Transcripciones
1. Introducción: Probablemente hayas escuchado el bombo que rodea la ciencia de datos, las conferencias, las pláticas, las grandes visiones de 10 años y promesas de una década glamorosa. Esta clase es diferente. Es concreto, es inmediato. Yo quiero mostrarte cómo los datos pueden ayudarte hoy, mañana, próxima semana, cómo puedes contar historias con datos. Hola, soy Allan. Soy científico de datos en pequeña startup y estudiante de doctorado en Ciencias de la Computación en la UC Berkeley. Presencial, he impartido clases a más de 5,000 estudiantes, y fuera del campus, he recibido más de 50 críticas de cinco estrellas por enseñar a la gente a codificar para Airbnb. En esta clase, te enseñaré lo esencial del análisis de datos, en particular, te mostraré cómo aprovechar los datos de una manera específica. Cómo contar una historia con la visualización correcta. Si eres un profesional de negocios que busca habilidades
basadas en datos o un aspirante a científico de datos, esta clase es para ti. Si eres principiante a codificar, ten en cuenta que esta clase sí espera alguna familiaridad de codificación. Puedes recogerlos en tan solo una hora tomando mis clases de Coding 101 y SQL 101. Después de esta clase, podrás tomar decisiones empresariales basadas en datos. Haremos esto en tres pasos. En primer lugar, diseñar la recolección de datos, segundo, preprocesamiento de datos, y tercero, analizar los datos. Cada una de estas fases evolucionará en torno a un caso de estudio ficticio centrado en una aplicación llamada Potato time. Me emociona darte un poco de pensamiento de la ciencia de datos, una prueba de gusto para los diferentes pasos en el análisis de datos. En la siguiente lección, discutiremos tu caso práctico para el curso y estarás jugando con datos en poco tiempo.
2. Proyecto: prueba de página web A/B: Tu objetivo es contar una historia con datos para apoyar una decisión de negocio. En particular, tomar una decisión entre dos versiones de una página de aterrizaje de una empresa. No obstante, la decisión no es tan blanca y negra como se podría pensar. El sitio web en cuestión se llama Potato Time. En tanto que la aplicación es real, el estudio de caso no lo es. El reto es doble. Una, educar al público sobre por qué es útil un contador sincronizador. Dos, aumentar el número de apuntes. Tu proyecto es darle sentido a grandes volúmenes de datos, luego producir una serie de visualizaciones que ilustren tu razonamiento para una recomendación de negocio basada en datos final. Este proyecto utiliza un conjunto de datos sintético. No obstante, te obligará a darte cuenta de por qué las
reacciones de las rodillas pueden llevar a conclusiones defectuosas, por qué un análisis de nivel de superficie simplemente no servirá. En este proyecto se destacará la importancia de escoger las visualizaciones correctas. Hablaremos del análisis de datos en tres pasos: uno, recopilación de datos de
diseño, dos, datos de
preproceso, y tres, analizar datos. Todo lo que necesitarás es una cuenta de Google con acceso a Google Colab. Si tienes una cuenta de Gmail de trabajo puedes usar, eso es perfecto. De lo contrario, un Gmail personal se ve simplemente bien. A continuación te presentamos tres consejos. Punta número uno, para ganarse el lado de la precaución, siempre copia el código exacto que tengo. El código se pondrá a disposición en esta URL. Consejo número dos, pausa el video cuando sea necesario. Te explicaré cada línea de código que escribo. Pero si necesitas tiempo para escribir y probar código tú mismo, no dudes en pausar el video. Consejo número tres, aprenderás mejor haciendo. Te sugiero configurarte para el éxito colocando tus ventanas de Skillshare y Google Colab uno al lado del otro como se muestra aquí. Una nota final. El comida para llevar más importante son los pasos que atravesamos y el concepto que tocamos. Los nombres de las funciones son cosas que siempre se puede Google más adelante. No me preocuparía por esos. Ahora, empecemos y sumérjase directamente en el código.
3. Repaso de Python: En esta lección, trabajarás a través de un rápido refresco de Python. Este actualizador cubrirá la sintaxis de Python para varios conceptos. Estos son los conceptos que estaremos revisando. No te preocupes si no recuerdas lo que
significan todos estos términos, simplemente deberían parecer familiares. Si en algún momento te quedas atascado, asegúrate de referirte
al curso original de Coding 101 o haz una pregunta en la sección de discusión. Adelante y navega a colab.research.google.com. Entonces debes ser recibido con una pantalla como ésta. Adelante y haz click en “Nuevo cuaderno” en la parte inferior derecha. Antes de empezar, permítanme explicar cuál es esta interfaz. Este tipo de entorno de ejecución se denomina cuaderno. Un cuaderno contiene diferentes celdas como la que he hecho clic aquí mismo. Estamos usando un cuaderno porque es más sencillo ver visualizaciones como parcelas. Son tres tipos de datos que necesitaremos para este curso. El primer tipo de datos es un número. El segundo tipo de datos que necesitarás es una cadena. Una cadena, si recuerdas, es una pieza de texto. Siempre necesitarás cotizaciones para denotar un trozo de texto. El tercer tipo de datos se denomina booleano. Un booleano es sólo un valor verdadero o falso. Existen varias formas de operar en estos tipos de datos. Aquí hay una expresión de este tipo. Tienes dos números y operación de adición. Como cabría esperar, una vez que Python evalúe esta expresión, la expresión tendrá el valor 7. Aquí hay otra expresión. Como cabría esperar, una vez que Python evalúe esta expresión, la expresión se hará realidad. Discutamos variables. Aquí, asignamos la variable x al valor cinco. Recuerda desde antes, escribimos 5 más 2. Sabemos que Python evaluará esta expresión para obtener siete. Esta vez, digamos que x es igual a 5, entonces
podemos reemplazar cinco por x Al
igual que antes, esta expresión evaluará a siete. Sigamos adelante y escribamos algún código. En primer lugar son los tipos de datos. Aquí hay un número, tipo en cinco. Una vez que pulsa Command Enter o Control Enter en un Windows, Python lee, evalúa y devuelve el resultado de esta expresión. Vamos a seguir adelante y hacer lo mismo por una cuerda. Recuerda tus cotizaciones, escribe el texto que
quieras y pulsa Command Enter o Control Enter. Por último, tecleemos un booleano. Ejecuta la celda, y ahí está tu salida. Segundo, escribamos una operación. Adelante y teclee en 5 más 2. Los espacios son opcionales. Una vez que pulsas Command Enter o Control Enter, Python de nuevo, lee, evalúa y devuelve el resultado de esta expresión. En este caso, esta expresión se evalúa para convertirse en siete, como cabría esperar. Ahora, tecleemos en 5 mayores que 2. Esto, como es de esperar, devuelve el verdadero booleano. En tercer lugar, sigamos adelante y definamos una variable x es igual a 5. Nuevamente, los espacios son opcionales. Ejecuta la celda y puedes ver que no hay salida. No obstante, podemos generar el contenido de la variable x escribiendo en x, Command Enter. Vamos a seguir adelante y utilizar esta variable. Escriba x más 2, y esto, como cabría esperar, nos da 7. A modo de refresco, una de las dos colecciones que introdujimos en Coding 101 fue una lista. Siempre usamos corchetes, uno para iniciar la lista y otro para finalizar la lista. También utilizamos comas para separar cada elemento de la lista. En este caso, nuestros artículos son números. A medida que refresca, un diccionario, la segunda colección que cubrimos en Coding 101, mapea claves de valores. Piénsalo como tu diccionario en casa que mapea palabras a definiciones. Siempre usamos llaves, una para iniciar el diccionario y otra para terminar el diccionario. También utilizamos dos puntos para separar la clave del valor. Aquí, la clave es una cadena denotada usando morado. Aquí, el valor es un número denotado usando rosa. El diccionario mapea la clave “jane” al valor tres. Utilizamos comas para separar las entradas en el diccionario. También podemos asignar una variable a este diccionario. En este caso, el nombre de la variable es nombre a cookies. A continuación, aquí te mostramos cómo obtener datos de un diccionario. Todo lo que necesitamos es la clave que nos interesa. En este caso, queremos el número de cookies de jane, por lo que necesitaríamos la clave “jane”. Utilizamos corchetes y la clave para obtener el artículo. Este código devolverá el número al que corresponde jane, que es tres. Observe aquí la notación corchetes, donde los corchetes se denotan en negro. De vuelta dentro de tu cuaderno, lo primero que vamos a hacer es definir una lista de números. Nuevamente, necesitamos corchetes, y los números o el contenido de la lista, y comas para separar cada elemento individual. Adelante y corre el celular. Adelante y hagamos lo mismo para un diccionario. Vamos a usar llaves para denotar inicio y fin de un diccionario. Entonces nuestras claves van a ser una cadena y nuestros valores van a ser números, agregue una coma para separar cada entrada en el diccionario. Ahora, sigamos adelante y definamos una variable que sea igual a este diccionario. Aquí tendremos nombre a las galletas es igual a “jane” de tres y “john” de dos. Ejecutar la celda una vez más. Nuevamente, porque hemos definido una variable, no
hay salida. Sigamos adelante y ahora emprendamos el contenido de esta variable. Ejecuta la celda y ahí están los contenidos de la variable. Adelante y acceda al valor de la clave “jane”. Por lo que nombra a las galletas de “jane”. Revisaremos funciones y métodos. Cubriremos ambos conceptos antes de ejecutar más código. Piensa en las funciones que aprendiste en clase de matemáticas desde la primaria. Las funciones aceptan algún valor de entrada y devuelven algún valor. Por ejemplo, considere la función absoluta, tome un número y devuelva la versión positiva de ese número. ¿ Cómo uso una función? Considera nuevamente la función de valor absoluto. En Python, el nombre de la función es solo abs. Utilice paréntesis para llamar a la función. Llamar a la función significa que ejecutamos la función. Entre los paréntesis, agregue cualquier entrada que necesite la función. Esta función de valor absoluto toma en una entrada. También nos referimos a la entrada como un argumento de entrada o simplemente el argumento. Cada uno de los tipos de datos de los que hemos hablado hasta ahora: números, cadenas, funciones, estos son todos tipos de objetos. Un método es una función que pertenece a un objeto. En este ejemplo, vamos a dividir una cadena en un número de cadenas más pequeñas. En primer lugar, se necesita un objeto. Aquí tenemos un objeto string. A continuación, agrega un punto. Este punto significa que estamos a punto de acceder a un método para el objeto string. Añada el nombre del método. En este caso, el nombre se divide. El método dividido separará la cadena en muchas cadenas, y el resto de estas diapositivas se parecerá mucho a llamar a una función. Para llamar a este método, igual que llamarías a funciones, agrega paréntesis. Entre sus paréntesis, agregue un argumento de entrada. Aquí están todas las partes anotadas. De izquierda a derecha, necesitamos el objeto, un punto, el nombre del método, y los argumentos de entrada. Intentemos usar funciones y métodos ahora. Aquí, escriba abs, paréntesis, y escriba cinco. Adelante y ejecuta la celda, y encontrarás que calculamos el valor absoluto de cinco. Adelante y repita lo mismo, pero ahora para el negativo cinco, corre la celda y obtenemos cinco positivos como se esperaba. También podemos ejecutar funciones que requieren dos argumentos de entrada. Aquí podemos escribir en max y pasar en 2 coma 5, y eso devolverá el máximo de los dos números. En este caso, esperaríamos cinco. También podemos llamar al método split como cubrimos en las diapositivas. Adelante y escribe una lista de letras y escribe in.split paretesis, y luego pasaremos en otra cadena, que es por qué dividir la cadena. En este caso, queremos dividirnos en cada coma. Adelante y ejecuta la celda, y ya puedes ver ahora que hemos dividido la cadena con éxito en una serie de partes diferentes. Volver a las diapositivas para el último segmento de esta revisión. El último tema de este refresco es cómo definir una función. Como mencionamos antes, piense en funciones de su clase de matemáticas. En particular, considere la función cuadrada. Toma un número x, multiplica x consigo mismo, y devuelve el número cuadrado. Aquí, empezamos con def. Es así como se define una función. Después lo seguimos con el nombre de la función. En este caso, será cuadrado. Después agregamos paréntesis seguido de un colon. Entre los paréntesis, agregamos nuestro argumento de entrada. En este caso, nuestro cuadrado de funciones sólo toma en un argumento, que llamaremos x. A continuación, sumamos dos espacios, estos dos espacios son sumamente importantes. Estos espacios son como Python sabe que ahora estás agregando código a la función. Dado que esta función es simple, la primera y única línea de nuestra función es una declaración de retorno. El comunicado return detiene la función y devuelve cualquier expresión que venga a continuación. En este caso, la expresión es x veces misma. Aquí te dejamos todas las partes anotadas una vez más. Tenga en cuenta que todas las partes en negro son necesarias para definir cualquier función y siempre se necesita def, paréntesis, y un dos puntos para denotar que la función está iniciando. También necesita la declaración de retorno para devolver valores al programador que llama a su función. El nombre de la función, las entradas y las expresiones pueden cambiar todos. De vuelta dentro de tu cuaderno, adelante y teclea def paréntesis cuadradas x colon. Una vez que golpees Enter, Colab automáticamente agregará dos espacios para ti, así que sigue adelante y mantén estos espacios en y escribe a cambio x veces x. ejecuta tu celular, ahora llama a la función, cuadrado de cinco, ejecuta la celda, y podemos probar esto por un número diferente también, cuadrado de dos. Estos son los conceptos que hemos cubierto en esta lección. Si quieres acceder y descargar estas diapositivas, visita esta URL, aaalv.in/data101. Eso concluye nuestro refresco de Python. En la siguiente lección, diseñarás el experimento y determinarás qué datos recolectar.
4. Diseño experimental que prioriza la privacidad: En esta lección, discutiremos la recolección de datos, los principios detrás del diseño de un experimento. Al final de la lección, tendremos un conjunto de hipótesis y los datos que necesitaremos recolectar. Aquí está el orden de los temas para esta lección; filosofía, principios, estudio de caso, hipótesis, y datos. Empezamos primero con la filosofía de un diseño experimental y cómo eso guía los datos que recopilamos. La idea subyacente es primero la privacidad. La primera consecuencia es que debes recolectar lo que sea mínimamente necesario. Aquí te dejamos el principio número uno, recolecta solo lo que necesites. No recolectes datos solo porque puedes, recolecta solo lo que se necesita para probar la hipótesis. Por ejemplo, digamos que su hipótesis es que las páginas más lentas dan como resultado menos clics, entonces como es de esperar, solo
necesitamos recopilar el tiempo de carga de la página y la información de clic. Otra información que podrías pedir como ubicación no es necesaria. Principio número dos, informe en conjunto. Las estadísticas deben ser reportadas como parte de una multitud. Además, y posible, puede aleatorizar filas individuales de datos para que las identidades individuales estén protegidas mientras que las estadísticas agregadas siguen siendo las mismas. Estos principios rigen cómo y cuándo se recopilan datos. Echemos un vistazo a nuestro caso de estudio específico. Estudiaremos una aplicación real llamada PotaToTime. Esta aplicación sincroniza los calendarios de Google para que
el tiempo ocupado en un calendario se muestre como ocupado en todos los calendarios. En esta clase, consideraremos dos variantes de la página de aterrizaje. También tendremos dos hipótesis que nos ayudarán a escoger entre las dos páginas de aterrizaje. Este es el paso uno. Formamos la hipótesis. Hipótesis número uno es que los usuarios no ven la utilidad en nuestro sincronizador de calendario, en particular, los usuarios no saben por qué un sincronizador de calendario es útil, lo que tu video guiado a través en la página de inicio impulsará las inscritas para web página A. La hipótesis número dos es que los usuarios necesitan ser educados para la fijación de precios, por lo que los índices de precios claros impulsarán las inscritas, esta es la página web B. Ahora
podemos considerar los datos necesarios para probar cada hipótesis. Este es el paso número dos, diseñando cómo vamos a recolectar datos. Podemos considerar primero la página web A, el video, ¿cuáles son algunas piezas de información que necesitamos? Necesitamos la duración del reloj, el tiempo de carga de la página, información de
clics, y cuándo se vio el video. El siguiente es para la página web B, ¿qué información necesitamos? Necesitamos información de desplazamiento, por lo que cuánto tiempo pasó el usuario mirando cada parte de la página, información de
clic, y también cuándo se accedió a la página. Observe que no se necesita información personal para llevar a cabo ninguno de estos estudios, mientras que información como grupo de edad o ubicación puede descubrir ideas ocultas únicas. No hemos formulado una hipótesis ni una razón por la que cualquiera de estas jugaría un factor. Para los efectos de esta clase, solo
analizamos la información accedida anteriormente. Estos son los conceptos que cubrimos en esta lección. Para una recapitulación, nuestro diseño experimental implica recolectar cantidades mínimas de información. Suena genial filosóficamente, ¿qué pasa en la práctica? Bueno, en la práctica, recolectar o acceder justo a lo que necesitas es definitivamente útil, riesgo de sobrecargar información de lo contrario, y parálisis de decisiones. Si quieres acceder y descargar estas diapositivas, visita esta URL. En la siguiente lección, escribiremos algún código que lea y limpie datos, cómo configurar una página web,
cómo se accede a la página web y cómo almacenamos información sobre esa página web el acceso está más allá del alcance de esta clase, nos centraremos en el análisis de datos en secciones posteriores.
5. Reprocesamiento de datos en Pandas: En este paso, cargarás datos en Python usando una biblioteca llamada Pandas. Recordemos, una biblioteca es sólo una colección de código que alguien más ha escrito, que podemos usar. Dado que Pandas facilita la carga de datos, nos centraremos en trabajar con los datos cargados. Estos son los conceptos que cubriremos: discutiremos qué es un marco de datos de la biblioteca de Pandas, qué estadísticas podemos obtener de un marco de datos
y, por último, cómo limpiar tus datos. Comience accediendo a aaalv.in/data101/notebook. Usando el cuaderno vinculado, cargarás un conjunto de datos que contiene algunos datos de tráfico web sintéticos para que los utilicemos. Una vez que accedes a esa URL, entonces debes ser recibido con una página como esta. Adelante y haga clic en “Archivo” y luego guarde una copia en Drive, esto creará una copia que ya podrá modificar. En esta página, voy a dar click en esta “X” de aquí para cerrar la barra de navegación. Adelante y desplácese hacia abajo, y primero descargue un archivo que contenga el conjunto de datos. Para ello, ejecuta esta primera celda que contiene URL recuperar, selecciona la celda y pulsa “Command Enter” o si estás en Windows pulsa “Control Enter”. También puedes hacer clic en el botón de reproducción aquí. Una vez que este archivo se haya descargado, verás esta salida aquí mismo, views.pkl, y esta otra tontería. Esto significa que el archivo se ha descargado con éxito. A continuación, al igual que codificar 101, importar código que otros han escrito que podemos usar. Adelante y teclee en importación Pandas como pd. Esta biblioteca tiene una función llamada pepinillo de lectura, sigamos adelante y usemos eso ahora para leer el conjunto de datos, escriba pd.read pepinillo. Como vimos anteriormente, el nombre del archivo es views.pkl. Esta función lee el archivo pepinillo y devuelve el conjunto de datos como un marco de datos. Un marco de datos es cómo Pandas representa una tabla de datos. Piensa en un marco de datos como una hoja de cálculo de Excel o una tabla de base de datos. Asignemos el marco de datos de retorno a una variable llamada df. Esta variable es común para codificar usando marcos de datos. Veamos ahora cómo se ve este marco de datos, escriba df y ejecute la celda. Mira para ver la estructura de los datos, el número de filas, número de columnas, nota la primera columna está en audacia, esto se llama nuestro índice. Por algunas razones el índice o el creado en columna es muy eficiente para ordenar o agrupar por, lo
apalancaremos más adelante. La segunda columna, Page Load MS, este es el número de milisegundos que la Página Web tardó en cargar. Videos vistos S, es el número de segundos el video que el usuario vio. Producto S, es el número de segundos que los usuarios gastaron en la sección de productos de la página web. Precios S, es el número de segundos que el usuario pasó en la sección de precios de la página. Ha hecho clic es un booleano, true, si el usuario hizo clic en el botón de registro. La última columna, página web, es A o B, indicando qué página de aterrizaje vio el usuario. Dataframes ofrecen algunos métodos para computar estadísticas agregadas. Por ejemplo, podemos calcular el promedio de cada columna, seguir
adelante y escribir df.mean, agregar paréntesis para llamar al método. La mayoría de los valores promedio aquí se ven razonables, sin embargo, nota que ha hecho clic tiene un valor de 0.34, esto parece extraño porque arriba Ha hecho clic es una columna de valores verdaderos o falsos. ¿ Cómo se convierten en número los valores verdaderos o falsos? En resumen, Pandas consideró que cada cierto era uno y cada falso era un cero, luego tomó el promedio, como resultado, 0.34 significa que el 34 por ciento de los valores son ciertos. Ahora sigamos adelante y calculemos el valor mínimo por columna. Escribe df.min de nuevo con paréntesis, ejecuta la celda y aquí puedes ver los valores mínimos. Ahora que hemos cubierto algunas estadísticas básicas que ofrecen los marcos de datos,
veamos ahora qué ofrecen los marcos de datos para la limpieza de datos. Hay tres pasos comunes que tomar en la limpieza de sus datos. En primer lugar, querrás eliminar todos los duplicados, llamar al método drop duplicates en tu marco de datos, escribir duplicados df.drop underscore y agregar paréntesis para llamar a la función. Adelante y corre el celular. Un pequeño consejo, no tienes que memorizar este método per se, siempre
puedes google Pandas data frame drop duplicados. Lo más importante es que recuerdes los pasos en la limpieza de datos. Ahora, en la siguiente celda, vamos a llenar los valores faltantes, estos valores faltantes se representan como NAN o N-A-N, esto significa no un número. Posiblemente pueden ocurrir NAN o valores faltantes debido a errores en el código de recolección de datos. Aquí, podemos rellenar los valores que faltan con el valor promedio en cada columna. Recuerda desde arriba df.mean otra vez, ahora
debes escribir esto dentro de tu celda, escribir df.mean con paréntesis, esto calcula la media de cada columna. Aquí hay un nuevo método llamado fill NA que llena todos los valores de Nan con los valores proporcionados, escribe df.fillna y luego sigue adelante y pasa en df.mean como argumento. filLNA no modifica el marco de datos, simplemente crea un nuevo marco de datos con los valores introducidos. En consecuencia, necesitamos asignar la variable df al resultado, tipo en df es igual. Por último, ejecuta la celda. En tercer lugar, cordura comprobamos los datos. En este caso, sabemos que el video tiene sólo 60 segundos de duración así que veamos la cantidad máxima de tiempo que un usuario pasó viendo el video, asegurándonos de que solo sean 60 segundos. Para acceder a una columna de datos en un marco de datos, trate un marco de datos como un diccionario, clave en el nombre de la columna. En este caso, nuestro nombre de columna es Video Wated S, como vemos aquí, pero sigamos adelante y tecleemos el nombre de la columna escribiendo en df cuadrado video visto s y esto nos trae una columna de datos. No obstante, queremos obtener el valor máximo así que adelante y utilizar el método max so type in dot max. Adelante y ejecuta la celda y un número mucho mayor que 60 segundos, parece ser un error en nuestro código de recopilación de datos así que
recortemos todas las duraciones mayores a 60 segundos. En un marco de datos, al igual que con los diccionarios, podemos asignar valores. Adelante y teclee df y corchete cuadrado luego el nombre de nuestra nueva columna, que será Video Views S trunc para truncado. Esto crea una nueva columna llamada video visto S trunc una vez que lo asignas a un valor. Ahora calcularemos los valores de la nueva columna. En primer lugar, consigue la columna vieja, que es df Video Mirado S, igual que hicimos en la celda anterior. Ahora llame al clip de punto o al método de clip para recortar todos los valores. El primer argumento es el valor más bajo posible por lo que en este caso cero, no
queremos que ningún número de segundos vigilados sea menor a cero. Tampoco queremos que ningún número de segundos de vigilado sea mayor a 60. Esto asegura que no haya valores menores a cero o valores mayores a 60. Adelante y pulsa “Enter” para crear una nueva línea y teclear df. Esto ahora dará salida al Dataframe. Adelante y corre el celular. Observe la columna del extremo derecho incluye nuestra nueva columna de duraciones de relojes recortados y voila, que concluye nuestro pre-procesamiento inicial de datos en Pandas. Estos son conceptos que hemos cubierto en este curso. El para llevar es cómo limpiar tus datos. Pasos típicos que incluyen el llenado de NAN, desduplicación de filas y la comprobación de la cordura contra su comprensión de los datos. Por ejemplo, comprueba que los promedios, los valores
máximos y mínimos estén de acuerdo con tu entendimiento. Si quieres acceder y descargar estas diapositivas, visita esta URL. Asegúrate de guardar tu libreta pulsando Archivo Guardar. La próxima vez realizaremos algún análisis inicial de datos.
6. Analizar datos en Pandas: En esta lección, analizaremos el conjunto de datos sintético. Estos son los conceptos que cubriremos. Empezaremos con algunas estadísticas de resumen como totales por día. Entonces vamos a calcular correlaciones entre diferentes piezas de datos para entender dónde buscar patrones,
y para desarrollar alguna intuición. Por último, en este paso, sacaremos algunas conclusiones iniciales. Si has perdido tu libreta o si apenas estás empezando la clase desde esta lección, accede al cuaderno de inicio para la lección 6 desde aaalv.in/data101/notebook6. Una vez que accedas a esa URL, deberías ver una página como ésta. Adelante y haga clic en archivo, y guarde una copia en Drive. Voy a dar click en X en la parte superior izquierda para cerrar esa barra de navegación. Una vez que estés en esta página, en la parte superior, haz clic en tiempo de ejecución y selecciona ejecutar todo, espera a que se ejecuten todas las celdas. Se lo puede decir una vez que haya visto la salida de todas las celdas. Adelante y desde esta celda, empieza por computar varias estadísticas de resumen. Por ejemplo, compute cuántos días se extiende el conjunto de datos. Para acceder a las fechas en el marco de datos, utilice df.index. Adelante y teclee in.max para obtener la última fecha, luego restar la primera fecha usan.min. Ejecuta la celda, y aquí obtenemos un objeto de datos de tiempo de un 100 días. El segundo estadístico de resumen es el número de páginas vistas por día. Para esto, necesitaremos definir una función. En la función se contará el número de eventos que ocurrieron cada día. Comience definiendo el nombre de la función, eventos por día. Esta función aceptará un argumento llamado df. Agrega paréntesis, escribe df, y asegúrate de agregar dos puntos al final de esa línea. Adelante y golpea Enter. Una vez más, Colab agrega automáticamente dos espacios para nosotros. En primer lugar, el tipo en datetimes es igual al df.index. Este es el marco de datos, df. DF.index recupera las fechas horas para cada vista. A continuación, defina una nueva variable. Days es igual a datetimes y use.floor, agrega tus paréntesis para llamar a la función y luego pasar en una cadena de minúsculas d, .floor convierte datetimes en fechas. Tipo eventos por día es igual a días.value_count. value_count cuenta el número de veces que aparece cada fecha. Es decir, contamos el número de vistas por día. Devolver llamadas events_per_day.sort_index. Esto ordenará los conteos por día. No te preocupes, esta función parecía mucho. El más importante de la comida para llevar es no memorizar el código. Este código es perfectamente Googleable. Lo más importante es que A, se
puede leer el código y entender más o menos lo que está haciendo. Entonces B, que sepas para qué Google en el futuro. En este caso, para contar el número de vistas por día, contamos el número de filas por día en el marco de datos. Veamos qué devuelve nuestra función. Definir una nueva variable, views_per_day, establecer esta variable en el valor de retorno de nuestra función anterior. Recuerde, esta función toma en un argumento, que es el marco de datos de los datos. Salida de los contenidos de la variable. Corre la celda, y aquí obtenemos conteos de vistas por día. A continuación, defina otra función que filtra el marco de datos para contener sólo filas que dieron como resultado un clic. Comience definiendo el nombre de la función, get_click_events. Esta función aceptará un argumento llamado df o el marco de datos. De nuevo, no olvides tu colon al final de la línea. Hit Enter, Colab agrega dos espacios para ti y ahora escribe, selector es igual a df, corchete cuadrado, y el nombre de la columna que contiene la información de clics. Aquí, los clics es igual a df y escriba en selector. Ahora, adelante y devuelve la nueva variable que has definido, que es clics. Esto devuelve un marco de datos con sólo las filas que tienen true en el selector, y las filas que tienen true en este selector son las que dieron como resultado un clic. En consecuencia, esta función devuelve un marco de datos con sólo las filas que dieron como resultado un clic. Adelante y corre el celular. Ahora, usa esta función para obtener solo las filas con clics. Para encontrar clics es igual a obtener _ click_events y pasar en su marco de datos. Definir una variable, clicks_per_ day es igual a, y al igual que antes, vamos a contar el número de eventos por día. Por último, genera el contenido de la variable, y ejecuta la celda. Aquí podemos ver número de clics por día. Para ver solo los valores, utiliza el attribute.values. A diferencia de los métodos, no necesitas paréntesis para acceder a un atributo. Escriba clicks_per_day.values. Nuevamente, no se necesitan paréntesis para acceder a este atributo, .values. Adelante y corre la celda, y aquí obtenemos todos los valores. Ahora, necesitamos un chequeo de cordura. Aquí, queremos comprobar que el número de clics por día sea menor o igual al número de vistas por día. Vamos a entrar y comprobar que ahora escribiendo clicks_per_day.values es menor o igual a views_per_day.values. Adelante y corre esta celda. Ahora se puede ver que todos estos son ciertos. Parece que el cheque de cordura pasó. Buen trabajo. A continuación, vamos a calcular la correlación entre las características en nuestro conjunto de datos. Si recuerdas de tus estadísticas o clase de probabilidad, correlación te indica cómo cambia una entidad cuando cambia otra entidad. Digamos que tienes dos características, tiempo de carga de
página y duración de video visto. A medida que aumenta el tiempo de carga de
páginas, se espera que menos personas vean el video. Para comprobar y calcular la correlación, adelante y teclear df.corr. Agrega tus paréntesis para llamar a la función, y ejecuta la celda. Este método corr computará correlaciones entre todos los pares de características. Para una comprobación de cordura, asegúrate de que los coeficientes de correlación a continuación reflejen nuestra intuición. Esperamos que a medida que aumenta el tiempo de carga de la página, disminuya
la probabilidad de hacer clic. Podemos ver que en la primera columna, segunda a última fila, ha pasado la comprobación de cordura. Otra cosa interesante a destacar es que el tiempo dedicado a
mirar la sección de precios de la página web está muy, muy débilmente correlacionado con el clic. Se puede ver que la correlación entre la fijación de precios y el clic es de 0.10. Por otro lado, ver videos está, relativamente hablando, altamente correlacionado con el clic, con aproximadamente tres veces el valor. Al examinar solo las correlaciones, parece que la página web A, con el video, es más efectiva. Por último, vamos a calcular la tasa de clics o CTR para cada página de destino. Esto nos dice la relación entre clics y vistas. Nuestro objetivo final es recomendar una página de aterrizaje
que maximice la tasa de clics para el tiempo de papa. Comience por computar un selector. Antes, utilizamos has_clicked, que es una columna que ya contiene verdadero o falso para cada fila, lo que podemos escribir lo siguiente para comprobar si una fila es para la página web A o no. Df, corchete cuadrado, y seleccione la columna de la página web. Ahora queremos comprobar si esta columna es igual a A. Si ejecuto la celda, verás que toda la columna está llena de trues y falses. Perfecto. Ahora podemos usar esto para seleccionar filas en el marco de datos. Ahora, podemos usar este selector. Adelante y copia eso y abajo en la siguiente celda, escribe una nueva vista variable A es igual a df, corchete
cuadrado, y luego pega en el selector. Esto seleccionará todas las filas de tal manera que la página web de la columna sea igual a A. A continuación, repita esto para la página web B. Queremos obtener todas las vistas para B. Establezca esto igual al marco de datos, y nuevamente, con el mismo selector excepto para la página web B. Tipo en ViewSA “has_ clicked” .mean. Recordemos de lecciones anteriores que podemos llamar print para realmente generar este valor. Vamos a hacer lo mismo, pero ahora para ViewSB “ha hecho clic” .mean. Adelante y corre la celda, y esto parece darnos la conclusión contraria. Recuerda desde antes, mirando los valores de correlación, página web A se veía mejor. No obstante, esto muestra que la tasa de clic a través de la página web A 0.28 o 28 por ciento es mucho menor que la página web B's, que está alrededor del 40 por ciento. El porcentaje de clics sugiere que la página web B es mejor. Estas dos conclusiones iniciales parecen contradecirse entre sí, lo que significa que tendremos que profundizar más para averiguar por qué. Estos son los conceptos que hemos cubierto en esta lección, y aquí hay un consejo que hemos mencionado varias veces en esta lección, la cordura chequea a menudo. Los errores comunes incluyen un filtrado inadecuado, tipográficos en los nombres de las columnas o incluso nombres de columnas poco claros. Los controles de cordura te ayudan a identificar, aislar y abordar estos errores rápidamente. En algunos, aquí están nuestras conclusiones iniciales. Primero examinamos las correlaciones y encontramos que ver
videos y hacer clic están altamente correlacionados. También encontramos que la lectura de precios y el clic parecen débilmente correlacionados. Esto ajusta que el video o la página web A es más efectivo. No obstante, computamos la tasa de clics y encontramos que la página web B tiene una tasa de clics más alta. Nosotros cordura revisamos todos nuestros cálculos hasta el momento. Entonces, ¿por qué la discrepancia? Esto suena como una contradicción que tendremos que resolver. Si quieres acceder y descargar las diapositivas, visita esta URL. Asegúrate de guardar tu libreta pulsando archivo, guarda. La próxima vez, codificaremos algunas visualizaciones, resolveremos este misterio y prepararemos figuras para tu lanzamiento final.
7. Visualizar datos en Matplotlib: En este paso, visualizarás un conjunto de datos de tráfico web sintético que vimos en lecciones anteriores. Estos son los conceptos que cubriremos. Usaremos una biblioteca llamada matplotlib para trazar utilidades. Después hacemos algunas parcelas para explorar tendencias a lo largo del tiempo, también luego
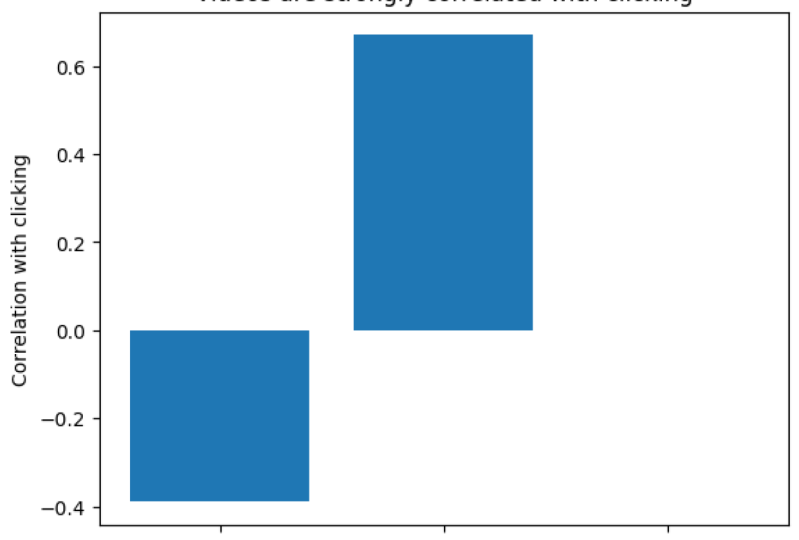
contaremos historias utilizando parcelas adecuadamente construidas. La elección de parcela será intencional para resaltar una comida para llevar que deseamos transmitir. Si has perdido tu último cuaderno o si estás empezando la clase a partir de esta lección, accede a un cuaderno de inicio para la lección 7 de aalv.in/data101/notebook7. Alternativamente, puedes usar tu propio cuaderno de la última lección. Una vez que accedas a esa URL, deberías ver una página como ésta. Adelante y haga clic en el Archivo y Guardar una copia y unidad. Esto creará entonces una nueva copia del cuaderno. En esta página, voy a dar click en X en la parte superior izquierda para cerrar la barra de navegación. Entonces, independientemente de si abres el nuevo cuaderno o si estás usando tu bloc de notas existente, haz clic en Tiempo de ejecución y Ejecutar todo. Adelante y luego desplácese hacia abajo hasta el muy inferior. Aquí vamos a empezar dando salida a las correlaciones que vimos antes. Adelante y teclee df.corr con dos rs, agrega tus paréntesis y ejecuta la celda. Observe dos cosas, la observación de video parece correlacionada con hacer clic. Tenemos video viendo y dando click aquí mismo en 0.32. El precio también parece estar débilmente correlacionado con hacer clic aquí tenemos 0.10. No obstante, el video sólo se puede ver en página web A y la sección de precios sólo se puede leer en la página web B. Como resultado, tiene más sentido calcular las correlaciones para cada página web por separado. Adelante y teclee en viewsa.corr. Aquí te dejamos las correlaciones para la página web A solamente, nota la correlación entre videos y hacer clic es mucho mayor en 0.67 de lo que pensábamos. A continuación, adelante y compute las correlaciones para solo la página web B escribiendo Viewsb.corr, y ahora ejecuta la celda. Estas son las correlaciones para la página web B. Observe que la correlación entre la sección de precios y el clic es muy baja. Es mucho menor de lo que pensábamos. De hecho, podemos decir que no están correlacionados en absoluto. Esto es lo suficientemente cercano a cero. Nuestro primer argumento para la página web A entonces es que los videos son altamente indicativos de si el usuario se
registrará o no y leer la sección de precios no lo es. Una correlación de 0.67 no tiene sentido por sí sola sin embargo, ¿es esta alta? ¿ Esto es lento? ¿Es esto razonable? No obstante, una correlación de 0.67 es definitivamente mucho mayor que una correlación de 0.0004. En consecuencia, podemos usar una gráfica de barras para enfatizar la diferencia entre ambos. Comience importando la utilidad de trazado matplotlib, escriba en importación matplotlib.pyplot como plt. Ahora, lo primero que vamos a hacer es llamar título
del método para darle un título a tu trama, escribe plt.title y puedes usar cualquier texto que quieras entre estas citas. No obstante, voy a escribir un título de videos están fuertemente correlacionados con el click. Sugiero altamente agregar la comida principal para llevar de su parcela en el título de la parcela. Ahora vamos a llamar a plt.bar. Esto creará una parcela de barras. El primer argumento para barra es una lista de cadenas, los nombres de cada barra. Aquí vamos a crear una lista y la cadena va a ser el título. Entonces diremos carga de página, diremos video viendo, y la última barra va a ser correlación con la lectura de la sección de precios. Bar también toma en una segunda lista. Vamos a pasar los números de nuestra tabla de correlación anterior. Por encima de nuestra tabla de correlación da una correlación de 0.39 negativo para carga de página y click. También es una correlación de 0.67 para ver videos y hacer clic. Por último, tenemos una correlación de 0.0004 entre leer la sección de precios y hacer clic. Por último, necesitamos una etiqueta para nuestro eje y. Entonces vamos a decir y etiqueta y correlación con click. Eso es todo. Este es el argumento número 1, que los videos están altamente correlacionados con los registros. Adelante y corre para crear tu primera trama. Esta es ahora tu parcela de bar. Para nuestro siguiente punto, necesitaremos explorar las estadísticas diarias como la tasa de clics a lo largo del tiempo. Para ello, necesitaremos escribir una nueva función para calcular las estadísticas diarias. Comience definiendo el nombre de la función, obtenga estadísticas diarias. Entonces def get_daily_stats, y vamos a aceptar un argumento df y como siempre, no
olvides tu colon. Esta función aceptará ese argumento llamado df o el DataFrame. A primera hora vamos a agrupar por día. Para ello, vamos a definir un mero, y esta es una nueva variable que es igual a pd.grouper, donde la frecuencia es igual a un día. Aquí, mayúscula D significa día. PD.grouper es una utilidad de panel genérica que nos
ayuda a agrupar filas en un DataFrame de acuerdo a alguna frecuencia. En este caso, nuestra frecuencia es diaria. A continuación, vamos a definir un nuevo grupo variable es igual a y luego vamos a llamar al DataFrame.GroupBy, mero. Es así como podemos calcular grupos de días. Por último, vamos a calcular estadísticas para cada grupo. Para ello, escribiremos en diario es igual a grupos.mean, para cada grupo, tomar el promedio de cada columna. Por último, devolver las estadísticas diarias. Una vez que hayas terminado con tu función, sigue
adelante y ejecuta tu función. Ahora vamos a utilizar esta función para obtener estadísticas diarias. Adelante y escribe vistas diarias A es igual para obtener estadísticas diarias, y escribe o pasa en todas las vistas para la página web A. Adelante y repite lo mismo para la segunda página web B. Escriba get_daily_stats y vistas de B. Para darte una idea de lo que contiene las vistas diarias A, vamos a dar salida a las vistas diarias A. Como es de esperar, si ejecutas la celda, obtendrás un DataFrame donde ahora tienes una fila por cada día y las estadísticas diarias para ese día. Al igual que el número promedio de segundos de video vistos, el tiempo promedio de carga de página, y el porcentaje de espectadores que hicieron clic. Ahora, exploraremos una parcela diferente, una parcela de línea. Adelante y teclee en plt.title para darle un título a tu nueva trama. En este caso, nuestro título de parcela va a ser tasas click-through a lo largo del tiempo. Afortunadamente, el matplotlib se integra bastante bien con los pandas. Todo lo que necesitamos hacer es decirle a matplotlib qué columna queremos trazar. Adelante y teclee en plt.plot y pasa en una de las columnas desde vistas diarias A, en este caso, se va a hacer clic en la columna. Ahora, normalmente podemos detenernos aquí. No obstante, queremos etiquetar cada una de las líneas en nuestra parcela de líneas. En este caso, sigue adelante y agrega una coma y escribe en etiqueta igual a A. Esta sintaxis, etiqueta igual a A no es algo que hayas visto antes. Esto se conoce como argumento de palabra clave. Nos saltaremos los detalles de un argumento de palabra clave por ahora, lo importante es que así es como etiquetas las líneas en una gráfica de líneas. Sigamos adelante y ahora repita lo mismo para la página web B. Escriba plt.plot Daily_viewsB, y seleccione la columna ha hecho clic. Por último, coma y etiqueta son iguales a B, y estas etiquetas son segunda línea como B. A continuación, agreguemos nuestra leyenda a la trama. Escriba en plt.plot leyenda llame a la función, y eso es todo. Ahora vamos a sumar dos líneas más para etiquetar nuestros ejes. Escriba plt.xlabel y el eje x van a ser las fechas, y el eje y va a ser la tasa click-through. Así que adelante y corre el celular y eso es una locura. Mira cuánto tasa de click-through para la página web A, la línea azul cae con el tiempo. ¿ Te pregunto qué pasó? Examinemos algunas otras estadísticas. Vamos a rehacer el mismo código, pero esta vez para los tiempos de carga de página, vamos a copiar y pegar el contenido de esta celda y luego reemplazar partes de ella que necesitarán ver los tiempos de carga de página. Adelante y copia y pega. Ahora vamos a reemplazar este título por tiempos de carga de página web. Entonces a continuación, vamos a reemplazar la columna has_clicked por la columna de carga de página para ambos. A continuación, esto cambia nuestro eje y, por lo que en lugar de hacer clic a través de la tasa en nuestro eje y, ahora
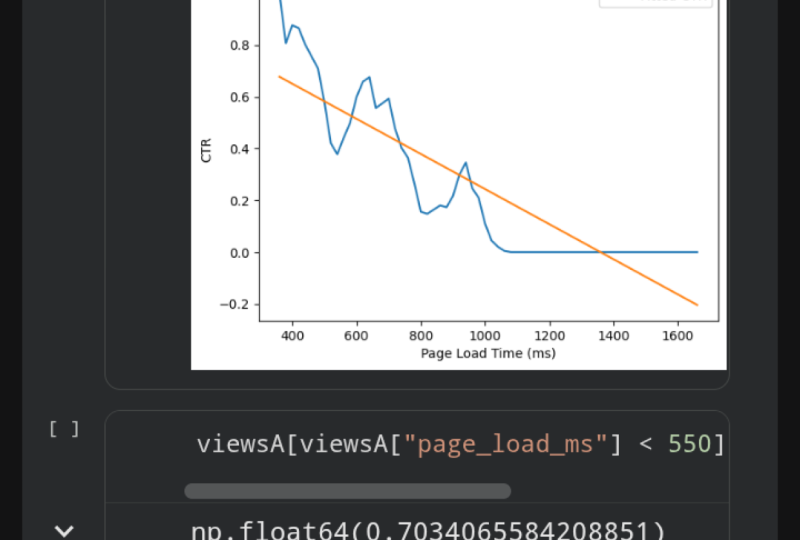
tenemos tiempos de carga de página. paréntesis, voy a sumar las unidades para este eje. Adelante y corre el celular y whoa, mira eso. Tiempo de página web, para página web A de azul dispara como loco. Entonces nuestro segundo argumento para la página web A es que tiempos
anormalmente lentos de carga de páginas parecen dañar involuntariamente su tasa de clic a través, lo que sugiere que hay un potencial incalculable para la página web A. Para cuantificar qué tan defectuosa la página web A en general click a través de tasa es, podemos cuantificar los tiempos de carga de página daño en clic a través de tasa. Para ello, primero trazamos la relación
entre las tasas de clic a través y los tiempos de carga pagados. Aquí, adelante y teclea vistas de A page_load_ds. Vamos a crear una columna totalmente nueva la cual contendrá tiempos de carga de
la página y sus tasas de clic a través de cada 20 milisegundos. Adelante y ahora escribe vistas de A page_load_ms. Vamos a dividir piso por 20. Entonces una división de piso significa que si tienes una fracción, redondea hacia abajo al siguiente entero. Una vez que tengas eso, sigamos adelante y multiplicémoslo otra vez por 20, y lo que esto básicamente significa es que todos tus valores están en incrementos de 20. Entonces antes, podrías haber tenido un valor de 34, pero ahora 34 piso dividido por 20 te dará 1, y luego multiplicarlo por 20 te dará 20. Cualquier valor entre 20 y 39 será igual a 20. Cualquier valor entre 40 hasta 59 se convertirá en 40, y así sucesivamente y así sucesivamente. Esto reparte eficazmente todos los tiempos de carga de nuestra página en grupos de 20 milisegundos. Ahora, vamos a seguir adelante y escribir en la carga de página es igual a viewsa.set_index. Por lo que éste ahora cambió el índice. En otras palabras, cambiará la columna por la que fácilmente podemos ordenar o agrupar. Adelante y teclea page_load_ds, que es nuestra nueva columna. Entonces vamos a calcular grupos para cada tiempo de carga de página binada. Tipo en carga de página es igual a viewsa.GroupBy page_load_ds. Asegúrese de tener estos corchetes aquí mismo. Eso es realmente importante para esta función. Esto calculará los grupos para cada tiempo de carga de página binada. Ahora para cada grupo, vamos a computar las estadísticas promedio. Así que adelante y escriba en carga de página es igual a page_load.mean, y eso calculará las estadísticas promedio para cada grupo. Por último, queremos ordenar todos los datos
por el tiempo de carga de la página binned llamando al índice de clasificación de puntos. Este DataFrame ahora te dice la tasa promedio de clics through para cada tiempo de carga de página. De nuevo, si estamos abrumados por esta función o por la célula, eso está completamente bien. Todo lo que necesitas recordar es el concepto general de lo que hemos hecho aquí. Lo que hicimos fue primero agrupar todos los valores en grupos de 20 milisegundos. Después calculamos estadísticas para cada uno de estos grupos. Estas dos cosas son perfectamente googleables. Entonces ahora, veamos cómo se ve este DataFrame. Escriba la carga de página y ejecute la celda. Aquí, ahora podemos ver las estadísticas de cada uno de estos cubos de 20 milisegundos. Ahora puedes hacer un trazado de líneas como antes de pasar por la columna DataFrame. En este caso, nos preocupamos por la tasa de clics through. Así que adelante y teclea plt.plot y page load has_clicked, y esto trazará el impacto de los tiempos de carga de página en la tasa de clics through. Adelante y golpea “Run”. Ahora, el eje x es el tiempo de carga de página en milisegundos, el eje y es la tasa de clics through. Como cabría esperar, haga clic a través de caídas de tasa a medida que aumenta el tiempo de carga de página A continuación, ajustemos una línea a esto para obtener un número aproximado rapidez con la que disminuye la tasa de clic a través a medida que aumentan los tiempos de carga de página. Adelante e importa otra biblioteca llamada NumPy. Esta biblioteca cuenta con un algoritmo de ajuste de línea que podemos usar. Adelante y teclea en m, b. En otras palabras, la pendiente y el sesgo de tu línea es igual a una función NumPy que en realidad encajará una línea para nosotros a un montón de puntos, llame a np.polyfit y pase en los valores x, que es todos los tiempos de carga de página. Entonces aquí tienes page_load.index, y el segundo argumento es el click through rate, que es la carga de página y luego has_clicked. El último argumento es el grado de un polinomio. En este caso, queremos líneas rectas. El polinomio del grado 1 es todo lo que necesitamos. Ahora, por fin podemos resumir la línea ajustada. Toma la pendiente. Recordemos que la pendiente es subida sobre corrida o alternativamente, el cambio en y sobre el cambio en x. Aquí, y es la tasa de clic a través y x es el tiempo de carga de la página. Por lo que la pendiente es el cambio en la tasa de clic a través por cambio en el tiempo de carga de página. Podemos multiplicar por 100 para obtener el cambio en
tasa de clic a través por 100 milisegundos de tiempo de carga de página. Escriba m veces 100 y siga adelante y ejecute la celda. Aquí, obtenemos negativo 0.068. Esto significa que cada 100 milisegundos más lento de carga de página cuesta siete por ciento de tráfico. Estamos haciendo algunas sobresimplificaciones bastante barridas aquí, pero esto transmite el punto de que los tiempos de carga de página
más lentos están perjudicando significativamente la tasa de clics a través de página web A. Acompañaría cualquier presentación que cita un número como éste con una trama que explicar. Hagamos una trama para que los espectadores puedan juzgar por sí mismos lo bien que esta línea encaja con los datos. En la siguiente celda, comenzaremos con un título, plt.title. En este caso, nuestro título va a ser cada 100 milisegundos de tiempo de carga de página cuesta siete por ciento de clic a través de tasa. Trazar la línea desde antes en la celda anterior una vez más. Aquí, la carga de página has_clicked y la etiqueta es la tasa de clic a través. Después traza la línea ajustada. Aquí llamamos page_load.index y recordamos, la ecuación para una línea es m veces x más b Así que aquí tendremos los m veces los valores x, solo page_load.index más b También
vamos a agregar una etiqueta aquí. El sello va a ser la tarifa de click through ajustada. Adelante y ahora agrega una etiqueta para tu eje x. Este va a ser el tiempo de carga de página en milisegundos y también vamos a etiquetar el eje y. Aquí te dejamos click through rate. Por último, agrega tu leyenda y ejecuta tu celular. Esto concluye nuestro segundo argumento. Ahora podemos ver que la tasa de clics está bajando mucho debido al aumento del tiempo de carga de página. A continuación, queremos entender para nuestro tercer argumento, ¿qué pasaría si la página web A no hubiera sido impactada por un tiempo de carga de página más lento, cuál creemos que habría sido la tasa de click-through de la página A? Observando la gráfica de arriba, más arriba, aquí mismo, notamos que los tiempos de carga de la página web A parecen caer dentro de 400-550 milisegundos antes de que parezca saltar. Como resultado, calcularemos la tasa de clics para la página web A usando solo esos datos,
por lo que vamos a seleccionar todas las vistas con tiempos de carga de página inferiores a 550 milisegundos. Adelante y teclee las vistas A y vamos a seleccionar todas estas columnas, todos los tiempos de carga de página que son menores a 550. Esto nos dará sólo las filas que tengan tiempo de carga de página menor a 550 milisegundos. Ahora, sigamos adelante y seleccionemos si se hizo clic o no en esa fila, y luego calculemos la tasa media de clics. Adelante y corre el celular. Esa es toda una tasa de click-through del 70 por ciento, bastante increíble. Para la comparación, calculemos la tasa de clics para la página web B. Seleccione la columna de clics y vuelva a computar la media. Corre la celda, y eso nos consigue apenas 40 por ciento de tasa de clics. En resumen, la página web A habría superado a la página B por un gran margen, en un 40 por ciento. No obstante, para transmitir realmente esta idea, necesitaremos de nuevo una trama de línea. En esta celda, utilizaremos las funciones que definimos anteriormente. A, obtén toda la información de clics para cada página web, luego B, calcularemos el número de clics por día para cada página web. Adelante y define una nueva variable, clickSa es igual a y luego obtener solo los eventos de click de todas las vistas de la página web A. Esto solo considera clics para la página web A. A continuación, vamos a calcular diariamente estadísticas. Entonces ClickSadaily es igual a y luego events_per_day y pasar en la variable que acabamos de definir, esto computa el número de clics por día para la página web A. Adelante y haz lo mismo para la página web B. clickSB es igual a todo el click para la página web B y luego calcular el número de clics por día para la página web B. Aquí, ClickSBDaily es igual a los events_per_day de ClickSB. Para ver cómo se ve ClickSadaily, adelante y escriba ese nombre de variable una vez más y ejecute la celda. Aquí obtenemos por cada día, el número de clics. Ahora, nuestra pieza final de código en esta última celda. En realidad vamos a trazar estos datos, tipo en plt.title para darle a esta trama un título, “Página web A Podría haber aumentado el CTR en un 30 por ciento”. Adelante y ahora traza los datos que acabamos de computar, el número de clics por día. Al igual que antes, vamos a etiquetar esta línea A. Repita lo mismo para B, lo que ClickSBDaily y etiqueta igual a B. A continuación, nuestra tercera línea para esta trama va a ser el número proyectado de clics para nuestra página web A. Vamos a multiplicar las vistas por día por 0.7, y luego vamos a multiplicar por 0.5 porque cada página web en realidad sólo obtuvo la mitad del tráfico. Entonces vamos a escribir en etiqueta igual a A proyectada, así estimado. Esto concluye nuestra línea. Ahora sigamos adelante y etiquetemos el eje, igual que siempre hacemos. Vamos a etiquetar la fecha, y luego vamos a etiquetar los clics, luego añadir la leyenda. Por último, eso concluye nuestra trama final, adelante y ejecútala. Podemos ver aquí en la línea verde que nuestros clics proyectados por día para la página A habrían sido locos, habría sido mucho más alto que la página web B. En conclusión, volvamos a las diapositivas. Cubrimos varios temas en esta lección: matplotlib, trama, y cómo contar una historia. En suma, aquí están nuestras conclusiones finales. Nuestras conclusiones iniciales habían sugerido que la página web B era mejor, afortunadamente, ahora hemos corregido ese error. En resumen, hemos producido tres cifras de calidad que respaldan nuestra decisión de negocio impulsada por datos. En suma, te recomendamos escoger página web A con el video informativo, hay tres razones. Ver video informativo está fuertemente correlacionado con cocinar el registro. Por el contrario, leer la sección de precios tiene una relación
cercana a cero en cuanto a si el usuario hace clic o no para registrarse. Empezando por la parte superior izquierda, entonces
mostramos que la tasa de click-through de la página web A bajó precipitadamente. En la parte inferior izquierda, mostramos que la tasa de clics bajada de la página web A ocurría al mismo tiempo los tiempos de carga de páginas de A aumentaron repentinamente. la derecha, entonces mostramos que el
aumento del tiempo de carga de páginas de la página A dio como resultado caídas drásticas en la tasa de clics. Esto sugiere que la tasa general de click-through de la página web A no se puede confiar. Por último, proyectamos qué página web la tasa de click-through de A habría sido a lo largo del experimento si los tiempos de carga de página no se hubieran disparado dos meses en el experimento. Podemos ver que la página web A habría
sostenido consistentemente una tasa de clics 30 por ciento más alta que la página web B, justificando nuestra recomendación final de la página web A. Eso concluye la recomendación empresarial impulsada por datos. Nuestro consejo final, conoce tus tipos de parcelas, la trama correcta puede contar una historia. Debes saber para cualquier punto que quieras enfatizar, qué trama es más adecuada para enfatizar ese punto. Siéntase libre de agregar anotaciones adicionales, cambiar colores o dar título a la trama apropiadamente para ayudar. Si quieres acceder y descargar estas diapositivas, visita esta URL. Intenta trazar tus propios datos para ver si hay insights ocultos. Si buscas el tipo de parcela perfecto, consulta ejemplos de Matplotlib. El objetivo no es hacer clic en ellos todos, pero tu objetivo es saber qué tramas te ayudarán a contar la historia correcta. A veces navegar por esa página puede darte la suficiente inspiración. Enhorabuena, con esto concluye su primer caso de estudio de una prueba AB para dos páginas web. A continuación, discutiremos los próximos pasos para que sigas aprendiendo más.
8. Conclusión: Enhorabuena por completar tus primeros pasos en el análisis de datos. Cubrimos una serie de temas; lectura, limpieza, análisis, y presentación de datos. También cubrió una serie de bibliotecas diferentes para el análisis de datos, incluyendo Matplotlib para trazar datos, y Pandas para realmente mantener datos. Ese es un conjunto de herramientas diverso bajo tu cinturón hoy. Este es el punchline, codificar con datos es una habilidad que cuando se hace de la manera correcta, puede contar historias convincentes. ¿Qué es más? Ahora tienes el inicio de esta habilidad. ¿Qué es más? Ahora tienes los fundamentos para contar historias convincentes, un conjunto de herramientas para comunicar datos complejos. Si tienes una mejor manera de visualizar este conjunto de datos o un conjunto de datos propio para visualizarlos, asegúrate de subir tus cifras en la pestaña de proyectos y recursos. Asegúrate de incluir tanto la figura una leyenda que describa lo que la figura está tratando de decirnos. Si deseas acceder a las diapositivas o al código completado, asegúrate de visitar esta URL. Si quieres aprender más sobre la ciencia de datos o el aprendizaje automático, asegúrate de revisar mi perfil de Skillshare con 101s y otros temas como visión por computadora. Gracias y felicitaciones una vez más por contar tu primera historia con datos. Hasta la próxima vez.
 Alvin Wan, Research Scientist
Alvin Wan, Research Scientist