Transcription
1. Bienvenue dans ce cours: Bonjour, bienvenue dans ce
cours sur TensorFlow. Tensorflow est un
programme qui aide les
ingénieurs à créer et à former des modèles
d'apprentissage automatique. Dans ce cours, vous
découvrirez les tenseurs et comment travailler avec des
danseurs à l'aide de TensorFlow. Nous allons commencer par
examiner ce que sont les tenseurs. Nous apprendrons ensuite comment
construire des tenseurs à l'aide de données. Nous verrons ensuite comment effectuer des opérations mathématiques
de base et intermédiaires à l'aide de TensorFlow. Tensorflow peut également fonctionner
avec les GPU et les TPU, qui sont
des types de puces informatiques conçus pour étendre les capacités denses
et faibles. Ces puces
accélèrent le fonctionnement de TensorFlow, ce qui est utile lorsque vous avez beaucoup de données à traiter. À la fin du
cours, vous
aurez une bonne
compréhension de ce qu'est
TensorFlow et de la manière dont nous l'utilisons pour créer des modèles
d'apprentissage en profondeur. Nous
élaborerons également un projet de
vision par ordinateur dans le cadre duquel
nous créerons un modèle TensorFlow simple pour reconnaître les images manuscrites. Il s'agit d'un cours de
niveau débutant, mais je suppose
des connaissances
de base en python et en apprentissage automatique. Vous n'avez pas besoin d'être un
expert en apprentissage automatique. Mais si vous comprenez
comment les données sont utilisées pour former des modèles à
des fins de prévision, vous serez en mesure de
comprendre ce cours. Si ce n'est pas le cas, vous trouverez des liens vers quelques vidéos d'introduction
dans la description du cours. Si vous êtes bloqué à un
moment ou à un autre du cours, envoyez-moi un e-mail à
admonition shiva.com, et je
vous recontacterai dès que possible. Alors allons-y.
2. Tenseurs et flux de tenseur: Dans cette leçon, nous
verrons ce qu'est un tenseur, suivi par la populaire bibliothèque de deep
learning tensorflow. Voyons d'abord
ce qu'est un tenseur. Une explication simple
serait qu' un tenseur est un tableau
multidimensionnel. Par exemple, nous avons des scalaires, qui ne sont qu'un seul nombre. Ensuite, nous avons un vecteur
également appelé tableau. Ensuite, nous avons une matrice qui sera un tableau
bidimensionnel. Enfin, nous avons une réponse qui est un tableau à n dimensions, ce qui signifie qu'il peut avoir
n'importe quel nombre de dimensions. Dans TensorFlow, tout peut être considéré comme un tenseur,
y compris un scalaire. Un scalaire sera un tenseur
de dimension zéro, un vecteur de dimension un et une matrice de dimension deux. Cela est maintenant utile
car nous ne sommes pas limités à travailler avec des ensembles de
données complexes dans TensorFlow. Tensorflow peut
gérer n'importe quel type de données et les transmettre à des modèles d'apprentissage
automatique. Tensorflow est une bibliothèque de logiciels open
source créer
des réseaux de
neurones profonds. C'est l'équipe de Google Brain qui
l'a créée, et c'est aujourd'hui la
bibliothèque d'apprentissage en profondeur la plus populaire du marché. Vous pouvez utiliser TensorFlow
pour créer des modèles d'IA notamment la reconnaissance d'images et de
voix, traitement du langage
naturel
et la modélisation prédictive. Tensorflow utilise un graphe de flux de données pour représenter les calculs. En termes simples, TensorFlow
a facilité la création modèles
d'
apprentissage automatique complexes et prend en
charge une grande partie
du travail en coulisse,
ce qui le rend utile
lors de la création et formation de tout type de modèle d'apprentissage en
profondeur. Diencephalon
gère également le calcul, y compris la parallélisation et l'optimisation pour
le compte de l'utilisateur. Tableau dispose également d'une API
de haut niveau appelée Keras. Get us était initialement un projet
autonome qui est désormais disponible dans
la bibliothèque TensorFlow. Get us permet de
définir et de former facilement des modèles. Bien que TensorFlow offre meilleur contrôle sur
les calculs, TensorFlow prend en charge une
large gamme de matériels, notamment des processeurs, des GPU et des TPU. TPU sont des unités de traitement tensoriel conçues spécifiquement pour les couches denses et TensorFlow. Vous pouvez également exécuter TensorFlow
sur des appareils mobiles et appareils
IoT en utilisant le principe de
TensorFlow Lite dispose
également d'une grande communauté de développeurs. Il
est mis à jour avec . Il dispose
également d'une grande communauté de
développeurs. Il
est mis à jour avec de
nouvelles fonctionnalités et permet aux personnes obèses presque tous les mois. J'espère que cette vidéo vous a aidé à comprendre les tenseurs et
TensorFlow en détail. La semaine prochaine, nous
commencerons à travailler avec TensorFlow sur un bloc-notes Google
Colab.
3. Travailler avec Tensorflow: Commençons à écrire du code. J'utiliserai un
bloc-notes Google Colab et vous trouverez le lien vers ce
bloc-notes rempli dans la description du
cours. Les alphas connectent cet
ordinateur portable au processeur. Attendons une minute. Maintenant, c'est l'initialisation et la
grille. Il est connecté. Si tu ne sais pas. Les blocs-notes Google
Colab nous aident à exécuter Python, puis à
soumettre du code sur le Web. Il est beaucoup plus facile de
travailler avec lui plutôt que de créer un environnement de
développement local. Commençons maintenant par importer TensorFlow et
imprimer le Washington. Vous pouvez appuyer sur Command Enter ou Abdomen pour exécuter le bloc de code. Super, nous utilisons un
quotient égal à 0,9, 0,2. Si vous avez une
version différente, ne vous inquiétez pas. Ils ne feront pas beaucoup de différence. Commençons par créer un
scalaire à l'aide de tf.constant. tf.Constant est une fonction que nous allons utiliser
pour charger le cours. Mais dans des scénarios réels, nous ne l'utiliserons pas
beaucoup, car TensorFlow gérera une grande partie de la création
de tensions à votre place. Mais pour l'instant,
créons un scalaire. Il peut être codé en sept. Et imprimons-le. Vous pouvez voir que
nous avons créé un scale-out avec la
langue sept. Il n'a pas de forme parce que
c'est juste une valeur unique. Et le type de données est un entier 32. Créons maintenant un vecteur dont l'entrée sera un
tableau avec deux valeurs. Et maintenant, imprimons-le. Greg, nous pouvons constater
que nous avons créé un vecteur de forme
lorsque je travaillais sur le numérique. Essayons maintenant de créer une matrice. L'entrée sera un tableau
bidimensionnel. Ensuite, nous en aurons 12, 30. Imprimons-le. Nous allons créer la matrice dont la
forme est gamma2. Il s'agit d'un tableau bidimensionnel et les vecteurs de données sont entiers 32. Créons maintenant une densité, appelons-la densa de compréhension. Faites en sorte que tout soit basé sur la langue. Et imprimons-le. Vous pouvez voir que nous avons
créé un véritable tenseur, qui est également un réseau
tridimensionnel, et qu'il a une forme de
trois par un par trois. C'est ainsi que nous créons un véritable
densificateur en utilisant tf.constant. Nous pouvons voir que le
type de données est un entier 32. Et si nous voulions utiliser
un type de données différent, disons float 32s. Nous pouvons utiliser ce type de données comme argument et mot de passe
lors de la création d'une escarre. Nous allons simplement copier que les
symptômes sont revenus. Je l'appellerais. Donc, les mêmes valeurs, mais je vais spécifier que le
type de données est le rendu flottant. Vous pouvez voir que maintenant les
données filtrées peuvent être modifiées
lorsque vous travaillez avec TensorFlow. Si vous rencontrez
des problèmes lorsque vous
travaillez avec de grands modèles
et des principes scientifiques, il peut les résoudre en
modifiant la base de données. Dans des scénarios réels,
nous aurons affaire à des tenseurs de dimensions plus élevées
et à des formes encore plus grandes. Dans les
leçons suivantes, je vais également vous
montrer comment convertir un ensemble de données du monde réel, tel qu'un groupe d'images, en tenseur. Nous avons vu tf.constant, qui est utilisé pour créer de la
constante et de la sauce. C'est ce que vous utiliserez
tout au long du cours. Mais si vous souhaitez créer
une variable plus dense, vous pouvez utiliser la variable tf dot. La différence entre les
constantes et les
variables permet de modifier les valeurs d'une variable plus dense
mais d'une constante. Vous ne pouvez donc pas
changer le vernis. Créons une danseuse variable. Je vais utiliser le même
ptérosaure et le
qualifier de plus dense que d'utiliser
la variable point F. Maintenant je vais l'imprimer. Vous pouvez voir que nous avons créé un tenseur variable
ayant la même forme. Et ils le sont
tous les deux dans votre W2. L'un des attributs les plus
importants d' un tenseur est sa dimension. Regardons quelle est
la dimension de chacun de ces vernis ou
du bâton au vecteur. Imprimons la dimension
en utilisant la propriété de fin. En eux. Le virulent. Nous pouvons voir qu'il s'agit d'une solution
sans dimension, ce à quoi on s'attend, et vous
pouvez regarder l'échelle. Dimensionnellement, il s'agit d'une valeur nulle car il ne s'agit que
d'une valeur unique. Et pour l'
outil de dimension Matrix AB , c'est parti. Et pour plus dense, l'
exposition diamantaire serait-elle trois ? Les dimensions sont le
nombre de colonnes. Par exemple, si vous utilisez un jeu de données pour
calculer les prix des logements, vous
saisirez le ciel,
l'alimentation , l'emplacement et peut-être
quelques autres entrées. Chacune de ces entrées
sera appelée dimensions. Elles peuvent également être
appelées fonctionnalités. J'espère donc que cette
leçon vous a aidé à comprendre comment créer des tenseurs et trouver des attributs de base
tels que des formes et des dimensions. Dans la leçon suivante, nous
verrons comment générer des danseurs et nous verrons également comment la charge nous
tend à partir des tableaux NumPy.
4. Générer et charger des tenseurs: Voyons maintenant comment générer
des réponses. Dans la plupart des cas, vous ne
créerez pas de tenseurs à partir de zéro. Vous devrez charger un ensemble de données, convertir d'autres ensembles de données
tels que des tableaux NumPy en tenseurs ou générer des réponses. Voyons comment
générer des tenseurs. Nous allons d'abord créer un
tenseur avec des valeurs aléatoires. Vous pouvez procéder de deux
manières courantes. Vous pouvez passer à une distribution
normale ou générer une
distribution uniforme des données. La distribution normale
est une courbe en forme de cloche. Cela représente donc la
distribution des données. Cela signifie que
la plupart des données seront proches la moyenne et que moins de données
s'éloigneront de la moyenne. Cela signifie essentiellement
que la probabilité d'obtenir une valeur proche de
la moyenne est plus élevée. La
distribution uniforme
est toutefois une ligne droite
qui représente la distribution des données. Donc, toutes les valeurs
peuvent-elles
avoir une probabilité égale de se produire dans
la plage donnée ? C'est encore une chose que
vous devez savoir avant commencer à générer des valeurs
aléatoires. C'est un concept appelé graine. La graine n'est qu'une valeur. Et si nous utilisons une valeur initiale, nous pouvons régénérer le même
ensemble de données plusieurs fois. Vous savez donc que nous allons
générer des valeurs aléatoires, n'est-ce pas ? Donc, si nous utilisons une graine, les mêmes valeurs aléatoires seront générées
encore et encore. C'est très
utile lorsque vous
travaillez avec un modèle
d'apprentissage automatique et que vous souhaitez tester ce modèle rapport au même ensemble de données. Alors laissez-moi créer la graine l, appelez-la seed db point random dog. Très bien, colombe issue d'une graine. Cela définira la
valeur, disons 42. Maintenant, je vais
créer un ensemble de valeurs
aléatoires basées sur
la distribution normale. Ou la mère finit par avoir
un point de semence normal. Et je vais mettre une forme. Disons p de deux. Il a été créé,
imprimons-le. Nous avons un tenseur de
forme trois par deux. Et si vous tracez
toutes ces valeurs, vous pouvez voir qu'elles
déforment une courbe en cloche. Tous ces éléments appartiennent donc à
la distribution normale. Créons maintenant
un autre tenseur aléatoire avec la distribution uniforme. Uniforme Tarasoff. Uniforme à points C. Je vais lui donner la même
forme, trois par deux. Et laisse-moi l'imprimer. Mais trouvez une formule précise. Il s'agit maintenant d'un tenseur uniforme ayant la forme de trois par deux. C'est ainsi que nous pouvons
générer un ensemble de cellules mortes
aléatoires en utilisant des distributions normales
et uniformes. Voyons maintenant comment créer des
tenseurs avec des zéros et des uns. Vous vous demandez peut-être pourquoi
nous en avons besoin dans TensorFlow. Les tenseurs remplis de
zéros et de uns sont souvent utilisés comme point de départ pour créer d'autres danseurs. Par exemple, ils peuvent également être utilisés comme espaces réservés pour
les entrées d'un graphe informatique. Créons donc d'abord un
plus dense. Je les verrais. Pour cela, nous utiliserions
la fonction df1 zeros. Appelons ça des zéros. Et nous allons lui donner une forme. Vous pouvez voir que nous avons créé un programme de trois par deux sur les
fluides tensoriels. Créons maintenant le
même tenseur avec un seul. Le point central est une fois, le navire et le navire sont égaux à deux. Imprimons-le. Nous y voilà. Nous avons un tenseur de
forme trois par deux pour
les nains. Il s' de types de crayons Freedom
plus différents que vous pouvez créer à
l'aide de TensorFlow, mais ce sont les crayons
les plus courants que vous utiliserez. Voyons maintenant comment convertir un tableau NumPy en tenseur. Si vous ne savez pas ce qu'est NumPy, c'est une bibliothèque Python
pour le calcul numérique. Cela nous aide à gérer de
grands ensembles de données et à y effectuer divers
calculs. Et avant Tensorflow, Numpy était tout ce que nous avions lorsque nous travaillions avec des modèles d'apprentissage
automatique. Importons donc d'abord numpy
et créons un antibiotique. Je vais créer un tableau NumPy, suivi d'un
soulignement impaire. Et j'utiliserai
la fonction range, qui indique à NumPy générer une liste de
valeurs, disons 1 à 25. Et le bip de l'octet de données
sera engourdi par Bob int. Imprimons. Nous y voilà. Nous avons un tableau avec
24 valeurs comprises entre 1 et 25. Nous allons maintenant le
convertir en
un produit créé par TensorFlow pour
prendre en charge NumPy. Ainsi, vous pouvez facilement convertir un impartial en objet de réponse. Appelons-les d'ici là. Donc, cette constante de point tf et mon entrée seront les données
non binaires que je viens de créer. Et la forme sera, je peux définir la
forme personnalisée, disons, deux par 34 par trois. Et imprimons-le. Nous y voilà. Nous avons converti un tableau NumPy
unidimensionnel en un tenseur deux
par quatre par trois. C'est ce que vous ferez
souvent lorsque vous travaillerez avec des problèmes d'apprentissage
automatique réels. Parce que souvent, d'autres
algorithmes d'apprentissage automatique ou d'autres frameworks
seront utilisés par des personnes. Et vous obtiendrez le jeu de
données final dans un tableau numpy. Il est donc très important de
comprendre comment nous sommes arrivés à quels tableaux d'objets NumPy. J'espère que cette leçon vous
a aidé à comprendre comment les
tenseurs des génotypes et comment
convertir des tableaux NumPy
en tenseurs. Dans la leçon suivante,
nous verrons comment effectuer des calculs de
base,
des
agrégations et des multiplications matricielles à l'aide de TensorFlow.
5. Opérations de base à l'aide de Tensorflow: Examinons quelques
opérations de base utilisant des tenseurs. Nous allons commencer par
examiner comment obtenir
des informations à partir de
nos tenseurs existants. Permettez-moi de créer un nouveau 40 plus dense. Utilisez la fonction df.columns
pour générer un tenseur 4D. Allons-y en essayant le tenseur. Et le point d'appui galbé à
deux virgules et à
trois couleurs qui est imprimé. Nous avons donc créé un 40 plus dense, mais en forme de deux virgules,
trois, quatre, cinq. Nous allons maintenant obtenir quelques informations
sur ce tenseur. Imprimez d'abord la
taille du tenseur. Donc, pour cela, nous utilisons la taille du point tf. Oui, permettez-moi également d'imprimer la forme de ce que l'on appelle
la forme du point tenseur. Imprimons ensuite la
dimension b ou b. J' ai vu ça retourné et Sadate et du cran.
Voyons ce qui va se passer. Nous y voilà. La taille de quels tenseurs est 120 car il existe des valeurs 12d. Nous avons la forme et
la dimension. Cela vous sera utile
lorsque vous travaillez avec des crayons compliqués. Et si vous souhaitez
vous équiper pour obtenir des informations sur la forme, la
taille et les dimensions. Nous allons maintenant effectuer quelques
opérations de base sur les tenseurs. Permettez-moi donc de définir notre
densité simple ou ce que nous appelons
le dense de base. Df, sèche, constante,
incréée, plus dense, disons une grille 101112. Essayons l'addition. Je voulais juste ajouter un nombre à chaque
valeur du tenseur. Vous pouvez donc simplement dire que les coups
de pied de base sont plus denses. Cela ajoutera dix
à tous les nombres du plus dense et nous
imprimerons le résultat. Essayons une fraction. Peut également inclure
la multiplication et la division. Multiplié par dix, en
le comparant pour le rajouter vers le bas,
imprimons jusqu'à ce qu'il soit. Mais voilà, on y va. Le premier est l'Edison. La deuxième est la soustraction. C'est-à-dire toutes les valeurs multipliées par là
et le plat complet, toutes les valeurs
divisées avec elles. La solution est un peu importante car nous l'
utiliserions dans notre projet. Il existe donc un concept
appelé normalisation. Ce seront de bons convertisseurs qui vont de zéro à un. J'expliquerai cela en détail
lorsque nous en viendrons à cette leçon, mais gardez cela à l'esprit. Examinons maintenant la multiplication
matricielle. C'est également quelque chose
que nous ferons souvent lorsque nous travaillerons sur des projets d'apprentissage
automatique. Permettez-moi de
créer rapidement deux crayons. Nous l'appelons zéro, pas un, constant, deux virgules deux. Abandonné ou pour Ben, je vais créer un nouveau matériau
plus dense appelé
Filler, disons 234 et acquis. Avant de passer à la multiplication
matricielle, gardez à
l'esprit que les dimensions internes
du tenseur que vous
essayez de multiplier doivent correspondre. Supposons, par exemple, que vous ayez deux tenseurs de forme
trois par cinq. Cette multiplication ne fonctionnera pas. Mais si vous avez deux dizaines us avec la forme trois par phi
n phi par trois, cela fonctionnera car les dimensions
intérieures correspondent. Le résultat final de
la multiplication sera différent de la forme
des dimensions extérieures. Donc, si vous avez deux tenseurs, chacun ayant une valeur de cinq
x 3,3 par phi au niveau des formes, le résultat final
sera de cinq par cinq. Essayons de multiplier
ces deux tenseurs en utilisant le
dysfonctionnement de df.count et le html
imprimé. Et donc le zéro double
un, et donc 012. Nous y voilà. Nous avons le
produit de ces deux matrices. Examinons les opérations
matricielles de Domo. Alors remodelez et transposez. Nous utiliserons souvent une forme en V pour modifier la structure de votre matrice. Ensuite, le nettoyage
des réseaux de neurones, par exemple un pixel d'image de
Netflix 28 x 28, sera converti en un tableau
unidimensionnel de valeurs par défaut sur 7 jours. Vous le verrez dans
notre prochain projet et je vais vous expliquer cela en détail. Mais pour l'instant, sachez que remodelage est un
concept très important dans TensorFlow. Et utilisez la phrase ou celle qui sera créée dans les blocs de code
précédents. Denser Zero Double One
m'a permis de le remodeler
en quatre par un. Pour cela, je vais
utiliser df dot reshape. Et mon premier argument
sera le tenseur réel, vais juste répondre à celui-ci. Et le deuxième argument sera la forme qu'ils
disent quatre par un. Donc, si vous voyez cela,
j'essaie de convertir un tenseur deux par deux en tenseur de
chute d'un. Nous y voilà. La valeur est donc deux
virgules 2,4 virgules quatre sont converties en
un tenseur quatre par un. C'est ainsi que nous remodelons un tenseur. Voyons maintenant comment transposer
puis Soft Baby à l'aide la fonction de transposition DF Dot. Ensuite, vous pouvez le
garder pareil, plus dense que, désolé, de zéro à un. Tout droit. Nous y voilà. Vous pouvez voir que les valeurs
ont été transposées, par exemple les valeurs deux par deux et
quatre par quatre sont désormais de 24,2 car, si vous ne savez pas ce que signifie
transposer une matrice, cela revient simplement à convertir en lignes et deux colonnes et en
colonne jusqu'au cheval. Voyons maintenant comment effectuer
certaines agrégations à l'aide de densus. Dans la plupart des cas, vous
souhaiterez trouver la somme, la moyenne, médiane et l'
écart type d'un crayon. Permettez-moi de créer un
danseur de symboles, DFP, constant. Nous allons juste faire un tableau
simple, 1 à 9, avant la bande 6, fixer
une date, travailler. Je vais configurer les couches de données pour. Maintenant. Permettez-moi d'imprimer quelques valeurs. Tout d'abord, je veux
trouver la
valeur minimale dans ce tenseur. Pour cela, je vais utiliser
la fonction Min réduite f point avec elle, mais en abuser, puis donner au lead le plus dense
une entrée sur trois. Imprimons-le. Vous pouvez voir que la valeur
minimale est un. Faisons quelques
agrégations supplémentaires comme celle-ci. Réduire. Copions ceci. Alors. Maintenant, il faut trouver le soleil. Essayons-les en anglais. La valeur minimale est donc de un, la valeur maximale est de neuf
et le soleil était de 45 sur la grille. Ouvrons maintenant un nouveau bloc de code et séchons un peu les agrégations. Je me suis alors demandé quel était
l'
écart type de ce tenseur. Pour cela, je vais utiliser tf point map, reduce, STD, et le plus dense
enfin en gras. Et je veux imprimer
la variance, qui se trouve également dans P de Dartmouth. Essayons ça. Nous y voilà. Nous avons l'
écart type et la variance. Essayons maintenant une
agrégation
plus simple si nous sommes enclins à trouver ce volt silencieux est silencieux et le journal de toutes les
femmes du tenseur. Tout d'abord, à la règle du squash, qui est T de Dark SQRT, plus
dense que l'inquiétude sera
juste tf point carré plus dense. Et je voulais imprimer le
journal, qui est en maths. Donc, le journal à points df.net de la
densa, imprimons-le. Vous pouvez constater que le DFS est assez
robuste du téléphone ou pour chaque valeur du tenseur. Et D sont tous deux des carrés calmes, tous les nombres étant dans le plus dense. Enfin, Math.min log trouve la valeur logarithmique de tous les
corps du danseur. Ce sont les opérations de base que vous devez connaître pour le moment. Dans la vidéo suivante,
nous aborderons un concept important
appelé encodage à chaud.
6. Codage à un chaud: Dans cette leçon, nous allons
examiner un concept important que vous rencontrerez dans le cadre de l'
apprentissage en profondeur, à savoir l'encodage instantané. Le codage à chaud est un
processus utilisé pour représenter un ensemble de valeurs sous forme de données binaires
basées sur des catégories. Ce codage crée
une nouvelle colonne binaire pour chaque catégorie unique. Chaque ligne du jeu de données
se voit ensuite attribuer un un ou un zéro. Par exemple, considérez un ensemble de données avec une couleur variable comportant trois catégories uniques, le
rouge, le vert et le bleu. Si nous utilisons un encodage à chaud, cette variable peut être représentée sous la forme de trois nouvelles colonnes binaires. Chaque ligne du jeu de données en
aura une dans la colonne correspondant
à l'attribution de la couleur. Par exemple, si vous regardez la première ligne, qui est
le fil, la première valeur est une et les
deux autres valeurs sont zéro. Et en vert, la première et la dernière valeur sont simplement zéro et le milieu est un. Et en bleu, la
dernière valeur est 1. Les algorithmes d'apprentissage profond,
en particulier les réseaux de neurones, fonctionnent avec des données numériques. Le codage instantané nous permet de
convertir
facilement type de variables
catégorielles en
représentations numériques simples. Ils peuvent donc
être utilisés comme entrées ou même sorties pour des modèles d'apprentissage en
profondeur. En utilisant un encodage instantané, nous pouvons gérer de nombreux types de variables de
catégorie. Cela est généralement difficile à gérer pour les autres modèles de codage. Enfin, le
codage instantané fournit un mappage clair entre
les catégories et leurs représentations
numériques correspondantes. Cela permet donc au modèle
d'
interpréter et d'
analyser plus facilement les résultats des modèles d'apprentissage en profondeur. Par exemple, si nous essayions de créer
un algorithme pour classer les chats et les chiens, une
sortie codée en un seul clic serait beaucoup plus facile à
convertir en résultat final. J'espère que cette leçon vous aidera à comprendre le fonctionnement de l'
encodage instantané. Dans la leçon suivante,
nous verrons comment TensorFlow peut fonctionner
avec les GPU et les TPU. Nous ne travaillerons pas avec des GPU
et des TPU dans le cadre de ce projet, mais il est intéressant pour vous de
comprendre comment vous pouvez
utiliser des GPU ou des TPU s'
ils sont disponibles.
7. Travailler avec les GPU et les TPU: Voyons donc comment travailler
avec les GPU et les TPU à l'aide TensorFlow. Nous ne verrons pas
ce que sont les GPU et les TPU, mais
examinons-les plus
en détail mais
examinons-les plus
en détail pour savoir comment les utiliser. Mais TensorFlow, les GPU ou les unités de traitement
graphique et les TPU sont des unités de
traitement tensorielles ou une conception matérielle spéciale destinée à
accélérer le processus
d'apprentissage automatique. Ils ont de nombreux objectifs
et peuvent traiter les données beaucoup plus rapidement que
les processeurs traditionnels. Commençons par examiner les appareils disponibles
dans
ce bloc-notes Colab. Pour cela, nous utiliserons
la liste de configuration F point. Appareils physiques. Vous pouvez voir que B, nous n'
avons qu'un processeur qui nous est alloué. Maintenant, utilisons notre environnement d'exécution
et allouons un GPU. Peut changer de temps en
temps et le convertir en GPU. Je ne vous montrerais pas
comment vous connecter à un TPU car le processeur sera
toujours disponible. Regardons donc le GPU et la façon dont nous
pouvons travailler avec lui. Sauvegardez-le. donc très important, une fois que
vous aurez modifié le runtime, assurer que
votre bloc-notes Colab est collecté et que vous exécutez TensorFlow. Vous n'avez qu'à lire
sur le dollar des importations. Tu n'as pas à
t'inquiéter pour le reste. Nourrissons-nous de cela. Génial. Voyons maintenant à quels appareils
nous avons accès. Nous y voilà. Nous pouvons voir que nous avons
un GPU ou c'est bon pour nous. En ce qui concerne TensorFlow
, vous n'avez pas à
passer d'un processeur à un autre, car TensorFlow s'en
occupe
automatiquement pour vous. S'il existe des TPU, le code
sera légèrement différent, mais vous n'utiliserez pas de
TPU à moins travailler avec des modèles d'apprentissage en profondeur extrêmement
volumineux. Si vous souhaitez spécifier un périphérique que vous souhaitez utiliser
pour votre code, vous pouvez utiliser la fonction de périphérique TF Dot
et lui donner le nom du périphérique. Cela dirait GPU Cielo. Vous pouvez ensuite
écrire le reste de votre code dans ce bloc de code. Ainsi, tout l'or contenu dans ce bloc de code
fonctionnera à l'aide du GPU. J'espère donc que cette leçon
vous aidera à comprendre ce que sont les GPU et les TPU et comment vous pouvez réellement
les utiliser dans votre code. Dans la leçon suivante, nous allons
commencer par notre projet actuel, qui est un réseau neuronal de
reconnaissance de l'écriture manuscrite utilisant TensorFlow, et nous y arriverons.
8. Préparer le modèle: Maintenant que nous avons appris
et maîtrisé les bases, commençons à construire
notre projet. Nous utiliserons l'ensemble de données MNIST composé de chiffres
manuscrits
pour entraîner notre modèle. Mnist est le jeu de données d'images contenant 60 000 images d'entraînement
et 10 000 images de test. Nous pouvons donc utiliser ces 60 000 images
d'
entraînement pour entraîner notre modèle. Et nous pouvons utiliser les
10 000 images
de test pour évaluer les performances de notre
modèle. Ces chiffres sont compris entre 0 et 9. Chaque image est de taille 28
par 28 et en niveaux de gris. Donc, si vous regardez ce bloc, l'axe x est 28 et
l'axe y est 028. Chaque pixel aura une
valeur comprise entre 0 et 255, par exemple, les blocs vides
seront nuls et les blocs les plus sombres
auront une valeur comprise entre 55 et 55. Voici donc comment chaque image est
représentée dans cet ensemble de données. Nous aurons un total de 784 valeurs de
pixels par image. Si cela est clair pour vous,
commençons par ajouter le code. Il va d'abord importer
l'ensemble de données MNIST. Je vais créer une variable
appelée MNIST. Et nous pouvons obtenir l'
ensemble de données de Geddes, Floride, nous obtenir des ensembles de données. Je vais maintenant
créer quatre variables. Extreme, White Train et
X Test et test de vélo. Le train x et le
train y seront donc utilisés pour entraînement tandis que le x test et le bureau y seront
utilisés pour les tests. Et je vais appeler la fonction
de chargement des données. Et nous devons ajouter la date téléchargement dans ces variables. Alors, testons-le. Et une valeur tirée de x train. Nous y voilà. Nous avons un 28 x 28. Ainsi, une large plage
ajoutera la valeur de cinq. Donc x contient des images et Y a la
valeur réelle des signatures. Il s'agit d'une
étape importante que nous devons franchir, appelée normalisation. Ainsi, chaque pixel de cette
image sera lié 0 à 255 et nous
allons déterminer ses caractéristiques
de zéro à un. Il s'agit donc de rendre l'ensemble de données simple et facile à comprendre pour le
modèle. Pour les normaliser, je vais simplement diviser toutes les valeurs de
l'image par deux. Ainsi, x train et x test
seraient divisés par largeur. Revérifions-le. Nous y voilà. Maintenant, nos valeurs d'image sont
comprises entre 0-1 et 002, 55. L'ensemble de données de test X est prêt. Nous allons maintenant commencer à
construire notre modèle. Nous allons construire un modèle séquentiel l'aide de getters, comme nous l'avons vu précédemment. Auparavant, Get Us était une bibliothèque
individuelle
permettant de créer des modèles
d'apprentissage en profondeur, mais elle a été intégrée
à TensorFlow. Keras, nous avions l'habitude de coder
toutes les couches elle-même. C'était assez compliqué et a permis de travailler avec TensorFlow
. Mais avec Geddes,
il est beaucoup plus facile pour nous d'empiler
plusieurs couches
et de construire un
réseau d'or, c'est moderne. Je vais appeler le modèle séquentiel. Et ma première couche, ce
sera une couche d'aplatissement. Kayla a donc arrêté. Mais ça s'aplatit quand même. La forme d'entrée est de 28 x 28. Cette couche va
donc prendre notre tenseur 28 x 28 et le convertir en un réseau
unidimensionnel. Notre couche d'entrée ne
sera donc pas une couche de 28 x 28, mais un réseau
unidimensionnel de 0784 couches. Cela sera donc transmis en tant qu'
entrée à notre réseau de neurones. Je vous montrerai une image à
la fin de ce modèle, afin que ce soit beaucoup
plus clair pour vous. La couche suivante
serait une couche dense. Et celui-ci aura 128 neurones
dotés d'une
fonction d'activation appelée relu. Les fonctions d'activation nous aident à capturer des modèles
et des relations. Et cette activation ReLU est une fonction
d'activation couramment utilisée. Il faudra donc prendre la sortie de la première couche et seule
elle obtiendra une valeur positive. Si la sortie est négative,
elle renvoie zéro. Cela nous permet donc d'éviter les valeurs
négatives et d'accélérer l'
entraînement du modèle. La couche suivante sera
une couche déroulante. Et nous allons fixer le taux de
baisse à 0,2. Ainsi, la couche de protection
empêche le surajustement. surajustement se produit
lorsque notre modèle commence à s'appuyer sur un
résultat spécifique. Par exemple, si nous entraînons notre
modèle avec 10 000 documentateurs et des milliers d'images, le modèle privilégiera automatiquement les chiens et nous classerons davantage de photos de
chats représentant des stocks. Cette couche troublée nous
aide donc à réduire cela. L'argument 0.2 indique
que le taux rapide est de 20 %, ce qui signifie que 20 %
des neurones la liste précédente seront
supprimés pendant l'entraînement. Enfin, nous allons construire une autre couche dense qui
sera notre sortie. Des enfants de 10 ans seront présents et
imprimons-le. Modèle. J'ai fait une erreur commune à
Messine. Notre modèle est donc prêt. C'est ce que nous
avons construit. Si vous regardez ce modèle, la première couche contient
tellement de neurones différents, qui seront la couche d'entrée. Et cette couche aplatit une image plus dense de
28 x image plus dense de
28 en un saumon AT pour un réseau
unidimensionnel. Cela sera donc
transmis en entrée. Ensuite, nous avons la couche
d'activation, puis la couche descendante et enfin, nous avons
la couche de sortie. Nous aurons besoin d'une couche
supplémentaire plus tard dans le projet, qui sera une couche softmax. Toutes ces sorties seront donc des prédictions et
non des probabilités. Il y aura donc des scores. Et nous avons besoin d'un moyen de
convertir les scores en probabilités
réelles afin de
savoir ce que le modèle
essaie de prédire. Nous venons donc de
construire un modèle. Il n'est pas
encore formé, mais nous allons simplement lui transmettre quelques données et
voir s'il fonctionne bien. Créez une variable
appelée prédictions, et j'appellerai le modèle et transmettrai une valeur à partir de la radiographie qui a
transmis la première valeur. La raison pour laquelle j'utilise
cet opérateur de tranche est que l'
opérateur de tranche renvoie un tableau. L'entrée doit être un
tableau de tenseurs. Donc, même s'il s'agit d'une
valeur unique, ça me convient. Mais d'une autre manière, c'est pourquoi j'utilise l'opérateur slice. Elle renvoie un tableau de valeurs. Et laissez-moi imprimer des prédictions. Vous verrez qu'il
imprimera un tas de partitions ici. Il existe donc des valeurs positives
et négatives. Voyons ce que l'on appelle SoftMax fonctionne. Softmax est donc
essentiellement une couche qui convertit un discours
en véritables bourdons. Créez donc une couche appelée softmax et transmettez-lui
les prédictions. Voyons à quoi ça ressemble. Nous avons donc maintenant des probabilités. Cela signifie donc que le modèle
essaie de nous dire quelle est la probabilité que
l'entrée appartienne à l'une de ces lunettes ? Donc, le premier signifie zéro. La deuxième c'est un moins deux, et la dernière c'est ce soir. Nous avons donc des probabilités pour
chaque chiffre de l'ensemble de données. Simplifions-nous donc
les choses et voyons ce que le modèle est
entraîné à prévoir. Pour cela, nous allons simplement convertir ces prédictions en
un tableau simple. J'utilise NumPy pour
simplifier les choses et je vais apprendre pour
la première fois. Comme vous pouvez le voir,
c'est dans une autre, je suis juste en train de saisir
cette première valeur et je vais la convertir
en une liste Python. Et je vais imprimer
la valeur maximale, l' indice de
la valeur
maximale pour tableau
simple qui correspond à
la valeur de la valeur inférieure. Nous pouvons donc maintenant voir ce que le
modèle essaie de prédire. Debbie, vas-y, elle
essaie de dire qu'il est sept heures. Voyons quelle était la valeur
réelle. Donc imprime x train d'un, donc train blanc d'un. Donc, le pic de valeur réel, mais notre modèle indique qu'il est de sept. C'est parce que notre
modèle est encore formé. Ainsi, une fois que vous aurez
formé notre modèle, vous verrez à quel point
l'impulsion spirituelle est forte. Ainsi, avec le
bloc de code B, on a déjà construit un réseau neuronal profond à
couches entièrement connectées. le chapitre suivant,
nous
examinerons les optimiseurs
et la fonction de perte et nous verrons pourquoi
ils sont importants pour entraîner notre modèle.
9. Fonction d'optimisation et de perte: Dans cette leçon, nous allons
discuter de l'utilisation des fonctions de perte et de la façon dont elles contribuent à l'entraînement des réseaux de
neurones profonds. Nous parlerons également
des optimiseurs et verrons comment les utiliser pour
minimiser la fonction de perte. Nous terminons la leçon en
examinant le populaire optimiseur Adam, que nous utiliserons
pour notre projet. La fonction I lost function est également
connue sous le nom de fonction de coût. Il s'agit d'une fonction mathématique qui mesure la
différence entre la sortie prévue d' un modèle et la valeur cible
réelle. Ainsi, lorsque nous entraînons
un réseau de neurones, mais uniquement des entrées et des sorties, le réseau de neurones
génère sa propre sortie. Il compare ensuite
cette sortie avec la sortie réelle que nous avons
donnée dans le kit d'apprentissage. C'est ainsi que le réseau
neuronal apprend. L'objectif du processus de
formation est de minimiser la valeur de
ces fonctions de perte. Plus les valeurs prédites
sont proches des valeurs réelles, plus
la valeur de la fonction de
perte sera faible. Dans le cadre de l'apprentissage profond, les fonctions de perte nous
aident à améliorer la
précision du modèle. Les paramètres du modèle sont ajustés de
manière à minimiser la
fonction de perte,
ce qui nous donne de meilleures prévisions. Le choix de la
fonction de perte
dépendra du type de problème
que vous rencontrerez. Il existe donc de nombreuses fonctions de perte, comme la fonction de perte
d'entropie croisée. Ou si vous travaillez sur un
autre problème de collision, vous utiliserez quelque chose comme une fonction moyenne quadratique
d'erreur ou de perte. Moyens agressifs, prévision des cours
boursiers, prévision des prix des
logements
et autres problèmes similaires. Vous pouvez trouver plus de ressources
sur la fonction de perte, la description du cours,
je vais ajouter un lien pour vous. Parlons maintenant des optimisations. Les optimiseurs sont des algorithmes qui nous
aident à minimiser
la fonction de perte. Ils fonctionnent donc en mettant à jour
les paramètres du modèle telle sorte que la valeur
de la fonction de perte continue de
baisser. Et comme nous l'avons vu précédemment,
plus la fonction de perte est faible, mieux
le
modèle est entraîné. Il existe donc de nombreux choix
optimaux, chacun ayant ses propres
forces et faiblesses. Un optimiseur à bulles
s'appelle Adam Optimizer. L'optimiseur Adam est très
efficace dans un large éventail de tâches d'apprentissage en
profondeur et c'est un excellent choix à
utiliser pour ce projet. optimiseur Adam combine les avantages de la descente en
gradient, qui est un ancien algorithme. Si vous avez étudié
lors de l'apprentissage initial, vous avez probablement entendu
parler de la descente en pente. Adam Optimizer est donc un
outil de descente en pente. Et il est également
très efficace sur le plan informatique. Même si pour comprendre
la logique qui sous-tend ces fonctions de coût et
les optimiser pour le moment, TensorFlow s'occupera de tout
pour vous. Pour l'instant. Il suffit de comprendre que
les fonctions de perte nous aideront à réduire
les prévisions relatives aux endosomes et optimisations aideront à minimiser
la fonction de perte. J'espère donc que vous comprenez comment fonctionnent les
optimiseurs Lost One Chosen. Dans la leçon suivante,
nous allons construire une fonction de perte et vous l'aurez optimisée. Nous
commencerons à compiler et à
entraîner notre modèle.
10. Compiler et former le modèle: Créons maintenant
la fonction de perte. Je vais utiliser la fonction d'
entropie croisée
catégorielle clairsemée , qui est couramment utilisée pour les modèles de
classification. Accédez ensuite à la
fonction de perte de buts dans Keras. Et je vais économiser
de l'argent, c'est vrai. J'appelle les logits à cause des prédictions réelles
ou des logiques des déesses. C'est pourquoi je
dis que nous allons calculer
les pertes à partir des logits. Compilons maintenant notre modèle. Et je vais
spécifier l'optimiseur, qui sera Adam. Et ma fonction de perte est celle
de la belle-famille. Je viens certainement de créer et je vais imprimer
quelques mesures de précision. Pour l'instant. Je veux juste qu'il
voie la précision. Cela nous indiquera donc à quel point notre modèle s'améliore
pendant l'entraînement. Nous l'avons fait, parce que j'ai
commis une erreur. Alors laissez-moi exécuter ceci et m'
assurer que le trait est correct. C'est un mot, dipôle. Ce n'est
tout simplement plus une haie, si éparpillée dans le monde
interconfessionnel, que tout cela là-bas. Et maintenant, compilons
l'argent. Nous y voilà. Fait partie du module Compiled. Commençons maintenant à nous entraîner. Notre modèle
s'appellera model dot fit, c'
est-à-dire qu'il adapte les données
au réseau neuronal. Et je vais lui transmettre des valeurs
extrêmes et blanches. Je vais également spécifier une
boîte faible pour combattre. L'époque signifie donc une itération. Les époques indiquent donc au
modèle combien de fois il doit s'
entraîner avec cet ensemble de données. Donc, si nous spécifions
le livre électronique comme 5k, le modèle d'apprentissage en profondeur, nous
parcourons cet ensemble de données phi times. Cela permet au modèle de
comprendre les modèles
qui n' ont pas été détectés lors du
premier ou du deuxième titrage. Vous pouvez donc améliorer le trading
en augmentant la boîte. Mais après un certain
temps, la précision
commencera à être constante. Cela signifie donc que le
modèle tient compte des poumons autant que possible
à partir des données fournies. Commençons donc par le box fight et
laissez-moi les entraîner. Vous pouvez voir que l'entraînement a commencé et le premier titrage est en cours. Et vous pouvez voir que notre
précision est désormais de 91 %. Il affiche un pourcentage
de loyer élevé lors de la deuxième itération,
et il ne cesse de s'améliorer au fur et à mesure que la fonction de perte n'est réduite. Nous avons maintenant ajouté la précision de 97 %. Augmentons la case à dix afin que vous puissiez comprendre à
quoi elle sert exactement. Et quand j'augmente la boîte, ce modèle est déjà entraîné. Cela peut donc être un entraînement. Donc, si vous continuez à
l'entraîner à partir de là, vous verrez que la précision
de départ varie. Je fais sept pour cent. Oui, nous avons ma bonne personne, mais ça se détériore un peu. Vous pouvez donc voir que la
précision est désormais de 98 %. Il n'y a rien de mieux que ça. C'est donc un bon point pour nous de mettre fin au nombre de
nos boîtes de réception. ne s'agit donc que d'un
certain nombre de vibrations que vous pouvez effectuer
avec un modèle d'apprentissage automatique. Remets-le à cinq. Vous pouvez donc constater que
la formation est maintenant terminée et que nous
avons atteint une précision de 98 %
dans des scénarios réels. Même si vous avez une
précision de plus de 80 %, vous devriez disposer d'un modèle d'
apprentissage en profondeur décent. Notre modèle est entraîné
et prêt à prédire. Dans la leçon suivante,
nous allons jouer avec quelques exemples de valeurs numériques et voir les performances de
notre modèle.
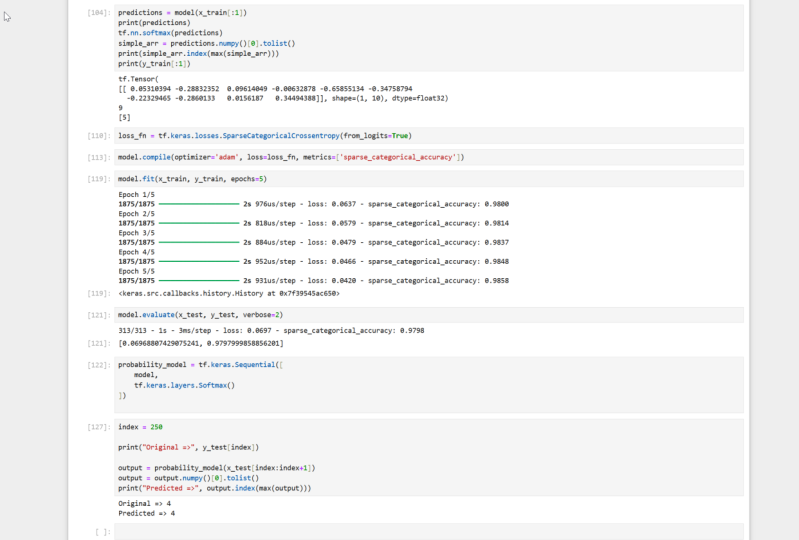
11. Prédire les chiffres manuscrits: Nous avons donc
intégré notre modèle. Maintenant, voyons à quel point notre modèle est
bon. Tout d'abord, nous utiliserons la fonction
d'évaluation intégrée, transmettrons les données de test et verrons dans
quelle mesure le modèle fonctionne. Essayons ça.
Poids à la naissance moderne, test X et poussière blanche. Beaucoup de verbosité pour que nous
sachions ce qui se passe
en arrière-plan. Nous avons donc une précision
d'environ 97 %. La perte est de 0,7. Génial. Cela signifie que nous
avons une hypothèque légale. Nous devons ajouter une étape
supplémentaire avant commencer à examiner
les valeurs de prévision. Comme nous l'avons vu précédemment, ce modèle imprime
les scores des prédictions. Cela ne nous donne pas
les probabilités. Nous allons donc ajouter une couche softmax ,
puis nous
examinerons le problème. Je vais maintenant créer
une autre couche de séquence. Et les clubs sont à la fois un
modèle existant et une
couche SoftMax. C'est ce que nous allons faire. C'est
ce que nous appellerons le modèle de probabilité. Ce modèle est donc le même
que notre modèle existant, mais nous allons simplement
ajouter une couche softmax. Disons donc la séquence de points de
Kayla. Et nous allons
ajouter notre modèle et une grille de couches Softmax. Notre modèle est maintenant prêt. Nous allons donc prendre quelques valeurs
de l'ensemble de test, savoir x test et y test, et voir si je suis
le seul à obtenir la valeur correcte. C'est quelque chose
que nous avons fait plus tôt, mais notre modèle prédisait
tout de manière erronée.
Voyons maintenant comment ça se passe. Après la formation, je vais
ajouter un autre bloc de code dans lequel je vais
d'abord imprimer l'original. Disons que c'est original. Et ce sera une
valeur de poussière blanche. Arrêtons-nous à zéro. Regardons de quelle
manière cela fonctionne. Il est sept heures. Génial. Nous allons maintenant séparer
la valeur du test x dans le mix donner à notre modèle et
lui demander de la prédire. Donc, si vous obtenez la même valeur, cela signifie que le modèle
fonctionne comme prévu. Supposons donc que la sortie
soit un modèle de probabilité. Et je vais le prendre en bus. La valeur de test X sera nulle. Il s'agit donc de la première valeur. Donc, l'élément zéro,
c'est pourquoi je dis qu' il s'appelle The One. Vous pouvez aussi dire
zéro, un doré. Maintenant, je vais utiliser la même
logique que précédemment, mais juste pour
convertir cela en tableau inter-octets et obtenir l'indice de la probabilité
maximale. Supposons que la sortie
soit un point de sortie non en saisissant le premier élément
et en le convertissant en liste. Et je vais transformer la valeur prédite de l'indice du maximum
en fonction du débit de sortie. Il s'agit donc d'imprimer la valeur d'origine plutôt
que de transmettre la valeur x qui appartient à cette sortie et configurer ou de demander
au modèle ce qu'
il pense de l'entrée donnée S. Donc, si nous avons un équivalent original
et productif, cela signifie
que notre modèle
fonctionne bien. Essayons cette grille ou plusieurs. Tu l'as, non ? Essayons-en un autre appelé
dual 1200. Fais le même travail. Nous y voilà. La religion est cinq et la valeur
prédite est cinq. Laisse-moi en essayer une autre. Optez pour 50. Melody avait l'habitude de voir de la valeur. Afficher. Nous y voilà. C'est 4.4. Vous pouvez jouer avec
différentes entrées et vous verrez que 97 fois
sur 100, notre modèle prédira correctement les
valeurs. Très bon travail. Nous avons créé un modèle fonctionnel d'apprentissage en
profondeur utilisant la vision par ordinateur qui
prédit les chiffres écrits à la main. Vous ne pouvez qu'imaginer comment d'autres
problèmes de classification tels que prédictions de
Datadog
et d'autres fonctionnent
d'autres
problèmes de classification tels que les prédictions de
Datadog
et d'autres
problèmes de classification d'
images simples. Et je suis sûr que vous
avez quelques questions après avoir suivi ce cours. N'hésitez donc pas
à me contacter. Vous pouvez me
contacter si vous êtes bloqué à tout moment
et au cosinus, je serais heureuse de vous aider. Faisons donc un bref résumé
de ce que nous avons vu jusqu'à présent.
12. Conclusion: Encore une fois, excellent travail pour
terminer le cours. Tu as beaucoup appris. Nous avons commencé par
examiner les tenseurs et la manière dont TensorFlow nous aide à créer
et à travailler avec des tenseurs. Nous avons ensuite vu comment
effectuer des opérations sur des tenseurs et
nous avons généralement tendance à utiliser des tableaux NumPy. Nous avons également examiné les fonctions
de perte et les optimisations et la manière dont elles contribuent à améliorer notre réseau
neuronal. Nous apprenons ensuite à charger le jeu de données MNIST et à
créer un modèle à l'aide de Keras. Enfin, nous compilons et entraînons notre modèle pour prédire les chiffres
écrits à la main. J'espère que ce cours
vous aidera à comprendre comment travailler avec TensorFlow. Si vous avez
des questions,
n'hésitez pas
à contacter week. Vous allez me contacter à l' adresse help admonition shiva.com. Merci d'avoir
suivi ce cours. J'aimerais connaître
vos commentaires pour améliorer encore le prochain
cours. Je vous remercie donc encore une fois d'
avoir suivi ce cours. À bientôt avec un nouveau sujet.
 Manish Shivanandhan, AI & Cybersecurity Engineer.
Manish Shivanandhan, AI & Cybersecurity Engineer.