Transcrições
1. Introduction to the Course: Olá, sou Dimple Sangui
e tenho mais de 25 anos de
experiência liderando programas de transformação em grande escala Eu liderei esses programas em organizações da
Fortune 500,
como Cognizant, HSBC, CAP Gemini, e
também treinei milhares de
profissionais em análise, IA Também fiz
treinamento de liderança em todo o mundo. Nesta aula, você
aprenderá a projetar agentes de IA
eficazes. Usando padrões práticos,
como encadeamento rápido,
roteamento, avaliadores e orquestradores Eles são baseados em princípios de design de
agentes do mundo real. Esta aula é para profissionais e líderes de produtos,
consultores e profissionais de IA
que desejam ir além das instruções e criar fluxos de trabalho de IA estruturados
e confiáveis Você não precisa de codificação avançada, apenas uma compreensão básica de como grandes modelos de linguagem funcionam Seu projeto de classe é criar um sistema de agente de IA funcional como um diagrama
para uma tarefa real. Mapeando o fluxo de trabalho,
escrevendo instruções e refletindo sobre
suas escolhas de design Eu mencionei os detalhes na seção de descrição
do projeto do Skillshare Se você quiser entender como IA
agente realmente
funciona na prática, esta aula fornecerá uma estrutura
clara e utilizável Vamos começar. Te vejo
na primeira aula.
2. Building effective LLM: Construindo agentes eficazes.
No último ano, trabalhamos com
dezenas de equipes criando grandes modelos de linguagem,
agentes de vários setores. forma consistente, as implementações mais
bem-sucedidas não
estavam usando estruturas complexas ou bibliotecas especializadas Em vez disso, eles estavam construindo com padrões simples de composição O que são agentes? Os agentes são definidos
de várias maneiras. Alguns clientes definem agentes como sistema
totalmente autônomo que opera forma independente por
longos períodos usando várias ferramentas para
realizar tarefas complexas. Outros usam o termo para descrever implementação
mais prescritiva que segue fluxos de trabalho
predefinidos Na anthropic, categorizamos todas essas variações
como sistema agente,
mas traçamos uma importante distinção
arquitetônica entre fluxos de trabalho e Os fluxos de trabalho são sistemas
em que LLMs e ferramentas são orquestrados por meio Os agentes, por outro lado,
são sistemas em que o LLM direciona
dinamicamente
seus próprios processos, ferramentas e usa Quando e quando não usar agentes. Ao criar
aplicativos com o LLM, recomendamos encontrar a solução
mais simples possível Só aumentando
a complexidade quando necessário. Isso pode significar não criar um sistema
agente de forma alguma. Os sistemas agentes
geralmente negociam latência, custo de melhor desempenho de tarefas E você deve considerar quando
essa troca faz sentido. Quando mais complexidade é necessária, os fluxos de trabalho
oferecem previsibilidade e
consistência para tarefas
bem definidas, consistência para tarefas
bem definidas, enquanto os agentes são melhores
opções quando a flexibilidade e a tomada de
decisões orientadas por modelos são Para muitos aplicativos, no entanto, otimizar uma única chamada LLM com um
exemplo de recuperação em contexto geralmente é suficiente Existem muitas estruturas
ao usar o sistema Augentic, mais fáceis de implementar o
gráfico Lang da cadeia estrutura básica de
agentes de IA da Amazon, reverta um
GIM Workflow Builder de arrastar e soltar,
Valm, outro construtor de GUI
para criar testes de fluxo de trabalho complexo para Essa estrutura
facilita o início
e a simplificação de tarefas
padrão de baixo nível,
como ligar para o LM, definir, elogiar e agrupar No entanto, eles geralmente criam uma camada
extra de
abstração que apenas observa o
prompt e as respostas subjacentes, ao mesmo tempo que os torna
mais difíceis de depurar Eles podem tornar tentador adicionar complexidade quando uma
configuração mais simples seria suficiente
3. Prompt Chaining Workflow: E vamos examinar mais de perto um fluxo
de trabalho de encadeamento imediato Muitos de vocês lideraram projetos
complexos de transformação em o risco não está
na visão geral, mas na execução
e na garantia de que a
disciplina seja seguida. O mesmo acontece com a verdade. Portanto, o encadeamento imediato não consiste
apenas em passar dados de
uma chamada de IA para outra Trata-se de incorporar
portas de controle entre cada etapa. E quando você incorpora controles de risco de verificação de
conformidade e auditorias de qualidade
nos processos de negócios, a primeira chamada de LLM
cria um Esse rascunho não
flui automaticamente para frente. Está validado. Se for aprovado, o
fluxo de trabalho continuará. Se falhar, o sistema
sai ou aumenta. É assim que evitamos
os erros de composição. Para executivos, o principal
insight é que a cadeia nos
permite tratar a IA
como um processo gerenciado, não como uma caixa preta. Cada estágio pode ser ajustado,
seja extraindo dados, aplicando regras de conformidade ou produzindo comunicação
voltada para o cliente Esse design torna a
IA previsível, auditável e mais aceitável
para reguladores e conselhos Para conectá-lo ao seu mundo, pense nas operações dos
prestadores de serviços de saúde. Uma IA extrai informações
do paciente. O portão garante que as regras da
HIPA sejam seguidas. A segunda IA prepara
o resumo do tratamento. O git valida
a codificação médica. Somente então, um nódulo de descarga é
gerado para o paciente. Cada ponto de verificação garante
precisão, conformidade e confiança. É por isso que o encadeamento rápido
é uma base fundamental. Ele transforma a experimentação em confiabilidade de
nível empresarial Como analisamos o fluxo de trabalho de
encadeamento imediato? Pense nisso como uma linha de montagem. Em vez de pedir
à IA que faça as coisas ao mesmo tempo, você divide o trabalho em etapas. Cada estágio é tratado
por uma chamada de IA separada, e a saída de um estágio se torna a entrada para o próximo Observe que o portão está amargo. Esse é o ponto de verificação de qualidade. Se a saída de IA em um estágio
não passar pela validação, o processo será interrompido ou retornará Se passar, flui para frente. Tarefas complexas se tornam gerenciáveis com o fluxo de trabalho em cadeia imediato. Assim como no Sigma, você não resolve tudo em uma única etapa, você divide tudo. O controle de qualidade é incorporado. Em vez de confiar em uma chamada de IA, você valida antes de
seguir em frente Contenção de erros. Se algo falhar, você o detecta cedo sem poluir
a saída final Vamos pensar, por exemplo, na primeira
etapa
da resolução de sinistros : a IA lê e
digitaliza o documento de reclamação O portão verifica se todos os campos
obrigatórios estão presentes. A IA prepara a
pontuação de risco para liquidação. A IA extrai os dados
financeiros do candidato. A marcha verifica a regra de
conformidade como a falta de informações do AIC Na etapa três, a IA elabora a avaliação de
elegibilidade do empréstimo Primeiro passo, a IA cria uma resposta. Segundo passo, o portão
verifica o tom, linguagem de
conformidade
e as regras do SLA Etapa três, a IA finaliza a mensagem para entrega
ao cliente Pense nisso como uma segurança
de aeroporto. Você não vai direto do
check-in para o embarque. Você passa por portões, verificações de
bagagem, verificação de
segurança, verificação do cartão de
embarque Cada portão garante que a
próxima etapa esteja limpa. encadeamento imediato é a versão da IA do processo de
controle de qualidade em etapas Agora que vimos como o encadeamento cria
confiabilidade, passaremos para o próximo
e mais avançado fluxo de trabalho, agente
autônomo em que a IA começa a se aperfeiçoar
em um ambiente real Pense nisso como uma corrida de revezamento. Uma saída de IA é
verificada no portão e somente se ela passar
vai para a próxima etapa de IA. Se falhar, sai mais cedo. Isso torna o processo mais seguro e confiável. Reclamação automobilística. Um cliente carrega os detalhes do acidente
nas fotografias O LLM, faz a verificação
do documento. IA extrai os detalhes da política e a descrição do acidente O portão faz a verificação de
conformidade. A IA extraiu todos os campos obrigatórios se a data do acidente estiver dentro
da política validada Se passar, vai
para a próxima etapa. Se falhar, ele sai ou é
sinalizado para uma revisão manual. A chamada dupla do LLM verifica
a estimativa de danos. A IA elabora as estimativas de custo
usando as diretrizes de reparo. O LLM Three redige
a reivindicação final. Ele cria o
resumo da liquidação para o avaliador. Somente
reivindicações válidas em conformidade com a política avançam, economizando tempo e reduzindo fraudes Agora vamos dar um exemplo de
atendimento ao cliente. Um cliente VIP reclama, meu pedido de empréstimo está
preso por dez dias LLM one classifica a IA identifica a consulta como uma
escalada VIP A verificação do SLA
acontece no portão. Ele atende aos critérios de escalonamento
de 15 minutos? Se passar, prossegue. Se falhar, ele emitirá um
alerta ao gerente. LLM dois, vamos redigir a nota de escalonamento
para suporte de nível dois LLM Three criará
uma resposta do cliente, um e-mail personalizado
para o cliente
e, se o resultado for o
caso certo, será escalado rapidamente, evitando violações de SLA
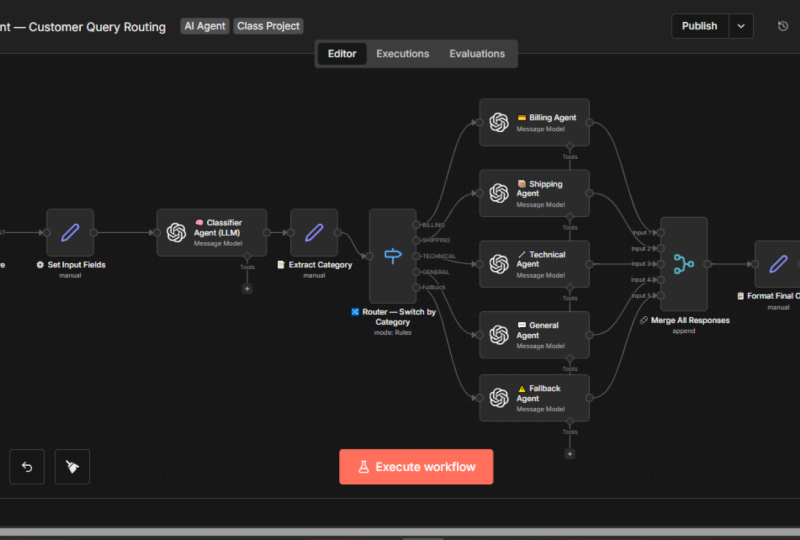
4. The Routing Workflow time: Agora vamos entender
um fluxo de trabalho de roteamento. O motor por trás de muitos
sistemas de IA autênticos. Você tem uma entrada, um roteador LM e há três chamadas LLM
diferentes Então, do jeito que funciona,
a entrada vem,
digamos, em uma consulta do cliente, um formulário de reclamação ou em um pedido de
empréstimo. O sistema simplesmente não o envia
cegamente para um único modelo. Em vez disso, ele primeiro
passa por um roteador de chamadas LLM. O roteador decide qual modelo de
IA é
mais adequado para essa tarefa. A partir disso, a solicitação pode ser encaminhada para um dos vários modelos
especializados Uma chamada LLM pode lidar com a classificação de
sumarização estruturada Para lidar com o raciocínio, análises
pesadas, como
detecção de fraudes e pontuação de risco Os três podem lidar com tarefas
criativas de comunicação como redigir a resposta do cliente Finalmente, o melhor resultado é
transmitido como saída. Para vocês, como líderes de
transformação, a conclusão não é a
seta nos gráficos É a vantagem comercial. No serviço prestador de serviços de saúde, o roteador enviaria a documentação
médica para um modelo treinado em linguagem
clínica enquanto roteava os dados de cobrança para um modelo focado na
conformidade Em um acidente
automobilístico de processamento de reclamações, fotos serão enviadas para um modelo de visão para estimativa de
danos, enquanto o texto da política
será enviado para um modelo de linguagem para
a verificação de elegibilidade Em um atendimento ao cliente, perguntas frequentes
rápidas seriam encaminhadas modelo leve
para maior velocidade, enquanto a
escalação VIP sensível seria direcionada para
um modelo voltado para a empatia Esse fluxo de trabalho é importante porque evita uma abordagem
única para todos. Em vez disso, ele garante que o modelo certo seja usado
para o trabalho certo, assim como você não
atribuiria todas as tarefas da
sua organização
ao mesmo departamento. O roteamento é uma
camada de governança para o fluxo de trabalho de IA. Isso os torna eficientes, precisos e prontos para os negócios. Agora que entendemos o roteamento, queremos ver como vários agentes de
IA podem trabalhar juntos, coordenar
diferentes etapas em
um processo, em vez de
agir isoladamente Pense nisso como um controlador
de tráfego. O sistema decide
qual faixa é melhor para a solicitação recebida, em vez tratar todas as
solicitações da mesma forma Rastreamento de uma reclamação de seguro
da Pfizer Motors de um cliente. O roteador LLM decide qual
modelo especializado de IA pode lidar com isso Se for uma alegação de risco de fraude, o roteador a encaminhará
para o modelo de detecção de fraudes. Se for uma reclamação padrão de
baixo valor,
encaminhe-a para a automação
em vez da liquidação. Se for uma reclamação médica complexa, encaminhada para o modelo de conformidade, cada reclamação segue
o caminho correto, reduzindo a
classificação manual e Eu perdi meu cartão de crédito. O roteador LLM o
encaminha para a IA correta, a IA
de segurança para bloquear
a placa imediatamente A FAI explica como
solicitar uma substituição. Uma IA de escalonamento conecta você
à mesa de fraudes se uma
atividade incomum for detectada cliente obtém a solução
certa em vez de ficar
entre os agentes Marque uma consulta e
envie-me os resultados do laboratório. O roteador LLM
dividirá a tarefa. Agendando a IA, marque a consulta
médica. O WiCoDEI
recupera os resultados do laboratório IA de cobrança verifica a elegibilidade
e a cobertura do seguro paciente conclui todas as
tarefas por meio uma interação roteada pela IA certa
a cada vez roteamento tem a ver com eficiência e precisão, em vez de forçar
um sistema a fazer tudo Ele direciona o fluxo de trabalho certo para a IA certa, assim como
o processo lean. Reduz o retrabalho, classificação incorreta e
acelera a resolução
5. The Parallelization: Agora vamos para um fluxo de trabalho de
paralelização. No último modelo, vimos como o roteamento envia
tarefas para o melhor modelo Aqui veremos um padrão
diferente, paralelização Aqui, em vez de
escolher um caminho, a entrada é enviada para vários
modelos ao mesmo tempo. Cada modelo contribui
com uma peça para o quebra-cabeça. Em seguida, o agregador combina o resultado em uma saída final Pense nisso como
administrar várias equipes em paralelo para resolver o mesmo problema de
forma rápida e completa. Por que isso importa? Porque alguns
problemas de negócios se
beneficiam da velocidade e da
diversidade de respostas. Entendemos que a paralisação está executando várias chamadas LLM
e, em seguida, o agregador a resume Então, digamos que o paciente
tenha febre, tosse e histórico recente de viagem
e alérgico a antibióticos. O LLM one recupera o
EHR do paciente para condições anteriores. O LLM two verifica a diretriz
para doenças infecciosas. LLM, três bandeiras, risco de alergia a
medicamentos. O agregador então se funde em uma sugestão de tratamento segura
para o médico O médico recebe um
único relatório consultivo não uma visão fragmentada paralelização tem a ver com
velocidade e compreensão em vez de esperar um sistema termine
antes que o próximo comece, uma IA múltipla é executada em
paralelo É como administrar várias equipes de
especialistas em paralelo durante o corte de custos da
transformação enxuta. Analisamos o roteamento quando o sistema decide
qual modelo usar Paralelização quando vários
modelos funcionam ao mesmo tempo.
6. The Orchestration and Routing2: Analisamos o roteamento quando o sistema decide
qual modelo usar parleização quando vários
modelos funcionam ao mesmo tempo Aqui estamos falando
sobre orquestração. Como é que a entrada
entra primeiro na orquestra. Pense nisso como um gerente de
projeto que, em seguida, atribui trabalho a
diferentes agentes de IA A orquestra decide
qual tarefa deve ser executada primeiro e qual
modelo deve executá-la Cada modelo, como o LLM um, dois, três, aborda diferentes
partes do trabalho Mas, em vez de
trabalhar isoladamente, eles são coordenados como equipe
multifuncional
em sua transformação. Finalmente, um sintetizador
reúne tudo em uma
única O valor comercial é poderoso. As anotações do paciente devem
ser divididas em interpretação
clínica, código de
cobrança, mapeamento e verificação de conformidade
e, em seguida sintetizadas em um relatório de alta
completo Vamos pensar em reclamações de automóveis. Um modelo revisa o documento, o outro verifica a fraude. O terceiro rascunho da comunicação
com o cliente. Esse sintetizador
então os combina em um pacote de
decisão de reivindicação pronto para uso Vamos pensar em negócios
hipotecários. Você quer que a
verificação de renda, a pontuação de risco verificações de conformidade
regulatória ocorram em sequência orquestradas
e sintetizadas em queda de um comunicado à imprensa
pode ser verificada por
um modelo adaptado em diferentes mercados
por outro e pelo
estilo por
canal social do terceiro. Em seguida, sintetizado em um pacote
multicanal. Orquestração tem a
ver com coordenação. Não se trata de computação. Ele reflete a forma como os líderes de
transformação já executam programas
funcionais
7. Thank you for your time: Antes de terminarmos, quero
compartilhar um pouco mais sobre mim e como
você pode se manter conectado. Estou ansioso para compartilhar minhas duas décadas de
experiência com todos vocês. E a experiência em que
ajudei líderes e equipes a realizar
projetos de
transformação comercial,
digital e artificial de grande
escala digital e artificial na Índia, EUA, Reino Unido, Austrália
e Oriente Médio. Ao longo do caminho,
treinei milhares de profissionais em
análise de dados, lean Sig Sigma, inteligência
artificial, inteligência
artificial engenharia
rápida
e gerenciamento de mudanças, treinamento de
liderança, tanto como programas
corporativos quanto como comunidades de aprendizado
aberto Se você está assistindo isso
como um aluno individual, adoraria que você
ficasse conectado Você encontrará links para se juntar ao meu grupo do Whatsapp ou comunidade de
telegramas onde eu
postaria continuamente sobre diferentes
oportunidades Eu compartilho regularmente alguns insights
práticos, recursos de
aprendizado e atualizações sobre análise e
transformação da IA. Também compartilho alguns
estudos de caso sobre liderança. Se você está aqui como
gerente, consultor ou líder de aprendizado e
desenvolvimento e está interessado
em design personalizado, treinamento
corporativo em IA agente, engenharia rápida, análise de
dados ou programa de
transformação, sinta-se à vontade para
entrar em contato comigo Eu trabalho em estreita colaboração
com organizações para criar programas
personalizados, práticos, contextuais
e focados nos negócios Estou deixando o link para Linden
na seção de discussão. Obrigado por aprender comigo. Espero que esta aula ajude você a projetar um sistema de IA com
mais cuidado, e estou ansioso para
ficar conectado com Obrigado pelo seu
tempo. Feliz aprendizado.
 Dimple Sanghvi, AI Consultant, Lean Six Sigma Master Black Belt
Dimple Sanghvi, AI Consultant, Lean Six Sigma Master Black Belt