Transkripte
1. Willkommen und Voraussetzungen: Hallo und willkommen zu dieser Sitzung auf einer George Data Factory. Mein Name ist der Shang Good. Und ich werde ein Kerl als der Forscher sein, ein George es eine Fabrik und einige andere Dienste, die wir verwenden werden, um Data
Factory-Lösung zu bauen . Wir werden diskutieren, was ein Jude hat eine Fabrik, seine Schlüsselkomponente Etikettierung Dienstleistungen, Aktivitäten oder per Flugzeug, wie es funktioniert, seine Vorteile und wie Sie tun und überwachen Workflow. Wir werden auch durch Demo gehen, um Data Factory zu verwenden, in der wir Daten
von einem George Data Warehouse in datenbeinschonende Speicherung verschieben und transformieren werden. Also im Grunde sehr Workflow entwickelt, der mich automatisch
,um Daten aus einer bestimmten Quelle zu nehmen , , eine Transformation zu
machen, und dann werden wir die Ausgabe einige andere Geschichten speichern,
Ort, von dem es für abgeholt werden kann die Analyse. Um diesen Kurs abzuschließen, werde ich dafür sorgen, dass Sie Aktivitäten in die Hand bekommen. Ich werde Sie nicht nur belehren, sondern Sie werden auch eine Chance bekommen, das selbst zu versuchen. Und dazu
brauchst du nur eine Joseph Fiction. Und das Joy-Abonnement könnte eines sein, das Sie bereits haben, oder Sie können sich für eine kostenlose
Testversion anmelden . Außerdem ist
es gut, mit Menschenkonzepten vertraut zu sein. Am Ende dieses Kurses haben
Sie ein solides Fundament auf einem George es beeinflusst Baum. Fangen wir von vorn an, General.
2. Datenlebenszyklus: Lasst uns diesen Schnee, der kleine Lebenszyklus. Im Leben Amerikas gibt es viele sieben Etappen. Daten können aus vielen internen und Aktionen und Quellen stammen. Es können Überzeugungsdaten aus Anwendungen sein oder vielleicht Protokolldaten aus dem System für fast kontinuierlichen Stream von Daten von Geräten wie ich denke, im Hals Off Things und all diese verschiedenen Quellen produzierten die gleiche Art von Daten, aber in verschiedenen Kommentare, weil sie die unterschiedliche basierte Kommunikation haben können. Also der Punkt ist in guten Daten sagen, aber bilden es wirklich anders. Die erste ein Formular. Wir brauchen eine Art von Geschichten. Werfen Sie das Leben zweite aus Daten, wo wir Daten in verschiedenen Phasen außerhalb des Lebenszyklus speichern können, dann viele etwas zu verbinden und die Daten aus verschiedenen Quellen greifen. Es ist eine Beckensammlung. Dann muss er vielleicht die Daten vorbereiten. Wenn es darum geht, Daten aus verschiedenen Quellen zu erhalten, alle Systeme, haben
sie möglicherweise eine etwas andere Form. Es liegt daran, dass Quellen vermissen die Daten anders gestohlen haben. Zum Beispiel kann
dieselbe Spalte unterschiedliche Genehmigungen in verschiedenen Quellen haben. Einige von ihnen können auf dem Stream haben. Einige von ihnen haben wir die Nummer einige erlaubt die Metallwerte und einige können auch zulassen, dass der Rohling verlieren wird. So haben wir eine saubere die Daten, bevor wir wirklich beginnen können, in die tatsächliche aufgenommen, weil
Geschichten, die wir den Beruf oder eine anfängliche Transformation nach der anfänglichen Transformation zu tun haben , konvertieren Daten in konsistente ehemalige hey tatsächlich
in den Speicher vorhanden war. Dann denken Sie über die Verarbeitung nach, wenn der Prozess, den wir tatsächlich die Daten transformieren und Transformation verschiedene Dinge bedeuten kann. Aber letztendlich passierten wir, transformierten diese Straßendaten in eine Struktur und normalisieren zweite. Größer in einer Weise, dass es die Forderung des ersteren bedeutet off und System, weil diese und Systeme wirklich gehen, um die Analyse zu tun, alle Interpretation. So gibt es viele Menschen Phasen, die die Daten, die wir durchlaufen, und einige davon können sogar Zyklen, die mich mehrmals zur Verarbeitung und Transformation gehen lassen. Tatsächlich in dieser Welt
sehr oft noch nicht, wissen wir
in dieser Welt
sehr oft noch nicht,was die geschäftlichen Fragen sind, die wir in
Zukunft stellen werden und welche Daten wir brauchen, um diese Fragen zu beantworten. Also ist die Idee, alle Daten zu behalten, so dass wir später wieder kommen und Einheit wie erworben. Wir analysieren ständig das spätere, das wir vom Vikar lernen, die kontinuierliche Retune eines Modells und nehmen weitere Veränderungen in der Transformation vor. Das ist also ein genereller Prozess, aber wirklich der wichtigste Teil Was wir hier tun, ist, dass wir Daten von der Quelle erhalten, die Senior und schließlich in das Ziel versinken, und all die Bits dazwischen
, die nicht in einer Methode passieren und der Moment, der nützlich für das gleiche, so dass wir diese Analyse von in Form ausführen können, so dass wir die Intelligenz, die mein Geschäft tatsächlich führen zu bekommen.
3. Azure Solutions: in dieser Lektion möchte
ich den Rand der Lösungen vorstellen, die unsere Familie Technologien lebten wir in seiner um den Kontrollfluss und den Datenfluss, ob Kontrolle langsam. Wir hatten eine Job-Datenfabrik. Das sorgt dafür, dass Orchestrierung und sie tut. Dann haben wir die eigentlichen Datenflusslösungen. Dies sind Adjudicator Brüche über den Rand der tatsächlich innerhalb oder eines der Dienste alle Funktionen zu besitzen. Die spätere zumindest der Kontrollfluss ist die Orchestrierung, die sie ausmacht Aktivitäten. Eine spätere Etage ist der Fluss aus dem tatsächlichen später innerhalb der Aktivität, wenn der Kaltstrom
gebildet werden sollte , zum Beispiel
mindestens eine Aktivität . Nehmen wir an, wenn Sie den Blockbrecher nehmen und ihn buchstäblich jetzt senden möchten, ist
dies ein Datenfluss. Nun, innerhalb dieser Aktivität, werden
sie verschiedene Schritte potenziell sein. Zum Beispiel müssen
wir Daten aus Block erhalten. Dies ist Schritt eins und dann eine wichtige Daten nur, die Schritt toe sein wird. Und zwischen diesem Schritt werden
sie wahrscheinlich zuordnen, um bestimmte Werte aus dem Blob zu nehmen und sie auf bestimmte Dateien innerhalb buchstäblich
zu treffen . In ähnlicher Weise gibt es in der Nähe der anderen Aktivitäten Vielleicht gibt es einen Transformationsdatenfluss, der die Daten aus
den Daten Lee nimmt . Und das ist eine Transformation, zum Beispiel, vielleicht soziale Gelenke für die Daten, aber älter oder verschmilzt mit anderen Dingen, die es tun kann. Aber der entscheidende Punkt ist, dass es die Rohdaten in Performer transformiert und die Struktur, die von der Endanalyselösung
weiter genutzt werden kann. Und das ist ein erfolgreicher
, der durch einen grünen Pfeil dargestellt wird. Dann sind sie auch Failure Flow, die durch den Roten Pfeil dargestellt wird. Wenn es also einen Fehler in der vorherigen Aktivität gibt, dann würde die Orchestrierung oder der Kontrollfluss jetzt verschoben, um es ein leitendes FBI zu nennen. Also im Grunde können wir das. Wir sind darauf, einen vollständigen Fluss aus den verschiedenen Aktivitäten zu haben, die den
End-to-End-Lebenszyklus von den Daten abschließen . Nein, die Orchestrierung schlechten Kontrollfluss ist verantwortlich für die Beanspruchung dieser Schönheiten, die jede Hand einen Datenfluss in ihnen. Dann gibt es verschiedene Arten von Datenfluss. Zum Beispiel das
Rendern von Daten Pose. Dies integriert sich in der Regel mit Dingen wie Power Equity, und das ist alles über Datenberuf, Hinzufügen von
Spalten, Spalten aufteilen oder vielleicht einen vollständigen No Name nehmen und es wird Vorname und
Nachname ändern , dann sind sie nichts dagegen. Zum Beispiel verbinden sich
Schwerter Marges Einsatz oder das Aggregat Suchen Sie all dies und alle ähnlichen Transformationen. Also haben wir die unterschiedliche Transformation auf unterschiedlicher Basis verwendet, wie, zweitens, diese streitenden Datenflüsse nahe dem Anfang, als es die Daten im Brief vorbereitete. Und dann denke ich an die Mapping-Datenflüsse, die tatsächlich den Führer transformieren, ihn in eine Form
bringen, die wir für diese Analyse benötigen.
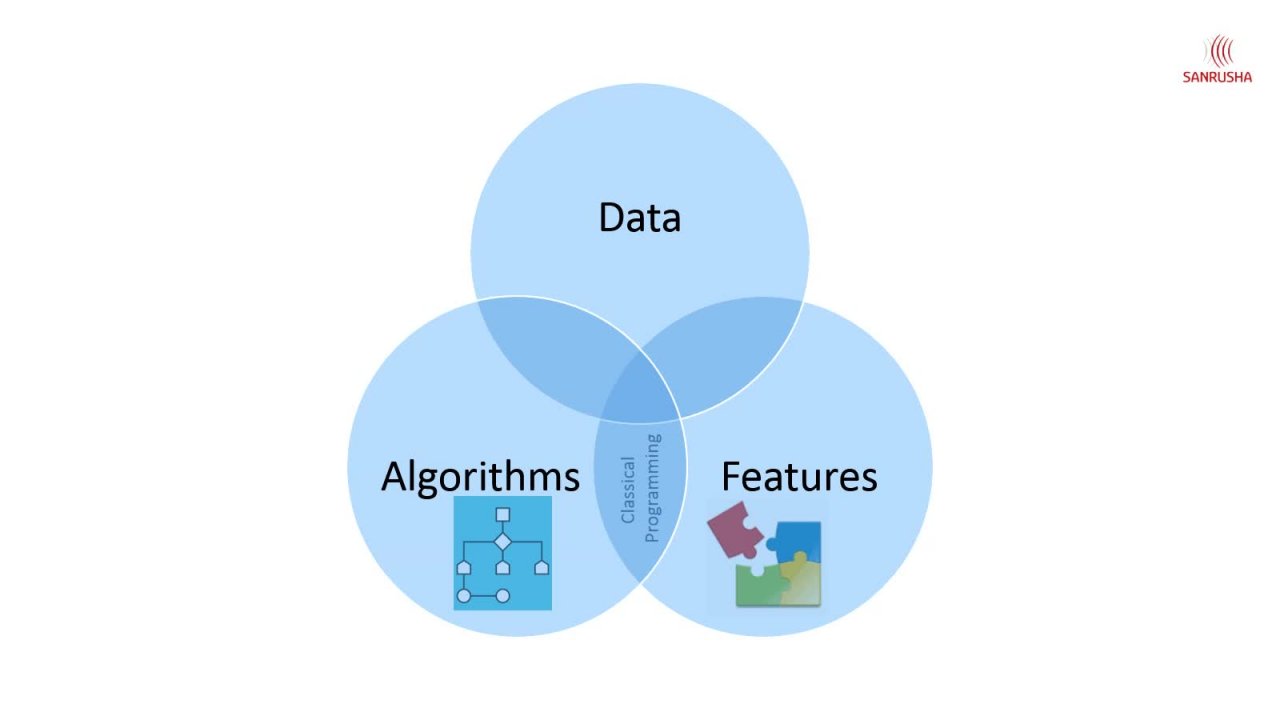
4. Was ist Azure Data Factory: Sie werden eine Fabrik ist ein verwalteter Datenempörungsdienst, der in der agilen
Cloud lebt . Ein George es wirkt Baum ist wie eine Gesellschaft ist alles Agent Job implode außer dass ein Judit beeinflussen Baum Es gibt viel speichern alle Daten von sich selbst oder es hat keine Transformation von selbst. Wenn Sie jemals auf S s Augen oder in Komitee Mädchen gearbeitet haben, alle anderen idealen Werkzeuge. Sie hatten ihre eigenen Transformationsfunktionen, aber Idee einfach mit anderen Quellen verbinden Destination und Übertragungsdienste Quellen und Zielverbindung könnte in vor Ort oder in Kleidung sein und es verbunden verschiedene andere Transformationsfunktionen Komponenten Alle Dienste außerhalb der Cloud wie sie verwenden gleich , hoch oder Schwein alle anderen Dienste wie das und die erforderliche Arbeit zu erledigen. Also, was bedeutet es? Ein Job bietet viele Technologien, die Ihnen dabei helfen, den Wert Ihrer Daten zu steigern. Zum Beispiel gibt es einen Jury Blob Storage, der billigere Cloud-Storys bietet. Sie speichern Ihre Daten. In der vorherigen Sitzung haben wir eine Datenleck-Analyse diskutiert, die wir zum Massieren und Transformieren Ihrer Daten verwenden. Und es gibt ein Juwel Geheimnis Ihres Hauses, das skalierbares relationales Data Warehousing bietet das Sie verwenden können, Ihr Geschäft
zu verstehen, und es gibt viele andere Anpassungsdienste, die für verschiedene Zwecke verfügbar sind. Sie können diese Ajo-Services nach Bedarf kombinieren und anpassen, um sowohl die Struktur als auch
unstrukturierte Daten zu analysieren . Aber es gibt keinen wichtigen Aspekt von Data Analytics, den keiner von ihnen angesprochen hat, nämlich Datenintegration. Data Indication bedeutet also, Daten aus der Quelle zu extrahieren, dann eine Transformation durchzuführen und sie dann in ein Data Warehouse für die Datenanalyse zu laden . Und wenn jede dieser Aufgaben mental erledigt werden kann,
ist es sinnvoller, sie zu automatisieren und ein Judita Factory Service hilft Ihnen, diese
Aufgabe zu automatisieren . Denken Sie an Data Factory. Wird es in einem Orchester in einem Orchester dirigiert? Dirigent spielt nicht die Musik, aber er verlässt die Gruppe von Musikern, die Musik auf verschiedenen Bühnen Off Symphony produzierten. Der Dirigent hat ein großes Bild aus dem ganzen einfach, und es ist ein Weg von der Musik große Leistung, aber die eigentliche Musik wird von indirekten Musikern gespielt. In ähnlicher Weise führt
das betroffene Datum nicht die eigentliche Arbeit aus, die zum Transformieren der Daten erforderlich ist, sondern weist andere Dienste wie Datenbrüche oder Datenlink-Analysen
an, die Daten so vorzubereiten und zu transformieren, dass es sich um Datenlink-Analysen oder Datenbrüche, die die tatsächliche Arbeit
ausführt, nicht die Data Factory Data Factory, Mittlere E orchestrieren oder Übersee die Ausführung aus Arbeit. Eine Jury Data Factory ist also ein Service in einem Job, den Sie verwenden können, um Ihren Big
Data-Workflow zu übernehmen und ihn in einer so genannten Pipeline zu kapseln. Und diese Pipeline umfasst alle erforderlichen Aktivitäten Kopieren und verarbeiten Sie die Daten und bringen Sie sie an den Ort, an dem Sie sie benötigen. Und Sie können diese Aktivität tun, so dass Ihre durch geplante Ereignisse auf, wenn Behandlung, wiederkehrende Basis, wenn Sie wiederholt die gleiche beste Transformation zu Ihren Daten auf
regelmäßige tun . Dies ist Data Factory ist nicht lt oder Extrahieren von Last- und Transformationswerkzeugen. Also, wie unterscheidet es sich von einem Deal? Es ist eine Größe. Sie erwarten, dass die später transformierten Daten mit Transformationen der Gebäudegesellschaft und laden die Daten im Ziel Es gibt in der Data Factory. Sie extrahieren einfach die Daten aus der Quelle und laden sie in das Ziel. Und die Transformation erfolgt im Target-Datenspeicher
5. Schlüsselkomponenten der Datenfabrik: Justin, wie geht es euch beiden? Machen wir uns mit einigen der wichtigen Idiotenkomponenten vertraut. Diese Komponenten arbeiten zusammen, um die Plattform bereitzustellen, auf der Sie die Arbeit
mit Schritten zum Verschieben und Transformieren der Datenlink-Dienste entwerfen können . Lose Services sind nichts anderes als nur ein Verbindungsstrom, eine Verbindungsinformationen definiert,
die für die Data Factory benötigt wird, um eine Verbindung mit externen Quellen herzustellen. Dies kann einen ganzheitlichen Datenbanknamen enthalten. Ordner-Anmeldeinformationen suchen UTC. Abhängig von der Art des Auftrags kann
jeder Datenfluss einen oder mehrere Link-Dienste haben, z. B. Kursivgeschichten. Verknüpfungen Umfragen haben eine Verbindungsdehnung angegeben, um eine Verbindung mit den alten Daten herzustellen. Lick Studenten Konto zu der Zeit war Aufnahme. Die Ideen der Schule können sich mit mehr als 80 verschiedenen Datenquellen verbinden. Grundsätzlich hat
es ein Capital T, um fast alle möglichen Datenquellen zu verbinden. Lassen Sie uns es die Struktur der Daten darstellt. Es spitz einfach Zehe einen Unterschied. Daten, die Sie in Ihren Aktivitäten verwenden möchten, wie in allen Ausgabedaten sagt, können einen Tabellennamen enthalten. Schließlich, Datenstruktur, ein Sektor, Aktivitäten der Gegenwart und Aktion, um auf Ihre Daten durchzuführen. Der Verarbeitungsschritt in der Pipeline könnte dies Datenbewegungstransformationen oder
Steuerungsflussaktionen Aktivitätskonfigurationen sein , die besagten Dinge wie Datenbankabfrage,
Speicher,
Genauigkeitsname enthalten Speicher, . Es gibt Standorte an. Es Sektor und Aktivität kann Jiro oder mehr Eingabedaten nehmen sagt, und produzieren eine oder mehrere oder setzen Datensätze. Idiotische Aktivitäten konnten verglichen werden. Toa bewerten Augen Datenfluss Aufgabe Opulenz wie Aggregat-Skriptkomponente. sei
denn, Sie können beispielsweise eine Kopieraktivität verwenden, um Daten aus einem Datenspeicher, einem
anderen Datenspeicher zu kopieren . In ähnlicher Weise können Sie die hohe Aktivität verwenden, die das Hoch darstellt, das bereits an der Kante oder den Kanten innerhalb des Clusters vorhanden ist, der den gesamten
Analysator noch tiefer transformiert hat. Wir haben drei Arten von Aktivitäten angenommen. Holen Sie sich eine Frau Aktivität, abschrecken Stadt Unterwerfung Aktivität und Kontrolle Aktivitäten. Mein Plan ist ein logisches Brooklyn außerhalb von FDP, das eine Reihe von Prozessen wie das Extrahieren von
Daten,
Umwandeln und Laden in eine Datenbank Data Warehouse oder irgendeine Art von Geschichten durchführt Daten, . Zum Beispiel, wenn ich planen kann eine Gruppe von Aktivitäten in nur Daten enthalten kommen erstaunliche Astri und dann ein Funken eine Abfrage innerhalb Azure Gate Oblates Toaster. So partitionieren Sie die Daten. Die Data Factory kann ein oder mehrere Doppelebenen haben, und jeder nach Plan würde eine oder mehrere
Aktivitäten enthalten . Verwendung von Pipelines macht es viel einfacher, Personen logisch verwandte
Aktivitäten zu tun und zu überwachen . Der Vorteil aus diesem ist, dass die Pipeline und ermöglicht es Ihnen, die Aktivitäten als Satz zu verwalten versichern die Verwaltung jeder einzeln. Die Menschen Erbsen in einer Pipeline können zusammen geändert werden, um sie sequentiell zu öffnen. Nun, sie können nicht unabhängig parallel operieren. Zum Beispiel, wenn mein Plan eine Gruppe von Aktivitäten enthalten könnte, die Daten aus lokalen kopieren, könnte
dies buchstäblich und dann gleiche Kredi verwenden, könnte diese Daten transformieren und schließlich die Daten in ein Data Warehouse
laden. Zahlen repräsentieren die Einheit aus Verarbeitung, dass kleine Köpfe, wenn eine Rohrlandausstellung gestartet werden
musste, weil sie repräsentieren, dass sie Konfiguration für Pipelines. Sie enthalten Konfigurationseinstellungen. Lasst uns anfangen und enden. Hat diese Situation, wenn Sie sehen, Zahlen sind nicht militärischen Teil von Abia Umsetzung, sie sind nur erforderlich, wenn Sie von Plänen müssen automatisch ausgeführt werden oder auf ist einige wirklich tun sollten
6. Pipeline Workflow – 4 Schritte: Ich denke, ein Jordache dieses Baumes führt typischerweise die Berufung durch. Vier Schritte das Netz und sammeln. Der größte Schritt besteht darin, alle erforderlichen verschiedenen Quellen aus Daten zu verbinden und die Daten nach
Bedarf an einen zentralen Ort zu verschieben war so geheime Verarbeitung. Aber die Datenfabrik. Sie können die Kopieraktivität in einer Daten verwenden, indem Sie die Daten aus Buch vor Ort spielen und
Cloud-Quelle später speichern mit Zentralisierungsdaten in der Cloud Corker gespeichert, dass Frau, zum Beispiel, können
Sie Daten in Ajo Datalink-Stories sammeln und Transformieren Sie die Daten später mithilfe eines George Vitelic Analytics-Abschlussdienstes. Sie können auch Daten in einem Jordan-Block Geschichten sammeln und es wenig transformieren, indem Sie eine agile tatsächlich in ihrem Pastor verwenden. 2. 5 ist transformieren und bereichern. Sobald Daten in einer zentralisierten Daten vorhanden sind, die in der Cloud gespeichert sind, sie mit kompetenten Diensten wie üblichen Inside do Data Lit Analytics und
Machine Learning transformiert . Denken Sie daran, Data Factory ist Justin Orchestra und es kann keine Transformationsaktivität
selbst durchführen . Veröffentlichen, nachdem die Daten des Herrn in eine sinnvolle Reform umgewandelt wurden. Laden Sie die Daten in verschiedene Plots, Geschichten wie ein George es von ihrem Haus. Perkins Option durch FBI und Analytics-Tools und andere Anwendungen wollte. Nach erfolgreicher Bereitstellung außerhalb der Pipeline können
Sie einmit den Xun-Fähigkeiten und Pipeline für Erfolg und Misserfolg. Wir können einen Auftrag in einer Fabrik Pipelines mit einem Job-Monitor AP überwachen Ich veröffentliche L als Monitor-Protokolle und andere Integritäts-Panel in der Kante des Portals.
7. Demo Einführung: Willkommen in diesem Modul. In diesem Duell werden
wir einige Hände auf Aktivität tun. Zuerst werden
wir bei Ihrem Datenspeicher ein schonendes Konto erstellen und ein George Storage Explorer
Toe Zugangsdatum ngentle Konto verwenden . Dann werden wir sequel Data Warehouse und Data Factory bereitstellen, was ziemlich einfach und unkompliziert ist. Nun, danach gehen
wir durch die Data Factory. Du, ich und wir werden verschiedene Menüoptionen verstehen. Und dann werden wir die Kopieraktivität in Ihrer Datenfabrik verwenden. Also werden wir nach Möglichkeiten suchen, Daten aus ihrem Haus zu nehmen wird Pipeline sein, um die Ausgabe in einigen anderen Geschichten zu verschieben und zu speichern. Ort, an dem wir es für die Analyse abholen können, werden
sie auch einen Blick auf Data Factory Monitoring-Optionen nehmen. Vielen Dank.
8. Azure Data Lake Storage Gen 2 Konto: in dieser Demonstration werde
ich Ihnen beibringen, wie Sie ein Azure Data Lake-Speicher-schonendes Konto erstellen. Gehen wir wieder zu den alten Gottesdiensten. Alles, was Sie direkt auf Speicherkonto von hier zugreifen können. Wenn Sie sich das Azure-Portal ansehen, gibt es eine separate Quelle namens Data Lake Storage. Gen Eins. Aber Sie erstellen Geschichten sanfte Konto. Wir mussten zuerst Storys Konto erstellen, da dies eine Eigenschaft aus dem allgemeinen Version zwei Speicherkonto ist. werden wir in einer Minute sehen. Microsoft konzentriert sich heutzutage auf Data Lake-Speicher schonend, weil sanft ist hart. Der Ort weg. Jen Eins. Lassen Sie uns ein Story-Konto erstellen. Klicken wir auf diese Schaltfläche und lassen Sie mich mein Abonnement und meine Quellgruppe auswählen. Lassen Sie mich eine neue Ressourcengruppe erstellen. Gib mir RG Story. Es ist Gentoo. Geben Sie den Namen des Speicherkontos an. Ich setze nur eine Nummer ein, um es global zu schaffen. Einzigartig. Nimm meinen Grund zu Hause. Das Neue an sanften Datenlink-Stories ist, dass Sie alle
Storys,
Kontoeigenschaften und Funktionen wie Leistungsüberschuss,
zwei Jahre und Replikation nutzen Storys, Kontoeigenschaften und Funktionen wie Leistungsüberschuss, können. Ich werde erweiterte Leistung Allzweck-Version zwei auswählen. Lokal, die Rendon Geschichten und halten Überschuss hier. Die nächste Stufe wird uns die Konnektivitätsangelegenheit bringen. Ich lasse es standardmäßig öffentlich und Punkt an diesem Punkt, wir gehen neben der Vorschauseite. Lassen Sie uns es vor der Einstellung für die Sicherheit als aktivieren Block weichen Lead wir tatsächlich ignorieren
wollen , weil der Punkt hier in der Tat aus diesem Story-Konto mit dem traditionellen
Blutdienst ist , werden
wir auf den hierarchischen Namen Space-Eigenschaft, indem Sie die Daten nebenan spiegeln . Es ist sanft von Behinderten zu aktivieren. Und wie Sie sehen, wenn Sie Gentoo aktivieren, deaktiviert
es automatisch Datenschutzoption Dies alles, was Sie tun müssen, um ein
Story-Konto ein Data Lake Storage sanfte Konto wieder machen . Ich musste kein normales Story-Konto Daten-See-Speicher machen, sanftes Konto. Alles, was Sie tun müssen, ist, diese Option zu aktivieren. Das war's. Die Ansicht in create wird nicht bedeuten, zu lange zu dauern. Aber trotzdem kann ich das Video bis dahin pausieren. Alles klar, die Bereitstellung ist abgeschlossen. Und wenn wir jetzt zu den Ressourcen gehen, Ich möchte Ihnen einen Unterschied zu dem, was Sie gewöhnen Zehe zeigen, wahrscheinlich die Arbeit mit den allgemeinen Zweck Geschichten. Sie haben vielleicht bemerkt, dass unter Dienst stattdessen nur ein Blob-Service ausgeschaltet ist. Es wird jetzt Daten wie sanftes Dateisystem genannt. Du zeigst dir die Verteidigung. Ich habe ein anderes Konto für allgemeine Geschichten, das Sie im allgemeinen Konto sehen. Es heißt Blob Services hier, aber weil die nicht in der Lage, Genitalgeschichten wird es Daten spät,
sanfte Dateisystem genannt . Von nun an wird das Konto
dieser Geschichte Daten wie Geschichten mit jedem BFS-kompatiblen Feuersystem sein . Also setzen Sie diesen Punkt. Wenn wir Umfragen ausgewählt
haben, können wir ein Dateisystem erstellen, was ich jetzt tun werde. Ich nenne es Gento File System. Okay, und denken Sie daran, was Sie schaffen, ist sanft. Dateisystem ist kein Block und Abendessen. Es ist ein echter Ordner hin und wieder. Wenn wir in das Dateisystem gehen, erhalten
wir eine Aufforderung, einen George Storage Explorer zu verwenden. Ajo Stories Explorer ist ein kostenloses Tool von Microsoft, das auf Windows Mac und
Limits verfügbar ist und, wie der Mittelwert vorschlagen bietet eine grafische Umgebung zum Durchsuchen und Ausführen von Aktionen gegen einen George Speicherkonten. Wenn Sie es noch nicht haben, bitte don Lord und die Installation ist sehr einfach und unkompliziert. Diese Toolfamilie verwendet ein Konto, um sich zu authentifizieren, um einen Job zu erhalten, und zeigt dann das Abonnement an, das dieses Konto hat. Dann werden die Storys in dem ausgewählten Abonnement Konten. Unter meinen Abonnement-Story-Konten können
wir mein Konto für sanfte Geschichten
aufwenden, das derzeit als BLS sanfte identifiziert wird. Ich würde annehmen, dass letztendlich das Storage Explorer-Ding in
diesem Knoten grün wird , den wir jetzt von Blockcontainern
, den Dateisystemen betrachten , denn das sollte es sein. Und wenn wir das Dateisystem Notiz jetzt auswählen, dass wir direkten Upload alle tun können, können
wir einen ketzerischen Ordnerraum organisieren. Also werde ich dies später einen neuen Ordner abrufen und diesen Ordner als Teil des Workflows verwenden . Ihre Ansicht kann hier veraltet sein. Willst du auffrischen? Wir sind bereit, hierher zu gehen.
9. Bereitstellen von Azure SQL Data: s Erstellen und Joe Sequel Data Warehouse. Zusätzlich zu Search a sequel Data Warehouse in allem, können
Sie es auch in der Datenbank als auch in der Analyse finden. Klicken wir auf Fortsetzung,
Get other house und fügen Sie New is Instruments hinzu und lassen Sie mich Ihnen zeigen, wie der Deployment-Workflow funktioniert. Ich werde New Resource Group für das Data Warehouse erstellen, und ich werde auch die Munim zu meinem Datum Ihres Hauses geben. Ich bin alles, was nur eine zufällige imaginäre Zahl am Ende, nur um den Namen global einzigartig zu machen. Lassen Sie uns einen neuen virtuellen Server erstellen wird ein Cluster sein. Nennen wir es tun die blauen s 108 Es sie dann einfach konventionell mit einem starken Passwort. Wir können uns darauf vorbereiten, diesen Rat darüber zu geben, wie stark die Hirten sein müssen. Lassen Sie mich meinen nächstgelegenen Standort finden, die Holy Show für den Zugang zu Data Warehouses aus unseren Schulen. Aber diese große Box hier wird all Ihre Dienste erlauben. Mit anderen Worten, Microsoft I P-Adressen, die diesen Diensten zugeordnet sind, ist der Zugriff auf den Server. Möglicherweise müssen Sie auch die Folge-Data-Warehouse-Firewall ändern, erlauben Sie Ihrem Client. Ich denke, von wo aus Sie auf der Welt sind. Zusätzlich zu anderen öffentlichen I p adressiert alle Schreibadressen Bereich. Ich zeige Ihnen die ganze Verwirrung. Es ist die Data Warehouse-Einheit ist die Recheneinheit, die zu einem Joe Folgedatum Ihres Hauses verwendet wird. Wählen wir unsere Leistungsstufe für Produktionsarbeitslasten aus. Wir sollten auf sanfte und nicht jen eins sein. Und ich kann mein System hier unten 200 klären, weil ich gerade in einer Test-Demo-Umgebung
von dieser live in der realen Welt arbeite . Ihr Ziel ist es, Ihr Haus in einer Weise zu pune, dass Sie nicht mehr bezahlen, als Sie brauchen. Aber Sie erhalten auch Ihre Rechenleistung, um Ihre Service-Level-Vereinbarungen zu erfüllen. Also lassen Sie uns hier bewerben und dann zum nächsten gehen. - Was? Ihre Datenquelle. Wir können uns ein Backup holen oder wir tun Nein, eigentlich, was wir tun können Simple. wird uns das Abenteuer Arbeit Datum geben,
jedes Haus, jedes Haus, einfaches Data-Warehouse. Ich wähle das, und es nimmt alle Koalition auf, die ich auswählen werde. Wir gehen Zehen-Tags und wir werden keine Steuer hier verwenden, wird zum nächsten gehen. Wir sehen unsere geschätzten Kosten, sind
aber hier. Du siehst Obertöne und dann sind wir wirklich komplett. Ich finde, dass es in der Regel dauert die 10 Minuten aus Fieber für Microsoft bereitgestellt ein Lager gut zurück. Sobald die Bereitstellungen abgeschlossen
sind,können sie zu den Ressourcen wechseln, die sie das Data Warehouse anhalten oder fortsetzen können, um das Gebäude anzuhalten und
fortzusetzen. Sobald die Bereitstellungen abgeschlossen
sind, können sie zu den Ressourcen wechseln, die sie das Data Warehouse anhalten oder fortsetzen können, um das Gebäude anzuhalten und Sie werden immer noch für die Geschichten in Rechnung gestellt, aber zumindest entstehen für den Computer keine Kosten. Wir suchen in unserer Umgebung nach Feuerball. Wir können auf Feuerbälle und virtuelle Netzwerke kommen, und das ist, wo ich erwähnte, dass Sie den Zugriff erlauben können, um Dienste anzupassen und Ihr Auto erkennt die Öffentlichkeit I p mit Ihrem Client-Gerät verbunden. Und dann können Sie anwenden I p Adressbereiche Öffentliche I T Adressbereich ist hier toe. Konnektivität zu diesem Server zulassen. Kommen wir zurück auf die Übersichtsseite, weil wir das nicht in diesem Hosting aus dem Data
Warehouse sein werden . Lassen Sie mich das in meine Zwischenablage kopieren und dann, wie Sie zu diesem Datum jedes Haus verbinden. Typischerweise habe ich das Sequel Server Management Studio verwendet, das als separater Down Lord verfügbar ist. Lassen Sie uns eine Verbindung zu der Fortsetzung Server-Datenbank-Engine machen, und für die sieben Mann werde ich in der voll qualifizierten Mann von einem Server gefischt wird
Fortsetzung wählen . Mehrere Authentifizierung und ich werde die gleichen Anmeldeinformationen liefern, die ich beim Erstellen des Datums des Hauses gebe. Das wird Oh, es zeigt einen Fehler, dass Ihr Client I p Adresse, hat keinen Zugriff auf diesen Server. Also gehen wir zurück zu einem kleinen Haus, feuern virtuelle Netzwerke und fügen unseren lokalen Client AP lenken und versuchen Verbindung mit Management Studio so schwer. Ich weiß es. Erinnerst du dich an die Fortsetzung? Mehrere Data Warehouse ist die gehostete Plattform im Service. Wenn Sie also mit der rechten Maustaste auf den virtuellen Server klicken, gibt es keine Eigenschaften. Ich erinnere mich, als ich überrascht war, als ich das erste Mal sah, dass es keine Eigenschaften gab, aber denken
Sie daran, Sie haben es mit Schwarz von Ist der Service hier zu tun? Wir erklärten Datenbanken und dann Daten. Sehr DW 108, die wir erstellt haben. Wir haben eine Liste von Tabellen, die Microsoft in diesem einfachen Data Warehouse integriert hat. Das ist sehr erleichtert. Die Weisheit wird jetzt hier sein. Vielen Dank
10. Datenfabrik: Lassen Sie uns unsere Datenfabrik jetzt erstellen. Zu diesem Zeitpunkt müssen Sie vertraut sein. Es ist ziemlich einfach und unkompliziert. Sie können entweder Datenfabrik suchen Oh, werden aus der Datenbank ausgewählt und klicken Sie voraus. Geben Sie ihm den Namen. Wählen Sie Abonnement und Ressourcengruppe im Abonnement aus. Lassen Sie es uns einfach geben. RG Unterstrich B A. Okay, ich werde ah Version zwei von Data Factory verwenden, um die Vorteile der neuesten Funktionen zu nutzen. Version zwei ist eine neue Abwasch Data Factory. Eines der größten Features aus Version zwei ist die Integration von S S S S und Steuerung Flow
Functional . Überwachung ist auch eine Editierverbesserung Inversion toe macht es integriert mit auf Ihrem Monitor. Okay, lassen Sie mich das nächste Match von meinem Standort wählen. Jetzt haben wir hier die Möglichkeit, Quellpunktesteuerung zu integrieren. Wir sind versichert, dass sie ups. Das werde ich in diesem Fall nicht tun. Und dann klicken wir, erstellen Sie die Zehe, stellen Sie die Fabrik
11. Lerne mit Azure Data Factory UI: Gehen wir in die Datenfabrik, und was wir hier haben, ist nur die Steuerungsebene für den Service. Und wenn ich das Wesentliche verheimliche Schmerzen, sehen
wir einen Link zum Autor und überwachen Erfahrung. Dies wird sehr tatsächlich von Arbeiten in einer George Data-Fabrik durchgeführt. Lassen Sie uns auf diese klicken, und wenn Sie bemerken, dass es ein separates Fenster geöffnet hat und Toe ADF Punkt als Ihr Punkt com, das Produkt, das Zehe diese über wenige Seite, die viele schnelle Links oder Verknüpfungen hat. Wir werden die Kopierdaten Operation Toe kopieren unsere Tabelle aus Ihrer Fortsetzung Data Warehouse. Später werden
wir näher eingehen. Aber in der Zwischenzeit hat
diese Seite auch Videos und eine Reihe von Tutorials geholfen. Beginnen wir damit, sich mit den USA
vertraut zu machen .
Das Hauptmenü enthält drei Optionen Data Factory,
die Sortierung Hauptbildschirm ist,
die ein paar interessante Verknüpfungen enthält. Das Hauptmenü enthält drei Optionen Data Factory, die Sortierung Hauptbildschirm ist, Das Autoren-Panel ist, wo wir neue Pipelines erstellen und verbringen die meiste Zeit, und schließlich, das Monitor-Panel dort können wir durch geplante Ausführung überwachen. Ordnung, im Hauptbildschirm haben
wir fünf Möglichkeiten. Lasst uns eins nach dem anderen durchgehen. Pipeline erstellen ist nur ein kurzer Rock, der uns zum Autorenfenster führt und automatisch eine
leere Pipeline erstellt . Für uns. Nach Ebene aus einer Vorlage erstellen öffnet den Vorlagenkatalog. Dort können
wir Pipeline aus einer Sammlung von ziemlich finden Vorlagen erstellen, die uns helfen können, mit unterschiedlichen Szenarien zu
beginnen. Schnell kopieren Data Tool bietet eine Schnittstelle, die den Prozess der Aufnahme von Daten
in den Datenspeicher optimiert . Wir erfahren mehr über die kopierte es ein Werkzeug in den kommenden Lektionen. Konfigurieren Sie SS Eyes Integration kann provisorisch als Ihre SS iess Integration um die Zeit und schließlich haben wir die Einrichtung Gericht Repository. Es ermöglicht uns, ein Call-Repository für Ihre Data Factory einzurichten und eine integrierte und die Entwicklung auf Release-Erfahrung zu beenden. Lassen Sie uns nun etwas Zeit damit verbringen, etwas über das Autoren-Panel zu lernen, wenn wir eine neue Pipeline erstellen. Dies ist das Panel, in dem wir die meisten Überstunden in der Werksressource verbringen. Sie können eine Liste von Pipelines, Datensätzen und Datenflüssen in einer Data Factory finden. Durch Klicken auf die drei Punkte in den Pipeline-Umfragen, können
wir neue Bedeutung neue mir neu zugreifen, die es uns ermöglicht, entweder eine neue Pipeline von
Grund auf oder von einer Vorlage zu erstellen , finden
wir ähnliche viele Optionen sowohl auf, dass Datensätze und -Daten floats Dienste. Wir werden hier auf dieses kleine Pluszeichen klicken, und dies wird eine neue Pipeline erstellen. Beachten Sie, dass es eine Option für eine Pipeline aus der Vorlage gibt und hier rechts können
Sie Arm-Vorlagen importieren. Dies kann die Verwendung und Wiederverwendung dieser Pipelines im Laufe der Zeit und wieder erleichtern. A. Ihre Datenfabrik ist ein kaltes freies Orchestrierungs-Tool. So, zum Beispiel, von unter Verschieben und Transformieren, können
wir einfach Drag & Drop diese Kopierdatenoperation auf die Steuerfläche und dann wählen Sie diesen Kopiervorgang unten. Sie werden verschiedene Ängste im Zusammenhang mit der ausgewählten Aktivität in diesem Fall zum Kopieren von Daten sehen. Da dies Cooperator ist, haben
wir Quelle mit anderen Worten, Beeren Ihre Daten kommen aus und dann denken Verizon Daten gehen und wir haben andere Einstellungen und geistig die Optionen. Wenn Sie auf die Ansichtsquelle klicken, die bewertet wurde, werden alle Ihre Daten Factory-Pipelines in
Jason geschrieben . Die Idee aus einer Pipeline ist, dass wir verschiedene Aktivitäten miteinander verknüpfen können. Wir können einen ganzen Workflow Haar mit dieser Verbindung Link in grün erstellen, Übrigens, Ich kann mit der rechten Maustaste auf diesen Link klicken und wählen Sie den Lead. Es wird verschwinden, und wenn ich darauf klicke, kann
ich die Ausgabetaste hören. Wir können eine Aktivität auf wunden eigenen Erfolg,
Misserfolg,
Abschluss hinzufügen Misserfolg, oder überspringen, so dass wir die nächste Aktivität wählen können. Wenn diese Aktivität abgeschlossen ist, wählen
wir die nächste Aktivität aus. Wenn Sie sich nicht genau sicher sind, wo es ist, können
wir hier eine Suche durchführen. In diesem Fall fügen
wir noch einmal eine Funktion hinzu. Nur Drachentropfen. Sie können sehen, wie einfach das funktioniert, und Sie können die Arbeit validieren. Man kann die gesamte Pipeline kalt betrachten, dann sollte es nur Buell für auch als ausgelöste Unterdrückung und so weiter. Wie bereits erwähnt, betrachten
wir Record Repository Toe, ermöglichen eine kontinuierliche Integration und Bereitstellung von Ihrer Data Factory. Und hier haben wir unsere Vorlage mir neue Option. Es erlaubt uns einfach, Arm-Vorlagen mit Pipeline-Definitionen zu importieren und zu exportieren. Das Verbindungsfenster hostet eine Liste von zuvor erstellten Links, Services und Integrationslaufzeiten, und hier ist die Standard- oder Integrationslaufzeit, die wir zuvor gesehen haben. Und schließlich, lassen Sie mich Ihre Aufmerksamkeit auf die Triggerabschnittsstelle von Pipeline-Ausführungsauslösern lenken. Wir haben momentan keinen Auslöser, daher ist diese Liste leer. Ich schließe alle Wasserhähne, verwerfe meine Änderungen und gehe zum nächsten Element. Nehmen wir uns eine Minute Zeit, um das Monitorpanel und alle Funktionen, die es bietet, zu überprüfen. Das Dashboard-Bedienfeld enthält Informationen zu Pipeline und Aktivität. Ausführung im Bereich „Pipeline Grants“ Wir können die Pipeline-Ausführung überwachen, und es ist sehr nützlich, um sicherzustellen, dass die Pipeline tatsächlich ordnungsgemäß funktioniert. Im Bedienfeld „Trigger Grants“ wird eine Liste von Pipelineausführungen angezeigt, die
automatisch ausgelöst wurden . Die Anzeige läuft Zeitfenster zeigt die Liste aus Integrationslaufzeiten zur Verfügung oder das Ergebnis ist, dass die Ford Integration Runtime und schließlich, in der Alerts und Metric Panel, können
wir Alert-Regeln erstellen, um ihre Fabrik-Pipeline proaktiv. Nun, da wir mit dem Datumseffekt in die USA
ein bisschen vertraut sind
,
Lassen Sie uns unsere erste Pipeline erstellen , Lassen Sie uns unsere erste Pipeline erstellen
12. ETL Operation: in dieser Demonstration möchte
ich Ihnen beibringen, wie Sie Ihre Datenfabrik verwenden, um eine Kopieraktivität durchzuführen. In diesem Fall werden
wir Datenangebot Tabelle aus Data Warehouse-Beispieldatenbank in unsere Daten extra kopieren . Es ist ein sanftes Konto. Also kommen wir einfach zurück auf die Übersichtsseite und klicken Sie auf Daten kopieren und es startet diese Kopie Daten Vagina. Lassen Sie uns diese Aufgabe und den Namen jetzt geben. Hier können wir zu ihnen Aufgabe nur einmal wählen, oder wir können eine wiederverwendbare Pipeline erstellen, indem Sie diese Option wählen und wählen Sie ein tun sollte. Selbst wenn Sie sich entscheiden, nur einmal zu begrenzen, wird
es nicht nach Willan gelöscht und beendet. Wir können es manuell sogar so oft in der Zukunft wollen wir oder erstellen einen Auslöser und so weiter und so weiter. Aber wenn Sie nach links schauen, haben
wir sechs Schritte und es führt uns ein Licht durch, ohne etwas
über die zugrunde liegende AP A oder Sicherheit verstehen zu müssen . Es gibt eine riesige Bibliothek von Verbindungshaaren. Sie sind in Gruppen organisiert, Haare wie Ihre Datenbankdatei und akzeptieren. Lassen Sie uns eine neue Verbindung in der neuen Link-Dienst in allen Typ Data Warehouse gezurrt zu filtern, und wir werden diese bei Ihrer Fortsetzung Data Warehouse Link Service Objekt auswählen. Der Link-Dienst ist genau das, wonach er sich anhört. Es wird ein wiederverwendbares Objekt sein, das eine Verbindung zu einem Satz erstellt und autorisiert, zu dem ein Satz eine Jury Quelle sein kann oder eine Jury Quelle oder vielleicht eigene Räumlichkeiten bekannt ist. Ressource. Lassen Sie mich ihm einen Namen geben. Die Anzeigelaufzeit ist der Computer früher. Lass es uns weiterleben, bevor wir uns für zwei Ergebnisse begeben. Dies wird häufiger in einem Hybrid-Szenario Problem, in dem Sie möglicherweise die
Mietdauer vor Ort bereitstellen müssen, die als selbst gehostete Operation bezeichnet wird. Als Faras-Authentifizierung, können
wir tun, Benutzer oder geben alte, aber vorher müssen wir zuerst wählen, wie wir in diese Ressource zu bekommen. Wählen wir das Abonnement und Data Warehouse-Server neu erstellt. Die Datenbank ist das einfache Datum Ihres Hauses. Die Authentifizierungstyp Optionen sind Dienstprinzip, verwaltete Identität oder Fortsetzung. Ich gehe weiter und wähle einfach eine Fortsetzung Authentifizierung mit dem gleichen Konto aus, das wir beim Erstellen von Data Warehouse
erstellt haben . Es gibt eine Reihe von optionalen Verbindungsumkreis, den Sie hinzufügen können, die wir in diesem Fall nicht verwenden werden. Wir werden die Verbindungsverbindung testen. Erfolgreiches Finish. Also haben wir unseren Quelldatenspeicher erstellt und wieder wird
dies wiederverwendbares Objekt sein, das wir in anderen Pipelines verwenden können. Also lasst uns als nächstes gehen, und wir haben in das Data Warehouse gezapft und hier sehen wir schwere Notwendigkeit, eine Tabelle zu wählen, die wir kopieren möchten, damit wir eine oder mehrere Tabellen auswählen können. Haare. Wir wollen bim Produkttabelle wählen. Also lassen Sie uns eine Suche nach Produkt machen. Also wähle ich den Stall aus. Und wenn wir den Splitbalken aufrufen, können
wir eine Vorschau von den Daten sehen. Und in der Registerkarte Schema können
wir die Spalten und die Datentypen sehen. Klicken wir auf Weiter. Also noch eine Sache, lass mich vorhin gehen. nicht nur vorhandene Tabellen auswählen, Beachten Sie, dass Sienicht nur vorhandene Tabellen auswählen,sondern auch eine Abfrage zusammen bestimmte Daten schreiben können, die Sie in dem
Job verwenden möchten . Aber wir werden einfach alles vom Tisch nehmen. Also wieder klicken wir auf Weiter. Der Zieldatenspeicher haben wir noch nicht erstellt, Also lassen Sie uns neue Verbindung neu erstellen, und dieses Mal lassen Sie uns eine Suche nach Daten lecken Speicher machen. Denk dran, es gibt Gen Eins und, Ah, Gentoo. Wir beschäftigen uns nicht mit allgemeinen Haaren. Wir haben bereits ein Konto für sanfte Geschichten erstellt. Also lasst uns das auswählen. Und wieder einmal werden
wir eine Auswahl aus unserem Abonnement für die Authentifizierung Angelegenheit machen. Wieder einmal werden
wir den Kontoschlüssel wählen. Wir haben unseren Speicherkontonamen ausgewählt. Geben wir einen Namen. Auch diesen verlinkten Service. Okay, und jetzt beste Verbindungsverbindung erfolgreich. Guter Deal. Also lasst uns klicken. Fertig stellen. So weit, so gut Der Klick. Als nächstes werden
wir in unsere Daten extra Gin Toe Konto tippen und Toe durchsuchen. Wählen Sie aus, welchen Ordner wir suchen. Also zuerst mit der Liste aus Dateisystemen, lassen Sie uns darauf klicken und wählen Sie dann den Ordner Ausgabedaten und klicken Sie auf Auswählen. Wir müssen einen Ausgabedateinamen angeben. Ich nenne es einfach für Kanal. Keine CSP für maximale Eroberung von Verbindungen. Lasst uns auch sagen. Klicken wir auf Weiter. Hier können wir das Dateiformat anpassen. Es ist ah, zwei kommagetrennte Werte zu
deportieren. Ich werde alles von der Standardeinstellung lassen,
aber die Quintessenz ist, dass Data Factory Ihnen hier viel Flexibilität bietet. Klicken Sie auf die nächste vierte. Doren's Also, was möchten Sie passieren, wenn beim Verschieben von Daten, die Sie
über die Aktivität möchten, ein Problem auftritt , sobald eine inkompatible Zeile vorhanden ist? Oder willst du die Reihe überspringen? Oder möchten Sie entkommen und geliebt sie, damit Sie sie später verfolgen können? Ich werde die Standardoptionen hier führen. Außerdem werde ich an dieser Stelle Performance-Einstellungen auf die zuvor leben und auf Weiter klicken. Hier ist unser Jemand Bildschirm, und wenn wir auf „Weiter“ klicken, geht
es tatsächlich aus und läuft die Pipeline. Wie Sie sehen können, wenn ich auf Monitor Data Factory klicken, es bringt uns zum Mond Interview und lassen Sie uns auf Aktualisieren und wir können sehen, dass die Straße ist es gelungen. Gut. Kommen wir zurück zum Speicher Explorer, kommen Sie in den Ausgabedaten-Ordner und sicher genug, sehen
wir unser Produkt Punkt CSP. Lassen Sie mich mit der rechten Maustaste klicken und diese Zehe Mein Backstop herunterladen. Eine weitere Sache, wenn Sie nicht alle unsere Aktivitäten in Geschichten Explorer nicht bemerkt haben , damit unten unten an der Unterseite. Okay, lassen Sie uns Excel öffnen, nur um eine schnelle Vernunft zu überprüfen. Oh, es scheint, als hätte ich vergessen, die Säule aufzuheben. Kopfzeilen. Damit beginnen noch keine Eierstöcke. Was an Data Factory schön ist, ist, dass wir zurückgehen und die Job-Eigenschaften bearbeiten können, um die Spaltenüberschrift
einzuschließen. Wir können Pipeline ändern und Grün drauf. Das werde ich in einer Minute tun. Zwischenzeit Lassen Sie uns in derZwischenzeiteinen kurzen Blick auf die Daten werfen, die wir sehen können. Es gibt etwas mehr als 500 Rose im Datensatz. Nun gehen wir zurück zur Data Factory-Schnittstelle. Und wenn Sie auf die Erfahrung des Autors zurückgehen, hier ist unsere Pipeline. Es ist genau hier, damit wir die erforderlichen Änderungen vornehmen können. Lassen Sie uns zu den Zielverbindungen gehen und schwere siehe Option. Erste Rolle als Hitter in einem Billet veröffentlichte Änderungen veröffentlichen bedeutet Verkauf. Und dann wieder, wir können gehen, um Tab zu überwachen und haben nicht den Job. Wenn erforderlich, können
wir aktualisieren und wir sehen, dass unsere Aufgabe wieder abgeschlossen ist. Gehen wir zurück zum Speicher-Explorer. Okay, wir sehen diese sportliche Zeit. Es bedeutet, dass neue Datei auf der alten Datei über sie hat. Laden wir es herunter. Und jetzt öffne es. Jetzt sehen wir, dass wir jetzt die Kopfzeilen haben. Vielen Dank
13. Berechnen: während einer letzten kleinen Operation konnten
wir digitale erpresst nahtlos authentifizieren. Wenn Sie jedoch auf ein Problem mit dieser Konnektivität stoßen, müssen
Sie möglicherweise Data Factory explizite Berechtigungen für dieses Daten-Repository erteilen. Mal sehen, was wir damit meinen. Gehen wir zurück zu den Portalhaaren. Der General Porter. Gehen wir zurück zu unserer Datenfabrik. Und wenn Sie zu den Eigenschaften gehen, können Sie hier Identitätsobjekt verwalten sehen. Ich würde in einfachen Worten sein. Verwaltete Identität wird von in Ihren Diensten verwendet, um andere Edge oder Dienste zu authentifizieren, die Ihre Steve Director-Authentifizierung
unterstützen. Die Manage Identity ist registriert. Sie sind ein Beauty-Verzeichnis und stellt diese sehr spezifische Datenfabrik dar. Wir können diese Manage Identity direkt für Data Lake Storage, sanfte Authentifizierung verwenden. Es ermöglicht diese bezeichnete Fabrik Toe xs und kopieren Sie Daten in und von Ihrem Data Lake Speicher. Sanft. Wir können diese Verwaltung Identitäts-Toe Rolle basierte Zugriffssteuerung weniger hinzufügen. Also werde ich das in meine Zwischenablage kopieren und dann zurück in den Storage Explorer. Wir können der Data Factory-Berechtigung sowohl auf Dateisystemebene als auch auf
Ordnerebene erteilen. Um dies zu tun, können wir mit der rechten Maustaste auf das Dateisystem klicken und gehen, um überschüssige in der
Zugriffssteuerungsliste zu verwalten . Unten unten können
wir in diesem Objekt einfügen, das ich aus der Datenfabrik d und dann dem Konto geben, was auch immer Ausmaß überschüssig direkt im Dateisystem ist. Und manchmal habe ich herausgefunden, dass man es an zwei Orten tun muss. Sie müssen dies sowohl auf Dateisystemebene als auch außerhalb der Ordnerebene tun. So können Sie mit der rechten Maustaste auf den Ordner klicken und genau das gleiche tun hier. Wir können es in das Objekt einfügen, das ich von der Edgell-Ressource d. In diesem speziellen Fall ist
es eine Fabrik getan und geben Sie es, was auch immer Niveau off überschüssige Sie nicht geben werden. Dies wird Ihnen helfen, die Data Factory nahtlos mit anderen Quellen zu verbinden. In diesem Fall Geschichte intento. Vielen Dank.
14. Data: in dieser Lektion. Ich wollte eine grundlegende Demonstration durchlaufen, wie wir die Überwachung
mit einer George Data-Fabrik durchführen würden . Also, was genau brauche ich, um Familie für die Überwachung zu überwachen? Wir denken an den Auslöserprinzen. Die Aktivität führt die Pipeline-Durchläufe und dann diese Abfragen aus. Im Laufe der Zeit werden sie im Mittelpunkt unserer Data Factory Monitoring-Lösung stehen. Und es gibt zwei Möglichkeiten, die Überwachung in der Datenfabrik zu überwachen und die Überwachung mit einem
Job-Monitor wird beide diskutieren. Also, erstens haben
wir tatsächlich eine Überwachung innerhalb der Data Factory-Benutzeroberfläche, während wir diese
Pipelines entwickeln , dass die größere kann sehr nützlich sein. Dies ermöglicht es mir, meine Pipeline zu betreiben. Ich kann Breakpoints haben. Ich kann genau sehen, was passiert, aber das überwacht nicht wirklich seine abgesonderte Entwicklererfahrung. Diese Diskutierungsfunktion ist hilfreich, um genau zu sehen, was im Inneren passiert, und das kann als Entwickler sehr nützlich sein. Aber die Masse aus über die Überwachung wird über die Überwachungsschnittstelle kommen. Es beginnt tatsächlich mit einem Dashboard. Dieses Dashboard zeigt standardmäßig die letzten 24 Stunden an, aber ich kann dieses Zeitfenster ändern, um mir die Pipeline-Ausführungen anzuzeigen. Ich würde Misserfolge sehen. Ich werde diese Prozentsätze sehen. Ich werde auch Details zu den Aktivitäten sehen. Ich werde auch Daten über die Trigger sehen. Dies gibt mir nur einen sehr schnellen Überblick darüber, was in der Umgebung passiert. Ich kann Details zu allen Triggerläufen sehen, wenn ich Trigger habe. Ich sehe tatsächlich, dass Details über diese Ausführungen und Ausführung auf sollte handeln oder vielleicht sogar basieren. Aber was mir wirklich wichtig ist, dass mit dem Flugzeug hier läuft, kann ich den Namen aus der Pipeline sehen. Wenn ich verschiedene Pipelines in meiner Umgebung
habe, schließe ich diese kleine Filterschaltfläche ab und kann dann ändern, um nur bestimmte Pipelines zu sehen , die ich verfügbar habe. Ich kann nach ihnen suchen. Ich kann die verschiedenen Aktionen sehen, die für die Pipeline verfügbar sind. Ich kann die durchgeführte Aktivität anzeigen. Ich kann wirklich darüber lesen. Ich kann sehen, wann es begonnen wurde, ich kann die Dauer sehen, die es dauerte. Wie es ausgelöst wurde,
der Status, wenn es irgendwelche Terrameter oder Einladungen gab, und noch einmal,
diejenigen, die ich filtern könnte, ist gut, Sie werden auch sehen, dass ich einen Gesamtfrachter hier zur Verfügung habe. Ich könnte einige der Details ändern, die mir angezeigt werden, wenn ich nur das späteste Datum sehen möchte ,
das ich ändern kann. Wenn es also eine gibt, die mir besonders wichtig ist, kann
ich in die Details eintauchen. Wenn ich also die kleine Pipeline mag, die ich mit dem Spiel kann, kann
ich den Aktivitätslauf ansehen. Sehen Sie, ich werde wählen, dass ich jetzt mehr aus dem Detail sehen kann. Ich kann den Aktivitätsnamen, die
Art der Aktivität sehen . In diesem Fall war
es eine Art von Kopie. Diese gesamte Pipeline ist das, was ich mir ansehe. Jetzt kann ich alle Aktivitäten sehen, die Teil davon waren. In diesem Fall war
es nur eine Aktivität innerhalb der Pipeline. Aber ich würde jede einzelne Aktivität sehen, die diese Pipeline bildete, abhängig von ihrem Typ. Ich könnte
hier
zum Beispieldie genauen Importe sehen zum Beispiel . Ich kann die genaue Ausgabe,
die Menge der Datenleitung,
die Menge der Gator geschriebenen Dauern wieder sehen die Menge der Datenleitung, , den Start, die Dauer der Offenheit, diese spezielle Aktivität innerhalb der Pipeline. Dann bin ich da, wo es vom Beispiel gelaufen ist. Der Hinweis einmal in diesem Fall,
ist, dass die Festung und ich könnte auch dieses kleine Paar Brille haben diese. Zeig mir die Details. Also hier kann ich sehen, dass es aus kam. Und deine Fortsetzung? Data Warehouse. Es ging in deinem Laden auf die Zehe. Es Gentoo, und ich kann die genauen Details sehen. folgt die Zahl. Lesen. Nummer aus. Rose aufgeschrieben. Ich kann den Durchsatz,
die Kopiertradition und die Details sehen . Verknüpfe es damit, damit ich großartig in die angegebene um diese bestimmte
Aktivität hineinkommen kann. Fertig. Das ist also ein Schlüsseltyp aus der Überwachung, die wir durchführen werden. Ich kann den Status von meiner Integration sehen, wenn ich mal hier nur die Automatik
zur Laufzeit verwende . Wenn ich zusätzliche Laufzeiten hätte, vielleicht vor Ort, vielleicht diese SS I Jahre, würde
ich diese auch sehen. Und noch einmal kann
ich Details über die falsche Zeit sehen, Details über die Aktivität,
Waffen, die diese Integration tatsächlich pünktlich nutzen. In meinem Fall wird
es alle sein, die ich in meiner Umgebung habe. Wenn ich wieder nach oben gehe, kann
ich mir auch die Details ansehen. Ich kann den Status sehen. Es ist aus geben Sie einen jur und die Gründe gehen, um automatisch zu lösen. Und noch einmal, ich könnte gehen und in Aktivitäten eintauchen außer Tre. Dies ist also die wichtigsten Arten von Überwachung, die ich innerhalb der Datenfabrik tun werde. Dies gibt mir die Einsicht, wie meine Pipeline läuft, mein Trigger die Aktivität läuft und dann die Integration ausführt. Manchmal gibt es jetzt auch Metriken. Wenn ich in diese eintauche, wenn ich auf diese Schaltfläche Metriken klicke, es jetzt nur gehen, um mich direkt zurück zum azurblauen Portal zu springen. Dort sind die Metriken meist egoistisch. Das führt uns zu Teil zwei von der Demonstration. Monitoring mit auf Ihrem Monitor. Hier schaue ich mir mein Alter oder das Datum der Fabrik an. Der Autor und Monitor ist, wie ich tatsächlich in die George es beeinflussen Sie, X. Wenn ich nach unten scrollen, dann werde ich meine Metriken sehen. Und von hier aus können Sie eine Reihe von wichtigen Dingen sehen, die uns um gescheiterte Aktivitäten kümmern. Dunns Phil Pipeline führt ausgefallene Triggerläufe aus, Integration einmal verfügbarer Speicher,
überlegene Position, überlegene Position, maximal zulässige Entitätsanzahl. Und für all diese verschiedenen Kritiker,sehen
Sie, sehen
Sie, ich kann tatsächlich eine Warnung für sie erstellen, so dass das sehr nützlich sein könnte. Und wenn ich eine faire Nummer sehe, kann ich darauf aufmerksam machen. Und im Falle eines Scheiterns kann
ich zu Datenfaktor ux gehen und für die Details sehen und untersuchen, damit ich diese Dinge verwenden kann ,
um die Metriken
zu erhalten. Ich könnte das verwenden, um den Alarm auszulösen
, der mich dann dazu bringt, in die Schnittstelle einzutauchen und genau zu sehen, was passiert . Und dann haben wir, ah, unsere Diagnoseeinstellungen, damit ich all diese Daten,
die Metriken und die Details über die verschiedenen Aktivitäten durch geplante Läufe oder die
Triggerläufesenden kann die Metriken und die Details über die verschiedenen Aktivitäten durch geplante Läufe oder die
Triggerläufe . Ich kann ihnen Zehe eins von diesen drei Zielen schicken, Geschichten,
Konto, Konto, sogar Zehe oder Look Analytics. Und als ich ihn zum Sperren und Militates schickte, konnte ich
das anpassen. Wie lange möchte ich diese Protokolle aufbewahren? Vielleicht möchte ich sie für eine bestimmte Dauer behalten. Ich kann das durch die Log Analytics-Feuerprobe tun. Vielen Dank.
 Eshant Garg
Eshant Garg