Transkripte
1. MLFirstLecture: OIR ist maschinelles Lernen. Ist es ein Computerprogramm, in dem wir alle möglichen Szenarien schreiben? Passen Sie alle Variablen enthalten sind, es ist nur eine Menge von Daten. Unsere es vorgestellt Phantasie Visualize ist nicht Was ist das? Ist es nur eine Menge von mathematischen Funktionen? Spielen zusammen mit den Daten zusammen mit dem Computerprogramm sind Es ist nur ein Roboter. Was ist das? Ist es nur ein Wunder, das mit den Maschinen passiert ist? Was genau ist maschinelles Lernen? Um dies realistisch einen Schritt zurück zu verstehen, es sei denn, verstehen, was ist klassisches Programm? Also, was ist klassische Programmierung? Klassische Programmierung in Watts Algorithmus auf die Variablen und die Verwendung dieser Algorithmen und jene Variablen v rechts Klassische Programme, wobei V enthalten sind Art von möglichen Szenarien. Diese Algorithmen können in jeder Programmiersprache beibehalten werden. Es kann C,
C plus Beytin sein. Und wenn wir alle möglichen Szenarien durch die Variablen einbeziehen, ist
das unsere klassische Programmierung. Fügen Sie nun Daten zu dieser Mischung hinzu. Jetzt schreiben wir ein Computerprogramm, einschließlich Variablen, aber dieses Mal haben wir Daten. Das bedeutet, dass wir das Verhalten von den Daten auf verstehen können. Wir können etwas mit unserer Programmierung und Daten tun. Jetzt schreiben wir keine Algorithmen für die Variablen, deren Wert wir nicht kennen. Wir haben bereits einige Daten, und wir schreiben Computerprogramme, die auf diesen Daten basieren, und das heißt Data Mining. Also extrahieren wir die vorhandenen Daten, wenn wir versuchen, ihr Verhalten zu verstehen. Was ist, wenn wir ihre Daten mit all ihren Merkmalen kombinieren? Alles ist Funktionen, und dann versuchen wir, die Muster hinter dem Verhalten hinter den Daten zu verstehen. Was kann aus diesen Daten noch abgeleitet werden? All die Einsicht, Intelligenz, jede Art von Verhalten. Was kann auf der Grundlage des Staates vorhergesagt werden? Unsere 30er Jahre Data Science Job? Zögern weist auf, was Masilela Ning ist. Machine Learning ist im Grunde Kombination aus all diesem maschinellen Lernen in Wänden
Datencomputerprogramme auf den Features nach Daten. Also willkommen in der Welt vor Masilela Knie. Es wird Spaß machen, es gemeinsam zu erforschen.
2. ML: Hallo dort Bevor wir beginnen und einen tieferen Tauchgang in maschinellem Lernen neueste Verstehen einige von den Begriffen auf einige der Schlüsselwörter in der Welt des maschinellen Lernens verwendet. Diese anderen Begriffe werde ich auch während der Vorlesungen verwenden, ist besser. Du verstehst das jetzt, Andi,
habe dasselbe Verständnis, als ich diese Stümpfe benutzt habe. Und diese Geber halten das für eine Daten, die Sie für Ihre Masilela gefangen haben. Irgendwelche Analyse in diesen Daten? Alle Werte hier, sie werden Beobachtungen genannt. Wenn wir sehen, wurden Beobachtungen über die Werte Datenwerte auf dem nächsten Hitter Teil hier sprechen. Wenn Sie sagen Schlafzimmer Badezimmer Dane, Adresse die Identität aus entwickelt. Diese werden als Beschriftungen bezeichnet, da dies nur eine tabellarische Daten ist. Sie haben ein Etikett. Wenn dies eine andere Art nach hart war, zum Beispiel, wenn dies ein Foto Bild ist, werden
Sie keine Etiketten haben, auf denen Sie Beobachtungen haben. Sie müssen verstehen, basierend auf den Beobachtungen, was genau es darstellt. diesen Fällen gibt es keine Etiketten. Okay, der letzte, der Sieg der Etiketten stellt unabhängige Variablen dar. Zum Beispiel. In diesem Fall, wenn ich Ihnen sage, diese Daten zu analysieren und den Preis von der Wohnung mit diesen
Funktionen vorherzusagen , wie viele Schlafzimmer es hat, wie viele Badezimmer es war. Und es hat Längen- und Breitengrad hinzugefügt. Aber im Grunde die Lage, dann alle diese Etiketten, alle diese Werte werden unabhängige Variablen, auch als Prädiktoren und Features auf dem Preis genannt wird Zielvariablen auch als Vorhersagen. Das sind also sehr wichtige Begriffe, wenn es um überwachtes Lernen in Super White
Landung geht , wird
es Etiketten geben. Es wird unabhängige Variablen geben und sie werden Ziel sein. Sehr anstritten. Diese Variablen sind in zwei verschiedenen Typen gruppiert. Wenn es so etwas wie Adresse ist, die feste Werte wie innerhalb einer Stadt hat, gibt es feste Adressen, auf denen keine Zahlen sind, die uns das richtig sind, richtig? Sie werden kategoriale Variablen genannt. Sie folgen bestimmten Kategorien auf. Wenn es sich um eine kontinuierliche Zahl wie Schlafzimmer, Badezimmer handelt, kann
es eine beliebige Anzahl von Veteranen geben. Es kann eine beliebige Anzahl von Bädern geben. Jede Zahlenaktualisierung in der Wohnung ist keine feste Nummer. Diese werden numerische Variablen genannt. Das war's vorerst. Das sind wichtige Begriffe. Sie sollten sich daran erinnern, wenn wir diese Begriffe weiter unten in den Vorträgen verwendet, Sie sollten in der Lage sein, es zu beziehen. Ok, ehrfürchtig. Wir sehen uns als Nächstes. Spätere
3. Maschinelles Lernen verschiedenen Typen: Hallo, es wird zu diesem Vortrag in diesem Rektor kommen. Ich gehe, um Sie durch verschiedene Arten Selbstmuskellernalgorithmus zu führen. Lassen Sie uns also auf einem sehr hohen Niveau beginnen. Die Maciel Learning Algorithmen können getrennt werden, sind in drei separate Kategorien gruppiert. Die 1. 1 wird beaufsichtigt, dann unbeaufsichtigt und dann drei Durchsetzungsmaßnahmen. Also lasst uns verstehen. Was sind diese beaufsichtigten Algorithmus wird befolgt. Videodaten können in einen weit entfernten Mullah passen. Wenn Sie diese Daten in ihrer Formel setzen, Sie können die nächsten gesetzten Daten voraussagen, dass acht off Handlungen, die überwacht wird unbeaufsichtigt sein, wenn Sie keine Formel auf Ihre Daten haben können, Ihr Datum, das ich nicht beschriftet. Sie können keine Formel haben. Zum Beispiel, als unmittelbare Papa Daten hat kein Etikett, um es angebracht und das ist unbeaufsichtigt so auf einem sehr hohen Niveau. Dieser Unterschied zwischen beaufsichtigt und unbeaufsichtigt, werde
ich sagen, ist einer. Es kann formuliert werden, dass es nicht auf anderen formuliert werden kann, ob Ihre Daten das Etikett . Das ist also ein grundlegendes anderes. Verstärkung ist im Grunde Versuch und Irrtum getan. Logik wird basierend auf Versuch und Fehler abgeleitet, so dass Sie weiterhin einige Dinge mit den Daten zu tun und basierend auf dem Ergebnis, Sie entscheiden, dass der nächste betreute Zugriff weiter in Schleppklassifizierungen und
Techniken klassifiziert werden kann und Regression -Technik. Regressierende Techniken sind, wenn Sie den nächsten realen Wert vorhersagen. Es kann alles sein, was es Gewinn und Verlust sein kann. Sie sagen voraus, dass es Ihre Vorhersage der Unfallrate sein kann. Sie können Kilometerstand Auto vorhersagen,
alles, wo Sie einen echten Wert Tod vorhersagen, waren, dass der Halbmond im Bild kommt. Sie werden über lineare rechristen auf verschiedenen Farmen lernen, linearen Anfragen und einfache, lineare, rücksichtslose und multiple genetische. Hören Sie auf ein Polynom. Sehr nachsichtig rechristen vom Kurs. Sie werden viel mehr darüber wissen, wenn Sie diese Techniken erlernen werden und Sie werden in diesem Kurs Projekte in
Händen haben . Ebenso in Klassifizierungen. Und Sie haben Logistik, rechristen disses, Eintrag Unterstützung Vektor Maschine Nacht Abfall que nächsten Nachbarn und zufälligen Wald. Die Klassifikationen ist im Grunde das, was Sie vorhersagen, ist ja, sind keine Art von Sache Binary. Entweder Sie prognostizieren ja oder nein, aber Sie haben einen Satz von Werten und Sie prognostizieren, welche dieser Werte
passieren werden . Also die Klassifizierungen und ist wie die Klassifizierung Ihrer Daten auf Ihrem Ergebnis in bestimmten Taschen , die Unterstützung Vector Maschine, Homosexuell nächsten Nachbarn und zufälligen Wald. Sie können für Einstufungen als Villen verwendet werden. Rechristen. Gehen wir für unbeaufsichtigte unbeaufsichtigte. haben keine Labeldaten, sodass Sie sie entweder in verschiedenen Clustern gruppieren können. Und es gibt Clustering-Algorithmen wie ein Mittel, wo Sie eine prio Art von
Algorithmen,
Associates und Algorithmen folgen können Algorithmen, . Verstärkung, wie gesagt, ist Versuch und Irrtum Art off. Logik sind Ihr Algorithmus läuft basierend auf dem Ergebnis aus dem vorherigen Akzent. Es heißt also auch Marco Decision Process. Das ist einer von dem Algorithmus, den Sie verwenden können. Also, das ist alles an. Wir werden in zukünftigen Vorlesungen einen tieferen Einstieg in jeden dieser Algorithmen nehmen. Ehrfürchtig. Wir sehen uns im nächsten Lecter.
4. Jupyterinstallation: Wie haben Sie Jupiter benutzen wollen? Notizbuch in diesem Gericht? Jupiter Notebook ist Browser-basiertes Notebook mit vielen guten Funktionen, die Sie während des Kurses in diesem Rektor erkunden werden, Sie gehen zu installieren. Download auf einem Start Jupiter Notebook. Beginnen wir, bevor Sie mit dem Download auf Peter beginnen. Du brauchst Zeh. Bestätigen Sie, ob Sie 64-Bit-Betriebssystem haben. Sind 32-Bit-Betriebssystem auf Windows Plate von Dies ist, wie Sie bestätigen können, auf oder hier
habe ich 64 Bit Einfache Weg ist Goto Google und Suche nach Download Anaconda auf Es wird Sie
zu www dot anaconda dot com nehmen . Macht Ihr klicken Sie auf Windows-Betriebssystem, Meine Liebe auf, obwohl ich 64-Bit-Betriebssystem, das sicherste Bit ist installieren 32 Bit 32 Bit wird auf 32-Bit-Betriebssystem als auch arbeiten. Ein 64-Bit-Betriebssystem. Manchmal sogar mit 64-Bit-Betriebssystem, haben
Sie möglicherweise Probleme, wenn Sie installiert 64 Wheat Anaconda. Deshalb bin ich mit 32 Bit, dass sie zustimmen. Stellen Sie sicher, dass Sie sehr klar wissen, Start und klicken Sie auf einen Stern Es dauert ein paar Sekunden. Vielleicht ein oder zwei Minuten. Hängt von Ihrem Computer ab. Spucken genau hier ist installiert. Und jetzt gehen Sie zu Programmen und Sie werden genau dort sehen. Anaconda. Wenn die Anaconda geöffnet wird, werden
Sie Ihre Jupiter Notizbuchoperationen sehen, und sie sind einfach auf Mittagessen klicken. Ehrfürchtig. Also, das bist du, Peter Notizbuch. Es verklagt den ganzen Kampf gegen andere Regisseure. Habe ich. Aber ich habe es getan. Wenn Sie frisch anfangen, wird das für Sie leer aussehen. Du wirst keinen Tag sehen. Nur da. Eine andere Art und Weise. Zehe offen für Peter Notebook ist, können Sie zu unseren Programmen gehen. Anaconda an. Genau da. Sie finden die Jupiter Notebook Cops und klicken Sie darauf, dass es die gleiche bemerkenswerte öffnen würde. Auf diese Weise müssen Sie kein Akkordeon öffnen. Geh zu Jupiter. Sie können sich direkt öffnen. Besiegt. Sieht sehr gut aus. Ihr seid alle bereit. Sie haben Ihr Jupiter-Notizbuch heruntergeladen und es funktioniert. Wir sehen uns im nächsten Brief
5. Numpy einzelner Dimensional: Hallo, es wird zu diesem reicher in diesem Regisseur kommen, Ich gehe, um Sie durch numpty zu nehmen. Nummer sein ist ein Kampf Bibliothek auf es ist hart von jeder Datenwissenschaft? Sind Massie Learning Projekt? Wenn Sie inspirieren, Daten zu werden, sind
Wissenschaftler professionell maschinelles Lernen. Du kannst Lumpy nicht ignorieren. Also lassen Sie es uns sprechen. Nennen wir es MP Demo und es ist eine Pitre Bibliothek, um numpty zu importieren und es ist C s leer. Dies wird also diese Bibliothek in Ihr Notebook importieren und Sie können t auf Funktionen
aus numpty in Ihrem Programm verwenden , bevor ich beginne. Es gibt wenige Dinge, die ich möchte, dass Sie verstehen, so dass Sie und ich auf der gleichen Plattform sind Tante haben das gleiche Verständnis von diesen Systemen. Also zuerst, ähm, ist Gott, es ist Mörder. Es ist Killer bedeutet, wenn man Werte wie eine Zehe wie einzelne Werte hat, heißt es „Kill Out“, oder? Und dann gibt es einen anderen Begriff namens Victor. Also Victor ist sehr Single Cent Esnal, Ari so. Also, wenn es ein einziger Cent ist Ellery mit Werten, es wird auch Victor genannt. Und dann sind meine Tricks mehrdimensional. Das bedeutet, dass es mehr als einen Cent Instant hat, wie es Zeilen und Spalten hat, richtig? So wie das. Ein Zeh, dann 34 tan, 56 Also das ist ein Beispiel von Matics. Okay? Ich könnte Distanz gebrauchen. Wie Victor sind eine Metriken oder Multi Diamondstein. Hillary ist austauschbar. Größer. Also fangen wir jetzt an. Das erste, was wir tun werden, ist, dass ich Sie durch ein paar Funktionen nehmen werde. Richtig? Okay. taub P geht es nicht nur um Ari und Metriken, Sie können numpty Funktionen ausführen, nur um einen einzelnen Wert zurückzugeben. Zum Beispiel kann
ich einfach eine Zufallszahl malen. Wie wenn ich sagen MP Dart zufällige Dart und ich m t und Essen, zum Beispiel 17 hier wird es mir jedes Interieur zurückgeben? Weniger als 17. Sehr gut. Also hier ist die Rückkehr 16. Jetzt. Wenn ich es noch mal renne, wird
es 10 3 kleine Schlepptau. Es wird sich 15 fühlen. So wie, dass es immer wieder gibt mir eine andere indigene, aber alle in mühsam, weniger als 17 auf Wie, was es getan hat Eine andere Funktion namens zufällig. Nicht am Ende, Deon. Und das wird mir Zufallszahlen geben. Wenn ich das weiterführe, wird
es mir immer wieder Zufallszahlen geben. Wie jetzt gibt es minus 1.2163 hier. So gibt es solche Funktionen zur Verfügung in ist Killer-Modell. Auch wie A und P können verwendet werden, um Ihnen eine einzelne zurückzugeben. Nun, jetzt ist es Zeit für unser E-Sehing. Ah, Dämonen. Nein. Bereit. Auch genannt Victor auf diesem ist, wo die reale Nutzung off Nummer beginnt er in Data Science und maschinelles Lernen Welt. Vor jeder Verzögerung lassen Sie uns voran und erstellen Sie unsere erste eindimensionale Ich werde toe Nennen Sie es DNP Victors eins auf, um es zu erstellen. Ari, Sie müssen nur sagen, n p Punkt r a und geben Sie Ihre Liste hier. Also gehe ich zu Präsident Oneto drei für fünf, sechs und sieben. Das war's. Mein Array ist wirklich,
wirklich, ich kann einfach diesen Bereich hier wie DNP Victor drucken. Was? Und das tat ich. Mein Bereich ist wirklich Es ist so einfach, ein zu erstellen, was, wenn ich bereits eine Liste in fightin, Sie können eine mindestens richtig und am wenigsten off Werte haben. Richtig? 10 11 12 13 14 15. Das ist meine Liste ist nicht Ari
, oder? Und die Aktie? Zwei verschiedene Dinge. Aber ich möchte einen Weg mit dieser Liste schaffen wir einfach wenigstens ist das Schlüsselwort. Also lasst uns ein wenigstens eins in Ordnung Jetzt kann
ich das Array mit dieser Liste leicht erstellen. Ich kann sagen, und p Punkt i d auf in der Aufzeichnung. Setzen Sie diese Liste einfach an eine. Das war's. Ich habe meine Gegend und ich kann diesen Bereich benennen. Was? Ich, was ich will, kann ich DNP Victor auch sehen. Wenn dieser Kerl und dann D und B Sieger drucken und das ist Mary. Und nicht nur das, ich kann das Gegenteil machen. Außerdem kann
ich dieses Array in eine Liste konvertieren, die auf dem Weg zu tun ist, dass dies einfach hier ist und dann den Kampf und die Funktion
aufrufen, die zur Liste aufgerufen wird, und das ist es. Der Bereich wurde in die Liste umgewandelt. Nun ist dies eine Liste, so dass Sie zwischen unserem A und Osten sehr leicht ohne große
Probleme austauschen können. Nächste Funktion, ich gehe die Zehe. Du bist also passiert. Was ist, wenn ich einen weiteren Wert für meinen Sieger will, ist mein einmalig Ellery DNP Victor ein sehr einfach. Sagen Sie einfach ni BSP Torte nach oben. Andi, setzen
Sie Ihre Bist du hier? Geben Sie den Wert ein, den Sie oben möchten. Zum Beispiel, wenn ich 100 kein Problem gewesen sein möchte. Ich habe 100. Ich habe mit meinem DNP Victor Run gemacht. Wenn ich dies meinem DNP Victor ein zugewiesen habe, dann drucken Sie meine DNP besser aus. Ich Schaltung, dass 100 Tage bemerken Jagd dieses 100 Gericht am Ende der was angehängt, wenn ich diese hinzufügen
will 100 in diesem Tempo FIC produziert innerhalb der Gegend auf übrigens, wenn ich es nennen produzieren es heißt Index und die Indexnummer, die er beginnt mit Null. Der Index Partisan für eins ist Null. Dann ist dies ein Index Partisan Index 20 ist und drei in Erfahrung und vier in verschiedenen. Sie können fünf Index Woodies und sechs und in verzweifelten Anwendungen. Würden Sie schon seit sieben. So läuft die Indizierung. Mal sehen, ob ich Zeheneinsatz will, so werde ich sehen und sein Dart-Einsatz und dann mein Honig und dann möchte
ich bei producen Hören einfügen, Baum auf. Ich möchte Wert 10 einfügen. Also sag mir, dass wir wirklich gehen. Das ist Null. Dies ist eine, die dies zu diesem ist drei. Also sollten die 10 nach Nummer drei hier hinzugefügt werden. Sehr gut. Ja. So wird dann bei Indyk Nummer drei hinzugefügt, die hier auf ist. Wenn ich meinen Bereich ändern möchte, kann
ich einfach diesen neuen Einsatz zuweisen und dann, wenn ich drucken möchte, warum DNP Victor eins? Ich bekomme 10 gleich dort. So weit, so gut. Ich denke nicht, dass du bisher Probleme haben solltest. Sieht einfach aus, oder? Sehr gut. Sehen Sie sich diese Werte an. Sie haben nicht angefangen. Wollte dazu neigen. Und für fünf Was ist, wenn ich es sortieren möchte Sehr einfach, in P Dar Saad zu sagen und übergeben die A D und B D und P Victor eines Tages Lefty hier. Kurs Arctic Neueste hat den angefangenen Sieger unserem Sieger zugeteilt. Okay, und jetzt bringen wir diesen Kerl mit. Es ist richtig sortiert. Was ist, wenn ich eins davon löschen möchte? Kein Problem. kannst du tun. Sag einfach mp dot Deal it D und B, Victor eins. Und was, wenn ich den Wert bei Index 1 löschen möchte, habe ich gerade diesen Index übergeben. Also, was wird Ihrer Meinung nach gelöscht werden? Dies ist Indexkörper und Null. Das sind keine Explosionen und man sollte auch gelöscht werden, oder? Lass uns das machen. Nehmen wir an, D und B Victor eins gleich und dann brillante DNP Victor laufen. Hier gehen wir, zu Gott erweitert. Es gibt noch einen sehr interessanten Funks und Autoverkettung. Also, zum Beispiel, ich habe einen anderen Sieger DNP Victor drei. Wenn es 11 gibt, gibt es 200 oder drei. Ich will das, Victor, Toby fügte mit der DNP Victor ein und erstellen Sie einen neuen Schauspieler sind zusammen. Also sage ich, die MP Victor vier gleich np dart gun que das Netz d und B besser ein auf DNP. Also hier wieder, Protector eins auf DNP Victor T. Und zusammen mit dem, wir müssen auch Mittel und der Zugang gleich Null. Und ich werde Ihnen diesen Zugang erklären, wenn wir über die Multi Diamanten sprechen. Nein, das wäre der richtige Zeitpunkt, um vorerst darüber zu reden. Setzen Sie einfach den Überschuss namens 20 auf. Dann drucken wir D und B Victor vier auf. Hier gehen Sie die und Direktor für ist Kommunisten und bieten DNP Victor drei und DNP Victor ein. Richtig. So können sie nicht in ihre
Funktionsarbeit kommen . Das ist ein sehr kleiner Sieger. Dies ist sehr klein früh im wirklichen Leben Projekte. Sie werden mit Tausenden von Datensätzen davonkommen, wenn Sie Index von einem bestimmten
Wert finden möchten , dass Tausende von Datensätzen das gemeinsame dafür aufzeichnen und das ist die Funktion hier draußen
behindern. So werden Sie in p Punkt sehen, auf dem wir sind. Dann sehen Sie Ihren Siegernamen D und B Victor vier, und setzen Sie dann den Wert, für den Sie einstellen. Zum Beispiel setze
ich für 101 Dies wird mir den Index von 101 Jahr zurückgeben. Es sagt, es ist am Index es SolarCity 012345678101 existieren am Index noch und der Datentyp diesem Wert ist I nt Gute Informanten und richtig so weit haben wir unsere ein unser Selbst Onda geschaffen. Wir haben damit herumgespielt, aber es gibt andere Möglichkeiten, ein zu erstellen, und das wird sehr nützlich für U. S. Grundsätzlich, wenn Sie eine visuelle Idee erstellen, da so mal sehen, es ist ein DnB auf bekommt ein und B Dart einen Bereich Andi, Dann wo er nur sagen, ein für Zehe 10 und zwei. Was wird passieren? Es wird automatisch Ari erstellen. Sehen wir uns ein D und B . Hier geht's. So hat es erstellt, dass Sie ein Off-Innenwerte zwischen eins und 10 mit dem Intervall aus sind
, um das bedeutet, dass es wirklich mit einem beginnt und dann wird es auch vorbeigehen. So 13579 und der letzte Wert ist nie enthalten. Alle Werte beginnen also mit dem ersten Wert im Bereich und sind niedriger als der letzte Wert in der Miete. Auf dem Abstand zwischen diesen Werten wird die Zahl, die Sie als Start bei drei gepriesen haben würde Zehe Aaron genial sein. Diese Luft hilfreich. Was ist, wenn ich ein Array aller Nullen erstellen möchte? Also sagen wir D und B. Tzeitel, es sind wirklich nur cmp dot Nullen. Und wie viele Sie wollen Wenn ich will 10 so wird es einen Tag mit 10 Nullen erstellen. Der NPC Hier geht's. Es hat Array mit allen Nullen erstellt. Es hat eine Niete erstellt 10 Werte und alle von ihnen sind Null. Da sauer geht auch. Ich kann hier mit allen erschaffen. Wenn Sie sich fragen, wo Sie sind, werden Sie diese Art von Funktionen verwenden. Es wird meistens beim Erstellen mit dem leichtesten seit verwendet werden. Okay, wir weiter die nächste Funktion, über die wir reden werden. Und das ist eine sehr wichtige Funktion liegt im Raum. Mal sehen, was es tut. Also D und b liegend Sein Tempo entspricht der MP dunklen Linie dieses Stück auf, Nehmen wir an, ich möchte von 1 zu 5 drucken. Es 20. Flucht auf de Sprinted. Hier geht er, was haben wir bekommen? Es wird Werte zwischen eins und fünf gedruckt. Beide sind enthalten, die 20 Werte zwischen eins und fünf sind und alle gleich distanziert sind. Jeder von ihnen ist also mit dem gleichen Abstand 0,20 getrennt So funktioniert der Lichtraum. Was passiert, wenn ich den Maximalwert in meinem Bereich zeilen möchte? Das heißt, er sagt einfach DNP. Sie können einfach sagen, Max auf Sie erhalten den maximalen Wert So Max Wert ist 5.0. Richtig? Gleichermaßen. Wenn Sie minimieren möchten, müssen
Sie nur sagen, bedeuten d und B neun SB Punkt i meine auf dem Mindestwert ist eins. Was ist, wenn ich den Index von Maximum und Minimum wissen will Nun, anstelle von Mac, werden
Sie Luft T max sagen. Und das gibt Ihnen den Index nach macht Nummer hier auf, wenn Sie das Minimum
noch einmal wollen . Das Gleiche. Aber hier drüben, sagst du „Edgy“. Los geht's. Es ist Null an. Was ist, wenn ich die Größe meines Bereichs wissen möchte? Das ist auch nicht so schwierig. Se d und B neun TL und nur eine Größe. Hier geht's. Die Seite von diesem Rennen, 20. Natürlich entwickelt es sich nicht, oder? Oh, ich habe vergessen, dir das Wichtigste und einfachste zu sagen. Wenn ich den Wert in einem bestimmten Index finden möchte, ist
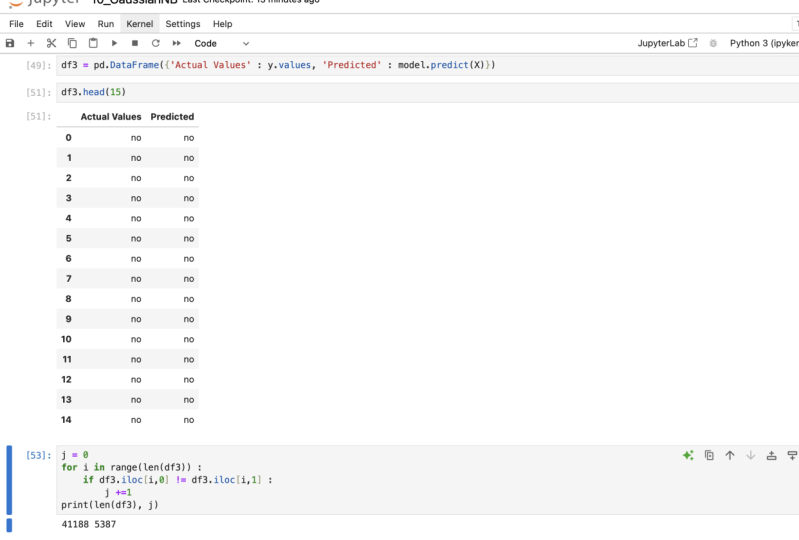
das einfach. DNP-Leitung. Lassen Sie uns sein, wenn ich den Wert finden möchte Zum Beispiel, dass Index 55 es Ihnen den Wert von Index fünf zeigen würde. Was passiert, wenn ich den Wert für den Bereich Off-Index möchte? Wie wenn ich Wert von 1 bis 5 wollen, So DNP Linie SB. Ich möchte sehr von 1 bis 5. Diego. Es gibt Ihnen Werte von 1 bis 5. So finden Sie die Werte in einem Diamantgehalt. Ich denke, wir haben alles abgedeckt, was wir brauchen, um in einer Dimensionalität abzudecken. Als nächstes werde ich Sie durch mehrdimensionale Array
6. Numpy Multi-Dimensional: Reden wir über meinen zweidimensionalen Ari. Sehen wir uns jetzt meine D-Forderungen an. Nein, aber er hat auch Sanitäter genannt. Lassen Sie uns zuerst eine mehrdimensionale ari aus Zufallszahlen erstellen. Also sagen wir DNP zufällig. Er ist in FY Dart zufälligen Punkt verrückt auf. Wir werden ein mehrdimensionales Array von fünf mal vier erstellen, das fünf Zeilen und
vier Spalten verpasst hat . Fahren Sie mit vier D und P. Benda. Sehr gut. Also das ist unsere Monte Forderungen jetzt an Denken Sie daran, jemals über Übermaß zu sprechen. Also alle Zeilen hier werden sie als überschüssig betrachtet. Nullspalten werden als überschüssiges eins betrachtet. Im Gegenteil. Beginnt im Weg. Dies ist 00 Das war Null Zeile Null Spalte. Dies ist 10, die erste Regel gewinnen. VERO COLUMN Dies ist 20, dass, wenn die zweite Zeile Null Spalte. Ebenso ist
dies 01, dass mit Null Zeile erste Spalte, die Zeile zuerst kommt und dann ihn anrufen. Zum Beispiel, wenn ich Wert bei dicken andro und erste Spalte D und B zufällig wissen will, kontrollieren
sie erste Spalte und Tod entwickeln. Jiro Ein Zeh, zweite Reihe 01 1. Spalte. Das ist der Wert, das Gleiche. Ich kann etwas anders gehen. Ich könnte sagen, dass DNP nach Hause auf eins zurückgekehrt ist. Es wird dasselbe zurückgeben, was ich Zeile und Spalte in separate Klammern setzen kann, sind ich kann
sie in der gleichen Aufzeichnung mit Komma halten . Was ist, wenn ich herausfinden möchte, dass ein Bereich wie der 1. 1 hier für Zeile 2. 1 hier ist für Spalte und ich kann den Bereich erwähnen, so dass ich D und B Vande sagen kann, um ich von Zeile 1 zu Zeile
drei und vier Spalten sehen möchte . Ich ging von der zweiten Zehe, um sie zu sehen, und das ist verärgert. Ich bekomme die Bäume der Reihen 10 und 103 012 von dieser Straße zu diesem Raum. Richtig? Und nennen Sie ihn Toto. 401 Zehe tun und vier Denken Sie daran, die vier sind nicht im Lieferumfang enthalten. Also waren es zwei und drei. Also zwei und drei von hier nach hier. Und 213 Das bedeutet also diese Werte, oder? So 31 ist nicht im Lieferumfang enthalten. Es wird also eins und zwei sein. Niemand schrieb und nennt ihn zwei und drei, weil das seitliche nicht eingeschlossen ist. Also, ich tue es hier. Das hier geht an. Hören Sie ,
so funktioniert es. Wie, wenn Sie einen Raum Fix bekommen wollen, verärgert Multi Diamond Gehalt. Das ist, wie Sie wollen. Du solltest weinen. Entwickelt. Hab es. Ok. Was ist die Größe von meinem ar e? Was ist, wenn ich die Größe wissen möchte? Das ist, wo einfache Gerechtigkeit. Schluck an. Das war's. Da steht der Sape von deinen Arrays. Fünf und vier. So weit, so gut auf. Was passiert, wenn ich die Datentypen aus meinem Bereich wissen möchte? Sehr gut. Sagen Sie d Typ. Und das war's. Die Daten tauchen ab. Alle Werte in diesem Bereich sind Frucht. Ich denke, das geht alles um mehrdimensionale Ari. Gehen wir durch ein paar unserer Gefängnisse. Sie können für gebildet auf diesen Bereichen. Das kann auf Sängerdimensionalität passieren, sind Multidimensionalität. Aber das sind einige interessante unsere Präsenz, die Sie durchführen können. Lass uns das machen. Sehen wir uns unsere Geschenke an. Und mal sehen, welche Art von unseren Gefängnissen wir mit unserer NPR durchführen können. Ich werde meine eigene Ari definieren. Ich werde nicht aufführen. Das sind Geschenke auf dieser Zufallszahl. Multi Dimensionalität. Also lass uns gehen meine eigene ary DNP i n t Medics bei n p dot buddy erstellen Ich werde eine
Multidimensionalität erstellen. Man muss seine zu seinen Choraufzeichnungen brechen, um mehrdimensionale Eddie-Werte zu schaffen . Wachstum im Inneren ist Karten-Aufzeichnungen. Einmal drei, dann 456 789 10 11 12 15 14 15 Und sie verbringen diesen Typ D und B und die Sanitäter. Okay, das ist
also mein mehrdimensionaler Bereich. Ich werde eine Menge von unserer Anwesenheit auf diesem Punkt tun, die 1. 1, die ich mag. Es ist einige, die ich sehen kann, und das wird mir die Summe aller Werte in diesem Bereich hier 1 20 Also das ist die Summe aller Werte in dieser Stadt. Was ist, wenn ich möchte, dass Toe wissen, welche dieser Werte erstellt werden? Die netten bezahlten sprechen gut. Zum Beispiel möchte
ich sehen, dass Veach dieser Werte größer als sieben D und B. Es ist Kopie dieses und größer als bald. Hier gehen Sie, für alle Werte, wo es nicht größer als 78 Nachdruck fällt und die Werte, die
größer sind als, sagen wir, ein, wird
es wirklich interessant drucken, richtig? Was ist, wenn ich eine R e mit den Werten daraus erstellen möchte? Sehr. Aber die Werte, die größer sind als, sagen wir, zum Beispiel, diese Stadt sagen einfach, es ist eine 2. 1 auf. , Vergessen
Sie nicht,dass es ziemlich Rekorde ist. Und dann diese Platte, und dann werde ich sagen,
verbunden, die Decke auf einem weniger Druck es. Es ist also nicht ari es, dies in einen Tag umzuwandeln. Warum musst du das tun, ist, dass du den ursprünglichen Ari drinnen sagen musst, dass du diesen Kerl steckst. Okay, jetzt sehen
Sie, Sie haben diese Tochtergesellschaft. Unser David schätzt mehr als sieben. Dieser Befehl ist eine veraltete ID. Aber ich wollte dir nur helfen, dass du das kannst. Was ist, wenn ich all diese Werte ändern möchte? Also anstelle von irgendjemandem zu Well, möchte
ich 100 zuweisen Zum Beispiel, das nennt man einen Rundfunk. Ich muss nur sagen, hier und dann muss ich wissen, über welche Folgepunkte ich rede. Also denk dran, 012 und drei. Also spreche ich von Regel Nummer drei. Das bedeutet also Regel Nummer drei. Es wäre, dass er ziemlich Aufzeichnungen hat. Regel Nummer drei und dann, von welchen Collins ich rede von 0012 wie von Null bis zu. Also, was werde ich hier setzen? Null bis zum letzten. Nun, hier sind sie in der Miete. Der zweite Wert kontaktiert nicht. Also würde ich sagen, drei okay, gleich 100 und dann weniger gedruckt. Ok. Hier geht's. Dass es sich um 200 geändert hat. Das ist der Rundfunk. So können Sie die Werte in mehrdimensionalen Larry ändern. Was ist, wenn ich 50 Toe alle diese Werte nur bei 52 hinzufügen möchte, das ist auch einfach. Sieh das nur um 50 Uhr an. Es ist, als ob alle anderen hartnäckig sind. Sagen Sie einfach, fügen Sie 50 wie diese auf gedruckt wieder. Hier geht's. Fünfziger daran, Gut entwickelt.
7. Numpy statistische Funktionen: als nächsten Teil von dieser unterhaltsamen Jenny off explodieren taupty wir gehen Toe erkunden einige statistische Funktionen. Ist das Hodenfunk? Da Sie auf der neun p.
R e durchführen können , habe ich Ihnen bereits einige nächste verkauft, die ich werde Zeh gehen. Du bist also. Es ist zärtlich, hinterhältig. Und so sagen Sie nur behindern Kunst, STD und geben Sie Ihren Namen auf es wird ein Standard hinterhältig und auf Ihrem heiligen berechnen. Also für diese sind eine Standardabweichung 37.31 Ebenso können
Sie mehrere andere statistische Funktionen ausführen. Zum Beispiel, wenn ich die Esquire Route von jedem dieser Wert sehen möchte, kann
ich sagen, MP dart ja, Q rt und dann pastie Namen aus Daddy hier wird es seine Ruhe abgeschrieben jeden dieser
Werte geben . Ebenso können
Sie Log tun. Also übrigens, wenn Sie nicht viel von den Details hinter dem verstehen, was ist seine zarten Fernseher und was ist log ? Mach dir keine Sorgen. Wir werden das in zukünftigen Wahlfächern vorerst abdecken. Denken Sie daran, dass dies die MP statistischen Funktionen, die Sie tun können, mit
M. P. P.M. P s Fighting Bibliothek hat Potenzial gewaschen, und diese setzen Insel wird von jedem Tag zu erhöhen. Wenn Sie
weitermachen, machen Sie das Echtzeitprojekt als Machine Learning Professional. Ich bitte Sie, halten Sie sich auf dem Laufenden mit dem, was in diesen Bibliotheken geschieht, wie MP s
Kaylan Banda Matt brachte lebendig Be on Seaborn diese Air fünf Bibliotheken, die Ihr Leben
sein werden. Halten Sie sich also auf dem Laufenden mit diesen Bibliotheken und informieren Sie sich über das, was sie waren. Neue Verbesserungen, die in diesen Bibliotheken geschehen. Welche Funktionen auch immer abgeschrieben werden, was auch immer neue Funktionen hinzugefügt werden. Artem, du bist fertig mit Taubheit. Ich seh dich nächste Vorlesung.
8. Pandas: Hallo da. Jetzt, wo Sie Jupiter-Notebook installiert haben, werden
wir zwei Dinge zusammen tun. Wir werden ein neues Jupiter-Notebook erstellen, auf dem wir eine sehr wichtige Machine Learning
Beytin Bibliothek namens Wanda erkunden werden. Hier ist dein Jupiter-Notizbuch. Gehe zu neuen und klicke auf Kampf. Und drei. So sieht Jupiter Notebook aus. Das nennt man Verkauf. Sie können beliebig viele hinzufügen. Sie können löschen, wenn Sie es nicht möchten. Andi. Als erstes werden wir schreiben, worum es geht. Nehmen wir an, Bündel ,
Andi, gehen Sie zum Segeln Zelltyp und machen es Marta Markdown ist wie Kommentare auf es nützlich sein wird, wenn Sie das komplette Notebook drucken. Arvin Terminates schaut sich dieses Notizbuch Mark unten hier drüben an. Sie können sehen, schlagen. Lesen Sie diese Nachricht. Das ist in Ordnung. Und jetzt werden wir die Pandas-Bibliothek für PD importieren Zur gleichen Zeit werden
wir eine sehr wichtige Bibliothek Numpty importieren, wenn Sie neu sind, Artikel zu kaufen, verstehen Sie
einfach. Dies sind sehr wichtige Bibliotheken, die Sie im maschinellen Lernen verwenden werden. So fand uns insbesondere ist, was Sie in diesem Vortrag erforschen werden Sie irgendwann in diesem Siegerzehe aufwenden. Verstehst du was? Es ist die Gründer-Bibliothek. Was können Sie tun? Mit dieser Bibliothek haben Sie die wichtigen Bibliotheken importiert Weiter, weniger rechts. Ein kleines Gericht. Wir werden einen Pandas-Datenrahmen erstellen, der wie eine Tabelle im maschinellen Lernen zu erstellen ist,
wie die Eingabe Zitate hat es sein wird und jetzt Zehe Bereiche gehen, zum Beispiel, zum Beispiel,
Die Städte sind eine sehr einfache, sehr off Zahlen für sechs, dann neun und macht Sie beginnen hier nah. Die diesjährige Zeit wird Lehrerin sein. So weit so gut. Wir haben eine Pause gesehen. Holen Sie sich hier auf dann Way wenigstens die Spalten Probleme werden einfach sein. Halten Sie es einfach für jetzt. Die sehen Lassen Sie uns bauen dieses sehr einfache Gericht auf Sie sind bereit zu laufen. Sie können es jetzt beenden klicken Sie auf diese. Es wird Sie Arias CEO fragen, Sie wollen den Kardinal neu starten? Denn hier drüben sehen Sie, dass es keine Nummern gibt, weil der Notizbuchoberst noch nicht
angefangen hat . Also Trick darauf wird es beginnen, dass. Und hier hast du die Zahlen genau hier. Oh, du willst, dass ein und zwei jetzt Teil des Landes werden? Dies ist jetzt Teil des Notizbuchs. Normale Bedingungen. Der erste Detektor und das. Komm schon. Und dieser Befehl hier ist unser Datenrahmen. Das ist genau das, was wir in diesem Jahr gegeben haben. 123456789 Auf Spalten ABC auf diesem hier drüben heißt Index. Wir werden mit diesem Brief herumspielen, aber für jetzt, verstehen Sie, wir haben gerade einen Datenrahmen erstellt Husten einen Tag frei Zahlen. Lassen Sie uns nun eine andere Daten erstellen, und das wird ein bisschen anders sein als das, was es
jetzt ist . Also im neuen Verkauf, na ja,
hier, wenn Sie gehen, erhalten
Sie mehr Optionen. Sie fügen ein, legen Verkauf ein, entwickeln sich darunter eingefügt. Also werde ich es unten einfügen. Und dann hier haben sie zwei Gleiche BD auf, dass raus aus ihrem Zeitland und dunkel. Heute wird auch dieser sein. Nehmen wir an, Quest in letzter Zeit nicht vergessen Syntex. Okay, und hör zu, sagen
wir, wird es sein und wir leben dort wo dann? 15 14 15 15 19 15 Darauf sagte eine weitere Regel 19 Don t Sehr gut auf hier. Das ist also Ende. Diesmal gehen wir zu einer weiteren wichtigen Sache. Wir werden unseren in Texas Index gleich nennen, dass sie nicht sind. 1234 Reihen Ich brauche vier in Nexis. Er que Andi wie, bevor wir Zeh brauchen. Neymar Spalte Halten Sie den Spaltennamen scheinen eine B Tante. Ich verstehe. Sieht gut aus. Ja, reichlich weiß ich nicht. Oh
ja, ja, wir haben mehr als nötig in Texas. Es gibt 1234 Regeln. Also B Q R s für okay jetzt Kundgebungen. Und los geht's. Wir haben den neuen Datenrahmen eingeschaltet. Geben Sie einen Rahmen an. Die Indizes sind assyrisch genannt es BQ Arias. Es sind keine numerischen Zahlen. Es basiert auf dem, was wir nannten ich tat, bevor wir mehr folgen einige gute. Zitieren Standard auf Einfügungen nach oben, einige markiert einige Kommentare, die nützlich sein werden. Brief, sagen
sie im dritten Siegel beinhaltet hier. Wir werden den 15 Bundesstaat James sehen,
diesen müssen wir zum Verkauf gehen und sagen, dass er Pater Mark auf den Verkauf markiert hat. Es gibt keine Zahlen. Nur die Gerichte des Dienstgerichts haben die Nummern, weil sie bestimmte
Vollstreckungen nacheinander folgen müssen . Gute Arbeit. Wir haben bis heute, Afghanen haben zwei Datensätze erstellt. DF Andi müssen Lassen Sie uns spielen, Andi, der nächste Komm auf ist der Wenn Sie nur diesen Befehl ausführen, werden
Sie alle Spalten wie ABC und Datentyp Datentyp aller diese Spalten mit Objekt mit PTSD der Spalten 30 von zwei Spalten. Es wird auf, wie Welcher Index geholfen werden? Wenn Sie den Index sagen, sehen
Sie, es ist seine reichen Tage 0 bis 3 und die Schritte eins, dass dies nur ein neuer medizinischer Index ist
erstellt werden . Es beginnt Null darauf, erhöht sich um eins. Wie wär's, wenn ich dort zu dunkel Hirsche gehe? Wer hier? Es hat indizierte Namen, BQ, Arien und, natürlich, Datentyp mit Objekt. Der wahre Spaß beginnt jetzt, wenn wir diese Daten schneiden und würfeln, sitzen mit Panda. Was wir jetzt tun werden, macht er das auf einem, aber wir haben damit zu tun. Das ist nur ein Kommentar. Wir hatten einen guten Verkaufs-Zelltyp bei Dr. und es gibt keine Zahlen. Noch einmal, klicken Sie
einfach auf diese und direkt unten. Okay, hier. Es ist sehr wichtig, was Sie in Masilela verwenden werden. Was, wenn ich es Raum will? Ruf ihn an. Wenn Sie Indizes sind numerisch wie folgt, können
Sie einfach sagen, die f eng. Ich schaue auf sie ein, dass wir diesen Teil in Kampfindizes erklären. Sie beginnen Null. Also, wenn Sie einen speichern, wird
es den zweiten Raum drucken. Jetzt ist das erste Mal sehen, dass klicken Sie contra Und hier gehen Sie Es wird drucken 456 Weil wir gab eine. Was, wenn ich sage, ich schaue? Null Es wird die 1. 1 123 Was ist, wenn ich nur Tokyu will? Mein Indexname, nicht die Indexnummer. In diesem Fall wird DF zu niedrig angezeigt. Zum Beispiel. Ich will nur mein P-Zimmer bezahlen. In diesem Fall werden
Sie sagen, lokale loc nicht ich loc in nicht Index Loc. Sie werden Ihre Lucy sagen und Sie werden den Namen des Index geben. By the way, können
Sie def klicken Sie auf die Steuerung. Geben Sie auf Ihre halten Sie es auf Sie, um das gleiche tun Sie mit der Surround-Farbe auf
hier drüben . ABC 10 11 12 darauf ist der Speedo. Auf diese Weise können Sie direkt eine Speed Freak Gruppe bekommen. So weit, so gut. Jetzt wissen Sie, wie man eine Spate Lautsprecherreihe befreundet. Wie wäre es, wenn ich
zum Beispiel eine Teilmenge dieser Daten möchte? Ich will nur diesen Teil. 10 11 13 14 16 17 Nur dieser Teil. Ich möchte eine Teilmenge daraus erstellen. Das ist er in Ordnung, lasst uns weitermachen. Ich hatte eine neue Zelle. Jetzt werden wir eine Teilmenge erstellen. Nachdem du gegangen bist, gehen wir zu Qualität von drei. Der Befehl ist zu dunkel, auf dem ich dabei sein würde. Es gibt zwei Argumente. Das erste Argument enthält die Zahl nach denen, die Sie in dieser Verstimmung wollen. Beginnen Sie mit Null auf ihren Namen. Baum tut ebenfalls Sie wollen nur zwei Spalten Null und macht Sie bekommen wie hier erhalten Sie ein e und b erinnern, eins
sein. Ja, diese Phase ist es? 10 11 13 14 und 16 17 drei tut und tun Spalten jetzt nur 50. Und Sie haben eine Subvention aus der F zwei erstellt und Sie geben den Namen des Fonds nicht hier zu
stoppen. Es gibt viele solche Befehle zu explodieren, bevor ich Gefühle. Dies wird Sahnehäubchen nach seinen Vermögenswerten, die wir Ihnen einen weiteren Aspekt erklären, den Sie in Massillon
verwenden werden . Wie wäre es, wenn ich sage, ihr vier auf und das F, auf das ich schaue? Dann sage ich, OK, 0 zu 3. Aber hier sagte ich, dass sie lieben für das, was Santee in diesem Befehl passiert ist. Ich sage, dass ich die letzte Spalte nicht einschließen soll, indem ich sage, dass ich mich einschmiege. Ich sehe, diesen hier nicht einzubeziehen. Wenn ich denke, minus zwei enthalten nicht die letzten beiden Spalten. B und C. machen
sie das? Ja, er hat nur frischen Carlo. Was, wenn ich nur minus eins sehe? Der einzige Prinz der letzte? Komm schon, Wenn ich die letzte Kolumnenstudie sehe, wenn ich minus eins sage, bedeutet
das, dass ich kein Anfang mit Null bis minus eins bin. Ich sage nur minus eins. Setzen Sie einfach Minus eins. Das bedeutet, es wird nur die große Spalte nehmen. Siehe 1. 3 Türen 12 15 18 bis 15. 18. Aber auf der letzten Farbe. Dies sind einige der lustigen Möglichkeiten, mit denen Sie Untersatz des größeren Datensatzes erstellen können. Das ist, was Sie in Massillon verwenden werden. Wir sind noch nicht fertig. Es ist das wichtigste auf dem kritischen Teil von Panda, die Sie gehen, um in Wasilla zu verwenden. Knie ist das, was ich zum letzten Mal geben würde, das die Kämpfe liest. Also lasst uns den Markt hier setzen. Karte auf. Siehst du, das wird runter sein. Denkst du? Fonda Du könntest jede Art von Kampf lesen, mit dem du zwei Jahre datieren kannst. Wir haben schließlich von der Website konvertiert. Sie können t html fünf, äh, in die Stadt einfach. Sie geben einfach auf DVD Dot Teat es drei. Dooney und wir hier, um zu kämpfen, ich habe Siehe bin ich an diesem Link. Und hier ist die CSC-Datei gespeichert. Dies ist der einzige Befehl, den Sie dort lesen müssen. Siehst du es? Ich bin nur ziemlich chaotisch. Und hier gehst du. Siehst du? Das ist ja, wir melden uns drauf. Wir haben nur eine Seite. Komm schon. Die vollständige Datei ist genau hier in dieser Datei befindet sich in diesem Datensatz. Haben Sie es geholt? Das war's. Nun hat der gesamte CS 35 Jugend Banda Datenrahmen den If it on genannt. Was auch immer Sie Präsidentschaft hier durchgeführt werden, Sie können auf dem durchführen, wenn es d wenn Sie Ihre Daten jetzt herumspielen und Sie werden
tun all das Schneiden, Würfeln, Indizierung auf all die Dinge tun Massillon auf diese Art von Daten. Also, dass du mit Panda einen Kampf mit vielen Daten lesen wolltest. Dann werden
Sie tun, ist Zug Fahrer und Schneiden und Würfeln all diese Art von Analyse sind Siealle diese Art von Operationen auf den Daten mit Panda,
lumpy und anderen Bibliotheken
sehenkönnen alle diese Art von Operationen auf den Daten mit Panda,
lumpy und anderen Bibliotheken
sehen . Aber der Panda ist die wichtigste Bibliothek, wenn es darum geht, die Datei beim
Anweisen,
Schneiden und Würfeln dieser Daten größer zu lesen Anweisen, . Wir sehen uns in der nächsten Vorlesung. Tschüss. Aber geh nirgendwohin, Kopf. Wir sind nicht fertig. Das Wichtigste auf aufregendsten Teil von Brenda, das ich zuletzt
aufbewahrt habe , ist das Lesen der Fünf. Wenn Sie maschinelles Lernen durchführen, müssen
Sie zuerst die Daten dazu lesen. Das erste, was Sie mit Fonda gehen. Gehen wir also weiter, während wir die Daten führen. Sie lesen die Daten und übertragen Sie sie in einen Datenruhm. Du weißt schon von ihm. Also, wenn es meine Daten sind von nun an den Befehl zu lesen. Die Datei ist BT Punkt Reid, ich werde CS drei Datei lesen. Also wird es PD Tür führen, um zu sehen, ob wir, wenn Sie lesen akzeptiert, akzeptiert werden
würde. Also,
so gibt es Befehle, verschiedene Kämpfe zu lesen. Sie können ausgezeichnete Qualität erhalten, wie wir Sie erkennen können. Akte. Du könntest Eier essen. Smaragd. Sie können jede Art von Datei dort bekommen. Komm schon dafür. Ich sehe, wenn wir hier sind, ist
das eine Open-Source-Art von Daten. Niemals zu dir. Sie können fast sofort. Also lese ich das diesjährige, das wir an diesem Tag eingereicht haben. Ich werde in dieser Datenruhm erzählt werden. Und ich sagte: Du musst nichts tun. Lassen Sie uns ziemlich sagen, ein sitzen auf viel genau hier. Hast du die Daten im Datenrahmen? D Wenn es jetzt an ist, was auch immer unsere Anwesenheit Sie hier auf dem Datenrahmen durchführen, können
Sie die gleiche Art unserer Präsenz auf den Daten durchführen, aus diesem ist der erste Schritt in jedem maschinellen Lernen. Sie müssen zuerst die Daten lesen. Dann fangen Sie an, die Daten zu schneiden, zu würfeln und zu analysieren. Ok? Mit dieser Vorlesung sind wir fast fertig. Wir haben genug Details in Panda auf erforscht. Unsere Akte ist fertig. Es ist Zeit, den Kampf zu sagen. Also geh hier. Kämpfen. Sue ist an. Dann können Sie hier den Namen bekommen. Sie sagten, das wird mein Kampf. Es gibt einige gute Dinge über sehr nützliche Dinge an dir, Peter. Aber ich werde Ihnen zu gegebener Zeit von ihnen erzählen. Eine sehr wichtige Dinge, die ich Ihnen jetzt sagen möchte, ist, dass Sie diese ganze
Datei herunterladen können Shtml als pdf sind alles zum Beispiel. Ich kann diese sht herunterladen, usw. Wenn ich öffne. So kann ich jetzt die Kämpfer in diesem Kampf für jeden auf David sehen. Ich habe Tag alle Kommentare. Gold argumentierte, dass der kalte Lauf abgeschlossen ist genau da. Aber das ist dein komplettes Notizbuch. Man kann mit jedem sagen, dass man in der Tat gute Hoffnung
setzen kann. werden wir zu gegebener Zeit tun. Das ist eine Schönheit von Jupiter. Also hier geht es nur um Panda auf Jupiter. Wir sehen uns in den nächsten Vorträgen.
9. DataExplorations-Seaborn2: Wie kam es, ich sitze in einem Restaurant und ich denke, wenn ich eine Daten von Kunden aus dieser Rhetorik und wie viel sie auf der Rechnung sind wie viel sie Schmerzen als Tipp haben. Einige Informationen über diese Kunden wie ihr Geschlecht, ob sie Raucher sind oder nicht, Wissenschaft aus der Partygröße, Wie viele Kunden essen zusammen? Kann ich ein Muster finden? Und kann ich sagen, wer mit Rauchern mehr zahlt, mehr
bezahlen oder Nichtraucher mehr zahlen auf was hat der Server gefallen? Kellner werden tiefer. Werden Sie eine Art von Einsicht finden, dass sie in die Welt gehen, außer dem Datum, den ich erreiche, ist die
Datenexploration nicht einer der wichtigsten Schritte für Datenwissenschaftler? Wenn Sie Ihre Daten nicht verstehen, können
Sie nicht viel damit tun und Biss und Bräute. Mehrere Bibliotheken für die Datenexploration Matt Part und See Bon sind diejenige, die
am meisten in diesem reicheren verwendet wird . Ich werde dich durch die Seaborn Library führen. Nehmen wir an, sie haben das Gefängnis angegriffen, indem ich „Go on Lektion 40-Bibliotheken“ sehe. Natürlich die erste Bibliothek wird Fonds Erde Schönheit auf Import Si bon SNP Lassen Sie uns importieren dumpy als und drei Hauptbibliotheken ist unser Brot und Butter aus jedem Datenwissenschaftler. Als nächstes werden wir den Datensatz vor allem jede Bibliothek importieren, wie eine Bibliothek als Beißer sehen. Bibliotheksfahrt. Ihr eigener Datensatz für Verkostungszwecke war, dass wir verabscheute Kartendips von der
Küste importieren . Da sind die Tipps gleich ja, in dieser Dunkelheit. Ihre Daten sagen, auf dem Datensatz. Name ist Tipps. Als Nächstes. Wir werden Fondas Datenrahmen für diese Daten erstellen. Sagte das, du weißt schon, dass
du
Sahne hast , und sie haben es dipsy gemacht. Sehen wir uns da zuerst an. Wenige Rollen nach Daten waren gut zu gehen. So weit, so gut. Okay, lassen Sie es uns laufen. Deine Krankheit. Oh. Ja. Ja. Das wäre eine Krankheit. Okay, also hier gehst du. Dies sind die Daten, die gesagt werden, dass wir an einem sehr einfachen Daten sitzen arbeiten werden. Es sah die tief bezahlte Gesamt Rechnungsbetrag sechs männlich oder weiblich auf, ob die Person, die
diese Summe bezahlt wird Betrag und Tafelberg Restaurant war ein Raucher oder nicht. Welches Datum war das? Eines Tages ist es tot. Und wie spät wares? War es ein Mittagsessen? um wie viel Uhr es war. Wie groß sind die Partygröße? 2345 Ok, so sehr einfach Data ist es. Mal sehen, wie viele Daten in diesen Daten vorhanden sind? Setz dich so, d f Dr. See, er geht zu Sue s verabscheut zu ihren 44 Reihen. Und natürlich gibt es sieben Spalten. Nicht sehr groß. Jetzt haben wir diese Daten. Das ist sehr leicht zu verstehen. Welche Art von Detritus? Aber als Sie ein Data Scientist auf Sie sind gehen Zehe vorhersagen Tipp Dann ist es nicht nur Blick auf diese Daten. Andi, denken Sie OK, jetzt verstehe ich, dass Sie das Verhalten von den Daten verstehen müssen, dass auch das
genug war . Die Daten darüber, wie tief durch den Gesamt Billy Bounder durch einen Raucher beeinflusst wird, sind von Tag nach V Auto von Zeit, sehr Mittag- oder Abendessen. Unsere Seite der Partei, Diese Dinge, die Sie verstehen müssen, und dieses Verständnis dieser Aspekte, nachdem es
Daten Exploration genannt wird auf. Das ist, wo Seaborn praktisch ist. Also zuerst, es müssen Sie in solchen Fällen tun, ist die Verteilung von den Daten zu verstehen. Und um dies zu tun, müssen
Sie das Verteilungsdiagramm plotten. Sag einfach ja. Ennis Dart Dist! Blot auf def! Die DF. Betrachten wir also das ganze Objekt. Sie von diesen Übungen, wir wollen Zehe vorhersagen, die Tiefe basierend auf bestimmten anderen Variablen. Also unsere Zielvariable ist tief und es gibt bestimmte Funktionen abhängige Variablen wie Billy mein eigenes Geschlecht sprach. Ja, ich weiß, welches Datum Zeit und Größe ist. Also das erste, was ich tun werde, ist zu verstehen, dass diese zwei Person nach Tipp in diesem
Datensatz , ob es normale Verteilung ist, ist es nicht normal. Verteilt. Lassen Sie uns diesen Befehl ausführen. Hier geht's. Dies ist der Bezirk war nicht aus tiefen Daten auf es sieht aus wie eine normale Verteilung. Wenn Sie eine Glockenkurve wie diese sehen, handelt
es sich um eine Normalverteilung, mehr oder weniger. Okay, also lasst uns als Nächstes mehr. Ich werde Veach von dieser ganzen Welt verstehen, das Band am meisten
beeinflussen. Und um zu verstehen, dass das Beste ist, was Heatmap genannt wird. Die nächste werden wir treffen Karte zu zeichnen. Aber bevor wir die Heatmap zeichnen, haben
wir zuerst die Zehe, stellen Sie sicher, dass diese Dinge aufeinander abgestimmt sind. Also komm schon, denn das ist koordinierte Metriken Equus d, wenn dunkel es beziehen könnte. Als nächstes gehen wir auf die Zehe. Erstellen Sie Heatmap auf diesem. Korrelierte Metrik. Okay, traf die Karte. Kernmediziner auf, dass es. Das ist also ein Hit-Mann. Es ist nicht sehr informeller, weil es fehlt die Zahlen hier, um die Zahl, die
Sie sagen, eine Kunst, die es kostet durch hier River hinzuzufügen . Jetzt hat es Zahlen. Schau dir die Spitze an und hier unten. Siehst du, natürlich, Tipp zu Tipp wird eins dort Darvill drei zueinander sein. Aber unter der Gesamtrechnung und Größe, können
Sie sehen, dass der gesamte Rechnungsbetrag wirkt sich auf die Spitze am meisten dann Seite auf. Warum haben wir keine anderen Variablen wie diese bekommen? Ist Raucher tagsüber und alles, weil diese kategorisch variabel sind. Wenn Sie die Data Scientist Analyse dieser Daten durchführen, ist
das erste, was Sie tun werden, dass Sie diese kategoriale Variable in medizinische
Variablen konvertieren . Wenn Sie tatsächlich solche Analysen für diese Daten durchführen, werden
alle diese Spalte Zahlen sein. Deshalb kommen sie nicht hierher. Aber der Punkt ist die neue in der Heatmap-Analyse. Sie werden verstehen, dass Ihre Zielvariable am meisten von Weizenfunktion betroffen ist. Wann sind, können Sie unabhängige Variable auf sagen. In diesem Fall sieht
es so aus, als ob die Summe wirklich mehr beeinflusst als die Website. Hab es. Also müssen wir Merson über unsere Daten informieren. Bisher ist
das die Normalverteilung auf die Summe. Wirklich Menge festgelegt sind, die Tiefe mehr als die Größe des Teils. Sehr gut. So weit, so gut. Wir werden mehr visualisieren Essenz auf schaffen, die uns mehr innen durch die
Daten geben wird . Also neben visualisieren ist und wir werden erstellen, ist eine Handlung. Ich glaube, Death Dot Bist du ein Teil? Und hier drüben werden
wir stolz sein. Unsere X-Achse wird totale Rechnung sein. Warum Exes auf unseren Daten sein wird. Ist DF sehr einfach, okay. Und oder hier? Sehr gut. Also haben wir das Grundstück abgenommen. Total Rechnung war so steil, aber es ist nicht sehr klar. Ich meine, es ist nicht sehr informativ. Lassen Sie uns einige weitere Kriterien hinzufügen, um eine richtige Information zu erhalten. Wir werden Farbzeit hinzufügen. Okay, mal sehen. Jetzt geht's los. Wir haben zwei Grundstücke, basierend auf der Zeit. Nun, es ist ein Mittag- oder Abendessen. Gut. Lass uns etwas arbeiten. Nein. Sagen Sie, wer ein Raucher geht, wir werden mehr Informanten haben. Und basierend darauf, wo die Person Wasit Raucher oder nicht. Okay, jetzt haben wir verschiedene Farben, basierend auf einem Raucher. Ja oder nein. Wir sehen ein Muster. Ich sehe hier in beiden Fällen ein lineares Muster. So weit, so gut. Lassen Sie uns Größe hinzufügen. Auch die Größe dieser Darts. Hier wird es größer sind die kleineren basierend auf dem nächsten Riss täglich. Jede Erwähnung hier haben wir in der Kriteriengröße überzeugt. Wir haben hier eine Spalte, richtig? Also basierend auf der Partygröße Visy, die verschiedenen Größen aus dem Arzt. Und hier geht's. Je größer die Partygröße, desto größer sind die Hunde hier. Basierend auf dieser Grafik jetzt verstehe
ich, dass es ein lineares Muster ist, wenn die Summe zunimmt, die Tipi-Menge zunimmt. Und es gibt einige Partons im Zusammenhang, ob die Möglichkeiten, Raucher oder nicht. Aber wir konnten nicht viel hier, um zu verstehen, dass teilweise in der Hand am Tag
Regressing Linie basierend auf den Kriterien zu schaffen , ob es wara Rauch oder nicht. Und das auch. Nehmen wir an, ein dünnstes sind hier, ähm, gebracht und wieder einmal wirklich anfangen mit X ist Foltergesetz. Sehr gut. Warum ist gleich tief? Andi hat, äh Quest. Haben Sie eine Okay, also die lineare Regression, die wir bereits kannten, richtig? Wir brauchen mehr Informationen. Ist das nicht? Fügen Sie diese Kriterien für die Gleichheitszeit hinzu. Also müssen wir jetzt Diagramme basierend auf der Zeit aus, dem Tag an oder hier. Okay, wir haben zwei Diagramme beim Abendessen ausgeliehen. Wieder an. Es ist immer das gleiche Verhalten, ob zum Mittag- oder Abendessen Italien in der Nähe neu ristened. Ich möchte verstehen, ob es einen Unterschied im Verhalten gibt, basierend darauf, ob die Person Wasit Raucher oder nicht, Lassen Sie uns dies hinzufügen. Ha ha! Jetzt verstehe ich das. Schauen wir uns das an. So ist die bewährte ist ein Raucher Person auf der ah Herkunft hier ist Nichtraucher und es gibt ein Muster Die Person, die wir rauchen Wenn der Rechnungsbetrag weniger, er gibt re buchstäblich Motiv. Aber ich fragte die Billy Menge erhöht die tiefe Kun durch Raucher Radi nutzt im Vergleich zu der Person mit Artie Rauchen. Also, jetzt haben wir einen sehr guten Einblick in diese Daten, basierend darauf, ob die Person ein Raucher ist oder nicht so weit, verstanden
wir normal diese beiden Busen, die Spitze Betrag ist mehr auf dem gesamten Willen auf jetzt basiert. Wir verstehen, dass, wenn der Rechnungsbetrag hoch ist, ist
es besser, so Nichtraucher. Wenn Sie nach einem guten Tipp suchen, lassen Sie uns mehr. Lassen Sie uns noch etwas mit ihren Ideen hinzufügen. Und dieses Mal ziehen wir etwas, das Katzenhandlung genannt wird. Wir haben verstanden, dass es einen Unterschied im Verhalten gibt. Gibt es einen Unterschied im Verhalten der Tipi Menge basierend auf dem Wochentag? Um das zu verstehen, lasst uns eine andere Art von Chat ziehen. Sie sagen, X gleich heute. Andi, Äh, warum ist genau und Daten gleich Liebe Lester und das ist nicht fertig, aber weniger Renate, oder hier haben wir etwas. Es ist nicht sehr sauber. Also lassen Sie uns Art und Weise in diesem Boden Art Ort eine sehr wichtige Rolle auf für hier. Ich werde sagen, nett es einige. Tun Sie. Siehst du jetzt ein besseres? Dies sagt mir, dass am Freitag hat ah Liste Zahl aus Menschen Kommunion Onda Tipp in Monte. Nicht so hoch, aber am Donnerstag die Bandbreite der Menschen, die Dollar T gegeben werden, zum Beispiel, das ist hoch am Samstag, das gemütliche wenig oben, aber die tiefe Menge steigt, wie vielleicht viele Leute kommen auf Samstag und Sonntag Outs. Viele Leute kommen, noch
ein Blick auf das Innere. Dies sind die Art Off-Analyse, die wir je nach verschiedenen Arten von Graphen bekommen können. Wie ich sage, spielt
die Katzenhandlung dieser Art hier eine sehr wichtige Rolle. Ich kann die Art Zehe Wilen ändern, zum Beispiel, hier auf sie wird anders aussehen. Oh, hier. Also die gleiche Art von Information, aber es ist ein anderer Safe. Aber ebenso kann
ich Dips Toe Bar nicht ändern. Also eine andere Bar Art von Ted Sieben ist sehr gute Bibliothek, wenn es um Datum
Exploration geht . Es gibt mehrere solche Fragen von Etiketten, mit denen Sie Ihre Daten visualisieren können und Sie einen Einblick in sie bekommen
können. Bevor Sie also mit der Anwendung des Algorithmus auf das Training beginnen, helfen Ihnen
Ihr Modell und all dies, die Daten zu verstehen, bevor ich fertig bin. Wenn du hier auf Google gehst, siehst du, siehst du, Bond-Kampf und Bibliothek. Dies ist die Website für diese Bibliothek auf einige der Beispiele, die ich bald hier war von der Website und Sie können gehen und weiter erkunden, die sehr gute Beispiele hier haben. Das ging um die Seaborn Bibliothek. Und wie können Sie Ihre Daten damit erkunden? Eine Bibliothek. Wir sehen uns in der nächsten Vorlesung.
10. Datenvorverarbeitung: nach Datenerfahrung, und das nächste Gesicht ist die Datenvorverarbeitung. Denken Sie daran, dass die Daten, die Sie betrachten, für Sie als Mensch gelesen werden können. Aber wenn Sie diese Daten für Messina senden und Sie müssen es lesbar machen unter stabil durch eine Maschine auf Maschine, nur Dinge in Bezug auf Zahlen, die es nicht verstehen kategorische Variablen, Variablen wie wir in unserem vorherigen Datensatz hatten, wie männliche weibliche Mittagszeit des Abendessens, diese Art von kategorischen Variablen, die es nicht versteht. Also im Teil der Vorverarbeitung, müssen
Sie es in die Zahlen konvertieren. Aber das ist nur ein Stück Vorverarbeitung. Sie müssen bestimmte andere Dinge als Teil der Vorverarbeitung Ihrer Daten tun, bevor Sie sie
an maschinelle Lernalgorithmen weitergeben. Also fangen wir an. Wir werden damit beginnen, sehr wichtige Bibliotheken zu importieren. 1. 1 natürlich, ist numpty wie die MP, und dann vergessen Sie nicht Teich uns als PD auf Lassen Sie uns importieren Savon Sehr gut. Nun, da Sie alle wichtigen Bibliotheken bisher importiert haben, lassen Sie uns zuerst in Fort. Unsere Daten darüber werden die gleiche Datenstadt sein, auf der Sie in der vorherigen Vorlesung sind. Die Geschenke haben es uns aus der Tennis-Bibliothek gemacht. Es ist da drüben. Ja. Dann fange ich an, unter der Schule zu laden. Hat es auf Datensatznamen gemacht. Es ist vertieft. Als nächstes werden
wir Banda Data Frame über die Daten passt OPD Dart erstellen Did,
uh, uh, kostenlos auf, natürlich, Setzen Sie
einfach Tipps hier, dass es einen Namen hat. Ich habe Spring den Kopf von Hitter Rekorde verlassen. So vereint hayderi Karten aus dem Datenfreund, so dass wir Feld haben, dass wir die
Datenfamilie bekommen . Lassen Sie uns diesen tollen guten Job laufen, oder? Es ist fertig als Teil der Vorverarbeitung. Das erste, was wir tun, ist sicherzustellen, dass es keine Nullwerte gibt, wie es keine leeren Werte in einem dieser Funktionen sind Zielvariablen tun das? Es ist ein D der Videodaten von Name ist Nein. So wird es ja sein und nein auf nicht. So heißt es 000 Das bedeutet, dass es keine Datensätze gibt, die einen Rahmen anzeigen, der keine Werte hat, so dass alle von ihnen einen gewissen Wert haben. Sehr gut. Wenn es eine Spalte gibt, die keinen Wert hat, müssen
Sie eine Entscheidung treffen. Wie fühlen Sie sich, dass Spalte wie entweder Sie eine rote Zahl sind Sie nur ignorieren ihre die Karte. Es hängt von Fall zu Fall ab. Normalerweise ist
es keine Statistik, dass Sie diesen Datensatz ignorieren, aber in einigen Fällen wird nicht vorgeschlagen, dass Sie mit dem Durchschnittswert beliebt sind. So müssen Sie die Daten während ihrer Steuer progressiv auf studieren, dann entscheiden. Wie fühlen Sie die fehlenden Daten? Und wir werden das für ihre Niederlage in unserem Projekt tun. Für jetzt. Denken Sie daran, es sollte nichts geben. Nein, lass uns mehr. Nächstes Gesicht ist Zeh,
verstehen Sie, welche Art? Danach haben
Sie Ihre Daten beschrieben und hier drüben wird es. So haben Sie die statistische Analyse von Ihren Daten wie viele gibt es zu 44 Zeilen? Gibt es die Mittelwerte außerhalb des Datums? Ich Standard Atheismus auf alle anderen Details. Geschlecht. Haben Sie innerhalb von 1.3, dass mit dem Motor Datum die Details in der Nähe nicht sehr weit
voneinander . Dies ist nur richtig halten, dass der Durchschnittswert von BP 2.99, aber Sie können die gleiche Art
von Analyse erhalten . Die statistische Analyse für alle Variablen tief ist Ihre Zielvariable, Aber Sie können auch diese Entitäten für jede Variable alle Features,
jede Zielvariable in diesem Datenrahmen erhalten . Und um das zu tun, sagen Sie Ihre Daten Ruhm und dann beschreiben und hier arbeiten Sie. Es gibt Ihnen die statistische Analyse von allen neuen medizinischen ging sehr gut. Lass uns weitermachen, mein Freund. Hier kommt der wahre Spaß. Die echte Datenverarbeitung einen Anfang mit einer Bibliothekskarte, die noch von skaliert wird, äh, also ist es K ein Punkt, der von diesen Sit-Off-Bibliotheken verarbeitet wird. Sie importieren den Fonds, da Sie also zuerst brauchen, müssen Sie alle diese
kategorialen Variablen in Zahlen umwandeln . Und dafür ist es Etikett in Vierteln. Mal sehen, was es tut. Ja, richtig. Okay. Label Gorder das F entspricht ihnen Arbeitsauftrag. Okay, wir haben die Distanz und jetzt weniger vor Gericht. Die Funktionen Beginnen wir mit Sex. Hier siehst du männliche Frau. Lassen Sie uns es in eine numerische Zahl konvertieren, die einschließlich so weiter aufgerufen wird. Das Gemeinsame dafür ist Arbeit. Im Viertel auf Disco Teoh, Dunkle Passform unterstrichen Transformation auf DF auf der gleichen. So de of Sex Spalte wird mit Label im Quartal transformiert werden. Lassen Sie uns das laufen und setzen Sie sich für den F-Punkt-Treffer aus. Und hier geht's. Es änderte sich von männlichem Weibchen. Es wurde Null und eins auf. Auf dieser Grundlage können
Sie sagen, dass es weiblich durch Null ersetzt und mailen Sie es eins. Jetzt kann der Lernalgorithmus diese Spalte verstehen. Ebenso enthalten
wir alle anderen Variablen. Lass uns das machen. Ein Raucher drauf ist
mehr, oder Tag? Ich verstehe. Wenn du gut im Kampf bist, wirst
du das verstehen. Stattdessen, nachdem
ich ET einzeln geschrieben habe, könnte ich eine Schleife verwenden und ich konnte es leicht in nur einer Zeile machen. Aber ich will nicht, dass du es kompliziert wirst. Wie besser kannst du mit Martin machen? Ich betrachte Sie nicht als einen Kampf als Experte. Deshalb konzentriere ich mich mehr auf das, was Sie im maschinellen Lernen mit sehr einfachen
Befehlen tun können . Auch wenn es mehr als eine Nacht frei ist, können
Sie es ehrlich für die in Ihrem wirklichen Leben verbessern, indem Sie den Kampf in unseren
Gefangenen-Tools wie Blau und all das verwenden. Natürlich musste
er beißen lernen, aber um Data Scientist zu werden, musst
du nicht Experte nach dem Kampf sein, also hör mal zu. Oh, hier. Sehr gut. Nun, sehen
Sie, alle diese Variablen werden durch eine numerische Werte ersetzt. Es ist immer noch Datenrahmen noch Banda Zustand von ihm und er hält immer noch die gleiche Struktur. Nur dass die Werte, die kategorialen Variablen Arctic mit Zahlen platziert. Und jetzt wird Ihr Maschine-Algorithmus Thes diese Art von Vorverarbeitung verstehen Sie müssen
tun, bevor Sie sich entschieden haben . Aufgenommen in der vorherigen Richter, wenn wir über Heatmap sprechen, haben
wir gesehen, dass die Hit-Karte nur wenige Spalten betrachtet, wie Gesamtbänder insgesamt bauen tief und Größe auf sie nicht die kategorialen Variablen berücksichtigt . Jetzt haben wir diese kategorialen Variablen in tow konvertiert. Die numerischen Zahlen weniger erzeugen jetzt die gleiche Heatmap, und mal sehen, was passiert. Okay, also jemand auf dieser Zeit, die wir machen, um unsere Hit-Mann-Menge zu schaffen, wird unterstrichen. Meine Platte, das ist Cornelius und Metriken waren Sicherheit, weil die DF Dart Cory, hören und es ist die Heatmap und Daten erstellen, natürlich. Fühle unsere Sanitäter auf. Nein, denn und hier gehst du. Jetzt hat es alle Funktionen, die richtig sind. Es hat alles. Und an diesem Punkt, wenn Sie sich dies ansehen, sehen
Sie, für Tipps Gesamt Rechnung hat die höchste Zahl. So ist die Spitze immer noch am meisten von der Tochter betroffen. William sieht logisch für mich aus, denn wenn du gefoltert
wirst, ist der Betrag hoch. Ihr Betrag wird hoch sein, warum es sich negativ durch den Tag und die Uhrzeit auf die
vollständige Gesamtrechnung auswirkt , die nächste Variabilität am meisten betroffen ist Größe. Es wird von sechs und einem Raucher auch positiv beeinflusst. Aber der Raucher ist derjenige, der Italien Netting beeinflusst Sie werden Ihre Daten in
vorgestellten Werten und Zielvariablen aufteilen Hier. Die Zielvariable ist die Zehenspitze erhält eine Zielvariable Name es. Warum auf Sie gehen Zeh haben Dips in diesem Ziel variable weiße Spitze Druck y Punkt Hit Und hier gehen Sie Alle Tipps gibt es auf Ruhe aus dem Feld Sie werden als Funktion so x
auf nur ADF auf Ihrem guten Zeh setzen . Löschen Sie die Zielvariable aktiv. Es ist eine, die mit Ihnen Betrachten Sie alle, die Sie nur fallen aus dem Feld und dass es tief ist und Ruhe nach Datenrahmen. Sie sind zuweisen als die Zukunft, die nur verstehen, dass und diese drucken Sie Ihre extra Punkt Hit Sehr gut. Wenn diese Awesome. Jetzt hast du deine Ex. Hast du deinen warum? Als nächstes gehen Sie Zehe teilen Sie Ihre vollständigen Daten im Schlepptau. Trainingsdaten auf getestete Daten Training, die ich von Ihren Daten verwendet werden Moderner Zehenzug selbst, so dass es entscheiden kann, den besten Koeffizienten basieren auf modernen zu Ihnen. Und sobald es sich für das beste Modell entschieden hat, basierend auf dem Zug besser zu verwenden, wird es die
Testdaten toe Geschmack dieses Modells verwenden, wenn Sie immer verwirrt
sind, keine Sorge, es wird klar, wenn wir das Projekt machen. Aber für jetzt verstehen? Ich sagte, Daten Personen, die die Schritte bewerten, die Sie gehen, teilen Ihre Daten in Trainingsdaten und testen sie. Also lassen Sie uns das so weit ist Spaltung Rotator im Schlepptau? Dating. Steigen Sie auf getestet. Du wolltest schon wieder eine Klasse aus Ja importieren, Killer-Bibliothek? Ja. Skillon Dark Mord Das Opfer importiert Dean, ich respektiere nur, wenn Sie sagen, dass Sie 16 Picks Nur warum tun Sie warum? Dist bittet Fleck dist! Es ist Stiefelhöschen direkt an. Oder hier. Sie werden sagen, dass Desta-Größe wie oft vollständige Datengröße. Wie viel möchten Sie testen, wie viel Sie Zehentraining setzen wollen? Es liegt an Ihnen und unterliegt den Daten. Aber normalerweise, als Sturm, sieht man, dass Menschen folgen 80 20. Sie setzen 80% Daten für das Trainingsset und 20% Daten ein. Vater für die Hoden. So lassen Sie uns finden zwei sehr gut weniger gedruckt in diesem Frühjahr. Die Bänder sagen, dass Sie das komplette nicht mitbringen müssen. Du kommst nicht hierher. Es ist also ein großer. Es sind 2 40 Fotos, richtig? Drucken wir einfach die Teekanne Data Street. Okay, ich denke, sie sind gut genug, der Tod, wirklich? Er in der Lage ist es ziemlich Daten in Test und Tren Daten, zum Beispiel, die zusätzliche und hat 95 Zeilen und sichere Spalten gewonnen. Natürlich, da hat man so 123456 Und es s 1 95 Reihen aufgeteilt auf 44 Reihen in 1 95 gehen
Zehentraining und 49 gehen zu testen. Ebenso, für die weiße Trimmung, hat
es 1 95 Reihen Zehentraining und 49 zu gesetzt Also, das ist ziemlich viel, was Sie in der
Datenvorverarbeitung tun ? Gibt es weitere Komplikationen wie das Etikett enthalten wird nicht genug sein. Sie haben ein Herz im Viertel zu benutzen. Denn wenn Sie das Etikett nur im Viertel verwenden, dann gibt es uns freundliche Zahlen. Was können wir auf unterschiedliche Weise aussehen, oder? Wenn es Null und eins ist, können
Sie auch sagen, dass Null eine höhere Präferenz hat als eine, die nicht korrekt ist, oder? Genauso könnte es andere Daten geben. So toe, bekommen über solche Art von off voreingenommene Analyse sind kompliziert ist, welche maschinelles Lernen sind groß von meinem Training Zeh. Sie werden ein Herz im Viertel tun, obwohl bestimmte Dinge, die wir während des Projekts tun werden. Ich will es zu diesem Zeitpunkt nicht kompliziert machen. Dies sind grundlegende Datenverarbeitung. Du tust für mehr Sachen. Machine Learning Projekt. Vorerst ist
dies Datenvorverarbeitung im maschinellen Lernen für Sie. Oh, bevor ich den Namen hier mit dem Blitz einlasse. Hat, äh drei. Das ist er genial. Ich sehe dich in eklektischen
11. SimpleLinearRegressionExplanation: Hallo da. Jetzt ist der richtige Zeitpunkt, um über eine andere Art von maschinellem Lernen Algorithmus zu sprechen, wenn wir über maschinelles Lernen Algorithmen sprechen. Die erste 1 zu beginnen ist eine einfache lineare Abnahme. Was ist Regression? Du sortierst, verstehst die Bedeutung von regressiv. Wenn Sie in Englisch Wörterbuch suchen, die Bedeutung von Regressing. Die statistische Bedeutung aus regressiv ist eine Kennzahl nach Relation zwischen dem Mittelwert einer Variablen auf entsprechenden Werten aus anderen Variablen. Bleiben wir also bei diesem. Es ist eine Beziehung mit dem Mittelwert von einer Variablen, mit dem entsprechenden Wert von anderen Video. Lassen Sie uns mehr so in früheren Wählern, Sie haben durch Datenexploration auf Daten vor der Verarbeitung gegangen. Auf, dass er diese Grafik aus gesehen hat. Warum war sein Ex, es war eine verstreute Handlung? Im Fall von Tibbs Daten sitzen DeVIvo Schritte um ein ex waas Gesamtdilemma. Der nächste Schritt in Machine Learning Algorithmus ist toe. Prognostizieren Sie ein Verhalten basierend auf diesen Punkten auf dem Handwerk. Du musst vorhersagen, was als Nächstes passiert ist. Die Art, wie dieser Punkt aussehen sieht aus wie es wird ein linearer Wieder Halbmond sein. Wenn ich also eine Linie ziehe, könnten wir vorausgesagter Trend sein. Diese ganze Sache wird folgen. Der kritische Punkt hier ist zu verstehen, dass Veach Line eine korrekte Linie ist. In diesem Fall kann
die Zeile entweder dies'll Zeile sein. Kann es mit dieser Linie oder es kann. Mit diesem Land ist
es immer gerade Linie. Irgendwas davon sieht richtig aus. Woher wissen wir, dass ein Ritual optimal ist? Welches ist die beste Linie? Welcher verklagt den Trend? Der optimalste Weg, um herauszufinden, dass es etwas namens mathematische am wenigsten Esquire . Das heißt, du nimmst eine dieser Linien und ziehst dann vertikale Linien von deiner Trendlinie so dass der eigentliche Sieger wie deine breiteste ist. Dann kannst du diesen Unterschied löschen und einen Knäuel nach dem Unterschied nehmen. Für jeden dieser Punkte und nehmen Sie insgesamt davon. Die Gesamtheit, die Chor nach Differenz ist. Video Airlines hat die geringste Summe, die am wenigsten Esquire hat. Ungefähre ist nicht die Linien, zumindest die Summe ist die richtige Linie und das optimalste Licht. Also, das ist, wie ich in Worten beschreiben, wenn es um maschinelles Lernen geht, müssen
Sie es formulieren, und das ist die Formel dahinter, dass Sie die Koeffizienten dieser beschäftigten Reihe finden müssen, diese V Null und Beavan ist, was Sie zu finden Zehe ziehen das optimale Licht auf dies ist die mathematische Formel, um das bizarro und sogar in der Beschreibung des Selektors zu finden, finden
Sie den Link. Sehr Sie können gehen und lesen Sie die Details dahinter, wie diese mathematische Formel 1-Treiber. Aber für diesen Rektor, lassen
Sie uns verstehen, dass dies eine mathematische Formel ist. Du musst deinen Muskellern-Zeh ernähren. Berechnen Sie die bizarro- und Beaven-Koeffizienten auf, dann abgetrabt, um bösartig. Wie haben wir das gemacht? Ich bin quitt? Es ist ja, x y bias xx Was ist ihr Sex Weg? Ja, X Y ist der mächtige Bricusse. Und nach dem Unterschied zwischen XX ist und warum exes von Ihrer Trendlinie Ein tatsächlicher Punkt auf? Ja, außer ist Esquire der Differenz von X Wert zwischen der Zuglinie und dem tatsächlichen Punkt . Und das ist dein Beaven. Sobald Sie den Beaven bekommen, ist
die B-Null leicht beschäftigt. Heben Sie y minus B eins hinein. Sie werden dies in mehr drei Jahren Begriffe verstehen, wenn wir durch 10 Programm mit dieser Formel auf. Wir werden das für Beißprogramm verwenden, um die Zuglinie für den gleichen Datenzustand von der
Gesamtrechnung und den Klippen Betrag zu ziehen . Wir sehen uns in der nächsten Vorlesung.
12. SimpleLinearRegressionProgram: Hallo da. Willkommen bei dieser Vorlesung. Nun, da Sie verstehen, was einfache lineare Regression auf mathematische Formeln, die
es einbeziehen , Lassen Sie uns unseren ersten Kampf und Programm schreiben, das wird
die Implementierung einfacher linearer Regressionsalgorithmus auf diese. Wir gehen gleich von Grund auf. Wir werden den kompletten Algorithmus in unseren Kampf und Programm schreiben. Als Datenwissenschaftler müssen
Sie es normalerweise nicht tun, weil es in Bibliotheken der Ebene gemacht werden. Sie müssen nur die Bibliothek anrufen, und wir werden das tun. Geh. Aber lassen Sie uns durch diesen Vortrag gehen über Lassen Sie uns dies auf eigene Faust tun, so dass Sie verstehen und schätzen die Komplexität sowie Sie werden ein Gebot up Kämpfer verstehen. Also lasst uns die erste Überschrift beginnen, natürlich. schreib, was du weitermachen
willst . Nächster Schritt. Du weißt es schon. Ja, du hast recht. Importieren Sie die Bibliothek ist ein Tempe unter PT Matt Block und ich d Seien Sie nicht ein bei Dft auf Import Menschen auf seiner in einem Benommenheit, richtig? nächsten acht Anweisungen für die erste Funktion, die wir schreiben werden, ist das Finden der Klippen. Das ist bizarro und Beaven. Und hier ist unser erster Fox und finden Griff, er wird X passieren und schreiben. Mit dieser Funktion wird
es uns schnell hindern und nach kann verdammt Größe sein. Dieser Befehl wird uns die Größe des Datensatzes auf geben. Als nächstes finden
Sie den Mittelwert Victor. Verlängern Sie den Weg. Dies haben normale GNB-Befehle, die Sie bereits gelernt haben, ist, wenn wir über normale und
die Bibliotheken sprechen . Also habe ich nicht wieder absichtlich darüber. Sie wissen bereits, dass diese Dinge Kunst behindern ganz auf bedeuten. Als nächstes gehen wir toe, berechnen das ja XX und ja, x Y Ich erinnere mich, dass die B gleich ist. Tun Sie s x y von als xx und hier werden wir zu berechnen Ja, x y und ja, XX s Ex-Frau. Nehmen wir an, das wird sein und Pete sind einige von X in y minus und das ist die Größe hier in Mittelwert X in Mittelwert rechts auf. Ebenso s XX wird gehtto MP Hund Daumen aus sein. Wenn X und X minus Yen in I off x two bedeuten, meine
ich off und jetzt ist es Zeit, den Koeffizienten zu berechnen. Großartig. Also, was ist das? B eins ist gleich s ex Frau von S. XX auf beschäftigt. Wer wird gleich sein? Meine ich, warum? Minus sogar in mittleres X? Erinnerst du dich an die Definition des freien Grayson? Geh zurück und überprüfe, was nach David genug Regression ist, und du wirst verstehen, was wir hier
tun. Ok? Auf ihrer diese Funktion wird uns B Null zurückgeben. Andi. Sehr gut. Wir haben den Koeffizienten. nächste Funktion wird also ihre Reue im Leben viel planen. Okay, schreiben
wir unsere konstante Zehenhandlung. Sehr christlich wie So werden wir einen BLT nennen. Unterstreichen Sie die Regression auf der Punktzahl hier drüben. Wir werden X passieren warum? Und b b der Bereich, der Besucher helfen wird und in der Lage sein, Partei ausgerichtet Die regressiven Linie Sie brauchen, setzen Sie X Wert gesetzt. Warum? Werte und die Koeffizienten B Null und gleichmäßig sein. Das sind alle Verhaftung. Dabei handelt es sich nicht um einzelne Werte. Schuldig ist Vieh. Also gehst du zu Blut. Der wird blockiert. Erster Gang X. Warum Farbe? Lasst uns das ist m. Okay auf dann Marker. Mal sehen, ob unser Familienliebling auf dann Größe des Marcus ihre Technik in Ordnung gelassen hat und dann sage ich voraus, richtig? Dies ist prognostizierter Wert aus. Warum? Weil auf Ihrer Bahnlinie Divi-Werte vorhergesagte Werte sind, oder? Also, warum vorhergesagt quoth b Null b Koeffizient plus Beavan auf ihre wir wollen und dann X Und jetzt ist
es Zeit, E Grayson zu plotten, Sie haben X. Sie haben y Poetik und wurden vorhergesagte Werte. Und Sie haben bizarro und sein, wenn Sie schnell sind, da jetzt können Sie die Schuss Jahr teeter
Handlung X y Zopf blockieren und es ist eine Farbe Seine auf Basis geliefert Speer Tito Nachbarn waren Karte
tot auf bärtigen sind, warum Sie es richtig. Und dann so das Produkt für so müssen Sie nur sehen gebaut es aus. So sehr gutes Video zu Funktionen Wollen Koeffizienten auf anderen berechnen Um das Reue
im Leben zu ziehen Wir sind jetzt fertig, wir müssen nur die Hauptfunktion schreiben und diese Maut aufrufen. Es ist sehr einfach. Jetzt werden wir das oh schreiben, hat diese Unterüberschrift strebt, hier zu hash. Ok. Und sie sehen Margo sehr gut auf es ist Zeit, die Hauptfunktion Sehr gut zu nennen. Das ist richtig. Die Hauptfunktion. Ich kann meine Aufregung nicht mehr halten. Okay,
meine, wir werden die gleichen Tipps verwenden. Datensatz. Ich weiß, dass du sehr aufgeregt bist. Also lasst uns weitermachen. Lassen Sie es uns beenden, Herr, Es hat gesagt, Dips auf Indien. Häufige PD. Nein, ich habe Sahne tief gemacht. Das ist eine ziemliche Dips. Deine Tipps und lass uns den Kopf bringen, damit wir wissen, dass wir es richtig haben. Ok. Als nächstes sind unsere aus den Gründen wählt die F Also was ist X? Denn dies ist eine einfache lineare Regression. Wir können nur eine unabhängige Variable haben, oder hier sagen wir Tochter Bill, warum er DF wird. Und als nächstes rufen wir unsere Schätzung Frau an, was ist das? Geh hier. Finden Sie schnell, um gleich zu sein. Finden Sie Grab auf Jim Path X und rechts auf. Dann blockierte den Platz in der Schlange. Und wir sind hier. Wir werden unser Bier D rigoros und Linienfunktion nennen. Copy basiert Andi X Y und wir haben unser jetzt so normal, wenn es mich gut geschlossen hat, sind
wir fertig. Lassen Sie uns es jetzt ausführen. Und los geht's. Eine Stunde abschweifen. Und neun. Das ist es, was es braucht. Tow erstellen Algorithmus in Fightin Toe. Haben Sie Ihre einfache Liga bereut im Leben. Ich weiß, was du denkst. Du musst nachdenken. Aber ich sagte, du hast es nicht. Wir bekämpfen einen Expertenzehen, werden Datenwissenschaftler. Lernen Massie? Professionell? Eigentlich hatte
ich recht. Sie müssen diesen Algorithmus nicht von Grund auf neu schreiben. Diese warten schon auf dich. Es gibt Kämpferbibliotheken, die bereits erhalten sind, die diesen
Algorithmusaufbau bereits haben . Du musst die Bibliothek nur anrufen. Ich werde dich durch eine solche Bibliothek führen. Eigentlich haben Sie die Bibliothek schon gesehen, als wir über „Sparen“ gesprochen haben. Es gibt verschiedene solcher Bibliotheken. Aber schauen wir uns das an. Das ist mein Favorit. Dies ist Farsi glaubte lineare rechristen auf sie wird von Sieben zur Verfügung gestellt. So sagen sie im Jahr. Kristen, du siehst heute Abend C Bauer, Baby auf oder hier musst du nur einen reiten. Komm schon, du musst nur einen einfachen Komm schon schreiben. Nehmen wir am selben Tag, tut es hier. Okay, diesmal gibt es eine DF auf dem einfachen Befehl, all diese Dinge zu tun, ist die Dissonanz. Starten Sie ein Glied, den Block ex Rekord, Zehe Gesamtbier. Und warum zu tief auf dem Date gehen? Ich könnte das Telefon anziehen. Nur diese 19 Komm schon und du wirst das gleiche hart bekommen. Hier geht's. Genau die gleiche lineare Regressionslinie. Die einfache Zeile, aber nur ein Befehl und das ist die Schönheit aus Gebäude, Kampf und Bibliothek während dieses Kurses sehr möglich. Wir werden das Bauen bereits oder Level-Bibliotheken für Sie verwenden. Andi, das war's. Das ist das Ende dieser Vorlesung. Als Nächstes. Später werden
wir etwas benutzen. Sie können sich auf die reale Welt besser als diese Tipps Datenbank beziehen. Werden Sie ein einfaches lineares Recristened für dieses reale Weltbeispiel verwenden? Daten aus der realen Welt sitzen. Und danach werden
wir zu verschiedenen Algorithmen übergehen und mit verschiedenen Kämpfen und
Bibliotheken herumspielen , so dass ich Sie in der nächsten Vorlesung sehen werde.
13. Einfache Linear Regression Height Step1: Hallo. Es wird zu diesem Vortrag in diesem Lecter kommen. Wir werden ein einfaches lineares Regressing umsetzen. Aber dieses Mal werden wir Kampfflug-Bibliothek benutzen. Wir werden nicht unseren eigenen Algorithmus schreiben. Wir werden Biss und zur Verfügung gestellte Bibliothek verwenden, und wir werden die Punktzahl messen. Die Performances punkten für dieses Modell, um sicherzustellen, dass es funktioniert. Fangen wir an. Das erste Band, wie Sie wissen,
ist, zu definieren, was wir tun werden. Also lasst uns gleich hier. Die Überschrift. Einfach in dir, Chris. Und hast du das? Andi und ja, ich weiß, was ich tun wollte. Das geht weiter. Weniger Import von Bibliotheken. Nein, B hey kann importiert werden. Fonda's hat Mitleid mit dem Import. Si bon wie in der Erde und fragte, aber nicht zuletzt sehr wichtig. Importieren Sie verrückte Handlung hier. Efeu nicht so sein. Blutreinheit groß. Jetzt passen wir an, holen Sie unseren Datensatz. Lebensmitteldaten Staatsmarkt Sperren Sie die Quelle für Tag. Tut es? Sie finden in der Beschreibung dieser Vorlesung. Laden Sie einfach die Daten herunter. Setz dich irgendwo auf deinem Computer und dann bestätigst du diesen Befehl für den Pandas-Datenrahmen ,
um diesen Kampf zu lesen, es wird Textdatei e d dot sein Obwohl es eine Textdatei ist, wirst
du immer noch sagen Billy Darcys Unterstrich CS drei sie sind und setzen Sie den Teil, in dem Sie die Datei gesagt
haben Der Dateiname ist Bill DJ Stories, nicht txt. Esser liefern. Du solltest als meine Kernbelastung setzen. Ja, und plus und schließen Sie es. Das war's. Auf verzweifelten Deif Kopf, um sicherzustellen, dass es dort in der tohave, es sei denn mieten sehr gut. So sterben sie dort im Grunde die Daten aus Bauhöhen oder sensiblen Geschichten in diesen anderen Jahren auf DA Dies ist nur ein sammelt genug Daten und das ist der Datensatz, den sie für verschiedene Jahre
erstellt haben . Sie sehen, wie Maney entschieden Gründe, dass es d nach Schaf 60. Es gibt also 60 Beobachtungen, die Ach haben, richtig. Von 9 19 neunziger Jahren bis zu mehreren anderen Jahren haben
sie tatsächlich Höhe von den Gebäuden kriminalisiert waren sexy Geschichten. Was ist das erste, was Sie Jake in der Datenexploration? Sicher zu nehmen ist auch ein Teil, nachdem Steuerregel nicht so ist. Wir haben schon begonnen. Der
Bodenbelag ist explodiert. Okay, also jetzt sind wir in diktieren explizit Step. Ich habe bereits den Safe überprüft und ich weiß, dass es 60 Beobachtungen gibt. Als nächstes werden wir überprüfen, ob es irgendwelche Nullwerte gibt. Und komm schon für das ist DF ist nicht auf so genial. Es gibt normale Werte. Das Hyatt, Irgendwelche Geschichten? Die Daten, die wir herumspielen werden, sind bereits numerische Daten. Also haben wir es nicht kodieren. Das ist eins. Wenn wir nicht als Nächstes tun müssen, werden
wir sehen, welche Art von Gemüse und es hat. Es sollte normale Distributionen haben und für uns Lini zu verwenden, erstellt einen Algorithmus und Befehl dafür ist, dass Sie bereits wissen. Ja,
genug, dass es Eban Dist darauf gebracht hat. T h t und dann Arzt werden. Sehr gut. Hier geht's. Es sieht sehr normale Distributionen aus. Es gibt hier einige Anomalien, aber wir können es vorerst ignorieren. Also, was ist es? Sieht aus, normale Verteilung. Gute Nachrichten. Jetzt, wo wir wissen, dass es ein normalisierter Wilson ist, werden
wir die Art der Beziehung zwischen Höhe überprüfen, Irgendwelche Geschichten? Frischste Aping, die zu zeichnen ist. Ich streuen Produkte waren gut. Sagen wir Zeit oder so. Und hier werden wir die verstreute Beziehung. Es sieht aus wie eine normale, einfache lineare Abnahme der Höhe steigt zusammen mit ihren Geschichten, so dass wir spielen und
einfache lineare Regression verwenden können . Okay, ich denke, wir haben genug Informationen über Daten. Jetzt können wir zum nächsten Gesicht übergehen. Das ist die Datenvorverarbeitung. Sie haben die Verarbeitung. Vielleicht werden wir abgestempelt. Aber nachdem die Vorverarbeitung zuerst die Daten aus den Daten in Ei beten und warum
wir die Anzahl der Stockwerke vorhersagen, die das Gebäude
aufgrund seiner Höhe haben kann . Die X-Variable wird also versteckt sein. Und warum wird dann die Anzahl der Etagen sein? Sie so weit, so gut Sie haben die X und Y gefangen, bevor wir weitermachen und bevor wir dieses X und Frau teilen, sind da in zu trainieren und Datum Datum, wie es wir haben, um sie in NPR A konvertieren An dieser Stelle, sie sind in Banda State. Ein Rahmen für Sie in der Lage sein, s Kaylan einfache lineare Regressionsalgorithmus zu verwenden. Sie müssen sie toe np ery auf konvertieren. Es ist sehr einfach, nur Zehe in diesem Jahr schließen und dann Werte sagen. Ich mache das Gleiche für die andere Kreuzfahrt und sage Werte. So weit, so gut. Als nächstes werden
wir den Datensatz in Zug- und Testdaten nutzen Wie es ist, schreckt
der Schmerz und Geschmack ihn von seiner Kalen Dart Modellauswahl ab. Importieren Korn gewellt und jetzt nimmt 10 x Gerade warum der Schmerz? Warum wird einfach Dean sein? Geschmack Desperate X und warum Gericht zu retten Er wird 0,2 auf einem zufälligen Zustand
wird Null auf diesem gedruckten Pick Chain X sein. Warum nur auf dieser Reise? Sehr gut. Also haben wir die Daten hier. Es ist gut. Also, anstatt alles zu mieten, hätten
wir nur entscheiden, staatliche Medienkompetenz. Nein, si 48 waren 48. Na ja, genial. Bisher, so gut neben gehen, um Modell Auswahl Daten vor der Verarbeitung zu tun ist wiederum. Es ist Zeit, die moderne zu wählen, und das ist, wo die A kritische Teil aus der Auswahl der aktuellen Alkohol Italien Sterne basierend auf dem was wir bisher gesehen haben, ist eine einfache Verteilung. Und es gibt eine lineare rechristen Beziehung zwischen dem Versteck. Irgendwelche Geschichten. Wenn man erhöht den Wert von anderen erhöht auch, so ist es eine einfache genetische, wirklich, da es So werden wir eine einfache lineare Regressionsmodell verwenden. Und das einfache lineare Regressionsmodell geht toe kommen von SK. Lernen Sie von Eskil, Dann dunkel, mager Jahre Mordor er bewegt und in der Luft, Griechenland, hier
drin. Sie sind immer noch hier drin. Klicken Sie darauf beendet, aber der Grund. Okay, jetzt ist die nächste Sache, die Moderne in Mörtel zu entleeren. Warum müssen wir im Mörser behandeln? Irgendeine Idee? Denk darüber nach. Es ist etwas, Religion Toe Berechnung des Koeffizienten und weiß trügerisch.
14. Einfache Linear Regression Height Step2: Warum müssen wir Schulungsdaten bereitstellen? Dieses Modell auf die Zehe setzen? Denk darüber nach. Ja, du hast es. Der Algorithmus ist da, aber
jeder einfache, jede bedauert und hat seine eigenen Koeffizienten. Warum abfangen und seinen eigenen Beaven? Der geschäftige Ruby, als wir über direkt auf diesem beschäftigten Araber gesprochen wurden, kann sogar
nur auf der Grundlage der Daten berechnet werden . Das ist, warum Sie Trainingsdaten zur Verfügung stellen, sagte toe dieses Modell, so dass es die schweren Sünden für Ihre Daten berechnen kann. Wir gehen, um diese Griffe zu bringen und lassen Sie uns tun, dass gepinnt gehen Fisch, da gelten Abfangen auf dem gemeinsamen für das ist linearer Punkt Abfangen auf dann nächste ist Print Griff und lassen sehen Grab Beamten sogar auf Sie können den Rat ingley in der Nähe krank bekommen, nicht aufhören, wenn Grab unter der Schule. Mal sehen, hier haben wir die Werte Dieb ich abfangen in diesem Fall minus 2,5 auf den Klippen Zelt ist 0,7 es so Ihr Modell ist fertig. Ihre Beytin Bibliothek hat es mit Ihren Daten belastet und es hat den
Koeffizienten bei Interesse zurückgegeben . Das bedeutet, es hat diese Abnahme in hier y gleich minus 2,55 65 plus Null. Sie gehen davon aus, dass es für zusätzlichen Tod ist, Equis. Und es hat für Ihre Daten abgeleitet. Als nächstes gehen wir toe Test dieser Koeffizienten,
diese linearen Modelle, schwindlig Quiz und durch die Bereitstellung der getesteten ist, dass das ist, warum wir aufgeteilt Der Zug Datensatz war um das Modell zu trainieren, so dass es die Koeffizienten berechnen und schmeckte, wie es ist , um es zu testen . Ob dieser Koeffizient, der dass mein Abfangen, den es berechnet hat, Ihnen die richtigen verbleibenden Werte gibt. Damit werden
wir die Y-Werte vorhersagen. Warum Brot beantragen die im Jahr zik dot Predict auf X dissed. Wir müssen die Frage sehen. Jetzt stellen wir hier X-Daten zur Verfügung und es wird Zehe geben Sie uns das Y
darauf . Warum? Wir rufen uns an. Warum Licitra vorhersagen Und dann werden wir in der Lage sein, diese Fähigkeit zu vergleichen. Dart zerstreut uns. Sie streuen auf Next wir gehen Zehe plotten die Regresslinie mit X gerade und warum
gut gespielt und so dieses Lassen Sie uns es von hier laufen gehen! Sie sagen, Farbe gleich rot Jetzt haben wir diese weißen vorhergesagten Werte Diese rote Linie
basiert darauf, warum vorhergesagte Werte und es sieht sehr gut aus, richtig? Es geht zwischen den verstreuten Darts. Es sieht so aus, dass es in der Lage ist, das Verhalten vorherzusagen. Wenn es mit einem Diagramm nicht sehr klar ist, gehen
wir zu Fuß, vergleichen die Werte. Vergleichen wir die warum prognostizierte Werte mit den weißen Testwerten. Und dann werden wir es wissen. Okay, also sagen wir, der F wird BD Dart,
äh,
Thema gemacht äh, . Wir werden tatsächliche Werte haben, weshalb Test und dass wir mit dem
vorhergesagten vorausschauenden Wert vergleichen werden. Warum Unterstrich vorhergesagt hier pret auf. Nun lasst uns zu diesem lieben Telefon bringen und vergleichen wir 70 bis 69 aus, dass große waren Teddy wollte 2130 54 55. Es ist ziemlich nah dran. Die prädiktiven Werte liegen ziemlich nahe an den tatsächlichen Werten. Sie wissen, was das tun auseinander Diagramm, das uns machen wird, dass es eine mehr Klarheit geben würde, also muss ich d gleich dem F ein Punkt Kopf haben 15 Türen auf diesem Grundstück. Es müssen sie nicht plotten Art ist bar auf. Dann sind es die Zahlen. Fünf ist 16 10 auf der nächsten setzen Sie einfach das Maß und kleinere get Linien auf die gleiche Sache für die Nebenlinien. Für Nebenlinien. Ja, eine Mine. Es hier, Andi drauf. Eine Sorte hier. Jetzt können Sie vergleichen. Es ist gerade sehr sauber. Sie können die tatsächliche unten sehen. Die blauen sind tatsächliche Werte. Und unser jeder nicht vorhersehbar. Ja, ziemlich
gut . Sieht aus, als würde unser Modell funktionieren. Es ist in der Lage, die Geschichten aus dem Gebäude basierend auf seiner Höhe vorherzusagen, aber dies sind nur die 15 Datenpunkte verglichen wurden. Wie können wir sicher sein, dass die ganze Moderne für die 60 Rekord-60 Beobachtungen sehr effektiv ist und es wird für zukünftige Daten richtig vorhersagen. Also, wie können wir Ihre Frieden, dass das Datenmodell, das wir die Koeffizienten erstellt haben, und das warum Abfangen wurde von ihm und die Geheimnisse und wir kamen aus ihm tatsächlich funktioniert gut für die gesamte Datenmenge von 60 Beobachtung. zu tun, gibt es etwas, das Metriken genannt wird. Sie können die Leistung immer aus Ihrem Modell für Matic berechnen. Du gehst den Import, die Metrik hat zugegeben. Also, wenn Sie töten, werden
Sie Sanitäter von seiner Tötung der modernen Darsteller importieren. Wir waren ich über sein Auto zu seinem Kern reden. Es wird auch Modell Score genannt, die wir benutzen werden, sind in die Schule von seinen Tötungsmedizinern. Es ist Mord Wache Import sind zwei unterstrichen Punktzahl. Wir werden dafür sorgen, dass ihre wenigen Dinge absolute spätere Bedeutungen bedeuten. Leiser an. Sie sollen eskortieren. Lassen Sie uns ihn drucken, um zuerst zu punkten. Der Sprint ist durch mit der Schule, und das gemeinsame dafür ist unsere Punktzahl auf dann zu unterstreichen, oder hier setzen Sie die weiße nur einen Wert. Und warum dann vorhergesagt? Nun, sehr gut. Weniger bedruckt. Der Arterienwert beträgt 84%. Nicht schlecht. Es ist kein Zufall. Sie könnten dies immer verbessern, aber 84% der anständigen Punktzahl. Und es hängt auch von der Art der Daten ab. Wenn Sie mit einem Data Scientist sprechen, gibt es eine geteilte Meinung dazu. Einige von den Daten. Wissenschaftler glauben, dass, wenn es um lineare Regression geht, Modell nicht nur Kunst mit Gericht ist, die tatsächlich die Leistung von Ihrem Modell beziehen. Sie müssen auch die Bedeutungen leiser betrachten und root bedeuten Es ist eine ziemlich Liste. Berechnen Sie, dass auf der sehr zu berechnen, das ist, Sie gehen nur diesen metrischen Start bedeuten absolute Ruhe und Stolz der l zusammengebaut nennen. Warum auf dem Weg dissed? Ich meine, absolut später ist 4.1. Okay, als nächstes gehen wir den Zehenabdruck... ich meine, es ist ruhig. Andere auf Wieder geht es sechs Punkt bedeuten, dass er es erworben hat, wenn Warum dist auf dem Weg ein bisschen. Ich meine, Qualität
ist 31 als Nächstes, wenn es unhöflich ist, dass es ruhig ist. Die in PDR Unruhe schrieb Bedeutung Truppführer. Dies sind also die Metrik, mit der Sie Innenraum sparen können. Moderne Leistung ist gut oder nicht. Dies sind alle in statistischer Hinsicht und ich werde setzen Wahl setzen eine detaillierte Produktplanung jeder nach oh vor dem mehr Lassen Sie uns nicht vergessen, das Notebook mit den
Eigennamen zu speichern . Übrigens, du hast jedes dieser Notizbücher beschränkt, was auch immer ich hier schreibe, all diese Jupiter-Notizbücher sind da auf meiner Hoffnung. Ich werde auch den Link toe the get up auf der Beschreibung von einigen der Vorträge setzen. Sehr gut. Wir sehen uns in der nächsten Vorlesung
15. Einführung von mehrfachen Regression: Hallo da. Willkommen zur multiplen linearen Regression. Herzlichen Glückwunsch zum Abschluss. Einfach. Führend es Regression und modern in einfachen linearen Regressionsmodell. Sie haben verstanden, dass die Daten verstreut sind. Die unabhängige Variable auf abhängige Variable kann durch eine Gleichung sehr abhängig verwandt . Variable ist gleich Zehe. Warum abfangen plus Koeffizient auf unabhängige Variable? Es ist eine sehr einfache Formel, um in die Daten zu passen, wenn Ihr Projekt unsere Fallstudie, an der Sie
arbeiten , nur eine unabhängige Variable hat, auf der Sie unsere abhängige Variable vorhersagen , die nur darauf
basiert, dass eine unabhängige Variable auf der Frage wie linear aussieht. Dann haben Sie Glück. Sie können einfache lineare rechristen machen und erhalten Sie Ihren NL-Assistenten. Holen Sie sich Ihre Prognosen unter, aber normalerweise könnten Sie in Projekten wie diesem enden. Ich nehme Beispiel vom Hauspreis hier, also hängt der Hauspreis von verschiedenen Funktionen ab. Eine der Zukunft könnte das Familieneinkommen sein. Wie hoch ist das Familieneinkommen von Menschen, die in dieser Ortschaft verlassen? Wenn das Familieneinkommen steigt, erhöht sich die Erschwinglichkeit, so dass der Immobilienpreis in dieser Ortschaft hoch sein könnte. Das durchschnittliche Familieneinkommen ist hoch, so dass die Preise verbergen könnten. Das ist die Wonder Weisheit. Zweites Feature. Es könnte auf seine Ausstattung angewiesen sein. Wenn es eine sehr gute Ausstattung der Arbeit gibt, dann ja, die Immobilienpreise könnten steigen. Gleichermaßen. Kriminalität es, wenn Kriminalitätsrate ist hoch in dieser Lokalität als Hauspreise geht jetzt, Betrachtet dies jetzt haben Sie eine abhängige Variable auf drei unabhängige, sehr ableto spielen, die mehrere lineare rechristen genannt wird. Wie werden Sie vorhersagen, warum Jetzt müssen Sie eine Formel haben, in der Sie alle diese
unabhängige Variable durch ihre Formel passen können . Sie werden daraus eine gerade Linie kommen, die tatsächlich all diese unabhängige
Variable berücksichtigt und die Formel könnte ungefähr so aussehen. Warum die abhängige Variable gleich Null ist, ist der Y-Abschnitt auf dann diejenige, die
Koeffizient für Variable 1 Feature 1 auf Feature Manuel Koeffizient weites Feature und
Feature-zu-Wert-Koeffizient für Feature drei und drei Wert ist Koeffizient für Variable 1 Feature 1 auf Feature Manuel Koeffizient weites Feature und . Das ist also ein mehrfacher Linearitätssichel. Es ist die Grenzen genug einfache lineare Regression. Aber einfache lineare Regression hatte nur ein variabler Zehenspiel um eine unabhängige Variable . Im Falle einer multiplen linearen Regression haben
Sie mehr als eine unabhängige Variable zum Spielen, aber es ist immer noch ein lineares Modell. Es ist immer noch kontinuierliche Zahlen und es ist immer noch eine lineare, Regression und modern in der realen Welt. Du könntest so etwas bekommen. Vielleicht bekommst du ein Streudiagramm. Warum, Sie Asses x Es gibt Punkte verstreut Punkte basierend auf verschiedenen Feature-Werten. So erhalten Sie eine Daten mit vielen Funktionen auf. Basierend auf dieser Funktion müssen
Sie abhängige Variable vorhersagen, und dann müssen Sie daraus kommen. Ist Formel durch Ihre Trainingsdaten, Sie werden diese bizarro B ein b zwei b drei berechnen, die Koeffizienten aus diesen Funktionen und dann werden Sie diese Formel ableiten. Sobald Sie die Formel basierend auf den Trainingsdaten abgeleitet haben, dann sind Sie gut, so über unseren Fluss zu gehen. Dasselbe. Aber der einzige Unterschied ist östlich von einer unabhängigen Variablen ein Feature. Nun, haben Sie mehrere Funktionen? Nun, wenn Zehe spielen herum, so erhalten Sie mehrere Koeffizienten. Ich hoffe, Sie haben klare Unterscheidung zwischen einfacher und mehrfacher linearer Regression darüber, wie mehrere lineare Regressionen und funktioniert. Gehen wir weiter und lassen Sie uns Hanson machen und dann bekommen Sie den Deal-Exporteur diese mehrfache lineare Regression. Wir sehen uns in der nächsten Vorlesung
16. MLR Step1: Hallo da. Willkommen toe Dieser Vortrag über konkrete Koaleszenz machen Sie einen sehr guten Fortschritt. Ich freue mich sehr für dich. Jetzt, da Sie die einfache lineare Regression verstehen, wird
es leicht für Sie sein, Dinge zu korrelieren und mehrere lineare Anfragen zu verstehen, nachdem unsere es nur ein paar unabhängige Variablen sind. Richtig? Sind so gut. Also fangen wir an. Sie wissen es schon? Ja. Bibliothek importieren. Also lasst uns das machen. Sehr erste Import numpty als MP I konnte ich genau unberechenbar Tempo. Aber ich esse mit dir, damit du das durchführst und du
tippst mit der gleichen Geschwindigkeit, die ich tippe. Ich möchte, dass du jedem Schritt folgst und ich möchte mit dir zusammen sein. Deshalb kopiere und füge ich hier keine Dinge ein. Ich schreibe es mit dir zusammen. Okay, Kumpel, lass es uns tun. Sie setzen Bindung uns als Schönheit Import Beeban als Satz auf Import Matt Blut l I B Dart B A Blut als Schönheit. Lassen Sie uns es laufen, um sicherzustellen, dass ich keine Art von Ok bekommen habe. Sieht gut aus. Als nächstes werden Sie den Datensatz in früheren Director importieren, Sie verstehen bereits, wo die Daten sitzen und wie Sie sie erhalten. Sobald Sie diesen Datensatz auf Ihrem Computer mitgeteilt haben, können
Sie ihn in einem Panda-Zustand lesen. Ein Rahmen Musik? Ja. Lesen. Unterstrich. CSP links damit, Der ethische zu PD Dark Beat unterstrichen CS wir hier kennen, setzen unsere auf. Setzen Sie die komplette Verzeichnisstruktur, einschließlich des Dateinamens oder hier Definition ist arto behindert? Unsere Daten in dieser Datei sind nicht versteckt. Also wirst du einen Befehl schreiben, der Hasser gleich keiner ist. Der tägliche Zähler wird rückwärts sein. Schrägstrich s und plus Buchstaben schreiben. Führen Sie das aus. Ich möchte dir etwas zeigen. Hör zu, Andy, wenn nicht getroffen, was kriegst du? Du bekommst die Daten. Aber die Kopfzeile. Sieh dir das an. Es steht 012345 Wenn Sie den Namen dieser Hasser behalten wollen, können
Sie ihn hier geben. Jessalyn nennt Befehl ein. Setzen Sie Ihre Namen hier. Die Namen werden die 1. 1 sein ist mein Sporn. Gallonen-Zylinder. Der nächste ist die Verschiebung. Diese Platzierung auf dann Krankenhaus uns. Unser Nächstes ist Gewicht. Jeder habe ich eigentlich zugehört Dann mehr das Jahr Martin hier auf Auditing, aber auf dann Kartenname. Ich glaube, wir sind fertig. Es ist bereit, wieder. Wir sind jetzt gut. Wir haben alle Namen, oder? Ehrfürchtig. Das ist also etwas Neues, das Sie gelernt haben, verglichen mit dem vorherigen Regisseur, der
nach ihm darüber nachdachte . Sie können den Hitter als keinen setzen, wenn Sie Ihren Datensatz nicht eingegeben haben. Und dann könnten Sie die Namen von diesen Headern mit den Namen stolz sein. Komm schon. Gut. Dieser, WAAS-Datenimport. Was in dem Staat beginnen wir jetzt. Daten-Exploration. Du hast es. Daten extra Show. Nicht das erste, was wir tun werden, ist herauszufinden, wie sich die Daten darauf befinden, oder? Es gibt 3 98 Datensätze auf neun Spalten, 88 Features und ein Ziel. Also total, wenn man sich diese Pferdestärke anschaut. Oh, tut mir leid. Ich habe einen Geist falsch. Lassen Sie wiederkehrend diese weise Es wird verwirrend sein. So gut. Jetzt haben wir es. Öffnen wir die Daten. Und wenn Sie die Daten öffnen und Sie sich diese Daten ansehen, werden
Sie sehen, einige von den Pferdestärken haben Fragezeichen. Die erste Sache ist, diese Werte später loszuwerden, dass es verschiedene Strategien gibt. Toe, loswerden dieser Art, nachdem es entweder Zehe gelöscht sind, sind diese Fragezeichen
durch den Mittelwert unseres Durchschnitts zu ersetzen . Nun, es gibt verschiedene Möglichkeiten, es zu tun. Aber für diesen Vortrag über nur zum Verständnis, Ich werde es entfernen und wir werden mit dem restlichen Satz von Daten herumspielen. Lassen Sie uns das entfernen. Wir werden diesen Befehl ausführen. Unser Datenrahmen DF entspricht zwei DF Dot Drop, da wir ein paar Beobachtungen fallen lassen werden. Natürlich. Also DF haben Sie die Pferdemacht Frage Dart in der nächsten zu hören Liberace hat ok auf weniger hübschen de dunkler Kopf. Er mochte einige Verwendung von Daten vom Objekt hat kein Attribut. Harsch, Bob. Aber ich habe es immer noch auf Haas. Aber okay, lassen Sie es uns nochmal laufen. Fahrzeug Also haben wir die After-Becken beseitigt, die Fragezeichen in der Vergangenheit hat. Sehen wir uns den Safe wieder an. De of God ist jetzt 3 92 Das bedeutet, dass es sechs Reihen von Daten gelesen Fragearbeit in Pferdestärken Wert, und wir haben sie einfach loswerden. Okay, lässt mehr. Wenn Sie sich diese Daten ansehen, die
Pferdestärke, ist es sehr verständlich. Pferdestärken-Wert wird eine numerische sein, aber da einige von den Werten Fragezeichen waren hängen einen Zustand ein Frame mit Wenn es
die Daten aus dem Datensatz hier nahm , könnte
es nicht die Pferdemacht als numerische Zehe betrachtet haben. Finden Sie das heraus. Wir werden diesen Befehl DF dart anwenden Karte ausführen. Wer hier? Du wirst sagen und p dot ist okay. Andan's. Sieh dir das an. Es sagt, MPT sind wahr, dass Frau sie sind Alle Werte sind numerische Israel Zahlen Zylinder . Ja. Numerische Verschiebung Americal Patasse Power. Sieh dir seinen Fall an. Das war das Datum up Frame hat nicht Pferdestärken als numerische betrachtet. Also, was machen wir? Wir müssen dame toe numerische dies in diesen d f Hashbar mit pd dot konvertieren Medic DF nochmals Harsh power die Thunfisch Sanitäter Funktion in Banda Aceh Data Frame-Klasse Wir konvertieren die Pferdestärke in eine numerische Spalte. Okay, lass uns weiterlaufen. Lassen Sie uns wieder um den gleichen Befehl. Es läuft. So wurde dies eine wahre numerische nur gefüllt Rest, die kein Roman ist, Lewis Carnie. Abgesehen davon sind
alle anderen Felder numerisch. Wer ist jetzt? Lass uns herausfinden, ob einer von ihnen keinen Brunnen hat, richtig. Dies ist alles Teil nach Steuern fluoreszierend. Sie wissen bereits, dass dieser D von Dart nicht auf einigen kontrollierenden Rasen ist oder hier keiner von ihnen keinen Wert hat. Sind Sem ur viel Glück. Wir sind fertig mit der Basie auf Daten in ihrer Krawattenforschung überprüft. Aber hier kommt der lustige Teil. Wenn Sie so viele Variablen haben, die alle spielen, sind diese Variablen möglicherweise nicht in Ihrem Datenmodell erforderlich, Sie müssen zwei sehr wichtige Dinge verstehen, falls Sie so viele von den ersten haben, nennen
wir sie unabhängig Variable, und wir erwarten, dass sie Notley miteinander verwandt sind. Also zuerst werden
wir herausfinden, ob eine dieser Variablen miteinander verwandt ist. Das bedeutet, wenn ein Wachstum anderes auch im Wert wächst, haben Sie freundliche Beziehungen zwischen der unabhängigen Variablen gesendet. Dann brauchen wir diese Variablen nicht. Wir brauchen keine Armen. Diese Variablen in unseren Daten moderner. Wir brauchen nur einen von ihnen. Also, das ist, was nennt man Multi Genialität. Und das ist, was wir herausfinden werden, ob eine von unserer unabhängigen Variable Mutti coole
Genialitäthat Genialität
17. MLR Udemy Step2: Okay, also gibt es eine sehr einfache Angelegenheit, Metical in der Wohltätigkeit zu finden, gibt es verschiedene Modelle. Verschiedene Angelegenheiten sind das Auffinden von Multi Colin. Wir werden überprüfen, um sie ein, das ich als ein einfaches Modell betrachte, das heißt
herauszufinden , die Cory hört unter diesen unabhängigen Variablen. Also, wenn Sie nur ein D von dunklem Kern und dann dies gibt Ihnen hier eine Metriken, können
Sie sehr gut sehen, wie diese Variablen zueinander verwandt sind? Also, wenn man sich Zylinder anschaut, ist
es sehr eng ausgerichtet und abhängig von der Verschiebung, Tante Horsepower auf vit. Also diese drei Variablen, sie sind sehr miteinander verwandt. Zylinder, Verdrängung, PS auf Vit. Also genau hier haben wir eine Multicore-Linearität. Es gibt noch eine Angelegenheit, die als Berechnungsvarianten aufblasen und Faktor weniger zu
diesem bezeichnet wird. Also, jetzt, an der sehr gut, wissen
wir, dass Zylinder verdrängen ein Krankenhaus und warten. Sie sind sehr miteinander verwandt. Und wir haben eine Multi-Corden-Beziehung auf unsere Daten. So jetzt gehen wir Zehe Arbeit an Varianten Inflationsfaktor auch Karte V i.
F. F. Radiance an Ort und Stelle und effektiv die I f. Mädchen Karrierismus. Was brauchen wir also für die Berechnung von Varianten? Aufbläht und Faktor in erster Linie, wir müssen die erforderlichen Funktionen aus der erforderlichen Bibliothek importieren, die damit übrig bleibt. Also in diesem Befehl, von Statistiken Modellpunkt beginnt ausgehenden Einfluss Importvarianten, Inflationsfaktor. Das sind die Funks, und wir werden verschiedene Aufblähungen und Faktoren verwenden. Sobald Sie die Funktion importieren, das nächste, was zu beachten ist, dass wir Varianten in Fleisch und Faktor unter
unabhängigen Variablen berechnen . Also das erste, was ist, brauchen
wir keine abhängige Variable wie mpg. Und zweitens, für die Berechnung, Variante, selbstlos und Faktor. Wir müssen zuerst alle in Tippett Dent Variablen in numerische Zahlen umwandeln. Es kann nicht bleiben, ist lustig, Merrick. Also lassen Sie uns tun, dass erste D f eins gleich d f Punkt Holen Sie sich neue Sanitäter Daten. Okay, dann wird unser X Toby dier Telefon Dot Drop Also was? Was sind die Attribute? Wir werden fallen lassen? Wir haben bereits über MPG diskutiert. Wir werden MPD fallen lassen, weil es eine abhängige Variable in Edison Toe ist, die ich
vorschlage, dass wir den Ursprung hier fallen lassen, weil ich glaube nicht, dass es viel zum
Modell beitragen wird . Wie wird das Auto Neymar Herkunft wird Zehe dazu beitragen, das Modell aus MPT, wenn wir so
viele andere Variablen zu spielen haben , wie Displacement Hospital? Wenn es tatsächlich auf Marty gehört hat, lassen Sie uns das jetzt loswerden, dann werden wir sagen, Zugriffskurs ist nicht Es ist nur ein sehr einfacher Befehl, um irgendwelche Attribute in
Ihren Daten von, bis jetzt,
so gut,loszuwerden Ihren Daten von, bis jetzt, so gut, . Aber lassen Sie uns es laufen, um sicherzustellen, dass wir die korrekte Funktion importiert haben. Lass uns das machen. Wir haben es richtig Jetzt kommt die lustige Party von Varianten aufblasen infizierten VfR für das,
was wir tun werden, ist eine sofortige off Datenrahmen Klasse pd dot data team über hier Tandon v i e.
F. F. ein Effekt
sein. Besserer witzt. Wir werden diese Funktionsvarianten an Ort und Stelle aufrufen und auf vergangene Abwertungen X-Werte betroffen sind . Wir müssen jeden X-Wert eins zu einer Zeit übergeben, und das ist, warum wir eine weit Raum Art von Sache hier für ich in X Darts laufen. Ip eins. Hab es gut. Nate BF Funktionen gleich ex angedockte Spalten auf dieser Karte VF Runde, aber okay, lassen Sie uns das laufen. Ok? Ich habe etwas falsch. Was es ist VF Features waren X. Oh, wieder, Typo! Nicht, dass wir das tun. Okay, jetzt schauen wir uns das an. Die Tumblr Elise. Jeder Wert mit VF größer als 10 sollten Sie sie loswerden. Beginnen Sie mit dem, der hier den höchsten Wert hat. Es hat die höchste. Nun, also werde ich zuerst das Gewicht entfernen. Okay, lassen Sie es uns nochmal laufen und sagen, was es weg ist. Als nächstes haben
wir noch mehr Modell, das hat Studie auf Zylindern. Zylinder hat einen höheren Wert. Als nächstes werden wir Zylinder entfernen. Sehr gut. Wir kommen in die Nähe. Wir sind bei dir
übrig . Arison auf Marder. Marder hat einen höheren Wert. Also lasst uns eine Nadel holen. Marty Model hier. Was haben wir jetzt? Verdrängung und Pferdestärke. Lassen Sie uns das Krankenhaus loswerden. Wir kommen näher, siehst du? Eigentlich ruht und ist schon weniger als 10. Also, das ist gut zu gehen. Okay, lassen Sie uns das Krankenhaus entfernen. So sagte, wir haben so viele Dinge für die Herzen Macht getan. Gortari wurde diese Frage loswerden, die Waas in den numerischen Wert konvertiert hat. Aber hey, jetzt brauchen wir das nicht lustig, oder? Ok. Ok. Lasst uns diesen Arsch machen. Um, also schließlich haben
wir zwei unabhängige Variablenverdrängungen an, tatsächlich vor kurzem, und diese werden Teil unseres Datenmodells sein. Sieh dir das an. Dies wird als Datenexploration bezeichnet. Wenn du deine Daten verstehst, wird
dein Leben sehr einfach. Wir begannen mit acht unabhängigen Variablen, aber jetzt, wenn es darum geht, unser Modell zu erstellen, wissen
wir, dass wir keine sechs davon brauchen. Wir müssen nur diese unabhängigen Variablen der Kritiker MPG ausschalten. Gute Arbeit, bevor wir ihre Steuer PLO Grund zu schließen und gehen Sie auf Daten vor Verarbeitung Brief an eine weitere Sache. Lasst uns zeichnen. Ich streue Grundstück von diesen zwei unabhängigen variablen Verschiebung und tatsächlichen entstanden auf. Mal sehen, es gäbe einen schwereren linken Zeh, den ich hier kenne. Wir werden die Speicherfunktion verwenden, die Bär Plot genannt wird. Pierre Brock, das ist das erste Mal, dass Sie es verwenden, bis Sie es lieben werden. Bär breit TF ein auf X. Dies werden, Toby, Diese Platzierung Andi Aktivitäten in auf, warum wir gehen, um unsere mpg sein. Wenige Größe ist Punkt C eins und speichern Schönheit. Roshal, hast du es hochgeschnappt? Lassen Sie uns die Größe erhöhen. Es sieht sehr klein aus. Okay, jetzt haben wir es richtig verstanden. Ja, sie sehen aus wie ein linearer Wieder Halbmond. Nun, ja. Sie sehen aus wie eine gute Passform für mehrere lineare rechristen wie diese. Hör zu, Selenia Verhalten. Das sieht auch nett aus, furchtbar nahe Verhalten. Ich kann hier eine Linie zeichnen, und hübsch, aber sieht aus wie ein riesiger ist zart. Davidson ist hier dran. Polynombaum getauft könnte eine bessere Passform sein,
aber,
hey, aber,
hey, hey, wir hatten eine gewählte mehrfache lineare Regression auf Ich denke, dass mehrere lineare Regression und passt gut für beide von ihnen. Unsere Funktion wählt einen Schritt, der bisher noch nicht abgeschlossen ist. Was wir getan haben, ist, dass das Gericht Multicore-Genialität vorgelesen hat. Das bedeutet, dass wir die unabhängigen Variablen abgelesen haben, die sehr
miteinander verwandt waren . Wir müssen immer noch tragbar sein. Wir müssen noch entscheiden, welche dieser Variablen die größten Auswirkungen auf Ihr zuverlässiges
Produkt haben . Sie könnten mit beginnen, zum Beispiel, 15 20 bei Belohnungen, und Sie sind mit diesem verbreiteten Belohnungen links sind vielleicht 56 bei Bericht, nachdem Sie
entlassen medizinische in Wohltätigkeitsorganisation. Jetzt müssen Sie die verbleibenden Triples in einer weiteren runden Auswahl und Prozess ausführen
und es gibt verschiedene Auswahlverfahren sind Ebene in mehreren linearen Regressionsmodellen , die Ihnen helfen, herauszufinden, ob Reichweite unter den verbleibenden unabhängigen -Variablen sollten für Ihre endgültigen Daten berücksichtigt werden. Mörtel eins von Diese Kriterien wird rückwärts genannt. Alamin ist nicht eingeschaltet. Das ist eine, die wir für diesen Mörser verwenden werden. Es gibt verschiedene. Es gibt weitaus schlimmere Wahlen. Es gibt rückwärts eliminiert und sie sind sie Bide-Dachböden. Nel ich eine Minute, seit ich gehe, um jeden von ihnen zu erklären.
18. MLR Udemy Step3: okay, Rückwärtselement zu verwenden, nicht
wahr? Lassen Sie zuerst die erforderlichen Mittel aus den benötigten Bibliotheken auf Wir sind auf den
Import gehen . Gibt es Märtyrer Punkt a p a. Also an diesem Punkt, wenn Sie sich dies ansehen, haben wir eine Formel gefangen, weshalb gleich B Null plus kommt. Diese b null drücken Beaven ausgezeichnet plus B zwei extra, wenn Warum ist eigentlich unser mpg gleich beschäftigt wenig wird eine Konstante sein auf dann sogar Koeffizienten auf diesem wird Platzierung auf noch einmal Beato Another quip da auf oder hier und diesem ein
Hier wird es sein. Eigentlich ist
es nicht, rückwärts zu eliminieren und zu arbeiten. Wir müssen die unabhängige Variable hier auch setzen, es kann nicht einfach sein, durch zu sein, so wie es funktioniert, müssen wir zuerst sagen mpg gleich p Null in eins Und dann diese Werte hier. Das wird also unsere Formel. Das bedeutet, dass wir eine weitere Funktion zu dieser Tabelle hinzugefügt haben und diese Funktion hat Wert nur ein Soto Add, dass es einen sehr einfachen Befehl gibt. Wir werden sagen, X gleich sm Dart bei konstanter und das ist es. Es wird eine konstante Zeile mit dem Wert eins für X hinzufügen, lassen Sie uns X drucken und dann werden Sie verstehen. Oh, hier. So hat es eine weitere Feature-Karte Konstante hinzugefügt, und er transportiert diese gut mit 1111 Inhalt, Verschiebung beschleunigt. Und das ist gut, als nächstes oder hier zu gehen. Wir werden hier nur weitermachen, lasst uns reinkommen. Dieser Typ Griechenland, Sir. Bodenlos. Das ist der Name, auf den wir sofort gehen. Wir werden erschaffen. Wir können jeden beliebigen Namen hier setzen. Und ich würde ja, ähnlich starten Quayle s Y auf X, wir werden es passen. Und jetzt drucken wir die Zusammenfassung aus, okay? Und lassen Sie uns das sehr gut laufen. Also, wonach suchen wir in diesem? Wir suchen nach diesem Wert größer als Bindestrich sein. T auf einen beliebigen Feature-Wert. Größer als 0,5 ist signifikant mit seiner Spitze von fünf. Es gibt also eine große Theorie darüber, was? Es ist P und ich werde einen Block darauf schreiben. Andi,
ich werde es als eine der Vorlesungen ausdrücken. Wenn Sie verstehen wollen, was ist, was es Nullhypothese und wie dies funktioniert. kannst du durchmachen. Aber für jetzt, verstehen Sie die Sache, die wir hier suchen, ist für jeden der zukünftigen Wert dieser hier
größer sein als D sollte nicht mehr als 10,5, wenn es mehr als 0,5 ist, was hier
für tatsächliche Entstanden der Fall ist. Wird verwendet, um diese Funktion loszuwerden, die ich hier kenne, schau dir die eine Bedingung an. Die Zahl ist groß. Eins. Finden Sie diese Zustandsnummer hier. Dies könnte darauf hindeuten, dass es starke Metical in der Realität sind andere neue medizinische Probleme . Das bedeutet, dass
wir selbst nach all den Übungen hier keinen von der kühlenden Erzählung loswerden konnten. Es ist sehr stark, wirklich aufrichtig, zwischen Verschiebung beschleunigt. Und, wie wir in Cory Grund hier gesehen haben, Verschiebung und tatsächlich zuhören, sie waren sehr verwandt. 0.95 Es ist eine sehr hohe Zahl, aber wir konnten das nicht loswerden, als wir Ivy berechnet haben. Aber oder hier, wenn wir diese Zusammenfassung machen, ist
es, immer noch darauf hinweist, dass Sie loswerden sollten beschleunigt und für Ihr endgültiges Modell. Also lasst uns das machen. Lasst uns vorlesen. Eigentlich entstanden auf. Lassen Sie uns diesen Kerl noch mal laufen. Sagen wir x gleich ex dark drop. Okay, lassen Sie 22. natürlich, sind Künstler Chor wird untergehen. Der Grund, warum unsere quadratische Geisterstadt Sie mehr Variablen hinzufügen. Künstler ganz wird nach oben gehen, wenn Sie die Anzahl der Variablen reduzieren. Künstler-Auto nach unten gedreht. Deshalb sagen wir in der Data Science Welt, dass, wenn es darum geht, zu verstehen, ob Ihr Datenmodell funktioniert oder nicht, es ist nicht nur unsere Ruhe. Es gibt verschiedene andere Dinge. Auch ich werde Platz bis 0.6 Es könnte eine gute moderne sein, weil es von vielen anderen Faktoren abhängt . Zehe Okay, lass eins. So gibt es keinen Höhepunkt später als Budget von Fife sowie konditionierte nach unten gegangen. Also diese Warnung ist, dass Laufen verschwunden ist, so sieht es aus, als hätten wir eine gute moderne. Jetzt haben wir Zehenspiel mit nur einer variablen Verschiebung. Sieh dir das an. Wir begannen mit acht unabhängigen Variablen. Aber wenn es darum geht, unser Modell zu schaffen und die Zehe zu passieren, dass Modell die variable vitesse eine starke Wirkung auf unsere Zielvariable. Wir sind mit nur einem links und dass es Verschiebung. Das ist das Wort, dass von ihrer Steuer. Florissant, du bist auf dem richtigen Teil, mein lieber Freund, weniger wollen wir schon tief Teil der größeren Menschen sitzen, weil wir unsere X und Y bereit haben Jetzt haben wir Zehe erstellen unsere Trainingsset am Testdatum uns es, die sehr ähnlich zu dem, was Sie in einfachen linearen rechristen von s Maßstab getan haben und nicht Modell wählt. Die Tage der Importebene werden gespiegelt. Ab Zug X dist. Warum Teenager? Warum dist es Quest Train Geschmack ist eklatant. X y Geschmack Größe gleich Punkt auf Onda. Dieser Tag wird Null sein. Ja, da ich so weit
bin, sehe ich Ex dist. Darcy. Warum 10? Warum? Nur dunkle Spitze. Äh, warum Justiz? Ja, wir haben es richtig verstanden. 3 13 für Zug extra in und 79 4 Decks Test. So weit, so gut. Nun ist dies zwischen unserem Modell von SK gelernt Dart im Jahr modernen Import Dean ziemlich gut auf sauberes Jahr Unterstrichen Rick gleich 18 Jahr Gnade. Und auf einem sehr guten Nächsten. Wir gehen Fuß in das Modell und es ist ähnlich, was wir in Simple in Eric getan haben. Hör zu, Asham, unser Model ist trainiert. Jetzt werden wir voraussagen, dass wir weiter gehen. Wir werden y basierend auf X-Test vorhersagen. Und das soll hier kommen. Sehr gut X. Warum dort vorhergesagt? Und jetzt vergleichen wir Devalues Lifton. Lassen Sie uns verstehen, wie nah wir in unserer Vorhersage sind, verglichen die Werte von Y ausgebeutet auf. Warum testen wir, wie wir es im linearen Modell gemacht haben, richtig? Links damit. Okay, habe diesen Befehl erledigt. Oder hier 28 29 22 26 12 13 38. Und da finde ich, es sieht ziemlich gut aus. An wenigen Orten ist
es weit weg, wie 38 28, aber nur wenige Orte ist es sehr nah. 28. 29 auf 12. 13 33 29. Nicht schlecht. 1920 waren nicht schlecht. Ja, sieht ziemlich gut aus für mich. Lassen Sie uns eine Entfernung drucken und plotten Sie den Y-Geschmackswert auf von Vorhersagen und Wert auf, die uns eine ziemlich gute Idee aus. Wie konnten wir die Y-Werte mittlerweile vorhersagen? Ich hoffe, Sie wissen schon, wie man Störung und Blut andeutet. Ich weiß, dass du dich auswählst. Das ist also der Senat. Beginnen Sie den Geschmack nicht auf Blut. Unser Warum nur Wir werden sagen, Farbe gleich, wenn sie es sind und Nachbar es tatsächlich
Werte zitiert . Und sagen wir, wir wollen sein Telegramm nicht. Also sein Equus, die Mittel und lassen Sie uns dasselbe tun, um es zu wischen. Aber diesmal gehen wir zu weit. Ich betete, wir werden Farbe als grün geben und wir gehen Zehe setzen das Etikett als vorhergesagte Werte aan den. Hier wäre es ein bisschen, und wenn ja, ist es erschienen. Dido ist gut. Mal sehen. Nun, ich glaube, wir haben es ziemlich nah dran, oder? Sieh dir das an, bis MPC 10. Wir sind sehr nahe beieinander, aber danach gibt es einige Varianten erhöht. Und danach haben
wir ein Spiel in der Nähe. Das ist also eine einigermaßen gute Moderne, an der wir gearbeitet haben, die wir entwickelt haben. Das ist ein sehr gutes Modell auf einer realen Welt Daten. Vergessen Sie nicht, dies ist eine echte Fallstudie von der Universität gemacht und wir sind in der Lage, sehr nah an
diesem Modell vorherzusagen ist ziemlich gutes Modell, an dem wir gearbeitet haben. Du solltest stolz auf dich sein. Wir sehen uns in der nächsten Vorlesung
19. PolynomialLinearRegressionIntroduction: Hallo. Es gab diesen Lecter auf polynomialen linearen rechristen kommen. Herzlichen Glückwunsch zum Abschluss einfachen linearen rechristen Sie bereits verstehen. Einfache lineare Regression bedeutet, dass es nur eine unabhängige Variable gibt, die dunkel
befreit ist . Die abhängige Variable vom Farmbesitzer ist abhängig. Variable ist gleich. Warum Abfangen plus Beaven-Koeffizient in unabhängige Variable? Das ist ein Bauer hier. Was ist multiple lineare Regression? mehrfache lineare Regression ist die Erweiterung einfach fast ausgeschaltet. Grissom. Hier gibt es mehr als eine Feature-Werte, die Zehe spielen Warum hängt
also direkt von Feature-Werten ab? Aber es gibt mehr als eine Feature-Werte, und deshalb gibt es mehr als eine ganz passend für den Fall, dass eine Partei, noch mich, ein mildes rechristen. Warum die abhängige Variable nicht nur direkt mit dem Feature in Beziehung steht, sondern auch auf dem Exponentialwert des Features basiert. sich beispielsweise Sehen Siesich beispielsweisediese Zeile an. Es ist keine gerade Linie ist eine Kartenlinie. Wenn Sie diese Mädchenlinie in eine Formel passen, wird
es so aussehen. Warum ich B-Null machen könnte. Deshalb geben Sie Tipp plus B ein Kaffee in Ja plus B zwei in X geschickt ist ruhig. Also ist es nicht nur X, es ist X in X, und deshalb hast du diese Goldlinie gefangen. Wenn Sie verstreute Punkte wie folgt aussehen, dann wird diese Linie in Schlepptau führen. Gekrümmte Linie. Aber es ist immer noch, es ist eine Linie. Deshalb wird es linear genannt. Aber es wird Polynom genannt, weil wir hier sind. Ihre abhängige Variable ist polynom aus unabhängiger Variable. Ich hoffe, Sie haben den Unterschied zwischen polynomialer linearer Regression bei anderen linearen Abweichungen gefunden. Wie einfache und vielfache genetische Vernunft. Es wird klarer, wenn Sie das Hand-Sohn-Projekt machen. Du gehst in der nächsten Vorlesung sehen. Wir sehen uns in der nächsten Vorlesung.
20. Polynomial Regression Live-Aufnahme2: Hallo da. Antwort. Sie sind sehr aufgeregt über polynomiale lineare Regressionsmodell, und ich fühle mich genauso. Sie werden das gleiche Notizbuch aus mehreren linearen Regressionsmodellen verwenden. Also öffne das Notizbuch, bevor wir mit dem Polynom beginnen. Wirklich zustimmen? Crescent, ich möchte, dass du noch eine Sache machst, und das ist, ein Streudiagramm komplett abzuziehen. Vertreiben Sie auf abgeschlossen. Warum prognostizierte Werte mit mehrfacher linearer Regression Also lasst uns das machen. Sagen wir es. Scatter-Block auf einem Pierre de Dart ist verstreut. Wir werden X setzen warum? Und sie sagen, Farbe wird sein. Sie sagen blau. Okay, als Nächstes. Dies ist also der vollständige X- und Y-Wert. Als Nächstes werden
wir es sagen. Scatter wieder X Und jetzt werden wir die vorhergesagten Rivalen setzen, nicht Revivals so zusammen durch Werte vorhergesagt Sehr toe kopiert. Das hier von hier. Legen Sie es hier auf Interred aus X-Test. Wir sagen x über die Farbe. Sagen wir, wird es sein, aber es auf Lassen Sie uns einen bärtigen Punkt und wenn ja, Sie tun. Hier gehen Sie die rote Linie waas Die vorhergesagten Werte und dieser blaue sind die tatsächlichen. Denken Sie daran? Ich habe Ihnen am Anfang gesagt, dass dies eher wie eine polynomiale lineare Abnahme in dem aussieht, was ich für uns meinte, anstatt eine wenn eine große Linie zu schaffen. Wenn Sie sich diese Punkte verstreut sehen, sehen
sie eher aus wie eine Karte Linie Auto Licht. Wenn wir also nur eine Linie wie diese setzen, ein Colin, das besser passt, dann nur eine gerade Linie. Und die Autolinie kommt von Paul in unserem Essen. Lineare rechristen. Das ist es, was wir jetzt tun werden. All die Datenexploration, die wir in mehreren linearen,
rücksichtslos gemacht haben, und wir gehen mit der gleichen Sache weiter. Wir werden das alles nicht wiederholen. Wir gehen davon aus, dass das beste Modell wird, um die unabhängige Variable wird
Verschiebung auf sein . Wir gehen auf die Zehe. Prognostizieren Sie das mpg, damit die Datenexploration nicht erforderlich ist. Wir werden weitermachen, von wo aus wir für ihn gelebt haben. Mlr das in mehreren linearen. Hör zu. Und jetzt werden wir Daten vor der Verarbeitung weit polynomialer linearer Reue Lefty Data drei Verarbeitung für Polly Norm Year in noch zu tun. Grissom. Okay, wir müssen zuerst die richtige Bibliothek importieren. Sk len Nicht, aber er Verarbeitung. Und von hier aus werden wir Polly oder Mia-Feature-Klasse importieren. Okay, als Nächstes werden
wir die Instanz aus dieser Klasse erstellen. Nennen wir es Polly Bali noch Mahlzeiten. Wir haben die Instanz. Und jetzt wird X Polly gehen, um Bali Dart fit,
Transform Picks sein . Mal sehen, wir haben es soweit richtig gemacht. Du musst also das komplette Notizbuch laufen, okay? Ja, ja. Auch hier. Lass uns gehen. Mal sehen. Sieht wieder wie eine Art von. Es ist tödlich, nicht Vorwürfe. Atme das Ding. Es ist okay. Ok. Gut. Nun, das nächste wird
dieses Ex-Poly sehen. Was enthält es jetzt? Also lassen Sie uns sagen, B d Herz hat, äh, Frame x Export ist das ist, warum ich es in eine Daten für ihn umwandle, um das Bessere zu bekommen. Ach, sehen Sie besser verstehen es in diesem Frühjahr, die ersten Beerdigungen hier. Lassen Sie uns einige Zeit damit verbracht haben, diese Null zu verstehen. Es ist ein konstanter Wert. 111 Wir werden uns darum keine Sorgen machen. Dieser ist der Verschiebungswert, Verschiebungswert ist der Wert Null, oder? A. Er brauchte einen 73 50 TV und tat die gleichen Werte, so dass das richtig war. Aber was es ist Die zweite Spalte, die durch das Polynom-Feature vor der Verarbeitung hinzugefügt wurde. Verstehst du das? Dies ist einfach Esquire aus diesen Werten hier, 94249 ist ganz nach 807 zu 50 zu tragen. Dieser Chor von 3 50 Denken Sie daran, Was war eine Frage für den Miller? Mehrere lineare Regression Mehrere lineare Regression Waas. Warum gleich B Null in eins danach, plus B eins in X jetzt polynomiale Schäler Qualität normalerweise Nicolas und Anfragen und wurde Warum gleich Null in eins plus eins in X sein. So ist es dort auf in einem anständigen Zeh, dass es hinzugefügt hat Beato in zwei X ist hier ruhig, so hat es die Gleichung erweitert. Übrigens, wenn wir die Instanz von Polynommerkmalen erstellen, müssen
wir ein Dekret verabschieden, und wenn Sie Dekret nicht passieren, nimmt
es auch an. Also lassen Sie uns sagen, dass es Grad angenommen hat. Aber wenn ich drei sage, mal sehen, was hier passiert. Es wird exponentiell setzen. Es wird X drei hier setzen, also werden wir nicht dorthin gehen. Wir werden uns im nächsten Lector auf zwei Grad beschränken, ich werde Ihnen das Geheimnis dahinter erzählen, äh auf Geheimnis hinter diesem Grad. Warum ist das wichtig? Also verstehen, die Frage hat sich geändert. Jetzt ist es nicht mehr beschränkt, nur eins zu sein. Ausgezeichnet. Es hat B zwei x esquire hinzugefügt. Und wenn Sie den Grad erhöhen, wird es sich weiter ausdehnen, dass es schwächen wird. Sei drei plus x Strahlen zu drei. Drücken Sie vorher auf den Überschuss zu vier. So wie das. So weit
so gut. Du verstehst, was gerade passiert ist. Du hast den X-Wert und den überschüssigen Chorwert. Nein. Okay, das ist
also dein Ex-Poly. Also Daten Menschen durch Dinge drehen, was als nächstes ist? Als nächstes haben wir toe fit diese Daten toe lineare Anfragen und moderne. Also nennen wir es mehr Dill fit. Polly Dark passt auf X Polly. Nicht ganz richtig. So Qualität beginnen Füße fachmännisch und dann rechts. Ok. Das ist also unser Polynommodell. Wir passen mit fachmännisch und weiß. Und jetzt rufen wir unseren Lynn Neary Grayson an. Also werden wir eine Instanz aus erstellen. Gleiche lineare Regression mathematische Klasse mageres Jahr rechristen hier. Und dann passen wir das mit unserem Ex-Poly und Rivalen, also x Unterstrich Polly. Und dann, wenn sie sehen, ist das gut. Okay, also ist unser Modell jetzt fit. Jetzt können wir dich, Theis, und meinen Wert vorhersagen. Also mal sehen, warum. Vorhersage. Okay, warum
also unterstrichen? Sagen wir, Polly hat gesagt, es wird Land sein. Tun Sie dies, wenn Sie wissen, beginnen vorherzusagen dasselbe s, was Sie während der linearen Regression getan haben und oder hier gehen wir Zehe Pfad der X polly Wert, die hier Körper Duff Transformation ist. Richtig? Also nur die X Party Well hier. Ok. Auf Tod Unser Warum Polly Papagei, die auch gut auf einem weniger vergleichen ging entwickelt den richtigen tatsächlichen Wert mit warum vorhergesagten Wert mit Corey normalen Abnahme und modernen Zehe vergleichen , dass wir die Gerichte hatten und wir sind hier. Wir werden dasselbe benutzen. Oh, hier, Baby. Also werden wir sagen, dieses Mal müssen Sie tun, müssen Sie auf dieser eine unsere y gebetet werden statt ich
gebetet Es wird y Polly auf statt aus gebetet werden. Warum testen? Wir werden den kompletten Weg nutzen. Sehr gut. Sieh dir das an. 18 15 59 15 14 18 15 16 15 Dieser sieht eine bessere Vorhersage Sagte mir, es wird klarer, wenn wir traben. Streudiagramm. Also lasst uns zeichnen. Sie streuen Grundstück wieder auseinander gehalten wird. Dies wird zu sehen sein, und jetzt sind dies in unserem folgenden nur noch Prognosen. Also, das wird in Ordnung mit Ruthie Rate sein. Sagen wir, grün handbemalt. Sehr gut. Sieh dir das an. Unser neues Polynom Wieder Crescent hat es die gekrümmte Linie gebracht. Die, von der ich gesprochen habe, und das sieht besser aus als die gerade Linie. Die Vorhersage. Weil die Natur der Streupunkte hier sieht es Gold aus. Und das hier, die Kartenlinie. Ich denke, es gibt eine bessere Vorhersage. Wie wäre es mit einem Blick auf unsere Punkte? Lass uns das sehen. Mal sehen, ob es eine Verbesserung in unserem zu punkten. Also unsere Toe Score Unternehmen, ja, K sehr gut. Dann drucken Sie bis zum Kern. Aber, äh und das wird unser sein, seinen Kern zu unterstreichen. Warum dann tatsächliche Werte? Also habe ich und dann geschützt Wells hier auf Nike Ways Left gedruckt, die sind für Peeler punkten. Wahrscheinlich bedauert normaler Auszubildender über diese hier wird Warum, Okay, lassen Sie uns das laufen. Oh, hier. So gibt es eine Verbesserung in unserem, um seinen Kern heraus. So sind die zu punkten vier mlr wurde für sie und für Säule für das gleiche Datum wie es 40.68 es so dieser Status, sieht
es besser geeignet für polynom neu ristened, dann Jumiller. Das ist also das Leben der Datenwissenschaft. Wenn Sie die Daten erhalten, können
Sie ihre Steuerflurries durchführen und die Daten verstehen. Aber Sie wissen vielleicht immer noch nicht, welcher Algorithmus besser zu diesen Daten passt. Und das ist die Praxis, die Sie am Ende machen werden. Sie werden einen Algorithmus anpassen lassen. Holen Sie sich Ihre sind zu punkten, bekommen ihre Vorhersagen, und dann werden Sie versuchen, eine andere aufgezeichnet. Und dann könnte dieser Algorithmus einen besseren Writer geben als der vorherige Algorithmus. Das heißt, Sie bewegen sich vorwärts. Du verbesserst dich. Und das haben wir in dieser Übung getan. Wir haben versucht, die Kraftstoffeffizienz vorherzusagen. Verwendung mehrerer linearer Regression Wir haben 64% sind zu punkten und die Vorhersage waas ziemlich gut. Aber wir haben es verbessert, indem wir polynomiale lineare rechristen verwenden. So Pollen normalerweise in der Nähe rücksichtslos und für uns ein besseres Ergebnis 10 multiplen linearen Regression für diesen Datensatz. Sehr gut. Wir sehen uns nächste Woche
21. KNN Einführung: Hallo da. Willkommen Toe K Nächster Nachbar Algorithmus. Bevor ich einen tieferen Tauchgang in K und einen Algorithmus, den wir Sie durch eine sehr wichtige
Unterscheidung zwischen verschiedenen unseren Rhythmus nehmen . Auf Es gibt parametrische und nicht-parametrische Modelle. Sie haben bereits durch einfache lineare Regression,
multiple lineare Regression und polynomiale Lini Dachboden gegangen . Hören Sie in früheren Wahlfächern auf einem Verhaltensmuster bemerkt ist, dass sie alle die Frage Zehe folgen. Basierend auf dieser Gleichung leiten
sie die abhängige Variable ab. Warum? Das ist also Parameter knifflige Frage. Es gibt bereits eine Formel, der sie folgen. Der Trainingsdatensatz passt dazu, dass Formelkoeffizienten abgeleitet und auf diesen
Koeffizienten gesetzt werden . Die Frage ist vollständig auf den Rest der Daten wie Testdaten. Unsere zukünftigen Daten sind Fuß auf diese Ausrüstung auf. Darauf basiert, wird
D y abgeleitet. So funktionieren parametrische Modelle. Dann gibt es nicht parametrische Modelle. Nicht parametrische Modelle haben keine solche Frage. Sie analysieren das Datenverhalten, und basierend auf diesem Verhalten nach Daten prognostizieren
sie die abhängige Variable. Das ist also der Unterschied zwischen parametrischen und nicht parametrischen Modellen. Verfall in und Modell ist nicht parametrisches Modell. Das heißt, es gibt keine feste Formel. Unsere Gleichung, die sie folgen sehr gut jetzt, dass Sie verstehen, dass Cayenne in ist eine
nicht-parametrische moderne Aufzug,
verstehen, wie kann und funktioniert. Nehmen wir an, Sie haben eine Marketingkampagne basierend auf bestimmten Parametern bestimmte Funktionen von Ihren Kunden durchgeführt,
vielleicht im Alter, vielleicht im Alter, männlich oder weiblich, ihren Standort, ihr Familieneinkommen. Vielleicht auf der Grundlage, dass Sie herausgefunden haben, ein Verhalten mit einer Partei ist Ihr Produkt, sind sie nicht. Aber es ist dein Produkt. Also, ob es ja und nein ist. Und wenn Sie ein Diagramm zeichnen, bekommen Sie das. Alle Tage s Punkte sind das No Punkt. Betrachten Sie nun, es gibt einen neuen Kunden neue Person in sozialen Medien,
unsere, wo immer Sie das Marketing Camping laufen und Sie müssen vorhersagen, wo diese Person Ihr Produkt kaufen wird oder nicht. Also im Grunde, müssen
Sie seltsam vorhersagen. Zu diesem Zeitpunkt gehören
diese Daten. Gehört es hierher? Was ist ja, aber gehört es hierher? Was nicht ist, wie wird der Algorithmus Nein, wir sortieren diesen Punkt gehört auf. Da kommt der Cayenne und der Algorithmus ins Spiel. Stellen Sie sich den Urlaub und Algorithmus funktioniert. Sie beschließt, diesen Punkt auf der Grundlage seiner Nachbarn abzuwehren. Aber die Frage ist, wie viele jemand in Betracht ziehen will? Und das ist die Cavell. Zum Beispiel, wenn ich sehe, möchte
ich drei Nachbarn um ihn Solidität de betrachten, dass drei Nachbarn auf dann Mehrheit führt, dass dies nicht in diesem Fall ist. Es gibt zwei Punkte auf der Ja Seite einen Punkt auf der Nordseite. So wird dieser Punkt s werden, dass mit diesem Kunden Sie analysieren, er wird Zehe Kauf Ihr Produkt, das mit einer Vorhersage Was Iphigenie Diese gato fünf die Vorhersagen und Änderungen, weil jetzt gibt es drei Punkte auf der Nordseite und zwei Punkte auf der F-Site. Jetzt wird dieser Punkt kein Dad bedeutet, dass die Vorhersage ist, dass dieser Kunde nicht Toe Party
s Ihr Produkt geht . Basierend auf dem Kabel ändert sich die Vorhersage. Es gibt eine Logik Tobie gefolgt. Hatte ich das? Gab eine Schleife und er wird landen, während wir durch Hansen Projekt in der nächsten Vorlesung gehen. Hat es eine andere Sache Zeh? Betrachten wir, sagen wir dem Algorithmus, der schwul als fünf betrachtet. Aber wie wird der Algorithmus wissen, welche benachbarten Punkte zu berücksichtigen sind? K ist fünf, so dass es fünf benachbarte Punkte berücksichtigt, aber welchen benachbarten Punkt zu berücksichtigen ist. Wir sagen, dass diese Punkte zu berücksichtigen sind, also betrachten sie diese Thes Thes Thes Thes Thes Thes Thes Thes Thes 5 Punkte, die fünf Punkte zu berücksichtigen
, und das ist, wo die Logik aus Berechnung der Entfernung zwischen diesem Punkt, der vorhergesagte Punkt und der benachbarte Punkt kommt in Peter. Es gibt drei verschiedene Logik, die wir in der Lage sind, diese Entfernung 1. 1 zu betrachten, ist, dass Sie die in der
Entfernung klar wird, dass es X ein nach diesem Punkt mit dem X aus dem benachbarten Punkt nehmen wird, finden Sie einen Unterschied Ist Chor, der ähnlich gewalttätig an diesem Punkt und warum ich nach dem benachbarten Punkt ging und es wird insgesamt abnehmen, dass es das für jeden von den Werten
hier tun wird und für die Sie Kommunisten waren Und es findet diesen Wert als die niedrigsten ihre Zähne, der Kommunismus aus Kampf Nachbarn wird es so betrachten offensichtlich in diesem Fall wird es feststellen , dass diese Tochter und dieser Chorweg der Summe für diesen Kommunismus am niedrigsten sein werden. Überlegen Sie also, wie viel Kompetenz und es zu tun hat Es muss zuerst den Unterschied für
jeden der Datenpunkte finden . Und dann muss es diese eindeutige Zahl einen Punkt finden, basierend auf dem K, für das diese Entfernung niedrigsten
ist. So viel Kalkül. Und es muss tun, um die gallischen Nachbarn zu bekommen. Und deshalb ist die Auswahl von K eine sehr wichtige Rolle in K und einem Algorithmus. Und natürlich werden
Sie verstehen, dass, wenn Sie die Hände auf Projekt für jetzt tun, ich denke, Sie wissen, wie diese coole Cayenne und Sache funktioniert, wie es die Entfernung berechnet, wie es herausfindet, welche Nachbarn in Betracht ziehen. Dies ist also eins nach der Logik, um die Entfernung euklidische Entfernung zu berechnen und es gibt mehrere andere Logik wie diese. Geben Sie mir Abstand auf Manhart und Entfernung haben eine sichere Entfernung ist maximal aus den absoluten Werten auf den Manhattan-Entfernungen die Summe nach absoluten gut, verwenden Sie den Unterschied. Ok, genial. Ich glaube, du verstehst K und genug. Ich sehe euch nächste Vorlesung
22. KNNRegression Schritt1: Hallo. Es wird dazu kommen. Richter. Herzlichen Glückwunsch zum Abschluss der einfachen linearen Regression. Multiple lineare Regression bei polynomialer linearer Regression. Du hättest schon bemerkt, dass ich das gleiche Notebook Open habe. Also gehen wir weiter mit dem gleichen Notizbuch. Dasselbe Datum wie auf. Wir gehen Zehe verbessern Die sind im Grunde unsere Vorhersage zu punkten, indem wir einen anderen
Algorithmus zu dieser Zeit verwenden , wird es Homosexuell genannt. Nächster Nachbar Regression Ein Algorithmus K nächster Nachbar. Ich werde auf das Ergebnis für Wieder Halbmond bei Celeste Klassifikationen gehen auf hier drüben. In diesem Fall haben
wir eine kontinuierliche Daten. So werden wir die Wieder Halbmond-Analyse verwenden, um den MPC-Wert vorherzusagen. Ich nenne es K. und dann, bevor wir Cayenne und Algorithmus starten, lassen Sie mich noch eine Sache machen. Wir haben unseren vorherigen Lecter hier beendet, wo wir die Kunst verglichen haben, um Millar und Peeler zu erzielen. Neueste verbessert. Diese Buchstaben hatten root Mittelwert ist ziemlich Fehler, um dies, weil das ein anderes Kriterium Visa vergleichen irgendwann Wurzel Mittelwert ist ziemlich Fehler ist wichtiger als Künstler erzielte. Deshalb lassen Sie uns das und vergleichen beide die Hälfte von ihm. Also lasst uns das machen. Also zuerst gehen wir Zehe-Import von diesem kailyn dunkle Sanitäter Importmittel ist es
auf geschlachtet . Wir müssen auch von erfüllt ist ruhige Route Sq Partei. Sehr gut. Wir haben unsere bereits geöffnet, um später zu punkten. Sprint die Route. Ich meine, es ist ruhig, oder? Oh, mein Gott. Darauf wird sein, ist ziemlich Weg weg, um hierher zu kommen. Es ist froh, abgeschrieben. Ich meine, es
ist ruhig von den zwei Brunnen. Gleichermaßen. Also, das ist weit, ähm, eine Menge auf,
wie,auf dem wie, Weg zu Fuß. Das gleiche für B A r steht b l r. Es wird sein, warum mein Körper Brit. Okay, los geht's. Also haben wir unsere zu punkten und Wurzel-Mittelwert ist ziemlich selten für einen Mann in einer kleinen PR hier. So gibt es eine Verbesserung in unserem zu punkten sowie Root-Minute-Quartal. Sehr gut. Jetzt können wir das K und den Algorithmus beginnen. Wir werden den gleichen Datensatz verwenden. Wir werden sehen, ob es irgendwelche Verbesserungen gibt. Durch die Verwendung von K und einem Algorithmus, um K und einen Algorithmus zu verwenden, müssen
wir zuerst den Homosexuell Nachbarn importieren. Aggressor von s Kellan-Bibliothek von s kailyn Punkt Alle Nachbarn importieren okay? Schwule Nachbarn, Aggressoren. Und dann eine Instanz für K und n Nachbar erstellen, der kraisser wichtig. Cayenne und gleicher Zehe Homosexuell Nachbar Reiniger. Ja. Könnten Sie es Instanz von diesem Oh tun, hier werden wir in Nachbarn gleich neun auf setzen. Keine Sorge, ich werde es Ihnen erklären. Was ist die Bedeutung dieses Wertes auf Warum wählen wir neun für jetzt? Setzen Sie einfach die End-Nachbarn einen Anruf an neun auf die nächste. Wir werden den Gewinn anpassen und mit dem Extrem auf zu Recht im Wert, erklärte
er. Und weiß. Okay, also haben wir den Märtyrer. Wir haben unseren Cayenne- und Modellfit. Lasst uns herum. Das sieht als nächstes gut aus, wir gehen die Zehe. Prognostizieren Wiederbelebung. Das ist ein Kredit WHYY. Und das ist gut, aber es ist okay, und dann hört es auf. Holen Sie sich und und, äh, vorhersagen Sie weiter. Und hier wird X einfach wirklich einfach sein, richtig? Oft haben wir Warum Werte vorhersagen? Als nächstes werden
wir den tatsächlichen Vergleich mit dem vorausschauenden Wert Tod hier vergleichen. Sie sind zu de von drei von drei. Oh, hier. 18 15 15 14 18 15 15 15 13 14. Sieht ziemlich gut für mich aus. Aber wie geht es mit einer gewissen, dass dies besser ist als die letzte? Die vorherige, an die ich mich erinnere. Das erste, was wir tun werden, ist ein Streudiagramm zu erstellen. Verlängern. Das ist Streudiagramm. Esto das. Okay, Angst T Tür ist Streuung X auf. Warum in diesem Fall innerhalb von zwei Tagen vorhersehbar sein wird und ich werde X trennen und diese versuchen, sagen
wir, ich werde sagen, Nestea
aufstellen. Wow, ich denke, hier sind die gelben Punkte enger mit den tatsächlichen Werten ausgerichtet. Die blauen Punkte verglichen mit der grünen gekräuselten Linie, die normalerweise für Qualität war. Deitrich, hören Sie auf der Razzia gerade Linie, die für mehr Menschen linear war, Abnahme in Lassen Sie uns unsere Zahlen laufen. Lassen Sie uns unsere unsere zu seinem Hof und Wurzel bedeuten Squire Fehler. Und mal sehen, ob es Verbesserungen gibt. Richtig. Also lasst uns das machen. Ok. Dieses Jahr Hier sind
dann los . Ja, siehst du? Ok. Und dann in Ordnung. Und dann vorherzusagen. Danke. Sehr gute Lektion. Das hier. Okay, jetzt vergleichen wir uns. Sind wir also nicht abseits des Kurses? Es ist die Verbesserung im Fall aus pl r 12.68 bei Kindern aus Kane, und es ist Punkte auf fünf auf zur gleichen Zeit, Wurzel Mittelquadrat Fehler hat sich von vier Punkt behandeln weg gegangen 3.8 es. Das ist also definitiv eine Verbesserung. Also Kienan gibt uns eine bessere Vorhersage und moderne, dann. MLR RPs. Also herzlichen Glückwunsch, du ziehst in getrocknetem Derickson. Eines möchte ich darauf hinweisen, wenn man sich dieses Kind anschaut und es ist keine Staatslinie und
deshalb wird es nicht lineare Regression genannt. Lineare Regression ist einfach. Lineare Abnahme in unserem Vielfaches in Ieroklis sind Pol Anomaly in der Nähe rücksichtslos und die tatsächlich gibt Ihnen eine Linie. Entweder heißt es Linie sind gerade Linie, aber sein Fall aus Kanone, weil es auf den nächsten Nachbarn Punkte basiert. Es ist keine gerade Linie, es ist nur vorausschauend. Ich werte es auf den nächsten Nachbarpunkten und deshalb sieht es wie ein Streudiagramm im Einklang mit den tatsächlichen Punkten aus. Und vielleicht ist das der Grund, warum es in diesem Fall eine bessere Vorhersage gibt. Richtig? Sie bewegen sich also in die richtige Richtung, mein lieber Freund. Jetzt werden Sie Datenwissenschaftler jetzt, wissen
Sie, wenn Sie Daten erhalten, wie Sie damit spielen und wie Sie in Ihrer
Vorhersage besser und besser werden. Aber bevor wir abschließen, erinnere
ich mich, dass ich über diese Nachbarn gesprochen habe, die gleich neun sind. Andi,
ich habe dir gesagt, dass ich dir das erklären werde.
23. KNNRegression Schritt2: in der Konzeptfläche sind
Sie bereits verstehen Der K-Nachbar-Algorithmus arbeitet basierend auf den Nachbarn. Wie wenn ich einen Punkt betrachte hier, es basiert auf es gibt die Nachbarn auf sie berechnet die Entfernung. Aber zwischen diesem Punkt und dem Nachbarn und dann entscheidet er, okay, wohin gehört dieser Punkt? Die Zahl hier gibt dem Algorithmus an, wie viele Punkte Sie als Nachbar betrachten sollten. Also, wenn ich neun gebe, bedeutet
das, dass der Algorithmus auf den Fuß geht. Betrachten Sie neun Punkte in seiner Nachbarschaft. Es würde neun Punkte berücksichtigen, und es wird mit den vorhergesagten Werten kommen. Sie können mit dem auf gehen beginnen, aber die vacay und und nie Algorithmus arbeiten, dass Wurzel bedeutet Squire Edgar hier sehr
hoch wird , wenn Cavell, der niedrig ist. Aber es bedeutet nicht, dass, wenn Sie interessante Kabel halten, Houthis wird weiter unten gehen. Es gibt den aktiven In-Punkt. Du musst es verstehen. Und wie kam ich mir das auf? Nummer neun. Lasst uns das durchmachen. Ich werde es dir erklären. Wie kam ich auf ihre Nummer neun? Es ist sehr einfach. Lassen Sie uns Videoband, um ein paar Zeilen vom Biss und Gericht zu schreiben, und wir werden verstehen. Nehmen wir an, für K im Bereich 20 werden wir die gleiche Logik ausführen wie die Vorhersage des y-Wertes. Aber anstatt nur vorbei und Nachbar als neun, werden
wir passieren und Nachbar von Nummer eins zu Nummer 19 und sehen, wie sich insgesamt der Esquire Route Miniter ändert. So links damit. Ok, gleich Tok plus eins auf. Dann kopieren Sie einfach das Gleiche hier auf dann mein gebetet auf de Sprint Druck Okay, Wert, das ist dieses Jahr. Okay, dann ist die harte MSC in unserer Botschaft genau da. Sehr gut weniger als diese Bisher Kabel ist ein fünf Punkt es. Es beginnt bei 5.1 es die höchste. Nun, oh, dann geht es weiter. Sieh dir das an, das geht
runter , runter, runter, runter, bis die acht und neun und dann erhöht es sich danach. Wenn ich also einen Graphen davon plotten würde, wäre
es klar. Lassen Sie uns also einen Graphen für das Plotten des Handwerks zeichnen. Ich brauche all diese Fehler gut schuldet in einigen np Entschuldigung, dass ich zuerst eine leere weg erstellen und dann diese Fehlerwerte hinzufügen kann. Okay, mal sehen, ich habe all diese Weiden. Ja, ich habe die Werte. Jetzt kann ich das Produkt zeichnen. Langwierig. Vorkommen, Lord Worlds, Speedy Dot Datenstrom heiße Emma C. Und dann nur Mädchen Plot Punkt gebracht. Hier geht's. Es begann mit mehr als 5.5 hier. 5.8, rechts. Weiter unten mit der Höhle viel von 2,5 geht nach unten und dann nach etwa acht oder 9 18 Plätze wieder, Rechts, So können Sie entweder acht oder neun wählen und das ist der optimale Wert dafür. Ich ging für die Nacht. So erhalten Sie den optimalen Wert für K in Cayenne und al Qaida.
24. KNNClassifierDemoUdemy Step1: Hallo da. Willkommen hierbei, Richter. Lassen Sie uns beginnen Auto und Akzeptanz auf. Prognostizieren Sie seine Partizipität basierend auf K und dann Klassifikator. Es wird ein Spaß machen. Das erste ist, dass wir unserem Notizbuch einen guten Namen geben und wir werden es in Ordnung nennen . Und dann nobel. Hier. Okay, als Nächster. Sehr schnell. Wir werden alle erforderlichen Bibliotheksimport klumpy importieren. Ich kann keinen Importspaß machen. Stimmt Aziz pd t bond dot und als nächstes gehen wir den wichtigen Diktator Basierend auf früheren gewählten Sie verstehen die Daten über Ich hoffe, Sie haben eine Geschichte. Drehen Sie Ihren Computer jetzt, wir werden Zehe importieren, dass Daten Zehe einen Datenrahmen auf dem gemeinsamen Vater es ist. Dies sind meine Daten aus dem Namen DF B d Torte, die Mitleid essen Punkt Lesen CSP und dann unsere und dann geben Sie Ihren Dateinamen oder hier Wenn ich Name ist Karte, unsere Datendatei hat keinen Hitter, so werden wir Header nennen, da keine tägliche Meter in der Datei ist Kama und dann werden wir Namen für die Spalte geben, die zu den Attributen auf dem Namen benannt ist, wird genau hier sein
Neugierige Wartungstür. Sieh mal, es wären 50 Autos. Ok, DF Dart Hit. Veteran es. Sehr gut. Also haben wir unsere Daten bekommen. Indien Tough. Schande über oder hier. Die nächste Sache ist, wir werden die Form von den Daten sehen. Wie B sind unsere Daten? 1728 Reihen und sieben Spalten. Sehr gut auf dem Auto. Oder hier ist unser Ziel. Variabel an. Es gibt 123456 unabhängige Variablen. Wie Sie hier sehen,sind
dies alle kategorialen Variablen. Wie Sie hier sehen, Wir müssen sie umwandeln numerische Variablen und wie das geht. Du weißt es schon. Es ist inklusive, also werden wir Etiketten in der Werbung machen. Also was, Sie werden von s Kaylen importieren? Verarbeiten Sie keine Importarbeit in Quote, und dann gehen wir vor Gericht. Jedes dieser Felder das d f. Kaufen gleich davor, müssen
wir eine Instanz aus dem Etikett im Quartal erstellen, oder? Es ist eine Klasse, also benötigt es eine Instanz, um sie neu zu erstellen. Zuerst beim Treffer. Okay, also l b c Punkt Füße und dieses Gericht transformieren. Und tust du auch? Wir tun das gleiche für andere Felder dio I m D Der nächste wird Zehe sein Türen Tag in Person und schauen, es ist Boot 50. Auto ist eine Zielvariable. Also gehen wir jetzt nicht vor Gericht beim Sprint, haben Sie getroffen? Sehr gut. Alle sind jetzt codiert. So weit, so gut. Wenn Sie die einzigartige Quellos in Auto Zielvariable sehen wollen, es ist ein sehr einfach Sie können nur diese Linie des Gerichts laufen. Siehst du, Gott nur Einzigartig. Dies sind ihre eindeutigen Werte in den Zielvariablen. So werden Ihre Autos unter inakzeptablen niedrigen Medium hi Akzeptanz getrennt werden. Akzeptabel Sehr gut und gut. Richtig? Sie haben Segregate abschleppen, dass seine Gruppe Autos unter diesen gleichen einmal aus. Akzeptabel Es gibt also mehr als 1728 Datensätze. Dein Zeh. Prognostizieren Sie diese Klassifikationen am zukünftigen Datum uns Wenn Sie diese sechs auf dem schlechtesten Niveau
nach dem Auto haben , sollten
Sie in der Lage sein, vorherzusagen, ob es unter einer der sieben Kategorie außerhalb des Kurses ist. Okay, also lasst uns mehr in Korporatisten haben. Wir werden also sicherstellen, ob alle sechs Feature-Werte nun numerische Werte sind. Also lassen Sie uns tun, dass DF Dart Apply Karte und sein Dart ist wirklich nicht getroffen. Okay, so wahr. Wahr, wahr, wahr, wahr und her Das wird erwartet. Wir haben nicht in Gericht Karte, so wird es Standard. Aber alle zukünftigen Brunnen sind wahr. Also alle Funktionen sind numerische Werte jetzt Sehr gut. Es ist Zeit, unsere x und y zu definieren. Also sagen wir X gleich d f dot drop Was hat das waren Drop Karte? Denn das ist ein Ziel, das wir waren. Und warum tun Sie gleich Fuß? Gut, gut. Also müssen wir unsere x und y als nächstes finden Wir gehen Zehe Definieren Sie unsere Trainingsdaten. Setzen Sie sich von Ihrem Können und dunkle Modellauswahl Import Ich meine gewellt seinen Geist. Gut. Jetzt Ex-Zug ex gewölbt, richtig? Jean, Warum schmecken eine schnelle und ist X y gewölbte Größe Als Ergebnis werden
wir tun 20% Textgröße und ich weiß nicht, stattdessen ging Baker Athm besuchen. So weit so gut als nächstes. Bevor wir tatsächlich nennen die Cayenne und Klassifikator und bestanden diesen Zug und Testdaten toe der Klassifikator Wir müssen herausfinden, den optimalen Wert off K. Denken Sie daran, dass wir diese Übung während des Tages und und und Regressing. Wir müssen dasselbe tun, um den optimalen Wert von Homosexuell herauszufinden, den Sie hier nutzen können. Lassen Sie das tun. Ich werde hier sehen. Finden Sie optimalen Wert aus. Okay, beginnen
wir von Gail und Punkt Nachbarn Import Schlüsselname, Geburt Schnuller von Mad Import. Sq. Unsere Zähne haben Weg von Eskil und kein Mediziner Import. Ich meine, es ist ruhig. Es ist sehr gut. Fangen wir an. Ich werde sagen, warum wir einen gleichen Zeh hier sehen haben. Transformieren Sie das, was wir tun müssen, denn für diesen Kuchen rücksichtslos, sogar die Zielvariablen müssen codiert werden. Es kann keine kategoriale Variable sein. Deshalb gehe ich auf das Etikett, auch für das Auto, das ich wirklich kriege? Aber auch in Ordnung, also ist mein Label enthalten. Auf der nächsten werde ich Zehe erstellen eine leere NPR e r Timothy, und lassen Sie uns für K im Bereich beginnen 20. Okay ist gleich K plus eins. hast du schon getan. Wenn Sie möchten, können
Sie kopieren und einfügen aus dem vorherigen Programm vorherigen Notizbuch, das Grad gewinnt und Notebook sogar öffnen und kopieren von dort. Also werde ich Instanz von einem Nachbarn Kreuz hier erstellen, gehen Sie. Also, das ist die Instanz, jetzt aus einem Nachbarschiff. Und wenn wir die Instanz erstellen, haben
wir die und die Nachbarnummer hinter uns, erinnerst du dich? Oh, hier. Wir werden es passieren, um zu passieren. Es ist K auf jetzt, K und dann Punkt passen Wir gehen zu x und Raben und berechnen e Wurzel. Mean ist ziemlich Irrtum. Wir gehen Zehe eine Farbe der Wert Zehe. Dieser hier, dies ist erforderlich, wenn Sie ein Diagramm plotten möchten. Wenn Sie nicht fotografieren wollen, dann brauchen Sie nicht Zehe setzen entwickelt sich zu diesem leeren Bereich. Aber Lester, das heißt, ist Squired Esser. Warum auch dann Cayenne und sind ziemlich auf. Und wir gehen hier gut zu Pfad X. Das ist also unser leerer Bereich. Bringen wir jetzt den Druckschlüsselwert, und das wird unser Kabel hier sein. Und dann Adam Aceval. Andi, das wird dieser Typ sein. Nicht schlecht. Ok. Und mal sehen, ob wir es richtig verstanden haben. Sehr gut, Lettie. So ist es entweder sieben r acht. So daran ist es am niedrigsten und dann geben Zunahme danach man schaut und Familien. Also werde ich das vergessen. Beginnen wir mit Werten. Also haben wir den Cayenne und Wert. Also lassen Sie uns unser Datenmodell trainieren. Kienan geht k Es trägt Klassifikator und in sie sind wert wird C ein sehr
gut sein . Und dann k n Punkt Wenn es und wir gehen, um unseren Austausch passieren und schreiben Sie es athm Sobald Sie unsere Datenmodell Füße auf die Trainingsdaten sitzen. Wir sind bereit, vorherzusagen. Also, warum Break wird schwul sein und ard vorhersagen Ex-Not. Gute Arbeit. Jetzt Messen Sie einfach die Genauigkeit aus unserem Modell von SK Len Import Medics auf, dann sprint die Genauigkeit, die ich nicht punkten konnte warum und dann K und dann vorherzusagen und ex Guter Job. Sehr gut. Wir haben Genauigkeit von 93% 93% Genauigkeit auf K und klassifiziertem Algorithmus. Du solltest stolz auf dich sein.
25. KNNClassifierDemoUdemy Step2: sehr gut. Lassen Sie uns plotten y Wert der tatsächlichen gut. Oh, und warum vorhergesagt Gut, und bestätigen, wie nah sie so zu plotten sind. Das erste, was wir müssen, ist Erste, wir müssen beide Acts konvertieren und warum in unserem momentan X und y ese Panda direkt nach, lassen Sie uns sie zu MP drei jetzt konvertieren. Okay, also wird das X- und Y-Toe umwandeln. NPR ist sehr gut, jetzt, dass Sie sie abschleppen umgewandelt haben. Wir können anfangen, sie zu plotten. Also sagen wir vier x e.
Warum e In Jeep X die Dunkelheit strahl. Es muss x e i e e im Schlepptau. Es war hart. XY Lassen Sie uns zuerst so viel planen, es wird einige Zeit dauern, weil es auf den Fuß geplottet wird. Scatter für jeden Punkt aus X e und y e Sehr gut gebracht. Lassen Sie uns es wenig mit schicker Marker wird Oh sein, und Größe gehen, um die Größe s
sein.Es ist eine vier Größe gehen, um links übergeben werden. Mit dem links, um eine weitere Sache, diese Farbe setzen. Ich denke, es gibt ursprüngliche Werte, also lassen Sie uns, wie wir im privaten Sektor verfolgt haben. Gib ihm einfach Kalorien. Gruppe. Guter Job. Jetzt werden wir die vorhergesagten Werte drucken. Das sind also wirklich X- und Y-Werte. Moment gehen wir Zehe drucken die vorhergesagten Werte, so dass wir Eier sehen und stattdessen aus
Warum es hier que en sein wird und vorhersagen Ben y Und sie fingen an, hier zu sehen. Siehst du hallo und inst es ab. Oh, wir werden Star sagen. Und wir werden die Größe zu reduzieren wieder, so dass es auf der Oberseite der tatsächlichen Plots Und dann werden
wir PST dunkel sehen. So wird einige Zeit in Anspruch nehmen. Hier siehst du einen gelben Stern. Dies sind vorhergesagte Werte und die blauen Punkte. Dies sind tatsächliche Werte, und Sie sehen vorhergesagte Werte oben auf jedem tatsächlichen Wert. Also, das funktioniert gut. 24 niedrig. Sie hatten keine prädiktiven Werte für alle anderen Fälle. Es ist vollkommen in Ordnung vorherzusagen. Und deshalb haben Sie diese Genauigkeit von 93%. Also habe ich
Hausaufgaben für dich. Was ist mit dem niedrigen Wert passiert? Warum d Vorhersage Waas nicht da für den niedrigen Wert. Schauen Sie sich einfach die Daten an und ich denke, Sie werden eine Antwort finden. Ich warte auf deine Antwort. Bitte senden Sie mir eine Nachricht. Wir sehen uns in X Director
26. Logistik LogisticRegressionIntroduction: Hallo, da. Größte Stick Regressing ist einer meiner Favoriten auf einem der Gründe, warum es mein Favorit ist die Mathematik in der Welt darin. Wenn Sie Ihre High-School-Mathematik vergessen haben, dann könnte es ein wenig schwierig für Sie sein, dies zu verstehen. Also werde ich Sie zuerst auf die Grundmathematik, die Sie brauchen, um künstlerische
rechristen verstehen . Keine Sorge, ich werde nicht viel Zeit in Anspruch nehmen. Ich werde nur erklären, was für Sie viel zu verstehen ist. Größter Victory Crescent. Also lassen Sie es uns sprechen. Das hier. Alle von uns verstehen 10 zum Ausschalten von zwei ist gleich 200. Es ist sehr schwierig, so weit zu vergessen. Also hoffe ich, dass wir alle das verstehen. Und es braucht keine weitere Erklärung auf, wenn ich sage abmelden 100 zu den besten 10. Das heißt, ich sage, was die Ausschaltung der 10 100 ausmacht. Und die Antwort
ist
natürlich natürlich die Zehe, wie wir hier gesehen haben. Und in diesem Fall, off log, wo die Grundlage 10 ist Gott gemeinsame Logarithmen. Was ist, wenn ich nur log off 100 schreibe? Ich schreibe nicht auf Basis 10. Dann, was in solchen Fällen passiert, wird angenommen, dass das Tempo Nummer Do Punkt Same 11 es, die e auf
ist. Diese Art von Lagerrhythmus wird natürliche Logarithmen genannt und es ist möglich,
dass es in s Ln 100 Das ist es. Das ist die grundlegende Mathematik, über die wir jetzt sprechen, dass Theorie auf der gleichen Grube links bewegen eine Zehe Verständnis künstlerischen rechristen. Bevor wir auf die logistische Regression springen, machen
wir einen Schritt zurück. Verstehen? Was haben wir in linearen rechristen Illini Regress. Und wir sahen diese Formel, warum er Toe B Null plus Beaven Tochter nannte, sei ein Nixon, richtig? Und wir verstehen, dass die rechte Seite dieser Gleichung kontinuierliche Zahl der x eins x zwei
x Baum und darüber hinaus ist. Dies sind unsere kontinuierlichen Zahlen auf dem Ergebnis aus dieser heiligen Frage zusammen mit Koeffizienten ist eine kontinuierliche Zahl und das Ergebnis wird auch eine kontinuierliche Zahl, die Sie auf dem Fall gearbeitet
haben, ist aus der Vorhersage Kraftstoffeffizienz. Sehr Es gab unabhängige Variablen wie die verschiedenen Merkmale des Autos waren und Sie kamen mit der geschützten Kraftstoffeffizienz, die eine kontinuierliche Zahl war. So geben Sie kontinuierliche Ember-Ausgabe, kontinuierliche Zahl. Lassen Sie uns zu logistischen rechristen größten Tikrit Grund kommen. Auch wenn der Name sagt ein großer Grund, es ist eigentlich Ah Klassifikationen Arboretum und durch Klassifikationen. Und ich meine, das Ergebnis ist keine kontinuierliche Zahl. Also fangen wir auf der rechten Seite an. Es ist dasselbe. Es ist immer noch die gleiche kontinuierliche Zahl. So Ergebnis der Website eine kontinuierliche Zahl sein. Aber auf der linken Seite, weil es die Klassifikationen und Technik ist, muss
das Ergebnis ein binäres Ergebnis sein, wenn es um das größte verordnete Gefängnis geht. Binäres Ergebnis bedeutet also Werte wie ja, nein, richtig. Falsch 01 Also diese Art von Ergebnis, die komplexe Stadt hier ist, wie Sie ein Banbury-Ergebnis mit den fortlaufenden Zahlen bekommen? Und das ist, wo der ganze Spaß hinter Mathematik ist. Beginnen Sie im Falle der logistischen Regression. Warum ist voll von so etwas? Sperren Sie B um eins minus B und dieser hier, das ist Wahrscheinlichkeit. P bedeutet Wahrscheinlichkeit für diese ganze Sache. Sei um eins Minus. B wird Kunst aus dem Ergebnis Kunst genannt. Also beim Abmelden dieses Wertes, denken Sie daran, es gibt keine Basis mit dem 10. Das ist also ein Naturgesetz. Ja. Das hier ist also ein natürliches Schloss. Und so wird die Formel jetzt geändert, warum durch Abmelden B durch eins durch P ersetzt wird. Also, das ist eine Formel hier. Das bedeutet, sperren Sie unsere Leute eins nach p, wo p die Wahrscheinlichkeit y genannt wird. Und wenn ich es weiter erweitern, dann komme ich einfach besser mit dieser Formel, dass P Wahrscheinlichkeit gleich eins nach dem anderen plus e zu minus y raced. Also jetzt ist dies der sehr interessante Teil. Warum habe ich das alles getan? Denn in dieser Formel, egal welchen Wert ich lege, werde ich immer eine Wahrscheinlichkeit bekommen. Wert und Wahrscheinlichkeit. Der Wert wird immer zwischen Null und Eins liegen. Das bedeutet, dass ich das Ergebnis immer noch als kontinuierliche Nummer bekommen kann, die meine Frau sein wird. Aber in dem Moment, in dem ich das sage, warum ich in dieser Gleichung die Wahrscheinlichkeit bekommen
werde, ist zwischen Null und eins. Du glaubst mir nicht? Okay, lass uns das machen. Ich habe hier mehrere Rivalen in diese Formel gesetzt, und das war mein Ergebnis. Das war mein P-Wert. Sie können mit mehr Y-Werte experimentieren auf diesem war das Handwerk. Jetzt habe ich ein Handwerk. Sind Wahrscheinlichkeitswerte, die von 0 bis 1 enden, dass dies meine Eigenschaftswerte sind, und dies sind Y-Werte. Also wahrscheinlich Tabelle, der 0 bis 1 Nacht ist. Mein Handwerk sieht so aus. Und dann kann ich einer einfachen Formel folgen, dass, wenn mein Wahrscheinlichkeitswert kleiner als 0,5 ist, ich nicht mehr als 0,5 sagen werde. Ich würde sagen, „s ja“. Und genau hier habe ich mein Ergebnis von fortlaufender Zahl in Bine geändert. 80 Ergebnis ja und nein. Und deshalb mag ich autistische rechristen. Die Grundmathematik hat ein kontinuierliches Zahlungsergebnis zu einem binären Ergebnis gemacht. Also kommen wir zu der größten Zecke Regression. Wir sehen uns im nächsten Lecter.
27. Logistik LogisticsRegressionDemoUsethisone schritt11: Hallo. Es wird zu diesem Vortrag über den Kongress kommen. Koaleszenz. Die Tatsache, dass Sie in dieser Vorlesung sind, zeigt an, dass Sie eine
Regressionsanalyse über Verstärkung und Klassifikator abgeschlossen haben . Neuer Anzug, der sich selbst gratuliert. Sie machen einen ziemlich guten Fortschritt. Also fangen wir an. Wir gehen zuerst auf die Zehe. Importieren Sie die ganze Bibliothek mit Recht? Lebe dazu. Aber vorher nennen
wir unser Notizbuch, nicht den Stock. Grayson-Tag. erinnere mich an mehr Schüler. Ok. Und jetzt Bibliothek importieren. Eines muss ich sagen: Warum warst du bei mir? Bitte üben Sie diesen Befehl aus und geben Sie ihn ein. Kopieren Sie nicht und fügen Sie den Grund, warum ich darauf bestehen, auf Ihrem Typ es, weil Sie so entwickelt die Gewohnheit. Du solltest dich an all diesen Befehl auswendig erinnern. Denn wenn Sie für ein Interview für Data Science gehen, unsere Machine Learning Job, gibt es eine sehr hohe Chance, dass sie Good fragen. So werden sie dir ein Problem geben. Und sie werden Sie bitten, einen Algorithmus zu entwickeln, und Sie haben möglicherweise nicht das Privileg, dort kopieren und einfügen zu können. Deshalb nutzen Sie all diese Vorträge. Ich tippe hier. Folge mir und entwickle die Gewohnheit und tippe jeden einzelnen Befehl. Diese Dinge sollten Sie sich längst auswendig erinnern. Okay, ich habe das mehrmals gemacht, also werde ich sehr schnell hier in Port Nr. P I m p Import Bond PD Matt blockiert und ich bin nicht ein Prat als ph d.
Okay,als
nächsteswerden Okay, nächstes wir unseren Kampf B d Hund lesen, aber essen. Ja, wir hier Q t gefeuert ihn zusammen mit, wenn Sie nicht wissen, dass die Akte. Vielleicht müsstest du die Bank voll bekämpfen. Darcy s, Wir und Bank. Es ist, ohne Zweifel CS drei, die volle hat etwa 400.000 D-Karten. Es ist zu groß für dich, um zu experimentieren. kannst du tun. Aber wenn Sie es auf Ihrem eigenen Computer tun, plotten
mehrere Dinge wie Analyse und wenn Sie schreiben ein Diagramm. Diese Dinger werden sehr langsam sein. Deshalb schlage ich vor, verwendet diese Bank und ihre zweifellos CSP, die nur 4000 Autos auf einer täglichen Messung in diesem Fall hat, ist die gleiche Colin. Okay, sie sagen, wir haben es richtig verstanden. Bisher, dann das. Ja. Etwas stimmt nicht. Oh, hier. Es ist das Gleiche. Nach der Wahrheit von hier drin gehen wir. 21 Spalten. Es gibt also 20 fetale Werte. Und warum hier drüben, das ist unsere Zielvariable. Ja. Nein, es wird die Werte haben. Ja und nein. So heißt es: Wo haben diese impliziert? Aber die Bank? War es Produkt oder nicht? So weit, so gut. Jetzt beginnen sie den Angriff. Florissant hat,
äh, was machen wir? Das erste, was. Als erstes haben wir den Schluck aus unseren Daten de von Punkt 4119 überprüft. Diese 21 Spalten werden angezeigt. Als nächstes werden
wir die Viertelstunden sehen. Oh, hier, mal sehen. Alter. Äh, ziemlich gut. Nicht mit irgendeiner Spalte korreliert. Do Risen Sieht ziemlich gut Kampagne. Ziemlich gut. Drei Tage, aber ein guter, er war ziemlich guter Preis. Verschiedenes. Und es sieht so aus, als wäre es abhängig von em vor und diesem. Aber wir wissen, dass dies Variable impliziert. Vor kurzem, Dies wird auf die Jungs verwendet oder nicht basieren. Also denke ich, das sollte gut sein. Wir müssen nichts davon tun, glaube
ich. Was? Sieht gut aus. Wir können jetzt trauern. Was sind die Themen? Flores und sieht gut aus. Ich denke, wir können jetzt die Datenvorverarbeitung über Datenleute durchführen. Also denke ich, das erste, was wir tun werden, wenn Label vor Gericht all das sehr beides. Aber vor diesem Brief trennen unsere x und Y, weil wir vor Gericht nur X beschriften werden. Sie unabhängig Sehr über Nicht warum. Okay, also ist es sehr einfach. Warum wird diese Zielvariable sein? Warum hier? Warum ist also sehr ZDF weiß auf diese Weise? Und X wird alles sein. Aber warum? Richtig? Ok, haben Sie Dot Drop? Warum Achse geht es eins das gute. Wir haben X und Y richtig. Und als nächstes gehen wir vor Gericht auf das Etikett. So von ihm ist Galen Punkt pre Verarbeitung Import zu Arbeit in Viertel ein Hals. Natürlich werden
wir eine Instanz außerhalb des Labels im Quartal erstellen. So weit so gut. Es gibt also 21 Spalten, von denen 20 vorgestellte Werte sind. Also müssen wir hier 20 Spalten einschließen. Ich werde ihnen nicht eins nach dem anderen 81 abschreiben. Stattdessen werde ich
dieses Mal eine weit bisher von Dean Range Mischung aus Dark Spalte verwenden, also wird dies 21
zurückgeben, weil es 21 Spalten gibt. Okay, also wird diese Steigung 20 Mal laufen. Es fängt an. Ich sehe ja aus. BC dot Fit bilden nicht ex dot Ich liebe diese. Hat Lettie? Wir haben die Spalten codiert. Sieht gut aus, aber sieh dir die Werte an. 12 1 dann für 24 Tage in 1 56 So sind sie alle auf einem anderen Maßstab. Also lasst uns sie auf die gleiche Skala setzen, richtig? Also machen sie das von Ja. Kailyn dunkle Vorverarbeitung importieren es Standard. Es ist aufstehen. Und wir sind auch hier. Zuerst werden wir bei der Instanz erschaffen. Aus der Ausschreibung ist Killer-Klasse. Ja. D d c l zu stander bekommen,
äh, und dann werden wir uns verwandeln. Ah, ja. Hat er Punkt Fit Transform X wenig darin. Ziemlich gut dabei, aber Sie geben Ihnen den Hit jetzt ist das zart. Ist Killer hat dieses X in Abschleppen umgewandelt, wie Sie kämpfen. Sehen Sie hier jetzt ist es ein Es ist keine Bindung mehr. Ein Staat Afrim. Das ist, warum sehr ich Kopf es gab ihr Soto erste paar sehen, weil wir zuerst
in Datenrahmen konvertiert haben . Wir haben es von Shame X gemacht und dann oder hier sehen wir es. Das würde hier einströmen. Ok. Sehr geht's. Ich liebe sie. Sieh mal an. Gleiche Skala. Nun, da um einen herum. Weniger als einer ist da. Einer sieht gut aus. Jetzt ist es der richtige Zeitpunkt, an dem Toe unsere Daten im Training aufteilt und sie probiert hat. Das war's. Lass uns das machen.
28. Logistik LogisticsRegressionDemoUsethisone schrittweiser Schritt2: vor dem Tod. Guillen dot Mord Sammeln Import zwischen Geschmack Es ist ein bisschen X Zahnarzt. Warum? Warum Geschmack wird Zug Geschmack dieser Split x und Y dist Seufzer wird der gleiche
Punkt Zehe auf einem zufälligen getan sein . Wenn Fido sie gut dran sind, bringen
wir dieses Band aus Ägypten im Austausch, wie ich sehe. Ich habe gerade richtig Teenager? Nein. Warum? Einfach sehr gut. Wir haben X Zug f Geschmack richtig und leichteste. Jetzt ist es Zeit, um tiene de Mörtel von Ja killen dot mageren Jahren Import nicht autistischen Grayson . Und wir schaffen zuerst seine Chance aus Logistik rechristen Autistic Nein, nur tickety Greif. Und dann werden wir die Zehe fit machen. Wissen Sie, ich sehe dunkel passen die X 10 auf, richtig. Sehr gut. So hat unser Modell Bean fit mit den Trainingsdaten auf. Jetzt ist dies nur d Mörtel und ich prognostizieren, warum unterstreichen Handel wird gelb Sea Dart sein. Prognostizieren Picks Dist! Ehrfürchtig. Also haben wir unsere „Warum“ Vorhersage bekommen. Jetzt prüft Lay die Genauigkeit unserer y-Werte. Wie Eigenkapital so betrachtet, wenn das Töten von Importmedizinern drucken, könnte
es C-Mitt Zecken haben. Das könnte nicht isi. Es ist gut. Warum Tante, lassen Sie uns unser Gelbes Meer sprinten, nicht X ls hier vorhersagen. Statt nur X-Test zu setzen, werden
wir UN komplettes X vorhersagen und im Vergleich mit dem tatsächlichen y-Wert 91% muss ich sagen, dass dies eine sehr gute Punktzahl der Logistikanforderungen
ist und sehr gut für diesen Datensatz Lift passt. Sehen Sie sich die ausreichenden Istwerte des Unternehmens mit den prognostizierten Werten an.
29. Logistik LogisticsRegressionDemoUsethisone Step3: sehr gut. Also werden wir eine neue Daten von D F 3 mit tatsächlichen auf vorhergesagten Werten erstellen. BD Punktdaten Ruhm. Tatsächlicher Wert wird sein Warum nicht auf vorhergesagte Werte verlieren werden dieser Kerl Elsie sein ,
vorherzusagen, dass Akt und es wird hier weiter gehen. Dann lassen Sie uns die drei drucken, tatsächlichen und vorhergesagten sind Paarung. Wenn ich den 1. $15 sage, ist alles passend. Warum also nicht etwas schreiben, damit wir die tatsächlichen und vorhergesagten für alle 4119 2
Autos vergleichen können ? Listo, dass wir eine kleine Pipe und Gericht schreiben, um unsere tatsächlichen Werte mit den
vorhergesagten Werten für jede 4119 D-Karten zu vergleichen , wird uns die Anzahl von Datensätzen geben, für die tatsächlich keine Rolle mit den vorhergesagten Werten. Also lasst uns anfangen. Zuerst werden
wir unseren Zähler auf Null setzen, und danach werden
wir ein weit laufen für mich im Wechsel Fusseln aus Tag 3
, der 4100 Mal hier zurückgeben wird. Also werde ich von 0 auf 4119 laufen. Das ist für alle, die auf geschrieben sind. Wir werden tatsächlich mit dem vorhergesagten vergleichen, so geben de von drei dart idoc I Null, das ist eigentlich nicht ausgestattet, um Sie haben drei dunkle ich liebe, ich will, was vorhergesagt wird, dann scheitert der Zähler um eins. Und am Ende werden wir die Theke schlagen. Also lassen Sie uns das hier gut laufen 3 56 Datensätze. Das bedeutet also, dass aus 4119 nur 3 56 3 Karten nicht mit dem vorausschauenden Wert erfüllt werden. So entspricht die tatsächliche nicht mit vorhergesagten für 3 56 Regeln Das ist sehr weniger für 4119. Also hast du einen sehr guten Mord bekommen. Natürlich verstehe ich diese 3 56, die Gewicht auf der Währung auch berechnen konnten. Aber ich wollte nur so, dass Sie auch einen Bissen schreiben und gehen, um das gleiche auf die
gewünschte zu tun . Ein hektischer Kampf vor Gericht ist, dass Sie tatsächlich sehen können, all diese Aspekte, wo diese gut nicht erfüllt
wurde. Sie können alle diese DF drei drucken. Ich schaue hier und sehe all diese Kosten. Gute Kongresskoaleszenz wieder haben Sie die Logistik mit der Erfolgsquote von 91% Sie konnten vorhersagen, ob die Kunden das
Bankeinlagenprodukt gekauft haben . Sie können die gleiche Sache, gleiche Logik in anderen Daten verwenden. Setzen Sie sich ebenfalls Datensätze und üben Sie es aus. Guter Job. Wir sehen uns in den nächsten Vorlesungen.
30. Vector: Hallo da. Willkommen zu diesem Vortrag. Lassen Sie uns weiter an derselben Datenquelle arbeiten. Die Datenquelle Wir arbeiteten während der Logistik rechristen A sehr in einem Banker waas versucht, eine Bankeinlage für ihre Kunden auf DA zu verkaufen Wir hatten eine Datenquelle von 4119 aus ihren Lektionen auf. Auf dieser Grundlage versuchten
wir vorherzusagen, ob der Kunde gegen das Produkt der Bankeinlage protestieren wird oder nicht . Während des größten Siegeshalbmonds konnten
wir bis zu einer Genauigkeit von 91% von 4119 vorhersagen. Wir haben 3 56 Vorhersagen Syndrom. Lassen Sie uns auf dem gleichen Datensatz arbeiten und mal sehen, ob wir einige Verbesserungen erhalten Wenn wir Unterstützung Vektor-Maschine
folgen. Okay, beginnen
wir zuerst müssen wir die Unterstützung Vektormaschine importieren. Also von der Skala und nicht Ja, VM comport. Ja, sehen
wir. Und als nächstes müssen wir die Instanz aus erstellen. Ja, sehen
wir. Also ja, wir sehen Klassifikator. Natürlich können Sie hier jeden Namen geben, oder? Das weißt du, oder? Ja, wir sehen, dann könnte ich nie diesen Prozess in der Nähe von Colonel zuerst. Also mager Jahre
danach, dann zufällig. Der Zustand Null auf. Dann passen wir es an. Ja, sehen
wir. Klassischer Feuerpunkt Fit frei, um ab Zug auf weißem Trended zu sein. Sehr gut. So weit so gut. Also haben wir das Ah, ja. Sie sehen, klassifiziert definiert. Und wir haben mit den Trainingsdaten ausgestattet. Jetzt, da unser Modell trainiert ist, lassen Sie uns den vorausschauenden Wert erhalten. Warum bieten? Ja, wir sehen Grassy für Haare gleich Ja, wir sehen Classy Feuerpfeil, ich sage voraus. Und wir werden X dist passieren! Sehr gut. Wir haben das hier. Nächste Briefe. Finden Sie die Genauigkeit dieses Mal heraus und wir haben sie bereits hier. Also, wer Energie mit der gleichen Sache? Wir müssen keine Sanitäter wieder importieren, weil es bereits in diesem Notizbuch importiert wurde, das wir
geführt haben , Sag meine Wangen, und dann sagen Sie einfach über diesen Kerl hier. Äh, warum? Und Bar siehe ST FX Text. Sie nicht plus X 9164 Mal sehen, was Wasit vor 9135 So wenig bitty Zimmer mint? Eigentlich nicht . Ja, also gibt es Verbesserungen, aber nicht viel. Jetzt mal sehen, wie Maney Weil unser immer noch falsch ist. Letztes Mal in der Logistik stimmt zu. Und es war 3 56 Und diesmal werde ich diesmal nicht die gleiche Logik schreiben. Wir werden verwirrende Matics benutzen. Lass uns das machen. Okay, also von DSK Land, keine Sanitäter Import verwirrende Matics auf hier. Sagen wir C Ah, Wasser. Ja, sehen
wir. Ich habe nicht f verwirrende Sanitäter gleich verwirren und meine Tricks. Und hier drüben werden wir vorbeigehen. Warum? Und der vorhergesagte Rivalen Lou. Also dieser Typ, sie sehen hier ihr Bestes. Okay, und dann drucken wir je unsere verwirrenden Sanitäter. Okay,
Hoffe, ich habe keine Art von Lesben gemacht. Okay, Hashem. Also 2 72 plus 72. So sind rund 3 44 falsch Autos immer noch da. Von 4119. Also 3 44 falsche Vorhersagen. Es gibt also eine Verbesserung. Letztes Mal war es 3 56 Dieses Mal ist es nur 3 44 So 14 Ah, bessere Vorhersagen jetzt, im Vergleich zum letzten Mal toe einige Verbesserung in der nächsten Lecter. Wir werden den verschiedenen Colonel benutzen, nicht einen linearen, sondern einen RB von Colonel. Wir werden sehen, ob es Verbesserungen gibt
31. Vector: Hallo da. Willkommen zu diesem Vortrag. Lassen Sie uns weiter an derselben Datenquelle arbeiten. Die Datenquelle Wir arbeiteten während der Logistik rechristen A sehr in einem Banker waas versucht, eine Bankeinlage für ihre Kunden auf DA zu verkaufen Wir hatten eine Datenquelle von 4119 aus ihren Lektionen auf. Auf dieser Grundlage versuchten
wir vorherzusagen, ob der Kunde gegen das Produkt der Bankeinlage protestieren wird oder nicht . Während des größten Siegeshalbmonds konnten
wir bis zu einer Genauigkeit von 91% von 4119 vorhersagen. Wir haben 3 56 Vorhersagen Syndrom. Lassen Sie uns auf dem gleichen Datensatz arbeiten und mal sehen, ob wir einige Verbesserungen erhalten Wenn wir Unterstützung Vektor-Maschine
folgen. Okay, beginnen
wir zuerst müssen wir die Unterstützung Vektormaschine importieren. Also von der Skala und nicht Ja, VM comport. Ja, sehen
wir. Und als nächstes müssen wir die Instanz aus erstellen. Ja, sehen
wir. Also ja, wir sehen Klassifikator. Natürlich können Sie hier jeden Namen geben, oder? Das weißt du, oder? Ja, wir sehen, dann könnte ich nie diesen Prozess in der Nähe von Colonel zuerst. Also mager Jahre
danach, dann zufällig. Der Zustand Null auf. Dann passen wir es an. Ja, sehen
wir. Klassischer Feuerpunkt Fit frei, um ab Zug auf weißem Trended zu sein. Sehr gut. So weit so gut. Also haben wir das Ah, ja. Sie sehen, klassifiziert definiert. Und wir haben mit den Trainingsdaten ausgestattet. Jetzt, da unser Modell trainiert ist, lassen Sie uns den vorausschauenden Wert erhalten. Warum bieten? Ja, wir sehen Grassy für Haare gleich Ja, wir sehen Classy Feuerpfeil, ich sage voraus. Und wir werden X dist passieren! Sehr gut. Wir haben das hier. Nächste Briefe. Finden Sie die Genauigkeit dieses Mal heraus und wir haben sie bereits hier. Also, wer Energie mit der gleichen Sache? Wir müssen keine Sanitäter wieder importieren, weil es bereits in diesem Notizbuch importiert wurde, das wir
geführt haben , Sag meine Wangen, und dann sagen Sie einfach über diesen Kerl hier. Äh, warum? Und Bar siehe ST FX Text. Sie nicht plus X 9164 Mal sehen, was Wasit vor 9135 So wenig bitty Zimmer mint? Eigentlich nicht . Ja, also gibt es Verbesserungen, aber nicht viel. Jetzt mal sehen, wie Maney Weil unser immer noch falsch ist. Letztes Mal in der Logistik stimmt zu. Und es war 3 56 Und diesmal werde ich diesmal nicht die gleiche Logik schreiben. Wir werden verwirrende Matics benutzen. Lass uns das machen. Okay, also von DSK Land, keine Sanitäter Import verwirrende Matics auf hier. Sagen wir C Ah, Wasser. Ja, sehen
wir. Ich habe nicht f verwirrende Sanitäter gleich verwirren und meine Tricks. Und hier drüben werden wir vorbeigehen. Warum? Und der vorhergesagte Rivalen Lou. Also dieser Typ, sie sehen hier ihr Bestes. Okay, und dann drucken wir je unsere verwirrenden Sanitäter. Okay,
Hoffe, ich habe keine Art von Lesben gemacht. Okay, Hashem. Also 2 72 plus 72. So sind rund 3 44 falsch Autos immer noch da. Von 4119. Also 3 44 falsche Vorhersagen. Es gibt also eine Verbesserung. Letztes Mal war es 3 56 Dieses Mal ist es nur 3 44 So 14 Ah, bessere Vorhersagen jetzt, im Vergleich zum letzten Mal toe einige Verbesserung in der nächsten Lecter. Wir werden den verschiedenen Colonel benutzen, nicht einen linearen, sondern einen RB von Colonel. Wir werden sehen, ob es Verbesserungen gibt
32. SVM RBF: Hallo. Es wird wieder kommen. Also haben wir das letzte Mal den linearen fleischlichen Lini Bereich benutzt. Sveum Colonel. Und wir haben 91% Genauigkeit und wir mussten 44 Rekorde. Immer noch falsch vorhersagen. Nun, jetzt werden wir RBF Colonel benutzen
und sehen, ob es Verbesserungen gibt. Also lasst uns weitermachen. Kopieren. Dieses Jahr, nicht dieser Typ. Kopiert ist gut. Hier auf uns sind die spc gemeldet. Wir müssen sie also nicht erneut importieren. Und wenn Sie dieses Notizbuch wieder öffnen, macht
natürlich jeden Lauf hier Andi benutzt Wählen Sie diesen Kerl. Ok, okay. Sagen wir, sein Zustand aus. Ja. Siehst du, Klassifikator, lass mich hier abschließen, okay? Und jetzt, statt linear, werden
wir sagen rbf on. Ich werde das anders nennen. Äh, das könnte ich sein, wenn und dann noch eine unterstrichen. Das wäre ich, wenn und das war's. Ok. Sehr gut. So Rbf Classifier Instanz wurde erstellt auf Lassen Sie uns die Vorhersage jetzt unterstrichen R B wenn auf sie, geben Sie auf Dixon. Ok. Wir haben unsere Vorhersage am Datum messen die Genauigkeit. Sehr gut. Also diesmal ist es besser. Es sind 93%. Das letzte Mal waren es 91%. Also haben wir eine 2% ige Verbesserung bekommen. Mal sehen, unsere verwirrenden Metriken ist jede Verbesserung der Anzahl von Falschen Vorhersagen. Ah, bu das. Könnte ich das sein? Ja, auf. Ok, da. Sehen Sie? 27 51. Also tun Sie 70 es. Oh, es gibt eine enorme Verbesserung, dass die Verbesserung? Ungefähr 66 Aufzeichnungen. - Ja. So jetzt die Gesamtzahl aus Runde Kritiker Sinne kam Zehe auf 78 im Vergleich zu einem 3 44
Nachnamen . Es gibt Verbesserungen gegenüber 64 D-Karten. Das ist eine Gruppe. Gute Verbesserung auf gibt es eine ziemlich off 50 93%. Es sieht so aus, als ob ich von Colonel sein werde, ist besser in diesem Fall von Daten passen, dann die Lee in der Nähe von Cannon Art in den größten sechs mehr. Also die Schlussfolgerung ist bis jetzt, dass wir RV von Colonel für diese Daten benutzt haben. Ok, sehr gut. Wir werden weiter auf andere Algorithmen schauen. - Onda. Feine Melodie. Dies sind, so werde ich Sie in der nächsten Vorlesung sehen
33. BayesThereom: Hallo da. Willkommen, zu diesem Richter. Es ist Zeit, darüber zu sprechen, basierend hier, aber bevor wir tatsächlich einen tieferen Tauchgang in Beith hier machen, ähm, lasst uns überprüfen Grundlagen sind Wahrscheinlichkeit, und das wird Ihnen helfen, Ihr Wissen von Wahrscheinlichkeit auf zu aktualisieren. Danach werden
wir das gleiche Problem erweitern. Zwei. Hier ansässig. Fangen wir an. Betrachten wir, dass Sie zwei Boxen haben. Box eins mit zu Art von Kugeln, neun roten Kugeln und fünf blauen Kugeln, und dann Box tun mit wieder Art von Kugeln. Vier. Rote Kugel auf 11 blauen Kugeln. So weit, so gut. Jetzt wählen Sie aus, dass Sie nicht von Beat-Box wissen. Du hast gerade alles abgeholt. Und jetzt musst du die Wahrscheinlichkeit finden, dass du den Ball aus Box 1 ausgewählt hast und
was dann ? Es ist eine Wahrscheinlichkeit, dass Sie einen blauen Ball aus Box eins auswählen. Ebenso, wie hoch ist die Wahrscheinlichkeit, dass Sie einen roten Ball von Box auswählen? Wie hoch ist die Wahrscheinlichkeit, dass nur wenige einen blauen Ball von Box zu wählen? Das sind also vier Optionen, die hätte passieren können. Du hast vielleicht einen roten Ball aus dem Boxen oder einen blauen Ball für Ambac's ausgewählt. Einer davon ist der rote Ball, von Bach bis zu unserer Global Front Box Toe auf. Wir gehen auf die Zehe. Finden Sie die Wahrscheinlichkeit von jedem von ihnen in einer sehr einfachen Angelegenheit. Also fangen wir an. Erster. Wir müssen sogar veranstalten. Eine, die wir aus dieser Box auswählen können, sind sogar Zehe. Wir können uns vom verdickten Boss holen. Also zwei möglich, auch Sie können entweder wählen aus diesen Büchern sind aus dieser Box. Nur zwei Boxen sind da. So Möglichkeit ein paar Kommissionierung der Ball von Box eins ist eins nach zwei. Denn es sind nur zwei Veranstaltungen möglich. Es gibt nur zwei Boxen, so dass die Gesamtzahl aus Kombinationen möglich ist, dass. Wenn Sie aus Feld eins auswählen, ist
die Wahrscheinlichkeit, dass dies passiert, eins nach zwei. Ebenso ist
die Wahrscheinlichkeit der Kommissionierung von Box zu eins nach zwei. Lassen Sie uns trauern, was die Wahrscheinlichkeit ist, rote Kugel aus Box zu holen, wenn es neun rote Kugeln gibt und es 14 Gesamtzahl der Teile, so wahrscheinlich ein paar Kommissionierung rote Kugel aus Box eins ist neun mal 14. Gleichermaßen Wahrscheinlichkeit. Ein paar pflücken blauen Ball aus Box 1/8 fünf von 14. Ebenso wahrscheinlich aus Kommissionierung großen Ball von Box zu essen vier durch 15 Gesamtzahl der Teile 15 Redwall vier so vier durch 50 und wahrscheinlich eine Kommissionierung blauen Ball von Bach zu l A. Won von 15. So weit, so gut. Jetzt fangen wir an, diese Wahrscheinlichkeiten zu berechnen. Beginnen Sie mit der 1. 1 wahrscheinlich aus Kommissionierung einer roten Kugel aus Box eins, so dass würde sogar mit
P. R.
sogar PR multipliziert P. R. werden, auch wenn Sie rote Kugel auswählen, unter Berücksichtigung der ersten Box unter Berücksichtigung der erste Ereignis geschah, so heißt es P sind in Betracht gezogen, auch passiert. Und das heißt, wenn Sie p gerade multiplizieren und P R konditioniert sogar passiert, Das gibt Ihnen die Wahrscheinlichkeit der Kommissionierung roten Ball aus Box eins, so dass würde von
zwei gewonnen werden . Multipliziert mit neun mit 14. Das wäre neun durch 28 32% Wahrscheinlichkeit. Was ist wahrscheinlich aus dir? Kommissionierst du wieder den blauen Ball aus Box eins? Eins nach zwei in fünf durch 14 fünf von 28 18% ungefähr 18% gleiche Weise wahrscheinlich aus Kommissionierung einer roten Kugel von Box zu eins nach zwei in vier durch 15 für bis 2013% Wahrscheinlichkeit auf die Wahrscheinlichkeit eine blaue Kugel von Box zu so eins nach zwei im Schlepptau zu
wählen, Loon von 15 37%. Diese Antworten also auf die Frage hinter jeder Wahrscheinlichkeit. Jetzt können Sie jede Art von möglicher Wahrscheinlichkeit berechnen. Also, wenn Sie einen Ball wählen, wissen
Sie, welche anderen Eigenschaften von der Kommissionierung einer roten Kugel sind blaue Kugel aus beiden nach Boxen ? Wer hat also die maximale Wahrscheinlichkeit? Mexikanische Wahrscheinlichkeit ist, dass dieser Status? 1%. Das waren die maximalen Wahrscheinlichkeiten. Sie werden am Ende einen blauen Ball von Boxtoe nehmen. Das ist er macht eine Bombenwahrscheinlichkeit. Wenn ich muss. Welches Geld dafür, dann werde ich mein Geld auf dieses setzen, weil dieses eine höhere Wahrscheinlichkeit hat, 37% zu passieren . Das ist also ein grundlegender Hintergrund außerhalb der Wahrscheinlichkeit. Wie das wahrscheinlich funktioniert. Okay, was ist die totale Wahrscheinlichkeit, dass du ein glaubwürdiges Tochtereigentum auswählst. Also diese halbe Wahrscheinlichkeit, Redwall aus Box eins zu holen und diese WAAS-Wahrscheinlichkeit, rote Kugel von Box zu
wählen, so dass die Gesamtwahrscheinlichkeit rote Kugel pflücken, ist spitzen Zehe drücken Sie 0,13 Punkt 45 auf. Erinnern Sie sich an diese Armee, die sich gegenseitig Das bedeutet, dass Sie Ihre Hand nicht in beide Boxen zusammen legen können und es gibt zwei Boxen.
Wenn Sie also Ihre Hand zu der Zeit legen, können
Sie Ihre Hand nur in eine Schachtel legen. Richtig? zweite Ereignis ist also nicht vom ersten Ereignis abhängig. Sie schließen sich gegenseitig aus. Deshalb, wenn Sie berechnen müssen, was ist die Gesamtwahrscheinlichkeit, dass Sie einen roten
Ball aus beiden Boxen auswählen ? Das wäre Punkt für fünf. Das wäre total von diesem Prestes. Ebenso wird die
Gesamtwahrscheinlichkeit von Ihnen Kommissionierung einer blauen Kugel 0,1 es plus 0,37 Punkt +55 Und hier kommt der beste Teil der Teil, auf den wir alle gewartet haben. Betrachten Sie diese gleiche haben Sie Box eins und bellen zu gleiche Zahl. Bieten Sie es Bälle und blaue Kugeln an. Genau. Dieselbe Situation. Aber die Frage ist anders. Die Frage ist, dass Sie einen roten Ball ausgewählt haben. Andi, wie hoch ist die Wahrscheinlichkeit, dass diese rote Wand von zweiter zurück ist? Das ist eine interessante Situation. Du hast schon einen roten Ball. Sie mussten nicht herausfinden, die Wahrscheinlichkeit, dass dieser rote Ball von Box zu Und diese
Art von Wahrscheinlichkeit wird Wahrscheinlichkeit von e bis zum geraden Zeh genannt, wenn
man bedenkt, ob der rote Ball so die rote Wand, die bereits als roter Ball gilt, ist bereits als Sie bereits besorgt haben. Jetzt müssen wir herausfinden, eine wahrscheinlich, dass rote Kugel vom Park zu sein, Also mal sehen, was wir in früheren Problem getan haben. Also im vorherigen Problem, haben wir verschiedene Arten von Wahrscheinlichkeiten herausgefunden, oder? Eigenschaft off Wenn ich alle Wahrscheinlichkeit ihres Seins von Box eine Box auf die Wahrscheinlichkeit abholen , dass
von Box ein Blau von Box auf unserem roten von Bachzehe und blau von Bachzehe auf was eine Gesamt gelesen wird, wahrscheinlich TF, dass gelesen wird
waren, sagt Prue. Jetzt hier müssen wir herausfinden, die Wahrscheinlichkeit, dass dieser Ball ist, dass Redwall von zweiten Box auf dieser Art von Eigenschaft ist, berechnet wird, basierend hier. Bested um sagt, dass P F E bis R gleich p f e ist. Zwei Wahrscheinlichkeit von e zwei und wahrscheinlich TF betrachten Ito durch die Gesamtwahrscheinlichkeit des Herzens , und Sie haben diese Werte bereits berechnet. Wahrscheinlich F E zwei ist eins nach zwei Eigenschaft unserer, dass Kommissionierung Rivalen Tia Kommissionierung Redwall aus zweiten Box Waas vier durch 15 auf Porter Wahrscheinlichkeit aus Kommissionierrate Ball entweder aus den Boxen Waas 45% Rechts auf. Das ist, wie, wenn Sie erstellen können, wird
es auf vier um 13,5 runter kommen. Also Tech 2%. Also beantworten Sie diese Frage, dass, wenn Sie einen roten Ball haben, die Wahrscheinlichkeit, dass dieser Ball von Box zu 30% auf diese Art Off-Frage ist, basierend hier beantwortet
wird . Also, das ist grundlegend aus hier basiert.
34. Naive Bayes Theorem Einführung: Hallo, da. Willkommen in District. Also haben Sie gelernt, dass es hier basiert? Ähm, in der vorherigen Vorlesung. Wie basiert das hier? Im maschinellen Lernen angewendet, um diese Frage zu beantworten. Neuester Blick auf dieses Beispiel enthält dieses Beispiel Daten von 1000 Früchten. Es kann Banane leidenschaftlich sein. Gibt es eine andere Art von Früchten auf diesem? Früchte werden auf der Grundlage der Merkmale identifiziert, wie ob es lang ist, ob es süß ist , sind nicht zu ihm oder ob es L o r nicht ist. Sieh mal. Also haben Sie diese drei Funktionen auf Sie bekommen die Klassen. Betrachten wir drei Klassen. Wenn Sie zufällig diese Funktionen wie lang,
süß und niedrig gegeben wurden, süß und niedrig gegeben wurden, werden Sie in der Lage sein zu sagen, welche Art von Frucht es ist? Ob es Banane ist, Orange sind jede andere Art von Obst und das ist ein Problem, das wir mit basierend
hier lösen werden. Aber wenn Sie bemerkt haben, oder hier wird Messer Basis genannt, nicht als Basis. Der Grund, warum es Ni basiert genannt wird, weil, wenn es darum geht, basierend hier ,
ähm ,
im maschinellen Lernen ,
gibt es ein großes A, etwas Sonne gemacht und es gibt einige Sonne ist, dass die Funktionen nicht miteinander verbunden sind das ist, warum es meine Basis genannt wird, weil vorausgesetzt, dass die Funktionen in Ihren Daten nicht miteinander verwandt sind, wenn etwas, das nicht sehr oft passiert, und deshalb wird es Messer genannt. Also, wenn es darum geht, Massie zu lernen, heißt
es jetzt basiert hier, lasst uns weitermachen. Also wieder haben Sie 1000 Beobachtungen von Früchten, Banane, Orange und jede andere Art von Obst auf diesen Früchten sind durch die Merkmale lang,
süß und niedrig identifiziert . Und wenn Sie eine lange süße auf einem niedrigen als Funktion gegeben, werden wir in der Lage zu sagen, ob es Bananenorange sind jede andere Art von Lebensmitteln? Und das ist eine Herausforderung, die wir mit Nacht hier lösen werden. Das ist also die Herausforderung hier. Habe eine zufällige Frucht, die falsch ist, süß und eine niedrige vorhersagen, ob es orange ist, Banane sind andere Art aus, um dieses Problem zu lösen. Das erste, was wir tun müssen, ist diese Daten in diesen Daten zusammengefasst. Sie sehen, dort sind die Klassifizierungen und zum Beispiel orange drauf. Null auf sind eins basierend darauf, ob die Orange eine niedrige,
süße entlang ist . Also in diesem Fall, dieser glühende waas Ein Blick. Also ist es Marcus eins Für andere ist
es Null. Ebenso für Banane Es ist eine lange diese Banane war lang, süß und verliebt. Also ist es unser Zeichen. Das Beste für hier Es gibt eine andere Banane, die lang ist, aber nicht süß und nicht viel. Vielleicht ist es nicht richtig reif, so dass es 1000 Datensätze gibt. So Anzug, um dieses Problem auf kommen die Wahrscheinlichkeit zu lösen, die wir zuerst haben, Daten zusammengefasst die Zählung von jeder dieser basierend auf den Klassifikationen, die Klassifizierungen ist, dass wir unsere weißen auf all diese Funktionen sein werden, ist, was Also lasst uns eins Dies sind die Daten jemand Jetzt helfe ich diesen Daten Ich hörte diese Klassifikationen
Also drei Klassifikationen, die ich habe Banane sind in anderen Diese drei Klassen sind wie unsere
drei Ereignisse. Also lasst uns eins Dies sind die Daten jemand Jetzt helfe ich diesen Daten Ich hörte diese Klassifikationen Also drei Klassifikationen, die ich habe Banane sind in anderen Diese drei Klassen sind wie unsere Also zuerst Sie zwanziger Jahre sagen wir Bananenchips Banane Wenn ich eine Frucht pflücken, was ist Wahrscheinlichkeit? Das ist Banane. Es sind 500 mal tausende, richtig? Es gibt Viertel 1000 Lebensmittel auf von diesem 500 sind Banane. Die Wahrscheinlichkeit, dass es Banane ist, beträgt 501.001 mal zwei. Lasst uns eins. Was ist wahrscheinlich danach, dass die Banane lang ist? Also 400 von 504 von fünf. Ebenso, hoch ist die Wahrscheinlichkeit? Nachdem Banane süß, er es sitzen Marana 3 50 von 500. Wie hoch ist die Wahrscheinlichkeit, nachdem Banane ein Tief ist? Hallo 4 50 von 500? Ebenso, wie ist die Wahrscheinlichkeit, dass das orange ist? Das ist einfach 300 mal 1000. Ebenso müssen
Sie die Wahrscheinlichkeit dafür berechnen. Sind nicht lange es Null von Kurs Eigenschaft aus, die nicht süß sind? 1 50 von 300 gewann mit zwei Wahrscheinlichkeit, dass jeder sein eine Liebesgeschichte endete mit 301. Also, das war alle Orangen sind gelb in der Farbe. Okay, eins, sagen
wir, andere andere Art von Obst. Wenn ich eine Frucht pflücke, wie ist die Wahrscheinlichkeit, dass das eine andere Art von Obst ist? Es ist eins nach fünf. Und was ist dann die Wahrscheinlichkeit, dass diese andere Art von Nahrung 100 mal 200 lang ist? Was ist wahrscheinlich all diese andere Art von Frucht süß? 1 50 von 200. Was ist die Wahrscheinlichkeit, dass diese andere Art von Frucht Hallo ist? 50 von 200. Also eins nach vier. Sehr gut. Wir haben diese Wahrscheinlichkeit jetzt. Lassen Sie uns die Wahrscheinlichkeit der E-Tochter berechnen. Ich habe ein Essen ausgesucht. Wie hoch ist die Wahrscheinlichkeit, dass diese Frucht lang ist? Wie berechnen Sie das? Du multiplizierst das BB im Schlepptau. Pierre, sei dann B o im Schlepptau. Seien Sie aus l mit bedingten wahrscheinlich von anderen in wahrscheinlich aus l mit anderen Bedingungen. Und so werden Sie die Wahrscheinlichkeit, dass diese Frucht, die Sie gepflückt haben, eine lange Frucht ist. Und hier drüben kommt es, um fünf zu finden. Ebenso Wahrscheinlichkeit, dass diese Frucht eine süße Frucht ist, ist dies, wie Sie Clip töten auf es kommt zu finden 65 und wahrscheinlich von diesem Essen, das l ein Essen ist. Es ist 0,8. Das ist also unsere totale Wahrscheinlichkeit. Wenn ich Früchte aufnehme, wie hoch ist die Wahrscheinlichkeit, dass diese Frucht lang ist? Sind süß sind ein niedriger So haben wir das Individuum Wahrscheinlich von jedem aus Diese Möglichkeiten sind Jetzt kommt unsere Frage, mit der wir diesen Vortrag beginnen. Die Frage ist, wenn Sie eine lange süße und l o Frucht pflücken, was ist die Wahrscheinlichkeit, dass es Banane sind glühend sind andere. Grundsätzlich müssen
wir vorhersagen, ob ich Anzug und eine niedrige Frucht mitnehme, was wird es sein? Ob es Banane sein wird, sind nicht andere Art von Nahrung. Diese Art von Brot. Dixon, du kannst Messer benutzen, die ihn basieren. Mal sehen, wie Sie bereits gesehen haben, dass in der basierten Serum, werden
wir die gleiche Formel gleiche Logik auf erweiterte Nacht basierte Ära verwenden und
dieses Problem zu lösen . So wahrscheinlich sind sie pflücken eine Banane wie sprechen zusammen süß unter einem niedrigen Essen Long, süß und niedrig. Wie hoch ist die Wahrscheinlichkeit, dass es sich um eine Banane handelt? Sie haben die Farmlinie hier gesehen? Ähm, es ist die gleiche Formel. Die Formel sagt Pebe in B l von B und dann süß sein mit konditionierten. Es ist eine Banane. Dann Eigenschaft eines niedrigen mit der Bedingung ist Banane und dann geteilt durch wahrscheinlich off Long Eigenschaft von süß und wahrscheinlich, warum dies Folter Wahrscheinlichkeit ist. Und wenn Sie das tun, wenn Sie alle diese Werte in die Formel setzen, erhalten
Sie 0,97 Wahrscheinlichkeit davon. Banane zu sein ist 0,97 Lassen Sie jemanden ebenfalls, was die Wahrscheinlichkeit sein wird, dass es orange ist, die Eigenschaft, Orens zu sein, wird
Null sein , weil Eigentum aus nicht lang ist. Ist Null so weg natürlich Es ist nicht ein glühender, weil wahrscheinlich aus sind lange, was eines der Kriterien in diesem und Klasse ist Null, Also ist es nicht in der Anzug. Was ist die Eigenschaft, dass es andere Fuß gleich ist. Setzen Sie die Formel hier auf setzen die Werte wahrscheinlich, dass es eine andere Frucht ist 0,7 Also, wer ist der Gewinner? Die Venus ist Banane. So können Sie die Klassifikationen und jede neue Frucht vorhersagen. Wenn Sie wissen, die Merkmale sind, dass Obst Features aus dem Punkt, Betrachten Sie dies als Datensatz direkt dort. Hat es 1000 Aufzeichnungen? Wenn Sie eine neue Daten hinzufügen und Sie wissen, die Funktion der Daten mit Nacht basiert hier, um, können
Sie sehr klassifizieren Hat, dass Daten gehören hier. Wir hatten drei Klassifizierungen und wir hatten drei Funktionen, um zu spielen und wir konnten vorhersagen, dass der neue Datenpunkt die Vit-Klassifikationen mit Nacht hier gehört. Als nächstes werden
wir darüber sprechen, wie und wo in maschinellem Lernen diese Nacht basierte Ära verwendet wird. Wir werden über reale Welt Beispiele sprechen, wo die Nacht basierte Helden Es ist ein sehr nützlich, wie es verwendet wird. Wir sehen uns in der nächsten Vorlesung.
35. GaussianNB: Hallo. Es wird kommen diese Vorlesung über Hände auf Praxis off night basiert hier, um, in Massillon e neun basiert hier, ähm, kann in Massillon in verschiedenen Formen auf einer der gemeinsamen Nutzung Farm erweitert werden heißt Wächternacht Bienen. Ursache Ian Messerbasiert geht davon aus, dass die Features in Ihren Daten der Normalverteilung folgen. Sie haben bereits die Verteilung aus den Daten aus der Funktion in früheren Vorlesungen
in früheren Händen auf Praxis ist mit Seaborn geplottet und Sie wissen, wie noch Bescheidenheit Wilson
aussieht . Also, wenn Ihre Daten, Ihre Features passen zu normalen Verteilungen, dann können Sie Goshen NY basierten Klassifikator verwenden, um Ihre Daten in dieser Vorlesung in
dieser Hand auf Nektar zu klassifizieren . Das ist es, was Sie tun werden. Also fangen wir damit an. Habe ich nicht schon das Programm der Abteilung geschrieben, zu diesem Mal werde ich durch
das Patentgericht gehen , das ich auf diesem Jupiter-Notizbuch geschrieben habe. Der Python-Code darin ist bereits vorhanden. Ich sagte, es ist auch dieser Vortrag, so dass Sie es nehmen können und Sie können es auf eigene Faust schreiben. Also fangen wir an. Natürlich, die erste müssen Sie alle Bibliotheken wichtige MP Pandas importieren. Matt brachte P ein Grundstück Seaborn und s Kaylan Matics. Richtig. Ok. Sobald Sie alle Bibliotheken als nächstes importieren, gehen
Sie zu Fuß. Lesen Sie die Bank. Zusätzliche Darts? Ja, wir haben im Schlepptau eingereicht. Pandas Datenrahmen auf dem gedruckten F wurde getroffen. Dies sind die gleichen Daten, die Sie in früheren Händen auf Praktiken verwendet Haben Gewinn und noblen Feuer und andere klassifizierte Sie gehen, um die gleichen Daten zu verwenden. Setz dich auf. Sehen Sie, ob es Verbesserungen mit Gaußsian Bay Classified gibt. Richtig? Also, wie Sie es vorher getan haben, schaffen Sie die Bindung einen Zustand hinter ihm und drucken Sie einfach die Hüfte. Sehr gut. 21 Spalten, korrekt auf. Lassen Sie uns die Korrelate sehen und noch einmal. Denken Sie daran, im Falle einer Nacht hier basiert, ähm, die Annahme ist und die wichtigste Ah, einige schickte Leichtigkeit, dass die Funktionen überhaupt nicht voneinander abhängen. Sie sind völlig unabhängig von. Das ist, warum Lassen Sie uns die Coriolis überprüfen und wieder auf mischen Ihre jede Abhängigkeit zwischen den Features entfernt wird. Also Randy's de nach Gericht auf Lassen Sie uns das jetzt oder hier überprüfen, wenn Sie dieses Jahr sehen. Oh, Bharti um ist 0,94 verwandt mit imply es, dass es sehr viel miteinander verwandt waren, also musst du eins von ihnen entfernen. Also gehe ich zum Umzug. Weißt du, Bombe, dieser hier auf der nächsten ist hier drüben, imply hatte recht, richtig. Das ist 0.97 mit diesem Kerl verwandt. Okay, so dass man auch die Zehe entfernt wurde. Okay, also lasst uns weitermachen. Lassen Sie uns diese beiden Features aus dem Datenrahmen entfernen. Führen Sie diesen Befehl auf aus. Lass uns die Corey leiten. Hören Sie noch einmal auf Ich denke, diesmal sieht es besser aus. Ich sehe keine stark korrelierten Funktionen mehr, So können wir wollen Wir können mit diesen Funktionen weiter auf. Es ist Zeit, Ihren Weg zu definieren und Ihre Ex zu definieren. Und jetzt dasselbe, was wir tun müssen Etikett einschließlich auf dies ist der gleiche Kampf vor Gericht
Urin in früheren Vorlesungen. Dasselbe hier. Machen Sie das Level. Nach einem weniger Druck danach. Mal sehen, wie unser X danach hier drüben aussieht. Ok, sie waren dabei. Entsprechend ist erledigt. Exits sind ein und sind die einzigen enthält die Zahlen, so Ebene, einschließlich der gut auf nächste. Ein Standard ist hier ein Mörder. Lassen Sie uns drucken die X wieder sehen, ob es gut ist. Ja. Alle Werte sind mehr oder weniger. Sieht aus, als hätte alles Bean skaliert. Gut drauf. Nun, das ist die Sache, über die wir gesprochen haben. Alle Funktionen sollten folgen. Normaler Bezirk war nicht, so schrieb ich, das ist mehr Programm hier sehr in. Ich laufe eine Schleife für alle Spalten. Also, wenn du diese Tür trinkst, Sape, wenn ich hierher gehe, sagen
wir, ich sehe nur X Don't nip. Ich verstehe das. 4119 Wachstum und 80 Säulen. So 18 Funktionen direkt an. Ich habe diese Handlung für alle 18 von ihnen zu ziehen, um sicherzustellen, dass das alles, was unsere Bescheidenheit folgt nicht an
war. Deshalb mache ich diese Schleife. Wenn ich sage Xscape eine, die gewinnt, wird
es 18 hier sein. Ich führe dieses Dach aus für den Bereich dieser Anzahl von Säulen. So Kinder für jede Säule darauf werden das Meer bon Störung und Plotten tun. Genau dann verklage ich. Das hat hierher gebracht. Wenn Sie schauen, folgen sie
alle einer normalen Verteilung wie diese. Dieser biblische Schluck zeigt Wilson normal an. Also sind wir gut, als Nächstes zu gehen. Wie immer würden wir die Fähigkeit und Mörtel Auswahl auf verdorbenen Hoden Pleat nennen, Wir gehen Zehe Split die Daten in Training und Testgröße Test-Website wird Punkt Toe sein . So weit so gut auf oder hier über in zu Fuß Gaußsian nb rechts, So von s Kellan Dark Knight Basis Import Vorsicht Und wir haben sie Instanz von Gaußsian erstellt
und wir auf dann füttern es Färbedaten das Ausmaß und weiß ging zu Gaußsian nb sehr gut. Eine nächste werden wir vorhersagen oder hier bestanden die Testdaten und prognostizieren y-Werte auf
hier drüben Wir berechnen die Genauigkeit. Leider ist
die Genauigkeit 88%, die niedriger ist 10 Zerfall in und und andere Algorithmus Wir folgten in früheren Richter. Aber trotzdem bekommt man die Idee, wie Gaußsian und wir für solche Probleme eingesetzt werden können . Niemand ist wir Zukunft Hände auf die Praxis haben wird, wo wir verwenden Gaußsian und wir Andi, mit der hohen Genauigkeit Rate auf dies ist richtig echtes Leben. Das passiert im wirklichen Leben. Sie wenden eine Menge Algorithmus viele Klassifizierungen auf basierend auf der Genauigkeit an, auf der Sie wissen werden, welcher Algorithmus passt diese Daten abschleppen wird. Das ist genau das, was wir jetzt hier tun. Du weißt, wie wir reingekommen sind und wir können für diese Art verwendet werden, nachdem sie sehr drin sind. Ihre Features waren eine Normalverteilung. Also, weil Sie Features sind, gefolgt von normalen Verteilungen. Wir haben versucht, Gaußsian zu verwenden und auf dies ist die Genauigkeit Rekord in der nächsten Vorlesung. Wir gehen Zehe verwendet sind verschiedene Arten von Nachtbasis, zwei verschiedene Probleme und sehen, wie gut diese Genauigkeit kommt. Okay, ich sehe dich in der nächsten Vorlesung.
36. MultinormailNaiveBayes: Hallo da. Herzlichen Glückwunsch zum Lernen über Biest Serum. Andi absolvierte eine Hand-Klang-Praxis in Gaußschen Nacht. Verpisst. Ich hoffe, Sie verstehen jetzt die Schönheit hinter ny basiert hier. Um, und wie einfach es ist zu verwenden, wie Sie gesehen haben, wird
die Gaußsche jetzt Basis verwendet, um Ihre Funktionen folgen einfacher Gaußschen Verteilung. Es gibt ein weiteres sehr interessantes Messerstück und das ist Multi Namir Nacht. Beth. In diesem Fall folgen
die Funktionen einfachen Martina bloße Verteilung auf diese Art von Klassifikationen. Demartino mia Nacht basierte Klassifizierungen ist am besten geeignet für Funktionen, die unsere Länder
zählen. So wird diese Art von Klassifizierungen im Falle aus verwendet. Zum Beispiel, ein Dokument Klassifizierungen. Einfach erstaunlich. Es gibt ein Dokument und Sie wollen Zeh. Verstehen? Worum geht es in diesem Dokument? Wovon redet es, richtig? Eine Möglichkeit, dies zu tun, ist, die ganze Welt in ihrem Dokument zu lesen und dann die
Häufigkeit von jeder Welt herauszufinden . Also, wenn es
zum Beispiel
die politischen Welten oft benutzt zum Beispiel , dann ist es politisches Dokument. Wenn es mit religiösen waren zu viele Male. Und es sind religiöse Dokumente. Ebenso können
Ihre E-Mails gefiltert werden, da Spam-E-Mails nicht normal sind. E-Mail basierend auf dem Inhalt. Es hat so etwas wie G-Morde. Das sind die Fälle für Martino Me, eine Nachtbasis hier ist eine Schönheit, und Sie können die Aufregung in meiner Frau spüren. Was auch immer ich Ihnen so weit erklärt, Lesen Sie die Wörter in dem Dokument und dann herauszufinden, wie oft dieses Wort in
, dass ihre Dokumente verwendet wird und die Schaffung eines Siegers aus ihm alles, was Gott ist, natürliche Sprachverarbeitung. Und das ist mein Lieblingsthema. Ich kann mich nicht davon abhalten, dich dorthin zu bringen. So natürliche Sprachverarbeitung ist eine sehr spannende Dinge, um in Massie zu lernen, leihen Sprache auf sie braucht seine eigenen sechs, und das ist, warum ich hier als erste Nacht Based Classifier Kurs stoppen, werden
wir weiterhin lernen Multi normalen Messer Sockel. Dann sprechen wir über die Verarbeitung natürlicher Sprachen. NLP in den nächsten sechs und ich werde Sie dort sehen
 Sanjay Singh, Data is everywhere!
Sanjay Singh, Data is everywhere!