Transcripts
1. Introduction to No-Code Data Science: Data science is this exciting new field, but it can be intimidating to get into because it oftentimes involves math and programming. This is something a lot of people are uncomfortable with, and some people don't even need when they want to manage a data science team, rather they'd get into the nitty-gritty details. We'll get to a high-level of understanding to understand the methods and the vocabulary of data science. You can speak as a peer, which is what we're doing in this data science master class. My name is Jesper Dramsch, I'm a machine learning engineer in Oxford in the United Kingdom. I have experience teaching Python and machine learning on this platform, on Skillshare, and as well in companies like Shell, the UK government, and a couple of universities. I spent my last couple of years working towards a PhD in geophysics and machine learning. I love data science because it has enabled me to find a job during the pandemic, which I'm incredibly grateful for. I want to share some of this knowledge with you because I think empowering people to get ahead with their career and possibly even make a change is really what this is about. This class will teach you the concepts and high-level of understanding without going into code, so you can speak with data scientists as peers and really understand the thought processes behind data-driven decision-making. I'm incredibly excited to have you and I hope to see you in class.
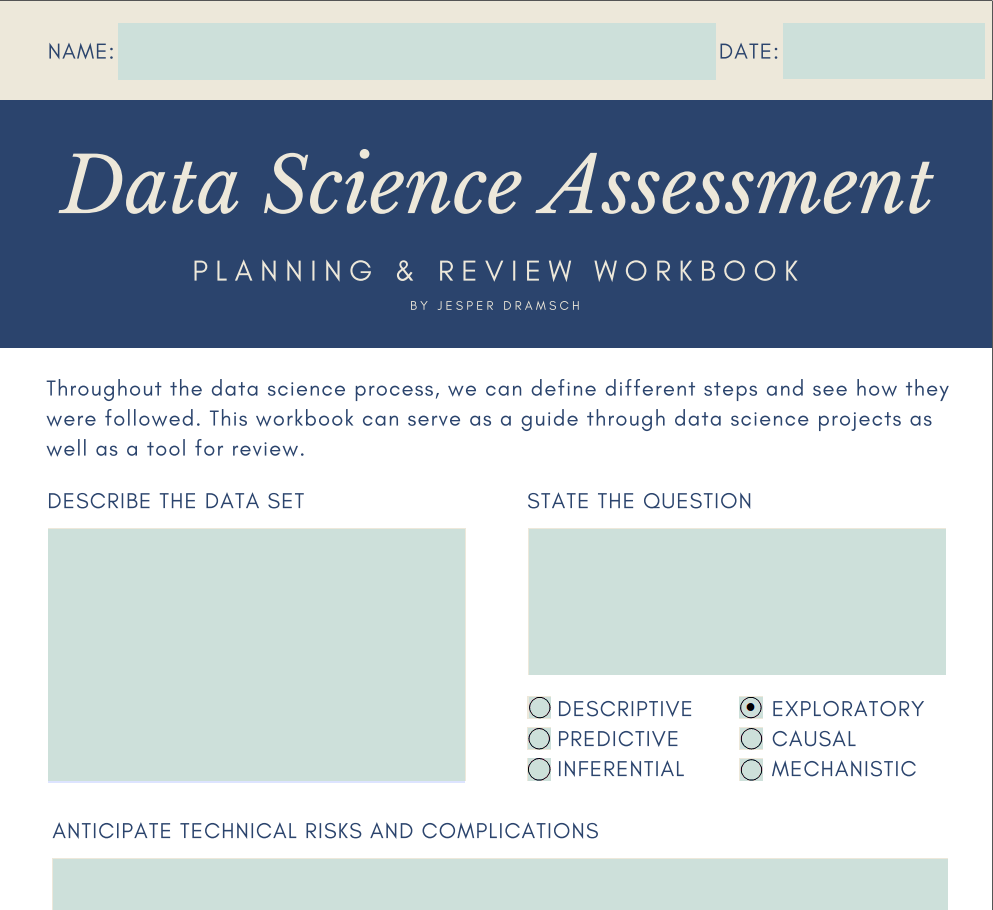
2. Class Project: Welcome to class. I'm so glad you made it. What are we actually going to do here? Well, I prepared a class project and I want you to have a look at it because essentially it's a workbook that you can use for your class project, but I hope you can actually utilize it in your day to day data science work as well. Either by guiding you through your own projects or to help you manage other projects. Let's dive right into the workbook and have a look through it. This is the data science assessment workbook for planning and reviewing your data science projects on data science projects that you are managing. These are three pages at the moment, and in the beginning, you can fill out your name and your date and ask some important questions about your data. Then we'll have some information where your data is from and how you make sure to validate your data. Some insights in the steps that you learn about in the next class that are part of the data science process. Then you'll basically document notable algorithms and visualizations that drove inside, negative findings that were found throughout the project. What is the main business or scientific impact, depending where you are and your main conclusion. These are fully customizable. I can say, this is my name and today is the eighth of January. Now describe the data set. In the example data set, for example, we have a indicator for happiness, and we have data points per country and here. This way you can really fill out each question in here. The question, for example, is, what is the main influence on the happiness score? This would be somewhere between descriptive and exploratory. I would say it's exploratory because, well, we're looking at how this prediction or how the score is calculated, so we're exploring it rather than just describing the data set. The technical risk is something where for example, your data or your machines are not capable of doing it. Think about if you have too large of a data set, it might not fit on your computer. What are the risks that can happen and risks don't have to be the worst thing. It is just roadblocks and if you anticipate the risks now, you can take interventions and make precautions to really address these risks if they happen. One of the risks could also be that the data isn't coming. What do you do when you have data loss? Because one of your hard drives is missing? Think about this. It's a good question to ask yourself and here we have methodological risks. What can happen in the data science process itself? What happens if we do not have algorithms available to ask these questions? What if our data set doesn't actually contain the information we need to make the prediction. Really more on a meta level, think about what can go wrong in the data science analysis itself and how and where the data and labels were acquired and the validation strategies used to make sure that your insights are generalizable. All these words and all this will be explained in the course as well. If these are weird sounding words to you now, you will understand them in the end. Make sure to come back here to fulfill your project and submit it to our projects database. What are ethical considerations is an important question. Really a happiness score, for example, are these aggregates statistics so on a country level or do you have the possibility of seeing personal level information. That would be rather, well, it would be a bit dubious. So write about this year and then in the different steps, write about what findings you found in doing Descriptive Statistics, EDA, machine learning, and then what steps for communication were taken. In the end, like I said, notable algorithms and visualizations. What has had the most impact on delivering your insight. Then negative findings, as I will point out, data science is an iterative process. You will see that sometimes you find negative things, sometimes something doesn't work out. Note these down. If you can write these down, you will look back and see, oh yeah, we already know this. You can share this with data scientists with key decision-makers and they will also appreciate this feedback where you can say, well, this doesn't work, this hasn't worked empirically. Therefore give an additional insight into your analysis. What is the main business impact, scientific impact? This should be mixed out of your question. How does your question impact the business, but also how do the findings and the answer to your question impact the business, all the science that you're doing. Then write up a main conclusion. Really, what is the main finding that you have in this data science analysis? Now that we're done with the PDF, you can download that in the description. We can have a look at the class structure. Because this class is set for so many different kind of students. Some lectures may not be the most relevant to you. Feel free to skip them. It's totally fine if you are getting bored even and you just go to the next one. Because even if the first one isn't the right one for you, there may be one that is better for you. For example, one of the very last ones is talking about operationalizing data pipelines and understanding risk and data science projects. Some of the really important questions that you have when you're managing teams. Make sure to check them out. If you're skipping ahead, no hard feelings. This is your class, so make it yours, and be sure to share your projects. I would be very happy to see how you make sense of other people's projects. Remember to be nice, remember to critique it in an academic and a scientific way, so you can really learn from it and show others what you learned from it. Now, let's dive into the actual class content. The first class is going to define what data science actually is.
3. What is Data Science?: In this class, we'll attempt to explore what Data Science actually is. It's a bit difficult to really say because data science is so new. There are a lot of different opinions, and that's also why I want to explore it from different ways. The easiest way is basically citing someone else. So Jim Gray, a Turing Award winner said that, "Data science is the fourth pillar of science next to empirical, theoretical, and computational science." What that basically means is that using data science, we can extract new insights directly from data. If you have your business data, if you have your scientific data, wherever you're coming from, you can take that data and use these new methods or old methods and new cloaks, and essentially, find relationships within that data that work, not only on this small data set, but can be generalized to new data. If you have customer data, you can then predict what new customers are doing. If you have chemistry data, you can predict what a new chemistry formula is going to do, things like that. This simply based on the relationship within the data. Now, a different way to look at is to look at the data signs hierarchy of needs. I really like this one because it also gives us a way to basically define where we have to spend time. One of the things is we have to acquire data. Without data, we can't do data science. We have to get a data set, we have to clean the data set because all raw data is noisy. There are misguided outliers in there, there is information in there that is not relevant to our question. Like data scientists joke about data cleaning being the longest they spend on it, some claim to spend 80-90 percent on data cleaning and only 20-10 percent on the fun part or on the really interesting part of generating insights. But yeah, it is the most important part. People tend to say garbage in, garbage out, and usually, that is very true. Then building on that, you have to have a reliable storage. If you have your data and it gets lost, it's very hard to reproduce your results, and results in data science have to always be reproducible. Also, maybe you have to validate your results or maybe you have to go back and combine it with new data that might change your conclusions. Storing, moving around the data is really like building your infrastructure is the next level. Especially for data science managers, they have to know that data engineers are extremely important at this stage. Employing the right kind of people at the right positions is essential for a business. Then on the next step, we have exploring and transforming data. Data exploration really is the step where you have a look at descriptive statistics of your data, like have a look at the average and how much your data varies, and what the different features of your data are doing. When you have a customer, when did they come to your side? Where are they from? What's the gender? Things like that that can give you insights on how customers may vary in between visits and what may change the prediction if they're going to buy shoes, if they're going to buy a new camera, or if they're going to take a course on Skillshare. On top of that, you then can do A/B testing. If you've ever gone to some like Amazon or these course websites, you may see that there are different prices displayed. Oftentimes, that's because websites are doing these experiments of seeing if showing a different website, changing the button, changing the pricing is going to make you more or less likely to buy. Things like A/B testing, experimentation, simple Machine Learning algorithms are the next step on this ladder. So doing prediction and doing inference to really being able to look into the future from the insights that we generated. Then the tip of the iceberg, so basically, the desert in your food pyramid, is going to be AI and deep learning. That basically means that these super exciting technologies are probably the last you want to try, but they can be extremely valuable. So if you have your Machine Learning engineers or your Machine Learning researchers, and they have built baseline models, and they do recommend based on their insights that it might be necessary to go too deep learning methods to build AI algorithms to really harness the data, the complex relationships that we have in data, this can be really good. A lot of the modern Machine Learning breakthroughs have been made with deep learning methods. Finally, when we're actually doing data science, not just looking at the needs of data science, it is a process. In this process, we want to answer a specific question based on our data. That means we often have to go forth and back. We might get our data and we do data exploration, but in the data exploration, finding descriptors in our data, we find that this data might not be enough and we have to go back and acquire new data or maybe merge it with the a data source, and then work on refining our data science process. The next part is going to be looking at modeling our data. These are the simple algorithms that we talked about, but it can also just be insights that you naturally gained. Simple rules are also modeling your data, statistical modeling for inference can be very appropriate at this place. This is really where you want your data scientist to go in and be able to build a model that can accurately describe and capture your data. Finally, a very important part is communicating your results. Building dashboards, making presentations, creating these notebooks that sometimes have code in them to share them with fellow data scientists or Machine Learning engineers. This way, you can really share what you found. This part is possibly the most important one because you always have to talk to the decision makers, you always have to talk with stakeholders what your question really came out to be. This can also be the most interesting part because finding these relationships in the data is fascinating and sharing it with stake holders, usually, stake holders are extremely thankful for having these new kind of insights into their business or into their science. Make sure that you take some time to make a good presentation out of this because usually, it's very important and very valuable to do this. This is mostly what data science is about, getting data, generating insights from data, modeling your data, and then communicating your results. Of course, there are pieces like productionalizing this. So if you are in a business, like on a website, you want to be able to use all of this, but this is for our future class. In the next class, we're going to have a look at what is actually a good question? How can we ask good questions of our data and make sure that these are actually worth our investment and worth our time?
4. On Asking Good Questions: Let's have a quick look what a good questionnaire is and also what bad questions are. Basically, if you're asking questions, you have the option of six questions. Why six you may ask? Well, science says so. In fact, the data scientists and professors, Jeffrey Leek and Roger Peng, who have an amazing course on executive data science, have published a paper which essentially outlines the types of questions you can ask. I want to talk about the types of questions as well but then go into detail, also what a bad question is. Because recently, more and more ethical questions are coming up in the space of data science and machine learning. I think it's very important for, well, for business leaders and for anyone that does data science to be aware of them and to challenge them if there are things that are not going according to our values. What kind of questions we can ask. The first question is descriptive. That essentially means that we have a dataset and we want to know key characteristics about the dataset. For example, the average height of users, or if you're working in a shoe shop, you want to know the range of the shoes you're selling. Like the range of sizes, for example, or the different colors that are sold. So really just indicators that are describing the dataset that you have. Questions here can really be very varied, but they are rather simple and very matter of fact. The next question we can ask is explorative. Essentially, the idea of what can we find within the data. This usually includes things like finding relationships and trends within the data, looking at correlation, and we'll have a larger class about this because it's such an essential part in data science. The next question someone might ask, and this is also where we venture into what machine learning can do, is predictive questions. If we do x, does y follow? For example, if we change this button on our website, or if we add this column over here, if we show a customer this kind of thing to also purchase, do we increase sales? Or if we increase our subscriber count on YouTube, do we get more views? These questions are now where we have to do a lot of validation because machine learning is really good at remembering data. Sometimes it is a bit more difficult to actually have a general prediction. This is really important to look at model validation and in the larger machine-learning and business analytics and Python course, I'm going into this kind model validation because to me, this is one of the most important parts of data science. Now, we're getting into really interesting parts. Because a lot of people know these tests that correlation is not causation. Predictive modeling is usually correlation, but the next question we can ask is a question of causal nature. So, if we have x does y follow, is the predictive question. But does x cause y, is the causal question. To me, this is a really interesting one because a lot of predictive modeling can also be spurious correlations. But with causal modeling, you're actually trying to find what does one thing cause. One example that I really liked was hotel prices. If you're collecting data from your surrounding hotels and you're having a look at the prices and how many people are in the room, so how many rooms are occupied right now, you will find that there is a correlation between higher prices and higher occupancy. But if you did your causal modeling and said, "Okay, so that means if we increase our prices, we will have higher occupancy." You will probably go out of business. Causal modeling really goes at the underlying data structures, what is happening at what place. Some things that people do here are counterfactuals, so really, having a look then. If we lower our prices, do we also get lower occupancy? Really digging into the data. This is to me, the next step also where data science is going to make the most strides in causal modeling. Mechanistic questions go one further than causal modeling. You're not only looking at the predictive. If x does y follow, you're not only looking at the causal arrow. So does x cause y? But in mechanistic questions, you're actually digging at how does x cause y. You're doing the science. In biostatistics, for example, this is very common that to be able to publish, you basically have to propose a plausible mechanism, medicine as well. A lot of the more natural sciences are quite used to this. Your statistician will be quite used to this. Whereas in machine learning often stops at the predictive questions. To do science, this can be extremely important because answering these questions, how something happens, is the ultimate insight. This is also where it gets interesting because our students are so diverse, from creatives to scientists to business people. As a scientist, you are most interested in the truth, in the underlying mechanisms that you find in the nature. As business people, you are most interested in the predictive. So will someone buy something if I change this? Possibly the causal effects as well. Not so much the mechanisms because those are usually much harder to obtain, take more time, take more brainpower, and simply said, don't really increase sales or acquire new customers. Really, this is a little bit where the questions are very specific to what you actually want, and you have to decide what is the right question for the kind of problem you are facing. This is basically an introduction on how to ask good questions and in the next class, we will look at how we ask bad questions.
5. On Asking Bad Questions: You probably see how you have to figure out which is the right question for your problem. But with these recent ethical dilemmas and also problems around predictions and things, we have to ask ourselves, what is a bad question? I want to go into a couple of examples of things where data scientists could have probably prevented some from happening by going further than just a shallow analysis or shallow prediction and possibly thought out a little bit more, what's going on? This is really why you're a data scientist. Sometimes you have to go one step further to make this world a better place after all. With the social dilemma, for example, and a lot of research that is coming out, we see that just increasing site usage eventually leads to websites not being that great for humans. We see a lot of human suffering from mental health problems based on social media and on YouTube, on Facebook, we've seen that there is a bias towards extremism. When you started to watch videos on food, you get more and more into very deep rabbit holes if you just optimize for why are people staying on your side. As a data scientist, you should go further than just asking the question, how do I keep people on the site? But yeah, you should go one further. Not just ask, how do I keep people on my site? How do I make people buy more? But possibly ask about customer satisfaction as well. It's not only how do I sell more, but how do I get the right product to the right person? This is not the most, not the nicest topic, but we have to talk about it because you have to think about the ethics. Can things be explained by population? We know that there are higher crime neighborhoods in poorest cities. Does it really make sense to build a predictive model where the next crime is going to happen, so make it on an individual level when we know that the underlying problem is poverty. This is unfortunately a question that is being asked and it's not a good question because we know what's causing this problem already. Building a predictive model on an individual basis completely ignores our causal knowledge of this already. This happens on much wider, much broader scales as well that are not as ethical, where we know what is happening as an effect, but like predicting the individual is not as valuable anymore. Because at this point we're really just treating a symptom rather than the mechanism. Another type of bad question sometimes happens in businesses where the answer is essentially predetermined. We already know what answer we want and now we're asking a question to get that answer. Data science should ideally be open to answers. These answers should potentially go in a direction that our management did not anticipate. Management should be open enough, secure enough to let this happen as well. Being data-driven sometimes means that we find inconvenient truths about our business, about the direction where we want to go. But this is eventually what makes data science a science. Sometimes asking these questions when we already know we want a certain answer is definitely a bad question because it does not enable us to do proper data science. In the next class will have a look how we can actually get data to ask these good questions and how we can obtain good data to get the best outcomes out of our analysis.
6. Obtaining Data and Labels: One of the most common questions I get from beginners in data science is, where do you get your data, and how do you get your labels? Now, these are two different demographics that ask these questions. Usually, people in business or scientists already have some data. Data collection is a very common thing. So you have your database having customer information, or you have your samples from your analysis. There the question usually is more, how do you get labels? For beginners who are just trying to get into data science, they're trying to find data. Where do you find data? Where do you get labels? We'll first dive into how you get data, where you get data. Because even in a business, this can be a really important question, and then we'll have a look how to get labels. Obtaining data is either measuring the data yourself or finding a dataset. So that means getting the data from somewhere. There are data storages where you can get prepared datasets that often already have labels attached. These are quite commonly the Google Search or also the Kaggle datasets section. Measuring data basically means that you have to go into the field or into your systems, and extract the data somehow. So in my work right now, for example, I'm working with satellite data, and we do actually have a company that is local and is going around with GPS to measure actual forests. Yeah, this costs money, but this is the best way to get accurate data that is high-quality and will give the best results on your data science product. In the end, having experts to label your data, to obtain data, to interpret your data, is quite important. A lot of research has shown that getting novices, usually lowly paid people on something like Amazon Mechanical Turk to interpret your data, is not ideal. It usually gives you noisy data, bad labels, and often can introduce bias into your data. You have to be very careful about bias in the data because this bias will be baked into your model. If you do machine learning modeling, for example, which I do a lot, bias will then be implicit in the model, and the model will repeat this bias on every prediction. So especially if you're touching humans, you have to be very careful about this. This is also something you should be careful of when you get pre-labeled data. So when you download one of the datasets from Kaggle, have a look at what the classes actually are, look through what the data is, what the class imbalances are. Because a lot of times you get labels that are easy to label, but they're not necessarily the labels that are interesting to label. Sometimes, especially in the terms of scientists and solopreneurs, you'll have to label the data yourself or outsource it to someone. Since you're the expert and usually scientists run on a tighter budget, it just means that you have to open up something like Labelbox, which you can see right here on screen, and draw labels on your data yourself, interpret the data, and be aware what kind of bias you might be introducing yourself. In this class, we had a look at how you can actually get data either by acquiring it yourself, or by downloading it from somewhere, and how to get labels. So you are either getting experts to get you the labels, how to get novices to get you the labels, but also how to label data yourself using apps like Labelbox. In the next class, we'll have a look at exploratory data analysis, where we actually have a first look at how people interpret your data.
7. Understanding Exploratory Data Analysis: Let's talk about exploratory data analysis or short EDA. In exploratory data analysis, usually the data scientists has a first look at the data. A lot of times people do the descriptive statistics on this pod. So calculate the mean, calculate variants, and really have a look at the features of your data, what's in the data? What's in the labels? This is also to see if cleaning the data has gone right. Are there outliers? Is there noise in the data and if you find this kind of thing in the data, you'll have to go back to the cleaning stage. As I said, data science is very iterative. So oftentimes you have to go forth and back to really see that everything is fixed. Then after having a look that all your data is in order, you also want to have a look if there's missing data, because this happens quite commonly. If you have customer data, for example, oftentimes profiles aren't filled out completely. You're missing some of the e-mails, some of the phone numbers, and those missing values can be indicated as false something. So they're quite valuable to know in data science and this goes for almost any application. Knowing where missing data is can be extremely good to incorporate into your analysis. This is a tip that I like to give everyone to also have a look just where you have data and where you don't have data. In the end, you also have a look at correlations. Have a look how your features, how your data is correlated with each other. Correlation simply means that if feature A is going up, and feature B is going up, they might have some correlation of their going in the same direction at the same time and this can be quite good to analyze so you understand relationships within your data. Usually you also want to do some clustering maybe. Have a look which data is fitting to which data. So have a very simple cursory look at how your data fits into groups. I personally also find it very valuable in exploratory data analysis to have a look at visualizations. Usually, of course, you can calculate a number for the correlation coefficient, but also just having a quick plot of your correlations and your cross-correlations between different features can be really good because then you have a quick overview, just like we see on the screen right now and you know this is going up. This is positively correlated. This is going down. If this is going up, this is negatively correlated. So really just getting a feel for the data and understanding the data better, so we can then go on and see if our hypothesis that we're building in this process is holding up on new data that we haven't seen before.
8. Intro to Machine Learning: One form of modeling our data includes machine learning. Machine learning has all the range right now because it has been very easy to use machine learning tools recently. It has become very accessible to a lot of people that know little code or even no code and a lot of applications. Where machine learning was just abstracted so you can build a neural network based on your data which approximates the outcome. In machine learning you have basically three different areas you can look at. The supervised learning, which essentially means you have your data and then you have your outcomes. For example, in customer data, this would be you have your information about a customer, which at every entry in that information we would call a feature. You have your label if they bought or if they didn't buy. This would be a binary decision in supervised machine learning where you can then try to predict if based on the features that you have someone bought or someone didn't buy. This was the first machine learning that you can do classification. Whether that is binary or you have multiple classes that you want to predict. Maybe it's cats, dogs, and birds. Those are really discrete values, discrete classes that you want to predict. The next method in supervised machine learning is regression, where you predict a number. In this example of customer data, this would be equivalent to predicting how much a customer is willing to spend based on the features that they have in the dataset. Really seeing this customer that has recently bought this, this, and this is going to spend $100. This can be quite important for your marketing budget, for example. If you know how much to spend on a certain demographic, you then can essentially see how much marketing budget you are willing to spend to make a conversion. The third method in machine learning is a part of unsupervised machine learning. This really means that we don't have the labels that we had before and we're trying to find internal structures of our data. Really what this means for clustering our data, we're trying to find which sample in our dataset is closer to another sample. Eventually, we can then even use this unsupervised clustering to assign labels to our data. That is one of the tricks that people often use for finding labels, which links back to the lesson that we did on labeling our data. This is one trick that you can use to find classes within your data, but it's the question, are those the classes that you're really interested in? These are three common types of machine learning. Machine learning has very different methods to achieve these predictions essentially, when you're talking about regression and classification. Supervised machine learning, you can use something like linear models. Literally fitting a line in your data. You can use decision trees which are really powerful and really interesting, because they make these rule-based decision of if this is over that, then put it in this class. If this feature's below that, put it in that class. They have become quite popular because they're very easy to use and give really good results. Neural networks are another class where you have brain like structure of connections that essentially do mathematical operations on your data to then predict a class. Finally, we also have something called a support vector machine, which basically tries to divide your data into two groups, ideally. Those are really very common strategies, very common tools that you use in machine learning. A very common method in unsupervised machine learning is k-means, where essentially you're finding the mean of your clusters, but the problem is you have to define k. Essentially you have to try out a lot of different numbers of clusters, which is k, and then see what gives you the best results. Usually a lower k is better because then you find bigger clusters. If you increase your k to 100, so you find like 100 clusters, that often means that you'll find sub-clusters in larger clusters and get less of a reliable result. Another method that I personally like a lot is t-SNE. t-SNE is automatic process which you can see on the background here, which essentially also attempts to find clusters of your data. It is less interpretable, but it is very good at finding data that belongs to another and finding outliers in certain data. Really good for establishing relationships and data as well. The most important part in machine learning is the training process. You have your data, you have your labels and you put them in and you hope that your machine learning process is going to predict the right models. Usually this is iterative. Your model predict something, sees if its getting it right. This is the supervision and then the model is adjusted. This is the learning process or the training process. Both words are used to really adjust the model to give you the right results. This is the interesting part because these models are mathematical models that don't know anything about physics, anything about customer behavior. But they learn to establish these relationships based on mathematical principles and really adjust to the type of data that you have, which can be very different. Machine learning works on so many different tasks from advertisement online to physics to biology, so really versatile. However, and this is extremely important when you train or people you employ train these models, they have to keep part of your data separate because you always have to have a test case, essentially, where you see if your model is actually working on data the model has never seen. Because the model can essentially memorize your data more or less. You're trying to avoid that. There are a lot of things that you do as a machine learning engineer to avoid this. But in the end, what gets measured, gets managed, and you really have to measure if your model is working on data it has never seen. This is why we usually keep part of our labeled dataset to the side because then we already know the answer on those. But the machine learning model has never seen it before. A neat trick to validate our model with this validation test set. This was a brief overview of a machine learning. You now know about the different types of machine learning and a couple of methods that are powerful that you can have a look into if you're interested. You know that you have to absolutely do machine learning validation. You cannot just train a model and say, oh yeah, the training school, and this is really good. You always have to have an extra dataset where you can validate your data on. This leads perfectly into the next class where we're going to have a look at how to prove yourself wrong. Because if we want to do data science as a science, we have to make sure that our ideas actually hold up to scrutiny.
9. Proving Yourself Wrong: So far we had a look at data science tools, principles, methods. But data science has lot more, because in data science you basically have to think about the system you're in. It is very mentally engaging in a sense. In this class and this lecture we'll have a look at proving yourself wrong. The idea behind proving yourself wrong, is essentially that we all go at data analysis with our own biases, and especially if we follow up exploratory data analysis, we might have gotten a hunches on subsets of the data. Some of the most successful participants in Kaggle competitions, it completely ignore EDA notebooks, so other people sharing their explorations because they do not want to be biased in their approach to see what the data may hold in store. Essentially in every data science project, you will have to hold yourself to a very high standard because you are looking at underlying truths, underlying relationships within the data. That doesn't matter which question you're answering, if you're doing a prediction or if you even answering mechanistic questions, it's always, is there a different explanation for this? The first thing you'll want to do when you try to prove yourself wrong, is apply Occam's razor. Occam's razor is the philosophical idea of that, evidence can usually be explained by the simplest idea. So when I'm not finding my keys on the morning, I probably misplaced them somewhere and they're probably in my jacket. It's very unlikely that it's aliens. This is the idea that you try to find the simplest explanation instead of going fancy complex, and this is also something in general data science, machine learning, which is a good idea to try to build the simplest model that satisfies your criteria. Because the simplest model is usually also the simplest to explain. In this case, data scientists are in a bit of a dilemma, with knowledge workers, we are paid to be smart, so having a complex explanation for these things is usually what we're going for. We want to find the super interesting things and you have to be very careful there, because we can be lured in by this smart explanation that makes us feel good, but which may just be the wrong explanation. There may be a much simpler one that can explain the exact same things. There it's usually good to have a look at what is the common explanation for things like this, so oftentimes data scientists have to talk to subject matter experts. If you're a data scientist working with economics, talk to your economist, if you're a data scientist at the Large Hadron Collider, talk to the physics people. They usually have a hunch, have an idea, and you can still challenge that if your data has the evidence for that challenge. But oftentimes it's really the simplest explanation, it's the best explanation for your problem. The next thing you'll want to do is have a look at things that disprove your theory. If you have a hypothesis about your data and you're looking at, what causes what or what's happening where, going back to the example from the beginning, if higher prices in a hotel cause more people, then the inverse can be true. So if you lower your prices, people should stay away as well. With these counterexamples which you can find in your data. You should do an analysis essentially, if there's evidence in your data that is proves your theory, you have to improve or you have to update your beliefs, you have to change your hypothesis, because these data points, if they're significant, will definitely show that. Your fancy idea, your initial idea sometimes has not been entirely correct, so you have to dig more and really look at the data if there is something that goes against what you had in mind. One example from my work right now is that we had this idea that maybe what's called forced migration. Essentially people having to leave their homes because of floods, because the floods cause cropland to deteriorate. Well, in our data analysis, we actually found that there were more crop lands flourishing in the area after a flood, because suddenly it got a lot of irrigation and everything was green and blooming, so we had to update our initial idea, our initial belief, to a new hypothesis that could actually, yeah, there was in line with the data. This really you have to be flexible and not be married to the ideas that you have. I know it can be very difficult about updating certain beliefs, but it is entirely necessary for data scientists to be flexible in that understanding and to listen to subject matter experts, because a lot of times they have years of experience, working in this field, and you need very strong evidence to counteract what they're saying about the field. A lot of times, basic researchers are really good, looking at your data if there are counterexamples in your data, and also seeing that you have the simplest, the most straightforward explanation for what you're actually seeing in your data. If you think about it, going this one step further, going at your data analysis with this scientific mind, being able to really cross check your beliefs that you initially formed from your exploration of the data really makes you a stronger data scientists and makes you a better data scientist eventually, because you are now able to question these ideas that come from yourself and therefore mitigate biases in your own analysis and have a much stronger argument as well. If you're communicating these results to decision-makers, to the bosses, or writing in paper, and you can say, well, I check this for counterexamples, and these were outliers or these were based on this hypothesis that we initially had, it had to be updated. This can be an extremely good and valuable trait in people, and it will command respect in these decision makers, because they know now they can trust you and you actually being interested in finding the answer and not just propagating your answer. In this class, we did have a look at proving yourself wrong and how to basically think outside of the box and question your own conclusions from data. The next class will have a look at one of my favorites data visualization.
10. Data Visualization: In this lecture, we'll go over data visualization. Data visualization for me is important in two aspects. First of all, a visualization can give you an extremely good overview over your data in the exploration stage. Correlations, I love it when you just have a visualization instead of a number for the correlation coefficient. Because then you can see a lot of correlations next to each other. Apart from that, when you do your reports and your presentations, well, they don't say it for nothing and image says more than a thousand words. Really, data visualization, you can pack much more of a data communication punch than anything else and you can make these visualizations interactive. If you're building dashboards, you'll want these visualizations, put it on a map if it's spatial data. Make a scatter plot. Scatter plots are amazing. They give you so much input and insight into your data. Like how are points going against other points. If you are doing clustering, how do these points cluster in the 2D space? Eventually, you'll end up getting better at visualizing data but you do want to follow a couple of rules. Usually, what you need to be careful with is labeling your axis. So it's always good to have text on the axis. I personally like this is the bane of my existence. Adding text to visualizations, I should be better about it. Usually, in review, there's always a, can you please put x on this label and it'll make it much clearer because people can glance at your visualization and see directly what's going on without reading the caption, without reading any of the text, do that. Never encode data in the transparency. Because it's very difficult to see transparency, especially if it's printed or if you have a scatter plot and you have several points over each other. If transparency has meaning in your plot, then you are losing that meaning by overlaying several data points. With color, you have to be extremely careful about colorblindness but also when you print it, a lot of scientific print is black and white because color is still expensive to print for some reason. Don't ask me why. But yeah, having these what's called linearly perceptive color maps is really good and if you're using Matplotlib and all these Python libraries, they use something called veritas, which is the color map. Veritas is linearly perceptive and perfect for this kind of thing. If you're doing your visualizations in a different software, it is quite possible that the standard is going to be the rainbow or jet often called. The rainbow is not a good color bar. A lot of times, the green is way too wide, so you do actually lose some of your visualization information in those color maps and you should definitely not use those. A lot of times people will challenge that, especially if you're talking to professors, older scientists, they think that rainbow is the standard color bar and you should be using that and there is research on challenging these thoughts because it is more accessible. You are being great to people with disabilities and it costs you nothing and in the end, they are better color bars because the change from one shade to another that you perceive as human is the same for everyone, and it's the same between each shade. In rainbow, the difference between red and blue is much different than green and red, something like that, just because of arbitrary assignments where your data is mapped to the color. But in Veritas, you have a linear perception of where your data is. So you actually intuitively understand how your data is looking and what your data is doing. In these kind of graphics that you're creating you'll always want to think about the person that is looking at the plot. How can you make this information as accessible as possible? Can they sit in a room full of people and follow a presentation and understand what you're trying to say with the slide that is going to be gone in less than a minute. Really, have a look at what other people are doing. There are amazing blogs out there. You can have a look at flowing data, for example, which is collecting a lot of very beautiful visualizations. There are a lot of resources out there as well. Really make sure to check those out in addition to this class because of course, this is a good overview, but there is always more and you can always go this step above and make it a little bit better. Adding interactivity to your data when you are doing dashboards, for example, can be so good. When you mouse your scatter plot and you can actually get information about each point by just pointing at them, is so good. Everyone is always stoked when I create a visualization like that. Essentially, data visualization is about making the most of your data and making it really understandable in a single picture. In our next lesson, we're going to have a look at productionalizing data pipelines. Really, how can we make our findings useful in a business?
11. Operationalizing Data Pipelines: So far we have been talking about one of analysis for data signs. Essentially the idea of having your data, one's having one dataset and then doing a nice analysis and a presentation on doing visualizations on it. But in a business, oftentimes, you're reliant on having pipelines, on operationalizing your data analysis, building at once and then being able to reproduce it over and over again. This is what there is less than this about. In a business, this often means that you have another person, like a data operations is very similar to a DevOps person so Data Ops is often used or ML Ops or machine-learning operations, and that means your team is now growing to another person in addition to the data engineer and the data scientists. But it is extremely valuable to think about this and also to know about this as a data scientist, because you'll still have to hand over your analysis and your code to this data operations person and possibly also help in implementing this. We'll go over operationalizing your data analysis and in this part. As outlined in the data science process, our data analysis often, or our data science process, often consists of getting data, labeling data, cleaning data, exploring our data, and then model-ling our data and making predictions or looking at the causality of data, depending which question you're trying to answer. In a business, you often get new data continuously, new customers signing up, new things coming in. At the Large Hadron Collider, you have continuous data streams one year doing experiments. You really want to automate this process. The pipeline is all about automating it. In the cleaning process, for example, you want to be automating a lot of this writing functions that can be applied to the entire dataset, not filter out individual pieces by hand. You want to make sure that your data is complying with a schema because your data analysis is now fit to a certain type of dataset. Essentially you have your customer data, for example, maybe you have gender, you have purchases or last purchase and then you have date when they signed up. These three features are what your data analysis relies on. If you get new features, then you have to start a new analysis because this analysis might give you new insights. Your pipeline has to validate that the new data that is coming in is within the range of your expected parameters. Already when taking in new data, you want to make sure that your data is conforming to what you expect. Make checks, do tests, and you can automate these tests and your data operations person can probably help you with it. Nice Python library for this as Great Expectations. People have recently been loving this and we do go over schemas in the Python course. Then I have on the Skillshare platform as well. I hope you'll check that out later if you already know some Python. But regardless, knowing about what you have to do is already great. Because if you want to manage a data science team, you have to know what essentially you want to have a high level view. Getting your data in, making sure your data is good, and then making sure that most of these processes, so some of the visualizations that you get in your live dashboard, for example, should be generated automatically from the data. All of this is possible if you write your code in a clean way that you have everything and individual functions that can be applied individually at each step in your data science process. This is really where senior data scientists distinguish themselves from junior data scientists. You write cleaner code and you'll understand how to put each piece of code into a box, into a function where you can then use this to automate the process of doing parts of the analysis. Another very important part in this analysis process, especially if you're doing predictions. We're the customer data predicting if someone will make a purchase, if you show them this or if you show them that is to have a look at key indicators. Something that is called model churn or concept drift. Your machine learning model is built on historical data. Your data science analysis, all the insights are traded from historical data. If right now we were looking at 2021, where most of the world is in lockdown. We're taking insights from 2000-2010, which is a lot of data, 10 years of data would be amazing. But none of this is applicable right now. This is where all of our models and all of our insights are really not as valuable anymore. Because right now, all of this is challenged by changes in the concepts of how people are actually living like the truth, the underlying relationships are completely changing because people are buying much more on line. People will have to use online Zoom calls and a lot of behaviors have been changed. People are working from home. This change is something that would completely disrupt your entire data analysis. Your entire data analysis that you production allies would not be true anymore. Now the pandemic is obviously a catastrophic change. But often you have changes over time in your data, in your customers, people change, trends change, especially if you're a clothing brand, for example, you have seasonality in there. No one is going to buy a nice Bikini in fall. Well, a few people, but you're going to have much more people buying bathing shorts in the spring to get ready for summer. Having these kind of concepts and this kind of testing for, for consistency in your input data. But also in Key Performance Indicators, KPIs in your output, that your data is still performing well. That is very important. Always have a feedback loop in your data pipeline where you check is what I'm doing still automatable, is the still valid or am I getting too many wrong predictions at this point? Really think about that because that is extremely important in looking at the data science process if you're automating this. Not so important in a one-off analysis where you're trying to convince decision-makers. But when you're automating these processes, which is much more important in businesses, and in these large-scale operations. There you really have to think about data validation. Am I getting the right things in? Output validation, concept drift and model churn, where you really want to look at is what I'm outputting also still valid. Oftentimes you can measure your results from the expected output. You're seeing, you're predicting how much a person would spend. Then you see how much that person spends. A lot of times you can basically see with AB testing, for example, if I have not done anything, would that still change anything? This is also going more into the aspects of causality. What I'm doing, is this actually having an effect, or is it possibly even hindering the results? Thinking about this really elevates you above junior data scientists because you're going to be much more valuable to a business if you can think about these tests to perform. When you're managing a data science team, you want to be sure to communicate that this is expected in automating the pipelines. If you're a data scientist, you want to make sure that on these projects that you're building to get a job or in your job. You are also suggesting these kinds of checks to management, to the data ops person because it is extremely important. Once again, if your consider it like this, you are proving yourself as a valuable member of the company and of the team. This will only help you in the future. We talked a little bit about dashboards in this part. In the next class will have a look at some dashboards, and what I mean with live dashboards and why you want to have experience building dashboards and why it's so much fun to be honest.
12. Dashboarding: In this lecture, we'll have a look at dashboards. Dashboards have become really popular, because they give you an overview of a multiple visualizations together, and really tell you about the changes and what's happening in your live system, but also with your data. You can have a tab with map-based views and you can have a tab worker relations or data influx changes. You can monitor your KPIs, you can monitor the health of your system, in total dashboards are this device. In my time consulting, people would always ask about dashboards, how to create dashboards, and it's become much easier. If you are going for low code or no code options, Tableau, Spotfire, and Power BI give you options to create dashboards. We'll have a few on-screen here. When you're going to Python, there are a few players on the block, which is rather new, to be honest, also new to me, but it's so exciting like I love building dashboards. It's very interesting to me. But yeah, essentially, what you can do that is either use Plotly Dash, which is very versatile and interactive as well, or you can use Streamlit, which even uses or can use machine learning outputs. So really powerful when you have knowledge in Python. In dashboards, you want to be careful. Because when I see dashboards, they tend to be overloaded a little bit. So what you want to focus on is first of all, when you open it up, the most important information should be over the fold, above the fold. This is usually something that you talk about in web design, which is based on the old newspapers. When you were going out to buy a newspaper, above the fold is the headline at the big picture. So really the attention grabber, the most important things that you need to know, and this should be exactly the same in your dashboard. First page, in the first frame that you open up, have the most important information that key decision-makers have to see. Then when you scroll down you have information related to this. But really information overload is a problem. Usually what you want to do is be minimalistic about data and about the information that you have on a page. You have all the necessary information to make a decision. But keep color bars in the same shape. Don't overload it and give visualization space, space to breathe. Because if everything is crammed in, that usually just gives everyone like a feeling of overwhelm. Do a couple of passes of how much you can reduce the information. You can always open another tab with another dashboard that has different information. But your dashboard should really have a focus. It should answer a question just like your data science analysis. It can be used as a communication tool. It should answer the key questions people open your dashboard for. It shouldn't throw all the information up. Then they could do the analysis themselves. But you are the data scientists. You need to tell a story with a dashboard and really chisel out what is important for people to see that can't do the data analysis, but that one to know what's happening in the data system in this process, in this project. But obviously, in dashboards, you can use interactive visualizations, which is a lot of fun. Usually, people love interactivity. So being able to select a few things and like hover over information and pan around, those are good decisions. If you can do that, that people can zoom into your data, into your visualizations instead of just having like a static picture, that's usually a really good decision. Zooming into maps, for example, is something that everyone is used to these days because of Google Maps. Make sure that when you do these dashboards that you have intuitive design, build into it. When you see your dashboard, it feels almost indistinguishable to what professional, which you are, would be serving. So does this look like a could be designed by Apple essentially? Is this good design? So, yeah, focus on minimalism. Only show the relevant information to make decisions easy and not overwhelm people. Of course, sometimes people have different opinions. If your key decision leader wants more information on the dashboard, you of course, have to follow this. You have to give them the information that they need. Oftentimes you have to iterate over dashboards as well with the people that actually use them and be flexible about it. You don't always know what key decision leaders, but also subject matter experts really need. So it's really good to get feedback. But with these modern tools, it's also really easy to build these dashboards. So adding another visualization or taking that virtualization, putting it away into a different tab is much easier than before. It's not that much work. But yeah, dashboards are a really good point to skip the perfectionism and rather rely on feedback of the people that are going to use your dashboards. The master discipline clearly is building live dashboards. Having these dashboards hooked up to these operational data pipelines, having live insights into your data, live update, and this is also quite possible, but it is a little bit harder like it has to be at the end of this entire data science pipeline. You will probably want to do that in aggregate, with your entire data science team and with a data ops people. Dashboards are fantastic visualization tool and a fantastic tool for communication because they give people breathing room to take in the story that you're trying to tell. In the next class, we are going to have a look at what other communication tools in total you can use to tell your data science story, to really convey your insights to decision-makers.
13. Communicating Results Effectively: The end result of your data science process is usually communication. With your insights, you usually want to show someone; often subject matter experts or key decision leaders to make a decision based on what you found. Change opinions, really tell a story, convince and communication is key in these aspects. In this class, we'll have a look at communication, and how you can communicate your results effectively. Because a lot of tools these days seem to make it easy, but if you go at least one step further you can communicate the results even better. The key behind all communication is knowing your audience. A lot of newer data scientists often take the Jupiter Notebook, which is a way to mix code, and text, and turn them into PDFs. In a sense, this is problematic because a business leader, for example, doesn't have time to look at your code. Frankly, they gain no benefit out of looking at your code. These Jupiter Notebooks should be used for communication with other data scientists. With coders, so you actually have the documentation for your code as well. But when you talk to people that are more on the management sectors, you do not want to show them code unless they ask for it. You want to be able to visualize effectively. Going back to the class about visualization, you want to really tell the story with images showing them the data in the way that makes it easy for them to decide. In the end, to convince someone is always to make a decision easier for them because they now have certainty because they're backed by data. Backed by math, statistics, machine learning, your work in analytics. In the end, this is also what science is about. As a scientist, writing in paper is all about convincing my peers that I have found something new, something that is better than before, a new insight. Convincing them means really speaking their language, so you have to conform to the straight outline of a paper. Adding good visualizations and the right equations at the right spots is very important, but most of them don't want to see the code. This is changing in somehow at least. In the paper, most people will ask you to remove code. Well, I think make your code presentable, and I like to put it in an appendix or somewhere. Most people don't want to look at code because most people like to have an easier decision by simply following your communication. So focus on visualizations, focus on telling a story, and reduce the amount of code you show to people unless it's appropriate. That way, you can also really go ahead and dive deep into the media that you're using. Then it doesn't only become about the audience where you think about the target, think about the purpose but also the medium. Interactive visualizations are great, but they don't work in PDFs. So really be careful how you communicate these results. If you're going to send off a PDF to someone, you don't have to take time to build a dashboard because it's going to be a PDF. Take time to build high-quality standalone visualizations that speak for themselves that you can integrate into your PDF documentation. If you're doing a PowerPoint presentation make sure that your data, your visualizations are clearly visible and outlined and visible on small screens from the very back of a badly lit conference room. With today, with all these things going on where we have a lot more video conferences, think about how you can share your insights live. Can you give people access to the dashboard so they can try it out? While you're giving your presentation, can they follow some of the analysis themselves? Really think about how you communicate your results, because communication is your key to really convince what's the story that you're trying to tell. As a data scientist communication, and therefore empathy is extremely important. You have all these amazing tools that can help you trade in science, and you have as many amazing tools to really communicate your results, build PDFs, build presentations and PowerPoint, build dashboards, build Jupiter Notebooks to talk and tutorials, and talk with fellow data scientists. But in the end, it is very important that you have communication in mind. If you share your analysis people will gain from your insights, and this is the way to really have a full project and finish the data science process. In the next class, we'll have a look at understanding risk in data science because not every project is going to be successful.
14. Understanding Risk in Data Science Projects: An important part of the data science management workflow is understanding risk. The risk profile of a data science project is much different than that of a software project, for example. If you know something is feasible with a computer, it just takes time and management to finish that project. In a data science project, it may have negative results. In the end, it is a scientific process, seeing if we can even answer a question given the data we have, and it may not be possible. There are the ethical things that I talked about, like maybe we find that answering this question is actually not beneficial to our business, to our question. Maybe it's actively harmful to communities, but also in a much more lighthearted sense it may just be that our model is not performing well. That we can clean the data, that we don't have enough data, and all these things you have to manage. Managing risk means that we have to be in an agile mindset in the end. Everything has to be iterative. It's very good to have daily stand-outs that are very short as you're doing the agile methodology. You want to identify blocks in your team early. You want to communicate on a regular basis. Don't micromanage, but it is important to empower your team to also say, "Hey, this is not working out. We need more data, we need different data, maybe we need to rephrase our question because the insight that we found from this is actually not really working." When you're going from a junior to a more senior position with more responsibilities, it is important to lead your team but also be aware that failure is entirely possible. When you're communicating to stakeholders and decision-makers, it is important to also make clear that failure is a possibility, that these things are exploratory, and depending where your project is. Early projects that do the first exploration, that do the first groundwork, they are much more likely to fail at the stage that they are not feasible at all whereas later projects, you have to be much more careful about the product analyzation of your pipelines. Is it still working? Is it going forward? Especially if you are in younger teams, in teams that are just getting established, be careful about communicating certainty and uncertainty because some things just don't work out. However, these failures can also be insights. This is where you really want to go back to the communication as well because being able to tell that this decision is not possible based on this data is something valuable that you can also sell as an outcome. But you have to leave it open. When you communicate with management and you promise success, you're closing the storm that you can essentially frame this as an additional insight because then this additional insight becomes an automatic failure. However, if you can communicate upfront that failure is a possibility, that there are problems that are not solvable, that sometimes the data is not enough, or there are timing issues, things like that. That you cannot meet performance indicators sometimes and that you have to update iteratively, this is something that you have to be careful with. When you are good at communicating this in advance and managing this risk, you are setting your team up for success. Because regardless of what they do, if they're doing their work and they are empowered to also deliver negative results, this is building a strong team and the team that is eventually building amazing products and is introducing and maintaining data-driven results in a business and will make a business stronger and elevate you and the team in total. In the end, you have to understand as a growing data scientist or as someone that is potentially getting into a management role, that you have to be careful what you communicate and what you promise. But by empowering, by being a good leader for the team that is working iteratively and really giving people their space and the necessary tools, you can make this team a success and really manage the risk of data science projects that are very different from normal projects. This is the final chapter. The next class is going to be concluding this Skillshare class and I'm very happy you attend it.
15. Conclusion: Congratulations for making it. I know this has been a lot of information and for a lot of you it may have been completely new information. But I hope I could show you how these data driven insights and this process of a scientific mind that goes all the way from raw data to communicating results to key decision leaders is such a valuable and interesting point. It just leaves me to hope that you go on this journey and explore this in low code or code opportunities. There's so many different ways to approach this. I'm very happy that you took this class and I hope that you got something out of it. Please consider my other class. I'm giving a class for people that already know some Python and want to learn the data science process here on Skillshare. But definitely explore all the other courses as well. There are some amazing data science visualization courses on here. It is really fantastic to delve deeper into this data driven decision-making community as well. Make sure to find people on LinkedIn, follow influences on different social media and learn more about data science because there are so many interesting and fascinating things coming out. When you keep looking at data, you will be much more secure in your decisions because these decisions are actually based in fact. Thanks for attending. I'm so grateful you were here. I hope you enjoyed this class. Please make sure to try out the project and post the project. I'll be very happy to see what you come up with.
 Jesper Dramsch, PhD, Scientist for Machine Learning
Jesper Dramsch, PhD, Scientist for Machine Learning