Transcription
1. Introduction au cours: La science des données est ce nouveau domaine passionnant, mais il peut être intimidant de s'y lancer parce qu'elle implique
souvent des mathématiques et de la programmation. C' est quelque chose avec lequel beaucoup de gens sont mal à l'aise, et certaines personnes n'en ont même pas besoin lorsqu'elles veulent gérer une équipe de science des données, plutôt qu'elles se penchent sur les détails minces. Nous arriverons à une compréhension de haut niveau pour comprendre les méthodes et le vocabulaire de la science des données. Vous pouvez parler en tant que pair, c'est
ce que nous faisons dans cette classe de maître en science des données. m'appelle Jesper Dramsch, je suis ingénieur en apprentissage automatique à Oxford au Royaume-Uni. J' ai de l'expérience dans l'enseignement de Python et d'apprentissage automatique sur cette plateforme,
sur Skillshare , ainsi que dans des entreprises comme Shell ,
le gouvernement britannique et quelques universités. J' ai passé mes deux dernières années à travailler vers un doctorat en géophysique et en apprentissage automatique. J' adore la science des données parce qu'elle m'a permis de trouver un emploi pendant la pandémie, ce dont je suis incroyablement reconnaissant. Je veux partager certaines de ces connaissances avec vous parce que je pense qu'il s'agit vraiment de donner aux gens les moyens d'aller de l'
avant dans leur carrière et peut-être même d'apporter un changement. Ce cours vous enseignera les concepts et le haut niveau de compréhension sans entrer dans le code, sorte que vous pouvez parler avec les scientifiques des données en tant que pairs et vraiment comprendre les processus de pensée derrière la prise de décision basée sur les données. Je suis incroyablement excité de t'avoir et j'espère te voir en classe.
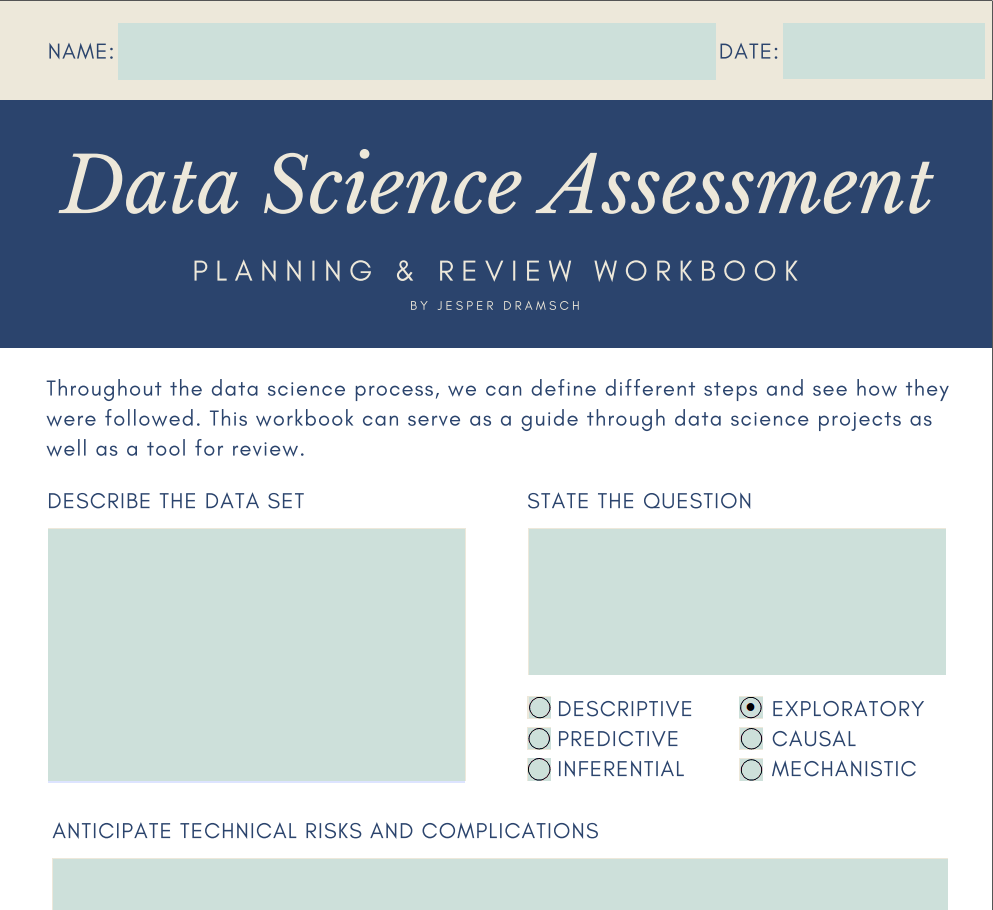
2. PROJET DE CLASSE: Bienvenue en classe. Je suis si contente que tu l'aies fait. Qu' est-ce qu'on va faire ici ? Eh bien, j'ai préparé un projet de classe et je veux que vous y jetiez un oeil parce que c'est essentiellement un classeur que vous pouvez utiliser pour votre projet de classe, mais j'espère que vous pouvez réellement l'utiliser dans votre travail quotidien de science des données aussi. Soit en vous guidant dans vos propres projets, soit pour vous aider à gérer d'autres projets. Plongons directement dans le cahier d'exercices et jetons un coup d'oeil à travers. Il s'agit du cahier d'évaluation de la science des données pour la planification et examen de vos projets de science des données sur les projets de science des données que vous gérez. Ce sont trois pages pour le moment, et au début, vous pouvez remplir votre nom et votre date et poser quelques questions importantes sur vos données. Ensuite, nous aurons quelques informations d'où proviennent
vos données et comment vous vous assurerez de valider vos données. Quelques informations sur les étapes que vous
apprendrez dans la prochaine classe qui font partie du processus de science des données. Ensuite, vous allez essentiellement documenter les algorithmes et les visualisations notables qui ont conduit à l'intérieur, les résultats
négatifs qui ont été trouvés tout au long du projet. Quel est l'impact commercial principal ou scientifique, selon l'endroit où vous êtes et votre conclusion principale. Ceux-ci sont entièrement personnalisables. Je peux dire que c'est mon nom et aujourd'hui c'est le 8 janvier. Décrivez maintenant l'ensemble de données. Dans l'exemple de l'ensemble de données, par exemple, nous avons un indicateur du bonheur, et nous avons des points de données par pays et ici. De cette façon, vous pouvez vraiment remplir chaque question ici. La question, par exemple, est, quelle est l'influence principale sur le score de bonheur ? Ce serait quelque part entre descriptif et exploratoire. Je dirais que c'est exploratoire parce que, eh bien, nous examinons comment cette prédiction ou comment le score est calculé, donc nous l'explorons plutôt que de décrire l'ensemble de données. Le risque technique est quelque chose où, par exemple, vos données ou vos machines ne sont pas capables de le faire. Pensez à si vous disposez d'un ensemble de données trop volumineux, il peut ne pas tenir sur votre ordinateur. Quels sont les risques qui peuvent arriver et les risques ne doivent pas être la pire chose. Il ne s'agit que de barrages routiers et si vous anticipez les risques maintenant, vous pouvez prendre des interventions et prendre des précautions pour vraiment s'attaquer à ces risques s'ils se produisent. L' un des risques pourrait également être que les données ne viennent pas. Que faites-vous en cas de perte de données ? Parce qu'il manque un de vos disques durs ? Pensez à ça. C' est une bonne question à vous poser et nous avons ici des risques méthodologiques. Que peut-il se passer dans le processus de science des données lui-même ? Que se passe-t-il si nous n'avons pas d'algorithmes disponibles pour poser ces questions ? Que se passe-t-il si notre
ensemble de données ne contient pas réellement les informations dont nous avons besoin pour faire la prévision ? Vraiment plus au niveau méta, pensez à ce qui peut mal tourner dans l'analyse de la science des données elle-même,
comment et où les données et les étiquettes ont été acquises et aux stratégies de validation utilisées pour vous assurer que vos connaissances sont généralisables. Tous ces mots et tout cela seront expliqués dans le cours aussi. Si ce sont des mots bizarres pour vous maintenant, vous les comprendrez à la fin. N' oubliez pas de revenir ici pour réaliser votre projet et de le soumettre à notre base de données de projets. Ce qui est des considérations éthiques est une question importante. Vraiment un score de bonheur, par exemple, sont ces agrégats statistiques donc au niveau du pays ou
avez-vous la possibilité de voir des informations de niveau personnel. Ce serait plutôt, eh bien, ce serait un peu douteux. Alors écrivez à propos de cette année, puis dans les différentes étapes, écrivez sur les résultats que vous avez trouvés en faisant des statistiques descriptives, EDA, machine learning, et ensuite quelles mesures de communication ont été prises. En fin de compte, comme je l'ai dit, algorithmes et des visualisations
notables. Ce qui a eu le plus d'impact sur la diffusion de vos connaissances. Ensuite, les conclusions négatives, comme je le ferai remarquer, la science
des données est un processus itératif. Vous verrez que parfois vous trouvez des choses négatives, parfois quelque chose ne fonctionne pas. Notez ces vers le bas. Si tu peux écrire ça, tu regarderas en arrière et verras, oh oui, on le sait déjà. Vous pouvez partager cela avec les scientifiques des données avec les décideurs
clés et ils apprécieront également ces commentaires où vous pouvez dire,
eh bien, que cela ne fonctionne pas, cela n'a pas fonctionné empiriquement. Donnez donc un aperçu supplémentaire de votre analyse. Quel est l'impact commercial principal, l'impact scientifique ? Cela devrait être mélangé hors de votre question. Quel est l'impact de votre question sur l'entreprise, mais aussi comment les conclusions et la réponse à votre question influent-elles sur l'entreprise, toute la science que vous faites. Ensuite, écrivez une conclusion principale. Vraiment, quelle est la principale conclusion que vous avez dans cette analyse de la science des données ? Maintenant que nous avons terminé avec le PDF, vous pouvez le télécharger dans la description. On peut jeter un oeil à la structure de la classe. Parce que cette classe est conçue pour tant d'étudiants différents. Certaines conférences peuvent ne pas être les plus pertinentes pour vous. N' hésitez pas à les sauter. C' est très bien si vous vous ennuyez même et que vous allez à la suivante. Parce que même si le premier n'est pas le bon pour vous, il peut y en avoir un qui est mieux pour vous. Par exemple, l'un des derniers est de parler opérationnalisation des pipelines de données et de la compréhension des risques et des projets de science des données. Certaines des questions vraiment importantes que vous avez quand vous gérez des équipes. Assurez-vous de les vérifier. Si vous sautez devant, pas de sentiments durs. C' est votre classe, alors faites-le à vous, et assurez-vous de partager vos projets. Je serais très heureux de voir comment vous donnez un sens aux projets des autres. N' oubliez pas d'être gentil, n'oubliez pas de le critiquer d'une manière académique et scientifique, afin que vous puissiez vraiment en apprendre et montrer aux autres ce que vous en avez appris. Maintenant, plongons dans le contenu réel de la classe. La première classe va définir ce qu'est réellement la science des données.
3. Qu'est-: Dans ce cours, nous essaierons d'explorer ce qu'est la science des données. C' est un peu difficile à dire parce que la science des données est si nouvelle. Il y a beaucoup d'opinions différentes, et c'est aussi pourquoi je veux l'explorer de différentes façons. Le moyen le plus simple est de citer quelqu'un d'autre. Jim Gray, lauréat du prix Turing, a déclaré que « la science des données est le quatrième pilier de la science, à côté de la science empirique, théorique et computationnelle ». Ce que cela signifie essentiellement, c'est qu'en utilisant la science des données, nous pouvons extraire de nouvelles informations directement à partir des données. Si vous possédez vos données commerciales, si vous possédez vos données scientifiques, où que vous veniez, vous pouvez les prendre et utiliser ces nouvelles méthodes ou vieilles méthodes et de nouvelles capes, et essentiellement, trouver des relations dans que les données qui fonctionnent, non seulement sur ce petit ensemble de données, mais peuvent être généralisées à de nouvelles données. Si vous disposez de données clients, vous pouvez alors prédire ce que font les nouveaux clients. Si vous avez des données sur la chimie, vous pouvez prédire ce qu'une nouvelle formule chimique va faire, des choses comme ça. Ceci est simplement basé sur la relation au sein des données. Maintenant, une autre façon de regarder est de regarder la hiérarchie des besoins des signes de données. J' aime vraiment celle-là parce que cela nous donne aussi un moyen de définir fondamentalement où nous devons passer du temps. L' une des choses est que nous devons acquérir des données. Sans données, nous ne pouvons pas faire de la science des données. Nous devons obtenir un ensemble de données, nous devons nettoyer l'ensemble de données parce que toutes les données brutes sont bruyantes. Il y a des points aberrants mal avisés
là-dedans, il y a de l'information qui n'est pas pertinente à notre question. Comme les scientifiques des données plaisantent sur le nettoyage des données étant le plus long qu'ils y consacrent, certains prétendent dépenser 80 à 90 % pour le nettoyage des données et seulement 20 à 10 % pour la partie amusante ou la partie vraiment intéressante de la génération d'informations. Mais oui, c'est la partie la plus importante. Les gens ont tendance à dire des ordures, ordures, et d'habitude, c'est très vrai. Ensuite,
vous devez disposer d'un stockage fiable. Si vous avez vos données et qu'elles sont perdues, il est très difficile de reproduire vos résultats, et les résultats en science des données doivent toujours être reproductibles. Aussi, peut-être que vous devez valider vos résultats ou peut-être vous devez revenir arrière et les combiner avec de nouvelles données qui pourraient changer vos conclusions. Stocker et déplacer les données, c'est vraiment comme construire votre infrastructure est le prochain niveau. En particulier pour les responsables de la science des données, ils doivent savoir que les ingénieurs de données sont extrêmement importants à ce stade. L' emploi du bon type de personnes aux bons postes est essentiel pour une entreprise. Ensuite, à l'étape suivante, nous explorons et transformons les données. exploration des données est vraiment l'étape où
vous examinez les statistiques descriptives de vos données, comme jeter un oeil à la moyenne et à la quantité de vos données varie, et ce que les différentes fonctionnalités de vos données font. Quand vous avez un client, quand sont-ils venus à vos côtés ? D' où viennent-ils ? Quel est le genre ? Des choses de ce genre qui peuvent vous donner des informations sur la façon dont
les clients peuvent varier d'une visite à l'autre et sur ce qui peut changer la prévision
s'ils veulent acheter des chaussures, s'ils veulent acheter un nouvel appareil photo ou s'ils veulent suivre un cours sur Skillshare. En plus de cela, vous pouvez alors faire des tests A/B. Si vous avez déjà visité certains sites comme Amazon ou ces sites Web de cours, vous pouvez voir qu'il y a différents prix affichés. Souvent, c'est parce que les sites Web font ces expériences pour voir si afficher un autre site Web, changer le bouton, changer le prix
va vous rendre plus ou moins susceptible d'acheter. Des choses comme les tests A/B, l'expérimentation, algorithmes d'apprentissage automatique
simples sont la prochaine étape sur cette échelle. Donc, faire des prédictions et faire des inférences pour
être vraiment capable de regarder dans l'avenir à partir des idées que nous avons générées. Alors la pointe de l'iceberg, donc fondamentalement, le désert dans votre pyramide alimentaire, va être l'IA et l'apprentissage profond. Cela signifie essentiellement que ces technologies super excitantes sont probablement les dernières que vous voulez essayer, mais elles peuvent être extrêmement précieuses. Donc, si vous avez vos ingénieurs Machine Learning ou vos chercheurs Machine Learning, et qu'ils ont construit des modèles de base, et qu'ils recommandent, en fonction de leurs connaissances, qu'il pourrait être nécessaire d'adopter des méthodes d'apprentissage
trop approfondies pour créer Algorithmes d'IA pour vraiment exploiter les données, les relations complexes que nous avons dans les données, cela peut être vraiment bon. Beaucoup des percées modernes de Machine Learning ont été réalisées avec des méthodes d'apprentissage profond. Enfin, lorsque nous faisons réellement de la science des données, et non seulement nous penchons sur les besoins de la science des données, c'est un processus. Dans ce processus, nous voulons répondre à une question spécifique basée sur nos données. Cela signifie que nous devons souvent aller de l'avant et de l'arrière. Nous pouvons obtenir nos données et nous faisons l'exploration de données, mais dans l'exploration de données, recherche de descripteurs dans nos données, nous trouvons que ces données peuvent ne pas être suffisantes et nous devons revenir en arrière et acquérir de nouvelles données ou peut-être les fusionner avec une source de données, puis travailler à affiner notre processus de science des données. La prochaine partie sera consacrée à la modélisation de nos données. Ce sont les algorithmes simples dont nous avons parlé, mais il peut aussi être juste des idées que vous avez naturellement acquises. Des règles simples sont également la modélisation de vos données, modélisation
statistique pour l'inférence peut être très appropriée à cet endroit. C' est vraiment là que vous voulez que votre expert en données intervienne et soit en mesure construire un modèle capable de décrire et de capturer avec précision vos données. Enfin, une partie très importante est de communiquer vos résultats. Construire des tableaux de bord, faire des présentations, créer ces blocs-notes qui contiennent parfois du code
pour les partager avec d'autres scientifiques des données ou des ingénieurs du Machine Learning. De cette façon, vous pouvez vraiment partager ce que vous avez trouvé. Cette partie est peut-être la plus importante parce que vous devez toujours parler aux décideurs, vous devez toujours discuter avec les parties prenantes de ce que votre question est vraiment apparue. Cela peut également être la partie la plus intéressante parce que trouver ces relations dans les données est fascinant et les partager avec les détenteurs de pieu.
Habituellement, les détenteurs de pieu sont extrêmement reconnaissants d'avoir ce nouveau
genre d'idées sur leur entreprise ou leur science. Assurez-vous de prendre un certain temps pour faire une bonne présentation à partir de cela parce que généralement, c'est très important et très précieux de le faire. Il s'agit principalement de la science des données, obtention de données, de la génération d'informations à partir de données, modélisation de vos données, puis de la communication de vos résultats. Bien sûr, il y a des morceaux comme la productionnalisation. Donc, si vous êtes dans une entreprise, comme sur un site Web, vous voulez pouvoir utiliser tout cela, mais c'est pour notre future classe. Dans le prochain cours, nous allons jeter un oeil à ce qui est en fait une bonne question ? Comment pouvons-nous poser de bonnes questions sur nos données et nous assurer qu'elles valent réellement notre investissement et valent notre temps ?
4. Poser des bonnes questions: Jetons un coup d'oeil à ce qu'est un bon questionnaire et aussi quelles sont les mauvaises questions. Fondamentalement, si vous posez des questions, vous avez l'option de six questions. Pourquoi six vous pouvez demander ? Eh bien, la science le dit. En fait, les scientifiques et professeurs de données, Jeffrey Leek et Roger Peng, qui ont un cours étonnant sur la science des données exécutives, ont publié un document qui décrit essentiellement les types de questions que vous pouvez poser. Je veux parler des types de questions aussi bien, mais ensuite entrer dans le détail, aussi ce qu'est une mauvaise question. Parce que récemment, plus en plus de questions éthiques
se posent dans l'espace de la science des données et de l'apprentissage automatique. Je pense qu'il est très important pour, eh bien, pour les chefs d'entreprise et pour tous ceux qui font de la science des données d'en être conscients et de les défier s'il y a des choses qui ne sont pas conformes à nos valeurs. Quel genre de questions on peut poser. La première question est descriptive. Cela signifie essentiellement que nous avons un jeu de données et que nous voulons connaître les caractéristiques clés de l'ensemble de données. Par exemple, la taille moyenne des utilisateurs, ou si vous travaillez dans un magasin de chaussures, vous voulez connaître la gamme des chaussures que vous vendez. Comme la gamme de tailles, par
exemple, ou les différentes couleurs qui sont vendues. Donc vraiment juste des indicateurs qui décrivent le jeu de données que vous avez. questions ici peuvent vraiment être très variées, mais elles sont assez simples et très factuelles. La prochaine question que nous pouvons poser est explorative. Essentiellement, l'idée de ce que l'on peut trouver dans les données. Cela inclut généralement des choses comme la recherche de relations et de tendances dans les données, recherche de corrélation, et nous aurons une classe plus importante à
ce sujet parce que c'est une partie essentielle de la science des données. La prochaine question que quelqu'un pourrait poser, et c'est aussi là que nous nous aventurons dans ce que l'apprentissage
automatique peut faire, est des questions prédictives. Si nous faisons x, est-ce que vous suivez ? Par exemple, si nous changeons ce bouton sur notre site Web, ou si nous ajoutons cette colonne ici, si nous montrons à un client ce genre de chose à acheter également, augmentons-nous les ventes ? Ou si nous augmentons notre nombre d'abonnés sur YouTube, obtenons-nous plus de vues ? Ces questions sont maintenant là où nous devons faire beaucoup de validation parce que l'apprentissage automatique est vraiment bon pour se souvenir des données. Parfois, il est un peu plus difficile d'avoir une prédiction générale. C' est vraiment important de regarder la validation du modèle et dans le cours plus large de l'apprentissage automatique et de l'analyse métier et Python, je vais dans ce type de validation de modèle parce que pour moi, c'est l'une des parties les plus importantes des données la science. Maintenant, nous entrons dans des parties vraiment intéressantes. Parce que beaucoup de gens connaissent ces tests que la corrélation n'est pas une causalité. La modélisation prédictive est généralement une corrélation, mais la question suivante que nous pouvons poser est une question de nature causale. Donc, si nous avons x ne y suit, est la question prédictive. Mais est-ce que x cause y, est la question causale. Pour moi, c'est vraiment intéressant parce que beaucoup de modélisation
prédictive peuvent aussi être des corrélations fausses. Mais avec la modélisation causale, vous essayez de trouver ce qui cause une chose. Un exemple que j'ai vraiment aimé était les prix d'hôtel. Si vous collectez des données de vos hôtels environnants et que vous jetez un coup d'oeil prix et au nombre de personnes dans la chambre, donc combien de chambres sont occupées en ce moment, vous constaterez qu'il y a une corrélation entre des prix plus élevés et une occupation plus élevée. Mais si vous avez fait votre modélisation causale et dit, « Ok, donc ça veut dire que si nous augmentons nos prix, nous aurons une occupation plus élevée. » Vous ferez probablement faillite. modélisation causale va vraiment aux structures de données sous-jacentes, ce qui se passe à quel endroit. Certaines choses que les gens font ici sont des contrefactuelles, donc vraiment, jeter un coup d'oeil alors. Si nous baissons nos prix, est-ce que nous obtenons également un taux d'occupation inférieur ? Vraiment creuser dans les données. C' est pour moi, la prochaine étape aussi où la science des
données va faire le plus de progrès dans la modélisation causale. questions mécanistes vont plus loin que la modélisation causale. Vous ne regardez pas seulement le prédictif. Si x suit, vous ne regardez pas seulement la flèche causale. Alors est-ce que x cause y ? Mais dans les questions mécanistes, vous êtes en train de creuser comment x cause y. vous faites la science. Dans la biostatistique, par exemple, c'est très courant que pour pouvoir publier, faut essentiellement proposer un mécanisme plausible, la médecine aussi. Beaucoup des sciences les plus naturelles sont assez habituées à cela. Votre statisticien sera très habitué à cela. Alors que dans l'apprentissage automatique s'arrête souvent aux questions prédictives. Pour faire de la science, cela peut être extrêmement important parce que répondre à ces questions, comment quelque chose se passe, est la vision ultime. C' est aussi là que cela devient intéressant parce que nos étudiants sont si diversifiés, des créatifs aux scientifiques en
passant par les gens d'affaires. En tant que scientifique, vous êtes le plus intéressé par la vérité, les mécanismes sous-jacents que vous trouvez dans la nature. En tant que gens d'affaires, vous êtes le plus intéressé par le prédictif. Alors quelqu'un achètera quelque chose si je change ça ? Peut-être les effets causaux aussi. Pas tant les mécanismes parce que ceux-ci sont généralement beaucoup plus difficiles à obtenir, prendre plus de temps, prendre plus de cerveau, et simplement dire, ne pas vraiment augmenter les ventes ou acquérir de nouveaux clients. Vraiment, c'est un peu où les questions sont très spécifiques à ce que vous voulez réellement, et vous devez décider quelle est la bonne question pour le genre de problème auquel vous êtes confronté. Il s'agit essentiellement d'une introduction sur la façon de poser de bonnes questions et dans la classe suivante, nous examinerons comment nous posons de mauvaises questions.
5. Poser de mauvaises questions: Vous voyez probablement comment vous devez comprendre quelle est la bonne question pour votre problème. Mais avec ces récents dilemmes éthiques et aussi des problèmes autour des prédictions et des choses, nous devons nous demander, quelle est une mauvaise question ? Je veux entrer dans quelques exemples de choses où les scientifiques
de données auraient probablement pu empêcher certains de se produire en allant plus loin qu'une simple analyse
superficielle ou une prédiction superficielle et éventuellement pensé un peu plus, ce qui est ça se passe ? C' est vraiment pour ça que vous êtes un scientifique des données. Parfois, vous devez aller un pas plus loin pour faire de ce monde un endroit meilleur après tout. Avec le dilemme social, par exemple, et beaucoup de recherches qui sont en train de sortir,
nous voyons que l'augmentation de l'utilisation
du site conduit finalement à ce que les sites Web ne soient pas aussi bien pour les humains. Nous voyons beaucoup de souffrances humaines de problèmes de santé
mentale basés sur les médias sociaux et sur YouTube, sur Facebook, nous avons vu qu'il y a un parti pris envers l'extrémisme. Lorsque vous avez commencé à regarder des vidéos sur la nourriture, vous obtenez de plus en plus dans trous de lapin
très profonds si vous optimisez simplement pourquoi les gens restent à vos côtés. En tant que spécialiste des données, vous devriez aller plus loin que simplement poser la question : comment puis-je garder les gens sur le site ? Mais oui, tu devrais aller plus loin. Pas seulement demander, comment puis-je garder les gens sur mon site ? Comment puis-je faire en sorte que les gens achètent plus ? Mais peut-être aussi poser des questions sur la satisfaction de la clientèle. Ce n'est pas seulement comment vendre plus, mais comment puis-je obtenir le bon produit à la bonne personne ? Ce n'est pas le plus, pas le plus beau sujet, mais nous devons en parler parce que vous devez penser à l'éthique. Les choses peuvent-elles être expliquées par population ? Nous savons qu'il y a des quartiers de criminalité plus élevés dans les villes les plus pauvres. Est-il vraiment logique de construire un modèle prédictif où le prochain crime se produira, alors faites-le au niveau individuel lorsque nous savons que le problème sous-jacent est la pauvreté ? C' est malheureusement une question qui est posée et ce n'est pas une bonne question parce que nous savons déjà ce qui cause ce problème. Construire un modèle prédictif sur une base individuelle ignore
complètement notre connaissance de cause à effet. Cela se produit à échelles
beaucoup plus larges et beaucoup plus larges qui ne sont pas aussi éthiques, où nous savons ce qui se passe comme un effet, mais comme prédire l'individu n'est plus aussi précieux. Parce qu'à ce stade, nous ne traitons un symptôme plutôt que le mécanisme. Un autre type de mauvaise question se produit parfois dans les entreprises où la réponse est essentiellement prédéterminée. Nous savons déjà quelle réponse nous voulons et maintenant nous posons une question pour obtenir cette réponse. Idéalement, la science des données devrait être ouverte aux réponses. Ces réponses devraient potentiellement aller dans une direction que notre direction ne prévoyait pas. La direction devrait être suffisamment ouverte, suffisamment
sûre pour que cela se produise également. Être axé sur les données signifie parfois que nous trouvons des vérités gênantes sur notre entreprise, sur la direction dans laquelle nous voulons aller. Mais c'est finalement ce qui fait de la science des données une science. Parfois, poser ces questions alors que nous savons déjà que nous voulons une certaine réponse est certainement une mauvaise question parce qu'elle ne nous permet pas de faire une bonne science des données. Dans la prochaine classe aura un coup d'oeil comment nous pouvons réellement obtenir des données pour poser ces bonnes questions et comment nous pouvons obtenir de bonnes données pour obtenir les meilleurs résultats de notre analyse.
6. Obtention de données et d'étiquettes: L' une des questions les plus courantes que je reçois des débutants en science des données est où obtenir vos données et comment obtenir vos étiquettes ? Maintenant, ce sont deux données démographiques différentes qui posent ces questions. Habituellement, les gens d'affaires ou les scientifiques ont déjà des données. La collecte de données est une chose très courante. Vous avez donc votre base de données contenant des informations sur les clients, ou vous avez vos échantillons de votre analyse. Là, la question est généralement plus, comment obtenez-vous des étiquettes ? Pour les débutants qui essaient juste de se lancer dans la science des données, ils essaient de trouver des données. Où trouvez-vous les données ? Où obtenez-vous des étiquettes ? Nous allons d'abord plonger dans la façon dont vous obtenez les données, où vous obtenez les données. Parce que même dans une entreprise, cela peut être une question très importante, et ensuite nous allons voir comment obtenir des étiquettes. obtention de données consiste soit à mesurer les données vous-même, soit à trouver un jeu de données. Donc, cela signifie obtenir les données de quelque part. Il existe des stockages de données où vous pouvez obtenir des jeux de données préparés qui ont souvent déjà des étiquettes attachées. Il s'agit généralement de la recherche Google ou aussi de la section des jeux de données Kaggle. Mesurer les données signifie essentiellement que vous devez aller sur le terrain ou dans vos systèmes, et extraire les données d'une manière ou d'une autre. Donc, dans mon travail en ce moment, par
exemple, je travaille avec des données satellitaires, et nous avons en fait une entreprise qui est locale et tour avec GPS pour mesurer les forêts réelles. Oui, cela coûte de l'argent, mais c'est la meilleure façon d'obtenir des données précises de haute qualité et qui donneront les meilleurs résultats sur votre produit de science des données. En fin de compte, il est très important d'avoir des experts
pour étiqueter vos données , obtenir des données, interpréter vos données. Beaucoup de recherches ont montré qu'obtenir des novices, généralement des gens mal payés sur quelque chose comme Amazon Mechanical Turk pour interpréter vos données, n'est pas idéal. Il vous donne généralement des données bruyantes, de mauvaises étiquettes et peut souvent introduire un biais dans vos données. Vous devez faire très attention au biais dans les données car ce biais sera incorporé dans votre modèle. Si vous faites de la modélisation d'apprentissage automatique , par
exemple, ce que je fais beaucoup, biais sera alors implicite dans le modèle, et le modèle répètera ce biais sur chaque prédiction. Donc surtout si vous touchez des humains, vous devez être très prudent à ce sujet. C' est également quelque chose que vous devriez faire attention lorsque vous obtenez des données pré-étiquetées. Donc, lorsque vous téléchargez l'un des jeux de données de Kaggle, jetez un oeil à ce que sont les classes, regardez ce que sont les données, quels sont les déséquilibres de classe. Parce que souvent, vous obtenez des étiquettes faciles à étiqueter,
mais ce ne sont pas nécessairement les étiquettes qui sont intéressantes à étiqueter. Parfois, surtout en ce qui concerne les scientifiques et les solopreneurs, vous devrez étiqueter les données vous-même ou les externaliser à quelqu'un. Puisque vous êtes l'expert et généralement les scientifiques fonctionnent avec un budget plus serré, cela signifie simplement que vous devez ouvrir quelque chose comme Labelbox, que vous pouvez voir ici à l'écran, et dessiner des étiquettes sur vos données vous-même, interpréter les données, et être conscient du genre de biais que vous pourriez vous présenter vous-même. Dans cette classe, nous avons examiné comment vous pouvez
obtenir des données soit en les acquérant vous-même, soit en les téléchargeant de quelque part, et comment obtenir des étiquettes. Donc, vous obtenez des experts pour vous procurer les étiquettes, comment obtenir des novices pour vous procurer les étiquettes, mais aussi comment étiqueter les données vous-même à l'aide d'applications telles que Labelbox. Dans le prochain cours, nous examinerons l'analyse exploratoire des données, où nous examinerons en fait la façon dont les gens interprètent vos données.
7. Comprendre l'analyse de données exploratoires: Parlons de l'analyse exploratoire des données ou de l'EDA courte. Dans le cadre de l'analyse exploratoire des données, les scientifiques des données ont
généralement un premier regard sur les données. Souvent, les gens font les statistiques descriptives sur ce module. Donc,
calculez la moyenne, calculez les variantes, et regardez vraiment les caractéristiques de vos données, qu'y a-t-il dans les données ? Qu' y a-t-il dans les étiquettes ? C' est également pour voir si le nettoyage des données s'est déroulé correctement. Y a-t-il des valeurs aberrantes ? Y a-t-il du bruit dans les données et si vous trouvez ce genre de chose dans les données, vous devrez revenir à l'étape du nettoyage. Comme je l'ai dit, la science des données est très itérative. Donc souvent, vous devez aller et retour pour vraiment voir que tout est réparé. Ensuite, après avoir regardé que toutes vos données sont en ordre, vous voulez également jeter un oeil s'il y a des données manquantes, car cela arrive assez souvent. Si vous avez des données client, par exemple, souvent les profils ne sont pas complètement remplis. Vous manquez certains e-mails, certains numéros de téléphone, et ces valeurs manquantes peuvent être indiquées comme faux quelque chose. Ils sont donc très précieux à connaître dans la science
des données et cela vaut pour presque toutes les applications. Savoir où se trouvent les données manquantes peut être extrêmement utile à intégrer dans votre analyse. C' est un conseil que j'aime donner à tout le monde
d'avoir aussi un regard juste où vous avez des données et où vous n'avez pas de données. En fin de compte, vous avez aussi un regard sur les corrélations. Regardez comment vos fonctionnalités,
comment vos données sont corrélées les unes avec les autres. La corrélation signifie simplement que si l'entité A augmente et que l'entité B augmente, ils peuvent avoir une certaine corrélation de leur aller dans la même direction en même temps et cela peut être assez bon à analyser afin que vous comprendre les relations au sein de vos données. Habituellement, vous voulez aussi faire un peu de clustering peut-être. Regardez quelles données sont adaptées à quelles données. Jetez donc un coup d'œil très simple sur la façon dont vos données s'intègrent dans les groupes. Personnellement, je trouve aussi très utile dans analyse
exploratoire des données d'examiner les visualisations. Habituellement, bien sûr, vous pouvez calculer un nombre pour le coefficient de corrélation, mais aussi avoir juste un graphique rapide de vos corrélations et de vos corrélations croisées entre différentes entités peut être vraiment bon car alors vous avez un aperçu rapide, comme nous le voyons à l'écran en ce moment et vous savez que cela va augmenter. Ceci est positivement corrélé. Ça va tomber. Si cela augmente, c'est négativement corrélé. Donc, vraiment juste avoir une idée des données et mieux comprendre les données, afin que nous puissions ensuite continuer et voir si notre hypothèse que nous
construisons dans ce processus retarde de de nouvelles données que nous n'avons pas vues auparavant.
8. Introduction à l'apprentissage de machine: L' une des formes de modélisation de nos données comprend l'apprentissage automatique. apprentissage automatique a toute la gamme en ce moment parce qu'il a été très facile d'utiliser les outils d'apprentissage automatique récemment. Il est devenu très accessible à beaucoup de gens qui connaissent peu de code ou même pas de code et beaucoup d'applications. Où l'apprentissage automatique vient d'être abstraite afin que vous puissiez construire un réseau neuronal basé sur vos données qui se rapproche du résultat. Dans l'apprentissage automatique, vous avez essentiellement trois domaines différents que vous pouvez regarder. L' apprentissage supervisé, ce qui
signifie essentiellement que vous avez vos données et ensuite vous avez vos résultats. Par exemple, dans les données client, il
s'agit de vous avoir des informations sur un client,
qui, à chaque entrée dans ces informations, nous appelons une fonctionnalité. Vous avez votre étiquette s'ils ont acheté ou s'ils n'ont pas acheté. Ce serait une décision binaire dans l'apprentissage automatique supervisé où vous pouvez ensuite essayer de prédire si en fonction des fonctionnalités que vous avez acheté ou que quelqu'un n'a pas acheté. C' était la première machine learning que vous pouvez faire la classification. Que ce soit binaire ou que vous ayez plusieurs classes que vous voulez prédire. C' est peut-être des chats, des chiens et des oiseaux. Ce sont vraiment des valeurs
discrètes, des classes discrètes que vous voulez prédire. La méthode suivante dans l'apprentissage automatique supervisé est la régression, où vous prédites un nombre. Dans cet exemple de données client, cela équivaudrait à prédire combien un client est prêt à dépenser en fonction des fonctionnalités qu'il possède dans le jeu de données. Vraiment voir ce client qui a récemment acheté
ceci, ceci, et cela va dépenser 100$. Cela peut être très important pour votre budget marketing, par exemple. Si vous savez combien dépenser pour une certaine démographie, vous pouvez alors essentiellement voir combien de budget marketing vous êtes prêt à dépenser pour effectuer une conversion. La troisième méthode de l'apprentissage automatique fait partie de l'apprentissage automatique non supervisé. Cela signifie vraiment que nous n'avons pas les étiquettes que nous avions auparavant et que nous essayons de trouver des structures internes de nos données. En fait, ce que cela signifie pour mettre en cluster nos données, nous essayons de trouver quel échantillon de notre jeu de données est le plus proche d'un autre échantillon. Finalement, nous pouvons même utiliser ce clustering non supervisé pour attribuer des étiquettes à nos données. C' est l'une des astuces que les gens utilisent souvent pour trouver des étiquettes, qui renvoie à la leçon que nous avons faite sur l'étiquetage de nos données. C' est une astuce que vous pouvez utiliser pour trouver des classes dans vos données, mais c'est la question, sont les classes qui vous intéressent vraiment ? Il s'agit de trois types courants d'apprentissage automatique. L' apprentissage automatique a des méthodes très différentes pour réaliser ces prédictions essentiellement, lorsque vous parlez de régression et de classification. L' apprentissage automatique supervisé, vous pouvez utiliser quelque chose comme des modèles linéaires. Adapter littéralement une ligne dans vos données. Vous pouvez utiliser des arbres de décision qui sont vraiment puissants et vraiment intéressants, parce qu'ils prennent ces décisions basées sur des règles de si c'est plus que cela, puis mettez-le dans cette classe. Si cette fonctionnalité est inférieure à cela, mettez-la dans cette classe. Ils sont devenus très populaires parce qu'ils sont très faciles à utiliser et donnent de très bons résultats. Les réseaux neuronaux sont une autre classe où vous avez une structure cérébrale de connexions qui effectuent essentiellement des opérations
mathématiques sur vos données pour ensuite prédire une classe. Enfin, nous avons aussi quelque chose appelé une machine vectorielle de support, qui essaie fondamentalement de diviser vos données en deux groupes, idéalement. Ce sont vraiment des stratégies très courantes, des outils
très courants que vous utilisez dans l'apprentissage automatique. Une méthode très courante dans l'apprentissage automatique non supervisé est k-means, où essentiellement vous trouvez la moyenne de vos clusters, mais le problème est que vous devez définir k. Essentiellement, vous devez
essayer beaucoup de différents nombres de clusters qui est k, puis voyez ce qui vous donne les meilleurs résultats. Habituellement, un k inférieur est mieux parce que vous trouvez alors des clusters plus grands. Si vous augmentez votre k à 100, sorte que vous trouvez comme 100 clusters, cela signifie souvent
que vous trouverez des sous-clusters dans des clusters
plus grands et obtenez un résultat moins fiable. Une autre méthode que j'aime personnellement beaucoup est T-sne. T-Sne est un processus automatique que vous pouvez voir en arrière-plan ici, qui tente essentiellement également de trouver des clusters de vos données. Il est moins interprétable, mais il est très bon pour trouver des données qui appartiennent à une autre et trouver des valeurs aberrantes dans certaines données. Vraiment bon pour établir des relations et des données aussi bien. partie la plus importante de l'apprentissage automatique est le processus de formation. Vous avez vos données, vous avez vos étiquettes et vous les mettez et vous espérez que votre processus d'apprentissage automatique va prédire les bons modèles. Habituellement, c'est itératif. Votre modèle prédit quelque chose, voit si c'est bien le faire. C' est la supervision, puis le modèle est ajusté. Il s'agit du processus d'apprentissage ou du processus de formation. deux mots sont utilisés pour vraiment ajuster le modèle pour vous donner les bons résultats. C' est la partie intéressante parce que ces modèles sont des modèles mathématiques qui ne savent rien sur la physique,
quoi que ce soit sur le comportement des clients. Mais ils apprennent à établir ces relations basées sur principes
mathématiques et s'adaptent vraiment au type de données que vous possédez, ce qui peut être très différent. L' apprentissage automatique fonctionne sur tant de tâches différentes, de la publicité
en ligne à la physique en passant par la biologie, donc vraiment polyvalent. Cependant, et cela est extrêmement important lorsque vous formez ou que les personnes que vous employez forment ces modèles, ils doivent garder une partie de vos données séparées parce que vous devez toujours avoir un cas de test, essentiellement, où vous voyez si votre modèle est travailler sur des données que le modèle n'a jamais vues. Parce que le modèle peut essentiellement mémoriser vos données plus ou moins. Tu essaies d'éviter ça. Il y a beaucoup de choses que vous faites en tant qu'ingénieur d'apprentissage automatique pour éviter cela. Mais à la fin, ce qui est mesuré, est géré, et vous devez vraiment mesurer si votre modèle fonctionne sur des données qu'il n'a jamais vues. C' est pourquoi nous gardons généralement une partie de notre jeu de données étiqueté sur le côté, car alors nous connaissons déjà la réponse sur ceux-ci. Mais le modèle d'apprentissage automatique ne l'a jamais vu auparavant. Une astuce soignée pour valider notre modèle avec cet ensemble de tests de validation. Il s'agissait d'un bref aperçu d'un apprentissage automatique. Vous connaissez maintenant les différents types d'apprentissage automatique et quelques méthodes qui sont puissantes que vous pouvez examiner si vous êtes intéressé. Vous savez que vous devez absolument faire la validation de l'apprentissage automatique. On ne peut pas juste former un mannequin et dire, oh oui, l'école de formation, et c'est vraiment bon. Vous devez toujours disposer d'un jeu de données supplémentaire sur lequel vous pouvez valider vos données. Cela mène parfaitement à la prochaine classe où nous
allons jeter un oeil sur la façon de vous prouver que vous avez tort. Parce que si nous voulons faire de la science des données une science, nous devons nous assurer que nos idées tiennent réellement à l'examen.
9. Se révéler Wrong: Jusqu' à présent, nous avons examiné les outils, les principes et les méthodes de la science des données. Mais la science des données a beaucoup plus, parce que dans la science des données, vous devez essentiellement penser au système dans lequel vous êtes. Il est très engageant mentalement dans un sens. Dans cette classe et cette conférence, nous allons jeter un oeil à vous prouver que vous avez tort. L' idée derrière vous prouver que vous avez tort, c'est essentiellement que nous allons tous à l'analyse des données avec nos propres biais, et surtout si nous suivons l'analyse exploratoire des données, nous aurions pu avoir une intuition sur les sous-ensembles des données. Certains des participants les plus réussis dans les compétitions de Kaggle, il ignore complètement les cahiers EDA, donc d'autres personnes partageant leurs explorations parce qu'ils ne veulent pas être biaisés dans leur approche pour voir ce que les données peuvent contenir dans magasin. Essentiellement, dans chaque projet de science des données, vous devrez vous tenir à un niveau très élevé parce que vous examinez les vérités sous-jacentes, les relations
sous-jacentes au sein des données. Peu importe la question à laquelle vous répondez, si vous faites une prédiction ou si vous répondez même à des questions mécanistes, c'est toujours, y a-t-il une explication différente à cela ? La première chose que vous voudrez faire quand vous essayez de vous prouver que vous avez tort, est d'appliquer le rasoir d'Occam. rasoir d'Occam est l'idée philosophique de cela, preuve peut généralement être expliquée par l'idée la plus simple. Donc, quand je ne trouve pas mes clés le matin, je les ai probablement égarées quelque part et elles sont probablement dans ma veste. C' est très peu probable que ce soit des aliens. C' est l'idée que vous essayez de trouver l'explication la plus simple au lieu d'aller complexe de fantaisie, et c'est aussi quelque chose dans la science des données générales, l'apprentissage automatique, qui est une bonne idée d'essayer de construire le modèle le plus simple qui satisfait vos critères. Parce que le modèle le plus simple est généralement aussi le plus simple à expliquer. Dans ce cas, les scientifiques des données sont dans un petit dilemme, avec les travailleurs du savoir, nous sommes payés pour être intelligents, donc avoir une explication complexe de ces choses est généralement ce que nous voulons. Nous voulons trouver les choses super intéressantes et vous devez être très prudent là-bas, parce que nous pouvons être attirés par cette explication intelligente qui nous fait sentir bien, mais qui peut être juste la mauvaise explication. Il peut y avoir une chose beaucoup plus simple qui peut expliquer exactement les mêmes choses. Là, il est généralement bon de jeter un coup d'
oeil à ce qui est l'explication commune de choses comme celle-ci, donc souvent les scientifiques des données doivent parler à des experts en la matière. Si vous êtes un Data Scientist qui travaille avec l'économie, parlez à votre économiste, si vous êtes un Data Scientist au Grand Hadron Collider, parlez aux gens de la physique. Ils ont généralement une intuition, ont une idée, et vous pouvez toujours le contester si vos données ont les preuves de ce défi. Mais souvent, c'est vraiment l'explication la plus simple, c'est la meilleure explication pour votre problème. La prochaine chose que vous voudrez faire est de jeter un oeil à des choses qui réfutent votre théorie. Si vous avez une hypothèse sur vos données et que vous regardez, ce qui provoque quoi ou ce qui se passe où, revenant à l'exemple depuis le début, si les prix plus élevés dans un hôtel causent plus de gens, alors l'inverse peut être vrai. Donc, si vous baissez vos prix, les gens devraient aussi rester à l'écart. Avec ces contre-exemples que vous pouvez trouver dans vos données. Vous devriez faire une analyse essentiellement, s'il y a des preuves dans vos données qui prouvent votre théorie, vous devez améliorer ou vous devez mettre à jour vos croyances, vous devez changer votre hypothèse, parce que ces points de données, s' ils sont significatifs, le montrera certainement. Votre idée de fantaisie, votre idée initiale n'a parfois pas été tout à fait correcte, donc vous devez creuser plus et vraiment regarder les données s'il y a quelque chose qui va à l'encontre de ce que vous aviez en tête. Un exemple de mon travail en ce moment est que nous avions cette idée que peut-être ce qu'on appelle la migration forcée. Essentiellement, les gens doivent quitter leur maison à cause des inondations, parce que les inondations causent la détérioration des terres cultivées. Eh bien, dans notre analyse de données, nous avons constaté qu'il y avait plus de terres cultivées dans la région après une inondation, parce que soudain il y avait beaucoup d'irrigation et tout était vert et florissant, donc nous avons dû mettre à jour notre idée initiale, notre croyance initiale, à une nouvelle hypothèse qui pourrait en fait, oui, il était conforme aux données. C' est vraiment vous devez être flexible et ne pas être marié aux idées que vous avez. Je sais qu'il peut être très difficile de mettre à jour certaines croyances, mais il est tout à fait nécessaire que les scientifiques des données soient flexibles dans cette compréhension et qu'ils écoutent les experts en la matière, car souvent ils ont des années de d'expérience, de travail dans ce domaine, et vous avez besoin de preuves très solides pour contrer ce qu'ils disent sur le terrain. Beaucoup de fois, les chercheurs de
base sont vraiment bons, regardant vos données s'il y a des contre-exemples dans vos données, et voyant également que vous avez l'explication
la plus simple et la plus simple de ce que vous êtes voir réellement dans vos données. Si vous y pensez, aller plus loin, aller à votre analyse de données avec cet esprit scientifique, être capable de vraiment vérifier vos croyances que vous avez initialement formées à partir de votre exploration de les données font vraiment de vous un scientifique de
données plus fort et vous font un meilleur scientifique de données finalement, parce que vous êtes maintenant en mesure de remettre en question ces idées qui viennent de vous-même et donc d'atténuer les biais dans votre propre analyse et d'avoir beaucoup argument plus fort aussi. Si vous communiquez ces résultats aux décideurs,
aux patrons, ou si vous écrivez en papier, et vous pouvez dire, eh bien, je vérifie ceci pour des contre-exemples, et ce sont des valeurs aberrantes ou celles-ci sont basées sur cette hypothèse que nous avions initialement, il fallait la mettre à jour. Cela peut être un trait extrêmement bon et précieux chez les gens, et il commandera le respect chez ces décideurs, parce qu'ils savent maintenant qu'ils peuvent vous faire confiance et que vous êtes réellement intéressé à trouver la réponse et pas seulement propager votre réponse. Dans cette classe, nous avons regardé comment vous prouver que vous avez tort et comment penser en dehors de la boîte et remettre en question vos propres conclusions à partir des données. La classe suivante va jeter un oeil à l'une de mes visualisations de données préférées.
10. Visualisation de données: Dans cette conférence, nous allons passer en revue la visualisation des données. Pour moi, la visualisation des données est importante à deux égards. Tout d'abord, une visualisation peut vous donner une très bonne vue d'ensemble de vos données au stade de l'exploration. Correlations, j'adore quand vous avez juste une visualisation au lieu d'un nombre pour le coefficient de corrélation. Parce qu'alors vous pouvez voir beaucoup de corrélations les unes à côté des autres. En dehors de cela, quand vous faites vos rapports et vos présentations, eh bien, ils ne le disent pas pour rien et l'image dit plus d'un millier de mots. Vraiment, la visualisation de données, vous pouvez emballer beaucoup plus d' un poinçon de communication de données que
toute autre chose et vous pouvez rendre ces visualisations interactives. Si vous créez des tableaux de bord, vous aurez besoin de ces visualisations, placez-les sur une carte s'il s'agit de données spatiales. Faire un nuage de points. parcelles de dispersion sont incroyables. Ils vous donnent tant d'informations et d'informations sur vos données. Comme comment les points vont contre d'autres points. Si vous faites un clustering, comment ces points se regroupent-ils dans l'espace 2D ? Finalement, vous finirez par améliorer la visualisation des données, mais vous voulez suivre quelques règles. Habituellement, vous devez être prudent avec l'étiquetage de votre axe. Il est donc toujours bon d'avoir du texte sur l'axe. Personnellement, j'aime que c'est le fléau de mon existence. Ajout de texte aux visualisations, je devrais être mieux à ce sujet. Habituellement, en revue, il y a toujours un, pouvez-vous s'il vous plaît mettre x sur cette étiquette et cela rendra beaucoup plus clair parce que les gens peuvent regarder votre visualisation et voir directement ce qui se passe sans lire la légende, sans lire le texte, faites cela. Ne jamais encoder les données dans la transparence. Parce qu'il est très difficile de voir la transparence, surtout si elle est imprimée ou si vous avez un nuage de points et que vous avez plusieurs points les uns sur les autres. Si la transparence a un sens dans votre tracé, alors vous perdez ce sens en superposant plusieurs points de données. Avec la couleur, vous devez être extrêmement prudent sur daltonisme mais aussi lorsque vous l'imprimez, beaucoup
d'impressions scientifiques sont en noir et blanc parce que couleur est encore cher à imprimer pour une raison quelconque. Ne me demandez pas pourquoi. Mais oui, avoir ce que l'on appelle des cartes de couleurs linéairement perceptives est vraiment bon et si vous utilisez Matplotlib et toutes ces bibliothèques Python, ils utilisent quelque chose appelé veritas, qui est la carte des couleurs. Veritas est linéairement perceptive et parfait pour ce genre de chose. Si vous faites vos visualisations dans un autre logiciel, il est tout à fait possible que la norme soit l'arc-en-ciel ou le jet souvent appelé. L' arc-en-ciel n'est pas une bonne barre de couleur. Beaucoup de fois, le vert est beaucoup trop large, donc vous perdez effectivement certaines de
vos informations de visualisation dans ces cartes de couleurs et vous ne devriez certainement pas les utiliser. Beaucoup de fois, les gens vont contester cela, surtout si vous parlez à des professeurs, à des scientifiques plus âgés, ils pensent que l'arc-en-ciel est la barre de couleur standard et vous devriez l'utiliser et il
y a des recherches pour défier ces pensées parce qu'il est plus accessible. Vous êtes formidable pour les personnes handicapées et cela ne vous coûte rien et en fin de compte, sont de meilleures barres de couleur parce que le changement d'une teinte à autre que vous percevez comme humaine est le même pour tout le monde, et c'est le même entre chaque nuance. Dans l'arc-en-ciel, la différence entre le rouge et le bleu est très différente du vert et du rouge, quelque chose comme ça, juste à cause d' affectations
arbitraires où vos données sont mappées à la couleur. Mais dans Veritas, vous avez une perception linéaire de l'endroit où se trouvent vos données. Vous comprenez donc intuitivement comment vos données se présentent et ce que vos données font. Dans ce genre de graphiques que vous créez, vous aurez toujours envie de
penser à la personne qui regarde l'intrigue. Comment rendre ces informations aussi accessibles que possible ? Peuvent-ils s'asseoir dans une pièce pleine de gens et suivre une présentation et comprendre ce que vous essayez de dire avec la diapositive qui va disparaître dans moins d'une minute ? Vraiment, regardez ce que font les autres. Il y a des blogs incroyables là-bas. Vous pouvez jeter un oeil à des données fluides, par exemple, qui recueille beaucoup de très belles visualisations. Il y a aussi beaucoup de ressources là-bas. Assurez-vous vraiment de vérifier ceux en plus de cette classe parce que bien sûr, c'est une bonne vue d'ensemble, mais il y en a toujours plus et vous pouvez toujours aller cette étape ci-dessus et le rendre un peu meilleur. Ajouter de l'interactivité à vos données lorsque vous effectuez des tableaux de bord, par
exemple, peut être si bon. Lorsque vous faites la souris sur votre nuage de points et vous pouvez réellement obtenir des informations sur chaque point en les pointant simplement sur eux, est si bon. Tout le monde est toujours excité quand je crée une visualisation comme ça. Essentiellement, la visualisation des données consiste à tirer le meilleur parti de vos données et à les rendre vraiment compréhensibles dans une seule image. Dans notre prochaine leçon, nous allons examiner la productionnalisation des pipelines de données. Comment pouvons-nous rendre nos conclusions utiles dans une entreprise ?
11. Réalisation des pipelines de données: Jusqu' à présent, nous avons parlé d'une analyse des signes de données. Essentiellement, l'idée d'avoir vos données, c'est d'avoir un jeu de données, puis de faire une bonne analyse et une présentation sur faire des visualisations dessus. Mais dans une entreprise, souvent, vous comptez sur des pipelines,
sur l'opérationnalisation de votre analyse de données, construction à la fois et sur la possibilité de les reproduire encore et encore. C' est ce qu'il y a moins que ça. Dans une entreprise, cela signifie souvent que vous avez une autre personne, comme une opération de données est très similaire à une personne DevOps, donc Data Ops est souvent utilisé ou ML Ops ou des opérations d'apprentissage automatique, ce qui signifie que votre équipe se développe maintenant à une autre personne en plus de l'ingénieur des données et des scientifiques des données. Mais il est extrêmement utile de penser à cela et aussi de savoir à ce sujet en tant que scientifique des données, parce que vous devrez toujours remettre votre analyse et votre code à cette personne chargée des opérations de données et peut-être aussi aider à implémenter ceci. Nous allons procéder à l'opérationnalisation de votre analyse de données et dans cette partie. Comme indiqué dans le processus de science des données, notre analyse de données souvent, ou notre processus de science des données, consiste
souvent à obtenir des données, étiqueter des données, à nettoyer des données, à explorer nos données, puis à modéliser nos données et faire des prédictions ou regarder la causalité des données, selon la question à laquelle vous essayez de répondre. Dans une entreprise, vous obtenez souvent de nouvelles données en continu, nouveaux clients s'inscrivent, nouvelles choses arrivent. Au grand collisionneur de hadrons, vous avez des flux de données continus un an faisant des expériences. Vous voulez vraiment automatiser ce processus. Le pipeline est tout au sujet de l'automatisation. Dans le processus de nettoyage, par exemple, vous voulez automatiser un grand nombre de
ces fonctions d' écriture qui peuvent être appliquées à l'ensemble du jeu de données, et non pas filtrer les éléments individuels à la main. Vous voulez vous assurer que vos données sont conformes un schéma, car votre analyse de données est désormais adaptée à un certain type de jeu de données. Essentiellement, vous avez vos données client, par
exemple, peut-être que vous avez le sexe, vous avez des achats ou le dernier achat, puis vous avez la date à laquelle ils se sont inscrits. Ces trois fonctionnalités sont sur lesquelles repose votre analyse de données. Si vous obtenez de nouvelles fonctionnalités, vous devez commencer une nouvelle analyse, car cette analyse peut vous donner de nouvelles informations. Votre pipeline doit valider que les nouvelles données qui arrivent
se situent dans la plage de vos paramètres attendus. Déjà lors de la saisie de nouvelles données, vous voulez vous assurer que vos données sont conformes à ce que vous attendez. Faites des vérifications, faites des tests, et vous pouvez automatiser ces tests et votre personne chargée des opérations de données peut probablement vous aider avec elle. Belle bibliothèque Python pour cela comme Great Attentes. Les gens ont récemment adoré cela et nous passons en revue les schémas dans le cours Python. Ensuite, j'ai sur la plate-forme Skillshare aussi. J' espère que vous allez vérifier cela plus tard si vous connaissez déjà du Python. Mais peu importe, savoir ce que vous avez à faire est déjà génial. Parce que si vous voulez gérer une équipe de science des données, vous devez savoir ce que vous voulez essentiellement avoir une vue de haut niveau. Obtenir vos données, assurer que vos données sont bonnes, puis s'assurer que la plupart de ces processus, sorte que certaines des visualisations que vous obtenez dans votre tableau de bord en direct, par
exemple, doivent être générées automatiquement à partir des données. Tout cela est possible si vous écrivez votre code d'une manière propre que vous avez tout et fonctions
individuelles qui peuvent être appliquées individuellement à chaque étape de votre processus de science des données. C' est vraiment là que les chercheurs de données chevronnés
se distinguent des scientifiques de données juniors. Vous écrivez du code plus propre et vous comprendrez comment placer chaque morceau de code dans une boîte, dans une fonction où vous pouvez ensuite l'utiliser pour automatiser le processus de réalisation de parties de l'analyse. Une autre partie très importante de ce processus d'analyse, surtout si vous faites des prédictions. Nous sommes les données du client qui prédisent si quelqu'un va faire un achat, si vous le montrez ou si vous lui montrez que c'est d'avoir un aperçu des indicateurs clés. Quelque chose que l'on appelle la dérive du modèle ou la dérive du concept. Votre modèle d'apprentissage automatique est basé sur des données historiques. Votre analyse de la science des données, toutes les informations sont échangées à partir de données historiques. Si en ce moment nous regardions 2021, où la majeure partie du monde est en prison. Nous prenons des informations de 2000-2010, ce qui est beaucoup de données, 10 années de données seraient étonnantes. Mais rien de tout cela n'est applicable en ce moment. C' est là que tous nos modèles et toutes nos idées ne sont plus aussi précieuses. Parce qu'à l'heure actuelle, tout cela est remis en question par changements dans les concepts de la façon dont les gens vivent réellement comme la vérité, les relations sous-jacentes changent complètement parce que les gens achètent beaucoup plus en ligne. Les gens devront utiliser les appels Zoom en ligne et beaucoup de comportements ont été modifiés. Les gens travaillent à la maison. Ce changement perturberait complètement votre analyse de données. Toute votre analyse de données que vous alliez de production ne serait plus vraie. Maintenant, la pandémie est évidemment un changement catastrophique. Mais souvent, vous avez des changements au fil du temps dans vos données, dans vos clients, les gens changent, les tendances changent, surtout si vous êtes une marque de vêtements , par
exemple, vous avez la saisonnalité là-dedans. Personne ne va acheter un joli bikini à l'automne. Eh bien, quelques personnes, mais vous allez avoir beaucoup plus de gens qui achètent shorts de
bain au printemps pour se préparer pour l'été. Avoir ce genre de concepts et ce genre de test pour, pour la cohérence dans vos données d'entrée. Mais aussi dans les indicateurs de performance clés,
indicateurs de performance clés dans votre sortie, que vos données fonctionnent toujours bien. C' est très important. Ayez toujours une boucle de rétroaction dans votre pipeline de données où vous vérifiez que ce que je fais
est toujours automatisable, est-ce toujours valide ou est-ce que je reçois trop de mauvaises prévisions à ce stade ? Réfléchissez vraiment à cela parce que c'est extrêmement important examiner le processus de science des données si vous automatisez cela. Pas si important dans une analyse ponctuelle où vous essayez de convaincre les décideurs. Mais lorsque vous automatisez ces processus, ce qui est beaucoup plus important dans les entreprises, et dans ces opérations à grande échelle. Là, vous devez vraiment penser à la validation des données. Est-ce que j'ai les bonnes choses dedans ? Validation de sortie, dérive de concept et rétrécissement du modèle, où vous voulez vraiment regarder est ce que je sors également toujours valide. Souvent, vous pouvez mesurer vos résultats à partir de la sortie attendue. Tu vois, tu prédis combien une personne dépenserait. Alors vous voyez combien cette personne dépense. Beaucoup de fois, vous pouvez essentiellement voir avec les tests AB, par
exemple, si je n'ai rien fait, cela
changerait-il encore quelque chose ? Cela porte aussi davantage sur les aspects de la causalité. Ce que je fais, est-ce en fait avoir un effet, ou est-ce peut-être même entrave les résultats ? Penser à cela vous élève vraiment au-dessus des scientifiques de données juniors parce que vous
allez être beaucoup plus précieux pour une entreprise si vous pouvez penser à ces tests à effectuer. Lorsque vous gérez une équipe de science des données, vous voulez être sûr de communiquer que cela est prévu lors de l'automatisation des pipelines. Si vous êtes un Data Scientist, vous voulez vous assurer que sur ces projets que vous construisez pour obtenir un emploi ou dans votre travail. Vous suggérez également ce genre de contrôles à la direction, à la personne chargée des opérations de données, car c'est extrêmement important. Encore une fois, si vous le considérez comme ceci, vous vous montrerez comme un membre précieux de l'entreprise et de l'équipe. Cela ne vous aidera qu'à l'avenir. Nous avons parlé un peu des tableaux de bord dans cette partie. Dans la classe suivante va jeter un oeil à certains tableaux de bord, et ce que je veux dire avec des tableaux de bord en direct et pourquoi vous voulez avoir de l'expérience dans la construction de tableaux de bord et pourquoi il est tellement amusant d'être honnête.
12. Tableau Dashboarding: Dans cette conférence, nous allons jeter un oeil aux tableaux de bord. Les tableaux de bord sont devenus très populaires, car ils vous donnent un aperçu de plusieurs visualisations ensemble, et vous parlent vraiment des changements et de ce qui se passe dans votre système live, mais aussi avec vos données. Vous pouvez avoir un onglet avec des vues basées sur une carte et vous pouvez avoir une relation de travail d'onglet ou des modifications d'afflux de données. Vous pouvez surveiller vos indicateurs de performance clés, vous pouvez surveiller l'état de votre système, dans les tableaux de bord totaux sont cet appareil. Dans mon temps de consultation, les gens demandaient toujours des tableaux de bord, comment créer des tableaux de bord, et c'est devenu beaucoup plus facile. Si vous optez pour des options de code bas ou sans code, Tableau, Spotfire et Power BI vous offrent des options pour créer des tableaux de bord. On en aura quelques à l'écran. Quand vous allez à Python, il y a quelques joueurs sur le bloc, ce qui est plutôt nouveau, pour être honnête, aussi nouveau pour moi, mais c'est tellement excitant que j'aime construire des tableaux de bord. C' est très intéressant pour moi. Mais ouais, essentiellement, ce que vous pouvez faire est soit utiliser Plotly Dash, qui est très polyvalent et interactif aussi, soit vous pouvez utiliser Streamlit, qui utilise ou peut utiliser des sorties d'apprentissage automatique. Donc vraiment puissant quand vous avez des connaissances en Python. Dans les tableaux de bord, vous voulez être prudent. Parce que quand je vois des tableaux de bord, ils ont tendance à être un peu surchargés. Donc, ce que vous voulez vous concentrer est d'abord, lorsque vous l'ouvrez, informations
les plus importantes devraient être sur le pli, au-dessus du pli. C' est généralement quelque chose dont vous parlez dans la conception web, qui est basé sur les vieux journaux. Lorsque vous sortiez acheter un journal, au-dessus du pli est le titre de la grande image. Donc, vraiment l'attention accrocheur, les choses les plus importantes que vous devez savoir, et cela devrait être exactement la même dans votre tableau de bord. La première page, dans le premier cadre que vous ouvrez, l'information la plus importante que les décideurs clés ont à voir. Ensuite, lorsque vous faites défiler vers le bas, vous avez des informations liées à cela. Mais la surcharge d'information est vraiment un problème. Habituellement, ce que vous voulez faire est minimaliste sur les données et sur les informations que vous avez sur une page. Vous avez toutes les informations nécessaires pour prendre une décision. Mais gardez les barres de couleur dans la même forme. Ne le surchargez pas et donnez de l'espace de visualisation, de l'espace pour respirer. Parce que si tout est entassé, cela donne généralement à tout le monde un sentiment d'écrasement. Faites quelques passes de combien vous pouvez réduire l'information. Vous pouvez toujours ouvrir un autre onglet avec un autre tableau de bord contenant des informations différentes. Mais votre tableau de bord devrait vraiment avoir une attention particulière. Il devrait répondre à une question tout comme votre analyse de la science des données. Il peut être utilisé comme un outil de communication. Il devrait répondre aux questions clés pour lesquelles les gens ouvrent votre tableau de bord. Ça ne devrait pas jeter toutes les informations. Ensuite, ils pourraient faire l'analyse eux-mêmes. Mais vous êtes les scientifiques des données. Vous devez raconter une histoire avec un tableau de bord et vraiment préciser ce est important pour les gens de voir qui ne peuvent pas faire l'analyse des données, mais celui pour savoir ce qui se passe dans le système de données dans ce processus, dans ce projet. Mais évidemment, dans les tableaux de bord, vous pouvez utiliser des visualisations interactives, ce qui est beaucoup de plaisir. Habituellement, les gens aiment l'interactivité. Donc, être capable de sélectionner quelques choses et comme survoler les informations et faire un tour, ce sont de bonnes décisions. Si vous pouvez le faire,
que les gens puissent zoomer sur vos données, dans vos visualisations au lieu d'avoir comme une image statique, c'est généralement une très bonne décision. zoom sur les cartes, par exemple, est quelque chose que tout le monde est habitué à ces jours grâce à Google Maps. Assurez-vous que lorsque vous faites ces tableaux de bord que vous
avez un design intuitif, insérez dans celui-ci. Lorsque vous voyez votre tableau de bord, il semble presque impossible de distinguer le professionnel,
que vous êtes, seriez au service. Donc, est-ce que cela ressemble à un pourrait être conçu par Apple essentiellement ? C' est un bon design ? Donc, ouais, concentrez-vous sur le minimalisme. Ne montrer que l'information pertinente pour prendre des décisions faciles et ne pas submerger les gens. Bien sûr, parfois les gens ont des opinions différentes. Si votre chef de décision clé veut plus d'informations sur le tableau de bord, vous devez bien sûr suivre cela. Vous devez leur donner les informations dont ils ont besoin. Souvent, vous devez itérer sur les tableaux de bord ainsi qu'avec les personnes qui les utilisent réellement et être flexible à ce sujet. Vous ne savez pas toujours quels sont les principaux responsables de décision, mais aussi les experts en la matière ont vraiment besoin. Donc, c'est vraiment bon d'obtenir des commentaires. Mais avec ces outils modernes, il est également très facile de construire ces tableaux de bord. Par conséquent, ajouter une autre visualisation ou prendre cette virtualisation, mettre dans un onglet différent est beaucoup plus facile qu'auparavant. Ce n'est pas beaucoup de travail. Mais oui, les tableaux de bord sont vraiment un bon point pour ignorer le perfectionnisme et plutôt compter sur les
commentaires des personnes qui vont utiliser vos tableaux de bord. La discipline de maître est clairement la construction de tableaux de bord en direct. Avoir ces tableaux de bord connectés à ces pipelines de données opérationnelles, avoir des informations en direct sur vos données, mettre à jour en
direct, et c'est également tout à fait possible, mais c'est un peu plus difficile comme il doit être
à la fin de tout ce pipeline de science des données. Vous voudrez probablement le faire dans l'ensemble, avec toute votre équipe de science des données et avec une personne chargée des opérations de données. Les tableaux de bord sont un outil de visualisation fantastique et un outil fantastique pour la communication car ils donnent aux gens la possibilité de respirer l'histoire que vous essayez de raconter. Au cours de la prochaine classe, nous allons examiner autres outils de communication
que vous pouvez utiliser pour raconter votre histoire de science des données, pour vraiment transmettre vos idées aux décideurs.
13. Communiquer efficacement des résultats: Le résultat final de votre processus de science des données est généralement la communication. Avec vos idées, vous voulez généralement montrer à quelqu'un, souvent des experts en la matière ou décideurs
clés pour prendre une décision en fonction de ce que vous avez trouvé. Changer les opinions, vraiment raconter une histoire, convaincre et la communication est essentielle dans ces aspects. Dans ce cours, nous examinerons la communication et la façon dont vous pouvez communiquer efficacement vos résultats. Parce que beaucoup d'outils de nos jours semblent le rendre facile, mais si vous allez au moins un pas plus loin, vous pouvez communiquer les résultats encore mieux. La clé de toute communication est de connaître votre public. Beaucoup de scientifiques de données plus récents prennent souvent le Jupiter Notebook, qui est un moyen de mélanger du code et du texte, et de les transformer en PDF. Dans un sens, c'est problématique parce qu'un chef d'entreprise, par
exemple, n'a pas le temps de regarder votre code. Franchement, ils ne gagnent aucun avantage en regardant votre code. Ces cahiers Jupiter doivent être utilisés pour la communication avec d'autres scientifiques des données. Avec les codeurs, donc vous avez réellement la documentation pour votre code aussi. Mais quand vous parlez à des gens qui sont plus dans les secteurs de la gestion, vous ne voulez pas leur montrer le code à moins qu'ils ne le demandent. Vous voulez être en mesure de visualiser efficacement. Pour revenir à la classe sur la visualisation, vous voulez vraiment raconter l'histoire avec des images leur
montrant les données de la manière qui leur permet de décider facilement. En fin de compte, convaincre quelqu'un est toujours de prendre une décision plus facile pour eux parce qu'ils ont maintenant la certitude parce qu'ils sont appuyés par des données. Soutenu par les mathématiques, les statistiques, l'apprentissage
automatique, votre travail dans l'analytique. En fin de compte, c'est aussi ce qu'est la science. En tant que scientifique, écrire sur papier, c'est convaincre mes pairs que j'ai trouvé quelque chose de nouveau, quelque chose de mieux qu'avant, une nouvelle idée. convaincre signifie vraiment parler leur langue, donc vous devez vous conformer à la ligne droite d'un document. Ajouter de bonnes visualisations et les bonnes équations aux bons endroits est très important, mais la plupart d'entre eux ne veulent pas voir le code. Cela change d'une manière ou d'une autre au moins. Dans le journal, la plupart des gens vous demanderont de supprimer le code. Eh bien, je pense que rendre votre code présentable, et j'aime le mettre dans un appendice ou quelque part. La plupart des gens ne veulent pas regarder le code parce que la plupart des gens aiment avoir une décision plus facile en suivant simplement votre communication. Concentrez-vous donc sur les visualisations, concentrez-vous sur la narration d'une histoire et réduisez la quantité de code que vous affichez aux personnes à moins que cela ne soit approprié. De cette façon, vous pouvez aussi vraiment aller de l'avant et plonger profondément dans les médias que vous utilisez. Ensuite, il ne s'agit pas seulement du public où l'on
pense à la cible, mais aussi du médium. visualisations interactives sont géniales, mais elles ne fonctionnent pas dans les PDF. Alors faites attention à la façon dont vous communiquez ces résultats. Si vous voulez envoyer un PDF à quelqu'un, vous n'avez pas besoin de prendre le temps de créer un tableau de bord, car ce sera un PDF. Prenez le temps de créer visualisations autonomes de
haute qualité qui parlent d'elles-mêmes que vous pouvez intégrer dans votre documentation PDF. Si vous faites une présentation PowerPoint, assurez-vous que vos données,
vos visualisations sont clairement visibles, esquissées et visibles sur de petits écrans à l'arrière d'une salle de conférence mal éclairée. Avec aujourd'hui, avec toutes ces choses qui se passent où nous avons beaucoup plus de vidéoconférences, réfléchissez à la façon dont vous pouvez partager vos idées en direct. Pouvez-vous donner aux gens accès au tableau de bord pour qu'ils puissent l'essayer ? Pendant que vous faites votre présentation, peuvent-ils suivre une partie de l'analyse eux-mêmes ? Pensez vraiment à la façon dont vous communiquez vos résultats, car la communication est votre clé pour vraiment convaincre quelle est l'histoire que vous essayez de raconter. En tant que data scientist communication, et donc l'empathie est extrêmement importante. Vous avez tous ces outils incroyables qui peuvent vous aider à faire du commerce de la science, et vous avez autant d'outils incroyables pour vraiment communiquer vos résultats, créer des PDF, créer des présentations et PowerPoint, construire des tableaux de bord, construire des ordinateurs portables Jupiter pour parler et des tutoriels, et discutez avec d'autres scientifiques des données. Mais en fin de compte, il est très important que vous ayez la communication à l'esprit. Si vous partagez votre analyse, les gens tireront profit de vos connaissances, et c'est ainsi que vous aurez vraiment un projet complet et terminerez le processus de science des données. Dans le prochain cours, nous examinerons la compréhension des risques dans science
des données, car tous les projets ne seront pas couronnés de succès.
14. Comprendre les risques dans les projets de science des données: Une partie importante du flux de travail de gestion de la science des données consiste à comprendre les risques. Le profil de risque d'un projet de science des données est très différent de celui d'un projet logiciel, par exemple. Si vous savez que quelque chose est faisable avec un ordinateur, il faut juste du temps et de la gestion pour terminer ce projet. Dans un projet de science des données, il peut avoir des résultats négatifs. En fin de compte, il s'agit d'un processus scientifique, voir si nous pouvons même répondre à une question compte tenu des données dont nous disposons, et ce n'est peut-être pas possible. Il y a des choses éthiques dont j'ai parlé, comme peut-être nous trouvons que répondre à cette question n'est pas bénéfique pour notre entreprise, pour notre question. Peut-être que c'est très nocif pour les communautés, mais aussi dans un sens beaucoup plus léger il se peut que notre modèle ne fonctionne pas bien. Que nous pouvons nettoyer les données, que nous n'avons pas assez de données, et toutes ces choses que vous devez gérer. La gestion des risques signifie que nous devons être dans un état d'esprit agile à la fin. Tout doit être itératif. Il est très bon d'avoir des points de repère quotidiens qui sont très courts car vous faites la méthodologie agile. Vous voulez identifier les blocs dans votre équipe tôt. Vous voulez communiquer régulièrement. Ne microgérez pas, mais il est important de donner à votre équipe les moyens de dire : « Hé, ça ne marche pas. Nous avons besoin de plus de données, nous avons besoin de données différentes, peut-être devrions-nous reformuler notre question parce l'aperçu que nous avons trouvé à partir de cela ne fonctionne pas vraiment. » Lorsque vous passez d'un poste junior à un poste plus élevé avec plus de responsabilités, il est important de diriger votre équipe, mais aussi d'être conscient que l'échec est tout à fait possible. Lorsque vous communiquez avec les intervenants et les décideurs, il est important d'indiquer clairement que l'échec est une possibilité, que ces éléments sont exploratoires et dépendent de l'endroit où se trouve votre projet. premiers projets qui font la première exploration, qui font le premier travail de base, ils sont beaucoup plus susceptibles d'échouer au stade qu'ils ne
sont pas réalisables du tout alors que les projets ultérieurs, vous devez être beaucoup plus prudent sur l'analyse des produits de vos pipelines. Est-ce que ça marche toujours ? Est-ce que ça va de l'avant ? Surtout si vous êtes dans des équipes plus jeunes, dans des équipes qui ne font que s'établir, faites attention à communiquer la certitude et l'incertitude parce que certaines choses ne fonctionnent pas. Cependant, ces échecs peuvent également être des idées. C' est là que vous voulez vraiment revenir à la communication aussi parce que pouvoir dire que cette décision n'est pas possible sur la base de ces données est quelque chose de précieux que vous pouvez également vendre comme résultat. Mais tu dois le laisser ouvert. Lorsque vous communiquez avec la direction et que vous promettez un succès, vous fermez la tempête que vous pouvez essentiellement encadrer cela comme un aperçu supplémentaire car alors cette information supplémentaire devient une défaillance automatique. Cependant, si vous pouvez communiquer à l'avance que l'échec est une possibilité, qu'il y a des problèmes qui ne sont pas résolus, que parfois les données ne sont pas suffisantes, ou qu'il y a des problèmes de synchronisation, des choses comme ça. Que vous ne pouvez pas atteindre les indicateurs de performance parfois et que vous devez mettre à jour itérativement, c'est quelque chose que vous devez faire attention. Lorsque vous êtes doué à communiquer cela à l'avance et à gérer ce risque, vous préparez votre équipe pour réussir. Parce que, indépendamment de ce qu'ils font, s'ils font leur travail et qu'ils sont habilités à fournir également des résultats négatifs, il
s'agit de bâtir une équipe forte et l'équipe qui finit par construire des produits incroyables et est introduire et maintenir des résultats axés sur les données dans une entreprise et rendre une entreprise plus forte et vous élever ainsi que l'équipe dans son ensemble. En fin de compte, vous devez comprendre, en
tant que scientifique des données en pleine croissance ou en tant
que personne susceptible d'assumer un rôle de gestion, que vous devez faire attention à ce que vous communiquez et à ce que vous promettez. Mais en habilitant, en étant un bon leader pour l'équipe qui travaille itérativement et qui donne vraiment aux gens leur espace et les outils nécessaires, vous pouvez faire de cette équipe un succès et vraiment gérer le risque de projets de science des données qui sont très différents des projets normaux. C' est le dernier chapitre. La prochaine classe va terminer
ce cours de Skillshare et je suis très heureux que vous y assistiez.
15. Conclusion: Félicitations pour l'avoir fait. Je sais que cela a été beaucoup d'informations et pour beaucoup
d'entre vous, il peut s'agir d'informations complètement nouvelles. Mais j'espère pouvoir vous montrer comment ces
informations basées sur
les données et ce processus d'esprit scientifique qui va jusqu' aux données brutes à la communication des résultats aux principaux responsables décisionnels est un point si précieux et intéressant. Cela me laisse juste à espérer que vous allez ce voyage et explorer cela dans des opportunités de code bas ou de code. Il y a tellement de façons différentes d'aborder cela. Je suis très heureux que tu aies suivi ce cours et j'espère que tu en as tiré quelque chose. S' il vous plaît, considérez mon autre cours. Je donne un cours pour les personnes qui connaissent
déjà Python et qui veulent apprendre le processus de science des données ici sur Skillshare. Mais certainement explorer tous les autres cours aussi bien. Il y a des cours étonnants sur la visualisation de la science des données ici. Il est vraiment fantastique de plonger plus profondément dans cette communauté décisionnelle axée sur les données. Assurez-vous de trouver des personnes sur LinkedIn, suivre les influences sur les différents médias sociaux et d'en apprendre davantage sur science
des données, car il y a tant de choses intéressantes et fascinantes qui sortent. Lorsque vous continuez à regarder les données, vous serez beaucoup plus sûr dans vos décisions parce que ces décisions sont en fait fondées. Merci d'être présent. Je suis si reconnaissante que tu sois là. J' espère que vous avez apprécié ce cours. S' il vous plaît assurez-vous d'essayer le projet et de publier le projet. Je serai très heureux de voir ce que vous venez avec.
 Jesper Dramsch, PhD, Scientist for Machine Learning
Jesper Dramsch, PhD, Scientist for Machine Learning