Transkripte
1. Kurseinführung: Data Science ist dieses aufregende neue Feld, aber es kann einschüchternd sein, in das zu kommen, weil es oft Mathematik und Programmierung beinhaltet. Das ist etwas, mit dem sich viele Leute unwohl fühlen, und manche Leute brauchen nicht einmal, wenn sie ein Data Science-Team verwalten wollen, sondern sie würden in die kleinsten Details geraten. Wir werden ein hohes Maß an Verständnis bekommen, um die Methoden und das Vokabular der Data Science zu
verstehen. Sie können als Peer sprechen, was wir in dieser Data Science Meisterklasse tun. Mein Name ist Jesper Dramsch, ich bin Maschinenlerningenieur in Oxford im Vereinigten Königreich. Ich habe Erfahrung beim Unterrichten von Python und maschinellem Lernen auf dieser Plattform,
auf Skillshare sowie in Unternehmen wie Shell, der britischen Regierung und einigen Universitäten. Ich habe meine letzten Jahre damit verbracht, an einer Promotion in Geophysik und maschinellem Lernen zu arbeiten. Ich liebe Data Science, weil es mir ermöglicht hat, während der Pandemie einen Job zu finden, wofür ich unglaublich dankbar bin. Ich möchte etwas von diesem Wissen mit Ihnen teilen, weil ich denke, dass es wirklich darum geht, Menschen zu ermächtigen , ihre Karriere
voranzutreiben und möglicherweise sogar eine Veränderung vorzunehmen. Diese Klasse wird Ihnen die Konzepte und das
hohe Verständnis vermitteln , ohne in Code zu gehen So können Sie mit Data Scientists als Peers sprechen und die Denkprozesse hinter datengesteuerten Entscheidungsprozessen wirklich verstehen. Ich bin unglaublich aufgeregt, dich zu haben, und ich hoffe, dich im Unterricht zu sehen.
2. KURSPROJEKT: Willkommen in der Klasse. Ich bin so froh, dass du es geschafft hast. Was machen wir eigentlich hier? Nun, ich habe ein Klassenprojekt vorbereitet und ich möchte, dass Sie es sich ansehen, weil es im Wesentlichen
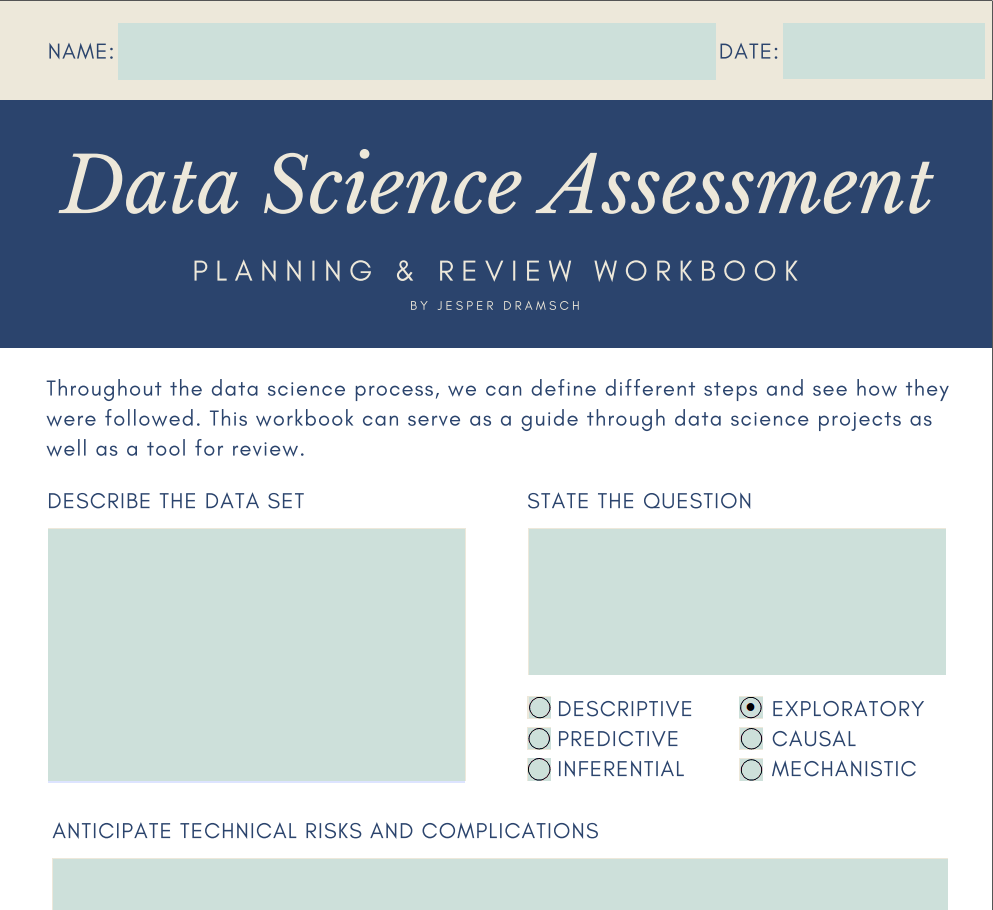
eine Arbeitsmappe ist , die Sie für Ihr Klassenprojekt verwenden können, aber ich hoffe, Sie können es auch in Ihrer täglichen Data Science-Arbeit nutzen. Entweder indem Sie Sie durch Ihre eigenen Projekte führen oder um Ihnen bei der Verwaltung anderer Projekte zu helfen. Lassen Sie uns direkt in die Arbeitsmappe eintauchen und einen Blick durch sie werfen. Dies ist die Data Science-Bewertungs-Arbeitsmappe für die Planung und Überprüfung Ihrer Data Science-Projekte für von Ihnen verwaltete Data Science-Projekte. Dies sind derzeit drei Seiten, und am Anfang können
Sie Ihren Namen und Ihr Datum ausfüllen und einige wichtige Fragen zu Ihren Daten stellen. Dann haben wir einige Informationen, woher Ihre Daten stammen und wie Sie sicherstellen, dass Ihre Daten überprüft werden. Einige Einblicke in die Schritte, die Sie in der nächsten Klasse
lernen , die Teil des Data Science-Prozesses sind. Dann werden Sie im Grunde bemerkenswerte Algorithmen und Visualisierungen dokumentieren
, die innerhalb des Projekts gefunden wurden. Was ist die wichtigste geschäftliche oder wissenschaftliche Wirkung,
je nachdem, wo Sie sind und Ihre wichtigste Schlussfolgerung. Diese sind vollständig anpassbar. Ich kann sagen, das ist mein Name und heute ist der achte Januar. Beschreiben Sie nun den Datensatz. Im Beispieldatensatz haben
wir zum Beispiel einen Indikator für Glück, und wir haben Datenpunkte pro Land und hier. Auf diese Weise können Sie wirklich jede
Frage hier ausfüllen . Die Frage ist zum Beispiel,
was ist der Haupteinfluß auf die Glückspunktzahl? Das wäre irgendwo zwischen deskriptiv und explorativ. Ich würde sagen, es ist explorativ, weil
wir uns ansehen, wie diese Vorhersage berechnet wird oder wie die Punktzahl berechnet wird, also untersuchen wir es, anstatt nur den Datensatz zu beschreiben. Das technische Risiko ist etwas, wo zum Beispiel Ihre Daten oder Ihre Maschinen nicht in der Lage sind, dies zu tun. Denken Sie darüber nach, ob ein Datensatz zu groß
ist, möglicherweise nicht auf Ihren Computer passt. Was sind die Risiken, die passieren können und Risiken müssen nicht das Schlimmste sein. Es sind nur Straßensperren, und wenn Sie die Risiken jetzt antizipieren, können
Sie Maßnahmen ergreifen und Vorkehrungen treffen um diese Risiken wirklich anzugehen, wenn sie eintreten. Eines der Risiken könnte auch sein, dass die Daten nicht kommen. Was tun Sie, wenn Sie Datenverlust haben? Weil eine Ihrer Festplatten fehlt? Denk darüber nach. Es ist eine gute Frage, sich selbst zu stellen und hier haben wir methodische Risiken. Was kann im Data Science Prozess selbst passieren? Was passiert, wenn wir keine Algorithmen zur Verfügung haben, um diese Fragen zu stellen? Was ist, wenn unser
Datensatz nicht die Informationen enthält, die wir benötigen, um die Vorhersage zu machen. wirklich mehr auf Meta-Ebene, Überlegen Siewirklich mehr auf Meta-Ebene,was in der Data Science-Analyse selbst schief gehen kann und
wie und wo die Daten und Labels erfasst wurden und Validierungsstrategien verwendet werden, um sicherzustellen, dass Ihre Erkenntnisse verallgemeinerbar sind. All diese Worte und all dies werden auch im Kurs erklärt werden. Wenn das jetzt seltsam klingende Worte für dich sind, wirst
du sie am Ende verstehen. Stellen Sie sicher, dass Sie hierher kommen, um
Ihr Projekt zu erfüllen und es in unsere Projektdatenbank einzureichen. Was ethische Überlegungen sind, ist eine wichtige Frage. Wirklich ein Glücksfaktor, zum Beispiel, sind diese Aggregate Statistiken so auf einer Länderebene oder
haben Sie die Möglichkeit, persönliche Level-Informationen zu sehen. Das wäre eher, naja, es wäre ein bisschen zweifelhaft. Schreiben Sie also über dieses Jahr und schreiben
Sie dann in den verschiedenen Schritten darüber, welche Ergebnisse Sie bei Deskriptive Statistik,
EDA, maschinelles Lernen gefunden haben und welche Schritte für die Kommunikation unternommen wurden. Am Ende, wie gesagt, bemerkenswerte Algorithmen und Visualisierungen. Was hat den größten Einfluss auf die Bereitstellung Ihrer Erkenntnisse gehabt. Dann negative Erkenntnisse, wie ich darauf hinweisen werde, ist
Data Science ein iterativer Prozess. Du wirst sehen, dass du manchmal negative Dinge findest, manchmal klappt etwas nicht. Notieren Sie sich die hier. Wenn du die aufschreiben kannst, wirst
du zurückblicken und sehen, oh ja, das wissen wir schon. Sie können dies mit Data Scientists mit
wichtigen Entscheidungsträgern teilen und sie werden auch dieses Feedback zu schätzen wissen, wo Sie sagen können ,
naja,
das funktioniert nicht , das hat empirisch nicht funktioniert. Geben Sie daher einen zusätzlichen Einblick in Ihre Analyse. Was ist der wichtigste geschäftliche Einfluss, wissenschaftliche Auswirkungen? Dies sollte aus Ihrer Frage gemischt werden. Wie wirkt sich Ihre Frage auf das Geschäft aus, aber auch wie wirken sich die Ergebnisse und die Antwort auf Ihre Frage auf das Geschäft aus, all die Wissenschaft, die Sie gerade machen. Dann schreiben Sie eine Hauptschlussfolgerung auf. Wirklich, was ist die wichtigste Erkenntnis, die Sie in dieser Data Science-Analyse haben? Jetzt, da wir mit dem PDF fertig sind, können
Sie das in der Beschreibung herunterladen. Wir können einen Blick auf die Klassenstruktur werfen. Denn diese Klasse ist für so viele verschiedene Arten von Schülern eingestellt. Einige Vorlesungen sind möglicherweise nicht die relevantesten für Sie. Fühlen Sie sich frei, sie zu überspringen. Es ist völlig in Ordnung, wenn Sie sich langweilen und Sie einfach zum nächsten gehen. Denn selbst wenn der erste nicht der Richtige für Sie ist, kann
es eine geben, die besser für Sie ist. Einer der letzten ist beispielsweise die
Operationalisierung von Datenpipelines und das Verständnis von Risiko- und Datenforschungsprojekten. Einige der wirklich wichtigen Fragen, die Sie haben, wenn Sie Teams verwalten. Vergewissern Sie sich, dass Sie sie sich ansehen. Wenn du vorwärtsspringe, keine harten Gefühle. Dies ist Ihre Klasse, also machen Sie es zu Ihrer, und stellen Sie sicher, dass Sie Ihre Projekte teilen. Ich würde mich sehr freuen zu sehen, wie Sie die Projekte anderer Leute verstehen. Denken Sie daran, nett zu sein, denken Sie daran, es akademisch und wissenschaftlich zu kritisieren, damit Sie wirklich davon lernen und anderen zeigen können, was Sie daraus gelernt haben. Lassen Sie uns nun in den eigentlichen Klasseninhalt eintauchen. Die erste Klasse wird definieren, was Data Science tatsächlich ist.
3. Was ist Data: In dieser Klasse werden wir versuchen zu untersuchen, was Data Science tatsächlich ist. Es ist ein bisschen schwierig, wirklich zu sagen, weil Data Science so neu ist. Es gibt viele verschiedene Meinungen, und deshalb möchte ich sie auch von verschiedenen Wegen erkunden. Der einfachste Weg ist, im Grunde jemand anderen zu zitieren. Jim Gray, ein Gewinner des Turing Awards, sagte: „Datenwissenschaft ist neben empirischer,
theoretischer und computergestützter Wissenschaft die vierte Säule der Wissenschaft.“ Das bedeutet im Grunde, dass
wir mithilfe von Data Science neue Erkenntnisse direkt aus Daten extrahieren können. Wenn Sie Ihre Geschäftsdaten haben, wenn Sie Ihre wissenschaftlichen Daten haben, wo auch immer Sie herkommen, können
Sie diese Daten verwenden und diese neuen Methoden oder alten Methoden und neuen Mänteln und im Wesentlichen Beziehungen innerhalb von dass Daten, die funktionieren, nicht nur auf diesem kleinen Datensatz, sondern können auf neue Daten verallgemeinert werden. Wenn Sie Kundendaten haben, können
Sie dann vorhersagen, was neue Kunden tun. Wenn Sie Chemiedaten haben, können
Sie vorhersagen, was eine neue Chemieformel tun wird, Dinge wie diese. Dies basiert einfach auf der Beziehung innerhalb der Daten. Nun ist eine andere Art zu betrachten, die Datenzeichen Hierarchie der Bedürfnisse zu betrachten. Ich mag dieses hier wirklich, weil es uns auch eine Möglichkeit gibt , im Grunde zu definieren, wo wir Zeit verbringen müssen. Eines der Dinge ist, dass wir Daten erfassen müssen. Ohne Daten können wir Data Science nicht machen. Wir müssen einen Datensatz bekommen, wir müssen den Datensatz bereinigen, weil alle Rohdaten laut sind. Es gibt irrgeleitete Ausreißer
da drin, es gibt Informationen, die für unsere Frage nicht relevant sind. Wie Datenwissenschaftler darüber scherzen, dass die Datenbereinigung am längsten ist, die sie dafür ausgeben, behaupten
einige, 80-90 Prozent für die Datenbereinigung und
nur 20-10 Prozentfür
den Spaß Teil oder für den wirklich interessanten Teil der Generierung von Erkenntnissen auszugeben nur 20-10 Prozent . Aber ja, es ist der wichtigste Teil. Die Leute neigen dazu,
Müll rein zu sagen , und normalerweise ist
das sehr wahr. Darauf aufbauend, müssen
Sie einen zuverlässigen Speicher haben. Wenn Sie Ihre Daten haben und sie verloren gehen, ist
es sehr schwer, Ihre Ergebnisse zu reproduzieren, und Ergebnisse in Data Science müssen immer reproduzierbar sein. Außerdem müssen Sie vielleicht Ihre Ergebnisse validieren oder vielleicht müssen Sie
zurückgehen und sie mit neuen Daten kombinieren, die Ihre Schlussfolgerungen ändern könnten. Speichern, Verschieben der Daten ist wirklich so, als wäre der Aufbau Ihrer Infrastruktur die nächste Ebene. Speziell für Data Science Manager müssen
sie wissen, dass Dateningenieure in dieser Phase extrem wichtig sind. Die richtige Art von Menschen an den richtigen Stellen zu beschäftigen, ist für ein Unternehmen unerlässlich. Im nächsten Schritt haben
wir die Erkundung und Transformation von Daten. Datenexploration ist wirklich der Schritt, in dem
Sie sich beschreibende Statistiken Ihrer Daten ansehen, z. B. einen Blick auf den Durchschnitt werfen und wie stark Ihre Daten variieren und was die verschiedenen Funktionen Ihrer Daten tun. Wenn Sie einen Kunden haben, wann sind sie auf Ihre Seite gekommen? Woher kommen sie? Was ist das Geschlecht? Dinge wie diese können Ihnen Einblicke geben, wie Kunden
zwischen den Besuchen variieren können und was die Vorhersage ändern kann,
wenn sie Schuhe kaufen , eine neue Kamera oder wenn sie einen Kurs auf Skillshare. Darüber hinaus können Sie dann A/B-Tests durchführen. Wenn Sie jemals zu einigen wie Amazon oder diesen Kurswebsites gegangen sind, können
Sie feststellen, dass unterschiedliche Preise angezeigt werden. Oft ist das, weil Websites tun diese Experimente zu sehen, wenn eine andere Website zeigen, ändern Sie die Schaltfläche, die Änderung der Preise
wird Sie mehr oder weniger wahrscheinlich zu kaufen. Dinge wie A/B-Tests, Experimentieren, einfache Algorithmen für maschinelles Lernen sind der nächste Schritt auf dieser Leiter. So machen wir Vorhersage und Rückschlüsse darauf, aus den Erkenntnissen, die wir generiert haben, wirklich in die Zukunft schauen zu können. Dann wird die Spitze des Eisbergs, also im Grunde, die Wüste in Ihrer Nahrungspyramide, KI und Deep Learning sein. Das bedeutet im Grunde, dass diese super spannenden Technologien wahrscheinlich die letzten sind, die Sie ausprobieren möchten, aber sie können äußerst wertvoll sein. Wenn Sie also Ihre Machine Learning-Ingenieure oder Ihre Machine Learning-Forscher haben
und Baseline-Modelle erstellt haben
und sie basierend auf ihren Erkenntnissen empfehlen, dass es notwendig sein könnte, zu Deep-Learning-Methoden
zu gehen , um KI-Algorithmen, um die Daten wirklich nutzen zu können, die komplexen Beziehungen, die wir in Daten haben, kann
das wirklich gut sein. Viele der modernen Machine Learning Durchbrüche wurden mit Deep Learning Methoden gemacht. Schließlich ist es ein Prozess, wenn wir tatsächlich Data Science betreiben nicht nur die Bedürfnisse von Data Science betrachten und
nicht nur die Bedürfnisse von Data Science betrachten. In diesem Prozess wollen wir auf Basis unserer Daten eine spezifische Frage beantworten. Das bedeutet, dass wir oft hin und zurück gehen müssen. Wir könnten unsere Daten erhalten und wir führen Datenexploration durch, aber bei der Datenexploration, Suche nach Deskriptoren in unseren Daten, stellen wir fest, dass diese Daten möglicherweise nicht ausreichen und wir müssen zurückgehen und neue Daten
erwerben oder sie vielleicht zusammenführen mit der Datenquelle, und arbeiten Sie dann an der Verfeinerung unseres Data Science-Prozesses. Der nächste Teil wird sich mit der Modellierung unserer Daten beschäftigen. Dies sind die einfachen Algorithmen, über die wir gesprochen haben, aber es kann auch nur Einblicke sein, die Sie natürlich gewonnen haben. Einfache Regeln sind auch die Modellierung Ihrer Daten, statistische Modellierung für die Inferenz kann an dieser Stelle sehr angemessen sein. hier möchten Sie, dass Ihr Data Scientist einsetzt und in der Lage ist ein Modell
zu erstellen, das Ihre Daten genau beschreiben und erfassen kann. Schließlich ist es ein sehr wichtiger Teil, Ihre Ergebnisse zu kommunizieren. Erstellen von Dashboards, Präsentationen, Erstellen von Notizbüchern, in denen manchmal Code enthalten ist,
um sie mit anderen Datenwissenschaftlern oder Machine Learning-Ingenieuren zu teilen. Auf diese Weise können Sie wirklich teilen, was Sie gefunden haben. Dieser Teil ist möglicherweise der wichtigste,
weil man immer mit den Entscheidungsträgern sprechen muss, man muss immer mit den Stakeholdern reden, was Ihre Frage wirklich herauskam. Dies kann auch der interessanteste Teil sein, denn es ist faszinierend,
diese Beziehungen in den Daten zu finden und sie mit den Pfahlhaltern zu teilen Regel sind Pfahlhalter äußerst dankbar, dass sie diese neuen Einblicke in ihr Geschäft oder in ihre Wissenschaft. Stellen Sie sicher, dass Sie sich etwas Zeit nehmen, um
eine gute Präsentation daraus zu machen , denn in der Regel ist
es sehr wichtig und sehr wertvoll, dies zu tun. Hierbei geht es vor allem um Data Science, um Daten
zu erhalten, Erkenntnisse aus Daten zu generieren, Ihre Daten zu
modellieren und dann Ihre Ergebnisse zu kommunizieren. Natürlich gibt es Stücke wie diese Produktion zu produzieren. Wenn Sie also in einem Unternehmen sind, wie auf einer Website, möchten
Sie in der Lage sein, all dies zu nutzen, aber das ist für unsere zukünftige Klasse. In der nächsten Klasse werden wir einen Blick darauf werfen, was eigentlich eine gute Frage ist? Wie können wir gute Fragen zu unseren Daten stellen und sicherstellen , dass diese unsere Investition tatsächlich wert sind und unsere Zeit wert sind?
4. Gute Fragen stellen: Werfen wir einen kurzen Blick, was ein guter Fragebogen ist und was auch schlechte Fragen sind. Grundsätzlich, wenn Sie Fragen stellen, haben
Sie die Möglichkeit, sechs Fragen. Warum sechs fragen Sie vielleicht? Nun, die Wissenschaft sagt es. In der Tat haben die Datenwissenschaftler und -professoren Jeffrey Leek und Roger Peng, die einen erstaunlichen Kurs über die Datenwissenschaft von Führungskräften
haben, ein Papier veröffentlicht, das im Wesentlichen die Arten von Fragen skizziert, die Sie stellen können. Ich möchte auch über die Arten von Fragen sprechen, aber dann ins Detail gehen, auch was eine schlechte Frage ist. Denn in jüngster Zeit stellen sich
immer mehr ethische Fragen im Bereich Data Science und Machine Learning auf. Ich denke, es ist sehr wichtig für Geschäftsführer und
für alle, die Data Science tun, sich ihrer bewusst zu sein und sie herauszufordern, wenn es Dinge gibt, die nicht unseren Werten entsprechen. Welche Art von Fragen können wir stellen. Die erste Frage ist deskriptiv. Das bedeutet im Wesentlichen, dass wir
einen Datensatz haben und wir die wichtigsten Merkmale des Datensatzes kennen wollen. Zum Beispiel die durchschnittliche Höhe der Benutzer oder wenn Sie in einem Schuhgeschäft arbeiten, möchten
Sie die Auswahl der Schuhe kennen, die Sie verkaufen. Wie der Bereich der Größen, zum Beispiel, oder die verschiedenen Farben, die verkauft werden. Also wirklich nur Indikatoren, die das Dataset beschreiben, das Sie haben. Fragen hier können wirklich sehr vielfältig sein, aber sie sind ziemlich einfach und sehr sachlich. Die nächste Frage, die wir stellen können, ist explorativ. Im Wesentlichen die Idee, was wir in den Daten finden können. Dazu gehören in der Regel Dinge wie das Finden von Beziehungen und Trends innerhalb der Daten, Betrachten von Korrelation, und wir werden eine größere Klasse
darüber haben , weil es eine so wichtige Rolle in der Data Science ist. Die nächste Frage, die jemand stellen könnte, und hier wagen wir uns auch in das, was maschinelles Lernen tun kann, sind vorausschauende Fragen. Wenn wir x tun, folgt y? Zum Beispiel, wenn wir diese Schaltfläche auf unserer Website ändern, oder wenn wir diese Spalte hier hinzufügen, wenn wir einem Kunden diese Art von Sache zeigen, um auch kaufen, erhöhen
wir den Umsatz? Oder wenn wir die Anzahl unserer Abonnenten auf YouTube erhöhen, erhalten
wir mehr Aufrufe? Diese Fragen sind jetzt, wo wir eine Menge
Validierung durchführen müssen , weil maschinelles Lernen wirklich gut darin ist, Daten zu speichern. Manchmal ist es ein bisschen schwieriger, tatsächlich eine allgemeine Vorhersage zu haben. Dies ist wirklich wichtig, um die Modellvalidierung zu betrachten und im größeren Machine Learning und Business Analytics und Python Kurs gehe
ich in diese Art Modellvalidierung, denn für mich ist
dies einer der wichtigsten Teile von Daten Wissenschaft. Jetzt kommen wir in wirklich interessante Teile. Weil viele Leute diese Tests kennen, dass Korrelation keine Ursache ist. Prädiktive Modellierung ist in der Regel Korrelation, aber die nächste Frage, die wir stellen können, ist eine Frage der kausalen Natur. Also, wenn wir x hat y folgen, ist die vorausschauende Frage. Aber tut x Ursache y, ist die kausale Frage. Für mich ist das wirklich interessant, denn viele
prädiktive Modellierungen können auch falsche Korrelationen sein. Aber mit der kausalen Modellierung versuchen
Sie tatsächlich zu finden, was eine Sache verursacht. Ein Beispiel, das ich wirklich mochte, waren Hotelpreise. Wenn Sie Daten von
Ihren umliegenden Hotels sammeln und einen Blick auf die Preise und wie viele Personen im Zimmer sind, also wie viele Zimmer gerade belegt sind, werden
Sie feststellen, dass es eine Korrelation gibt zwischen höheren Preisen und höherer Belegung. Aber wenn Sie Ihre kausale Modellierung machen und sagen: „
Okay, das heißt, wenn wir unsere Preise erhöhen, werden
wir eine höhere Belegung haben.“ Sie werden wahrscheinlich aus dem Geschäft gehen. Kausale Modellierung geht wirklich auf die zugrunde liegenden Datenstrukturen, was an welchem Ort passiert. Einige Dinge, die die Leute hier tun, sind Kontrafakturen, also wirklich, einen Blick dann. Wenn wir unsere Preise senken, bekommen
wir auch eine geringere Belegung? Graben Sie sich wirklich in die Daten. Dies ist für mich der nächste Schritt, in dem Data Science die meisten Schritte in der kausalen Modellierung machen wird. Mechanistische Fragen gehen noch weiter als die kausale Modellierung. Du siehst nicht nur die Vorhersage an. Wenn x folgt, schauen
Sie nicht nur auf den kausalen Pfeil. Also verursacht x y? Aber in mechanistischen Fragen, Sie graben tatsächlich, wie X Ursache y. Sie tun die Wissenschaft. In der Biostatistik zum Beispiel ist
dies sehr häufig, dass man, um veröffentlichen zu
können, grundsätzlich einen plausiblen Mechanismus vorschlagen muss, auch Medizin. Viele der mehr Naturwissenschaften sind daran gewöhnt. Ihr Statistiker wird daran gewöhnt sein. Während im maschinellen Lernen oft bei den prädiktiven Fragen stoppt. Um Wissenschaft zu machen, kann dies äußerst wichtig sein, denn die Beantwortung dieser Fragen, wie etwas passiert, ist die ultimative Erkenntnis. Hier wird es auch interessant, weil unsere Studenten so vielfältig sind, von Kreativen über Wissenschaftler bis hin zu Geschäftsleuten. Als Wissenschaftler sind Sie am meisten an der Wahrheit interessiert,
an den zugrundeliegenden Mechanismen, die Sie in der Natur finden. Als Geschäftsleute sind Sie am meisten an der Vorhersagekraft interessiert. Wird jemand etwas kaufen, wenn ich das ändere? Möglicherweise auch die kausalen Wirkungen. Nicht so sehr die Mechanismen, weil diese sind in der Regel viel schwieriger zu erhalten, nehmen mehr Zeit, nehmen mehr Gehirnkraft, und einfach gesagt, nicht wirklich erhöhen Umsatz oder neue Kunden zu gewinnen. Wirklich, das ist ein bisschen, wo die Fragen
sehr spezifisch sind , was Sie tatsächlich wollen, und Sie müssen entscheiden, was die richtige Frage für die Art von Problem ist, mit dem Sie konfrontiert sind. Dies ist im Grunde eine Einführung, wie man gute Fragen stellt, und in der nächsten Klasse werden
wir uns ansehen, wie wir schlechte Fragen stellen.
5. Schreckliche Fragen: Sie sehen wahrscheinlich, wie Sie herausfinden müssen, was die richtige Frage für Ihr Problem ist. Aber mit diesen jüngsten ethischen Dilemmata und auch Problemen rund um Vorhersagen und Dinge, müssen
wir uns fragen, was ist eine schlechte Frage? Ich möchte auf ein paar Beispiele
von Dingen eingehen , bei denen Datenwissenschaftler wahrscheinlich verhindern könnten einige passieren, indem sie weiter gehen als nur eine flache Analyse oder flache Vorhersage und möglicherweise ein wenig mehr durchdacht, was Gehst du los? Deswegen sind Sie Datenwissenschaftler. Manchmal muss man noch einen Schritt weiter gehen, um diese Welt schließlich zu einem besseren Ort zu machen. Mit dem sozialen Dilemma, zum Beispiel, und eine Menge Forschung, die herauskommt, sehen
wir, dass nur eine Erhöhung Website-Nutzung schließlich dazu führt, dass Websites nicht so groß für Menschen sind. Wir sehen eine Menge menschlicher Leiden an psychischen Problemen, basierend auf sozialen Medien und auf YouTube, auf Facebook, haben wir gesehen, dass es eine Neigung zu Extremismus. Wenn Sie anfingen, Videos über Lebensmittel zu sehen, erhalten
Sie mehr und mehr in sehr tiefe Kaninchenlöcher, wenn Sie nur für die Optimierung, warum sind Menschen bleiben auf Ihrer Seite. Als Data Scientist solltest
du weiter gehen, als nur die Frage zu stellen, wie halte ich Leute auf der Website? Aber ja, du solltest noch einen weiter gehen. Fragen Sie nicht nur, wie kann ich Leute auf meiner Website halten? Wie kann ich Leute dazu bringen, mehr zu kaufen? Aber vielleicht fragen Sie auch nach der Kundenzufriedenheit. Es geht nicht nur darum, wie verkaufe ich mehr, sondern wie bekomme ich das richtige Produkt an die richtige Person? Dies ist nicht das schönste, nicht das schönste Thema, aber wir müssen darüber reden, weil Sie über die Ethik nachdenken müssen. Können die Dinge durch die Bevölkerung erklärt werden? Wir wissen, dass es in ärmsten Städten höhere Kriminalitätsviertel gibt. Macht es wirklich Sinn,
ein vorausschauendes Modell zu entwickeln , in dem das nächste Verbrechen passieren wird, so machen Sie es auf individueller Ebene, wenn wir wissen, dass das zugrunde liegende Problem Armut ist? Dies ist leider eine Frage, die gestellt wird, und es ist keine gute Frage, weil wir wissen, was dieses Problem bereits verursacht. Aufbau eines Prädiktivmodells auf individueller Basis ignoriert unser kausales Wissen davon bereits. Dies geschieht auch auf viel breiteren, viel breiteren Skalen, die nicht so ethisch sind, wo wir wissen, was als Effekt geschieht, aber wie die Vorhersage des Individuums nicht mehr so wertvoll ist. Denn an diesem Punkt behandeln wir wirklich nur ein Symptom und nicht den Mechanismus. Eine andere Art von schlechter Frage tritt manchmal in Unternehmen denen die Antwort im Wesentlichen vorgegeben ist. Wir wissen bereits, welche Antwort wir wollen, und jetzt stellen wir eine Frage, um diese Antwort zu erhalten. Data Science sollte idealerweise offen für Antworten sein. Diese Antworten sollten potenziell in eine Richtung
gehen, die unsere Geschäftsleitung nicht erwartet hat. Management sollte offen genug sein, sicher genug, um dies auch passieren zu lassen. Datengetrieben zu sein bedeutet manchmal, dass wir unbequeme Wahrheiten über unser Geschäft finden, über die Richtung, in die wir gehen wollen. Aber das ist letztendlich, was Data Science zu einer Wissenschaft macht. Manchmal ist es, diese Fragen zu stellen, wenn wir bereits wissen, dass wir
eine bestimmte Antwort wollen , definitiv eine schlechte Frage weil sie uns nicht in die Lage versetzt, eine angemessene Datenwissenschaft zu machen. In der nächsten Klasse wird einen Blick haben, wie wir tatsächlich Daten bekommen, um diese guten Fragen zu stellen und wie wir gute Daten erhalten können, um die besten Ergebnisse aus unserer Analyse zu erhalten.
6. Daten und Labels sammeln: Eine der häufigsten Fragen, die ich von Anfängern in Data Science bekomme, ist, wo erhalten Sie Ihre Daten und wie erhalten Sie Ihre Etiketten? Nun, das sind zwei verschiedene Demografien, die diese Fragen stellen. In der Regel haben Leute in Wirtschaft oder Wissenschaftler bereits einige Daten. Datensammlung ist eine sehr häufige Sache. So haben Sie Ihre Datenbank mit Kundeninformationen, oder Sie haben Ihre Proben aus Ihrer Analyse. Da ist die Frage in der Regel mehr, wie erhalten Sie Etiketten? Für Anfänger, die nur versuchen, in Data Science zu gelangen, versuchen
sie, Daten zu finden. Wo finden Sie Daten? Woher bekommst du Etiketten? Wir tauchen zuerst ein, wie Sie Daten erhalten, wo Sie Daten erhalten. Denn selbst in einem Unternehmen kann
dies eine wirklich wichtige Frage sein, und dann werden wir einen Blick darauf werfen, wie man Etiketten bekommt. Das Abrufen von Daten bedeutet entweder, die Daten selbst zu messen oder einen Datensatz zu finden. Das bedeutet also, die Daten von irgendwo zu bekommen. Es gibt Datenspeicher, in denen Sie vorbereitete Datasets
erhalten können , denen häufig bereits Beschriftungen zugeordnet sind. Dies sind ziemlich häufig die Google-Suche oder auch der Kaggle-Datasets Abschnitt. Messen von Daten bedeutet im Grunde, dass Sie ins Feld oder in Ihre Systeme gehen und die Daten irgendwie extrahieren müssen. In meiner Arbeit arbeite ich
zum Beispiel mit Satellitendaten,
und wir haben tatsächlich eine Firma, die lokal ist und mit GPS
herumläuft , um tatsächliche Wälder zu messen. Ja, das kostet Geld, aber das ist der beste Weg, genaue Daten zu erhalten, die qualitativ hochwertig sind und die besten Ergebnisse für Ihr Data Science Produkt liefern. Am Ende ist es sehr wichtig, Experten zu haben,
um Ihre Daten zu kennzeichnen , Daten zu erhalten, um Ihre Daten zu interpretieren. Eine Menge Forschung hat gezeigt, dass es nicht ideal ist, Neulinge, normalerweise niedrig bezahlte Menschen auf etwas wie normalerweise niedrig bezahlte Menschen auf etwas wie
Amazon Mechanical Turk, um Ihre Daten zu interpretieren. Es gibt normalerweise laute Daten, fehlerhafte Beschriftungen und kann häufig Verzerrungen in Ihre Daten einführen. Sie müssen sehr vorsichtig mit der Verzerrung in den Daten sein, da diese Verzerrung in Ihr Modell eingebrannt wird. Wenn Sie
zum Beispiel maschinelles Lernen Modellieren , was ich viel mache, wird
Bias dann implizit im Modell sein, und das Modell wird diese Vorspannung bei jeder Vorhersage wiederholen. Vor allem, wenn man Menschen berührt, muss
man sehr vorsichtig sein. Dies ist auch etwas, auf das Sie achten sollten, wenn Sie vorbeschriftete Daten erhalten. Wenn Sie also eines der Datensätze von Kaggle herunterladen, schauen Sie sich an, was die Klassen tatsächlich sind,
schauen Sie sich an, was die Daten sind, was die Klassenungleichgewichte sind. Denn oft erhalten Sie Etiketten, die leicht zu beschriften sind, aber sie sind nicht unbedingt die Etiketten, die interessant zu beschriften sind. Manchmal, vor allem in Bezug auf Wissenschaftler und Soloprenäure, müssen
Sie die Daten selbst beschriften oder an jemanden auslagern. Da Sie der Experte sind und in der Regel Wissenschaftler mit einem engeren Budget arbeiten, bedeutet das nur, dass Sie etwas wie Labelbox öffnen müssen, die Sie hier auf dem Bildschirm sehen können, und Etiketten auf Ihre Daten selbst zeichnen müssen, interpretieren die Daten und seien Sie sich bewusst, welche Art von Voreingenommenheit Sie sich vorstellen könnten. In dieser Klasse hatten wir einen Blick darauf, wie Sie Daten tatsächlich
erhalten können , entweder indem Sie sie selbst erwerben oder sie von irgendwo herunterladen und wie Sie Etiketten erhalten. Also bekommen Sie entweder Experten, um Ihnen die Etiketten zu bekommen, wie Sie Anfänger bekommen, um Sie die Etiketten zu bekommen, aber auch, wie Sie Daten selbst mit Apps wie Labelbox beschriften. In der nächsten Klasse werden wir einen Blick auf die explorative Datenanalyse werfen,
bei der wir tatsächlich einen ersten Blick darauf werfen, wie Menschen Ihre Daten interpretieren.
7. Understanding verstehen: Lassen Sie uns über explorative Datenanalyse oder kurze EDA sprechen. In der explorativen Datenanalyse die Datenwissenschaftler
in der Regel einen ersten Blick auf die Daten. Viele Male machen Leute die beschreibenden Statistiken auf diesem Pod. Berechnen Sie also den Mittelwert, berechnen Sie Varianten und werfen Sie einen Blick auf die Merkmale Ihrer Daten, was ist in den Daten? Was ist in den Etiketten? Dies ist auch, um zu sehen, ob die Reinigung der Daten richtig gelaufen ist. Gibt es Ausreißer? Gibt es Rauschen in den Daten und wenn Sie diese Art von Sache in den Daten finden, müssen
Sie zurück zur Säuberungsphase. Wie gesagt, Data Science ist sehr iterativ. So oft muss man hin und her gehen, um wirklich zu sehen, dass alles behoben ist. Nachdem Sie dann nachgesehen haben, dass alle Ihre Daten in Ordnung sind, möchten
Sie auch einen Blick darauf werfen, ob Daten fehlen, weil dies ziemlich häufig passiert. Wenn Sie beispielsweise Kundendaten haben, werden Profile
oftmals nicht vollständig ausgefüllt. Sie fehlen einige der E-Mails, einige der Telefonnummern, und diese fehlenden Werte können als falsch angegeben werden. Sie sind also sehr wertvoll, in
Data Science zu wissen , und das gilt für fast jede Anwendung. Zu wissen, wo fehlende Daten vorhanden sind, kann sehr gut in Ihre Analyse einbezogen werden. Dies ist ein Tipp, den ich gerne jedem geben möchte, um auch einen Blick zu werfen, wo Sie Daten haben und wo Sie keine Daten haben. Am Ende werfen Sie auch einen Blick auf Korrelationen. Sie einen Blick,
wie Ihre Funktionen und wie Ihre Daten miteinander korreliert sind. Korrelation bedeutet einfach, dass, wenn Feature A nach oben geht und Feature B nach oben geht, sie möglicherweise eine Korrelation ihres
Gehens in die gleiche Richtung zur gleichen Zeit haben , und dies kann
ziemlich gut zu analysieren sein , so dass Sie Beziehungen innerhalb Ihrer Daten zu verstehen. Normalerweise möchten Sie vielleicht auch etwas Clustering machen. Sie einen Blick, welche Daten zu welchen Daten passen. Also werfen Sie einen sehr einfachen flüchtigen Blick darauf, wie Ihre Daten in Gruppen passen. Ich persönlich finde es auch sehr wertvoll in der explorativen Datenanalyse, einen Blick auf Visualisierungen zu werfen. Normalerweise können Sie natürlich eine Zahl für den Korrelationskoeffizienten berechnen, aber auch nur ein schnelles Diagramm Ihrer Korrelationen und Ihre Querkorrelationen zwischen verschiedenen Merkmalen kann wirklich gut sein, denn dann haben Sie einen schnellen Überblick genau wie wir jetzt auf dem Bildschirm sehen, und Sie wissen, dass das nach oben geht. Dies ist positiv korreliert. Das geht runter. Wenn dies nach oben geht, ist
dies negativ korreliert. Also wirklich nur ein Gefühl für die Daten zu bekommen und die Daten besser zu verstehen, so können wir dann weitermachen und sehen, ob unsere Hypothese, die wir in diesem Prozess
aufbauen, auf neuen Daten festhält, die wir noch nicht gesehen haben.
8. Einführung in das maschinelles Lernen: Eine Form der Modellierung unserer Daten umfasst maschinelles Lernen. Machine Learning hat jetzt die ganze Bandbreite, weil es in letzter Zeit
sehr einfach war , maschinelles Lernen Tools zu verwenden. Es ist sehr zugänglich für viele Leute geworden , die wenig Code oder gar keinen Code und viele Anwendungen kennen. Wo maschinelles Lernen gerade abstrahiert wurde, so dass Sie
ein neuronales Netzwerk basierend auf Ihren Daten aufbauen können , das dem Ergebnis annähert. Im maschinellen Lernen haben Sie grundsätzlich drei verschiedene Bereiche, die Sie betrachten können. Das überwachte Lernen, was im Wesentlichen bedeutet, dass Sie Ihre Daten haben und dann haben Sie Ihre Ergebnisse. Zum Beispiel, in Kundendaten, Sie haben Ihre Informationen über einen Kunden, die bei jedem Eintrag in dieser Information würden wir eine Funktion nennen. Sie haben Ihr Etikett, wenn sie gekauft haben oder wenn sie nicht gekauft haben. Dies wäre eine binäre Entscheidung in überwachtem maschinellem Lernen, wo Sie dann
versuchen können , vorherzusagen, ob basierend auf den Funktionen , die Sie jemand gekauft haben oder jemand nicht gekauft hat. Dies war das erste maschinelle Lernen, das Sie klassifizieren können. Ob dies binär ist oder Sie mehrere Klassen haben, die Sie vorhersagen möchten. Vielleicht sind es Katzen, Hunde und Vögel. Das sind wirklich diskrete Werte, diskrete Klassen, die Sie vorhersagen möchten. Die nächste Methode beim überwachten maschinellen Lernen ist die Regression, bei der Sie eine Zahl vorhersagen. In diesem Beispiel von Kundendaten wäre
dies gleichbedeutend mit der Vorhersage, wie viel ein Kunde bereit
ist, basierend auf den Features, die er im Dataset hat, auszugeben. Wirklich zu sehen, dieser Kunde, der vor kurzem gekauft hat, dies, und das wird $100 ausgeben. Dies kann zum Beispiel für Ihr Marketing-Budget sehr wichtig sein. Wenn Sie wissen, wie viel Sie für eine bestimmte demografische ausgeben, können
Sie dann im Wesentlichen sehen wie viel Marketing-Budget Sie bereit sind, für eine Umwandlung auszugeben. Die dritte Methode des maschinellen Lernens ist Teil des unbeaufsichtigten maschinellen Lernens. Das bedeutet wirklich, dass wir nicht die Etiketten haben, die wir
zuvor hatten , und wir versuchen, interne Strukturen unserer Daten zu finden. Wirklich, was das für das Clustering unserer Daten bedeutet, wir versuchen zu finden, welches Beispiel in unserem Datensatz näher an einem anderen Beispiel liegt. Schließlich können wir dann sogar
dieses unbeaufsichtigte Clustering verwenden , um unseren Daten Labels zuzuweisen. Das ist einer der Tricks, die Leute oft verwenden, um Etiketten zu finden, die auf die Lektion zurückverweist, die wir zum Kennzeichnen unserer Daten gemacht haben. Dies ist ein Trick, mit dem Sie Klassen in Ihren Daten finden können, aber es ist die Frage, sind das die Klassen, an denen Sie wirklich interessiert sind? Dies sind drei gängige Arten von maschinellem Lernen. Machine Learning hat sehr unterschiedliche Methoden, um diese Vorhersagen im Wesentlichen zu erreichen, wenn Sie über Regression und Klassifizierung sprechen. Überwachtes maschinelles Lernen, können Sie so etwas wie lineare Modelle verwenden. Buchstäblich eine Zeile in Ihren Daten anpassen. Sie können Entscheidungsbäume verwenden, die wirklich mächtig und wirklich interessant sind, weil sie diese regelbasierte Entscheidung treffen, wenn dies vorbei ist, dann legen Sie es in diese Klasse. Wenn diese Funktion darunter liegt, fügen Sie sie in diese Klasse ein. Sie sind sehr beliebt geworden, weil sie sehr einfach zu bedienen sind und wirklich gute Ergebnisse liefern. Neuronale Netzwerke sind eine weitere Klasse, in der Sie eine hirnähnliche Struktur von
Verbindungen haben , die im Wesentlichen
mathematische Operationen an Ihren Daten durchführen , um dann eine Klasse vorherzusagen. Schließlich haben wir auch eine Support-Vektormaschine genannt, die im Grunde versucht, Ihre Daten in zwei Gruppen zu unterteilen, idealerweise. Das sind wirklich sehr gängige Strategien, sehr gebräuchliche Werkzeuge, die Sie im maschinellen Lernen verwenden. Eine sehr häufige Methode im unbeaufsichtigten maschinellen Lernen ist k-Mean, bei dem Sie im Wesentlichen den Mittelwert Ihrer Cluster finden, aber das Problem ist, dass Sie k definieren müssen. Im Wesentlichen müssen Sie eine Menge unterschiedlicher Anzahl von Clustern
ausprobieren die k ist, und sehen Sie dann, was Ihnen die besten Ergebnisse gibt. Normalerweise ist ein niedrigeres k besser, weil dann größere Cluster gefunden werden. Wenn Sie Ihr k auf 100 erhöhen, so
dass Sie wie 100 Cluster finden, bedeutet das oft, dass Sie Subcluster in
größeren Clustern finden und weniger zuverlässige Ergebnisse erhalten. Eine andere Methode, die ich persönlich mag, ist T-SNE. T-SNE ist ein automatischer Prozess, den Sie hier im Hintergrund sehen können
, der im Wesentlichen auch versucht, Cluster Ihrer Daten zu finden. Es ist weniger interpretierbar, aber es ist sehr gut, Daten zu finden, die
zu einem anderen gehören, und Ausreißer in bestimmten Daten zu finden. Wirklich gut für die Schaffung von Beziehungen und Daten als auch. Der wichtigste Teil des maschinellen Lernens ist der Trainingsprozess. Sie haben Ihre Daten, Sie haben Ihre Etiketten und setzen sie ein und Sie hoffen, dass Ihr maschinelles Lernen die richtigen Modelle vorhersagt. Normalerweise ist dies iterativ. Ihr Modell prognostiziert etwas,
sieht, ob es richtig ist. Dies ist die Überwachung und dann wird das Modell angepasst. Dies ist der Lernprozess oder der Trainingsprozess. Beide Wörter werden verwendet, um das Modell wirklich anzupassen, um Ihnen die richtigen Ergebnisse zu geben. Dies ist der interessante Teil, denn diese Modelle sind mathematische Modelle, die nichts über Physik wissen, nichts über Kundenverhalten. Aber sie lernen, diese Beziehungen basierend auf mathematischen Prinzipien aufzubauen und sich wirklich an die Art der Daten anzupassen, die Sie haben, was sehr unterschiedlich sein kann. Machine Learning arbeitet an so vielen verschiedenen Aufgaben, von Werbung online über Physik bis hin zu Biologie, so wirklich vielseitig. Dies ist jedoch äußerst wichtig, wenn Sie trainieren oder Personen, die Sie beschäftigen, diese Modelle trainieren, müssen
sie einen Teil Ihrer Daten getrennt halten, da Sie immer einen Testfall haben müssen, im Wesentlichen, wo Sie sehen, ob Ihr Modell tatsächlich an Daten arbeiten, die das Modell noch nie gesehen hat. Weil das Modell Ihre Daten im Wesentlichen mehr oder weniger speichern kann. Du versuchst, das zu vermeiden. Es gibt eine Menge Dinge, die Sie als Machine Learning Engineer tun, um dies zu vermeiden. Aber am Ende wird das, was gemessen wird, verwaltet, und Sie müssen wirklich messen, ob Ihr Modell an Daten arbeitet, die es noch nie gesehen hat. diesem Grund halten wir normalerweise einen Teil
unseres beschrifteten Datensatzes zur Seite, weil wir dann bereits die Antwort auf diese kennen. Aber das maschinelle Lernmodell hat es noch nie gesehen. Ein netter Trick, um unser Modell mit diesem Validierungs-Testset zu validieren. Dies war ein kurzer Überblick über ein maschinelles Lernen. Sie wissen jetzt über die verschiedenen Arten von maschinellem Lernen und einige Methoden, die leistungsfähig sind, die Sie einen Blick in, wenn Sie interessiert sind. Sie wissen, dass Sie unbedingt Machine Learning Validierung durchführen müssen. Man kann nicht einfach ein Model trainieren und sagen, oh ja, die Ausbildungsschule, und das ist wirklich gut. Sie müssen immer einen zusätzlichen Datensatz haben, auf dem Sie Ihre Daten validieren können. Dies führt perfekt in die nächste Klasse, in der
wir einen Blick darauf werfen werden, wie man sich falsch beweisen kann. Denn wenn wir Data Science als Wissenschaft betreiben wollen, müssen
wir dafür sorgen, dass unsere Ideen tatsächlich geprüft werden.
9. Proving: Bisher hatten wir einen Blick auf Data Science Tools, Prinzipien und Methoden. Aber Data Science hat viel mehr, denn in der Data Science müssen Sie im Grunde über das System nachdenken, in dem Sie sich befinden. Es ist sehr geistig eingreifend in gewissem Sinne. In dieser Klasse und dieser Vorlesung werden wir einen Blick darauf werfen, sich falsch zu beweisen. Die Idee dahinter, sich falsch zu beweisen, ist im Wesentlichen, dass wir alle mit unseren eigenen Vorurteilen auf Datenanalyse gehen, und vor allem, wenn wir die explorative Datenanalyse verfolgen, haben
wir vielleicht einen Haufen auf Teilmengen der Daten bekommen. Einige der erfolgreichsten Teilnehmer an Kaggle-Wettbewerben, es ignoriert vollständig EDA-Notebooks, so dass andere Menschen ihre Erkundungen teilen, weil sie nicht in ihrem Ansatz
voreingenommen werden wollen , um zu sehen, was die Daten in speichern. Im Wesentlichen in jedem Data Science-Projekt müssen
Sie sich an einen sehr hohen Standard halten weil Sie die zugrunde liegenden Wahrheiten betrachten, zugrunde liegende Beziehungen innerhalb der Daten. Das spielt keine Rolle, welche Frage du beantwortest, wenn du eine Vorhersage machst oder wenn du überhaupt mechanistische Fragen beantwortest, ist
es immer, gibt es eine andere Erklärung dafür? Das erste, was Sie tun wollen, wenn Sie versuchen, sich falsch zu beweisen, ist Occams Rasiermesser anwenden. Occams Rasiermesser ist die philosophische Idee davon, Beweise können in der Regel durch die einfachste Idee erklärt werden. Also, wenn ich meine Schlüssel am Morgen nicht finde, habe ich sie wahrscheinlich irgendwo verlegt und sie sind wahrscheinlich in meiner Jacke. Es ist sehr unwahrscheinlich, dass es Aliens sind. Dies ist die Idee, dass Sie versuchen,
die einfachste Erklärung zu finden , anstatt Phantasie komplex zu gehen, und das ist auch etwas in der allgemeinen Datenwissenschaft, maschinelles Lernen, was eine gute Idee ist, um zu versuchen, das einfachste Modell zu bauen, das befriedigt Ihre Kriterien. Denn das einfachste Modell ist in der Regel auch am einfachsten zu erklären. In diesem Fall befinden sich Datenwissenschaftler in einem kleinen Dilemma, mit Wissensarbeitern werden
wir dafür bezahlt, klug zu sein, so dass wir eine komplexe Erklärung für diese Dinge haben, ist in der Regel das, was wir tun. Wir wollen die super interessanten Dinge finden und man muss dort sehr vorsichtig sein, denn wir können uns durch diese kluge Erklärung hineinlocken, die uns gut fühlen lässt, aber die vielleicht nur die falsche Erklärung sein kann. Es kann eine viel einfachere geben, die genau die gleichen Dinge erklären kann. Dort ist es in der Regel gut, einen
Blick darauf zu werfen, was die allgemeine Erklärung für solche Dinge ist, so dass Datenwissenschaftler oft mit Fachexperten sprechen müssen. Wenn Sie ein Data Scientist sind, der mit Wirtschaft arbeitet, sprechen Sie mit Ihrem Ökonom, wenn Sie Datenwissenschaftler am Large Hadron Collider sind, sprechen Sie mit den Physikleuten. Sie haben in der Regel eine Ahnung, haben eine Idee, und Sie können das immer noch herausfordern, wenn Ihre Daten die Beweise für diese Herausforderung haben. Aber oft ist es wirklich die einfachste Erklärung, es ist die beste Erklärung für Ihr Problem. Das nächste, was Sie tun wollen, ist, einen Blick auf Dinge zu werfen, die Ihre Theorie widerlegen. Wenn Sie eine Hypothese über Ihre Daten haben und Sie sich ansehen, was verursacht, was oder was wo passiert, geht zurück zum Beispiel von Anfang an, wenn höhere Preise in einem Hotel mehr Menschen verursachen, dann ist die umgekehrte kann wahr sein. Also, wenn Sie Ihre Preise senken, sollten
die Leute auch weg bleiben. Mit diesen Gegenbeispielen, die Sie in Ihren Daten finden können. Sie sollten eine Analyse im Wesentlichen machen, wenn es Beweise in Ihren Daten gibt, die Ihre Theorie beweist, Sie müssen sich verbessern oder Sie müssen Ihre Überzeugungen aktualisieren, müssen
Sie Ihre Hypothese ändern, weil diese Datenpunkte, wenn sie signifikant sind, wird das auf jeden Fall zeigen. Ihre Phantasie, Ihre ursprüngliche Idee war manchmal nicht ganz richtig, also müssen Sie mehr graben und wirklich auf
die Daten schauen , wenn es etwas gibt, das gegen das, was Sie im Sinn hatten, geht. Ein Beispiel aus meiner Arbeit im Moment ist, dass wir diese Idee hatten,
dass vielleicht das, was man „Zwangsmigration“ nennt. Im Wesentlichen müssen die Menschen ihre Häuser wegen Überschwemmungen verlassen, weil die Überschwemmungen dazu führen, dass Ackerland verschlechtert. Nun, in unserer Datenanalyse fanden
wir tatsächlich heraus, dass es in der Gegend nach einer Überschwemmung mehr Ernte gab, weil plötzlich eine Menge Bewässerung bekam und alles grün und blühend war, also mussten wir unsere ursprüngliche Idee aktualisieren, unsere anfängliche Überzeugung, auf eine neue Hypothese, die tatsächlich, ja, es war im Einklang mit den Daten. Das muss man wirklich flexibel sein und nicht mit den Ideen verheiratet sein, die Sie haben. Ich weiß, dass es sehr schwierig sein kann, bestimmte Überzeugungen zu aktualisieren, aber es ist absolut notwendig, dass
Datenwissenschaftler in diesem Verständnis flexibel sind und Fachexperten zuhören, weil sie oft Jahre Erfahrung, in diesem Bereich
arbeiten, und Sie brauchen sehr starke Beweise, um dem entgegenzuwirken, was sie über das Feld sagen. Viele Male sind
Grundlagenforscher wirklich gut, betrachten Ihre Daten, wenn es Gegenbeispiele in Ihren Daten gibt, und sehen auch, dass Sie die einfachste, einfachste Erklärung für
das haben , was Sie sind tatsächlich in Ihren Daten zu sehen. Wenn Sie darüber nachdenken, gehen Sie diesen einen Schritt weiter, gehen Sie auf Ihre Datenanalyse mit diesem wissenschaftlichen Geist, in der
Lage, wirklich überprüfen Sie Ihre Überzeugungen, die Sie ursprünglich aus Ihrer Erkundung von die Daten machen Sie wirklich zu einem stärkeren Data Scientists und macht Sie schließlich zu einem besseren Data Scientist, weil Sie jetzt in der Lage sind, diese Ideen, die von sich selbst kommen, in Frage zu stellen und daher Verzerrungen in Ihrer eigenen Analyse zu mildern und haben eine viel stärkere Argumente als auch. Wenn Sie diese Ergebnisse an Entscheidungsträger, an die Chefs oder in Papier schreiben,
und Sie können sagen, nun, ich überprüfe das nach Gegenbeispielen, und das waren Ausreißer oder diese basieren auf dieser Hypothese dass wir anfangs hatten, musste
es aktualisiert werden. Dies kann eine äußerst gute und wertvolle Eigenschaft in den Menschen sein, und es wird Respekt in diesen Entscheidungsträgern befehlen, weil sie jetzt wissen, dass sie Ihnen vertrauen können und Sie tatsächlich daran interessiert sind, die Antwort zu finden und nicht nur Ihre Antwort zu verbreiten. In dieser Klasse haben wir einen Blick darauf gehabt, sich falsch zu beweisen und wie grundsätzlich außerhalb der Box denken und Ihre eigenen Schlussfolgerungen aus Daten in Frage stellen können. Die nächste Klasse wird einen Blick auf eine meiner Favoriten Datenvisualisierung werfen.
10. Datenvisualisierung: In dieser Vorlesung gehen wir über die Datenvisualisierung. Datenvisualisierung ist für mich in zwei Aspekten wichtig. Zunächst einmal kann eine Visualisierung Ihnen äußerst guten Überblick über Ihre Daten in der Explorationsphase geben. Korrelationen, ich liebe es, wenn Sie nur eine Visualisierung anstelle einer Zahl für den Korrelationskoeffizienten haben. Denn dann können Sie viele Korrelationen nebeneinander sehen. Abgesehen davon, wenn Sie Ihre Berichte und Ihre Präsentationen machen , sagen sie es nicht umsonst und Bild sagt mehr als tausend Worte. Wirklich, Datenvisualisierung, können Sie viel mehr von
einem Datenkommunikationsstempel als alles
andere packen einem Datenkommunikationsstempel als alles und Sie können diese Visualisierungen interaktiv machen. Wenn Sie Dashboards erstellen, möchten
Sie diese Visualisierungen und
legen Sie sie auf eine Karte ab, wenn es sich um räumliche Daten handelt. Erstellen Sie ein Streudiagramm. Scatter Plots sind erstaunlich. Sie geben Ihnen so viel Input und Einblick in Ihre Daten. Wie sind Punkte gegen andere Punkte gehen. Wenn Sie Clustering durchführen,
wie werden diese Punkte im 2D-Raum gruppiert? Schließlich werden Sie am Ende besser in der Visualisierung von Daten, aber Sie möchten ein paar Regeln befolgen. In der Regel müssen Sie vorsichtig sein, Ihre Achse zu beschriften. Es ist also immer gut, Text auf der Achse zu haben. Ich persönlich mag das ist der Fluch meiner Existenz. Wenn Sie Text zu Visualisierungen hinzufügen, sollte
ich besser sein. Normalerweise gibt es in der Überprüfung immer ein, können Sie bitte x auf dieses Etikett setzen und es wird es viel klarer machen, weil die Leute
auf Ihre Visualisierungschauen
und direkt sehen können auf Ihre Visualisierung , was los ist, ohne die Beschriftung zu lesen, ohne den Text zu lesen, tun Sie das. Kodieren Sie niemals Daten in der Transparenz. Weil es sehr schwierig ist, Transparenz zu sehen, besonders wenn sie gedruckt wird oder wenn Sie ein Streudiagramm haben und mehrere Punkte übereinander haben. Wenn Transparenz in Ihrem Diagramm eine Bedeutung hat, verlieren
Sie diese Bedeutung, indem Sie mehrere Datenpunkte überlagern. Mit Farbe, müssen Sie sehr vorsichtig sein, um Farbenblindheit, aber auch, wenn Sie es drucken, eine Menge von wissenschaftlichen Druck ist schwarz und weiß, weil Farbe ist immer noch teuer zu drucken aus irgendeinem Grund. Frag mich nicht, warum. Aber ja, diese so genannten linearen perzeptiven Farbkarten zu
haben, ist wirklich gut und wenn Sie Matplotlib und all diese Python Bibliotheken verwenden, verwenden
sie etwas namens Veritas, das die Farbkarte ist. Veritas ist linear wahrnehmbar und perfekt für diese Art von Sache. Wenn Sie Ihre Visualisierungen in einer anderen Software durchführen, ist
es durchaus möglich, dass der Standard wird der Regenbogen oder Jet oft genannt. Der Regenbogen ist kein guter Farbbalken. Oft ist
das Grün viel zu breit, so dass Sie tatsächlich einige
Ihrer Visualisierungsinformationen in
diesen Farbkarten verlieren Ihrer Visualisierungsinformationen in und Sie sollten diese definitiv nicht verwenden. Viele Male werden die Leute herausfordern, dass, besonders wenn Sie mit Professoren sprechen, älteren Wissenschaftlern, sie denken, dass Regenbogen der Standard-Farbbalken ist und Sie sollten das verwenden und es gibt Forschung, um diese Gedanken herauszufordern weil es zugänglicher ist. Sie sind großartig für Menschen mit Behinderungen und es kostet Sie nichts und am Ende sind
sie bessere Farbbalken, weil der Wechsel von einem Farbton zum anderen, den Sie als menschlich wahrnehmen, für alle gleich ist, und es ist das gleiche zwischen jedem Farbton. In Regenbogen unterscheidet sich der Unterschied zwischen Rot und Blau viel von Grün und Rot, so
etwas, nur wegen
willkürlicher Zuweisungen, bei denen Ihre Daten der Farbe zugeordnet sind. Aber in Veritas haben Sie eine lineare Wahrnehmung dessen, wo sich Ihre Daten befinden. So verstehen Sie tatsächlich intuitiv wie Ihre Daten aussehen und was Ihre Daten tun. Bei diesen Grafiken, die Sie erstellen, möchten Sie immer über die Person
nachdenken, die sich die Handlung ansieht. Wie können Sie diese Informationen so zugänglich wie möglich machen? Können sie in einem Raum voller Menschen sitzen und folgen einer Präsentation und verstehen, was Sie versuchen, mit
der Folie zu sagen , die in weniger als einer Minute weg sein wird. Wirklich, schauen Sie sich an, was andere Leute tun. Es gibt erstaunliche Blogs da draußen. Sie können einen Blick auf fließende Daten werfen, die viele sehr schöne Visualisierungen sammeln. Es gibt auch eine Menge Ressourcen da draußen. Stellen Sie wirklich sicher, dass Sie diese zusätzlich zu dieser Klasse überprüfen, weil
dies natürlich ein guter Überblick ist, aber es gibt immer mehr und Sie können
diesen Schritt immer oben gehen und es ein wenig besser machen. Das Hinzufügen von Interaktivität zu Ihren Daten, wenn Sie
beispielsweise Dashboards ausführen , kann so gut sein. Wenn Sie mit der Maus Ihre Streudiagramm und Sie können tatsächlich
Informationen über jeden Punkt erhalten , indem Sie nur auf sie zeigen, ist so gut. Jeder ist immer begeistert, wenn ich so eine Visualisierung erstelle. Im Wesentlichen geht es bei der Datenvisualisierung darum,
Ihre Daten optimal zu nutzen und sie in einem einzigen Bild wirklich verständlich zu machen. In unserer nächsten Lektion werden
wir einen Blick auf die Produktion von Datenpipelines werfen. Wirklich, wie können wir unsere Erkenntnisse in einem Unternehmen nützlich machen?
11. Datenleitungen operieren: Bisher haben wir von einer Analyse für Datenzeichen gesprochen. Im Wesentlichen ist die Idee,
Ihre Daten zu haben, ein Datensatz zu haben und dann eine schöne Analyse und eine Präsentation zu Visualisierungen darauf zu machen. Aber in einem Unternehmen sind
Sie oft darauf angewiesen, Pipelines zu haben, Ihre Datenanalyse zu operationalisieren, sofort zu
bauen und sie dann immer wieder zu reproduzieren. Das ist es, worum es weniger geht als das hier. In einem Unternehmen bedeutet dies oft, dass Sie eine andere Person haben, wie ein Datenvorgang ist sehr ähnlich wie eine DevOps-Person, so dass Data Ops oft verwendet wird oder ML-Ops oder maschinelles Lernen Operationen, und das bedeutet, dass Ihr Team jetzt wächst eine andere Person neben dem Datentechniker und den Data Scientists. Aber es ist äußerst wertvoll, darüber nachzudenken und auch als Data Scientist darüber zu wissen, da Sie immer noch Ihre Analyse und Ihren Code an
diese Datenoperationsperson übergeben müssen und möglicherweise auch bei der Implementierung das hier. Wir gehen über die Operationalisierung Ihrer Datenanalyse und in diesem Teil. Wie im Data Science-Prozess beschrieben, unsere Datenanalyse oft oder unser Data Science Prozess besteht
unsere Datenanalyse oft
oder unser Data Science Prozess
oft darin, Daten zu beschriften, Daten zu bereinigen, unsere Daten zu untersuchen und dann Modellierung unsere Daten und machen Vorhersagen oder Betrachten der Kausalität von Daten, je nachdem, welche Frage Sie zu beantworten versuchen. In einem Unternehmen erhalten Sie oft ständig neue Daten, neue Kunden melden sich an, neue Dinge kommen ins Spiel. Beim Large Hadron Collider haben
Sie ein Jahr kontinuierliche Datenströme, die Experimente durchführen. Sie möchten diesen Prozess wirklich automatisieren. Bei der Pipeline geht es darum, sie zu automatisieren. Im Bereinigungsprozess möchten
Sie zum Beispiel viele
dieser Schreibfunktionen automatisieren , die auf den gesamten Datensatz angewendet werden können, nicht einzelne Teile von Hand herausfiltern. Sie möchten sicherstellen, dass Ihre Daten
einem Schema entsprechen , da Ihre Datenanalyse jetzt an einen bestimmten Dataset-Typ angepasst ist. Im Wesentlichen haben Sie Ihre Kundendaten, zum Beispiel, vielleicht haben Sie Geschlecht, Sie haben Einkäufe oder letzten Kauf und dann haben Sie Datum, wann sie sich angemeldet haben. Diese drei Funktionen sind das, worauf Ihre Datenanalyse basiert. Wenn Sie neue Features erhalten, müssen
Sie eine neue Analyse starten, da diese Analyse Ihnen möglicherweise neue Erkenntnisse liefert. Ihre Pipeline muss überprüfen, ob die neuen Daten, die eingehen innerhalb des Bereichs der erwarteten Parameter liegen. Bereits bei der Aufnahme neuer Daten möchten
Sie sicherstellen, dass Ihre Daten dem entsprechen, was Sie erwarten. Machen Sie Überprüfungen, führen Sie Tests durch, und Sie können diese Tests automatisieren und Ihre Datenoperationen Person kann Ihnen wahrscheinlich dabei helfen. Nette Python -Bibliothek dafür als große Erwartungen. Die Leute haben das in letzter Zeit geliebt und wir gehen über Schemas im Python Kurs. Dann habe ich auch auf der Skillshare Plattform. Ich hoffe, Sie werden das später überprüfen, wenn Sie bereits etwas Python kennen. Aber egal, zu wissen, was Sie tun müssen, ist bereits großartig. Denn wenn Sie ein Data Science-Team verwalten möchten, müssen
Sie wissen, was Sie im Wesentlichen eine Ansicht auf hoher Ebene haben möchten. Abrufen Ihrer Daten, Sicherstellen, dass Ihre Daten gut sind, und dann sicherstellen, dass die meisten dieser Prozesse, also einige der Visualisierungen,
die Sie in Ihrem Live-Dashboard erhalten , automatisch generiert werden aus den Daten. All dies ist möglich, wenn Sie Ihren Code auf saubere Weise
schreiben, dass Sie alles und
individuelle Funktionen haben , die bei jedem Schritt Ihres Data Science Prozesses
individuell angewendet werden können . Hier unterscheiden
sich Senior Data Scientists von Nachwuchswissenschaftlern. Sie schreiben saubereren Code und Sie werden verstehen, wie Sie jedes Stück Code in eine Box
einfügen, in eine Funktion, in der Sie diesen dann verwenden können, um den Prozess der Durchführung von Teilen der Analyse zu automatisieren. Ein weiterer sehr wichtiger Teil in diesem Analyseprozess,
vor allem, wenn Sie Vorhersagen machen. Wir sind die Kundendaten, die vorhersagen, ob jemand einen Einkauf tätigt, wenn Sie ihm dies zeigen oder wenn Sie ihnen zeigen, dass Sie einen Blick auf Schlüsselindikatoren werfen. Etwas, das Modell Churn oder Konzeptdrift genannt wird. Ihr Modell für maschinelles Lernen basiert auf historischen Daten. Ihre Data Science-Analyse, alle Erkenntnisse werden aus historischen Daten gehandelt. Wenn wir uns im Augenblick 2021 ansehen würden, wo der größte Teil der Welt in Absperrung ist. Wir nehmen Einblicke von 2000-2010, das ist eine Menge von Daten, 10 Jahre Daten wären erstaunlich. Aber nichts davon ist momentan anwendbar. Hier sind alle unsere Modelle und alle unsere Erkenntnisse wirklich nicht mehr so wertvoll. Denn im Moment wird all dies durch
Veränderungen in den Konzepten herausgefordert , wie Menschen tatsächlich leben wie die Wahrheit, die zugrunde liegenden Beziehungen verändern sich völlig, weil die Menschen viel mehr online kaufen. Die Leute müssen Online-Zoom-Anrufe verwenden und viele Verhaltensweisen wurden geändert. Die Leute arbeiten von zu Hause aus. Diese Änderung würde Ihre gesamte Datenanalyse vollständig stören. Ihre gesamte Datenanalyse, die Sie Produktionsverbündete wäre nicht mehr wahr. Nun ist die Pandemie offensichtlich eine katastrophale Veränderung. Aber oft haben Sie Änderungen im Laufe der Zeit in Ihren Daten, in Ihren Kunden, Menschen ändern sich, Trends ändern sich, besonders wenn Sie eine Bekleidungsmarke sind, zum Beispiel haben Sie Saisonalität. Niemand wird im Herbst einen schönen Bikini kaufen. Nun, ein paar Leute, aber Sie werden viel mehr Leute haben, die
Badehosen im Frühjahr kaufen , um sich für den Sommer vorzubereiten. Mit dieser Art von Konzepten und dieser Art von Tests für, für Konsistenz in Ihren Eingabedaten. Aber auch in Key Performance Indicators, KPIs in Ihrer Ausgabe, dass Ihre Daten immer noch gut funktionieren. Das ist sehr wichtig. Haben Sie immer eine Feedbackschleife in Ihrer Datenpipeline, wo Sie überprüfen, ist das, was ich tue, immer noch automatisierbar, ist das immer noch gültig oder bekomme ich zu viele falsche Vorhersagen an diesem Punkt? Denken Sie wirklich darüber nach, denn das ist extrem wichtig den Data Science Prozess betrachten, wenn Sie dies automatisieren. Nicht so wichtig in einer einmaligen Analyse, bei der Sie versuchen, Entscheidungsträger zu überzeugen. Aber wenn Sie diese Prozesse automatisieren, was in Unternehmen
und in diesen großen Betriebsabläufen viel wichtiger ist . Dort müssen Sie wirklich über die Datenvalidierung nachdenken. Bekomme ich das Richtige rein? Ausgabe-Validierung, Konzept-Drift und Modellabwanderung, wo Sie wirklich betrachten möchten, ist das, was ich auch immer noch gültig ausgebe. Oftmals können Sie Ihre Ergebnisse aus der erwarteten Ausgabe messen. Du siehst, du prognostizierst, wie viel eine Person ausgeben würde. Dann siehst du, wie viel diese Person ausgibt. Viele Male können Sie im Grunde mit AB-Tests sehen, zum Beispiel, wenn ich nichts getan habe, würde das immer noch etwas ändern? Dies geht auch mehr in die Aspekte der Kausalität ein. Was ich tue, hat das tatsächlich eine Wirkung, oder behindert es vielleicht sogar die Ergebnisse? Nachdenken über diese wirklich erhebt Sie über Junior Data Scientists, weil Sie viel wertvoller für ein Unternehmen sein werden, wenn Sie über diese Tests nachdenken können, um durchzuführen. Wenn Sie ein Data Science-Team verwalten, möchten
Sie sicherstellen, dass dies bei der Automatisierung der Pipelines erwartet wird. Wenn Sie ein Data Scientist sind, möchten
Sie sicherstellen, dass bei diesen Projekten, die Sie bauen, um einen Job zu bekommen oder in Ihrem Job. Sie schlagen auch diese Arten von Überprüfungen an das Management, an die Datenopers-Person vor, weil es extrem wichtig ist. Wieder einmal, wenn Sie es so betrachten, erweisen
Sie sich als wertvolles Mitglied des Unternehmens und des Teams. Dies wird Ihnen nur in Zukunft helfen. Wir haben in diesem Teil ein wenig über Dashboards gesprochen. In der nächsten Klasse wird einen Blick auf einige Dashboards, und was ich meine mit Live-Dashboards und warum Sie Erfahrung
haben wollen, Dashboards zu bauen und warum es so viel Spaß, ehrlich zu sein.
12. Dashboarding: In dieser Vorlesung werfen wir einen Blick auf Dashboards. Dashboards sind sehr beliebt geworden, weil sie Ihnen einen Überblick über mehrere Visualisierungen zusammen geben und Ihnen wirklich über die Änderungen und was in Ihrem Live-System passiert, aber auch mit Ihren Daten. Sie können eine Registerkarte mit kartenbasierten Ansichten haben
und Sie können eine Registerkarte Workerbeziehungen oder Datenzufluss Änderungen haben. Sie können Ihre KPIs überwachen, Sie können den Zustand Ihres Systems überwachen, insgesamt Dashboards sind dieses Gerät. In meiner Zeitberatung würden
die Leute immer nach Dashboards fragen, wie man Dashboards erstellt, und es ist viel einfacher geworden. Wenn Sie Optionen für niedrigen Code oder keinen Code wünschen, erhalten Sie in
Tableau, Spotfire und Power BI Optionen zum Erstellen von Dashboards. Wir haben hier ein paar auf dem Bildschirm. Wenn du zu Python gehst, gibt es ein paar Spieler auf dem Block, was ziemlich neu ist, um ehrlich zu sein, auch neu für mich, aber es ist so aufregend, als würde ich gerne Dashboards bauen. Es ist sehr interessant für mich. Aber ja, im Wesentlichen, was Sie tun können, ist entweder Plotly Dash zu verwenden, was sehr vielseitig und interaktiv ist, oder Sie können Streamlit verwenden, das sogar maschinelles Lernen verwendet oder verwenden kann. So sehr mächtig, wenn Sie Kenntnisse in Python haben. In Dashboards möchten Sie vorsichtig sein. Denn wenn ich Dashboards sehe, neigen
sie dazu, ein wenig überlastet zu sein. Worauf Sie sich also konzentrieren möchten, ist zunächst, wenn Sie es öffnen, sollten
die wichtigsten Informationen über die Falte, über der Falte liegen. Dies ist in der Regel etwas, über das Sie im Web-Design sprechen, das auf den alten Zeitungen basiert. Als Sie eine Zeitung kaufen wollten, steht
über der Falte die Schlagzeile auf dem großen Ganzen. Also wirklich der Aufmerksamkeitsgrabber, die wichtigsten Dinge, die Sie wissen müssen, und das sollte genau das gleiche in Ihrem Dashboard sein. Erste Seite, im ersten Frame, den Sie öffnen, haben die wichtigsten Informationen, die wichtige Entscheidungsträger zu sehen haben. Wenn Sie dann nach unten scrollen, haben Sie Informationen zu diesem Thema. Aber wirklich Informationsüberlastung ist ein Problem. Normalerweise ist das, was Sie tun möchten, minimalistisch über Daten und über die Informationen, die Sie auf einer Seite haben. Sie haben alle notwendigen Informationen, um eine Entscheidung zu treffen. Aber halten Sie Farbbalken in der gleichen Form. Überlasten Sie es nicht und geben Sie der Visualisierung Raum, Raum zum Atmen. Denn wenn alles vollgestopft ist, gibt
das in der Regel jedem ein Gefühl von Überwältigung. Machen Sie ein paar Durchgänge, wie viel Sie die Informationen reduzieren können. Sie können immer eine andere Registerkarte mit einem anderen Dashboard öffnen, das unterschiedliche Informationen enthält. Aber Ihr Dashboard sollte wirklich einen Fokus haben. Es sollte eine Frage beantworten, genau wie Ihre datenwissenschaftliche Analyse. Es kann als Kommunikationsinstrument verwendet werden. Es sollte die wichtigsten Fragen beantworten, für die Benutzer Ihr Dashboard öffnen. Es sollte nicht alle Informationen aufwerfen. Dann könnten sie die Analyse selbst durchführen. Aber Sie sind die Datenwissenschaftler. Sie müssen eine Geschichte mit einem Dashboard erzählen und wirklich meißeln, was für Leute wichtig
ist, um zu sehen, dass die Datenanalyse nicht durchführen kann, sondern dass eine, um zu wissen, was in diesem Prozess
im Datensystem passiert , in diesem Projekt. Aber offensichtlich können
Sie in Dashboards interaktive Visualisierungen verwenden, was viel Spaß macht. Normalerweise lieben die Menschen Interaktivität. Also in der Lage, ein paar Dinge auszuwählen und wie den Mauszeiger über Informationen zu bewegen und zu schwenken, sind gute Entscheidungen. Wenn Sie das tun können, dass Menschen in Ihre Daten,
in Ihre Visualisierungen zoomen können , anstatt nur wie ein statisches Bild zu haben, ist
das normalerweise eine wirklich gute Entscheidung. Zoomen in Karten
ist zum Beispiel etwas, das jeder aufgrund von Google Maps an heutzutage gewöhnt ist. Stellen Sie sicher, dass Sie bei diesen Dashboards ein intuitives Design haben. Wenn Sie Ihr Armaturenbrett sehen, fühlt
es sich fast nicht zu unterscheiden, was professionell, was Sie sind, dienen würde. Sieht das so aus, als könnte man von Apple im Wesentlichen entworfen werden? Ist das ein gutes Design? Also, ja, konzentrieren Sie sich auf Minimalismus. Zeigen Sie nur die relevanten Informationen, um Entscheidungen einfach zu machen und Menschen nicht zu überwältigen. Natürlich haben die Leute manchmal unterschiedliche Meinungen. Wenn Ihr entscheidender Entscheidungsträger weitere Informationen auf dem Dashboard wünscht , müssen
Sie dies natürlich befolgen. Sie müssen ihnen die Informationen geben, die sie brauchen. Oft müssen Sie über Dashboards auch mit
den Leuten, die sie tatsächlich verwenden, iterieren und flexibel sein. Sie wissen nicht immer, was wichtige Entscheidungsträger, sondern auch Fachexperten wirklich brauchen. Also ist es wirklich gut, Feedback zu bekommen. Aber mit diesen modernen Tools ist
es auch wirklich einfach, diese Dashboards zu erstellen. So ist es viel einfacher,
eine weitere Visualisierung hinzuzufügen oder diese Virtualisierung aufzunehmen und sie in eine andere Registerkarte zu verschieben. Es ist nicht so viel Arbeit. Aber ja, Dashboards sind ein wirklich guter Punkt, um
den Perfektionismus zu überspringen und sich eher auf das
Feedback der Leute zu verlassen , die Ihre Dashboards verwenden werden. Die Master-Disziplin ist eindeutig das Erstellen von Live-Dashboards. Nachdem diese Dashboards an diese operativen Datenpipelines angeschlossen sind, Live-Einblicke in Ihre Daten
haben, Live-Updates, und das ist auch durchaus möglich, aber es ist ein bisschen schwieriger, wie es am Ende sein
muss dieser gesamten Data Science-Pipeline. Sie werden das wahrscheinlich zusammen tun wollen, mit Ihrem gesamten Data Science-Team und mit einem Data Ops Menschen. Dashboards sind fantastisches Visualisierungstool und ein fantastisches Werkzeug für die Kommunikation weil sie den Menschen Raum geben, um die Geschichte, die Sie zu erzählen versuchen, zu nehmen. In der nächsten Klassewerden
wir einen Blick daraufwerfen, werden
wir einen Blick darauf welche anderen Kommunikationstools Sie insgesamt nutzen können, um Ihre Data Science-Geschichte zu erzählen, um Ihre Erkenntnisse wirklich an Entscheidungsträger zu vermitteln.
13. Ergebnisse effektiv kommunizieren: Das Endergebnis Ihres Data Science Prozesses ist in der Regel Kommunikation. Mit Ihren Erkenntnissen möchten Sie in der Regel jemandem zeigen, oft Fachexperten oder wichtige Entscheidungsträger, eine Entscheidung basierend auf dem, was Sie gefunden haben, zu treffen. Ändern Sie Meinungen, erzählen Sie wirklich eine Geschichte, überzeugen Sie und Kommunikation ist in diesen Aspekten der Schlüssel. In dieser Klasse werfen wir einen Blick auf die Kommunikation und wie Sie Ihre Ergebnisse effektiv kommunizieren können. Denn viele Werkzeuge scheinen es heutzutage einfach zu machen, aber wenn Sie mindestens einen Schritt weiter gehen, können Sie die Ergebnisse noch besser kommunizieren. Der Schlüssel hinter der Kommunikation ist, dass Sie Ihr Publikum kennen. Viele neuere Datenwissenschaftler nehmen oft das Jupiter Notebook, das eine Möglichkeit ist, Code
und Text zu mischen und sie in PDFs zu verwandeln. In gewisser Weise ist dies problematisch, weil ein Geschäftsführer zum Beispiel keine Zeit hat, sich Ihren Code anzusehen. Ehrlich gesagt, sie erhalten keinen Vorteil aus dem Blick auf Ihren Code. Diese Jupiter-Notebooks sollten für die Kommunikation mit anderen Datenwissenschaftlern verwendet werden. Mit Codern, so dass Sie tatsächlich die Dokumentation für Ihren Code als auch haben. Aber wenn Sie mit Leuten sprechen, die sich mehr auf den Management-Sektoren befinden, möchten
Sie ihnen nur Code zeigen, wenn sie danach fragen. Sie möchten in der Lage sein, effektiv zu visualisieren. zur Klasse über Visualisierung zurückkehren, möchten
Sie die Geschichte wirklich mit Bildern erzählen die ihnen die Daten so
zeigen, dass sie sich leicht entscheiden können. Am Ende ist es immer, jemanden zu überzeugen,
eine Entscheidung leichter zu machen , weil
sie jetzt Sicherheit haben, weil sie durch Daten gesichert sind. Unterstützt durch Mathematik, Statistik, maschinelles Lernen, Ihre Arbeit in der Analytik. Letztendlich geht es auch darum, worum es bei der Wissenschaft geht. Als Wissenschaftler geht es beim Schreiben in Papier darum, meine Kollegen
davon zu überzeugen, dass ich etwas Neues gefunden habe, etwas Besseres als zuvor, eine neue Erkenntnis. zu überzeugen bedeutet, wirklich ihre Sprache zu sprechen, also muss man sich dem geraden Umriss eines Papiers anpassen. ist sehr wichtig, gute Visualisierungen und die richtigen Gleichungen an den richtigen Stellen hinzuzufügen, aber die meisten von ihnen wollen den Code nicht sehen. Das ändert sich zumindest irgendwie. In der Zeitung werden die meisten Leute Sie bitten, Code zu entfernen. Nun, ich denke, machen Sie Ihren Code vorzeigbar, und ich lege ihn gerne in einen Anhang oder irgendwo. Die meisten Leute wollen sich den Code nicht ansehen, weil die meisten Leute gerne
eine einfachere Entscheidung haben , indem sie einfach Ihrer Kommunikation folgen. Konzentrieren Sie sich also auf Visualisierungen, konzentrieren Sie sich darauf, eine Geschichte zu erzählen, und reduzieren Sie die Menge an Code, die Sie den Menschen zeigen, es sei denn, es ist angemessen. Auf diese Weise können Sie auch wirklich voran gehen und tief in die Medien eintauchen, die Sie verwenden. Dann geht es nicht nur um das Publikum, in dem man über das Ziel nachdenkt, über den Zweck
nachzudenken, sondern auch um das Medium. Interaktive Visualisierungen sind großartig, aber sie funktionieren nicht in PDFs. also wirklich vorsichtig, wie du diese Ergebnisse kommunizierst. Wenn Sie eine PDF-Datei an jemanden senden möchten, müssen
Sie sich keine Zeit nehmen, um ein Dashboard zu erstellen, da es sich um eine PDF-Datei handelt. Nehmen Sie sich Zeit,
qualitativ hochwertige eigenständige Visualisierungen zu erstellen , die für sich selbst
sprechen, die Sie in Ihre PDF-Dokumentation integrieren können. Wenn Sie eine PowerPoint-Präsentation durchführen, stellen Sie sicher, dass
Ihre Daten, Ihre Visualisierungen deutlich sichtbar und umrissen sind und
auf kleinen Bildschirmen von der Rückseite eines schlecht beleuchteten Konferenzraums sichtbar sind. Überlegen Sie, wie Sie Ihre Erkenntnisse live teilen können, mit all diesen Dingen, wo wir noch viel mehr Videokonferenzen haben . Können Sie Personen Zugriff auf das Dashboard geben, damit sie es ausprobieren können? , während Sie Ihre Präsentation Können sie einige der Analysen selbst verfolgen, während Sie Ihre Präsentationhalten? Denken Sie wirklich darüber nach, wie Sie Ihre Ergebnisse kommunizieren, denn Kommunikation ist Ihr Schlüssel, um
wirklich zu überzeugen, was die Geschichte ist, die Sie zu erzählen versuchen. Als Data Scientist ist Kommunikation und damit Empathie äußerst wichtig. Sie haben all diese erstaunlichen Tools, die Ihnen beim Handel mit Wissenschaft helfen können, und Sie haben so viele erstaunliche Tools, um Ihre Ergebnisse wirklich zu kommunizieren, PDFs zu
erstellen, Präsentationen und PowerPoint zu erstellen, Dashboards zu
erstellen, Jupiter Notebooks zu erstellen, um zu sprechen und Tutorials, und sprechen Sie mit anderen Datenwissenschaftlern. Aber am Ende ist es sehr wichtig, dass Sie Kommunikation im Auge haben. Wenn Sie Ihre Analyse teilen, profitieren die Menschen von Ihren Erkenntnissen, und auf diese Weise können Sie wirklich ein vollständiges Projekt durchführen und den Data Science Prozess beenden. In der nächsten Klasse werden
wir einen Blick auf das Verständnis von Risiken in der Data Science werfen, weil nicht jedes Projekt erfolgreich sein wird.
14. Risiken in Data Science verstehen: Ein wichtiger Teil des Data Science-Management-Workflows ist das Verständnis von Risiken. Das Risikoprofil eines Data Science-Projekts
unterscheidet sich wesentlich von dem eines Softwareprojekts. Wenn Sie wissen, dass etwas mit einem Computer machbar ist, braucht
es nur Zeit und Verwaltung, um dieses Projekt abzuschließen. In einem Data Science-Projekt kann
es negative Ergebnisse haben. Letztendlich ist es ein wissenschaftlicher Prozess, der
sieht, ob wir angesichts der Daten, die wir haben, sogar eine Frage beantworten können, und das ist möglicherweise nicht möglich. Es gibt die ethischen Dinge, über die ich gesprochen habe, wie vielleicht finden wir, dass die Beantwortung dieser Frage eigentlich nicht
vorteilhaft für unser Geschäft ist , für unsere Frage. Vielleicht ist es aktiv schädlich für Gemeinschaften, aber auch in einem viel leichteren Sinne kann
es nur sein, dass unser Modell nicht gut funktioniert. Dass wir die Daten bereinigen können, dass wir nicht genügend Daten haben, und all diese Dinge, die Sie verwalten müssen. Risikomanagement bedeutet, dass wir am Ende in einer agilen Denkweise sein müssen. Alles muss iterativ sein. Es ist sehr gut, tägliche Stand-outs zu haben, die sehr
kurz sind , da Sie die agile Methodik tun. Sie möchten Blöcke in Ihrem Team frühzeitig identifizieren. Sie wollen regelmäßig kommunizieren. Nicht mikromanagen, aber es ist wichtig, dass Ihr Team dazu befähigt, auch zu sagen: „Hey, das klappt nicht. Wir brauchen mehr Daten, wir brauchen andere Daten, vielleicht müssen wir unsere Frage neu formulieren, weil die Erkenntnisse, die wir daraus gefunden haben, tatsächlich nicht funktionieren.“ Wenn Sie von einem Junior zu einer höheren Position mit mehr Verantwortlichkeiten gehen, ist
es wichtig, Ihr Team zu führen, aber auch bewusst sein, dass ein Scheitern völlig möglich ist. Wenn Sie mit Stakeholdern und Entscheidungsträgern kommunizieren, ist
es wichtig, auch klarzustellen, dass Scheitern eine Möglichkeit ist, dass diese Dinge explorativ sind
und je nachdem, wo sich Ihr Projekt befindet. Frühe Projekte, die die erste Erkundung machen, die die ersten Grundarbeiten machen, sind viel wahrscheinlicher,
dass sie in der Phase scheitern, dass sie überhaupt nicht machbar
sind, während spätere Projekte, müssen
Sie viel vorsichtiger sein über die Produktanalyse Ihrer Pipelines. Funktioniert es noch? Geht es voran? Vor allem, wenn Sie in jüngeren Teams sind, in Teams, die sich gerade etablieren, achten Sie
darauf, Gewissheit und
Unsicherheit zu kommunizieren , weil einige Dinge einfach nicht funktionieren. Diese Fehler können jedoch auch Erkenntnisse sein. Hier möchten Sie auch wirklich auf
die Kommunikation zurückgehen , denn es ist
etwas wertvolles, das Sie auch als Ergebnis verkaufen können, dass
diese Entscheidung aufgrund dieser Daten nicht möglich ist . Aber du musst es offen lassen. Wenn Sie mit dem Management kommunizieren und Erfolg versprechen, schließen
Sie den Sturm, dass Sie dies im Wesentlichen
als zusätzliche Einsicht einrahmen können , denn dann wird diese zusätzliche Einsicht zu einem automatischen Ausfall. Wenn Sie jedoch im Voraus mitteilen können, dass Fehler eine Möglichkeit ist, dass es Probleme gibt, die nicht lösbar sind, dass manchmal die Daten nicht genug sind, oder es gibt Timing-Probleme, Dinge wie diese. Dass Sie
manchmal Leistungsindikatoren nicht erfüllen können und dass Sie iterativ aktualisieren müssen, ist
dies etwas, mit dem Sie vorsichtig sein müssen. Wenn Sie gut darin sind, dies im Voraus zu kommunizieren und dieses Risiko zu
meistern, setzen Sie Ihr Team zum Erfolg auf. Denn unabhängig davon, was sie tun, wenn sie ihre Arbeit tun und sie ermächtigt sind, auch negative Ergebnisse zu liefern, baut
dies ein starkes Team und das Team auf, das schließlich erstaunliche Produkte baut und Einführung und Aufrechterhaltung datengestützter Ergebnisse in einem Unternehmen und
wird ein Unternehmen stärker machen und Sie und das Team insgesamt steigern. Am Ende müssen Sie alswachsender Data Scientist oder als
jemand
, der potenziell in eine Management-Rolle eintritt, verstehen wachsender Data Scientist oder als
jemand , dass Sie vorsichtig sein müssen, was Sie kommunizieren und was Sie versprechen. Indem Sie jedoch ermächtigen, indem Sie ein guter Führer für das Team sind, das
iterativ arbeitet und den Menschen wirklich ihren Platz und die notwendigen Werkzeuge gibt, können
Sie dieses Team zu einem Erfolg machen und das Risiko von Data Science Projekten, die unterscheiden sich sehr von normalen Projekten. Dies ist das letzte Kapitel. Die nächste Klasse wird
diesen Skillshare Kurs abschließen und ich bin sehr froh, dass du daran teilnimmst.
15. SCHLUSSBEMERKUNG: Herzlichen Glückwunsch für die Herstellung. Ich weiß, dass dies eine Menge Informationen waren und für viele von Ihnen könnte es völlig neue Informationen gewesen sein. Aber ich hoffe, ich könnte Ihnen zeigen, wie diese datengesteuerten Erkenntnisse und dieser Prozess eines wissenschaftlichen Geistes, derden
ganzen Weg von Rohdaten bis hin zur Kommunikation von Ergebnissen an
wichtige Entscheidungsträger geht den
ganzen Weg von Rohdaten bis hin zur Kommunikation von Ergebnissen an , ein so wertvoller und interessanter Punkt ist. Es lässt mich nur hoffen, dass Sie auf
diese Reise gehen und dies in Low-Code oder Code-Möglichkeiten erkunden. Es gibt so viele verschiedene Möglichkeiten, dies anzugehen. Ich bin sehr froh, dass du diesen Kurs genommen hast und ich hoffe, dass du etwas daraus hast. Bitte bedenken Sie meine andere Klasse. Ich gebe eine Klasse für Leute, die bereits
etwas Python kennen und den Data Science Prozess hier auf Skillshare lernen möchten. Aber auf jeden Fall auch alle anderen Kurse erkunden. Es gibt einige erstaunliche Data Science Visualisierungskurse auf hier. Es ist wirklich fantastisch, auch tiefer in diese datengetriebene Entscheidungsgemeinschaft einzutauchen. Achten Sie darauf, Menschen auf LinkedIn zu finden, Einflüsse auf verschiedene Social Media zu
verfolgen und mehr über
Data Science zu erfahren , denn es gibt so viele interessante und faszinierende Dinge. Wenn Sie ständig Daten betrachten, werden
Sie bei Ihren Entscheidungen viel sicherer da diese Entscheidungen tatsächlich basieren. Danke für Ihren Besuch. Ich bin so dankbar, dass du hier warst. Ich hoffe, Sie haben diesen Kurs genossen. Bitte vergewissern Sie sich, dass Sie das Projekt ausprobieren und das Projekt posten. Ich freue mich sehr, zu sehen, was du dir einfällt.
 Jesper Dramsch, PhD, Scientist for Machine Learning
Jesper Dramsch, PhD, Scientist for Machine Learning