Transcripciones
1. Introducción: Yo estoy ordenando en esta clase. Yo quiero hablar de finery, buscar codos relacionados. Este tipo de álbumes vienen mucho, y es tu con tu tiempo pasar unos minutos refrescando tus conocimientos. Conocer cómo funciona una búsqueda binaria te permite entender a otros albertanos basados en el mismo principio. Después de este curso, tendrás un buen recordatorio de cómo sucede esto, trabajar y estar un poco mejor preparado para realizarlos en una entrevista o en tu palabra Dele en las notas necesitan mostrar. Proporcionar un enlace el código fuente. Puedes usar esto para seguir respetando el álbum. A ver cómo implementaría eso. De acuerdo, empecemos.
2. Explicación de algoritmo: Echemos un vistazo a la investigación de Byner. Búsquedas binarias utilizadas para localizar algo en una especie de lista. Eso es un requisito. El listado tiene que ser ordenado en nuestra lista de ejemplos. Aquí tenemos letras, y son un orden alfabético cada vez mayor. Si la lista no es una especie de binario, búsqueda no funcionará. investigación de Beina recibe su nombre porque dividimos la lista a la mitad cada vez que hacemos un paso en la hora de ellos. Entonces veamos eso con el ejemplo. Busquemos la letra G en esta lista, así que queremos buscar la letra G. Esta lista es de 10 largos, así que vamos a empezar por el medio. Elemento. Medio va a ser toda la longitud dividida por dos. Digamos sólo cinco. Ya sea que esto sea arriba o abajo por uno no marcará una gran diferencia. Obtén el contorno. Lo que sigue dividiendo la lista por la mitad, y eventualmente encontrará algo. Entonces si iniciamos el quinto Índice que 012345 esto no es en siguiente de cinco. Vamos a empezar aquí. Esto parece que está en la otra mitad de la lista A. Eso está bien. Hay cinco en ambos lados. Anomalía visual otra vez. No importa si está apagado por uno en I igual a cinco. Tenemos una K, que no es G. La K es mayor que la G, sin embargo, así que eso nos dice algo porque la K es mayor que la G. Sabemos que la G no me puede derecho de ello. El G tiene que salir de ella si está ahí. Entonces la búsqueda binaria dice entonces, Bueno, echemos un vistazo a este primer tiempo. Entonces cuando una escisión esta primera mitad aquí y sólo veamos por este camino aquí, son cinco de largo. Vamos a empezar en medio de esto otra vez ahora cinco divididos por dos podrían ser 2.5 semanas alrededor. Un tres o dos no hace una gran diferencia. Nosotros también vamos por
ahí . Y ese 012 I igual a dos. ¿ Qué es, en este punto de aquí? No tenemos e en este punto, y la facilidad menos que el G. Así que de nuevo, esto nos dice algo. qué mitad de la lis restante está? No es la mano izquierda porque es mayor que G, así que se acabó a la derecha. Si está ahí, alguna investigación de compra envió, por lo que es estrecho. Nuestra búsqueda hasta aquí. Es demasiado largo y relativo a esta parte que queremos. El elemento uno está demasiado dividido por dos es uno más. Aquí vamos a mirar por aquí en I igual a cuatro y vamos a encontrar la letra G. Presta atención para más tarde. Cuántos pasos nos dio hacer eso Hicimos 123 Comparaciones. Hicimos tres comparaciones para encontrar el artículo que queríamos. Ahora busquemos la letra C. Sabemos que C no está en esta lista, pero veamos qué hace el algoritmo de ordenar binario en este caso otra vez, vamos a empezar en medio de lista por aquí en I igual a cinco. Que es más grande que ve, así que sabemos que tiene que estar en la mitad izquierda, así que va a ser sólo en esta media línea contra que sepamos dónde está, y vamos a empezar a mitad de esa mitad ahora. Vamos a señalar aquí ahora, y esto es todo. Índice es igual a dos. Esta no es la carta que buscamos es mayor que ver, Así que eso nos dice de nuevo, está en la mitad izquierda aquí. Entonces estrechamos nuestra búsqueda de nuevo aquí mismo y ahora ni siquiera tenemos lista más pequeña, y vamos a escoger dónde está el medio otra vez. El medio aquí junto a nuestro órgano iba a terminar empezando por aquí. Empieza en I igual a uno. Esta no es la carta que tenemos ahora. Es más grande que C, y esto es trabajo. Es un poco confuso ver que todavía tenemos dos lados a esto. A pesar de que las fronteras aquí a la derecha de D no es nada. En realidad hay una lista vacía aquí. No estamos mirando por ese lado a la izquierda de D. Sólo
tenemos que estar y sabemos que tenemos que mirar a la izquierda porque D es genial en el mar. Por lo que reducimos la búsqueda a sólo este criterio aquí y hacemos un paso más en I igual cero y no encontramos el mar. Ahora la estrella binaria en este punto dice:
Bueno, Bueno, ¿qué mitad está en su en la mitad izquierda? Pero no importa porque no queda nada en ninguna de las dos partes para buscar porque la longitud de la lista A restante es ahora cero. Sabemos que no tenemos ver en esta lista. No está aquí por referencia a la complejidad. Vuelve a contar el número de pasos. Contamos con 1234 pasos. Pasos del curso. Es un poco más que la guerra. Tres ponen tontos cuatro pasos.
3. Complejo el algoritmo: Así es más o menos como funciona la búsqueda binaria. Siempre escoges un punto de pivote. En primer lugar, escoges el punto en el medio y comparas el valor. Si el valor find es menor al que estás buscando. Por lo que es menos que su vas a buscar este medio valor K es más de lo que buscas. Vas a ver la mitad correcta, así que si es mayor que ella, entonces siempre es mayor en menos que la comparación. Y luego tomas la mitad y repites el procedimiento, y esto lo convierte en un algoritmo recursivo. Puente paso el disco respetando la mitad de la lista de tallas. Permítanme sacar algunas las cajas de donde esto se ve para el propósito complejidad. Entonces entiendo lo que sucede. Entonces tuvimos la K y luego si era mayor de lo que tenemos algunas cajas a la izquierda, solo
hay cinco de ellas, y del otro lado sólo tenemos cuatro de ellas. Ponemos la lista a la mitad. Ahora va a pasar lo mismo aquí. Vamos a tomar el del medio, escoger uno en el medio aquí, y luego te quedarás con dos para comparar por aquí, dos por aquí y también para y luego solo uno. Por lo que la rama termina aquí y siempre a unos. Son casos casi especiales, pero suceden mucho. Escogiste el del medio. Y si no es el medio, terminas teniendo que hacer una búsqueda más en cada uno de ellos. Y este es un patrón al que deberías estar acostumbrándote en los álbumes. Te estás dividiendo a la mitad en cada camino. Sólo tienes que bajar a aquí a las cajas de uno. Una vez que llegues al uno casillas tus búsquedas realizadas, ¿
has encontrado el elemento o no lo has hecho. ¿ Cuántos pasos hay aquí? cualquier momento que te dividas en dos o
duplicas, definitivamente debes reconocer este largo con patrón exponencial. Entonces ah, tipo
binario es un más largo el patrón. Entonces tenemos bitácora. Y de nuevo, aquí es donde dije que no importa si está apagado por uno, y así podría ser arriba o abajo un poquito. El conteo puede cambiar de ida y vuelta. Y por eso decimos:
Bueno, Bueno, es grande o de fin largo. Ese es el encuadernado superior no va a ir más allá de ese punto estamos quitando las restricciones. También puedes tener suerte. A veces. Si buscas la K, encontrarás una atención de inmediato, en cuyo caso solo hace una comparación. Pero estamos buscando el peor de los casos. Recuerda en entrevista si piden tiempo,
complejidad ahí, complejidad ahí, generalmente pidiendo el peor de los casos. Pero si estás incierto, normalmente
puedes preguntar y por algoritmo de búsqueda. Están pidiendo el número de comparaciones. Y ahí es donde no creíamos que comparáramos aquí. Comparado aquí. Comparamos aquí que comparamos aquí cuatro comparaciones. Es así generalmente como medimos la complejidad del tiempo de buscar álbumes. ¿ Cuántas comparaciones tenemos que hacer?
4. Enlace ado inferior y superior: Hay algunos casos especiales para buscar por ejemplo. Busquemos ahora una M y sabemos que aquí hay dos. Entonces vamos a ver qué hace el algoritmo primero iban a 0.2. Yo igual a cinco, y esta es la K que es menos que M. Así que sabemos que aquí tenemos que mirar el lado derecho. Entonces lo dividimos, iría aquí, y el punto medio va a estar aquí arriba en I igual a ocho R es mayor que M, así que sabemos que tenemos que mirar a la izquierda de su y ahora lo hemos limitado a esta parte aquí . Aquí es donde está la parte interesante. Entonces revisamos este aquí porque esto simplemente pasa a ser consciente va a funcionar. Podríamos haber estado revisando esa y dije: Lo
encontramos y encontramos al M. Así que encontraste la búsqueda básica está bien. Son dos álbumes ahí, muy cerca temprano a la búsqueda que surgen muy a menudo mientras se implementan otros algoritmos. Esos dos algoritmos son lo que llamamos margen inferior y borde superior y M es el caso e introduce es menor. Bounce dice que me apuntará al primer lugar donde los encontraríamos. Entonces si estamos buscando el borde inferior de em, en realidad
queremos esta ubicación y no esta. El valor del margen inferior es cuando se tienen duplicados. Ya sabes, puedes apuntar al 1er 1 Pero también el encuadernado inferior también es bueno. Cuando estás buscando cosas que no están ahí. Volvamos a eso. Ver, caso Sabemos que no ve aquí dentro, pero eso no nos dice mucho. ¿ Y si quisiéramos saberlo? Bueno, ¿a dónde veríamos entrar aquí? ¿ Cuáles son sus vecinos más cercanos? Algo así como Lower Bound llega a decirnos dónde están sus vecinos más cercanos. Entonces el margen inferior para empezar en medio, empieza aquí, luego revisa aquí y luego sabemos aquí y aquí y saltando las ofertas cómo se hace esto. Pero Lower Bound quiere básicamente darnos esta posición aquí porque aquí es donde se
daría el mar , y va a terminar dándonos esta posición aquí. I igual a uno porque Inferior Bound dice específicamente ¿Cuál es el primer elemento, que no es menor que este? valor B es menor que este valor, por lo que no es lo que queremos D es mayor que este valor. Entonces es lo que queremos. Ese fraseo de no menos de lo que era importante en el caso M porque está Malta, unos de ellos. Significa el 1er 1 que no es menor que porque M no es menor que em. Deja que coincida. Por lo que esta función de encuadernación inferior es útil para encontrar un lugar en una lista donde podría existir un ítem si no está ahí o si está ahí para asegurarse de que encontraste el 1er 1 Si eso es relevante, muy estrechamente relacionado con Inferior Bound es cinturón superior Bound nos dice el primer elemento que es mayor que el que buscamos. Entonces, por ejemplo, si estás buscando el tope superior off em esta vez, sabemos que M está ahí. Pero queremos encontrar el punto en el que M ya no es el animal correcto. ¿ Es ahí donde se detiene? Por lo que el encuadernado superior de M quiere apuntar aquí. Entonces en esta ubicación aquí, donde insertamos cosa, este es el primer elemento de la lista que no es menor o igual o mayor que M . Esto significa para cualquier cosa que venga tras em que pudiera ir allí. Esto es más importante o más interesante para los artículos que no están en la lista. Por ejemplo, si queremos saber bien, a dónde va mi fin, también se
puede decir, Bueno, entra en eso Así por buscar algo y está ahí, dice
el borde superior. En qué momento es, después de ese ítem, esto es útil para algunos tipos de clasificación. O si quieres insertar otro AM, quieres asegurarte de que viene después de las existentes. También puedes mirar el borde superior de las cosas que no existen. Entonces como ver, sabíamos que el borde inferior de C estaba apuntando a la D porque ese era el 1er 1 que
no era menor
que C. Eso también sucede ser el 1er 1 que es mayor que ver. Entonces en el caso de los artículos que no existen, así que no están aquí. El encuadernado inferior y superior van a ser lo mismo porque no están en la lista. Siempre va a apuntar a la misma ubicación en la clase de clasificación de inserción. Vamos a ver por qué esto marca la diferencia por qué tal vez quieras usar el borde superior versus inferior para hacer un tipo de clasificación Upper a lower bound son muy usados cuando muchos
álbumes que están tratando de localizar elementos que no están en la lista sólo están tratando de encontrar una ubicación en una lista para algo tiene que ser, aunque no esté ahí, entenderlos y poder implementarlos, te
daremos acceso a una variedad de otros álbumes para ayudarte en mucha codificación entrevistas.
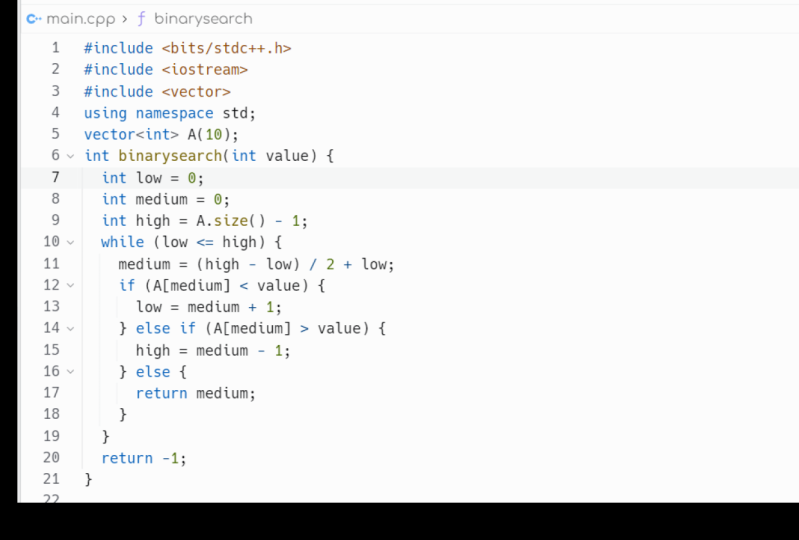
5. Código de búsqueda binario: Obtuve un vistazo al código ahora para la búsqueda binaria y el borde inferior y el borde superior antes de mirar el segmento. Antes de mirar el código, asegúrate de probar este ejercicio por tu cuenta yendo bien. Tu propia búsqueda binaria. Tratar el encuadernado superior e inferior como preguntas de bonificación. Tendré un enlace a este código abajo en las notas, así que echa un vistazo también. Pero de nuevo como tu proyecto, asegúrate de escribir primero este código. Hacer la búsqueda binaria. Pruebe pocas entradas. Hagamos algunos casos de prueba. Asegúrate de que funcione la variedad de insumos y convénzate de que entendiste de lo que
hablé en el segmento anterior y que podrías escribir una investigación de vinilo en una situación de
entrevista. De acuerdo, veamos el código. Entonces en los archivos de la clase, hay un P Y principal en Italia. El pitón principal tiene riqueza y pitón, pero debería ser bastante fácil de seguir. Independientemente, la parte superior de esto es todo tipo de boilerplate solo para configurar el entorno python para comparables. Una cosa sabe de los comparables. La única operación de comparación que va a estar usando es menor que esto es muy común al escribir algoritmos para bibliotecas estándar por lo que son comparables solo necesita definir una
operación menor que y nada mawr. Entonces echemos un vistazo a la compra de investigación. Subiré esto un poco. Aquí tenemos la búsqueda de Byner. ¿ Qué toma comprar una investigación? Toma el valor que buscamos y los artículos en alguna una p. Todavía
veo esto llamado la aguja en un pajar. Funciona, pero me gusta el valor en los artículos. Debe ser lo suficientemente claro, y devuelve un final opcional. Por qué es opcionales porque puede que no encuentre los artículos que tiene para poder devolver ninguno. De lo contrario, devuelve la posición del elemento que han encontrado, que se compara igual al valor pasado en el 1er 2 pasos configurados para Loop estaban diciendo ¿en qué parte de la lista estaba buscando? Zero fue el primero, siguiente y el largo. Yo era uno de los mejores. Son los índices superiores exclusivamente. No compruebes que fuera de esto es un rango de codificación estándar. Nosotros configuramos esto y su bucle entonces dice, Mientras que el bajo sea menor que el alto, seguimos en bucle porque eso significa que aún nos quedan artículos por revisar. Como mostré en la pizarra blanca, lo que tenemos que hacer es mirar la posición media. Entonces esto es hi menos bajo, dividido por dos más baja la slash latiendo pitón. Es sólo división de energía, y esto nos da el punto medio entre el rango se estaban comprobando. Esto se hace en bucle porque lo vamos a hacer repetidamente. Entonces este es el punto medio. Y el primer cheque se decía, es el ítem en el punto medio menor que nuestro valor en este medio cuando los puntos de pivote actuales en esta provincia es menor que o valor, significa que todo este dejó mitad fuera los ítems no lo tienen. Por lo que estamos en un turno a la mitad derecha al segmento y desplazamos a la derecha medio segmento
tomamos bajo lo dijo a mediados más uno. Sabemos que mid no puede ser el valor porque mid fue menor que el valor. Por lo que a medio más uno, esto cambia la ventana que estaban buscando por encima de la derecha. De lo contrario, si nuestro valor es menor que el medio, entonces sabemos que estamos demasiado altos en la lista y podemos ir al lado izquierdo y aquí es donde nos
movemos hacia arriba hacia abajo. Tan alto se convierte en medio menos uno y sabemos que medio no puede ser el circo ítem en medio menos uno
Si solo pones medio también, debería funcionar, pero será un poco menos eficiente. De lo contrario regresamos a mitad. Ahora es aquí donde es importante. Donde dije, sólo
usamos menos que comparaciones en la primera comparación. Vemos si los ítems mediados es menor que el valor en el segundo, cuando lo vemos, los valores disminuyen los ítems mediados parece un poco raro. Entonces en el último caso más, ¿qué significa eso? Si ninguno de los dos valores es menor que el otro, eso significa el mismo valor, significa que es el valor que estamos buscando y podríamos regresar a mitad. Hemos encontrado el valor que buscamos, y si no hemos encontrado ese valor, no devolvimos ninguno. Entonces esta es una búsqueda binaria básica. Lo he hecho sin Rikers, y lo he hecho con un bucle while y se lleva el segmento alto y bajo. Da un paso al segmento dividiéndolo por la mitad cada vez en la parte inferior del archivo. He proporcionado una prueba. Ejecuta esta tu prueba de trabajo y tarta o simplemente corre directamente y hago algunos artículos y hago algunas pruebas
básicas. Si estás escribiendo guerra completa de lo que tendrías una suite de pruebas más grande en esto, solo tienes que dar algunos conceptos básicos. Un punto interesante, dije para dos prueba es lo que pasa si estás buscando un y tú en esta lista, El aire de A duplicado y la U está duplicada. Se podía ver el par de años ahí dentro. El problema con la forma en que he implementado la búsqueda binaria en este ejemplo es que
no hay garantía de que encuentre. Por lo que esto por vía aérea búsqueda para un podría ser 01 Podría encontrar cualquiera de estos valores. Lo mismo con EU. El tú podrías tener ocho o nueve. Podría encontrar cualquiera de estos valores, y eso es algo que vamos a ver en el borde inferior y superior. Entonces vamos a pasar a esos
6. Código de unión inferior y superior en la Upper: relacionados con la búsqueda binaria son operaciones de enlace inferior y superior. ¿ Dónde están las búsquedas binarias en busca de artículo en particular? Los límites inferior y superior buscan un lugar en la lista donde pertenecería un elemento, esté ahí o no, y dan garantías un poco más fuertes en una búsqueda binaria. Entonces echemos un vistazo nuevamente al encuadernado inferior. El encuadernado inferior multa la primera posición de la lista donde el elemento de la lista no
sea menor que el valor. Ese es el primer lugar donde es mayor o igual a. Y decimos no menos que otra vez, porque sólo queremos usar el menos que operador. Pero es lo mismo es mayor que o igual a en este caso, por lo que el ligado inferior A tiene la misma entrada, pero notas que la salida es una energía. Er éste no puede regresar, y ninguno. No es opcional. Siempre hay un lugar a menos que o algo le pertenezca. Si no lo es, podría
haber en el medio. Podría ser el principio correcto o el final, por lo que siempre tiene un valor. Esta configuración luce igual. Empezamos con esta gama completa, y lo vamos a segmentar por la mitad cada vez buscando así la mitad. Entonces los bajadores lección alta y estamos buscando el punto medio. Por lo que ahora comprobamos si los artículos a mediados es menor que el valor. Y si es así, esta es como la condición que teníamos antes Bueno es tan baja Ban tiene que estar a la derecha de ella . Entonces decimos medio más uno porque es menos que eso. Sabemos que el encuadernado inferior es estrictamente después de mediados porque tiene que ser mayor o igual a . Entonces eres menos más uno ahora él está donde algo cambia de la búsqueda binaria. Si volvemos a mirar hacia arriba con el otro en la búsqueda binaria, no
tenemos l Si eso comparó el valor de nuevo aquí abajo, no lo
hacemos. Si no era el lado derecho, tiene
que ser el lado izquierdo. No tenemos un corto camino de retorno. No podemos identificar el valor Busca en el medio. Siempre tenemos que buscar exhaustivamente. Y por eso también decimos hola igual a medio y no medio menos uno. Porque en este punto no sabemos realmente que medio no es el encuadernado inferior. En realidad podría ser porque todos los artículos a la izquierda de mediados podrían ser menores que el valor mediados. Podría ser el que buscamos. Por lo tanto, no
restamos una. Simplemente decimos máximos menos que mediados. Y seguimos haciendo esto hasta que lo y hola sean el mismo valor. Digo baja lección. Hola. Esta es una especie de técnica de codificación defensiva para asegurarse de que nunca va para siempre, Pero son sólo van a ser iguales en algún momento. Por lo que regresamos bajo en ese punto de este encuadernado inferior, luego encuentra el primer lugar en la lista donde los ítems no menos que el valor. Entonces el fondo, los casos de prueba. Si miramos la mirada a los ítems ahora, si tomamos el margen inferior de un que dijimos antes en la búsqueda binaria podríamos haber tenido un 01 Pero en el encuadernado inferior, tiene
que darnos un cero. Tiene que ser el primer lugar donde existe en este caso, el primer ítem de la lista. Y para ti también fuiste el 1er 1 aquí. El primer puesto es ocho. Y así hay duplicados está garantizado cuál devuelve siempre tiene que ser el 1er 1 Ahí es donde no servirías uno de ese valor. Ahora la primera prueba de una inexistente es ver, y lo que debería ver retornos para tener un B C C estaría aquí mismo, y eso significa que debería ser la posición de la F, y eso es un tres. Entonces encontramos los tres y otra vez con el ¿Por qué el Por qué debería aquí y un doble zed, que tiré solo para conseguir algo al final de la lista? Porque es más grande que todos ellos. Debería aparecer al final de la lista, y esto es mayor que un tamaño de lista, por lo que esa es una prueba válida para eso. Por lo que también echemos un vistazo al borde superior Upper Bound no es todo lo contrario, el inferior. Está muy relacionado. Y lo que dice es la primera posición esa lista donde el ítem es mayor que el valor no mayor o igual a, pero mayor que eso. Es un estricto encuadernado superior comparado con el inferior y de nuevo, todo
esto se expresa en términos de menos que porque, como dijimos, eso comparable lo único que tiene para apoyarnos en menos de lo que va a encontrar en mucho de bibliotecas estándar. Esta configuración es exactamente la misma otra vez. Vamos a configurar nuestro rango de ventanas y van a encontrar el punto medio. Ahora, nuestra primera condición varía un poco de las últimas es que en lugar de ir al
lado derecho , primero vamos al lado izquierdo, y es decir, si nuestro valor es menor que el artículo en el punto, vamos a ir al lado izquierdo. Pero no vamos a restar uno, porque la posición donde a mitad podría ser en realidad el borde superior si todo lo demás pasa a realmente mucho más bajo que él. De lo contrario, vamos al lado derecho y decimos locales medio más uno. Aquí podemos hacer un medio más uno porque es una garantía de que el encuadernado superior esté estrictamente después de medio, y lo hacemos hasta que alto sea igual a bajo, y luego regresamos bajo, y eso nos da el rizado superior. Entonces, veamos los ejemplos de lo que allí sucede. Entonces tienes un atado superior de a Where is the lower bone of a was zero upper bound of a If is a menos que dirías justo después de A. Y esa es una posición al extremo superior de es esa posición al extremo superior de ti está justo después de ti a los 10. Entonces es a después de los ocho. Y para un elemento que no es ninguna lista para ver, el borde superior es el mismo que el borde inferior porque no está en la lista. Por lo que estos dos nos dicen dónde insertarlo en el único cambio, cuando los ítems ya en la lista nos dice qué lado de la misma debido a ponerlo. Si vamos a hacer en ordenamientos de inserción, normalmente
querrías usar el borde superior para hacer una clasificación estable para insertar elementos después en la lista donde difusa, inferior. Se movería la lista todo el tiempo. Y eso no es lo que quieres en mi clase para ordenar inserción. Hablaré de por qué el Límite Superior es importante aquí se opone al encuadernado inferior. Tienen que ver con fuente estable
7. Código de búsqueda de bloqueo de binario alternativo: volviendo a este problema con la búsqueda binaria en valores duplicados. Cuando ayudé para este A en esta lista, dije que podría ser un valor de cero o uno Generalmente codifica si estás construyendo una biblioteca, esta no es una buena situación. A have. No quieres tener ambigüedad. AP ICE. No quieres tener investigación de compra. Podría devolver 011 influencias de la persona devuelven cero. Otra persona apunta devuelve uno. Ese es un mal estado tener este tipo de pensamiento resultado en mucho aire se está colando en tu plataforma cruzada de código o diferentes compiladores. Por lo que no es bueno tener cosas como la búsqueda que podrían devolver resultados diferentes. Son ambiguos. Queremos tener un resultado estricto en el caso de los duplicados. Tiene sentido devolver el 1er 1 de la lista. Si hicieras una búsqueda en capas, cuál encontrarías? Por lo que se podría decir bien son la optimización de búsqueda binaria Búsqueda lineal? ¿ En qué caso el 1er 1? A. Regresó cero el 1er 0 Regresó ocho. Entonces, ¿cómo podemos hacer eso? A la compra, escribió
un investigador, no le importa. No sabe cuál encuentra. Entonces hay otra forma de hacerlo usando el margen inferior porque el encuadernado inferior siempre devuelve el 1er 1 de la lista si está ahí. Entonces en el código, proporcioné una búsqueda binaria fuera. El principal diferencia es que si hay un duplicado en la lista, garantizará que regresa. El 1er 1 y he implementado es en términos de menor rebote. Si tienes una operación de encuadernación inferior, en realidad no
tienes que influir en la búsqueda binaria. Esto es bueno para una situación de entrevista. O, si pudieras preguntarle a la persona, ¿puedo suponer que existe el margen inferior? Y puedes evitar la parte problemática de escribir búsqueda binaria y simplemente usar el margen inferior. Si está buscando un valor en particular llame al margen inferior en el valor. Esto dice que el primer lugar fue que los ítems deben insertarse en la lista. Y si hay elementos en la lista, la primera ocurrencia fuera de eso porque es válido aunque no fuera la lista. Entonces lo primero que comprobamos es que si el encuadernado inferior es mayor que la longitud de una lista , es mayor ángulo a. Significa que no está en la lista porque decía que el lugar que este ítem existiría está fuera la lista, por lo que no puede estar ahí dentro. Entonces devolvimos Ninguno. Si el artículo al siguiente devuelto es menor que el valor, bueno, entonces ese tampoco es el elemento que queremos, por lo que no debería estar en la lista. Si el valor es menor que los artículos ahí, entonces podrías regresar, también
conocido, porque no es el artículo correcto. De lo contrario, regresas más bajo porque no es menor que en ninguna dirección, menor o mayor que lo que significa que es igual. Y así es como usas el margen inferior para encontrar un elemento en una lista.
 Edaqa Mortoray, Programmer, Chef, Writer
Edaqa Mortoray, Programmer, Chef, Writer