Transcription
1. Aperçu du cours: Bienvenue chez leur ingénieur
365, je m'appelle Benjamin. Dans ce cours SQL,
vous apprendrez le langage de programmation SQL, les bases et les fondamentaux SQL de
manière pratique. Nous commencerons par une
brève introduction au langage de programmation SQL, puis nous obtiendrons un
aperçu des bases de données et du système de
gestion des bases de données relationnelles, également appelé SGBDR. Ensuite, nous allons installer Microsoft SQL Server
dans le conteneur Docker pour commencer à apprendre que cette section
d'installation vous
fournira une brève
introduction à Docker. Docker est une
plateforme open source permettant de développer, d'expédier et d'exécuter
des applications. Il fournit un
environnement isolé pour exécuter des
applications ultérieurement à applications ultérieurement l'aide d'un cas d'utilisation
du système de santé, il créera une
base de données, créera des tables
et, enfin, insérera des
données dans ces tables. Une fois que nous aurons effectué une installation de
base, plongerons au
cœur de ce cours, puis
effectuera des opérations de
base sur les données pour apprendre les fondamentaux
SQL,
la syntaxe SQL et les
opérations SQL DML utilisé pour accéder aux base de
données, les
modifier ou les extraire. À la fin de ce cours, vous pourrez effectuer des
C-Corporations pour récupérer,
mettre à jour et insérer
des données dans une base de données. Ce cours fournira des connaissances de
première main aux nouveaux ingénieurs de données et aux développeurs de
logiciels, apprendra directement en utilisant des exemples dans une base de données
réelle. C'est un cours passionnant
et j'ai hâte que vous commenciez et que vous appreniez les
bases SQL à partir de zéro .
Veuillez vous référer aux
horodatages la description vidéo pour
passer à d'autres sections
du
cours, suivez et apprenez les bases
SQL en une heure. Si vous avez
des boucles de
commentaires ou des commentaires dans la section commune, j'aimerais avoir des nouvelles de votre part. Très bien, commençons à
apprendre SQL d'une manière
pratique.
2. Pourquoi je dois apprendre SQL: Maintenant que nous sommes là,
la question que vous vous posez
peut-être est pourquoi devrais-je apprendre SQL ? Ce cours s'adresse aux
personnes intéressées à
apprendre SQL à partir de zéro, des étudiants débutent
un ingénieur
de données et d'autres professionnels de l'informatique
intéressés par l'apprentissage des données et
de l'ingénierie des données. Sql est très demandé pour l' analyse
des données et l'ingénierie
des données. Les ingénieurs de données et
les ingénieurs
logiciels doivent connaître SQL. Avec une croissance du
cloud computing et la
génération de pétaoctets
de données chaque jour. Sql est un
langage de programmation de facto permettant d'accéder aux données
stockées dans le cloud
et de les manipuler. Selon Glassdoor.com,
le salaire de base moyen d' un ingénieur de données
est de 102 000$. Par conséquent, il est
impératif que vous appreniez SQL.
3. Pourquoi vous devriez m'écouter: Pourquoi devriez-vous m'écouter ? Je suis ingénieur maître en
gestion des données et expert en informatique des
soins de santé et j'ai travaillé pour des entreprises du
Fortune 500
telles que g et paradigme depuis dix ans pour concevoir et construire des produits de données
utilisant ETL, HL7, un système EMP, des plates-formes SGBDR
et OS
disparates. J'ai travaillé avec des téraoctets de données de
santé exécutées dans environnement
en
cluster dans Amazon Web Services et Microsoft Asia
pour permettre des soins de santé sécurisés, fiables et
connectés. J'ai travaillé avec des
jeux de données complexes nécessitant la création applications
fiables de
correspondance des patients pour les échanges de données à l'échelle de l'État. Ces applications volumineuses
nécessitent une compréhension de toutes les caractéristiques
et aspects des données pour travailler et traiter les
grands ensembles de données via ETL Les données doivent être analysées pour assurer la cohérence et la précision. Et le
langage de programmation SQL est un langage
incontournable pour
comprendre ces données. Soyez assurés que vous êtes des mains
imparfaites.
4. Aperçu des bases de données: Parlons de la base de données. Qu'est-ce qu'une base de données ? Des applications telles que
Facebook, Google, Netflix stockent des données sur les utilisateurs
et les produits dans des bases de données
relationnelles. La base de données relationnelle est
constituée d'une collection d' objets ou de relations
qui ont stocké les données. Par conséquent, une collection d' objets
associés est stockée
dans une table de base de données. Je vais vous donner un exemple. Lorsque vous vous connectez à Facebook, toutes les informations de connexion
ou de connexion sont stockées dans une
table de connexion ou une table de personnes. peut s'agir de choses
telles que votre nom d'utilisateur, mot de passe, votre date de connexion, connexion
chronométrée et votre
emplacement de connexion. La base de données est composée d' un ensemble de tables
bidimensionnelles. Par conséquent, la base
de données peut comporter une à plusieurs tables. Il peut contenir 12345
tables ou plus dans la base de données. La table est une structure de
stockage de base d' un système de
gestion de base de données relationnelle ou de SGBDR. Nous couvrirons plus de SGBDR plus tard. Chaque table est composée
de lignes et de colonnes, et les données de ces lignes
sont accessibles et
manipulées via SQL. Jetons un coup d'
œil à cet exemple. Sur le côté droit,
vous avez cette image qui représente
une table de patients. Il faut environ cinq secondes pour vraiment regarder la table des
patients. Les lignes de cette table de
patients représentent un
enregistrement de transaction ou une entrée de données unique. Par exemple, nous avons cinq
rangées dans cette table de patients. Chaque ligne représente
un objet distinct ou une personne distincte. Regardez la ligne numéro un. Vous avez FirstName, LastName
comme sexe et une date. Au fait, toutes ces
données sont de fausses données. Ce n'est pas réel. Les lignes sont des valeurs de
colonnes dans une table. Par conséquent, dans ce tableau, vous avez plusieurs colonnes. Vous avez un numéro de
dossier médical. Colonne 1 sur le côté
gauche, suivie de la colonne
prénom, LastName en tant que SN, sexe, BOB ou date de naissance. Toutes ces colonnes
constituent les valeurs des lignes. Les tables sont connectées les unes aux
autres à l'aide de relations. C'est pourquoi c'est ce qu'on appelle
une base de données relationnelle. Dans ce cas, les colonnes représentent les propriétés
de ces données. Par conséquent, pensez à
cette table ici. Nous avons la table des patients. Quelles sont
les propriétés que vous voyez à propos de ces données ? Vous voyez des noms, vous voyez
des numéros Scruton sociaux, vous voyez le sexe, les dates. Vous pouvez également disposer d'autres
informations telles que des informations d' adresse ou des informations sur le permis de
conduire. Tous suivent
cette table des patients. Juste pour le rendre très basique
pour cette représentation. Par conséquent, les valeurs de colonne telles que vous les voyez
ici,
prénom , nom, ssn, représentent
les lignes d'une table. Le champ est une intersection
entre une ligne et une colonne. Peut contenir ou non des données, ce qui signifie qu'
elles seront nulles ou vides. Par exemple, vous pouvez avoir une incidence si
vous avez un deuxième prénom, si la personne n'a pas
fourni de deuxième prénom, cette intersection, ce
champ sera vide. Si nous regardons la ligne numéro 1, prénom est Alyssa, nom de famille est la phrase. Si l'enregistrement, si la personne n'a pas
fourni votre nom de famille, ce champ sera vide. Dans cette affaire, nous
examinons une table des patients. Et la table des personnes
fait partie d'une base de données plus vaste. Par exemple, s'il s'agit
d'un système de soins de santé, vous pourriez avoir une
table des patients, des médicaments , une assurance
stable, une table
d'atténuation médicale stable, etc. Jetons maintenant un coup
d'œil au système de
gestion de bases de données
relationnelles ou au SGBDR.
5. Cas d'utilisation des bases de données du système de santé: Cas d'utilisation
de la base de données du système Jetons un coup d'œil à
un exemple pratique de système hospitalier. Lorsqu'un patient arrive à
l'établissement médical pour traitement
médical ou pour un rendez-vous, une infirmière
ou un service d'assistance. Le personnel les
enregistre généralement. Cet enregistrement implique
que le patient
fournisse les informations démographiques ou
d'assurance. Cet enregistrement implique une recherche
efficace dans le système d'enregistrement des patients ou une recherche de patients
dans le même système. Si un patient est trouvé, enregistrement est renvoyé, ce qui signifie que l'enregistrement existe
dans la base de données. Si aucun enregistrement n'est trouvé, cela signifie que nous devons ajouter un
nouvel enregistrement à la base de données. Ces deux types de transactions, l'
une la recherche du patient et
l'enregistrement du patient, se produisent
tous deux dans le système
enregistré des patients. La base de données
du système de santé dans ce scénario peut contenir
différents types d'informations. Premièrement, la table des patients, qui est l'une des
nombreuses tables de ce système, contient les données démographiques du patient, le
prénom, le deuxième prénom, nom, le suffixe, la date de
naissance, le sexe ou l'adresse. Deuxièmement, le conseil détient des informations
d'assurance, qui sont des numéros d'assurance
ou un groupe d'assurance. Il peut également s'appliquer
dans ce scénario. Rappelez-vous pour ce
cours, les médicaments, ce qui signifie que le patient consulte un médecin. Par conséquent, ces
informations sur les patients peuvent contenir un certain nombre de jeux de données
au sein de ce système hospitalier. Ces trois tableaux et ce scénario constitueront
la base de ce cours.
6. Aperçu de RDBMS: Système de
gestion de bases de données relationnelles ou SGBDR. Qu'est-ce que le SGBDR ? Rdbms est un acronyme
qui signifie système de gestion de base de données
relationnelle. RDBMS, logiciel qui gère les bases de données
relationnelles. Par conséquent, il s'agit d'un système de
gestion de base de données
relationnelle ou SGBDR. Le logiciel gère l'exécution de code
SQL entre les bases de données et l'application système informatique. Il existe différents
types de fournisseurs qui fournissent des logiciels SGBDR. Et chaque saveur du SGBDR
est légèrement différente, mais sa mise en œuvre
est largement la même. Jetons un coup d'
œil à quelques exemples de logiciels RDBMS courants. Voici quelques exemples. Il y en a des dizaines d'autres que vous pouvez également trouver
en ligne, mais je vais me concentrer sur
ceux-ci sont mentionnés ici. Oracle tangy est l'une
des saveurs des logiciels SGBDR de
la société Oracle, Microsoft SQL Server et
Microsoft Access. Et dans Microsoft SQL Server, il existe différentes versions
de Microsoft SQL Server. Amazon Redshift par AWS
ou Amazon Web Services. Mysql. Et MySQL est un système de
gestion de bases de données
relationnelles open source largement
utilisé . Le dernier de cette
liste est IBM Db2. Vous l'avez peut-être fait, si je n'
avais pas entendu parler de DB2, mais c'est une saveur de logiciel de
SGBDR d'IBM. Pour nos besoins, nous utiliserons le serveur de cours
fourni par Microsoft. Les réadmissions RF disponibles, que je vais fournir dans la description
individuelle. Les mêmes principes SQL
devraient s'appliquer aux autres logiciels SGBDR
utilisés car SQL est un langage
standard ANSI, ce qui signifie qu'il est largement
accepté et standardisé. Par conséquent, tous les principaux logiciels de
SGBDR prennent en charge une certaine saveur de SQL.
7. bases de données relationnelles à la valeur de NoSQL: Bases de données relationnelles ou NoSQL. Il existe deux grandes
catégories de bases de données. Nosql et bases de données
relationnelles. Jetons un coup d'œil aux bases de données
relationnelles. Dans le coin supérieur droit, vous disposez d'un exemple de table provenant de
notre base de données relationnelle, qui possède une structure. Les bases de données relationnelles sont généralement stockées ou hébergées sur
un seul serveur. Ces bases de données sont basées sur des tables, ce qui signifie qu'elles possèdent des tables. Ils stockent également des données
structurées conformes à un
schéma ou à une structure. Les bases de données relationnelles sont constituées d' une
collection d'objets ou
les relations stockent les données. Ces
collections d'objets associés sont stockées dans une table de base de données. Des exemples courants de bases de données
relationnelles sont Microsoft SQL
Server et IBM Db2. Il existe d'autres
types de bases de données relationnelles, comme Oracle et MySQL. D'autre part, nous
disposons de bases de données NoSQL. Comme un terme l'indique, les bases de données
NoSQL stockent
les données sous forme de documents. Ils n'ont pas de relations. Les bases de données Nosql possèdent des schémas
dynamiques permettant de stocker les données non structurées. Hadoop est un exemple de
base de données NoSQL, qui repose sur le système de fichiers
Hadoop ou HDFS, qui traite des fichiers. Ces fichiers sont
souvent distribués sur des nœuds de traitement
à travers le réseau. l'ensemble, le
système de fichiers Hadoop utilise une partie de plusieurs
machines pour lire et effectuer des calculs en
fonction des données. s'agit donc des deux principales catégories
de bases de données, à
savoir les bases de données relationnelles
et les bases de données NoSQL. L'essor des entreprises du Web 2
a rendu la base de données NoSQL très populaire car les jeux de données gérés par les entreprises
Internet ont augmenté encore
plus en taille et en agrandissant. Une nouvelle approche de conception des
bases de données a car la conception stricte des schémas bases de données
relationnelles a été écartée en faveur d'une base de données
sans schéma. Par conséquent, les bases de données NoSQL se présentent sous différentes formes et
traitent différents cas d'utilisation. Voici quelques-uns d'
entre eux qui sont déjà mentionnés. Cependant, la portée
est également ce cours. Il s'agit notamment des magasins de valeur clé-valeur. Les exemples courants
sont Redis, Amazon, DynamoDB, les magasins de
colonnes tels que
HBase et Cassandra, les magasins de
documents tels que
MongoDB et la base de canapé. Bases de données graphiques,
telles que Neo4j et les bases de données de
moteurs de recherche telles que Solar
Elastic Search et Splunk. Il s'agit des
types courants de bases de données et différences entre les bases de données
relationnelles
et les bases de données NoSQL.
8. Qu'est-ce que le SQL ?: Qu'est-ce que SQL ? SQL prononcé par SQL signifie Structured
Query Language. Sql est un langage standard ANSI permettant d'accéder aux
données stockées dans une base de données et de les manipuler. Dans ce cas, le mot clé de réponse signifie l'American National
Standards Institute. Et C, organisme privé à
but non lucratif qui administre et coordonne les normes volontaires américaines
et
le système
d'évaluation de la conformité. Puisque SQL est un langage
standard ANSI, il s'agit d'une norme
acceptée par l'industrie. Il est également universellement accepté. Par conséquent, comme SQL est
un langage standard, il a été largement accepté
comme langage standard pour accéder à nos
données mensuelles stockées dans une base de données. Sql est donc le langage de programmation de
facto permettant d'accéder aux
données stockées dans une base de données et de les manipuler.
9. Les principes fondamentaux de SQL: Les fondamentaux du référencement. Jetons un coup d'œil au bloc de requête SQL de
base, la structure SQL. Une requête SQL est constituée
de quatre clauses de base. La clause select identifie les colonnes à accéder ou
à récupérer. La clause from identifie les tables
auxquelles il faut accéder. La clause WHERE
limite ou limite les lignes
répondant à certains critères. La clause Order BY facultative, triez les lignes des données de
vérité par ordre
croissant ou décroissant
sur une ou plusieurs colonnes. Et nous examinerons
cela plus tard. Il s'agit donc des éléments
de
base d'une requête SQL. Ces quatre clauses. Mais pour la plupart, vous constaterez que vous avez un choix parmi une clause a where. La clause Order BY est facultative.
10. Les commandes DCL: Cette année, commandes de langage
de contrôle des données. Ces commandes offrent des privilèges
ou des droits d'accès aux utilisateurs
de bases de données pour effectuer certaines actions dans une
base de données en fonction de leurs rôles. Les exemples courants de
commandes DCL sont l'octroi et la révocation. La commande grant confère un utilisateur des privilèges d'accès
à la base de données. La commande révolt supprime les privilèges
d'accès utilisateur
de la base de données. La portée de ces commandes
dépasse ce cours, mais il s'agit des
deux types courants de commandes DCL utilisées aujourd'hui.
11. Les commandes DDL: Catégories de commandes Sql. Il existe quatre catégories
de commandes de requête SQL. Commandes Ddl, ou langage de
définition de données. Les mains d'amalgame ou Data
Manipulation Language, commandes
DQL ou le langage de
requête de données, les commandes
DCL ou le langage de
contrôle des données. Examinons le
premier exemple. Commandes du langage de définition de données ou des commandes DDL. Ces
commandes permettent de spécifier
le schéma de base de données, la structure
de la base de données. Permet de créer ou de modifier la structure des objets de
base de données. Il existe deux
types de commandes DDL de base. Le premier est créer une table, qui permet de
créer et de créer des tables dans une base de données. Le deuxième type est alter table, qui permet de modifier la
structure d'une base de données. Table dans une base de données. Voici quelques exemples, mais ces commandes DDL sont
hors de portée de ce cours. Il s'agit du résultat d'un cours intermédiaire
ultérieur. Nous utiliserons
plutôt l'instruction SQL create
table plus tard dans ce cours pour créer notre table de base de données.
12. Les commandes DML: Les commandes Dml, les commandes langage de manipulation de
données sont utilisées pour modifier les
données d'une base de données. Des exemples courants de commandes DML sont l'insertion, la mise à jour et la suppression. La commande insert permet d'
insérer des données dans
une table de base de données. La commande update permet
de mettre à jour ou de modifier les données d'une base de données. La commande delete
consiste à supprimer des données d'
une table de base de données. Nous examinerons quelques exemples
plus tard dans ce cours.
13. Les commandes DQL: commandes Dql, Data Query Language
sont utilisées pour accéder et récupérer
des données dans une base de données. commande DQL la plus couramment
utilisée est l'instruction select. L'instruction Select est utilisée pour extraire des données d'une base de données. Ce cours se
concentrera principalement sur l'énoncé de sélection.
14. Installer SQL Server sur Docker: La chose a commencé à installer la base de données
SQL Server. Selon le système
d'exploitation de votre système d'exploitation, vous devrez installer SQL
Server de différentes manières. Pour vous
faciliter ce cours, j'ai inclus des liens pour télécharger le
logiciel requis pour installer SQL Server sur un Windows
vers Linux et trois Mac. J'utilise un Mac et
je vais installer SQL Server sur
une image sombre sur un Mac. Pour ce cours, j'utiliserai Microsoft SQL Server sur un Mac, ou le matériel de cours
devrait également fonctionner sur une
machine Windows et Linux. Vous trouverez ci-dessous des ressources
et des liens pour l'installation du logiciel dit
courtier. Commençons maintenant et
installons SQL Server sur Docker. Vous pouvez vous demander,
qu'est-ce que Docker ? Docker est une
plateforme ouverte pour le développement, expédition et l'exécution d'
obligations. Darker vous permet de séparer vos applications d'
une infrastructure. Vous pouvez fournir rapidement des
logiciels. Par conséquent, Darker permet aux
logiciels de s'exécuter dans leur
propre environnement isolé,
SQL Server 2019. Et n'importe quelle autre version
de SQL Server peut être exécutée sur Docker dans son
propre conteneur isolé. Une fois Docker installé, il
vous suffit de télécharger ou de
regrouper l'image
Docker SQL Server sur Linux sur votre Mac, puis de l'exécuter en tant que conteneur
Docker. Ce conteneur se trouve dans un environnement
isolé qui contient tout ce dont
SQL Server a besoin pour exécuter. Bon, commençons. La première chose que
vous devrez faire est installer Docker et vous obtenez l'édition de la
communauté gratuite plus sombre à partir du lien
ici, qui est hub, le docker.com cliquez sur devenir plus sombre une fois que le le téléchargement est
terminé pour l'installer, double-cliquez sur le fichier
DNG, puis faites glisser l'icône de l'application à points plus sombres vers votre dossier d'applications et l'installation devrait
commencer dès maintenant, vous pouvez voir tous les
fichiers être copié dans le
dossier de vos applications sur votre Mac. Et pour Windows, vous pouvez
ignorer cette étape car vous disposez d'une
machine Windows et que vous pouvez installer
directement SQL Server, ce qui devrait prendre environ
une minute. Et une fois Docker installé, nous passerons au dossier
Applications. Double-cliquez sur l'
icône la plus sombre pour lancer Docker. On dirait que l'
installation est terminée. Je vais aller de l'avant et ouvrir
le logiciel plus sombre. Double-cliquez dessus. Une fois que vous ouvrez plus sombre, vous serez peut-être invité à entrer
votre mot de passe afin d'
accorder l'accès aux composants
réseau votre machine.
Assurez-vous de le faire. Vous pouvez voir
ici que Docker est une application téléchargée
à partir d'Internet. Je veux généralement l'ouvrir, il suffit d'aller de l'avant et de cliquer sur Ouvrir. Et tout de suite, vous
obtiendrez cette fenêtre. Tout en haut, il est dit plus sombre. Et l'icône est qu'un vaisseau
ressemble à un gros vaisseau et il va dire que Docker
Engine commençant par défaut, Docker aura deux gigas de mémoire alloués au SQL Server. Cependant, cela ne fera pas de mal si
vous augmentez la mémoire. Pour mon cas, je vais
augmenter la mémoire à six concerts car j'ai environ
48 concerts sur cette machine. Je clique sur cette icône en forme de roue dentée, je vais accéder à Ressources avancées, puis sélectionner six concerts,
postuler et redémarrer. Désormais, selon la version
de votre Mac dont vous disposez, les menus peuvent être différents, mais je pense que vous
utilisez peut-être la dernière version. Et une fois que c'est fait, il revient par défaut à cette vue. Retournez
voir le général. Maintenant, voici la partie amusante. Téléchargez SQL Server. Maintenant que
Docker est installé, nous allons télécharger
SQL Server pour Linux. Pour télécharger SQL Server, vous devez accéder à la fenêtre de
votre terminal et exécuter cette commande, que je vais fournir dans
la description vidéo. Et je vais devoir
saisir mon mot de passe. Une fois le mot de passe entré, la dernière image SQL Server
2019 Linux Docker sera transférée
vers votre ordinateur. Ce processus peut prendre quelques minutes en
fonction de la vitesse de votre Internet. Soyez juste patient pour
dire que les dirigeants de 2019 tirant de Microsoft SQL Server pour serveur
slash, pool
complet extraction. Et c'est fini. L'étape suivante consiste à lancer
l'image Docker. Exécutez la commande suivante pour lancer une instance
de l'image Docker, vous venez de télécharger
un problème de la commande. Je vais mettre en
pause l'enregistrement car je dois
entrer mon mot de passe. Ensuite, nous devrons
exécuter une série de commandes pour installer SQL CLI, qui est une
interface de ligne de commande permettant d'interagir avec l'image Docker pour
cette année-là sur un tableau de bord d'installation de type NPM G SQL, CLI, entrez, je suppose que ce
n' est pas comme NPM,
puis au-delà va fonctionner. Et si vous
voyez vraiment cette sortie se connecter à l'hôte local effectué SQL CLI, le
numéro de version est fourni. Et vous verrez également l'
option d'aide et l'invite passe à
MSS SQL, Microsoft SQL. Cela signifie maintenant que vous
avez réussi connecter à votre
instance de SQL Server. Lançons maintenant un test rapide et voyons si nous avons des options. Et nous dirons sélectionner la version
SAT ACT pour
nous montrer la version de SQL Server exécution et
vous verrez une sortie. Il va dire que Microsoft
SQL Server 2019
va vous donner une date et qu'il va dire
un retour de ligne, vous
fournir
le temps d'exécution. Et c'est à peu près tout. Nous avons installé SQL
Server sur plus sombre. Ensuite, nous devons disposer d'une interface utilisateur graphique pour interagir avec SQL Server. Pour nos besoins, nous
utiliserons Azure Data Studio, anciennement SQL
Operations Studio, et c'est une option GUI gratuite pour interagir avec
votre SQL Server. Je vais donc aller sur la page de téléchargement d'Azure Data
Studio pour qu'un Mac ait besoin d'
obtenir cette option, cette version, qui
est un fichier zip. Une fois le téléchargement terminé, double-cliquez dessus pour le lancer, Azure Data Studio est une application téléchargée
depuis Internet. Faites-y confiance. Oui,
une fois que c'est fait, vous devriez voir cela. En fait, j'avais déjà
installé ça. Ajoutons maintenant une connexion
à SQL Server plus sombre. Vous souhaitez taper
ce
type d'authentification de l'
hôte local du serveur est la connexion SQL, nom d'utilisateur est ASA
contre votre mot de passe, lorsque je dis mémoriser le mot de passe, base de données est par défaut, donc un
groupe est par défaut, par exemple se connecter . Tout de suite sur la batte. Nous avons une connexion à
notre SQL Server local. Jusqu'à présent, nous
avons réussi installer SQL Server
sur une image Docker, ce qui nous permettra d'exécuter SQL Server et de
poursuivre le cours. Et c'est tout pour cette section. Passons à la suivante.
15. Créer des bases de données SQL Créer des bases de données: Pour ceux d'entre vous qui
débutent dans Azure Data Studio, azure Data Studio était autrefois
secret operations studio, qui est une interface
utilisateur graphique gratuite ou un outil de gestion de l'interface graphique
qui vous permet de vous connecter ou de gérer
SQL Server sur votre Mac ou toute autre machine
Linux,
ce qui signifie que vous
pouvez simplement l'utiliser pour
créer une base ce qui signifie que vous
pouvez simplement l'utiliser pour de données gérée, écrire des requêtes, sauvegarder et restaurer vos bases de données, etc. Il s'agit d'un premier G2 crânien. Une fois que vous lancez
Azure Data Studio, sur le côté gauche, vous
disposez de vos connexions, de
vos solveurs, de votre
hôte local, puis vos bases de données se trouvent
sous cet arborescence ou cette branche. Je vous ai fourni
un tas de scripts SQL que j'aurai besoin que vous utilisiez pour suivre ce
cours, la première chose que vous voulez
faire est d'aller votre navigateur et de vous ouvrir. Extensions. L'écoute que je veux faire consiste simplement à
créer une base de données car nous n'aurons pas de table ou de tables avant d'
avoir une base de données. Cette requête SQL vous permet de
créer une nouvelle base de données. première chose à faire est de vérifier si la base de données réelle existe, puis elle exécute son instruction
create,
puis de définir d'autres paramètres, ou SQL Server ou simplement SQL. Allons de l'avant et lançons ça. Une fois que j'aurai actualisé les
bases de données à gauche, nous aurons une nouvelle base de données
appelée Healthcare DB.
16. Table SQL Créer de la table: Je fais référence à ce que je veux
faire, c'est m'assurer que vous êtes connecté à
la base de données de santé. Si vous utilisez
Microsoft SQL Server, cela devrait se trouver à
gauche comme celui-ci ici. Ou SSMS, SQL Server
Management Studio. Vous verrez le nom de votre base ici et toutes vos tables
se trouveront en dessous. Dans ce cas, le tableau des
patients n'existe pas, comme vous pouvez le voir ici dans
cette section déroulante. La syntaxe que nous utilisons pour
cette section consiste à supprimer la table qu'elle existe, puis à la
recréer à partir de zéro. Maintenant, la syntaxe de
création d'une table, ou plutôt d'une nouvelle table,
est celle-ci ici. Créer une table, un nom de table. Ensuite, le nom de la
colonne est suivi. Le type de données. Colonne vers type de données. Et vous pouvez avoir la troisième colonne, le
type de données, etc. Cela signifie simplement créer une table que vous définissez
dans le « want » nommé. Il s'agit des paramètres de colonne, spécifiez les noms de colonnes
et les types de données. Par type de données, je veux dire le type de données ou la colonne peut contenir. Dans notre cas, il s'agit de la
syntaxe de l'artiste, créez une table. Les patients doivent être préfixés
par cette syntaxe ici, le biote des patients
dans notre cas, la
première colonne aura
un identifiant personnel, qui est un entier. Il n'est pas vide, ce qui signifie qu'il n'est pas nul et qu'il s'agit d'une clé primaire. Chaque table et chaque base de données SQL
Server, ou dans la plupart des bases de données, possède une clé primaire
suivie des autres colonnes. Nous avons le numéro de dossier médical, dont le
caractère variable 100. Et il n'est pas vide, c'
est-à-dire du lait. Maintenant, la différence
entre n var char et caractère
variable est n var
char utilise principalement de l'espace, généralement deux octets par
unité Unicode, et le
caractère variable utilise un octet. Dans ce cas, des choses comme le genre, je spécifie simplement un caractère
variable. Mais alors le
prénom, le deuxième prénom, nom de famille seront n diagramme à
barres jusqu'à 100. Cela signifie qu'un prénom peut contenir jusqu'à 100
caractères. Il est très difficile de trouver un
prénom avec plus de 100 cactus, à moins qu' il ne s'agisse de vos données
factorielles sous-factorielles. Ce sont les colonnes. Prénom, deuxième prénom,
nom, sexe, DOB, adresse. L'adresse est également un caractère
variable et graphique à
barres dont la date de naissance
est un type de données date/heure, qui peut être vide. Ville après 20 personnages restés, cactus d'
Appleton, les numéros de
téléphone et les textos. C'est notre syntaxe. Très simple. Il est possible d'avoir de très
grandes tables ayant un type de syntaxe différent
ou bien d'autres colonnes. J'ai vu des colonnes allant jusqu'à 60
colonnes dans un seul tableau. Maintenant, allons de l'avant et assurez-vous que le type de connexion est aidé à obtenir EB, puis à l'exécuter. Nous sommes donc en train de vérifier si la table existe
, puis de la laisser tomber. Dans ce cas, si j'actualise
cette section ici,
puis que j' ouvre la branche, nous avons ici une nouvelle table
connue sous le nom de patients. Et si vous comparez la syntaxe à la définition réelle
de la table, il
s'agit d'une intersection de table. L'ID de personne C a pk, abréviation de la clé primaire et toutes les autres colonnes
sont définies ici.
17. Ajouter des données à la table des patients à l'aide de SQL INSERT INSERT: Si vous exécutez cette requête, il n'y a pas de données
ici, ce qui est correct. m'amène à cette autre
section pour insérer. En gros, je
voulais vous montrer qu'il n'y a pas de données ici. Une fois que j'ai exécuté, l'instruction insert recevra des données. Maintenant, l'
instruction d'insertion secrète et ces données
dans une table de base de données. La syntaxe de base est
insérée dans le nom de la table de schéma, suivie des
colonnes spécifiées. Les colonnes spécifiées doivent
correspondre aux valeurs fournies. qui signifie que l'identification de la personne
correspond à ce numéro de cent
dix cents
dossiers médicaux correspondant à celui-ci, FAC 1010 ou 10 010. Le prénom correspond à sept. deuxième prénom est roi, le nom de famille est Daniel, le
sexe est masculin. Dob 1921 ou 110. L'adresse, la ville, l'état
figurant sur le numéro de téléphone. Vous allez répéter
cette opération encore et encore pour chaque insert de table. Désormais, pour les autres
cours avancés portant sur les opérations ETL, ils traitent de
grands inserts de table. Et c'est un autre cours que je vais probablement créer un
moment dans le
temps sur la façon d'insérer
ou d'effectuer l'extraction, la transformation et le chargement de jeux de données
massifs dans
une table de base de données. Mais pour ce cours,
très simple. En étudiant le nombre de lignes, 12345 lignes, on dira
qu'une ligne est affectée. Retournez à ma précédente hauteur
électrique et je l'ai couru, je reprends deux rangées.
18. Table de médicaments SQL Créer de l'ordre: Il s'agit d'un tableau supplémentaire
connu sous le nom de table de médicaments, que nous utiliserons pour travailler sur
les opérateurs de comparaison. Maintenant, la première chose que nous allons utiliser pour connecter à la base de données de soins et
la syntaxe est en fait la même que la table du patient,
c' simplement changer la signature pour créer la table réelle. Dans ce cas, il s'agit
d'une table de médicaments qui présente les paramètres
suivants. La première chose que je vais faire est
de vérifier si la table existe dans notre base de données. Si c'est le cas, le supprimerait
, puis créerait une table elle-même. Ce sont les différentes colonnes. N'oubliez pas que la syntaxe de la
table de crédit est le nom de la colonne, qu'elle
soit nulle ou non, et le type de données réel. Ce cas, le numéro d'atténuation, le numéro
Medicaid, le numéro de dossier
médical, assurance et les détails de l'
atténuation. Allons de l'avant et connectons
la base de données de soins de santé. Maintenant, nous l'avons créé. Je vais juste actualiser les bases de données et
regarder les tables. Nous avons une table d'amortissement ayant la même signature ou la même syntaxe
que notre table principale ici. Ensuite, nous allons insérer des
données dans ce tableau. Vous remarquerez qu'il s'agit d'une syntaxe
de l'opération d'insertion. Commencez, tronquez la
table réelle si des données existent. Nous commençons donc par une ardoise fraîche. faites jamais ça. Si vous travaillez sur une base
de données de production. C'est juste pour nos propres
fins, pour ce cours. Il suffit de tronquer. Nous pouvons commencer par une table
de base de données propre lorsque je l'exécute. Et vous verrez ici que nous
avons inséré cinq rangées. Comme vous pouvez le voir dans cette syntaxe. syntaxe est celle que j'ai décrite dans les sections
précédentes pour insérer des données dans la table du patient. Vous définissez les colonnes. Juste ici. Insérez dans le nom de
la table, les colonnes
réelles
et les valeurs, et les colonnes correspondent aux valeurs de la
séquence, comme indiqué ici. C'est à peu près qu'il a créé
une nouvelle table de médicaments et inséré des données
dans ce tableau. Passons maintenant à
la section suivante.
19. Déclaration SQL SELECT: Parlons de la commande
SQL select, qui est la commande SQL la plus basique et la plus
utilisée. Je vais ouvrir l'instruction
SQL select ici. La première chose que
nous voulons faire est assurer que vous disposez de la
bonne connexion, votre propre hôte local et de sélectionner la base de données de soins de santé, qui est notre
base de données principale pour ce cours. Maintenant, l'instruction SQL select récupère
essentiellement les
données de la base de données. Et la
syntaxe de base de l'instruction select est la suivante. Sélectionnez, fournissez les commandes plutôt que les colonnes
de la table. Dans ce cas
sera la table du patient. Vous avez également une condition où la
condition qui
limite ou limite la suite interroge deux lignes répondant
à certains critères. Exemple critique, nous avons
une très petite table. N'oubliez pas que vous
ne devriez jamais exécuter une étoile de sélection sur très grandes
tables de base de données, car cela va nuire aux performances de votre
application ou probablement
verrouiller votre base de données. Le mien est très simple. Sélectionnez une étoile parmi les patients, ce qui signifie essentiellement
sélectionner toutes les colonnes. L'étoile de cette table. Comme vous pouvez le voir dans
les résultats ici. Colonne d'identification de personne, numéro de dossier
médical, prénom et toutes les
autres bonnes choses, tout l'
ordre démographique jusqu'à la fin, le sexe, DOB, l'adresse, la ville,
l'état et le numéro de téléphone. Il y a aussi une autre table, table de
médicaments, une
étoile choisie parmi les médicaments. Et il présente
un ensemble de résultats d'
atténuation à partir de cette dB de soins de santé. Si vous allez à gauche,
vous pouvez voir les bases de données, la dB des
soins de santé, les tables, table des
médicaments sur
la table du patient. Ce sont les définitions de table sur le côté gauche et
parcourez toujours et voyez les
colonnes dont vous avez
besoin pour suggérer de lancer une
étoile sélectionnée parmi les patients, et vous spécifiez l'ordre
par dans ce cas, Disons LastName. Exécutez ceci, votre commande. Les résultats définis par le nom de famille peuvent voir qu'
ils sont par ordre alphabétique. Arthur Daniel DO revient
avec James Cook et Patrick. Il était possible de sélectionner vos colonnes spécifiques
dans ce cas, lorsque je dis ID
de personne, disons simplement n'importe quel prénom, nom et date de naissance. Il s'agit d'un jeu de résultats. Je suis assez simple, sélectionnez l'instruction SQL select pour récupérer les données
de la base de données.
20. TOP SQL Select: Maintenant, nous avons notre table. Dans la section suivante, nous
étudierons la sélection en haut. Désormais, l'instruction top select limite le nombre de croissances
renvoyées par une requête SQL. Ceci est très important pour les tables très volumineuses où
vous vouliez limiter la sortie afin de ne pas impact sur les
performances de l'application. Dans ce cas, si
je sélectionne le haut, il a défini les colonnes. Vous pouvez choisir de préférer indiquer nombre
limité de colonnes ou simplement avoir autant de
colonnes que nécessaire. Suivi du mot-clé du
nom de la base de données ici, du schéma et de
la table elle-même. Si vous exécutez cette requête,
je récupère deux lignes. Il est également possible,
comme je l'ai mentionné, limiter le nombre de
colonnes
dont vous avez besoin en utilisant uniquement
les noms de vos colonnes. Il est également possible
de fournir un décrochage. Nous voulons simplement me donner toutes les autres colonnes
de ce tableau. Si vous avez dix colonnes, vous obtiendrez des colonnes en utilisant
la syntaxe étoile ici. Et voici les colonnes. Maintenant, nous faisons un top dix. Si vous augmentez pour parler trois, vous obtiendrez les trois premières lignes de cette
table dans l'ordre séquentiel. Vous pouvez voir les numéros de ligne 1234. Une autre
ligne vous sera renvoyée.
21. Clause SQL WHERE: La prochaine commande que nous
utiliserons est une clause SQL where. Je vais ouvrir ma dernière requête. J'ai une requête SQL ici. Nous avons une connexion,
localhost, connect, sélectionnez votre base de données de connexion,
base de données de santé, SQL où la clause
limite ou limite essentiellement la requête SQL deux lignes qui répondent à un certain
critère ou condition. N'oubliez pas avant de mentionner que vous ne devriez pas
simplement exécuter
SQL Select SQL Star sur une table sans fournir une
condition ou une limite. Dans ce cas, j'
exécute essentiellement un compte de sélection. Le nombre est en quelque sorte agrégé sur les colonnes
et les lignes ici. Sélectionnez donc le nombre de patients
dont le sexe est masculin. Vous pouvez voir ici que j'ai quatre rangées plutôt pour les
enregistrements
du sexe masculin. Vous pouvez également fournir un
alias pour cette colonne. Dans ce cas, vous pouvez
dire patients masculins. Si vous exécutez cette opération, vous aurez un en-tête de colonne plus défini. Il est également possible d'
utiliser une clause Where où l'opérateur AND pour
limiter davantage votre jeu de résultats. Dans ce cas, je veux
lancer un compte sélectionner tous les patients dont le sexe est masculin et
le prénom est John. Ce cas est un bon
scénario où vous souhaitez voir la distribution de
l'utilisation des noms génériques. Par exemple, John,
vous avez Jain, ces autres noms génériques
que vous pouvez trouver dans le jeu de données. C'est l'utilisation de la
clause WHERE pour limiter ou restreindre la requête SQL aux lignes qui répondent à certains
critères ou conditions.
22. keyword en ligne: peut arriver que vous souhaitiez récupérer des
valeurs distinctes ou uniques à partir d'une colonne. Dans ce cas, vous utilisez
le mot-clé distinct qui
renvoie des le mot-clé distinct qui résultats uniques dans un jeu de données. Par exemple, je
voulais connaître les prénoms distincts ou uniques
du genre masculin. Dans ce cas, je vais
changer ma connexion en dB sain et simplement
exécuter cette commande. Je verrais que ce
sont essentiellement
les noms communs que vous avez dans cet ensemble de données
qui sont uniques. Nous avons John,
Johnson et Steven. Maintenant, si je copie ce SQL et que je supprime simplement le mot-clé
distinct et que je les exécute tous les deux. Vous verrez que nous avons dans
le premier jeu de données, trois noms reviennent.
Ils sont distincts. Mais dans le second, vous voyez qu'il y a
44 lignes renvoyées, essentiellement sont des mots clés distincts qui se
débarrassent des doublons. Vous pouvez voir que c'est l'
utilisation du mot-clé distinct. De plus, si vous dites exemple, changeons ce genre en féminin et voyons ce que nous récupérons. Un résultat différent. premier est le nom le
plus courant est la chaîne distincte ou unique ? Nous avons des doublons, ce qui
signifie qu'il y en a deux. Si je sélectionne une étoile
, l'étoile ici
signifie obtenir toutes les colonnes. Vous verrez que Jane est répétée, mais en gros, je veux vous
montrer que
c'est un
disque distinct, Jane Doe. Et voici Jane Patrick,
distincte aussi. Et c'est l'utilisation
du mot-clé distinct.
23. Commande SQL par: La clause SQL order BY
recherchait des lignes avec la clause order BY dans ordre
croissant
ou décroissant. Dans ce cas, nous reviendrons à notre table de facto,
l'écurie du patient. Changeons notre connexion
à la dB des soins de santé. Dans ce cas, nous
choisirions tous les prénom, deuxième
prénom, nom, ville
et état par ville. Maintenant, si nous regardons ici,
vous verrez que la séquence de commandes
est alphabétique, avec un D et se terminant
par San Francisco ici. Alors Denver jusqu'
à San Francisco. La clause order BY ordonne des colonnes basées soit
par ordre croissant, ce qui est indiqué par ASC
ou par ordre décroissant. Si vous revenez, vous verrez que
San Francisco est au sommet. Il est également possible de trier
par plusieurs colonnes. Dans ce cas, si
je dis FirstName, peux dire FirstName ascending. Donc, d'abord, je vais commander
PAR ville en descendant, suivi d'
un prénom ascendant. J'ai regardé ces données, ville descendante, San Francisco. Donc, City Rochester, New York, Lubbock, Denver. Et puis FirstName Johnson vient avant Stephen
et ainsi de suite. Et c'est l'ordre ou la séquence lorsque vous
utilisez la clause order BY, très important si
vous souhaitez examiner des jeux de données spécifiques en fonction vos besoins ou
de différentes colonnes, etc. quatrième. Vous pouvez également utiliser des alias de colonne ou un numéro pour la position de la colonne dans
la clause order BY, dB de
soins de santé par exécution, sélectionner le prénom, le deuxième
prénom, le nom, la ville-état,
par ville pour son nom. C'est ce que je récupère. Il est également possible d'utiliser des
alias pour les colonnes, ce qui signifie, par exemple, ville. Pour cette position, vous
devez compter les colonnes 1234. Vous pouvez dire ordre
par quatre décroissant, puis FirstName peut en faire un, ce qui signifie que les colonnes sont classées
par position dans la clause
select ici. Pour courir ça, j'obtiens toujours les
mêmes résultats ici. C'est quelque chose de
cool à retenir. Si vous avez
autant de lignes frères choix entre
autant
de colonnes lorsque vous sélectionnez, vous voulez vous fier à un alias de
colonne ou à un numéro pour la position de la colonne
dans la clause Order BY.
24. Commande Sql par position: Vous pouvez également utiliser des alias de colonnes. Numéro de la position de la colonne
dans la clause Order BY. Par exemple, si j'
exécute cette requête ici, laissez-moi d'
abord nettoyer ma base de données. Soins de santé dB. Si je l'exécute, sélectionnez le
prénom, le deuxième prénom, le nom, la ville, l'état par
ville pour son nom. C'est ce que je récupère. Il est également possible d'utiliser
des alias pour les colonnes, c'
est-à-dire par exemple ville. Pour cette position, vous
devez compter les colonnes 1234. Vous pouvez dire ordre
par quatre décroissant, puis FirstName peut en faire un. Ce qui signifie que les colonnes sont classées
par position dans la clause
select ici. Si je cours ça, j'obtiens toujours les mêmes
résultats ici. C'est quelque chose de
cool à retenir. Si vous avez
autant de lignes frères choix entre
autant
de colonnes lorsque vous sélectionnez, vous voulez vous fier à un alias de
colonne ou à un numéro pour la position de la colonne
dans la clause Order BY.
25. Groupe SQL par: Une
instruction core group by renvoie un ensemble de lignes pour donner un
résultat par groupe. Je vous ai fourni
un script SQL Groupby à exécuter pour cette section. Sélectionnez ma base de données. L'oxygène doit d'abord
se connecter à la base de données. Sélectionnez la base de données
de santé de connexion. Maintenant, dans ce cas,
ce que je veux faire c'est dire que pour la première
requête, c'est juste, laissez-moi exécuter ces trois. La première question ici, je récupère les deux
premiers dossiers de la table des médicaments. la section suivante, je vais faire un compte sélectionné
du numéro de dossier médical, suivi des noms d'assurance, puis je le regrouperai
par nom d'assurance. Il s'agit d'un
cas d'utilisation assez courant lorsque vous souhaitez voir la répartition des patients
ayant différents types de fournisseurs
d'assurance. C'est peut-être à l'heure actuelle, Medicare, Medicaid, des choses comme ça. Cela signifie que
vous pouvez compter les enregistrements suivis
du nom de l'assurance, puis les regrouper par le nom de l'
assurance lui-même. La section ici. Par exemple, si
vous souhaitez vérifier les fournisseurs
d'assurance
en fonction
du prix moyen d'une couverture médicamenteuse. Si je lance cette requête ici, ce que je cherche,
c'est le nom de l'assurance, le prix moyen des médicaments. Si je vais à la définition de ma table, je veux vous montrer
la table des médicaments. Il comporte plusieurs colonnes. L'une de ces colonnes est
le prix d'atténuation. Laissez-moi simplement lancer une
simple requête ici. Sélectionnez à nouveau une étoile parmi les
médicaments, c'est un tableau très simple, ne
devrait jamais fonctionner
en production. Sélectionnez une étoile. Vous pouvez voir que nous avons un identifiant de mutation, numéro
Medicaid, un numéro de dossier
médical. C'est-à-dire qu'il s'agit d'une
clé primaire dans la table du patient, ce qui signifie qu'il s'agit d'une clé
étrangère ici. Nom de l'assurance,
Aetna, Croix
Bleue , Bouclier Bleu, Medicare,
etc. Et ensuite, le prix d'atténuation. Ce tableau montre essentiellement
les médicaments et les prix
ainsi que les médicaments et les prix les fournisseurs d'assurance pour ces cas d'utilisation assez simples. J'ai exécuté cette requête. Je suis à la recherche du groupe de prix
moyen par nom d'assurance. Dans une section ultérieure, nous examinerons la fonction
moyenne, qui est assez couramment
utilisée lorsque vous
travaillez avec
des données financières ou des chiffres. Et vous voulez
voir la moyenne d' une valeur ou d'un paramètre. C'est l'examen du
groupe par qui signifie
regrouper les résultats définis par
un résultat par groupe. Dans ce cas, je veux voir le prix moyen ici. Je peux simplement fournir
un alias et appeler cette moyenne ce prix. Ce qui signifie que je veux obtenir un nom de colonne
plus définitif. Juste comme ça. Passons à
la section suivante.
26. SQL avoir une clause de l'esprit: Il apparaît assez souvent dans des questions d'
entretien
pour les ingénieurs de données ou programmation
SQL, car c'est
une clause très délicate à utiliser. Et il est souvent utilisé avec
un groupe BY aussi. Maintenant, la clause SQL
Have est utilisée pour
restreindre davantage les résultats de
la clause group by. Tout d'abord, vous avez regroupé en utilisant la clause group by. Ensuite, vous limitez les
résultats à l'aide la syntaxe de la clause d'avoir. Maintenant, la syntaxe de base de clause d'
avoir est de sélectionner un
tas de colonnes. La fonction groupe d'une table, la condition where clause, groupe par lequel vient en
premier puis la
condition de groupe vient ensuite. Vous pouvez également Order By the end, ce qui signifie que les lignes sont groupées. La fonction groupe par est
appliquée au groupe. Et les groupes qui défilent pour
avoir dans le conditionneur ou le retour. Permettez-moi de vous donner un exemple
commun. Dans ce cas, supposons
que vous souhaitiez trouver le
nombre de patients par fournisseur
d'assurance avec
le médicament le plus cher ou un médicament très coûteux. Cela signifie que vous souhaitez effectuer une analyse des
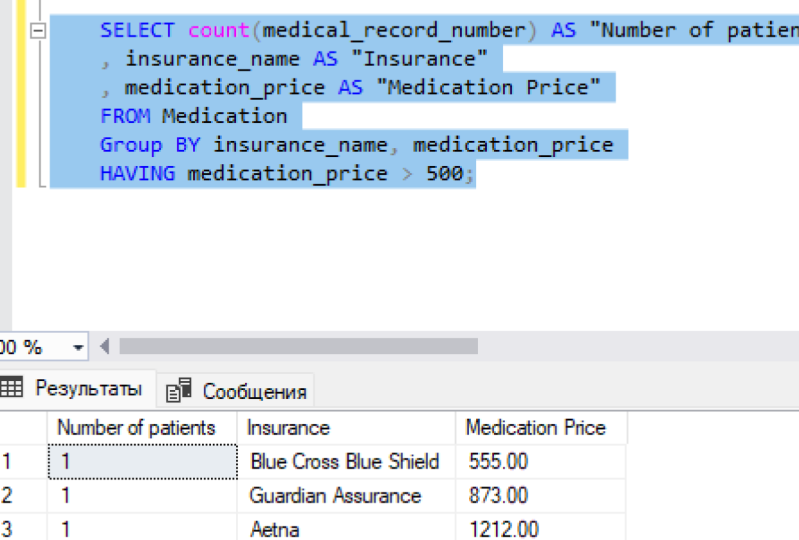
coûts de votre jeu de données, de vos données de patients. Maintenant, dans ce cas, nous sommes autour d'une simple requête. Je sélectionne le
nombre de dossiers, nombre de patients, c'est-à-dire
le numéro du dossier médical, qui est une
clé primaire, une clé unique. C'est le nombre de
patients, le nom de l'assurance, juste l'assurance, le prix de l'atténuation en tant que prix de dépendance
du tableau des médicaments. Dans ce cas, je suis regroupé par nom
d'assurance et prix de
méditation. Maintenant, dans la section suivante,
je vais dire que j'ai une atténuation de plus de 1000$, j'ai
lancé cette requête. Je dois d'abord me connecter
à ma base de données. Je vais revenir ici
et lancer cette requête. Vous pouvez voir ici, j'ai un patient
qui est couvert par assurance et il a
des médicaments de 1200$. Par exemple, si vous
limitez cela à 500$,
cela signifie essentiellement que je dois rendre compte des patients et des noms d'assurance ou des fournisseurs
d'assurance qui ont
un médicament de plus de 500$. Vous pouvez voir que nous n'avons qu'un seul dossier. Bouclier bleu Croix Bleue. Ainsi, le prix des médicaments. Je peux même
venir ici. Je vais vous montrer
la table des médicaments. Cherchez ce 555. Vous verrez juste ici. Le deuxième médicament de cette liste est notre injection de paramètres,
qui coûte 555. Il est couvert par l'
assurance et c'est lié à cette rapidité ici. Dans les sections suivantes, nous examinerons instructions
jointes, telles
que celle-ci, qui devraient vous permettre effectuer
des opérations spéciales sur vos données, ce qui signifie combiner
différentes tables et données différentes provenant de
différentes tables. Maintenant, par exemple,
revenez ici, présentez au
fournisseur d'assurance le médicament le plus cher. Vous verrez que c'est le coût de ce médicament
sous assurance ethnique. Et c'est un regard. Je vais avoir une clause, qui est souvent utilisée en
combinaison avec le groupe BY pour limiter davantage le résultat de
votre jeu de données.
27. SQL et opérateurs: Les opérateurs SQL AND, OR et NOT. Nous avons ici notre lien avec
la dB des soins de santé. La première chose que vous allez faire est de sélectionner une
étoile dans la table des patients. Nous voulons voir le
groupe de données ici. Vous pouvez voir que nous avons le sexe. Ici, la colonne de l'ordre du jour. Maintenant, l'opérateur et
renvoie des enregistrements si toutes les conditions sont remplies, ce qui signifie que toutes les conditions séparées par le et sont remplies. Et ces conditions le sont également. Par exemple, vous
pouvez voir ici, je fais une requête rendre compte des patients masculins. Tout d'abord, si vous exécutez cela, vous obtiendrez quatre disques. Maintenant, dans ce cas, si nous ajoutons l'opérateur et, cela signifie que vous voulez
vérifier cette condition. Cette autre condition,
si les deux sont vraies, vous obtiendrez des résultats. Nous pouvons voir que nous avons un disque
qui est un disque masculin. Le prénom est John. Si je reviens, sélectionnez. Vous verrez ici que nous
avons un John, deuxième rangée. Maintenant, l'opérateur or
renvoie des enregistrements si
l'une des conditions est séparée
par l'opérateur ou R2. Maintenant, par exemple,
utilisons la même requête. Je vais attraper
tous les patients. Sélectionnez l'étoile parmi les patients
dont le sexe est masculin. Le prénom est
John ou Steven. Dans ce cas, nous devrions
voir deux enregistrements. Et vous avez deux disques. Maintenant, si vous avez des heures pour
copier cette requête, exécutez-la pour la première
avec l'opérateur AND. Vous n'obtiendrez aucun
enregistrement car il vérifie où se trouve
le prénom, John
et Stephen. Maintenant, revenez à cela
ou vous obtiendrez deux enregistrements. Que se passe-t-il si vous changez cela par ? Supprimons simplement cette clause
ou cette clause est égale à celle d'une femme. Que pensez-vous ? Nous y retournerons ?
Lançons ça et vérifions. J'obtiendrai quatre disques. Parce qu'il y a
probablement quelques colonnes, quelques lignes qui n'ont pas le
genre de nœud ici. C'est inconnu. Relancez-le, vous obtiendrez quatre sacs de disques. C'est donc le
regard de l'opérateur AND et OR. Alors que l'opérateur et renvoie true lorsque toutes les
conditions sont remplies, l'opérateur or en renvoie une. Si l'une ou l'autre des
conditions est remplie. Passons à
la section suivante.
28. Les opérateurs SQL et NON: Opérateurs Sql AND, OR et NOT. Nous avons ici notre lien avec
la dB des soins de santé. La première chose que vous allez faire est de sélectionner une
étoile dans la table des patients. Nous voulons voir les données
du groupe ici. Vous pouvez voir que nous avons le sexe. Ici, la colonne « Genre ». Maintenant, l'opérateur et
renvoie des enregistrements si toutes les conditions sont remplies, ce qui signifie que toutes les conditions séparées par le et sont remplies. Et ces conditions le sont également. Par exemple, vous
pouvez voir ici, je fais une requête, je
fais un compte des patients
de sexe masculin. Tout d'abord, si vous exécutez cela, vous obtiendrez quatre disques. Maintenant, dans ce cas, si nous ajoutons l'opérateur et, cela signifie que vous voulez
vérifier cette condition. Cette autre condition.
Si les deux sont vrais, vous obtiendrez des résultats. Nous pouvons voir que nous avons un dossier
qui est un record de l'usine. Le prénom est John.
Si je reviens, sélectionnez. Vous verrez
ici que nous avons un seul John. Deuxième rangée. L'opérateur ou
renvoie des enregistrements si l'une des conditions est séparée
par l'opérateur ou R2. Maintenant, par exemple,
utilisons la même requête. Je vais attraper
tous les patients. Sélectionnez l'étoile parmi les patients
dont le sexe est masculin. Le prénom est
John ou Steven. Dans ce cas, nous devrions
voir deux enregistrements. Et vous avez deux disques. Maintenant, si vous avez des heures pour
copier cette requête, exécutez-la pour la première
avec l'opérateur AND. Vous n'obtiendrez aucun
enregistrement car il vérifie où se trouve
le prénom, John
et Stephen. Maintenant, modifiez cette option en
ou vous obtiendrez deux enregistrements,
NOT opérateur, qui affiche
un ou plusieurs enregistrements. Si la ou les
conditions ne sont pas vraies. Voyons ce que nous
avons dans les dossiers. Dans ce cas, ce que
vous voulez faire c'est utiliser l'opérateur non. Pour ce faire. Nous voulons faire quelque chose comme si le sexe
n'est pas égal au courrier. Que
penses-tu que tu reviendras ? J'ai pris quelques secondes
pour y réfléchir. Si vous exécutez cette
requête, vous verrez vous obtiendrez les enregistrements
alors que le sexe n'est pas masculin, pouvez voir que vous avez des enregistrements connus
et féminins. Si je change cette option par femme, sélectionnez l'étoile parmi les patients dont
le sexe n'est pas féminin, vous obtiendrez tous les enregistrements masculins ainsi que celui-ci
qui est inconnu. C'est l'utilisation de
l'opérateur not, qui affiche un ou plusieurs
enregistrements. Si la ou les
conditions ne sont pas vraies.
29. Opérateur SQL COMME SQL COMME: Dans cette section,
nous allons
examiner l'opérateur de type SQL, qui est utilisé en combinaison
avec une clause where pour trouver un modèle ou des
motifs dans une colonne. Dans ce cas, j'ai
ce médicament de table. Et si je l'exécute
simplement pour voir les données
qui se trouvent ici, nous avons ces deux colonnes, numéro du dossier
médical
et le nom de l'assurance. Dans ce cas, j'essaie de trouver le nom d'assurance Croix Bleue. Comment faire cela en utilisant
l'opérateur like, il est toujours utilisé en combinaison
dans la clause where, ce qui signifie qu'il apparaîtra dans
la section clause where. Rechercher des données consiste à utiliser un devis unique, un
pourcentage, puis les
données ou le texte, puis le symbole de pourcentage, et se termine par un devis unique. Dans ce cas, par exemple, j'essaie de trouver
Aetna Insurance. Maintenant, n'oubliez pas que si vous n'
avez pas de signe de pourcentage, vous
essayez essentiellement de trouver des données qui
commencent par un B suivi du LUB. Si bleu dans ce cas, que dans ce cas, vous trouverez Blue Cross Arizona Blue
Shield. L'autre variation
consiste à trouver des patients assurés par
le fournisseur,
puis avec Medicaid ou Medicare. Dans ce cas. Vous avez
ouvert Cote pour cent, puis les mots que vous
recherchez dans ce nom
d'assurance. Si vous exécutez cette requête, vous trouverez Medicare. C'est ainsi que vous utilisez
l'opérateur lac. N'oubliez pas de toujours
si vous essayez trouver du texte entre les
textes que vous
souhaitez utiliser présents entre la
chaîne que vous recherchez. Si vous essayez de
trouver des colonnes où les données commencent par
des chaînes spécifiques, vous devez vous assurer
qu'il ne s'agit que d'un seul code suivi du texte. S'il se termine, vous
voulez vous assurer que les textes finaux sont à la fin, suivis de
la guillemets unique et que
le pourcentage est au
début. Un autre exemple que nous
pouvons examiner ici est que j'ai fait une sélection des médicaments
de la table des médicaments, la description réelle, nous
avons ces médicaments. Maintenant, si vous voulez trouver, laissez-moi lancer cette requête ici. Essentiellement, trouvez n'importe quel
médicament qui commence par un K, commence par un a
et se termine par un a. Dans ce cas,
essayer simplement de trouver AstraZeneca tel qu'un se termine par un a. C'est un format que
vous utilisez pour cela. Et c'est un aperçu de
l'opérateur de type SQL, utilisé pour trouver des
modèles dans les colonnes.
30. Les personnages sauvages SQL: Écrivons une autre
requête ici pour voir ce qu'
il y a dans ce
tableau, la table des médicaments. Je vais juste faire une étoile choisie. C'est une très petite table,
donc je peux le faire. Dans ce cas. Essayons de trouver une assurance. Au contraire, tous
les médicaments sont couverts par Aetna. Si vous faites quelque chose
comme une star du litige où le
nom d'assurance comme Aetna, que pensez-vous revenir ? Lançons cette requête. obtiendrez cette
ligne qui vous montre le nom d'assurance Aetna
et le médicament lui-même. Maintenant, ici, nous pouvons
considérer les caractères génériques SQL. Et un caractère générique
est souvent utilisé en combinaison avec un opérateur
similaire à SQL. Nous avons
déjà examiné cela lorsque vous aviez le symbole du pourcentage. Le symbole de pourcentage
indique souvent le caractère générique. Il est utilisé pour rechercher des caractères entre le symbole spécifié. Par exemple, si
j'exécute cette requête, sélectionnez le numéro du dossier
médical d'atténuation, nom
d'assurance pour la table de
méditation, où le
nom de l'assurance est Croix Bleue, ce qui signifie la chaîne
ou le texte entre le caractère sauvage entre le symbole de
pourcentage est renvoyé. Dans ce cas, vous trouverez
tous les médicaments dont le nom d'assurance est Blue Cross Blue Shield
ou Blue Cross Arizona, si vous aviez un autre État, Blue Cross Florida,
tomberait ici. Un autre format du
caractère générique utilise un trait de soulignement, ce qui signifie qu'il trouve des caractères entre
le symbole spécifié. Par exemple, dans ce cas, faisons, retirons tous les dossiers de
la table du patient. Je sélectionne donc
FirstName parmi les patients. Maintenant, si vous voulez trouver tous
les noms se terminant par ON, par
exemple, John Don
Kohn et autres. Vous utilisez l'opérateur similaire, le pourcentage de code
unique, puis le soulignement
suivi des caractères
qui et ce nom. Dans ce cas, vous
trouverez Johnson et Johnson. Vous trouvez juste que je fais
simplement toutes
les données actives à cellule unique distinctes. J'aurais un inconvénient. C'est donc ce que vous voulez faire. Il suffit de faire une chose distincte là-dessus. Un autre format
du caractère générique consiste à utiliser un crochet carré droit et
le crochet gauche. Maintenant, le caractère générique entre crochets trouve les caractères entre
le symbole spécifié et les
instructions SQL suivantes sélectionnent tous les patients
portant un prénom, commençant par a et D. Maintenant, si On exécute ça, rien ne revient. C'est la minuscule. Permettez-moi de changer cela en AD. Reviens, essayons j. J'obtiens tous les enregistrements où le prénom
commence par un J. Maintenant, voyons quelles sont
les données ici. Nous avons donc aussi Stephen. Ajoutons un S et
voyons ce qui se passe. Vous avez Stephen et John. C'est très utile et arrive assez souvent
dans les questions d'entrevue. Comment trouver les données qui commencent par
une lettre soudaine ? Dans ce cas, prénom, commençant par j ou S, et suivi de
n'importe quel autre caractère. Et c'est comme ça que tu fais ça. Et c'est l'utilisation
du caractère sauvage avec les crochets. Supposons que nous voulions trouver tous les noms
commençant par j, prénoms. Et ils ne contiennent pas de O,
utilisent un type spécial
de caractère sauvage, c'est-à-dire la carotte supérieure, ce qui signifie qu'elle renvoie tout
caractère non entre parenthèses. Par conséquent, il va
ignorer les noms sans avoir
un frère aîné. Donc, si nous exécutons cette
requête, vous obtiendrez Jane. Si vous voulez voir
toutes les données ici. Nous avons deux Janes,
Johnson, John, si vous mettez un OH
va juste ignorer tous les de
John Johnson ou d'autres
noms dans ce format. C'est l'utilisation du joker de la carotte
supérieure
pour ignorer les majuscules qui
ne se trouvent pas entre crochets. Passons à
la section suivante.
31. L'opérateur SQL PAS de SQL: Iterator renvoie les enregistrements si la ou
les conditions ne l'sont pas. Prenons un
exemple rapide ici. Je vais copier la première
requête ici. Voyons ce que nous
avons dans les dossiers. Dans ce cas, ce que
vous voulez faire c'est utiliser l'opérateur non. Pour ce faire. Nous voulons faire quelque chose comme
ne pas être égal au sexe masculin. Que pensez-vous ?
Vous y retournerez ? J'ai pris quelques secondes
pour y réfléchir. Si vous exécutez cette
requête, vous verrez que vous obtiendrez tous les enregistrements alors que le sexe n'est pas masculin. Je vois que vous avez un disque connu
et féminin. Si je change cette option par femme, sélectionnez l'étoile parmi les patients dont
l'agenda n'est pas féminin, vous obtiendrez tous les enregistrements masculins ainsi que celui-ci
qui est inconnu. Ainsi, l'utilisation de
l'opérateur not, qui affiche un ou plusieurs
enregistrements. Si la ou les
conditions ne sont pas vraies.
32. Compte SQL et Avg, Min, Max et um: Les fonctions du groupe Sudo
fonctionnent sur un ensemble de lignes pour fournir
un résultat par groupe. exemples courants de
fonctions de groupe SQL sont le nombre
SQL, la moyenne SQL, le
minimum et le maximum SQL. Maintenant, la
fonction de compte égal vous donne un
compte de quelque chose. Par exemple, je vais me connecter à
ma base de données, à mon hôte local, à
ma base de données. Dans ce cas, je dirige une sélection de patients étoiles
où c'est la ville. Dans ce cas, la fonction
count renvoie un certain nombre de lignes qui
correspondent à mes critères, là où se trouve la ville. Laissez-moi diriger ces deux-là ici. En fait, laissez-moi
diriger celui-ci ici. Dans ce cas, je compte
le nombre de numéros
de dossiers
médicaux distincts ou uniques pour un patient où se trouve
la ville. Je peux également utiliser un compte avec
une combinaison d'un groupe par, dans ce cas, pour
exécuter cette commande. Compter essentiellement
le nombre d'enregistrements indiquant leur prénom du groupe de villes
par le prénom. Cela est important
lorsque vous essayez d'
examiner la distribution
de vos données, c'est-à-dire que les prénoms comptent pour différentes
villes, des choses comme ça. Si je me débarrasse de la WhereClause
et que je réexécute ça, vous pouvez voir que je récupère
plus de données. C'est l'utilisation du compte. Le prochain est maintenant
le minimum SQL. Par exemple, si vous souhaitez
trouver un minimum de quelque chose, cela
signifie que
la valeur minimale
d'une colonne sélectionnée est renvoyée . Dans ce cas, j'ai
cette table de médicaments, laquelle je viens d'obtenir le prix
minimum d'atténuation de cette colonne et le prix
efficace, la moyenne fonctionne,
sur une colonne spécifique. Dans ce cas, la moyenne des
prix des médicaments est de 601, ce qui signifie qu'elle
agrège toutes les valeurs la colonne des prix d'atténuation et me donne une moyenne de cela. La fonction moyenne renvoie la valeur moyenne de n
Ignorer les valeurs NULL. L'exemple courant est la
moyenne de l' âge moyen des personnes
figurant dans notre table de patients, ou le prix moyen d'atténuation
dans le tableau d'amortissement. Nous avons examiné le minimum, le nombre maximal de rendements, la valeur
maximale d'une colonne
sélectionnée. Dans ce cas, vous voulez trouver le médicament le plus cher. Vous allez faire quelque chose comme sélectionner, sélectionner l'instruction Max,
fournir le nom de la colonne. Et vous pouvez voir le
médicament
le plus élevé ou le plus cher comme celui-ci. Vous pouvez également afficher le médicament le plus cher avec sa description. Dans ce cas, je dois regrouper par groupe par
description de méditation. Dans ce cas, vous verrez que le prix moyen
d'atténuation, je vais l'alias comme
lui donner un nouveau nom de colonne. Nous allons donc dire que c'est
le prix moyen. La description de la médecine. Si vous réexécutez cela, je reçois le médicament le plus élevé ou le plus cher et je le regroupe selon la description du
médicament. Vous avez donc l'AstraZeneca, suspension de
sulfate de baryum, le vaccin contre la grippe et tous les autres
médicaments que nous avons ici. Maintenant, la fonction de groupe finale
est la fonction somme, qui vous obtient
les valeurs de somme de n Ignorer les valeurs nulles
de ma colonne numérique. N'oubliez pas que la fonction somme
fonctionne sur des colonnes numériques. La fonction somme renvoie somme totale d'une
colonne numérique dans ce cas, pour trouver le prix total
de la colonne de médicaments. Et vous verrez que c'est 3 006. Et c'est un aperçu des fonctions de groupe
les plus couramment
utilisées. Vous pouvez les utiliser dans des applications
financières ou
d'autres types d'applications. Vous devez trouver des
mesures spécifiques sur vos données.
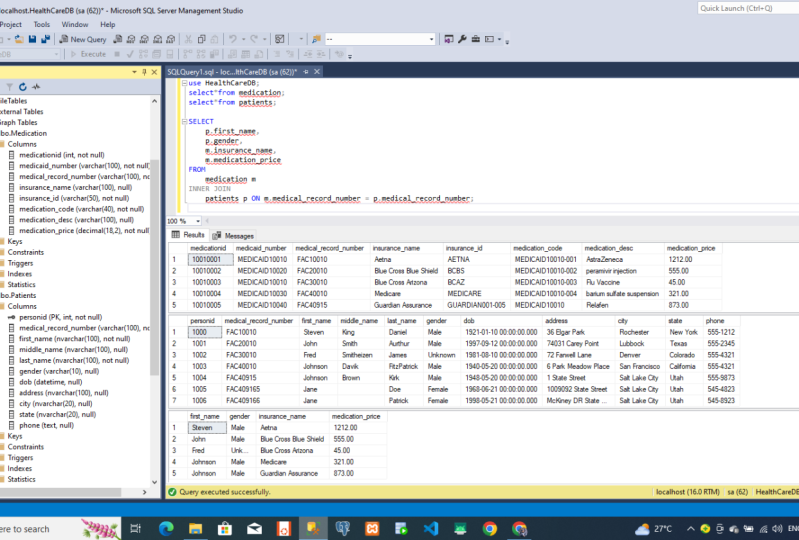
33. JOIN SQL et INTERNE: Joins Sql. La jointure SQL est utilisée pour combiner deux tables ou plus ensemble en
fonction de colonnes communes Des informations
plus importantes sont
dérivées de
la jonction des tables à partir
des commandes DDL fournies, vous remarquerez que le système
médical numéro d'enregistrement, le numéro du
dossier médical du patient est commun chez les patients, stable et stable à l'atténuation. Dans ce cas, la
syntaxe de jointure deux tables est basée sur
les colonnes communes. Dans notre cas, le numéro du dossier médical
est une colonne commune. Jetons un coup d'
œil à un exemple. Mais avant de faire la syntaxe
de base est de sélectionner les noms des colonnes dans le tableau 1. Nom de table 1. Rejoignez. La deuxième table de
la colonne nomme un, colonne nommée deux, ce qui signifie que la première colonne
provient de la première table, deuxième colonne provient de
l'autre table. Un bon exemple que nous examinerons est le retour de tous
les patients et de
leurs médicaments à Salt Lake City dans le cadre de l'assurance
Aetna. Et avant de faire cela, faisons une
étoile de base à partir de médicaments. Vous allez regarder
cette table ici. Les médicaments n'ont pas de ville. Comment trouver la ville ? Vous obtenez la ville en utilisant
le numéro du dossier médical, car cette colonne ici
est une clé étrangère ici, mais c'est une clé
primaire de notre autre table. Si vous sélectionnez une étoile parmi les patients autour de
ces deux sélections, vous verrez à la toute
fin ici, vous avez ceci, les informations sur la ville, mais les médicaments
ne le sont pas. Maintenant, dans notre
cas d'utilisation, il faut retourner tous les patients et leurs médicaments
de Salt Lake City et de l'Assurance Aetna, ce qui signifie que vous voulez obtenir tous les médicaments
de ce premier tableau qui proviennent d'Aetna
ou dans ce cas, je suppose que nous utilisons une assurance
tuteur. Cette affaire. Il suffit de copier
ça ici. Comment faites-vous cela ? Vous le faites en combinant le tableau des patients et
des médicaments. Dans ce cas, nous utilisons
une jointure interne qui
renvoie des enregistrements dont les valeurs sont
correspondantes dans les deux tables. Les valeurs correspondantes sont
le numéro du dossier médical. Donc, ce que vous faites, c'est choisir parmi les patients PAT comme pseudonyme
et le médicament adjacent MED. La colonne commune, qui
est le numéro du dossier médical. Il est courant dans les deux tableaux où la ville des patients se souvient que informations sur
la ville ne sont pas stables
dans les médicaments. C'est dans la table du patient, où PAT dot cd est Salt Lake City et une assurance médicaments
ou métadonnées. Le nom de l'assurance est tuteur. Si nous exécutons cela, il
obtiendra un enregistrement. Ce dossier a guidé l'assurance et il
provient de Salt Lake City. Si vous revenez ici. Si vous deviez faire par
exemple Athena, ce record est 110. Il vient de New York. Il faudrait changer
ça un peu. Donc, si vous deviez essayer de trouver
les dossiers qui ont Aetna Insurance
de Salt Lake City, vous ne le trouverez pas. Cela
reviendrait vide. Vous voyez ça ? Revenons juste en arrière. Donc, la raison est que
si je refais ça, tu essaieras de trouver Aetna. Il n'y a qu'un seul dossier
dans une assurance. Il s'agit du
dossier médical numéro 110. Ces trois là, ils n'
ont pas Salt Lake City comme ville. Ils ont le Colorado, le
Texas et New York.
34. LE JOIN SQL et l'ADJOINTE SQL: Dans SQL, jointure gauche,
jointure gauche ou jointure externe
gauche. Sélectionnez des enregistrements à partir de la première table ou la table la plus à gauche
avec des enregistrements de table à droite. Maintenant, dans ce cas, regardons cet
exemple ici. C'est le médicament stable. Lançons cette racine carrée ici. Je suis juste en train de rejoindre l'
écurie du patient sur le médicament, ce qui signifie ici, en sélectionnant
essentiellement des enregistrements de la première table à gauche avec les enregistrements
correspondants de la table droite, je récupère sept rangées. Maintenant, cela signifie ici que c'est assez important
pour vous de le voir. Permettez-moi de faire une étoile choisie ici
à partir de la table du patient. Je vais lancer ces
trois questions ici. premier est qu'une
écurie patiente comporte sept rangées. Le deuxième est que le
médicament en a cinq. Et la jointure de gauche ici
renvoie sept lignes en bas. La raison en
est cet enregistrement ici. Jane, rangée 67. Si vous regardez ce
dossier médical, le numéro est 165166. Il n'existe pas dans le substitut stable du
médicament, ce qui signifie que si vous exécutez une jointure
gauche des patients et que le
médicament
retourne les dossiers de la table la plus à gauche, la table du patient avec la
marge droite enregistrements de table. Donc, si vous partez à la fin, ces valeurs ici apparaissent
nulles parce que ce record, Jane Doe et Jane Patrick,
n'ont pas de médicaments. C'est pourquoi vous avez des valeurs nulles. Il est donc possible de
renvoyer
des valeurs NULL dans la jointure gauche ici, la jointure droite SQL,
la jointure externe droite SQL, sélectionner des enregistrements de la
deuxième table la plus à droite avec des enregistrements de gauche correspondants. syntaxe consiste à sélectionner
des colonnes de la table 1, table de jointure
droite vers nom de colonne à
un point correspond au nom de colonne de la
table à deux points. Exécutez ça. C'est vrai. Cinq lignes sont renvoyées en fonction l'
explication précédente que j'ai fournie. Parce que si vous
deviez exécuter dans ce cas, ce que nous faisons
est de
renvoyer les enregistrements
de la table la plus à droite. Dans ce cas, vous
n'obtiendrez que cinq rangées parce que vous conservez
les dossiers de la table des médicaments qui correspondent à la
stabilité du patient dans ce cas. Vous pouvez voir ici
que vous obtiendrez ces
dossiers, y compris les médicaments sur
le côté droit. Dans ce cas, je
fais une étoile sélectionnée, ce qui signifie que toutes
les colonnes sont renvoyées. Si vous souhaitiez simplement
renvoyer des données spécifiques, vous voulez faire le point PAT FirstName,
LastName par exemple. Laissez-moi juste revenir ici. Allons faire des médicaments Dot. Examinons le nom de l'assurance. Exécutez ça. C'est plus descriptif
dans ce cas. C'est un regard sur la
bonne jointure extérieure. Souvenez-vous de la
jointure externe droite SQL ou de la
droite SQL John renvoie des enregistrements de la deuxième table ou la table la plus à droite avec des enregistrements de table gauche
correspondants. Maintenant, la jointure gauche SQL renvoie des enregistrements de la
première table la plus à gauche avec des enregistrements de
table de droite correspondants.
35. UNION SQL: Union civile, l'
opérateur syndical est utilisé pour combiner le jeu de résultats de deux ou
plusieurs déclarations de sélection. L'opérateur syndical effectue Indian sur des colonnes avec
le même type de données. Cela signifie que
les colonnes d'union doivent avoir le même type de données. Dans notre cas, le
numéro d'enregistrement médical des deux tables est
du même type de données
et les colonnes doivent être dans le
même ordre de colonnes. Et la syntaxe de base de
l'opérateur d' union est de sélectionner les noms de colonne de
la première table, de la première
table, d'associer le nom de la
colonne de sélection à partir de la table deux. Par exemple, l'instruction SQL
suivante renvoie les numéros des
dossiers médicaux distincts de la table du patient plutôt que des tables de
méditation. Il y a deux
formats que j'ai ici, mais nous allons en tenir
au deuxième format, qui est de sélectionner le numéro
de dossier médical des patients, l'union. Sélectionnez le
numéro du dossier médical dans le médicament. Fondamentalement, il suffit d'écrire
deux instructions de sélection et de combiner les résultats
avec un opérateur syndical. Et je commande par numéro
de dossier médical. Exécutez cette requête. C'est l'ordre que je reçois. Les numéros des dossiers médicaux
sont uniques pour les cas. Il s'agit de l'opérateur SQL Union que vous pouvez utiliser pour interroger les tables de
vos bases de données.
36. SORT SQL ASC ou DESC: Tri SQL,
croissant ou décroissant. L'
opérateur SQL ascending est utilisé pour trier les valeurs
des colonnes par ordre croissant. Nous l'avons examiné tout
au long du cours, où nous avons examiné nos
différentes déclarations. Par exemple, si vous exécutez simplement numéro de dossier médical
sélectionné à partir d'un médicament, vous pouvez commander par cette
colonne dans l'ordre croissant. C'est ce qui va être l'ordre. Vous pouvez utiliser l'opérateur
décroissant SQL pour trier les valeurs des
colonnes par ordre décroissant. Dans ce cas, si j'exécute ces
deux requêtes, vous verrez que c'est
par ordre croissant. Et c'est par
ordre décroissant ici. C'est un regard sur les opérateurs
de tri SQL qui sont
ascendants et descendants.
37. Mise à jour SQL: Une mise à jour SQL permet de
modifier les enregistrements d'une table. Utilisez toujours une
clause WHERE pour limiter l'opération de mise à jour
à des enregistrements spécifiques. Utilise l'instruction de mise à jour
avec prudence. Et seulement quand
c'est absolument nécessaire. Vous souhaitez éviter de manipuler des données
directement sur la base de données. Utilisez toujours une application
sauf si vous effectuez des opérations
backend
dans une zone de transit ou pendant ETL ou
quelque chose de ce genre. La syntaxe consiste par exemple
à mettre à jour le nom de la table, définir cette colonne à cette valeur
ou à définir l'autre
colonne dans cette colonne. La condition. Un bon exemple est de mettre à jour une valeur de colonne d'enregistrements unique
avec la nouvelle valeur de colonne. Par exemple, mettre à jour le médicament, dit le numéro Medicaid, qui font qu'il
est proche de cela. Donc, au fond, nous essayons
simplement de changer le numéro Medicaid
de FAC 172, c'est
un seul qui porte sur le médicament. Et si je vais à la table, nous allons juste copier ça. Je vais
vous montrer l'utilisation de
cette déclaration de mise à jour ici. Il suffit de tirer tous les médicaments. Disons que je voulais mettre à jour ce numéro de dossier
médical, qui n'est pas une bonne
pratique car en tant que clé étrangère sur
l'autre table, c'est
pourquoi j'ai dit que vous vouliez
mettre à jour les données directement en utilisant une application ou un autre outil d'opération d'
intégrité. Dans ce cas,
des opérations simples comme celle-ci. Vous pouvez simplement dire, par exemple, si vous souhaitez mettre à jour le nom, ce nom ici, la description du
médicament. Mettez à jour l'ensemble des médicaments, la description du
médicament. Disons que nous copions ça. Disons qu'au lieu d'être facile
et que je copie cela ici, description de
l'atténuation
est égale à cela. Donc, en gros, il suffit de changer le nom de la description du
médicament partir d'un E2 et je mets
à jour les tableaux de médicaments définissent la description de l'atténuation
à celle où c' est
en fait là où c'est que
si vous exécutez simplement ceci, vous verrez qu'une ligne est affectée. Si nous y retournons et que nous le courons ici. Vous voyez que nous avons changé
cela, ce record. Ainsi, l'utilisation de l'
instruction de mise à jour, mais encore une fois, utiliser une instruction APA
vous avertirait que vous devez toujours
avoir une condition où vous devez vous
assurer que vous mettez à jour une ligne ou simplement
une quantité définie de données.
38. SUPPRIMENT SQL: Supprimer. L'instruction la
moins sécurisée est utilisée pour supprimer
des lignes d'une table. Utilisez cette commande avec précaution. La raison pour laquelle je montre
cela est parce que je veux vous montrer comment
supprimer un seul enregistrement, seul rôle d'une table. Par précaution,
définissez toujours une condition pour votre instruction delete afin
d'éviter de laisser des rôles indésirables. Combinez deux conditions
ou plus avec votre instruction de suppression. Permettez-moi de vous montrer
un exemple ici. Je dirige une étoile sélectionnée parmi patients pour voir tous
les dossiers des patients. Je veux supprimer la
ligne numéro sept. La syntaxe de suppression est le mot-clé delete du nom de table où la
condition est telle ou telle. Dans ce cas, j'ai préparé
la déclaration de suppression. Supprimez des patients dont numéro de dossier
médical est
égal à celui-ci ici. Copiez ça. Je vais également
ajouter une autre condition. Disons que la pièce d'identité personnelle est
égale à telle ou telle. Dans ce cas, c'est
cent dix cent six. Je vais juste copier ça
pour m'assurer que nous
avons plus d'une condition. Exécutez ensuite cette commande. Vous verrez la sortie d'
une ligne affectée, ce qui signifie que nous avons
correctement supprimé une ligne. Si je reviens en arrière et que je
lance cette sélection, vous verrez que nous avons maintenant
six lignes au lieu de sept, et Jane Fitzpatrick
a été supprimée. Il s'agit d'un aperçu de l'instruction
SQL delete.
 Data Engineer 365, Cloud Computing | Data | Entrepreneur
Data Engineer 365, Cloud Computing | Data | Entrepreneur