Transcripciones
1. ¡Bienvenido a este curso!: Bienvenido a las APIs,
ya lo básico. El único curso que necesita para
entender las APIs desde cero. Soy Alex, un desarrollador senior de
software que ha consultado y trabajado para algunas
de las firmas tecnológicas más grandes, tanto en Londres como en
Silicon Valley. Dejé mi trabajo el año pasado para enseñar a tiempo completo y mostrar a otros cómo tener éxito en esta industria. Y desde entonces, 20 mil programadores
han tomado mis cursos. Verás, ya he estado en
tus zapatos antes. Todavía hay mucha información por ahí en Internet. No hagas mini cursos, videos
tutoriales, gafas. Pero cuando recién estás
empezando, ¿qué eliges? Se necesita un material robusto, muy parecido al que se
presenta aquí. Y no soy el
único que lo está diciendo. La mayoría de mis comentarios
pueden confirmarlo. La mayoría de los cursos sobre este tema simplemente no cubren todo el espectro de particularidades
tecnológicas para convertirse un maestro en APIs o incluso
entender lo que son Ahora en este curso, no
vamos a estar tomando
ningún atajo, pero tampoco vamos a
perder tiempo en información que está
desactualizada tampoco. Se trata de eficiencia. Si valoras tu tiempo, todo aquí está directamente
relacionado con lo que puedes hacer como desarrollador para dar un salto inicial
o crecer en tu carrera. Vas a
aprender habilidades reales que están en demanda en este momento, luego utilizadas por algunas de las firmas
más grandes como Google, Amazon, Facebook o Netflix. Repasaremos todas las nociones desde la
definición de una API, Servicios
Web, Formatos de archivo de datos y Seguridad API Ahora, cuando te inscribas, obtendrás acceso de por vida
a decenas de videos HD, así
como ejercicios de codificación
y artículos relacionados. También actualizo este
curso de manera regular. Desde sus inicios, el número de lecciones se
ha duplicado en tamaño. Recuerda, nadie
nace desarrollador. Todos empezamos a cero. Nadie es bueno en
nada. Al principio. Lucharás,
cometerás errores, conocerías cada video. Aprenderás cada vez más, haciendo que tu cerebro sea
un poco más inteligente. Y te garantizo que te
ayudaré a llegar ahí. Quienquiera que seas,
en cualquier parte del mundo que estés, puedes convertirte en un desarrollador de
software.
2. Explicación breve de las API (4 niveles de complejidad): A pesar de que fui a la universidad
para Ciencias de la Computación, siempre
me encontré un poco
confundido por el término API. Como este concepto realmente
comienza a mezclarse con la
práctica práctica de la codificación, no me
lo
explicaron claramente en ningún lado. En este video, trataré de
explicarte esta noción en cuatro
niveles diferentes de complejidad, comenzando desde un niño de cinco años
hasta alguien que tiene un
trasfondo algo relacionado con la tecnología, de cinco años. Digamos que eres un
maestro que necesita hacer una lección sobre fenómenos
climáticos severos, pero solo estudiaste
huracanes No sabes
nada de tsunamis. Habría la opción de ir
a estudiarlos tú mismo, lo que llevaría al
menos un mes. O simplemente podrías llamar a un amigo que sepa
todo sobre ellos y estaría encantado de explicarte este fenómeno en
tu lección él mismo. 16 años, estás construyendo un proyecto de
preparatoria muy importante. Para poder obtener
la calificación máxima, es
necesario tener también una
pequeña subsección sobre
un tema con el que no esté realmente familiarizado y la
fecha límite es mañana último minuto, recuerdas que tu hermano mayor ya
hizo este proyecto y puedes reutilizar su subsección
del proyecto en el
tuyo después de que él
acuerde 25 años de edad Digamos que estás codificando una
aplicación desde cero. La aplicación está pensada para
sistematizar la productividad de tus usuarios mediante la implementación la técnica pomodoro
en sus Lo codificas, pero te das cuenta de que
sería bueno
tener también el clima exhibido en una esquina por
si acaso hace sol. Su descanso de cinco minutos podría tomarse afuera
en su balcón. Este sería el caso en el que
usarías una API meteorológica. Devolvería el
clima actual de tu usuario en
función de su ubicación y
la hora específica del día. Alguien que tiene un fondo algo relacionado con
diez, API significa Interfaz de
programación de aplicaciones, y representa un conjunto de
métodos o funciones llamadas endpoints que se ponen a
disposición para ser solicitadas Se puede pensar en
estos endpoints como funciones o métodos que
están conectados a la web Y puedes llamarlos en cualquier
momento para obtener información de ellos
dándoles los parámetros
correctos. Como imaginas, esto es muy
útil por dos razones. En primer lugar, sigues implementando toda
la funcionalidad para la que estás llamando a la API. Este enfoque ahorra
tiempo que puede dedicarse al desarrollo de otras funciones
relacionadas con tu app. Y en segundo lugar, tienes
la seguridad de que el código de la API que
estás llamando está escrito de manera óptima
y tardará la menor cantidad de tiempo
posible en ejecutarse, haciendo que tu aplicación sea
más fluida y rápida de cargar
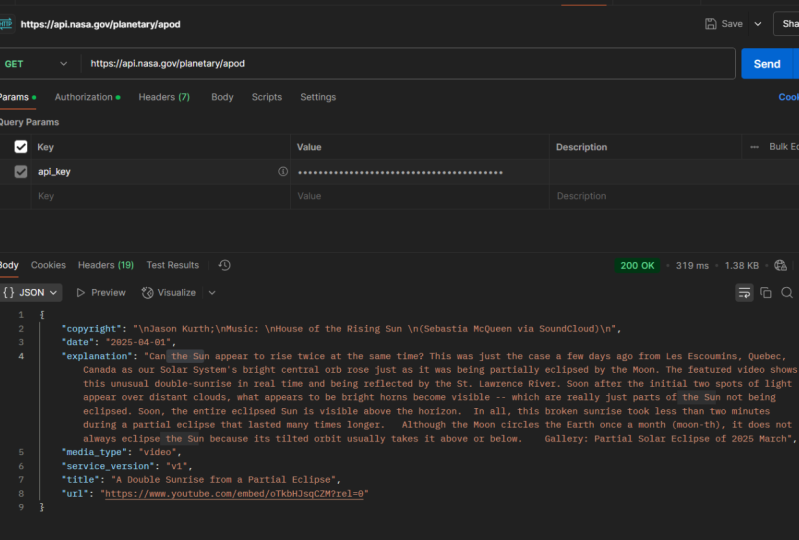
3. ¿Qué es una API?: Bienvenido a esta lección sobre el
concepto de programación de una API. Aquí veremos
qué
es exactamente una API y cómo
es útil en el contexto actual de Internet a medida el espacio de codificación se vuelve aún más carente
de nuevos desarrolladores. Al entender esto,
obtendrás una clara ventaja frente
a quienes no lo hacen, sobre todo teniendo en cuenta lo importante que representa
esta pieza. En el esquema más grande de las cosas, soy un desarrollador que
lleva tres años escribiendo código
. A pesar de que fui a la Universidad
de Ciencias de la Computación, siempre
me encontraba
desconcertado por el término API Como este concepto realmente
comienza a mezclarse con la
práctica práctica de la codificación, no me
lo
explicaron claramente en ningún lado. Esta es exactamente la
razón por la que sentí la necesidad de hacer esta sencilla lección destinada
a que comenzaras. Comenzando con
la abreviatura, API significa Interfaz de
programación de aplicaciones. Y representa un conjunto de métodos llamados endpoints que se ponen a
disposición para ser solicitados Puedes pensar en
estos endpoints como funciones o métodos que
están conectados a la web, y puedes llamarlos en
cualquier momento para obtener información de ellos
dándoles los parámetros
correctos Se pusieron a
disposición Api para facilitar la
comunicación
entre servicios web. Imaginemos que
eres un codificador que quiere implementar un
nuevo proyecto sencillo de reloj
Apomadoro para ayudar a
los usuarios a concentrarse durante 30 minutos seguidos por alguna razón en También quieres hacerles saber el clima actual en
función de su ubicación. Para ello,
llamarías al punto final de una API meteorológica que se
verá algo así como obtener el clima y pasar como parámetro la
ubicación de ese usuario y su hora actual. Ahora puede ver el poder y el apalancamiento que
una API puede proporcionar. Al usarlos, puede omitir la
implementación de fragmentos enteros de funcionalidad importante que otro modo
le
llevaría bastante tiempo De esta manera, si
eliges una gran API, también
tienes la tranquilidad de saber que la implementación
se realiza a la perfección Hay API para la seguridad, como un SMS gratuito, autenticación de
dos factores
para las API de tu aplicación que tienen enormes bases de datos detrás sobre diferentes temas listas para ser
consultadas por ti y así sucesivamente más
probable es que haya una API sobre el tema de tu
proyecto actual que te pueda ayudar. Sólo hay que saber cómo aprovecharlo al
máximo, y esto es lo que
vamos a aprender aquí. Una gran API también tiene
una gran documentación. La documentación se compone de explicaciones para cada
punto final sobre cómo llamarlo, qué devolverá y qué parámetros debes pasar para que eso sea posible. Hay una abundancia
de API gratuitas a través
de Internet a las que puedes llamar para comenzar y
ver cómo funcionan. También cuentan con la documentación necesaria para facilitar tu
viaje. Los fragmentos de código en
el código exacto de la llamada están
disponibles en algunos lugares El que
más me
encuentro usando es un sitio web
llamado Rapid API. Puedes seguir adelante y
revisar su hub. Te agradezco que te quedes
conmigo hasta el final, y espero
verte en futuras conferencias.
4. Mejores API y cómo llamarlos: Hola chicos y
bienvenidos a este video donde vamos a
platicar sobre como
se puede acceder a algunas APIs públicas con bastante
facilidad y
las llamó sin mucho dolor de
cabeza ya que tienen su documentación
puesta a disposición. Y para eso, vamos
a dirigirnos a API rabiosa, que es una herramienta en línea
que me parece muy útil. Cuenta con un hub que cuenta cientos y miles
de APIs públicas, como he dicho junto con
su documentación. Y también formas para
que los llames en cualquier idioma en el que puedas
tener tu solicitud. Para que no tengas que buscar
más allá de esto. Además de su hub, también
tienen un blog y aquí tienen artículos
interesantes, como las 50 API
más populares. Y si echamos un vistazo, tienen todo tipo
de APIs que van desde la información de vuelo hasta
si a la API de la nasa, el servicio de acortador de URL, MBA, APIs de
música como genio para conseguir letras a
tu canción favorita. Estas son, y cosas
así que tienes que
hacer es buscar la API
que necesitas aquí. Puedes ver que puedes
activar las APIs públicas y seguir buscando la que
encajaría en tu proyecto. Y solo puedes
llamarlo así. Hay que prestar atención. Porque algunos de ellos, pesar de que son públicos, te
cobran algo de dinero después una cantidad de solicitudes que
se les hacen. Entonces por ejemplo, aquí tenemos la receta de la API de nutrición para pies, y necesitas
suscribirte a la prueba. Y estos pueden ver que tienes
el básico que es gratis, pero te van a cobrar una cantidad muy
pequeña después superar las 500 solicitudes
diarias en el punto final de resultados. Pero con eso dicho, algunos de ellos son completamente
gratuitos y no hace falta
que te preocupes de que
te puedan cobrar en algún momento. Por ejemplo, tomemos
la API de Google Translate, que sé a ciencia
cierta que Tp es gratis, podemos seguir suscribiéndonos gratis. Como puede ver, no me
incitó a ingresar los datos de mi tarjeta de
crédito. Y lo bueno de estas API rápidas es que
además de sus puntos finales, también
tienen la documentación de la
API tu
disposición. Se puede ver que tenemos
tres puntos finales aquí, los lenguajes detectores
y para traducir, cada uno de ellos está documentado aquí. Cosas en la línea
de qué parámetros
necesitas poner para
obtener una solicitud exitosa. Si echamos un vistazo
al punto final de detección, por ejemplo, que es post, se supone que
esto
detecta
el idioma del texto que estás
enviando como parámetro. En la API rápida, también tienes parámetros de
manejador que
necesitas enviar
para que la API
sepa quién
eres y desde dónde llamas. Puedes pensar en estos como, lugar de darte
nuestra API en clave API, vas a
usar la API X-Ray, la clave API y el
host para sepan desde dónde estás llamando y quien
eres básicamente. Pero además de eso, este
método, como dije, tiene un parámetro y eso se
llama cola aparentemente. Y este es un texto que
puedes escribir en el
idioma de tu elección. Y lo que devolverá
es el idioma en el
que está escrito si puede
detectarlo. Y como puedes ver, si escribimos inglés es duro pero detectablemente así podemos
probar el punto final. Nosotros recuperamos el idioma EN, que significa inglés. El fragmento de código para esto, es
decir, el código que necesitas escribir
para llamar a este punto final exacto de esta API exacta es dado por
ellos y solo puedes copiarlo. Y además de eso, también tienes, como se mencionó anteriormente,
una amplia gama de idiomas entre los que
puedes elegir. Para ello, vamos a ir con JavaScript ya que es mucho más fácil y
en realidad no tienes que
instalar nada para llamarlo. Y vamos a ir
con petición HTTP XML. Este es el código
que vamos a poner en un script que está en el lenguaje
JavaScript. Y nos va a llamar a la
API sin problemas. También configura los
encabezados de solicitud. Por lo que le da la
rápida clave API y host, y también los datos,
es decir, el parámetro para el
que llamar al punto final. Y esto es inglés, es duro, pero detectablemente. Entonces, como puedes ver, para llamar realmente a este punto final
desde nuestra máquina local, vamos a dirigirnos
a la terminal. Y ya hice esto. Puedes hacer el
comando ls para ver qué directorios
tienes al final. Puedes cambiar
directorios con CD a cualquier directorio que desees, esta carpeta de este
proyecto a bean. Lo hice en escritorio
y luego puedes MKDIR con
el fin de hacer
una carpeta y luego escribir su nombre, ID API llama. Y luego después de cambiar los directorios a esta carpeta del curso
API, puedes tocar un índice
que HTML y script.js. Puede crear esto
con el Comando D, O, C, H, y luego el
nombre del archivo. Entonces index.HTML. Yo ya hice esto. Yendo aún más lejos. abro con
Visual Studio Code. Y como pueden ver, tengo un fragmento básico
de un documento HTML. Estos son todos locales, así que no los vamos
a desplegar. Esto es muy sencillo
y amigable para principiantes. Oh, lo hice. Aquí estaba hice referencia al script.js y dejé vacío el
resto del cuerpo. Si vamos al script.js, acabo de copiar el contenido de la llamada API
dada por la API rápida. Esta es en realidad
otra llamada a la API, pero la vamos a
actualizar con esta. Y cuando abres el
archivo index.html en tu navegador, puedes ver que
podemos recargar esto. Y si pulsamos el botón
para abrir la consola hacia arriba, se
puede ver que tenemos la respuesta dada
por el punto final. En la línea ocho. Tenemos el registro de la consola, es
decir, se conectó
a la cuenta. Entonces la respuesta del punto final, que es similar a
lo que teníamos aquí, si lo llamamos, se puede ver que tenía el
idioma en para el inglés. Y aquí, esto es
lo que obtenemos también. También te da
unas variables confiables y de confianza con el fin de
evaluar mejor su confianza
y confiabilidad en el hecho de que este
es
el lenguaje del texto que
diste como parámetro. Entonces hay una amplia gama en estos Hub además de
Google Translate, puedes verificar los datos de vuelo, puedes obtener datos de CT. Puedes obtener SMS gratis en tu número de teléfono para hacer factor de autenticación
y aplicación. Entonces eso podría ser muy
útil si estás implementando la
parte de seguridad de tu proyecto. Y no quieres tener
ningún dolor de cabeza al implementar darte más o quieres
una forma rápida autenticación
de dos factores esté disponible para ti. Pero además de eso, también puedes hacer una cuenta
con API rápida y revisarlas si quieres echarle un vistazo
al otro punto final. Pero además de esto,
les agradezco mucho que se hayan quedado conmigo hasta
el final de este video. Si lo disfrutaste o tienes alguna otra idea respecto a
videos sobre APIs, siéntete libre de dejarlos en
los comentarios y hasta la próxima
vez, Ten uno bueno.
5. Mejores prácticas de API: Hola chicos y bienvenidos de
nuevo a este curso de API. En esta conferencia,
vamos a echar un vistazo a las mejores prácticas de API
para garantizar que API sean efectivas,
eficientes y mantenibles Adherirse a estas mejores
prácticas es muy importante. En esta lección, profundizaremos
en estas mejores prácticas para diseñar e
implementar APIs. Ahora, uno de los principios básicos diseño
de API es la consistencia. Los métodos
y respuestas de los puntos finales de Api deben seguir las
convenciones y patrones de nomenclatura establecidos Esta consistencia simplifica
tanto el desarrollo como el consumo de APIs, y aquí puedes usar nombres descriptivos
y significativos Eso significa que los
endpoints y métodos de API deben tener nombres claros
que reflejen su propósito Evite nombres crípticos o
ambiguos que
requieran que los usuarios consulten documentación
extensa También debes seguir los principios de
Restful. transferencia de estado representacional es un estilo
arquitectónico ampliamente adoptado para
diseñar aplicaciones de red. Adherirse a
principios de descanso ayuda a mantener una estructura estandarizada para los endpoints y recursos de
API También debe incluir el control de
versiones en API RL para garantizar que los cambios la API no rompan
los clientes existentes Por ejemplo, use V
un recurso y V dos recursos para diferenciar
entre versiones de API. Otro aspecto crítico del diseño de API es el manejo efectivo de
errores. Las respuestas de error adecuadas ayudan a
los clientes a comprender y
resolver los problemas de manera eficiente. Debe usar los códigos de estado
HTTP apropiados. Estos proporcionan información
valiosa sobre el resultado de una solicitud. Utilice códigos como 200 para
K, 201 para creado, 400 para solicitud incorrecta y 44 para no encontrado con precisión para transmitir el
resultado de la solicitud. Además del estado, los códigos incluyen mensajes de
error descriptivos en el cuerpo de respuesta. Estos mensajes
deben explicar lo que salió mal y, si es posible, ofrecer más orientación
para su resolución. La seguridad es otro
aspecto fundamental del diseño de API. Predecir datos confidenciales y garantizar una
comunicación segura es crucial Utilice siempre HTTPS para
cifrar datos en tránsito, evitando escuchas Además, implementar mecanismos de
autenticación robustos para verificar la identidad de los clientes y
emplear la autorización para controlar el acceso a recursos
específicos. Las opciones incluyen claves API 00 y JWT para evitar el abuso o la
sobrecarga de Implementar limitación de velocidad
para restringir el número de solicitudes que los clientes pueden realizar
dentro de un período de tiempo definido. documentación clara y completa es esencial para los desarrolladores
que consumen tu API. Debe servir como una guía de
referencia que
les permita comprender cómo
usar la API de manera efectiva, incluir información detallada
sobre los puntos finales disponibles, los métodos de
solicitud, los parámetros, los formatos de
respuesta
y los códigos de error También puede proporcionar ejemplos
reales de solicitudes y respuestas de API para ilustrar cómo interactuar
con la API con éxito. A continuación, las pruebas exhaustivas y los procesos de aseguramiento de la
calidad garantizan que su API funcione
correctamente y de manera confiable. Para las
pruebas unitarias de escritura en todos sus endpoints API para validar que
funcionan como se esperaba, devuelven datos precisos y
manejan errores con gracia Además, realice pruebas de integración para verificar que la API funcione sin problemas con otros componentes y servicios con los que interactúa Cuando se trata de versiones
y compatibilidad con versiones anteriores, debes tener en cuenta que las
API evolucionan con el tiempo, igual que la mayoría de la
tecnología lo hace hoy en día Pero es esencial mantener esta
compatibilidad con versiones anteriores para evitar romper
clientes existentes que
ya están usando UR API para esto. Nuevamente, el versionado de API
entra en juego. Implementar estrategias de versionado
para introducir cambios en la API sin
afectar a los clientes existentes Esto se puede hacer, como
acabamos de mencionar, a través de versiones de URL
o encabezados A continuación, comunique claramente los planes de
desaprobación y puesta de sol para
versiones anteriores de API Informar a los usuarios sobre cuándo y cómo deben migrar
a versiones más nuevas. Optimizar
el rendimiento de las API es vital e impacta en los
tiempos de respuesta y la escalabilidad Para ello, debes tener
en cuenta el tamaño de la respuesta. Minimizarlo excluyendo datos
innecesarios. Utilice la paginación para listas
largas de elementos y proporcione opciones de filtrado Otra cosa a
tener en cuenta es
implementar mecanismos de almacenamiento en caché para reducir la carga en tu servidor y mejorar los tiempos de
respuesta Utilice los peligros de almacenamiento en caché HTPP
como el control de etiquetas y caché. monitoreo y los
análisis continuos proporcionan información sobre el rendimiento del uso de API
y tal vez los posibles problemas. Por lo tanto, debe realizar un seguimiento de
métricas clave como la tasa de solicitud, las tasas de
error y los tiempos de respuesta. Para ello, puedes usar herramientas
como Google Analytics o soluciones
personalizadas para obtener información sobre cómo se está utilizando tu
API. Configura sistemas de alerta para notificarte sobre problemas de
rendimiento, interrupciones o comportamiento inusual Las mejores prácticas para las API son esenciales para
construir sistemas confiables, seguros y mantenibles siguiendo las pautas de las
que acabamos de hablar Los desarrolladores como
tú pueden diseñar e implementar API que
sean consistentes, seguras y eficientes,
y también que proporcionen documentación clara
para sus usuarios. Una API efectivamente diseñada
y bien documentada no solo mejora la experiencia del
desarrollador, sino que también contribuye
al éxito de los sistemas y aplicaciones
que dependen de ella. Con todo esto dicho, agradezco muchísimo a ustedes que se hayan quedado conmigo hasta
el final de esta conferencia, y espero
verlos en la siguiente.
6. Equilibrio de cargas de API: Hola chicos, y bienvenidos de
nuevo a este curso de ABI. En esta conferencia,
vamos a
hablar de dos componentes críticos
de la infraestructura API. Están escalando
y equilibrando la carga. Le sugiero encarecidamente que
implemente
ambos conceptos en su propio desarrollo
futuro de API. Pero antes que nada,
hablemos de lo que realmente son cuando se
trata de escalar API. Este es el proceso de
expansión de la capacidad de una infraestructura API para
adaptarse al aumento del tráfico, demanda de los
usuarios y los requisitos de
procesamiento de datos. El objetivo es mantener un rendimiento
sin fisuras incluso a medida
que crece la carga de la API. El escalado puede ocurrir tanto
vertical como horizontalmente. Verticalmente significa
agregar más recursos a un solo servidor y horizontalmente significa
agregar más servidores. El equilibrio de carga, por otro lado, complementa
los esfuerzos de escalado al distribuir las solicitudes
entrantes de manera uniforme en múltiples servidores o recursos. Garantiza que
ningún servidor se vea abrumado mientras optimiza la utilización de
recursos Los balanceadores de carga actúan
como administradores de tráfico, dirigiendo de
manera inteligente las solicitudes
entrantes
al servidor más adecuado en
función Quizás se estén preguntando ahora ¿por qué son importantes el escalado y el
equilibrio de carga? En primer lugar,
aseguran que las API permanezcan disponibles incluso si ante un
alto tráfico o fallas del servidor, redundancia minimiza el tiempo de inactividad. tráfico distribuido uniformemente significa que cada servidor opera
con una capacidad óptima. Maximizar los tiempos de respuesta
y reducir la latencia. La capacidad de escalar horizontalmente
permite a las organizaciones hacer crecer su infraestructura API en respuesta al aumento de la demanda. Efectivamente, a prueba de futuro
los balanceadores de carga de servicios pueden detectar y re, enrutar el tráfico lejos de servidores no
saludables, asegurando un
servicio ininterrumpido en caso de falla del servidor Existen bastantes estrategias para escalar y equilibrar la carga. En primer lugar, tenemos escalado
vertical. Esto implica agregar
más recursos, ya sean
memoria de CPU o almacenamiento, a un solo servidor. Este enfoque es adecuado
para aplicaciones con tráfico moderado y
puede ser rentable. A continuación, tenemos escalado
horizontal, agregando más servidores
para manejar el tráfico. Es un enfoque escalable, pero requiere una
coordinación cuidadosa y también equilibrio de carga. Hay algoritmos de
arancer de carga. Los balanceadores de carga utilizan
algoritmos como conexiones
Robin Hood List o IP tiene para distribuir
las solicitudes entrantes del servidor Comprender estos algoritmos ayuda a optimizar el equilibrio de carga. Algunas aplicaciones
requieren sesiones adhesivas, donde las solicitudes de los usuarios
se dirigen
al mismo servidor para
mantener el estado de la sesión. Los equilibradores de carga se pueden configurar para la persistencia de la sesión
cuando sea necesario Las mejores prácticas a la
hora escalar y
equilibrar la carga son las siguientes. Debe implementar
redundancia en todos los niveles, incluidos los
equilibradores de carga y los servidores, para garantizar una alta disponibilidad También debe monitorear
continuamente estado
del servidor y los patrones de
tráfico para detectar y abordar problemas. Implemente de manera proactiva mecanismos de escalado
automáticos
que puedan
ajustar dinámicamente los recursos en función del tráfico en tiempo
real y las métricas de
rendimiento Asegúrese de que las medidas de seguridad
como los cortafuegos y protección
Dos estén
integradas en la configuración de escalado y
equilibrio de carga. Por último,
pruebe rigurosamente la configuración de escalado y equilibrio de
carga en diversas condiciones, incluidos los escenarios de tráfico
pico También aquí no
rehuyas pensar en
los casos de borde. Estos son, la mayoría de las veces,
lo que termina arruinando
el camino feliz que hemos implementado
o cierto ABI Con todo esto dicho,
creo que el escalado de API y el balanceo de carga son componentes
integrales de la
construcción de servicios confiables y de
rendimiento en esta era digital. Comprendiendo los
principios, estrategias y mejores prácticas
asociadas con organizaciones de
escalado y
equilibrio de carga. Y puede crear infraestructuras
API que hagan crecer el tráfico
sin problemas, garanticen una alta disponibilidad
y ofrezcan el rendimiento que esperan
los usuarios de la API. Realmente espero que ustedes obtengan
algo de esta conferencia, y pensarán en el
futuro al desarrollar su propia API sobre el escalado
y el equilibrio de carga. Le agradezco
mucho que se haya quedado conmigo hasta el
final de esta conferencia. Tengo muchas ganas de
verte en la siguiente.
7. Haz que tu API sea fácil de usar: Hola chicos y bienvenidos de
nuevo a este curso de API. En esta conferencia,
hablaremos sobre el diseño APIs
fáciles de usar
porque en mi opinión, el verdadero valor de una API
va más allá de la funcionalidad, radica en su
facilidad En esta lección, exploraremos el arte de diseñar APIs
fáciles de usar, enfatizando por qué es importante y cómo
lograrlo de manera efectiva. La facilidad de uso en las API no
es un mero lujo. Es una necesidad.
Y aquí está el por qué. Una API fácil de usar es más fácil de
entender y usar para los desarrolladores, reduce el tiempo y el esfuerzo necesarios para
integrarla en sus aplicaciones. API bien diseñadas tienen menos probabilidades de generar
confusión o errores, lo que
reduce la necesidad de un reduce la necesidad amplio soporte
y solución de problemas. Los desarrolladores tienen más probabilidades
de elegir y abogar por API que sean intuitivas
y fáciles de trabajar, lo que lleva a una mayor
adopción y uso. API fáciles de usar tienen más probabilidades de mantenerse
y actualizarse, lo que garantiza su viabilidad
a largo plazo en un panorama tecnológico en rápida evolución como el que tenemos hoy en día. En cuanto a
los principios de diseño para API
fáciles de usar,
tenemos consistencia. Debe mantener un patrón de diseño
consistente en toda su API. Esto incluye convenciones
de nomenclatura, estructuras de respuesta a
solicitudes
y manejo de errores Utilice nombres claros y concisos para recursos, puntos finales
y parámetros Evitar la ambigüedad y la complejidad
excesiva. Hacer que el
comportamiento de la API sea predecible. Los desarrolladores deben
poder anticipar cómo responderá
la API
a sus solicitudes. Asegúrese de que la API
se explica por sí misma. Use nombres significativos y proporcione documentación
detallada,
incluidos ejemplos de uso. Implemente versiones
para permitir actualizaciones y mejoras mientras se mantiene la compatibilidad con
versiones anteriores para los usuarios existentes La documentación es una tienda de esquina. Aquí la
documentación completa es clave. Documente a fondo su
API, incluidos los puntos finales, las estructuras de respuesta de
solicitud, los métodos de
autenticación
y los códigos de error Proporcione ejemplos claros
y casos de uso. Puedes ir a la sección donde te explico cómo
puedes
documentar tus API usando especificación
Open API Swagger
Hub en este mismo curso A continuación, considere proporcionar documentación
interactiva utilizando herramientas como
Swagger o Open Permitir a los desarrolladores probar endpoints
API directamente
desde la documentación Mantenga un bloqueo de cambios para
informar a los usuarios sobre actualizaciones, correcciones de errores y nuevas funciones. Esto genera confianza y ayuda a
los desarrolladores a adaptarse a
los cambios mucho más rápido. También, les
concientiza. También tenemos aquí un manejo
consistente de errores. Use
códigos de estado HTPP estándar para errores, 44 para no encontrados, 400 para solicitud errónea, 200 para una buena respuesta Y solicita incluir un mensaje
descriptivo de error en el cuerpo de respuesta. Cualquiera que sea el código de estado que
reciba el cliente será. Proporcione detalles adicionales de
error, incluida una descripción
legible por humanos y potencialmente un enlace a la documentación
relevante. Si en tu API
existe limitación de tarifas o estrangulamiento ,
que debería ser, como hablamos en otra
conferencia de discurso, comunicada claramente en la
documentación y respuestas respecta a la autenticación
y autorización, debe tener una autenticación
clara, especificar los métodos de autenticación con claridad documentación
Si es posible, implementar
mecanismos de autorización granulares para permitir a los desarrolladores controlar el acceso a un
nivel de grano fino Las pruebas de Leslie y los
bucles de retroalimentación son esenciales, nuevamente, mientras se desarrolla
una ABI fácil Pruebe rigurosamente su
API para asegurarse de que se comporta como se esperaba
en Y no rehuyas
pensar en los casos H. Busca activamente comentarios
de los desarrolladores que usan tu API y usan sus
aportes para realizar mejoras. Diseñar APIs fáciles de usar
es un arte que combina competencia
técnica
con la empatía por los desarrolladores que lo
van a Una API fácil de usar reduce fricción en el proceso de
integración, fomenta la satisfacción del desarrollador
y contribuye
al éxito tanto del
proveedor de API como de sus usuarios Esto es exactamente por lo que elegí
hablar de ello aquí en
una conferencia separada. Espero que ustedes implementen
algunas de las estrategias discutidas aquí en su
propio desarrollo de API. Les agradezco
mucho que se hayan quedado
conmigo hasta el
final de esta conferencia, y espero
verlos en la siguiente.
8. Diseño de RESTful: Hola chicos, y bienvenidos de
nuevo al discurso sobre APIs. En esta conferencia, vamos
a echar un vistazo más de cerca a los principios de diseño restful cuando se trata del diseño
general de API Estos
principios de diseño reparador han surgido como una filosofía orientadora Estamos creando sistemas elegantes, escalables y
mantenibles El descanso, que significa Transferencia
Representacional
del Estado, es un estilo arquitectónico que
enfatiza la simplicidad, la claridad y la comunicación
basada en recursos En esta lección,
exploraremos los principios básicos del diseño
reparador y por qué son esenciales en el desarrollo de
software moderno A la hora de
entender el diseño restful, es crucial saber que se centra en varios principios
clave que facilitan la creación
de servicios web fáciles de entender,
flexibles y escalables En primer lugar,
tenemos apatridia. Los servicios de descanso son
apátridas, es decir, bueno, cada solicitud de un cliente
a un servidor debe contener toda la información necesaria para comprender y
cumplir con esa Este principio simplifica la implementación
del servidor y también mejora drásticamente la
escalabilidad Además, todo es un recurso, que puede ser un objeto físico, una entidad conceptual
o un elemento de datos. Los recursos son identificados por identificadores
uniformes de recursos o como habrás escuchado, R, sí. Pueden ser manipulados. Los métodos HTTP estándar obtienen post, put, patch, delete, y así sucesivamente. recursos pueden tener
múltiples representaciones como XML, Jason o HTML. Los clientes interactúan con
estas representaciones en lugar de directamente con
el propio recurso. Esta flexibilidad permite el desacoplamiento entre
clientes y servidores La comunicación es
apátrida en sí misma. Los clientes y el servidor
se comunican a través solicitudes
y respuestas
sin estado Cada solicitud debe ser independiente y el
servidor no debe retener ninguna información sobre el estado del cliente
entre las solicitudes. Todo, desde el
token portador de
autenticación del cliente hasta la respuesta proporcionada por el servidor, se llevará a
cabo en esa solicitud. Una
interfaz uniforme y consistente es un principio básico. Esto incluye el uso de métodos HTTP
estándar, mensajes
autodescriptivos e hipermedia como motor del estado
de la aplicación Esto permite a los clientes navegar por los recursos de las aplicaciones
siguiendo los enlaces en las respuestas. Hablaremos de por qué importa el diseño
reparador. Las APIs Restful son
inherentemente escalables porque son sin estado
y están orientadas Esto facilita la distribución
y
el equilibrio de carga de las solicitudes de los descansos. Los principios de diseño sencillos facilitan a
los desarrolladores la
comprensión y el uso de las API. Esta simplicidad reduce la curva de aprendizaje
para los nuevos desarrolladores. El uso de múltiples
representaciones y el desacoplamiento de
clientes y servidores proporcionan flexibilidad para evolucionar las API sin romper
los clientes existentes Las APIs Restful utilizan métodos y formatos
HTTP estándar, promoviendo la interoperabilidad entre diferentes
sistemas e idiomas Los recursos y sus
representaciones pueden ser versionados y
actualizados de forma independiente, lo que simplifica el mantenimiento y reduce el riesgo de
introducir cambios de ruptura Las mejores prácticas para el
diseño reparador son las siguientes. En primer lugar, debes usar
sustantivos para los nombres de recursos. Elija sustantivos significativos
y pluralizados
para los nombres de recursos para Por ejemplo, usuarios para una
colección de recursos de usuario. Utilice los métodos HTTP de manera apropiada. Obtener recuperación de recursos, Publicar para crear nuevos recursos, poner para actualizar recursos y eliminar para
eliminar recursos Siga estas convenciones para
mantener una interfaz uniforme,
proporcionar
documentación clara, documente su API a fondo,
incluidos los URI de recursos, los métodos HTTP
disponibles y la estructura de las
representaciones de recursos. Tenemos una
sección completa en este curso que te ayudará a
entender cómo
puedes documentar tu API usando la especificación Open
API. Swagger Hub,
puedes comprobarlo. A continuación tenemos versionado. Si es necesario realizar cambios, versione su API para garantizar la compatibilidad
con versiones anteriores de los clientes existentes. Nuevamente, tenemos una
conferencia sobre esto. Utilice los códigos de estado
HTTP apropiados para transmitir el resultado
de una solicitud. 200 por éxito,
44 por no encontrado, y 400 por mala solicitud. Con todo esto dicho,
creo que los principios de diseño Restful ofrecen un marco sólido para construir servicios web y API que sean eficientes,
mantenibles y Al adherirse a estos principios, los desarrolladores pueden
crear sistemas que no solo satisfagan las necesidades
de los usuarios actuales, sino que también proporcionen una base
sólida para el crecimiento futuro y la
evolución de las API. Muchas
gracias chicos por seguir conmigo hasta el
final de esta conferencia. Realmente espero que
implemente algunos de
los
principios de diseño reparador de los que
hablamos hoy en sus API's. Espero con
ansias verle en la próxima conferencia.
9. Versionamiento de API: Hola chicos, y bienvenidos de
nuevo a Discourse on APIs. En esta conferencia,
vamos a echar
un vistazo al versionado de API Veremos por qué
importa el versionado en primer lugar. Entonces entenderemos
cuáles son las estrategias para el versionado de
API y
las mejores prácticas hora de versionar Al comenzar con
lo que realmente es, versionado de
API es
la práctica de administrar los cambios en
las API de una manera que garantice la
compatibilidad con versiones anteriores al tiempo permite las
actualizaciones y mejoras necesarias Sirve como un puente
entre lo antiguo y lo nuevo, asegurando que las integraciones
y los clientes
existentes continúen funcionando sin problemas,
al tiempo que se adaptan
a las necesidades cambiantes de desarrolladores y usuarios Pasando a por qué es importante el
versionado. Si bien los clientes existentes confían
en el comportamiento de la API, los cambios
abruptos pueden romper a
estos clientes e interrumpir los servicios que
dependen de ellos. Aquí es donde entra en juego
el versionado. Ayuda a mantener
la estabilidad al aislar los cambios de
las implementaciones existentes. Además, las API necesitan adaptarse
y mejorar con el tiempo para cumplir con los requisitos cambiantes y también los
avances tecnológicos versionado, nuevamente,
permite
a los desarrolladores introducir nuevas
características, corregir errores y optimizar el rendimiento sin afectar a los usuarios existentes que ya están usando
ese versionado específico de API proporciona una forma clara y estandarizada comunicar los cambios
a los Fomenta la
documentación integral y la transparencia
en la evolución de las API. Hablando de estrategias
para el versionado de API, hay bastantes que comienzan con
la más utilizada, que es el versionado de URL Esta estrategia implica incluir el número de versión de
la API en la URL. Por ejemplo, puedes
tener el dominio de tu API y luego poner
una V y el número de versión en la que estás El
continuar con el recurso que estás tratando de hacer
una operación CRD Es sencillo
y fácil de entender,
pero puede conducir a URL desordenados a medida Esta es exactamente la razón por la
que hay más estrategias
para el versionado de API El segundo es el versionado de
cabecera. Aquí la versión se especifica en un encabezado HTTP
en lugar de una URL. Se puede pensar en este encabezado
como aceptar versión menos. Y luego se puede especificar
la versión real, que puede ser V y luego el número de la
versión en la que se encuentre. Este enfoque mantiene
las URL más limpias, pero puede requerir un
esfuerzo adicional para los clientes que están tratando de llamar a su API para analizar el encabezado correctamente Incluso podrían olvidarse de ponerlo
ahí, ya que el versionado de URL es sencillo y proviene directamente de la URL a la
que está tratando de acceder Tiene una
tasa de errores mucho menor. También hay versionado de
tipo de medios. Este enfoque incrusta
la versión en el tipo de medios tales como
aplicaciones ejemplo VND, luego la versión más Esto proporciona una manera
clara de especificar la versión en solicitudes
y respuestas, pero puede ser más complejo de
implementar ya que los archivos reales necesitan tener
la versión en sus nombres. Leslie, hay versionado
semántico. El uso de
versiones semánticas es común en bibliotecas de código
abierto y se
puede aplicar a API Ofrece
información detallada de la versión
que facilita la comprensión de
la naturaleza de los cambios. Vamos a echar un vistazo ahora a las mejores prácticas a la
hora de versionar API Y lo primero es
implementarlo desde el comienzo mismo del desarrollo de
tu API. Solo planifique el versionado
desde el principio. Esto evita desafíos a la
hora de introducir versiones en una API existente
que es mucho más difícil de hacer Será más fácil si
lo tienes todo el tiempo. Si es posible, adaptar el versionado
semántico para mayor claridad sobre el tipo de
cambios en cada Estos cambios pueden
ser mayores, menores o simplemente un parche simple
siempre que sea posible. Además, mantenga compatibilidad
con versiones anteriores,
desuprima las funciones
y otorgue a los desarrolladores un período de
gracia para actualizar
sus implementaciones Además, si mantienes esta
compatibilidad con versiones anteriores, será mucho
más fácil para ellos integrarse con tu versión
más reciente de API. Siguiente documento,
estrategias de versionado y cambios. Proporcione minuciosamente guías de
migración para desarrolladores que hacen la transición
a nuevas versiones Considere ofrecer soporte a
largo plazo para API
críticas,
lo que garantiza la estabilidad los clientes con ciclos de vida
prolongados. Pruebe rigurosamente cada
versión para detectar regresiones y
garantizar Supervisar el uso de API para
identificar las necesidades de desaprobación. Esto sería sobre eso cuando se
trata de versionar
tu propia API Realmente espero que ustedes hayan sacado
algo de esta conferencia. Si tienes alguna duda, no dudes en
contactarme. Muchas gracias por seguir conmigo hasta el final de la misma, y espero
verte en la siguiente.
10. Configuración de un entorno de codificación: Hola chicos y bienvenidos de nuevo
a este curso sobre APIs. En esta sección, echaremos un
vistazo a cómo
podemos crear una API
desde cero y también ponerla a la venta en el sitio web Rapid
API de la que
ya te he hablado en este curso. En primer lugar, enlazaré en la
carpeta de recursos de este curso, el repositorio Github, con el código que te
presentaré. Puedes seguir adelante y clonarlo en tu máquina local y
cambiarlo como quieras. Como se puede ver en la pantalla, este es el repositorio real. Esto te facilitará
configurar una nueva API y
publicarla para venderla. El método de
implementación de una API pública se presenta aquí será muy
rápido y sencillo. Además, será
completamente gratis. Al final de esta sección, tendrás una URL quariable
en línea que podrás hacer solicitudes
para usar esta Publicarás tu
primera API en repid pi.com y yo también,
como dije, te mostraré cómo
puedes monetizarla Como puedes ver aquí, la API se despliega en vivo en esta URL. Y si hacemos clic en este enlace, ese es realmente nuestro. Puedes ver que
tenemos aquí la URL. Y también toma un parámetro. Nos da los dividendos
de los últimos diez años por cierto símbolo de acciones que tengo aquí para ingresos de realidad Pero también puedes ir con Apple, digamos ahora mismo, en realidad
está tomando los datos
de los dividendos que Apple dio durante los
últimos diez años Como puede ver, tenemos
la tasa de dividendos,
el monto, la fecha de
declaración,
la fecha de registro y
la fecha de pago Estaremos usando una
técnica llamada web scraping aquí para obtener
la información real que nuestra API expondrá
directamente de Internet sin almacenarla en
ninguna base Para una rápida configuración del servidor, utilizaremos
Express Framework. Toda esta funcionalidad
encajará en el archivo Javascript. Como pueden ver, es
el archivo JS de dividendos que les presentaré con
más detalle en futuras conferencias Una vez que obtengamos la
información que necesitamos de
nuestra API para exponer de Internet, tendremos que analizarla solo a los campos que necesitaremos
para agilizar este proceso Usaremos el framework
Cheerio. Esta es, como puede ver, biblioteca para analizar y
manipular HTML y XML Obviamente lo
usaremos para HTML. Es muy rápido y tiene una sintaxis muy intuitiva y
fácil de usar. Ahora, una vez que tenemos la API construida localmente y la recuperación de información del sitio web en Internet funciona en
nuestro punto final local. Necesitamos
implementarlo públicamente en la web para que podamos tener un enlace
propio para una API rápida. Como viste que tengo aquí
la app dividendo Netlify. Para ello, encontré un sitio web de hosting gratuito llamado Netlify y nos
integraremos con él Esto es muy parecido a Roku, pero probé Roku y ya no ofrece un plan
gratuito Desafortunadamente, Netlify sí. Esta es una muy buena
opción para desplegar nuestro sitio web y todo
de forma gratuita. Si vas al precio,
puedes ver que el plan de inicio es gratuito y
tienes 100 gigabytes de ancho de banda
y 300 minutos de compilación Los minutos de compilación se refieren a cuándo se construye
su sitio web
antes de implementarlo. 100 gigabytes de
ancho de banda se refiere a la cantidad de datos que
consumen otros usuarios al ver
tu sitio web 100 gigabytes de
ancho de banda es suficiente, sobre todo si
recién estás comenzando. Y me pareció que ese
era el caso para mí, sobre todo para el propósito
de lo que estamos haciendo aquí. De hecho, puedes hacer algunas
ventas en Rapid API seguro, antes de quedarte sin
estos 100 gigabytes La funcionalidad específica
de la API que vamos a
construir aquí será
recuperar, como usted vio, la información del dividendo
como fecha y monto de los últimos diez años
para el símbolo de acciones que le
proporcionamos como parámetro Ahora el sitio web
que decidí
raspar se llama Street Insider Es este sitio de aquí mismo el
que parece bastante antiguo, pero tiene una estructura bastante
simple. Por lo que será fácil apuntar a
la información que necesitamos de sus filas de tablas usando
el framework Cheerio Esta es en realidad la
razón por la que
no necesitamos una base de datos
detrás de escena. Y no necesitamos almacenar
todos los datos de dividendos para todo el símbolo de acciones en el
que pudiéramos pensar Ahora si hacemos una función F 12 sobre esto y vamos a
navegar por el Des. Una vez que llegamos a las filas que contienen los dividendos
reales, se
puede ver que tiene una tabla con una clase
llamada dividendos Este tiene un cuerpo, y las filas de la tabla, como se puede ver a la izquierda, contienen la información real del
dividendo Una vez que abrimos una fila de mesa, se
puede ver la información que podemos seguir adelante y raspar Utilizaremos Chi
para detectar los identificadores
de datos de tabla
en este documento HTML. Es muy útil porque no
es tan complicado, y estas son en realidad las únicas filas de tabla
que tiene el sitio. Pero con eso dicho, voy a explicar todo el código que tenemos aquí y cómo
implementarlo también en Netlify y luego cómo
implementar realmente esta API que
desarrollamos en API rápida Se puede ver desplegado aquí
y además tiene un plan pago. Si los usuarios quieren hacerle
más solicitudes,
entonces un límite básico
que va a configurar. Si estás deseando
aprender sobre este tema, espero
verte en la próxima conferencia. Gracias por quedarte conmigo
hasta el final de este.
11. Codificación de nuestra propia API: Hola chicos y bienvenidos de
nuevo a este curso de API. En esta conferencia,
vamos a echar un vistazo más de cerca
al guión que les
mostré en la
introducción de esta sección sobre
cómo vender una API. Y vamos a entender
qué hace exactamente para que puedas
replicarlo con
una URL diferente Raspar
información diferente de la web y crear tu propia API para implementarla
en vivo en Internet Y además,
publícalo en Rapid Api.com y haz algunas
ventas con él también Lo primero que debes
hacer para poder ejecutar este código será instalar Nog
en tu máquina local Puedes ir al sitio web de
No Jtg y en la página de descargas
podrás seleccionar tu sistema
operativo Tengo Mac aquí, plataforma Windows o Linux. Puedes elegir
diferentes opciones, y una vez presionas sobre esto, el ejecutable
comenzará a descargarse
en tu máquina local. Y seguirás adelante a
partir de ahí e
instalarlo con un asistente de configuración bastante
simple. Una vez que tengas el nodo
instalado en tu máquina local, puedes seguir adelante y
clonar nuestro repositorio. Desde este enlace,
puedes ir adelante a esta URL de Github que
también enlazaré en la
carpeta de recursos de este curso. Haga clic en este botón de código, copie esta URL y
continúe en su terminal. Si tienes se instala y ejecuta git clone y luego esta URL, clonará todo el
repositorio a tu máquina local. Entonces puedes
abrirlo en un editor. Tengo aquí el código visual studio para ejecutar este repositorio y verlo de una manera
más hermosa. Una vez que lo descargues, clónalo a tu máquina local, no
tendrás la carpeta de módulos de
nodo y te explicaré
por qué en tan solo un segundo. Pero además de esto,
tendrás todos los archivos. El archivo gitignore se
utiliza para ignorar algunos de
los archivos que tiene
dentro de la carpeta y
no Por qué esto es útil porque una vez que tenga una carpeta de módulos de
nodo, no
necesitará
realmente confirmar eso. Especificamos que en
el git ignore para ejecute
este código
vas a ejecutar NPM en primer lugar el paquete que Json obtendrá creado y también se
creará
el bloqueo del paquete J Aquí, se
especificarán todos los paquetes necesarios para este proyecto. Entonces puedes ver aquí
que estamos usando Express y Axis
Cheerio también, que son todos paquetes que aún no
tienes instalados. Para eso puedes ejecutar NPM install y luego el
nombre de cada uno de ellos, pero también puedes simplemente
ejecutar NPM Esto creará
la
carpeta de módulos de nodo con todos los
paquetes que él, que va a necesitar. Se puede ver que
por defecto
instalará todos los
demás paquetes como Express y así
sucesivamente y así sucesivamente. No, una vez que llegues a este punto, deberías
poder ejecutar NPM Start para que esta aplicación
funcione localmente Pero lo que estamos
tratando de hacer aquí es un paso adelante hacia eso
y hacerlo vivir. Despliégalo en la web real, para que pueda llamarlo desde allí. Dicho esto, echemos
un vistazo al código real. Se puede ver que tenemos funciones
de código de carpeta, y eso es para la aplicación Netlify donde
desplegaremos nuestro Puedes ver aquí necesitamos
especificar la compilación, y en la carpeta functions, es el script que
queremos desplegar. El ML de Netlify es otro archivo
esencial para usted, y lo necesitará
para implementarlo en Se puede ver que aquí tenemos la constante del router declarada, que es el router express. Y esto creará
servidor que tenga rutas. Con él podrás crear
más de una ruta. Puedes ver que
tenemos una ruta predeterminada en nuestro sitio web desplegado. Puedes ver que esta es
la ruta predeterminada, y solo dice bienvenido a la API de Dividendo de Acciones
como puedes ver aquí Pero también tiene una Ruta que toma un símbolo. Si recuerdas de
la última conferencia, te
di un símbolo
y recuperó información
del dividendo
para ese símbolo de acciones Si el usuario ingresa la ruta del
símbolo, antes que nada, tomará el parámetro de
símbolo de la solicitud y lo pondrá en
un símbolo con nombre constante. El URL, como ya les he dicho chicos es del sitio web
que va a ser raspado. Esto es a lo que
vamos a hacer una solicitud para poder
recuperar la información. La URL está tratando insider.com
slash dividend history. Y luego el primer
parámetro de consulta es especificado por el signo de interrogación
y Q y luego igual. Puedes ver si vamos a esto, esta es la URL exacta. Aquí toma el símbolo de las acciones de las que quieres
recuperar el dividendo Lo recibimos como parámetro, y luego usamos axis para hacer
una solicitud gat a esta URL. Y la ruta real es
la URL más el símbolo. Esto recuperará el HTML
real de esta página. Una vez que logramos eso, obtenemos todo
este documento HTML, luego lo tenemos aquí
en la respuesta, esos datos, lo asignamos
a una variable HTML. Y luego usamos Chi, el framework del que te he
hablado que puede escoger
fácilmente los elementos HTML y la información
dentro de él para cargarlo, y lo ponemos en la variable de signo de
dólar. Esta variable de signo de dólar, esta es la cereza de la sintaxis. Vamos a
buscar los datos de la tabla. Como ya le he dicho de nuevo
en la conferencia anterior, es donde se van a
almacenar los
dividendos en esta tabla
que ve aquí Hay algunas filas de tabla, elementos que almacenan esta
información que necesitamos para ser analizados para cada dato de tabla, vamos a sacarle el
texto y luego
meterlo en una matriz
que es datos de dividendo, y lo declaré aquí, y está vacío Entonces iteraremos a través de
esta matriz de datos de dividendos. Y vamos
a hacer un objeto llamado dividendo con todas
estas propiedades de cadena Y vamos a almacenar, emitir los
datos reales de dividendos que no va a recuperar, como ve aquí Por ejemplo, si doy el símbolo de acciones directamente
las fechas del dividendo En esta forma,
deberá analizarse un poco más porque también
contendrá algunas otras
cosas Pero se me ocurrió este código específico
para simplemente obtener la fecha real. Entonces empujaré este objeto dividendo en
otra matriz vacía declarada Al final, el resultado
será esta matriz con todos los
datos analizados en el formato Json Esto es lo que nos devolverá la
ruta del balón. También necesitarás
usar esta aplicación aquí,
que es la aplicación express, para que este Netlify sea Para poder implementar toda
esta app en Netlify
como primer parámetro Esto tomará el nombre de la función que tiene
y el nombre de la función de la carpeta y que
Netlify Antes eso también tomará un enrutador El router es el router
express. También el módulo exporta. El manejador debe especificarse para que sea menos servidor
para esta aplicación aquí Una vez que clonas este código exacto, lo que te sugiero que hagas, solo hazlo
desplegable en Netlify Desplegarlo ahí y
ver si funciona. Y si lo hace, entonces adelante, cambia esta URL
con otra cosa y raspa un sitio web diferente Pero esto es sobre el código. En una futura conferencia,
veremos cómo
puedes implementarlo realmente en Netlify Después de eso,
vamos a echar
un vistazo a cómo
puedes publicarlo a la
venta en la alerta de spoiler de Pipi.com
Studio Se hace desde aquí. Del proyecto API. Pero con eso
dicho, gracias chicos por quedarse conmigo hasta
el final de esta conferencia. Si tienes alguna duda
respecto a este proyecto, tengo muchas ganas de
responderlas. Puedes enviarme un mensaje aquí. Eso sería al
respecto con esta conferencia. Gracias por quedarse
conmigo hasta el final de la misma.
12. Despliegue de nuestra API en la Web: Hola chicos y bienvenidos de nuevo
al curso sobre API's. En esta conferencia,
echaremos un vistazo a cómo podemos implementar la vida, la API que construimos
en la última conferencia, y cómo podemos hacerlo
de forma gratuita en un método muy sencillo y
fácil de entender,
especialmente para
principiantes para eso, especialmente para
principiantes para eso, encontré el sitio Netlify.com que es muy similar a Roku, pero Heroku ya
no tenía Todos los planes fueron pagados. Netlify, por otro lado, tiene un plan de inicio el
cual es gratuito Ofrece 100 gigabytes de
ancho de banda para 3.300 minutos de
compilación, lo que me pareció suficiente Sobre todo si
recién estás empezando. Puedes implementar varias API y ponerlas a la
venta en APIs rápidas. Y una vez que empieces a obtener
algunos ingresos de ellos, puedes seguir adelante y
actualizar al plan pro si encuentras que este es
un poco pequeño para ti, pero incluso entonces creo
que será suficiente
por bastante tiempo. No se puede ejecutar a través 100 gigabytes de
ancho de banda tan rápido, sobre todo si la información que devuelve se ve así Así que no hay imágenes, nada tan grande. Puedes ver aquí que hacen que los sitios web
desplegables
vivan en la web No obtendrás
dominio personalizado con el plan de inicio. Como puedes ver aquí tenemos app
Netlify punto, pero es Eso es todo lo que importa. Especialmente porque una vez que lo
implementas en Rapid API, los
usuarios finales reales no verán la URL que diste Rapid
API para tu endpoint. Será una URL diferente que Repid API les proporcione. Entonces con eso dicho, puede ver que
dicen que se puede escalar sin esfuerzo y
hacen sitios web que ejecutan campañas y tiendas,
cosas así Así que una gran variedad
de posibilidades aquí. Simplemente usaremos esto para
implementar nuestra API web simple. Para eso, puedes seguir
adelante e inscribirte. Ya lo hice. Puedes ver que mi
API de Dividendo ya está desplegada. Jugué un
poco con él y se puede ver que
solo consumí 1 megabyte de
cada 100 gigabytes, y dos
minutos de compilación de 300 Esto es más que suficiente. Todo este ancho de banda y
minutos de construcción se restablecen mensualmente, por lo que no es una sola vez, solo es mensual. Pero si quieres seguir adelante
e implementar tu propio sitio web, puedes seguir adelante e ingresar la aplicación, Netlify.com
barra diagonal Inicio Aquí. Puedes conectarte,
antes que nada, a tu cuenta de Github y
darás clic en
Implementar con Github. Después de eso, dilatará el repositorio real
que desea implementar Aquí ya necesitarás el repositorio real
en Github. Poner ahí, necesitarás
tomar mi solución y tu propio
repositorio Github o simplemente
puedes usar mi
repositorio para una prueba. Si tú, entonces lo
desplegarás con Github. Es una
autenticación de dos factores la que se hace aquí. Y luego para todos los repositorios
públicos que obtendrás
una opción aquí Puedes seguir adelante haz clic aquí. También puede especificar la sucursal
que desea implementar. El directorio de funciones
es muy importante aquí porque el nombre
del mismo puede diferir. En tu caso, solo ingresa
cuál
es el nombre del mismo en tu caso y luego
podrás seguir adelante y desplegarlo. Una vez que hagas eso, se
desplegará. Estas son las actas de construcción reales que estaban
hablando ahora mismo. El despliegue del sitio desencadena una compilación y
eso lleva algún tiempo. Estás limitado a
300 minutos en eso, pero viste que solo
usé dos. Se puede ver qué tan rápido
ya se desplegó. Ahora bien, si quieres un dominio personalizado, que imagino que no lo haces, pero si vas
a necesitar comprar uno y luego asegurar
tu sitio con HTTPS. Pero para el propósito
de este video, para el propósito de
lo que estamos tratando de
hacer aquí, esto es redundante. Ahora puedes ver que nuestro
sitio web se implementó aquí. En realidad podemos especificar un subdominio diferente
que nos dan aquí. Pero no vas
a poder deshacerte de la app
Netlify dot, pero no puedes darle
un nombre más bonito
como lo hice aquí
con el Hago Netlify dot app. Y después de hacer esto, su sitio web debería estar
prácticamente desplegado como
puede ver aquí. Y deberías tener dos rutas. El predeterminado que, si recuerdas, devolvió bienvenido a la API
de dividendos bursátiles Y otra ruta que, en un símbolo que especifiques, recuperaría los datos de
dividendos que sacamos del sitio web de Street
insider Se trataba de ello para el despliegue de la API
en Internet en vivo. En la próxima conferencia,
vamos a echar un vistazo a cómo puedes ir en API
rápida e implementar esta
API y además, ponerla a la venta junto a las otras grandes
que están disponibles aquí. Pero si tienes
curiosidad por verlo, espero
verte en la próxima conferencia. Muchas gracias por seguir conmigo hasta el
final de este.
13. 4ff: Hola chicos y bienvenidos de
nuevo al curso API. En esta conferencia, veremos
cómo puede poner
su API en vivo implementada en
el sitio web de la API rápida. Y cómo puedes generar
ingresos a partir de él, cómo puedes monetizarlo Si seguiste
nuestra última conferencia, deberías tener una vida
API dividendo en Internet con una URL real que puedas ingresar en tu navegador Chrome
o cualquier navegador que uses Y debería devolver
toda la información de otro sitio web
que raspes Una vez que tengas eso,
deberías seguir adelante y dirigirte a Rapid API.com Aquí están todas las API que se publican para la venta
o incluso de forma gratuita, y también quieres publicar
tu API Debes crear una cuenta
en Rapid API.com y luego dirigirte a la sección
Mi API Como pueden ver, ya
tengo desplegada esta API de dividendo Le di una imagen, le
di una categoría que es
finanzas una breve descripción datos de
dividendos para más de 75,000 acciones entregadas,
inconveniente Como viste, el formato en el que vienen
estos dividendos es Json. Ahora, también se puede tener una descripción larga y aquí
está la parte más importante. Le darás una versión, solo
tendrás
una versión uno. Entonces eso no importa, pero la URL es muy importante. Debes proporcionar la URL base, que es esta de aquí, como viste desde el navegador
web, también. Sin este símbolo, ese
era un camino diferente. Una vez que tengas esto, puedes seguir adelante y pasar a definiciones. Aquí tenemos la
definición del símbolo. Puede seguir adelante y
crear un punto final. Aquí tenemos el nombre, obtener la
información de dividendos para una empresa Asegurar descripción que
este punto final devolverá información de
dividendos basada en el símbolo que proporcione
durante los últimos diez años También tiene un parámetro
que es el símbolo. También puedes dar
un ejemplo aquí. Por ejemplo, el valor de la
manzana debería devolver algo. También es de tipo string. Este parámetro, también le di una respuesta exitosa tomada
del navegador web. Aparte de eso, si tienes y vas a crear otros endpoints, también
debes
especificarlos aquí
agregando diferentes puntos finales en
el botón Crear punto final También puede crear
puntos finales similares en grupos. Para eso, presionarás
el botón Crear Grupo. Ahora la documentación
para tu API, dejé la vacía aquí, pero si tienes una
documentación que especifique con más detalle
qué hace tu endpoint, deberías escribirla aquí. El gateway, nuevamente, lo dejé como Rapid API lo proporcionó
para la comunidad. No cambié nada en absoluto entonces
para el deb Monetize, que es para lo que ustedes
realmente vinieron aquí, donde realmente pueden crear ingresos a partir de esta API
que crearon aquí, en realidad pueden
crear algún plan, planes
pagados para su Puedes dar
una básica con 20 solicitudes al mes para que el usuario pueda ver cómo devuelve tu API
y cómo es. Entonces puedes especificar
algunos otros. Se ve que tengo un plan pro cual tiene un límite de tarifa de
diez solicitudes por segundo. También podemos hacer de este el plan
recomendado u otro, pero también puedes especificar
un precio de suscripción. Una vez que lo hagas, puedes seguir
adelante y publicar tu API. Después de eso,
podrás echar un vistazo en los análisis y ver
cómo está tu API. ¿Cuál es la latencia promedio? También recibirá marca tu API -9.5
lo cual es bastante bueno, pero se basa en cuántas solicitudes
exitosas
hay y también la latencia de la que te
estaba hablando Pero con eso dicho, ahora tienes una API que
se despliega en Internet, y también se
pone a la venta en PPP.com que era todo nuestro
objetivo para esta sección Muchas gracias por estar
conmigo hasta el final de esta sección y
espero verlos en los futuros. Además, si tienes alguna duda, no
dudes en
contactarme Aquí. Estoy disponible para ustedes chicos. Y nuevamente, muchas
gracias por inscribirse en este curso y por escucharlo
conmigo. Que tengas una buena.
14. Vulnerabilidades comunes de API: Hola chicos, y bienvenidos de
nuevo al discurso sobre APIs. En esta lección, exploraremos las vulnerabilidades
comunes de seguridad de API,
como la inyección SQL y la falsificación de solicitudes entre
sitios Y también discutir
estrategias para la prevención. Creo que esto es muy importante, sobre todo si estás
desarrollando tu propia API. Comencemos por comprender las
vulnerabilidades comunes de seguridad de API. En primer lugar, comenzaremos
con la inyección SQL, la más común. La inyección SQL ocurre
cuando un atacante inserta sentencias SQL
maliciosas en
un campo o solicitud de entrada, potencialmente otorga acceso
no autorizado a una base de datos o compromete la integridad de
los datos. Para evitar esto, podemos usar consultas
parametrizadas o sentencias
preparadas para separar entrada
del usuario de los comandos SQL Implementar la validación de entrada
y desinfectar los datos antes procesamiento son algunas de las otras estrategias utilizadas para
prevenir este tipo de ataques A continuación, tenemos falsificación de solicitud de
sitio cruzado. Estos ataques engañan a los usuarios ejecuten acciones no deseadas
en una aplicación web, normalmente cuando se autentican
sin su consentimiento Para evitar esto, puede utilizar Ant cross site
request fake tokens
y asegurarse de que todas las solicitudes de cambio de
estado A modo de ejemplo, aquí
tenemos post put and delete require
autentificación. En el siguiente ejemplo,
hemos roto la autenticación. Estas vulnerabilidades ocurren cuando los mecanismos de
autenticación
no se implementan correctamente, lo que permite a los atacantes
obtener acceso no autorizado. Para evitar esto,
puede implementar una autenticación segura
y administración de sesiones, usar el almacenamiento seguro de contraseñas, habilitar la
autenticación multifactor y probar regularmente
las vulnerabilidades. Otro tipo de vulnerabilidad de
seguridad de API
es la desrealización insegura. Los atacantes aquí explotan
las vulnerabilidades
en los procesos de desrealización para ejecutar código
arbitrario u obtener acceso
no autorizado Emplee prácticas
seguras de desrealización, incluyendo listas amplias, clases
permitidas y el uso de
datos firmados cuando sea posible La última vulnerabilidad de seguridad
es la exposición de datos sensibles. Estas vulnerabilidades ocurren
cuando la información sensible, como en contraseñas o tokens, no
está adecuadamente protegida. Debe usar cifrado, por ejemplo TLS para datos en
tránsito y datos en confianza, y emplear algoritmos de
cifrado fuertes Limitar el acceso a
datos confidenciales sobre la base de la necesidad de conocer. Pasando a la parte más
importante de esta conferencia, las estrategias para la prevención. Primero, siempre debes
validar y desinfectar las entradas de los usuarios para evitar que los datos
maliciosos
ingresen al sistema Utilice
modelos de seguridad positivos como listas
blancas siempre que sea posible. E intenta por cada entrada que tengas que especificar
un tipo para ello. El usuario no puede ingresar cadenas cuando debe ingresar
una fecha, y así sucesivamente. Utilice consultas parametrizadas o declaraciones
preparadas para separar entradas
del usuario de las consultas SQ Esto reducirá drásticamente
el riesgo de inyección SQL. Implemente
mecanismos de autenticación sólidos y haga cumplir las comprobaciones de autorización
adecuadas para garantizar que solo los usuarios autorizados puedan
acceder a recursos específicos. Incluya tokens CSRF
en las solicitudes para verificar la autenticidad de las solicitudes
entrantes y
mitigar los ataques CSRF Implemente limitación de velocidad
para evitar abusos o ataques DDOS en su API En este curso,
tenemos otra conferencia especialmente dedicada a la
limitación de tarifas y estrangulamiento Utilice CSP o encabezados de política de seguridad de
contenido para
mitigar los ataques de secuencias de comandos entre sitios especificando qué fuentes de contenido pueden cargarse
en una página web Realice
auditorías de seguridad periódicas, revisiones de código y pruebas de penetración para identificar vulnerabilidades
y debilidades. Capacitar a desarrolladores y
mantenedores sobre prácticas de codificación
segura y la importancia de la seguridad
en el ciclo de desarrollo Mantenga actualizados todos los componentes, bibliotecas y marcos de trabajo
para beneficiarse de la seguridad, parches y las actualizaciones que
podrían publicarse con el tiempo. epi son el alma de los sistemas de software
modernos, pero su
uso generalizado los expone a diversas vulnerabilidades de seguridad
Al comprender vulnerabilidades comunes
como la inyección escalar, Los epi son el alma de los sistemas de software
modernos,
pero su
uso generalizado los expone a
diversas vulnerabilidades de seguridad
Al comprender vulnerabilidades
comunes
como la inyección escalar,
CSRF y otras. Y mediante la implementación de estrategias de
prevención robustas como la que aquí se menciona. Los desarrolladores como tú
y las organizaciones pueden fortalecer sus API
contra amenazas potenciales Se trataba de ello para la API común, amenazas de
vulnerabilidad de seguridad. Y realmente espero que ustedes
hayan sacado algo de ello. Y llegarás a implementar
algunas de las estrategias de las que hablamos aquí
en tus propias API's. Con todo eso dicho, gracias chicos por seguir
conmigo hasta el final
de esta conferencia, y espero
verlos en la siguiente.
15. Limitación de tasas de API: Hola chicos, y bienvenidos de
nuevo al discurso sobre APIs. En esta conferencia,
vamos a
hablar de un tema muy importante que es la limitación de velocidad
y la limitación de la API. La limitación de velocidad y el traqueteo son técnicas utilizadas para
controlar el número de solicitudes realizadas a una API
dentro de un marco de tiempo específico Estos mecanismos sirven para
varios propósitos cruciales. Ayudan a prevenir el uso abusivo
o malicioso de una API, como ataques distribuidos
de denegación de servicio o raspado. Aseguran un acceso justo a los recursos de la API
entre todos los usuarios. Evitar que un solo cliente monopolice la capacidad de los
servicios Mantienen el rendimiento de la API
evitando la sobrecarga. Permitirle atender las
solicitudes de manera confiable. Nuevamente, solicitudes que vienen a un ritmo
normal por ellos. Muchas API tienen
límites de uso descritos en los términos de servicio a
los que los usuarios deben cumplir. Estos límites son, a nivel concreto, implementados por
limitación de tarifas y estrangulamiento La limitación de la velocidad y el estrangulamiento a menudo se usan indistintamente, pero sirven para propósitos ligeramente
diferentes Hablemos ahora
de cada uno de ellos para entender la diferencia entre ellos y lo que cada uno de
ellos es exactamente. limitación de la tasa restringe
el número de solicitudes que un cliente puede realizar
dentro de una ventana de tiempo específica, como 100 solicitudes por minuto Una vez alcanzado el límite, el cliente deberá esperar o recibir una respuesta de error si
intenta realizar más de 100
solicitudes por minuto, y el conteo se restablecerá después de que pase ese
minuto específico. Esto es sólo un ejemplo. Por supuesto, el límite real puede ser diferente de
una API a otra. El estrangulamiento, por otro lado, controla la velocidad a la que se procesan
las solicitudes
en el sitio del servidor Por ejemplo, un
servidor puede procesar un máximo de 50
solicitudes por segundo, independientemente de cuántas
solicitudes se reciban. Las solicitudes de acceso están
informadas o retrasadas. Hay muchas estrategias para la implementación cuando se trata limitar y estrangulamiento de tarifas, y realmente deberías echarles un
vistazo si estás tratando de
construir tu propia API Primero, tenemos el algoritmo
token bucket. Este algoritmo
implica asignar tokens a clientes
a una tasa fija Cada solicitud consume un token. Si no hay tokens
disponibles de un cliente, este cliente debe esperar. Este enfoque es flexible y puede manejar ráfagas o tráfico La segunda estrategia se llama contadores de ventana
fija. Aquí, el límite de tasa se calcula dentro de ventanas de tiempo
fijas, por ejemplo, por minuto. Una vez que la ventana expira,
el contador se restablece. Esta estrategia puede llevar a picos
de tasa si no se
gestiona con cuidado. Por lo que realmente deberías prestar
atención a qué tan grande es
tu mostrador en una ventana de tiempo
específica. Por último, también tenemos el algoritmo de cubeta
con fugas. Es similar a un bucket físico con fugas, las solicitudes se procesan a
una tasa constante, solicitudes de
acceso se desbordan
y se descartan Este método asegura una tasa
constante de procesamiento. Las mejores prácticas cuando se trata limitar y
limitar la velocidad son, en primer lugar comunicar claramente los límites
de velocidad
y las
políticas de limitación a y las
políticas de limitación Esto generalmente se hace a través documentación y encabezados de
respuesta. Luego puede implementar respuestas de error
fáciles de usar y proporcionar mecanismos de reintento para clientes que excedan los límites de tasa Por supuesto, debe monitorear
continuamente uso de
API para detectar y mitigar el abuso o los problemas de
rendimiento. Recopile y analice datos para ajustar
los límites de velocidad dinámicamente. Otro consejo que te
daría aquí sería
vincular la tasa limitante a la autenticación de
usuarios. Permitiendo diferentes límites basados en roles de usuario o llantas. Se puede implementar
un límite mayor para alguien que tenga un privilegio
mayor. Por ejemplo, un
administrador podría recibir 100 solicitudes por minuto, mientras que un usuario normal
obtendría 50 o 25. También debe planificar límites de ráfagas
para acomodar
picos ocasionales en el tráfico. Dicho todo esto, limitación y el estrangulamiento de la tasa de
API son herramientas vitales para
mantener la estabilidad, seguridad y la equidad de los servicios
API en el ecosistema digital actual Al comprender
estos mecanismos, implementarlos de
manera efectiva y adherirse a las mejores prácticas, los proveedores de
API como
usted pueden lograr el equilibrio adecuado entre
brindar acceso a sus recursos y proteger sus sistemas del
mal uso o incluso abuso. Esta es exactamente la
razón por la que creo que la emisión roja y estrangulamiento son una parte
perjudicial de la implementación
de tu propia API Gracias chicos por seguir
conmigo hasta el final
de esta conferencia. De veras espero que
consigas algo de esto. Y limitar y traquetear
será algo que implementarás en el
futuro en tu propia API Espero
verle en la próxima conferencia.
16. ¿Cómo mantener tu API segura?: Hola chicos y bienvenidos de nuevo
al discurso sobre API's. En esta conferencia,
vamos a echar un vistazo a cómo exactamente
puedes mantener seguras las API que
desarrollas o malware, o personas con malas intenciones. Ese es un
tema muy importante hoy en día que siento que no hay suficiente
gente hablando. Hay múltiples
aspectos en ello. Entonces los vamos a
repasar en esta conferencia, y ojalá que al final de la misma, tengas una mejor
comprensión de cuáles son exactamente las implicaciones de mantener segura
la API que desarrollas. En primer lugar,
debe comprender la importancia
de
la seguridad de las API. Api son como puentes
que permiten que los datos y la
funcionalidad fluyan entre
diferentes aplicaciones, tanto interna como externamente. Asegurar estos puentes es
crucial por varias razones. Primero es la protección de datos. Los Api suelen transmitir datos
confidenciales. Un puente puede resultar en la exposición de información
privada, datos
financieros o propiedad
intelectual. También tiene aquí la gestión de la
reputación, incidentes de
seguridad pueden empañar la reputación de su
organización, erosionando la confianza entre clientes, socios y Aquí puedes pensar en los múltiples
éxitos de reputación que tuvieron lugar en muchas empresas que en
realidad tuvieron una brecha en su base de datos de usuarios y
sus contraseñas se filtraron. Como ejemplo aquí, sigo pensando en el stock X de la compañía que
está vendiendo zapatillas. La tercera cosa que
tenemos aquí para
entender la importancia del cumplimiento de los valores
ABI. Muchas industrias están sujetas a estrictas
regulaciones de protección de datos. No asegurar
las API puede llevar a consecuencias
legales
y fuertes multas El segundo punto que
debes tener en cuenta a la hora hablar de seguridad de API
es la anatomía de la misma. Se trata de múltiples capas, como dije antes,
y componentes. Aquí
puedes pensar en la autenticación, que es verificar correctamente la identidad de las
partes involucradas. Y esta es la primera línea de técnicas de defensa
como las claves API, el protocolo juramento y tokens web de
Jason se
utilizan comúnmente para este propósito También tenemos autorización
que es posterior a la autenticación. Y su función es
determinar a qué acciones y datos
se le permite acceder a cada usuario o sistema. El control de acceso y los
alcances basados en roles ayudan a hacer cumplir esto. Porque en las aplicaciones, diferentes roles tienen
diferentes privilegios. Un usuario y un administrador
son muy diferentes. También hay que
pensar en el cifrado de datos. Puede usar HTPS para cifrar
datos en tránsito y considerar el cifrado de datos
en reposo para los datos almacenados A continuación, es crucial que
hagas validación de entrada. Debe proteger
sus API de ataques
comunes como
inyección de scull y
scripting entre sitios validando
y desinfectando la entrada que sus usuarios
están dando a la La limitación de tarifas es otra técnica
muy común que es prevenir el abuso
o el uso en exceso de su API, lo que puede provocar el agotamiento de los
recursos
y la interrupción del servicio Creas un límite de llamadas que tus clientes
pueden hacer a tu API. Por último, tala y monitoreo. Cuando desarrolle su API, debe mantener
registros detallados y monitorear tráfico de la
API para detectar
patrones inusuales o incidentes de seguridad. Herramientas como SEE M, que proviene de la información de
seguridad y los sistemas de gestión de eventos son invaluables para este propósito. La tercera cosa que debes tener en cuenta
a la
hora de hablar seguridad de
API se llama Mejores Prácticas de
Autenticación de API. La autenticación es
la piedra angular de la seguridad de API y estas son
algunas de las mejores prácticas Debe usar API para
autenticar a los clientes que
acceden a su API y asegurarse de que se almacenen de
forma segura y se roten Periódicamente,
debe implementar hacia fuera para la autenticación de
usuario segura y estandarizada y autorización 0 es ampliamente adoptada y proporciona
varios tipos de concesión para diferentes casos de uso. También tengo un tutorial sobre
esto aquí que explica exactamente cómo está funcionando este
flujo de autorización y autenticación. Y por último, los JWTs, que provienen de los tokens web Json Si tu API emite tokens para la
autenticación, úsalos. Son compactos,
independientes y pueden llevar
las reclamaciones de los usuarios de forma segura. Al hablar de la
seguridad de una API, también
debes
pensar en la autorización
y el control de acceso. Una vez que se autentica a un usuario, debes controlar lo
que puede hacer dentro de tu API Puede implementar cualquiera de los controles de acceso basados en
roles. Asigne roles a usuarios o sistemas y defina permisos en
función de esos roles. Revisar y
actualizar periódicamente los permisos. Como hablamos antes, un administrador y el usuario son muy diferentes en lo que
pueden hacer en una aplicación. O puedes usar, como
dije, alcances. Los alcances se utilizan para
ajustar el control de acceso
dentro de su API Limitar el acceso a
recursos o acciones específicos en
función del consentimiento del usuario
y del alcance del cliente. Entonces cada cliente obtiene un alcance
y con base en ese alcance, se calculan
los privilegios de
él. Al hablar de cifrado de
datos, podemos en primer lugar sobre el HTTPS, la seguridad de la capa de transporte. Siempre debes usarlo para
cifrar datos en tránsito. Tls garantiza que los datos
intercambiados entre el cliente y su API protegidos y no puedan
ser interceptados Confianza en los datos, debes considerar encriptar los datos confidenciales
almacenados en tu servidor, así que no solo en
el tráfico cuando los datos están
pasando en las solicitudes, también
debes mantenerlos
almacenados si son sensibles, como contraseñas o datos de tarjetas
en tus servidores cifrados, solo usa
encriptación estándar de la industria que
podrás encontrar con bastante facilidad
al buscar en Google Al hablar de validación
de entrada, primero
debe
desinfectar la entrada del usuario, lo que
significa que nunca debe
confiar en la entrada del usuario Debe hacer esto para prevenir ataques
comunes como las inyecciones de
Cl. Y otra cosa que
puedes hacer cuando se
trata de validación de entrada
es usar las puertas de enlace API Implementarlos puede filtrar, desinfectar las
solicitudes entrantes antes que lleguen a sus puntos finales de API o a
su base de datos para recuperar información de ella o
cambiar información de La implementación de límites de tarifas
define una barrera que es muy importante para prevenir ataques de abuso o
denegación de servicio. Considere diferentes límites
comerciales para diferentes tipos de
clientes o usuarios. Por último, tala y monitoreo. Mantenga registros detallados de la actividad
de la API, incluidos los eventos de autenticación
y autorización. Y conservar los registros durante un periodo adecuado para
ayudar en las investigaciones e implementar
monitoreo y alertas en tiempo real para detectar y responder adecuadamente a los incidentes de
seguridad La seguridad de Api no es
un esfuerzo único, sino un
proceso continuo que requiere vigilancia y adaptación
a las amenazas en evolución Como sabe, la
base de texto se está desarrollando bastante rapidez y
necesitamos mantenernos al día con
bastante rapidez y
necesitamos mantenernos al día entendiendo los componentes críticos de
la seguridad de las
API y
siguiendo las mejores prácticas, puede proteger sus
activos digitales o sus bases de datos, preservar la reputación de su
organización y garantizar el
cumplimiento de las regulaciones. Tenga en cuenta que la seguridad es una responsabilidad compartida
y cada parte interesada su organización
debe ser educada y consciente de su papel en el
mantenimiento de la seguridad de las API. Con las estrategias
y herramientas adecuadas implementadas, puede
navegar con confianza por el mundo de las aplicaciones impulsadas por
API mientras mantiene sus datos
y sistemas seguros Realmente espero que esta conferencia te
ayude a lograrlo. Muchas gracias por seguir conmigo hasta el final de la misma, y espero
verte en una futura.
17. Servicios web: Todo giz. Y bienvenidos de
nuevo a este curso de API. En esta conferencia,
echaremos un
vistazo a los servicios web porque
son el principio fundamental
de los sistemas
interconectados modernos, permitiendo que las aplicaciones y componentes de
software se
comuniquen e intercambien datos sin problemas a
través de Internet. Han revolucionado
la forma en que construimos, integramos y ampliamos el software, allanando el camino para un mundo de servicios
y aplicaciones interconectados En esta lección,
exploraremos los aspectos clave de los servicios web, sus tipos, protocolos
y su papel en el software
moderno en su núcleo. Un servicio web es un
sistema de software diseñado para soportar la interoperable máquina a
máquina a interacción
interoperable máquina a
máquina a
través de una red Permite que las aplicaciones se
comuniquen y compartan datos independientemente de
sus plataformas subyacentes, lenguajes de
programación
o sistemas operativos. Esta interoperabilidad es una característica
fundamental de los servicios
web y los
distingue de las aplicaciones
monolíticas tradicionales Los servicios web se pueden
clasificar ampliamente en
tres tipos primarios. Primero, contamos con los servicios de
Soap Web. Se trata de un protocolo
para el intercambio información
estructurada en la implementación
de servicios web. Se basa en XML como
formato de mensaje, y a menudo usa HTTP o SMTP
como protocolo de transporte Los servicios web Soap son conocidos por sus estrictos estándares y fuerte soporte para
la seguridad y confiabilidad. Sin embargo, hoy en día se quedaron en desuso ya que la gente tiende a preferir los servicios web Rest que utilizan Jason como formato de
mensaje El resto es un estilo arquitectónico diseña aplicaciones de red. Los servicios web de descanso se adhieren
a un conjunto de restricciones, incluida la apateldia, la arquitectura del servidor
cliente y la interfaz uniforme Utilizan
métodos HTPP estándar como get, put, post y delete para realizar
operaciones en recursos Esto los hace ligeros
y muy fáciles de implementar. Por último, contamos con los servicios web Json
y XML. Se trata de protocolos de
llamadas a procedimientos remotos que utilizan Json y XML como
formato de mensaje. Proporcionan una forma sencilla de invocar métodos en servidores
remotos, haciéndolos adecuados para
diversas aplicaciones Particularmente cuando la simplicidad y la eficiencia son esenciales. Ahora para permitir la comunicación entre los servicios web
y los clientes, entran en juego
varios protocolos clave. El primer protocolo
que entra en juego, tengo todo un curso encendido, y lo tenemos mencionado incluso
aquí en varias conferencias. Y es el protocolo de
transferencia de hipertexto. El HTTP es la base
de la comunicación web. Los servicios web, naturalmente,
suelen depender
del HTTP como protocolo de transferencia
para enviar y recibir datos entre
clientes y servidores. Proporciona una forma estandarizada hacer solicitudes y
manejar las respuestas. También tenemos el protocolo
Soap que emplea XML para el formateo de
mensajes, y a menudo depende más de
HTTP o SMTP para Incluye un conjunto de reglas para las transacciones de seguridad
y la confiabilidad de los mensajes. También tenemos Resto aquí, que es mucho más importante. El descanso proviene del traslado
estatal representacional. Los servicios web que son restful utilizan métodos HTTP para interactuar con recursos
identificados por URI Abarcan los principios
de la apátrida, es
decir, que cada solicitud
es independiente entre
sí y no se
basa en un estado anterior También tienen como aspectos clave una interfaz uniforme y una arquitectura
en capas. Por último, tenemos Jason
y XML que son formatos de datos
comunes para estructurar mensajes
intercambiados entre servicios
web y clientes. Son legibles por humanos
y analizables por máquina, proporcionando flexibilidad
en la representación de datos Cuando se trata del papel de los servicios
web hoy
en día en el software moderno, se
han convertido en la columna vertebral
absoluta del ecosistema moderno,
facilitando la integración, extensibilidad y escalabilidad en la arquitectura de
microservicios pequeños servicios
desplegables de forma independiente se comunican a través de servicios
web Este enfoque permite agilidad, escalabilidad y
fácil mantenimiento Las aplicaciones móviles a menudo dependen de los servicios
web para acceder a los recursos de back end, incluidos los datos de los
usuarios de bases , archivos
multimedia e información en
tiempo real. Los dispositivos y sensores de Internet de las cosas se comunican con
los servicios en la nube con los servicios web, lo que permite la recopilación de datos y control desde ubicaciones remotas. Por último, las plataformas de comercio electrónico utilizan servicios
web para facilitar las transacciones
en línea, incluyendo pasarelas de pago, administración de
inventario
y envío Si bien estos servicios web
ofrecen numerosas ventajas, también
vienen con algunos
desafíos. Primero, debe garantizar la
seguridad de los servicios web, incluida la autenticación
y el cifrado de datos. Esto es muy
importante para
evitar el acceso no autorizado y las violaciones de datos La optimización del rendimiento
de los servicios web
también incluye
tiempos de respuesta y escalabilidad Es esencial para brindar una experiencia de usuario receptiva, manejar cambios y
actualizaciones de los servicios web. Api mientras se mantiene
una compatibilidad con versiones anteriores es un delicado equilibrio y aquí
es donde entra en juego el
versionado Por último, la documentación completa y
actualizada es esencial para ayudar a
los usuarios a comprender cómo usar los
servicios web de manera efectiva. En resumen, los servicios web
han transformado la forma en que construimos e
interactuamos con el software. Proporcionan un enfoque flexible
y estandarizado para integrar
aplicaciones y sistemas. Al comprender
estos diferentes tipos de servicios web de los que
hablamos, sus protocolos subyacentes y el papel en la arquitectura de
software moderna, puede aprovechar esta
poderosa tecnología para crear sistemas interconectados, eficientes y escalables. Con todo esto dicho, agradezco muchísimo a ustedes que se hayan quedado conmigo hasta
el final de esta conferencia, y espero
verlos en la siguiente.
18. Cómo depurar una solicitud: Hola chicos, y bienvenidos de
nuevo a este curso. En esta conferencia,
vamos a discutir problemas y la
depuración de solicitudes HTTP Porque en mi opinión, al
menos como desarrollador, es muy importante
entender cómo
solucionar y depurar las solicitudes
HTTP de manera efectiva Esta habilidad es esencial para garantizar que
las aplicaciones web funcionen sin problemas, diagnosticar y solucionar problemas y brindar una experiencia de
usuario perfecta Las solicitudes Http están en el centro
de cada interacción web, ya sea cargando una página web, enviando un formulario, recuperando
datos de un AP I o incluso transmitiendo contenido
multimedia Todo comienza con
una solicitud HTTP. Sin embargo, estas solicitudes no siempre
están libres de errores. Varios factores
pueden provocar problemas como
errores de configuración del servidor, problemas de
red, errores en el sitio del
cliente o conflictos entre
diferentes componentes Y aquí es exactamente
donde
entra esta conferencia para
ayudarlo a comprender primero los problemas comunes
que pueden surgir en solicitudes
HTTP es el primer paso, la problemas
ineficaz. Aquí tenemos cosas
como errores del servidor, porque los servidores pueden encontrar
varios errores como 44, que es el código para no encontrado, 500 para error interno del servidor, o 53, que es el
servicio no disponible. Estos errores pueden ser el resultado de servidores
mal configurados
o problemas de aplicaciones También tenemos errores
en el lado del cliente. Los clientes como los navegadores web también
pueden generar estos errores, como 400 por mal pedido
o 43 para prohibido. Estos suelen ocurrir debido a problemas con la
solicitud o permisos del cliente. Los problemas de red son
otro factor que puede interrumpir la comunicación
entre el cliente y el servidor. Esto incluye problemas como
DNS, fallas de resolución, conexiones
lentas o incluso interrupciones
completas de la red Las violaciones de
uso compartido de recursos de origen cruzado también
pueden bloquear solicitudes
a un dominio diferente. Si no se configura correctamente, esto puede generar problemas de seguridad
y funcionalidad. Por último, tenemos errores SSL
y TLS. Estas dos capas de
seguridad pueden provocar errores. Pueden ocurrir cuando las conexiones
HTTP no están establecidas
correctamente. Estos errores pueden interrumpir la transferencia
segura de datos. Ahora la parte más importante de la lección, la depuración de solicitudes
HTTP Esto puede ser un proceso
sistemático para identificar y resolver los
problemas de manera efectiva. Estos son los pasos a seguir. Primero, revisa las herramientas del
desarrollador del navegador. La mayoría de los navegadores web modernos ofrecen herramientas
para desarrolladores que
le permiten inspeccionar las solicitudes de la red. Puede ver solicitudes
y encabezados de respuesta, cargas útiles y mensajes de error Esto sucederá en Google
Chrome, por ejemplo, si presionas el control
F 12 o la función F 12 si estás en una Mac
y luego vas a la red. A continuación, debes revisar
los códigos de estado HTTP. Estos códigos en la
respuesta proporcionan información
valiosa sobre
el resultado de la solicitud. Familiarícese
con los códigos de estado comunes para identificar el problema rápidamente También puede inspeccionar los encabezados de solicitud
y respuesta. Preste mucha atención a los encabezados de
solicitud y respuesta. Pueden revelar
detalles críticos sobre el problema, como tokens de
autenticación faltantes, tipos de contenido
incorrectos
o problemas del curso. A continuación se puede examinar los datos de carga útil es la solicitud
implica la transferencia de datos. Inspeccione las
anomalías o problemas de carga útil. Los formatos de datos no coincidentes, los datos
corruptos o los parámetros faltantes
pueden causar problemas También debe verificar los registros
del servidor. Los registros del servidor pueden
ofrecer información sobre lo que sucede en
el lado del servidor. Pueden revelar errores, problemas de
rendimiento o,
nuevamente, configuraciones erróneas A continuación, puede verificar la conectividad de
red, Asegúrese de que su conexión de
red en la máquina desde la que está enviando solicitudes sea estable. A veces, los problemas de
conectividad intermitentes pueden provocar fallas en las solicitudes. Por último, puede utilizar herramientas de depuración
en línea. Varias
herramientas en línea están disponibles para probar y
depurar solicitudes HTTP Estas herramientas pueden ayudar a
simular solicitudes, verificar encabezados y
validar respuestas. Aquí algo digno de
mencionar es que si estás desarrollando la
aplicación web donde está ocurriendo
el error HTTP, puedes volver a presionar la
función F 12 para entrar en las herramientas del desarrollador del navegador
y luego presionar el comando P y buscar el script donde creas
que está ocurriendo el error, pon ahí un punto de quiebre, y luego continuar con
la depuración lo que puedes hacer
refrescando la página. Cuando se trata de herramientas de
depuración comunes, hay varias que pueden ayudar depurar solicitudes HTTP Primero, tenemos
por supuesto, Cartero. Esta popular herramienta de prueba de API le permite enviar y
recibir solicitudes HTTP, inspeccionar encabezados
y ver respuestas. A continuación tenemos Curl. La herramienta de línea de comandos es
excelente para enviar solicitudes
HTTP y ver
respuestas en un terminal. También tenemos a Hitler, que es un proxy de
depuración web que registra e inspecciona el tráfico HTTP y HTTPS
entre la computadora la
que está instalada
e Por último, tenemos Wireshark, que es un
analizador de protocolo de red y puede ayudarlo a solucionar problemas a
nivel de red que afectan que es un
analizador de protocolo de red y puede ayudarlo a
solucionar problemas a
nivel de red que afectan
las solicitudes HTTP. Cuando se trata de solución de
problemas y depuración, colaboración
efectiva
con su equipo es vital para resolver problemas complejos de solicitudes
HTTP Mantenga una documentación exhaustiva
de sus hallazgos, incluidos los mensajes de error,
los registros y los pasos de depuración Comparta esta información
con colegas que puedan ayudar a diagnosticar
y solucionar el problema En conclusión, la resolución de
problemas y depuración solicitudes
HTTP es una
habilidad fundamental para los desarrolladores web, ya que HTTP es el
protocolo fundamental de las interacciones web Ser capaz de
identificar y resolver problemas de manera rápida y
efectiva es esencial para ofrecer aplicaciones web
confiables y una experiencia de usuario perfecta. Mediante el uso de herramientas para desarrolladores,
examinando códigos de estado, inspeccionando encabezados y cargas útiles, comprobando los registros del servidor y
utilizando herramientas de depuración Los desarrolladores como tú
pueden diagnosticar y solucionar problemas de solicitudes
HTTP mientras mantienen sus aplicaciones
funcionando sin problemas. Con todo esto dicho, les
agradezco muchísimo a ustedes que se hayan quedado conmigo hasta
el final de esta conferencia. Espero que esto te haya dado una
ventaja en la resolución de problemas y depuración de solicitudes HTTP que vendrán de la mano
en el futuro Yo era Gs y
espero verte en la siguiente.
19. Códigos de estado HTTP: Hola chicos, y bienvenidos de
nuevo al discurso. En esta conferencia,
vamos a echar
un vistazo a los códigos de estado HTTP, también llamados códigos de retorno. Estas son una
parte fundamental de la comunicación web. La razón por la que estos códigos de
datos son tan importantes es porque
son emitidos por un servidor en respuesta a la solicitud de un
cliente realizada a ese servidor específico y son los
datos más relevantes
y cortos sobre cómo fue
la solicitud. El primer dígito del código de
estado especifica una de las cinco
clases estándar de respuestas. Las frases de mensaje
mostradas son típicas, pero se puede proporcionar cualquier
alternativa legible por humanos. Como decía, los
códigos de retorno HTTP tienen tres dígitos. Si estos tres dígitos
empiezan por uno, el estado que está
recibiendo es informativo, es
decir, que se recibió la
solicitud Si comienza con dos, significa
que la solicitud
fue una operación exitosa, es
decir, fue
recibida, entendida
y aceptada satisfactoriamente . Con tres, significa
una redirección, ya que en nuevas acciones, se
necesita tomar
para completar la solicitud Si comienza con cuatro, significa
que su solicitud
tuvo un error de cliente. Algo salió mal en el lado del
cliente y la solicitud contiene mala sintaxis o
simplemente no se puede cumplir. Por último, si tu código de tres dígitos comienza con el dígito cinco, significa que tu solicitud
tuvo un error en el servidor. Algo salió mal en
el lado del servidor, como en, el servidor puede no
cumplir con una solicitud aparentemente
válida. Ahora vamos a abrirnos paso a través de las diferentes
categorías de respuestas y enumeremos algunos
ejemplos para cada una de ellas. Para
respuestas informativas, tenemos el código 100 con la
palabra clave continue Esto significa que el servidor ha
recibido los encabezados de solicitud y el cliente debe proceder
a enviar el cuerpo de la solicitud. Este código se utiliza en
situaciones en las que el servidor necesita confirmar que está dispuesto a
aceptar la solicitud. Por ejemplo, un usuario puede enviar un archivo grande para subirlo a
un servicio de intercambio de archivos. Piensa en transferimos, el servidor responde con 100 continuum para indicar
que está listo para recibir este archivo grande
y el usuario puede proceder con la subida real At respuestas informativas También tenemos 11 con las
palabras clave de protocolos de conmutación. El servidor está indicando
aquí un cambio en el protocolo como el cambio
de HTTP a socket web. El cliente debe seguir este nuevo protocolo para una
mayor comunicación. Para la siguiente categoría, tenemos respuestas exitosas, y aquí tenemos un código
muy conocido, que es 200,
seguido de la palabra clave de bien. Este es el código de éxito más
común, indicando que la
solicitud fue exitosa, el servidor ha
cumplido con la solicitud y la respuesta contiene los datos
o información solicitados. Por ejemplo, piense en un
usuario que accede a una entrada de blog, y el servidor responde con un código de estado de 2000 K entregando el contenido del
blog solicitado con éxito. También tenemos 21,
lo que significa creado. Este código de estado indica que la solicitud resultó en la
creación de un nuevo recurso. A menudo se usa con solicitudes
post o put. Se puede pensar en un usuario que envía un formulario de registro en un sitio web y el servidor
responde con 21 creados, ojalá para indicar que una nueva cuenta de usuario ha
sido creada con éxito También en los mensajes de éxito, tenemos 24 para ningún contenido mientras el servidor
procesó satisfactoriamente la solicitud. En este caso,
no tiene cuerpo de respuesta para enviar de
vuelta al cliente. Esto se usa a menudo
para las solicitudes de eliminación. Si un usuario elimina un comentario en una plataforma de redes sociales y el servidor responde
con 24 sin contenido, confirma la eliminación sin devolver ningún dato
redundante adicional Pasando a los mensajes de
redirección, tenemos 31 con las palabras clave
de movido permanentemente El recurso solicitado se ha movido
permanentemente a una nueva URL. El cliente debe actualizar sus marcadores o
enlaces en consecuencia Se puede pensar en un sitio web de
comercio electrónico que cambie su estructura de URL y el usuario
intente acceder a una antigua. Página del producto. El servidor
responde con 31 movidos, redirigiendo
permanentemente al usuario a la nueva URL del producto También tenemos aquí el
código de 34 no modificado. Este estado se utiliza para indicar que la versión del recurso en
caché
del cliente sigue siendo válida y no es necesario volver a
descargarlo Si un usuario accede a un
sitio web Us visitado frecuentemente, el servidor, reconociendo que la caché del
navegador del usuario está actualizada, responde con estos tres
o cuatro no modificados, indicando que la versión en
caché sigue siendo válida y no se requieren
nuevos datos Para las respuestas de error del cliente, tenemos 400 lo cual
es mala solicitud. El servidor no pudo entender la solicitud aquí debido
a una sintaxis no válida, parámetros
faltantes o tal vez
otros problemas en el sitio del cliente. Piense en un usuario que
envía una consulta de búsqueda con parámetros no válidos
en un sitio de reservas de viajes, y el servidor
responde con 400 solicitudes incorrectas
para indicar que la solicitud carece de información
esencial Además, tenemos 41
para no autorizados. La solicitud requiere autenticación
de usuario. El cliente que
envía esta solicitud deberá proporcionar credenciales
válidas, por
ejemplo, un nombre de usuario
y contraseña o un token. Todo ello con el fin de
acceder al recurso. Por ejemplo, un usuario
intenta acceder a un documento privado en un servicio de almacenamiento en la nube
sin la autenticación adecuada, el servidor
responderá
naturalmente con 41
no autorizados pidiéndole al usuario que proporcione credenciales de registro
válidas antes recuperar toda la respuesta Por último, tenemos 43 prohibidos. El servidor entendió
la solicitud pero se niega a cumplirla. La solicitud del cliente es válida, pero el servidor ha decidido
no dar servicio al recurso. Si un usuario intenta acceder a una sección
de solo administración de una aplicación web, y el servidor responde
con 43 prohibidos, indica
que el
usuario no cuenta los permisos necesarios
para esa acción. Se puede ver que 41 no autorizados se reciben
cuando no proporciona ninguna credencial y 43 prohibido se recibe
cuando proporciona credenciales, pero no tienen los permisos
necesarios adjuntos. También tenemos 44 no se encuentran aquí. El recurso solicitado
no se pudo encontrar en el servidor. Indica que la URL
no es válida o que el
recurso ya no existe. Si un usuario hace clic en un enlace
roto que condujo a una página de producto eliminada en
un sitio web de comercio electrónico, el servidor responderá
con 44 no encontrados, el
fin de notificar al usuario que el recurso solicitado ya
no existe. Para las respuestas de error del servidor, tenemos 500, que significa
Error interno del servidor. Este es un
mensaje de error genérico e indica que una
condición inesperada impidió que el servidor
cumpliera con la solicitud. Es una captura para todos los errores
del lado del servidor. Puedes
pensar aquí en un usuario que intenta enviar un
pedido en una tienda en línea, pero debido a un
problema inesperado en el servidor, esta solicitud da como resultado un error interno del servidor
500. Se aconseja al usuario que vuelva
a intentarlo más tarde. Además, tenemos 52
para puerta de enlace mala. Este código de estado indica que un servidor que actúa como puerta de enlace o proxy recibió
una respuesta no válida de un servidor ascendente, a menudo indica problemas de red. Se puede pensar en un usuario
que accede a un servidor web o una API que actúa como
puerta de enlace u otro servicio. El servidor de puerta de enlace
encuentra un problema al reenviar la solicitud
al servidor ascendente, lo que lleva a una respuesta de
puerta de enlace de 52 camas. Por supuesto, hay muchos
más códigos de retorno que los que enumeré, pero en caso de que te encuentres con uno
que no se menciona aquí, puedes buscarlo en Google y
estarás seguro de
entender exactamente qué
pasó con tu solicitud Cuando se trata de la
distinción entre métodos HTTP
seguros e inseguros, esto no está directamente
relacionado con el código de estado HTTP. Los métodos seguros
como get and hand están diseñados para no tener un
impacto significativo en los recursos. Generalmente se
asocian con respuestas
exitosas o
informativas Mientras que los métodos inseguros
como put o post pueden tener una variedad de respuestas dependiendo de la situación
específica, incluyendo errores de éxito, cliente
y servidor. Como conclusión para esta lección, códigos de retorno
HTTP son esenciales para comprender los
resultados de las solicitudes HTTP. Proporcionan información sobre
el éxito, la redirección, los errores del
cliente e
incluso los errores del servidor asociados con una solicitud determinada Estos códigos son una parte
fundamental del desarrollo
web y la resolución de
problemas, ya que ayudan tanto a desarrolladores como usted
como usuarios a diagnosticar problemas e interpretar los resultados de sus interacciones
con Con todo esto dicho, les
agradezco chicos que se
hayan quedado conmigo hasta el final
de esta conferencia, y espero
verlos en la siguiente.
20. Métodos de solicitud HTTP: Hola chicos y bienvenidos de
nuevo a este curso. En esta
conferencia veremos un concepto muy importante, y ese es el método HTTP. A menudo se
les conoce como verbos HTTP. Y son la base
de la comunicación entre clientes y servidores
en la web mundial, definen las acciones que el cliente puede solicitar
a un servidor, que van desde recuperar datos
hasta modificar recursos En esta lección, exploraremos los diversos métodos HTTP,
son ejemplos prácticos, su papel en la comunicación web, así
como su clasificación
como seguros o inseguros. Y el
concepto fundamental clave de la potencia del ítem. Para comenzar, primero
entremos en el acrónimo CRM. Representa las cuatro operaciones
fundamentales para administrar datos en una base de datos
o sistema de almacenamiento de datos. Se usa comúnmente en el
contexto de APIs, bases y
desarrollo de software para describir las acciones básicas que se
pueden realizar en los datos. Cada letra del acrónimo corresponde a una operación
específica. C es para crear. La operación de creación
implica agregar nuevos datos, registros o recursos a una
base de datos o un almacén de datos. Es la acción de
insertar una nueva pieza de información o una nueva entidad
en el contexto de una API, esto normalmente significa enviar una solicitud para crear
un nuevo recurso. Nuestra carta es para leer en
esta operación en pastillas recuperando o accediendo a datos de una base de datos o data store Esta operación
no modifica la fecha. Se trata de buscar y
revisar la información existente. En APIs. Esta Aspirina
corresponde al envío una solicitud para recuperar
datos de un recurso. U significa actualización. Esto implica modificar
los datos existentes en una base de datos. Es la acción de realizar
cambios en un registro existente, como actualizarlo, atributos o
contenido. En una API. Por lo general, la actualización
requiere enviar una solicitud para modificar un recurso. D significa eliminación. Y esta operación es
la acción de eliminar registros de
datos o recursos de una base de datos o un data store. Se traduce en la eliminación
permanente de la información especificada. En el contexto de las API, esto corresponde al envío una solicitud para eliminar un recurso. Las operaciones de la CRPD son fundamentales en la gestión
y manipulación de datos Sirven como
base para construir e interactuar con
bases de datos, servicios web y aplicaciones
que necesitan realizar
estas
tareas esenciales al diseñar APIs o trabajar con bases de datos, las operaciones de
CRPD son
un concepto crucial para desarrolladores como Q, ya que proporcionan una forma
estandarizada de
administrar los datos de manera eficiente
y precisa Hablamos primero de las operaciones de la
CRPD, ya que se entrelazan con los verbos HTTP de
los posts de Create, get from Reed, put from
Update and Delete, como veremos a continuación Volvamos ahora
a los métodos HTTP. En primer lugar, todavía tenemos, se utiliza para
recuperar los datos de un recurso que
probablemente sea identificado por un parámetro ID o una lista general que contiene todos los elementos
de ese recurso. Algunas notas sobre las solicitudes GET son que se pueden almacenar en
caché y marcar como marcadores Permanecen en el
historial del navegador y
nunca deben usarse cuando se trata
de datos confidenciales. Además, tienen
algunas restricciones cuanto a la longitud y esta
salida a la hora de definirlos, se
utilizan únicamente para
recuperar datos y no modificarlos en
ninguna forma o forma. Imagine que está
usando un navegador web para acceder a un sitio web de
noticias en línea. Al hacer clic en
un artículo de noticias, su navegador envía
una solicitud GET
al servidor del sitio web solicitando
el contenido del artículo. El servidor responde
enviando de vuelta el artículo
solicitado, permitiendo que el cliente lo lea. Siguiente tenemos post método
HTTP saludar al nuevo recurso y lo envía
para que sea procesado por el servidor. No es seguro y puede tener efectos secundarios en el
servidor o en el recurso Ahora las observaciones cuando se
trata de
métodos post son que como getMethod, no se
pueden almacenar en caché, marcar, o incluso cuidar en el historial del
navegador Y además no tienen ninguna
restricción en la longitud. Además, el botón Atrás, si se pulsa en la solicitud posterior
volverá a enviar los datos A diferencia de una solicitud GET, donde aquí no hará daño para
un escenario de la vida real, imagina que estás usando
una aplicación de redes sociales y decides
crear una nueva publicación. Al crear el botón de publicación
real, la aplicación envía una
solicitud de publicación al servidor, incluyendo los medios de texto e
imagen adjuntos. El servidor procesa que
solicitarás guarda el post Visible para tus seguidores. A continuación, tenemos el método HTTP, pero estas actualizaciones son recursos
especificados, lo que significa que reemplaza las tres presentaciones
actuales recurso
de destino
con la carga útil de la solicitud. La principal diferencia
a
la hora de los métodos post y PUT son los resultados que obtienes al hacerlos
repetidamente una y
otra vez. Si bien el método put siempre
producirá el mismo resultado ya que actualiza un recurso una y otra vez, el método post tendrá efectos
secundarios si intenta duplicar la misma
entidad en un sistema. Imagina que tienes un
blog personal y notas un error tipográfico en uno de tus artículos
publicados, usas un sistema de
gestión de contenido y haces correcciones al contenido
del artículo cuando guardas los cambios que tiene CM, envía una solicitud para
actualizar el artículo en el servidor asegurando que ahora
se muestre
la versión corregida A continuación tenemos este
método solicita la eliminación de un recurso
en la URL especificada. Debería eliminar el
recurso si existe. Digamos que tienes una
aplicación de correo electrónico abierta como Gmail y quieres hacer desorden tu bandeja de entrada eliminando
un correo electrónico desactualizado Cuando selecciona
ese correo electrónico específico y hace clic en eliminar,
la aplicación envía una solicitud al
servidor de correo electrónico que elimina el
correo electrónico de su bandeja de entrada. En cuanto al
método HTTP, batch girls, se utiliza para aplicar
modificaciones parciales a un recurso. A menudo se usa cuando se
desea actualizar solo un subconjunto de
la fecha de los recursos. Imagine que está utilizando una aplicación de administración de tareas
para realizar un seguimiento de su trabajo. Te das cuenta de que sales
o una tarea ha cambiado. Por lo que abres la app y actualizas solo la fecha de vencimiento sin
alterar ninguna otra tarea VPLS La aplicación enviará una solicitud
por lotes al servidor, que modifica únicamente la fecha de
vencimiento de la tarea A continuación que hemos tenido at
es similar a gap, pero solo requiere los encabezados del recurso sin
los datos reales, se utiliza para verificar los
recursos hechos los datos o existencia sin transferir todo
el contenido real. Esto podría usarse, por ejemplo, si estuvieras navegando, un sitio web de compras,
querría comprarme un producto. Antes de ver los detalles
del producto, da clic en el botón de verificar
disponibilidad. El sitio web envía una
solicitud al servidor pidiéndome datos
como disponibilidad del producto, precio y la
información de stock sin cargar toda
la página del producto y todos sus datos
correspondientes. Por último, tenemos el método
HTTP de opciones. Este método recupera
información sobre las opciones de comunicación
disponibles para un recurso Permite a un cliente
descubrir qué métodos
HTTP son
compatibles con el servidor. Si está construyendo una
aplicación web y necesita
determinar qué acciones son
compatibles con un servicio web, entonces este método HTTP
es crucial para usted. La aplicación envía
una solicitud de opciones al servicio
preguntando qué métodos están disponibles para un recurso
específico. Esto ayuda a que su
aplicación se adapte a las capacidades de los servicios y conozca qué tipo de solicitudes
puede enviarle. Estos fueron todos los métodos HTTP, pero son conceptos más claves que hay que
entender aquí. A continuación, veamos cómo
podemos clasificar un método HTTP. Cuando se trata de
estos verbos HTTP, se
pueden
categorizar ampliamente en a. En primer lugar, los métodos seguros son dos, métodos
HTTP que
están diseñados para
no tener un impacto significativo en los recursos a
los que se dirigen. En otras palabras, cuando se utiliza un método
seguro, no debe causar
ningún cambio o efectos
secundarios en el servidor
sobre el propio recurso. Y los siguientes métodos HTTP
se consideran seguros. Get it no debe alterar
el estado del recurso
o de la API del servidor únicamente
para la recuperación de datos. Además, cabeza, recupera metadatos sin transferir todo
el contenido, haciéndolo nuevamente seguro También tenemos métodos
HTTP inseguros. Estos en contraste, o métodos
HTTP que
potencialmente pueden conducir a cambios en el estado del
recurso o el servidor. No son seguros en el sentido de que
pueden tener efectos secundarios, como la creación o
modificación o eliminación de recursos. Los siguientes métodos HTTP
se consideran inseguros. No se considera seguro
porque suele llevar a la creación de un nuevo recurso o a la modificación
de uno existente Ponerlo modifica directamente
o crea recursos, y por lo tanto,
no es un método seguro Eliminar, conduce a la eliminación del recurso
especificado, haciéndolo inherentemente inseguro Por último, el lote, aunque
es más dirigido que publicar o poner, aún puede alterar los datos de los
recursos, convirtiéndolo en un método inseguro. Entremos ahora en el
término muy importante de la potencia del ítem. En el contexto de los métodos HTTP, la potencia
del ítem se refiere a la
propiedad de una operación. Estamos realizando la
misma acción varias veces como el mismo efecto
que realizarla una vez. Esto significa que si envía una solicitud potente de artículo
varias veces, ese estado del sistema y el recurso
con
el que interactúa deben permanecer sin cambios
después de la primera solicitud Echemos un
vistazo a algunos ejemplos de elementos potentes métodos HTTP
que obtienen método. Es un elemento potente cuando recupera información
con una solicitud GET, haciendo la misma solicitud
una y otra vez no debería cambiar el estado
del servidor o el recurso
que está obteniendo El método put
también es potente
si usas ambos para actualizar un
recurso con ciertos datos, enviar el mismo pero
solicitar varias veces dará como resultado que el recurso contenga los mismos
datos cada vez. Por último, tenemos las hojas. Aquí. Es un método
potente de ítem porque si solicita la eliminación
de un recurso usando el lead, enviar las solicitudes
repetidamente no cambiará el hecho de que el recurso
ha sido eliminado. En contraste con los
métodos potentes del ítem, no iónicos, tanto en métodos como tienen diferentes resultados
cuando se repiten Por ejemplo, el método post es conocido elemento
potente y repetidas solicitudes de
post para
crear un recurso pueden conducir a la creación de
múltiples recursos idénticos. Cada solicitud da como resultado que se agregue un
nuevo recurso. Por lo general, la solicitud de parche
no es potente para el artículo también. Repetir una solicitud de parche puede actualizar un
recurso diferente cada vez si los cambios son incrementales o dependen del
estado actual del recurso. Veamos ahora por qué importa la potencia de los
artículos. En primer lugar, los métodos
potentes del ítem contribuyen a la resiliencia del sistema. En escenarios donde problemas de
red, tiempos de espera
o fallas de comunicación por
elemento, o fallas de comunicación por las operaciones potentes se
pueden
volver a intentar de manera segura sin causar efectos secundarios
no deseados
o La potencia del artículo también está estrechamente
relacionada con el almacenamiento en caché. Cuando una respuesta a una solicitud potente de
artículo, estas solicitudes de
subsecuencia en caché se
pueden satisfacer desde el efectivo, lo que reduce la carga en el servidor y
mejora Item potentes métodos en
breve, comportamiento predecible, desarrolladores y usuarios pueden confiar en el hecho de que repetir
una solicitud no dará lugar a diferentes resultados o cambios
inesperados en
el estado de los sistemas. Por último, la potencia del artículo
simplifica el manejo de errores. Cuando una solicitud falla o se
interrumpe, nosotros intentamos, ¿introduce inconsistencias
o resultados inesperados En general, a la hora de diseñar APIs, es esencial elegir los métodos HTTP
adecuados para diferentes operaciones
y documentar el potente comportamiento de
su ítem. Esto ayuda a clientes y desarrolladores
como usted a entender cómo deben
manejarse las
solicitudes y qué
esperar cuando
interactúan con la API. Sin esto, realmente espero que algunos de los conceptos presentados
en esta conferencia les
ayuden en el
futuro y
espero verlos
en próximas conferencias.
21. Parámetros de consultas de encabezados: Hola chico, y bienvenido de
nuevo al discurso sobre APIs. En esta conferencia,
echaremos un vistazo a encabezados de
solicitud y los parámetros de
consulta. Exploraremos
el papel crítico que tienen en las solicitudes de API, cómo se utilizan y
las mejores prácticas para
aprovecharlas de manera efectiva. Comenzando con lo que son, los encabezados
HTTP son datos de mate incluidos en las
solicitudes y respuestas de API. Transmiten información
sobre la solicitud, como las credenciales de
autenticación del tipo de contenido o el idioma preferido. Los parámetros
de consulta, por otro lado, son pares de valores clave agregados
al final de la ruta de una URL, separados por signos de
interrogación y ampersand Proporcionan información
adicional a la API sobre la solicitud, normalmente con fines de filtrado,
clasificación o paginación Pasando a los encabezados
En las solicitudes API, juegan un
papel muy importante por diversas razones. En primer lugar, tenemos autorización
de autenticación. Los encabezados suelen llevar tokens o credenciales necesarias
para autenticar al cliente con la API Como
ejemplo concreto aquí se puede pensar en la O del protocolo de
seguridad. El token portador que
use allí para
autenticarse se
almacenará en un encabezado de token A continuación tenemos
negociación de contenido. Los
encabezados accept y content type permiten a los clientes especificar el formato de datos
que pueden aceptar o enviar, como Json o X
ML Headers como control de
caché y comportamiento de
almacenamiento en caché de control Eg para
mejorar el rendimiento Api pueden usar encabezados como límite de velocidad
X
y límite de tasa X restante para hacer cumplir los límites
de tasa en las solicitudes. Tenemos toda una
conferencia dedicada a la limitación de tarifas en
API's en este curso, también
puedes
comprobarlo. Avanzando. Encabezados como aceptar
idioma especifican el idioma preferido donde se encuentra el contenido de
respuesta que
obtendrá de la API. Cuando se trata de
parámetros de consulta en solicitudes de API, proporcionan valiosas opciones de
personalización
para las solicitudes de API,
tenemos
API de filtrado a menudo permiten
a los clientes filtrar datos
especificando parámetros de consulta
como signo de pregunta, filtro es igual a palabra clave para
recuperar registros específicos. Los clientes también pueden ordenar las respuestas
API usando parámetros de
consulta como
signo de pregunta ordenar es igual al campo, o el orden del signo de pregunta es igual a
ascendente o descendente. Los parámetros de consulta como el signo de
interrogación, la página y el signo de interrogación
por página permiten el acceso
paginado
a grandes conjuntos Api's puede admitir la búsqueda de
texto completo sin parámetros de
consulta como preguntas
Q es igual al término de búsqueda. Cuando hablamos de
mejores prácticas para encabezados y parámetros de
consulta, tenemos bastantes. Lo primero que te
sugiero que hagas es siempre una autenticación
segura,
encabezados y credenciales. Utilice
tokens de autenticación, tiempos de vida cortos y prácticas de
almacenamiento seguro de tokens Mantenga la coherencia en
el uso de encabezados y nombres de parámetros de
consulta en su API, endpoints
y documentación Validar y
desinfectar la entrada del usuario, especialmente cuando los parámetros de consulta están involucrados para
evitar la seguridad Vulnerabilidades como
eQUL Injection proporcionan documentación
clara y completa sobre encabezados
y parámetros de consulta compatibles, incluyendo su uso,
tipos de datos y valores esperados Si se aplica la limitación de tasa, comunique los límites de tasa y las cuotas
restantes usando encabezados de
respuesta. Considere la posibilidad de crear versiones de su API para garantizar la
compatibilidad con versiones anteriores y use encabezados específicos de versión o parámetros de consulta
cuando sea necesario Nuevamente, aquí tenemos toda
una conferencia en el discurso sobre el versionado de
API, así que puedes echarle un vistazo a eso Además, los encabezados y los parámetros de
consulta son los
componentes básicos de las solicitudes de API que permiten a los clientes
comunicarse de manera efectiva con API mientras personalizan
sus interacciones Comprender su
función, uso adecuado y mejores prácticas es esencial
para los desarrolladores que buscan aprovechar todo el potencial de API en sus aplicaciones. Gracias, Chris,
por seguir
conmigo hasta el final
de esta conferencia. De veras espero que hayas sacado
algo de ello. Y te veré
en la siguiente.
22. Especificación de OpenAPI: Hola chicos, y bienvenidos de nuevo a este
tutorial de especificación de API Abierta donde entendemos cómo podemos
documentar mejor nuestras API de Rest web. En esta conferencia,
vamos a hablar sobre qué es
exactamente una especificación de
API abierta. Esta
especificación API abierta se denominó especificación Swagger
antes de lo que es,
es un
formato de descripción de API para APIs de resto Es igualmente adecuado tanto para diseñar
nuevas API antes de implementarlas como
también para documentar tus API
existentes para que los usuarios puedan entender
más fácilmente cómo
pueden hacer llamadas para recuperar recursos y datos en general de ellas. API abierta le permite
describir toda su API, incluidos los endpoints
disponibles, las operaciones en los formatos de
solicitud y respuesta que pueda recibir soporte, los métodos de
autenticidad, los contextos de
soporte y también otra información La especificación de API abierta ha sufrido varias versiones
desde el lanzamiento original. La
plataforma en línea Sweater hub que
usaremos en este tutorial
actualmente está soportando
las tres versiones de Open API que
es la más reciente, pero también soporta
las dos versiones nivel más concreto hablando ahora, este archivo Open API que
vamos a crear en
el lenguaje Yamo, lo veremos
en solo un momento Le permite describir toda
su API, incluidos
los endpoints disponibles Por ejemplo, aquí tenemos usuarios y operaciones
en cada punto final. Entonces estos son los métodos
HTTP de los que hablamos en
la última conferencia. Por ejemplo, en los usuarios de punto
final, podemos haber documentado un método get que
obtendría la lista de usuarios y el método post
que crearía un nuevo usuario. También le permite describir los parámetros de
operación, entrada y salida
para cada operación. Por ejemplo, si quieres obtener la información sobre
un usuario específico, puedes darle un parámetro, ingresar como ID, y recuperará la información sobre
ese usuario específico. También te permite documentar métodos de
autenticidad para esa API en
caso de que haya alguno También le permite documentar información de
contacto, términos de uso de la
licencia en. Como veremos cuando
pondremos manos con la
plataforma en línea, sweerhup, veremos exactamente
la sintaxis para
cada parte de la documentación que
podamos escribir sobre
nuestra API de Web Estas especificaciones API de las
que hablamos
se pueden escribir ya sea en los lenguajes
Yamo o Jason. Este formato es fácil de aprender y legible tanto para
humanos como para máquinas. Vamos a hablar de
ambos en
las próximas conferencias. Gracias por seguir
conmigo hasta el final de este tutorial y
espero verlos
chicos en el siguiente.
23. Descripción general de SwaggerHub: Hola chicos y bienvenidos de nuevo a este tutorial de
especificación API abierta. En esta sección, vamos
a echar un vistazo a cómo
podemos usar la herramienta Swagger Hub y a quienes
entienden de qué se trata Más específicamente.
En esta conferencia, vamos a discutir la definición de la herramienta
Swagger hop y una visión general de esta plataforma
en línea comenzando por la
definición de la misma Swagger Hub es una plataforma
que está disponible en línea y te ayuda a
desarrollar tu propia API, ya sea pública para tu uso personal o interna y privada
para tu empresa Lo hace ayudando a desarrollar tu API
documentándola en detalle El principio en el que se basa en gran medida Swagger
Hub es el principio de diseño primero código posterior como
verás en solo un momento Con Swagger Hub,
empiezas
pensando en cómo
va a quedar tu API Además,
exponiendo sus recursos, operaciones y modelos de datos. Solo una vez que todo el
diseño de tu API esté completo y tengas una estructura
clara para ello, podrás iniciar la implementación
real de la lógica de negocio de la misma. Ahora las definiciones
de esta API que
escribes se guardan en
la Nube y
también se pueden sincronizar con sistemas de versionado
externos
como Github o Bitbucket que hace que sea mucho más fácil colaborar con tu
equipo en él y además mantener más versiones del mismo una vez que consigue tracción
y empieza a evolucionar. Como pueden ver aquí, tengo la página Swagger Swagger Hub
abierta en mi navegador Chrome solo para darles una
mirada rápida en segundo plano mientras les
explico chicos para qué se utiliza básicamente esta herramienta Las herramientas Swagger Hub integran
las herramientas Swagger para que sean más conocidas
y de uso Admite el código del editor UI
En y también los datos válidos en su plataforma
colaborativa en línea que vamos a echar un
vistazo en tan solo unos momentos. La sintaxis para describir estas API en la herramienta
Swagger Hoop es la API Swagger Open a
como probablemente esperabas, siendo este el
formato predeterminado de las definiciones de API, usaremos Y L para escribir la estructura de
tu API en el discurso en general Es el lenguaje elegido para escribir en esta swagger
para que puedas sin embargo, pegar en el editor texto
Json si eso es
con lo que te sientes más cómodo y sabe
analizarlo y reconocerlo Pero una vez que guardes el
trabajo que has hecho, el Json que escribiste se
convertirá también en YAML Ahora por supuesto, la plataforma
swagger hop que te estoy presentando en
este tutorial está
disponible en línea y también es de
uso gratuito durante 14 días Ahora vamos a tomar una
visión general de la plataforma. Como puedes ver aquí, estoy en
la casa de mi app Swegerhup. En mi navegador,
primero notas el panel lateral en la parte izquierda de la pantalla. Y comienza con
la página my hub que enumera todas las APIs a las
que tienes acceso. Pueden ser creados por
ti mismo o aquellos en los que fuiste invitado a
colaborar por otras personas. Por ahora,
solo tengo una tienda propia que creé usando
las mascotas a una plantilla. Entonces es algo bastante
básico que vamos a echar un vistazo en un momento. También puedes buscar
desde el panel lateral en el swagger hub una API usando esta
opción de Esta es una forma de
ver muchas
API públicas excelentes desarrolladas por los usuarios de
Swagger Hub y te ayudará mucho, especialmente si recién
estás comenzando a documentar
tu Puedes inspirarte en la estructura de su API o simplemente echar un vistazo rápido a algunas
de las sintaxis que usan. Ahora al hacer clic en una API
aleatoria desde aquí, solo
voy a
seleccionar esta aleatoria, vas a notar. Que obtendrá esta página
que tiene una vista dividida. En la parte izquierda,
vas a ver el código Y AML de la definición
Open API En la parte derecha,
la documentación generada en un hermoso estilo de
referencia. Por supuesto, puede cambiar el tamaño estos paneles desde esta barra
lateral aquí mismo Otra observación aquí
sería que Swegerhb te
permite probar estas llamadas API
directamente en el navegador Pero sólo voy a cambiar
a la plantilla petitora para que cada uno sea más representativo
de lo que quería mostrarles Aquí tenemos una
plantilla de tienda de mascotas, por ejemplo. Podemos usar la
operación get para obtener un usuario. Una vez que hagas clic en Probar, puedes buscar un nombre de usuario
que necesite ser buscado También te redirige al
usuario uno para realizar pruebas. Si escribimos el usuario uno aquí
y damos clic en Ejecutar, obtenemos las respuestas. La respuesta del servidor
tenía un código de 200, lo cual está bien, lo que significa que nuestra solicitud terminó bien. Y este es el cuerpo de
respuesta que obviamente tiene el
ID del usuario, el nombre de usuario que es una cadena, un nombre que es una cadena, apellido que es
una cadena, correo electrónico, contraseña, teléfono y datos de usuario. Estas son, por
supuesto, cadenas codificadas, pero en el caso de
realmente hacer una solicitud a tu
API de Postman y tener realmente en tu
base de datos usuarios reales, vas a ver valores que son específicos
para esos usuarios aquí Aparte de eso, también
tenemos algunos encabezados de respuesta. La duración de la solicitud,
cuánto tiempo
tardó hasta nuestra respuesta
desde el servidor. Además, has detallado
aquí las respuestas que puedes obtener con su
descripción de código y enlaces. En primer lugar, tenemos
el código 200 que es la operación exitosa
como descripción. Y también te da un ejemplo de valor de
lo que vas a obtener si la solicitud que hiciste terminó con éxito y
la respuesta que obtienes, es una valorada. Pero también podrías darle otro usuario que no esté
disponible en la base de datos. En cuyo caso terminarás con un código de error de cuatro oh cuatro o
400. Además, el panel de navegación
del lado izquierdo tiene el rol de
mostrarte la lista de operaciones y modelos de datos que están disponibles
en esta API abierta. Además, al hacer clic en ellos
, automáticamente te
llevará a esa parte del script YAML Por ejemplo, si hacemos clic en el método HTTP que
acabo de describir anteriormente, puede ver que
automáticamente nos llevó a la porción
del código Amo donde se describe
para
que se muestre bellamente en
esta vista de estilo de referencia. Ahora algunos otros botones que
están disponibles aquí
serían los del lado
más a la izquierda de la pantalla Lo que pone a su disposición para
que ocultes la navegación, que es este panel de
navegación izquierdo del que acabo de hablar. Ocultar el editor, que es
por supuesto la navegación
y también el código Amel Y también puedes ocultar la interfaz de usuario, que es el documento de
estilo de referencia en la parte derecha de la pantalla. Subiendo un poco,
vamos a tener una información rápida sobre nuestra
descripción de Open API aquí mismo, donde tenemos algunos detalles, algunas integraciones y el propietario creado por menos seguros y otros hermosos
detalles como ese Por supuesto, puedes
abrir tu API, renombrar tu API, o
compararla, y fusionarla. No vamos a
meternos en eso ahora mismo, sino yendo aquí a
la versión de la misma. Si hacemos clic en este botón de abajo, puedes ver que tienes algunas opciones aquí que están
disponibles para tu API. Puedes hacer que tu API sea privada, lo cual tengo
que decirte que solo puedes hacer si tienes el plan premium
adjunto a tu cuenta. Entonces puedes publicar tu API, que es un botón muy
importante. Una vez que hayas terminado de escribir
tu especificación API, entonces puedes eliminar
esta versión. Y también puedes agregar una nueva
versión en caso de que tu API esté involucrada y quieras desarrollar una versión completamente
nueva para ello. Ahora puedes ver
la documentación aquí en otra página entera. Que básicamente solo toma
el documento de estilo de referencia y te lo muestra en toda
una página para que lo veas de una
manera más relajada. Aparte de eso, puedes
hacer clic en las opciones de API donde puedes editar
tu push de Github y también restablecer los cambios. Puedes desactivar las
notificaciones y compartir y colaborar
en esta API. Por último, está
el botón Exportar, que te presenta
diferentes métodos descargar tu API, ya sea en Yama o Jason, alguna documentación,
el stub del servidor, y también el SDK del cliente En la siguiente conferencia,
vamos a echar un vistazo más de cerca a
una API abierta y a su correspondiente código
Y AML para aprender cómo podemos hacer una documentación para tu propia API
usando esta herramienta Gracias chicos por seguir
conmigo hasta el final de esta conferencia, y tengo muchas
ganas de verlos en la siguiente.
24. Información, servidor y etiquetas: Hola chicos y bienvenidos de nuevo a este
tutorial de especificación de API abierta donde
hablamos de la plataforma en línea Swagger
Hub que puedes usar para documentar
tu API en detalle En esta conferencia, vamos a discutir los servidores de información y partes de
texto de nuestro
Yamoscript que se utilizan para crear
la documentación
de Swagger para la documentación
de Swagger Como dije en la conferencia
anterior, esta
parte negra izquierda es el editor. Escribimos el script Yaml
que se utiliza para renderizar la interfaz de referencia donde se incluyen la API y sus
endpoints Cada definición de API,
como puedes ver, comienza con la versión de API
abierta, que en el caso de la API, es
decir, por cierto, la
plantilla predeterminada de pet store que
proporcionan en la plataforma
para que puedas comenzar y hacerte una
idea bastante buena de las características que pueden ofrecer con la
plataforma es de tres. Esa es la forma en que el script GM comienza cuando se escribe una especificación
API abierta. La siguiente sección
se llama info y contiene el metodatos
sobre tu API Este Metoddata tiene
información sobre la API, título,
versión de descripción, y así sucesivamente Esta sección de información
también puede contener
información de contacto, el nombre de la licencia, URL y también otros detalles. Como puedes ver en nuestro caso, tiene la descripción de, esta es una tienda de mascotas simple, un simple servidor de tienda de mascotas. Y puedes encontrar
más sobre swagger, que podemos ver que se renderizó justo debajo
del título aquí Entonces la versión de nuestra
API es bastante obvia. Ese es uno de los datos que se renderizan en este cuadro
gris aquí mismo. Entonces tenemos el título, La tienda de mascotas Swagger, Y luego algunos Términos del servicio, que están aquí mismo Y también especifican el enlace para redirigir
a luego algún contacto, que es el contacto de
los desarrolladores aquí mismo, que es un correo electrónico. Y luego algo de información sobre la licencia y la
URL que es Apache para hacer eso es bastante
autoexplicativa para la primera parte de
la documentación de la API. A continuación, como puedes ver, necesitamos definir la dirección del servidor
API y la URL base para las
llamadas API que además vamos
a realizar. Esta sección de servidor
también puede tener una descripción. Ahora supongamos que nuestra API se
ubicará en
httpsmypiample.com Entonces se puede describir
como la etiqueta del servidor, luego URL, como
puedes ver en la línea 19, y luego la ruta que acabo de
contarte más concretamente, en el caso de esta plantilla de
Pet store, puedes ver que
la descripción es la la
API Swagger hub Y luego te da URL, que es el Swagger
Hub.com mi nombre, tienda de
ropa, tienda de
ropa Y puedes ver que también
puedes seleccionar este como tu servidor principal y también
está disponible aquí. El siguiente tramo, justo
antes de entrar en el camino uno es el tramo Te. Lo que esto hace es básicamente
que puedes asignar una lista de etiquetas a cada operación API
que tengas en tu estructura. Las operaciones tecnológicas pueden ser manejadas manera diferente por herramientas
y bibliotecas. En nuestro caso, Swagger UI
utiliza estos textos que
das para agrupar las
operaciones mostradas de esta Tener un diseño más elegante
y armado para tus endpoints
Opcionalmente aquí, también
puedes especificar una tecnología de docs
externa para cada una de tus etiquetas
usando la
sección de texto global en el nivel raíz, que es esta
aquí en la línea 21 Los nombres tecnológicos aquí deben coincidir con los utilizados en todas
sus operaciones. Esta es la forma en que
Swaggerhub es capaz de mapear cada método HTTP a su tecnología correspondiente
y mostrarlos Como ves en la
pantalla aquí mismo, tenemos la agrupación de mascotas,
la agrupación de tiendas
y la agrupación de usuarios. Las operaciones son en realidad, como veremos en
la siguiente conferencia, los métodos HTTP
que se realizan en una específica cada una de esas
operaciones, por ejemplo, dispuestos aquí
se puede ver que tiene la sección tags de
path y sabe que la operación post para la ruta path va
a estar en el grupo pat. Ahora, el orden de las etiquetas en la sección de texto global también controla la
clasificación predeterminada en SwegerUI Como puedes ver, pet
es la primera etiqueta, store es la segunda, y usuario es la última nota
aquí que es posible
usar una etiqueta en una operación aunque no esté
definida a nivel raíz. Y también se mostrará
muy bien como puedes ver aquí. Más concretamente en nuestro ejemplo, en el nivel raíz del texto, tenemos el
primero que es pet Y la descripción,
todo sobre tus mascotas que se muestra justo
al lado del título de la etiqueta. Además, tienes esta descripción que se muestra en la parte
derecha de la etiqueta. Eso es averiguar más. Y también puedes proporcionar
la URL que se muestra aquí. Esto fue al respecto con
la primera conferencia de la herramienta Swegerhub sobre servidores de
información y etiquetas En la siguiente conferencia, vamos
a discutir rutas y operaciones
que se están
realizando en este script Yama
que
además van a mostrar en la interfaz de usuario render de la documentación de la API de
Seger Gracias chicos por seguir
conmigo hasta el final de este tutorial, y tengo muchas ganas verlos en el próximo.
25. Rutas y sus operaciones: Hola chicos, y bienvenidos de nuevo a esta
especificación API abierta a Trio, donde aprendemos más sobre
la plataforma Swegerharb y cómo podemos
documentar mejor nuestras API En esta conferencia,
vamos a discutir caminos y operaciones en
la plataforma Swegerharp Más específicamente la
sintaxis de las mismas en el documento Yama
para que sean renderizadas. Como puedes ver en la
parte derecha de la pantalla aquí, en términos de Open API, las
rutas son los recursos
también conocidos como endpoints que expone
la
interfaz segura de programación de
aplicaciones Esto puede ser por ejemplo, una información de
barras de usuario o ID de usuario Las operaciones son
los métodos HTTP
disponibles dentro de sus rutas que se utilizan para
manipular estas rutas, como get, post o delete. Para cada ruta específica, podemos articular métodos HTTP
o como su nombre está aquí, operaciones que están
disponibles para esa ruta Por ejemplo, aquí
tenemos la palabra clave paths, luego tenemos la path path. Y luego tenemos
múltiples operaciones. Por ejemplo, las rutas y
operaciones de la API put y
post se definen en la sección de ruta global de
su especificación de API. En el caso de este
guión aquí mismo, esto está en la línea 34. Todas las rutas que
encontramos aquí son relativas a la URL del servidor API. La URL de solicitud completa tiene la
sintaxis de la URL del servidor. Y luego el camino que
ves aquí mismo, los servidores
globales de los que
hablamos en la última conferencia también pueden ser anulados
tanto en el nivel de ruta como en el nivel operación Las rutas pueden tener un resumen
opcional más corto y una descripción más larga
para fines de documentación. Estos campos están nuevamente
disponibles en el documento Yama, específicamente para cada uno de ellos. Como puedes ver aquí
en la ruta de la etiqueta, tenemos el resumen, agregamos la nueva ruta a la tienda. Además, tenemos la descripción de la respuesta, 45 entrada no válida. Estas informaciones
aquí se supone que
son relevantes para todas
las operaciones en este camino. La descripción puede ser multilínea
ya que puede ser una más larga y admite la reducción de marca
común para la cual representación de
texto Ahora en lo que respecta a las plantillas, puedes usar llaves para marcar partes de una URL como parámetros de
ruta, pero también puedes usar
la etiqueta de parámetros, como puedes ver aquí mismo Y luego solo especifique múltiples entidades sobre
ese parámetro para cada una. Como ya he dicho antes, se
pueden definir operaciones. Así que los métodos HTTP que se pueden utilizar para acceder a esa ruta y leerla o alterarla o eliminarla. Openapi tres soporta
las operaciones get, post, put page, delete head options
y trace Una sola ruta puede soportar
múltiples operaciones. Por ejemplo, obtener de
usuarios para obtener una lista de usuarios y publicar de
usuarios para agregar un nuevo usuario. Algo a lo que hay que prestar atención aquí sería que la API abierta define una operación única como una combinación de una ruta
y un método HTTP. Esto significa que no se
permiten dos métodos get
o dos post para la misma ruta aunque tengan parámetros
diferentes. Como parámetros no tienen ningún efecto aquí sobre la
característica de singularidad. Cada operación
de su API también admite algunos elementos opcionales para fines de documentación. Al igual que los caminos,
tienen un breve resumen y una descripción más larga
de lo que hace una operación. La descripción puede ser multilínea y también admite la marca
Common. También tienen textos que se utilizan para agrupar
operaciones lógicamente, recursos, o cualquier otro
calificador como puedes ver aquí Por ejemplo, en la línea 51
tenemos la etiqueta pat. También el atributo
docs externos aquí se utiliza para hacer referencia a un recurso
externo que contiene documentación
adicional Ahora abierto. Pi tres soporta
parámetros de operación P vía ruta, encabezados de cadena de
consulta
y cookies. También puede definir
el cuerpo de solicitud para las operaciones que transmiten
Td al servidor, como post, put y patch. Los parámetros de cadena de consulta
no deben incluirse en las rutas. Deben definirse
como parámetros squary. En cambio, con el atributo
query que podemos ver aquí en la línea 77. Para el parámetro denominado status, tenemos el especificador de consulta Otra observación rápida
y bastante obvia aquí, sería que es
imposible tener múltiples rutas que difieran
solo en la cadena de consulta. Como API abierta considera
una operación única, una combinación de una ruta y el método HTTP y parámetros
adicionales no
hacen que la operación sea única. Otro atributo
para las operaciones humanas aquí es el ID de operación, que es una cadena
única opcional utilizada para identificar una operación. Por ejemplo, aquí
tenemos el ID de operación de una ruta aquí para el
método post del path path. Si decides
proporcionar estos ID, presta atención al
hecho de que deben ser únicos entre todas las operaciones
descritas en tu API. Algunos generadores de código utilizan este valor de atributo para nombrar los
métodos correspondientes en código. También puede marcar operaciones
específicas como en desuso para
indicar que
deben ser transacciones fuera de uso con la sintaxis
de otra
de estas características que quedaría desuso y luego el valor
completo de true, la matriz de servidores globales desde el inicio del script Amo
del que hablamos en
la última conferencia, y que está presente en línea 16, puede ser anulado
tanto en el nivel de ruta como en el nivel de
operación Esto es útil si
algunos endpoints usan un servidor o ruta base
diferente al resto de su API Este puede ser el caso
cuando hablamos la operación de carga o
descarga de archivos,
o tal vez un endpoint en desuso pero
aún funcional Esto fue sobre ello
con la sección de caminos y operación de nuestro
swagger hub Gracias chicos por
seguir conmigo hasta el final de este tutorial. En la próxima conferencia,
vamos a hablar de esquemas. Tengo muchas ganas de
verlos ahí, chicos.
26. Esquemas para modelos de datos: Ayuda a los chicos y bienvenidos de nuevo a este
tutorial de especificación de API abierta donde entendemos cómo funciona la plataforma
Swagger up Y cómo podemos escribir
código Yama con el fin de escribir una mejor documentación
para nuestra API con swagger En esta conferencia,
vamos a hablar sobre esquemas y la
sección de esquemas de tu guión Yama Como puedes ver aquí en la plantilla Pet store de la documentación de
la API. Si te desplazas hasta la parte inferior, tenemos así como en el
script Yama y también en la interfaz de usuario. Y estos rápidos C dos
esquemas que definen los modelos de datos que están disponibles en el back
end de nuestra base de Y estos modelos de datos son
objetos que pueden ser expuestos y manejados a través de los
endpoints de nuestra API que
documentamos aquí en PI abierto tres y por lo tanto
en swagger La sección
de esquema del script UR yao se refiere a los modelos de
modelos de datos que están disponibles, como dije, a través de puntos finales de Ur Los tipos de datos de estos modelos se describen usando
un objeto de esquema. Ahora, al describir
un objeto de esquema, debe usar palabras clave
y términos estándar de los
cambios en el esquema. Comenzando con
los tipos de datos que están disponibles en
los objetos de esquema. El tipo de datos del esquema está
definido por la palabra clave type. La sintaxis aquí
sería, por ejemplo, type, y luego string o
cualquier tipo que sea. En Open API, tenemos acceso
a los siguientes tipos básicos. Tenemos cadena, número, entero,
matriz de lingotes y objeto Por ejemplo aquí,
la entidad de orden tiene la propiedad ID y tiene el
tipo de tipo de datos enteros. Es bastante sencillo. Estos tipos existen en la mayoría de los lenguajes de
programación, aunque puede que no tengan el
mismo nombre que vemos aquí. Usando estos tipos,
puede describir
prácticamente cualquier estructura de datos con la
que pueda estar tratando cuando se
habla del campo de
un modelo de datos desde
atrás y base de datos. Al tratar con números, existen los atributos
de mínimo y máximo que especifican el rango de cierto campo
del modelo que puede tomar. Además, la longitud de
la cadena puede
restringirse usando los atributos de longitud media y longitud
máxima. Al igual que el atributo type
here, puedes ir como
longitud media y longitud máxima. Eso debería limitar la
longitud de tu pantalla. Lo mismo siendo válido para
la gama de Integra, si acaso quieres que los campos de tus
modelos estén un
poco restringidos y quieras
informar a los usuarios
que va a hacerlo. Además, quiero
usar tu API y ayudarlo en la documentación para
decirle que, por ejemplo, al obtener un ID de pedido, el pedido debe estar en 1-11 porque esas son
las únicas entradas que
tienes en la base de datos
para que él evite 44 errores Ahora, un
tipo muy útil cuando se trata esquemas en Swagger Hub
son las Puede utilizar la palabra clave para
especificar valores posibles de un parámetro de solicitud o una propiedad de modelo
que no sean las enumeraciones
y los tipos de datos Esta API abierta tres que se utiliza en la plataforma
Swagger Hub Vamos a definir
diccionarios donde las claves son cadenas en caso de que
no conozcas este diccionario, también conocido como mapa, mapa hash o matriz asociativa, es un conjunto de pares de valores clave Para definir un
diccionario para tu campo, necesitas usar el objeto type, como puedes ver en la línea 536, y la palabra clave
properties adicionales para especificar el tipo de valores
en los pares de valores clave de palabras. Junto con estos diccionarios, Open API proporciona varias
palabras clave que puede usar los esquemas combinados
al validar un valor de un parámetro
contra múltiples criterios Aquí tendríamos uno de los que valida el valor contra exactamente uno de los subesquemas Todo eso valida el valor contra todos los
subesquemas y cualquiera de ellos valida
el valor contra uno o más de
los Hablando más concretamente
sobre nuestras mascotas hacia plantilla de documentación API
que tenemos aquí Se puede ver que los esquemas, por lo que los objetos que podemos hacer un crudo operaciones con
nuestra API serían orden, el orden de tu
mascota, que tiene un ID, eso es un entero, un ID de mascota, una cantidad, una fecha de envío,
que es una hora del día, Un estado que es, um, como te he dicho de
este tipo antes, que se puede colocar,
aprobar y entregar Y aquí está la
sintaxis de eso ahora. También podemos tener una categoría. También podemos tener un usuario
que haga el pedido. También podemos tener una etiqueta. También podemos tener una mascota que tenga un esquema
de categoría dentro de ella. Tenemos un nombre,
URL de fotos que pueden tomar al usuario y
darle una fotografía de esa palmadita en caso de que
quiera x ese campo Tenemos algún texto que tiene
el esquema tecnológico en él. Y por último, tenemos la
respuesta de API documentada aquí. Como dije, la sintaxis de Amo aquí
es bastante sencilla. Tenemos los componentes, nivel
raíz destacados,
luego los esquemas en él. Simplemente escribes el nombre
de tu esquema por ejemplo. Tenemos orden, entonces
el tipo del mismo, y luego las
propiedades que son, como he dicho aquí, si quieres tener una mirada lado a lado y tal vez
mapearlas con tu mente, tienes las propiedades
de ID, eso es un entero. Tiene un formato de 64. Lo mismo para la cantidad de identificación de mascota solo la cantidad
tiene un formato de 32. Ahora tenemos la fecha de envío
que tiene el formato de una fecha y hora y es
de tipo string. Aquí se sugiere al usuario de la API
que debe ser una hora del día, pero en realidad es una cadena. Y también tenemos el
estado que escribe cadena, tiene una descripción, como se puede ver, estado de orden
que se escribe aquí. Y además explica para
qué se utiliza este campo. Tenemos la implementación
del tipo de datos en el mismo, que en este caso es el anual que puede tomar
ya sea valores colocados, aprobados o entregados Por último, tenemos un lingote
que representa si el pedido es completado
o no por la tienda También podemos, como ve aquí, especificar el valor por defecto para el campo en este caso es false. Esto se parece bastante a los siguientes esquemas
que tenemos aquí Esto fue sobre el
último componente de nuestro script Amo que
vamos a necesitar saber
para que podamos escribir
un script de Yam que se
traduzca en para que podamos escribir
un script de Yam que una especificación
API usando también la plataforma Swegerhop Gracias chicos por seguir
conmigo hasta el final de este tutorial. Tengo muchas ganas de
verles en la próxima.
27. APIs RESTO de descanso: Hola chicos y bienvenidos de
nuevo a este tutorial. En esta conferencia,
vamos a ver las APIs de descanso, qué son, cómo funcionan, y si
obviamente son útiles. Y también
vamos a entender la diferencia entre una API
simple y la API resto. Así que al comenzar al
hablar de APIs de descanso, la palabra resto proviene de
Representational State Transfer, que es un estilo
arquitectónico de software que utiliza un subconjunto de HTTP. Se utiliza comúnmente para crear aplicaciones
interactivas
que utilizan servicios web. servicio web que sigue estos lineamientos
se llama RESTful. Dicho servicio web debe proporcionar sus recursos web en una representación
textual y permitir que sean rojos
y modificados con un protocolo apátrida y el conjunto predefinido
de operaciones. Este enfoque permite
la interoperabilidad entre los sistemas informáticos en internet que
prestan estos servicios. En este tutorial,
vamos a trabajar las
APIs de descanso de semana más precisamente
documentándolas en detalle. Al tratarse de una regla de muy buena
práctica para nuestra API sea clara y
muy bien estructurada. Gracias chicos por quedarse
conmigo hasta el final de esta conferencia. Y realmente espero
veros chicos en el siguiente donde
vamos a
discutir los métodos de solicitud HTTP y devolver los códigos que están disponibles
al tratar con las API de descanso.
28. APIs de jabón: Chicos, bienvenidos de nuevo
a este tutorial. En esta conferencia,
vamos a discutir las API de jabón. Como ya vimos algunas
cosas sobre las APIs de descanso. Npr también va a
hacer una comparación en una conferencia posterior entre
estos tipos de API antes de morir, vamos a ver algunas
cosas específicas sobre las API de jabón. Qué son cuando
se utilizan. Para que sepas qué API
puedes elegir al intentar
implementar una de las tuyas. Entonces, en primer lugar, jabón representa una herramienta
que hace que los sistemas que utilizan diferentes sistemas operativos se comuniquen a través de solicitudes HTTP. Utilizando exclusivamente paquetes
XML de API basadas en
datos se
realizan para crear, recuperar, actualizar
y eliminar registros. Básicamente realizar
operaciones de crudo sobre ellos. Al igual que las APIs de descanso son. Pocos ejemplos de modelos de datos
que puedan ser manipulados. Podría ser usuario, algunos objetos generales en las solicitudes
de la API de jabón. Entonces se utiliza con todos esos lenguajes que
soportan servicios web, como JavaScript o Python, o C Sharp por nombrar algunos. La principal ventaja de estas API es la flexibilidad
que tienen los desarrolladores. Cuando se trata del lenguaje
de programación. Puedes escribirlos en. Su concretización
es la fabricación de protocolos basados en web como HTTP que ya son compatibles con todos los
lenguajes y sistemas operativos. Además, la S en el nombre celular Dove soap
APIs significa simple. El protocolo de jabón solo proporciona la base simple para implementaciones
complejas. El espacio está
conformado por cinco partes. El sobre es la primera parte, que es la etiqueta que
especifica si un XML, esto es respuesta de jabón, como te dije antes, la forma en que
se comunican las API de jabón y la forma en que ponen su
la información es cierta. Archivo Xml, que es una granja Extensible
Markup Language que tiene sus propias etiquetas y se
utiliza para transferir datos. Tendremos toda una conferencia sobre el tipo de expediente más adelante. Ahora, también tenemos la
parte pesada de un protocolo de jabón, y éste es
en realidad opcional. A continuación tenemos el cuerpo, que es la parte más
importante, es básicamente la mayor parte
del mensaje de jabón. Por lo que contiene la mayor parte de la información que se envía. Y también por último,
tenemos la cubierta de fallas, que es el último componente
de las API de jabón entran esta baraja de ambos se
coloca dentro de la fiesta. Lo que fallece
especifica los mensajes de error que podrían aparecer dentro de
esa solicitud o respuesta. Ahora, hablando de
algunas ventajas más cuando se trata
del protocolo de jabón. Propiedades de neutralidad significa que funciona en una amplia
variedad de protocolos, desde HTTP hasta SMTP. Y también otra propiedad
que constituye una ventaja a la hora de hablar las API de
jabón con su
extensibilidad. Así que gracias chicos por quedarse conmigo hasta el
final de este tutorial. Se trataba de la
presentación de las API de jabón. Espero veros
chicos en la siguiente, donde echaremos un vistazo a
una comparación entre las API
del Sur, las API de descanso. Además podemos entender cuál es mejor elegir dependiendo de nuestra situación
actual y de nuestras necesidades de implementación.
29. jabón en comparación de RESTO: Hola chicos y bienvenidos de
nuevo a este tutorial. En esta conferencia,
vamos a ver la comparación en API de descanso y API jabón para entender
cuál sería mejor para nosotros si queremos
empezar a desarrollar nuestra propia API. La principal diferencia
entre las API de descanso sería que el jabón es un protocolo y el descanso es un estilo
arquitectónico. Además, las API de resto
usan múltiples estándares, como HTTP, Jason,
URL, CSV y XML. A pesar de
que se preferiría el signo de cambio, puedes usar con lo que
más te sientas cómodo. La API de jabón es, por otro lado, se basan en gran medida en el HTTP y sólo XML para la transferencia de
datos. De estas diferencias
entre ellos. Viene una
desventaja, obviamente, hora de tratar con las API de jabón el hecho de que las solicitudes
están en el mismo XML. Y de esa manera son mucho más grandes que nuestra
respuesta JSON por sí misma. De esta manera, el jabón terminará usando mucho más
ancho de banda, luego descansará. El descanso es mucho más rápido y
eficiente en este sentido. Ahora, en general, debemos
usar el descanso cuando no necesitamos un estado que se mantenga
entre llamadas API. Para dar un ejemplo de mostrador aquí, puedes pensar en un sitio de
compras que necesita
retener la información
de que te compraron. En otras palabras, al
ingresar a la página, ¿dónde pagas por ella sin embargo? Este sería un caso donde
auto API sería mejor que una API de descanso porque
necesitaría que esta fecha de menos carrito se mantuviera
a la página de pago. Ahora se ha estandarizado y también se ha construido
en el manejo de errores. Las APIs de descanso son mucho más
fáciles de usar, ligeras, flexibles. Y todas esas
razones hace que tenga
una curva de aprendizaje más pequeña para los
nuevos desarrolladores que apenas se están metiendo en la programación de API. Las API de descanso también tienen estándares
fáciles de entender como Swagger, especificación
OpenAPI. Estas normas te permiten
documentar de manera estrecha que eras un chico. De esta manera, haciendo que sea mucho más fácil ser adoptado
por los nuevos programadores. En conclusión, si estás
pensando elegir jabón o descansar
para tu proyecto, diría que
en última instancia
se reduce al servicio web
que quieres implementar. Basado en nuevo trabajo oh, necesidades. Tienes que decidir con
cuál ir. Además. Estos puntos sobre
la diferencia entre las APIs de auto y resto. Gracias chicos por quedarse
conmigo a través de este tutorial. Y espero veros
chicos en la siguiente.
30. Json: Chicos y bienvenidos de nuevo
a este tutorial. En esta conferencia, vamos
a discutir archivos de datos json, empezando por el nombre j
sine proviene de JavaScript. Notación de Objeto. mds son lenguaje independiente, lenguaje
legible por el ser humano
utilizado por su simplicidad. Nps también se usa más
comúnmente en aplicaciones
basadas en web para intercambiar
datos entre partes. Ahora las extensiones de signo G, obviamente n dot JSON. Jason es un
sustituto fácil de usar de XML, ACTS más ligero
y fácil de leer. Además, al ser más
livianos, rápidos, tomamos el
cambio de la antorcha de la superficie a los clientes puede terminar siendo
mucho más pequeño en tamaño. Y es por eso que los EPs son forma
preferida de comunicar
datos en la web mundial. Desde esa perspectiva. Buenas ventajas para el GI. Algún lenguaje gira en torno al hecho de que es
fácil para los humanos leer y el Dr. And D también es fácil para máquinas a
bares y JSR enero. Ahora al hablar de la
estructura de un archivo g sine, me
dijo a
toda su estructura. La primera parte a
eso tiene una colección de pares de valores de nombre en
varios idiomas. Esto se realiza como un objeto, registro, struct,
diccionario o tabla hash. Además, puede ser una clave o
una matriz asociativa. La segunda parte entonces delta
g sin cinco puede tener, es una lista ordenada de valores. Y se puede asociar
eso en la mayoría de los idiomas. Trigo en una lista de vectores de rayos o ventana de
secuencia que al intercambiar datos entre el
navegador y
el servidor, los datos solo pueden ser cubiertas
y chasten es texto. De esta manera, podemos
convertir fácilmente cualquier objeto JavaScript en JSON y enviar ese JSON
al servidor, el cliente. Ahora, podemos trabajar con los datos. Se trata de objetos JavaScript
sin análisis
ni traducciones complicadas. Además, si recibe
datos en formato adyacente, es un cliente del servidor. Puedes convertirlo fácilmente
en un objeto JavaScript. Por lo que funciona muy bien al
revés también. Entonces esto fue sobre lo que los archivos de datos JSON se utilizan en las API a los clientes
para obtener información. Gracias chicos por
quedarse conmigo. 30 final de este tutorial y
espero verte en el siguiente.
31. XML: Hola chicos y bienvenidos de
nuevo a este tutorial. En esta conferencia vamos
a discutir archivos XML, STR, una opción popular a la hora de
hablar de transmitir datos en Internet
desde servidores a clientes. Y Pi al cuadrado. Así que a partir del nombre, XML proviene de Extensible
Markup Language y deselecciona cuál de
sí mismo que define un conjunto de reglas para codificar
documentos en un formato que sea fácil de entender por
ambos humanos y máquinas. El diseño de XML, lo que es mucho acento en la
simplicidad, la generalidad, uso de
la construcción a través de Internet es un formato textual con fuerte
soporte a través de código único. Si bien el diseño de
XML se centra en documentos, el lenguaje es ampliamente utilizado para la representación de estructuras de datos
arbitrarias, como las utilizadas
en los servicios web. Todas las características
lo convirtieron en uno de los idiomas más utilizados
para intercambiar datos
sobre solicitudes en internet. Usted puede estar preguntando qué facilidad
exactamente en Mark blank. Bueno, el marcado es información
agregada a un documento que realza Es cuerpo de
significado de ciertas maneras, en que identifica las partes y cómo
se relacionan entre sí. Más concretamente,
una manta de Markov, que es un conjunto de símbolos que se
pueden colocar en el texto del documento para demarcar
y etiquetar las partes
de ese documento. Xml fue diseñado para
ser autodescriptivo. También se asemeja mucho a
HTML. Si nos fijamos en la
respuesta de XML, la diferencia entre los dos. El lenguaje XML no tiene etiquetas
predefinidas como lo hace HTML H. Viste si estás familiarizado con ese lenguaje de marcado, detalles, párrafos que son encabezados que son edad y luego un número por
lo grandes que son y así sucesivamente. Pero aún así, XAML
en realidad no hace nada en absoluto. Es solo una forma intuitiva, fácil y comprensible de colocar etiquetas de envoltura de
información que son estadísticamente nombrar a alguien en parte más seca de
software para enviar, recibir, almacenar, o
mostrar el estado. Eso se hace con código real escrito dentro de los puntos finales de una eventual API a la que se pueden realizar solicitudes para
recuperar los datos. Ahora existen dos características
clave del lenguaje XML que lo
diferencian y lo hacen útil en una variedad
de situaciones. Epc extensible, como
su nombre indica, lo que
significa que te permite crear tus propios mazos
dentro del ritmo. Y esas cubiertas son por supuesto, representativas para
las citas proporcionan como tú las haces ser. Si tuvieras un usuario
XML bien escrito va a entender, solo encuentra la
información que obtuvo del XML que enviaste. Lleva los datos
independientes de la forma en que serán
mostrados por quien lo recupere. En efecto, el estándar social sí
se hizo público y abierto. En conclusión, la razón por XML mismo pico y
popular hoy en día, es la forma en que hace
uniforme
la abundancia de sistemas con los
lenguajes de programación Grunt y los
lenguajes de programación Grunt ysistemas
operativos a un solo, sencillo y fácil de entender lenguaje de
marcadosencillo y fácil de entenderque es
muy flexible en cuanto a
las etiquetas y que contiene
la información de que es
Nadie de lo que se
trataba con los archivos XML. Gracias chicos por
quedarse conmigo. Al final de este tutorial. Estaré deseando
veros chicos en la siguiente.
32. XML vs. JSON: Hola, y bienvenidos de
nuevo a este tutorial. En esta conferencia vamos a discutir diferentes Cs y también piensa que
tienen en común sobre lenguajes
XML y JSON. Hablamos en las conferencias
anteriores sobre cada una de ellas, cada una de sus ubicaciones
específicas, lo que el JAR podría contextualizar, se
pueden utilizar. Pero ahora, haciendo una
comparación entre ellos, tal vez además puedas decidir
fácilmente
cuál es mejor para ti en
tu propia representación API. Sbc, tanto JSON XML se pueden utilizar
para que usted reciba datos de un
servidor web o
para que usted envíe el
cliente a un servidor web. Básicamente son solo formas de poner la fecha
que se comunica entre las fiestas web cuando se trata de cosas que
tienen en común. Ambos están muy estructurados de
manera jerárquica. Significado por supuesto,
que tienen esas etiquetas en el
caso de XML y llaves
rizadas en caso de JSON que representan
valores dentro de valores. Por lo que están muy estructurados, ambos
también son legibles por humanos, también conocidos como autodescriptores. También. Otra cosa que podemos
observar en ambos es que se pueden obtener
con una solicitud HTTP, lo que también
las hace útiles al hablar de APIs y
comunicación a través de Internet. También por supuesto, pueden ser analizados y utilizados por muchos lenguajes
de programación. Pero aquí viene la diferencia
media entre estos dos lenguajes
de marcado. Eso es obviamente estar muerto
al eczema tiene que ser analizado, escrito analizador XML real. Si bien JSON puede ser analizado por una función de
JavaScript estándar, ¿necesito esto analizado por la función JavaScript
estándar? Está analizado en un objeto JavaScript listo
para usar. Y como se puede
concluir a partir de
eso, esa es una gran ventaja para
JSON es que es mucho más fácil transcribir en código real
cuando se está trabajando con él y
está recibiendo puerta. eccema es mucho más difícil analizar el JSON en ese sentido. Ahora, otra diferencia clave entre estos dos podría ser que los objetos JSON
que se analizan con el JavaScript siempre
tienen algún tipo de tipos, ya sea si se trata de una cadena, una matriz numérica de OR Boolean, si los datos XML son sin tipificación y esto
debe ser cadena. También XML admite
comentarios mientras que el estándar G no admite ningún
tipo de comentarios sobre usted. Si tal vez leías
algunos archivos JSON, pensaste que allí no había
absolutamente ningún comentario. Si bien JSON es compatible con la
mayoría de los navegadores hoy en día, análisis
XML entre navegadores puede ser complicado y es posible que tengas algunos problemas cuando tratas
con los navegadores especiales. Personalmente nunca me
encontré con eso, pero al parecer es posible. Y la última diferencia que
tenemos aquí sería que el JSON es menos
seguro que un XML. Y ese es probablemente el punto más fuerte
que verías, es tratar de elegir
XML sobre adyacente. Pero de nuevo, g seno, es mucho más fácil ser analizado. Y también es la manera de ir a transmitir datos en la web
al venir, sobre todo a. Considerando que el estado es por qué XML
también se usa con las API de jabón. Personalidad Prefiero más JSON, pero dependiendo de lo
que estés tratando de construir, qué tipo de API humano construir. Creo que es mejor
que elijas por ti mismo y por tus
necesidades entre estos dos idiomas. Así que gracias chicos
por quedarse conmigo hasta el final de esta conferencia. Y de verdad espero veros chicos en la siguiente.
33. Cómo podemos llamar a una API: Hola chicos y bienvenidos de
nuevo a este curso de API. En esta sección,
vamos a tratar el
aspecto más práctico de las API's. Es decir, cómo
puedes hacer
solicitudes a APIs específicas y obtener información de ellas como
algunas respuestas como se indicó
en conferencias anteriores, cuando se trata de APIs,
es como tratar
con un sitio web. Por ejemplo, cuando
ingresas a Facebook, básicamente
haces clic en un enlace. Al hacer clic en ese enlace, se abre
el sitio web. Lo que realmente sucede cuando
haces clic en él es que
haces una solicitud a los servidores de
Facebook. El sitio web que
obtienes frente tus ojos es la respuesta
que obtienes de vuelta. Ahora es lo mismo cuando
llamas a un punto final API. El punto final de una EPA
es solo como un enlace. Cuando lo llamas, significa que
haces una solicitud a, es como si haces clic en un sitio web. La respuesta que
obtienes es en forma de página web cuando
ingresas a Facebook, o es en forma de
respuesta cuando
haces una solicitud al endpoint de
una API. Pero es más
o menos lo mismo. Sin que eso se diga, hay dos formas que
discutiremos en este curso con las que realmente
puedes hacer solicitudes, dos endpoints diferentes de API Ahora el primero es a través de curl y el segundo
es a través de postma Se trata de dos programas
que te permiten, obviamente, realizar estas solicitudes, tal como lo harías desde un
navegador, Digamos URL. Ahora curl viene
instalado por defecto si estás usando un Mac OS o si estás usando
un Windows Ten. Si estás usando
ya sea un Binto o una ventana que es anterior
a la versión diez, pero tienes instalado Git para Windows o para un
Buntu
instalado El curl ya está descargado de
nuevo de Github
y puedes llamarlo, como verás, que voy a
hacer en la futura conferencia. Al intentar hacer una
solicitud a un sitio web, de nuevo, ni siquiera
estás teniendo Git en tu máquina y estás usando Windows anterior
a diez o un bundle, puedes curl con el administrador de paquetes y esa es la forma más
sencilla de hacerlo. Por ejemplo, puedes descargar chocolate y luego ejecutar
Choco install curl O de nuevo, otros
gestores de paquetes también están bien. Pero si no quieres
hacerlo a través de un gestor de paquetes, también
puedes descargar Curl
desde la página de inicio de Curl. Puedes ir a Curl que SE, luego hay un
botón de descarga y puedes descargar el archivo curl archivado y
luego seguir adelante e instalarlo. En las próximas conferencias, vamos a tomar
una API pública y hacerle algunas peticiones
tanto con Carl como Postman Solo para ver exactamente cómo nosotros, cómo podemos realmente usar no solo los verbos HTTP y acceder a los endpoints de API
y verlos en la práctica, sino también todas las
nociones de las que hemos hablado teóricamente
hasta Si todo eso te suena
interesante, realmente
espero
verte en las próximas conferencias. Te
agradezco mucho que te hayas
quedado conmigo hasta el final de este.
34. Llamadas con curl: Hola chicos y bienvenidos de
nuevo al curso API. En esta conferencia,
vamos a hacer nuestra primera
solicitud de API usando Carl. Tengo aquí en la pantalla
el sitio web de la NASA. Y la NASA en realidad está proporcionando algunos puntos finales de API
para diferentes desarrolladores Quizás te preguntes, ¿por qué querrías acceder
a los datos a través de
un endpoint de una API en lugar de simplemente tal vez ingresar un enlace
en tu URL y ver esa información
por ti mismo con imágenes en una forma
que es mucho más agradable, entonces aparecería como la respuesta de una API como
verás en un momento La respuesta a eso es porque
cuando estás usando una API, generalmente la usas en tu
código para obtener información de otras partes que te
están proporcionando esa
información. Y no puedes calcularlo o no deseas hacerlo. Recupero esa
información en su código haciendo estas
peticiones que
vamos a hacer sólo dentro Carl y Postman para
mostrarles cómo se hacen Pero como he dicho, se
harían desde tu código y tal vez
llamarías NSAPI para mostrar información sobre el
primer alunizaje Y recuperarías
esa información de la API y la
mostrarías en
tu propio sitio web. Para eso son buenas las API. Ahora, volviendo
a nuestro tutorial, tengo aquí la API, NASA.gov Y si ingresas esta
URL en tu navegador web, serás redirigido
a esta página,
donde antes que nada, podrás
ver que necesitas una Si te desplazas un poco y
ves diferentes API, que están proporcionando
diferentes puntos finales Por ejemplo, la base de datos
meteorológicos espaciales de notificaciones, conocimientos
e información. Aquí, por ejemplo,
un punto final es la eyección de masa coronal Aquí puedes ver
que como argumento, necesitas la clave API
que se proporciona en sección después de ingresar el
primer apellido, también correo electrónico. Si realmente estás trabajando en una aplicación o un sitio web
que va a utilizar esta URL, también
podrías ingresarlo. Pero es opcional porque
algunas personas solo pueden hacer esto para tal vez entender las API o simplemente recuperar alguna
información de ellas. Después de
que te mostré eso, vemos claramente algunos pasos para
hacer una llamada API. En primer lugar,
necesitamos proporcionar aquí nombre y
apellido y luego correo electrónico. Voy a hacerlo muy rápido. Entonces cuando hacemos clic en registrarse, puede ver que la clave API que se
nos proporciona es esta. Bien podríamos copiarlo. Ahora ves que también nos lleva además
con algunas instrucciones y nos dice que podemos
empezar a usar esta clave para realizar diferentes solicitudes
a su servicio web. Necesitamos simplemente pasar esta clave en la URL al
hacer una solicitud web. E incluso un simple
ejemplo solicitan aquí. Ahora si copiamos esto y luego
agregamos curl delante de él, podemos hacer una solicitud al
punto final de la API de la NASA. Como se puede ver, la parte es el cuadro astronómico
del día, por ejemplo Esta es una de ellas. Se puede ver que también puede
tomar diferentes parámetros, pero necesita la clave API. De hecho, copiamos
este punto final desde antes de que fue proporcionado por ellos cuando ingresamos
nuestras credenciales. Entonces ahora entrando en cómo podemos
realmente hacer la solicitud. Podemos encender a la
línea de comandos que abrí en modo
administrador, pero si estás en
Macos o
Bundle, puedes abrir tu terminal. Y después de eso, después de que te
asegures de que tu rizo esté instalado, puedes seguir adelante y
escribir curl. Y luego. Derecha, el punto final API, pero también archivado por tu clave. Al hacer clic en Enter, puedes ver que obtenemos alguna información en
nuestra respuesta aquí, y eso es en el scripting
tipo Json Y se puede ver que nos
lleva a los derechos
de autor de la foto, que es este tipo llamado Nick, creo que se pronuncia entonces la fecha de la foto,
cuando fue tomada, y después la explicación
de la fotografía. También podemos obtener algunas otras
cosas como el título, la URL, que
podemos copiar desde aquí, y creo que
nos llevará a la imagen real. Se puede ver que este es el
cuadro astronómico de la fecha. Ahora bien, esta es una forma bastante sencilla en la que puedes acceder
al endpoint de una API. Como te dije, al igual que hiciste este
parámetro de consulta de la clave API, en realidad
puedes escribir
otra pregunta, marcar la fecha y luego es igual. Y luego escribe una fecha específica a
partir de la cual deseas recuperar el cuadro astronómico de ese día o una matriz de ellos con la fecha de inicio y la
fecha de finalización Entonces claro, el
EPIK, como ya he dicho. Y luego algunos otros
parámetros de consulta también, que puedes colarte después de termine
este punto final, después del APOD Esto fue sobre eso. Como ya he dicho, generalmente hay algunos pasos adicionales cuando
intentas una API. Puedes agregar esos siendo algunos
tokens que necesitan ser intercambiados contigo y el servidor al que intentas
hacer la solicitud. Solo para que ese servidor se
asegure de que está intentando acceder a la
información en sus derechos, al
igual que las claves API aquí. El proceso de token es un poco más complicado y
no vamos a entrar en él aquí, Pero tengo otro curso
que es solo sobre el proceso que maneja estos
tokens dentro de las API's. Se trataba de cómo
puedes hacer una solicitud simple con L en tu máquina personal. Pero en la próxima conferencia, también
vamos a echar
un vistazo a cómo se puede hacer esta solicitud dentro un nuevo programa que
se llama Cartero Y si te estás preguntando, por qué querrías hacer eso, es porque ese
programa
te mostrará más detalles sobre tu solicitud y más
opciones al respecto. Al igual que el verbo HTTP con
el que quieres llamar a tu API. Toda la información
será formateada con cuadro de texto y será
mucho más fácil de leer por ti. Y también muchas otras opciones más que veremos en
la próxima conferencia. Como ya he dicho, realmente
espero que ustedes hayan sacado
algo útil
de esta conferencia. Espero que estés un paso más cerca de llamar
a una API, dentro de tu propia aplicación web. O incluso más cerca de
entender cómo exactamente puedes
manipular las API, llamarlas y cuáles
son en realidad. Muchas gracias
por seguir
conmigo hasta el final
de esta conferencia. Tengo muchas ganas de
verlos en la próxima.
35. Llamadas con Postman: Hola chicos y bienvenidos de
nuevo a este curso de API. En esta conferencia,
vamos a echar un
vistazo a cómo exactamente podemos hacer solicitudes a diferentes
ABI's públicos utilizando la herramienta Cartero En primer lugar,
necesitas descargar Postman en tu máquina local
actual Para ello, puedes saltar
a tu navegador web, ingresar el nombre del cartero, y luego simplemente hacer clic en el
subenlace de la publicación de descarga del primer enlace Entonces serás redirigido a esta página donde podremos descargar Este ejecutable
también se puede descargar para
Macos o Linux. No importa qué SO
estés usando actualmente
porque funcionará para ti. No obstante, ahora se puede ver que
se descargó el ejecutable. Podemos seguir adelante y abrirlo, y se puede ver que va
directo a instalarlo. Ahora lo abrirá. Como puedes ver, así como así, tienes la herramienta en
tu máquina local, puedes crear una cuenta. Pero solo voy a saltarme
e ir directo a la app. Aquí tienes un espacio de trabajo
ya abierto, pero para que las cosas sean más fáciles de entender
en esta parte correcta, puedes agregar una nueva pestaña donde
crees una solicitud. Y como puede ver, esto está mucho más orientado a
crear solicitudes, servidores y recuperar
sus respuestas. Entonces la instrucción actual
del CLD fue. Ya puedes seguir adelante e ingresar la URL del último
tutorial aquí. Como voy a hacer en tan sólo un momento. Lo que vamos a hacer aquí es ingresar esta solicitud
y vamos a usar el HTTP get ya que
queremos recuperar recursos
del endpoint específico. Si hacemos clic en Enviar, puedes ver aquí que en
la parte inferior de la solicitud de la página está nuestra respuesta a la
solicitud que acabamos de enviar. Aquí puedes ver, en primer lugar, la red y luego el estado con el que viene nuestra
respuesta. 200, lo que significa bien, si te pones el cursor sobre él, también
puedes ver exactamente de qué proviene este
estado Si no es estándar y
es posible que no lo
hayas visto antes, en realidad
puedes ver
una explicación de ello aquí. Entonces podemos ver en
cuánto tiempo
volvió la respuesta y luego las
diferentes partes de la misma, si estás interesado
en esas cosas. Y también el tamaño de la
respuesta que obtuvimos aquí, es el cuerpo
que es por supuesto, puede ser crudo y esta
es la que vimos en nuestra respuesta actual antes en la conferencia anterior en el CMD También podemos ver una vista previa, podemos visualizar, pero el visualizador para esta solicitud en realidad no
está
configurado en estos momentos Pero por defecto está en
la pestaña bonita lo que
hace que todo el texto esté
formateado en este archivo JS. Y como ya he dicho,
se puede ver que
también se analiza y destaca
en diferentes porciones, lo cual es muy útil para realmente veamos diferentes
detalles de nuestra solicitud Aquí puedes ver que tenemos diferentes parámetros de consulta
que él por defecto, al analizar el
punto final
al que
estamos haciendo la solicitud está sacando Puedes ver que detectó nuestro parámetro APIke y
también el valor del mismo aquí Por supuesto, se le puede agregar
alguna descripción. También podemos agregar diferentes
parámetros desde aquí, en lugar de realmente, además ingresarlos en la solicitud. Y esto puede ayudar a administrar
la longitud del punto final, porque aunque la longitud del punto final
será más grande aquí, en realidad
podemos
cometer menos errores. Como podemos ver mejor la clave
y el valor. Ahora en la parte de autorización, podemos dejarlo como estaba. Esta es una API pública en. La clave IP que recuperamos del sitio web está
directamente en el enlace. Pero si
usáramos un sistema de seguridad tokenizado
para acceder a esta API, necesitaríamos
usar realmente los dos tokens o cualquier protocolo que estén usando al intentar hacer
una solicitud real Entonces aquí están algunos encabezados, el cuerpo y diferentes
cosas así. Aquí en la configuración tenemos
diferentes configuraciones de métodos HTTP, pero eso no es tan importante. Esto es solo una vista previa de lo que puedes hacer con Postman y cómo puedes crear
solicitud con esta herramienta, también
puedes crear otra solicitud además
y también guardar esta Y si creas una cuenta, todas estas solicitudes se
guardarán para
ti por si acaso
necesitas volver sobre ellas y
revisarlas o tal vez realmente copiarlas en tu aplicación
actual en la que
estás trabajando. De esto se trata de cómo
se puede hacer la solicitud con
el servicio de cartero también Muchas gracias
chicos por quedarse conmigo hasta el
final del tutorial. De veras espero que hayas sacado
algo de ello. Y si tienes alguna
duda sobre el proceso de creación de la
solicitud de una API, puedes seguir adelante y
dejarlas aquí en este curso. Y haré todo lo posible para responderte de
manera oportuna. También, si te interesa. También tengo otro curso
sobre el proceso O que la mayoría de las API están
usando hoy en día y agrega una capa extra de seguridad cuando intentas hacerles
una solicitud. También puedes comprobarlo. Pero por ahora, muchas
gracias Como ya he dicho y
espero ver chicos en las próximas
conferencias y tutoriales.
 Programming Made Easy, Software Developer
Programming Made Easy, Software Developer