Transcripts
1. Introduction to Data Science with Python: Data science in a sense, is like a detective story to me. You unravel hidden relationships in the data, and you build a narrative around those relationships. My name is Jesper Dramsch and I'm on machine learning researcher and data scientists. I spent the last three years working towards my PhD in machine learning and geophysics. I have experience working as a consultant, teaching Python and machine learning in places like Shell and the UK government, but also midsize businesses and universities. All this experience has given me the ability to finish my IBM Data Science Professional Certificate in 48 hours for a course that's supposed to take about a year. I also create exactly these notebooks that you learn to create in this course for data science and machine learning competition, one type called Kaggle, which is owned by Google. There I gained the rank 81 worldwide out of more than a 100,000 participants. After this course, you will have come through every step of the data science workflow. That means you'll be able to recreate all the visualization, and have all the code snippets available for later for use with your own data in your own reporting. We'll do a very applied step-by-step. We'll start at the very beginning, starting with getting your data into Python. That means looking at Excel files and looking at SQL tables, but also looking at those weird little data formats that sometimes can be a bit tricky to work with. Then we'll preprocess our data, clean our data, and do exploratory data analysis or short EDA. EDA is that part where you really refine your question, and where we have a look at the relations in our data and answer those questions. Afterwards for fun, we'll have a bit of a look at machine learning modeling and how to validate those machine learning models, because in this modern time, this is more important than ever. We'll have a look at different data visualizations, how to best tell your story, how to best generate presentations and reports to really convince, to really punctuate your story that you can tell that data. Very finally, we'll have a look at automatically generating presentations and PDF reports directly from Python. I have the unfortunate lack of graduating into recession twice now. But Python has given me the ability to finish a PhD while working as a consultant and making these amazing world-class data science portfolios for myself that have now generated so much attention. It's amazing. One of my notebooks has been viewed over 50,000 times. I hope to share this with you. Data signs for me is the super exciting new field and Python is very accessible. So I hope to see you in class.
2. Class Project: Welcome to class and thanks
for checking it out. I'm really happy to have you. This class will be an
bite-sized videos that are part of larger chapters
because then you can come back and have a look at the small details and not have to search in
the larger the news. And each chapter will be one of the steps in the data
science workflow. In the end. Because they just
sines isn't applied sine one over protein. And then this project, you'll recreate what we do
in these video lectures. Go through the entire
data science workflow, and in the end, generate PDF for a
presentation with your fine, It's good on your own data, on a dataset that I
provide on top of that, and make all of these notebooks available to use so you can code along during the videos because
it's best to experiment. Sometimes you see something, you want to create,
something different, you want to
understand it better. And then experimenting
with the code that I have on screen is really
the best way to do it. For the first
couple of lectures, I want to make sure that everyone has an equal
starting drought. Work a look at the tools. We'll have some
introductory lectures where we really get
African objects. And then we'll start
with the entire dataset. What though very brutal
loading, cleaning, exploratory data analysis and all the way to machine learning. And we call generation.
3. What is Data Science?: In this class we'll look at data science from two
different perspectives. So there's one where
we'll have a look at what actually constitutes
they designed to act. What are the important
fundamentals? And there's the other one,
the process approach. How do you actually
do data scientists? Defining data science as a
bit of a beast because it's such a new discipline
that everyone has bid of different leukemia. And I liked the
way that Jim Gray, the Turing Award went out, basically defines it
as a Ford Pinto signs. And that data science or
information technology. And three, Need Changes
Everything about science. And I think the impact of data-driven decisions
on signs, business, it has shown up my favorite
ways to look at data science, data science hierarchy of needs by unwanted care
rogue our teeth. And she really defines
it as this pyramid. All base level
needs and Ben Wolf, more niche needs
as you go higher. And at the very base of that hierarchy of needs
is collecting data. And we have to be aware
that already under collective process
by this out-of-date, lot of people like to think that data is unbiased, that true. But that's really not the girls. A lot of times even then
physical systems bias our data, are read by collecting and
then go on to level tooth, moving and store it big. So making sure that we
have reliable storage, reliable slow of data, having a ETL extract, transform and load
process in place to really help the
infrastructure of data science. Next level level of breed is exploring and
transforming data. So doing anomaly
detection at cleaning, preparing our data
for the actual MLS. Step four is aggregating
and labeling the data, deciding for metrics
that we'll use and looking at the features
and the training data, the panel ultimate step is
doing the actual modelling. So doing AB testing, testing between one version
of the website and another, and experimentation
simple machine learning algorithms
to gain insides to model the data and to make predictions based on the
tip of the pyramid heads, AI and, and people nodding. So the really juicy stuff, but also that stuff that most companies
actually don't think. This roughly summarizes
how much time you should spend on each step within
the perimeter as well. So if you don't spend anytime acquiring data
of thinking about data, then you'll probably have
a problem down the line. Another way to look at data
sciences asking questions. The data science process
is fundamentally about asking questions
about your data. And it's a very
iterative approach. So in the beginning, you pose the question, acquiring these data, but how is the data
actually sampled? This goes into the buyers data. Which data is relevant, and then you go on to explore the data to the
exploratory data analysis. Andrey inspect. Sometimes you have to go back. It's an iterative process. During exploration, you'll see that some data
source would really help that information
you have in your data. So you go back and
forth between steps. Then you model the data, build a simple machine
learning model or just like the hierarchy of needs and really gained insights by modeling your data with
simple algorithms. Finally, and this is not part
of the hierarchy of needs, but it is definitely part of the data science process is
communicating your results. What did we learn? How can we make
sense of the data? What are our insights? And how can we convince
people of the insights about how we all know that sometimes knowing
the truth isn't enough. You have to tell a compelling
story to convince people of Jane science and to really make an impact with
your day two sides. So this class will show you the entire process
and also how to generate those
stories out-of-date.
4. Tool Overview: Let's have an overview over the tools that we're
using in this class. Obviously, everything Data science-related
will be universal. But also learning Python is extremely valuable
to your skill set. Python has gained a lot of popularity because it's
free, it's open source, it's very easy to use and it can be installed on
pretty much any device. So Mac, Windows, unix, your phone even
on not a problem. And hi thinness code for humans. So a lot of places, Google Ads, YouTube,
instagram, Spotify, they all use at least
and Pub Python because it's so easy to get new
people on board with Python. Because if you write
good Python code, it can almost be read like text. Will install Python 3.8 using
the Anaconda installation. Anaconda is nice because
it distributes a lot of data science packages that we already need and it's free. If you're on a later
version of Python, that should be completely fine as long as it's Python, pray, you may be wondering if you
need to install some kind of IDE or some kind of
compiler for Python. And that's not the case. We'll be using Jupiter, which is a web-based
interface to Python and makes teaching Python and learning path
and extremely easy. And going from that, you can always go
to another editor. One of my favorites is VS code. It's gotten really good
for Python development. And VS code actually counts
with an interpreter. And views code
actually comes with an extension for
Jupiter as well. But that's for another day at the base of anything
we do this NumPy, it is scientific computing
library and Python. And we won't be interfacing
with that directly, but I want you to
know it's there. So always when you need to
make some kind of calculation, you could do it in Python. It has been used to
find black holes. It is used for sports analytics and for
finance calculations. And it is used by every package that we will
be using in this course. You will quickly notice
on this course that everything we do is
depending on pandas. Pandas is this powerful
tool that is kind of a mix between Excel
and SQL for me. And it's really a data analysis
and manipulation tool. So we store our information with mixed columns in a DataFrame. And this DataFrame then can
be manipulated, change, added onto just within this tool for the
machine-learning portion and the model validation
when using scikit-learn and libraries built
upon scikit-learn, Scikit-learn has
changed a lot how we do machine learning
and has enabled part of the big boom that we see in machine-learning interests
in the world right now. Matplotlib is a data visualization
tool and we'll mostly be using libraries that
build upon matplotlib. But it's very
important to know it's there and it has an
extensive library with examples where you can have a look what
you'd want to build. Seaborn as a one-off
these libraries that build upon matplotlib. And it's extremely
powerful in that it often takes a single
line or a couple of lines to make very beautiful
data visualizations of your statistical data. These are the cornerstone tools that we'll be using
data science. There are open source, they are free and they're the big ones. But we'll be using a couple of other smaller tools that I've grown to really like as well, but I'll introduce
them along the course. The documentation of these
open source tools is amazing because it's also built
by volunteers like me. I've written part of the pandas and the scikit-learn
documentation, and you'll find that
it's really helpful with a small nifty examples that'll really make you
understand the code better. If you're using these in a corporate setting,
they're still free. But consider becoming
an advocate for sponsorship because
these packages really rely on having paid developers and
core maintainers.
5. How To Find Help: It can feel really daunting
doing this course. I totally understand. I'm constantly learning. I'm doing these courses
and being alone in these courses is terrible. But Skillshare has
the project page where you can ask for help. And in this class will also have a look at all
the different ways, how you can find help and how you can learn help yourself. Because every programmer
will tell you that they got increasingly
better at programming. One, they learned how to
Google for the RIF payments. To start out, we'll have a
look at the Jupiter notebook because the Jupiter notebook
directly wants to help us. So if we have any
kind of function, even the print function, we can use Shift Tab. And when we hit it,
once, it opens up, basically the basic description, so we get the signature
of our function. That means print this the name. This is the first argument, and then the dot-dot-dot
is just small. And these are the
keyword arguments. And it gives back the first, I'm the first sentence out of the documentation
in the docstring. So while we can hit
Shift Tab several times, two times, just opens up
the entire docstring. Three times makes
That's the docstring is open longer and you
can click here as well. And all that. And four times will cast it to the bottom here. So you have it available while you're working
and you can just pop it out here
into its own side, but also just close it down. And an addition. Well, so we'll be
working with Pandas. So when we start typing, we can often hit Tab
for autocompletion. And this is really
my personal way of being a bit lazy when typing. So when I want to import pandas, I can hit tab and see which
kind of things are installed. Pandas as pd
executing right here, I'll deal with Control Enter
to stay in the same place. And Shift Enter. It's going to executed and
get me to the next cell. And here I can also, so P D is now our pandas. When I hit period and Tab, it'll open up all the
available methods on PD. So here I can really
check out anything, like if I want to
merge something, I can then hit the parenthesis, shift tab into it and
read how to merge it. Now, this can be a
bit rough to read, even though we can put it all
the way on the bottom here. And that is why there is
the pandas documentation, which is essentially built from the docstring with a little
bit of formatting tricks. So you can see right here
that you see what this is, the signature of it. And you can read
into it and even have a look at the examples
and copy over the examples. One thing to know in software is that these kind of
codes that are here, I mean, then nothing great. You don't have to well, you don't really have
to type them out. You can just copy
them over and say, alright, I needed this. Now, I have a nice DataFrame
with age is cetera. So copying something like
this is super common. It is just what we
do in software. The next way to get
help is goodwill. And I sometimes make the joke that in
interviews you should just have people at Google Python and see if it shows snakes or if
it shows the Python logo. Because at some point google
starts to get to know you and shows you
more and more Python. And it's a good way to see that you have a lot of
experience in five. So when you want to ask
any kind of question, when you're stuck with anything. Like you have a very
obscure data format that you want to load. Or you just have
an error that you don't really know what to
do with your copy it over. And let's say you have
a type error, e.g. just have a look here and then there is usually a
highlighted one. But of course, Google
always changes and you are often
lead to the docs. So in this case it's
the Python docs. And then one of the links is going to be
StackOverflow as well. And StackOverflow
is this website that well, it's
extremely helpful, but it's also not the
best place for newbies because some of the best experts in the world on this website
answering your question. But if your question is
not well formulated, some of the people
on this website can sometimes be a bit
unfriendly about it. However, for browsing and
for finding solutions, like your question has
probably been asked before. If you can't find it
on StackOverflow, try changing your Google
query a little bit. So you find different kinds of results like what kind
of type error or did you have a copy over the entire name of the
type error and all that. So really then you want to
scroll down to the answers. And this one isn't really
upvoted that much. But oftentimes you
have an upvoted on. So that is very, very popular. And sometimes you can even
get accepted answers. Like have a look at this one. Here you have a
green check mark, which means that
the question asker has marked this as
the excepted answer. And you can see right
here that people put a lot of work into
answering these questions. You have different ways to see this with code examples and you can really check out what to do next with
your kind of error. Let's go back to Jupiter
and close this one out. Because this is also something that I do
want to show you. In Python. Arrows are cheap because we
can just readily do them. If we have something like this, it'll tell us right
away what's going on. So there's something
weird in the beginning. But what I really
first do on any error, however long this is, this is a very short arrow. Scroll to the very last
line and have a look. Oh, okay, this is
a syntax error and it says unexpected
EOF while policy EOF, EOF means and a file. So if you don't really
know what this is, copy this over, checkout
Google and have a look. If Google tells
you what this is. Oftentimes the Google search is better than the search on
their websites itself. And here, it means
that the end of your source code was reached before all codes were completed. So let's have a look
at our code again. Here. If we close the parentheses, our code is now completed
and it works quite well. Let's, let's generate
a nother error. Yeah, something that we can
definitely not do is have this string divided
by some number. So if we execute this, this gives us a type error. So we'll scroll all the
way to the bottom and say, Well, see what's
happening right here. And it tells you that the division is not possible for strings and for integers. And really going
through arrows is your way to be able to discern why Python does not like what
you've written right here. Since we're on the topic of help and I won't be able
to look over his shoulder. And the classes that I gave a very common error that
you can catch yourself is that these Python notebooks do not have to be
executed in order. So you see the little
number right here next to what it has been
executed and what hasn't. Lets make a small example, add some new, new things here. Let's say right here
I define a, N, here. I want to define b. And b is going to
be a times five. And I go through here, I experiment with this. I have a look at PD merge, have an error here,
which is fine. We can leave that for now. Run this code, maybe
print something. And you can see these
numbers are out of order. This is important later. Then I execute this cell and
it gives me an error name, error name a is not defined. And that's because this cell
does not have a number. It has never been executed. So just something to
notice that you have to execute all the cells that you
do that you want. Because. When we run this one
and then run this one, this is completely fine. So really have a look at the
numbers and the next arrow. And that is very
related to this, is that sometimes we change something
somewhere like here. And we change a to B to six. And then we run this code again. And suddenly we have
a look and b is 30, although a is five here. And this is one of
the big problems that people have with
out of order execution. And you have to be
careful about this. So either you just have to
track which cells you did. And especially with this, like there's like 107849, this gets really hard
to keep in mind. Especially you can
delete these cells. And a is still going
to be in memory. So we can still execute this despite the cells not
existing anymore. So sometimes you
just have to go to the caramel and say
restart and clear output, which clears all of the variables and clears all of the outputs that
we have right here. So we can go here, hit this big red button, and now we have a fresh notebook with all the code in here. Now we can execute this in order get all our
errors that we have, and see right here
that a is not defined. So we have to basically add a new line here and
define a again. And that way you can
catch a lot of errors in Jupiter by having a look
at the numbers right here, did you forget to execute something or did you
do it out-of-order? Yeah. In total. What you want to
do to find help in Python is, remember shift tap. Remember that tab,
autocomplete your queries and can give you
information about what's, what methods are available
on basically anything. Then you want to get really
good at Googling things. In some of my classes, some of the people
that I got a bit well that I became friends with, they laughed at me at
some point and said, your class could have essentially
been just Google this because at some point everyone has to Google stuff and there are some funny posts
on Twitter as well of maintainers of libraries having to Google very
basic things about their own libraries
because our brains are only so reliable
and things change. And if you want to have
the newest information, there's no shame in
looking at up when you're done with googling, with looking at up
on StackOverflow, copying over some kind of code. You'll be better off for it. Now all these tools
to find help and Python and help yourself. And this gives you
the necessary tools. Dive into data
science with biking.
6. | Data Loading |: The first couple of classes will be getting data into Python. So whether you have data in the tables are in your SQL
database, it doesn't match up. We'll put it into Python
in a tool called pandas, which is essentially
excellent steroids in Python. And let's for your data.
7. Loading Excel and CSV files: This is the first class
where we touched code. So open up your Jupyter notebook if you want to code along. We'll start with loading data. So I have provided
some extra files and CSV comma separated value fonts and we'll get into loading them. We could write this by
hand and I'll show you on a much simpler example as well how to write something
like this by hand. But luckily, with Python
being now over 20 years old, a lot of people have already
put a lot of thought into extending Python
functionality. So we can use this
pandas here and extend Python to load
data into Python. So what we do here is we
just say import pandas. And this would be enough for, because we'll be
using Pandas a lot. Usually we give it a shorthand
up to some kind of alias. Pd is a very common one
that a lot of people use. And then we execute the cell and we now have
pandas and Python. And to import or read data, we can do the PD, don't read, hit tab and see all the different ways you
can load data into Pandas. In this course,
we'll have a look at the most common ones that I found in my work
as a data scientist. But I'll show you how to
find the others as well. Because if we don't really
know what we're doing, we can always have a look
at pandas documentation. While we can have a look
at everything that we can do with pandas, since we have read
X0 here already, we can also hit Shift Tab and have a
look at this signature. And you'll see that this
looks eerily similar to the documentation
because pandas and all of Python actually comes with its
documentation built. And so it's very stand-alone
and very user-friendly. So in the beginning we just need to give the filename where
we actually have the file. And this is gonna be data
slash housing dot XLSX, the new kind of extra file. And loading this will execute. And we see we have all
these data now in Pandas. We didn't save it into
a variable right now. But what we usually do if we just have a temporary dataset, we call it df. Because in Python, this
is called a DataFrame. So it is basically an XO representation of a
single sheet in your Python. Because we want to have a
look at it. Afterwards. We'll just call head on
our DataFrame and have a look at the first five rows. We can see here ride the
headers and our data. Csv files are a little bit different because CSV
files are raw data. Let's have a look
here. I have the data. We can actually have a look at CSV comma separated values in notepad because it's
just text and it's fantastic for sharing
data between systems, especially if you have
programmers that might not have Microsoft Office available. This is the best
way to share data. We pd read CSV and we can just give it
the file name again. So housing dot CSV. And this should, let's call
it head right on this one. This should give us the
same data and we can see they are the same. I want to show you a
really cool trick though. If, you know some
data is online like this dataset of medium
articles on free code camp. He can actually colored pd, read CSV, and just
give it the URL. But this is going to fail. I'll show you, we have to learn that arrows and
Python, that's fine. It's totally okay
to make errors. Read the last line, pass error tokenizing data. So something like expecting
something different. And you may already see here
that this is not a CSV, this is a TSV file. So someone was actually
separating this with tabs. And to put tabs, make this backslash t
character as the separator. And we can import
this data right from the Internet by just
giving the correct keyword. And this is something
really important to see, really important to learn. If we have a look at this, there's a lot of keywords
that we can use. These keywords are extremely useful and cleaning
up your data already. You can see right here that there is something called NaN. This is not a number
that we have to clean later curing
the loading of this, we can already have a
look at things like, do we want to skip blank lines? So it's really,
pandas has a very user-friendly if you want to
experiment with this one. I'll leave this in
the exercise section. And you can check out if you
can already clean it off. Some nans will have
a dedicated section of cleaning data later as well. The loading data into
Python with pandas is so extremely easy. Try it out with your own data. If you have an XL file lying
around on your computer, remember all of this
is on your computer. Nothing gets out. So you can just pd dot print and getting your
data and play around with it. This class we worked through loading Excel tables and comma separated value
of files and even had a look how to load
data from the Internet. Next class, we'll have
a look at SQL tables. A few nano work with them. Feel free to skip it. The next class will
be that ride for you.
8. Loading Data from SQL: Sql databases are
a fantastic way to store data and
make it available to data scientists working with
SQL to what be too much. There's entire courses here on Skillshare that I'll link to. You can find them right here
in the notebook as well. However, it's good to have
an overview because it's really easy to load the data
once you know how to do it. And if you work with SQL, this will be really
valuable to you. Most companies do not
store that data in Excel files because Mexico
gets copied, it gets copied. And suddenly you end up with
final, final, final version. And it's probably on
someone's PC somewhere, maybe on a laptop. Instead. A lot of places have databases. On a server, this database that contains all this
information that you need. Usually this way of accessing
information is called SQL, which is short for
Structured Query Language. This is some language in itself. It would be too much to
explain this in this course. If you want to learn more, there's courses on Skillshare and there's also
resources like this, which are linked where
you can try it out, do the exercises step-by-step, learn how to ride up a query, get data into Python
in advanced way. It is absolutely enough to
once again import Pandas. Then we can have a look and
there is SQL down here. What you can do here is
actually three different ones. There's a general one, SQL, there's a SQL query. There's a table read SQL
in the documentation. That's usually a very
good place to start with. See that there's
two kinds of waste. If we scroll down, we can see that
there's different to SQL table and SQL query. Let's have a look at the
query and this needs you to write a SQL query. Some of them can be very simple and can save you a lot of space. So if you have a big
database SQL table just loads the entire
table from your server. In addition to Pandas, we actually want to
import SQL alchemy. And then below this will
create the connection. So it's called it an engine. And let's have a look
what we need in here. So if you have a
postgres SQL database, we can just copy this. This should be the
location of your database. Here. We go read sequel table
just to make it easy. And now, if you had
your SQL database, you can put your
name here, like e.g. sales as the connection here. If we wanted to actually
use the SQL language, we would have to
use read SQL query. And that means in this case
that we need to define a query that goes
into our connection. So this query can be
very, very simple. Of course, this query can be
as complicated as you want. So we actually take the multiline string
here from Python. So we can say Select customers and total spend from sales. And because it's
such a big table, we want to limit it to 1,000 entries because we
just want to have an initial look
and we don't want to overload our computer. Addition to that. We want to
say that the year is 2019. Now we can copy over this
entire thing over here and select our data from our imaginary
database right here. Using SQL query is, hopefully in this
class is all about. Sql can be quite easy. You can just get the table from the database and work
with it in Pandas. Now, the next class
is going to be how to load any kind of data. And we'll show that pandas makes everything a
little bit easier.
9. Loading Any Data File: Sometimes you have weird
data and I'm a geophysicist, I work with seismic data. And there are packages
that can load seismic data into Python
just like our CSV files. And in this class, we'll have a look how to load any data and how to
make it available. In Python, pandas is great for tables and structured
data like that. But sometimes we have
different data formats, like just a text file or
images or proprietary formats. So when I was mentoring class at the US
Python conference, someone asked me about this super specific format
that they work with. The first thing I
did is I googled it. There was a Python
library for it, and I'll show you how to use. Most common Python libraries
will use the text file. Unlike the text
file we have here, it's a CSV, but it's
still a text file. As you can see,
what we say is open and then we have to give it the place where it
is and the name. Now let's shift tab into this. There are different
modes to stand up. Mode is R. Let's have a look what
these modes actually mean because you can open
files on any computer, just most programs
do it for you. And read mode, right mode, and in append mode. So you want to make sure that if you're reading data that
you don't want to change, this is set to r. Let's make this explicit. Then we give this file that we opened a name so we can
just call this housing. And Python, whitespace
is very important. So now we have a block
which I'll file is opened. And within this block, e.g. we can say data equals
housing dot read, and this reads our data. Now if we go out of
this block there, we can actually work with our variable without
having the file open. And this is
incredibly important. A lot of people that are new to programming don't know this, but most files can
only be opened by one person and one
program at one time. If to try to access
the same data, it will break the data. So it's really important
that you open your data, save it into variables
loaded into Python, and then close everything. So if we have adhere
in the state of variable and go
out of this block, Paul just execute this
and go to the next cell. We can do stuff with data bike, have a look at what is in data. And we can see it right
here that this is a text file without
having the file open, which is just a very easy
and accessible way to do it. We can also have a look housing as our
file handler right here. And we can see that this tell us if housing
is closed or not. So right here, we can see that after this
block is executed, it will be closed. Let's have a look at how
this looks inside here. So inside here,
it is not closed. That means we can read
different lines and all that. However, instead of just using
the standard Python open, we can use a lot of different libraries that also
give us finally handlers. So I can use something
like, I'm sick. Why IO, which you have probably
never heard of before. And that's why I want it I want to show it
to you real quick, which is just a way
to import this. After importing this, we can
say with segue I 0 dot open, give it the file, name it S, and then load all the
physical data into Python. And after their
system, the file, once again, this
closed and was safe. So this is really, this is a very general way to go about loading your
data into Python. And as you can see here, our CSV doesn't look as nice as, as it does in Pandas. But with a bit of processing, we can actually make
look as nice as pandas so we can split it e.g. on these new line characters, which is backslash n. And we can see that
this already gives us all these lines in here. And we can go on and
split up each of these line on the comma because of this comma
separated and so on and so on. But that's why I showed
you Pandas first. Because it's so much easier. And I think it's very nice to go to these high-level
abstractions first, but also see how to do
the work and the back. And this class we're
had an overview of what the width L Can statement
does and how to load any kind of data search for data loaders for
the weird formats that we sometimes have. And I think we definitely saw how easy
Pandas makes it for us because splitting a CSV file like Vout is really cumbersome. And then cleaning the data like missing values is even worse. And the next class on have
a look at huge datasets. So what happens when
our files becomes so large that they don't
fit into memory anymore, how can we load this data
and how can we deal with it?
10. Dealing with Huge Data: It is quite common that
especially in larger companies, you have datasets
that do not fit into your computer's
memory anymore. Or that if you do
calculations with them and the calculation will take
so long that essentially you borrow and in some cases, you would take longer have then the Universe
already exists. So that means we have to find ways to work with the data to make it
either small and memory. We'll talk about that. But also how to sample the data. So you have a subset because oftentimes it is a valid
to just take a sample, a representative
sample of big data, and then make calculations, do the data science on that. And this is one
we're getting into. We'll import pandas as pd, and then we'll
load our data into the df DataFrame with read CSV. We will do this
explicitly now because we can change it later to see the differences between
different loading procedures and how we can
optimize our loading. This gives us the following
memory footprint of our loaded DataFrame
will have to say deep equals true because we have some objects in there
that have to be measured. You see right here that ocean proximity is quite a lot larger than
everything else. And that's because ocean
proximity contains string data. So we know it is categorical. We'll have a look at
the head real quick. Right here. It is categorical and
everything else is numbers. The numbers are very efficient, but having strings and there can be very
memory intensive. If we have a look
at the deep types. So the datatypes,
we see that right now ocean proximity
is just an object. Everything else is
float, so a number. But the object right
here is what makes it so large in memory,
because an object, we can change the datatypes of our DataFrame when we
loaded it will do this by saying df of ocean proximity because we want to
change ocean proximity. Copy all of that
and we'll override our ocean proximity
with this dot as type. And we can use a special datatype that
pandas has available, which is called
categorical or category. What? This improves our memory usage. Deep equals true. So we see only the memory
footprint of the columns. And we can see that this
improves our memory usage of ocean proximity
significantly even below the usage of the numbers. And this is how you can make your dataframe more
optimal in a simple way. Now an obvious problem with
this is that we already have this data in memory
and then we're changing it. So the memory footprint
of this is still large. We're just reducing
it afterwards. What we can do is change the
datatypes during low time. So let's have a quick
look in the docstring. And there we go. It's D type. And we'll assign a dictionary where the key is our column. We'll use ocean proximity again. And the value is going
to be the datatype. That means you can use
as many as you will. I made a typo there and a typo
and housing that will go. And using this, you can also
assign the integer type two numbers and really change your loading at loading time. So d of small, Let's have a look at the
memory footprint of this. So USD of small memory
usage, deep equals true. And we can see right here
that this automatically at loading time changed our memory footprint
of the DataFrame. So what if instead of loading the entire DataFrame
with all columns, all features
available, we choose to only take a subset
of the columns. Maybe we don't need everything. Maybe we don't need the median
house price in this one. So we'll define a new DataFrame and we'll load the
data as always. But in this case, we'll define the columns. So that's columns. And in this case
we'll need a list. Let's have a look, use
longitude and latitude. And we'll, we could also use total bedrooms or
something like that, but we'll just use the
ocean proximity as before. Just paste this in edited. So it's actually the
column names per list entry and add ocean proximity. Now, this is going to
go wrong and I want you to learn that it's absolutely
okay to make mistakes here. Because in Python,
mistakes are cheap. We can see that type error. It says that it doesn't
recognize one of the keywords. And that's because I use
columns instead of use Coles. I, I honestly can't remember all the keywords
because there are so many, but that's why we have the
docstring and corrected. Looking at the DataFrame, we only loaded longitude, latitude, and osha proximity. Another very nice way to save
some space while loading. And this way we can load a lot of rows with only a few columns. Sometimes the problem isn't really loading the data though. All the data fits
into our DataFrame. But the problem is
doing the calculation. Maybe we have a very
expense function, very expensive plot
that we want to do. So we'll have to
sample our data. And Pandas makes this
extremely easy for us. Each DataFrame has the
method sample available. You just provided a number
and it gives you as many rows from your
DataFrame as you say. In that, let's have a quick
look at the docstring. We can define a number or a
fraction of the DataFrame. And since it's a stochastic
sampling process, you can provide
that random state, which is really important
if you want to recreate your analysis and provide it to another colleague or
another data scientist. And then you will have to input the random
state right there. So we can see right here that it changes every time
I execute the cell. But if we set the random
state to a specified number, it can be any integer
that you want. I like 42. And just see right here
that this number is 2048. And if I execute this again, this number does not change. So this is a really good
thing to get used to. If you have any random process. That random process is great when you use
it in production. But if you want to
recreate something, you want to fix that random
process, so it's reusable. What I often do is I go in the very first cell
where I import all my libraries and I fixed the random state and
there as a variable. And I just provide that variable
in stochastic processes. That makes it a little
bit easier and very easy to read for the next data
scientists who gets this. Sometimes you have to get
out the big tools though. So we'll use task of x and
we won't use it right here, but you can try it on the
website if you go to try now. And dusk basically
as lazy DataFrames, so it doesn't load the
entire DataFrame into memory when you pointed to the
dataframe or to the data. But it knows where it is and when you want to
do the execution, it'll do the execution
and a very smart way, distributed over
even big clusters. In this class, we
had a look at how to minimize the memory
footprint of data. So how we can load less data or how we can load
data more efficient. I also showed you a quick look
at some tools you can use if you want to use
lazy DataFrames, e.g. so DataFrames that are
in rest when you load them and then when you do the computation and
does that chunk wise. So it's a smart way to deal
with large data at rest. The next part, we'll
have a look at how to combine different data sources. So how we can really
flourish and get different information sources
to really do data science.
11. Combining Multiple Data Sources: The biggest impact really comes from combining
data sources. So maybe you have
data from sales and advertisement and you
combine this data to generate new insights. And in this class
we'll have a look how we can merge data, join data together, and appending new data
to our DataFrame. As always, we'll
import pandas as pd and save our DataFrame in df. Now we'll split out the
geo data with latitude, longitude, and the
ocean proximity into the df underscore. Go, let's have a
look at the head. And we can see that's
three columns, exactly like we defined. And now we can join it. Joining data sources
means that we want to add a column to our DataFrame. So we'll take our df
underscore GO and join a column from the
original dataset into this. Now this is technically
cheating a little bit, but it's just making it
easier to show how we do it. Well, choose the median
house price for this one. Let's have a look at
the whole dataframe. And we can put that into our
G. We can see how this now contains the original
geo DataFrame joined with the column
median house value. This is a little bit
easier than normal. Normally you don't have
all the columns available, but it will have a look at
how to merge DataFrames. Now, while you can be a
little bit more specific, Let's create a price DataFrame
first with longitude, latitude, and the
median house price. And what we'll do now, one, merge both of these
into one dataframe. So we take the geo DataFrame
called geo dot merge. Let's have a quick
look at the docstring, how to actually do this. So we want a left DataFrame
and the right DataFrame. And we create all
we define a method. How to join these? The inner method means
that we only keep the data that is available
in left and right. Let's have a quick look at the left and the
right DataFrame. The natural join
is the inner join. So only the rows and
the columns from both DataFrames are
there, that are there. The left one is everything from left and only the
right matching ones. And the right join is everything from the right
and the left matching ones. The outer join is everything. So we fill it up
with a lot of nouns. And we have to define
the column that the left and the right
DataFrame are merged on. So we'll take latitude
in this case. So we have something that we can actually combine
our datasets on. If you have your data sources, left and right should
be the same data, but they can have
completely different names or that work quite well. You can see that
everything is now merged. We can also
concatenate our data. So that means we'll use pd dot
concat for concatenate and provide the DataFrames that we want to combine into
a larger DataFrame. Now, in this case we have two. We can combine as
many as we want. And right now, you
see a good way to add new data or new data points
to the rows of the DataFrame. Wherever you don't have
data, NaNs are provided. However, since we want
to join the data, we provide a join and the axis. And you can see
everything is now joined into one large dataframe. This class, we had
an overview of how to combine different
data sources and generate one big dataframe so we can do an analysis combined. And that concludes our
data loading tutorial. And the next chapter, we'll have a look
at data cleaning. Probably the most important
part of data science.
12. | Data Cleaning |: After loading the data, we have to deal with
the data itself. And any date and data
scientists will tell you that 90% of their work is done
in the cleaning step. If you do not clean
your data thoroughly, you will get bad results. And that's kinda why
we spend a lot of time having a look at
different missing values, outliers, and how
to get rid of them. And how to really improve
our dataset after we loaded. Because sometimes the
measurements are faulty, sometimes data goes
missing or gets corrupted, and sometimes we
just have someone in data entry that isn't
really paying attention. It doesn't matter. We have the data
that we have and we have to improve the data to a point where we can make
good decisions based on data.
13. Dealing with Missing Data: The first step in the data cleaning process for me usually is looking
at missing data. Missing data can have
different sources. Maybe that data is available, maybe it got lost, maybe it got corrupted. And usually it's not a problem. We can fill in that data. But hear me out. I think oftentimes missing data is very informative in itself. So while we can fill in data with average or
something like that, and I'll show you
how to do that. Oftentimes, preserving
that information that there is missing data, there is much more informative
than filling in that data. Like if you have an
online shop for clothes, if someone never clicked
on the baby category, they probably don't have a kid. And that is a lot of
information you can just take from that information
not being there. As usual, we'll
import pandas as pd. And this time we will
import missing number, the library as MS, NO. And we'll read the data
in our TF DataFrame. Missing number is this
fantastic library that helps visualize missing values
in a very nice way. So when we have a look at the F, we can see that total bedrooms has some missing
values in there. Everything else seems
to be quite fine. And when we have a
look at the bar chart, we can see that to really have a look at how well
this library works, we have to look at another dataset and
there is an example dataset in missing numbers
that will now load. To see. We'll load this data from quilt. You have this installed as well. But down in the exercise you can see how to get this data. We will load this New
York City collision data. It is vehicle collisions that we'll get
into our variable. And this data has significantly
more missing values. We'll have a quick look. There are a lot of very
different columns and we can already see that there's
a lot of nouns for us to explore with
missing numbers. We'll replace all
the nan strings with the NumPy value np dot nan. Numpy is this numeric
Python library that provides a lot of utility. And np dot nan is just a native data type where we can have not a number
represented in our data. This is the same thing
that NumPy does when you, this is the same
thing that pandas does when you tell it to, um, give nan values. In my data. Oftentimes this
can be a -9.9 to five. But it can be anything really. And you can specify it
to anything you want, which is then replaced as NAM. So you know it is
a missing value. So let's have a look at yeah, I'll leave that for later. Let's have a look at the matrix. We see there's more
columns in here and the columns are much
more heterogeneous. So we have some columns with
almost all values missing. And on the side we can also see which row has the most values filled out and which row has the least value is filled out. Sorry about that being so low. Let's have a look
at the bar chart. And we can see
which columns have the most data filled out and which have the
most missing data. Now the dendrogram is
a fantastic tool to see relationships
in missing data. The closer that the
branching is to zero, the higher the correlation
is of missing numbers. So that means on the top right, you can see a lot of values
that are missing together. This is an easy way to count all the values that are
missing in this DataFrame. Let's switch back to
our original DataFrame, the house prices, where we can also just count
the null numbers. And we can see that
total bedrooms is the only one that has
missing values with 207. So in addition to
looking at missing know, we can get numeric
values out of this. Let's have a look at the
total bedrooms right here and add a new column
to our DataFrame, which is total
bedrooms corrected. Because I don't like
overwriting the original data. I'd rather add a new
column to my dataset. And here we say, fill our missing values with the median value
of our total bedroom. Because total bedroom
is account so the mean value,
the average value, doesn't make sense,
will rather filled with the most common
value in bedrooms. There we go. This would be the mean
and this is the median. Luckily, pandas makes all
those available as a method, so it's very easy
to replace them, will replace it in
place this time, but you have to be
careful with that. It's sometimes not the
best practice to do this. And now we can see total
bedrooms corrected does not have any
missing values. When we have a look
at total bedrooms and total bedrooms
corrected right here. We can see that these
are the same values. The values that were
did not have any zeros, did not have any nans, did not get changed. Only the values with
nan were replaced. In this class, we had a
look at missing numbers. So what happens when
we have missing data? Can we find relationships
between missing values? So just some data and go missing when other datas
also going missing, is there a relationship in
missing numbers itself? In the next class, we'll have a look at formatting our data. Also removing duplicates
because sometimes it's very important to not have
duplicate entries in our data. So we can actually see each
data point for itself.
14. Scaling and Binning Numerical Data: In this class first, we'll have a look at
scaling the data. That is really important because sometimes some of
our features are in the hundreds and
other features are like in the tens or you
can add decimal points. And comparing those features
can be really hard, especially when we're building
machine learning models. Certain machine-learning
models are very susceptible to the
scaling factors. So bringing them on the
same kind of numeric scale can be beneficial to making a better
machine-learning model. I'll introduce each
scaling factor or each scaling method in the method itself so we can
learn it in an applied way. The second part and this class is going to be binning data. So that means assigning classes to data based on numeric value. In this example, we'll use the house value and
assign it medium, high, and low end luxury. Just to be able to
make an example how we can assign classes
based on numbers. And you'll see this
can be done with different methods that
give different results. As per usual, we're
importing pandas as pd and get our housing data
into the df DataFrame. Make a little bit of space so we can actually scale our data. Have a look. We'll start
with a very simple method. Well, we scale our data
between the minimum and the maximum of the
entire data range. So I'll modify the x is
going to be x minus the minimum of x divided
by the range. So maximum of x minus
a minimum of x. And that'll give us a value 0-1. For the entire column. We'll choose the median
house value for this one. So df dot median
house value is our x. And we'll have to copy
this a few times. So I'm just going to
be lazy about this. X minus the minimum of x divided by the maximum of x
minus the minimum of x. And we have to use parentheses
here to make this work. Because otherwise it would
just divide the middle part. You can see it right here. Our scaled version in the
new column that will name median house value minmax. Right here. We can clearly spot
that I made a mistake, not add in parentheses
to the top part. So when I add parentheses here, we can see that the data
actually scales 0-1. Now we can do some actual
binning on the data. There are several options available to do binning as well. We'll use the first one, which is the pd dot cut method, where you provide the
bin values yourself. So those are discrete
intervals where we been our data based on thresholds that we put we using the minmax that we just created because that makes
our life a little bit easier. Because then we can
just define the bins. 0-1 will have three-quarters,
so quartiles. And that means we have
to provide five values, 0-1 and 0.25 increments. When we execute this, we can see that the
intervals are provided. If we don't necessarily want those intervals
to be provided, but provide names for them. So in the case of these values, we can say that the first
one is quite cheap. Then we have a medium
value for the houses, a high value for the houses, and then we are in
the luxury segment. Of course, you can define these
classes however you want. This is just an example
for you to take. Make this a little bit more
readable at the common data. Otherwise we'll get an error. And now with the labels, we can see that each data
point now is assigned to a category that's actually assign those to price
or price range in this case, and
indented correctly. And we can see that we now
have a new column with new classes that we
would be able to predict with a
machine-learning model later. The second method we'll look
at is the q cap method. This is a quanta are cut. So we can define how
many bins we want. And the data will be assigned in equal
measures to each bin, will use the data from before. So the house values minmax. Now, in the case of cue card, it doesn't matter
which one we take because the scaling is
linear in this case. So that's fine. But to compare, we can see that the top
bin is now between 0.5, 15.1 instead of 0.7, 5.1, we can assign the labels to make it
absolutely comparable. And we can see right
here that this is now a lot more luxury and 01234
instead of high as before. So this makes a big
difference and you have to be aware how the child's work. They are really, really useful. But yeah, it's something
to be aware of. Let's assign that to price range quantile and indented properly. And we have a new column
that we can work with. Instead of doing this by hand, we can use a machine
learning libraries, scikit-learn to use
the pre-processing. Because as you saw, sometimes you make mistakes,
just forget parentheses. And if it's already in a library using it will avoid
these kind of silly mistakes that have very severe consequences
if you don't catch them. From SKLearn, which is
short for scikit-learn. We will import preprocessing
and we'll use the minmax scalars so we can compare it to our min-max scaling
that we did by hand. We use the fit
transform on our data. And the fit transform first
estimates the values and then transforms the values that it has to the
minmax scalar. Now are right here. We can see that, I mean, I'm used to
reading these mistakes, but like mistakes, bad, you quickly find
out what happened. You can Google for the mistakes. And this case, I provided a serious and scikit-learn was expecting a DataFrame instead. Let's have a look,
compare our data. And some values are
equal, some are not. And this seems to be a
floating point error. Let's have an actual look at it. The first value is false. So we can just slice into
our array and have a look. The first values are. And right here we can see that the scikit-learn
method provides less, less digits after the comma. Now, this isn't bad because our numerical precision isn't that precise to be honest. So we can use the NumPy method, NumPy dot all close to compare our data
to the other data. So that means our errors will be evaluated within
numerical precision. Whether they match or not. Just copy that over. And we can see, yes, in fact they match. So within numerical precision, they are in fact equal. Instead of the minmax scalar, we can have a look
and there are a ton of pre-processing
methods available, like Max app scalar, normalizing
quantile transformers. But one that is very good and I use quite often is
the standard scaler. And choosing that will
show you that it is. In fact, use the exact same
just fit transform ends. You get your data out instead
of the standard scaler. If you have a lot of
outliers in your data, you can use the robust scalar in this class well and look
at different ways to scale our data and how to assign classes to our data
based on the data. So we really did a deep dive and how to prepare data for
machine learning and the end. And you'll see how we do
that in a later class. In the next class, we'll dive
into some advanced topics. We'll have a look at how to
build schemas for our data. So we can actually
check if our data is within certain ranges or
adheres to certain criteria that we said that the
data has to have if we automate our data science
workflow in the end, this is really important
because right at the beginning, we can say that our data is okay or that our
data has changed to what it is before and that there is data control,
quality control issue.
15. Validating Data with Schemas: In this class won't be
looking at schemas. So that means when
we load our data, we can see if each column
that we define fits a certain predefined class or some predefined criteria that we think this kind of
feature has to have. And we'll be exploring
different ways to do this. And what think about
when doing this. So we can automate
our data science workflow from the
beginning to the end. In addition to the usual
import of panels have, we'll import pandas era. This is obviously
a play on pandas, and it is the library
that we'll use in this example to create schemas and validate
our DataFrame. There are other libraries like rate expectations that
you can check out, but in this case,
pandorable two. First, we need to
create the schema. The schema is basically
our rule set, how our DataFrame is
supposed to look like. So in this case, we'll use an easy example with ocean proximity and we'll
make it fail first, we say that the column is
supposed to be integers. So we get a schema error. And we can see right here that
it tells us all the way in the end that it was
expecting an int 64. Not bothered, God. If we replace this by a string, we can see that now it validates
and everything is fine. Now, in addition to the type, we can also provide criteria
that we want to check. So we type in PA dot check. And since we want to check that ocean proximity only
has a couple of values, we copy these values over and say it's supposed
to be within this list. If we validate this schema, we see everything is fine. Let's make it fail. Delete the near bay, and we see that
there's a schema error because this could
not be validated. Let's run that back,
make that work again. Text isn't the only thing
that needs to be validated. We can also have a look
at other numeric values. So if we wanted to check for the latitude to be
in a certain area, or the longitude to
be in a certain area. That totally makes
sense in like, you can check if it's
within certain boundaries. Let's have a look at total rooms and check that it is an integer. Now, right now it is not. But we can of course, make the data load as integer
and then validate the data. So our loading as
always as an integer. So what we'll do is we'll define the column and say it
has to be an integer. Now in this case,
obviously we get a schema error because
it's a float right now. So we have to do a type
conversion or we have to reload the data
with an integer. We'll get the housing dot CSV. And we'll define the datatype
for total rooms to be int. The problem here is that
there are in 32s and in 64. So how many bits
are in an integer? And these have to be the same. So when we look at the
error of our schema, we can see that it is
expecting an insecurity for. So we'll import numpy and define our loading as in 64 right here. And our schema once again validates because we have
now matched the type. So if we do in 64 loading
and the beginning, we can match this up with it in 64 that we expect
and our schema. It's just things to be aware
of when you are loading. Another way to validate our data at this using
a lambda function. So an anonymous
function that can do arbitrary checks and return
true or false values. In this case, we'll start
out with housing median age. Do at how a column
and add the check. Now I'm making a mistake
here unfortunately, but you'll see in a second. So P dot check will add
lambda n is our variable. And we check if n is none, All is not none. And we get a type
error right here. This is important to note. It is not a schema error. And that's because I forgot to add a type check right here. So we'll check for float. And now everything
validates again because none of the values in the housing median
age are numb can make it fail by
removing the none. And that will break our schema. We can do a lot of other tests, arbitrary function
tests in here, like if our squared
n is over zero, which it should if
math is still working. There are several
reasons why you wanna do schema validation on
DataFrames are on tables. And it is quite common to do
those already in databases. And it's a good practice
to do this in DataFrames. It can be that you
just get faulty data or that the data
changes in some way. And a very simple example
right here is percentages. In geophysics.
Sometimes you have to calculate porosity, e.g. of rocks, which can be
given as a percentage 0-1, so as a decimal, or it can be given as
a percentage, 0-100. Both are completely fine, but you have to take one to have your correct
calculations afterwards. So let's create a DataFrame
here with mixed percentages, where you see that
it'll throw an error. If you validate this data. Save this DataFrame
and D of simple. And we'll create a
schema for this. Making all the data floats 0-1. So create the DataFrame schema and add percentages
for the column. And really why we're doing
this example is for you to see other data than just the housing data that we can do this on
physical data as well. And to make you think
about your data, how you can validate that
your data is in fact correct. So we'll have a
check right here. And we can check that this is
less than or equal to one. Once again, we have to
validate our DataFrame on the schema and see
that it will fail. And the nice thing is
that our failure cases are clearly outlined right here. So we could go in manually
and correct that data. All we can correct
all the data that we know is wrong in
our percentages or drop and get our schema validated with the
correct input data. So we'll get all the
data that is over one and just divide
everything by 100. So we have only
decimal percentages. And now everything
validates easily. In this class, we had a look at different schemas and how we can validate our data
already from the beginning. And we had a look with a
simple example of percentages, why this is so important to do. In the next class, we'll have
another advanced strategy, which is encoding the topic that is quite important
for machine learning, but also can be applied
in a few different ways.
16. Encoding Categorical Data : In this class, we'll have a
look at encoding our data. So if we have a
categorical variable like our ocean proximity are
machine learning process often can't really deal with that because it
needs the numbers. And we'll have a
look at how we can supply these numbers
in different ways. And in addition to that, once we've done that, we can also use these numbers in different
ways to segment our data. We'll start with
the usual pandas. And then we'll have a look at the ocean proximity
because these are strings and our strings
are categorical data. And machine learning systems sometimes have problems
with parsing strings, so you want to convert them to some kind of number
representation. Pandas itself has something
called one-hot encoding. And this is a dummy encoding. So essentially each
value in the categories gets its own column where
it's true or false. So each value that was
near bay now has a one in the near bay column
and zero and everything else. Let's merge this data to
the original DataFrame. So we can compare this to other types of encodings and see how we can
play around with it. We'll join this and
to their DataFrame. And we can see right
here near bay. One for near bay, inland is one for inland
and zero everywhere else. Alternatively, we can use the pre-processing package
from scikit-learn. Scikit-learn gives us encoder
objects that we can use. So we'll assign this one-hot
encoder object to ink, and we'll fit this to our data. The nice part about
these objects is that they have a couple of methods that are really useful that will now be
able to explore. Let's fit this to
the unique data that we have in our ocean proximity. And then see how this encoder actually
deals with our data. After fitting our encoder
to our unique values, we can transform our data. If we spell it right. Yeah, converting this
to an array gives us the one-hot encoding
for our unique values. So only a one in each
column and each row. Now transforming actual data. So not just the unique values should give us something very similar to what we saved in
the DataFrame. Further up. Convert this to an array. So we have values and
the fourth column. Right here you can see near bay. Same. Now, you may wonder why we're doing
this redundant work. But with this encoder
object, like I mentioned, we have some really nice
things that we can do at a couple of lines and we can use the array that
we have from before. I'm going to use
NumPy because I'm just more used to dealing
with NumPy objects. And we can convert
this array back now, which is not as easy
with other methods, but because we have
this nice object that has all these
methods available, we can use the
inverse transform, provide that array to
this inverse transform, and get back the
actual classes because the object remembers the class
instead of it was fit on. And we can also get all
the data that is stored within the object
without actually providing values to it. So really just a neat way
to deal with preprocessing. Obviously, sometimes we want something different
than one-hot encoding. One-hot encoding can be a
bit cumbersome to work with. So we'll have a look at the preprocessing
package and we can see that there is labeled by
an a risers label encoders. But right now we'll just have a look at the ordinal encoder. The ordinal encoder will assign
a number instead of the, instead of the category. And that basically
just means that it's 0-1234 depending on
the number of classes. And you have to be
careful with this, like in a linear model, e.g. the numbers matter. So four would be higher than 04 would be higher than three. So encoding it as an ordinal would be a bad
idea and a linear model. But right now, for
this, it's good enough, like if we use a different
kind of model later than we are completely justified
in using an ordinal encoder. This marked our last class and
the data cleaning section. So we had a look at how we can encode information
in different ways. So we can use it in
machine-learning models, but also save it in our DataFrame as
additional information. In the next class,
we'll have a look at exploratory data analysis. So doing the deep
dive into our data.
17. | Exploratory Data Analysis |: In this class, we'll have a look at automatically
generated reports. And oftentimes that
can be enough. You want an overview
over your data and the most common
insights into your data and will generate these
reports and it'll be reproducible for you on any kind of dataset
that you have. This tool is very powerful. Afterwards, we'll
have a look how to generate these insights
ourselves as well. Because sometimes
you want to know more than this report
just gives you. And also, if it was only
about running this utility, data science, wouldn't
be paid that. Well, to be honest, this is a good first step. Getting this overview over
your data is really important. But then we need to dive deeper
into our data and really dig out the small features
that we have to find. We'll import pandas and
then get our DataFrame and the DF variable
S we always do. Then we'll import profile report from the pandas
profiling Library. And I'm pretty sure you
will be stunned how hands-off this process actually is of generating this report. And if you take anything
away from this, I think this is it. This utility really
takes away from lots of things that we usually
did manually in Pandas. And I'll show you how
to do those anyways, because it's really good to understand what you're actually
doing in the background. But this tool is amazing. So you automatically generate all the statistics on your data. You see that it counts your
variables and gives you the overview of how many are numeric and how many
are categorical. Notice that we did not supply any category features
or datatype changes. And we even get inflammation. How our data is distributed. However, it's a bit hard
to see in our notebook. So that is why we are going to use a notebook
specific version, which is profile da2 widgets. And here we have a very
nice overview widget with the same information as the profile report from before. We can see right
here that it even tells us the size and memory and tells us when the analysis
was started and finished. How you can recreate
this analysis. It tells you all the warnings like high, high correlations. Now between latitude and
longitude, that's fine. Missing values. And then on variables, you can have a look at the
distribution of your data. So you can talk with the results and have a
look at the histogram. The histogram is
also small up there, but it's really nice to have
a large look at it as well. And you can flip through
all your variables, see that it has missing
values on the left, you have warnings about it. And really get all
the information that you need to get an
insight into your data. See if there are
any common values that show up all the time. Now, this was 55 values
really isn't that Coleman? See the minimum and maximum
values that you have. So kinda get a feel
for the range. And when we have a
look at our income, which is more of a distribution, we can see the distribution
there as well. And on our categorical feature, the ocean proximity, we can see you something
very important. Island only has five entries. So we have kind of an
imbalanced dataset here that there are not
many homes on the island. Then we'll click over and have a look at the interactions. So see how one variable
changes with the other. If we have a look at
longitude against latitude, that's negatively
correlated, longitude, longitude, the same value is always positively correlated. Now if we have a look at housing median value
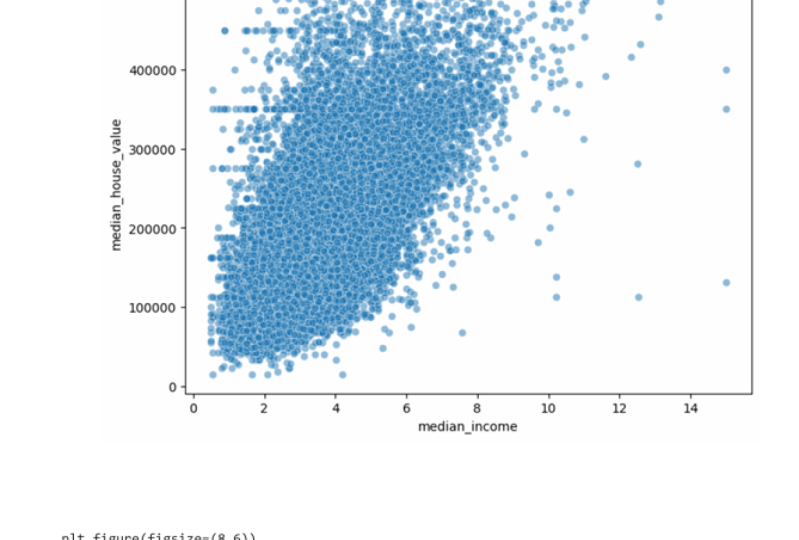
against everything else, we can really see
how these interact, how these changed
against each other. Total bedrooms
against households, e.g. is positively correlated. Something good to know. And this is just a
powerful tool to really see each variable
against another. Then we'll click over
to the correlations. And the standard linear
correlation measure between one and minus one
is the Pearson Correlation. And here we can see what we saw before that a
variable with itself, so longitude against
longitude will always be one and all the other values should be somewhere
between one and minus one. And that way you can really see the relationships between data. Spearman is a bit
more non-linear, but usually people prefer
candles two specimens, and then there's pi k. So phi is a measure between
two binary variables, usually toggled on the top right to read more about these. Have a look at missing values. And this may remind you of
something that we did earlier. And I'm not the only
one that thinks the missing numbers
library is awesome, obviously, because this gives very similar insights
on this tab. And then we can also have a
look at a sample of our data. Finally, lead to this. We can take our
profile report and we can generate an explorative
profile report. This one is more
interesting when you have different data types. So if you also have text or files or images in
your dataframe, in your data analysis. So really not that
applicable right here. In general, however,
you can see that this report already goes over a lot of the
things that you want to know in your exploratory
data analysis. Generally, you want to know
the statistics of your data, the correlations of your data, missing values in your data, and really see how
the data impacts with each other and what
data can predict each other. It's fine if this
is the only thing that you take away
from this course. But really, let's dive into how we can generate these
kinds of insights ourselves. In the next classes. I quickly show you how
to get this into a file. So you have profile dot to
file and then give it a name. And then you get this
beautiful website where you can click around and you can share it
with colleagues where they can have a look
at your analysis. It will say that it is apprentice profile or in the
report, and that's good. Don't just use this, use this as a starting
point to make a deeper analysis and to
really inspect your data. But this takes a
lot of work away from our everyday
data science work.
18. Visual Data Exploration: For EDA, I'd like to
first look at plots. So we'll have a look at
visualizations that give us an intuitive understanding of
relationships in the data. Relationships between
features, correlations, and also the distributions
of each feature. And we'll be using Seaborn, which makes all of
this extremely easy to just usually with one
or two lines of code. First, we're importing pandas
as usual and load our data. In addition, we'll load
Seaborn plotting library. Seaborn is commonly
abbreviated as SNS. And the first plot for our data visualization is
going to be a pair plot. Now, a pair plot will plot every column against every
column, even against itself. So when you plot the total
rooms against itself, you will get the distribution
of the total rooms. And if you plotted
against any other column, you will get a scatter plot. This scatter plot, as well as the distribution can
be very informative. One of my favorite plots
to do for a visualization, right here we can see that e.g. our latitude and longitude data apparently has two spikes. So it seems like our geolocation data is
focused around two spots. We can see that there are some
very strong correlations. And the middle of our plot, that is because we have some linear scattering
right here. And every other feature
that we see right here is distributed in certain ways like
this one is scattered all over the place
and we can see some clipping at the edges. So probably someone took
like a maximum of some data. In addition to the pair plot, we can create a pair plot
that is colored by a class. Right now, the only class
we have available as the ocean proximity in your
exploration for the project, it would be really great if
you experiment with this, maybe combine this with the
binning exercise that we did. It takes a bit for this to load. That's why I only sampled
1,000 samples right now, because we want to get the
plot relatively quick. However, this gives a
really good overview how different classes are
distributed against each other. The legend on the right
gives us which colors which. And I want to drop their latitude and
longitude right now because those features are strongly
correlated with each other and right now they only
take up space in our plots. So we can really make more use of our plot by
getting rid of these. Now, in the drop, I have to add the x's because we want to
drop this from the column. And then our plot should
be able to plot with a few less plots on
the, on the grid. So each plot is a
little bit larger. And that gives us lots
of information already. So we can see that our data is relatively
equally scattered, except for the island data. That island data seems to
have a very sharp peak. However, remember
that our island data has very few samples. It really skews
the results a lot. However, maybe we want to just plot the
distribution of our data. For this, we can
use the KDE plot, which is short for the
kernel density estimate. So we'll have a look at how our median house values
are distributed. In addition to this plot, we can also once again
split this up by hue. Unfortunately, there's no
nice in-built way to do this, like for the pair plot. So we'll iterate over the unique values in
our ocean proximity. And this is a bit
of a workaround, but I really liked this plot, so I'll show you how
to do this anyways. And in my teaching usually this question comes up anyways. So I hope this plot will, I hope this plot works
out for you as well. So we'll subset our data. Use the ocean proximity
that is equal to the class, which is our iterator
over the unique values. That means we get our plot
split up by our class. However, right now the legend doesn't look particularly nice. Each legend just says
median house value. And ideally we'd
want the legend, of course to say the class. So we can provide a label right here that contains
our class name. And that way we have
a nice little plot, has all our distributions. Well, we can see that inland has a very different distribution
than most of the others. And of course, the island
is skewed to the right, which indicates a higher price. But once again, not
a lot of data there, so it's a bit of
a skewed result. Now, maybe we want to have a look at more of
the scatterplots. Making a scatter
plot is very easy. Well, we can even
go a step further. There's something
called a joint plot, where we have the scatter
plots and the undersides. We can plot the
distribution of the data. So usually a histogram, you can do a different
ones as well. These are extremely nice to
point out how data co-varies. In the case of e.g. total bedrooms and population, we see a very clear distribution that indicates a
basically a linear trend. So some kind of linear
correlation between the two. And this plot is very easy. You just give the feature, the column name and
the DataFrame and seaborne place in very
well with pandas. Right here, you can also
see the distributions and the labels are
automatically applied. This plot has a couple
of different options. You already saw that
there's a hex option. We can also do a
linear regression, so fit a trend line with
uncertainty to our data. So we can really see if a linear model really fits our data or is
something else should be. Now here we can see that outliers skew the results
a little bit at least. And in addition, we can have a look at a different
feature just to see how our linear
regression, e.g. changes. This feature seems to be very strongly correlated
to total bedrooms. So replace population
with households. And we can see that this is, this is as linear as
true data actually gets. I think if we now copy this over replaced
population with households, then fit a line. We can see that the shade behind the line is
basically not visible, so the uncertainty is basically
not there on this data. A really nice way to see how our linear regression
fits to the data. Instead of the pair plot, we can also do a heat
map of the correlation. So that just gives us the
number representation of our Pearson
correlation coefficient. And we can see that the diagonal is one as
it's supposed to be. Our latitude and
longitude are negatively correlated because the
longitude is negative. And in the middle
we have a square of strong correlation that we
should definitely investigate. That is very interesting. And generally, just a good way to inspect
your data as well. We can copy this over and just play around a
little bit with it just to show you that
nothing is baked in here, you can really play
around with, with it. It's an open playing field to really explore your
visualizations. This magnitude 0-1,
now shows us that median income is
correlated quite highly compared to the
median house value. And I didn't really
see that before. So just checking this out, switching it around a little bit can give you more insights. So trying this out
from the standard, from the standard visualizations can be extremely valuable. We can add annotations to this. Now this is a bit of a mess. So we'll round our numbers to the first decimal and see you that this is
looking much nicer. You can do this with the
original data as well. This class gave an overview
of different plots that you can use to
understand your data better. In the next class,
we'll actually look at the numbers underlying
under these plots and how to extract
specific numbers that will tell you
more about your data.
19. Descriptive Statistics: In this class we'll follow up on the visualization
that we just stayed. So we'll have a look at the
numbers behind the graphs. Statistics can be a
bit of a scary word, but really it's just
significant numbers or Key Performance Indicators of your data that tell
you about the data. So the mean, e.g. is just the average
of all your data, whereas the median e.g. is the most common value. And this standard deviation, so STD just describes how
much your data varies. So how likely is it that you find data
away from the mean? And we'll explore all of this
in this class and really do a deep dive into descriptive statistics and how to get them from your data. The beginning, we'll
import our data and then we can actually just calculate statistics on
rows by providing the row. So df dot house, median age. And then we have the
mean and median and standard deviation available as methods to calculate
directly on the data. The mean is the
average in this case, and median is the
most common value. Basically, if we want to get aggregate statistics on
all of the DataFrame, we just call it dot describe on the DataFrame or a
subset of the dataframe. This gives us the count, the mean, the standard, and the quartiles of our data. When you play around with this, make sure to check out the
docstring for described. You can do a lot more with it. Then we can group by our data. And group by action has to be done by something that
can be grouped by us. So we'll use ocean
proximity in this case. And we can calculate the mean for these groups
over each column. So this doesn't really make
sense a longitude too much, but for all the other values, we can therefore get
groups to statistics. And additional, we can use
the AC method for aggregate. And in there we can basically
define a dictionary with all the statistics that we want to calculate
on a given column. Longitude, e.g. we'll have
a look at min-max mean. And we can copy this over on to use it for other
features as well. And really, so you're
not limited to these and you can even supply functions
to this aggregator. And they don't have
to overlap as well. So for total rooms, you can change this to be the median value
instead of the mean. Because, well, that makes a bit more
sense to get the median. And for our median income. Well, just try and get the
skew of our distribution. And here we can see that our new DataFrame that
comes out of this is filled with nan
were no values are available where they
don't really make sense. But we can really
dive into stats here. Another neat little tool
just to give an overview of columns is the
value counts methods. So in ocean proximity, e.g. we can then call the
value counts method to get an overview of how many samples
are in each of these. So very good to get a feel for how our data is
distributed among classes. For the heatmaps that
we generated before we needed to calculate the
correlation between each, each column against
each other column. And we can see
right here that we have this data
available readily. And the call method
also gives us the opportunity to change
the correlation that we use. So you can change
it to spam and e.g. really very similar to what we had in the automatically
generated report. Here you can dive
into the data and really see how our data
correlates by number. In this class, we had a look
at descriptive statistics, so at actual numbers, average values, and
how we can extract these specific numbers and
make decisions based on them. In the next class,
we'll have a look at subsets of that data. So how do we select parts
of the data and how can we calculate these
numbers on those parts? Because sometimes,
as we saw here, Island only has five samples
in our entire dataset. So how can we make
sure that we extract that data out of our DataFrame
and explore those further.
20. Dividing Data into Subsets: In this class, we will be
learning how to extract subsets from our dataset
because sometimes e.g. we only want to focus on
one certain location or we want to focus on one
subset of customers. And those segments
are really easy to extract using Pandas. And I will show you
how to do this. So first we'll load our data, and then we'll take our df dataframe and have
a look at the longitude. Because we can take our df dataframe and just
perform normal logic on it. So in this case, we want it to be lower than
minus one to two and we get a serious out of it with
true and false values. So a Boolean series. We can use this to choose rows
in our original DataFrame. And we can see right here
that this is only a view. So we have to assign
it to a new variable. Let's have another look at
another way to select subsets. In this case, we want
to have a look at the ocean proximity because
selecting subsets of our categories is really important for something
we'll do later which pertains to the AI
fairness and ethical AI. So we can choose here that only near bay and inland
should be in there. We get once again a Boolean series out of
this that we can use to slice into our DataFrame or get a subset
of our DataFrame. Can see this right here, and we can see that it has
less robust than before. We can also combine different
kinds of lottery x2. Well, to be arbitrarily complex. And why we have to do right
here is use the AND operator. But in this case, it has to be the ampersand. The ampersand is a
special operator in Python to do bitwise
comparisons. And you can see right
here that and will fail because the bitwise operators just a really short hand
to compare the Booleans. And you have to be
careful that you use parentheses in conjunction
with a bitwise operator. Here, we'll just play around a little bit
with true and false. So you can see how these
are combined when we use and which will use the
same with an OR operator. But of course we have to
take the bitwise operator, which is this well, pipe symbol. I don't know if you have a
different name for it maybe, but it is onscreen, you have it in your notebook. And here we get the choice
of things that are in. The choice of ocean proximity
that is near bay inland, or D of longitude
is -120 to one, we have a look at
the unique values in our subset of ocean proximity. We can see that there are values that are not in
near bay and inland because they were in the longitude under
minus hundred and 22. We can also use the
dot loc method. This is a way to
select subsets of our data frame by using
the names of the indices. Index on the columns and
the index on the rows. We can copy this right over. And I'll show you right here where the difference
is to the method before, because this will fail, because it expects us to
give slices for all indexes. So a DataFrame has
two dimensions, the columns and the rows. Right now we only
gave it the columns, the colon right here. It is used to just select
everything and the row section. And we can of course
use this to slice into the rows as well by using
the numbers of the index. Right here, we can see
that this selected from the index name five to 500. And keep in mind that our
index can be anything. We'll have a look at
that in a second. Here we can see that this did not change our DataFrame at all. This is just a method
to return a view. And of course we can also save this in a variable as always. So the dot loc method just works in a different way
than our way before. Now let's have a
look at indexing, because up there we can
see that our index is just a running integer from zero to whatever the
maximum number is, 20,640 in this case. However, we can use the dot set index method to change our index
to any other row. And this is really
powerful and that we can assign any kind of indexing, even text and select
on that text, or in this case, the latitude. Instead of just a number. You can still use numbers and I'll show you afterwards
how to do that. But this is kind of a way
to change thinking about your DataFrame because right now our rows are indexed
by the latitude. So we can, we can't do
what we did before with the number because
our index right now is not the integer anymore. Our index now is the latitude. So if we choose
the number at war, any kind of number
from our latitude, this will work again. Here I have a look at the index, just copy a number out
of here, like EF 37.85. And we can then use this to select a subset
using dot loc. Just use all the columns. And we can see right
here that this just shows everything from
our index right here. You can see that indexes
in Pandas do not have to be unique as well. Something really important to think about when
you work with them. Slicing into our
DataFrame like that, it is extremely powerful
because our index, we'll just return the data at that index and whatever
sorting we have. So we don't really have to be aware of how our
data is structured. Nevertheless, we can
use the iloc method, which is basically
index location, where we can still go into our DataFrame and
select row five to 500, 499 because it's exclusive. We can also use
this on the column. So if we think we know
exactly where everything is, we can use this kind of slicing
as well and to just use the number slicing
to get our subsets, I usually recommend using dot
loc because what dot loc, you can always be sure
regardless of sorting, that you'll get the
things that you want back with the exact index that it is. And you don't have to
make sure that you're sorting of your DataFrame
is the correct way. Right here we can
see that latitude is now not part of
our columns anymore because we have assigned
it to be our index. Now, if we want to get latitude
back into our columns, we can do that as well
by resetting the index and then our index will be
back to just running integers. This also works when
you re-sorted it. So you can reset the
index back to going 0-500 or BO maximum number when you changed around your
column ordering. And this is really
important to think about when you're
doing index slicing that you can always change the sorting
of your, your data. But when you do dot loc, you will be able to retrieve
exactly what's on the index. On the topic of
selecting columns. Of course, we can
do the standard way of just providing
the columns we want. But sometimes your
DataFrame gets very long leg your view of
back to the missing numbers. Example we had, I
think over 20 columns. So selecting all that one can be really cumbersome
to be honest. So we can also go
the other way and select which columns
we do not want. And that is with a drop method. So we provide the
names of the columns that should be dropped from
the DataFrame. Right here. We'll just take the inverse
of longitude and population, provide the axis
that we want to drop it from because we can
also drop columns. Right here. You can see how you can change around
lot of the things as well you can do in place
dropping as well if you want to change the DataFrame
directly in memory. Right here you can
see that we can drop, well, do the exact
opposite from what we did before by dropping rows. Overall, we're doing this because if you select
subsets of your data, you can do analysis
on the subsets. So if we just use the describe method from
our descriptive statistics, we can see right here, e.g. the standard deviation and
the mean of all the columns. And we can of course also called the describe method on
a subset of our data. And see how our, well, how our descriptive
statistics change. You can then start plotting
on these subsets and do your entire dataset
analysis on these subsets. This class really went deep into how we can select subsets of our data and really decide what to take
based on features, but also on indexes. And we had a look
how to switch in, they say, and how
to reset it again, because that is really
important when you want to do your exploratory data
analysis and have a closer look at some
subsets of your data. In the next class, we will be looking at how we can generate those
relationships in our data. And really focus in
on what to extract.
21. Finding and Understanding Relations in the Data: In this class, we'll
have a look at the relationships
within our data. So we'll really check out how correlation works
within our data. But go beyond this as well. So go beyond linear
correlations and really dive deep into
dissecting our data. We'll start out
again by importing pandas and loading
the DataFrame. We can see that dot core is really central to doing
correlation analysis. In Pandas. We can use Corr
and change around the correlation coefficient
that we actually want to use. Now, the standard
Pearson's correlation is a linear correlation. Spearman and Kendall use a rank correlation which
can be non-linear. In addition to calculating these, these aggregate
correlations, maybe sometimes you just want
to find out how one cell, one column is correlated
with another. And here we can simply provide the column and calculate the correlation on
another column. Right here. We can even take
this one further. So machine-learning
tools have been really easy to use in
the past ten years. And we can use this
machine learning tool to basically predict one feature based on the other features. And if we do that
with every feature, we can actually see how informative one feature
is based on the other. And this has been built into a neat little tool
that we can use here called Discover
future relationships or beyond correlations. It has recently changed name, so you'll be able to find
it on GitHub as well. And this means we can use
the discover method of this library to really dive into their relationships
in our data. So we use the discover
method on, on our DataFrame. And we can supply a
method or a classifier, but in this case we'll
just leave it on standard. You can play around with this later if you're
interested in, it, takes a few seconds
to execute this, but then we will just use the sample from our DataFrame to make
it a little bit faster. You can let it run
on larger samples. And we get how one feature predicts
another feature right here. And we get that for
every feature around, we can use the pivot tables
that you may know from X0 to get out a full grown library, full grown table that will give you all the
information you need. Right here. Very similar
to the correlation. However, the central one
is not not filled out, so we'll just fill that
with ones because you can predict feature
easily on itself. Of course. Then we'll go on to plot this because
looking at this as a plot is always quite nice, just like we can look at the heat map from
the correlations. This is very similar to the
correlations except that we use machine learning to
cross predict this time. So we'll save this
into the variable and then make a nice
plot. All of those. We can see that as
opposed to the, the correlation plot, this
is not fixed between -1.1. So we'll fix that real quick. And then you can really see how each feature can be extracted
from the other feature. We do this, this fixing
from minus one to one by using the
V min and V max. And there we see it. So e.g. analyzing how our population can be predicted by
anything else is really a good way to see
relationships within the data where you can dig in further why something is predictive or not. Really a nice tool
for data science. This was the last class and now a chapter on
exploratory data analysis. When I look at how
we can extract information about
correlations and relationships in our data. And the next class, we'll actually look at how we build machine
learning models. So something that we
already used implicitly here will now learn
how to actually apply.
22. | Machine Learning |: This chapter of the
data science process or we'll have a look
at machine-learning. Specifically, we want
to model our data and find relationships and
the data automatically. Machine-learning models are
so-called black box models. That means they don't have
any knowledge of your data. But when you show them the data and what you want to
get out of the data, they will learn
relationship and how to categorize or how to find
the right kind of numbers. So do a regression
with your data. And machine learning
is really powerful and super easy to
apply these days. Which is why we'll
spend a lot of time on validating
our models as well. Because these models
tend to learn exactly what you
tell them to learn, which might not be what
you want them to learn. And validation as the
due diligence for you to do to make sure that they actually learned what
you want them to them. So let's fire up our notebooks and have a look
at machine learn.
23. Linear Regression for Price Prediction: Welcome to the first-class and the chapter on machine learning. We'll have a look at how
to build simple models. Because in machine learning, often the rulers, the simpler
the model, the better. Because simple
models are easier to interpret and are often
very robust to noise. So let's dive into it. After loading our data, we can import the linear
regression model because we want to predict house values
in this exercise. However, before we have to prepare our data
in a certain way, we need to split our
data in two parts. We want one training
part and we want one. Well, one set of data that the model has never
seen during training time. So we can validate that our model learns
something meaningful. This is to avoid an effect
that is called overfitting. So when our model basically remembers the training
data and does not learn meaningful relationships
between the data that it can then apply to new
data it has never seen. So that way, we take our DataFrame and we split
it into two parts randomly. We could of course do this with subsetting that we did
in the previous section. However, taking a
random sample that is absolutely sure to not overlap in any way is
a much better way. And the train test split function that
Scikit-learn supplies is really good for
this and it has some really need other
functions that we can use. This is also a really nice
way to select our features. For the simple model, we'll just use the
features of housing, median age, and then
the total rooms as our training features. And the house value is
going to be our target. Those are usually
saved an x and then y. So we know we have
x train and x test, and then we have y
train and y test. This is quite common. And we'll have a
look at the shapes. So we have a bit over
20,000 rows here. Our train data is going to be about 75% of that
with 15,000 values. And our y train should
have the same amount of targets because those are sampled randomly but
in the same row. So the data obviously mattress. Our x tests should now have the remaining rows that
are not in the train set. Now, doing this is
extremely important and there's no way around splitting your data
for validation. Now it's time to
build our model. Our model is going to be the linear regression model
that we imported before. And Scikit-learn makes
it extremely easy for us to build models
and assign models. We just have to assign the
object to some variable. In this case, we'll
just call it model. And you can see that you can change some of the
hyperparameters in the model, but we'll keep it
standard right now. Now we fit our
model to the data. This is the training step where automatically our
model is adjusted and the parameters in our
model are changed so that our model can predict
y train from x train. And to score our model. So to test how well it's doing, we can use the score method
on our fitted model and provide it well data where
we know the answers as well. So we can use x test and y test to see how well our
model is doing on unseen data. This case, the regression is
going to be the r-square. R-square is a, well, in statistics, it's basically
a measure of determinism. So how well does it
really predict our data? And the best value there is one. And then it goes down and
can even be negative. 0.03 isn't really, well. It's not impressive. When we change our training data to include the median income, we increase the
score significantly. Obviously, this is the
most important part. We have to find
data that is able to give us information on
other data that we want. However, once we find that, we can further improve our, our model by doing
pre-processing on our data. We have to be careful
here though, because one, I'll do preprocessing
and we'll test out different things if they
work or if they don't. What can happen is that
we manually overfit. Model. That means to do proper
data science right here. We want to split our test
data into two parts. One, validation holdout
set and test set. The test set will
not be touched and the entire training process and not in our experimentation, but only in the very, very last part of our
machine learning journey. Here we define x Val and y Val. And I made a little
mistake here, leaving that to y
train that should of course be x test in
the train test split. Changing this means
that this works. And this is also
a nice part about the train test split function. It really makes sure that
everything is consistent or the well that all
our variables match. And we can see right here that our test dataset is now quite
small with 1,000 values. So we can go back to the
train test split up here, and actually provide a ratio of data that we can use in your data science and
machine learning efforts. You should always see that you can use
biggest test size you can afford really because that means you'll be able to have more certainty
and your results. Here we can see that
it's now split 5050 and splitting our test set now further down into
the validation set. And the test set shows that
our final test set has about 2,500 samples in
there, which is, it. It's good enough for this case. We'll define our
standard scaler here and our model as the
linear regression. And we fit our scalar
onto the training data. That means we can now
rescale our entire data too, so that none of the columns are significantly
larger than the others. This is just a well, in a linear model, we sit the slope
and the intercept. And when we, when
we scale our data, that means that our linear model now can work within
the same ranges of data and not
be biased because one feature is significantly
larger than the others, will create x scaled
from our X train data. So we don't have to call the scalar transform in
the train training loop. We can compare them
here we can see that our scale data is now within, well, centered around zero
and all at the same scale. Whereas before it was
all over the place. We can now fit our
data on our model, on the scale data. And well, the normal
labeled style we have, obviously the label has to
be y train in this case. And then we can do
the usual validation on our holdout data. And this case it's going
to be x vowel, and y val. So we don't touch the
test data while we see what kind of scaling and what kind of pre-processing works, we have to transform
our data because now our model expects scale data. So when we forget that, we get terrible results, and we can see that we
improved our model by, by a small margin, but it is still improve by just applying this
scaling to the data. If we tried to use the
robust scalar instead, we can do this by just, well, just experimenting and
using a different scalar. And this is the part
which I mean where we need an extra holdout set because just trying
different things, it's a really good way
to see what works. And is how you do data science. Just seeing what sticks is really tantamount to building a good machine learning model. Because sometimes
you might not expect that you do have
outliers in your data. And you try the robust
scalar and you'll see that it actually
performs better. Or you realize that it works
that are performed worse. Here we can train on
our transformed data with our Y train again
and score our results. To check whether this works. Try the minmax scalar
that we used in our previous class as well. After we've done
the experimentation and train for final model, we can use this model
to predict it on any kind of data that
has the same columns, hopefully the same
distribution as our training data and
the validation set. So to do this, we'll use model.predict and provided with some kind of data. In this case, we'll
use the training data. Just have a look at how
the model stacks up against the actual ground
truth data, the labeled data. But of course, doing it on the train data isn't the most interesting
because the model has seen this kind of beta. Eventually, we will do
this on the test set. But finally, he
wanted to do this on completely unseen data to actually get predictions from your machine learning model. Another very nice way
and why I really like the train test split
utility is that you can provide it with
a keyword stratify. Stratification is a means to make sure that some
kind of feature is equally represented in each part of the train and test split. So if we want to make sure
that our ocean proximity on the island is in part in
train and in part in tests. We can do this by supplying this kinda this kind of feature. And a reason why, and people like linear
models so much is because linear models essentially
fit a line to your data. So if you think back
to like fifth grade, you may remember that a line is basically just the intercept on the y and a coefficient
for the slope. So what we can do is interpret our linear model and have
looked at these coefficients. So each column has a slope parameter right
here that we can, well basically, this
parameter tells you how much the slope of this data influences
the prediction result. And of course, we
can have a look at the intercept with a y, which gives us full
overview of our model. So this, essentially you
could write it out on paper. Now, in this class
we learn how to use scikit-learn on a simple
machine learning model, a linear regression. So basically fitting
a line to our data, we had a look at how scaling
can improve our model and even predicted on some data that the model has
never seen the. So it's validating if
we're actually learning something meaningful or if
it just remembers the data. In the next class,
we'll have a look at some more sophisticated models, namely decision trees
and random forests.
24. Decision Trees and Random Forests: In this class we'll
have a look at decision trees and
random forests, which are just a bunch
of decision trees that are trained in a specific way
to be even more powerful. And decision trees are very good learners because
you usually don't have to change the basic parameters
too much. In this class. You'll see how easy
it really is to use scikit-learn to
build all kinds of different models and to utilize that in your exploration
of the data. For this video, I
already prepared all the inputs and
the data loading. And I split the data
into the train set, which is 50 per cent, and then a validation
and a test set, which are each 25 per
cent of the total data. And now we'll go on to build a decision tree to start out. So we'll import the trees from scikit-learn from
the tree library. As always, we'll
define our model. In this case, it's going to be a decision tree regressor
because on this, to make it comparable, will again, do a regression
on the house value. Model, train. What the training is going to be the
same as always, model.fit, x train and y train. And I think at this
point you really see why Scikit-learn is so popular. It has standardized
the interface for all machine learning models. So scoring, fitting, predicting your decision tree is just
as easier as a linear model. Decision trees are
relatively mediocre learners and we really only look at them. So we can later look at the
random forest that build several decision
trees and combine them into a ensemble learning. And the nice thing about decision trees is that they're usually quiet scale independent, and they work with
categorical features. So we could actually
feed ocean proximity to our training here. But then of course we couldn't compare the method to the
linear model as well. So we'll not do this right now, but this is definitely something
you can try out later. So scaling this data
doesn't cost us anything. So we might as well try. Here. You can actually
see what happens when you don't transform your
validation data. So basically a now expects even the decision
tree I expect scale data. So it performs really poorly. When we transform our train data and we transform our
validation data. Our score is slightly
worse than before. Next, we can build
a random forest. A random forest
is an ensemble of trees where we use a statistical
method called bagging that basically tries to build
uncorrelated decision trees that in ensemble are stronger learners then
each tree individually. So we'll import the random
forest regressor from the ensemble sub library
from scikit-learn. And just like before, we'll assign our model to a, what their model
object to a variable. And then we can fit
our model to the data. As you can see, the fitting
of this is quite fast and scoring of this should
give us a really good result. Here we can see here that
this is slightly better even than the score
we got on our, on our linear model
after scaling. And if we now look at the
score of the training data, you can see why we
need validation data. So this random forests tree is extremely strong on the
training data itself, but okay, on VAP
validation data. Instead, we can also have a look at the scaling
just to see how it works. It doesn't cost us anything, it's really cheap to do. So you might as well. If this improves your machine learning model or
it reduces overfit, it's always worth to do because
it's, yeah, it's cheap. So we'll scale our training data and fit our data,
our model to it. We can use the
same scale up from before because the scalars and independent of the
machine learning model is just the scalar. And we see right here that our training score basically didn't change like it's
in the fourth comma. So it's basically random
noise at that point. On the validation set. We shouldn't expect
too much either. So it's slightly
deteriorated the result. So it is worth preserving
the original data. In this case. A fantastic thing about
random forests is that random forests have
something called introspection. So you can actually
have a look how important a random forest, I think each feature is. This, these are
relative numbers. They might fluctuate a bit, but we can see that these features are
differently weighted within the random forest to
predict a correct price. This was a really quick one. I think Scikit-learn is amazing because it makes
everything so easy. You just thought fit, dot predict, and don't score. And those are super useful for all of our machine
learning needs. In the next class, we'll have a look how we
not only predict price, but how we can
predict categories. So in a more business
sends that may be predicting as someone who
is credit worthy or not.
25. Machine Learning Classification: In this class we'll have
a look at classification. So that means
assigning our data to different bins depending on what's contained
within the data. In our example, we'll have
a look at ocean proximity. So we'll try to
predict if one of our houses is closer or
further from the ocean. And that basically
means that we'll have the chance to test
different algorithms and how they are affected by preprocessing of
our data as well. We'll import everything
and load our data. Now in this split, we want to replace the house value with ocean proximity because we
want to do I'm classification, so we need to predict classes. In this case, we'll predict the near a house
is to the ocean. But generally you can
predict almost any class. We'll turn it around
this time and use all of the training features. But of course, we need to drop ocean proximity
from our DataFrame. If we left that in,
there wouldn't be a very easy classification
task, I'd say. So the easiest model, or one of the simplest model, that is the nearest
neighbor model, our K nearest neighbor model. The nearest neighbors are
essentially just taking the closest data points to
the point that you want to classify and take the, well, usually you just
take a majority vote. So that means the class
that is most prominent around your point is probably
the class of your point. And for classification, Scikit-learn is no different
than the regression. We'll assign the model to what
the object to a variable. And then we'll try
to fit our data. But something went from In finance or infinity or anything. And k-nearest neighbor does
not deal well with this. Like I said, I leave all the preprocessing steps in the preprocessing
chapter to keep these chapters
short and concise. But in this case, we'll
drop the nans without any different preprocessing just so those rows get deleted. Might not be a good
idea in most cases, but in this case
it's just to get our data out of the door. Here we can fit our model
with the usual training data. It just works this time. And then we can score our model. Now, scoring n
classification is a little bit different
than in regression. We do not have the R-squared
because the r-squared is a measure of determinism
in regression. In this case, we
have the accuracy. And the accuracy is at 59
per cent, which is alright, so 60% of the time this nearest neighbor model is correcting the correct class. We can probably do better, but that's a start. One thing you can try in
your exercise is change the nearest neighbor
number and have a look what kinda
nearest of well, how many nearest neighbors to the point give
the best value. We can have a look at many different
classification algorithms. On the left you see
the input data, which is three different
forms of inputs. And then you see the
decision surfaces of a binary classification
on the right. So you can see that the random
forest is very jacket e.g. and a Gaussian process
is very smooth. So just for you to understand
how these understand data, we'll try out the random
forest because it looks very different than in
the decision surface. And random forests are once
again very powerful models. This is going to be the same schema as the
nearest neighbors. So we'll have a quick chat
about scoring functions. Because the accuracy
score is, alright, it's a good default, but essentially just counts
how many you get, right? And let's say you work
in an environment where errors are especially bad,
especially expensive. You want to have a look if another scoring function
would be more appropriate. And you can have a look on the scikit-learn
document, mentation. There are different scoring
functions that you can check. Here we have a look
and the random forest just outperformed
with default values. Anything the nearest
neighbors gets close to with 96 per cent. That is on unseen data. So it is a very good score. We can once again have a look at the feature importances
to see what our model thinks is the
most important indicator that something is close to
the, close to the shore. And obviously part of it is going to be the longitude
and the latitude. So let's just drop those as
well from our DataFrame, from our training data. Because we want to
make it a little bit more interesting,
maybe something else. Is a better indicator if you come to your
boss and say, Hey, I figured out that
location tells us really well that my house is
close to the ocean. They'll probably look at you
a little bit more pitiful. So have a look. And obviously our random
forest score is a little bit worse, but pretty alright. So let's have a look at
another linear model. The logistic regression
model is a binary model. You can use it for
multi-class as well with a couple of tricks. That basically goes 0-1
and finds that transition. You can see it right
here in the red. Logistic regression models are really interesting because they once again give a
good baseline model because they are
linear classifiers. But more interestingly,
you saw that there's this transition line
0-1 in this image. And you can define a
threshold in their standard. It is at 0.5, but you
can do a tests how you want to set the threshold for
your logistic regression. And this is a really
good thing to think about in your
machine-learning model. And we'll have a look how to determine this threshold after this segment of programming,
the logistic regression. So we'll add this and have a quick look because we have a multiclass problem right here. And we want this multi-class
problem to be solved. Obviously. Luckily, multi-class is
automatically set to auto because most people
don't deal with binary problems and real life. So yeah, scikit-learn
really tries to set good default values, will fit our model with x
train and y train data. And unfortunately,
it did not converge. So it did not work in
this in this instance. So I'll go into the docstring and have
a look. There we go. Max iter is going to be the keyword that
we have to increase. So it gets more iterations
to find the optimum. The, to find the weather logistic
regression is supposed to be. Thousand wasn't enough either. Just add a zero. This is
going to take awhile. So we'll, we'll think about
our, our optimum threshold. Because in a sense, when you have machine learning, you want all your
positives to be positively classified
and all your negatives to be negatively classified. And then you have to think
about which one is worse, getting something right, on
getting something wrong. And in this case, we can use the ROC curve for logistic regression where we can plot the true
positive rates. So the positives that are positive against the
false positive rate. So everything that was
classified positive falsely, and then choose our optimum. In this class,
we're having a look at different
classification algorithms. There are many more as I
showed you on that slide. And you can really dive
into the different kinds of classification really
easily as you see, it's always thought
fit doctrine. And then you score and you
predict on unseen data. And really in the end, it's always the same. And then it comes to how
you scale your data, which is part of the exercise. And also how you
choose hyperparameters like k for the k-nearest
neighbors algorithm. In the next class,
we'll have a look at clustering our data. So really seeing the
internal structure of our data and how each data
point belongs to the others.
26. Data Clustering for Deeper Insights: In this class, we'll
have a look at how we can cluster each data. Sometimes data points cluster. Well, sometimes there have
been harder to discern. And we'll have a look how
different algorithms treat the data differently and
assign it to different bins. After importing our data. This time we'll skip the part where we split the
data because it will rather look at the
clustering algorithm as a data discovery tool. If you want to build
clustering algorithms for our actual prediction or for
assigning new new classes. You have to do the
splitting as well. You know that it actually does
what it's supposed to do. In our case, we'll just
have a look at k-means. K-means was kinda the
unsupervised little brother of k nearest neighbor, where it essentially gives what it measures the closeness
to other points and just assigns them to a cluster if
they're close enough, will fit our data
on the DataFrame. And we'll use fit predict because we want to do
everything in one step. Now the problem right
here is that we have ocean proximity in
there with strings in there. So we'll be dropping know. We'll actually just have a
look at the spatial data. So longitude and latitude, because those are very
easy to visualize in 2D. So that just makes our
life a little bit easier. We'll get out some
labels for these. And what we can do then is we can plot these using matplotlib. They'll get to know matplotlib
in a later class as well. But just for an easy plot, it does have the PLT scatter, which takes an x
and a y coordinate. And then you can also
apply assign a color, which is labeled, in our case. K-means. You can define how many clusters
you want to get out. Now the default is eight. We'll play around
a little bit with it and you can see
how it changes, how the clusters change. The higher you go, the
more fragmented it gets. And you can argue how much it really make sense at some point to still cluster
data with light. Hundreds of clusters. I'm going three. It's easy enough
just to show what happens when we actually
have like proper clusters. We'll split our
data a little bit. So essentially use the
subsetting that we discussed before to delete some of the middle part
in the longitude. For that, we can use
the between method that basically defines a
start point and an end point. When we negate this between, we are left with at
cluster on the left of our geographic scatter plot and on the right of our
geographic scatter plot. For that, we'll just
choose -121 and -100 18th as the left
and the right borders. We can see right here that
this gives us a split dataset. Assign that to a variable
so we can use it. Let's have a look and
not this actually. So we see what's, what's happening with our data. Just delete for now that we have have colors are labeled because those
don't apply here. And we can see the clear
split between two clusters. Then we can use our k-means to classify these two
or to match these two. And I'll just copy this over and use the fit predict
to get our data on the split data and
also copy over our scatter plot and
add back in the labels. We can see with two clusters, it's quite easy for k-means to get one cluster on the left and one
cluster on the right. If we play around
with the numbers, we can really test the
behavior of Howard, find sub-clusters in this and
how it interprets the data. But because it's so easy
with a scikit-learn, Let's have a look
at other methods. This is, this is a graphic from the
scikit-learn website where you have different
kinds of clustering algorithms and how they work
on different kinds of data. The spectral clustering
comes to, comes to mind. But I personally
also really like DB scan and gotten
Gaussian mixture models. They work quite well
on real data and especially the further
development of TB scam called HDB scan is a very
powerful method. Hdb scan is a separate library that you have to have a look at and then
install yourself. But yeah, definitely
worth a look. So we can do the same as before. We'll import DB scan from our cluster library
in scikit-learn, assign it to the
dB value variable. And it doesn't have a lot of different hyperparameters
that we can set. Maybe change the metric
in there that you saw in the docstring. But for now Euclidian
is totally fine. We can see right here without
setting any clusters, there are the outliers
and the right. And basically it finds
three clusters without us telling it much
about our data. Let's also have a look at the spectral clustering right here. It works just the same. We'll assign it to a
object and instantiate it. We have to supply
clusters for this one. We want to just copy over all of this to the prediction on our SP and execute
the entire thing. This takes a little bit longer. Spectral clustering, can be, um, yeah, can be, can be a bit slower
on large datasets. Check out the documentation. They have a really
good overview which clustering method is best
for the size of data. And also, yeah,
basically what you have to think about when applying different
clustering methods. Since the methods are always
evolving and always growing, It's a really good
idea to just check the documentation because
that is always up-to-date. Here we can see that
the clustering is quite well, quite good. Clustering data can
be really hard. As you saw, it can lead to very different
outcomes depending on what kind of
autorhythmic views. So which kind of
underlying assumptions are in that algorithm, but also how your
data is made up. Is it easy to separate the data or is it really
hard to separate the data? In the end, I think
it's a tool that can generate new insights into your data that you didn't have before based on the
data you feed to it. The next class, we'll
have a look at how we validate
machine-learning models. Because just building
the model isn't enough. We have to know if it's actually learning
something meaningful.
27. Validation of Machine Learning Models: In this class we'll
have a look at validating your
machine-learning models. And you have to
do it every time. Because building machine
learning models is so easy, the hard part is
now validating that your machine learning model actually learned
something meaningful. And then one of the
further classes we'll also see if our machine
learning models are fair. And in this class we'll have
a look at cross-validation. So seeing what happens if
we shift our data around, can we actually predict
meaningful outcomes? And then we'll have a look at baseline dummy models that
are basically a coin flip. So does our model performed
better than random chance? After importing everything
and loading the data, we'll drop the nouns
and split our data. Right now, we'll do
the the regression. So we'll build a random
forest regressor. And this is just to have a model that we can compare to the dummy model to
do the validation. So we'll fit it right away to our train data and
add the labels here. Having a fitted model, we can now score this and then go on to do
cross-validation. Cross-validation is a
very interesting way. If you just learned about
test train splits, this, this is going to take test train splits
to the next level. So cross-validation is
the idea that you have your training data and your test data will keep the
test data, the test data. And as you know, we split our train data in a training set and
a validation set. In cross-validation, we're now splitting our training
data into folds. So basically it
just in sub parts. And each part is once used as test set against everything
else as a train set. So we're building five models
if we have five-folds. You can also do this
in a stratified way, like the test train split
that we used before. Now, it is quite
easy to do this. Once again, the API, so the interface that you work
with is held very simple. So we'll import the
cross-validation score. And right here, the cross
Val score takes your model, the validation data,
and that is your x. So the features and of
course, the targets, because we have to validate
it on some kind of number. This takes five times
as long because we build five models or yeah, we evaluate five models and we get out five scores
for each model. You may notice that all of these scores are slightly lower than our average score
on the entire data, and this is usually the
case and closer to reality. We can also use
cross-fold predict to get predictions on
these five models. So this is quite nice too
to do model blending, e.g. so if you have five
trained models, you can get predictions
out as well. It is not a good measure for
your generalization error. So you shouldn't take
cross-fold predict as a way to see how well
your model is doing. Rather to visualize how
these five models on the k folds on the
cross-validation predict. Another validation strategy
is building dummy models. Whether you do this before
doing cross-validation or, or after, that is up to you. It is one way to
validate our model. So a dummy model is
essentially the idea that will that weight that we want our machine learning model
to be better than chance? However, sometimes knowing how chance looks like,
it's a bit rough. So we'll have a look here. You can do different strategies to use in your classifier. You can just do it brute
force and try them all. But a good one is
usually using prior. I think this will
become the default and future methods for
the dummy classifier. But since we're doing
regression first, let's have a look
at the regressor. So right here you can
also define a strategy. The default strategy is
just to have the mean. So a while, the worst kind of model
returns just the mean. So we'll use this
as our dummy model. Just like any machine
learning model, you fit this to the data
with x train and y train. Then we can score this function. We can even do a
cross-validation on this. And see how well this
chance model does. And based on these scores, it's a good gauge how well, while how well your
actual model is doing. If the chance of model is
performing better than your, better or equal than your model, you'll probably build
a bad model and you have to go back and
rethink what you're doing. We can do cross-validation, but obviously scoring would
be more appropriate here, which is something you can
try out in the notebooks. We'll do this again
and we'll create a really quick
classification model using the ocean
proximity data again. Here we'll build the classifier, just whether we're
the normal strategy. I personally think the
dummy models are really useful because sometimes
while Chance isn't just 5050, if you have class imbalances like we do with the
island data, e.g. your, your coin flip is
essentially skewed. It is biased. And the dummy classifier is just a very easy way
to validate that. Even with class imbalances, you did not build
a useless model. So right here we can score
this and we get a accuracy of, well, pretty low
accuracy right here. And we can check out how the different strategies
affect our result. So 32% is pretty bad already. But even like you should probably take the
dummy classifier with a best model because
that is still a chance, chance result. So these 40% on the chance
prediction are not a good, not a good sign. Let's say that. So right here we'll build a new model using the
Random Forests again. There we go with a classifier
and we'll directly fit the data to it so we don't have to
execute more cells. Now scoring on the data will
show that our random forest is at least a little bit
better than the dummy. So 20 per cent better accuracy. I'd say we're actually learning something
significant here to predict if we're closer or further away from
ocean proximity. Now, as I said, the scoring is more appropriate, so we'll use the
scoring right here with our dummy model
on the test data. And the warning right here
is interesting because our cross-validation score
tells us that ocean proximity, the island class does not have enough data to actually
do a proper split. So this is really
important to notice. Apart from that, we do see, so that is something
to take into account. But apart from that, we see that even on cross-validation, our model is outperforming
the dummy model. Validating machine
learning models is very close to my heart. It's so important since it's
become so easy to build machine learning models that you do the work and see
that those models, I've actually learned
something meaningful and I'm just reading
something into noise. And these strategies are really the base level that you have to do with every
machine learning model. And in the next class, we'll have a look at
how to actually build fair models and how to make sure that our model
doesn't disadvantage anyone because of some
protected class e.g. and that will be extremely
important if you touched humans with your
machine learning model.
28. Machine Learning Interpretability: In this class we'll have a look at Machine Learning
interpretability. So we're going to look at
this black box model that we built and we'll inspect
what it actually learned. And if you're like me
and you've ever built a model and show that to
your boss and said, Yeah, it learned and it performed such and such
well on this call, like it had 60% accuracy. They won't be impressed. They want to know what this machine learning model
actually things. And in this class, we'll have a look at each and
every different feature in our data influences the decision in our machine learning model. And we'll actually dive deep
into the really cool plots that you can make that influence the decision in a
machine-learning model. So here we'll pretend
we already did the entire model validation and model building and
the data science before. So we can check if
our model is fair. So the notion of fairness
really is the idea that even though our model has not seen the ocean
proximity class, it may implicitly
disadvantage this class. So you can check right here. Our split, we directly
drop ocean proximity. We do not train on it. But maybe our data
somehow implicitly disadvantages some class that
is within ocean proximity. So check for this. I'm doing some, some, well, a couple of pandas tricks have been using
panelists for a bit. So here you see the stuff
you can do with partners. Because right here you have the validation data and that is only a part of our DataFrame. I want to find all indices
from our DataFrame that are in this class and find
the intersection of this index with the
validation data. That way, I can
choose the subset of the class in our validation set without actually
having the data in, well present in the DataFrame
from our test train split. And doing this,
I'm playing around a little bit with it and
trying to make it work, just printing over an oversize,
see what's happening. And so I can actually
validate with the data that this is
the data that I want. Right here. You see that now I'm
taking the subset of it, taking the index of it. And then I'm printing
the intersection of x val and class-based index
that I create before that. So save this in idx. So I can just go into the DataFrame and subset the
data frame with the index. We'll use the model scoring
function in this case to get an initial idea
how well our hour, well, how well our model
is really performing on the class subset of our,
our validation data. Right here. Print this because
we're now in a loop. So I have to use dot loc here. And it's really important for you also to see I
still may make mistakes very commonly and you
cannot be scared of mistakes in Python because it doesn't hurt.
Mistakes are cheap. So just try it around. In this case, I messed up by, I sometimes have
problems keeping the columns and the rows apart. And right here, interestingly, we see wildly varying values. So we have three that are around 60 per
cent, which is nice. But the third value is around 23% at the
last one is zero. So I have a look at the indices. And we can see right
here that must be Island because Ireland only has
five values in total. So we definitely have a
prediction problem here, despite our model
doing well overall. It does terrible on the island data because
it doesn't have enough data right there. Here you can see that I'll try to improve the model
by stratifying it on the ocean proximity just to try to see if this
changes everything. And it does not. Because now I made
sure that the, they're equally
distributed across classes and we have
even less data. So before I got
lucky that I had two of the samples and in
the validation set. And now I have less. Now can't do this because the Well, this is already
a subset of the data, so we'll just skip this
because with five samples trying to spread them out
over all the datasets, it's kind of moot. And really in this case, you have to think about if you can either get more samples, somehow create more samples,
collect more samples, or if there's any way to get the samples
out of the system. But the sense they are data, they should be represented
in your model usually. So really in this case, get more data. In that case. What can see right here that the stratification has
improved the model overall, which is nice to see
and with this way. So the backslash
n is a new space just to make it look
a little bit nicer. Here we can see
that this is giving us good predictions for the, for everything that is
near to the, to the ocean, near bay and near ocean, and under 1 h of the ocean. But the inland is
performing significantly worse than our than
the other data. Let's ignore the
island for now because we discussed the problems
with the island. Let's have a look
at the test data. Because right now we're not
doing model tuning anymore. So this is really
the n validation and we can see that
on the test data, inland really has a problem. So our model is
performing well over all. But some things going on
here with our inland data. And it would also be good
here to do cross-validation. So we can actually get
uncertainty on our score and see if there are any
fluctuations in there. But let's move on to L5. L5 or IL-5 is a machine-learning
explanation package. This is the documentation. And for decision trees, it says right here we can
use the explain weights. So this is what we're
doing right here. I'm calling this on
our model right here. We have to supply
their estimators. So what we trained our model and we can see the weights for each feature and how
this feature is called. And this is an extremely
good way to look into your model to be able to explain what influences
our model the most. We can also use Eli five to explain individual
predictions. So right here, we can obviously is to apply
our estimator object, but then also supply
individuals samples and get an explanation how the different features
influenced this prediction. Here right now we'll just use a single sample from our data. We can see right here how each individual
feature contributes to the outcome of 89,000. And of course you can do this
for classifiers as well. Or we can iterate over several different numbers and see how these are
explained by Eli five, I'll just use the display here. Like I said, the format
is really nice as well, but I don't really want to
get into it in this class. And here you can
interpret how each of these is influenced by other
different model parameters. After having a look at these, we can have a look at
feature importance. You may remember from
the, from before, from the random forest
that you can do introspection on the
feature importance. And Scikit-learn also provides a permutation importance
for everything. So for all, you
can apply this to every single machine
learning model available in scikit-learn. And the way this works is that essentially the permutation
importance looks at your model and takes
each feature in the data and one-by-one
scrambled those features. So first it goes to the
households and scrambled stores, so they are essentially noise. And then sees how much this
influences your prediction. And you can see here that it gives you the mean importance, the standard deviation, and
also the overall importance. So you can really dive deep
into how your model is effected by these,
by each feature. So you can also decide to drop
out certain features here. Next, we'll have a look at
partial dependence plots. These plots are
really nice because they give you a one-way look into how a feature
effects your, your model. And introspection is relatively
new in, in scikit-learn. That's why there's
scikit, yellow brick, scikit minus yb, which makes
these fantastic plots. Top middle you see the
precision recall curve e.g. and generally, a
really good way to visualize different things that explain your
machine-learning. Here we see all the
different features in our training and how they influence the prediction result. So bottom-right, the
median income you can see, has a strong positive influence. And right here you can interpret how changing one feature would influence the
price outcomes. So households, e.g. it has a slight increase when there's more
households, is cetera. It's a really neat little plot. But the final library and my favorite library for
machine learning explanation, they did get a nature paper
out of this even is shap. Shap has different explainer modules for different models, so they're basically
very fine tuned to each. You can even do deep learning
explanation with shap. We'll use the tree explainer
for our random forest model. And we have a wanting that we have a lot
of background samples. So we might actually be able to sub-sample this
to speed it up. But right now, we'll pass
our validation data to this, explain our object that we
created, and calculate this. So this takes a second and I'll actually cancel
it right here because I want to save those
in a variable so I can reuse them later and that's don't have to
recalculate them. But generally the plot that I want to show
you is a force plot. This plot can be used to basically explain
the magnitude and the direction each feature of your machine learning
model of your data, how it shifts the prediction. And I really love to use these plots and reports because
they are very intuitive. You'll see that in a second. So here we have to pass
the expected value in our explainer object and the shap values that
we calculated before. And one of our data points
in the validation data. So you can once again
do this for several of your of your validation
data points. I made a mistake here and
not having a underscore. And also, I should
have activated JavaScript for Shapley because
they make some nice plots. They are, they're falling back
on JavaScript to do this. And it has to be
initialized right here. But afterwards, we have this plot and I hope you
can try it yourself. Because here you can see that this particular prediction was most influenced by the
median income negatively. And then pull population
a little bit less positively in number of
households negatively. And just overall, a
really nice package. So we've had a look
at different ways to visualize and include data in your reports and how
you can generate them and definitely check out the documentation so they
have so much more for you. In this class, we inspected
the machine-learning model, so we had a look at how different features influence our machine learning decision. But also how strong
is this influence on the decision and how do different features
influence other features? So maybe we can
even drop some from our original data acquisition. And the next class, we'll
have a look at fairness. So this important part of where machine-learning models
might actually disadvantaged some protected classes because they learn something that
they shouldn't learn. And we'll have a look
at how to detect this and some strategies, how to mitigate this.
29. Intro to Machine Learning Fairness: In this class will have
an introductory look at machine learning, fairness. Machine learning has gotten a bit of a bad rap
lately because it has disadvantaged some
protected classes that shouldn't have been
disadvantaged by the model. And this has only come out
by the people noticing, not by data science doing
the work beforehand. In this class, we'll have a
look how you can do the work. How you can see if your
model is performing worse on certain protected
characteristics. And also have a look if your machine-learning
model is less certain in certain areas. So sometimes you
get a model that predicts that someone is worse off because they're
in a predicted class. And that is a big no-go. If that ever happens, you have machine-learning model may never reach production. But sometimes your machine
learning model is just less certain for some people
if offered certain class. And then you should try to
increase the certainty of the model by doing the machine learning and data
science work beforehand. This will be building
on what we did and the interpretability part. Well, we already did part
of the fairness evaluation. We start with a random forest
and we do the scoring. So we have a baseline on knowing how well our
overall model is doing. Then we'll start to
dissect it by class. So we already have
this stratification on the class because we'll
keep that from before, because it improved the
model significantly. But then we'll iterate over
the classes and actually have a look at how well they're
doing. In the beginning. We want to know the score and basically do the same work that we did in the
interpretability part. So we'll get our
classes right here. And then we can actually
have a look and interpreted. Our data. Right here will do the work of
getting our indices. So we do the whole thing with the intersection
and getting our, our class indices
and the beginning. So this is going to be
saved in idx for index. And then we're taking the
union and the intersection, not the union of these values for validation
and for our test. Because right now we just one to really test our algorithms. So having both holdout datasets, that's actually
fine for this part. You usually, you do it in the end after
fixing your model. And after hyperparameter
tuning to see if your model is
disadvantaged anyone. So we take the intersection with a class index right here, copy this over, and make
sure that data is in there. And then we can score model on the validation
data and on the test data. These scores should, ideally all these scores
should perform equally well. And absolutely ideally all of them perform as well as
the overall model score. But we remember that inland was significantly worse
than everything else. And of course, we have the
problems with Ireland not having enough samples to
actually do the validation. That's why I included
just a script file. And for now, later, I'll also show you how
to do the how to catch errors in your processing
so we can do with this. And then we'll expand this
to include cross-validation. Because with
cross-validation, we can really make sure that there aren't weird
fluctuations within our data. So maybe inland just has some funny data in there that really makes it very
wildly and its prediction. So getting that out is
really important right here. And this is only the
beginning for you. If you want to have a
play around with it, you can I'm Bill dummy models
as well and just really dig into why inland is
doing so much worse. Using the interpretability
to really investigate why something is happening in this
model right here. So that we have the scores. And while looking at
these scores, it's nice. It's getting a bit
much with the numbers. So what do we can do? First of all, is at the
try-except that Python has. So if there's an error, because Ireland doesn't
have enough data, we can catch that error. And with the except, we'll just put a path so
everything else still runs. After we processed
Islands as well. There we go. So now we'll
save these as variables, as Val and test. Because then we
can actually just calculate statistics on this. So get the mean and the
standard deviation. So an indicator for
uncertainty here would be, or something funny
happening here, would be if the
standard deviation of our cross-validation
would be very high. Which interestingly, it isn't. In this class we had
a look at how to dissect our machine
learning model and evaluate it on different
protected classes without training on them. And we saw that a model
that overall does quite well can perform really
poorly on some classes. And that sometimes we even don't have enough data to really
evaluate our model. So we have to go
back all the way to the data acquisition and
get more data to really be able to build a
good model and do good data science in
regard to that class. And the business case
here is really clear. You never want a disadvantage, someone that would
be a good customer, because you lose
a good customer. This concludes the chapter on machine learning and machine
learning validation. The next class we'll
have a look at visualisation and how to build beautiful plots
that you can use in your data science report
and presentations.
30. | Visuals & Reports |: In this final chapter
and we'll have a look at data visualization and also how to generate presentations and PDF reports
directly from Jupiter. And that concludes this course.
31. Visualization Basics: In this class, you'll learn the underlying mechanisms for data visualization in Python. We'll import our data as always, and then we'll use the standard plotting
library in Python. Matplotlib at underlies most of the other plotting
libraries that are more high-level like
seaborne as well. So it's really good to
know it because you can use it to interface
with Seaborn as well. So we'll make an easy line plot with median house value here. Now, usually you
want a line plot for data that is actually
related to each other. So we'll start
modifying this one. First. We'll open up a figure. And we'll also call the plot show because Jupyter Notebook, it's making it a
bit easy for us, showing us the plot object right after the seller's executed. But this is really
the way to do it. So we can change
the figure size by by initiating our figure object with a different figure size. Those are usually
measured in inches. Just yeah. Just an aside. And then we can change
this from a line plot. We'll modify this further. So since, well, since
line plots are unrelated, procreate here, because if we plot this against each other, it looks a little bit funky. We can change the
marker to be an x. And we get a nice
scatter plot right here. And you can see
that seaborne e.g. makes it much easier for us to get a nice-looking scatter plot. This plot still
needs a lot of work. But you to know this
is how we change the colors and change
different markers. You can look up the markers
on the matplotlib website. There is a myriad of
different markets. But then we can also start
adding labels to this. So the plot object that we
have is a simple plot objects. So we can just add on a label. So x label is our population, and y label is going to be
our house value right here. And we can add a title because we want our plots to look nice and be informative. And additionally, we can add additional layers of
plotting on top of this. So instead of population
against median house value, we can plot population against our total bedrooms and
change the marker size, marker color, and
the marker style. But obviously, our
total bedrooms is scaled very differently
than our median house value. So we can just make
a hot fix right now. Of course you never do
that in an actual plot. But just to show how to overlay different types of
data in the same plot, you can modify this. In this way. You can save your data and have it available
as a normal file. Changing the DPI means that
we have the dots per inch. That is kinda the resolution of our of our plot that is saved. Then we can also plot imageData. We don't have an image
right now for this, but it is worth plt.show. And essentially you just give it the image data and it'll
plot the 2D image for you. Let's have a look
at how to change this plot if more like overlaying different
data on this as well. Like if we only
have one scatter, this is completely fine
and we can add a legend. But it gives us a
nice warning that there are no labels or
in this plot object. So that means we can
add a label to our, to our data plot right here. And we'll just call it house. So now we have a legend here. It makes more sense if
we overlay more data. So if we want to plot
some data on top, we can just call another
plot function right here. Change the marker so it looks a little bit
different and you can see that our legend
is updated as well. So this is how you can
make singular plots. And as I mentioned, C1 is a high level
abstraction for matplotlib. That means we can actually use matplotlib to work a
little bit with a C1. And this will only only give you one example of how to
save a Seaborn plot. But you can easily look
up other ways too. Add information to
your seaborne plots or modify your Seaborn plots through the
matplotlib interface. So right here we'll do the pair plot with only 100 samples because
we want it to be quick. And we can once again open up a matplotlib figure and change the figure
size as we wanted. And then save the figure. Here we can see that this
is now available as a PNG. Open up the PNG and you
use it wherever we needed. Right here. And this, while opening, this just looks like the plot, but as an image. If you want to make quick
plots directly from DataFrames without calling
Seaborn or matplotlib. You can call the pandas
plot function actually, which interfaces with seaborne. So d of plot gives you the ability to make
different kinds of plots. Really you can make
bar charts and histograms and also
scatter plots, which we'll be doing this time. This means we'll just
provide the label of our x and our y data and tell
it to make a scatter plot. We'll use the population
against our house value again. Sorry, total rooms again. And just provide the
word scatter plots, a scatter, scatter plot for us. In this class, we learned the different ways to plot data. In Python. We use matplotlib, we use pandas directly, and we even saw that these interact with each other because seaborne and pandas both
depend on matplotlib. So you can take the
objects returned by those plots and save them and even manipulate
them further. In the next class,
we'll have a look at plotting spatial information.
32. 52 Geospatial new: In this class we'll have a look at mapping geospacial data. So data when you have
geo locations available. So you can make nice maps and really show where
your data's out, which adds another dimension of understanding
through your data. We'll start out by
loading our data. Our data already contains
longitude and latitude. However, they're in
the wrong order, so we'll have to
keep that in mind. We'll import folium. Folium is a way to plot our data on maps
interactively actually. So we'll start out
with a folium base map and give the location
of our first data. And I like to walk and easy way for me to
just make the base map for my data is providing the mean of the latitude and longitude as the
center point of our map. And then we can have
a look at yeah, at the impact of display. You can see that this has OpenStreetMap as the background. And you can walk around in it. And then we can start
adding things to it. One example is adding markers. Markers are a good way to
just add locations from your data points and just give some sample locations
at tooltips to it. And this is what
we'll do right here. So volume has the marker class and have a look at all the different classes
that you can use. The library is still growing, but it has some really
neat functionality in it already to build
some really cool maps. And we'll use the
market to walk. We'll add the first data points from our market to them up. So this is why it has
to at two method. And we'll copy over the base
map into the cell because everything has to be
contained into one cell to be able to change it. And we can see it right here. So we'll change that around, add latitude and longitude
and just use I locked to get the very first row from
our DataFrame that we go, add it to our base map. And when we move our zoom out, we can see our first
marker on the map. So this is quite nice. We can change around the map. We can change around
for markers as well. Now, different kinds of markers. So you can add circles for
marketing to your map as well. Definitely experiment with it. It's quite fun. I think another quite a neat
way to visualize data. So while our map zoomed in way too much
at the standard value, so at 12 was somewhere
nowhere to be found. So zoom out a little bit in the beginning so we can
actually see in the Marcos, we can also add multiple markers by iterating over our DataFrame. So for that we're just
use it arose method we have in the
dataframe and this will return the
number of our row and also the row and
the row content itself. So for that to work, and I'll probably add a sample
to the DF because if we, if we added 20,000
markers to our map, that map would be
quite unreadable. There we go. So maybe do
five for the beginning. And fried. Here, I'll add the ISO that is unpacked in them in
the loop itself. And I can remove, I lock right here because we don't have to access any
location of our thing. The iteration already
does that for us. And we have a nice
cluster of a few, of a few Mockus right here. Then you can also go and
change these markers, like add a tool tip
when you hover over it. And this tooltip can contain any information that
we have available. So e.g. we can use the
ocean proximity right here. Now when you hover over it, you can see what kind of
flowers this marker has, according to our
date in this class, we had a look at how to
create maps and add markers to these maps and make them
really nice and interactive. In the next class,
we'll have a look at more interactive plots, bar plots and all that to
be able to interact with the data directly and make
these nice interactive graphs.
33. Exporting Data and Visualizations: Oftentimes we need to
save this data because we don't want to rerun the
analysis the entire time. All we want to share the
data with a colleague. That means we need to export the data or the
visualizations that we do. And this is what we'll
do in this class. Having our data slightly
modified, we can e.g. use the one-hot encoding
that we used before. Just so we know that we have some different
data in there. And we can use to, to CSV or what one of these
methods you can ride out, exhale as well, and
write this to a file. So that way we have the
data after processing it available and don't have to rerun the
computation every time. And to CSV takes a lot of different arguments
just like read CSV, it's very convenient and
that way you can really replace the nans
in here with e.g. just the word nan. So people know that this is a, not a number and not
just a missing value where you forgot
to add something. And then we can have
a look at this file. And the Jupiter browser
as well, search for nana. And we can see right
here that it added nan into the file directly. So really a convenient
wrapper to get out our DataFrame into
a sharable format. Again, instead of this, we can also use the
writing functionality. So this is basically how you can write out any kind
of file that you want. We'll use the outdoor text and this dot TXT and switch out
the mode to write mode. So w, and we'll just use F S, a file handle right now. And F dot, right? It should give us the
opportunity or the possibility to write out a string
into this file. And we can convert
our DataFrame to a string with a wall values. I think there should be a two string method
to really give, yeah, a toString
method right here, which is innocence and
other export method. But really this is
just to show that you can write out any kind of thing that you can form it
as a string into a file. So we'll see right
here that this wall, this is not as nicely
formatted as before. We have the tabs in-between
instead of the commenter. So really it needs a
bit of string magic to make this work as nicely
as the pandas to CSV. But yeah, this is how you
export files in Python. Now something to
notice here is that right will always
override your file. So if you change it
to anything else, and we'll have another
look at the file. We can see that refreshing
this gives us only this. So the file is replaced
by the writing operation. There's another, another mode that we
should have a look at, which is append mode. And append mode just
has the signifier a, where we can add onto a file. So this is quite nice
if you want to preserve the original data
or some kind of some kind of process
that is ongoing to write out data and added to your file, to an existing file without deleting that
file essentially. So we can see right here that
we wrote out our DataFrame. And then we can
copy this over and change this to append executed, go over, refresh this, and have a look at the very end. It should say anything or be. And it does. So yeah,
those are files. We already did this in the
basics of visualization, but in case you skip that, when you have figures, you can export these figures usually with the safety command. So this one takes a
filename, file handlers, some kind of signifier, and of course you need
some kind of plot. I really want to point you to the tight layout
method right here, because that one is really good, too young to tighten up the
layout of your safe plots. So if you save your data and it'll figure and it
looks a bit wonky. Plt.show tight layout
will really clean up the borders of your figure and usually
makes them more presentable. I basically run them on
almost any exported figure. And here you can see that our figure was
exported just fine. You can change around all
these, all these parameters. Of course, to save the figure in exactly
the way you need. Maybe you have a corporate color that you want your figure to be. In. This case, I chose black, which of course is a poor choice that if you're
legends or unblock. But yeah, just to show
you how to do it, how to play around with it. We have a look at how
easy it is to save data in different
formats from Python. And then the next class we'll actually have a look how we can generate presentations from
Jupiter Notebooks directly.
34. Creating Presentations directly in Jupyter: It can be complicated to
generate whole presentations, but it is possible to get presentations of
ride out of Jupiter. And in this class, I'll show you how you can use any
kind of notebook. We'll use the one created and
the visual exploration one. So you want to go to
View Cell Toolbar and then slideshow. And you can change the
slide type for each cell. So if you want to
have a displayed or skipped slide is going to be the one of the
main slides. Then. So everything you want
on its own slide, you can put as slot, slide or sub slide. And sub slide is going to
be a different navigation. So notice these plots
while I will look at the presentation
and in a second. And fragment, is going to
add another element to the, to the parents
slide essentially. So we'll check that out as well. So after signifying these, we can go to File Download S and called the Reveal JS slides. When we open this up, we get a presentation
right in the browser. Let's get rid of that. So this is a main slide scrolling to the
right essentially, and we can still have a look at the data and it shows us
the code and everything. Sometimes you have to play
around a little bit with, uh, with, uh, plots
that they work. These are the slides that
we talked about before. And now the fragment
is going to add another element to your
slide essentially. So this is also the fragment
and another fragment. In this class we had an
overview of how to generate presentations in JavaScript
and HTML from Jupiter. We saw that we can
really preserve the data and the code
in our presentations, even have these plots
automatically included. We saw that we can
do a sub slides and fragments and really make this super
interesting presentations that are different from
what you usually see. In the next class. We'll see how to get PDF
reports out of Jupiter.
35. Generating PDF Reports from Jupyter: In this final class, you'll learn how to generate PDFs directly from
Jupiter notebook. And how you can get these
beautiful visualizations ride into your PDFs without
any intermediate steps. We'll start out with
a Jupiter notebook and go to Print Preview. Here we can already
save it as a PDF. If we print this. Alternatively, we
can download as PDF, but here you have to make
sure that you have installed. And I know a lot of people don't I don't on
this computer, e.g. so you get a server error. You can go the extra step
of going download as HTML. Open the HTML and
this is equivalent to your to the print preview
and save it as a PDF. And in the PDF you can see that this now contains your code and all the information that you had previously
available as well. Additionally, we do
have NB convert, so the notebook convert functionality that comes
with Jupiter notebook, and I think that's a really
nice way to work with it. It has a read me when
you are just called Jupiter space and be converted. And it'll tell you how
to use it essentially. So what you'll want
to do is go to your data right here in my code repository for
this Skillshare course. And there you can just Jupiter
and be converted and then choose one of the way you want to generate the
report from that HTML. Html is usually the default. So if you'd just called Jupiter and be converted
on your notebook, it'll converted to HTML. You can also supply
the minus minus two. But if you say PDF, it'll run into the same
error as before that you don't have latex installed. So if you install that, you can easily get these PDF reports
directly from to put up. Another very nice way is that, well, if you're in
Jupiter notebook, he often play around a
little bit and your or the, the cells can be, can run quite high numbers. So be like 60, 70. And that basically shows how much experimentation
you did. If you want a clean notebook
that gets run top to bottom, you can provide them
minus-minus execute option, which executes
your notebook cell by cell before exporting. And this is how you
generate PDFs in Jupiter. So maybe you have to install latest to be able to do it. All. You use the print functionality
from the HTML reports. But this concludes the class on data science and Python
here on Skillshare. Thank you for
making it this far. I hope you enjoyed it and I hope this brings it forward
in your career.
36. Conclusion and Congratulations! : Congratulations, You made a
throw the entire course on Data Science with Python
here on Skillshare. And I understand
that this is a lot. We went through the entire
data science workflow, including loading data, cleaning data, than doing exploratory data analysis and building machine
learning models. Afterwards, validating them,
looking at interpretability, and also generating reports and presentations from our analysis. This is huge and I understand that this
can be overwhelming. But you can always go back to the bite-sized videos
and have another look at those to understand and depth and your knowledge. Right now. In my opinion, the
best data scientists just build projects. You will learn more
about data science by actually applying your
knowledge right now, and that is why we
have a project. At the end of this course, you will build a nice
data science project, analysis of your own data
or the data that I provide here and build a PDF with at least one visualization
that you like. Honestly, the more
you do, the better. Deep dive into the data, find interesting relationships
in your data set, and really work out how to
visualize those the best. And this is how you will become a better data scientist by really applying
your knowledge. Thank you again for
taking this course. I hope you enjoyed it. And check out my other
courses here on Skillshare, if you have time, now, makes sure to go out and
build something interesting, something that you really like. Thanks again for
taking this course. I've put a lot of
work in this and I am glad that you made
it through the end. I hope to see you again
and build something else.
 Jesper Dramsch, PhD, Scientist for Machine Learning
Jesper Dramsch, PhD, Scientist for Machine Learning