Transkripte
1. Einführung: Sie haben wahrscheinlich den Hype um Data Science, die Konferenzen,
die Gespräche, die großen 10-jährigen Visionen und Versprechen eines glamourösen Jahrzehnts gehört . Diese Klasse ist anders. Es ist konkret, es ist sofort. Ich möchte Ihnen zeigen, wie Daten Ihnen heute, morgen,
nächste Woche helfen können , wie Sie Geschichten mit Daten erzählen können. Hey, ich bin Allan. Ich bin Data Scientist bei Small Startup und Informatik PhD Student an der UC Berkeley. Auf dem Campus habe ich mehr als 5.000 Studenten beigebracht, und außerhalb des Campus habe
ich über 50 Fünf-Sterne-Bewertungen erhalten, um Menschen beizubringen, wie man für Airbnb programmiert. In dieser Klasse werde ich Ihnen das Wesentliche der Datenanalyse beibringen, insbesondere zeigen, wie Sie Daten auf eine bestimmte Weise nutzen können. Wie man eine Geschichte mit der richtigen Visualisierung erzählt. Wenn Sie ein Business-Profi auf der Suche nach datenbasierten Fähigkeiten sind oder ein aufstrebender Data Scientist sind, ist
diese Klasse genau das Richtige für Sie. Wenn Sie ein Anfänger zum Programmieren sind,
beachten Sie, dass diese Klasse eine gewisse Codierungsvertrautheit erwartet. Sie können diese in nur einer Stunde abholen, indem Sie meine Coding 101 und SQL 101 Klassen nehmen. Nach diesem Kurs können Sie datengesteuerte Geschäftsentscheidungen treffen. Wir machen das in drei Schritten. Erstens: Entwerfen der Datenerfassung, zweitens, Vorverarbeitung von Daten, und drittens die Analyse von Daten. Jede dieser Phasen wird sich um
eine fiktive Fallstudie entwickeln , die sich auf eine App namens Potato Time konzentriert. Ich freue mich, Ihnen ein wenig Data Science Denken zu geben, einen Geschmackstest für die verschiedenen Schritte in der Datenanalyse. In der nächsten Lektion besprechen wir Ihre
Fallstudie für den Kurs und Sie werden in kürzester Zeit mit Daten spielen.
2. Projekt: A/B-Webseitentest: Ihr Ziel ist es, eine Geschichte mit Daten zu erzählen, um eine geschäftliche Entscheidung zu unterstützen. Entscheiden Sie sich insbesondere zwischen zwei Versionen einer Unternehmens-Landingpage. Allerdings ist die Entscheidung nicht so schwarz und weiß, wie Sie vielleicht denken. Die fragliche Website heißt Potato Time. Während die App real ist, ist
die Fallstudie nicht. Die Herausforderung besteht in zweierlei Hinsicht. Erstens: Erklären Sie das Publikum darüber, warum ein Zähler Synchronizer nützlich ist. Zweitens, erhöhen Sie die Anzahl der Anmeldungen. Ihr Projekt besteht darin, große Datenmengen sinnvoll zu machen und
dann eine Reihe von Visualisierungen zu erstellen, die
Ihre Argumentation für eine endgültige datengesteuerte Geschäftsempfehlung veranschaulichen . In diesem Projekt wird ein synthetisches Dataset verwendet. Es wird Sie jedoch zwingen zu erkennen, warum Knie-Ruckel-Reaktionen zu fehlerhaften Schlussfolgerungen führen können, warum eine Oberflächen-Ebenen-Analyse einfach nicht ausreicht. Dieses Projekt wird die Wichtigkeit der Auswahl der richtigen Visualisierungen hervorheben. Wir werden über die Datenanalyse in drei Schritten sprechen: Eins, Entwurfsdatenerfassung, zwei, Vorprozessdaten und drei, Daten analysieren. Alles, was Sie benötigen, ist ein Google-Konto mit Zugriff auf Google Colab. Wenn Sie ein geschäftliches Gmail-Konto haben, das Sie verwenden können, ist das perfekt. Ansonsten sieht ein persönliches Gmail einfach gut aus. Hier sind drei Tipps. Tipp Nummer eins, um die Seite der Vorsicht zu verdienen, kopieren Sie
immer den genauen Code, den ich habe. Der Code wird unter dieser URL zur Verfügung gestellt. Tipp Nummer zwei, pausieren Sie das Video bei Bedarf. Ich werde jede Codezeile erklären, die ich schreibe. Aber wenn Sie Zeit brauchen, um selbst Code zu schreiben und auszuprobieren, zögern Sie nicht, das Video zu pausieren. Tipp Nummer drei, du wirst am besten lernen, indem du es tust. Ich schlage vor, sich für den Erfolg einzurichten, indem Sie Ihre Skillshare und Google Colab Fenster nebeneinander platzieren, wie hier gezeigt. Ein letzter Zettel. Das wichtigste Takeaway sind die Schritte, die wir durchlaufen und das Konzept, auf das wir ansprechen. Die Funktionsnamen sind Dinge, die Sie später immer Google können. Da würde ich mir keine Sorgen machen. Lasst uns jetzt loslegen und direkt in den Code eintauchen.
3. Python Refresher: In dieser Lektion arbeiten Sie durch eine schnelle Python Aktualisierung. Diese Aktualisierung wird Python -Syntax für mehrere Konzepte abdecken. Hier sind die Konzepte, die wir überprüfen werden. Keine Sorge, wenn Sie sich nicht erinnern, was all diese Begriffe bedeuten, sollten
sie einfach vertraut aussehen. Wenn Sie zu irgendeinem Zeitpunkt stecken bleiben, vergewissern Sie sich, dass Sie auf
den ursprünglichen Coding 101 Kurs zurückgreifen oder eine Frage im Diskussionsabschnitt stellen. Gehen Sie weiter und navigieren Sie zu colab.research.google.com. Sie sollten dann mit einem Bildschirm wie diesem begrüßt werden. Gehen Sie weiter und klicken Sie unten rechts auf „Neues Notebook“. Bevor wir beginnen, lassen Sie mich erklären, was diese Schnittstelle ist. Diese Art der Ausführungsumgebung wird als Notizbuch bezeichnet. Ein Notizbuch enthält verschiedene Zellen wie die, die ich hier angeklickt habe. Wir verwenden ein Notizbuch, weil es einfacher ist, Visualisierungen wie Plots zu sehen. Es gibt drei Datentypen, die wir für diesen Kurs benötigen. Der erste Datentyp ist eine Zahl. Der zweite Datentyp, den Sie benötigen, ist eine Zeichenfolge. Eine Zeichenfolge, wenn Sie sich erinnern, ist ein Stück Text. Sie benötigen immer Anführungszeichen, um ein Stück Text zu bezeichnen. Der dritte Datentyp wird als boolescher Wert bezeichnet. Ein boolescher Wert ist nur ein true oder false Wert. Es gibt mehrere Möglichkeiten, mit diesen Datentypen zu arbeiten. Hier ist ein solcher Ausdruck. Sie haben zwei Zahlen und Additionsoperation. Wie Sie vielleicht erwarten können, hat der Ausdruck,
sobald Python diesen Ausdruck ausgewertet hat, den Wert 7. Hier ist noch ein Ausdruck. Wie Sie vielleicht erwarten, wird der Ausdruck wahr,
sobald Python diesen Ausdruck ausgewertet hat. Lassen Sie uns Variablen besprechen. Hier weisen wir die Variable x dem Wert fünf zu. Denken Sie daran, von vorher, wir schrieben 5 plus 2. Wir wissen, dass Python diesen Ausdruck auswertet, um sieben zu erhalten. Dieses Mal, sagen wir x ist gleich 5, wir können dann fünf durch x ersetzen. Genau wie zuvor wird dieser Ausdruck auf sieben ausgewertet. Lass uns weitermachen und Code schreiben. Zuerst sind Datentypen. Hier ist eine Zahl, geben Sie fünf ein. Wenn Sie auf einem Windows Befehlseingabe oder Steuereingabe drücken, liest
Python das Ergebnis dieses Ausdrucks, wertet und gibt es zurück. Gehen wir weiter und machen das Gleiche für eine Schnur. Merken Sie sich Ihre Anführungszeichen, geben Sie den gewünschten Text und drücken Sie die Eingabetaste oder die Eingabetaste. Schließlich geben wir einen booleschen Wert ein. Führen Sie die Zelle aus, und da ist Ihre Ausgabe. Zweitens schreiben wir eine Operation. Gehen Sie weiter und geben Sie 5 plus 2 ein. Die Räume sind optional. Sobald Sie Befehlseingabe oder Steuereingabe drücken , liest
Python erneut, wertet und gibt das Ergebnis dieses Ausdrucks zurück. In diesem Fall wird dieser Ausdruck wie erwartet als sieben ausgewertet. Nun geben wir 5 größer als 2 ein. Dies
gibt, wie Sie vielleicht erwarten, den booleschen Wert true zurück. Drittens, lassen Sie uns voran und definieren Sie eine Variable x gleich 5. Auch hier sind die Leerzeichen optional. Führen Sie die Zelle aus, und Sie können sehen, dass es keine Ausgabe gibt. Allerdings können wir den Inhalt der Variablen x ausgeben, indem wir x, Command Enter eingeben. Gehen wir voran und verwenden Sie diese Variable. Geben Sie x plus 2 ein, und dies, wie wir vielleicht erwarten, gibt uns 7. Als Auffrischung war eine von zwei Kollektionen, die wir in Coding 101 eingeführt haben, eine Liste. Wir verwenden immer eckige Klammern,
eine, um die Liste zu starten und eine, um die Liste zu beenden. Wir verwenden auch Kommas, um jedes Element in der Liste zu trennen. In diesem Fall sind unsere Artikel Zahlen. Als Auffrischung
ordnet ein Wörterbuch, die zweite Sammlung, die wir in Coding 101 behandelt haben, die zweite Sammlung, die wir in Coding 101 behandelt haben,Schlüssel zu Werten zu. Denken Sie daran, wie Ihr Wörterbuch zu Hause, das Wörter Definitionen zuordnet. Wir verwenden immer geschweifte Klammern,
eine, um das Wörterbuch zu starten und eine, um das Wörterbuch zu beenden. Wir verwenden auch einen Doppelpunkt, um den Schlüssel vom Wert zu trennen. Hier ist der Schlüssel eine Zeichenfolge, die mit lila bezeichnet wird. Hier ist der Wert eine Zahl, die mit rosa bezeichnet wird. Das Wörterbuch ordnet den Schlüssel „jane“ dem Wert drei zu. Wir verwenden Kommas, um Einträge im Wörterbuch zu trennen. Wir können auch eine Variable zu diesem Wörterbuch zuweisen. In diesem Fall ist der Variablenname Name für Cookies. Als Nächstes erfahren Sie, wie Sie Daten aus einem Wörterbuch abrufen. Alles, was wir brauchen, ist der Schlüssel, an dem wir interessiert sind. In diesem Fall wollen wir janes Anzahl von Cookies, also würden wir den Schlüssel „jane“ brauchen. Wir verwenden eckige Klammern und den Schlüssel, um den Artikel zu erhalten. Dieser Code gibt die Nummer zurück, der jane entspricht, die drei ist. Beachten Sie hier die Schreibweise der eckigen Klammer, bei der die eckigen Klammern schwarz dargestellt sind. Zurück in Ihrem Notizbuch, das erste, was wir tun werden, ist, eine Liste von Zahlen zu definieren. Auch hier brauchen wir eckige Klammern und die Zahlen oder den Inhalt der Liste
und Kommas, um jedes einzelne Element zu trennen. Gehen Sie weiter und fahren Sie die Zelle. Gehen wir weiter und machen dasselbe für ein Wörterbuch. Wir werden geschweifte Klammern verwenden, um Anfang und Ende eines Wörterbuchs zu bezeichnen. Dann werden unsere Schlüssel eine Zeichenfolge sein und unsere Werte werden Zahlen sein, fügen Sie ein Komma hinzu, um jeden Eintrag im Wörterbuch zu trennen. Lassen Sie uns nun eine Variable definieren, die diesem Wörterbuch entspricht. Hier haben wir den Namen Cookies ist gleich „jane“ von drei und „john“ von zwei. Führen Sie die Zelle noch einmal aus. Auch da wir eine Variable definiert haben, gibt es keine Ausgabe. Lassen Sie uns voran und geben Sie nun den Inhalt dieser Variablen aus. Führen Sie die Zelle aus, und es gibt den Inhalt der Variablen. Lassen Sie uns voran und greifen Sie auf den Wert für den Schlüssel „jane“ zu. So nennen Sie Cookies von „jane“. Wir werden Funktionen und Methoden überprüfen. Wir werden beide Konzepte abdecken, bevor mehr Code ausgeführt wird. Denken Sie an die Funktionen, die Sie im Mathematikunterricht von der Grundschule gelernt haben. Funktionen akzeptieren einen Eingabewert und geben einen Wert zurück. Betrachten Sie beispielsweise die absolute Funktion, nehmen Sie eine Zahl ein und geben Sie die positive Version dieser Zahl zurück. Wie verwende ich eine Funktion? Betrachten Sie die Absolutwertfunktion erneut. In Python ist der Name der Funktion nur abs. Verwenden Sie Klammern, um die Funktion aufzurufen. Das Aufrufen der Funktion bedeutet, dass wir die Funktion ausführen. zwischen den Klammern alle Eingaben
hinzu, die die Funktion benötigt. Diese Absolutwertfunktion nimmt eine Eingabe ein. Wir beziehen uns auch auf die Eingabe als Eingabeargument oder nur das Argument. Jeder der Datentypen, über die wir bisher gesprochen haben: Zahlen, Strings, Funktionen, das sind alle Arten von Objekten. Eine Methode ist eine Funktion, die zu einem Objekt gehört. In diesem Beispiel werden wir eine Zeichenfolge in eine Reihe von kleineren Strings aufteilen. Zuerst benötigen Sie ein Objekt. Hier haben wir ein String-Objekt. Fügen Sie als Nächstes einen Punkt hinzu. Dieser Punkt bedeutet, dass wir im Begriff sind, auf eine Methode für das String-Objekt zuzugreifen. Fügen Sie den Methodennamen hinzu. In diesem Fall wird der Name geteilt. Die Methode Split wird die Zeichenfolge in viele Zeichenfolgen trennen, und der Rest dieser Folien sieht sehr ähnlich wie beim Aufruf einer Funktion aus. Um diese Methode aufzurufen, wie Sie Funktionen aufrufen würden, fügen Sie Klammern hinzu. Sie zwischen den Klammern ein Eingabeargument
hinzu. Hier sind alle Teile mit Anmerkungen versehen. Von links nach rechts benötigen wir das Objekt, einen Punkt, den Methodennamen und die Eingabeargumente. Lassen Sie uns jetzt versuchen, Funktionen und Methoden zu verwenden. Geben Sie hier abs, Klammern ein, und geben Sie fünf ein. Gehen Sie weiter und führen Sie die Zelle aus, und Sie werden feststellen, dass wir den absoluten Wert von fünf berechnen. Gehen Sie weiter und wiederholen Sie das gleiche, aber jetzt für negative fünf, führen Sie die Zelle und wir bekommen positive fünf wie erwartet. Wir können auch Funktionen ausführen, die zwei Eingabeargumente erfordern. Hier können wir max eingeben und 2 Komma 5 übergeben, und das wird das Maximum der beiden Zahlen zurückgeben. In diesem Fall erwarten wir fünf. Wir können auch die Split-Methode aufrufen, wie wir in den Folien abgedeckt. Gehen Sie weiter und geben Sie eine Liste von Buchstaben ein und geben Sie in.split parethes, und dann werden wir in einer anderen Zeichenfolge übergeben, die ist, was die Zeichenfolge geteilt werden soll. In diesem Fall möchten wir bei jedem einzelnen Komma aufteilen. Gehen Sie voran und führen Sie die Zelle, und Sie können jetzt sehen, dass wir die Zeichenfolge
erfolgreich in eine Reihe von verschiedenen Teilen aufgeteilt haben . Zurück zu den Folien für das letzte Segment dieser Überprüfung. Das letzte Thema in diesem Refresher ist, wie eine Funktion definiert wird. Wie bereits erwähnt, denken Sie an Funktionen aus Ihrer mathematischen Klasse. Betrachten Sie insbesondere die quadratische Funktion. Nehmen Sie eine Zahl x, multiplizieren Sie x mit sich selbst, und geben Sie die quadrierte Zahl zurück. Hier fangen wir mit def an. So definieren Sie eine Funktion. Dann folgen wir ihm mit dem Funktionsnamen. In diesem Fall wird es quadratisch sein. Dann fügen wir Klammern gefolgt von einem Doppelpunkt hinzu. Zwischen den Klammern fügen
wir unser Eingabeargument hinzu. In diesem Fall nimmt unser Funktionsquadrat nur ein Argument ein,
das wir x nennen werden. Dann fügen Sie zwei Leerzeichen hinzu, diese beiden Leerzeichen sind extrem wichtig. In diesen Leerzeichen weiß Python, dass Sie der Funktion jetzt Code hinzufügen. Da diese Funktion einfach ist, die erste und einzige Zeile unserer Funktion eine return-Anweisung. Die return-Anweisung stoppt die Funktion und gibt den Ausdruck zurück, der als nächstes kommt. In diesem Fall ist der Ausdruck x mal selbst. Hier sind alle Teile nochmals mit Anmerkungen versehen. Beachten Sie, dass alle Teile in Schwarz benötigt werden, um eine beliebige Funktion zu definieren und Sie immer def,
Klammern und einen Doppelpunkt benötigen , um anzugeben, dass die Funktion gestartet wird. Sie benötigen auch die return-Anweisung, um Werte an den Programmierer
zurückzugeben, der Ihre Funktion aufruft. Der Funktionsname, die Eingaben und die Ausdrücke können sich ändern. zurück in Ihr Notizbuch Gehen Siezurück in Ihr Notizbuchund geben Sie def eckige Klammern x Doppelpunkt ein. Sobald Sie Enter drücken, wird
Colab automatisch zwei Leerzeichen für Sie hinzufügen, so gehen Sie weiter und halten Sie diese Leerzeichen in und geben Sie in Rückkehr x mal x. Führen Sie Ihre Zelle, rufen Sie jetzt die Funktion, Quadrat von fünf, führen Sie die Zelle, und wir können dies auch für eine andere Zahl versuchen, Quadrat von zwei. Dies sind die Konzepte, die wir in dieser Lektion behandelt haben. Wenn Sie auf diese Folien zugreifen und herunterladen möchten, besuchen Sie diese URL aaalv.in/data101. Das schließt unsere Python Auffrischung ab. In der nächsten Lektion entwerfen Sie das Experiment und bestimmen, welche Daten erfasst werden sollen.
4. Privacy-First Experimentelles Design: In dieser Lektion besprechen wir die Datenerfassung,
die Prinzipien, die hinter dem Entwerfen eines Experiments stehen. Am Ende der Lektion haben wir eine Reihe von Hypothesen und die Daten, die wir sammeln müssen. Hier finden Sie die Reihenfolge der Themen für diese Lektion: Philosophie, Prinzipien, Fallstudie, Hypothesen und Daten. Wir beginnen zunächst mit der Philosophie
eines experimentellen Designs und wie das die von uns erfassten Daten leitet. Die Grundidee ist zuerst die Privatsphäre. Die erste Konsequenz ist, dass Sie sammeln sollten, was minimal benötigt wird. Hier ist Prinzip Nummer eins, sammeln Sie nur, was Sie brauchen. Sammeln Sie keine Daten, nur weil Sie können, sammeln Sie nur das, was zum Testen der Hypothese erforderlich ist. Angenommen, Ihre Hypothese lautet, dass langsamere Seiten zu weniger Klicks führen Wie
Sie vielleicht erwarten, müssen
wir nur die Ladezeit der Seite erfassen und auf Informationen klicken. Andere Informationen, die Sie wie Standort fragen könnten, werden nicht benötigt. Prinzip Nummer zwei, Bericht in aggregierter Form. Statistiken sollten als Teil einer Menge gemeldet werden. Darüber hinaus und möglich, können Sie einzelne Datenzeilen randomisieren, so dass die einzelnen Identitäten geschützt sind, während Aggregatstatistiken gleich bleiben. Diese Grundsätze regeln, wie und wann Sie Daten erfassen. Schauen wir uns unsere spezifische Fallstudie an. Wir werden eine tatsächliche App namens PotatoTime studieren. Diese App synchronisiert Google-Kalender, so dass die besetzte Zeit auf einem Kalender als besetzt auf allen Kalendern angezeigt wird. In dieser Klasse werden wir zwei Varianten der Landing Page betrachten. Wir werden auch zwei Hypothesen haben, die uns helfen, zwischen den beiden Landing Pages zu wählen. Das ist Schritt eins. Wir formulieren die Hypothese. Hypothese Nummer eins ist, dass Benutzer das Dienstprogramm in unserem Kalendersynchronizer nicht sehen, insbesondere Benutzer nicht wissen, warum ein Kalendersynchronizer nützlich ist, so dass Ihr geführtes Walk-Through-Video auf der Homepage die Anmeldungen für Web Seite A. Hypothese Nummer zwei ist, dass Benutzer für die Preisgestaltung ausgebildet werden müssen, so dass klare Preisstufen die Anmeldungen erhöhen, dies ist Webseite B. Wir können jetzt Daten berücksichtigen, die benötigt werden, um jede Hypothese zu testen. Dies ist Schritt Nummer zwei, um zu
entwerfen, wie wir Daten sammeln werden. Wir können zuerst betrachten Webseite A, das Video, was sind einige Informationen, die wir brauchen? Wir benötigen die Dauer der Wiedergabezeit, die Ladezeit der Seite ,
Klickinformationen und wann das Video angesehen wurde. Die nächste ist für die Webseite B, welche Informationen brauchen wir? Wir benötigen Scroll-Informationen, also wie lange der Benutzer damit verbracht hat, jeden Teil der Seite anzuschauen, Klick-Informationen zu klicken und auch wann auf die Seite zugegriffen wurde. Beachten Sie, dass keine personenbezogenen Daten erforderlich sind, um eine dieser Studien durchzuführen, während Informationen wie Altersgruppe oder Standort einzigartige versteckte Erkenntnisse entdecken können. Wir haben weder eine Hypothese noch einen Grund formuliert, warum eines davon einen Faktor spielen würde. Für die Zwecke dieser Klasse analysieren
wir nur die oben aufgerufenen Informationen. Dies sind die Konzepte, die wir in dieser Lektion behandelt haben. Für eine Zusammenfassung besteht unser experimentelles Design darin, minimale Mengen an Informationen zu sammeln. Hört sich philosophisch großartig an, was ist in der Praxis? Nun, in der Praxis ist das Sammeln oder Zugreifen genau das, was Sie brauchen, definitiv hilfreich, Sie riskieren andernfalls eine Überlastung von Informationen und Entscheidungslähmung. Wenn Sie auf diese Folien zugreifen und diese herunterladen möchten, besuchen Sie diese URL. In der nächsten Lektion schreiben wir Code, der Daten liest und bereinigt, wie eine Webseite eingerichtet wird, wie auf die Webseite zugegriffen wird und wie wir Informationen über
diesen Webseitenzugriff speichern , liegt außerhalb des Bereichs dieser Klasse, konzentrieren wir uns stattdessen auf die Datenanalyse in späteren Abschnitten.
5. Vorverarbeitung von Daten in Pandas: In diesem Schritt laden Sie Daten in Python mit einer Bibliothek namens Pandas. Erinnern Sie sich, eine Bibliothek ist nur eine Sammlung von Code, den jemand anderes geschrieben hat, den wir verwenden können. Da Pandas das Laden von Daten einfach macht, konzentrieren
wir uns auf die Arbeit mit den geladenen Daten. Hier sind die Konzepte, die wir behandeln: Wir besprechen, was ein Pandas-Bibliotheksdatenrahmen ist, welche Statistiken wir aus einem Datenrahmen erhalten können und schließlich, wie Sie Ihre Daten bereinigen können. Beginnen Sie mit dem Zugriff auf aaalv.in/data101/notebook. Mit dem verknüpften Notizbuch laden
Sie einen Datensatz, der einige synthetische Web-Traffic-Daten enthält, die wir verwenden können. Sobald Sie auf diese URL zugreifen, sollten
Sie dann mit einer Seite wie dieser begrüßt werden. Gehen Sie weiter und klicken Sie auf „Datei“ und speichern Sie dann eine Kopie in Drive Dadurch wird eine Kopie erstellt, die Sie jetzt ändern können. Auf dieser Seite werde ich hier auf dieses „X“ klicken, um die Navigationsleiste zu schließen. Gehen Sie weiter und scrollen Sie nach unten, und laden Sie zuerst eine Datei herunter, die das Dataset enthält. Um dies zu tun, führen Sie diese erste Zelle mit URL abrufen, wählen Sie die Zelle und drücken Sie „Command Enter“ oder wenn Sie unter Windows sind drücken Sie „Control Enter“. Sie können hier auch auf den Play-Button klicken. Sobald diese Datei heruntergeladen wurde, sehen
Sie diese Ausgabe direkt hier, views.pkl und diesen anderen Unsinn. Dies bedeutet, dass die Datei erfolgreich heruntergeladen wurde. Als nächstes
importieren Sie, genau wie die Codierung 101, Code, den andere geschrieben haben, den wir verwenden können. Gehen Sie voran und geben Sie Import Pandas als pd ein. Diese Bibliothek hat eine Funktion namens lesen Pickle, lassen Sie uns voran und verwenden Sie diese jetzt, um den Datensatz zu lesen, geben Sie pd.read pickle ein. Wie wir oben gesehen haben, ist
der Name der Datei views.pkl. Diese Funktion liest die Pickle-Datei und gibt den Datensatz als Datenrahmen zurück. Ein Datenrahmen ist, wie Pandas eine Tabelle mit Daten darstellt. Stellen Sie sich einen Datenrahmen wie eine Excel -Tabelle oder eine Datenbanktabelle vor. Lassen Sie uns den Rückgabedatenrahmen einer Variablen namens df zuweisen. Diese Variable ist für die Codierung mit Datenrahmen üblich. Lassen Sie uns nun sehen, wie dieser Datenrahmen aussieht, geben Sie df ein und führen Sie die Zelle aus. Schauen Sie, um die Struktur der Daten, die Anzahl der Zeilen, Anzahl der Spalten zu sehen, beachten Sie, dass die erste Spalte fett ist, dies wird unser Index genannt. Aus einigen Gründen ist der Index oder die erstellte
at-Spalte sehr effizient zu sortieren oder zu gruppieren, wir werden dies später nutzen. Die zweite Spalte, Page Load MS, dies ist die Anzahl der Millisekunden, die die Webseite geladen hat. Videos angesehen S, ist die Anzahl der Sekunden, die das Video, das der Benutzer angesehen hat. Produkt S ist die Anzahl der Sekunden, die die Benutzer im Produktbereich der Webseite verbracht haben. Pricing S ist die Anzahl der Sekunden, die der Benutzer für den Preisabschnitt der Seite verbrachte. Hat geklickt ist ein boolescher Wert, true, wenn der Benutzer auf die Anmeldeschaltfläche geklickt hat. Die letzte Spalte, Webseite, ist entweder A oder B, die
angibt, welche Zielseite der Benutzer gesehen hat. Datenrahmen bieten einige Methoden zum Berechnen von Aggregatstatistiken. Zum Beispiel können wir den Durchschnitt für jede Spalte berechnen, gehen Sie voran und geben Sie df.mean ein,
fügen Sie Klammern hinzu, um die Methode aufzurufen. Die meisten der Durchschnittswerte hier sehen vernünftig aus, aber beachten Sie, dass geklickt hat, hat einen Wert von 0,34, dies scheint seltsam, weil oben Hat geklickt ist eine Spalte mit true oder false Werten. Wie werden wahre oder falsche Werte zu einer Zahl? Kurz gesagt, Pandas betrachtete jeder wahr eine Eins und jeder Falsch eine Null, dann dauerte es den Durchschnitt, als Ergebnis
0,34 bedeutet, dass 34 Prozent der Werte wahr sind. Lassen Sie uns jetzt voran gehen und den Mindestwert pro Spalte berechnen. Geben Sie df.min erneut mit Klammern ein, führen Sie die Zelle aus und hier können Sie die Minimalwerte sehen. Nun, da wir einige grundlegende Statistiken behandelt haben, die Datenrahmen bieten, lassen Sie uns jetzt sehen, was Datenrahmen für die Bereinigung von Daten bieten. Bei der Bereinigung Ihrer Daten sind drei gängige Schritte erforderlich. Zuerst möchten Sie alle Duplikate entfernen, die Methode Drop-Duplikate auf Ihrem Datenrahmen
aufrufen, df.drop Unterstriche Duplikate
eingeben und Klammern hinzufügen, um die Funktion aufzurufen. Gehen Sie weiter und fahren Sie die Zelle. Ein kleiner Tipp, Sie müssen sich diese Methode nicht per se merken, Sie können immer Pandas Datenrahmen Drop-Duplikate googeln. Wichtiger ist, dass Sie sich an die Schritte bei der Datenbereinigung erinnern. Nun, in der nächsten Zelle, werden
wir fehlende Werte füllen,
diese fehlenden Werte werden als NaN oder N-A-N dargestellt, dies steht für keine Zahl. NANs oder fehlende Werte können möglicherweise aufgrund von Fehlern im Datenerfassungscode auftreten. Hier können wir fehlende Werte mit dem Durchschnittswert in jeder Spalte eingeben. Denken Sie daran, von oben df.mean nochmals Sie sollten dies nun innerhalb Ihrer Zelle
eingeben, df.mean mit Klammern eingeben, dies berechnet den Mittelwert jeder Spalte. Hier ist eine neue Methode namens fill NA, die alle NaN-Werte mit den angegebenen Werten füllt, df.fillna
eingeben und dann weiter gehen und df.mean als Argument übergeben. FillNA ändert den Datenrahmen nicht, sondern erstellt einfach einen neuen Datenrahmen mit den eingegebenen Werten. Als Ergebnis müssen wir die Variable df dem Ergebnis zuweisen, geben Sie df gleich ein. Schließlich, führen Sie die Zelle. Drittens überprüfen wir Vernunft die Daten. In diesem Fall wissen wir, dass das Video nur 60 Sekunden lang ist also schauen wir uns die maximale Zeit an, die ein Benutzer für das Ansehen des Videos verbracht hat, stellen Sie sicher, dass es nur 60 Sekunden ist. Um auf eine Datenspalte in einem Datenrahmen zuzugreifen, behandeln Sie einen Datenrahmen wie ein Wörterbuch, Sie den Spaltennamen ein. In diesem Fall ist unser Spaltenname Video Watched S, wie wir hier sehen, aber lassen Sie uns voran und tippen Sie auf den Spaltennamen durch Eingabe in df eckige Klammer Video angesehen s und dies holt uns eine Spalte von Daten. Wir möchten jedoch den maximalen Wert erhalten, also gehen Sie voran und verwenden Sie die Methode max, so geben Sie Punkt max ein. Gehen Sie voran und führen Sie die Zelle und eine Zahl, die viel größer als 60 Sekunden
ist, scheint es ein Fehler in unserem Datenerfassungscode zu sein, also lassen Sie uns alle Dauern größer als 60 Sekunden
schneiden. In einem Datenrahmen, genau wie bei Wörterbüchern, können
wir Werte zuweisen. Gehen Sie voran und geben Sie df und eckige Klammer dann den Namen unserer neuen Spalte, die Video Watched S trunc für abgeschnitten sein wird. Dadurch wird eine neue Spalte namens video angesehen S trunc erstellt, sobald Sie sie einem Wert zuweisen. Wir werden nun die Werte der neuen Spalte berechnen. Zuerst erhalten Sie die alte Spalte, die df Video Watched S ist, genau wie wir es in der vorherigen Zelle getan haben. Rufen Sie nun den Punkt Clip oder die Clip-Methode auf, um alle Werte zu schneiden. Das erste Argument ist der niedrigste mögliche Wert, so dass in diesem Fall Null, wir wollen nicht, dass eine Anzahl von Sekunden beobachtet kleiner als Null ist. Wir wollen auch nicht, dass eine Anzahl von Sekunden beobachtet größer als 60 ist. Dadurch wird sichergestellt, dass keine Werte kleiner als Null oder Werte größer als 60 vorhanden sind. Gehen Sie weiter und drücken Sie „Enter“, um eine neue Zeile zu erstellen und df einzugeben. Dadurch wird nun der Datenrahmen ausgegeben. Gehen Sie weiter und fahren Sie die Zelle. Beachten Sie, dass die Spalte ganz rechts
unsere brandneue Spalte mit abgeschnittenen Uhrzeiten und Voila enthält , die unsere erste Datenvorverarbeitung in Pandas abschließt. Dies sind Konzepte, die wir in diesem Kurs behandelt haben. Die Takeaways sind, wie Sie Ihre Daten bereinigen. Typische Schritte, darunter das Ausfüllen von NANs, Deduplizieren von Zeilen und die Überprüfung der Vernunft gegen Ihr Verständnis der Daten. Überprüfen Sie beispielsweise, ob Durchschnittswerte, Maximal- und Minimalwerte mit Ihrem Verständnis übereinstimmen. Wenn Sie auf diese Folien zugreifen und diese herunterladen möchten, besuchen Sie diese URL. Stellen Sie sicher, dass Sie Ihr Notizbuch speichern, indem Sie auf Datei Speichern klicken. Nächstes Mal führen wir eine erste Datenanalyse durch.
6. Analysieren von Daten in Pandas: In dieser Lektion analysieren wir das synthetische Dataset. Hier sind die Konzepte, die wir behandeln werden. Wir beginnen mit einigen zusammenfassenden Statistiken wie Summen pro Tag. Dann berechnen wir Korrelationen zwischen verschiedenen Teilen von Daten, um zu verstehen, wo nach Mustern gesucht werden soll, und um eine Intuition zu entwickeln. Schließlich werden
wir in diesem Schritt einige erste Schlussfolgerungen ziehen. Wenn Sie Ihr Notizbuch verloren haben oder gerade mit dieser Lektion beginnen,
greifen Sie auf das Starter-Notizbuch für Lektion 6 von aaalv.in/data101/notebook6 zu. Sobald Sie auf diese URL zugreifen, sollten
Sie eine Seite wie diese sehen. Gehen Sie weiter und klicken Sie auf Datei, und speichern Sie eine Kopie in Drive. Ich klicke oben links auf X, um die Navigationsleiste zu schließen. Sobald Sie sich auf dieser Seite befinden,
klicken Sie ganz oben auf Runtime und wählen Sie alle ausführen, warten Sie, bis alle Zellen ausgeführt werden. Sie können sagen, sobald Sie die Ausgabe aller Zellen gesehen haben. Gehen Sie voran und von dieser Zelle aus, beginnen Sie mit der Berechnung mehrerer zusammenfassender Statistiken. Berechnen Sie beispielsweise, wie viele Tage sich das Dataset erstreckt. Um auf die Datumsangaben im Datenrahmen zuzugreifen, verwenden Sie df.index. Gehen Sie voran und geben Sie in.max ein, um das letzte Datum zu erhalten, subtrahieren
Sie dann das erste Datum mit.min. Führen Sie die Zelle, und hier erhalten wir ein Zeitdatenobjekt von einem 100 Tage. Die zweite Zusammenfassungsstatistik ist die Anzahl der Seitenaufrufe pro Tag. Dazu müssen wir eine Funktion definieren. Die Funktion zählt die Anzahl der Ereignisse, die an jedem Tag aufgetreten sind. Beginnen Sie mit der Definition des Funktionsnamens, Ereignisse pro Tag. Diese Funktion akzeptiert ein Argument namens df. Fügen Sie Klammern hinzu, geben Sie df ein, und stellen Sie sicher, dass Sie am Ende dieser Zeile einen Doppelpunkt hinzufügen. Gehen Sie weiter und drücken Sie Enter. Wieder einmal fügt Colab automatisch zwei Räume für uns hinzu. Zuerst geben Sie datetimes gleich dem df.index ein. Dies ist der Datenrahmen, df. DF.index ruft die Datumszeiten für jede Ansicht ab. Definieren Sie als Nächstes eine neue Variable. Days ist gleich datetimes und use.floor, fügen Sie Ihre Klammern hinzu, um die Funktion aufzurufen, und übergeben Sie dann eine Zeichenfolge
von Kleinbuchstaben d, .floor konvertiert Datetimes in Datumsangaben. Typ Ereignisse pro Tag ist gleich days.value_counts. value_counts zählt, wie oft jedes Datum angezeigt wird. Mit anderen Worten, wir zählen die Anzahl der Aufrufe pro Tag. Rufen Sie return events_per_day.sort_index auf. Dadurch werden die Zählungen nach dem Tag sortiert. Keine Sorge, diese Funktion schien viel zu sein. Das Wichtigste zum Mitnehmen ist, den Code nicht auswendig zu lernen. Dieser Code ist perfekt googleable. Am wichtigsten ist, dass A, Sie können den Code lesen und grob verstehen, was er tut. Dann B, dass Sie wissen, was Google für in der Zukunft. Um die Anzahl der Ansichten pro Tag zu zählen,
haben wir in diesem Fall die Anzahl der Zeilen pro Tag im Datenrahmen gezählt. Mal sehen, was unsere Funktion zurückgibt. Definieren Sie eine neue Variable, views_per_day, setzen Sie diese Variable auf den Rückgabewert unserer obigen Funktion. Denken Sie daran, dass diese Funktion ein Argument
enthält, das der Datenrahmen ist. Gibt den Inhalt der Variablen aus. Führen Sie die Zelle aus, und hier erhalten wir die Anzahl der Ansichten pro Tag. Definieren Sie als Nächstes eine andere Funktion, die
den Datenrahmen so filtert , dass er nur Zeilen enthält, die zu einem Klick geführt haben. Beginnen Sie mit der Definition des Funktionsnamens get_click_events. Diese Funktion akzeptiert ein Argument namens df oder den Datenrahmen. Vergiss deinen Doppelpunkt am Ende der Zeile nicht. Drücken Sie die Eingabetaste, Colab fügt zwei Leerzeichen für Sie hinzu und geben Sie nun ein, Selektor entspricht df, eckige Klammer
und den Namen der Spalte, die die Klickinformationen enthält. Hier sind Klicks gleich df und geben Sie den Selektor ein. Gehen Sie nun weiter und geben Sie die neue Variable zurück, die Sie definiert haben, d. h. Klicks. Dies gibt einen Datenrahmen mit nur den Zeilen zurück, die true im Selektor haben, und die Zeilen, die true in diesem Selektor sind diejenigen, die zu einem Klick geführt haben. Infolgedessen gibt diese Funktion einen Datenrahmen mit nur den Zeilen zurück, die zu einem Klick geführt haben. Gehen Sie weiter und fahren Sie die Zelle. Verwenden Sie diese Funktion, um nur die Zeilen mit Klicks zu erhalten. Um Klicks zu finden, entspricht get_ click_events und übergeben Sie Ihren Datenrahmen. Definieren Sie eine Variable, clicks_per_ Tag entspricht, und genau wie zuvor werden
wir die Anzahl der Ereignisse pro Tag zählen. schließlich den Inhalt der Variablen aus, und führen Sie die Zelle aus. Hier können wir die Anzahl der Klicks pro Tag sehen. Um nur die Werte zu sehen, verwenden Sie das attribute.values. Im Gegensatz zu Methoden benötigen Sie keine Klammern, um auf ein Attribut zuzugreifen. Geben Sie clicks_per_day.values ein. Auch hier sind keine Klammern erforderlich, um auf dieses Attribut, .values, zuzugreifen. Gehen Sie weiter und führen Sie die Zelle, und hier bekommen wir alle Werte. Jetzt brauchen wir einen Vernunft Check. Hier möchten wir überprüfen, ob die Anzahl der Klicks pro Tag
kleiner oder gleich der Anzahl der Aufrufe pro Tag ist . Lassen Sie uns in und überprüfen, dass jetzt, indem clicks_per_day.values eingeben, kleiner oder gleich views_per_day.values. Gehen Sie weiter und fahren Sie diese Zelle. Jetzt können Sie sehen, dass alle diese wahr sind. Sieht so aus, als hätte der Vernunft bestanden Gute Arbeit. Als nächstes berechnen wir die Korrelation zwischen den Features in unserem Dataset. Wenn Sie sich aus Ihrer Statistik oder Wahrscheinlichkeitsklasse zurückrufen, erfahren Sie in der
Korrelation, wie sich ein Feature ändert, wenn sich ein anderes Feature ändert. Angenommen, Sie haben zwei Funktionen, Seitenladezeit und Videowiedergabedauer. zunehmender Ladezeit von Seiten erwarten
Sie weniger Personen, die sich das Video ansehen. Um die Korrelation zu überprüfen und zu berechnen, gehen Sie voran und geben Sie df.corr ein. Fügen Sie die Klammern hinzu, um die Funktion aufzurufen, und führen Sie die Zelle aus. Diese corr-Methode berechnet Korrelationen zwischen allen Feature-Paaren. Vergewissern Sie sich, dass die folgenden Korrelationskoeffizienten unsere Intuition widerspiegeln. Wir erwarten, dass mit zunehmender Seitenladezeit die Wahrscheinlichkeit eines Klickens abnimmt. Wir können sehen, dass in der ersten Spalte, zweiten bis letzten Zeile, die Überprüfung der Vernunft bestanden hat. Eine weitere interessante Sache zu beachten ist, dass die Zeit, die auf den Preisabschnitt der Webseite
verbracht wird, sehr, sehr schwach mit dem Klicken korreliert ist. Sie können sehen, dass die Korrelation zwischen Preisgestaltung und Klicken 0,10 beträgt. Auf der anderen Seite ist die Videowiedergabe relativ stark mit dem Klicken korreliert,
mit etwa dem Dreifachen des Wertes. Indem man die Zusammenhänge allein untersucht, scheint die Webseite A mit dem Video effektiver zu sein. Lassen Sie uns schließlich die Klickrate oder CTR für jede Landing Page berechnen. Dies sagt uns das Verhältnis von Klicks zu Ansichten. Unser oberstes Ziel ist es, eine Zielseite zu empfehlen, die die Klickrate für die Kartoffelzeit maximiert. Beginnen Sie mit der Berechnung eines Selektors. Zuvor haben wir has_clicked verwendet, was eine Spalte ist, die bereits true oder false für jede Zeile enthält, so können wir folgendes schreiben, um zu überprüfen, ob eine Zeile für Webseite A ist oder nicht. Df, eckige Klammer, und wählen Sie die Website-Spalte. Jetzt wollen wir überprüfen, ob diese Spalte gleich A ist. Wenn ich die Zelle ausführe, werden
Sie sehen, dass die gesamte Spalte voll von Wahrheiten und Falschen ist. Perfekt. Wir können dies nun verwenden, um Zeilen im Datenrahmen auszuwählen. Jetzt können wir diesen Selektor verwenden. Gehen Sie voran und kopieren Sie das und unten in der nächsten Zelle, geben Sie eine neue Variable viewA ist gleich df, eckige Klammer, und fügen Sie dann in den Selektor ein. Dadurch werden alle Zeilen so ausgewählt, dass die Spaltenwebseite gleich A ist. Als nächstes wiederholen Sie dies für Webseite B Wir möchten alle Ansichten für B erhalten. Setzen Sie dies gleich Datenrahmen, und wieder, mit dem gleichen Selektor außer die Webseite B. Geben Sie ViewSA ein „hat_ geklickt“ .mean. Erinnern Sie sich an frühere Lektionen, die wir drucken aufrufen können, um diesen Wert tatsächlich auszugeben. Wir werden das gleiche tun, aber jetzt für ViewsB „hat geklickt“ .mean. Gehen Sie weiter und führen Sie die Zelle, und das scheint uns die gegenteilige Schlussfolgerung zu geben. Denken Sie daran, von vorher, Blick auf die Korrelationswerte, Webseite A sah besser aus. Dies zeigt jedoch, dass die Klickrate der Webseite A 0,28 oder 28 Prozent viel niedriger ist als bei Webseiten B, was etwa 40 Prozent ist. Die Klickrate deutet darauf hin, dass Webseite B besser ist. Diese beiden ersten Schlussfolgerungen scheinen sich gegenseitig zu widersprechen,
was bedeutet, dass wir tiefer graben müssen, um herauszufinden, warum. Dies sind die Konzepte, die wir in dieser Lektion behandelt haben, und hier ist ein Tipp, den wir mehrmals in dieser Lektion erwähnt haben, Vernunft Check oft. Häufige Fehler sind unsachgemäße Filterung, Tippfehler in Ihren Spaltennamen oder sogar unklare Spaltennamen. Sanity-Überprüfungen helfen Ihnen, diese Fehler schnell zu identifizieren ,
zu isolieren und zu beheben. In einigen sind hier unsere ersten Schlussfolgerungen. Wir haben zuerst die Korrelationen untersucht und festgestellt, dass das Ansehen und Klicken von
Videos stark korreliert sind. Wir fanden auch heraus, dass das Lesen und Klicken der Preise schwach korreliert erscheinen. Dadurch wird festgelegt, dass das Video oder die Webseite A effektiver ist. Wir haben jedoch die Klickrate berechnet und festgestellt , dass Webseite B eine höhere Klickrate hat. Wir haben alle unsere Berechnungen bisher überprüft. Warum also die Diskrepanz? Das klingt nach einem Widerspruch, den wir lösen müssen. Wenn Sie auf die Folien zugreifen und diese herunterladen möchten, besuchen Sie diese URL. Stellen Sie sicher, dass Sie Ihr Notebook speichern, indem Sie Datei, speichern. nächste Mal codieren wir einige Visualisierungen, lösen dieses Geheimnis auf und bereiten Figuren für Ihre letzte Tonhöhe vor.
7. Visualisierung von Daten in Matplotlib: In diesem Schritt visualisieren Sie ein synthetisches Web-Traffic-Dataset, das wir in früheren Lektionen gesehen haben. Hier sind die Konzepte, die wir behandeln werden. Wir verwenden eine Bibliothek namens Matplotlib für das Plotten von Dienstprogrammen. Wir machen dann ein paar Plots, um Trends im Laufe der Zeit zu erkunden, werden dann auch Geschichten mit richtig konstruierten Plots erzählen. Die Wahl des Grundstücks wird beabsichtigt, ein Takeaway hervorzuheben, das wir vermitteln möchten. Wenn Sie Ihr letztes Notizbuch verloren haben oder die Klasse aus dieser Lektion starten,
greifen Sie auf ein Starter-Notizbuch für Lektion 7 von aalv.in/data101/notebook7 zu. Alternativ können Sie Ihr eigenes Notizbuch aus der letzten Lektion verwenden. Sobald Sie auf diese URL zugreifen, sollten
Sie eine Seite wie diese sehen. Gehen Sie weiter und klicken Sie auf die Datei und speichern Sie eine Kopie und Laufwerk. Dadurch wird eine neue Kopie des Notizbuchs erstellt. Auf dieser Seite klicke ich oben links auf X, um die Navigationsleiste zu schließen. dann unabhängig davon, ob Sie
das neue Notizbuch öffnen oder ob Sie Ihr vorhandenes Notizbuch verwenden, auf Runtime und Run all. Gehen Sie weiter und scrollen Sie dann ganz nach unten. Hier beginnen wir mit der Ausgabe der Korrelationen, die wir zuvor gesehen haben. Gehen Sie voran und geben Sie df.corr mit zwei rs ein, fügen Sie Ihre Klammern hinzu und führen Sie die Zelle aus. Beachten Sie zwei Dinge, die Videowiedergabe scheint mit Klicken korreliert zu sein. Wir haben Video ansehen und klicken Sie hier auf 0.32. Die Preise scheinen auch schwach korreliert zu sein mit dem Klicken hier haben wir 0,10. Das Video kann jedoch nur auf
Webseite A angesehen werden und der Preisabschnitt kann nur auf Webseite B
gelesen werden Infolgedessen ist es sinnvoller, Korrelationen für jede Webseite separat zu berechnen. Gehen Sie voran und geben Sie ViewSA.Corr ein. Hier sind die Korrelationen für Webseite A nur,
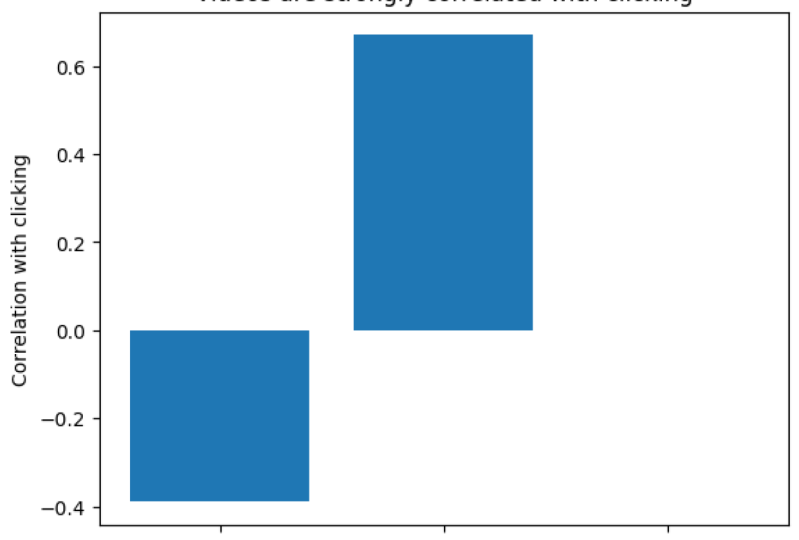
beachten Sie, dass die Korrelation zwischen Videos und Klicken
viel höher bei 0,67 ist , als wir dachten. Als nächstes fahren Sie fort und berechnen Sie die Korrelationen nur für Webseite B, die ViewsB.corr eingibt, und führen Sie nun die Zelle aus. Hier sind die Korrelationen für Webseite B. Beachten Sie, dass die Korrelation zwischen Preisabschnitt und Klick sehr gering ist. Es ist viel niedriger, als wir dachten. In der Tat können wir sagen, dass sie überhaupt nicht korreliert sind. Dies ist nahe genug an Null. Unser erstes Argument für Webseite A ist dann, dass Videos sehr
indikativ dafür sind , ob sich der Benutzer
registrieren wird oder nicht und das Lesen des Preisabschnitts ist es nicht. Eine Korrelation von 0,67 ergibt jedoch für sich keinen Sinn, ist das hoch? Ist das langsam? Ist das vernünftig? Allerdings ist eine Korrelation von 0,67 definitiv viel höher als eine Korrelation von 0,0004. Als Ergebnis können wir ein Balkendiagramm verwenden, um den Unterschied zwischen den beiden hervorzuheben. Beginnen Sie mit dem Importieren des Plotdienstprogramms Matplotlib, geben Sie import matplotlib.pyplot als plt ein. Nun, das erste, was wir tun werden, ist
den Methodentitel aufrufen , um Ihrem Plot einen Titel zu geben, geben Sie plt.title ein und Sie können zwischen diesen Anführungszeichen den Text verwenden, den Sie möchten. Allerdings werde ich einen Titel von Videos eingeben, die stark mit Klicken korreliert sind. Ich schlage vor, den Haupt Takeaway Ihrer Handlung in den Plot Titel hinzuzufügen. Jetzt werden wir plt.bar anrufen. Dadurch wird ein Balkendiagramm erstellt. Das erste Argument für bar ist eine Liste von Strings, die Namen der einzelnen Balken. Hier werden wir eine Liste erstellen und die Zeichenfolge wird der Titel sein. Also werden wir sagen, Seite laden, sagen Video ansehen, und der allerletzte Balken wird Korrelation mit dem Lesen der Preisabschnitt sein. Bar nimmt auch eine zweite Liste. Wir werden die Zahlen aus unserer Korrelationstabelle oben übergeben. Oberhalb unserer Korrelationstabelle gibt eine Korrelation von negativem 0,39 für das Laden und Klicken der Seite. Es ist auch eine Korrelation von 0,67 zum Ansehen und Klicken von Videos. Schließlich haben wir eine Korrelation von 0.0004 zwischen dem Lesen des Preisabschnitts und dem Klicken. Schließlich brauchen wir ein Etikett für unsere Y-Achse. Also werden wir y Label und Korrelation mit Klick sagen. Das war's. Dies ist Argument Nummer 1, dass Videos stark mit Anmeldungen korreliert sind. Gehen Sie weiter und laufen Sie selbst, um Ihre erste Handlung zu erstellen. Das ist jetzt dein Balkendiagramm. Für unseren nächsten Punkt müssen
wir die täglichen Statistiken wie die Klickrate im Laufe der Zeit untersuchen. Um dies zu tun, müssen wir eine neue Funktion schreiben, um tägliche Statistiken zu berechnen. Beginnen Sie mit der Definition des Funktionsnamens, erhalten Sie tägliche Statistiken. Also def get_daily_stats, und wir werden ein Argument df akzeptieren und wie üblich, vergessen Sie
nicht Ihren Doppelpunkt. Diese Funktion akzeptiert, dass ein Argument namens df oder den DataFrame. Als erstes werden wir uns für Tag gruppieren. Um dies zu tun, werden wir einen Zackenbarsch definieren, und dies ist eine neue Variable, die gleich pd.grouper ist, wobei die Frequenz gleich einem Tag ist. Hier bedeutet Großbuchstaben D Tag. PD.Grouper ist ein generisches Panel-Dienstprogramm, das uns
hilft, Zeilen in einem DataFrame nach einiger Häufigkeit zu gruppieren. In diesem Fall ist unsere Frequenz täglich. Als nächstes werden wir eine neue Variable Gruppen
zu definieren ist gleich und dann werden wir die DataFrame.GroupBy aufrufen, grouper. So können wir Gruppen von Tagen berechnen. Schließlich werden wir Statistiken für jede Gruppe berechnen. Um dies zu tun, geben wir täglich ist gleich groups.mean, für jede Gruppe, nehmen Sie den Durchschnitt jeder Spalte. Schließlich geben Sie die tägliche Statistik zurück. Sobald Sie mit Ihrer Funktion fertig sind, gehen Sie weiter und führen Sie Ihre Funktion aus. Jetzt werden wir diese Funktion verwenden, um tägliche Statistiken zu erhalten. Gehen Sie voran und geben Sie Tagesansichten ein A ist gleich, um tägliche Statistiken zu erhalten, und geben Sie alle Ansichten für Webseite A
ein oder übergeben Sie das Gleiche für die zweite Webseite B. Geben Sie get_daily_stats und Ansichten von B Um Ihnen eine Vorstellung davon zu geben, was tägliche Ansichten A enthält, werden
wir tägliche Ansichten A ausgeben. Wie Sie vielleicht erwarten, Sie,
wenn
Sie die Zelle ausführen erhaltenSie,
wenn
Sie die Zelle ausführen, einen DataFrame, in dem Sie jetzt eine Zeile für
jeden einzelnen Tag haben und die täglichen Statistiken für diesen Tag. Wie die durchschnittliche Anzahl der beobachteten Videosekunden, die durchschnittliche Ladezeit der Seite
und der Prozentsatz der Zuschauer, die darauf geklickt haben. Jetzt werden wir eine andere Handlung erkunden, ein Liniendiagramm. Gehen Sie weiter und geben Sie plt.title ein, um Ihrem neuen Plot einen Titel zu geben. In diesem Fall wird unser Plot Titel Click-Through-Raten im Laufe der Zeit sein. Glücklicherweise integriert sich matplotlib ziemlich gut mit Pandas. Alles, was wir tun müssen, ist Matplotlib zu sagen, welche Spalte wir plotten wollen. Gehen Sie voran und geben Sie plt.plot ein und übergeben Sie eine der Spalten aus den täglichen Ansichten A, in diesem Fall wird die Spalte angeklickt werden. Normalerweise können wir hier anhalten. Wir möchten jedoch jede der Linien in unserem Liniendiagramm beschriften. In diesem Fall gehen Sie weiter und fügen Sie ein Komma hinzu und geben Sie Label gleich A ein. Diese Syntax, Label gleich A, ist nicht etwas, das Sie zuvor gesehen haben. Dies wird als Schlüsselwortargument bezeichnet. Wir überspringen die Details eines Keyword-Arguments vorerst.
Wichtig ist, dass Sie auf diese Weise Linien in einem Liniendiagramm beschriften. Lassen Sie uns fortfahren und wiederholen Sie das gleiche für Webseite B. Geben Sie plt.plot Daily_ViewsB, und wählen Sie die Spalte hat geklickt. Schließlich, Komma und Label gleich B, und diese Beschriftungen sind zweite Zeile als B. Als Nächstes fügen wir unsere Legende zum Plot hinzu. Geben Sie plt.plot Legende rufen Sie die Funktion auf, und das war's. Wir werden nun zwei weitere Linien hinzufügen, um unsere Achsen zu beschriften. Geben Sie plt.xlabel ein und die X-Achse wird die Datumsangaben sein, und die Y-Achse wird die Klickrate sein. Also geh weiter und lauf die Zelle und das ist verrückt. Sehen Sie sich an, wie viel Klickrate für Webseite A, die blaue Linie im Laufe der Zeit sinkt. Frage dich, was passiert ist? Lassen Sie uns einige andere Statistiken untersuchen. Wir werden den gleichen Code wiederholen, aber dieses Mal für Seitenladezeiten werden
wir den Inhalt dieser Zelle kopieren und einfügen und dann Teile davon
ersetzen, die Seitenladezeiten sehen müssen. Gehen Sie weiter und kopieren Sie und fügen Sie sie ein. Wir werden jetzt diesen Titel durch Ladezeiten der Webseite ersetzen. Dann unten werden wir
die has_clicked Spalte durch die Seitenladespalte für beide ersetzen . Als Nächstes ändert sich dadurch unsere Y-Achse, also haben
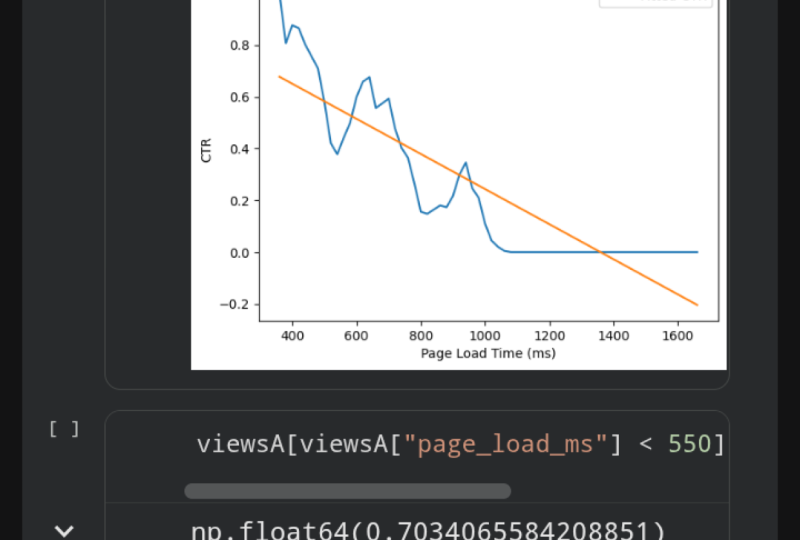
wir anstelle von Klickrate auf unserer Y-Achse jetzt Seitenladezeiten. In Klammern füge ich die Einheiten für diese Achse hinzu. Geh weiter und lauf die Zelle und whoa, sieh dir das an. Webseitenzeit, für Webpage A in blau schießt wie verrückt auf. Unser zweites Argument für Webseite A ist, dass ungewöhnlich langsame Ladezeiten der Seite unbeabsichtigt seine Klickrate zu beschädigen scheinen,
was darauf hindeutet, dass es unsagbares Potenzial für Webseite A gibt um zu quantifizieren, wie fehlerhafte Webseite A insgesamt Klickrate ist, können
wir die Seite Ladezeiten Schaden beim Klick durch Rate quantifizieren. Dazu zeichnen wir zunächst die Beziehung zwischen Klickraten und bezahlten Ladezeiten. Gehen Sie hier vor und geben Sie Ansichten von A page_load_ds ein. Wir werden eine brandneue Spalte erstellen, die
die Seitenladezeiten und deren Klickraten für alle 20 Millisekunden enthält . Gehen Sie voran und geben Sie jetzt Ansichten von A page_load_ms ein. Wir gehen auf den Boden, teilen sich durch 20. Eine Bodenteilung bedeutet also, dass Sie, wenn Sie einen Bruchteil haben, auf die nächste ganze Zahl runden. Sobald Sie das haben, lassen Sie uns fortfahren und nochmals mit 20 multiplizieren, und das bedeutet im Grunde, dass alle Ihre Werte in Schritten von 20 liegen. Also vorher, Sie könnten einen Wert von 34 gehabt haben, aber jetzt 34 Boden geteilt durch 20 wird Ihnen 1 geben, und dann multiplizieren Sie es mit 20 wird Ihnen 20 geben. Jeder Wert zwischen 20 und 39 ist gleich 20. Jeder Wert zwischen 40 und 59 wird 40 und so weiter und so weiter. Dies bindet effektiv alle unsere Seitenladezeiten in Gruppen von 20 Millisekunden. Nun, lassen Sie uns voran und geben Sie in Seite laden ist gleich viewsa.set_index. Also hat dieser nun den Index geändert. Mit anderen Worten, es ändert sich die Spalte, nach der wir leicht sortieren oder gruppieren können. Gehen Sie weiter und geben Sie page_load_ds ein, die unsere neue Spalte ist. Dann werden wir Gruppen für jede binned Seite Ladezeit berechnen. Typ in Seite laden ist gleich viewSA.GroupBy page_load_ds. Stellen Sie sicher, dass Sie diese eckigen Klammern genau hier haben. Das ist eigentlich wirklich wichtig für diese Funktion. Dadurch werden die Gruppen für jede binnte Seite Ladezeit berechnet. Jetzt werden
wir für jede Gruppe die Durchschnittsstatistiken berechnen. Gehen Sie also voran und geben Sie die Seitenlast gleich page_load.mean ein, und das berechnet die durchschnittlichen Statistiken für jede Gruppe. Schließlich möchten wir alle Daten nach der binned Seite Ladezeit
durch den Aufruf von dot sort index sortieren. Dieser DataFrame gibt Ihnen jetzt die durchschnittliche Klickrate für jede Seitenladezeit an. Auch wenn wir von dieser Funktion oder von der Zelle überwältigt sind, ist das völlig okay. Alles, was Sie sich erinnern müssen, ist das allgemeine Konzept dessen, was wir hier getan haben. Was wir getan haben, ist, dass wir zuerst alle Werte in Gruppen von 20 Millisekunden binten. Dann haben wir Statistiken für jede dieser Gruppen berechnet. Diese beiden Dinge sind perfekt googleable. Sehen wir uns jetzt an, wie dieser DataFrame aussieht. Geben Sie das Laden der Seite ein, und führen Sie die Zelle aus. Hier können wir nun die Statistiken für jeden einzelnen dieser 20-Millisekunden-Buckets sehen. Sie können jetzt ein Liniendiagramm erstellen, wie vor dem Umgehen in die DataFrame-Spalte. In diesem Fall kümmern wir uns um die Klickrate. Gehen Sie also voran und geben Sie plt.plot und Seitenlast has_clicked ein, und dies wird die Seitenladezeiten Auswirkungen auf die Klickrate darstellen. Gehen Sie weiter und drücken Sie „Run“. Nun ist die X-Achse die Seitenladezeit in Millisekunden, die Y-Achse ist die Klickrate. Wie Sie vielleicht erwarten, klicken Sie durch die Rate sinkt, wenn die Ladezeit der Seite zunimmt. Als nächstes passen wir eine Zeile an diese, um eine ungefähre Zahl zu erhalten wie schnell das Klicken durch Rate durch klicken verringert, wenn die Seite Ladezeiten erhöhen. Gehen Sie weiter und importieren Sie eine andere Bibliothek namens NumPy. Diese Bibliothek hat einen Zeilenanpassungsalgorithmus, den wir verwenden können. Gehen Sie voran und geben Sie m, b. Mit anderen
Worten, die Neigung und die Neigung Ihrer Linie ist gleich einer numPy-Funktion, die tatsächlich eine Linie für uns zu einer Reihe von Punkten passt, np.polyfit
aufrufen und die x-Werte übergeben, , die alle Ladezeiten der Seite sind. Also hier haben Sie page_load.index, und das zweite Argument ist die Klickrate, die Seite laden und dann has_clicked ist. Das letzte Argument ist der Grad eines Polynoms. In diesem Fall wollen wir gerade Linien. Das Polynom von Grad 1 ist alles, was wir brauchen. Jetzt können wir endlich die Anpassungslinie zusammenfassen. Nimm den Hang. Daran erinnern, dass die Steigung über Lauf steigt oder alternativ die Änderung in y über die Änderung in x ist. Hier ist y die Klickrate und x ist die Ladezeit der Seite. Die Steigung ist also die Änderung der Klickrate pro Änderung der Seitenladezeit. Wir können mit 100 multiplizieren, um die Änderung der
Klickrate pro 100 Millisekunden Seitenladezeit zu erhalten. Geben Sie m mal 100 ein und gehen Sie voran und führen Sie die Zelle aus. Hier bekommen wir negativ 0,068. Dies bedeutet, dass alle 100 Millisekunden langsamer Seitenlast sieben Prozent Traffic kosten. Wir machen hier einige ziemlich beeindruckende Übervereinfachungen, aber dies vermittelt den Punkt, dass langsamere Seitenladezeiten die Klickrate für
Webseite A erheblich verletzen . Ich würde
jede Präsentation begleiten , die eine Zahl wie diese mit einer Handlung zitiert, um zu erklären. Lassen Sie uns eine Handlung erstellen, damit Zuschauer
selbst beurteilen können , wie gut diese Zeile zu den Daten passt. In der nächsten Zelle beginnen wir mit einem Titel plt.title. In diesem Fall wird unser Titel alle 100 Millisekunden Seitenladezeit kostet sieben Prozent Klickrate. Plotten Sie die Linie von vorher in der vorherigen Zelle noch einmal. Hier wird die Seitenlast has_geklickt und das Label ist die Klickrate. Plotten Sie dann die Anpassungslinie. Hier rufen wir page_load.index auf und denken Sie daran, die Gleichung für eine Zeile m mal x plus b. Hier haben wir
also die m mal die x-Werte, nur page_load.index plus b. Wir werden auch hier ein Label hinzufügen. Das Etikett wird die angepasste Klickrate sein. Gehen Sie weiter und fügen Sie nun eine Beschriftung für Ihre X-Achse hinzu. Dies wird die Seitenladezeit in Millisekunden sein und wir werden auch die Y-Achse beschriften. Hier ist Klickrate. Fügen Sie schließlich Ihre Legende hinzu und führen Sie Ihre Zelle aus. Damit kommt unser zweites Argument zum Schluß. Wir können jetzt sehen, dass die Klickrate aufgrund der erhöhten Seitenladezeit stark
sinkt. Als nächstes möchten wir für unser drittes Argument verstehen, was wäre, wenn Webseite A nicht von einer langsameren Seitenladezeit betroffen wäre, was glauben wir, dass die Klickrate von Webseite A gewesen wäre? das Diagramm oben beobachten, weiter oben, genau hier, sehen
wir
weiter oben, genau hier,dass die Seitenladezeiten von Webseite A alle Wenn wirdas Diagramm oben beobachten,sehen
wir
weiter oben, genau hier,dass die Seitenladezeiten von Webseite A alle
innerhalb von 400-550 Millisekunden liegen, bevor sie zu springen scheint. Als Ergebnis berechnen wir die Klickrate für Webseite A mit nur diesen Daten.
Daher werden wir alle Ansichten mit Seitenladezeiten von weniger als 550 Millisekunden auswählen. Gehen Sie vor und geben Sie Ansichten A und wir werden alle diese Spalten auswählen, alle Seitenladezeiten, die weniger als 550 sind. Dies gibt uns nur die Zeilen, die Seitenladezeit weniger als 550 Millisekunden haben. Lassen Sie uns nun voran gehen und wählen, ob auf diese Zeile geklickt wurde oder nicht, und berechnen Sie dann die durchschnittliche Klickrate. Gehen Sie weiter und fahren Sie die Zelle. Das ist eine ganze 70 Prozent Klickrate, ziemlich unglaublich. Zum Vergleich berechnen wir die Klickrate für Webseite B. Wählen Sie die Klickspalte aus und berechnen Sie den Mittelwert erneut. Führen Sie die Zelle, und das bringt uns nur 40 Prozent Klickrate. Kurz gesagt, Webseite A hätte die Webseite B um 40 Prozent übertroffen. Um diese Idee wirklich zu vermitteln, benötigen
wir jedoch wieder ein Liniendiagramm. In dieser Zelle werden wir die Funktionen verwenden, die wir zuvor definiert haben. Um A, erhalten Sie alle Klickinformationen für jede Webseite, dann B, wir berechnen die Anzahl der Klicks pro Tag für jede Webseite. Gehen Sie voran und definieren Sie eine neue Variable, clickSA ist gleich und erhalten Sie dann nur die Klickereignisse aus allen Ansichten für Webseite A. Dies berücksichtigt nur Klicks für Webseite A. Als nächstes werden wir täglich berechnen Statistiken. Also ClickSadaily ist gleich und dann events_per_day und übergeben Sie die Variable, die wir gerade definiert haben, dies berechnet die Anzahl der Klicks pro Tag für Webseite A. Gehen Sie voran und tun Sie das gleiche für Webseite B. ClicksB ist gleich allen Klicks -Ereignisse für Webseite B und berechnen dann die Anzahl der Klicks pro Tag für Webseite B. Hier ist ClicksBDaily gleich dem events_per_day von ClicksB. Um zu sehen, wie ClickSadaily aussieht, gehen Sie weiter und geben Sie diesen Variablennamen noch einmal ein und führen Sie die Zelle aus. Hier erhalten wir für jeden einzelnen Tag die Anzahl der Klicks. Nun, unser letzter Code in dieser letzten Zelle. Wir werden diese Daten tatsächlich plotten, geben Sie plt.title ein, um dieser Handlung einen Titel zu geben „Webseite A könnte die CTR um 30 Prozent gesteigert haben“. Gehen Sie voran und zeichnen Sie nun die Daten, die wir gerade berechnet haben, die Anzahl der Klicks pro Tag. Genau wie zuvor werden wir diese Zeile A beschriften. Wiederholen Sie das gleiche für B, also ClicksBDaily und Label gleich B. Als nächstes wird unsere dritte Zeile für dieses Diagramm
die projizierte Anzahl von Klicks für unsere Webseite Asein die projizierte Anzahl von Klicks für unsere Webseite A Wir werden die Ansichten pro Tag mit 0,7 multiplizieren, und dann werden wir mit 0,5 multiplizieren weil jede Webseite tatsächlich nur die Hälfte des Traffics hat. Dann werden wir in Label gleich A projiziert eingeben, so geschätzt. Das schließt unsere Linie. Gehen wir jetzt weiter und beschriften die Achse, genau wie wir es immer tun. Wir werden das Datum beschriften, dann werden wir die Klicks beschriften und dann die Legende hinzufügen. Schließlich, das schließt unsere letzte Handlung, gehen Sie voran und führen Sie es. Wir können hier in der grünen Linie sehen , dass unsere projizierten Klicks pro Tag für Webseite A wahnsinnig gewesen wären, es wäre viel höher gewesen als Webpage B. Abschließend gehen wir zurück zu den Folien. Wir haben mehrere Themen in dieser Lektion behandelt: Matplotlib, Handlung und wie man eine Geschichte erzählt. Zusammenfassend, hier sind unsere endgültigen Schlussfolgerungen. Unsere ersten Schlussfolgerungen hatten vorgeschlagen, dass Webseite B besser war ,
glücklicherweise haben wir diesen Fehler jetzt korrigiert. Zusammenfassend haben wir
drei Qualitätszahlen erstellt , die unsere datengesteuerte Geschäftsentscheidung unterstützen. Zusammenfassend empfehlen wir, Webseite A mit dem Informationsvideo auszuwählen, es gibt drei Gründe. Ansehen von Informationsvideos ist stark mit dem Kochen der Anmeldung korreliert. Im Gegensatz dazu hat das Lesen des Preisabschnitts fast Null Einfluss darauf, ob der Benutzer klickt, um sich anzumelden. Beginnend mit der oberen linken zeigten
wir dann, dass die Klickrate von Webseite A stark gesunken ist. Unten links haben wir gezeigt, dass die heruntergekommene Klickrate von Webseite A zur gleichen Zeit
geschah, während die Seitenladezeiten von Webseite A plötzlich zunahmen. Auf der rechten Seite zeigen wir dann, dass die
erhöhte Ladezeit von Webseite A zu einem drastischen Rückgang der Klickrate geführt hat. Dies deutet darauf hin, dass die allgemeine Klickrate von Webseite A nicht vertrauenswürdig ist. Schließlich projizieren wir, welche Click-Through-Rate von Webseite A während
des gesamten Experiments gewesen wäre , wenn die Seitenladezeiten nicht zwei Monate in das Experiment aufgenommen hätten. Wir können sehen, dass Webseite A konsequent eine 30 Prozent höhere Klickrate als Webseite B
erhalten hätte ,
was unsere endgültige Empfehlung von Webseite A rechtfertigt die datengesteuerte Geschäftsempfehlung abgeschlossen. Unser letzter Tipp, kennen Sie Ihre Plot Typen, die richtige Handlung kann eine Geschichte erzählen. Sie sollten für jeden Punkt wissen, den Sie betonen möchten, welches Diagramm am besten geeignet ist, um diesen Punkt zu betonen. Fügen Sie zusätzliche Anmerkungen hinzu, ändern Sie die Farben oder benennen Sie den Plot entsprechend, um Ihnen zu helfen. Wenn Sie auf diese Folien zugreifen und diese herunterladen möchten, besuchen Sie diese URL. Versuchen Sie, Ihre eigenen Daten zu plotten, um zu sehen, ob es versteckte Einblicke gibt. Wenn Sie nach dem perfekten Plottyp suchen, lesen Sie Matplotlib Beispiele. Das Ziel ist nicht, sie alle anzuklicken, aber Ihr Ziel ist es zu wissen, welche Plots Ihnen helfen, die richtige Geschichte zu erzählen. Manchmal kann das Durchsuchen dieser Seite Ihnen gerade genug Inspiration geben. Herzlichen Glückwunsch, damit ist Ihre erste Fallstudie eines AB-Tests für zwei Webseiten abgeschlossen. Als Nächstes besprechen wir die nächsten Schritte, um weitere Informationen zu erhalten.
8. Schlussbemerkung: Herzlichen Glückwunsch, dass Sie Ihre ersten Schritte in der Datenanalyse abgeschlossen haben. Wir haben eine Reihe von Themen behandelt: Lesen, Bereinigen, Analysieren und Präsentieren von Daten. Sie haben auch eine Reihe von verschiedenen Bibliotheken für die Datenanalyse abgedeckt, einschließlich Matplotlib zum Plotten von Daten
und Pandas, um tatsächlich Daten zu speichern. Das ist heute ein vielfältiges Toolset unter deinem Gürtel. Dies ist die Punchline, Codierung mit Daten ist eine Fähigkeit, die, wenn sie richtig gemacht wird, überzeugende Geschichten erzählen
kann. Was gibt es mehr? Sie haben jetzt den Anfang dieser Fertigkeit. Was gibt es mehr? Sie haben jetzt die Grundlagen, um überzeugende Geschichten zu erzählen, ein Toolset für die Kommunikation komplexer Daten. Wenn Sie eine bessere Möglichkeit haben dieses Dataset oder ein eigenes Dataset zur Visualisierung zu visualisieren, stellen Sie sicher, dass Sie Ihre Zahlen auf der Registerkarte Projekte und Ressourcen hochladen. Achten Sie darauf, sowohl die Figur eine Beschriftung anzugeben, die beschreibt, was uns die Figur zu sagen versucht. Wenn Sie auf die Folien oder den ausgefüllten Code zugreifen möchten, besuchen
Sie bitte diese URL. Wenn Sie mehr über Data Science oder maschinelles Lernen erfahren möchten, sollten
Sie sich mein Skillshare Profil mit 101s und anderen Themen wie Computer Vision ansehen. Danke und herzlichen Glückwunsch noch einmal, dass du
deine erste Geschichte mit Daten erzählst . Bis zum nächsten Mal.
 Alvin Wan, Research Scientist
Alvin Wan, Research Scientist