Transcripciones
1. Introducción: La ciencia de datos es este nuevo y emocionante campo, pero puede ser intimidante entrar porque muchas veces involucra matemáticas y programación. Esto es algo con lo que mucha gente se siente incómoda, y algunas personas ni siquiera necesitan cuando quieren manejar un equipo de ciencia de datos, y algunas personas ni siquiera necesitan cuando quieren manejar un equipo de ciencia de datos,
más bien se metían en los detalles de la basura. Llegaremos a un alto nivel de comprensión para entender los métodos y el vocabulario de la ciencia de datos. Se puede hablar como un par, que es lo que estamos haciendo en esta clase magistral de ciencia de datos. Mi nombre es Jesper Dramsch, soy ingeniero de aprendizaje automático en Oxford en Reino Unido. Tengo experiencia enseñando Python y machine learning en esta plataforma, en Skillshare, y así como en empresas como Shell, el gobierno del Reino Unido, y un par de universidades. Pasé mi último par de años trabajando hacia un doctorado en geofísica y aprendizaje automático. Me encanta la ciencia de datos porque me ha permitido encontrar trabajo durante la pandemia, lo que estoy increíblemente agradecido. Yo quiero compartir algunos de estos conocimientos con ustedes porque creo que empoderar a la gente para salir adelante con su carrera y posiblemente incluso hacer un cambio es realmente de lo que se trata. Esta clase te enseñará los conceptos y de
alto nivel de comprensión sin entrar en código, para que puedas hablar con los científicos de datos como pares y realmente entender los procesos de pensamiento detrás de la toma de decisiones impulsada por datos. Estoy increíblemente emocionado de tenerte y espero verte en clase.
2. PROYECTO DE CLASE: Bienvenido a clase. Me alegra tanto que lo hayas hecho. ¿ Qué realmente vamos a hacer aquí? Bueno, preparé un proyecto de clase y
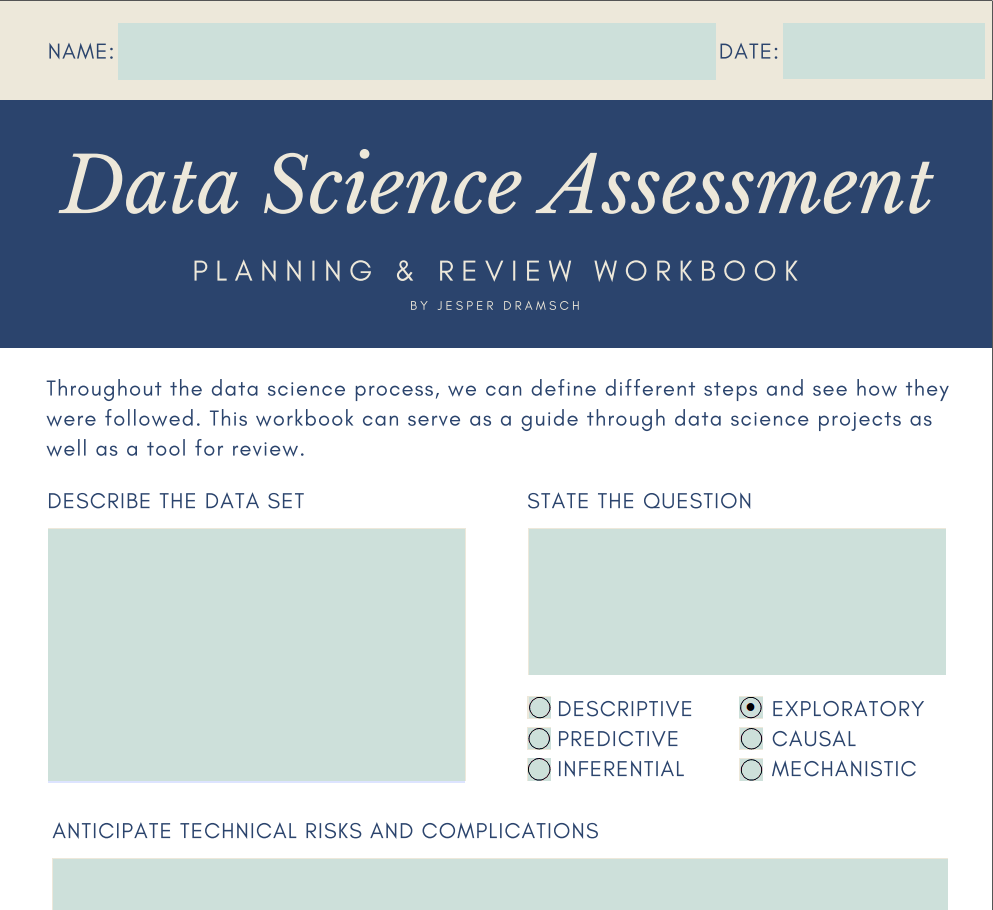
quiero que lo echen un vistazo porque esencialmente es un libro de trabajo que puedes usar para tu proyecto de clase, pero espero que realmente lo puedas utilizar en tu trabajo diario de ciencia de datos también. Ya sea guiándote a través de tus propios proyectos o para ayudarte a gestionar otros proyectos. Vamos a sumergirnos directamente en el cuaderno de trabajo y echemos un vistazo a través de él. Este es el libro de trabajo de evaluación de la ciencia de datos para planificar y revisar tus proyectos de ciencia de datos sobre proyectos de ciencia de datos que estás gestionando. Estas son tres páginas por el momento, y al principio, puedes llenar tu nombre y tu fecha y hacer algunas preguntas importantes sobre tus datos. Después tendremos alguna información de dónde son
tus datos y cómo te aseguras de validar tus datos. Algunos insights en los pasos que
aprendes en la siguiente clase que forman parte del proceso de ciencia de datos. Entonces básicamente documentarás algoritmos y visualizaciones notables que condujeron al interior, hallazgos
negativos que se encontraron a lo largo del proyecto. Cuál es el principal impacto empresarial o científico, dependiendo de dónde se encuentre y su principal conclusión. Estos son totalmente personalizables. Puedo decir, este es mi nombre y hoy es el octavo de enero. Ahora describe el conjunto de datos. En el conjunto de datos de ejemplo, por ejemplo, tenemos un indicador de felicidad, y tenemos puntos de datos por país y aquí. De esta manera realmente puedes llenar cada pregunta aquí. La pregunta, por ejemplo, es, ¿cuál es la principal influencia en el puntaje de felicidad? Esto sería en algún lugar entre descriptivo y exploratorio. Yo diría que es exploratorio porque, bueno, estamos viendo cómo se calcula esta predicción o cómo se calcula la puntuación, así que lo estamos explorando en lugar de simplemente describir el conjunto de datos. El riesgo técnico es algo donde por ejemplo, sus datos o sus máquinas no son capaces de hacerlo. Piensa en si tienes un conjunto de datos demasiado grande, es posible que no quepa en tu computadora. Cuáles son los riesgos que pueden suceder y los riesgos no tienen por qué ser lo peor. Se trata sólo de bloqueos de carreteras y si anticipas los riesgos ahora, puedes tomar intervenciones y tomar precauciones para abordar realmente estos riesgos si suceden. Uno de los riesgos también podría ser que los datos no estén llegando. ¿ Qué haces cuando tienes pérdida de datos? ¿ Porque falta uno de tus discos duros? Piensa en esto. Es una buena pregunta preguntarte y aquí tenemos riesgos metodológicos. ¿ Qué puede pasar en el propio proceso de ciencia de datos? ¿ Qué pasa si no tenemos algoritmos disponibles para hacer estas preguntas? ¿ Y si nuestro
conjunto de datos en realidad no contiene la información que necesitamos para hacer la predicción. Realmente más a nivel meta,
piense en lo que puede salir mal en el análisis de la ciencia de datos en sí y cómo y dónde se adquirieron los datos y
las etiquetas las estrategias de validación utilizadas para asegurarse de que sus insights sean generalizables. Todas estas palabras y todo esto se explicarán también en el curso. Si estas son palabras que te sonan raras ahora, las
entenderás al final. Asegúrate de volver aquí para cumplir con tu proyecto y presentarlo a nuestra base de datos de proyectos. ¿ Cuáles son las consideraciones éticas es una cuestión importante. Realmente un puntaje de felicidad, por ejemplo, son estas estadísticas agregadas por lo que a nivel de país o
tienes la posibilidad de ver información de nivel personal. Eso sería más
bien, bueno, sería un poco dudoso. Entonces escribe sobre este año y luego en los diferentes pasos, escribe sobre qué hallazgos encontraste al hacer Estadística Descriptiva, EDA, machine learning, y luego qué pasos para la comunicación se tomaron. Al final, como dije, notables algoritmos y visualizaciones. Lo que ha tenido más impacto en entregar tu visión. Entonces hallazgos negativos, como señalaré, ciencia de
datos es un proceso iterativo. Verás que a veces encuentras cosas negativas, a veces algo no funciona. Anote estos hacia abajo. Si puedes anotarlas, mirarás hacia atrás y verás, oh sí, ya lo sabemos. Esto se puede compartir con los científicos de datos con los decisiones
clave y también apreciarán esta retroalimentación donde se puede decir, bueno, esto no funciona, esto no ha funcionado empíricamente. Por lo tanto, dar una visión adicional de su análisis. ¿ Cuál es el principal impacto empresarial, impacto científico? Esto debería estar mezclado fuera de tu pregunta. ¿ Cómo impacta tu pregunta al negocio, pero también cómo los hallazgos y la respuesta a tu pregunta impactan al negocio, toda la ciencia que estás haciendo. Después escribe una conclusión principal. En serio, ¿cuál es el principal hallazgo que tienes en este análisis de la ciencia de datos? Ahora que terminamos con el PDF, puedes descargar eso en la descripción. Podemos echar un vistazo a la estructura de clases. Porque esta clase está fijada para tantos tipos diferentes de estudiantes. Algunas conferencias pueden no ser las más relevantes para usted. Siéntete libre de saltarlas. Está totalmente bien si te estás aburriendo incluso y solo vas al siguiente. Porque aunque el primero no sea el adecuado para ti, puede que
haya uno que sea mejor para ti. Por ejemplo, uno de los últimos es hablar de
operacionalizar los ductos de datos y entender los proyectos de riesgo y ciencia de datos. Algunas de las preguntas realmente importantes que tienes cuando estás manejando equipos. Asegúrate de comprobarlos. Si te estás saltando adelante, no hay resentimientos. Esta es tu clase, así que hazla tuya, y asegúrate de compartir tus proyectos. Yo estaría muy contento de ver cómo le dan sentido a los proyectos de otras personas. Recuerda ser agradable, recuerda criticarlo de manera académica y científica, realmente
puedas aprender de ella y mostrar a los demás lo que aprendiste de ella. Ahora, vamos a sumergirnos en el contenido real de la clase. En la primera clase se va a definir qué es realmente la ciencia de datos.
3. ¿Qué es la ciencia de los datos?: En esta clase, intentaremos explorar qué es la Ciencia de Datos en realidad. Es un poco difícil de decir realmente porque la ciencia de datos es tan nueva. Hay muchas opiniones diferentes, y por eso también quiero explorarlo desde diferentes maneras. La forma más fácil es básicamente citar a alguien más. Por lo que Jim Gray, ganador del Premio Turing dijo que, “La ciencia de datos es el cuarto pilar de la ciencia junto a la ciencia empírica, teórica y computacional”. Lo que básicamente significa es que usando la ciencia de datos, podemos extraer nuevos insights directamente de los datos. Si tienes tus datos de negocio, si tienes tus datos científicos, de
donde sea que vengas, puedes tomar esos datos y usar estos nuevos métodos o métodos antiguos y nuevas capas, y esencialmente, encontrar relaciones dentro de que los datos que funcionan, no sólo en este pequeño conjunto de datos, sino que pueden generalizarse a nuevos datos. Si tienes datos de clientes, entonces
puedes predecir qué están haciendo los nuevos clientes. Si tienes datos de química, puedes predecir qué va a hacer una nueva fórmula química, cosas así. Esto simplemente basado en la relación dentro de los datos. Ahora, una forma diferente de mirar es mirar la jerarquía de los signos de datos de las necesidades. A mí me gusta mucho este porque también nos da una forma definir básicamente dónde tenemos que pasar el tiempo. Una de las cosas es que tenemos que adquirir datos. Sin datos, no podemos hacer ciencia de datos. Tenemos que conseguir un conjunto de datos, tenemos que limpiar el conjunto de datos porque todos los datos brutos son ruidosos. Ahí hay atípicos equivocados,
hay información ahí dentro que no es relevante para nuestra pregunta. Al igual que los científicos de datos bromean sobre que la limpieza de datos es la más larga que gastan en ella, algunos afirman gastar 80-90 por ciento en limpieza de datos y solo 20-10 por ciento en la parte divertida o en la parte realmente interesante de generar insights. Pero sí, es la parte más importante. La gente tiende a decir basura adentro, basura afuera, y por lo general, eso es muy cierto. Después a partir de eso, hay
que tener un almacenamiento confiable. Si tienes tus datos y se pierde, es muy difícil reproducir tus resultados,
y los resultados en la ciencia de datos tienen que ser siempre reproducibles. Además, tal vez tengas que validar tus resultados o tal vez tengas que volver atrás y combinarlo con nuevos datos que podrían cambiar tus conclusiones. Almacenar, moverse alrededor de los datos es realmente como construir su infraestructura es el siguiente nivel. Especialmente para los gerentes de ciencia de datos, tienen que saber que los ingenieros de datos son extremadamente importantes en esta etapa. Emplear al tipo adecuado de personas en los puestos correctos es esencial para un negocio. Después en el siguiente paso, tenemos explorar y transformar datos. exploración de datos realmente es el paso donde tiene un vistazo a las estadísticas descriptivas de sus datos, como echar un vistazo al promedio y cuánto varían sus datos, y qué están haciendo las diferentes características de sus datos. Cuando tienes un cliente, ¿
cuándo vinieron a tu lado? ¿ De dónde son? ¿ Cuál es el género? Cosas como esa que te pueden dar perspectivas sobre cómo pueden variar los clientes entre las visitas y lo que puede cambiar la predicción si van a comprar zapatos, si van a comprar una cámara nueva, o si van a tomar un curso sobre Skillshare. Además de eso, entonces puedes hacer pruebas A/B. Si alguna vez has ido a algunos como Amazon o a estos sitios web de cursos, es posible que veas que se muestran diferentes precios. A menudo, eso se debe a que los sitios web están haciendo estos experimentos de ver si mostrar un sitio web diferente, cambiar el botón, cambiar el precio
va a hacer que más o menos probabilidades de comprar. Cosas como pruebas A/B, experimentación, algoritmos
simples de Machine Learning son el siguiente paso en esta escalera. Entonces haciendo predicción y haciendo inferencia para realmente poder mirar hacia el futuro a partir de los insights que generamos. Entonces la punta del iceberg, así que básicamente, el desierto en tu pirámide alimenticia, va a ser IA y aprendizaje profundo. Eso básicamente significa que estas tecnologías súper emocionantes son probablemente las últimas que quieres probar, pero pueden ser extremadamente valiosas. Entonces, si tienes tus ingenieros de Machine Learning o tus investigadores de Machine Learning, y ellos han construido modelos de línea base, y sí recomiendan en base a sus conocimientos que podría ser necesario ir a métodos de aprendizaje
demasiado profundo para construir Algoritmos de IA para aprovechar realmente los datos, las complejas relaciones que tenemos en los datos, esto puede ser realmente bueno. Muchos de los avances modernos de Machine Learning se
han hecho con métodos de aprendizaje profundo. Por último, cuando realmente estamos haciendo ciencia de datos, no sólo mirando las necesidades de la ciencia de datos, es un proceso. En este proceso, queremos responder a una pregunta específica basada en nuestros datos. Eso significa que muchas veces tenemos que ir adelante y atrás. Podríamos obtener nuestros datos y hacemos exploración de datos, pero en la exploración de datos, encontrando descriptores en nuestros datos, encontramos que estos datos podrían no ser suficientes y tenemos que volver atrás y adquirir nuevos datos o tal vez fusionarlos con el a fuente de datos, luego trabajar en refinar nuestro proceso de ciencia de datos. En la siguiente parte se va a estar buscando modelar nuestros datos. Estos son los algoritmos simples de los que hablamos, pero también pueden ser solo insights que ganaste de forma natural. Reglas simples también están modelando tus datos, modelado
estadístico para la inferencia puede ser muy apropiado en este lugar. Aquí es realmente donde quieres que tu científico de datos entre y sea capaz construir un modelo que pueda describir y capturar con precisión tus datos. Por último, una parte muy importante es comunicar tus resultados. Construir cuadros de mando, hacer presentaciones, crear estos cuadernos que a veces tienen código en ellos para compartirlos con compañeros científicos de datos o ingenieros de Machine Learning. De esta forma, realmente puedes compartir lo que encontraste. Esta parte posiblemente sea la más importante porque siempre hay que hablar con los tomadores de decisiones, siempre hay que hablar con las partes interesadas cuál fue su pregunta realmente salió a ser. Esta también puede ser la parte más interesante porque encontrar estas relaciones en los datos es fascinante y compartirla con los titulares de participaciones, por lo general, los titulares de participaciones están sumamente agradecidos por tener este nuevo
tipo de insights en su negocio o en su ciencia. Asegúrate de tomarte algún tiempo para hacer una buena presentación de esto porque normalmente, es muy importante y muy valioso hacer esto. Esto es principalmente de lo que se trata la ciencia de datos, obtener datos, generar insights a partir de datos, modelar sus datos y luego comunicar sus resultados. Por supuesto, hay piezas como produccionalizando esto. Entonces si estás en un negocio, como en un sitio web, quieres poder usar todo esto, pero esto es para nuestra futura clase. En la siguiente clase, vamos a echar un vistazo a lo que en realidad es una buena pregunta? ¿ Cómo podemos hacer buenas preguntas de nuestros datos y asegurarnos que estos realmente valgan nuestra inversión y valen nuestro tiempo?
4. Sobre cómo hacer una buena pregunta: Echemos un vistazo rápido qué es un buen cuestionario y también cuáles son las malas preguntas. Básicamente, si estás haciendo preguntas, tienes la opción de seis preguntas. ¿ Por qué seis se puede preguntar? Bueno, la ciencia lo dice. De hecho, los científicos y profesores de datos, Jeffrey Leek y Roger Peng, que tienen un increíble curso sobre ciencia de datos ejecutivos, han publicado un artículo en el que esencialmente se esbozan los tipos de preguntas que se pueden hacer. Yo quiero hablar también del tipo de preguntas pero luego entrar en detalle, también qué mala pregunta es. Porque recientemente, cada vez están
surgiendo más preguntas éticas en el espacio de la ciencia de datos y el aprendizaje automático. Creo que es muy importante para, bueno, para los líderes empresariales y para cualquiera que haga ciencia de datos estar al tanto de ellos y desafiarlos si hay cosas que no van de acuerdo a nuestros valores. Qué tipo de preguntas podemos hacer. El primer interrogante es descriptivo. Eso significa esencialmente que tenemos un conjunto de datos y queremos conocer características clave sobre el conjunto de datos. Por ejemplo, la altura promedio de los usuarios, o si estás trabajando en una zapatería, quieres conocer la gama de los zapatos que estás vendiendo. Al igual que la gama de tamaños, por ejemplo, o los diferentes colores que se venden. Entonces realmente solo indicadores que están describiendo el conjunto de datos que tienes. Las preguntas aquí realmente pueden ser muy variadas, pero son bastante simples y muy cuestión de hecho. La siguiente pregunta que podemos hacer es explorativa. Esencialmente, la idea de qué podemos encontrar dentro de los datos. Esto generalmente incluye cosas como encontrar relaciones y tendencias dentro de los datos, mirar la correlación, y tendremos una clase más grande al
respecto porque es una parte tan esencial en la ciencia de datos. La siguiente pregunta que alguien podría hacer, y aquí también es donde nos aventuramos en lo que aprendizaje
automático puede hacer, son preguntas predictivas. Si hacemos x, ¿sigue y? Por ejemplo, si cambiamos este botón en nuestra página web, o si agregamos esta columna por aquí, si mostramos a un cliente este tipo de cosas para comprar también, ¿incrementamos las ventas? O si aumentamos nuestro conteo de suscriptores en YouTube, ¿obtenemos más vistas? Estas preguntas son ahora donde tenemos que hacer
mucha validación porque el aprendizaje automático es realmente bueno para recordar datos. A veces es un poco más difícil tener realmente una predicción general. Esto es realmente importante mirar la validación de modelos y en el curso más grande de machine learning y business analytics y Python, me voy a este tipo de validación de modelos porque para mí, esta es una de las partes más importantes de los datos ciencia. Ahora, nos estamos metiendo en partes realmente interesantes. Porque mucha gente conoce estas pruebas que la correlación no es causalidad. El modelado predictivo suele ser correlación, pero la siguiente pregunta que podemos hacer es una cuestión de naturaleza causal. Entonces, si tenemos x hace y sigue, es la pregunta predictiva. Pero sí x causa y, es la pregunta causal. Para mí, esto es realmente interesante porque una gran cantidad de modelado
predictivo también pueden ser correlaciones espurias. Pero con el modelado causal, en realidad
estás tratando de encontrar lo que causa una cosa. Un ejemplo que me gustó mucho fueron los precios de los hoteles. Si estás recopilando datos de tus hoteles circundantes y estás echando un vistazo a los precios y cuántas personas hay en la habitación, entonces cuántas habitaciones están ocupadas en este momento, encontrarás que existe una correlación entre precios más altos y mayor ocupación. Pero si hiciste tu modelado causal y dijiste: “Está bien, entonces eso significa que si
aumentamos nuestros precios, tendremos mayor ocupación”. Seguramente saldrás del negocio. modelado causal realmente va en las estructuras de datos subyacentes, lo que está sucediendo en qué lugar. Algunas cosas que la gente hace aquí son contrafácticas, así que realmente, echarle un vistazo entonces. Si bajamos nuestros precios, ¿también obtenemos menor ocupación? Realmente cavando en los datos. Esto es para mí, el siguiente paso también donde ciencia de
datos va a dar más pasos en el modelado causal. Las preguntas mecanicistas van uno más allá que el modelado causal. No sólo estás mirando el predictivo. Si x hace y sigue, no sólo
estás mirando la flecha causal. Entonces x causa y? Pero en preguntas mecanicistas, en realidad
estás cavando en cómo causa x y Estás haciendo la ciencia. En bioestadística, por ejemplo, esto es muy común que para poder publicar, básicamente hay que proponer un mecanismo plausible, también la medicina. Muchas de las ciencias más naturales están bastante acostumbradas a esto. Su estadístico estará bastante acostumbrado a esto. En tanto que en el aprendizaje automático a menudo se detiene en las preguntas predictivas. Para hacer ciencia, esto puede ser extremadamente importante porque responder a estas preguntas, cómo sucede algo, es la última perspicacia. Aquí también es donde se pone interesante porque nuestros estudiantes son tan diversos, desde creativos hasta científicos hasta empresarios. Como científico, te interesa más la verdad, en los mecanismos subyacentes que encuentras en la naturaleza. Como gente de negocios, usted está más interesado en lo predictivo. Entonces, ¿alguien comprará algo si cambio esto? Posiblemente los efectos causales también. No tanto los mecanismos porque esos suelen ser mucho más difíciles de obtener, tomar más tiempo, tomar más cerebro, y simplemente decir, realmente
no aumenten las ventas ni adquieran nuevos clientes. De verdad, esto es un poco donde las preguntas son muy específicas de lo que realmente quieres, y tienes que decidir cuál es la pregunta correcta para el tipo de problema que estás enfrentando. Esto es básicamente una introducción sobre cómo hacer buenas preguntas y en la siguiente clase, veremos cómo hacemos malas preguntas.
5. Sobre hacer las malas preguntas: Probablemente veas cómo tienes que averiguar cuál es la pregunta correcta para tu problema. Pero con estos dilemas éticos recientes y también problemas en torno a las predicciones y las cosas, tenemos que preguntarnos, ¿qué es una mala pregunta? Quiero entrar en un par de ejemplos
de cosas en las que los científicos de datos probablemente podrían haber evitado algunos pasaran yendo más allá de un simple análisis
superficial o predicción superficial y posiblemente pensado un poco más, qué es pasando? Esta es realmente la razón por la que eres científico de datos. A veces hay que ir un paso más allá para hacer de este mundo un lugar mejor después de todo. Con el dilema social, por ejemplo, y mucha investigación que está saliendo,
vemos que sólo aumentar el uso
del sitio conduce a que los sitios web no sean tan grandes para los humanos. Vemos mucho sufrimiento humano por problemas de salud
mental basados en redes sociales y en YouTube, en Facebook, hemos visto que hay un sesgo hacia el extremismo. Cuando empezaste a ver videos sobre comida, te metes cada vez más en agujeros de conejo
muy profundos si solo optimizas por qué las personas se quedan de tu lado. Como científico de datos, deberías ir más allá de solo hacer la pregunta, ¿cómo mantengo a la gente en el sitio? Pero sí, deberías ir más allá. No sólo preguntar, ¿cómo mantengo a la gente en mi sitio? ¿ Cómo hago que la gente compre más? Pero posiblemente pregunte por la satisfacción del cliente también. No sólo es cómo vendo más, sino cómo consigo el producto adecuado a la persona adecuada? Este no es el más, no el tema más bonito, pero tenemos que hablar de ello porque hay que pensar en la ética. ¿ Se pueden explicar las cosas por población? Sabemos que hay barrios de mayor criminalidad en las ciudades más pobres. ¿ Realmente tiene sentido construir un modelo predictivo donde vaya a suceder el próximo crimen,
así que hazlo a nivel individual cuando sepamos que el problema subyacente es la pobreza. Esta es lamentablemente una pregunta que se está haciendo y no es una buena pregunta porque sabemos lo que está causando este problema ya. Construir un modelo predictivo sobre una base individual ignora
por completo nuestro conocimiento causal de esto ya. Esto sucede en escalas mucho más amplias, mucho más amplias también que no son tan éticas, donde sabemos lo que está sucediendo como efecto, pero como predecir el individuo ya no es tan valioso. Porque en este punto realmente sólo estamos tratando un síntoma más que el mecanismo. Otro tipo de mala pregunta sucede a veces en los negocios donde la respuesta está esencialmente predeterminada. Ya sabemos qué respuesta queremos y ahora estamos haciendo una pregunta para conseguir esa respuesta. Idealmente, la ciencia de datos debería estar abierta a respuestas. Estas respuestas deberían
ir potencialmente en una dirección que nuestra gestión no anticipó. La administración debe ser lo suficientemente abierta, lo suficientemente
segura como para que esto suceda también. Ser impulsado por datos a veces significa que encontramos verdades inconvenientes sobre nuestro negocio, sobre la dirección hacia donde queremos ir. Pero esto es eventualmente lo que hace de la ciencia de los datos una ciencia. A veces hacer estas preguntas cuando ya sabemos que queremos una respuesta determinada es definitivamente una mala pregunta porque no nos permite hacer una ciencia de datos adecuada. En la siguiente clase tendrá un vistazo cómo podemos realmente obtener datos para hacer estas buenas preguntas y cómo podemos obtener buenos datos para sacar los mejores resultados de nuestro análisis.
6. Obtención de datos y etiquetas: Una de las preguntas más comunes que obtengo de los principiantes en ciencia de datos es, ¿de
dónde obtienes tus datos, y cómo obtienes tus etiquetas? Ahora, estas son dos demografías diferentes que hacen estas preguntas. Por lo general, las personas en los negocios o los científicos ya tienen algunos datos. La recolección de datos es algo muy común. Por lo que tienes tu base de datos teniendo información de clientes, o tienes tus muestras de tu análisis. Ahí la pregunta suele ser más, ¿cómo consigues etiquetas? Para los principiantes que sólo están tratando de entrar en la ciencia de datos, están tratando de encontrar datos. ¿ Dónde encuentra los datos? ¿ De dónde sacan las etiquetas? Primero nos sumergimos en cómo obtienes los datos, dónde obtienes los datos. Porque incluso en un negocio, esta puede ser una pregunta realmente importante, y luego vamos a echar un vistazo a cómo conseguir etiquetas. Obtener datos es o bien medir los datos usted mismo o encontrar un conjunto de datos. Entonces eso significa obtener los datos de algún lugar. Hay almacenamientos de datos donde se pueden obtener conjuntos de datos preparados que a menudo ya tienen etiquetas adjuntas. Estos son bastante comúnmente la Búsqueda de Google o también la sección de conjuntos de datos de Kaggle. Medir datos básicamente significa que tienes que ir al campo o a tus sistemas, y extraer los datos de alguna manera. Entonces en mi trabajo ahora mismo, por ejemplo, estoy trabajando con datos satelitales, y en realidad sí tenemos una empresa que es local y está
dando vueltas con GPS para medir bosques reales. Sí, esto cuesta dinero, pero esta es la mejor manera de obtener datos precisos que alta calidad y que den los mejores resultados en su producto de ciencia de datos. Al final, contar con expertos para etiquetar tus datos, para obtener datos, para interpretar tus datos, es bastante importante. Mucha investigación ha demostrado que conseguir novatos, generalmente gente mal pagada en algo como Amazon Mechanical Turk para interpretar tus datos, no es ideal. Por lo general, te da datos ruidosos, etiquetas malas
y, a menudo, puede introducir sesgos en tus datos. Tienes que tener mucho cuidado con el sesgo en los datos porque este sesgo será horneado en tu modelo. Si haces modelado de aprendizaje automático, por ejemplo, que hago mucho, sesgo entonces será implícito en el modelo, y el modelo repetirá este sesgo en cada predicción. Entonces sobre todo si estás tocando humanos, tienes que tener mucho cuidado con esto. Esto también es algo de lo que debes tener cuidado cuando obtienes datos preetiquetados. Entonces cuando descargues uno de los conjuntos de datos de Kaggle, echa un
vistazo a lo que son realmente las clases, mira a través de lo que son los datos, cuáles son los desequilibrios de clase. Porque muchas veces obtienes etiquetas que son fáciles de etiquetar, pero no necesariamente son las etiquetas que son interesantes para etiquetar. ocasiones, sobre todo en términos de científicos y solopreneurs, tendrás que etiquetar los datos tú mismo o externalizarlos a alguien. Ya que eres el experto y por lo general los científicos corren con un presupuesto más ajustado, solo significa que tienes que abrir algo como Labelbox, que puedes ver aquí mismo en pantalla, y dibujar etiquetas en tus datos tú mismo, interpreta los datos, y ten en cuenta qué tipo de sesgo podrías estar presentándote. En esta clase, echamos un vistazo a cómo realmente se pueden obtener datos ya sea adquiriéndolos usted mismo, o descargándolos desde algún lugar, y cómo obtener etiquetas. Por lo que o bien estás consiguiendo expertos para conseguirte las etiquetas, cómo conseguir novatos para conseguirte las etiquetas, pero también cómo etiquetar los datos tú mismo usando apps como Labelbox. En la siguiente clase, vamos a echar un vistazo al análisis exploratorio de datos, donde realmente tenemos un primer vistazo a cómo las personas interpretan tus datos.
7. Comprender el análisis de datos exploratorio: Hablemos de análisis de datos exploratorios o de EDA corta. En el análisis exploratorio de datos, generalmente los científicos de datos tienen una primera mirada a los datos. Muchas veces la gente hace las estadísticas descriptivas sobre este pod. Entonces calcula la media, calcula variantes, y realmente echa un vistazo a las características de tus datos, ¿qué hay en los datos? ¿ Qué hay en las etiquetas? Esto también es para ver si la limpieza de los datos ha ido bien. ¿ Hay valores atípicos? Hay ruido en los datos y si encuentras este tipo de cosas en los datos, tendrás que volver a la etapa de limpieza. Como dije, la ciencia de datos es muy iterativa. Por lo que muchas veces hay que ir adelante y volver para ver realmente que todo está arreglado. Entonces después de echar un vistazo que todos tus datos están en orden, también
quieres echar un vistazo si faltan datos, porque esto sucede bastante comúnmente. Si tienes datos de clientes, por ejemplo, muchas veces los perfiles no se rellenan por completo. Te faltan algunos de los correos electrónicos, algunos de los números telefónicos, y esos valores faltantes se pueden indicar como algo falso. Por lo que son bastante valiosos para conocer en la ciencia de
datos y esto va para casi cualquier aplicación. Saber dónde están los datos faltantes puede ser extremadamente bueno para incorporarlos a su análisis. Este es un consejo que me gusta dar a todos para que también un vistazo justo donde tienes datos y donde no tienes datos. Al final, también se echa un vistazo a las correlaciones. Echa un vistazo a cómo tus características, cómo se correlacionan tus datos entre sí. Correlación simplemente significa que si la característica A está subiendo, y la característica B está subiendo, podrían tener alguna correlación de su ir en la misma dirección al mismo tiempo y esto puede ser bastante bueno para analizar por lo que usted entender las relaciones dentro de sus datos. Por lo general también quieres hacer algunos clustering tal vez. Echa un vistazo a qué datos se ajustan a qué datos. Por lo tanto, ten una mirada somera muy simple a cómo encajan tus datos en grupos. Personalmente también me parece muy valioso en el análisis
exploratorio de datos echar un vistazo a las visualizaciones. lo general, por supuesto, puedes calcular un número para el coeficiente de correlación, pero también solo tener una gráfica rápida de tus correlaciones y tus correlaciones cruzadas entre diferentes características puede ser realmente bueno porque entonces tienes una visión general rápida, al igual que vemos en la pantalla ahora mismo y sabes que esto está subiendo. Esto está positivamente correlacionado. Esto va a bajar. Si esto va a subir, esto se correlaciona negativamente. Entonces realmente solo tener una idea de los datos y entender mejor los datos, para luego
podamos seguir y ver si nuestra hipótesis que estamos construyendo en este proceso está aguantando nuevos datos que no hemos visto antes.
8. Introducción al aprendizaje automático: Una forma de modelar nuestros datos incluye el aprendizaje automático. aprendizaje automático tiene todo el alcance ahora mismo porque ha sido muy fácil usar herramientas de aprendizaje automático recientemente. Se ha vuelto muy accesible para mucha gente que conoce poco código o incluso ningún código y muchas aplicaciones. Donde el aprendizaje automático se acaba de abstraer para que puedas construir una red neuronal basada en tus datos que se aproxime al resultado. En el aprendizaje automático tienes básicamente tres áreas diferentes que puedes mirar. El aprendizaje supervisado, lo que esencialmente significa que tienes tus datos y luego tienes tus resultados. Por ejemplo, en datos de clientes, esto sería que tuvieras tu información sobre un cliente, que en cada entrada en esa información llamaríamos una función. Tienes tu etiqueta si compraron o si no compraron. Esta sería una decisión binaria en el aprendizaje automático supervisado donde luego puedes intentar predecir si en función de las características que tienes alguien comprado o alguien no compró. Este fue el primer aprendizaje automático que se puede hacer clasificación. Tanto si eso es binario como si tienes múltiples clases que quieres predecir. A lo mejor son los gatos, los perros y los pájaros. Esos son valores realmente
discretos, clases discretas que quieres predecir. El siguiente método en aprendizaje automático supervisado es la regresión, donde se predice un número. En este ejemplo de datos de clientes, esto equivaldría a predecir cuánto
está dispuesto a gastar un cliente en función de las características que tienen en el conjunto de datos. Realmente viendo a este cliente que recientemente ha comprado esto, esto, y esto va a gastar $100. Esto puede ser bastante importante para su presupuesto de marketing, por ejemplo. Si sabes cuánto gastar en un determinado demográfico, entonces esencialmente puedes ver cuánto presupuesto de marketing estás dispuesto a gastar para realizar una conversión. El tercer método en el aprendizaje automático es parte del aprendizaje automático no supervisado. Esto realmente significa que no tenemos las etiquetas que teníamos antes y estamos tratando de encontrar estructuras internas de nuestros datos. Realmente lo que esto significa para agrupar nuestros datos, estamos tratando de encontrar qué muestra de nuestro conjunto de datos está más cerca de otra muestra. Eventualmente, podemos entonces incluso usar este clustering no supervisado para asignar etiquetas a nuestros datos. Ese es uno de los trucos que la gente suele utilizar para encontrar etiquetas, que enlaza con la lección que hicimos sobre el etiquetado de nuestros datos. Este es un truco que puedes usar para encontrar clases dentro de tus datos, pero es la pregunta, son esas las clases que realmente te interesan? Estos son tres tipos comunes de aprendizaje automático. El aprendizaje automático tiene métodos muy diferentes para lograr estas predicciones esencialmente, cuando estás hablando de regresión y clasificación. Aprendizaje automático supervisado, puedes usar algo así como modelos lineales. Literalmente encajar una línea en sus datos. Puedes usar árboles de decisión los cuales son realmente poderosos y realmente interesantes, porque toman estas decisiones basadas en reglas de si esto es sobre eso, entonces ponlo en esta clase. Si esta característica está por debajo de eso, ponla en esa clase. Se han vuelto bastante populares porque son muy fáciles de usar y dan resultados realmente buenos. Las redes neuronales son otra clase en la que tienes estructura similar al cerebro de conexiones que esencialmente hacen operaciones
matemáticas en tus datos para luego predecir una clase. Por último, también tenemos algo llamado máquina de vectores de soporte, que básicamente intenta dividir tus datos en dos grupos, idealmente. Esas son estrategias realmente muy comunes, herramientas
muy comunes que utilizas en el aprendizaje automático. Un método muy común en el aprendizaje automático no supervisado es k-means, donde esencialmente estás encontrando la media de tus clústeres, pero el problema es que tienes que definir k Esencialmente tienes que
probar muchos números diferentes de clústeres que es k, y luego ver qué te da los mejores resultados. Por lo general un k inferior es mejor porque entonces encuentras cúmulos más grandes. Si aumenta su k a 100, por lo que encuentra como 100 clústeres, eso a menudo significa que encontrará subclústeres en clústeres más grandes y obtendrá menos de un resultado confiable. Otro método que personalmente me gusta mucho es T-sne. T-sne es proceso automático el cual puedes ver en segundo plano aquí, que esencialmente también intenta encontrar clústeres de tus datos. Es menos interpretable, pero es muy bueno para encontrar datos que pertenecen a otro y encontrar valores atípicos en ciertos datos. Realmente bueno para establecer relaciones y datos también. El elemento más importante en el aprendizaje automático es el proceso de capacitación. Tienes tus datos, tienes tus etiquetas y las pones y esperas que tu proceso de aprendizaje automático vaya a predecir los modelos correctos. Por lo general esto es iterativo. Tu modelo predice algo, ve si lo está haciendo bien. Esta es la supervisión y luego se ajusta el modelo. Este es el proceso de aprendizaje o el proceso de capacitación. Ambas palabras se utilizan para ajustar realmente el modelo para darte los resultados correctos. Esta es la parte interesante porque estos modelos son modelos matemáticos que no saben nada de física, nada de comportamiento de los clientes. Pero aprenden a establecer estas relaciones basadas en principios
matemáticos y realmente se ajustan al tipo de datos que tienes, que pueden ser muy diferentes. aprendizaje automático funciona en tantas tareas diferentes desde la publicidad en línea hasta la física hasta la biología, tan realmente versátil. No obstante, y esto es extremadamente importante
cuando entrenas o personas que empleas
entrenan estos modelos, tienen que mantener parte de tus datos separados porque siempre tienes que tener un caso de prueba, esencialmente, donde ves si tu modelo es en realidad trabajando en datos que el modelo nunca ha visto. Porque el modelo esencialmente puede memorizar sus datos más o menos. Estás tratando de evitar eso. Hay muchas cosas que haces como ingeniero de aprendizaje automático para evitar esto. Pero al final, lo que se mide, se maneja, y realmente hay que medir si tu modelo está trabajando en datos que nunca ha visto. Es por ello que generalmente mantenemos a un lado parte de nuestro conjunto de datos etiquetado porque entonces ya sabemos la respuesta en esos. Pero el modelo de aprendizaje automático nunca lo había visto antes. Un truco ordenado para validar nuestro modelo con este conjunto de pruebas de validación. Este fue un breve resumen de un aprendizaje automático. Ahora conoces los diferentes tipos de machine learning y un par de métodos que son poderosos en los que puedes echar un vistazo si te interesa. Sabes que tienes que hacer absolutamente validación de aprendizaje automático. No se puede simplemente entrenar a una modelo y decir, oh sí, la escuela de entrenamiento, y esto es realmente bueno. Siempre tienes que tener un conjunto de datos extra en el que puedas validar tus datos. Esto lleva perfectamente a la siguiente clase donde
vamos a echar un vistazo a cómo demostrar que te equivocas. Porque si queremos hacer ciencia de datos como ciencia, tenemos que asegurarnos de que nuestras ideas realmente aguanten al escrutinio.
9. Demostración equivocada: Por el momento echamos un vistazo a las herramientas de ciencia de datos, principios, métodos. Pero la ciencia de datos tiene mucho más, porque en la ciencia de datos básicamente tienes que pensar en el sistema en el que estás. Es muy involucrada mentalmente en cierto sentido. En esta clase y en esta conferencia vamos a echar un vistazo a demostrarte que te equivocas. La idea detrás de demostrarte que te equivocas, es esencialmente que todos vamos al análisis de datos con nuestros propios sesgos, y sobre todo si damos seguimiento al análisis exploratorio de datos, podríamos haber conseguido unas corazonadas sobre subconjuntos de los datos. Algunos de los participantes más exitosos en competencias Kaggle, ignora por completo los cuadernos EDA, por lo que otras personas compartiendo sus exploraciones porque no quieren ser sesgados en su enfoque para ver qué pueden contener los datos en tienda. Esencialmente en cada proyecto de ciencia de datos, tendrás que mantenerte a un estándar muy alto porque estás mirando verdades subyacentes, relaciones
subyacentes dentro de los datos. Eso no importa qué pregunta estés respondiendo, si estás haciendo una predicción o si incluso respondes preguntas mecanicistas, siempre
es, ¿hay una explicación diferente para esto? El primero que querrás hacer cuando intentes demostrarte mal, es aplicar la navaja de Occam. La navaja de Occam es la idea filosófica de eso, evidencia suele ser explicada por la idea más simple. Entonces cuando no estoy encontrando mis llaves por la mañana, probablemente las
he extraviado en algún lugar y probablemente estén en mi chaqueta. Es muy poco probable que sean extraterrestres. Esta es la idea de que intentas encontrar la explicación más simple en lugar de ir de lujo complejo, y esto también es algo en la ciencia de datos general, el aprendizaje automático, lo cual es una buena idea para tratar de construir el modelo más simple que satisfaga sus criterios. Porque el modelo más simple suele ser también el más simple de explicar. En este caso, los científicos de datos están en un poco de dilema, con los trabajadores del conocimiento, se
nos paga para ser inteligentes, por lo que tener una explicación compleja para estas cosas suele ser lo que vamos a buscar. Queremos encontrar las cosas súper interesantes y hay que tener mucho cuidado ahí, porque nos puede atraer esta inteligente explicación que nos hace sentir bien, pero que puede ser simplemente la explicación equivocada. Puede haber una mucho más sencilla que pueda explicar exactamente las mismas cosas. Ahí suele ser bueno echar un
vistazo a cuál es la explicación común para cosas como esta, lo que muchas veces los científicos de datos tienen que hablar con expertos en materia. Si eres un científico de datos que trabaja con economía, habla con tu economista, si eres científico de datos en el Gran Colisionador de Hadrones, habla con la gente de física. Por lo general tienen una corazonada, tienen una idea, y aún puedes desafiar eso si tus datos tienen la evidencia para ese reto. Pero muchas veces es realmente la explicación más simple, es la mejor explicación para tu problema. Lo siguiente que querrás hacer es echar un vistazo a las cosas que desacreditan tu teoría. Si tienes una hipótesis sobre tus datos y estás mirando, qué causa qué o qué está pasando dónde, volviendo al ejemplo desde el principio, si los precios más altos en un hotel causan más gente, entonces lo inverso puede ser cierto. Entonces si bajas tus precios, gente también debería mantenerse alejada. Con estos contraejemplos que puedes encontrar en tus datos. Deberías hacer un análisis esencialmente, si hay evidencia en tus datos que es prueba tu teoría, tienes que mejorar o tienes que actualizar tus creencias, tienes que cambiar tu hipótesis, porque estos puntos de datos, si son significativas, definitivamente demostrarán eso. Tu idea de fantasía, tu idea inicial a veces no ha sido del todo correcta, así que tienes que cavar más y realmente mirar los datos si hay algo que va en contra de lo que tenías en mente. Un ejemplo de mi trabajo en este momento es que tuvimos esta idea que tal vez lo que se llama migración forzada. Esencialmente la gente tiene que salir de sus hogares por las inundaciones, porque las inundaciones hacen que las tierras de cultivo se deterioren. Bueno, en nuestro análisis de datos, realidad
encontramos que había más tierras de cultivo floreciendo en la zona después de una inundación, porque de repente se puso mucho riego y todo estaba verde y floreciendo, así que tuvimos que actualizar nuestra idea inicial, nuestra creencia inicial, a una nueva hipótesis que en realidad podría, sí, había en línea con los datos. Esto realmente tienes que ser flexible y no estar casado con las ideas que tienes. Sé que puede ser muy difícil actualizar ciertas creencias, pero es totalmente necesario que los científicos de datos sean flexibles en ese entendimiento y escuchen a los expertos en materia, porque muchas veces tienen años de experiencia, trabajar en este campo, y se necesita evidencia muy fuerte para contrarrestar lo que están diciendo sobre el campo. Muchas veces, los investigadores
básicos son realmente buenos, mirando tus datos si hay contraejemplos en tus datos, y también viendo que tienes la explicación más simple, la más directa de lo que eres en realidad viendo en tus datos. Si lo piensas, yendo esto un paso más allá, yendo a tu análisis de datos con esta mente científica, pudiendo realmente cruzar comprobar
tus creencias que inicialmente formaste a partir de tu exploración de los datos realmente te hace un científico de
datos más fuerte y te convierte en un mejor científico de datos eventualmente, porque ahora eres capaz de cuestionar estas ideas que provienen de ti mismo y por lo tanto mitigar sesgos en tu propio análisis y tener un mucho argumento más fuerte también. Si estás comunicando estos resultados a los tomadores de decisiones, a los jefes, o escribiendo en papel, y puedes decir, bueno, reviso esto para contraejemplos, y estos fueron valores atípicos o estos se basaron en esta hipótesis que teníamos inicialmente, tenía
que actualizarse. Esto puede ser un rasgo extremadamente bueno y valioso en las personas, y va a mandar respeto en estos tomadores de decisiones, porque saben ahora que pueden confiar en ti y en ti realmente estar interesado en encontrar la respuesta y no solo propagando tu respuesta. En esta clase, sí echamos un vistazo a probarte mal y cómo
básicamente pensar fuera de la caja y cuestionar tus propias conclusiones a partir de los datos. En la siguiente clase se echará un vistazo a uno de mis favoritos de visualización de datos.
10. Visualización de datos: En esta conferencia, repasaremos la visualización de datos. La visualización de datos para mí es importante en dos aspectos. En primer lugar, una visualización puede brindarle una visión extremadamente buena de sus datos en la etapa de exploración. Correlaciones, me encanta cuando solo tienes una visualización en lugar de un número para el coeficiente de correlación. Porque entonces se pueden ver muchas correlaciones uno al lado del otro. Aparte de eso, cuando haces tus reportes y tus presentaciones, bueno, no lo dicen por nada y la imagen dice más de mil palabras. Realmente, visualización de datos, puedes empacar mucho más de
un punzón de comunicación de datos que cualquier
otra cosa y puedes hacer que estas visualizaciones sean interactivas. Si estás construyendo cuadros de mando, querrás estas visualizaciones, ponlo en un mapa si se trata de datos espaciales. Hacer una trama de dispersión. parcelas de dispersión son increíbles. Te dan tanta entrada y perspicacia en tus datos. Al igual que cómo van los puntos contra otros puntos. Si estás haciendo clustering, ¿cómo se agrupan estos puntos en el espacio 2D? Eventualmente, terminarás mejorando en la visualización de datos pero sí quieres seguir un par de reglas. lo general, con lo que debes tener cuidado es etiquetar tu eje. Por lo que siempre es bueno tener texto en el eje. Personalmente me gusta esto es la ruina de mi existencia. Agregando texto a visualizaciones, debería ser mejor al respecto. Por lo general, en revisión, siempre hay un, puedes por favor poner x en esta etiqueta y lo hará mucho más claro porque la gente puede echar un vistazo a tu visualización y ver directamente lo que está pasando sin leer el título, sin leer nada del texto, hacer eso. Nunca codificar datos en la transparencia. Porque es muy difícil ver la transparencia, sobre todo si está impresa o si tienes una gráfica de dispersión y tienes varios puntos unos sobre otros. Si la transparencia tiene significado en tu gráfica, entonces estás perdiendo ese significado superponiendo varios puntos de datos. Con el color, hay que tener mucho cuidado con
la daltonismo pero también cuando lo imprimes, mucha impresión científica es en blanco y negro porque color sigue siendo caro de imprimir por alguna razón. No me preguntes por qué. Pero sí, tener estos lo que se llama mapas de color perceptivos linealmente es realmente bueno y si estás usando Matplotlib y todas estas bibliotecas de Python, usan algo llamado veritas, que es el mapa de color. Veritas es linealmente perceptiva y perfecta para este tipo de cosas. Si estás haciendo tus visualizaciones en un software diferente, es muy posible que el estándar vaya a ser el arco iris o jet que se suele llamar. El arco iris no es una buena barra de color. Muchas veces, el verde es demasiado ancho, por lo que realmente pierdes parte de tu información de visualización en esos mapas de color y definitivamente no debes usarlos. Muchas veces la gente va a desafiar eso, sobre todo si estás hablando con profesores, científicos mayores, piensan que el arco iris es la barra de color estándar y deberías estar usando eso y
hay investigación sobre desafiar estos pensamientos porque es más accesible. Estás siendo genial con las personas con discapacidad y no te cuesta nada y al final, son mejores barras de color porque el cambio de un tono a otro que percibes como humano es el mismo para todos, y es lo mismo entre cada sombra. En el arco iris, la diferencia entre rojo y azul es muy diferente que verde y rojo, algo así, solo por asignaciones
arbitrarias donde tus datos se asignan al color. Pero en Veritas, tienes una percepción lineal de dónde están tus datos. Por lo que en realidad entiendes intuitivamente cómo se ven tus datos y qué están haciendo tus datos. En este tipo de gráficos que estás creando siempre querrás
pensar en la persona que está mirando la trama. ¿ Cómo puede hacer que esta información sea lo más accesible posible? ¿ Pueden sentarse en una sala llena de gente y seguir una presentación y entender lo que estás tratando de decir con la diapositiva que se va a ir en menos de un minuto. De verdad, echa un vistazo a lo que están haciendo otras personas. Hay blogs increíbles por ahí. Se puede echar un vistazo a los datos fluidos, por ejemplo, que está recogiendo muchas visualizaciones muy hermosas. También hay muchos recursos ahí fuera. Realmente asegúrate de revisar esos además de esta clase porque por supuesto, esta es una buena visión general, pero siempre hay más y siempre puedes ir este paso arriba y hacerlo un poco mejor. Agregar interactividad a tus datos cuando estás haciendo dashboards, por ejemplo, puede ser tan bueno. Cuando haces el mouse de tu gráfica de dispersión y en realidad puedes obtener información sobre cada punto simplemente apuntando a ellos, es tan bueno. Todo el mundo siempre está avivado cuando creo una visualización así. Esencialmente, la visualización de datos se trata de aprovechar al máximo sus datos y hacerlos realmente comprensibles en una sola imagen. En nuestra siguiente lección, vamos a echar un vistazo a la producción de ductos de datos. En serio, ¿cómo podemos hacer que nuestros hallazgos sean útiles en un negocio?
11. Operación de los productos de datos: Hasta el momento hemos estado hablando de uno de análisis para señales de datos. Esencialmente la idea de tener tus datos, uno de tener un conjunto de datos y luego hacer un buen análisis y una presentación sobre hacer visualizaciones en él. Pero en un negocio, muchas veces, dependes de tener ductos, operacionalizar tu análisis de datos, construir a la vez y luego poder reproducirlos una y otra vez. De esto se trata menos que esto. En un negocio, esto a menudo significa que tienes otra persona, como una operación de datos es muy similar a una persona de DevOps por lo que a menudo se usa
Data Ops o operaciones de aprendizaje automático de ML Ops, y eso significa que tu equipo ahora está creciendo hasta otra persona además del ingeniero de datos y los científicos de datos. Pero es extremadamente valioso pensar en esto y también saber sobre esto como científico de datos, porque aún tendrás que entregar tu análisis y tu código a esta persona de operaciones de datos y posiblemente también ayudar en la implementación de esto. Vamos a repasar operacionalizando su análisis de datos y en esta parte. Como se describe en el proceso de ciencia de datos, nuestro análisis de datos a menudo, o nuestro proceso de ciencia de datos,
a menudo consiste en obtener datos,
etiquetar datos, limpiar datos, explorar nuestros datos y luego modelar nuestros datos y haciendo predicciones o mirando la causalidad de los datos, dependiendo de la pregunta que intentes responder. En un negocio, a menudo obtienes nuevos datos continuamente, nuevos clientes se inscriben, nuevas cosas entrando. En el Gran Colisionador de Hadrones, tienes flujos de datos continuos un año haciendo experimentos. Realmente quieres automatizar este proceso. El ducto se trata de automatizarlo. En el proceso de limpieza, por ejemplo, se
quiere estar automatizando muchas de
estas funciones de escritura que se pueden aplicar a todo el conjunto de datos, no filtrar piezas individuales a mano. Desea asegurarse de que sus datos cumplan con un esquema porque su análisis de datos ahora se ajusta a un determinado tipo de conjunto de datos. Esencialmente tienes tus datos de clientes, por ejemplo, tal vez tengas sexo, tienes compras o última compra y luego tienes fecha en la que se inscribieron. Estas tres características son en las que se basa tu análisis de datos. Si obtienes nuevas características, entonces tienes que iniciar un nuevo análisis porque este análisis podría darte nuevos insights. Tu ducto tiene que validar que los nuevos datos que están llegando estén dentro del rango de tus parámetros esperados. Ya al tomar nuevos datos, quieres asegurarte de que tus datos se ajusten a lo que esperas. Haz cheques, haz pruebas, y puedes automatizar estas pruebas y tu persona de operaciones de datos probablemente te pueda ayudar con ello. Bonita biblioteca de Python para esto como Grandes Expectativas. Recientemente la gente ha estado amando esto y sí repasamos los esquemas en el curso de Python. Entonces tengo en la plataforma Skillshare también. Espero que lo compruebes más tarde si ya conoces algo de Python. Pero sin importar, saber de lo que tienes que hacer ya es genial. Porque si quieres gestionar un equipo de ciencia de datos, tienes que saber qué esencialmente quieres tener una vista de alto nivel. Entrar tus datos, asegurarte de que tus datos sean buenos, y luego asegurarte de que la mayoría de estos procesos, por lo que algunas de las visualizaciones que obtienes en tu panel de control en vivo, por ejemplo, deben generarse automáticamente de los datos. Todo esto es posible si
escribes tu código de una manera limpia que tienes todo y funciones
individuales que se pueden aplicar individualmente en cada paso de tu proceso de ciencia de datos. Aquí es realmente donde los científicos de datos senior
se distinguen de los científicos de datos junior. Escribes código más limpio y entenderás cómo poner cada pieza de código en una caja, en una función donde luego podrás usar esto para automatizar el proceso de hacer partes del análisis. Otra parte muy importante en este proceso de análisis, sobre todo si estás haciendo predicciones. Somos los datos del cliente que predice si alguien va a hacer una compra, si les muestras esto o si les muestras eso es echar un vistazo a los indicadores clave. Algo que se llama modelo churn o concepto deriva. Su modelo de aprendizaje automático se basa en datos históricos. Su análisis de ciencia de datos, todos los insights se negocian a partir de datos históricos. Si en este momento estábamos mirando al 2021, donde la mayor parte del mundo está encerrado. Estamos tomando insights de 2000-2010, que es una gran cantidad de datos, 10 años de datos serían increíbles. Pero nada de esto es aplicable en este momento. Aquí es donde todos nuestros modelos y todos nuestros insights realmente ya no son tan valiosos. Porque en este momento, todo esto se ve desafiado por cambios en los conceptos de cómo la gente vive realmente como la verdad, las relaciones subyacentes están cambiando
por completo porque la gente está comprando mucho más en línea. La gente tendrá que usar las llamadas con Zoom en línea y se han cambiado muchos comportamientos. La gente está trabajando desde casa. Este cambio es algo que perturbaría por completo todo su análisis de datos. Todo su análisis de datos que ustedes aliados de producción ya no sería cierto. Ahora la pandemia es obviamente un cambio catastrófico. Pero muchas veces tienes cambios a lo largo del tiempo en tus datos, en tus clientes, personas cambian, las tendencias cambian, sobre todo si eres una marca de ropa, por ejemplo, tienes estacionalidad ahí dentro. Nadie va a comprar un bonito Bikini en otoño. Bueno, unas cuantas personas, pero vas a tener mucha más gente comprando pantalones de
baño en primavera para prepararte para el verano. Tener este tipo de conceptos y este tipo de pruebas para,
para la consistencia en sus datos de entrada. Pero también en Indicadores Clave de Rendimiento, KPI en su salida, que sus datos siguen funcionando bien. Eso es muy importante. Siempre ten un bucle de retroalimentación en tu canalización de datos donde
compruebes es lo que estoy haciendo todavía automatizable, es el todavía válido o estoy recibiendo demasiadas predicciones equivocadas en este punto? Piensa realmente
en eso porque eso es extremadamente importante para mirar el proceso de ciencia de datos si estás automatizando esto. No es tan importante en un análisis puntual donde estás tratando de convencer a los tomadores de decisiones. Pero cuando estás automatizando estos procesos, que es mucho más importante en los negocios, y en estas operaciones a gran escala. Ahí realmente hay que pensar en la validación de datos. ¿ Estoy metiendo las cosas correctas? Validación de salida, concepto drift y churn modelo, donde realmente quieres mirar es lo que estoy dando salida también sigue vigente. A menudo puedes medir tus resultados a partir de la salida esperada. Estás viendo, estás prediciendo cuánto gastaría una persona. Entonces ves cuánto gasta esa persona. Muchas veces se puede ver básicamente con las pruebas AB, por ejemplo, si no he hecho nada, ¿eso cambiaría algo? Esto también va más hacia los aspectos de la causalidad. Lo que estoy haciendo, ¿esto realmente está teniendo un efecto, o posiblemente incluso está obstaculizando los resultados? Pensar en esto realmente te eleva por encima de los científicos de datos junior porque
vas a ser mucho más valioso para un negocio si puedes pensar en estas pruebas para realizar. Cuando estás gestionando un equipo de ciencia de datos, quieres estar seguro de comunicar que esto se espera en la automatización de los ductos. Si eres científico de datos, quieres asegurarte de que en estos proyectos que estás construyendo para conseguir un trabajo o en tu trabajo. También estás sugiriendo este tipo de cheques a la gerencia, a la persona de operaciones de datos porque es extremadamente importante. Una vez más, si tu lo consideras así, te estás demostrando como un valioso miembro de la empresa y del equipo. Esto sólo te ayudará en el futuro. Hablamos un poco de dashboards en esta parte. En la siguiente clase se echará un vistazo a algunos dashboards, y lo que quiero decir con dashboards en vivo y por qué quieres tener experiencia construyendo dashboards y por qué es tan divertido ser honesto.
12. Tablero de tablero: En esta conferencia, echaremos un vistazo a los dashboards. Los paneles se han vuelto realmente populares, porque te dan una visión general de un múltiples visualizaciones juntos, y realmente te hablan de los cambios y lo que está sucediendo en tu sistema en vivo, pero también con tus datos. Se puede tener una pestaña con vistas basadas en mapas y se puede tener una pestaña relaciones de trabajo o cambios de afluencia de datos. Puedes monitorear tus KPI, puedes monitorear el estado de tu sistema, en total dashboards son este dispositivo. En mi tiempo consultando, gente siempre preguntaba por dashboards, cómo crear dashboards, y se ha vuelto mucho más fácil. Si vas a buscar opciones de código bajo o no hay opciones de código, Tableau, Spotfire y Power BI te ofrecen opciones para crear paneles. Tendremos unos cuantos en pantalla aquí. Cuando vas a Python, hay unos cuantos jugadores en la cuadra, que es bastante nuevo, para ser honesto, también nuevo para mí, pero es tan emocionante como me encanta construir dashboards. Es muy interesante para mí. Pero sí, esencialmente, lo que puedes hacer eso es usar Plotly Dash, que es muy versátil e interactivo también, o puedes usar Streamlit, que incluso usa o puede usar salidas de aprendizaje automático. Tan realmente poderoso cuando se tiene conocimiento en Python. En los cuadros de mando, se quiere tener cuidado. Porque cuando veo cuadros de mando, tienden a estar sobrecargados un poco. Entonces en lo que quieres enfocarte es en primer lugar, cuando lo abres, la información más importante debe estar sobre el pliegue, sobre el pliegue. Esto suele ser algo de lo que se habla en diseño web, que se basa en los periódicos antiguos. Cuando salías a comprar un periódico, por encima del redil está el titular en el panorama general. Entonces realmente el captador de atención, las cosas más importantes que debes saber, y esto debe ser exactamente lo mismo en tu tablero. Primera página, en el primer marco que abres, tienen la información más importante que tienen que ver los tomadores de decisiones clave. Entonces cuando te desplazas hacia abajo tienes información relacionada con esto. Pero realmente la sobrecarga de información es un problema. Por lo general, lo que quieres hacer es ser minimalista sobre los datos y sobre la información que tienes en una página. Tienes toda la información necesaria para tomar una decisión. Pero mantener las barras de color en la misma forma. No lo sobrecargues y dale espacio de visualización, espacio para respirar. Porque si todo está abarrotado, eso normalmente solo da a todos como una sensación de abrumación. Haz un par de pases de cuánto puedes reducir la información. Siempre puedes abrir otra pestaña con otro tablero que tenga información diferente. Pero tu tablero de instrumentos realmente debería tener un enfoque. Debería responder una pregunta al igual que tu análisis de la ciencia de datos. Se puede utilizar como herramienta de comunicación. Debe responder a las preguntas clave para las que las personas abran su tablero de instrumentos. No debe arrojar toda la información. Entonces podrían hacer el análisis ellos mismos. Pero ustedes son los científicos de datos. Necesitas contar una historia con un tablero y realmente cincelar lo es importante para que la gente vea que no puede hacer el análisis de datos, pero ese para saber lo que está pasando en el sistema de datos en este proceso, en este proyecto. Pero obviamente, en los cuadros de mando, puedes usar visualizaciones interactivas, lo cual es muy divertido. Por lo general, la gente ama la interactividad. Por lo que poder seleccionar algunas cosas y como pasar el ratón por encima de la información y panear alrededor, esas son buenas decisiones. Si puedes hacer eso,
que la gente pueda acercar tus datos, en tus visualizaciones en lugar de solo tener como una imagen estática, esa suele ser una decisión realmente buena. Acercar mapas, por ejemplo, es algo a lo que todo el mundo está acostumbrado en estos días debido a Google Maps. Asegúrese de que cuando haga estos paneles que
tenga un diseño intuitivo, integre en él. Cuando ves tu tablero, se
siente casi indistinguible a lo profesional, que eres, estaría sirviendo. Entonces, ¿esto parece que un podría ser diseñado por Apple esencialmente? ¿ Es este buen diseño? Entonces, sí, concéntrate en el minimalismo. Sólo mostrar la información relevante para tomar decisiones fáciles y no abrumar a la gente. Por supuesto, a veces la gente tiene opiniones diferentes. Si tu líder clave de decisión quiere más información en el tablero, tú por supuesto, tienes que seguir esto. Tienes que darles la información que necesitan. A veces hay que iterar sobre dashboards también con las personas que realmente los usan y ser flexibles al respecto. No siempre se sabe qué líderes clave en la toma de decisiones, sino también expertos en la materia realmente necesitan. Por lo que es realmente bueno obtener retroalimentación. Pero con estas herramientas modernas, también
es realmente fácil construir estos dashboards. Por lo que agregar otra visualización o tomar esa virtualización, guardarla en una pestaña diferente es mucho más fácil que antes. No es tanto trabajo. Pero sí, los dashboards son un punto realmente bueno para saltarse el perfeccionismo y más bien confiar en la
retroalimentación de las personas que van a usar tus dashboards. La disciplina maestra claramente está construyendo cuadros de mando en vivo. Tener estos dashboards enganchados a estos ductos de datos operativos, tener insights en vivo en tus datos, actualización en
vivo, y esto también es bastante posible, pero es un poco más difícil como tiene que ser
al final de todo este ducto de ciencia de datos. Probablemente querrás hacer eso en conjunto, con todo tu equipo de ciencia de datos y con una gente de data ops. dashboards son fantástica herramienta de visualización y una herramienta fantástica para la comunicación porque dan a la gente espacio para respirar para tomar la historia que estás tratando de contar. En la siguiente clase, vamos a echar un vistazo a qué otras herramientas de comunicación en total puedes usar para contar tu historia de la ciencia de datos, para transmitir realmente tus ideas a los tomadores de decisiones.
13. Comunicar resultados de forma eficaz: El resultado final de tu proceso de ciencia de datos suele ser la comunicación. Con tus ideas, normalmente quieres mostrarle a alguien; a menudo expertos en materia o líderes
clave de decisión para tomar una decisión basada en lo que encontraste. Cambiar opiniones, realmente contar una historia, convencer y la comunicación es clave en estos aspectos. En esta clase, vamos a echar un vistazo a la comunicación, y cómo puedes comunicar tus resultados de manera efectiva. Porque muchas herramientas en estos días parecen facilitarlo, pero si vas al menos un paso más allá puedes comunicar los resultados aún mejor. El clave detrás de toda comunicación es conocer a tu público. Muchos científicos de datos más recientes a menudo toman el Cuaderno de Júpiter, que es una forma de mezclar código, y texto, y convertirlos en PDF. En cierto sentido, esto es problemático porque un líder empresarial, por ejemplo, no tiene tiempo para mirar tu código. Francamente, no obtienen ningún beneficio al mirar tu código. Estos Cuadernos Júpiter deben utilizarse para la comunicación con otros científicos de datos. Con los codificadores, por lo que realmente tienes la documentación para tu código también. Pero cuando hablas con personas que están más en los sectores gerenciales, no
quieres mostrarles código a menos que lo pidan. Se desea poder visualizar de manera efectiva. Volviendo a la clase sobre visualización, realmente
quieres contar la historia con imágenes les
muestren los datos de la manera que les facilita la decisión. Al final, convencer a alguien siempre es hacer una decisión más fácil para
ellos porque ahora tienen certeza porque están respaldados por datos. Respaldado por matemáticas, estadísticas, machine learning, su trabajo en analítica. Al final, de esto se trata también la ciencia. Como científico, escribir en papel es todo sobre convencer a mis compañeros de que he encontrado algo nuevo,
algo que es mejor que antes, una nueva perspicacia. Convencerlos significa realmente hablar su idioma, así que hay que conformarse al contorno recto de un papel. Agregar buenas visualizaciones y las ecuaciones correctas en los puntos correctos es muy importante, pero la mayoría de ellas no quieren ver el código. Esto está cambiando de alguna manera al menos. En el periódico, la mayoría de la gente te pedirá que elimines el código. Bueno, creo que hagas presentable tu código, y me gusta ponerlo en un apéndice o en algún lugar. La mayoría de la gente no quiere mirar el código porque a la mayoría de la gente le gusta tener una decisión más fácil simplemente siguiendo su comunicación. Así que concéntrate en visualizaciones, concéntrate en contar una historia y reduce la cantidad de código que muestras a las personas a menos que sea apropiado. De esa manera, también puedes realmente seguir adelante y sumergirte en los medios que estás usando. Entonces no sólo se convierte en el público donde piensas en el objetivo, piensa en el propósito sino también en el medio. Las visualizaciones interactivas son geniales, pero no funcionan en PDF. Por lo que realmente ten cuidado de cómo comunicas estos resultados. Si vas a enviar un PDF a alguien, no
tienes que tomarte tiempo para construir un dashboard porque va a ser un PDF. Tómese tiempo para construir visualizaciones independientes de
alta calidad que hablen por sí mismas que pueda integrar en su documentación PDF. Si estás haciendo una presentación de PowerPoint asegúrate de que tus datos, tus visualizaciones sean claramente visibles y delineadas y visibles en pantallas pequeñas desde la parte trasera de una sala de conferencias mal iluminada. Con hoy, con todas estas cosas pasando donde tenemos muchas más videoconferencias, piensa en cómo puedes compartir tus insights en vivo. ¿ Se puede dar acceso a las personas al tablero para que puedan probarlo? Si bien estás dando tu presentación, ¿pueden seguir ellos mismos algunos de los análisis? Piensa realmente en cómo comunicas tus resultados, porque la comunicación es tu clave para convencer
realmente cuál es la historia que intentas contar. Como cientista de datos la comunicación, y por lo tanto la empatía es sumamente importante. Tienes todas estas increíbles herramientas que te pueden ayudar a comerciar en ciencia, y tienes tantas herramientas increíbles para realmente comunicar tus resultados, construir PDF,
construir presentaciones y PowerPoint, construir cuadros de mando, construir cuadernos de Júpiter para hablar y tutoriales, y hablar con compañeros científicos de datos. Pero al final, es muy importante que tengas en mente la comunicación. Si compartes tu análisis las personas ganarán de tus insights, y esta es la forma de tener realmente un proyecto completo y terminar el proceso de ciencia de datos. En la siguiente clase, vamos a echar un vistazo a entender el riesgo en la ciencia de
datos porque no todos los proyectos van a tener éxito.
14. Comprender el riesgo en los proyectos de ciencia de datos: Una parte importante del flujo de trabajo de gestión de la ciencia de datos es entender el riesgo. El perfil de riesgo de un proyecto de ciencia de datos es muy diferente al de un proyecto de software, por ejemplo. Si sabes que algo es factible con una computadora, solo toma tiempo y gestión terminar ese proyecto. En un proyecto de ciencia de datos
, puede tener resultados negativos. Al final, es un proceso científico, viendo si podemos incluso contestar una pregunta dados los datos que tenemos, y puede que no sea posible. Están las cosas éticas de las que hablé, como tal vez encontramos que responder a esta pregunta en realidad no es beneficioso para nuestro negocio, para nuestra pregunta. A lo mejor es dañino activamente para las comunidades, pero también en un sentido
mucho más alegre puede ser que nuestro modelo no esté funcionando bien. Que podemos limpiar los datos, que no tenemos suficientes datos, y todas estas cosas tienes que manejar. Gestionar el riesgo significa que tenemos que estar en una mentalidad ágil al final. Todo tiene que ser iterativo. Es muy bueno tener destacamentos diarios que son muy cortos ya que estás haciendo la metodología ágil. Se desea identificar bloques en su equipo de manera temprana. Se quiere comunicar de manera regular. No microadministres, pero es importante empoderar a tu equipo para que también diga: “Oye, esto no está funcionando. Necesitamos más datos, necesitamos datos diferentes, tal vez necesitamos reformular nuestra pregunta porque la visión que encontramos de esto en realidad no está funcionando”. Cuando vas de un puesto junior a un puesto más alto con más responsabilidades, es importante liderar a tu equipo pero también ser consciente de que el fracaso es completamente posible. Cuando te estás comunicando con los interesados y los tomadores de decisiones, es importante también dejar claro que el fracaso es una posibilidad, que estas cosas son exploratorias, y dependiendo de dónde esté tu proyecto. Proyectos tempranos que hacen la primera exploración, que hacen la primera base, son mucho más propensos a fallar en la etapa que no
son factibles en absoluto mientras que proyectos posteriores, hay
que ser mucho más cuidadoso sobre el análisis del producto de sus ductos. ¿ Sigue funcionando? ¿ Va hacia adelante? Especialmente si estás en equipos más jóvenes, en equipos que apenas se están estableciendo, ten cuidado con comunicar certeza e incertidumbre porque algunas cosas simplemente no funcionan. No obstante, estas fallas también pueden ser insights. Aquí es donde realmente quieres volver a la comunicación también porque poder decir que
esta decisión no es posible en base a estos datos es algo valioso que también puedes vender como resultado. Pero hay que dejarlo abierto. Cuando te comunicas con la gerencia y prometes éxito, estás cerrando la tormenta que esencialmente puedes enmarcar esto como una visión adicional porque entonces esta visión adicional se convierte en una falla automática. No obstante, si se puede comunicar de antemano que el fracaso es una posibilidad, que hay problemas que no se pueden resolver, que a veces los datos no son suficientes, o hay problemas de tiempo, cosas así. Que
a veces no puedes cumplir con los indicadores de desempeño y que hay que actualizar iterativamente, esto es algo con lo que hay que tener cuidado. Cuando eres bueno en comunicar esto de antemano y gestionar este riesgo, estás preparando a tu equipo para el éxito. Porque independientemente de lo que hagan, si están haciendo su trabajo y están empoderados para también entregar resultados negativos, esto es construir un equipo fuerte y el equipo que
eventualmente está construyendo productos increíbles y es introducir y mantener resultados basados en datos en un negocio y hará que un negocio sea más fuerte y te elevará a ti y al equipo en total. Al final, hay que entender como un científico de datos en crecimiento o como alguien que potencialmente está entrando en un rol gerencial, que hay que tener cuidado con lo que comunicas y lo que prometes. Pero al empoderar, al ser un buen líder para el equipo que está trabajando iterativamente y realmente dando a la gente su espacio y las herramientas necesarias, puedes hacer de este equipo un éxito y gestionar realmente el riesgo de proyectos de ciencia de datos que son muy diferentes a los proyectos normales. Este es el capítulo final. La siguiente clase va a estar concluyendo esta clase de Skillshare y estoy muy contenta de que la asistan.
15. Conclusión: Enhorabuena por haberlo hecho. Sé que esto ha sido mucha información y para muchos de ustedes pudo haber sido información completamente nueva. Pero espero poder mostrarles cómo estos
insights impulsados por datos y este proceso de una mente científica que va desde
los datos crudos hasta la comunicación de resultados hasta los líderes
clave de decisión es un punto tan valioso e interesante. Simplemente me deja esperar que vayas en este viaje y explores esto en oportunidades de código bajo o código. Hay tantas maneras diferentes de abordar esto. Estoy muy contenta de que tomaras esta clase y espero que hayas sacado algo de ella. Por favor considere mi otra clase. Doy una clase para personas que ya conocen algo de Python y quieren aprender el proceso de ciencia de datos aquí en Skillshare. Pero definitivamente explora todos los demás cursos también. Aquí hay algunos increíbles cursos de visualización de ciencia de datos. Es realmente fantástico
profundizar en esta comunidad de toma de decisiones impulsada por los datos también. Asegúrate de encontrar gente en LinkedIn, sigue las influencias en diferentes redes sociales y aprende más sobre la ciencia de
datos porque salen tantas cosas interesantes y fascinantes. Cuando sigas mirando datos, estarás mucho más seguro en tus decisiones porque estas decisiones están realmente basadas. Gracias por asistir. Estoy tan agradecido de que estuvieras aquí. Espero que hayas disfrutado de esta clase. Por favor, asegúrate de probar el proyecto y publicar el proyecto. Estaré muy contenta de ver lo que se te ocurre.
 Jesper Dramsch, PhD, Scientist for Machine Learning
Jesper Dramsch, PhD, Scientist for Machine Learning