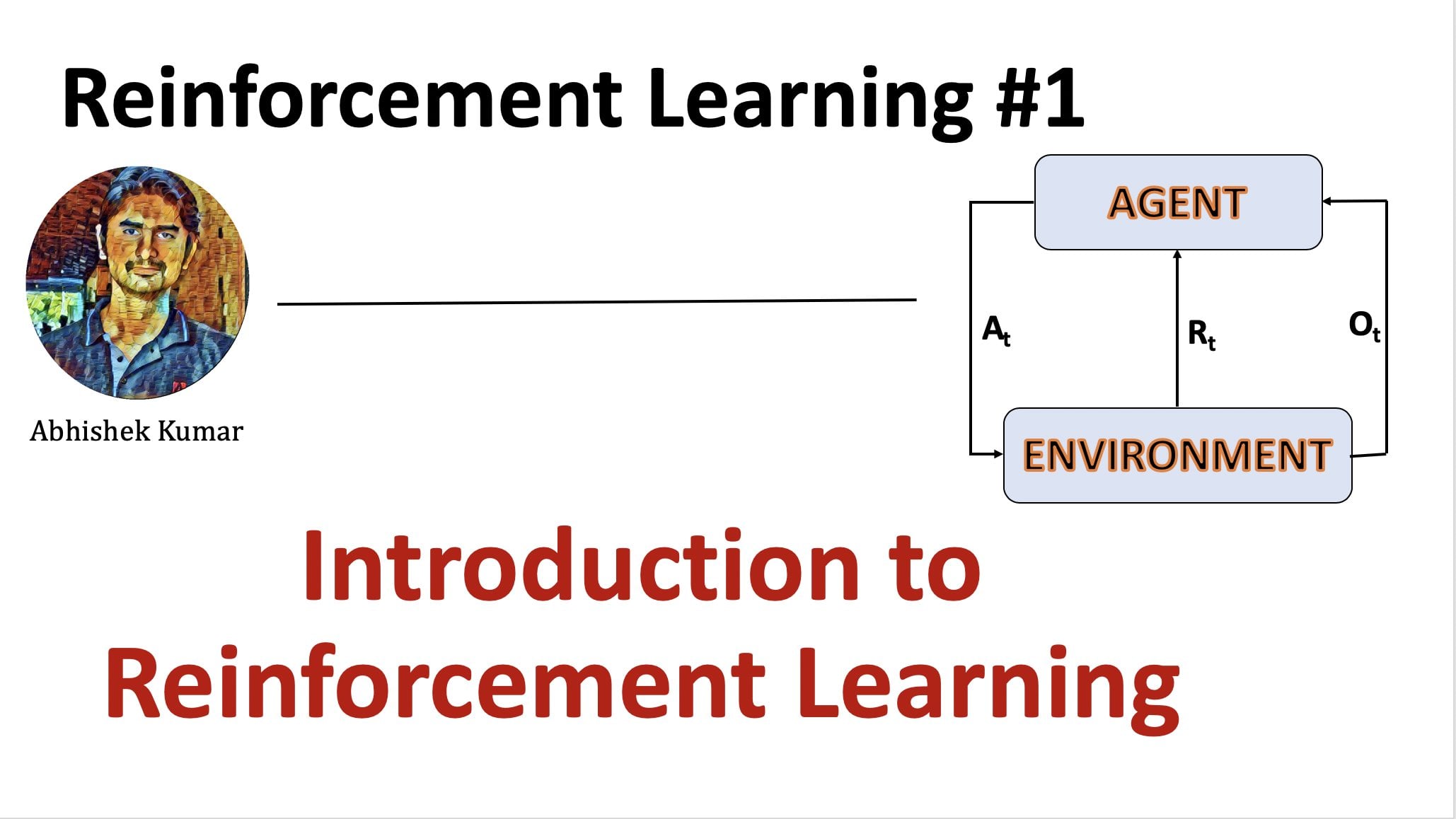
Transcripts
1. Introduction: Hello, everyone, and I'm glad to see inside these cores artificial intelligence, machine learning, deep learning, neural networks and big data. All these terms and technologies are being used more and more often these days. Just 40 years ago, we could only read about these things in some futuristic books or magazines while now, whether we understand them or not, they are already becoming an important part of our everyday life. When research for news, news aggregators in the Internet show us exactly the news that we might be most interested in. The same thing happens on social networks on YouTube music services, where we are showing exactly those videos, songs or images that you most likely will like. Computers can already recognize our speech, and the automatic translation of Google translate works much better than just five years ago. Image and environment recognition techniques are used in autonomous cars that already drive around, are very cities in the number of autonomous cars, is increasing, get a tremendous space, and almost all car manufacturers are developing these technology. In addition, AI is used by banks to decide the credit worthiness off a possible war war sales and marketing departments in companies use it to predict sales and make more personalized recommendations for each client. Huge budgets are spent on targeted advertising, which is becoming more and more targeted. Thanks to machine learning technologies. E. I becomes especially relevant in medicine, where neural networks can detect the presence of serious diseases much more accurately than the most professional doctors. As you can see, the range of use of AI is very extensive, and these technologies are already used in multiple industries and since the range of use covers almost all areas, this requires a large number of specialties who are well rounded in how their divisional intelligence and machine learning algorithms work. And that is why today, anyone who wants to develop their carrier needs to have a priest, a basic understanding, cough, artificial intelligence and machine learning. According to various estimates, there are only about 300,000 AI experts around the world, and of these, only 10,000 are very strong professionals who work on large scale projects. It is estimated that in the very near future, demand for such specialists will grow to 30 million people and will continue to grow in the future, which means it's for Now there is a huge shortage of experts who understand and are able to work with the technologies of both AI and machine learning. Many technological giants such as Google, Netflix, Alibaba, Tencent, Facebook complained about the lack of high class specialist and salaries for such vacancies are one of the highest in the market today, especially with two or three years of experience in the field of big Data. And AI can receive more than $150,000 a year in America, Europe and China, and the best specialist learned from a $1,000,000 a year and more. Needless to say about the numerous start ups in the field of AI, which are launched every week and attract huge rounds of investments, those to summarize A is already used in our lives by many companies and services. Sometimes even when we did not notice it. In general, it makes our experience off contract include the surrounding quality, more personalized and convenient. There are many areas and industries where the Norwich off a I can be put into practice, and there is an obvious shortage of specialists in this field, and they will be in demand in the next two decades, at least in this course, you will give the basic idea of what a I and machine learning car tell you about its main dives. Algorithms, that models show you where to look for data for analysis and practice with you. How to solve some real machine learning problems. We will also provide you a brief introduction to wearing the by phone, which is a programming language used to build most machinery in fondles. After passing this course, you will be able to communicate freely on these topics, and you'll be able to build your own simple machine learning predictive models C inside the course.
2. History of Artificial Intelligence: in the last few years, the terms artificial intelligence, machine learning, neural networks, big data have become perhaps one of the most discussed topics in the whole world today. On the lazy people are not talking about a I. However, it must be remembered that artificial intelligence is not something you and this discipline has been around for several decades. It was in the middle of the 20th century that scientists started thinking about whether machines can have intelligence. Back in 1950 the English mathematician volunteering proposed that hearing test, the purpose of which was to determine whether a machine can think and deceive a person, making him believe that he is communicating with the same person as himself and not with the computer. In the same year, science fiction writer I Sock Icing Off introduced the three Laws of Robotics, in which he indicated what the relationship between humans and robots should be. In 1955 a group of scientists held a seminar where they discussed the future of computers. One of those present was John McCarty, who first coined the term AI artificial intelligence. Therefore, it is 1955 that is considered to be the year off the birth of a I. Three years later, the same McCarty created the programming language least, which became the main language to work with the for the next two years. In 1956 engineer Artur Samil created the world's first self foreign computer that could play checkers. Checkers were chosen due to the fact that they had elementary rules, and at the same time, if you wanted to win them, then you have to follow a certain strategy. This computer, created by Samil Learned on Simple books, will describe hundreds of games with good and bad moves in the same year. In 1956 Helber Simon Alan, You Oh and Clifford Chou came up with a program called The Logic Theories. It is believed that this is one of the first programs with a I. The logic theories did a good job with the limited range of problems, for example, problems in geometry and was even able to prove the equal, literal triangle theory, um, more elegantly than their trend. Russell. In the next year, 1957 front krosen lot came up with Perceptron, which was a learning system that acted not only in accordance with given algorithms and formulas but also based on past experience. It is important to note here that Perceptron was the first system to use neural networks. Even then, scientists understood that some problems are sold by a person very quickly while they take a lot of time from a computer. Therefore, they thought that perhaps it is necessary to reproduce the structure of the human brain in order to teach the computer toe work as fast. They call the simplest elements of the Perceptron neurons because they behaved in a similar way as the neurons in the human brain. The computer model off the Perceptron was implemented in 1960 in the form of the first newer computer, which was named Mark one. Almost at the same time, a mighty institute founded a laboratory. Let's give an example here. The question. How do small Children learn? They are shown some kind of object, and they say that this is a bull and this a cube. After all, we did not explain to the child that the Cube has all angles off 90 decrees and all sides are equal and the ball has the concept of radios in diameter, therefore, the shell simple looks at a lot of similar objects. A lot of different balls and other objects a typewriter, a table, an airplane of us get. And after a while, the child begins to independently distinguish all this object, even if they are a different color or slightly different in their form. When the computer algorithm learns from a large volume of examples, this is called machine learning. Artificial intelligence, in turn, means that the algorithm learning from examples can solve various intellectual problems. So let's go through that into the next decade. It was in 1961 that General Motors introduced the first robot in its manufacturing process of cars. In 1965 the first child born ELISA, was invented. ELISA was supposed to imitate a psychotherapist who asked the patient about his condition and suggested possible solutions or simply could sympathize with the interlocutor. It turned out that the conversation with ELISA people experience the same emotions and feelings as with a real person. In 1974 the first unmanned vehicle was invented in the laboratory off Stanford University. It would soon become the prototype for the following corner models in 1978 Douglas Lynn and created the Your Risk Herself warring system. The system not only clarified already known patterns but also proposed new ones. A few years later, you risk a learned to solve such problems as more doing biological evolution, Cleaning the service of chemicals, placing elements on integrated circuits and so on. You're Iskan is a set of logical rules. If then Yuri sticks and rule that works in many cases, but not in all. It allows you to quickly make a decision when there is no way to conduct a full analysis off the situation. For example, how to distinguish tasty from tasteless food? If there is sugar than it's delicious, It works, but not always. For example, sell it or fried meat or sugar is also not always stays deep. For example, meet with sugar Yuri sticks can be complicated or supplemented. For example, fruit or some combination of products can becomes either delicious. The machine itself learned to invent them from experience. We give example, so the algorithm and it already finds patterns. The machine can sort out the look more options than people. If customers didn't like it, then perhaps this is a bad combination of duck with apples. What? There is not enough source. So let's move on to the end of the 20th century, in 1989 Carnegie Mellon created an unmanned vehicle using neural networks. In 1988 the deep thought computer plays against Kasparov, Jess Champion, but loses to him after eight years. They have another game in the game. Kasparov is stronger than the computer, but just the year leader. In 1997 the highly upgraded A I D blue from IBM defeats Gary Kasparov and becomes the first computer. The win against the current world chess champion, De Boop, worked many moves forward and try to find the most preferred move. Scenes of 2000 computers have consistently outperformed humans. In 1999 Sunny announces the dog Aibo, whose skills and behaviour develop over time in the same year. For the first time, M. I. T showed an emotional AI called Kiss meant which can recognize people's emotions and respond to them. According clean. In 2000 and two, the mass production of Autonomous My Robot Vacuum Cleaners begins, which can move around the house on their own, avoiding obstacles In 2000 and nine Google joined the race of companies to develop their own unmanned vehicle in 2011. Smart virtual assistants like Siri, Google Now and Cortana appear in 2014. Alexa, from Amazon, will join them and in 2017 at least from Yandex. Remember, we talked about the Turing test, which was invented by volunteering in 1950. It was intended to understand whether a I can deceive a person and convince him that it is not a computer in front of him by the person. So in 2014 the computer child boat Eugene Guzman passed this test, forcing 1/3 of the jury to believe that the computer was controlled by a person, not a I. In 2016 the Google Deepmind with an AI called Alphago defeated ago champion Go Game is much more complicated than chess. There are more options inside the game and nevertheless, go became the second game in which people can no longer win. In 2017 offered more than 10 years off attempts and feelers. The two teams independently developed their own AI models, Deep Stack and Liberties computers, which were able to beat poker professionals. Unlike going chest where everything is subject to strict rules. The human factor comes to the fore in poker because poker is largely a psychological game based on emotions, nonverbal communication, the ability to bluff and to recognize bluffs. One of the participants in a poker game with these computers describe his impressions as follows. It is like playing with someone who sees all your cars. I do not blame the neural network for full plate. It's just that it's really so good. In 2015 ill unmasking Sam Altman president Off Y Combinator founded Open I to create open and friendly artificial intelligence. In 2017 the Open I a development team decided to train in Serial Network in the largest Eastport Game daughter, too. In this game, teams of five people play, and they use many combinations off more than 100 heroes. Each of them has its own set of skills. In two weeks, the neural network was able to learn and defeat several of the best players in the world in one on one mood, and now its creators are preparing to release a version for the main mode. Five by five. We moved even closer to our days at the beginning of 2018. The algorithms from Taliban Microsoft surprise the person in the test for reading comprehension in March 2018 a small robot that similar Rubik's Cube in just your 20180.38 seconds. The record among people before that was 4.69 seconds. One of the most important breakthroughs in development off AI, which can bring many benefits to humanity, was that in May 2018 artificial intelligence became better than people to recognize skin cancer. In addition to recognizing diseases in patients, a algorithms are used today to study protein folding. They try to find the cure for Alzheimer and Parkinson's disease is is also used to reduce energy consumption and to create new revolutionary materials. Artificial intelligence is also actively used in business. Banks use it to approve loans into retail companies, use it for more targeted advertising campaigns and offers for their customers. Why exactly in our time? A. I began to pick up speak so quickly. There are two reasons for these. Firstly, now a huge amount of information is being produced in the world every two years. The amount of information the world doubles. And as we know, AI is learning from the available data and the second reason is the presence of strong computing power. Our computers today are strong enough to be able to process huge problems off information in a fairly limited time. So we looked at a brief history of the development off a I. In one of the Full Inc lectures, we will see what can be expected from the development off in the future.
3. Difference between AI, Machine learning and Deep Learning: today, the terms artificial intelligence, machine learning, deep learning, neural networks and big data are very common or from these terms are used interchangeably. And although they are really very connected, let's look at what each of these concepts means and how they differ from each other. Firstly, to cut it very short, AI is quite a broad industry, which endurance covers both machine learning can Deep learning machine learning is a Considine part of AI, and deep learning is a constituent part of machine learning. Artificial intelligence implies that a computer can perform similar tasks that a person can perform and hear them African soon. It's not just on mechanical actions. For example, taking can curing some object but tasks that require intellectual thinking. That is when you need to make the right decision, for example, that us can be too in chess or to recognize what is shown in the picture or to understand what was said by the speaker and give the correct answer. To do so. Computer is given a lot of fruit or algorithms by following which it can solve such intellectual problems. I can be weak or it's also called narrow ai that is when the machine can only cope with a limited type of test better than a person, for example, recognize what is in the picture or play chess and twin. Now we are at this very stage of the development off a I. The next stage is the General AI. When the can solve any intellectual problem as well as person in the final stage. Is a strong artificial intelligence. When the machine copes with most, asks much better than a person. As we have already said, artificial intelligence is a rather vast area of knowledge. He didn't close the following care s natural language processing when the computer must understand what is written and give the correct and relevant answer. This also includes translations of text and even compilation of complex text by computers, second expert systems or computer systems that similarly, the ability of a person to make decisions mainly using the if then rules. Rather than using some kind of cold speech, the computer must recognize this speech of people and be able to talk next one Computer vision computer should recognize certain objects in the image or when they are moving. Robotics is also very popular area off a. I. The creation of robots that can perform There is functions including moving can communicating, overcoming obstacles, automated planning. Usually it is used by autonomous robots and unmanned aerial vehicles when they need machine learning to perform sequence infections, especially when it happens in a multi dimensional space and when they have to solve complex problems. And finally, machine learning machine learning appeared after we had tried for a long time to make our computers more intelligent, giving them more and more rules and regulations. However, it was not such a good idea because it took a huge amount of time and we couldn't come up with rules for every detail and for every situation. And then scientists came up with the idea. Why not try the algorithms that learn independently based on their experience? Thus was born machine learning. That is when machines can learn from large data sets instead of explicitly written instructions. And Truls Machine Learning is the era of AI, where we train our algorithm using data sets, making it better, more accurate and more efficient with machine learning. Our algorithms are trained on data, but without pre programmed instructions, that is, we give the machine a large set of data and say the correct answers. And then the machine itself creates algorithms that would satisfy these answers. And with each new additional amount of data, the machine guns further and continues to improve its prediction. Accuracy. If we take chest in tradition programming or in a program called A I would give the machine the set of logical rules and based on them, it is learning to play in the example of the machine. Learning is when we give the machine the set of examples of past games he takes, reminds them and analyzes why some player swing and others whose what steps lead to success and want to defeat. And based on these examples, the machine itself creates algorithms and rules on how to play chess in order to win. In an example, suppose we need to understand how the price of an apartment will behave when changing certain parameters. For example, depending on the area, the distance from the metro number of stories of the house and so on. We don't load data from different apartments in the computer, create a model by which it will be possible to predict prices depending on these factors, we regularly update the data, and our algorithm will be trained on the basis of these new data, and each time it will improve its prediction accuracy. Deep learning is the subsector of machine learning, where the computer learns but learns a little bit in a different way than in the standard machine. Learning. Deep Learning uses neural networks, which represent algorithms repeating the logic of human neurons in the brain. Large amounts of data best for these neural networks and in the output were given the answers to the task. Neural networks are much harder to comprehend unusual machine learning, and we cannot always understand what factors have more weight on the onset. But the use of neural networks also helps to solve very complicated problems. Sometimes neural networks are even called the black box because we cannot always understand what is happening inside these networks. Suppose your computer evaluates how well an essay is written. If you're using deep learning, the computer will give you the final decision that the essay is good or not, and probably the answer would be very similar to how a person would rate it. But you will not be able to understand why such decision was made, because deploring uses multiple levels off neural networks, which makes it very difficult to interpret. You will not know which note of the neural network was activated and how the snows behave together to achieve this result. Where is if use machine learning, for example, the algorithm off a decision tree? Then you can see which factor played a decisive role in determining the quality of their say. So neural networks have been known since the 20th century, but at that time they were not so deep. There was only one or two layers, and they didn't give such good results as other algorithms off machine learning. Therefore, for sometime, neural networks faded into the background. However, they have become popular recently, especially since about 2000 and six, when huge data sets and strong computer capacities appeared in particular graphic cards and powerful processors, which became able to create deeper layers off neural networks and make calculations faster and more efficiently. For the same reasons. The Poulenc is quite expensive because, firstly, it is difficult to collect big data on specific items and secondly, the serious computing capabilities of computers are also expensive to cut it short. How does deploring quirk suppose? Our task is to calculate how many units of transport and which particular transport that is . Buses, trucks, cars or bicycles passed through a certain road per day in order to distribute lanes for different types of vehicles. For this purpose, we need to teach our computer to recognize types of transport. If we were to solve this problem with the help of machine learning, we would write an algorithm that would indicate the correct heuristics of cars, buses, trucks and bicycles. For example, if the number of wheels is to then it is a bicycle. If the length of a vehicle is more than 56 meters, then it is a truck or a bus. If there are many windows, then it's a bus insolent. But as you know, there are many people's. For example, the bus can be tinted, and it will be difficult to understand where the windows are or a truck may look like a bus or vice versa. In Florida, pickup cars look like some small trucks, and it can be difficult for computer to distinguish between a bicycle and a motor bike. Therefore, another option for solving this problem is to upload a large number of images with different types of transport into our computer and seemingly tell him which images depict the bike, car, truck or a bus. The computer itself will begin to select the characteristics by which it can determine what kind of transport is depicted and how they can be distinguished from each other. After that, we will upload some more images and test how well the computer copes with the task. If it makes a mistake, we will tell it that here you made a mistake here. It's not a truck, it's of us. The computer intern will go back to the its algorithms. This is called by the way back propagation and make some changes there, and we will start again in a circle until the computer begins to guess what is shown in the picture with a very high prediction accuracy. This is called deep learning based on neural networks. As you understand, this can take quite a long time, maybe several weeks, depending on the complexity of the task. It also requires a lot of data. It is desirable that there are at least millions off images, and all these images should either be marked, for it should be done by a person, but it will be very time consuming. All right. So to summarize, deep learning is a branch of machine learning, and they both fall under the broader definition off Artificial intelligence Machine Learning uses algorithms to learn from data and make informed decisions or prediction based on what it has learned. Deep learning does the same since it is also a variation of machine learning. But what is different is that deep learning uses algorithms, which are structured into several layers to create an artificial neural network that can also learn and make smart decisions. Machine Lauren can be used with small data sets and on small amounts of data. Machine whirring and deep learning have almost similar prediction accuracy but with increasing amounts of data. Deep learning is also much greater prediction accuracy in machine learning. We ourselves said the characteristics on which our algorithms will be based in the example with determining the price of an apartment, we ourselves indicate the parameters when which the price will depend. For example, the footage distance from the metro age of the house area and so on. And in deep learning, the computer or one might say neural network itself, by trial and error comes up with certain parameters and the your weight on which our output will depend. As for the lording time off algorithms, deep learning usually takes longer than machine learning, deciphering or interpreting their algorithms off machine learning is easier because we see which perimeter plays an important role in determining the output. For example, in dimensional determining the price of an apartment, we can see that the weight of the footage in the price is, say, 60% in deep learning. Deciphering exactly what led to such a result can sometimes be very difficult because there are several layers off neural networks and many parameters that computer can consider important, but which we don't necessarily see. That is why, as we said earlier, deep learning is sometimes called the black books, since we don't know what parameters were considered important by the machine in deep learning. Therefore, the use of deploring commission during will also depend on the purpose of your task. For example, if you need to understand why the computer made this or that decision what factor played an important role, then you will need to do is machine learning instead of deep learning. Since deployment requires much more data as well as more powerful computing capabilities of the computer, and in general, it takes longer to learn. It is also more expensive compared to machine learning. Thus, if we summarise the entire lecture, then wherever speech or image recognition is used robotics, text or speech, interpretation or translation chart boards fund meant driving call vehicles prediction of some parameters based on available data. All these examples contain the I elements because AI is a very broad concept that covers all these areas. When a computer imitate thinking and behavior off a person in cases when we instead of giving to the computer written instructions and truth to solve the problem, we give it a set of data in the computer, learns from these data, find some patterns in data and based on such Lauren can then make predictions. Such cases are referred to as machine learning, and one of the methods for analysing can. Finding patterns in data by computer is called deploring, which uses several layers off artificial neural networks, which makes such calculations on the one hand, more efficient but on the other hand, more difficult to decipher. I hope the short summer was helpful. But if you still have difficulties understanding these concepts off machine, Gordon can deploring. Please do not hesitate to ask me in the comments section off this course and also feel free to continue watching the scores for them. See you in the next lectures.
4. Supervised vs Unsupervised Machine Learning: If you were interested in the topic of artificial intelligence and machine learning, you may have already come across such concepts a supervised learning and unsupervised learning. In this video, we're going to learn how these two names differ. First off, they are both types of machine learning. Secondly, supervised learning doesn't necessarily imply that someone is standing behind the computer and controls every action. Summarized learning means that we have already prepared the data for further work on the computer, that is, each object has a label. The label distinguishes the subject from other objects or gives it some name or numerical value. And the computer can find veterans between the features off objects in their names based on these prepared or, as they're called labeled data. Supervised learning includes two main types of tasks. Progression and classification. Let's look at a typical example Overclassification problem. This is an example off Irish flower data set introduced by the British statistician and biologist Ronald Fisher in his 1936 paper, these data set has already become classical and is often used to illustrate the work of very statistical algorithms. You can find it by the rink indicated on the screen or simply by Googling kids on the Internet. So let's have a look at it in the nature. There are three types of iris flowers. They differ from each other in terms of size of the petal and samples. Will characteristics of the flowers are listed in the table. The columns indicate the length and width of the petal, as well as the length and width of the samples. The last corn shows one of the three types of Cherries Irish Sentosa, Iris, Virginia and Iris Vertical are these names Off types are labels for our detail. Based on these, data said, we need to build declassification rule that determines the type of flower depending on its size. This is the task off multi class classification, since there are free classes three types of Ari's flowers. In classification algorithm, we divide our irises into three types, depending on the length and width of the battle and samples. Next time, if you're coming, crossing you are is flour. With the help of our model, we can immediately predict which plays these flower belongs to. Why do we consider this example a supervised learning? Because for each flower in our training Data said. We have a label, whether it is Irish, Sentosa, IRS, Virginia Iris particular, that is, We act as a teacher and we teach our model until it that if you see that the science of the petal is such and such, and the samples are such and such, then this is iris for Jessica. And if the science are such and such, then this is Iris, where sequel or this is called supervised learning. Or sometimes it's called Learning Curve a teacher when we show our model all the answers, depending on the characteristics the model is wearing on this data and create a formula or algorithm that will help us in the future to predict the type of a new flower depending on its size. In addition to classification problems, which we have just mentioned with the example of the artist flowers, there is another type of supervised learning. It is called regression in classification problems. We have several classes of objects where is in regression problems. We have only one class, but each object is different from the others, and we need to predict the concrete number or concrete value off a new object for objects depending on its features and based on the data set that will provide to our computer. The classic example of progression is when we predict the price of an apartment, depending connects footage. So we have some kind of a table with the data from different departments. In one column is the footage, and another is the price of these apartments. This is a very simplified example of progression, obviously, that the price of an apartment will depend on many other factors, like location, quality of the building, number of stories and so on. But nevertheless, it clearly demonstrates what regression is. So in the last column, we have the actual or real prices for apartments. We were given footage. Why is it supervised learning? Because we, as a teacher, show our model that if you see that the footage is such and such, then the price will be sergeant. Such the price X like label for each object in our data set and whenever Diddy's labeled it , is a case of supervised learning. Based on these data, the model learns and then produces an algorithm based on which we can predict what the price of the apartment will be depending on a given footage, thus to summarize in supervised learning. The key point is that we have labeled data in our data set. That is, we load data with answers into our model, whether it is the class to which the object belongs or it is a specific number, like in the case of apartment pricing, depending on the footage based on this information, the model learns and create an algorithm that can make predictions. All right, so let's move on. The second type of machine learning is unsupervised learning. This is when we allow our model to learn independently and find information that may not be visible to a person. Unlike supervised learning models that are used in unsurprised learning derive patterns and make conclusions based on unlabeled data. Remember, we had an example with iris flowers. So in the data sets that we gave to the computer, there were answers what kind of virus we have, depending on one or in other sides of the pedal and samples and in unlabeled data. We have objects and their features, but we do not have an answer what kind or class they belong to. Therefore subject eighties called unlabeled in on supervised learning, the mean types of tasks or clustering and dimensionality reduction. You know that show dimensionality reduction means that we remove unnecessary or redundant features from our data set in order to facilitate the classifications off our data and make it more understandable for interpretation. And now let's look at an example of cross shrink in the problems of clustering. We have a data set of objects and we need to identify its internal structure. That is, we need to find groups off objects within this data said that are most similar to each other and differ from other groups off objects from the same day to set, for example, to sort all vehicles into categories all vehicle similar to a bicycle into one group or cluster and similar to a bus in a separate group. Moreover, we do not tell the computer what it is. It must understand on its own, to find similar signs and identify similar objects in a particular group. Therefore, this is called Learning Without a teacher were unsupervised learning because we did not initially tell the computer to which group this or those objects belong, Such tasks can be very useful for large retailers, for example, if they want to understand who their customers are made off, suppose there is a large supermarket, and in order to make targeted promotions for its consumers, it will need to break them down into groups or clusters. And if they now have sales for sports good, only they will send the advertisements. Not all consumers, but only do those who have already both sports goes in the past. That's the main difference between supervised learning and unsupervised learning. Is that in supervised learning? We use label data where each object is marked and belongs to a particular class or has a specific numerical value. And based on this label data, our model bills and algorithm that helps us predict results on new data and in answer to rise learning, the data we have is unlabeled or unmarked in the computer itself, find certain patterns and common features, and divide all objects into different groups similar within one group and different from objects in other groups. There are two main types of tasking supervised learning, which are classifications when we divide our dating to classes and progression when we're making a miracle forecast based on previous data. The main types of tasks off unsupervised learning include clustering when a computer divides our dating, the groups or clusters and dimensionality reduction, which is necessary for a more convenient demonstration off large amounts of data. Well, consider each of these task in more detail in the following fractures.
5. Linear regression and predicting flat prices in Excel: so one of the most popular machine learning algorithms is regression. It is a task to predict a specific attribute, often object using the available data and other attributes of the object. For example, we can predict a person's weight based on his height, where we can predict departments price based on the distance from the metro for the area of the apartment. In this episode, we're going to see how we can solve our aggression problem in ordinary Excel file. Let's take an example with the prediction of the coast of an apartment, depending cornets footage. Every machine learning task needs data in the more data, the better. So it's an agent that we have an excel table with data in one column, the area of the apartment in the other, the price of this apartment. We please these data on the craft, and in principle we can notice that there is a certain linear dependence, which is quite off those because the larger the area, the heart, the cost of the apartment. Of course, it is clear that much more factors will affect the price of an apartment such as distance from the city centre and mental number of stories, age of the house and so on, but for simplicity reasons, with equally one sector, the area of the apartment. So our task is to learn how to predict the price to do these really the formula, which can give us the forecasted price based on the area of the apartment. In cases when we see Alina relationship, the following formula is usually used, which is why is equal to a X Plus B in which, why physical to price and X is the area. Actually, the dependence may not be necessarily linear. It can be a cure or have a very strange look. So in order to have a concrete working formal are we need to find the coefficients A and B . How can we find them? The easiest and classic weight, which you probably learned on the lessons of algebra or statistics, is the least squares method. In fact, this method was invented 200 years ago, and now more effective solutions have appeared, but nevertheless, the least worst method is still quite relevant and is used quite often in regression problems. The least square method is when you find a formula in which the sum of the squared deviations is the smallest from the desire to rivals. Let's see how it might look like in Excel. So we have a table with a certain number of apartments there, area and price. But its place these data on the craft and see the points with the corresponding failures. We see that there is a sort independence at the larger the area, the heart, the cost of the apartment. Let's draw a line in Excel. You can do this as follows. We click on the chart. A plus sign appears on the site. Click on it and put a tick to show the trend line. Okay, the line is visible, but how can we find the specific or efficient so far formula so that we can predict prices for new apartments? In theory, you can make long calculations and solve this equation Here in Excel, using metrics calculations, However, this can be done much easier in two weeks. Again, trick on the plus sign Quicken additional options. And here we put a tick to show the formula. Okay, here we go. Now we can see our formal, um, at the top of the craft. Why is equal to 0.715 x plus. You're a 0.8111 So 0.7 is our coefficient A and 0.81 is our coefficient B. You can also see there is a letter are square below the formula. It stands for R squared values. This indicator takes failures from 0 to 1 and implies the valley from 0 to 100%. If the value is one, then this means that our line or are formula 100% correctly describes the ratio for indicators in our keys. The ratio of price and area. As you can see on this graph the indicator are square is your 0.976 which is a fairly high indicator which suggests that our formal is very effective. According clean. Now we can predict prices depending on the area known this formula and the coefficients. We simply substitute the area off some new apartments and see what the price should be in accordance with our formula. As you understand, this formula will also change each time you enter some new data off real apartments of real prices. It will change and adjust in such a way as to best match all the objects in our sample. You can customize your aggression former so that old prices affect your formula less because it is those that they're less relevant in the new apartment. Prices would have more waiting your sample, so to summarize, in aggression problems, we predict the specific numerical value of a particular attributes using available data and other attributes, and we do all these through the help of a formula that we derive from an existing set of real data.
6. Classification problems in Machine learning: classifications is a large group of tests that are used quite often, I would say is open his regression or even more often, as we can understand from the name specification is used in order to attribute an object to a certain class. For example, will the border will be able to repeat alone or not? Or is it a dockworker getting the picture, or will the company become bankrupt or not? And so on? If we compare with regression in regression, we do not have any classes. We simply predicting a miracle value. For example, in the previous lecture, we predicted prices off apartments and the declassification problems. The number of classes is limited. We provide the names of the classes to the computer, and the computer determines which of these classes the new object belongs to. Let's look at some key says, when classifications tusks can be used. Today, many banks use classifications algorithms to determine whether to approve a loan to a borrower or not. In this case, there are usually two classes. The first class is a credit worth Bora work, and the second class is a potentially untrustworthy Bora. Work now imagine, and your client comes to the bank and wants to take alone how banks determine which Christ one or another potential border water belongs to, especially if they didn't have previous experience interacting with him. That's right. They look at a large database off their clients and draw conclusions on what class of world wars. This new client is more similar to how this classification algorithms work. The bench has tens or even hundreds of thousands of data from their customers, and they know which of the customers pay on time and reach, delay the payment or even become insolvent. They aggregate this data on the basis off. For example, the one who's loan amount doesn't exceed 30% off his monthly income, usually based regularly in the one who already has another long orphan delays. And there are a lot of psychological chains based on this information. The computer in the bank built a specification model, so the computer builds a model. Then the bank manager asks too few out a questionnaire from a new client. Then he enters all these data into the model, and the algorithm gives an answer. This new client is credit worthy or potentially untrustworthy borrowers. The model can even indicate with what probability this new customer will likely to delayed alone and whether he will bait at all these days. The credit scoring king most banks is carried out automatically, even without the involvement of banking. Specialist clients simply fill out an application online, and the computer automatically gives approval or not. In complex and contentious cases, a bank manager is of course. Wolf, in that example of constipation problems, was mentioned in under the previous lectures where we mentioned Irish flowers. This is also a typical question cation task. We have free classes of flowers, and we need to learn how to predict which class a flower belongs to. Depending on the size of its petals and samples, declassification problems can be solved using different methods. The most commonly used are the following decision tree logistic regression and do not confuse it with the usual linear regression which we have already mentioned. And we would predict a specific numerical value. Logistic regression is a little different. Using algorithms, we find the line that divides our data set into classes, then a random forest, ensembles and begging support, vector machine and keen ears neighbors. We will examine this matters in more detail in the following fractures. In the meantime, in a nutshell. In the constipation problems, we predict which Christ and object belongs to. The number of places is limited. That is, for example, to approve. Alone or not. The picture shows a bus, car or a bicycle, and so on. These days, classification problems are being used more and more in many industries, perhaps even more often than regression problems, and therefore, it's a good idea to learn this question Gatien methods.
7. Clustering in Machine Learning: clustering is one of the main types of unsupervised machine learning in clustering tasks. We have a data set, and we need to understand its internal structure. We divide the data into groups or clusters in such a way that inside each cluster we have elements that are most similar to each other but differ from the elements in the other groups. You may have a reasonable question. What's the difference between classifications and clustering problems? I will try to explain it with an example. Imagine that we have a table with the characteristics of planets and stars. And thanks to each object, we have an answer, whether it is a planet or a star. The answers are the so called labels, which are used in supervised machine learning. Based on these labels, the computer builds a model that can predict within useless. Still, body is a planet or a star. This is an example of classification problem because we have a limited and pre defined number of classes that is stars and planets, and we predict toe what class the new object belongs to. But imagine that we didn't have answers. What are these objects in space? We only had their characteristics, such as weight, temperature, composition and so on. In this case, the computer with just divided well objects into two groups, depending on their similar and different features. Our computer would say that there are two obvious clusters which differ from each other, and it would be our task to call these two clusters somehow afterwards because clustering is an example off unsupervised machine learning in which we do not have tags or answers for each object. In our data set, we simply divide all objects into groups, and we're not trying to predict anything. In respect of new objects, we simply divide the existing objects into clusters. In what other kind of cases do we need to use clustering, one of the most active users of class? Ring for retailers and department stores, which want to figure out who their customers are? Take, for example, a large department store which wants to make targeted promotions for its consumers. It will need to break them down into groups or clusters. For example, consumers can be divided into the following groups family cluster. They tend to bite household goods and good with Children. Athletes who often by sport products and sport nutrition gardeners and so on. And next time, when there's a sale, promotion of sporting Goods store will send the problem messages about this promotion. Not all of its customers, but only did those who have already both sporting goods in the past. Class drink is also very actively using social networks. It is done primarily to break users into groups based on their interest in that defectors, and then offer them more appropriate and relevant videos, pictures, use and other content so that they spend more time in these APS. Secondly, this is done through just target advertising more effectively to make it more targeted. Precisely for those groups off users, it might be most interested in the advertised products. Smartphones also use clustering algorithms to separate photos and videos into different folders, for example, depending from the date for place where the photos taken so that users can find these photos more easily These days. Smartphones can even distinguish what is depicted in the photo, and they can separate photos based on what is seen, whether it's people landscapes for home in biology, class room keys used in order to separate newly discovered representatives off animal and plant kingdoms into existing species, depending on their characteristics. Very often clustering algorithms are used in genetic research, in particular for the gentleman notation. Anything evolutionary biology, thus in clustering, will not predict something. But we simply distribute the existing objects into different clusters or groups based on their similar features and characteristics. It helps us to understand the infrastructure off our data set in the mandalas toe, work more efficiently with our later.
8. Ensemble methods in Machine Learning: Hi there. Let's suppose that we have a certain algorithm, and in principle, it copes well with its tasks. But what if we want to improve the accuracy of the predictions of our algorithms? In this case, we're going to use some additional and more advanced methods. In the next few lectures, we're going to learn some of them, including ensembles, bagging and random forest. Ensemble methods. In machine learning means that we use a combination of several different algorithms to solve the same problem in order to improve the accuracy of the prediction. The use of ensembles in machine learning is based on the Condorcet jury theorem, which was published as early as in the 18th century. According to this theorem, if we have a jury and each member of the jury has an independent opinion, that is, their answers are independent and the probability of making the right decision for each member of the jury is more than 50 percent, then the probability of making the right decision by old jurors overall will approach a 100 percent as the number of jury members increases. The same thing applies in the opposite case. If the probability of making the right decision is less than 50 percent, then an increase in the number of jurors, the probability of making the right decision will tend to 0. Another illustrative example is the so-called wisdom of the crowd example. In 1906, the city of cleanup hosted a fear which included many different entertainment events. And it's one of these events, around 800 people took part in a competition to guess the weight of a bool. None of the visitors to the exhibition could guess the exact weight of the bull. But statistician Francis Galton calculated that the arithmetic average of all assumptions differ by less than 1% from the real weight of the bull. The bull waited one hundred and two hundred and seven pounds, and the arithmetic average was 1198 pounds. This led to a surprising conclusion that if one person can not give the correct answer, then if you collect data from many people and average them, you get a very good and very close to true result. The wisdom of the crowd is used today in many industries. For example, when the player ask the audience for helping the famous TV show Who Wants to Be a Millionaire. And even the whole idea behind the creation of a Wikipedia or Yahoo Answers or similar services. They all are based on the information provided by a large number of users. And if we consider that most users provide to information to the best of their knowledge, then with each new user, the reliability and accuracy of this content and the information will increase and the quality of information will tend to improve. So data scientists decided to apply this theorem of Condorcet jury and the idea of the wisdom of crowds in machine learning in order to improve the accuracy of algorithms. Let's suppose that we have several algorithms. We know that one algorithm is run on one data segment and the other is wrong conduct the data segment. So if we combine the results, we can show that they are combined. Error will fall because they cancel each other out. Thus, when using the ensemble method, the combined result of several models is almost always better in terms of prediction accuracy compared to using only one model. Let's take another example. A funny story about a group of blind people and an elephant. In the story, several blind people are asked to touch an elephant and say how it looks like someone touches his ears, someone touches his trunk, and someone touches his tail or legs. For each of these people, the idea of how the elephant looks like will be different. However, if we combine the opinions are full of them, we will get a very complete idea of what an elephant looks like. This is an example of an ensemble by combining different models together will make the accuracy of our prediction better.
9. Bagging and Boosting: Slightly more advanced ensemble classification methods include bagging, boosting, random forest and stacking. Bagging stands for bootstrap aggregation. Suppose we have a large dataset. We begin to randomly pull objects from the set and make smaller datasets from them. As a result, we get several new, smaller datasets, which in terms of internal structure will be very similar to our original dataset, but at the same time will be slightly different. Some objects will be found in several new datasets. That is, they will intersect and this is normal. And then we will train our algorithms on these new smaller datasets. And this method tends to improve our accuracy. Suppose we are a pharmaceutical company and we have data on 10 thousand patients and their reactions to a new drug that we invented. For some of the patients, the drug works very well. For others, it doesn't work at all. We have a decision tree and having trained our algorithm, we get a model that gives the correct predictions in 75 percent of cases. This is certainly not bad, but still 25 percent of prediction error is a rather large spread. Therefore, we divide our patients dataset, several smaller dataset. For example, each containing 2000 patients. And then we train our algorithms on every new dataset. And then we aggregate the obtained algorithms into the final model, which will now make the correct predictions in more than 80 percent of cases. Begging is usually used when the variance of the error of the base method is high. Begging is also useful in cases where the initial sample is not so large, and therefore, we create many random samples from the original dataset. Although the elements in such Sub datasets can be duplicated as a rule, the results after aggregating are more accurate compared to the results based on the original dataset only. Boosting is another way to build ensemble of algorithms when each subsequent algorithm seeks to compensate for the shortcomings of previous algorithms. In the beginning of the first algorithm is trained on the entire dataset. And each subsequent algorithm is built on the samples in which the previous algorithm made an error. So that the observations that were incorrectly predicted by the previous model are given more weight. In recent years, boosting has remained one of the most popular machine learning methods along cuz neural networks. Its main advantages are simplicity, flexibility, and versatility. One of the most popular examples of the boosting algorithm is the adaptive Adaboost algorithm developed by Shapiro and fluid back in the late 90s of the last century.
10. Majority voting and Averaging in Ensembling: Ensembles can be viewed in different ways. The simplest methods are the majority voting or averaging and weighted averaging. Majority voting means that every model makes a prediction for each test instance. And the final prediction output will be the one that will be the most common or receives more than half of the votes. If none of the predictions gets more than half of the world's than in this case, we may conclude that the ensemble method wasn't a good choice for making prediction, and we probably should choose another method. Take the following example. Suppose we want to buy a new phone. We choose between American, Chinese, and Korean models. If we didn't use the ensemble method, we would, for example, come to the store, ask the CEO resistant what you would recommend and taking that model. If we use an ensemble, then before choosing what phone to buy, we will first conduct a survey with different people, with all friends, see user reviews on the internet, sera use of models on YouTube and experts recommendations. If we choose the majority voting method. In this case, we will choose the form model which was recommended by most people. The next method is simple averaging. Suppose we have a movie portal and we assign the rating of one to ten for each film. Or users who watched the film submit their ratings. And then we derive an average rating based on all these data. For example, two people gave a rating of 76 people, right? At eight, 12 people rate at 99 people gave a maximum rating of 10. As a result, the average score is 8.96. And the next method is weighted averaging. Again, let's take the movie rating example. Here we can give different groups of yours different weights. For example, professional film critics received a weight of one. Users who have been on the platform for a long time receive a weight of 0.75. End-users who have registered on, we recently received a weight of 0.5. Next, we derive a weighted average from their estimates. And thus we get a better assessment since it is assumed that film critics and regular movie goers are better versed in films.
11. Random Forests: Random forest algorithms are used very often in machine learning problems, and they can be used in a wide range of tasks, clustering, regression and classification problems. The random forest is built in much the same way as begging, but this is, it's slightly complicated version. The similarity to begging is that we create several smaller datasets from our large initial original dataset. The difference is that in lending, we use all the features when building algorithms. And in random forest, we randomly select only a few features on the basis of which we will build each individual tree. We had an example with a pharmaceutical company where we needed to understand whether our new medical product would have any effect on people with different characteristics, in particular, age, gender, cholesterol level, and blood pressure. In bagging, we create subsamples and build a decision tree for each subsample based on all the attributes in a random forest, we will also create subsamples. But for each subsample, we will randomly take only certain features, not all. For example, one way gender and age, or only agent cholesterol level. Then as usual, we will aggregate our result and as a rule, we will obtain even greater accuracy of the predictions of our algorithms. In classification problems, we will choose our final model by majority voting. And in regression problems, we will use the averaging. However, random forest has a significant drawback. Interpretation of predictions becomes very difficult as we have many trees over different structure and depth. And each tree uses a different combination of features. And therefore, in cases where transparency over decision-making keys needed, random forest is practically not use. For example, in credit scoring when banks decide whether to give a loan to a borrower or not. In this case, we need to know why our model has given these or their decision. And if we use the random forest, it becomes incomprehensible. Thus, a random forest is like a black box. It predicts very well, but practically it doesn't explain anything. That is, it's not clear what these predictions are based on. However, for ducks were high accuracy of prediction is needed. The random forest is one of the preferred algorithms.
12. Python setup. Anaconda distributive: There are a lot of programming languages. But defector and historically, Brighton has become the standard in machine warden, candidate analysts is. Many libraries have been collected for python. Of course, other languages can also be used, such as our scaler or C Sharp. But we will focus on Python because it is probably the most popular and simple enough to learn. There is a wonderful side called Anaconda. On this side, you can download not only Python but also various libraries for it, which are used by data scientists as well as all those who are engaged in machine learning . What is a lie? Every biting libraries are ready made solutions, that is, models with code templates. They were created so that programmers do not have to retire the same code each time they simply open the file, insert your data and get the desired result, So consider them as depositories off court templates. So the on a condom includes all the basic tools for writing code, data analysis and various libraries that can help in these process. The first instrument is Jupiter Notebook. This is an environment in which will write code and tested. Then we have various libraries. The most popular E spenders. This is a library for working with tabular data. It is very similar to Excel. The second library is much sleep. It is used for visualizing data, creating charts and graphs. The first library is psychic. Learn. It contains the basic machine learning algorithms. With the help of psychic learn, you can use algorithms such as linear regression, simple neural networks and decision trees, and one more library tensor full. It is used to work with neural networks of various architectures, so let's download Brighton. Latest version undecided can be downloaded for Windows, Mac OS and Kleenex. After downloading can a condom, you see the Anaconda Navigator shortcut, either on the desktop or in the start menu. Click on it and this window will appear. We will be mostly interested in the Jupiter notebook, and don't that you shouldn't confuse it with Jupiter lamp. So after Quicken Contributor notebook, a browser will open and such a window will appear. Jupiter allows you to create notebooks, which are files with the python code that you can immediately run and test where you can create, grabs and do other things. Let's create a folder and name it. Now, In this folder, we create a file for a so called notebook, and you will write code in the cells of this notebook. In the following kept results, we will begin to learn the basics off Python programming, the most basic commands for initial introduction. If for some reason you don't want to install Python or Anaconda distributive, maybe there isn't enough space in their computer or for some other reason, you can also use Google Collapse services. This is the environment that Google rents to you and where you can also code in python without installing kid on your computer. That is, this is a ready made system on which you can immediately start working. That is, your environment from Microsoft works in the same way. If you have a Microsoft account, you can use their points and notebooks in there azure environment without installing anything. All right, then, in the next episode, we're going to learn some basic commands in Brighton
13. Basic commands in Python: So if you worse about Python, this is a fairly convenient language for those who are just starting to learn programming, I would say it has a slightly simpler Syntex. There are no semi colons and the common seem to me to look simpler. And he did not need to constantly monitor so that all the brackets are open our closed and so that all models are correctly stacked and so on. Let's look at the simplest commencing by phone. Firstly, as it many languages. If you put the hash symbol, then you can write anything. It will be considered as comment and who can be reproduced as cold. Usually, these comments are needed so that you yourself understand why you wrote this or that code when you will reviewed when other programmers will look at it so that they can also understand why you rode the coat this way and not otherwise. Then the print comment displays what you wrote in brackets on the scream. If this is a text, then you must put it in quotation marks to execute the comment. You can press shift plus enter in. Pyfrom is in any programming language you can perform any mathematical operations, for example, at deduct, multiply or divide. If we print $100.300 price shift, enter and we get 400. We can also declare of arrivals by writing a letter or some name and then putting equal mark. For example, A is equal to a quotation marks hill a world. And then we can print this arrival by writing print anti in brackets A. Or we can say that now the letter A will be the number 100 the letter B will be the number of 313. And with the help of the print command displayed there, some on the screen or any other mathematic election numbers can also be compared with each other. You may also know that if you want to declare of arrival, he put one equal sign. And if you compare to the rivals with each other and ask where the one is equal to the other, then we used to equal marks together. And if you want to compare that, the two numbers are unequal, we put an exclamation mark, and an equal mark together is with any programming language. There are different types of objects in python. What types of objects are the most common? Well, we can divide them into two mean times. Mutable and immutable object whose value can change are called mutable. Where is objects whose value is unchangeable once they're created? Are called immutable. The mutability of an object is determined by its time. Immutable types include integer float. Logical varietals also called his billions that is, for example, tour falls and strength. Beautiful types include priests, set and dictionaries that is, along the way. We can change them. Let's see how we can check what time the object belongs to. We can use the type function to find out the class of arrival. Moreover, as you can see, unlike in C Sharp or Java, for example, the python language is also characterized by the fact that when you declare if arrival yourself, do not need to initially safe what type of arrival you'll now declare by phone understands itself. You just tried the name of the arrival and then give it to value. Therefore, by phone is classified is a dynamically typed language. If we wrote in C Sharp or Java, who would initially indicate what type of arrival it would be, and in by phone. We simply declare a musical to 10 and by phone itself, understands that in this case, the type of arrival is an integer and keeps it that way. What else we may need. There is such a think as output formatting and working with strings. This is a very convenient function that allows us not to constantly write code again, but to somehow template it, for example, in order not to write the name each time we want our coat to substitute the name whenever we need it. It can be designed in different ways, depending on the python that you have installed. Here are the main output options, for example, name, musical, toe team or and print. Hello plus name is the most difficult way when we simply add the word Hello and the varietal name, please know that our phrase is enclosed in quotation marks and do not forget to leave a space after the word hello and before the second quotation marks and the arrival name should be without quotation marks. The second and first options are using the additional letter F or the word four months is well, a securely brackets. Thus, if we want to change the name of the varietal, we will no longer need to write a new line of code. It will automatically substituted for the new name and one more basic function. Let's see which version off python we use in their imports sees and then print and in brackets cease version and just for fun. Let's see which version off by phone is used on Google collapse. So in this lecture we learn how to print how to perform mathematical operations and how to compare numbers with each other, how to declare different arrivals and what types of object they can relate to, how to use for minute input and how to find out which portion of life and we are using now . See you in the next lecture, where we are going to learn some more basic commands in by phone
14. If statement: for basic knowledge of programming in by phone. We also need to learn the so called operators to control the flow of commands. These include if else while and four operators. Let's start with the first operator, if else it is used to verify conditions. If the condition is true, then we execute the If. Look, if the condition is not true, then we execute the else block, which means that we are telling the computer if one condition happens, then execute a certain commend. Otherwise execute another command. So let's see what the if statement looks like on a concrete example. Now we're going to check whether given numbers are even or order, as we know from the school course, even numbers are those numbers for which the remainder, when divided by 20 and for old numbers, the remainder, when divided by two, is one by fund. There is a person that operator that shows the remainder over dividing one number by another number. For example, if we write 25% to, then we'll get one, because if you do I 25 by two you get 12 and the remainder is one. If we write 26% to then you will get zero because 26 is divided by two without the remainder. Let's try other numbers. So let's not write down a formula that will give us the answer. Whether the entered number is even order number is equal to let it be. For example, Number 22 if number percent too, is equal to zero print. The number is even else print. The number is else in this case means that in all other cases, if the remainder is not equal to zero, then you need to give the answer that the number is old. Let's check the coat on different numbers. Great, everything corpse. Now, if you want to also write down the number that he provided in your input, you can also use the former function. It looks as follows. We had securely brackets to the print line after the world number and after the quotation marks, put a period former and tried the number in parenthesis. That's the number that we indicated. The beginning will be automatically boot in curly brackets. Number is equal to 22 if number percent to physical 20 print. The number curly brackets is even period. Former and in parentis is number else. Print the number curly brackets is old period former and in brackets in parenthesis number . If you get an ever check that he used purely brackets after the world number and also put the period mark before four months, try checking out the numbers just by changing your number of arrival. Let's add one more condition here. For example, if we entered zero, many would argue whether zero is an even or odd number. Let's just write down that when entering zero, we will get that you entered zero please under a different number. So when we add a new condition, we use that a leaf operator. A leaf number is zero print you entered zero. Try a different number, but look what happens. We are still given that your is Even. This is because Python executes comments in order that is. First, the program reads the first line and divides our number by two. And as we know when dividing zero by two, we get zero, that is. The remainder is also zero, so he gives us the first command that the number is even. What do you think can be done to avoid these and that when dividing by zero, he gives us the comment we need. Take a short bulls, stop the video and think about it. You can even try it yourself on your computer. So, as you probably guessed, who will just swept the lines, Thirst will put the wind to check. Whether the answer Tom Berry, zero or not, and only then we will check what remainder we have. All right, then. So here's another task that you'll now do yourself. You'll have to write a goat in which we indicate the speed of the car. And if the speed is less than or equal to 60 kilometers per hour, then we need to write. Be careful on the roads, and if the speed is more than 60 kilometers per hour, then we will write. Please observe the speed limit. 100 per hour is optional. It is not necessary to indicated in the cold just the speed in numbers and now pose the video and you can try to complete the task. So how are you doing? Did you manage to write this coat and tested? The court will look like these speed is equal to 61 here we can actually write any number if speed is less or equal to 60. Print, be careful on the road. If speed is more than 60. Print, please observe the speed limit here in principle. In the second line of code, we can use either one more statement or else statement. There is no real difference. Let's check the different speeds and check of the speed of 16. As you can see, everything works if you want. You can try to think of other examples for yourself and practice them at home, for example, trying to write the code whether it is possible to sell alcohol or cigarettes to a buyer, depending on his age and in thanks lecture will continue our agreements with other commands in Bytom.
15. While statement: the next control flow operator is the wild statement. It allows us to carry out the repeated cycles of tasks. Wild Statement works as follows While the following condition is being fulfilled, it is necessary to execute the following command. The simplest example is when we ask the computer to display all the numbers from 1 to 50 the court will look like these. First we declare his arrival numb and that is equal to one. Next, we write that while our variable is less than or equal to 50 then we'll display this number using the print command ending the next line. We give command to increase this number by run with each next cycle. The sign plus and equal means that we give our variable and you value by agent Kwan Treat. These two lines, which are written under while print and increased of arrival by one, are called one iteration for one pass off the loop. They're only executed if the wild statement is true. Inside one cycle, there can be any number affections and even additional cycles inside the main cycle. While statement is very often used in computer games, in data transfer and in many other cases as a rule. Inside the Wild statement, there is a varietal which changes its value inside the loop because if it always stays the same, the group will be constant and infinite. Let's try to do another similar task. Try writing the code using the while operator so that now you're given numbers in the opposite direction from 52 0 but so that the numbers do not go in order. But after one digit, that is 50 48 46 so on. Pause the video and try writing this cold, so I think you managed to do it. The court will look like these now musical to 15 while Mom is more or equal to zero. Print Nam in the next line, numb, minus equal to okay and create. Now what else do we need to know when we talk about the wild statement? Firstly, how to stop it? Because the cycles can last forever. We have already said that you can stop it by specifying a restriction at the very beginning , for example, while the number is less than 15. But what if we do not have numbers, But instead we have words where We have numbers, but they change in random order. What should we do in this situation? In this case, we may need the Break Command, which stops the group. How does it look like? Let's take a similar example. Type numbers from 1 to 10. We said The arrival number is equal to one now to start the constant loop we can print. While true, then the comment print the number itself. In the next line, we add one to the number each time. And then we use the if statement, which would have already learned in the previous lecture. Give the number is 10. The break comment will interrupt our cycle, and after the cycle he stopped. You can write the phrase, for example, done. No the margin from the edge of the line because the phrase done has to be return on the same level is the original while statement and then it will be executed only after the wild cycle is complete. So let's move on now. The next function is how to make the computer ask us something and then use what is entered for for the operation. To do these, we'll need the input function suppose we want to play a game called Guess My Age thirst would provide to the computer our true age. And then the computer will ask the person to guess it. Depending on the answer that we type, the computer will either continue to ask us or tell us that we have guessed that age. Correct way. How can we implement this game in a few lines of code? First we said the varietal age, which is any number that is not equal to our true age. Next we write while truth, which basically means that we give the command to execute the cycle forever. Then the if statement even the ages 13 and this is the age that we guessed is true. Then on the next line, we type break, which means we break the loop. And if this if statement doesn't work, then we write age equal to and then the following formula int input and get the age. This former means that now the varietal age will have a value that the user enters in response to the phrase gates age. The in work at the beginning means that it will be an integer. It is a number on the next line and at the same level with the wild statement we write, you guessed it. This phrase will be executed only when the while loop breaks because if the ages not guessed, the computer will continue to run the cycle and ask to get the age again and again. Let's test it as you can see everything quirks. The only thing here is to insert a small space after the world age. One more thing, you may ask, Why do we write while truth? What does it mean? This is done to set a constant loop, actually instead of the world true. After a while, you can put any true statement, for example, while one is less than two and the computer will execute this while loop as long as one is less than two. That is always and therefore is just customary in such cases to write simply, while true, so what we have learned in this episode, the while loop how it can be stopped using the initially specified, constrained or using the break command. We also went over how to capture and use what the user has typed using the input command so now some homework for you. Using the wild statement, try to write the code so that the computer keeps asking Cue the password until you enter it correctly. And if you entered the correct password, then the computer displays the phrase Welcome. A small hint in the line where you will capture the password entered by the user. Pay attention to the type of arrival, whether your password will be a number or a set off letters.
16. Predicting flat prices with linear regression in Python: in this episode, we're going to learn how to predict apartment prices using python and simple in a regression model. Remember that we did the same task in itself. So we're going to use the same file and see how it looks in my iPhone at the end of the episode. I will also give you another task to do is your homework. Here we have an Excel file that tells us the price of an apartment, depending on its area. As you know, this is a very simplified correlation. We all understand that the price of the apartment is influenced by a very large number of factors besides the area, such as the city. How old is the building location from the city centre and from the nearest metro station, condition of the flat number of stories and so on. But for simplicity reasons, we take only one factor. The area, because it is obviously one of the most important factors, and the correlation is quite strong when we make such predictions, where there is a linear dependence or we need to do is place our values on the chart and draw a line between them that with most accurately reflect the correlation. And when we have such line, we can predict what the price will be, depending on any area. But you may ask why the line looks like that because it doesn't go through all the points. Is it the best line that describes the correlation between price and area? As we already said in one of our previous lectures on the regression? In order to find the line that describes our dependence as I characterize possible, we use the formula. Why is equal to a X Plus B in our keys? Why is the price and X is the area? And to find the coefficients, we will use the most classical method, which is the least squares method. The least squares method is the method. When you find the formula enriched, the sum of the squared deviations off our actual values is the smallest from the line we're building. Let's see how it will work in. Fife in first will train our model using the available data on flats with actual prices, and then it will make predictions for other partners with a different area. Remember when we installed python on their neck on the website we said that Anaconda also contains various libraries for machine learning. They were pundits model, sleep on by and others. These libraries contained readymade code models for various machine learning algorithms. Therefore, the first thing we should do is too important. It's libraries into our bison notebook in Jupiter. Bundle is necessary for working with tabular data like Excel. Now buy facilitates mathematical operations in by phone and will be needed to visualize our date on graphs and charts. And one more important library is psychic Learn. It contains basic algorithms, off machine learning from psychic learn. We're going to import the linear regression algorithm. Next. What we need to do is to upload our Excel file into our Jupiter notebook. We need to upload this file into the folder where our Python notebook is located. Click the upload and upload the file into this fuller. Now we need to upload these Excel file into our by the notebook using the following code PD greed, Excel and in Barrington says the name of the file do you have here will mean the data frame that we're creating. You can give it any other name as you like and with the D of comment. We now can display this table. By the way, if you have a fire with the CSC extension, which is also common when working with tables, then you will need to use the code pedido Treat CSE and the name of the file. Now let's visualize the data from this table on the chart. To do this, we will need them upward Creep library, which were also important in the beginning so the court will be percent month will sleep in line and then the next line. Plt don't scatter and in parentis is DF area Kalmadi of price in BLTs getter in parenthesis , we first indicate the X axis and then there y axes. Great. We can see our values on the chart. By the way, we can make points of a different color by eating into guilty scatter function, the world color and the color we need in quotation marks. We can also, if you want change points to other Aikens, for example, pluses or stars or even arrows. To do this, use the word marker in the skater function. What else are we missing? Let's give our X and y xs your names. Plt dot exe. Label in parent is area square meter and BLT adult y label in parenthesis. Price 1,000,000 roubles. Great. Now it looks like a real chart. Okay, so now we can start training car model. We have already imported a linear model template from the psychic Lauren Library. Let's create a varietal called rag, and it will be our leaner aggression model. Brake is equal toe linear. Underscore model dot Linear regression. Parentis is no the capitalization in the work linear regression. If you enter lower case letters, the court will not work. So next we need to train this model using the data we have. Roughly speaking, we need to show our model all prices depending on the area. And we will ask you to calculate the best linear regression formula that describes the correlation between the price and the area. So we use feet function to load into our model. Our data, when air and prices in double square brackets we give the values off are factors in our case, the area and after coma, the answers in our keys, the prices. In fact, there may be several factors. And then we would write each factor after coma. All right, here's the confirmation that the model has been trained, and now it can make predictions. As you can see, the train cough, a model takes just a few seconds, and in machine learning in general training is only one part of the deal. What is even more important is preparing the data for training, choosing the right model and then interpreting the results correctly. Okay, let's move on. And let's try to predict how much an apartment for 38 square meters will cost. Correct, predict and in parentis is 38. Excellent. And if 120 meters, let's compare with our prediction made in excel. They're very similar with a high accuracy. So we mentioned that a leaner aggressions are based on the formula. Why physical X plus B in our dusk, that azkadellia regression algorithm used to find such coefficients A and B, it will give the minimum deviation off our values from the line that we are building. Let's see what coefficients are model has for coefficient eight. We write wreck dot cueva underscore, and for coefficient b, we write rectal intercept underscore. Thus, our model is as follows the price of the apartment is your a 0.71 times the area and plus 0.8111 Let's check what formula we had. An excel. As you can see very similar results. They're just little around it. In excel. Let's check again. We multiply 120 meters by the first coefficient and add the second coefficient to eat. And yes, we got exactly the number that was given to us in the prediction above. By the way we can draw the line that shows our predictions. We use the linear regression algorithm, so we will have a straight line to see it in our chart. Let's copy the code that we used above to get the chart. And in the last line, ed BLT dot plot and in parentis is DF era comma Greg. Predict DF area. This coat means that we're drawing the line on which will have an area along our X X is, and the long white access will have prices that our model predicted. Pay attention to the number of square brackets and parentis is it is very easy to be mistaken when you enter this cold. Well, as we can see this line describes the better and quite well narrow, slight deviation from the true values, but they will inevitably be by the police. We can say for sure that this is the best option off all possible straight lines for these points. So let's continue and support that. We have a fire with apartments in which we know they are area but do not know the prices. We will need to feeling the second column using the prices that our model predicts. Let's first upload this file into our Jupiter notebook. To do this, this file must be in the same folder as your notebook. Now use the read Excel Command to upload the file into our Python notebook. It's named this new table with new flats. Pred from the world predicted. Now let's display our table. There are 10 rows in the table, and when the files are too long, we can simply ask the computer to display the very first lines using the head. Commend or we can even indicate how many rows off the table we want to display. For example, printed head and free inference is free rose. Next, we use our existing model to make predictions for these new apartment areas. We use our red model and sending the area, or for a new flats, rectal predict and in parentis is print. Okay. As you can see, these are the answers with predicted prices. Great now are dusk is to make another column in this table so that we can insert these predicted prices there to do these first. Let's save our predicted prices. Is a varietal p now creating you column and insert these prices there To do this? We simply write the name off our preds table. Then in square brackets and in quotation marks. The name of the new column predicted prices. And after that we assigned to this column, there was predicted prices that we received above. As you remember, we designated them with the letter B. Excellent. Now it's just see these file in Excel Prayer to told to excel. Ending current is's Let it be the file you. Now this file should appear in our folder in Jupiter. Here it is. We open it great. The only thing it also exported. The index column that is the first column, which actually is not needed. We can remove here in excel or again for the code. It is removed, like these index physical to falls. Let's check again, create the index's appeared. So what we went through in these episodes? Firstly, when working with Machine Learning Project will almost always have to import libraries before the start of each project. The most common libraries are pandas lump, I might politely, psychic learn and others. They allow you to work with tabular data, visualize date on graphs and use ready made templates off various machine Lauren Calgary thumbs. Next, we learned how to load Excel files into our Jupiter notebook and visualized tabular data on a graph. We also learned to train our model, using the available data and using the linear regression algorithm. And we were in to predict the various for new data. And we also learned how to create new columns in tables in by phone and enter our predicted data there and then save it in an Excel file on our computer. So now I would like to give you some homework to consolidate what we have learned. We all know that a substantial share of fractures budget is made up of revenues from the sale of energy, oil and guest. It's part of our homework. Let's predict the dependence of Russia's GDP on oil prices. To do this, we will use the data from the past 15 years. I have prepared to file for you in excel. It is attached to this lecture. If anyone is interested, I took the data from the World Bank website. There is a lot of statistical information on the economy and other aspect off life in different countries, as well as from the websites that is dot com. The fire looks like these. We have GDP off Russian, one column and oil prices. In another column, you will need to upload it into your new notebook in Jupiter, display these dating and craft, then trained the model and then try to predict our GDP depending on different oil prices. Well, that's all for now. They got an Excel file for the task of predicting department prices as well as the Excel file on oil. Price and GDP are all the stage. There's a resource is to this lecture. Hope you enjoyed this episode seeing the next ones
17. Predicting country's GDP based on oil prices: So how is your progress? Did you manage to train the model for predicting crushers GDP, depending on oil prices, let's see how are cool to look like place, creating you file and you name it. First thing we do is we import the libraries into our project. Next, let's open Excel file with the oil crisis and GDP. Remember that this file should be located in the same folder is your Python notebook. All right, let's begin to build a graph using them up or tweet model. We had the names of the access, the oil price and Russia's GDP in billions of dollars. So the graph looks pretty realistic, as we can see with the same oil price. But in different years, GDP was slightly different. Perhaps this is due to the effect that Russia was able to diversify its economy or for some other reasons. Next, let's create our linear regression model, and with the help of the feet comment, we will train it using the data on the oil prices in the Russia's GDP. Here we go. We have the confirmation that our model has been trained. Now we can make predictions. Let's first predict for all years and compare how close the predicted failures are with the true values. Well, this pretty certainly rather from about 200 to $400 billion. What does it probably mean? Well, we can agree that there is some correlation between GDP and oil prices, but this correlation is far from being very strong. Well, of course they should be over. There is because the Russian economy is still not completely dependent on Lee on energy prices. There are many other factors which should be taken into account. But what we can see for sure is that the lower oil prices, the smaller GDP, tends to be by the way, you can compare it with countries which are oil importers for example, India or Japan or South Korea or Germany. How did oil prices influence them? If they are net importers off oil, it would probably mean that cheap oil prices would be better for them. But it's just a hypothesis you contested, by the way. So let's continue now. We can build a line that will show what our model looks like with the BLT Comment. Don't put as you can see, the skater is rather Deke let's predict using some concrete prices. For example, what will be the GDP if the price is $10 free college and 70 billion? Well, this is quite small for Russia. And what about the price is $150 almost $3 trillion? This is much better, by the way. Now we made predictions based on Lee on the Price of oil, but we can also in co independence on the year in our model. After all, let's look again at our initial detail. You see, in 2000 and five and 2017 the oil price was the same, about $54. But GDP is complete with the front in 2000 and five, only $764 billion. And in 2017 already more than 1.5 trillion nearly two times more, which means you're in this time. Russian economy has probably become less dependent on oil prices. So how can we train our model to predict based on to the rivals are model in this case, Will Lucas follows Why is equal to a X plus B plus C where why is our GDP X is the price of oil, and that is the year and A, B and C are new miracle coefficients. And now how do we specify it in our code? Actually, very symbol. Remember, we had a line of code that we used to train the model We just add to the wreck feet inside the double square brackets. Another factor. The word year. In quotation marks we press enter. Okay, the model has been trained, and now let's predict first the entire series for all years. You see, it's already much better inaccuracy. The spread is only a few does, and so billions. Let's try to predict what GDP will be. For example, in 2025. And if the price of oil is $100 right, predict and in records, 2025 comma, 100 nearly 2 trillion $700 billion almost one truly more than now. Okay, I think that's all for leaner aggression. If you have any questions, please feel free to ask in the comments or writing directly. You can also try to find data, for example, of different currency exchange rate or stock prices, and try to create and train a model based on these data in order to make predictions for the future
18. Predicting Titanic survivors: Classification task: Hello, everyone in this lecture, we're going to solve a classification problem. We're going to predict which passengers survived in the crash of the Titanic. To begin with, let's recall what the classification tasking machine lording keys. As the name implies, classification is used to attribute an object to a particular cost. For example, in our keys, who classify the best singer is either a survivor or not. Classification can be used, for example, to understand whether the incoming message is a spam or not, or to understand whether the bank should give the loan to a possible border were there are only two classes, then the problem is called buying a reclassification. If there are several classes, then this is a multi class classification. If we compare with regression, then in progression, we do not have classes. We simply predict a numerical value. For example, in previous episodes, we predicted the cost of an apartment with the volume of GDP off our country. There is a specific number, and in the classification, the number off answers or classes is limited. We ourselves provide these classes to the computer, and the computer determines which of these classes the new object belongs to. So let's get down to solving color classification problem. First, we need to download. The data will file about the Titanic survivors from the Kegel website. This is a very useful site here. You can find a lot of examples for machine learning with explanations and solutions by other users. Next, we need to upload this file into our folder where our files for Jupiter are stored. All right, let's create a wife, a notebook in Jupiter and name it. Now let's important. Fonda and Mumbai libraries Great. So let's upload all file with detaining survivors into our FIFA notebook, data is equal to P D Door Treat CSC and in brackets Titanic. TSV Now let's see what our fire looks like. As you can see. Here is the data for 891 passengers. We have their gender age. What class of giving the occupied And the most important problem for us is the column survived. As you might guess one. It means that the present your survived and zero that unfortunately, he didn't let's call this revived. Call him our target column and let's take four more columns, which in our opinion, influenced whether the messenger could be saved or enough. These columns will be age, sex, cabin class and ticket fear. Let's call them Training Collins. Please know that we enter the coal names exactly as they are indicated in the file. That is, I mean, where there are capital letters, it is necessary to enter capital letters. Otherwise the data will not be read, but it's not. Create the rivals. It will store the data that is starting these columns ex physical toe data and in brackets , schooling train and why is it called a Data? And in brackets column Stargate. Another very important point in machine learning is you understand when we create models, not only the correct algorithms are important, but also the quality of the data on which we train them. This means that in our data, there should be no spaces or values that certainly cannot be there. For example, when feeling called the stable, they might simply forget toe enter the villian some cells where suddenly the age value was transferred to a cell with a fair by mistake. Therefore, in large projects, when it comes to large amounts, these data is very strictly checked. So in our case. What can we do to check the quality of the dating our project? At least we can verify that we do not have empty cells. This is done using the following formula X in brackets. Sex dot is now brackets, not some briquettes, and we do it for all columns. So it turned out that in the age column there are 177 passengers whose age is not in Dickie , that what shall we do if we remove all these 177 messengers? These can greatly affect our selection because nevertheless is already a fairly large number. So what can we do? We can give them the average or medium value for these column. There is a special function in the panda that fuels these empty cells with medium or mean values. In the column, let's use the median values First. We were given a small warning, but it can be safely ignored. Let's check if all the cells in the each column Arfield again. Shall we move on now? Not at all. We need to make another manipulation in our s killer model. We cannot use a strength arrival as a categorical Dorival. What I mean that develops in the passenger gender column are indicated as the world male or female. Our model will not be able to use them for training. It can only use the miracle data. Therefore, what we're going to do. We will simply rename the Swartz into zeros and ones. Let's replace women with the number one and men with the number zero. To do this, we will need to create a dictionary. The dictionary is when you say that one meribel means another Dorival, like in a real dictionary, where you have translations for fourth from one language to another. The dictionary seen by phone you securely brackets and inside we have to arrivals that they're separated by a colon. Let's call our dictionary, dig dicked physical toe purely brackets email, colon, zero comma female And now we're going to replace names, male and female, with numbers zero and one with the following formula. This work Lambda just means that we're going to replace our words like in a mirror, as indicated in our dictionary. You can ignore these being Corning's. They do not prevent us from continuing our work. Later on, I will show you how to during them off. So let's check with our Coolum with the sex of passengers. Looks like now Well, now is your send once are everywhere. That's what you need. Let's check our date again. As you remember. For the training data set, we left only four columns. Age, gender, class of Karen's and Fear. So what is too important in machine learning is to divide our data set into two parts. The first is the training part will train our model on this part, and the second part is a test part of the data set. We will use it to check how well our model is doing its accuracy. So let's important the model, which is going to divide our data set into training sample and test sample from his color dot model. Underscore selection Import train underscored. Test underscores please. These are standard indicators that we take the size of the test sample is 1/3 or, if you like, you can take it 20 or 30% and the random state indicator is 42. You can consider them as basic default indicators, so now we need to train our model on our training set our model will be based on the leaner support vector machine algorithm which linearly divides our data into different groups. The idea of this matter is that we are trying to find such a line or if we have several classes such a hydroplane, the distance from which to each class is maximum. Such a straight line or hyper plane is called the optimal separating hyper plane. The points were, as you can say, representatives of classes or vectors that, like closes to the separating Keiper clean our cold support vectors. This is where the name of this method comes from. What is good about programming in by phone is that it has many libraries and trading made models that already contained all these methods. That is, we don't need to compose and calculate all these formulas ourselves. We simply import the model we need into our project. So let us import. The ECM algorithm is our by the notebook and CO are model pred model from SK Lauren Import SPM. Fred motto is equal to as siendo weiner s V C. Now let's train our model with our training set and feet function great. We were given confirmation that the model is trained again. Ignore these purple modifications. Now is the time to make predictions on the test sample. The fact that in brackets is indicated zero call on 10 means that we predict the 1st 10 values from our test sample. Well, we see zeros and ones, which means whether the Bessinger survived or not. But how do we know if the model correctly predicted this failures? To do this, we use the score function, as you can see, almost 77% which is not bad for our first model. By the way, you can run this coat again, and he will be given a little bit different accuracy, because when the machine divides your sample into training and test samples, it doesn't train them. We toe each time. The accuracy will be a little bit different. Also, remember where we found 177 empty cells with age, we inserted the median aging them. What will the accuracy be if we insert the mean age using the mean comment and see what the result will be? Still, it's a little bit different, that's all. For now. The python code for this task is, as usual, attached to this lecture, but in any case, try to type and run this court yourself to consolidate the material that you have learned.
19. Neural Network - create your own neural network to Classify Images: Hello, everyone. I'm happy to tell you that by the end of this episode, you'll build your own neural network that will be able to recognize images of clothes. For this task will use a data set called facial Menaced. It contains 70,000 images of various types of clothing, such as T shorts, pants, shoes, bags, sweaters, code sniggers and so on. Any machine learning specialist begins his training. With these data set. It is the so called standard for training specialties. Let's remember that neural networks consist of several layers. The data in our keys images is supplied to the input layer. Then these data passes through several layers off neurons. During this process, their assigned certain weights, and then we have an output layer that should give answers. In our case, the output layer will tell us what is shown in the image. In terms of machine learning, the stars relates to classification problems. An image is supplied to the input layer off our neural network, and the output layer determines what class of close this image belongs to, whether it be a code shoes, T shirt or some other item of clothing. There are 10 such crisis. In this set, these data set is open and it can be freely downloaded and used to create our neural network. It was created by the salon, the company located in Berlin, and the set includes 70,000 different images off clothes. In one of the previous lectures on deploring, we mentioned that neural networks, in order to be well trained, meat as much data as possible. Therefore, 70,000 images in principle is a good number. You can download this data set on the get top or Kegel websites. We mentioned in previous lectures that when we train our models, we divide our data's head into two parts. The training sample and the test sample and therefore they set is also divided into two parts. The first part consisting cough. 60,000 images, will be used for training, and the second part of 10,000 images will be used for testing In order to understand how well our model was trained, These data set contains two files. The first file with images in the second file with class labels, that is with the correct answers. All images are 28 by 28 pixels in size and are executed in shades of cream and the great intensity image pixel various on a scale from 0 to 255 where zero is a completely white big cell and 255 is a strong craig color. And since these pictures are so simple, that is only 28 by 28 pixels and in the shades of Cray. This allows you to work with them and be with neural networks, even if your computer is not too powerful. So we already mentioned that in the fashion. Police later said. There are 10 classes off clothing items here. You can see there on the screen. They are numbered from 0 to 9 in the court in Queen, when we submit this or that image to our neural network, but will be given the class number to which it belongs zero if it's a T shirt, five of these shoes and so on. So what kind of input data will be fed into our neural network? As we already said, Firstly, 28 by 28 pixels. If you multiply together, it's 784 picks cells, and secondly, it is the in density off the shades of gray in each pixel in density will vary from 0 to 255. We understand tried that the computer receives all the information in numerical terms, which is why our neural network will receive. Each image is a set off 784 pixels, and each big cell will have a specific number from 0 to 255 depending on the intensity of the shades of crazy. All right, then, let's move on. The architecture off Our neural network will be very simple. It will consist off only three layers. The input layer, one hidden layer and the output layer. The input layer will only transform our two dimensional images into one dimensional. Every the next layer will consist of hundreds and 28 neurons, and this number can actually be changed. For example, you can make 512 or 800 the output layer will consist of 10 neurons. Because we have 10 different classes of cloves, we're going to use a dance neural network, which means that all neurons of the current player will be connected to all neurons of the previous layer. Each of the 128 neurons off the main layer will receive the values off all 784 pixels off the image and each of the 10 Urinson. The output layer will give us the probability that this image represents the given class of clothing. The probability will be reflected in the range from 0 to 1. Let's remember how a neural network can make such predictions and how everything works. We will use such concepts as weights, back propagation and eight books first, like a human urine. The task, often artificial neuron, is to obtain information, process it in a certain way and pass it on to the next neuron and the connections of such neurons in artificial intelligence that receive input data, process it and then provide the output data. Such structures are called neural networks, so we already mentioned that each neuron receives an image in the format of 784 peak cells , and each pixel has in a miracle value, depending on the color intensity that is roughly speaking. Each neuron receives a specific area or combination of numerical information. Then at first, each neuron or no dip is given some kind of friend and wait. That is significant, or how much of the value of the neuron corresponds to one or another image, and this way it is randomly distributed. I want to stress again that in the first stage, the suite is just trained them after that, when these values transferred to the output layer because we actually know what is shown in the picture. Because we have answers to each picture, we say to a neural network whether the prediction was true or false. So if the network predicted correctly than the weight of this failure for this connection between neurons in different layers increases. And if our model made a false prediction, we reduce the weight, and this is called back propagation. That is, we sent information back to the newer layers and say either to increase or decrease the weight, depending on whether the prediction was made correctly or not. And this movement, doors changing equates secures constantly back and forth during the training. When the entire data said, that is, all images goes for this procedure. It is called one, a book enduring the training off neural networks. Several eight books are usually used, for example, 10 or even 100. That is the same images or run 100 times through all layers each time, changing the weight off neurons and making them more accurate, thereby reducing the prediction error. So let's see how you can create and train such neural network incurious in tensorflow. These are the libraries in by phone that are designed to work with neural networks. Yes, and before we are going to start, I want to make a reservation right away that we're going to solve this project in Google collapse. We already mentioned in the first lecture on by phone that this is a cloud environment from Google, which provide the opportunity to test machine learning projects directly in the browser. Why do we decide to choose Google collapse now? Because in order to solve this problem with neural networks, we need the tensor for library and the caress my audio. And if you want to install them on your computer, often this can be very problematic. And there are a lot of errors with different versions or compatibility with the graphic art and other errors. Where is if you deal with Google collapse? You don't need to install anything you just create a notebook and immediately start coding . Therefore, in principle, if you want, you can try downloading tensorflow onto your computer. This can be done using the peep. Install tensorflow command on the Anaconda Common Flynt in such black window, but were very high probability. You may have certain difficulties with further importing these models into your project. And if such installation errors do a cure here, you can see the most typical errors and how they can be sold. Therefore, for simplicity's sake. And in order to avoid these difficulties with installing tensorflow on the local computer, we will show how to do this in a Google collapse, and here you're certainly shouldn't have any problems. In addition, this called Framework from Google gives you the opportunity to use more rum than is available on your computer. Okay, let's get started and was created, you know, book in Google collapse. Now, in the very beginning, we need to import the libraries and Mondial Sweeney. First, let's import all main libraries. We will need not, by and month lately toe work with Cherries and visualize our drawings. As we mentioned, Tensorflow and Cara's are necessary to build neural networks. The fashion police data set is already available in care us because it is one of such popular data sets on which old data scientists learn neural networks. Next we import the sequential model. This is a neural network model in which layers go one off turn out there. Then we're going to import the dense type player, which means that our layers will be fully interconnected. And finally, who also import various utilities that will help translate our data into former suitable for care us. All right, So since we have already important patient data set in the beginning, we can now load the data into our project. As we said in previous lectures in machine learning, our data sets will be divided into two parts training and test samples. And each of these parts will contain part X. These are the images and part why this out The answers to which class these are that image belongs to. They are also known as labels. Place names are not included in the data set. So let's write them ourselves. Okey, then So what's next? Now we need to prep process our data before creating a neural network, and before doing that, Let's first see what our images look like in the square brackets wins or the index from 0 to 59,999. Because we have 60,000 images in the training set, some images are easy enough to understand, and some are almost incomprehensible on the side of the image. You can also see the pixel intensity values from 0 to 255. If the big so is as dark as possible. It has a value of zero antibodies as light as possible. It has a value of 255. So, having seen our images now we're going to do data normalization. What does it mean? This means that in order to improve the optimization algorithms that are used in training neural networks, we divide the intensity off each pixel in the image by 255 so that the intensity now is in the range from 0 to 1, and we will do it both for the training set and test it. Let's check it. Great. Now the pixel in density is from 0 to 1, and it will be easier for neural networks to work with such values by the way we can depict several images on one screen at ones. To do this, you need to write a few lines of code. We are going to show the 1st 25 images five in a troll, and we will also display the names of their classes below them. Looks fabulous, doesn't if you want, you can make the images in black and white, so that's great. We have prepared the data, and then we can begin to create a neural network in neural networks. The main building book is the linear, and the main part of deploring is combining simple layers. Incurious, just like in machine were Inc In general, neural networks are called models, and as we have already mentioned, we're going to use this sequential type of model, which means that our layers will go in sequence one by one. So let's create a sequential model. The first layer, which is indicated as flatten converse the format off images from a two dimensional area where each image was an area of 28 by 28 pixels into a one dimensional area off 28 by 28. That is now the image will enter the neuron is a string off 784 peak cells next go to too dense layers. The first dense layer is the fully connected input layer. Here we have to decide how many neurons will have in this layer. In fact, a lot of experiments have already been done when these data set, and one of the most successful predictions was the input layer off 128 neurons. Although if you want, you can make 512 or 800 neurons at your discretion. Next, we ride the activation function. In our case for the main input layer, we specify the real you activation function. It showed good efficiency in such simple neural networks, and then the last layer is the dense output layer. It will have 10 neurons exactly as the number of our classes. The activation function will be the soft marks function. This function enables us to return and very often probability estimate the some of which is one. Each note on urine will contain an estimate that indicate the probability that the current image belongs to one of our 10 classes. Before training the model, we need to make some more minor settings. This is called mortal compilation. When compiling the model, we specified the training parameters. It's for optimizer. In our case, we use the S G D, which stands for stochastic gradient descent. This optimizer is very popular for solving problems off image recognition. Using neural networks outdoor instantly If you like, you can use the Adam Optimizer. The error function is indicated by the loss parameter in our model. Instead of standard truth mean square deviation, we're going to use categorical cross entropy. These error function works well in classification problems. When there are more than two classes in the S parameter is the quality. We indicate accuracy. That is the proportion off correct answers. After the model is compiled, we can print its parameters using model summary function. In principle, everything is ready. We'll date is prepared. We created and compiled a neural network. Now we can start its training. The training off neural networks is done just like in other machine learning tasks with the help of the feet function. And since we have a classification problem which belongs to the supervised learning, we pass on to this function. Both the training sample, next train and the answers or labels. Why train? We must also specify the perimeter. The number off a box, as we mentioned before. One e book is when our entire leader said basis for a neural network ones. We indicate 10 8 books, which means that we're going to train our neural network 10 times on the entire data, said. That is, on all 60,000 pictures, you may ask how many books are needed. The answer will very dependent on different data sets. But the basic principle is that the more diverse our data cities, the more desirable it is to use more eight books, and also you should probably take into account the power off your computer. If you have a very large amount of data and they are all very different, then each a book will take longer time. Therefore, for the simplicity reason, we will use only 10 8 books. You may use more e books if you want. It will just take more time, and the quality will probably not be significantly better so we can see that our training has begun. Here comes the first, a book and then of the line of each a book that ever function is indicated through the lost parameter and the accuracy of predictions. As we can see while our neural network is being trained, that is, with each subsequent a book, the very off the error decreases. Where is the prediction? Accuracy increases. So the last a book has ended, and this means that the training off our neural network is also completed. We see that the accuracy is slightly less than 90%. Well, for a neural network consisting cough, only two main layers, these qualities rather good. Let's now check what accuracy would have on the test sample. Remember that for training, we used 60,000 images from the training sample and 10,000 images were in a test sample, and our neural network didn't see them. Therefore, let's see what will be the prediction accuracy on these test images. As you can see, the quality of the prediction is slightly lower, but still quite high. So, congratulations to you you have built and trained your very first neural network. Now, after completing the training, we can use our neural network to predict what is shown in the images. To do this, we use the predict method off our model. We will predict on the images from the training sample on which our model was trained. So we write X train in brackets and now let's print what our model will predict in the square brackets. We put the index off the image that starts with the image with the index zero so we can see 10 different values, each value representing the probability off our image belonging to each of our 10 classes, each value and then has a minus eight or minus nine, which means that they are in the minus nine decree that is, after a zero. We have a few more zeros, and that is the probability is close to zero and only one value with the minus one degree, you see 9.90 something minus one. This means 0.99 hundreds that is very close to one. And as you remember in our keys, number one represents 100% probability. Thus, our model we have probability off almost 100% predicts that these image corresponds to these class in case it's difficult for you to find which over the valleys from our output is the maximum we can use the ARG marks function from the number library. It just gives the maximum value. And so we are given the maximum value with index nine. Now let's check and derive the correct answer from our labels. So are to answer for this image turned out to be the same as was predicted by our model. That means that our model is working. You can test with other images. Just replace the number in the index with any other number from our sample of 60,000 images . Let's dance number 12. Okay, it tells us that this is a class with Index five. Let's look at the image. What is it? It's a sandal. Actually, if you don't want to look for the images each time, we can simply print the class name by inserting the Corey's Point Inc image index. All right, that's create my congratulations. See, once again, hope your neural networks work just perfect. And now it's summarized what we have covered. We imported the entire data said with images, divided them into training and test samples. Then we optimize these images a little bit. After that, we created the architectural for a neural network, which in our case can see set off only three layers compiled the model, which means that we specify the training parameters. Then we trained our neural network using culturing example and finally tested eight on our test sample. Now you can try to predict other images in the training contest samples. You can also adjust the model a little bit. For example, you can use another optimizer, Let's say, Adam, or change the number off eight books and so on. By the way, on the Keg, a website, there are various Gershon's off other types of neural networks with different numbers off layers and different architectures for the fashion. These projects, therefore, you can look and try to make another neural network for these data set. I hope this lesson was useful and did contributed to a better understanding of what neural networks are, how to train and use them, particularly for image recognition. If you have questions, your comments and I look forward to seeing you inside our new lectures and courses,
20. Neural Networks for Text Analysis: Hi there. In this lecture we are going to learn how to use neural networks to analyze text. We will also create our very own neural network that will analyze movie reviews and understand whether their views positive or negative. But before we move on to the practical part of creating our neural network, let's have a look at what kind of text analysis tasks neural networks are used for today. Firstly, for text classification. Trained neural networks help us to define what topic or getting R3, the given text refers to. For example, news articles can be classified into such getting a raise as politics and economics, sport, lifestyle, and so on. One of the most popular task today is of course, automatic translation from one language to another. If you compare, for example, the translation of Google Translate, which was used five or seven years ago, and the translation that it gives today, you will notice that they are completely different translations in terms of quality. Today, automatic translation is performed with a very high-quality, and this is thanks to the use of neural networks with complex architectures. It is also important for many companies and brands today to understand how their customers and users treat them, to understand the brand loyalty among the customers. And neural networks are used today for determining the emotional sentiment of texts, such as comments or reviews. Whether they are positive, negative, or neutral. Task is called sentiment analysis. And many brands use sentiment analysis in social networks to understand the level of their brand's reputation. Tasks of text generation are also popular today when neural networks can generate and create completely new text and communicate with users, for example, via chat bots. As we can see, neural networks can be used in various text analysis related tasks. And neural networks show you the best results in such tasks in comparison with other machine-learning algorithms. All right, then, now a few words about how we are going to use neural networks to analyze texts. First, we are going to use Keras and TensorFlow libraries, which we have already used in previous lectures to build neural networks to classify images. They have pre-installed modules that will make our training much easier. Secondly, well, remember that a neural network can only operate with numbers and the text is a set of characters and symbols. Therefore, we will need to transform our set of symbols, words, and sentences into a set of numbers. This can be done in different ways. And thirdly, to build neural networks, we will use the Google collaboratory platform, a free cloud platform from Google, where a popular machine learning libraries are already pre-installed. And you also get quite powerful GPUs on this platform for free. The performance for Google Collab is much higher than most graphic cards that can be installed on a personal laptop or computer where he's Google provides such computing resources for free, working with machine learning problems. So let's see how we can represent the text in a digital form suitable for a neural network. We remember that the input data to the neural network can only be numbers. And neural network can only work with numbers. There are forming various mathematical operations with them. Therefore, when we use a neural network to analyze texts, we must transform our text data into a set of numbers. In the previous lecture, when we analyze images of clothes, everything was quite simple there because we can digitize every image as a set of numbers that correspond to pixel intensities from 0 to 255. If we work with data in a categorical form, for example, it's x of a man or a woman. Then everything here is also quite symbol. Remember when we analyzed which of the passengers survived on Titanic, we replaced sexes of male, female passengers with zeros and ones. That is, we transformed words into numbers. When we deal with complex texts, it is a little bit more complicated here. We also convert text into a set of numbers, and this process is called vectorization. Let's see how it is done. In the first step, we break the text into separate parts, each of which will be digitally presented separately. This is called tokenization, where each separate part is a token. And there may be several options for how to split the tags into tokens. We can split the text into separate characters such as letters, numbers, punctuation marks, and give numerical value to each of these characters separately. Or we can divide the text into words and give a number or a numerical set now to individual characters, but to entire words. Or now there is also an approach when the text is split into whole sentences and each sentence is given as separate number or a set of numbers. In our case, we will split the text into separate words. In the next stage will be vectorization, where each token will be converted into a set of numbers, either by simple encoding or by vector a presentation in the format of one-hot encoding, or by dense vector.
21. Neural Networks for Sentiment Analysis (IMDB movie reviews): So now that we have got to know a little about how neural networks are used to analyze text. Let's try to build our very own neural network. In this episode, we're going to create and use a neural network to determine whether the film reviews on IMDB are positive or negative. This website contains information about most films. They are description costs, trailers, and of course, reviews from viewers. As we have already mentioned, the task of sentiment analysis is very popular in the modern world. Many companies and brands want to know how their customers and users treat them based on their comments on forums and social networks. The dataset of movie reviews from IMDB is quite popular among those who study machine learning and neural networks. You can download the dataset from this website. And alternatively, we can download it immediately from the libraries in Keras using just one line of code. The developers from carriers have already preprocessed the reviews, and therefore, it will be easier for us to work with this database. So this dataset is divided into two parts, 25000 reviews for training and 25000 from use for testing. The number of positive and negative reviews is the same. And this dataset includes only positive and only negative reviews. Neutral reviews were not included in this dataset. So as not to complicate the training, reviews that were rated seven stars or higher out of 10 were considered positive. While I've used that were rated four stars are lower. Consider it negative. The dataset looks as follows. In one column, we can see that I've used, and in the next column they are raging either positive or negative. This dataset represents supervised learning because for every review, we have got the correct answer. 0 means negative, one positive. In machine learning, this is known as a binary classification task because we have only two classes, either negative or a positive review. All right, Then we have done the theoretical part and get acquainted with the dataset. Now let's move on to the practical training. First things first, and let's import the necessary libraries, Keras and TensorFlow. Keras includes tools for working group popular datasets encoding datasets from the IMDB. We also connect the NumPy library to vectorize our data and metabolically visualize the results of our training. So with this line of code, we load a set of IMDB reviews. In brackets. We indicate that we are loading GAN training set x train and y train and the testing set x test, y test. We also indicate the maximum number of unique words that we'll use to analyze the text. Because if we do not limit this number, then the number of unique words in all 50 thousand reviews will be huge and it will be more difficult and much longer for our neural network to analyze large dataset. Therefore, we will limit our dataset to 10 thousand words that are used most often in order of US. Wars that are less common will not be included in this dataset. Let's see how Keras loaded the data. Let's take some reuse. A number nine, we see that instead of the text of the review, we have a set of numbers. Each of these numbers represents one word from the original review. That is, there is tokenization at the word level. Each number corresponds to one word. As we already said, that developers at carers have already translated words into numbers and thus prepared these dataset for us. Let's now see what is the format of the correct answers. As we mentioned in the beginning, one means positive for you and 0 means that they have used negative. Let's take a look at some other views. The IMDB dataset uses word frequency coding. This means that in the text, each word is replaced with a number that corresponds to the frequency of its occurrence in this text, the most common word is replaced by one. A word that is slightly less common is replaced by two, and so on. We can download the dictionary that was used for encoding by calling the IMDB word index method. This is a Python dictionary in which the key is a word and the value is a frequency with which that word appears in reviews. And as we see, these are exactly the numbers that are used in reviews instead of words. The larger the number, the less frequently that corresponding quarter appears in reviews. But let's create a reverse dictionary which will determine the word by number. This is done using the following code. In the cycle, we will go over all elements of word index and we'll create a dictionary reverse word index in which the key will be the number and the value will be the word that corresponds to this number. Okay, Now let's type 30 words that are the most common in our reviews. As you can guess, most likely these words will be various conjunctions, prepositions, and articles. And the most popular words that we use most often in our daily speech. Now let's use our reverse dictionary to decode some reviews. Okay, now we can see what was written in their view. Or right, as we have seen, our reviews are now represented by sets of numbers from 0 to 9,599. But to make it easier for our neural network to work, we are going to represent their views as a vector in the format of one-hot encoding. Roughly speaking, now, each of you will be a vector, the size of which will be 10 thousand. In this vector will contain only zeros and ones in those positions that correspond to the words present in this review. To create such vectors, we will use the vectorized sequences function. The function we pass sequences, that is our dataset x train index test, and the desired dimensions of the vectors, in our case 10 thousand. With their results line, we have created a vector which contains all zeros for each word position. Then, using the cycle, we go through all the elements of the sequence. And for each word that is present in the review, we said the corresponding value to one and we return the result. Now we will use this function to process the training dataset and the test dataset. Okay, then, and now let's see how our datasets look like. Let's take review number 19. Earlier our reviews looked like arrays with numbers that represented words. Now our review is an array with only zeros and ones. Using the Len function, we can check that the length of each review is now 10 thousand, as we have indicated. And these corresponds to the maximum number of words that we use for analysis. We can also look at the shape of our entire training set. As you can see, there are 25000 reviews and each of them is 10 thousand elements long. Well, now that we have prepared our data, let's build our neural network that will classify, review, and determine whether their reviews positive or negative. We will create the sequential model, which will have three dense layers. The first second players will have 16 neurons, and the output layer will have only one neuron because we have a binary classification task. That is, we have only two classes because they're not only two types of reviews and we choose one. If the output is 0, then the feedback is negative. If one, then the feedback is positive. Instead of three layers, you can use more. You can also change the number of neurons in the first, second layers and see how the result changes as an activation function. In layers 1 and 2, we are going to use a semi liner relu function. And in the output layer, a sigmoid function will be used. The sigmoid activation function gives the value in the range from 0 to one, which is a perfect match for binary classification tasks. After creating the model, we are going to compile our neural network. We use the LMS prop optimizer, but you can also use the Adam optimizer you want. The error function is binary cross entropy. Binary because we only have two classes. The metric of the quality of the neural network is accuracy. That is the proportion of correct answers. And now we only need to train our neural network using the fit method. Let's set the number of epochs to 20, the batch size 128. And we are going to divide the dataset and use 10 percent of it as a validation set. So as we can observe, the percentage of correct answers in the training dataset close to 100 and in the validation set that burst in digital, correct, on sources about 85 percent. Let's visualize the quality of training. And now the last step is to test the accuracy of the model on the test dataset that was not used for training. Is we can see the accuracy is a little bit below 85 percent, which is generally not bad, but it can certainly be better. So in this lecture, we have learned how to build a neural network to make the sentiment analysis or for use so that our model can determine whether their view was positive or negative based on the text of the review. As we already mentioned, this is quite popular problem in the modern world, and companies and brands use it to understand how they are consumers and customers treat them and what is their brand loyalty. I hope this lecture was useful and I look forward to seeing you in the next episodes.
 Timur K., Teacher, Life-Long Learner, Traveller
Timur K., Teacher, Life-Long Learner, Traveller