Transcripts
1. Introduction: I am ordering in this class. I want to talk about finery, search related elbows. These types of albums come up a lot, and it's your with your while to spend a few minutes refreshing your knowledge. Knowing how a binary search works lets you understand other Albertans based on the same principle. After this course, you'll have a good reminder of how this happens, work and be a bit better prepared to do them in an interview or in your Dele word in the notes need show. Provide a link the source code. You can use this to further respect the album. See how I would implement that. Okay, let's get started.
2. Algorithm Explanation: Let's take a look at Byner research. Binary searches used to locate something in a sort of list. That's a requirement. The list has to be sorted in our example list. Here we have letters, and they're an increasing alphabetical order. If the list is not sort of binary, search will not work. Beina research gets its name because we split the list in half every time we do a step in the hour of them. So let's see that by example. Let's look for the letter G in this list, so we want to look for the letter G. This list is 10 long, so we're gonna start at the middle. Element. Middle is going to be all the length divided by two. Let's just say five. Whether this is up or down by one won't make a big difference. Get the outline. What keeps splitting the list in half, and it'll eventually find something. So if we started the fifth Index that 012345 this isn't in next of five. We're going to start here. This looks like it's on the other half A list. That's fine. There's five on both sides. Visual anomaly again. It doesn't matter whether it's off by one at I equals five. We have a K, which is not G. The K is greater than the G, though, so that tells us something because the K is greater than the G. We know that the G can't me right of it. The G has to left of it if it's there. So binary search then says, Well, let's look to this first half. So when a split off this first half here and let's just look through this path here, it's five long. We're going to start in the middle of this again now five divided by two could be 2.5 week around. A three or two doesn't make a big difference. We're going around, too. And that 012 I equals two. What is, at this point here? We haven't e at this point, and the ease less than the G. So again, this tells us something. Which half of the remaining lis is it in? It's not the left hand because he is greater than G, so it's over to the right. If it's there, some buying research sent, so it's narrow. Our search down to over here. It's too long and relative to this part we want. The one element is too divided by two is one plus. Here's we're gonna look over here at I equals four and we're going to find the letter G. Pay attention for later. How many steps it took us do that We did 123 Comparisons. We did three comparisons to find the item that we wanted. Now let's look for the letter C. We know C is not in this list, but let's see what the binary sort algorithm does in this case again, we're gonna start in the middle of list over here at I equals five. Que is bigger than sees, so we know it has to be on the left half, so it's gonna be just in this half lines against we know where it is, and we're gonna start at the middle of that half now. We're gonna point up to here now, and this is it. Index equals two. This is not the letter we're looking for is greater than see, So that tells us again, it's in the left half here. So we narrow down our search again right here and now we haven't even smaller list, and we're going to pick where the middle is again. The middle here by our organ was gonna end up starting over here. It starts at I equals one. This is not the letter we have now. It's bigger than C, and this is work. It's a little bit confusing to see that we still have two sides to this. Even though the borders here to the right of D is nothing. There's actually an empty list here. We're not looking in that side to the left of D. We have just to be and we know we have to look in the left because D is great in the sea. So we narrow down the search to just this criteria here and we do one more step at I equals zero and we don't find the sea. Now the binary star at this point says, Well, what half is it on its on the left half? But it doesn't matter because there's nothing on either half left to search because the length of the remaining A list is now zero. We know that we do not have see in this list. It's not here for reference to complexity. Count the number of steps again. We have 1234 steps. Course steps. It's a bit more than the war. Three put silly four steps.
3. Algorithm Complexity: That's pretty much how the binary search works. You always pick a pivot point. First, you pick the point in the middle and you compare the value. If the value find is less than the one you're searching for. So it's less than its you're going to search this half value K is more than that you looking for. You're gonna look at the right half, so if it's greater than it, so it's always is greater in less than comparison. And then you take the half and you repeat the procedure, and this makes it a recursive algorithm. Bridge step the album respecting half the size list. Let me draw out some the boxes of where this looks for the purpose complexity. So I understand what happening. So we had the K and then if it was greater than we have some boxes to the left, there's only five of them, and on the other side we have only four of them. We put the list in half. Now the same thing's going to happen here. We're gonna take the one in the middle, pick one in the middle here, and then you'll be left with two to compare over here, two over here and also to and then just one. So the branch ends here and always to ones. They're almost special cases, but they happen a lot. You picked the middle one. And if it's not the middle one, you end up having to do one more search on each of them. And this is a pattern you should be getting used to in albums. You're splitting in half each way. You only have to go down to here to the one boxes. Once you get to the one boxes your searches done, have you found the element or you have not. How many steps are there here? Any time you split in two or you duplicate, you should definitely recognize this long with exponential pattern. So ah, binary sort is a longer the pattern. So we have log. And again, this is where I said it doesn't matter whether it is off by one, and so it might be up or down a little bit. The count can change back and forth. And so that's why we say, Well, it's big o of long end. That's the upper bound is not gonna go beyond that point we're removing the constraints. You also may get lucky. Sometimes. If you're looking for the K, you'll find a care right away, in which case it does only one comparison. But we're looking for worst case scenario. Remember in an interview if they ask for time, complexity there, generally asking for worst case scenario. But if you're uncertain, you can usually ask and for searching algorithm. They're asking for the number of comparisons. And that's where we didn't thought we compared here. Compared here. We compare here that we compared here four comparisons. This is generally how we measure the time complexity of searching albums. How many comparisons do we have to do?
4. Lower and Upper Bound: There's a few special cases for searching by example. Let's look for a M now and we know there's two in here. So let's see what the algorithm does were first gonna 0.2. I equals five, and this is the K que is less than M. So we know we have to look at the right side here. So we split it off, it would go here, and the midpoint is going to be up here at I equals eight R is greater than M, so we know we have to look to the left of its and now we've constrain it to this part here . This is where the interesting part is. Then we check this one here because this is just happens to be aware gonna works. We could have been up checking that one and I said, We find it and we found the M. So you found the basic searching is fine. They're two albums there, very close early to search that come up very often while implementing other algorithms. Those two algorithms are what we call lower bound and upper bound and M is the case and introduces is lower. Bounce says will point me to the first place where we'd find em. So if we're looking for the lower bound of em, we actually want this location and not this one. The value of lower bound is when you have duplicates. You know, you can point to the 1st 1 But also lower bound is also good. When you're looking for things that aren't there. Let's go back to that. See, case We know it sees not in here, but that doesn't tell us much. What if we'd like to know? Well, where would see go in here? What are its closest neighbors? Something like Lower Bound gets to tell us where its closest neighbors are. So the lower bound to start middle, start here, then check here and then we know here and here and skipping over deals how this is done. But Lower Bound wants to basically give us this position here because this is where the sea would dio, and it's gonna end up giving us this position here. I equals one because Lower bound specifically says What's the first element, which is not less than this? Value B is less than this value, so that's not what we want D is greater than this value. So it is what we want. That phrasing of not less than was important in the M case because there's Malta, ones of them. It means the 1st 1 that is not less than because M is not less than em. It lets it match. So this lower bound function is useful to find a place in a list where an item might exist if it's not there or if it is there to ensure you found the 1st 1 If that is relevant, very closely related to Lower Bound is upper belt upper Bound tells us the first item that is greater than the one we're looking for. So, for example, if you're looking for the upper bound off em this time, we know M is there. But we want to find the point at which M is no longer the correct animal. Is that where it stops? So the upper bound of M wants to point to here. So in this location here, where we insert thing, this is the first element in the list which is not less than or equal to or greater than M . This means for anything coming after em that might go there. This is more important or more interesting for items that aren't on the list. For example, if we want to know well, where my end go, you can also say, Well, it goes into that So for searching for something and it is there, the upper bound says. At which point is, after that item, this is useful for some types of sorting. Or if you want to insert another AM, you want to make sure it comes after the existing ones. You can also look at the upper bound of things that don't exist. So like see, we knew that the lower bound of C was pointing to the D because that was the 1st 1 that was not less than C. That also happens to be the 1st 1 that is greater than see. So in the case of items that don't exist, so they're not here. The lower and upper bound are going to be the same because they're not in the list. It's always gonna point in the same location in the insertion sort class. We'll look at why this makes a difference why you might want to use upper bound versus lower bound for doing a type of sorting Upper a lower bound are very used when a lot of albums they're trying to locate items that aren't on the list are just trying to find a location in a list for something has to be, even if it's not there, understanding them and being able implement them, we'll give you access to a variety of other albums to help you along in a lot of coding interviews.
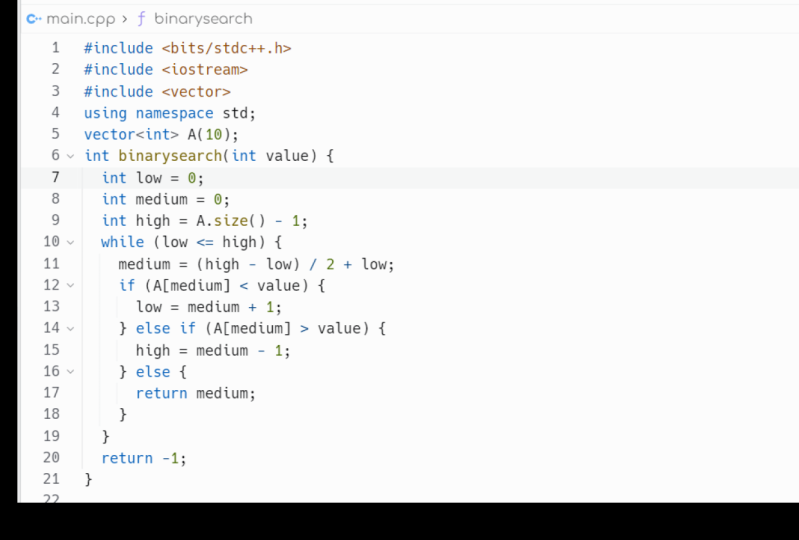
5. Binary Search Code: I got a look at the code now for the binary search and the lower bound and the upper bound before you look at the segment. Before you look at the code, make sure you try this exercise on your own going right. Your own binary search. Treat the upper and lower bound as bonus questions. I'll have a link to this code down in the notes, so check it out as well. But again as your project, make sure you write this code first. Do the binary search. Try few input. Let's make a few test cases. Make sure it works the variety of inputs and convince yourself that you understood what I talked about in the previous segment and that you could write a vinyl research in an interview situation. Okay, let's look at the code. So in the class files, there's a main P Y in Italy. The main python have richness and python, but it should be easy enough to follow. Regardless, the top part of this is all sort of boilerplate just to set up the python environment for comparables. One thing know about the comparables. The only compare operation going to be using is less than this is very common when writing algorithms for standard libraries so are comparable only needs to define a less than operation and nothing mawr. So let's take a look at buying research. I move this up a bit. Here we have the Byner search. What does buying a research take? It takes the value we're looking for and the items in some a p. I still see this called the needle in a haystack. It works, but I like value in items. It should be clear enough, and it returns an optional ends. Why it's optionals because it may not find the items it has to be able to return none. Otherwise, it returns the position of the item that have found, which compares equal to the value passed in the 1st 2 steps set up for Loop were saying what part of the list were searching in? Zero was the first, next and the lengthy. I was a top one. It's the top indexes exclusively. Don't you check that out of this is a standard coding range. We set this up and her loop then says, As long as low is less than high, we keep looping because that means we still have items left to check. As I showed in the white board, what we need to do is look at the mid position. So this is hi minus low, divided by two plus low the slash lashing python. It's just energy division, and this gives us the midpoint between the range were checking. This is done in a loop because we're gonna do it repeatedly. So this is the midpoint. And the first check was say, is the item at the midpoint less than our value in this means when the current pivot points in this province is less than or value, it means this entire left half off the items don't have it. So we're in a shift to the right half to the segment and shifted right half a segment we take low said it to mid plus one. We know mid can't be the value because mid was less than the value. So mid plus one, this shifts the window that were searching over the right. Otherwise, if our value is less than the mid one, then we know we're too high in the list and we can go to the left side and this is where we move high down. So high becomes mid minus one and we know mid can't be the item circus in mid minus one If you just put mid as well, it should work, but it be a tad bit less efficient. Otherwise we return mid. Now this is where it's important. Where I said, we only use less than comparisons in the first comparison. We see if the items mid is less than the value in the second, when we see it, values lessen the items mid seems a bit weird. So in the last case else, what does that mean? If neither value is less than the other one, that means the same value, it means is the value we're looking for and we could return mid. We have found the value that we're looking for, and if we have not found that value, we returned none. So this is a basic binary search. I've done it without Rikers, and I've done it with a while loop and it takes the segment high and low. It steps to the segment's splitting it in half each time at the bottom of the file. I've provided a test. Run this your work and pie test or just run directly and I do some items and I do some basic tests. If you're writing full out war than you'd have a larger test suite in this, just just give some basics. One interesting point, I said for two test is what happens if you're looking for a and you in this list, The A's air duplicated and the U is duplicated. You could see the couple years in there. The problem with the way I have implemented binary search in this example is that there's no guarantee of which it finds. So this by air search for a could be 01 It could find either one of these values. Same with EU. The you could be eight or nine. It could find either one of these values, and that's something we're gonna look at at the lower and upper bound. So let's go over to those
6. Lower and Upper Bound Code: related to binary search are lower and upper bound operations. Where's binary searches looking for particular item? The lower and upper bounds looking for a place in the list where an item would belong, whether it's there or not, and they give a bit stronger guarantees in a binary search. So let's take a look at the lower bound again. The lower bound fines the first position in the list where the item in the list is not less than the value. That is the first place where it's either greater than or equal to. And we say not less than again, because we only want to use the less than operator. But it's the same is greater than or equal to in this case, so lower bound A has the same input, but you notice the output is an energy. Er this one cannot return, and none. It's not optional. There's always a place unless or something belongs. If it's not, there could be in the middle. Could be right beginning or the end, so it always has a value. This set up looks the same. We start with this full range, and we're going to segment it in half each time looking for so the mid. So the lowers lesson high and we're looking for the midpoint. So now we check if the items at mid is less than value. And if it is, this is like the condition we had before Well is so lower Ban has to be to the right of it . So we say mid plus one because it's less than that. We know the lower bound is strictly after mid because it has to be greater than or equal to . So you're less plus one now he else's where something changes from the binary search. If we look back up with the else in the binary search, we haven't l If that compared the value again down here, we don't. If it wasn't the right side, it has to be the left side. We have no short return path. We can't identify the value Look for in the middle. We always have to exhaustively search. And this is also why we say hi equals mid and not mid minus one. Because at this point we don't actually know that mid is not the lower bound. It could actually be because all the items to the left of mid could be less than the value in mid. Could be the one we're looking for. Therefore, we don't subtract one. We just say highs less than mid. And we keep doing this until lo and hi are the same value. I say lowers lesson. Hi. This is sort of defensive coding technique to make sure it never goes forever, But they're just they're gonna be equal at some point. So we returned low at that point in this lower bound, then finds the first place in the list where the items not less than the value. So the bottom, the test cases. If we look at the look at the items now, if we take the lower bound of a we said before in the binary search we could have had a 01 But in the lower bound, it has to give us a zero. It has to be the first place where it exists in this case, the first item in the list. And for you you was also the 1st 1 here. The first position is eight. And so there's duplicates is guaranteed which one it returns has always has to be the 1st 1 That's where you would unserved one of that value. Now the first test of one non existing is see, and what should see returns to have a B C C would be right here, and that means it should be the position of the F, and that's a three. So we found the three and again with the Why the Why should here and a double zed, which I threw in just to get something at the end of the list? Because it's larger than all of them. It should appear at the end of the list, and this is larger than a list size, so that's a valid test for that. So let's also take a look at upper bound Upper Bound isn't quite the opposite, lower bound. It's very related. And what it says is the first position that list where the item is greater than the value not greater than or equal to, but greater than so. It's a strict upper bound compared with lower bound and again, this all be expressed in terms of less than because, as we said, that comparable the only thing it has to support us in less than which will find in a lot of standard libraries. This set up is exactly the same again. We're gonna set up our window range and they're gonna find the midpoint. Now, our first condition varies a bit from the last ones is that instead of going to the right side, first we go to the left side, and that is, if our value is less than the item in the point, we're going to go to the left side. But we're not going to subtract one, because the position where at in mid could actually be the upper bound if everything else happens to actually much lower than it. Otherwise, we go to the right side and we say locals mid plus one. Here we can do a mid plus one because it's a guarantee that the upper bound is strictly after mid, and we do this until high equals low, and then we return low, and that gives us the upper bound. So let's look at the examples of what happens there. So you have an upper bound of a Where's the lower bone of a was zero upper bound of a If is unless you'd say right after A. And that's a position to the upper bound of is that position to upper bound of you is right after you at 10. So it's to after the eight. And for an item that's not no list for see, the upper bound is the same as the lower bound because it's not in the list. So these both tell us where to insert it in the only change, when the items already in the list it tells us which side of it due to put it in. If we're going to do in insertion sorts, you'd usually want to use upper bound to make a stable sort to insert items afterwards in the list where diffuse, lower bound. It would move the list the whole time. And that's not what you want in my class for insertion sort. I'll talk about why Upper Bound is important here is opposed to lower bound. They has to do with stable source
7. Alternate Binary Search Code: coming back to this problem with binary search in duplicate values. When I helped for this A in this list, I said it could be a value of zero or one Generally encode if you're building a library, this is not a good situation. A have. You don't want tohave ambiguous. AP ICE. You don't wanna have buying research. It could return 011 person influences return zero. Another person points returns one. That's a bad state to have this type of thinking result in a lot of air is sneaking into your code cross platform or different compilers. So it's not good to have things like search that could return different results. They're ambiguous. We want to have a strict result in the case of duplicates. Makes sense to return the 1st 1 on the list. If you did a layer search, which one would you find? So you could say well are binary search optimization Linear search? In which case the 1st 1? A. She returned zero the 1st 0 She returned eight. So how can we do that? The buying, a researcher wrote, doesn't care. It doesn't know which one it finds. So there's another way to do that using the lower bound because the lower bound always returns the 1st 1 in the list if it's there. So in the code, I provided an off binary search. The key difference is that if there's a duplicate in the list, it'll guarantee that it returns. The 1st 1 and I've implement is in terms of lower bounce. If you have a lower bound operation, you don't actually have to influence the binary search. This is good for an interview situation. Or, if you could ask the person, can I assume lower bound exists? And you can avoid the problematic part of writing binary search and just use lower bound. If you're looking for a particular value call lower bound in the value. This says the first place was items should be inserted into the list. And if there's items in the list, the first occurrence off that because it's valid even if he was not the list. So the first thing we check is that if the lower bound is higher than the length of a list , it's higher angle to. It means it's not on the list because it said the place this item would exist is outside the list, so it can't be in there. So we returned None. If the item at the next returned is less than the value, well, then that's also not the item we want, so it shouldn't be in the list. If the value is less than the items there, then you could return, known as well, because it's not the right item. Otherwise, you return lower because it's neither less than in either direction, less than or greater than which means it's equal. And this is how you use lower bound to find an item in a list.
 Edaqa Mortoray, Programmer, Chef, Writer
Edaqa Mortoray, Programmer, Chef, Writer