie
das
Konfidenzintervall von fünfundneunzig Prozent sehen , es heißt 0,7% bis 10%, oder? Sie haben einen
Anteil von 88,7%. Und das 95%
-Konfidenzintervall des Anteils liegt weit vor 6,5,
es beginnt bei 7. Wir können also den Schluss ziehen, dass erhebliche Auswirkungen die Werbung erhebliche Auswirkungen hat, und wir können diese Werbefirma
durchgehen . Fahren wir mit
unserer nächsten Lektion fort.
33. Zwei Probeanteilstest-2p-Test: Lassen Sie uns diese Übung
noch einmal mit Assistant machen. Wir haben also die nummerierten
80 Rindfleischprodukte von Lieferant E, die
wir überprüft haben. 725 sind defekt
oder nicht defekt. Wie viele sind das wirksam? Also, wenn ich eine Subtraktion mache, wäre
es 777802 minus 725 ist 77712 Produkte der Stichprobe des Lieferanten B wurden von 73
ausgewählt. Perfekt. Also wie viel ist
defekt? Eins, 39. Versuchen wir also, unseren Test mit
zwei Anteilen Minitab-Assistenten durchzuführen, da dieser
dann Hypothesentest, Probenstücke, Stuhl,
Probenprozentsatz fehlerhafter Lieferant E, 0 bis 7771 bis 139. Die Person ist defekt von Lieferant E ist weniger
als der Prozentsatz des
Defekts von Lieferant B. Ich werde fortfahren
und auf Okay klicken. Und das verstehe ich. Ja, dieser Prozentsatz an
Defekten oder Lieferanten ist deutlich geringer
als der Prozentsatz an Defekten von Lieferant B. Und wenn ich nach unten scrolle, Ja. Es sagt also den Unterschied aus, dieser Lieferant ist
Lesebereitschaft. Aus dem Test können Sie schließen, dass der prozentuale
Anteil von Lieferant a bei einem Signifikanzniveau von
5% unter Lieferant B
liegt. Wenn Sie
diesen Prozentsatz sehen. Sie können auch
deutlich sehen, dass
wir in der nächsten Woche mit den
nächsten Hypothesentests fortfahren werden . Tun
34. Zwei Probeanteil-Test-2p-Test-Beispiel: Lassen Sie uns nun
das nächste Beispiel verstehen. Dies ist ein Beispiel, bei dem
ein
Betriebsleiter ein Produkt
untersucht, das aus
Rohstoffen von zwei Lieferanten hergestellt wurde, feststellt, ob einer
der Rohstoffe größerer Wahrscheinlichkeit
einen besseren produziert Qualitätsprodukt. So wurden 802 Produkte vom Lieferanten
E 725
beprobt oder perfekt, das
ist nicht defekt. 712 Produkte wurden von
Lieferant B, 573 oder Buffet beprobt. Das heißt, es ist nicht defekt. Wir wollen also Leistung erbringen,
denn wie hoch ist Prozentsatz der
nicht fehlerhaften personenbezogenen Daten? Ja, ich habe zwei Proportionen, Supply Array und Lieferant B. Gehen wir zur main. Ich kann zu Stat, Basic Statistics zwei
Proportionstest gehen. Ich habe meine zusammenfassenden Daten, die Ereignisse von der ersten Leichtigkeit, 725 oder beide handeln aus 802 heraus. Nehmen wir also
725025723712572371. Die Option, mit der sie
sehen, ist, dass es
einen Unterschied gibt , und
lassen Sie uns das herausfinden. Die BVA, die Nullhypothese, besagt also, dass es keinen Unterschied
zwischen dem Anteil gibt. Alternative Hypothese ist, dass es einen Unterschied zwischen den
beiden Proportionen gibt. Als ich mir den p-Wert angesehen habe, der p-Wert Z, um niedrig Null zu sein. Es kommt zu dem Schluss, dass
ich die
Nullhypothese zurückweisen muss. Es gibt einen Unterschied in der Leistung
der beiden Lieferanten. Nun, wenn ich darüber nachdenke,
weil ich von perfekt oder
nicht defekt spreche , ist
Probe eins derzeit zu 90% perfekt und Probe zwei zu 80% perfekt. Also zu dem Schluss, dass Lieferant E ein besserer Lieferant
ist
als Lieferant B. Richtig? Also, vielen Dank. Wir werden in
der nächsten Lektion fortfahren.
35. Verwendung von Excel = eine Sample: Oft verstehen wir den
Test der Hypothese, aber es gibt eine
Herausforderung, die wir haben. Die Herausforderung ist, dass
ich kein MiniTab habe. Kann ich
Hypothesentests nicht auf einfache Weise durchführen,
anstatt eine manuelle Berechnung mit einem
statistischen Rechner durchzuführen. Mach dir keine Sorgen, dass das möglich ist. Ich werde Ihnen zeigen,
wie ich mit
Microsoft Excel
Hypothesentests durchführen kann . Gehe zu Datei. Gehe zu Optionen. Wenn Sie zu Optionen gehen,
gehen Sie zu Add-ins. Wenn Sie auf Add-ins klicken. Lass mich hier klicken. Sie haben eine Option
, die in der Option Verwalten als
Excel-Add-In
bezeichnet wird. Wählen Sie also Excel-Add-In
und klicken Sie auf Los. Klicken Sie auf Analysis ToolPak und stellen Sie sicher, dass dieser
Haken aktiviert ist. Sobald Sie das haben, finden
Sie es
auf Ihrer Registerkarte Daten. Sie haben
Datenanalysen zur Verfügung. Lassen Sie mich darauf klicken, damit Sie verstehen,
was möglich ist. Bei der Datenanalyse. Ich habe eine OR-Korrelation, Kovarianz, deskriptive
Statistik, Histogramm, T-Test, Z-Tests,
Zufallszahlengenerierung, Stichprobenregression
und all diese Dinge. Daher wird es für
Sie sehr einfach , Hypothesentests durchzuführen. Zumindest die Hypothese der kontinuierlichen
Daten auch problemlos über
Microsoft Excel
getestet werden. Ich führe Sie vorerst Schritt für
Schritt durch die Übung. Kehren wir
zur Präsentation zurück. Nehmen wir das erste Problem. Das heißt, ich habe die beschreibenden Statistiken
für die Huntington-Krankheit des Anrufs, den Manager der
Prozesse,
an denen sein Team
arbeitet , um die Lösung des Anrufs in sieben Minuten abzuschließen . Der Kunde
sieht jedoch, dass er lange Zeit in
der Warteschleife gehalten wird, und verbringt daher
mehr als sieben Minuten. Wenn ich mir die
beschreibenden Statistiken ansehe
, werden mir zehn Minuten angezeigt, Median ist sieben, der Durchschnitt ist 7,1. Jetzt würde ich
diese Analyse mit
Microsoft exit durchführen wollen . Also lasst uns anfangen. Ich habe diesen Anwendungsfall in den Projektdaten,
die ich hochgeladen habe, klicke auf ASD, natürlich bringt
es dich an diesen Ort. Jetzt werde ich Ihnen zunächst
beibringen, wie Sie beschreibende Statistiken
mit Microsoft Excel erstellen. Ich klicke auf
Datenanalyse unter der Registerkarte Daten. Ich werde nach
beschreibenden Statistiken suchen. Klicke auf, okay. Mein Eingabebereich reicht von
hier nach unten. Ich habe ausgewählt. Meine Daten sind nach Spalten gruppiert. Das Etikett befindet sich
in der ersten Reihe. Und ich möchte, dass meine Ausgabe in
eine neue Arbeitsmappe aufgenommen wird. Ich möchte zusammenfassende
Statistiken und ich möchte Vertrauensniveau von
mir haben. Ich klicke auf OK. Excel führt einige Berechnungen und bereitet sie darauf vor. Ja. Hier ist mein Output. Ich klicke hier drüben auf Former
, um zu sehen, was die Ausgabe ist. Sie können also sehen, dass Sie Mittelwert, Medianmodus,
Standardabweichung, Kurtosis, Schiefe, Bereich,
Minimum, Maximum,
Summe, Anzahl und Konfidenzniveau sind. All diese Dinge lassen sich leicht mit einem
Klick auf eine Schaltfläche
berechnen. Ich muss nicht
so viele Formeln schreiben. Kehren wir nun
zu unserem Datensatz zurück. Ich möchte die
Hypothesentests machen. Was ist meine Nullhypothese? Wenn die Nullhypothese lautet , dass die ADHS sieben Minuten
entspricht. Alternative Hypothese. Das ADHS beträgt keine sieben Minuten. Es gibt einen anderen
Alpha-Wert, den ich als 5% einrichte. Und damit werde ich die Tests
durchführen, die ich verbinden
werde , ein T-Test mit
einer Stichprobe. Wenn Sie einen T-Test
mit
einer Stichprobe mit Microsoft Excel durchführen , müssen
Sie einen kleinen Trick
befolgen. Der Trick ist, ich
füge hier eine Spalte ein. Und das nenne ich
als Dummy. Weil Microsoft Excel
mit einer Option für einen t-Test mit
zwei Stichproben geliefert wird. Ich habe HD des Anrufs in Minuten und Dummy, wo ich auf Nullen, Nullen
geschrieben habe. Der durchschnittliche Median,
alles für 0 ist jedoch immer 0. Klicken Sie auf Datenanalyse. Ich werde nach unten gehen und
zwei Stichproben-T-Tests
unter der Annahme gleicher Varianz sagen . Ich wähle das aus. Ich klicke auf, okay. Mein Eingabebereich,
einer ist diese Zeile. Mein Eingabebereich reicht
durch diesen Dummy. Mein vermuteter mittlerer
Unterschied beträgt sieben Minuten. Bezeichnung ist in
beiden Alpha-Werten enthalten , die auf fünf Prozent
festgelegt sind. Und ich sage, dass
meine Ausgabe in einer neuen Arbeitsmappe enthalten
sein muss . Ich klicke auf Okay, es macht die Berechnung
und bringt mir die Ausgabe. Sie können sehen, dass die Zahlen als Übung vermittelt
wurden Ich klicke einfach auf das Karma
im Abschnitt Format, damit
die Zahlen sichtbar sind. Ich ändere die Ansicht , weil Dummy
keine Daten hat. steht mir frei, diese Spalte zu löschen. Lassen Sie uns jetzt verstehen
, wonach wir immer suchen? Wir suchen nach diesem
Wert, dem p-Wert. Erinnerst du dich an die Formel? Lass mich meine
Formeln hier rüber bringen. Ja. Was ist die Schlussfolgerung? Das Fazit ist P hoch. Ich lehne die
Nullhypothese nicht ab. Der Abschluss des ADHS
des Anrufs beträgt sieben Monate. Ich lehne die
alternative Hypothese weil mein p-Wert über 0,05
liegt. folgenden Lektionen werde ich weitere Beispiele
aufgreifen. Ich freue mich darauf, dass
Sie diese Serie fortsetzen. Wenn Sie Fragen haben, bitte
ich Sie,
Ihre Fragen in den
Diskussionsbereich unten zu stellen, und ich beantworte sie
gerne. Danke.
36. Korrelationsanalyse: Willkommen zur nächsten Lektion
unserer analysierten Phase
im DMAc-Lebenszyklus eines
Lean Six Sigma-Projekts Manchmal geraten wir in
eine Situation, in wir eine
Korrelationsanalyse durchführen möchten Deshalb dachte ich,
ich sollte
Sie heute eingehend damit befassen, was
Korrelation ist . Was
ist der Unterschied zwischen Korrelation
und Zufall? Wie interpretiere ich Korrelation, wenn ich mir das Streudiagramm
ansehe Welches
Signifikanzniveau kann ich
festlegen , wenn ich meine
Hypothesen teste Pearson-Korrelation,
Spearman-Korrelation, serielle
Punkt-B-Korrelation und wie werden diese Berechnungen online mit einigen
der verfügbaren Tools Lassen Sie uns also anfangen. Was genau ist
Korrelationsanalyse? Korrelationsanalyse ist eine
statistische Technik, die Ihnen Informationen über die Beziehung
zwischen den Variablen gibt. Korrelationsanalyse kann
berechnet werden , um die
Beziehung zwischen Variablen zu untersuchen und zu untersuchen, wie stark die Korrelation durch den Korrelationskoeffizienten bestimmt
wird, der durch den Zahlenbuchstaben r dargestellt wird
, der von
minus eins bis plus eins variiert. Die Korrelationsanalyse kann
somit verwendet werden, um Aussagen über die Stärke und Richtung
der Korrelation zu treffen. Sie möchten beispielsweise herausfinden, ob ein Zusammenhang
zwischen dem Alter, in dem ein Kind
seinen ersten Satz spricht , und dem
späteren Schulerfolg besteht. Dann können Sie die
Korrelationsanalyse verwenden. Wenn wir jetzt mit
Korrelation arbeiten, gibt
es immer eine Herausforderung. Manchmal werden wir mit
Dingen verwechselt, die ein Problem darstellen. Wenn die
Korrelationsanalyse beispielsweise zeigt, dass zwei Merkmale miteinander verwandt
sind, kann im Wesentlichen geprüft
werden, ob eine Variable zur
Vorhersage der anderen Variablen verwendet werden kann. erwähnte Korrelation Bestätigt sich beispielsweise
die im Beispiel erwähnte Korrelation, kann überprüft werden, ob der Schulerfolg
anhand des Alters, in dem das Kind seinen ersten Satz
spricht, vorhergesagt werden
kann , was bedeutet, dass
es eine
lineare Regressionsgleichung gibt Ich habe ein separates Video, in dem erklärt wird, was
eine lineare Regation ist Aber Vorsicht, Korrelation muss keinen kausalen Zusammenhang haben Das bedeutet
, dass jede Korrelation , die entdeckt
werden kann,
vom
Fachexperten genauer untersucht,
aber niemals
sofort inhaltlich interpretiert werden
sollte werden kann,
vom
Fachexperten genauer untersucht , , auch wenn sie sehr offensichtlich ist Sehen wir uns einige Beispiele für Korrelation und Kausalität Wenn die Korrelation zwischen der Verkaufszahl und
dem Preis analysiert wird, wird
eine starke
Korrelation festgestellt Es wäre logisch
anzunehmen, dass die Verkaufszahlen vom Preis
und nicht von der weisen Person
beeinflusst werden . Der Preis passiert
nicht andersherum. Diese Annahme kann jedoch der Grundlage einer
Korrelationsanalyse keineswegs bewiesen werden auf
der Grundlage einer
Korrelationsanalyse keineswegs bewiesen werden. Darüber hinaus kann es vorkommen
, dass die Korrelation zwischen den Variablen x und y durch die Variable
erzeugt wird. Daher werden wir dies
in teilweiser Korrelation
ausführlicher behandeln . Je nachdem,
welche Variable verwendet werden kann, können
Sie jedoch möglicherweise von Anfang an von
einem Kausalzusammenhang sprechen Anfang an von
einem Kausalzusammenhang Schauen wir uns ein
Beispiel an, ob es einen Zusammenhang zwischen dem H und
dem Gehalt Es ist klar, dass das Alter das Gehalt
beeinflusst, nicht umgekehrt. Das Gehalt hat keinen
Einfluss auf das Alter. Nur weil mein
Alter steigt
oder nur weil ich ein höheres Gehalt
habe, oder nur weil ich ein höheres Gehalt
habe heißt
das nicht, dass
ich alt werde. Sonst
würde jeder so wenig
Gehalt wie möglich
verdienen wollen . Das ist einfach Liebe. Interpretiere die Korrelation. Mit Hilfe der
Korrelationsanalyse können
zwei Aussagen getroffen werden. Eine über die Richtung
der Korrelation und eine über die Stärke. Über die lineare Beziehung
der beiden Metriken oder der Variablen
mit normaler Skalierung Die Richtung gibt an, ob die Korrelation
positiv oder negativ ist Ob die Stärke
bestimmt, ob die Korrelation zwischen der
Variablen stark oder schwach ist Wenn ich also sage eine positive Korrelation besteht zwischen beiden
eine positive Korrelation besteht, dann wollen wir damit sagen , dass die größeren Werte der
Variablen x mit den größeren Werten der
Variablen y
einhergehen den größeren Werten der
Variablen y
einhergehen und nicht
umgekehrt Körpergröße und Schuhgröße korrelieren
beispielsweise positiv Der
Korrelationskoeffizient liegt bei 0-1. Das heißt, es ist ein positiver Wert. negative Korrelation
besteht dagegen , wenn ein größerer
Wert der Variablen x vom
kleineren Wert der Variablen
y begleitet wird und umgekehrt. Der Produktpreis und die Verkaufsmenge korrelieren normalerweise
negativ. Je teurer ein Produkt ist, desto geringer ist die
Verkaufsmenge. In diesem Fall liegt der
Korrelationskoeffizient zwischen
minus eins und Null,
vorausgesetzt, es handelt sich um einen negativen Wert. Es ergibt sich also ein negativer Wert. Wie ermittle ich die
Stärke der Korrelation? Hinsichtlich der Stärke
des Korrelationskoeffizienten r kann
die folgende Tabelle als Richtschnur dienen. Wenn Ihr Wert
zwischen 0,0 und 0,1 liegt, können wir eindeutig sagen
, dass keine Korrelation besteht. Wenn der Wert
zwischen 0,1 und 0,3 liegt, sagen
wir, dass eine geringe
oder geringfügige Korrelation oder eine Korrelation besteht. Wenn der Wert zwischen 0,32 und
0,5 liegt, mittlere Korrelation, wenn der Wert zwischen 0,5 und 0,7 liegt, sagen
wir, dass es eine
hohe Korrelation
oder eine starke Korrelation gibt , und wenn der Wert
zwischen 0,7 und eins liegt, sagen
wir, dass es sich um eine sehr
hohe Korrelation Am Ende dieses Moduls zeige
ich Ihnen, wie Sie
das Korrelations-Kation auch
direkt in einem Online-Modus berechnen das Korrelations-Kation auch
direkt in einem Online-Modus Gehen wir also weiter. Wenn Sie dies online tun, erhalten
Sie
eines der Tools, mit denen wir
die Korrelation analysieren,
ein Streudiagramm, da
sowohl X Y
vom variablen Datentyp
oder metrischen Datentyp sind ,
wie Sie es nennen Genauso wichtig wie grafische Darstellung
des Korrelationskoeffizienten
ist, können
wir ein Streudiagramm verwenden So wie das Alter die X-Achse
immer die Eingabevariable
und die Y-Achse
die Ausgangsvariable, und die Y-Achse
die weil
y gleich der Funktion von x ist. Und ich sehe, dass mit steigendem Alter
auch meine Gehälter steigen Mit dem Streudiagramm
können Sie grob abschätzen ,
ob es eine Korrelation
gibt
und ob es eine lineare oder
eine nichtlineare Korrelation gibt eine nichtlineare Korrelation und ob es irgendwelche Ausreißer
gibt Wenn wir eine Korrelation durchführen, möchten
wir vielleicht auch
unsere Hypothesen testen und die Korrelation
auf
Signifikanz testen Wenn
in der Stichprobe eine Korrelation besteht, muss dennoch geprüft werden, ob genügend Beweise dafür vorliegen, dass
die Korrelation auch in der Grundgesamtheit besteht. Daher stellt sich die Frage, wann der Korrelationskopion
als statistisch signifikant
angesehen wird als statistisch signifikant
angesehen Die Signifikanz der vorhandenen
Korrelation kann mit dem t-Test getestet werden In der Regel wird getestet, ob sich der Korrelationskoeffizient
signifikant von Null unterscheidet Das heißt, es wird eine lineare
Abhängigkeit getestet. In diesem Fall lautet die
Nullhypothese, dass
keine Korrelation zwischen den untersuchten
Variablen besteht. Im Gegensatz dazu geht die
alternative Hypothese davon aus, dass eine Korrelation besteht. Wie bei allen anderen
Hypothesentests wird
das Signifikanzniveau zunächst auf 5% festgelegt. Der Alpha-Wert ist auf 5% festgelegt. Das bedeutet, dass ich mich zu
95% auf die
Analyse verlassen sollte , die ich durchführe. Wenn der berechnete
p-Wert unter 5% liegt, wird
die Nullhypothese zurückgewiesen und die alternative
Hypothese gilt. Wenn der p-Wert unter 5% liegt, davon ausgegangen, dass
eine Beziehung zwischen
x und dem besteht . Die t-Testformel, die wir für Hypothesentests
verwenden, lautet r in die Unterwurzel von n minus zwei geteilt durch die Unterwurzel
von eins minus r im Quadrat. Dabei ist n die Stichprobengröße, r r die ermittelte
Korrelation der Stichprobe und der entsprechende
p-Wert kann einfach im
Korrelationsrechner
berechnet werden. Direktionale und
ungerichtete Hypothese. Mit der Korrelationsanalyse
kann die Hypothese einer
direktionalen oder ungerichteten
Korrelation getestet werden . Was meinen wir mit der Hypothese einer ungerichteten Korrelation? Sie sind nur daran interessiert
zu wissen, ob es eine Beziehung oder eine Korrelation
zwischen zwei Variablen gibt. Zum Beispiel, ob
ein Zusammenhang zwischen
Alter und Gehalt besteht , Sie
aber nicht an der Richtung
der Beziehungen
interessiert sind . Wenn Sie eine Hypothese der direktionalen
Korrelation
aufstellen, interessiert Sie auch die Richtung
der Korrelation. Gibt an, ob
zwischen den Variablen eine positive oder eine negative Korrelation besteht. Ihre alternative Hypothese
ist dann ein Beispiel. Das Alter wirkt sich positiv
auf das Gehalt aus. Worauf Sie achten
müssen , ist, dass
Sie bei einer
Richtungshypothese vom
Ende des Beispiels ausgehen. Sie werden also weitermachen, ob es einen positiven
Einfluss gibt oder nicht? Normalerweise sagen wir also, es gibt keine Korrelation und
es gibt eine Korrelation. Aber hier sagen wir, dass
es keine Korrelation gibt, und die alternative
Hypothese besagt , dass es einen positiven
Einfluss auf den Salat gibt. Gehen wir jetzt
zum nächsten Teil. Das ist Pearsons
Korrelationsanalyse. Mit der
Korrelationsanalyse nach Pearson erhalten
Sie eine Aussage über die lineare Korrelation zwischen
den metrischen Skalenvariablen Für die Berechnung wird die jeweilige Kovarianz
verwendet. Die Kovarianz ergibt
einen positiven Wert wenn eine
positive Korrelation
zwischen den Variablen besteht ,
und einen negativen Wert,
wenn eine negative Korrelation
zwischen den Variablen besteht Die Kovarianz wird als COV
berechnet, oder Kovarianz von X wird
anhand der auf dem Bildschirm angegebenen Formel berechnet Mach dir keine Sorgen. Wir müssen es nicht manuell
berechnen. Dann haben wir Systeme und Tools, die
diese Analyse für uns durchführen können. Die Kovarianz ist jedoch
nicht standardisiert und kann Werte zwischen
plus und minus unendlich
annehmen Dies macht es
schwierig, die Stärke
der Beziehung
zwischen den Variablen zu vergleichen Stärke
der Beziehung
zwischen den Variablen zu Aus diesem Grund
ist der
Korrelationskoeffizient auch eine
Produktbewegungskorrelation Und das wird auf andere
Weise berechnet. Der Korrelationskoeffizient wird durch Normalisierung
der Kovarianz
erhalten Für diese Normalisierung wird
die Varianz der beiden Variablen wie
folgt Der
Korrelationskoeffizient nach Pearson kann nun Werte von
minus eins bis plus eins annehmen und kann Der Wert minus eins
bedeutet, dass
ein vollständig positiver
linearer Zusammenhang besteht , und je größer der Wert minus eins ist, bedeutet, dass
ein vollständig negativer
Zusammenhang besteht ein vollständig negativer Je mehr und desto weniger. Mit dem Wert Null gibt es keine lineare Beziehung. Die Variable
korreliert nicht mit beiden. Die Korrelation von plus eins wird ungefähr so
aussehen, was nur theoretisch
möglich ist Korrelation von 0,7 plus
sieht ungefähr so aus, sie weist
eine positive Seite auf und die meisten
Punkte befinden sich näher an der Achse
des Regressionslichts Eine Korrelation von plus
drei wird verstreut sein, aber sie geht in eine
positive Richtung Wenn Sie eine Korrelation durchführen,
haben Sie eine Korrelation von -0,7 Sie sind alle gestreut und
bewegen sich nach unten Wenn also der Wert von x steigt, nimmt der Wert von y ab,
und die meisten Punkte
sind auf der Regressionsseite
verstreut Wir erhalten den
Korrelationswert Null auf mehrere Arten, entweder sind die Punkte
vollständig verstreut, oder Sie erhalten
perfekte Linien wie diese oder so, was wiederum nicht der Fall
wäre, was
bedeutet, dass Sie zur Interpretation der Variablen eine andere Analyse durchführen
müssen zur Interpretation der Variablen Nun kann endlich die Stärke
der Beziehung interpretiert
werden, und dies kann durch die
folgende Geschichte
veranschaulicht werden . Die Stärke der Korrelation. Wenn es 0-0 0,1 ist, liegt
keine Korrelation Wenn es 0,1 bis 0,3 ist, besteht eine geringe Korrelation 0,3 bis 0,5 mittlere Korrelation,
0,52 0,7, sehr hohe Korrelation, Entschuldigung,
hohe Korrelation, und 0,7 zu eins ist eine sehr
hohe Um vorab zu überprüfen, ob ein
linearer Zusammenhang besteht, sollten
Streudiagramme in Betracht gezogen
werden Auf diese Weise kann der
jeweilige Zusammenhang zwischen den Variablen
auch visuell überprüft werden Die Korrelation nach Pearson
ist nur dann sinnvoll und zielführend, wenn Demor-Beziehungen vorliegen Die Korrelation nach Pearson
hat bestimmte Vorteile,
die Sie im Hinterkopf behalten sollten Bei PSM müssen
die Variablen, wann immer
Sie diese Methode verwenden, normalverteilt sein, und es muss eine
lineare Beziehung zwischen den Die Normalverteilung
kann entweder
analytisch oder grafisch
anhand des QQ-Diagramms getestet werden. Ich werde
Ihnen zeigen
, Ich werde
Ihnen zeigen
, Ob die Variablen
eine lineare Korrelation aufweisen, lässt sich am besten
mit dem Streudiagramm überprüfen Wenn die Bedingungen nicht erfüllt sind, Spearman-Korrelation verwendet werden Ich hoffe, Sie haben es
bis hier verstanden, und lassen Sie uns
weiter lernen. Lass uns weitermachen. Was tun wir, wenn
meine Daten nicht
normal sind und ich
eine Korrelationsanalyse durchführen möchte In diesem Fall verwenden wir die Rangkorrelation nach
Spearman. Die
Rangkorrelationsanalyse von Spearman wird verwendet, um
die Beziehung
zwischen zwei Variablen zu berechnen die Beziehung
zwischen zwei Variablen , die ein
ordinales Maß haben Wenn Sie variable Daten haben, oder ich kann sagen, kontinuierliche Daten, verwenden
wir eine normale
Korrelationsanalyse
wie die Korrekturanalyse von Pearson Wenn meine Daten jedoch ordinal
oder nicht parametrisch sind, kann ich mit der
Korrelationsanalyse von
Spearman fortfahren Dieses Verfahren wird
daher verwendet, wenn die Voraussetzung der
Korrelationsanalyse, d. h. die parametrischen
Verfahren, nicht
erfüllt sind oder wenn keine metrischen Daten oder
kontinuierlichen Variablen vorliegen und die Daten und In diesem Zusammenhang
bieten wir an, es als
Spearman-Korrelation
oder Spearmansche Zeile zu bezeichnen Spearman-Korrelation
oder Spearmansche Zeile Die Rangkorrelation nach Spearman ist gemeint. Die Frage kann dann so behandelt
werden, als Rangkorrelation von
Spearman der des Korrelationskoeffizienten von
Percy ähnlich von
Percy Beispiele. Besteht eine Korrelation zwischen zwei Variablen
oder Merkmalen? Besteht beispielsweise ein Zusammenhang zwischen Alter und
Religiosität in der französischen Bevölkerung? Die Berechnung der
Rangkorrelation basiert auf dem Rankingsystem
der Datenreihe Das bedeutet, dass die
Rangmaßvariablen nicht bei der Berechnung verwendet, sondern in Ränge umgewandelt werden. Der Test wird dann
anhand der Ränge durchgeführt. Für den
Rangkorrelationskoeffizienten p sind
die Werte zwischen minus
eins und eins positiv. Wenn ein Wert
kleiner als Null ist, ist
p kleiner als Null, es besteht eine negative
lineare Beziehung. Wenn der Wert
größer als Null ist, liegt eine positive
lineare Beziehung vor. Wenn der Wert Null oder nahe
Null ist, z. B. 0,1 bis -0,1, können
wir sagen, dass
keine Beziehung
zwischen den Variablen besteht keine Beziehung
zwischen den Variablen Wie beim
Korrelationskoeffizienten für Sparen die Stärke der Korrelation kann Wenn es also 0-0 0,1 ist, liegt keine Korrelation vor. Wenn es 0,12 0,3 ist, besteht eine geringe Wenn es 0,3 bis 0,5
gibt, liegt eine mittlere Retation Es besteht eine hohe
Korrelation von 0,5 bis 0,7 und eine
sehr hohe Korrelation von 0,7 zu eins Bei negativen Werten sprechen
wir von geringer
negativer Korrelation, hoher negativer Korrelation usw. Es gibt eine andere Art
von Korrelation, die als
biserielle Punktkorrelation bezeichnet wird . Die biserielle
Punktkorrelation wird verwendet , wenn eine der Variablen
dichotom ist Beispiel: Haben Sie
studiert oder nicht studiert? Die andere ist eine metrische
Variable wie das Gehalt. In diesem Fall verwenden wir einen Punkt
nach serieller Korrelation. Die Korrelation eines Punktes
durch serielle Korrelation entspricht der berechneten Korrelation nach
Pearson Um sie zu berechnen, wird einer
der beiden Ausdrücke
des dichotomen Werts als Null
kodiert Der andere ist als Eins kodiert. Berechnete
Korrelationsanalyse zeigen wir Ihnen mit Excel oder anderen Tools , die kostenlos erhältlich sind. Ich werde Ihnen die
Berechnung nach einiger Zeit zeigen, aber lassen Sie uns zuerst den Fall untersuchen. Ein Student möchte wissen, ob
es einen Zusammenhang zwischen Größe und dem Gewicht der Teilnehmer
des Statistikkurses Zu diesem Zweck zog der
Student eine Stichprobe, die im Folgenden verteilt ist Ich habe also die Körpergröße der Menschen, ich habe die
Gewichte der Menschen. Um die
lineare Beziehung
mithilfe der
Korrelationsanalyse zu analysieren , können
Sie die
Korrelation mit
Excel oder den anderen
verfügbaren Tools online berechnen . Kopieren Sie zunächst die Tabelle in
den Statistikrechner. Klicken Sie dann auf Korrelation
und wählen Sie sie aus. Und schließlich
können Sie die
folgenden Beilagen erhalten. Also lass es uns online machen. Also bin ich zu data tab.net gekommen. Es ist ein
statistischer Online-Rechner. Die Daten hier haben eine hundertprozentige Datensicherheit, da die
Berechnungen in Ihrem Browser und die Daten in Ihren Browser-Cookies eingefügt und gespeichert werden. Die Daten sind zu 100%, und das ist der Grund, warum die
Berechnung sehr schnell funktioniert. Die Daten benötigen daher
keinen großen
Server und damit Sie. Ich habe also das Körpergewicht, ich habe das Gewicht
und ich habe das Alter. Also ich möchte es verstehen. Also wenn ich runtergehe, lasse
ich mich kortieren. Ich möchte wissen, ob
es einen Zusammenhang zwischen Körpergröße
und Körpergewicht Welche Art von Korrelation möchte ich? Lass uns zuerst mit Pearsons gehen.
Es besteht eine Korrelation Es besteht eine positive Korrelation. Das Signifikanzniveau ist festgelegt. 5% Wir können testen, ob Annahmen vorliegen, und es führt sofort
die Analyse durch. Es macht das QQ-Diagramm für mich. Es zeichnet das Histogramm und zeigt
die Ergebnisse, richtig? Wir können also sagen, dass die Daten
mehr oder weniger
normalverteilt sind Ich kann das kopieren,
indem ich auf PNG herunterladen klicke, und die Datei wird kopiert. Und du wirst es auf diese Weise
sehen können. Lassen Sie mich jetzt diesen Tumba schließen, damit er
die Annahmen überprüft hat Die Zusammenfassung in Versen, das Ergebnis der
Korrelation nach Pearson , zeigte, dass es eine sehr hohe positive Korrelation zwischen Körpergewicht,
Größe und Gewicht Die Ergebnisse zeigten, dass die Beziehung zwischen
Körpergewicht, Größe und Gewicht
bei einem
positiven R-Wert statistisch signifikant R ist 0,86 und der
p-Wert ist 0,01. 001. Wenn Sie sich also die
Stärke der Korrelation ansehen und der Wert größer
als 0,7 und eins ist, sagen
wir, dass es sich um eine sehr
hohe Korrelation handelt
und es sich um ein positives Dekor handelt. Wenn ich
Hypothesen teste, gibt es keine oder eine
negative Korrelation zwischen Körpergröße und Gewicht. Es besteht eine positive Korrelation zwischen Körpergröße und Gewicht. Wie viele Fälle
haben wir zehn Fälle. Der R-Wert ist 0,86 und der p-Wert ist 0,001, was weniger als 0,5 ist Daher lehnen wir die Hypothese ab, dass es keine Korrelation
gibt, und es
gilt die alternative Hypothese, dass eine positive Korrelation
zwischen
Körpergröße und Körpergewicht
besteht zwischen
Körpergröße und Körpergewicht Der Vorteil, einen
Datenentwurf zu haben, besteht darin, dass Sie
eine KI-Interpretation haben. Diese Tabelle fasst
die Ergebnisse
der Analyse von Körpergröße und Körpergewicht zusammen und zeigt den
Korrelationskoeffizienten r und P va Der Wert des
Korrelationskoeffizienten gibt
die Stärke und Richtung der
Beziehung zwischen der Variablen
Größe und Gewicht an, und der
Koeffizientenwert beträgt 0,86, was auf
eine sehr hohe positive
Korrelation hindeutet eine sehr hohe positive Dies bedeutet,
dass im Allgemeinen zunehmender Körpergröße auch
das Gewicht
zunimmt und umgekehrt. Der P-Wert. Der
p-Wert geht hier davon aus, dass die verfügbaren Daten ausreichende Beweise liefern, um die Nullhypothese
zurückzuweisen. In diesem Fall wurde die
einseitige Hypothese getestet, und die Nullhypothese besagt
, dass
keine oder eine negative Korrelation zwischen der Größe und dem
Gewicht in der Population besteht. In den meisten Fällen liegt der
p-Wert unter 0,05.
Wir gehen davon aus, dass eine
statistische Signifikanz besteht In unserem Fall beträgt der
p-Wert 0,001, was offensichtlich
weniger als 0,5 ist Die Nullhypothese wird zurückgewiesen, und das Ergebnis der
Pearson-Korrelation zeigt, dass
eine
positive Korrelation zwischen
Körpergröße und Körpergewicht statistisch signifikant ist eine
positive Korrelation zwischen
Körpergröße und Körpergewicht statistisch positive Korrelation zwischen
Körpergröße und Körpergewicht Das Ergebnis der
Korrelation nach Pearson zeigt also , dass
eine sehr positive Korrelation
zwischen Körpergröße und Gewicht besteht eine sehr positive Korrelation
zwischen Körpergröße und Gewicht Diese Korrelation wird durch eine
statistisch signifikante
positive Korrelation zwischen dem
R-Wert 0,86 und dem
P-Wert von 0,05 gespeichert statistisch signifikante
positive Korrelation zwischen dem
R-Wert 0,86 und dem
P-Wert von 0,05 Jetzt gibt es ein Streudiagramm das Ich kann hier drüben klicken und meine Regressionslinie
abrufen. Ich kann meine Achse ändern, wenn ich nicht bei Null beginnen
möchte Möchte ich eine Nulllinie Dann ist die Null enthalten, aber ich will sie nicht.
Ich kann es ändern. Wie will ich mein Bild haben, das extra große PDM und so Ich kann auf TNG herunterladen klicken
, um dieses Bild herunterzuladen. Wie ich Ihnen bereits sagte, können
wir jetzt auch
die Kovarianzberechnung durchführen die Kovarianzberechnung Wenn ich mir also
Körpergröße und Körpergewicht ansehe, ist
die Kovarianz 1,29 Es bedeutet also, dass es eine
Beziehung gibt. So
machen Sie die Berechnung also. Nun, für den
Point-by-Serialrechner haben
wir vielleicht eine andere Art von Daten, die wir analysieren
möchten Hat die Änderung des Gehalts .
Hat die Änderung des Gehalts
etwas mit dem Geschlecht zu
tun? In diesem Fall würde
ich dann den metrischen Wert als
Gehalt und die nominale
Variable als Geschlecht auswählen Gehalt und die nominale
Variable als Geschlecht und dann meine Berechnung
durchführen. Es würde den Mann auf
Null und die Frau auf eins setzen. Boxplot, aus dem hervorgeht, dass ja, Männer
im Vergleich zu Frauen tendenziell
ein höheres Gehalt haben . Wenn also ein Student wissen
möchte, ob es einen Zusammenhang
zwischen einem erhöhten S gibt, haben
wir diese Analyse durchgeführt Die Hypothese: Wenn man von einer normalen Hypothese
ausgehen kann, besteht kein Zusammenhang zwischen Körpergröße und Körpergewicht Es besteht ein Zusammenhang
zwischen Körpergröße und Gewicht, aber ich hatte in meinem Test eine
Richtungshypothese aufgestellt. Der P-Wert ist dieser, und wir haben gesehen, wie wir die Ausgabe
erzeugen können. Zunächst erhalten Sie die Null
- und die Alternativhypothese. Die Nullhypothese besagt , dass es keine Korrelation
zwischen Größe und Gewicht gibt, und dann haben wir die
alternative Hypothese , die das Gegenteil verhindert Wenn Sie auf U-Boot-Vögel klicken, erhalten
Sie die Interpretation,
die wir gerade Wir können weitermachen und
tatsächlich haben wir
die direktionale oder einseitige
Korrelationshypothese ausprobiert die direktionale oder einseitige
Korrelationshypothese Und in Excel und anderen Tools, die Ihnen bei der Berechnung helfen
können. Also haben wir gerade die Tests durchgeführt und festgestellt
, dass es keine
oder eine negative Korrelation zwischen dem Körpergen gibt
und dass es eine
positive Korrelation zwischen der Körpergröße gibt. Und als wir das gesehen haben, haben wir festgestellt
, dass es eine positive, sehr starke positive
Korrelation gibt, weshalb der p-Wert unter
0,01 lag In diesem Fall müssen Sie zunächst
überprüfen, ob die Korrelation in allen Richtungen
der Alternativhypothese besteht, d.
h. Größe und Gewicht
sind positiv korreliert, und in diesem Fall wird der
p-Wert durch zwei geteilt Daher wird nur eine einseitige
Verteilung berücksichtigt. Dieses Tool kümmert sich jedoch diese beiden Schritte
und die Zusammenfassung in Versen wird so wiedergegeben, wie wir es gesehen haben. Wir stellen fest, dass eine
positive Korrelation zwischen der Größe und dem Gewicht des Datensatzes an
der Stichprobe besteht. Daher können wir sagen, dass eine
positiv korrelierte Signifikanz besteht, und wir können feststellen, dass zwischen den
Variablen Körpergröße und Körpergröße eine sehr positive
Korrelation besteht Somit besteht eine sehr hohe
positive Korrelation zwischen der
Stichprobenhöhe und dem Damit schließen wir unsere Korrelationsanalyse ab und wir sehen uns
im nächsten Kurs.
37. Pearsons Korrelationsanalyse-Konzept: Lassen Sie uns unsere
Korrelationsreise fortsetzen. Ich werde heute über
Pearsons Korrelation berichten. Die
Korrelationsanalyse von Pearson ist eine Untersuchung der Beziehung
zwischen zwei Variablen Zum Beispiel ist es eine Korrelation zwischen dem Alter und dem Gehalt einer
Person Bei beiden handelt es sich um
kontinuierliche Variablen, weshalb das Diagramm verstreut sein
wird. also das Gehalt mit zunehmendem Alter der
Person Steigt also das Gehalt mit zunehmendem Alter der
Person? Nun müssen Sie sich daran erinnern, dass
y eine Funktion von x ist, sodass Ihre Y-Achse das Ergebnis
hat und die X-Achse
die unabhängige Variable hat. Genauer gesagt können wir
den
Korrelationskoeffizienten von Pearson verwenden , um
die lineare Beziehung
zwischen zwei Variablen zu messen die lineare Beziehung
zwischen zwei Variablen Wenn die Beziehung nicht linear
ist, diese Korrelationsgleichung
nicht von Nutzen. Ich denke, Sie hätten
bemerkt, dass ich meinen AR für
diese Aufnahme
geändert habe. Wenn es dir gefallen hat, gib einfach einen Daumen hoch in den
Kommentarbereich Lassen Sie uns weitermachen, die Stärke und die Richtung
der Korrelation Mit der Korrelationsanalyse können
wir feststellen, wie stark die Beziehung ist und in welche Richtung
die Korrelation geht. Wir können die Stärke und Richtung
der Korrelation
am
Korrelationskoeffizienten R nach Pearson ablesen , dessen Wert von
minus eins bis plus eins variiert Die Stärke der Korrelation, die Stärke der Korrelation, das kann
man in der Tabelle ablesen Der R-Wert liegt zwischen Null und minus
Eins, was bedeutet, dass
keine Korrelation besteht. Wenn der Betrag des Werts von
r zwischen 0,7 und Eins liegt,
handelt es sich um eine sehr stark korrelierte,
sehr starke Korrelation Wenn die Werte nun positiv sind, ist
sie positiv korreliert, und wenn die Werte negativ sind, ist
sie negativ Nehmen wir also an, der R-Wert
ergibt -0,66. Dann können wir sagen, dass es stark
negativ korreliert ist. Das habe ich also aus dem Buch
der Statistik übernommen .
Lassen Sie uns das eindämmen. Was meinst du mit
Korrelationsrichtung? Eine positive Korrelation
liegt vor, wenn große Werte
einer Variablen mit großen Werten
einer anderen Variablen
verknüpft sind oder wenn eine kleine Änderung
einer Variablen mit einer kleinen
Änderung der anderen Variablen
verbunden ist . Wenn es sich also um eine positive
Korrelation handelt und ein größerer
Wert auf der X-Achse vorhanden ist, entspricht
dies einem
größeren Wert auf der Y-Achse. Und ein kleinerer Wert auf der X-Achse korreliert mit einem kleineren
Wert auf der Y-Achse, wie Sie in
diesen beiden Bildern sehen können Eine positive Korrelation ergibt Beispiele für Körpergröße
und Schuhgröße Dies führt zu einer
positiven Korrelation. Mit zunehmender
Körpergröße nimmt also auch
die Schuhgröße zu. Das Ergebnis ist ein positiver
Korrelationskoeffizient, und r ist größer als Null Nun, haben Sie gesehen, dass dieses
Diagramm einen Fehler enthält? Der Fehler ist, dass die
Schuhgröße das Ergebnis ist und die Körpergröße die
unabhängige Variable, aber wir haben sie mutwillig falsch abgebildet, um
dies zu vermeiden Lassen Sie mich also meine
Kommentare hier platzieren. Was ist falsch im Pow-Graph? Die Frage ist, ob die Größenzunahme
der
Show einer Erhöhung der Körpergröße
der Person führt oder die Zunahme der
Körpergröße der Person Erhöhung der Schuhgröße
dient. Bitte schreiben Sie in die
zehn folgenden Abschnitte. Ja. Denken Sie daran, y ist
eine Funktion von x. Und hier ist y die Körpergröße
der Person und x ist mein Fehler. X ist die Körpergröße der
Person und y ist die Körpergröße. Ich hoffe, jetzt ist klar, was
wir sagen wollen. Also y ist eine Funktion von x. Lassen Sie mich aus dem Buchstaben
ein kleines Y machen
, denn das ist das Projekt Y. X ist
die Körpergröße der Person. Also hier
ist der Fehler , dass wir
es falsch dargestellt haben. Die negative Korrelation
liegt vor, wenn ein großer Wert eine Variable mit
einem kleinen Wert für die andere
Variable
verknüpft ist und umgekehrt. Wenn also die Y-Achse groß ist, ist
der X-Achsenwert klein. Und wenn der X-Achsenwert groß ist, ist
der Y-Achsenwert klein. Dies wird
als negative Korrelation bezeichnet. Die Punkte fließen. Im Gegensatz zum vorherigen , bei dem die Punkte nach oben
flossen. Jetzt
besteht die negative Korrelation zwischen
Produktgröße und Verkaufswert. Dies führt zu einer negativen
Korrelation. Was passiert, wenn
der Preis steigt, das Verkaufsvolumen sinkt. Und wenn der Preis gesenkt wird, neigen
die Leute dazu, mehr Volumen zu kaufen. Das führt zu mehr Verkäufen. Lass mich schreiben, dass es Steigerungen gibt. Sehr gut. Das Ergebnis
ist also eine negative Korrelation, der Koefionswert von
r ist kleiner als Null Je stärker die Korrelation ist, näher rückt
der Wert an minus eins heran Und hier ist die Grafik korrekt. Wenn der Preis steigt, sinken
die Mengen. Wie berechnen wir nun den Korrelationsclient von
Pearson? Das ist eine sehr wichtige
Sache, oder? Der
Korrelationsfaktor nach Pearson wird anhand der
folgenden Gleichung berechnet Dabei ist r der Korrelationskoeffizient nach Pearson. X i ist der
Einzelwert einer Variablen. Zum Beispiel könnte es
das Alter der Person sein. Der X-Balken ist das Durchschnittsalter
des Stichprobendatensatzes. Y ist der individuelle Wert der anderen Variablen oder der Ergebnisvariablen,
und
der Y-Balken ist nichts anderes als das Durchschnittsgehalt
des Stichprobendatensatzes. Hier
sind also X-Balken und Y-Balken jeweils der Mittelwert zweier
Variablen. Das Ganze wird geteilt
durch die Unterwurzel von x eins minus x Balkenquadrat, y eins minus y bar ganzem Quadrat. Wenn ich es also quadriere
und eine Unterwurzel mache, wird sich darum gekümmert Also x eins sind die
einzelnen Werte und y eins sind die
einzelnen Werte der Ergebnisvariablen R ist die Korrelation nach Pearson
und der Mittelwert. In dieser Gleichung können wir sehen,
dass die jeweiligen
Mittelwerte der ersten Variablen von der anderen Variablen subtrahieren In unserem Beispiel haben wir
den Hauptwert
von Alter und Gehalt berechnet den Hauptwert
von Alter und Gehalt Dann subtrahieren wir
den Hauptwert
jedes Alters und Gehalts
vom Mittelwert Dann multiplizieren wir
beide Werte. Wir summieren dann die einzelnen Ergebnisse
der Multiplikation Der Ablauf
des Nenners stellt sicher, dass der
Korrelationskoeffizient immer
zwischen minus eins und plus eins liegt Denken Sie daran, dass Sie nichts davon
manuell berechnen müssen. Derzeit sind diese
Funktionen in
Excel und auf mehreren
Online-Websites verfügbar . Wenn Sie mehrere positive
Werte wünschen, erhalten
wir einen positiven Wert. Und wenn wir
zwei negative Werte multiplizieren, erhalten wir
ebenfalls einen positiven Wert
minus in minus e plus. Alle Werte, die in diesem Bereich
liegen, haben also einen positiven Einfluss auf
den Korrelationskoeion steigendem Alter steigt
das Gehalt, das Gehalt sinkendem Alter sinken
die Gehälter Wenn wir einen positiven
Wert mit einem negativen Wert multiplizieren, erhalten
wir einen negativen Wert,
der minus bis plus minus ist. Die ganze Zeit gibt
es eine Reihe
negativer Einflüsse auf
den Korrelationskoeion Also die Dinge, die in der lila Box
hervorgehoben sind, wenn die Daten dort
runterfallen, dann führt das zu
einer negativen Korrelation Wenn unser
Wert also überwiegend aus zwei grünen Bereichen der beiden
vorherigen Zahlen besteht. Wir erhalten einen positiven
Korrelationskoeffizienten und damit eine
positive Wenn unsere Werte überwiegend
im roten Bereich der Zahlen liegen , erhalten
wir einen negativen
Korrelationskoeffizienten
und somit eine negative Korrelation und somit eine Verteilen sich die Punkte auf
alle vier Bereiche,
positive und
negative Terme, heben
sie sich gegenseitig auf, und es kann sein, dass wir am Ende sehr geringe oder gar keine
Korrelation Das ist also ein sehr
wichtiger Teil
, den Sie verstehen müssen. Stimmt das? Wenn die Punkte insgesamt
verteilt sind, ergibt sich überhaupt keine
Korrelation. Nun, wie signifikant sind Tests von Korrelation und Koeffizient? Im Allgemeinen wird der
Korrelationskoeffizient von
Daten aus einer Stichprobe
berechnet In den meisten Fällen wollen
wir jedoch die Hypothese
über die Population testen Da wir
die Grundgesamtheit nicht untersuchen können ,
nehmen wir eine Stichprobe, und wir nehmen eine Stichprobe, und
durch die Untersuchung der Stichprobe wollen
wir
Rückschlüsse auf die Grundgesamtheit ziehen In diesem Fall, der
Korrelationsanalyse, wollen
wir dann wissen, ob
es eine Korrelation
in der Grundgesamtheit gibt es eine Korrelation
in der Grundgesamtheit Dazu testen wir, ob der
Korrelationskoeffizient in der Stichprobe statistisch signifikant ist und
sich von Null
unterscheidet Wie führen wir nun Hypothesentests durch? Für Pearsons Korrelation? Die Nullhypothese und die Alternativhypothese für die Korrelationen nach
Pearson Die Nullhypothese besagt, dass
es
keine Korrelation gibt und dass sich
der R-Wert daher nicht signifikant von Null
unterscheidet Es besteht keine Beziehung. Die alternative
Hypothese besagt, dass es einen signifikanten
Unterschied oder eine lineare
Korrelation zwischen den Daten gibt. Achtung. Wir testen
immer, ob die Nullhypothese
abgelehnt wird oder nicht. Das ist sehr, sehr wichtig. Ich akzeptiere nie etwas Ähnliches oder wir
arbeiten nie daran. Die Sache ist, wir arbeiten immer daran, die Nullhypothese zu
beweisen oder abzulehnen. Wir versuchen nie, die Alternative zu
beweisen, obwohl unsere Forschung beginnt,
weil es eine Alternative gibt. In unserem Beispiel könnten
wir also
die Frage stellen, wenn es um das Gehalt und das
Alter der Person geht. Gibt es einen Zusammenhang
zwischen Alter und Gehalt für die
deutsche Bevölkerung? Um das herauszufinden, ziehen wir eine
Stichprobe und testen, ob sich
der Korrelationskoeffizient in dieser Stichprobe
signifikant
von Null unterscheidet. Die Nullhypothese lautet dann dass
es in
der deutschen Bevölkerung keine Korrelation zwischen Gehalt und Alter gibt. Die alternative
Hypothese besagt, dass der
deutschen Bevölkerung
ein Zusammenhang zwischen Gehalt in der
deutschen Bevölkerung
ein Zusammenhang zwischen Gehalt
und Alter besteht. Signifikanz und Test. Wenn sich der
Korrelationsfähigkeitstest nach Pearson signifikant
von der
Nullstichprobenerhebung unterscheidet signifikant
von der
Nullstichprobenerhebung unterscheidet, testen
wir ihn mit
der T-Testformel Dabei ist r der
Korrelationskoeffizient
und n der Stichprobenumfang und Auch hier würde ich sagen, dass
es gut ist,
die Formel zu kennen, sich aber nicht darin
zu verlieren Richtig? Ein P-Wert kann
anhand der Teststatistik t berechnet werden, und der p-Wert ist kleiner als das angegebene
Signifikanzniveau, das normalerweise 5% beträgt, dann wird die Nullhypothese
zurückgewiesen, andernfalls nicht. Wir möchten also sicherstellen , dass der p-Wert, wenn
er größer als 0,05 ist, die Nullhypothese nicht zurückweisen Wenn der p-Wert
größer als 0,05 ist, können wir
die Nullhypothese nicht zurückweisen Was sind nun einige Annahmen, die in der Korrelation nach
Pearson enthalten sind Was ist mit den Annahmen
der Korrelation nach Pearson? Hier müssen wir
unterscheiden, ob wir den Korrelationskoeffizienten nach
Pearson berechnen oder ob wir eine Hypothese testen wollen Um den
Korrelationskoeion nach Pearson zu berechnen, nur Metrische Variablen
können beispielsweise das Gewicht, das
Gehalt, der
Stromverbrauch usw. einer Person sein . Kurz gesagt, kontinuierliche Variable. Der
Korrelationsclient nach Pearson sagt
uns dann , wie groß die lineare
Beziehung ist, und gibt es eine
nichtlineare Wir können nicht aus dem Korrelationskoion von
Pearson ablesen. Das ist also eine lineare Korrelation, und wenn Ihre Daten auf diese Weise berechnet werden
oder auftauchen,
dann tendieren wir dazu, weiterzumachen In diesem Fall
gibt es also keine Korrelation. Wenn wir jedoch testen
wollen, ob der
Korrelationskoeffizient von Pearson in der Stichprobe
signifikant
von Null unterscheidet, wollen
wir die
Hypothese testen, dass die beiden Variablen ebenfalls
normalverteilt sind Weil Sie
die Korrelation
nach Pearson nicht auf Daten testen können , die nicht dem Normalwert entsprechen In diesem Fall können die berechneten
Teststatistiken t und der p-Wert nicht zuverlässig interpretiert
werden Wenn die Annahme nicht getroffen wird, wird die
Rangkorrelation nach
Pearson verwendet Das bedeutet, dass
ich
für nicht normale Daten die
Rangkorrelation nach Pearson verwenden werde Wie berechne ich die Korrelation nach
Pearson online mit Excel
und anderen Tools Ich werde
es Ihnen in Kürze zeigen.
38. Punkt-Biserial-Korrelation: Lassen Sie uns nun etwas über die
biserielle Punktkorrelation lernen. Ich werde die Theorie
und das Beispiel erläutern und erläutern, wie wir das mit
einem Online-Rechner
praktisch umsetzen können wir das mit
einem Online-Rechner
praktisch .
Bleiben Sie in Verbindung. Was genau ist eine
biserielle Punktkorrelation? Hast du schon einmal davon gehört oder dein Gesicht hat sich in
etwa so verändert? Wir hören meistens von linearer Regression,
logistischer Wenn wir etwas über Korrelation lernen, denken
wir an
einfache Korrelation,
positive Korrelation, negative Korrelation Und wann immer wir Korrelation
machen, denken
wir nur an Variablen,
kontinuierliche Variablen sowohl auf der X- als auch auf der Y-Achse. Lassen Sie uns also verstehen, was
Punkt bei serieller Korrelation ist. Es handelt sich um einen Spezialfall der Korrelation nach
Pearson, und es untersucht die
Beziehung zwischen einer dikotonmen Variablen und einer metrischen Variablen Okay. Die Regel für die
Korrelation lautet, dass Ihre beiden Variablen
kontinuierlich oder metrisch sein sollten. Aber mit der
Punkt-für-Seriell-Korrelation kann
ich sogar nach einer
dichotymen Variablen suchen, die ja oder nein sein können Lassen Sie uns das Beispiel einer dikotonösen Variablen verstehen
. Eine dikotyme Variable ist eine
Variable mit zwei Werten Geschlecht (männlich und weiblich) und Raucherstatus (Raucher, Nichtraucher Metrische Variablen
sind
dagegen das Gewicht der Person, das Gehalt
der Person, der Stromverbrauch usw. Wenn wir also eine
dichotonme Variable
und eine metrische Variable haben , wollen
wir wissen, ob es eine Beziehung
gibt Wir können die punktuelle serielle Korrelation verwenden. Lassen Sie uns also
die Definition davon verstehen. punktuelle serielle Korrelation ist eine besondere Art
der Korrelation und untersucht die
Beziehung zwischen einer dichotyen Variablen
und einer metrischen Variablen Dichotonome Variablen sind
Variablen mit zwei Werten, und metrische Variablen sind
kontinuierliche Variablen mit unendlichen Werten,
wie Größe, Gewicht, Gehalt, Stromverbrauch usw. und metrische Variablen sind
kontinuierliche Variablen
mit unendlichen Werten,
wie Größe, Gewicht, Gehalt, Stromverbrauch usw. Wie genau wird der Punkt durch Es verwendet das Konzept der
Pearson-Korrelation, aber in der
Pearson-Korrelation haben
wir auch eine Variable, die nominaler Natur ist Nehmen wir zum Beispiel an, Sie möchten
den Zusammenhang zwischen der Anzahl
der
in einem Test unternommenen Stunden
und den Ergebnissen untersuchen den Zusammenhang zwischen der Anzahl
der
in einem Test unternommenen Stunden ,
d. h. ob die Person
bestanden oder nicht bestanden hat Hier kann ich also sehen, wie
viele Stunden die Person dem Lernen
verbracht hat und
ob sie bestanden oder nicht bestanden hat? Wir haben Daten für
die Stichprobe von 20 Studierenden gesammelt. 12 Studierende haben bestanden, acht Studierende sind durchgefallen. Wir haben die
Anzahl der Stunden für
jeden Schüler,
der an dem Test teilgenommen hat, aufgezeichnet und dem Schüler, der den Test bestanden hat, eine Punktzahl
von eins und dem Schüler, der den Test nicht
bestanden hat, eine Punktzahl von Null zugewiesen und dem Schüler, der den Test nicht
bestanden hat, eine Punktzahl von Null . Jetzt können wir entweder
die Pearson-Korrelation zwischen
der Zeit und
den Testergebnissen berechnen die Pearson-Korrelation zwischen
der Zeit und
den oder wir können die Gleichung für
den
Punkt anhand der CDN-Korrelation verwenden Gleichung für
den
Punkt anhand der CDN-Korrelation Jetzt können wir entweder
die Pearson-Korrelation zwischen
Zeit und Testergebnissen
mit der Gleichung berechnen die Pearson-Korrelation zwischen
Zeit und Testergebnissen
mit der Zeit und Testergebnissen
mit Nun, hier ist x y der Mittelwert der
Personen, die durchgefallen sind, und X eins ist der Mittelwert der
Personen, die bestanden haben N steht für die
Gesamtzahl der Beobachtungen. N eins steht für die Anzahl
der Personen, die bestanden haben, n zwei steht für die Anzahl
der Personen, die durchgefallen sind. Genau wie der
Korrelationskoeffizient nach Pearson, r, ist
Punkt für serielle Korrelation rp. Auch B variiert zwischen
minus eins und plus eins Mit Hilfe von Cefent können
wir zwei Dinge wir So stark ist die
Beziehung. Ist es eine positive Korrelation? Handelt es sich um eine schwache positive
Korrelation und in welche Richtung geht
die Korrelation? Handelt es sich um eine positive Korrelation oder um eine negative Korrelation? Die Stärke der Korrelation
kann in der Tabelle abgelesen werden. Liegt der Wert zwischen
0,0 und weniger als 0,1, liegt
keine Korrelation vor. Wenn der Wert zwischen
0,1 und weniger als 0,3 liegt, liegt
eine geringe Korrelation vor. Der Wert liegt zwischen
0,3 und 0,5, es besteht eine mittlere
Korrelation von 0,52 bis 0,7, eine hohe Korrelation von 0,7 zu einer,
sehr hohen Korrelation Wenn der Wert zwischen
Null und minus Eins liegt, sprechen wir von einer
negativen Korrelation Wenn der Koeffizient zwischen
minus eins und kleiner als Null liegt, handelt es sich um eine negative Korrelation, daher
besteht eine negative Beziehung zwischen der Variablen Wenn der Wert zwischen
Null und plus eins liegt,
handelt es sich um eine positive Korrelation Somit
besteht eine positive Beziehung zwischen der Variablen, und wenn das Ergebnis nahe Null
liegt, sagen
wir, dass keine Korrelation besteht. Der
Korrelationskoeffizient wird normalerweise
anhand der Daten aus der
Stichprobe berechnet Wir möchten jedoch häufig Hypothesen über
die
Grundgesamtheit testen Wir wollen eine
Hypothese über
die Population testen , weil wir die Population
nicht untersuchen können, wir verwenden eine Stichprobenmethode. Wir berechnen den
Korrelationsgrad der Stichprobendaten. Jetzt können wir testen, ob sich der Korrelationskoeffizient
signifikant
von Null unterscheidet signifikant Die Nullhypothese besagt, dass sich der Korrelationskoeffizient nicht signifikant unterscheidet Es besteht keine Beziehung. Eine alternative Hypothese besagt, dass die Korrelationskohäsion
signifikant von Null abweicht. Es besteht eine Beziehung. Wenn wir also den Punkt
durch serielle Korrelation berechnen, erhalten
wir denselben
p-Wert wie den T-Test für unabhängige
Stichproben für dieselben Daten. Unabhängig davon, ob wir die
Korrelationshypothese mit einem Punkt durch serielle Korrelation oder eine Differenzhypothese
des T-Tests testen, erhalten
wir den gleichen p-Wert. Was ist mit den Annahmen
, die wir
berücksichtigen müssen, wenn wir einen
Punkt mit serieller Korrelation ermitteln? Hier müssen wir unterscheiden,
ob wir
nur den Korrelationskoeffizienten berechnen wollen
oder ob wir auch die Hypothese
testen wollen Um den
Korrelationskorenten zu berechnen, nur eine metrische Variable und
eine dichotome müssen
nur eine metrische Variable und
eine dichotome Variable vorhanden sein. Wenn Sie jedoch testen
möchten, ob der Korrelationskoeffizient signifikant von Null
unterscheidet, eine metrische Ist dies nicht gegeben, die berechneten
Teststatistiken oder der p-Wert nicht zuverlässig
interpretiert werden Wir können
Online-Rechner wie die Registerkarte „Daten“ verwenden, die Ihnen bei
der Analyse helfen können und auf die
ich jetzt eingehen werde Wir sind auf Datenfass. Ich
habe einige Daten in Bezug auf die Anzahl
unserer Studientestergebnisse eingegeben Null
und Eins
als bestanden und nicht
bestanden in Null und Eins umgerechnet . Ich kann meine Daten mit
dieser Schaltfläche importieren und damit
die Tabelle löschen. Sie haben Einstellungen, mit denen Sie entscheiden können,
welche Art von Einstellungen Sie für Grafiken verwenden
möchten.
Gehen wir jetzt runter. Ich korreliere,
und ich habe Optionen. Hier sind meine nominale Variable
die Testergebnisse. Meine metrische Variable
ist unser strded. Ich möchte
Pearsons Pfannen und Konvolu berechnen. Vorerst
behalte ich es einfach als Pearsons. Meine nominale Variable
sind Testergebnisse Sobald ich die nominale
Variable als Testergebnisse ausgewählt habe, konnte ich dies
als
serielle Punkt-Pi-Korrelation identifizieren als
serielle Punkt-Pi-Korrelation Die Hypothese besagt, dass es keine Korrelation zwischen unseren
Studien- und Testergebnissen gibt. Die alternative Hypothese
besagt, dass
ein Zusammenhang
zwischen der Anzahl der untersuchten Stunden und
den Testergebnissen besteht. Der Punkt, an dem die serielle Korrelation fehlschlägt, nimmt den
Wert Null an, Ps nimmt den Wert Eins an. Der Wert für die serielle
Punktkorrelation beträgt 0,31 Freiheitsgrade, r 18 t
ist 0,14, der p-Wert ist 1,79 Ich habe den Boxplot
hier drüben , der besagt, dass mein Boxplot für die ehemaligen 50% der Teilnehmer
lernen zwischen
8,5 und 19,25 Stunden, was zu einem erfolgreichen Studium geführt
hat Leute, die durchgefallen sind,
lernen 7-13 Stunden, richtig? Ich kann es sogar herunterladen,
indem ich auf den
PNG-Download-Button Und Sie werden sehen, dass
ich dazu in der Lage bin. Nun, wie funktioniert die Berechnung für die
serielle Korrelation von Punkt B? Wenn Sie den Punkt
durch serielle Korrelation berechnen, wählen Sie eine metrische Variable und eine nominale Variable
mit zwei Werten. Bevor ich darauf eingehe, möchte ich
eine Zusammenfassung in Worten zusammenfassen. Die serielle
Korrelation nach Punkt B wurde durchgeführt, um den
Zusammenhang zwischen
unseren Studien und den Testergebnissen zu
bestimmen . Es besteht eine positive Korrelation zwischen unserer Studie
und dem Testergebnis, die nicht signifikant und
statistisch signifikant war, da der p-Wert größer als 0,05
ist Wenn ich mehr Daten wie diesen hätte, bei denen ich
mehrere Werte verwende, um Männer und
Frauen gleich Null und Eins zu bestimmen, und dann hätte es berechnet Es heißt also, gibt es einen Zusammenhang zwischen dem
Gehalt und dem Geschlecht? Und wir können sehr
deutlich sehen, dass ja, Männer
im Vergleich zu Frauen ein
deutlich höheres Gehalt haben . Wenn Sie jedoch den p-Wert sehen, er sehr nahe bei 0,05, aber er liegt bei 0,07 Wir können
die Nullhypothese also nicht zurückweisen und
sagen, dass dies möglicherweise auf den Ding-Fehler
der Stichprobe zurückzuführen ist . O
39. Logistische Regression: Willkommen zur nächsten Lektion über logistische
Regression. Lassen Sie uns
das Theoriebeispiel verstehen und wie wir es interpretieren Wann verwenden wir
logistische Vorschriften? Nehmen wir ein Beispiel. Wo auch immer wir
überprüfen müssen, ob es
ein alter Mensch ist , der an Krebs erkranken
wird, oder ob es ein Mann oder eine Frau ist, der
stärker erkrankt? Ist es ein Raucher, der die Krankheit
verursacht? Wenn ich nach mehreren Variablen
suchen möchte, die mich infizieren können
, und mir sagen ob die Krankheit möglich ist, wie
hoch ist dann die Wahrscheinlichkeit
, an einer Krankheit zu Lassen Sie uns also tiefer eintauchen. Was genau ist Regression? Eine Regressionsanalyse
ist eine Methode zur
Modellierung von Beziehungen
zwischen Variablen Sie ermöglicht es, auf der
Grundlage
einer oder mehrerer anderer Variablen auf eine Variable zu schließen oder vorherzusagen ,
ob
der Kunde glücklich oder traurig
ist ,
ob
der Kunde glücklich oder Ich versuche also
anhand der
Qualifikation der Person, der dafür benötigten Zeit oder des Alters zu überprüfen,
ob dies möglich anhand der
Qualifikation der Person, der dafür benötigten Zeit oder des Alters zu überprüfen, ob dies Welcher
Faktor beeinflusst es? Die Variable, die
wir ableiten oder
vorhersagen möchten, wird
als abhängige Variable
oder Kriterium bezeichnet ,
und die Variablen, die wir für
die
Vorhersage verwenden , werden als
unabhängige Variablen
oder Prädiktoren bezeichnet unabhängige Variablen
oder Prädiktoren Was ist der Unterschied zwischen linearer Regression und
logistischer Regulation Bei einer linearen Regelung
ist
die abhängige Variable eine metrische Beispiel: Gehalt, Strom,
Verbrauch usw. Das bedeutet, dass es sich um eine
kontinuierliche Variable handelt. In einer logistischen Regression ist
die abhängige Variable
eine dichotonme Was ist eine dichotonyme Variable? Das bedeutet, dass die Variable nur zwei Werte
hat. Zum Beispiel, ob
eine Person ein
bestimmtes Produkt
kaufen wird oder nicht, oder ob eine Krankheit
vorliegt oder nicht. Wie können logistische
Vorschriften genutzt werden? Mit Hilfe der
logistischen Regulierung können
wir feststellen, was
einen Einfluss darauf hat , ob eine bestimmte Krankheit
vorliegt oder Wir könnten den
Einfluss von Alter,
Geschlecht und Raucherstatus auf
diese bestimmte Krankheit untersuchen ,
Geschlecht und Raucherstatus auf
diese bestimmte Krankheit In diesem Fall steht Null für „ nicht erkrankt“ und „Eins“ für
„erkrankt Die Wahrscheinlichkeit des
Auftretens einer Krankheit oder eines Merkmals ist eins bedeutet, dass das Merkmal vorhanden
ist Unsere Datenbasis sah
ungefähr so aus, wobei meine unabhängigen
Variablen
ein geschlechtsspezifischer Raucherstatus sein könnten , und meine abhängige
Variable könnte
eine Variable sein , die sich aus Nullen und Einsen
zusammensetzt. Wir könnten nun untersuchen welchen Einfluss die
unabhängige Variable hat
und wie sich die Krankheit auf
die Krankheit auswirkt Wenn es einen Einfluss gibt, können
wir vorhersagen, wie wahrscheinlich es ist, dass eine Person an
einer bestimmten Krankheit leidet. Jetzt stellt sich natürlich die
Frage. Warum brauchen wir in diesem Fall eine logistische
Regulierung? Warum funktioniert die lineare
Erholung nicht? Lassen Sie uns also kurz zusammenfassen,
was bei der linearen Regression passiert ist Lassen Sie uns kurz zusammenfassen,
was lineare Regulierung ist. In der linearen Regression ist
dies unsere Regressionsgleichung Y geht zu b1x1 plus
b2x2 plus b3x3 und so weiter und so fort. B und xn plus c. Wir haben
die abhängige Variable y
und wir haben unabhängige
Variablen wie
x eins, und wir haben unabhängige
Variablen wie
x eins x 2x3tx neun. Und wir haben die
Regressionskosion, b eins,
b2b Bn . Wenn Sie
sich nun jedoch diese Variable ansehen, wird
die abhängige Variable mit Null oder Eins
erstellt Und daher wird Ihre Ausgabe ungefähr so
aussehen. Sie haben viele Punkte auf der Nulllinie und viele
Punkte auf der einen Linie, aber Sie haben
keine Daten dazwischen. Unabhängig davon, wie viel
Wert Sie haben, kann
die unabhängige Variable dazu beitragen, dass
die Variable einen Wert von 0-1 Die Ergebnisse sind
immer Null oder Eins. In einer Regressionsgleichung müssen
wir einfach eine
gerade Linie durch
die Punkte ziehen und wir sehen, dass
es viele Fehler gibt Wir können jetzt sehen, dass bei
einer linearen Regression Werte zwischen plus und
minus unendlich auftreten können Und daher funktioniert diese Formel nicht.
Was ist die Lösung? Ziel
der logistischen Regression
ist es jedoch , die
Eintrittswahrscheinlichkeit abzuschätzen Der Wertebereich der Vorhersage
sollte daher zwischen 0 und 1 liegen. Und deshalb wollen wir eine
Linie, die auf
diese Linie passt , und keine
Diagonale wie diese Wir brauchen also eine Funktion
, die nur Werte dazwischen akzeptiert, was zu
einem Wert von Null und Eins führt. Genau das macht die
logistische Funktion. Egal, wo Sie
sich auf der X-Achse befinden, Sie werden sich befinden, Ihre Y-Achse wird entweder Null oder Eins ergeben Zwischen dem Minus und
dem Plus Unendlich liegen
die einzigen Ergebnisse bei 0-1 Und genau das wollen wir. Die Gleichung der
logistischen Abrechnung wird ungefähr so aussehen Die logistische Funktion wird jetzt in der logistischen Erholung verwendet Lassen Sie uns also
die lineare
Erholungsformel noch einmal aufschlüsseln die lineare
Erholungsformel noch einmal Eins plus y ergibt b1x1 plus
b2x2 plus t b x und so weiter. Diese Gleichung wird nun in die Funktion eingefügt. Wenn Sie das tun, ist
es die Potenz von e minus Ihrer größten linearen
Erholungsgleichung, 1/1 plus e mit der Potenz
der Minus-Gleichung Somit
ist die Wahrscheinlichkeit, mit
der die abhängige Variable auftritt, gleich eins Wie
sieht das in unserem Beispiel aus? Wie hoch ist die
Wahrscheinlichkeit einer bestimmten Erkrankung? P ist disa. Wie groß ist die Wahrscheinlichkeit, dass die Person
erkrankt ist, gleich
1/1 plus E bar
minus B eins zu H, B zwei zum Geschlecht, P drei zu Raucher Das ist eine Funktion von A, Geschlecht und Für Z wird
jetzt einfach
die Gleichung der linearen Gleichung eingefügt. Und wenn Sie das tun, stellen wir
fest, dass die Wahrscheinlichkeit
einer abhängigen Variablen an diesem Beispiel
eins ist. In unserem Beispiel wird die Wahrscheinlichkeit, an einer bestimmten Krankheit anhand des Parameters
Geschlecht und Raucherstatus berechnet. Wie
sieht das in unserem Beispiel aus? E potenziert mit minus B eins, B zwei, B drei, sind alles die
Bestimmtheitskoeffizienten , sodass das Modell am besten zu den gegebenen Daten passt. Um dieses Problem zu lösen, nennen
wir es die Methode der maximalen
Lighthod-Methode Zu diesem Zweck gibt es
gute numerische Methoden, um das Problem
effizient zu lösen Aber wie interpretiert man die Ergebnisse einer
Logistikregulierung Schauen wir uns die
Fixitios-Nummer an. Er gibt das Geschlecht des Rauchens,
den Status und die Krankheit an. 22 Frauen sind Nichtraucher
und erkrankt, 25 Raucherinnen sind erkrankt,
18 männliche Raucher sind nicht erkrankt,
so weiter und so fort 25 Raucherinnen sind erkrankt,
18 männliche Raucher sind nicht erkrankt,
so weiter und so fort. Wenn wir das auf
einen statistischen Online-Rechner eingeben und zur Regression übergehen und dann auswählen, was
meine abhängigen Variablen
und was meine unabhängigen Variablen sind ? ? Was ist eher eine
Vorhersage, krank oder nicht krank, und Und wenn wir darauf klicken, wird
es die
Erholungsgleichung für uns ausführen Wir möchten also die
logistische Erholung berechnen, also müssen wir
auf die Registerkarte Erholung klicken Dann kopieren wir unsere Daten dorthin und die Variablen werden hier unten
angezeigt Je nachdem, wie Ihre
abhängigen Variablen verwendet werden, statistische
Online-Rechner wie berechnen statistische
Online-Rechner wie die Registerkarte „
Daten“ entweder die logistische
oder die
lineare Rekonstruktion unter
der Registerkarte Erholung Wir wählen „erkrankt“ als abhängige Variable, A,
Geschlecht, Raucherstatus als Jetzt übernimmt der Rechner die logistische
Regressionsgleichung Gehen Sie jetzt langsam die gesamte
Tabelle durch und verstehen Sie, und fangen wir von oben an Wenn Sie nicht wissen, wie Sie die Ergebnisse
interpretieren sollen, gibt es ein Muster, das als
Zusammenfassung in Versen bezeichnet wird. Sie können es in Word kopieren, Sie können die
Ergebnisse in Excel kopieren und Sie können auch die
Klassifizierungstabelle kopieren. Fangen wir also an. Das
erste, was in der
Ergebnistabelle
angezeigt wird, sind
die Ergebnisse ,
wo wir sagen, dass insgesamt 36 Personen untersucht
wurden. 26 wurden korrekt
geschätzt
, und das sind 72,22 Prozent
in Prozent Mit Hilfe der
Berechnung, des Regressionsmodells, wurden
26 von 36%
korrekt zugeordnet Das sind 72%. Gehen wir nun zur folgenden
Klassifizierungstabelle. Sie haben die Möglichkeit,
es nach Word und Excel zu exportieren. Hier können Sie sehen, wie
oft die Kategorien „Nicht erkrankt“ und „Krankheit beobachtet und wie oft
sie vorhergesagt werden Die beobachteten
Werte sind also 11, fünf,
fünf, 15, und die vorhergesagten
Kategorien lauten wie folgt Wir können also sagen, dass sie ein korrektes
Prognosemittel getroffen
haben. In Wirklichkeit
ist die Person nicht krank,
und das Modell hat auch
vorausgesagt, dass sie nicht erkrankt ist In Wirklichkeit ist die
Person verstorben, und das Modell hat eine Krankheit
vorhergesagt Beide sind positiv. Wahr positiv und wahr negativ. Aber wir haben ein Konzept, das
als falsch negativ und falsch
positiv bezeichnet wird. In Wirklichkeit
ist die Person nicht krank, aber das Modell
sagt, dass sie krank ist Das ist also ein
falsch-positiver Fall, was in Ordnung ist, weil
Sie sich definitiv für eine zweite Meinung
entscheiden können und die Person vorsichtig ist Die Sorge gilt
dem falsch negativen Ergebnis. In Wirklichkeit ist die
Person krank, aber mein Modell ist nicht in der
Lage, dies vorherzusagen Daher werden diese fünf
Patienten
die Behandlung verpassen , wenn sie sich nicht für die aktuelle Diagnose
entscheiden Insgesamt sind es 16 11 plus 516 ohne
Krankheitsbeobachtung. Von diesen 16 das Freizeitmodell 11
korrekt als
nicht erkrankt bewertet und fünf fälschlicherweise als Krankheit
gespeichert Von 20 erkrankten Personen wurden
15 korrekt als Krankheit und
Pi falsch
bewertet. Zu beachten ist, dass bei der Entscheidung, ob eine
Person erkrankt ist oder nicht, ein Schwellenwert von 50% Wenn die Wahrscheinlichkeit höher als 50%
ist, kennzeichnen
wir die Person als erkrankt Da die Wahrscheinlichkeit
weniger als 50% beträgt, kennzeichnen
wir sie als nicht erloschen. Wenn das Regressionsmodell also mehr als 50%
schätzt, wird
die Person als verstorben eingestuft,
andernfalls nicht verstorben Kommen wir zum
Chi-Square-Test. Wir haben ein ausführliches
Video zum Chi-Quadrat. Der Chi-Quadrat-Wert beträgt 8,79
Freiheitsgrade drei und der p-Wert 0,32 Wenn P niedrig ist, geh. Wir werden uns mit dem Testen der
Hypothesen befassen. Hier können wir nachlesen,
ob das Modell insgesamt
signifikant ist oder nicht. Die Antwort lautet: Ja.
Jetzt wollen wir mal sehen. Es gibt zwei Modelle
, die verglichen werden können. In einem Modell werden alle
unabhängigen Variablen verwendet. In dem anderen Modell nur wenige der unabhängigen
Variablen verwendet. Mit Hilfe des
Chi-Square-Tests vergleichen
wir, wie gut
die Vorhersage ist, wenn die abhängigen Variablen verwendet
werden, und wie gut sie ist, wenn die abhängigen
Variablen nicht verwendet werden. Und der Chi-Quadrat-T-Test sagt uns, ob es einen
signifikanten Unterschied zwischen den beiden Ergebnissen Die Nullhypothese besagt, dass beide
Modelle identisch sind. Der p-Wert ist kleiner als 0,05. Dies bedeutet, dass die
Nullhypothese zurückgewiesen wird. Wenn also die
Nullhypothese abgelehnt wird, gehen
wir davon aus, dass es einen signifikanten Unterschied
zwischen den Modellen gibt. Somit ist das Modell als
Ganzes signifikant. Als nächstes folgt die Modellzusammenfassung. In dieser Tabelle sehen Sie eine Hand mit minus zwei
Log-Likelihood-Werten und auf der anderen Seite haben
Sie einen anderen
Bestimmtheitskoeffizienten oder Quadratwert. Die Modellzusammenfassung
sieht wie folgt aus. Sie können
es einfach in Word und Cel exportieren. Minus zwei ist eine
Log-Likelihood von 40,67, Quadratwert von
Cosell R ist 0,22 Und die anderen Werte
werden ebenfalls angezeigt. Das R-Quadrat wird verwendet, um herauszufinden wie gut das Erholungsmodell die abhängige Variable
erklärt. Bei der linearen Rekonstruktion gibt
das R-Quadrat
den Teil
der Variation an, der durch die
unabhängigen Variablen erklärt
werden kann . Je mehr Varianz erklärt werden
kann, desto besser ist das Regulierungsmodell. R-Quadrat wird verwendet, um
herauszufinden, wie gut das Regulationsmodell
die abhängige Variable erklärt Bei einer linearen Regelung gibt
das R-Quadrat
den Teil der Varianz an, der durch die
unabhängigen Variablen
erklärt werden kann durch die
unabhängigen Variablen
erklärt Je mehr Varianz
erklärt werden kann und desto besser ist
das Regulierungsmodell Im Fall der
logistischen Regulierung ist
die Bedeutung jedoch ist
die Bedeutung Es gibt verschiedene Möglichkeiten,
das R-Quadrat zu berechnen. Leider gibt
es
noch keine Einigung darüber , welcher Weg am
besten ist. Das R-Quadrat ist
laut Knopfzelle 0,22, Nagker Ki ist
0,29 und Und jetzt kommt die
wichtigste Tabelle, die
Tabelle mit dem Modell Coent Der wichtigste Parameter
des Klienten ist das Chancenverhältnis von B, p-Wert Die B-Werte des Koeenten sind hier, die p-Werte sind hier und das Chancenverhältnis Wir können sehen, dass der
P-Wert für Geschlecht größer als 0,05 ist. Das bedeutet, dass das Geschlecht
kein Faktor ist , der
zur Krankheit beiträgt In der ersten Spalte können wir die Koeffizientenwerte als
0,040 0,871 0,4 -2,73
lesen , und dann können wir
diese Werte anstelle
von B eins, b2bk, einfügen diese Werte anstelle
von Wenn wir das Cypion einsetzen, erhalten
wir eine Gleichung wie diese:
1/1 plus Radierung 20,04 zu H, 0,87 zu Geschlecht plus
1,34 zu Raucher minus der Konstante 2,73, 0,87 zu Geschlecht plus
1,34 zu Raucher minus der Konstante 2,73 und dann fahren wir fort erhalten
wir eine Gleichung wie diese:
1/1 plus Radierung 20,04 zu H,
0,87 zu Geschlecht plus
1,34 zu Raucher minus der Konstante 2,73, und dann fahren wir fort und berechnen. Damit können wir nun die Wahrscheinlichkeit berechnen
, dass eine Person verstorben ist . Wir wollen wissen, wie wahrscheinlich es , dass eine Person im
Alter von 55 Jahren, weiblich und Raucher
verstorben Wir ersetzen den Wert
Alter durch 55,
Geschlecht durch Null, weil
es sich nicht um einen Mann und eins als Raucher und
berechnen Wenn wir diese Berechnung durchführen, beträgt
der Wahrscheinlichkeitswert 0,69 Das bedeutet, dass eine 55-jährige Raucherin
mit
einer Wahrscheinlichkeit von
69% erkrankt 55-jährige Raucherin
mit
einer Wahrscheinlichkeit von
69% erkrankt Auf der Grundlage dieser Prognose würde nun
entschieden werden, ob eine umfassende Untersuchung durchgeführt werden soll oder nicht Das Beispiel ist rein imaginär. In der Realität
könnten bestimmte, viele andere Faktoren und verschiedene unabhängige
Variablen wie das Gewicht der das Alter der Person und viele weitere Faktoren dazu beitragen,
festzustellen, ob die
Person krank ist oder nicht Aber jetzt kommen wir
zurück zum Tisch. In der Spalte können wir den
Koeffizienten der signifikanten
Differenz von Null ablesen . Die Nullhypothese lautet Koeffizient
in der Grundgesamtheit Null ist. Bei der folgenden
Nullhypothese handelt es sich um einen Test. In der Grundgesamtheit ist
der Koeffizient Null. Da die Variable
kleiner als 0,05 ist, der vorhergesagte Koeffizient
einen signifikanten Einfluss In unserem Beispiel sehen wir, dass keiner
der Koeffizienten
einen signifikanten Einfluss hat , da alle p-Werte
größer als 0,05 sind Lassen Sie uns nun
das Chancenverhältnis verstehen. Das Chancenverhältnis ist
1,042 0,39 83,81. Das
Chancenverhältnis liegt beispielsweise bei 1,04,
was bedeutet, dass bei einem
Anstieg der Variablen Alter um eine Einheit die Wahrscheinlichkeit, dass
eine Person erkranken
kann, um eine Person erkranken
kann Und wir können sehen, dass das Chancenverhältnis für Raucher sehr hoch ist Damit sind wir
am Ende der logistischen Erholung angelangt. Wir sehen uns in der
praktischen Sitzung. Bleib dran. Danke.
40. Logistische Regressionspraxis: Wir werden einen Online-Rechner
für die Regressionsanalyse verwenden , insbesondere für die
logistische
Regressionsanalyse insbesondere für die
logistische
Regressionsanalyse in diesem Video. Ich habe ein
separates Video darüber hochgeladen wie Sie diese
Analyse mit Excel durchführen können. Fahren wir also mit dem
statistischen Online-Rechner fort. Ich kann meine
Daten importieren, indem ich auf die Importschaltfläche klicke und Excel-Dateien,
SV-Datei oder
Daten-Tab-Datei SV-Datei oder
Daten-Tab-Datei Ich kann auf Durchsuchen klicken
und meine Daten abrufen. Stimmt das? Ich habe also
bereits meine Daten geladen, die Sie auf dem Bildschirm sehen können. Ich habe den Raucherstatus, ob eine Person verstorben
ist oder nicht, Alter, Geschlecht. Wir können sehen, dass der
Datentyp vom
statistischen Rechner automatisch identifiziert
wurde. Es heißt, das Alter ist eine
metrische Variable, das
Geschlecht ist nominell und der
Raucherstatus ist ebenfalls normal. Die Krankheit ist nominell. Jetzt klicke ich
auf Regression und scrolle nach unten. Ich habe also eine gute
Anzahl von Fällen. Lass mich einfach nach unten scrollen. Wenn ich auf Regression klicke, kann
ich einfache
lineare Regression,
multilineare Regression und logistische Regulation Was sind meine abhängigen Variablen? Das Alter ist meine abhängige Variable. Das Geschlecht ist eine abhängige Variable. Der Rauchstatus ist eine
abhängige Variable. Was möchte ich vorhersagen? Ich möchte vorhersagen, ob die
Person krank ist oder nicht. Wähle ich das Richtige aus? Nein. Ich möchte überprüfen, was die abhängige Variable ist? Was ist mein Y? Mein Y ist, ob die Person verstorben
ist oder nicht. Und meine unabhängigen Variablen sind Geschlecht und Raucherstatus. Als Referenz für das Geschlecht nehme
ich also männlich als eins an. Referenz für den Raucherstatus betrachte ich Raucher als Einzelperson, und das Modell wird vorhergesagt ob die Person erkrankt
ist oder nicht Jetzt kann ich auf
Zusammenfassung in Worten klicken, und es führt eine korrekte
Analyse durch und zeigt sie mir Stimmt das? eine logistische
Regreationsanalyse
durchgeführt wurde , um den
Einfluss von Alter, Geschlecht,
Frau und Raucherstatus als
Nichtraucher als Variablen zu untersuchen , dass
Krankheiten
für den Wertverlust vorhergesagt werden, ein logistisches
Analysemodell gezeigt hat, dass das Chi-Quadrat für
die drei Variablen 8,79 ist ein logistisches
Analysemodell gezeigt hat, dass das ,
der p-Wert 0,32
ist Es zeigt deutlich, dass
eine logistische
Regreationsanalyse
durchgeführt wurde, um den
Einfluss von Alter, Geschlecht,
Frau und Raucherstatus als
Nichtraucher als Variablen zu untersuchen, dass
Krankheiten
für den Wertverlust vorhergesagt werden,
ein logistisches
Analysemodell gezeigt hat, dass das Chi-Quadrat für
die drei Variablen 8,79 ist,
der p-Wert 0,32
ist und die Anzahl der Beobachtungen 36. Der Koeffizient
der Variablen p
beträgt 0,04 , was positiv ist. Dies bedeutet, dass der
Anstieg des Alters
mit einer Erhöhung
der Wahrscheinlichkeit einer
abhängigen variablen Erkrankung einhergeht mit einer Erhöhung
der Wahrscheinlichkeit einer abhängigen variablen Erkrankung Der p-Wert beträgt jedoch 0,092,
was darauf hindeutet, dass der Einfluss statistisch nicht signifikant
ist Das Chancenverhältnis beträgt 1,04,
was bedeutet, dass bei
einem Anstieg
der Variablen acht um eine Einheit die Wahrscheinlichkeit, dass
die abhängige Variable abnimmt , um 1,04 zunimmt
. Der Koeffizient der
Variablen Geschlecht weiblich, B-Wert ist 0,87 negativ Da diese Variable negativ
ist, bedeutet
dies, dass mit dem Wert
der Variablen Geschlecht weiblich
die Wahrscheinlichkeit sinkt, dass die
abhängige Variable krank wird Der p-Wert von 2,0
bis 0,28 weist jedoch darauf hin
, dass der Einfluss statistisch nicht signifikant
ist Das Chancenverhältnis liegt bei 0,42,
was bedeutet, dass bei der
Variablen Geschlecht weiblich die Wahrscheinlichkeit einer abhängigen
variablen Erkrankung um das 0,42-fache steigt 0,42-fache Der Koeffizient der
Variablen Raucherstatus,
p-Wert, ist -1,32,
was negativ ist. Das heißt, wenn der
Wert der Variablen für den Raucherstatus „Nichtraucher“ lautet, sinkt
die Wahrscheinlichkeit, dass
die abhängige Variable verstorben
ist die . Der p-Wert beträgt jedoch 0,089, was darauf hindeutet,
dass der Einfluss statistisch nicht signifikant ist . . Das Chancenverhältnis von
0,26 bedeutet, dass es sich bei der Variablen um einen Raucherstatus
handelt. Die Wahrscheinlichkeit, dass die abhängige Variable verstorben ist, steigt bei
Nichtrauchern um
das Lassen Sie mich nun die
Angabe „Nichtraucher“ und die Kategorie „Diese Krankheit
und keine Krankheit“ aufgreifen Kategorie „Diese Krankheit
und Kommen wir nun zur Zusammenfassung. Wir stellen fest, dass sich die Analyse geringfügig
geändert hat. Sie sind jetzt alle negativ
geworden. Stimmt? Das
Chancenverhältnis hat sich geändert Bei einer Erhöhung des Alters um eine
Einheit bedeutet
0,96, dass
die Person
nicht verstorben sein wird , denn jetzt
zielen wir auf nicht
verstorbene Personen ab, oder? Sie sollten also vorsichtig sein was Sie
als Referenz nehmen Was halten
Sie von Ihrer Hypothese, dass männliche Menschen
häufiger erkranken? Wenn Sie also
das Geschlecht als männlich annehmen, beträgt der B-Wert -0,87 Nun, hier ist mein Ziel nicht
erkrankt. Es scheint also, dass die
Wahrscheinlichkeit, dass die männliche Person nicht
erkrankt ist, um 0,97 sinkt Aber wenn ich mir Krankheiten ansehe, werden
Sie feststellen, dass dies jetzt ein positiver
Wert ist Raucher ist auch ein positiver Wert. Wir sollten also wissen, welche Zielvariable
wir untersuchen wollen Lass uns jetzt runterkommen. Lassen Sie uns die Ergebnisse sehen, und ich habe sogar eine
KI-Interpretation, die mir hilft. Die Tabelle fasst die Gesamtleistung
des binären logistischen
Regressionsmodells Hier lautet die Interpretation, dass Gesamtzahl der Fälle 36 beträgt, was der Gesamtzahl der Beobachtungen entspricht. Die
Tabelle fasst die Gesamtleistung
des
binären Hier entspricht die Interpretation
der Gesamtzahl der Fälle von 36. Dies ist die Gesamtzahl der Beobachtungen oder Instanzen, an
denen das Modell getestet wurde. In diesem Zusammenhang handelt es sich bei der
Anzahl der Personen um
Elemente, bei denen das Modell versuchte,
das Ergebnis vorherzusagen,
unabhängig davon, ob es sich bei der Person um eine Tat
handelt oder nicht. korrekte Zuordnung liegt bei
26 von 36 Fällen 26 Fällen hat
das Modell
das Ergebnis vorhergesagt. Diese korrekte Vorhersage umfasste sowohl echte positive Ergebnisse, bei denen
die betroffene Person
korrekt identifiziert wurde, als auch echte negative Ergebnisse, bei
denen Fälle ohne Krankheit korrekt identifiziert wurden In Prozent 72,22% Dies ist die Genauigkeit des Modells,
das besagt
, dass die Anzahl der Aufgaben 26 geteilt
durch die Gesamtzahl der Fälle 36 beträgt durch die Gesamtzahl der Fälle Ich multipliziere es mit zehn
, um den Prozentsatz zu erhalten. Es sagt uns, wie das Modell die richtige Vorhersage
macht. Lassen Sie uns nun die
Klassifizierungstabelle verstehen. Dort
versuchen wir zu klassifizieren. Ich kann die Hilfe der
KI-Interpretation in Anspruch nehmen, um es zu verstehen. In der Tabelle ist das Maß
für
die Güte der Anpassung aus der logistischen
Regressionsanalyse Hier
sind 11 Fälle, in denen wir
richtig vorausgesagt haben, dass
sie nicht erkrankt sind, die
wahren positiven und wahrhaft negativen sind 11 Fälle, in denen wir
richtig vorausgesagt haben, dass
sie nicht erkrankt sind richtig vorausgesagt haben, dass Falsch positiv sind fünf Fälle , in denen uns
ein Fehler ersten Typs unterlaufen ist Falsch negativ sind
fünf Fälle, in denen wir fälschlicherweise vorausgesagt haben, dass
sie nicht als Fehler des
zweiten Typs erkrankt sind als Fehler des
zweiten Typs erkrankt Richtig positive Ergebnisse werden korrekt als erkrankt vorhergesagt. Richtigkeit der Vorhersage. Die korrekte Vorhersage, ob
nicht erkrankt ist, liegt bei 68,75%. Die Gesamtzahl der nicht erkrankten Fälle wurde korrekt
identifiziert. Richtige Krankheitsvorhersagen, Sensitivität oder, wie wir sagen, 75%
der tatsächlichen Krankheitsfälle
wurden korrekt identifiziert Die Gesamtgenauigkeit liegt bei 72,22% aller Schutzmaßnahmen, unabhängig davon,
ob wir
die Krankheit korrekt erkannt haben oder nicht Lassen Sie uns nun den
Chi-Quadrat-Test verstehen. Das Schöne an diesem
statistischen Rechner ist, dass er Ihnen
eine KI-Interpretation ermöglicht. Ich muss dazu nicht
zu ChangeP gehen. Die Tabelle zeigt die Ergebnisse
des Chi-Quadrat-Tests im Zusammenhang mit dem binären
logistischen Regressionsmodell Der Test wird häufig verwendet, um die
Gesamtsignifikanz des Modells zu beurteilen Hier die Interpretation
der einzelnen Komponenten. Ich habe die Statistik quadriert , wobei die Antwort in unserem
Fall 8,79 ist Damit wird der
Unterschied zwischen beobachteten und
der erwarteten
Häufigkeit des Ergebnisses gemessen Je höher der
Chi-Quadrat-Wert desto größer ist die Diskrepanz zwischen dem erwarteten und dem beobachteten Wert,
was darauf hindeutet, dass die Prädiktoren des
Modells eine signifikante Beziehung aufweisen Freiheitsgrade, hier haben
wir drei
Freiheitsgrade, die die Anzahl der Prädiktoren in
der einfachen logistischen Regression darstellen Prädiktoren in
der einfachen logistischen Regression P-Wert ist die
Wahrscheinlichkeit die
Chi-Quadrat-Teststatistik genauso
extrem beobachtet wird wie bei der Nullhypothese
. Die Nullhypothese besagt , dass kein
Zusammenhang zwischen der
beobachteten und der erwarteten Häufigkeit
des
anhand des Volumens vorhergesagten Ergebnisses besteht beobachteten und der erwarteten Häufigkeit . Der P-Wert liegt bei 0,032,
was darauf hindeutet, dass die beobachtete
Chi-Quadrat-Statistik mit
einer Wahrscheinlichkeit von 3,22% extrem ist einer Wahrscheinlichkeit beobachtete
Chi-Quadrat-Statistik Und die
Nullhypothese war wahr. Der p-Wert liegt um 0,32 unter dem Schwellenwert von
0,05, was darauf
hindeutet, dass
ein statistisches
Signifikanzergebnis vorliegt ein statistisches
Signifikanzergebnis Lassen Sie uns nun eine Modellzusammenfassung erstellen. Hier heißt es also, dass die Wahrscheinlichkeit eines
Logarithmus minus zwei bei 40,67 liegt. Es misst die Fitness des Modells. Je niedriger der Wert,
desto besser passt das Modell zu den Daten. In unserem Fall ist der Wert 40,67, was bedeutet, dass es sich um
ein relativ gesättigtes Modell handelt, ein Modell mit perfekter Passform Diese Zahl allein sagt uns
nicht viel aus. Daher müssen wir sie mit
anderen Zahlen
vergleichen. Der quadratische
Wert von Cocin-Zelle R ist 0,22. Dies ist ein
Pseudo-R-Quadratmaß , das das Ausmaß der
Variation in der
vorhergesagten Variablen angibt , das durch das Modell erklärt wird.
Sie liegt im Bereich von 0 bis 1. Der Wert 0,22 gibt an, dass
die Varianz von 22% durch das Modell
erklärt wird Es ist jedoch
erwähnenswert, dass diese Kennzahl selbst bei einem perfekten Modell
niemals
einen Wert erreicht Gehen wir zum quadratischen Wert von Nagar
K R. Es ist 0,29. Auch hier versuchen wir, das
R-Quadrat so einzustellen, dass es eins erreicht Denken Sie jedoch daran
, dass 29% der Variation durch dieses Modell
erklärt werden. Das bedeutet, dass Sie
mehr Variablen einbeziehen
müssen , um
das Modell besser zu verstehen. Wenn wir uns das ansehen, wir den
Modellunterschied. Die fragliche Komponente
steht für die verschiedenen Größen, Standardfehler, den Z-Wert, P-Wert, das erwartete Verhältnis
und die Zuverlässigkeit von 95%. Lassen Sie uns die Interpretation machen. Das Modell prognostiziert
das grundlegende Ergebnis -2,73, wobei der
Prädiktor Null ist und
das Chancenverhältnis das Chancenverhältnis Dies deutet auf eine geringere
Wahrscheinlichkeit eines Ergebnisses hin, wenn sich der Prädiktor auf dem Referenzwert befindet Mit jeder
Erhöhung des Alters um eine Einheit steigt
die Wahrscheinlichkeit, dass die Person
verstorben ist , um 0,04 Das ist ein Anstieg der Gewinnchancen um 4%. Wenn das Geschlecht männlich ist, gibt es einen
Anstieg um 0,87%, und so Lassen Sie uns die Vorhersage machen. Wenn die Person 45 Jahre alt
ist und die Person männlich
ist und die Wahrscheinlichkeit
, dass die Person Raucher ist, wie hoch ist die Wahrscheinlichkeit, dass die Person
erkrankt? Es gibt 0,81 Ist es mehr als 0,45? 50%? Ja. Es besteht die Wahrscheinlichkeit, dass die
Person krank ist Aber wenn die Person eine Frau ist, dann sinkt die Wahrscheinlichkeit Wenn die Person nicht raucht,
ist die Wahrscheinlichkeit,
dass die Person krank ist, außerdem sehr
gering dass die Person krank ist Jetzt sind wir zum nächsten Beispiel übergegangen ,
in dem wir versuchen zu überprüfen, ob die Person
ein Produkt kaufen wird oder Und die Variablen sind Geschlecht, Alter und die Zeit, die
sie online verbracht haben. Also werde ich
auf Erholungsgleichung klicken. Was ist die abhängige
Variable, Geschlecht, Alter und die
online verbrachte Zeit und das Kaufverhalten,
sind meine abhängige Variable. Es gibt drei Arten von
Vorhersagen, dass sie eintreten, und nicht zwei wie beim letzten Mal. Wir müssen jetzt
kaufen, später kaufen und nichts
kaufen. Referenzkategorie
für weibliches Geschlecht, ich nehme es als weiblich und lassen Sie uns zur Zusammenfassung übergehen. Die logistische
Regressionsanalyse ergab
hier also , dass der Einfluss
des Geschlechts männlich, des Alters und der im Internet verbrachten Zeit auf das variable Kaufverhalten
im Wert von inzwischen liegt Die logistische Regressionsanalyse zeigt, dass das Modell insgesamt signifikant
war zeigt, dass das Modell insgesamt signifikant
war. Die Zahl der Beobachtungen beträgt 24. Der Koeffizient, dass die
Variable Geschlecht
männlich ist, beträgt 1,53, was Dies bedeutet, dass der Wert
der Variablen Geschlecht ma,
die Wahrscheinlichkeit, dass die
Person kauft, steigt Der p-Wert beträgt 0,201,
was darauf hinweist, dass der Einfluss statistisch nicht signifikant
ist Das Chancenverhältnis liegt bei 4,63,
was bedeutet, dass das Geschlecht männlich ist.
Die Wahrscheinlichkeit, dass die
abhängige Variable abhängig ist, steigt
inzwischen um das 4,63-fache Der Koeffizient der Variablen Alter ist p gleich -0,11, Dies bedeutet, dass ein Anstieg des Alters
mit einer Verringerung
der Wahrscheinlichkeit einhergeht , dass die
abhängige Variable Der p-Wert liegt jedoch bei 0,07 was darauf hindeutet, dass der Einfluss statistisch nicht signifikant
ist Das Chancenverhältnis liegt bei 0,9
, was bedeutet, dass mit jeder
Erhöhung des Alters die Person derzeit nur um das
0,9-fache zunimmt Der Koeffizient der variablen
Zeit, die im Online-Shop verbracht wird,
liegt bei -0,02, Das bedeutet, je mehr
Zeit im Internet verbracht wird, desto geringer ist die
Wahrscheinlichkeit, dass sie Der P-Wert ist 0,56 was bedeutet, dass er
statistisch nicht signifikant ist, und die
online verbrachte Zeit erhöht die Wahrscheinlichkeit um das 0,98-fache 24 Fälle, 17 korrekt
vorhergesagt, in Prozent 70. Lassen Sie uns die Analyse durchführen. Also um die Gesamtzahl der Fälle 24, korrekte Zuordnung
17 Prozent 70. Gehen wir nun zur
Klassifizierungstabelle. Wir können verstehen, was ein Fehler vom ersten Typ
und ein Fehler vom zweiten Typ sind? Richtig negativ Bei 13 Fällen wurde richtig vorhergesagt
, dass sie nicht kaufen werden . Falsche positive Ergebnisse
sind drei Fälle, was falsch
vorhergesagt wurde, da sie jetzt feststehen, aber in Wirklichkeit haben
sie nicht gekauft Und falsche Fälle sind, dass vier
von ihnen tatsächlich gekauft haben, aber unser Modell sagte
, dass sie nicht gekauft haben Vier Fälle wurden jetzt korrekt als Pi
vorhergesagt. Die Richtigkeit liegt jetzt bei 82%, Richtigkeit von inzwischen bei
50%, die Gesamtgenauigkeit bei 70%. Wenn Sie sich die
Chi-Quadrat-Gleichung ansehen, erhalten
wir einen
p-Wert von 0,42 Hier ist die Wahrscheinlichkeit
eines Chi-Quadrat-Tests als einer der beobachteten Werte
der Nullhypothese
äußerst wichtig beobachteten Werte
der Nullhypothese Die Nullhypothese besagt , dass kein
Zusammenhang zwischen der beobachteten und der
erwarteten Frequenz und der
vom Modell vorhergesagten Leistung besteht. Ein P-Wert von 0,42 liegt unter dieser Konvention von 0,5, was
statistisch signifikant Wenn ich mich für das Modell entscheide, können
wir sehen, dass die
Werte im Quadrat R sehr w sind. Und ich
habe den p-Wert.
Lassen Sie uns nun eine Vorhersage machen Wenn die Person männlich und
45 Jahre alt ist und die aufgewendete
Zeit 2 Wie hoch ist die Wahrscheinlichkeit
, dass eine Person kauft? Es besteht keine große Wahrscheinlichkeit. Aber wenn die Person 20 Jahre alt
ist,
steigt die Wahrscheinlichkeit Wir können also verstehen, dass die Menschen der neuen Generation
bereit sind , mehr zu kaufen
als die älteren Wenn wir eine
80-jährige Person haben, dann ist die Wahrscheinlichkeit
absolut gleich 0,01 Ich hoffe, Sie lernen in diesem Video, wie man logistische Regression durchführt. Oh.
41. ROC-Kurve: D. Lassen Sie uns die ROC-Kurve verstehen Wir haben gerade das Lernen
über logistische Regression abgeschlossen. Eine Möglichkeit, die Genauigkeit des Modells zu validieren ,
ist die Verwendung der ROC-Kurve Lassen Sie uns die
Theorie anhand von Beispielen verstehen. ROC steht also für Receiver
Operating Characteristics. Es handelt sich um eine grafische
Darstellung der Leistung
eines binären Klassifikationsmodells, auch als logistisches
Regressionsmodell bezeichnet wird, sowie anderer
Klassifikationsschwellenwerte Lassen Sie uns das anhand eines
Beispiels verstehen. Nehmen wir an, wir
führen einen Screening-Test an Patienten durch, um festzustellen, ob der Patient
gesund oder krank ist Für diese
Einstufung führt
der Apotheker
einige Blutuntersuchungen durch
und entscheidet dann
, wer von ihnen erkrankt und wer
gesund ist und entscheidet dann
, wer von ihnen erkrankt und wer
gesund Als sie die
Stichprobe von zehn Daten erhielten, haben
sie beschlossen,
einen Schwellenwert festzulegen,
und jeder, der diesen
Schwellenwert unterschreitet , wird als gesund und jeder,
der den Schwellenwert überschreitet, als krank
bezeichnet Nun, wie entscheiden wir, was der Schwellenwert sein
sollte? Auf welcher Grundlage
können Sie vorhersagen, dass die Zukunft darin besteht, dass der
Patient verstorben ist? Nehmen wir an, wir
haben eine Stichprobe von zehn Personen mit
ihren Blutwerten Wir sehen, dass
die meisten erkrankten
Menschen einen
höheren Blutspiegel haben Und die meisten
gesunden Menschen haben niedrigere Blutwerte Also beschließen wir, dass wir
einen Schwellenwert von 45 festlegen. Wenn wir also einen
Schwellenwert von 45 festlegen, sagen
wir, dass
wir
jeden, der unter 45 ist, als gesund
einstufen werden Jeder, der über 45 Jahre alt ist, werden
wir als Krankheit einstufen
. Jetzt können wir sehen, dass es hier
bestimmte Probleme gibt, und lassen Sie uns
diese Probleme im Detail verstehen In diesem Fall werden also von
sechs Personen, die als
Krankheit
eingestuft wurden , zwei, vier korrekt als Krankheit
eingestuft, aber zwei von ihnen werden fälschlicherweise als Krankheit
eingestuft, aber in Wirklichkeit sind
sie gesund. Wir haben also vier von sechs
Fällen als Krankheit eingestuft, und dies wird als positive Rate bei
zwei Fällen bezeichnet. Sie wird auch
als Sensitivität bezeichnet. Andererseits
haben wir von den
vier gesunden Personen eine
Person fälschlicherweise als krank eingestuft Eine kranke Person wurde als gesund eingestuft, und wir haben
drei gesunde Personen korrekt als gesund eingestuft drei gesunde Personen korrekt als gesund Wenn wir nun
eine von vier Personen falsch als gesund einstufen, spricht man von einer
Falsch-Positiv-Rate, durch
FPR oder durch eins
minus Spezifität dargestellt wird FPR oder durch eins
minus Spezifität dargestellt wird Bei einem Schwellenwert von 45 erhalten
wir eine
Wahr-Positiv-Rate von 4/5, also 80%
, und eine
Falsch-Positiv-Rate von 2/5 als 40% Was genau ist also eine TPR
- oder Zwei-Positiv-Rate? Wahre positive Rate
ist nichts anderes als wahre positive Quote geteilt durch
wahrhaft positive und
falsch negative zwei positiven Personen handelt es
sich um Personen, die korrekt als Krankheit
eingestuft wurden. Wir haben
vier von ihnen korrekt als Krankheit eingestuft. Falsch negativ sind
Personen, die fälschlicherweise als gesund
eingestuft
werden Also haben wir
bei einer Person einen Fehler gemacht. Also ist die Summe 4/1. Wirklich positiv ist also nichts anderes, vier von ihnen korrekt als krank
eingestuft wurden Das Problem bestand jedoch darin, dass von den vier Personen, die
korrekt eingestuft wurden, eine der erkrankten
Personen übersehen wurde. Der Grund, warum wir
die TPR kennen müssen , ist folgender:
Wie viel Prozent der Menschen
werden ohne Behandlung auskommen Die Spezifität ist sehr wichtig, um zu verstehen
, dass es
20% der Bevölkerung gibt , die
möglicherweise nicht gut behandelt werden, oder wir klassifizieren
80% der von uns getesteten Population
korrekt 80% der von uns getesteten Population Lassen Sie uns FPR verstehen,
das ist falsch positiv. Falsch positive Personen sind gesunde Personen,
die fälschlicherweise als krank eingestuft werden, und zwei negative Personen sind Personen wurden korrekt
als gesund eingestuft. Zwei von ihnen wurden also
fälschlicherweise als DCs eingestuft. Also beginnen wir mit der Behandlung, geteilt durch die
Gesamtzahl der
tatsächlich Gesunden fünf Also die Gesamtzahl der
gesunden Menschen geteilt durch die Anzahl der
falsch positiven Ergebnisse. Bei 40% der Menschen
waren es also 0,4, was der FPR-Rate entspricht. Wie berechnen wir also TPR
und FPR für jeden Schwellenwert? Sollte ich den
Schwellenwert auf 38 setzen? Sollte ich den Schwellenwert
auf 65 setzen und so weiter. In diesem Fall berechnen wir also den TPR und den FPR für
jeden der Schwellenwerte Wenn ich diesen Wert auf Null setze, steigt meine wahre positive
Rate, aber meine
Falsch-Positiv-Rate ist fast Das sind also genau
die beiden Werte , die
auf der ROC-Kurve dargestellt Die wahre positive Rate
ist auf der Y-Achse
und die falsch positive Rate
auf der X-Achse aufgetragen Wir möchten entscheiden, dass
bei einem Wert von 0,240 0,2
unsere Falsch-Positiv-Rate hier ist, die wahre positive
Rate
jedoch steigt, und zwar in ähnlicher Weise bei 0,4, 0,6, 0,8
und Lassen Sie uns nun die komplette
ROC-Kurve für unser Beispiel zeichnen. Wenn wir den
Schwellenwert sehr klein wählen
, also
ganz nach links schieben, klassifizieren
wir alle
fünf erkrankten Personen korrekt Aber wir klassifizieren auch
alle fünf gesunden
Personen falsch alle fünf gesunden
Personen Die tatsächliche positive Rate
liegt also bei fünf von fünf, also eins Auf die gleiche Weise
haben wir jedoch fünf gesunde
Personen fälschlicherweise als krank eingestuft Die Falsch-Positiv-Rate
liegt also bei fünf von fünf,
das ist wieder eins. Aus diesem Grund liegt der erste
Datenpunkt bei einem Punkt eins. wir also den Schwellenwert überschreiten, werden
wir immer noch korrekt
klassifizieren, wenn ich bei 0,2 liege Ich klassifiziere immer noch
alle fünf Personen korrekt als krank, aber ich klassifiziere vier der gesunden Personen Jetzt komme ich zum nächsten Datenpunkt. Wenn ich also 0,8
als Schwellenwert nehme, liegt
meine tatsächliche positive Quote bei fünf von fünf Ich habe
also
alle
Verstorbenen korrekt als verstorben eingestuft . Aber von fünf
gesunden Personen haben
wir jetzt
nur vier von fünf falsch klassifiziert Somit liege ich bei der
Falsch-Positiv-Rate bei 0,8 Für den nächsten Schwellenwert, wo wir eine
positive Rate von 0,1 haben, liegen
wir bei 0,3, und
wir stellen fest, dass wir alle
fünf Personen
korrekt als krank eingestuft haben , meine gesunden
Personen
jedoch Das wird also mein
dritter Datenpunkt sein. Fünf kranke Personen sind
korrekt klassifiziert. Falsch-Positiv-Rate liegt bei
drei von fünf Fällen, die
fälschlicherweise als Krankheit
eingestuft wurden , also 0,6 Beim nächsten Schwellenwert wird
die erkrankte Person zum ersten Mal
fälschlicherweise als gesund eingestuft Das ist der Schwellenwert. Das ist der Ort, an dem
die kranke Person fälschlicherweise
als gesund eingestuft
wird Und daher sehen wir einen Rückgang der tatsächlichen positiven
Rate von Die wahre positive Rate liegt bei
vier von fünf, also 0,8, und die Falsch-Positiv-Rate liegt bei drei von
fünf, also 0,6 Das können wir jetzt für
alle anderen Schwellenwerte tun, und entsprechend
entwerfen wir unsere ROC-Kurve Zu diesem Zeitpunkt
wurden beispielsweise 80% der DAS-Personen 80% der DAS-Personen korrekt als Krankheit
eingestuft, 20% der gesunden Personen wurden fälschlicherweise als Krankheit
eingestuft Anhand der ROC-Kurve können
wir verschiedene
Klassifizierungsmethoden vergleichen Klassifikationsmodelle sind besser je höher die Kurve
ist Daher ist das
Klassifikationsmodell umso besser, je größer
die
Fläche unter der Kurve ist. Mithilfe der ROC-Kurve können
wir verschiedene
Klassifizierungsmethoden vergleichen, und genau
die Fläche
spiegelt sich im Wert der
AUC-Fläche unter der Kurve Die Fläche unter der Kurve wird
bei der Bewertung des linearen Regressionsmodells
verwendet bei der Bewertung des linearen Regressionsmodells Der AUC-Wert variiert zwischen 0 und 1. Je größer der Wert, desto besser
das Modell. Was ist mit der ROC-Kurve und
der logistischen Regression? Zum Beispiel könnten wir mithilfe der logistischen
Regression ein neues Klassifikationsmodell
erstellen Regression ein neues Klassifikationsmodell
erstellen Hier könnten wir
die zusätzlichen Werte
wie Blutwert, Alter
und Geschlecht der
einzelnen Personen verwenden die zusätzlichen Werte
wie Blutwert, Alter und versuchen,
vorherzusagen, ob die Person gesund oder
krank ist Lassen Sie uns weitermachen, was die ROC-Kurve und die logistische Regression angeht Bei einer logistischen Regression gibt
der geschätzte Wert dann an, wie
wahrscheinlich es ist , dass eine bestimmte Person verstorben ist Sehr oft geben 50% von
ihnen einfach als Schwellenwert an,
ob eine Person verstorben
ist oder nicht Aber das ist natürlich nicht das,
woran wir denken Sie können also nicht immer den
Schwellenwert von 50% annehmen. Deshalb erstellen
wir trotz der
logistischen Vorschriften die ROC-Kurve für verschiedene Schwellenwerte
und schauen, auf welcher Ebene wir die maximale Fläche haben Wie kann ich die
ROC-Kurve also online abrufen? Lassen Sie uns jetzt verstehen,
wie ich
diese ROC-Berechnung
anhand der Daten durchführen kann diese ROC-Berechnung
anhand der Daten Also habe ich
einige Datenwerte für mehr als 40,
fast 40 Personen, mit
unterschiedlichen Blutwerten und
unabhängig davon, unterschiedlichen Blutwerten und ob die Person krank
ist oder nicht Also kann ich mich entweder für
mein Befreiungsmodell entscheiden und sagen, dass ich
die Variable als krank angeben möchte Der Status der Variablen ist ja oder nein, und ich möchte die
Testvariable als Blutwert verwenden Wir erhalten also sofort den ROC, und der ROC zeigt an, auf welchem Niveau Spezifität Sensitivität ist nichts anderes als
meine wahre positive Rate. Wie viele dieser kranken Menschen habe ich richtig
klassifiziert? Spezifität hingegen
ist, wie viele von ihnen
oder wie viele gesunde Menschen
fälschlicherweise als krank eingestuft wurden Und wir wollen, dass es sie gibt. Kranke Menschen sind 19 Jahre
alt, nicht krank sind 22, und positiv ist größer
als gleich eins, die Sensitivität ist eins und
mir werden alle Daten angezeigt. Wir können einige Beispieldaten verlieren. Und das tue ich. Ich kann das auch
unter meinem Korrelationsmodell finden. Also gehe ich zur Regulierung über
und sage, dass meine
abhängige Variable
verstorben ist und der Blutwert
meine unabhängige Variable ist. Die Zusammenfassung in Worten, ob die logistische
Regulierungsanalyse durchgeführt wurde, um zu
untersuchen, ob
der Blutwert einer Variablen den Wert nicht
vorhersagen lässt, lautet ja Analyse der logistischen Erholung zeigt, dass der Chi-Quadrat-Wert 5,23 und der
P-Wert 0,02 beträgt P-Wert Das bedeutet, dass Blut vorhersagen kann , dass der
Blutspiegel
keinen Einfluss auf die Krankheit Wir lehnen die Nullhypothese ab
, weil der p-Wert lo ist. Der Kozient des Blutwerts B ist 0,03, was Das bedeutet, dass der
Anstieg des Blutwerts mit der Erhöhung der Wahrscheinlichkeit für
die
abhängige Variable mit Ja
einhergeht mit der Erhöhung der Wahrscheinlichkeit für
die
abhängige Variable mit Ja
einhergeht Wahrscheinlichkeit für
die
abhängige Variable mit Ja Der p-Wert von 0,32 gibt an, dass der Einfluss statistisch signifikant
ist Das ungerade Verhältnis ist 1,03,
was bedeutet, dass eine Erhöhung
des Blutwerts um eine
Einheit die Wahrscheinlichkeit, dass die abhängige Variable „Ja“
ausfällt,
um das
0,13-fache Wenn wir also die
logistische Regression erstellen, können
wir sehen, dass wir gerade die Zusammenfassung
gelesen haben ,
dass der p-Wert
0,03 beträgt , was darauf hindeutet, dass der
Blutwert für den
erkrankten Menschen von Bedeutung ist Blutwert für den
erkrankten Menschen von Bedeutung Die Tabelle fasst zusammen, dass
von den 41 Fällen, die bei der Erstellung des Modells untersucht
wurden ,
in diesem Zusammenhang die
Anzahl der Personen beobachtet wurde, die entweder als krank oder gesund vorhergesagt
wurden 28 von 41 Fällen wurden
korrekt eingestuft, erkrankte Personen wurden als krank
und gesunde Personen
als gesund
eingestuft und gesunde Personen
als gesund Der Prozentsatz beträgt 68,29. Es gibt die Gesamtzahl der Personen an, die
korrekt klassifiziert wurden,
durch 28 geteilt, und dann mit 100
multipliziert, um einen Prozentsatz zu erhalten Wenn ich Ihnen sage, wie oft das Modell
die richtige Vorhersage macht, ob es sich bei der Vorhersage um
das Vorhandensein oder Fehlen von S handelt so können wir sehen, dass daraus eine
Klassifikationstabelle entsteht Menschen, die tatsächlich nicht
erkrankt sind und korrekt als nicht erkrankt
vorhergesagt wurden,
Menschen, die erkrankt sind und als nicht erkrankt
vorausgesagt Diese Acht sind mein Anliegen. Warum? Weil dies die Menschen
sind, die sich nicht behandeln
lassen werden. Und fünf von ihnen wurden als krank
eingestuft, obwohl sie in Wirklichkeit nicht
litten Also werden wir dann das ROC-Modell
erstellen,
und das ROC ist derzeit das AOC,
A unter der Kurve liegt A unter der Je höher die Kurve, desto besser das Modell. Von 41 Fällen wurde
in 28 Fällen
die richtige Zuordnung und in 13 Fällen die falsche Zuordnung
vorgenommen. Somit wurden 68% der Personen
korrekt klassifiziert. Lassen Sie uns nun eine
KI-Interpretation durchführen. Die KI-Interpretation besagt
ganz klar , dass das Modell
zwei logarithmische Wahrscheinlichkeiten hat. Je niedriger der Wert,
desto besser das Modell. Hier ist der Wert 51,39, was bedeutet, dass das Modell relativ gesättigt
ist, also ein Modell mit perfekter Passform Die Zahl allein
sagt nicht viel aus. Wir müssen es
mit anderen Modellen vergleichen. Lassen Sie uns nun die
Interpretation des Modells vornehmen. Die Tabelle zeigt
, dass wir
eine binäre logistische
Rekursionsanalyse durchgeführt haben , bei der
untersucht wurde, wie Prädiktoren die Wahrscheinlichkeit eines bestimmten
Ergebnisses
beeinflussen Komponenten, Cefion B.
Dies stellt den Effekt der einzelnen Prädiktoren dar Ein positiver Kozient erhöht die wahrscheinliche oder
logarithmische Wahrscheinlichkeit des Ergebnisses,
und ein negativer und Standardfehler. Damit wird die Standardabweichung
der geschätzten Kohäsion gemessen, d. h.
relativ, wie
genau das Modell den Kohäsionswert
schätzt Der Z-Wert. Dies ist der Z-Score als Koeffizient
geteilt durch den Standardfehler
berechnet wird.
Er wird verwendet, um
die Nullhypothese zu testen , dass
der Koeffizient Null ist. Der P-Wert gibt
die Wahrscheinlichkeit an, dass die Daten oder
etwas Extremeres
beobachtet Wenn die Nullhypothese wahr ist, deutet
der niedrigere
Wert für P und Wort darauf hin, dass der P-Wert
die Wahrscheinlichkeit angibt die Daten oder
etwas Extremeres
beobachtet werden. Wenn die Nullhypothese wahr ist, deutet
der niedrigere p-Wert darauf hin, dass die Nullhypothese, dass keine
Wirkung vorliegt, weniger wahrscheinlich ist. Interpretation.
Das Modell prognostiziert die logarithmische Wahrscheinlichkeit der
Basislinie mit -1,31,
da alle Prädiktoren Das ungerade Verhältnis ist 0,27,
was darauf hindeutet, dass die
Wahrscheinlichkeit des Ergebnisses geringer wenn alle Prädiktoren den Referenzwert Blutwert, der
um drei steigt. Lassen Sie uns jetzt die Vorhersage machen. Wenn mein Blutwert 85 ist, besteht eine Wahrscheinlichkeit von 75%
, dass ich leide. Ich werde auch die ROC-Kurve
sehen. Der ROC, die Fläche unter
der Kurve, beträgt 0,699. Sie, Psst
42. Die nicht normalen Daten verstehen: Unsere Normalität oder nicht. Lassen Sie uns versuchen zu
verstehen, wie wir arbeiten, wenn meine Daten nicht normal sind? Oder noch bevor ich dort
ankomme, möchte ich Ihnen diesen
Herrn vorstellen. Irgendwelche Vermutungen? Wer ist der Gentleman? Sie können in das
Chatfenster tippen, wenn Sie wissen. Und selbst wenn Sie es nicht wissen, ist
das völlig in Ordnung. Für falsche Vermutungen gibt es keine
Strafpunkte. Ja. Einige von Ihnen haben es richtig
erraten? Er ist die berühmte Person hinter
unserer Normalverteilung. Herr Carl cos. Er ist der große Mathematiker. Und er war die
Person, die das Konzept der
Gaußschen Verteilung
oder der Normalverteilung entwickelt hat. Hier ist also das Gehirn
hinter dem Konzept der Normalverteilung und all den parametrischen Tests
, die wir durchführen. Wenn meine Daten nicht normal sind, können sie verzerrt sein. Es könnte negativ oder
positiv verzerrt sein. Wenn ich negativ schief sage, bedeutet das, es technisch gesehen
einen Schwanz auf der linken Seite hat. Positiv schief bedeutet, dass sich der
Schwanz auf der rechten Seite befindet. Das bedeutet, dass sich meine Daten nicht
normal verhalten. Meine Daten können nicht
normal sein, weil sie einer Gleichverteilung
oder einer flachen Verteilung
wie dieser
folgen . Dann folgt es auch nicht
der Normalverteilung. Meine Daten können mehrere Peaks haben, etwa so,
was bedeutet,
dass mein Datensatz mehrere
Datengruppen enthält. Und es ist kein normales Verhalten. Weil meine Daten
all diese Dinge enthalten. Ich muss diese Daten
anders behandeln , wenn ich
meinen Hypothesentest durchführe. Und warum sind diese Daten nicht normal? Dies könnte am
Vorhandensein einiger Ausreißer liegen. Es könnte an
der Schiefheit meiner Daten liegen, oder es könnte an
der Kurtose liegen, die in den Daten
vorhanden ist. Der Grund dafür,
dass sich Ihre Daten nicht normal verhalten,
könnte also einer dieser Gründe sein. Lassen Sie uns zusammenfassen,
was haben wir gelernt? Meine Daten sind nicht normal, wenn die
Verteilung schief, unimodal
ist, sie ist nicht unimodal, sondern tatsächlich diese bimodale oder
multimodale Verteilung. Es handelt sich um eine Heavy-Tail-Verteilung
, die Ausreißer enthält. Oder es könnte eine
flache Verteilung wie eine Gleichverteilung sein. Dies sind einige grundlegende Gründe, warum sich
meine Daten nicht normal verhalten. Seltsamerweise handelt es sich nicht um eine
Normalverteilung, dann gibt es mehrere
Verteilungen. Es gibt auch andere
Verteilungen, bei denen von der
Exponentialverteilung die Rede ist, die die Zeit
zwischen den Ereignissen modelliert. Die logarithmische Normalverteilung. Das heißt, wenn ich
den Logarithmus auf die Daten
anwende, folgen meine Daten
einer Normalverteilung. Poisson-Verteilung, Binomialverteilung,
Multinomialverteilung. Lassen Sie uns einige Beispiele verstehen, reale Szenarien, in denen die nichtnormalen Verteilungen angewendet werden
können. Wenn Sie sich das ansehen, wann immer ich versuche,
etwas über ein
festes Zeitintervall vorherzusagen . Dann verwende ich die Poisson-Verteilung für meine Analyse und Hypothese. Einige Beispiele für die
Poisson-Verteilung oder die
Anzahl der im Call Center
eingegangenen Kundendienstanrufe. Die Anzahl der
Patienten, die an einem bestimmten Tag in die
Notaufnahme eines Krankenhauses
kommen, die Anzahl der Anfragen für einen bestimmten Artikel in einem
Online-Shop an einem bestimmten Tag. Die Anzahl der Pakete, die
von der Lieferfirma
an einem bestimmten Tag geliefert wurden, die Anzahl der defekten Artikel von einem
Produktionsunternehmen an einem bestimmten Tag
hergestellt wurden. Wenn Sie beobachten, gibt es hier
ein übliches Verhalten. Wann immer wir
versuchen,
etwas in einem
bestimmten Zeitraum zu verstehen , könnte
es ein bestimmter Tag sein,
es könnte ein bestimmter
Monat sein, ein gegebenes B.
Dann ziehen wir es vor, Dann ziehen wir unsere Analyse mit der
Poisson-Verteilung durchzuführen. Einige Beispiele für die
logarithmische Normalverteilung. Die Größe der aus dem Internet
heruntergeladenen Dateien, die Größe der Partikel
in einer Sedimentprobe, die Höhe des Baums, die Höhe der
finanziellen Erträge, die Größe des Versicherungsspiels. Wenn Sie sich diese Beispiele ansehen, wenn
ich zum Beispiel die
finanziellen Renditen
ihrer Investitionen nehme , Sie vielleicht feststellen, dass mir
einige Investitionen aus meinem
Anlageportfolio eine
sehr gute Rendite von 100%, 100%, 150 Prozent, 80 Prozent eingebracht haben. Und Sie werden auch
sehen, dass ich in einen Teil
meines Portfolios
investiert habe in einen Teil
meines Portfolios
investiert , weil
dies zu
einer Nullrendite oder einer negativen
Rendite geführt hat, weil ich verloren habe. Insgesamt bietet mir mein
Portfolio jedoch eine Rendite von 12 bis 15 bis 15 Prozent
oder 15 bis 20 Prozent. Sie versuchen zu sagen, dass Ihre Verteilung technisch gesehen
keine Normalverteilung ist . Sie haben sehr niedrige Renditen
und sehr hohe Renditen. Wenn Sie den
Logarithmus jedoch auf Ihre Daten anwenden, verhält er sich wie eine Normalverteilung, sodass Ihr Portfolio
insgesamt zu einer Rendite von
etwa X Prozent
führt . Ähnliches gilt auch für
den Versicherungsanspruch. Versuchen wir,
die Anwendung der
Exponentialverteilung zu verstehen . Die Zeit zwischen
der Ankunft von Kunden in der Warteschlange, die Zeit zwischen Ausfällen an
einer Maschine, Ihrer Fabrik, die Zeit zwischen Einkäufen
im Einzelhandelsgeschäft, Die Zeit zwischen Telefonanrufen
und dem Contact Center, die Zeit zwischen
Seitenaufrufen auf der Website. Wenn Sie nun zwischen
der Poisson-Verteilung und
der Exponentialverteilung sehen der Poisson-Verteilung und , gibt es ein gemeinsames Element. Was ist das gemeinsame Element? Wir versuchen,
mit Bezug auf die Zeit zu lernen. Wann immer Sie
eine Normalverteilung durchführen, bezieht
sie sich nicht auf die Zeit. Stimmt es? Das sind also einige Anwendungen. Aber der Unterschied
zwischen einem Gift und einer Exponentialverteilung liegt in einer
Poisson-Verteilung. Es ist an einem bestimmten Tag, an einem bestimmten Tag, an einer bestimmten Woche sind bestimmte Monate. Hier versuchen wir,
die Zeit zwischen den beiden Ereignissen zu verstehen . Was ist eine Zeitlücke
zwischen den beiden Ereignissen? Dann kann Ihnen die
Exponentialverteilung weiterhelfen. Wir können, lassen Sie uns
die Anwendung einer
gleichmäßigen Verteilung verstehen , wie zum Beispiel die Größe des
Schülers in der Klasse. Bedarf an Paketen in
einem Lieferwagen. Manche Pakete sind sehr groß, manche Pakete sind klein. Wenn Sie es in eine Distribution packen, werden
Sie auch feststellen, dass
es sich um eine flache Distribution oder eine einheitliche Distribution handelt, da Sie
für jede Kategorie von Paketen ungefähr
die
gleiche Anzahl von Paketen haben werden . Waren, die Sie liefern. Die Verteilung der Testergebnisse für eine Multiple-Choice-Prüfung. Die Verteilung der
Wartezeit an einer Ampel, die Verteilung
der Ankunftszeit eines Kunden in einem Einzelhandelsgeschäft. Wenn Sie also all diese Beispiele
nach einer gleichmäßigen Verteilung sehen , handelt es sich nicht um eine Glockenkurve. Weil Sie
ständig
Leute haben ,
die im Einzelhandelsgeschäft ankommen. Es ist nicht so, dass
es einen plötzlichen Höhepunkt gibt. Und die realen Szenarien eines starken
Vertriebs sind der Vertrieb, bei dem
die Ausreißer vorhanden sind, die Anzeichen eines
finanziellen Verlusts und einer Versicherungsbranche oder andere
Anzeichen eines finanziellen Verlusts. Wenn ein paar einen Händler fragen, würden
sie diese extrem
hohe und eine extrem
niedrige Zahl sehen . Die Größe der
extremen Regenfälle. Wir haben also nicht jedes Jahr
extreme Regenfälle. Wir könnten also nicht sagen
, dass alles, was passiert
ist, auf einen Ausreißer zurückzuführen ist. Und der starke
Vertrieb wird
in der Regel durch
das Vorhandensein von Ausreißern beeinträchtigt. Wenn Ihre Daten also Ausreißer
aufweisen, können Sie auch sehen
, dass es sich
bei der Lastverteilung um eine starke
Verteilung handelt. Und wir werden
in der nächsten Sitzung verstehen, welche Art von nichtparametrischen
Tests ich durchführen sollte? Abhängig von der Art
der nicht normalen Daten
, mit denen wir beginnen. Die Größe des
Stromverbrauchs, die Größe der
wirtschaftlichen Schwankungen des Börsencrashs. Dies sind alles Beispiele für
Ihren heftigen Vertrieb. Beispiele für bimodale Daten. Hier müssen Sie verstehen, bimodal bedeutet, dass es
zwei Ergebnisse gibt , die
wir zu untersuchen versuchen. Die Verteilung
der Prüfungsergebnisse von Studierenden, die studiert haben,
und von Studierenden, die nicht studiert haben. Altersverteilung der Personen in
einer Population, die aus
zwei verschiedenen Altersgruppen stammt, Größe zweier verschiedener Arten, Gehaltsverteilung der Mitarbeiter aus zwei verschiedenen Abteilungen. Viel Glück auf einer Autobahn mit zwei Gruppen langsamer
und schneller Fahrer. Hier können Sie also sehen
, dass ich
zwei Gruppen von Daten habe , die unterschiedlich sind. Und ich versuche,
das Verhalten zu verstehen , bevor
ich meine Untersuchung
als Teil meiner Hypothese oder der Ressource
, die ich versuche, durchzuführen. Wenn ich mehr als zwei
Gruppen habe, zwei verschiedene, mehr als zwei verschiedene Gruppen, drei verschiedene Gruppen
für verschiedene Gruppen, dann wird es eine
multimodale Verteilung. Stimmt es? Ich denke also, Sie
hätten inzwischen
eine Vorstellung davon bekommen , was die verschiedenen
Verteilungen
sind, die keine Normalverteilungen sind. Wie stelle ich fest, ob
meine Daten nicht normal sind? Der erste Punkt, der uns in den Sinn
kommt, ist ein Normalitätstest. Aber noch bevor Sie
einen Normalitätstest durchführen, können
Sie mit einfachen
grafischen Methoden herausfinden, ob Ihre
Daten normal sind oder nicht. Sie können ein Histogramm verwenden. Und hier zeigt das Histogramm
deutlich mehrere Züge. Ich kann also deutlich sehen, dass dies keine
Normalverteilung ist. Wenn ich versuchen würde, eine passende Linie zu ziehen, kann ich auch sehen, dass
meine Daten schief sind. Ich kann auch Boxplot verwenden, um festzustellen, ob meine
Daten nicht normal sind. Hier können Sie also sehen, dass
ich
auf der linken Seite einen schweren Schwanz habe , der
darauf hinweist, dass meine Daten verzerrt sind. Ich kann auch Ausreißer haben, die ein Boxplot leicht hervorheben kann. So kann ich mich verstecken und
die starke Verteilung
anhand des Boxplots identifizieren . Ebenfalls. Ich kann einfache
deskriptive Statistiken verwenden , in denen ich die Zahlen
des mittleren Medianmodus sehen kann. Und wenn ich sehe, dass sich
diese Zahlen
nicht überschneiden oder nicht
nahe beieinander liegen , bedeutet
das auch einfach,
dass meine Daten nicht normal sind. Ich kann mir die Kurtose und die
Schiefheit meiner Datenverteilung ansehen Schiefheit meiner Datenverteilung und dann zu dem Schluss kommen, ob sich
meine Daten
normal verhalten oder nicht. Deshalb habe ich Ihnen
andere Möglichkeiten gezeigt , um festzustellen,
ob Ihre Daten Normalverteilung folgen und nicht , oder ob Ihre Daten einer
Normalverteilung folgen. Jetzt würde ich noch eine Sache sagen. Bring dich nicht um,
wenn dein Mittelwert 23,78 und der Median 24 ist und der Modus 24,2 oder 24
wäre. Wenn es also zu einer
leichten Deflation kommt, halten
wir
dies immer noch für normal. Stimmt es? Eine Neigung nahe Null ist ein Hinweis darauf, dass
meine Daten normal sind. Aber wenn meine Schieflage über
minus zwei oder plus zwei liegt, ist das definitiv unser Beweis dafür,
dass wir
keine Normalität haben. Ketose ist auch eine weitere Methode festzustellen, ob meine Daten der Normalverteilung
folgen. Meistens bevorzugen wir die Kurtosis-Zahl
zwischen 0 und 3 liegt. Aber wenn Ihre
Ketose negativ ist, bedeutet das, dass es sich um eine flache Kurve handelt. Audits folgen einer
einheitlichen Verteilung. Audit könnte eine
starke Verteilung
hoher Kurtosis sein, könnte auch
ein Hinweis darauf sein , dass Ihre
Daten zu perfekt sind. Und vielleicht müssen Sie
untersuchen, ob sie
Ihre Daten vor der
Übergabe nicht manipuliert haben . Ein weiterer beliebter AdText- oder
Anderson-Darling-Test, bei dem wir versuchen zu verstehen,
ob meine Daten normal sind oder nicht. Die grundlegende Nullhypothese
ist also,
wenn ich einen NAT-Test mache, dass meine Daten
einer Normalverteilung folgen. Dies ist also der einzige
Test, bei dem ich möchte , dass
mein p-Wert größer
als 0,05 ist.
Ich lehne die
Nullhypothese nicht ab und komme zu dem
Schluss, dass meine
Daten normal sind, und ich greife auf meinen
bevorzugten parametrischen Test zurück, mir die Analyse erleichtert. Aber was ist, wenn
Ihre Daten und Ihre Datenanalyse während des ADA-Tests Ihre Daten und Ihre Datenanalyse zeigen, dass der p-Wert signifikant
ist, dass er kleiner als
0,05 ist, vielleicht 0,02 ist. Dann kommt es zu dem Schluss, dass meine Daten
keine Normalverteilung sind. Und ich muss untersuchen, welche Art von
Nichtnormalität es hat. Dementsprechend
muss ich
den Test machen und dann
weitermachen. Wir werden unsere Sitzung am nächsten Tag
in Venedig fortsetzen. Ich hoffe es hat dir gefallen. Wenn Sie Fragen haben, gerne im WhatsApp
- oder Telegram-Kanal
oder im
Kommentarbereich - oder Telegram-Kanal hier kommentieren. Jedes Thema, das
Sie im Rahmen der Sitzung
am Mittwoch
lernen möchten . Ich würde mich freuen
, das zu prüfen. Wenn Sie diese Kommentare in das Chat-Feld, in die
WhatsApp-Gruppe oder das Telegramm einfügen können. Ich liebe es wirklich, dich zu unterrichten, und ich danke dir, dass du wunderbar bist. Studierende. Pass auf dich auf.
43. Kruskal Wallis-Test mit 3 oder mehr Gruppen nicht-normalen Daten: In diesem Tutorial geht es um
den Crus-Walus-Test. Wenn Sie wissen möchten,
was der
Crus-C-Walus-Test ist und wie er berechnet und interpretiert werden
kann Am Ende dieses Videos sind Sie
am richtigen Ort. Ich zeige Ihnen,
wie Sie den Walus-Test ganz einfach online
berechnen können den Walus-Test ganz einfach online
berechnen Und wir fangen sofort an. Der Crus-Walus-Test ist ein
Hypothesentest, der verwendet wird, wenn Sie testen möchten,
ob es
einen Unterschied zwischen
mehreren unabhängigen Gruppen gibt einen Unterschied zwischen
mehreren unabhängigen Jetzt wundern Sie sich vielleicht ein
wenig und sagen: Hey, wenn es mehrere
unabhängige Gruppen gibt, verwende
ich eine Varianzanalyse Das ist richtig. Aber wenn Ihre Daten nicht
normalverteilt sind und die Annahmen für die
Varianzanalyse nicht erfüllt sind Der Wus-Test wird verwendet. Der Wace-Test ist das nichtparametrische
Gegenstück zur Einzelfaktorvarianzanalyse Ich werde dir jetzt zeigen,
was das bedeutet. Es gibt einen wichtigen Unterschied
zwischen den beiden Tests. Die Analyse von Varianztests, falls es einen
Unterschied in den Mittelwerten gibt Wenn wir also unsere Gruppen haben, berechnen
wir den
Mittelwert der Gruppen
und prüfen, ob alle Mittelwerte
gleich sind Wenn wir uns dagegen den
Crus-C-Wals-Test
ansehen, prüfen wir nicht, ob die Mittelwerte gleich sind Wir prüfen, ob die Rangsummen
aller Gruppen gleich sind. Was bedeutet das?
Was ist nun ein Rang? Und was ist eine Rangsumme
im klassischen ALS-Test? Wir verwenden nicht die
tatsächlichen Messwerte, sondern wir sortieren alle Personen nach Größe, und dann erhält die Person mit dem kleinsten Wert
den neuen Wert oder Rang eins. Die Person mit dem
zweitkleinsten Wert erhält Rang zwei. Die Person mit dem
drittkleinsten Wert erhält Rang drei usw. und so weiter und so weiter vierten Platz, bis jeder Person ein Rang zugewiesen
wurde. Jetzt haben wir jeder Person einen
Rang zugewiesen, und dann können wir einfach die Ränge aus
der ersten Gruppe
zusammenzählen. Addieren Sie die Ränge aus der zweiten Gruppe und addieren Sie die Ränge aus
der dritten Gruppe. In diesem Fall erhalten wir eine Rangsumme von 54 für
die erste Gruppe. 70 für die zweite Gruppe und 47 für die dritte Gruppe. Der große Vorteil besteht darin
, dass, wenn wir nicht den Hauptunterschied,
sondern die Rangsumme
betrachten, die Daten nicht
normalverteilt sein
müssen , wenn wir
den Kreuzwarstest verwenden. Unsere Daten müssen keiner Verteilungsform
entsprechen und müssen daher auch nicht
normalverteilt sein Beispiele für den
Rusk-Wallace-Test für den Rusk-Walus-Test Natürlich können dieselben
Beispiele
wie für die
Einfaktorvarianzanalyse verwendet werden ,
allerdings mit dem Zusatz, dass
die Daten nicht normalverteilt sein müssen Medizinisches Beispiel. Für ein
Pharmaunternehmen möchten
Sie testen, ob ein Medikament XY einen
Einfluss auf das Körpergewicht hat. Dazu wird das Medikament 20 Probanden
verabreicht. T-Testpersonen
erhalten ein Placebo und 20 Testpersonen erhalten
kein Medikament oder Placebo Zielsetzung: Feststellen,
ob Medikament XY im Vergleich zu
Placebo- und Kontrollgruppen
einen statistisch
signifikanten Effekt auf das
Körpergewicht hat einen statistisch
signifikanten Effekt auf im Vergleich zu
Placebo- und Kontrollgruppen
einen statistisch
signifikanten Effekt auf das
Körpergewicht Beispiel aus der Sozialwissenschaft. Unterscheiden sich drei Altersgruppen? In Bezug auf den täglichen
Fernsehkonsum, Forschungsfrage
und Hypothese. Die Forschungsfrage für
den Ruskal lautete vielleicht Test. Gibt es einen Unterschied in der zentralen Tendenz
mehrerer unabhängiger Stichproben? Diese Frage führt zur Null- und
Alternativhypothese. Keine Hypothese. Die unabhängigen Stichproben
weisen alle dieselbe zentrale Tendenz und stammen daher aus
derselben Grundgesamtheit. Alternative Hypothese:
Mindestens eine der unabhängigen
Stichproben weist nicht dieselbe zentrale Tendenz auf wie
die anderen Stichproben und
stammt daher aus einer
anderen Grundgesamtheit Bevor wir besprechen,
wie der Crus-Kull berechnet
wird, machen Sie sich keine Sorgen Es ist wirklich nicht kompliziert. Wir schauen uns zunächst die Annahmen
an. Annahmen. Wann verwenden
wir den Crus C Walus-Test? Wir verwenden
den Crus-Walus-Test wenn wir eine nominale
oder ordinale Variable
mit mehr als zwei Werten haben mit mehr als Und eine metrische Variable, eine nominale oder ordinale Variable mit mehr als zwei Werten, ist zum Beispiel die Variable,
bevorzugte Zeitung, mit den Werten
Washington Post, New
York Times, Es könnte sich auch um die
Häufigkeit handeln, mit
der täglich
mehrmals pro Woche Fernsehen geschaut Wirklich nie ist eine
metrische Variable beispielsweise das Gehalt, das Wohlbefinden, Wohlbefinden oder das Gewicht von Personen. Was sind jetzt die Annahmen? nur mehrere unabhängige
Zufallsstichproben mit zumindest normal skalierten Merkmalen verfügbar
sein Die Variablen müssen keiner Verteilungskurve entsprechen Die Nullhypothese ist also, dass
die unabhängigen Stichproben alle dieselbe
zentrale Tendenz aufweisen. Und stammen daher aus derselben Population
oder mit anderen Worten. Es gibt keinen Unterschied
in den Rangsummen, und die alternative Hypothese
könnte sein, dass mindestens eine
der unabhängigen
Stichproben nicht
dieselbe zentrale Tendenz aufweist
wie die anderen Stichproben und daher aus
einer anderen Population stammt. Oder um es noch einmal mit
anderen Worten zu sagen. Mindestens eine Gruppe
unterscheidet sich in ihren Rangsummen. Die nächste Frage ist also, wie berechnet man einen
Zwieback? Wallace-Test Es ist nicht schwer.
Nehmen wir an, Sie haben die
Reaktionszeit von drei Gruppen gemessen. Gruppe A in Gruppe C, und jetzt
möchten Sie wissen, ob es einen Unterschied zwischen den Gruppen in Bezug auf die Reaktionszeit gibt. Nehmen wir an, Sie haben
die gemessene
Reaktionszeit in einer Tabelle notiert . Gehen wir einfach davon aus, dass die Daten nicht
normalverteilt und Sie daher den Crus-K-Was-Test
verwenden müssen Dann lautet unsere Nullhypothese, dass es keinen Unterschied
zwischen den Gruppen gibt, und das werden wir jetzt
testen Zuerst weisen wir jeder Person einen
Rang zu. Das ist der kleinste Wert. Diese Person bekommt also Rang eins. Das ist der
zweitkleinste Wert. Diese Person bekommt also Rang zwei, und das machen wir jetzt
für alle Leute. Wenn die Gruppen keinen
Einfluss auf die Reaktionszeit haben, sollten
die Ränge eigentlich rein zufällig
verteilt werden. Im zweiten Schritt berechnen
wir nun
die Rangsumme und die mittlere Rangsumme
für die erste Gruppe, die Rangsumme ist zwei plus
vier plus sieben plus neun, was 22 entspricht, und wir haben vier
Personen in der Gruppe. Die mittlere Rangsumme ist
22/4, was 5,5 entspricht. Jetzt machen wir dasselbe
für die zweite Gruppe. Hier erhalten wir eine Rangsumme von 27 und die mittlere
Rangsumme von 6,75, und für die dritte Gruppe erhalten
wir eine Rangsumme von 29 und die mittlere Rangsumme von 7,25 Jetzt können wir den
erwarteten Wert der Rangsummen berechnen. Wenn
es keinen Unterschied zwischen
den Gruppen gäbe, wäre der erwartete Wert , dass jede Gruppe
eine Rangsumme von 6,5 hätte. Wir haben jetzt fast
alles, was wir brauchen. Wir interviewen 12 Personen. Die Anzahl der Fälle beträgt 12. Der erwartete Wert
der Ränge ist 6,5. Wir haben auch
die mittleren Rangsummen
der einzelnen Gruppen berechnet . Die Grade vor
Domina sind zwei, und diese ergeben sich einfach der Anzahl der
Gruppen minus eins, was drei minus eins ergibt Schließlich benötigen wir die Varianz. Die Varianz der Ränge
ergibt sich aus dem Quadrat n im Quadrat -1/12. N ist wieder eine Anzahl
von Personen, also 12. Wir erhalten eine Varianz von 11,92. Jetzt haben wir mit diesen Werten alles, was
wir brauchen. Wir können jetzt
unseren Testwert
g berechnen . Die Teststatistik
entspricht
dem g-Quadrat-Wert und ist
durch diese Formel n mal die Summe von r bar minus e r geteilt
durch Sigma zum
Quadrat In unserem Fall beträgt die
Anzahl der Fälle 12. Wir haben immer vier
Personen pro Gruppe. Wir können also das E herausziehen. 5,5
ist der mittlere Rang von Gruppe A, 6,75 ist der mittlere
Rang von Gruppe B und 7,25 ist der
mittlere Rang von Gruppe C. Dies gibt uns einen
gerundeten Wert von 0,5, wie wir gerade Wie wir gerade gesagt haben,
entspricht dieser Wert dem quadratischen Jetzt können wir den kritischen,
quadratischen Wert in der Tabelle
der kritischen, quadratischen Werte leicht
ablesen . Sie finden diese Tabelle auch im
Internet. Wir haben zwei Freiheitsgrade. Und wenn wir annehmen, dass wir
ein Signifikanzniveau von 0,05 haben , erhalten
wir einen kritischen, quadratischen Wert von 5,991 Natürlich ist unser Wert kleiner als der
kritische G-Quadrat-Wert, sodass auf der Grundlage
unserer Beispieldaten die Nullhypothese beibehalten wird. Jetzt zeige ich Ihnen, wie
Sie den
Cresco-Wallace-Test einfach
online mit der Registerkarte Daten berechnen können Cresco-Wallace-Test einfach
online mit der Registerkarte Daten berechnen Online-Berechnung. Dazu besuchen
Sie einfach data tab.net, besuchen
Sie einfach data tab.net, klicken dann auf den Statistikrechner und fügen Ihre eigenen Daten
in diese Tabelle Außerdem klicken Sie auf diese Registerkarte, und unter dieser Registerkarte finden
Sie viele
Hypothesentests. Wenn Sie die
Variablen auswählen, die Sie testen möchten, schlägt
das Tool
den entsprechenden Test Nachdem Sie Ihre
Daten in die Tabelle kopiert haben, sehen
Sie
hier unten die Reaktionszeit und die Gruppe. Jetzt klicken wir einfach auf
Reaktionszeit und Gruppe und es wird automatisch
eine Varianzanalyse für uns berechnet eine Varianzanalyse für Aber wir wollen keine
Varianzanalyse. Wir wollen den nichtparametrischen Test. Wir klicken einfach hier. Jetzt
berechnet der Rechner
automatisch den
Ruskal-Wallace-Test Wir erhalten außerdem einen
E-Quadratwert von 0,5, die Freiheitsgrade sind zwei
und der berechnete p-Wert ist, und hier unten können Sie die Interpretation
nachlesen Ruskal Walus hat
gezeigt, dass es keinen signifikanten Unterschied
zwischen den Kategorien Basierend auf dem p-Wert können
wir daher mit den verwendeten Daten die mit den verwendeten Daten die Nullhypothese nicht zurückweisen Probieren Sie es einfach selbst aus.
Es ist sehr einfach. Bleiben Sie in Verbindung, lernen Sie
weiter, wachsen Sie weiter, wir sehen uns
in der nächsten Lektion.
44. Design von Experimenten: Hallo und willkommen. In diesem Video. Wir werden in die
faszinierende Welt
der Versuchsplanung eintauchen Allgemein als DOE bezeichnet, besprechen
wir, was
Versuchsplanung oder DOE ist, die Prozessschritte
eines DOE-Projekts Wie DOE Ihnen helfen kann,
die Anzahl der Experimente zu reduzieren. Wie lässt sich die Anzahl
der benötigten Experimente abschätzen? Und wir gehen die
gängigsten Arten von Designs durch. Was genau ist also
Versuchsplanung im Kern, Versuchsplanung DOE ist eine strukturierte
Methode zur Planung, Durchführung und
Interpretation von Experimenten. Der Hauptzweck von DOE besteht darin herauszufinden, wie sich verschiedene
Eingangsvariablen, sogenannte Faktoren, auf
eine Ausgangsvariable, die
sogenannte Antwortvariable, auswirken . Hier ist eine
einfachere Erklärung. Systematischer Ansatz. DOE ist organisiert und methodisch. Es folgt einem schrittweisen
Prozess, um sicherzustellen, dass die Experimente auf logische und effiziente
Weise durchgeführt werden Eingabevariablen, Faktoren. Dies sind die Elemente
, die Sie in
einem Experiment ändern , um zu sehen, wie
sie sich auf das Ergebnis auswirken. Wenn Sie
beispielsweise einen Kuchen backen, können dies
die Zuckermenge,
die Backzeit oder
die Ofentemperatur sein. Ausgangsvariable,
Antwortvariable. Dies messen Sie
im Experiment, um die Auswirkungen
der Änderungen zu ermitteln, die
Sie an den Faktoren vorgenommen haben. Im Kuchenbeispiel könnte
die Antwortvariable
der Geschmack oder die Textur
des Kuchens sein . Ziel von DOE ist es,
die Beziehung
zwischen diesen Faktoren
und der Antwortvariablen zu verstehen die Beziehung
zwischen diesen Faktoren . Wir helfen Ihnen dabei
, festzustellen, welche Faktoren
den größten Einfluss haben den größten Einfluss und wie sie
miteinander interagieren. Stellen Sie sich vor, Sie fahren Fahrrad. Die sanfte
Drehung der Räder hängt vom Zustand
der Lager ab. Wenn die Lager
gut geschmiert sind, entsteht ein minimales
Reibungsmoment,
sodass das sodass Wenn die Schmierung jedoch
unzureichend ist oder die
Temperatur zu hoch ist, ist aufgrund der erhöhten
Reibung mehr Aufwand erforderlich, um die Geschwindigkeit
aufrechtzuerhalten In solchen Fällen können wir
mit DOE systematisch Faktoren
wie Schmierarten
wie Öl oder Fett
und schwankende Temperaturen (niedrig,
mittel, hoch)
untersuchen wie Schmierarten
wie Öl oder Fett
und schwankende Temperaturen (niedrig, und schwankende Temperaturen (niedrig , um deren Einfluss
auf die Reibung genau zu quantifizieren Aber warum ist das wichtig? Das Design von Experimenten
ermöglicht es uns,
effiziente Testpläne zu entwerfen , die diese
Erkenntnisse effektiv
aufdecken Durch die sorgfältige Manipulation von
Faktoren und ihren Werten hilft uns
DOE dabei, herauszufinden, welche
Variablen das Ergebnis maßgeblich
beeinflussen Sei es in mechanischen Systemen
wie Lagern oder in komplexeren Szenarien, in denen Menschen auf Medikamente reagieren Die Anwendungsmöglichkeiten von DOE
sind umfangreich und vielfältig Ob es nun um die Optimierung von
Herstellungsprozessen, Verbesserung von Produktdesigns oder die Weiterentwicklung medizinischer Behandlungen DOE dient als leistungsstarkes
Instrument zur Identifizierung
kritischer Faktoren und zur Festlegung optimaler Bedingungen für die
Erzielung der gewünschten Ergebnisse Es ermöglicht Forschern
und Ingenieuren,
fundierte Entscheidungen auf der Grundlage
empirischer Daten zu treffen, anstatt
sich auf Vermutungen zu verlassen In unseren nächsten Abschnitten werden
wir uns mit den
wesentlichen Schritten des
ADOE-Projekts befassen, von der Planung von von der Planung von Experimenten Im weiteren Verlauf des Kurses decken
wir die Feinheiten der
Versuchsplanung auf
und erfahren, decken
wir die Feinheiten der wie
dieser methodische Ansatz Ihren Experimentier- und Forschungsansatz
revolutionieren kann Forschungsansatz
revolutionieren . Bleiben Sie dran für weitere Einblicke und praktische Tipps.
45. Die Anwendungsbereiche für ein DOE: Lassen Sie uns nun verstehen, in
welchen Anwendungsbereichen DOE eingesetzt werden kann. Die Anwendungen von DOE sind
breit gefächert und vielfältig, sei es zur Optimierung von
Herstellungsprozessen, zur Verbesserung von Produktdesigns oder zur Verfeinerung medizinischer Behandlungen DOE ist ein leistungsstarkes
Instrument zur Identifizierung von Schlüsselfaktoren und zur Bestimmung der besten Bedingungen, um die gewünschten Ergebnisse zu
erzielen Es hilft Forschern
und Ingenieuren,
fundierte Entscheidungen auf der Grundlage
realer Daten statt auf Vermutungen zu Schritte eines DOE-Projekts Lassen Sie uns einen Blick auf den
Prozess eines DOE-Projekts, die
Planung, Überprüfung,
Optimierung und Im ersten Schritt die Planung. Die Dinge sind wichtig. Verschaffen Sie sich zunächst ein klares
Verständnis des Problems und des Systems. Zweitens bestimmen Sie eine oder
mehrere Antwortvariablen. Drittens identifizieren Sie Faktoren, die
die Antwortvariable erheblich beeinflussen
können. Die Bestimmung
potenzieller Faktoren, die
die Antwortvariable beeinflussen, kann sehr komplex und zeitaufwändig sein. In einem Team
kann beispielsweise ein Fischgrätendiagramm erstellt werden. Jetzt kommt der zweite Schritt. Screening, wenn es
viele Faktoren gibt , die einen Einfluss
haben könnten. In der Regel mehr als
vier bis sechs Faktoren. Screening-Experimente sollten
durchgeführt werden , um
die Anzahl der Faktoren zu reduzieren. Warum ist das wichtig? Die Anzahl der
zu untersuchenden Faktoren hat einen großen Einfluss auf die Anzahl
der erforderlichen Experimente. Beachten Sie, dass bei
der Versuchsplanung die einzelnen Experimente
auch einfach als Durchläufe im
vollfaktoriellen Versuchsplan bezeichnet werden, worauf wir gleich
noch näher eingehen Die Anzahl der
Experimente oder Durchläufe entspricht n der
Potenz von k, wobei n die Anzahl der Durchläufe und k die Anzahl der Faktoren ist Hier ist ein kleiner Überblick
, ob wir drei Faktoren haben. Zum Beispiel müssen wir
mindestens acht Durchläufe
mit sieben Faktoren machen . Es sind bereits mindestens 128
Läufe mit zehn Faktoren. Es sind bereits
mindestens 1024 Läufe. Bitte beachten Sie, dass diese
Tabelle für AD OE gilt, wo jeder Faktor nur
zwei Stufen hat, andernfalls. , wie komplex ein
einzelnes Experiment ist, wird es noch mehr Durchläufe geben Je nachdem, wie komplex ein
einzelnes Experiment ist, wird es noch mehr Durchläufe geben. Es kann sich daher
lohnen, sogenannte Screening-Designs
für vier oder mehr Faktoren auszuwählen . Später werden wir uns dem fraktionierten faktoriellen Design und dem ruhigen Berman-Design befassen. Welches kann für Screening-Experimente verwendet werden. Sobald die signifikanten
Faktoren anhand von
Screening-Designs identifiziert
wurden anhand von
Screening-Designs identifiziert
wurden , wurde die Anzahl der
Faktoren hoffentlich reduziert. Weitere Experimente
können nun durchgeführt werden. Die gewonnenen Daten können dann
verwendet werden , um ein
Regressionsmodell zu erstellen, mit
dessen Hilfe
die Eingangsvariablen
so bestimmt werden können, dass die
Antwortvariable optimiert wird Nach der Optimierung folgt der
letzte Schritt der Überprüfung. Dabei wird noch
einmal überprüft, ob die berechneten optimalen
Eingangsgrößen wirklich den
gewünschten Einfluss
auf die Antwortvariable haben . Je nachdem, ob wir uns
im Screening-Schritt oder
im Optimierungsschritt befinden. Es gibt verschiedene
Arten von Designs. Danke für Ihre Aufmerksamkeit. In der nächsten Lektion werden
wir uns eingehender praktischen Anwendungen
der Versuchsplanung und der
effektiven Interpretation der Ergebnisse befassen. Bleib dran.
46. Arten von Designs in einem DOE: Arten von Designs in
DOE-Experimenten. Wenn wir uns entweder
im Screening-Schritt oder im Optimierungsschritt befinden. Wir verwenden verschiedene Arten
von Entwurfsmethoden. Die bekanntesten
sind das vollfaktorielle Design, das
fraktionierte faktorielle Design, das
Placet-Berman-Design, das
Box-Benkin-Design und das zentrale Verbunddesign Schauen wir uns zunächst den vollfaktoriellen Versuchsplan und
den teilfaktoriellen Versuchsplan an vollfaktoriellen Versuchsplan und
den teilfaktoriellen Versuchsplan . Wir müssen auch beantworten, warum
wir all diese Anstrengungen unternommen haben. Warum verwenden wir
Versuchsplanung, DOE, und warum
brauchen wir Statistiken? Der Grund dafür ist, dass Experimente Zeit in
Anspruch nehmen und Geld kosten. Deshalb müssen wir die Anzahl der Durchläufe, der
einzelnen Experimente,
so gering wie möglich
halten . Wenn wir jedoch zu wenige Durchläufe durchführen, übersehen
wir möglicherweise
wichtige Unterschiede und erhalten keine genauen Ergebnisse. Nehmen wir zum Beispiel an, wir möchten
herausfinden , welche Faktoren
das Reibungsverhalten eines
Lagers beeinflussen das Reibungsverhalten eines
Lagers Wir müssen unsere Experimente sorgfältig
planen, um diese
Faktoren effizient zu
identifizieren, diese
Faktoren effizient zu
identifizieren ohne unnötige Durchläufe durchführen zu müssen Wie wird die Anzahl der
Experimente in DOE geschätzt? Schauen wir uns ein Beispiel an. Wir wollen untersuchen
, welche Faktoren den Reibungswiderstand eines
Lagers
beeinflussen Fangen wir mit einem
Faktor an, der Schmierung. Wir wollen wissen, ob die
Schmierung
das Reibungsmoment beeinflusst , wenn ein
Lager geölt oder gefettet ist Um das herauszufinden, nehmen wir eine
Stichprobe von zehn Lagern? Wir ölen die Hälfte der Lager
und fetten die andere Hälfte ein. Jetzt können wir
die Reibungszunahme der fünf geölten Lager und
der fünf gefetteten Lager messen geölten Lager und
der fünf gefetteten Lager Aber warum zehn Kugellager verwenden, in den meisten Fällen
kostet jeder Lauf eine Menge Geld Vielleicht kommen wir
mit weniger Durchläufen zurecht. Wie viele Experimente müssen wir
durchführen, um herauszufinden, ob der Schmierstoff einen
Einfluss auf die Reibungszunge hat Fangen wir einfach mit
den zehn Kugellagern an. Wir können jetzt
den Mittelwert des Reibungsmoments
der
geölten und gefetteten Lager berechnen Reibungsmoments
der
geölten und gefetteten Lager Dann können wir
die Differenz zwischen
den beiden Mittelwerten berechnen die Differenz zwischen
den In diesem Beispiel können wir
einen Unterschied zwischen geölten
und gefetteten Lagern erkennen einen Unterschied zwischen geölten
und gefetteten Lagern Wir stellen jedoch auch fest, dass das Reibungsmoment in
den geölten und
gefetteten Lagern sehr unterschiedlich Wenn wir eine weitere
Zufallsstichprobe von zehn Lagern nehmen, könnte
der Unterschied größer sein oder er könnte in die entgegengesetzte Richtung Mit anderen Worten, die
Reibungseigenschaften
der Lager sind sehr unterschiedlich Je größer die Streuung, desto schwieriger ist es, einen bestimmten
Unterschied oder Effekt zu erkennen Zum Glück können wir
die Variabilität
des Mittelwerts verringern ,
indem wir die Stichprobengröße erhöhen Je größer der Stichprobenumfang, desto genauer ist die
Schätzung des Mittelwerts Daher muss der
Stichprobenumfang umso größer sein,
je geringer
der Effekt und je breiter
die Streuung der Antwortvariablen und je breiter
die Streuung der Aber wie viel größer, wie können Sie die
Anzahl der benötigten Durchläufe abschätzen? Sie können diese Formel als
Näherung verwenden , um
die Anzahl der benötigten Durchläufe zu schätzen n entspricht Sigma geteilt Ein Quadrat ist hier, n ist
die Anzahl der Durchläufe. Sigma ist die Standardabweichung. Delta ist der
zu bestimmende Effekt. Zum Beispiel, wenn wir
eine Standardabweichung von drei Newtonmillimetern und eine relevante Differenz von
fünf Newtonmillimetern haben. Wir brauchen 22 Läufe. Wenn die Standardabweichung
zwei Newtonmillimeter beträgt. Wir benötigen nur zehn Durchläufe, wenn die Standardabweichung
einen Newtonmillimeter beträgt Wir brauchen vier Läufe. Wir würden also zwei Läufe mit
gefetteten Lagern und zwei
Läufe mit geölten Lagern verwenden gefetteten Lagern und zwei
Läufe mit geölten Lagern Aber wie kann DOE Ihnen helfen, die Anzahl der
Läufe zu reduzieren? Wir werden es in der nächsten Lektion
im Detail sehen. Danke für Ihre Aufmerksamkeit. In der nächsten Lektion werden
wir uns eingehender praktischen Anwendungen
der Versuchsplanung und der
effektiven Interpretation der Ergebnisse befassen. Bleib dran.
47. Wie man die Anzahl der Durchläufe reduzieren kann: Aber wie kann DOE Ihnen helfen, die Anzahl der Läufe zu
reduzieren? Nehmen wir an, dass die
Berechnung der Anzahl der Durchläufe zu
16 Experimenten führt. Acht Läufe mit geölten Lagern und acht Läufe mit
gefetteten Aber was ist, wenn wir
einen zweiten Faktor haben? Nehmen wir an,
wir haben zusätzlich
zur Schmierung Temperaturen mit
niedrigen und hohen Werten. Dann benötigen wir weitere acht Durchläufe , um diese Faktoren zu
berücksichtigen. Wir benötigen also 16 Durchläufe , um zu überprüfen, ob das
Schmiermittel eine Wirkung hat. Und 16 Läufe, um zu überprüfen, ob sich die
Temperatur auswirkt. Das gibt uns
insgesamt 24 Läufe. Nun stellt sich die Frage, ob es möglich
ist, dies mit weniger Durchläufen zu erreichen, und das bringt uns zum
vollständigen faktoriellen Design Die Frage ist, warum sollten wir uns darauf
beschränken,
jeweils einen Faktor zu testen Stattdessen könnten wir ein Design
entwickeln , das alle
möglichen Kombinationen berücksichtigt, z. B. Fett und
hohe Temperaturen Natürlich benötigen wir immer noch
16 Durchläufe pro Faktor. Das erreichen wir, indem mit jeder
der
vier Kombinationen vier Durchläufe machen. Dann haben wir acht Läufe mit
Öl und acht mit Fett und auf der anderen Seite acht mit niedriger Temperatur und acht mit hoher Temperatur. Wir haben jetzt insgesamt 16
Läufe, bevor wir 24 Läufe hatten. Wir benötigen jetzt weniger Experimente und erhalten noch mehr Informationen. Warum mehr Informationen? Wir wissen jetzt auch,
ob es eine Wechselwirkung zwischen
Temperatur und Schmierung gibt. Beispielsweise kann es bei geölten
Lagern Schwankungen des Reibungsmoments bei unterschiedlichen Temperaturen kommen,
was bei gefetteten Lagern nicht der Fall ist Diese Information wäre zuvor verloren
gegangen. Wenn wir jetzt drei statt zwei
Faktoren haben, sind
die Einsparungen noch höher. Wenn wir jeweils einen der
drei Faktoren testen, benötigen
wir 32 Durchläufe. Wenn wir jetzt zwei
Experimente für
jede Kombination in einem
vollfaktoriellen Versuchsplan durchführen , benötigen
wir immer noch nur 16 Durchläufe Für jeden Faktor haben
wir jedoch immer noch acht
Durchläufe pro Faktorstufe Für den
Schmierfaktor haben
wir beispielsweise acht Läufe mit Öl
und acht Durchläufe mit Fett. Natürlich können wir auch
vollfaktorielle Versuchspläne
mit mehr als zwei Stufen erstellen vollfaktorielle Versuchspläne
mit mehr als zwei Stufen Der
Temperaturfaktor
könnte beispielsweise drei Stufen haben:
niedrig, mittel und hoch Wie eingangs erwähnt, nimmt die Anzahl der
erforderlichen Durchläufe jedoch
selbst
bei einem
vollfaktoriellen Versuchsplan mit zwei Stufen für jeden Faktor
sehr schnell zu, nimmt die Anzahl der
erforderlichen Durchläufe wenn die Anzahl
der Faktoren zunimmt Schauen wir uns daher nun den
teilfaktoriellen Versuchsplan an Das fraktionierte faktorielle Design wird für Screening-Versuchspläne verwendet Das heißt, wenn Sie
mehr als ungefähr
vier bis sechs Faktoren haben , Verringerung
der Anzahl der Durchläufe natürlich auch bedeutet eine Verringerung
der Anzahl der Durchläufe natürlich auch eine
Verringerung
der Bei teilfaktoriellen Versuchsplänen ist
die Auflösung reduziert Was ist die Auflösung? Die Auflösung ist ein
Maß dafür, wie gut DOE
zwischen verschiedenen Effekten unterscheiden kann. Genauer gesagt gibt die
Auflösung an, wie stark die Haupteffekte und
Wechselwirkungseffekte in einem Design miteinander vermischt
sind Aber was sind Mitteleffekte
und Interaktionseffekte? Was bedeutet „verwechselt“? In der Versuchsplanung bezieht sich
der Begriff Effekt
auf die Auswirkung, die ein bestimmter Faktor oder
eine Kombination von Faktoren auf die
Antwortvariable eines Experiments hat Im Wesentlichen messen sie, wie stark sich die
Antwortvariable ändert , wenn Sie die Faktoren ändern. Ein Haupteffekt ist
der Einfluss
eines einzelnen Faktors auf die
Antwortvariable. Welchen Einfluss hat beispielsweise die Schmierung eines Lagers auf
die Reibungszunge Wechselwirkungseffekte treten auf
, wenn die Wirkung eines Faktors auf die Antwortvariable von der Höhe
eines anderen Faktors abhängt Beispielsweise
könnte die Wirkung
des Schmiermittels auf
die Reibung von der Temperatur abhängen Aber was heißt das? Danke für Ihre Aufmerksamkeit. In der nächsten Lektion
werden wir uns eingehender praktischen Anwendungen der Versuchsplanung befassen.
Bleib dran.
48. Art der Effekte: Aber was sind Haupteffekte
und Interaktionseffekte, und was bedeutet „verwechselt“ Bei der Planung von Experimenten. Der Begriff Effekt bezieht sich auf den Einfluss, den ein
bestimmter Faktor oder eine Kombination von Faktoren auf
die Antwortvariable
eines Experiments hat . Im Wesentlichen messen sie, wie stark sich die
Antwortvariable ändert , wenn Sie die Faktoren ändern? Ein Haupteffekt ist
der Einfluss
eines einzelnen Faktors auf die
Antwortvariable. Welchen Einfluss hat beispielsweise die Schmierung eines Lagers auf
das Reibungsmoment Wechselwirkungseffekte treten auf
, wenn die Wirkung eines Faktors auf die Antwortvariable von der Höhe
eines anderen Faktors abhängt Beispielsweise
könnte die Wirkung des Schmiermittels auf
die Reibungszunge von Schmiermittels auf
die Reibungszunge von der Temperatur abhängen Aber was heißt das? Nehmen wir an, wir haben ein durchschnittliches
Reibungsmoment von 102 Newtonmillimetern für die Lager mit Öl
und einen Durchschnittswert von 108 Newtonmillimetern für
die Lager mit Fett Dann haben wir einen Haupteffekt der
Schmierung von sechs
Newtonmillimetern Aber jetzt können wir das in hohe und
niedrige Temperaturen
aufteilen. Bei hohen Temperaturen könnten
wir
98 für Öl und 102 für Fett bekommen . Der Unterschied zwischen Öl und Fett beträgt nur vier
Newtonmillimeter. Bei niedriger Temperatur
könnten wir 104 und 112 bekommen. Ein Unterschied von acht,
der Schmierfaktor wird also von der Temperatur
beeinflusst, und wir haben eine Wechselwirkung zwischen Schmierung
und Temperatur. Die Wechselwirkung führt
zu einem Unterschied von zwei neuen 10 Millimetern
zum ursprünglichen Ergebnis. Wir haben also einen
Wechselwirkungseffekt von zwei Newtonmillimetern. Bei vollfaktoriellen Versuchsplänen alle Wechselwirkungen berücksichtigt In unserem Beispiel zur Lagerreibung neben den Faktoren der
Schmierstofftemperatur haben wir uns neben den Faktoren der
Schmierstofftemperatur auch mit
der Wechselwirkung
zwischen Schmierstoff
und Temperatur befasst zwischen Schmierstoff
und Mit zunehmender Anzahl
von Faktoren treten jedoch schnell
zahlreiche Wechselwirkungen Wenn wir beispielsweise fünf Faktoren
haben,
A, B, C, D und E, erhalten
wir die Wechselwirkung
zwischen zwei Faktoren. Zwischen drei Faktoren, zwischen vier Faktoren und
zwischen allen fünf Faktoren. Jetzt natürlich. Die Frage ist,
brauchen wir wirklich alle Interaktionen oder können wir die Auflösung reduzieren? Genau das macht
der teilfaktorielle Versuchsplan in einem
teilfaktoriellen Versuchsplan . Wechselwirkungen
können mit
anderen Wechselwirkungen oder mit
Haupteffekten von Faktoren verwechselt anderen Wechselwirkungen oder mit Was bedeutet „verwirrt“? Das bedeutet, dass die Auswirkungen
verschiedener Faktoren oder die Wirkung des Zusammenspiels von Faktoren nicht
voneinander getrennt werden können Inwieweit die
Anzahl der Durchläufe auf Kosten der
Auflösung
reduziert werden kann auf Kosten der
Auflösung
reduziert , ist
in dieser Tabelle dargestellt. Die Auflösung wird in der Regel mit römischen Ziffern
angegeben. Beispiel drei, vier,
fünf usw. Hier auf der Diagonale. Wir sehen die vollständigen
faktoriellen Designs. Wir werden gleich durchgehen, was die
Auflösungen drei ,
vier und fünf bedeuten Wenn wir beispielsweise sechs Faktoren
haben, benötigen
wir mindestens 64 Durchläufe für
einen vollfaktoriellen Versuchsplan Wenn wir einen
teilfaktoriellen Versuchsplan
mit einer Auflösung von sechs wählen mit einer Auflösung Wir benötigen 32 Durchläufe mit
einer Auflösung von vier. Wir benötigen 16 Durchläufe mit einer Auflösung von drei. Wir brauchen nur acht Läufe. Aber was heißt das? Wie funktioniert es? Der
vollfaktorielle Versuchsplan wird immer als
Ausgangspunkt verwendet Schauen wir uns das
Beispiel mit acht Durchläufen an. In der nächsten Lektion
werden wir uns eingehender praktischen Anwendungen der Versuchsplanung befassen.
Bleib dran.
49. Fraktionales faktorielles Design: Lassen Sie uns die
wichtigsten Punkte zu
fraktionalfaktoriellen
Versuchsplänen in einfachen Worten zusammenfassen fraktionalfaktoriellen
Versuchsplänen Was sind teilfaktorielle Versuchspläne? Bruchfaktorielle Versuchspläne sind eine effiziente Methode, um mehrere Faktoren gleichzeitig zu testen Sie
reduzieren die Anzahl
der erforderlichen Versuchsdurchläufe erheblich Versuchsdurchläufe Warum
fraktionalfaktorielle Versuchspläne verwenden? Die Verwendung von
teilfaktoriellen Versuchsplänen spart Versuchsplänen
sowohl Zeit als auch Ressourcen im Vergleich Darüber hinaus ermöglichen sie
das Testen von Wechselwirkungen
zwischen Faktoren, sodass
mit weniger Experimenten wertvolle Erkenntnisse gewonnen Erstens: Auflösung in fraktionierten
faktoriellen Versuchsplänen. Definition: Auflösung bezieht sich darauf, wie viele Informationen in einem
Versuchsplan
erfasst werden Einfacher ausgedrückt sagt sie
uns, wie viele Faktoren wie A, B, C wir zusammen testen können und wie gut wir
ihre Auswirkungen voneinander trennen können . H höhere Auflösung,
zum Beispiel drei oder drei. Das bedeutet, dass wir
mehr Faktoren zusammen testen können, aber es bedeutet auch
, dass die Auswirkungen
dieser Faktoren mit Wechselwirkungen
verwechselt werden können Diese Faktoren
interagieren miteinander. Bei
Auflösung drei könnten beispielsweise die Auswirkungen von
Hauptfaktoren
mit Wechselwirkungen verwechselt werden , an denen
zwei andere Faktoren beteiligt sind. Beispiel: Niedrigere Auflösung. I V oder 4, hier können
wir nicht so viele
Faktoren zusammen testen, aber es ist klarer,
die Haupteffekte der
einzelnen Faktoren zu erkennen , da sie
weniger mit Wechselwirkungen vermischt sind . Bei
Auflösung vier beispielsweise werden
die Auswirkungen der Hauptfaktoren mit Wechselwirkungen
verwechselt, an denen drei Faktoren beteiligt sind an denen drei Faktoren beteiligt Zweitens, verwirrende
Effekte, Definition. Wenn wir sagen, dass Effekte verwechselt
werden, bedeutet das, dass wir nicht genau sagen können , welcher Faktor eine
bestimmte Änderung der Ergebnisse verursacht Dies liegt daran, dass
verschiedene Kombinationen von Faktoren ähnliche
Auswirkungen auf das Ergebnis haben können Stellen Sie sich zum Beispiel vor, wir
testen die Faktoren A, B und C, wenn wir einen vierten Faktor, D, hinzufügen könnten
die Ergebnisse
Veränderungen zeigen , die wir nicht ausschließlich D
zuordnen können . Die Wirkung von D
könnte mit der Art und Weise, wie A,
B und C miteinander interagieren
, verwechselt werden . Drittens, Einfluss der Auflösung
auf das Versuchsdesign. Erklärung. Die Wahl einer
Auflösung wirkt sich darauf aus, wie effizient unser Experiment ist und wie klar unsere Ergebnisse sind. Eine höhere Auflösung ermöglicht es uns, mehr Faktoren gemeinsam zu
testen, erfordert
jedoch mehr Tests, um uns auf unsere Ergebnisse verlassen zu
können. Eine niedrigere Auflösung
erfordert weniger Tests, kann es
aber schwieriger machen,
die Auswirkungen
verschiedener Faktoren miteinander zu die Auswirkungen
verschiedener Faktoren Vier praktische
Beispiele, Illustration Stellen
Sie sich zum besseren Verständnis vor, verschiedene Rezepte
für das Backen eines Kuchens auszuprobieren Wenn Sie eine Zutat ändern, z. B. Zucker, kann sich der
Geschmack ändern. Wenn Sie jedoch
sowohl Zucker als auch Mehl ändern, ist
es schwieriger zu sagen, welche
Änderung zu welchem Ergebnis geführt hat. Das Design hilft
uns dabei, ein Gleichgewicht zwischen dem Testen vieler Faktoren und dem Verständnis
ihrer einzelnen Auswirkungen herzustellen. diese Punkte verstehen, Forscher diese Punkte verstehen, können sie
Experimente entwerfen, die
klare Antworten darauf geben , wie sich
Faktoren auf die Ergebnisse auswirken, selbst wenn
mehrere Faktoren gleichzeitig getestet werden. Wir werden gleich durchgehen, was die
Auflösungen drei ,
vier und fünf bedeuten. Wenn wir beispielsweise sechs Faktoren
haben, benötigen
wir mindestens 64 Durchläufe für
einen vollfaktoriellen Versuchsplan Wenn wir einen
teilfaktoriellen Versuchsplan
mit einer Auflösung von sechs wählen , benötigen
wir 32 Durchläufe Bei einer Auflösung von vier benötigen
wir 16 Durchläufe, und bei einer Auflösung von drei benötigen
wir nur acht Aber was bedeutet das
und wie funktioniert es? Der vollfaktorielle Versuchsplan wird immer als
Ausgangspunkt verwendet Schauen wir uns ein
Beispiel mit acht Durchläufen an. Angenommen, wir haben
die Faktoren A, B und C mit einem
vollfaktoriellen Versuchsplan, wir können testen, ob Faktor A, B oder C eine Wirkung hat Wir können auch testen, ob Wechselwirkungen zwischen
zwei Faktoren
eine Wirkung haben und ob Wechselwirkungen zwischen allen drei
Faktoren eine Wirkung haben Wenn wir nun
nicht nur drei Faktoren
mit acht Durchläufen testen wollen , sondern einen weiteren vierten
Faktor, den S-Faktor D, müssen
wir
einige Informationen
aus einer der Wechselwirkungen opfern . Zum Beispiel die
Wechselwirkung von A und B, und wenn wir einen fünften
Faktor mit acht Versuchen testen wollen, sagen wir Faktor A, müssten
wir eine
weitere Wechselwirkung opfern. Zum Beispiel die Wechselwirkung
zwischen B und C, aber wir
lassen die Informationen nicht wirklich fallen. Wir mischen den neuen Faktor
mit der Wechselwirkung. Das heißt, wir haben den
Faktor mit
der Interaktion verwechselt .
Was bedeutet das? Das bedeutet, dass wir nicht feststellen können,
ob ein beobachteter Effekt auf Faktor D oder die
Wechselwirkung von A, B und C zurückzuführen
ist. Ebenso
können wir nicht sagen, ob ein Effekt auf Faktor A oder auf die
Wechselwirkung von B und C zurückzuführen ist. Es ist viel weniger problematisch
, einen Faktor mit
einer Wechselwirkung von drei Faktoren zu vermischen einer Wechselwirkung von drei Faktoren als mit einer Wechselwirkung
von zwei Faktoren. Ebenso können wir nicht
unterscheiden, ob ein Effekt auf
Faktor A oder auf
die Wechselwirkung von B und C zurückzuführen ist. Jetzt haben
wir einen guten Übergang
zur Auflösung. Was bedeuten die Auflösungen drei, vier und fünf? Bei Auflösung drei können
Haupteffekte mit
Wechselwirkungen zweier Faktoren verwechselt
werden Zum Beispiel könnte Faktor D mit der
Wechselwirkung der Faktoren
A und B
verwechselt werden. Experimente mit Auflösung drei werden
daher als kritisch
angesehen Sie können nur verwendet werden,
wenn die Wechselwirkung
zweier Faktoren deutlich
geringer ist als die Wirkung
der Hauptfaktoren Andernfalls
kann die Wechselwirkung
zweier Faktoren das Ergebnis eines Faktors erheblich verfälschen Experimente mit Auflösung
vier sind viel weniger kritisch. Hier werden nur die Haupteffekte mit den
Wechselwirkungen von drei Faktoren
und den mehreren Faktoren, die an einer Wechselwirkung
beteiligt sind,
verwechselt und den mehreren Faktoren, die an einer Wechselwirkung
beteiligt sind Je geringer
ist der Effekt wahrscheinlich. Darüber hinaus werden in Auflösung vier Wechselwirkungen zweier Faktoren mit Wechselwirkungen
zweier anderer Faktoren
verwechselt O Experimente mit Auflösung fünf werden nicht
als kritisch angesehen Haupteffekte werden nur mit
Wechselwirkungen
von vier Faktoren verwechselt Ebenso werden Wechselwirkungen zwischen zwei
Faktoren
nur mit
Wechselwirkungen von drei Faktoren verwechselt Aber wie verwechselt man einen
Faktor und eine Wechselwirkung? Schauen wir uns dieses Beispiel
an. Hier haben wir den
vollständigen faktoriellen Entwurf der drei Faktoren
A, B und C. Diese acht Durchläufe
werden insgesamt durchgeführt Wir berücksichtigen immer noch nur
Faktoren mit zwei Stufen, minus eins für eine Stufe und eins für die andere Stufe
steht Für unser Beispiel mit Frictional Talk würde
der Testplan für den Faktor Temperatur
so aussehen , minus eins ist die
niedrige Temperatur und eins ist die hohe Wenn wir die Experimente jetzt durchführen, erhalten
wir für jeden Durchlauf einen Wert für die
Antwortvariable Wenn Faktor A eins oder minus eins ist, hat
das eine gewisse Auswirkung
auf den Zielwert. Das Gleiche gilt, wenn Faktor
B eins oder minus eins ist. Der Wechselwirkungseffekt sagt uns, ob es
einen zusätzlichen Effekt gibt. die Faktoren A und B gleichzeitig
sind, eins oder minus eins, oder wenn beide genau in die
entgegengesetzte Richtung gehen. Auf der einen Seite haben wir die
Paarungen mit demselben Vorzeichen
und auf der anderen Seite die Paarungen mit einem
ungleichen Wir können überprüfen, ob es einen Unterschied in der
Antwortvariablen
zwischen den Werten in der grünen Gruppe und
den Werten in der
roten Gruppe Wenn es einen Unterschied gibt, dann gibt es eine Wechselwirkung
zwischen A und B. Wenn wir
jedoch im Voraus wissen, dass es nur eine sehr
geringe oder keine Wechselwirkung gibt, können
wir diese Kombinationen verwenden. Um einen vierten
Faktor, D, zu testen, multiplizieren
wir dazu einfach. A und B. Wir haben immer eine
Eins, wenn die Faktoren A und B dasselbe Vorzeichen haben und minus eins, wenn sie
ein anderes Vorzeichen haben. Natürlich kann ein Problem auftreten. Bei der Analyse der Ergebnisse. Wenn es einen Unterschied zwischen
den grünen und den roten Werten gibt. In der Antwortvariablen können
wir nicht bestimmen, ob
dieser Effekt auf
die Wechselwirkung zwischen A und
B oder auf Faktor D zurückzuführen die Wechselwirkung zwischen A und ist, wenn wir a sind. Zeigen Sie, dass es keine
Wechselwirkung zwischen A und B geben kann Das ist kein Problem. Dann können wir sicher sein, dass der Unterschied in ähnlicher Weise
auf Faktor D zurückzuführen ist. Wir können also die Wechselwirkung
von A und C nehmen und auch Faktor A und
die Wechselwirkung von A, Faktor A und
die Wechselwirkung von A,
B und C messen, um
Faktor F zu messen. In diesem Fall messen wir sechs Faktoren mit
nur acht Durchläufen, aber wir können
Faktor D nicht mehr von der Wechselwirkung von
A und B, Faktor A
von
der Wechselwirkung von A und C oder Faktor F
von der Interaktion von A,
B und C unterscheiden Faktor D nicht mehr von der Wechselwirkung von A und B, Faktor A
von
der Wechselwirkung von A und C oder Faktor F
von der Interaktion von A, . In der nächsten Lektion werden
wir uns
die anderen in DOE verfügbaren
Versuchstypen genauer ansehen . In der nächsten Lektion
werden wir uns eingehender mit den praktischen Anwendungen der Versuchsplanung befassen.
Bleib dran.
50. Plackett Burman Central Komposit-Design: Willkommen heute. Wir befassen uns mit
verschiedenen Arten der Versuchsplanung. Oder DOE, fangen wir mit
dem Placet Berman Design an. Was ist ein Placet Berman-Design? Placet- und Berman-Versuchspläne werden in der Regel mit zwei Stufen
und einer Auflösung von drei verwendet und Der Hauptvorteil
dieser Versuchspläne besteht darin
, dass sich die Wechselwirkung zwischen zwei Faktoren mehrere andere Faktoren
verteilt Beispielsweise ist die Wechselwirkung
zwischen den Faktoren A und B mit
allen anderen Faktoren außer
A und B selbst verwechselt allen anderen Faktoren außer
A und B selbst Aus diesem Grund eignen sich Plackett
Burman-Versuchspläne ideal, wenn es um
viele Faktoren und wenn nur die
Haupteffekte Diese Versuchspläne
sollten jedoch mit Vorsicht verwendet werden,
wenn Sie davon ausgehen, dass Wechselwirkungen zwischen zwei
Faktoren vernachlässigt werden
können Diese Anforderung
ist jedoch weniger streng als bei klassischen
fraktionalfaktoriellen Versuchsplänen mit
Auflösung 3. Nun, was ist ein
Box-Benkin-Design? Das Box-Benkin-Design wird
zusammen mit dem zentralen
Verbunddesign verwendet, um
einige Faktoren im Detail zu analysieren und zu optimieren Und um
nichtlineare Abhängigkeiten zu identifizieren um
nichtlineare Zusammenhänge zu erkennen Bei einem vollfaktoriellen Versuchsplan
mit
drei Stufen sind mindestens drei Stufen
pro Faktor erforderlich vollfaktoriellen Versuchsplan
mit
drei Stufen sind mindestens drei Stufen Die Anzahl der Studien
kann schnell ansteigen. Beispiel: Bei zwei
Faktoren auf jeweils drei Stufen benötigen
Sie neun Durchläufe, benötigen
Sie neun Durchläufe und
bei drei Faktoren auf jeweils drei Stufen erhöht
sich die Anzahl auf 27 Durchläufe. Box, Benkan-Versuchspläne
lösen dieses Problem,
indem sie einen vollfaktoriellen
Versuchsplan mit zwei Stufen Und das Einbeziehen von Zentralpunkten, z. B. dreimal
für zwei Faktoren
oder mit drei Faktoren, oder mit drei Faktoren, wodurch die
Anzahl der Durchläufe 27-15 reduziert Dadurch wird zwar
die Anzahl der Durchläufe reduziert, es können aber auch weniger
nichtlineare Beziehungen identifiziert Lassen Sie uns als Nächstes das
zentrale Verbunddesign besprechen. Dieser Versuchsplan umfasst in der Regel drei Typen von Testpunkten: zwei
ebenflächige, faktorielle Punkte,
die die Ecken
eines Würfels oder Hyperwürfels in
mehrdimensionalen Räumen bilden eines Würfels oder Hyperwürfels in
mehrdimensionalen Zentrale Punkte, die sich
in der Mitte des durch
die faktoriellen Punkte definierten Raums Axiale Punkte, die auf
den Achsen des
Faktorraums außerhalb der Warteschlange liegen den Achsen des
Faktorraums außerhalb der Warteschlange Diese beiden letzten
Punkttypen helfen bei Schätzung nichtlinearer
Effekte in Ihrem Modell. In der nächsten Lektion werden
wir uns eingehender mit
praktischen Anwendungen der
Versuchsplanung befassen.
Bleib dran.
51. Schlussbemerkung: Ich möchte mich bei Ihnen
vielmals dafür bedanken , dass Sie das Programm
abgeschlossen haben. Es zeigt, dass Sie sich auf Ihrem
Lernweg sehr engagieren. Du willst dich weiterbilden
und ich vertraue darauf, dass du viel gelernt
hast. Ich hoffe, alle Ihre Konzepte
sind auch klar. Ich möchte sicherstellen, dass ich Ihnen sage welche anderen
Programme ich gerne teilen möchte. Auf Skillshare habe ich also viele andere Programme
, die bereits
da sind , und viele werden in den kommenden Wochen
und kommenden Monaten erscheinen. Wie die Programme
Storytelling mit Daten sind, wie kann ich die Analysen,
Datenvisualisierung,
Predictive Analytics ohne
Codierung und vieles mehr nutzen Datenvisualisierung, . Abgesehen davon arbeite ich auch
als Corporate Trainer. Ich stelle sicher, dass alle
meine Programme
hochgradig interaktiv sind und alle Teilnehmer
sehr engagiert sind. Ich habe die Bücher entworfen, die für meinen Workshop
maßgeschneidert sind , wodurch auch sichergestellt wird
, dass alle Konzepte von den Teilnehmern klar verstanden
werden. Meine Spiele sind so konzipiert, dass
die Konzepte
in einer Weile,
in der sie spielen, Kredite erhalten. Es gibt viele Spiele, die für meine Programme entwickelt wurden. Und wenn Sie Interesse
haben, können Sie mich gerne kontaktieren. Ich habe in den letzten zwei
Jahren während der Pandemie auch mehr
als zweitausend Stunden Training absolviert. Dies sind nur einige
der Workshops. Wenn Ihre Organisation also an einem
Firmenschulungsprogramm teilnehmen
möchte , das offline oder online
ist. Oder wenn Sie das Gefühl haben, dass
Sie persönlich Ihr Lernen verbessern möchten, können Sie
mich gerne unter meiner E-Mail-ID kontaktieren. Bleiben Sie mit mir auf LinkedIn in Verbindung, wenn Ihnen mein Training
gefallen hat, stellen
Sie bitte sicher, dass Sie eine Bewertung auf LinkedIn
schreiben. Außerdem betreibe ich auch einen
Telegram-Kanal in dem ich viele
Fragen stelle, in denen Leute die
Konzepte lernen können, und
sie werden vielleicht nur ein paar
Sekunden brauchen, um es zu tun. Abgesehen davon, stellen
Sie bitte sicher, dass Sie schreiben, um eine
Bewertung auf Skillshare zu hinterlassen Wie war Ihre
Trainingserfahrung? Bitte vergessen Sie nicht, Ihr Projekt
abzuschließen. Ich liebe Menschen, wenn sie
engagiert sind und du bewiesen hast
, dass du einer von ihnen bist. Bitte bleiben Sie in Verbindung. Bleib sicher und Gott segne dich.
 Dimple Sanghvi, AI Consultant, Lean Six Sigma Master Black Belt
Dimple Sanghvi, AI Consultant, Lean Six Sigma Master Black Belt