Transcrições
1. Introdução: Você provavelmente já ouviu o hype em torno da ciência de dados, as conferências, as palestras, as grandes visões de 10 anos e promessas de uma década glamourosa. Esta aula é diferente. É concreto, é imediato. Quero mostrar como os dados podem ajudá-lo hoje, amanhã, semana que
vem, como você pode contar histórias com dados. Olá, sou o Allan. Eu sou um cientista de dados em pequenas startups e um estudante de doutorado em Ciência da Computação na UC Berkeley. No campus, ensinei mais de 5.000 alunos, e fora do campus, recebi mais de 50 avaliações cinco estrelas para ensinar as pessoas a programar para o Airbnb. Nesta aula, vou ensinar-lhe os fundamentos da análise de dados, em particular, mostrar-lhe como aproveitar os dados de uma maneira específica. Como contar uma história com a visualização certa. Se você é um profissional de negócios que procura habilidades
baseadas em dados ou um aspirante a cientista de dados, esta aula é para você. Se você é um iniciante para codificar, observe que esta classe espera alguma familiaridade de codificação. Você pode pegá-los em apenas uma hora tomando minhas aulas de Coding 101 e SQL 101. Após essa aula, você poderá tomar decisões de negócios orientadas por dados. Faremos isso em três passos. Primeiro, projetando a coleta de dados, segundo, pré-processamento de dados e terceiro, analisando dados. Cada uma dessas fases irá evoluir em torno um estudo de caso fictício centrado em um aplicativo chamado Potato Time. Estou animado para dar-lhe um pouco de pensamento em ciência de dados, um teste de gosto para os diferentes passos na análise de dados. Na próxima lição, discutiremos seu estudo de caso para o curso e você estará brincando com dados em pouco tempo.
2. Projeto: teste A/B de uma página: Seu objetivo é contar uma história com dados para apoiar uma decisão de negócios. Em particular, tome uma decisão entre duas versões de uma página de destino da empresa. No entanto, a decisão não é tão preto e branco como você pode pensar. O site em questão chama-se “Hora da batata”. Enquanto o aplicativo é real, o estudo de caso não é. O desafio é duplo. Primeiro, instrua o público sobre por que um sincronizador de contador é útil. Dois, aumentar o número de inscrições. Seu projeto é dar sentido a grandes volumes de dados e,
em seguida, produzir uma série de visualizações que ilustram seu raciocínio para uma recomendação final de negócios orientada por dados. Este projeto utiliza um conjunto de dados sintéticos. No entanto, isso vai forçá-lo a perceber por que as
reações joelheiras podem levar a conclusões defeituosas, por que uma análise de nível de superfície simplesmente não serve. Este projeto destacará a importância de escolher as visualizações certas. Vamos falar sobre análise de dados em três etapas: um, coleta de dados de
projeto, dois, dados de
pré-processamento e três, analisar dados. Tudo o que você precisa é de uma conta do Google com acesso ao Google Colab. Se você tem uma conta profissional do Gmail que pode usar, isso é perfeito. Caso contrário, um Gmail pessoal parece muito bem. Aqui estão três dicas. Dica número um, para ganhar o lado da cautela, sempre copie o código exato que eu tenho. O código será disponibilizado neste URL. Dica número dois, pausar o vídeo quando necessário. Explicarei cada linha de código que escrevo. Mas se você precisar de tempo para digitar e tentar codificar você mesmo, não
hesite em pausar o vídeo. Dica número três, você aprenderá melhor fazendo. Sugiro configurar-se para o sucesso colocando suas janelas Skillshare e Google Colab lado a lado, como mostrado aqui. Uma nota final. O passo mais importante são os passos que seguimos e o conceito em que tocamos. Os nomes das funções são coisas que você sempre pode Google mais tarde. Eu não me preocuparia com isso. Agora, vamos começar e mergulhar no código.
3. Resumo do Python: Nesta lição, você trabalhará através de uma atualização rápida do Python. Esta atualização irá cobrir a sintaxe Python para vários conceitos. Aqui estão os conceitos que vamos rever. Não se preocupe se você não se lembrar do que todos esses termos
significam, eles simplesmente devem parecer familiares. Se em algum momento você ficar preso, certifique-se de voltar para o curso original de Coding 101 ou faça uma pergunta na seção de discussão. Vá em frente e navegue até colab.research.google.com. Você deve então ser recebido com uma tela como esta. Vá em frente e clique em “Novo Caderno” no canto inferior direito. Antes de começarmos, deixe-me explicar o que é essa interface. Esse tipo de ambiente de execução é chamado de notebook. Um caderno contém células diferentes, como a que cliquei aqui. Estamos usando um caderno porque é mais simples ver visualizações como gráficos. Existem três tipos de dados que precisaremos para este curso. O primeiro tipo de dados é um número. O segundo tipo de dados que você precisará é uma string. Uma string, se você se lembra, é um pedaço de texto. Você sempre precisará de citações para indicar um pedaço de texto. O terceiro tipo de dados é chamado de booleano. Um booleano é apenas um valor verdadeiro ou falso. Existem várias maneiras de operar nesses tipos de dados. Aqui está uma dessas expressões. Você tem dois números e operação de adição. Como você pode esperar, uma vez que o Python avalia essa expressão, a expressão terá o valor 7. Aqui está outra expressão. Como você pode esperar, uma vez que o Python avalia essa expressão, a expressão se tornará verdadeira. Vamos discutir variáveis. Aqui, atribuímos a variável x ao valor cinco. Lembre-se de antes, escrevemos 5 mais 2. Sabemos que Python irá avaliar esta expressão para obter sete. Desta vez, digamos que x é igual a 5, podemos então substituir cinco por x. assim como antes, esta expressão irá avaliar como sete. Vamos escrever algum código. O primeiro é os tipos de dados. Aqui está um número, digite cinco. Depois de pressionar Command Enter ou Control Enter em um Windows, Python lê, avalia e retorna o resultado dessa expressão. Vamos em frente e fazer o mesmo por uma corda. Lembre-se de suas aspas, digite o texto que
quiser e pressione Command Enter ou Control Enter. Finalmente, vamos digitar um booleano. Execute a célula, e aí está a sua saída. Segundo, vamos escrever uma operação. Vá em frente e digite 5 mais 2. Os espaços são opcionais. Depois de pressionar Command Enter ou Control Enter, Python novamente, lê, avalia e retorna o resultado dessa expressão. Neste caso, esta expressão é avaliada para se tornar sete, como você poderia esperar. Agora, vamos digitar 5 maior que 2. Isso, como você pode esperar, retorna o verdadeiro booleano. Terceiro, vamos em frente e definir uma variável x é igual a 5. Novamente, os espaços são opcionais. Execute a célula e você pode ver que não há saída. No entanto, podemos produzir o conteúdo da variável x digitando x, Command Enter. Vamos em frente e usar essa variável. Digite x mais 2, e isso, como poderíamos esperar, nos dá 7. Como atualização, uma das duas coleções que introduzimos na Coding 101 foi uma lista. Nós sempre usamos colchetes, um para iniciar a lista e outro para terminar a lista. Também usamos vírgulas para separar cada item na lista. Neste caso, nossos itens são números. Como uma atualização, um dicionário, a segunda coleção que cobrimos em Coding 101, mapeia chaves para valores. Pense nisso como seu dicionário em casa, que mapeia palavras para definições. Usamos sempre chaves, uma para iniciar o dicionário e outra para terminar o dicionário. Também usamos dois pontos para separar a chave do valor. Aqui, a chave é uma string denotada usando roxo. Aqui, o valor é um número denotado usando rosa. O dicionário mapeia a chave “jane” para o valor três. Usamos vírgulas para separar entradas no dicionário. Também podemos atribuir uma variável a este dicionário. Neste caso, o nome da variável é nome para cookies. Em seguida, veja como obter dados de um dicionário. Tudo o que precisamos é da chave em que estamos interessados. Neste caso, queremos o número de biscoitos da Jane, então precisamos da chave “Jane”. Usamos colchetes e a chave para obter o item. Este código retornará o número a que Jane corresponde, que é três. Observe a notação de colchetes aqui, onde os colchetes são denotados em preto. De volta ao seu caderno, a primeira coisa que vamos fazer é definir uma lista de números. Mais uma vez, precisamos de colchetes, e os números ou o conteúdo da lista, e vírgulas para separar cada item. Vá em frente e comanda a cela. Vamos em frente e fazer a mesma coisa para um dicionário. Vamos usar chaves para denotar o início e o fim de um dicionário. Então nossas chaves serão uma string e nossos valores serão números, adicione uma vírgula para separar cada entrada no dicionário. Agora, vamos em frente e definir uma variável que é igual a este dicionário. Aqui vamos ter nome para biscoitos é igual a “jane” de três e “john” de dois. Execute o celular mais uma vez. Novamente, porque definimos uma variável, não
há saída. Vamos em frente e agora produzir o conteúdo desta variável. Execute a célula e há o conteúdo da variável. Vamos em frente e acessar o valor para a chave “jane”. Então, o nome para biscoitos de “Jane”. Vamos rever funções e métodos. Vamos cobrir ambos esses conceitos antes de executar mais código. Pense nas funções que aprendeu na aula de matemática na escola primária. Funções aceitam algum valor de entrada e retornam algum valor. Por exemplo, considere a função absoluta, pegue um número e retorne a versão positiva desse número. Como faço para usar uma função? Considere novamente a função de valor absoluto. Em Python, o nome da função é apenas abs. Use parênteses para chamar a função. Chamar a função significa que executamos a função. Entre parênteses, adicione todas as entradas que a função precisa. Esta função de valor absoluto leva em uma entrada. Nós também nos referimos à entrada como um argumento de entrada ou apenas o argumento. Cada um dos tipos de dados que falamos até agora: números,
strings, funções, estes são todos os tipos de objetos. Um método é uma função que pertence a um objeto. Neste exemplo, vamos dividir uma string em um número de strings menores. Primeiro, você precisa de um objeto. Aqui temos um objeto string. Em seguida, adicione um ponto. Este ponto significa que estamos prestes a acessar um método para o objeto string. Adicione o nome do método. Nesse caso, o nome é dividido. A divisão do método irá separar a string em muitas strings, e o resto desses slides será muito parecido com chamar uma função. Para chamar esse método, assim como você chamaria funções, adicione parênteses. Entre parênteses, adicione um argumento de entrada. Aqui estão todas as partes anotadas. Da esquerda para a direita, precisamos do objeto, um ponto, o nome do método e os argumentos de entrada. Vamos tentar usar funções e métodos agora. Aqui, digite abdominais, parênteses e digite cinco. Vá em frente e execute a célula, e você descobrirá que calculamos o valor absoluto de cinco. Vá em frente e repita a mesma coisa, mas agora para cinco negativos, execute a célula e obtemos cinco positivos como esperado. Também podemos executar funções que exigem dois argumentos de entrada. Aqui podemos digitar no máximo e passar em 2 vírgula 5, e que irá retornar o máximo dos dois números. Neste caso, esperaríamos cinco. Também podemos chamar o método de divisão como abordamos nos slides. Vá em frente e digite uma lista de letras e digite paretheses .split, e então vamos passar em outra string, que é o que dividir a string por. Neste caso, queremos dividir em cada vírgula. Vá em frente e execute a célula, e você pode ver agora que nós dividimos a string com sucesso em um número de partes diferentes. Voltar aos slides para o último segmento desta revisão. O último tópico nesta atualização é como definir uma função. Como mencionamos antes, pense em funções de sua aula de matemática. Em particular, considere a função quadrada. Pegue um número x, multiplique x com ele mesmo e retorne o número quadrado. Aqui, começamos com def. É assim que você define uma função. Em seguida, seguimos com o nome da função. Neste caso, será quadrado. Em seguida, adicionamos parênteses seguidos de dois pontos. Entre os parênteses, adicionamos nosso argumento de entrada. Neste caso, nosso quadrado função só leva em um argumento, que vamos chamar x. seguida, adicione dois espaços, esses dois espaços são extremamente importantes. Esses espaços são como Python sabe que você está adicionando código para a função. Uma vez que esta função é simples, a primeira e única linha da nossa função é uma declaração de retorno. A instrução return pára a função e retorna qualquer expressão vem em seguida. Neste caso, a expressão é x vezes em si. Aqui estão todas as partes anotadas mais uma vez. Observe que todas as partes em preto são necessárias para definir qualquer função e você sempre precisa def, parênteses, e dois pontos para denotar a função está começando. Você também precisa da instrução return para retornar valores para o programador chamando sua função. O nome da função, as entradas e as expressões podem mudar. De volta para dentro do seu caderno, vá em frente e digite entre parênteses quadrados def x dois-pontos. Uma vez que você pressionar Enter, Colab irá adicionar automaticamente dois espaços para você, então vá em frente e mantenha esses espaços em e digite em retorno x vezes x. executar sua célula, agora chamar a função, quadrado de cinco, executar a célula, e podemos tentar isso para um número diferente também, quadrado de dois. Estes são os conceitos que abordamos nesta lição. Se você quiser acessar e baixar esses slides, visite este URL, aaalv.in/data101. Isso conclui nossa atualização Python. Na próxima lição, você projetará o experimento e determinará quais dados devem ser coletados.
4. Design experimental com privacidade em primeiro plano: Nesta lição, vamos discutir a coleta de dados, princípios por trás
da concepção de um experimento. No final da lição, teremos um conjunto de hipóteses e os dados que precisaremos coletar. Aqui está a ordem dos tópicos para esta lição: filosofia, princípios, estudo de caso, hipóteses e dados. Começamos pela filosofia de um projeto experimental e como isso orienta os dados que coletamos. A ideia subjacente é privacidade primeiro. A primeira conseqüência é que você deve coletar o que é minimamente necessário. Aqui está o princípio número um, recolher apenas o que você precisa. Não colete dados apenas porque você pode, colete apenas o que é necessário para testar a hipótese. Por exemplo, digamos que sua hipótese é que páginas mais lentas resultam em menos cliques e, como você pode esperar, só
precisamos coletar informações sobre o tempo de carregamento da página e clique. Outras informações que você poderia pedir para tal localização não são necessárias. Princípio número dois, relatório agregado. As estatísticas devem ser relatadas como parte de uma multidão. Além disso, e possível, você pode aleatorizar linhas individuais de dados para que as identidades individuais sejam protegidas enquanto as estatísticas agregadas permanecem as mesmas. Esses princípios regem como e quando você coleta dados. Vejamos o nosso estudo de caso específico. Vamos estudar um aplicativo real chamado PotatoTime. Este aplicativo sincroniza calendários do Google para que o tempo ocupado em um calendário seja mostrado como ocupado em todos os calendários. Nesta classe, consideraremos duas variantes da página de destino. Também teremos duas hipóteses que nos ajudarão a escolher entre as duas páginas de destino. Este é o primeiro passo. Nós formulamos a hipótese. hipótese número um é que os usuários não vêem o utilitário em nosso sincronizador de calendário, em particular, os usuários não sabem por que um sincronizador de calendário é útil, então seu vídeo guiado na página inicial aumentará as inscrições para web A. A hipótese número dois é que os usuários precisam ser educados para preços, então níveis de preços claros aumentarão as inscrições, esta é a página da Web B. Agora
podemos considerar os dados necessários para testar cada hipótese. Este é o passo número dois, projetar como vamos coletar dados. Podemos primeiro considerar a página A, o vídeo, quais são algumas informações que precisamos? Precisamos da duração da visualização, do tempo de carregamento da página, informações de
cliques e do momento em que o vídeo foi assistido. A próxima é para a página web B, que informações precisamos? Precisamos de informações de rolagem, então quanto tempo o usuário passou olhando para cada parte da página, informações de
clique e também quando a página foi acessada. Observe que nenhuma informação pessoal é necessária para realizar qualquer um desses estudos, enquanto informações como faixa etária ou localização podem revelar insights ocultos exclusivos. Nós não formulamos uma hipótese ou uma razão para que qualquer um desses desempenhasse um fator. Para os fins desta classe, analisamos apenas as informações acessadas acima. Estes são os conceitos que abordamos nesta lição. Para uma recapitulação, nosso projeto experimental envolve a coleta de quantidades mínimas de informações. Parece ótimo filosoficamente, e na prática? Bem, na prática, coletar ou acessar exatamente o que você precisa é definitivamente útil, você arrisca sobrecarga de informações de outra forma, e paralisia de decisão. Se você quiser acessar e baixar esses slides, visite este URL. Na próxima lição, vamos escrever algum código que lê e limpa dados, como configurar uma página da Web,
como a página da Web é acessada e como armazenamos informações sobre esse acesso à página da Web está além do escopo desta classe, em vez disso, vamos nos concentrar na análise de dados em seções posteriores.
5. Pré-processamento de dados na biblioteca Pandas: Nesta etapa, você carregará dados em Python usando uma biblioteca chamada Pandas. Lembre-se, uma biblioteca é apenas uma coleção de código que alguém escreveu, que podemos usar. Como o Pandas facilita o carregamento de dados, vamos nos concentrar em trabalhar com os dados carregados. Aqui estão os conceitos que abordaremos: discutiremos o que é um quadro de dados da biblioteca de Pandas, quais estatísticas podemos obter de um quadro de dados
e, finalmente, como limpar seus dados. Comece acessando aaalv.in/data101/notebook. Usando o caderno vinculado, você carregará um conjunto de dados que contém alguns dados sintéticos de tráfego da web para que possamos usar. Uma vez que você acessar esse URL, você deve então ser recebido com uma página como esta. Vá em frente e clique em “Arquivo” e, em seguida, salve uma cópia no Drive, isso criará uma cópia que você pode modificar agora. Nesta página, vou clicar neste “X” aqui para fechar a barra de navegação. Vá em frente e role para baixo, e primeiro baixe um arquivo contendo o conjunto de dados. Para fazer isso, execute esta primeira célula contendo URL recuperar, selecione a célula e pressione “Command Enter” ou, se você estiver no Windows, pressione “Control Enter”. Você também pode clicar no botão play aqui. Uma vez que este arquivo foi baixado, você verá esta saída aqui, views.pkl, e este outro absurdo. Isso significa que o arquivo foi baixado com sucesso. Em seguida, assim como a codificação 101, importe o código que outros escreveram que podemos usar. Vá em frente e digite importação Pandas como pd. Esta biblioteca tem uma função chamada ler pickle, vamos em frente e usá-lo agora para ler o conjunto de dados, digite pd.read pickle. Como vimos acima, o nome do arquivo é views.pkl. Esta função lê o arquivo pickle e retorna o conjunto de dados como um quadro de dados. Um quadro de dados é como Pandas representa uma tabela de dados. Pense em um quadro de dados como uma planilha do Excel ou tabela de banco de dados. Vamos atribuir o quadro de dados de retorno a uma variável chamada df. Esta variável é comum para codificação usando dataframes. Vamos agora ver como esse quadro de dados se parece, digite df e execute a célula. Olhe para ver a estrutura dos dados, o número de linhas, número de colunas, observe que a primeira coluna está em negrito, isso é chamado de nosso índice. Por algumas razões, o índice ou o criado na coluna é muito eficiente para classificar ou agrupar por, vamos aproveitar isso mais tarde. A segunda coluna, Página Load MS, esse é o número de milissegundos que a página da Web levou para carregar. Vídeos assistidos S, é o número de segundos que o usuário assistiu. Produto S, é o número de segundos que os usuários gastaram na seção de produtos da página da Web. Pricing S, é o número de segundos que o usuário gastou na seção de preços da página. Tem clicado é um booleano, verdadeiro, se o usuário clicou no botão de inscrição. A última coluna, página da Web, é A ou B, indicando qual página de aterrissagem o usuário viu. dataframes oferecem alguns métodos para calcular estatísticas agregadas. Por exemplo, podemos calcular a média para cada coluna, ir em frente e digitar df.mean, adicionar parênteses para chamar o método. A maioria dos valores médios aqui parecem razoáveis, no entanto, notar que clicou tem um valor de 0,34, isso parece estranho porque acima Tem clicado é uma coluna de valores verdadeiros ou falsos. Como os valores verdadeiros ou falsos se tornam um número? Em suma, Pandas considerou cada verdadeiro como um e cada falso como um zero, então levou a média, como resultado, 0,34 significa que 34 por cento dos valores são verdadeiros. Vamos agora ir em frente e calcular o valor mínimo por coluna. Digite df.min novamente com parênteses, execute a célula e aqui você pode ver os valores mínimos. Agora que cobrimos algumas estatísticas básicas que os quadros de dados oferecem, vamos agora ver o que os quadros de dados oferecem para a limpeza de dados. Há três etapas comuns a serem executadas na limpeza de seus dados. Primeiro, você vai querer remover todas as duplicatas, chamar o método soltar duplicatas em seu dataframe, digitar df.drop sublinhado duplicatas e adicionar parênteses para chamar a função. Vá em frente e comanda a cela. Uma pequena dica, você não tem que memorizar este método per se, você sempre pode Google Pandas duplicatas de queda de quadros de dados. O que é mais importante é que você se lembre das etapas na limpeza de dados. Agora, na próxima célula, vamos preencher valores ausentes,
esses valores ausentes são representados como NaN ou N-A-N, isso significa não um número. NANs ou valores ausentes podem ocorrer devido a bugs no código de coleta de dados. Aqui, podemos preencher valores ausentes com o valor médio em cada coluna. Lembre-se de cima df.mean novamente, você deve agora digitar isso dentro de sua célula, digite df.mean com parênteses, isso calcula a média de cada coluna. Aqui está um novo método chamado preencher NA que preenche todos os valores NaN com os valores fornecidos, digite df.fillna e, em seguida, vá em frente e passe em df.mean como o argumento. FillNA não modifica o dataframe, ele simplesmente cria um novo dataframe com os valores inseridos. Como resultado, precisamos atribuir a variável df ao resultado, digite em df igual. Finalmente, dirija o celular. Terceiro, verificamos a sanidade dos dados. Nesse caso, sabemos que o vídeo tem apenas 60 segundos de duração então vamos ver o tempo máximo que um usuário passou assistindo ao vídeo, certificando-se de que são apenas 60 segundos. Para acessar uma coluna de dados em um dataframe, trate um dataframe como um dicionário, chave no nome da coluna. Neste caso, o nome da nossa coluna é Vídeo Assistido S, como vemos aqui, mas vamos seguir em frente e chave no nome da coluna digitando em df colchetes vídeo assistido s e isso nos traz uma coluna de dados. No entanto, queremos obter o valor máximo, então vá em frente e use o método max para digitar ponto max. Vá em frente e execute a célula e um número muito maior do que 60 segundos, parece ser um bug em nosso código de coleta de dados, então vamos cortar todas as durações maiores que 60 segundos. Em um dataframe, assim como com dicionários, podemos atribuir valores. Vá em frente e digite df e colchetes, em seguida, o nome da nossa nova coluna, que será Video Watted S trunc para truncado. Isso cria uma nova coluna chamada vídeo assistido S trunc depois de atribuí-la a um valor. Agora vamos calcular os valores da nova coluna. Primeiro, pegue a coluna antiga, que é df Video Watched S, assim como fizemos na célula anterior. Agora chame o clipe de ponto ou o método de clipe para recortar todos os valores. O primeiro argumento é o menor valor possível, portanto, neste caso zero, não
queremos que nenhum número de segundos assistidos seja menor que zero. Também não queremos que nenhum número de segundos de assistidos seja maior que 60. Isso garante que não há valores menores que zero ou valores maiores que 60. Vá em frente e pressione “Enter” para criar uma nova linha e digite df. Isso agora irá gerar o Dataframe. Vá em frente e comanda a cela. Observe que a coluna na extrema direita inclui nossa nova coluna de durações de relógios recortados e voila, que conclui nosso pré-processamento inicial de dados em Pandas. Estes são conceitos que abordamos neste curso. As conclusões são como limpar os seus dados. Etapas típicas, incluindo preenchimento de NANs, duplicação de linhas e verificação de sanidade em relação à sua compreensão dos dados. Por exemplo, verifique se as médias, os valores
máximos e mínimos estão de acordo com a sua compreensão. Se você quiser acessar e baixar esses slides, visite este URL. Certifique-se de salvar seu caderno pressionando Arquivo Salvar. Da próxima vez vamos fazer uma análise inicial de dados.
6. Analisando dados na biblioteca Pandas: Nesta lição, analisaremos o conjunto de dados sintéticos. Aqui estão os conceitos que abordaremos. Vamos começar com algumas estatísticas resumidas, como totais por dia. Em seguida, calcularemos correlações entre diferentes partes de dados para entender onde procurar padrões e desenvolver alguma intuição. Finalmente, nesta etapa, tiraremos algumas conclusões iniciais. Se você perdeu seu caderno ou se você está apenas começando a aula a partir desta lição, acesse o caderno inicial da lição 6 em aaalv.in/data101/notebook6. Depois de acessar esse URL, você deverá ver uma página como esta. Vá em frente e clique no arquivo e salve uma cópia no Drive. Vou clicar no X no canto superior esquerdo para fechar a barra de navegação. Uma vez que você está nesta página, no topo, clique em tempo de execução e selecione executar tudo, aguarde todas as células para executar. Você pode dizer uma vez que você viu a saída de todas as células. Vá em frente e a partir desta célula, comece computando várias estatísticas resumidas. Por exemplo, calcule quantos dias o conjunto de dados se estende. Para acessar as datas no quadro de dados, use df.index. Vá em frente e digite em.max para obter a última data e subtraia a primeira data usando.min. Execute a célula, e aqui temos um objeto de dados de tempo de 100 dias. A segunda estatística de resumo é o número de visualizações de página por dia. Para isso, precisaremos definir uma função. A função contará o número de eventos que ocorreram em cada dia. Comece definindo o nome da função, eventos por dia. Esta função aceitará um argumento chamado df. Adicione parênteses, digite df e certifique-se de adicionar dois pontos no final dessa linha. Vá em frente e aperte Enter. Mais uma vez, o Colab adiciona automaticamente dois espaços para nós. Primeiro, digite datetimes é igual ao df.index. Este é o quadro de dados, df. DF.Index recupera as horas de data para cada exibição. Em seguida, defina uma nova variável. Dias é igual a datetimes e use.floor, adicione seus parênteses para chamar a função e, em seguida, passar em uma seqüência de minúsculas d, .floor converte datetimes em datas. Eventos de tipo por dia é igual a dias.value_counts. Value_counts conta o número de vezes que cada data aparece. Em outras palavras, contamos o número de visualizações por dia. Chamada de retorno events_per_day.sort_index. Isso classificará as contagens por dia. Não se preocupe, esta função parecia muito. O mais importante é não memorizar o código. Este código é perfeitamente Googleable. mais importante é que A, você pode ler o código e entender grosseiramente o que ele está fazendo. Então B, que você sabe para que o Google no futuro. Nesse caso, para contar o número de visualizações por dia, contamos o número de linhas por dia no quadro de dados. Vamos ver o que nossa função retorna. Defina uma nova variável, views_per_day, defina esta variável para o valor de retorno da nossa função acima. Lembre-se, esta função leva em um argumento, que é o quadro de dados de dados. Saída do conteúdo da variável. Execute a célula, e aqui temos contagens de visualizações por dia. Em seguida, defina outra função que filtra o quadro de dados para conter apenas linhas que resultaram em um clique. Comece definindo o nome da função, get_click_events. Esta função aceitará um argumento chamado df ou o quadro de dados. Novamente, não se esqueça do cólon no fim da linha. Pressione Enter, Colab adiciona dois espaços para você e agora digite, seletor é igual a df, colchete e o nome da coluna que contém as informações de clique. Aqui, cliques é igual a df e digite no seletor. Agora, vá em frente e retorne a nova variável que você definiu, que é cliques. Isso retorna um quadro de dados com apenas as linhas que têm true no seletor, e as linhas que têm true neste seletor são as que resultaram em um clique. Como resultado, essa função retorna um quadro de dados com apenas as linhas que resultaram em um clique. Vá em frente e comanda a cela. Agora, use essa função para obter apenas as linhas com cliques. Para encontrar cliques é igual a get_ click_events e passar em seu quadro de dados. Defina uma variável, clicks_per_ day é igual a, e assim como antes, vamos contar o número de eventos por dia. Finalmente, produza o conteúdo da variável e execute a célula. Aqui podemos ver o número de cliques por dia. Para ver apenas os valores, use o atributo.values. Ao contrário dos métodos, você não precisa de parênteses para acessar um atributo. Digite clicks_per_day.values. Novamente, não são necessários parênteses para acessar esse atributo, .values. Vá em frente e execute a célula, e aqui temos todos os valores. Agora, precisamos de uma verificação de sanidade. Aqui, queremos verificar se o número de cliques por dia é menor ou igual ao número de visualizações por dia. Vamos entrar e verificar se agora digitando clicks_per_day.values é menor ou igual a views_per_day.values. Vá em frente e comanda esta cela. Agora você pode ver que tudo isso é verdade. Parece que o cheque de sanidade passou. Bom trabalho. Em seguida, vamos calcular a correlação entre os recursos em nosso conjunto de dados. Se você se lembrar de suas estatísticas ou classe de probabilidade, correlação informa como um recurso muda quando outro recurso muda. Digamos que você tenha dois recursos, tempo de carregamento
da página e duração assistida pelo vídeo. À medida que o tempo de carregamento da página aumenta, você espera que menos pessoas assistam ao vídeo. Para verificar e calcular a correlação, vá em frente e digite df.corr. Adicione seus parênteses para chamar a função e execute a célula. Este método corr irá calcular correlações entre todos os pares de feições. Para uma verificação de sanidade, certifique-se de que os coeficientes de correlação abaixo refletem nossa intuição. Esperamos que, à medida que o tempo de carregamento da página aumenta, a probabilidade de clicar diminui. Podemos ver que na primeira coluna, segunda a última fila, a verificação de sanidade passou. Outra coisa interessante a notar é que o tempo gasto olhando para a seção de preços da página da web está muito, muito fracamente correlacionado com o clique. Você pode ver que a correlação entre a definição de preço e o clique é 0,10. Por outro lado, a visualização de vídeo é, relativamente falando, altamente correlacionada com o clique, com cerca de três vezes o valor. Ao examinar as correlações sozinho, parece que a página A, com o vídeo, é mais eficaz. Finalmente, vamos calcular a taxa de cliques ou CTR para cada página de destino. Isso nos diz a proporção de cliques para visualizações. Nosso objetivo final é recomendar uma página de destino que maximize a taxa de cliques para o tempo de batata. Comece computando um seletor. Antes, usamos has_clicked, que é uma coluna que já contém true ou false para cada linha, possamos escrever o seguinte para verificar se uma linha é para a página A ou não. Df, colchete e selecione a coluna da página da Web. Agora queremos verificar se esta coluna é igual a A. Se eu executar a célula, você verá que toda a coluna está cheia de verdades e falsas. Perfeito. Agora podemos usar isso para selecionar linhas no quadro de dados. Agora, podemos usar este seletor. Vá em frente e copie isso e abaixo na próxima célula, digite uma nova variável viewUma é igual a df, colchete e, em seguida, cole no seletor. Isso irá selecionar todas as linhas de modo que a página da coluna é igual a A. Em seguida, repita isso para a página da Web B. Queremos obter todas as visualizações para B. Defina isso igual ao quadro de dados, e novamente, com o mesmo seletor exceto para a página da Web B. Digite em viewUma “has_ clicou” .mean. Lembre-se de lições anteriores que podemos chamar de impressão para realmente produzir esse valor. Vamos fazer a mesma coisa, mas agora para ViewSB “clicou” .mean. Vá em frente e comanda a cela, e isto parece dar-nos a conclusão oposta. Lembre-se de antes, olhando para os valores de correlação, página A parecia melhor. No entanto, isso mostra que a taxa de cliques da página A 0,28 ou 28 por cento é muito menor do que a página da Web B, que é em torno de 40 por cento. A taxa de cliques sugere que a página B é melhor. Estas duas conclusões iniciais parecem contradizer-se, que
significa que precisaremos cavar mais fundo para descobrir o porquê. Estes são os conceitos que abordamos nesta lição, e aqui está uma dica que mencionamos várias vezes nesta lição, verificação de sanidade com frequência. Erros comuns incluem filtragem inadequada, erros digitação nos nomes de coluna ou até mesmo nomes de coluna pouco claros. As verificações de sanidade ajudam você a identificar, isolar e resolver esses erros rapidamente. Em alguns, aqui estão as nossas conclusões iniciais. Primeiro, examinamos as correlações e descobrimos que visualização e o clique de
vídeo estão altamente correlacionados. Também descobrimos que a leitura de preços e o clique parecem fracamente correlacionados. Isso ajusta que o vídeo ou página da Web A é mais eficaz. No entanto, calculamos a taxa de cliques e descobrimos que a página B tem uma taxa de cliques mais alta. A sanidade verificou todos os nossos cálculos até agora. Então, por que a discrepância? Isso parece uma contradição que precisaremos resolver. Se você quiser acessar e baixar os slides, visite este URL. Certifique-se de salvar seu caderno pressionando arquivo, salvar. Da próxima vez, codificaremos algumas visualizações, resolveremos esse mistério e prepararemos figuras para sua apresentação final.
7. Visualizando dados na biblioteca Matplotlib: Nesta etapa, você visualizará um conjunto de dados de tráfego da Web sintético que vimos em lições anteriores. Aqui estão os conceitos que abordaremos. Usaremos uma biblioteca chamada matplotlib para plotar utilitários. Em seguida, fazer algumas parcelas para explorar tendências ao longo do tempo, também
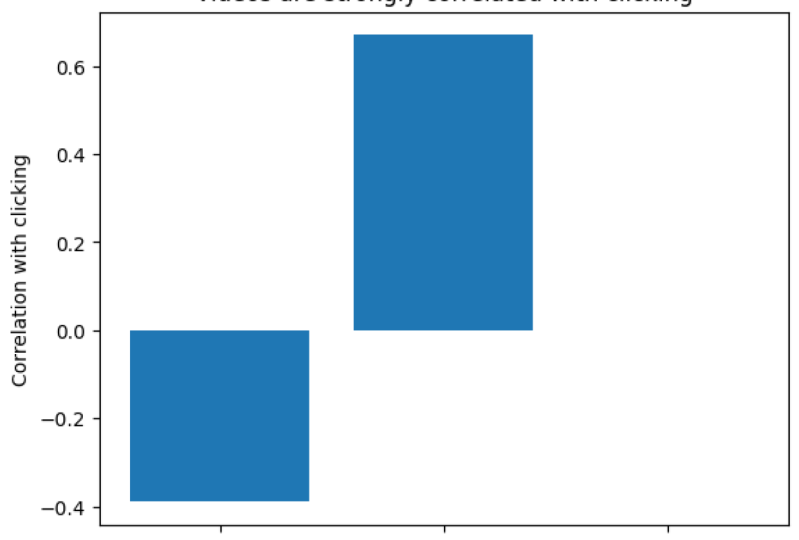
contará histórias usando parcelas devidamente construídas. A escolha do enredo será intencional para destacar um takeaway que queremos transmitir. Se você perdeu seu último caderno ou se está começando a aula com essa lição, acesse um caderno inicial para a lição 7 em aalv.in/data101/notebook7. Alternativamente, você pode usar seu próprio caderno da última lição. Depois de acessar esse URL, você deverá ver uma página como esta. Vá em frente e clique em Arquivo e Salvar uma cópia e unidade. Isso criará uma nova cópia do caderno. Nesta página, vou clicar em X no canto superior esquerdo para fechar a barra de navegação. Em seguida, independentemente de você abrir o novo notebook ou se estiver usando seu notebook existente, clique em Tempo de execução e Executar tudo. Vá em frente e, em seguida, role para baixo até o fundo. Aqui vamos começar por produzir as correlações que vimos antes. Vá em frente e digite df.corr com dois rs, adicione seus parênteses e execute a célula. Observe duas coisas, a visualização de vídeo parece estar correlacionada com o clique. Temos vídeo assistindo e clicando aqui mesmo em 0,32. O preço também parece estar fracamente correlacionado com clicar aqui temos 0.10. No entanto, o vídeo só pode ser assistido na página A e a seção de preços só pode ser lida na página da Web B. Como resultado, faz mais sentido calcular correlações para cada página da Web separadamente. Vá em frente e digite Viewsa.corr. Aqui estão as correlações para a página A somente, observe que a correlação entre vídeos e clicar é muito maior em 0,67 do que pensávamos. Em seguida, vá em frente e calcule as correlações apenas para a página B digitando Viewsb.corr, e agora execute a célula. Aqui estão as correlações para a página Web B. Observe que a correlação entre a seção de preços e clique é muito baixa. É muito mais baixo do que pensávamos. Na verdade, podemos dizer que eles não estão correlacionados. Isto está perto o suficiente de zero. Nosso primeiro argumento para a página A, então, é que os vídeos são altamente indicativos de se o usuário vai ou não registrar e ler a seção de preços não é. Uma correlação de 0,67 não faz sentido por conta própria, no entanto, esta é alta? Isto é lento? Isto é razoável? No entanto, uma correlação de 0,67 é definitivamente muito maior do que uma correlação de 0,0004. Como resultado, podemos usar um gráfico de barras para enfatizar a diferença entre os dois. Comece importando o utilitário de plotlib plotlib, digite import matplotlib.pyplot como plt. Agora, a primeira coisa que vamos fazer é chamar o título do método para dar um título ao seu enredo, digite plt.title e você pode usar qualquer texto que você gostaria entre essas aspas. No entanto, vou digitar um título de vídeos estão fortemente correlacionados com o clique. Sugiro que acrescente a vantagem principal da sua trama no título da trama. Agora vamos chamar plt.bar. Isso criará um gráfico de barras. O primeiro argumento para barra é uma lista de strings, os nomes de cada barra. Aqui vamos criar uma lista e a string vai ser o título. Então, vamos dizer carga de página, vai dizer vídeo assistindo, ea última barra vai ser correlação com a leitura da seção de preços. Bar também leva em uma segunda lista. Vamos passar os números da tabela de correlação acima. Acima da nossa tabela de correlação dá uma correlação negativa
de 0,39 para carregar e clicar na página. É também uma correlação de 0,67 para assistir e clicar em vídeo. Finalmente, temos uma correlação de 0,0004 entre ler a seção de preços e clicar. Finalmente, precisamos de um rótulo para o nosso eixo y. Então vamos dizer y rótulo e correlação com o clique. É isso. Este é o argumento número 1, que os vídeos estão altamente correlacionados com inscrições. Vá em frente e corra para criar seu primeiro enredo. Este é agora o seu enredo de bar. Para o nosso próximo ponto, precisaremos explorar as estatísticas diárias, como a taxa de cliques ao longo do tempo. Para fazer isso, precisaremos escrever uma nova função para calcular estatísticas diárias. Comece definindo o nome da função, obtenha estatísticas diárias. Então def get_daily_stats, e nós vamos aceitar um argumento df e, como de costume, não se esqueça de seus dois pontos. Esta função aceitará que um argumento chamado df ou o DataFrame. A primeira coisa que vamos agrupar durante o dia. Para fazer isso, vamos definir um grouper, e esta é uma nova variável que é igual a pd.grouper, onde a frequência é igual a um dia. Aqui, maiúscula D significa dia. PD.Grouper é um utilitário de painel genérico que nos
ajuda a agrupar linhas em um DataFrame de acordo com alguma frequência. Neste caso, nossa freqüência é diária. Em seguida, vamos definir um novo grupo de variáveis é igual a e, em seguida, vamos chamar o dataFrame.groupby, grouper. É assim que podemos calcular grupos de dias. Finalmente, vamos calcular estatísticas para cada grupo. Para fazer isso, vamos digitar diariamente é igual a groups.mean, para cada grupo, tomar a média de cada coluna. Finalmente, retornar as estatísticas diárias. Uma vez que você terminar com sua função, vá em frente e execute sua função. Agora vamos usar esta função para obter estatísticas diárias. Vá em frente e digite as exibições diárias A é igual para obter estatísticas diárias, e digite ou passe em todas as exibições para a página da Web A. Vá em frente e repita a mesma coisa para a segunda página B. Digite get_daily_stats e exibições de B. Para lhe dar uma ideia do que as visualizações diárias A contém, vamos exibir exibições diárias A. Como você pode esperar, se você executar a célula, você receberá um DataFrame onde agora você tem uma linha para cada dia e as estatísticas diárias desse dia. Como o número médio de segundos de vídeo assistidos, o tempo médio de carregamento da página e a porcentagem de espectadores que clicaram. Agora, vamos explorar um enredo diferente, um gráfico de linhas. Vá em frente e digite plt.title para dar um título ao seu novo enredo. Neste caso, o título da trama será taxas de cliques ao longo do tempo. Felizmente, matplotlib se integra bastante bem com pandas. Tudo o que precisamos fazer é dizer matplotlib qual coluna queremos traçar. Vá em frente e digite plt.plot e passe em uma das colunas de visualizações diárias A, neste caso, a coluna vai ser clicou. Agora, normalmente podemos parar aqui. No entanto, queremos rotular cada uma das linhas em nosso gráfico de linhas. Neste caso, vá em frente e adicione uma vírgula e digite um rótulo igual a A. Esta sintaxe, rótulo igual a A não é algo que você já viu antes. Isso é conhecido como um argumento de palavra-chave. Vamos pular os detalhes de um argumento de palavra-chave por enquanto, o que é importante é que é assim que você rotula linhas em um gráfico de linhas. Vamos em frente e agora repita a mesma coisa para a página Web B. Digite plt.plot Daily_viewsB, e selecione a coluna clicou. Finalmente, vírgula e rótulo é igual a B, e esses rótulos são a segunda linha como B. Em seguida, vamos adicionar nossa lenda ao enredo. Digite plt.plot legenda chamar a função, e é isso. Agora vamos adicionar mais duas linhas para rotular nossos eixos. Digite plt.xlabel e o eixo x vai ser as datas, e o eixo y vai ser a taxa de cliques. Então vá em frente e dirija a cela e isso é loucura. Veja quanta taxa de cliques para a página da Web A, a linha azul cai ao longo do tempo. Pergunto-me o que aconteceu? Vamos examinar algumas outras estatísticas. Vamos refazer o mesmo código, mas desta vez para tempos de carregamento da página, vamos copiar e colar o conteúdo desta célula e, em seguida, substituir partes dela que precisarão ver os tempos de carregamento da página. Vá em frente, copie e cole. Agora vamos substituir este título por tempos de carregamento de páginas da Web. Em seguida, abaixo, vamos substituir
a coluna has_clicked com a coluna de carregamento de página para ambos. Em seguida, isso muda nosso eixo y,
então, em vez de clicar através da taxa em nosso eixo y, agora
temos tempos de carregamento da página. Entre parênteses, vou adicionar as unidades para este eixo. Vá em frente e dirija a cela e olha para isso. Hora da página da Web, para a página A em azul brota como louco. Então, nosso segundo argumento para a página A é que tempos
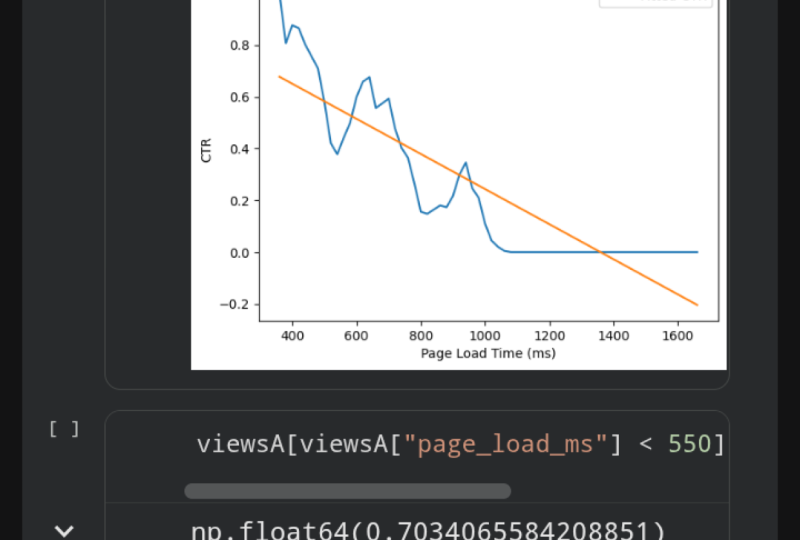
anormalmente lentos de carregamento de página parecem danificar acidentalmente sua taxa de cliques, sugerindo que há um potencial incalculável para a página A. Para quantificar como falhas na página A clique através da taxa é, podemos quantificar os tempos de carregamento da página danos no clique através da taxa. Para fazer isso, primeiro traçamos a relação entre as taxas de clique e os tempos de carregamento pagos. Aqui, vá em frente e digite as visualizações de A page_load_ds. Vamos criar uma nova coluna que irá conter os tempos de carregamento da página e as taxas de cliques a cada 20 milissegundos. Vá em frente e agora digite exibições de A page_load_ms. Vamos dividir por 20. Então, uma divisão de piso significa que se você tem uma fração, você arredonda para baixo para o próximo inteiro. Uma vez que você tem isso, vamos em frente e multiplicar por 20 novamente, e o que isso basicamente significa é que todos os seus valores estão em incrementos de 20. Então, antes, você poderia ter tido um valor de 34, mas agora 34 andar dividido por 20 lhe dará 1, e depois multiplicá-lo por 20 lhe dará 20. Qualquer valor entre 20 e 39 será igual a 20. Qualquer valor entre 40 até 59 se tornará 40, e assim por diante e assim por diante. Isso efetivamente arquiva todos os nossos tempos de carregamento de página em grupos de 20 milissegundos. Agora, vamos em frente e digite carga de página é igual a viewsa.set_index. Então este agora mudou o índice. Em outras palavras, ele mudará a coluna que podemos facilmente classificar ou agrupar. Vá em frente e digite page_load_ds, que é a nossa nova coluna. Em seguida, vamos calcular grupos para cada tempo de carregamento de página binned. Digite no carregamento da página é igual a viewsa.groupBy page_load_ds. Certifique-se de ter estes colchetes aqui. Isso é realmente importante para esta função. Isso calculará os grupos para cada tempo de carregamento de página encadernada. Agora, para cada grupo, vamos calcular as estatísticas médias. Então vá em frente e digite carga de página igual a page_load.mean, e isso irá calcular as estatísticas médias para cada grupo. Finalmente, queremos classificar todos os dados pelo tempo de carregamento da página binned chamando dot sort index. Este DataFrame agora informa a taxa média de cliques para cada tempo de carregamento de página. Novamente, se estamos sobrecarregados por esta função ou pela célula, tudo bem. Tudo que você precisa lembrar é o conceito geral do que fizemos aqui. O que fizemos foi primeiro colocar todos os valores em grupos de 20 milissegundos. Em seguida, calculamos estatísticas para cada um desses grupos. Essas duas coisas são perfeitamente pesquisáveis. Então, agora, vamos ver como esse DataFrame se parece. Digite o carregamento da página e execute a célula. Aqui, podemos agora ver as estatísticas para cada um desses baldes de 20 milissegundos. Agora você pode fazer um gráfico de linhas como antes de ignorar na coluna DataFrame. Neste caso, nos preocupamos com a taxa de cliques. Então vá em frente e digite plt.plot e carga de página has_clicked, e isso irá traçar o impacto dos tempos de carregamento da página na taxa de cliques. Vá em frente e aperte “Run”. Agora, o eixo x é o tempo de carregamento da página em milissegundos, o eixo y é a taxa de cliques. Como você pode esperar, clique nas quedas de taxa à medida que o tempo de carregamento da página aumenta. Em seguida, vamos ajustar uma linha a isso para obter um número aproximado para a rapidez com que a taxa de cliques diminui à medida que os tempos de carregamento da página aumentam. Vá em frente e importe outra biblioteca chamada NumPy. Esta biblioteca tem um algoritmo de ajuste de linha que podemos usar. Vá em frente e digite m, b. Em outras palavras, a inclinação e o viés de sua linha é igual a uma função NumPy que vai realmente caber uma linha para nós para um monte de pontos, chamar np.polyfit e passar os valores-x, que é todos os tempos de carregamento da página. Então aqui você tem page_load.index, e o segundo argumento é a taxa de cliques, que é carga de página e, em seguida, has_clicked. O último argumento é o grau de um polinômio. Neste caso, queremos linhas retas. O polinômio do grau 1 é tudo o que precisamos. Agora, podemos finalmente resumir a linha ajustada. Pegue a inclinação. Lembre-se que a inclinação é subir sobre a corrida ou, alternativamente, a mudança em y sobre a mudança em x. Aqui, y é a taxa de cliques e x é o tempo de carregamento da página. Portanto, a inclinação é a mudança na taxa de cliques por alteração no tempo de carregamento da página. Podemos multiplicar por 100 para obter a alteração na
taxa de cliques por 100 milissegundos de tempo de carregamento da página. Digite m vezes 100 e vá em frente e execute a célula. Aqui, temos 0,068 negativo. Isso significa que cada 100 milissegundos mais lento do carregamento da página custa sete por cento de tráfego. Estamos fazendo algumas simplificações excessivas muito varrendo aqui, mas isso transmite o ponto de que tempos de carregamento de página
mais lentos estão prejudicando significativamente a taxa de cliques para página da Web A. Eu acompanharia qualquer apresentação que cita um número como este com um enredo para explicar. Vamos fazer um gráfico para que os espectadores possam julgar por si mesmos o quão bem essa linha se ajusta aos dados. Na próxima célula, vamos começar com um título, plt.title. Nesse caso, nosso título será a cada 100 milissegundos de tempo de carregamento de página custa sete por cento de taxa de cliques. Traçar a linha de antes na célula anterior mais uma vez. Aqui, o carregamento da página has_clicked e o rótulo é a taxa de cliques. Em seguida, traça a linha ajustada. Aqui nós chamamos page_load.index e lembre-se, a equação para uma linha é m vezes x mais b. Então aqui nós vamos ter o m vezes os valores x, apenas page_load.index mais b. Nós também vamos adicionar um rótulo aqui. A etiqueta vai ser a taxa de cliques ajustada. Vá em frente e agora adicione um rótulo para o seu eixo x. Este vai ser o tempo de carregamento da página em milissegundos e nós também vamos rotular o eixo y. Aqui está a taxa de cliques. Finalmente, adicione sua lenda e execute seu celular. Isso conclui nosso segundo argumento. Agora podemos ver que a taxa de cliques está caindo muito devido ao aumento do tempo de carregamento da página. Em seguida, queremos entender para
o nosso terceiro argumento, e se a página A não tivesse sido afetada por um tempo de carregamento de página mais lento, qual seria a taxa de cliques da página A? Observando o gráfico acima, mais para cima, bem aqui, notamos que os tempos de carregamento da página parecem cair dentro de 400-550 milissegundos antes de parecer saltar. Como resultado, calcularemos a taxa de cliques para a página da Web A usando apenas esses dados, então selecionaremos todas as exibições com tempos de carregamento de página inferiores a 550 milissegundos. Vá em frente e digite as exibições A e nós vamos selecionar todas essas colunas, todos os tempos de carregamento de página que são menores que 550. Isso nos dará apenas as linhas que têm tempo de carregamento de página inferior a 550 milissegundos. Agora, vamos em frente e selecionar se essa linha foi ou não clicada
e, em seguida, calcular a taxa média de cliques. Vá em frente e comanda a cela. É uma taxa de cliques de 70%, bastante incrível. Para comparação, vamos calcular a taxa de cliques para a página da Web B. Selecione a coluna de clique e novamente calcule a média. Execute a célula, e isso nos dá apenas 40% de taxa de cliques. Em suma, a página da Web A teria superado a página B por uma grande margem, em 40 por cento. No entanto, para realmente transmitir essa idéia, vamos precisar de um gráfico de linha novamente. Nesta célula, vamos usar as funções que definimos anteriormente. Para A, obtenha todas as informações de clique para cada página da Web e, seguida, B, calcularemos o número de cliques por dia para cada página da Web. Vá em frente e defina uma nova variável, ClickSA é igual a e, em seguida, obter apenas os eventos de clique de todas as visualizações para a página da Web A. Isso considera apenas cliques para a página da Web A. Em seguida, vamos calcular diariamente estatísticas. Então ClicksAdaily é igual a e seguida, events_per_day e passar na variável que acabamos de definir, isso calcula o número de cliques por dia para a página da Web A. Vá em frente e faça o mesmo para a página B. ClickSB é igual a todos os cliques para a página da Web B e, em seguida, calcular o número de cliques por dia para a página da Web B. Aqui, ClickSBDaily é igual ao events_per_day do ClickSB. Para ver como é o ClicksAdaily, vá em frente e digite o nome da variável mais uma vez e execute a célula. Aqui temos para cada dia, o número de cliques. Agora, nosso último pedaço de código nesta última célula. Nós vamos realmente traçar esses dados, digite plt.title para dar a este enredo um título, “Página da Web A poderia ter impulsionado CTR em 30 por cento.” Vá em frente e agora plote os dados que acabamos de calcular, o número de cliques por dia. Assim como antes, vamos rotular esta linha A. Repita o mesmo para B, então ClickSBDaily e rótulo é igual a B. Em seguida, nossa terceira linha para este gráfico será o número projetado de cliques para nossa página da Web A. Nós vamos multiplicar as visualizações por dia por 0,7, e então nós vamos multiplicar por 0,5 porque cada página na verdade só tem metade do tráfego. Em seguida, vamos digitar em rótulo igual a A projetado, tão estimado. Isso conclui nossa linha. Vamos agora seguir em frente e rotular o eixo, como sempre fazemos. Nós vamos rotular a data, e então nós vamos rotular os cliques, e depois adicionar a legenda. Finalmente, isso conclui nosso enredo final, vá em frente e executá-lo. Podemos ver aqui na linha verde que nossos cliques projetados por dia para a página A teria sido insano, teria
sido muito maior do que a página B da Web. Em conclusão, vamos voltar aos slides. Abordamos vários tópicos nesta lição: matplotlib, enredo e como contar uma história. Em suma, aqui estão as nossas conclusões finais. Nossas conclusões iniciais sugeriram que a página B era melhor, felizmente, agora corrigimos esse erro. Em resumo, produzimos três números de qualidade que suportam nossa decisão de negócios orientada por dados. Em suma, recomendamos escolher a página da Web A com o vídeo informativo, há três razões. Assistir vídeo informativo está fortemente correlacionado com cozinhar a inscrição. Por outro lado, ler a seção de preços tem quase zero influência sobre se o usuário clica ou não para se inscrever. Começando com o canto superior esquerdo, mostramos que a taxa de cliques da página A caiu precipitadamente. No canto inferior esquerdo, mostramos que a taxa de cliques descartados da página ocorreu ao mesmo tempo que os tempos de carregamento da página A aumentaram de repente. À direita, mostramos que o
aumento do tempo de carregamento da página A resultou em quedas drásticas na taxa de cliques. Isso sugere que a taxa geral de cliques da página A não pode ser confiável. Finalmente, projetamos qual taxa de cliques da página A teria sido durante todo o experimento se os tempos de carregamento da página não aumentassem dois meses após o experimento. Podemos ver que a página da Web A teria consistentemente sustentado uma taxa de cliques 30% maior do que a página B, justificando nossa recomendação final da página da Web A. Isso conclui a recomendação de negócios orientada por dados. Nossa dica final, conheça seus tipos de enredo, o enredo certo pode contar uma história. Você deve saber para qualquer ponto que você deseja enfatizar, qual enredo é mais adequado para enfatizar esse ponto. Sinta-se à vontade para adicionar anotações adicionais, alterar as cores ou nomear o enredo adequadamente para ajudar. Se você quiser acessar e baixar esses slides, visite este URL. Tente traçar seus próprios dados para ver se há insights ocultos. Se você está procurando o tipo de enredo perfeito, veja exemplos de Matplotlib. O objetivo não é clicar em todos eles, mas seu objetivo é saber quais parcelas irão ajudá-lo a contar a história certa. Às vezes, navegar nessa página pode lhe dar inspiração suficiente. Parabéns, isso conclui seu primeiro estudo de caso de um teste AB para duas páginas web. Em seguida, discutiremos as próximas etapas para que você continue aprendendo mais.
8. Conclusão: Parabéns por concluir seus primeiros passos para a análise de dados. Nós abordamos uma série de tópicos: leitura, limpeza, análise e apresentação de dados. Você também cobriu várias bibliotecas diferentes para análise de dados, incluindo Matplotlib para plotlib para plotar dados, e Pandas para realmente armazenar dados. Esse é um conjunto de ferramentas diversificado sob o seu cinto hoje. Este é o ponto de partida, codificação com dados é uma habilidade que, quando feito da maneira certa, pode contar histórias convincentes. O que é mais? Agora você tem o início desta habilidade. O que é mais? Agora você tem os fundamentos para contar histórias atraentes, um conjunto de ferramentas para comunicar dados complexos. Se você tiver uma maneira melhor de visualizar esse conjunto de dados ou um conjunto de dados próprio para visualizar, certifique-se de fazer upload de seus números na guia Projetos e recursos. Certifique-se de incluir a figura e uma legenda descrevendo o que a figura está tentando nos dizer. Se você quiser acessar os slides ou o código concluído, visite este URL. Se você quiser saber mais sobre ciência de dados ou aprendizado de máquina, confira meu perfil Skillshare com 101s e outros tópicos como visão computacional. Obrigado e parabéns mais uma vez por contar sua primeira história com dados. Até a próxima vez.
 Alvin Wan, Research Scientist
Alvin Wan, Research Scientist