Transcrições
1. Visão geral do curso: Bem-vindo ao engenheiro
365, meu nome é Benjamin. Neste curso SQL,
você aprenderá a linguagem de programação SQL, os fundamentos e os fundamentos
do SQL de maneira prática. Começaremos com uma
breve introdução
à linguagem de programação SQL
e, posteriormente, teremos uma
visão geral dos bancos de dados e
do sistema de
gerenciamento de banco de dados relacional, também chamado de RDBMS. Em seguida, instalaremos o Microsoft SQL Server
no contêiner do Docker para começar a aprender que esta seção de
instalação
fornecerá uma breve
introdução ao Docker. Docker é uma
plataforma de código aberto para desenvolvimento, envio e execução de
aplicativos. Ele fornece um
ambiente isolado para executar aplicativos depois usando um caso de uso
do sistema de saúde, criará um
banco de dados, criará tabelas
e, finalmente, inserirá alguns
dados nessas tabelas. Assim que tivermos feito alguma instalação
básica, mergulhará no
coração deste curso e, seguida,
realizará operações
básicas nos dados para aprender
os Fundamentos SQL, sintaxe
SQL e
as operações SQL DML usado para acessar ,
modificar ou recuperar os
dados do banco de dados. No final deste curso, você poderá executar
C-Corporations para recuperar, atualizar e inserir
dados em um banco de dados. Este curso fornecerá conhecimento
em primeira mão para novos engenheiros de dados e desenvolvedores de
software, aprenderá em primeira mão usando exemplos em um banco de dados
do mundo real. Este é um curso emocionante
e mal posso esperar que você comece e aprenda os
conceitos básicos do SQL desde o início, consulte
os carimbos de data/hora na descrição
do vídeo para pular frente para outras seções
do curso, acompanhe e aprenda os conceitos básicos do
SQL em uma hora. Se você tiver algum loop de
feedback ou comentário na seção comum, eu adoraria ouvir de você. Tudo bem, vamos começar a aprender SQL de forma
prática.
2. Por que eu deveria aprender SQL: Agora que estamos aqui,
a pergunta que você pode estar se perguntando é por que eu deveria aprender SQL? Este curso é adequado para
aqueles interessados em aprender SQL desde o início, desde os alunos iniciam engenheiros
de dados e outros profissionais de TI
interessados em aprender sobre engenharia de dados e dados. Sql está em alta demanda por análise de
dados e engenharia de
dados. dados e engenheiros de
software são obrigados a conhecer o SQL. Com um crescimento da computação em
nuvem e geração de petabytes
de dados todos os dias. Sql é uma
linguagem de programação de fato para acessar e manipular dados
armazenados na nuvem. De acordo com o Glassdoor.com,
o pagamento base médio de um engenheiro de dados
é de US $102 mil. Portanto, é imperativo
que você aprenda SQL.
3. Por que você deve me ouvir: Por que você deveria me ouvir? Sou engenheiro de
gerenciamento de dados mestre e especialista em TI de
saúde e trabalhei para empresas da
Fortune 500,
como g e paradigma
nos últimos dez anos, para projetar e construir produtos de dados
utilizando ETL, HL7, sistemas EMP, diferentes plataformas RDBMS
e SO. Trabalhei com terabytes de dados de
saúde executados em ambiente em cluster
na Amazon Web Services e na Microsoft Asia
para permitir a assistência médica segura, confiável e
conectada. Trabalhei com
conjuntos de dados complexos que exigem a criação aplicativos
confiáveis de
correspondência de pacientes para trocas de dados em todo o estado. Esses grandes aplicativos
exigem uma compreensão de todas as características
e aspectos dos dados para trabalhar e processar os
grandes conjuntos de dados via ETL, os dados precisam ser analisados para consistência e precisão. E a
linguagem de programação SQL é uma linguagem
ideal para
entender esses dados. Fique tranquilo, vocês são mãos
imperfeitas.
4. Visão geral do banco de dados: Vamos falar sobre o banco de dados. O que é um banco de dados? Aplicativos como
Facebook, Google Netflix armazenam dados sobre usuários e produtos em bancos de dados
relacionais. O banco de dados relacional é
composto por coleta de objetos ou relações
que armazenaram os dados. Portanto, uma coleção de objetos
relacionados é armazenada
em uma tabela de banco de dados. Vou te dar um exemplo. Quando você faz login no Facebook, todas as informações de login
ou informações de login são armazenadas em uma
tabela de login ou em uma tabela pessoal. Podem ser coisas
como seu nome de usuário, senha, data de login, login cronometrado e
localização do login. O banco de dados é composto por uma coleção de tabelas
bidimensionais. Portanto, o banco de dados pode ter
de uma a várias tabelas. Ele pode ter 12345 ou mais
tabelas dentro do banco de dados. A tabela é uma estrutura de
armazenamento básica de um sistema de
gerenciamento de banco de dados relacional ou RDBMS. Cobriremos mais do RDBMS mais tarde. Cada tabela é composta
de linhas e colunas, e os dados nessas linhas
são acessados e
manipulados via SQL. Vamos dar uma
olhada neste exemplo. No lado direito,
você tem essa imagem que representa
uma tabela de pacientes. Leve cerca de cinco segundos para realmente olhar para a mesa
do paciente. As linhas nesta tabela de
pacientes representam um único
registro de transação ou entrada de dados. Por exemplo, temos cinco
linhas nesta tabela de pacientes. Cada linha representa
um objeto distinto ou uma pessoa distinta. Olhe para a linha número um. Você tem FirstName, LastName
como gênero e uma data. A propósito, todos esses
dados são dados falsos. Não é real. As linhas são valores de
coluna em uma tabela. Portanto, nesta tabela, você tem várias colunas. Você tem um número de
registro médico. Coluna um no
lado esquerdo, seguida pela coluna do
primeiro nome, LastName como SN, sexo, BOB ou data de nascimento. Todas essas colunas
compõem os valores da linha. As tabelas são conectadas entre
si usando relacionamentos. É por isso que isso é chamado
de banco de dados relacional. As colunas neste caso representam as propriedades
desses dados. Portanto, pense
nessa tabela aqui. Temos a mesa do paciente. Quais são algumas de
suas propriedades que você vê sobre esses dados? Você vê nomes, vê números
sociais do Scruton, você vê sexo, vê datas. Você também pode ter outras
informações, como endereço ou informações da carteira de
motorista. Todos seguem dentro
desta tabela de pacientes. Só para torná-lo muito básico
para essa representação. Portanto, os valores da coluna como você os vê
aqui, primeiro nome, sobrenome, ssn, representam
as linhas em uma tabela. O campo é interseção
entre uma linha e uma coluna. Pode ou não conter dados, o que significa que
serão nulos ou vazios. Por exemplo, você pode ter uma forma de incidência se
você tiver um nome do meio, se a pessoa não tiver
fornecido um nome do meio, essa interseção, esse
campo ficará vazio. Se olharmos para a linha número 1, o
primeiro nome é Alyssa, sobrenome é sentença. Se o registro, se a pessoa não
fornecer seu sobrenome, esse campo ficará vazio. Neste caso, estamos
olhando para uma mesa de pacientes. E a tabela pessoal
faz parte de um banco de dados maior. Por exemplo, se for
um sistema de saúde, você pode ter uma
mesa de paciente, medicação, seguro
estável, seguro
estável mesa de mitigação médica
estável
e assim por diante e assim por diante. Agora vamos avançar
e dar uma olhada no sistema de
gerenciamento de banco de dados
relacional ou no RDBMS.
5. Caso de uso do banco de dados do Sistema de saúde: Caso de uso do
banco de dados do sistema de Vamos dar uma olhada em
um exemplo prático de um sistema hospitalar. Quando um paciente chega
ao centro médico para tratamento
médico ou para uma consulta ou enfermeira
ou o suporte técnico. O pessoal normalmente os
verifica. Este check-in envolve
o paciente que fornece as informações demográficas ou de
seguro. Este check-in envolve uma pesquisa
eficiente
no sistema de registro ou uma pesquisa de paciente
no mesmo sistema. Se um paciente for encontrado, registro será retornado, o que significa que o registro existe
no banco de dados. Se um registro não for encontrado, isso significa que precisamos adicionar um
novo registro ao banco de dados. Esses dois tipos de transações, uma a busca do paciente e
o registro do paciente, ambas acontecem no sistema
cadastrado do paciente. O banco de dados
do sistema de saúde
nesse cenário pode conter
diferentes tipos de informações. Um deles, a tabela do paciente, que é uma tabela entre
muitas tabelas desse sistema, contém a demografia do paciente, que é o primeiro
nome, nome do meio ,
sobrenome, sufixo, data de
nascimento, sexo ou endereço. Em segundo lugar, o conselho detém informações de
seguro, que é o número do seguro
ou grupo de seguros. Ele também pode se manter
nesse cenário. Lembre-se deste
curso, medicamentos, o que significa prescrições para o paciente consultar um médico. Portanto, essas
informações do paciente podem conter vários conjuntos de dados
dentro desse sistema hospitalar. Essas três tabelas e esse cenário formarão
a base deste curso.
6. Visão geral DO RDBMS: Sistema de
gerenciamento de banco de dados relacional ou RDBMS. O que é RDBMS? Rdbms é um acrônimo
que significa sistema de gerenciamento de banco de dados
relacional. Rdbms, software que gerencia bancos de dados
relacionais. Portanto, é chamado de sistema de
gerenciamento de banco de dados
relacional ou RDBMS. software gerencia uma execução de código
SQL entre os bancos de dados e o aplicativo do sistema de computador. Existem diferentes
tipos de fornecedores que fornecem software RDBMS. E cada sabor do RDBMS
é um pouco diferente, mas sua implementação
é em grande parte a mesma. Vamos dar uma
olhada em alguns exemplos de software RDBMS comum. Esses são alguns exemplos. Há dezenas de outras pessoas que você pode encontrar
online também, mas vou me concentrar nestes
são mencionados aqui. Oracle tangy é um sabor do software RDBMS
pela empresa Oracle, Microsoft SQL Server,
Microsoft Access. E no Microsoft SQL Server, existem versões diferentes
do Microsoft SQL Server. Amazon Redshift pela AWS
ou Amazon Web Services. Mysql. E o MySQL é um sistema de
gerenciamento de banco de dados
relacional de código aberto amplamente
utilizado . O último desta
lista é o IBM Db2. Você pode ter, se eu não
tivesse ouvido falar do DB2, mas é um sabor do software
RDBMS da IBM. Para nossos propósitos, usaremos o servidor do curso
fornecido pela Microsoft. As readmissões de RF disponíveis, que fornecerei na descrição
individual. Os mesmos princípios SQL
devem se aplicar a outros softwares RDBMS
usados porque SQL é uma linguagem
padrão ansi, o que significa que é amplamente
aceito e padronizado. Portanto, todos os principais softwares
RDBMS suportam algum tipo de SQL.
7. Relacionais de dados de NoSQL em bases de dados: relacionais vs. NoSQL. Existem duas
categorias principais de bancos de dados. Nosql e bancos de dados
relacionais. Vamos dar uma olhada nos bancos de dados
relacionais. No canto superior direito, você tem uma tabela de amostra do
nosso banco de dados relacional, que tem uma estrutura. Os bancos de dados relacionais geralmente são armazenados ou hospedados em
um único servidor. Esses bancos de dados são baseados em tabelas, o que significa que eles têm tabelas. E eles armazenam dados estruturados que estão em conformidade com um
esquema ou uma estrutura. Os bancos de dados relacionais são compostos de coleta de objetos ou
as relações armazenam os dados. Essas
coleções relacionadas de objetos são armazenadas em uma tabela de banco de dados. Exemplos comuns de bancos de dados
relacionais são Microsoft SQL
Server e o IBM Db2. Existem outros
tipos diferentes de bancos de dados relacionais, como Oracle e MySQL. Por outro lado,
temos bancos de dados NoSQL. Como um termo indica, bancos de dados
NoSQL armazenam
dados como documentos. Eles não têm relações. Os bancos de dados Nosql têm esquemas
dinâmicos para armazenar os dados não estruturados. Exemplos de um
banco de dados NoSQL é o Hadoop, que é construído sobre o sistema de arquivos
Hadoop ou HDFS, que lida com arquivos. Esses arquivos
geralmente são distribuídos em nós de
processamento
em toda a rede. Em geral, o
sistema de arquivos Hadoop usa uma parte de
mais de uma
máquina para ler e executar computação em
relação aos dados. Portanto, essas são
as duas principais categorias
de bancos de dados,
ou seja, bancos de dados relacionais
e bancos de dados NoSQL. O aumento das empresas da Web 2
fez com que o banco de dados NoSQL seja muito popular, pois os conjuntos de dados manipulados por empresas da
Internet cresceram ainda
maiores em tamanho e maiores. Uma nova abordagem para projetar
bancos de dados veio para
o , pois o design estrito do esquema bancos de dados
relacionais foi evitado em favor de um banco de dados
sem esquema. Portanto, os bancos de dados NoSQL vêm em diferentes formas e
abordam diferentes casos de uso. A seguir estão alguns
deles que já foram mencionados. No entanto, o escopo também
é esse curso. Isso inclui armazenamentos de chave-valor. Exemplos comuns são
Redis, Amazon, DynamoDB, armazenamentos de
colunas como
HBase e Cassandra, armazenamentos de
documentos como
MongoDB e base de sofá. dados gráficos,
como Neo4j e bancos de dados de
mecanismos de pesquisa , como solar
Elastic Search e Splunk. Esses são os
tipos comuns de bancos de dados e diferenças entre bancos de dados
relacionais
e bancos de dados NoSQL.
8. O que é SQL?: O que é SQL? SQL pronunciado SQL significa Structured
Query Language. Sql é uma linguagem padrão ansi para acessar e manipular
dados armazenados em um banco de dados. A palavra-chave answer neste caso significa o American National
Standards Institute. E C, que é uma organização privada
sem fins lucrativos que administra e
coordena os padrões voluntários dos EUA e o sistema de
avaliação de conformidade. Como o SQL é uma linguagem
padrão ansi, é um padrão
aceito pelo setor. Também é universalmente aceito. Portanto, como o SQL é
uma linguagem padrão, ele tem sido amplamente aceito
como uma linguagem padrão para acessar nossos
dados mensais armazenados em um banco de dados. Sql é, portanto, a linguagem de programação de
fato para acessar e manipular
dados armazenados em um banco de dados.
9. Fundamentos do SQL Fundamentos: Fundamentos de Seo. Vamos dar uma olhada no bloco
básico de consulta SQL, a estrutura SQL. Uma consulta SQL é composta por
quatro cláusulas básicas. A cláusula select identifica quais colunas
devem ser acessadas ou recuperadas. A cláusula from identifica quais tabelas devem ser acessadas. A cláusula where limita ou restringe as linhas que
atendem a determinados critérios. A cláusula opcional order BY classifica as linhas dos dados
verdadeiros em ordem
crescente ou decrescente
para uma ou mais colunas. E veremos
isso mais tarde. Portanto, esses são os blocos
básicos de uma consulta SQL. Essas quatro cláusulas. Mas, na maior parte, você descobrirá que você tem um select de uma cláusula where. A cláusula order BY é opcional.
10. Comunicados DCL: deste ano, comandos de linguagem
de controle de dados. Esses comandos oferecem privilégios
ou direitos de acesso para que os usuários do
banco de dados executem determinadas ações em um banco de dados
com base em suas funções. Exemplos comuns de
comandos DCL são conceder e revogar. O comando grant dá um usuário privilégios de acesso
ao banco de dados. O comando revolt remove os privilégios
de acesso do
usuário do banco de dados. O escopo desses comandos
está além deste curso, mas esses são os
dois tipos comuns de comandos DCL em uso hoje.
11. : Categorias de comando Sql. Existem quatro categorias
de comandos de consulta SQL. Comandos Ddl ou linguagem de
definição de dados. As mãos de amálgama ou Linguagem de
Manipulação de Dados, comandos
DQL ou linguagem de
consulta de dados, comandos
DCL ou linguagem de
controle de dados. Vejamos o
primeiro exemplo. de linguagem de definição de dados ou
comandos DDL. Esses comandos são
usados para especificar o esquema do banco de dados, a estrutura do
banco de dados. Usado para criar e ou modificar a estrutura de objetos de
banco de dados. Existem dois
tipos básicos de comandos DDL. A primeira é criar tabela, que é usada para
criar e criar tabelas em um banco de dados. O segundo tipo é alter table, que é usado para alterar a
estrutura de um banco de dados. Tabela em um banco de dados. Esses são alguns exemplos, mas esses comandos DDL estão
fora do escopo deste curso. Este é o resultado do curso intermediário
subseqüente. usaremos a instrução SQL create
table Em vez disso, usaremos a instrução SQL create
table posteriormente neste curso para criar nossa tabela de banco de dados.
12. Comandos DML: Dml, comandos linguagem de manipulação de
dados são usados para modificar
dados em um banco de dados. Exemplos comuns de comandos DML são inserir, atualizar e excluir. O comando insert é usado para inserir dados em
uma tabela de banco de dados. O comando update
é usado para atualizar ou modificar dados em um banco de dados. O comando delete é, é excluir dados de
uma tabela de banco de dados. Analisaremos alguns exemplos
mais adiante neste curso.
13. Comandos DQL: Dql, comandos Data Query Language
são usados para acessar e recuperar
dados em um banco de dados. O comando DQL mais
usado é a instrução select. A instrução Select é usada para recuperar dados de um banco de dados. O foco principal neste curso será na instrução select.
14. Instale o SQL Server no Docker: A coisa começou a instalar o banco de dados do
SQL Server. Dependendo do sistema
operacional do sistema operacional, você precisará instalar o SQL
Server de maneiras diferentes. Para
facilitar este curso,
incluí links para
baixar incluí links para o
software necessário para instalar SQL Server em um Windows
para Linux e três Mac. Estou usando um Mac e, para
meus propósitos, vou instalar o SQL Server em
uma imagem escura em um Mac. Para este curso, usarei o Microsoft SQL Server em um Mac, ou o material do curso também
deve funcionar em uma
máquina Windows e Linux. Você encontrará recursos
e links abaixo para a instalação do
broker diz software. Agora vamos começar e
instalar o SQL Server no Docker. Você pode se perguntar,
o que é Docker? Docker é uma
plataforma aberta para o desenvolvimento, envio e execução de
obrigações. Darker permite que você separe seus aplicativos de
uma infraestrutura. Você pode entregar
software rapidamente. Portanto, mais escuro permite que o
software seja executado em seu próprio ambiente isolado, o
SQL Server 2019. E qualquer outra versão
do SQL Server pode ser
executada no Docker em seu
próprio contêiner isolado. Depois que o Docker estiver instalado, basta baixar ou agrupar a imagem do SQL Server no Linux
Docker no Mac e executá-la como um contêiner do
Docker. Este contêiner está em um ambiente
isolado que contém tudo o que o
SQL Server precisa para ser executado. Tudo bem, vamos começar. A primeira coisa que
você precisa fazer é instalar o Docker e obter a edição da
comunidade gratuita mais
escura do link
aqui, que é hub, o docker.com clique em ficar mais escuro uma vez que o download
conclui para instalar, clique duas vezes no arquivo
DNG e, em seguida, arraste o ícone do aplicativo ponto mais escuro para a pasta de aplicativos e a instalação deve
começar agora mesmo, você pode ver todos os arquivos
são sendo copiado para a
pasta de aplicativos no Mac. E para o Windows, você pode
pular esta etapa porque você tem uma
máquina Windows e você pode instalar
diretamente o SQL Server, isso deve levar cerca de
um minuto para ser executado. E depois que o Docker estiver instalado, iremos até a pasta
Aplicativos. Clique duas vezes no
ícone mais escuro para iniciar o encaixe. Parece que a
instalação está concluída. Vou em frente e abrirei
o software mais escuro. Clique duas vezes nele. Depois de abrir mais escuro, você pode ser solicitado a digitar
sua senha para conceder acesso aos componentes
de rede em sua máquina.
Certifique-se de fazer isso. Você pode ver
aqui, ele diz que o docker é um aplicativo baixado
da Internet. Eu geralmente quero abri-lo, basta ir em frente e clicar em abrir. E imediatamente você
receberá esta janela. No topo, diz mais escuro. E o ícone é um navio
parece uma embarcação grande e vai dizer que o Docker
Engine iniciando por padrão, o Docker terá dois gig de memória alocados para o SQL Server. No entanto, não vai doer se
você aumentar a memória. Para o meu caso, vou
aumentar a memória para seis shows porque tenho cerca de
48 shows nesta máquina. Vou clicar neste ícone de engrenagem, ir para Recursos avançados e selecionar seis shows,
aplicar e reiniciar. Agora, dependendo da versão
do seu Mac que você tem, os menus podem ser diferentes, mas acredito que você esteja
executando a versão mais recente. E, uma vez feito, ele só retorna para essa visualização. Volte
para o general. Agora, aqui vem a parte divertida. Faça o download do SQL Server. Agora que temos o
Docker instalado, iremos em frente e baixaremos o
SQL Server para Linux. Para baixar o SQL Server, você precisará ir até
a janela do terminal e executar este comando, que fornecerei na descrição
do vídeo. E precisarei
digitar minha senha. Depois de digitar a senha, a imagem mais recente do SQL Server
2019 Linux Docker será puxada
para o seu computador. Esse processo pode levar alguns minutos,
dependendo da velocidade da Internet. Basta ser usado pelo paciente
dirá que os líderes de 2019 puxando do Microsoft SQL Server para servidor de
barra, extração
completa de pool. E está feito. O próximo passo é iniciar
a imagem do Docker. Execute o seguinte comando para executar uma instância
da imagem do Docker, você acabou de baixar
um problema do comando. Vou em frente e
pausar a gravação porque preciso
digitar minha senha. Em seguida,
precisaremos executar uma série de comandos para instalar o SQL CLI, que é uma
interface de linha de comando para interagir com a imagem do Docker para
aquele ano em um tipo npm install dash G SQL, CLI, insira, acho que
não gosta do NPM, então além vai funcionar. E se você realmente
vir essa saída conectando-se ao host local feito SQL CLI, o
número da versão fornecido. E você verá a
opção de ajuda também e o prompt muda para
MSS SQL, microsoft SQL. Agora, isso significa que
você se
conectou com êxito à sua
instância do SQL Server. Agora vamos fazer um teste rápido e ver se temos algumas opções. E diremos que selecione a versão
SAT ACT para
nos mostrar a versão do SQL Server que está sendo executada e
você verá uma saída. Vai dizer que o Microsoft
SQL Server 2019 lhe dará uma data e dirá que
uma linha de retorno, forneça
o tempo de execução. E isso é praticamente isso. Instalamos o SQL
Server em mais escuro. Em seguida, precisaremos ter uma interface gráfica do usuário para interagir com o SQL Server. Para nossos propósitos,
usaremos o Azure Data Studio, que anteriormente era o SQL
Operations Studio, e é uma opção de GUI gratuita para interagir com
o SQL Server. Então, vou para a página de download do Azure Data
Studio para um Mac precisará
obter essa opção, esta versão, que
é um arquivo zip. Quando você terminar o download, clique duas vezes nele para
iniciá-lo, dirá que o Azure Data Studio é um aplicativo baixado
da Internet. Confie nisso. Sim,
uma vez feito isso, você deve ver isso. Na verdade, eu tinha
instalado isso antes. Agora vamos adicionar uma conexão
ao SQL Server mais escuro. Você deseja digitar
que o tipo de autenticação
de
host local do servidor é login SQL, nome de usuário é ASA
anti sua senha, quando digo lembrar senha, banco de dados é padrão, então um
grupo é padrão, digamos conectar . Logo de cara. Temos uma conexão com
nosso SQL Server local. Até este ponto,
instalamos com êxito o SQL Server
em uma imagem do Docker, o que nos permitirá executar o SQL Server e prosseguir
com o curso. E é isso para esta seção. Vamos avançar para o próximo.
15. SQL Crie banco de dados SQL Criar: Para aqueles que são
novos no Azure Data Studio, azure Data Studio era anteriormente
secreto operations studio, que é uma interface gráfica gratuita
do usuário ou ferramenta de gerenciamento de
GUI
que permite conectar ou Gerenciar
SQL Server no Mac ou em qualquer outra máquina
baseada em Linux, que significa que você
pode usá-lo apenas para criar bancos de dados gerenciados, escrever consultas, fazer backup e restaurar seus bancos de dados e muito mais. Este é um primeiro G2 craniano. Depois de iniciar o
Azure Data Studio, no lado esquerdo, você
terá suas conexões,
seus solucionadores, localhost e, em seguida, seus bancos de dados estarão
abaixo dessa árvore ou ramificação. Eu forneci a você
um monte de scripts SQL que precisarei que você use
para acompanhar
neste curso, a primeira coisa que você quer
fazer é simplesmente ir ao seu navegador e abrir. Extensões. Ouvir que eu quero fazer é apenas
criar um banco de dados porque não
teremos uma tabela ou tabelas antes de termos
um banco de dados. Essa consulta SQL permite
criar um novo banco de dados. A primeira coisa que ele faz é verificar se o banco de dados real existe, então ele executa sua instrução
create e em seguida, definir alguns outros parâmetros, ou SQL Server ou apenas SQL. Então, vamos seguir em frente e executar isso. Depois de atualizar os
bancos de dados à esquerda, teremos um novo banco de dados
conhecido como banco de dados de saúde.
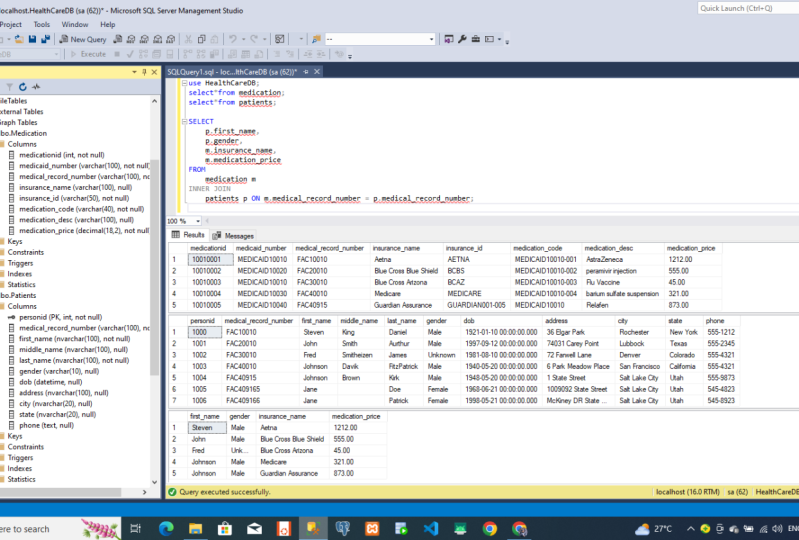
16. Tabela de criação SQL: Estou referenciando querer
fazer é ter certeza de que você está conectado ao
banco de dados de saúde. Se você estiver usando o
Microsoft SQL Server, isso deve estar no
lado esquerdo como este aqui. Ou SSMS, SQL Server
Management Studio. Você verá o nome do banco aqui e todas as suas tabelas
ficarão abaixo. Nesse caso, os
pacientes da tabela não existe, como você pode ver aqui
nesta seção suspensa. A sintaxe que usamos para
esta seção é soltar a tabela que ela existe e
recriá-la do zero. Agora, a sintaxe para
criar uma tabela, ou melhor, nova tabela
é essa aqui. Crie tabela, nome da tabela. Em seguida, seguido pelo nome
da coluna. O tipo de dados. Coluna para tipo de dados. E você pode ter a coluna três, tipo de dados e assim por diante e assim por diante. Isso significa apenas criar uma tabela que você define
dentro do desejo nomeado. Estes são os parâmetros da coluna, especifique os nomes das colunas
e os tipos de dados. Por tipo de dados, quero dizer, o tipo de dados ou a coluna pode ser mantida. No nosso caso, esta é a
sintaxe do artista, crie tabela. Os pacientes devem ser prefixados
por essa sintaxe aqui, a biota dos pacientes
no nosso caso, primeira coluna terá
é um ID pessoal, que é um número inteiro. Não está vazio, o que significa que não é nulo e é uma chave primária. Cada tabela e banco de dados
do SQL Server, ou na maioria dos bancos de dados, tem uma chave primária seguida
pelas outras colunas. Temos o número do registro médico, que é o
caractere variável 100. E não está vazio, ou
seja, leite. Agora, a diferença
entre n var char e caractere variável é n var
char usa principalmente espaço, normalmente dois bytes por caractere Unicode de
unidade, e o
caractere variável usa um byte. Nesse caso, coisas como sexo, eu apenas especifico o caractere
variável. Mas então o primeiro
nome, nome do meio, sobrenome será n gráfico de
barras até 100. Portanto, isso significa que um primeiro nome pode ter até 100
caracteres de comprimento. É muito difícil encontrar um
primeiro nome com mais 100 cactos, a menos que sejam seus dados fictícios
subfatoriais. Essas são as colunas. Nome, nome do meio,
sobrenome, sexo, DOB, endereço. O endereço também é um caractere
variável e gráfico de
barras com data de nascimento
é um tipo de dados de data e hora, seja, pode estar vazio. Cidade depois de 20 caracteres permaneceram, cacto de
Appleton, os números de
telefone e o texto. Essa é a nossa sintaxe. Muito simples. É possível ter tabelas muito
grandes que tenham um tipo diferente de sintaxe
ou muitas, muitas outras colunas. Vi colunas de até 60
colunas em uma única tabela. Agora vamos seguir em frente e garantir que o tipo de conexão seja ajudado a obter o EB e, em seguida, basta executá-lo. Então, estamos basicamente verificando se a tabela existe e
depois soltando-a. Nesse caso, se eu atualizar
esta seção aqui, na verdade, e depois abrir o ramo, temos uma nova tabela aqui
conhecida como, conhecida como pacientes. E se você comparar a sintaxe com a definição de
tabela real, essa é uma interseção de tabela. C Person ID tem pk, abreviação para chave primária e todas as outras colunas
são definidas aqui.
17. Adicione dados em tabela de pacientes usando o SQL INSERT INSERT IN: Se você executar essa consulta, não
haverá dados
aqui, o que é bom. Me leva a esta outra
seção para inserção. Basicamente, eu
queria mostrar a vocês que não há dados aqui. Uma vez que eu executar a instrução insert receberão alguns dados. Agora, a
instrução de inserção secreta e esses dados
em uma tabela de banco de dados. A sintaxe básica é
inserida no nome da tabela do esquema, seguida das
colunas especificadas. As colunas especificadas precisam
corresponder aos valores fornecidos. que significa que o ID da pessoa
corresponde a esse número de
registro médico de cem, dez centenas corresponde a este, FAC 1010 ou 10.010. O nome corresponde a sete. O nome do meio é rei, o
sobrenome é Daniel, o
gênero é masculino. Dob 1921 ou 110. O endereço, cidade, estado
no número de telefone. Você vai repetir
isso repetidas vezes para cada inserção de tabela única. Agora, para outros cursos avançados abordam operações de ETL, eles lidam com
grandes inserções de mesa. E é outro curso provavelmente
criarei
algum
momento sobre como inserir
ou executar extração, transformação e carga de conjuntos de dados
massivos em
uma tabela de banco de dados. Mas para este curso,
muito simples. Estudando quantas linhas, 12345 linhas, vai
dizer que uma linha afetada. Volte para a minha alta
elétrica anterior e eu corro, recebo duas filas de volta.
18. Tabela de medicação SQL Crie o SQL: É uma tabela adicional
conhecida como tabela de medicamentos, que usaremos para trabalhar
nos operadores de comparação. Agora, a primeira coisa que usaremos para conectar ao banco de dados de saúde e a sintaxe é realmente a mesma que a tabela do paciente, são apenas alterar a assinatura para criar a tabela real. Nesse caso, é
uma tabela de medicamentos que tem os
seguintes parâmetros. A primeira coisa que vou fazer é
verificar se a tabela existe em nosso banco de dados. Se isso acontecer, o soltaria e
, em seguida, criaria uma tabela em si. Essas são as diferentes colunas. Lembre-se de que a sintaxe da
tabela de crédito é o nome da coluna, seja nulo ou não, e o tipo de dados real. Este caso, ID de mitigação, número do
Medicaid, número de registro
médico, seguro e os detalhes de
mitigação. Vamos prosseguir e conectar
o banco de dados de saúde executá-lo. Agora nós o criamos. Só vou atualizar
os bancos de dados e
ver as tabelas. Temos a tabela de amortização tem a mesma assinatura ou sintaxe
da nossa tabela principal aqui. Em seguida, inseriremos alguns
dados nesta tabela. Você notará que essa é uma sintaxe
para a operação de inserção. Comece, trunque a
tabela real se houver dados. Então, começamos com uma nova ardósia. Nunca faça isso. Se você estiver trabalhando em um banco de dados de
produção. Isso é apenas para nossos próprios
propósitos, para este curso. Apenas truncando. Podemos começar com uma tabela de
banco de dados limpa quando eu a executo. E você verá aqui
que inserimos cinco linhas. Como você pode ver nesta sintaxe. sintaxe é como descrevi em seções
anteriores para inserir dados na tabela do paciente. Você define as colunas. Bem aqui. Insira no nome da tabela, as colunas reais
e os valores, e as colunas correspondem aos valores na
sequência, conforme mostrado aqui. Isso é praticamente que ele criou
uma nova tabela de medicamentos e inseriu alguns dados
nessa tabela. Vamos prosseguir com
a próxima seção.
19. Status de SQL SELECT: Vamos falar sobre o comando
SQL select, que é o comando SQL mais básico e mais
usado. Vou seguir em frente e abrir a instrução
SQL select aqui. A primeira coisa que
queremos fazer é garantir que você tenha a conexão
correta, seu próprio host local e um banco de dados de saúde selecionado, que é nosso
banco de dados principal para este curso. Agora, a instrução SQL select basicamente recupera
dados do banco de dados. E a
sintaxe básica da instrução select é a seguinte. Selecione, forneça os comandos em vez
de colunas da tabela. Neste caso,
será a tabela do paciente. Além disso, você tem uma condição em que limita ou restringe a consulta de sequela duas linhas que atendem
a determinados critérios. Exemplo crítico, temos
uma mesa muito pequena. Lembre-se, você
nunca deve executar select star em nossas
tabelas de banco de dados
muito grandes, pois isso irá prejudicar o desempenho
do aplicativo ou provavelmente
bloqueará seu banco de dados. O meu é muito simples. Selecione a estrela dos pacientes, o que basicamente significa
selecionar todas as colunas. A estrela desta tabela. Como você pode ver
nos resultados aqui. Coluna de identificação da pessoa, número do registro
médico ,
Nome e todas as
outras coisas boas, toda a
ordem demográfica até o final, sexo, DOB, endereço, cidade,
estado e número de telefone. Há também outra tabela, tabela medicamentos,
estrela selecionada da medicação. E traz à tona
um conjunto de resultados de mitigações
desse dB de saúde. Se você for para a esquerda, você pode ver os bancos de dados, saúde dB, as tabelas, tabela de
medicamentos
na mesa do paciente. Estas são as definições de tabela no lado esquerdo e sempre navegue e veja quais
colunas você precisa sugerir executar a
estrela selecionada dos pacientes, e você especifica ordem
por neste caso, digamos LastName. Execute isso, seu pedido. Os resultados definidos
pelo sobrenome podem ver que está
em ordem alfabética. Arthur Daniel DO se encaixa
com James Cook e Patrick. Isso foi possível selecionar suas colunas específicas
neste caso, quando eu digo ID de pessoa, Digamos apenas qualquer um
dos nomes, nome e data de nascimento. Este é um conjunto de resultados. Eu fico bastante simples, selecione
a instrução SQL select para recuperar dados
do banco de dados.
20. SQL Select TOP: Agora temos nossa mesa. Próxima seção,
estudaremos o top selecionado. Agora, a instrução top select limita o número cresce
retornado de uma consulta SQL. Isso é muito importante para tabelas
muito grandes em que
você queria limitar a saída para não afetar o
desempenho do aplicativo. Nesse caso, se
eu selecionar o topo, ele definiu as colunas. Você pode optar por preferir dizer um número
limitado de colunas ou apenas ter quantas
colunas precisar. Seguido pela palavra-chave do
nome do banco de dados aqui, o esquema e
a própria tabela. Se você executar essa consulta,
recebo duas linhas de volta. Também é possível,
como mencionei, limitar quantas
colunas você precisa disso, usando isso é apenas
fornecer seus nomes de coluna. Também é possível
fornecer uma barraca. Simplesmente significa dar-me todas as outras colunas desta
tabela. Se você tiver dez colunas, você obterá colunas usando
a sintaxe estrela aqui. E essas são as colunas. Agora estamos fazendo um top 10. Se você aumentar para falar três, você obterá as três principais linhas dessa
tabela em ordem sequencial. Pode ver os números de linha 1234. Você receberá outra
linha retornada.
21. Cláusula DO SQL WHERE.: O próximo comando que
usaremos é uma cláusula SQL where. Vou abrir minha consulta recente. Tenho uma consulta SQL aqui. Temos uma conexão,
localhost, conexão, selecione o banco de dados de saúde do
banco de dados de conexão, SQL where cláusula basicamente
limita ou restringe a consulta SQL duas linhas que atendem a determinados
critérios ou condições. Lembre-se antes de mencionar que você não deve
apenas executar
SQL select SQL star em uma tabela sem fornecer uma
condição ou um limite. Nesse caso, estou basicamente
executando uma contagem de seleção. A contagem é uma espécie de agregado sobre as colunas
e as linhas aqui. Então selecione contagem de pacientes
em que o sexo é masculino. Você pode ver aqui eu tenho quatro linhas em vez de registros que são
do gênero masculino. Você também pode fornecer um
alias para essa coluna. Nesse caso, você pode
dizer pacientes do sexo masculino. Se você executar isso, você terá um cabeçalho de coluna mais definido. Também é possível
usar uma cláusula where onde o operador AND para
limitar ainda mais o conjunto de resultados. Nesse caso, quero
executar conta selecione todos de pacientes onde o sexo é masculino e
o primeiro nome é John. Este caso é um bom
cenário em que você deseja ver a distribuição
do uso de nomes genéricos. Por exemplo, John,
você tem Jain, esses outros nomes genéricos
que você pode encontrar no conjunto de dados. Esse é o uso da
cláusula where para limitar ou restringir a consulta SQL a linhas que
atendam a determinados
critérios ou condições.
22. SQL distinta SQL: Às vezes, você pode querer recuperar
valores distintos ou exclusivos de uma coluna. Nesse caso, você usa a palavra-chave distinta que retorna
resultados exclusivos em um conjunto de dados. Por exemplo, eu
queria descobrir os nomes distintos ou únicos
do gênero masculino. Nesse caso,
alterarei minha conexão para dB saudável e apenas
executarei esse comando. Eu veria que
esses são basicamente os nomes comuns que você tem neste conjunto de dados
que são exclusivos. Temos John,
Johnson e Steven. Agora, se eu copiar esse SQL e apenas remover a palavra-chave
distinta e executar ambas. Você verá que temos
no primeiro conjunto de dados, três nomes voltam.
Estes são distintos. Mas então, no segundo, você vê que há
44 linhas retornadas, basicamente são palavras-chave distintas
se livrar de duplicatas. Você pode ver que esse é o
uso da palavra-chave distinta. Além disso, se você disser instância, vamos mudar esse gênero para mulher e ver o que recebemos de volta. Um resultado diferente. primeiro é o nome
mais comum é a cadeia distinta ou única? Temos duplicatas, o que
significa que existem duas delas. Se eu selecionar estrela, basicamente a estrela aqui
significa obter todas as colunas. Você verá que Jane se repete, mas basicamente eu quero
mostrar a vocês que este é, este é um
registro distinto, Jane Doe. E esta é Jane Patrick,
distinta também. E esse é o uso
da palavra-chave distinta.
23. Ordem SQL Por: A cláusula SQL order BY
buscou linhas com a cláusula order BY em ordem crescente
ou
decrescente. Neste caso, voltaremos à nossa tabela de fato,
o paciente estável. Vamos mudar nossa conexão com
o banco de dados de saúde. Nesse caso,
faríamos um select todo o primeiro nome, nome do meio, sobrenome e cidade
e estado pela cidade. Agora, se olharmos aqui,
você verá que a sequência de pedidos
é alfabética, configurando com um D e terminando
com San Francisco aqui. Então denver todo o caminho
até São Francisco. A cláusula order BY ordena, colunas baseadas
em ordem crescente, que é denotada por ASC
ou ordem decrescente. Se você reverter, verá que
San Francisco está no topo. Também é possível classificar
por mais de uma coluna. Nesse caso, se
eu disser FirstName, posso dizer FirstName ascendente. Então primeiro vou ordenar
POR cidade descendente, seguido pelo
primeiro nome ascendente. Eu olhei para esses dados, cidade descendente, São Francisco. Então vamos City Rochester, Nova York, Lubbock, Denver. E então o FirstName Johnson vem antes de Stephen
e assim por diante e assim por diante. E essa é a ordem ou a sequência quando você
usa a cláusula order BY, muito importante se
você quiser examinar conjuntos de dados
específicos dependendo suas necessidades ou colunas diferentes, e assim por diante e assim por diante em diante. Você também pode usar aliases de coluna ou um número para a posição da coluna
na cláusula order BY, saúde dB por execução, selecionar primeiro nome, nome do meio, sobrenome, cidade-estado,
por cidade para sua nome. Isso é o que eu recebo de volta. Também é possível usar
aliases para as colunas, o que significa, por exemplo, cidade. Para essa posição, você
deseja contar as colunas 1234. Você pode dizer ordem
por quatro decrescentes, então FirstName pode fazer um, o que significa ordenar
por posição
das colunas na cláusula
select aqui. Para executar isso, ainda tenho os
mesmos resultados definidos aqui. Isso é algo
legal para lembrar. Se você tiver
tantas linhas brother, tantas colunas para escolher
quando você selecionar,
você deseja confiar no alias de
coluna ou em um número para a posição da coluna
na cláusula order BY.
24. Ordem de sql por posição: Você também pode usar aliases de coluna. Número da posição da coluna
na cláusula order BY. Por exemplo, se eu
executar essa consulta aqui, deixe-me limpar meu banco de dados
primeiro. Cuidados de saúde dB. Se eu executar isso, selecione primeiro
nome, nome do meio, sobrenome, cidade, estado por
cidade para o nome dele. Isso é o que eu recebo de volta. Também é possível usar
aliases para as colunas, o que significa, por exemplo, cidade. Para essa posição, você
deseja contar as colunas 1234. Você pode dizer ordem
por quatro decrescentes e,
em seguida, FirstName pode fazer um. O que significa ordenar
por posição
das colunas na cláusula
select aqui. Se eu executar isso, ainda
obtenho os mesmos
resultados definidos aqui. Isso é algo
legal para lembrar. Se você tiver
tantas linhas brother, tantas colunas para escolher
quando você selecionar,
você deseja confiar no alias de
coluna ou em um número para a posição da coluna
na cláusula order BY.
25. SQL Group: Uma
instrução core group by retorna um conjunto de linhas para dar um
resultado por grupo. Eu forneci a você
um script SQL groupby para ser executado nesta seção. Selecione meu banco de dados. O primeiro oxigênio precisa se
conectar ao banco de dados. Selecione a conexão de
saúde db. Agora, neste caso,
o que eu quero fazer é dizer para a primeira
consulta é apenas, deixe-me executar todos esses três. A principal consulta aqui, estou recuperando os dois
primeiros registros da tabela de medicamentos. Na próxima seção aqui, farei uma contagem selecionada do número
do registro médico, seguido de nomes de seguros
e, em seguida, agrupando
por nomes de seguros. Este é um
caso de uso bastante comum quando você quer ver a distribuição de pacientes que têm diferentes tipos de provedores de
seguros. Poderia ser agora, Medicare, Medicaid, coisas assim. que significa que
você pode fazer uma contagem
dos registros seguidos
pelo nome do seguro
e, em seguida, agrupar pelo nome do
seguro em si. Seção aqui. Por exemplo, se
você quiser verificar os provedores de
seguros
pelo preço médio de uma cobertura de medicamentos. Se eu executar essa consulta aqui, o que estou procurando
é o nome do seguro, o preço médio do medicamento. Se eu for para a definição da minha tabela, quero mostrar a vocês
a mesa de medicamentos. Ele tem várias colunas. Uma dessas colunas é
o preço de mitigação. Deixe-me apenas executar uma consulta
simples aqui. Selecione a estrela da
medicação novamente, é uma tabela muito simples, nunca
deve executar
isso em produção. Selecione estrela. Você pode ver que temos ID de mutação, Medicaid, número de registro
médico. Isto é, esta é uma
chave primária na tabela do paciente, que significa que é uma chave
estrangeira aqui. Nome do seguro,
Aetna, Blue Cross, Blue Shield, Medicare,
e assim por diante e assim por diante. E então o preço de mitigação. Esta tabela basicamente mostra os medicamentos, os prêmios e os provedores de seguros para aqueles casos de uso bastante simples. Eu executei essa consulta. Estou procurando o agrupamento de preços
médios pelo nome do seguro. Em uma seção posterior, analisaremos a função
média, que é bastante
usada quando você está trabalhando com
dados ou números financeiros. E você quer
ver a média de algum valor ou parâmetro. Esse é o olhar para o
Grupo Por que significa
agrupar os resultados definidos por
um resultado por grupo. Nesse caso, quero ver o preço médio aqui. Posso apenas fornecer
um alias e chamar essa média desse preço. O que significa que eu quero obter um nome de coluna
mais definitivo. Assim mesmo. Vamos passar para
a próxima seção.
26. SQL tendo a cla: Ele aparece com bastante frequência em perguntas de
entrevista
para engenheiros de dados ou programação
SQL porque é
uma cláusula muito complicada de usar. E é frequentemente usado com
um grupo BY também. Agora, a cláusula SQL having
é usada para
restringir ainda mais os resultados
da cláusula group by. Então, antes de tudo, você agrupou usando a cláusula group by. E então você limita os
resultados que usam ainda mais a sintaxe da cláusula having. Agora, a sintaxe básica da cláusula
having é você selecionar
várias colunas. A função group de uma tabela, a cláusula condition where, grupo pelo qual vem
primeiro e
depois a
condição do grupo vem em seguida. Você também pode encomendar até o final, que significa que as linhas são agrupadas. A função group by é
aplicada ao grupo. E os grupos marchando para
ter no condicionador ou retorno. Deixe-me dar um exemplo
comum. Neste caso, digamos que você queira encontrar o
número de pacientes pelo provedor de
seguros com
o medicamento mais caro ou um medicamento muito caro. O que significa que você deseja fazer a análise de
custos do conjunto de dados, dos dados do paciente. Agora, neste caso, estamos em torno de uma consulta simples. Estou selecionando o
número de registros, número de pacientes, que é
o número do registro médico, que é uma
chave primária, chave única. Esse é o número de
pacientes, nome do seguro, apenas seguro, preço de mitigação como prêmio de dependência
da tabela de medicamentos. Neste caso, estou agrupando por nome do
seguro e preço de
meditação. Agora, na próxima seção,
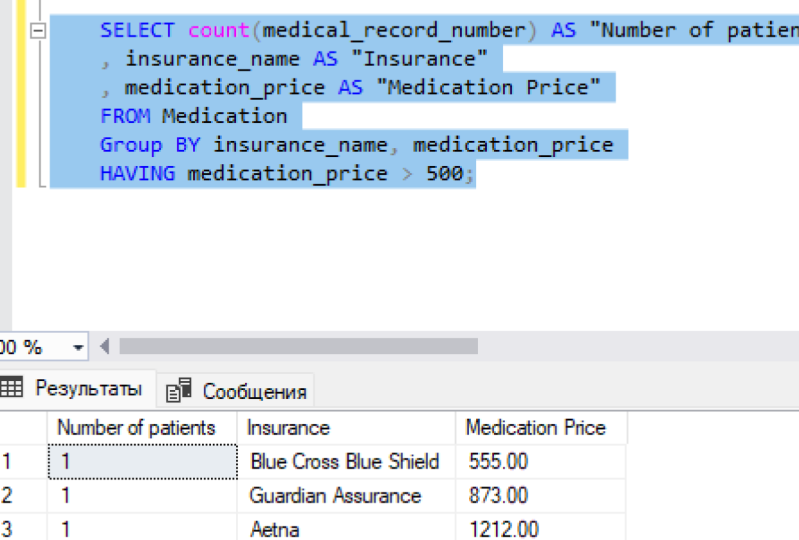
vou dizer tendo uma mitigação de dizer, mais de US $1000, eu
executei essa consulta. Preciso primeiro me conectar
ao meu banco de dados. Vou voltar aqui
e apenas executar essa consulta. Você pode ver aqui, eu tenho um paciente
que está coberto pelo seguro e eles
têm medicação de US $1200. Por exemplo, se você
limitar isso a dizer 500, isso basicamente significa me dar
responsabilizar os pacientes e
os nomes de seguros ou provedores de
seguros que têm
um medicamento de mais de US $500. Você pode ver que temos um registro. Escudo azul cruz azul. Assim, o preço do medicamento. Na verdade, posso até
vir aqui. Vou mostrar a vocês
a mesa de medicamentos. Procure por este 555. Você verá aqui. O segundo medicamento nesta lista é a nossa injeção de parâmetros,
que custa 555. Está coberto pelo
seguro e está vinculado a isso rápido aqui. Nas seções posteriores, analisaremos declarações
unidas,
coisas assim,
que devem permitir que você execute
operações especiais em seus dados, o que significa combinar
diferentes tabelas e dados diferentes de tabelas
diferentes. Agora, por exemplo,
volte aqui, exiba o
provedor de seguros com o medicamento mais caro. Você verá que esse é o, que é um custo para essa droga
sob seguro étnico. E isso é um olhar. Estarei tendo a cláusula, que geralmente é usada em
combinação com o grupo BY para limitar ainda mais
o resultado do conjunto de dados.
27. SQL E operadores: Os operadores SQL AND, OR e NOT operadores. Aqui temos nossa conexão com o banco
de dados de saúde. A primeira coisa que você fará é selecionar
estrela da tabela de pacientes. Queremos ver o
grupo de dados aqui. Você pode ver que temos gênero. Bem aqui, a coluna da agenda. Agora, o operador e
retorna registros se todas as condições forem atendidas, que significa que todas as condições separadas por e são atendidas. E essas condições também são. Por exemplo, você
pode ver aqui, eu tenho, estou fazendo uma consulta fazendo conta os pacientes do sexo masculino. A primeira coisa, se você executar isso, você receberá quatro registros de volta. Agora, neste caso, se adicionarmos o operador e, isso significa que você deseja
verificar essa condição. Essa outra condição,
se ambas forem verdadeiras, você receberá resultados de volta. Podemos ver que temos um registro
que é um registro masculino. O primeiro nome é John. Se eu voltar, selecione. Você verá aqui
que temos um John, segunda linha. Agora, o operador ou
retorna registros se alguma
das condições for separada
pelo operador ou R2. Agora, por exemplo, vamos
usar a mesma consulta. Vou pegar
todos os pacientes. Selecione estrela de pacientes em
que o sexo é masculino. O nome próprio é
John ou Steven. Nesse caso, devemos
ver dois registros de volta. E você tem dois registros. Agora, se horas para
copiar essa consulta, execute-a para a primeira
com o operador AND. Você não receberá
registros porque está verificando onde está
o primeiro nome, John
e Stephen. Agora, mude isso de volta para
ou você receberá dois registros. E se você mudar isso para? Vamos apenas remover essa cláusula
ou gênero igual a feminino. O que você acha? Vamos voltar? Vamos
executar isso e verificar. Receberá quatro registros. Porque
provavelmente há algumas colunas, algumas linhas que não têm qualquer
gênero de nó aqui. Isso é desconhecido. Executá-lo novamente, você receberá quatro discos saco. Portanto, esse é o
olhar para o operador AND e OR. Enquanto o operador and retorna true quando todas as
condições forem atendidas, o operador ou retorna qualquer. Se alguma das
condições for atendida. Vamos pular para
a próxima seção.
28. SQL E NÃO operadores: Operadores Sql AND, OR e NOT. Aqui temos nossa conexão com
o banco de saúde dB. A primeira coisa que você fará é selecionar
estrela da tabela de pacientes. Queremos ver os dados do
grupo aqui. Você pode ver que temos gênero. Aqui, a coluna de gênero. Agora, o operador e
retorna registros se todas as condições forem atendidas, que significa que todas as condições separadas por e são atendidas. E essas condições também são. Por exemplo, você
pode ver aqui, eu tenho, estou fazendo uma consulta, fazendo uma contagem dos pacientes
do sexo masculino. A primeira coisa, se você executar isso, você receberá quatro registros de volta. Agora, neste caso, se adicionarmos o operador e, isso significa que você deseja
verificar essa condição. Essa outra condição.
Se ambos forem verdadeiros, você receberá resultados de volta. Podemos ver que temos um registro
que é um registro do moinho. O primeiro nome é John.
Se eu voltar, selecione. Você verá
aqui que temos um John. Segunda linha. O operador ou
retorna registros se alguma das condições for separada
pelo operador ou R2. Agora, por exemplo, vamos
usar a mesma consulta. Vou pegar
todos os pacientes. Selecione estrela de pacientes em
que o sexo é masculino. O nome próprio é
John ou Steven. Nesse caso, devemos
ver dois registros de volta. E você tem dois registros. Agora, se horas para
copiar essa consulta, execute-a para a primeira
com o operador AND. Você não receberá
registros porque está verificando onde está
o primeiro nome, John
e Stephen. Agora, altere isso de volta para
ou você receberá dois registros, operador
NOT, que exibe
um registro ou registros. Se a condição ou
as condições não forem verdadeiras. Vamos ver o que
temos nos registros. Nesse caso, o que
você quer fazer é fazer uso do operador não. Para fazer isso. Queremos fazer algo como
não gênero igual ao correio. O que
você acha que vai receber de volta? Demorou alguns segundos
e pense nisso. Se você executar essa
consulta, você verá, você obterá os registros
enquanto o sexo não é masculino, pode ver que você tem registros conhecidos
e femininos. Se eu mudar isso para mulher, selecione estrela de pacientes onde
o sexo não é feminino, você obterá todos os registros masculinos bem
como este
que é desconhecido. Esse é o uso
do operador não, que exibe um
registro ou registros. Se a condição ou
as condições não forem verdadeiras.
29. SQL Como operador de SQL: Nesta seção,
vamos dar uma
olhada no operador semelhante a SQL, que é usado em combinação
com uma cláusula where para encontrar um padrão ou
padrões em uma coluna. Neste caso, eu tenho
este medicamento de mesa. E se eu apenas executá-lo apenas para ver os dados
que estão aqui, temos essas duas colunas, número de registro
médico
e o nome do seguro. Neste caso, estou tentando encontrar o nome do seguro Blue Cross. Como faço isso usando
o operador like, ele sempre é usado em combinação
na cláusula where, o que significa que ele virá
na seção de cláusula where. Localizar dados é usar uma única cotação, porcentagem e, em seguida, os
dados ou o texto, depois o símbolo de porcentagem e terminado por uma única cotação. Neste caso, por exemplo, estou tentando encontrar a
Aetna Insurance. Agora, lembre-se, se você não
tem sinal de porcentagem, você está basicamente
tentando encontrar dados que começam com um B seguido pelo LUB. Tão azul neste caso, que neste caso você encontrará Blue Cross Arizona Blue
Cross Blue Shield. A outra variação
é encontrar pacientes segurados pelo provedor
e depois com o Medicaid ou Medicare. Neste caso. Você tem o percentual de Cote de
abertura, depois as palavras que você está procurando nesse nome do
seguro. Se você executar essa consulta, encontrará o Medicare. É assim que você usa
o operador lac. Lembre-se de você sempre
se estiver tentando encontrar texto entre
textos que deseja usar presente entre a
string que você está procurando. Se você estiver tentando
encontrar colunas em que os dados começam com cadeias de caracteres
específicas, você quer ter certeza de
que é apenas um único código seguido pelo texto. Se estiver terminando, você
quer ter certeza que os textos finais estão
no final, seguidos
pela cotação única e o percentual está no
início disso. Outra única instância que
podemos ver aqui é que fiz um seleto dos medicamentos
da tabela de medicamentos, a descrição real,
temos esses medicamentos. Agora, se você quiser encontrar, deixe-me executar esta consulta aqui. Basicamente, encontrar qualquer
medicamento que comece com um K, começa com um a
e termina com um a. Neste caso, apenas
tentando encontrar AstraZeneca como um termina com um a.
Este é um formato que você usa para isso. E isso é uma olhada
no operador semelhante a SQL, que é usado para encontrar
padrões em colunas.
30. Caracteres do SQL Wild: Vamos escrever outra
consulta aqui para ver o que está nesta
tabela, tabela de medicamentos. Só vou fazer uma estrela seleta. É uma mesa muito pequena,
então eu posso fazer isso. Neste caso. Vamos tentar encontrar um seguro. Em vez disso, todos os medicamentos se
formam cobertos pela Aetna. Se você fizer algo
como selecionar estrela do litígio onde o
nome do seguro como Aetna, o que você acha que volta? Vamos executar essa consulta. Receberá esta
linha que mostra o nome do seguro Aetna
e a medicação em si. Agora, aqui em baixo, podemos
considerar curingas SQL. E um caractere curinga
é frequentemente usado em combinação com um operador
semelhante a SQL. Nós olhamos para isso
antes quando você tinha o símbolo de porcentagem. O símbolo de porcentagem geralmente
denota o curinga. Ele é usado para encontrar caracteres entre o símbolo especificado. Por exemplo, se
eu executar essa consulta, selecione o número do registro
médico de mitigação, nome do
seguro para a tabela de
meditação, onde o
nome do seguro é Blue Cross, o
que significa a string
ou o texto entre o selvagem entre o símbolo de
porcentagem é retornado. Neste caso, encontrarão
todos os medicamentos onde o nome do seguro é Blue Cross Blue Shield
ou Blue Cross Arizona, se você tivesse outro estado, Blue Cross Florida,
chegaria a esse resultado aqui. Outro formato do
curinga usa um sublinhado, o que significa que ele encontra caracteres entre
o símbolo especificado. Por exemplo, neste caso, vamos fazer, vamos retirar todos os registros
da tabela do paciente. Então, estou selecionando
FirstName dos pacientes. Agora, se você quiser encontrar todos
os nomes que terminam em ON, por exemplo, John Don
Kohn e similares. Você usa o operador similar, porcentagem de código
único e,
em seguida,
sublinhado seguido pelos caracteres
que e esse nome. Nesse caso, você
encontrará Johnson e Johnson. Você acabou de descobrir, eu estou
basicamente fazendo todos
os dados ativos de célula única que eu selecionam distintos. Eu teria uma desvantagem. Então é isso que você quer fazer. Basta fazer um distinto nisso. Outro formato
do curinga é
usar o colchete quadrado direito e
o colchete esquerdo. Agora, o curinga de colchetes encontra caracteres entre
o símbolo especificado e as
instruções SQL a seguir selecionam todos os pacientes
com um primeiro nome, começando com a e D. Agora se nós executamos isso, nada volta atrás. Essa é a minúscula. Deixe-me mudar isso para AD. Volta, vamos tentar j.
Eu recebo todos
os registros quando Eu recebo todos
os registros o primeiro nome
começa com um J. Agora vamos ver quais
dados estão aqui. Então, também temos Stephen. Vamos adicionar um S e
ver o que acontece. Você pega Stephen e John. Isso é muito útil e surge com bastante frequência
em perguntas de entrevista. Como você encontra os dados que começam com
uma letra súbita? Nesse caso, primeiro nome, começando com j ou S, e seguido por
qualquer outro caractere. E é assim que você faz isso. E esse é o uso
do personagem selvagem com os colchetes. Vamos supor que queremos encontrar todos os nomes começando
com j, primeiros nomes. E eles não contêm um O,
usa um tipo especial
de caractere selvagem, que é a cenoura superior, o que significa que ela retorna qualquer
caractere que não entre colchetes. Portanto, ele vai
ignorar qualquer nome sem que tenha
um irmão mais velho. Então, se executarmos essa
consulta, você receberá a Jane. Se você quiser ver
todos os dados aqui. Temos duas Janes,
Johnson, John, se você colocar um OH
vai ignorar todos os nomes de
John Johnson ou qualquer outro nome nesse formato. Esse é o uso do curinga de cenoura
superior para ignorar qualquer capital que
não esteja entre colchetes. Vamos passar para
a próxima seção.
31. Operador SQL NÃO Operador: Iterator retornará os registros se a condição ou
as condições não forem muito. Vamos executar um
exemplo rápido aqui. Vou copiar a primeira
consulta aqui. Vamos ver o que
temos nos registros. Nesse caso, o que
você quer fazer é fazer uso do operador não. Para fazer isso. Queremos fazer algo como
não gênero igual ao masculino. O que você acha?
Você vai voltar? Demorou alguns segundos
e pense nisso. Se você executar essa
consulta, você verá, você receberá todos os registros enquanto o sexo não for masculino. Pode ver que você tem registros conhecidos
e femininos. Se eu mudar isso para mulher, selecione estrela de pacientes onde
a agenda não é feminina, você obterá todos os registros masculinos bem
como este
que é desconhecido. Assim, o uso
do operador não, que exibe um
registro ou registros. Se a condição ou
as condições não forem verdadeiras.
32. Contagem SQL , Avg, Min, Max e soma: As funções do grupo Sudo
operam em um conjunto de linhas para fornecer
um resultado por grupo. Exemplos comuns de
funções de grupo SQL são contagem de
SQL, média SQL,
mínimo SQL e máximo. Agora vamos a
função de contagem igual lhe dá uma
contagem de algo. Por exemplo, vou me conectar ao meu banco de dados, localhost,
meu banco de dados. Nesse caso, estou executando uma contagem selecionada de pacientes estrelas
onde a cidade é essa. Nesse caso, a função
count retorna várias linhas que
correspondem aos meus critérios, onde a cidade é essa. Deixe-me executar esses dois aqui. Na verdade, deixe-me
executar este aqui. Neste caso, estou contando
o número de números de
prontuários médicos
que é distinto ou único para um paciente onde
a cidade é essa. Também posso usar conta com
uma combinação de um grupo por, neste caso, para
executar este comando. Basicamente contando
o número de registros mostrando seu primeiro nome do grupo da cidade
pelo FirstName. Isso é importante
quando você está tentando
olhar para a distribuição
de seus dados, ou
seja, os primeiros nomes, conta para
cidades diferentes, coisas assim. Se eu me livrar do WhereClaUse
e executar isso novamente, você pode ver que estou recebendo
mais dados de volta. Esse é o uso da conta. Agora, o próximo é
o mínimo SQL. Por exemplo, se você quiser
encontrar um mínimo de algo, que significa que retorna
o valor mínimo de uma coluna selecionada. Neste caso, eu tenho
esta tabela de medicamentos, qual estou apenas obtendo o preço
mínimo
de mitigação desta coluna e o preço
eficiente, a média funciona,
em uma coluna específica. Nesse caso, a média do
prêmio de medicação é 601, que significa que
agrega todos os valores
na coluna de preço de mitigação e me dá uma média disso. A função média retorna o valor médio de n
Ignorando valores nulos. Exemplo comum é a média da idade
média das pessoas
em nossa tabela de pacientes, ou preço médio para mitigação
na tabela de amortização. Analisamos o mínimo, o máximo de retornos, o valor
máximo de uma coluna
selecionada. Nesse caso, você quer encontrar qual é o medicamento mais caro. Você fará algo como select,
selecione a instrução Max,
forneça o nome da coluna. E você pode ver o
medicamento máximo ou o mais caro como este. Você também pode exibir o medicamento mais caro com sua descrição também. Nesse caso, preciso agrupar
por grupo por
descrição da meditação. Nesse caso, você verá que o preço médio de
mitigação, vou dar um alias para
dar um novo nome de coluna. Então, diremos que esse é
o preço médio. A descrição médica. Se você executar isso novamente, estou recebendo o medicamento máximo ou o mais caro e agrupando-o pela descrição do
medicamento. Então você tem AstraZeneca, suspensão de sulfato de
bário, vacina contra a gripe e todas as outras
drogas que temos aqui. Agora, a função de grupo final
é a função sum, que obtém os valores de
soma de n Ignorando valores nulos
da minha coluna numérica. Lembre-se, a função sum
funciona em colunas numéricas. A função soma retorna uma soma total de uma
coluna numérica neste caso, para encontrar o preço total
da coluna de medicação. E você verá que são 3.006. E isso é uma olhada nas funções de grupo mais
usadas. Você pode usá-los em aplicativos
financeiros ou em
outros tipos de aplicativos. Você precisa encontrar
métricas específicas em seus dados.
33. SQL JUNTAMENTE COM a INNER: Junções Sql. A junção Sql é usada para combinar duas ou mais tabelas juntas
com base em colunas comuns, maiores insights são
derivados
da junção das tabelas
a partir dos comandos DDL fornecidos, você notará que o
médico número de registro, o número do
prontuário médico do paciente é comum entre os pacientes, estável e mitigação estável. Nesse caso, a
sintaxe para unir duas tabelas é baseada
nas colunas comuns. Para o nosso caso, o número do registro médico
é uma coluna comum. Vamos dar uma
olhada em um exemplo. Mas antes de fazermos, a sintaxe
básica é selecionar os nomes das colunas da tabela um. Nome da tabela um. Junte-se. A segunda tabela
no nome da coluna um, coluna chamada dois,
o que significa que a primeira coluna é
da primeira tabela, segunda coluna é
da outra tabela. Um bom exemplo que veremos é devolver todos
os pacientes e seus medicamentos de Salt Lake City sob a
Aetna Insurance. E antes de fazermos isso, vamos fazer uma
estrela básica selecionada da medicação. Você olhará para
esta mesa aqui. Medicamentos não têm cidade. Como você consegue a cidade? Você obtém a cidade usando
o número do registro médico, porque esta coluna aqui
é chave estrangeira aqui, mas é uma chave primária
em nossa outra tabela. Se você selecionar estrela de pacientes em torno
desses dois seletos, você verá no
final aqui, você tem isso, as informações da cidade, mas
os medicamentos não. Agora, em nosso
caso de uso é devolver todos os pacientes e seus medicamentos
de Salt Lake City
e da Aetna Insurance, que significa que você deseja obter todos os medicamentos
desta primeira tabela que são da Aetna
ou neste caso, acho que estamos usando seguro de
guardião. Este caso. Vamos apenas copiar
isso aqui. Como você faz isso? Você faz isso combinando os pacientes e a tabela de
medicamentos. Nesse caso, estamos usando
uma junção interna que retorna registros que têm valores
correspondentes em ambas as tabelas. Os valores correspondentes são
o número do registro médico. Então, o que você faz é selecionar entre os pacientes PAT como o alias
e medicação adjacente MED. A coluna comum, que
é o número do registro médico. É comum em ambas as tabelas onde a cidade dos pacientes se lembra, as informações
da cidade não estão
em medicação estável. Está na tabela do paciente, que é aqui
onde o PAT dot cd é Salt Lake City e seguro de medicação
ou metadados. O nome do seguro é guardião. Se executarmos isso, ele
receberá um registro. Este registro tem seguro
guiado e é
de Salt Lake City. Se você voltar aqui. Se você fosse fazer,
por exemplo, Athena, esse registro é 110. É de Nova York. Você teria que mudar
isso um pouco. Então, se você tentasse encontrar
os registros que têm Aetna Insurance
de Salt Lake City, você não encontraria. Isso realmente
voltaria vazio. Vê isso? Vamos apenas voltar. Assim, a razão é que
se eu executar isso de novo, você tentará encontrar Aetna. Apenas um registro tem
em um seguro. Este é o
registro médico número 110. Esses três aqui, eles não têm Salt Lake City como cidade. Eles têm Colorado,
Texas e Nova York.
34. SQL left, ALEGRE-SE e ALEGRE-SE: Em SQL, junção à esquerda, a junção
esquerda ou a junção externa esquerda. Selecione registros da primeira ou tabela mais
à esquerda com registros de tabela à direita em
marcha. Agora, neste caso, vamos ver
este exemplo aqui. Este é o medicamento estável. Vamos executar essa raiz quadrada aqui. Estou apenas me juntando ao paciente
estável na medicação, o que, o que significa aqui, basicamente selecionando registros
da primeira tabela mais à esquerda com registros
correspondentes da tabela à direita, recebo sete linhas de volta. Agora isso significa que aqui, isso é bastante importante
para você ver. Deixe-me fazer uma estrela selecionada aqui
da mesa do paciente. Vou executar essas
três consultas aqui. primeiro é um paciente
estável tem sete filas. O segundo é que o
medicamento tem cinco. E a junção à esquerda aqui
retorna sete linhas aqui em baixo. A razão para isso
é esse registro aqui. Jane, linha 67. Se você olhar para este número de
registro médico é 165166. Não existe na substituição estável da
medicação, que significa que se você executar uma junção
esquerda de pacientes e medicação estiver
retornando os registros da tabela mais à esquerda, a tabela do paciente com
margem direita registros de tabela. Então, se você for no final, esses valores aqui aparecem como
nulos porque esse registro, Jane Doe e Jane Patrick
não tem medicamentos. É por isso que você tem nulos. Portanto, é possível
ter valores nulos
retornados na junção à esquerda aqui,
a junção à direita
do SQL, a junção externa à direita do SQL, selecionar registros da
segunda tabela mais à direita com registros à esquerda correspondentes. sintaxe é selecionar
colunas da tabela um, junção
direita à tabela um nome de coluna de ponto é igual ao nome da coluna de dois pontos da
tabela. Execute isso. Certo. Cinco linhas são retornadas com base
na explicação anterior que eu forneci. Porque se você fosse
executar neste caso, o que estamos fazendo
é retornar o, retornando os registros
da tabela mais à direita. Nesse caso, você receberá
apenas cinco linhas porque está retendo
os registros
da tabela de medicamentos que correspondem ao paciente
estável neste caso. Você pode ver aqui, você receberá esses
registros, incluindo os medicamentos
do lado direito. Nesse caso, estou
fazendo uma estrela selecionada, que significa que você tem todas
as colunas retornadas. Se você quisesse apenas
retornar dados específicos, você deseja fazer o ponto PAT FirstName,
LastName, por exemplo. Deixe-me voltar aqui. Vamos fazer o ponto de medicação. Vejamos o nome do seguro. Execute isso. É mais descritivo
neste caso. Isso é uma olhada na junção externa
direita. Lembre-se da
junção externa à direita do SQL ou do SQL
direito John retorna registros da segunda ou da tabela mais à direita com registros de tabela à esquerda
correspondentes. Agora, a junção à esquerda do SQL retorna registros da
primeira tabela mais à esquerda com registros de
tabela à direita correspondentes.
35. SQL UNION: Uma união civil, o
operador sindical é usado para combinar o conjunto de resultados de duas ou
mais declarações selecionadas. O operador sindical executa indiano em colunas com
o mesmo tipo de dados. Isso significa que
as colunas de união devem ter o mesmo tipo de dados. No nosso caso, o
número do registro médico em ambas as tabelas é do mesmo tipo de dados
e as colunas devem estar na
mesma ordem de coluna. E a sintaxe básica do operador
união é selecionar os nomes das colunas
da primeira tabela,
tabela um, unir o nome da
coluna selecionada da tabela dois. Por exemplo, a instrução SQL a
seguir retorna os números de
prontuários médicos distintos da tabela do paciente e não do paciente, das tabelas de
meditação. Existem dois
formatos que tenho aqui, mas vamos manter
o segundo formato, que é selecionar o número
do registro médico dos pacientes, união. Selecione o
número do registro médico da medicação. Basicamente, basta escrever
duas instruções selecionadas e combinar os resultados
com um operador sindical. E estou pedindo pelo número
do registro médico. Execute essa consulta. Esta é a ordem que recebo. Os números dos registros médicos
são exclusivos para o caso. Esse é o operador de união SQL que você pode usar para consultar
suas tabelas de banco de dados.
36. SQL SORÇÃO ASC ou DESC: Classificação Sql,
ascendente ou descendente. O
operador SQL crescente é usado para classificar valores de coluna
em ordem crescente. Analisamos isso ao
longo do curso, onde
analisamos nossas diferentes declarações
selecionadas. Por exemplo, se você acabou de executar um
número de registro médico
selecionado da medicação, poderá encomendar por esta
coluna em ordem crescente. Este vai ser o pedido. Você pode usar o operador
decrescente SQL para classificar valores de coluna
em ordem decrescente. Nesse caso, se eu executar
ambas as consultas, você verá que ela está
em ordem crescente. E está em
ordem decrescente aqui. Isso é uma olhada nos operadores de
classificação SQL são os
ascendentes e descendentes.
37. ATUALIZAÇÃO SQL: Uma atualização SQL é usada para
modificar registros em uma tabela. Sempre use uma
cláusula where para limitar a operação de atualização
a registros específicos. Usa declaração de atualização
com cautela. E somente quando
absolutamente necessário. Você quer evitar manipular dados
diretamente no banco de dados. Sempre use um aplicativo,
a menos que você esteja executando operações de
back-end
em uma área de teste ou durante ETL ou
algo desse tipo. A sintaxe é, por exemplo,
atualizar o nome da tabela, definir essa coluna igual a essa ou definir a outra
coluna nela. A condição. E um bom exemplo é atualizar um único valor de coluna de registros
com o novo valor da coluna. Por exemplo, atualize a medicação, disse o número Medicaid, que faz com que o número
seja próximo disso. Então, basicamente, estamos
apenas tentando mudar o número Medicaid
da FAC 172, que é um único que é
o olhar para a medicação. E se eu for para a tabela real, vamos apenas copiar isso. Vou mostrar a
vocês o uso
dessa declaração de atualização aqui. Basta puxar todos os medicamentos. Digamos que eu queria atualizar esse número de registro
médico, o que não é uma boa
prática porque, como chave estrangeira
na outra tabela, é por isso
que eu disse que você deseja atualizar os dados diretamente usando uma aplicação ou alguma outra ferramenta de operação de
integridade. Nesse caso,
operações simples como essa. Você pode apenas dizer, por exemplo, se você quiser atualizar o nome, esse nome aqui, descrição do
medicamento. Atualize o conjunto de medicamentos, a descrição do
medicamento. Digamos que copiemos isso. Digamos que, em vez de uma facilidade
e eu copio isso aqui de volta, descrição
da mitigação
é igual a isso. Então, basicamente, apenas mudando o nome da descrição do medicamento aqui de um E2 e eu
atualizo as tabelas de medicamentos definir
a descrição da mitigação para aquela onde é que ,
na verdade, é que
se você apenas executar isso, você verá uma linha afetada. Se voltarmos e executamos aqui. Você vê que mudamos
isso, esse registro. Assim, o uso da
instrução update, mas novamente, usar a instrução APA avisaria que
você sempre deve
ter uma condição que apenas para
se certificar de que você está atualizando uma linha ou apenas
uma quantidade definida de dados.
38. SQL DELETE: Excluir. A instrução
least segura é usada para excluir
linhas de uma tabela. Use esse comando com cautela. A razão pela qual estou mostrando
isso é porque quero mostrar a você como
excluir um único registro, única função de uma tabela. Como precaução, sempre
defina uma condição para sua instrução delete para
evitar deixar papéis indesejados. Combine duas
ou mais condições com sua instrução delete. Deixe-me mostrar a vocês
um exemplo aqui. Estou executando uma estrela seleta dos pacientes para ver todos
os registros dos pacientes. Quero excluir a
linha número sete. A sintaxe para excluir é a palavra-chave delete do nome da tabela em que a
condição é tal e tal. Nesse caso, preparei
a instrução delete. Exclua de pacientes em que número do registro
médico
é igual a este aqui. Copie isso. Também vou
adicionar outra condição. Digamos que o ID pessoal
seja igual a tal e tal. Neste caso, são
cento, dezentos e seis. Só vou copiar isso
só para garantir que
temos mais de uma condição. Em seguida, execute este comando. Você verá a saída de
uma linha afetada, o que significa que excluímos
com sucesso uma linha. Se eu voltar e
executar este select, você verá que agora temos
seis linhas em vez de sete, e Jane Fitzpatrick
foi excluída. Isso é uma olhada na instrução
SQL delete.
 Data Engineer 365, Cloud Computing | Data | Entrepreneur
Data Engineer 365, Cloud Computing | Data | Entrepreneur