Transcription
1. Bienvenue et prérequis: bonjour et bienvenue à cette session sur une usine de données George. Mon nom est le Shang Good. Et je vais être un gars en tant qu'explorateur, un George c'est une usine et quelques autres services que nous allons utiliser pour construire une
solution d'usine de données . Nous discuterons de ce qu'un Juif a fait une usine, ses services d'étiquetage de composants clés, activités ou par avion, de sonfonctionnement, fonctionnement, ses avantages et de la façon dont vous devriez faire et surveiller le flux de travail. Nous allons également passer par une démonstration pour utiliser l'usine de données dans laquelle nous allons déplacer et transformer les données d'un entrepôt
de données George à un stockage doux de jambe de données. Donc, fondamentalement développé très flux de travail qui va m'auto pour prendre des données de source particulière , faire une transformation, et ensuite nous allons stocker la sortie d'autres histoires, emplacement à partir duquel il peut être ramassé pour l'analyse. Afin de compléter ce cours, je m'assurerai que vous mettiez la main sur les activités. Je ne vais pas seulement te donner des cours, mais tu auras aussi la chance d'essayer ça par toi-même. Et pour ce faire,
tout ce qu' il vous faut, c'est une Joseph Fiction. Et l'abonnement Joy pourrait être celui que vous avez déjà ou vous pourriez vous inscrire pour un
essai gratuit . En outre, il est bon de se familiariser avec les concepts des gens. À la fin de ce cours, vous aurez une base solide sur un George il affecte arbre. Alors commençons, général.
2. Cycle de vie des données: Allons cette neige, le petit cycle de vie. Dans la vie de l'Amérique, il y a plusieurs sept étapes. Les données peuvent provenir de nombreuses sources internes, d'action et de sources. Il peut s'agir de données de conviction provenant d'applications ou peut-être de données de journal du système pour flux presque continu de données de périphériques comme je pense dans le cou Off Things et toutes ces sources
différentes ont produit le même type de données, mais dans différents commentaires, car ils peuvent avoir les différents basés sur la communication. Donc, le point est dans de bonnes données est de dire, mais la forme vraiment différente. Le premier est un formulaire. Nous avons besoin d'une sorte d'histoires. Jetez la vie en seconde de données où nous pouvons stocker des données à différentes étapes hors cycle de vie, puis beaucoup de choses à connecter et saisir les données de différentes sources. C' est une collection de bassins. Ensuite, il pourrait avoir besoin de préparer les données. S' il faut obtenir des données de différentes sources, tous les systèmes, ils peuvent avoir une forme légèrement différente. C' est parce que les sources ratent volé les données différemment. Par exemple, une même colonne peut avoir un permis différent dans différentes sources. Certains d'entre eux peuvent avoir sur le cours d'eau. Certains d'entre eux, nous avons le nombre que certains ont permis les valeurs métalliques et certains peuvent également permettre le blanc va perdre. Donc, nous avons un nettoyage des données avant que nous puissions vraiment commencer à ingérer dans le réel parce que les
histoires que nous avons à faire la profession ou une transformation initiale après la
transformation initiale , convertir les données en ancien hé cohérent effectivement existait dans le stockage. Ensuite, pensez au traitement lorsque le processus que nous transformons réellement les données et transformation peut signifier des choses différentes. Mais en fin de compte, nous sommes arrivés, transformé ces données de route en une structure et normaliser deuxième. Plus grand d'une manière que cela signifie l'exigence de l'ancien hors et le système, parce que ceux-ci et les systèmes vont vraiment faire l'analyse, toutes les interprétations. Il y a donc beaucoup de gens étapes que les données que nous traversons et certains d'entre eux peuvent même cycles qui me laissent aller au traitement et à la transformation plusieurs fois. En fait, dans ce monde, très souvent, nous ne savons pas encore quelles sont les questions commerciales que nous allons poser à l' avenir et quelles données nous avons besoin pour répondre à ces questions. Donc, l'idée est de garder toutes les données afin que nous puissions revenir plus tard et l'unité telle qu'acquise. Nous analysons constamment plus tard nous apprenons du vicaire, la réexécution continue d'un modèle et d'autres changements dans la transformation. Donc, c'est un processus en général, mais vraiment la partie clé Ce que nous faisons ici est que nous obtenons des données de la source ceux qui senior et finalement les sombrer dans la destination et tous ces bits entre les deux incapables qui se produisent dans une méthode et le moment qui est utile pour le même pour que nous puissions exécuter cette analyse de en forme afin que nous puissions obtenir l'intelligence que mon entreprise mène réellement.
3. Solutions Azure: dans cette leçon, je veux introduire le bord des solutions que nos technologies familiales nous avons vécu dans son autour du flux de contrôle et le flux de données, si le contrôle lent. On avait une usine de données sur le travail. Cela fournit cela, que l'orchestration et elle fait. Ensuite, nous avons les solutions de flux de données réelles. Il s'agit de fautes d'arbitre sur le bord de l'intérieur ou de l'un des services que toutes les fonctions doivent posséder. Plus tard, au moins le flux de contrôle est l'orchestration qu'elle fait hors activités. Un étage ultérieur est le débit de la plus récente de l'activité lorsque le débit froid doit être constitué, au moins une activité, par
exemple. Disons que si vous voulez prendre le disjoncteur et l'envoyer littéralement maintenant, c'est un flux de données. Maintenant, dans le cadre de cette activité, ils vont être des étapes distinctes potentiellement. Par exemple, nous devons obtenir des données à partir du bloc. C' est l'étape 1 et ensuite une donnée vitale seulement qui sera steptoe. Et entre cette étape, ils vont probablement mapper pour prendre certaines valeurs du blob et les rencontrer
à certains fichiers à l'intérieur littéralement. De même, là, près des autres activités Peut-être qu'il y a un flux de données de transformation qui prend
les données des données Lee. Et c'est une transformation, par
exemple, peut-être des articulations sociales pour les données mais plus anciennes ou fusionne avec d'autres choses qu'il peut faire. Mais le point clé est qu'il transforme les données brutes en performer et la structure qui est encore plus utilisable par la solution d'analyse finale. Et c'est un succès, qui est représenté par une flèche verte. Ensuite, ils sont également flux de défaillance, qui est représenté par la flèche rouge. Donc, s'il y a un échec dans l'activité précédente, alors l'orchestration ou le flux de contrôle se déplace maintenant pour appeler ça un FBI senior. Donc, fondamentalement, on peut. Nous sommes sur ce point pour avoir un flux complet des diverses activités qui compléteront le cycle de vie de fin à fin des données. Non, le mauvais flux de contrôle de l'orchestration est responsable d'appeler ces beautés que chaque main un flux de données à l'intérieur d'eux. Ensuite, il existe différents types de flux de données. Par exemple, le rendu des données pose. Cela s'intègre généralement avec des choses comme l'équité en matière de puissance, et tout cela concerne la profession de données , l'
ajout colonnes, la
division de colonnes ou peut-être prendre un nom complet et le changement sera prénom et
nom de famille, alors ils sont rien ne s'oppose. Par exemple, épées rejoignent l'insert de Marge ou l'agrégat Rechercher tout cela et toutes les
transformations similaires . Nous avons donc utilisé la transformation différente à des bases différentes comme, deuxièmement, ces flux de données querelles près du début comme il préparait les données dans la lettre. Et puis je pense aux flux de données cartographiques qui transforment réellement le leader, mettent dans une forme dont nous avons besoin pour cette analyse.
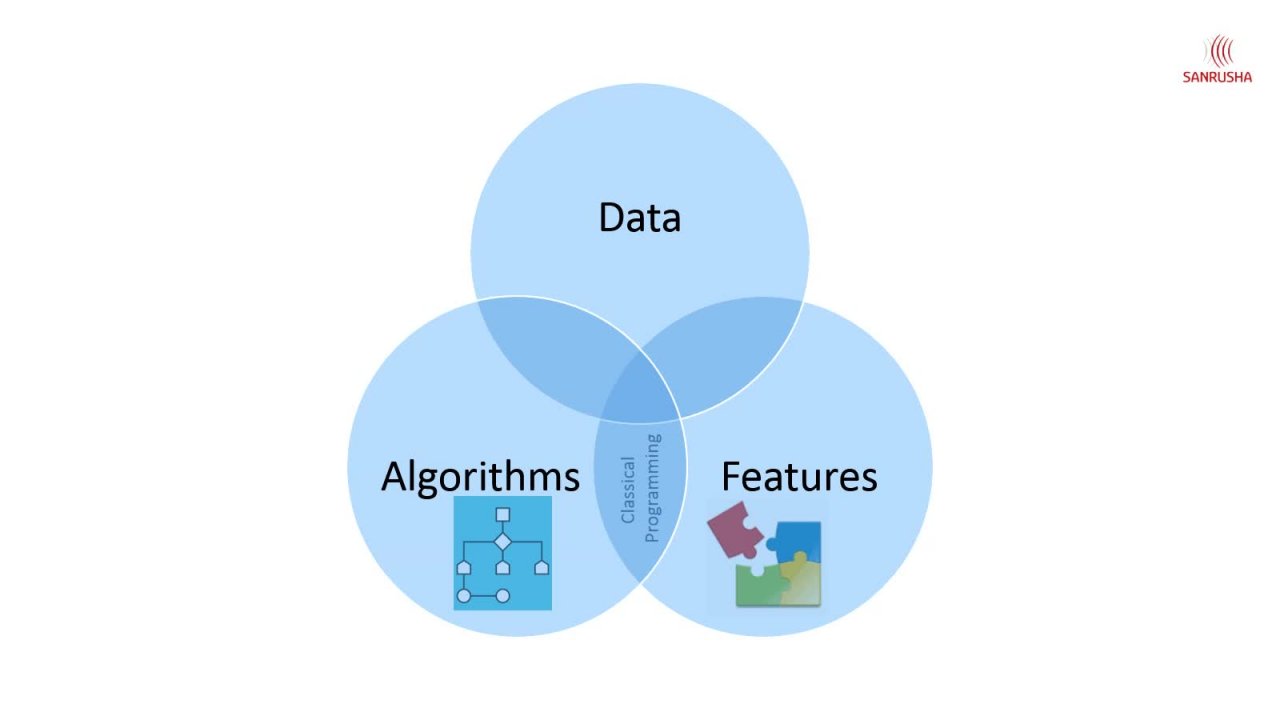
4. Qu'est-ce que Azure Data Factory: vous allez devenir une usine est un service d'indignation de données géré qui vit dans le
cloud agile . Un George il affecte arbre est comme une société est tout agent implode travail sauf qu'un arbre
affecte Judit Il y a beaucoup stocker toutes les données par lui-même ou il n'a pas de transformation par lui-même. Si vous avez déjà travaillé sur les yeux S ou en comité fille, tous les autres outils idéaux. Ils avaient leurs propres fonctions de transformation, mais idée simplement se connecter avec d'autres sources Destination et services de transmission sources et connexion de destination pourrait être dans les locaux ou dans les vêtements et il reliait divers autres fonctions de transformation composants Tous les services hors cloud comme elle utilisent égal , high ou cochon tous les autres services comme ça et obtenir le travail requis fait. Alors, qu'est-ce que ça veut dire ? Un travail fournit beaucoup de technologies pour vous aider à générer de la valeur à partir de vos données. Par exemple, il existe un stockage blob jury qui fournit des histoires de cloud moins chères. Vous stockez vos données. Lors de la session précédente, nous avons discuté d'une analyse des fuites de données, que nous
utilisons pour masser et transformer vos données. Et il y a un secret joyau de votre maison qui fournit un stockage de données relationnelles évolutif que vous pouvez utiliser orteil, comprendre votre entreprise, et il existe de nombreux autres services d'ajustement disponibles à des fins différentes. Vous pouvez mélanger et associer ces services Ajo au besoin pour analyser à la fois la structure et données
non structurées. Mais aucun aspect important de Data Analytics n'a été abordé, à savoir l'intégration des données. L' indication de données signifie donc extraire des données de la source, puis effectuer une transformation et ensuite les charger dans un entrepôt de données pour l'analyse des données . Et lorsque chacune de ces tâches peut être effectuée signifiait mentalement, il est plus logique de les automatiser et un service d'usine Judita vous aider à automatiser cette tâche. Pensez à Data Factory. Est-il dirigé dans un orchestre dans un orchestre ? orchestre ne joue pas la musique, mais il laisse le groupe à l'écart des musiciens qui ont produit de la musique à divers stades Off Symphony. Le chef d'orchestre a une grande image de l'ensemble simplement, et c'est un moyen de sortir de la musique big performance, mais la musique actuelle est interprétée par des musiciens indigents. De même, la date affectée n'effectuera pas le travail réel requis pour transformer les données,
mais demandera à d'autres services tels que les sauts de données ou l'analyse de liaison de données, préparer et de transformer les données de sorte qu'il s'agisse d'analyses de liaison de données ou de sauts de données qui effectue le travail réel, pas l'usine de données de l'usine de données, Moyen E orchestrent ou à l'étranger l'exécution hors travail. Donc, une usine de données du jury est un service dans un travail que vous pouvez utiliser pour prendre votre
flux de travail Big Data et le capturer dans quelque chose appelé un pipeline. Et ce pipeline comprend toutes les différentes activités qui sont nécessaires, copier et traiter les données et les amener à l'endroit où vous en avez besoin. Et vous pouvez faire ces activités de sorte que votre par événements planifiés sur si le traitement, base
récurrente lorsque vous devez faire à plusieurs reprises la même meilleure transformation à vos données sur régulière. Ceci est l'usine de données n'est pas lt ou extraire les outils de charge et de transformation. Alors, en quoi est-ce différent d'un accord ? C' est une taille. Vous attendez les données transformées plus tard avec les sociétés de construction transformations et charger les données dans la cible Il y a dans l'usine de données. Il suffit d'extraire les données de la source et de les charger dans la cible. Et la transformation se fait dans le magasin de données Target
5. Les composants clés de la Data Factory: Justin, comment allez-vous tous les deux ? Familiarisons-nous avec certains des composants idiots importants. Ces composants fonctionnent ensemble pour fournir la plate-forme sur laquelle vous pouvez concevoir le travail fin de compte avec des étapes pour déplacer et transformer les services de liaison de données. Les services de perte ne sont rien d'autre qu'un flux de connexion, qui définit les informations de connexion nécessaires à l'usine de données pour se connecter à des sources externes. Cela peut inclure un nom de base de données distinct. Rechercher les informations d'identification du dossier UTC. Selon la nature du travail, chaque flux de données peut avoir un ou plusieurs services de liaison, par
exemple, histoires en italique
endurées. Les enquêtes de liens spécifiaient une souche de connexion pour se connecter aux données d'âge ancien. Lick étudiants compte à l'époque était l'enregistrement. Les idées de l'école peuvent se connecter à plus de 80 sources de données différentes. Fondamentalement, il a un Capital T pour connecter presque toutes les sources de données possibles. Laissez-nous représenter la structure des données. Il a simplement pointé le bout une différence. Les données que vous souhaitez utiliser dans vos activités, comme le dit toutes les données en sortie, peuvent contenir un nom de table. Enfin, la structure
des données, un secteur, activités du présent et l'action à effectuer sur vos données. L' étape de traitement dans le pipeline cela pourrait être des transformations de mouvement de données ou des actions de contrôle de
flux des configurations d'activité contenues dit des choses comme requête de base de données, magasin, nom de
précision. Il fait des emplacements d'état. Il secteur et l'activité peut prendre Jiro ou plus de données d'entrée dit, et produire un ou plusieurs ensembles de données ou mettre. Les activités idiots pourraient être comparées. Toa évaluer les yeux flux de données opulence tâche comme composant de script agrégé. Sauf, par
exemple, vous pouvez utiliser une activité de copie pour copier des données d'un magasin de données, autre magasin de données. De même, vous pouvez utiliser l'activité élevée, qui présente le haut déjà sur le bord ou les bords à l'intérieur du cluster qui a transformé tous les analyseurs plus profondément encore l'effet. On supposait trois types d'activités. Obtenez une activité féminine, dissuadez l'activité de soumission en ville et contrôlez les activités. Mon plan est un Brooklyn logique hors FDP effectuant un ensemble de processus tels que l'extraction données, transformation et le chargement dans un entrepôt de données de base de données ou une sorte d'histoires. Par exemple, si je prévois peut contenir un groupe d'activités dans les données juste venir étonnant Astri, puis une étincelle d'une requête dans Azure Gate Oblates grille-pain. Pour partitionner les données. L' usine de données peut avoir un ou plusieurs biplans et chacun par plan contiendra une ou plusieurs activités. L' utilisation de pipelines rend beaucoup plus facile de faire et de surveiller les
activités liées logiquement aux personnes . L' avantage de cela est que le pipeline et vous permet de gérer les activités comme un ensemble assurer la gestion de chacun individuellement. Les pois des gens dans un pipeline peuvent être changés ensemble pour l'ouvrir séquentiellement. Ils ne peuvent pas opérer indépendamment en parallèle. Par exemple, si mon plan pouvait contenir un groupe d'activités qui copiaient des données de local, cela pourrait littéralement puis utiliser Kredi égal pourrait transformer ces données et enfin charger les données dans un entrepôt de données. Les chiffres représentent l'unité hors traitement que peu d'esprits quand une exposition de terrain de tuyaux devait être démarrée parce qu'ils représentent qu'elle faisait la configuration des pipelines. Ils contiennent des paramètres de configuration. Commençons et finissons. Est-ce que cette situation, si vous pouvez voir les chiffres ne sont pas partie militaire de la mise en œuvre Abia, ils sont nécessaires que si vous avez besoin par des plans pour être exécuté automatiquement ou sur est certains devrait
vraiment faire
6. Flux de travail sur le pipeline - 4 étapes: Je pense qu'un Jordache de cet arbre effectue généralement l'appel. Quatre étapes du net et de recueillir. La plupart de l'étape consiste à connecter toutes les différentes sources nécessaires hors données et déplacer les données au
besoin vers un emplacement centralisé était un tel traitement secret. Mais l'usine de données. Vous pouvez utiliser l'activité de copie dans une donnée en jouant les données orteils à partir de livre sur site et de
source cloud stocker plus tard avec des données de centralisation stockées dans le cloud Corker que Mme, par
exemple, vous pouvez collecter des données dans Ajo Datalink histoires et transformer les données ultérieurement à l'aide d'un service d'achèvement George
Vitelic Analytics. Vous pouvez également collecter des données dans un bloc d'histoires de Jordanie et le transformer peu en utilisant un agile réellement à l'intérieur de son pasteur. 2ème 5 est transformer et enrichir. Une fois que les données sont présentes dans une donnée centralisée stockée dans le cloud, sont transformées en utilisant des services compétents comme d'habitude à l'intérieur faire analyse des données éclairées et l'apprentissage
automatique. N' oubliez pas que Data Factory est Justin Orchestra et qu'elle ne peut effectuer aucune activité de transformation seule. Publier après que les données du Seigneur ont été transformées en une réforme significative. Chargez les données dans différentes parcelles, des histoires comme un George it de leur maison. Option Perkins par le FBI et les outils d'analyse et d'autres applications souhaitées. Après un déploiement réussi hors pipeline, vous pouvez unevers les capacités Xun et le pipeline pour le succès et l'échec. Nous pouvons surveiller un travail dans un pipeline d'usine à l'aide d'un moniteur de travail AP Je publie L comme vos journaux de
moniteur et d'autres panneaux de santé dans le bord du portail.
7. Introduction de la démo: Bienvenue dans ce module. Dans ce duel plus, nous ferons quelques mains sur l'activité. abord, nous allons créer à votre stockage de données compte doux et utiliserons un compte George Storage Explorer date d'accès
orteil ngentle. Ensuite, nous allons déployer l'entrepôt de données suite et l'usine de données, ce qui est assez facile et simple. Maintenant, après ça, nous allons passer par l'usine de données. Vous moi et nous allons comprendre différentes options de menu. Ensuite, nous utiliserons l'activité de copie à votre usine de données. Nous allons donc chercher des moyens de retirer des données de leur maison sera pipeline pour déplacer et stocker la sortie dans d'autres histoires. Emplacement où nous pouvons le ramasser pour l'analyse, ils vont également jeter un oeil aux options de surveillance de l'usine de données. Merci.
8. Créer un compte de Azure Data Lake Storage Gen 2 2: dans cette démonstration, je vais vous apprendre à créer un compte délicat de stockage Azure Data Lake. Revenons aux anciens services. Tout ce que vous pouvez accéder directement au compte de stockage à partir d'ici. Si vous regardez dans le portail Azure, il y a une source distincte appelée Data Lake Storage. Gen 1. Mais vous créez des histoires compte doux. Nous devions d'abord créer un compte stories car il s'agit d'une propriété hors du compte de stockage de version générale deux. Nous verrons cela dans une minute. Microsoft de nos jours se concentre sur le stockage Data Lake doux parce que doux est dur. L' endroit loin. Jen un. Créons un compte d'histoires. Cliquez sur ce bouton et laissez-moi choisir mon abonnement et mon groupe source. Permettez-moi de créer un nouveau groupe de ressources. Donne-moi une histoire de RG. C' est Gentoo. Indiquez le nom du compte de stockage. Je mets juste un numéro pour le faire globalement. Unique. Utilise ma raison à la maison. Une des nouveautés concernant les histoires de liaison de données douces est que vous pouvez tirer parti de toutes
les histoires, propriétés de
compte et fonctionnalités telles que l'excès de performance, deux ans et la réplication. Je vais sélectionner les performances étendues à usage général Version 2. Localement, les histoires de Rendon et tenir excès ici. La prochaine étape nous prendra la question de connectivité des orteils. Je vais laisser le public par défaut et pointer à ce stade, nous allons à côté de la page d'avance. Laissons-le avant de définir pour la sécurité comme activer bloc soft lead que nous pouvons réellement
vouloir ignorer parce que le point ici est en effet hors de ce compte d'histoire en utilisant le service de
sang traditionnel , nous allons activer le nom hiérarchique en retournant les données à côté . Il est doux de désactivé pour activer. Et comme vous le voyez lorsque vous activez Gentoo, il a automatiquement désactivé l'option de protection des données Ceci tout ce que vous avez à faire pour faire un
compte stories un compte doux de stockage de lac de données à nouveau. Je n'avais pas besoin de faire un compte d'histoires normales stockage lac de données, compte
doux. Tout ce que vous avez à faire est d'activer cette option. C' est ça. La vue dans create it ne signifie pas prendre trop de temps. Mais je peux encore mettre la vidéo en pause jusque-là. Très bien, le déploiement est terminé. Et si nous allons maintenant aux ressources, je veux vous montrer une différence par rapport à ce que vous êtes habitué orteil, probablement travailler avec les histoires générales. Vous avez peut-être remarqué que sous service est à la place sur un service blob. Il est maintenant appelé données comme système de fichiers doux. Vous montrez la défense. J' ai un autre compte d'histoires générales que vous voyez dans le compte général. Il est appelé Blob Services ici, mais parce que l'incapable d'histoires génitales, il est appelé données tard, système de fichiers
doux. Donc, à partir de maintenant, le récit de
cette histoire sera des données comme des histoires avec chaque système de pompiers compatible BFS . Alors mettez ce point. Si nous avons sélectionné des sondages, nous pouvons créer un système de fichiers, ce que je vais faire maintenant. Je l'appellerai Gento File System. Et rappelez-vous que ce que vous créez est doux. Le système de fichiers n'est pas un bloc et le dîner. C' est un vrai dossier de temps en temps. Si nous allons dans le système de fichiers, nous obtenons l'invite à utiliser un explorateur de stockage George. Ajo Stories Explorer est un outil gratuit de Microsoft qui est disponible sur Windows Mac et Limites et, comme la moyenne suggère fournit un environnement graphique pour parcourir et effectuer des actions contre un George comptes de stockage. Si vous ne l'avez pas déjà, s'il vous plaît don Seigneur et installer est très facile et simple. Cette famille d'outils utilise un compte pour s'authentifier pour obtenir une tâche, puis affiche l' abonnement Ce compte possède. Ensuite, les comptes d'histoires dans l'abonnement sélectionné. Dans mes comptes d'histoires d'abonnement, nous pouvons dépenser mon compte d'histoires douces, qui est actuellement identifié comme un BLS doux. Je suppose que finalement la chose Storage Explorer devient orteil vert dans ce nœud que nous regardons maintenant à partir de conteneurs de blocs, systèmes de fichiers
orteils, parce que c'est ce qu'il devrait être. Et quand nous sélectionnons l'avis du système de fichiers maintenant que nous pouvons tout télécharger directement, nous pouvons organiser un espace de dossier hérétique. Donc, je vais appeler cela un nouveau dossier plus tard et j'utiliserai ce dossier dans le cadre du flux de travail . Votre point de vue n'est peut-être pas à jour ici. Tu veux te rafraîchir ? On est prêts à y aller.
9. Déploiement d'Azure SQL Data Data Warehouse: s Créer et Joe Sequel Data Warehouse. En plus de rechercher une suite Data Warehouse dans tout, vous pouvez également le trouver dans la base de données ainsi que dans l'analyse. Cliquez sur suite, Get other house and add New is Instruments et laissez-moi vous montrer comment
fonctionne le workflow de déploiement . Je vais créer un nouveau groupe de ressources pour l'entrepôt de données, et je donnerai également le Munim à ma date de votre maison. Je suis quelque chose juste un nombre imaginaire aléatoire à la fin, juste pour rendre le nom globalement unique. Nous allons créer un nouveau serveur virtuel va être un cluster. Appelons ça faire le bleu s 108 Il ils ensuite facile classique avec un mot de passe fort. Nous nous préparons à donner ce conseil sur la force des pasteurs. Permettez-moi de trouver mon emplacement le plus proche, le Holy Show pour accéder aux entrepôts de données de nos écoles. Mais cette grande boîte ici permettra tous vos services. En d'autres termes, les adresses
Microsoft I P qui sont associées à ces services doivent accéder au serveur. Vous devrez peut-être également modifier le pare-feu de l'entrepôt de données de suite, autoriser votre client. Je pense où que vous soyez dans le monde. En plus d'autres adresses publiques I p toutes les adresses d'écriture plage. Je vais vous montrer toute la confusion. C' est l'unité d'entrepôt de données est l'unité de calcul utilisée pour une date de la suite Joe de votre maison. Sélectionnez notre niveau de performance pour les charges de travail de production. Nous devrions être sur doux et pas Jen un. Et je peux habiliter mon système ici 200 parce que je travaille juste dans un environnement de démonstration de test hors de ce live dans le monde réel. Votre but est de Pune votre maison de telle manière que vous ne payez pas plus que vous avez besoin. Mais vous obtenez également votre calcul pour satisfaire vos accords de niveau de service. Donc, nous allons postuler ici et ensuite passer à la suivante. Quoi ? Votre source de données. Nous pouvons prendre un renfort ou nous pouvons faire Non, en fait, ce que nous pouvons faire Simple. Ce qui nous donnera la date de travail d'aventure, chaque maison, entrepôt de données
simple. Je choisirai ça, et ça ramasse toute la coalition, que je choisirai. Nous allons passer aux étiquettes d'orteils et nous n'utiliserons pas la taxe ici passera à la suivante. Nous voyons notre coût estimé, mais nous sommes ici. Vous voyez des harmonies et ensuite nous sommes vraiment complets. Je trouve que cela prend généralement la fièvre 10 minutes de congé pour Microsoft a déployé un entrepôt bien en arrière. Ensuite, une fois les déploiements terminés, ils peuvent accéder aux ressources qu'ils peuvent mettre en pause ou reprendre l'entrepôt de données pour mettre en pause et reprendre le bâtiment. Vous êtes toujours facturé pour les histoires, mais au moins l'ordinateur n'entraîne aucun coût. Nous cherchons dans notre cadre une boule de feu. Nous pouvons descendre à des boules de feu et des réseaux virtuels, et c'est là que j'ai mentionné que vous pouvez autoriser l'accès à ajuster les services et votre auto détecte le public I p associé à votre appareil client. Et puis vous pouvez appliquer les plages d'adresses I p Public I T plage d'adresse est ici orteil. Autoriser la connectivité à ce serveur. Revenons à la page d'aperçu parce que nous ne serons pas dans cet hébergement hors de l'
entrepôt de données . Laissez-moi copier ceci dans mon presse-papiers et ensuite comment vous vous connectez à cette date chaque maison. Typiquement, j'ai utilisé le Sequel Server Management Studio, qui est disponible en tant que seigneur séparé. Faisons une connexion au moteur de base de données du serveur suite, et pour les sept hommes, je vais pêcher dans l'homme qualifié complet hors d'un serveur choisira suite. Plusieurs authentification et je vais fournir les mêmes informations d'identification, que je donne tout en créant la date de la maison. Ça va Oh, il montre une erreur que votre client I p adresse, n'a pas accès à ce serveur. Revenons donc à un peu d'une maison, tirant des réseaux virtuels et en ajoutant notre client local AP steer et réessayer la connexion en utilisant studio de
gestion si lourd. Je sais. Tu te souviens de cette suite ? Plusieurs entrepôts de données est la plate-forme hébergée dans le service. Donc, si vous faites un clic droit sur le serveur virtuel, il n'y a pas de propriétés. Je me souviens quand j'ai été surpris quand j'ai vu qu'il n'y avait pas de propriétés, mais
rappelez-vous, vous avez affaire au noir du service est-il ici ? Nous avons expliqué les bases de données, puis les données. Très DW 108 que nous avons créé. Nous avons une liste de tables que Microsoft a intégré dans cet entrepôt de données simple. C' est très soulagé. La sagesse le fera maintenant. Merci
10. Déploy Data Factory: Créons notre usine de données maintenant. À ce moment-là, vous devez être familier. C' est assez facile et simple. Vous pouvez soit rechercher usine de données Oh, sont sélectionnés dans la base de données et cliquez à l'avance. Donnez-lui le nom. Sélectionnez abonnement et groupe de ressources dans l'abonnement. Donnons-le simple. RG soulignement B A. Okay, je vais utiliser ah version deux hors usine de données pour profiter des dernières fonctionnalités. La deuxième version est une nouvelle usine de données de lavage. L' une des plus grandes fonctionnalités de la version deux est l'intégration de S S S S et de contrôle de flux Fonctionnalité. La surveillance est également un orteil d'inversion d'amélioration d'édition qui le rend intégré à votre moniteur. Ok, laisse-moi choisir le match le plus proche de chez moi. Maintenant, nous avons la possibilité d'intégrer le contrôle de score source. On leur assure des hauts. Je ne vais pas faire ça dans ce cas. Et puis nous allons cliquer, créer orteil, déployer l'usine
11. Se familiariser avec Azure Data Factory UI: Allons dans l'usine de données, et ce que nous avons ici, c'est juste le plan de contrôle pour le service. Et si je cache la douleur essentielle, nous voyons un lien vers l'auteur et surveiller l'expérience. Ceci est très en fait effectué du travail dans une usine de données George. Cliquez sur cela, et si vous remarquez qu'il a ouvert une fenêtre séparée et la navigation orteil ADF point que votre point com, le produit qui atteint orteil cette sur quelques pages, qui a beaucoup de liens rapides ou de raccourcis. Nous allons faire la copie des données Operation Toe copier notre tableau hors de votre
entrepôt de données suite . Plus tard, nous reviendrons plus en détail. Mais en attendant, cette page a également aidé des vidéos et un tas de tutoriels. Commençons par se familiariser avec les
U.S. U.S. Le menu principal contient trois options Data Factory, qui est trier hors écran principal, qui contient quelques raccourcis intéressants. Le panneau d'auteur est l'endroit où nous créons de nouveaux pipelines et passons la plupart de notre temps, et enfin, le panneau de surveillance là-bas, nous pouvons surveiller par exécution planifiée. Bon, dans l'écran principal, nous avons cinq options. Examinons les un par un. Créer un pipeline est simplement une jupe courte qui nous amène au panneau auteur et crée automatiquement un pipeline
vide. Pour nous. Créer par plan à partir d'un modèle ouvre la galerie de modèles. Là, nous pouvons créer un pipeline à partir d'une collection de jolis modèles de trouver qui peuvent nous aider à
commencer avec un scénario distinct. Copier rapidement l'outil de données fournit une interface qui optimise le processus hors données d'ingestion dans le magasin de données. Nous en apprenons plus sur le copié un outil dans les leçons à venir. Configurer SS Eyes Integration peut provisoire que votre intégration SS iess autour du temps et enfin nous avons le dépôt de tribunal mis en place. Il nous permet de mettre en place un référentiel d'appels pour votre usine de données et d'avoir une expérience
de développement intégré et de fin sur version. Passons maintenant un peu de temps à apprendre sur le panneau auteur lorsque nous créons un nouveau pipeline. C' est le panneau dans lequel nous passons la plupart des heures supplémentaires dans la section des ressources d'usine. Ils peuvent trouver une liste des pipelines, ensembles de
données et flux de données dans une usine de données. En cliquant sur les trois points dans les enquêtes de pipeline, nous pouvons accéder à nouveau sens nouveau me nouveau qui nous permet soit de créer un nouveau pipeline à partir de la base vers le haut ou à partir d'un modèle, nous trouvons de nombreuses options similaires à la fois que les ensembles de données et services flottants de données. Nous allons cliquer sur ce petit signe plus ici, et cela va créer un nouveau pipeline. Notez qu'il existe une option pour un pipeline à partir du modèle et ici vers la droite, vous pouvez importer des modèles de bras. Cela peut rendre ces pipelines plus faciles à utiliser et à réutiliser à maintes reprises. R. Votre usine de données est un outil d'orchestration sans froid. Ainsi, par
exemple, depuis le déplacement et la transformation, nous pouvons simplement glisser-déposer cette opération de copie de données sur la surface de contrôle, puis vous sélectionnez cette opération de copie ci-dessous. Vous verrez différentes craintes liées orteil activité sélectionnée dans ce cas pour les données de copie. Puisque c'est coopérateur, nous avons la source en d'autres termes, Baies vos données venant de et puis penser Verizon données aller à et nous avons d'autres paramètres et mentalement les options. Si vous cliquez sur la source de vue marquée tous vos pipelines de données Factory sont écrits en Jason. L' idée d'un pipeline est que nous pouvons relier différentes activités. Nous pouvons créer un flux de travail complet cheveux en utilisant ces lien de connexion en vert, Par ailleurs, je peux faire un clic droit sur ce lien et choisir le plomb. Il disparaîtra, et si je clique dessus, je peux entendre le bouton de sortie. Nous pouvons ajouter une activité sur son propre succès,
échec, échec, achèvement ou sauter afin que nous puissions choisir l'activité suivante. Si cette activité se termine, choisissons l'activité suivante. Si vous n'êtes pas sûr d'où il se trouve, nous pouvons faire une recherche ici. Dans ce cas, ajoutons à nouveau une fonction. Juste Dragon Drop. Vous pouvez voir à quel point cela fonctionne facilement et vous pouvez valider le travail. Vous pouvez regarder l'ensemble du pipeline froid alors il ne devrait Buell pour même comme une
oppression déclenchée et ainsi de suite. Comme mentionné précédemment, nous considérons le dépôt d'enregistrements toe, permettre l'intégration continue et la livraison à partir de votre usine de données. Et ici, nous avons notre modèle moi nouvelle option. Il nous permet simplement d'importer et d'exporter des modèles de bras avec des définitions de pipeline. Le panneau Connexion héberge une liste des liens créés précédemment, services et des temps d'exécution d'intégration, et voici le temps d'exécution par défaut ou de résultat de l'intégration que nous avons vu précédemment. Et enfin, laissez-moi attirer votre attention sur la section de déclenchement des déclencheurs d'exécution de pipeline. Nous n'avons pas de déclencheur pour le moment, donc cette liste est vide. Je vais fermer tous les robinets, rejetant mes modifications et passer à l'élément suivant. Prenons une minute pour examiner le panneau du moniteur et toutes les fonctionnalités qu'il offre. Le panneau du tableau de bord contient des informations sur le pipeline et l'activité. Exécution dans le panneau Subventions de pipeline Nous pouvons surveiller l'exécution du pipeline, et il est très utile de s'assurer que le pipeline fonctionne correctement. Le panneau Autorisations de déclenchement affiche une liste des exécutions de pipeline qui ont été déclenchées automatiquement. Le panneau de temps d'exécution d'indication affiche la liste des temps d'exécution d'intégration disponibles pour nous ou le résultat est que le moteur d'exécution Ford Integration et enfin, dans le panneau Alertes et Métriques, nous pouvons créer des règles d'alerte pour surveiller leur pipeline d'usine de façon proactive. Maintenant que nous sommes un peu plus familiers avec l'effet de date de l'
U.A. U.A. E. Créons notre premier pipeline
12. Fonctionnement ETL: dans cette démonstration, je voudrais vous apprendre comment utiliser votre usine de données pour effectuer une activité de copie. Dans ce cas, nous allons copier la table d'offre de données à partir de la base de données échantillon d'entrepôt de données à nos données supplémentaires . C' est gentil compte. Donc, revenons juste à la page d'aperçu et cliquez sur copier les données et il démarre ce vagin de données de
copie. Donnons cette tâche et le nom maintenant. Ici, nous pouvons choisir pour eux tâche qu'une seule fois, ou nous pouvons créer un pipeline réutilisable en choisissant cette option et sélectionnez un devrait faire. Même si vous choisissez de limiter une seule fois, il ne sera pas supprimé après Willan et terminer. Nous pouvons manuellement même autant de fois dans le futur que nous voulons ou créer un déclencheur et ainsi de suite et ainsi de suite. Mais si vous regardez à gauche, nous avons six étapes et il nous guide à travers une lumière sans avoir à comprendre quoi que ce soit sur l'AP A ou la sécurité sous-jacente. Il y a une énorme bibliothèque sur les cheveux de connexion. Ils sont organisés en groupes, cheveux comme votre fichier de base de données et accepter. Laissez-nous créer une nouvelle connexion dans le nouveau service de liaison accroché dans tous les entrepôt de données de type à filtrer, et nous allons sélectionner cela à votre suite Data Warehouse Link objet service. Le service de liaison est exactement ce qu'il a l'air. Ce sera un objet réutilisable qui crée et autorise la connexion dans un ensemble auquel un ensemble peut être
une source de jury ou connu une source de jury ou peut-être posséder des locaux. Ressource. Laissez-moi lui donner un nom. L' exécution d'indication est l'ordinateur antérieur. Vivons-le avant de partir pour deux résultats. Cela devient plus souvent un problème dans un scénario hybride où vous devrez peut-être déployer le
temps de location sur site appelé l'opération auto-hébergée. Comme l'authentification faras, nous pouvons faire, utilisateur ou donner vieux, mais avant cela, nous devons d'abord choisir comment nous allons entrer dans cette ressource. Sélectionnez l'abonnement et le serveur d'entrepôt de données recréé. La base de données est la date simple de votre maison. Les options de type d'authentification sont le principe de service, l'identité
gérée ou la suite. Je vais aller de l'avant et juste choisir une authentification suite en utilisant le même compte que nous avons créé lors de la création de l'entrepôt de données. Il y a un périmètre de connexion optionnel que vous pouvez ajouter, que nous n'utiliserons pas dans ce cas. Nous allons tester la connexion. Finition réussie. Nous avons donc créé notre magasin de données source et encore une fois, cela va être un objet réutilisable que nous pouvons utiliser dans d'autres pipelines. Alors allons ensuite, et nous avons tapé dans l'entrepôt de données et ici nous voyons le besoin lourd orteil choisir une table, que nous voulons copier afin que nous puissions sélectionner une ou plusieurs tables. Cheveux. Nous voulons choisir la table de produits bim. Alors faisons une recherche de produit. Donc, je vais sélectionner l'écurie. Et si on fait apparaître la barre de séparation, on peut voir un aperçu des données. Et dans l'onglet schéma, nous pouvons voir les colonnes et les types de données. Cliquez sur suivant. Donc encore une chose, laissez-moi aller orteil avant. En plus de choisir simplement des tables existantes, notez que vous pouvez également écrire une requête ensemble des données spécifiques que vous souhaitez utiliser dans le travail. Mais on va tout prendre de la table. Donc, encore une fois, nous allons cliquer sur suivant. Le magasin de données de destination que nous n'avons pas encore créé, Alors nous allons choisir de créer une nouvelle connexion à nouveau, et cette fois nous allons faire une recherche pour le stockage de lick de données. Souviens-toi, il y a Gen 1 et, Ah, Gentoo. Nous ne sommes pas concernés par les cheveux généraux. Nous avons déjà créé un compte d'histoires douces. Alors sélectionnons ça. Et encore une fois, nous allons faire une sélection de notre abonnement pour la question d'authentification. Encore une fois, nous allons choisir la clé de compte. Nous avons sélectionné le nom de notre compte de stockage. Donnons un nom. Aussi orteil ce service lié. Ok, et maintenant la meilleure connexion avec succès. Bonne affaire. Alors, nous allons cliquer. Terminer. Jusqu' à présent, si bon Le clic. Ensuite, nous allons puiser dans notre compte supplémentaire gin toe de données et naviguer orteil. Choisissez le dossier que nous recherchons. Donc, d'abord avec la liste des systèmes de fichiers, cliquez dessus, puis sélectionnez le dossier Données de sortie et cliquez sur Choisir. Nous devons spécifier un nom de fichier de sortie. Je l'appelle simplement pour conduit. Ne pas CSP pour les connexions conquérantes maximales. Mettons aussi. Cliquez sur suivant. Ici, nous pouvons personnaliser le format de fichier. C' est ah, déporter deux valeurs séparées par des virgules. Je vais laisser tout cela hors de la valeur par défaut, mais l'essentiel est que l'usine de données vous donne beaucoup de flexibilité ici. Cliquez sur le quatrième suivant. Alors, que voulez-vous se passer s'il y a un problème lors du déplacement des données que vous voulez concernant l'activité dès qu'il y a une ligne incompatible ? Ou voulez-vous sauter la ligne ? Ou voulez-vous vous échapper et les aimer afin que vous puissiez les suivre plus tard ? Je vais diriger les options par défaut ici. En outre, je vais vivre les paramètres de performance à l'avant à ce stade et cliquez sur Suivant. Voici notre écran de quelqu'un, et quand nous cliquons sur suivant, il sort et exécute le pipeline. Comme vous pouvez le voir, si je clique sur Monitor Data Factory, il nous amène à l'interview de lune et nous allons cliquer Rafraîchir et nous pouvons voir que la rue est elle a réussi. Bien. Revenons à l'explorateur de stockage, venez dans le dossier de données de sortie et assez sûr, nous voyons notre produit point CSP. Laissez-moi faire un clic droit et télécharger cet orteil Mon backstop. Une chose de plus si vous ne l'avez pas remarqué toutes nos activités dans les histoires Explorer , peur vers le bas en bas. Ok, ouvrons Excel juste pour faire une vérification de santé mentale rapide. Oh, on dirait que j'ai oublié les orteils ramasser la colonne. En-têtes. Aucun ovaire ne commence encore à cela. Ce qui est bien à propos de Data Factory, c'est que nous pouvons revenir en arrière et modifier les propriétés du travail pour inclure l'en-tête de colonne. Nous pouvons changer sur Pipeline et vert dessus. Je le ferai dans une minute. Pendant ce temps, regardons rapidement les données que nous pouvons voir. Il y a un peu plus de 500 rose dans l'ensemble de données. Revenons maintenant à l'interface de l'usine de données. Et si vous revenez à l'expérience de l'auteur, voici notre pipeline. C' est juste ici pour que nous puissions apporter les changements nécessaires. Allons aux connexions de destination et lourd voir option. Premier rôle en tant que frappeur dans un billet publié changements publier signifie vente. Et encore une fois, on peut aller surveiller Tab et n'a pas fait le boulot. Si nécessaire, nous pouvons actualiser et nous voyons que notre travail est à nouveau terminé. Revenons à l'Explorateur de stockage. Ok, on voit ce temps d'athlétisme. Cela signifie que le nouveau fichier a sur l'ancien fichier. Téléchargeons-le. Et maintenant, ouvrez-le. Maintenant, nous voyons que nous avons les lignes d'en-tête maintenant. Merci
13. Permissions: au cours d'une dernière petite opération, nous avons pu authentifier le numérique extorqué de façon transparente. Mais si vous rencontrez un problème avec cette connectivité, vous devrez peut-être donner des autorisations explicites à l'usine de données à ce référentiel de données. Voyons ce que nous entendons par là. Revenons aux cheveux du portail. Le général Porter. Retournons à notre usine de données. Et si vous allez aux propriétés, vous pouvez voir ici gérer l'objet d'identité. Je serais en mots simples. Les identités gérées sont utilisées par vos services pour authentifier d'autres services périphériques ou services qui prennent en charge votre authentification Steve Director. L' identité de gestion est enregistrée orteil. Vous êtes un répertoire de beauté et représente cette usine de données très spécifique. Nous pouvons utiliser directement cette gestion de l'identité pour le stockage du lac de données, l'authentification
douce. Il permettra à cet orteil xs d'usine désigné et de copier les données vers et depuis votre
stockage de lac de données . Doux. Nous pouvons ajouter cela gérer le contrôle d'accès basé sur le rôle d'orteil d'identité moins. Je vais donc copier ceci dans mon presse-papiers, puis revenir à l'Explorateur de stockage. Nous pouvons donner à l'usine de données l'autorisation au niveau du système de fichiers ainsi qu'au
niveau du dossier . Donc, pour ce faire, nous pouvons faire un clic droit sur le système de fichiers et aller à gérer l'excès dans la liste de
contrôle d'accès . bas, nous pouvons coller dans cet objet que je d hors de l'usine de données et ensuite donner au compte quel degré hors excès directement au système de fichiers. Et parfois, j'ai trouvé que tu devais le faire à deux endroits. Vous devez le faire au niveau du système de fichiers ainsi qu'en dehors du niveau du dossier. Vous pouvez donc faire un clic droit sur le dossier et faire exactement la même chose ici. Nous pouvons le coller dans l'objet que j'ai retiré de la ressource Edgell. Dans ce cas particulier, il est fait une usine et lui donner n'importe quel niveau hors excès que vous ne donnerez pas. Cela vous aidera à connecter en toute transparence l'usine de données à d'autres sources. Dans ce cas, l'histoire intento. Merci.
14. Surveillance de l'usine de données: dans cette leçon. J' ai voulu passer par une démonstration de base sur la façon dont nous pourrions effectuer la surveillance avec une usine de données George. Alors, de quoi ai-je besoin exactement pour surveiller la famille ? On pense au prince déclencheur. L' activité exécute les exécutions de pipeline, puis ces interrogations. Pendant ce temps, ils seront au centre de notre solution de surveillance d'usine de données. Et il y a deux façons de surveiller la surveillance dans l'usine de données et la surveillance avec un
moniteur de travail discutera les deux. Donc, tout d'abord, nous avons effectivement une surveillance au sein de l'interface utilisateur de l'usine de données tout en développant ces pipelines que le plus grand peut être très utile. Cela me permet d'exécuter mon pipeline. Je peux avoir des points de rupture. Je peux voir exactement ce qui se passe, mais ce n'est pas vraiment surveiller son expérience hors développement. Cette fonctionnalité de débat est utile pour voir exactement ce qui se passe à l'intérieur, et cela peut être très utile en tant que développeur. Mais l'essentiel de la sursurveillance passera par l'interface de surveillance. En fait, ça commence par un tableau de bord. Ce tableau de bord affichera par défaut les dernières 24 heures, mais je peux changer cette fenêtre horaire va me montrer les exécutions du pipeline. Je verrais des échecs. Je vais voir ces pourcentages. Je vais également voir des détails sur les activités. Je vais également voir des données sur les déclencheurs. Cela me donne juste un aperçu très rapide de ce qui se passe dans l'environnement. Je peux voir des détails sur les exécutions de déclencheur si j'ai des déclencheurs. Je vois en fait que les détails sur ces exécutions et l'exécution peuvent être basés sur devrait traiter ou peut-être même basés. Mais ce que je me soucie vraiment de notre que par avion passe ici, je peux voir le nom hors pipeline. Si j'ai différents pipelines dans mon environnement, je conclus ce petit bouton de filtre et puis je peux changer pour voir seulement les pipelines particuliers que j'ai disponibles. Je peux rechercher en fonction d'eux. Je peux voir les différentes actions disponibles pour le pipeline. Je peux voir l'activité effectuée. Je peux en fait lire dessus. Je peux voir quand ça a commencé, je peux voir la durée qu'il a fallu. Comment il a été déclenché, le statut s'il y avait des terra mètres ou des invitations, et encore une fois, ceux que je pourrais filtrer est bien, vous verrez aussi que j'ai un cargo global disponible ici. Je pourrais changer certains des détails qu'il me montre si je veux seulement voir
la dernière date que je peux modifier. Donc, s'il y en a un qui me tient en particulier, je peux plonger dans les détails. Donc, si j'aime le petit pipeline que je peux avec le jeu, je peux voir la course d'activité. Vous voyez, je vais sélectionner que maintenant je peux voir plus sur les détails. Je peux voir le nom de l'activité, le type d'activité. Dans ce cas, il s'agissait d'un type de copie. Donc, ce pipeline global est ce que je regarde. Maintenant, je peux voir toutes les activités qui en faisaient partie. Dans ce cas, il ne s'agissait que d'une activité dans le pipeline. Mais je verrais toutes les activités qui constituaient ce pipeline, selon son type. Je pourrais voir, par
exemple, ici les importations exactes. Je peux voir la sortie exacte, la quantité de plomb de données, la quantité de durées écrites de Gator à nouveau, le début, le temps de congé de durée, cette activité particulière dans le pipeline. Puis je ds où il courait à partir de l'exemple. L' indication une fois dans ce cas, est que le fort et moi pourrions aussi avoir cette petite paire de lunettes. Montrez-moi les détails. Donc ici, je peux voir qu'il venait de. Et ta suite ? Entrepôt de données. Il allait aux pieds dans votre magasin. C' est Gentoo, et je peux voir les détails exacts. Le nombre suit. Lire. Numéro désactivé. Rose a écrit. Je peux voir le débit, la tradition de la copie et les détails. Associez-le pour que je puisse devenir génial à l'intérieur dans le spécifié autour de cette
activité particulière . Fait. C' est donc un type clé de surveillance que nous allons effectuer. Je peux voir l'état de mon intégration lorsque les fois ici j'utilise simplement l'automatique à votre moment d'exécution. Si j'avais des temps de fonctionnement supplémentaires, peut-être sur place, peut-être ces années SS
I, je les verrais aussi. Et encore une fois, je peux voir des détails sur le mauvais moment, détails sur l'activité, armes qui utilisent réellement cette intégration à temps. Dans mon cas, ce seront tous ceux que j'ai dans mon environnement. Si je remonte, je peux aussi regarder les détails. Je peux voir le statut. Il est désactivé tapez un jur et les raisons vont automatiquement résoudre. Et encore une fois, je pourrais aller plonger dans des activités sauf Tre. Donc, ce sont les types clés de surveillance que je vais faire dans l'usine de données. Cela me donne l'aperçu de mon pipeline exécute mon déclencheur exécute l'activité
, puis l'intégration. Parfois, il y a aussi des métriques. Quand je plonge dans ceux-ci, si j'étais orteil cliquez sur ce bouton métriques, il va maintenant juste me sauter directement sur le portail azur. C' est là que les métriques sont généralement égoïstes. Donc ça nous amène à la deuxième partie de la manifestation. Surveillance avec à votre moniteur. Ici, je regarde mon âge ou la date d'usine. L' auteur et le moniteur est comment j'arrive réellement à l'dans le George il affecte pour vous, X. Si je fais défiler vers le bas, alors je vais voir mes métriques. Et à partir de là, vous pouvez voir un certain nombre de choses clés que nous nous soucions de l'activité échouée. Phil Pipeline de Dunn exécute des essais de déclenchement échoués, intégration mémoire disponible une seule fois, position
supérieure, nombre
maximal d'entités autorisé. Et pour tous ces différents critiques rencontrés, voyez-vous, je peux créer une alerte pour eux, ce qui pourrait être très utile. Et si je vois un bon nombre, je peux le mettre en alerte. Et en cas d'échec, je peux aller au facteur de données ux et voir pour les détails et enquêter pour pouvoir utiliser les choses
orteils , obtenir les métriques. Je pourrais utiliser cela pour déclencher l'alerte, ce qui me conduira ensuite à aller plonger dans l'interface et à voir exactement ce qui se passe . Et puis nous avons, ah, nos paramètres de diagnostic pour que je puisse envoyer toutes ces données, métriques et
les détails sur les différentes activités atterrissent par les essais planifiés ou les essais de déclenchement . Je peux les envoyer orteil un de ces trois destinations, histoires, compte, même toe ou look analytics. Et quand je l'ai envoyé à verrouiller et militant, c'est là que je pouvais personnaliser. de Combiendetemps est-ce que je veux garder ces journaux ? Peut-être que je veux les garder pour une certaine durée. Je peux le faire via la conflagration Log Analytics. Merci.
 Eshant Garg
Eshant Garg